この記事のポイント
 NLP・画像生成・動画解析を問わず、2026年のAI開発でTransformerアーキテクチャの理解は必須。避けて通るべきではない
NLP・画像生成・動画解析を問わず、2026年のAI開発でTransformerアーキテクチャの理解は必須。避けて通るべきではない- テキスト生成ならデコーダ型(GPT系)、テキスト分類・検索ならエンコーダ型(BERT系)を選ぶべき。用途で構造が決まる
- セルフアテンション機構による並列処理がTransformerの最大の強み。RNN系モデルからの移行を検討すべき
- 実務で使うならHugging Face Transformersライブラリが第一候補。事前学習済みモデルを数行で呼び出せるため開発コストが最小
- Transformerの基礎を押さえたうえで、LoRAやRAGなど応用技術に進むのが最短の学習ルート

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
近年、自然言語処理の分野で大きな注目を集めているのがTransfoemer(トランスフォーマーモデル)です。
トランスフォーマーは、Attentionメカニズムを用いることで、文脈に応じた柔軟な言語処理を可能にしました。また、並列処理に適した構造により、大規模なデータセットを効率的に学習できます。
この記事では、トランスフォーマーの基本的な仕組みから、その応用例まで幅広く解説します。トランスフォーマーの登場により、機械翻訳や感情分析、要約生成など、様々なタスクで飛躍的な性能向上が達成されています。
本記事を通じて、トランスフォーマーの可能性と、その活用方法について理解を深めていただければ幸いです。
目次
Position-wise Feed Forward Network層
BERT (トランスフォーマーからの双方向エンコーダー表現)
【Trandformeの応用】BERT (Transformer双方向エンコーダ表現)の紹介
Transformer(トランスフォーマー)とは
トランスフォーマーは、Googleの研究者たちによって開発された非常に革新的な深層学習アーキテクチャです。
なぜトランスフォーマーは革新的だったのでしょうか。
それは、自然言語処理の分野でデータの処理方法 と学習方法 に新たな手法を取り入れたからです。
具体的には、トランスフォーマーは、単語を1つずつ順番に処理するのではなく、文中の他のすべての単語と関連 させて処理します。
この革新的な手法は、2017年に attention is all you need というタイトルの論文で初めて紹介されました。
この有名な論文を理解したいけれども、内容が難しそう、結局トランスフォーマーという言葉は聞くけど理解できていないという方も多いのではないでしょうか。
本記事では、このatten is all you needの内容を参考にしながらトランスフォーマーについてわかりやすくかつ徹底的に解説していきます。
【関連記事】
Diffusionモデルとは?その仕組みや実装方法、活用事例を解説

Transformerの従来の手法との違い
