この記事のポイント
 LLMのRLHF需要がアノテーション市場を牽引しており、AI開発の成否はアノテーション品質で決まる
LLMのRLHF需要がアノテーション市場を牽引しており、AI開発の成否はアノテーション品質で決まる- 手法選定はAIモデルの出力から逆算すべき。物体の位置ならバウンディングボックス、形状ならセグメンテーションが最適
- 自社でアノテーション基盤を構築するならLabelboxかV7、日本語対応ならFastLabelを第一候補にすべき
- 合成データはアノテーションを置き換えるものではなく補完する関係。最終品質検証には人間のアノテーションが不可欠
- 導入はAI支援アノテーションで効率化しつつ、品質管理プロセス(複数人レビュー・IAA指標)を必ず組み込むべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIとは何かを理解するうえで欠かせない基盤技術であるアノテーション(データラベリング)は、AIの学習データの品質を直接左右する重要なプロセスです。
2026年現在、大規模言語モデル(LLM)のRLHF(人間のフィードバックによる強化学習)や自動運転の物体検出など、高品質なアノテーションへの需要は急拡大しています。Fortune Business Insightsによれば、データアノテーションツール市場は2025年の約17億ドルから年平均26.8%で成長し、2034年には143億ドルに達する見通しです。
本記事では、画像・テキスト・音声に対するアノテーション手法の体系的な整理から、LabelBox・FastLabel・V7などの主要ツールと代行サービスの比較、品質管理のベストプラクティス、段階的な導入ステップまでを2026年の最新動向を交えて解説します。
アノテーションとは(2026年最新ガイド)
アノテーションとは、AIに「正解」を教えるためにデータへラベルや説明を付与する作業です。画像に「犬」「猫」と記載したり、テキストから人名や地名を識別したり、音声の発話内容を文字起こししたりする作業がアノテーションに該当します。タグ付け、ラベリング、マーキングなどと呼ばれることもあります。
2026年現在、ChatGPTやClaudeなどの大規模言語モデル(LLM)がRLHF(人間のフィードバックによる強化学習)で品質を高めるために大量のアノテーション済みデータを必要としていることから、この作業の重要性はかつてないほど高まっています。データアノテーションツール市場は急速に拡大しており、Fortune Business Insightsの調査では2025年の約16.9億ドルから2034年の142.6億ドルへ、年平均26.76%の成長率で推移すると予測されています。
以下の表で、アノテーションの基本情報を整理しました。この表を確認したうえで、次のセクションで教師データとの関係や2026年の市場動向を詳しく解説します。
| 項目 | 内容 |
|---|---|
| 概念 | データに正解ラベルを付与し、AIの学習データを作成する作業 |
| 別称 | タグ付け、ラベリング、データラベリング、マーキング |
| 対象データ | 画像、動画、テキスト、音声、3Dポイントクラウド |
| 主な用途 | 物体検出、自然言語処理、音声認識、自動運転、医療画像診断 |
| 2026年市場規模 | 約20〜30億ドル(調査機関により推定幅あり) |
| 主要プレイヤー | Scale AI、Labelbox、V7、FastLabel、Appen、Toloka |
| 2026年注目トレンド | RLHF対応、AI支援アノテーション、合成データとの併用 |
この表から分かるのは、アノテーションが単なる「ラベル貼り」ではなく、AI開発の成否を左右する戦略的なプロセスへと進化している点です。特に2026年は、LLMの品質向上を目的としたRLHFアノテーションと、AI自身がラベリングを補助するAI支援アノテーションの2つのトレンドが市場を牽引しています。

