この記事のポイント
 Ignite 2025発表のクラウドネイティブPostgreSQL。disaggregated storage+Rust製エンジンを採用
Ignite 2025発表のクラウドネイティブPostgreSQL。disaggregated storage+Rust製エンジンを採用- 上限は3,072 vCore・128TB・15レプリカ・サブミリ秒コミットで大規模ワークロードに対応
- pgvector・DiskANN・pg_fts・azure_ai拡張を組み込み、Microsoft Foundryとも連携可能
- 既存のFlexible Server/Cosmos DB for PostgreSQL(Citus)とは置き換えでなく別軸で並走
- 2026年6月時点Preview・対象5リージョン・日本未提供。現行Flexible ServerでPoC+HorizonDB待ちの二段構えが現実解

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure HorizonDB(アジュール ホライゾンDB)は、Microsoftが2025年11月のMicrosoft Ignite 2025で発表したクラウドネイティブの新しいPostgreSQLサービスです。
共有ストレージとスケールアウト・コンピュートを組み合わせ、最大3,072 vCore・128TBストレージ・15レプリカ・サブミリ秒のマルチゾーンコミットレイテンシといった大規模ワークロード向けの設計を打ち出しています。
本記事では、Azure HorizonDBのアーキテクチャ(Rust製エンジン・disaggregated storage)、AI機能(DiskANN高度フィルタリング・Microsoft Foundry連携)、Aurora・AlloyDB・既存Azure系PostgreSQLサービスとの違い、Preview利用の始め方、料金体系、そして日本企業が実務で「どう構えるか」までを2026年6月時点の最新情報で解説します。
目次
Azure HorizonDBのアーキテクチャ——disaggregated storageとRustエンジン
Microsoft Fabric OneLakeへのMirroring
Azure HorizonDBと既存のAzure系PostgreSQLサービスの違い
vs Azure Database for PostgreSQL Flexible Server
vs Azure Cosmos DB for PostgreSQL(Citus基盤)
Aurora/AlloyDBと比較したAzure HorizonDBの位置づけ
Azure HorizonDBの始め方とPreview利用の流れ
Azure HorizonDBを実務でどう構えるか——導入判断と備え方
Azure HorizonDBとは?
Azure HorizonDB(アジュール ホライゾンDB)は、Microsoftが2025年11月のMicrosoft Ignite 2025で発表した、フルマネージドのクラウドネイティブPostgre SQLデータベースサービスです。

Azure HorizonDBのアナウンスメントビジュアル(出典:Microsoft Tech Community Blog)
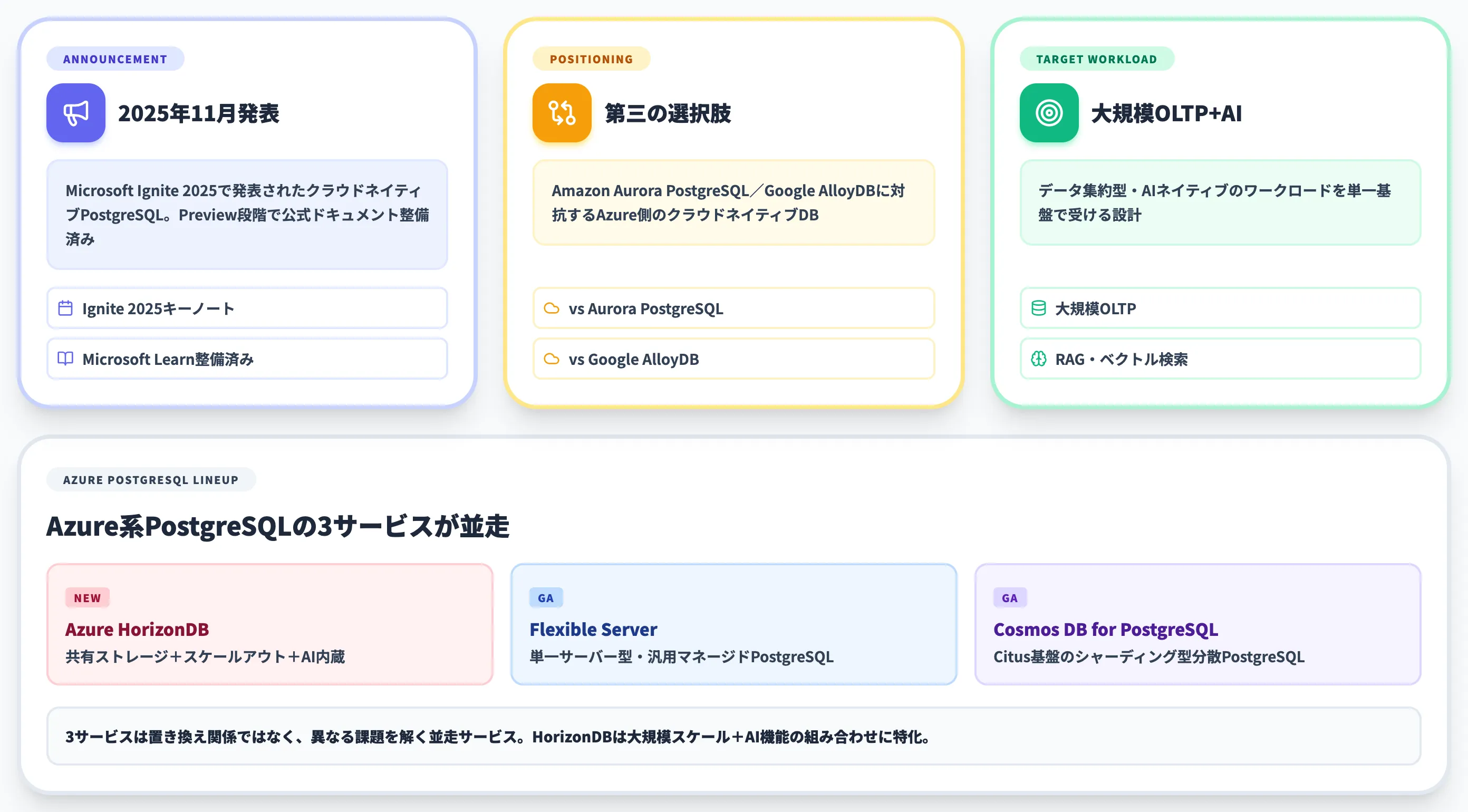
公式名称は「Azure HorizonDB」で、PostgreSQLエンジンをベースに、ストレージとコンピュートを分離した新しいアーキテクチャを組み込みました。AmazonのAurora PostgreSQL、GoogleのAlloyDBに対抗する位置づけで、Microsoft側からも同じカテゴリーの選択肢が揃った形になります。
既存のAzure Database for PostgreSQL(Flexible Server)やAzure Cosmos DB for PostgreSQL(Citus基盤)と並ぶ第三の選択肢として、データ集約型・AIネイティブのワークロードを正面から狙っています。

Azure HorizonDBが発表された背景
MicrosoftはこれまでもPostgreSQLマネージドサービスを複数持っていましたが、大規模OLTPとAIワークロードの両方を1つの基盤で受けられる選択肢は揃っていませんでした。
Aurora PostgreSQLやAlloyDBが「コンピュートとストレージを分離した共有ストレージアーキテクチャ」で先行する中、Azure側でも同水準の選択肢を提供する必要があり、HorizonDBがその回答として登場しました。
Microsoftはこれを「PostgreSQLとAzureを共同設計(co-design)した新エンジン」と位置づけており、既存PostgreSQLのコードベースをそのまま動かしつつ、ストレージ層を作り直すアプローチを採っています。
Azure HorizonDBの提供形態と現状
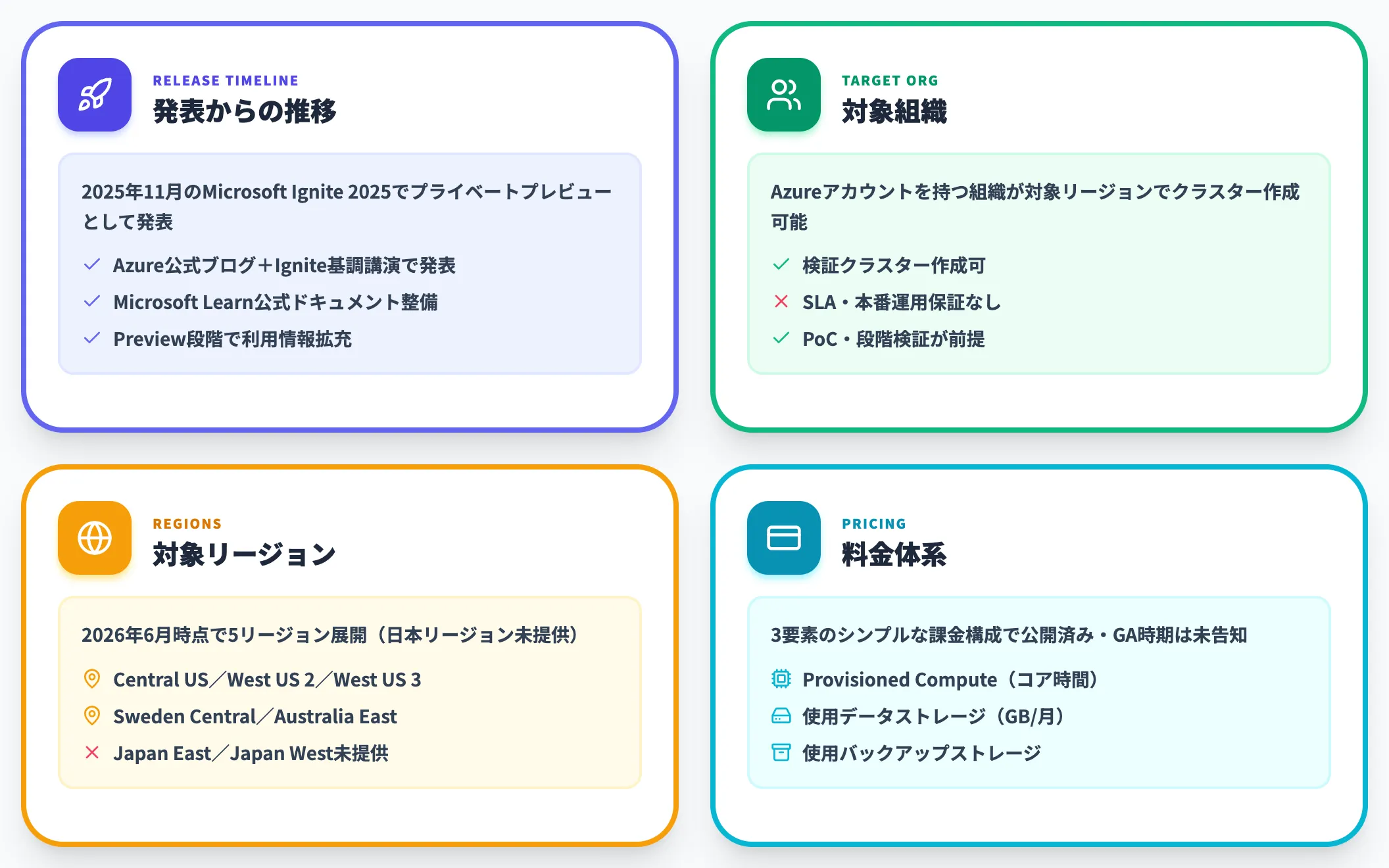
Azure HorizonDBは、現時点でPreview段階の提供です。Ignite 2025発表当初はプライベートプレビュー扱いでしたが、2026年6月時点では公式ドキュメントが整備され、料金体系も公開されています。
-
発表からの推移
2025年11月、Microsoft Ignite 2025のキーノートおよびAzure公式ブログで正式発表。当初はプライベートプレビュー扱い。その後Microsoft Learnの公式ドキュメントが整備され、preview段階のまま利用情報が拡充
-
対象
Azureアカウントを持つ組織が対象リージョンでクラスター作成して試せる段階。ただしSLA・本番運用保証なし
-
対象リージョン
Central US/West US 2/West US 3/Sweden Central/Australia Eastの5リージョン(2026年6月時点・公式リージョン一覧)
