この記事のポイント
 ループエンジニアリングは「プロンプトを打つ人」から「ループを設計する人」へ役割を置き換える設計手法
ループエンジニアリングは「プロンプトを打つ人」から「ループを設計する人」へ役割を置き換える設計手法- ループの構成要素は自動化・隔離・知識・連携・分業・記憶の6つで、Claude Code・OpenAI Codex app・Cursorは6要素に近い公式プリミティブを備えている
- ループ化したエージェントは標準セッションの数倍〜数十倍のトークンを消費するため、停止条件を設計しなければ請求書が暴走する
- 生成役と検証役を分けない「自己採点ループ」は構造的に破綻する。Maker-Checker分離は必須
- 業務適性は反復性・検証可能性・経済価値の3軸で判定し、L1(報告のみ)→L2(検証付き修正)→L3(無人実行)と段階的に上げる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
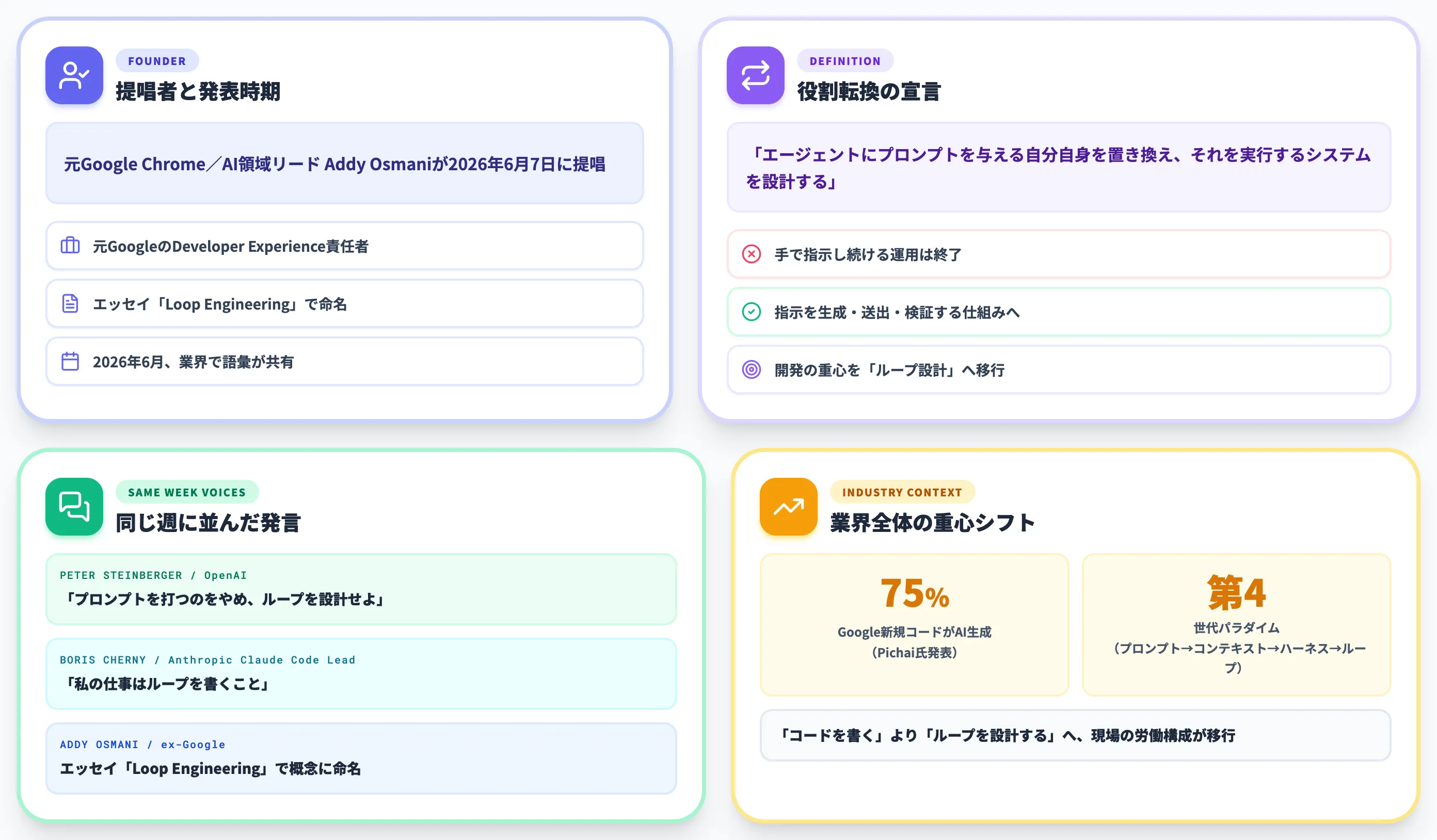
ループエンジニアリング(Loop Engineering)は、元GoogleでChrome/AI領域のエンジニアリング・Developer Experienceを率いたAddy Osmaniが2026年6月7日に提唱した、AIコーディングエージェントの新しい設計パラダイムです。
「もうエージェントに指示するのをやめ、エージェントを動かすループを設計しよう」というSteinberger(PSPDFKit創業者)の発言と、Anthropic Claude CodeリードのBoris Cherny「私の仕事はループを書くこと」の発言が同じ週に並び、業界で一気に語彙が共有されました。
本記事では、プロンプト・コンテキスト・ハーネスとの違い、ループを構成する6要素、Claude Code/Codex/Cursor/Devin/OpenCodeの対応マトリクス、コスト爆発と停止条件、設計の落とし穴、SIerとして見るケース別の導入判断軸までを、2026年6月時点の最新情報で体系的に解説します。
目次
ループエンジニアリングとは?プロンプトの先にきた第4世代パラダイム
ループの解剖学|Addy Osmaniが示した6つの構成要素
動くループの内部|公式5ステップとMaker-Checkerの上乗せ
実装上の整理:act → observe → decide → verifyの4ステップ
主要ツールの対応マトリクス|Claude Code / Codex / Cursor / Devin / OpenCode
Claude Codeとループエンジニアリングは設計思想が一致している
OpenAI Codex appはworktree・Subagents・Automations・Skillsを揃える
Cursor 2.4以降はサブエージェント+worktreeを公式実装
Devinは「自律実行+Interactive Planning」で自動化を提供
ループエンジニアリングとは?プロンプトの先にきた第4世代パラダイム
ループエンジニアリング(Loop Engineering)は、AIコーディングエージェントに人手でプロンプトを打ち続けるのをやめ、エージェントにプロンプトを出し続ける「ループ」そのものを設計する考え方です。
提唱者は、元GoogleでChrome/AI領域のエンジニアリング・Developer Experienceを率いてきたAddy Osmani氏。2026年6月7日に公開したエッセイ「Loop Engineering」で、概念に名前を与えました。
オリジナルの定義は次の通りです。
Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.
(ループエンジニアリングとは、エージェントにプロンプトを与える役割の自分自身を置き換えることである。代わりに、それを実行するシステムを設計する)
つまり、エンジニアが手で指示を出し続ける運用から、指示そのものを生成・送出・検証する仕組みを構築する運用へ、開発の重心が移ったという宣言です。
この提唱は単独のひらめきではなく、PSPDFKit創業者で現在OpenAI在籍のPeter Steinberger氏が「エージェントにプロンプトを出すループを設計せよ」と発信し、Anthropic Claude CodeリードのBoris Cherny氏も「私の仕事はループを書くこと」と続くなど、同じ週に複数の発言が重なって生まれた業界共通の認識です。

プロンプト・コンテキスト・ハーネスエンジニアリングとの違い
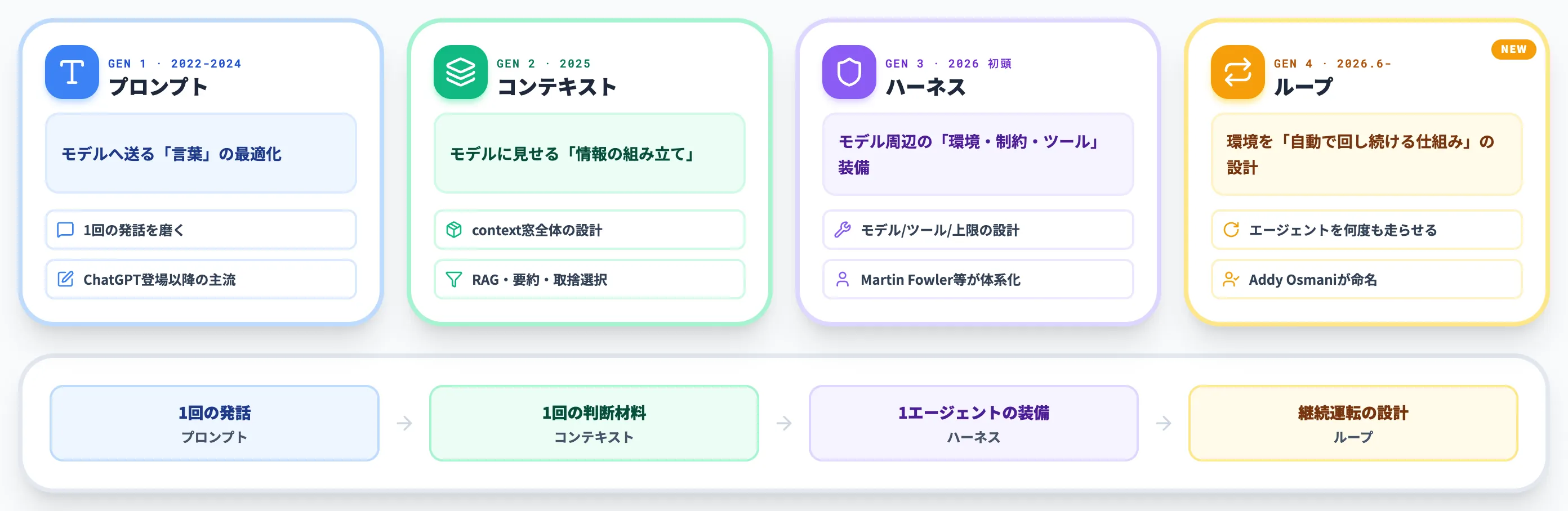
ループエンジニアリングは、AIアプリケーション開発の歴史で4世代目にあたる設計概念です。
先行する3世代——プロンプト、コンテキスト、ハーネス——との違いを押さえると、ループ層がどのレイヤーを担うのかが明確になります。
以下の表で、4世代パラダイムの責務分担を整理しました。
| 世代 | 名称 | 最適化対象 | 中心人物・時期 |
|---|---|---|---|
| 第1世代 | プロンプトエンジニアリング | モデルへ送る「言葉」 | 2022〜2024 |
| 第2世代 | コンテキストエンジニアリング | モデルに見せる「情報の組み立て」 | 2025 |
| 第3世代 | ハーネスエンジニアリング | モデル周辺の「環境・制約・ツール」 | 2026年初頭(Martin Fowler等) |
| 第4世代 | ループエンジニアリング | 環境を「自動で回し続ける仕組み」 | 2026年6月〜(Addy Osmani) |
この4世代の関係を別の言い方にすると、プロンプトは「1回の発話」、コンテキストは「1回の判断材料の組み立て」、ハーネスは「1人のエージェントの装備一式」、ループは「装備済みエージェントを何度も走らせる運転設計」を担うレイヤーです。
