この記事のポイント
 メモリ機能は保存メモリ・チャット履歴参照・Memory Sourcesの3層構造。役割を分けて理解すると毎回の指示出しを最小化できる
メモリ機能は保存メモリ・チャット履歴参照・Memory Sourcesの3層構造。役割を分けて理解すると毎回の指示出しを最小化できる- 2026年5月追加のMemory Sourcesで回答参照ソース(保存メモリ・過去チャット・指示・ファイル・Gmail)を確認可、修正/削除対応
- 保存メモリは長期前提、カスタム指示は出力ルール、プロジェクト機能は案件文脈分離。3機能を併用すれば指示の重複が消える
- 業務での実装は「ユーザー属性固定/案件文脈分離/ナレッジ蓄積/壁打ち」の4パターンに集約され、用途に合わせて使い分けるのが現実的
- 業務継続利用はPlus以上が現実的、Freeでは容量・参照範囲が限定的でPlusで拡張メモリと過去チャット参照が解放される

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTのメモリ機能は、保存メモリ・チャット履歴参照・Memory Sourcesの3層構造に進化し、業務で「同じ前提を毎回伝え直す」負担を構造的に減らせる段階に来ました。
2026年5月にはMemory Sourcesが追加され、接続Gmail(2025年8月以降Plus/Pro向けに提供)やライブラリ内ファイルも、パーソナライズ文脈として回答に参照されるようになりました。
本記事では、メモリ機能の全体像と3層構造の使い分け、Memory Sourcesで何が変わったか、設定手順、カスタム指示・プロジェクト機能との役割分担を整理します。
あわせて、業務で活かす4つの実装パターン、プラン別の料金、共有時の情報露出・機密管理など業務利用時の注意点まで一気通貫で解説します。
目次
保存メモリ・チャット履歴参照・Memory Sourcesの3層構造
Memory Sourcesと接続済みGmail・ファイルの参照で何が変わったか
Personalization画面の2トグルと管理リンクでオン・オフを切り替える
一時チャット(Temporary Chat)で記録を残さない選択肢
ChatGPTのメモリ機能とは
ChatGPTのメモリ機能とは、過去のやり取りを蓄積し、以後の応答に自動反映させる仕組みです。
毎回同じ前提や指示を伝え直さなくてよくなるため、業務利用での体験が一段変わります。
ChatGPTに職業・出力フォーマット・進行中の案件情報を覚えさせておけば、別日の新規チャットでも同じ前提で回答が返ってきます。
2026年6月時点のメモリ機能は、役割の異なる3層構造で構成されています。


保存メモリ・チャット履歴参照・Memory Sourcesの3層構造
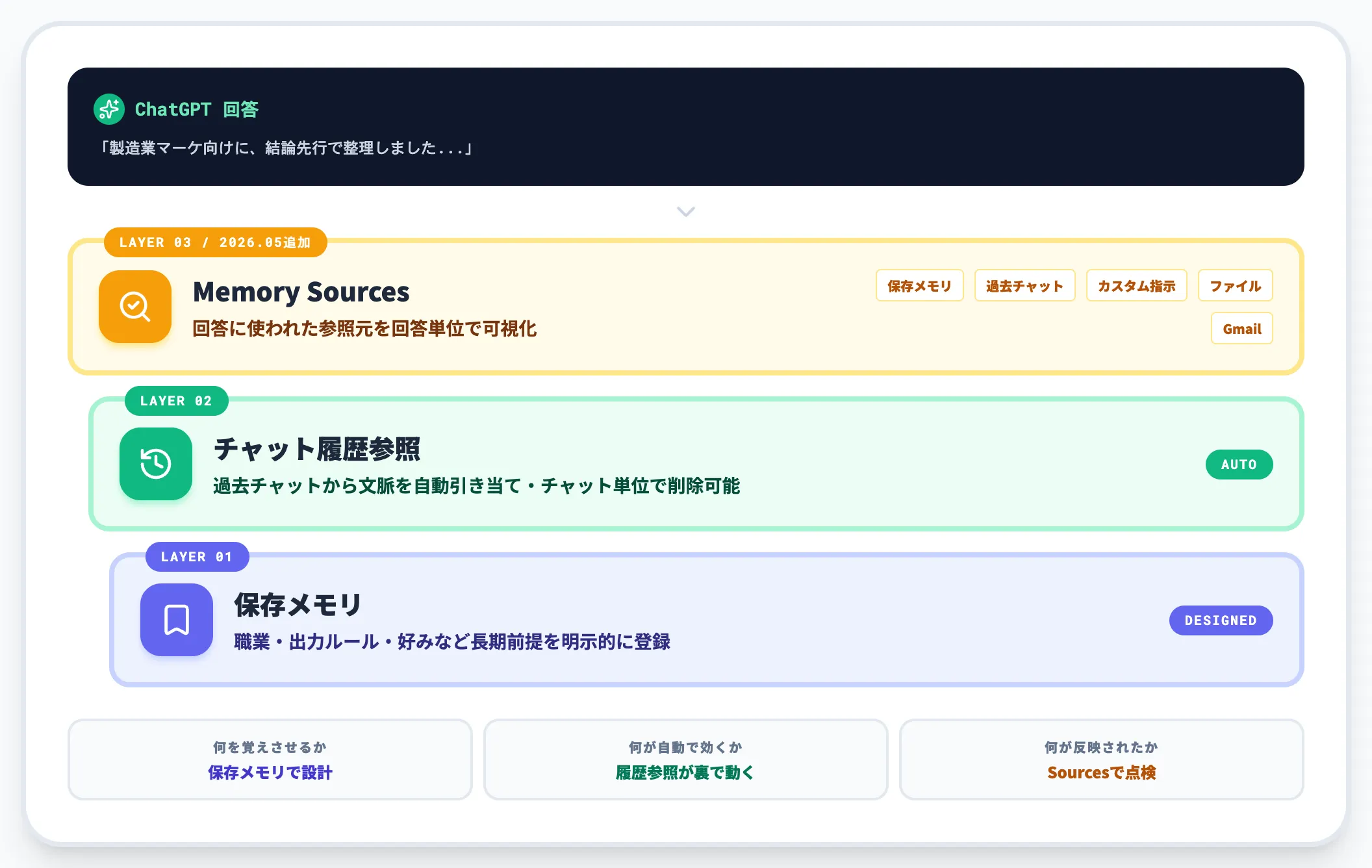
メモリ機能を構成する3層を、以下の表で整理しました。
| レイヤー | 役割 | 主な保持対象 | 確認・編集 |
|---|---|---|---|
| 保存メモリ | 明示的に覚えさせる長期記憶 | 名前・職業・好み・出力ルール | Personalization画面で個別管理 |
| チャット履歴参照 | 過去チャットから文脈を自動引き当て | 過去のやり取り全般 | チャット単位で削除 |
