この記事のポイント
 コスト重視でLLMを大量処理するなら、V4-FlashがClaude Opus 4.6の標準料金比で大幅に安価に動くDeepSeek V4が有力候補
コスト重視でLLMを大量処理するなら、V4-FlashがClaude Opus 4.6の標準料金比で大幅に安価に動くDeepSeek V4が有力候補- PoCや日次バッチはV4-Flash(入力$0.14/出力$0.28)で十分、品質要件が厳しいエージェントや長文推論のみV4-Proへ切り替えるのが費用対効果的
- 既存deepseek-chat/reasonerは2026年7月24日15:59 UTCで完全停止、V4-Flashへの移行計画を6月までに着手
- 機密情報を扱う業務では公式APIではなく、Hugging Face公開のMIT重みを自社テナント内でホストするのが現実的な選択
- Claude Code/OpenCode/OpenClawと連携済みで、DeepSeek公式ガイドの環境変数設定だけで既存エージェントをV4に載せ替え可能

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
DeepSeek V4は、中国のAI開発企業DeepSeekが2026年4月24日にプレビュー公開したオープンウェイトのMoE(Mixture-of-Experts)大規模言語モデルです。V4-Pro(総1.6T/アクティブ49B)とV4-Flash(総284B/アクティブ13B)の2モデル構成で、どちらも1Mトークンのコンテキスト長を標準搭載しています。
新アーキテクチャDSA(DeepSeek Sparse Attention)によって、前世代V3.2比で単一トークン推論FLOPsを27%、KVキャッシュを10%まで削減。
価格もV4-Flashが入力$0.14/出力$0.28、V4-Proが入力$1.74/出力$3.48(100万トークンあたり)に設定され、V4-FlashはClaude Opus 4.6の標準料金と比べて大幅に安価、V4-Proも競合フロンティアモデルに対して数倍安いという水準になっています。
本記事では、2026年4月時点の公式情報をもとに、V4の技術特徴・ベンチマーク・使い方・料金・日本企業が押さえるべき導入注意点までを体系的に整理します。
Claude Code・OpenCodeへの統合手順、既存 deepseek-chat / deepseek-reasoner の廃止スケジュール、V4-Pro/Flashの選定基準まで含めて解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
DSA(DeepSeek Sparse Attention)による長文脈効率化
Manifold-Constrained Hyper-ConnectionsとMuon Optimizer
Non-think/Think(High/Max)の推論モード
既存モデル(deepseek-chat/deepseek-reasoner)からの移行
DeepSeek V4とは?
DeepSeek V4は、中国のAI開発企業DeepSeekが2026年4月24日に公式発表したオープンウェイトの大規模言語モデルシリーズです。
前世代V3.2に続くフラッグシップモデル群として、V4-ProとV4-Flashの2種類が同時にプレビューリリースされました。

DeepSeek V4が注目されている最大の理由は、「オープンで、1Mコンテキストが標準で、なおかつ価格が大幅に安価」という3点が同時に成立している点にあります。
重みはMITライセンスでHugging Faceに公開されており、商用利用を含めて誰でもダウンロードし、自社環境で動かせる状態になっています。
V4-ProとV4-Flashの位置づけ
DeepSeek V4シリーズは、用途に応じて使い分けられる2つのモデルで構成されています。
以下の表で、両モデルの主要スペックと用途の違いを整理しました。

| 項目 | V4-Pro | V4-Flash |
|---|---|---|
| 総パラメータ | 1.6T(1.6兆) | 284B(2,840億) |
| アクティブパラメータ | 49B | 13B |
| コンテキスト長 | 1M(100万トークン) | 1M(100万トークン) |
| 最大出力トークン | 384K | 384K |
| 推論モード | Non-think/Think(High/Max) | Non-think/Think(High/Max) |
| ライセンス | MIT | MIT |
| 主用途 | フラッグシップ推論・長文分析 | 高速・大量バッチ・PoC |
