この記事のポイント
 1ペタフロップAI性能・128GB統合メモリで120Bパラメータ級ローカルLLMを動かすWindows PC向け新型SoC
1ペタフロップAI性能・128GB統合メモリで120Bパラメータ級ローカルLLMを動かすWindows PC向け新型SoC- 搭載デバイスはASUS・Dell・HP・Lenovo・Microsoft Surface・MSIから2026年秋に発売予定
- Snapdragon X EliteにはCUDA/TensorRT成熟度で優位、AMD Strix HaloにはAI演算で一部優位
- ロードマップはBlackwell→Vera Rubin Spark(2027〜28)→Rosa Feynman(2029〜30)の3世代計画
- 企業の現実解はローカル推論前提のAIエージェント基盤とArm互換性検証を2026年中に整えること

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
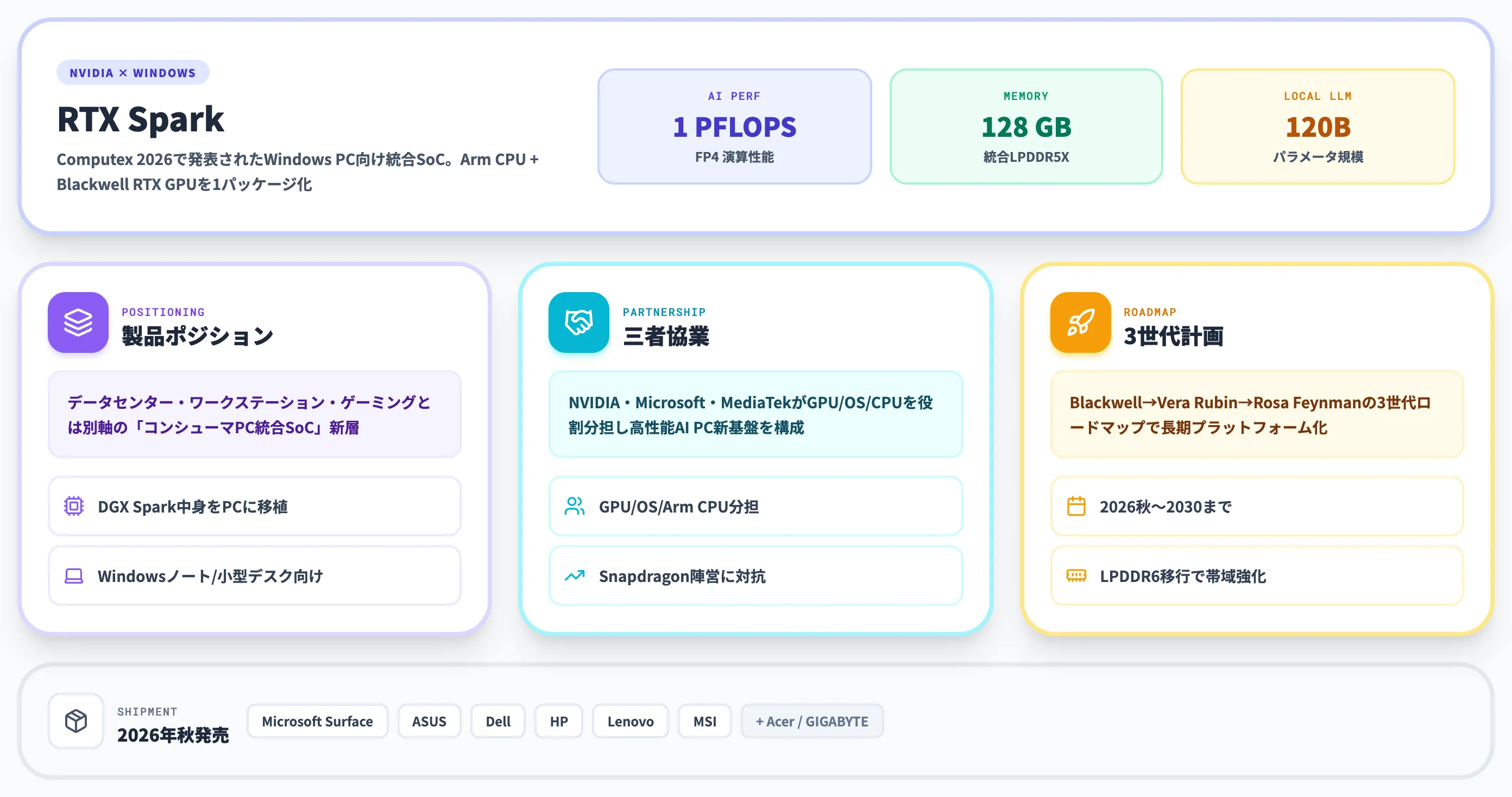
NVIDIA RTX Sparkは、NVIDIAが2026年5月31日のComputex 2026基調講演で発表した、Windows PC向けの新型「スーパーチップ」です。
20コアのArm CPUとBlackwell世代RTX GPU、最大128GBの統合メモリを1パッケージに収め、1ペタフロップのAI性能と1,200億パラメータ規模のローカルLLM実行能力を持ちます。
Microsoft Surface Laptop UltraやASUS ProArt P16、Dell XPS 16、HP OmniBook X 14、Lenovo Yoga Pro 9n、MSI Prestige N16 Flip AI+など、主要OEM6社の搭載デバイスが2026年秋から順次発売予定です。
本記事では、RTX Sparkの基本情報と発表の経緯、技術仕様、ローカルLLMとAI推論での実務的価値、ゲーミング・クリエイティブ用途での性能、搭載デバイスのラインアップ、Snapdragon X Elite・AMD Strix Halo・Apple M5系との比較、Windows on Arm互換性の現状、価格と入手方法・後継ロードマップ、そして企業がいま備えるべきことまでを、2026年6月時点の最新情報で体系的に解説します。
目次
RTX Sparkとは——NVIDIAが本格参入したWindows AI PC向けSoC
RTX Sparkの発表とComputex 2026での位置づけ
DGX Spark・GeForce RTXシリーズとの位置づけの違い
NVIDIA×Microsoft×MediaTekの三者協業の意味
CUDA・TensorRT・llama.cppがネイティブで動く意味
クリエイティブワークロード——12K動画編集・90GB超3Dレンダリング
RTX Spark搭載デバイスと2026年秋以降のラインアップ
RTX Spark vs 既存AI PCチップ——Snapdragon X Elite・AMD Strix Halo・Apple M5系との比較
Snapdragon X Elite/X2 Eliteとの比較
AMD Strix Halo(Ryzen AI Max)との比較
Apple M5 / M4 Max系MacBook Proとの比較
搭載デバイスの正式価格と参考になるDGX Sparkの位置づけ
Vera Rubin Spark・Rosa Feynmanのロードマップ
RTX Sparkとは——NVIDIAが本格参入したWindows AI PC向けSoC
RTX Sparkは、NVIDIAが2026年5月31日のComputex 2026基調講演で発表した、**Windows PC向けの新型SoC(システムオンチップ)**です。

NVIDIA RTX Sparkの公式発表ビジュアル(出典:NVIDIA Newsroom)
正式名称は「NVIDIA RTX Spark」で、ArmベースのCPUとBlackwell世代RTX GPUを1パッケージに統合し、1ペタフロップのAI性能と最大128GBの統合メモリを搭載しています。
RTX Sparkが他のNVIDIA製品と根本的に違うのは、データセンター用のGB200/GB300・ワークステーション用のDGX Spark・ゲーミング用のGeForce RTX 50シリーズと棲み分けていたNVIDIAが、AI PC時代のWindowsノート/コンパクトデスクトップに直接組み込むSoCを本格投入してきた点にあります。
過去にもWindows RT時代のTegra 3など、NVIDIAがWindowsデバイスにSoCを供給した事例はありますが、近年のArm系Windows PCはQualcomm Snapdragon Xシリーズが中心でした。RTX Sparkは、NVIDIA・Microsoft・MediaTekの三者協業で高性能AI PC向けWindows on Armへ本格再参入する新プラットフォームと位置づけられます。

RTX Sparkの発表とComputex 2026での位置づけ
RTX Sparkは、NVIDIA公式ニュースルームで2026年5月31日に正式発表されました。
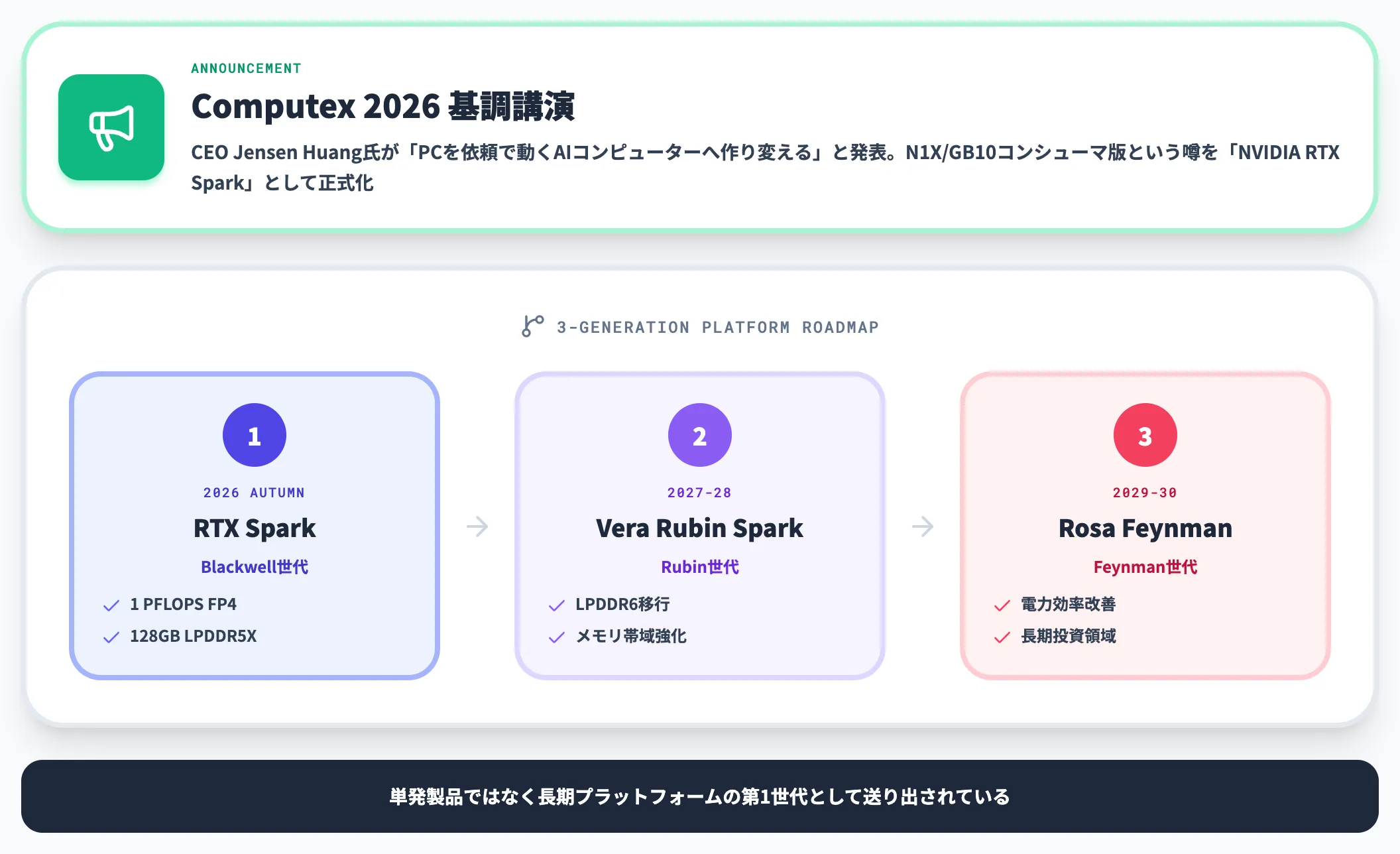
CEOのJensen Huang氏は、RTX SparkとMicrosoft Windowsの組み合わせによってPCが「ユーザーが依頼すれば作業を実行するAIコンピューター」へと作り変わるという趣旨を説明しており、Microsoft共同開発の新プラットフォームとして位置づけられています。
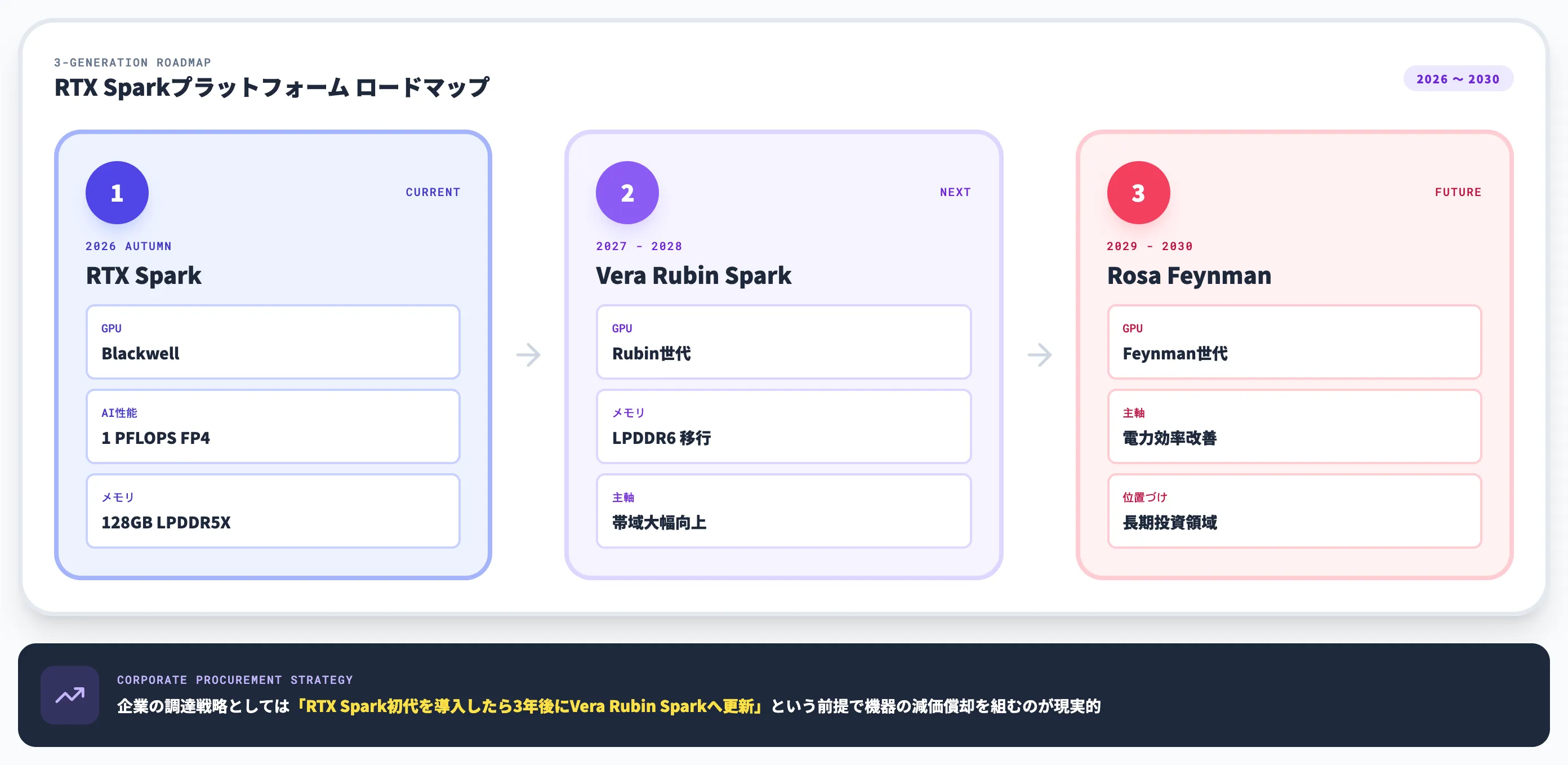
これまで噂段階では「N1X」「GB10コンシューマ版」と呼ばれていた製品ですが、正式名称は「NVIDIA RTX Spark」に決まりました。NVIDIAは同時に、RTX Sparkの後継世代として「Vera Rubin Spark(2027〜28年)」「Rosa Feynman(2029〜30年)」の3世代ロードマップも公開しており、単発の製品ではなく長期プラットフォームの第1世代として送り出されています。
DGX Spark・GeForce RTXシリーズとの位置づけの違い

