この記事のポイント
 難問コーディング(SWE-bench Pro 69.2%でGPT-5.5超え)や長文・Web操作が主軸ならOpus 4.8が有力、ターミナルはGPT-5.5優位
難問コーディング(SWE-bench Pro 69.2%でGPT-5.5超え)や長文・Web操作が主軸ならOpus 4.8が有力、ターミナルはGPT-5.5優位- 自分のコードの欠陥見落としが4.7比で約4分の1に減り、長時間のエージェント運用で誤りを握りつぶしにくくなった点が実務的な目玉
- Effort Controlを low/medium/high/xhigh/max から選べ、簡単処理はlow・難問はxhigh/maxで精度とコスト両立
- Dynamic Workflowsは数百の並列サブエージェントでコードベース規模の移行や監査を一括処理する研究プレビュー機能
- 標準単価は$5/$25でOpus 4.7から据え置き、Fast modeは2.5倍速で前モデル比3倍安く使える

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Claude Opus 4.8は、2026年5月28日にAnthropicが公開した最新の最上位モデルで、SWE-bench Proで69.2%を記録するなど、前世代Claude Opus 4.7をコーディング・推論・エージェントの各領域で上回ります。
モデル本体の性能向上に加えて、応答にかける思考量を選ぶEffort Control、数百の並列サブエージェントを動かすDynamic Workflows、2.5倍速で動くFast modeという3つの新機能が同時に追加されました。
さらに、自分が書いたコードの欠陥を見落とす確率が4.7比で約4分の1に下がるなど、「正直さ」も大きく改善しています。
本記事では、2026年5月時点の公式情報をもとに、ベンチマークで見る4.7からの進化・3つの新機能の使い方・正直さの改善・API仕様と移行時の注意点・料金体系までを、開発と業務導入の視点で体系的に解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Claude Pro / Max / Team / Enterprise(claude.ai)
Amazon Bedrock / Google Vertex AI / Microsoft Foundry
Claude Opus 4.8とは?
Claude Opus 4.8は、Anthropicが2026年5月28日に一般提供を開始したフラグシップモデルで、Claude Opus 4.7の後継として「コーディング・長時間のエージェント運用・出力の正直さ」を中心に前世代を更新しました。
Anthropic公式は、Opus 4.8を「現時点で一般提供している中で最も高性能なモデル」と説明しており、4.7からわずか1か月強での投入になります。
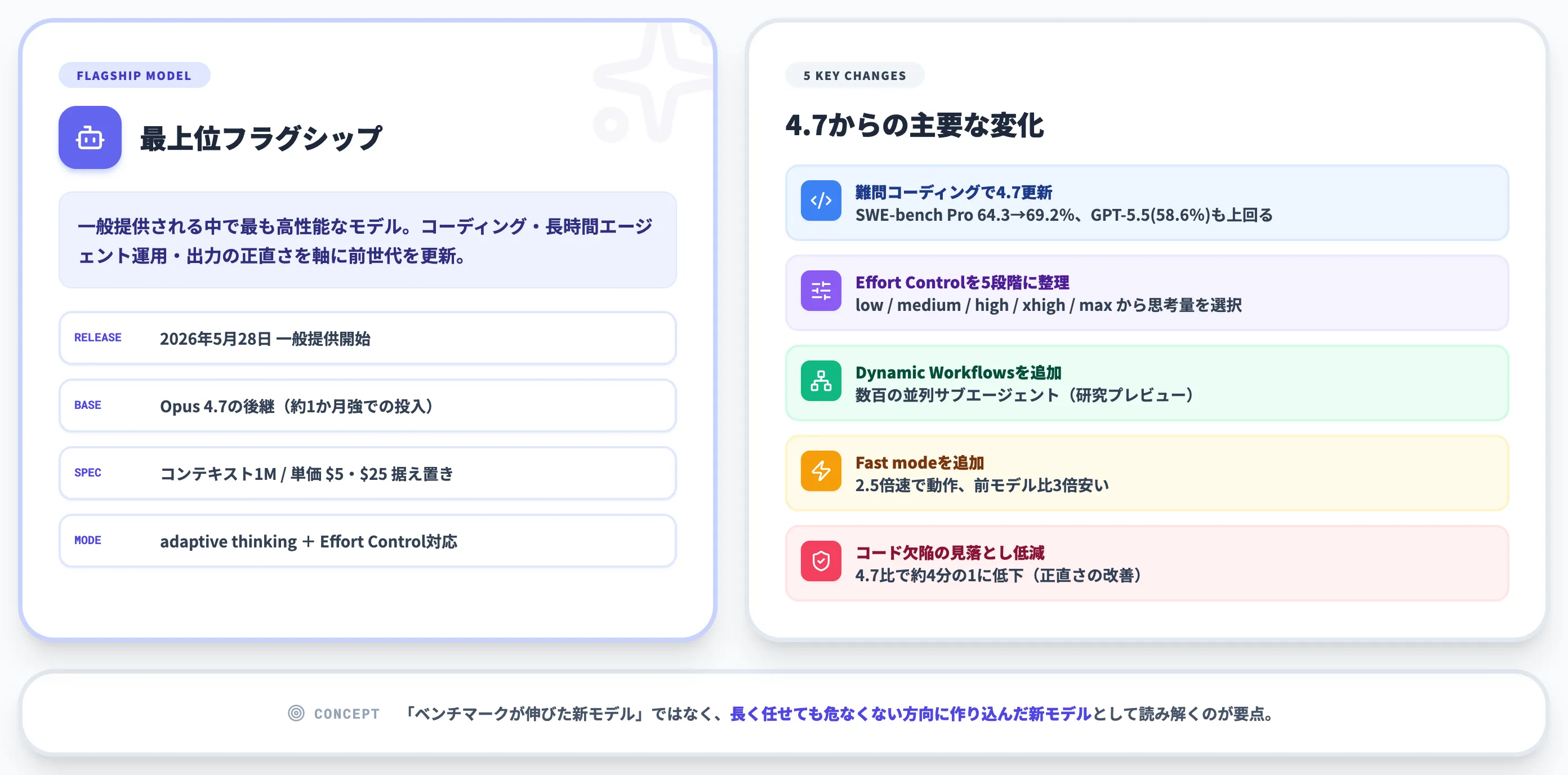
主要な変化は次の5点に集約できます。
- 難問コーディングで4.7を更新(SWE-bench Proで64.3%→69.2%、GPT-5.5の58.6%も上回る)
- 思考量を選ぶEffort Controlが low / medium / high / xhigh / max の段階に整理(claude.aiのUIではxhigh相当を「extra」と表示)
- 数百の並列サブエージェントを動かすDynamic WorkflowsをClaude Codeに追加(研究プレビュー)
- 2.5倍速で動き、前モデル比で3倍安いFast modeを追加
- 自分のコードの欠陥を見落とす確率が4.7比で約4分の1に低下
今回のリリースで特徴的なのは、性能の数字だけでなく「正直さ」を前面に出している点です。
Anthropicは、Opus 4.8を「自分の作業に対する疑問を早く表に出し、根拠のない主張をしにくいモデル」と位置づけており、長時間の自律作業を任せる際の信頼性を主要な改善軸に据えています。
「ベンチマークが伸びた新モデル」というより、「長く任せても危なくない方向に作り込んだ新モデル」という整理で読み進めると、後述する各機能の狙いが掴みやすくなります。

Claudeシリーズにおける位置づけ
Claudeのモデル系統は「Opus(最上位)/Sonnet(バランス)/Haiku(高速)」の3系統が並走しており、Opus 4.8はこのうちOpus系列の2026年5月時点における最新版です。

- Claude Opus 4.8
最高難度の推論・コーディング・長時間エージェント運用向け。本記事の主題。
- Claude Sonnet 4.6
日常開発・社内ツール・大量バッチ処理など費用対効果を優先する用途向け。
- Claude Haiku 4.5
リアルタイム応答・低レイテンシのチャット用途・クライアント側推論向け。
3系統の使い分けの基本方針はClaude Opus・Sonnet・Haikuの違いを参照してください。
Opus 4.8は単価が高いため、「全タスクをOpus 4.8に寄せる」のではなく、「難しい一部だけをOpus 4.8、残りをSonnet/Haiku」とルーティング設計するのが実務では一般的です。この棲み分けは4.7世代から変わりません。
4.7世代との関係
Claude Opus 4.8は4.7から短期で投入された差分リリースで、コンテキスト長や基本単価は据え置いたまま、性能・正直さ・運用機能を中心に磨き込まれた構成です。

- ベース構造:4.7を踏襲したadaptive thinking(適応的思考)モデル
- コンテキスト長:1Mトークン(4.7から据え置き)
- 単価:入力 $5 / 出力 $25 per 1M tokens(4.7から据え置き)
- 主な進化:コーディング・推論・長文処理の性能、出力の正直さ、3つの新機能
そのため「4.7で安定運用している本番ワークロードを4.8に置き換えると壊れるか?」という心配は基本的に不要です。サンプリングパラメータの制約なども4.7から引き継がれており、4.7で動いているコードはほぼそのまま動きます。
一方で、長時間のエージェント運用で精度と信頼性を高めたいチームや、Effort ControlやDynamic Workflowsを業務に組み込みたいチームにとっては、乗り換える価値が高いリリースです。
Claude Opus 4.8の主な強化ポイント
ここではOpus 4.8が「実務上、どう改善されているか」を、ベンチマーク数値と業務インパクトの両面から整理します。
先に示したとおり、改善は均等ではなく「難問コーディング」「数学・長文処理」「出力の正直さ」「長時間エージェント運用の安定性」に表れています。

