この記事のポイント
 GLM-5.2は1Mトークン文脈・MITオープンウェイト公開予定の大規模MoEモデルで、DeepSeek V4・Kimi K2.6と並んで本記事で比較する代表3モデルのひとつ
GLM-5.2は1Mトークン文脈・MITオープンウェイト公開予定の大規模MoEモデルで、DeepSeek V4・Kimi K2.6と並んで本記事で比較する代表3モデルのひとつ- アーキテクチャはGLM-5.1譲りのMoEだが、文脈長が200K→1Mに5倍拡張・Maxモード新設で長時間エージェント実行の安定性が向上
- 公式ベンチマークは2026年6月16-17日にZ.aiが追加公開し、SWE-Bench Pro 62.1・Terminal-Bench 2.1 81.0で、GPT-5.5を上回りClaude Opus 4.8(85.0)に肉薄する水準
- 利用はGLM Coding Plan(標準Lite $18・Pro $72・Max $160/旧プラン移行対象には50%支援価格$9〜$80)が即日対応、Claude Code・Cline・OpenCodeなど主要なエージェントツールに接続できる
- 日本企業の現実解は「主力は既存商用モデル、長文・コード一括レビューはGLM-5.2」の併用が出発点

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
GLM-5.2(ジーエルエム ゴーテンニ)は、中国のZhipu AIが2026年6月13日に発表した、コーディングとエージェント用途に特化した大規模言語モデルです。MITライセンスでのオープンウェイト公開は翌週予定で、発表時点ではGLM Coding Plan経由で先行利用できます。
1,000,000トークン(1M)の文脈・MoEアーキテクチャ・MITライセンスでのオープンウェイト公開予定という3点で、現行のオープンモデル群のなかでも最上位帯に位置すると見られます。
主要なエージェントコーディングツール8本にリリース初日から対応しており、既存のAI開発ワークフローを止めずに切り替えられる点も特徴です。
本記事では、GLM-5.2の技術仕様・性能評価の現状・料金体系・Claude Code等のクライアントからの使い方・DeepSeek V4やKimi K2.6との位置づけ・日本企業がどう扱うべきかまでを、2026年6月時点の最新情報で体系的に解説します。
GLM-5.2とは?Zhipu AIの1Mコンテキスト・オープンモデル
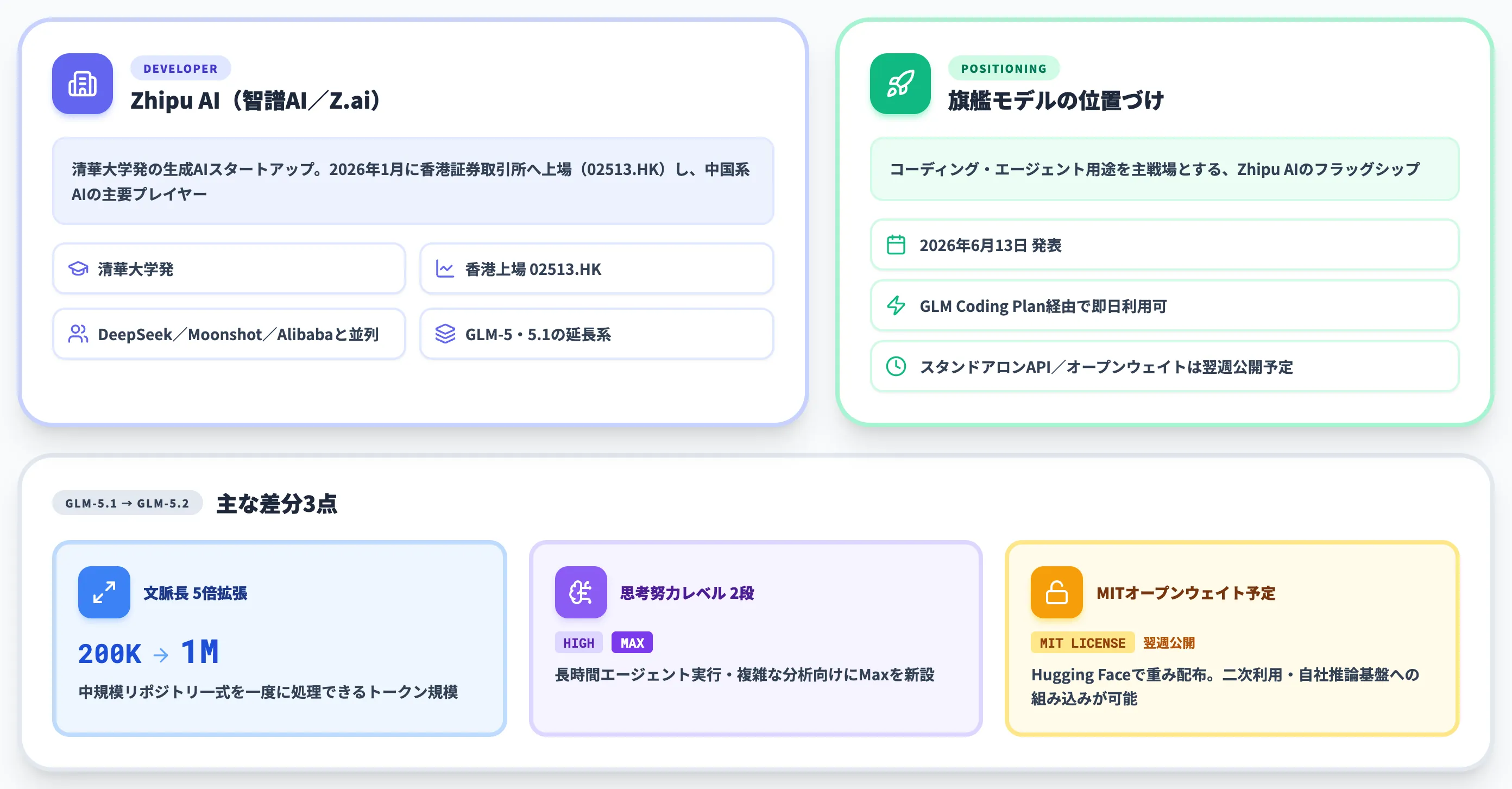
GLM-5.2は、中国のZhipu AI(智譜AI/商用ブランドは「Z.ai」)が2026年6月13日に発表した、コーディング・エージェント用途を主戦場とするフラッグシップの大規模言語モデルです。
Zhipu AIは清華大学発のスタートアップで、2026年1月に香港証券取引所へ上場(02513.HK)し、中国国内ではDeepSeek・Moonshot(Kimi)・Alibaba(Qwen)と並ぶ生成AIの主要プレイヤーです。
GLMは「General Language Model」の略で、GLM-5・GLM-5.1の延長線上に位置するのが今回のGLM-5.2にあたります。
GLM-5.1からGLM-5.2への主な変更点は次の表のとおりです。
| 項目 | GLM-5.1 | GLM-5.2 |
|---|---|---|
| 文脈長 | 200,000トークン | 1,000,000トークン(5倍) |
| 出力上限 | 128,000トークン | 131,072トークン |
| 思考努力レベル | 単一 | High / Max の2段階 |
| アーキテクチャ | MoE 754B(公式モデルカード) | MoE(報道ベースで754B規模・公式モデルカードの公開待ち) |
| ライセンス | MIT | MIT(オープンウェイト公開予定) |
| 提供形態 | GLM Coding Plan + API | GLM Coding Plan(即日)+ API・オープンウェイト(翌週予定) |
5.1から5.2にかけての最大の差は、実用可能な文脈長が200Kから1Mに5倍拡張された点と、思考努力レベル「High / Max」の2段階構成が導入された点です。ポストトレーニング工程の改善により、長文タスク・エージェント実行・コーディングの安定性が引き上げられたと各種報道では伝えられています。
APIやエージ ェントツールから呼び出す際のモデル名は「glm-5.2」が基本で、Claude Code等のAnthropic互換ツールでは1Mコンテキスト版を示すサフィックス「[1m]」を付ける案内も出ています。ツールごとの正確な指定方法はZ.ai公式ドキュメントを確認してください。

GLM-5.2の技術仕様
ここからは、GLM-5.2の技術構成を整理します。
MITライセンスでのオープンウェイト公開が予定されており、公開後はHugging Face等で重みを取得して、ファインチューニングや自社推論基盤への組み込みも検討できます。
