この記事のポイント
 AIエージェントの精度を上げたいなら、プロンプトの改善より先にコンテキスト設計全体を見直すべき
AIエージェントの精度を上げたいなら、プロンプトの改善より先にコンテキスト設計全体を見直すべき- 「検索と生成」「処理」「管理」の3層パイプラインで情報を設計すれば、LLMの出力品質を体系的に向上させられる
- RAGとメモリシステムの組み合わせが、AIエージェント開発におけるコンテキストエンジニアリングの最重要実装パターン
- KVキャッシュの最適化と失敗記録の活用は、本番環境でのコスト削減と精度改善に直結する実践テクニック
- MCP・Agent SDKの普及により、コンテキストエンジニアリングは理論段階から実装可能なフェーズに入っている

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI開発の世界は、単に優れたモデルを作る競争から、そのモデルをいかに賢く使うかという新たなステージへと移行しています。
この変化の中心にあるのが、本記事で解説する「コンテキストエンジニアリング」です。Anthropicはこの技術を「プロンプトエンジニアリングの自然な発展形」と位置づけ、AIエージェント開発に不可欠なスキルとして提唱しています。
本記事では、1400本以上の学術論文を分析した最新の調査報告を基に、コンテキストエンジニアリングの全体像を紐解いていきます。
その理論的な背景から、AIの性能を飛躍させる具体的な技術、さらにはAIエージェント開発の最前線で培われた実践的なテクニックまで、網羅的に解説します。
この記事を読めば、AIの真の能力を引き出すための「情報設計」の重要性を理解し、ご自身のビジネスや開発プロジェクトに応用するための具体的なヒントを得られるでしょう。
目次
AI開発のパラダイムシフト:静的な「指示」から動的な「情報設計」へ
プロンプトエンジニアリングとコンテキストエンジニアリングの違い
① 文脈の検索と生成(Context Retrieval and Generation)
応用例③:世界と対話するAI(Tool-Integrated Reasoning)
応用例④:チームで課題解決するAI(Multi-Agent Systems)
コンテキストエンジニアリングの実践:AIエージェント「Manus」から学ぶ6つのテクニック
1. KVキャッシュを中心に設計し、コストと速度を最適化する
4. 「失敗の記録」をあえてコンテキストに残し、自己学習を促す
コンテキストエンジニアリングとは?
コンテキストエンジニアリングとは、AIがその能力を最大限に発揮できるよう、AIに与える情報(コンテキスト)全体を体系的に設計・最適化する次世代の技術です。
これは、従来の「プロンプトエンジニアリング」がAIへの「問いかけ方」を工夫する技術だったのに対し、より一歩進んだ包括的なアプローチと言えます。Anthropicの公式エンジニアリングブログでは、コンテキストエンジニアリングを「プロンプトエンジニアリングの自然な発展形であり、LLM推論時に最適なトークンセットをキュレーション・維持する一連の戦略」と定義しています。
LLMが単純な指示実行システムから、複雑なアプリケーションの頭脳として機能する現代において、なぜこの新しいアプローチが必要とされているのか、その背景から見ていきましょう。

AI開発のパラダイムシフト:静的な「指示」から動的な「情報設計」へ
かつてのAIとの対話では、単一の静的なテキスト、つまり「プロンプト」をいかに工夫するかが重要でした。しかし、現代のAIシステム、とりわけAIエージェントは、ユーザーの指示だけでなく、過去の対話履歴、外部データベースから検索した情報、利用可能なツール(API)の定義など、動的で構造化された複数の情報を同時に扱います。
