この記事のポイント
 AIモデルと外部ツールの接続を標準化するなら、業界横断で採用が進むMCPが現時点で最も有力な選択肢
AIモデルと外部ツールの接続を標準化するなら、業界横断で採用が進むMCPが現時点で最も有力な選択肢- Claude Desktop・OpenAI Codex・ChatGPT Connectorsで、エージェント開発はDesktop、コーディング支援はCodex
- 本番導入ではOAuth 2.1と最小権限原則によるセキュリティ設計が必須で、プロトコル自体は無料だがAPI従量課金・開発費50万円〜の予算確保が成否を分ける

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Anthropicが提唱した「Model Context Protocol(MCP)」は、AIモデルと外部データソースやツールを接続するためのオープンな標準プロトコルです。
OpenAI・Microsoft・Googleを含む業界全体での採用が進み、2025年12月にはLinux Foundation傘下のAgentic AI Foundation(AAIF)に寄贈されました。
本記事では、MCPの基本概念からアーキテクチャ、クライアント別の使い方、天気予報サーバーのハンズオン、セキュリティ設計、導入費用までを2026年3月時点の最新動向を交えて体系的に解説します。
目次
標準化の動き:Agentic AI Foundation(AAIF)
Claude Desktop / Claude CodeでのMCP活用
OpenAI CodexとAgents SDKでのMCP連携
ChatGPT(Connectors・Deep Research)とMCP
ハンズオン:Claude Desktop+天気予報MCPサーバーを動かしてみる
claude_desktop_config.jsonの設定と接続テスト
MCP(Model Context Protocol)とは

MCP(Model Context Protocol)は、AIモデルと外部ツール・データソースをつなぐためのオープンプロトコルです。2024年11月にAnthropicが最初の仕様と実装を公開し、その後OpenAI・Microsoft・Googleを含む主要ベンダーが相次いで採用したことで、AIエージェント時代の事実上の標準プロトコルとなりつつあります。
AIから見ると、ファイル・データベース・SaaSなどにアクセスするための共通インターフェースに相当します。アクセス方法をMCPで揃えることで、次のような狙いがあります。
- ツールの再利用性を高める
- ベンダーごとの独自仕様によるロックインを避ける
- セキュリティや権限設計を1つのレイヤーに集約する
MCPサーバーの数は急速に拡大しており、2024年11月の約100個から2026年2月には8,600以上に増加しました。一度構築したMCPサーバーを複数のAIクライアントから再利用できるため、開発コストを抑えながらエージェント機能を拡張できる点が企業から支持されています。

MCPが標準化する「Model Context」とは
ここでいう「Model Context(モデルのコンテキスト)」は、モデルが推論に利用できる作業環境一式を指します。代表的には次のような要素が含まれます。
- 呼び出し可能なツール(関数・API)
- 参照できるデータリソース(ファイル、DB、HTTPエンドポイントなど)
- それらにアクセスするためのメタデータや設定情報
MCPは、この外部環境とモデルのあいだでやり取りされる情報を、共通フォーマットで扱えるようにするプロトコルです。具体的には、次のような項目が標準化の対象になります。
- ツールのインターフェース(引数・戻り値・説明文など)
- データリソース(ファイル・DB・HTTPエンドポイントなど)の扱い方
- モデルとサーバー間のメッセージ形式(JSON-RPCベースのリクエスト/レスポンス)
- 通信方式(標準入力/標準出力(stdio)、Streamable HTTPなど)
この標準化により、「ツールやデータソースの実装(MCPサーバー)」と「それを利用するクライアント(各社のチャットUIやIDE拡張、エージェント基盤など)」を分離しやすくなります。クライアントを入れ替えても、MCPサーバー側は作り直さず再利用できるという設計思想です。
主要ベンダーとMCP対応(2026年時点)

2026年3月時点で、MCPを正式に採用・サポートしている主なプレイヤーは次のとおりです。
| プレイヤー | 位置づけ | 代表的なMCP対応 |
|---|---|---|
