この記事のポイント
 資料作成やコード生成など「成果物を出す業務」を効率化するなら、GPT-5.2のInstantモデルを日常業務の第一候補にすべき
資料作成やコード生成など「成果物を出す業務」を効率化するなら、GPT-5.2のInstantモデルを日常業務の第一候補にすべき- 分析や戦略立案など正確性が求められるタスクにはThinkingモデルが最適で、推論ステップの可視化により判断根拠を確認できる
- 長文ドキュメントやログ解析ではGPT-5.2の拡張コンテキストが有効で、従来モデルで発生していた見落としリスクを大幅に低減できる
- エージェント運用を検討する企業はProモデルを選ぶべきで、ツール連携と複数ステップの自動実行により複雑なワークフローを構築可能
- 無料プランでも試用可だが業務利用ではPlus以上の契約が現実的、最新GPT-5.4が既にリリース済で新規導入時は両モデル比較を推奨

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2025年12月11日、OpenAIは実務タスクの品質とエージェント運用を大幅に強化した最新フロンティアモデル「GPT-5.2」シリーズを正式発表しました。
日常業務向けのInstant、思考特化のThinking、最難関タスク向けのProという3モデル構成で、スプレッドシートやスライド作成、コーディングなどの実務的なタスクにおいて人間エキスパート級の性能を示しています。
本記事では、GPT-5.1から何が変わったのか、具体的な違いや料金体系、そして長文コンテキストとツール連携を活かした新しいエージェント設計のポイントまでを体系的に解説します。
✅最新モデル「GPT-5.5」については、以下の記事をご覧ください。
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説
目次
【コーディング】本番コード修正・機能追加まで任せられるレベルに
【長文コンテキスト】数十万トークン規模ドキュメントでの精度向上
【画像理解(ビジョン)】ダッシュボード・UI・図表の読解精度アップ
【ツール連携・エージェント】マルチツールワークフローの完遂率
GitHub Copilot / Microsoft Copilot
GPT-5.2の安全性・コンプライアンスとメンタルヘルス対応
GPT-5.2(ChatGPT-5.2)とは?
GPT-5.2(ChatGPT-5.2)は、OpenAIが2025年12月に公開した新しいフロンティアモデルシリーズです。
「プロの知的労働」と「長時間動き続けるエージェント」を前提に設計されており、スプレッドシートやプレゼン作成、コーディング、長文ドキュメント分析などの実務タスクで、従来モデルより高い性能を発揮します。

GPT-5・GPT-5.1との違い:何が変わったのか?

結論:GPT-5.2は、実務タスクの品質・安定性・ツール連携を大きく強化した「実戦強化版」です。
OpenAIは、GPT-5.2が長文コンテキスト理解・エージェント運用・ツール連携を強く意識した設計であると説明しています。
では、この改善がGPT-5系の中でどの位置づけなのかを掴むために、まず世代構造を整理します。
-
- GPT-4系からの大きな世代ジャンプ
- 推論・コーディング・エージェント的タスクの“基幹モデル”として性能を底上げ(ChatGPT / APIで利用)
-
- 推論・コスト・レイテンシのバランス改善
- 思考モード(Thinking)やCodex向け最適化モデルが登場
-
GPT-5.2
- 実務タスクの品質・安定性・ツール連携を大きく強化した実戦強化版
- 長文コンテキストやエージェント運用を強く意識した設計
- GPT-5.4(2026年3月5日リリース)
- ネイティブ・コンピュータ操作、100万トークンコンテキスト、Tool Search機能を新たに搭載
- GPT-5.2比でクレーム単位の誤り率33%減少、レスポンス全体のエラー率18%低下
実務目線で見ると、GPT-5.2は「全く新しい概念」というより、GPT-5.1を現場投入しやすい形に磨き込んだバージョンと捉えるとイメージしやすいです。
特に、表計算・プレゼン作成・ソフトウェア開発・長文ドキュメント分析・ツール連携といった「経済価値の高いタスク」で、定量的な改善が報告されています。
GPT-5.2のモデルシリーズ
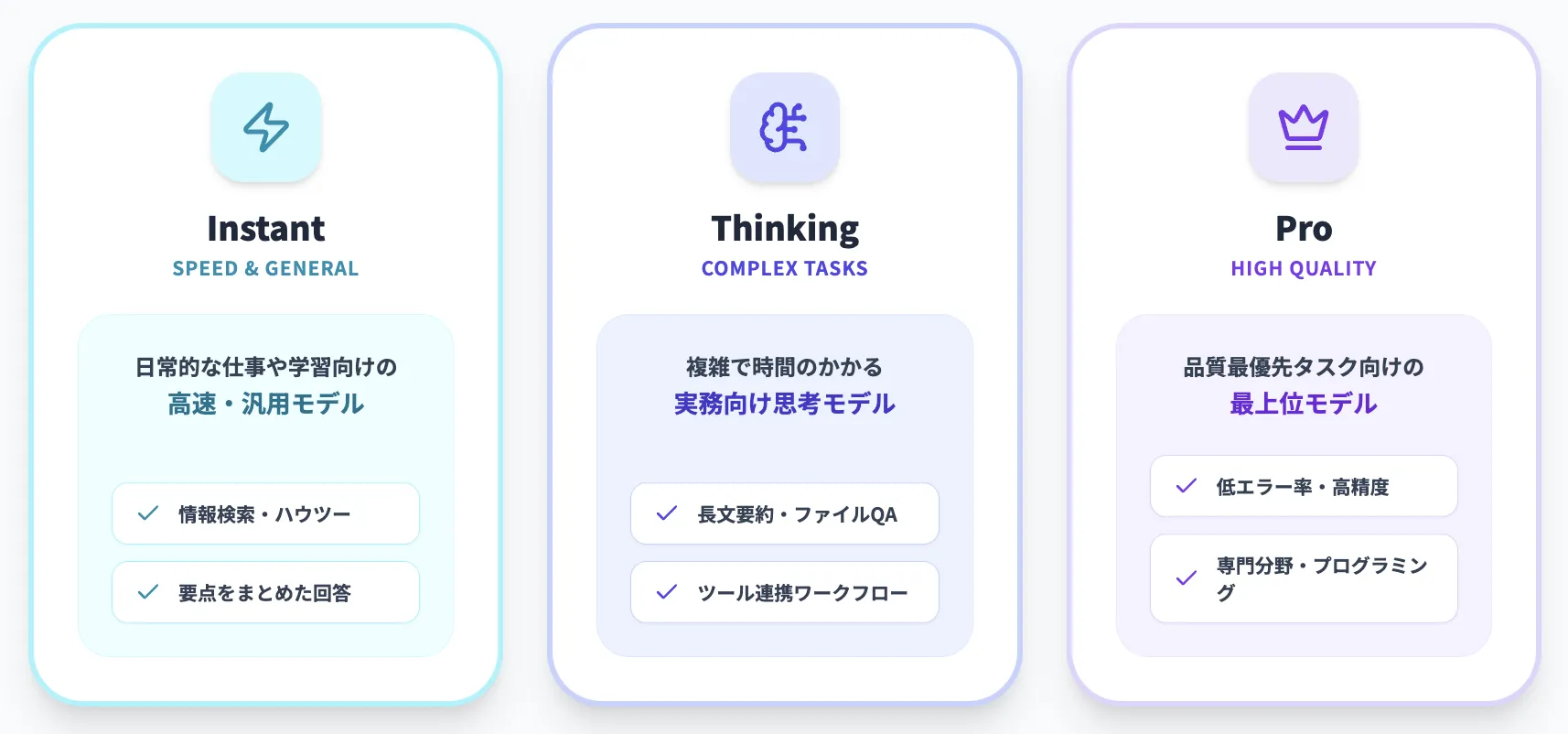
GPT-5.2は、「Instant」「Thinking」「Pro」の3つのモデルからなるシリーズとして提供されます。
いずれもGPT-5.1をベースに、知能(推論)、長文コンテキスト、ツール呼び出し、ビジョン(画像・画面理解)の4つの軸で性能が強化されています。
-
GPT-5.2 Instant
日常的な仕事や学習向けの高速・汎用モデルです。
情報検索やハウツー、技術文書、翻訳などで、GPT-5.1 Instantよりも分かりやすく要点をまとめた回答を返すよう設計されています。
-
GPT-5.2 Thinking
コーディング、長文ドキュメント要約、ファイルQA、数学・ロジックのステップ解説、意思決定支援など、より複雑で時間のかかるタスク向けの思考モデルです。
長いコンテキストとツール呼び出しを組み合わせたワークフローに最適化されています。
-
GPT-5.2 Pro
プログラミングや専門分野の難しい質問など、品質最優先のタスク向けに設計された最上位モデルです。
Thinkingよりもエラー率が低く、難度の高い領域での精度が重視されています。
GPT-5.2(ChatGPT-5.2)の料金・回数制限
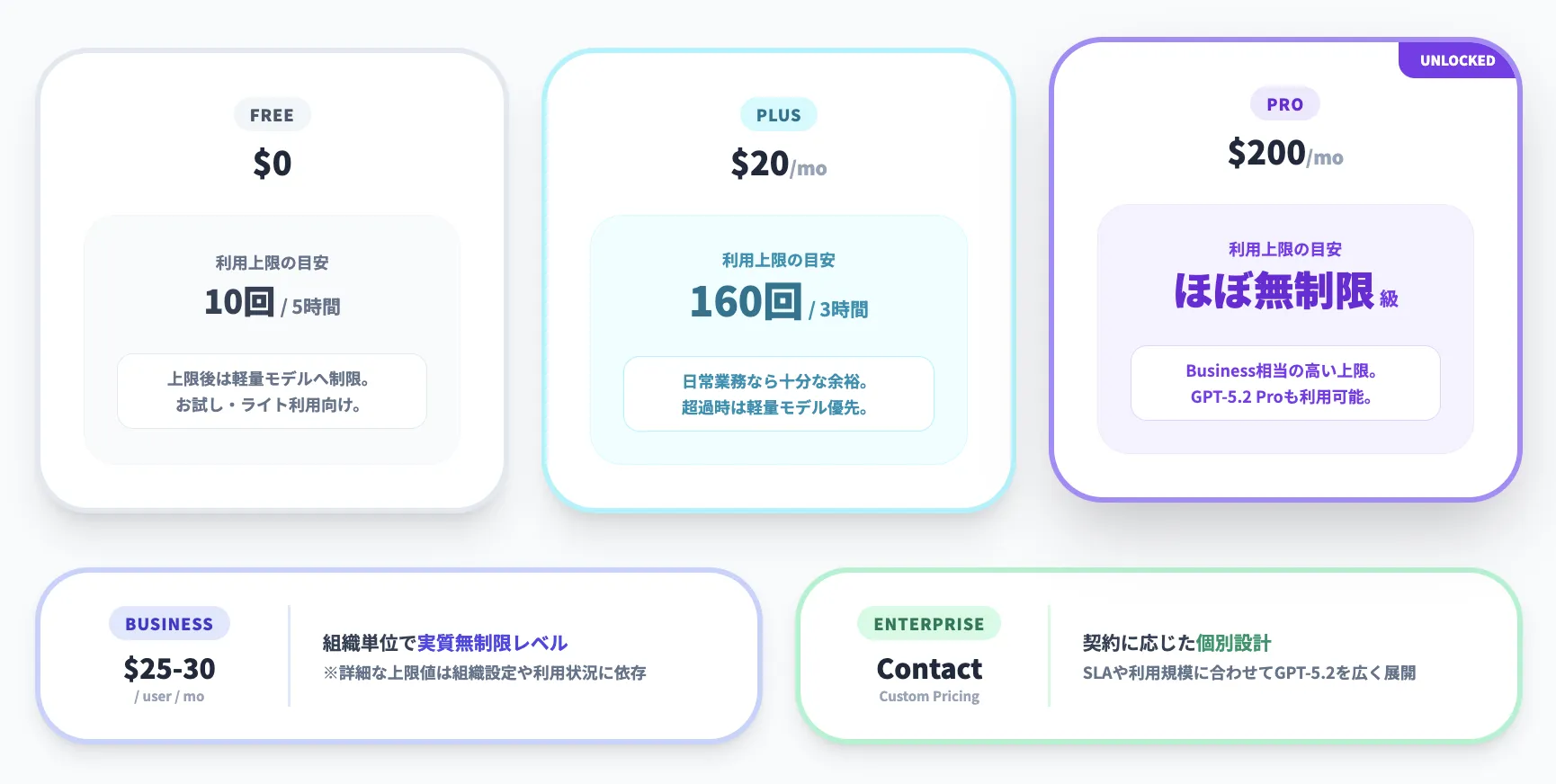
ChatGPT上では、GPT-5.2シリーズは無料版およびすべての有料プラン(Go・Plus・Pro・Business・Enterprise)で利用可能です。
ここでは、各プランごとの料金および回数制限を整理します。
| プラン | 月額料金(USD) | 回数制限(GPT-5.2関連) |
|---|---|---|
| Free | $0 | GPT-5.2シリーズへのアクセスは5時間あたり10メッセージ程度。 上限を超えると、しばらく軽量モデル中心の利用に制限。 |
| Go | $8(米国) 1,500円(日本アプリ) |
GPT-5.2 Instantのみ利用可能(ThinkingやProは非対応)。 メッセージ・画像生成が無料版の10倍、コンテキスト32K。 |
| Plus | $20 / 月 | GPT-5.2シリーズへのアクセスは3時間あたり160メッセージ。 上限超過時は一時的にGPT-5.2利用が制限され、軽量モデルが優先。 |
| Pro | $200 / 月 | GPT-5.2 Pro を含むGPT-5.2シリーズを、Business相当の高い上限で利用可能。 実務上は「ほぼ無制限」に近い使い方が前提。 |
| Business | 年払い: $25 / ユーザー / 月 月払い: $30 / ユーザー / 月 |
組織単位でGPT-5.2シリーズを実質無制限レベルで利用可能。 詳細な上限値は組織設定や利用状況に依存。 |
| Enterprise | 個別見積もり | 契約内容に応じて個別に上限が設計される。 SLAや利用規模に合わせてGPT-5.2シリーズを広く利用可能。 |
各料金プランの詳細については、以下の記事をご覧ください。
ChatGPTの料金プラン一覧を比較!無料・有料版の違い・支払い方法を解説
API料金
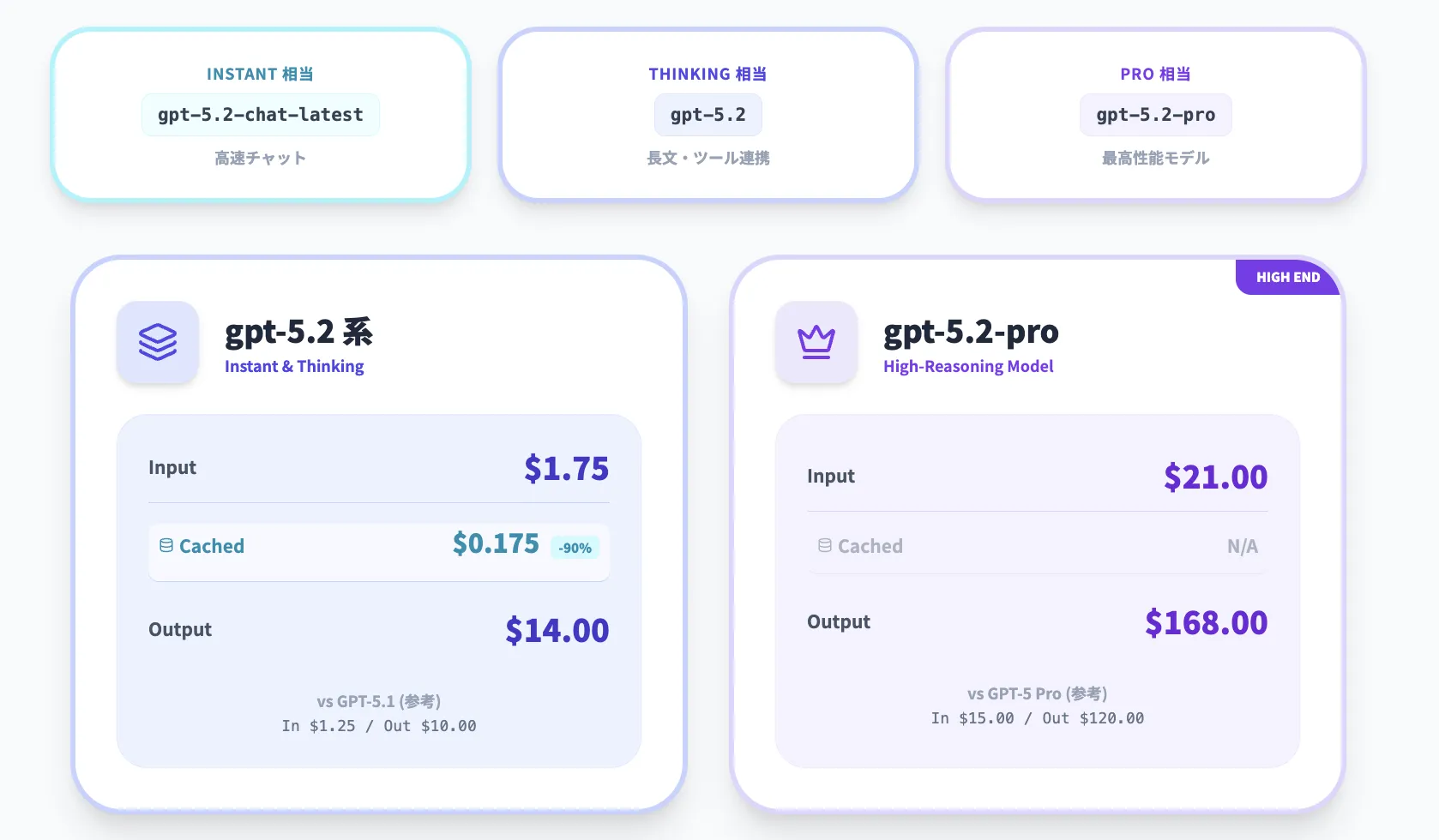
API経由でGPT-5.2を利用する場合は、1Mトークンあたりの従量課金が基本になります。
GPT-5.2シリーズは主に次の3つのモデルIDで提供されており、それぞれがInstant / Thinking / Proに対応します。
- gpt-5.2-chat-latest:GPT-5.2 Instant 相当(高速チャットモデル)
- gpt-5.2:GPT-5.2 Thinking 相当(長文・ツール連携向け)
- gpt-5.2-pro:GPT-5.2 Pro 相当(最高性能モデル)
トークン単価は、公式アナウンスベースで次のように整理できます(1Mトークンあたり)。
| モデル | 入力 | キャッシュ入力 | 出力 |
|---|---|---|---|
| gpt-5.2 gpt-5.2-chat-latest |
$1.75 | $0.175(90%割引) | $14 |
| gpt-5.2-pro | $21 | ー | $168 |
| gpt-5.4 | $2.50 | $0.625 | $15 |
| gpt-5.4-pro | $30 | ー | $150 |
比較対象として、GPT-5.1 / GPT-5 Pro の価格帯は次のように示されています。
| モデル | 入力 | キャッシュ入力 | 出力 |
|---|---|---|---|
| gpt-5.1 gpt-5.1-chat-latest |
$1.25 | $0.125 | $10 |
| gpt-5-pro | $15 | ー | $120 |
一見するとGPT-5.2の方が高く見えますが、OpenAIは「同じ品質を達成するために必要なトークン数が減るため、トータルコストはむしろ下がるケースも多い」と説明しています。
特に、長文コンテキストや複雑なエージェントタスクでは、思考の無駄や再試行回数が減ることによるコスト削減が期待できます。
GPT-5.2(ChatGPT-5.2)の性能進化ポイント