| Memory Sources | 回答ごとに参照元を可視化(2026年5月追加) | 上記+ファイル・接続Gmail等 | Sourcesから確認。保存メモリは修正・削除/過去チャットは削除・関連性FB/ファイル・Gmail・カスタム指示は表示中心 |
3層構造の実務的な意味は、「何を覚えさせるか」「何が自動で効くか」「何が回答に反映されたか」を別々のレイヤーで管理できるようになった点です。
保存メモリは設計するもの、チャット履歴参照は自動的に効くもの、Memory Sourcesは結果を点検するもの、という棲み分けで捉えると運用がぶれません。
詳細はOpenAI公式のMemoryページに整理されています。
メモリ機能が解決する「前提の伝え直し」コスト
メモリ機能の効用は、毎回の指示出しコストを構造的に削減できる点に集約されます。
業務で日常的にChatGPTを使う担当者は、職業・担当領域・出力フォーマット・進行案件など、同じ前提情報を毎回入力し直していました。
保存メモリに登録しておけば、別チャット・別日でも同じ前提で回答が始まるため、初期入力の手間がほぼゼロに近づきます。
社内のナレッジ検索や提案書作成に毎日30分以上ChatGPTを使っているなら、メモリ設計だけで月数時間のオーバーヘッドが削減できる計算になります。
Memory Sourcesと接続済みGmail・ファイルの参照で何が変わったか
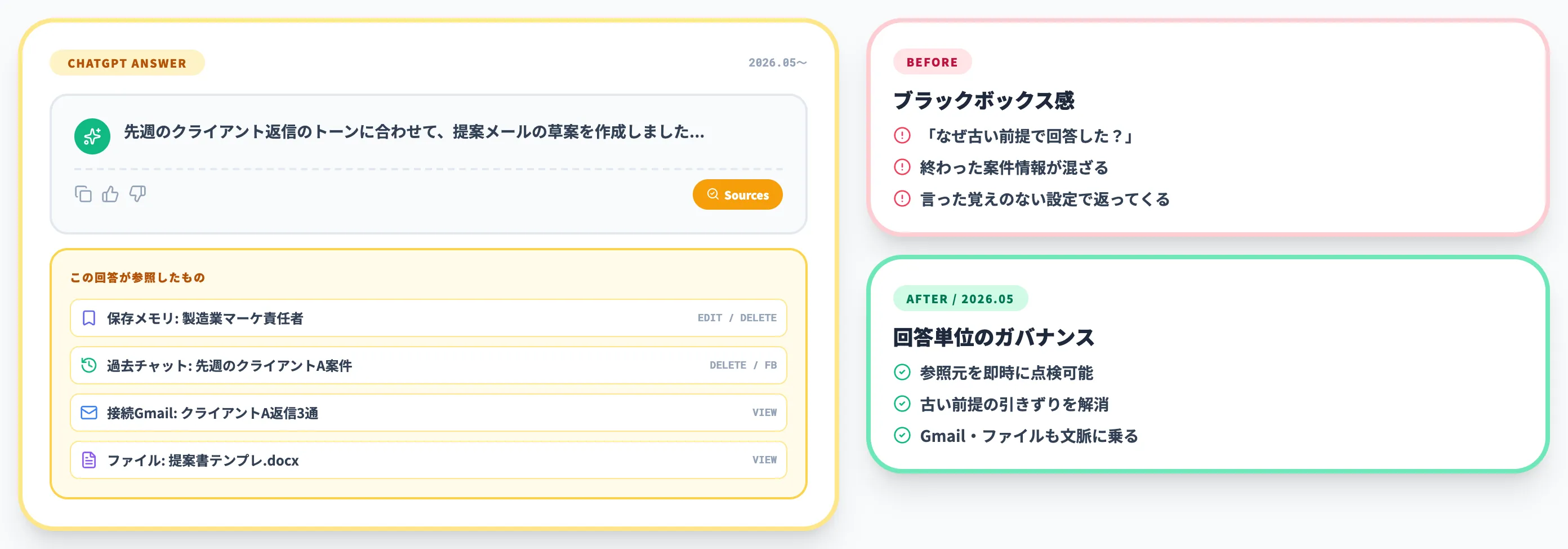
2026年5月にOpenAIが追加したMemory Sourcesは、回答に使われたパーソナライズ文脈の参照元を回答単位で見える化する機能です(事実出典や引用元の表示ではない点に注意)。OpenAIのChatGPT Release Notesで正式リリースが告知されています。
これまで「なぜか古い前提で回答された」「言った覚えのない設定で返ってきた」というブラックボックス感がありましたが、Memory Sourcesで回答ごとに参照元をたどれるようになりました。
業務利用での「終わった案件の情報が混ざる」「古い前提が引きずられる」といった事故を、回答単位で解消できるようになった点が大きな変化です。
Sourcesアイコンから参照元を一覧する

ChatGPTの回答下に表示される「Sources」アイコンをタップすると、その回答が参照した情報源が一覧表示されます。
表示される項目は以下のとおりです。
-
保存メモリ
明示的に登録した長期記憶のうち、その回答に反映されたもの
-
過去チャット
チャット履歴参照で自動的に引き当てられた過去会話
-
カスタム指示
Personalizationで設定した「あなたについて」「ChatGPTにどう振る舞ってほしいか」
-
ファイル
ライブラリにアップロードしているファイルのうち回答に使われたもの(Plus/Pro)
-
接続Gmail
連携したGmailアカウントから参照されたメール(Plus/Pro)
操作はレイヤーごとに異なります。保存メモリは内容の修正と削除、過去チャットは削除と「関連性あり/なし」のフィードバック、カスタム指示・ファイル・接続Gmailは参照内容の表示が中心です。
業務で「なんでこの前提で回答した?」と感じた時に、その場で参照元を点検できるため、AIの応答品質を回答単位でガバナンスできるようになりました。
ただし、Memory Sourcesは回答に影響したすべての要素を必ずしも網羅しません。OpenAI公式のMemory FAQでも「過去チャットは関連性が高い1〜2件程度が表示される場合がある」と説明されており、見えない要素もある前提で扱うのが安全です。
