この記事のポイント
 1プロンプトを1〜8モデル(標準プリセットは3モデル)へ並列実行し、ジャッジモデルが構造化分析で1つの回答にまとめる新型ルーター
1プロンプトを1〜8モデル(標準プリセットは3モデル)へ並列実行し、ジャッジモデルが構造化分析で1つの回答にまとめる新型ルーター- Quality(Opus 4.8/GPT-5.5/Gemini 3.1 Pro)とBudget(Gemini 3 Flash/Kimi K2.6/DeepSeek V4 Pro)の2プリセットを標準提供
- DRACO 100タスクでFable 5+GPT-5.5合議が69.0%、Fable 5単体65.3%を上回ったとOpenRouterが公表
- 料金はパネル各モデルとjudge、Web toolsのpass-through合算。Budget構成ならFable 5級を約50%コストで再現
- 適用は深層リサーチや法務・医療・金融など引用品質重視の文脈。リアルタイム対話や短文応答には不向き

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OpenRouter Fusion APIは、1つのプロンプトを複数のAIモデルに並列実行し、ジャッジモデルが構造化分析で1つの回答にまとめる複数モデル合議型のルーターです。
2026年3月末に実験公開され、Claude Fable 5・Mythos 5の利用停止と同日の2026年6月12日に「単体フロンティアモデルを超えた」とOpenRouterが公式発表したことで、一気に注目を集めました。
本記事では、Fusion APIの仕組み・QualityとBudgetのプリセット・DRACO 100タスクのベンチ結果・使い方と料金・Vercel AI GatewayやPortkeyなど他ゲートウェイとの違い・業務適用の判断軸を、2026年6月時点の公式情報で体系的に解説します。
目次
Fusion APIの基本コンセプト──「単体選択」から「複数合議」へ
OpenRouter内での位置づけ──Auto Routerとの違い
パネル段階──1〜8モデルが並列実行する(標準プリセットは3モデル)
Recursion protection──合議の入れ子は1段まで
Budget preset──廉価モデル3本でフロンティア級を狙う
カスタムパネル──「analysis_models」 と 「model」 で完全オーバーライド
3つのエントリーポイント──モデルエイリアス・サーバーツール・プラグイン
カスタムパネル──「analysis_models」 と 「model」 で独自構成を組む
Recursion protection──再帰呼び出しは設計で防がれる
OpenRouter Fusion APIとは
OpenRouter Fusion APIは、1つのプロンプトを複数のAIモデルに並列で投げ、ジャッジモデルがそれらを構造化分析して1つの回答に統合するAPIです。
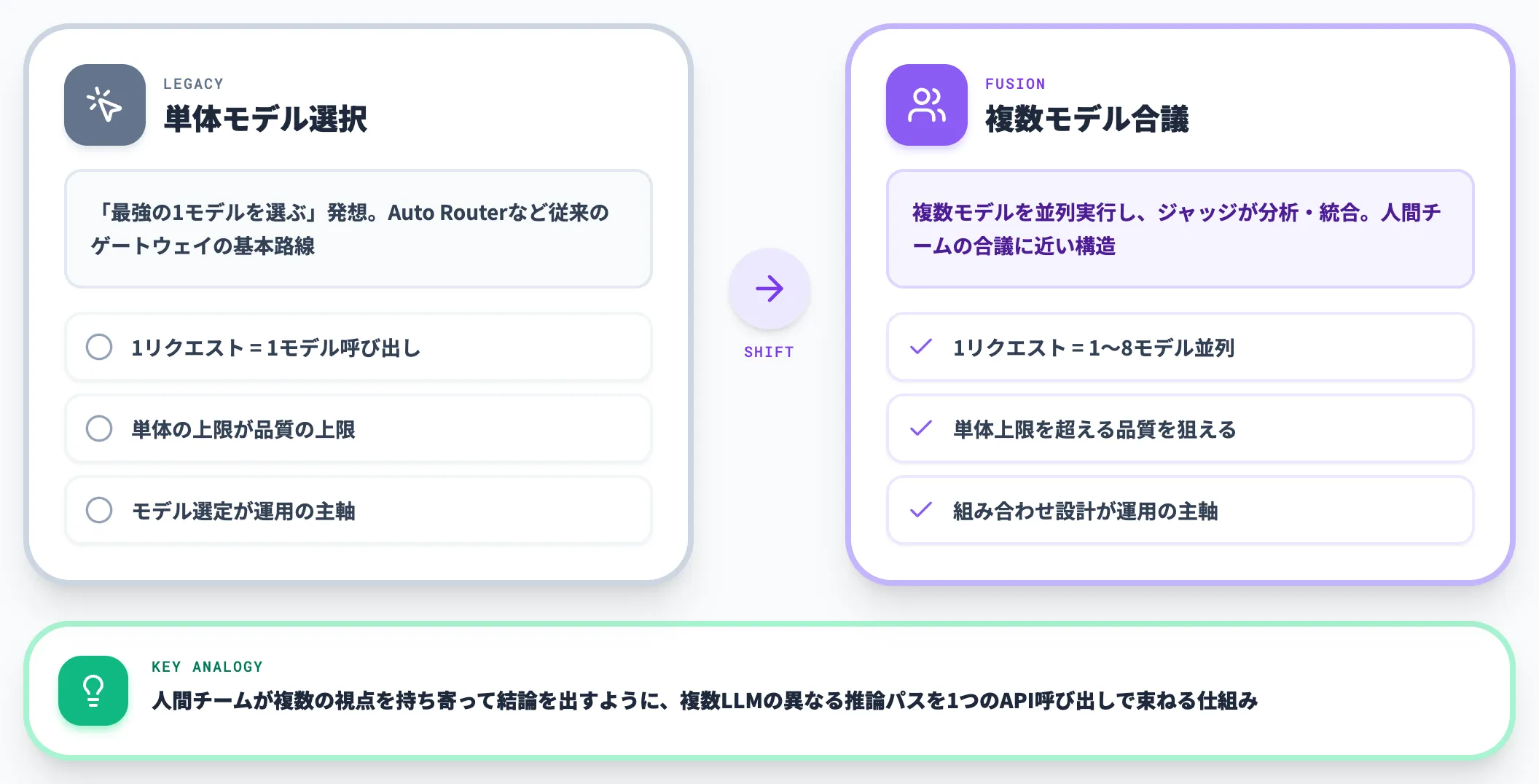
「最強の単体モデルを選ぶ」というこれまでのモデル選択戦略を、「複数モデルをどう組み合わせて合議させるか」に置き換える新しい設計思想と言えます。

本セクションでは、Fusion APIが何を狙ったAPIなのか、OpenRouterの中での位置づけ、そして2026年6月時点で急速に注目が集まった背景を整理します。
Fusion APIの基本コンセプト──「単体選択」から「複数合議」へ
これまでのAIゲートウェイやモデルルーターは、ユーザーのプロンプトに対して「どの1つのモデルを呼ぶか」を選ぶことが主な役割でした。
Fusion APIはこの前提を変え、1リクエスト内で複数モデルを並列実行し、それぞれの出力をジャッジモデルが分析・統合することで、単体モデルを超える品質を狙う構造を取ります。
OpenRouterの公式ブログでは、この狙いを「複数モデルの結果を統合すると、個別モデル単体を大きく上回るパフォーマンスが得られる」と説明しています。
実際にOpenRouterが実施した検証では、Claude Fable 5とGPT-5.5を合議させた構成が、Fable 5単体を上回るスコアを叩き出しました。
言い換えれば、Fusion APIは、人間のチームが複数の視点を持ち寄って結論を出すように、複数LLMの異なる推論パスを1つのAPI呼び出しで束ねる仕組みです。
OpenRouter内での位置づけ──Auto Routerとの違い
OpenRouter自体は、数百のLLMを統一APIで呼び出せるゲートウェイサービスです。
同社にはすでに「タスクに応じて最適な単体モデルを自動選択する」Auto Routerが存在していますが、Fusion APIはその発展形ではなく別軸のルーティング戦略として位置づけられています。
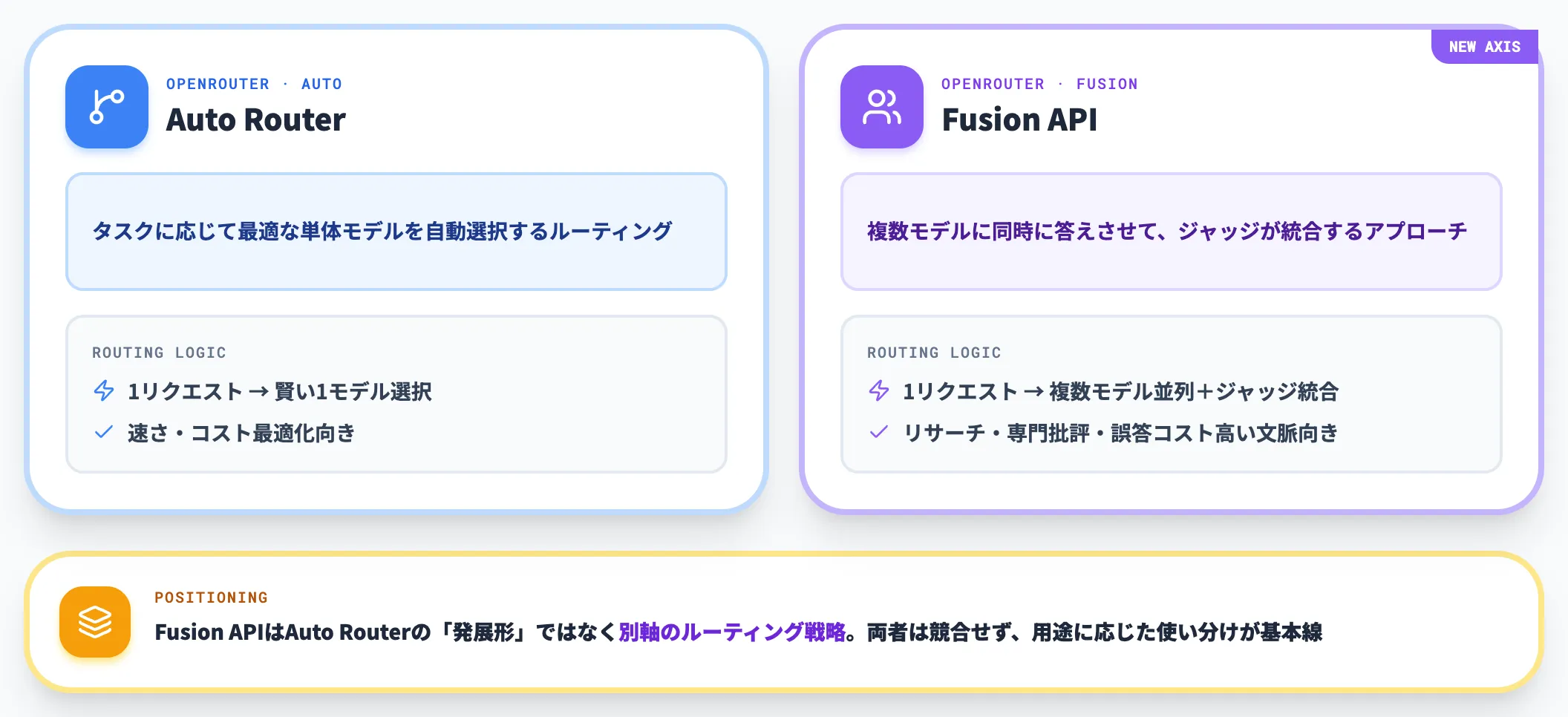
Auto Routerが「1モデルを賢く選ぶ」のに対し、Fusion APIは「複数モデルに同時に答えさせて統合する」アプローチです。
公式ドキュメントでは「Fusionは単体モデルでは不足するタスク──リサーチや専門批評、誤りの代償が大きいタスク──に使うべきツール」と適用範囲を明示されています。

Fusion APIの仕組み
Fusion APIの内部処理は、大きく分けて「パネル段階」と「ジャッジ段階」の2段構成になっています。本セクションでは、1リクエストが投げられてから最終回答が返るまでの流れを整理します。
パネル段階──1〜8モデルが並列実行する(標準プリセットは3モデル)
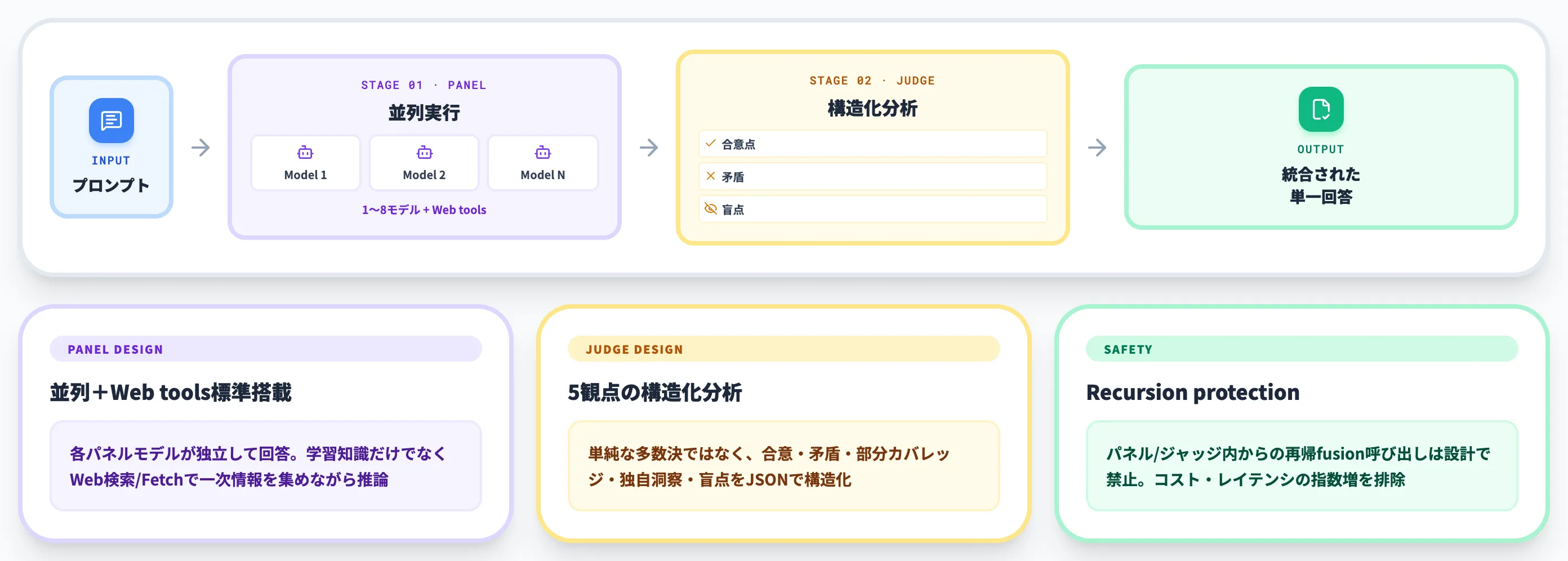