コンテキストエンジニアリングは、これらの多様な情報要素(コンポーネント)を、タスクに応じて最適に組み合わせ、AIに「情報ペイロード」として供給する一連の技術体系です。
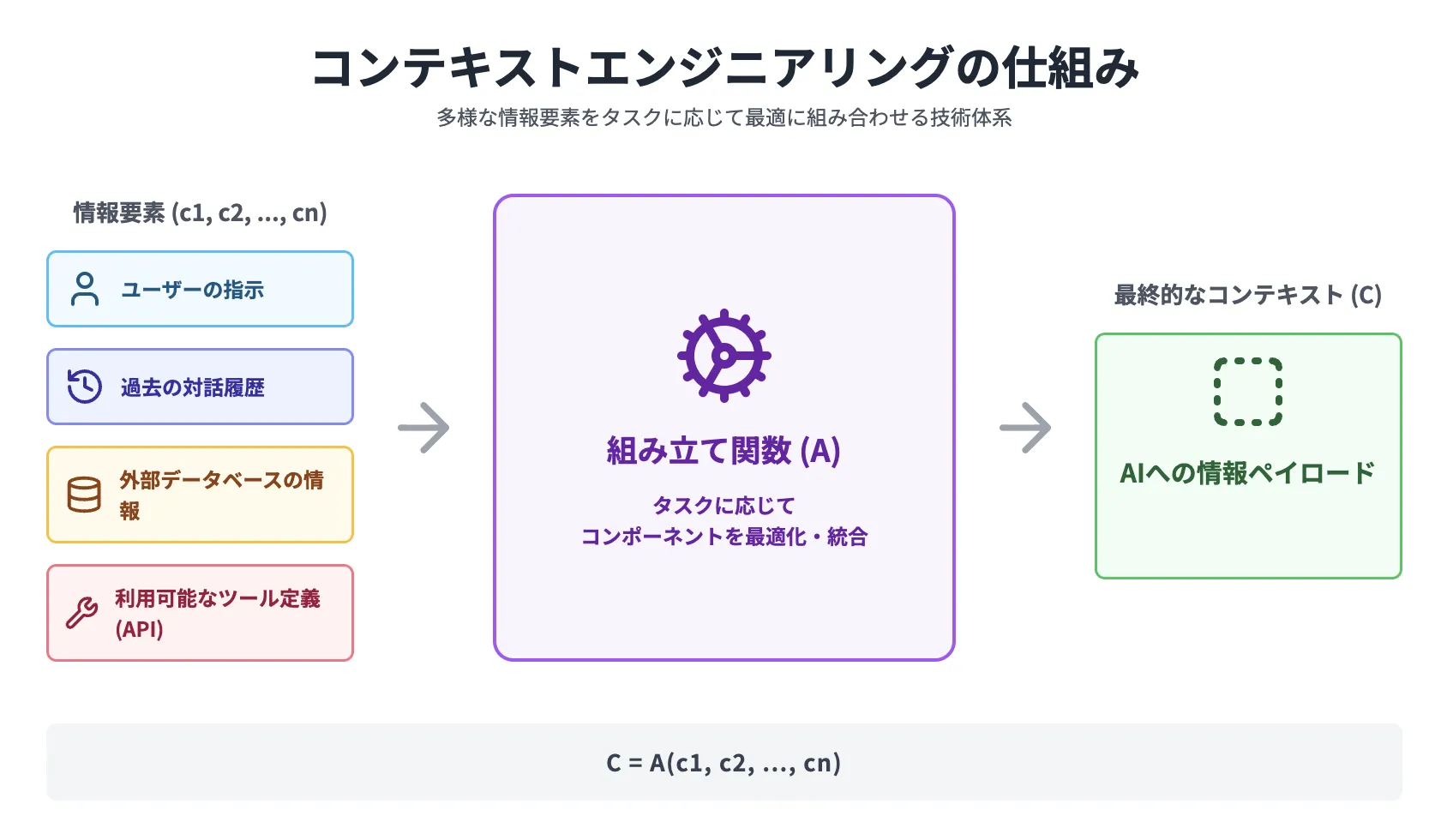
学術的には C = A(c1, c2, ..., cn) と表現されます。
これは、最終的なコンテキスト(C)が、システム指示(c1)、外部知識(c2)、ツール定義(c3)といった複数の要素を、ある組み立て関数(A)によって統合したものであることを示しています。
プロンプトエンジニアリングとコンテキストエンジニアリングの違い
以下の表は、プロンプトエンジニアリングとコンテキストエンジニアリングの主な違いをまとめたものです。
| 観点 | プロンプトエンジニアリング | コンテキストエンジニアリング |
|---|---|---|
| 対象 | 静的な単一のテキスト(プロンプト) | 動的で構造化された複数の情報要素の集合 |
| 目的 | 特定のタスクで良い応答を得る | システム全体の性能を最大化する |
| アプローチ | 手作業による職人的な調整が中心 | 関数の組み合わせによる体系的な最適化 |
| 状態管理 | 主にステートレス(一回限り) | ステートフル(記憶や状態を管理) |
| 主な適用先 | 単発のチャット、文章生成 | AIエージェント、マルチターン対話、複雑なワークフロー |
この表が示すように、コンテキストエンジニアリングは単なるプロンプトの拡張ではなく、システム設計思想そのものの転換を意味します。状態を管理し、複数の情報源を動的に扱うことで、より複雑で信頼性の高いAIアプリケーションの構築が可能になるのです。
コンテキストエンジニアリングの全体像
以下の図は、コンテキストエンジニアリングを学ぶ上での「地図」となります。
情報を扱うための個別の武器である「基盤コンポーネント」と、それらを組み合わせて戦う戦略である「システム実装」、そしてその性能を測る「評価」や「今後の課題」といった要素で構成されています。この記事では、この地図に沿って解説を進めていきます。
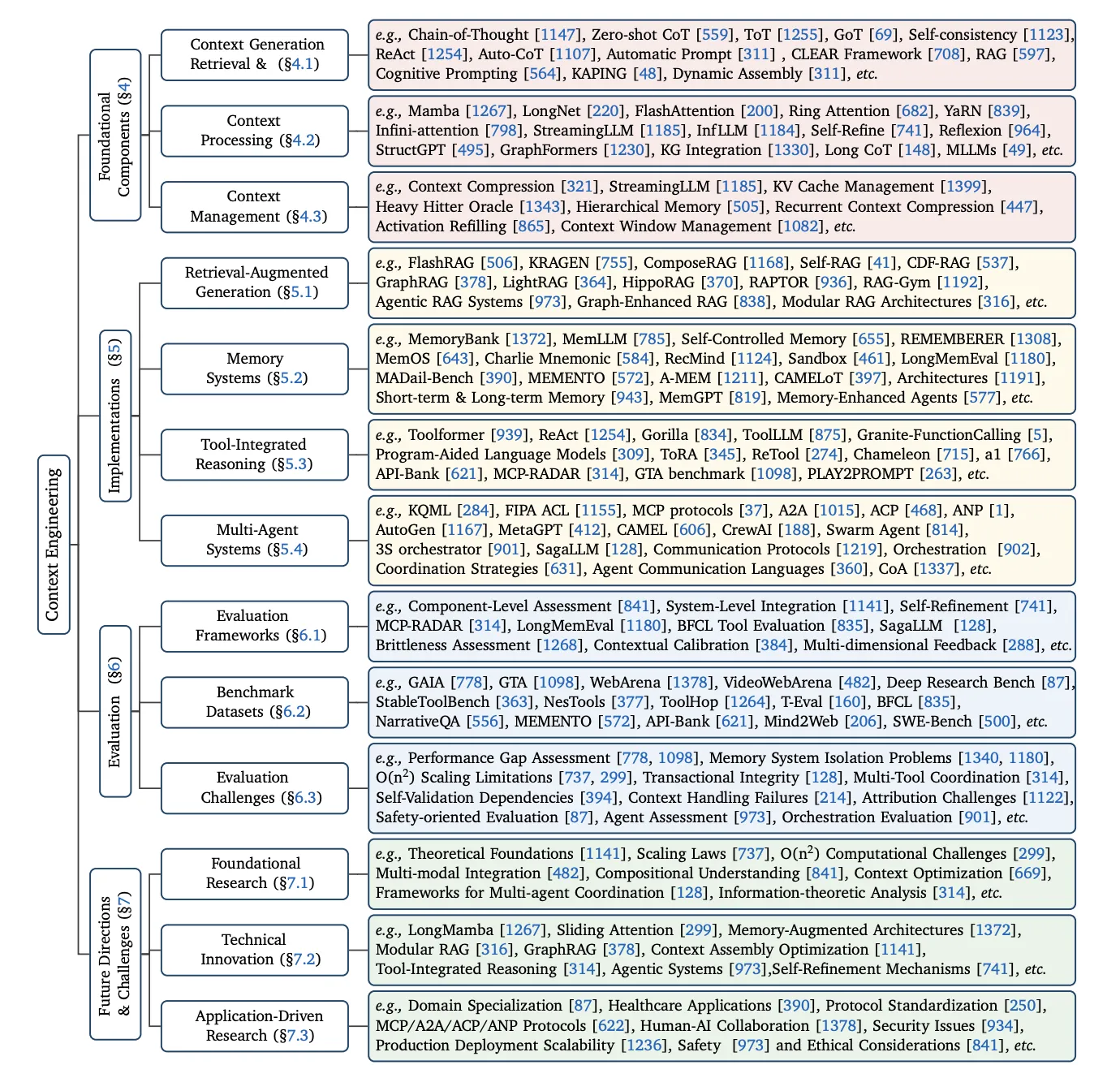
コンテキストエンジニアリングの全体像 出典: A Survey of Context Engineering for Large Language Models
このように、コンテキストエンジニアリングは、AI開発を「指示文の作成」というアートから、「情報システムの設計」というサイエンスへと引き上げる、重要なパラダイムシフトと言えるでしょう。
コンテキストエンジニアリングの発展の歴史
このようなコンテキストエンジニアリングの考え方は、ここ数年で急速に発展してきました。下の年表は、RAGやメモリシステムといった主要な実装が、いつ頃登場し、進化してきたかを示しています。
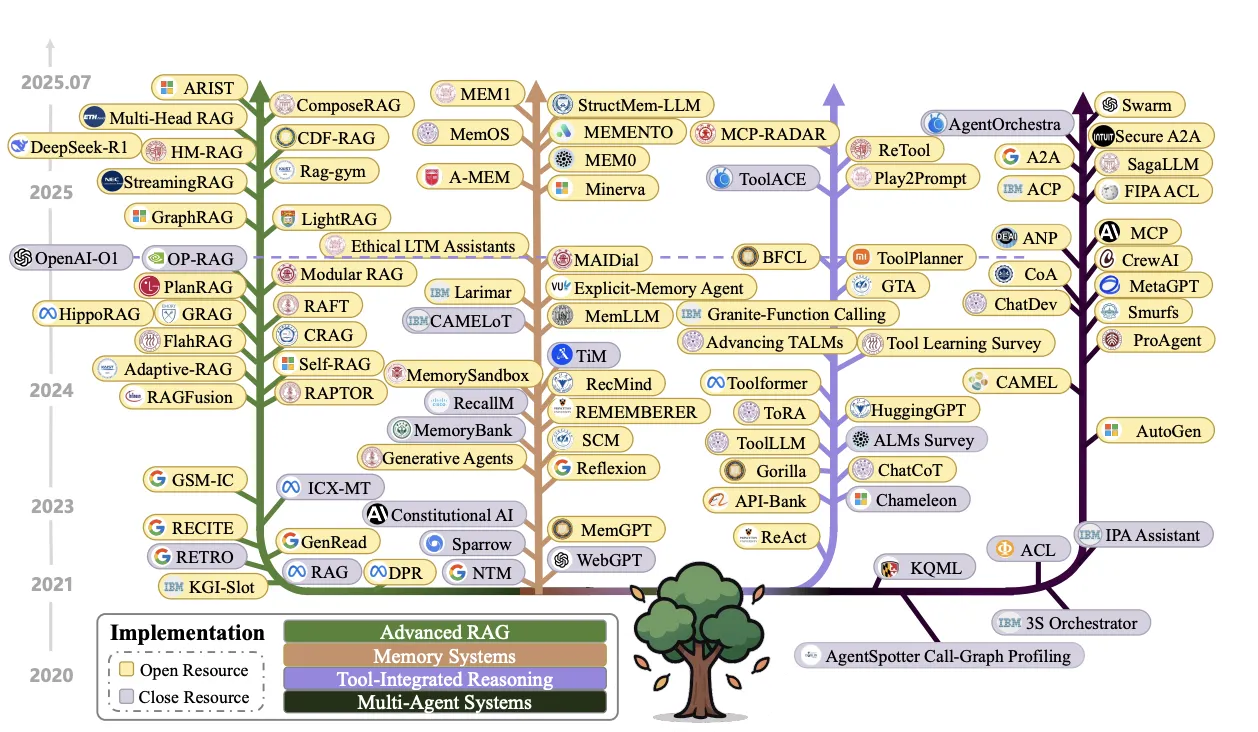
コンテキストエンジニアリングの進化年表(出典: A Survey of Context Engineering, Figure 2)
この年表を見ると、特に2023年以降、多様な技術が爆発的に生まれていることが分かります。これは、GPT-4などの高性能な基盤モデルが登場し、それらをいかに賢く応用するかに開発の焦点が移ってきたことを示唆していると言えるでしょう。
コンテキストエンジニアリングを支える3つのコア技術
最新の学術調査によると、コンテキストエンジニアリングは、情報を「調達し」「加工し」「管理する」という、3つのコア技術(基盤コンポーネント)のパイプラインで構成されていると整理できます。
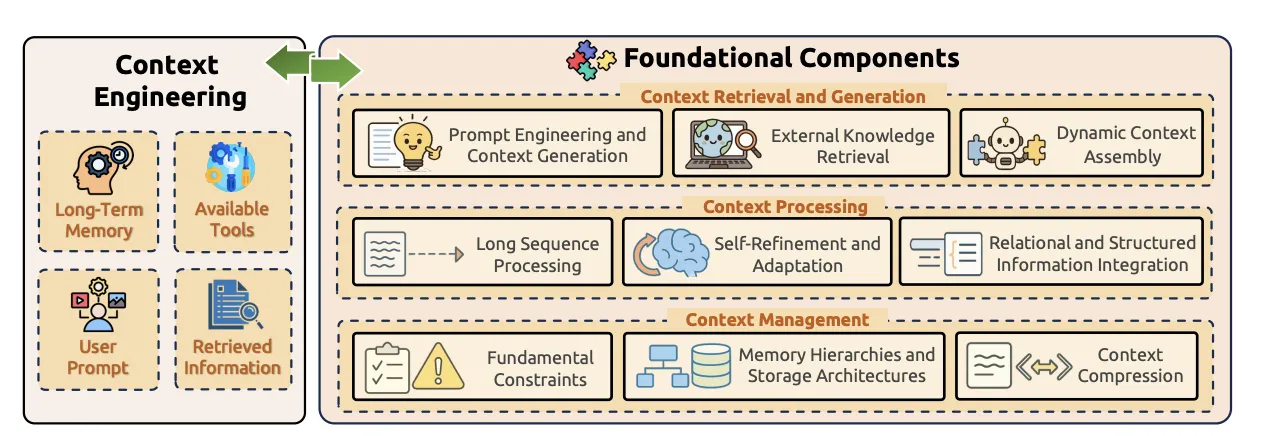