この表が示すように、V4-ProはClaude Opus 4.6やGPT-5.4と同じフロンティアゾーンを狙う上位モデル、V4-FlashはClaude HaikuやGPT-4o-miniと競合するコスト効率モデルという位置づけです。
実務的な選定軸としては、Proは「Opus/GPT-5.4の代替候補」、Flashは「バッチ処理・PoCで大量に回すコスパ枠」と覚えておくと判断が早くなります。
DeepSeekシリーズにおけるV4の位置
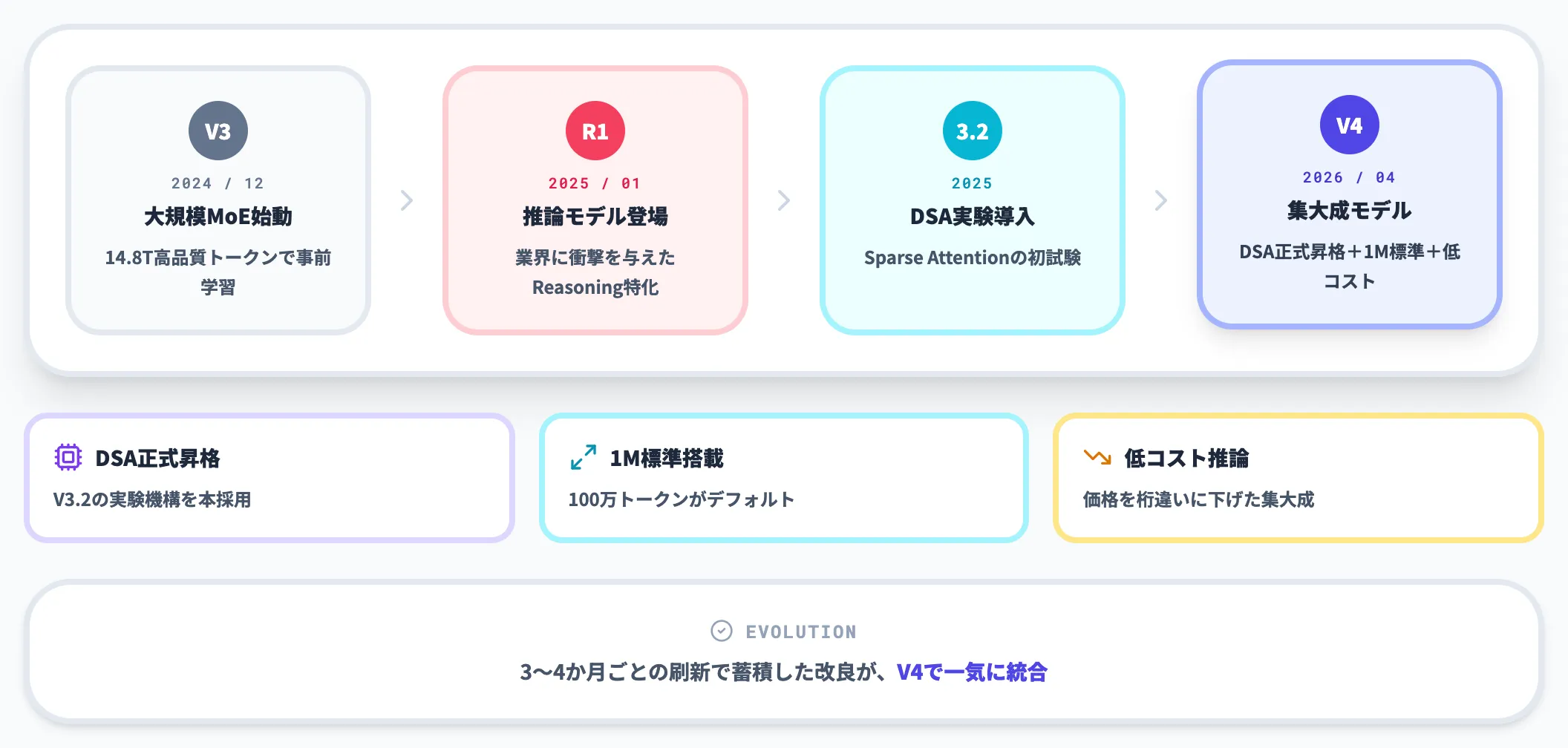
DeepSeekはV3(2024年12月)→ R1(2025年1月)→ V3.1 → V3.2 → V3.2-Expと、およそ3〜4か月ごとにモデルを刷新してきました。
その中でV4は、V3.2で実験的に導入されたDSA(DeepSeek Sparse Attention)を正式アーキテクチャとして昇格させ、パラメータ規模とコンテキスト長を大幅に引き上げた集大成的モデルです。
1Mコンテキストの標準搭載、DSAによる長文脈効率化、低コスト推論を同時に達成した点が、V4がDeepSeekシリーズとしては最大のアップデートと評価される理由です。

DeepSeek V4の進化ポイント(V3.2からの変化)
DeepSeek V4が技術的に注目される理由は、単にパラメータを大きくしただけでなく、アテンション機構・学習手法・推論モード運用といった基盤部分を刷新している点にあります。
この節では、V3.2からどこが変わったのかを4つの観点で整理します。
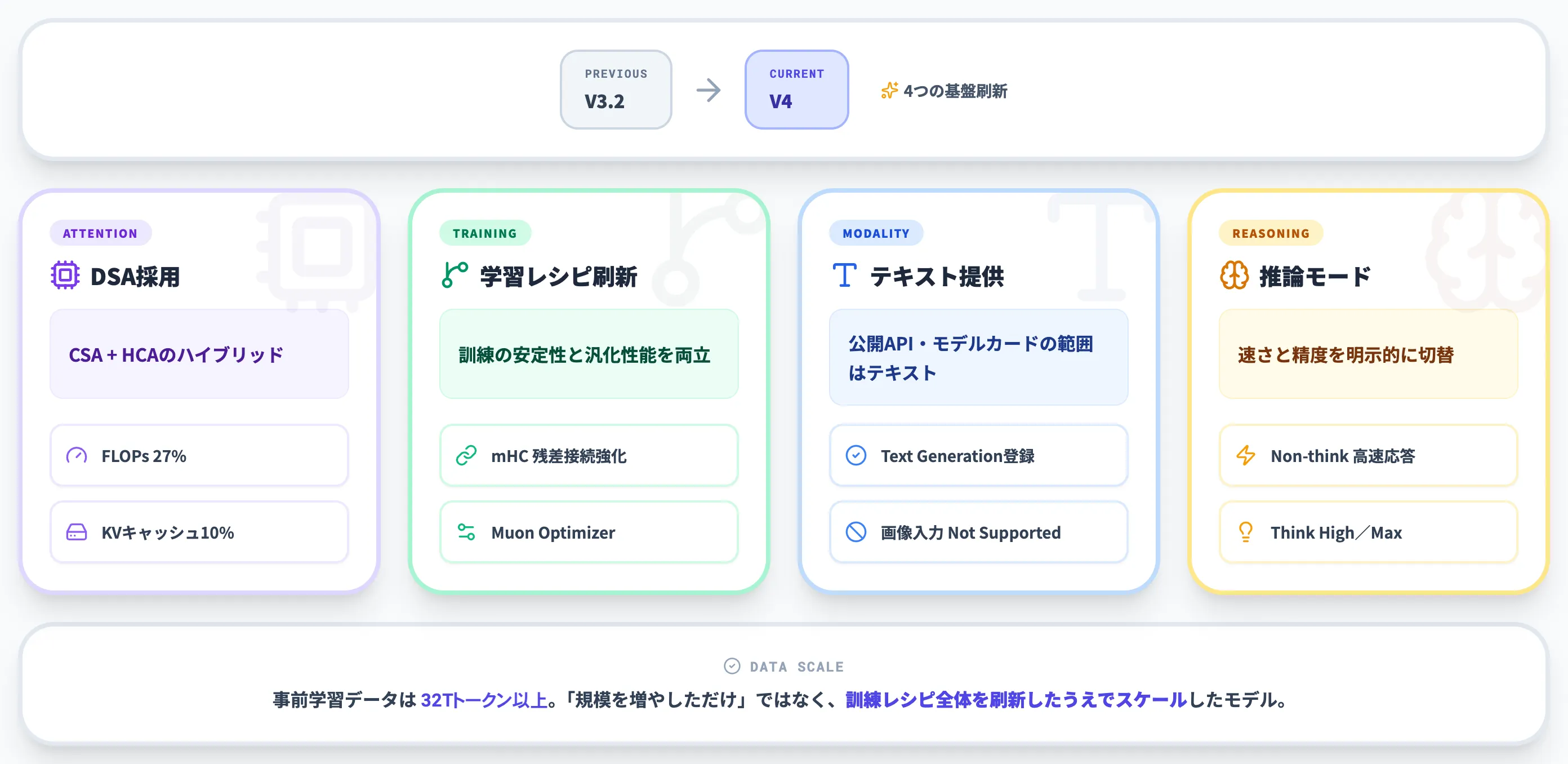
DSA(DeepSeek Sparse Attention)による長文脈効率化
DeepSeek V4で最も重要なアーキテクチャ変更が、V3.2で実験的に導入されていたアテンション機構DSAを正式採用したうえで、構造を一段拡張した点です。
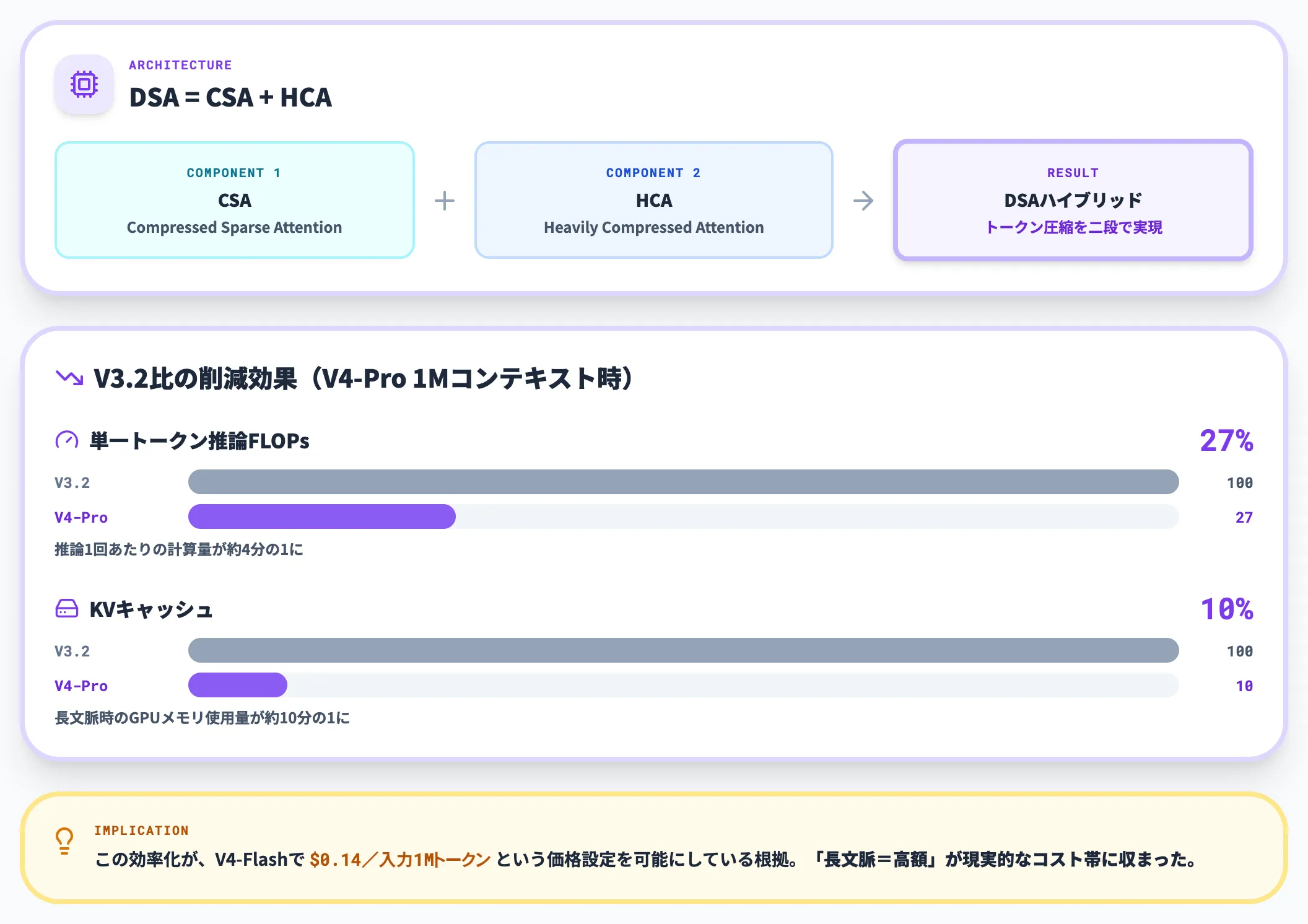
Hugging Faceのモデルカードによると、V4のDSAはトークン単位の圧縮に加え、**Compressed Sparse Attention(CSA:重要なトークンだけ残して厳密に処理する仕組み)とHeavily Compressed Attention(HCA:それ以外のトークンを大胆にまとめて圧縮する仕組み)**を組み合わせたハイブリッド構造で実装されています。
この仕組みの効果は数値として明確に出ています。V4-Proは1Mトークンコンテキスト設定において、V3.2と比較して以下のように計算資源を削減しています。
- 単一トークン推論FLOPs(推論1回あたりの計算量)
V3.2の約27%まで削減。つまり推論1回あたりの計算量が約4分の1になった計算です。
- KVキャッシュ(過去のトークンを覚えておくためのGPUメモリ領域。長文ほど膨らむ)
V3.2の約10%まで圧縮。長文脈を扱うときのGPUメモリ使用量が10分の1程度に縮小しました。
この効率化が、V4-Flashで$0.14/入力100万トークンという価格設定を可能にしている根拠です。従来は「長文脈=高額」が常識でしたが、DSAによって「1Mコンテキストを日常的に使う」ことが現実的なコスト帯に収まりました。
Manifold-Constrained Hyper-ConnectionsとMuon Optimizer
アテンション機構だけでなく、モデルの訓練安定性を支える要素も更新されています。簡単に言えば、1.6Tパラメータの巨大なMoEモデルを学習させる際に、途中で学習が暴走したり伸び悩んだりしないようにする仕組みです。公式モデルカードでは、V4において以下の2つの新技術が導入されたと明記されています。
- Manifold-Constrained Hyper-Connections(mHC)
ニューラルネットの層と層をつなぐ「残差接続」に追加の制約を加え、深いネットワークでも信号がきれいに伝わるよう工夫した仕組みです。深い層でも勾配が爆発・消失しにくくなるため、大規模MoEで起きがちな訓練不安定を抑える役割を担います。
- Muon Optimizer(最適化アルゴリズム)
従来主流だったAdamW系に代わる新しいオプティマイザです。同じGPU時間でも収束速度と訓練の安定性を両立させやすく、汎化性能の伸びにも寄与するとされます。
事前学習には32Tトークン以上の高品質データが使われており、V3系(DeepSeek-V3が14.8T高品質トークンで事前学習・V3.2はV3.1-Terminusからの継続事前学習)からさらに拡張された規模です。実務で重要な点は、「単にパラメータ数を増やして大きくした」のではなく、「訓練レシピ全体を刷新したうえでスケールした」モデルだという点です。
マルチモーダル対応の現時点での位置づけ