ユーザーがFusion APIにプロンプトを送ると、OpenRouterは指定されたパネル(1〜8モデル)にそのプロンプトを並列で同時投入します。
各モデルは独立して回答を生成しますが、このとき各モデルにはOpenRouterのサーバーツールである 「openrouter:web_search」 と 「openrouter:web_fetch」 がデフォルトで有効化されています。

そのため各パネルモデルは、自身の学習知識だけに頼るのではなく、Web検索と取得ツールで一次情報を集めながら回答を組み立てる動作になります。これにより、最新情報や引用が求められる深層リサーチタスクで高い精度を出せる設計です。
パネル各モデルがWeb検索や取得ツールを呼び出せる回数の上限は 「max_tool_calls」 パラメータで制御され、デフォルトは8回、範囲は1〜16回となっています。
ジャッジ段階──5観点の構造化分析
パネル全モデルが回答を返した後、ジャッジモデルが起動します。ジャッジは単純に「平均を取る」「投票で多数決を取る」のではなく、5つの観点で構造化分析を行います。

以下のリストで、ジャッジが実施する分析観点を整理しました。
-
合意点(consensus)
複数モデルが共通して言及している論点を抽出。「全モデルが同意した点」は高信頼度として扱う
-
矛盾(contradictions)
モデル間で見解が分かれた論点を明示。読者にとって判断材料になる「論争点」が可視化される
-
部分的カバレッジ(partial coverage)
一部のモデルだけが触れた論点。網羅性を高めるための補完材料
-
独自洞察(unique insights)
特定のモデルだけが提示した独自の視点。複数モデル合議の差別化価値が出る部分
-
盲点(blind spots)
どのパネルモデルも言及しなかった論点で、本来扱うべき内容。ジャッジが追加で補う
ジャッジモデルもWeb検索とWebフェッチが使えるため、必要に応じて一次情報を取りに行きながら分析を組み立てます。
最終回答生成──ジャッジ分析を踏まえた合成
ジャッジが構造化分析(JSON)を生成した後、呼び出し元のモデル(「model: "openrouter/fusion"」 ではジャッジモデル自身が兼務)がその分析を読み込み、最終回答を書きます。
この最終回答は単純な要約ではなく、合意点を高信頼として優先しつつ、矛盾点には根拠を添え、独自洞察を活かす形で構成されるのが特徴です。
この設計上、Fusion APIは「複数モデルが書いた回答を並べる」のではなく、「複数モデルの分析を踏まえてジャッジが新しく書き直す」アーキテクチャになります。
ユーザーから見ると、複数モデル合議の結果としては最も自然な単一の回答が返ってきます。
同一モデルでも効くプロセスの価値
OpenRouterが実施したDRACOベンチでは、Claude Opus 4.82本のパネル(同一モデルを2回走らせる構成)でOpus 4.8単体より6.7ポイント高いスコアを記録しました。
この結果について公式ブログは、「同じプロンプトを2回走らせても、推論パス・ツール呼び出し・ソース選択は毎回異なる」と説明しています。
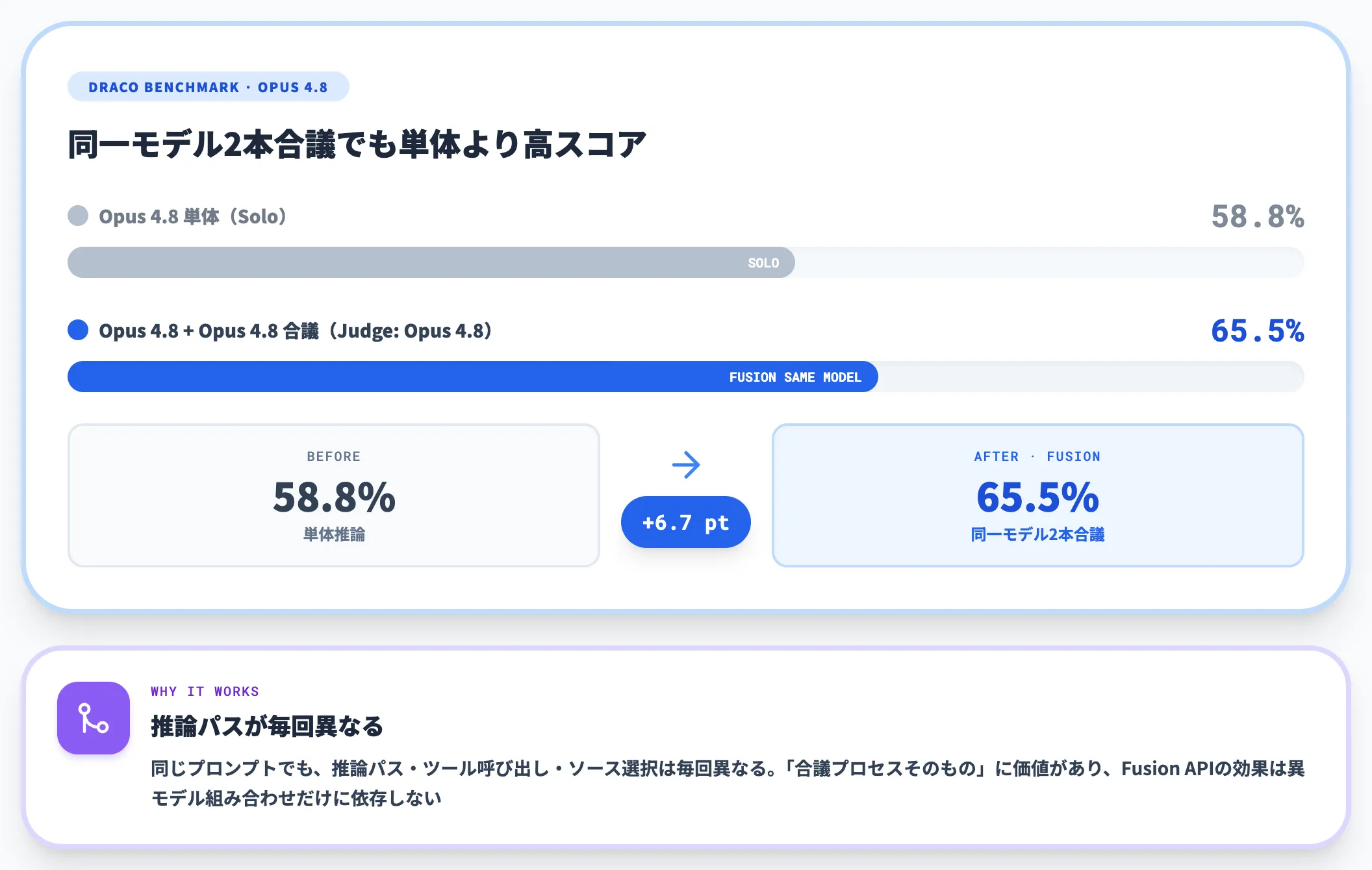
これは合議プロセス自体に価値があることを示す結果であり、Fusion APIの効果は「異なるモデルを組み合わせる」ことだけに依存していないと読み取れます。
ただし、ベンチで最高スコアを記録したのは異なるモデルを組み合わせた構成だったため、多様なモデル組成と合議プロセスは併用してこそ最大効果が出る、という整理になります。
Recursion protection──合議の入れ子は1段まで

パネルモデルやジャッジモデルから内部でFusion APIを再度呼び出すことは、設計上禁止されています。
OpenRouter公式docsによれば、「x-openrouter-fusion-depth」 ヘッダーで深さを管理し、内部fusion呼び出しを検知するとプラグインがツール注入を拒否します。
この仕組みにより「合議の中で更に合議を走らせる」という多段ネストは起きない設計で、コストとレイテンシが指数的に膨らむリスクが構造的に排除されています。
Fusion APIのプリセットと料金体系
Fusion APIは、ゼロからパネルを組まなくても標準で2つのプリセットを提供しています。
本セクションでは、QualityとBudgetそれぞれのモデル構成、料金体系の仕組み、カスタムパネル設定の余地までを整理します。

Quality preset──フロンティアモデル3本構成
Qualityプリセットは、「model: "openrouter/fusion"」 をプラグイン設定なしで呼ぶときのデフォルトです。OpenRouter公式docsでは、以下の「latest」エイリアスがパネルとジャッジに割り当てられます。
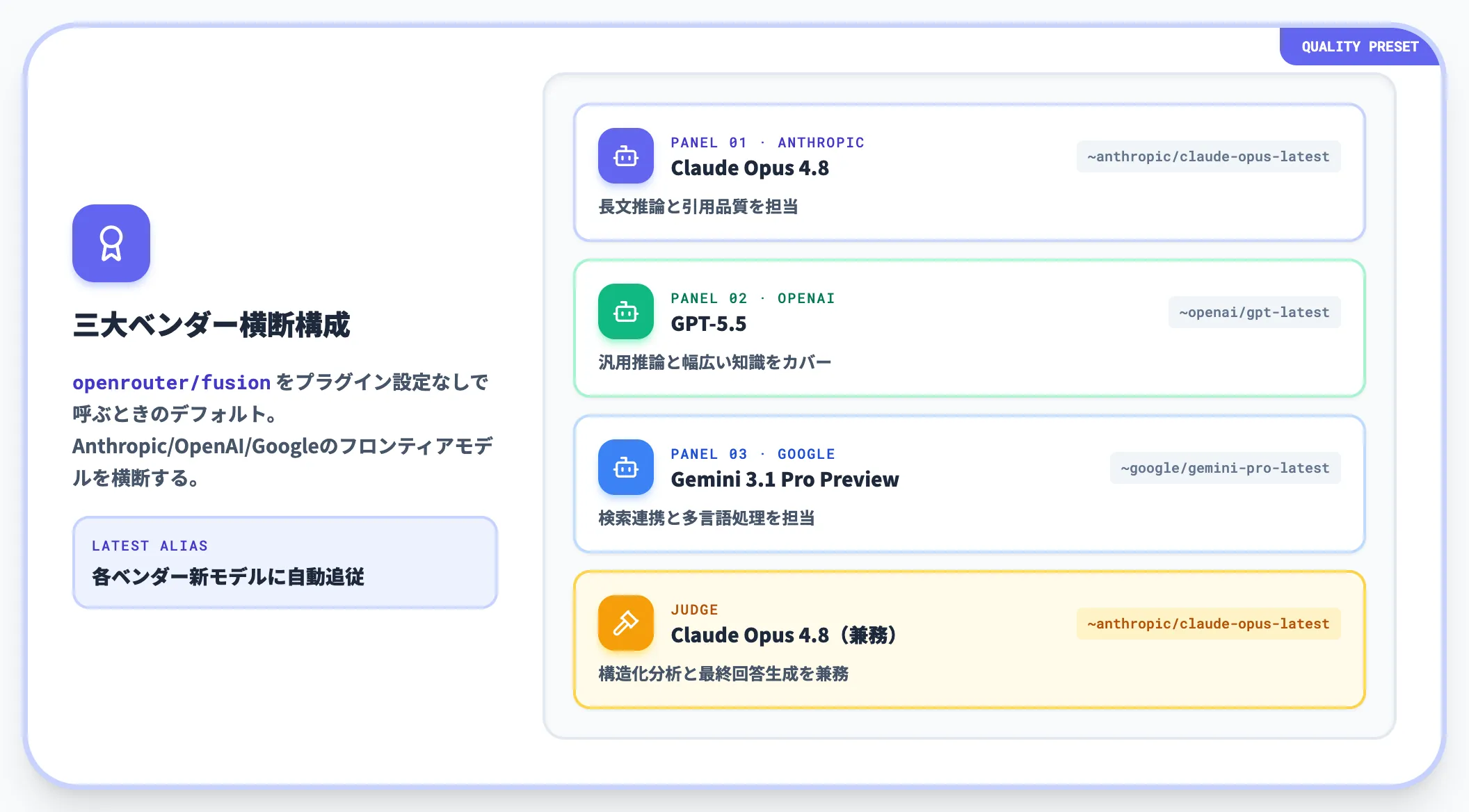
以下のリストで、Qualityプリセットの構成を整理しました。
-
パネル1: 「~anthropic/claude-opus-latest」
執筆時点ではClaude Opus 4.8。Anthropic系のフロンティアモデルとして、長文推論と引用品質を担当
-
パネル2: 「~openai/gpt-latest」
執筆時点ではGPT-5.5。OpenAI系フロンティアモデルとして、汎用的な推論と幅広い知識をカバー
-
パネル3: 「~google/gemini-pro-latest」
執筆時点ではGemini 3.1 Pro Preview。Google系フロンティアモデルとして、検索連携と多言語処理を担当
-
ジャッジ: 「~anthropic/claude-opus-latest」