-
料金体系
Provisioned Compute(コア時間)/使用データストレージ(GB/月)/使用バックアップストレージの3要素で公開済み。GA時期は未告知
日本リージョン(Japan East/Japan West)は2026年6月時点で提供範囲に含まれておらず、東京リージョンでの利用を前提とした本番採用は現実的ではありません。
Azure HorizonDBのアーキテクチャ——disaggregated storageとRustエンジン
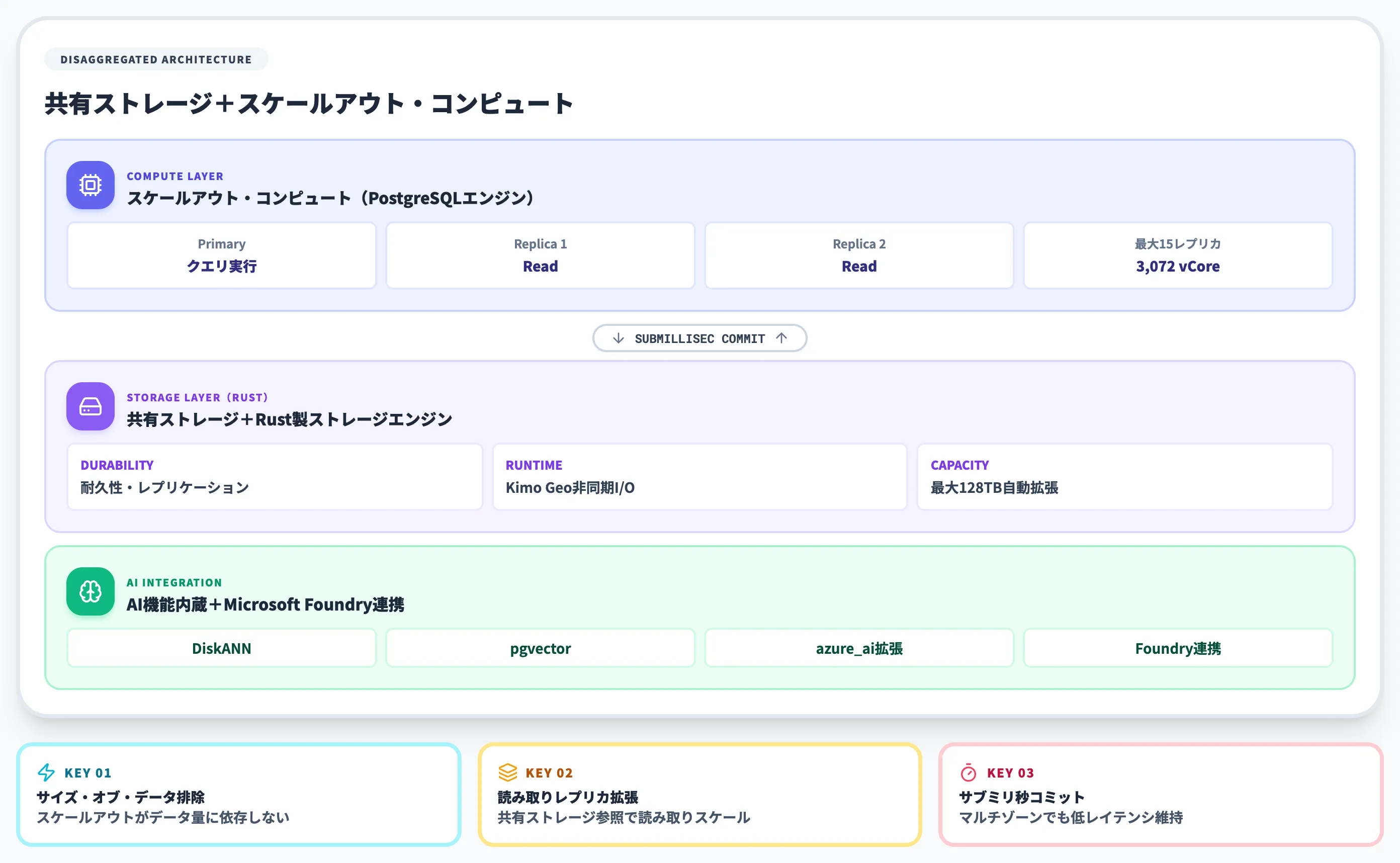
Azure HorizonDBの設計の核は、共有ストレージへの再設計(disaggregated storage)とRust製のストレージエンジンです。
PostgreSQL本体のクエリ実行・トランザクション処理はそのまま使いつつ、レプリケーションや耐久性に関わる重い処理をストレージ層に押し出すことで、コンピュート側がクエリ実行に集中できる構造を作っています。
本セクションでは、アーキテクチャの主要素を分解して解説します。
コンピュートとストレージの分離

従来のセルフマネージドPostgreSQLは、コンピュートとストレージが密結合した「1台のサーバー上で完結」する設計です。これに対しAzure HorizonDBは、コンピュートとストレージを別レイヤーに分けたdisaggregated storageアーキテクチャを採用しています。
分離設計には次のような利点があります。
-
「サイズ・オブ・データ」操作の排除
スケールアウトやフェイルオーバーが、扱うデータ量に依存しなくなる。100GBでも10TBでも、コンピュート切り替えのコストが大きく変わらない
-
読み取りレプリカの拡張
ストレージがプライマリノードに紐づかないため、レプリカ数の拡張が容易。共有ストレージを参照する形で読み取りスケールが効く
-
コミットレイテンシの安定化
レプリケーションのコミット待ちをストレージ層に閉じ込めることで、マルチゾーン環境でもサブミリ秒のコミット遅延を実現
この設計思想自体は、AWS Auroraが2014年にMySQL互換版で持ち込み、Aurora PostgreSQL互換版でも展開した流れの延長線上です。HorizonDBはこれをMicrosoft自身がPostgreSQLとAzureを共同設計するという形で再実装しています。
Rust製のストレージエンジンとKimo Geoランタイム
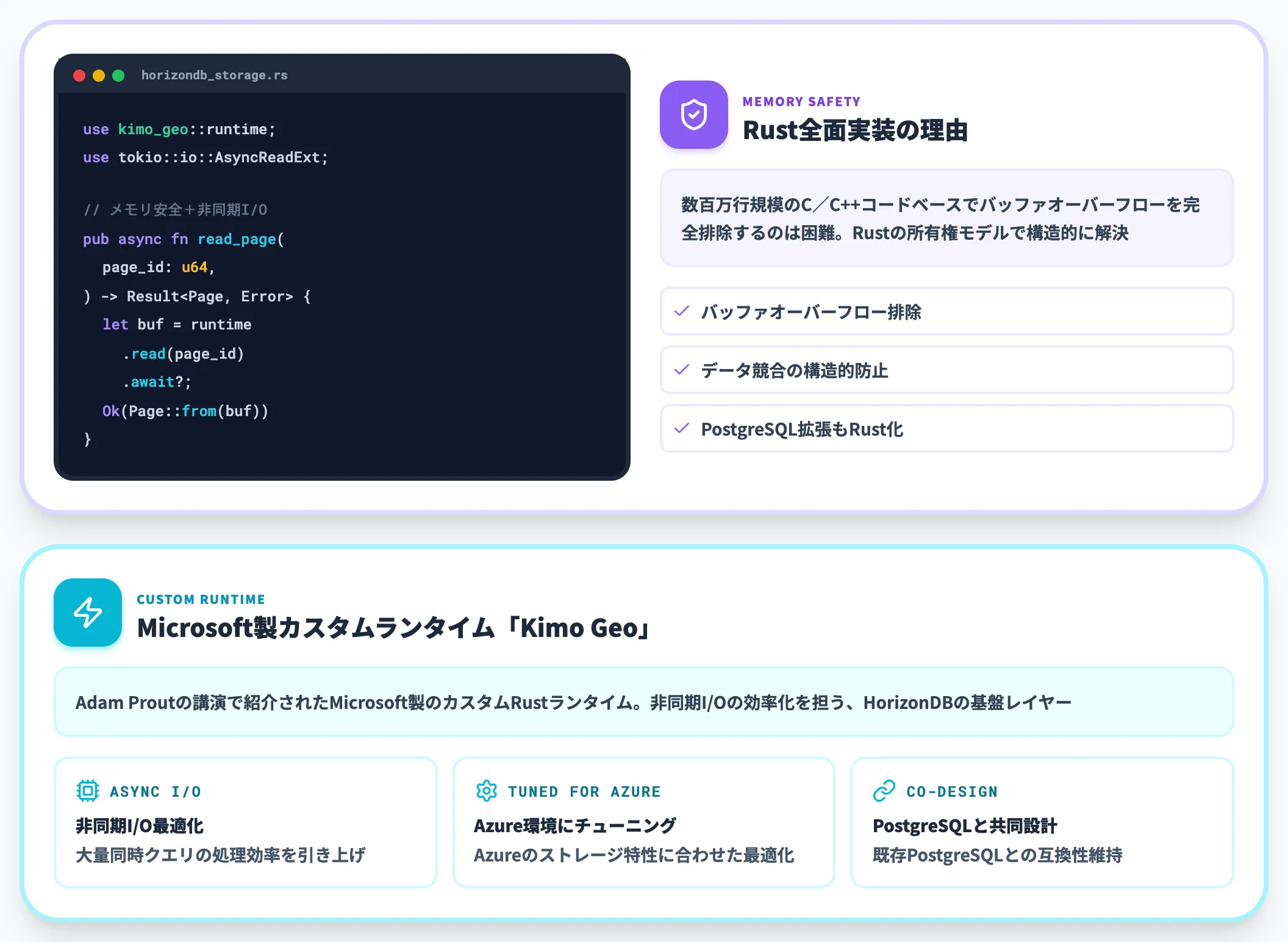
HorizonDBのもう一つの核は、ストレージエンジンとMicrosoft製の一部PostgreSQL拡張をRustで全面実装している点です。
Microsoftの主任エンジニアAdam Proutが説明しているとおり、数百万行規模のC/C++コードベースでバッファオーバーフローを完全に排除するのは現実的に困難です。メモリ安全な言語で書き直すことで、バッファオーバーフローやデータ競合のリスクを構造的に減らせます。
Rustランタイムには、Adam Proutの講演で紹介された Microsoft 製のカスタムランタイム「Kimo Geo」を採用し、非同期I/Oを効率化しています。
スケールアウトの上限値
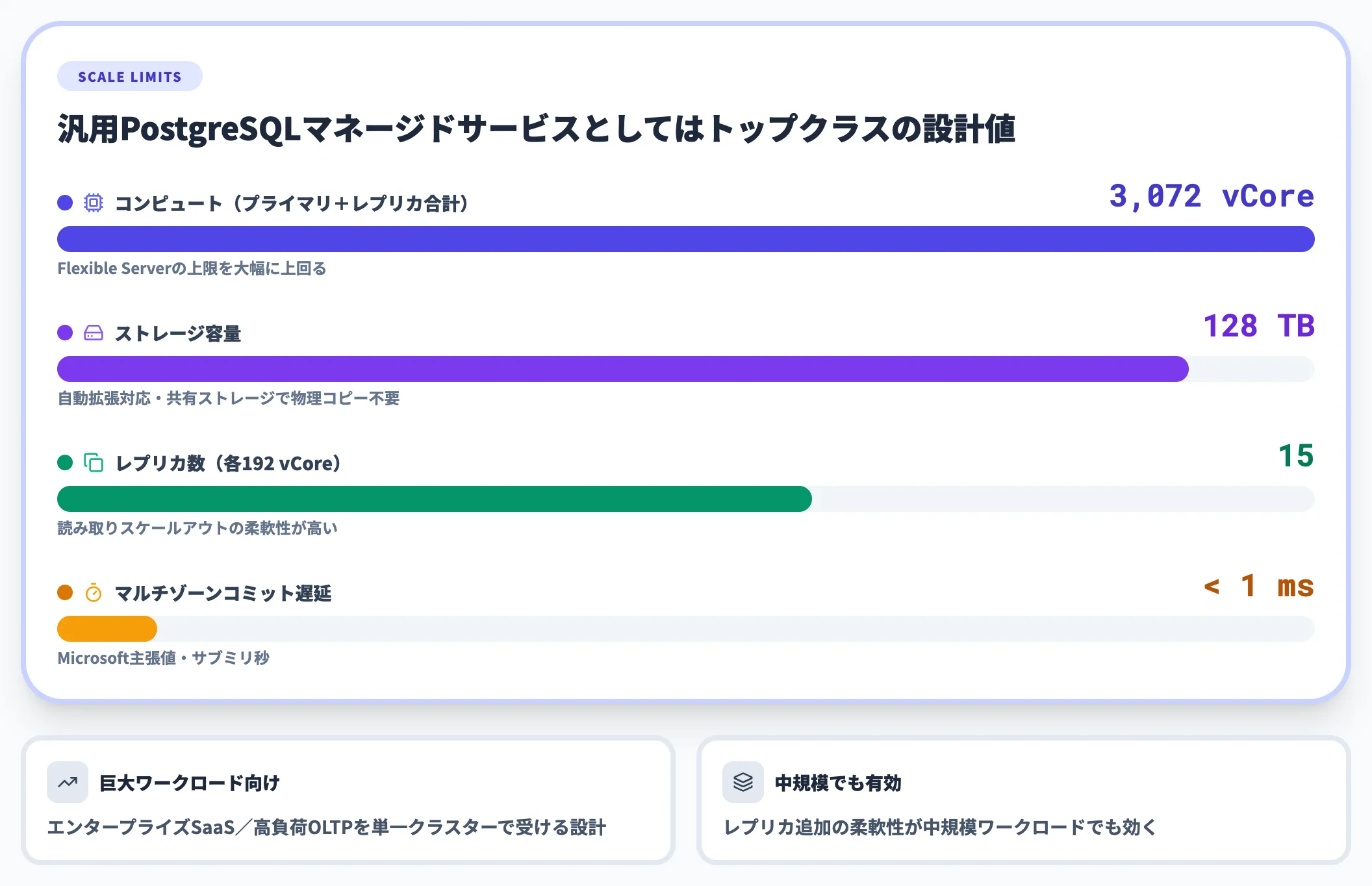
スケール上限値は以下のとおりで、汎用PostgreSQLマネージドサービスとしてはトップクラスの設計値です。
| 項目 | 上限値 | 備考 |
|---|---|---|
| コンピュート | 最大3,072 vCore | プライマリ+レプリカ合計 |
| ストレージ | 最大128 TB | 自動拡張対応 |
| レプリカ数 | 最大15 | レプリカあたり192 vCore |
| マルチゾーンコミット遅延 | サブミリ秒(<1ms) | Microsoft主張値 |
この上限は、既存のAzure Database for PostgreSQL Flexible Serverよりも大幅に大きく、エンタープライズSaaSや高負荷OLTPを単一クラスターで受けるシナリオを想定した数値です。
実務では「単一クラスタで何百TBを扱う」ような巨大ワークロードよりも、「スケールアウト余地を残したまま運用したい」中規模ワークロードでも、レプリカ追加の柔軟性が効くのが現実的なメリットです。
「自己管理PostgreSQLの3倍」性能主張の読み解き
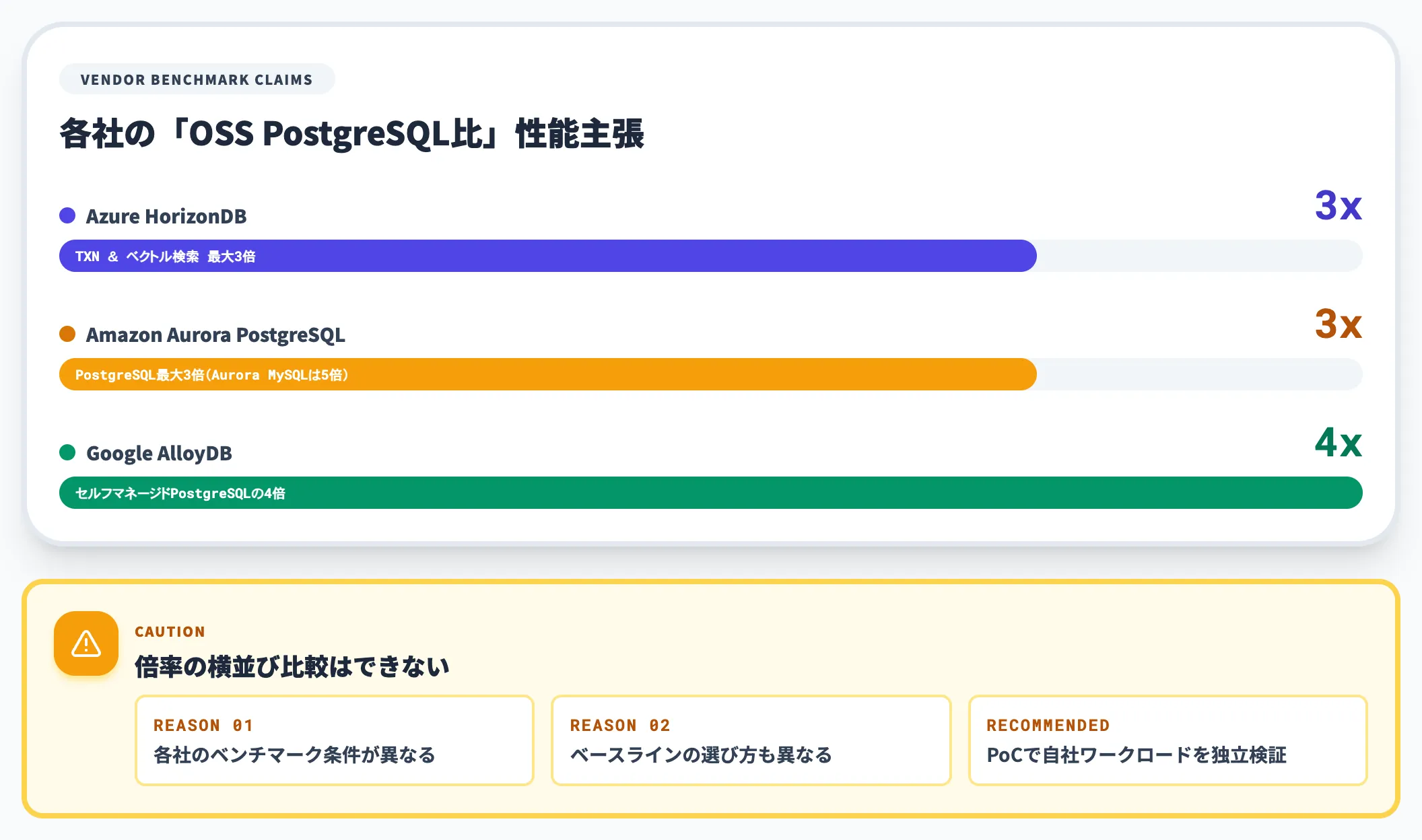
Microsoftは公式に「セルフマネージドPostgreSQLと比べて、トランザクションとベクトル検索が最大3倍高速」と主張しています。
ただしこの数値はMicrosoftの内部ベンチマーク値で、ワークロードと構成に依存します。Aurora PostgreSQLの「最大3倍」(Aurora MySQLが最大5倍)、AlloyDBの「4倍」主張と並べたとき、各社が前提とするベースラインも測定条件もそれぞれ異なるため、3社の倍率をそのまま横並びで比較する根拠にはなりません。
実務で性能評価を行う場合は、自社のワークロードを使った独立検証(プレビュー期間中ならPoC)を計画段階に組み込むことが安全です。
Azure HorizonDBに組み込まれたAI機能
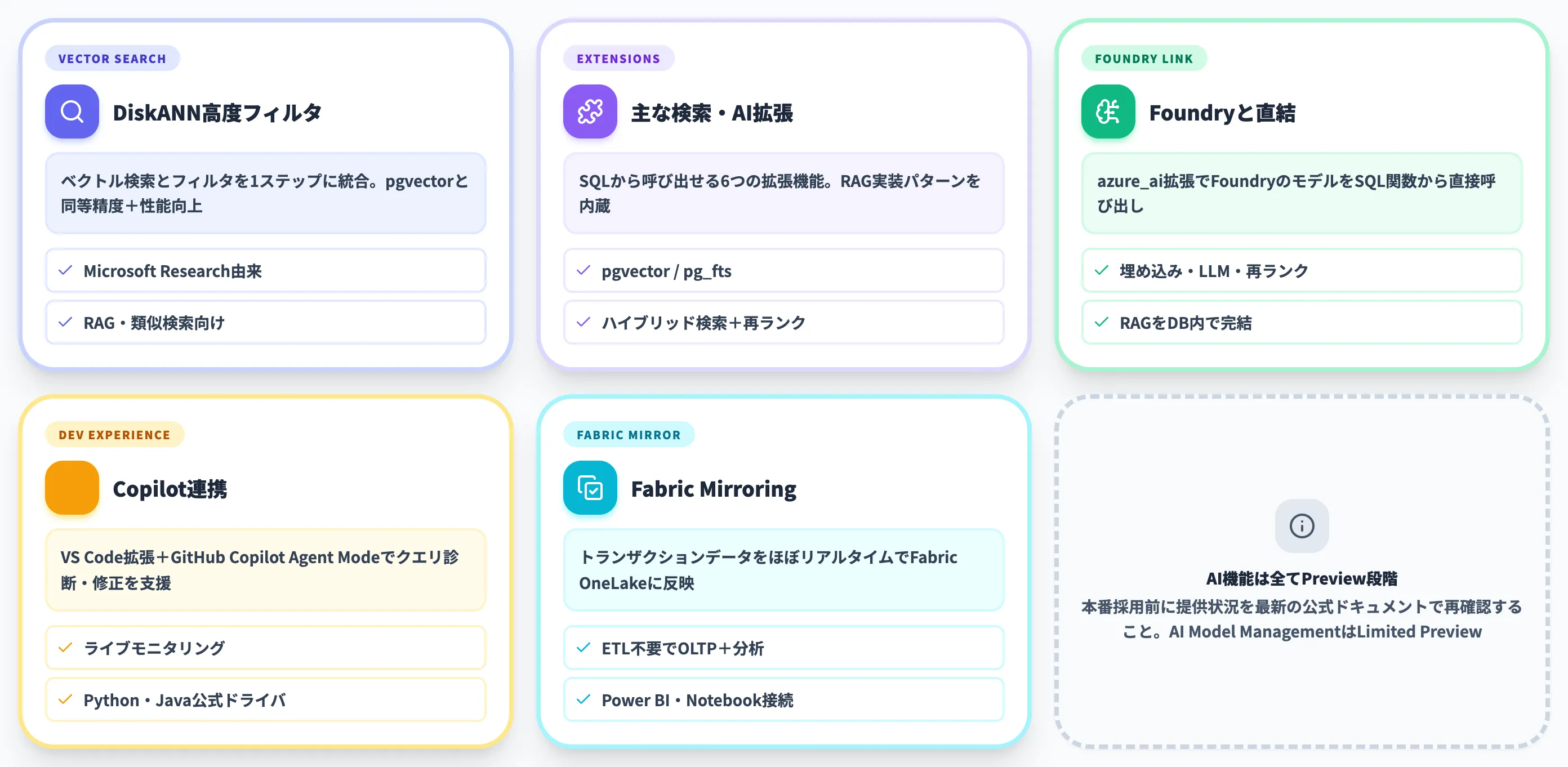
Azure HorizonDBの2つ目の柱が、AIワークロードを前提に設計されたデータベース内蔵機能です。
「PostgreSQLにAI機能を“あとから足す”」ではなく、ベクトル検索・全文検索・ハイブリッド検索・セマンティック再ランクといったAI関連の処理が公式ドキュメントの中で位置づけられ、Azure内のAI基盤と直接つながる構成になっています。各機能は2026年6月時点でPreview段階のため、本番採用前に提供状況を最新ドキュメントで再確認してください。