GPT-5.2は、単に「スコアが少し良くなった」レベルではなく、実務寄りのベンチマーク群で世代交代レベルの伸びを見せています。
以下では、実務ユースケースに引き寄せながら順番に見ていきます。
【実務タスク】スライドやエクセル作成が“プロ級”に
まず押さえておきたいのが、実務に直結する評価指標 「GDPval」です。
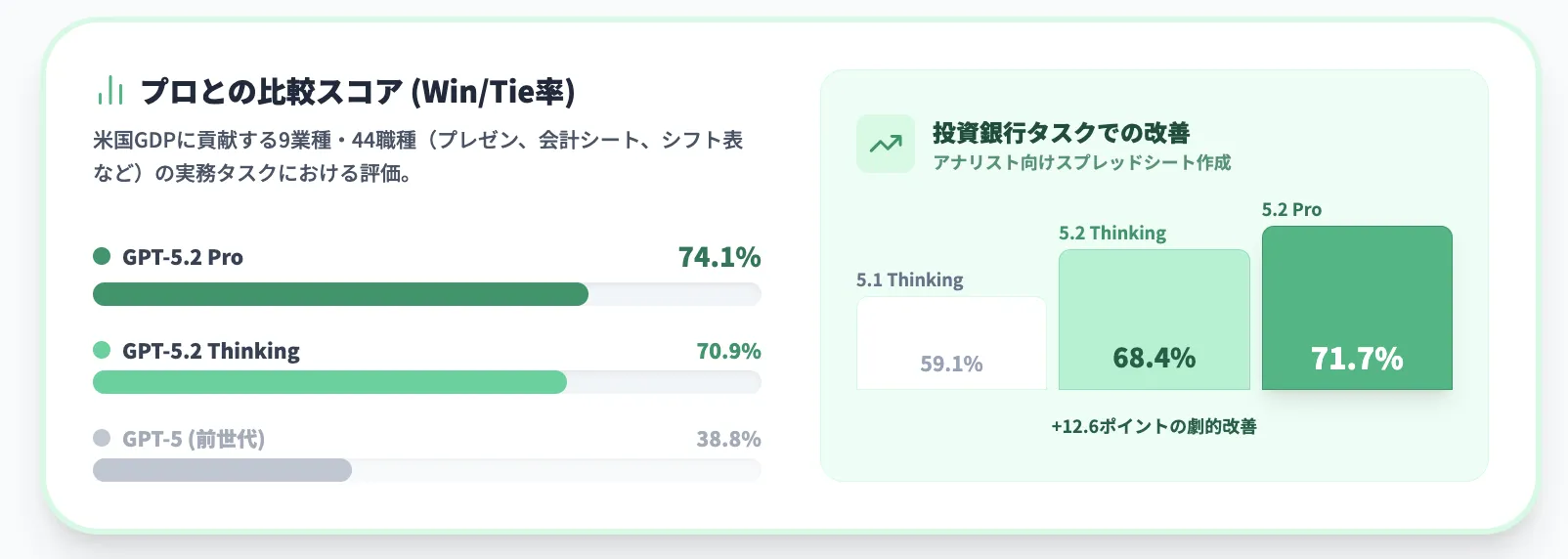
GDPvalは、「米国GDPに大きく貢献している9業種・44職種」をカバーし、以下のような実際の成果物レベルでAIと人間の専門家を比較するベンチマークです。
- 営業用プレゼン資料
- 会計スプレッドシート
- 病院のシフト表
- 製造ラインの図面
- 短尺動画 など
GPT-5.2シリーズのスコアは次のとおりです(「勝ち or 引き分け」の割合)。
- GPT-5.2 Pro:74.1%
- GPT-5.2 Thinking:70.9%
- GPT-5(前世代):38.8%
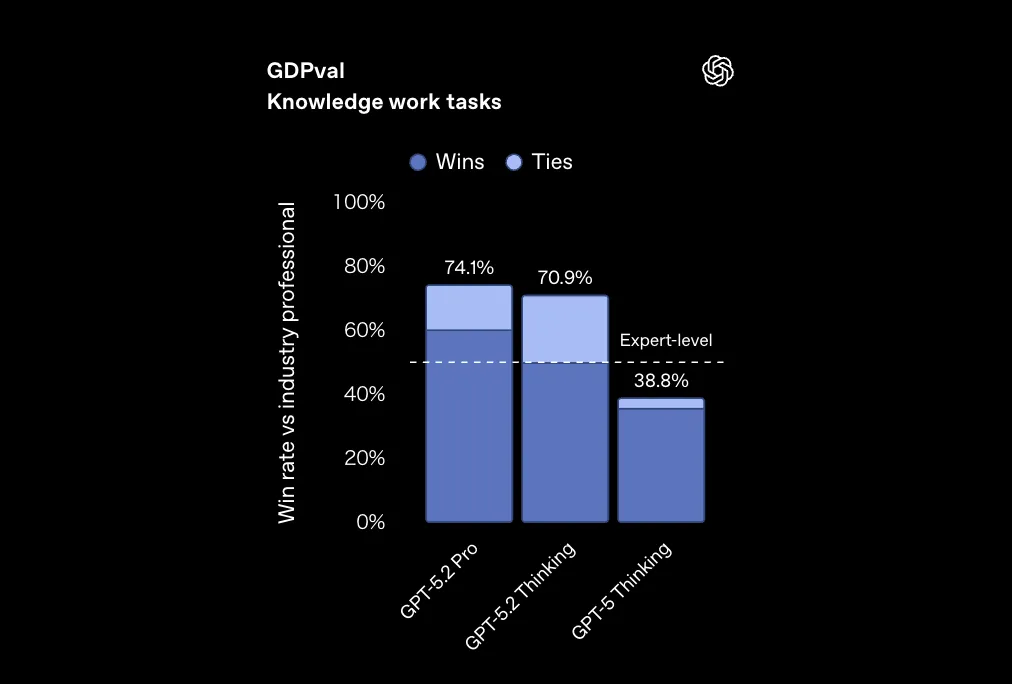
GDPvalでのGPT-5.2 Pro / Thinking / GPT-5の比較 (参考:OpenAI)
グラフから分かるように、GPT-5.2 Thinking/Proは「業界プロのアウトプット」と比べても、7割前後のケースで“勝ちまたは同等”と判定される水準まで伸びています。
さらに、社内ベンチマークの投資銀行アナリスト向けスプレッドシートタスクでは、
- GPT-5.1 Thinking:59.1%
- GPT-5.2 Thinking:68.4%
- GPT-5.2 Pro:71.7%
と、約9ポイント前後のスコア改善が報告されています。
実務タスクへのインパクト

以下の例のように、GPT-5.1と同じプロンプトでも「そのまま報告資料に貼れるかどうか」レベルの差が出やすくなっているのがGPT-5.2の特徴です。
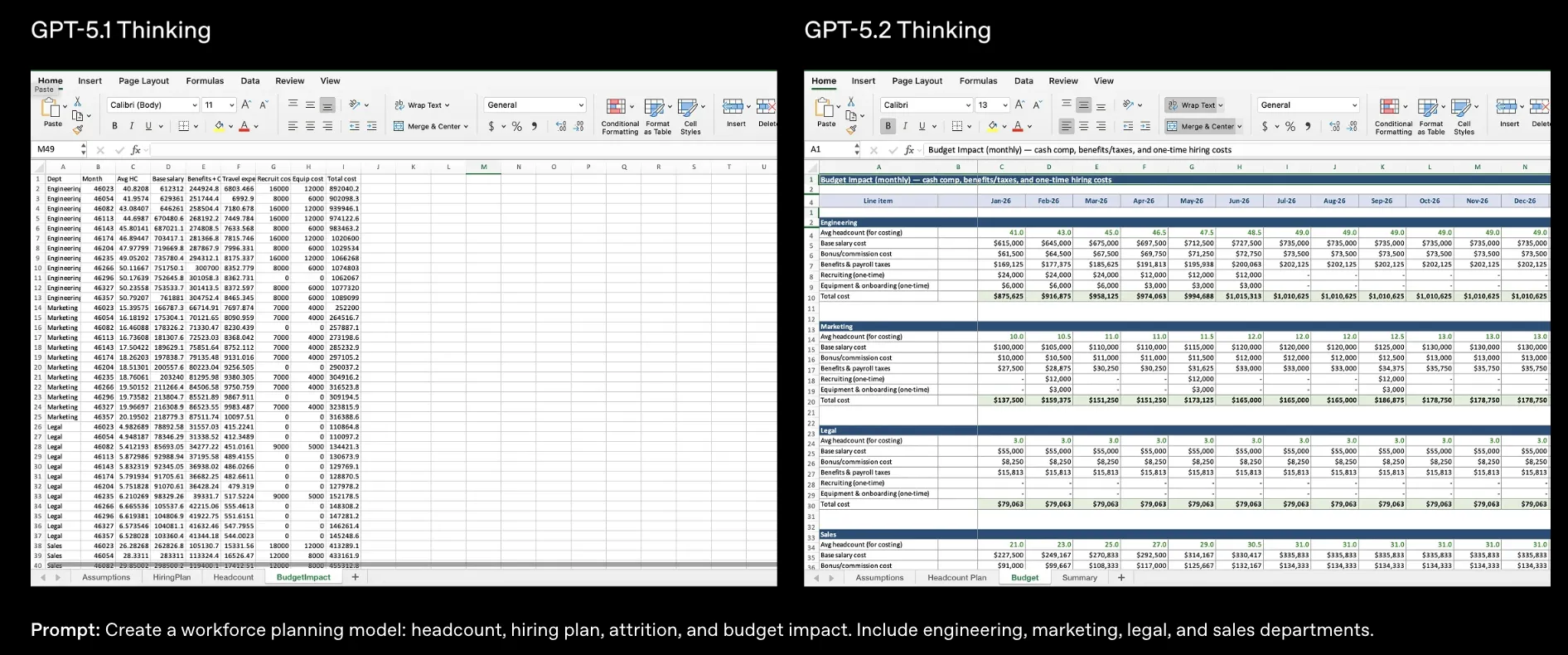
同じワークフォースプランニングタスクに対するGPT-5.1とGPT-5.2のスプレッドシート出力例 (参考:OpenAI)
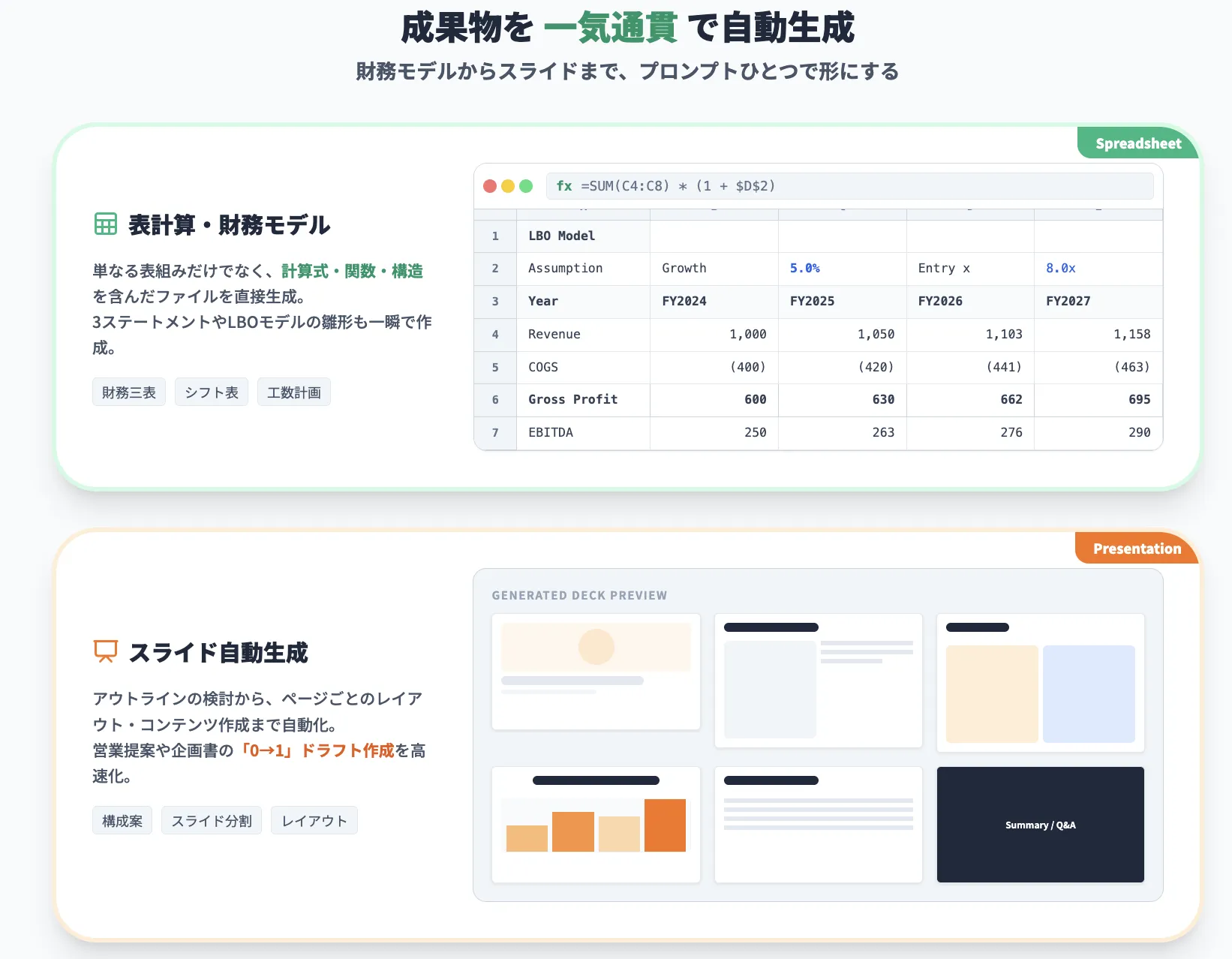
実務イメージとしては、次のようなタスクで「下書き〜7〜8割の完成品」を一気に出すイメージです。
- 財務三表モデルの雛形作成とシナリオ設定
- 営業提案資料の構成案とドラフトスライド
- 病院のシフト表・勤務表の作成
- 製造ラインの工数計画や簡易工程図の作成
もちろん、人間による確認・修正は前提ですが、ゼロから作る時間を大きく圧縮する方向のアップデートと考えると分かりやすいでしょう。
【コーディング】本番コード修正・機能追加まで任せられるレベルに
ソフトウェア開発系では、GPT-5.2 ThinkingがSWE-Bench Pro / SWE-bench VerifiedでSOTAを更新しています。

