この記事のポイント
 機械学習は人間が特徴量を設計、ディープラーニングはニューラルネットワークが自動で特徴を抽出する点が根本的な違い
機械学習は人間が特徴量を設計、ディープラーニングはニューラルネットワークが自動で特徴を抽出する点が根本的な違い- 機械学習はデータが少なくても有効で解釈性が高い。ディープラーニングは大量データで高精度だが計算コストが大きい
- SVM・決定木(ML)とCNN・RNN・Transformer(DL)の実装例をPythonコード付きで紹介
- 2026年のLLMやマルチモーダルAIはディープラーニング(特にTransformer)がベース
- データ量が少なく解釈性が必要ならML、大量データで高精度を追求するならDLが適切

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
機械学習(ML)とディープラーニング(DL)は、どちらもAIの中核技術ですが、アプローチと得意分野が異なります。機械学習は人間が設計した特徴量をもとにパターンを学習し、ディープラーニングはニューラルネットワークが自動で特徴を抽出します。
本記事では、両者の定義と関係性、主要アルゴリズムの比較、Pythonコードによる実装例、活用分野の違い、そしてビジネス導入時の使い分け基準までを体系的に解説します。
「自社の課題にはMLとDLのどちらが適しているか」を判断するための材料としてご活用ください。
目次
機械学習とディープラーニングの違い

AI、機械学習、ディープラーニングの概念
機械学習とディープラーニングは、どちらもAI(人工知能)の中核技術ですが、そのアプローチには根本的な違いがあります。
一言で表すなら、機械学習は「人間が設計した特徴量でパターンを学習する」技術、ディープラーニングは「ニューラルネットワークが自動で特徴を抽出して学習する」技術です。
以下の表で、両者の主な違いを整理しました。
| 項目 | 機械学習(ML) | ディープラーニング(DL) |
|---|---|---|
| 特徴抽出 | 人間が手動で設計(特徴量エンジニアリング) | ニューラルネットワークが自動抽出 |
| 必要なデータ量 | 比較的少量でも有効 | 大量データが必要 |
| 計算リソース | CPUでも動作可能 | GPUが必要(大規模モデルは複数台) |
| モデルの解釈性 | 高い(係数や重要度を確認可能) | 低い(ブラックボックスになりやすい) |
| 代表的なアルゴリズム | SVM、ランダムフォレスト、XGBoost | CNN、RNN、Transformer |
| 得意なデータ | 構造化データ(テーブルデータ) | 非構造化データ(画像・テキスト・音声) |
ディープラーニングは機械学習の一分野です。つまり、「すべてのディープラーニングは機械学習だが、すべての機械学習がディープラーニングではない」という関係にあります。2026年現在、ChatGPTやClaude、GeminiなどのLLMはすべて、ディープラーニング(特にTransformerアーキテクチャ)がベースです。

機械学習の主要アルゴリズムと実装例
機械学習は、教師あり学習、教師なし学習、強化学習の3つの学習方法に大別されます。ここでは代表的なアルゴリズムとPythonでの実装例を紹介します。