DiskANN高度フィルタリングによるベクトル検索
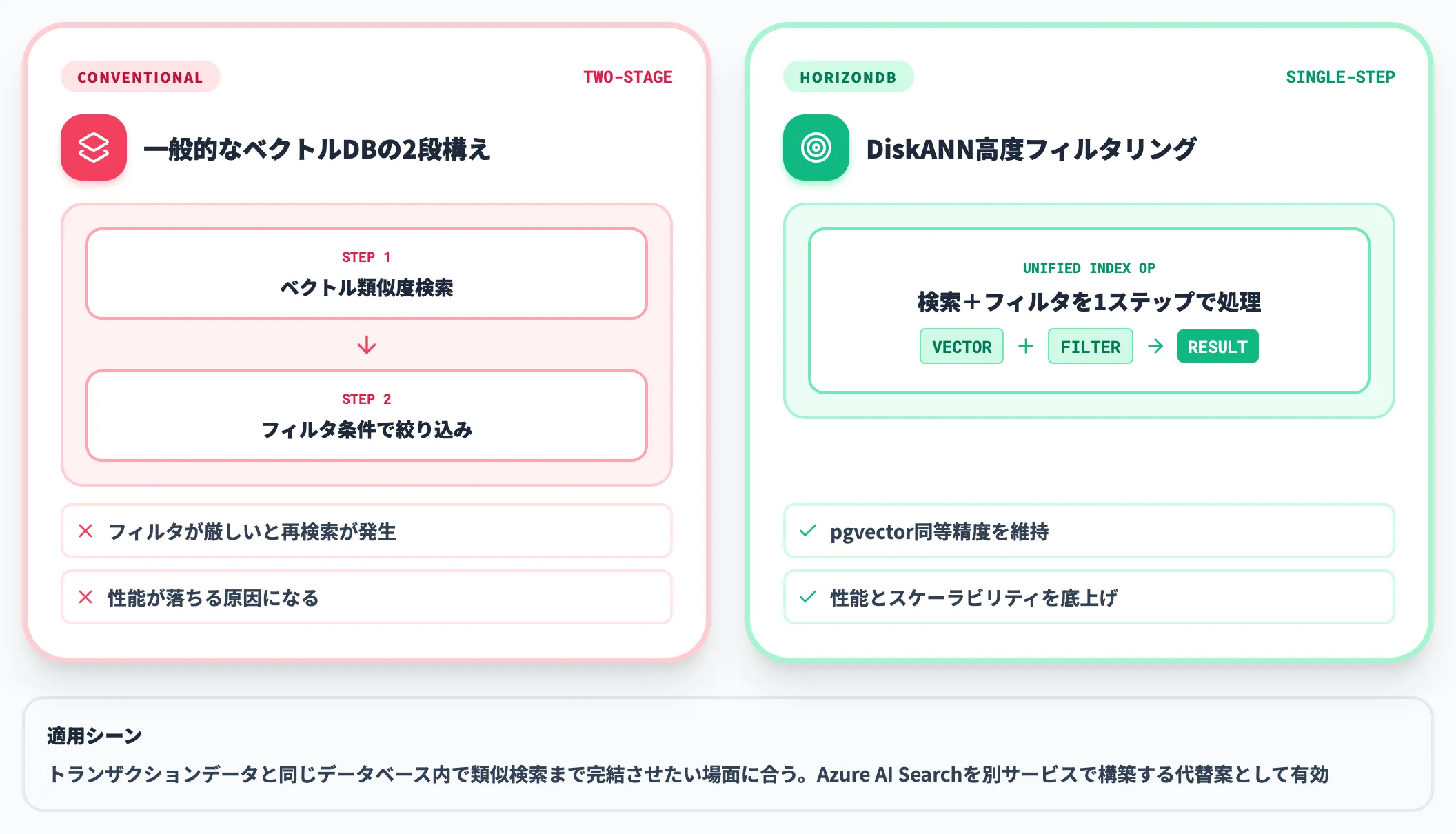
ベクトル検索の基盤として、Microsoftが研究開発してきたDiskANN(Disk-based Approximate Nearest Neighbor)を採用しています。HorizonDBの大きな違いは、ベクトル検索とフィルタ条件を1ステップに統合している点です。
ベクトルデータベースの一般的な実装では、ベクトル類似度検索を実行した後にフィルタ条件で絞り込む2段構えになりがちで、フィルタが厳しい場合は再検索が発生して性能が落ちます。HorizonDBのDiskANN高度フィルタリングは、検索とフィルタを1つのインデックス操作として処理することで、pgvectorと同等の精度を保ちつつ性能とスケーラビリティを底上げする設計です。
Azure AI Searchのベクトル検索を別サービスで構築するのではなく、トランザクションデータと同じデータベース内で類似検索まで完結させたいシーンに合います。
利用できる主な検索・AI拡張
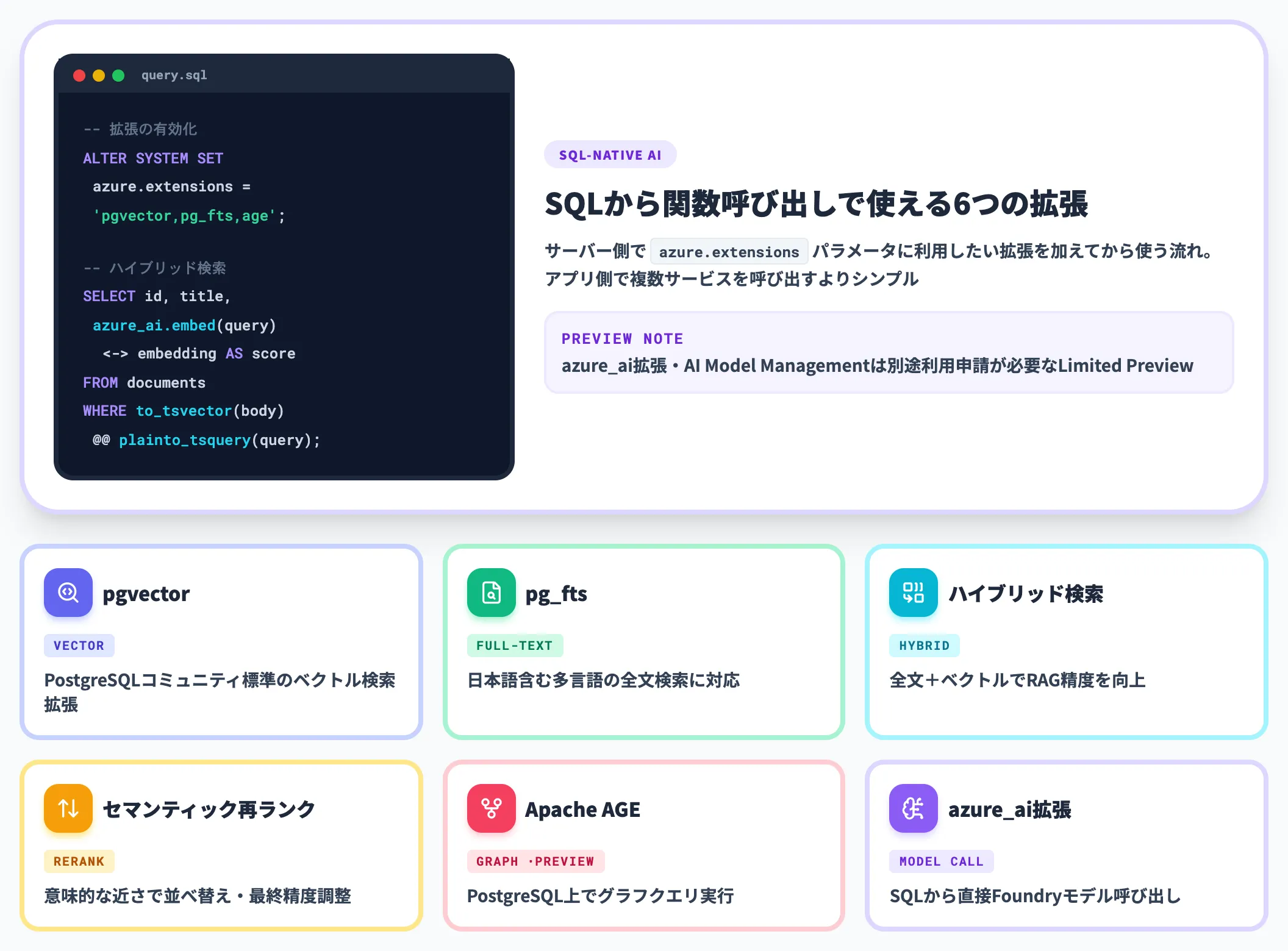
HorizonDBの公式ドキュメントでは、ベクトル検索以外にもAIワークロードを支える検索機能が提供されています。各機能は拡張機能の許可・作成・有効化が前提で、サーバー側で azure.extensions パラメータに利用したい拡張を加えてから使う流れになります。
-
pgvector
PostgreSQLコミュニティ標準のベクトル検索拡張。既存のpgvectorベースの実装をそのまま動かせる
-
pg_fts
PostgreSQL標準の全文検索(Full-Text Search)の拡張機能。日本語を含む多言語の全文検索に対応
-
ハイブリッド検索
全文検索とベクトル検索を組み合わせて精度を高めるハイブリッド方式。RAG実装で使われるパターンが、HorizonDBのAI検索機能としてドキュメント化されている
-
セマンティック再ランク(Semantic Reranking)
検索結果を意味的な近さで並べ替える機能。検索精度の最終調整に使う
-
Apache AGE(グラフデータベース拡張・Preview)
PostgreSQL上でグラフクエリを実行できる拡張。ナレッジグラフ実装に使える。対応するPostgreSQLバージョンや有効化条件は公式拡張機能ドキュメントで都度確認する必要がある
-
azure_ai拡張・AI Model Management
SQLから直接モデルを呼び出すための拡張機能。汎用機能はPreview、ワンクリックでモデルを登録・更新する AI Model ManagementはLimited Preview で別途利用申請が必要
これらがSQLの中から関数呼び出しで使えるため、アプリケーション側で複数サービスを呼び出すよりもシンプルな構成になります。
Microsoft Foundryとの直結

Azure HorizonDBは、Azure側のAI基盤であるMicrosoft Foundryとネイティブに接続できる設計です。
データベースに蓄積したテキストや構造化データに対し、azure_ai拡張を有効化したうえでFoundry上のモデル(埋め込みモデル・LLM・再ランクモデル)をSQL関数から呼び出します。Foundry側のモデル登録・APIキー設定・拡張機能の有効化が前提となる点に注意してください。
これにより、RAG(検索拡張生成)パイプラインの中核を「外部のオーケストレーションサービス+ベクトルDB+LLM」のような分散構成ではなく、HorizonDBの中でほぼ完結させることが可能になります。Foundryで開発したAIエージェントを、HorizonDB上のデータを直接読み書きする形で動かすシナリオも想定されています。
GitHub Copilot連携とVS Code開発体験
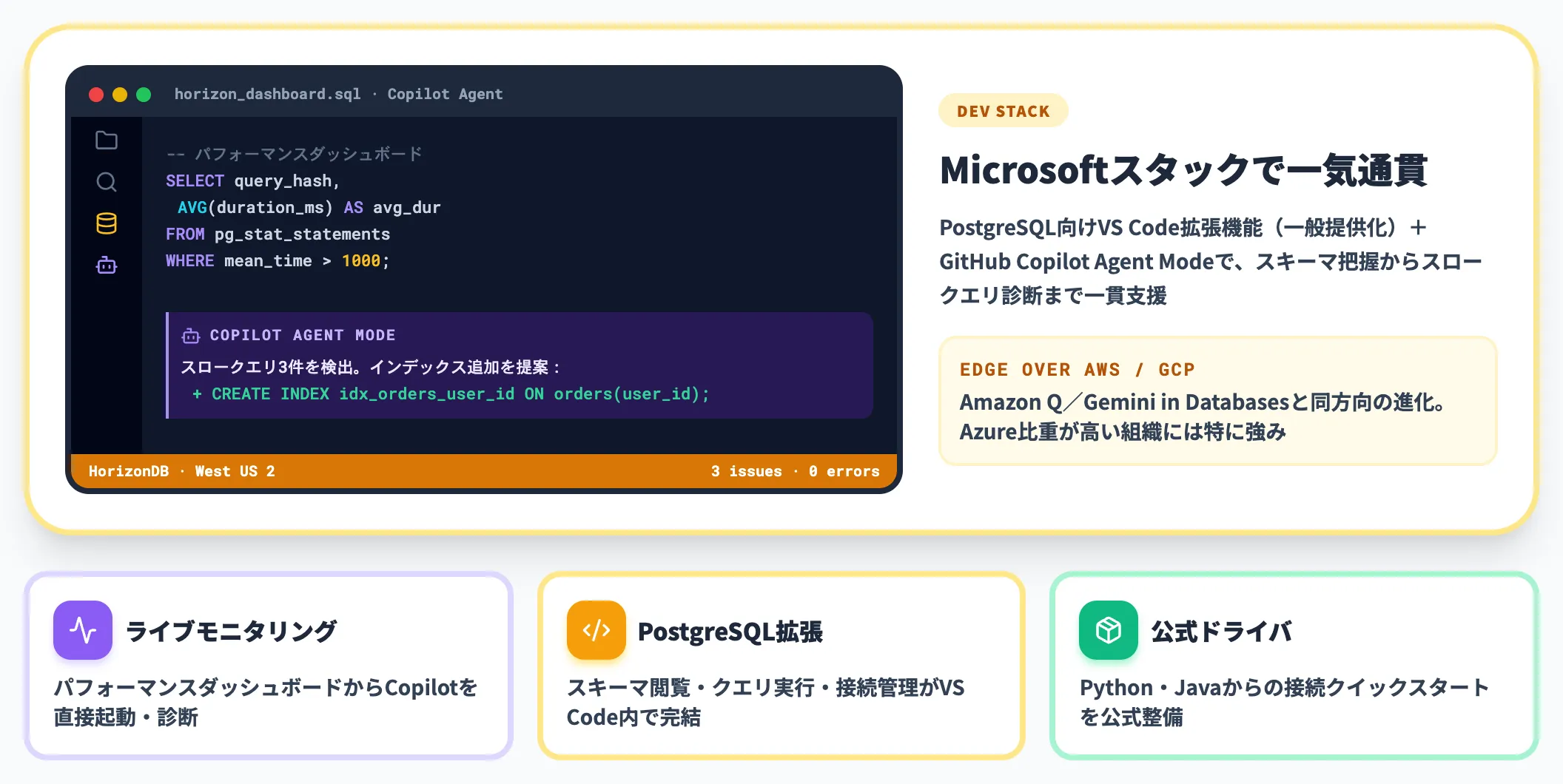
開発者体験では、Microsoftがほぼ同タイミングで強化した**PostgreSQL向けのVS Code拡張機能(一般提供化)**とGitHub Copilotエージェントモードの連携が組み込まれています。
-
ライブモニタリング機能
HorizonDBのパフォーマンスモニタリングダッシュボードから、GitHub Copilot Agent Modeを直接起動し、スロークエリ・ロック競合などの問題を診断・修正できる
-
PostgreSQL VS Code拡張
スキーマ閲覧・クエリ実行・接続管理がVS Code内で完結。Copilotがスキーマコンテキストを認識した状態でSQL補完を行う
-
Python・Java公式ドライバ
HorizonDBのドキュメントに、PythonとJavaからの接続クイックスタートが整備されている
AWSのAmazon QやGoogle CloudのGemini in Databasesも同方向のAI支援を進めていますが、VS Code拡張・GitHub Copilot・Azure側PostgreSQLサービスを同じMicrosoftスタックの中で一気通貫に扱えることが、Azure比重の高い開発組織にとっての実務的な強みになります。
Microsoft Fabric OneLakeへのMirroring
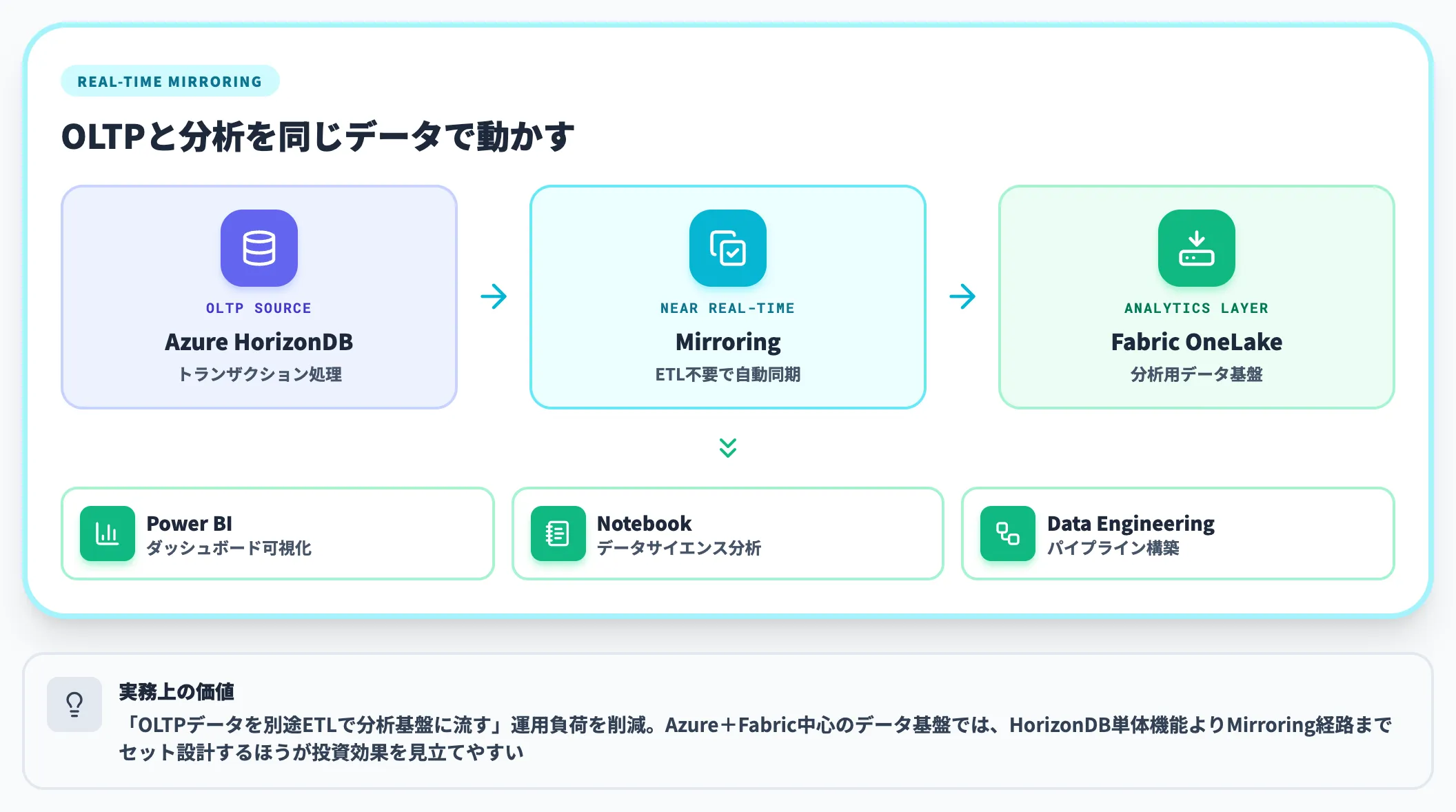
Azure HorizonDBの公式製品ページでは、もうひとつの主要機能としてMicrosoft FabricへのMirroringが挙げられています。トランザクションデータをほぼリアルタイムでFabric OneLakeに反映し、HorizonDB側でOLTPを動かしながら、同じデータをFabric上のPower BI・Notebook・データエンジニアリングで分析できる構成です。