パネル先頭と同じClaude Opus latest。構造化分析と最終回答生成を兼務
Qualityプリセットは「Anthropic・OpenAI・Googleの三大ベンダーのフロンティアモデルを横断する」構成になっています。
「latest」エイリアスを使っているため、各ベンダーが新モデルをリリースするたびに自動追従する仕組みになっています。
Budget preset──廉価モデル3本でフロンティア級を狙う
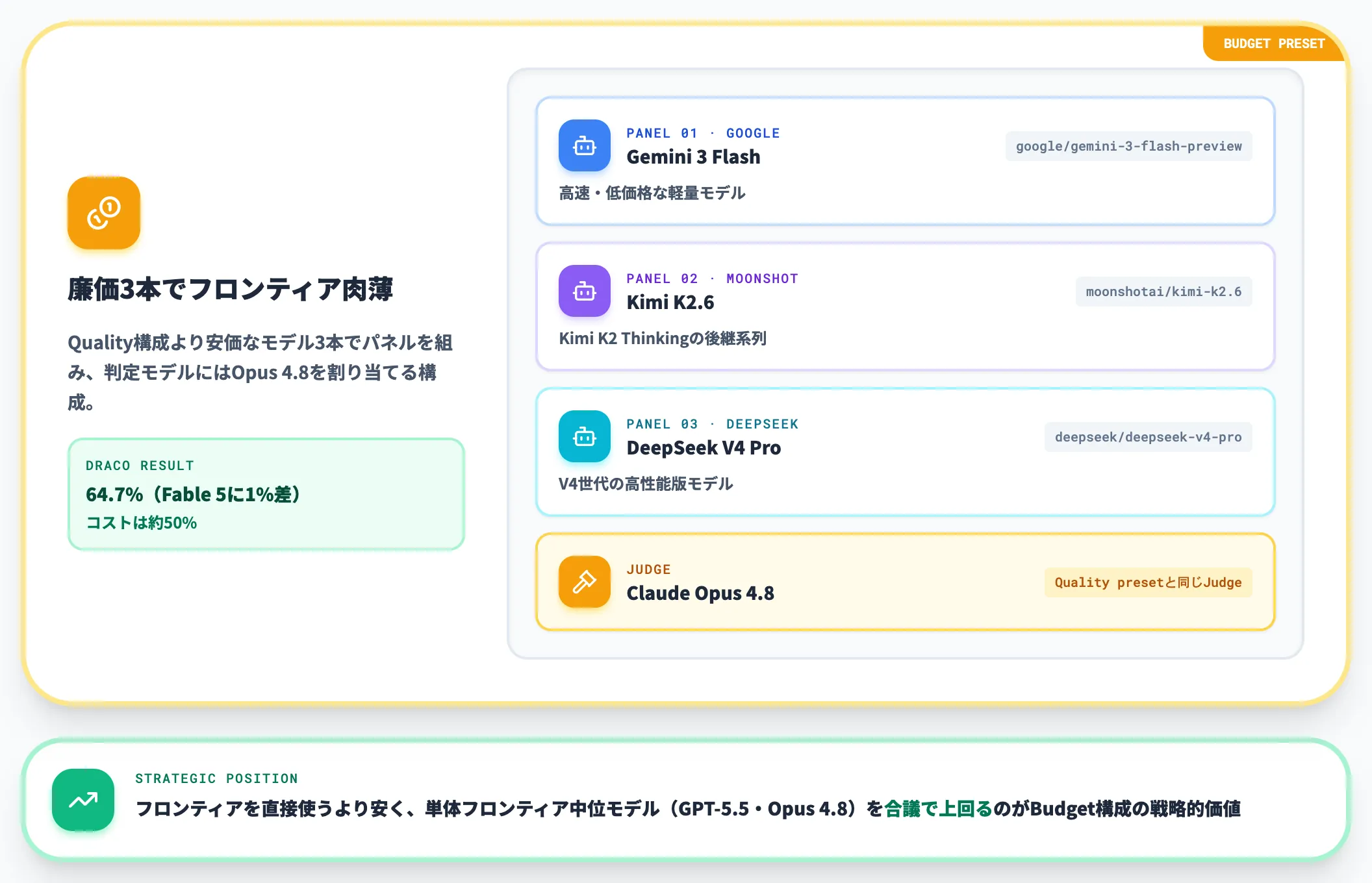
Budgetプリセットは、Quality構成より安価なモデル3本でパネルを組みます。OpenRouter公式ブログがDRACOベンチで実証したBudget panelの構成は以下の通りです。
- Gemini 3 Flash(「google/gemini-3-flash-preview」)
- Kimi K2.6(「moonshotai/kimi-k2.6」)
- DeepSeek V4 Pro(「deepseek/deepseek-v4-pro」)
判定モデルにはOpus 4.8が割り当てられています。Budget panelで使われているKimiはKimi K2 Thinkingの後継系列で、DeepSeek V4 ProはDeepSeek V4世代の高性能版モデルです。
このBudget構成は、後述するDRACO 100タスクで「Fable 5に1%差の64.7%」「コストはFable 5の約半額」というスコアを出しています。
フロンティアモデルを直接使うより安く、しかも単体フロンティアモデルの中位モデル(GPT-5.5やOpus 4.8)を上回るというのが、Budget構成の戦略的な意味合いです。
料金体系──pass-through合算という基本構造
Fusion APIの料金は、パネル各モデルの実行料金とジャッジモデルの実行料金、そしてWeb検索・Webフェッチの実行料金をすべて合算したpass-through方式です。OpenRouterのFusionモデルページでは「リクエストは個別モデルではなく、その下にある複数completionの合計として課金される」と明記されています。

具体的には、3モデルパネル+ジャッジで4completion分、5モデルパネル+ジャッジで6completion分の料金が発生し、Web toolsの実行回数に応じて追加コストが乗ります。実際に何モデルが走ったかはOpenRouterのActivityページで確認可能です。
以下の表で、QualityとBudgetそれぞれの設計差を整理しました。
| 観点 | Quality preset | Budget preset |
|---|---|---|
| 構成モデル | Opus 4.8・GPT-5.5・Gemini 3.1 Pro | Gemini 3 Flash・Kimi K2.6・DeepSeek V4 Pro |
| 価格帯 | フロンティアモデル3本のpass-through合算 | 廉価モデル3本でFable 5の約50%コスト |
| 強み | 最高水準の品質を確実に取りに行く | コスト効率重視で「フロンティア級にどこまで肉薄できるか」を狙う |
| 適した用途 | 法務・医療・金融・専門批評など誤答コストが高い文脈 | 大量バッチ処理・ナレッジリサーチの一次稿生成 |
| 留意点 | 1リクエストあたり数倍〜十数倍のコストになる場合がある | Fable 5級ではあるが、最高水準のQuality構成には及ばない |
この比較から分かるのは、Qualityは「品質を上限まで取りに行く」構成、Budgetは「コスト効率で勝負する」構成という棲み分けです。実務では、ファクトの正確さが法的責任に直結する文脈ならQuality、量を回す調査や下書きならBudget、という選び分けが基本線になります。
カスタムパネル──「analysis_models」 と 「model」 で完全オーバーライド

プリセットを使わず、自社のユースケースに合わせて独自のパネルを組むこともできます。「analysis_models」 で1〜8モデルを指定し、「model」 でジャッジモデルを指定すれば、Quality/Budgetの組み合わせを無視してフルカスタムが可能です。
例えば「特定ドメインに強いオープンソースモデル3本」「同じモデルを3本並列に並べて合議プロセスの価値だけを取りに行く」「ジャッジは別ベンダーの軽量モデル」のような任意の組み合わせも実装できます。具体的な指定方法は次の「使い方」セクションで扱います。
DRACO 100タスクで見るFusion APIの性能
OpenRouterはFusion APIの性能を、Perplexity AIが開発した深層リサーチベンチマーク「DRACO」で評価しています。本セクションでは、ベンチの設計・全モデルのスコア・読み解きを整理します。
DRACOとは──深層リサーチに特化した100タスク評価
DRACOはPerplexity AIが開発したベンチで、深層リサーチに必要な推論・ツール利用・知識を組み合わせたタスクを100問用意し、回答品質を多面評価する設計です。
以下のリストで、DRACOの構造を整理しました。
-
100タスク・10ドメイン
学術研究・金融・法律・医療・テクノロジー・UXデザイン・一般知識・needle-in-a-haystack検索・パーソナルアシスタント・製品比較
-
約39基準・4カテゴリ
Factual Accuracy(~20基準)/Breadth & Depth(~9基準)/Presentation Quality(~6基準)/Citation Quality(~5基準)
-
負の重み(マイナス点)あり