代表的なスコアは次のとおりです。
-
SWE-Bench Pro(Public)
- GPT-5.2 Thinking:55.6%
- GPT-5.1 Thinking:50.8%
-
SWE-bench Verified
- GPT-5.2 Thinking:80.0%
- GPT-5.1 Thinking:76.3%
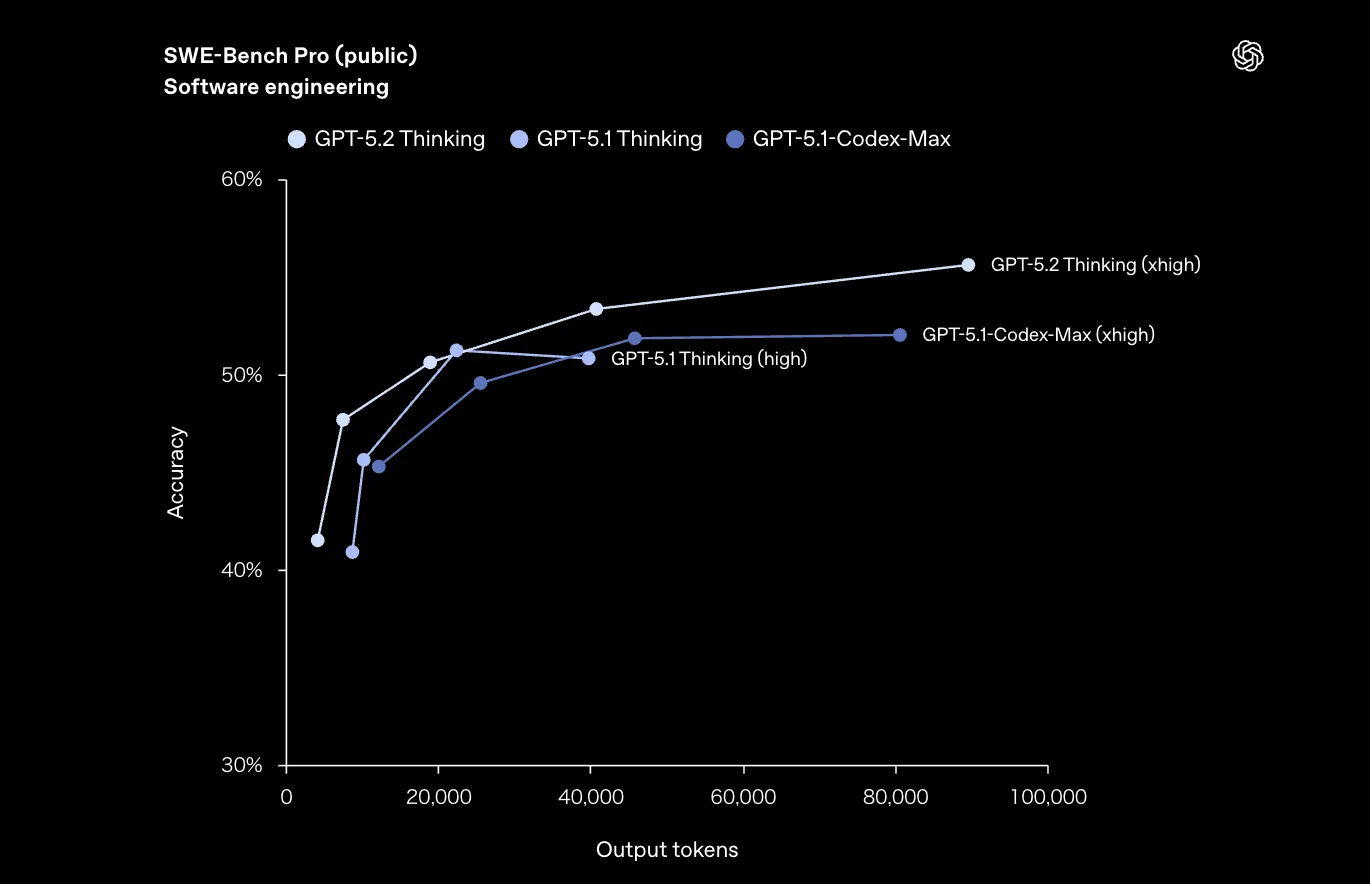
SWE-Bench ProにおけるGPT-5.2 ThinkingとGPT-5.1系モデル(Thinking / Codex-Max)の精度とトークン量の関係 (参考:OpenAI)
グラフを見ると、同じトークン量でも5.2の方が精度が高いことに加え、xhigh設定では5.1系を明確に上回ることが分かります。
開発タスクでの使い勝手
この性能向上は、単純な一問一答だけでなく、以下のような「エンドツーエンドの開発タスク」で成功率が上がることを意味します。
- 既存リポジトリのバグ修正
- 機能追加とテストコード生成
- リファクタリング+PR作成
また、公式の事例やパートナー企業のコメントでは、フロントエンドや3D UIなど「変則的なUI」を含むタスクでの品質向上も報告されています。
GPT-5.2で構築したミニアプリの例 (参考:OpenAI)
単一HTMLファイルで動くインタラクティブなミニアプリや、Three.js / WebGLを使った3D表現なども、1プロンプトでかなり作り込みやすくなっています。
【長文コンテキスト】数十万トークン規模ドキュメントでの精度向上
長文コンテキストまわりでは、OpenAI独自の評価指標 OpenAI MRCRv2(Multi-Round Co-Reference Resolution)が使われています。
これは、非常に長い「会話ログやドキュメント群」の中に複数の“needle”を埋め込み、モデルが指定されたneedleに対応する正しい回答を再現できるかを測るテストです。