NVIDIAの製品ラインアップは、これまで用途と提供形態で明確に棲み分けられてきました。
RTX Sparkはその構図に「コンシューマPC向けの統合SoC」という新しい層を追加します。以下の表で、RTX Sparkと既存NVIDIA製品の位置づけを整理しました。
| 製品 | 主用途 | 提供形態 |
|---|---|---|
| NVIDIA RTX Spark | コンシューマPC向け統合SoC(ノート・コンパクトデスクトップ) | OEM経由で2026年秋発売 |
| NVIDIA DGX Spark | 個人開発者向けAIスーパーコンピューター(GB10) | スタンドアロン製品として既に発売中 |
| GeForce RTX 50シリーズ | デスクトップ・ノート向けディスクリートGPU | 単体GPUとして販売 |
| RTX Pro 6000 Blackwell | ワークステーション向けプロフェッショナルGPU | 単体GPUとして販売 |
| NVIDIA DGX Station / GB300 | 高性能デスクトップAIワークステーション | スタンドアロン製品として展開予定 |
RTX Sparkは、機能的にはDGX Sparkで使われている「GB10スーパーチップ」と同等の構成をPCに組み込めるようにした派生版です。
PC Watchの報道でも「RTX Sparkの中身はGB10相当」と整理されており、DGX Sparkをスタンドアロン製品から「Windowsノート/コンパクトデスクトップに直接乗せるチップ」に作り直したのがRTX Sparkだと理解すると分かりやすい構図です。
【関連記事】
AI PC(AIパソコン)とは?できることや選び方、おすすめPCを徹底解説
NVIDIA×Microsoft×MediaTekの三者協業の意味

RTX SparkはNVIDIA単独の製品ではなく、Microsoft・MediaTekとの三者協業として開発されています。それぞれの役割は明確に分担されています。
-
NVIDIA
GPUコア・AI推論スタック(CUDA・TensorRT・cuDNN・TensorRT-LLM)を提供し、Blackwell世代RTX GPUとNVLink-C2Cでチップ全体を統合する。
-
Microsoft
Windows on Armの最適化、新しいNVIDIA OpenShellの統合、Windowsセキュリティプリミティブとの接続を担当。Surface Laptop UltraやSurface RTX Spark Dev Boxといった旗艦デバイスも自社で出す。
-
MediaTek
カスタムArm CPUコアを設計し、消費電力効率と接続性を担当。NVIDIA Grace CPUブランドで提供される20コアCPUの設計協力。
この三者構成は、近年Qualcomm Snapdragon系が中心だったArm系Windows PCの構図に、NVIDIA陣営の高性能AI PCという新しい選択肢を加える戦略的な動きでもあります。
Business Insider Japanの分析では、発表当日にMediaTekの株価が急騰したことが報じられており、台湾半導体エコシステムにとってもRTX Sparkは大きな転換点として受け止められています。
RTX Sparkのスペックと技術アーキテクチャ
ここからは、RTX Sparkが具体的にどのような技術仕様で構成されているかを、CPU・GPU・メモリ・AI性能の4軸で整理します。
NVIDIA公式ページの仕様表記とNVIDIA Japan Blog、Computex基調講演のスライドを突き合わせると、RTX Sparkは「DGX Spark(GB10)の主要構成を電力効率優先で再パッケージしたSoC」という性格が明確に見えてきます。
CPU・GPU・メモリの基本構成