| Anthropic(Claude) | 提唱者・リファレンス実装 | Claude Desktop・Claude Code・IDE拡張からローカル/リモートMCPサーバーに接続 |
| OpenAI(ChatGPT / Codex / Agents SDK) | SaaS / 開発者向け基盤 | ChatGPTコネクタ(Apps)・Deep Research・Agents SDKからリモートMCPサーバーをツールとして利用 |
| Microsoft(Azure / GitHub Copilot) | クラウド・エンタープライズ向け | Azure MCP Server・Azure AI Foundry・GitHub CopilotからMCPツールを利用 |
| Google(Gemini) | マルチモーダルAI基盤 | Gemini CLIやGoogle AI StudioからMCPサーバーに接続。AAIFの支援メンバーとして参画 |
| OSSエコシステム | 実装とユースケースの供給源 | Awesome MCP Servers・mcpservers.orgを中心に8,600以上のMCPサーバー実装が公開 |
このように、4大AIベンダー(Anthropic・OpenAI・Microsoft・Google)が全てMCPを採用している状況は、プロトコルの事実上の標準化を裏付けています。
標準化の動き:Agentic AI Foundation(AAIF)
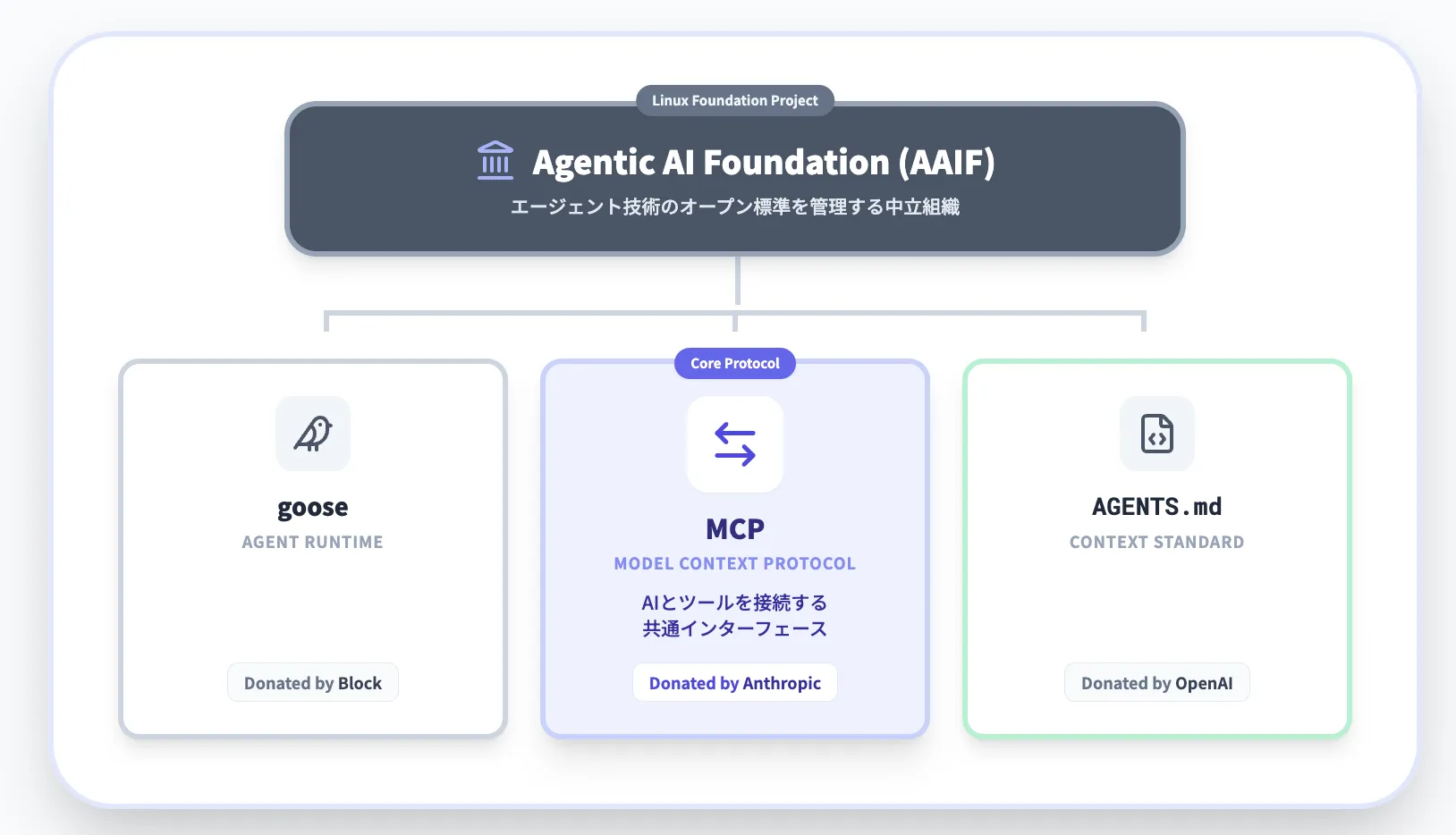
2025年12月、AnthropicはMCPをLinux Foundation傘下のAgentic AI Foundation(AAIF)に寄贈しました。AAIFはAnthropic・Block・OpenAIが共同設立し、Google・Microsoft・AWS・Cloudflare・Bloombergが支援メンバーとして参画しています。
これにより、MCPは特定ベンダーの所有物ではなく、エージェント関連技術のオープン標準として業界横断で育てていくプロジェクトという性格がより明確になりました。
2026年のロードマップでは、Transport Scalability(Streamable HTTPの水平スケーリング対応)、MCP Server Cards(サーバーのメタデータを.well-known URLで公開する仕組み)、MCP Apps(ツールからインタラクティブなUI要素を返せる拡張)などが重点テーマに挙げられています。
従来のAPI連携やプラグインとの違い
MCPの位置づけを理解するうえで、従来の連携手法との違いを押さえておくと整理しやすくなります。
ZapierやMake(旧Integromat)などのiPaaSは、人間がワークフローをあらかじめ設計し、そのフローに沿って自動実行する仕組みです。一方MCPでは、どのツールを使うか・どの順番で呼び出すかといった判断をエージェント側(モデル側)に委ねる設計になっています。
また、ChatGPTの旧プラグイン機能やFunction Callingは、特定のLLMに紐づく仕様でした。MCPはベンダーニュートラルなプロトコルのため、一度作ったサーバーをClaude・ChatGPT・Geminiなど複数のクライアントから共通利用できます。
MCPの仕組みとアーキテクチャ
ここからは、MCPのアーキテクチャを構成要素ごとに整理します。イメージとしては、一般的なクライアント/サーバー構成をAIエージェント向けに再定義したものです。
MCPホスト・クライアント・サーバーの役割
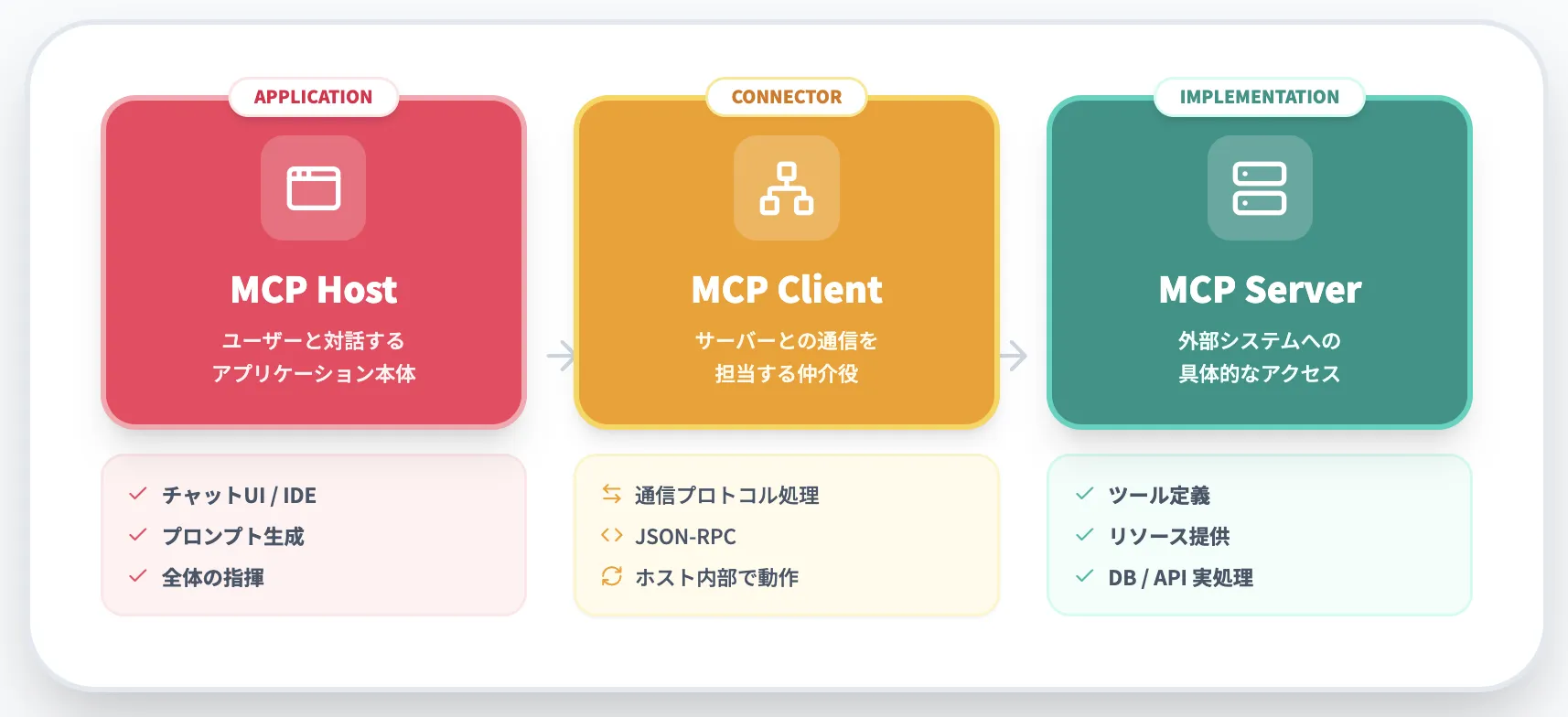
MCPでは、構成要素を大きく3種類に分けて考えます。それぞれが異なる責務を持ち、連携することで「モデル+ツール+外部システム」全体の振る舞いが決まります。
MCPホスト
ユーザーと対話するアプリケーション本体です。チャットUI、デスクトップアプリ、IDE拡張、CLIツールなどが該当します。モデルへのプロンプト生成やツール呼び出しのオーケストレーションを担当します。
MCPクライアント
ホストの内部(または近く)で動作し、MCPサーバーとの通信を担当するコンポーネントです。JSON-RPCメッセージやコンテンツ配列(text / image / resource など)のフォーマットを処理します。
MCPサーバー
外部システムへの具体的なアクセス(DB、ファイルシステム、SaaSのAPIなど)を担います。「ツール」「リソース」「プロンプトテンプレート」を定義し、呼び出しに応じて実処理を行います。