MoEアーキテクチャ
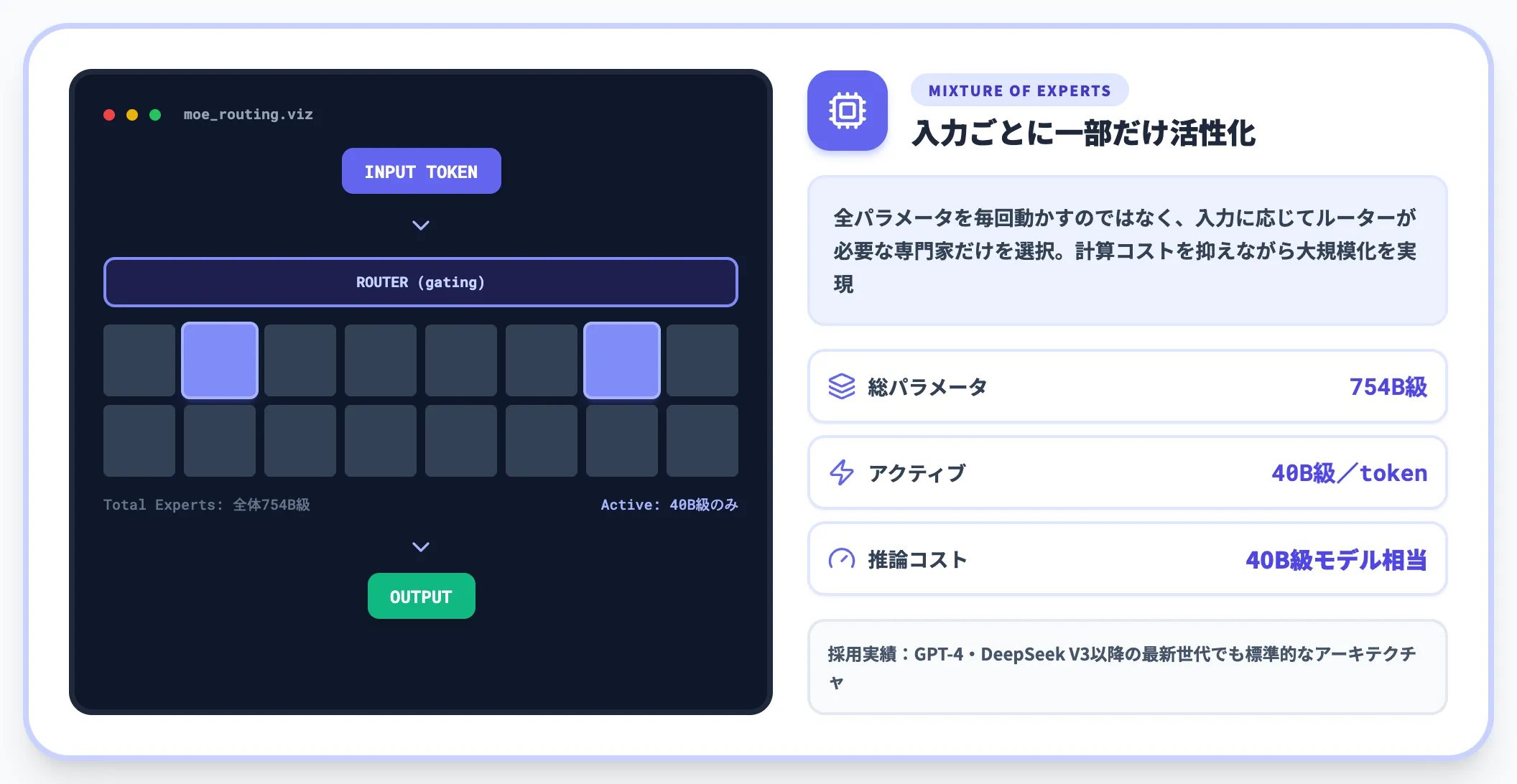
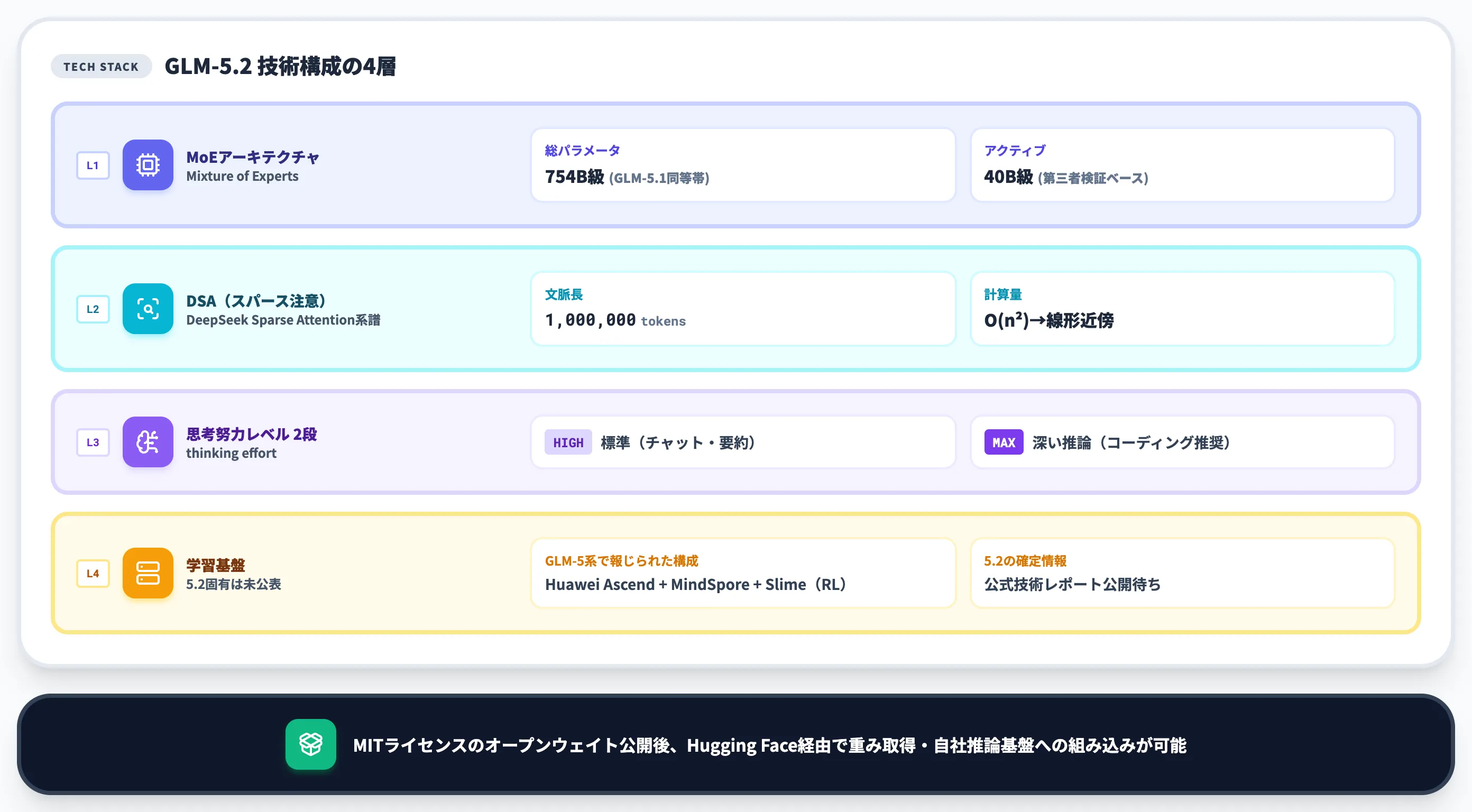
GLM-5.2は、MoE(Mixture of Experts、混合専門家)アーキテクチャを採用しています。
MoEとは、推論時にすべてのパラメータを動かすのではなく、入力に応じて一部の専門家パラメータだけを活性化することで、計算コストを抑えながら大規模化を実現する設計です。GPT-4・DeepSeek V3以降の最新モデルでも広く採用されています。
公式モデルカードはオープンウェイト公開時に併せて開示される予定で、現時点で確認できる範囲の構成は以下のとおりです。
-
総パラメータ数
GLM-5.1の公式モデルカードで確認できる754Bと同等帯と各種報道で伝えられている
-
アクティブパラメータ数(トークンあたり)
40B級と複数の第三者検証記事で報告(オープンウェイト公開後の追試で確定)
-
トレーニング基盤
GLM-5.2固有の情報は未公表。GLM-5系ではHuawei Ascend + MindSpore等の中国製スタックが報じられているが、5.2の確定情報はモデルカード公開待ち
総パラメータが750B規模であれば、現行のオープンソースモデルでも最大級です。アクティブが40B程度に抑えられているMoE構成であれば、推論コストはトークンあたり40B級のモデルと近い水準で済むことになります。具体的な総パラメータ数・エキスパート数は、公式モデルカードの公開を待って確定的に扱うのが安全です。
参考までに、前世代のGLM-5.1の公式モデルカードはHugging Face上で公開されており、総パラメータ754B・MITライセンス・glm_moe_dsa アーキテクチャタグといった情報が確認できます。
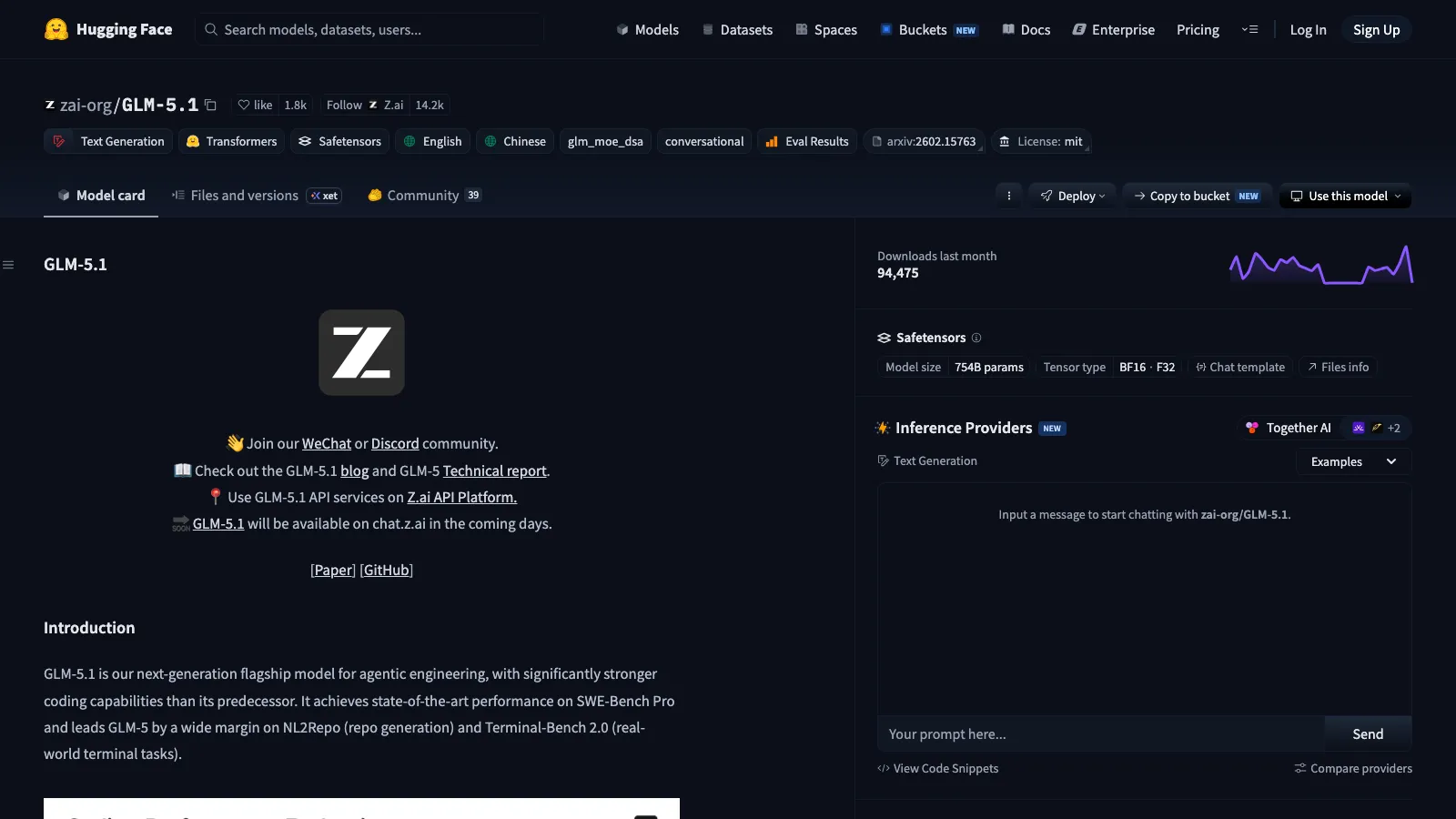
GLM-5.1の公式モデルカード。総パラメータ754B、MITライセンス、glm_moe_dsa アーキテクチャタグが確認できる。GLM-5.2は同シリーズの後継として、MITライセンスでのオープンウェイト公開が予定されている(出典:Hugging Face zai-org/GLM-5.1)
1Mコンテキストを支えるDSA

GLM-5.2の1Mコンテキストを実用速度で支えていると見られるのが、**DeepSeek Sparse Attention(DSA)**と呼ばれるアテンション機構です。GLM-5系では論文等でDSAの採用が報告されており、5.2もこの系譜上の最適化を継承していると見られます(5.2固有の論文・モデルカードは公開待ち)。
通常の密注意(dense attention)は文脈長に対して計算量が二次関数的(O(n²))に増えるため、100万トークン規模では実用にならない計算コストになります。
この系譜上のスパース注意最適化により、GLM-5.2は100万トークン入力を実用速度で扱う設計とされています。100万トークンはおおむね中規模リポジトリのソースコード一式・設定・テストを丸ごと載せられる規模で、エージェントが長時間にわたって複数ファイルを横断する用途に向きます。
思考努力レベルの2段階構成
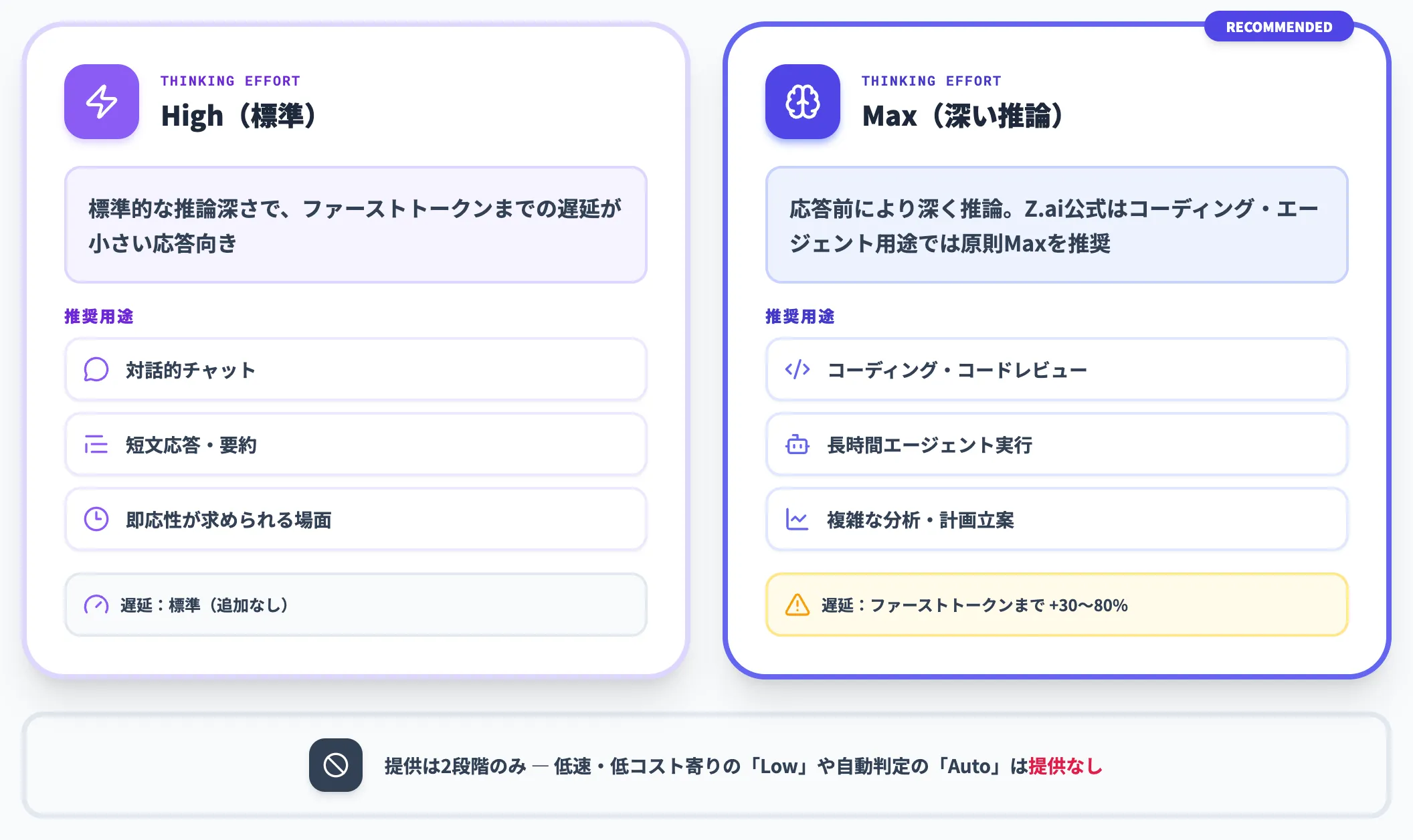
GLM-5.2では、新たに**思考努力レベル(thinking effort)**という概念が導入されました。
これはモデルが応答前に内部で行う推論時間の深さを制御する設定で、「High」と「Max」の2段階が用意されています。低速・低コスト寄りの「Low」や自動判定の「Auto」は提供されていません。
| レベル | 推論時間 | 推奨用途 |
|---|---|---|
| High | 標準的な深さ | チャット・短文応答・要約 |
| Max | より深い推論 | コーディング・長期エージェント実行・複雑な分析 |
Z.aiの公式ガイダンスは「コーディング・エージェント用途では原則Maxを推奨」としています。Maxを使うとファーストトークンまでの遅延が30〜80%増えると第三者の検証記事で報告されていますが、対話的なIDE統合よりも、長時間バッチ実行の安定性を優先する設計です。
学習基盤は未公表
GLM-5.2固有の技術レポート・モデルカードは執筆時点(2026年6月)でまだ公開されておらず、学習基盤の確定情報は出ていません。
GLM-5系ではHuawei社のAI専用プロセッサ「Ascend」(昇騰)と、深層学習フレームワーク「MindSpore」を組み合わせた中国製チップ向けの推論対応・最適化が報じられています。強化学習側ではZhipu独自の「Slime」と呼ばれる非同期RLフレームワークの利用も確認されており、GLM-5.2もこの系譜上の最適化を引き継ぐ可能性は高いと見られます。
