この記事のポイント
 CNNは「畳み込み・プーリング・全結合」の三層で画像の局所特徴を階層化する深層学習モデル
CNNは「畳み込み・プーリング・全結合」の三層で画像の局所特徴を階層化する深層学習モデル- 2026年時点でも物体検出はYOLO26、CNN画像分類はConvNeXt V2がSOTAクラスで現役
- Vision Transformerとの使い分け軸はデータ規模・推論環境・リアルタイム性・解釈性の4点
- 医療(内視鏡AI CAD EYE)・製造業(トヨタ外観検査)でCNNは今も実務の主力
- 導入で詰まる論点はデータ量確保・過学習・計算リソース・モデル選定・解釈性の5点

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
CNN(Convolutional Neural Network、畳み込みニューラルネットワーク)とは、画像・映像から特徴を階層的に抽出し、分類・検出・セグメンテーションを行う深層学習モデルです。
2012年のAlexNetがImageNetでtop-5エラー率を26.2%から15.3%に押し下げて以来、画像認識分野の中心であり続けています。
2026年時点では、Vision Transformer台頭とMeta DINOv3・Ultralytics YOLO26のリリースを経て、CNNの立ち位置は「画像認識の唯一解」から「Vision Foundation Model時代の実用的なバックボーン」へと変化しています。
本記事では、CNNの定義と2026年時点の立ち位置、畳み込み・プーリング・全結合の仕組み、LeNet-5からYOLO26・ConvNeXt V2までの主要モデル系譜、Vision Transformerとの使い分け、医療画像診断・製造業外観検査などの活用事例、そして導入で詰まる論点までを、2026年7月時点の情報で体系的に解説します。
目次
CNN(畳み込みニューラルネットワーク)とは?画像認識に強い理由と2026年時点の位置づけ
Vision Transformer時代におけるCNNの現代的な役割
CNNの仕組み:畳み込み・プーリング・全結合が特徴を階層化する三層構造
CNNの主要モデル系譜:LeNet-5からYOLO26・ConvNeXt V2まで
LeNet-5とAlexNet:CNNの起源と深層学習ブーム
EfficientNetとMobileNet系:エッジ推論の主役
ConvNeXt V2とYOLO26:2026年時点のCNN系SOTA
CNN vs Vision Transformer:2026年時点の実務での使い分け
自動運転の物体検出:NVIDIA DRIVEとYOLOシリーズ
CNN(畳み込みニューラルネットワーク)とは?画像認識に強い理由と2026年時点の位置づけ
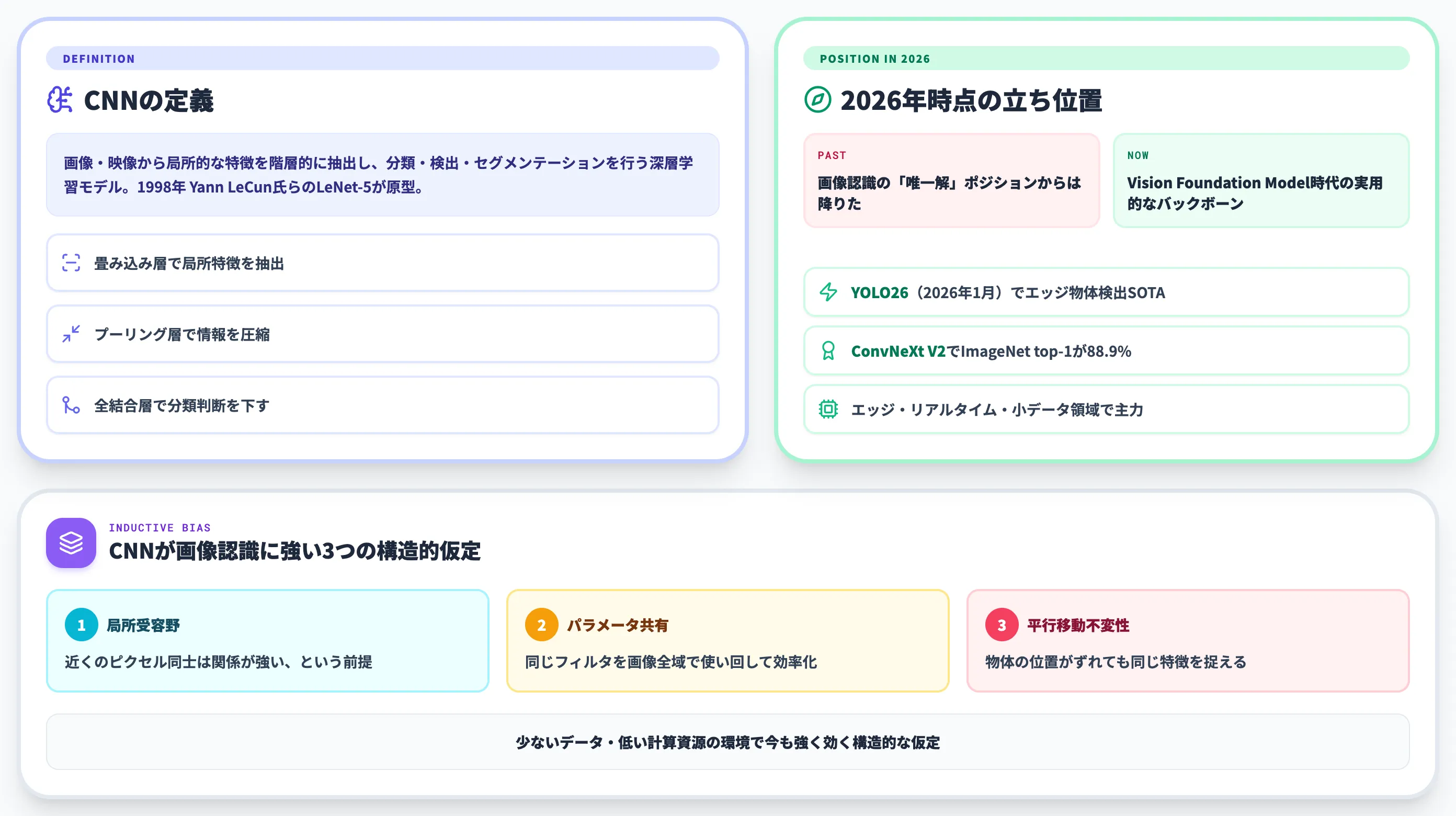
CNN(Convolutional Neural Network、畳み込みニューラルネットワーク)とは、画像・映像から局所的な特徴を階層的に抽出し、分類・検出・セグメンテーションを行う深層学習モデルです。
畳み込み演算とプーリングを繰り返して特徴マップを圧縮し、最後に全結合層で分類判断を下す構造が中核で、Yann LeCun氏らが1998年に提案したLeNet-5が原型として知られています。
2026年現在、CNNは画像認識の唯一解というポジションからは降り、Vision Transformer・Meta DINOv3・CLIPといったTransformer/自己教師あり学習系のVision Foundation Modelと役割分担する状況に変化しています。
一方で、Ultralytics YOLO26(2026年1月リリース)やMeta ConvNeXt V2のようなCNN系最新モデルは、エッジ・リアルタイム・小データ領域で依然として実務の主力です。
Vision Transformer時代におけるCNNの現代的な役割

2020年代後半に入り、CNNはVision Foundation Model時代の「実用的なバックボーン」という性格を帯びてきました。
画像の局所受容野・パラメータ共有・平行移動不変性という構造的な仮定(Inductive Bias)が、少ないデータ・低い計算資源で動く条件下で今も強く効くためです。
-
Ultralytics YOLO26
2026年1月14日リリースの物体検出モデル。NMS-free推論とDistribution Focal Loss廃止でエッジ推論を最適化し、YOLO26nはIntel Xeon CPU上でYOLO11nの約43%高速推論を達成しています(Ultralytics公式ブログ)。
-
Meta ConvNeXt V2
Fully Convolutional Masked AutoEncoder(FCMAE)でCNNに自己教師あり事前学習を持ち込んだモデル。ImageNet top-1で88.9%を達成し、Swin/ViTと同等の分類精度を維持しつつCNNのシンプルさを保っています(arXiv 2301.00808)。
ここでのポイントは、「大きなモデルはTransformer、実装するモデルはCNN」という2層構造が実務上の有力な選択肢として広がりつつある、という点です。
Vision Foundation Modelから蒸留したCNN variantが配布されるケースも増えており、Meta DINOv3にもConvNeXt variantが含まれます。CNNは終わった技術ではなく、Transformer時代の実装レイヤーを担う技術に位置づけが移りました。

CNNの仕組み:畳み込み・プーリング・全結合が特徴を階層化する三層構造
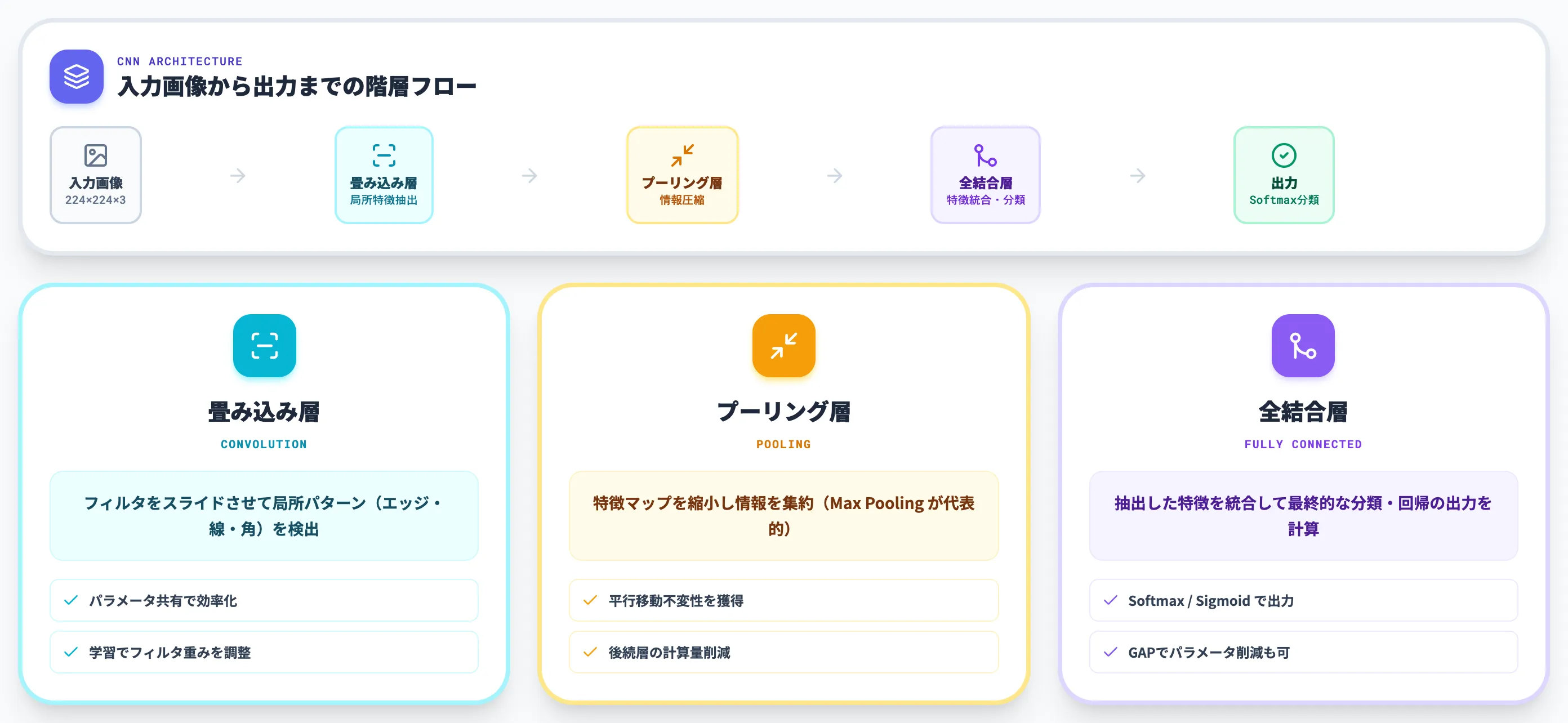
CNNは、大きく分けて畳み込み層・プーリング層・全結合層の3種類の層を組み合わせて構成します。
畳み込み層で局所特徴を抽出し、プーリング層で情報を圧縮しながら、全結合層で最終的な分類判断を下すという流れが基本です。
本セクションでは、各層の役割と、それらが「なぜ画像認識に強く効くのか」の理由を整理します。
畳み込み層(Convolutional Layer)

