この記事のポイント
 ローカル統制重視ならClaude Code、ChatGPTエコシステムで長時間タスクを投げるならCodexが第一候補
ローカル統制重視ならClaude Code、ChatGPTエコシステムで長時間タスクを投げるならCodexが第一候補- ベンチマークはSWE-bench ProでClaude優位、SWE-bench Verified・Terminal-Bench 2.0でGPT-5.5優位の拮抗
- 料金表面額は同水準だが、実測ではClaude側のトークン消費が約1.4倍多く実質コスト差は約23%
- サブエージェントはCodexが手動並列(6スレッド)、Claude CodeはAgent Teams(experimental)で上限なし+直接通信という設計差
- エンタープライズはClaude CodeのZDR/SSO/監査ログかCodexのChatGPT Enterprise統制かを、既存契約と監査要件で選ぶ

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Claude CodeとOpenAI Codexは、2026年に入ってから「コード補完」を超え、リポジトリ全体を理解して複数ファイルを編集・テスト・PR作成まで自律的に進めるエージェント型コーディングツールの代表格です。
2026年5月時点では、Codex側がGPT-5.5の搭載とGoal modeのGA・Codex mobile・Windowsサンドボックス強化で攻め、Claude Code側がClaude Opus 4.7とRoutines・Agent Teams(experimental扱い)・Remote Controlで地続きの開発フロー統合を強めるなど、両者の設計思想の差が一段と鮮明になっています。
本記事では、2026年5月時点の公式情報をもとに、Claude CodeとCodexの製品概要・モデル/ベンチマーク・実行環境・料金・エコシステム・エンタープライズ機能・ケース別の選び方・導入で詰まる論点までを、AI総合研究所の導入支援観察も交えて整理します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Claude CodeとCodexの違いを2026年5月時点で総括
SWE-bench VerifiedとSWE-bench Pro
Terminal-Bench 2.0:ターミナル操作タスクの差
Claude CodeとCodexの違いを2026年5月時点で総括
Claude CodeとOpenAI Codexを一言で対比すると、**「ローカル中心でフルアクセスを開発者に預けるClaude Code」と、「クラウドサンドボックスで隔離し並列処理を前提に動かすCodex」**という設計思想の差に行き着きます。
どちらも2026年5月時点で「リポジトリ全体を理解して複数ファイル編集・テスト実行・PR作成まで一連で任せる」エージェント機能を備えていますが、実行場所・サブエージェント設計・料金体系の組み方が根本から違うため、選定を間違えると運用にハマります。

本セクションでは、まず両者の差を早見表で示し、次のセクション以降で各論点を深掘りしていきます。
2026年5月時点の早見表
以下の表で、Claude CodeとCodexの主要論点を一覧化しました。後段の各セクションで詳述するため、ここでは「どこに差があるか」のアタリを付ける用途で読み進めてください。
| 比較軸 | Claude Code | OpenAI Codex |
|---|---|---|
| 主要モデル | Claude Opus 4.7(2026年4月16日リリース) | GPT-5.5(2026年4月23日リリース) |
| 実行環境 | ローカル中心(CLI/IDE/Web/Desktop/iOS/Slack/Chrome) | クラウドサンドボックス中心(CLI/IDE/Web/Cloud/Mobile) |
| サブエージェント | Agent Teams(experimental・デフォルト無効、並列数上限なし、直接メッセージ) | Subagents(手動トリガー、デフォルト6スレッド、read-heavy向け) |
| 料金体系 | Pro $20/Max 5x $100/Max 20x $200/Team Standard $25/席 ほか | ChatGPTプランに内包(Free/Goにも軽量利用枠、Plus/Pro/Businessで段階拡張) |
| トークン消費(同タスク) | Composio 2026年5月実測でCodex比約1.4倍多い(コスト差は約23%プレミアム) | 同タスクで約1.4倍少なめ |
| SWE-bench Verified | 87.6% | 88.7% |
| SWE-bench Pro | 64.3% | 58.6% |
| Terminal-Bench 2.0 | 69.4% | 82.7% |
| 強み | 大規模リポジトリの自律実行・supervised autonomy・マルチサーフェス | クラウド長時間タスク・並列処理・ChatGPTエコシステム統合 |
この表からまず読み取ってほしいのは、「性能の絶対値より、設計思想の差で選ぶべきツール」だという点です。
SWE-bench Verifiedで1.1ポイントGPT-5.5が上回り、SWE-bench Proで5.7ポイントClaude Opus 4.7が上回るという拮抗関係は、用途を限定しない限り「どちらが優れている」と言い切れない水準です。
差が大きいのはむしろ、実行をローカルでフルコントロールしたいかクラウドに長時間任せたいか、サブエージェントを階層型でガチガチに組みたいかピアtoピアで柔軟に組みたいか、ChatGPTエコシステムを軸にしたいかAnthropicエコシステムを軸にしたいかといった「自社の開発フローと統制方針」の論点です。

本記事のスコープと前提
本記事は「Claude CodeとCodexのどちらを業務に組み込むか」という意思決定に必要な比較軸を1本で整理することを目的にしています。
そのため、それぞれの単独解説はClaude Codeとは・Codexとはに譲り、本記事では「2つを並べた時にどう違うか」「どちらを選ぶべきか」に絞ります。
料金・モデル仕様は2026年5月時点の公式一次情報を基準にしつつ、ベンチマーク数値・実測コスト・サブエージェント仕様などは公式発表と主要な第三者比較(Composio・morphllm等)を併用し、出典を本文中のアンカーリンクで示しています。
Claude CodeとCodexそれぞれの製品概要
比較に入る前に、両者の製品定義・利用できるサーフェス・採用モデル系列を同じ粒度でそろえておきます。
「同じカテゴリの製品」と捉えがちですが、製品としての設計思想と提供形態が異なるため、前提合わせが選定の出発点になります。

Claude Codeの製品定義
Claude Codeは、Anthropicが提供するエージェント型のAIコーディング支援ツールです。
公式ドキュメントでは「コードベースを読み取り、ファイルを編集し、コマンドを実行し、開発ツールと統合する agentic coding ツール」と定義されており、ターミナル・IDE・デスクトップアプリ・ブラウザの全環境で同じエンジンを呼び出せる点が大きな特徴です。
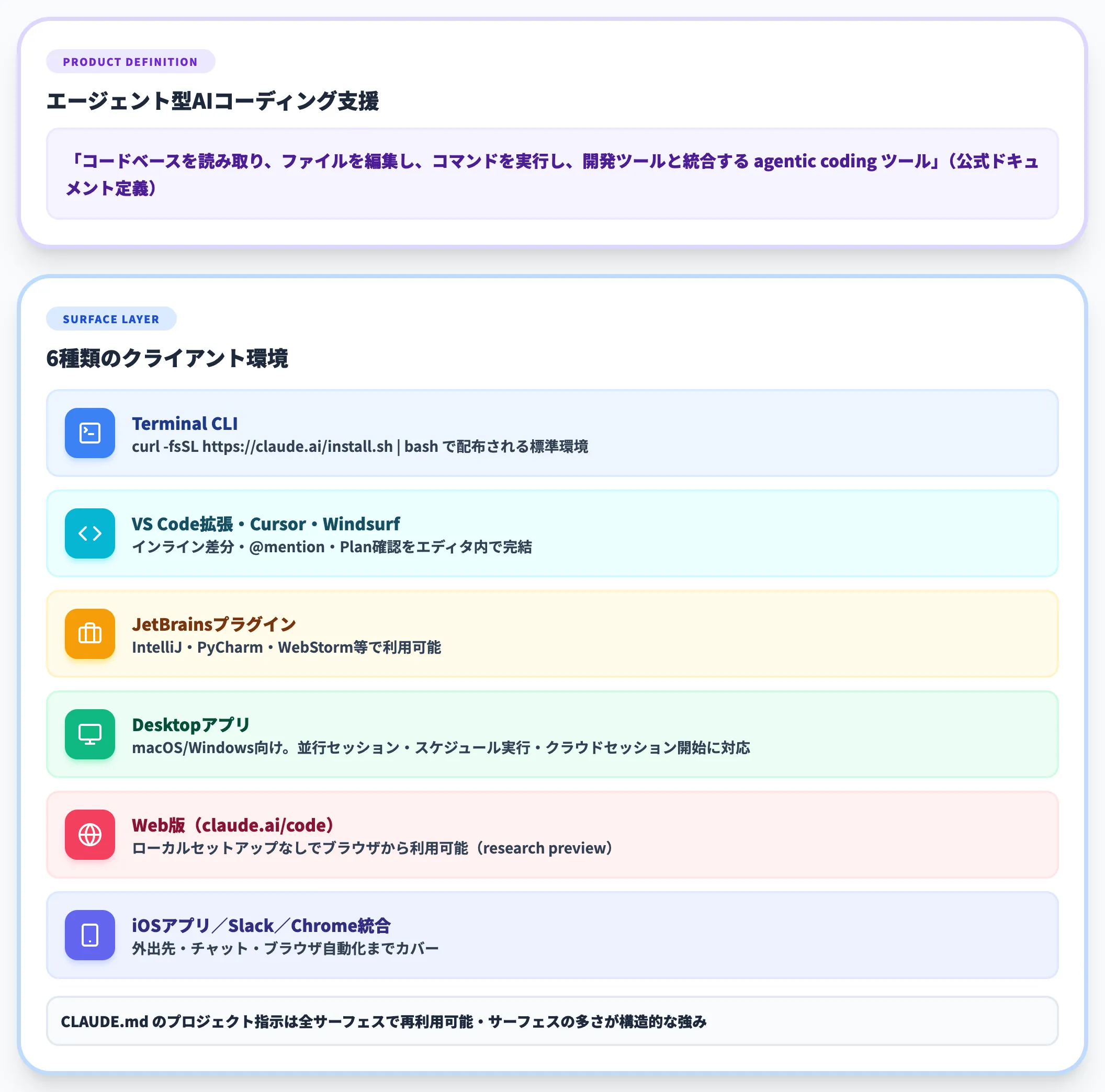
利用可能なサーフェスは次のとおりです。
-
Terminal CLI
ネイティブインストーラ(「curl -fsSL https://claude.ai/install.sh | bash」等)で配布される標準環境
-
VS Code拡張・Cursor・Windsurf
VS Code拡張はVS Code系IDE上でインライン差分・@-メンション・プラン確認をエディタ内で完結。
CursorとWindsurfはVS Codeフォークのため同じ拡張がそのまま動作
-
JetBrainsプラグイン
IntelliJ・PyCharm・WebStorm等で利用可能
-
Desktopアプリ
Claude Code on DesktopはmacOS/Windows向けスタンドアロンアプリ。
並行セッション・スケジュール実行・クラウドセッション開始に対応
-
Web版(claude.ai/code)
Web版Claude Codeはローカルセットアップなしでブラウザから利用可能(research preview)
-
iOSアプリ/Slack/Chrome統合
外出先・チャット・ブラウザ自動化までカバー
サーフェスの多さがClaude Codeの構造的な強みで、CLAUDE.mdなどのプロジェクト指示はサーフェス間で再利用しやすい設計です。
Codexの製品定義
CodexはOpenAIが提供するAIコーディングエージェントで、自然言語でタスクを指示すると、計画分解→編集→テスト→PR作成までを一連のフローとして処理します。

代表的なクライアントは次のとおりです。
-
Codex CLI
ターミナルで「codex」コマンドを実行する対話型クライアント
-
Codex IDE Extension
VS Code・Cursor等で動作する拡張機能。
エディタと統合された形でファイル編集・テストを支援
-
Codex Web / Cloud
クラウド上の隔離環境(Cloud tasks)でコードを実行。
重い処理や長時間タスクを非同期で処理。
Cloud tasks/Code reviewはGPT-5.3-Codexで実行され、Plusから軽量枠あり(Cloud tasks 10〜60/5h、Code reviews 20〜50/5h)、Pro 5x → Pro 20xと枠が拡大。
GPT-5.5自体はCLI/IDE/Web/API向けでCloud tasksには対応せず、Cloud側のモデル選択は変更不可
-
Codex App(Desktop)/ Chrome拡張
スタンドアロンアプリと、2026年5月7日に追加されたChrome拡張による Web 自動化サポート
-
ChatGPT Mobile(Codex連携)
2026年5月にCodexがChatGPTモバイルアプリに統合され、移動中の進捗確認・コマンド承認が可能に
-
GitHub / Slack / Linear連携
PR上の「@codex」メンションでのレビューや、SlackからのタスクキックなどMCPベースの統合が用意されている
Codexの大きな特徴は、単独サブスクリプションを持たず、ChatGPTの各プラン(Free・Go・Plus・Pro・Business・Edu・Enterpriseすべて)に内包される点です。
Free・Goは期間限定でCodex同梱が継続されており、Plus以上でローカル利用とGPT-5.3-Codexの軽量Cloud tasks/Code reviewsまで利用可、Pro 5x → Pro 20xと段階的に利用枠が拡大します。
Codexだけを単独契約する経路はなく、ChatGPTプランの選定がそのままCodex利用条件の選定になります。
採用モデルとモデル系列
両者がデフォルトで参照するモデルとモデル系列を整理すると、思想の違いが見えてきます。

以下の表で、2026年5月時点の主要モデルを並べました。Claude Code側はAnthropic直接利用と各クラウド経由でエイリアス解決が変わる点に注意が必要です。
| 区分 | Claude Code | Codex |
|---|---|---|
| 最新フラグシップ | Claude Opus 4.7(2026年4月16日) | GPT-5.5(2026年4月23日) |
| バランス型 | Claude Sonnet 4.6 | GPT-5.4 |
| 効率モデル | Claude Haiku 4.5 | GPT-5.4-mini |
| コーディング特化 | (Opus 4.7が兼ねる) | GPT-5.3-Codex / GPT-5.1-Codex-Max |
| クラウド経由 | Bedrock/Vertex/Foundryでは Opus 4.6 / Sonnet 4.5 にエイリアス解決(最新は明示指定) | ChatGPTプランに含まれるためエイリアス問題なし |
Claude Code側で注意したいのが、Amazon Bedrock・Google Vertex AI・Microsoft Foundry経由で利用する場合の挙動です。
公式model-config上、エイリアスの「opus」はAnthropic直接利用でOpus 4.7、Bedrock/Vertex/Foundry経由ではOpus 4.6に解決されます。
最新モデルを各クラウド経由で使う場合は、フルモデル名(例:「claude-opus-4-7」)や環境変数で明示指定が必要です。
Codex側は、Codex modelsページで「大多数のタスクではGPT-5.5を推奨」「軽量タスクと応答性重視のサブエージェントにはGPT-5.4-mini」と公式に使い分けが示されており、モデル選択はCodex側の標準UIで完結します。
「コーディングエージェント」と「補完ツール」の境界
両者を補完型ツール(GitHub Copilot・Cursor等)と区別する核心は、「1ファイルの補完」から「複数ファイル+シェル+テスト+PR」まで一連で進める自律実行性にあります。
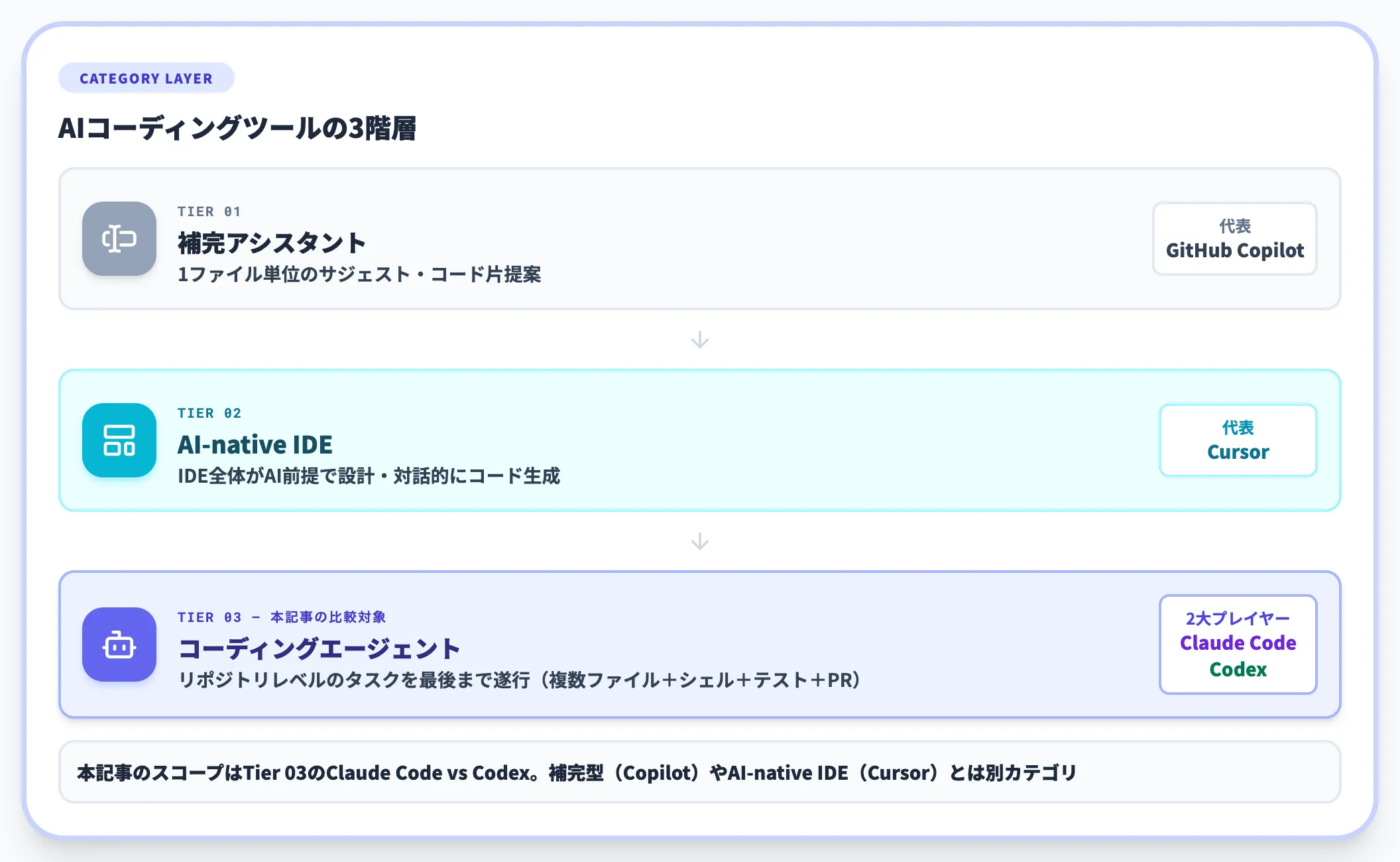
GitHub Copilotが「補完アシスタント」、Cursorが「AI-native IDE」と整理されるのに対し、Claude CodeとCodexは「リポジトリレベルのタスクを最後まで遂行するエージェント」というカテゴリで競合しています。
このカテゴリでの2大プレイヤーが Claude Code と Codex であり、本記事は両者の差分を細部まで分解していきます。
モデルとベンチマーク性能の比較
エージェント型コーディングツールを選ぶうえで、最初に問われる論点が「実際にどれくらいコードを書けるのか」というモデル性能です。
このセクションでは、SWE-bench・Terminal-Benchなどの公開ベンチマーク、トークン効率の実測値、第三者の盲審査評価を整理します。
SWE-bench VerifiedとSWE-bench Pro
エージェント型コーディングモデルの性能評価で最もよく参照されるのが、SWE-bench(Software Engineering Bench)です。
実際のGitHub Issueをベースに「リポジトリを与えてバグを修正させ、テストが通るか」を測定する評価で、公開ベンチマークとしては現状もっとも実務的に近いとされています。