接続済みGmail・ファイルがパーソナライズ文脈に乗る
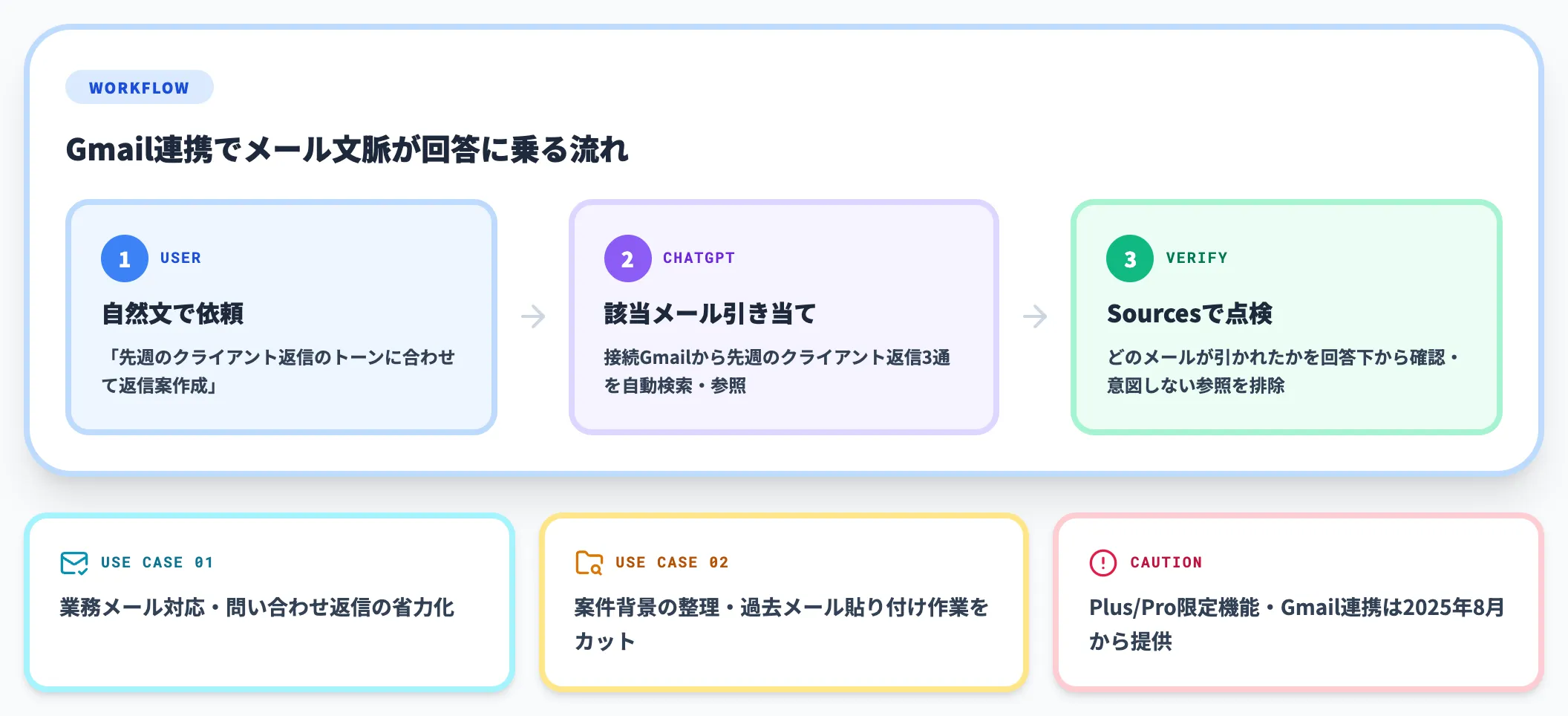
GmailなどのコネクタはPlus・Pro向けに2025年8月から提供されていましたが、2026年5月のアップデートで、接続済みのGmail本文やライブラリのファイルも保存メモリ・過去チャットと同様にパーソナライズ文脈として回答に参照されるようになりました。
たとえば「先週のクライアント返信のトーンに合わせて返信案を作って」と伝えるだけで、ChatGPTが該当メールを引き当てて整合した回答を返します。
Memory Sourcesでは、その回答が参照したメールが具体的に表示されるため、意図しないメールが引かれていないかを点検できます。
業務メール対応・問い合わせ返信・案件背景の整理など、これまで「いちいち過去メールを貼り付けて指示」していた作業が一段省力化できる構造です。
共有チャット・スクショ時の参照元の扱い
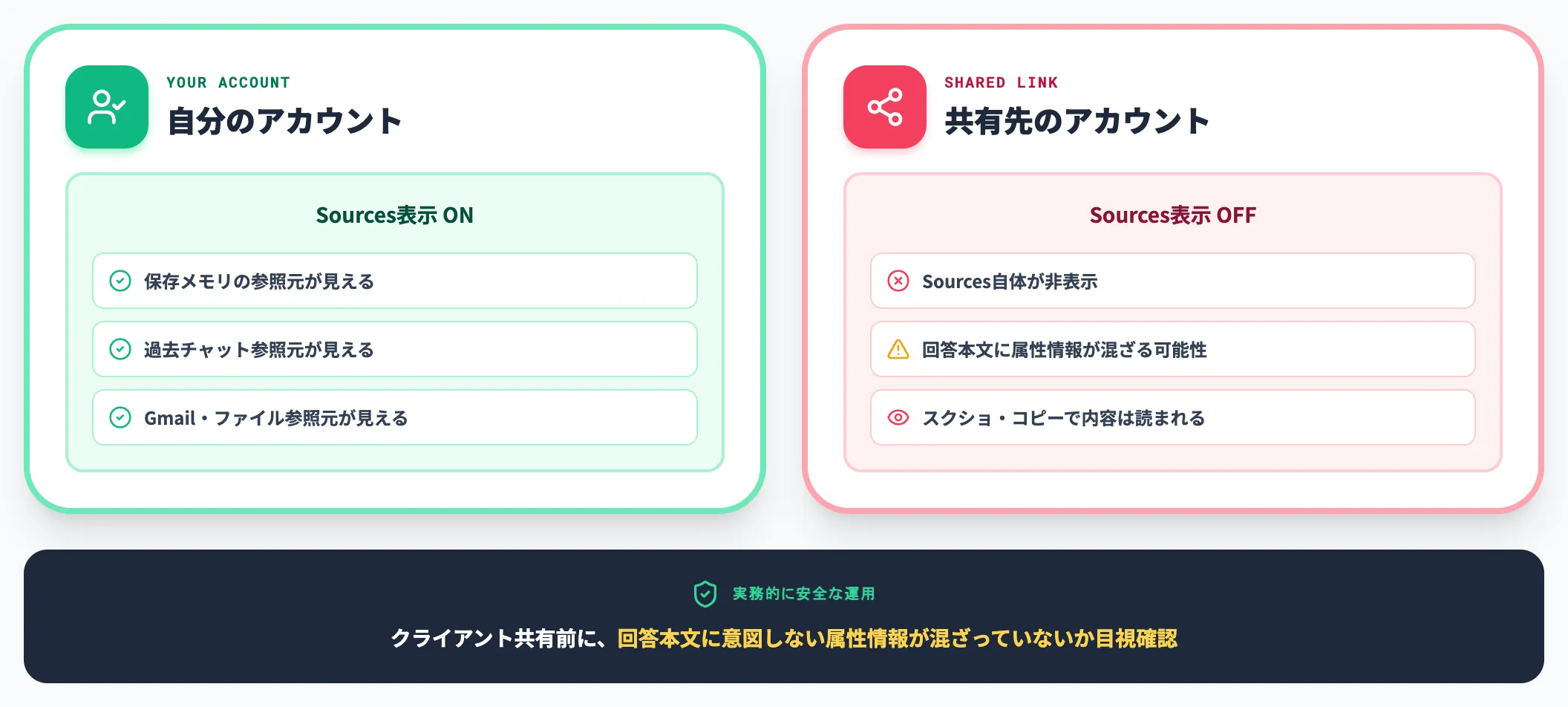
Memory Sourcesに表示される情報は、自分のアカウント内でのみ見える設計です。
OpenAI公式のMemory FAQによれば、共有チャットを生成した場合、共有先には参照元(Sources)が表示されません。
ただし、回答本文に保存メモリの情報が反映されている場合、共有チャットの文面そのものから内容が読み取れる可能性は残ります。クライアントに共有する前に、回答文に意図しない属性情報が混ざっていないかを目視確認するのが実務的に安全です。
ChatGPTメモリ機能の使い方と設定手順
ChatGPTメモリ機能の操作は、Personalization画面の2つのトグル+管理リンクと、チャット内の3コマンドに集約されます。
設定は右上のアカウントアイコンから「Settings」→「Personalization」と辿った先のMemoryセクションで行います。
Personalization画面の2トグルと管理リンクでオン・オフを切り替える

Personalizationを開くと、メモリに関する以下の項目が並びます(2つのトグルと1つの管理リンク)。
-
Reference saved memories(トグル)
保存メモリを参照するかどうか
-
Reference chat history(トグル)
過去チャットから自動で文脈を引き当てるかどうか
-
Manage memories(リンク)
保存メモリの一覧を開き、個別の編集・削除を行う管理画面へ
業務で継続利用するなら、両トグルを「オン」にしておくのが基本です。
保存メモリは個別に削除でき、全削除も同じ画面から実行できます。詳細な管理仕様はOpenAI公式のMemory FAQに整理されています。
覚えさせる・思い出させる・忘れさせるの3コマンド
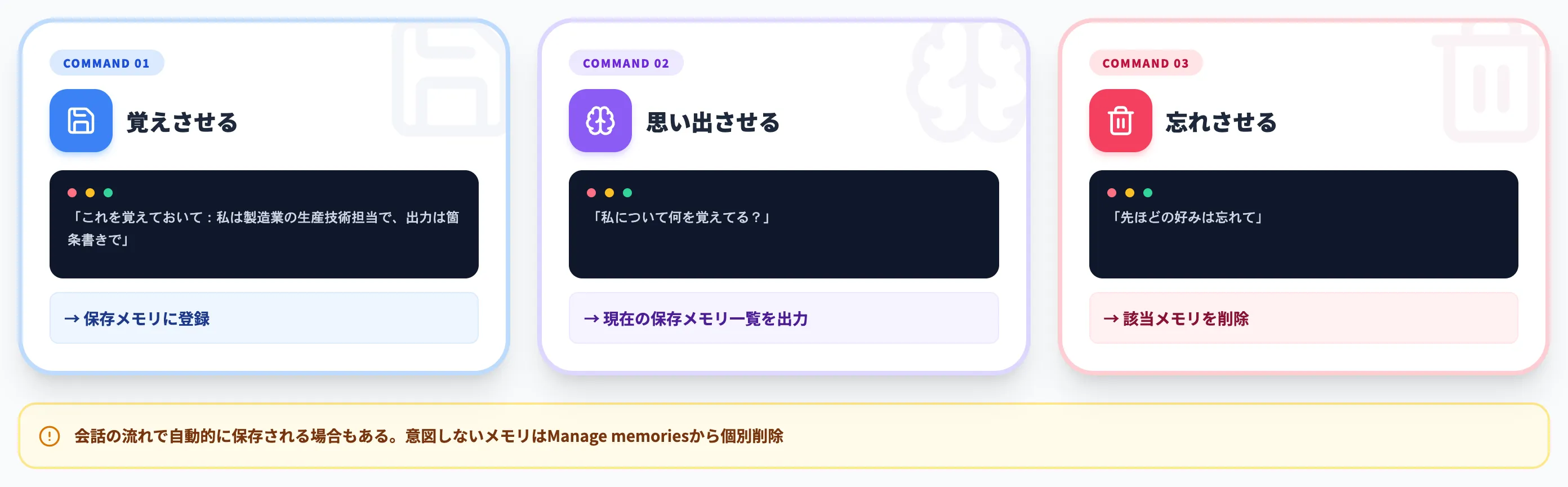
メモリの追加・確認・削除は、チャット内で直接指示するだけで完結します。
-
覚えさせる
「これを覚えておいて:私は製造業の生産技術担当で、出力は箇条書きで」と伝えると保存メモリに登録される
-
思い出させる
「私について何を覚えてる?」と尋ねると、現在の保存メモリ一覧を出力する
-
忘れさせる
「先ほどの好みは忘れて」と伝えると該当メモリを削除する
明示的に指示しなくても、会話の流れで自動的に保存される場合もあります。