この3者の関係性は、抽象的に聞くと少しつかみにくいかもしれません。後半のハンズオンでは、これらの役割がそれぞれ「デスクトップクライアント」と「天気予報MCPサーバー」にどう対応するかを具体的に確認していきます。
JSON-RPCとトランスポート
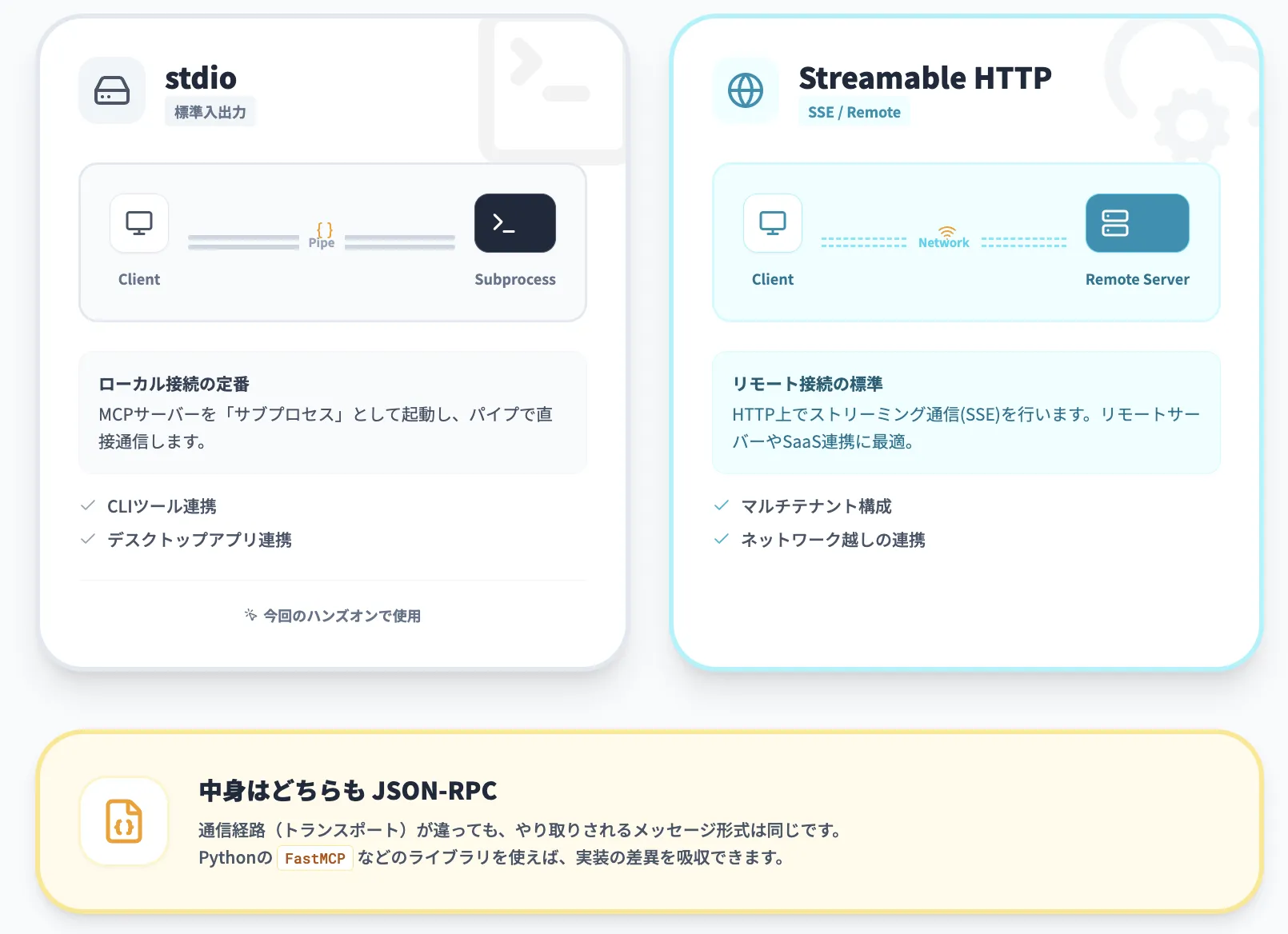
MCPはメッセージフォーマットとしてJSON-RPCを採用しています。そのうえで、実際の通信路(トランスポート)としては、主に次の2種類が使われています。
-
stdio(標準入力/標準出力)
MCPサーバーをサブプロセスとして起動し、プロセス間通信でリクエスト/レスポンスをやり取りする方式。ローカルのCLIやデスクトップクライアントとの連携に向いている
-
Streamable HTTP
HTTP上でストリーミング通信を行う方式。リモートMCPサーバーやマルチテナント構成のサーバー実装に適している。2025年6月の仕様改訂でSSE(Server-Sent Events)からStreamable HTTPへ移行され、現在はこちらが標準トランスポートとなっている
-
OAuth 2.1による認証
2025年3月の仕様改訂でOAuth 2.1ベースの認証仕様が追加され、リモートMCPサーバーへのセキュアな接続が標準化された。2025年11月の改訂ではProtected Resource Metadata(RFC 9728)やClient ID Metadata Documents(CIMD)も導入されている
実装用ライブラリとしては、Python製のFastMCPやTypeScript製のフレームワークなどが用意されています。自社の言語スタックに合わせて選択するとよいでしょう。後述のハンズオンでは、これらの仕組みのうち「stdio+サブプロセス起動」のパターンを実際に触っていきます。
MCPが扱う3つのプリミティブ
MCP公式ドキュメントでは、サーバーがクライアントに公開する要素として、主に次の3種類が定義されています。

-
ツール(tools)
モデルから呼び出せる「関数」に相当する。get_weather、search_docs、run_sqlなどが典型例
-
リソース(resources)
ファイルやDBレコードなど、参照可能なデータのエントリ。一覧取得・詳細取得・ストリーミング配信などに対応する
-
プロンプト(prompts)
よく使う指示やテンプレートをまとめたもの。エージェントが高品質なプロンプトを再利用できるようにする
2025年11月の仕様改訂(2025-11-25版)では、4つ目のプリミティブとしてTasksが追加されました。Tasksは長時間かかるリクエストの状態追跡と結果の遅延取得を可能にする仕組みで、バッチ処理やバックグラウンドジョブとの連携に適しています。
これらを組み合わせることで、たとえば次のような複数ステップのワークフローを表現できます。

MCPサーバー側でツールを定義しておけば、エージェント側ではそれらを順番に呼び出すだけで処理フローを構成できます。この「ツール定義をサーバー側に寄せる」という考え方が、後述するAgents SDKやAgent Skillsとの相性の良さにもつながっています。
MCPの使い方と活用パターン
同じMCPサーバーであっても、「どのクライアントから利用するか」によって体験は大きく変わります。ここでは、代表的なクライアントごとの位置づけと、具体的な活用パターンを整理します。

Claude Desktop / Claude CodeでのMCP活用
Claude Desktopは、ローカルファイルやGitリポジトリ、SQLiteへのアクセスと相性の良いクライアントです。設定ファイル claude_desktop_config.json にサーバーの起動コマンドを追記するだけで、チャットからMCPツールを呼び出せるようになります。
Claude Desktopの MCP 設定画面
Claude Codeと組み合わせることで、次のような開発向けMCPツールを構築できます。
- リポジトリ検索・コードナビゲーション
- テスト実行・結果の要約
- LSPサーバーとの連携による型情報・補完の活用
「ローカル環境の資産をエージェントに解放する窓口」として位置づけると、設計の方針が立てやすくなります。
OpenAI CodexとAgents SDKでのMCP連携
OpenAIは開発者向けドキュメントで、「ChatGPTのコネクタ/Deep Research/API統合向けにMCPサーバーを使う方法」を公式に案内しています。