誤情報や危険な医療アドバイスなどは大きな減点。冗長に間違ったことを書くモデルほどスコアが下がる設計
-
判定モデルが3回独立採点
各回答を基準ごとに3回採点し、平均0-100スコアを算出。OpenRouterはGemini 3.1 Pro Previewを判定モデルとして採用
整理すると、DRACOは「回答が長ければ高得点」ではなく、「正確で網羅的で引用根拠のある回答」を評価する設計です。Fusion APIが狙う深層リサーチタスクとの相性が良いため、合議プロセスの効果を測るベンチとして選ばれたという位置づけになります。

スコア全件──Fusion構成と単体モデルの比較
OpenRouter公式ブログが公開したDRACO 100タスクのスコアは以下の通りです。
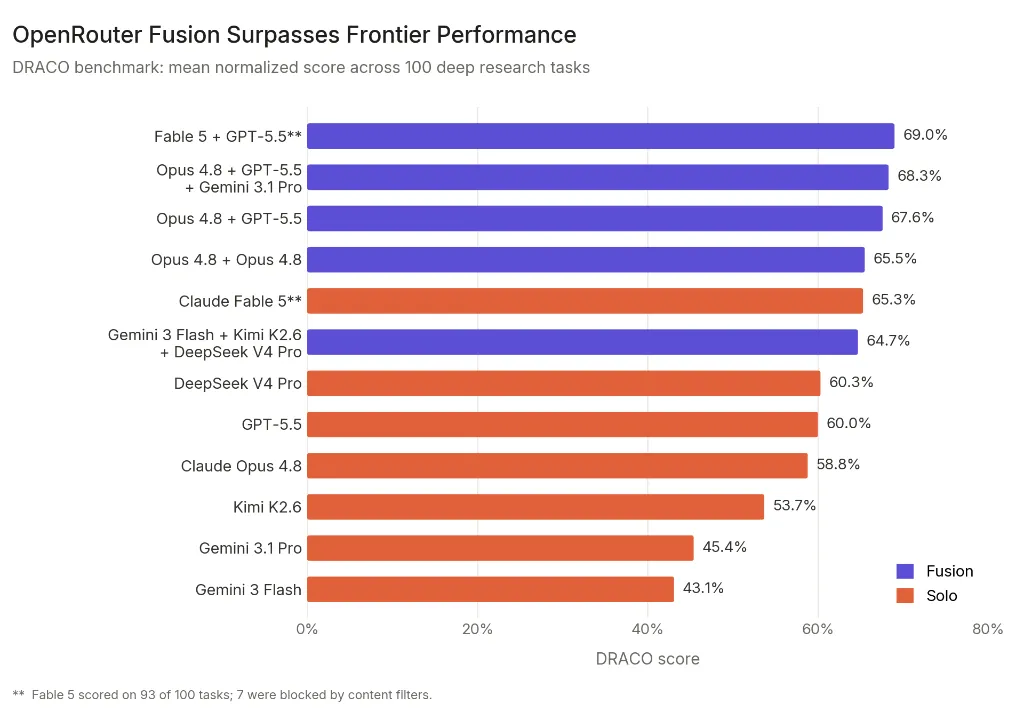
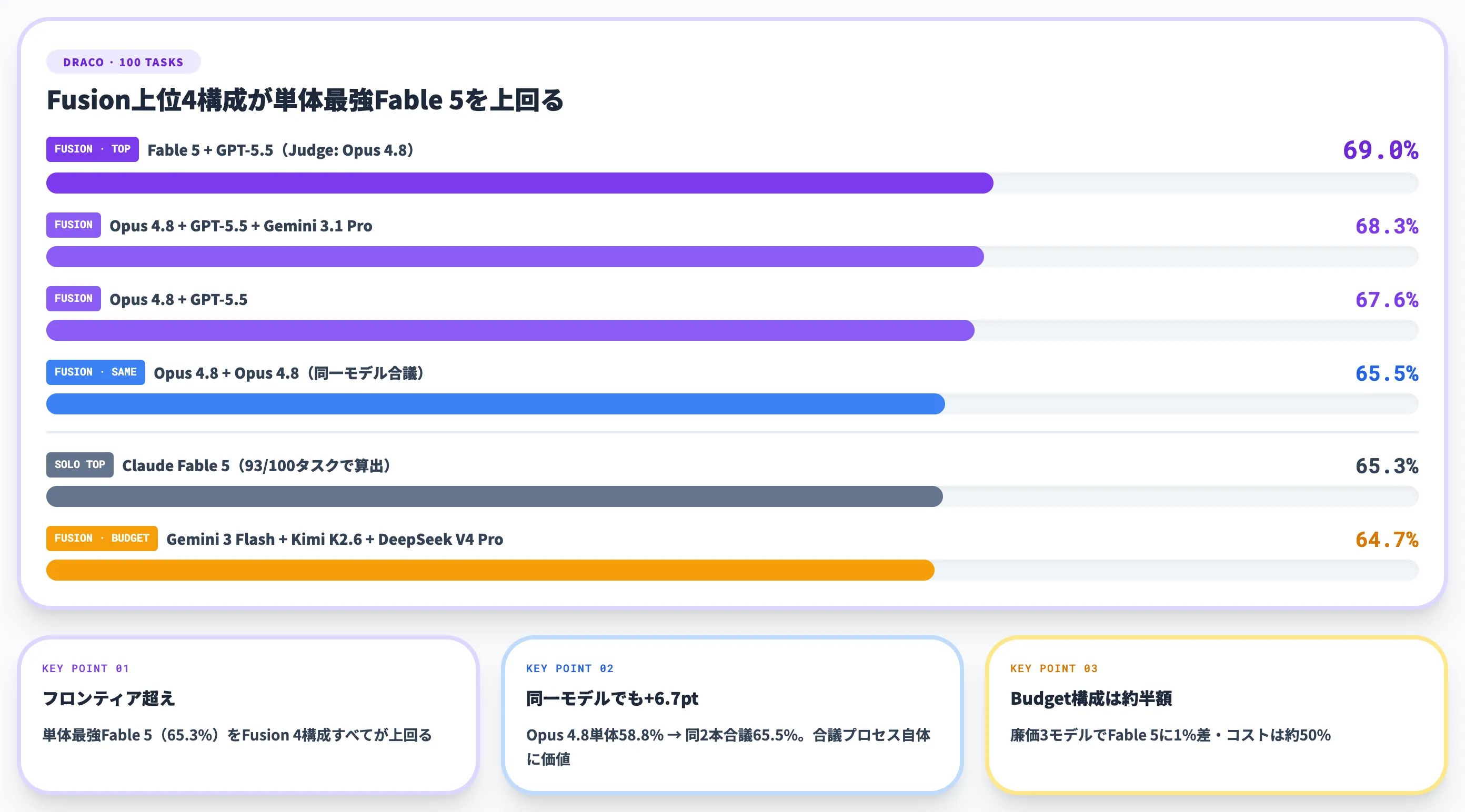
DRACO 100タスクの平均正規化スコア比較。紫=Fusion構成、オレンジ=単体モデル(出典:OpenRouter Blog)
このグラフが示すように、上位4ポジションのうち3つを「複数モデルを組み合わせたFusion構成」が占めており、最上位の「Fable 5+GPT-5.5」は単体最強のFable 5を3.7ポイント上回っています。
さらに同一モデル2本のOpus 4.8+Opus 4.8(65.5%)が、単体Opus 4.8(58.8%)から大きくジャンプしている点も、合議プロセスそのものに価値があることを視覚的に示しています。
| 種別 | 構成 | スコア |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5(Judge: Opus 4.8) | 69.0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro(Judge: Opus 4.8) | 68.3% |
| Fusion | Opus 4.8 + GPT-5.5(Judge: Opus 4.8) | 67.6% |
| Fusion | Opus 4.8 + Opus 4.8(Judge: Opus 4.8)=同一モデル合議 | 65.5% |
| Solo | Claude Fable 5(※93/100タスクで算出) | 65.3% |
| Fusion | Budget: Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro(Judge: Opus 4.8) | 64.7% |
| Solo | DeepSeek V4 Pro | 60.3% |
| Solo | GPT-5.5 | 60.0% |
| Solo | Claude Opus 4.8 | 58.8% |
| Solo | Kimi K2.6 | 53.7% |
| Solo | Gemini 3.1 Pro | 45.4% |
| Solo | Gemini 3 Flash | 43.1% |
なお、Fable 5の単体スコア65.3%は100タスク中93タスクで算出された数値である点は注意が必要です。
Fable 5のコンテンツフィルターが7タスクの実行をブロックしたため、OpenRouterは「未完了タスクをOpus 4.8にフォールバックさせず、Fable 5固有のパフォーマンスを正確に示すために93タスクのスコアを採用した」と説明しています。
直接比較する際は、Fable 5のスコアは他モデルと条件がやや異なる点を理解しておく必要があります。
読み解き──合議プロセスそのものに価値がある
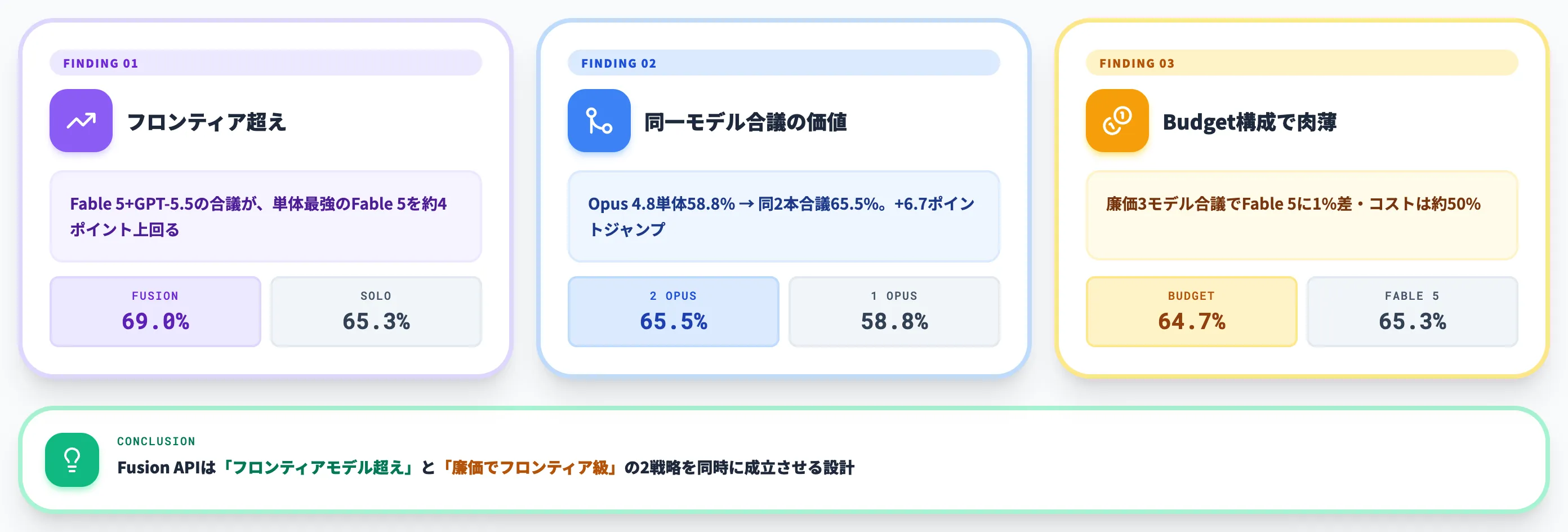
この結果から読み取れるポイントは3つあります。
-
フロンティアモデル単体を合議が上回る
Fable 5+GPT-5.5の合議(69.0%)は、Fable 5単体(65.3%)を約4ポイント上回り、Opus 4.8+GPT-5.5の組み合わせ(67.6%)もFable 5単体を超えています。
-
同一モデル2本でも単体より高いスコアが出る
Opus 4.8単体は58.8%でしたが、Opus 4.8を2本パネルに置いた構成は65.5%と、6.7ポイントのジャンプを記録しました。
「同じプロンプトを2回走らせても、推論パス・ツール呼び出し・ソース選択は毎回変わる」というメカニズムが、合議プロセス自体の価値として現れた形です。 -
Budget構成でFable 5に肉薄できる
Gemini 3 FlashとKimi K2.6とDeepSeek V4 Proの組み合わせ(64.7%)は、Fable 5単体(65.3%)に約1%差まで届き、しかもOpenRouterの説明では「Fable 5のコストの約50%」で済むとされています。
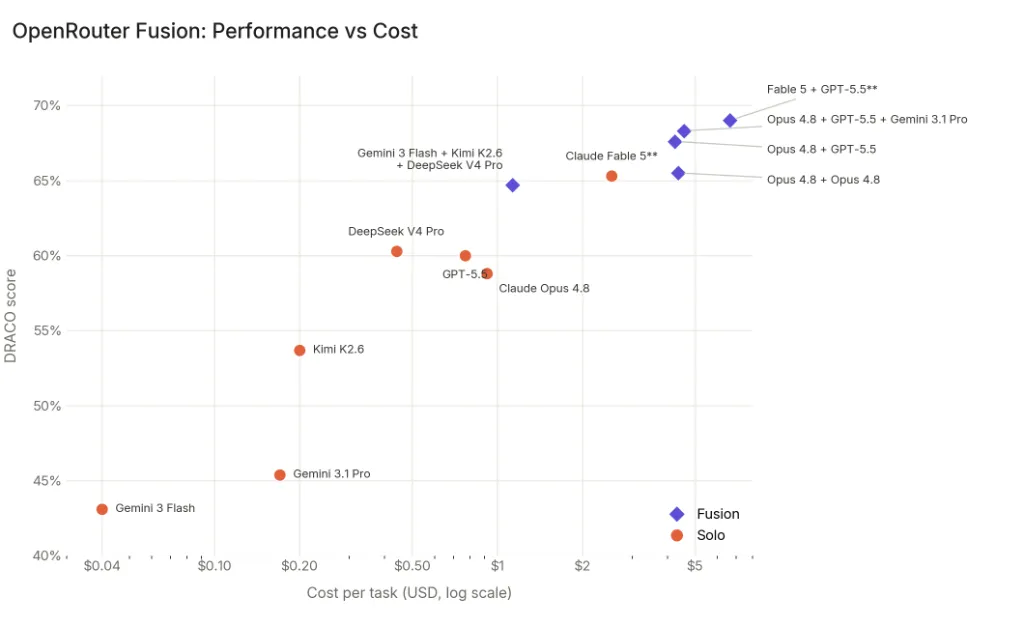
DRACOスコア(縦軸)とタスクあたりコスト(横軸・USD・対数スケール)の関係。Budget panelがフロンティア級スコアと廉価ポジションを両立している(出典:OpenRouter Blog)
横軸が対数スケールのコスト、縦軸がスコアで、Budget panel(Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro)はClaude Fable 5単体の左側(より安いコスト)に同じ縦位置で並んでいます。コスト効率を考えると、フロンティア級のスコアを廉価ポジションで実現していることが視覚的に確認できます。
ここから読み取れるのは、Fusion APIが「フロンティアモデル超え」と「廉価モデルでフロンティア級」の2つの戦略を同時に成立させる設計だという点です。