畳み込み層は、入力画像に対してフィルタ(カーネル)をスライドさせながら畳み込み演算を実行し、特徴マップを生成する層です。
エッジ・線・角・テクスチャなど、画像の局所的なパターンを検出するのがこの層の役割で、フィルタの重みは学習によって調整されます。
ここで重要なのが、パラメータ共有という設計です。同じフィルタが画像内のあらゆる位置に適用されるため、全結合ネットワークと比べてパラメータ数が桁違いに少なくなります。
これがCNNの計算効率・データ効率の高さを支える構造的な仕組みです。
プーリング層(Pooling Layer)

プーリング層は、畳み込み層で得られた特徴マップを縮小し、情報を集約する層です。
代表的なのは指定領域内の最大値を選び取る**最大プーリング(Max Pooling)**で、他に平均値を取るAverage Poolingなどがあります。
プーリングの主な効果は、以下の2点に集約されます。
-
平行移動不変性
入力画像が少し位置ずれしていても同じ特徴マップが得られるため、ロバストな認識が可能になる
-
計算量の削減
特徴マップのサイズが縮小されることで、後続層の計算量とメモリ使用量が減る
この2つは、画像認識で「同じ物体が違う位置に写っていても認識できる」というCNNの実用的な強みを支えます。
全結合層(Fully Connected Layer)
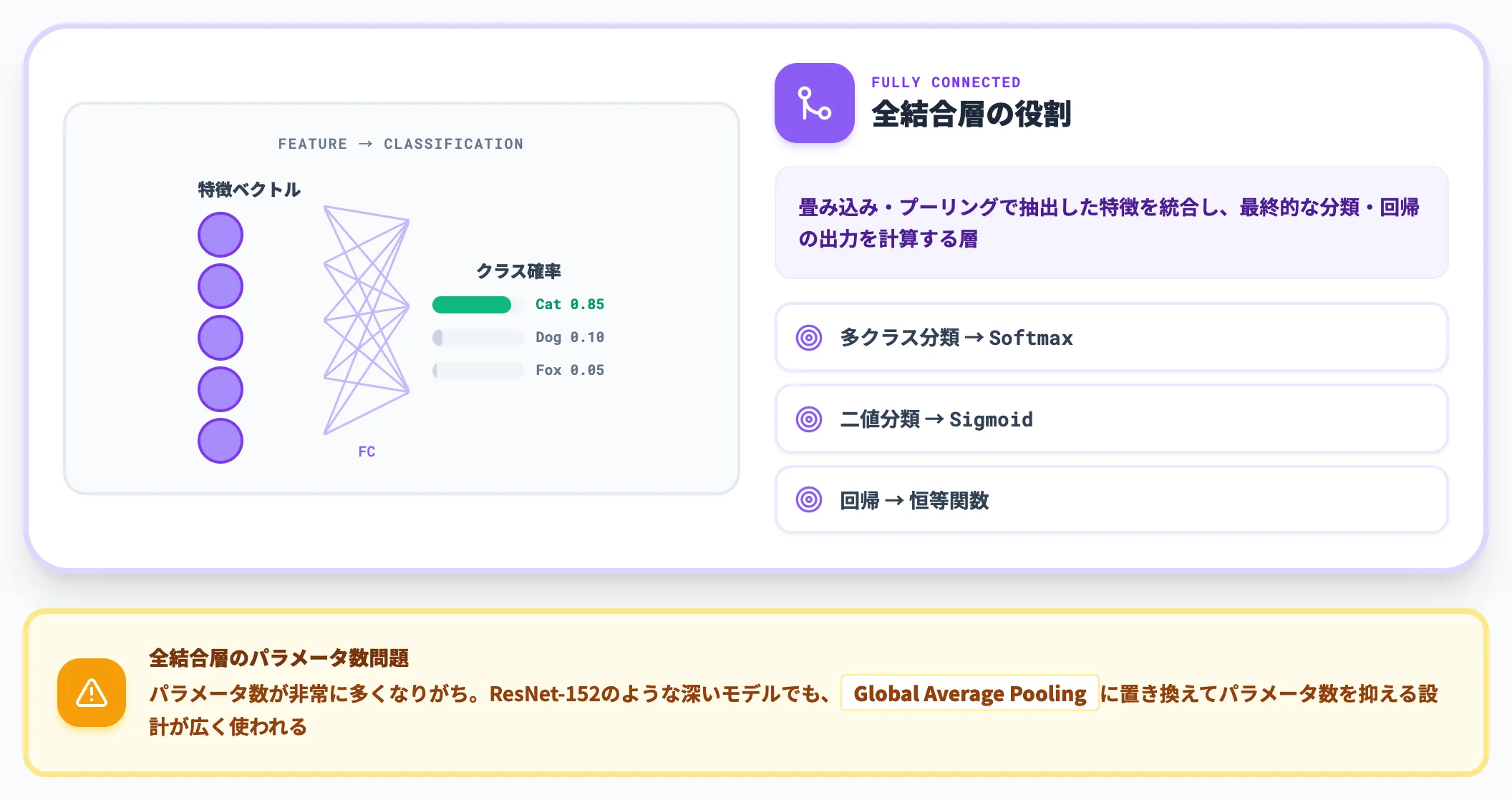
全結合層は、畳み込み・プーリングで抽出した特徴を統合し、最終的な分類・回帰の出力を計算する層です。
CNNの構造の最後に置かれ、多クラス分類ならSoftmax、二値分類ならSigmoid、回帰なら恒等関数を活性化関数として使うのが一般的です。
ここで押さえておきたいのは、全結合層はパラメータ数が非常に多くなりがちである点です。ResNet-152のような深いモデルでも、全結合層をGlobal Average Poolingに置き換えてパラメータ数を抑える設計が広く使われています。
活性化関数と誤差逆伝播による学習
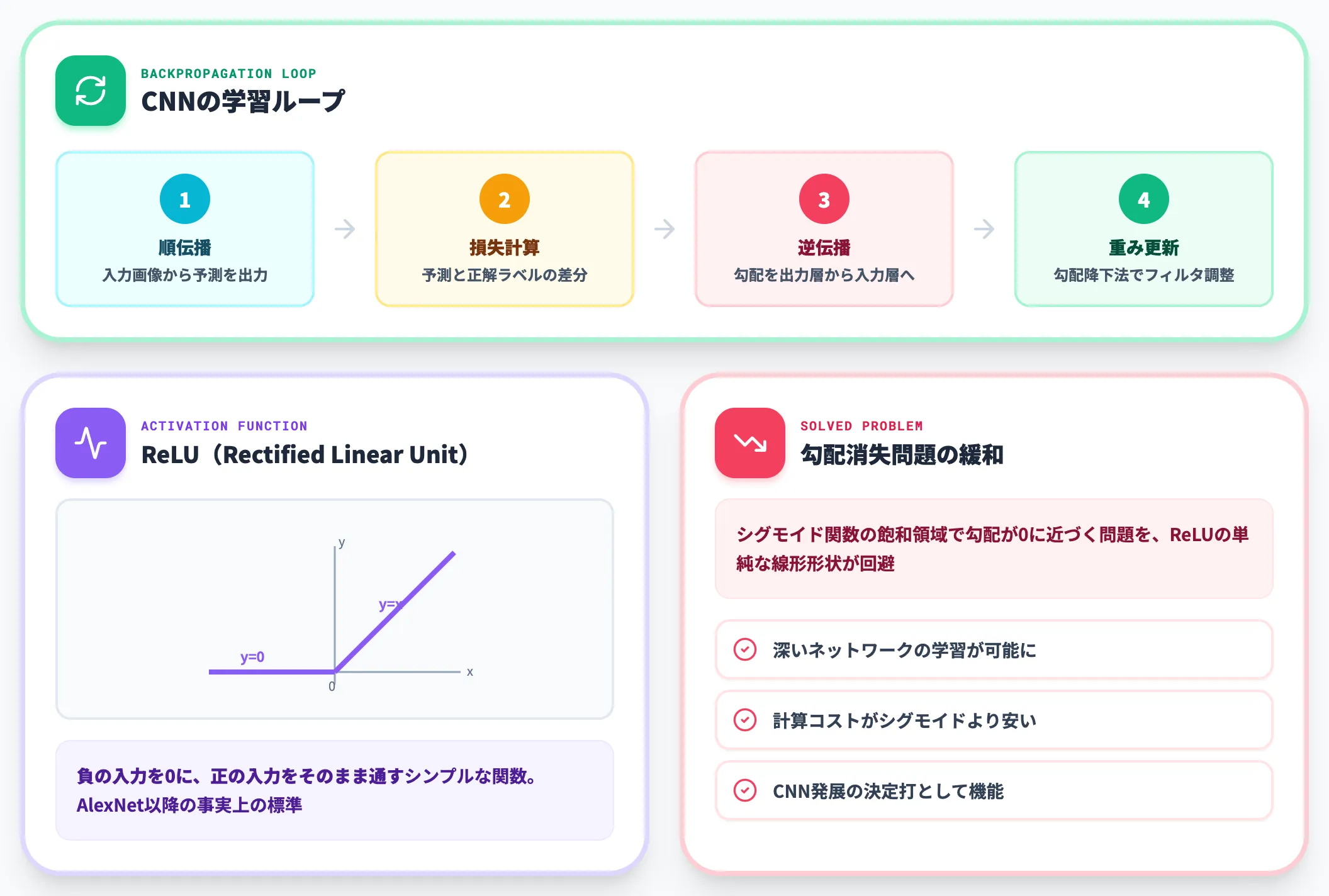
CNNの学習は、誤差逆伝播法(Backpropagation)と勾配降下法を組み合わせて実施します。
入力画像に対する予測と正解ラベルの差分(損失)を計算し、その勾配を出力層から入力層に向けて逆伝播させながら、各層のフィルタ重みと全結合層の重みを更新します。
この際に重要な役割を果たすのが活性化関数で、AlexNet以降はReLU(Rectified Linear Unit)が事実上の標準になりました。
ReLUは負の入力を0に、正の入力をそのまま通すシンプルな関数ですが、勾配消失問題を緩和して深いネットワークの学習を可能にした点で、CNNの発展に決定的な役割を果たしています。
CNNの主要モデル系譜:LeNet-5からYOLO26・ConvNeXt V2まで
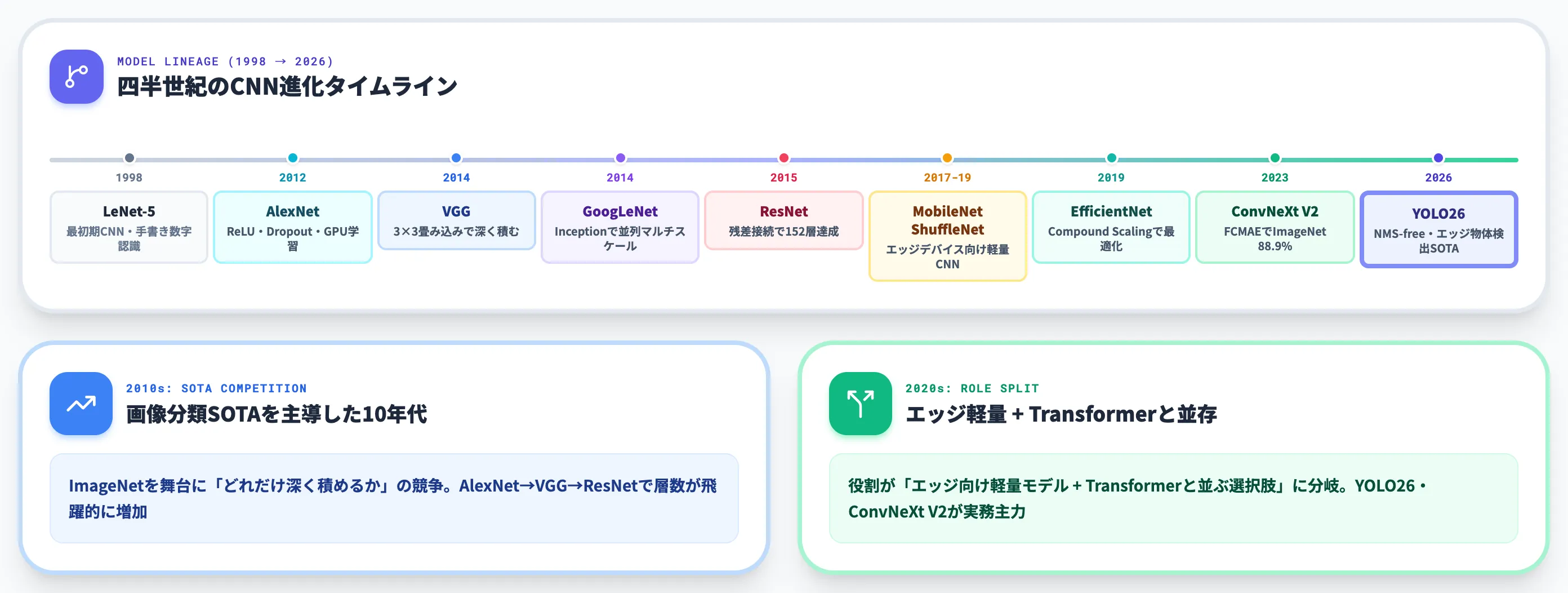
CNNは1998年のLeNet-5から始まり、四半世紀の間に「画像認識のSOTAを更新し続けるモデル系譜」を築いてきました。
以下の表で、主要CNN系モデルの登場年と特徴を整理します。
| 年 | モデル | 特徴 |
|---|---|---|
| 1998 | LeNet-5 | 手書き数字認識で実用化された最初期CNN。畳み込み+プーリング+全結合の原型を確立 |
| 2012 | AlexNet | ImageNet top-5エラーを26.2%→15.3%に。GPU学習・ReLU・Dropoutを導入 |
| 2014 | VGG | 3×3畳み込みだけを深く積む単純設計。転移学習のベースとして長く使われる |
| 2014 | GoogLeNet (Inception) | Inceptionモジュールで並列マルチスケール処理を実現 |
| 2015 | ResNet | 残差接続(Skip Connection)で152層の学習に成功。以降の深層モデルの標準に |
| 2017-19 | MobileNet / ShuffleNet | エッジデバイス向け軽量CNN。Depthwise Separable Convolutionが中核 |
| 2019 | EfficientNet | 幅・深さ・解像度を系統的にスケーリング。精度と効率のパレート最適 |