V4について「テキスト・画像・動画・音声をネイティブに扱う」という言及が一部の紹介記事で見られますが、2026年4月時点で公開されているHugging Face上のモデルカードは「Text Generation」として登録されており、DeepSeekのAnthropic API互換仕様でも画像・ドキュメント入力は「Not Supported」と明記されています。
つまり、内部アーキテクチャ上でマルチモーダルな要素を持っている可能性は否定できないものの、公開API・公開モデルカードで確認できる範囲では、V4-Pro/V4-Flashの両モデルとも実質的にテキスト専用モデルとして提供されているのが現状です。「ドキュメント+画像が混在する業務プロセス」をV4だけで処理したい場合は、マルチモーダル対応の正式発表を待つ必要があります。
Non-think/Think(High/Max)の推論モード

V4の両モデル(Pro/Flash)は、同一モデルで複数の推論モードを切り替えられます。公式モデルカードでは Non-think/Think High/Think Max の表記が用いられています。
- Non-think
直感的で高速な応答を返すモード。従来のdeepseek-chatに相当する挙動で、シンプルなQ&Aや要約タスク向けです。
- Think High/Think Max
内部で論理的な思考過程を展開してから回答するモード。従来のdeepseek-reasonerに相当し、複雑な推論・コーディング・長文分析で精度が上がります。Highは標準的な思考量、Maxはより深い思考量を許容するレベル設定です。
公式モデルカードでは、Proでは最大推論に相当する「Think Max」モードを使う場合、384Kトークン以上のコンテキストウィンドウを推奨しています。推論モードをアプリケーション側で選択できるため、用途に応じて「速さ」と「精度」のバランスを明示的にコントロールできます。
DeepSeek V4のベンチマーク性能
DeepSeek V4-Proは、主要なベンチマークで既存フロンティアモデルと肩を並べる水準に達しています。ここでは公開された各種ベンチマーク結果から、実務で参考になる数値を整理します。
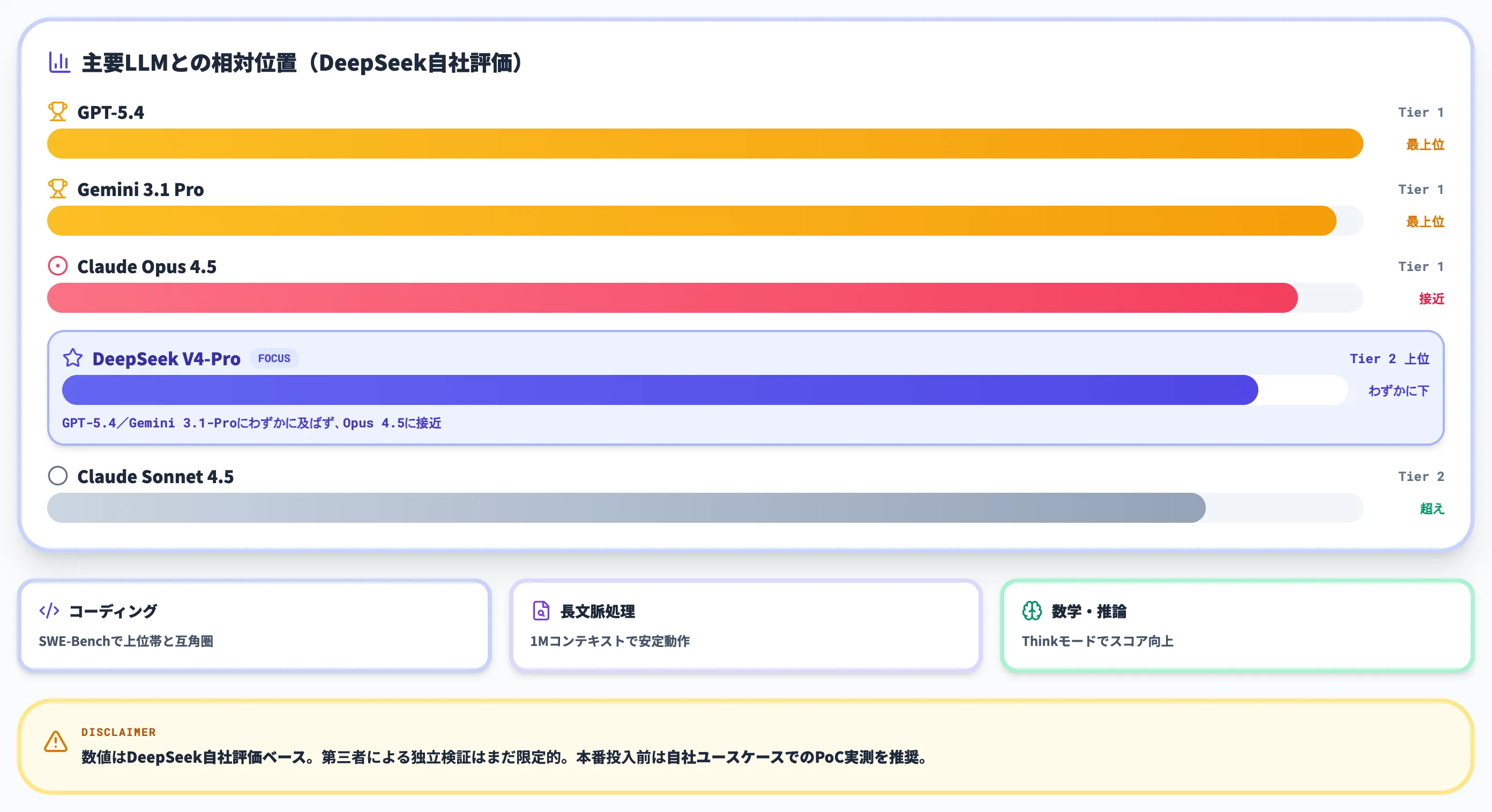
主要ベンチマーク結果
以下の表は、V4-Proと主要フロンティアモデルの代表的スコアを複数の独立評価およびDeepSeek公式モデルカードから整理したものです。
| ベンチマーク | V4-Pro | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| LiveCodeBench(コーディング) | 93.5 | 88.8 | 非公開 | 91.7 |
| SWE-Bench Verified(実ソフト工学) | 80.6 | 80.8 | 非公開 | 80.6 |
| MMLU-Pro(知識) | 87.5 | 89.1 | 87.5 | 91.0 |
| Codeforces(競プロ) | 3206 | 非公開 | 3168 | 3052 |
この結果から読み取れるのは、V4-Proはコーディング寄りの一部ベンチ(LiveCodeBench・Codeforces)では競合を上回る水準に到達している一方で、MMLU-Proや実ソフト工学系ではGemini 3.1 ProやClaude Opus 4.6が上回る場面もあるという位置関係です。DeepSeek公式モデルカードにも、V4-Pro-MaxがMMLU-Pro・Terminal Bench 2.0・GDPval-AA・Toolathlonなど複数の総合指標で劣後するケースが示されており、「ベンチによって優劣が分かれる」のが実態です。Simon Willisonは全体感として「フロンティアから3〜6か月遅れの水準」と評しており、現場感覚としてもこの評価が妥当です。
エージェント性能
エージェントタスクにおけるV4-Proの相対評価については、DeepSeek公式のリリース記事とHugging Faceのモデルカードで、Claude Opus 4.6・GPT-5.4・Gemini 3.1 Proを対象とした比較図が示されています。一方で、Claude Sonnet 4.5やOpus 4.5非Thinkingモードとの粒度の比較は、公開一次ソースの範囲では確認できません。
実運用面で裏付けになるのは、Claude Code・OpenCode・OpenClawなどの主要エージェントフレームワークにV4が最適化されていると公式ガイドに明記されている点です。ただし公開されている比較のほとんどはDeepSeekの自社評価であり、第三者による独立検証はまだ限定的なため、実運用に乗せる前にはタスク固有のA/Bテストを推奨します。
ベンチマーク結果の読み解き