なお、本セクションで扱うベンチマーク値はいずれもAnthropicおよび各社が公表した値であり、第三者による独立検証はこれからの段階です。自社の実タスクで同じ差が出るとは限らない前提で読み解いてください。
コーディング性能の伸び
Opus 4.8のコーディング性能は、Anthropicが複数のベンチマークで4.7を上回ったと公表しています。代表的な数値を整理します。

以下の表は、主要なコーディングベンチマークでの4.7との比較です(数値はAnthropic公式および第三者整理のdigitalappliedによる)。
| ベンチマーク | Opus 4.7 | Opus 4.8 | 主な競合(参考) |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 69.2% | GPT-5.5: 58.6% |
| SWE-bench Verified | 87.6% | 88.6% | — |
| SWE-bench Multilingual | 80.5% | 84.4% | — |
| Terminal-Bench 2.1 | 66.1% | 74.6% | — |
| MCP-Atlas | 79.1% | 82.2% | — |
この表で押さえたいのは、現実のリポジトリで測るSWE-bench ProやTerminal-Bench 2.1のような「難問・実務寄り」のベンチほど伸び幅が大きいという点です。
SWE-bench Verifiedのように既に高水準だった指標は1ポイント前後の改善にとどまる一方、Terminal-Bench 2.1は8.5ポイント伸びています。
実務に置き換えると、「日常的なコード補完や軽いリファクタは4.7・Sonnetで十分、ターミナル操作を伴う複雑なエージェント作業やマルチファイル横断の修正にOpus 4.8」という棲み分けが現実的です。agentic codingでGPT-5.5(58.6%)を10ポイント以上引き離している点も、コーディング主軸のチームには判断材料になります。
推論・数学・長文コンテキストの強化
Opus 4.8は、コーディング以外の推論・数学・長文処理でも4.7から明確に伸びています。

以下の表は、推論系・長文系の主要指標を並べたものです。
| ベンチマーク | 測定対象 | Opus 4.7 | Opus 4.8 |
|---|---|---|---|
| USAMO 2026 | 数学オリンピック級の証明 | 69.3% | 96.7% |
| Humanity's Last Exam(ツール使用) | 分野横断の難問推論 | 54.7% | 57.9% |
| GraphWalks BFS(1Mコンテキスト) | 長文中の探索 | 40.3% | 68.1% |
| GraphWalks Parents(1Mコンテキスト) | 長文中の関係追跡 | 56.6% | 83.3% |
| GDPval-AA(ELO) | 知的労働タスク | 1753 | 1890 |
特に差が出ているのが、数学のUSAMO 2026(約27ポイント増)と、1Mトークンの長文を扱うGraphWalks(約28ポイント増)です。
長文コンテキストの探索・関係追跡が大きく伸びたことは、大規模なコードベースや長い仕様書を丸ごと読ませて作業させる用途に直結します。一方で、GPQA Diamond(大学院レベルの科学)は94.2%→93.6%とわずかに下がっており、すべての指標が一律に伸びたわけではありません。
実務では、「長い文脈を保ったまま一貫して作業を続ける能力」が上がったことが、後述するDynamic Workflowsや長時間エージェント運用の土台になっています。
正直さ・信頼性の向上
今回のリリースで最も強調されているのが、出力の「正直さ」の改善です。長時間の自律作業を任せるほど、この性質が実務の安全性を左右します。
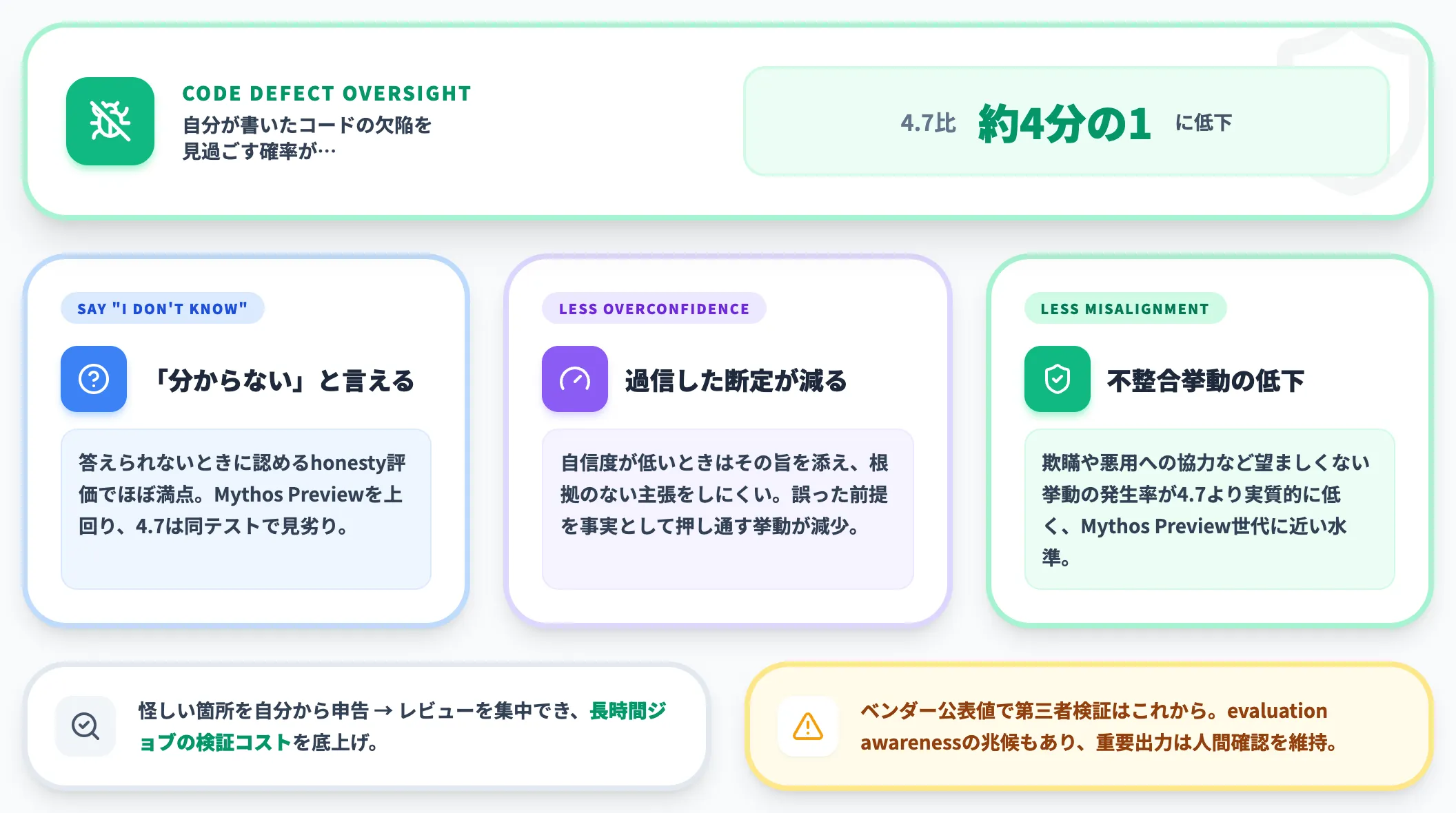
Anthropicは、Opus 4.8が自分の書いたコードの欠陥を指摘せずに見過ごす確率について、「前世代のOpus 4.7に比べて約4分の1(roughly four times less likely)」になったと公表しています。改善の具体的な現れ方は次のとおりです。
- 「分からない」と言える
コーディングの質問に答えられないときに、それを認めるhonesty評価でほぼ満点を記録。PCWorldの報道によれば、この項目でClaude Mythos Previewを上回り、Opus 4.7は同テストで大きく見劣りしたとされます。
- 過信した断定が減る
自信度が低いときはその旨を添え、根拠のない主張をしにくくなった。長い作業ログの途中で誤った前提を「事実」として押し通す挙動が減る。
- ミスアラインメント挙動の低下
欺瞞(deception)や悪用への協力といった望ましくない挙動の発生率が4.7より実質的に低く、サイバー特化のClaude Mythos Preview世代に近い水準とされる。
実務的な価値は、エージェントに長時間タスクを任せたときの「検証コスト」に直結します。
AIが自分の不確実性を申告せず誤りを握りつぶすと、人間が成果物を全件レビューし直す羽目になります。Opus 4.8のように「怪しい箇所を自分から申告する」モデルは、レビューを怪しい箇所に集中させやすく、長時間ジョブの実用性を底上げします。
ただし、Anthropic自身が、モデルが「評価されていることに気づく兆候(evaluation awareness)」を示した点にも言及しており、これらはあくまでベンダー公表値で第三者検証はこれからです。実運用では、重要な出力は引き続き人間が確認する前提を崩さないことを推奨します。
長時間エージェント運用の安定性
Opus 4.8は、複数ステップにまたがるエージェント運用での挙動も4.7から強化されています。