「トランザクション処理用のDBを別途ETLで分析基盤に流す」運用の負荷を下げる仕組みで、Azure+Fabric中心のデータ基盤を組む場合、HorizonDB単体機能よりもこのMirroring経路までセットで設計するほうが投資効果を見立てやすくなります。
Azure HorizonDBと既存のAzure系PostgreSQLサービスの違い

Azure上にはこれまでも複数のPostgreSQLサービスがあり、Azure HorizonDBはこれらを置き換えるものではありません。役割が分かれた3つのPostgreSQLサービスが並走する構図になります。
以下の表で、3サービスの位置づけと向き先を整理しました。
| サービス | アーキテクチャ | 主な用途 | 提供状況 |
|---|---|---|---|
| Azure HorizonDB | 共有ストレージ/スケールアウト・コンピュート(Rust製エンジン) | 大規模OLTP+AIワークロード | Preview(2026年6月時点・5リージョン) |
| Azure Database for PostgreSQL Flexible Server | 単一サーバー型のフルマネージドPostgreSQL | 汎用マネージドPostgreSQL(広い用途) | 一般提供(GA) |
| Azure Cosmos DB for PostgreSQL | Citus基盤のシャーディング型分散PostgreSQL | 水平シャーディングが必要な分析・大量書き込み | 一般提供(GA) |
3サービスはアーキテクチャの思想が異なります。Flexible Serverは「使い慣れたPostgreSQLをそのまま」、Cosmos DB for PostgreSQLは「シャーディングで水平拡張」、HorizonDBは「共有ストレージでスケールアウトしつつAI機能を内蔵」と、それぞれ異なる課題に答える設計です。
vs Azure Database for PostgreSQL Flexible Server

Azure Database for PostgreSQL Flexible Serverは、PostgreSQLをそのままマネージドで使うための標準サービスです。
汎用ワークロードでまず選ばれる選択肢で、コスト・運用シンプルさ・対応リージョンの広さで圧倒的にHorizonDBを上回ります(HorizonDB側はプレビュー段階で日本未提供)。「単一インスタンスで十分回る」「リードレプリカが数台あれば足りる」「単一AZでも問題ない」ワークロードでは、Flexible Serverのほうが現実的です。
一方、書き込みスループットがFlexible Serverの単一書き込み上限に当たる、コミット遅延を詰めたい、AI機能を別サービスで構築するのを避けたいシナリオでは、HorizonDBに移すメリットが出てきます。
vs Azure Cosmos DB for PostgreSQL(Citus基盤)
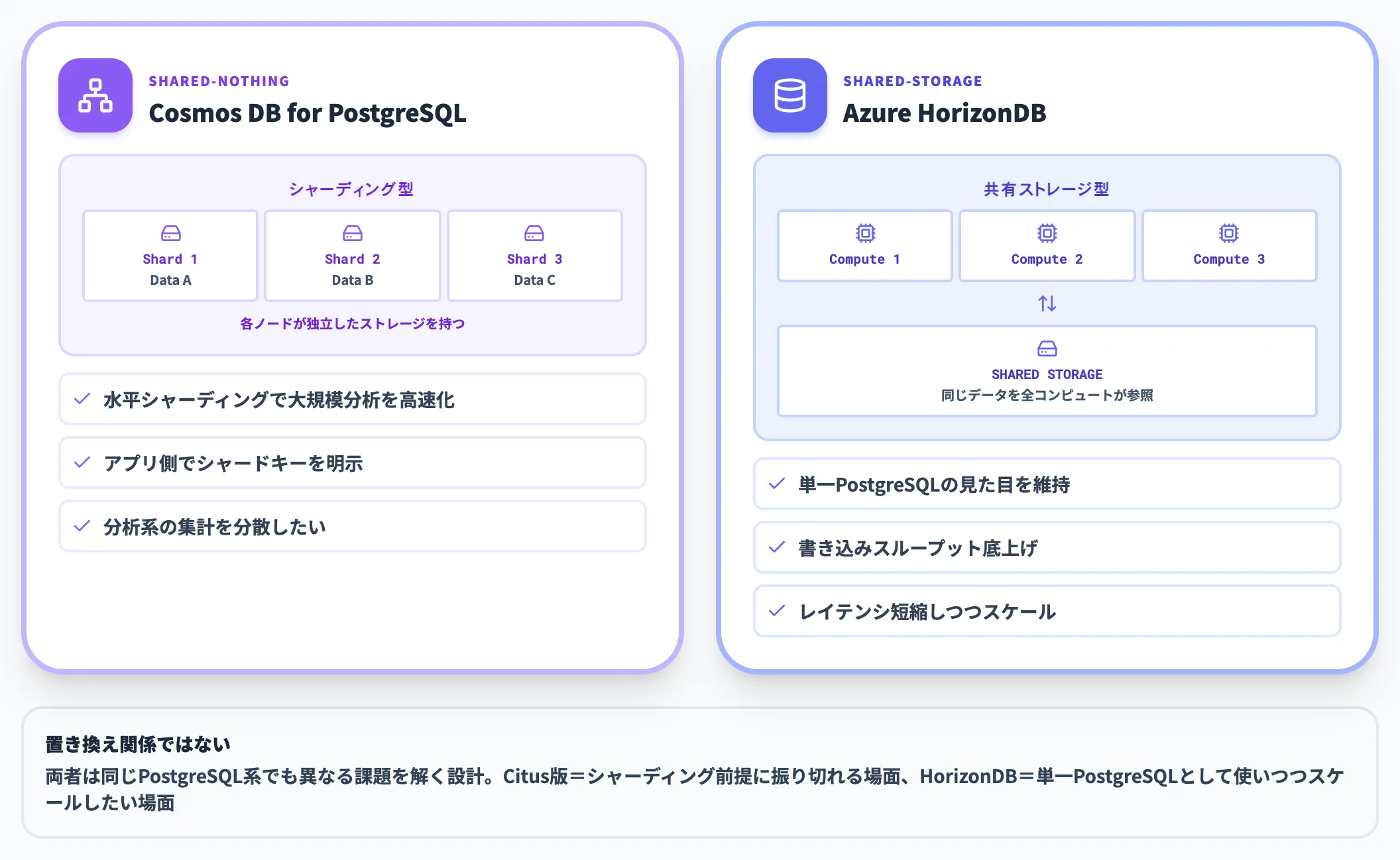
Azure Cosmos DB for PostgreSQLは、Microsoftが2019年に買収したCitus Dataの技術をベースに、シャーディング型の水平拡張を可能にしたサービスです。
Citusは「Shared-nothing(共有しない)」型アーキテクチャで、データをシャードに分割して複数ノードに配置し、クエリを並列実行することで大規模分析を高速化します。これに対しHorizonDBは「Shared-storage(共有ストレージ)」型で、コンピュートが同じストレージを参照しながらスケールアウトする設計です。
両者は同じPostgreSQL系でも異なる課題を解く設計で、置き換え関係ではありません。Citus版は「アプリケーション側でシャードキーを明示できる」「分析系の集計を分散したい」シナリオに向き、HorizonDBは「単一PostgreSQLとしての見た目を維持しつつ、書き込みスループットとレイテンシを底上げしたい」シナリオに向きます。
Azure内3サービスの使い分けの目安
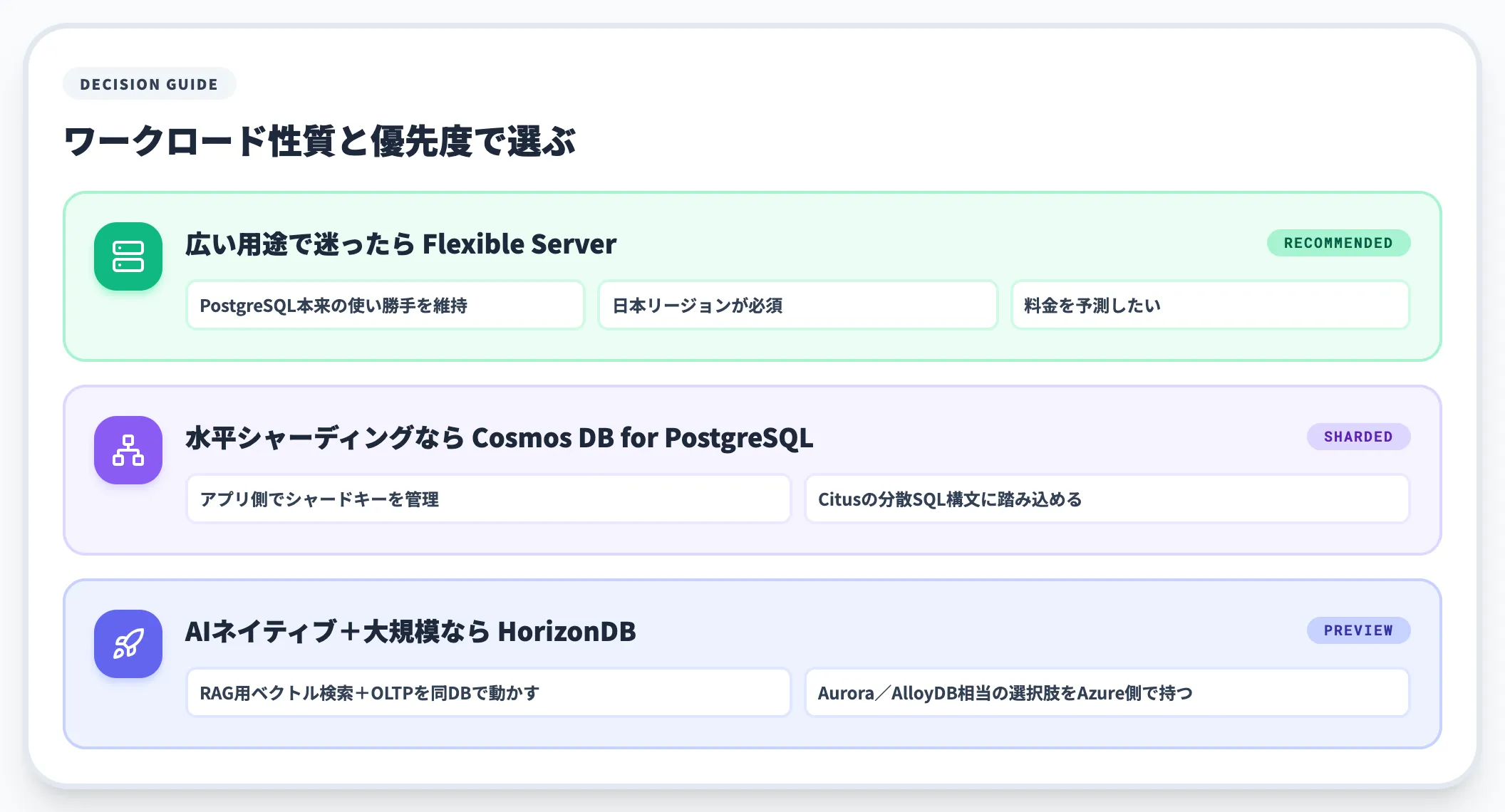
実務での選び方は、ワークロードの性質と運用の優先度で決まります。
-
広い用途で迷ったらFlexible Server
PostgreSQL本来の使い勝手を維持したい、日本リージョンが必須、料金を予測したい
-
アプリ側でシャードキーを管理して分析・大量書き込みを並列化するならCosmos DB for PostgreSQL
水平シャーディング前提の設計に振り切れる、Citusの分散SQL構文に踏み込める
-
AIネイティブ機能と大規模スケールを両立したいならHorizonDB
RAG用ベクトル検索とOLTPを同じDBで動かしたい、Aurora/AlloyDB相当の選択肢をAzure側で持ちたい
Aurora/AlloyDBと比較したAzure HorizonDBの位置づけ
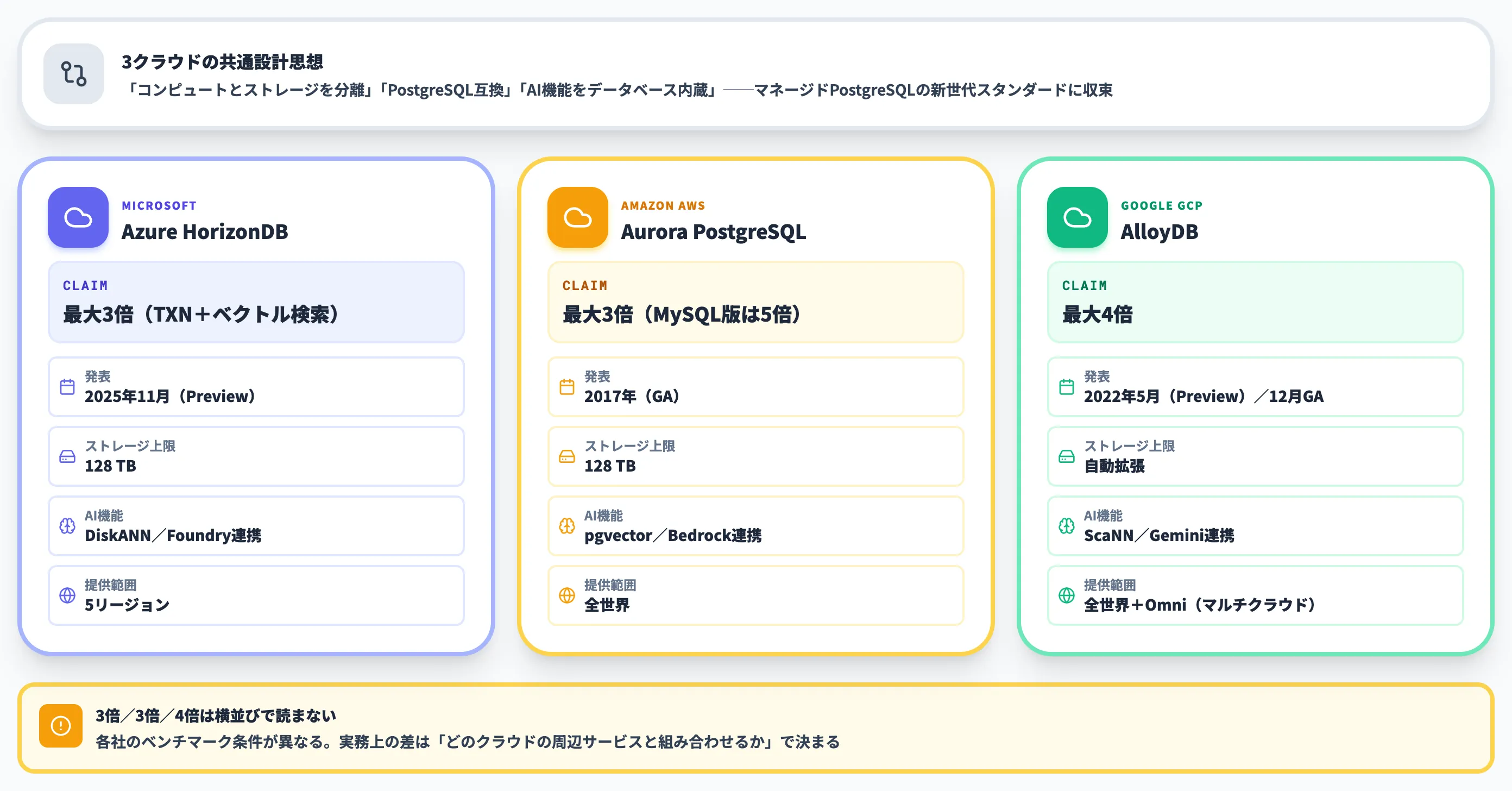
クラウドネイティブPostgreSQLの3大選択肢——Amazon Aurora PostgreSQL、Google AlloyDB、Azure HorizonDB——は、設計思想が驚くほど似てきています。
3社ともに「コンピュートとストレージを分離」「PostgreSQL互換」「AI機能をデータベース内蔵」の組み合わせを採用しており、「マネージドPostgreSQLの新世代スタンダード」と呼べる方向性で揃いました。
以下の表で、3サービスの主要スペックと特徴を比較しました。

| 項目 | Azure HorizonDB | Amazon Aurora PostgreSQL | Google AlloyDB |
|---|---|---|---|
| 発表時期 | 2025年11月(Preview) | 2017年(GA) | 2022年5月(Preview)/2022年12月(GA) |
| アーキテクチャ | 共有ストレージ/スケールアウト | 共有ストレージ/スケールアウト | 共有ストレージ/スケールアウト |