GPT-5.2 Thinkingは、このMRCRv2で次のような特徴を示します。
- 4-needleタスク:256kトークン近傍まで、ほぼ100%に近い精度
- 8-needleタスク:GPT-5.1 Thinkingを大きく上回る精度を維持
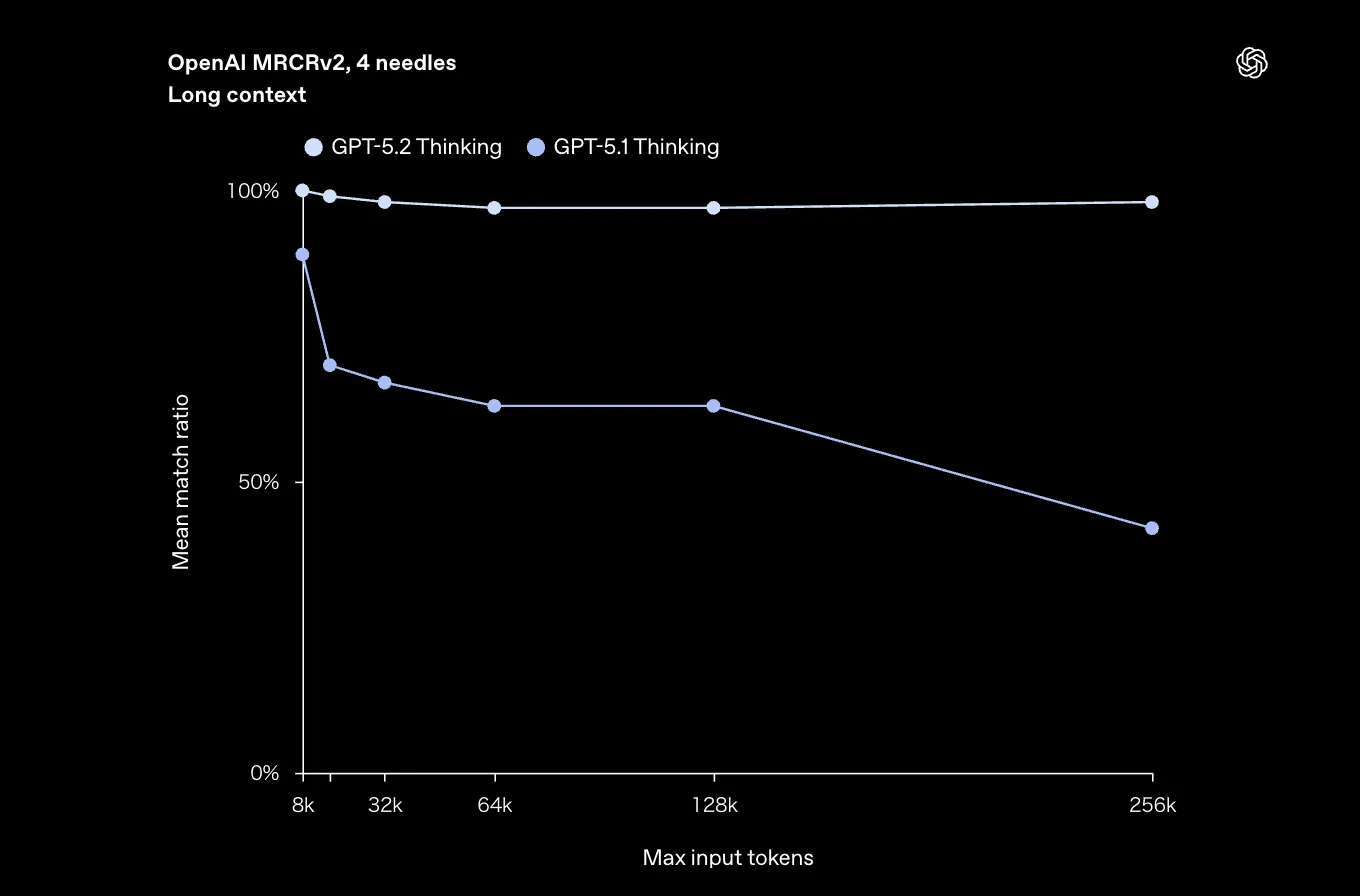
OpenAI MRCRv2(4 needles)での長文コンテキスト性能。256kトークン近傍まで高い「Mean match ratio」を維持 (参考:OpenAI)
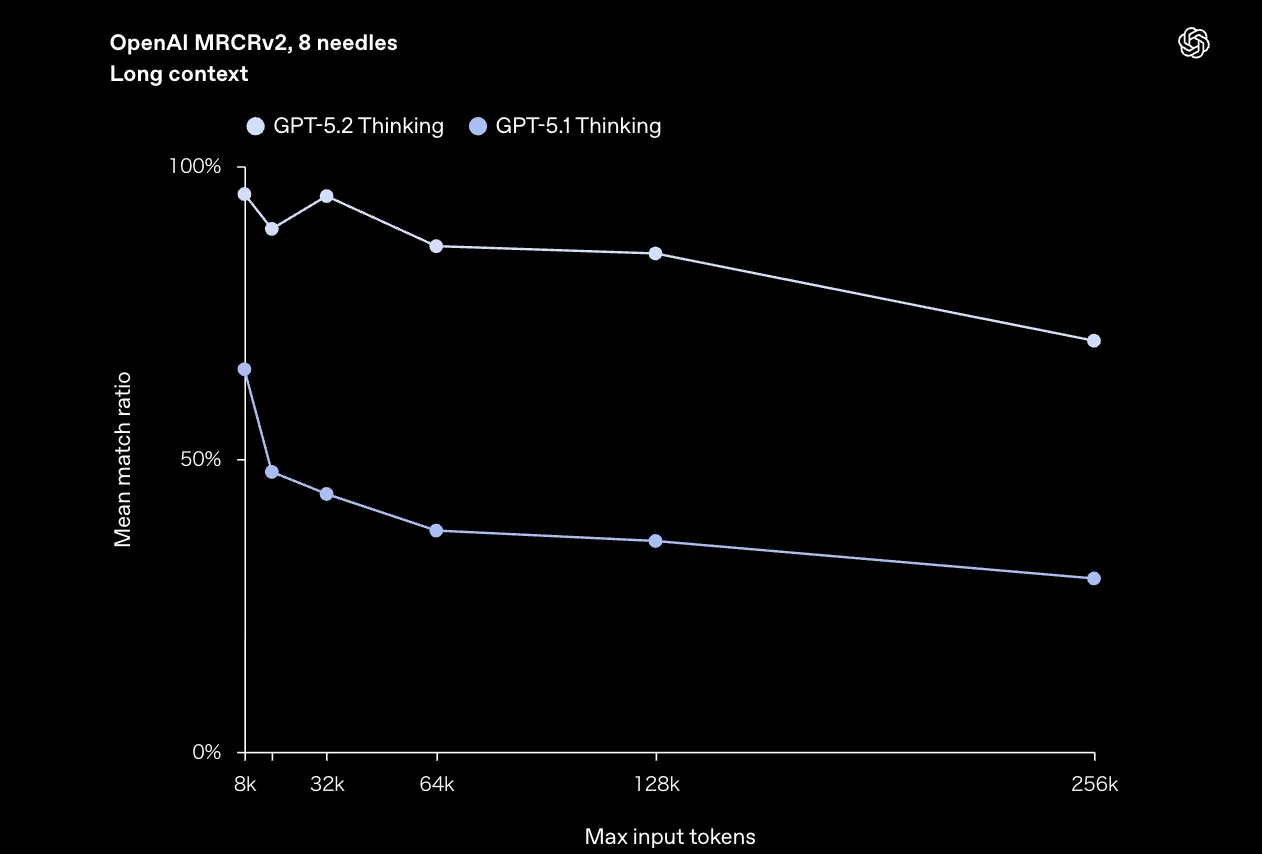
OpenAI MRCRv2(8 needles)での長文コンテキスト性能。入力トークンが増えるほど両者の差が開く (参考:OpenAI)
長文ドキュメント・ログ分析での使いどころ
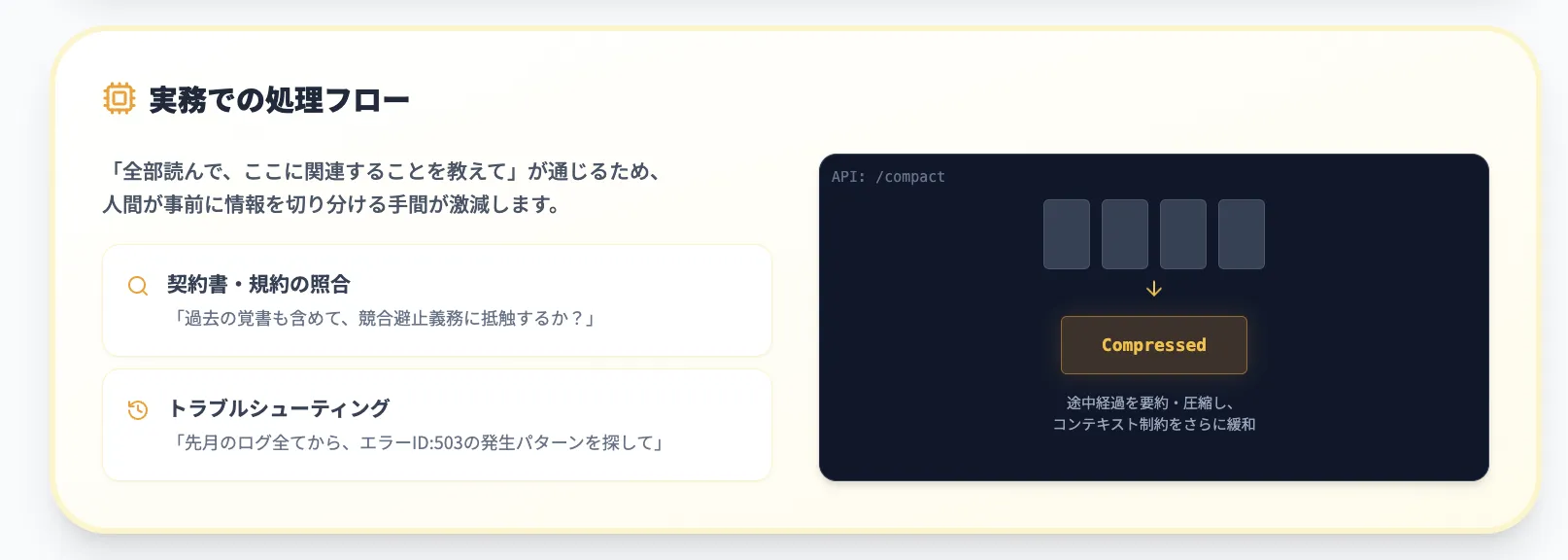
ここでいう「256kトークン」は、ざっくり日本語換算で数十万〜100万文字規模に相当します。
契約書群・議事録・Slackログ・複数レポートなどをまとめて投入しても、関連箇所をきちんと拾い上げて回答できる確率が高いというイメージです。
さらにAPI側では、Responses APIの [/compact] 機能と組み合わせることで、
- 長いコンテキストの途中経過を要約しながら処理を進める
- 「重要な部分だけを保持しつつ、残りは圧縮する」
といった動きが可能になり、実質的なコンテキスト制約をかなり緩和できます。
【画像理解(ビジョン)】ダッシュボード・UI・図表の読解精度アップ
GPT-5.2 Thinkingは、画像理解(ビジョン)系の指標でも大きくスコアを伸ばしています。
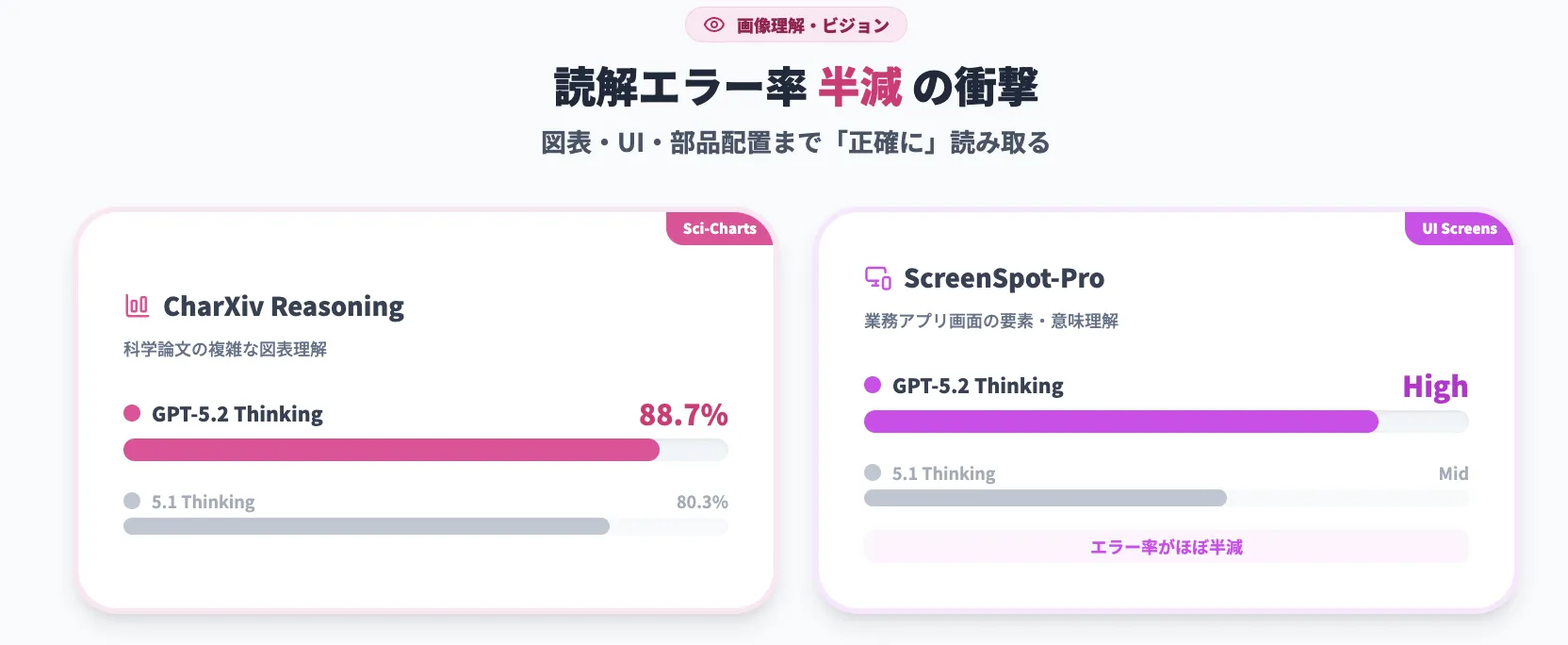
特に、
- 科学論文の図表理解を測る CharXiv Reasoning
- 業務アプリの画面キャプチャ理解を測る ScreenSpot-Pro
で、GPT-5.1 Thinkingに対してエラー率をほぼ半減させています。
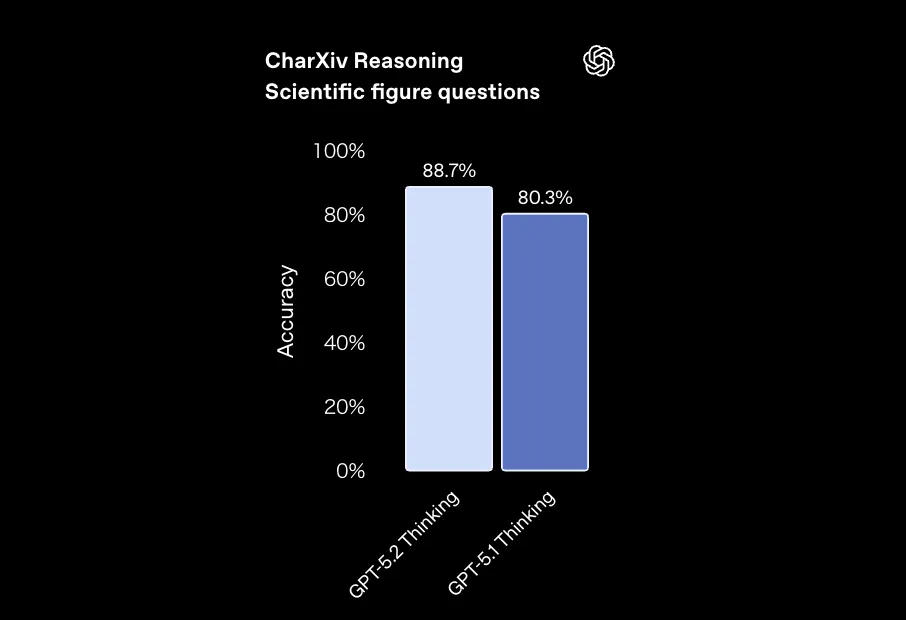
CharXiv ReasoningにおけるGPT-5.2 ThinkingとGPT-5.1 Thinkingの精度比較 (参考:OpenAI)
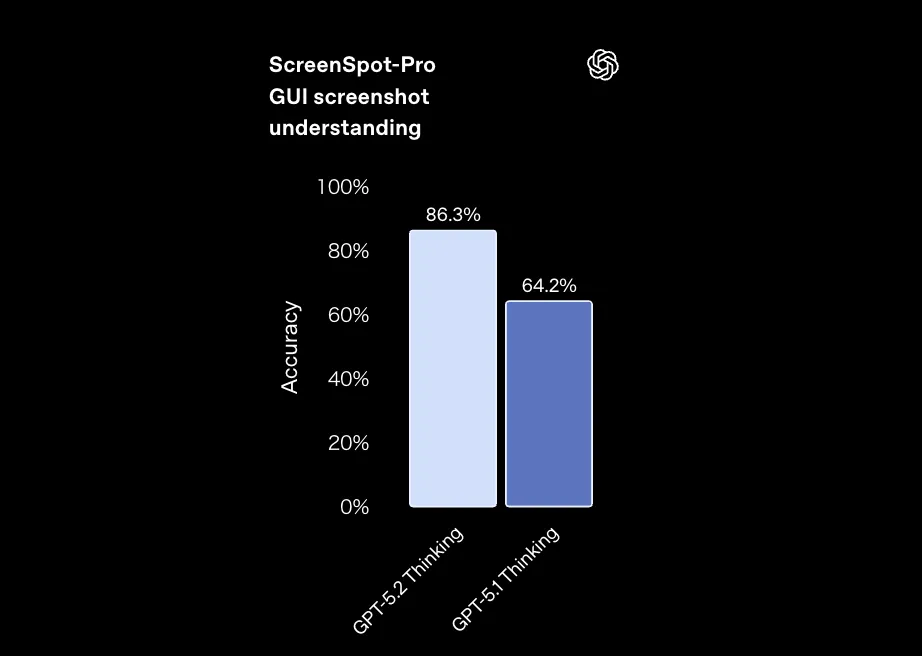
ScreenSpot-ProにおけるGPT-5.2 ThinkingとGPT-5.1 Thinkingの精度比較 (参考:OpenAI)
業務でのビジョン活用イメージ
これにより、次のようなタスクでの「読み間違い」が減りやすくなります。
- BIツールのダッシュボードや売上チャートをキャプチャして、指標解釈や改善案を出してもらう
- 業務システムの画面キャプチャから、操作手順やマニュアルのドラフトを生成する
- 技術資料や科学論文の図・回路図・アーキテクチャ図を読み取り、要約や解説をさせる
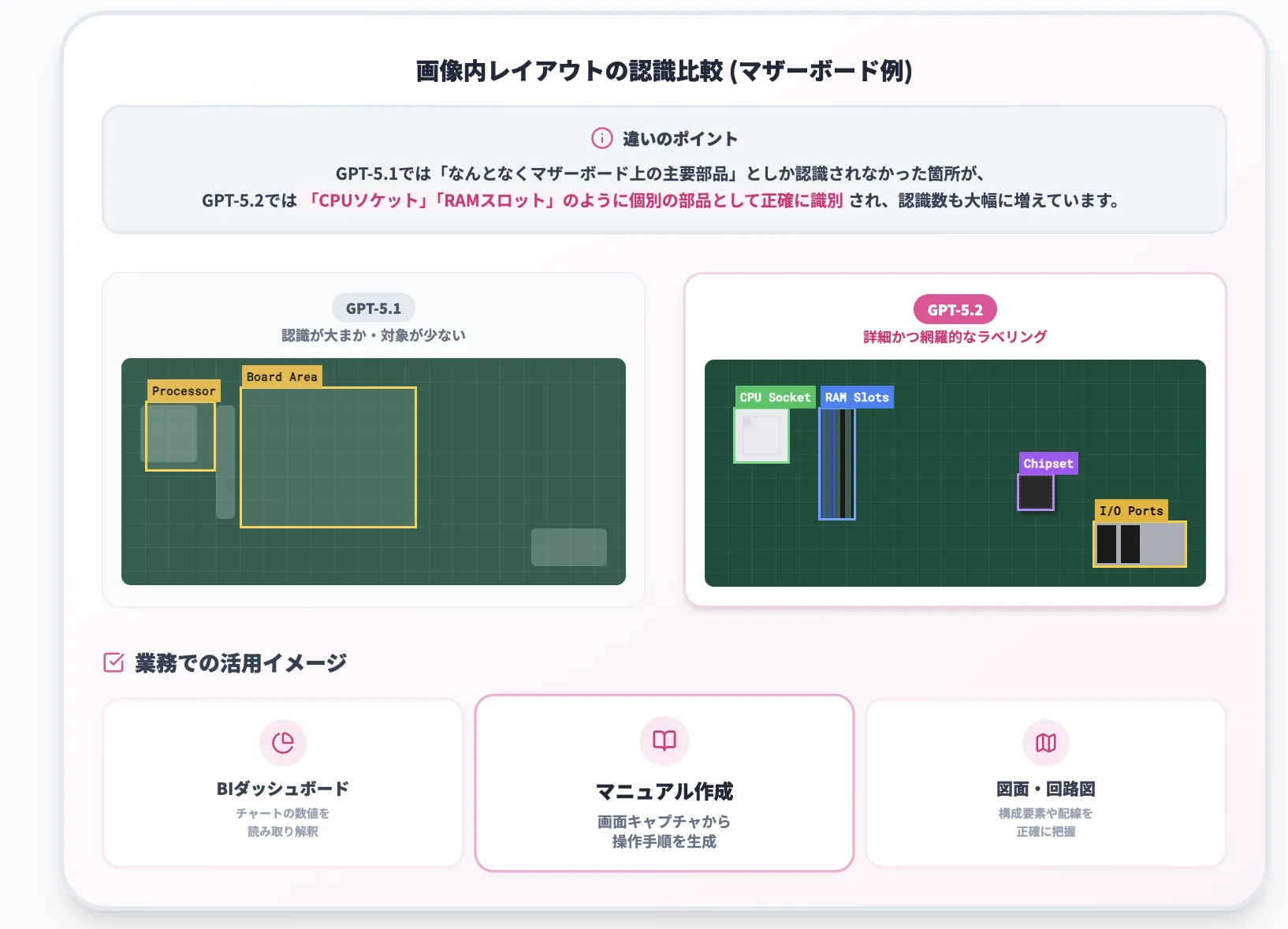
以下の例をみると、画像内レイアウトの理解が一目でわかります。