Codex CLI / Codex IDE、MCP対応版Agents SDKからも、設定ファイル経由でMCPサーバーをツールとして登録できます。
- Codex側の設定ファイル(mcp_agent.config.yamlなど)にサーバーのコマンドや引数を定義する
- Agents SDKや周辺フレームワークでは、エージェント定義の中にmcp_serversの設定を追加し、MCPサーバーをツールとして登録する
- 同じMCPサーバーをCodex CLI/IDE/バックエンドエージェントから共通利用できる
VS Code拡張向けに作ったMCPサーバーを、そのままCodexやAgents SDKでも使い回せるため、開発・運用コストを抑えやすい構成です。
ChatGPT(Connectors・Deep Research)とMCP
ChatGPTの「コネクタ(Apps)」や「Deep Research」機能では、リモートMCPサーバー経由で外部データにアクセスする構成が公式ガイドで紹介されています。
次のようなステップで自社専用コネクタを用意できます。
- FastMCPなどでリモートMCPサーバーを構築する
- search、fetchといった標準ツールを実装する
- ChatGPTのコネクタ設定から、そのサーバーを登録する
これにより、特定のベクターストアや業務システムを対象にした「自社専用Deep Research」に近い体験を構築できます。
なお、ChatGPTで利用できるMCP関連機能(Apps / Connectors、Developer mode、Deep Researchカスタムコネクタなど)は更新頻度が高い領域です。最新の条件はOpenAI公式ドキュメントを確認してください。
クライアント別の比較表
PoCの入口を検討する際に、「まずどこから触るか」を決めるためのざっくりとした比較です。
| クライアント | 主な用途 | 強み | 想定ユーザー像 |
|---|---|---|---|
| Claude Desktop | ローカルPCの作業自動化 | ファイル・Git・ローカル開発との相性が良い | 個人開発者、ナレッジワーカー |
| Claude Code | IDE内でのコード支援 | コードリーディングやリファクタリングに強い | エンジニア、SRE |
| OpenAI Codex(CLI/IDE) | コーディングエージェント | GitHub連携やCI/CDと組み合わせやすい | チーム開発、DevOps担当 |
| Agents SDK | バックエンドのエージェント基盤 | サーバーサイドのワークフロー自動化に適する | プロダクト開発チーム |
| ChatGPT Connectors | ナレッジ検索・調査タスク | エンドユーザーに近いUIで共有しやすい | ビジネス部門、アナリスト |
同じMCPサーバーでも、どのクライアントで使うかによって体験はかなり変わります。最初は1〜2種類のクライアントに絞って検証するのがおすすめです。
日常業務の自動化
情報系の業務では、次のような使い方が典型的です。
- 社内ポータル・ナレッジベースの横断検索と要約
- 過去提案書やレポートから類似案件を探し、要点を抽出する
- パートナー企業との議事録やFAQを横断検索し、回答案を自動生成する
これらは、ChatGPTのコネクタやClaude Desktopから「読み取り専用の社内MCPサーバー」を叩くことで、自社版Deep Researchに近い体験として実現できます。
ソフトウェア開発・SRE・データ基盤運用
開発・運用の現場では、MCPサーバーを挟むことで次のようなことがしやすくなります。
- GitHub / GitLabのIssue・PR・CIログを横断的に検索する
- 監視アラート(Sentry、Datadogなど)を取得し、関連PRやドキュメントと紐づけて要約する
- データ基盤のジョブステータスを確認し、失敗ジョブの原因候補を洗い出す
Claude CodeやCodex IDEと組み合わせれば、「コードを読みながら、関連Issueやドキュメントを一括で引いてきて要約する」といったエージェント体験も構築しやすくなります。
既存RAGとの組み合わせ
すでにベクターストアや検索エンジンを使ったRAGシステムを持っている場合でも、その検索APIをMCPサーバーのsearch・fetchツールとして公開することで、ChatGPTのDeep Researchや自前のAgents SDKベースエージェントから利用できます。
「既存のRAG+MCP」を組み合わせることで、これまでの投資を活かしつつエージェント化を進めることが可能です。
MCPサーバーの種類と代表例