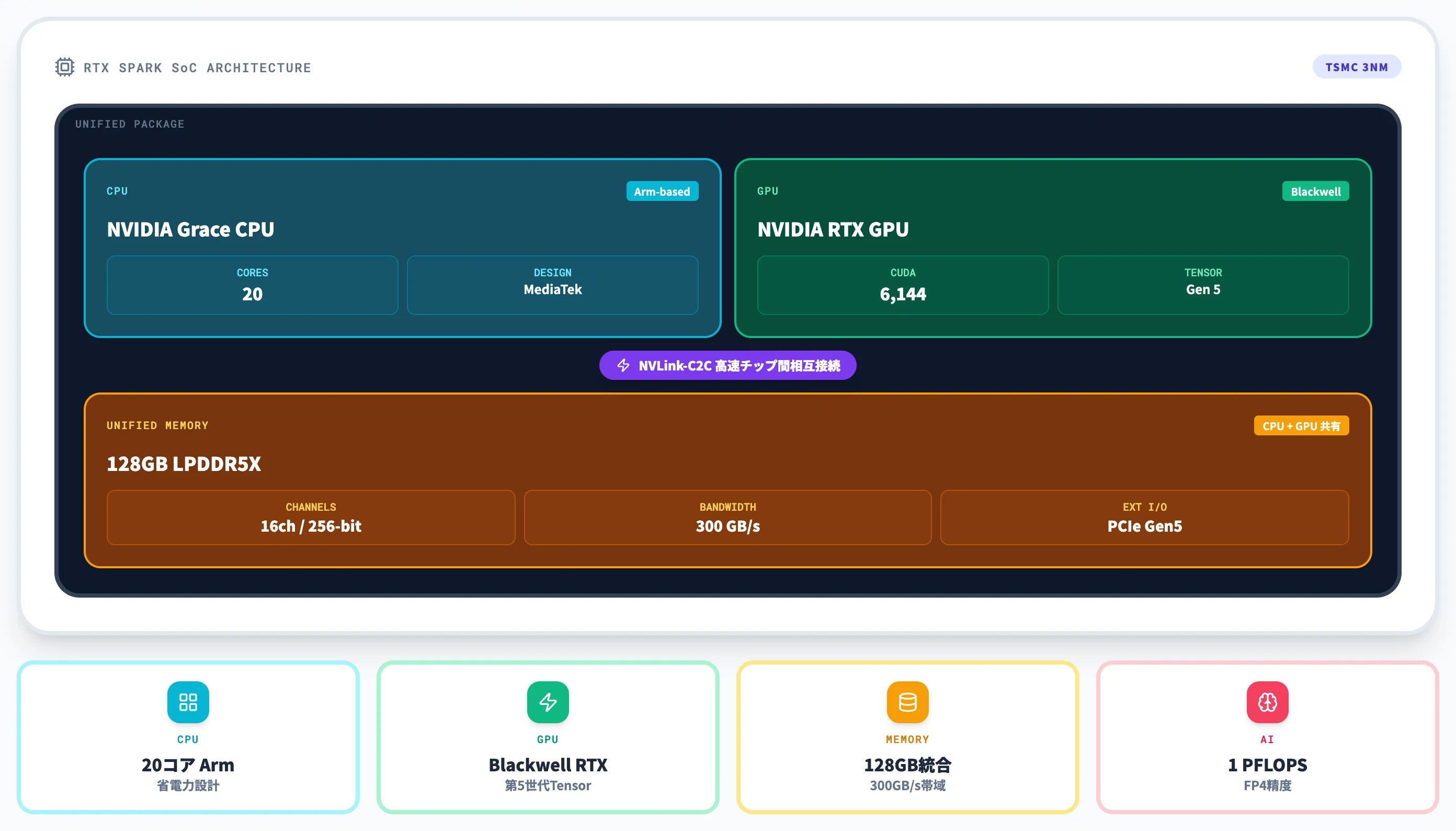
RTX Sparkの中核仕様は、Computex 2026のNVIDIA公式ニュースルームと製品ページで公表されています。
以下の表で、RTX Sparkの主要スペックを整理しました。
| 構成要素 | 仕様 |
|---|---|
| CPU | 最大20コア NVIDIA Grace CPU(MediaTek協業のArmベースカスタムコア) |
| GPU | NVIDIA Blackwell RTX GPU、最大6,144 CUDAコア、第5世代Tensor Core |
| 統合メモリ | 最大128GB LPDDR5X、16チャネル(256-bit) |
| メモリ帯域 | 最大300GB/s |
| AI性能 | 1ペタフロップ(FP4精度) |
| チップ間相互接続 | NVIDIA NVLink-C2C |
| 外部接続 | PCI Express Gen5+Gen4 |
| 製造プロセス | TSMC 3nm |
このスペックで注目すべきは、CPUとGPUが個別のチップではなく、NVLink-C2Cで直結された統合パッケージになっている点です。
ノートPCサイズのSoCで300GB/sのメモリ帯域を確保しているのは、画像生成やLLM推論のように「メモリと演算ユニットの往復」が律速になりやすいワークロードを想定した設計選択です。
1ペタフロップAI性能と第5世代Tensor Core
AI性能の「1ペタフロップ」という数字は、Blackwell世代の第5世代Tensor CoreがFP4(4-bit浮動小数点)精度で達成する理論性能です。
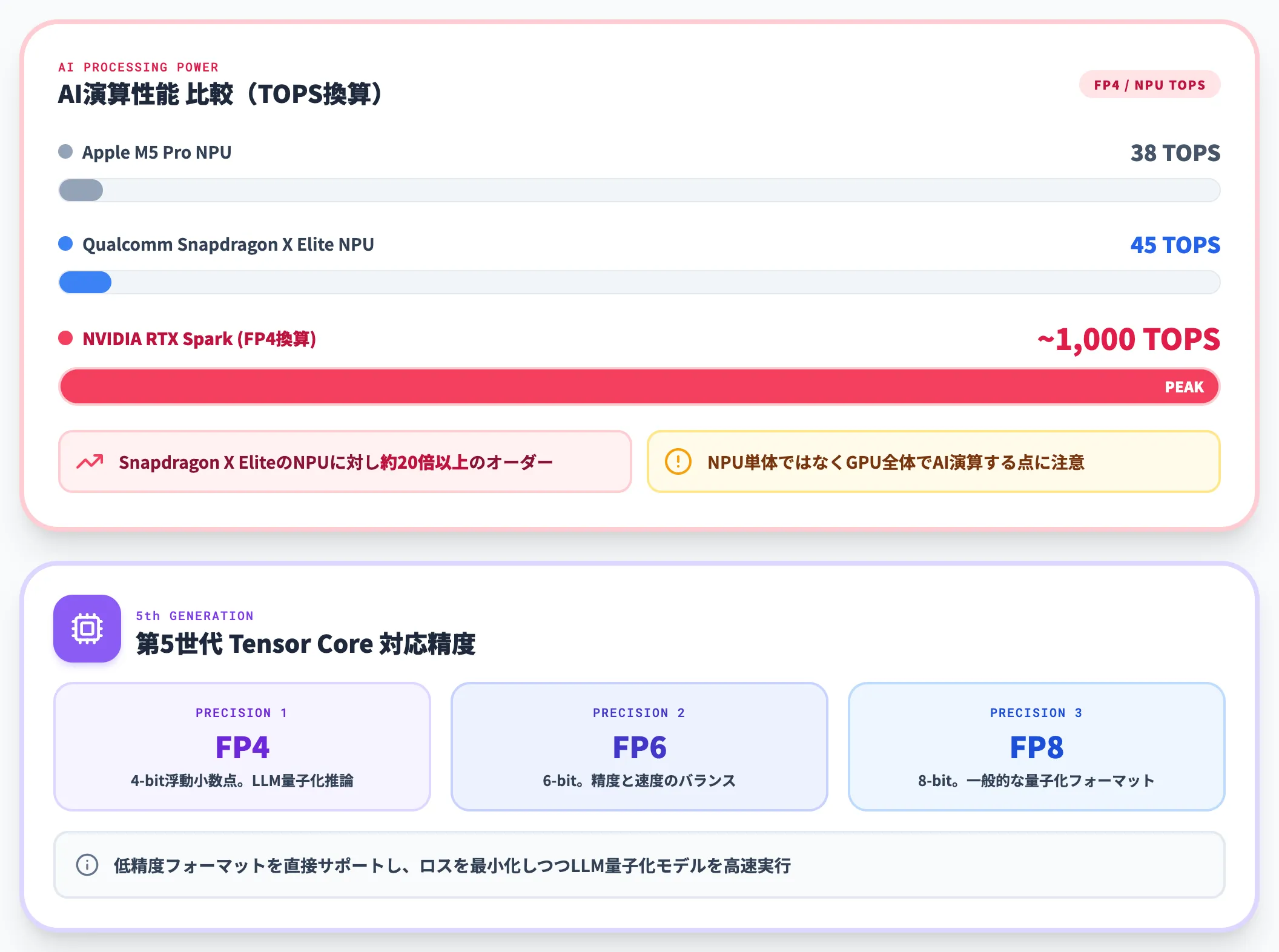
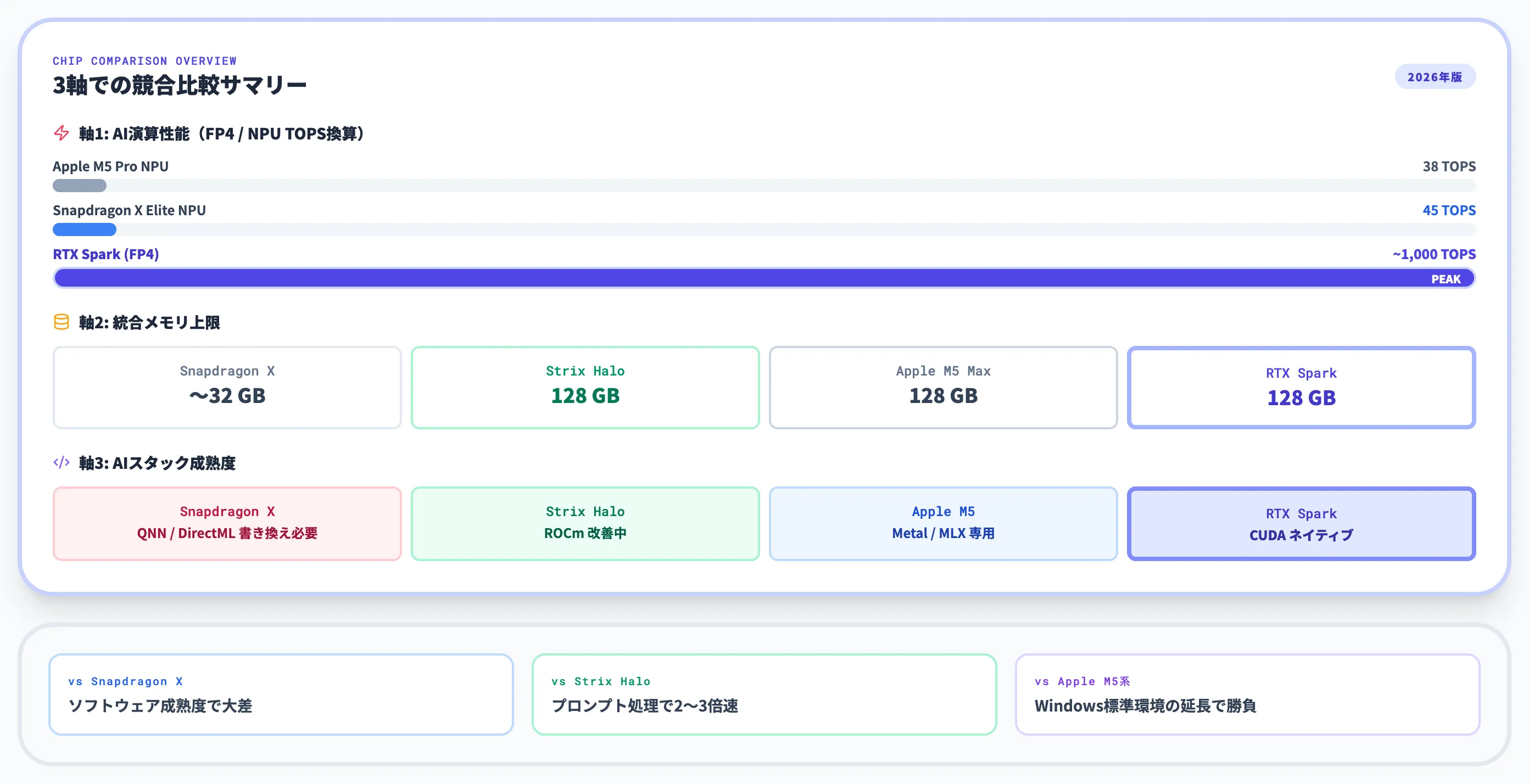
Tom's Hardwareの整理によれば、RTX SparkのAI演算性能は現行ハイエンドNPUと比較しても桁違いの水準にあります。
- Apple M5 Pro NPU: 約38 TOPS
- Qualcomm Snapdragon X Elite NPU: 約45 TOPS
- NVIDIA RTX Spark(FP4換算): 約1,000 TOPS相当
NPU単体ではなくGPU全体でAI演算を行うアーキテクチャのため、単純比較には注意が必要ですが、Snapdragon X EliteのNPUに対して約20倍以上のオーダーで、AI推論性能だけを切り出すと別次元の数字が並びます。
第5世代Tensor CoreはFP4・FP6・FP8といった低精度フォーマットを直接サポートしており、LLM推論で頻用される量子化モデルをロスを最小化しつつ高速実行できます。
NVLink-C2Cと128GB統合メモリの実務的価値