| 2023 | ConvNeXt V2 | FCMAEによる自己教師あり事前学習。ImageNet top-1で88.9%を達成 |
| 2026 | YOLO26 | NMS-free推論・DFL廃止・MuSGDでエッジ最適化。物体検出のSOTAクラス |
この表からも分かるように、CNNは2010年代に画像分類のSOTA争いを主導し、2020年代に入って役割が「エッジ向け軽量モデル + Transformerと並ぶ選択肢」に分岐しました。
LeNet-5とAlexNet:CNNの起源と深層学習ブーム
LeNet-5は、Yann LeCun氏らが1998年に発表した論文「Gradient-Based Learning Applied to Document Recognition」で提案されたCNNの原型モデルです。
郵便番号認識研究を前身に、銀行小切手などの手書き数字・文字認識で実用化された、CNNの最初期の成功事例として知られています。
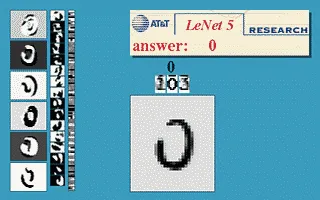
LeNet 5の手書き数字認識デモ(出典:Yann LeCun公式)
Yann LeCun公式ページの実動デモでは、左側に各種の手書き数字入力、中央に予測入力画像、上部に「answer」として認識結果が表示されます。「変形・回転・ノイズにロバスト」というCNNの構造的な強みが、AT&T Bell Labs時代の実装からすでに示されていました。
そこから約15年後の2012年、Alex Krizhevsky氏らが発表したAlexNetがImageNet Large Scale Visual Recognition Challenge(ILSVRC)でtop-5エラー率を26.2%から15.3%に押し下げ、深層学習ブームの起点となりました。
AlexNetは、8層構造・6,000万パラメータで、ReLU活性化関数・Dropout正則化・GPU並列学習を導入した設計です。この3つの技術要素は、その後のあらゆるCNN・深層学習モデルで標準採用されるようになりました。
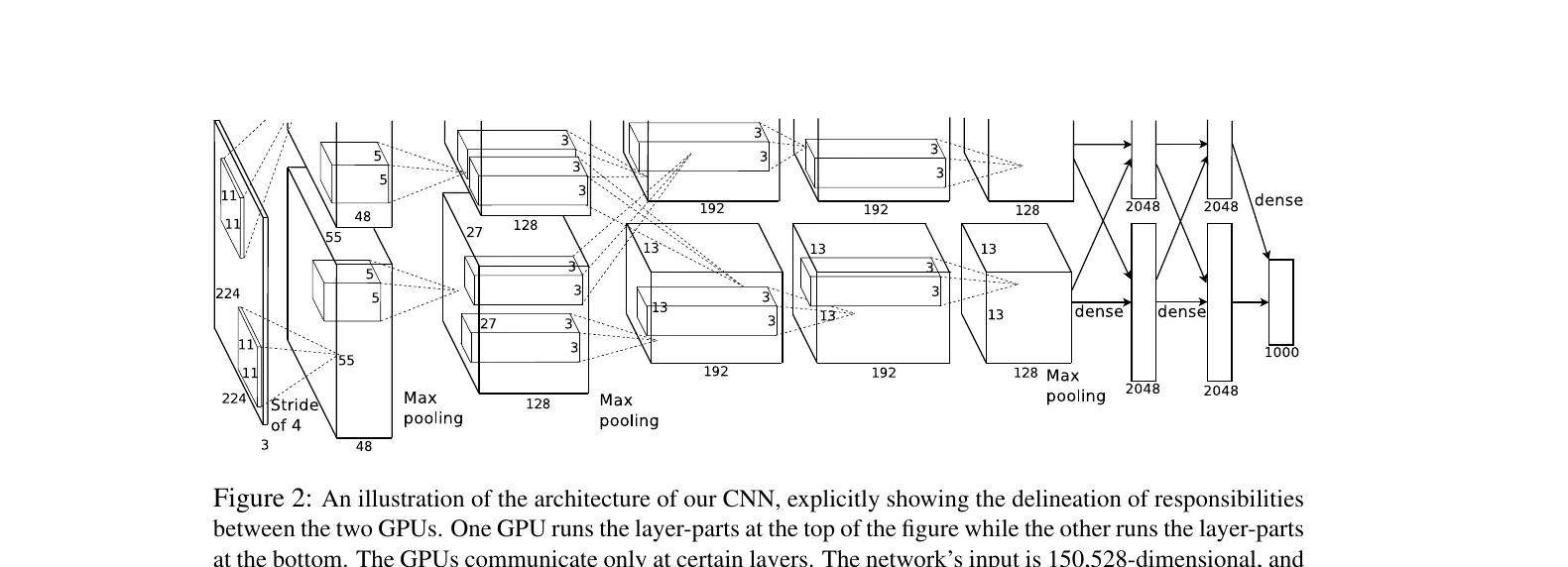
AlexNetの8層アーキテクチャ(出典:Krizhevsky et al. 2012 NIPS)
アーキテクチャ図では、入力224×224×3の画像を、11×11の大きな畳み込みフィルタ・Max Pooling・192〜128チャネルの畳み込み層を段階的に積み、最後に2GPUに分割された2,048ユニット×2(合計4,096ユニット)の全結合層2段と1,000クラス分類のsoftmaxで出力する構造が読み取れます。上下に分岐しているのは2GPU並列学習の構成で、限られた計算資源で深いネットワークを回すための当時の実装工夫が表れています。
VGG・GoogLeNet・ResNet:層を深くする競争
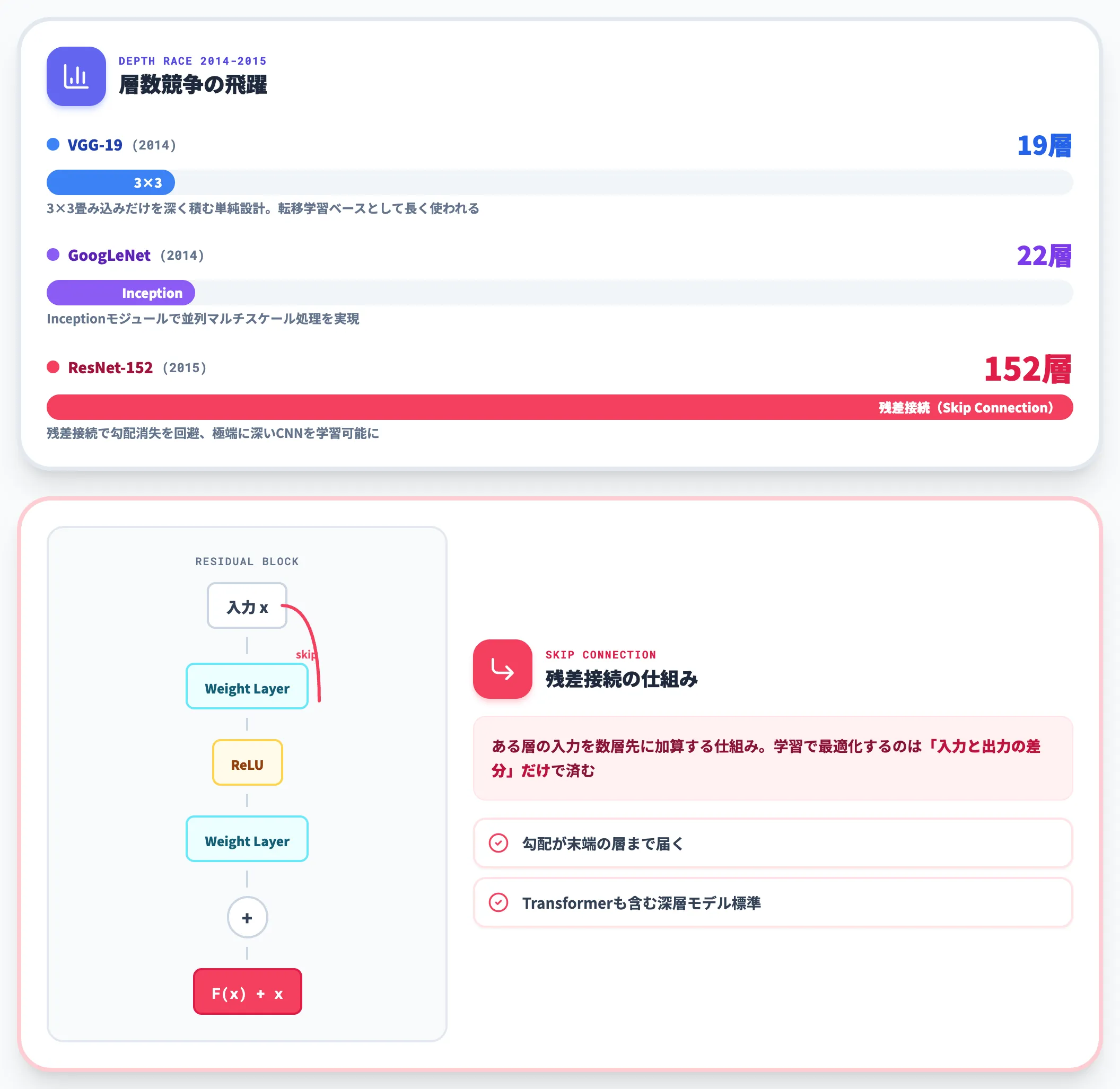
2014年以降、CNNは「どれだけ深く積めるか」の競争フェーズに入ります。
VGGは3×3畳み込みだけを16〜19層積む単純な設計で、GoogLeNetはInceptionモジュールという並列マルチスケール処理で22層を実現しました。
そして2015年、Kaiming He氏らが発表したResNet(Residual Network)は、**残差接続(Skip Connection)**という設計で152層の極端に深いCNNを学習可能にしました。
残差接続は、ある層の入力を数層先に加算する仕組みで、勾配消失を回避しつつネットワークを深くする決定打になりました。この構造は現在も、Transformer含むほぼすべての深層モデルで採用されています。
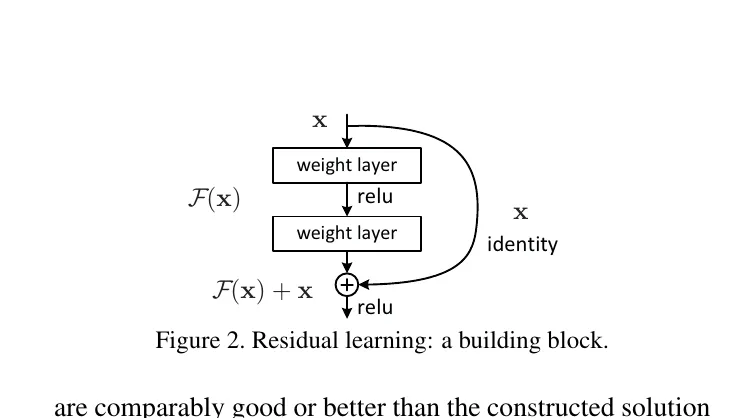
ResNetの残差接続(Skip Connection)(出典:He et al. 2015 arXiv)
残差ブロックの構造は、入力xを2層のweight layer + ReLUに通した出力F(x)に、xそのものをidentityとして加算する(F(x) + x)というシンプルな設計です。
学習で最適化するのは「入力と出力の差分」だけで済むため、層を極端に深くしても勾配が消えずに末端の層まで届きます。
EfficientNetとMobileNet系:エッジ推論の主役