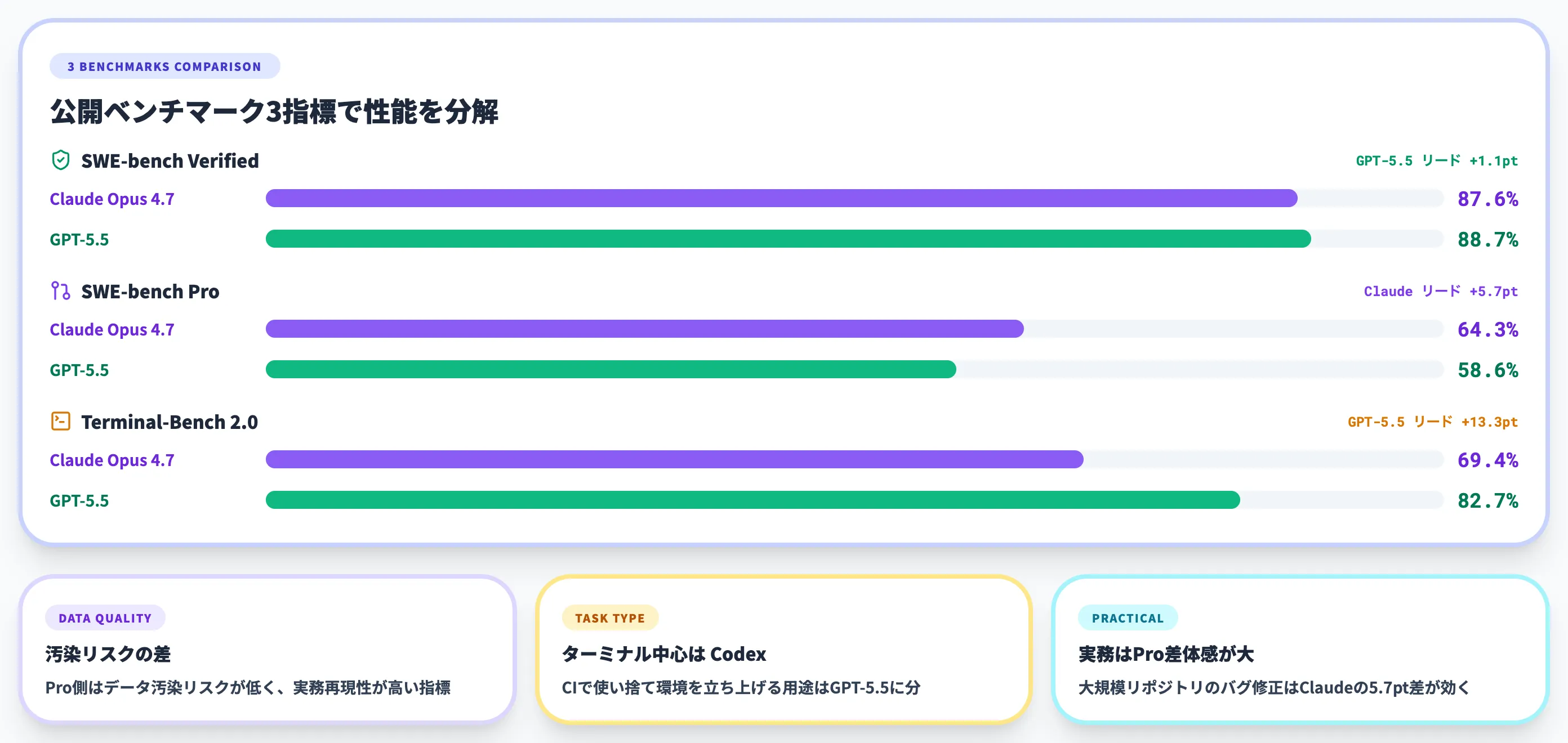
以下の表で、2026年5月時点の主要モデルの結果を整理しました。
| ベンチマーク | Claude Opus 4.7 | GPT-5.5 | リーダー |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 88.7% | GPT-5.5(+1.1pt) |
| SWE-bench Pro | 64.3% | 58.6% | Claude Opus 4.7(+5.7pt) |
| Terminal-Bench 2.0 | 69.4% | 82.7% | GPT-5.5(+13.3pt) |
※ 数値はAnthropic公式リリースおよびOpenAI公式リリースの公表値を、morphllm Codex vs Claude Code 比較(2026年5月)が集約したものを参照。最新値は各社公式ページで都度確認することを推奨します。
この結果から読み取れるのは、「Verified」ではGPT-5.5がわずかに優位、より難易度が高くデータ汚染リスクの少ない「Pro」ではClaude Opus 4.7が大きく優位という非対称な構図です。
SWE-bench Verifiedは公開済みの解答が学習データに混入している懸念があり、SWE-bench Proは新規問題でその懸念が低いとされています。
実務に近い大規模リポジトリのバグ修正という観点では、Claude Opus 4.7の5.7ポイントリードのほうが体感に近いという評価が支援現場では多めです。
Terminal-Bench 2.0:ターミナル操作タスクの差
Terminal-Bench 2.0は、ターミナル操作(環境セットアップ・コマンド実行・エラー対処)を含むタスクを評価するベンチマークです。
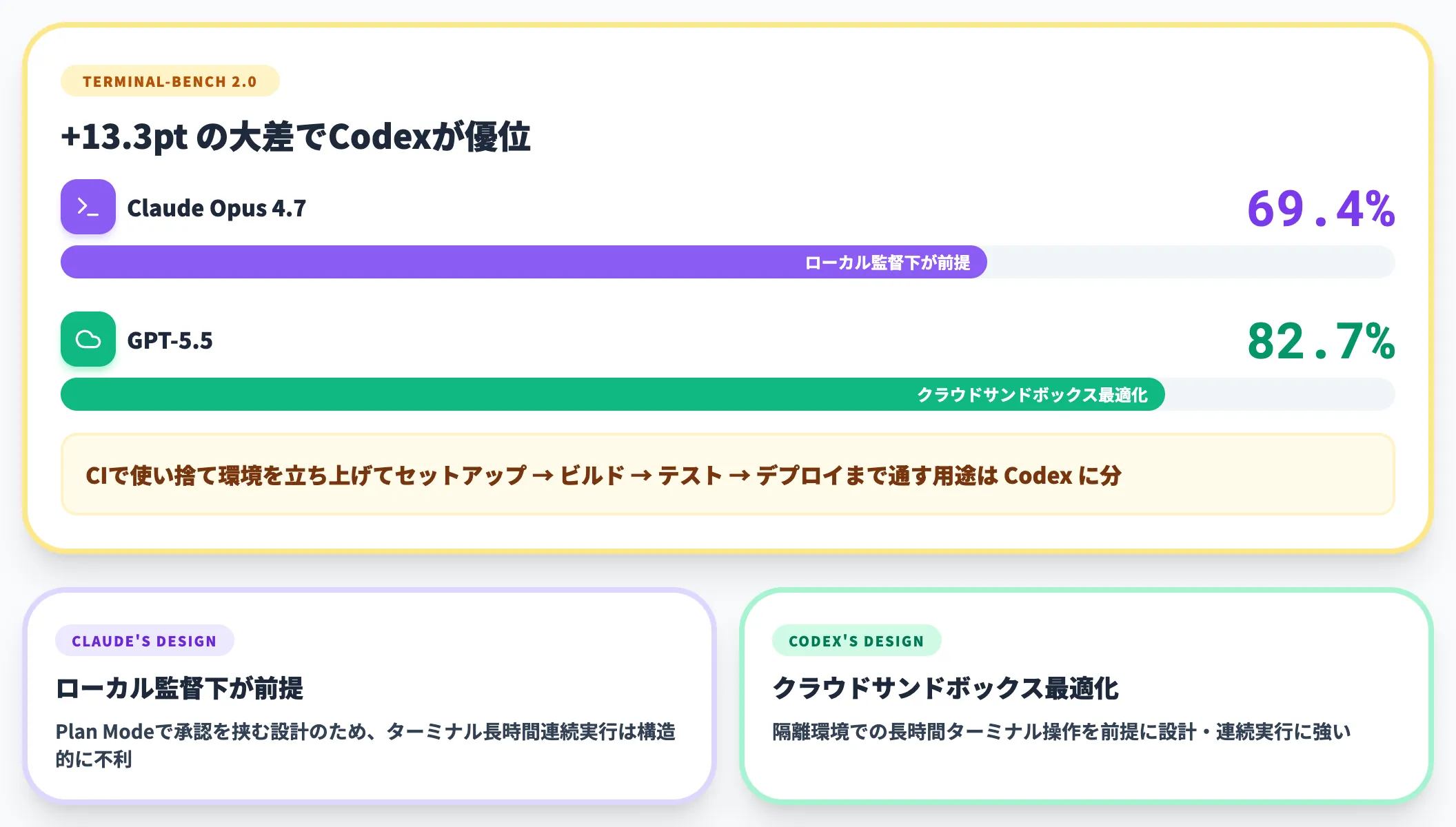
ここではGPT-5.5が82.7%、Claude Opus 4.7が69.4%と、13.3ポイントの大差でCodex側が優位になっています。
この差は、Codexがクラウドサンドボックス上での隔離実行を前提に「ターミナル操作の長時間連続実行」に最適化されているのに対し、Claude Codeが「ローカルでユーザーの監督下で動く」前提で設計されている影響と考えられます。
CIで使い捨ての環境を立ち上げてセットアップ→ビルド→テスト→デプロイまで通したいような用途では、Codex側に分があります。
トークン消費とコスト効率
性能評価で意外と見落とされがちなのが、同じタスクを完了するのに必要なトークン数です。
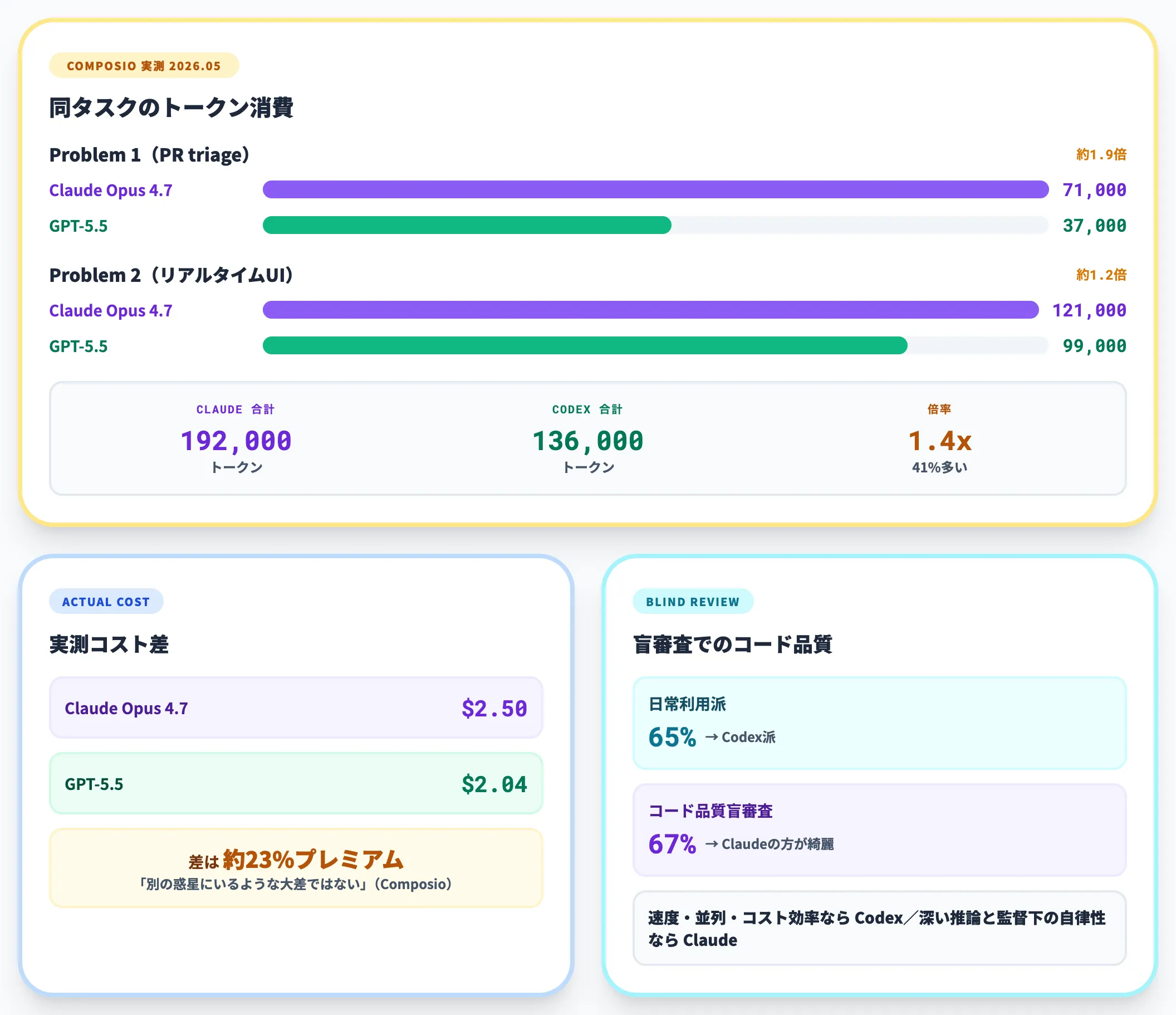
第三者のベンチマーク企業Composioが同じプロジェクトを両ツールで構築した2026年5月時点の実測値は以下のとおりです。
| 検証タスク | Claude Opus 4.7 | GPT-5.5 | 倍率(Claude/Codex) |
|---|---|---|---|
| Problem 1(PR triage) | 約71,000トークン | 約37,000トークン | 約1.9倍 |
| Problem 2(リアルタイムUI) | 約121,000トークン | 約99,000トークン | 約1.2倍 |
| 合計 | 約192,000トークン | 約136,000トークン | 約1.4倍(41%多い) |
※ 出典:Composio: Claude Code vs OpenAI Codex 実測(2026年5月)
Composioは「コストの差はトークン単価ではなくトークン量から来ている」と指摘しており、実測コストはClaude約$2.50/Codex約$2.04、差は約23%プレミアムにとどまります。
つまりトークン消費差は確かに存在するものの、Composioが付記しているとおり「別の惑星にいるような大差ではない」水準で、ベンチマーク当初に騒がれた「12倍」級の差は実APIでは観測できていません。
それでも「Claudeの高めのトークン使用は、より徹底的で決定論的な出力と相関する」という側面はあり、トークン効率だけで評価するのは不公平です。
実際、500名超の開発者を対象にした調査では「日常的にはCodex派が65%」だった一方、コード品質の盲審査(生成元を伏せた評価)では「Claude Codeのほうが綺麗」と回答した割合が67%に達したという報告もあります。
速度・並列・コスト効率を取るならCodex、深い推論と監督下の自律性を取るならClaude Codeという構図がここでも見えてきます。
モデル選択の実務指針
性能比較から導かれる実務的な使い分けは次のとおりです。
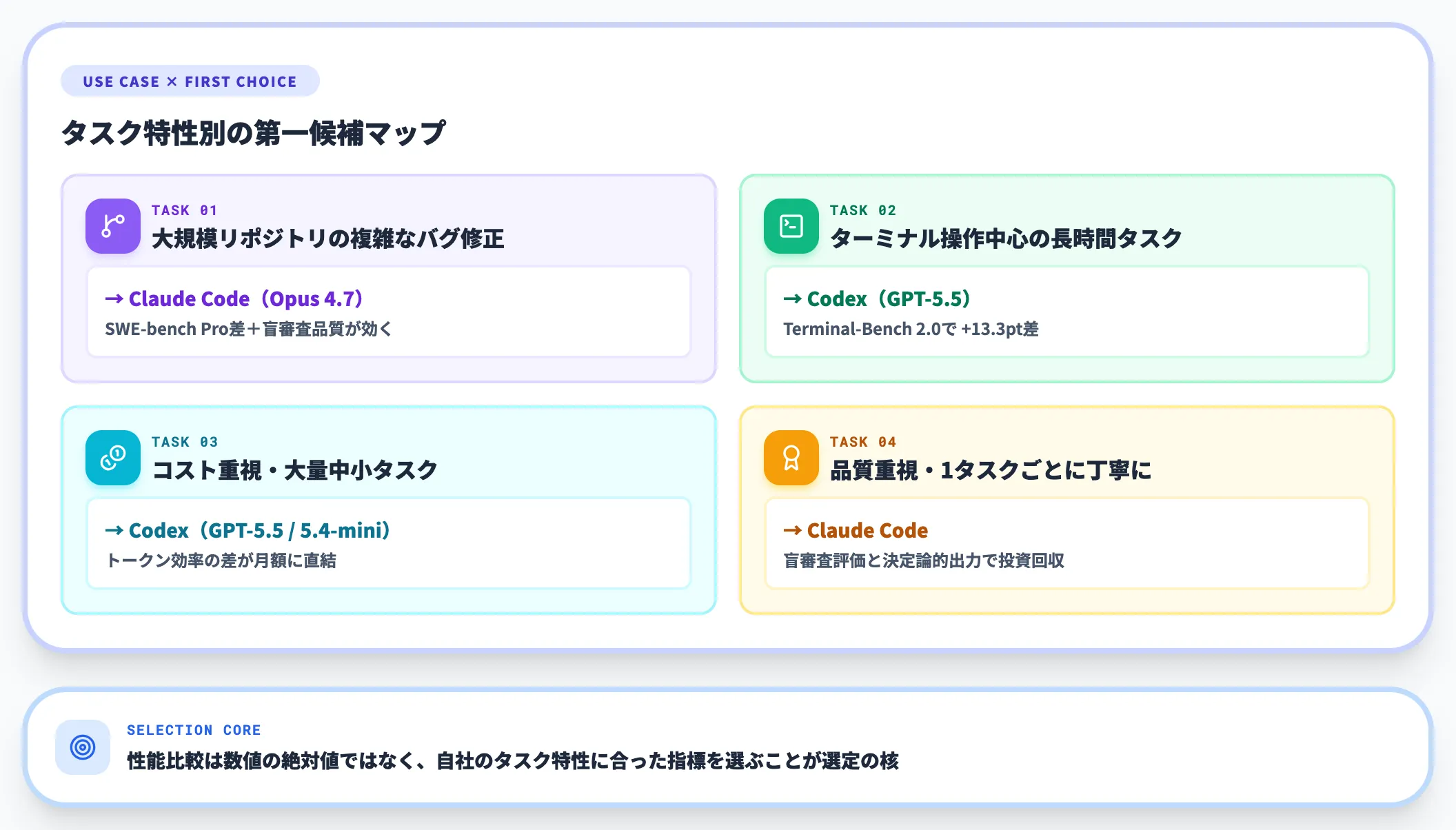
- 大規模リポジトリの複雑なバグ修正・設計判断中心: Claude Code(Opus 4.7)が第一候補。SWE-bench Proの差と盲審査品質の高さが効く
- ターミナル操作中心の長時間タスク・CIワークフロー: Codex(GPT-5.5)が第一候補。Terminal-Bench 2.0の差が体感に出やすい
- コスト重視で大量の中小タスクを回したい: Codex(GPT-5.5またはGPT-5.4-mini)が第一候補。トークン効率の差がそのまま月額に効く
- 品質重視で1タスクごとに丁寧に進めたい: Claude Code。トークン消費は増えるが、盲審査評価と決定論的出力で投資回収しやすい
性能比較は数値の絶対値ではなく、自社のタスク特性に合った指標を選ぶことが選定の核です。
次のセクションでは、性能を支える「実行環境」の差を整理します。
実行環境とサンドボックス、自律性の比較
性能と並んで決定的な差を生むのが、「どこで・どの隔離レベルで・どこまで自律的に動かすか」という実行環境の設計思想です。
Claude CodeとCodexの差は、性能差以上にこの「実行モデル」に表れます。
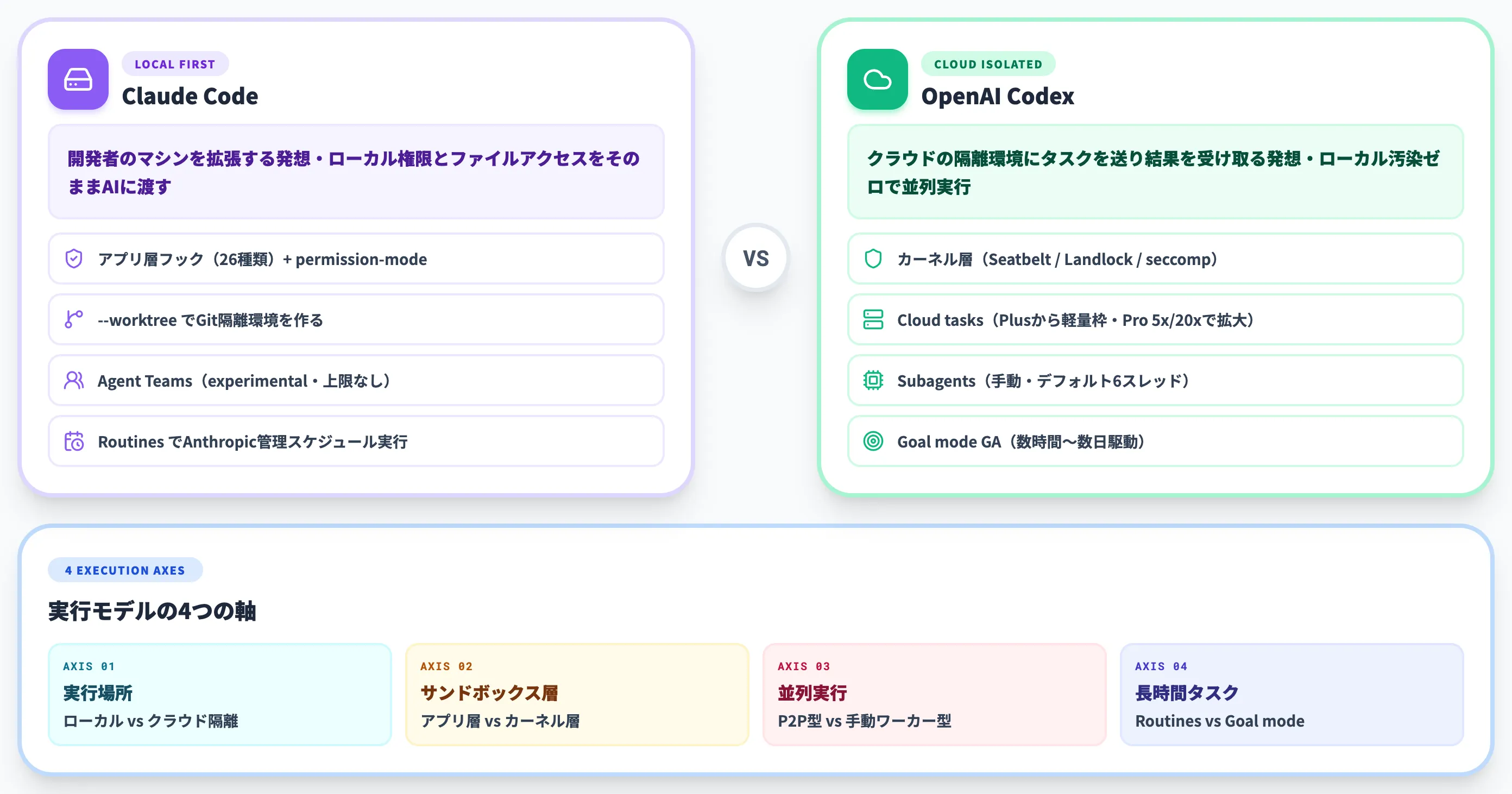
ローカル中心 vs クラウド中心
実行モデルの基本構図は次の通りに整理できます。