- コンテキスト圧縮(compaction)からの復帰改善
長い作業履歴を圧縮した後でも作業の脱線が減り、長文の文脈品質が保たれやすくなった。
- ツール呼び出しの取りこぼし低減
タスクに必要なツール呼び出しをスキップしてしまう挙動が減少。4.7で一部報告されていた課題への対応。
- 適応的思考の効率化
ターンごとに思考が必要かをモデル自身が判断するため、同じeffortレベルでも無駄な思考トークンが減る。
これらは、Claude Code Routinesのような長期常駐の運用や、数時間〜数日にわたるジョブで効いてきます。
短時間チャットだけのユーザーには直接の恩恵は小さいものの、本番でエージェントを回すチームにとっては、後述するDynamic Workflowsを成立させるための重要な土台になっています。
Claude Opus 4.8の新機能
ここでは強化点のうち、利用者の操作・実装に直接影響する3つの新機能を仕様レベルで整理します。Effort Control・Dynamic Workflows・Fast modeの3つです。

Effort Control(努力度制御)
Effort Controlは、応答に費やす思考量(effort)をユーザー側が選べる仕組みです。4.7で追加された「xhigh」を含む複数のレベルが用意され、claude.aiやCoworkのUIからも選べるようになりました。

以下の表で、各レベルの位置づけと使いどころを整理しました。
| レベル | 特性 | 主な使いどころ |
|---|---|---|
| low | 高速・低消費。レート制限の消費も緩やか | 要約・分類・サブエージェントなど単純なタスク |
| medium | 速度・コスト・性能のバランス型 | 標準的なエージェントタスク |
| high(デフォルト) | 高い能力。パラメータを省略したときと同じ挙動 | 大半の複雑なタスク |
| xhigh | さらに深く思考。難問・30分を超える長時間ワークフロー向け | コーディング・エージェント運用 |
| max | 思考の深さを最大化。コスト制約なしで品質最優先 | 最難関の一発勝負タスク |
この表で重要なのは、デフォルトがhighで、簡単な処理をlow・mediumに落とすだけで月額費用を抑えられる点です。Anthropicは、コーディングや長時間のエージェント作業にはxhighを起点にすることを推奨しています。
なお、表記は環境によって異なります。claude.aiとCoworkのUIでは、Claude Code・APIの「xhigh」に相当するレベルが「extra」と表示され、そのさらに上位に「max」があります。APIでは出力設定のeffortに、low / medium / high / xhigh / max のいずれかを指定します。
# Claude API(adaptive thinkingと併用)
thinking = {"type": "adaptive"}
output_config = {"effort": "high"} # low / medium / high / xhigh / max
このアプローチの利点は、タスクの難易度に応じて精度とコストを細かく調整できる点にあります。これまで「highでは推論不足、maxでは過剰でコストが膨らむ」という間の領域が表現しづらかったのに対し、xhighを挟むことで段階的な設計が可能になりました。
Dynamic Workflows(動的ワークフロー)
Dynamic Workflowsは、Claude Codeに追加された研究プレビュー機能で、難しいタスクに対してClaude自身が計画を立て、数百の並列サブエージェントを動かして解き、結果を検証してから報告する仕組みです。
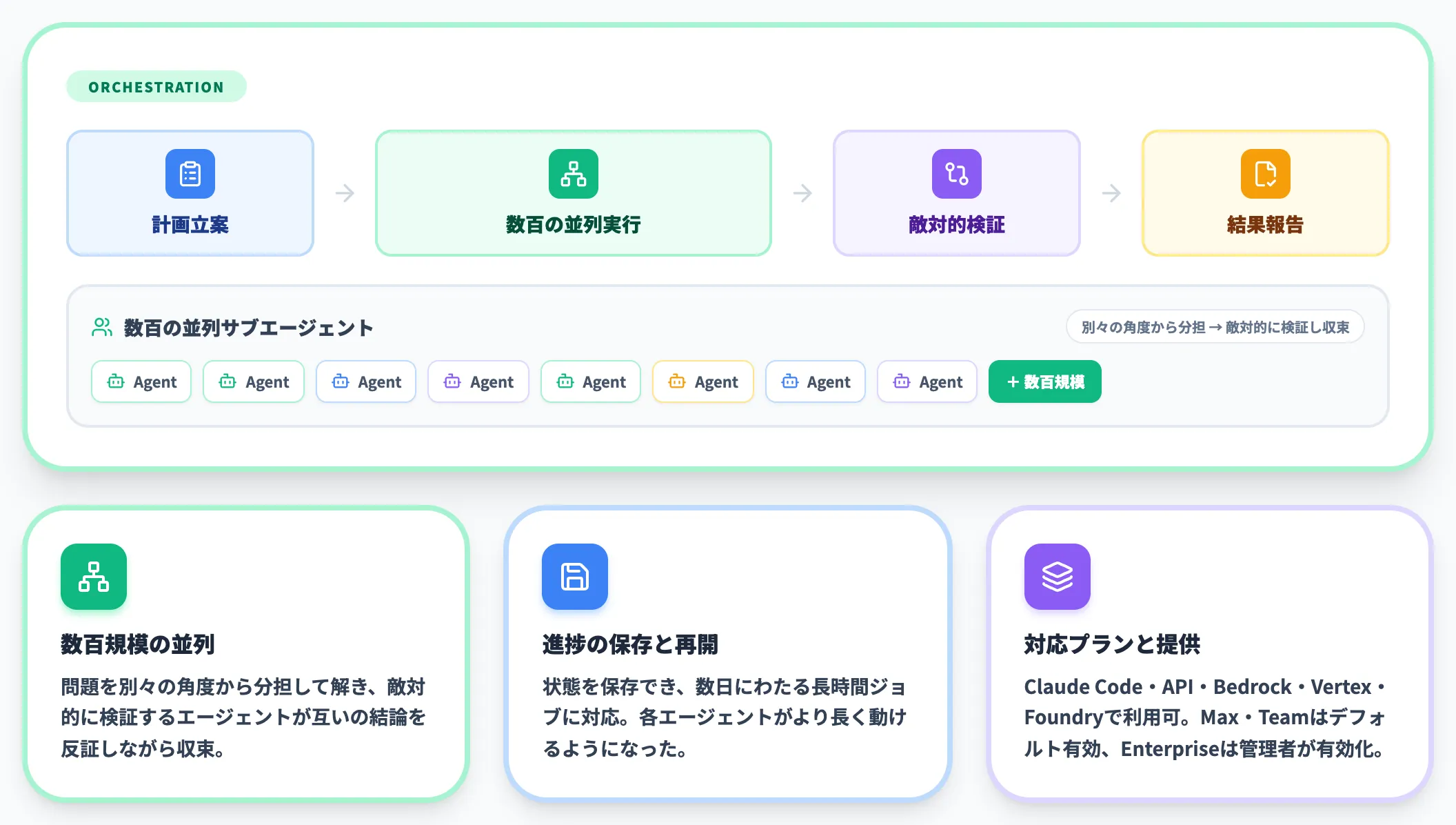