「コードを直接プロンプトに書く」段階から「context window全体を設計する」段階へ進み、さらに「context組立→ツール呼び出し→評価→次の組立」のサイクル全体を制御する段階に上がってきた、と整理できます。
ハーネスとループの境界
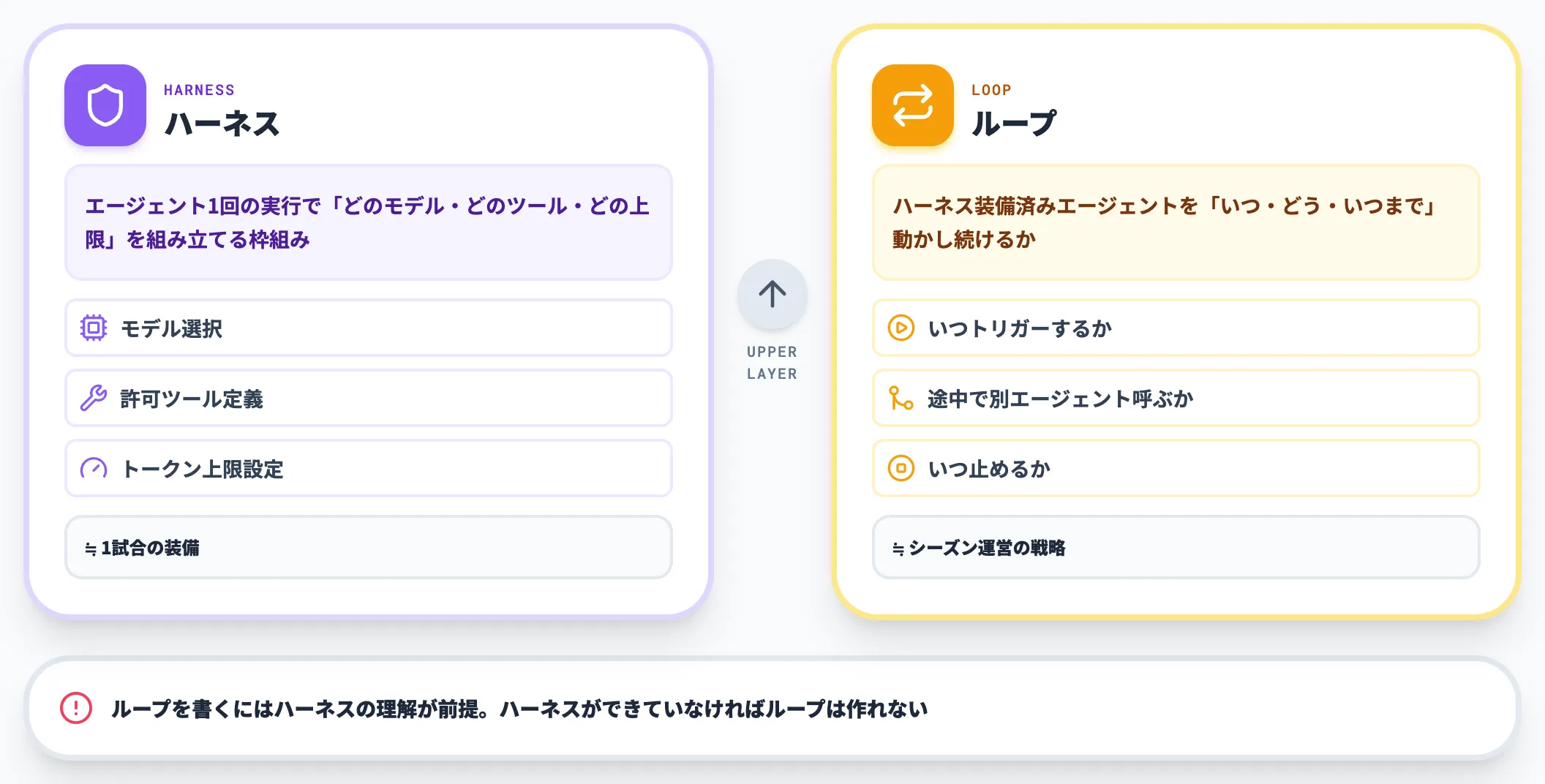
業界の議論でも、ハーネスとループは入れ替わって使われがちですが、責務は明確に違います。
ハーネスは、エージェント1回の実行で「どのモデルを使うか/どのツールを許すか/どのトークン上限を設けるか」を組み立てる枠組みです。
これはMartin Fowlerの「Harness engineering for coding agent users」で詳しく整理されています。
一方ループは、ハーネスを装備したエージェントを「いつトリガーするか/途中で別エージェントを呼ぶか/成果物をどう検証するか/いつ止めるか」のレベルで動かし続ける、より上位の制御層です。
つまりハーネスは「1試合の装備」、ループは「シーズン運営の戦略」に相当します。ループを書くにはハーネスの理解が前提で、ハーネスができていなければループは作れません。
コンテキストエンジニアリングはループの中にも生きている
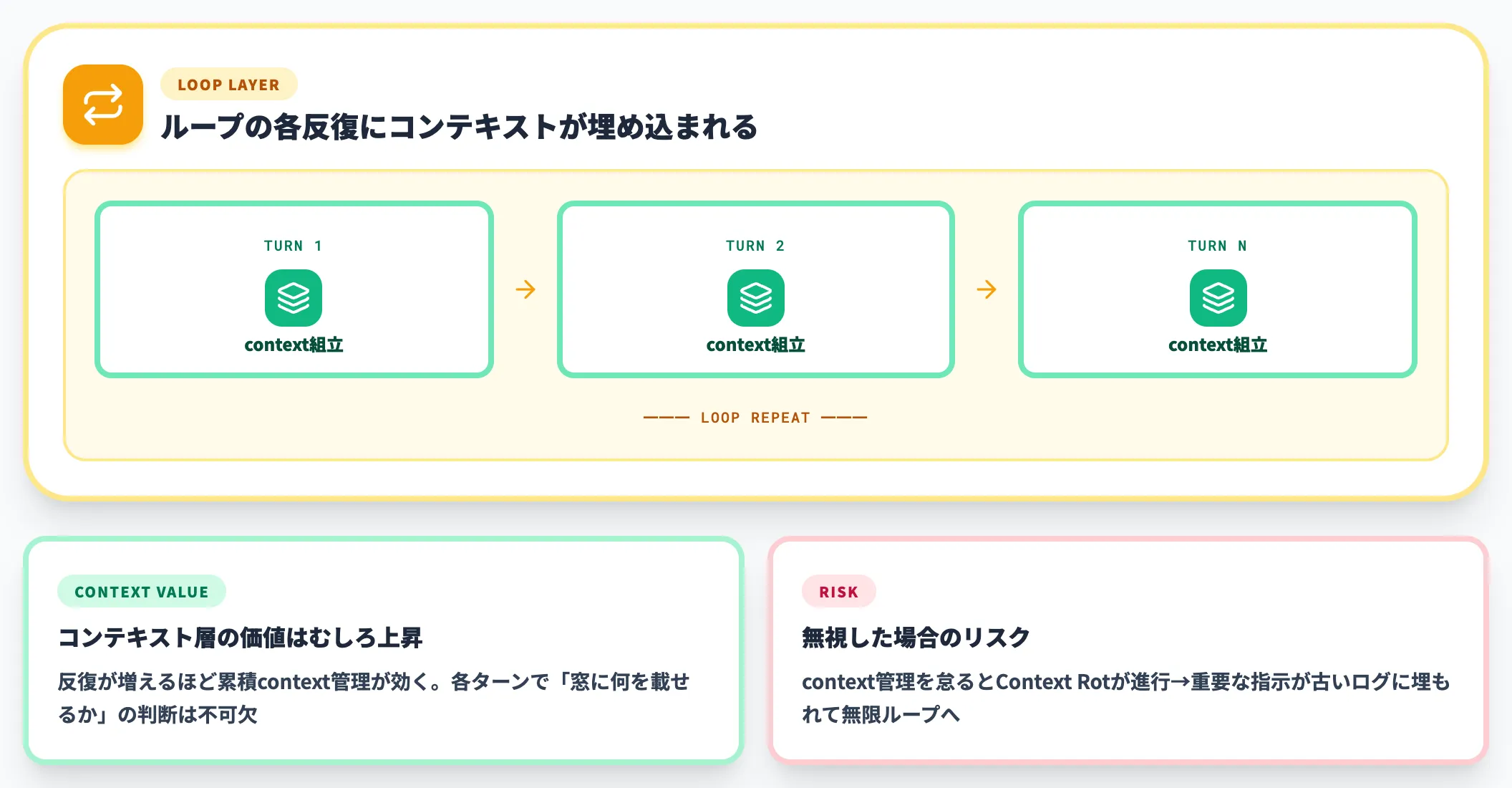
ループ層が新しく登場したからといって、コンテキストエンジニアリングが不要になったわけではありません。
ループ内の各反復でも「context窓に何を載せるか」の判断は必要で、context層の知見はループ内部の各ステップに埋め込まれます。
むしろループ反復が増えるほど、累積context管理の重要度が増すため、コンテキストエンジニアリングの価値は上がっています。
ループの解剖学|Addy Osmaniが示した6つの構成要素

Addy Osmaniの原文エッセイは、動くループを構成するパーツとして6つの要素を列挙しています。エージェントが自走するために最低限必要な部品群です。
以下の表で、6要素の役割と代表的な実装を整理しました。
| 要素 | 英語表記 | 役割 | 代表的な実装例 |
|---|---|---|---|
| 自動化トリガー | Automations | スケジュールやイベントでループを起こす | GitHub Actions、cron、CIフック |
| 並列隔離 | Worktrees | 複数エージェントの作業空間を分離 | git worktree、コンテナ |
| 知識バンドル | Skills | プロジェクト固有の手順・命名を保存 | SKILL.md、CLAUDE.md |
| 外部連携 | Plugins / Connectors | 既存ツール・データ基盤との接続 | MCP、各種SDK |
| 分業設計 | Sub-agents | 生成役と検証役を分離 | Maker / Checker、専門エージェント |
| 状態保存 | Memory | セッションを超えて結論・履歴を残す | STATE.md、ベクタDB、Memory APIs |
この6要素のうち、どれか1つが欠けてもループはどこかで詰まります。たとえば自動化トリガーがないと「結局誰かが手で動かす」状態に戻り、状態保存がないと「先週やった作業を毎回ゼロから繰り返す」運用になります。
ここから、6つの要素それぞれをもう少し具体的に見ていきます。
自動化トリガー|ループを起こす「ハートビート」
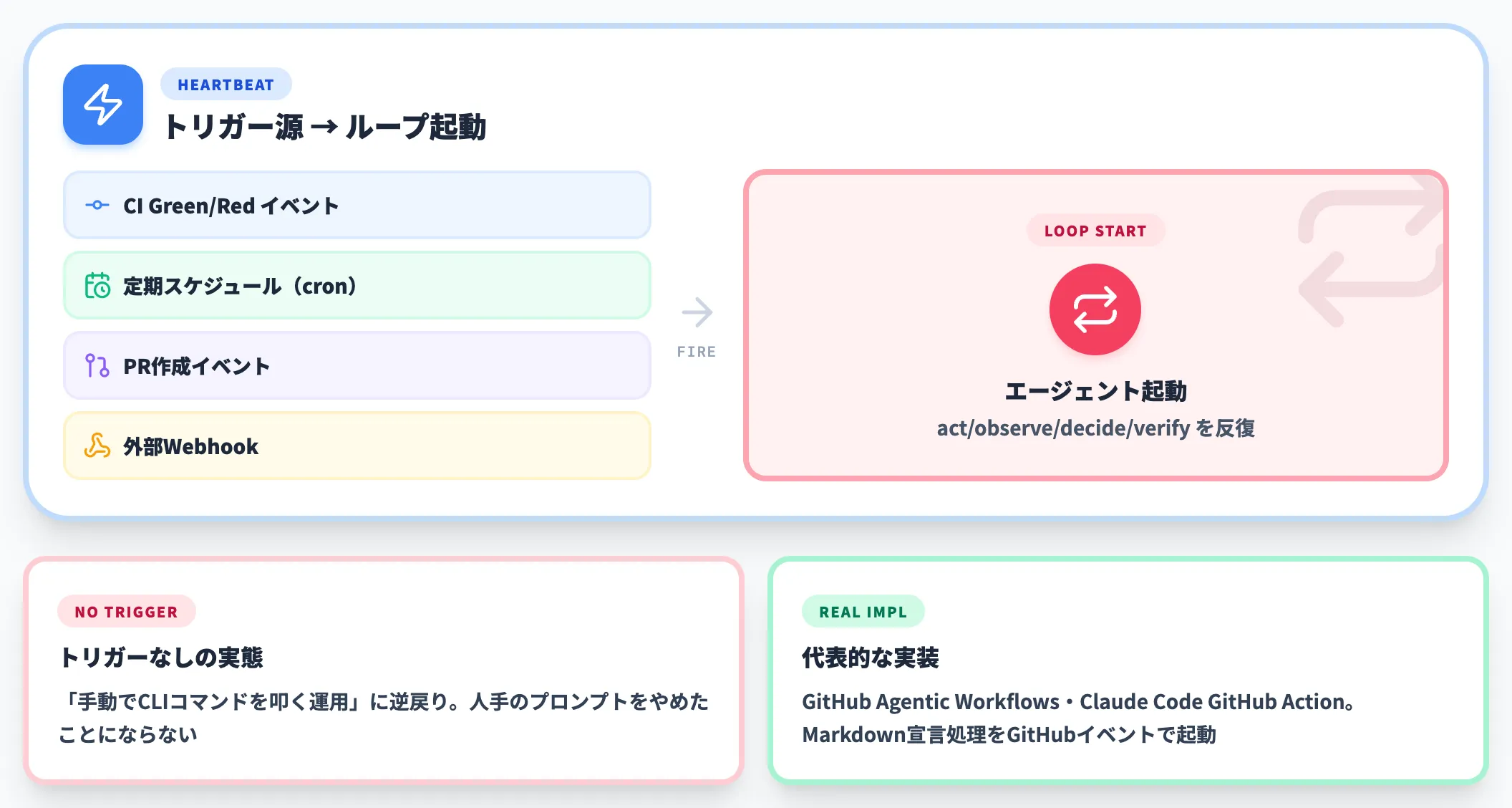
自動化トリガーは、ループの心臓にあたる部品です。CIのGreen/Redイベント、定期スケジュール、PR作成、外部Webhookなど、何らかのきっかけでエージェントを呼び出す仕掛けが必要になります。
このトリガーがないと、ループという言葉を使っていても実態は「手動でCLIコマンドを叩く運用」で、人手のプロンプトをやめたことにはなりません。
代表的な実装としては、GitHub Agentic WorkflowsやClaude Code GitHub Actionのように、Markdownで宣言した処理をGitHubのイベントで起動する方式が広がっています。
並列隔離|エージェント同士の衝突を避ける作業空間
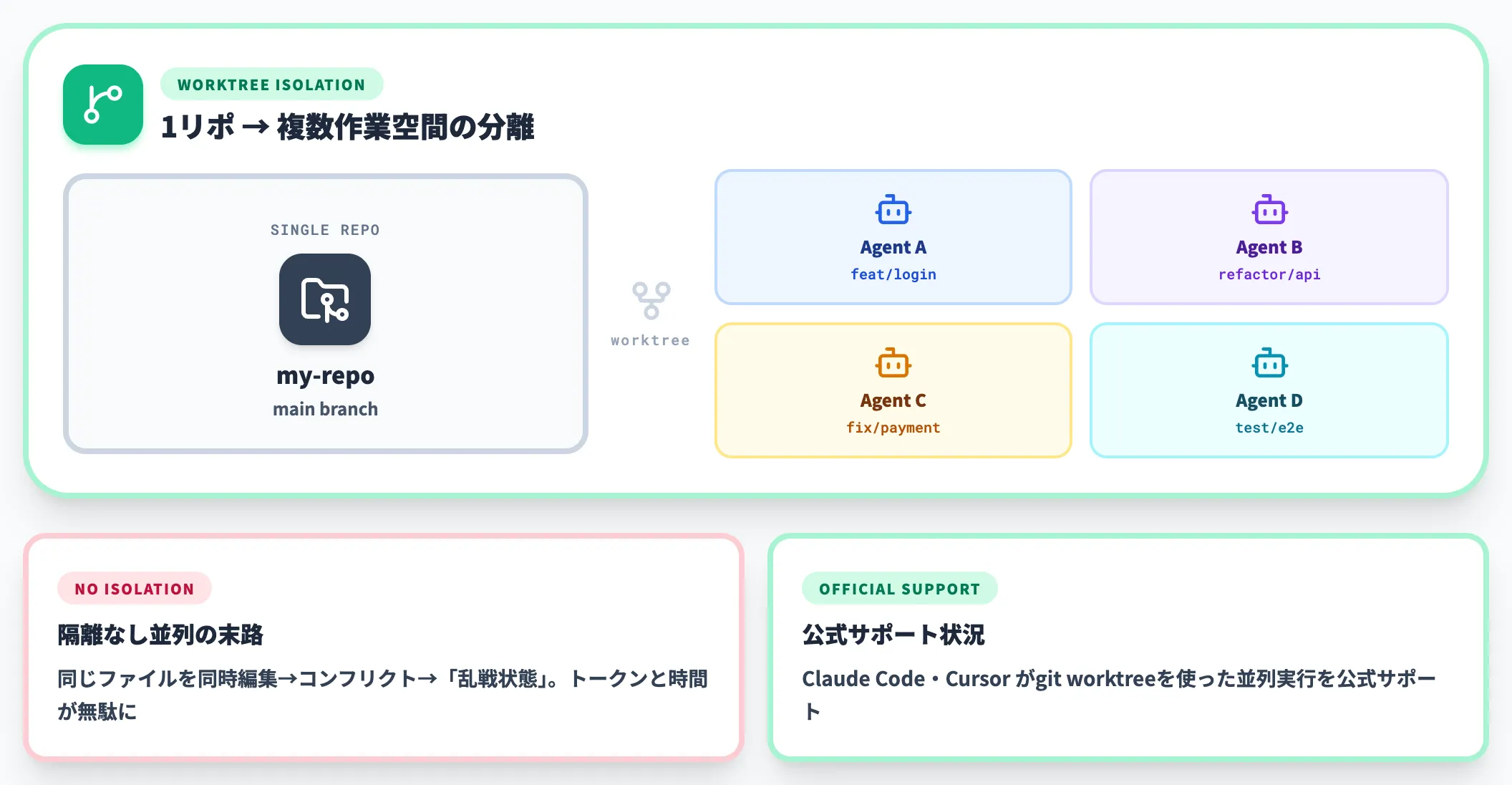
複数のエージェントを並列で走らせる場合、同じファイルを同時に編集してコンフリクトを起こす問題が必ず発生します。
git worktreeは、1つのリポジトリから複数の独立した作業ディレクトリを切り出す仕組みで、各エージェントを別々の作業空間に隔離するのに使われます。Claude CodeとCursorはこのworktreeを使った並列実行を公式サポートしています。
隔離なしで並列ループを回すと、エージェント同士が互いの編集を上書きしあう「乱戦状態」になり、トークンと時間が無駄になります。
知識バンドル|「プロジェクトの常識」を毎回伝えるための装備
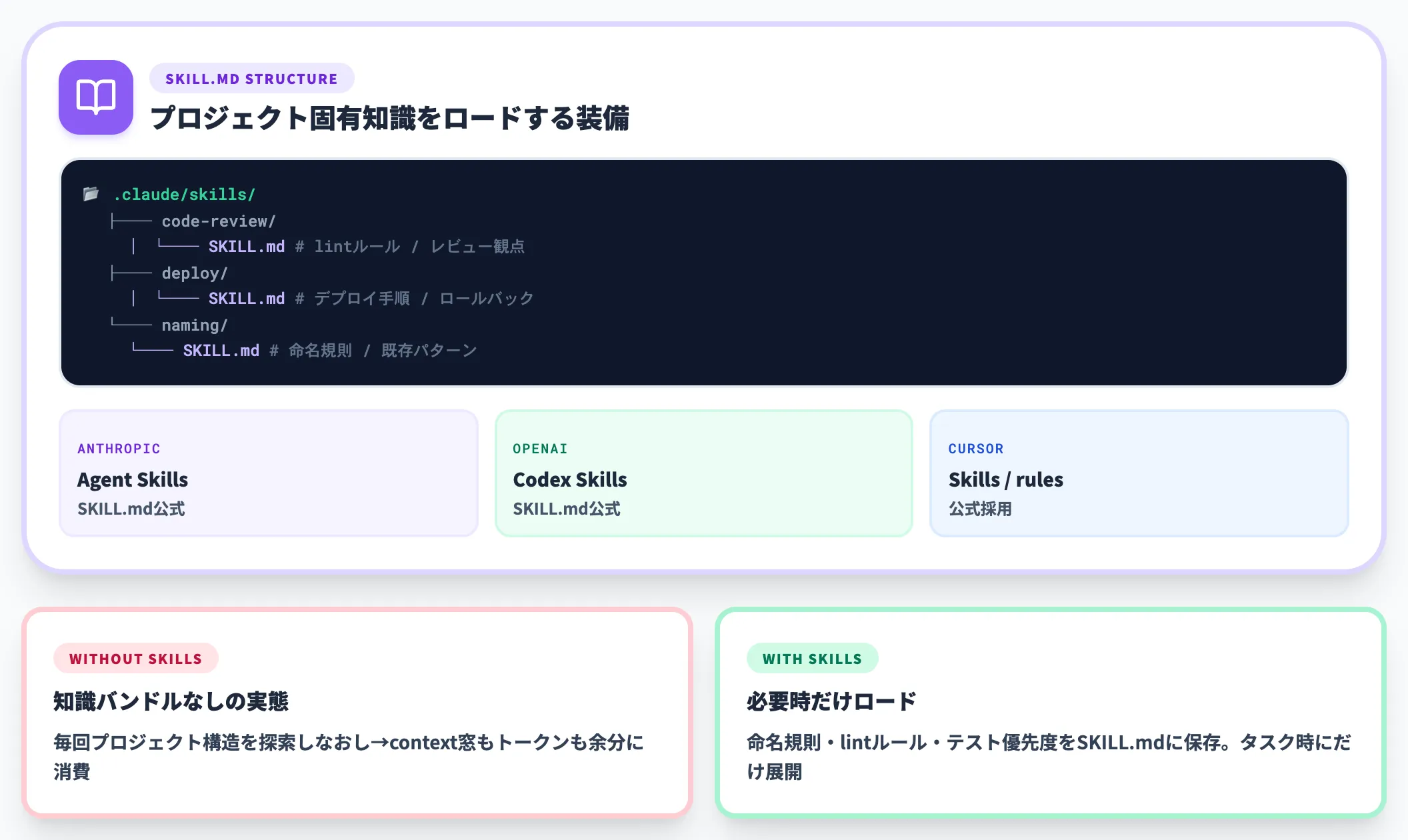
エージェントは新しいセッションを開くたびに「このプロジェクトの命名規則は何か」「lintルールは何か」「どのテストを優先で走らせるか」を知りません。
Anthropic Agent Skills・Claude Code Skills・OpenAI Codex Skillsは、こうしたプロジェクト固有知識をSKILL.mdの形で保存し、必要なときだけロードする仕組みです。
知識バンドルがないと、エージェントは毎回プロジェクト構造を探索しなおすことになり、context窓もトークンも余分に消費します。