| 観点 | Claude Code | Codex |
|---|---|---|
| 主要実行場所 | 開発者のローカルマシン | ローカル+OpenAI管理のクラウドサンドボックス(Cloud tasksはChatGPT Plusから軽量枠あり、Pro 5x/Pro 20xで枠が拡大) |
| ファイルアクセス | フルアクセス(ローカルファイルに直接書き込み) | コンテナ内に限定(インターネット無効化が標準) |
| 長時間タスク | ローカルプロセス+Routines(Anthropic管理) | クラウドタスクで非同期実行(数時間〜数日対応) |
| モバイル連携 | Remote Control経由でローカルを遠隔操作 | ChatGPT Mobile + Codex App(2026年5月14日追加) |
| CI/パイプライン | Hooks・GitHub Actions・GitLab CI/CD | codex remote-control(v0.130.0、2026年5月) |
Claude Codeは「開発者のマシンを拡張する」発想で設計されており、開発者がローカルに持っている権限とファイルアクセスをそのままAIに渡せます。
Codexは「クラウドの隔離環境にタスクを送り、結果を受け取る」発想で設計されており、ローカル環境を汚さず、複数タスクを並列で走らせやすい構造になっています。
サンドボックスとガバナンスのレイヤー差
実行モデルの差は、安全性を担保するレイヤーの差にも表れます。

blakecrosley.comによる2026年版の分析では、両者のサンドボックス設計を次のように整理しています。
-
Codex
カーネルレベルのサンドボックス。
macOSでは Seatbelt、Linuxでは Landlock + seccomp、Windowsでは専用sandbox(2026年5月強化)を使い、OSの機能で「読めるディレクトリ」「書けるパス」「ネットワーク」を制限する
-
Claude Code
アプリケーション層フック。
26種類のライフサイクルイベントごとに「permission-mode」(「default」/「acceptEdits」/「plan」/「auto」/「dontAsk」/「bypassPermissions」)で承認を制御し、「--worktree」でGit隔離環境を作る
カーネルレベル制限を持つCodexは、サンドボックス外への書き込みを物理的にブロックできる利点がある一方、ローカルマシンへの自由なアクセスを必要とするタスク(特定ツールチェーン依存・ローカルDB接続等)は実行しづらくなります。
アプリ層フックで制御するClaude Codeは、開発者が「どこまで自由を渡すか」を細かく調整できる柔軟さがある一方、誤設定で意図しない領域に書き込まれるリスクは Codex より高くなります。
サブエージェントと並列実行
長時間・大規模タスクを並列でこなす能力も、両者の差が大きい論点です。

| 観点 | Claude Code Agent Teams(experimental) | Codex Subagents |
|---|---|---|
| 提供状況 | experimentalでデフォルト無効。環境変数 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 で有効化(v2.1.32以降) | 公式機能として利用可、手動トリガー |
| 構成 | 調整型サブエージェント(タスク依存関係を追跡) | メインエージェントが手動で起動するワーカー型 |
| 並列数 | ハード制限なし(利用枠に応じる) | 並列実行に対応(公式config上のagent threadsはデフォルト6) |
| 起動方式 | コマンドで自動起動・調整 | 公式仕様上、自動spawnせず明示指示で起動("spawn two agents" 等) |
| 通信 | 直接メッセージング+ブロードキャスト | 集約はメインエージェント側、結果は要約推奨 |
| 実行環境 | Gitワークツリー(ローカル) | Codexのagent threads(ローカルでも実行可、Cloud環境で並列化する場合はCloud tasks枠を使う) |
| 推奨用途 | 役割分担を伴う複雑な並行作業 | read-heavyタスク(探索・テスト・トリアージ・要約) |
Claude CodeのAgent Teamsは「タスクリストを共有してエージェント同士が直接やり取りする」P2P型に近い構造で、複雑な並行作業を柔軟に組めます。
公式ドキュメント上はexperimental扱いで、デフォルト無効・環境変数 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 で有効化する前提です。
本番運用では既知の制約(session resumeで teammates が復元されない・task statusのラグ・shutdownの遅延等)を踏まえた設計が必要になります。
Codexのサブエージェントは公式ドキュメントで「自動spawnせず、明示指示で起動」と明記されており、メインエージェントがワーカーを呼び出して結果を集約する設計です。
公式は「サブエージェントワークフローは単一エージェントよりトークン消費が増える」「書き込み競合のリスクがあるためread-heavyタスク(探索・テスト・トリアージ・要約)向け」と注記しています。
両者とも「並列だから速い」という単純な構図ではなく、Claude Code側はローカルのCPU・メモリ・利用枠の3つを監視する必要があり、Codex側はread/writeのタスク特性とトークン消費の増分を見極めて運用する必要があります。
長時間タスクとGoal mode
「数時間〜数日かかるタスクをAIに任せきれるか」も、エージェント型ツールの実用度を測る指標です。
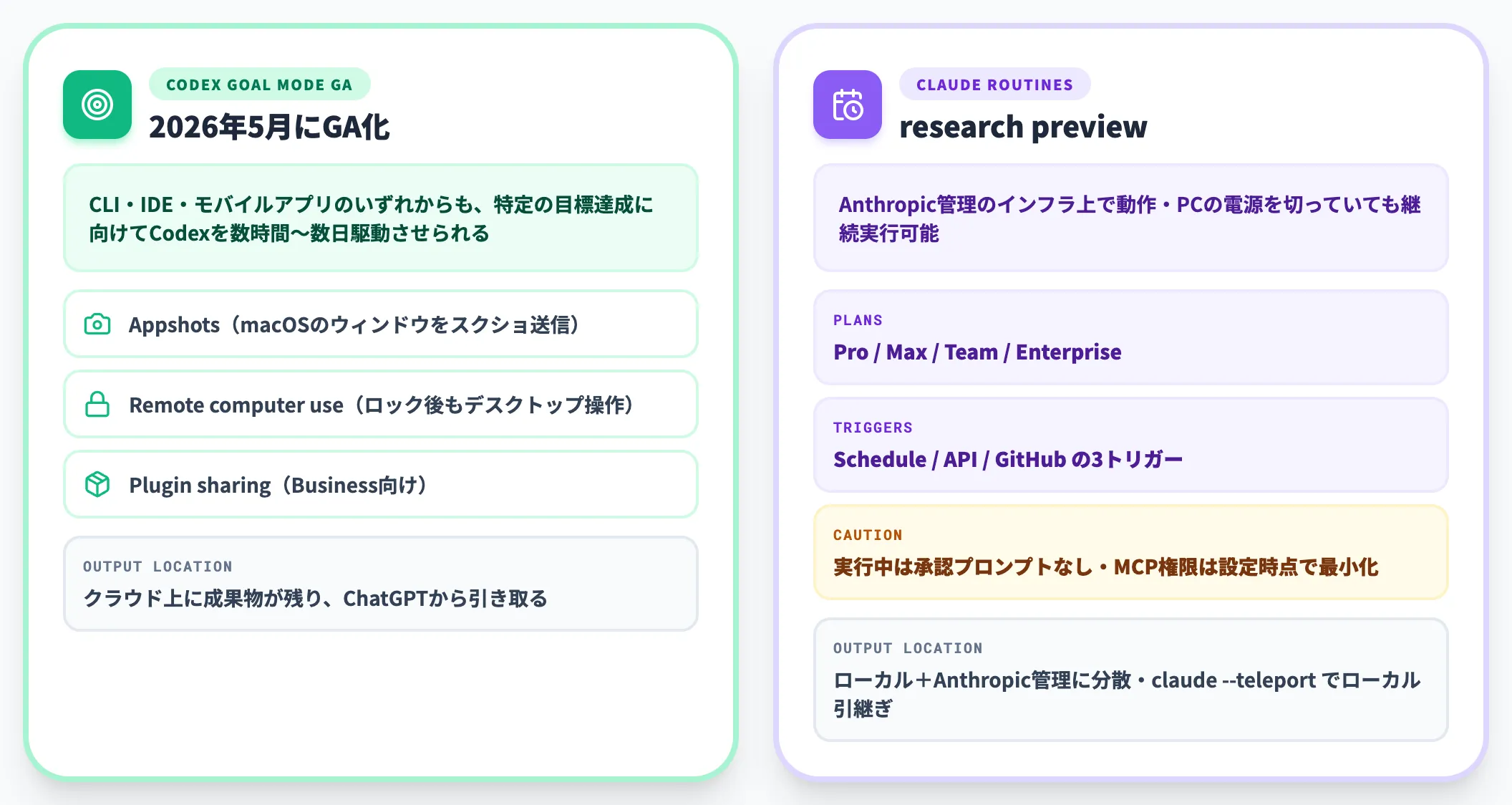
Codexは2026年5月に**Goal modeをGA化(experimental解除)**し、CLI・IDE・モバイルアプリのいずれからも、特定の目標達成に向けてCodexを数時間〜数日駆動させられるようになりました。
同月のアップデートでは、macOSアプリで現在のウィンドウをスクショ付きで送れるAppshots、Macがロック後でもCodexがデスクトップを操作できるRemote computer use、Business向けのPlugin sharing、ブラウザ利用の改善も追加され、長時間タスクの運用フローが整理されました。
Claude Code側はRoutines(research preview)でスケジュール実行を可能にしており、Anthropic管理のインフラ上で動作するため、PCの電源を切っていても継続実行できます。
対応プランはPro/Max/Team/Enterpriseで、Schedule/API/GitHubの3トリガーに対応。
Routines実行中は承認プロンプトが出ない仕様のため、コネクタやMCPの権限はルーティン設定時点で必要最小限に絞っておく必要があります。
両者の違いは「長時間タスクが終わった時にどこに結果が落ちるか」で、Codexはクラウド上に成果物が残り、開発者はChatGPTから結果を引き取る形になります。
Claude Code/Routinesはローカル環境とAnthropic管理インフラに分散し、必要に応じてWebセッションを「claude --teleport」でローカルに引き継げます。
料金プランと総保有コストの比較
料金は表面の月額だけ見ると拮抗していますが、サブスクへの内包形態・トークン消費差・年払い割引の組み合わせで、実質コストは構成次第で大きく分岐します。
このセクションでは、両社の料金体系を並べたうえで、トークン効率を踏まえた実コスト試算の考え方を整理します。