AIに学習させるためには、正解が分かっている「教師データ」が必要です。たとえば「これは猫です」「これは犬です」といった具合にデータへ正解をラベルとして付けたものが教師データであり、AIはこの教師データをもとに教師あり学習を行います。つまり、アノテーションは教師データを作成するための具体的な作業工程であり、AIが正しく学習するための土台を築く役割を果たしています。
以下の画像は、AI開発全体のなかでアノテーションと教師データがどのような位置付けにあるかを示したものです。
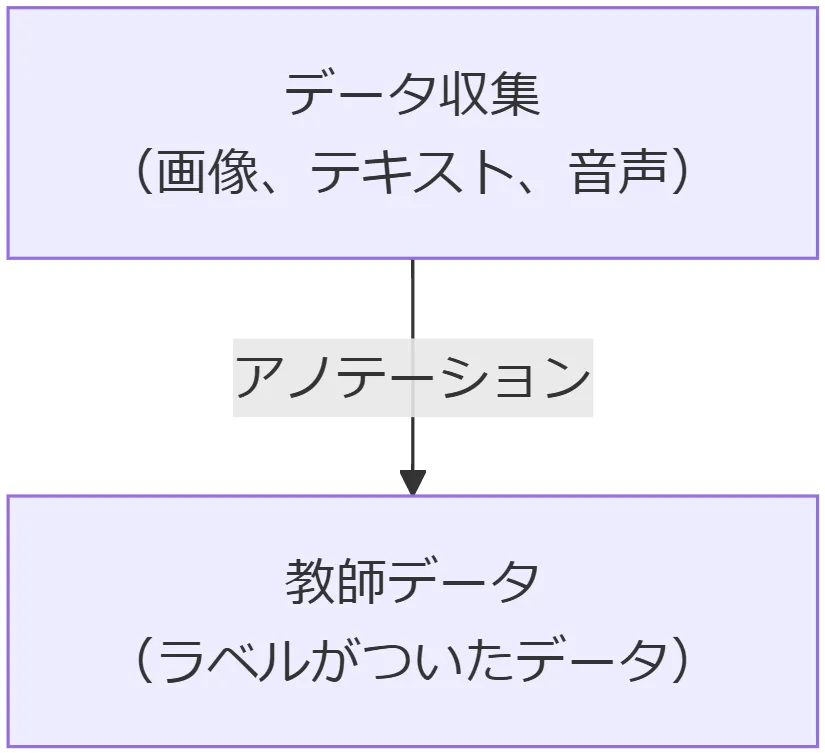
アノテーションと教師データの関係性
教師あり学習とは、正解となる情報(教師データ)を含むデータを与えて学習させる方法です。これに対して、ラベルなしのデータからパターンを見つけ出す教師なし学習もありますが、高精度なAIモデルの構築には教師あり学習が不可欠であり、そのためにアノテーション作業が求められます。
RLHF・合成データが変える教師データとアノテーションの役割
2026年のアノテーション市場を語るうえで、RLHF(Reinforcement Learning from Human Feedback)と合成データの2つのトレンドは避けて通れません。ChatGPT、Claude、Geminiなどの大規模言語モデル(LLM)は、事前学習だけでなくRLHFプロセスを通じて人間の好みや価値観に沿った回答を生成できるよう調整されています。このRLHFプロセスでは、専門的な知識を持つアノテーターがモデルの出力を評価・ランク付けする作業が大量に必要となります。
RLHFアノテーションのコストは従来のラベリングと比較して桁違いに高額です。ある調査では、600件のRLHF用アノテーションに約6万ドルのコストがかかり、データラベリングのコストは2023年から2024年にかけて88倍に急増したと報告されています。これはRLHFが専門的な判断力を要求するためであり、医療、法律、コーディングなどの分野では、その領域の専門家がアノテーターを務める必要があります。
一方で、合成データの台頭もアノテーション業界に変化をもたらしています。Gartnerの予測では、2026年にはAIプロジェクトで使用されるデータの75%が合成データになるとされています。ただし、合成データだけでは精度の限界があり、モデルの検証やグラウンドトゥルースの作成には依然として人間によるアノテーションが必要です。つまり合成データはアノテーションを置き換えるものではなく、補完する関係にあります。
市場規模の面では、Mordor Intelligenceが2025年の23.2億ドルから2030年の97.8億ドルへの成長を予測しており、CAGR(年平均成長率)は33.27%に達します。Grand View Researchも2023年の10.2億ドルから2030年の53.3億ドルへの成長(CAGR 26.5%)を見込んでおり、いずれの調査でも年平均25%以上の高成長が継続する見通しです。この成長を支えているのが、LLMのRLHF需要、自動運転の物体検出データ、医療画像のセグメンテーションデータといった高度なアノテーション需要の拡大です。
DPO(Direct Preference Optimization)やRLAIF(AI Feedback)など、人間のアノテーション量を削減する新技術も登場していますが、最終的な品質検証や倫理的判断には人間の関与が不可欠です。こうした背景から、アノテーション作業は「量」から「質」へとシフトしており、より高度なスキルを持つアノテーターの需要が高まっています。
主要手法とツールの実践
アノテーションの手法は、対象データの種類によって大きく異なります。画像認識AIでは物体の位置や領域をピクセル単位で特定する手法が用いられ、自然言語処理ではテキスト内の固有表現や感情を識別する手法が求められます。
以下の表で、データ種類別の主要なアノテーション手法を整理しました。この表で全体像を把握したうえで、次のH3セクションで各手法の詳細と実践例を解説します。
| データ種類 | 主要手法 | 主な用途 | 2026年の注目動向 |
|---|---|---|---|
| 画像 | バウンディングボックス、セグメンテーション、ポリゴン、ランドマーク、分類 | 自動運転、医療画像、製造検品 | SAM 2による自動セグメンテーション支援 |
| 動画 | 物体追跡、フレーム単位アノテーション、行動認識 | 監視カメラ、スポーツ分析、自動運転 | リアルタイム物体追跡の自動化 |
| テキスト | 固有表現認識(NER)、感情分析、関係抽出、意図分類 | チャットボット、文書分類、RLHF | LLMのRLHF評価が最大の需要源 |
| 音声 | 文字起こし、話者分離、感情認識、音素ラベリング | 音声アシスタント、コールセンター、字幕生成 | 多言語対応の自動文字起こし精度向上 |
| 3Dデータ | ポイントクラウドアノテーション、LiDARラベリング | 自動運転、ロボティクス、都市計画 | LiDARとカメラの融合アノテーション |
実務でアノテーション手法を選ぶ際のポイントは、AIモデルが最終的に何を検出・判断するかを起点に考えることです。たとえば自動運転であれば歩行者の「位置」が重要なのでバウンディングボックス、医療画像であれば腫瘍の「形状」が重要なのでセグメンテーション、といった具合に用途から逆算して手法を選定します。
画像・テキスト・音声アノテーションの手法と活用
画像・動画アノテーション
画像・動画データのアノテーションでは、画像に写っている物体へのタグ付けを行います。動画データでは、画像アノテーションに加えて物体の動きを時系列で追跡するプロセスが必要となり、作業の複雑さが増します。機械学習を活用した画像認識を構築するには、以下の5つの手法を目的に応じて使い分けることが重要です。
- バウンディングボックスアノテーション
画像内の物体を長方形(バウンディングボックス)で囲み、「人間」「電車」「食べ物」などのラベルを付与します。物体検出において最も一般的な手法であり、自動運転車が「この画像には歩行者がいる」と理解するために活用されています。以下の画像では「車」を認識し、バウンディングボックスで囲んでいます。