トランスフォーマーの手法をご紹介します。特徴は大きく3つです。
- 全体を一度に見る
トランスフォーマーは、文章を一語ずつ順番に読むのではなく、全ての単語を一度に見渡します。これにより、文章のどの部分が重要か、すぐに全体の文脈で理解できるようになります。
- 計算の速度アップ
一度に全体を見ることで、計算を並列に(同時にたくさん)処理できるようになりました。これは、長い文章や大量のデータを扱うときに、学習の速度を大幅に向上させます。
- 文の深い理解
セルフアテンションという技術を使い、文章のどの単語が他の単語とどう関連しているかを詳細に分析します。これにより、文の意味をより深く、正確に把握できるようになります。
セルフアテンションの具体的な処理フロー
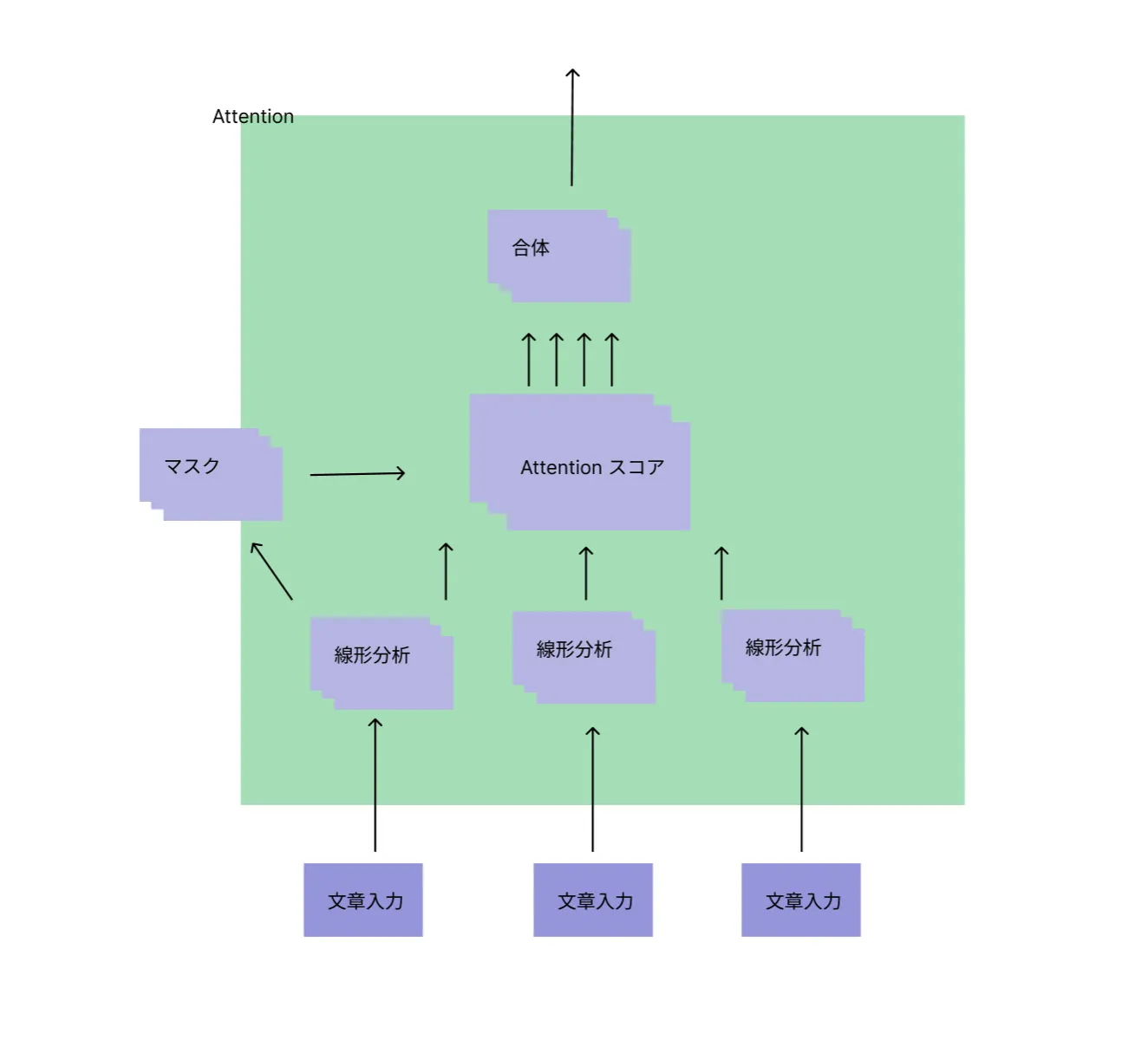
セルフアテンションがトランスフォーマーの大きな革新的な技術ですが、その詳細をご説明します。画像でイメージしながらご参考にしてください。
- 文書入力:モデルに入れたい文書やテキストのデータを入力します。
例えば「私はAIが大好きです」と入力します。
- 埋め込み層:文書内の各単語を数値のベクトルに変換します。これにより、モデルがテキストを処理しやすくなります。
文中の各単語「私」「は」「AI」「が」「大好き」「です」は、それぞれの意味を捉えたベクトルに変換されます。
(例:りんご➡️(2,3)みたいに数値に変換)
- 位置エンコーディング:トランスフォーマーは元々順序情報を持たないため、単語の順番情報を埋め込みベクトルに追加するためのエンコーディングが行われます。
「私」は文の最初にあり、「です」は文の最後にあるというようなことです。
- 線形分析(Linear Layers): 埋め込みされた各単語は、線形変換を通じてクエリ、キー、バリューの3つの異なるベクトルに変換されます。これらは後のステップでアテンションの計算に用いられます。
「私」の埋め込みベクトルだと、クエリ、「AI」はキー、「大好き」はバリューに変換されます。
-
マスク(Masking): デコーダにおいては、未来の情報を予め見ないようにするためにマスクが施されます。これは、正しい学習プロセスを保証するためです。
-
アテンションスコア(Attention Scores): クエリと各キーの関係のスコアが計算されます。内積を取ることで、どのキーがクエリにとって重要かが数値化されます。
「私」のクエリベクトルと他のキーベクトル(例えば、「AI」)の間でスコアが計算されます。これは、「私」と「AI」がどれほど関連があるかを示します。
- スコアの正規化(Normalization): スコアはソフトマックス関数などを使って正規化され、確率的な解釈が可能になります。正規化されたスコアによって、各バリューがどの程度重視されるべきかが決まります。
「AI」と「大好き」は「私」にとって高い関連性を持っているので、高いスコアを得ます。
- 重み付けされたバリュー(Weighted Values): 各バリューは対応するスコアで重み付けされ、文書のどの部分に重点を置くかが決定されます。