この図は、コンテキストエンジニアリングの心臓部を示しています。左側にある「長期記憶」や「ユーザープロンプト」といった情報ソース(入力)を、右側にある3つの基盤コンポーネントが連携して処理し、最終的にAIに与える最適なコンテキストを工学的に構築する、というシステム全体を表しています。
各コンポーネントがどのような役割を担っているのか、詳しく見ていきましょう。
① 文脈の検索と生成(Context Retrieval and Generation)
このコンポーネントは、コンテキストの「材料」を集め、組み立てる役割を担います。単に情報を探してくるだけでなく、より能動的なプロセスを含みます。
主な技術には、以下のようなものがあります。
-
プロンプトエンジニアリングと文脈生成
「思考の連鎖(CoT)」のような高度なプロンプトを用いて、AI自身の思考を引き出し、文脈の一部として生成させます。
-
外部知識の検索
RAG(検索拡張生成)を用いて、Webサイトやデータベースから最新の、あるいは専門的な情報を検索します。
-
動的な文脈の組み立て
上記で得られた複数の情報を、タスクの目的に応じて動的に組み合わせ、最終的な入力コンテキストを構築します。
この分野の研究は日進月歩です。例えば、ナレッジグラフから情報を取得する手法も進化しており、KARPAのように学習なしで高い精度を実現する手法や、RAG-KGのように過去の対話履歴自体をナレッジグラフとして構築し、検索精度を向上させるアプローチが報告されています。
② 文脈の処理(Context Processing)
ここでは、集めてきた情報をLLMが最大限活用できるよう、その質を高め、形式を整える「加工」が行われます。
-
長文脈の処理
非常に長い文章や対話履歴を効率的に処理するための技術です。「FlashAttention」のようなアルゴリズムは、計算量を削減し、より長い文脈を扱えるようにします。
-
自己改善と適応
モデル自身が生成した内容を評価・修正(Self-Refinement)させ、文脈の質を繰り返し向上させます。論文では10種類以上の手法がリストアップされており、単純なフィードバックと修正を繰り返す「Self-Refine」から、複数のAIで評価する「N-CRITICS」、さらにはAIが改善方法自体を開発する「Self-Developing」まで、その手法は多岐にわたります。
-
構造化情報の統合
テキストだけでなく、テーブル、グラフ、JSONといった構造化データをLLMが理解できる形式に変換し、文脈に統合します。
また、思考が長くなりすぎると非効率になるため、その思考連鎖(Long CoT)を効率化する研究も重要です。思考の論理構造を解析して不要な部分を刈り取るPrune-on-Logicや、プロンプト自体を最適化してトークン量を87.5%も削減するPREMISEといったアプローチが開発されています。
③ 文脈の管理(Context Management)
最後に、構築・加工されたコンテキストを、LLMのワーキングメモリ(コンテキストウィンドウ)上でいかに効率的に「管理」するかという、システムレベルの最適化を行います。
-
根本的な制約への対処
コンテキスト長の限界や、「中間で忘れる」といったLLMの根本的な制約を考慮した管理戦略を立てます。
-
メモリ階層とストレージ設計
人間の記憶のように、短期記憶(コンテキストウィンドウ)と長期記憶(外部データベースなど)を階層的に設計し、情報を適切に配置します。
-
文脈の圧縮と構造化
重要な情報を損なうことなく、コンテキスト全体のトークン量を削減したり、テーブルやグラフのような構造化データをLLMが扱いやすい形式に変換したりします。
コンテキストエンジニアリングの応用例:4つの最先端システム