外部連携|既存ツールへの「窓口」を開ける
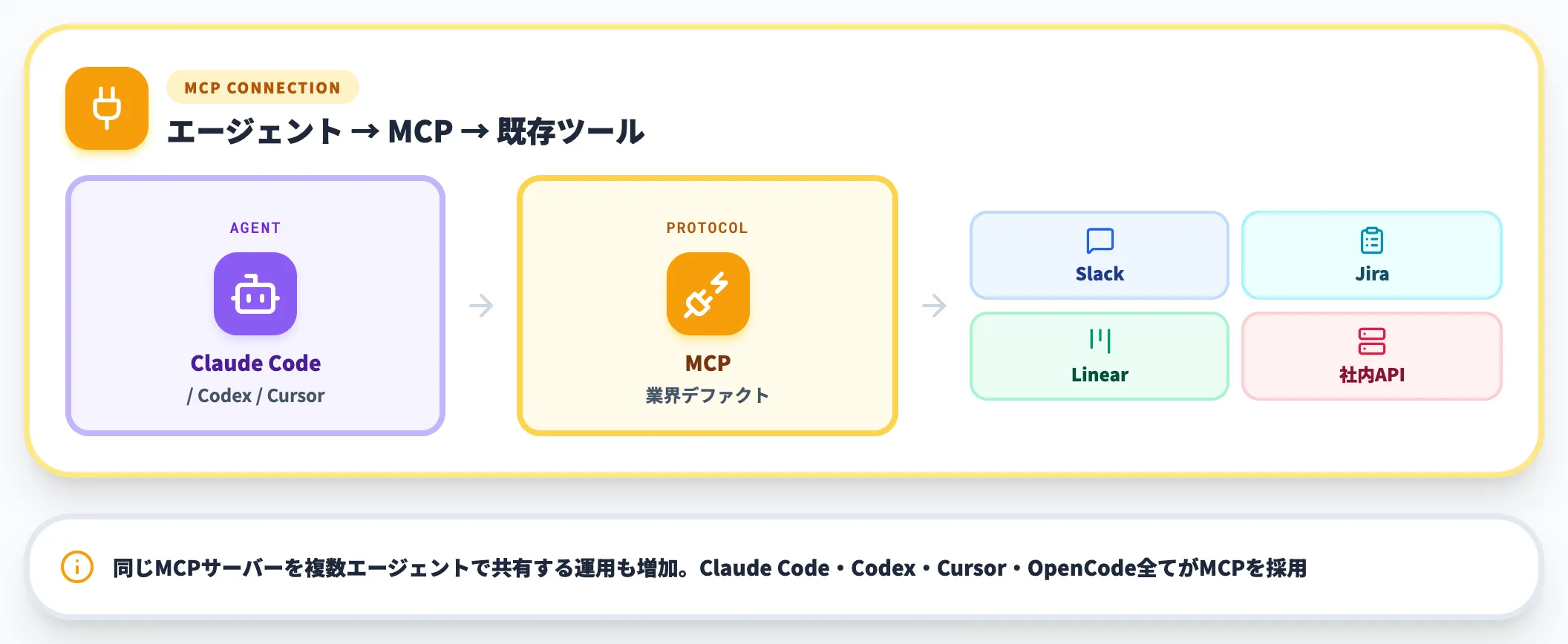
ループは閉じた世界では役立ちません。SlackやJira、Linear、自社の社内APIといった既存ツールに接続できないと、自動化の対象がほぼコード生成に限定されてしまいます。
MCP(Model Context Protocol)は、エージェントが外部ツールを呼び出すための標準プロトコルとして、2025年以降の業界デファクトになりました。Claude Code・OpenAI Codex・Cursor・OpenCodeのいずれもMCPを採用しており、同じMCPサーバーを複数エージェントで共有する運用も増えています。
分業設計|生成と検証を分ける「Maker-Checker」

ループで最も裏切られやすいのが、「自分で生成して自分で採点する」エージェントです。Addy Osmaniは原文で「The model that wrote the code is way too nice grading its own homework(コードを書いたモデルは、自分の宿題を採点するときに優しすぎる)」と表現しています。
そのため、生成役(Maker)と検証役(Checker)を別エージェントとして分離するのが鉄則です。検証役には別のシステムプロンプトと別の権限を与え、生成役の出力を独立した観点で評価させます。
Claude CodeのSubagents、Cursor 2.4以降のsubagents機能、OpenAI Codexの並列subagentsなどは、いずれもこのMaker-Checker分離を念頭に設計されています。
状態保存|セッションを越えて「文脈」を残す

ループは1回のセッションで完結しません。昨日中断した作業の続き、先週の判断材料、別エージェントが残したメモなど、セッションを越えて保持すべき情報があります。
CLAUDE.mdに永続ルールを書く、STATE.mdに作業履歴を記録する、ベクタDBやMemory APIに過去判断を入れる——いずれも「ループが何度走っても同じ前提を再現できる」ための装備です。
状態保存を作り込まないと、ループが進むほど「同じバグを2度直す」「3日前に没にした案を再提案する」という現象が起こります。

動くループの内部|公式5ステップとMaker-Checkerの上乗せ
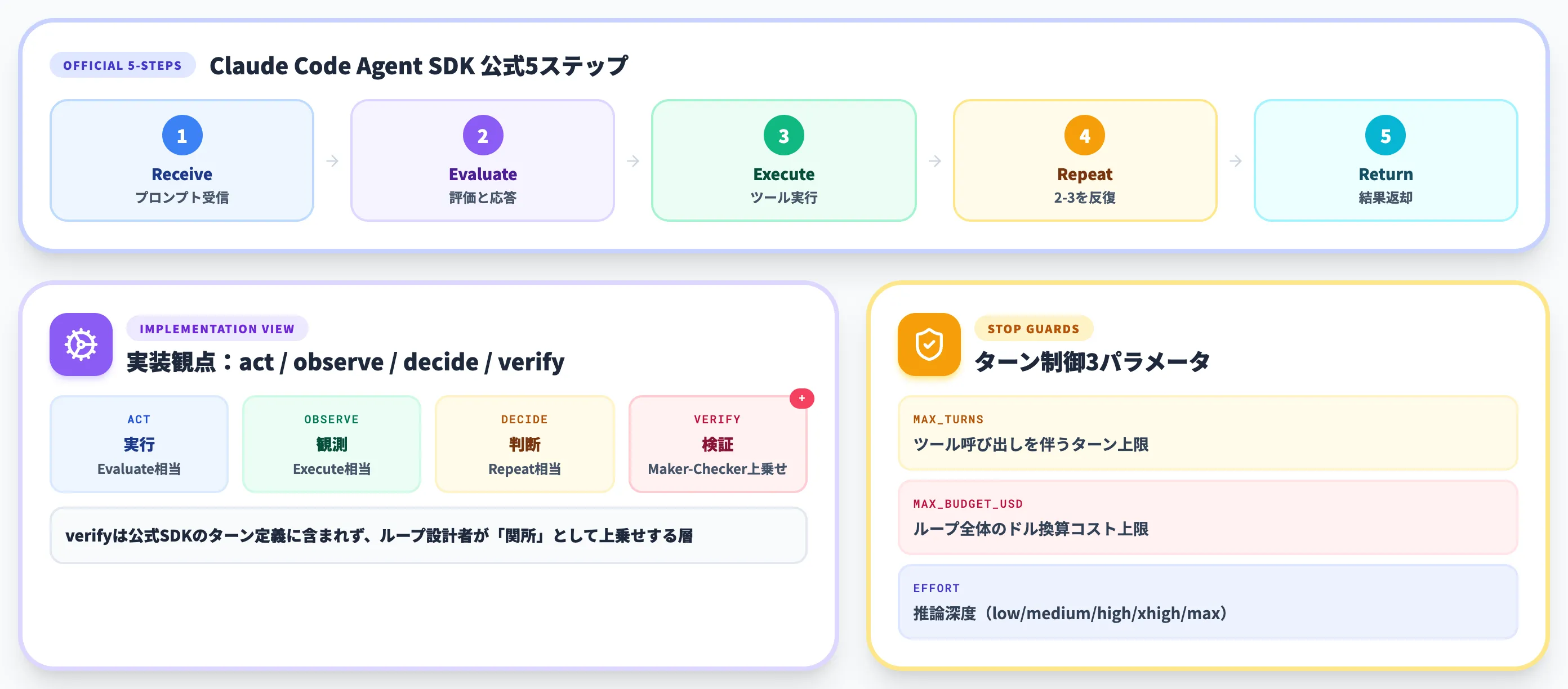
6つの要素が揃ったうえで、ループの中身はどう動いているのか。Anthropic公式のClaude Code Agent SDKドキュメントが、エージェントループの基本サイクルを明示しています。
Claude Code Agent SDKの公式5ステップ
公式ドキュメントは、ループを以下の5ステップで定義しています。
-
Receive prompt(プロンプト受信)
ユーザーのプロンプト、システムプロンプト、ツール定義、会話履歴を受け取り、セッションが開始される
-
Evaluate and respond(評価と応答)
モデルが現状を評価し、テキストで応答するか、ツール呼び出しを要求するかを決める
-
Execute tools(ツール実行)
SDKがツールを実行し、結果を回収する
-
Repeat(反復)
評価と応答→ツール実行のサイクルを、ツール呼び出しがなくなるまで繰り返す
-
Return result(結果返却)
ツール呼び出しのない最終応答が返り、ResultMessageでトークン使用量・コスト・セッションIDが付与されてループ終了
1回の評価と応答→ツール実行のサイクルが「ターン」と呼ばれ、複雑なリファクタリングではターンが数十回続くこともあります。
実装上の整理:act → observe → decide → verifyの4ステップ
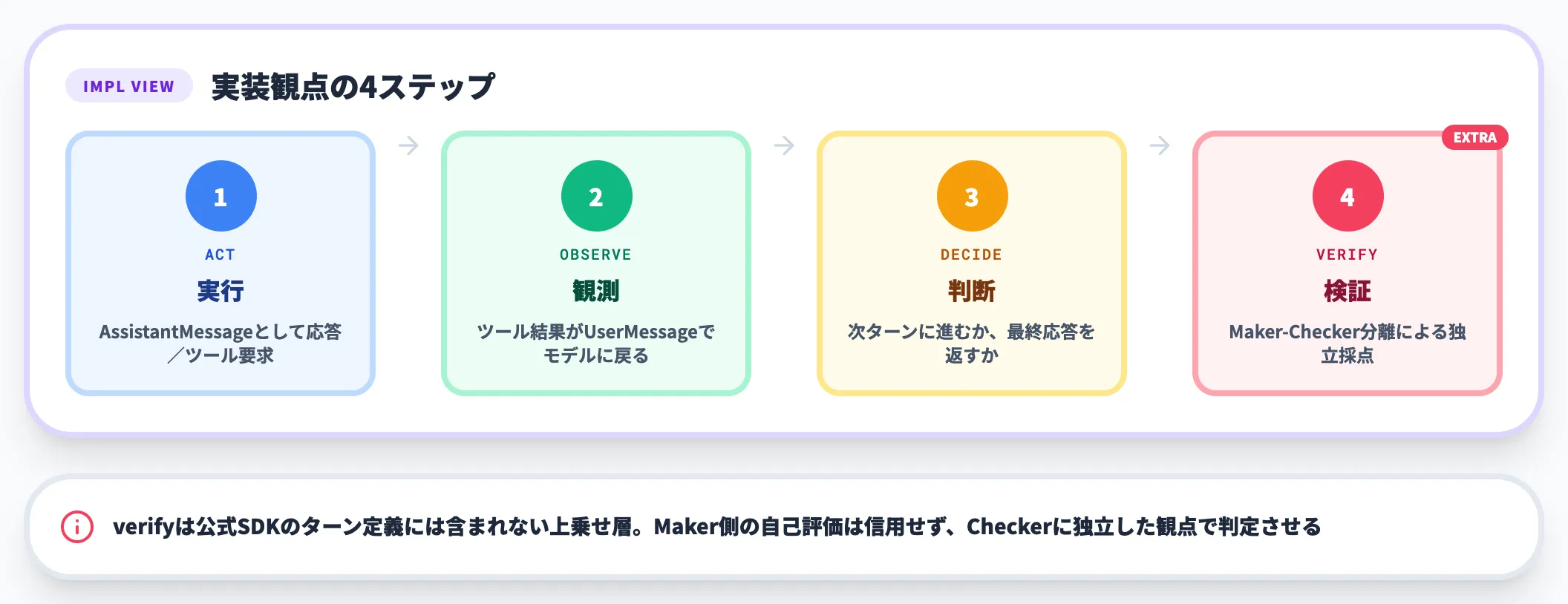
この公式5ステップを、ループエンジニアリングの実装観点で整理すると、以下の4ステップに対応します。verifyは公式SDKのターン定義には含まれず、Maker-Checker分離として上乗せで設計する関所です。
-
act(実行)
公式ステップの「Evaluate and respond」に対応。SDKではAssistantMessageとして記録される
-
observe(観測)
公式ステップの「Execute tools」に対応。ツール結果がUserMessageとしてモデルに戻る
-
decide(判断)
公式ステップの「Repeat」のうち、次のターンに進むか最終応答を返すかをモデルが判断する局面
-
verify(検証・上乗せ)
Maker-Checker分離による独立採点を組み込み、成果物が許容できるかを確認する。Maker側の自己評価は信用しない
ターン制御の3パラメータ

Claude Code Agent SDKでは、ターンの暴走を防ぐために3つのパラメータが用意されています。
- max_turns: ツール呼び出しを伴うターン数の上限。超えるとerror_max_turnsで停止
- max_budget_usd: ループ全体のドル換算コスト上限。超えるとerror_max_budget_usdで停止
- effort: 推論深度(low / medium / high / xhigh / max)。低くするほどトークン消費とレイテンシが下がる
これらはApplication Programming Interface側の機能で、停止条件をコードで明示できることが特徴です。手動運用では「気付いたら走り続けていた」事故が起きやすいのに対し、SDKで上限を設定すれば事故は構造的に防げます。
Hooksで途中介入する
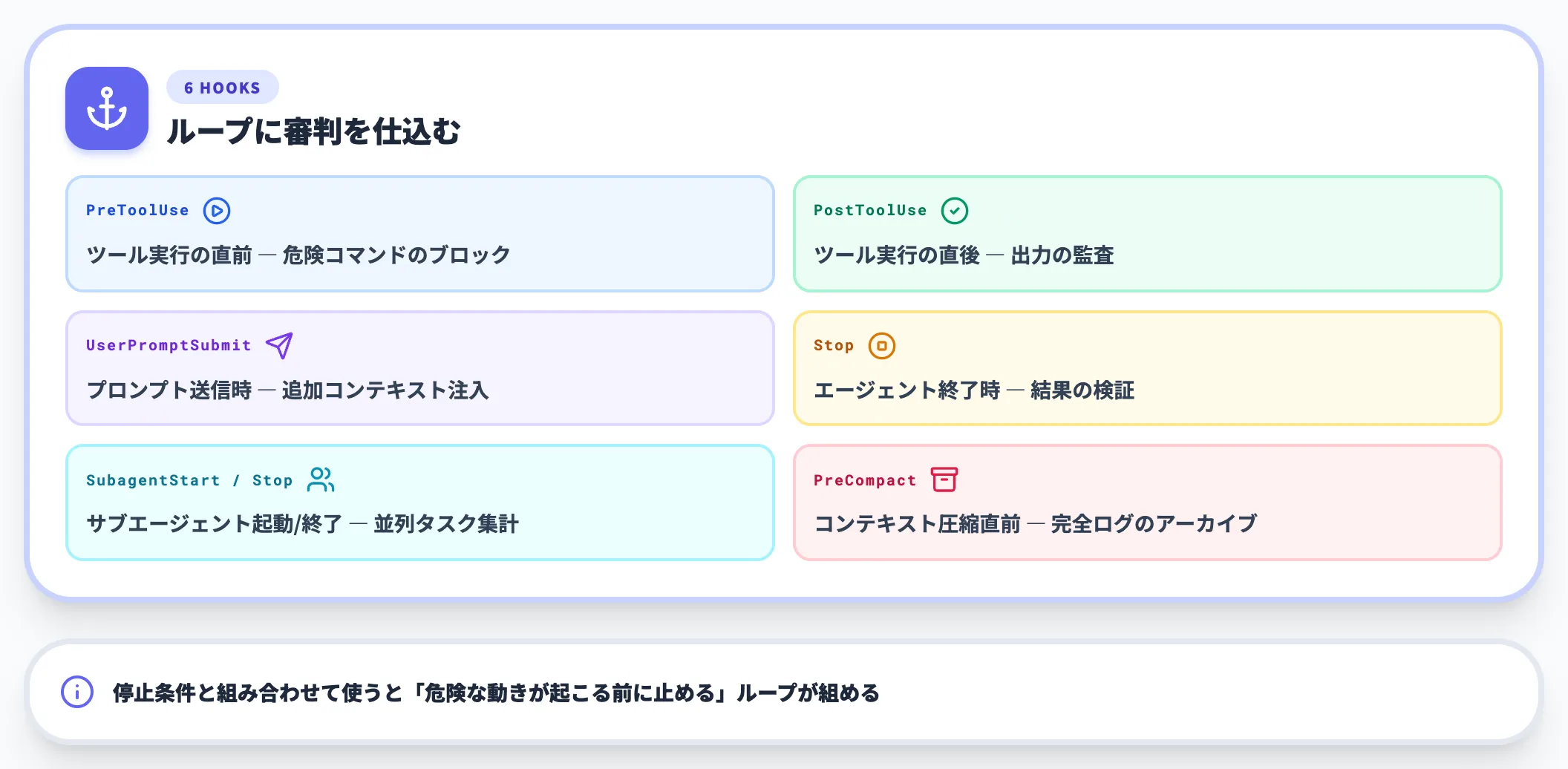