ただし「GLM-5.2自体がHuawei Ascendで学習されたか」「NVIDIA GPUを使っていないか」までは公開情報で確認できる範囲ではなく、確定的に扱うのは公式技術レポートの公開を待つのが安全です。中国系AI開発企業全体としては「自前スタックの整備」が進む傾向にあり、その文脈の一例として位置づけられます。
GLM-5.2の性能とベンチマーク

GLM-5.2の性能評価は、リリース時点ではやや特殊な状況にあります。
このセクションでは、公式が公表したこと・公表していないこと・GLM-5.1の実績・第三者の評価を分けて整理します。
公式ベンチマーク数値(リリース直後は未公表、6月16-17日に追加公開)

GLM-5.2のリリース時点(2026年6月13日)では、通常フラッグシップモデルで公表されるSWE-bench Verified・LiveCodeBench・AIDER Polyglot・HumanEval等の主要ベンチマークスコアが一切公表されませんでした。
Coderseraの検証記事は「No SWE-bench Verified, no LiveCodeBench, no HumanEval, no AIDER polyglot scores exist for 5.2 itself.」と直接的に書いており、リリース直後の48時間は公式数値による直接評価ができない状態が続きました。
代わりにZhipu AIが示したのは、「925行のSVGベース機械式時計の生成」「Three.js + Cannon.jsを用いた3Dペナルティキックゲームの構築」といった、実演デモを軸にした能力アピールでした。
その後2026年6月16-17日にZ.ai公式が長時間コーディング系ベンチマークの結果を追加公開し、状況が変化しています。
| ベンチマーク | GLM-5.2 | 比較・位置づけ |
|---|---|---|
| SWE-Bench Pro | 62.1 | GLM-5.1(58.4)から+3.7、GPT-5.5(58.6)を明確に上回る |
| Terminal-Bench 2.1 | 81.0 | Claude Opus 4.8(85.0)に約4点差、Gemini 3.1 Proを上回りオープンモデル最高クラス |
| FrontierSWE | Opus 4.8の約1%下 | GPT-5.5を上回る |
| PostTrainBench | トップランキング | GPT-5.5・Claude Opus 4.7を上回る |
| SWE-Marathon | オープンソース最高水準 | 全モデル中3位圏 |
SWE-Bench Proの62.1は前世代5.1(58.4)から+3.7ポイントの改善で、同世代商用フロンティアのGPT-5.5(58.6)も明確に上回る数値です。Terminal-Bench 2.1の81.0は閉源最高峰のClaude Opus 4.8(85.0)に4点差まで肉薄しており、オープンウェイトモデルとして突出した位置にあります。「長時間エージェント実行・ターミナル操作・コードの一括レビュー」というGLM-5.2が主戦場に置く用途では、商用フロンティアと並ぶか僅差まで詰めた水準まで来た、と読めます。
ただしSWE-bench Verified・LiveCodeBench・AIDER Polyglot・HumanEvalといった汎用コーディング系の標準ベンチマークは依然として未公表で、独立追試が出揃うまでは公開済みベンチの解釈にも幅を持たせる必要があります(出典:Z.ai公式ブログ・VentureBeat報道・GIGAZINE 2026/6/17)。
系譜上の参考値となるGLM-5.1ベンチマーク
GLM-5.2はGLM-5.1の改良版なので、5.1のベンチマークは「系譜上の参考値」として読めます(最低保証ではない点に注意)。GLM-5.1の主要スコアは以下の表のとおりです。
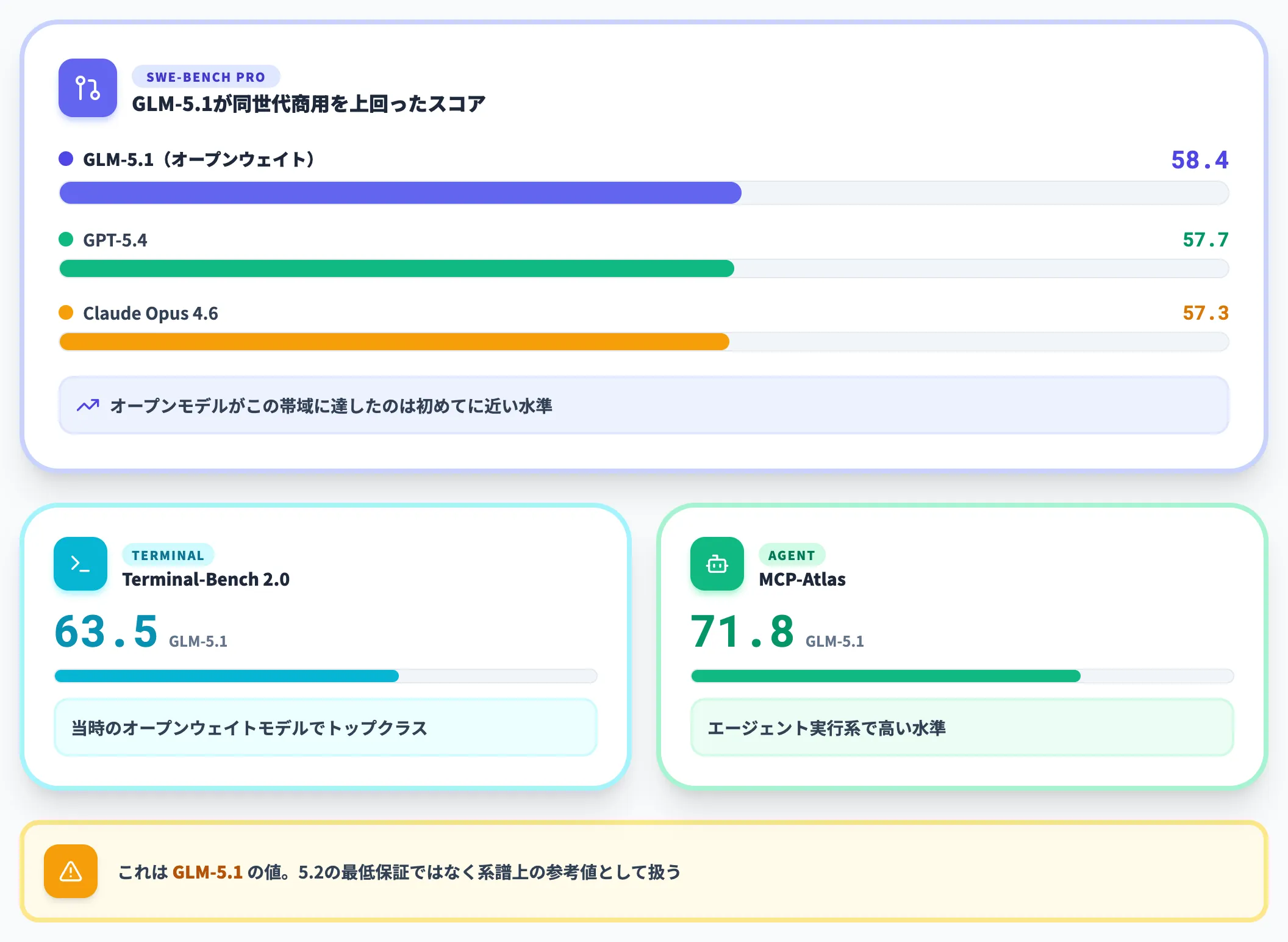
| ベンチマーク | GLM-5.1 | 比較 |
|---|---|---|
| SWE-Bench Pro | 58.4 | GPT-5.4 57.7・Claude Opus 4.6 57.3を上回る |
| Terminal-Bench 2.0 | 63.5 | 当時のオープンウェイトモデルでトップクラス |
| MCP-Atlas | 71.8 | エージェント実行系で高い水準 |
SWE-Bench Proで58.4というスコアは、リリース時点の同世代商用モデル(GPT-5.4・Claude Opus 4.6)をわずかながら上回る数値です。あくまでZhipu AI公表の自社測定値ではありますが、オープンモデルがこの帯域に達したのはGLM-5.1が初めてに近い水準でした。
GLM-5.2では文脈長と推論深度(Max)が伸びているため、SWE-bench Pro・LiveCodeBenchで上振れする可能性が指摘されてきました。前述の通り、追加公開された公式SWE-Bench Proは62.1(5.1比+3.7)と実際に上振れしており、長時間エージェント系(Terminal-Bench 2.1・SWE-Marathon)でも顕著な改善が確認されています。一方でLiveCodeBenchやAIDER Polyglot等の汎用コーディング系は依然として未公表のため、5.1の値も「最低保証」ではなく系譜上の参考値として扱うのが安全です。