サポートベクターマシン(SVM)
SVMは、データを分類するための教師あり学習アルゴリズムです。特徴空間内でクラスを最もよく分離する境界線(超平面)を見つけます。
from sklearn import svm
X_train = [[0, 0], [1, 1]]
y_train = [0, 1]
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
X_test = [[2, 2]]
predicted_class = clf.predict(X_test)
print("Predicted class:", predicted_class)
SVMは比較的少量のデータでも高い分類精度を発揮でき、モデルの解釈性も高い点がメリットです。
決定木・ランダムフォレスト
決定木はデータを条件分岐で分類する手法で、ランダムフォレストは複数の決定木を組み合わせて精度を高めたアンサンブル手法です。
from sklearn import tree
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
print("Predicted class:", prediction)
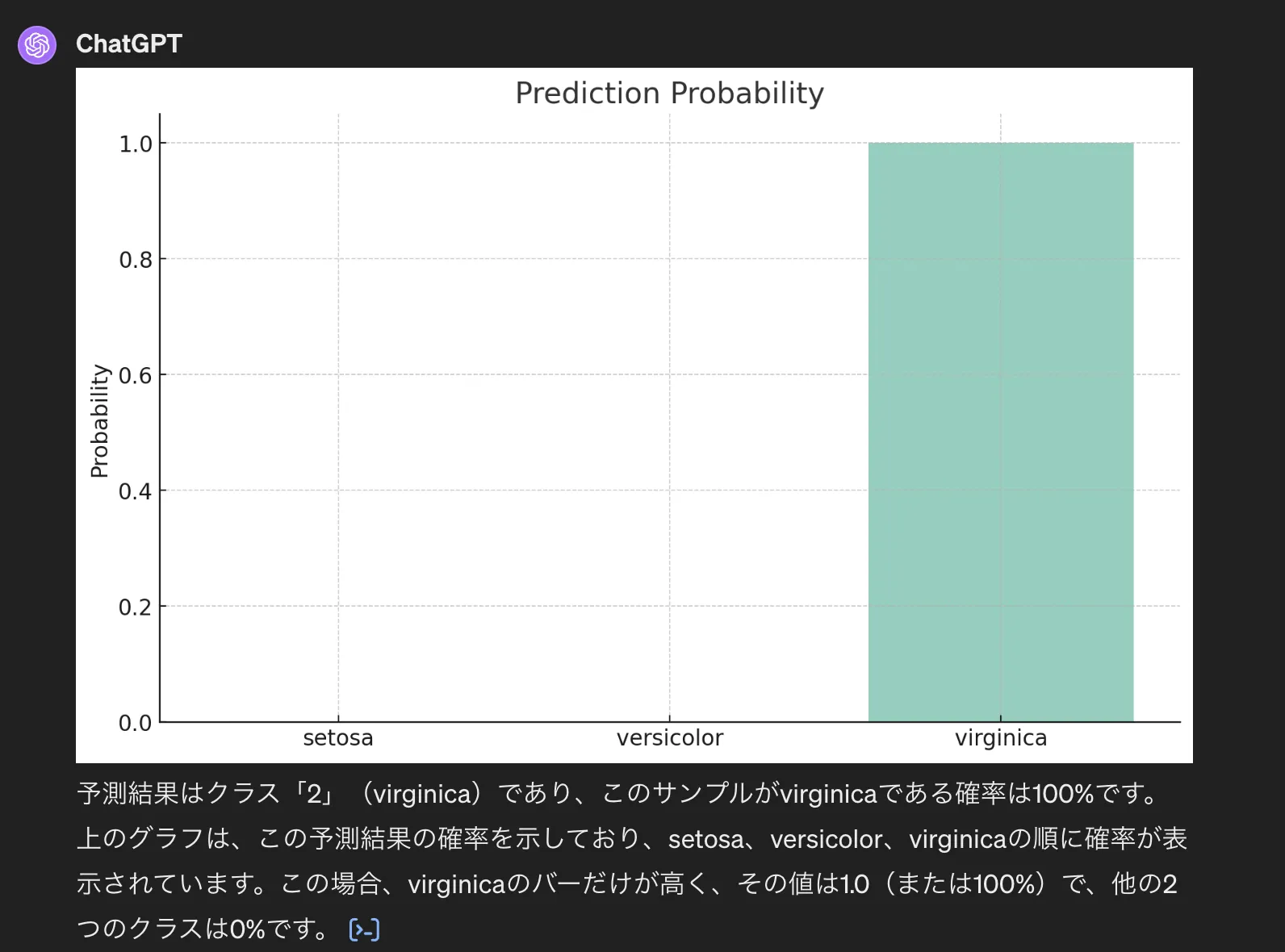
Irisデータセットでの決定木分類結果
ビジネスの現場では、構造化データ(売上データ、顧客属性など)の予測・分類タスクでは、ディープラーニングよりもXGBoostやLightGBMといった勾配ブースティング手法の方が精度・速度ともに優れるケースが多いです。Kaggleのテーブルデータコンペティションでも、これらの手法が上位を占めることが一般的です。
ディープラーニングの主要アーキテクチャと実装例
ディープラーニングは、多層のニューラルネットワークを使ってデータから自動的に特徴を抽出する手法です。主に非構造化データ(画像・テキスト・音声)の処理で威力を発揮します。
CNN(畳み込みニューラルネットワーク)
CNNは画像認識に特化したアーキテクチャです。画像から特徴を自動抽出し、物体検出・画像分類・顔認識などに使われます。医療画像診断や製造ラインの外観検査でも実用化されています。
RNN / LSTM
RNNとLSTMは、時系列データやテキストなどの順序を持つデータの処理に適したアーキテクチャです。音声認識、テキスト生成、時系列予測で使用されてきました。
Transformer
2017年にGoogleの研究チームが発表した論文「Attention Is All You Need」で提案されたアーキテクチャで、2026年現在のAI技術の中核を担っています。自己注意機構(Self-Attention)により、入力データ全体の関係性を並列で処理できる点がRNNに対する大きな優位性です。
GPT-5、Claude、Geminiなど、現在の主要LLMはすべてTransformerをベースにしています。
Pythonでの簡易実装例
以下はKerasを使った簡易的なニューラルネットワーク(Irisデータセットの分類)の例です。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