意図しないメモリが残ってしまった時は、Personalization画面の「Manage memories」から個別削除するのが確実です。
一時チャット(Temporary Chat)で記録を残さない選択肢
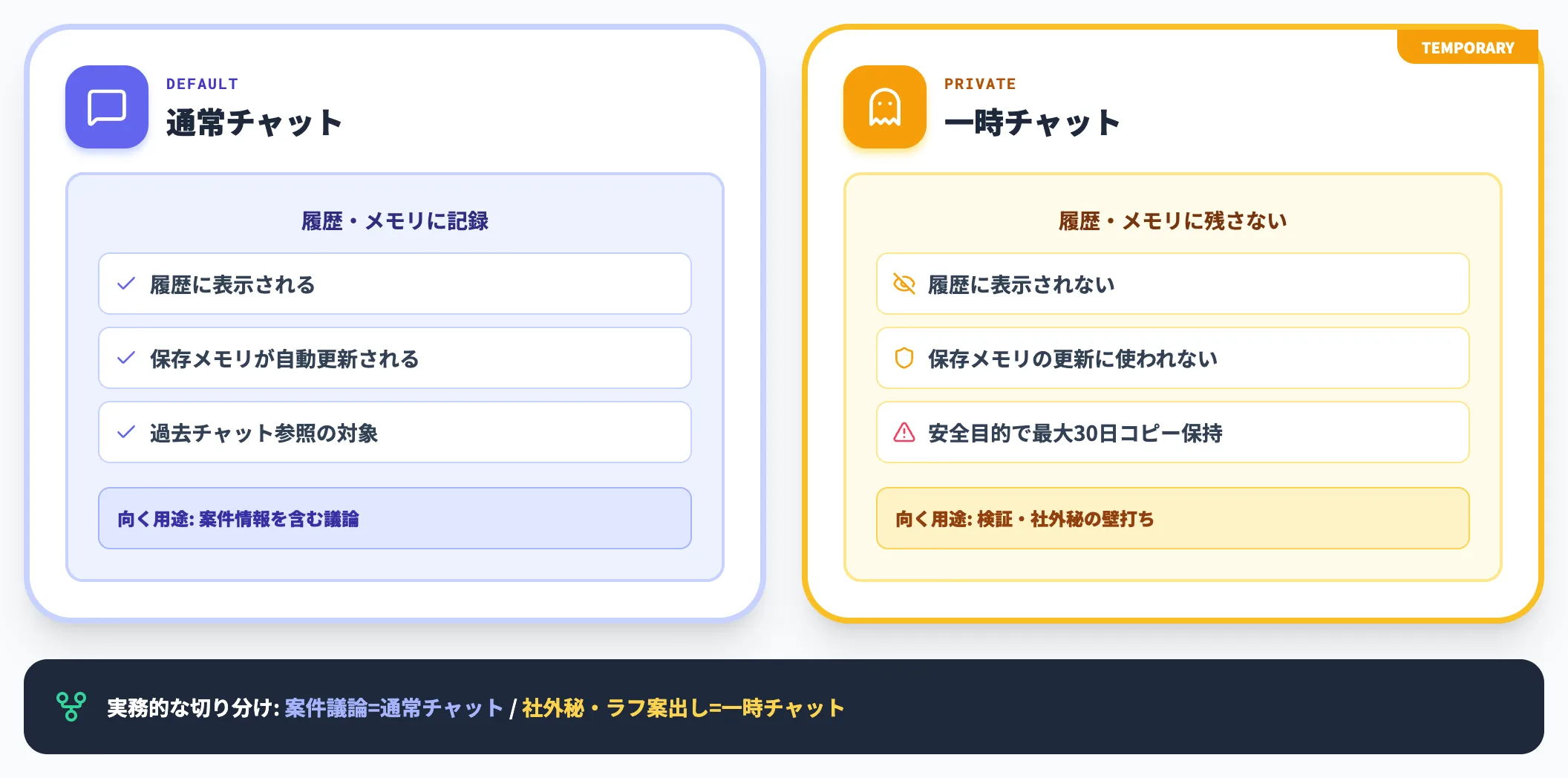
履歴・メモリに残したくない検証や、機密性の高い壁打ちには一時チャットを使います。
新規チャットボタンの隣にあるアイコンから起動すると、その会話は履歴に表示されず、保存メモリの更新にも使われません。ただしOpenAI公式の一時チャットFAQによれば、安全目的でコピーが最大30日保持される場合がある点には注意が必要です。
実務的な使い分けとしては、案件情報を含む議論は通常チャット、社外秘や検証用のラフ案出しは一時チャット、という切り分けが現実的です。
履歴機能のオン・オフ運用は別記事で詳しく整理しています。
カスタム指示・プロジェクト機能との役割分担
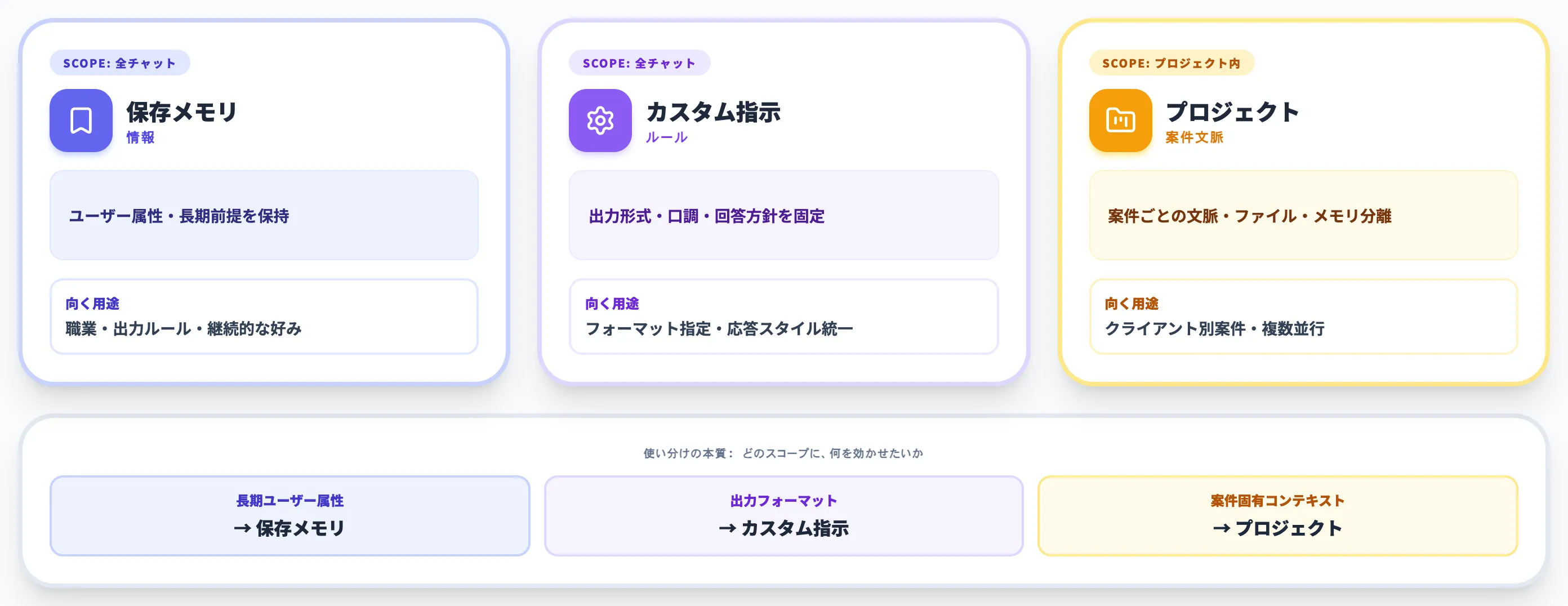
メモリ機能・カスタム指示・プロジェクト機能は、似ているようで役割が異なります。
3機能の特性を以下の表で整理しました。
| 機能 | 主な役割 | 適用範囲 | 向く用途 |
|---|---|---|---|
| 保存メモリ | ユーザー属性・長期前提の保持 | 全チャットに自動適用 | 職業・出力ルール・継続的な好み |
| カスタム指示 | 出力形式・口調・回答方針の固定 | 全チャット(または有効化したチャット) | フォーマット指定・応答スタイル統一 |
| プロジェクト機能 | 案件ごとの文脈・ファイル・メモリ分離 | プロジェクト内のチャットのみ | クライアント別案件・複数並行プロジェクト |
3機能の使い分けの本質は、「どのスコープに、何を効かせたいか」です。
長期的なユーザー属性は保存メモリ、出力フォーマットはカスタム指示、案件固有のコンテキストはプロジェクト、という棲み分けで使い分けると、毎回の指示出しが構造的に減ります。

プロジェクト専用メモリで案件を分離する
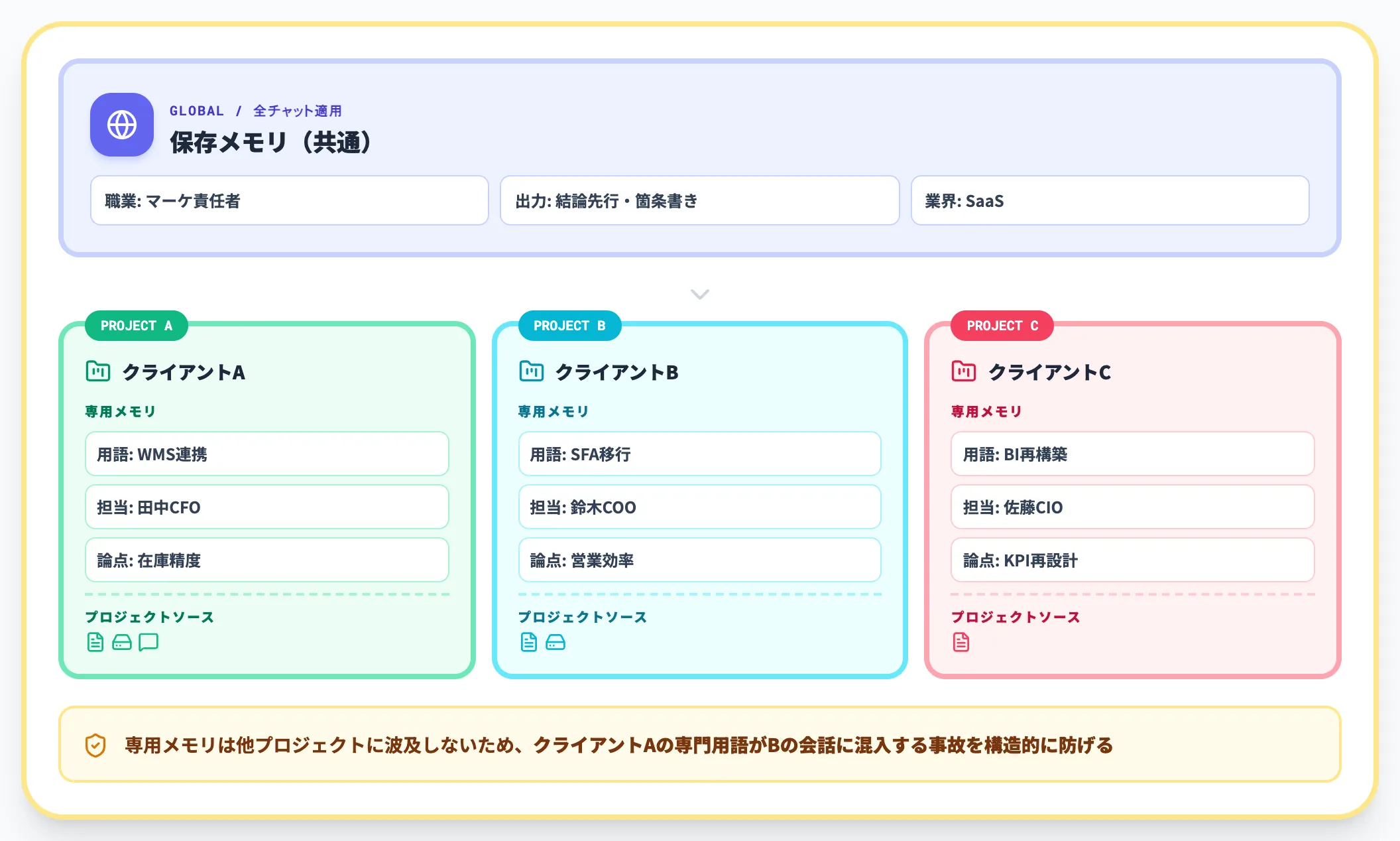
プロジェクト機能には、そのプロジェクト内でのみ有効な「プロジェクト専用メモリ」があります。
通常の保存メモリと違って全チャットには波及しないため、クライアントA向けの専門用語や案件背景を、別クライアントのチャットに持ち込まれずに保持できます。
プロジェクト機能はこれに加えて、ファイル・Google Drive・Slack等を「プロジェクトソース」としてリンクし、回答内容をプロジェクトソースに保存する機能を備えています。詳細はOpenAI公式のProjects利用ガイドに整理されています。
複数案件を並行する担当者は、案件ごとにプロジェクトを切り、その中で専用メモリとプロジェクトソースを育てるのが事故防止の観点でも合理的です。
導入判断で詰まりやすい論点は、「全社共通の高レベル前提は保存メモリ、案件固有の文脈・参照ドキュメントはプロジェクト専用メモリとプロジェクトソース」というラインで線引きすると整理しやすくなります。
カスタム指示は「ルール」、メモリは「情報」と分けて持つ
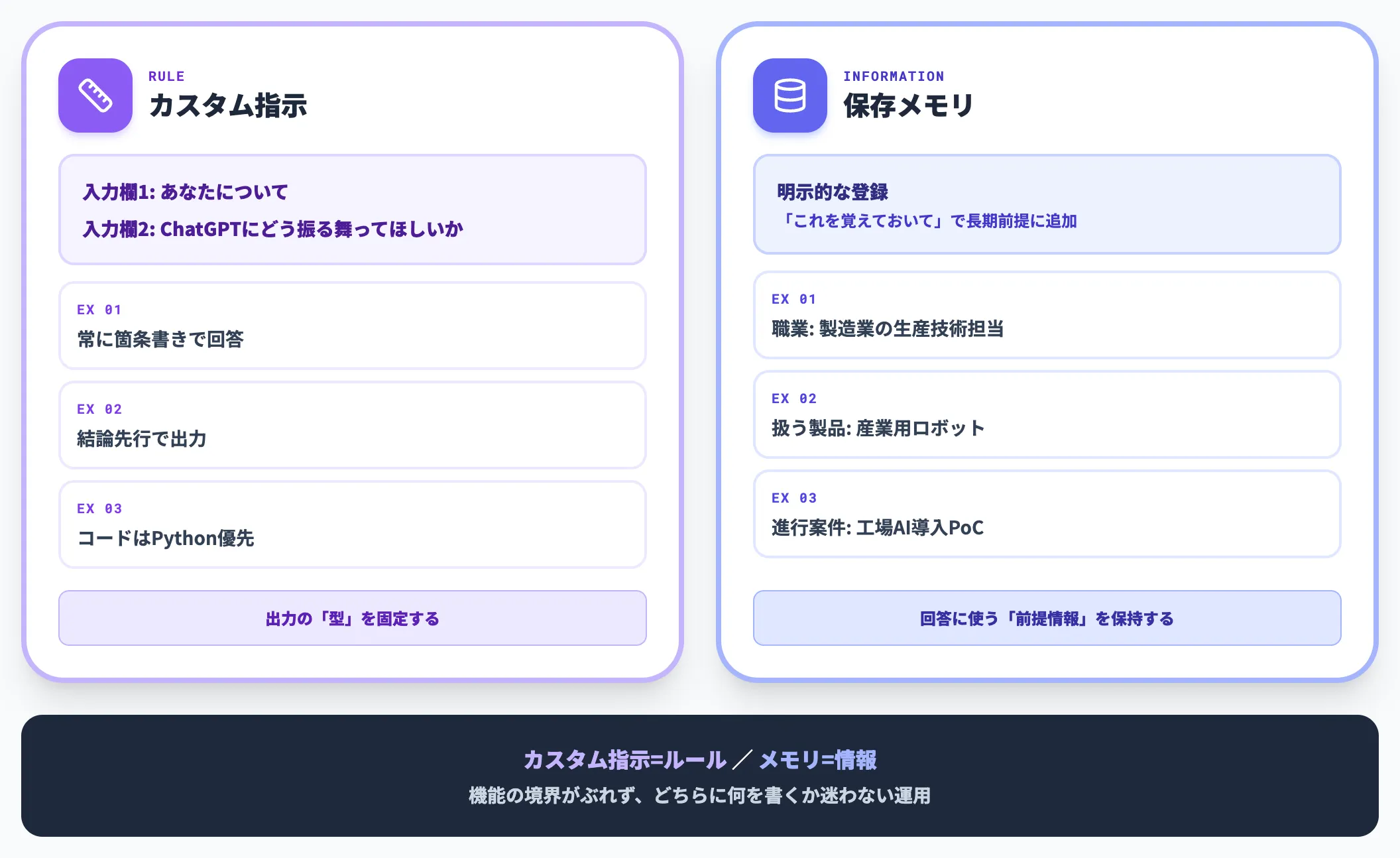
カスタム指示には、「あなたについて」と「ChatGPTにどう振る舞ってほしいか」の2つの入力欄があります。