EfficientNet(Google, 2019)は、モデルの幅・深さ・解像度を系統的にスケーリングする「Compound Scaling」で、精度と計算効率のパレート最適を実現しました。
同じくGoogleが提案したMobileNetシリーズは、Depthwise Separable Convolutionで計算量を大幅に削減し、スマホ・組み込み機器上でのリアルタイム推論を実現する代表的な軽量CNNです。
MobileNet系はモバイル・組み込み向けの代表的な軽量CNNとして位置づけられており、2026年時点でもエッジデバイスにおけるCNNの持ち場は揺らいでいません。
ConvNeXt V2とYOLO26:2026年時点のCNN系SOTA

ConvNeXt V2(Meta AI, 2023)は、Transformerの設計思想(自己教師あり事前学習・Global Response Normalization)をCNNに逆輸入したモデルで、ImageNet top-1で88.9%を達成しています。
Fully Convolutional Masked AutoEncoder(FCMAE)というマスク画像復元事前学習を持ち込んだことで、ViTと同水準の精度を、CNNのシンプルな構造と推論効率のまま実現しました。
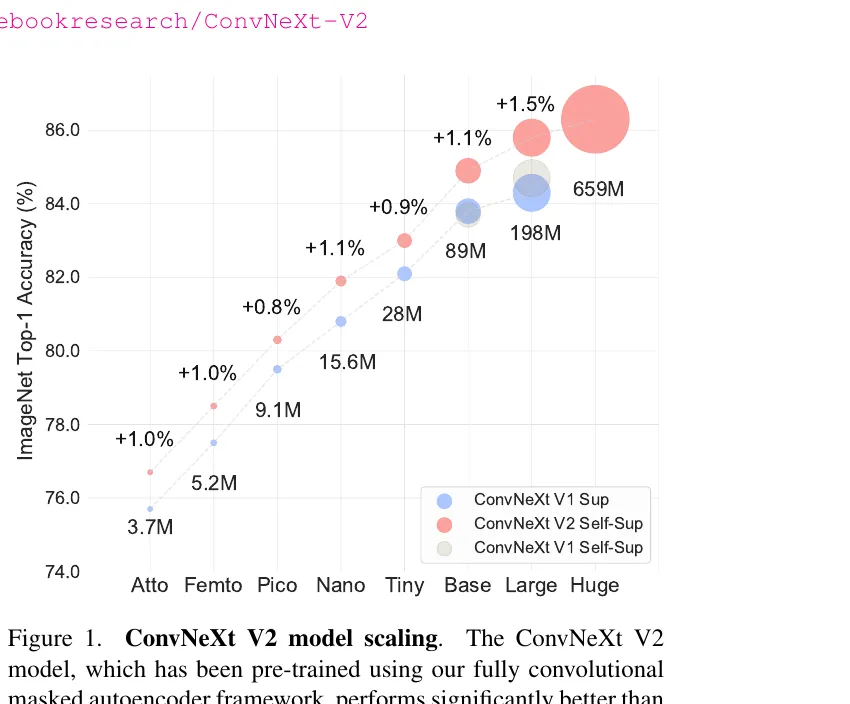
ConvNeXt V2のFCMAE事前学習によるモデル別スケーリング比較(出典:Woo et al. 2023 arXiv)
散布図はモデルサイズ3.7M〜659Mの範囲で、V2の自己教師あり事前学習(赤)が従来のV1教師あり学習(青)を全モデルサイズで一貫して上回ることを示しています。改善幅は+0.8%〜+1.5%で、大きなモデルほど自己教師あり事前学習の効果が乗る傾向が読み取れます。
そして2026年1月14日、Ultralytics YOLO26がリリースされました。

Ultralytics YOLO26のリリース告知(出典:Ultralytics公式ブログ)
YOLO26の主要な変更点は、以下のとおりです。
-
NMS-free推論
Non-Maximum Suppression(重複検出フィルタリング)を廃止し、モデル自身が1対1の予測を出力する設計に変更。後処理コストを削減
-
Distribution Focal Loss(DFL)の廃止
検出ヘッドの構造を簡素化し、エッジ・低電力ハードウェアとの互換性を改善
-
MuSGD Optimizer + Progressive Loss + STAL
最適化と小物体検出を安定化する新しい学習パイプラインを採用
YOLO26nは、Intel Xeon CPU上でYOLO11nと比べてCPU ONNX推論が約43%高速化されており、エッジ推論を主戦場とする物体検出モデルとして依然としてCNN系が有力な選択肢であることを示しています。

