この記事のポイント
 プロジェクト規模のコード生成・リファクタ自動化ならGPT-5.3-CodexがOpenAI製の最有力候補、5.2-Codexからの移行を推奨
プロジェクト規模のコード生成・リファクタ自動化ならGPT-5.3-CodexがOpenAI製の最有力候補、5.2-Codexからの移行を推奨- SWE-Bench Pro・Terminal-Bench 2.0・OSWorld-Verifiedで前世代超え、Claude Code対抗で検証する価値
- コーディングだけでなくGDPvalやCTFでも高スコアのため、セキュリティ監査やビジネス文書生成を兼ねるマルチユースケースに最適
- Codex Web・CLI・IDE拡張・ChatGPTの4チャネルから利用可能なため、開発チームの既存ワークフローに最も合うチャネルを選択すべき
- サイバーセキュリティ用途ではTrusted Access for Cyberが必須要件。攻撃用途への転用防止が担保されている点が、企業採用の判断材料として重要

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OpenAIは2026年2月、フロンティアコーディングモデルの最新世代となる「GPT-5.3-Codex」を発表しました。GPT-5.2-Codexを引き継ぎつつ、エージェント的なコーディング性能と長時間タスクへの対応を大きく強化したモデルです。
SWE-Bench Pro(Public)、Terminal-Bench 2.0、OSWorld-Verified、Cybersecurity Capture The Flag Challengesなどの実務寄りベンチマークでは、GPT-5.2系から大きくスコアを伸ばし、端末操作やOS操作を含む"プロジェクト規模"のタスクで成功率が向上しています。
本記事では、GPT-5.3-Codexの位置づけ・主な機能・料金と提供チャネル・評価ベンチマーク・安全性・他モデルとの比較を、2026年2月時点の公式情報をもとに整理し、どのようなユースケースで採用を検討すべきかを解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
GPT-5.3-Codexとは?フロンティアコーディングモデルの最新世代
Trusted Access for Cyber(TAC)の概要
GPT-5.3-Codexとは?フロンティアコーディングモデルの最新世代
GPT-5.3-Codexは、OpenAIの大型言語モデル「GPT-5.3」をベースにしたフロンティアコーディングモデルです。ソフトウェア開発と防御的サイバーセキュリティ、さらに知識労働タスクまでまとめて扱えるよう最適化されており、「コードだけを書くモデル」ではなく、エージェントとして長時間タスクを完遂させることを想定しています。
GPT-5.2-Codexと同様に、ターミナル操作やリポジトリ横断のリファクタリング、テスト自動生成、脆弱性調査といったプロジェクト規模のタスクを、Codex Web・Codex CLI・IDE拡張などの専用環境から対話的に進められる設計です。
さらに、SWE-Bench ProやTerminal-Bench 2.0、OSWorld-Verifiedなどの"本物に近い"評価セットで、前世代より一段高い成功率を実現しています。