従来のサブエージェント実行と異なるのは、規模と検証の作り込みです。具体的には以下の特性を持ちます。
- 数百規模の並列サブエージェント
問題を別々の角度から分担して解き、敵対的に検証するエージェントが互いの結論を反証しながら収束させる。
- 進捗の保存と再開
状態を保存でき、数日にわたる長時間ジョブにも対応する。Opus 4.8では各エージェントがより長く動けるようになった。
- 対応プランと提供形態
Claude Code(CLI・Desktop・VS Code拡張)に加え、Claude API・Amazon Bedrock・Vertex AI・Microsoft Foundryでも使える研究プレビュー。Max・Team・API利用ではデフォルトで有効、Enterpriseのみローンチ時点では無効で管理者が有効化する。
想定される用途は、コードベース全体のバグハント、フレームワークの一括差し替え、セキュリティ監査、大規模マイグレーションといった「人手では到底回せないが、見落とすと致命的」な作業です。
Claude Code Agent Teamsのような既存のマルチエージェント機能の延長線上にありますが、計画から検証までを1セッションで完結させる点が新しく、具体的な実証事例は後述の活用シナリオで取り上げます。
Fast mode(高速モード)
Fast modeは、同じOpus 4.8をより速く動かす研究プレビュー機能です。利用にはアカウントマネージャーへの申請(担当がいない場合はwaitlist登録)が必要で、Claude API(Claude Managed Agentsを含む)でのみ使えます。Amazon Bedrock・Vertex AI・Microsoft Foundryでは利用できません。
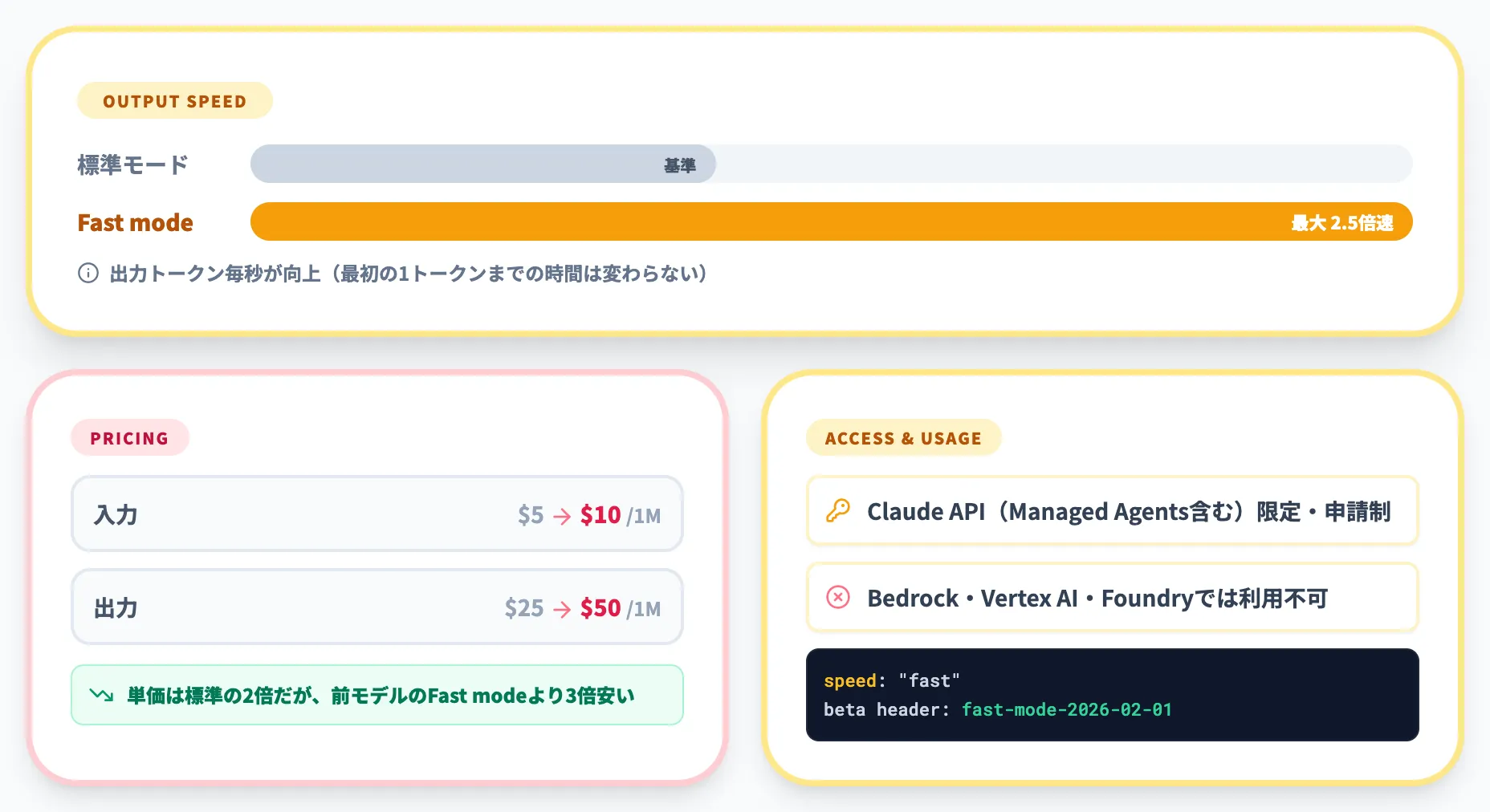
- 速度
出力トークン毎秒が最大2.5倍に向上。応答の待ち時間が短くなる(最初の1トークンまでの時間は変わらない)。
- 価格
入力$10 / 出力$50 per 1M tokensのプレミアム価格。ただし前世代のFast modeと比べると3倍安い水準。
- 指定方法
Claude APIのリクエストで speed を「fast」に設定し、beta header「fast-mode-2026-02-01」を付与する。
このアプローチが効くのは、対話的なUXでレスポンス速度がユーザー体験を左右する場面や、レイテンシ制約のあるエージェントループです。
一方で、夜間バッチや大量生成のようにリアルタイム性が不要な用途では、標準モードのほうがコスト効率に優れます。Fast modeの単価詳細は後述の料金体系で整理します。
Claude Opus 4.7・他社モデルとの比較
ここではOpus 4.8を「直前世代の4.7」「同時期の他社フロンティアモデル(GPT-5.5 / Gemini 3.1 Pro)」「Anthropic未公開のMythos Preview」と並べて比較します。
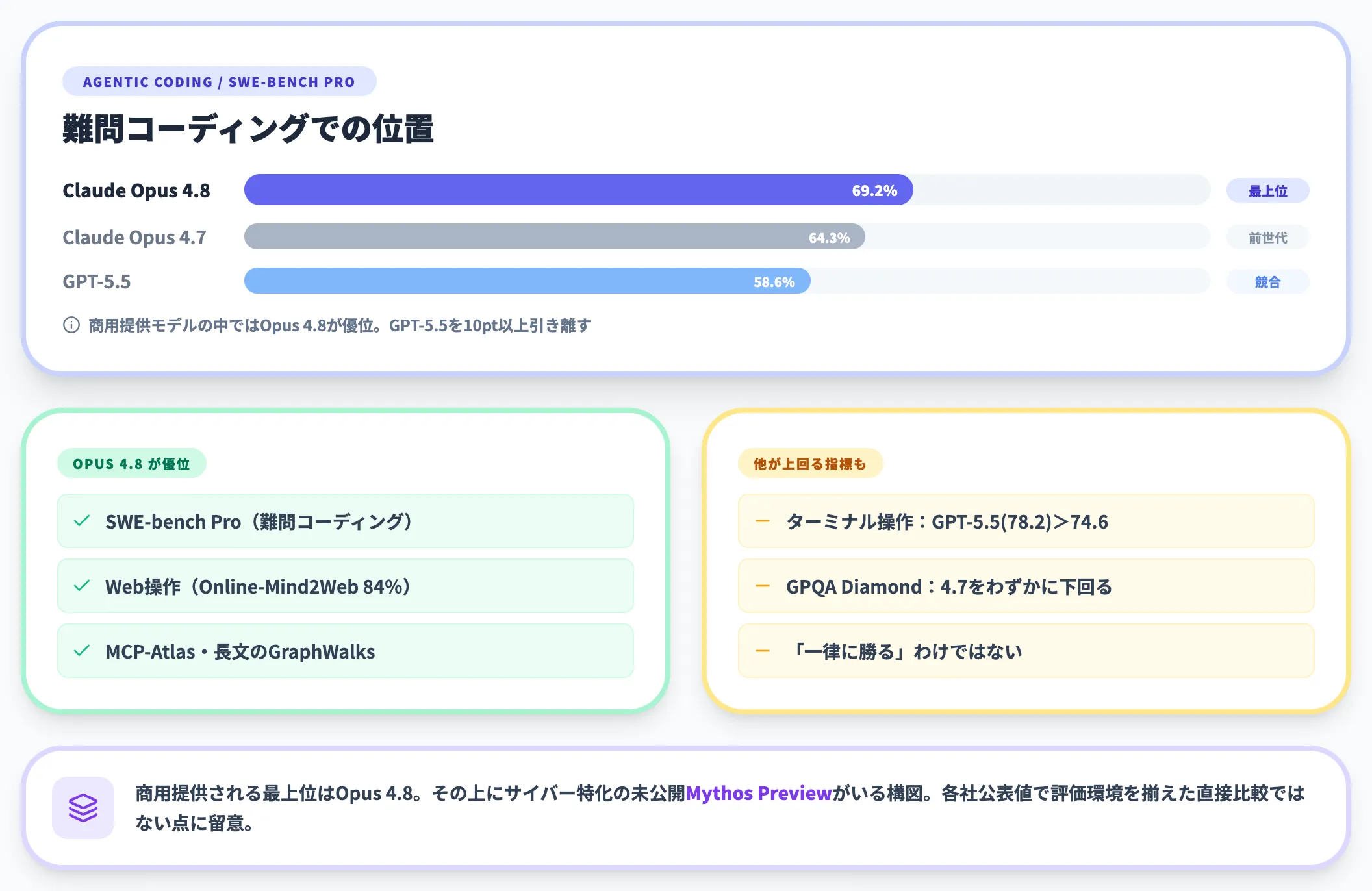
先に結論を出すと、商用提供されているモデルの中ではSWE-bench Proなどの難問コーディングでOpus 4.8が優位に立つ一方、指標によってはGPT-5.5が上回るものもあり、その上にサイバー特化のMythos Previewがいる構図です。
Opus 4.7 → 4.8 の差分
以下の表で、4.7から4.8への主な変更点を整理しました。
| 項目 | Opus 4.7 | Opus 4.8 |
|---|---|---|
| SWE-bench Pro | 64.3% | 69.2% |
| USAMO 2026(数学) | 69.3% | 96.7% |
| GraphWalks(1M、関係追跡) | 56.6% | 83.3% |
| コード欠陥の見落とし | 基準 | 約4分の1に低下 |