ここに出力形式の固定ルール(例:常に箇条書き、結論先行、コードはPython)を入れておき、保存メモリには情報・前提(職業、扱う製品、進行案件)を入れる、という分担が無理のない運用です。
カスタム指示は「ルール」、メモリは「情報」、と機能を分けて捉えると、どちらに何を書くかで迷いません。
プロンプトエンジニアリングの基礎を押さえている担当者は、カスタム指示の「振る舞い指示」を高密度に書いてベース回答品質を一段上げる運用が向きます。
1チャットを「気持ちよく終わらせる」設計
カスタム指示・メモリ・プロジェクトを揃えると、1チャットあたりの寿命を短くできます。
長い案件を1チャットで延々と続けず、用途が変わったら新規チャットに移し、メモリと過去チャット参照で文脈を引き継ぐ運用が、結果としてコンテキストウィンドウ上限の影響も避けやすくなります。
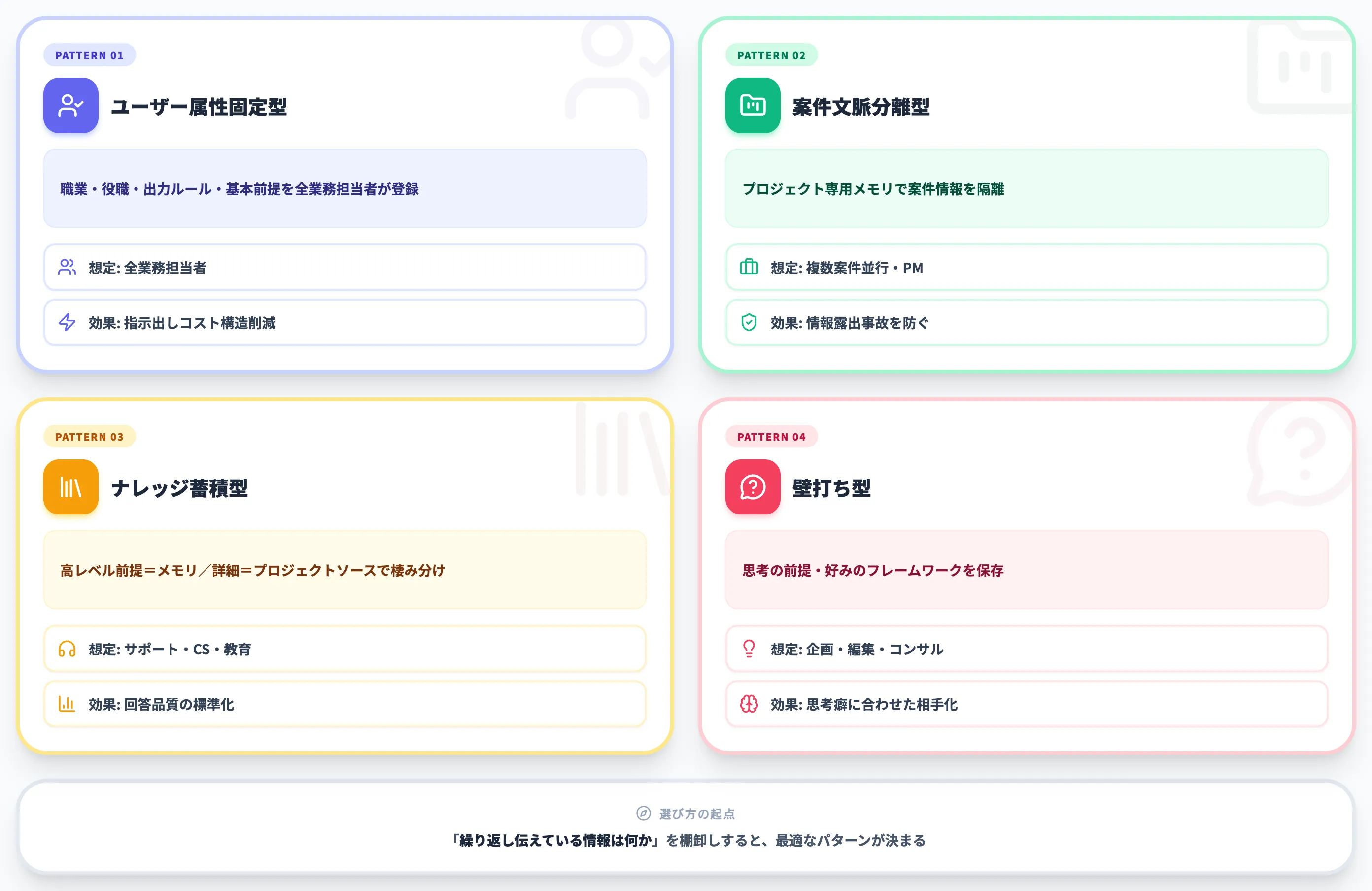
業務でChatGPTメモリを活かす4つの実装パターン
業務での活用方法を整理すると、メモリ機能の実装は4つのパターンに集約できます。
各パターンの特性を以下の表で整理しました。
| パターン | 何を保存するか | 想定ユーザー | 主な効果 |
|---|---|---|---|
| ユーザー属性固定型 | 職業・役職・出力ルール・基本前提 | 全業務担当者 | 毎回の指示出しコストを構造的に削減 |
| 案件文脈分離型 | プロジェクト専用メモリで案件情報を隔離 | 複数案件並行の営業・コンサル・PM | 案件情報の混線・情報露出事故を防ぐ |
| ナレッジ蓄積型 | 高レベル前提・回答方針(詳細FAQはプロジェクトソース/社内DB) | サポート・社内ヘルプデスク・教育 | 同じ質問に対する回答品質の標準化 |
| 壁打ち型 | 思考の前提・好みのフレームワーク | 企画・編集・コンサル | 自分の思考癖に合わせた壁打ち相手として育成 |
パターンの選び方の起点は、「繰り返し伝えている情報は何か」を棚卸しすることです。
毎日同じ前提を入力しているなら属性固定型、案件ごとに前提が違うなら文脈分離型、何度も同じ質問に答えているならナレッジ蓄積型、思考の壁打ちが主用途なら壁打ち型が向きます。
ユーザー属性固定型——日常業務で最も効く基本パターン

最初に導入すべきは、ユーザー属性固定型です。
職業・役職・担当領域・社内呼称・好みの出力フォーマットを保存メモリに登録するだけで、新規チャットでも同じ前提で会話が始まります。
「私は日本のSaaS企業のマーケ責任者。出力は結論先行・箇条書き・日本語」のように保存しておけば、別チャットで「先月のリード分析の傾向を整理して」と聞いても、同じ前提で答えが返ります。
業務継続性が一段上がる最も効果の高いパターンで、まず1週間使ってみるだけで効果を実感しやすい構成です。
案件文脈分離型——複数クライアントを抱える担当者向け
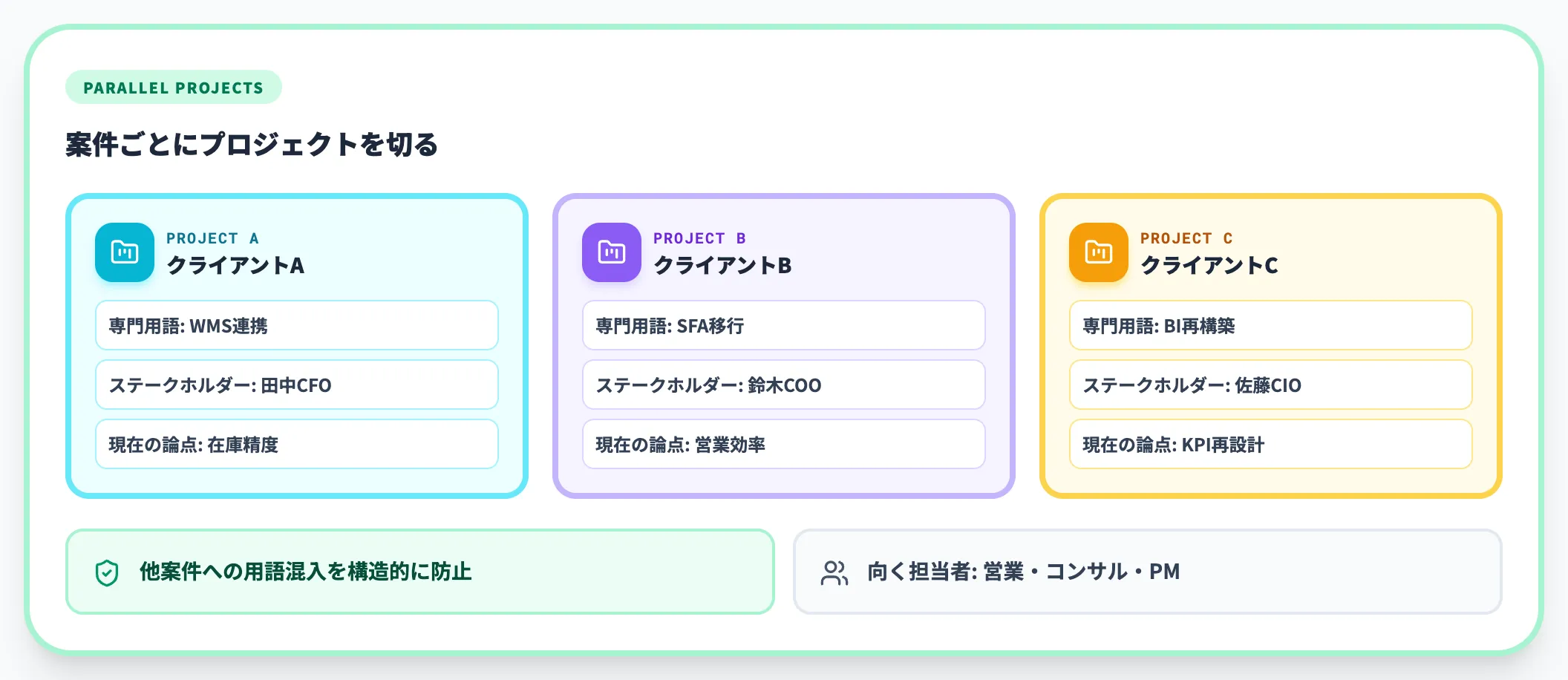
複数案件を並行する営業・コンサル・PMには、案件文脈分離型が向きます。
プロジェクト機能を案件ごとに切り、その中の専用メモリにクライアント固有の用語・ステークホルダー・現在の論点を保存します。
クライアントAの会話でクライアントBの情報がうっかり混ざる事故を、構造的に防げます。
ナレッジ蓄積型——社内サポート・ヘルプデスク向け
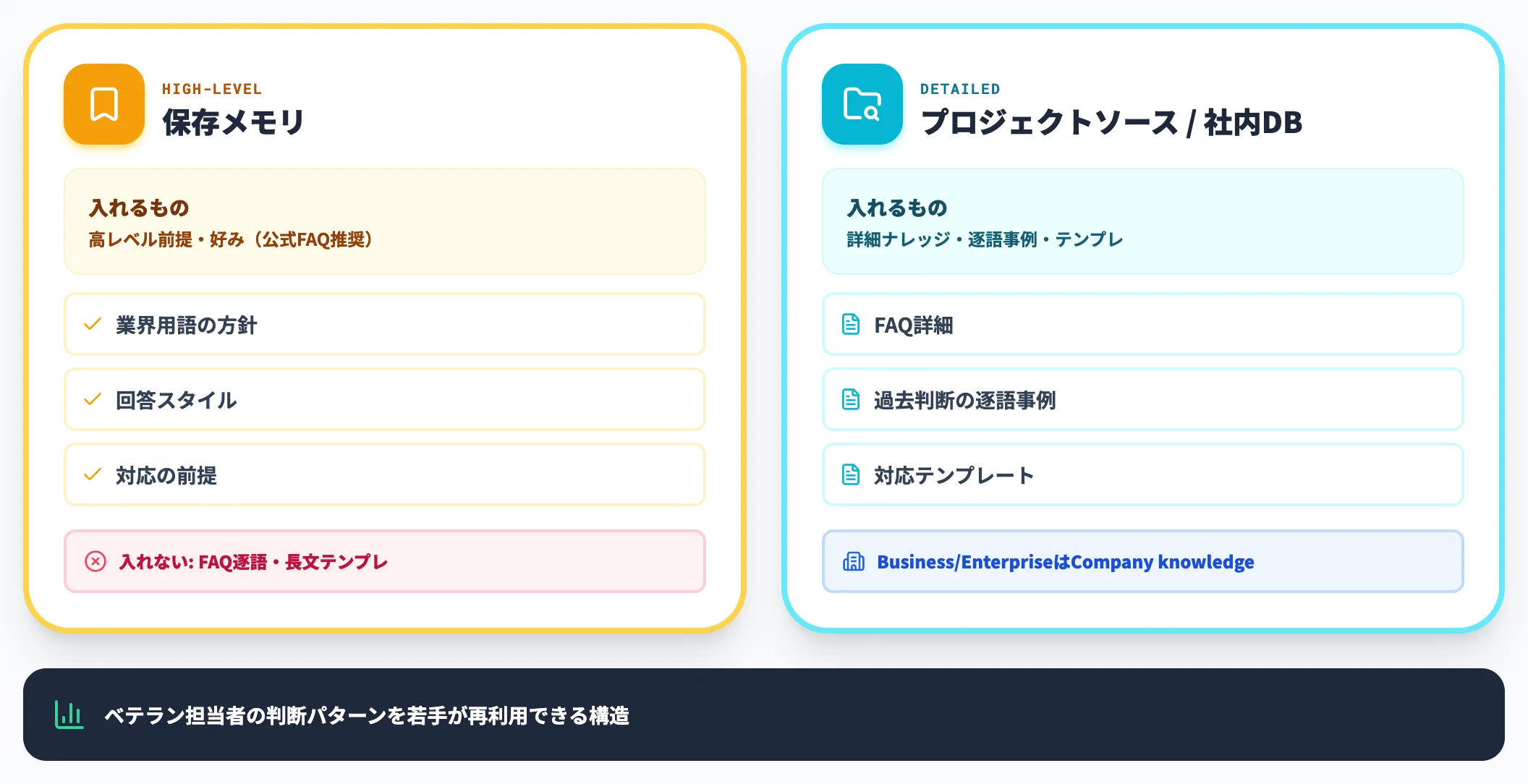