| 性能主張(vs OSS PostgreSQL) | 最大3倍 | 最大3倍 | 最大4倍 |
| ストレージ上限 | 128 TB | 128 TB | 自動拡張 |
| 主要AI機能 | DiskANN高度フィルタ/Microsoft Foundry連携 | pgvector/Bedrock連携 | ScaNN/Gemini連携 |
| マルチクラウド版 | なし | なし | AlloyDB Omni(自己管理) |
| 提供リージョン | 5リージョン(Preview) | 全世界 | 全世界 |
3社の倍率主張(3倍/3倍/4倍)はベンチマーク条件が異なるため、そのまま序列として読まないほうが安全です。実務上の差は「どのクラウドの周辺サービスと組み合わせるか」で決まります。
Amazon Aurora PostgreSQLとの違い
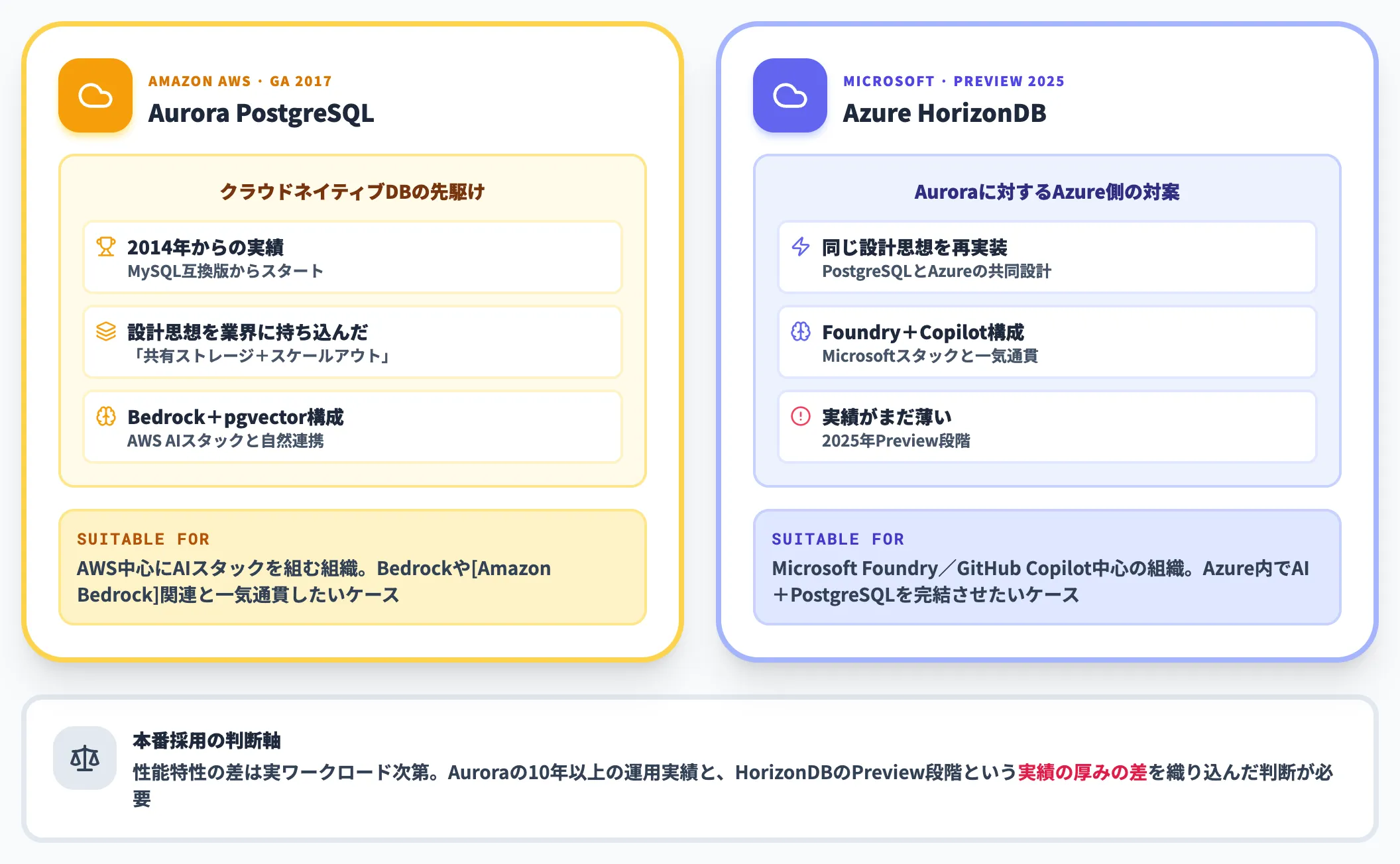
Auroraは2014年にAWSがMySQL互換版として投入したクラウドネイティブDBの先駆けで、業界に「共有ストレージ+スケールアウト」の設計思想を持ち込みました。Aurora PostgreSQL互換版は2017年にGAしています。
AzureユーザーがAWSへ移行する/併用する文脈では、HorizonDBはAuroraに対する「Azure側の対案」として機能します。BedrockやAmazon Bedrockを中心にAIスタックを組んでいる企業はAurora+pgvectorの構成が自然な一方、Microsoft FoundryやGitHub Copilotを中心に組んでいる企業はHorizonDBに寄せやすい設計差があります。
性能特性での差は実ワークロード次第ですが、Auroraが10年以上の運用実績を積んでいるのに対し、HorizonDBは2025年発表のプレビューである点を踏まえると、本番採用の判断には実績の厚みを織り込む必要があります。
Google AlloyDBとの違い
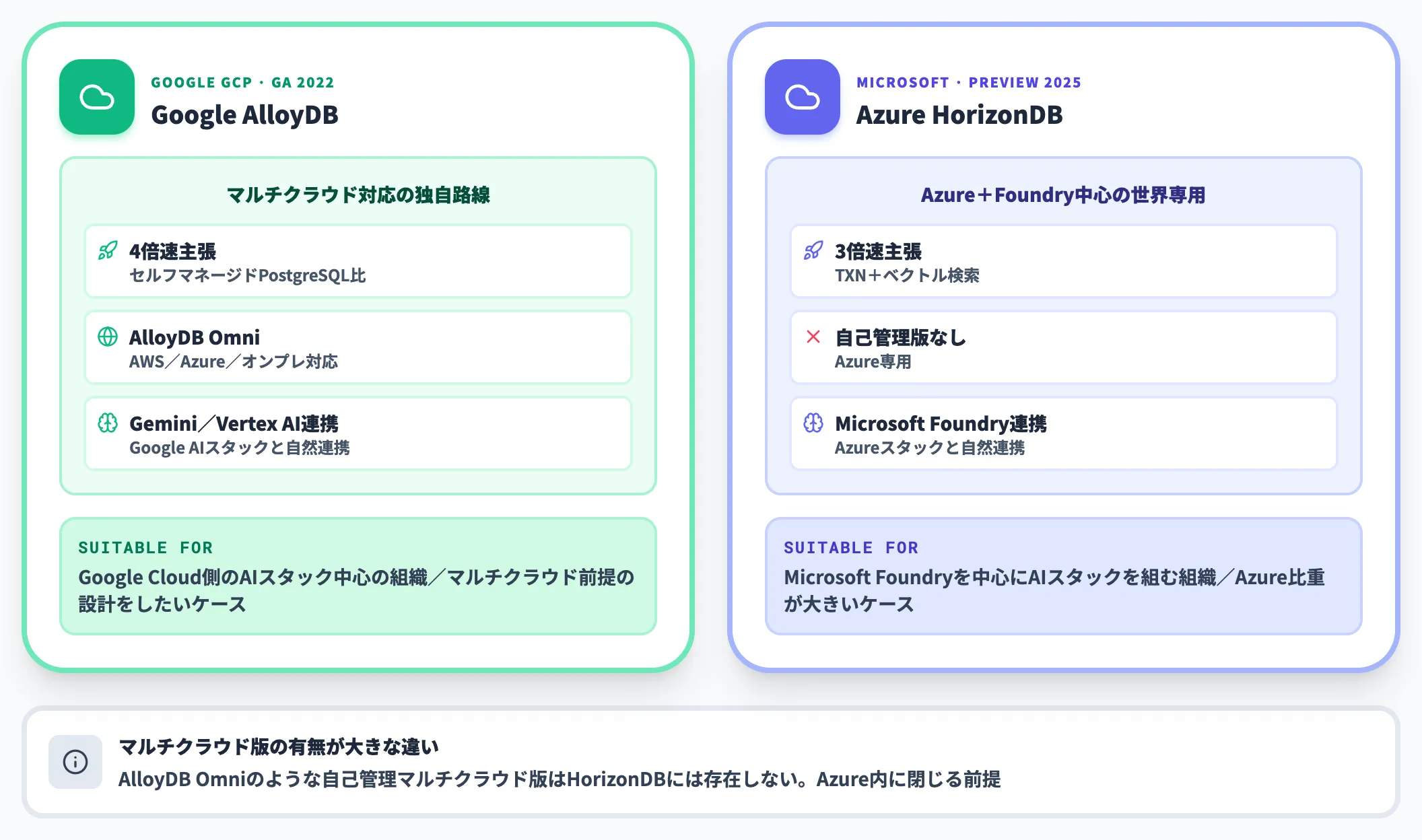
AlloyDBはGoogleが2022年に投入したマネージドPostgreSQLで、「セルフマネージドPostgreSQLの4倍速」という主張で知られています。
特徴的なのは、マルチクラウド・オンプレ対応版の「AlloyDB Omni」を提供している点で、AWS・Azure・オンプレでもAlloyDBエンジンを動かせるよう設計されています。HorizonDBにはこの種の自己管理版は今のところ存在しません。
Google Cloud側のAIスタック(Gemini/Vertex AI)と組み合わせる文脈ではAlloyDBが自然な選択肢で、HorizonDBはあくまでAzure+Microsoft Foundry中心の世界での選択肢として捉えるのが現実的です。
3クラウドの「PostgreSQL+AI」が揃った意味
3クラウドのマネージドPostgreSQLが揃って同じ方向に進化したことで、「クラウド選定」と「データベース選定」がほぼ一致する状況になりました。
すでにAzureを中心に運用している組織にとってHorizonDBは、データを別クラウドへ動かさずに新世代マネージドPostgreSQLの選択肢を確保できる意味を持ちます。逆にAWS/GCP中心の組織がHorizonDBに切り替える積極的な理由は、現時点で見つけにくいのも事実です。
AI総研の支援現場では、既存のクラウド選定を起点に、その上で動くPostgreSQLのアーキテクチャ選択を後追いで詰める進め方が増えています。
Azure HorizonDBの始め方とPreview利用の流れ
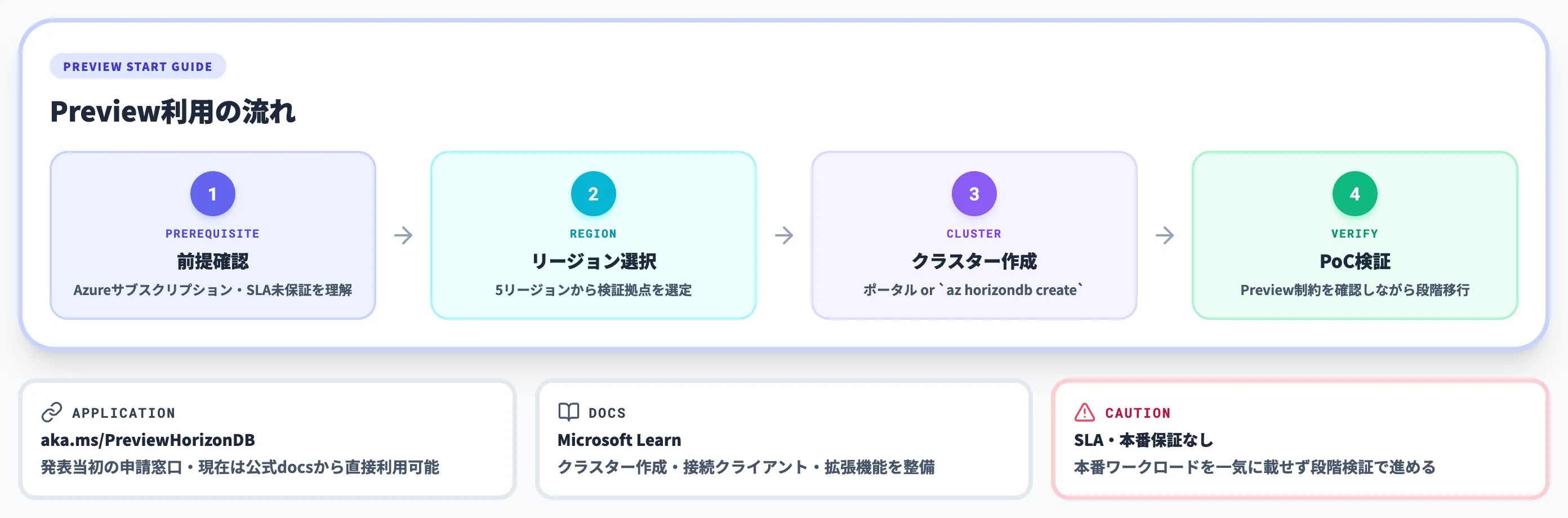
Azure HorizonDBは2026年6月時点でPreview段階です。当初のプライベートプレビューから、現在はMicrosoft Learnの公式ドキュメントでクラスター作成手順・接続クライアント・拡張機能一覧が整備された状態に移行しています。
本セクションでは、Preview利用の前提・対象リージョン・クラスター作成・クライアント接続・運用時の制約を順に整理します。
Preview利用の前提と注意点

Microsoftは発表当初、申請窓口として**aka.ms/PreviewHorizonDB** という短縮URLを公開していました。2026年6月時点ではMicrosoft Learnの公式ドキュメントが整備され、対象リージョンを持つAzureサブスクリプションがあれば検証クラスターを作成できる形に近づいています。
-
対象組織
Azureアカウントを持つ組織なら検証用途で試せる段階。本番運用保証(SLA)はないため、PoCや段階検証が前提
-
アクセスルート
Azureポータルから直接クラスター作成、またはMicrosoftアカウントチーム経由で利用条件を個別合意
-
本番採用前の確認
Preview制約(後述)とGA時の料金変動可能性を踏まえ、本番ワークロードを一気に載せずPoC・限定的な検証で段階移行する
対象リージョンと日本での扱い
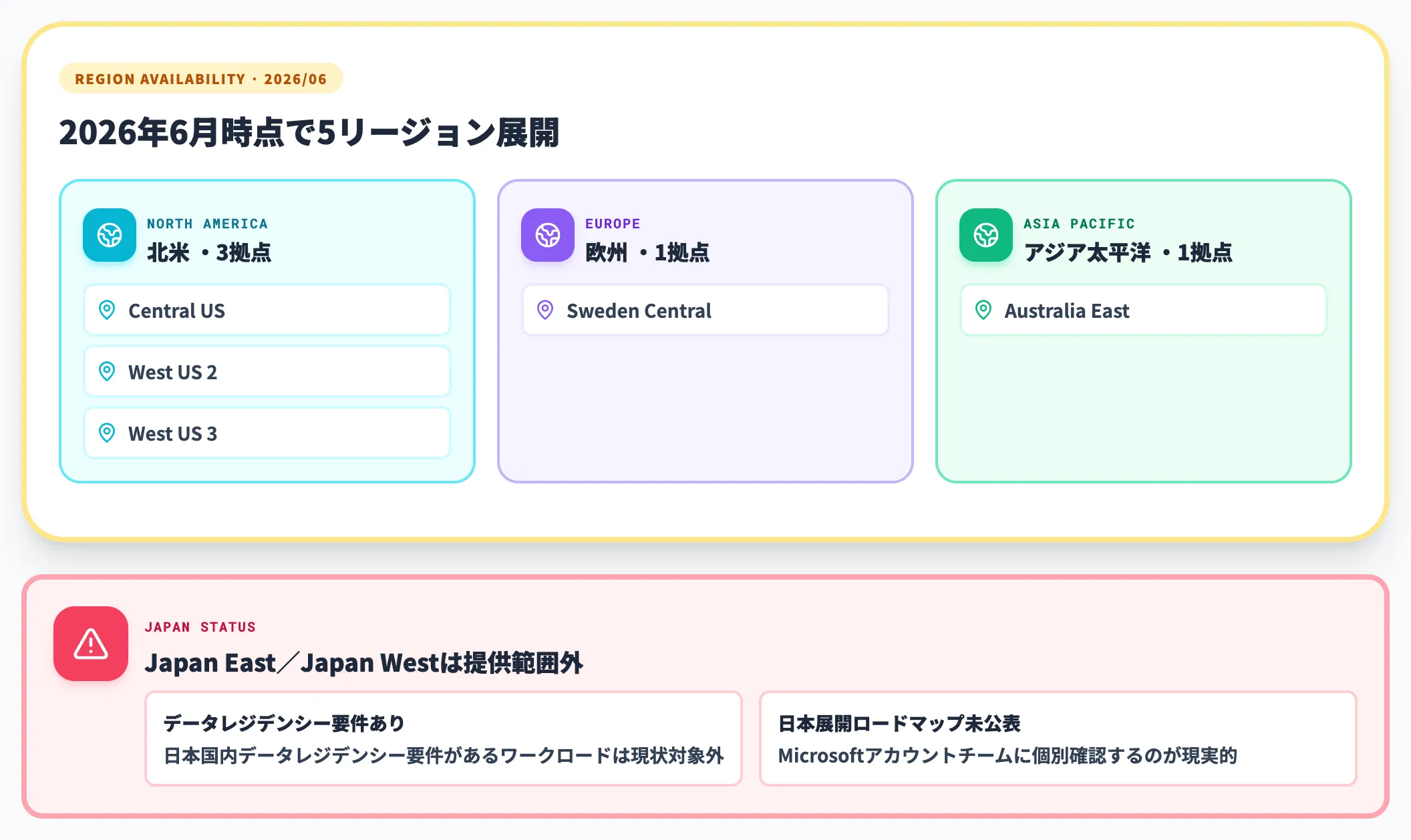
2026年6月時点でAzure HorizonDBが利用できるのは、以下の5リージョンです。
| 地域 | リージョン |
|---|---|
| 北米 | Central US/West US 2/West US 3 |
| 欧州 | Sweden Central |
| アジア太平洋 | Australia East |
Japan East/Japan Westは現時点で提供範囲に含まれていません。日本国内のデータレジデンシー要件があるワークロードは、現状ではHorizonDBの対象外と考える必要があります。Microsoft Learnのリージョン一覧も「対応リージョンは順次拡張予定」と明記しており、最新情報の参照が必須です。