第三者ハンズオンが示した実用評価
公式の長時間コーディング系ベンチは公開された一方で、SWE-bench Verified・LiveCodeBench・AIDER Polyglot等の汎用標準ベンチは依然として未出揃いです。リリース後48時間以内には第三者の実用評価やコミュニティ独自ベンチ(例: llm2014/llm_benchmark のコードベンチCSVに GLM-5.2(max) 行が掲載)も公開され始めています。公式ベンチが当たる「長時間コード一括処理」とは別軸で、日常的なコーディング体感がどう動くかを示す情報なので、両方を見て判断するのが安全です。代表的な所感を整理します。
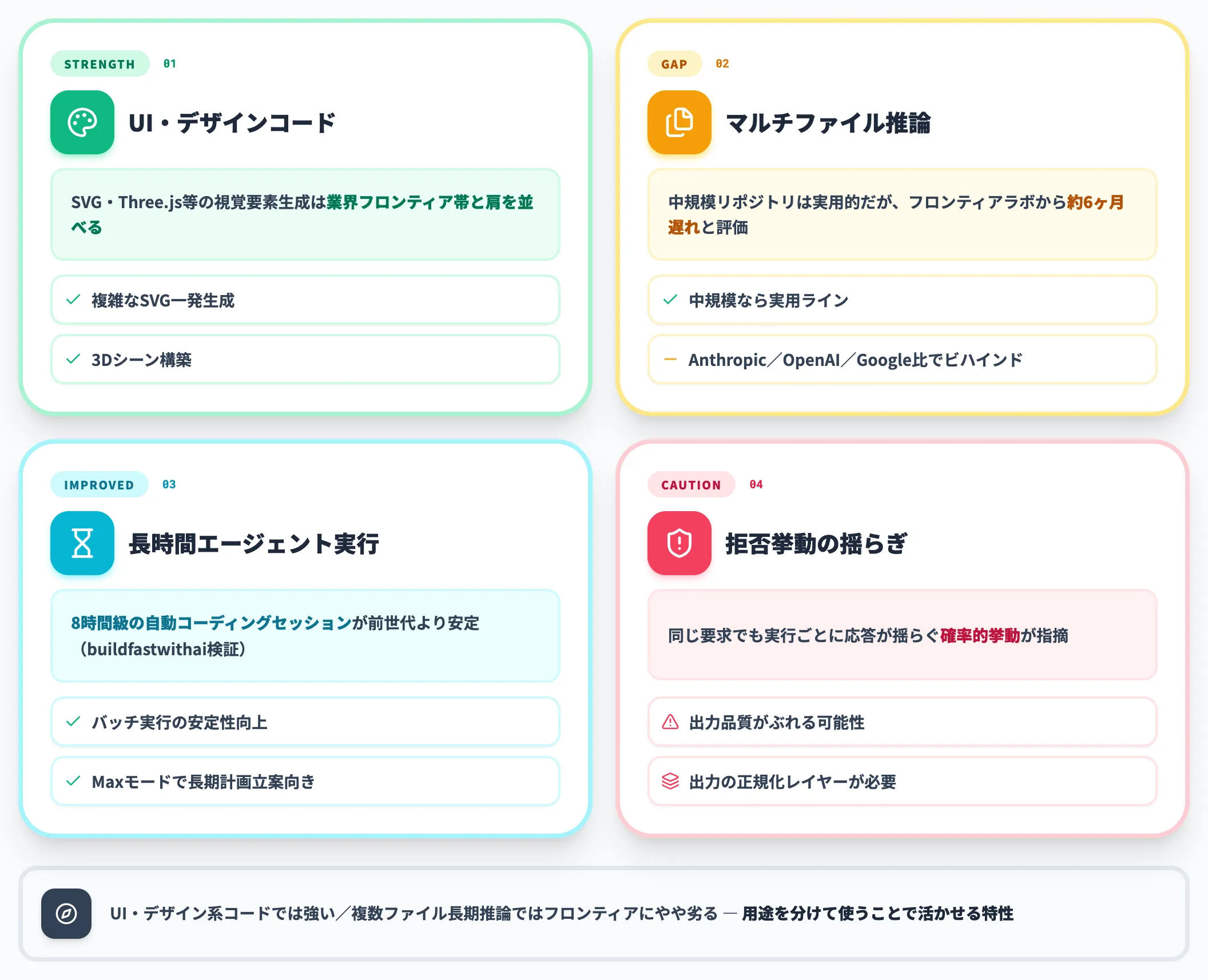
-
UI・デザインコード生成
SVG・Three.js等の視覚要素生成は「業界フロンティア帯と肩を並べる」レベル
-
マルチファイル推論
中規模リポジトリ規模では実用的だが、フロンティアラボ(Anthropic・OpenAI・Google)には「約6ヶ月遅れ」と評する開発者ランキングあり
-
長時間エージェント実行
「8時間級の自動コーディングセッション」が前世代より安定したとbuildfastwithaiの検証記事は報告
-
拒否挙動
同じ要求でも実行ごとに応答が揺らぐ確率的挙動が指摘されており、エンタープライズ用途では出力の正規化レイヤーが必要
実用評価では「UI・デザイン系コードでは強い」「複数ファイルにまたがる長期推論ではフロンティアにやや劣る」というベクトルが見えます。これは公式ベンチを待たずとも、用途を分けて使うことで活かせる特性です。
第三者集計サイトでの予想ポジション
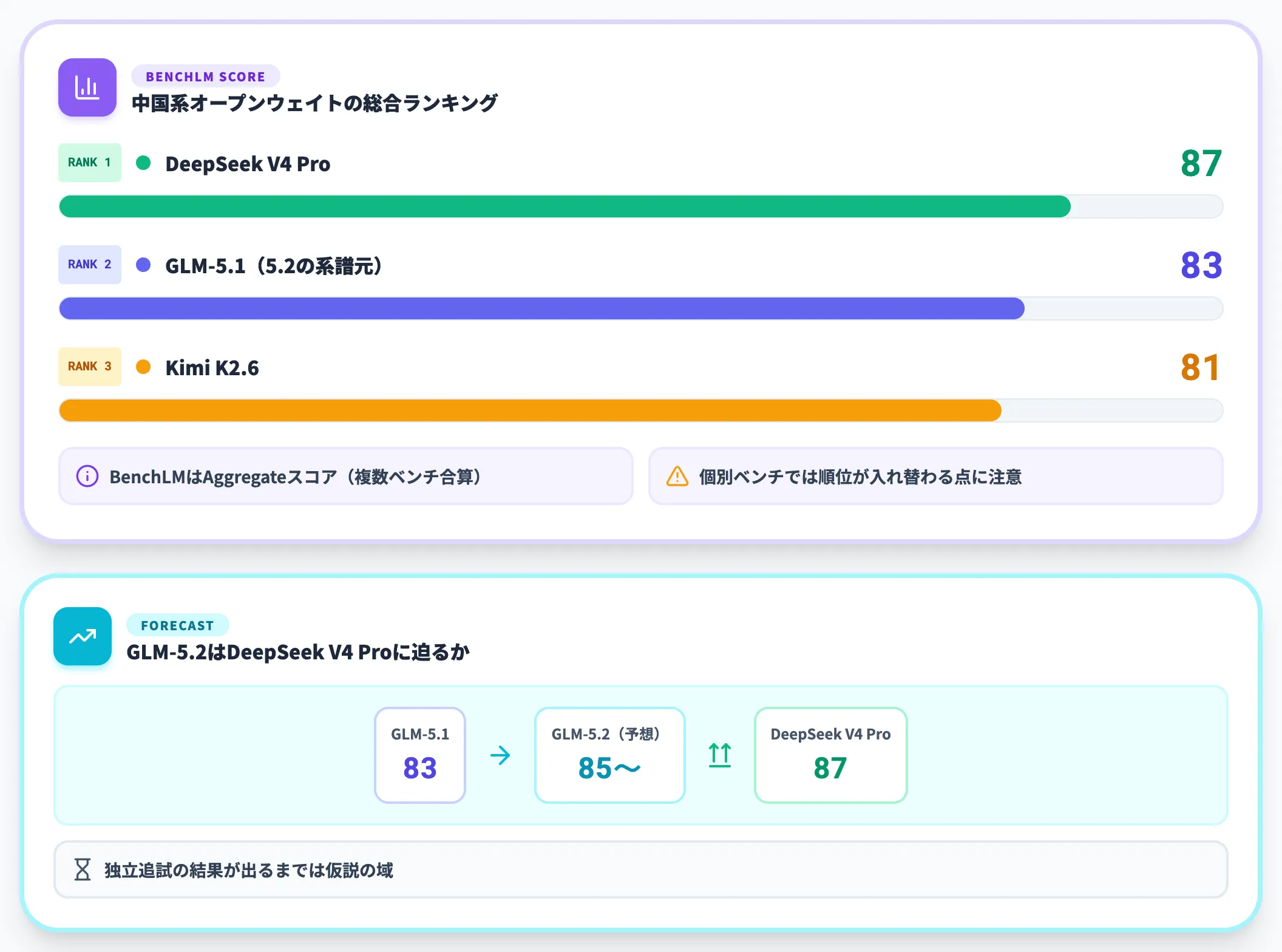
第三者集計サイトBenchLM.aiは、中国系オープンウェイトモデルの総合スコアを公開しています。執筆時点でのGLM-5.1と主要競合の参考スコアは次のとおりです(BenchLM scoreベース)。
| モデル | BenchLM score |
|---|---|
| DeepSeek V4 Pro | 87 |
| GLM-5.1 | 83 |
| Kimi K2.6 | 81 |
BenchLMはAggregateスコアであり、ベンチマークごとに順位が入れ替わる点には注意が必要です。GLM-5.1から5.2への改善幅次第で、こうした集計指標でもDeepSeek V4 Proに迫る可能性はありますが、独立追試が出るまでは仮説の域を出ません。
公式の長時間コーディング系ベンチは出揃ったものの、汎用標準ベンチ(SWE-bench Verified・LiveCodeBench・HumanEval等)と第三者独立追試はまだ揃っていない段階です。実務的なスタンスとしては、「公開済みの公式ベンチ(SWE-Bench Pro 62.1・Terminal-Bench 2.1 81.0)でフロンティア帯に手が届く実力は確認しつつ、未公表系のベンチ・GLM-5.1の系譜上参考値・第三者ハンズオン情報を組み合わせて、1MコンテキストとMaxモードの効き具合を自社ユースケースで実測する」というのが現実的です。

代表的なオープンウェイトLLMとの比較
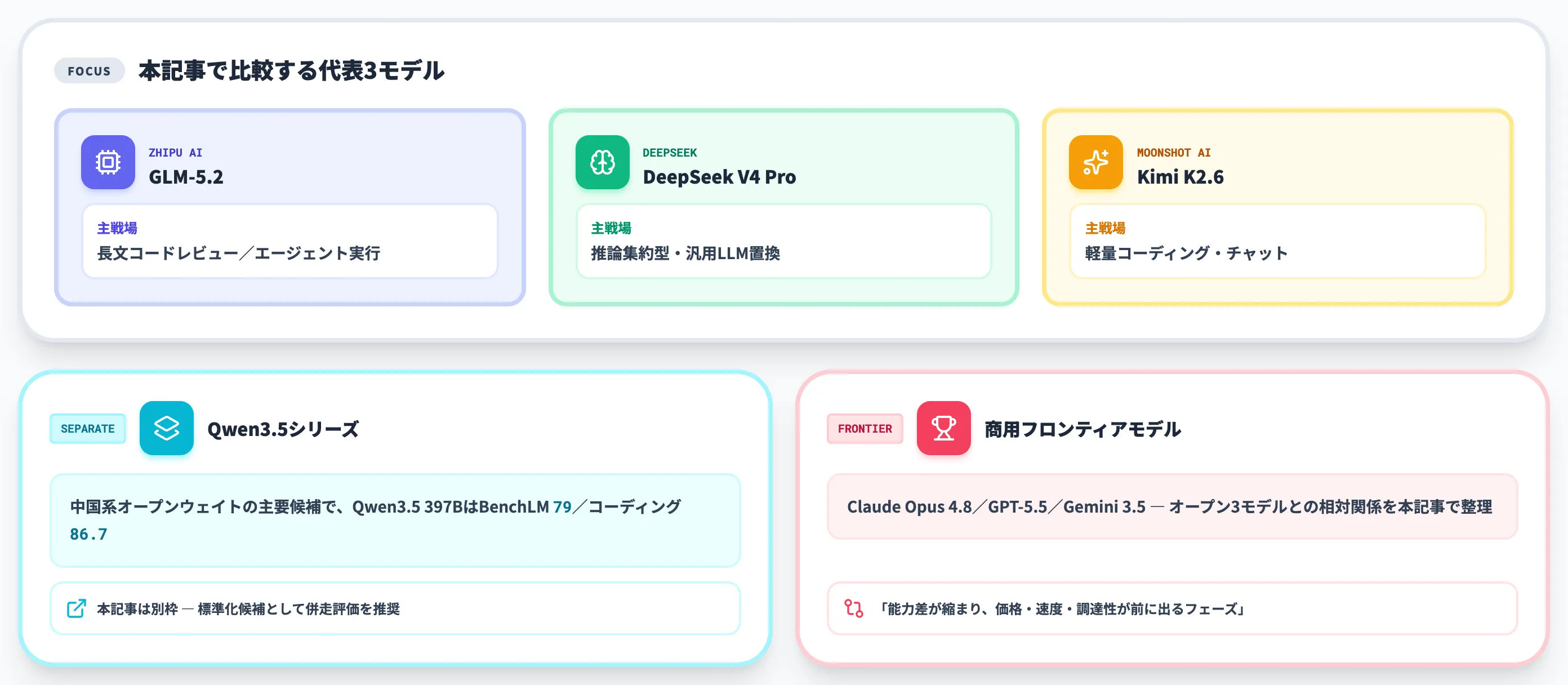
2026年6月時点で、企業が「標準化するオープンウェイトLLM」を検討する際に挙がる代表的な候補のうち、本記事ではDeepSeek V4(V4-Pro / V4-Flash)・Kimi K2(K2.6・K2.7)・GLM-5.2の3モデルに絞って比較します(GLM-5.2のオープンウェイトは2026年6月時点で公開予定)。
Alibaba Qwen3.5系も上位候補として注目されますが、別セクションで扱います。
比較対象3モデルの特徴比較

3モデルの設計思想と得意領域は以下の表で整理しました。
| モデル | 開発元 | 強み | 想定主用途 |
|---|---|---|---|
| GLM-5.2 | Zhipu AI | 1Mコンテキスト、コーディング特化、MITオープンウェイト公開予定、主要エージェントツールに即日対応 | 長文コードレビュー・エージェント実行 |
| DeepSeek V4 Pro | DeepSeek | 総合性能・推論・コスト効率 | 推論集約型タスク・汎用LLM置換 |
| Kimi K2.6 | Moonshot AI | コーディング・価格性能比 | 軽量コーディング・チャット主用途 |
「コーディング能力」では3モデルとも商用フロンティアに迫る水準ですが、得意領域が分かれています。
GLM-5.2の特徴的な強みは「1Mコンテキスト」と「Claude Code・Cline等の主要エージェントツールへの即日対応」の2点です。長いソースコードを一度に処理させたい・既存のAIコーディングワークフローを止めずに乗せ替えたい、というケースで他2モデルより有利になります。