社内サポート・カスタマーサクセス・ヘルプデスクには、ナレッジ蓄積型が有効です。
ただしOpenAI公式のMemory FAQでも案内されているとおり、保存メモリは「高レベルの前提・好み」を保持する用途向けで、長文テンプレートやFAQ逐語の保管には向きません。保存メモリには「業界用語の方針」「回答スタイル」「対応の前提」などの高レベル前提に絞り、FAQ詳細・過去判断の逐語事例・対応テンプレートは、プロジェクトのファイル/ソースやBusiness/EnterpriseのCompany knowledge、社内ナレッジDBに置く構成が安定します。
GPT-5.5の応答品質と「高レベル前提=保存メモリ/詳細ナレッジ=プロジェクトソース」の組み合わせで、ベテラン担当者の判断パターンを若手が再利用できる構造が作れます。
壁打ち型——企画・編集・コンサル向け
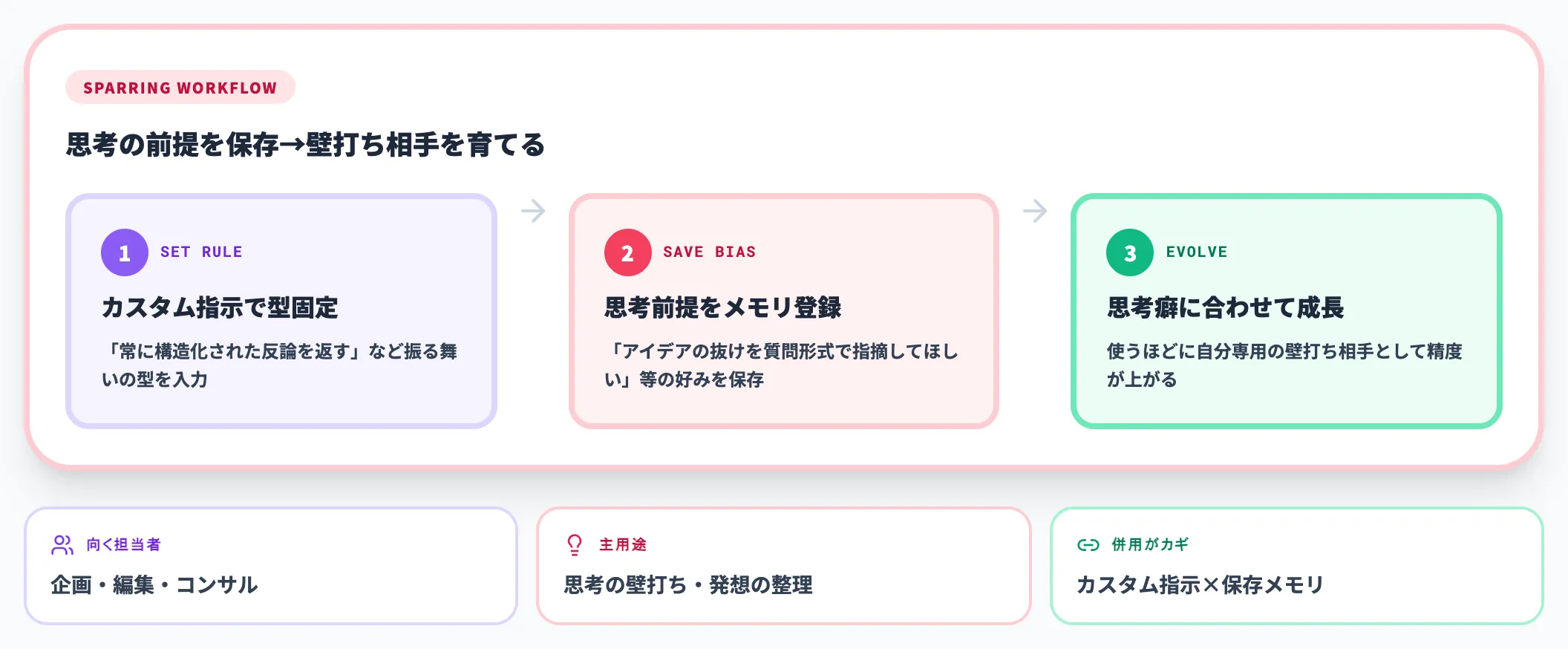
企画・編集・コンサルなど、思考の壁打ちが主用途の業務には壁打ち型が向きます。
「自分は構造化された反論を求めるタイプ」「アイデアの抜けを質問形式で指摘してほしい」のような思考の前提・好みのフレームワークを保存メモリに登録すると、ChatGPTが自分の思考癖に合わせた壁打ち相手として育っていきます。
カスタム指示で振る舞いの型を固定し、保存メモリで個別の前提を育てる、という併用が最も効きます。
プラン別のChatGPTメモリ機能と料金

ChatGPTのメモリ機能は全プランで利用可能ですが、保存メモリの容量・チャット履歴参照の範囲・Memory Sourcesでの参照元にプラン差があります。
プラン別の料金と主要メモリ機能を以下の表で整理しました。値はOpenAI公式のChatGPT Pricingの表記に揃えています。
| プラン | 月額(2026年6月時点) | 保存メモリ | 過去チャット参照 | Memory Sources |
|---|---|---|---|---|
| Free | $0 | 限定的 | 限定的 | 限定的 |
| Go | $8 | あり | より広く参照 | あり |
| Plus | $20 | Expanded(拡張メモリ+コンテキスト) | より広く参照 | あり(+ファイル・接続Gmail) |
| Pro | $100〜$200(2ティア) | Expanded(容量上限ほぼ意識不要) | より広く参照 | あり(+ファイル・接続Gmail) |
| Business | $25/ユーザー/月(年払い時) | Expanded(法人向け管理機能あり) | Coming soon | No |
| Enterprise | 個別見積 | Expanded(管理者制御) | Coming soon | No |
業務でメモリ機能を本格活用するなら、Plus以上が実質的な前提になります。
Freeでも保存メモリ自体は使えますが、容量・コンテキスト・Memory Sourcesの参照範囲が限定的で、長い案件の運用には向きません。
Plusで「Expanded memory+より広い過去チャット参照+ファイル・接続Gmail対応のMemory Sources」が解放されるため、月$20で業務継続性が一段上がります。
注意点として、Business・Enterpriseは保存メモリ(Expanded)は使えますが、過去チャット参照は順次対応予定(Coming soon)、Memory Sourcesは現時点で提供対象外です。法人プランで「Plusと同じ参照体験」が必要なら、提供時期を別途確認した上で計画する必要があります。