マザーボード写真に対する部品認識結果の比較。左:GPT-5.1、右:GPT-5.2 (参考:OpenAI)
上のマザーボードの例では、GPT-5.2は
- CPUソケット
- RAMスロット
- 電源回路
- 背面の各種ポート
などを細かくラベリングし、位置関係も含めて把握できていることが分かります。
UIや図面のどの部分に何があるかを前提に議論したいときに、5.1世代より扱いやすくなっています。
【ツール連携・エージェント】マルチツールワークフローの完遂率
エージェント運用の鍵になるのが、ツール呼び出しの正確さと長期タスクでの粘りです。
OpenAIは、「顧客サポート分野の疑似タスク」を使った τ2-bench(Tau2-bench) でこれを評価しています。
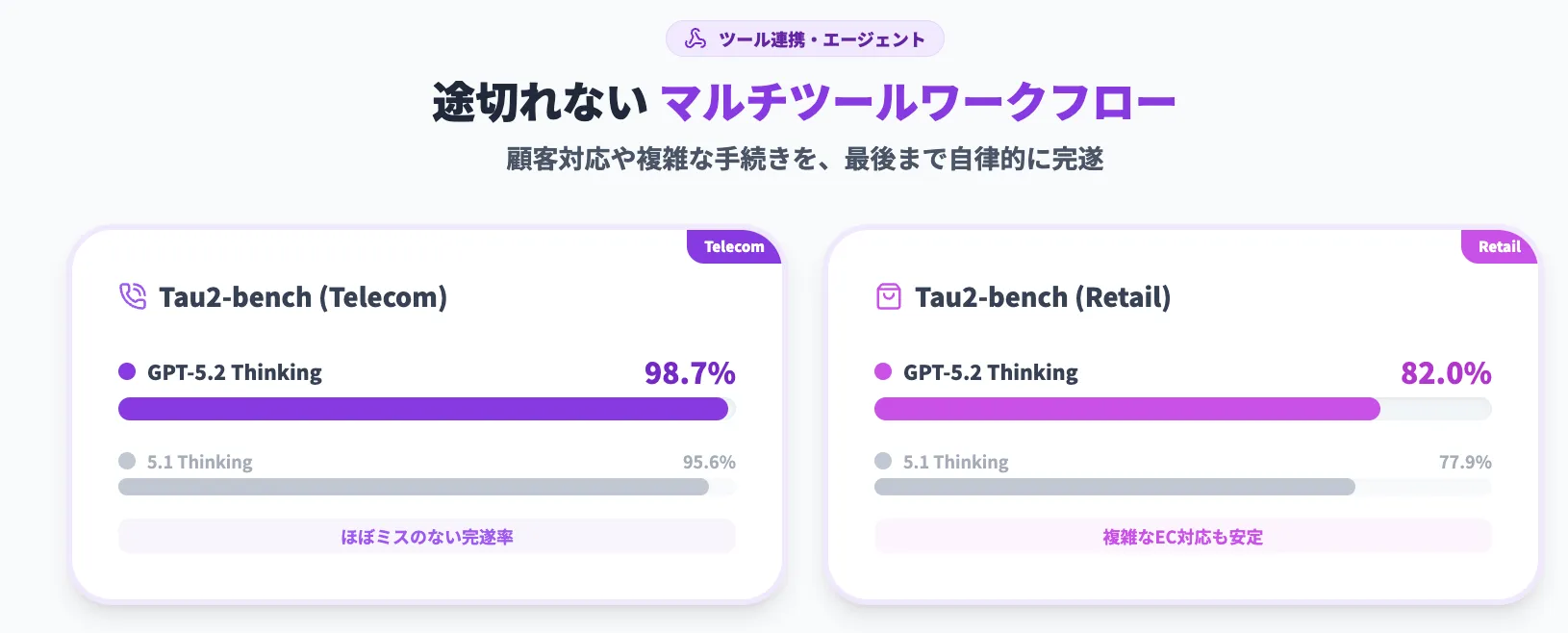
GPT-5.2 Thinkingは、Telecom / Retailの両ドメインでSOTAを達成しました。
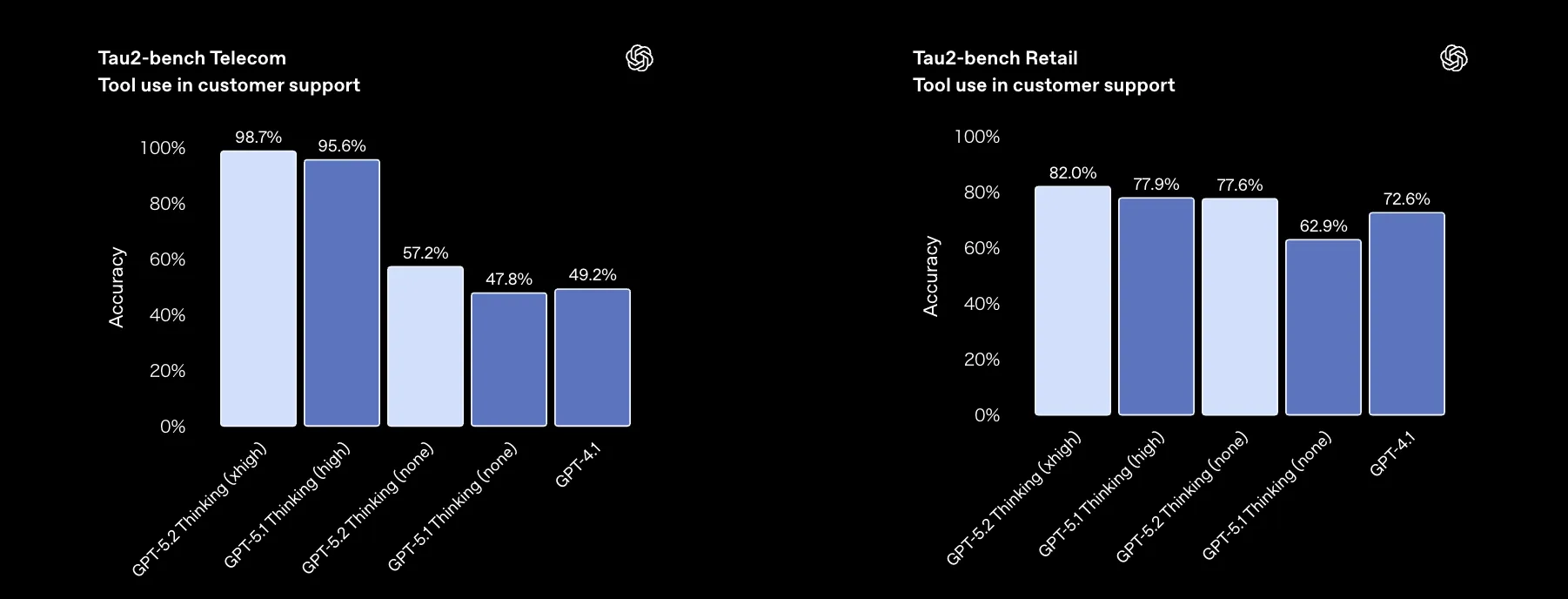
Tau2-bench Telecom / Retail におけるGPT-5.2 Thinking / GPT-5.1 Thinking / GPT-4.1の比較。 (参考:OpenAI)
- Tau2-bench Telecom(xhigh):98.7%(GPT-5.1 Thinkingは95.6%)
- Tau2-bench Retail(xhigh):82.0%(GPT-5.1 Thinkingは77.9%)
さらに、[reasoning.effort='none']の軽量モードでも、5.2は5.1 / 4.1を大きく上回っていることがわかります。
実世界シナリオでみるワークフローの進化
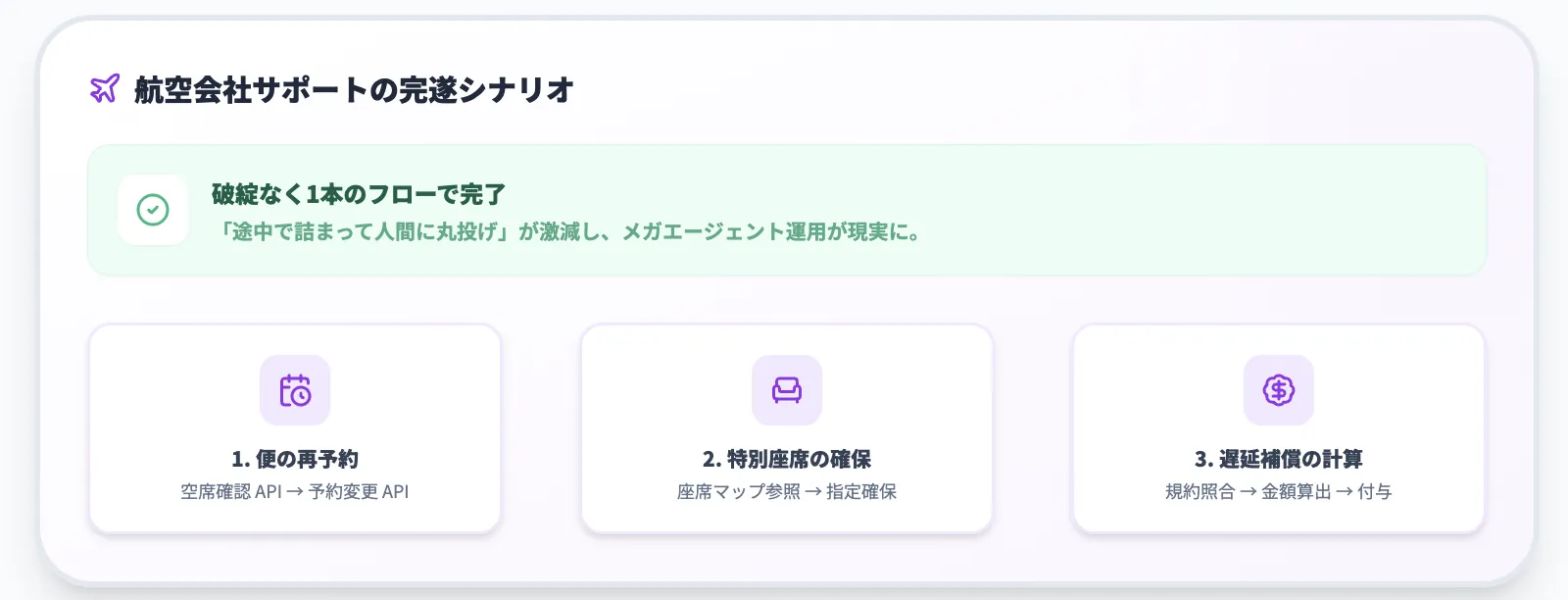
航空会社のサポートシナリオを使ったタスクにおいて、GPT-5.2は
- 便の再予約
- 特別座席の確保
- 遅延補償の計算と付与
といったタスクを1本のワークフローとして破綻なくつなげています。
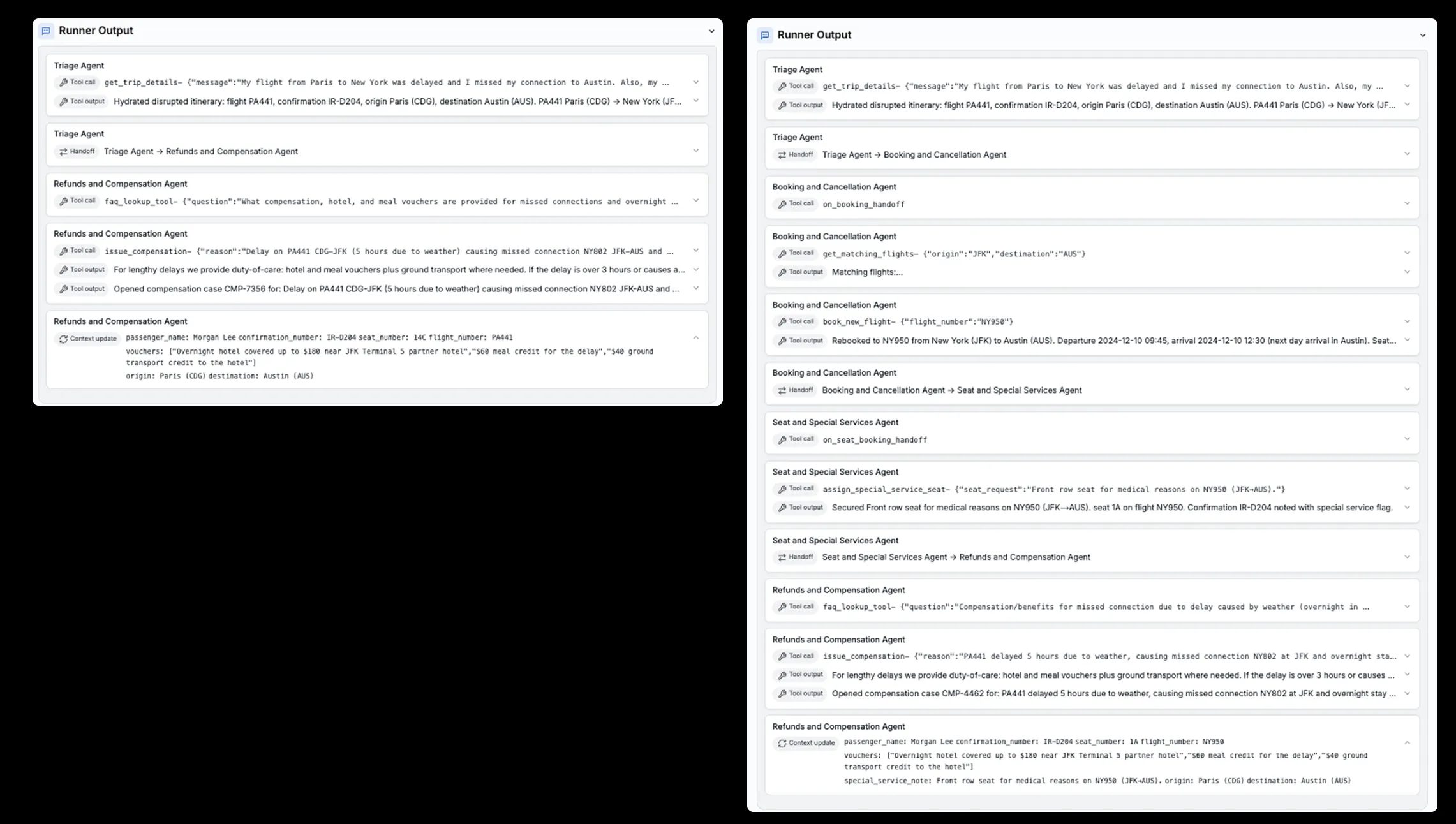
同じ航空会社サポートシナリオにおけるツール呼び出しログの比較。左:GPT-5.1、右:GPT-5. (参考:OpenAI)
従来のように「途中で詰まって人間に丸投げ」になるケースが減りやすく、“1メガエージェント+多数ツール”構成との相性が良いモデルと言えます。
これは、たとえば次のようなワークフローで差が出ます。
- 航空会社の問い合わせ対応で、遅延・乗り継ぎ・手荷物紛失・宿泊補償・特別座席手配などをまとめて処理
- サブスクサービスで、請求情報・利用履歴・利用規約をまたいで返金可否を判断
- B2B SaaSで、契約条件・利用ログ・過去の問い合わせ履歴を統合してアップセル提案を行う
【サイエンス・数学】高度数理・科学タスクでの到達水準
研究・数学系のベンチマークでも、GPT-5.2 Thinking / ProはSOTA級のスコアを記録しています。
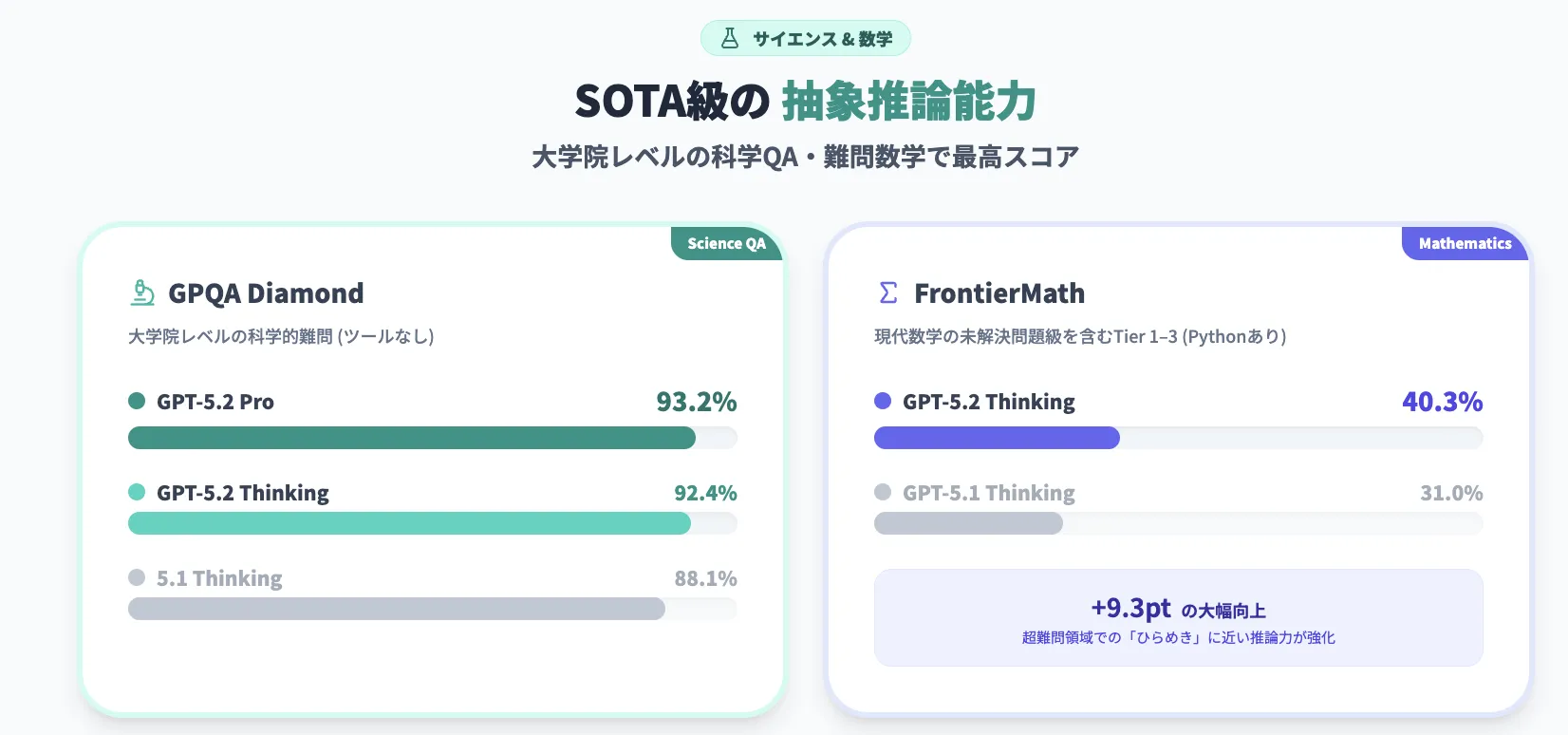
代表的な指標は次のとおりです。
- GPQA Diamond(大学院レベルの科学QA、ツールなし)
- GPT-5.2 Pro:93.2%
- GPT-5.2 Thinking:92.4%
- GPT-5.1 Thinking:88.1%
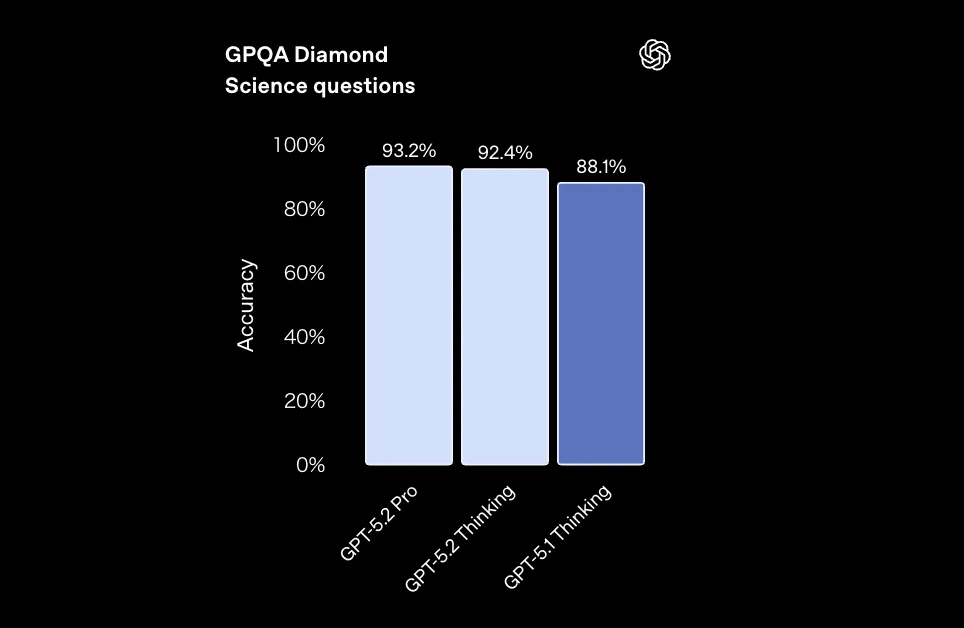
GPQA DiamondでのGPT-5.2 Pro / Thinking / GPT-5.1 Thinkingの精度比較 (参考:OpenAI)
- FrontierMath(Tier 1–3、Pythonツールあり)
- GPT-5.2 Thinking:40.3%
- GPT-5.1 Thinking:31.0%
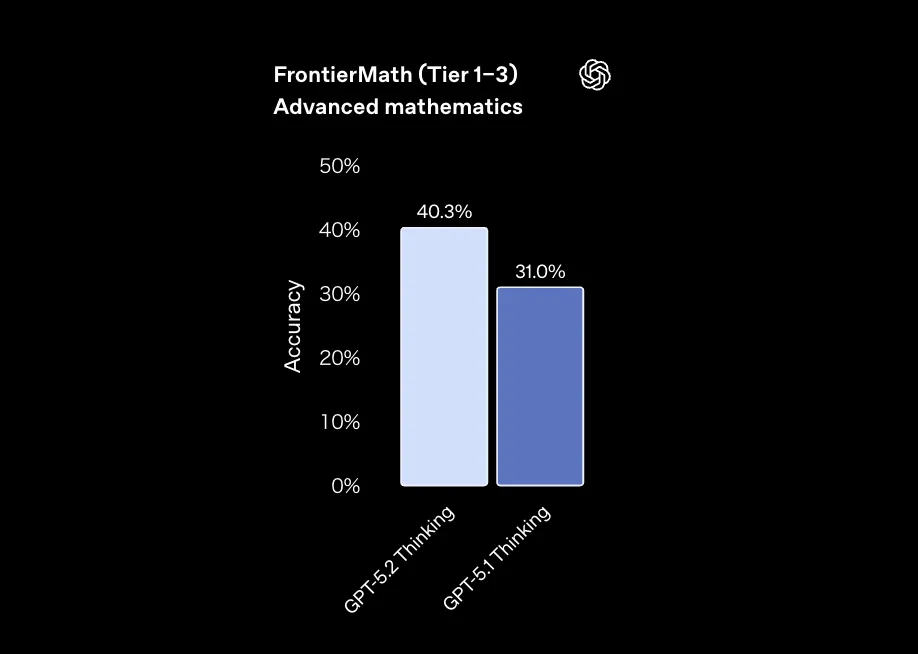
FrontierMath Tier 1–3でのGPT-5.2 ThinkingとGPT-5.1 Thinkingの精度比較 (参考:OpenAI)
研究・高度解析タスクでの活用イメージ