数値だけを並べると判断が難しいため、3つのレイヤーで整理しておきます。
- コーディング実装
V4-ProがLiveCodeBenchで93.5を記録し、Gemini 3.1 Pro・Claude Opus 4.6を上回っています。新規コード生成や関数補完のタスクではV4-Proが有力候補です。
- 実ソフト工学(SWE-Bench Verified)
V4-Pro・Gemini 3.1 Pro・Claude Opus 4.6がほぼ横並び(80.6〜80.8)。「既存リポジトリに対して変更パッチを書ける」能力では差が付きにくくなっています。
- 世界知識・推論(MMLU-Pro)
Gemini 3.1 Proが91.0で頭一つ抜けた状態。V4-ProはGPT-5.4と同水準(87.5)です。
実務的な含意は、コード生成中心のエージェント基盤ならV4-Proで十分、ビジネスリサーチや複雑な推論チェーンを求める用途では依然としてClaude Opus 4.6やGemini 3.1 Proの優位が残るという判断軸になります。
DeepSeek V4の使い方
DeepSeek V4は、公式API・OpenRouter等のプロキシ・Hugging Face重みの3経路で利用できます。この節では、実際にコードから呼び出す手順と、既存のエージェントフレームワークに載せ替える方法をまとめます。
公式APIでの基本的な呼び出し
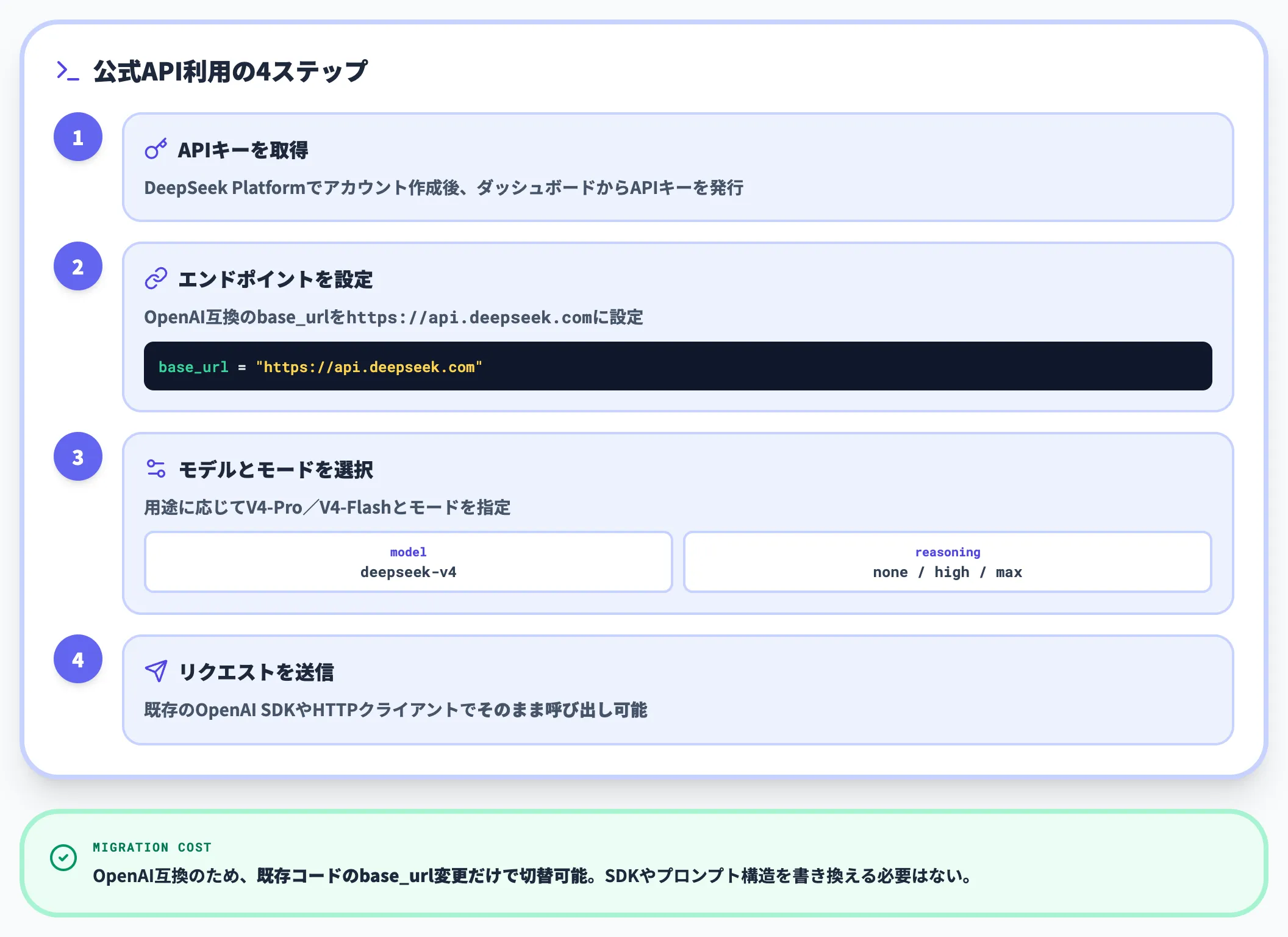
公式DeepSeek APIは、OpenAI互換のChatCompletions形式とAnthropic API形式の両方に対応しています。既にOpenAI SDKで組んでいるコードなら、base_urlとmodel名の2か所を差し替えるだけで動作します。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "DeepSeek V4の特徴を3つ挙げて"}],
temperature=1.0,
top_p=1.0,
)
このアプローチの利点は複数あります。一つは、既存のOpenAI互換プロダクションコードをほとんど書き換えずに移行できるため、検証コストが極めて低い点です。もう一つは、temperatureとtop_pにDeepSeek推奨の「1.0/1.0」を指定するだけで、チューニングせずに公式想定どおりの出力品質が得られる点です。
モデル識別子は V4-Pro が deepseek-v4-pro、V4-Flash が deepseek-v4-flash です。APIキーはplatform.deepseek.comで発行でき、課金・Top Upの詳細は公式ドキュメントの課金ページを参照してください。
Claude CodeとOpenCodeへの統合
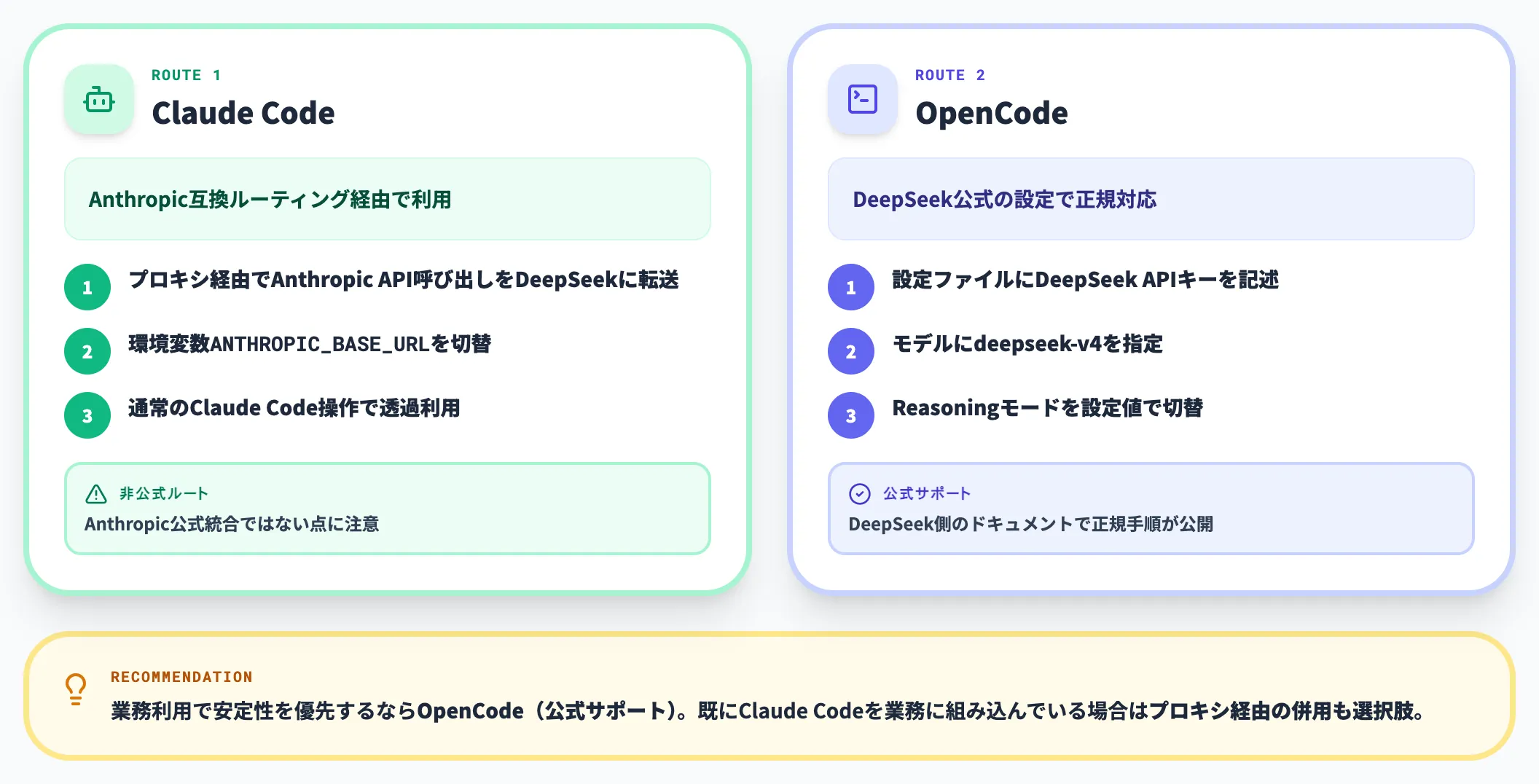
DeepSeek V4は公式の coding agents 統合ガイドでClaude Code・OpenCode・OpenClawの設定例が案内されており、設定ファイルの書き換えだけで統合できます。Claude Codeのユーザーが最も簡単にV4を試す経路は、環境変数を差し替える方法です。
DeepSeek公式の統合ガイドが示している基本形は、メインモデルだけdeepseek-v4-pro[1m](1M長文脈バリアント)を指定し、Claude Codeが内部で参照するOpus/Sonnet/Haiku相当およびサブエージェントには標準のdeepseek-v4-pro/deepseek-v4-flashを割り当てる構成です。
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_AUTH_TOKEN="YOUR_DEEPSEEK_API_KEY"
export ANTHROPIC_MODEL="deepseek-v4-pro[1m]"
export ANTHROPIC_DEFAULT_OPUS_MODEL="deepseek-v4-pro"
export ANTHROPIC_DEFAULT_SONNET_MODEL="deepseek-v4-pro"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="deepseek-v4-flash"
export CLAUDE_CODE_SUBAGENT_MODEL="deepseek-v4-pro"
公式ガイドではこれに加えて、Claude Codeの挙動を最適化するための追加フラグ(プロンプトキャッシュ制御・コンテキスト圧縮関連など)の利用方法も案内されているため、正式に採用する前に公式ガイドの最新版を確認してください。
上記を簡略化して動かすなら、以下のような独自例も成立します。