Claude Codeの料金プラン
Claude Codeは、Claude本体のサブスクリプションに含まれる形で提供されます。

2026年5月時点の主要プランは次のとおりです。
詳細はClaude Code料金プラン完全ガイドで別途整理しています。
| 区分 | プラン | 月額(月払い) | 月額(年払い) | Claude Codeの扱い |
|---|---|---|---|---|
| 個人 | Free | $0 | $0 | 利用不可 |
| 個人 | Pro | $20 | $17 | 利用可(標準利用量) |
| 個人 | Max 5x | $100 | — | Pro比5倍の利用量 |
| 個人 | Max 20x | $200 | — | Pro比20倍の利用量 |
| 法人 | Team Standard seat | $25/席 | $20/席 | 利用可、5〜150席 |
| 法人 | Team Premium seat | $125/席 | $100/席 | 利用可、追加使用量付き |
| 法人 | Enterprise | 個別 | 個別 | SSO/SCIM/監査ログ/HIPAA対応版あり |
※ 出典:claude.com/pricing 2026年5月時点
個人ヘビーユースで月20時間以上の自律実行を回すならMax 5xが目安、複数プロジェクト並行ならMax 20xという段階が定石です。
チーム導入では、Team plan Standard seatに2026年1月のリリースノート以降Claude Codeアクセスが含まれるようになり、開発業務とドキュメント業務の境界が曖昧な日本企業でも導入設計しやすくなりました。
Codexの料金プラン(ChatGPT統合)
CodexはChatGPTサブスクリプションに内包されるため、「Codexを使う=どのChatGPTプランを契約するか」という選択になります。

2026年5月時点でCodex利用に関係する主要なChatGPTプランは次のとおりです。
| 区分 | プラン | 月額 | GPT-5.5 ローカル/5h | Cloud tasks/Code reviews(GPT-5.3-Codex)/5h |
|---|---|---|---|---|
| 個人 | Free | $0 | 期間限定でCodex利用可(具体枠はusage dashboardで確認) | 期間限定でCodex利用可(具体枠はusage dashboardで確認) |
| 個人 | Go | $8 | 期間限定でCodex利用可(具体枠はusage dashboardで確認) | 期間限定でCodex利用可(具体枠はusage dashboardで確認) |
| 個人 | Plus | $20 | 15〜80メッセージ(CLI/IDE/Web/iOS) | Cloud tasks 10〜60/Code reviews 20〜50 |
| 個人 | Pro 5x | $100 | 80〜400メッセージ | Cloud tasks 50〜300/Code reviews 100〜250 |
| 個人 | Pro 20x | $200 | 300〜1,600メッセージ | Cloud tasks 200〜1,200/Code reviews 400〜1,000 |
| 法人 | Business | 標準seat $25/席(月払)/$20/席(年払) | 15〜80メッセージ(Plusと同等枠) | Cloud tasks 10〜60/Code reviews 20〜50(Plusと同等枠) |
| 法人 | Enterprise/Edu | 個別(usage scales with credits) | 固定利用枠なし | 固定枠なし、クレジット制 |
※ 出典:OpenAI Codex Pricing 2026年5月時点。GPT-5.5自体はCloud tasks/Code reviewには対応せず、Cloud側はGPT-5.3-Codex(モデル選択変更不可)で実行される。Pro $100は2026年5月31日まで2x、Pro $200は同日まで25x相当の上方枠が暫定適用中で、ブースト解除後は標準値に戻る。Free/GoへのCodex同梱も期間限定の措置で、具体枠はusage dashboardで確認するのが正確。
表面の月額は両社ほぼ同水準ですが、CodexがChatGPT契約に内包される点が違いを生みます。
すでにChatGPT Plus以上を契約している組織は、その利用枠の範囲内で追加のサブスク契約なしにCodexのローカル利用とCloud tasks/Code reviewsまで試せます。
Cloud tasksとCode reviewはGPT-5.3-Codexで実行され、Plus/Business標準seatでも軽量枠(Cloud tasks 10〜60/5h、Code reviews 20〜50/5h)が含まれ、Pro 5x → Pro 20xと段階的に枠が大幅に拡大します。
Business標準seatの枠を超える大量利用が必要な場合は、usage-basedのCodex seatsやChatGPT creditsの追加購入で拡張します(API Key経由はcloud-based featuresの対象外なので、Cloud tasksの追加手段にはなりません)。
加えて、Codexの利用枠はChatGPT for ExcelやWorkspace AgentsなどのほかのChatGPT agentic機能と共有される点も実務上の見積もりで重要です。
Codex単体での利用想定が他のagentic機能とぶつかると、想定より早く枠を使い切るため、Business/Enterprise導入時はチーム全体のagentic usageの内訳を見積もったうえで席数や追加クレジットを決める必要があります。
Claude Codeを使うには Claude側のサブスクが追加で必要になるため、ChatGPT既存契約者にとってはローカル利用に加えてCloud tasks/Code reviewsの軽量枠まで「追加サブスクなし」で取れる点がコスト構造上の優位になります。
重い長時間バッチや並列subagentsを本格運用するならPro 5x以上または Business+Codex usage seatsへ段階的に拡張する設計が現実的です。
総保有コストの考え方
表面額だけで判断するのは早計で、トークン消費差と年払い割引を組み合わせた実コスト試算が重要です。
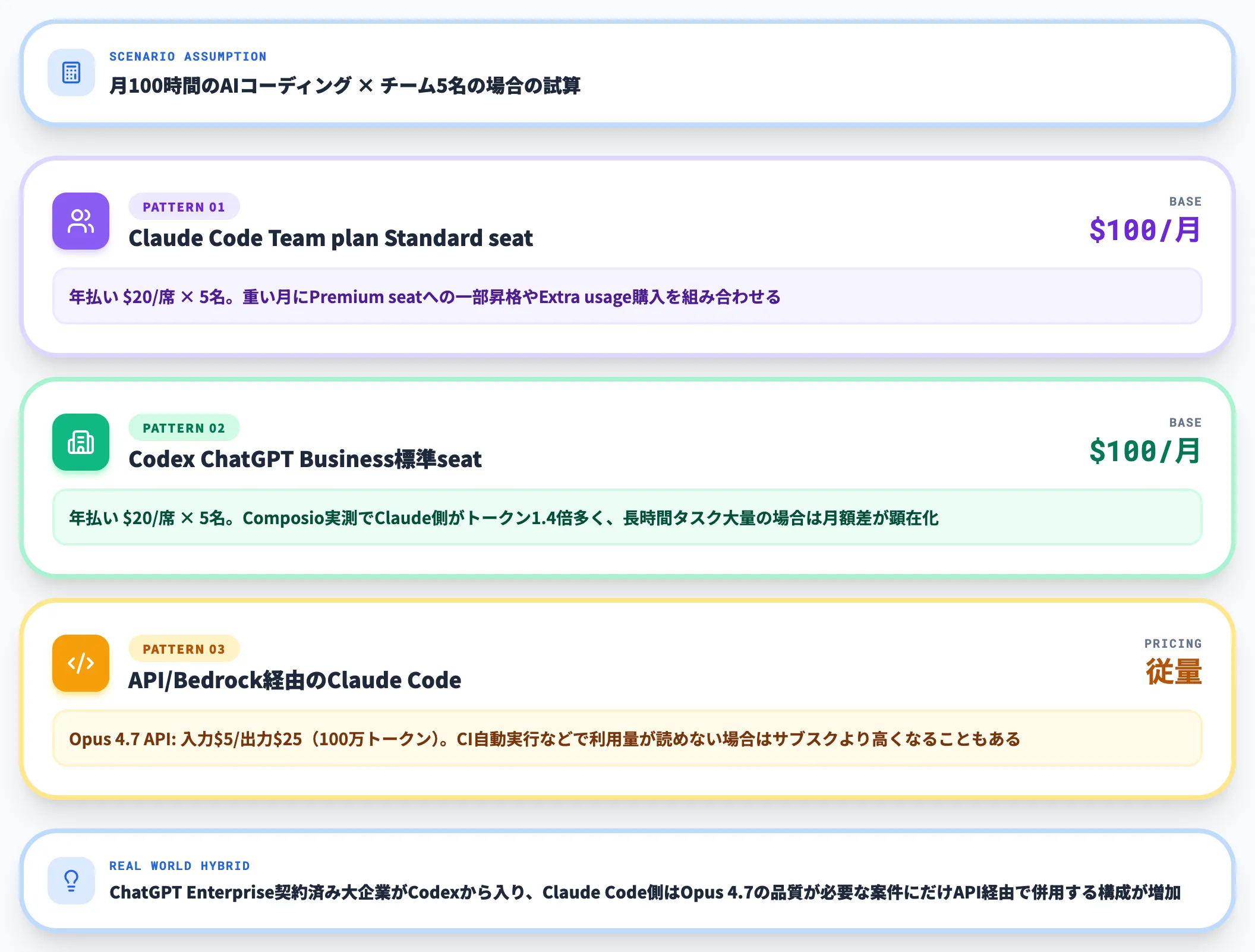
例えば、月100時間のAIコーディングを使うチーム5名で試算すると、概ね次のような構図になります。
-
Claude Code: Team plan Standard seat(年払い$20/席)×5名 + 重い案件月の追加使用量
基礎コスト$100/月。
重い月にPremium seatへの一部昇格やExtra usage購入を組み合わせる
-
Codex: ChatGPT Business標準seat(年払い$20/席)×5名 + 必要に応じたクレジット
基礎コスト$100/月(Codex-only seatはusage-basedで固定月額なし)。
Composio 2026年5月実測ではClaude側のトークン消費が約1.4倍多く、長時間タスクを大量に回すケースでは月額差として徐々に効いてくる。
Cloud tasksを並走させる場合は標準seatに含まれる枠の範囲で運用するか、usage-basedのCodex seatsを追加する
-
API/Bedrock経由のClaude Code
Claude Opus 4.7のAPI価格は入力$5/出力$25(100万トークンあたり)。
CI自動実行など利用量が予測しづらいケースで使うと、サブスクより高くつくこともある
「ChatGPTを既に契約している組織は実質Codex無料に近い」「Claude Code側は単独契約が必要だが、Max 5x相当の重い個人利用なら$100で済む」というのが、コスト面の現実的な構図です。
支援現場でも、ChatGPT Enterprise契約済みの大企業がCodexから入り、Claude Code側はOpus 4.7の品質が必要な案件にだけAPI経由で併用する、というハイブリッド構成が増えています。
API直接利用との関係
サブスクリプションを使わず、APIキー経由で従量課金する選択肢もあります。
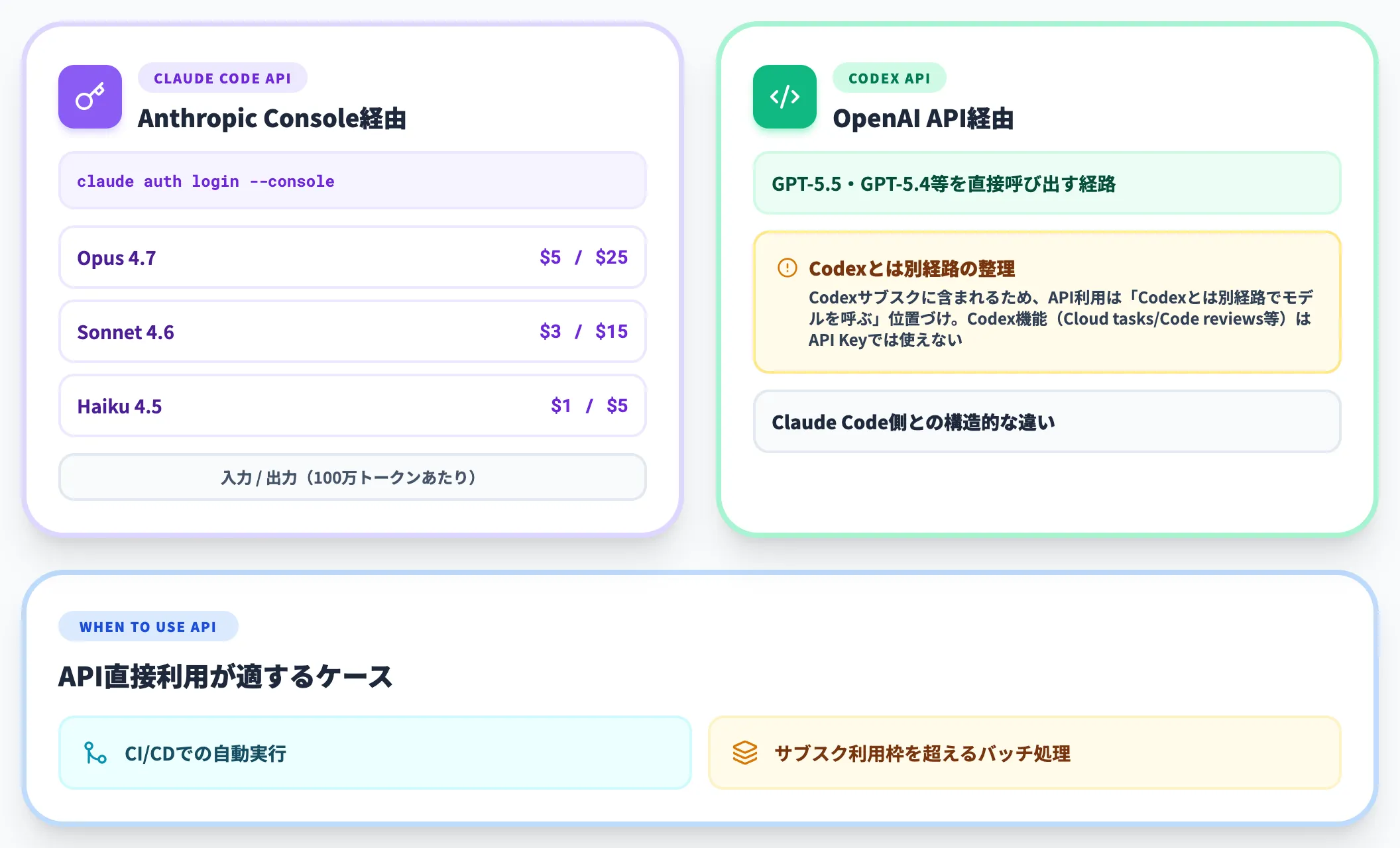
- Claude Code API: Anthropic ConsoleでAPIキーを発行し、「claude auth login --console」で接続。Opus 4.7 入力$5/出力$25、Sonnet 4.6 入力$3/出力$15、Haiku 4.5 入力$1/出力$5(100万トークンあたり)
- Codex API: OpenAI APIで GPT-5.5・GPT-5.4等を呼び出す。Codexというよりはモデル直接呼び出しに近い経路
CI/CDでの自動実行や、サブスクの利用枠を超えるバッチ処理では、API従量課金のほうが扱いやすくなります。Codex側はChatGPTサブスクに含まれるため、API利用は「Codexとは別経路でモデルを呼ぶ」整理になる点が、Claude Code側との構造的な違いです。