「大好き」というバリューが、「私」と「AI」の関連性の高さに基づいて重み付けされます。つまり、「大好き」という感情は「AI」と強く結びつけられます。
- 出力(Output): 最後に、これらの重み付けされたバリューが集約されて、アテンションの出力となります。この出力は文脈に応じた情報を持っており、次の処理ステップに渡されます。
これらの過程を経ることで、すべての単語からの情報が集められ、「私はAIが大好きです。」という文全体の意味を捉える出力が作成されます。これにより、トランスフォーマーは文のどの部分が重要で、どのように全体の意味に関わってくるのかを学習します。
【関連記事】
➡️ベクトル検索とは解説記事
このようなプロセスを通じて、モデルは文書全体にわたる複雑な関連性を捉えることができ、結果として高度な理解と処理が可能になります。アテンションメカニズムによって、文章中の各単語が全体の意味にどのように寄与するかをモデルが学習します。
従来の手法
従来の自然言語処理の代表的な手法にはCNNやRNNと言われる手法があります。
- RNN(リカレントニューラルネットワーク)
どういうもの?:文章を読むとき、一語ずつ順番に見ていくようなモデル。
どうして問題?:文章が長くなると、初めの方にあった大切な情報を忘れがち(勾配消失)、または情報が溢れすぎる(勾配爆発)。さらに、次々と単語を読んでいくスタイルは、計算が遅くて時間がかかる欠点があります。
- CNN(畳み込みニューラルネットワーク):
どういうもの?:画像を見るときに、小さな範囲を区切って特徴を捉える手法を、テキストにも適用したモデル。画像処理技術でよく使用される技術です。
どうして問題?:小さな範囲内ではうまくいく反面、文章の全体を通じて重要な関係性(例えば、文の最初と最後にある単語の関係)を捉えるのが苦手な欠点があります。
Transformerモデルの構造
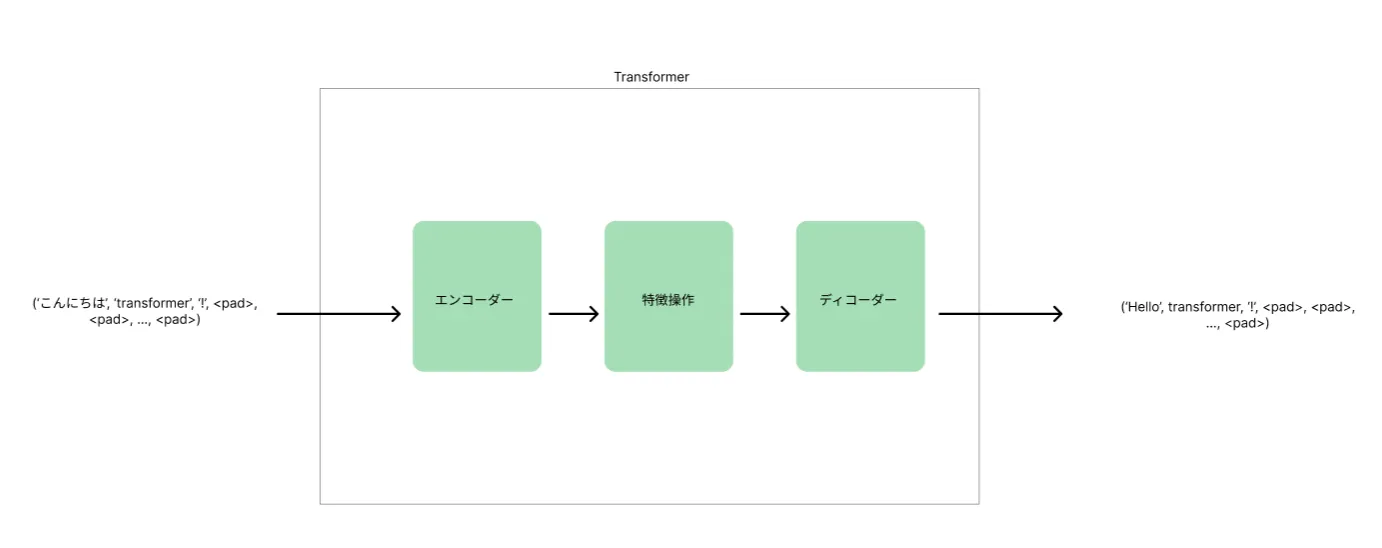
Transformerアーキテクチャ
('私', 'は', 'AI', 'が', '大好き', 'です', <pad>, <pad>, ..., <pad>
)
トランスフォーマーモデルでのデータの表現方法例
トランスフォーマーモデルは「エンコーダー」と「デコーダー」の二つの主要な部分から構成されています。例文「私はAIが大好きです。」を用いて、エンコーダーとデコーダーがどのように機能するかを説明しましょう。
エンコーダー
エンコーダーは入力文「私はAIが大好きです。」を受け取り、それを理解するための処理を行います。ここでのステップは以下の通りです:
- 文書入力: 文がモデルに入力されます。
- 埋め込み層: 各単語がベクトルに変換されます。
- 位置エンコーディング: 各単語ベクトルに文中の位置情報が追加されます。
- セルフアテンション: 各単語(クエリ)が文中の他の単語(キー)に対するアテンションスコアを計算します。
- アテンションの正規化と集約: スコアを正規化し、重み付けされたバリューを集約して文脈を含む新しいベクトルを作成します。
