この記事のポイント
 長文脈処理のコスト削減を最優先課題とする企業はDeepSeek-V3.2-Expを第一候補として検証、DSA技術で性能維持しつつ推論コストを劇的削減
長文脈処理のコスト削減を最優先課題とする企業はDeepSeek-V3.2-Expを第一候補として検証、DSA技術で性能維持しつつ推論コストを劇的削減- API料金はキャッシュヒット活用で入力$0.028/1Mトークンと破格。大量のドキュメント処理やRAG構築にはコスト面で最適な選択肢
- MITライセンスのため、自社環境でのローカル実行・商用利用が可能。データを外部に出せない企業にとって有効な選択肢
- ただし実験的モデルのため、本番環境への即時投入は避けるべき。まずPoC段階での性能検証から始めるのが賢明
- vLLMやHugging Faceでの実行環境が整っており、既存のMLOpsパイプラインとの統合がスムーズ。技術検証のハードルが低い点も評価すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI技術の進化は止まるところを知りません。特に、より長く、より複雑な文脈を理解する能力は、次世代AIの重要な鍵とされています。
そんな中、DeepSeek社から、長文脈シナリオにおける効率を飛躍的に高めることを目的とした実験的モデル「DeepSeek-V3.2-Exp」が発表されました。
本記事では、このDeepSeek-V3.2-Expの概要から、その核心技術である「DeepSeek Sparse Attention (DSA)」、料金体系、そして具体的な使い方に至るまで、詳しく解説していきます。
特に、性能を維持したまま、いかにして計算効率を高めたのかという「革新的なアーキテクチャ」と、開発者がすぐに試せる「ローカルでの実行方法」に焦点を当てていきます。
長文脈処理の新たな可能性を切り拓くDeepSeek-V3.2-Expの世界を、一緒に見ていきましょう。
最新モデル「DeepSeek V3.2」については、こちらの記事で詳しく解説しています。 ▶︎DeepSeek-V3.2とは?使い方や料金、ベンチマーク性能を徹底解説!
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
革新技術「<strong>DeepSeek Sparse Attention (DSA)」の仕組み</strong>
ステージ1:継続的な事前学習 (Continued Pre-Training)
DeepSeek-V3.2-Expとは?
DeepSeek-V3.2-Expは、DeepSeekシリーズの最新モデルであり、長文脈(Long Context)における学習と推論の効率を最適化するために設計された実験的な大規模言語モデルです。
このモデルは、前モデルである「DeepSeek-V3.1-Terminus」をベースに構築されており、次世代アーキテクチャへの中間ステップとして位置づけられています。
最大の特徴は、新たに導入されたスパースアテンション技術「DeepSeek Sparse Attention (DSA)」です。
この実験的リリースは、より効率的なTransformerアーキテクチャへの継続的な研究を象徴しており、特に拡張されたテキストシーケンスを処理する際の計算効率の向上に焦点を当てています。

正式版「DeepSeek-V3.2」が登場
本記事で解説する「DeepSeek-V3.2-Exp」は、新技術検証のための実験的モデルです。
2025年12月1日、この成果を元に推論能力とエージェント機能を大幅に強化した正式版「DeepSeek-V3.2」がついにリリースされました。
これからDeepSeekを利用される方は、GPT-5級の性能と低コストを両立した以下の最新記事をご覧ください。
▶︎DeepSeek-V3.2とは?使い方や料金、ベンチマーク性能を徹底解説!
DeepSeek-V3.2-Expのパフォーマンス
DeepSeek-V3.2-Expの主な目的は、性能向上ではなく効率の検証にあります。そのため、意図的に学習構成を前モデルのV3.1-Terminusと揃え、新しいアーキテクチャが性能を損なわないことを証明しています。
各種ベンチマーク結果
以下の表は、各種ベンチマークにおけるV3.1-Terminusとの性能比較です。
全体として、DeepSeek-V3.2-Expは、V3.1-Terminusと実質的に同等の性能を達成しています。
| ベンチマーク | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp |
|---|---|---|
| ツール使用なしの推論モード | ||
| MMLU-Pro | 85.0 | 85.0 |
| GPQA-Diamond | 80.7 | 79.9 |
| Human-Last-Exam | 21.7 | 19.8 |
| LiveCodeBench | 74.9 | 74.1 |
| AIME 2025 | 88.4 | 89.3 |
| HMMT 2025 | 86.1 | 83.6 |
| CodeForces | 2046 | 2121 |
| Aider-Multilingual | 76.1 | 74.5 |
| エージェントツールの使用 | ||
| Comp-Ref-en | 38.5 | 40.1 |
| Comp-Ref-zh | 45.0 | 47.9 |
| SimpleQA | 96.8 | 97.1 |
| SWE-bench-verified | 68.4 | 67.8 |
| SWE-bench-multilingual | 57.8 | 57.9 |
| Terminal-Bench | 36.7 | 37.7 |
推論コストの劇的な削減
DeepSeek-V3.2-Expの真価は、その推論効率にあります。公式論文で公開されている推論コストの比較グラフは、この効率性を明確に示しています。
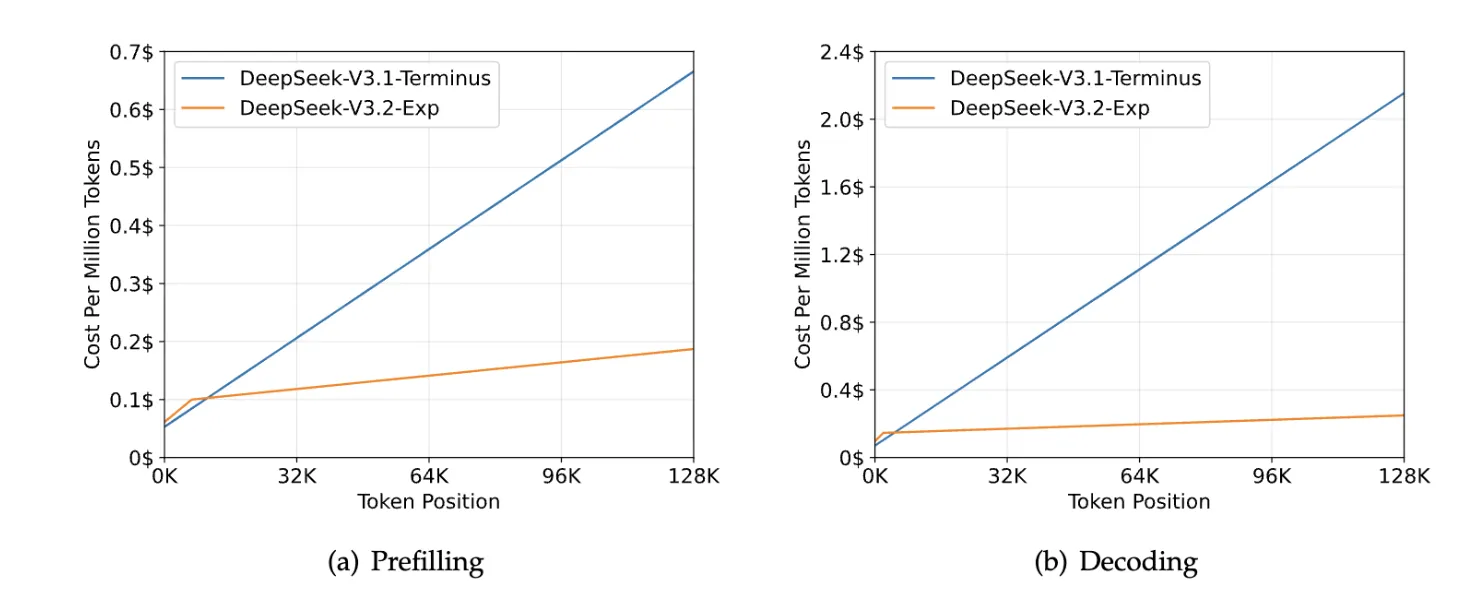
DeepSeek-V3.2-ExpとV3.1-Terminusの推論コスト比較(参考:DeepSeek)
特にデコーディング(Decoding)において、文脈が長くなるほど(Token Positionの値が大きくなるほど)、V3.1-Terminusとのコスト差は劇的に開いていきます。
これは、DSAが長文脈処理において極めて高い効率性を発揮することの直接的な証拠です。
DeepSeek-V3.2-Expの核心技術
DeepSeek-V3.2-Expの効率性は、その革新的なアーキテクチャによって支えられています。
革新技術「DeepSeek Sparse Attention (DSA)」の仕組み
DSAは、アテンション計算を本当に必要な部分だけに絞ることで、計算量を劇的に削減します。この仕組みは、公式論文のアーキテクチャ図で視覚的に解説されています。
%20%E3%81%AE%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3.webp)
DeepSeek Sparse Attention (DSA) のアーキテクチャ (参考:DeepSeek)
この図に示されている通り、DSAは主に以下の2つのコンポーネントで構成されています。
-
Lightning Indexer (ライトニング・インデクサー)
軽量かつ高速なメカニズムで、現在のトークン(クエリ)にとって、過去のどのトークン(キー)が重要かを大まかに予測し、スコア付けします。
-
Top-k Selector (トップk・セレクター)
Indexerが算出したスコアに基づき、最も重要と判断された上位k個(Top-k)のキーとバリューのペアだけを選択します。
最終的なアテンション計算は、この厳選されたトークンのみを対象に行われます。これにより、モデルの性能をほとんど損なうことなく、計算コストだけを大幅に削減することを可能にしています。
オープンソースカーネル
DeepSeek社は、研究者や開発者がこの新技術を深く理解し、活用できるよう、DSAを構成する主要な計算カーネルをオープンソースで公開しています。
- TileLang: 読みやすさと研究目的を重視して設計されたカーネル。
- DeepGEMM: 高性能なCUDAカーネル。
- FlashMLA: スパースアテンションカーネル本体。

DeepSeek-V3.2-Expの学習プロセス
この効率的なモデルは、論文で明らかにされた以下の2段階の学習プロセスを経て構築されています。
ステージ1:継続的な事前学習 (Continued Pre-Training)
V3.1-Terminusをベースに、さらに追加の事前学習を行います。
- Dense Warm-up Stage:
まず、DSAの頭脳であるLightning Indexerを初期学習(ウォームアップ)させます。この段階ではまだスパース化せず、通常の密なアテンションで学習を進めます。
- Sparse Training Stage:
次に、ウォームアップ済みのIndexerを起動し、モデル全体をスパースアテンションで学習させます。