これらは、数学・統計・物理などの高度な問題設定で、以下のようなタスクを手伝わせる際の「当たり率」の向上につながります。
- 論文の証明チェック
- 反例候補の探索
- 実験計画やシミュレーション条件の検討
ただし、どれだけスコアが高くても、
- モデルの回答をそのまま論文やレポートに載せる
- コードや証明を人間のチェックなしで採用する
といった使い方は依然としてリスクが大きいです。「アイデア出し・骨組み作りをAIに任せ、人間が検証と最終判断を行う」というスタンスは変えずに活用するのが前提になります。
【ファクト性】誤り率が約3割減
モデルの性能が上がるほど重要になるのが、どれくらい「事実を間違えないか」という観点です。
GPT-5.2 Thinkingは、匿名化されたChatGPTクエリを使った内部評価で、
「1つ以上の誤りを含む回答」の割合がGPT-5.1 Thinkingよりも約30%相対的に減少しています。
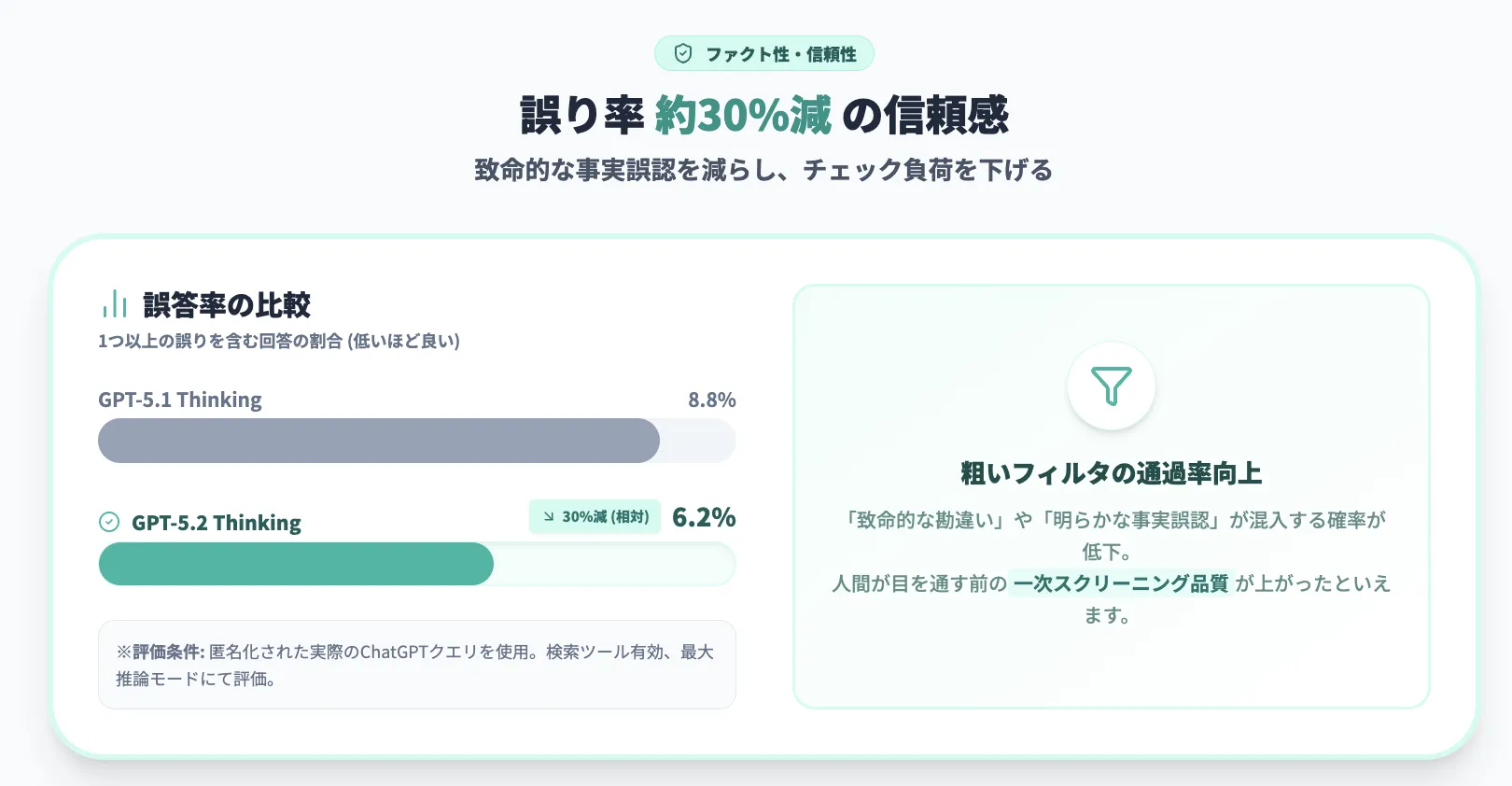
- GPT-5.2 Thinking:6.2%
- GPT-5.1 Thinking:8.8%
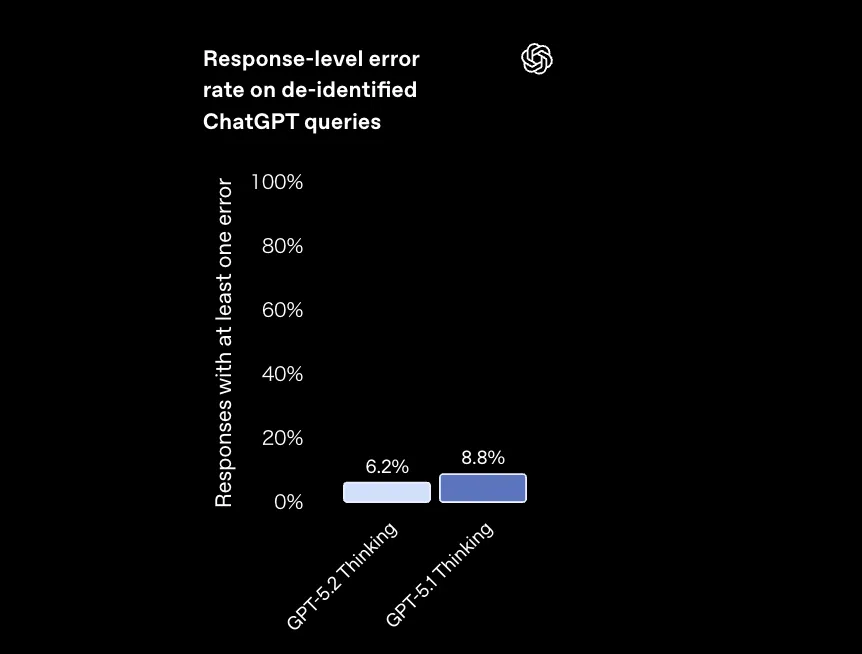
ChatGPTの匿名化クエリに対する「1つ以上誤りを含む回答」の割合。 (参考:OpenAI)
人間のファクトチェックは依然として必要
この評価では、検索ツールを有効にし、最大の推論モードで回答させたうえで、別のモデルが誤りをチェックしています(チェック側も完全ではない点には注意が必要です)。
それでも、研究・レポート・意思決定支援のような場面で、
- 「致命的な勘違いをしていないか」
- 「明らかな事実誤認が混じっていないか」
といった粗いフィルタの通過率が上がったと考えることができます。重要な内容は引き続き人間側のファクトチェックが必須ですが、「明らかに変な回答」を引く確率は下がっています。
GPT-5.2(ChatGPT 5.2)の使い方
GPT-5.2シリーズは、「ChatGPTから直接使う方法」と「OpenAI API経由で自社システムに組み込む方法」の2通りがあります。
ここでは、実務でよくあるパターンに絞って、最低限押さえておきたい使い方を整理します。
ブラウザ / アプリでGPT-5.2を使う
ChatGPTからGPT-5.2を使う場合は、画面上部のモデル切り替えメニューから「ChatGPT 5.2」系モデルを選ぶのが基本です。
Free / Plus / Pro / Business / Enterprise のいずれでも、対応プランであれば同じ流れで利用できます。
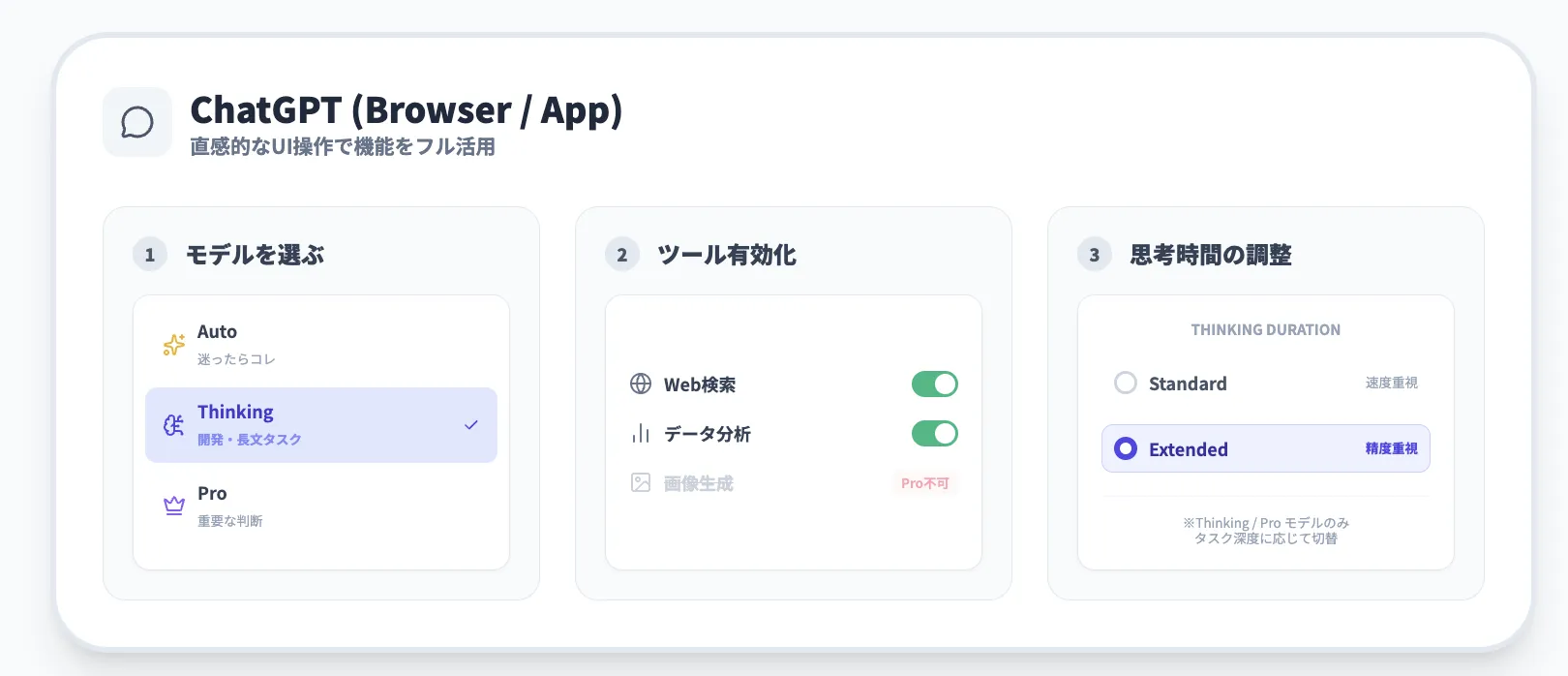
1. モデルを選ぶ
新規チャットを開き、画面上部のモデル選択メニューから、以下のいずれかを選択します。
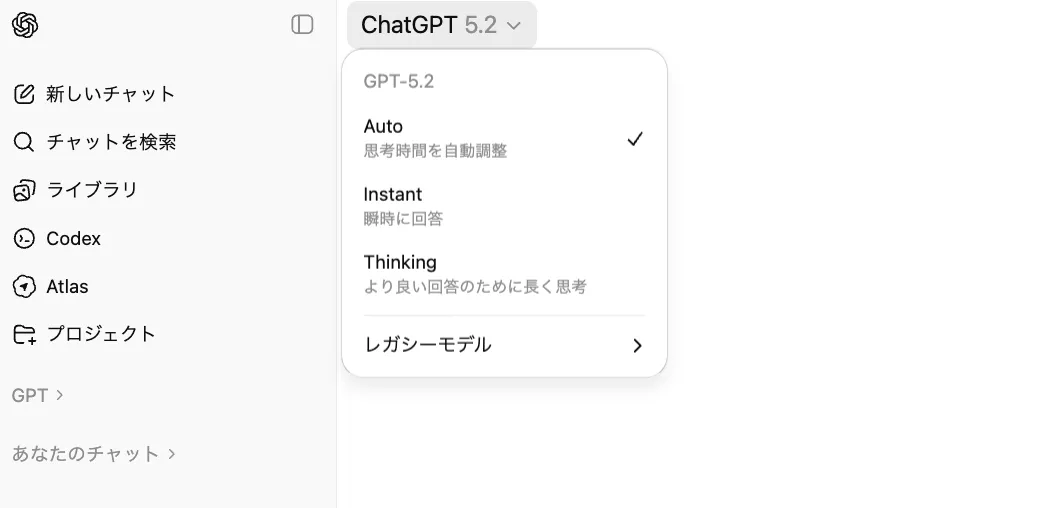
- 「GPT-5.2 Auto」(用途に応じてInstant / Thinkingを自動切り替え)
- 「GPT-5.2 Instant / GPT-5.2 Thinking / GPT-5.2 Pro」
2. ツール(検索・ファイル・スプレッドシート・コード実行など)を有効化する
GPT-5.2は、Web検索・ファイルアップロード・スプレッドシート作成・コード実行などの各種ツールと組み合わせる前提で設計されています。
サポートされているツールは以下の通りです。
- ウェブ検索
- データ分析
- 画像分析
- ファイル分析
- Canvas
- 画像生成
- メモリ
- カスタム指示
チャット画面のツール設定から、
「検索 / データ分析 / ファイル」など、実行したい作業に必要なツールだけONにしておくと、意図しない呼び出しを減らせます。
ツール選択画面
3. 思考時間を調整する
GPT-5.2 Thinking / Proでは、思考時間のプリセット(Standard / Extended)を切り替えることで、
- レスポンス速度重視
- 精度・網羅性重視
を簡単にトレードオフできます。
「まず全体像をざっくり知りたい」ときはStandard、「最終案としてそのまま使いたい」レベルの重要タスクではExtended、いった使い分けが実務的です。
プロンプトのひな形イメージ
GPT-5.2は、「タスク内容」「期待する成果物の形式」「制約条件」をまとめて指定したほうが力を発揮しやすいモデルです。
例えば次のような指定が実務向きです。
- スプレッドシート生成
【プロンプト例】
「添付したCSVから、月次売上と主要KPIを可視化したスプレッドシートを作ってください。
1シート目にサマリー、2シート目に月次推移(グラフ付き)、3シート目に生データを残してください。」
- コーディング / リポジトリ修正
【プロンプト例】
「このリポジトリのIssue #123のバグを修正し、テスト追加とPR本文のドラフトまで作成してください。
必要に応じて差分の内容も日本語で要約してください。」
また、GPT-5.2は画像認識(ビジョン)性能も大きく強化されているため、ダッシュボードやデザインカンプ、IDEのスクリーンショットなどを添付して、
- 「このUIの改善案を3パターン出して」
- 「このエラー画面の原因候補と対処手順を整理して」
といった使い方をするのも有効です。
APIでGPT-5.2を使う
GPT-5.2を自社システムやプロダクトから使う場合は、OpenAI API(主にResponses API)経由で呼び出します。
詳細な実装は開発者向けドキュメントに委ねつつ、ここでは最低限の流れだけ押さえておきます。
APIキーとライブラリを準備
- OpenAIのダッシュボードでAPIキーを発行し、サーバー側の環境変数([OPENAI_API_KEY]など)に設定します。
- 公式SDK(JavaScript / Python など)をインストールします。
モデルIDを指定してリクエストする
GPT-5.2シリーズは主に次のようなモデルIDで提供されます。
- gpt-5.2-chat-latest:ChatGPTと同等のチャット向けモデル(Instant相当)
- gpt-5.2:Thinking相当の汎用フロンティアモデル
- gpt-5.2-pro:Pro相当の最高性能モデル
Responses APIでの最小構成イメージは以下のようになります。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.2",
input="日本のSaaSスタートアップ向けに、LTV/CACの改善施策を3案提案してください。",
reasoning={"effort": "medium"}, # 思考の深さ
)
print(response.output[0].content[0].text)
3. ツール・コンテキストを組み合わせる
実務で真価を発揮するのは、GPT-5.2にツール(データベース検索、社内API、スプレッドシート操作など)を渡し、「データ取得 → 分析 → レポート生成」の一連の流れを任せたときです。
Responses APIの[tools]や[reasoning.effort]、[text.verbosity]などのパラメータを組み合わせることで、「どこまで自動化するか」「どれくらいの精度・説明量を要求するか」を細かくチューニングできます。
4. まずは既存ワークフローの1ステップから置き換える
導入初期は、いきなりフルエージェントを作るのではなく、
- レポートのドラフト生成だけをGPT-5.2に任せる
- 既存のバッチ処理の「要約」「補足コメント作成」部分だけをAPIコールに差し替える
といった小さなステップから始めるのがおすすめです。
そのうえで、ログ分析やA/Bテストを行いながら、徐々にエージェント化・自動化の範囲を広げていくと、品質とコストのバランスを取りやすくなります。
GitHub Copilot / Microsoft Copilot
GPT-5.2はChatGPTやAPIだけでなく、GitHub CopilotやMicrosoft(Microsoft 365)Copilot側でも順次利用できます。
ただし、表示タイミングは段階ロールアウトで、同じGPT-5.2でも「UI・上限・管理者設定」は製品ごとに異なります。
GitHub Copilot(開発向け)
GitHub Copilotでは、対応プランであればCopilot ChatのモデルピッカーからGPT-5.2を選べます。
- 対象プラン:Copilot Pro / Pro+ / Business / Enterprise
- 使い方:Copilot Chatのモデルピッカーで「GPT-5.2」を選択(段階ロールアウト)
Microsoft Copilot
Microsoft 365 Copilotでは、CopilotのUIからGPT-5.2が利用できるよう、順次ロールアウトが進められています。
ExcelやPowerPoint、Word、Teamsなどの業務アプリに統合された体験が中心で、社内データや権限制御(Microsoft Graph)を前提に動く点が、ChatGPT単体利用と大きく異なります。
既存モデルとの使い分け
GPT-5.2登場後、既存ユーザーは「いつ・どう移行するか」を考える必要があります。
ChatGPTユーザー向け
ChatGPTアプリでのおすすめの使い分けは、ざっくり次のようになります。
-
日常利用・軽めの業務
→ デフォルトで「ChatGPT-5.2 Instant」を選択
-
コード・長文ドキュメント・難しめの仕事
→ 「ChatGPT-5.2 Thinking」を優先的に利用
-
特に重要な決裁・研究・高度分析
→ 「ChatGPT-5.2 Pro」をスポット的に利用(レイテンシとコストを許容できる範囲で)
一方で、GPT-5.1やGPT-4.1をあえて残すべきケースもあります。
- 古いプロンプトやワークフローがGPT-5.1前提で最適化されている
- 特定のタスクでGPT-5.2の挙動がまだ安定していない(初期の回帰バグが気になる)
- コストやレイテンシを少しでも抑えたい用途で、5.1で十分な品質が出ている
このような場合は、しばらくは5.1 / 4.1と併用しつつ、徐々に5.2比率を増やしていくのが現実的です。
API/自社プロダクト向け
API利用では、次のようなステップで移行を進めるのが一般的です。
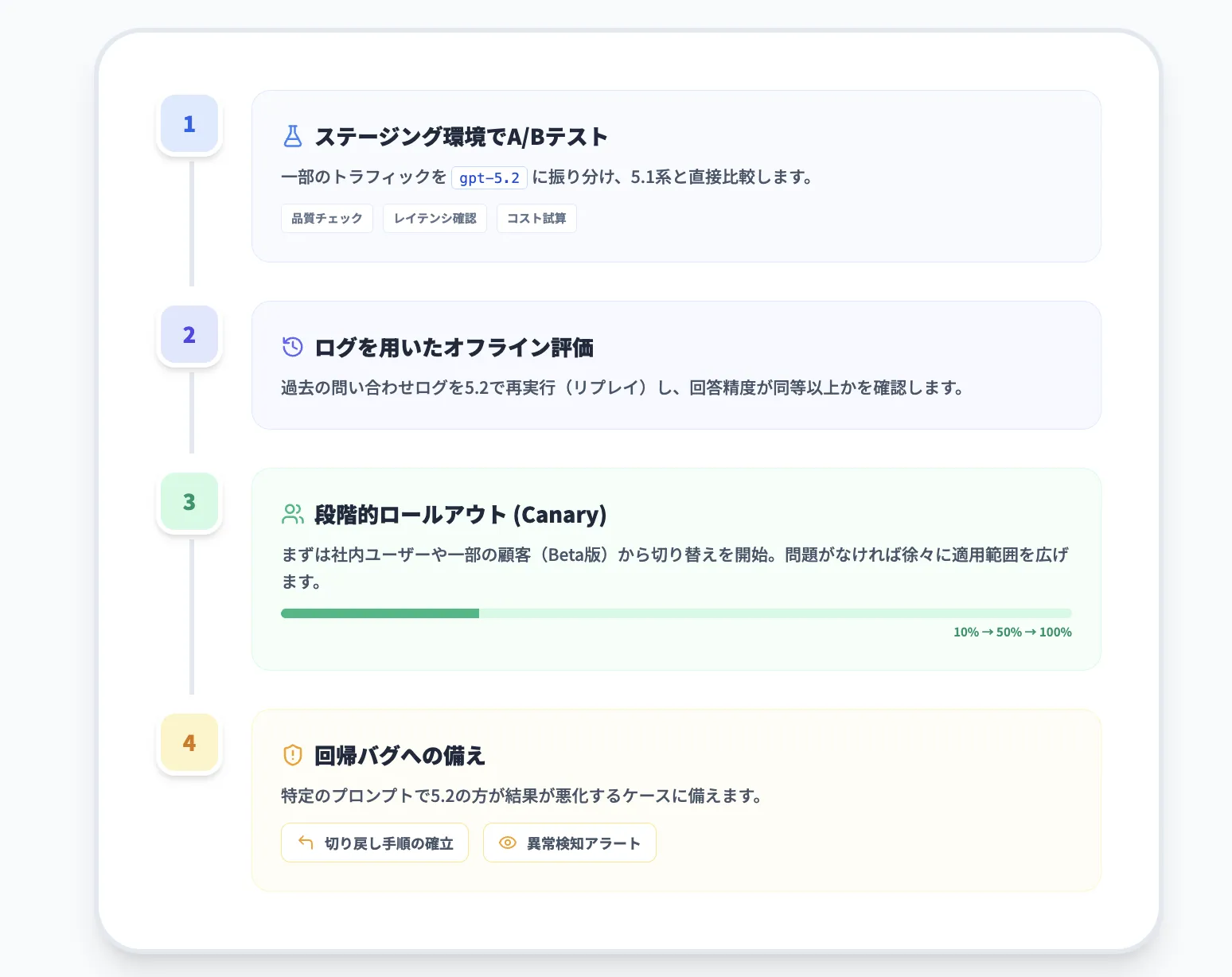
-
ステージング環境でA/Bテスト
- 一部トラフィックを[gpt-5.2] / [gpt-5.2-pro`]に振り、
5.1系と品質・レイテンシ・コストを比較
- 一部トラフィックを[gpt-5.2] / [gpt-5.2-pro`]に振り、
-
ログを用いたオフライン評価
- 過去の問い合わせログを再生し、5.1と5.2がどの程度同等あるいは改善しているかを確認
- 過去の問い合わせログを再生し、5.1と5.2がどの程度同等あるいは改善しているかを確認
-
本番環境での段階的ロールアウト
- まずは一部組織・一部機能から5.2に切り替え、
問題がなければ全体に展開
- まずは一部組織・一部機能から5.2に切り替え、
-
回帰バグへの備え
- 特定のプロンプトで5.2の方が悪化するケースも起こり得るため、
- モデルを切り替えるバックアップ経路
- 手動レビューや再実行の仕組み
を用意しておく
- 特定のプロンプトで5.2の方が悪化するケースも起こり得るため、
OpenAI自身も「GPT-5.1 / GPT-5 / GPT-4.1をすぐに廃止する予定はなく、事前告知のうえで段階的に扱う」と述べています。
そのため、今すぐすべてを5.2に変えなければならないわけではないものの、新規開発や中長期運用を前提とした設計では、5.2を前提に検討しておくのが自然です。