加えて、Excel/PowerPoint/Wordレベルの成果物を直接生成する機能や、Trusted Access for Cyberを通じた高機能サイバー能力の提供が組み合わされており、「開発チームとビジネスチームの両方を支える長時間エージェント」として位置づけられています。


GPT-5.3-Codexの強化ポイント
ここでは、GPT-5.3-Codexが得意とするタスク領域と、GPT-5.2系からの主な強化ポイントを整理します。ベンチマークの数字だけでなく、「どのような仕事を任せやすくなったのか」という観点で見ていきます。
対応タスク領域の全体像
公開されている情報とシステムカードを見ると、GPT-5.3-Codexが主にカバーする領域は次のとおりです。
-
ソフトウェア開発・運用。
既存リポジトリの理解、リファクタリング計画の立案、テストコード自動生成、CI/CDの設定提案など、開発ライフサイクル全体を対象とする。
-
防御的サイバーセキュリティ。
ペネトレーションテストやレッドチーミング、脆弱性調査、マルウェア解析などを、防御目的の範囲で支援する。
-
知識労働とビジネスドキュメント。
財務モデルやNPV分析、営業資料、ルックブック、研修テキストなど、非コードの"知的成果物"をOfficeファイルとして生成する。
-
長時間・マルチステップのエージェントタスク。
ターミナル操作やOS操作を含む長時間セッションで、ログを追いながら段階的にタスクを進める。
このように、GPT-5.3-Codexは「コーディングだけのモデル」ではなく、コードを軸にしつつも知識労働やOfficeワークまで含めた広い範囲の仕事を自動化することを前提に設計されています。
コーディング
まず、GitHub上の実際のバグ修正タスクをベースにした S WE-Bench Pro(Public)での性能を見ます。
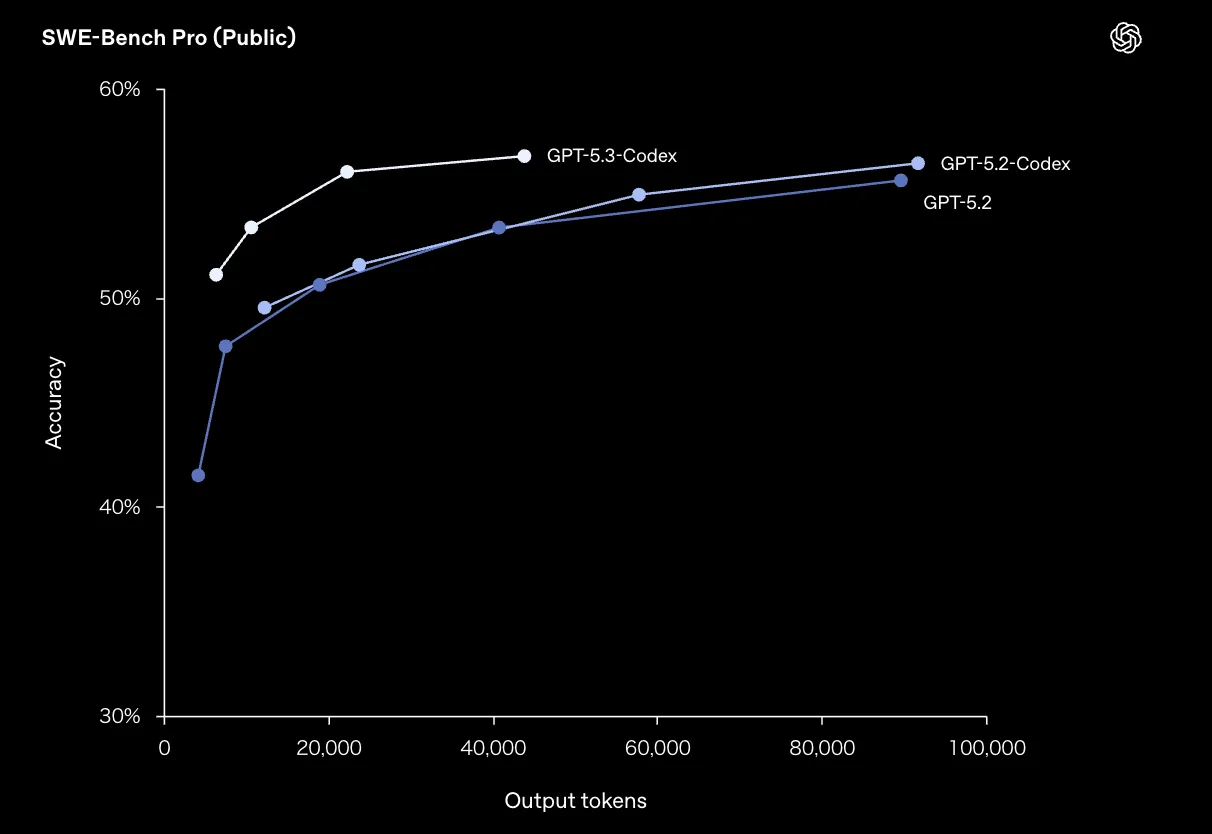
横軸が出力トークン数、縦軸がAccuracy(正答率)で、GPT-5.3-Codex・GPT-5.2-Codex・GPT-5.2の3モデルが比較されています。
- 出力トークン数が増えるにつれて、3モデルとも精度は上昇するが、GPT-5.3-Codexは少ないトークン数の段階から安定して高い精度を維持している。
- 約2万トークンの時点でGPT-5.3-Codexが50%台半ばに到達しており、同条件のGPT-5.2系より一歩先行している。
- 8〜10万トークン付近では3モデルとも精度が飽和してくるが、その中でもGPT-5.3-Codexが最も高いカーブを描いている。
実務に引き直すと、「出力を無駄に長くしなくても、比較的短いステップ数でバグ修正まで辿り着きやすい」「同じトークン量を投下したときに、成功率が一段高い」という意味合いになります。長時間タスクのコストを抑えたい場合ほど、GPT-5.3-Codexのメリットが出やすい設計です。
エージェントタスク
次に、ターミナル操作とOS操作を含むエージェントタスクの性能を見ていきます。
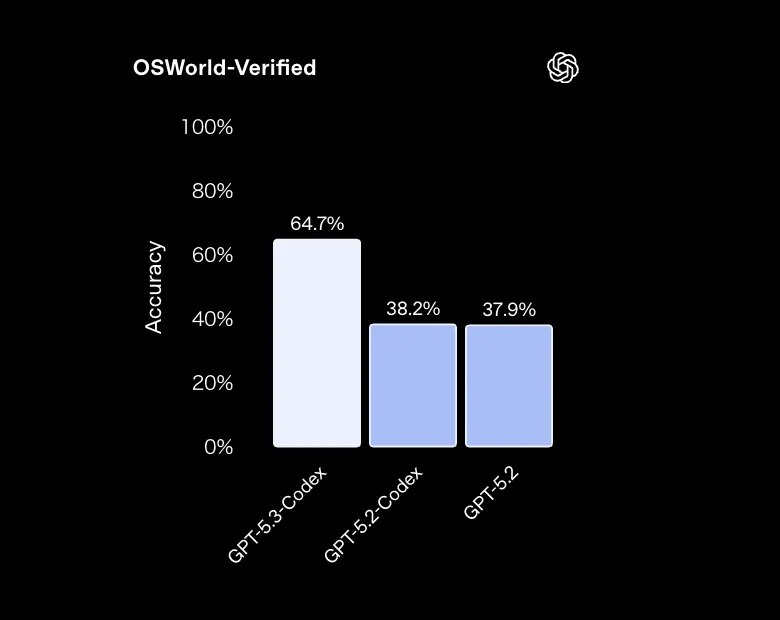
OSWorld-Verifiedは、実際のOS環境でのアプリ操作や設定変更を含むタスクの成功率を測るベンチマークです。
- GPT-5.3-Codex:64.7%
- GPT-5.2-Codex:38.2%
- GPT-5.2:37.9%
OS操作を含むタスクでは、GPT-5.3-CodexがGPT-5.2系に対して約1.7倍の成功率を記録しており、「エージェントに任せたOS操作がどの程度成功するか」という観点で大きな差が出ています。