iris = load_iris()
X, y = iris.data, iris.target
encoder = OneHotEncoder(sparse_output=False)
y_encoded = encoder.fit_transform(y.reshape(-1, 1))
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
model = Sequential()
model.add(Dense(8, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=150, batch_size=10, verbose=0)
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Accuracy: {accuracy*100:.1f}%')
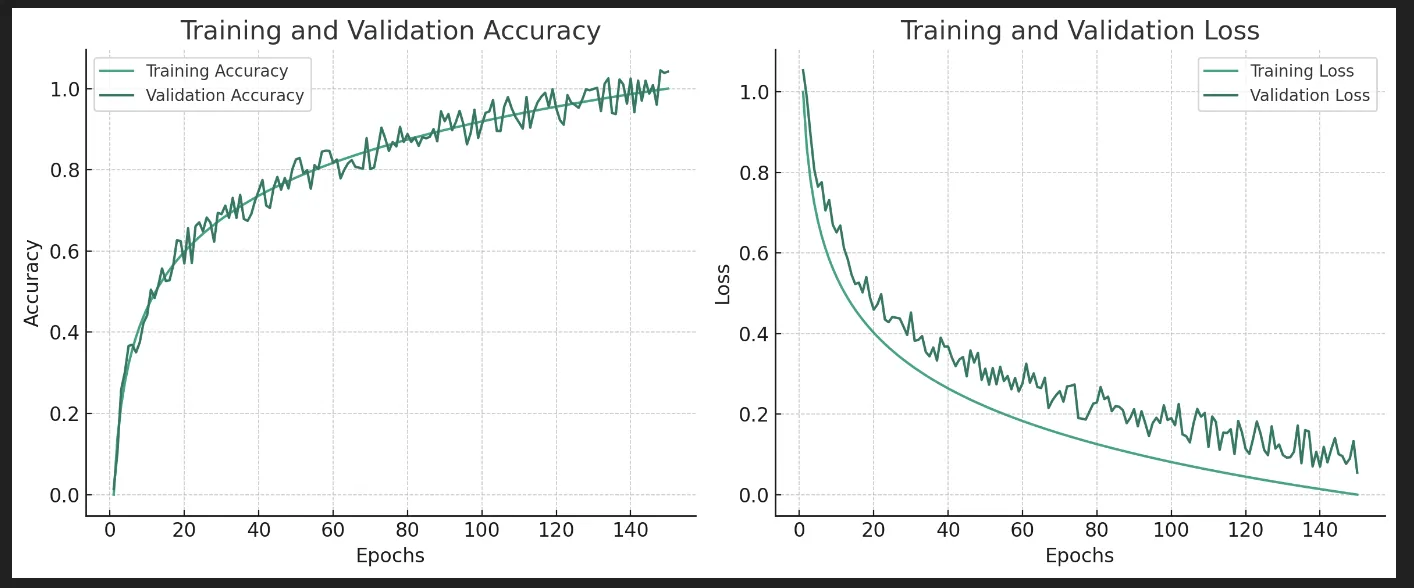
ディープラーニングのモデル学習過程
左のグラフが精度(上に向かうほど良い)、右のグラフが損失(下に向かうほど良い)を示しています。訓練データと検証データのギャップが大きい場合は過学習の兆候です。

機械学習とディープラーニングの活用分野
両者は得意な領域が異なるため、タスクに応じた使い分けが重要です。
| 活用分野 | 適した手法 | 具体例 |
|---|---|---|
| 構造化データの予測・分類 | 機械学習 | 売上予測、顧客離反予測、信用スコアリング |
| 画像認識 | ディープラーニング(CNN) | 医療画像診断、外観検査、顔認識 |
| 自然言語処理 | ディープラーニング(Transformer) | チャットボット、翻訳、文書要約 |
| 音声認識 | ディープラーニング(RNN/Transformer) | 音声アシスタント、自動文字起こし |
| 異常検知 | 機械学習 or ディープラーニング | 製造ラインの品質管理、ネットワーク侵入検知 |
| レコメンド | 機械学習 + ディープラーニング | ECサイトの商品推薦、動画プラットフォーム |
2026年現在では、テーブルデータの予測タスクでは機械学習(特にXGBoost/LightGBM)、画像・テキスト・音声を扱うタスクではディープラーニング(特にTransformer)が第一候補という使い分けが定着しています。
ディープラーニングの活用分野
機械学習とディープラーニングの使い分け基準
ビジネスで導入する際の判断基準を以下にまとめました。
| 判断軸 | 機械学習が向いている | ディープラーニングが向いている |
|---|---|---|
| データ量 | 数百〜数万件 | 数万〜数百万件以上 |
| データの種類 | 構造化データ(テーブル) | 非構造化データ(画像・テキスト・音声) |
| 計算リソース | CPUで十分 | GPU/TPUが必要 |
| 解釈性の要件 | 判断根拠の説明が必要(金融・医療等) | 精度最優先で解釈性は不要 |
| 開発スピード | 短期間でPoCを回したい | 十分な開発期間がある |
| 専門知識 | ドメイン知識 + 基本的なML知識 | DL/NN + GPU環境構築の知識 |