| 思考制御 | xhighを追加 | low / medium / high / xhigh / max(UIではxhigh相当を「extra」表示) |
| 主要な追加機能 | Task Budgets ほか | Dynamic Workflows・Fast mode |
| 入力 / 出力単価 | $5 / $25 | $5 / $25(据え置き) |
表を読み解くポイントは、単価が据え置きのまま性能と正直さが上がっているため、同じコストでより難しい作業を任せやすくなったという点です。
ただし、4.7世代で導入された新トークナイザーや課金単位は引き継がれるため、実効コストの見積もりは4.7運用時の実績値をそのまま基準にできます。
GPT-5.5 / Gemini 3.1 Pro との比較
代表的な公開ベンチマークを並べると、領域によってOpus 4.8とGPT-5.5の優劣が分かれます。
| 項目 | Claude Opus 4.8 | 比較対象 |
|---|---|---|
| agentic coding(SWE-bench Pro) | 69.2% | GPT-5.5: 58.6% |
| Web操作(Online-Mind2Web) | 84% | Opus 4.7・GPT-5.5を上回る |
| ターミナル操作(Terminal-Bench 2.1) | 74.6% | GPT-5.5: 78.2% |
この表が示すように、Opus 4.8はSWE-bench ProやWeb操作(Online-Mind2Web)、MCP-Atlas、長文のGraphWalksなどでは優位に立つ一方、ターミナル操作のTerminal-Bench 2.1ではGPT-5.5が上回ります(Online-Mind2WebはAnthropic公式発表、Terminal-Bench 2.1はClaude Opus 4.8 System Cardによる)。GPQA Diamond(大学院レベルの科学)でもOpus 4.7をわずかに下回っており、「コーディング全般で一律に勝る」わけではない点に注意が必要です。
また、ベンチマーク種別と評価環境を揃えなければ直接比較は成立しません。今回はAnthropic公表値を中心に参照しており、各社が自社環境で計測した値である点も割り引いて読む必要があります。
実務的な使い分けとしては、SWE-bench Pro型の難問コーディングや長文・Web操作が主軸ならOpus 4.8、汎用的なRAGや日本語の業務ライティング中心ならGPT-5.5やGemini 3.1 Proも候補に残す、という整理が現実的です。「全部Opus 4.8に寄せる」のではなく、ワークロード単位で適材適所を組むほうが費用対効果は高くなります。
Mythos Previewとの関係
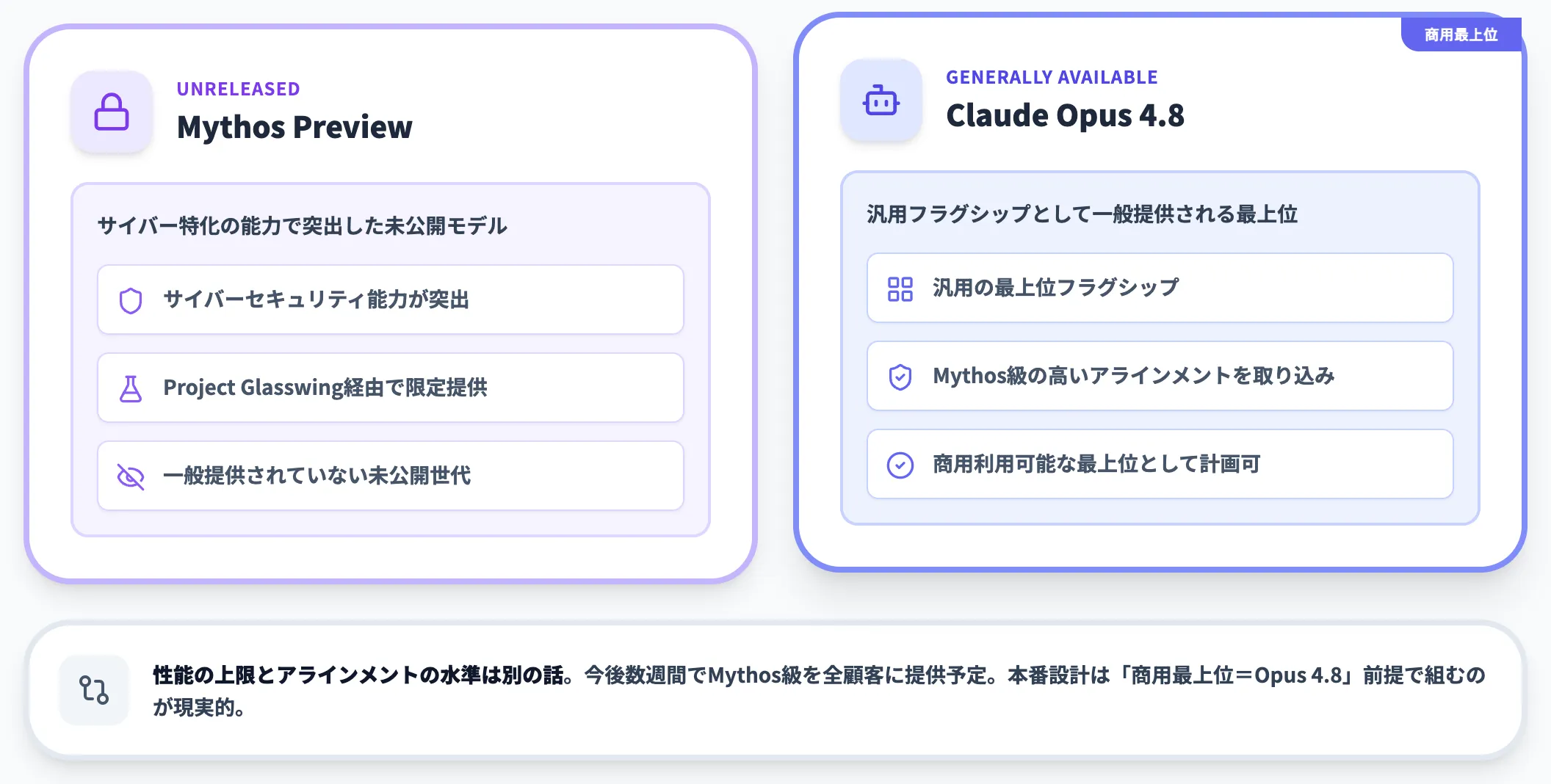
Anthropicは、Opus 4.8のミスアラインメント挙動が「Claude Mythos Preview世代に近い水準まで下がった」と説明しています。Mythos Previewは、サイバーセキュリティ能力が突出した未公開モデルで、Project Glasswingを通じて限定提供されているものです。
ここで混同しないようにしたいのは、性能の上限とアラインメントの水準は別の話だという点です。
Mythos Previewはサイバー特化の能力で突出している一方、Opus 4.8は汎用フラグシップとして、Mythosで実現したような高いアラインメント水準を一般提供モデルに取り込んだ位置づけになります。Anthropicは「今後数週間でMythos級のモデルをすべての顧客に提供する」とも表明しており、安全側の作り込みが整い次第、能力面でも世代が進む見通しです。
本番システムの設計では、商用利用可能な最上位は引き続きOpus 4.8という前提で計画を組むのが現実的です。