日本リージョン展開のロードマップは公表されていないため、利用を見込む場合はMicrosoftのアカウントチームに展開予定を個別確認するのが現実的です。
クラスター作成と接続クライアント
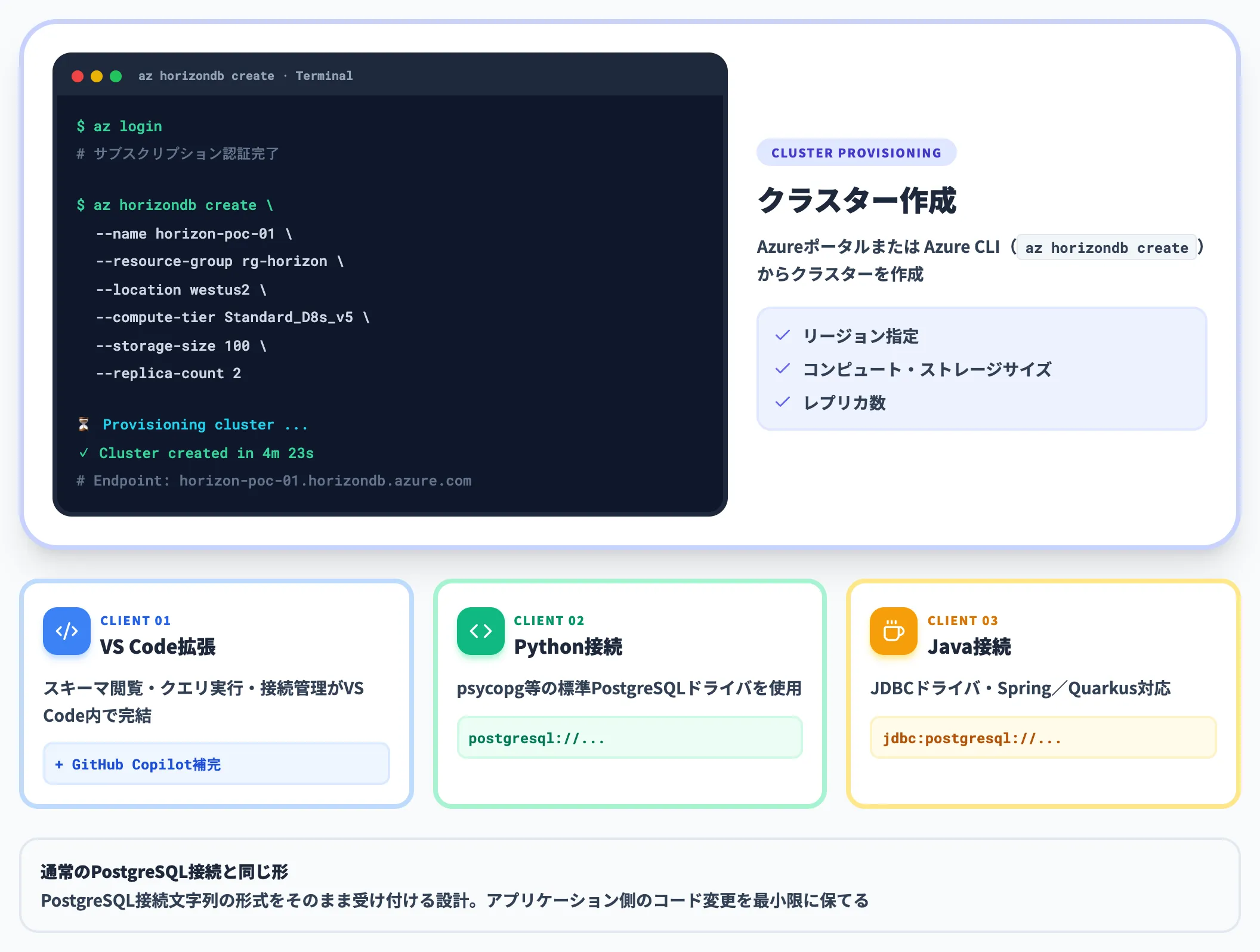
対象リージョンを持つAzureサブスクリプションでは、Azure ポータルまたはAzure CLI(az horizondb create)からクラスターを作成できます。公式ドキュメントには以下のクイックスタートが整備されています。
-
クラスター作成
Azure ポータルから「Azure HorizonDB cluster」を選び、リージョン・コンピュートサイズ・ストレージ初期容量・レプリカ数を指定して作成。CLIならaz horizondb createで同等の操作が可能
-
VS Code拡張による接続
PostgreSQL向けのVS Code拡張機能を使い、クラスターに接続。スキーマ閲覧・クエリ実行・GitHub Copilotによる補完がVS Code内で完結
-
Python接続
psycopgなどの標準PostgreSQLドライバを使用。HorizonDBはPostgreSQL接続文字列の形式をそのまま受け付ける
-
Java接続
JDBCドライバ経由で接続。SpringやQuarkusなど主要フレームワークからの利用パターンも公式に整理
接続体験そのものは「通常のPostgreSQLサーバーに接続する」のと同じ形で、アプリケーション側のコード変更を最小限に保てる設計になっています。
マネージド機能の対応状況とPreview制約

Preview段階でも、エンタープライズ運用に必要な機能はある程度整っています。
- バックアップ・リストア(カスタム復元ポイント対応)
- 高可用性とフェイルオーバー(マルチゾーン対応)
- データ暗号化・TLS/SSL接続
- ロール・SCRAM認証によるアクセス制御
- 削除保護(accidental delete protection)
- Private Linkによるネットワーク接続
一方で、本番運用を検討するうえで必ず押さえておきたいPreview制約も多く残っています。
| 機能 | 現状 |
|---|---|
| バックアップ保持期間の設定 | 未対応(現状は7日固定。1〜35日設定への対応を準備中) |
| クロスリージョン読み取りレプリカ | 未対応(リージョン横断のDR構成は組めない) |
| カスタマー管理キー(CMK) | 未対応(サービス管理キーのみ) |
| カスタムメンテナンスウィンドウ | 未対応(システム管理ウィンドウのみ) |
| Connection Pooling(PgBouncer) | 未対応(外部プーラ併用が必要) |
| Long-term retention(LTR) | 未対応 |
| Index Tuning | 未対応(近日提供予定) |
| VNet injection | 未対応(Private Linkは対応) |
これらの制約は2026年6月時点の公式ドキュメント記載で、GA時にどこまで解消されるかは未公表です。本番採用の判断はPreview期間中の挙動だけで決めず、GA時の仕様を改めて確認することが安全です。
Azure HorizonDBの料金体系
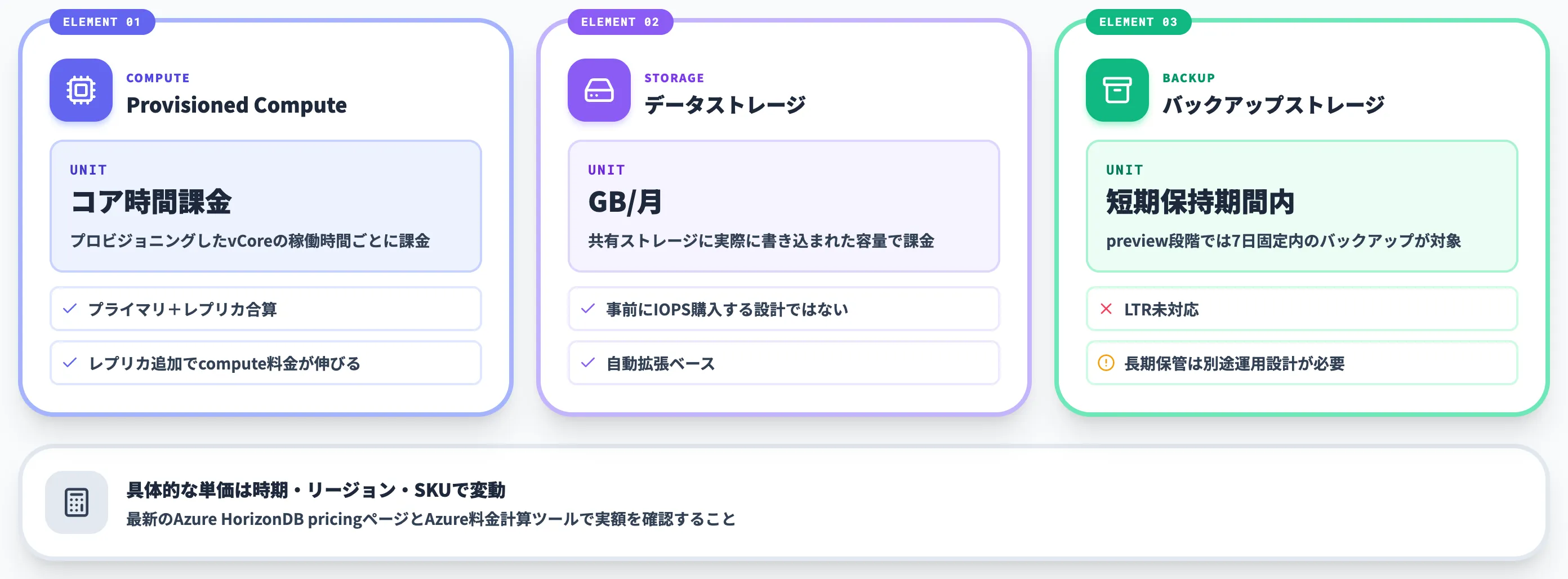
Azure HorizonDBの料金は、2026年6月時点で3要素のシンプルな構成で公開されています(公式pricing)。本セクションでは、課金要素の中身と、Flexible Server・Aurora・AlloyDBと並べて比較する際の見方を整理します。
課金される3要素
公式ドキュメントによれば、Azure HorizonDBは現時点で次の3要素で課金されます。
-
Provisioned Compute(コア時間課金)
プロビジョニングしたvCoreの稼働時間ごとに課金。レプリカを追加すれば、レプリカ分のコア時間が積み上がる
-
使用データベースストレージ(GB/月)
共有ストレージに実際に書き込まれた容量で課金。事前にIOPSを購入する設計ではなく、自動拡張ベース
-
使用バックアップストレージ
短期保持期間(preview段階では7日固定)内のバックアップが対象。Long-term retention(LTR)は現状未対応のため、長期保管したい場合は別途運用設計が必要
具体的な単価は時期・リージョン・SKUで変わるため、最新のAzure HorizonDB pricingページとAzure料金計算ツールで実額を確認してください。
既存PostgreSQLサービスとの違い

Azure HorizonDBの3要素は、Azure Database for PostgreSQL Flexible Serverの「vCore+ストレージ+IOPS/スループット」構造とは設計が違います。
-
Flexible Serverはストレージ種別と容量でIOPSが決まる
Premium SSDはストレージ容量に紐づいた固定IOPS、Premium SSD v2では一定範囲のIOPS・スループットが含まれたうえで、超過分を追加プロビジョニングする運用になり、書き込み負荷に応じたチューニングが必要
-
HorizonDBはIOPSを別途見積もる必要がない
ストレージ層に集約された設計のため、IOPS・スループットを個別購入する概念がなく、代わりにcomputeコア時間が広く効く
-
共有ストレージのため、レプリカ追加コストはcompute分のみ
データの物理コピーが発生しないため、レプリカ追加時に「データ量×レプリカ数」のストレージ料金は発生しない
Aurora PostgreSQLの「vCPU時間+ストレージ容量+I/O数」、AlloyDBの「vCPU時間+ストレージ容量」と比べると、HorizonDBはAlloyDBに近いシンプル構成になっています。
試算で注意したい点