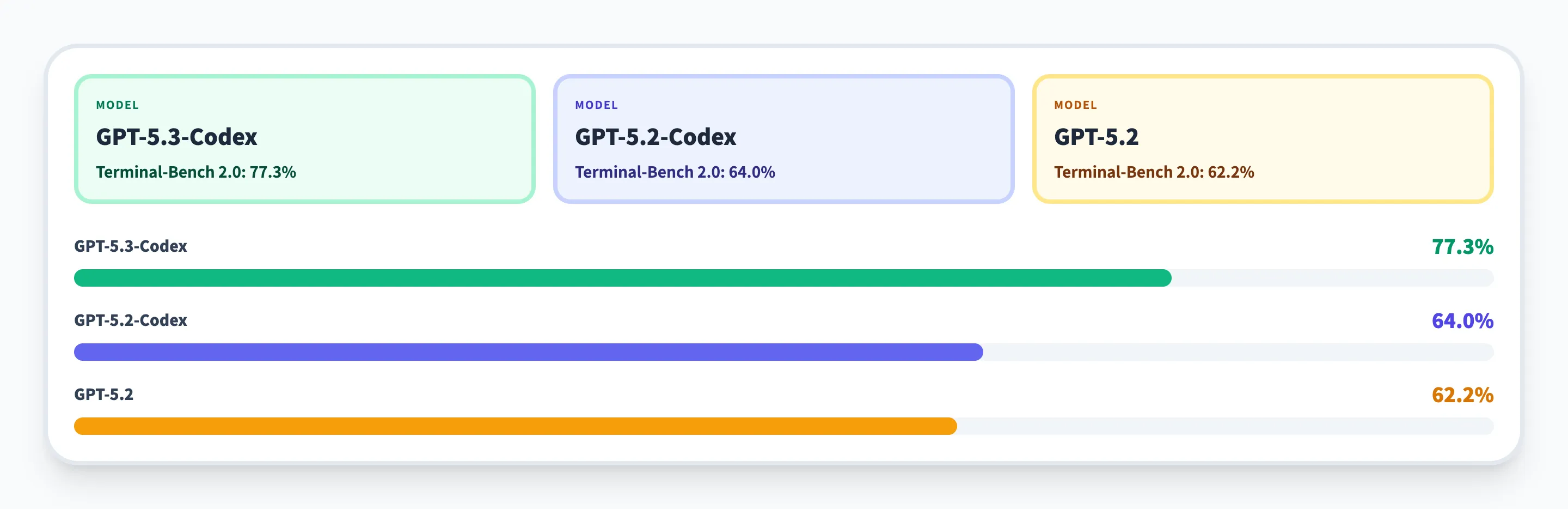
Terminal-Bench 2.0は、ターミナルとファイルシステム操作を伴う長時間コーディングタスクの成功率を測るベンチマークです。
- GPT-5.3-Codex:77.3%
- GPT-5.2-Codex:64.0%
- GPT-5.2:62.2%
こちらでもGPT-5.3-Codexが10ポイント以上リードしており、「シェル操作+ファイル編集+テスト実行」といった一連のフローをまとめて任せやすくなっています。
サイバーセキュリティ・知識労働
コーディング以外にも、GPT-5.3-Codexはサイバーセキュリティや知識労働系のベンチマークでも高いスコアを記録しています。
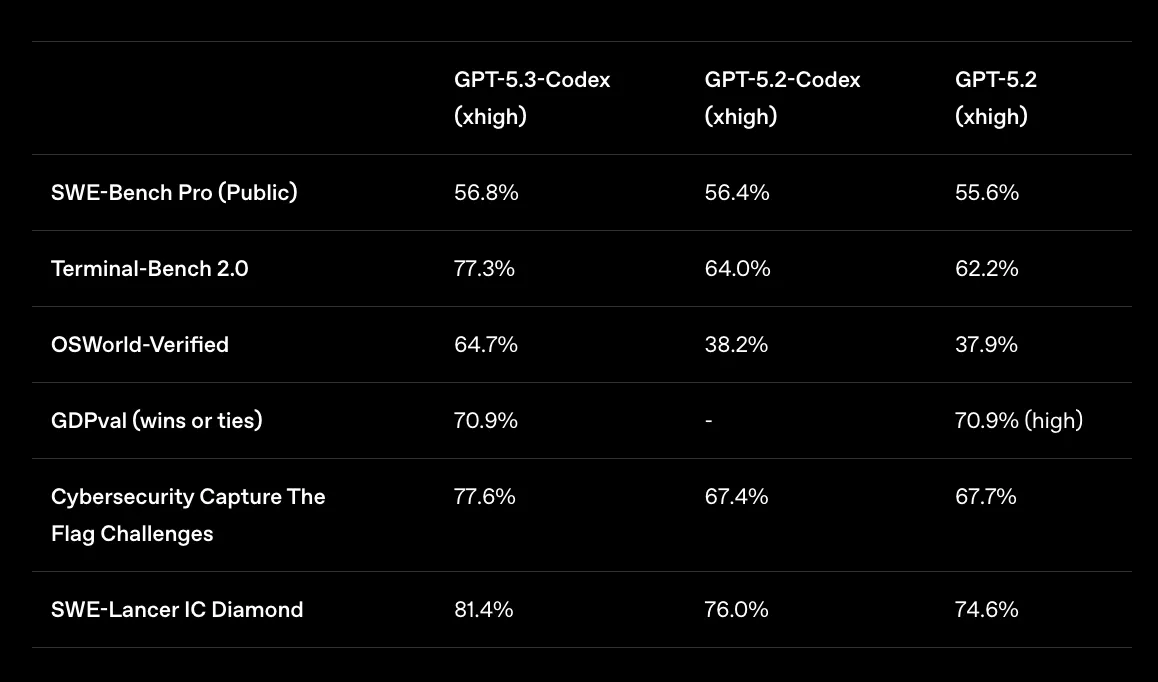
主要ベンチマークの結果比較(GPT-5.3-Codex / GPT-5.2-Codex / GPT-5.2)
表に示されている代表的な指標を抜き出すと、次のようになります(いずれもxhigh設定)。
- SWE-Bench Pro(Public):GPT-5.3-Codex 56.8%、GPT-5.2-Codex 56.4%、GPT-5.2 55.6%。
- GDPval(wins or ties):GPT-5.3-Codex 70.9%、GPT-5.2(high)も70.9%で、知識労働タスク全体でトップクラス。
- Cybersecurity Capture The Flag Challenges:GPT-5.3-Codex 77.6%、GPT-5.2-Codex 67.4%、GPT-5.2 67.7%。
- SWE-Lancer IC Diamond:GPT-5.3-Codex 81.4%、GPT-5.2-Codex 76.0%、GPT-5.2 74.6%。
CyberやSWE-Lancerのような"実務に近い"タスクで伸びていることから、GPT-5.3-Codexは単純なコード生成だけでなく、問題の読み解きや優先順位付け、複数ステップの計画といった「知的労働」部分の能力も底上げされていることが分かります。
GPT-5.3-Codexのアウトプット例

ここからは、実際の生成結果イメージとして公開されているスライドやスプレッドシート、ドキュメントを見ながら、「どのレベルまで任せられるのか」を具体的にイメージしていきます。
PowerPointスライド
このスライドは、金融商品の途中解約ペナルティと流動性を比較した資料の一部です。棒グラフと説明ボックス、アドバイザー向けトーキングポイントまで含めて1枚に整理されており、次のような特徴があります。
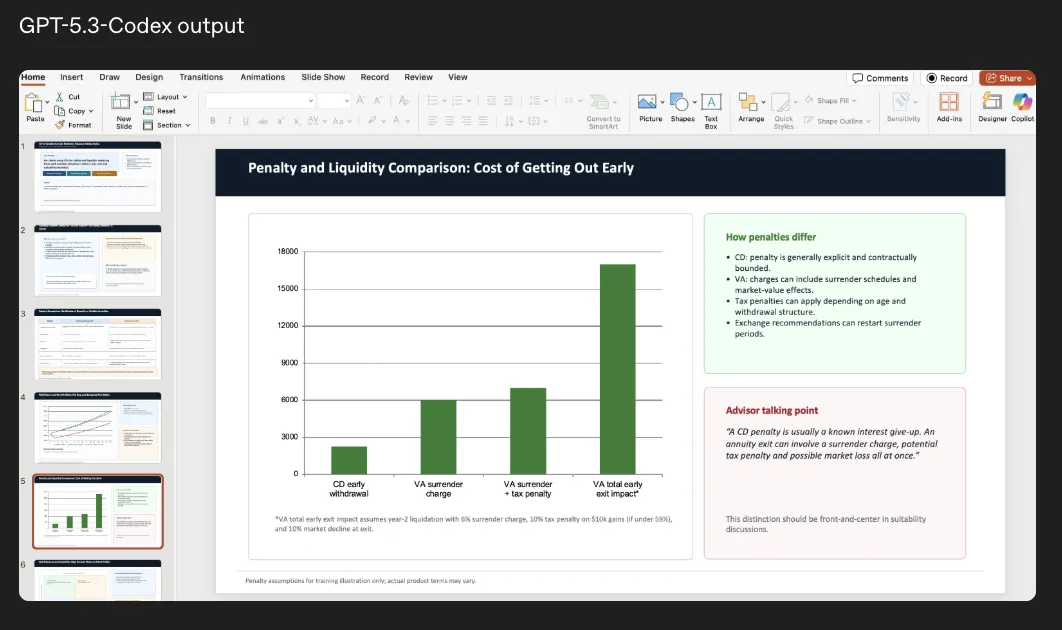
- Excel相当の計算ロジックを前提に、グラフ用データと視覚化をまとめて生成している。
- 右側には「How penalties differ」「Advisor talking point」といった解説ボックスが配置されており、そのまま顧客説明に使える粒度で文章が書かれている。
- 文章とグラフのストーリーラインが揃っており、単なる"図の貼り付け"ではなくプレゼン全体の文脈を意識した出力になっている。
営業資料や社内勉強会のスライドなど、ある程度フォーマットが決まっているアウトプットであれば、GPT-5.3-Codexにドラフトを丸ごと任せるところからスタートし、人間側で微調整する運用が現実的です。