CNN vs Vision Transformer:2026年時点の実務での使い分け
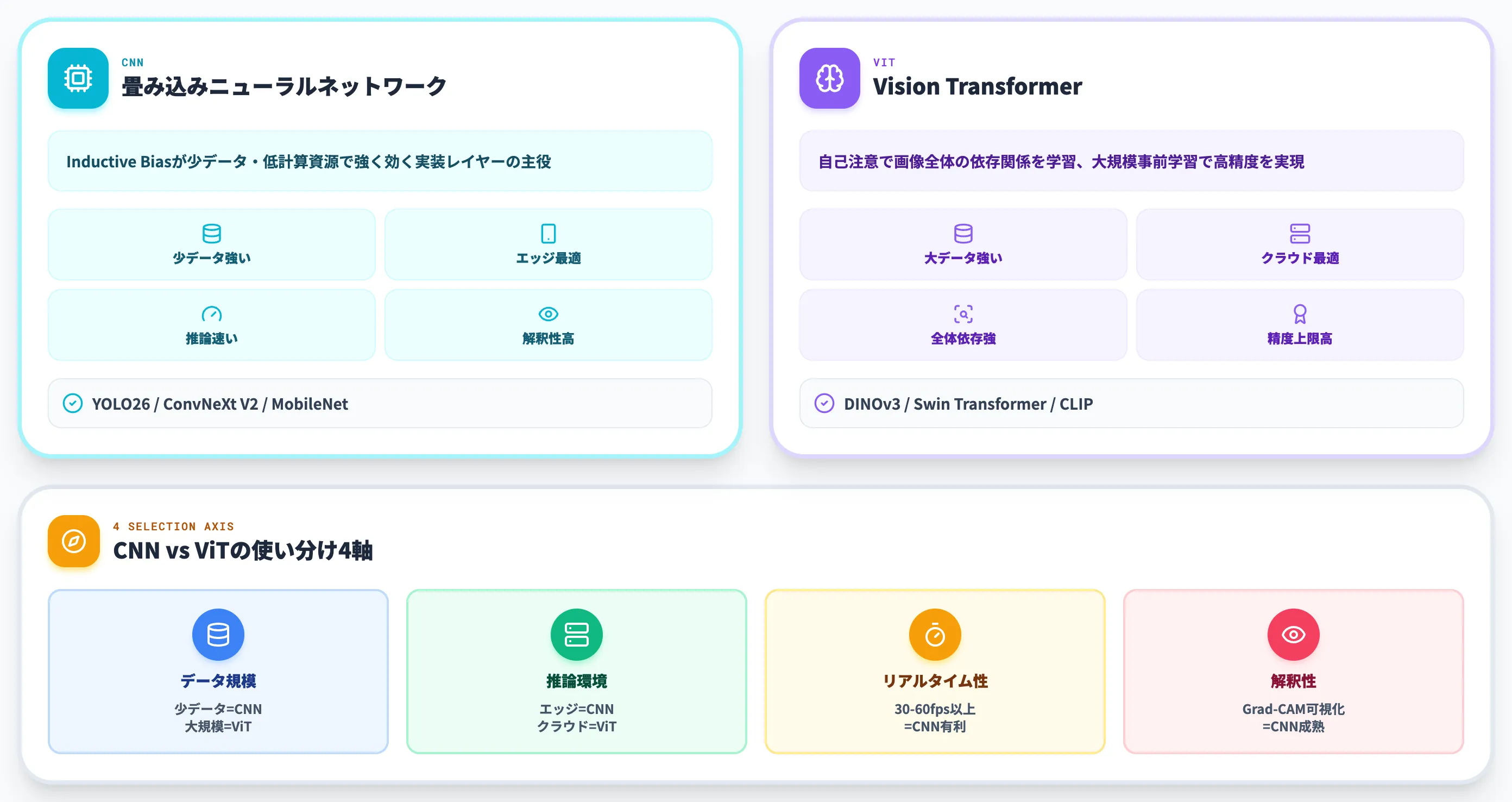
2020年にVision Transformer(ViT)がGoogle Researchから発表されて以降、「CNNは終わったのか?」という論点が繰り返し語られてきました。
2026年時点での実務的な答えは、**「CNNは終わっていないが、使いどころは変わった」**です。データ規模・推論環境・リアルタイム性・解釈性の4軸で見ると、CNNが依然として第一候補になるケースがはっきりしています。
データ規模による判断軸
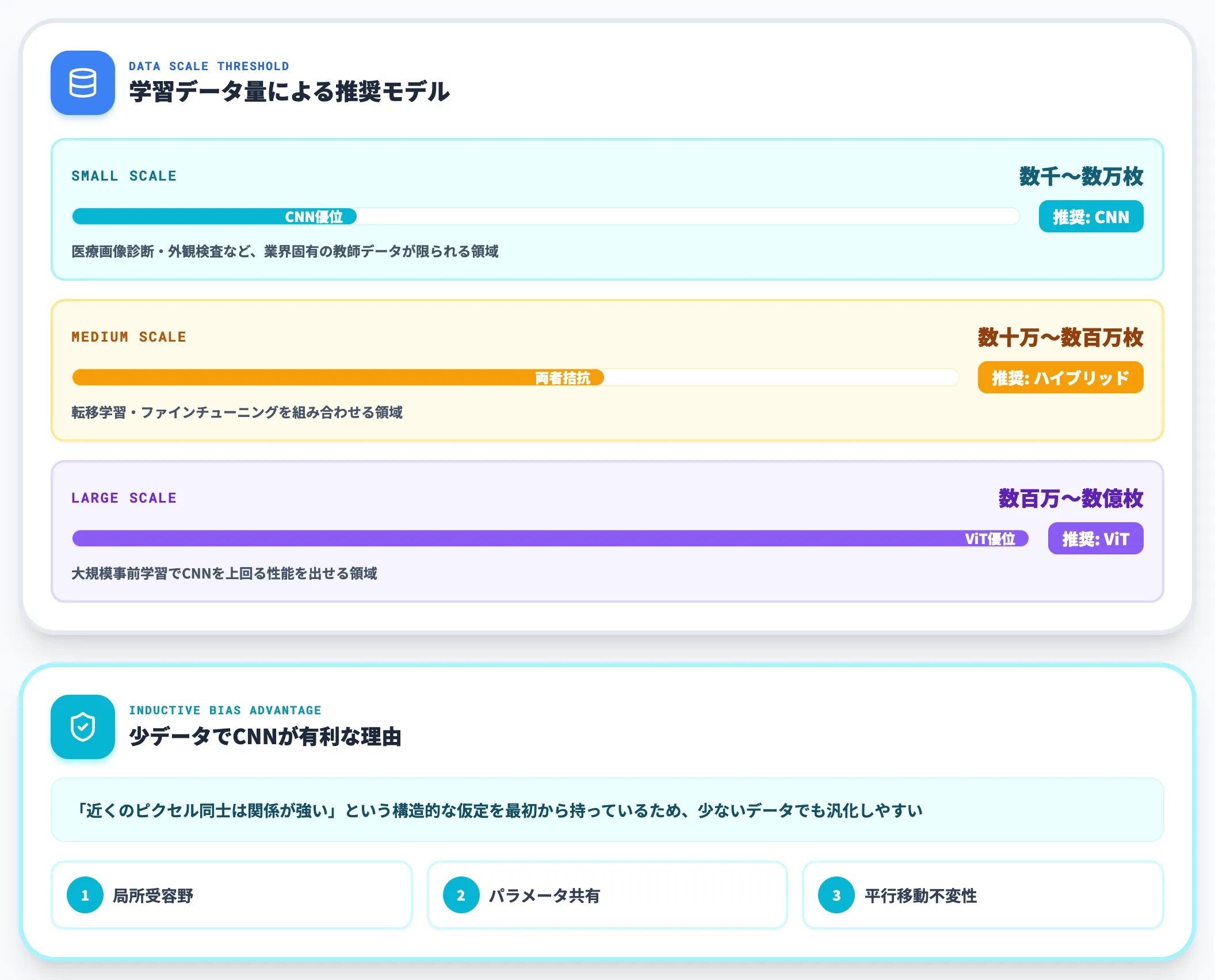
ViTは自己注意(Self-Attention)で画像全体の依存関係を学習するため、大規模事前学習に強く依存するモデルです。
数百万〜数億枚規模の事前学習データを使える環境では、ViTがCNNを上回る性能を出します。
一方で、数千〜数万枚規模の学習データしか持てない実務プロジェクトでは、CNNのInductive Bias(局所受容野・パラメータ共有・平行移動不変性)がむしろ有利に働きます。
CNNは「近くのピクセル同士は関係が強い」という構造的な仮定を最初から持っているため、少ないデータでも汎化しやすい設計になっています。医療画像診断や外観検査など、業界固有の教師データが限られる領域でCNNが今も選ばれる理由がここにあります。
推論環境による判断軸
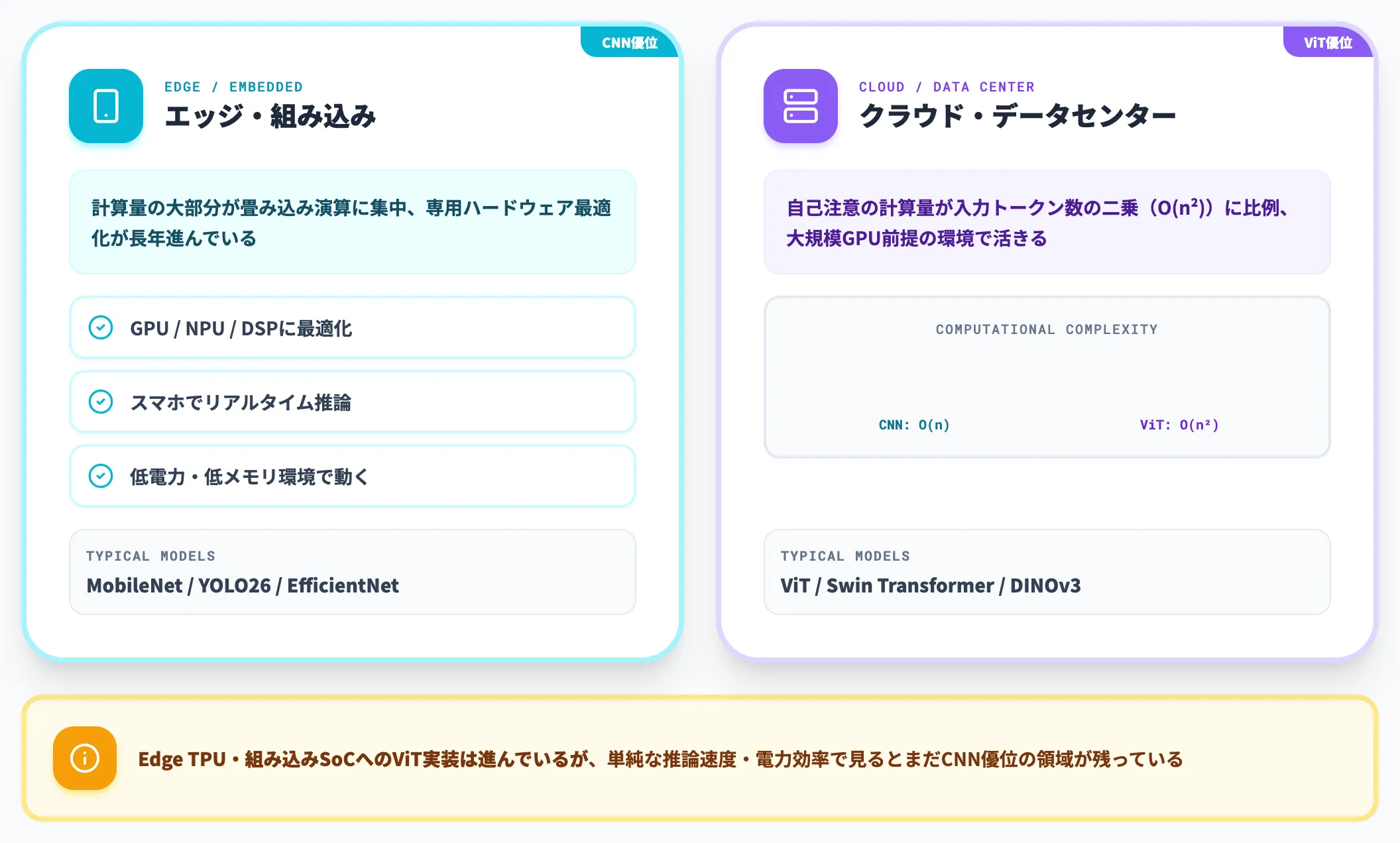
CNNは、計算量の大部分が畳み込み演算に集中するモデルで、GPU・NPU・DSPなど専用ハードウェアによる最適化が長年進んでいます。
MobileNet・YOLO26・EfficientNetのようなエッジ最適化CNNは、スマホ・エッジデバイス・組み込みシステムでリアルタイム推論できるのが強みです。
それに対してViTは、自己注意の計算量が入力トークン数の二乗(O(n²))に比例するため、高解像度画像を扱う際の計算コストがCNNより大きくなります。
Edge TPU・組み込みSoCへのViT実装は進んでいますが、単純な推論速度・電力効率で見るとまだCNN優位の領域が残っています。
リアルタイム性と解釈性の判断軸
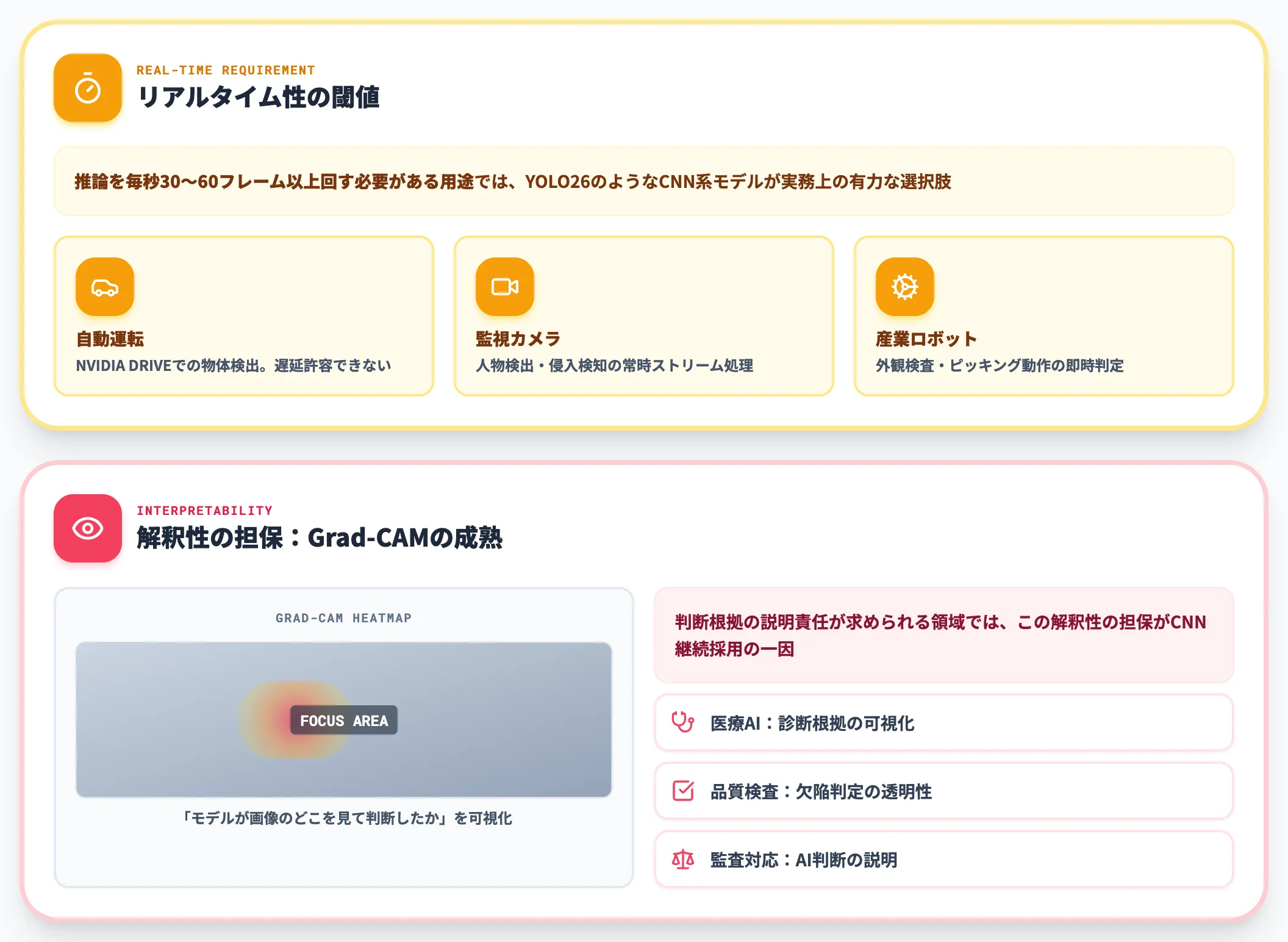
物体検出・セグメンテーションなど、推論を毎秒30〜60フレーム以上回す必要がある用途では、YOLO26のようなCNN系モデルが実務上の有力な選択肢になります。
自動運転の物体検出(NVIDIA DRIVEプラットフォーム)、監視カメラの人物検出、産業ロボットの外観検査など、遅延を許容できない現場ではCNNの推論効率が決定的に効きます。
解釈性という点でも、CNNはGrad-CAMなどの可視化技術が成熟しており、「モデルが画像のどこを見て判断したか」を後付けで検証しやすい構造です。
医療AIや品質検査など、判断根拠の説明責任が求められる領域では、この解釈性の担保がCNN継続採用の一因になっています。
ハイブリッド構成の潮流と選定で見落とされやすい観点
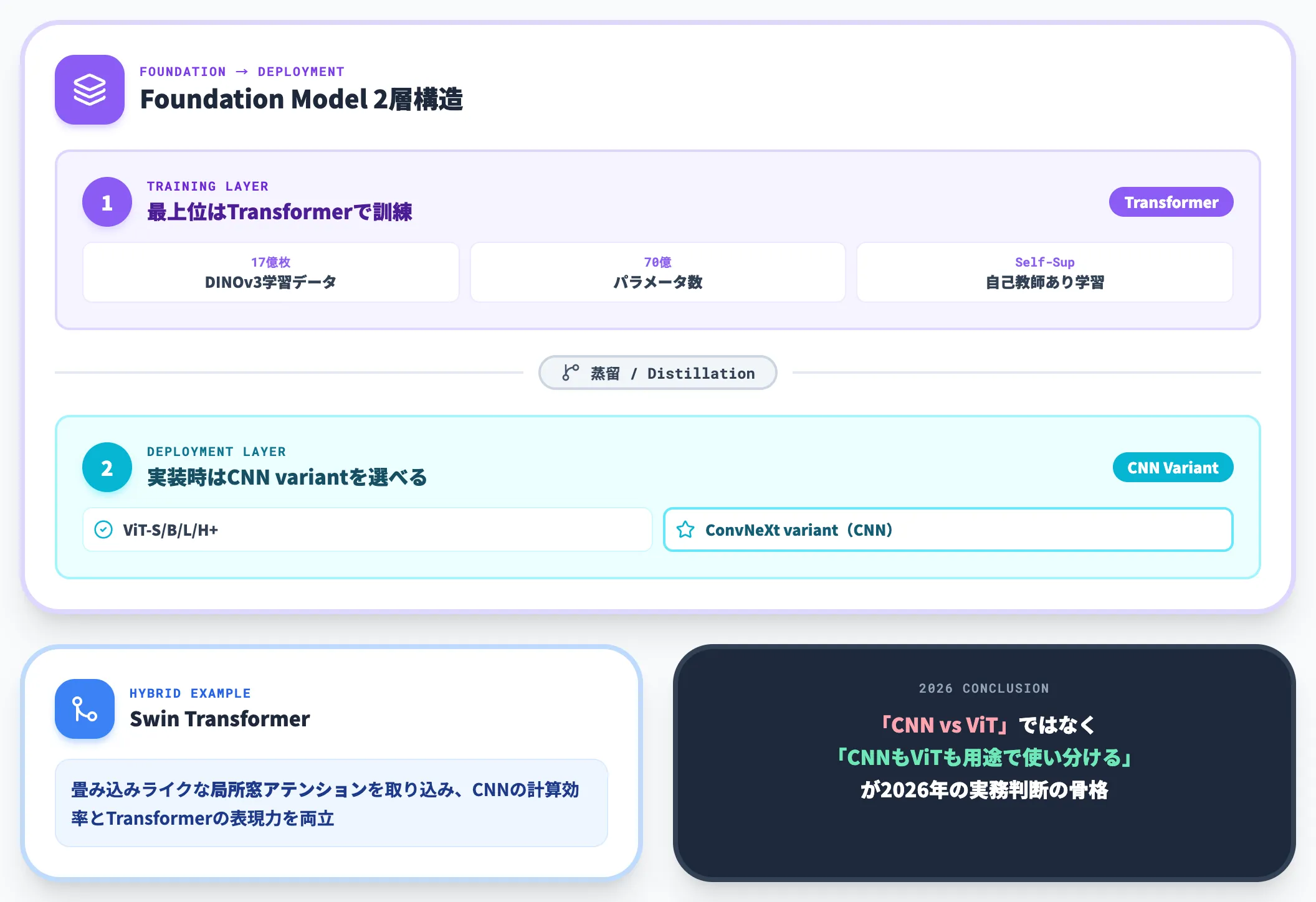
2026年の実務では、CNNとTransformerを組み合わせたハイブリッド構成が主流になりつつあります。
代表例として、Swin Transformerは畳み込みライクな局所窓アテンションを取り込み、CNNの計算効率とTransformerの表現力を両立させたモデルです。
またMeta DINOv3(2025年)は、17億枚の画像と70億パラメータで自己教師あり学習したVision Foundation Modelですが、ViT-S/B/L/H+に加えてConvNeXt variantにも蒸留されて配布されています。