ベンチ実施時の注意点──汚染対策と判定モデルの差
OpenRouterはベンチ実施時に、パネルモデルのWeb検索がDRACOの評価ルーブリックを偶然ヒットしてしまう「汚染リスク」を発見し、「excluded_domains」 と 「blocked_domains」 で関連ドメインを除外しています。公開されているスコアは全て除外設定後のものです。
また、DRACO原典論文は判定モデルとしてGemini 3 Proを使っていますが、OpenRouterはより新しいGemini 3.1 Pro Previewを判定モデルとして採用しているため、OpenRouterの公開スコアはDRACO原典の数値とは直接比較できない点も公式ブログに明記されています。
あくまで「同条件下でのFusion vs 単体モデルの相対比較」として読むのが正しい姿勢です。

Fusion APIの使い方
Fusion APIは、最短ルートから細かいカスタムまで3つのエントリーポイントが用意されています。本セクションでは、それぞれの呼び出し方とパラメータの調整方法を整理します。
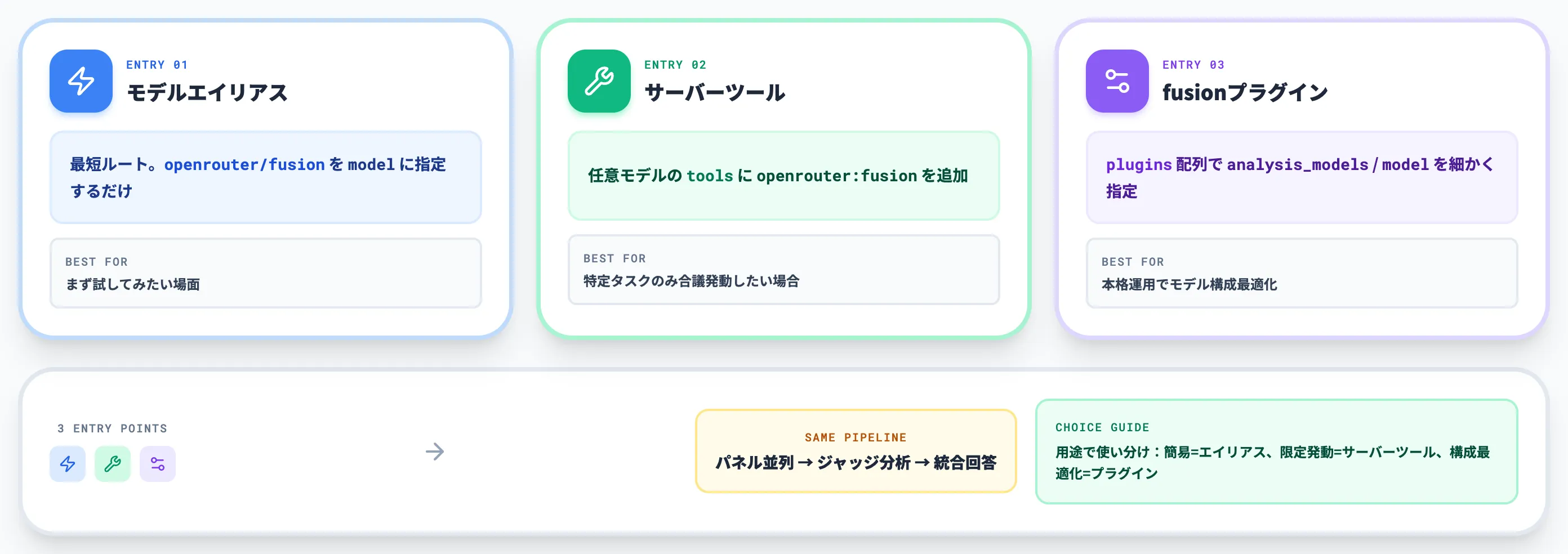
3つのエントリーポイント──モデルエイリアス・サーバーツール・プラグイン
OpenRouter公式docsによれば、Fusion APIは以下3つの呼び出し方が用意されており、内部的にはすべて同じパイプラインに繋がります。
以下のリストで、3つのエントリーポイントを整理しました。
-
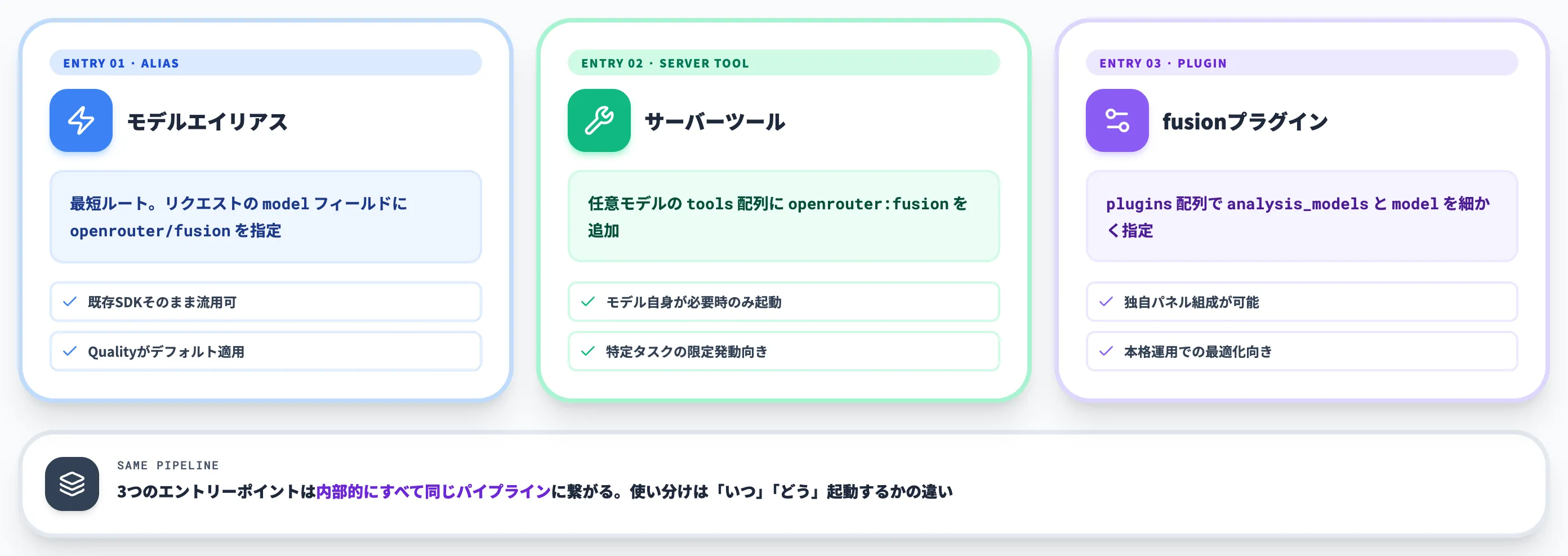
モデルエイリアス(最短ルート)
リクエストの 「model」 フィールドに 「"openrouter/fusion"」 を指定するだけ。プリセットはQualityがデフォルトで適用される
-
サーバーツール
任意のモデルに対し、「tools」 配列に 「{"type": "openrouter:fusion"}」 を追加する。モデルが「合議が必要」と判断した場合のみFusionを起動する仕組み
-
fusionプラグイン
「plugins」 配列で 「{"id": "fusion", ...}」 を指定し、「analysis_models」 や 「model」(judge)を細かくカスタマイズする。Quality/Budgetをオーバーライドして独自パネルを組む場合に使う
まず試したいだけならモデルエイリアス、特定タスクでのみ合議を発動させたいならサーバーツール、本格運用でモデル構成を最適化したいならプラグイン、という使い分けが基本線です。
最短ルート──モデルエイリアスで呼ぶ

OpenAI互換のChat Completionsエンドポイントに対して、以下のように 「model」 だけを切り替えれば、Quality presetでFusionが起動します。
{
"model": "openrouter/fusion",
"messages": [
{ "role": "user", "content": "What are the strongest arguments for and against carbon taxes?" }
]
}
このアプローチの利点は2つあります。
-
既存のOpenAI SDKやLangChainクライアントをそのまま流用できる
OpenRouterはOpenAI互換APIなので、エンドポイントとAPIキーとmodel名を差し替えるだけで動きます。新しいSDKの学習コストはありません。
-
Fusion発動の判断をOpenRouter側に任せられる点です。プロンプトが短く合議が不要な場合は、判定モデルが直接答えることもあります(モデルエイリアス経由ではプラグイン経由と同じく、「openrouter:fusion」 ツールを呼ぶかどうかをモデル自身が判断する設計)。
カスタムパネル──「analysis_models」 と 「model」 で独自構成を組む
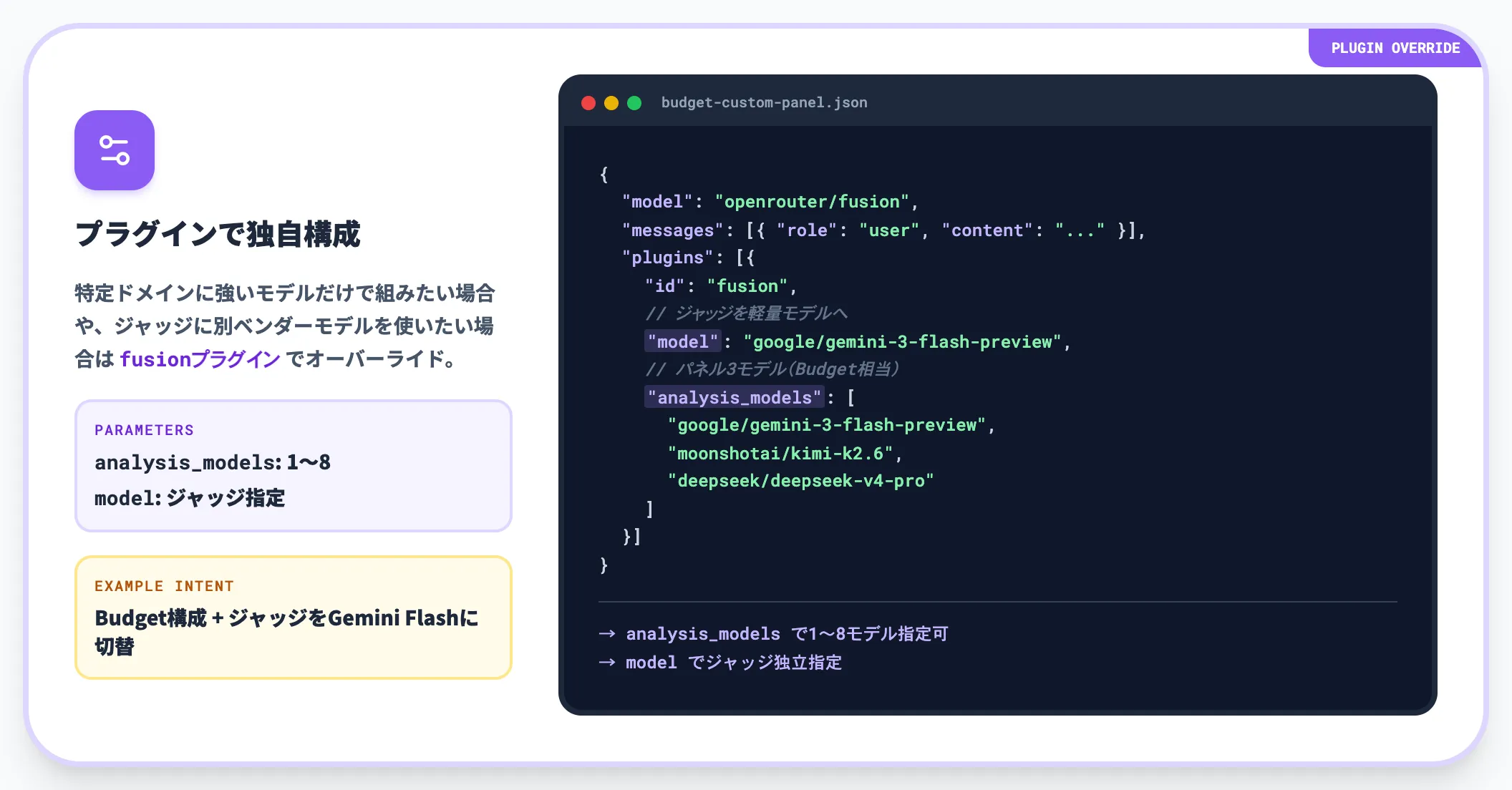
特定ドメインに強いモデルだけでパネルを組みたい場合や、ジャッジに別ベンダーのモデルを使いたい場合は、fusionプラグインを使ってオーバーライドします。
{
"model": "openrouter/fusion",
"messages": [{ "role": "user", "content": "..." }],
"plugins": [{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshotai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}]
}
この設定例は、Budget presetと同じパネルをカスタム指定で組み、ジャッジをGemini 3 Flashに切り替えた構成です。「analysis_models」 は1〜8モデルまで指定でき、「model」 でジャッジを別途指定できます。
主要パラメータ一覧
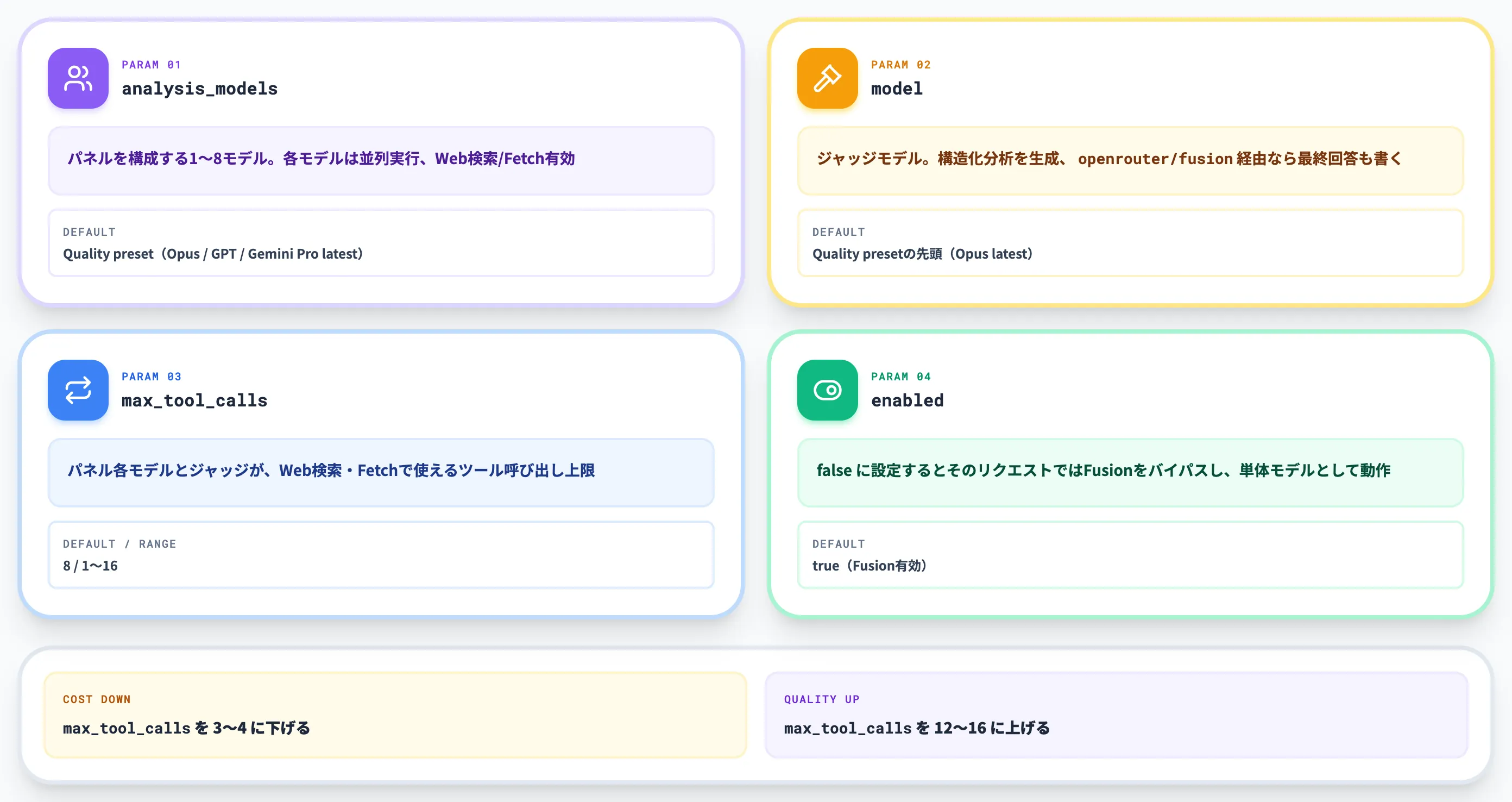
fusionプラグインで使える主要パラメータを表でまとめました。
| パラメータ | デフォルト | 説明 |
|---|---|---|
| 「analysis_models」 | Quality preset(Opus latest・GPT latest・Gemini Pro latest) | パネルを構成する1〜8モデル。各モデルは並列実行され、Web検索とWebフェッチが有効 |
| 「model」 | Quality presetの先頭(Opus latest) | ジャッジモデル。構造化分析を生成し、「openrouter/fusion」 経由なら最終回答も書く |