コーディング性能の相対位置
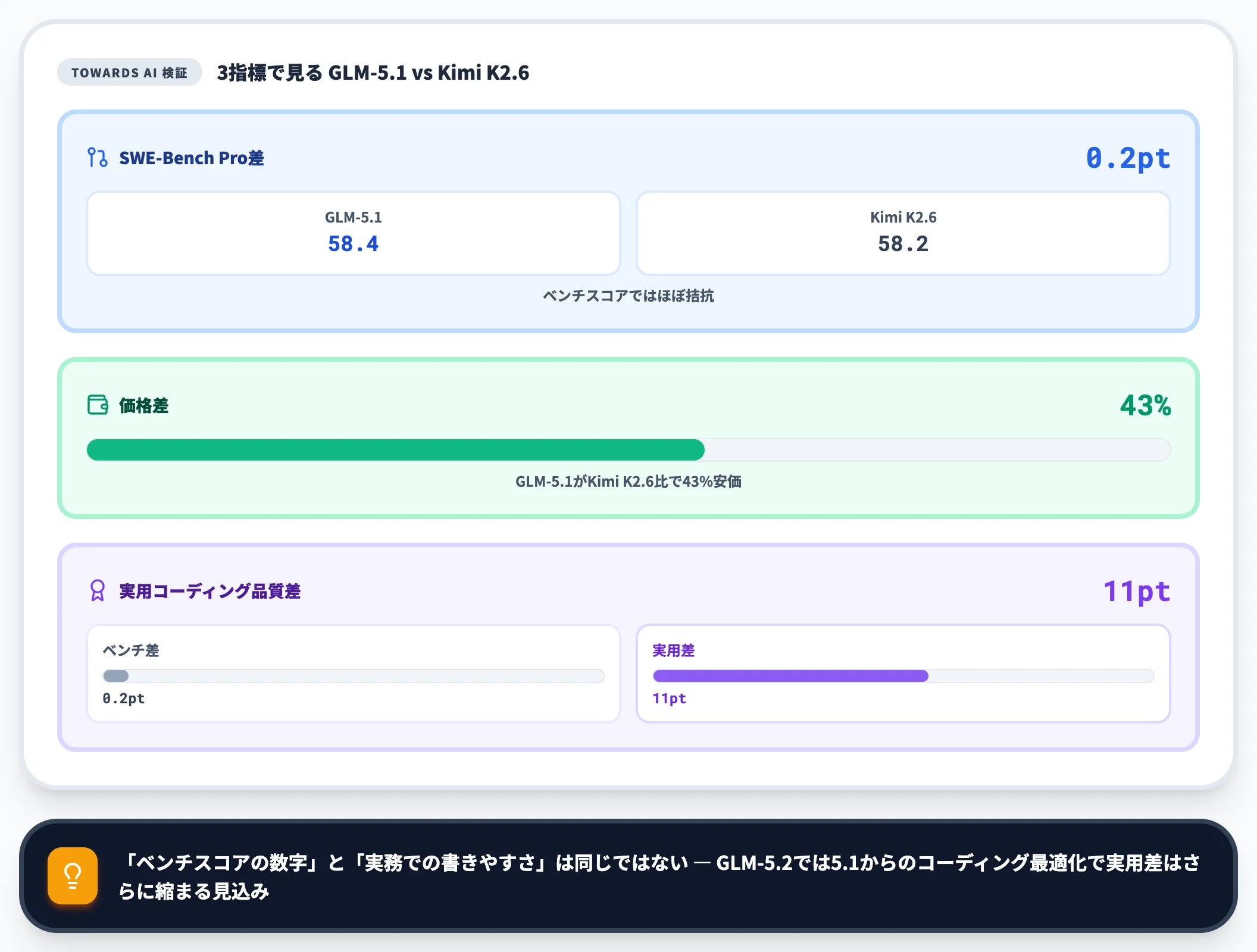
Towards AIの実機検証によれば、GLM-5.1とKimi K2.6のSWE-Bench Pro差はわずか0.2ポイント(5.1: 58.4 vs K2.6: 58.2)で、価格差は43%・実用コーディング品質では11ポイント差がついたと報告されています。
つまり「ベンチスコアの数字」と「実務での書きやすさ」は同じではありません。
GLM-5.2では2026年6月16-17日にZ.aiが公式SWE-Bench Pro 62.1(5.1の58.4から+3.7)を追加公開しており、ベンチ上はK2.6(58.2)に対して約4ポイント差をつけた形になります。実用品質差は5.1時点で既に11ポイントあったため、5.2では数値・実用ともにK2.6に対する優位が拡大する方向です。一方で「総合推論」「数学的推論」ではDeepSeek V4 Proが優位な領域が残っており、要件次第で使い分けが必要です。
なお、Moonshotは2026年にKimi K2.7 CodeというK2.6後継のコード特化モデルを公開しており、最新のコーディング比較では本記事のK2.6スコアではなくK2.7 Codeの値も確認しておく必要があります。
商用フロンティアモデルとの相対位置
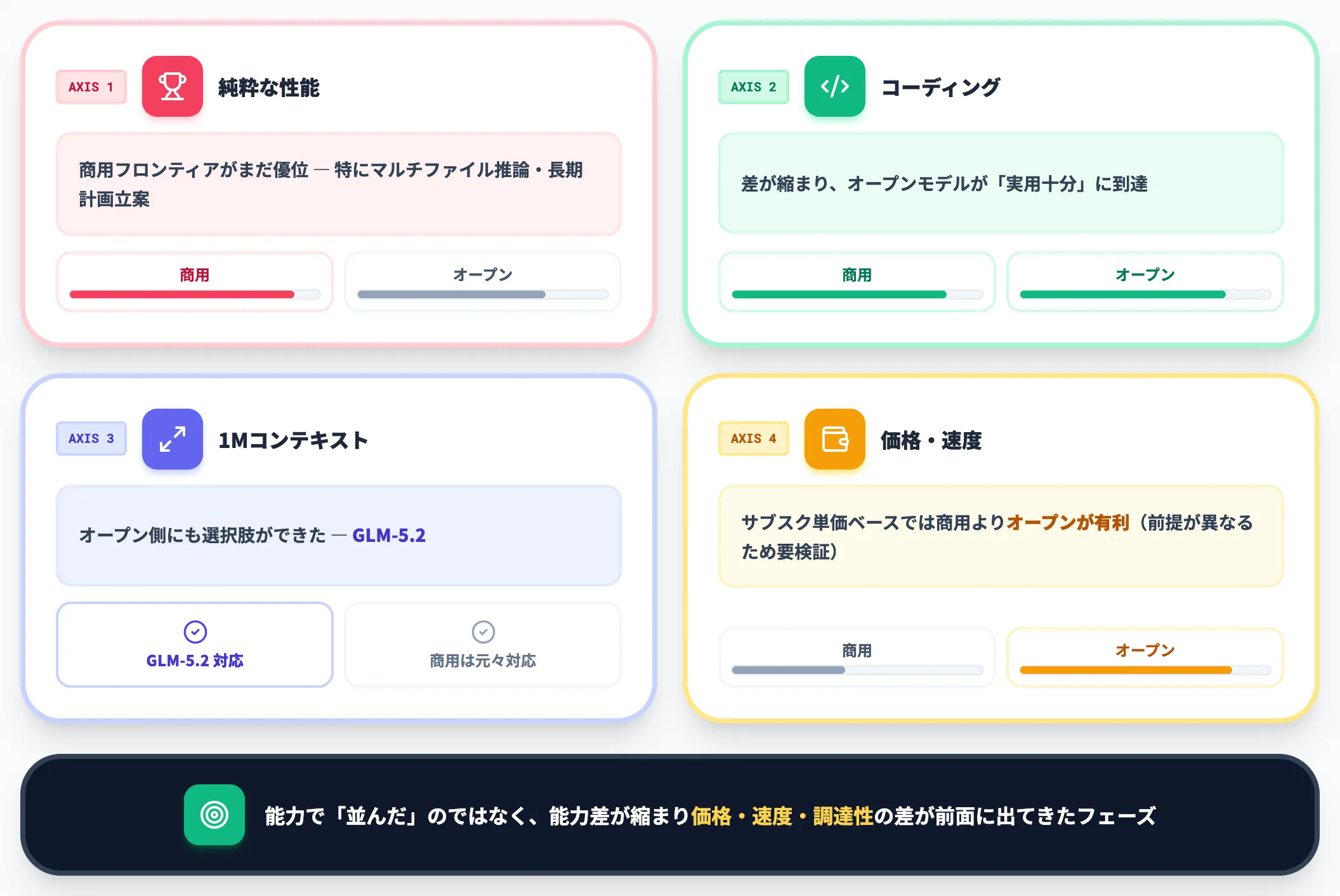
本記事で扱う代表3モデルとClaude Opus 4.8・GPT-5.5・Gemini 3.5などの商用フロンティアモデルを比較すると、リリース時点では以下の関係になります。
- 純粋な性能では商用フロンティアがまだ優位(特にマルチファイル推論・長期計画立案)
- コーディングサブカテゴリでは差が縮まり、オープンモデルが「実用十分」に達した
- 1Mコンテキストではオープンモデル側にも選択肢ができた(GLM-5.2)
- 価格と速度では、サブスクリプション単価ベースで見ると商用フロンティアより有利になりやすい(ただしGLM Coding Planの「プロンプト枠」とGPT/ClaudeのAPI「1Mトークン単価」は前提が異なるため、用途別の比較条件を揃えた検証が必要)
商用フロンティアとオープンが「能力で並んだ」のではなく、「能力差が小さくなり、価格・速度・調達性の差が前に出てきた」フェーズです。
GLM-5.2はその文脈で、コーディング・エージェント用途の「現実解」を担う候補のひとつになっています。
GLM-5.2の使い方
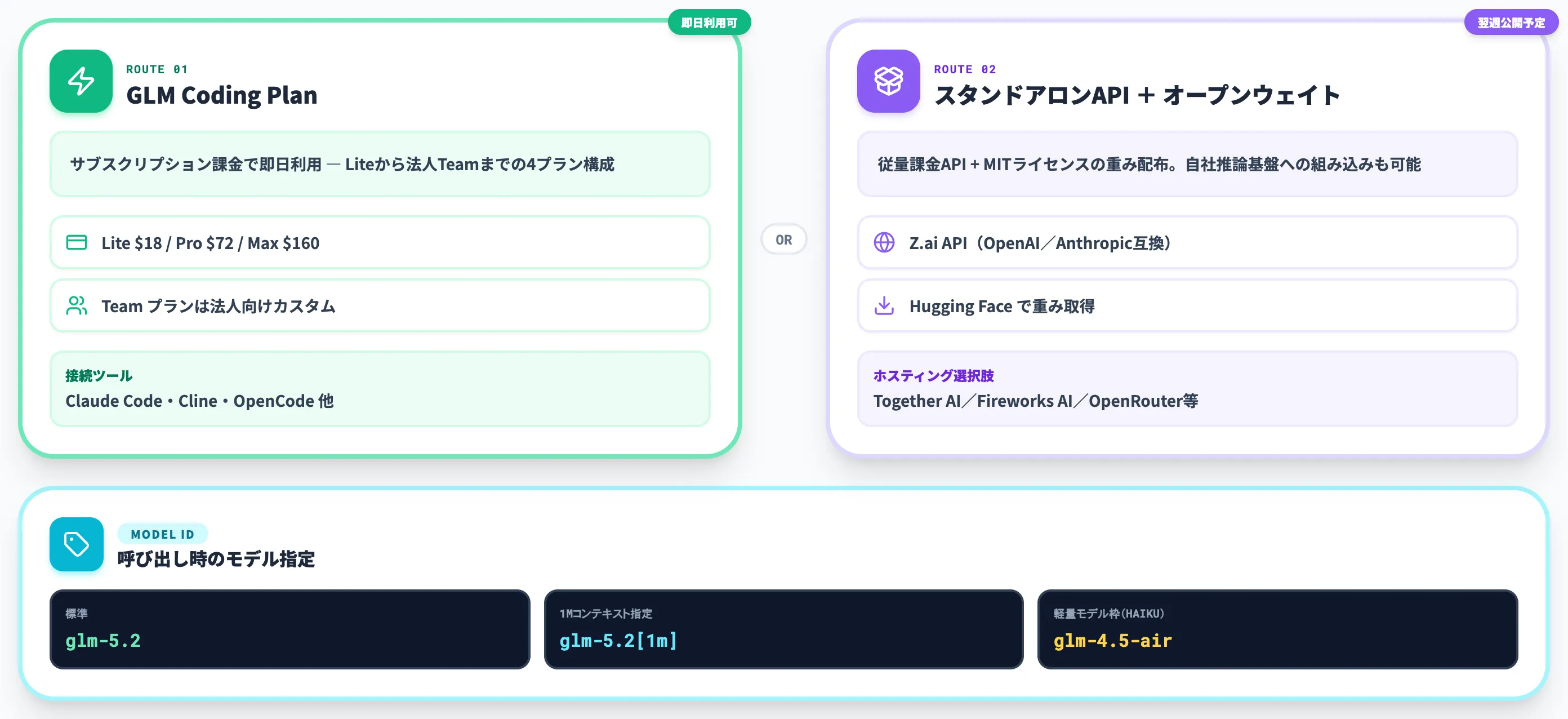
GLM-5.2を実際に使い始めるルートは、リリース時点で大きく2つあります。
ひとつはGLM Coding Plan経由でサブスクリプション課金として呼び出す方法、もうひとつは翌週公開予定のスタンドアロンAPIまたはMITウェイトを使う方法です。本セクションではそれぞれの導線を整理します。
GLM Coding Planの4プラン構成
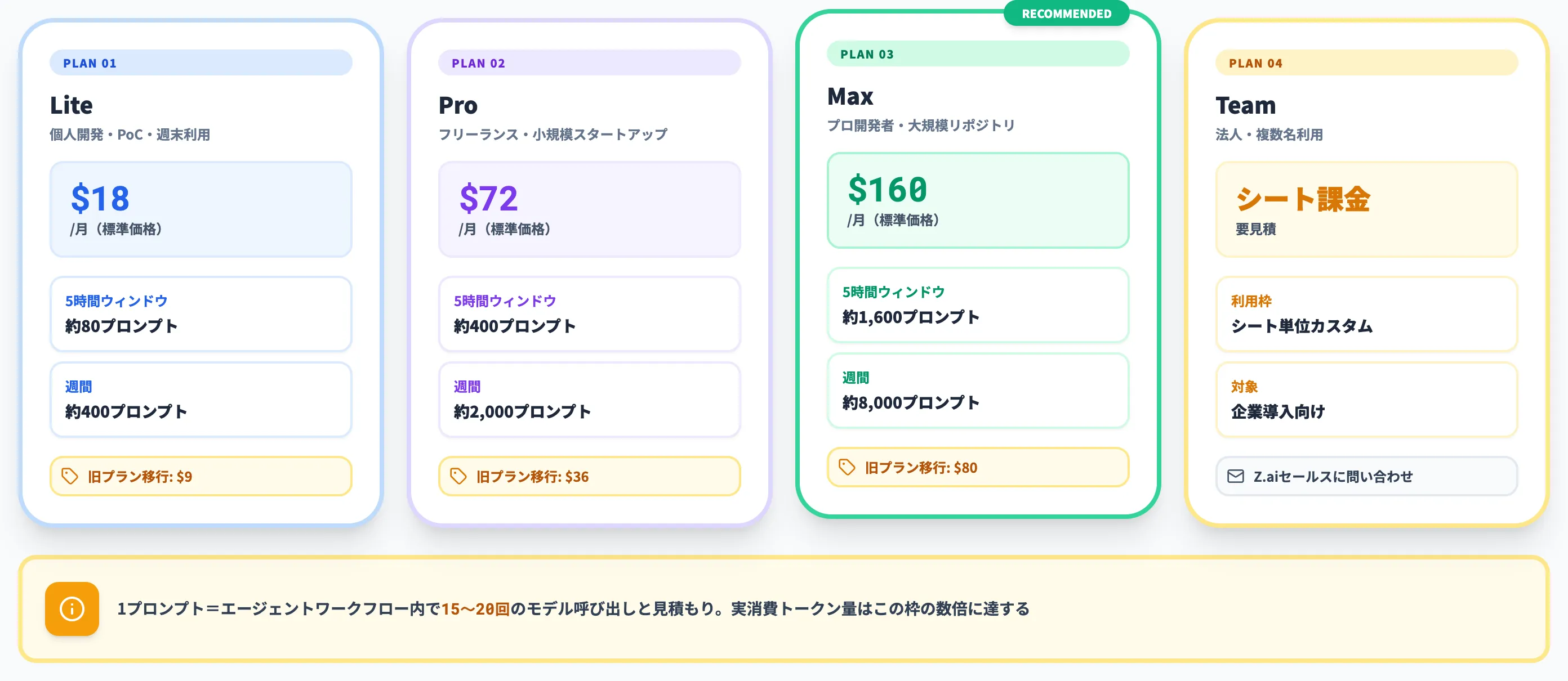
GLM Coding Planは、Zhipu AIが提供する開発者向けサブスクリプションプログラムです。
リリース当日(2026年6月13日)からGLM-5.2がLite/Pro/Max/Teamの全プランで利用可能になりました。既存のCoding Plan契約者は、環境変数の切り替えだけでGLM-5.2に到達できます。
Z.ai公式ドキュメントによれば、各プランで利用できるプロンプト数の上限はおおよそ以下のとおりです。
| プラン | 5時間ウィンドウ | 週間 |
|---|---|---|
| Lite | 約80プロンプト | 約400プロンプト |
| Pro | 約400プロンプト | 約2,000プロンプト |
| Max | 約1,600プロンプト | 約8,000プロンプト |
| Team | シート単位カスタム | カスタム |
1プロンプトはエージェントワークフロー中で15〜20回程度モデルを呼び出すとZ.ai公式Overviewが見積もっており、実際の生消費トークン量はこの枠の数倍に達します。
「プロンプト数」ベースで枠を切ることで、ユーザーは細かなトークン計算を意識せずにサブスクリプションを設計できる仕組みになっています。
対応する主要エージェントツール
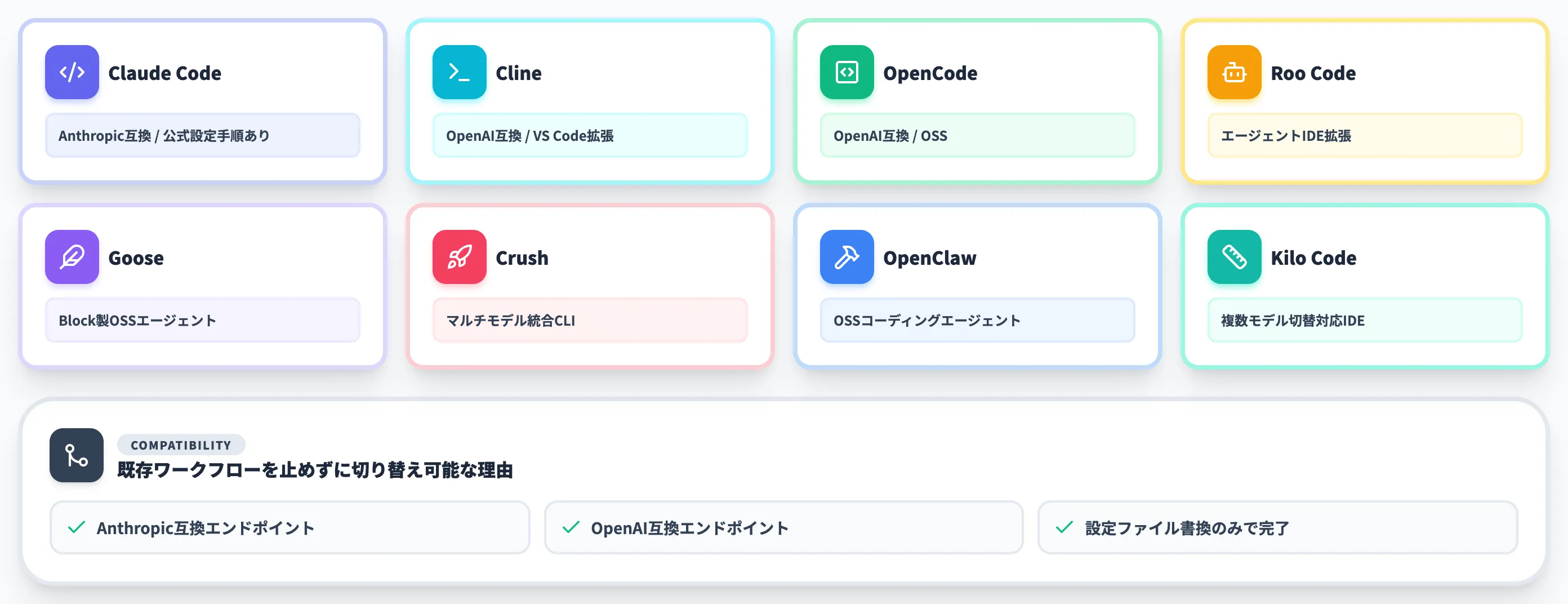
GLM-5.2の特徴的な利便性は、リリース当日からClaude Code・Cline・OpenCodeなどの主要なエージェントコーディングツールにそのまま接続できる点です。リリース告知で名前が挙がっていた主なツールは以下のとおりです。
- Claude Code
- Cline
- OpenCode
- Roo Code
- Goose
- Crush
- OpenClaw
- Kilo Code