これまで見てきた3つの基盤コンポーネントは、単独で使われるだけでなく、互いに組み合わさることで、より高度で知的なAIシステムを構築します。
ここでは、その代表的な4つの応用例(システム実装)を紹介します。
応用例①:進化するRAG(検索拡張生成)
RAGはもはや、単純に情報を検索して追加するだけの技術ではありません。ただ外部情報を参照するだけでなく、より柔軟で、自律的に思考するシステムへと進化しています。
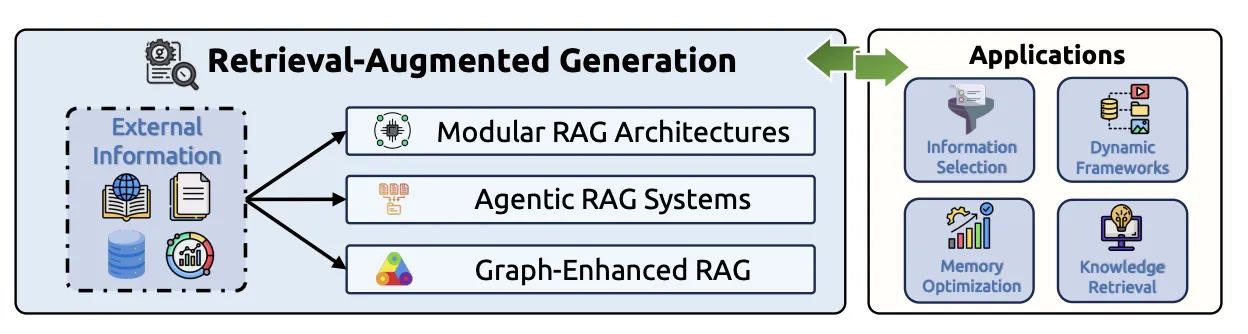
進化するRAGのフレームワーク(出典: A Survey of Context Engineering for Large Language Models)
以下に主要なRAGの進化形をまとめました。
-
モジュラーRAG
検索、拡張、生成といった各プロセスを独立したモジュール(部品)として扱い、タスクに応じて自由に組み合わせるアプローチです。
-
エージェントRAG
RAGのプロセスを自律的なAIエージェントが実行します。どの情報を検索し、どう組み合わせるかをAI自身が判断します。
-
グラフRAG
単純なテキストではなく、知識間の関係性を構造化した「ナレッジグラフ」を参照することで、より深い多角的な回答を生成します。
この進化は、AIが単なる「物知り」から、自ら情報を取捨選択し、文脈を組み立てる「調査員」へと役割を変えつつあることを示しています。
応用例②:記憶を持つAI(Memory Systems)
AIが過去の対話を忘れず、継続的な関係性を築くためには、「記憶」が不可欠です。コンテキストエンジニアリングは、LLMに長期的な記憶能力を与えます。
以下の図が示すように、メモリシステムはLLMの「脳」に長期記憶領域を追加するようなものです。これにより、一回限りの対話ではなく、継続的な関係性を持つパートナーとしてのAIが実現可能になります。

メモリシステムのフレームワーク(出典: A Survey of Context Engineering for Large Language Models)
論文では、メモリの実装パターンが多岐にわたることが示されています。対話履歴全体をテキストで保存する手法(RecMindなど)から、検索によって得た情報のみを扱う手法(MemoryBankなど)、さらにはモデルのファインチューニングや編集を伴う高度な手法まで、用途に応じて様々なアプローチが取られています。
応用例③:世界と対話するAI(Tool-Integrated Reasoning)
コンテキストエンジニアリングにより、AIはもはやテキストを生成するだけの存在ではありません。外部のツールを使いこなし、現実世界と対話する「行為者(エージェント)」へと進化します。

ツール統合推論のフレームワーク(出典: A Survey of Context Engineering for Large Language Models)
この仕組みは、AIに関数呼び出しや環境との相互作用といった「手足」を与えることに相当します。計算、検索、API実行といった具体的なアクションが可能になることで、AIはデジタル世界における物理的な存在感を持つようになります。
この分野では、AIが外部ツールに接続するための標準プロトコルも整備されつつあります。Anthropicが提唱したMCP(Model Context Protocol)は、AIアプリケーションと外部ツール・データソースの接続を標準化するオープンプロトコルであり、ツール統合のコンテキスト設計を大幅に簡素化します。
そして、この分野では様々なモデルが多様なツールを使いこなす研究が進んでいます。以下の表は、代表的なモデルがどのカテゴリのツールを利用できるかを示したものです。