| 「max_tool_calls」 | 8 | パネル各モデルとジャッジが、Web検索・Webフェッチで使えるツール呼び出しの上限。範囲1〜16 |
| 「enabled」 | true | falseに設定するとそのリクエストではFusionをバイパスし、単体モデルとして動作 |
この表が示すように、本格運用ではパネル構成・ジャッジ選定・ツール呼び出し回数の3点が主な調整パラメータになります。
例えばコストを抑えたい場合は 「max_tool_calls」 を3〜4程度に下げる、引用品質を上げたい場合は逆に12〜16に上げる、といった調整が可能です。
適不適の判断──Fusion発動が過剰になるケース
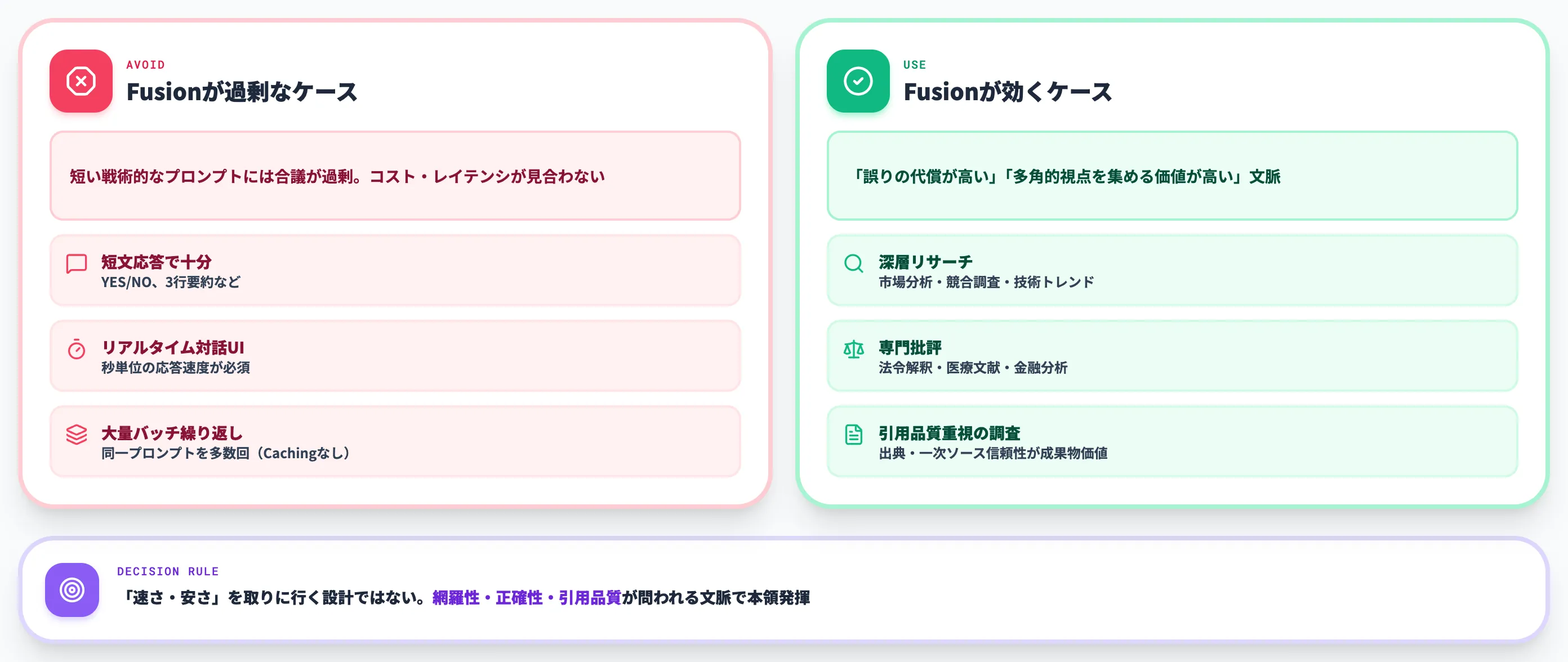
OpenRouter公式docsは「短い戦術的なプロンプトにはFusionは過剰」と明示しています。具体的には以下のようなケースでFusion発動を避けるべきです。
- 短文応答で十分なタスク(「YES/NOを返す」「3行で要約する」など)
- リアルタイム対話UIで秒単位の応答速度が必要なケース
- 同じプロンプトを大量に繰り返すバッチ処理(Response Cachingを使わない場合はコストが線形に増えやすい)
逆にFusionが効くのは、深層リサーチ・専門批評・引用品質が問われる調査・複数の論点を比較検討する分析タスクなど、「誤りの代償が高い」「多角的な視点を集める価値が高い」文脈です。
Recursion protection──再帰呼び出しは設計で防がれる
Fusionのパネル内モデルやジャッジモデルが、内部で再度 「openrouter:fusion」 を呼ぶことは設計で禁止されています。
OpenRouter公式docsによれば、「x-openrouter-fusion-depth」 ヘッダーで深さを管理し、深さ1の状態で内部fusion呼び出しが検知されるとプラグインがツール注入を拒否します。
「合議の中で更に合議を走らせる」多段ネストは構造的に発生せず、コストとレイテンシが指数的に増えるリスクは排除されています。実装側で 「max_tool_calls」 以外の暴走対策を自前で組み込む必要はありません。
他のAIゲートウェイとの違い
AIゲートウェイ市場には複数のプレイヤーがいますが、それぞれ役割が異なります。
本セクションでは、Fusion APIと主要競合(Vercel AI Gateway・LiteLLM・Portkey)の構造的な違いを整理します。
AIゲートウェイ市場の現在地
2025年以降、複数LLMを統一APIで扱う「AIゲートウェイ」市場は急速に成熟してきました。Vercel AI GatewayがGA、Portkeyがエンタープライズ向けに伸び、LiteLLMがOSSとして定番化、Inworld Routerなどの新規プレイヤーも参入しています。
ただし、これらの主流ゲートウェイは公式ドキュメント上、ルーティング・フォールバック・統制・観測の機能が中心です。
Fusion APIが取った「1リクエストで複数モデルを合議させる」アプローチは、本記事で比較する主要ゲートウェイの中では珍しいポジションになっています。
4社比較──主目的・モデル選択方式・強み・Fusionとの違い・向く用途
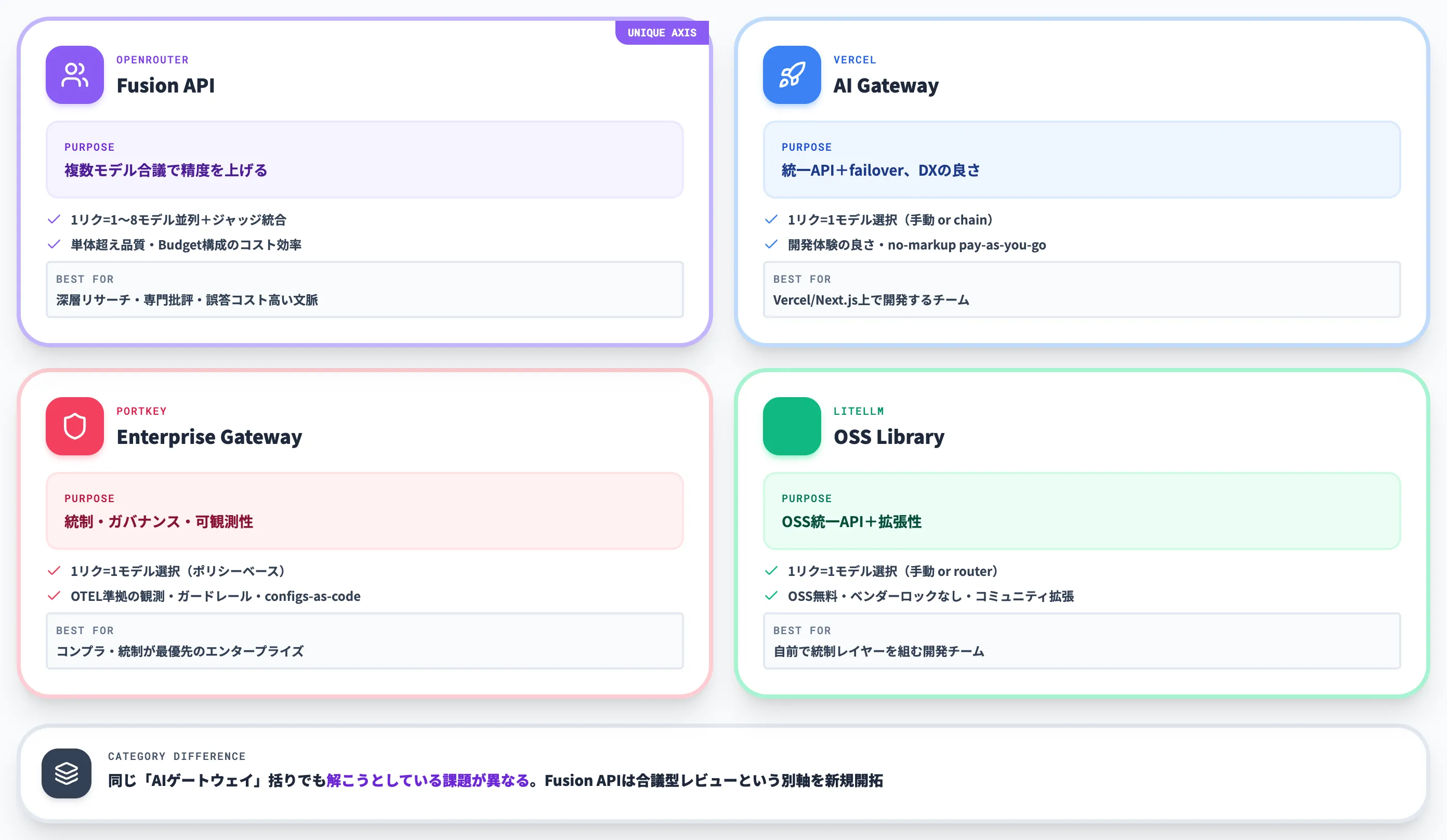
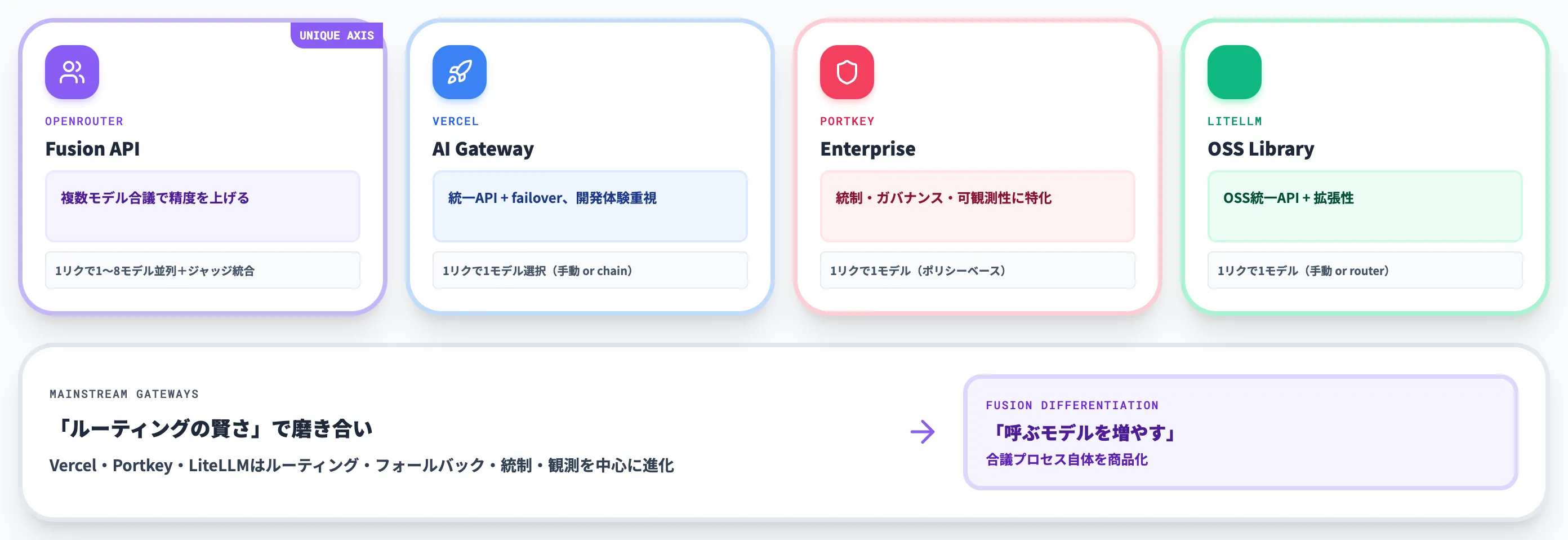
以下の表で、主要4ゲートウェイの設計差を整理しました。各社それぞれ「何を主目的にしているか」が大きく異なる点を押さえると棲み分けが明確になります。
| サービス | 主目的 | モデル選択方式 | 強み | Fusionとの違い | 向く用途 |
|---|---|---|---|---|---|
| OpenRouter Fusion API | 複数モデル合議で精度を上げる | 1リクエストで1〜8モデル並列+ジャッジ統合(標準は3モデル) | 単体モデル超えの品質、Budget構成のコスト効率 | 「複数同時実行+合議」を標準APIとして提供 | 深層リサーチ・専門批評・誤答コストが高い文脈 |
| Vercel AI Gateway | 統一API+failover | 1リクエスト=1モデル選択(手動またはフォールバックチェーン) | 開発体験の良さ、no-markupなpay-as-you-go料金 | 単体モデル選択型。標準合議APIは備えない | Vercel/Next.js上でAI機能を出す開発チーム |
| Portkey | 統制・ガバナンス・可観測性 | 1リクエスト=1モデル選択(ポリシーベース) | OTEL準拠の観測、ガードレール、configs-as-code | 単体モデル選択+統制重視。標準合議APIは備えない | コンプラ・統制が最優先のエンタープライズ |
| LiteLLM | OSS統一API+拡張性 | 1リクエスト=1モデル選択(手動またはルーター) | OSS無料、ベンダーロックなし、コミュニティ拡張 | 単体モデル選択型。標準合議APIは備えない | 自前で統制レイヤーを組む開発チーム |
この比較から分かるのは、各サービスは「同じAIゲートウェイ」という括りでありながら、解こうとしている課題が異なるという点です。
Fusion APIが取った独自ポジション
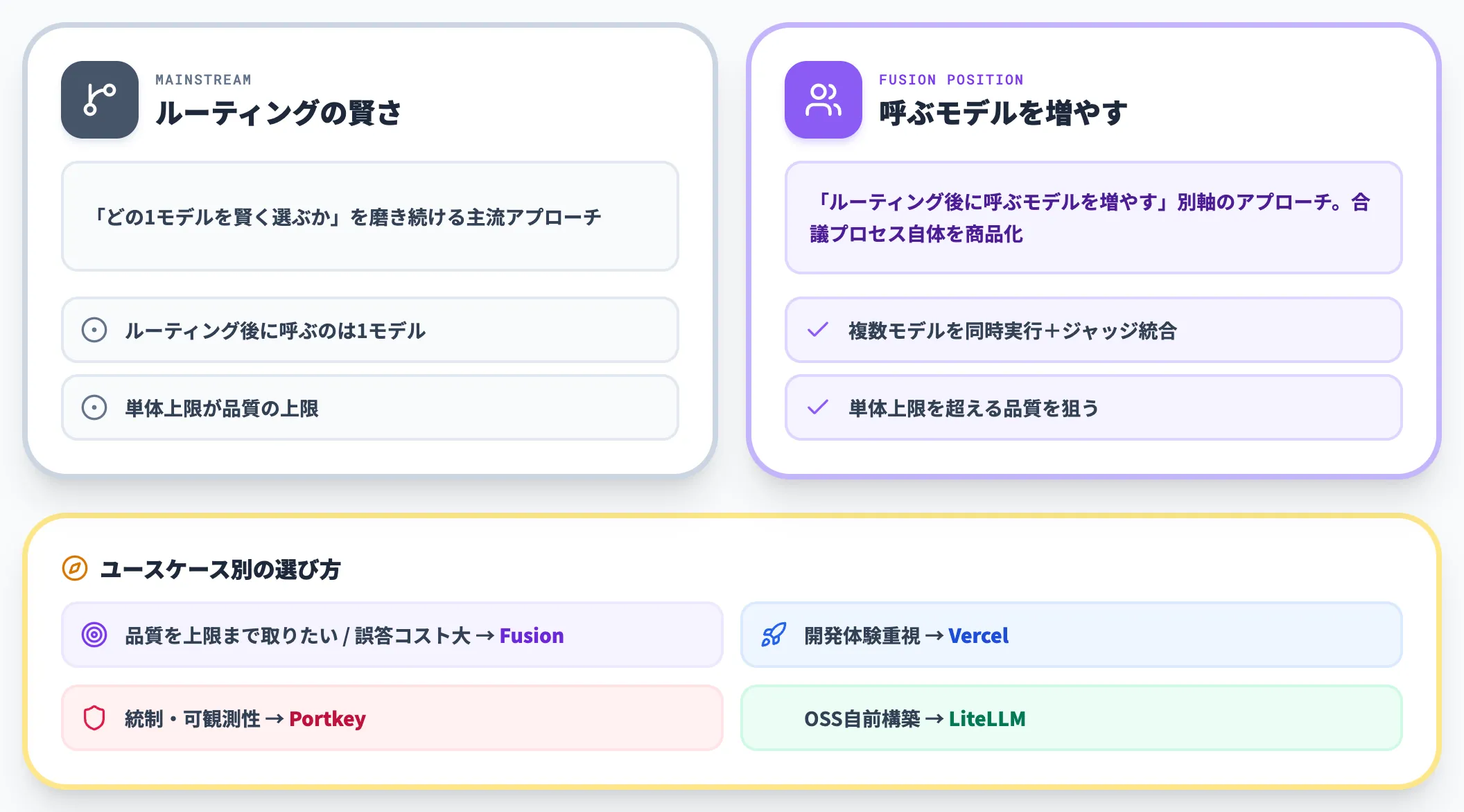
主流ゲートウェイは「ルーティングの賢さ」を磨いてきましたが、ルーティング後に呼ばれるのは1モデルです。Fusion APIは**「ルーティング後に呼ぶモデルを増やす」**という別軸のアプローチを取り、合議プロセスそのものを商品化しています。