これらのツールはもともとAnthropic互換またはOpenAI互換のAPI仕様を採用しており、GLM-5.2はその両方の仕様で互換エンドポイントを提供しています。
つまり既存のClaude Code・Cline利用ワークフローを止めずに、設定ファイルのモデルIDとエンドポイントだけを書き換えることでGLM-5.2に切り替えられます。
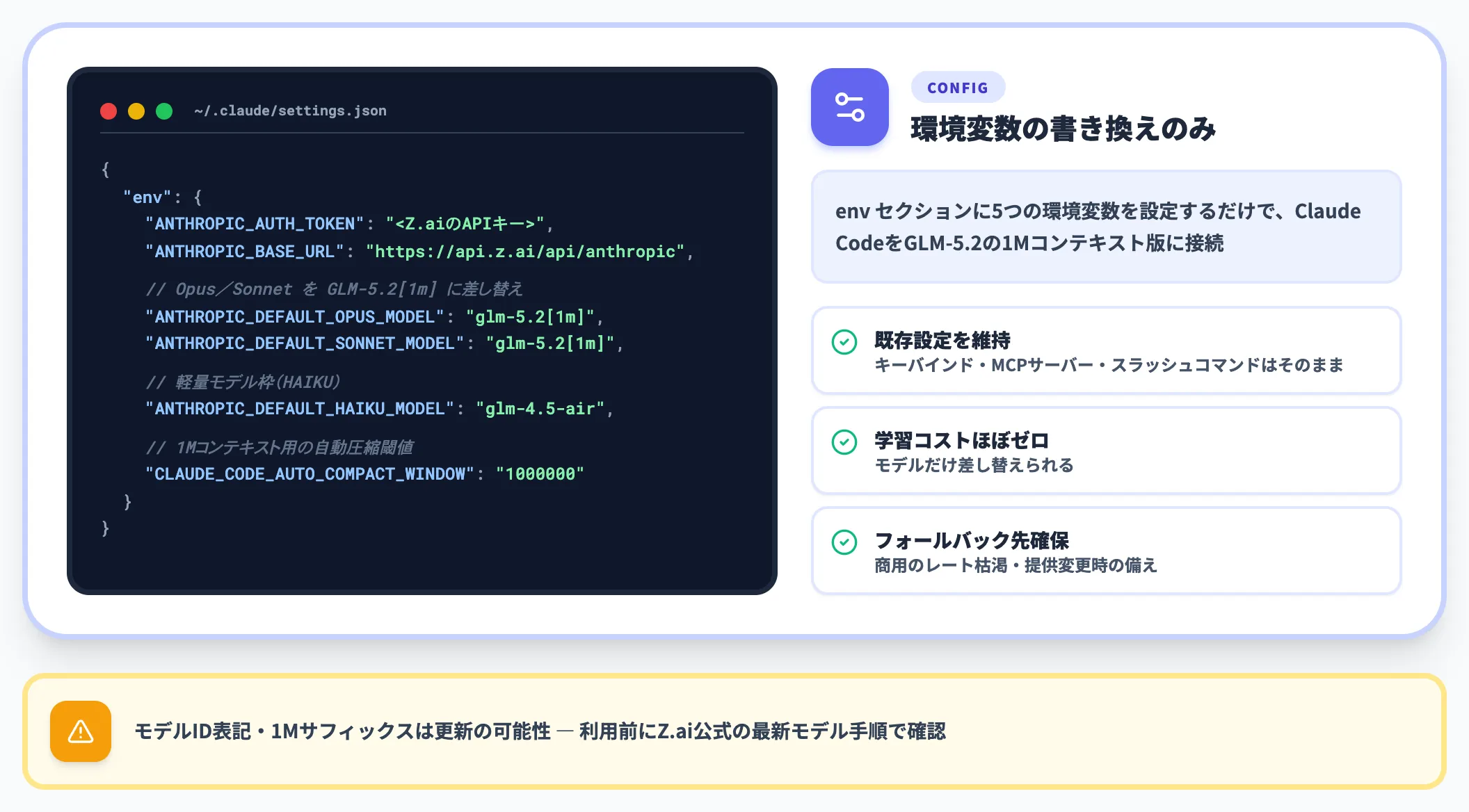
Claude CodeからGLM-5.2を呼ぶ設定例
Z.aiの公式手順では、Claude CodeをGLM-5.2の1Mコンテキスト版に接続する場合、~/.claude/settings.json の env セクションに以下の環境変数を設定します。
1Mコンテキスト指定には glm-5.2[1m] サフィックスを付け、軽量モデル枠(HAIKU)は別モデルを割り当てます。
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "<Z.aiのAPIキー>",
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.2[1m]",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.2[1m]",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "1000000"
}
}
このアプローチには複数の利点があります。
第一に、既存のClaude CodeのキーバインドやMCPサーバー・スラッシュコマンド構成を維持したまま、モデルだけ差し替えられる点です。学習コストがほぼ発生しません。
第二に、商用モデルのレートリミット枯渇や提供条件変更が発生した場合のフォールバック先として、開発を止めずに継続できる選択肢を確保できる点です。
最新のモデルID表記や1Mコンテキスト指定方法は更新される可能性があるため、利用前にZ.ai公式の最新モデル手順を確認してください。
Cline等のOpenAI互換ツール経由
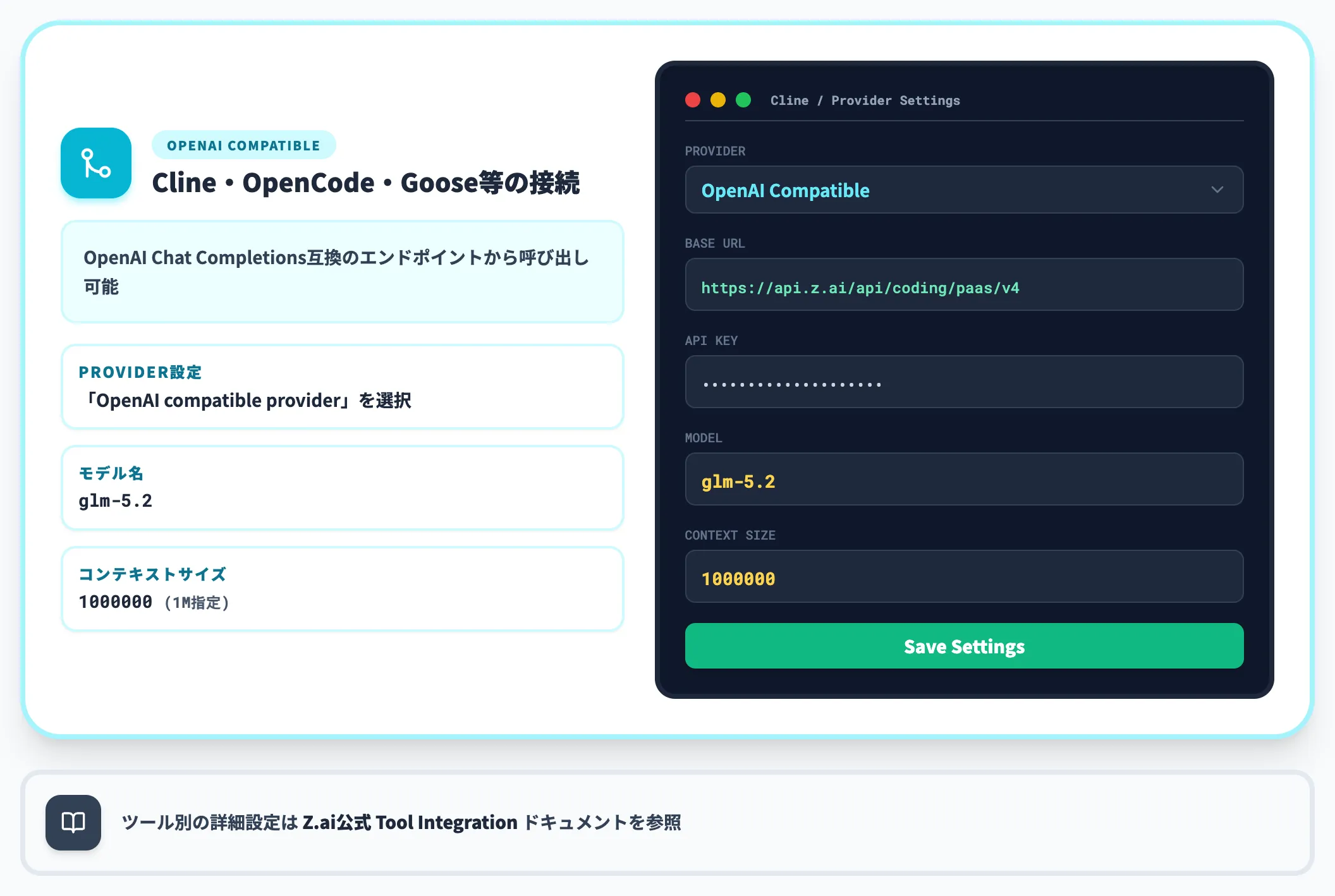
Cline・OpenCode・Goose等は、OpenAI Chat Completions互換のエンドポイントから呼び出せます。
Zhipu AIは公式に「https://api.z.ai/api/coding/paas/v4」というOpenAI互換のコーディング用エンドポイントを公開しており、各ツール側の「OpenAI compatible provider」設定でモデル名に glm-5.2、コンテキストサイズに 1000000(1Mコンテキスト利用時)を指定して動作させます。詳細なツール別設定例はZ.ai公式のTool Integrationを参照してください。
スタンドアロンAPIとオープンウェイトの公開
リリース時点(2026年6月13日)では、GLM Coding Planだけが即時利用可能で、スタンドアロンAPI・Z.aiチャット・MITライセンスのオープンウェイトは翌週公開と発表されています。
オープンウェイトの公開後は、Hugging Face経由でモデルファイルを取得し、自社推論基盤(AWS・Azure・自社オンプレ)にデプロイすることも可能になります。
ただし700B級パラメータの推論には大規模なGPU/NPUクラスタが必要で、現実的には自社運用ではなく、Together AI・Fireworks AI・OpenRouter等のホスティング事業者経由で利用するケースが多くなると予想されます。
GLM-5.2の料金体系
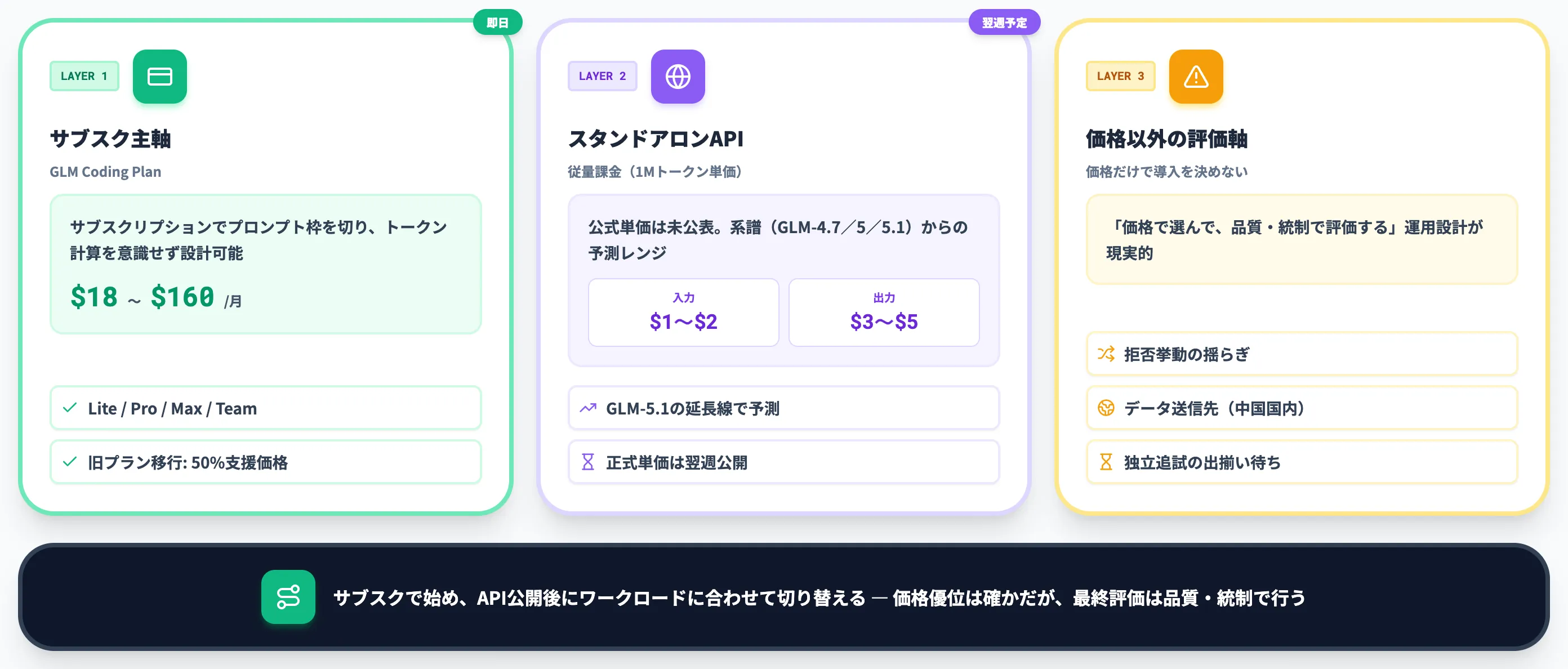
GLM-5.2の課金は、リリース時点ではGLM Coding Planのサブスクリプション一本に集約されています。
スタンドアロンAPIの従量課金は翌週公開予定のため、本セクションではCoding Planの内容と実効単価の読み解きに絞ります。
サブスクリプション4プランの月額と利用枠
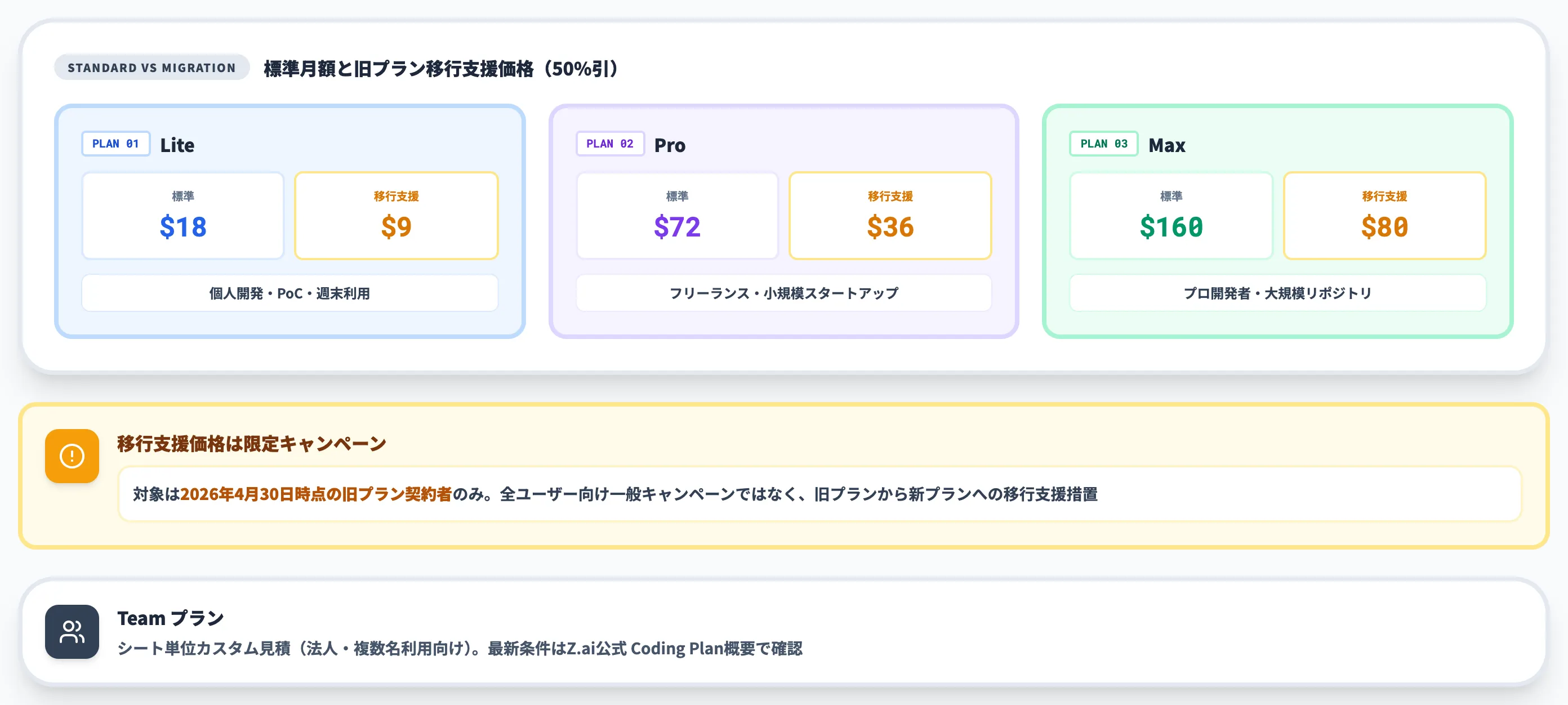
各プランの月額(標準価格)と利用枠は、以下の表のとおりです。
| プラン | 標準月額(USD) | 週間プロンプト枠 | 想定対象 |
|---|---|---|---|
| Lite | $18 | 約400 | 個人開発・PoC・週末利用 |
| Pro | $72 | 約2,000 | フリーランス・小規模スタートアップ |
| Max | $160 | 約8,000 | プロ開発者・大規模リポジトリ |
| Team | シート課金(要見積) | カスタム | 法人・複数名利用 |
標準価格はZ.ai公式ドキュメントが「starting at 18 USD/month」と明記しており、Liteで$18・Proで$72・Maxで$160です。