次に、MCPサーバー側のパターンを整理します。大きくはローカルとリモートに分けて考えるとイメージしやすくなります。
ローカルMCPサーバー
ローカルMCPサーバーは、ユーザーのPCやオンプレ環境の中で動作するサーバーです。外部ネットワークに出さずに、次のような対象を扱えます。
- ローカルファイル(議事録、契約書、社内ドキュメントなど)
- ローカルGitリポジトリ(コード検索、差分取得)
- SQLiteなどの軽量DB(ログ・小規模ストア)
- Memoryサーバー(ローカルナレッジの永続化)
これらをMCPサーバーとして切り出すことで、機密性の高いデータをモデル本体に直接渡さずに活用でき、オフライン/閉域環境でもエージェント体験を実現しやすくなります。プライバシー重視のPoCや、個人開発者のワークスペースに向いたパターンです。
リモートMCPサーバー
リモートMCPサーバーは、クラウドや社内ネットワーク上で動作し、複数ユーザーから利用される前提のサーバーです。代表的な連携先は次のとおりです。
- SalesforceなどCRM / SFA のレコード検索・更新
- GitHub / GitLabのIssue・PR・CIログの取得・更新
- 監視サービス(Sentry や Datadog)のアラート取得と絞り込み
- Google Drive / SharePoint / Confluenceなどのドキュメントストレージ
- BigQuery・Snowflakeなどデータウェアハウスへのクエリ実行
リモートサーバーを用意しておくと、ChatGPT・Claude・Codexなど複数のクライアントから同じビジネスロジックを共有できます。「バックエンドは共通MCPサーバー、フロントのUIだけ各クライアントで変える」といった構成も取りやすくなります。
OSSエコシステムとAwesome MCP Servers
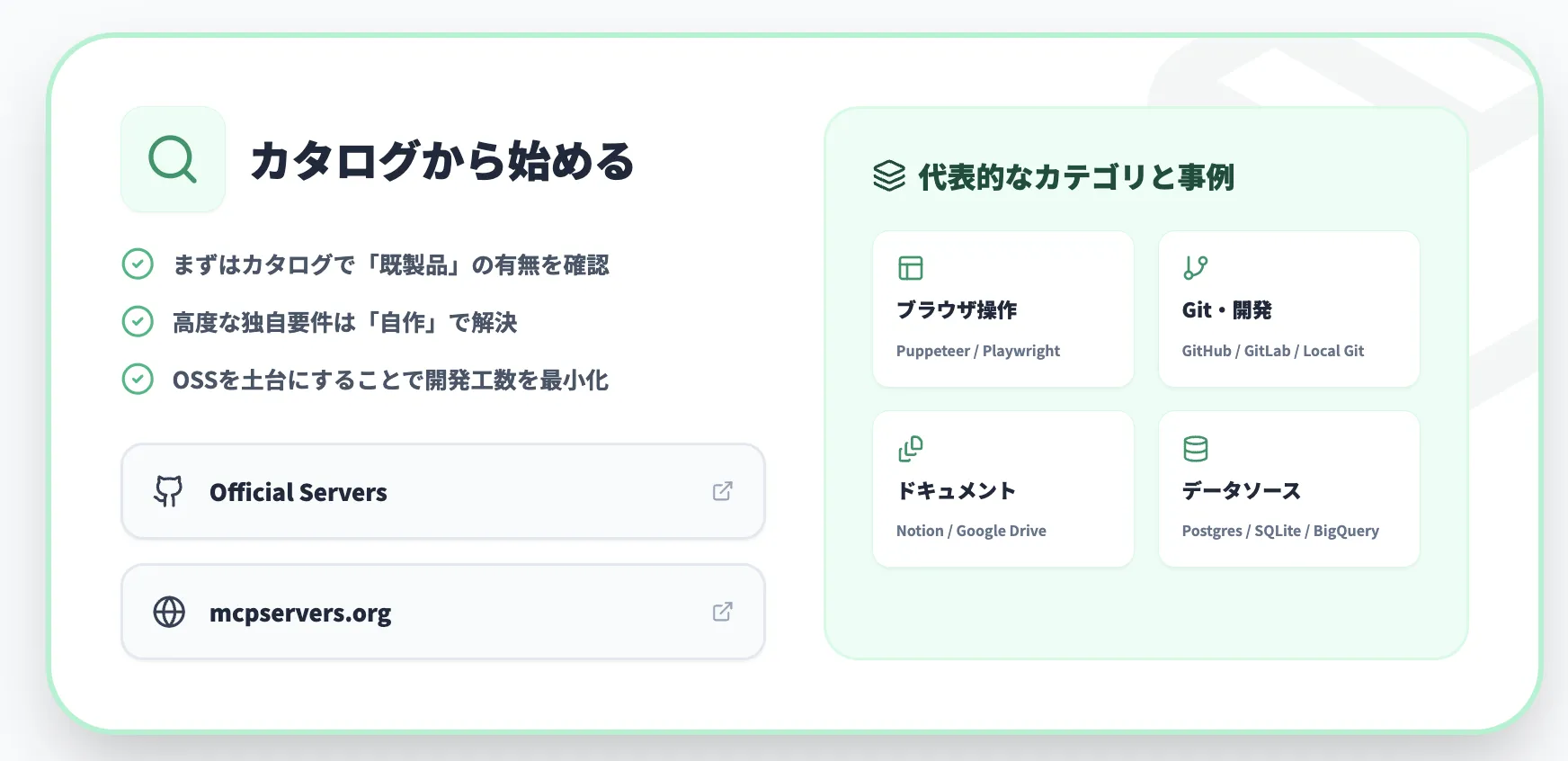
OSSコミュニティでは、Awesome MCP Servers・mcpservers.orgなどに多様なMCPサーバー実装が集約されています。2026年2月時点で8,600以上のサーバーが公開されており、月間追加数も加速しています。
カテゴリの例を挙げると、次のようなものがあります。
- Webページ取得・ブラウザ自動化系
- Git / GitHub / GitLab 操作系
- Google Drive・Notion・Confluence 連携系
- ベクターストア・RAG向けサーバー
- 監視・ログプラットフォーム連携系
ゼロから自作するのではなく、既存のOSSサーバーをフォークして、認証方式・APIキーやトークンの管理方法・アクセスを許可するデータ範囲だけ自社用に調整する始め方も現実的です。
ハンズオン:Claude Desktop+天気予報MCPサーバーを動かしてみる
ここからは、実際にMCPサーバーを動かしてみるハンズオンです。米国国立気象局(National Weather Service, NWS)のAPIを叩くweather MCPサーバーを例に、構築〜Claude Desktopへの接続〜動作確認までの流れを確認します。
前提条件と開発環境の準備
前提となる環境は次のとおりです。
- Python 3.11 以上(公式クイックスタートの要件は「Python 3.9 以上」だが、3.11以降を使っておくと互換性の面で安心)
- パッケージ/仮想環境管理ツールとしてのuv
- HTTPクライアントとしてhttpx
- MCPサーバー実装用ライブラリとしてmcp[cli](公式Python SDKに含まれるFastMCPを利用)
ターミナル(黒い画面)で以下を実行し、プロジェクトを準備します。
# uv がまだ入っていない場合のインストール例(macOS / Linux)
curl -LsSf https://astral.sh/uv/install.sh | sh
# プロジェクトフォルダ作成
mkdir weather && cd weather
# プロジェクト初期化と依存関係の追加
uv init --python 3.11
uv add "mcp[cli]" httpx
これで、weather.pyにMCPサーバーのコードを書ける状態になります。
weather MCPサーバーの構成とポイント
weather.pyの中身は、おおまかに次の4つのブロックに分かれます。
-
FastMCPでサーバー本体を定義
NWS APIのベースURLやUser-Agentを定数として保持する
-
HTTPリクエスト用のヘルパー関数
make_nws_requestでエラーハンドリングやタイムアウト処理を共通化する