Claude Code Agent SDKは、ループの特定タイミングで処理を割り込ませる「Hooks」も提供しています。
| Hook名 | 起動タイミング | 典型用途 |
|---|---|---|
| PreToolUse | ツール実行の直前 | 危険コマンドのブロック・入力バリデーション |
| PostToolUse | ツール実行の直後 | 出力の監査・副作用のトリガー |
| UserPromptSubmit | プロンプト送信時 | 追加コンテキストの注入 |
| Stop | エージェント終了時 | 結果の検証・セッション保存 |
| SubagentStart / SubagentStop | サブエージェント起動/終了 | 並列タスクの集計 |
| PreCompact | コンテキスト圧縮の直前 | 完全ログのアーカイブ |
Hooksは「ループの中に審判を仕込む」装置と捉えると分かりやすく、停止条件と組み合わせて使うことで「危険な動きが起こる前に止める」ループが組めます。
「Maker-Checker分離」がループの品質を決める
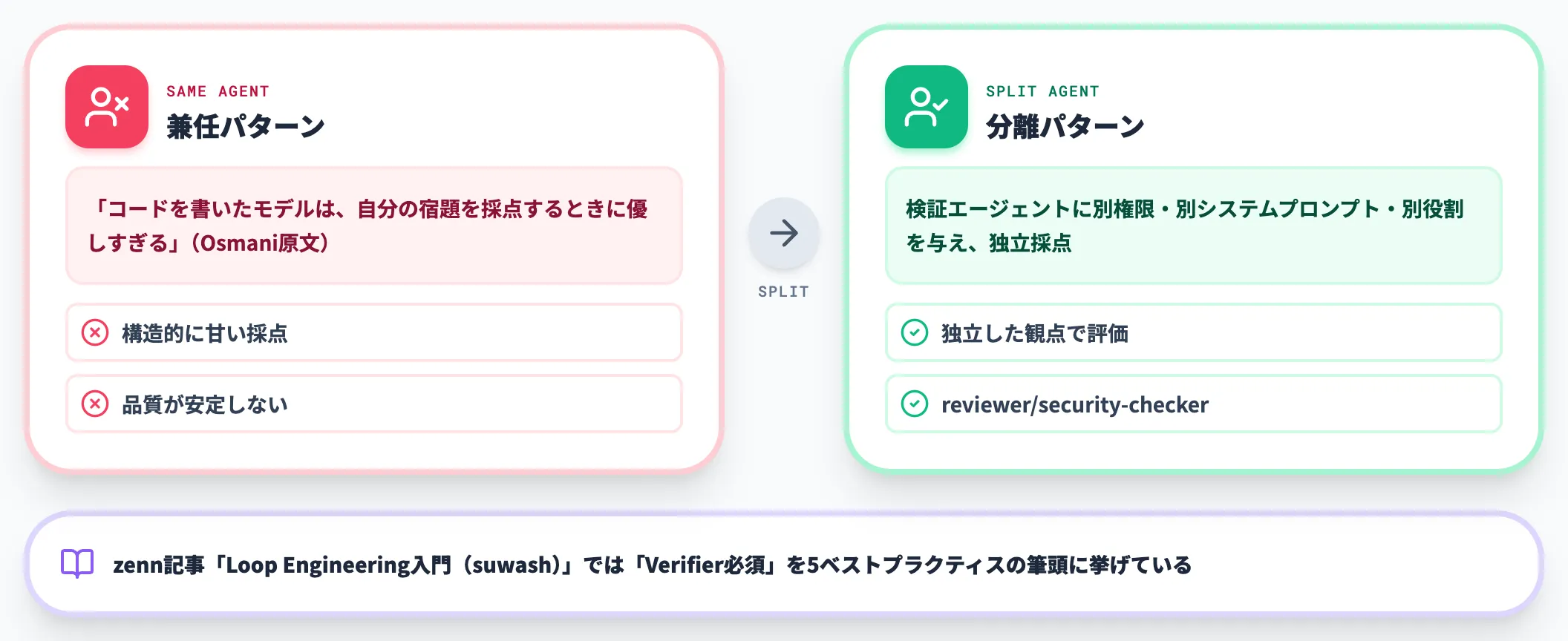
サイクル設計の中で、品質を最も左右するのが verify ステップです。
生成役と検証役を同じエージェントが兼ねた場合、構造的に甘い採点が出ます。Addy OsmaniがChernyの実装を引いて強調したのは、検証エージェントには別の権限・別のシステムプロンプト・別の役割を与え、独立した観点で生成役の成果を評価させるという原則です。
zenn記事のLoop Engineering入門(suwash)では、この分離を「Verifier必須」として5つのベストプラクティスの筆頭に挙げています。
実装としては、Claude CodeのSubagents機能で「reviewer」「security-checker」など専用subagentを定義し、生成役と並走させる構成が一般的です。
主要ツールの対応マトリクス|Claude Code / Codex / Cursor / Devin / OpenCode
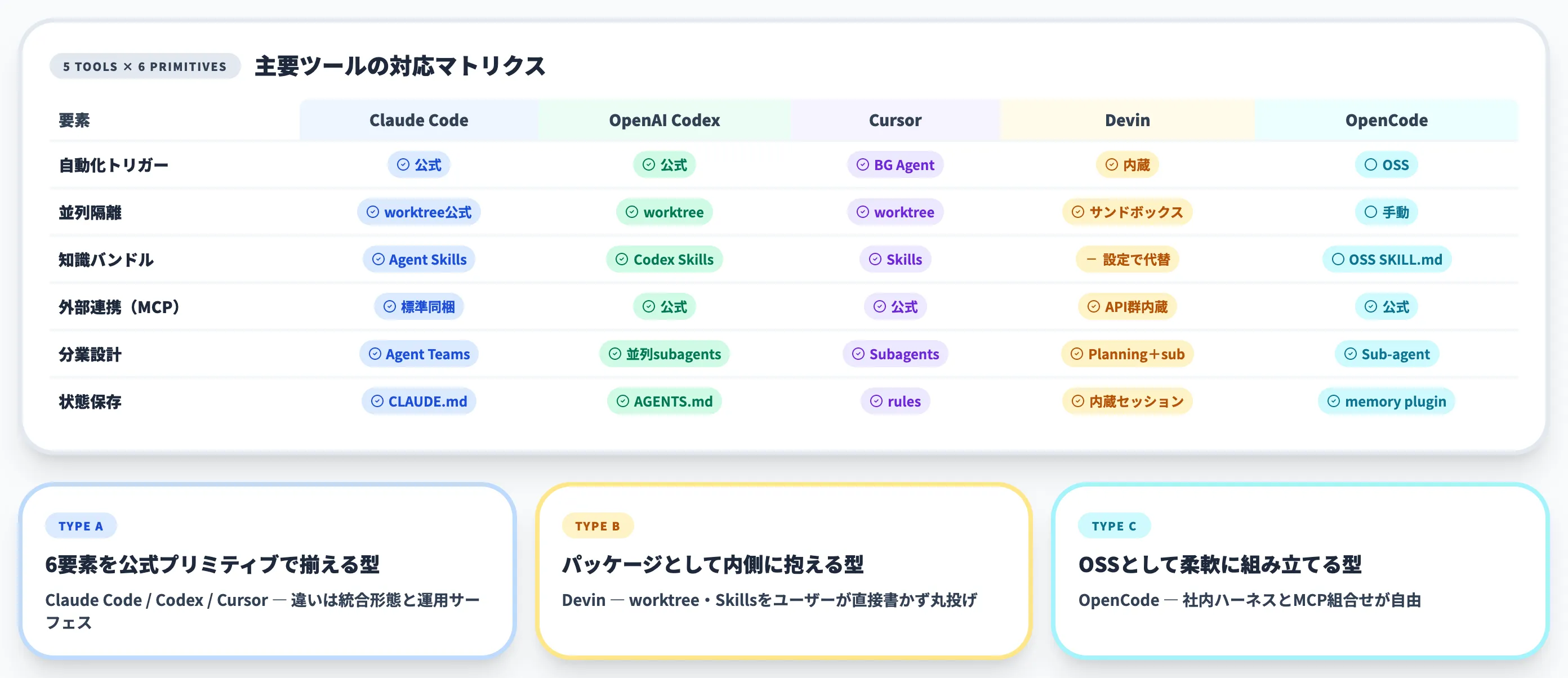
ループエンジニアリングを支える6要素を、どのツールがどれだけサポートしているかは、ツール選定の出発点になります。以下の表で、5ツールの対応状況を整理しました。
| 要素 | Claude Code | OpenAI Codex | Cursor | Devin | OpenCode |
|---|---|---|---|---|---|
| 自動化トリガー | GitHub Actions・Hooks公式 | Codex app Automations公式 | Background Agents(クラウド側) | 自律実行を内蔵 | フック / OSS拡張 |
| 並列隔離 | git worktree公式(Agent Teams連携) | git worktree(Codex app worktree・background worktree) | git worktree公式(Subagents並列) | サンドボックス環境内蔵 | git worktree手動 |
| 知識バンドル | Agent Skills(SKILL.md公式) | OpenAI Codex Skills(SKILL.md公式) | Skills(SKILL.md・rules) | プロジェクト設定で代替 | OSS SKILL.md |
| 外部連携(MCP) | MCP公式・標準同梱 | MCP公式 | MCP公式 | 主要API群を内蔵 | MCP公式 |
| 分業設計 | Agent Teams(experimental)・Subagents | 並列subagents | Subagents公式 | Interactive Planning+subagents | Sub-agent |
| 状態保存 | CLAUDE.md+auto memory | AGENTS.md+メモリ | rules+共有workspace | 内蔵セッション管理 | AGENTS.md/CLAUDE互換rules+memory plugin |
この表から見えてくるのは、Claude Code・Codex app・Cursorの3つはいずれも6要素に近い公式プリミティブを揃えており、違いは統合形態と運用サーフェスにあるという点です。
Devinは6要素を内側にパッケージとして抱え込む方向、OpenCodeはOSSとして柔軟に組み立てる方向、と棲み分けが見えてきます。
Claude Codeとループエンジニアリングは設計思想が一致している
Claude Codeは、ループエンジニアリングの言説を生んだAnthropic製の開発エージェントです。
Boris Cherny自身が「私の仕事はループを書くこと」と発信した通り、Agent Skills・Subagents・MCP・git worktree統合・Hooks・CLAUDE.md/auto memoryが利用でき、ループ設計のプリミティブが最も整っています。
Claude Code GitHub Actionを組み合わせれば、PR作成からテスト・レビューまでをループで回す運用が公式パターンとして実装できます。
OpenAI Codex appはworktree・Subagents・Automations・Skillsを揃える
OpenAI Codex・Codex CLIは、2025年12月にOpenAI Codex Skills(SKILL.md仕様)を公式サポートし、Claude Code Skillsと相互運用可能な形でループ部品を揃えました。