なお、Z.aiは別途Legacy Plan Migration Noticeを公開しており、2026年4月30日時点の旧プラン契約者向けに50%相当の移行支援価格(Lite $9 / Pro $36 / Max $80)を提示しています。これは全ユーザー向けの一般キャンペーンではなく、旧プラン契約者を新プランへ移行させるための限定的な支援措置である点に注意してください。
最新の価格・条件はZ.ai公式のCoding Plan概要で必ず確認してください。
Claude Code・Codexとの単価比較
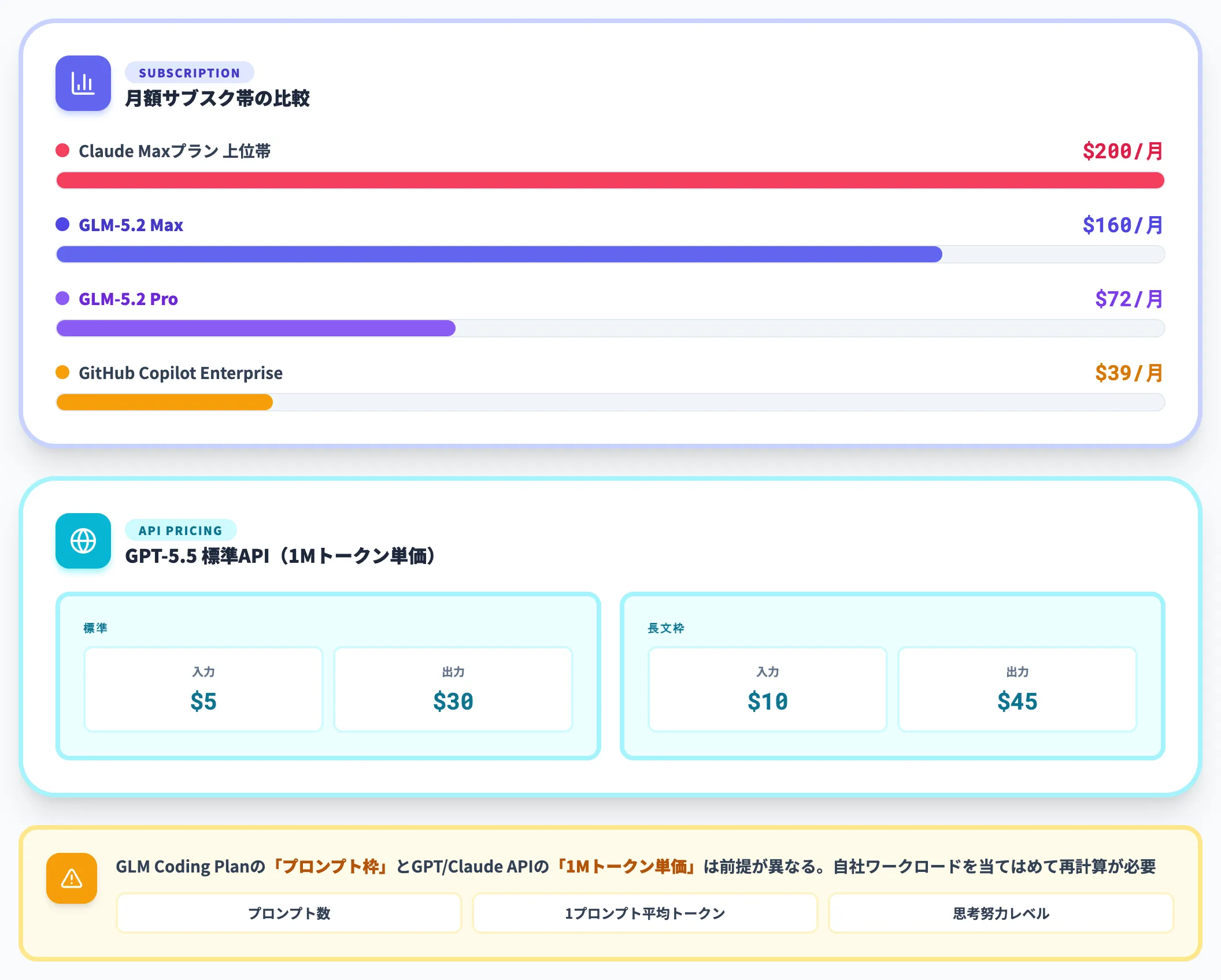
Claude Codeの料金プラン・ChatGPT API料金等と比較すると、GLM-5.2のCoding Planは月額の見かけ価格でも、サブスクリプション帯のなかでは安価な部類に位置します。
たとえばClaude Maxプランの上位帯($200/月)・GitHub Copilot Enterprise($39/月)の月額レンジに対し、GLM-5.2のPro $72・Max $160は、ユースケース次第で見合う水準です。
GPT-5.5 APIの標準価格(入力$5・出力$30 / 1Mトークン、長文枠は入力$10・出力$45)と比較する場合は、GLM Coding Planの「プロンプト枠」とAPI従量課金の「1Mトークン単価」では前提が異なるため、自社の想定ワークロード(プロンプト数・1プロンプトあたりのトークン消費・思考努力レベル)を当てはめて再計算する必要があります。
ただし「プロンプト」あたりにモデルが呼び出される回数(15〜20回)と思考努力レベル(Max推奨)を考えると、見かけのプロンプト数より実効消費は大きくなります。実務では「Proで足りない → Maxに上げる」よりも、まずLite/Proで実消費を計測してから上げる運用が現実的です。
スタンドアロンAPIの料金は未公表

リリース時点(2026年6月13日)では、スタンドアロンAPIの従量課金単価は公表されていません。
Z.ai公式Pricingで確認できる過去モデルの単価は、以下のとおりです(いずれも1Mトークンあたり)。
| モデル | 入力 | 出力 |
|---|---|---|
| GLM-4.7 | $0.6 | $2.2 |
| GLM-5 | $1.0 | $3.2 |
| GLM-5.1 | $1.4 | $4.4 |
GLM-5.2が直近世代の延長線上で価格設定されるなら、入力$1〜$2・出力$3〜$5前後のレンジが目安になります。これはGPT-5.5の標準価格(入力$5・出力$30)やClaude Opus 4.8の上位帯と比べて、入出力ともに数分の1の水準です。
正式な単価は翌週のAPI公開時にZ.ai Pricingで確認できる見込みです。
価格優位だけで判断しない
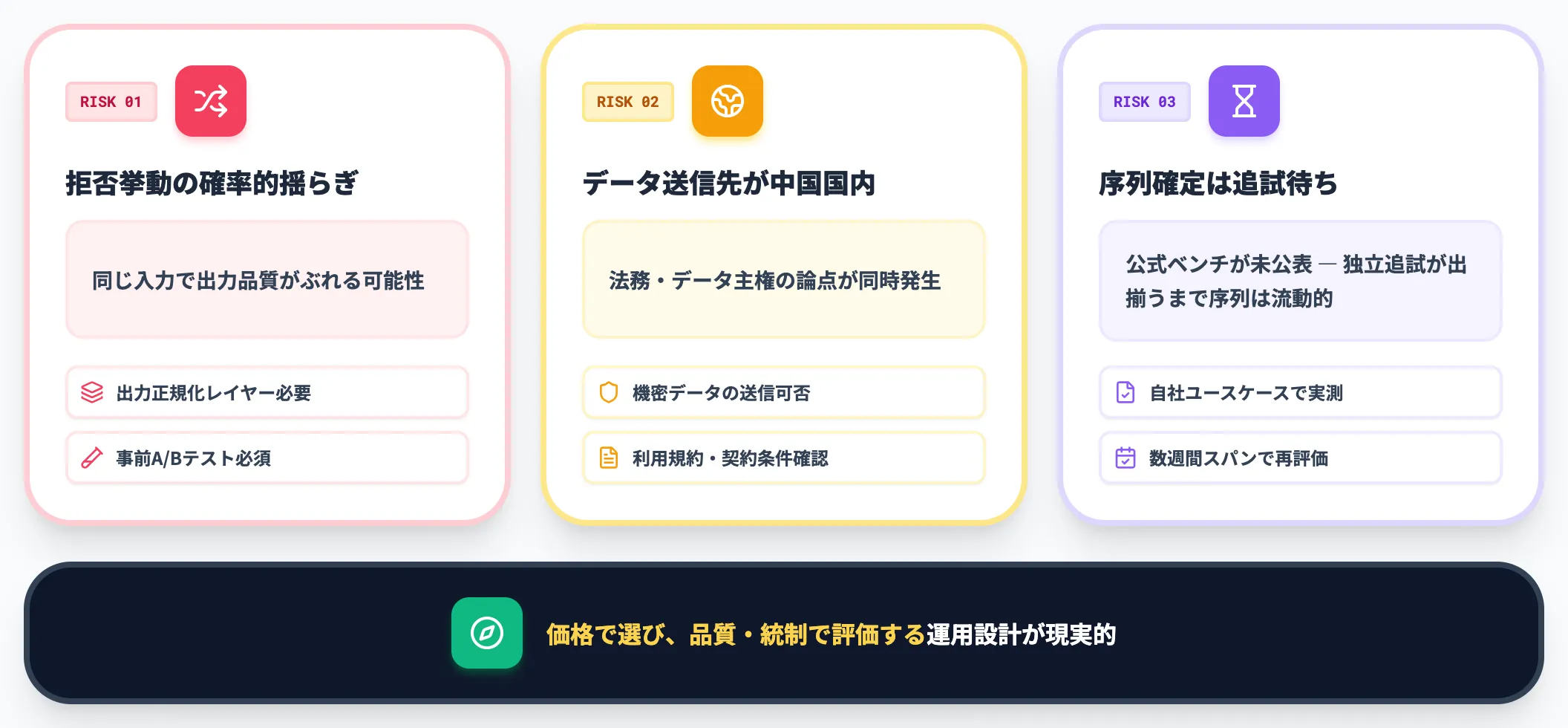
GLM-5.2の価格は確かに魅力的ですが、価格だけで導入を決めるのはリスクがあります。次のような観点も同時に評価する必要があります。
- 拒否挙動が確率的に揺らぐ点(同じ入力で出力品質がぶれる可能性)
- データ送信先が中国国内(Zhipu AI)になる点(法務・データ主権の論点)
- 公式の長時間コーディング系ベンチ(SWE-Bench Pro 62.1・Terminal-Bench 2.1 81.0)は2026年6月16-17日に公開されたものの、SWE-bench Verified・LiveCodeBench等の汎用標準ベンチと独立追試結果が出揃うまで序列の最終評価は確定しない点
これらを踏まえると「価格で選んで、品質・統制で評価する」運用設計が現実的です。
日本企業がGLM-5.2をどう扱うべきか
GLM-5.2の登場は、日本企業にとっても無視できない選択肢になりつつあります。
ただし「中国製モデルを業務に組み込む」という判断には、性能評価とは別軸の論点が複数絡みます。本セクションでは、AI総合研究所の支援現場で見えてきたケース別の判断軸を整理します。

ケース別の判断早見表

以下の表で、5タイプの企業がGLM-5.2をどう扱うべきかと、その判断根拠を整理しました。
| 対象企業 | 推奨スタンス | 判断根拠 |
|---|---|---|
| 大手金融・公共系 | 利用見送り(情報収集のみ) | API経由で中国法人にプロンプトが届くため、金融庁ガイドラインのサードパーティリスク管理と整合させにくい。社内検証環境での性能評価まで止める必要はない |
| 大手製造・流通系 | 限定PoC(社外秘を含まない範囲) | 主力はMicrosoft 365 Copilot・Azure OpenAI Service・Claudeを据え、コスト試算用の併走候補として扱うのが現実解 |
| SaaS・スタートアップ | 主力モデルの併用候補として検証 | 1Mコンテキスト・コーディング特化・低価格はプロダクト開発のコスト圧縮に直結。エンドユーザー透明性とデータ送信先の規約整備は最初に揃える |