-
レスポンス整形用関数
format_alertなどで、APIレスポンスを人間が読みやすいテキストに変換する
-
MCPツール本体の定義
@mcp.tool()デコレータでget_alerts / get_forecastを公開する
たとえば、天気警報を取得するツールは次のようなイメージです。
@mcp.tool()
async def get_alerts(state: str) -> str:
url = f"{NWS_API_BASE}/alerts/active/area/{state}"
data = await make_nws_request(url)
if not data or "features" not in data:
return "Unable to fetch alerts or no alerts found."
if not data["features"]:
return "No active alerts for this state."
alerts = [format_alert(feature) for feature in data["features"]]
return "\n---\n".join(alerts)
HTTPクライアント部分(make_nws_requestなど)と、MCPツールとして公開する部分(@mcp.tool())を分けておくと、ツールの追加や他クライアントからの再利用がしやすくなります。このあたりは、既存のWeb APIクライアント開発とかなり感覚が近いはずです。
claude_desktop_config.jsonの設定と接続テスト
サーバーがローカルで動作するようになったら、Claude Desktopの設定ファイルに登録します。~/Library/Application Support/Claude/claude_desktop_config.jsonに、次のようなエントリを追加します(パスは自分の環境に合わせて変更)。
{
"mcpServers": {
"weather": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/weather",
"run",
"weather.py"
]
}
}
}
設定を保存してClaude Desktopを再起動すると、MCPサーバー一覧にweatherが表示されます。そのうえで、チャット画面から次のように指示すると動作確認ができます。
- 「テキサス州の天気警報を教えてください。」
- 「緯度37.7749、経度-122.4194の天気予報を教えてください。」
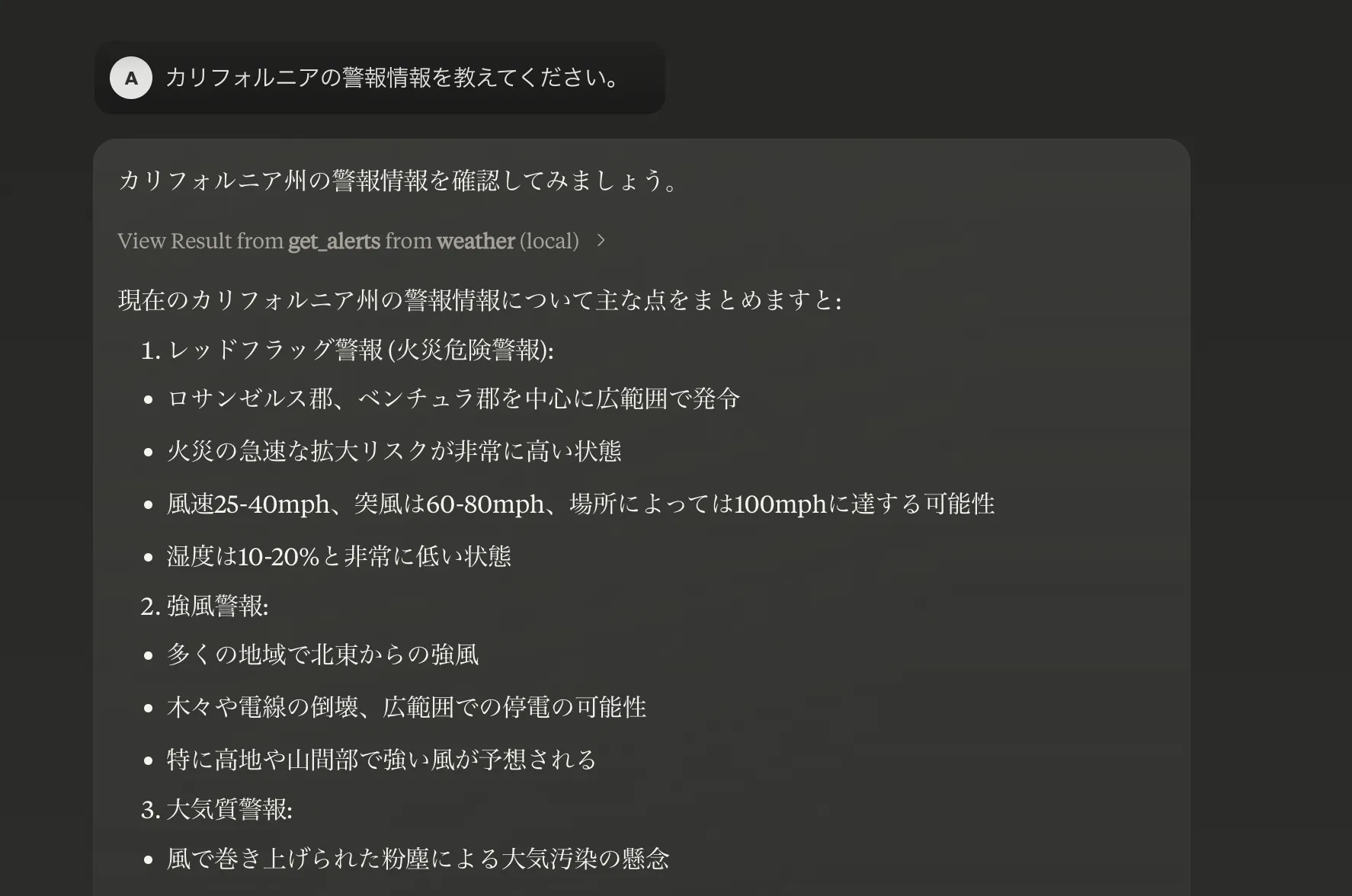
weatherサーバーからの応答例
ここまで来ると、MCPホスト(Claude Desktop)、MCPクライアント(Claude Desktop内部のMCP機能)、MCPサーバー(weather)という役割分担が、具体的な動きとセットでイメージできるようになるはずです。
MCPサーバー構築に必要な技術レベル
外部APIを1つ叩くだけのシンプルなMCPサーバーであれば、PythonまたはTypeScriptで簡単なWeb APIクライアントを書いたことがあるレベルで実装可能です。
一方で、コード実行やジョブ管理・複雑なワークフローのオーケストレーション・機密データの取り扱い(マスキング・権限分離など)を含むサーバーでは、一般的なアプリケーション開発と同程度の知識が求められます。セキュリティ設計やエラーハンドリング、ログ設計なども含めて検討する必要があります。

MCPと周辺コンポーネント:Agent Skills・Agents SDK・MCO

各社のドキュメントを読むと、Agent Skills・MCP・Agents SDK・MCOといった近い用語が頻繁に登場します。それぞれ「どのレイヤーの概念か」を押さえておくと、設計時に迷いにくくなります。
Agent Skills
Agent Skillsは、エージェントが再利用するタスクのまとまり(スキル)をフォルダ単位で定義する仕組みです。SKILL.mdとスクリプト群、参考資料をひとまとめにし、「どのような依頼でこのスキルを使うか」「どのファイル/スクリプトを呼び出すか」を明示します。
コーディングエージェントやIDE連携ツールでは、Agent Skillsを使うことで、リポジトリ移行・テスト自動化・大規模リファクタリングなどの複雑な開発タスクを段階的にこなせるように設計できます。
Agents SDKとMCP