ルックブック・マーケ資料
こちらは、ファッションブランドのルックブック風スライドの例です。
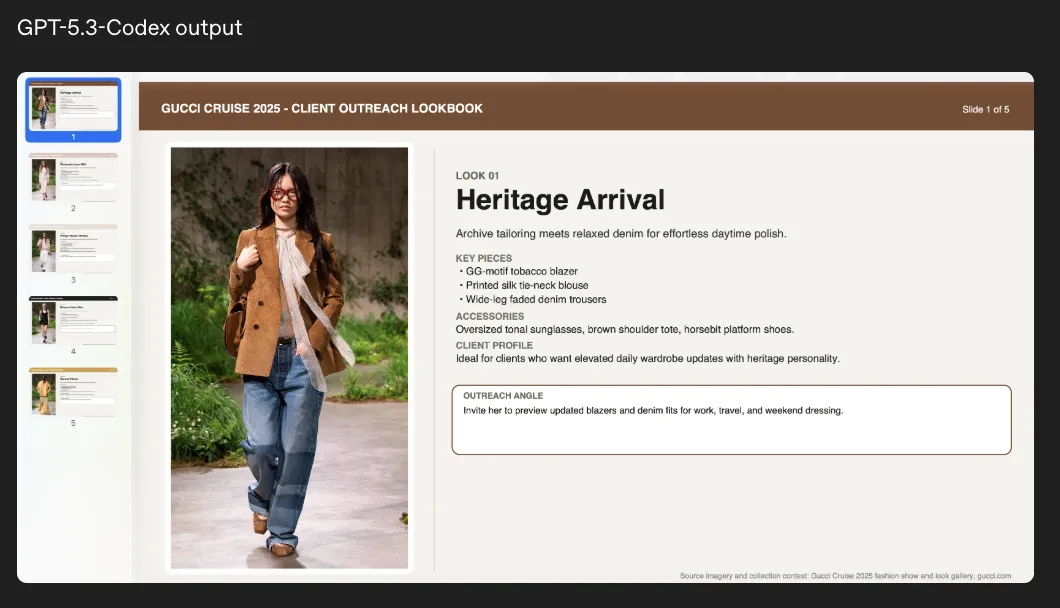
- 左側に全体のページ一覧、右側にメインビジュアルとテキストレイアウトが配置されており、実際の商用資料に近い構成になっている。
- タイトル・キーピース・アクセサリー・クライアントプロフィールなど、マーケティング的な情報設計がなされている。
- 「OUTREACH ANGLE」など営業現場の会話を想定した要素も含まれており、単なる説明文以上の"使えるコピー"が出力されている。
ブランドトーンやレイアウトルールをプロンプト側で与えておけば、シーズンごとの商品説明資料や提案書のベースを素早く量産する用途で活用しやすくなります。
スプレッドシート
この例は、ヘッドランプ調達のNPV分析を行うExcelシートです。
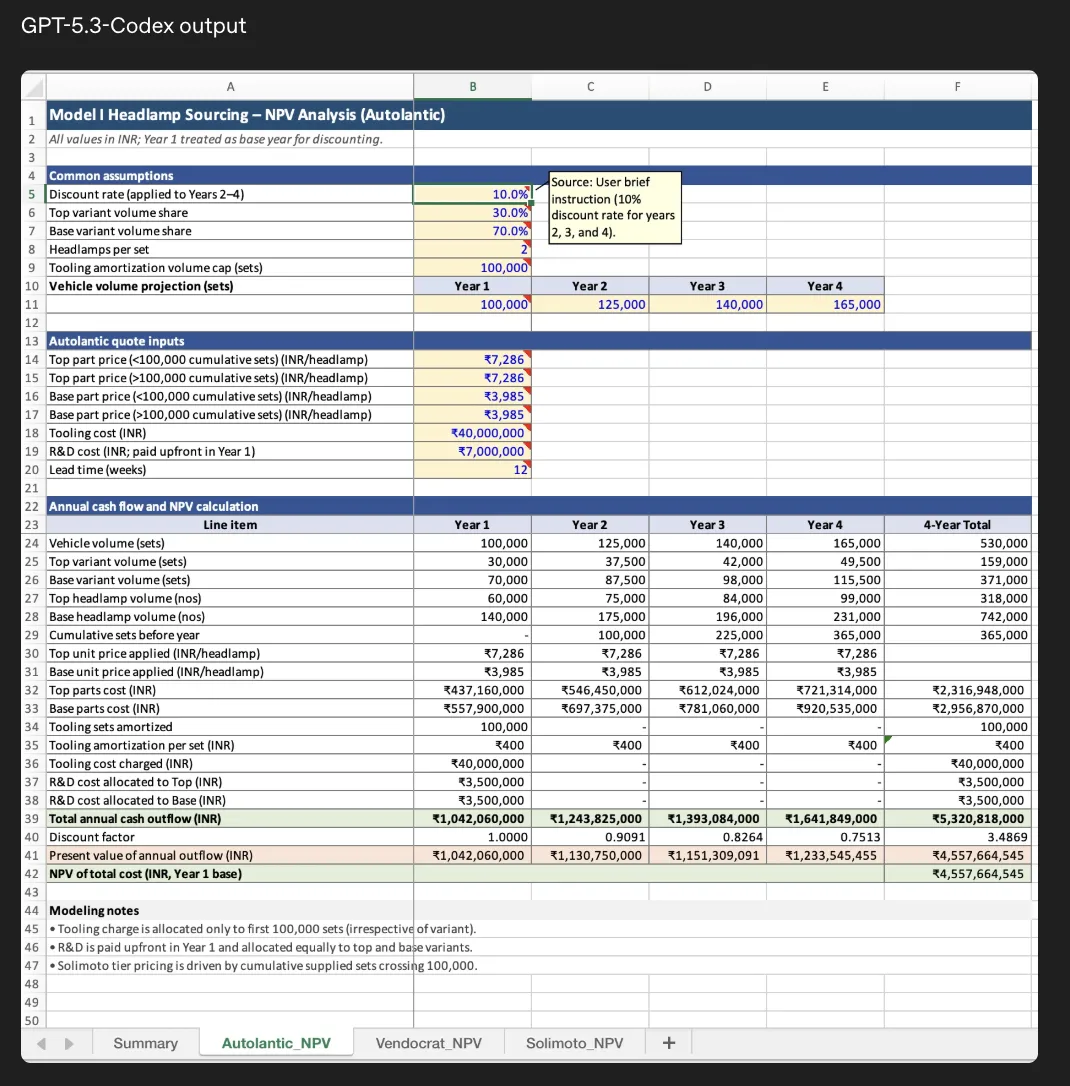
- 上部に共通前提(ディスカウントレート、ボリュームシナリオ、アモチゼーション期間など)が整理されている。
- 中段では、各年のキャッシュフローやコスト項目が表形式で展開され、最終行でNPVが計算されている。
- シート下部には「Modeling notes」として、前提の補足説明が文章でまとめられている。
GPT-5.3-Codexは、数式を一つずつ書かせるだけでなく、「前提整理→キャッシュフロー展開→NPV計算→注記」という一連の構造をまとめて組み立てられるため、財務モデリングの"設計と実装"を同時に手伝わせるイメージで使えます。
Wordドキュメント
最後に、ブライダルセールス向けの研修ブリーフをまとめたWordドキュメント例です。

- 冒頭で対象読者と目的が明確に定義され、その後に概要・ objection のタイプ・具体例といった構造で章立てされている。
- 中盤には表形式で「Objection Type/Description/Examples You May Hear」が整理されており、研修現場ですぐ使えるフォームになっている。
- 見出しスタイルや段落スタイルも整っており、そのまま社内配布可能なレベルの体裁になっている。
このように、GPT-5.3-Codexはコードだけでなく、研修資料やマニュアルといった"知識労働のアウトプット"もエンドツーエンドで生成できる点が特徴です。
GPT-5.3-Codexの料金

GPT-5.3-Codexは、ChatGPTの有料プランに紐づく「Codexファミリーのモデルのひとつ」という位置づけです。
Plus/Pro/Business/Enterprise/Eduといった有料プランの契約が前提になり、そのサブスクリプションにCodexの利用権が含まれます。
料金の基本は「プランのシート単価」と「どれだけCodexに負荷の高いタスクを投げるか」の組み合わせで決まり、必要に応じて追加クレジット(ChatGPT Credits)を購入して上限を拡張できます。
【関連記事】
ChatGPTの料金プラン一覧を比較!無料・有料版の違い・支払い方法を解説
無料・Goユーザー向けキャンペーン(2026年2月時点)
2026年2月時点では、ChatGPT FreeおよびGoユーザー向けに、期間限定でCodexを試せるキャンペーンが用意されています。
また、この期間中は既存のCodexユーザーに対して、有料プランのレート制限が一時的に引き上げられています。