バウンディングボックスアノテーション (引用元:ANOLYTICS)
- セマンティックセグメンテーション
画像内のすべてのピクセルにラベルを付け、どのピクセルがどの物体や背景に属するかを特定します。「これは道路」「これは歩道」といった具合に、画像内の領域に名前を付けていく手法です。以下の画像では、車のピクセル(青)には「車」、人間のピクセル(オレンジ)には「人間」のラベルが付けられています。

セマンティックセグメンテーション (引用元:ANOLYTICS)
- ポリゴンセグメンテーション
画像内の物体の形状をより正確に捉えるために、多角形の領域で物体を囲むアノテーション手法です。バウンディングボックスの精度を高めたバージョンともいえます。アノテーターが物体の輪郭に沿って複数のポイントを配置し、それらをつないでポリゴンを作成します。複雑な形状でも詳細なアノテーションが可能です。

ポリゴンセグメンテーション (引用元:ANOLYTICS)
- ランドマークアノテーション
画像内の特定のポイント(目印、関節、特徴点など)に注目してアノテーションを行う手法です。人間の顔の重要なポイントを検出して顔認識やポーズ推定に活用します。目、眉、鼻、口など細かくポイントを検出することで、些細な表情の変化や感情の読み取りも可能になります。

ランドマークアノテーション (引用元:ANOLYTICS)
- 画像分類(クラシフィケーション)
画像全体を一つのカテゴリに分類するタスクです。物体検出やセグメンテーションと異なり、画像内の個々の物体ではなく画像全体に対して単一のラベルを付けます。物体の境界を気にせず分類問題として処理できるため、大量のデータを効率的にアノテーションできます。