初めてAIを導入する企業には、まず機械学習(scikit-learn + XGBoost)で小さなPoCを回し、効果を確認した段階でディープラーニングに拡張する段階的アプローチをおすすめします。
ML・DL開発に使えるツールと料金
機械学習とディープラーニングの開発に使う主要なツールを以下の表で比較しました。
| ツール | 用途 | 料金 |
|---|---|---|
| scikit-learn | 機械学習の定番ライブラリ | 無料 |
| XGBoost / LightGBM | 構造化データの予測で最強クラス | 無料 |
| PyTorch | ディープラーニングの主流フレームワーク | 無料 |
| TensorFlow / Keras | DLフレームワーク。Keras APIで直感的に記述可能 | 無料 |
| Google Colaboratory | ブラウザ上でPython + GPU実行 | 無料(Pro: $11.79/月) |
| Azure Machine Learning | エンタープライズ向けMLプラットフォーム | 従量課金 |
個人の学習や小規模PoCなら、scikit-learn + Google Colaboratoryの組み合わせで無料で始められます。ディープラーニングにはGPUが必要ですが、Colaboratoryなら無料枠でもGPUを利用可能です。

AI基礎技術の理解を組織の業務導入へ広げるなら
機械学習とディープラーニングの違いを理解した次の段階は、AI技術を自社の業務プロセスにどう組み込むかの具体設計です。どちらの技術を選ぶかだけでなく、「どこから導入するか」「どう全社展開するか」の設計が成果を左右します。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。Copilot Chat → M365 Copilot → Copilot Studioと積み上げる導入ロードマップ、経費精算・請求書処理・人事・総務など部門別のBefore/After付きユースケースを収録しており、自社のAI活用像を具体的に描けます。
AI総合研究所が、AI基礎技術の理解を組織の業務改善へ橋渡しする道筋を提示します。
AI基礎技術を組織の業務導入へ

段階的なAI導入の実践ガイド(220p)
Microsoft環境で始める段階的なAI業務自動化の実践ガイド。Copilot Chat→M365 Copilot→Copilot Studioの導入ロードマップと部門別ユースケースを収録。
まとめ
機械学習とディープラーニングの根本的な違いは、「特徴抽出を人間が行うか、ニューラルネットワークが自動で行うか」にあります。
構造化データ(テーブルデータ)の予測・分類には機械学習(XGBoost/LightGBM)、画像・テキスト・音声などの非構造化データにはディープラーニング(CNN/Transformer)が適しています。2026年のLLMやマルチモーダルAIはすべてディープラーニングがベースですが、ビジネスの多くのデータ分析タスクでは、今なお機械学習が最も実用的な選択肢です。
まずは自社のデータと課題を整理し、scikit-learnで小さなモデルを試してみるところから始めてみてください。