- Free/Goユーザーでも、キャンペーン期間中はCodex AppやCLIなどの一部チャネルからCodexを試用できます。
- 有料ユーザーについては、同期間中に限りCodex関連のレート制限が通常の2倍に拡張されます。
ただし、これらはあくまで期間限定の措置です。
長期的な運用を前提にする場合は、「Codexは有料ChatGPTプラン+必要に応じた追加クレジットが前提」と考えておく方が安全です。
Codex App/CLI/IDE/Webでの利用パターン
GPT-5.3-Codexは、開発フローに応じて複数のUIから利用できます。
以下のチャネルから、自社の開発環境や業務スタイルに合ったものを選んで利用するイメージです。
- Codex App(macOS)
エージェントを起動し、リポジトリ単位・プロジェクト単位で長時間タスクを走らせるためのデスクトップアプリです。
- Codex CLI
ターミナルからプロジェクトを指定し、リファクタリングやマイグレーション、テスト強化などをエージェントと対話しながら進めるためのインターフェースです。
- IDE拡張(VS Code/JetBrainsなど)
既存のIDEの中からCodexエージェントを呼び出し、ファイル編集やdiffの提案、テスト生成などをその場で任せる使い方になります。
- Codex Web
ブラウザベースのUIからCodexエージェントを操作し、リポジトリや環境に対してタスクを投げるための窓口です。
どのチャネルから呼び出しても、裏側では同じGPT-5.3-Codexが動きます。
GPT-5.3-Codexのセキュリティ・コンプライアンス

GPT-5.3-Codexは、サイバーセキュリティ分野で高い能力を持つ一方で、その能力が攻撃側にも悪用されうる"両刃の剣"であることがシステムカードの中でも強調されています。
このセクションでは、その前提とTrusted Access for Cyber(TAC)の位置づけを整理します。
高機能サイバー能力の二面性
サイバー能力は、防御と攻撃の両方に応用できる典型的なデュアルユース技術です。
- ペネトレーションテストやレッドチーミング、脆弱性調査、マルウェア解析は、防御側の強化に不可欠な一方で、攻撃者の手に渡ると実害につながる。
- GPT-5.3-Codexは、こうした高度なサイバータスクを自動化・高速化できるポテンシャルを持つため、その提供方法や利用者の資格に関するガバナンスが重要になる。
OpenAIは、モデル側の安全訓練とプロダクト側のモニタリング・アカウント制御を組み合わせることで、「防御側が使いやすく、攻撃側には使いにくい状態」を目指した設計を取っています。
Trusted Access for Cyber(TAC)の概要
Trusted Access for Cyberは、高リスクなサイバー能力を、防御目的で利用する信頼できる組織に限定して提供するためのプログラムです。
- 参加には身元確認や利用目的の確認が必要で、主に企業のセキュリティチームや信頼できる研究者を対象としている。
- ペネトレーションテスト、レッドチーミング、脆弱性評価、マルウェア解析、暗号研究など、防御・評価目的のユースケースを想定している。
- プログラム参加者であっても、ポリシーに反する利用が検知された場合には警告やアクセス制限の対象となり、悪用を防ぐ仕組みが設けられている。
GPT-5.3-Codexの「Cyber High」レベルの能力をフル活用したい場合は、TAC参加を前提とした上で、社内のセキュリティポリシーと整合する形で利用範囲を設計する必要があります。