エンコーダーの出力は、入力文の各単語が持つ文脈を考慮した情報を含んだベクトルのセットです。この情報は、デコーダーに渡されます。
デコーダー
デコーダーは、エンコーダーからの深い文脈情報を受け取り、それを基に目的のタスク(例えば、翻訳や要約)に合わせた出力文を生成します。具体的には、翻訳タスクにおいてデコーダーがどのように機能するかをご紹介します。
- 先行する出力の利用
- デコーダーは、翻訳を開始するためのトークンや、前のステップで生成された単語を入力として受け取ります。
- デコーダーは、翻訳を開始するためのトークンや、前のステップで生成された単語を入力として受け取ります。
- 埋め込みと位置エンコーディングの適用
- 入力された単語やトークンは埋め込まれ、文内の位置情報が追加されます。
- 入力された単語やトークンは埋め込まれ、文内の位置情報が追加されます。
- マスクドセルフアテンションの実行
- 未来のトークンを予測する際に情報を先取りしないよう、マスクを適用しながらセルフアテンションを行います。
- 未来のトークンを予測する際に情報を先取りしないよう、マスクを適用しながらセルフアテンションを行います。
- エンコーダー-デコーダーアテンションの計算:
- エンコーダーからの出力情報を利用して、どの入力単語が現在のトークン生成に最も関連しているかを特定します。
- エンコーダーからの出力情報を利用して、どの入力単語が現在のトークン生成に最も関連しているかを特定します。
- 出力トークンの予測と文の生成
- ソフトマックス関数を用いて、次に来るべきトークンの確率分布を計算し、最も可能性の高い単語を選択します。デコーダーは文末トークンを生成するか、あらかじめ定義された最大長に達するまで、このプロセスを繰り返します。
エンコーダーからの豊富なコンテキスト情報と、自動回帰方式でのトークンごとの出力生成により、デコーダーは精確で文脈に合った出力文を生成することができます。
Position-wise Feed Forward Network層
「Position-wise Feed Forward Network層」とは、トランスフォーマーのアーキテクチャ内の一部で、エンコーダーとデコーダーの各層に含まれています。
この層は、シーケンスの各位置(単語)に独立して同じ操作を行う全結合のフィードフォワードネットワークです。
(8667, 1362, 106, 0, 0, …, 0)
トランスフォーマーに入力したシーケンスが数字で表示されるイメージ
Position-Wise Feed-Forward Networkに関する重要なポイントは次のとおりです。
-
構造
FFNは通常、2つの密な層で構成されます。最初の層の隠れ層のサイズ (d_ffn) は、通常、モデルの埋め込み次元 (d_model) の約4倍の値に設定されます。 -
位置方向の変換
「位置方向」という用語は、FFNが同じMLPを使用してシーケンス内の各トークンの表現を独立して変換するという事実を指します。つまり、変換の過程で各トークンに同じ重みセットが適用されることを意味します。 -