RTX Sparkで最大128GBになる「統合メモリ」は、CPUとGPUが同じLPDDR5Xメモリを共有する設計です。
これがGeForce RTX 50シリーズのようなディスクリートGPUと決定的に違う点で、VRAMの容量制約からLLM推論が解放されることを意味します。
NVIDIA Levels Up Local AI Agentsブログでも、RTX Sparkは「最大1,200億パラメータのLLMを最大100万トークンのコンテキストで実行可能」と説明されており、128GBユニファイドメモリが4-bit量子化下で105B〜120Bクラスのモデルを快適に格納できる設計です。
GeForce RTX 5090は32GBのVRAMが上限で、70B以上のモデルを単機で動かすには複数枚構成かCPUオフロードが必要でした。RTX Sparkはここを単機・単チップで解決します。
NVLink-C2Cはこの統合メモリ構成を支えるチップ間相互接続技術で、データセンター向けGB200で実証された技術をPC SoCに移植したものです。CPU側のレイテンシ低減とGPU側の帯域確保を両立する点で、従来のPCIe Gen5接続より構造的に有利になります。
RTX Sparkでローカル推論はどう変わるか
ここからは、RTX Sparkが「AIエージェントをローカルで動かす」という用途においてどんな実務的価値を生むかを、3つの観点で整理します。
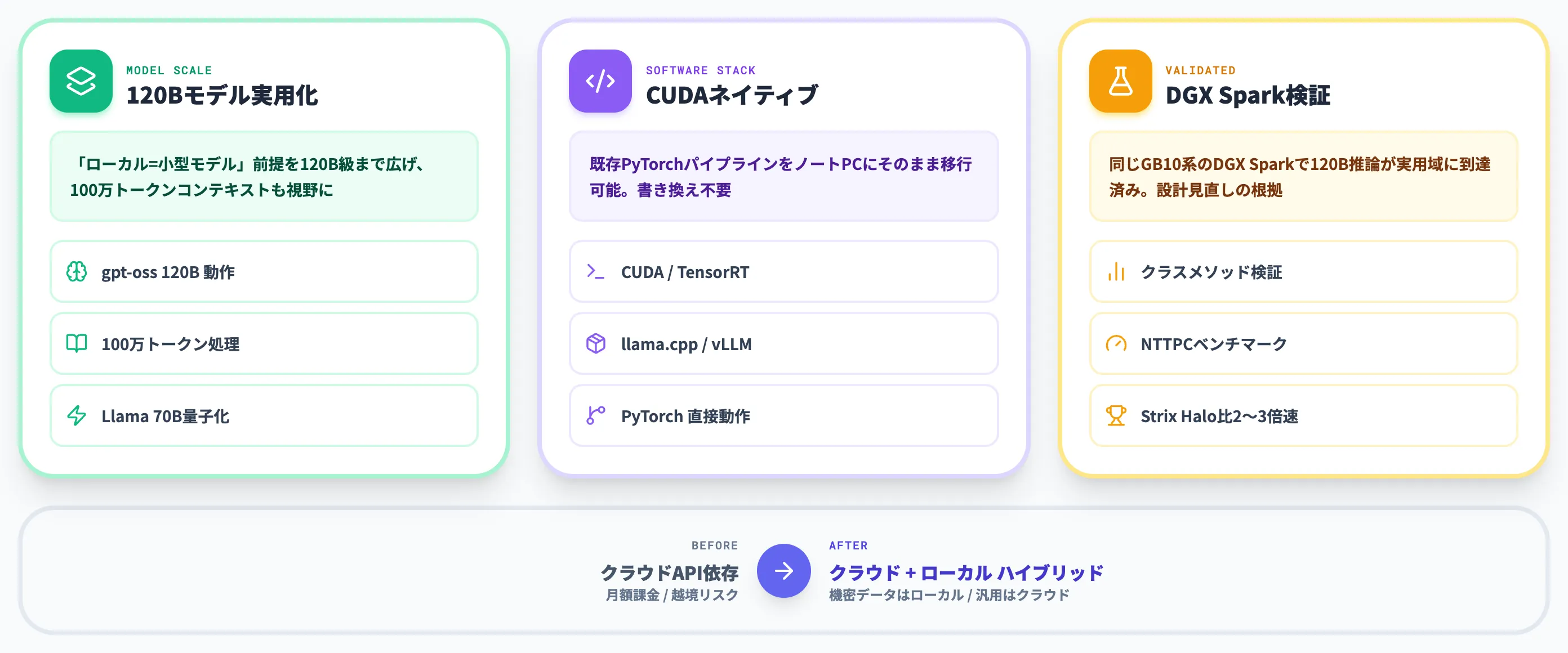
クラウドAPIに依存していたAIエージェント運用が、RTX Spark世代でローカル推論にどこまで寄せられるかが、企業の検討論点になりつつあります。
120Bパラメータ・100万トークンコンテキストの実用性
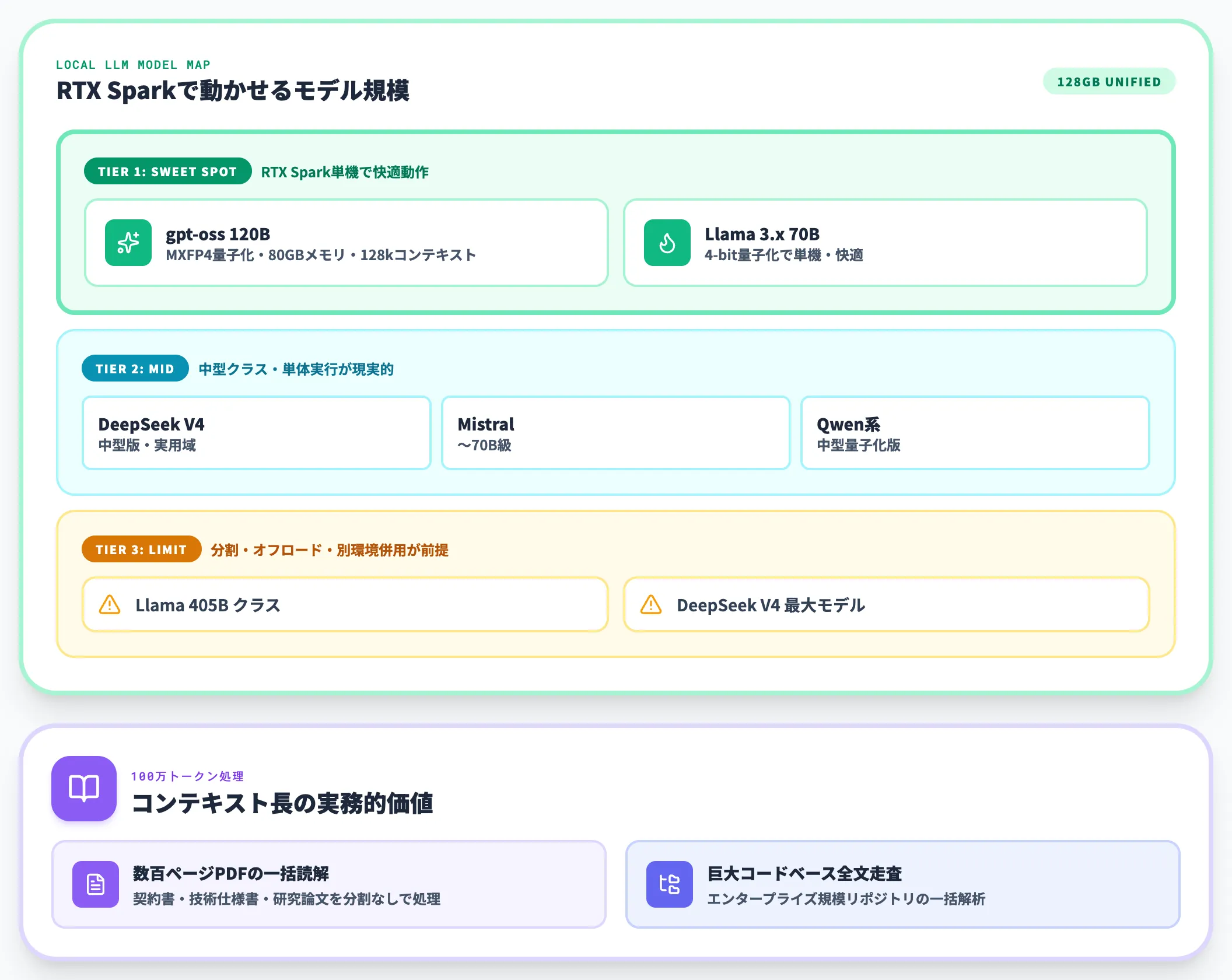
NVIDIAの公式説明では、RTX Sparkは「1,200億パラメータのLLMを最大100万トークンのコンテキストで実行可能」とされています。
これが何を意味するかというと、現時点で多くの開発者が手元で動かしたい中〜大型モデルの主要層が視野に入る水準です。
- gpt-oss 120B(OpenAI公開オープンモデル): 120B級モデルの代表的な候補。OpenAI公式ではMXFP4量子化・80GBメモリ内動作・128kコンテキスト対応と説明されており、RTX Sparkの128GB統合メモリで動作させやすい構成
- Llama 3.x 70B(4-bit量子化): 単機で快適に動作する想定範囲
- DeepSeek V4・Mistral・Qwen系の中型モデル: 中型クラス(〜70B級)は単体実行が現実的
- コンテキスト100万トークン: 数百ページのPDF読解、巨大コードベースの全文走査が射程に入る
NVIDIA公式がうたう上限は「120B級+100万トークン」までで、Llama 405BクラスやDeepSeek V4の最大モデルなど100B級を大きく超えるモデルは、量子化を強めても単体実行ではなく分割・オフロード・別環境(DGX Stationなど)併用が前提になります。
これまで「ローカル動作」と聞いて多くの開発者が思い浮かべるのは7B〜30Bクラスの中型モデルでした。RTX Sparkはここを一段押し上げて、「ローカル=小型モデル」という前提を120B級まで広げる製品と理解するのが正確です。
【関連記事】
ローカルLLMとは?メリットやおすすめモデル、導入方法を解説
CUDA・TensorRT・llama.cppがネイティブで動く意味
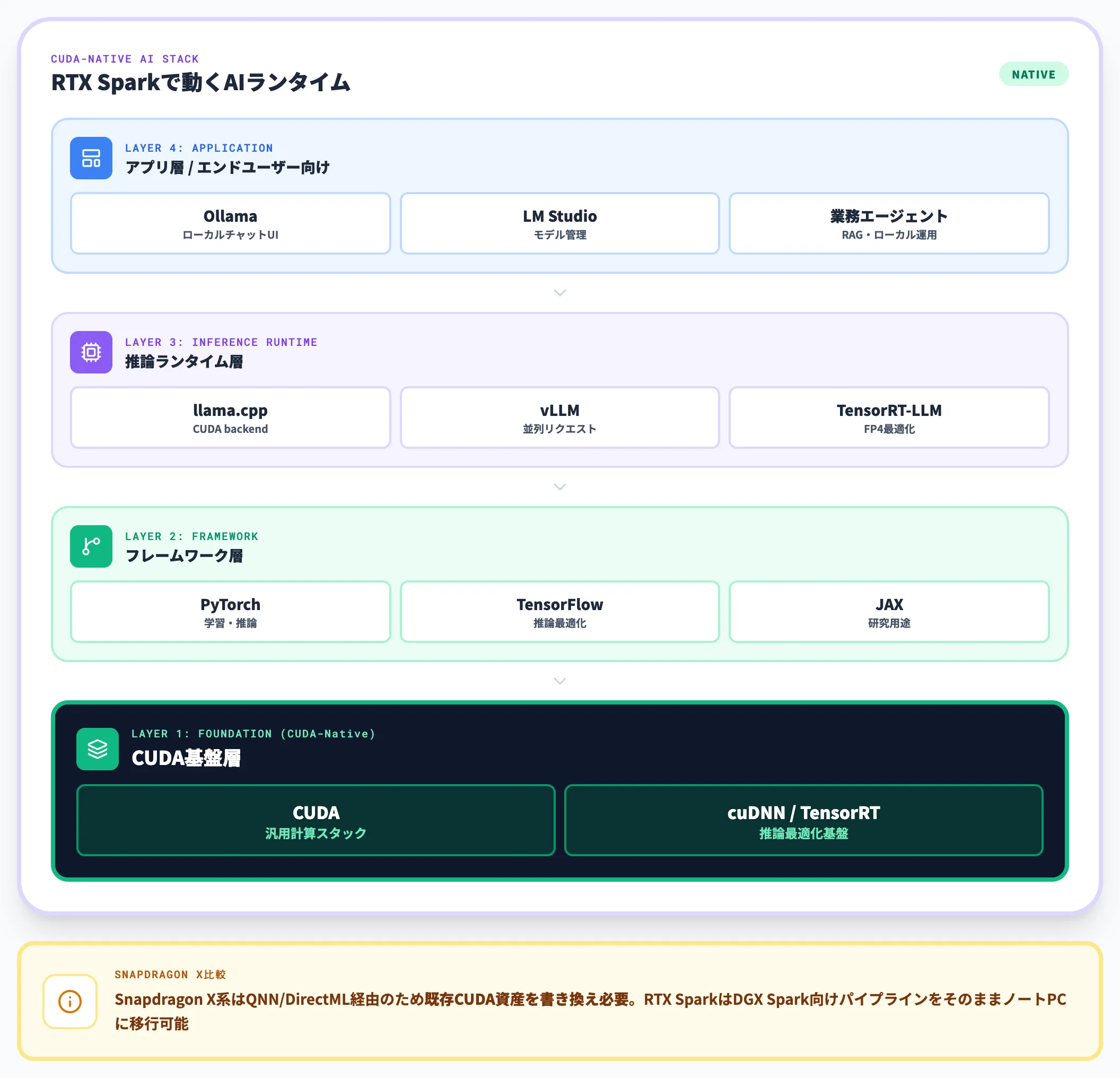
RTX Sparkがソフトウェア面でSnapdragon X Eliteと決定的に違うのは、NVIDIA公式ページで「CUDAがネイティブで動く」と明示している点です。
具体的には以下のスタックがそのまま動作します。
-
CUDA
NVIDIA GPUの汎用計算スタック。PyTorch・TensorFlow・JAXなどフレームワークが依存する基盤。
-
TensorRT / TensorRT-LLM
NVIDIA公式の推論最適化ランタイム。FP4・INT4量子化と組み合わせて推論速度を引き上げる。
-
llama.cpp(CUDAバックエンド)
ローカルLLM運用の事実上の標準OSSランタイム。CUDA経路がそのまま使える。
-
vLLM・Ollama・LM Studio(NVIDIA最適化プラグイン経由)
量子化済みモデルの動作・並列リクエスト処理・ローカルチャットUIなどを担当。
llama.cpp創設者のGeorgi Gerganov氏はNVIDIA公式コメントで「RTX Sparkのコンテキスト処理能力がプライベートエージェントの普及を促進する」と述べており、OSSコミュニティ側でも対応はすでに進行中です。
Snapdragon X Eliteを採用したPCでLLMを動かす場合、QNNやDirectML経由のため既存CUDA資産を一から書き換える必要がありました。RTX Sparkは「いま動いているDGX Spark向けPyTorchパイプラインを、そのままノートPCに移せる」点で、開発者にとって移行コストの低さが際立ちます。
DGX Sparkの先行検証が示すローカル推論の現実性
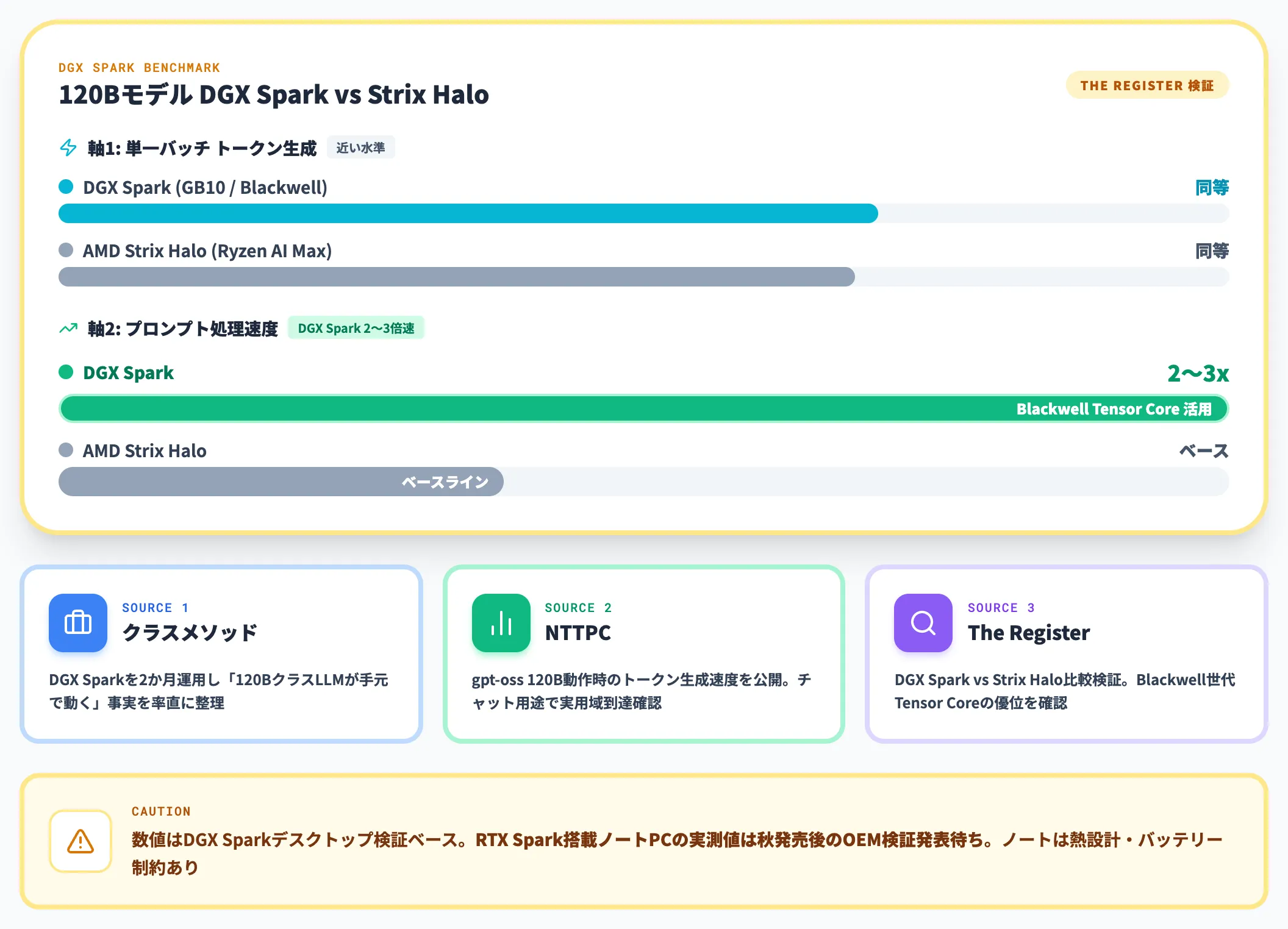
RTX Sparkはまだ秋発売のため実機ベンチマークは限定的ですが、同じGB10を採用したDGX Sparkでは既に多くの先行検証が行われています。
DevelopersIO(クラスメソッド)の検証記事では、DGX Sparkを2か月運用した上で「向いている仕事」「向いていない仕事」を率直に整理しており、120BクラスのLLMが「個人開発者の手元で動く」という事実そのものが大きな変化だと評しています。
NTTPCのLLM推論ベンチマークでは、DGX Sparkでgpt-oss 120Bを動かした際のトークン生成速度が公開されており、チャットアプリ用途であれば実用域に到達していることが確認できます。
The Registerの比較検証では、120Bモデルの単一バッチ生成ではDGX SparkとStrix Haloで近い水準、プロンプト処理ではDGX SparkがBlackwell世代Tensor Coreを活かしてStrix Haloに対し2〜3倍速い、という傾向が報告されています。
これらはあくまでDGX Sparkでのデスクトップ検証で、RTX Spark搭載ノートPCの実測値はまだ公開されていません。ノートPCでは熱設計とバッテリー駆動の制約が入るため、定常運用での性能はOEM各社の検証発表を待つ必要があります。とはいえ、「同じGB10系を採用するDGX Sparkで120Bクラスの推論が実用域に達している」という傾向が見えている点は、AIエージェントの設計を見直す根拠として十分です。
RTX Sparkのゲーミング・クリエイティブ性能
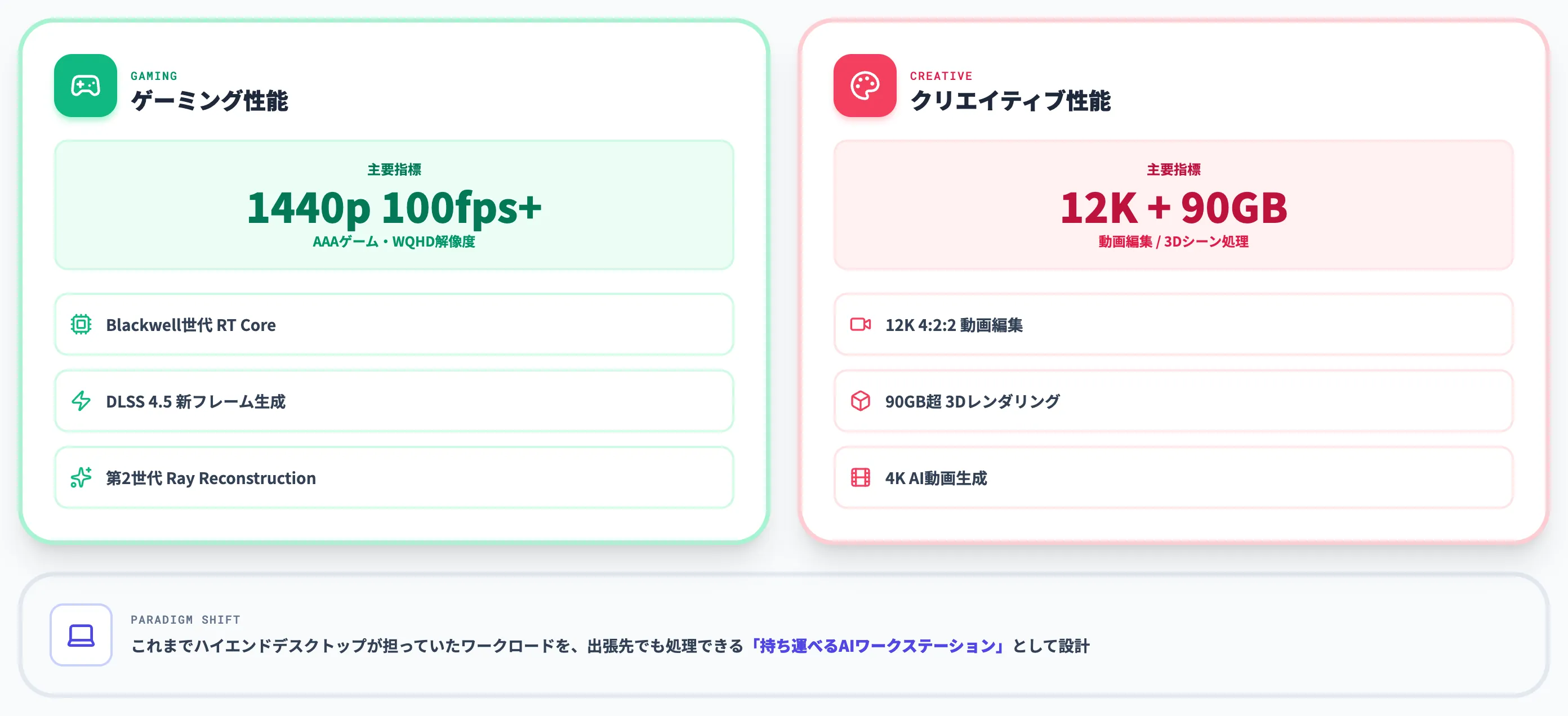
ここまでAI推論を中心に整理してきましたが、RTX Sparkはゲーミングとクリエイティブワークロードを同時に押し出している製品でもあります。
NVIDIAが「ゲーミングノートが薄くなる」とアピールしているとおり、GeForce RTX 50系のノート向けディスクリートGPUを搭載しなくても1440p高フレームレートを狙える点が大きな特徴です。
1440p 100fps超のレイトレーシング性能