エコシステムや拡張機能、CI/CD連携の比較
コーディングエージェントは、単体性能だけでなく既存の開発ツール群とどう繋がるかで実用度が大きく変わります。
このセクションでは、MCP対応・GitHub/Slack連携・Skills/Plugins・CI/CD統合を順に比較します。
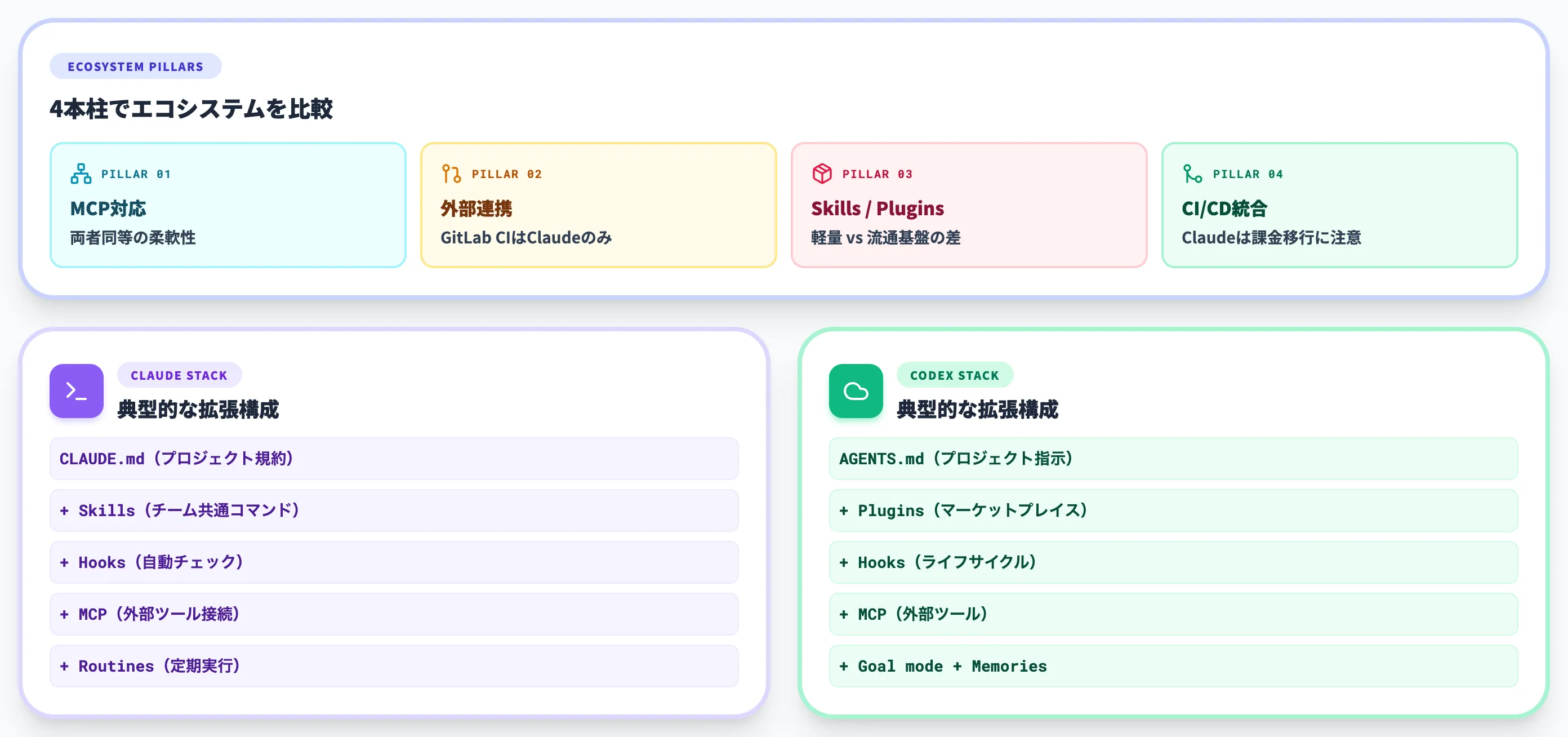
MCP(Model Context Protocol)対応
両者ともAnthropicが提唱したModel Context Protocol(MCP)に対応し、外部データソース・ツールへの接続を共通インターフェースで設計できます。
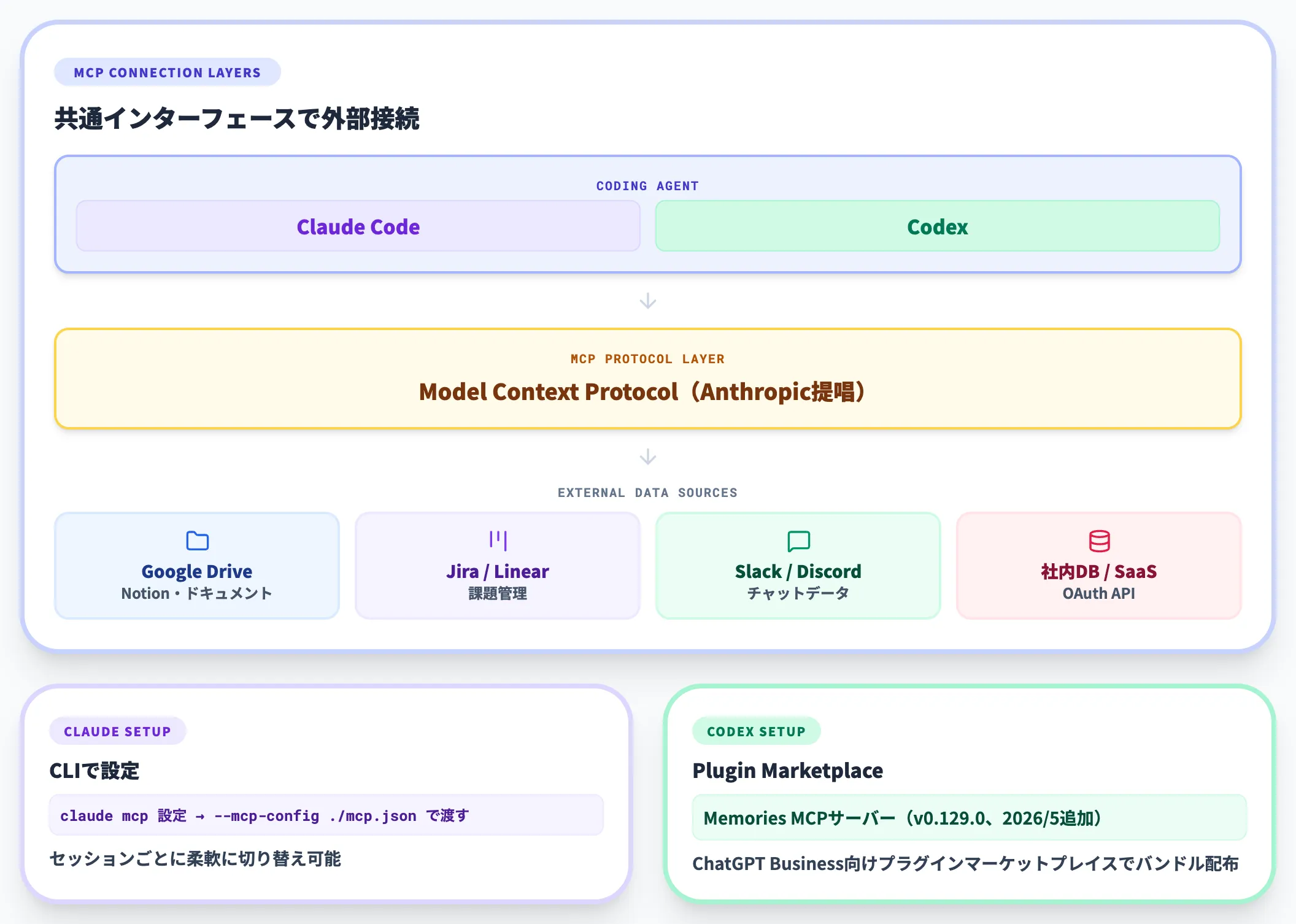
代表的な接続先は次のとおりです。
- Google Drive・Notion等のドキュメント参照
- Jira・Linear等の課題管理
- Slack・Discordからのデータ取得
- 社内DB・カスタムAPI・OAuthベースのSaaS連携
Claude Code側は「claude mcp」コマンドでMCPサーバーを設定し、「--mcp-config ./mcp.json」でセッションに渡します。
Codex側は2026年5月にMemories MCPサーバー(v0.129.0)を追加し、ChatGPT Business向けにプラグインマーケットプレイスを提供。
再利用可能なプラグインバンドルをチーム配布できる仕組みになっています。
MCP対応では両者ほぼ同等の柔軟性を持ちますが、Codex側のプラグインマーケットプレイスがOpenAI公式の流通基盤を持っている点が異なり、社内専用ツールを横断的に配布したい組織にとっては運用負荷が低い設計です。
GitHub・Slack・Linearなど外部連携
開発フローへの統合という点では、両者ともよく似た連携を持ちます。

| 連携先 | Claude Code | Codex |
|---|---|---|
| GitHub | GitHub Actions、PR上のメンション、Code Review機能 | 「@codex」メンション、GitHub PR連携、Chrome拡張(2026年5月7日) |
| GitLab | GitLab CI/CD連携(beta) | (主要対応はGitHub中心) |
| Slack | 「@Claude」メンションでバグレポートからPR作成 | Slack統合あり |
| Linear | MCP経由 | Linear統合あり |
| iOS / Mobile | Claude iOSアプリ・Remote Control | ChatGPT Mobile(Codex連携、2026年5月) |
| Chrome | Chrome統合(beta、Anthropic直接プラン限定) | Chrome拡張(2026年5月) |
GitLab CI/CD連携が現時点ではClaude Code側にのみ存在する点が、GitLab中心の組織にとっての差別化要素になります。
CodexはGitHubエコシステム側に寄せた設計です。
逆に、ChatGPT BusinessでCodexを使えば、すでに導入済みの GPT-5.5・Operatorなど他のOpenAI製品との行き来がスムーズで、開発以外のチームも巻き込みやすい構造があります。
Skills・Plugins・拡張機能
繰り返し使う作業をパッケージ化する仕組みも、両者で設計思想が違います。

-
Claude Code Skills
Markdownで定義し、プロジェクト単位・ユーザー単位・グローバル単位で配置できる。
「/review-pr」や「/deploy-staging」のようなコマンドにチーム共通の手順を集約する
-
Claude Code Hooks
Claude Codeのアクション前後にシェルコマンドを実行。
ファイル編集後のフォーマッタ実行・コミット前のリント実行など
-
Codex Plugin Sharing
ChatGPT Businessでプラグインマーケットプレイス経由の共有。
再利用可能なプラグインバンドルをチーム配布できる
-
Codex Hooks GA
ライフサイクルフックがGA化(2026年)。
タスク前後のスクリプト実行に対応
Claude Code側は「Markdownファイルで定義」という軽量設計、Codex側は「プラグインバンドル+マーケットプレイス」という流通重視設計で、チーム規模が大きいほどCodex流の流通基盤が効きやすく、開発者個人の柔軟性を重視するならClaude Code流が効きやすいという棲み分けになります。
CI/CD統合
CI/CDへの組み込みは、両者の差が運用に直結する論点です。

-
Claude Code
GitHub Actions(公式)、GitLab CI/CD(beta)、SDK headlessモード(「claude -p」)。
2026年6月15日以降、ClaudeサブスクでのAgent SDK・GitHub Actions連携は別途「Agent SDK credit」を消費する課金扱いに移行する点に注意
-
Codex
「codex remote-control」(v0.130.0、2026年5月)でヘッドレスCI/パイプライン統合。
GitHub Actions経由のレビュー自動化はGitHubエコシステムとの統合が深い
Claude Code側は2026年6月15日以降のAgent SDK credit課金が運用設計に影響を与えるため、サブスクで非対話実行を回す場合は残量管理が必須になります。
Codex側はChatGPTクレジットで一元管理されるため、課金体系の理解は比較的シンプルです。
拡張機能の典型構成
両者の拡張機能を組み合わせた典型構成は次のとおりです。
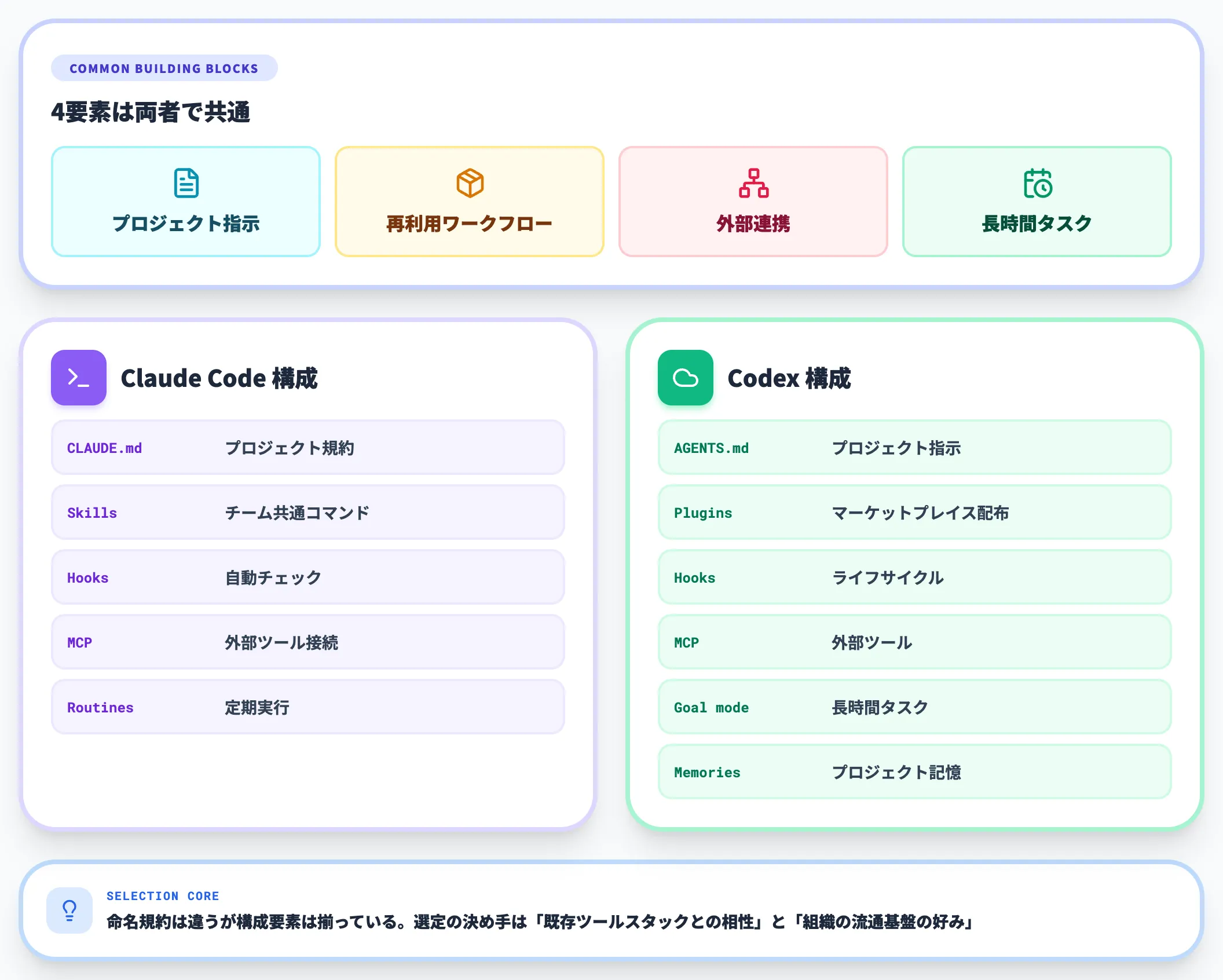
- Claude Code構成: CLAUDE.md(プロジェクト規約)+ Skills(チーム共通コマンド)+ Hooks(自動チェック)+ MCP(外部ツール接続)+ Routines(定期実行)
- Codex構成: AGENTS.md(プロジェクト指示)+ Plugins(マーケットプレイス配布)+ Hooks(ライフサイクル)+ MCP(外部ツール)+ Goal mode(長時間タスク)+ Memories(プロジェクト記憶)
命名規約は違うものの、「プロジェクト指示+再利用ワークフロー+外部連携+長時間タスク」という構成要素は両者で揃っており、選定の決め手は「既存ツールスタックとの相性」と「組織の流通基盤の好み」に落ち着きます。
エンタープライズ機能とセキュリティ、データ統制の比較
法人での本格導入では、SSO/監査ログ/データ越境制御/モデル学習対象外契約などのコンプライアンス要件が、ツール選定の決め手になることが多くなります。
このセクションでは、両者のエンタープライズ機能を整理し、選定の判断軸を提示します。
認証・統制機能の比較
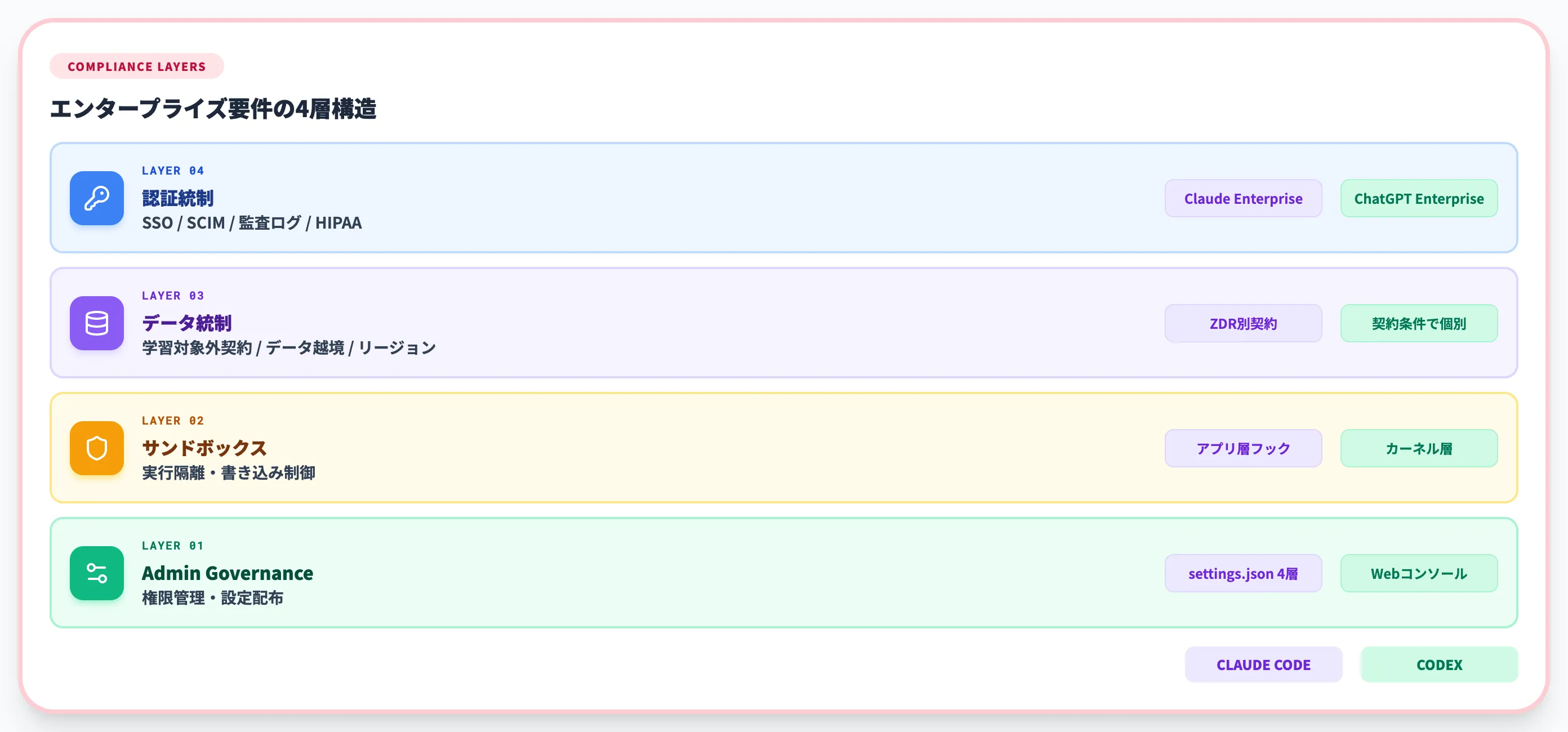
両者のエンタープライズ機能の対比は次のとおりです。