最新モデルのGPT-5.5とその標準モデルGPT-5.5 InstantもPlus以上で常用しやすく、コスト対効果はPlusで頭打ちしません。
プランごとの詳細な機能差はChatGPT料金完全ガイドを参照してください。
上位プランへの移行シグナル
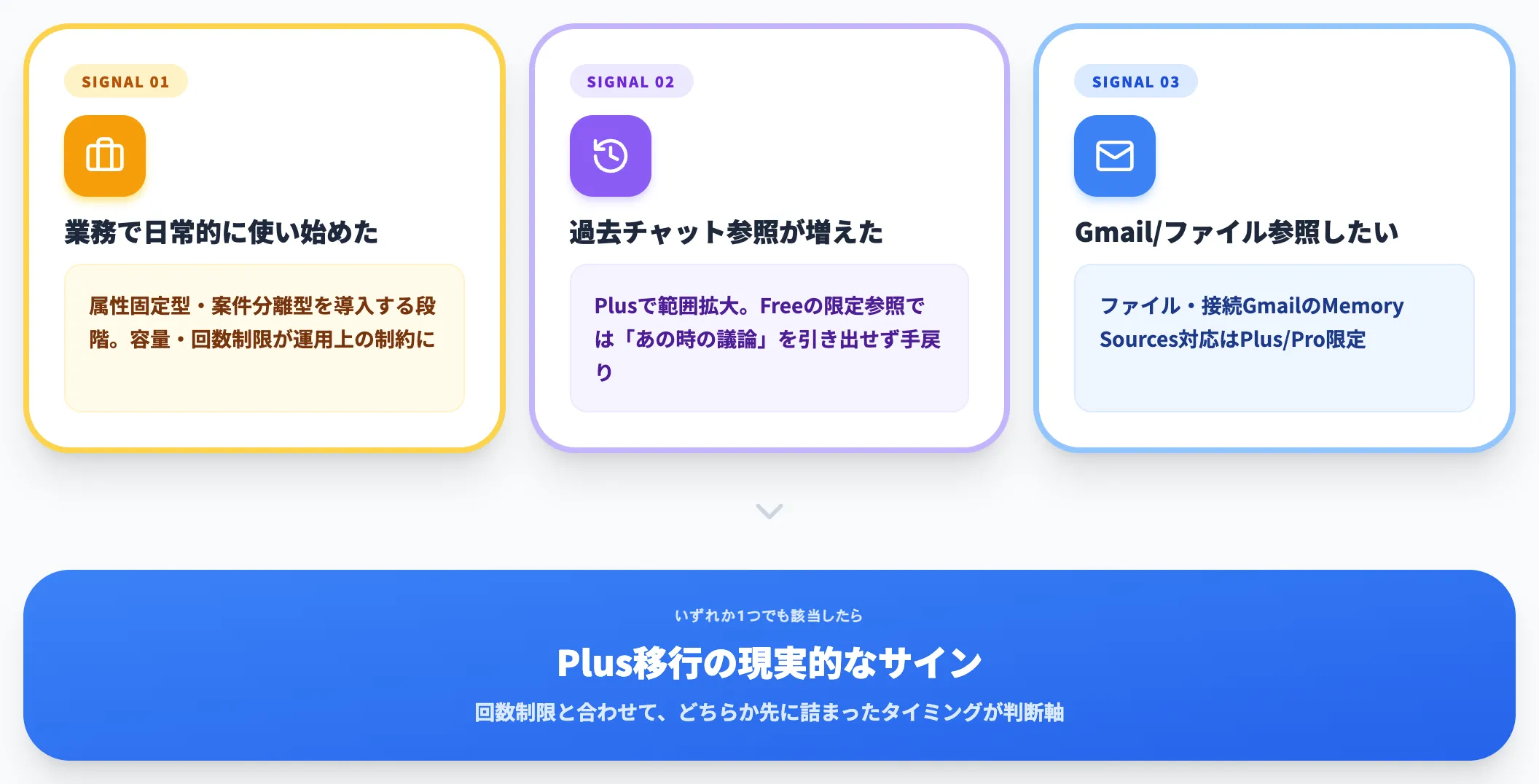
メモリ機能を本格活用しようとした時に、Plus以上への移行を検討すべき典型的なシグナルは以下です。
-
業務で日常的にChatGPTを使い始めた
属性固定型・案件文脈分離型を導入する段階。保存メモリ容量・回数制限の両方が運用上の制約になる
-
過去チャットから引き当てたい情報が増えた
より広い過去チャット参照はGo以上、Plusでさらに範囲が広がる。Freeの限定参照では「あの時の議論」を引き出せず手戻りが発生しやすい
-
接続GmailやファイルをMemory Sourcesに含めたい
ファイル・接続GmailのMemory Sources対応はPlus/Pro限定。業務メール対応・社内ファイル参照を頻繁に使うなら判断のシグナル
メモリ機能とあわせて回数制限も上位プランで緩和されるため、どちらか片方が先に詰まったタイミングがPlus移行の現実的なサインです。
Pro・Business・Enterpriseの選び方

Pro($100/月の標準Proティア、$200/月の最高利用量ティアの2段階制、OpenAI公式のPro tiers解説参照)は、Advanced tools and modelsを週次で使う研究・開発・専門業務向けのプランです。
メモリ機能の差分は容量上限がほぼ気にならない水準で運用できる点で、メモリ目的だけでProに上げる必然性は薄めです。
組織展開を視野に入れるならBusiness($25/ユーザー/月、年払い時単価)、全社統制が必要なら個別見積のEnterpriseが妥当です。法人プランは管理者がメモリ機能の有効/無効・データ保持ポリシーを統制でき、個人プランでは得られないガバナンス前提が満たせます。
ただし上述のとおり、現時点で法人プランは過去チャット参照とMemory SourcesがPlus/Pro同等ではありません。「個人で先行検証→組織展開」のフェーズで一度Plusで参照体験を確認してから法人プランに移ると、提供範囲の違いに後から驚かずに済みます。
業務でChatGPTメモリを使う際の注意点
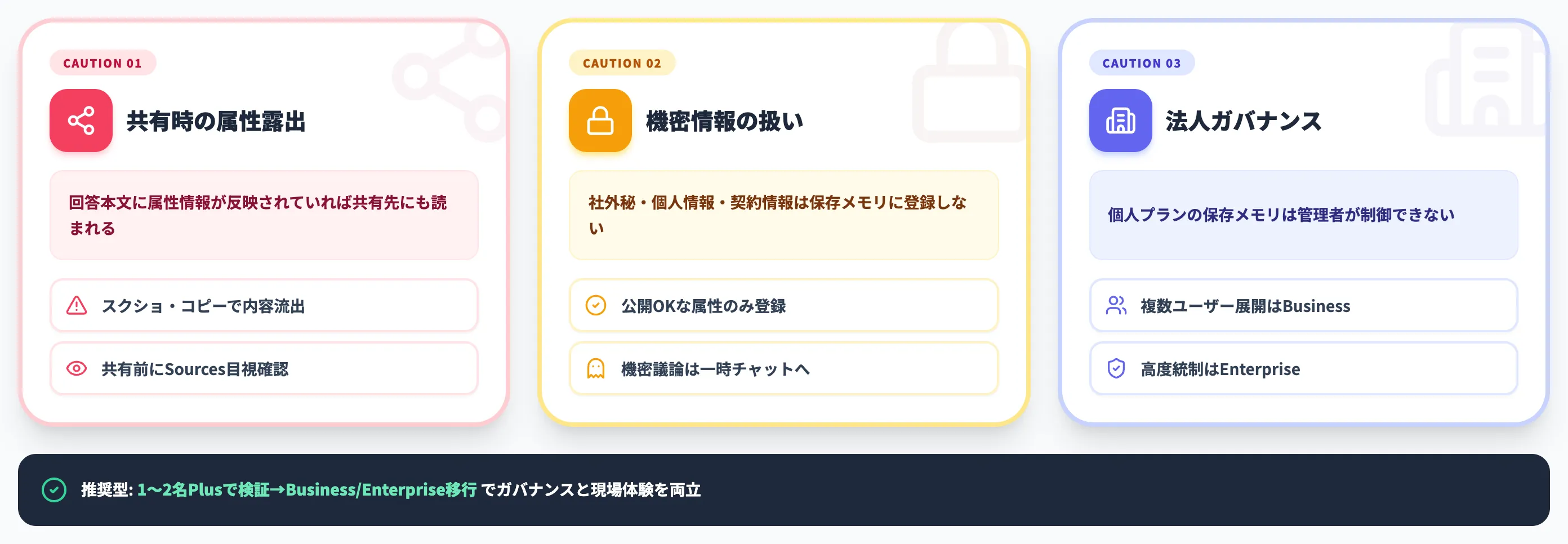
メモリ機能は便利な反面、業務利用では情報管理の観点で押さえるべき点が3つあります。
共有チャット・スクショで意図しない属性情報を露出させない

保存メモリの内容自体は共有チャットには表示されません。Memory Sourcesも共有時には参照元が消えます。
ただし、回答そのものが保存メモリの情報を反映していれば、回答本文を共有・スクショすれば結果的に内容が伝わります。
クライアントへの共有チャットを使う前に、回答下のMemory Sourcesで「何が反映されているか」を確認し、回答本文に意図しない属性情報が混ざっていないかを目視チェックするのが安全です。
機密情報・個人情報は保存メモリに残さない

社外秘・個人情報・契約情報は、保存メモリに登録すべきではありません。
業務利用では原則として「保存メモリには公開しても問題ない属性情報のみ」のラインを引くのが現実的です。