ブロードキャスト
FFNの重みは、Tensor 乗算中にシーケンス内の各位置にわたってブロードキャストされます。これにより、FFNに入力された同じシーケンスが同じ出力を生成することが保証されます。 -
活性化関数
通常、FFNの高密度層間でReLU (Rectified Linear Unit) 活性化関数が使用されます。ReLU関数は、負の値をゼロに設定することで非線形性を導入し、トレーニング中の勾配の消失を防ぐのに役立ちます。 -
元のサイズに戻す
FFNの2番目の高密度層は、Tensor を元のサイズ (モデルの埋め込み次元と同じ) に戻します。
Transformerの登場AI領域への影響
トランスフォーマーがAI領域に与えた影響を幅広くご紹介します。
トランスフォーマーは自然言語処理分野だけには留まっていません。
Transforerを活用したアプリケーション例をご紹介します。
| TRANSFORMER 名 | カテゴリー | 使用例 | 製作された年 | パラメーター数 | 製造元 |
|---|---|---|---|---|---|
| BERT | BERT | 一般的な質問応答と言語理解 | 2018 | Base = 110M, Large = 340M | |
| RoBERTa | BERT | 一般的な質問応答と言語理解 | 2019 | 356M | UW/Google |
| Transformer XL | – | 一般的な言語タスク | 2019 | 151M | CMU/Google |
| BART | BERTをエンコーダーに、GPTをデコーダーに使用 | テキスト生成と理解 | 2019 | BERTより10%多い | Meta |
| T5 | – | 一般的な言語タスク | 2019 | 最大11B | |
| CTRL | – | 制御可能なテキスト生成 | 2019 | 1.63B | Salesforce |
| GPT-3 | GPT | テキスト生成、コード生成、画像および音声生成 | 2020 | 175B | OpenAI |
画像・動画生成やその他の分野への応用
【画像生成AI】DALL-E3
DALL-E3は、OpenAIが開発した革新的な画像生成AIです。テキストで指示した内容に基づき、リアルで高品質な画像を生成することができます。
写真編集ソフトでは実現できないような、想像を超えた表現も可能にする、クリエイターの夢を叶えるツールです。
【関連記事】
➡️DALL-E3とは?その魅力や使い方を徹底解説
【動画生成AI】Sora
「Sora」は、テキストから最長1分間の動画を生成できるAIです。
これまでは、動画生成といえばRunway Gen-2やStable Video Diffusionといったサービスがその圧倒的な性能を誇って居ました。
しかし、Transformerの技術を応用して開発された「Sora」の登場により、動画生成AI領域におけるパワーバランスに変化が訪れようとしています。
【関連記事】
➡️OpenAIのSoraとは?その驚くべき機能を解説!