加えてCodex appはworktree・Subagents・Customization(AGENTS.md/Memories)・Automations(日次・週次・分単位・cron構文対応)を公式機能として持っており、Claude Codeと同等レベルでループの6要素を構築できる構成です。Claude CodeとCodexの比較については、別記事で詳しく整理しています。
Cursor 2.4以降はサブエージェント+worktreeを公式実装
Cursorは、2026年1月リリースのCursor 2.4でSubagents機能を公式に追加し、SKILL.md形式のSkillsも同時に公式採用しました。Subagentsは独立した文脈・ツール・モデル設定を持って並列実行でき、git worktree統合の安定性も継続的に強化されています。
2026年春以降のCursor 3.x系では、Automations・Customize画面でPlugins/Skills/MCPs/Subagents/Rules/Commands/Hooksの一元管理が進み、ループ構築の運用サーフェスが整ってきました。
MCP対応も済んでおり、IDEを起点にループ設計を統合したい組織にとっては、Claude Code・Codex appと並ぶ有力候補になります。
Devinは「自律実行+Interactive Planning」で自動化を提供
Devinは、Cognition Labsが提供する自律ソフトウェアエンジニア型のエージェントで、ユーザーとのInteractive Planning(Initial Assessmentと詳細プラン作成)を経てから実装に入る設計を採用しています。
ループの6要素はDevinの内側に閉じる形で提供され、ユーザーがworktreeやSKILL.mdを直接書かなくても自動的にコードベース調査・実装・テストが回ります。
「ループを自前で組みたくない」「サンドボックス環境付きでまるごと任せたい」場合に向いた選択肢です。
OpenCodeはOSSとして柔軟にループを組める
OpenCodeはオープンソースのコーディングエージェントで、Claude Code互換のSubagent・Skills・MCP対応を持ち、CLIから自由にカスタマイズできます。
エンタープライズ向けに自前のループ装備を組みたい、特定MCPサーバーと組み合わせて社内ハーネスを作りたい、といった用途に向きます。
ツール選定の出発点
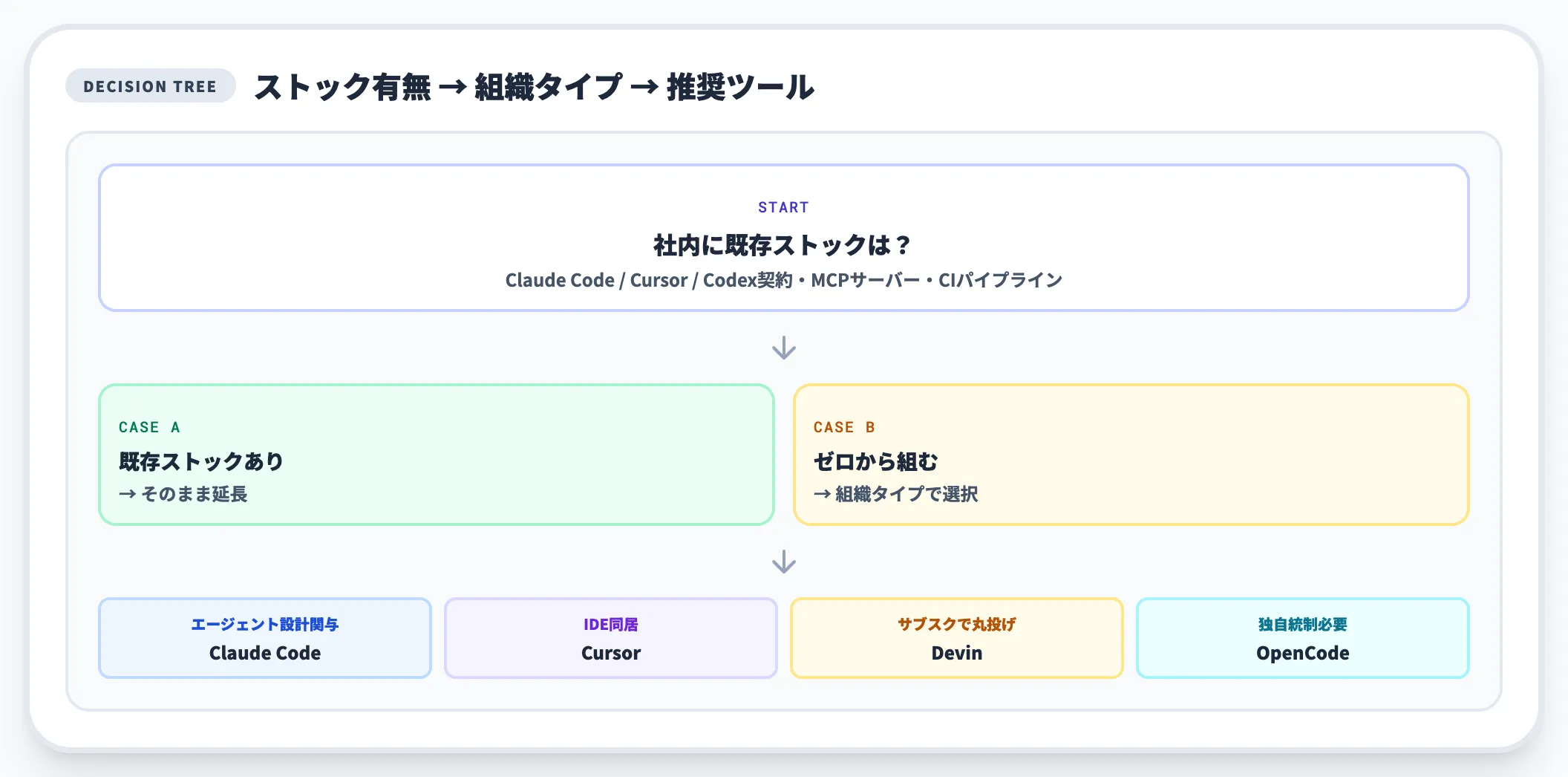
ツール選定の前提として、まず社内に既にあるストック(Claude Code・Cursor・Codex契約、MCPサーバー、CIパイプライン)を確認するのが現実的です。
ストックがほぼ無いゼロから組む場合、開発者がエージェント設計に関わる頻度が高いならClaude Code、IDEに同居させたい組織はCursor、サブスクリプションで丸投げしたいならDevin、独自統制が必要ならOpenCode、という分け方が実務的な目安になります。
コスト爆発と停止条件|「ループ税」の現実
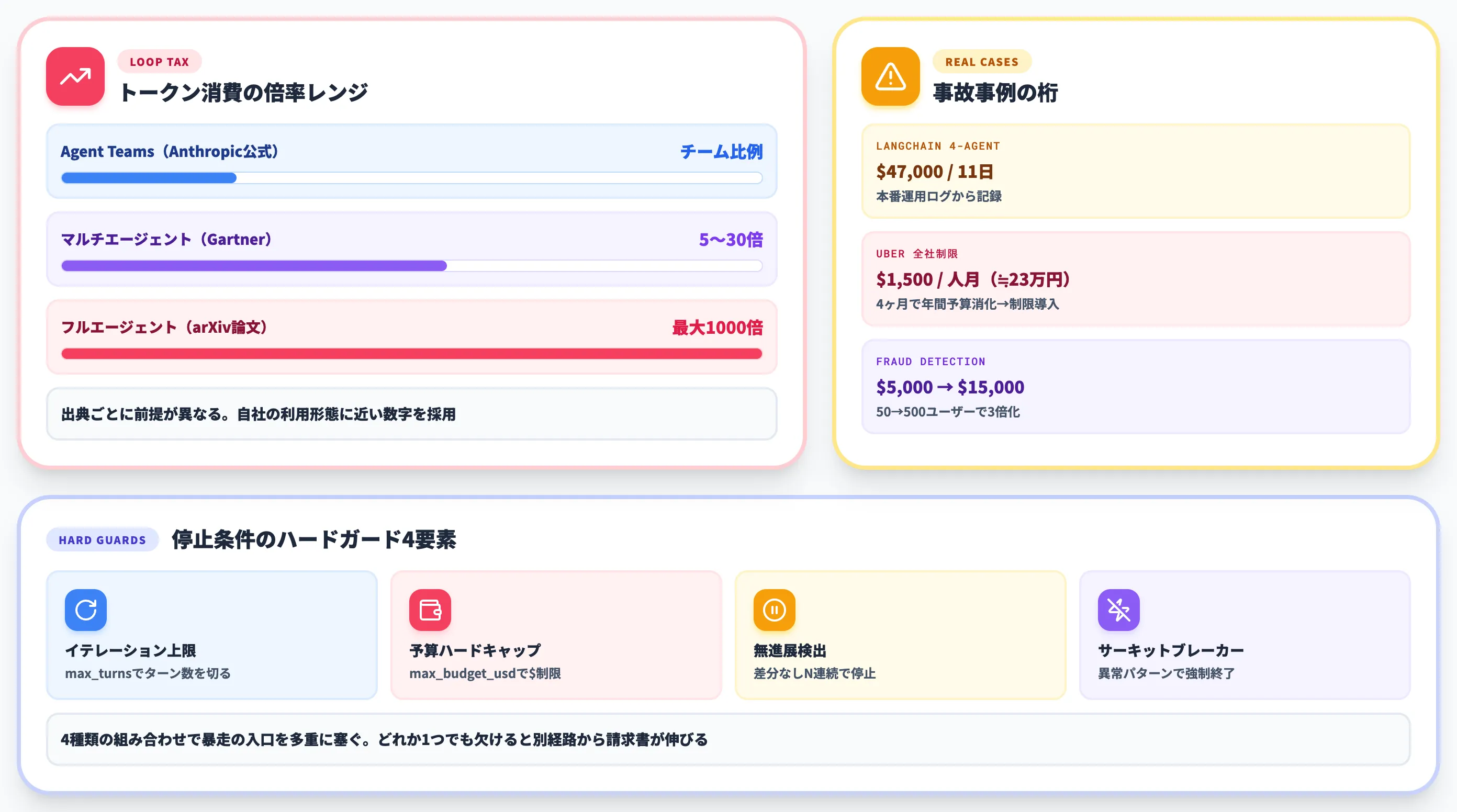
ループエンジニアリングの議論で必ず出てくる警告が、トークン消費の爆発です。Addy Osmaniの原文も「ループは生産性とミスの両方を増幅する」と明記しています。
ループ化したエージェントはトークン消費が大きく跳ねる
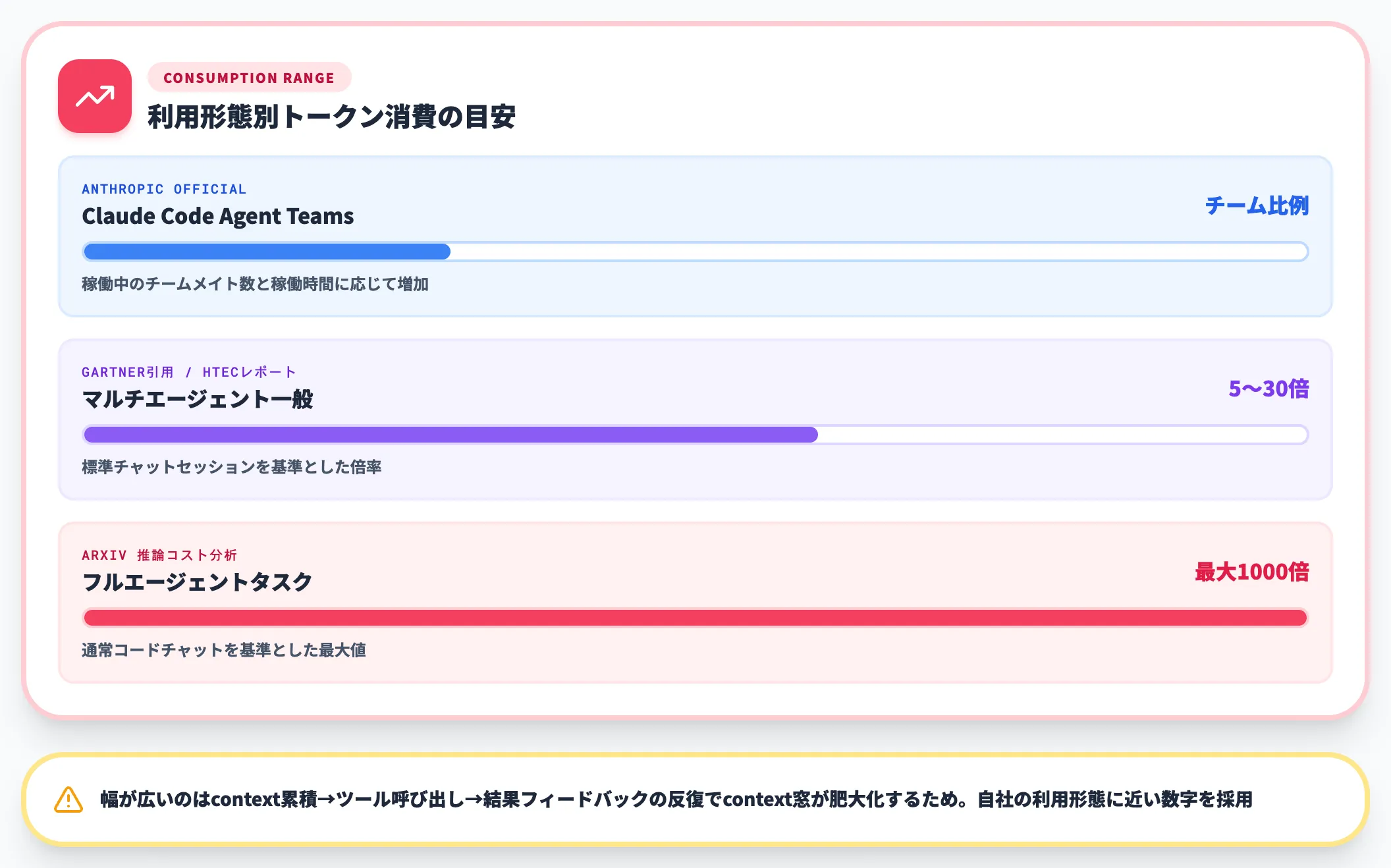
ループ化したエージェントは、通常のチャットセッションよりトークン消費が大幅に跳ね上がります。
Anthropic公式のコスト管理ドキュメントは、複数のClaude Codeインスタンスをチームで動かす「Agent Teams」について、稼働中のチームメイト数と稼働時間に応じてトークン消費が増え、チームサイズにおおむね比例すると説明しています。
業界調査の数値はもっと幅広く、Gartner系の引用では「マルチエージェントは5〜30倍」、推論コスト分析の論文では「フルエージェントタスクで通常コードチャットの最大1000倍」と整理されています。出典ごとに前提が異なるため、自社の利用形態に近い数字を採用するのが現実的です。
| 利用形態 | トークン消費の目安 | 出典 |
|---|---|---|
| Claude Code Agent Teams | チームサイズと稼働時間に比例 | Anthropic公式コスト管理docs |
| マルチエージェント(一般) | 標準チャットの5〜30倍 | Gartner引用のHTECレポート |
| フルエージェントタスク(最大) | 通常コードチャットの最大1000倍 | arXiv:推論コスト分析論文 |
幅が広い理由は、ループの反復ごとに「context累積→ツール呼び出し→結果フィードバック→次の判断」を繰り返すため、context窓が肥大化していくことが主因です。各ターンが進むほど、Claude Codeも自動圧縮(compact)を挟みながら走ることになり、平均トークン消費は冒頭時より膨らんでいきます。
「ループ税」と呼ばれる所以
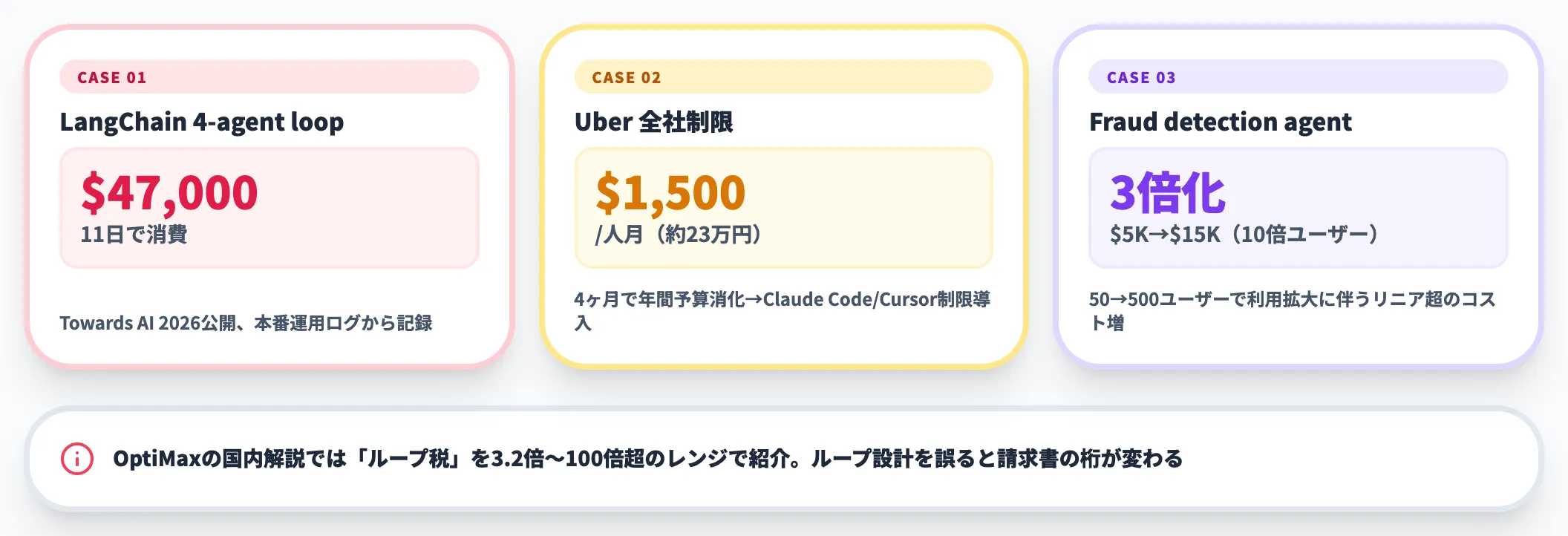
国内の解説記事でも、このコスト構造を「ループ税」と呼ぶ表現が広がっています。たとえばOptiMaxの解説記事は、ループ税を3.2倍〜100倍超のレンジで紹介し、コスト吸収力を判断軸の1つに置いています。
実際の事故例も少なくありません。
- LangChain 4-agent loopが11日で$47,000を消費した実体験レポート: Towards AIが2026年に公開した本番運用ログから、ループ設計の暴走パターンを記録した一次寄りの事例