DINOv3の自己教師あり特徴抽出出力(出典:Meta AI Blog)
可視化コラージュには、自転車部品・人物シルエット・山と川といった多様な画像に対して、DINOv3が教師ラベルなしで抽出したセグメンテーション特徴マップが並んでいます。教師なしでこの精度の特徴が出せる基盤の実装レイヤーに、Transformerだけでなく ConvNeXt variant が並んでいる、というのが2026年の実務にとっての意味です。
つまり最上位のFoundation ModelはTransformerで訓練するが、実装時にはCNN variantを選べる、という2層構造が実務上の選択肢として広がっています。「CNN vs ViT」ではなく「CNNもViTも用途で使い分ける」というのが2026年の実務判断の骨格です。
CNNの活用事例:医療画像診断から製造業外観検査まで

ここまで技術面を整理してきましたが、2026年時点でCNNが実際にどこで使われているかを、公式出典付きの事例で確認していきます。
医療・製造業・自動運転・セキュリティ・セグメンテーションの5領域を代表として取り上げます。
医療画像診断:富士フイルム CAD EYEの内視鏡AI

医療画像診断は、CNNが最も早く社会実装が進んだ領域のひとつです。
富士フイルムの内視鏡AI画像診断支援システム「CAD EYE」は、ディープラーニングをコア技術として、大腸ポリープの検出・鑑別支援、胃腫瘍性病変などの検出支援を提供しています。
ELUXEO 8000/7000・LASEREO 7000/6000といった富士フイルム製内視鏡システムに搭載され、リアルタイムで検出候補を医師に提示するのが特徴です。第三者査読論文でもCAD EYEが畳み込みニューラルネットワークをコアに設計されていることが確認されており、内視鏡検査中に瞬時に判定を返す必要があるため、CNN系モデルの推論速度と解釈性がフィットしている典型例と言えます。
また、富士フイルムは2025年5月に膵臓向けの超音波内視鏡診断支援ソフトウェア(販売名:超音波内視鏡画像検査支援プログラム EW10-US01)の開発・薬事承認を発表し、2025年12月15日に発売しました。CAD EYE系の内視鏡AIは今も拡張フェーズにあります。
製造業の外観検査:トヨタ+CEC WiseImaging