品質を上限まで取りに行きたい文脈や、誤答の代償が大きい高stakeなタスクで、Fusion APIは他ゲートウェイにはない選択肢を提供します。
一方で、開発体験や統制・可観測性、コスト最適化の単純な経路を取りに行きたい場合は、それぞれVercel・Portkey・LiteLLMの方が適切なケースが多いでしょう。
併用パターン──ゲートウェイ+Fusionを2層で組む
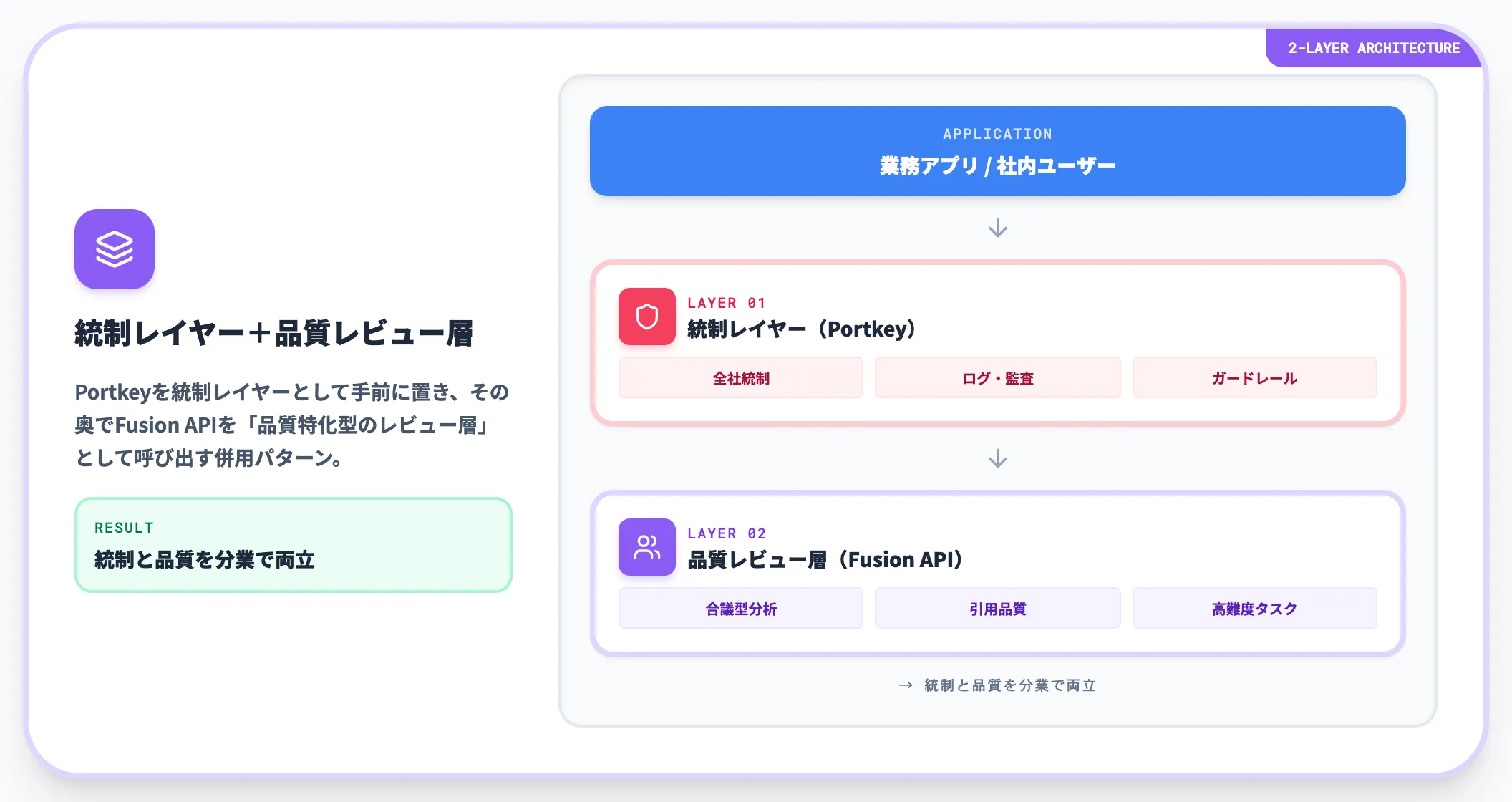
実務では、これらは排他関係ではなく併用するアーキテクチャも成立します。例えば、Portkeyを統制レイヤーとして手前に置き、その奥でOpenRouter Fusion APIを「品質特化型のレビュー層」として呼び出すパターンです。
このような2層構成では、Portkeyが全社統制・ログ・ガードレールを担当し、Fusionが高難度タスクでの品質保証を担当する役割分担になります。
Fusion APIを業務に組み込む判断軸
ここからは、Fusion APIを実際の業務に組み込む際の判断軸を整理します。AI総合研究所として複数のAI導入支援を進めてきた経験から、適用領域・注意点・推奨アーキテクチャの3点を示します。
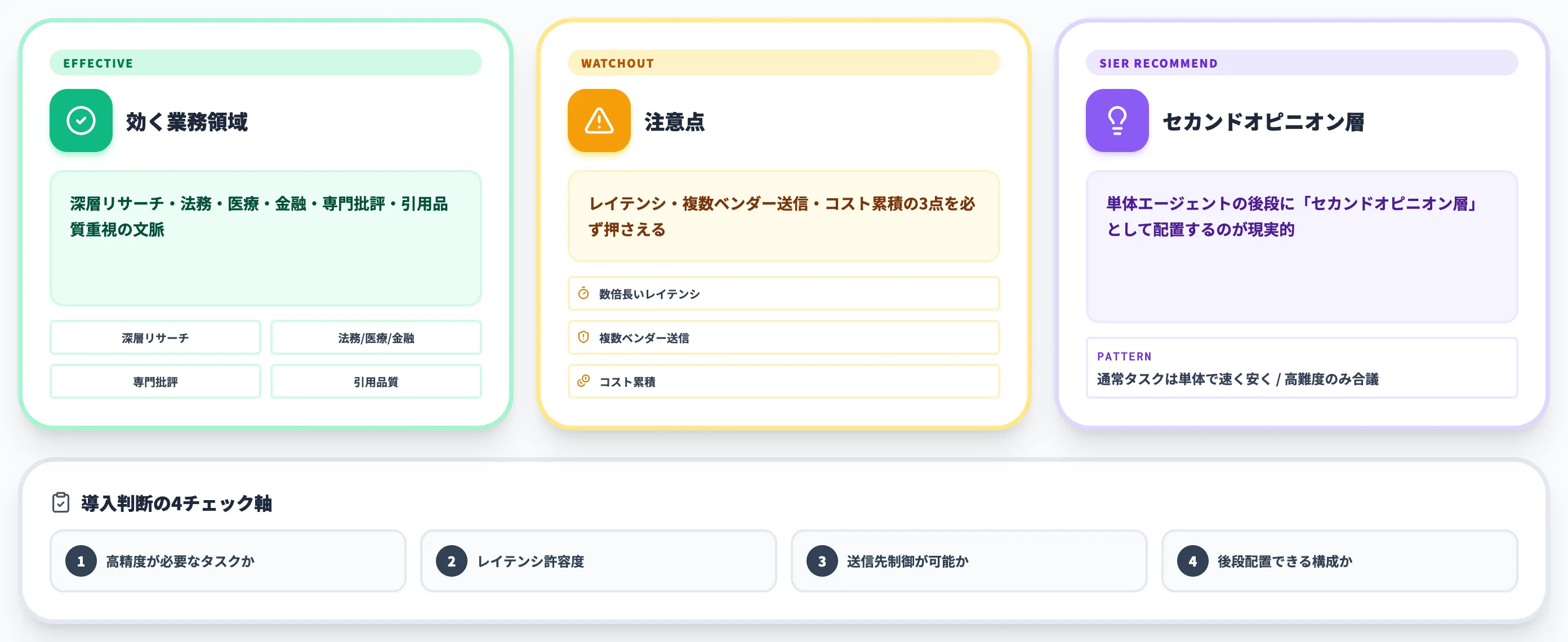
Fusion APIが効く業務領域
Fusion APIの特性──複数モデル並列実行・構造化分析・Web toolによる一次情報収集──を踏まえると、効果が最大化される業務領域は限定的です。
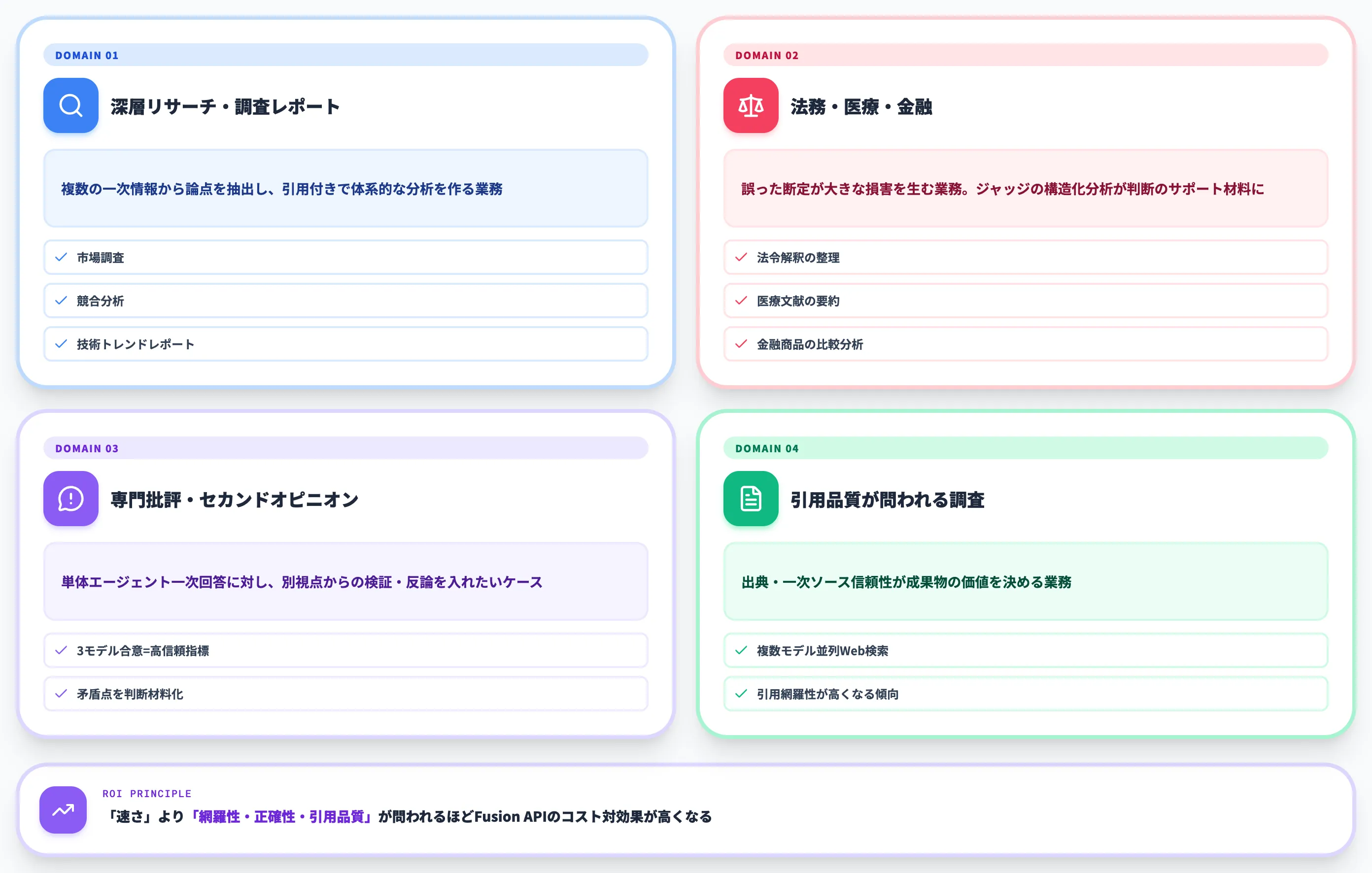
以下のリストで、Fusion APIが効く代表的な業務文脈を整理しました。
-
深層リサーチ・調査レポート作成
複数の一次情報から論点を抽出し、引用付きで体系的な分析を作る業務。市場調査・競合分析・技術トレンドレポートなどが該当
-
法務・医療・金融など誤答コストが高い文脈
法令解釈の整理、医療文献の要約、金融商品の比較分析など、誤った断定が大きな損害を生む業務。ジャッジの構造化分析(合意・矛盾・盲点)が法的・専門的判断のサポート材料になる
-
専門批評・セカンドオピニオン用途
単体エージェントが出した一次回答に対し、別の視点からの検証・反論を入れたいケース。「3モデルが合意した点は信頼度が高い」という指標が判断材料になる
-
引用品質が問われる調査
出典の正確性・一次ソースの信頼性が成果物の価値を決める業務。パネル各モデルがWeb検索とフェッチを並列実行するため、引用網羅性が単体モデルより高くなる傾向がある
「速さ」よりも「網羅性・正確性・引用品質」が問われる文脈ほど、Fusion APIのコスト対効果が高くなります。
注意点──レイテンシ・データ流出・コスト累積
一方で、Fusion APIには業務組み込み前に押さえておくべき注意点が3つあります。
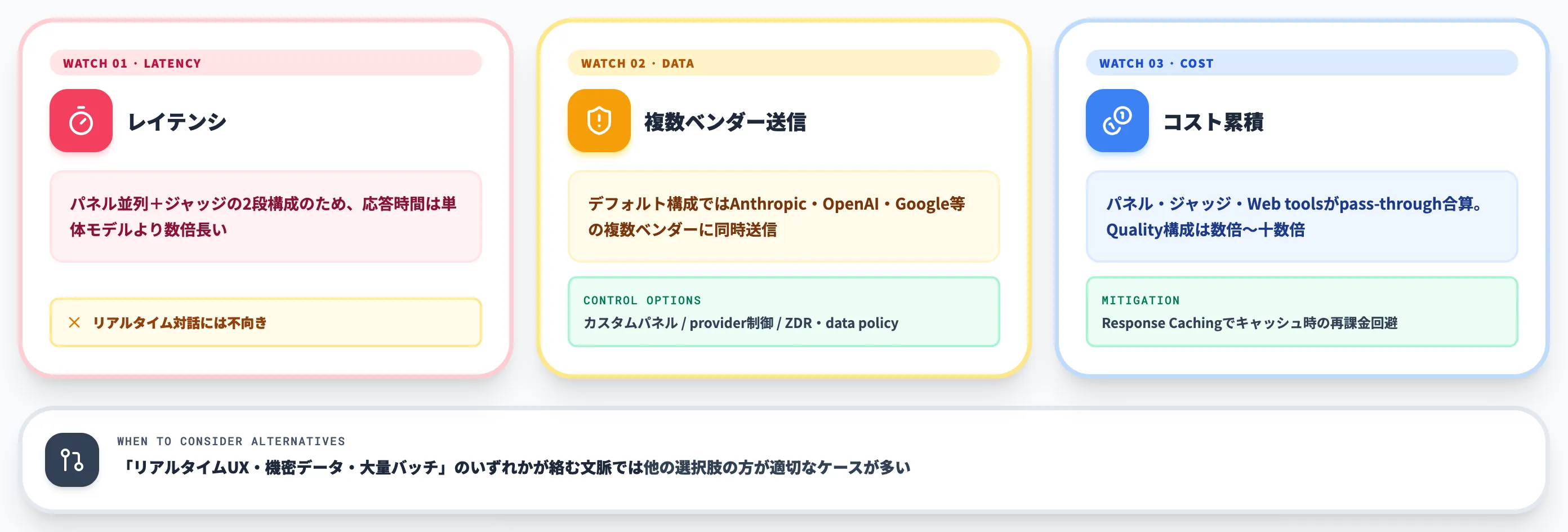
-
レイテンシ
パネル並列+ジャッジの2段構成のため、応答時間は単体モデルより数倍長くなる。リアルタイム対話には不向き
-
複数ベンダーへのデータ送信(デフォルト構成)
QualityプリセットやBudgetプリセットなどのデフォルト構成では、プロンプトがAnthropic・OpenAI・Google等の複数ベンダーに同時送信される。
社内機密・個人情報を扱うタスクでは、「analysis_models」 でのカスタムパネル、provider制御、ZDR/data policyの設定で送信先・データ保持を限定する設計が必要
-
コスト累積
パネル各モデルとジャッジ、Web toolsの実行料金がすべて加算される。Quality構成では1リクエストあたり数倍〜十数倍のコストになる場合がある。
同一リクエストが繰り返されるユースケースではResponse Cachingを有効化することでキャッシュHIT時の再課金を回避できる(ZDR等の制限に注意)
Fusion APIは「リアルタイムUX・機密データ・大量バッチ」のいずれかが絡む文脈では他の選択肢の方が適切なケースが多くなります。
推奨──「セカンドオピニオン層」としての位置づけ
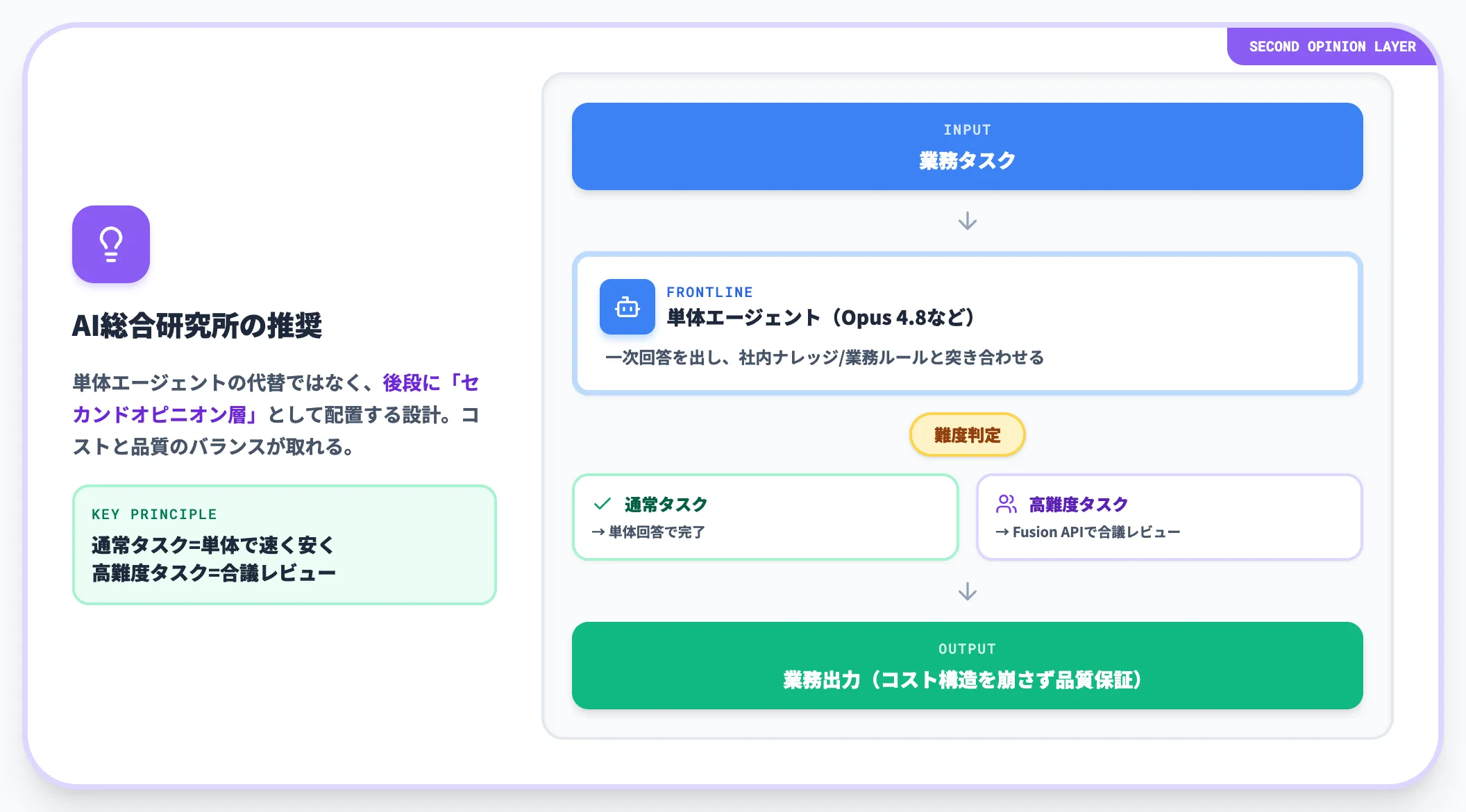
Fusion APIを「単体エージェントの代替」として置き換えるよりも、既存の単体エージェントの後段に「セカンドオピニオン層」として配置する設計の方が、コストと品質のバランスが取れると考えられます。
具体的には、フロントの単体エージェント(Opus 4.8など)が一次回答を出し、その結果を社内ナレッジや業務ルールと突き合わせる過程で、高難度タスクのみ自動的にFusion APIを発火させる構成が現実的な選択肢になります。
これにより、通常タスクは単体エージェントで安く速く回し、難度が高い・誤答コストが大きいタスクのみ合議型レビューに乗せる仕組みが成り立ちます。
このアーキテクチャは、Fusion APIの「品質特化」という強みを業務全体のコスト構造を崩さずに組み込む実装パターンとして、再現性が高い設計です。
導入判断チェックリスト
Fusion APIの導入を社内で検討する際、最低限押さえるべき判断軸を以下にまとめました。
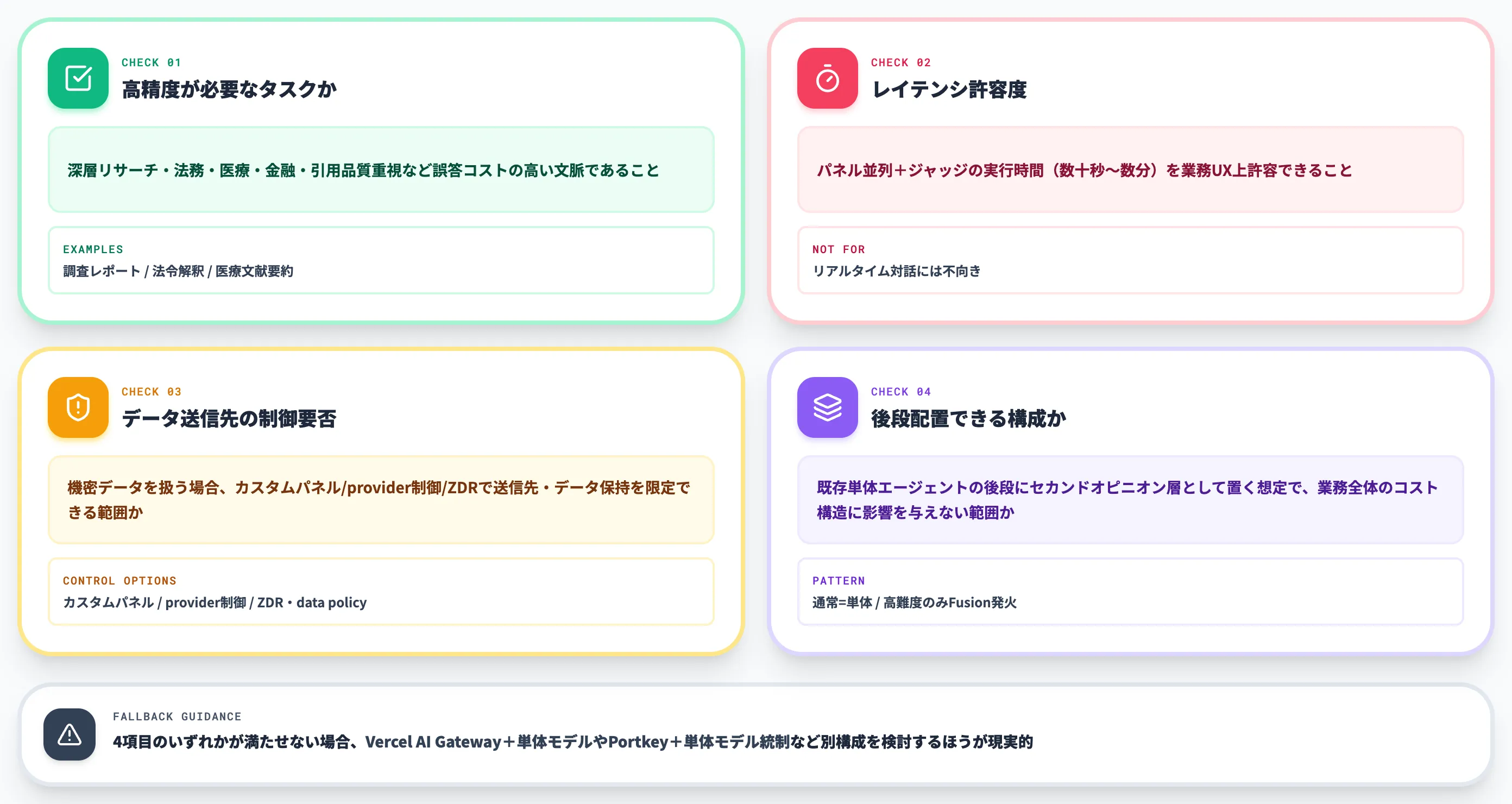
-
高精度が必要なタスクか
深層リサーチ・法務・医療・金融・引用品質重視の業務など、誤答コストが高い文脈であること
-
レイテンシ許容度
パネル並列+ジャッジの実行時間(数十秒〜数分単位)を業務UX上許容できること。リアルタイム対話には不向き
-
データ送信先の制御要否