これら5つの手法は相互に排他的ではなく、プロジェクトの要件に応じて組み合わせて使用するケースも多くあります。たとえば自動運転では、バウンディングボックスで物体の位置を検出した後、セグメンテーションで道路領域を特定し、ランドマークで歩行者の姿勢を推定するといった多層的なアノテーションが行われます。
音声・テキストアノテーション
音声データのアノテーションは、音声認識によって音声を書き起こし、それぞれの単語にタグ付けを行います。「家」や「犬」などの名詞のほか、「えー」や「ああ」などの感嘆詞にもタグ付けを行うのが特徴です。コールセンターでは音声認識システムで会話をテキスト化し、AIがテキストを読み取ることでマニュアルの回答を自動表示する仕組みが実用化されています。
以下の画像ではノイズと人の話し声を話者ごとに認識しています。
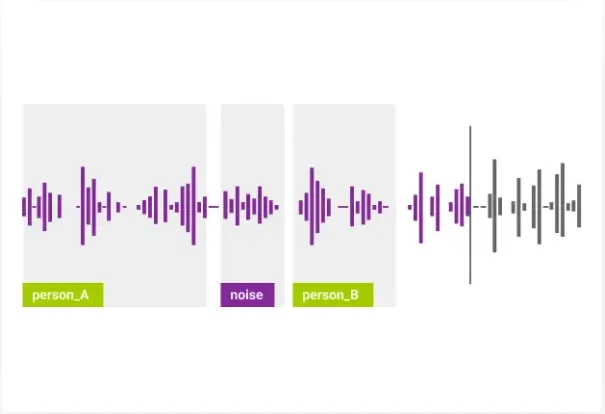
引用元:MINDY SUPPORT
テキストデータのアノテーションでは、事前に設定した項目をもとにテキストの文章や段落をタグ付けします。人名、組織名、地名など特定のカテゴリに関連する単語やフレーズを識別してタグ付けするNER(固有表現認識)が代表的な手法です。テキストアノテーションは、ニュース記事の自動分類、文書からの情報抽出、チャットボットの意図理解など幅広い用途で使われています。2026年現在、LLMのRLHFにおけるテキストアノテーション(モデル出力の評価・ランク付け)が最大の需要源となっており、コーパスの構築と並んで自然言語処理分野の基盤を支えています。

引用元:ANOLYTICS
機械学習とディープラーニングのどちらのアプローチを採用する場合でも、学習データの品質がモデル性能を直接左右します。そのため、アノテーション作業の精度と一貫性を確保することが、AI開発成功の鍵を握っています。
アノテーションの実践例
アノテーションを自分で行う場合、データに対して手動でラベルを付けます。この方法は、小規模なデータセットやカスタマイズされたアノテーションが必要な場合に向いています。以下の動画では、アノテーション作業の基本的な流れを確認できます。
今回はAI総合研究所のロゴをアノテーションする例を紹介します。

PythonのOpenCVライブラリを使って、画像にバウンディングボックス(矩形)を描画する基本的なコードは以下のとおりです。
import cv2
from google.colab.patches import cv2_imshow
# アノテーションする画像を読み込む
image_path = 'ご自身のimgパスをいれます'
image = cv2.imread(image_path)
clone = image.copy()
annotations = []
# 手動で文字部分のバウンディングボックスを指定(例: [(x1, y1, x2, y2), ...])
# 例: 文字「A」の位置
annotations.append((50, 50, 100, 100)) # 左上(x1, y1)、右下(x2, y2)
# アノテーションを画像に描画して確認
for (x1, y1, x2, y2) in annotations:
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 画像を表示
cv2_imshow(image)
# アノテーション結果を出力
print("Annotations:", annotations)
このコードを実行すると、指定された範囲(左上(50, 50)から右下(100, 100)までの領域)に緑色のバウンディングボックスが画像に描画されます。このように、PythonとOpenCVを組み合わせることで、アノテーション作業のプロトタイプを素早く構築できます。ただし、大規模なプロジェクトでは専用のアノテーションツールを使用したほうが効率的です。