| 機能 | Claude Code | Codex |
|---|---|---|
| SSO(SAML2.0/OIDC) | Enterpriseプランで対応 | ChatGPT Enterpriseで対応 |
| SCIM(自動プロビジョニング) | Enterpriseプランで対応 | ChatGPT Enterpriseで対応 |
| 監査ログ | Enterpriseプランで保持 | ChatGPT Enterpriseで保持 |
| HIPAA対応 | Claude for Enterpriseで対応版あり | ChatGPT Enterpriseで対応版あり |
| データ保持なし契約 | ZDR(Zero Data Retention)を別契約 | エンタープライズ契約条件次第(学習不使用が原則) |
| Admin governance | Managed設定(OS別固定パス)+ プロジェクト/ユーザー/ローカル設定の4層 | Admin Setup、Agent approvals & security、Remote connections設定 |
| サンドボックス | アプリ層フック+Gitワークツリー | カーネル層(Seatbelt/Landlock/seccomp/Windows sandbox) |
Claude Code側のZDR契約は推論部分に限定され、Claude.ai Chat・Cowork・Analytics・ユーザー管理・外部連携は対象外で、ZDR有効時にはClaude Code on the Web・Desktop appのRemote sessions・「/feedback」など一部機能が無効化されます。
Amazon Bedrock・Google Vertex AI・Microsoft Foundry経由で利用する場合は、各クラウドのデータ保持ポリシーに従う点も契約時に確認すべきポイントです。
Codex側は ChatGPT Enterprise の契約条件で「ビジネスデータをモデル学習に使用しない」原則が示されていますが、機能ごとの細部ルールは契約書面で個別確認する必要があります。
モデル学習・データ越境の扱い
個人プランでの業務利用の可否は、両者でほぼ同じ整理になります。
- 個人プラン(Free・Pro・Max・Plus・Pro個人): 入力データがモデル学習に使われる可能性があり、機密データを扱う業務利用は推奨されない
- チーム・ビジネス・エンタープライズ: 学習対象外契約が原則。データ保持期間・データ越境ポリシーは契約書で確認
業務利用が確定した時点で、Claude Code側はTeam plan Standard seat以上、Codex側はChatGPT Business以上に切り替えるのが安全です。
データ越境(米国リージョン送信)が許容できない組織は、Claude Code側はBedrock/Vertex/Foundry経由のクラウドリージョン要件、Codex側はChatGPT Enterprise契約のリージョン条件を個別確認する必要があります。
サンドボックス設計の安全性比較
サンドボックスの設計差は、エンタープライズ運用での安全性に直接影響します。

Codexはカーネルレベルで「読めるディレクトリ」「書けるパス」「ネットワーク」を制限するため、AIが暴走してもOS機能で物理的にブロックできます。
Claude Codeはアプリケーション層フックで制御するため柔軟性は高いものの、誤設定によるリスクは Codex より高くなります。
本番リポジトリではPlan Modeを軸に「--worktree」でGit隔離環境を作る運用が必須です。
金融・ヘルスケアなど規制の厳しい業界では、サンドボックス設計の差が監査対応コストにも効いてくる点を、選定時に意識しておく価値があります。
Admin governance(管理者統制)
組織での権限管理は、両者で設計思想が異なります。

-
Claude Code
4層構造のsettings.json(Managed/ユーザー/プロジェクト/ローカル)。
Managed設定はOS別固定パスでIT管理者が配布し、ユーザー側で上書きできない最上位スコープを持つ。
プロジェクト設定をリポジトリにコミットしてチーム共有
-
Codex
Admin Setup、Managed configuration、Agent approvals & security、Access token認証、Remote connectionsの組み合わせ。
ChatGPT Enterpriseの管理コンソールで一元管理
Claude Code側は「設定ファイルの層構造」、Codex側は「Web管理コンソール」が中心で、IT管理者がコードに近い形で統制を維持したいならClaude Code、SaaS的なコンソール運用のほうがフィットするならCodexという選び方になります。
Codexのエンタープライズ展開と提携
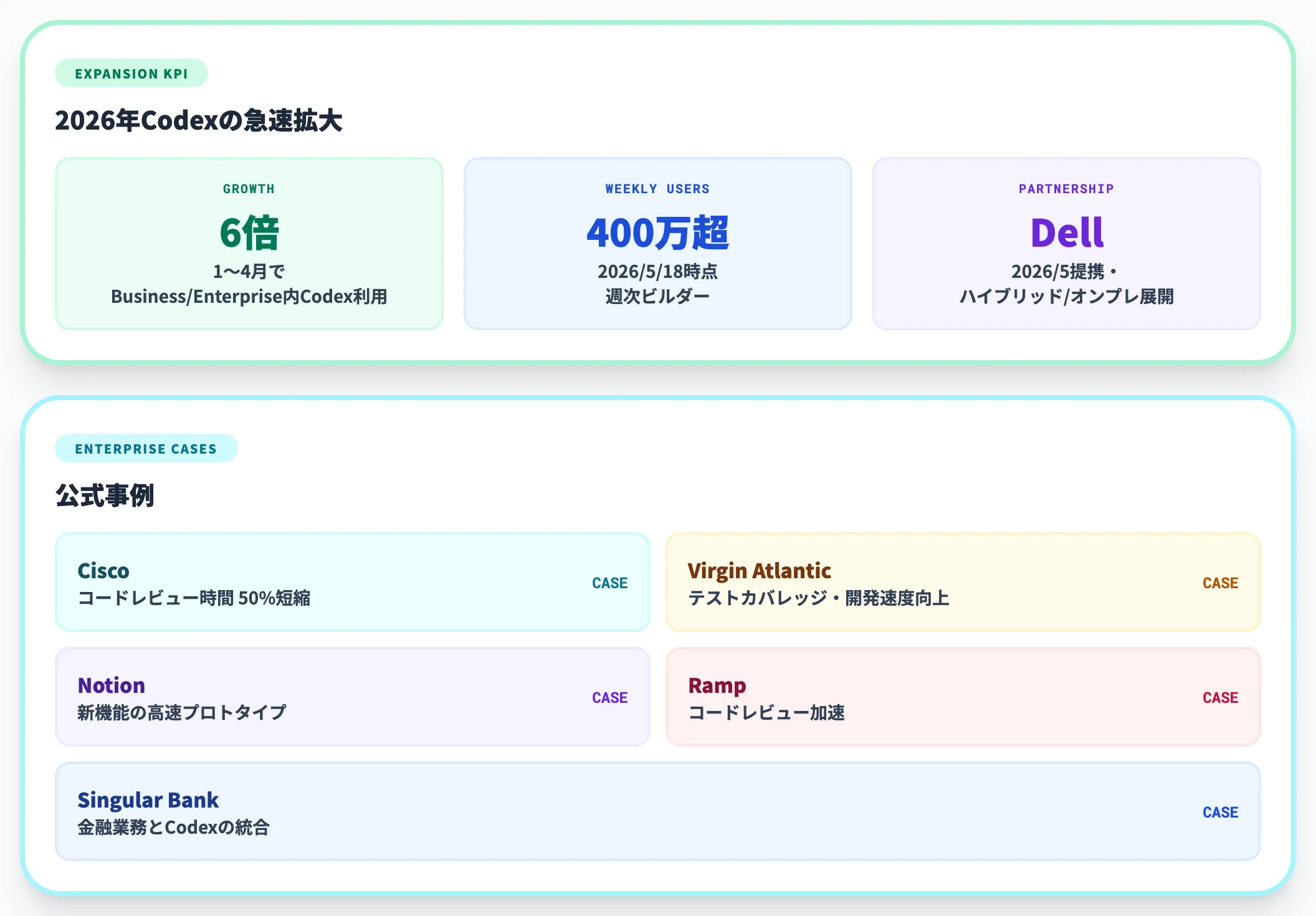
Codexは2026年に入ってからエンタープライズ展開を急速に拡大しており、OpenAIの公式発表によれば1月から4月でChatGPT Business/Enterprise内のCodex利用が6倍に成長、2026年5月18日のDell提携発表時点では週次400万超のビルダーが利用しています。
2026年5月にはDell Technologiesとの提携を発表し、Codexをハイブリッド/オンプレミス環境に展開する道筋も整えられています。
公式に名前が挙がっている事例として、Cisco(コードレビュー時間50%短縮)、Virgin Atlantic(テストカバレッジと開発速度の向上)、Notion(新機能の高速プロトタイプ)、Ramp(コードレビュー加速)、Singular Bank(金融業務とCodexの統合)などがあります。
Claude Codeの大型導入事例
Claude Code側でも、エンタープライズ規模の事例が出ています。
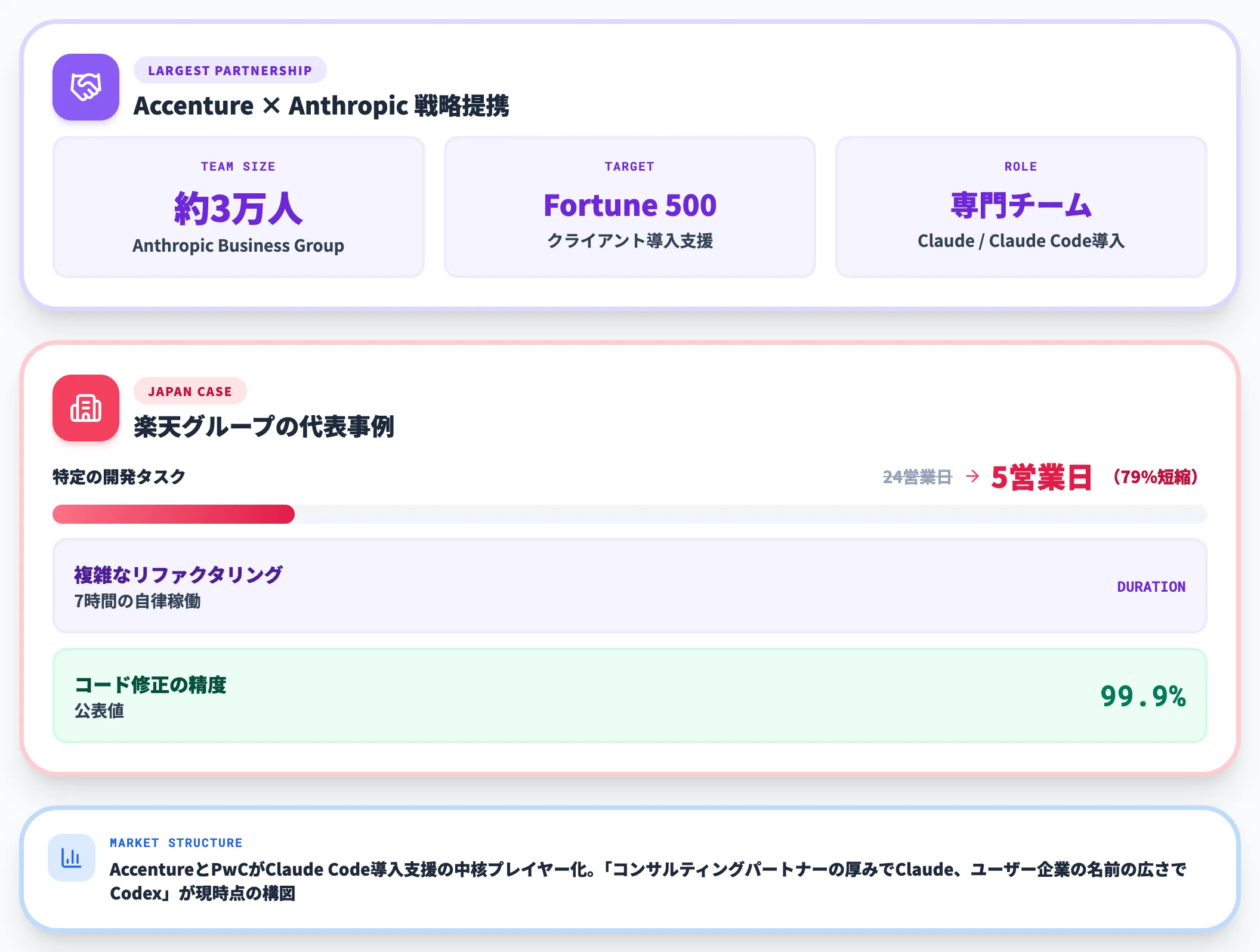
最大規模がAccenture × Anthropicの戦略パートナーシップで、Accenture内に「Anthropic Business Group」と呼ばれる約3万人規模の専門チームが編成され、Fortune 500クライアントへのClaude/Claude Code導入支援を担っています。
日本企業の事例では楽天グループが代表的で、特定の開発タスクで24営業日→5営業日(79%短縮)、複雑なリファクタリングで7時間自律稼働、コード修正の精度99.9%といった数値が公表されています。
AccentureとPwCがClaude Code導入支援の中核プレイヤーになりつつある一方、Cisco・Virgin Atlantic・NotionなどがCodex側に名を連ねており、「コンサルティングパートナーの厚みでClaude、ユーザー企業の名前の広さでCodex」という現時点の構図が見えてきます。
ケース別の選び方とAI総研の推奨
ここまで整理した比較軸を踏まえ、「あなたの場合はどちらから入るべきか」をケース別に整理します。
支援現場で実際に問われる典型ケースをもとに、第一候補と併用パターン、移行を考えるべきシグナルを示します。
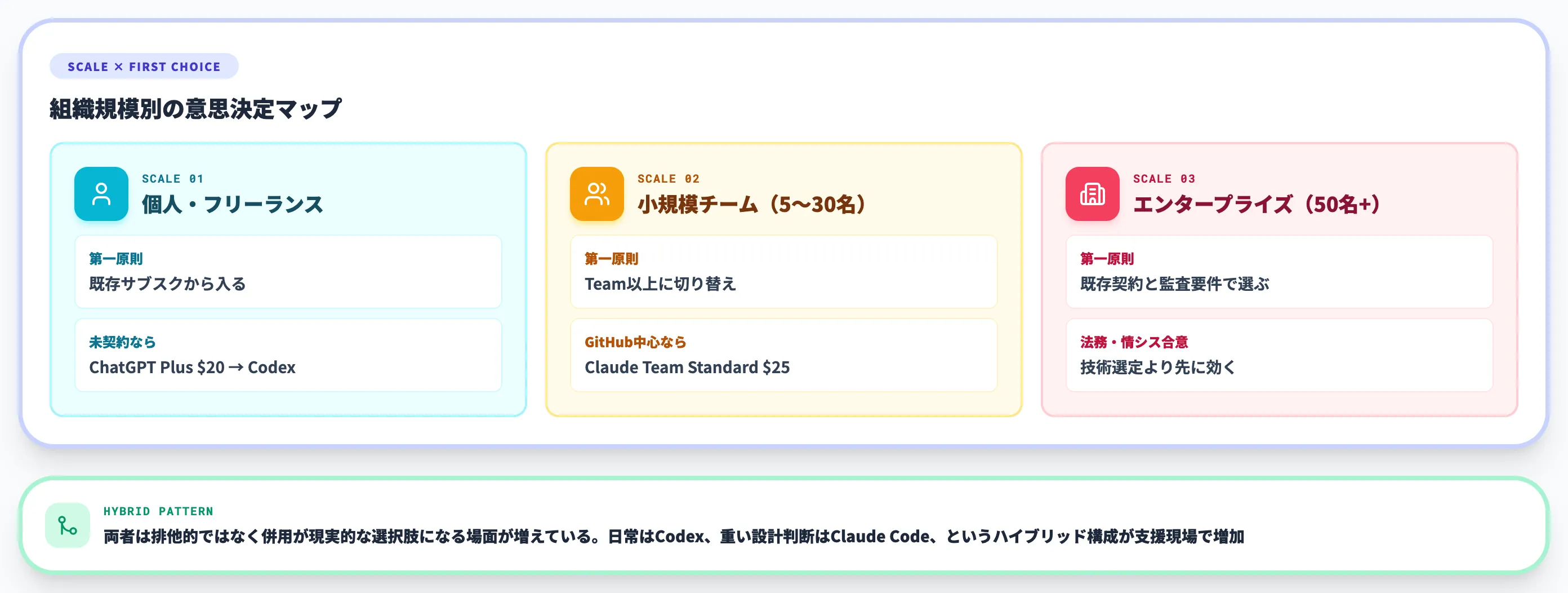
個人開発者・フリーランスの場合
個人開発者は、「すでに契約しているサブスクから入る」のが最短ルートです。
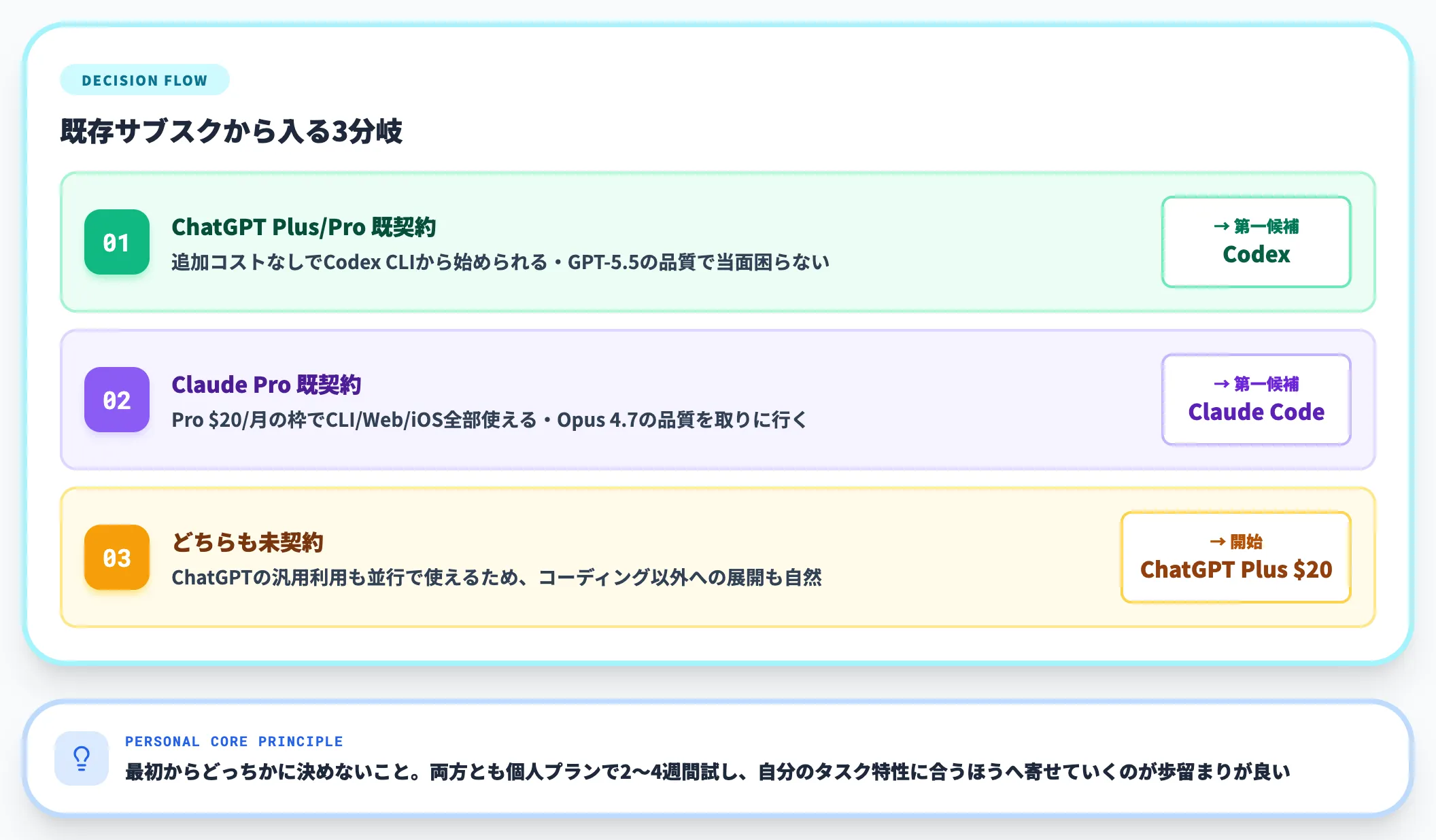
-
ChatGPT Plus/Proを既に契約している → Codex(無料で使える)
追加コストなしでCodex CLIから始められる。
GPT-5.5の品質で当面困らない
-
Claude Proを既に契約している → Claude Code(無料で使える)
Pro $20/月の枠でCLI/Web/iOS全部使える。
Opus 4.7の品質を取りに行く
-
どちらも契約していない → Codex(ChatGPT Plus $20)から開始
ChatGPTの汎用利用も並行で使えるため、コーディング以外への展開も自然
個人ユースで重要なのは「最初からどっちかに決めない」ことです。両方とも個人プランで2〜4週間試し、自分のタスク特性に合うほうへ寄せていくのが歩留まりが良い進め方です。
スタートアップ・小規模チーム(5〜30名)の場合
5名以上のチーム規模になったら、業務利用の確定とともにチームプランへ切り替える段階に入ります。