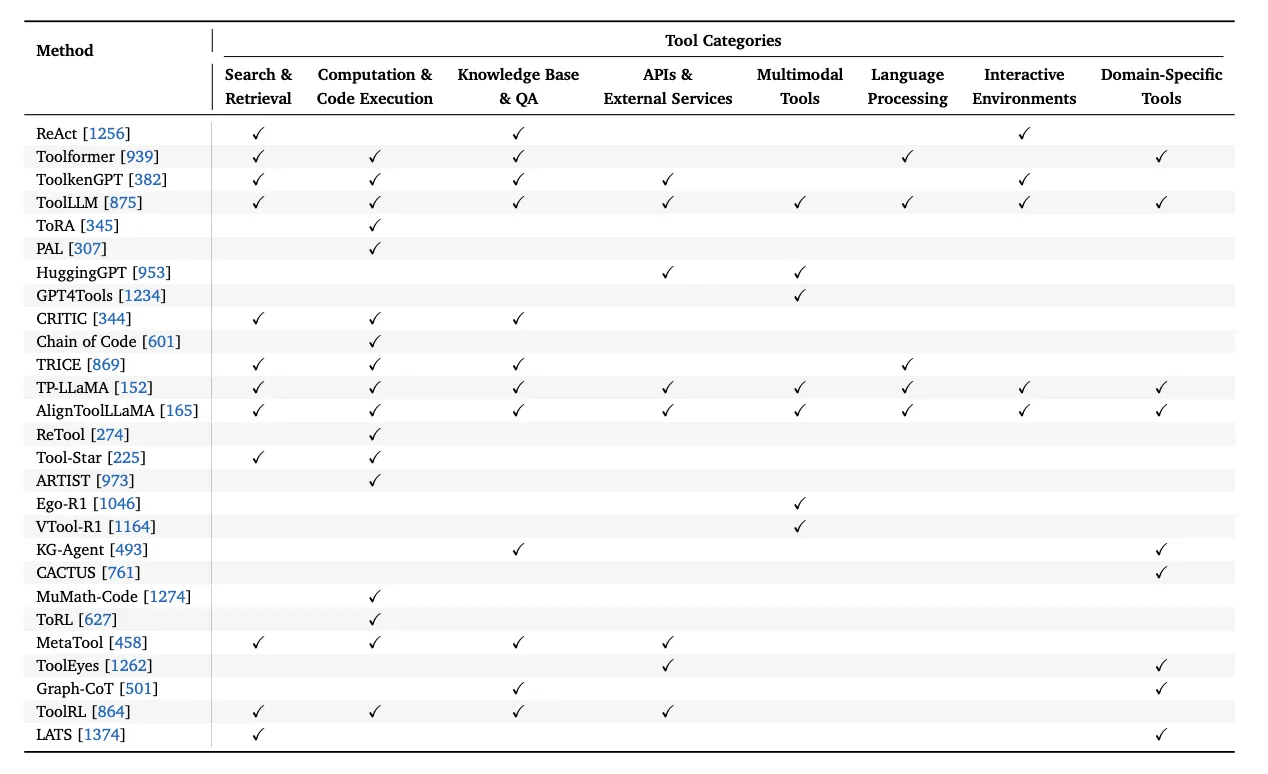
主要なツール統合型モデルとその対応ツールカテゴリ(出典: A Survey of Context Engineering for Large Language Models)
この表から、モデルによって得意なツールの種類が異なることが分かります。例えば、ToRAやPALは計算に特化している一方、ToolLLMは非常に幅広いツールを扱える汎用的なモデルとして設計されています。このように、目的に応じて適切なツールを使えるモデルを選択することが重要です。
応用例④:チームで課題解決するAI(Multi-Agent Systems)
一つの高度なAIエージェントで解決できない複雑な問題も、複数の専門エージェントがチームを組むことで解決可能になります。
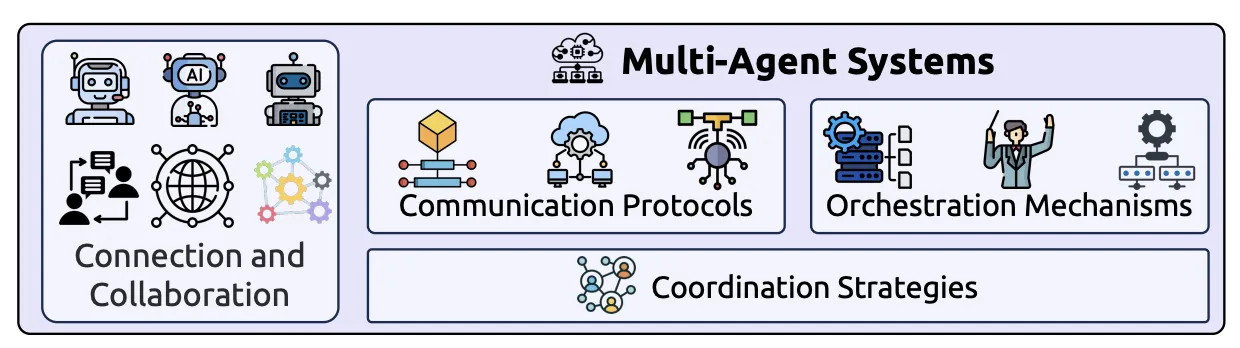
マルチエージェントシステムのフレームワーク(出典: A Survey of Context Engineering for Large Language Models)
これは、一人の天才に頼るのではなく、専門家チームで課題解決に当たるアプローチです。各エージェントが持つ専門知識を結集させることで、単一のエージェントでは到達できない、より高度で複雑な問題解決が期待できます。
マルチAIエージェントを実現するためには、エージェント間の「コンテキスト共有」が重要な課題となります。以下にその主要要素をまとめました。
-
通信プロトコル
エージェント同士が情報を交換するための共通言語やルールです。
-
オーケストレーション
プロジェクトマネージャーのように、どのエージェントにどのタスクを割り振り、全体の進捗を管理するかという指揮・調整機能です。
マルチエージェントにおけるコンテキストエンジニアリングでは、各エージェントが持つコンテキストの分離(Isolation)と、必要な情報の共有のバランスが性能を大きく左右します。
コンテキストエンジニアリングの実践:AIエージェント「Manus」から学ぶ6つのテクニック
ここまでは理論と応用例を中心に見てきましたが、この章では実際の開発現場から得られた貴重な知見をご紹介します。
AIエージェント「Manus」の開発チームが、AIの性能を最大限に引き出すために試行錯誤の末にたどり着いた、6つの具体的な実践テクニックを解説します。
1. KVキャッシュを中心に設計し、コストと速度を最適化する
AIエージェントとの対話では、応答速度とAPIコストが非常に重要です。Manusチームは、この問題を解決するために「KVキャッシュ」のヒット率を最大化する設計を徹底しました。
具体的には、プロンプトの先頭部分(システムプロンプトなど)を常に固定し、タイムスタンプのような毎回変化する情報を入れないようにしました。たった1トークンでも異なるとキャッシュが無効になるため、この安定化が極めて重要です。
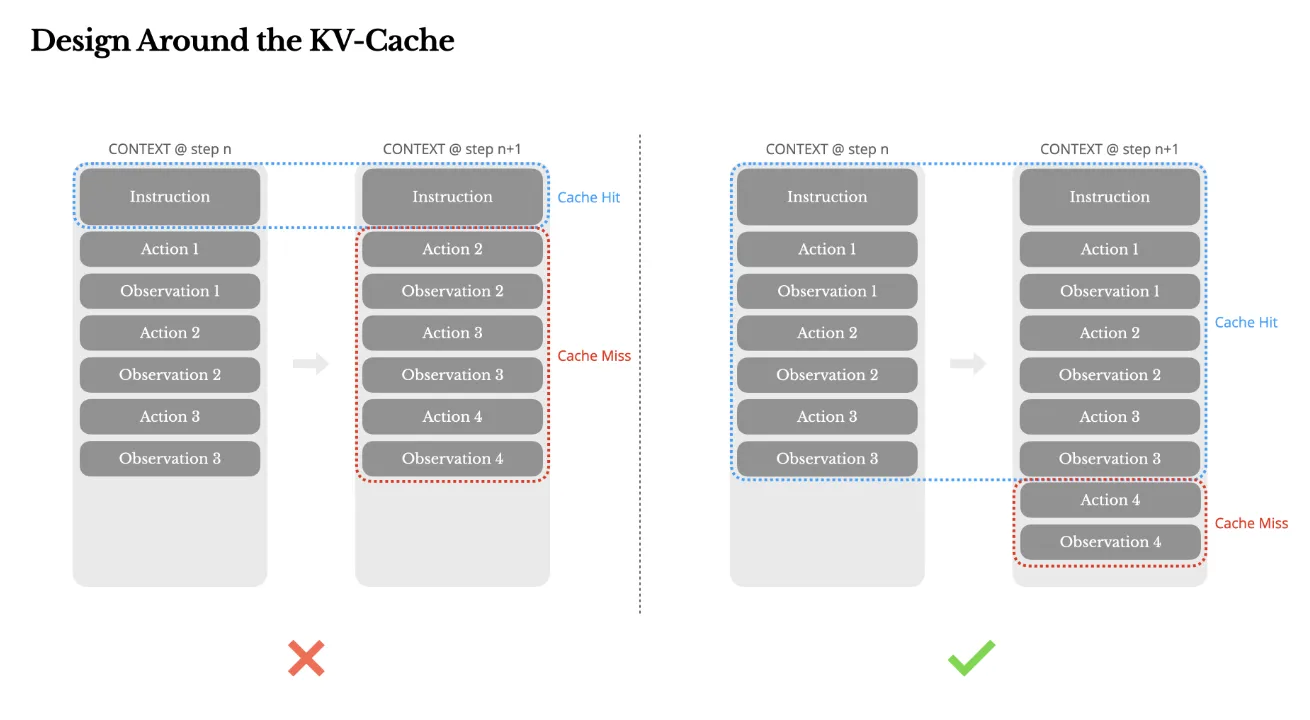
KVキャッシュ中心の設計(出典: Manus)
この図の右側のように、変更点をコンテキストの末尾に集中させることで、手前の大部分(InstructionからObservation 3まで)でキャッシュヒットが発生します。これは「Context Management」のコア技術を現場レベルで最適化した好例であり、計算量が大幅に削減され、高速かつ低コストな応答が実現できるのです。
2. 「削除」せず「マスク」してツールを動的に制御する
エージェントが使えるツールが増えすぎると、性能が低下することがあります。単純な解決策は、状況に応じて不要なツール定義をコンテキストから動的に「削除」することですが、これはKVキャッシュを無効化し、逆効果になりかねません。