# 簡略化した独自例(公式ガイドのフル構成ではない)
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_AUTH_TOKEN="YOUR_DEEPSEEK_API_KEY"
export ANTHROPIC_MODEL="deepseek-v4-pro"
export CLAUDE_CODE_SUBAGENT_MODEL="deepseek-v4-flash"
この簡略例の狙いは、「メインタスクは品質重視のV4-Pro、サブエージェントの大量呼び出しは安価なV4-Flash」というコスト最適な組み合わせを最小の設定で作ることにあります。
OpenCodeの場合は ~/.config/opencode/opencode.jsonc にDeepSeekプロバイダ設定を追記すれば動作します。
Hugging Faceからのローカル実行
機密データを外部APIに流せない業務では、Hugging Face公開のMIT重みを自社環境で動かす選択肢があります。
DeepSeek-V4-ProとDeepSeek-V4-Flashの両方がHugging Face上のDeepSeekコレクションで配布されており、推論コードも同リポジトリのinferenceフォルダで提供されています。
Hugging Faceの基本的な使い方を押さえていれば、重みのダウンロードから推論までは一般的なオープンLLMと同じ手順で済みます。
既存モデル(deepseek-chat/deepseek-reasoner)からの移行
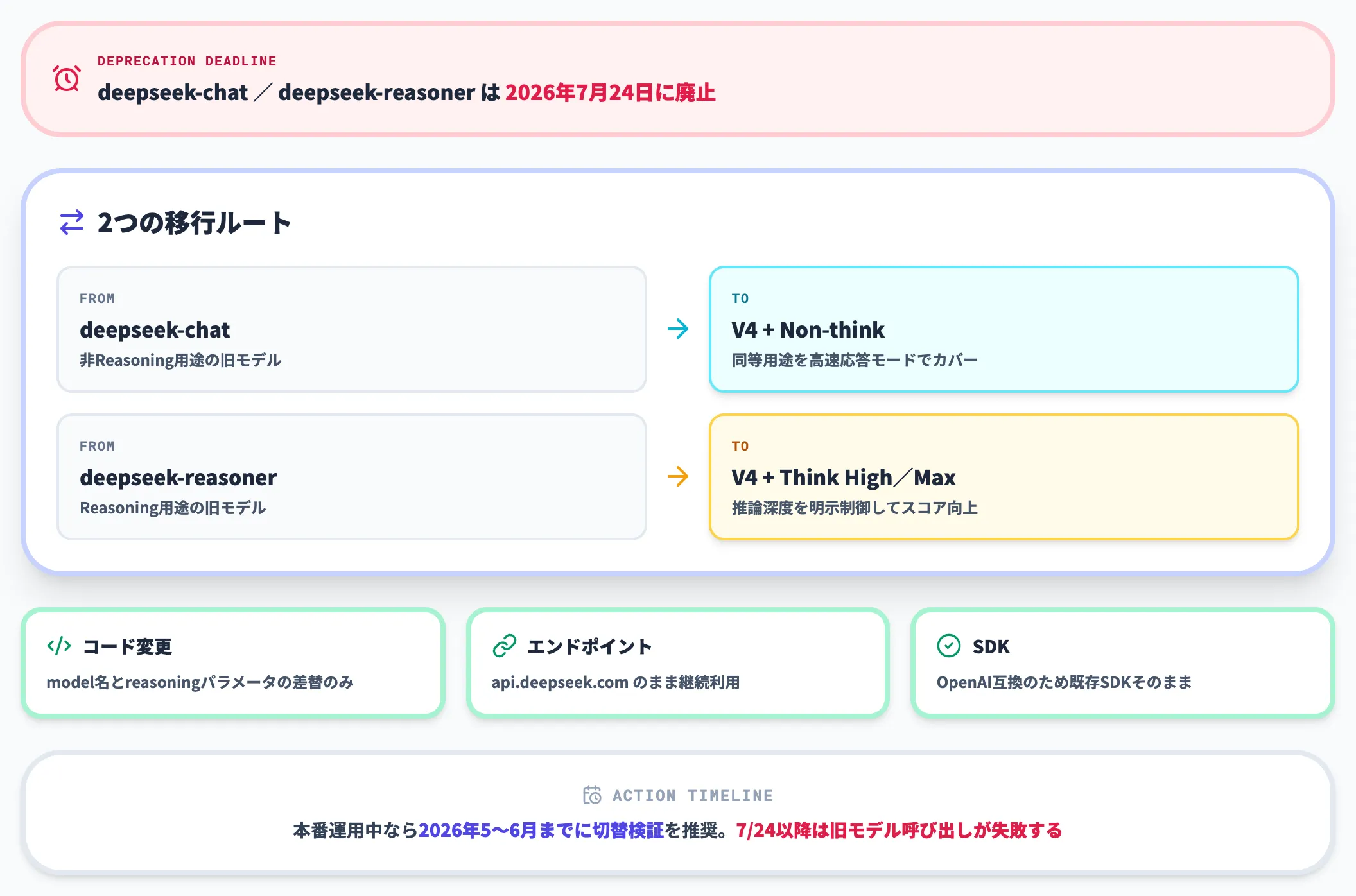
V4のリリースに伴い、公式APIは既存モデルを段階的に廃止します。重要な期日とマッピングを以下にまとめます。
- 廃止期日
deepseek-chatおよびdeepseek-reasonerは2026年7月24日15:59(UTC)で完全停止。この日時以降は当該モデルIDを指定したリクエストが失敗します。
- マッピング
deepseek-chat(Non-Thinking相当)→ deepseek-v4-flashのNon-thinkモード。
deepseek-reasoner(Thinking相当)→ deepseek-v4-flashのThink High/Maxモード、もしくはdeepseek-v4-proのThink High/Maxモード。
- 移行手順
コード側では「model識別子を置換」「temperature/top_pをDeepSeek推奨値に調整」「長文脈を前提にコンテキスト切り出しロジックを見直す」の3ステップで済みます。
廃止期日から逆算すると、遅くとも2026年6月中にはステージング環境でV4への切り替えを完了し、本番切り替え→フォールバック撤去の順で進めるのが現実的なスケジュールです。

DeepSeek V4の料金体系
DeepSeek V4の特筆すべき強みはベンチマーク性能だけでなく、価格設定にあります。
特にV4-Flashは、Claude Opus 4.6の標準料金と比較して非常に低コストで、GPT-5.4の標準料金と比べても十倍以上の差があるため、大量処理用途での費用対効果が突出しています。V4-Proについてもフロンティア帯のモデルとしては入出力ともに数倍安い水準にあり、導入判断の大きな軸になります。
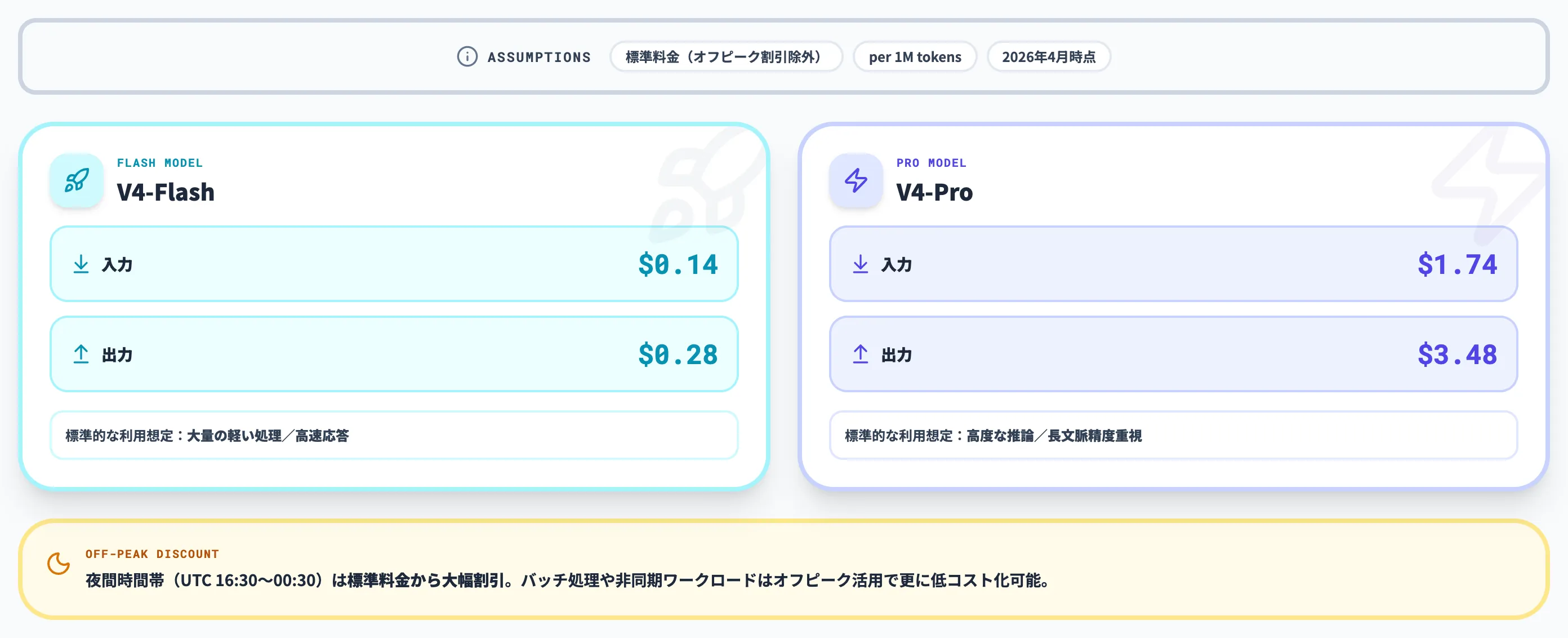
公式API価格(2026年4月時点)
以下の表は公式API価格ページに基づく、100万トークンあたりの価格(USD)です。
| モデル | 入力(キャッシュヒット) | 入力(キャッシュミス) | 出力 |
|---|---|---|---|
| deepseek-v4-flash | $0.028 | $0.14 | $0.28 |
| deepseek-v4-pro | $0.145 | $1.74 | $3.48 |
この価格設定で特徴的なのは、自動キャッシュ機構による大幅な割引です。同じプレフィックス(システムプロンプトや長文の前提資料)が繰り返し使われるケースでは、キャッシュヒット時の入力トークンがキャッシュミス時の約1/10〜1/12になります。
エージェント用途やRAG用途では同じコンテキストを何度も再送するため、この割引が効きやすい構造です。
Claude/GPTとの価格比較(標準料金・100万トークン換算・2026年4月時点)

V4の価格競争力を直感的に掴むため、主要モデルの料金を並べて比較します。
以下の表は、2026年4月時点の各社公式価格ページの標準料金を**100万トークンあたり(USD)**で揃えたものです。長文脈プレミアム料金やキャッシュ割引は含めていません。
| モデル | 入力(標準・$/1M) | 出力(標準・$/1M) | 最大コンテキスト |