ステージ2:ファインチューニング (Post-Training)
事前学習で基礎能力を身につけた後、特定のタスクへの適応力を高めます。
- Specialist Distillation:
数学やコーディングといった特定のドメインに特化した「専門家モデル」を育成し、その知識を蒸留します。
- Mixed RL Training:
最後に、強化学習(RL)を用いて、モデルの推論能力や対話能力をさらに磨き上げます。
ここで採用されているアルゴリズムは、DeepSeek-R1でも使われた実績のある「GRPO (Group Relative Policy Optimization)」です。
DeepSeek-V3.2-Expの料金
DeepSeek-V3.2-ExpはAPI経由でも利用可能で、料金はトークン数に応じた従量課金制です。
2025年9月29日 10:00 (UTC) から適用される料金は以下の通りです。
| 項目 | 料金(100万トークンあたり) |
|---|---|
| 入力 (キャッシュヒット) | $0.028 |
| 入力 (キャッシュミス) | $0.28 |
| 出力 | $0.42 |
DeepSeekのAPIは、過去に全く同じ入力があった場合に適用される「キャッシュヒット」により、入力コストを大幅に削減できるのが特徴です。
DeepSeek-V3.2-Expの使い方
DeepSeek-V3.2-Expは、主にローカル環境での実行が想定されており、Hugging Face、SGLang、vLLMといったフレームワークを通じて利用できます。
1. Hugging Face
リポジトリからモデルをダウンロード後、提供されているスクリプトを使って重みを変換し、対話インターフェースを起動する手順が案内されています。
2. SGLang
SGLangを利用する場合、ハードウェアに応じたDockerイメージが提供されており、それを用いてサーバーを起動することができます。
3. vLLM
人気の推論高速化ライブラリvLLMも、DeepSeek-V3.2-Expを初期からサポートしています。利用方法の詳細は、vLLMの公式レシピを参照してください。

まとめ
本記事では、DeepSeekの実験的最新モデル「DeepSeek-V3.2-Exp」について、公式論文を基に解説しました。
DeepSeek-V3.2-Expは、性能を維持しつつ長文脈処理の効率を劇的に向上させることを目的としたモデルです。その核心技術である「DeepSeek Sparse Attention (DSA)」は、計算量を削減しながらも高い精度を保つことを可能にしました。
- 実験的モデル: 次世代アーキテクチャへの中間ステップとして、効率化を検証するために開発。
- **核心技術「DSA」: 「Lightning Indexer」と「Top-k Selector」により、計算量を大幅に削減。
- 性能維持: 効率化を図りつつも、前モデルV3.1-Terminusと同等の性能を達成。
- 独自の学習プロセス: 効率と性能を両立させるための、綿密に設計された学習パイプライン。
- オープンな利用: MITライセンスで公開され、Hugging FaceやvLLMなどを通じて誰でもローカルで実行可能。
- 低コストなAPI: キャッシュヒットを活用することで、非常に低コストなAPI利用が可能。
DeepSeek-V3.2-Expの登場は、より大規模で複雑なテキストを扱うAIアプリケーション開発を加速させ、今後のAI技術の発展に大きく貢献する可能性を秘めています。
長文脈LLMの技術理解を自社業務のAI化に結びつけるなら
DSAのような新アーキテクチャがLLMの長文脈処理を劇的に効率化しつつある今、AIの活用範囲は技術調査や文書要約にとどまりません。契約書レビュー・議事録分析・ナレッジ検索など、長文テキストが関わる業務プロセスこそ、LLMの進化から最も恩恵を受ける領域です。
AI総合研究所では、LLMを業務に組み込むための導入設計から運用定着までを支援しています。最新モデルの技術動向を押さえた上で、自社業務のどこからAI化を始めるべきかを検討される方は、AI業務自動化ガイドで具体的な導入プロセスをご確認ください。
長文脈LLMの技術進化を業務へのAI導入計画に結びつける

AI業務自動化ガイドで導入の全体像を把握
DSAのような新技術がLLMの長文脈処理を飛躍させる一方で、自社業務にAIを組み込むには戦略的な計画が必要です。AI総合研究所のガイドでは、業務分析から段階的なAI導入までのプロセスを実務視点で整理しています。