-
GitHub中心・コードベース横断のリファクタリング多め → Claude Code(Team plan Standard seat $25/席)
GitHub Actions連携の安定度とClaude Coworkの併用が強み
-
ChatGPT Businessですでに業務全体のAI活用を進めている → Codex(ChatGPT Business標準seat $25/席(月払)/$20/席(年払))
標準seatにもCloud tasks/Code reviewsの軽量枠(Plus相当)が含まれる。
大量利用時はusage-basedのCodex seatsやChatGPT creditsを追加。
開発以外のチームとAI活用の足並みを揃えやすい
-
長時間の自動化タスクを並列で回したい → Codex優位(Cloud tasks+並列subagentsはPlusから利用可、本格運用ならPro 5x/Pro 20xへ拡張)
-
品質と監督下の自律性を重視 → Claude Code優位(Plan ModeとSupervised autonomy)
小規模チームの落とし穴は「個人プランで業務利用を続ける」ことです。データ学習リスクと会計問題の両面で支障が出るため、業務利用が確定した時点でTeam以上に切り替えるのが安全運用の第一歩です。
エンタープライズ(50名以上)の場合
エンタープライズ規模では、契約・コンプライアンス・データ保護の整備が技術選定より先に効いてきます。
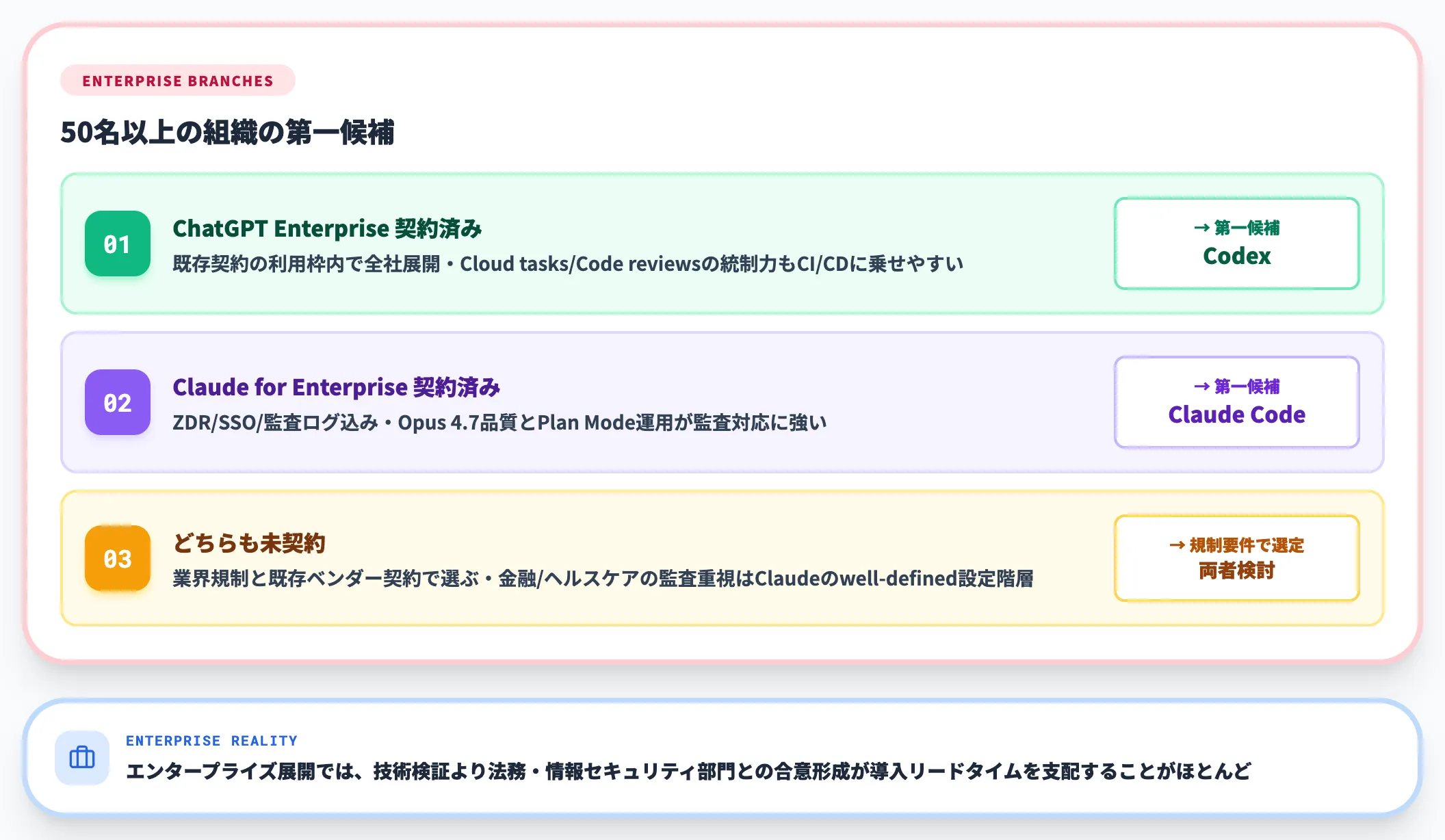
-
ChatGPT Enterprise契約済み → Codex(既存契約の利用枠内で全社展開)
GPT-5.5のローカルターミナル能力に加え、Enterprise/Business seatsならCloud tasks・Code reviewの統制力もCI/CD自動化に乗せやすい
-
Claude for Enterprise契約済み → Claude Code(ZDR/SSO/監査ログ込み)
Claude Code 企業利用ガイドで整理しているとおり、Opus 4.7の品質とPlan Mode運用が監査対応に強い
-
どちらも未契約 → 業界規制と既存ベンダー契約で選ぶ
金融・ヘルスケアで監査ログ重視ならClaude Codeのwell-defined設定階層、SaaS的コンソール運用ならCodexのChatGPT Enterprise統制
エンタープライズ展開では、AI総合研究所の導入支援観察として、技術検証より法務・情報セキュリティ部門との合意形成が導入リードタイムを支配することがほとんどです。
併用パターンと棲み分け
両者は排他的ではなく、併用が現実的な選択肢になる場面が増えています。
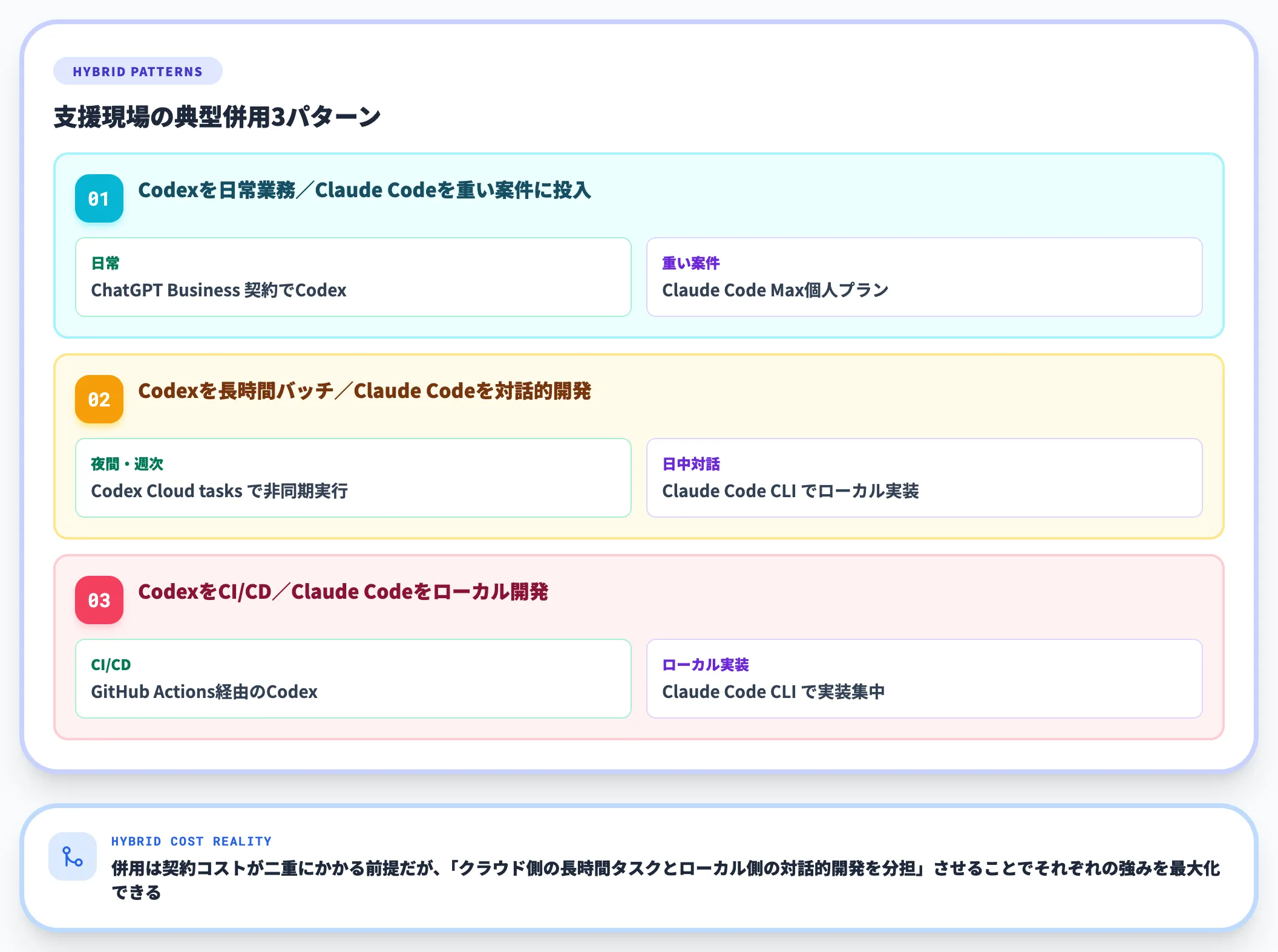
支援現場で見かける典型的な併用パターンは次のとおりです。
-
Codexを日常業務、Claude Codeを重い案件に投入
ChatGPT Business契約でCodexを日常に、Claude Code Max個人プランをリードエンジニアに付与してOpus 4.7の品質が必要な設計判断で使う
-
Codexを長時間バッチ、Claude Codeを対話的開発
夜間のCI・週次レビュー・大規模リファクタリングをCodexのクラウドタスクで非同期実行、日中の対話的な実装はClaude Code CLIで進める
-
CodexをCI/CD、Claude Codeをローカル開発
GitHub Actions経由のCodexがレビュー・テスト自動化を担当、開発者はClaude Code CLIでローカル実装に集中
併用は契約コストが二重にかかる前提ですが、「クラウド側の長時間タスクと、ローカル側の対話的開発を分担させる」ことで、それぞれの強みを最大化できる構成です。
移行を考えるべきシグナル
選定後の運用で「もう一方への移行 or 併用追加」を検討すべきシグナルを整理しておきます。
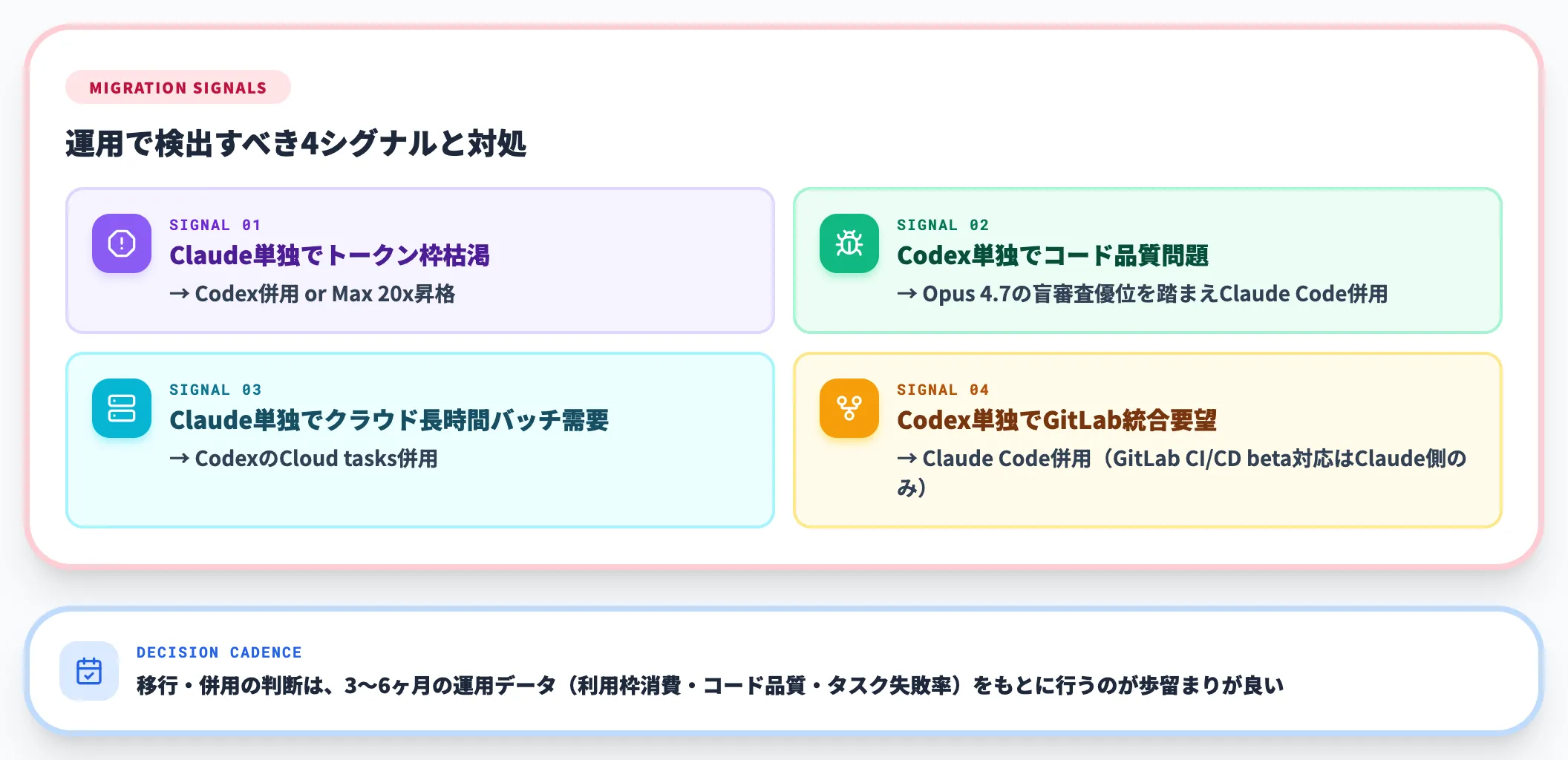
- Claude Code単独で「トークン枠が頻繁に枯渇する」: Codex併用 or Max 20xへの昇格
- Codex単独で「コード品質の問題が頻発する」: Opus 4.7の盲審査優位を踏まえClaude Code併用
- Claude Code単独で「クラウドで長時間バッチを回したい」: CodexのCloud tasks併用
- Codex単独で「GitLabに統合したい」: Claude Code併用(GitLab CI/CD beta対応はClaude Code側のみ)
移行・併用の判断は、3〜6ヶ月の運用データ(利用枠消費・コード品質・タスク失敗率)をもとに行うのが歩留まりが良い進め方です。
導入で詰まる論点と失敗パターン
最後に、Claude CodeとCodexのいずれを選ぶにせよ、導入時に詰まりがちな論点と、よく見られる失敗パターンを整理します。
事前に把握しておくと、運用設計の段階で対処できる項目が多くなります。
選定で迷う論点
「両者で迷ったまま結論が出ない」状態は、判断軸が整理されていないことが原因のことが多めです。