製造業の品質検査もCNNが主力の領域です。
トヨタ自動車が導入したCEC WiseImagingは、焼結部品のATキャリア(磁気探傷検査)をディープラーニングを用いたAI画像検査で自動化しており、約3万枚の学習画像で2020年12月から量産ラインで稼働しています。

検査対象となる焼結部品ATキャリア(出典:CEC WiseImaging トヨタ事例)
写真はまさに検査対象となる焼結部品ATキャリアで、円環状の金属部品にプレス痕・凹部・溝が入り組んだ形状をしています。従来のマシンビジョンでルールベースに欠陥を捉えるには複雑すぎる形状で、AI画像検査が実務で選ばれた理由が視覚的にも理解できます。
公式事例では、**見逃し率0%・過検出率5%**を達成し、目視検査員ゼロの量産対応を実現したと報告されています。従来のマシンビジョンカメラでは検出できなかった微細な欠陥や汚れも検出できる点が、AI画像検査導入のインパクトになっています。
より詳細な導入判断のポイントは、外観検査AIとは?仕組みや導入事例、おすすめツールを比較とAI外観検査の費用は?実装方式別の相場・PoC・ROIを解説で整理しています。
自動運転の物体検出:NVIDIA DRIVEとYOLOシリーズ

自動運転では、車載カメラの映像から歩行者・車両・信号を検出する物体検出モデルの候補として、YOLO/R-CNNなどのCNN系モデルが広く使われています。
NVIDIA DRIVEプラットフォームのCV(コンピュータビジョン)パイプラインでも、YOLO・R-CNN系のCNNモデルが認識レイヤーの候補として組み込み可能になっています(NVIDIA Developer Blog)。
一方、2026年時点の自動運転では、NVIDIA AlpamayoのようなVLA(Vision-Language-Action)モデルも発表されており、CNNとVision Foundation Modelの役割分担が進行中です。
低レイテンシー・低電力で動く車載環境ではCNN系モデルの推論効率が今も強みになりますが、認識モデル全体がCNN一択という状況ではなくなっています。
顔認識・防犯:スマートフォンから空港まで

スマートフォンの顔認証、空港の生体認証ゲート、監視カメラの人物再識別(Person Re-Identification)などは、いずれもCNNベースの技術で動いています。
顔認証は、局所特徴(目・鼻・輪郭)と大域特徴(顔全体の配置)の両方を捉える必要があるタスクで、CNNの階層的な特徴抽出がフィットする典型例です。
特にモバイル端末では、MobileNet系の軽量CNNがエッジで動作することで、クラウド送信なしで低遅延の認証を実現しています。プライバシー保護と応答速度を両立する要件が、モバイル顔認証でCNNが選ばれ続ける理由です。
セマンティックセグメンテーション:U-Netと医療画像
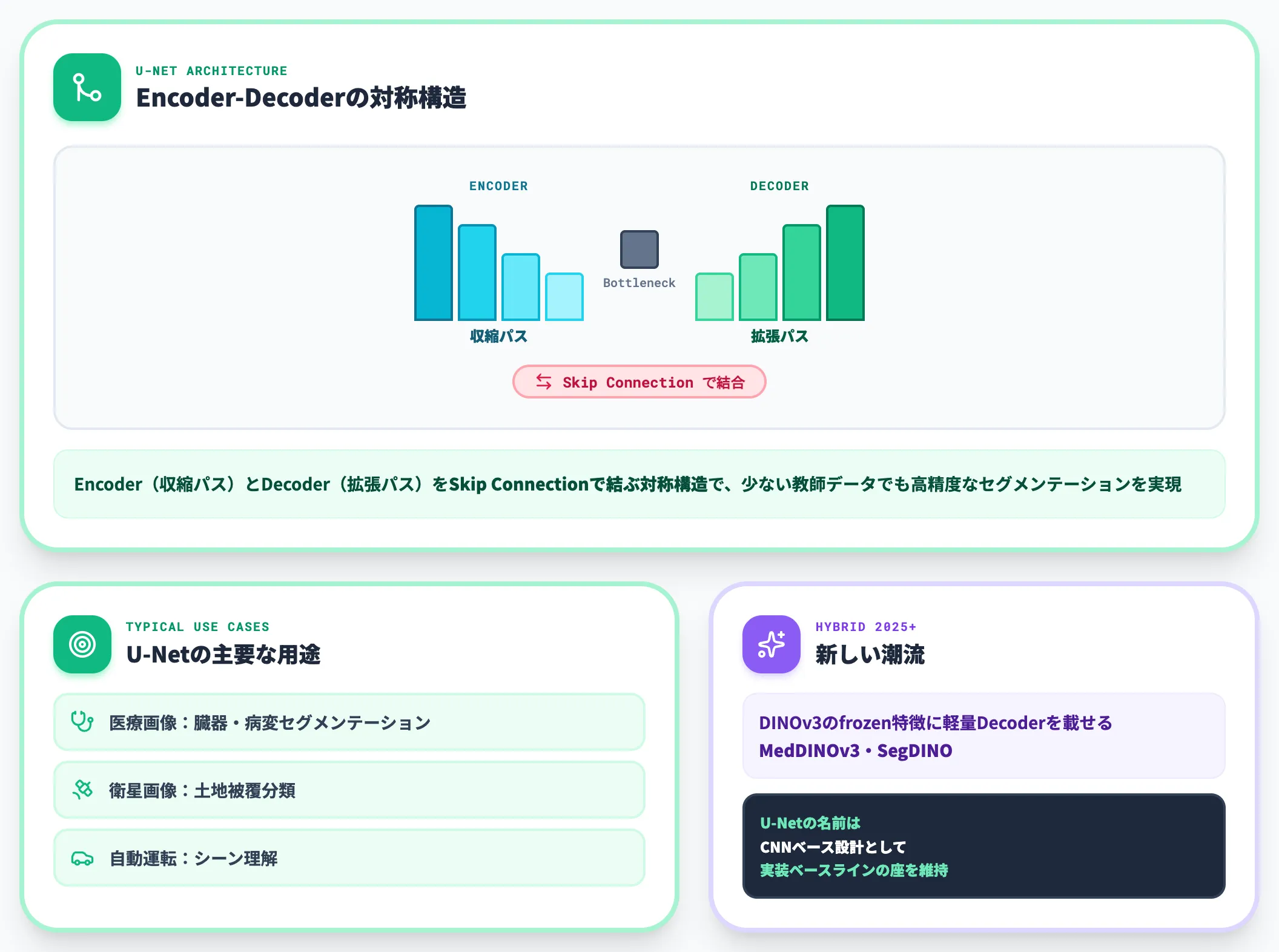
セマンティックセグメンテーションは、画像の各ピクセルにラベルを付けるタスクで、CNNのU-Netアーキテクチャがデファクト標準になっています。
U-Netは、収縮パス(Encoder)と拡張パス(Decoder)をSkip Connectionで結ぶ対称構造で、少ない教師データでも高精度なセグメンテーションを実現できる設計です。
医療画像の臓器・病変セグメンテーション、衛星画像の土地被覆分類、自動運転のシーン理解など、幅広い領域で使われています。
2025年以降は、Meta DINOv3のfrozen特徴に軽量Decoderを載せるMedDINOv3・SegDINOのようなハイブリッド構成も登場していますが、U-Netという名前のCNNベース設計は依然として実装ベースラインの座を維持しています。
CNNを導入するときに詰まる論点:データ量・過学習・解釈性・モデル選定