GAME Watchの報道では、RTX SparkがAAAゲームを1440p解像度・100fps超で動作させると紹介されています。
NVIDIAはレイトレーシングとDLSSを組み合わせ、WQHDで100fpsを実現する水準だと説明しており、ノートPC級SoCとしてはSnapdragon X Elite搭載機を超える描画性能を狙う設計です。
性能の支えになっているのは、以下の3要素です。
-
Blackwell世代RTX GPUのレイトレーシングコア改良
パスレイ・パストレーシングなどリアルタイムレイトレーシングをノートPC級で実用化。
-
DLSS 4.5の新フレーム生成
NVIDIA GeForce Newsで発表された最新DLSSバージョン。AIアップスケールでネイティブ描画負荷を下げつつ画質を維持する。
-
第2世代Ray Reconstruction
レイトレーシングノイズの除去をAIで強化。8月から既存RTXシリーズにも展開予定。
ゲーミングノートを「薄く・軽く・バッテリー駆動でも遊べる」状態に近づける、というのがNVIDIAの主張です。
クリエイティブワークロード——12K動画編集・90GB超3Dレンダリング
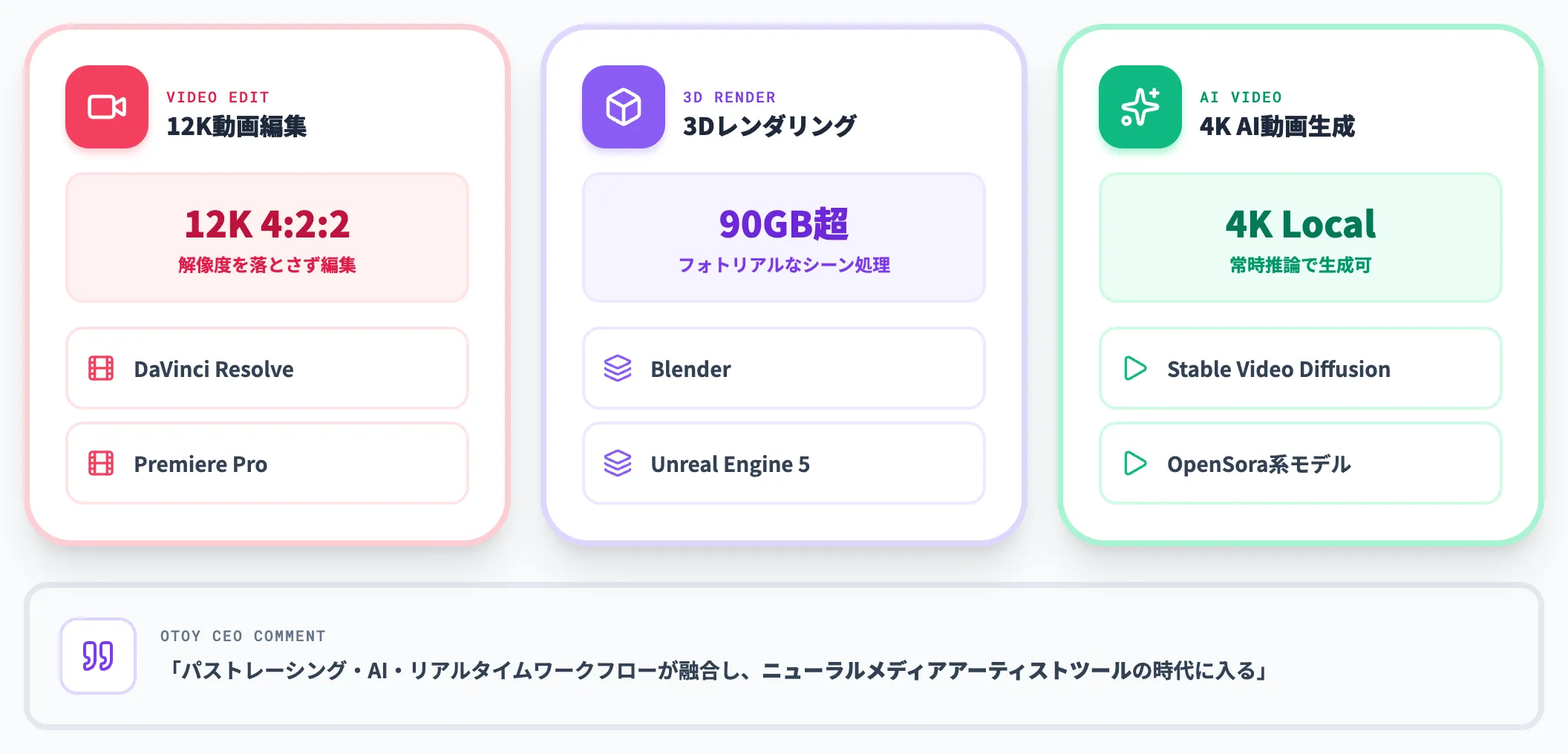
クリエイター用途では、ノート級ハードウェアで扱えなかった超大型ワークロードが視野に入ります。
NVIDIA公式が掲げる主な対応領域は次のとおりです。
-
12K 4:2:2動画編集
DaVinci Resolve・Premiere Proの素材を解像度を落とさず編集できる
-
90GB超の3Dシーンレンダリング
Blender・Unreal Engine 5・Octaneなどでフォトリアルなシーンをノート上で扱える
-
4K AI動画生成
ローカル動作するStable Video Diffusion・OpenSora系モデルの常時推論
OTOY CEOのJules Urbach氏はNVIDIA公式コメントで「パストレーシング・AI・リアルタイムワークフローが融合し、ニューラルメディアアーティストツールの時代に入る」と述べています。
RTX Spark搭載機は、これまでハイエンドデスクトップワークステーションが担っていたワークロードを、出張先でも処理できる「持ち運べるAIワークステーション」として設計されている、と理解するのが正確です。

RTX Spark搭載デバイスと2026年秋以降のラインアップ

RTX Spark搭載デバイスは、2026年秋にOEM6社(ASUS・Dell・HP・Lenovo・Microsoft Surface・MSI)から発売予定で、Acer・GIGABYTEが後続で参入を予定しています。各社の具体的なモデル数・販売規模はOEMから個別に発表される段階で、現時点でNVIDIA公式は具体台数を公表していません。
各社の旗艦モデルが出揃った時点で、RTX Sparkは「Windows AI PCの主力ラインアップ」として量産フェーズに入る見通しです。
確定済みの主要搭載モデル(OEM6社)
NVIDIA公式の製品ページで公開されている、ローンチ時点での確定済みモデルは以下のとおりです。
| OEM | モデル名 | 想定ターゲット |
|---|---|---|
| Microsoft | Surface Laptop Ultra | 15インチ mini-LEDタッチ、ハプティクスタッチパッド、エンタープライズ・クリエイター用途 |
| ASUS | ProArt P16 | クリエイター向けハイエンドノート |
| Dell | XPS 16 | プレミアム薄型ノート、ビジネス・パワーユーザー |
| HP | OmniBook X 14 | 法人・モバイル用途 |
| Lenovo | Yoga Pro 9n | クリエイター・プロシューマー |
| MSI | Prestige N16 Flip AI+ | 2-in-1コンバーチブル |
注目はMicrosoft Surface Laptop Ultraで、15インチmini-LED PixelSense Ultraタッチスクリーンと、Surface史上最大のhapticタッチパッドを搭載した、Microsoft自社の旗艦Arm機です。
Microsoft Surface RTX Spark Dev BoxもRTX Sparkベースで、開発者がローカルでLLMを動かすための開発機として打ち出されています。
続報予定のOEM(Acer・GIGABYTE)
NVIDIA公式の発表では、初期OEM6社に続いてAcerとGIGABYTEも参入を予定していると明示されています。
8社体制になると、Windows AI PC市場の主要OEMをほぼ網羅する構成になります。
Tom's Guideのリスト記事では、初期投入段階のRTX Spark搭載ノート8機種が整理されています。OEM6社の主要モデルが秋に出揃う見込みで、市場投入の規模感はQualcomm Snapdragon Xのローンチ時に近い構成です。
法人導入候補としての位置づけ