- Uberは4ヶ月で年間AI予算を使い切り、Claude CodeとCursorを1人あたり月$1,500(約23万円)に制限: TechCrunchが2026年6月に詳報した大規模利用組織の象徴的な対策事例
- fraud detection agentが月$5,000→$15,000に3倍化(50ユーザー→500ユーザー): HTECレポート等で引用される、利用拡大に伴うリニア超のコスト増加の典型
これらは「ループ設計を誤ると、請求書の桁が変わる」という現実を示しています。
日本円ベースで考える「ループ税」

ループ運用のコスト感を、日本円ベースで月額に換算しておくと、PoCや本導入の議論がしやすくなります。
| 運用パターン | 月額目安 | 想定用途 |
|---|---|---|
| 個人開発者の自走ループ(1人) | 月3万〜10万円 | OSS保守・個人プロダクトのCIループ |
| 小規模チームの並列ループ(5人) | 月20万〜80万円 | スタートアップのMVP開発・PoC |
| 中堅企業の本番運用ループ | 月100万〜500万円 | エンタープライズ開発・複数プロジェクト並列 |
| 大企業の全社展開ループ | 月1,000万円〜 | UberやGoogleレベルの大規模展開 |
この目安はClaude Code 5xや20xプラン、Cursorのチームプラン、API直接利用などを組み合わせた場合の概算です。
ループ税は使い方次第で2倍以上ぶれるため、PoC段階で実測値を取り、ハードキャップを設定してから本番展開に進む流れが現実的です。
停止条件は実務でハードガード4要素から組む
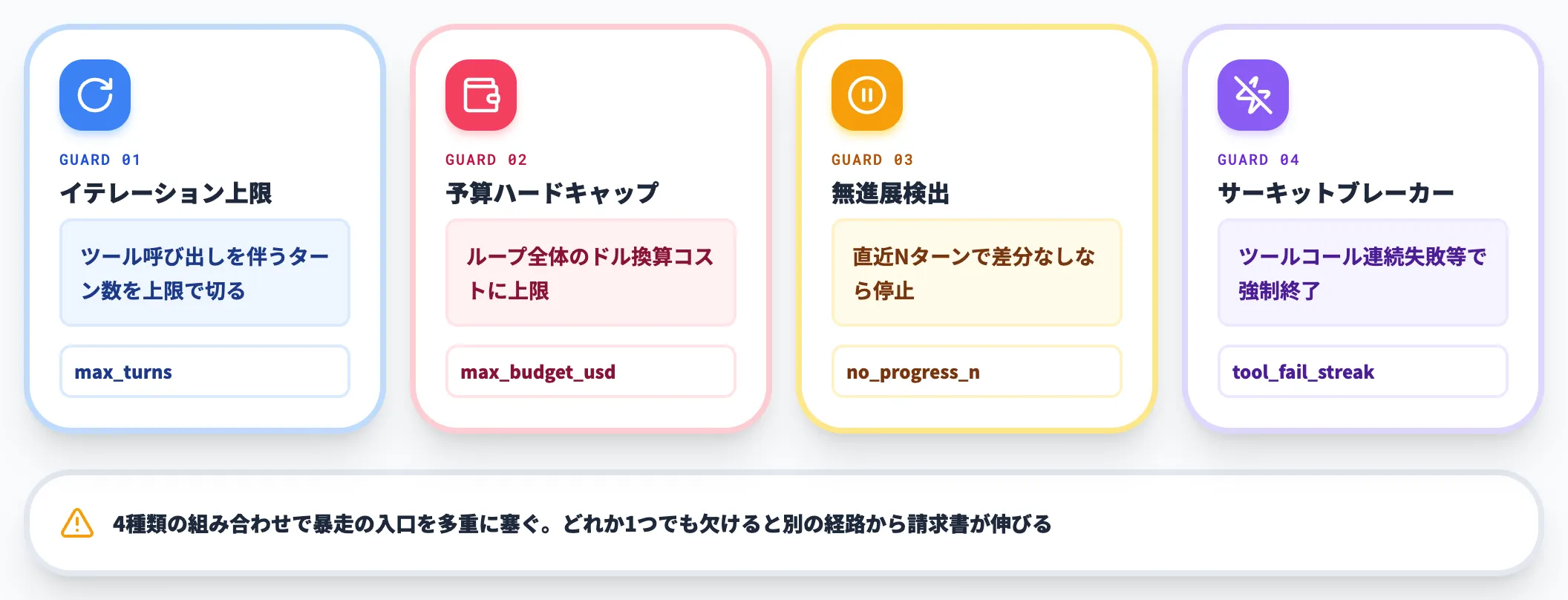
ループ税を制御するには、ループに「終わり方」を必ず複数仕込む必要があります。
AI Heartlandの解説はループ制御を「停止条件・再計画・予算ゲート・自己修正・エスカレーション」の5軸で整理していますが、本記事では、その中でも実務で先に押さえたいハードガード4要素に絞って紹介します。
-
イテレーション上限
ツール呼び出しを伴うターン数を上限で切る。Claude Code SDKのmax_turnsがこれに該当
-
予算ハードキャップ
ループ全体のドル換算コストに上限を設定。SDKではmax_budget_usdで実装
-
無進展検出
直近Nターンで差分が出ていないなら停止する。同じ失敗を無限に繰り返す挙動を止める
-
サーキットブレーカー
ツールコールが連続失敗するなど、特定の異常パターンで強制終了する
4種類を組み合わせることで、暴走の入口を多重に塞げます。逆に言えば、どれか1つでも欠けると、別の経路から請求書が伸びる可能性が残るということです。
Claude Codeの料金プランやClaude Codeの利用制限と対処法については、別記事で詳しく解説しているので、コスト管理の前提知識として参照してください。
ループ設計の落とし穴|暴走・理解負債・認知投降

ループエンジニアリングは強力な反面、設計と運用の落とし穴が多い領域です。コスト爆発以外にも、現場で繰り返し報告される失敗パターンを把握しておくと、初手で大事故を防げます。
Context Rot(コンテキスト腐敗)と無限ループ
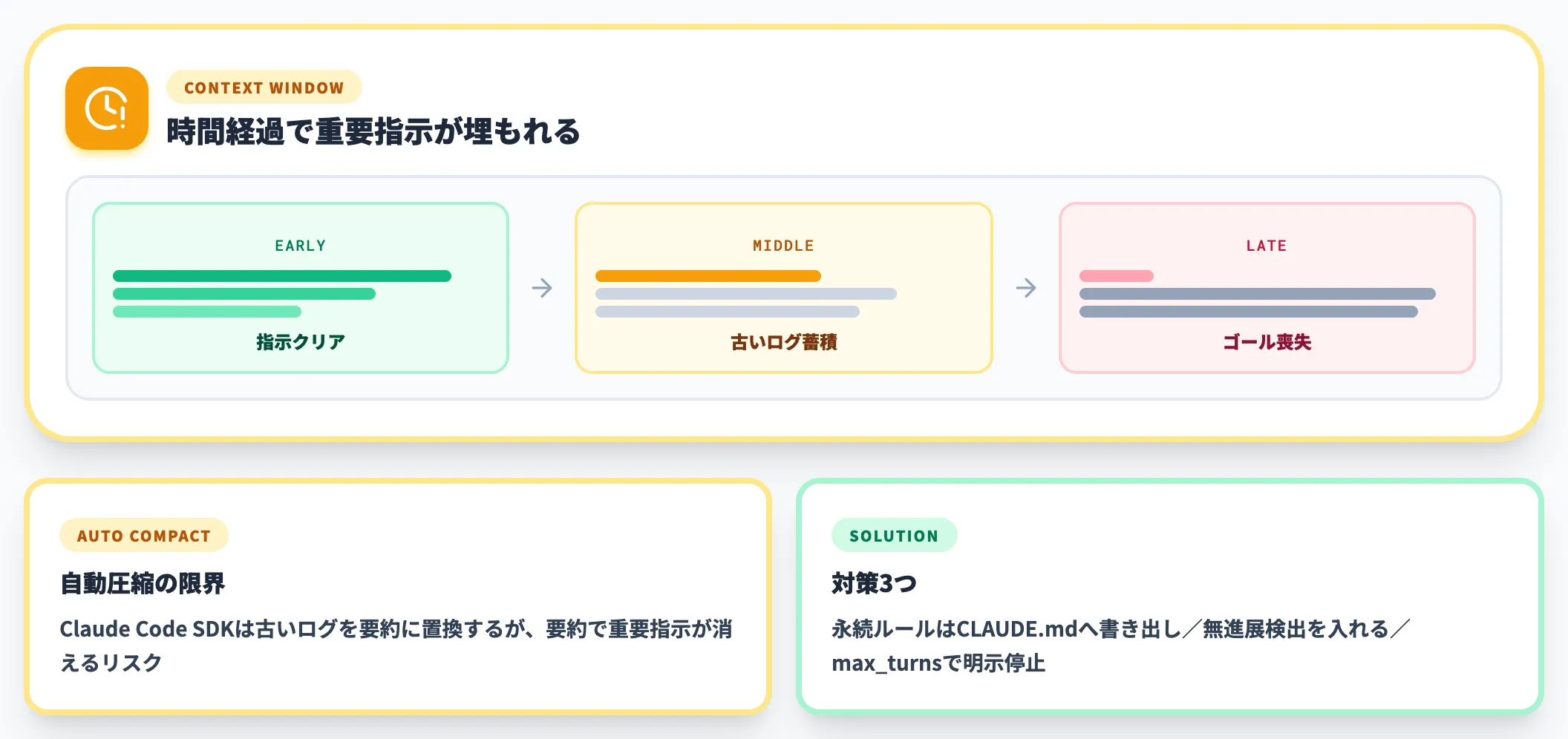
ループが長く続くほど、context窓に過去のツール結果や失敗ログが積み上がります。重要な指示が古い情報に埋もれて、エージェントが本来のゴールを見失う現象を「Context Rot」と呼びます。
Claude Code SDKは自動圧縮(compact)機能を備えており、context窓が上限に近づくと古いログを要約に置き換えます。ただし要約に押し込まれる過程で重要な指示が消えるリスクもあるため、永続化したいルールはCLAUDE.mdに書き出しておく必要があります。
無進展検出を入れないループでは、同じテストエラーを30回・40回繰り返し直しに行く「無限ループ」現象が起きます。Anthropic公式は、こうした暴走を構造的に防ぐためにmax_turns・max_budget_usdといった停止条件のパラメータを提供しており、運用側は必ず併用する前提で設計します。
Verifierすり抜け|検証が形骸化する
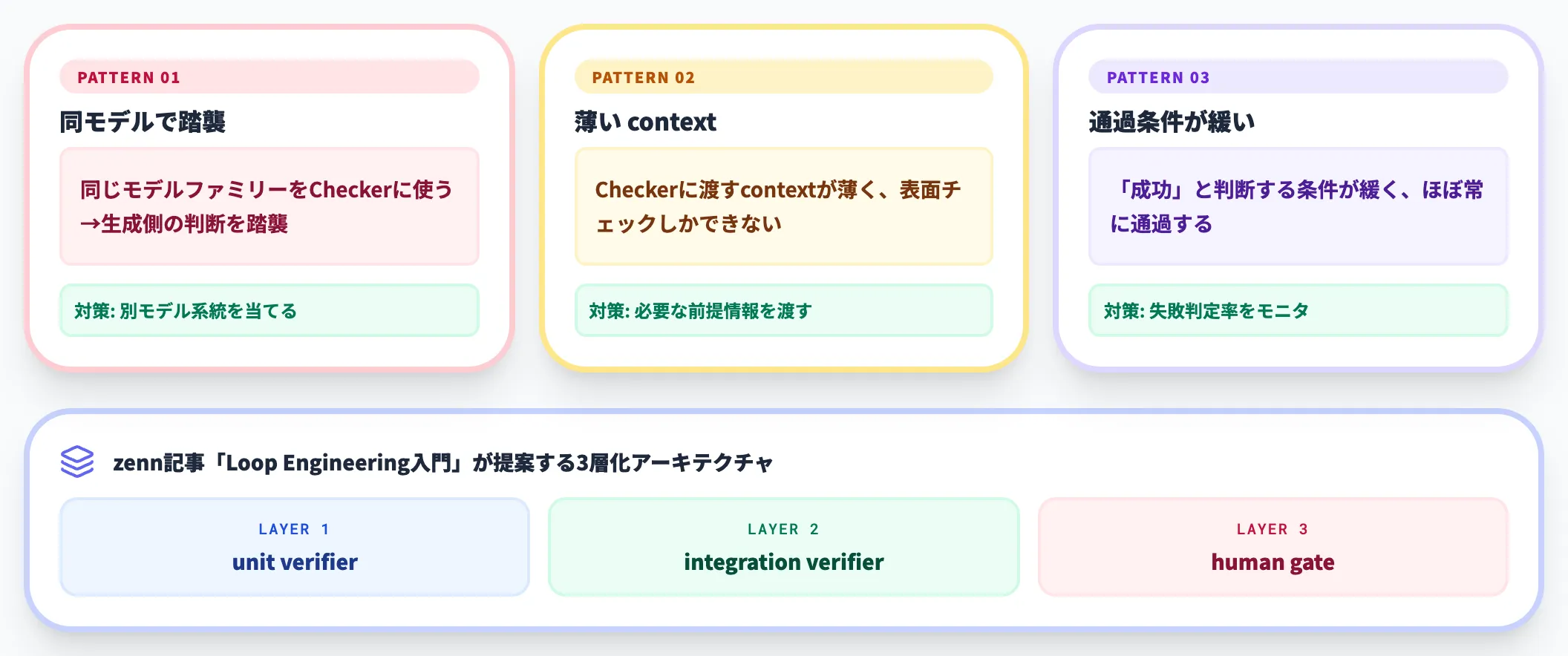
Maker-Checker分離を実装しても、Checkerが「異常なし」を出しがちな構造で組まれていると検証は機能しません。
ありがちなパターンは以下の3つです。
- 同じモデルファミリーをCheckerに使い、生成側の判断を踏襲してしまう
- Checkerに渡すcontextが薄く、表面チェックしかできない
- Checkerが「成功した」と判断する条件が緩く、ほぼ常に通過する
対策として、Checkerには別モデル系統を当てる、CheckerのプロンプトをMakerに見せない、Checkerの「失敗判定率」を継続的にモニタリングするといった工夫が必要になります。
zennのLoop Engineering入門は、検証役を3層に分けるアーキテクチャ(unit verifier・integration verifier・human gate)を提案しており、参考になります。
Multi-loopの競合|エージェント同士が踏み合う

複数のループを並列で走らせると、エージェント同士が同じファイル・同じブランチ・同じMCPサーバーに同時にアクセスして競合します。
回避するためには、以下の5原則を構成時点で決める必要があります。
- ブランチ排他所有: 各エージェントが触れるブランチを明確に分離
- 状態ファイル分離: 状態保存先(STATE.md等)をループごとに別パス
- 役割分離: Maker / Checker / Reviewerの責務を重複なく定義