| 個人開発・OSS | 即日試用 | GLM Coding PlanのLite(標準$18/月)はClaude Code Pro($20/月)と同等以下、1Mコンテキストの試用環境がすぐ得られる(旧プラン契約者は移行支援価格$9/月の対象になる場合あり) |
| 研究機関・大学 | 重み公開後にファインチューニング検証 | 700B級オープンウェイトモデルとして貴重。MITライセンスのため二次利用しやすい |
多くの日本企業にとって、GLM-5.2は「主力モデル」ではなく「特定用途に投入する補助モデル」として扱うのが現実的な出発点になります。
商用フロンティアモデルとの併用設計
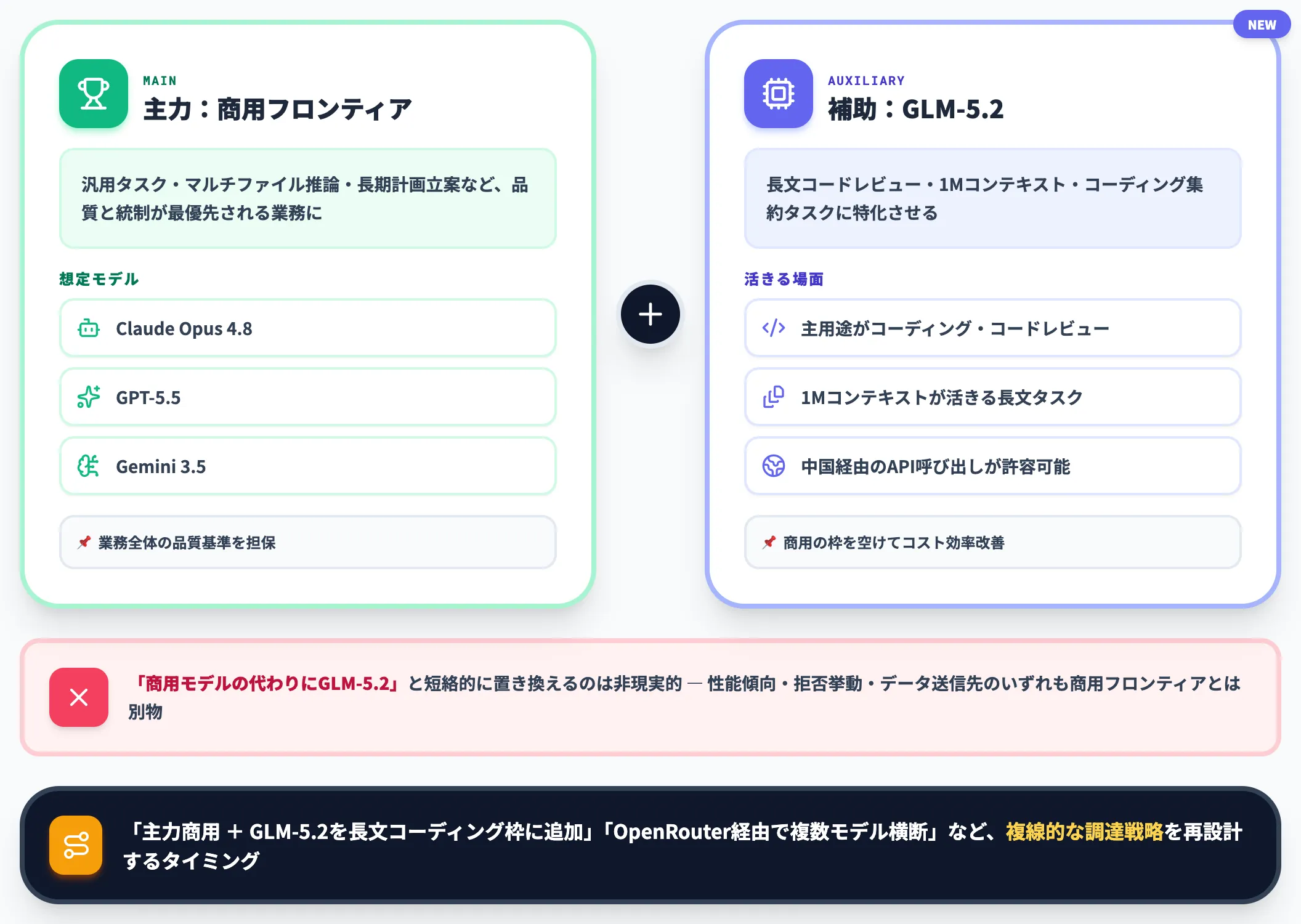
GLM-5.2を導入する際の現実的なスタンスは、主力商用モデルを置き換えるのではなく併用することです。以下のような場面でGLM-5.2が有力な補完候補になります。
- 主用途がコーディング・コードレビュー・エージェント実行であること
- 1Mコンテキストが活きる長文タスクが多いこと
- データ主権・法務要件が中国経由のAPI呼び出しを許容できること
一方で「商用モデルの代わりにGLM-5.2」と短絡的に置き換えるのは現実的ではありません。性能の傾向・拒否挙動・データ送信先のいずれも商用フロンティアモデルとは別物だからです。
「主力は商用フロンティア + GLM-5.2を長文コーディング枠に追加」「OpenRouter経由で複数モデルを横断」など、複線的な調達戦略を再設計するタイミングと捉える方が、長期的には安全です。

GLM-5.2世代のオープンモデルを業務AI戦略に組み込む
GLM-5.2のようなオープンモデルがフロンティア帯に迫る性能を示し始めたことで、企業がAIモデルに「これ一本」で依存する時代は終わりつつあります。
主力商用モデル・オープンソースモデル・自社推論基盤の三層を組み合わせ、業務単位で使い分ける設計が、今後の標準形になります。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。GLM-5.2のようなオープンソースモデルを業務に組み込む際の、評価・統制・運用設計の整理にお役立てください。
GLM-5.2世代のオープンモデルを業務AI戦略に組み込む

PoCから全社展開までの設計を1冊で
GLM-5.2のようなオープンソースモデルを業務に取り込むには、モデル選定だけでなくPoCの設計・コスト試算・運用体制が同時に必要です。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開までの進め方、部門別ユースケース、モデルの使い分け、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、2026年6月13日にZhipu AIが投入したGLM-5.2について、技術仕様・性能・料金・使い方・日本企業の判断軸まで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
GLM-5.2は1MコンテキストのMoEモデルで、MITライセンスでのオープンウェイト公開を予定し、コーディング・エージェント用途を主戦場とするZhipu AIの旗艦モデル
-
アーキテクチャはGLM-5.1譲りの700B級MoEで、DSAの採用が報じられている。GLM-5系では中国製チップ向け推論対応・Slime等の自前スタックが確認されているが、GLM-5.2固有の学習基盤は未公表
-
公式ベンチマークは2026年6月16-17日にZ.aiが追加公開し、SWE-Bench Pro 62.1・Terminal-Bench 2.1 81.0でClaude Opus 4.8に肉薄。一方でSWE-bench Verified・LiveCodeBench等の汎用標準ベンチと独立追試はまだ未出揃い。第三者評価ではUI・デザインコードに強み、マルチファイル推論はフロンティアにやや劣る
-
GLM Coding Plan(標準Lite $18〜Max $160/旧プラン移行対象には50%支援価格$9〜$80)で即日利用可能、Claude Code・Cline・OpenCodeなど主要エージェントツールへの即日対応で既存ワークフローを止めずに切り替えられる
-
日本企業の現実解は「主力は商用フロンティア、長文コードレビュー・PoCはGLM-5.2」の併用が出発点。データ主権・調達ガバナンスを踏まえると業界・規模別に判断軸が大きく異なる
GLM-5.2は単体で「最強の代替モデル」になるわけではありません。しかし「主力商用モデル+オープンソース+自社推論基盤の三層構成」を組む際に、コーディング・1Mコンテキスト軸で1枚加える価値のある選択肢になりました。
まずはGLM Coding PlanのLite/ProでGLM-5.2を試し、自社のコーディングワークフローでどの程度の品質と速度が得られるかを2026年6月時点の現状で計測しておくことが、商用フロンティアとオープンモデルを併用する時代を見据えた最も実用的な第一歩になります。