|---|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 | 1M |
| DeepSeek V4-Pro | $1.74 | $3.48 | 1M |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M |
| GPT-5.4 | $2.50 | $15.00 | 1,050,000 |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | 1M |
V4-Proを標準料金ベースで比較すると、Claude Opus 4.6に対して入力で約2.9倍安く、出力で約7.2倍安い計算になります。
GPT-5.4との比較では入力で約1.4倍安く、出力で約4.3倍安、Gemini 3.1 Pro Previewとの比較では入力で約1.2倍安く、出力で約3.4倍安という水準です。「フロンティア帯の他社モデルより数倍安い」と捉えるのが実態に合った表現です。
V4-Flashは桁が変わります。Claude Opus 4.6と比較すると入力で約36倍、出力で約89倍安く、GPT-5.4とは入力で約18倍、出力で約54倍の差が付きます。Simon Willisonもこの価格差を「a fraction of the price」と表現しており、大量処理用途での費用効率はV4-Flashが突出しています。
コスト削減シミュレーション
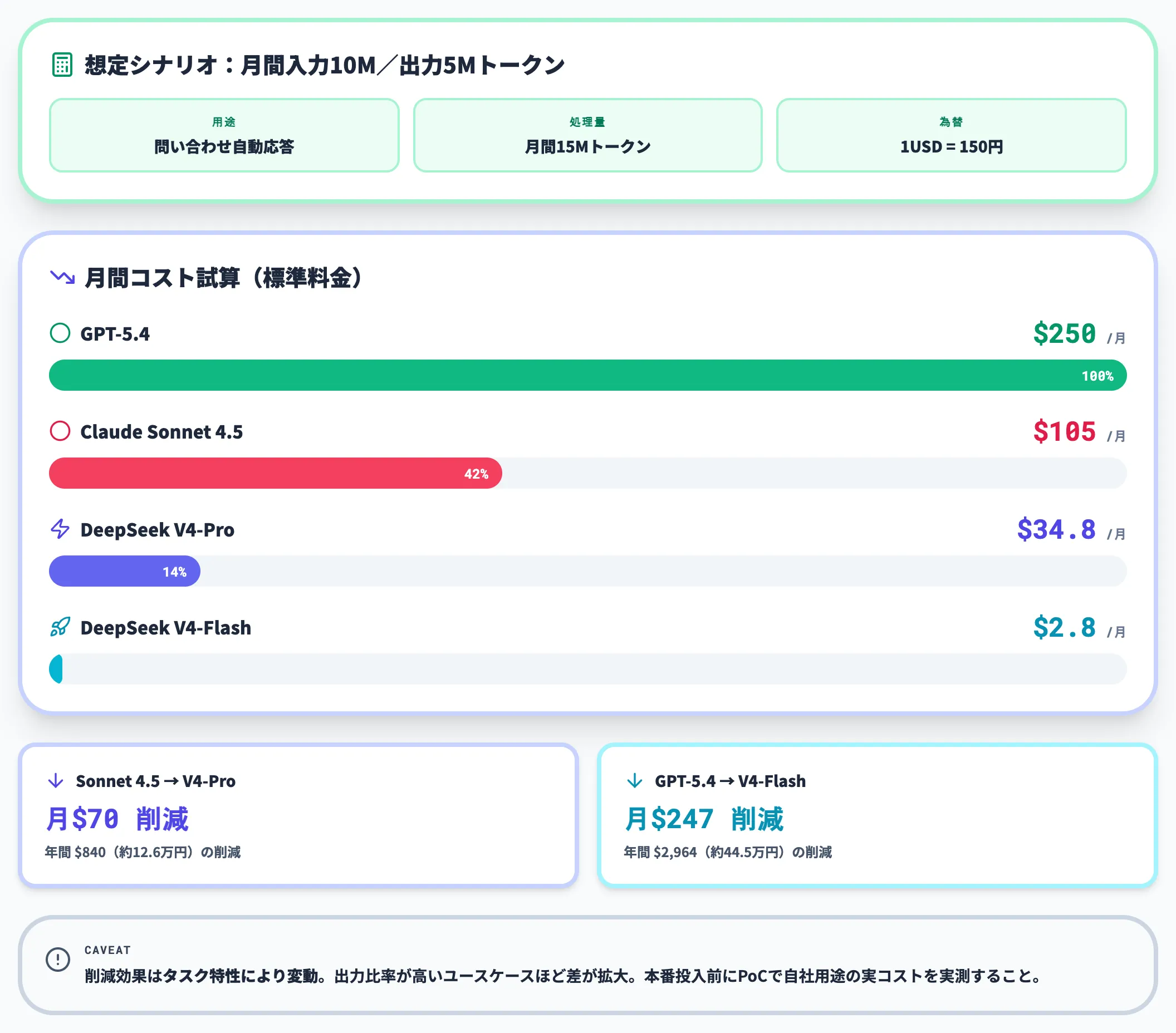
現実の業務で、例えば月間1,000万トークンの入力+500万トークンの出力を処理する生成AIアシスタントを運用しているケースで、標準料金ベースで比較します。
- Claude Opus 4.6
入力 $50 + 出力 $125 = 月額 $175(年額約$2,100)
- GPT-5.4
入力 $25 + 出力 $75 = 月額 $100(年額約$1,200)
- V4-Pro
入力 $17.4 + 出力 $17.4 = 月額 $34.8(年額約$418)
- V4-Flash
入力 $1.4 + 出力 $1.4 = 月額 $2.8(年額約$34)
年間でみれば、Opus 4.6からV4-Proに切り替えると約$1,700、V4-Flashに切り替えれば約$2,000のコスト削減になります。規模が10倍のエンタープライズ利用なら、年間$20,000(約300万円)クラスの削減が視野に入る計算です。長文脈を常用する場合は各社の長文脈プレミアム料金が加算されるため、V4-Proの優位はさらに広がります。
この数値差は無視できませんが、「性能が同等でない部分」もセットで理解する必要があります。Opus 4.6から完全に置き換えるのではなく、定型処理・要約・一次生成はV4-Flashに寄せ、高度な推論や長文分析のみOpus 4.6を残すハイブリッド運用が費用対効果の最適解になるケースが多いです。
DeepSeek V4導入時の注意点
DeepSeek V4は性能・コストで非常に魅力的ですが、導入前に押さえるべき論点がいくつかあります。技術的な問題というより、ベンダーのバックグラウンドやプレビュー版特有の制約に由来するものです。

日本企業での利用制限事例
DeepSeekは2025年1月のR1ショック直後から、日本の大手企業で利用制限が相次ぎました。日本政府の各省庁が2025年2月に職員に対しDeepSeekの利用を控えるよう通達を出した経緯や、民間でもトヨタ自動車・ソフトバンク・三菱重工業など複数の大手が情報セキュリティの観点から社内利用に制限をかけた事例は、各社の公式アナウンスや主要メディアの報道で確認できます(背景の経緯はAI総合研究所のDeepSeek解説記事にまとめがあります)。
これはV4固有の問題ではなく、DeepSeekというベンダーそのもの、および中国系LLMに対する企業セキュリティポリシーの問題です。V4を業務導入する前に、自社の情報セキュリティ規程と輸出規制ガイドラインを確認し、情報システム部門の承認を得ておくことが前提になります。
データ主権と中国国家情報法
中国では2017年に国家情報法が施行されており、中国の組織・個人は国家安全保障活動への協力義務を負います。これにより、中国政府が法的にDeepSeekに対してデータ提供を求められる根拠が存在します。
この論点は、公式APIを使った場合にプロンプトや出力内容が中国国内のサーバーを経由することを意味します。社内文書・顧客情報・開発中のソースコードなど、外部流出時の影響が大きいデータは公式APIで扱うべきではありません。一方で、Hugging Faceから重みをダウンロードして自社テナント内で動かす場合は、この懸念は基本的に回避できます。
プレビュー版特有の制約