ツール・サービス比較と品質管理
アノテーション作業を効率的に進めるためには、プロジェクトに適したツールやサービスの選定が不可欠です。2026年現在、AI支援アノテーション機能を搭載したツールが主流となっており、手動のみの作業と比較してコストと工数を約50%削減できるケースが報告されています。大規模プロジェクトの60%がAI駆動の品質保証をアノテーションパイプラインに統合しているとされ、ツール選定は開発効率に直結します。
以下の表で、主要なアノテーションツール・サービスの特性を比較しました。プロジェクト規模、対応データ形式、自動化機能の有無を軸に選定することが実務上のポイントです。
| ツール・サービス | 種類 | 主な強み | 料金目安 | AI支援機能 |
|---|---|---|---|---|
| LabelBox | ツール | クラウドベース、チーム協業、品質管理 | 無料枠あり、Enterprise年額約2.5万ドル〜 | あり(自動アノテーション) |
| V7 Darwin | ツール | AI自動アノテーション、MLライフサイクル管理 | 無料枠あり、有料プランあり | あり(事前学習不要) |
| CVAT | ツール | オープンソース、無料、画像・動画対応 | 無料(Enterprise月額23ドル〜) | あり(半自動ラベリング) |
| FastLabel | ツール・サービス | 日本市場特化、200社以上導入、多データ対応 | 要問い合わせ | あり(AI自動ラベリング) |
| TASUKI Annotation | サービス | ソフトバンク系、高品質教師データ | 要問い合わせ | 一部あり |
| ANNOTEQ | サービス | クラウドソーシング連動、大量処理高速 | 要問い合わせ | なし |
| harBest for Data | サービス | 全国クラウドワーカー、データ収集込み | 要問い合わせ | なし |
この比較から分かるのは、自社でアノテーション基盤を構築する場合はLabelBox・V7・CVATなどのツール型が適しており、アノテーション作業そのものを外部委託したい場合はFastLabel・TASUKI・ANNOTEQなどのサービス型が適している点です。小規模なPoC段階ではCVAT(無料)やLabelBoxの無料枠で始め、本格運用時にEnterprise版やサービス型へ移行するのが一般的なアプローチです。
導入企業の成果と活用事例
主要アノテーションツール
AI画像認識サービスや転移学習を活用したモデル開発では、高品質なアノテーション済みデータが不可欠です。以下では、主要なアノテーションツールの特徴と導入実績を紹介します。
- LabelBox
画像、動画、テキストなどに対するアノテーションを提供するクラウドベースのプラットフォームです。累計1.89億ドルを調達し、2024年の売上は約5,000万ドルに達しています。自動アノテーション機能とチーム協業機能を搭載しており、50社以上のエンタープライズ顧客が利用しています。無料枠から始められるため、小規模プロジェクトでの評価にも適しています。
参考:LabelBox
- V7 Darwin
AI開発のためのデータ管理、アノテーション、モデルトレーニングを包括的にサポートするプラットフォームです。Radical VenturesとTemasekの共同リードで3,300万ドルのシリーズAを完了し、累計調達額は3,600万ドルに達しています。事前トレーニング不要のAI自動アノテーション機能が特徴で、物体検出やセグメンテーションタスクを大幅に効率化できます。
参考:V7
- AIMMO Enterprise
韓国トップクラスのアノテーションサービス会社AIMMOが提供するツールです。ブラウザ上で動作するウェブアプリであり、インストールもバージョン管理も不要です。2D・3Dデータの両方に対応しており、自動運転向けのLiDARアノテーションにも強みがあります。

- ProLabel
日本のProfieldが提供するアノテーション作業とデータセット管理の効率化ツールです。収集したデータを拡張するためのツールも提供しており、少量のデータでも枚数を増やして大規模なデータセットを構築できます。データ不足の課題を解決する機能として、日本の製造業を中心に導入が進んでいます。
参考:ProLabel
アノテーション代行サービス
大規模なデータセットを扱うプロジェクトでは、手動作業の限界からアノテーション代行サービスの活用が一般的です。AI開発に強い企業への外部委託を検討する際には、プライバシーとデータ保護への対応、品質管理体制、対応可能なデータ形式、コストパフォーマンスの4点を重点的に評価することが重要です。生成AIの企業導入が加速する2026年において、代行サービスの需要は一段と高まっています。
- TASUKI Annotation
ソフトバンク内のAI開発経験を基に構築されたアノテーションサービスです。危険運転を予知する判定AIや、作業現場での自動判定サービスの開発に利用された実績があります。高品質の教師データ提供に定評があり、特に通信・自動車業界での導入実績が豊富です。
- FastLabel
累計1,410万ドルを調達した日本発のAIデータプラットフォームです。画像・動画・音声・テキストなど幅広いデータ形式に対応し、200社以上の企業に導入されています。自動車、製造、インフラ、医療・製薬、建設・不動産など多業界での活用実績を持ち、AI自動ラベリング機能によりアノテーション工数の大幅な削減を実現しています。StockmarkやRicohとのLLM開発パートナーシップも展開しています。
参考:FastLabel
- harBest for Data
全国のクラウドワーカーがデータの収集やアノテーション作業を行うサービスです。開発したいAIに合わせて幅広いデータ形式での収集・アノテーションを実現できます。企業の内部リソースを大幅に削減できる点と、多数のクラウドワーカーによるデータ収集・ラベリングの迅速性が強みです。