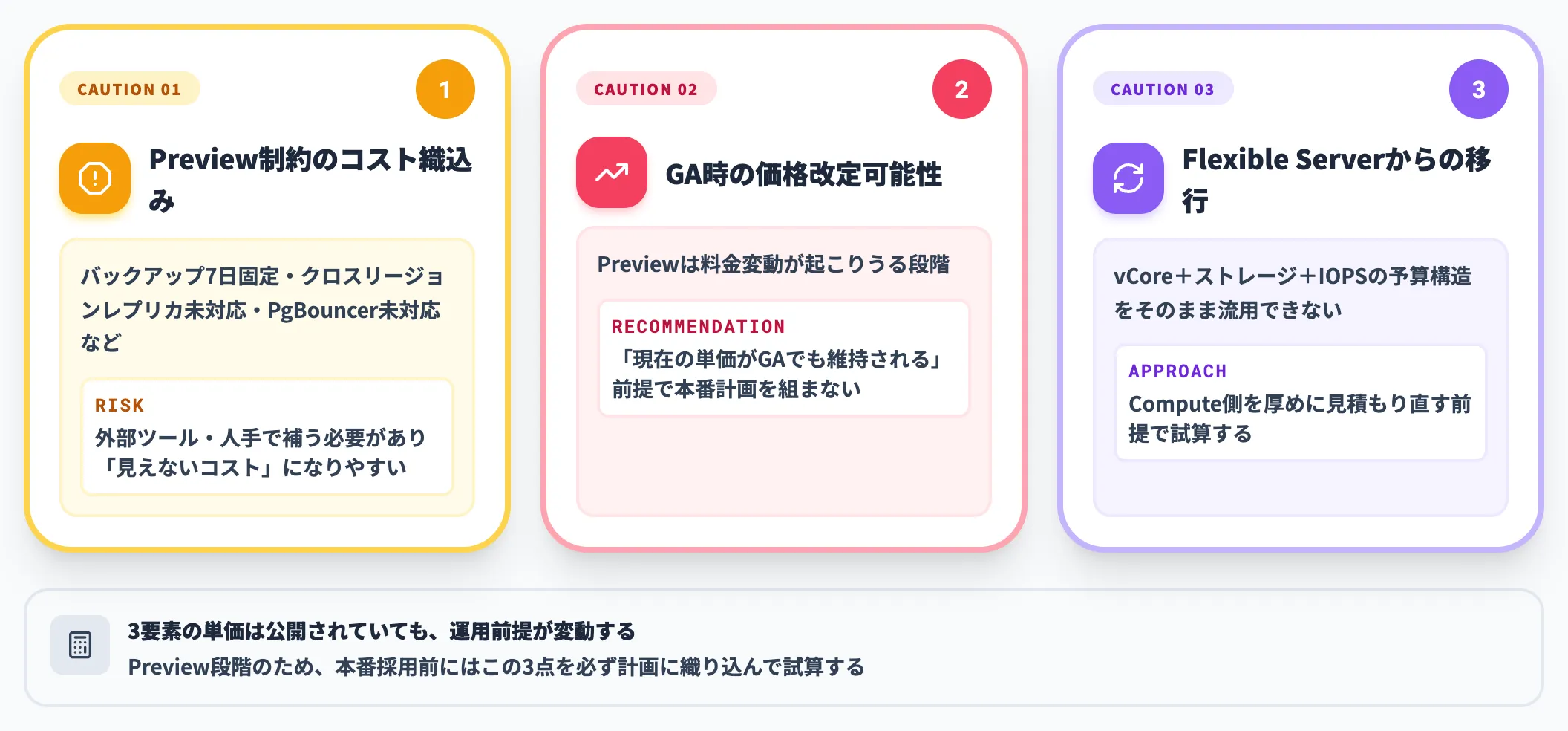
料金構造は公開されていても、Preview段階のため運用上の前提が変わるリスクは残ります。本番採用前に押さえるべき注意点は次のとおりです。
-
Preview制約をコスト計算に織り込む
バックアップ保持7日固定・クロスリージョンレプリカ未対応・PgBouncer未対応など、運用設計に影響する制約は別途人手や外部ツールで補う必要があり、見えないコストになりやすい
-
GAタイミングで価格改定が入る可能性
Previewは料金変動が起こりうる段階。本番計画は「現在の単価がGAでも維持される」前提で組まない
-
Flexible Serverからの移行は料金体系の置き換えが必要
vCore+ストレージ+IOPSの予算構造をそのまま流用できない。Compute側を厚めに見積もり直す前提で試算する
Azure HorizonDBを実務でどう構えるか——導入判断と備え方

Azure HorizonDBは確かに新しい選択肢ですが、Preview段階・日本リージョン未提供・複数のPreview制約(バックアップ7日固定/CMK未対応/PgBouncer未対応など)が残るという実務的な制約があります。すべての企業がいま検討すべきサービスではなく、ケース別に身の構え方が異なります。
以下の表で、企業の現状別の「いまの打ち手」と「Azure HorizonDB GA時の判断基準」をまとめました。
| 企業の現状 | いまの打ち手 | HorizonDB GA時の判断基準 |
|---|---|---|
| 既存Azure Database for PostgreSQL Flexible Serverを運用中 | Flexible Server継続。HorizonDB GAと日本リージョン展開を待つ | 日本リージョン提供/本番運用実績/Flexible Server料金差を見て移行検討 |
| 新規でAI機能付きPostgreSQLを構築したい | Flexible Server+pgvector+Microsoft FoundryでPoCを開始 | DiskANN高度フィルタの性能差と運用簡素化効果でHorizonDB移行を検討 |
| 海外リージョンでも本番運用可能 | 5対応リージョン(Central US/West US 2/West US 3/Sweden Central/Australia East)でクラスター作成してPreview検証 | Preview制約(バックアップ/CMK/PgBouncer等)の解消状況と性能評価で本番採用判断 |
| Aurora/AlloyDB導入を検討中 | Azure比重が高ければHorizonDB GAを待つ判断もあり | Aurora/AlloyDB対HorizonDBの実ワークロード性能比較 |
| データレジデンシー要件が厳しい日本企業 | HorizonDB待ち戦略はリスクが高い。Flexible Server+Foundryに集中 | 日本リージョン提供時に再評価 |
各ケースで重要なのは、「HorizonDBに移るかどうか」よりも、いま動かしている/これから動かす仕組みをHorizonDBにいつでも乗り換えられる形にしておくことです。
既存Azure Database for PostgreSQL利用企業の打ち手
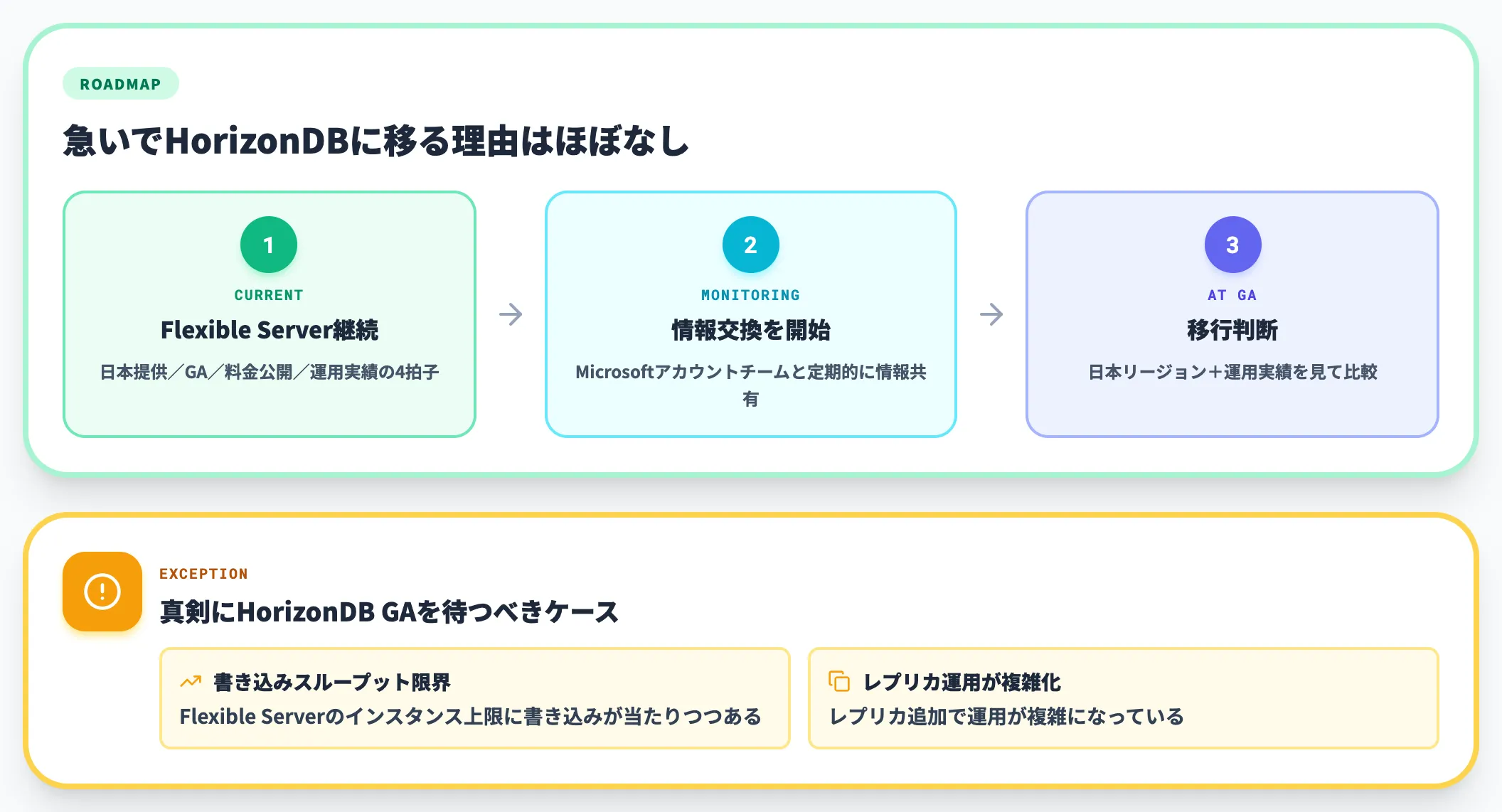
既にAzure Database for PostgreSQL Flexible Serverで本番運用している企業は、急いでHorizonDBに移る理由はほとんどありません。
Flexible Serverは日本リージョン提供・GA・料金公開・運用実績の4拍子が揃っており、HorizonDBが現時点で持っていない安心材料を全部持っています。HorizonDBが日本リージョンに来て、GAし、本番運用実績が出てから比較しても遅くないペースです。
ただし、Flexible Serverのインスタンス上限に書き込みスループットが当たりつつある/レプリカ追加で運用が複雑化しているケースは、HorizonDB GAを真剣に待つ意味があります。プレビュー期間中にMicrosoftのアカウントチームと情報交換を始め、GA時点で動ける状態を作っておくのが現実的です。
AI機能を必要とする新規アプリ開発企業の打ち手
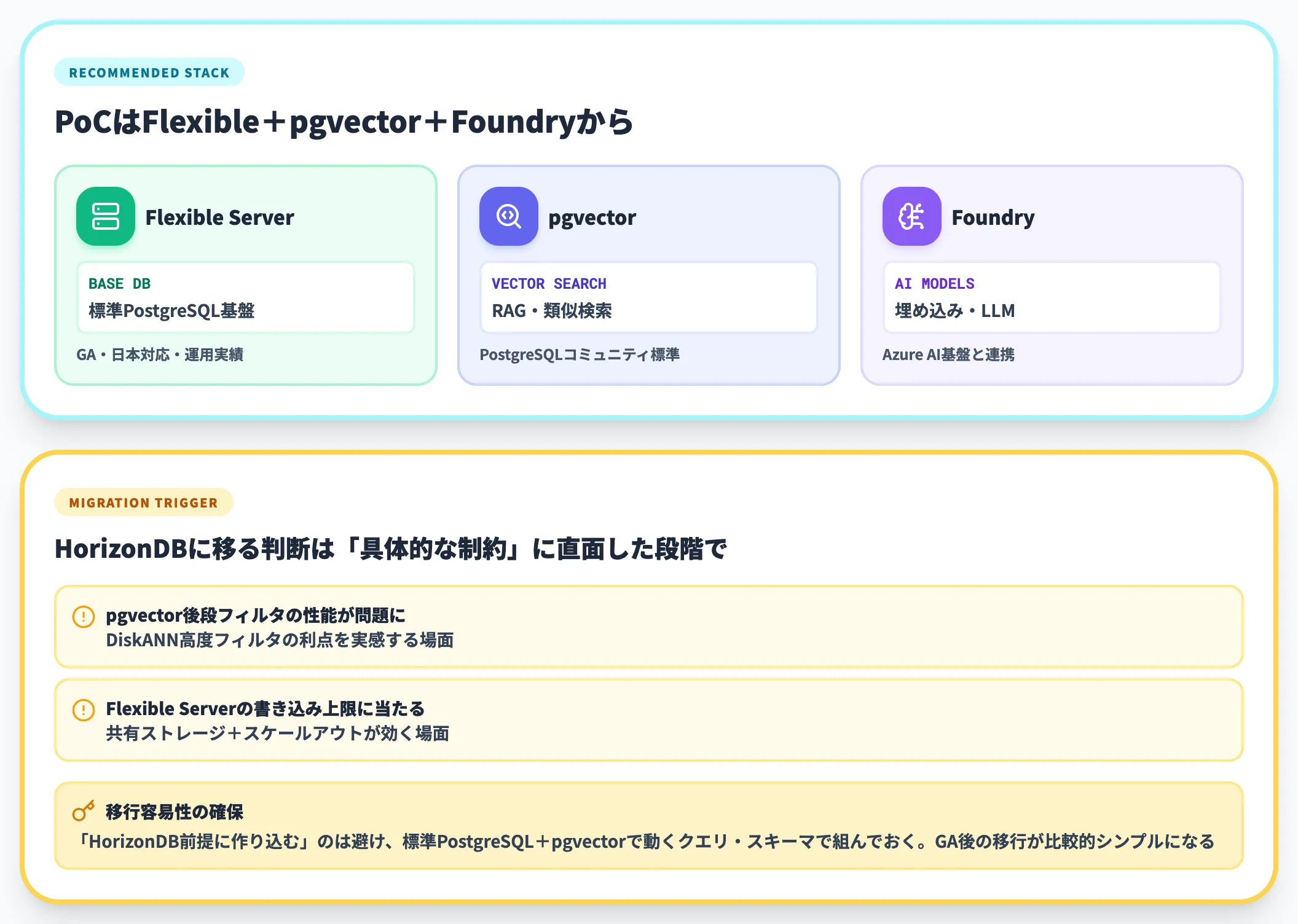
新規でAI機能(RAG・セマンティック検索・ベクトル検索)を組み込むアプリケーションを開発する企業は、まず現行のFlexible Server+pgvector+Microsoft Foundryの組み合わせでPoCを開始するのが安全です。
この組み合わせでもRAGやベクトル検索は十分実装できます。HorizonDBに移る判断は、PoCで「pgvector後段フィルタの性能が問題になる」「Flexible Serverの書き込み上限に当たる」といった具体的な制約に直面した段階で行えば十分です。
データモデルを「HorizonDB前提に作り込む」ことは避け、標準PostgreSQL+pgvectorで動くクエリ・スキーマで組んでおけば、HorizonDB GA後の移行は比較的シンプルになります。
Aurora/AlloyDB検討中の組織の打ち手
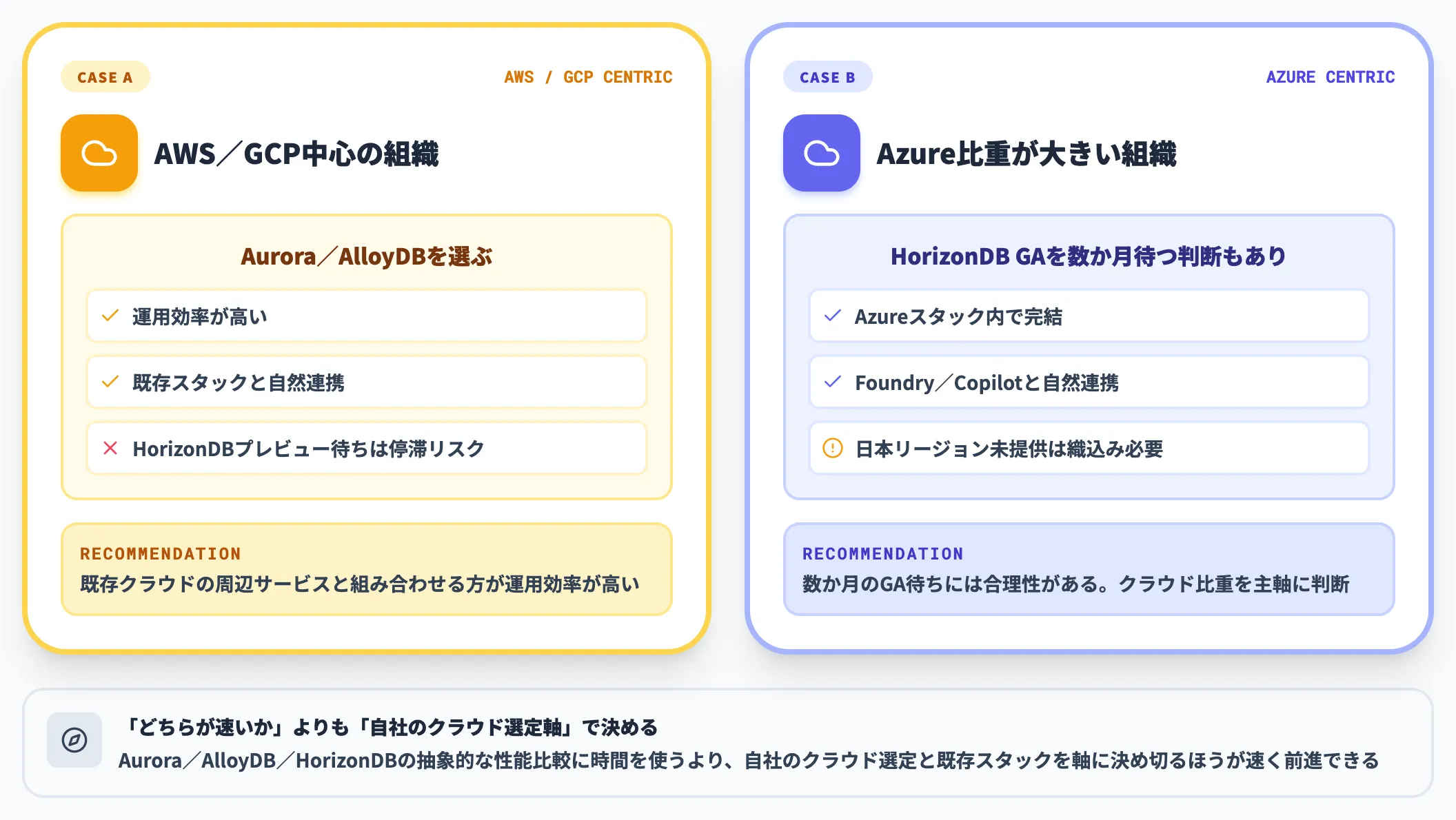
すでにAurora/AlloyDBの導入を比較検討中の組織は、自社のクラウド比重を主軸に判断するのが現実的です。
AWS/GCP中心の組織であれば、HorizonDBのプレビュー待ちで停滞するより、Aurora/AlloyDBを選ぶほうが運用効率が高めです。一方、Azure比重が大きい組織は、HorizonDB GAを数か月待つ判断にも合理性があります。
「Aurora/AlloyDBとHorizonDBのどちらが速いか」という抽象的な比較に時間を使うより、自社のクラウド選定と既存のスタックを軸に決め切るほうが速く前進できます。