CNNは技術としては成熟していますが、実務で導入する際には毎回同じ論点で詰まる傾向があります。
AI総合研究所の支援現場でも、以下の5点が繰り返し議論になります。
学習データの量と質を担保する
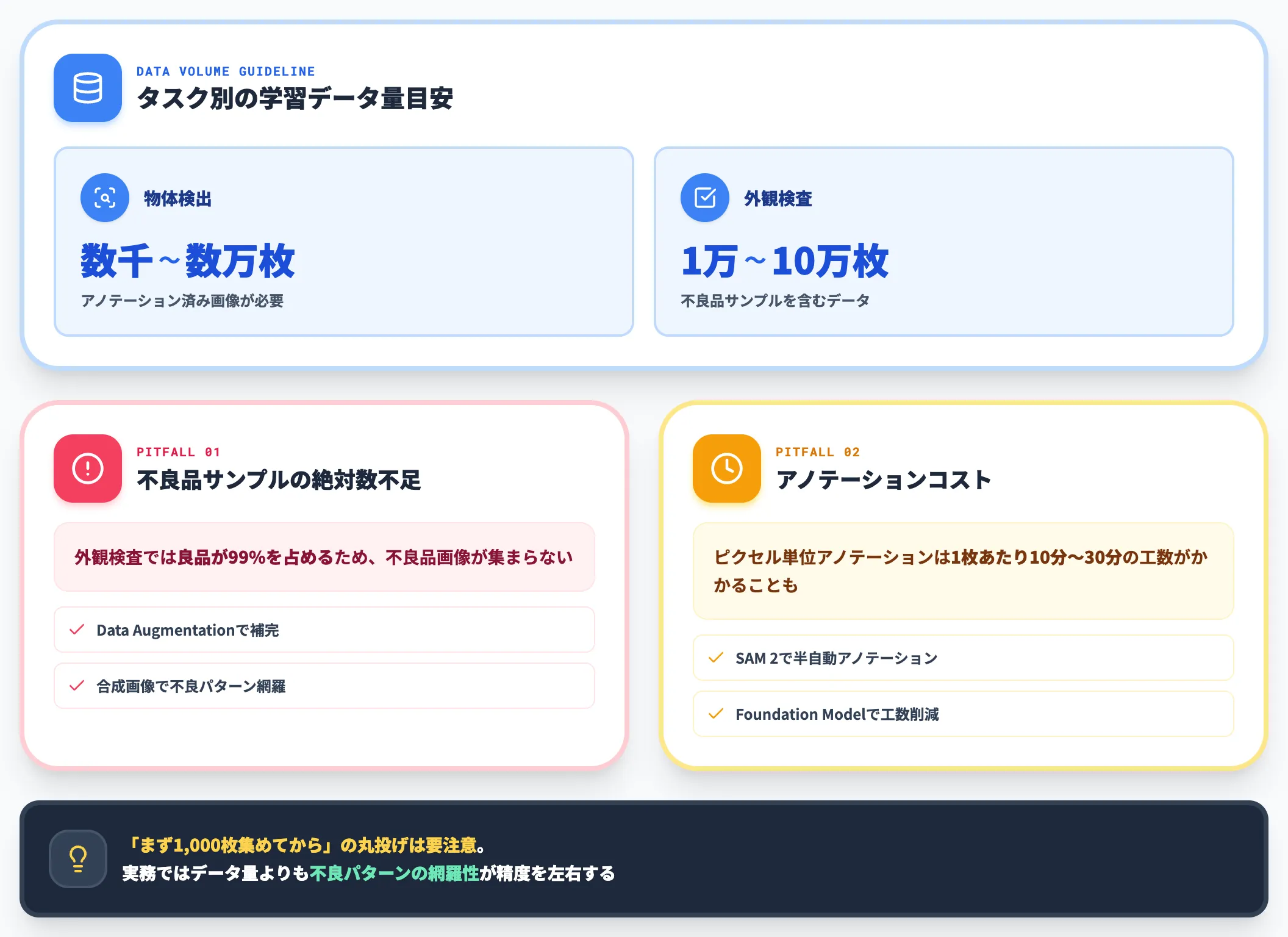
CNNの精度は、学習データの量と質でほぼ決まると言っても過言ではありません。
実務での学習データ量は案件により大きく変動しますが、AI総合研究所の支援経験上、物体検出なら数千〜数万枚のアノテーション済み画像、外観検査なら不良品サンプルを含む1万枚〜10万枚規模のデータが1つの目安になります。
実務で詰まりやすいのは、以下の2点です。
-
不良品サンプルの絶対数不足
外観検査では良品が99%を占めるため、不良品画像が集まらない。データ拡張(Data Augmentation)や合成画像で補完する設計が必要
-
アノテーションコスト
セマンティックセグメンテーションのピクセル単位アノテーションは、画像の複雑度によっては1枚あたり10分〜30分規模の工数がかかることもある。SAM 2などVision Foundation Modelによる半自動アノテーションで工数を削減する方針が現実的
「まず1,000枚集めてから始めましょう」と外部業者に丸投げしがちですが、実務ではデータ量よりも不良パターンの網羅性が精度を左右します。
過学習と汎化性能のバランス
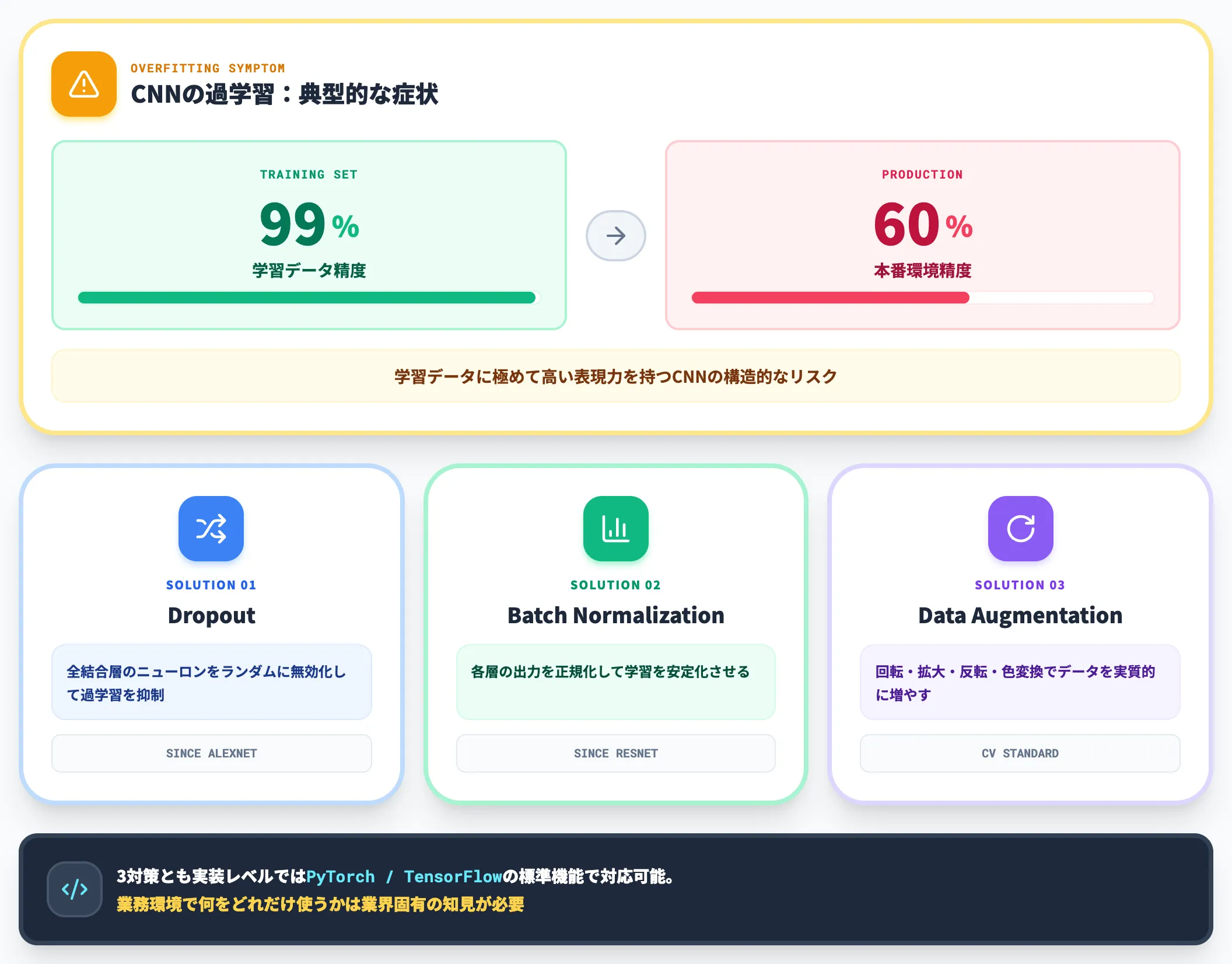
CNNは学習データに対して極めて高い表現力を持つため、**過学習(Overfitting)**を起こしやすいモデルです。
学習データでは99%の精度が出るのに、本番環境で60%まで落ちるというケースは珍しくありません。
対策の定石は、以下の3つです。
-
Dropout
全結合層のニューロンをランダムに無効化して過学習を抑制。AlexNet以降の標準技術
-
Batch Normalization
各層の出力を正規化して学習を安定化。ResNetで採用されて以降、CNNの標準構成要素として広く採用されている
-
Data Augmentation
学習画像に回転・拡大・反転・色変換を加えてデータを実質的に増やす
これらは実装レベルではPyTorch・TensorFlowの標準機能で対応可能ですが、業務環境で何をどれだけ使うかは業界固有の知見が要求されます。
計算リソースとインフラコストの見積もり

CNNは畳み込み演算の計算量が大きく、実務規模の学習ではGPUが事実上の前提になります。
案件によって必要な計算資源は大きく変動しますが、一般的な学習環境の目安は以下のとおりです。
-
試作・研究段階
NVIDIA RTX 4090(24GB)またはA100(40GB)を1枚。学習時間は数時間〜数日
-
本格運用
NVIDIA A100 / H100を複数枚並列。もしくはAWS SageMaker・Google Vertex AI・Azure Machine LearningのGPUインスタンス
-
推論のみ
モデルサイズによりCPU・GPU・NPU・Edge TPUのいずれか。エッジAIで推論するならJetson OrinやCoral USB Acceleratorが候補
クラウドGPUインスタンスの利用料は、学習期間次第で数百万円規模のコストになるケースもあります。エッジ推論に振り切ればランニングコストとレイテンシーを両方削減できるため、CNN導入時は「学習はクラウド・推論はエッジ」という設計が現実的な出発点になります。
モデル選定と解釈性の担保

CNNは、タスクとデータ規模に応じて選ぶモデルが大きく変わります。
以下の表で、代表的な選定パターンを整理しました。
| タスク | 推奨モデル | 選定理由 |
|---|---|---|
| 画像分類(大規模データ) | ConvNeXt V2 / Swin Transformer | ImageNet相当の事前学習で高精度 |
| 画像分類(小規模データ) | ResNet-50転移学習 / EfficientNet | ImageNet事前学習+ファインチューニングで少データに強い |
| 物体検出(リアルタイム) | YOLO26 / YOLO11 | エッジ推論・低レイテンシー |
| セマンティックセグメンテーション | U-Net / DeepLabV3+ | 少データ・医療画像に強い |
| モバイル・組み込み | MobileNetV3 / EfficientNet-Lite | 軽量・低消費電力 |
選定で詰まりやすいのは、「精度を追求するとViT系、実装コストを抑えるとCNN系」というトレードオフの判断です。実務では、まずResNet-50転移学習でベースラインを作り、必要に応じてYOLO・U-Net・ConvNeXt V2に切り替えるという段階的アプローチが現実的です。
同時に、判断根拠の可視化としてGrad-CAMによる特徴マップ可視化を初期段階から組み込むと、モデル選定の議論が「精度数値」だけでなく「モデルが見ている部分の妥当性」を含めて進められます。

CNNの理解を業務のAI導入・エージェント設計につなげる
CNNは「画像認識モデルの技術理解」で終わらせず、業務プロセスにどう組み込むかまで踏み込んで初めて価値が出ます。
外観検査AIで見逃し率を下げるにしても、内視鏡AIで診断支援を組み込むにしても、モデル本体だけでなくPoC設計・データ整備・運用フロー・エージェント連携までの一気通貫の設計が必要です。
AI総合研究所では、PoCから全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。CNNの技術理解を、具体的な業務のAI導入・エージェント設計に落とし込む第一歩として活用ください。
AI画像認識の技術理解を業務のAI活用に落とし込む

PoCから全社展開までの設計を1冊で
CNNの技術理解を業務のAI活用に落とし込むには、PoCから全社展開までの設計が必要です。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、CNN(畳み込みニューラルネットワーク)の定義と2026年時点の位置づけ、畳み込み・プーリング・全結合の三層構造、LeNet-5からYOLO26・ConvNeXt V2までの主要モデル系譜、Vision Transformerとの実務での使い分け、医療画像診断・製造業外観検査などの活用事例、そして導入で詰まる論点までを整理してきました。要点を改めてまとめます。
-
CNNは「畳み込み・プーリング・全結合」の三層で画像の局所特徴を階層化する深層学習モデルであり、局所受容野・パラメータ共有・平行移動不変性というInductive Biasが少ないデータ・低い計算資源の環境で今も強く効く
-
**2026年時点のCNN系SOTAは、画像分類でConvNeXt V2(ImageNet top-1で88.9%)、物体検出でYOLO26(NMS-free推論+MuSGDでエッジ最適化)**であり、CNNは「終わった技術」ではなく実務のバックボーンとして更新され続けている
-
CNN vs Vision Transformerの使い分け軸は、データ規模・推論環境・リアルタイム性・解釈性の4点で、大規模事前学習が可能ならViT、少データ・エッジ・低レイテンシー・解釈性が要件ならCNNが今も第一候補
-
**医療(富士フイルム CAD EYEの内視鏡AIによる大腸ポリープの検出・鑑別支援、胃腫瘍性病変などの検出支援)・製造業(トヨタ+CEC WiseImagingの焼結部品ATキャリア検査で見逃し率0%)・自動運転(NVIDIA DRIVEのCV パイプラインでYOLO/R-CNN系が候補)**など、遅延を許容できない実務領域でCNN系モデルは今も主力
-
導入で詰まる論点は、学習データ量と質・過学習と汎化性能・計算リソース見積もり・モデル選定と解釈性の5点で、ResNet-50転移学習でベースラインを作りYOLO・U-Net・ConvNeXt V2に切り替える段階的アプローチが現実的
2026年、CNNは「Vision Transformerに取って代わられた技術」ではなく、「Vision Foundation Model時代の実装レイヤーを担う技術」です。「大きなモデルはTransformer、実装するモデルはCNN」という2層構造を前提に、自社の課題と制約に合わせてCNN・ViT・ハイブリッドを使い分けていく姿勢が、これからの画像認識AI導入で最も実務的な判断軸になります。