2026年4月時点のV4はプレビュー版のため、本番運用に向けた注意点がいくつかあります。
- SLA・サポート体制
プレビュー版のためSLAは限定的。業務クリティカルな用途では、GA版のリリースを待つかリトライ戦略を含めた設計が必要。
- 価格の変動可能性
公式ドキュメントに「Product prices may vary and DeepSeek reserves the right to adjust them」と明記。長期契約でコスト前提を固定する運用は避ける。
- 自社ベンチマークの扱い
公開されているベンチマーク数値の多くは自社評価。独立検証はArtificial Analysis等の第三者機関の結果を併読し、タスク固有の検証も行う。
実装系で詰まりやすい論点としては、temperature=1.0/top_p=1.0という推奨値がOpenAI系の感覚とは異なる点(従来は0.0〜0.3が多い)、1Mコンテキストを実際に使うとレスポンスタイムが大きく延びる点、Think Maxモードは推奨コンテキストが384K以上である点などがあります。
2026年7月24日廃止モデルへの対応
前述のとおり、deepseek-chat/deepseek-reasonerは2026年7月24日15:59(UTC)で完全廃止されます。既存の本番環境でこれらのモデルを使っている場合、以下のタイミングで動きましょう。
- 2026年5月中
検証環境でV4-Flashに切り替え、主要タスクで精度・レイテンシの差分を測定。
- 2026年6月中
本番の一部トラフィック(10〜30%)をV4-Flashに振り分け、安定性を確認。
- 2026年7月上旬
100%切り替え。旧モデル参照コードを撤去。
公式アナウンスから廃止まで3か月しかないため、認識したら即スケジュールに組み込むべきです。

DeepSeek V4の選定シナリオ
ここまでの性能・料金・注意点を踏まえ、実際にどのケースでV4を採用すべきかを整理します。中立的な「最強モデル」を決める話ではなく、業務要件からケース別の推奨を示します。
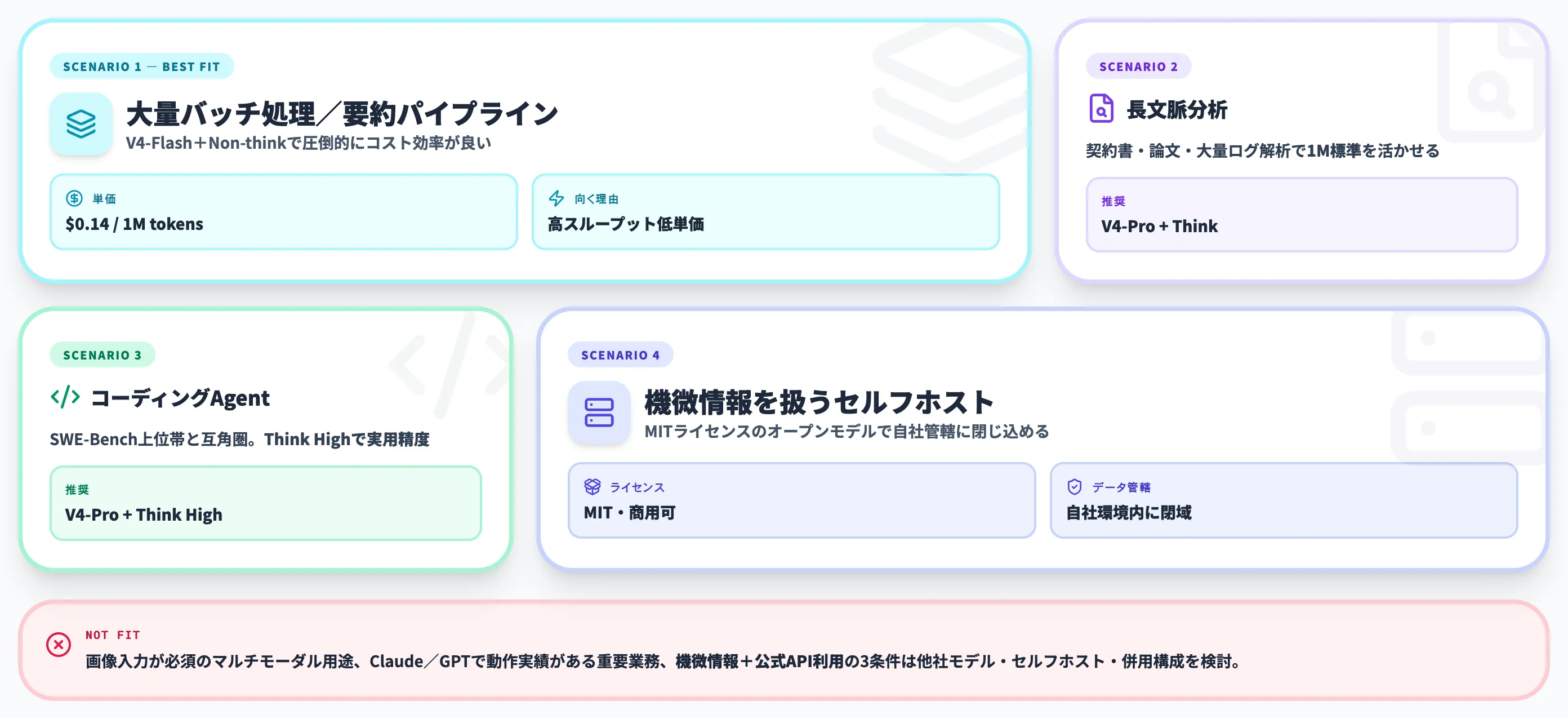
V4-Flashを選ぶべきケース
V4-Flashは「大量処理×コスト最優先」の用途で有力な候補となります。具体的には以下のようなケースが該当します。
- PoC・初期検証
アイデアが本当に動くか素早く検証したい段階。1サンプルあたり入力1,000トークン・出力500トークンを想定すると、1,000本のサンプルを生成しても入力$0.14+出力$0.14=約$0.28程度で収まります。
- 日次バッチ処理
ログ要約、定型メール生成、記事タイトル案出しなど、大量だが個々の精度はそれほど厳格でない処理。
- サブエージェントの内部呼び出し
メインモデルが品質保証を担い、サブエージェントが多数のファイル読込・検索を担当する構成。Claude CodeのCLAUDE_CODE_SUBAGENT_MODELにV4-Flashを割り当てるのが好相性です。
V4-Proを選ぶべきケース
V4-Proは「Opus/GPT-5.4に近い品質を必要としつつ、コストは半額以下にしたい」ケースに向きます。
- 長文ドキュメント分析
契約書・仕様書・論文など、1Mコンテキストを実際に使うタスク。V4-ProはDSAによって長文脈でも性能劣化が少ない設計です。
- コーディングエージェント
LiveCodeBenchで93.5と最上位クラス。Claude Codeのメインモデルとして、自律的なリファクタやテスト生成に投入できます。
- Opusからの部分置換
品質要件の高いメインフローでOpus 4.6を使い続けつつ、周辺のエージェントやファーストドラフト生成をV4-Proに寄せる構成。コストを落としながら品質を維持できます。
ClaudeやGPTとどう使い分けるか
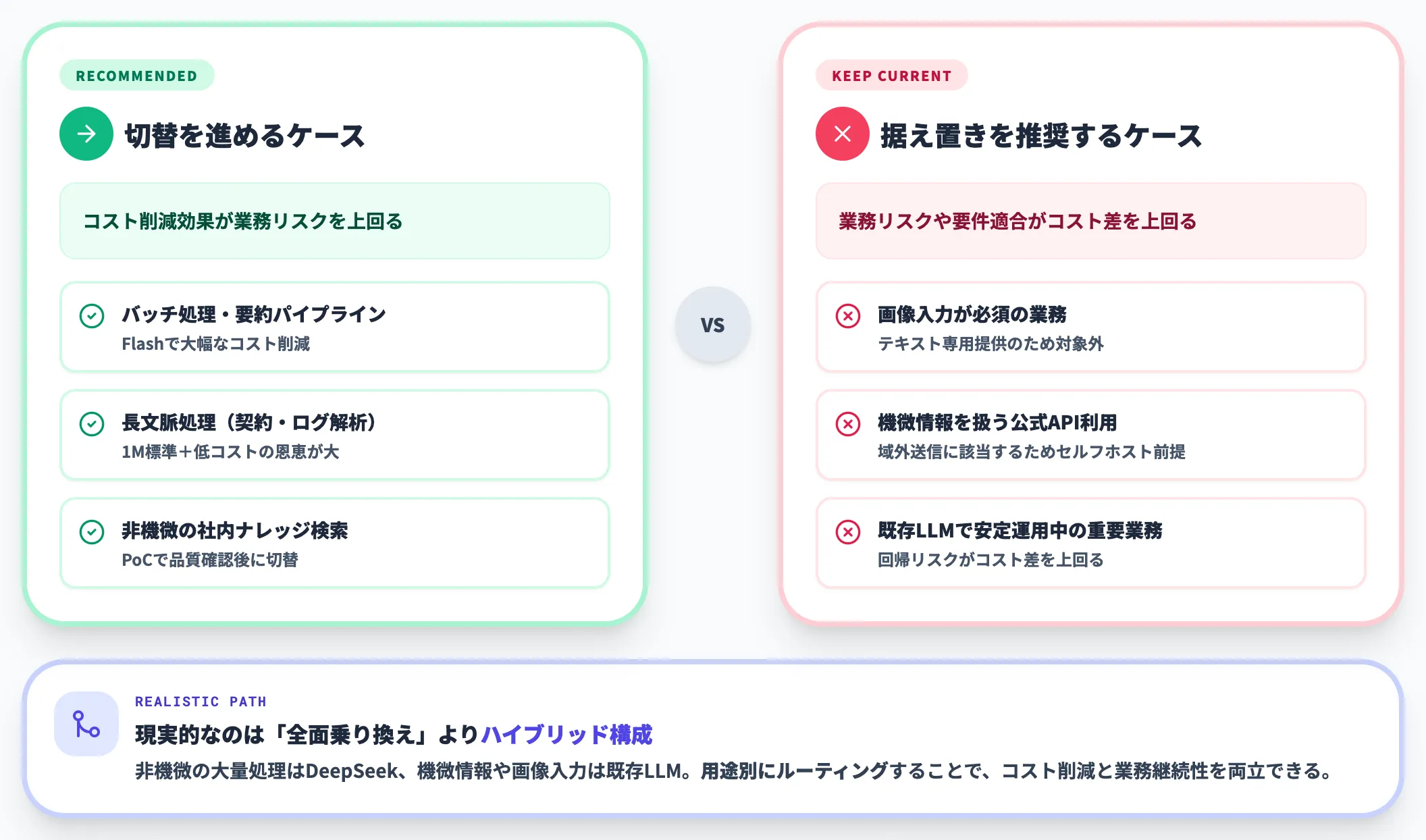
ここが導入判断で最も詰まりやすい論点です。現実には全部をV4に寄せる選択は普通せず、業務単位で使い分けるのが妥当です。支援経験に基づく実務的な使い分けとしては、以下の3パターンに分岐させるのが現実的です。
- データ主権が問われる業務
顧客情報・医療情報・機密コードなど、外部流出時の影響が大きいデータを扱う業務では、公式APIではなくHugging Face版を自社Azureテナント内でホストする構成を検討。どうしても難しければ既存のClaude/GPTを維持。
- コスト最適化が優先される業務
社内FAQ・ドキュメント検索・大量バッチなど、多少の精度差より月額コストの方がインパクトが大きい領域は、V4-Flashへ積極的に寄せる。
- フロンティア性能が必要な業務