Sora

Transformerモデルの性能とスケーラビリティ
Transformer の性能を向上させ、将来の課題に対処するために、いくつかの主要な研究開発分野があります。以下にそのアイデアを紹介します。
モデルアーキテクチャ
- バリアント アーキテクチャ
元のTransformer設計を超えた新しいアーキテクチャを探索し、特定のタスクのパフォーマンスを向上させます。Transformer-XL、Longformer、Reformerなどのバリアントは、コンテキストウィンドウの制限やメモリ効率、長いシーケンスの処理などの問題に対処するために提案されています。
- 効率的なアテンション メカニズム
計算の複雑さとメモリ要件を軽減するために、より効率的なアテンション メカニズムを開発します。スパースアテンション、適応アテンション、近似アテンションなどの手法は、Transformerがより大きな入力をより効率的に処理できるようにします。
- ハイブリッド アーキテクチャ
Transformerと畳み込みニューラルネットワーク(CNN)やリカレントニューラルネットワーク(RNN)などの他のニューラルネットワークアーキテクチャを組み合わせ、それらの補完的な強みを活用して、さまざまなタスクのパフォーマンスを向上させるハイブリッドアーキテクチャを調査します。
トレーニング戦略
- 大規模な事前トレーニング
より豊富な表現を学習し、タスク全体の一般化を向上させるために、大規模なテキストコーパスに関する大規模な事前トレーニング戦略の探索を続けます。自己教師あり学習、マルチタスク学習、カリキュラム学習などの手法を利用して、トレーニング前の目標を高め、パフォーマンスを向上させることができます。
- 自己正則化
過学習を防止し、Transformer モデルの一般化を改善するための自己正則化手法を開発します。アテンションメカニズムに特有のドロップアウト、ラベルスムージング、正則化手法などの手法は、トレーニングを安定化し、モデルの堅牢性を向上させるのに役立ちます。
- 適応学習率
収束を加速し、トレーニング効率を向上させるために、Transformer アーキテクチャに合わせた適応学習率スケジュールと最適化アルゴリズムを調査します。学習率のウォームアップ、レイヤーごとの学習率スケジュール、適応オプティマイザーなどの手法は、トレーニングのダイナミクスを最適化し、発散を防ぐのに役立ちます。
Transformerの実装フレームワーク
Hugging FaceなどのTransformerモデルが使いやすいフレームワークライブラリを紹介します。
Hugging FaceのTransformersライブラリは、さまざまな自然言語処理(NLP)、コンピュータービジョン、オーディオ、マルチモーダルタスク向けの最先端のトランスフォーマーモデルを幅広く提供しています。以下は、いくつかのTransformerモデルの説明です。
BERT (トランスフォーマーからの双方向エンコーダー表現)
- PyTorchのサポート: ✅
- TensorFlowのサポート: ✅
- Flax のサポート: ✅