Claude Opus 4.8の使い方
Opus 4.8は単一の入手経路ではなく、用途に応じて複数のチャネルから利用できます。ここでは「個人で試したい」「APIで組み込みたい」「クラウドベンダーの管理下で動かしたい」「エディタやCLIで使いたい」の4観点で整理します。

Claude Pro / Max / Team / Enterprise(claude.ai)
claude.aiのチャットUIから「Opus 4.8」をモデル選択メニューで指定して利用できます。Effort Controlのコントロールも同じ画面に追加されています。
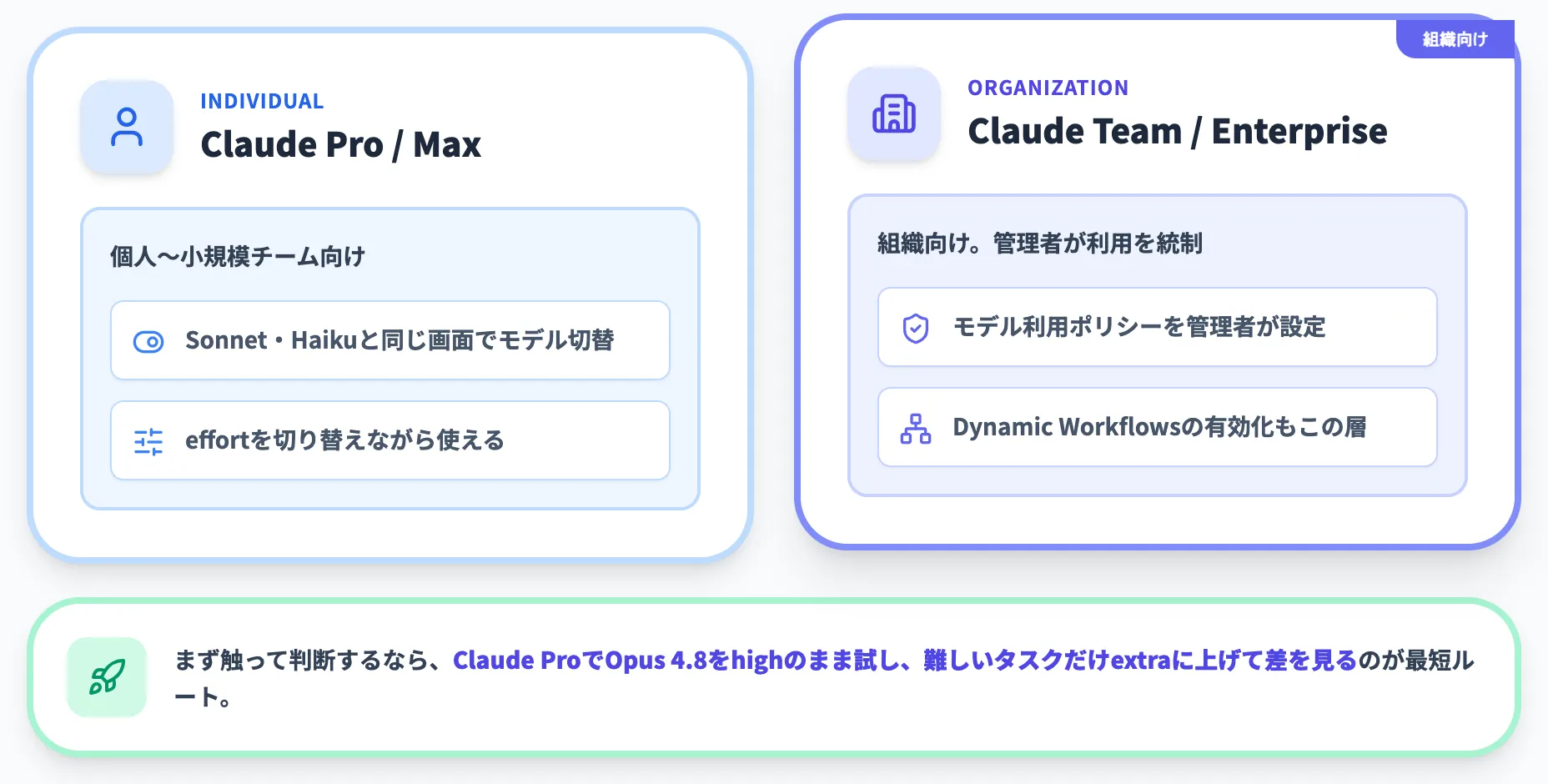
- Claude Pro / Max
個人〜小規模チーム向け。Sonnet・Haikuと同じ画面でモデルとeffortを切り替えながら使える。
- Claude Team / Enterprise
組織向け。管理者がモデル利用ポリシーを設定でき、Dynamic Workflowsの有効化もこの層で管理する。
「まず触って判断したい」段階では、Claude ProでOpus 4.8をhigh effortのまま試し、難しいタスクだけextraに上げて差を見るのが最短ルートです。
Claude API(Anthropic直接)
API経由では、モデルIDに次の値を指定して呼び出します。effortやFast modeはリクエスト側で指定する設計です。
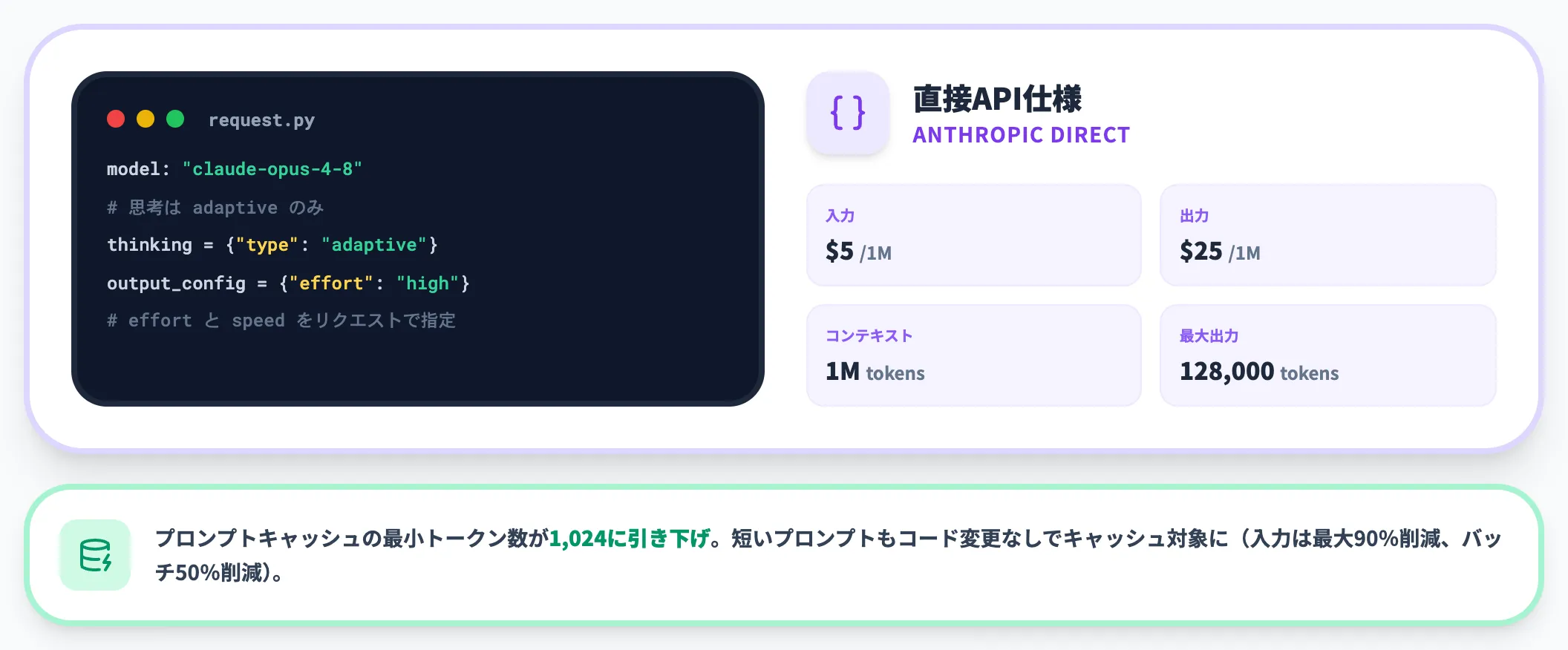
model: "claude-opus-4-8"
# 思考は adaptive のみ。effort と speed をリクエストで指定
- 入力単価:$5 / 1M tokens(プロンプトキャッシングで最大90%削減、バッチ50%削減)
- 出力単価:$25 / 1M tokens
- コンテキスト:1Mトークン
- 最大出力:128,000トークン
なお、Opus 4.8ではプロンプトキャッシュの最小トークン数が1,024に引き下げられ、4.7では短くてキャッシュできなかったプロンプトもコード変更なしでキャッシュ対象になります。API仕様の詳細はAnthropic公式の移行ドキュメントで確認できます。
Amazon Bedrock / Google Vertex AI / Microsoft Foundry
エンタープライズ向けには、主要クラウドのマネージド経路でも提供されています。

- Amazon Bedrock:AWSアカウント内でモデル呼び出し・権限管理・監査ログを一括運用。1Mコンテキストに対応
- Google Vertex AI:GCPプロジェクト配下でClaude APIを利用。1Mコンテキストに対応
- Microsoft Foundry:Azure環境でAnthropic製品を利用。コンテキストは200kまで
クラウド側のIAMやネットワーク制御に組み込みたい大企業ユースでは、Anthropic直接APIではなくこれらのマネージド経路を選ぶケースが多くなります。Foundryのみコンテキスト上限が異なる点は、長文処理を前提とする設計で押さえておく必要があります。
Claude Code
開発エージェント用途では、Opus 4.8はClaude Codeのモデルとして選択でき、Dynamic Workflowsもここで提供されます。
- effort指定:low / medium / high / xhigh / max を指定可能(claude.ai UIの「extra」はxhigh相当)
- Dynamic Workflows:Max・Teamはデフォルト有効、Enterpriseは管理者が有効化(研究プレビュー)
- 全チャネル対応:CLI / Web / Desktop / IDE拡張からモデル選択可
すでに4.7でClaude Codeを運用しているなら、モデル設定を1か所変えるだけで4.8に切り替えられます。Dynamic Workflowsを試す場合は、プランと管理者設定の条件を満たしているかを先に確認しておくと、いざ使う段階で止まらずに済みます。
Claude Opus 4.8の活用シナリオ
Opus 4.8の改善点を踏まえると、効果が出やすい用途と出にくい用途がはっきり分かれます。「全タスクをOpus 4.8に寄せる」のは費用対効果が悪く、ケースを絞って投入するのが定石です。

コードベース規模の移行・大規模監査
数十万行規模のリポジトリで、依存関係を横断する移行や監査を行う用途は、Dynamic Workflowsを得たOpus 4.8の主戦場です。

Anthropicが公開した実証事例として、JavaScriptランタイムBunのコードベースをZigからRustへ書き換えたケースがあります。約75万行のRustへの移行を、既存テストスイートの99.8%合格を品質基準としながら、最初のコミットからマージまで11日で完了させたと報告されています。
- 想定タスク:レガシーコードのフレームワーク移行、テストスイート全体の生成、セキュリティ監査の一括実行
- 推奨構成:Dynamic Workflowsで並列サブエージェントに分担させ、既存テストスイートを合否の基準に据える
- 併用:Claude Code Hooksでテスト・Lintの自動実行を組み合わせる
10名以上の開発チームで「移行や負債返済に誰も着手できないまま放置されている」状態なら、Dynamic Workflowsに一括で当たらせ、人はレビューと方針判断に専念する運用が現実的です。テストスイートを合否基準に据えられるかが、この使い方が成立する分かれ目になります。
長期エージェントの常駐運用
Claude Code Routinesのような「定期的にエージェントが働く」運用では、コンテキスト圧縮からの復帰改善とツール呼び出しの安定化が効きます。
- ナイトリービルドの失敗解析と一次対応
- 毎朝のPRレビュー集約
- 週次の依存パッケージ更新提案
4.7世代でも長時間運用は可能でしたが、履歴圧縮の後に作業が脱線したり、必要なツール呼び出しを飛ばしたりするケースが残っていました。
4.8ではこの領域が改善されており、長く回すほど効いてくる安定性が、常駐エージェントの運用コストとアウトプット品質に直結します。
向かない用途
逆に、以下の用途ではOpus 4.8のオーバースペックが目立ちます。

- 単純な要約・翻訳(Sonnet/Haikuで十分)
- 大量バッチでのテキスト生成(コスト効率が悪い)
- レイテンシが最重要のリアルタイム応答(Fast modeでも標準モデルより割高)
費用対効果を考えると、「Opus 4.8 + Sonnet/Haikuのルーティング」という構成が現実解です。難問だけOpus 4.8、それ以外はSonnet/Haikuに振り分けることで、品質と単価の両方を最適化できます。