RTX Spark搭載デバイスの2026年出荷規模は、第三者調査会社の予測値が断片的に報じられているものの、現時点で一次資料として確認できる公式数値はありません。NVIDIA・各OEMからの具体的な出荷予測は出荷開始後に判明する見通しです。
ただし、Microsoft Surface Laptop Ultra・Dell XPS 16・HP OmniBook X 14といった法人導入候補になり得るラインアップが初期から揃っている点は重要です。クリエイター・開発者・エンジニア向けの高性能機として打ち出されつつ、法人IT部門の検討にも乗せやすい構成で、これがQualcomm Snapdragon X系のローンチ時とは違う構図を作っています。
法人の購買担当としては、2026年秋〜2027年春の発売サイクルで「次の標準機選定」にRTX Spark搭載モデルを含めるかどうかが、現実の意思決定論点になります。
RTX Spark vs 既存AI PCチップ——Snapdragon X Elite・AMD Strix Halo・Apple M5系との比較
RTX Sparkの位置づけを理解するには、競合チップとの比較が欠かせません。
ここではWindows on Armの先発であるQualcomm Snapdragon X Elite、x86陣営のAMD Strix Halo、macOS陣営のApple M5系それぞれと比較します。
Snapdragon X Elite/X2 Eliteとの比較
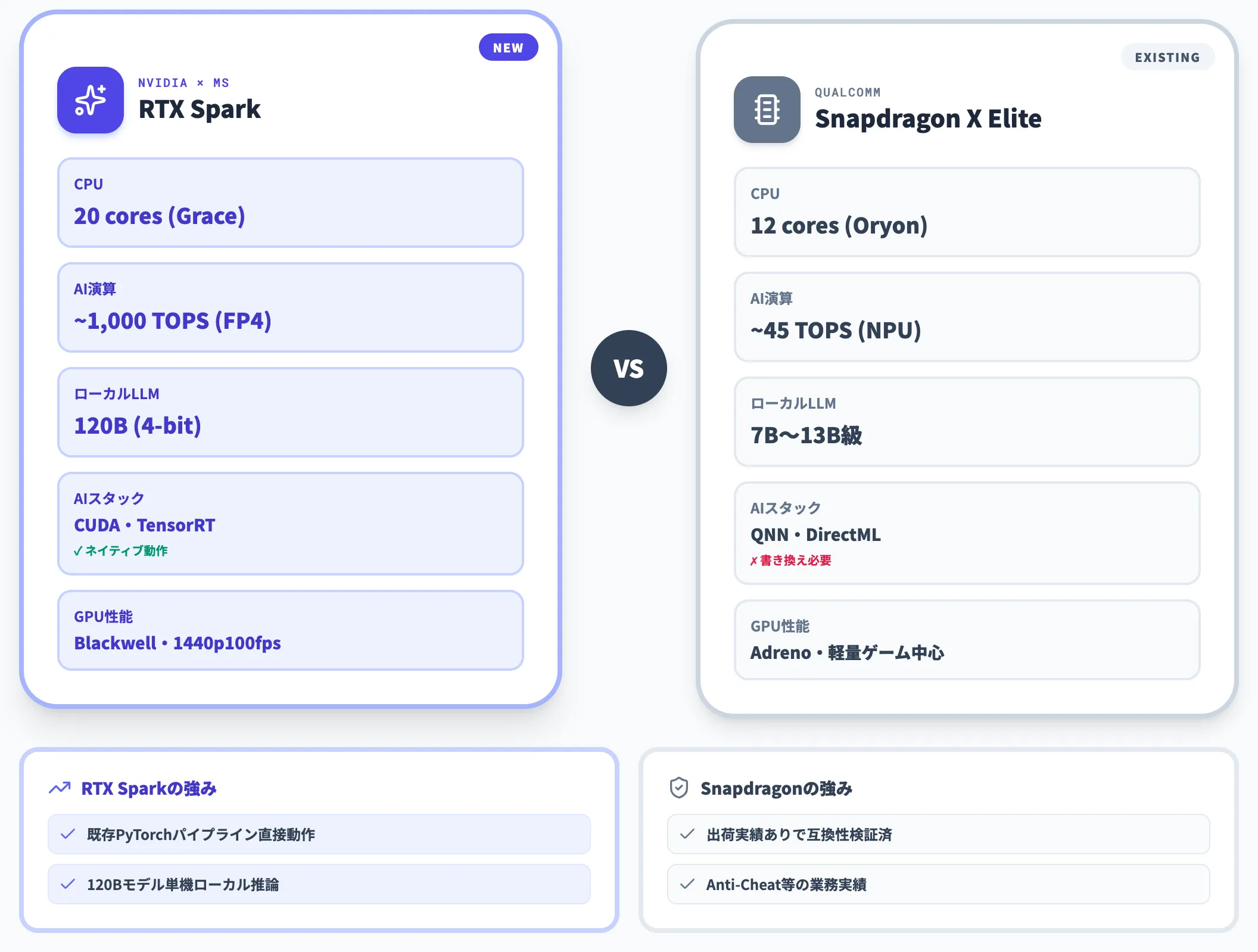
Qualcomm Snapdragon X EliteはWindows on Armの先発プラットフォームで、2024年から市場に出回っています。
両者の差は性能と互換性の両面で明確です。
| 項目 | RTX Spark | Snapdragon X Elite |
|---|---|---|
| CPUコア数 | 最大20コア(NVIDIA Grace) | 12コア(Oryon) |
| CPUシングルコア性能 | 先行ベンチ段階で未確定(Snapdragon X Elite比で上回る可能性が報じられている) | ベースライン |
| AI演算性能 | 約1ペタフロップ(FP4) | 約45 TOPS(NPU) |
| ローカルLLM最大規模 | 120B(4-bit量子化) | 7B〜13B程度が実用範囲 |
| AIスタック | CUDA・TensorRT・llama.cpp(ネイティブ) | QNN・DirectML(移植・書き換え必要) |
| GPU性能 | Blackwell RTX、ゲーム1440p100fps級 | Adreno、軽量ゲーム中心 |
性能差で特に大きいのが、AIスタックの成熟度とローカルLLMの上限です。
Windows Newsが指摘するとおり、Snapdragon X系列で「すでに動いているCUDA資産」を動かすには大幅な書き換えが必要ですが、RTX Sparkは既存PyTorchパイプラインをほぼそのまま動かせます。
ただしSnapdragon Xは現時点で出荷実績があり、Anti-Cheatや業務アプリの動作実績が積み上がっている点はアドバンテージです。RTX Sparkは秋発売のため、互換性の実績は半年以上遅れて積み上がります。
AMD Strix Halo(Ryzen AI Max)との比較
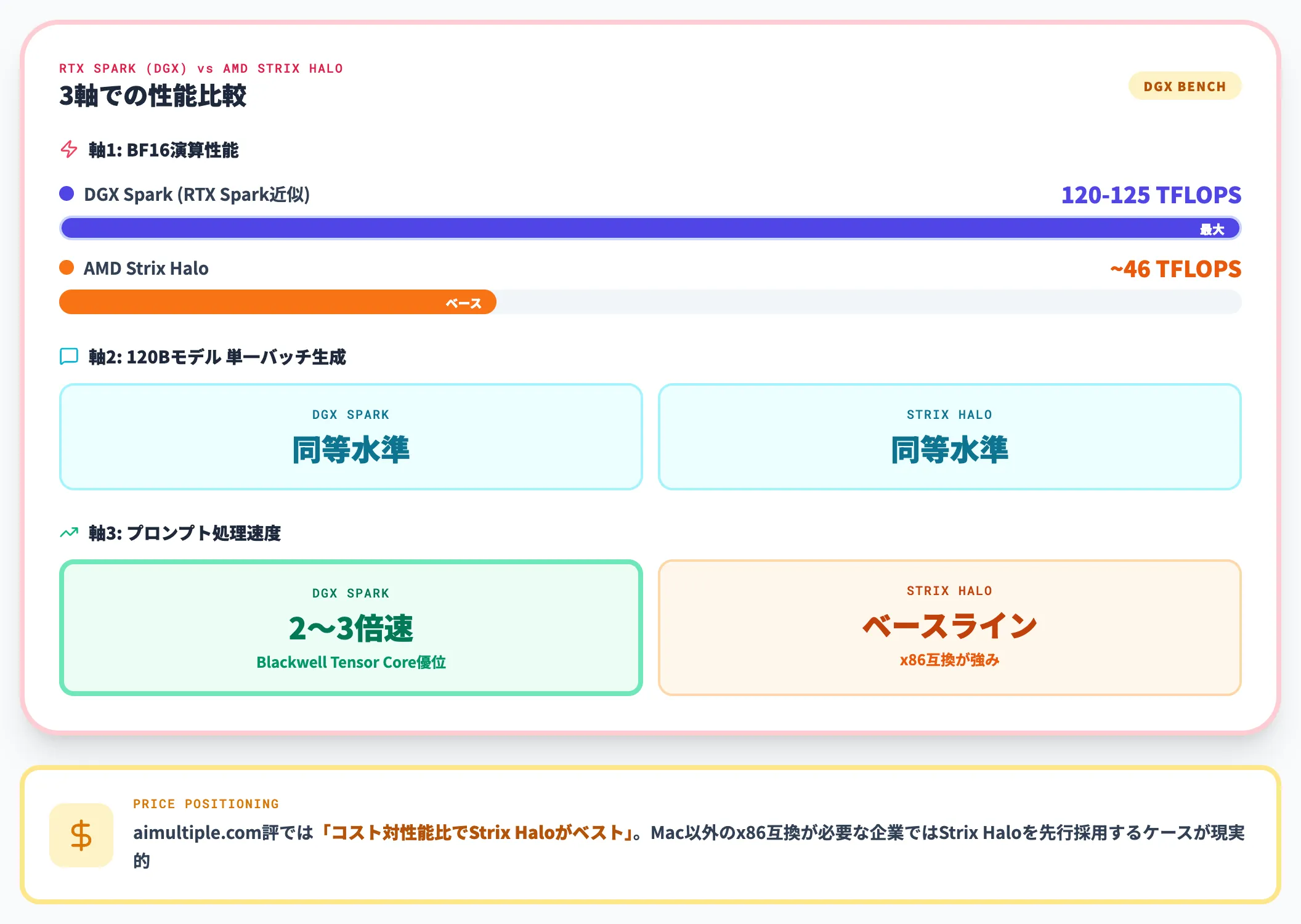
AMD Strix Halo(Ryzen AI Max 385/395)は、x86陣営から128GBユニファイドメモリを成立させたAI PCチップです。
Framework DesktopなどからStrix Halo搭載モデルが販売されており、128GB構成も選べる点が特徴です。価格は構成・在庫・メモリ市況によって変動するため、購入検討時は公式構成ページで最新価格を確認する前提です。
AI推論性能の差は次のとおりです。
| 項目 | RTX Spark(DGX Sparkで近似) | AMD Strix Halo |
|---|---|---|
| 演算性能(BF16) | 約120〜125 TFLOPS | 約46 TFLOPS |
| 120Bモデル単一バッチ生成 | 同等水準 | 同等水準 |
| 120Bモデルプロンプト処理 | Strix Haloに対し2〜3倍速い傾向 | ベースライン |
| 統合メモリ | 最大128GB LPDDR5X | 最大128GB LPDDR5X |
| 価格帯 | RTX Spark搭載機は未公表 | Framework Desktop等で販売中、構成・在庫・市況で変動 |
The Registerの比較検証では、単一バッチのトークン生成は近い水準だが、プロンプト処理ではBlackwell世代Tensor Coreの優位でDGX Sparkが2〜3倍速いという傾向が報告されています。なお具体数値はDGX Sparkデスクトップでの検証結果で、RTX Spark搭載ノートPCの実測は未公開です。
長いコンテキストを読ませてから回答するエージェント用途では、このプロンプト処理速度の差が体感に効きます。一方で、コスト感を最優先するならStrix HaloはRTX SparkやDGX Sparkに対して構成によっては価格面の選択肢を広げられる点が強みで、x86互換が前提の企業環境では現実的な代替案です。
aimultiple.comの比較記事では「コスト対性能比でStrix Haloがベスト」とまで評しており、Mシリーズではないx86互換が必要な企業ではStrix Haloを先行採用するケースが現実的に増えています。
Apple M5 / M4 Max系MacBook Proとの比較