【ユースケース別】GPT-5.2の活用事例
このセクションでは、GPT-5.2を実務でどう活かせるか、具体的な活用事例を紹介します。
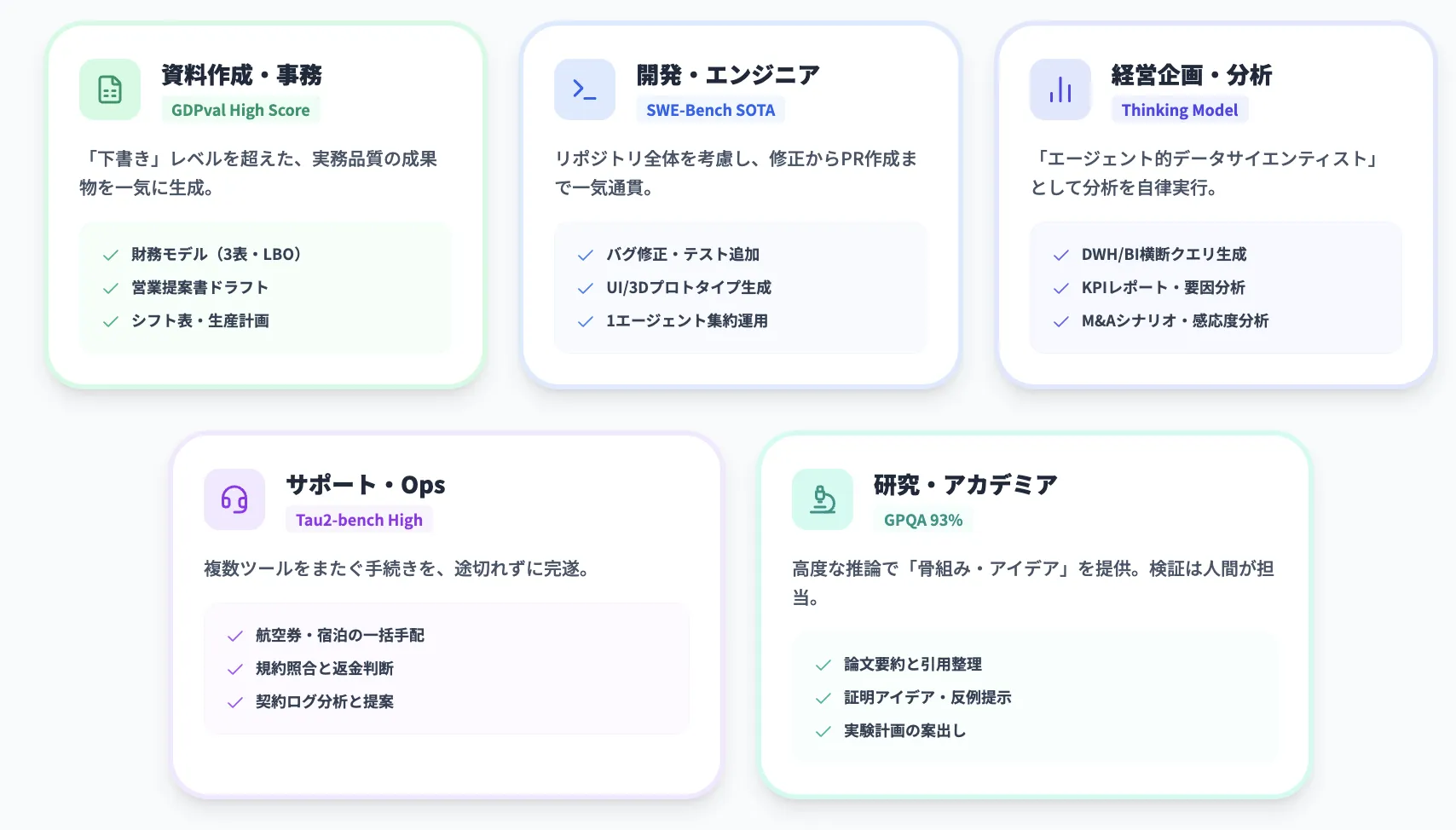
スプレッドシート・スライド作成
前述の通り、GPT-5.2では、表計算・スライド・ドキュメントの生成能力が大きく強化されています。
GDPvalのタスク内容に近い、次のような業務アセットを自動生成できます。
- 財務モデル(3ステートメント・LBO等)
- 営業提案資料(構成案〜ドラフトスライド)
- シフト表・勤務表・設備稼働スケジュール
- 製造ラインの負荷計画や簡易工程図
ChatGPTでは、「GPT-5.2 Thinking / Pro」を選び、スプレッドシート・スライド機能を有効化することで、
- プロンプトから一気に表計算・グラフ・数式入りのスプレッドシートを生成
- プレゼンテーションのアウトラインから、ページごとのスライド案まで自動作成
といった操作が可能になります。
ただし、複雑な生成は数分かかる場合もあるため、時間に余裕を持って実行し、最終確認は人間が行うことが重要です。
コーディング・エージェント開発