そこでManusでは、ツール定義はすべてコンテキストに残したまま、現在の状況で利用できないツールを「マスク」する手法を採用しました。これにより、モデルはそのツールを選択肢から除外するだけで、キャッシュ効率を損なうことなく、賢明なツール選択が可能になります。
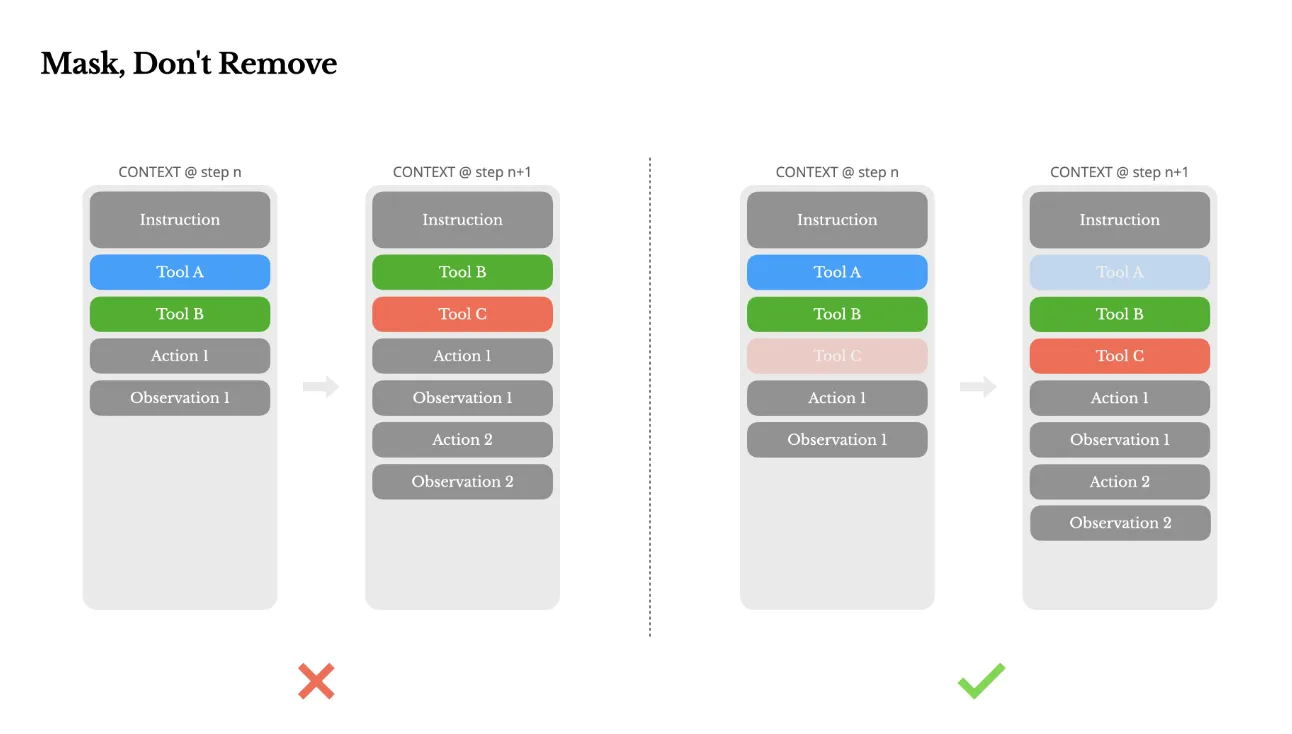
ツールのマスクによる制御(出典: Manus)
図の左側のようにツール定義を丸ごと入れ替えると、後続のコンテキストもすべて再計算(キャッシュミス)になってしまいます。しかし右側の「マスク」方式なら、ツール定義部分は変わらないためキャッシュが有効に働き、非効率な再計算を防げます。
これは「Tool-Integrated Reasoning」において、ツールの可用性を効率的に管理する高度なテクニックです。
3. ファイルシステムを無限の「外部メモリ」として活用する
LLMのコンテキストウィンドウには物理的な上限があります。ウェブページやPDFの内容など、長大な情報を無理にコンテキストに詰め込むと、すぐに限界に達してしまいます。
Manusでは、ファイルシステムをAIエージェント自身が読み書きできる「外部メモリ」として扱います。これにより、コンテキスト長の制約を実質的に乗り越え、必要な情報を必要な時にファイルから読み出すという、効率的な情報管理を実現しています。
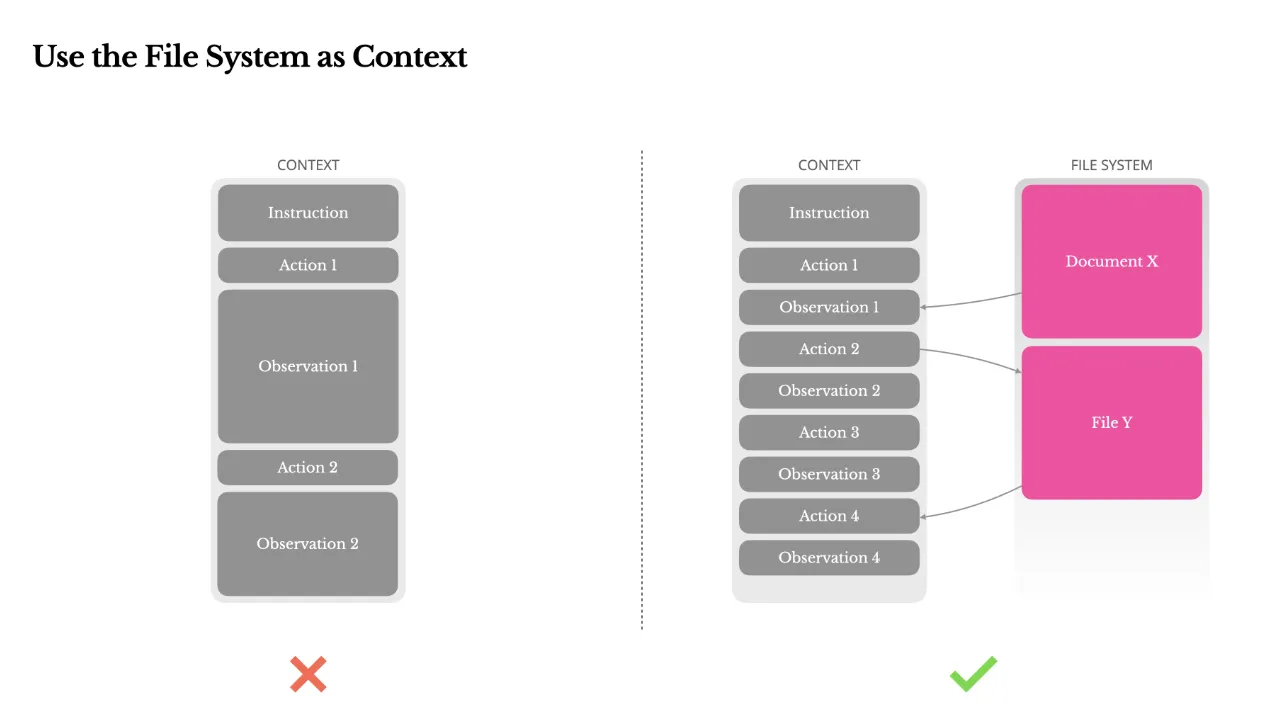
ファイルシステムをコンテキストとして活用(出典: Manus)
この図のように、すべての情報をコンテキストに入れるのではなく、外部のファイルシステムに情報を保存し、コンテキストにはそのファイルへの参照(パスなど)を含めるだけにします。これは「Memory Systems」の考え方を応用したもので、コンテキスト長の制約を実質的に乗り越え、効率的な情報管理を実現しています。
4. 「失敗の記録」をあえてコンテキストに残し、自己学習を促す
AIエージェントは間違いを犯します。その際、エラーログを消去してクリーンな状態にしたくなるのが一般的ですが、これは貴重な学習機会を奪うことになります。
Manusチームは、エージェントが実行に失敗したアクションや、その結果として得られたエラーメッセージを、あえてコンテキストに残すアプローチを取りました。モデルが自身の失敗を「見る」ことで、同じ過ちを繰り返す確率が自然と低下し、自己学習が促進されるのです。

失敗をコンテキストに残す(出典: Manus)
5. 「唱和」させてAIの注意をタスク目標に引き戻す
長いタスクの実行中、AIは当初の目標を忘れ、「中間で迷子になる」ことがあります。これは、コンテキストが長くなるにつれて、初期の指示への注意が薄れるために起こります。
この問題に対処するため、Manusはタスクの進行に合わせてToDoリストを更新し、それをコンテキストの最後に常に含めるように設計されています。タスク目標を繰り返し「唱和」させることで、モデルの注意を常に大局的な計画に引き戻し、脱線を防ぎます。

唱和による注意操作(出典: Manus)
6. Few-Shotプロンプトの「模倣の罠」を避ける
コンテキスト内に成功例(Few-Shotプロンプト)をいくつか含めるのは、有効な手法です。しかし、似たような成功例ばかりが並んでいると、モデルは思考停止に陥り、そのパターンをただ「模倣」するだけの脆弱なエージェントになってしまいます。
Manusでは、この「模倣の罠」を避けるため、意図的にコンテキストに多様性を持たせています。例えば、出力形式に僅かなノイズを加えたり、情報の順序を少し変えたりすることで、モデルがパターンに過剰適合するのを防ぎ、より柔軟な思考を促します。

Few-Shotの罠を避ける(出典: Manus)