macOS陣営のApple M5系は、これまで「ローカルAI推論の現実解」として一定の支持を得てきました。
RTX Sparkは性能面でM5を上回るベンチマーク数値が早期に出回っていますが、扱う土俵が違うため単純比較は注意が必要です。
XenoSpectrumの初期ベンチマーク解析では、SNS由来のClangコンパイル系ベンチという限定的なデータポイントながら、RTX SparkがApple M5を54.13%上回るスコアを示しています。一方で同記事では、上位構成のApple M5 Proには届かない数値であることも併記されており、Windows ARM陣営の勢力図変化の可能性として慎重に紹介されています。
ただし、Notebookcheckが報じる一部のリークではApple M5 Maxとの差は埋まりきらないというデータもあり、最終評価は実機検証を待つ必要があります。
| 観点 | RTX Spark | Apple M5系 |
|---|---|---|
| 対応OS | Windows on Arm | macOS |
| 統合メモリ最大 | 128GB | 128GB(M4 Max/M5 Max構成) |
| AIスタック | CUDA・TensorRT | Metal Performance Shaders・MLX |
| ローカルLLM運用 | gpt-oss 120B・Llama 70B等 | 同等規模が動作(実績多数) |
| 企業導入の文脈 | Windows標準環境からの延長 | Mac前提の組織のみ |
つまり、Apple M5系との競争は「同じローカルLLM性能をWindows側で得られるかどうか」という選択肢の話に近く、組織のIT標準がWindowsかmacOSかで自動的に分かれます。
Windows標準環境の企業にとって、これまでローカル推論が必要なときだけMacBook Proを併用していたケースを、RTX SparkでWindows一本に統一できる可能性が出てきた——というのが構造変化です。
Windows on Arm互換性とソフトウェア対応の現状
RTX Sparkを選ぶ前に必ず確認すべきなのが、Windows on Arm環境でのソフトウェア互換性です。
性能がいくら高くても、業務アプリやゲームが動かなければ採用判断はできません。ここでは現時点で見えている互換性の現状と、NVIDIA・Microsoftが進めている対応策を整理します。
Prismエミュレーターによる既存アプリの動作見通し
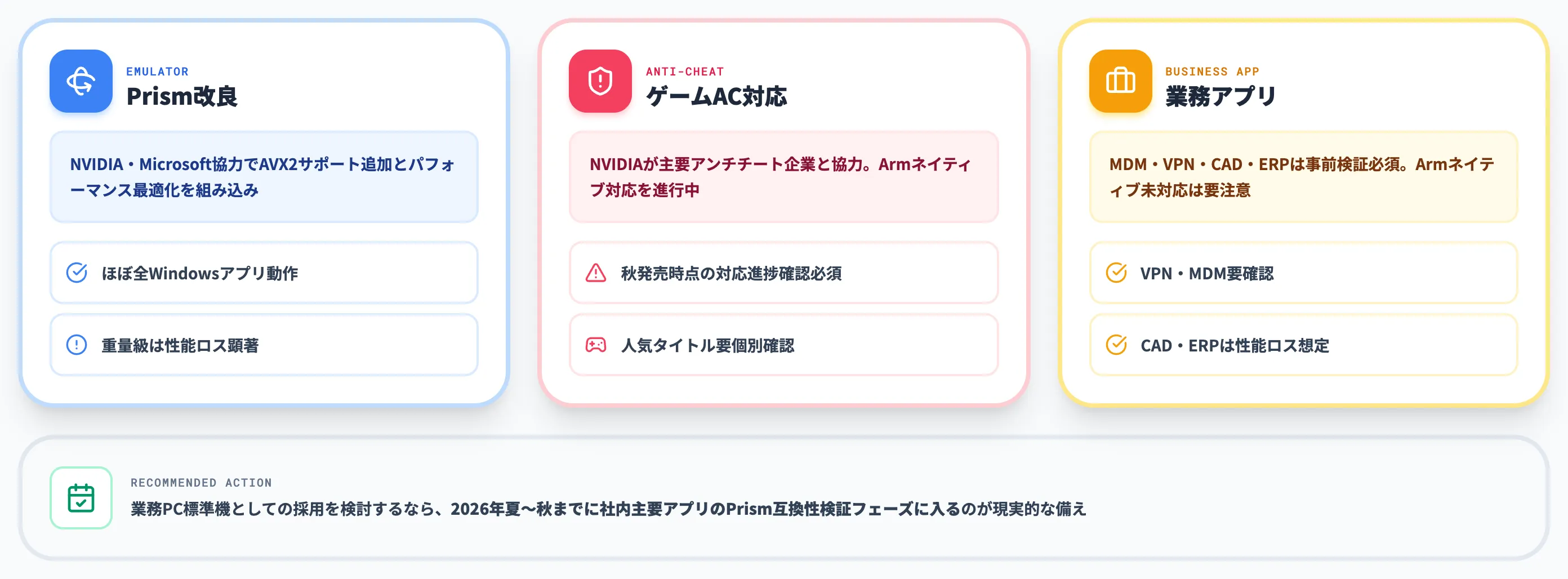
Windows on Armでは、Intel/AMD(x86・x64)バイナリを実行するためにMicrosoftの「Prismエミュレーター」を使います。
Game*Sparkの報道によれば、NVIDIAはMicrosoftと協力してPrismの改良を進めており、AVX2サポートの追加と新たなパフォーマンス最適化が組み込まれています。
Windows Centralでは、Jensen Huang氏が「Prismを通じて、ほぼすべてのWindowsアプリがRTX Spark上で動作すると見込んでいる」と発言したと報じられています。
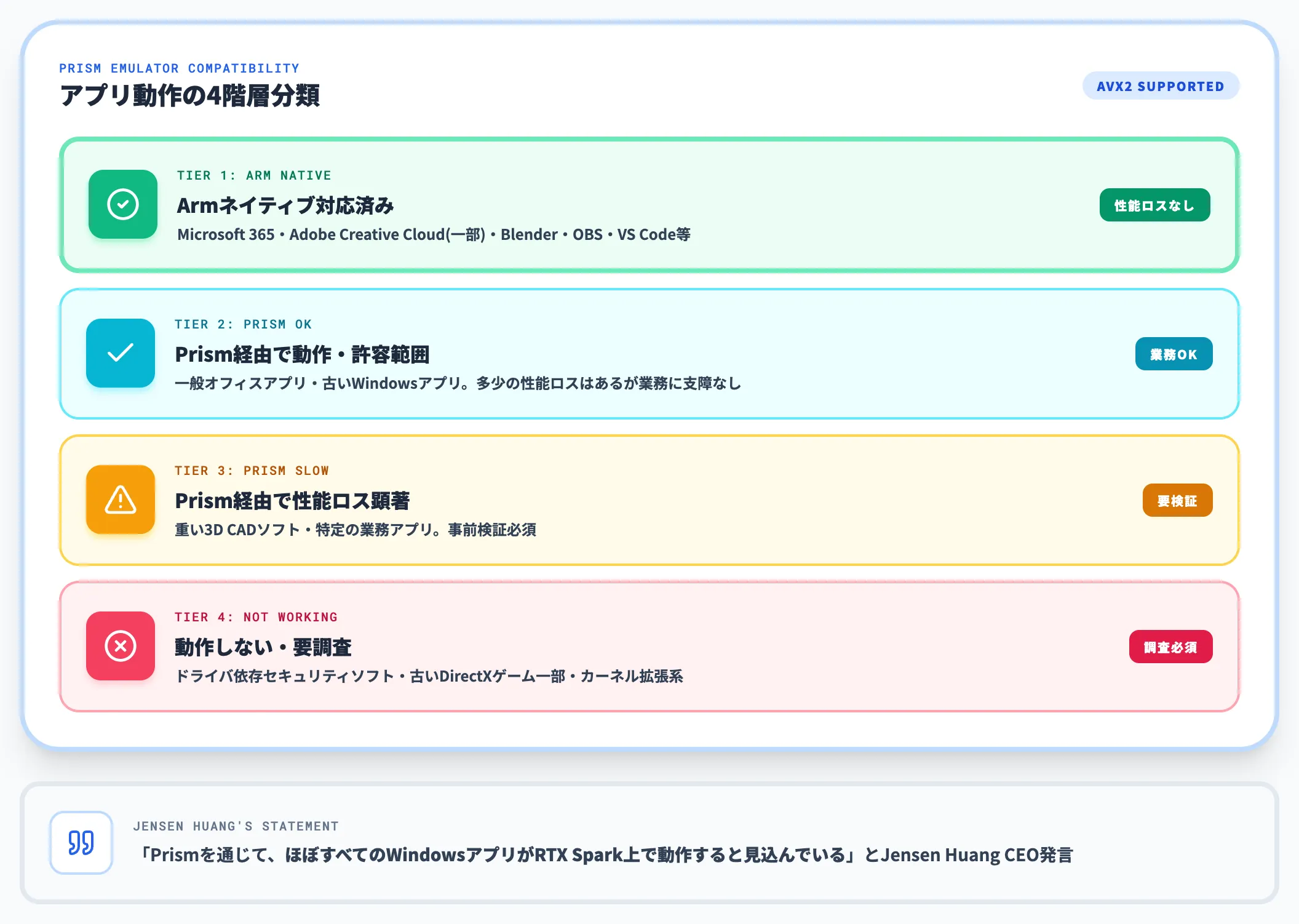
ただし「ほぼすべて」の中身は分解が必要で、現実的には以下のような階層になります。
- Armネイティブ対応済み: Microsoft 365・Adobe Creative Cloud(一部)・Blender・OBS・VS Code等。性能ロスなく動く
- Prism経由で動作・許容範囲: 一般的なオフィスアプリ・古いWindowsアプリ。多少の性能ロスはあるが業務に支障なし
- Prism経由で性能ロス顕著: 重い3D CADソフト・特定の業務アプリ
- 動作しない・要調査: ドライバ依存のセキュリティソフト・古いDirectXゲームの一部・カーネル拡張系
業務PCの標準機としてRTX Sparkを採用する場合、社内主要アプリを2026年夏〜秋にPrism互換性検証フェーズに入れておくことが現実的な備えになります。
ゲームのアンチチート対応進捗

ゲーミング用途でRTX Sparkを検討する場合、最大の懸念はオンラインゲームのアンチチート(不正対策)ソフトウェアです。
これまでWindows on Armでは、Easy Anti-Cheat・BattlEye・Denuvoといった主要アンチチートがArmネイティブで動かず、人気タイトルが起動しないかクラッシュする問題が続いていました。
NVIDIAはComputex 2026での発表で、開発元との協力で主要アンチチートのArmネイティブ対応を進めていると明言しています。
具体的にRTX Spark発売時にどこまで対応が出揃うかは確約されておらず、秋発売までの対応進捗が採用判断の焦点になります。ゲーミング用途でRTX Spark搭載機を選ぶ場合は、購入検討時点で主要タイトル・主要アンチチートのArmネイティブ対応状況を必ず確認する前提です。