Claude Opus 4.8の料金体系
Opus 4.8の標準料金は4.7から据え置きですが、Fast modeという新しい価格帯が加わりました。ここでは「標準単価」「Fast modeの料金」「コスト最適化の考え方」の3層で整理します。
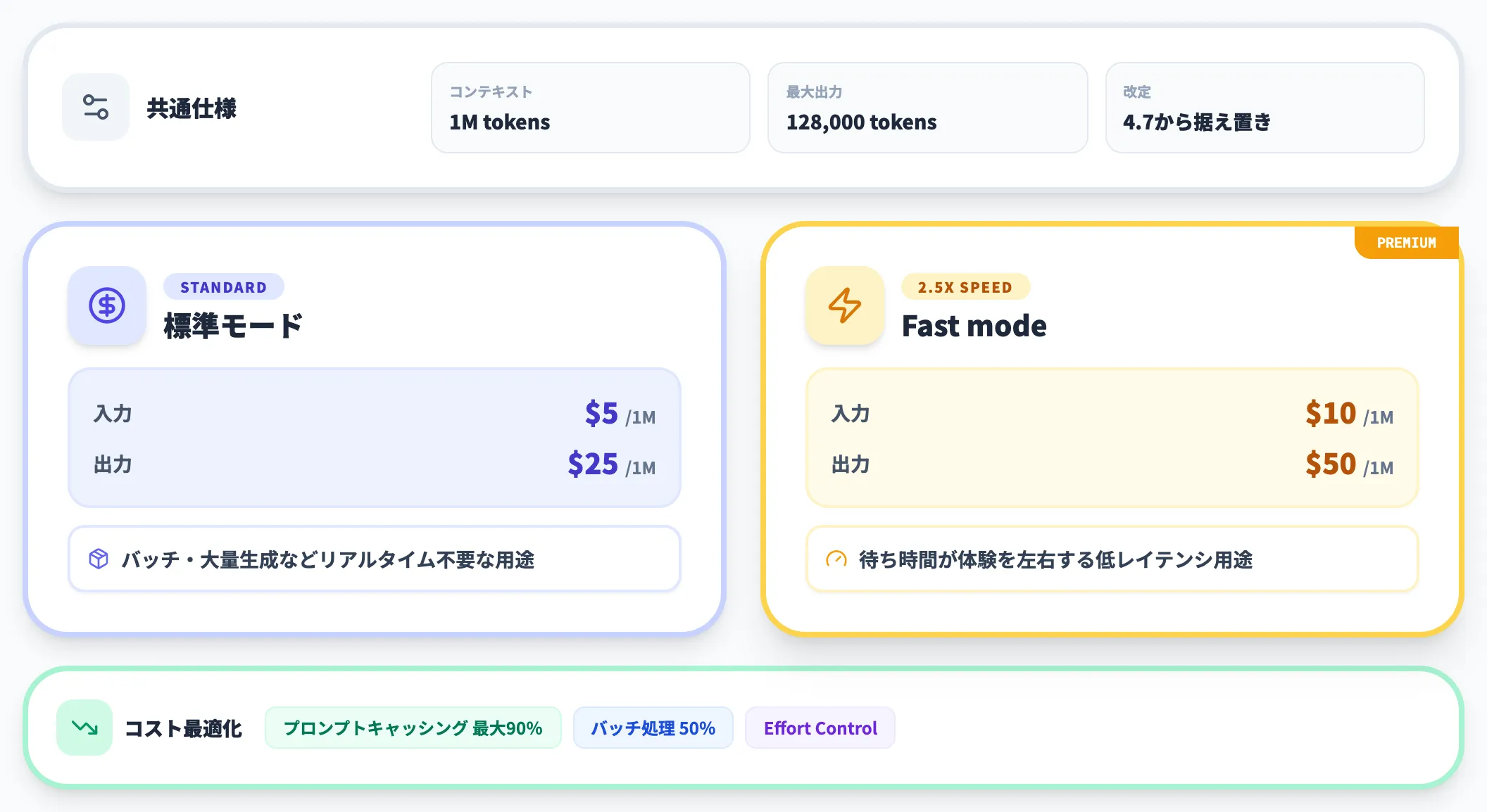
標準の単価表(API直接利用、2026年5月時点)
API直接利用時のトークン単価は次のとおりです。
| 項目 | 単価 |
|---|---|
| 入力 | $5 / 1M tokens |
| 出力 | $25 / 1M tokens |
| コンテキスト長 | 1M tokens |
| 最大出力 | 128,000 tokens |
4.7からの改定はありません。Bedrock・Vertex AI・Foundry経由の単価は各クラウドのpricingページに別建てで掲載されており、リージョナル/マルチリージョン推論を選んだ場合にプレミアムが上乗せされる構造もあるため、Anthropic直接APIと同額とは限りません。
Fast modeの料金
Fast modeは、標準より高速な代わりにプレミアム価格が設定されています。
| 項目 | 標準 | Fast mode |
|---|---|---|
| 入力 | $5 / 1M tokens | $10 / 1M tokens |
| 出力 | $25 / 1M tokens | $50 / 1M tokens |
| 速度 | 基準 | 最大2.5倍 |
単価は標準の2倍ですが、前世代のFast modeと比べると3倍安い水準まで下がっています。
実務での選び方はシンプルで、待ち時間がユーザー体験やループ全体のスループットを左右する場面ではFast mode、リアルタイム性が不要なバッチ用途では標準、と切り分けるのが基本です。
コスト削減・最適化オプション
Anthropicは複数のコスト削減手段を提供しています。ただし一部はFast modeと併用できないため、利用モードに応じて使い分けます。

- プロンプトキャッシング
繰り返し使うプロンプトをキャッシュし、最大90%の入力コスト削減。4.8では最小1,024トークンから対象になり、短いプロンプトでも効かせやすくなった。Fast modeとも併用できるが、標準とFast modeを切り替えるとキャッシュは無効化される。
- バッチ処理
非同期APIでまとめて投げる方式で50%削減。リアルタイム応答が不要なバッチ向け。ただしFast modeとは併用できず、標準モード専用となる。
- Effort Controlでの最適化
簡単な処理をlow・mediumに落とすことで、思考トークンの消費とレート制限の消費を同時に抑えられる。標準・Fast modeのどちらでも使える。
これらを組み合わせると、例えば毎晩のリポジトリ全体スキャンをバッチ処理+プロンプトキャッシング+low effortで回し、難問のレビューだけmaxで実行する、といったメリハリのあるコスト設計ができます。同じ作業をすべてmax effortの同期APIで回す場合と比べ、請求額を数分の1に抑えられるケースもあります。
Claude Opus 4.8導入で詰まる論点
ここではOpus 4.8導入を検討する際に、判断や設定で迷いやすい論点を「乗り換え判断」「effortの選び方」「実装互換性」の3軸で整理します。