- ANNOTEQ
日本で唯一のマイクロタスク型クラウドソーシング連動アノテーションサービスです。実働100万人以上のクラウドワーカーを最大活用し、大量作業を高速で実施しています。ラベリング作業をマイクロタスクとして細分化・分散処理することで、複雑なアノテーション作業もスピーディーに完了できます。
参考:ANNOTEQ
- 矢崎の画像アノテーションサービス
矢崎株式会社が提供するアノテーションサービスです。経験豊富な矢崎の社員が作業を担当しており、高品質かつ精度の高いラベリングが行われます。低解像度の画像や対象物が多く含まれる複雑な画像にも対応しており、一般的な自動アノテーションツールでは難しい精密アノテーション作業もカバーしています。
参考:YAZAKI
導入時の注意点と活用ガイド
アノテーションの導入にあたっては、品質管理やコスト最適化、データプライバシーなど複数の観点から注意が必要です。AIと機械学習を活用したプロジェクトでは、アノテーションの品質が最終的なモデル性能に直結するため、以下の注意点を事前に理解しておくことが重要です。
以下の表で、導入時に押さえるべき5つの注意点を整理しました。
| 注意点 | リスク | 対策 |
|---|---|---|
| 一貫性の確保 | アノテーター間でラベル基準がブレると、モデルの学習に混乱が生じる | 標準化されたアノテーションガイドラインを策定し、Inter-Annotator Agreement(IAA)を定量的に測定する |
| データバイアスの回避 | 民族性・性別・年齢などのバイアスがモデルに反映され、不公平な判断を招く | データセット全体のバランスをレビューし、バイアス検出ツールを併用する |
| プライバシー保護 | 個人情報を含むデータの漏洩リスク | アクセス制限、匿名化処理、GDPR/個人情報保護法への準拠を徹底する |
| コスト管理 | RLHFなど高度なアノテーションは従来の数十倍のコストがかかる | AI支援アノテーションで初期ラベリングを自動化し、人間は検証・修正に集中する |
| 品質検証体制 | アノテーションエラーが蓄積するとモデル精度が低下する | ダブルチェック体制の構築、ゴールドスタンダードデータとの照合、定期的なサンプリング検査を実施する |
特にコスト管理の面では、RLHFアノテーションのコスト急騰が多くの企業にとって課題となっています。600件のRLHF用アノテーションに約6万ドルかかるという報告もあり、年間予算の見積もりを大幅に超過するリスクがあります。また、無料・低コストのツールから始めた場合でも、データ量が増えるにつれてストレージコストやエンタープライズ機能の費用が発生する点に注意が必要です。
バイアスの問題は技術的な対策だけでなく、アノテーター自身の多様性を確保することも有効です。異なるバックグラウンドを持つアノテーターチームを編成することで、特定の視点に偏ったラベリングを防ぐことができます。
段階的導入ステップとよくある質問
アノテーションをプロジェクトに導入する際は、以下の3ステップで段階的に進めることを推奨します。プロンプトエンジニアリングと同様に、まずは小規模な実験から始めて知見を蓄積し、徐々にスケールアップしていくアプローチが失敗リスクを最小化します。
-
ステップ1 ツール選定とパイロット(1〜2週間)
CVAT(無料)やLabelBoxの無料枠を使い、50〜100件のサンプルデータでアノテーション作業のフローを検証します。アノテーションガイドラインのドラフトを作成し、チーム内でラベリング基準の合意を形成します。この段階で、自社内製かサービス外注かの方針を決定します。
-
ステップ2 本格アノテーションとPOC(2〜4週間)
選定したツールまたはサービスで、数百〜数千件規模のアノテーションを実施します。ChatGPTなどのLLMをアノテーション支援に活用し、事前ラベリングの自動化を検討します。Inter-Annotator Agreement(IAA)を測定して品質基準を設定し、モデルの初期学習に使用するデータセットを完成させます。
-
ステップ3 運用体制の構築とスケールアップ(1〜2か月)
アノテーションガイドラインを正式版として確定し、品質検証フロー(ダブルチェック、ゴールドスタンダード照合)を運用に組み込みます。AI支援アノテーションの導入でコスト最適化を図り、継続的なモデル改善に向けたデータパイプラインを構築します。大規模プロジェクトでは、FastLabelやTASUKIなどの代行サービスの併用も検討します。
アノテーション導入に関するよくある質問を以下にまとめます。
-
アノテーションの費用はどの程度かかるか
画像の物体検出(バウンディングボックス)の場合、1枚あたり数円〜数十円が相場です。テキストのNERは1件あたり数十円〜数百円、RLHFの評価アノテーションは1件あたり数千円〜1万円以上と、タスクの専門性に応じて大きく異なります。AI支援アノテーションを導入すると、コストを約50%削減できるケースが報告されています。
-
アノテーションは社内で行うべきかサービスを利用すべきか
データの機密性が高い場合やドメイン知識が必要な場合は社内実施が適しています。大量データの処理や専門性の低いタスクでは、FastLabelやANNOTEQなどの代行サービスの活用が効率的です。多くの企業では、コアなアノテーション設計は社内で行い、実作業は外注するハイブリッド型を採用しています。
-
アノテーションの品質はどう測定するか
Inter-Annotator Agreement(IAA)が最も一般的な指標で、複数のアノテーターが同じデータに対して付けたラベルの一致率を測定します。Cohenのκ係数やFleissのκ係数が広く使われており、0.8以上が高品質とされています。また、事前に正解が確定しているゴールドスタンダードデータとの照合も有効な品質検証手法です。
まずはCVATやLabelBoxの無料枠で小規模なアノテーションを実践し、チーム内でラベリング基準を固めることから始めてみてください。AI支援アノテーション機能を活用すれば、初期コストを抑えながら効率的にデータセットを構築できます。