Azure HorizonDB導入判断で詰まる論点
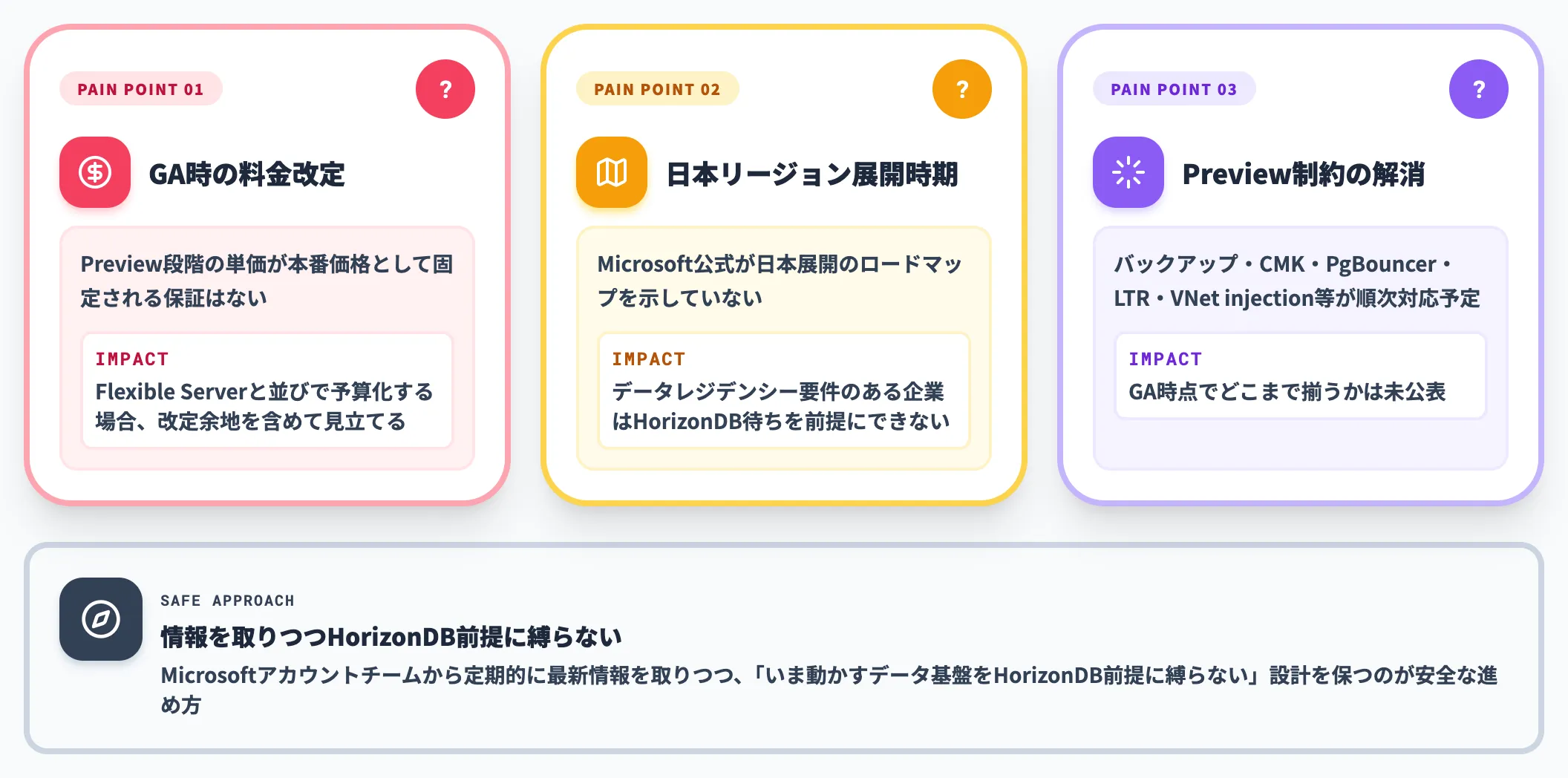
プレビュー段階のHorizonDBで多くの組織が判断に詰まりやすい論点は、次の3つです。
-
GA時に料金が改定される可能性
Preview段階の単価が本番価格として固定される保証はない。Flexible Serverと並びで予算化する場合は、改定余地を含めて見立てる
-
日本リージョン展開時期が読めない
Microsoft公式が日本展開のロードマップを示していない。データレジデンシー要件のある企業はHorizonDB待ちを前提にできない
-
Preview制約の解消タイミングが流動的
バックアップ保持・CMK・PgBouncer・LTR・VNet injectionなどが順次対応予定だが、GA時点でどこまで揃うかは未公表
これらは「いつ判断するか」を決めるための情報が揃っていない、という意味で詰まりやすい論点です。Microsoftのアカウントチームから定期的に最新情報を取りつつ、「いま動かすデータ基盤をHorizonDB前提に縛らない」設計を保つのが安全な進め方になります。
AI総研の支援現場でも、現時点ではHorizonDBの本番採用相談は少なく、Flexible Server+Microsoft FoundryでAI機能を回しつつ、HorizonDB GAに備える設計提案が中心です。

HorizonDBを待たずに、現行AIで業務を変える
Azure HorizonDBは、Aurora系クラウドネイティブDBに対するAzure側の対案として、確かに大きな意味を持つ発表です。一方で、Preview段階・日本リージョン未提供・複数のPreview制約(バックアップ7日固定/CMK未対応/PgBouncer未対応など)が残るという実務的な制約は、多くの日本企業にとって「すぐに動く理由」にはなりません。
データレジデンシー要件が厳しい業界の場合は特に、HorizonDBの日本リージョン展開を待つ前に、現行のAzure Database for PostgreSQL Flexible Server+Microsoft Foundryで社内のAI活用を進める方が、投資対効果も学習効果も高めです。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。HorizonDB GA時に動ける体制を作りつつ、いまできるAI活用を整理する第一歩として活用ください。
待たずに業務をAIで自動化する

PoCから全社展開までの設計を1冊で
Azure HorizonDBは2026年6月時点でPreview段階。日本リージョンは未提供で、GA時期も未告知です。一方で多くの企業はすでに、現行のAzure Database for PostgreSQLやMicrosoft Foundryを組み合わせて社内データ+AIの仕組みを動かし始めています。AI業務自動化ガイド(220ページ)では、PoCから全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しました。
まとめ
本記事では、Microsoftが2025年11月のIgnite 2025で発表した新世代マネージドPostgreSQL「Azure HorizonDB」について、アーキテクチャ・AI機能・既存サービスとの違い・Aurora/AlloyDBとの位置づけ・始め方・料金・実務での備え方まで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
Azure HorizonDBは共有ストレージ+Rust製エンジンの新世代クラウドネイティブPostgreSQLで、最大3,072 vCore・128TB・15レプリカ・サブミリ秒コミットを実現。Microsoft Ignite 2025で発表され、2026年6月時点ではPreview段階
-
DiskANN高度フィルタリング・pgvector・ハイブリッド検索・azure_ai拡張・Microsoft Foundry連携・GitHub Copilot+VS Code連携がデータベースに組み込まれている(いずれもPreview。AI Model ManagementはLimited Preview)。RAGやベクトル検索をHorizonDB内でほぼ完結できる設計
-
Flexible Server/Cosmos DB for PostgreSQL(Citus基盤)/HorizonDBは置き換え関係ではなく3つの並走サービス。広い用途はFlexible Server、水平シャーディングはCitus版、大規模OLTP+AIネイティブはHorizonDBという棲み分け
-
Aurora/AlloyDB/HorizonDBはほぼ同じ設計思想に揃った。「クラウド選定」と「マネージドPostgreSQL選定」がほぼ一致する状況で、自社のクラウド比重を主軸に判断するのが現実的
-
料金はProvisioned Compute+データストレージ+バックアップストレージの3要素で公開済み。一方で日本リージョン未提供・Preview制約(バックアップ7日固定/CMK・PgBouncer・LTR未対応など)が残るため、多くの日本企業の打ち手は現行Flexible Server+Microsoft FoundryでAI機能のPoCを進めつつ、HorizonDBのGAと日本展開を待つ二段構え
Azure HorizonDBの登場は、Azureを中心に据える企業にとって「データを別クラウドに動かさずに新世代マネージドPostgreSQLの選択肢を確保できる」意味を持つ動きです。いまできることはFlexible Server+Microsoft Foundryでデータ基盤+AIの組み合わせを業務に組み込み、HorizonDB GAに備える設計を保つこと。これがPreview段階で取り得る最も現実的なアクションになります。