OpenAIのAgents SDKは、エージェントの状態管理・ツール呼び出し・リトライ戦略・ログ/トレースを扱う「エージェント本体」側のフレームワークです。
一方MCPは、エージェントから見たツール接続の標準仕様にフォーカスしています。役割分担を整理すると次のとおりです。
- Agents SDKはエージェント全体の設計・実行・監視を担う
- MCPはエージェントが利用する外部ツールのインターフェースを共通化する
この2つを組み合わせることで、「ツールはMCPで共通化しつつ、エージェントのロジックはAgents SDKで組む」という構成が取りやすくなります。
MCO(Model Context Operator)
一部の研究・技術解説では、Model Context Operator(MCO)という用語も登場します。MCOは、MCPで接続された複数のサーバーやツールを束ねるコンポーネントとして構想されている概念です。どのツールを使うか・どの順番で呼び出すか・どの条件で切り替えるかを制御します。
現時点では、MCPのように仕様が固まったオープン標準というよりは、各社やコミュニティで実装検討が進んでいる段階の「アーキテクチャ上のパターン名」に近い位置づけです。
レイヤーごとの整理
実務の設計では、次のように責務を分けておくと整理しやすくなります。
- ツールや外部システムとの接続はMCPサーバーに寄せる
- タスクの分解・実行順序・エラーリトライはAgents SDKや独自エージェントロジックに任せる
- 再利用性の高いタスクの塊はAgent Skills(SKILL.md)として整理する
このレイヤリングを意識することで、ツール側の実装とエージェントロジックを分離でき、長期的に保守しやすいアーキテクチャになります。
MCPのセキュリティと導入時の注意点
MCPは非常に便利な一方で、「外部システムへの自動操作権限」をエージェントに与える仕組みでもあります。PoCの段階から、最低限のセキュリティとガバナンスを組み込んでおくことが重要です。
権限設計とアイデンティティ管理
MCPサーバーは多くの場合、APIキー・OAuthトークン・サービスアカウントなどを用いて外部サービスにアクセスします。誤って管理者権限のトークンを渡すと、エージェント経由でリソースの削除やファイルの強制上書きが可能になってしまうリスクがあります。
事前に次のような方針を決めておくと安全です。
- 読み取り専用サーバーと更新可能サーバーを分けて運用する
- 本番環境と検証環境で別々の資格情報を使う
- ユーザー個人のアカウントではなく「エージェント専用アカウント」を発行する
ログ・監査・コード実行サンドボックス
各社の技術ブログでは、MCPとコード実行環境を組み合わせる場合でも、PII(個人情報)をトークナイズしてモデルから隠す設計などが紹介されています。
自社でMCPを導入する際も、次のようなポイントを押さえておくと安全性が高まります。
- MCPサーバー側で、リクエスト/レスポンスのログを適度な粒度で記録する
- ログには必要最小限の情報のみを残し、PIIはマスクやトークナイズを行う
- コード実行を伴う場合は、コンテナやサンドボックス環境でCPU・メモリ・ネットワークなどのリソース制限をかける
こうした設計により、「どのツールがいつ・どのデータにアクセスしたか」を後から追跡しやすくなります。生成AIのセキュリティリスクについてはこちらの記事もあわせてご覧ください。
社内ポリシーと運用ルール
組織としてMCPを展開する場合、重すぎない範囲で次のようなルールを整えておくと、運用が安定します。
- 本番系のMCPサーバーはPull Requestベースでレビュー必須にする
- セキュリティ/プラットフォームチームと連携し、利用可能な外部サービスをホワイトリスト化する
- 公開OSSのMCPサーバーも、そのまま使う前に一度コードレビューを行う
「便利だけれど中身がよく分からないツール」が野放しにならないよう、社内ルールやAIガバナンスの枠組みで最低限のルールを事前に決めておくと安心です。
導入で陥りやすいアンチパターン
MCPの導入で失敗しやすいパターンを3つ紹介します。
-
全社展開から始めてしまう
MCPは小さなPoCからスタートするのが鉄則。まずは1つのチーム・1つのユースケースで効果を確認し、段階的に広げるアプローチが有効
-
サーバーを作りすぎる
1つのツールに1つのサーバーを立てるのではなく、関連するツールをまとめて1つのサーバーに実装する方が管理しやすい。サーバー数が増えるほど設定・認証・モニタリングの負荷が上がる
-
OSSサーバーを検証なしで本番利用する