アノテーションの知識を業務でのAI導入に活かす

生成AIの業務活用を体系的に学べるガイド
アノテーションがAI精度を左右する仕組みを理解すると、自社業務にAIを導入する際のデータ準備の重要性が明確になります。AI総合研究所では、データ整備を含めた業務AI導入の手順をまとめたガイドを無料で提供しています。
アノテーションの知識を業務でのAI導入に活かすなら
アノテーションがAIの精度を左右する仕組みを理解すると、自社でAIを導入する際に「どんなデータをどう整備すべきか」が具体的に見えてきます。データ品質への投資がAI導入の成否を分ける最大のポイントであることは、多くの導入事例が示しています。
AI総合研究所では、データ整備からAI導入・運用までを段階的に進めるための「AI業務自動化ガイド」を無料で提供しています。アノテーションの重要性を理解した今、業務データの整備とAI導入の計画を並行して進めてみてください。
アノテーションの知識を業務でのAI導入に活かす
生成AIの業務活用を体系的に学べるガイド
アノテーションがAI精度を左右する仕組みを理解すると、自社業務にAIを導入する際のデータ準備の重要性が明確になります。AI総合研究所では、データ整備を含めた業務AI導入の手順をまとめたガイドを無料で提供しています。
まとめ
本記事では、AIの学習データ品質を支えるアノテーションについて、2026年の最新動向を交えて体系的に解説しました。データアノテーション市場は2025年の約17〜23億ドルから年平均26〜33%の成長率で拡大を続けており、RLHFによるLLMの品質向上需要がこの成長を牽引しています。
画像・テキスト・音声データそれぞれに最適なアノテーション手法があり、プロジェクトの目的に応じた使い分けが重要です。ツール選定では、LabelBox・V7・CVATなどのプラットフォーム型と、FastLabel・TASUKI・ANNOTEQなどの代行サービス型を、規模と要件に応じて選定します。AI支援アノテーション機能の導入でコストと工数を約50%削減できる点は、2026年の重要な実務上の知見です。
導入にあたっては、ラベリング基準の一貫性確保、データバイアスの回避、プライバシー保護の3点を重点的にケアし、パイロット(1〜2週間)→POC(2〜4週間)→本格運用(1〜2か月)の段階的なアプローチで進めることを推奨します。
出典
- Fortune Business Insights - Data Annotation Tool Market Size, Share & Industry Analysis, 2034
- Grand View Research - Data Annotation Tools Market Size & Share Report, 2030
- Gartner - Top Predictions for Data and Analytics, 2026
- Mordor Intelligence - Data Labeling Market Size, Share & Trends Analysis, 2030
- FastLabel - AI Data Platform(公式サイト・企業情報)