コンテキストエンジニアリングの課題と展望
コンテキストエンジニアリングはAIの能力を飛躍させる可能性を秘めていますが、まだ多くの課題が残されています。その現在地を、まず具体的なデータから見てみましょう。
Webサイトの操作能力を測る有名なベンチマーク「WebArena」の結果は、AIエージェントの実力を雄弁に物語っています。
| リリース日 | オープンソース | 手法 / モデル | 成功率 (%) |
|---|---|---|---|
| 2025-02 | ❌ | IBM CUGA | 61.7 |
| 2025-01 | ❌ | OpenAI Operator | 58.1 |
| 2024-08 | ❌ | Jace.AI | 57.1 |
| 2024-12 | ❌ | ScribeAgent + GPT-4o | 53.0 |
| 2025-01 | ✅ | AgentSymbiotic | 52.1 |
| 2024-10 | ✅ | AgentOccam-Judge | 45.7 |
WebArenaベンチマーク リーダーボード(出典: A Survey of Context Engineering, Table 8より)
この結果が示すように、最先端のAIエージェントですら成功率は60%前後にとどまります。これは、決められた単純作業はこなせても、予期せぬUIの変更や複雑な条件分岐など、現実世界のWebサイトが持つ「曖昧さ」や「動的な変化」への対応に、まだ大きな課題があることを示唆しています。
そして、この性能の限界の根底には、より本質的な問題が存在します。
コンテキストエンジニアリングの未解決課題:「理解と生成の非対称性」
1400本以上の論文を分析した調査報告が指摘する、最も重要な未解決問題が「理解と生成の根本的な非対称性(fundamental asymmetry)」です。
これは、現在のLLMが、非常に長く複雑な文脈を「理解」する能力は飛躍的に向上した一方で、それと同じくらい長く、複雑で、首尾一貫した質の高いアウトプットを「生成」する能力は、著しく劣っているという問題です。
例えば、100万トークンの論文を読んで要約することはできても、100万トークンの一貫した論文をゼロから書き上げることは極めて困難です。このギャップを埋めることが、今後のコンテキストエンジニアリング、ひいてはAI研究全体の大きなテーマとなるでしょう。
コンテキストエンジニアリングを深く学ぶためのおすすめ文献
本記事で解説したコンテキストエンジニアリングについて、さらに深く学びたい方向けに、信頼性の高い学術論文や企業の技術資料を厳選してご紹介します。理論的な背景から具体的な実装方法まで、学習のフェーズに合わせてご活用ください。
コンテキストエンジニアリングの理論を掴む学術論文・サーベイ
-
A Survey of Context Engineering for Large Language Models
本記事の基盤ともなった、1400本以上の論文を分析した包括的なサーベイ論文です。コンテキストエンジニアリングを体系的に理解するための、最初の一歩として最適です。
A Survey of Context Engineering for Large Language Models
-
A Systematic Survey of Prompt Engineering in Large Language Models
コンテキストエンジニアリングの土台である、プロンプト技術を網羅的に整理したサーベイ論文です。思考の連鎖(CoT)など、基本的な技術を深く理解できます。
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
コンテキストエンジニアリングの実装を知る企業の技術ブログ