4.7から乗り換えるべきか
「とにかく最新モデルに乗せ替えるべき」という単純な判断は推奨しません。単価が据え置きで互換性も高いため乗り換え障壁は低いものの、効果が出る用途は偏っています。
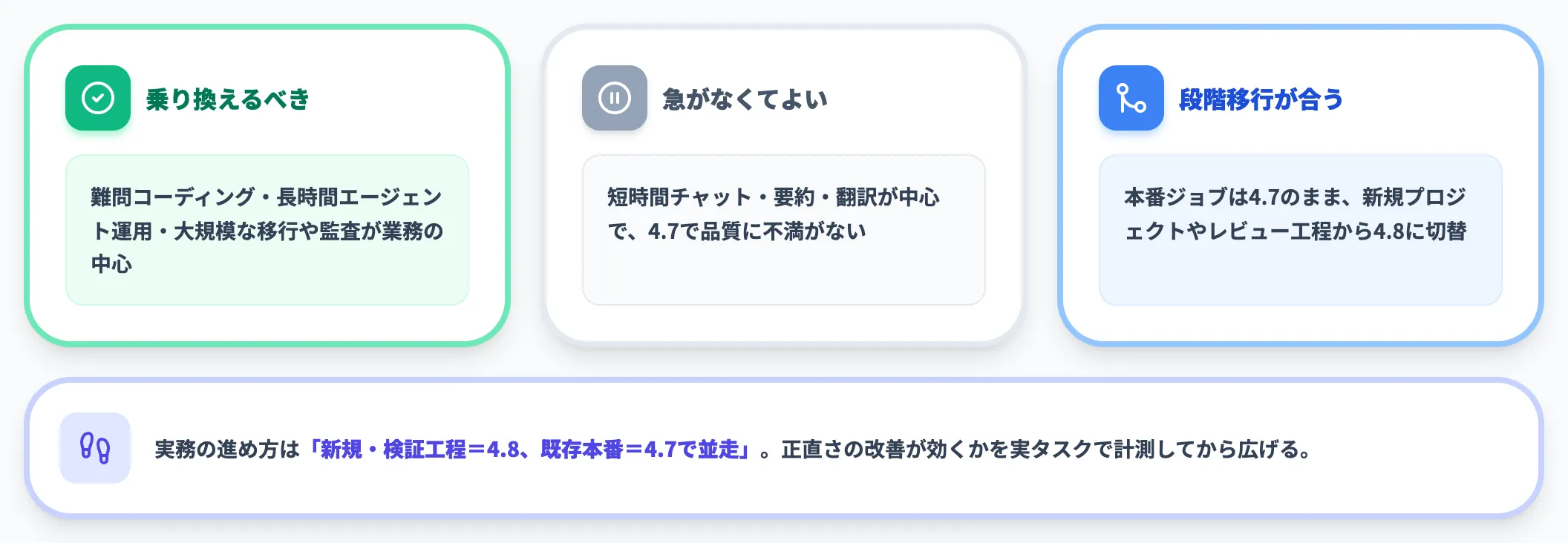
- 乗り換えるべきケース
難問コーディング・長時間エージェント運用・大規模な移行や監査が業務の中心
- 乗り換えを急がなくてよいケース
短時間チャット・要約・翻訳が中心で、4.7で品質に不満がない
- 段階移行が合うケース
4.7で運用中の本番ジョブを残しつつ、新規プロジェクトやレビュー工程から4.8に切り替える
実務的な進め方は「新規プロジェクトと検証工程=4.8、既存本番=4.7で並走し、正直さの改善が効くかを実タスクで計測してから広げる」というステップです。単価据え置きで実効コストの基準も変わらないため、4.7世代より移行判断は素直に下せます。
effortレベルの選び方
Effort Controlは便利な反面、「結局どのレベルを使えばいいか」で迷いやすい機能です。
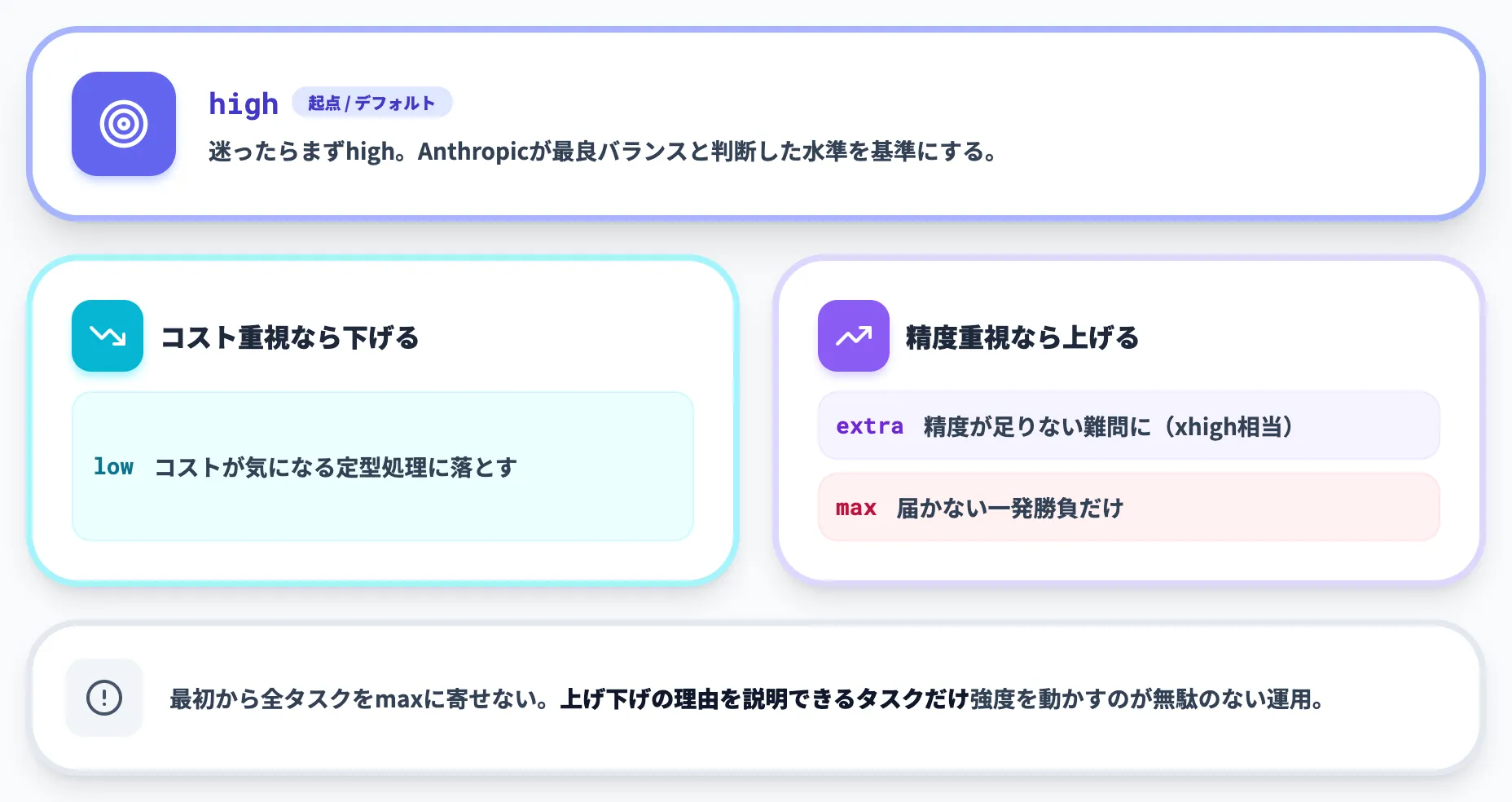
- 迷ったらデフォルトのhighのまま使う(Anthropicが最良バランスと判断した水準)
- コストが気になる定型処理はlowに落とす
- 精度が足りない難問はextra(xhigh)、それでも届かない一発勝負だけmax
ポイントは、最初から全タスクをmaxに寄せないことです。maxは思考トークンを最も消費するため、難易度に見合わないタスクに使うとコストだけが膨らみます。まずhighを基準に、上げる・下げる理由が説明できるタスクだけ強度を動かすのが、無駄のない運用になります。
実装互換性で詰まる箇所
4.7から4.8への移行で、実装側に影響しやすい箇所を整理します。基本的に4.7のコードはそのまま動きますが、確認しておくと安全な点が3つあります。

- モデルID
クライアントSDK・MCPサーバ・ツール統合先で、新IDへの差し替えが必要。
- サンプリングパラメータ
温度などのサンプリング指定は4.7同様に非対応で、指定するとエラーになる。拡張思考の固定予算も使えず、適応的思考とeffortで制御する。
- 会話途中のシステムメッセージ
4.8では会話の途中でシステムメッセージを追加できるようになった。長い会話でプロンプトキャッシュを保ちつつ指示を更新でき、移行時に活用すると入力コストを抑えられる。
特に、温度や固定思考予算を前提に組まれた社内ツールは、指定方法の確認が必要です。詳細な移行手順はAnthropic公式の移行ガイドに整理されているため、本番投入前に一度目を通しておくと、想定外のエラーを避けられます。
Claude Opus 4.8の検証から業務全体のAI化に広げるなら
Opus 4.8のコーディング精度や長時間エージェント運用の手応えを社内で確認すると、「同じ発想を開発以外の業務にも適用できないか」という議論が必ず出てきます。
経費精算、契約書レビュー、稟議の一次承認、社内ヘルプデスクといった「型のあるオペレーション」は、AIエージェントを設計しやすい領域です。
AI総合研究所が提供する「AI業務自動化ガイド」は、Microsoft環境でのAI業務自動化の全体像と、AIエージェントを使った業務効率化の実践例を整理した220ページの資料です。Azure OpenAIやAI Agent Hubを使ったROI向上の考え方も含め、Claude Opus 4.8のような最上位モデルを「開発以外の業務」へどう接続するかの見取り図として活用できます。
Opus 4.8で開発業務の生産性が一段上がるタイミングは、業務側のAI化ロードマップを更新する好機です。まずは無料の資料で、自社の業務プロセスのどこから着手するのが現実的かをご確認ください。
Claude Opus 4.8の業務適用を全社のAI活用につなげる

AI業務自動化ガイドで段階的な導入を設計
Claude Opus 4.8で開発・分析業務の精度と自律性が一段上がる一方、AIの活用範囲はコーディングだけではありません。AI総合研究所のガイドでは、Microsoft環境で業務プロセス全体のAI化を段階的に進める手順を220ページで紹介しています。
まとめ
Claude Opus 4.8は、コーディング・推論・長文処理の3軸で4.7を更新しつつ、「出力の正直さ」を主要な改善軸に据えたフラグシップモデルです。SWE-bench Pro 69.2%でGPT-5.5を上回る難問コーディング性能、USAMO 2026やGraphWalksでの大幅な伸び、そして自分のコードの欠陥見落としが4.7比で約4分の1に下がった正直さの改善は、長時間タスクをAIに任せるチームにとって実用的な意味を持ちます。
新機能としては、思考量を選ぶEffort Control、数百の並列サブエージェントを動かすDynamic Workflows(研究プレビュー)、2.5倍速で前モデル比3倍安いFast mode(研究プレビュー)の3つが加わりました。一方で「Dynamic Workflows・Fast modeはまだ研究プレビュー」「ベンチマークはベンダー公表値で第三者検証はこれから」「評価への気づき(evaluation awareness)の兆候が報告されている」といった留保は、導入計画段階で織り込む必要があります。
標準単価は$5/$25でOpus 4.7から据え置かれ、互換性も高いため移行障壁は低めです。まずはClaude ProやClaude Codeで自社の難問タスクをhigh effortで試し、正直さの改善が効くと判断できたら、新規プロジェクトや大規模移行からDynamic Workflowsを含めて段階的に広げていくのが、無理のない進め方になります。