機密性の高い議論は一時チャットに切り替え、履歴・メモリに残さない運用に振り分けるべきです(一時チャットでも安全目的で最大30日コピーが保持される場合があるため、真の機密情報はそもそも入力しない方針が安全です)。
情報漏洩リスクとセキュリティ対策は、業務利用前に通読しておく価値があります。
法人ガバナンスはBusiness/Enterpriseで設計する

法人で複数ユーザーに展開する場合、個人プランの保存メモリは管理者が制御できません。
Businessではワークスペース単位でメモリ・パーソナライズの可用性を管理でき、Enterpriseではさらにカスタムデータ保持ポリシーなど高度な統制まで設定できます。組織的な情報管理が前提なら、個人プランではなく法人プランを選ぶべきです。
AI総研の支援経験からは、まず1〜2名がPlusで利用感を検証し、定着後にBusiness/Enterpriseへ移行する段階的な導入が、ガバナンスと現場体験を両立しやすい型として定着しています。

ChatGPTメモリ活用を業務AI化の入口にする
ChatGPTのメモリ機能を使いこなせるようになると、次に見えてくるのは「個人の作業効率化」を超えた業務プロセスのAI化です。
属人化していた前提共有がAIに移譲できるようになると、調査・ドラフト作成・問い合わせ対応といった定型業務をAIエージェントに任せるフェーズが現実的になります。
そうした現場主導の業務AI化を支援するのが、AI総合研究所が提供するエンタープライズAI基盤AI Agent Hubです。導入企業のユースケース・実装パターン・ROIをまとめたガイドを無料で公開しているので、業務AI化の次の一歩を検討されている方はご活用ください。
ChatGPTメモリ活用を業務プロセスのAI化に発展させる

個人の効率化を組織のAI化につなぐ
ChatGPTのメモリ機能で前提共有を自動化できるようになったら、次は属人化していた判断・調査・ドラフト作成をAIエージェントに任せるフェーズです。AI総研の導入支援ノウハウをまとめたガイドを無料でご活用ください。
まとめ
本記事では、ChatGPTのメモリ機能を3層構造・Memory Sources・使い方・カスタム指示やプロジェクト機能との役割分担・業務での4実装パターン・プラン別料金・業務利用時の注意点まで整理しました。要点を改めて整理します。
-
メモリ機能は保存メモリ・チャット履歴参照・Memory Sourcesの3層構造で、役割を分けて理解すると毎回の指示出しを構造的に削減できる
-
2026年5月追加のMemory Sourcesで、回答が参照した保存メモリ・過去チャット・カスタム指示・ファイル・接続Gmailを回答単位で確認できるようになり、保存メモリの修正・削除や過去チャットの関連性フィードバックも回答下から実行できる
-
**カスタム指示は「ルール」、メモリは「情報」、プロジェクトは「案件文脈」**として併用すると、3機能の境界がぶれず指示の重複が消える
-
業務での実装は4パターン(ユーザー属性固定型・案件文脈分離型・ナレッジ蓄積型・壁打ち型)に集約され、用途に合わせて選ぶのが現実的
-
業務継続利用ならPlus以上が前提で、機密情報は保存メモリに残さず一時チャットで扱う、組織展開はBusiness/Enterpriseで管理者ガバナンスを効かせる、という運用ラインを押さえれば業務利用の事故も避けられる