高度な推論、画像・ドキュメント混在のマルチモーダル処理、最新知識の要求される用途は、当面はClaude Opus 4.6・Opus 4.7やGPT-5.4のままにする。V4は公開API・モデルカードの範囲ではテキスト専用提供のため、画像入力が必要な業務では選択肢に入らない。V4がGA版に到達し、第三者ベンチマークで総合的に追いついた段階で再評価する。
重要な判断軸は、「全体を1つのモデルで揃える」という発想を捨てて、業務単位でモデルを使い分けるという前提に立つことです。DeepSeek V4の登場で、LLMは「品質と価格のトレードオフが明確に分岐した時代」に入ったと捉えるのが実態に近いでしょう。
社内のAIエージェント運用を進める場合、どのモデルを使うかより前に「モデルを業務に接続する運用基盤」を設計する段階に入っているはずです。モデルが増えると権限・ログ・コスト配分が複雑になるため、そこを抑える仕組みを最初に置いておくと、モデル切り替えに振り回されにくくなります。
複数モデルを業務に載せるなら運用基盤が先
DeepSeek V4のような安価なモデルが出ても、Claude/GPTとの併用を前提にすると、ボトルネックになるのは推論コストではなく社内システム連携・権限管理・実行ログを統合管理する運用基盤の設計です。ここを飛ばすと、結局Excelと手作業でモデル出力を貼り直す運用に戻ってしまいます。
AI総合研究所のAI Agent Hubは、DeepSeek V4を含む複数モデルを業務フローに接続し、エージェントの実行・監視・権限管理を一元化するエンタープライズAI基盤です。モデルが変わっても運用基盤を使い続けられる構造になっているため、V4→GA版への移行や、Claude/GPTとのハイブリッド運用もそのまま取り込めます。
- モデル非依存のエージェント運用
DeepSeek V4でもClaude Opus 4.6でもGPT-5.4でも、同じダッシュボードから呼び出し・ログ収集・コスト集計が可能。モデル切り替えの都度、監視基盤を作り直す必要がありません。
- 自社Azureテナント内で完結する構成
Azure Managed Applicationsとして顧客テナント内で動作。DeepSeek公式APIを使いづらい業務では、Hugging Face重みを自社テナント内にホストする構成もサポートします。
- PoCから本番運用への移行を専任チームが伴走
600社以上の相談実績をもとに、モデル選定・業務プロセス設計・権限管理・運用監視までを一気通貫で支援します。
AI総合研究所の専任チームが、モデル比較・PoC設計・本番運用までをワンストップで伴走支援します。無料の資料で、DeepSeek V4を含む最新モデルを業務に載せるための全体像をご確認ください。
複数モデルを業務に載せるなら運用基盤が先

モデルを切り替えても使い続けられるエージェント基盤
DeepSeek V4が安くても、Claude/GPTとの併用を前提にすると、ボトルネックは推論コストではなく社内システム連携・権限管理・実行ログを統合管理する運用基盤の設計です。AI Agent Hubは、モデルを差し替えてもダッシュボードを使い続けられるエンタープライズAI基盤です。
まとめ
DeepSeek V4は、2026年4月24日にプレビュー公開されたオープンウェイトのMoE大規模言語モデルシリーズで、V4-Pro(1.6T/49B)とV4-Flash(284B/13B)の2モデル構成で提供されます。DSA(DeepSeek Sparse Attention)による長文脈効率化、32Tトークン以上の事前学習、Non-think/Think(High/Max)の推論モードを備え、1Mコンテキストを標準搭載したうえで、V4-ProはClaude Opus 4.6やGPT-5.4の標準料金に対して入出力ともに数倍安く、V4-Flashはさらに大幅に低コストという価格水準で利用できます。
実務的な導入判断としては、まず既存のdeepseek-chat/deepseek-reasonerを使っているなら2026年7月24日の廃止期日に向けてV4-Flashへの移行を6月までに完了させること。コスト最適化が効く定型処理はV4-Flash、長文分析やコーディングエージェントはV4-Pro、フロンティア性能と安定したSLAが必要な基幹業務は当面Claude Opus 4.6やOpus 4.7/GPT-5.4を維持するハイブリッド運用が現実的です。
また、中国ベンダー由来のデータ主権リスクは軽視できない論点です。機密情報を扱う業務では公式APIではなくHugging Face版の自社ホストを検討し、情報セキュリティ規程との整合を取ったうえで導入を進めましょう。
モデル選定だけで止まらず、業務システム連携・権限管理・実行ログまで含めた運用基盤を並行して設計することが、V4時代のLLM活用を成功させる鍵になります。