Awesome MCP Serversには多様なサーバーが公開されているが、セキュリティ監査やコードレビューなしに本番環境で使うのは危険。フォークして中身を確認してから利用する
企業での段階的導入ステップ
多くの組織では、次のようなステップで段階的に広げていくとスムーズです。
- ローカルMCPサーバーで、社内ドキュメントの読み取り専用検索を構築する(デスクトップクライアントから利用)
- 限定されたチーム向けに、GitHubや監視サービスと連携するリモートMCPサーバーを試験導入する
- 成果が見えた段階で、Agents SDKなどと組み合わせた本格的なエージェント基盤を検討する
このように段階を踏むことで、リスクを抑えつつMCP活用の範囲を広げていくことができます。
MCP導入にかかる費用
MCPをビジネスに導入する際の費用感を整理します。MCPプロトコル自体はオープンソースで無料ですが、実際の運用では生成AIのAPI利用料や開発費が発生します。以下の表で、一般的な費用構造をまとめました。
| 費用区分 | 内容 | 費用目安(2026年3月時点) |
|---|---|---|
| MCPプロトコル | オープンソース。ライセンス料なし | 無料 |
| AIツール利用 | ChatGPT Team等のSaaS型ツール経由で利用 | 月額2,000〜6,000円/ユーザー |
| API従量課金 | Claude API / OpenAI API等の利用料 | 入力$3〜$15 / 出力$15〜$75(100万トークンあたり。モデルにより異なる) |
| MCPサーバー開発(小規模) | 既存OSSのカスタマイズ、1〜2ツールのPoC | 50万〜200万円 |
| MCPサーバー開発(中規模) | 複数ツールの構築、社内システム連携 | 200万〜1,000万円 |
| 運用・保守 | サーバー監視・改善・セキュリティ更新 | 月額10万〜50万円 |
MCPプロトコル自体は無料のため、まずはClaude DesktopやChatGPTの既存プランでOSSのMCPサーバーを試すところから始められます。API料金の詳細はChatGPT APIの料金ガイドも参考にしてください。

AIとシステムの接続技術を組織の業務変革に役立てる
MCPのようなAIと外部システムをつなぐプロトコルの理解は、「AIが業務システムと連携して実務を自動化する」という将来像を描く上で重要な基盤になります。個別のツール連携から一歩進んで、組織全体でAIを業務に組み込む段階設計を検討するタイミングです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階設計する実践ガイド(220ページ)を無料で提供しています。部門別のBefore/After付きユースケースから、PoC→全社展開のロードマップまで、具体的な導入ステップを解説しています。
AI総合研究所が、AI連携技術の知見を組織の業務自動化に発展させる道筋を設計からサポートします。
MCP実装の知見を組織のAI戦略に接続する

技術検証から業務プロセス設計へ
MCPの実装方法を理解した技術力があるなら、次は組織全体の業務プロセスにAIを組み込む設計が重要です。Microsoft環境での導入設計と運用保守のサイクルを220ページの実践ガイドにまとめています。
まとめ
本記事では、MCP(Model Context Protocol)の仕組みと活用パターンを、アーキテクチャ・クライアント別の使い方・ハンズオン・セキュリティ・費用の観点から解説しました。
ポイントを改めて整理します。
-
オープンな接続プロトコル
MCPは4大AIベンダーが採用し、Linux Foundation傘下のAAIFで標準化が進むオープンプロトコル。一度構築したMCPサーバーを複数のクライアントから再利用できる
-
段階的な導入が可能
ローカルMCPサーバーでのPoCからスタートし、リモートサーバーでのチーム展開、Agents SDKとの連携へと段階的に広げられる。MCPプロトコル自体は無料で、OSSサーバーも8,600以上公開されている
-
セキュリティ設計はPoCから
権限分離・ログ監査・OSSのコードレビューなど、セキュリティとガバナンスの基本はPoC段階から組み込んでおくと、後からの手戻りを防ぎやすい
社内の業務システムやデータソースをAIエージェントから活用したいが「どこから手をつければよいか分からない」という場合は、まず社内ドキュメントの読み取り専用検索をローカルMCPサーバーで構築するところから始めてみてください。天気予報サーバーのハンズオンで感覚をつかんだ後、自社のユースケースに置き換えていくのが最短ルートです。