BERTは、テキストの双方向表現を事前トレーニングするために設計された、先駆的なトランスフォーマーベースのモデルの1つです。テキスト分類、固有表現認識、質問応答などのさまざまなNLPタスクで最先端のパフォーマンスを達成しました。
GPT (生成事前トレーニング済みトランスフォーマー)
- PyTorchのサポート: ✅
- TensorFlowのサポート: ✅
- Flax のサポート: ❌
GPTは、主に自然言語生成タスクに使用される変換モデルです。前のトークンを考慮してシーケンス内の次のトークンを予測する自己回帰言語モデリング機能で知られています。GPTのバリアントにはGPT-2とGPT-3があり、モデルのサイズと機能が増加しています。
RoBERTa (堅牢に最適化されたBERTアプローチ)
- PyTorchのサポート: ✅
- TensorFlowのサポート: ✅
- Flax のサポート: ❌
RoBERTaは、改良された事前トレーニング技術とハイパーパラメーターを備えたBERTの拡張機能です。より多くのデータを長期間トレーニングすることで、パフォーマンスが向上します。RoBERTaは、さまざまなNLPベンチマークで最先端の結果を達成することが示されています。
【Trandformeの応用】BERT (Transformer双方向エンコーダ表現)の紹介
BERT(Bidirectional Encoder Representations from Transformers)は、エンコーダ部分のみに焦点を当てた、Transformerアーキテクチャの特定の実装です。
これは、Transformerのアーキテクチャを使用してテキストの深い双方向表現を事前トレーニングするために設計されています。
BERTは、事前トレーニングされたモデルの上にタスク固有のレイヤーを追加することで、テキスト分類、固有表現認識、質問応答などのさまざまなダウンストリームNLPタスクに合わせて微調整できます。
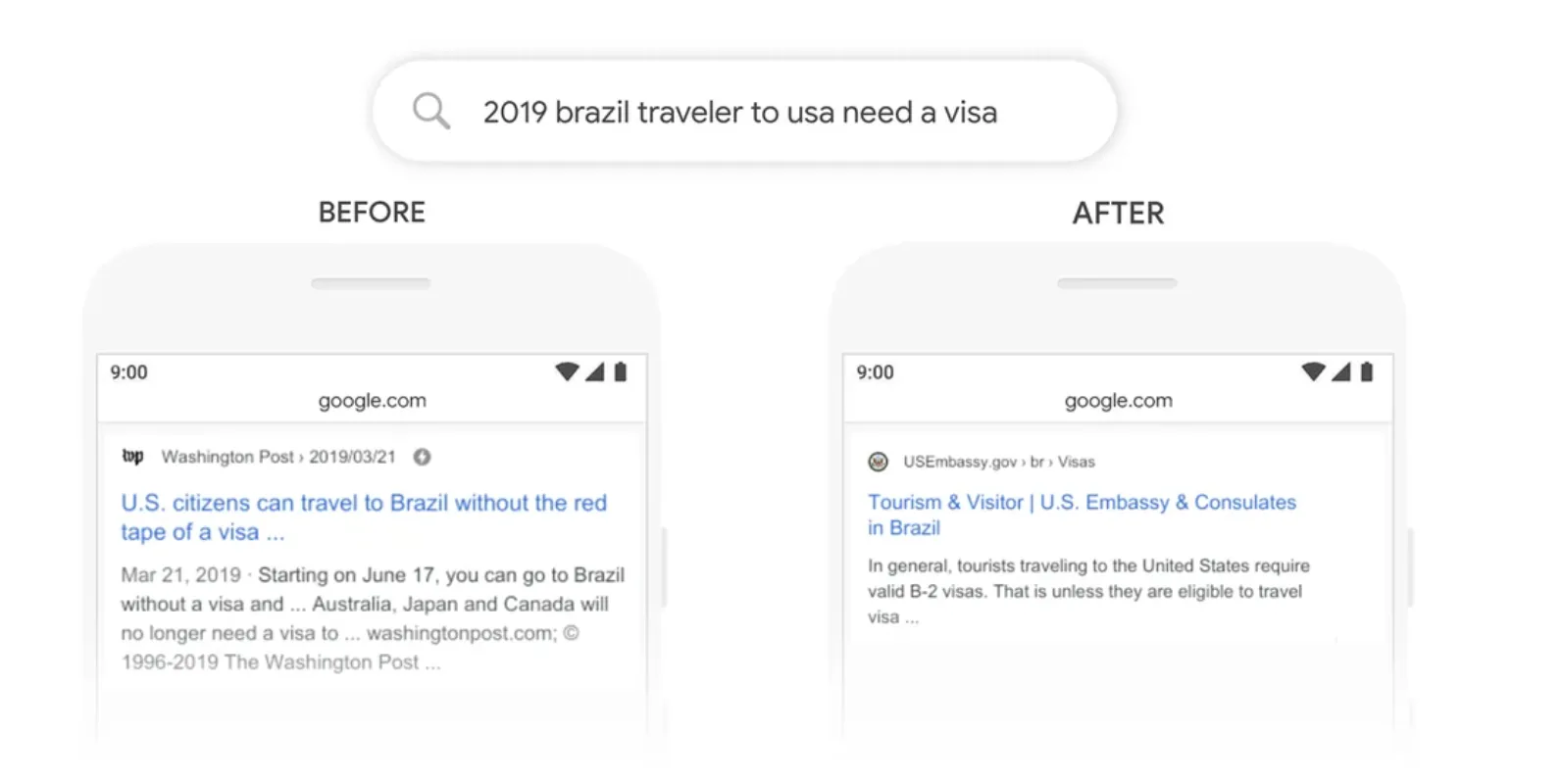
Google検索にもBERTは使用
TransformerとBERTの主な違い
範囲
- Transformer : 元々は機械翻訳などのシーケンス間の変換タスク用に設計されました。
- BERT : 主にテキストの双方向表現を事前トレーニングするために設計されており、さまざまな下流のNLPタスクに合わせて微調整できます。
モデルコンポーネント
- Transformer : アテンションモジュール、フィードフォワードレイヤー、残差接続、正規化レイヤー、位置エンコーディングを備えたエンコーダーとデコーダーの両方で構成されます。
- BERT : セルフアテンションレイヤー、フィードフォワードレイヤー、正規化、および位置エンコーディングを利用して、Transformerのエンコーダー部分のみに焦点を当てます。
トレーニングアプローチ
- Transformer: 元々は特定のタスクのためにゼロから訓練されました。
- BERT: 教師なし学習を使用して大規模なラベルなしテキストコーパスで事前トレーニングされ、その後、教師あり学習を使用して下流のタスクに合わせて微調整されます。
【関連記事】
➡️自然言語処理におけるBERTとは?その全貌をわかりやすく解説!