デフォルト構成では複数ベンダー(Anthropic・OpenAI・Google等)に同時送信される。社内機密データを扱う場合、カスタムパネル・provider制御・ZDR/data policyで送信先とデータ保持を限定できる範囲で運用可能か
-
セカンドオピニオン層として位置づけられるか
既存単体エージェントの後段に置く想定で、業務全体のコスト構造に影響を与えない範囲で組み込めること
この4項目のいずれかが満たせない場合、Fusion APIは選択肢から外し、Vercel AI Gateway+単体モデル選択や、Portkey+単体モデル統制など別の構成を検討する方が現実的です。

複数モデル切替に強い業務エージェント基盤を整えるなら
Fusion APIが示したように、これからのAI業務基盤は「単体最強モデルを掴む」から「複数モデルをどう設計して組み合わせるか」に重心が移っていきます。
Fable 5・Mythos 5の利用停止のように、特定モデルが突然使えなくなる事態も含めて、単一モデル依存は運用リスクとして避けるべきポイントです。
ここで効いてくるのが、自社のAzureテナント内で動くエンタープライズAIエージェント基盤です。AI総合研究所のAI Agent Hubは、Claude Opus 4.8・GPT-5.5など複数のフロンティアモデルを切替可能な実行基盤として、社内システム連携・権限管理・実行ログを1つのダッシュボードで統合管理できる設計になっています。
-
複数モデル前提のフォールバック設計
要件に応じてモデルを切り替えるアーキテクチャを設計段階から組み込み、Fusion APIのような合議型レビュー層も併用可能な構成を支援します
-
構築と管理の分離で複数基盤を1つに集約
Microsoft Foundry・n8n・Copilot Studioなど構築基盤が違っても、実行ログ・アクセス権限・セキュリティスキャンは1つのダッシュボードに集約。シャドーAIの乱立を防ぎます
-
データは100%自社テナント内に保持
Azure Managed Applicationsとして顧客のAzureテナント内で構築するため、AIの学習対象から完全除外。基幹システムのデータが外部に出る心配なく実行統制を担保できます
AI総合研究所の専任チームが、Fusion APIのような合議型レビュー層を含む複数モデル切替基盤の設計を支援します。AI Agent Hubのサービスページで、自社の業務にどう活用できるか具体例とあわせてご確認ください。
複数モデル切替に強いAIエージェント基盤

合議型レビュー層を業務フローに統合
Fusion APIのような複数モデル合議は、深層リサーチや法務・医療・金融など高精度タスクで効果を発揮しますが、単体エージェントとの組み合わせ設計が要点になります。AI Agent Hubは、Claude Opus 4.8・GPT-5.5など複数モデルを切替可能な実行基盤として、社内システム連携・権限管理・実行ログを1つのダッシュボードに集約します。自社Azureテナント内でデータを保持しながら、合議型レビュー層を業務フローに統合する設計をAI総合研究所の専任チームが支援します。
Fusion APIの要点まとめ
本記事では、2026年6月にOpenRouterが公式発表したFusion APIについて、仕組み・プリセット・DRACOベンチ・使い方・他ゲートウェイとの違い・業務適用の判断軸を、2026年6月時点の公式情報で整理しました。要点を改めて整理します。
-
Fusion APIは、1プロンプトを1〜8モデル(標準プリセットは3モデル)に並列実行し、ジャッジモデルが5観点で構造化分析して1つの回答に統合する複数モデル合議型ルーター。OpenRouterの既存のAuto Router(1モデル選択)とは別軸のアプローチ
-
QualityプリセットはOpus 4.8・GPT-5.5・Gemini 3.1 Proのフロンティア3本、BudgetはGemini 3 Flash・Kimi K2.6・DeepSeek V4 Proの廉価3本。料金はパネル+ジャッジ+Web toolsのpass-through合算
-
DRACO 100タスクで、Fable 5+GPT-5.5合議は69.0%でFable 5単体65.3%を上回り、Budget構成は64.7%でFable 5の約50%コストを実現。同一モデル2本でも単体より6.7ポイント高いスコアが出ており、合議プロセスそのものに価値があると示唆された
-
API呼び出しはモデルエイリアス・サーバーツール・fusionプラグインの3エントリーポイント。OpenAI互換APIなので既存SDKがそのまま流用でき、「analysis_models」 と 「model」 で独自パネルを組むことも可能
-
業務組み込みは「セカンドオピニオン層」としての位置づけが現実的。深層リサーチ・法務・医療・金融など誤答コストが高い文脈に絞り、レイテンシ・データ送信先の制御要否・コスト累積の3点を判断軸として評価する(複数ベンダー送信はデフォルト構成の挙動で、カスタムパネルやprovider制御で限定可能)
業務担当者にとってFusion APIは、「最強の単体モデルを掴む」から「複数モデルを組み合わせて合議させる」というAI活用設計の転換点を象徴する存在です。Fable 5停止のような単一モデル依存リスクが顕在化した今、Fusion APIのような合議型API活用と、複数モデル切替を前提とした業務エージェント基盤の設計は、中長期で同時に検討する価値があるテーマと言えます。
Fusion APIは2026年6月時点で実装が公開された比較的新しい機能のため、プリセットや料金の細部はOpenRouterの公式ドキュメントとFusionモデルページで最新情報を確認したうえで導入判断することをおすすめします。