- 統一denylist: 触ってはならないファイル・コマンドのリストを全エージェントで共有
- 予算合算管理: 各ループ単独ではなく、全体の月予算を合算で監視
これらの原則は、IDEで複数エージェントを動かす設計だけでなく、本番のCIループでも有効です。
マルチAIエージェントの設計知見はそのままループ運用に転用できます。
理解負債(Comprehension Debt)の蓄積
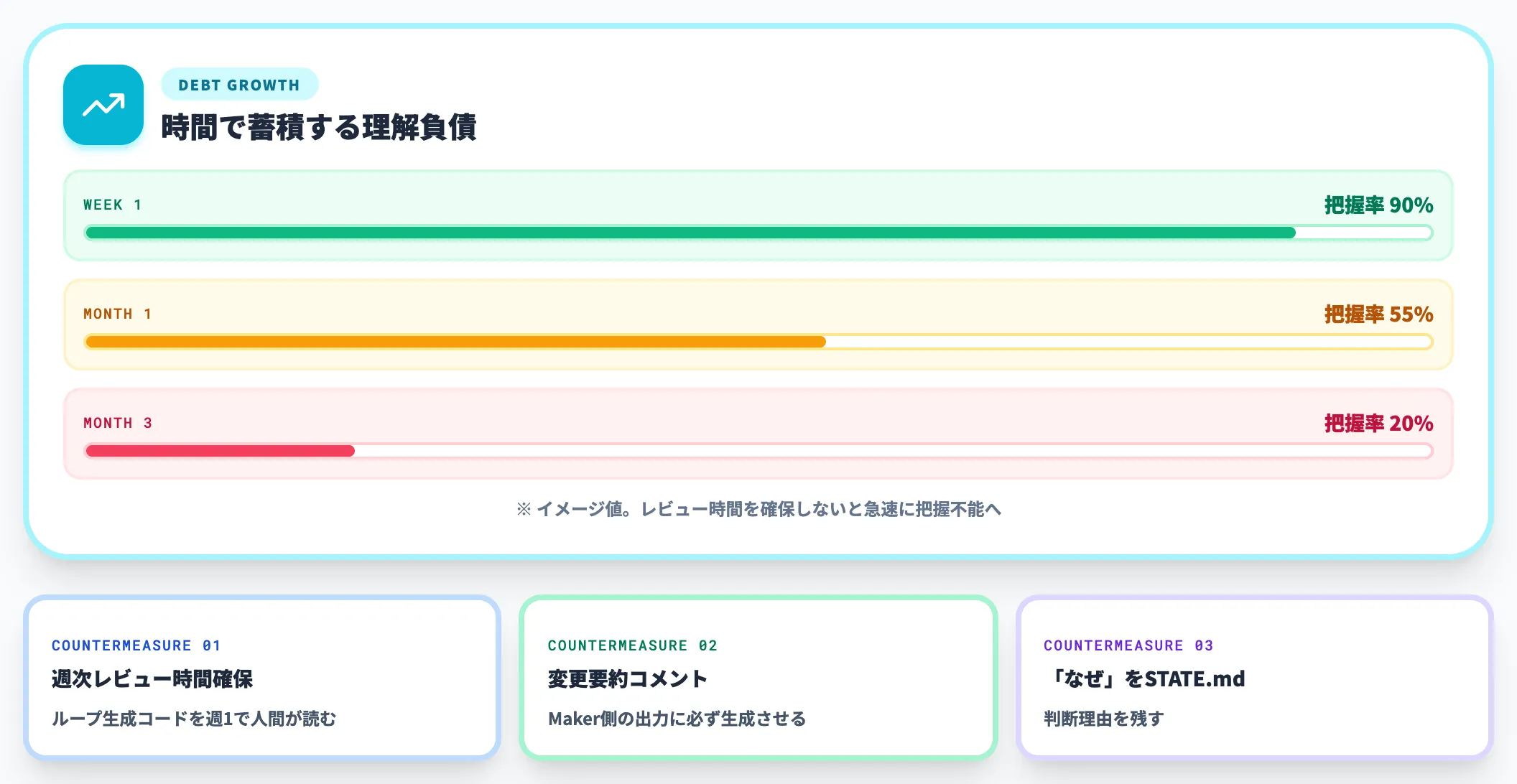
ループが「動いている」状態を放置していると、生成されたコードを誰も読まない期間が長くなり、組織として「何が動いているか分からない」状態に近づいていきます。
この現象は**Comprehension Debt(理解負債)**と呼ばれ、Addy Osmaniの原文でも「ループの最大のリスクの1つ」として警告されています。技術的負債とは別軸で蓄積し、最終的にはエージェントを止めても誰も復旧できない事態を招きます。
対策は地道です。週次でループ生成コードのレビュー時間を確保する、Maker側の出力に「変更要約」コメントを必ず生成させる、STATE.mdに「なぜそうしたか」を残す、といった運用設計が要ります。
認知投降(Cognitive Surrender)への警戒

Osmaniが原文で最も強く警告したのが、開発者がループの出力を盲信して自分の判断を放棄する**Cognitive Surrender(認知投降)**です。
ループが期待通り回り始めると、PRのマージ・本番デプロイ・障害対応まで「ループに任せれば大丈夫」という気持ちになりがちです。しかしAIモデルは決定論的ではなく、確率的に間違えます。最終確認は必ず人間が担う、PRの差分は目で見る、本番反映はゲートを通す、という原則は崩してはいけません。
「ループを設計する側」が思考を止めた瞬間に、ループは品質ではなくスピードと量だけを増幅する装置になります。AI総研の支援現場でも、ループ展開を進めた組織ほど「最終レビュアーの育成」「変更要約の質向上」「テスト品質のKPI化」を並行で進めるケースが増えています。

ループエンジニアリングを「いつ始めるか」|適性判定とケース別推奨
ループは強力ですが、すべての業務に向くわけではありません。
導入の前に「自社のどの業務がループ向きか」「いつ手を出すべきか」を判定し、段階的に展開するのが現実的です。
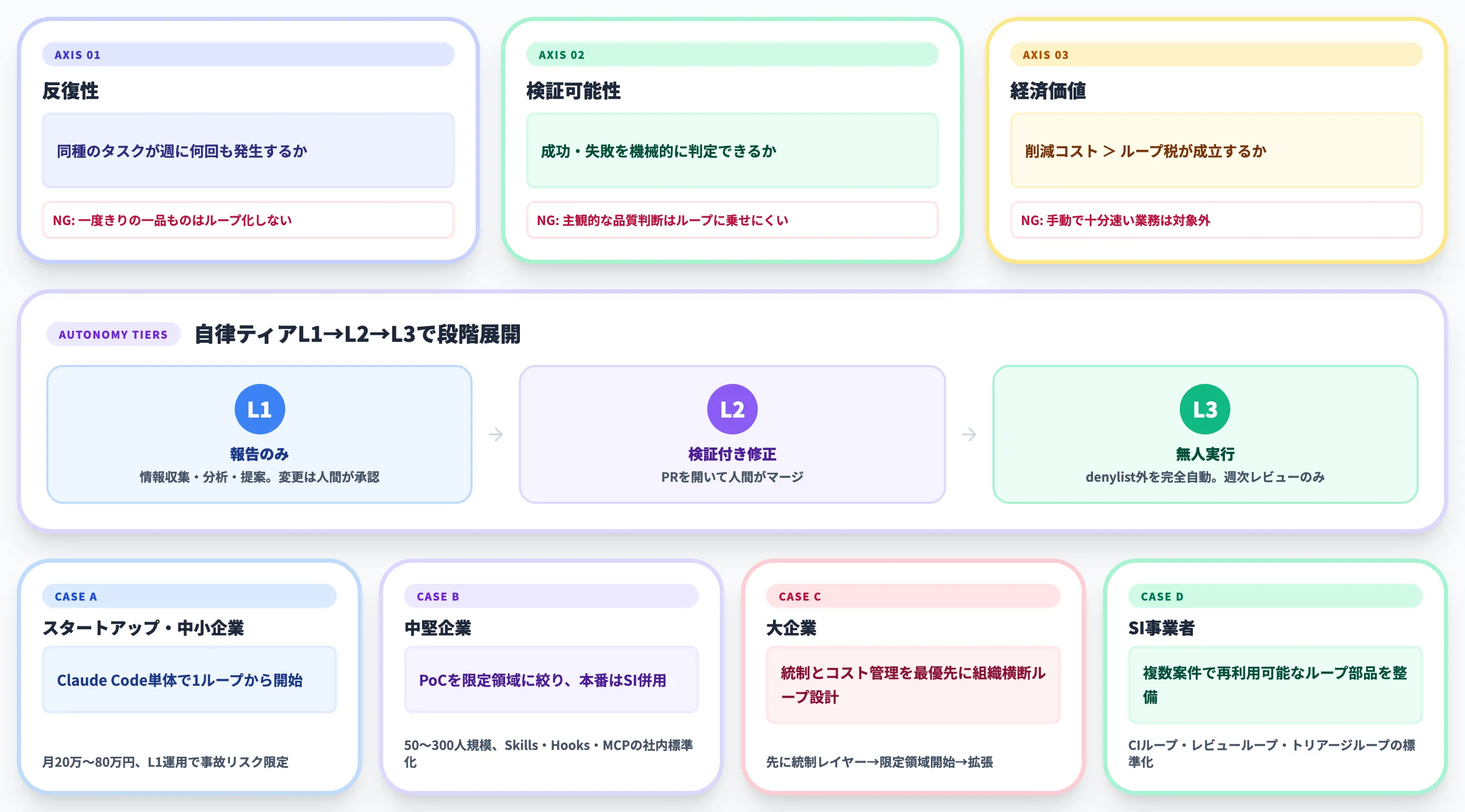
適性判定の3軸|反復性・検証可能性・経済価値

ループ向きのタスクを見極める3軸を、以下の表で整理しました。
| 軸 | チェック内容 | NGなら避けるべき |
|---|---|---|
| 反復性 | 同種のタスクが週に何回も発生するか | 一度きりの一品ものはループ化しない |
| 検証可能性 | 成功・失敗を機械的に判定できるか | 主観的な品質判断はループに乗せにくい |
| 経済価値 | ループで自動化したときの削減コスト > ループ税 | 手動で十分速い業務は対象外 |
3軸すべてを満たすタスクが、ループ化の第一候補です。たとえば「PR作成時の依存関係チェック」「夜間ビルドの失敗テスト自動修復」「Issueトリアージ」などが典型例で、検証可能性が高くトークン消費を回収しやすい領域です。
逆に、1回限りの企画作業、デザインの好みが関わる判断、人的責任が重い意思決定は、ループ化に向きません。
自律ティアL1→L2→L3で段階的に上げる
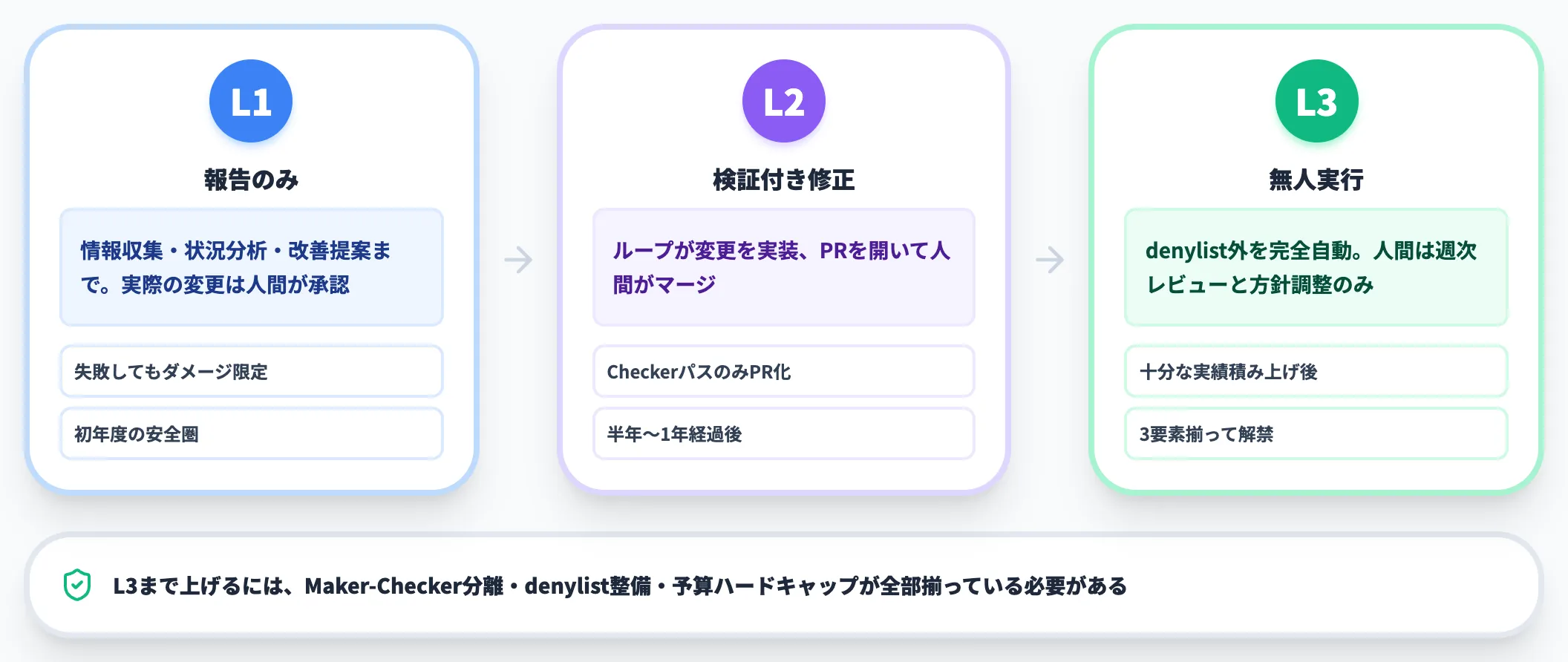
ループ運用は、いきなりフル自動化を狙わずに、自律のレベルを3段階で段階的に上げるのが安全です。
-
L1 報告のみ
ループは情報収集・状況分析・改善提案までを実施。実際の変更は人間が承認・実行。失敗してもダメージは限定的
-
L2 検証付き修正
ループは変更を実装するが、PRを開いて人間がマージする。CheckerをパスしたものだけがPR化される
-
L3 無人実行
denylist外のタスクをループが完全自動で実行。人間は週次レビューと方針調整のみに専念
初年度はL1、半年〜1年経って運用が安定したらL2、十分な実績が積み上がってからL3、という展開が現実的です。L3まで上げるには、Maker-Checker分離・denylist整備・予算ハードキャップが全部揃っている必要があります。
ケース別推奨|AI総研の支援現場から見る適性
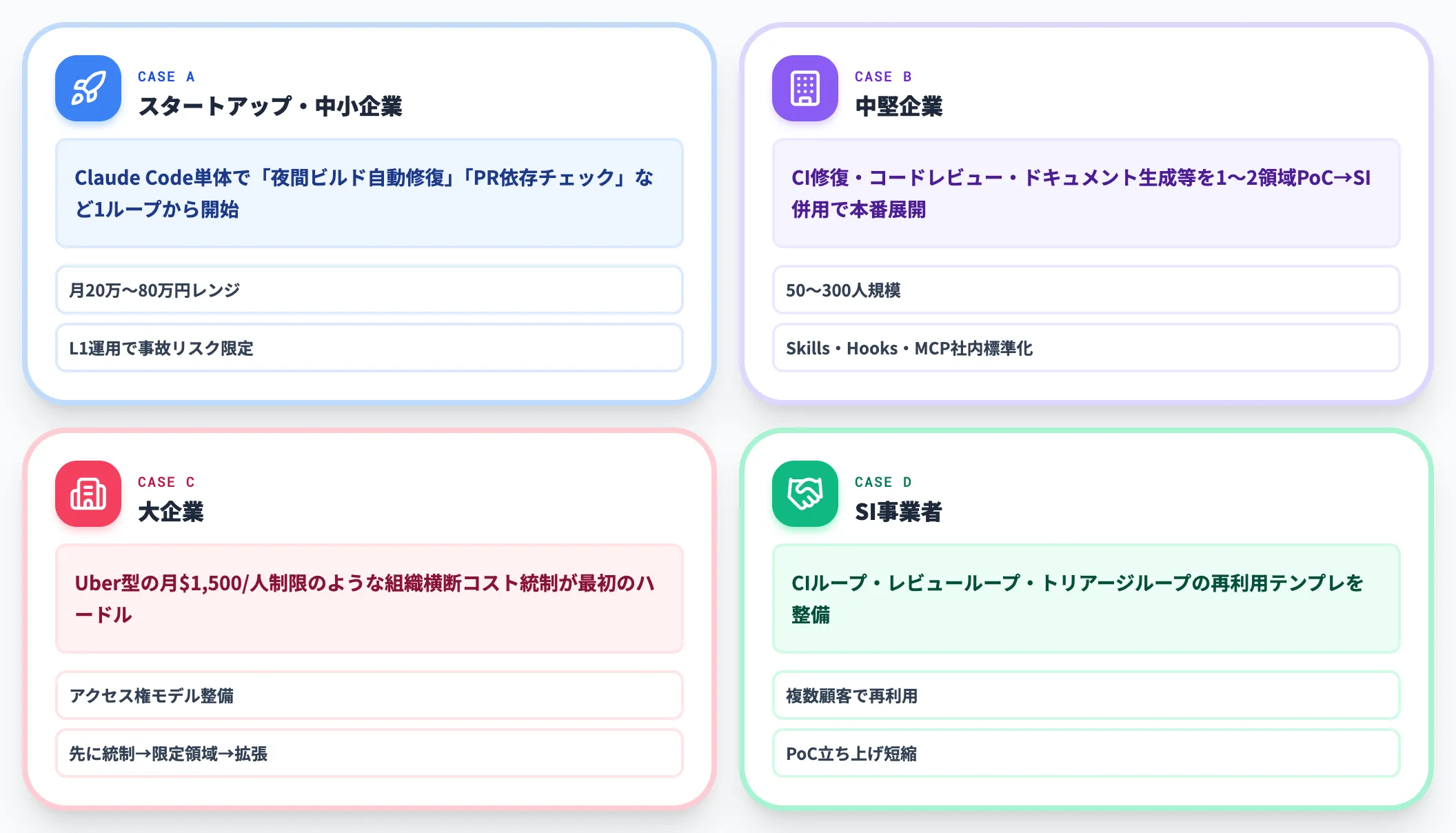
AI総研のAI Agent Hub支援現場で見ている、組織タイプごとの導入適性を整理します。
スタートアップ・中小企業|まずClaude Codeで1ループ
開発者が少なく、エージェント設計に手を入れられるエンジニアがいる組織は、Claude Code単体で「夜間ビルドの自動修復」「PRの依存関係チェック」など、検証可能性が高い1ループから始めるのが妥当です。
月額20万〜80万円のレンジで効果が見える領域があり、L1運用に止めれば事故リスクも限定的です。Cursor 2.4以降を既に契約しているならCursor内蔵subagentsを使っても同等のことができます。
中堅企業|PoCを限定領域に絞り、本番はSI併用
50〜300人規模の開発組織は、ループの効果が出る業務(CI修復・コードレビュー・ドキュメント生成等)を1〜2領域に絞ってPoCを回し、本番展開はSI事業者と共同で運用設計するのが現実的です。
PoC段階でループ税の実測値を取り、本番展開時に必要な月予算と停止条件を確定させてから移行します。最終的にはAgent Skills・Hooks・MCP連携の社内標準化が中堅企業向けには大きな効果を発揮します。
大企業|統制とコスト管理を最優先に組織横断ループを設計