企業導入時に確認すべきポイント
企業でGPT-5.3-Codexを導入する際は、次のような観点を事前に整理しておくとよいでしょう。
- どの範囲の環境で、どのレベルの権限を持つタスクをCodexに任せるのか。
- ログ取得や監査の仕組みをどう設計し、誰がレビューするのか。
- TACを利用する場合、対象チーム・対象プロジェクト・許可されたユースケースをどう定義するのか。
モデル単体の安全性だけに依存せず、組織側のプロセスやアクセス制御とセットで運用設計を行うことが前提になります。

GPT-5.2-Codex・GPT-5.2との比較と使い分け

ここでは、GPT-5.3-Codexを既存のGPT-5.2-CodexやGPT-5.2とどう使い分けるかを考えるために、ベンチマークとユースケースの観点から整理します。
主なベンチマークの比較
先ほどのベンチマーク表を踏まえると、GPT-5.3-Codexの特徴は次のようにまとめられます。
- SWE-Bench Pro(Public)では、3モデルの差は比較的小さいが、GPT-5.3-Codexが常にわずかにリードしている。
- Terminal-Bench 2.0とOSWorld-Verifiedでは、GPT-5.3-Codexが大きくスコアを伸ばしており、「実環境でのエージェントタスク」に強い。
- GDPvalやCybersecurity Capture The Flag、SWE-Lancer IC Diamondなどの知識労働・セキュリティ・フリーランス開発タスクでも、GPT-5.3-Codexがトップクラスの精度を示している。
簡単に言えば、「純粋なコード生成の差は限定的だが、長時間タスクとエージェント的な仕事の品質で世代差が出ている」という見方ができます。
プロジェクト規模のコーディングでの使い分け
プロジェクト規模のコーディングタスクでは、次のような切り分けが現実的です。
- 既存リポジトリの構造理解や、複数ファイルにまたがるリファクタリング計画、テスト自動生成などはGPT-5.3-Codexを第一候補にする。
- 小さなユーティリティ関数の実装や、既存コードの一部修正など、スコープが限定されたタスクはGPT-5.2-Codexや他の汎用モデルでも十分対応できる。
- 長時間タスクでは、途中のチェックポイントごとにdiffやサマリを人間がレビューし、「どの程度まで自動化を許容するか」を決める。
このように、タスクのスケールとリスクに応じて、GPT-5.3-Codexへの"任せ方"を変えることが重要です。
知識労働・サイバーセキュリティでの使い分け
知識労働やサイバーセキュリティの観点では、次のような使い分けが考えられます。
- 財務モデルや営業資料、研修テキストなど、Officeファイルとして完結した成果物を作りたい場合はGPT-5.3-Codexを中心に据える。
- 一般的なリサーチや文章生成は、必ずしもCodexである必要はなく、GPT-5.2などの汎用モデルで十分なケースも多い。
- 高度なサイバータスクやレッドチーミングを行う場合は、TACを前提としたGPT-5.3-Codexの利用が想定される。
結果として、「コードとサイバーに強い汎用知的労働モデル」という立ち位置がGPT-5.3-Codexであり、それ以外のタスクは他モデルとのハイブリッド構成を検討するのが現実的です。
GPT-5.3-Codexのユースケース