-
Anthropic — Effective Context Engineering for AI Agents
Anthropicが公式に発表した、AIエージェント開発におけるコンテキストエンジニアリングの実践ガイドです。「プロンプトエンジニアリングの発展形」としての定義や、具体的な設計パターンが解説されています。
Anthropic Engineering Blog
-
LangChain & LlamaIndex Blogs
LangChainやLlamaIndexといった、AIアプリケーション開発フレームワークの公式ブログでは、RAGやエージェント設計におけるコンテキストエンジニアリングの実践的なテクニックが頻繁に議論されています。
The rise of "context engineering"(LangChain)
LlamaIndex
-
PromptingGuide.AI — Context Engineering Guide
実装者向けの実践的な手引きで、RAG、メモリ、プロンプトを組み合わせた構造設計のテンプレートなどが豊富に紹介されています。
PromptingGuide.AI — Context Engineering Guide

コンテキスト設計の知見を業務全体のAI化に広げるなら
コンテキストエンジニアリングの理解が深まると、AIの精度を上げるだけでなく、業務プロセスそのものをAI前提で再設計する視点が生まれます。プロンプト設計の最適化から一歩進んで、社内の業務フロー全体にAIを組み込むことを検討してみてはいかがでしょうか。
AI総合研究所では、AIを業務プロセスに段階的に導入するための実践ガイドを無料で提供しています。コンテキスト設計の知見を活かしながら、組織全体の業務自動化を進める具体的な方法を確認できます。
コンテキスト設計の知見を業務プロセスのAI化に結びつける

AI業務自動化ガイド
コンテキストエンジニアリングの理解は、AIを業務に組み込む際の設計精度を大きく左右します。プロンプト設計から業務フロー全体のAI化まで、段階的な導入の進め方をガイドにまとめました。
まとめ
本記事では、AI開発の最前線で重要性を増す「コンテキストエンジニアリング」について、その体系的な全体像から現場の実践テクニックまでを網羅的に解説しました。
-
コンテキストエンジニアリングとは
プロンプトエンジニアリングから一歩進み、AIに与える情報全体を体系的に設計・最適化する技術です。Anthropicが「AIエージェント開発における必須スキル」として提唱しており、静的な「指示」から動的な「情報設計」へのパラダイムシフトを意味します。
-
技術の全体像
この技術は、情報を「調達・生成」「処理」「管理」する3つのコア技術と、それを応用した「RAG」「メモリシステム」「ツール統合」「マルチエージェント」という4つの先端システムから構成されます。
-
実践の鍵
実際の開発現場では、「KVキャッシュの最適化」によるコスト・速度改善や、「失敗記録の活用」による自己学習促進など、理論に基づいた具体的なテクニックがAIエージェントの性能を大きく左右します。
-
未来への課題
AIは長い文脈を「理解」する能力は向上しましたが、同等に質の高いアウトプットを「生成」する能力には課題が残っており、この「非対称性」の克服が今後の大きなテーマです。MCPなどのインフラ整備が進む中、コンテキスト設計の重要性はますます高まっています。
AI開発の主戦場は、もはやモデルのパラメータ数を競うだけの競争ではありません。そのモデルが持つ潜在能力を、コンテキストエンジニアリングによっていかに最大限引き出すか。これからの時代、AIを真に活用するためには、AIを取り巻く情報環境そのものを設計する視点が不可欠となるでしょう。