数千人規模のエンジニア組織では、Uberの月$1,500/人制限のように、組織横断のコスト統制とアクセス権設計が最初のハードルになります。
ループ運用を解禁する前に、誰がどのMCPサーバーを使ってよいかのアクセス権モデル、予算ハードキャップの自動enforcement、ログ収集と監査のパイプラインを先に整える必要があります。AI総研の支援現場でも、大企業のループ展開は「先に統制レイヤーを敷く→限定領域で開始→拡張」という順序を取るケースが大半です。
SI事業者|複数案件で再利用可能なループ部品を整備
SI事業者は、自社の社内利用に加えて、顧客案件で再利用できるループテンプレート(CIループ、レビューループ、Issueトリアージループ等)を整備するのが投資回収の早い道です。
複数顧客で再利用できる形でAgent Skills・MCP連携・Maker-Checker分離を標準化しておくと、PoC案件の立ち上げが圧倒的に短縮されます。
「いつ始めるべきか」の判断軸

ループエンジニアリングは2026年6月時点でまだ概念形成の途上にあり、ベストプラクティスは流動的です。
それでも、以下の条件のいずれかに当てはまる組織は「いま始める」ことを推奨します。
- 月間のAIエージェント利用料が30万円を超え、ループ税の制御が必要になってきた
- Claude Code・Codex・Cursorのいずれかを既に開発に組み込んでおり、複数エージェントの並列運用が始まっている
- CI・PR・Issueトリアージのうち2つ以上が「人手のボトルネック」になっている
逆に、「エージェント利用が個人プロンプト中心で月5万円未満」「単発タスクが大半でCI・PRループに乗らない」段階の組織は、まずプロンプトエンジニアリング・コンテキストエンジニアリングを固めてから、ループに進む方が遠回りに見えて結果的に早い経路です。
ノーコードAIエージェントから入る選択肢もありますが、ループ運用そのものはコード側で組む方が拡張性が高い、というのがAI総研の現場感覚です。
ループ設計を組織横断の運用基盤に育てるなら
ループエンジニアリングは、個人の生産性ハックから組織のエージェント運用基盤までを射程に持つ概念です。PoCで小さなループを動かすところまでは多くの組織が到達できますが、Maker-Checker分離・MCP接続のアクセス権モデル・予算ハードキャップの自動enforcementを含めた本番運用設計までを内製で組みきるのは、人材と経験が要る難所です。
ここで効いてくるのが、Microsoft Teamsから呼び出せるエンタープライズAI Agent内製化プラットフォーム AI Agent Hub です。9種類の業務特化Agentを自社のAzureテナント内に展開し、実行ログ・アクセス権限・セキュリティスキャンを管理ダッシュボードで一元管理しながら、ループを段階的に拡張できます。Human-in-the-Loop承認も標準で組み込めるため、ループ税の暴走と認知投降を構造的に防げます。
AI総合研究所の専任チームが、ループ設計の初手選びから本番運用への移行までを伴走します。AI Agent HubのLPで、自社の業務にどう組み込めるかの具体例とあわせてご確認ください。
ループ設計を本番運用まで届ける

個人の生産性ハックを組織の運用基盤に
ループ設計を自社で動かし始めても、Maker-Checker分離・MCP接続のアクセス権・予算ハードキャップを含めた本番運用設計までを内製で組みきるのは難所です。AI Agent Hubは、Microsoft Teams・自社Azureテナント・管理ダッシュボードを土台に、ループを組織横断の運用基盤として展開できる構成を提供しています。
まとめ
本記事では、2026年6月にAddy Osmaniが提唱したループエンジニアリングについて、定義・パラダイム位置づけ・6つの構成要素・主要ツール対応・コスト構造・落とし穴・SIerとして見るケース別推奨を、2026年6月時点の最新情報で整理しました。要点を改めて整理します。
-
ループエンジニアリングはプロンプト・コンテキスト・ハーネスに続く第4世代パラダイムで、「エージェントに指示するのをやめ、指示するループを設計する」役割転換を意味する
-
ループは6要素(自動化トリガー・並列隔離・知識バンドル・外部連携・分業設計・状態保存)で構成され、Claude Code・OpenAI Codex app・Cursor 2.4以降の3つがいずれも6要素に近い公式プリミティブを揃えている
-
動くループはClaude Code Agent SDK公式の5ステップ(Receive prompt / Evaluate and respond / Execute tools / Repeat / Return result)で動き、実装設計上は act/observe/decide にMaker-Checkerによる verify を上乗せする
-
ループ化したエージェントは標準セッションの数倍〜数十倍のトークンを消費し、停止条件4種(イテレーション上限・予算キャップ・無進展検出・サーキットブレーカー)の組み合わせで暴走を防ぐ必要がある
-
自社のループ導入は、反復性・検証可能性・経済価値の3軸で適性判定し、L1報告→L2検証付き修正→L3無人実行の順で段階展開するのが現実的
ループエンジニアリングは概念形成の途上にあり、ベストプラクティスは2026年下半期も流動的に変わっていきます。それでも、ループ税の制御・Maker-Checker分離・段階的自律ティアという3つの軸は、当面の運用設計の土台として安定して使えます。
「プロンプトを打つ人」から「ループを設計する人」へ役割を置き換える流れは、もう後戻りしません。自社の開発・運用の中で、検証可能性が高くトークン消費を回収できる1ループを限定領域で動かしてみるところから、無理なく始めてください。