ここでは、実際の業務フローにGPT-5.3-Codexを組み込んだときのイメージをつかみやすくするために、代表的なユースケースをいくつか挙げます。
ベンチマークのスコアを実務シーンに落とし込んだ形で整理することで、どのような場面でGPT-5.3-Codexの強みが発揮されるかが見えてきます。
大規模リポジトリのリファクタリング・マイグレーション
既存システムの技術的負債を解消したり、新しいアーキテクチャへ移行したりする場面では、GPT-5.3-Codexの「プロジェクト規模のコーディング能力」が活きてきます。
以下のような活用パターンが考えられます。
- モノリスからマイクロサービスへの移行計画を立て、段階的な分割案とテスト戦略を提案してもらう。
- 古いフレームワークから新しいフレームワークへの移行に際して、API互換性やデプロイ手順を含めた移行手順書を生成してもらう。
- SWE-Bench Proに近い形で、既存バグレポートを入力し、修正方針とパッチ候補を複数案出してもらう。
これらの活用により、通常であれば数週間から数ヶ月かかるリファクタリングやマイグレーションの初期設計フェーズを大幅に短縮でき、エンジニアは最終的な品質チェックと意思決定に集中できるようになります。
セキュリティ診断・脆弱性調査の支援
GPT-5.3-Codexは、Cybersecurity CTFで高いスコアを記録しており、防御的なサイバーセキュリティタスクでの活用が期待されています。
Trusted Access for Cyberの枠組みを前提として、以下のような診断・調査業務を支援できます。
- TACの枠内で、Webアプリケーションやインフラのペネトレーションテストを行い、発見された脆弱性の概要・再現手順・推奨対策をレポート化してもらう。
- 既存のログやアラートを入力し、インシデントのストーリーラインや根本原因候補を整理してもらう。
- マルウェアサンプルの挙動分析やデオブフスケーションを支援してもらい、防御側のシグネチャ作成や検知ロジック設計に活用する。
セキュリティチームの人手不足が深刻化する中、GPT-5.3-Codexによる診断業務の自動化・高速化は、脅威への対応スピードを大きく改善する可能性があります。
ただし、悪用リスクを考慮し、TACへの参加や社内ガバナンスの整備が前提となる点には注意が必要です。
財務・経営企画・営業資料作成の効率化
GPT-5.3-Codexは、コーディングだけでなく知識労働タスクにも対応しており、Excel・PowerPoint・Wordといったビジネス文書の生成が可能です。
以下のような業務フローでの活用が想定されます。
- 投資案件や新規事業のシナリオ分析において、NPVやIRR計算を含む財務モデルをExcelで生成してもらう。
- その結果を踏まえた経営会議向けスライドや営業向け説明資料をPowerPointで自動生成し、人間側で最後のチューニングを行う。
- 社内研修や営業トレーニング用のテキストをWordで生成し、表やチェックリストを含めてドキュメント化してもらう。
これらの活用により、財務・企画・営業部門が「資料作成に追われる時間」を削減し、戦略立案やクライアントとの対話により多くの時間を割けるようになります。
特に、計算ロジックとプレゼンテーション資料を一気通貫で生成できる点は、従来のAIツールにはない大きな強みです。
GPT-5.3-CodexのFAQ

最後に、GPT-5.3-Codexを検討する際によく浮かびがちな疑問を簡単に整理します。
GPT-5.3-CodexはGPT-5.3と何が違いますか?