支援現場でよく問われる論点を、判断材料とセットで整理しました。
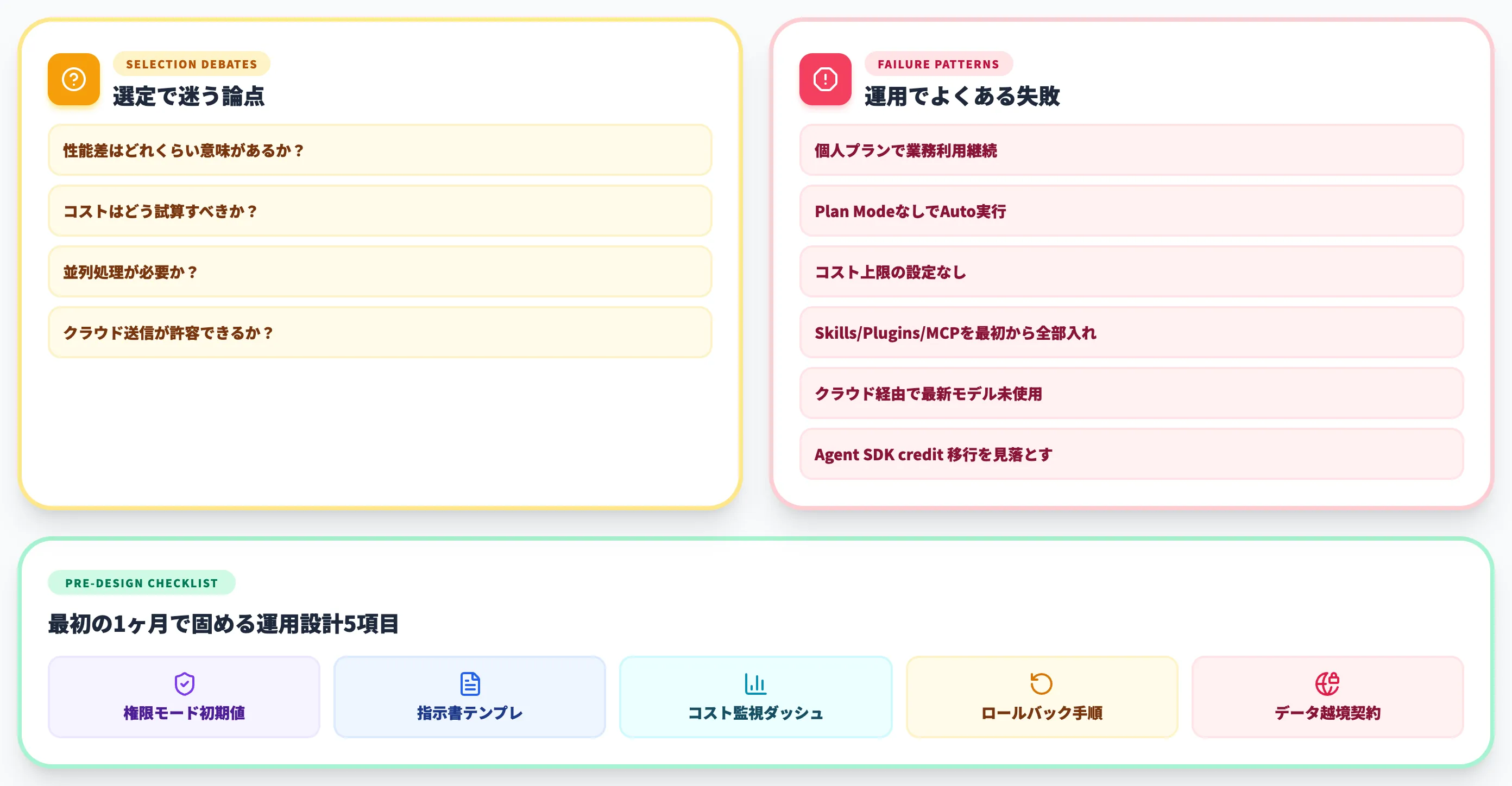
-
「性能差はどれくらい意味があるか」
SWE-bench Verifiedの1.1ポイント差、SWE-bench Proの5.7ポイント差は、日常タスクの体感では「ほぼ同等」のレンジ。
性能の絶対値ではなく、自社のタスクが「Pro寄り」か「ターミナル中心」かで決める
-
「コストはどう試算すべきか」
表面額より「トークン消費差×実利用時間」で試算する。
Composio 2026年5月実測ではClaude側が約1.4倍多く、コスト差は約23%プレミアム程度。
長時間タスクを大量に回す構成ほどこの差が月額に効いてくる
-
「並列処理が必要か」
Claude CodeのAgent Teams(experimental・並列上限なし)とCodexのSubagents(手動トリガー、デフォルト6スレッド)の差は、長時間タスクを大量に回す組織でのみ顕在化する。
Claude Code側はexperimentalで本番依存はリスクがある点、Codex側はread-heavy向けの設計である点を踏まえて選定する
-
「クラウド送信が許容できるか」
両者ともクラウドにプロンプトを送るため、オンプレ完結は不可。
データ越境制御が必要なら、ClaudeはBedrock/Vertex/Foundry、CodexはDell提携経由のオンプレ展開を検討する
運用でよくある失敗パターン
導入後の運用で観察される典型的な失敗パターンは次のとおりです。

-
個人プランで業務利用を継続
データ学習リスクと会計問題が同時に発生。
業務利用確定でTeam/Business以上に切り替えるルールを最初に決める
-
Plan ModeなしでAuto実行をフル稼働
Claude Codeで本番リポジトリに想定外の変更が走る事故が起きる。
Plan Modeを軸にworktree隔離で運用する
-
コスト上限の設定なし
Maxプラン・Business・API従量課金で予算オーバー。
Claude Codeはprint modeでの「--max-budget-usd」設定とAgent SDK credit監視、CodexはChatGPTクレジット残量監視を運用に組み込む
-
Skills/Plugins/MCPを最初から全部入れる
設定の見直しコストが高くなる。
Pro/Plus個人で2〜4週間使ってボトルネックを見極めてから段階追加する
-
クラウド経由のClaude Codeで最新モデルが使われない
Bedrock/Vertex/Foundry経由ではエイリアスがOpus 4.6/Sonnet 4.5に解決される。
最新モデルを使うにはフルモデル名指定が必要
-
2026年6月15日以降のAgent SDK creditを見落とす
ClaudeサブスクでのAgent SDK・GitHub Actions連携が別途クレジット消費に移行。
CI自動化を組んでいる組織は残量管理を運用に組み込む必要がある
詰まる箇所を先回りで設計する
ツール選定が終わった後の運用設計で、次の項目を最初の1ヶ月で固めておくと、後段の運用負荷が大きく下がります。

- 権限モードの初期値: Plan Modeを基本、Auto実行はresearch previewのため低リスクタスクに限定
- CLAUDE.md / AGENTS.mdのテンプレ: チーム共通の規約をリポジトリ直下に配置
- コスト監視ダッシュボード: 利用枠・追加クレジット・Agent SDK creditを一覧化
- 失敗時のロールバック手順: AI生成コードのコミットを「--worktree」隔離して確認後にマージするフロー
- データ越境・モデル学習対象外契約: Enterprise/Business契約時にZDR・データ保持期間・リージョン要件を契約書面で明示
これらは「技術選定で勝ち負けが決まる」ではなく「運用設計で歩留まりが決まる」領域です。Claude CodeとCodexのどちらを選んでも、ここの設計を曖昧にすると同じ失敗を踏みます。

コーディングAIの選定と、組織のAI業務基盤は別レイヤーで設計する
Claude CodeとCodexのどちらを選んでも、開発業務がエージェント化されるだけで組織全体のAI業務基盤が完成するわけではありません。
経理・営業・人事といったバックオフィスのAI自動化や、社内システム連携、権限・実行ログの統制は、開発エージェントとは別レイヤーで設計する必要があります。
このレイヤーを担うのが、AI総合研究所が提供する自社のAzureテナント内で動くエンタープライズAIエージェント基盤 AI Agent Hub です。
フロー判定Agent・AI-OCR Agent・自動入力Agentなど業務特化エージェントをTeamsから呼び出せる構造で、SAP Concur・freee会計・Dynamics 365・Salesforceなどの基幹システムと接続し、シャドーAI化を防ぎながら全社のAIエージェントを1つのダッシュボードで一元管理できます。
AI総合研究所の専任チームが、コーディングエージェント導入と並行して進めるべき組織のAI業務基盤設計まで伴走支援します。
無料の資料で、PoCから本番運用までのAIエージェント基盤の全体像をご確認ください。
コーディングAIの次は業務AI基盤

Teamsから呼び出すエンタープライズAIエージェント
Claude CodeやCodexで開発フローを自動化しても、経理・営業・人事といったバックオフィスのエージェント化は別レイヤーで設計が必要です。AI総合研究所のAI Agent Hubは、TeamsからAgentを呼び出し、SAP ConcurやSalesforceと連携してバックオフィス業務を自動実行するエンタープライズAI基盤です。LPで全体像をご確認ください。
まとめ
本記事では、Claude CodeとOpenAI Codexを2026年5月時点の公式発表と主要な第三者比較(Composio・morphllm等)を併用しながら、「製品概要・モデル/ベンチマーク・実行環境・料金・エコシステム・エンタープライズ・ケース別選び方・導入で詰まる論点」の観点から比較しました。
要点を改めて整理します。
- 設計思想の差: Claude Codeはローカル中心でフルアクセスを開発者に預ける、Codexはクラウドサンドボックスで隔離し並列処理を前提に動かす
- 性能はほぼ拮抗: SWE-bench VerifiedでGPT-5.5が+1.1pt、SWE-bench ProでClaude Opus 4.7が+5.7pt、Terminal-Bench 2.0でGPT-5.5が+13.3pt。性能の絶対値より「自社タスクが何寄りか」で選ぶ
- トークン効率はCodex優位: Composio 2026年5月実測でClaude側が約1.4倍多く、コスト差は約23%プレミアム。長時間タスク・大量バッチほど月額差として顕在化
- 料金は内包形態で変わる: CodexはChatGPTの各プラン(Free・Go・Plus・Pro・Business・Edu・Enterprise)すべてに内包され、Plusから軽量Cloud tasks/Code reviews枠あり(GPT-5.3-Codex実行)、Pro 5x/Pro 20xで枠が大幅に拡大。ChatGPT Business標準seatは$25/席(月払)/$20/席(年払)でCodex-only seatはusage-based
- サブエージェント設計差: Claude CodeのAgent Teamsは並列上限なし+P2P型だがexperimental(デフォルト無効・環境変数で有効化)、CodexのSubagentsは公式機能で手動トリガー+デフォルト6スレッドのread-heavy向け設計
- エンタープライズ統制: 両者ともSSO/監査/学習対象外契約に対応するが、サンドボックスはCodexがカーネル層、Claude Codeがアプリ層という違い
- ケース別第一候補: ChatGPT既存契約者はCodex、Claude既存契約者はClaude Code、品質重視ならClaude Code、コスト効率と並列重視ならCodex
- 併用が現実解: 日常業務はCodex、重い設計判断はClaude Code、というハイブリッド構成が支援現場で増えている
選定の核は「どちらが優れているか」ではなく「自社の開発フローと統制方針に合うエコシステムをどちらで揃えるか」という問いです。
2026年に入ってからは、両者の進化が「単一ツールの完成度」から「組織のAI開発基盤としての統合度」に軸足を移しています。
本記事の比較軸を参考に、まずは自社が既に持っているサブスク契約を起点に検証を始め、3〜6ヶ月の運用データをもとに併用 or 単独利用を判断していくのが、結果的に最短のルートになります。