Transformerのコミュニティ
Transformerコミュニティは活気があり、さまざまな自然言語処理タスクにTransformerモデルを活用することに関心を持つ開発者や研究者に対して、豊富なリソースとノートブックを提供しています。
以下は、コミュニティリソースの一部です。
- 説明: Transformers Docs Glossaryに基づいたフラッシュカードのセット。トランスフォーマー関連の概念の学習と改訂を容易にするように設計されています。これらのフラッシュカードは、長期的な知識保持のためのオープンソースアプリであるAnkiで使用できます。
- 著者: ダリゴフ・リサーチ
2 . コミュニティノート:
事前にトレーニングされたTransformerを微調整して歌詞を生成します。
- 説明: GPT-2モデルを微調整して、選択したアーティストのスタイルで歌詞を生成する方法を示します。この特定のタスクに合わせてモデルを微調整するための段階的な手順が示されています。
- 著者: アレクセイ・コルシュク
- 説明: TensorFlow 2を使用してT5モデルをトレーニングする方法について説明します。これには、SQUADデータセットを使用した質問と回答タスクの実装が含まれています。
- 著者: モハマド・ハリス
- 説明: TransformersとNlpライブラリを使用して、SQUADデータセット上でT5モデルをトレーニングする方法を示します。特に、パフォーマンスを向上させるためのTensor Processing Unit(TPU)のトレーニングを紹介します。
- 著者: スラジ・パティル
- 説明: PyTorch Lightningでテキスト間形式を使用して、分類および複数選択タスク用にT5モデルを微調整する方法について説明します。これは、T5をさまざまなNLPタスクに適応させるための実践的なガイドを提供します。
- 著者: スラジ・パティル
- 説明: 新しいデータセットでDialoGPTモデルを微調整して、オープンダイアログの会話型チャットボットを作成するプロセスを示します。事前トレーニングされたモデルを特定の会話アプリケーションに適応させるための洞察を提供します。
- 著者: ネイサン・クーパー

Transformer技術の理解を組織のAI活用判断に生かす
Transformerの仕組みを理解することは、AI製品やサービスの性能を見極め、自社に適したAI活用方針を決める際の判断材料になります。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。AI技術の基盤を理解した上で進める段階的な導入プロセスと、部門別のBefore/After付きユースケースを収録しています。
AI総合研究所が、AI技術の基礎知識を組織の業務自動化に生かすための道筋を示します。
Transformerの理解を業務AI設計に接続する

Microsoft環境でのAI業務自動化ガイド
LLMの基盤技術を理解した次は、組織の業務プロセスにAIを組み込む段階設計が鍵です。Copilot Chatからの段階的な導入方法を220ページで解説します。
まとめ
自然言語を機械語に変換し、その後再び人間の言語に戻すことで、翻訳家のような役割を果たしてくれるのが、自然言語処理技術です。この技術の根底にあるのがTransformerであり、Transformerの理解は、自然言語処理を深く理解する上で非常に役立ちます。
我々が日常的に利用する翻訳サービスや検索エンジンも、Transformerなどの自然言語処理モデルの進化によって大きく進歩しています。最近では、自然言語処理の分野では、人間と同等のレベルまで近づいてきており、2021年には、マイクロソフト社とGoogle社が開発したディープラーニングモデルが、自然言語処理のベンチマークとされる人間のスコア89.8を共に上回るなど、驚異的な成果が出ています。