GPT-5.3は汎用のフロンティアモデルであり、チャット・推論・生成タスク全般を対象としたモデルです。一方、GPT-5.3-Codexはソフトウェア開発とサイバーセキュリティ、知識労働タスクに特化してチューニングされており、ターミナル操作やOS操作、長時間タスクの計画・遂行に強みがあります。
日本語のコードベースやドキュメントでも使えますか?
公開されている情報の多くは英語ベースですが、前世代モデル時点で多言語対応が進んでいたこともあり、日本語を含む多言語環境でも実用的な性能が期待できます。とはいえ、日本固有の制度や商習慣が絡むタスクでは、プロンプト設計と人間によるレビューが不可欠です。
すでにGPT-5.2-Codexを使っていますが、乗り換えるべきですか?
長時間のリポジトリ操作やOS操作、セキュリティ診断など、「エージェントとしての行動」が多いワークロードでは、GPT-5.3-Codexに切り替えるメリットが大きいと考えられます。一方、短時間のコード補完や軽量なQ&Aが中心であれば、既存のGPT-5.2-Codexでも十分な場合があります。実際には、両者を並行してABテストし、自社ワークロードでの差分を確認するのが確実です。
セキュリティポリシーや規制との整合性はどう考えればよいですか?
GPT-5.3-Codex自体には多層的な安全策が組み込まれていますが、自社のセキュリティポリシーや法令順守を自動的に保証してくれるわけではありません。
扱うデータの機密性、ログの取り扱い、アクセス権限の設計などは、別途組織側でポリシーとプロセスを定義する必要があります。TACを利用するかどうかも含めて、情報セキュリティ部門と連携して設計することが前提になります。

AIコーディングモデルの知見を業務全体のAI化に活かす
GPT-5.3-Codexの性能やチャネル選定を評価できる力は、開発業務だけでなく組織全体のAI戦略設計にも活かせます。コーディング自動化の成果を土台に、ドキュメント処理やデータ分析など他の業務領域への展開を検討する企業が増えています。
AI総合研究所では、コーディング支援を含むAI業務活用の全体像を220ページにまとめた「AI業務自動化ガイド」を無料で提供しています。開発チームの生産性向上を起点に、組織全体のAI化を推進するための実践資料としてご活用ください。
AIコーディングモデルの知見を業務全体のAI化に活かす

AI業務自動化ガイド
GPT-5.3-Codexのようなフロンティアモデルの評価力は、開発チームだけでなく組織全体のAI戦略にも直結します。AI総合研究所のAI業務自動化ガイドでは、Microsoft環境でのビジネスプロセスの自動化を中心に、AI導入の全体像を220ページで体系化しています。
GPT-5.3-Codexのまとめ
GPT-5.3-Codexは、GPT-5.2-Codexの後継として、ソフトウェア開発・サイバーセキュリティ・知識労働の3領域を同時にカバーするフロンティアコーディングモデルです。SWE-Bench Pro、Terminal-Bench 2.0、OSWorld-Verified、Cybersecurity CTF、SWE-Lancerなどのベンチマークで高いスコアを記録しており、単なるコード生成ではなく「長時間タスクを完遂するエージェント」としての性能が強化されています。
料金面では、ChatGPTの各種プランやCodex CLI・APIから利用でき、コストはシート単価やトークン消費量に応じて決まります。すべてをGPT-5.3-Codexに寄せるのではなく、軽量なタスクは他モデルに任せつつ、プロジェクト規模の開発やセキュリティ診断、財務・営業資料の作成といった"人の時間が重い仕事"に集中して使う設計が現実的です。
また、Trusted Access for Cyberを含む多層的な安全策によって、高度なサイバー能力を防御目的で利用しやすくする一方、悪用リスクを抑えるためのガバナンスも整備されています。
今後は、単一モデルの性能だけを見るのではなく、Codexや他モデル、社内のエージェント基盤を組み合わせた全体設計の中で、「GPT-5.3-Codexにどの役割を担わせるか」を検討することが重要になります。まずは限定的なユースケースからPoCを行い、自社のコードベースと業務フローに対してどの程度"人の時間を浮かせてくれるか"を確かめていくのが現実的なアプローチです。