コーディング系では、GPT-5.2 Thinking / Proを中心に、次のようなユースケースが現実的になります。
- 既存リポジトリを読み込ませて、バグ修正・テスト追加・PR作成まで一気通貫で任せる
- React / Three.js / WebGL等を組み合わせたUIや3D表現のプロトタイプを数分で生成
- 社内CLIツールやGitHub Actions・Codexエージェントと組み合わせた自動運用フロー
特に、「マルチエージェント構成をやめて、1つの大きなエージェント+多数ツールに集約する」という設計が現実的になりつつあります。
これにより、システムプロンプトや状態管理がシンプルになり、保守コストを下げられる可能性があります。
データ分析・経営企画・ファイナンス

DatabricksやHexなどのユーザー企業からは、GPT-5.2が「エージェント的なデータサイエンティスト」として機能する事例が報告されています。
具体的には、次のようなワークフローが想定されます。
- データウェアハウス(Snowflake / BigQuery等)とBIツールをまたいだクエリ生成とグラフ作成
- KPIレポートの自動生成と要因分析コメントの作成
- M&Aや投資案件におけるシナリオ分析、感応度分析のたたき台作成
これらのタスクでは、長文コンテキストとツール呼び出し性能が両方効いてくるため、GPT-5.2 Thinkingを中心に設計するのが基本線になります。
顧客サポート・オペレーション自動化

Tau2-benchの結果からも分かるように、GPT-5.2はマルチターン・マルチツールの顧客サポートタスクに強みを持っています。
例えば、次のようなケースです。
- 航空会社の問い合わせ対応で、遅延・乗り継ぎ・手荷物紛失・宿泊補償・特別座席手配などをまとめて処理
- サブスクサービスで、請求情報・利用履歴・利用規約をまたいだ返金可否判断と提案
- B2B SaaSで、契約条件・利用ログ・過去の問い合わせ履歴を統合してアップセル提案
こうしたシナリオでは、
- CRM・請求システム・在庫管理などへのツール呼び出し
- ユーザーとの複数ターンの対話
- 社内ポリシーに沿った最終回答の生成
を一気通貫でこなせることが重要です。GPT-5.2 Thinking / Proは、この「つなぎ部分」の精度が上がったことで、実運用へのハードルを下げています。
GPT-5.2時代のエージェント設計のポイント
GPT-5.2の特徴は、「単にモデルが賢くなった」だけでなく、長文コンテキスト × 強力なツール呼び出し × [/compact] 等の周辺機能によって、エージェント設計の前提が変わることです。

コンテキスト設計

長文コンテキストが強化されたからといって、「とにかく全部突っ込めばいい」というわけではありません。ただし、設計の自由度は大きく広がります。
- 仕様書・設計書・議事録・チケット・コードベースなど、数十万トークン規模の情報を一度に扱える
- Responses APIの[/compact]を活用することで、途中経過を要約しつつ「実質コンテキスト無制限」に近い振る舞いも可能
現実的な設計としては、次のような戦略が考えられます。
- 生データを全部投げるのではなく、セグメント+要約+インデックスを組み合わせる
- よく参照される部分は要約+原文リンクをセットで管理し、必要に応じて原文を再取得する
- 重要度に応じて「常時コンテキスト」「オンデマンド取得」に分ける(例:ポリシー類は常時、ログ類はオンデマンド)
こうした設計を行うことで、トークンコストを抑えつつ、必要なときに必要な情報だけを深く読むエージェントが構築できます。
ツール設計
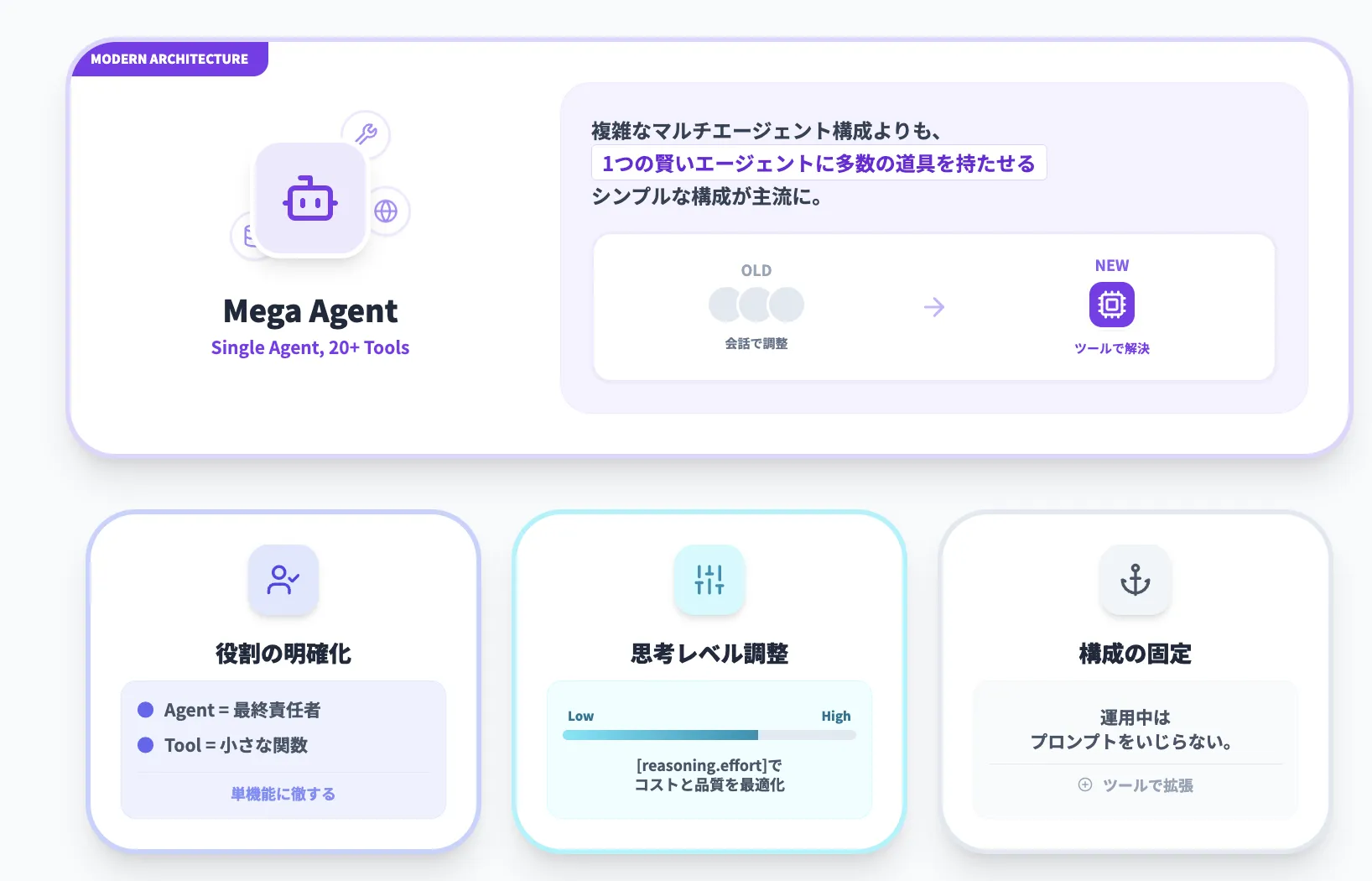
GPT-5.2では、ツール呼び出しの安定性と長期タスクでの一貫性が向上したため、「シンプルな1エージェント+多数ツール」構成が現実的になりました。
設計のポイントは次のとおりです。
-
エージェント自体の役割は「最終責任者」として明確にし、ツールは極力「1つの明確な役割」を持つ小さな関数にする
-
[reasoning.effort]をnone / low / medium / high / xhighで使い分け、
- 単純なツール呼び出しや補助的な処理 → [none]や[low]
- 複雑な分析・意思決定 → [high]や[xhigh]
というように、コストと品質のバランスをとる
- 設計段階で「ツールをどこまで増やすか」を決めてしまい、運用中はプロンプトをなるべくいじらない構成にする
Triple Whaleの事例のように、20以上のツールを1つのメガエージェントが扱う構成でも成立するようになってきているため、
従来の「エージェント同士が会話し合うマルチエージェント構成」よりも、シンプルな設計で済む場面が増えていきそうです。
【運用】ログ分析・A/Bテスト・フェイルセーフ設計

GPT-5.2とGPT-5.1を併走させながら、品質・コスト・レイテンシを比較するフェーズも重要です。
-
A/Bテスト
一部のユーザーを5.2系、残りを5.1系に割り当てて、- 成功率(タスク完遂率)
- 再実行回数
- レスポンス時間
- トークン使用量
などを比較
-
ログ分析
ツール呼び出しの失敗パターンや、ユーザーが再質問している箇所を定期的にレビュー
-
フェイルセーフ
重要なアクション(注文・変更・削除など)は、- 人間による最終確認
- 2段階認証的な手続き
を挟む設計にする
このように、「モデルの性能を信じすぎない運用設計」を前提にすることで、GPT-5.2のポテンシャルを安全に活かしやすくなります。
GPT-5.2の安全性・コンプライアンスとメンタルヘルス対応
GPT-5.2は、GPT-5世代で導入されたsafe completion(安全な応答を優先する訓練)の枠組みを引き継ぎつつ、
特にメンタルヘルス関連の応答で改善が図られています。

具体的には、次のような点が強化されています。
-
自殺念慮・自己否定・強い不安などが含まれるプロンプトに対し、
- 危険な行動を助長しない
- 支援先や専門家への相談を促す
など、より望ましい応答を返す確率が向上
-
モデルへの過度な依存(「あなたしか話せる人がいない」など)に対して、
- 適度な距離感を保つメッセージ
- 人間のサポートネットワークへの橋渡し
を行うように訓練
-
未成年ユーザーに対して、年齢推定モデルを用いて自動的にコンテンツ制限を適用する取り組みの強化
一方で、OpenAI自身も「依然として完璧ではなく、重要な意思決定や医療・法律・投資などの領域では、人間の専門家によるレビューが必須」と明言しています。
企業導入の観点では、次のような対策が重要です。
- 利用ポリシーで「モデルを医療・法律・投資アドバイスの唯一の判断根拠にしない」ことを明記
- ログ・監査機能を活用し、不適切な利用がないかを定期的にチェック
- メンタルヘルス領域の利用については、専門家監修のもとでプロンプト・ガードレールを設計する
GPT-5.2-Codex:コーディング特化モデル
2026年1月14日、OpenAIはGPT-5.2の派生モデルとしてGPT-5.2-Codexを発表しました。これは、大規模なリファクタリング、コードベース移行、機能実装、セキュリティ監査など、長時間にわたるマルチステップのソフトウェアエンジニアリングセッションに最適化されたモデルです。
GPT-5.2-Codexは、OpenAIのCodexエージェントと組み合わせることで、GitHubリポジトリに対して自律的にコード変更を行い、PRを作成するといった運用が可能です。
【関連記事】
GPT-5.2-Codexとは?使い方や料金、GPT-5.2との違いを徹底解説!

最新AIモデルの進化を踏まえて組織のAI業務自動化を構想する
GPT-5.2の性能と料金体系を把握した今、自社の業務にAIをどう組み込むかの全体設計が次の課題です。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。部門別のBefore/After付きユースケースと、段階的な導入ロードマップを収録しています。
AI総合研究所が、最新のAI技術動向を組織の業務効率化に落とし込む道筋をご提案いたします。
【無料DL】AI業務自動化ガイド(220P)

Microsoft環境でのAI活用を徹底解説
Microsoft環境でのAI業務自動化・AIエージェント活用の完全ガイドです。Microsoft環境でのAI業務自動化の段階設計を詳しく解説します。
まとめ
GPT-5.2は、GPT-5.1からの小改良ではなく、「長文コンテキスト × ツール × エージェント」前提で設計を組み直すべき境目の世代です。
まずは、財務モデル作成・レポート・コーディング・問い合わせ対応など、テンプレ+繰り返しが多いタスクを洗い出し、GPT-5.2 Thinking / Pro でどこまで自動化できるかを試すのが一歩目です。
あわせて、ChatGPTのプラン(Free / Plus / Pro / Business)とAPI単価を「人件費やミス削減と比較」して評価し、5.1世代とのA/Bテストやログ分析を通じて、徐々に1メガエージェント+多数ツール構成へ移行していく──この流れを押さえておけば、GPT-5.2を「なんとなく新しいモデル」として眺めるのではなく、実務の再設計に結びつけやすくなります。