業務アプリの移行で注意すべき点
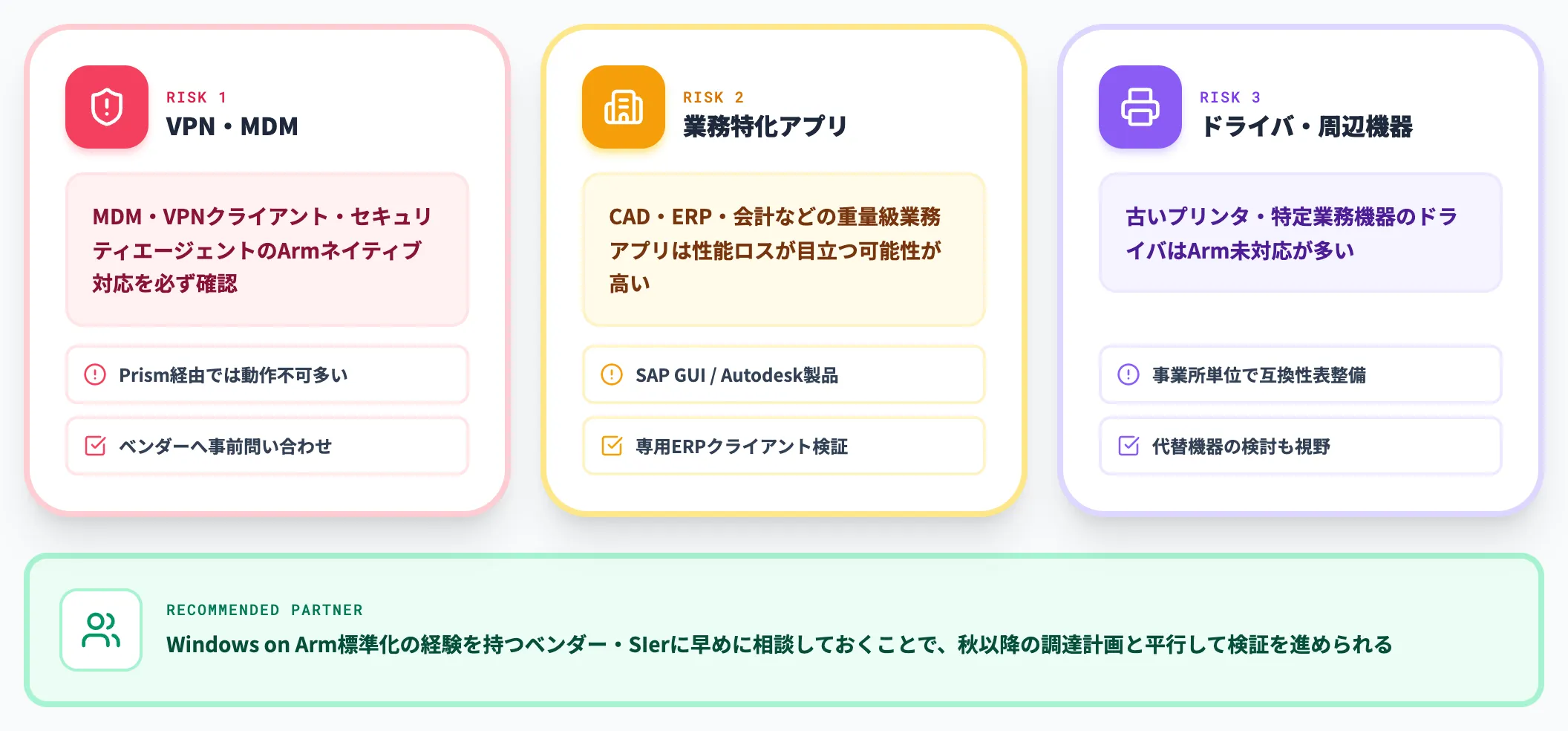
法人IT管理者がRTX Spark搭載機の標準機採用を検討する場合、特に注意したい論点を3つ挙げます。
-
VPN・MDMクライアント
社内のMDM(モバイルデバイス管理)・VPNクライアント・セキュリティエージェントがArmネイティブ対応しているか必ず確認する。Prism経由では動かないケースが多い。
-
業務特化アプリ(CAD・ERP・会計)
重量級の業務アプリは性能ロスが目立つ可能性がある。SAP GUI・Autodesk製品・専用ERPクライアント等は事前検証必須。
-
印刷ドライバ・ハードウェア連携
古いプリンタや特定の業務機器のドライバはArm未対応のケースが多い。事業所単位での互換性表を整備する。
これらの検証は、Windows on Arm標準化の経験を持つベンダー・SIerに早めに相談しておくことで、秋以降の調達計画と平行して進められます。
RTX Sparkの価格・入手方法と後継ロードマップ
ここでは、RTX Spark搭載デバイスの予想価格帯・購入経路、すでに発売中のDGX Sparkとの比較、そしてVera Rubin Spark以降の後継ロードマップを整理します。
NVIDIAがRTX Sparkを「単発の製品」ではなく「3世代続くプラットフォーム」と位置づけている点が、企業の長期投資判断にとって重要な意味を持ちます。
搭載デバイスの正式価格と参考になるDGX Sparkの位置づけ
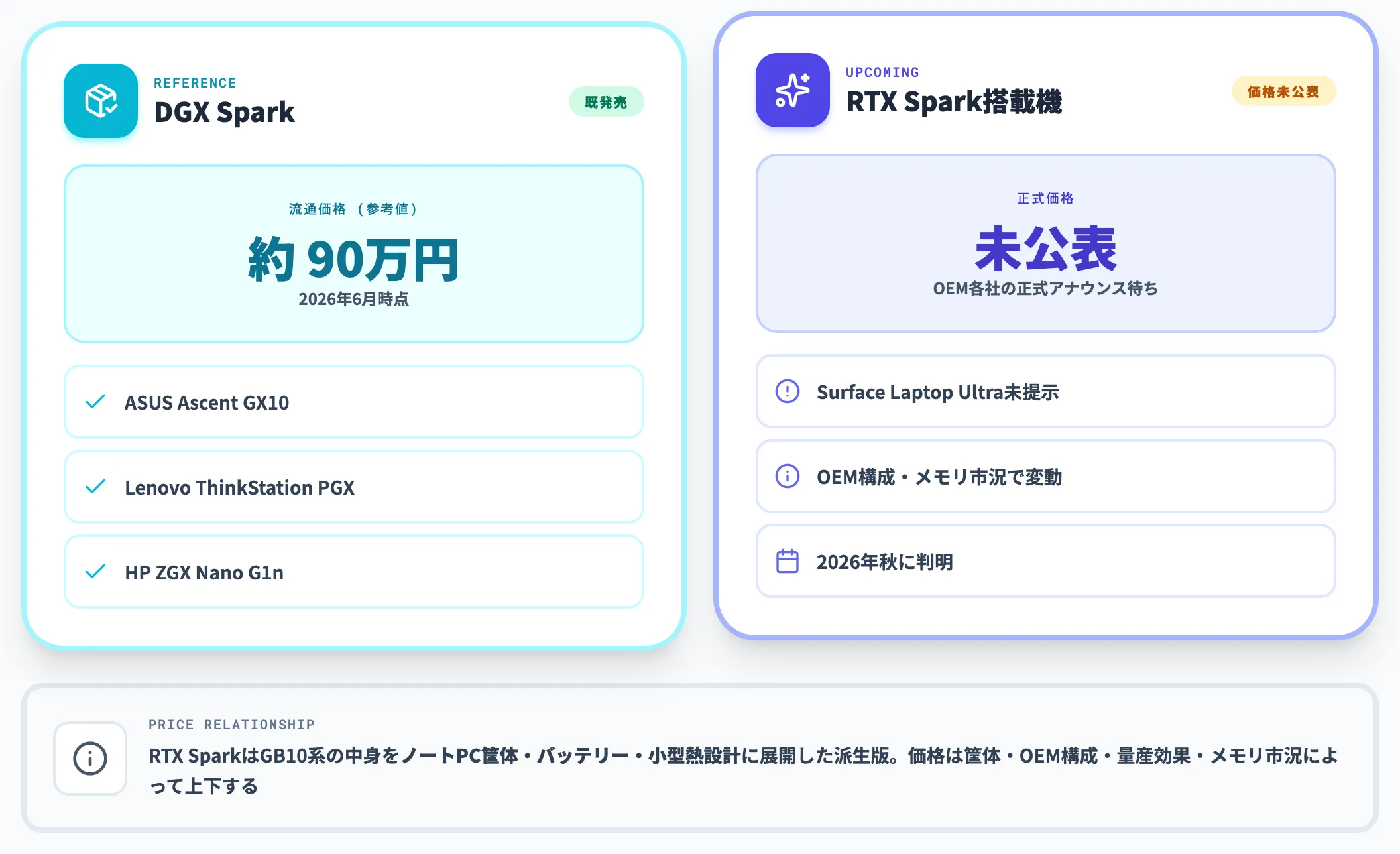
RTX Spark搭載デバイスの正式価格は、2026年6月時点でNVIDIAおよび各OEMからまだ公表されていません。Surface Laptop Ultraについても、Microsoft公式ブログは仕様と発売時期を発表したのみで価格は未提示です。
参考になるのが既に発売中のDGX Spark(GB10)の流通価格です。価格.comなどの流通情報では、2026年6月時点でDGX Spark本体は概ね90万円前後で掲載されており、ASUS Ascent GX10・Lenovo ThinkStation PGX・HP ZGX Nano G1nなどOEM各社のGB10搭載モデルではより低価格な構成も流通しています。具体的な価格は容量構成・販売チャネル・為替変動により流動するため、購入検討時は各販売ページで最新情報を確認する前提です。
RTX SparkはこのGB10系の中身をPC組み込み(ノートPC筐体・バッテリー・小型熱設計)に展開した派生プラットフォームです。DGX Sparkの価格はあくまで参考値にとどまり、RTX Spark搭載機の価格は筐体・OEM構成・量産効果・メモリ市況によって上下する可能性があります。具体的な価格水準はOEM各社の正式アナウンスを待つ必要があります。
DGX Spark(GB10)との使い分け

RTX SparkとDGX Sparkは中身が同等のGB10系チップを採用しますが、想定ユースケースが明確に違います。
| 観点 | DGX Spark | RTX Spark搭載PC |
|---|---|---|
| 用途 | 個人開発者のローカルAIスーパーコンピューター | ノートPC・コンパクトデスクトップの標準機 |
| OS | DGX OS(NVIDIA最適化Linux) | Windows on Arm |
| 想定購入者 | AI研究者・ML エンジニア・データサイエンティスト | 一般法人ユーザー・クリエイター・パワーユーザー |
| ポータビリティ | デスクトップ据え置き | ノートPCならモバイル |
| ソフト互換性 | Linux/CUDAエコシステム | Windows業務アプリ+AI |
つまり「AI研究目的の個人開発機」を買うならDGX Spark、「業務PCを兼ねつつローカルAIも回したい」ならRTX Spark搭載機、という棲み分けです。
法人導入の候補としては、業務PC・モバイル運用との親和性が高いRTX Spark搭載機が本命になります。
Vera Rubin Spark・Rosa Feynmanのロードマップ
NVIDIAはRTX Sparkを発表した時点で、後継世代の計画も公開しています。
Tom's Hardwareが伝えるロードマップは以下のとおりです。
| 世代 | 主なポイント | 想定タイミング |
|---|---|---|
| RTX Spark(Blackwell) | 1ペタフロップFP4・128GB LPDDR5X | 2026年秋 |
| Vera Rubin Spark | Rubin世代GPU・LPDDR6メモリで帯域向上 | 2027〜28年 |
| Rosa Feynman Spark | Rosa Feynman世代GPU・さらなる電力効率改善 | 2029〜30年 |
3世代のロードマップが既に名指しで公開されている点は、NVIDIAがWindows AI PCを「データセンター事業に並ぶ長期投資領域」として位置づけている表れです。
Fudzillaの整理では、Rubin世代はLPDDR6移行による帯域大幅向上が主軸で、メモリと帯域の両面でローカルLLM推論の上限が更に押し上げられる見通しです。
企業の調達戦略としては、「RTX Spark初代を導入したら、3年後にVera Rubin Sparkへ更新する」という前提で機器の減価償却を組むのが現実的です。1機種で長期保有するよりも、Windows AI PCのアップグレードサイクルそのものが再設計される時期に入った、と理解しておく必要があります。
企業がRTX Spark世代に備えるべきこと
ここまで、RTX Sparkの技術仕様・搭載デバイス・競合比較・互換性・価格を整理してきました。最後に、AI総合研究所が支援している企業の傾向も踏まえ、ケース別に「いま何をすべきか」を整理します。
RTX Spark搭載機が秋に揃ったあと、企業が後手に回らないためには2026年第3四半期までに以下の判断を進めておく必要があります。
「RTX Sparkが発売される前にやること」一覧
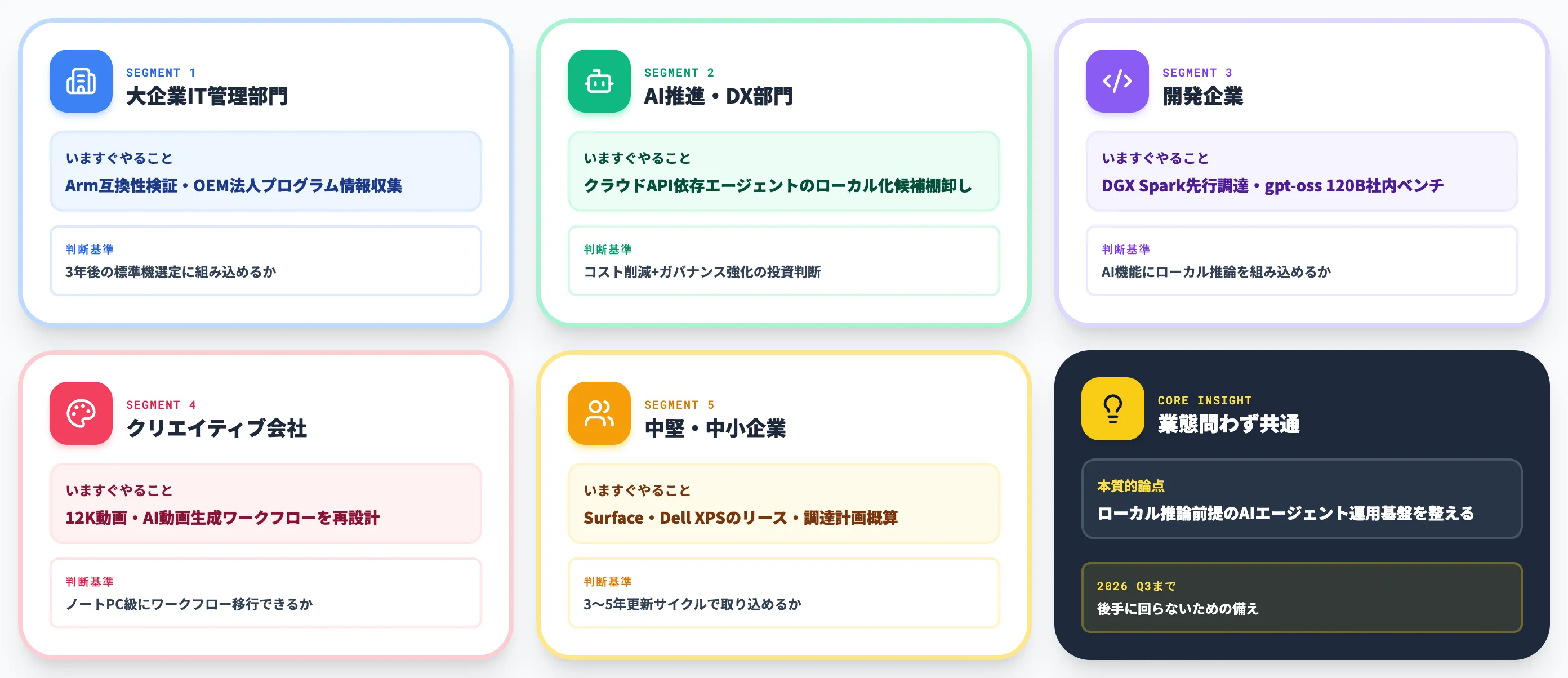
業態別に優先度の高いアクションを整理しました。秋発売を待つだけでなく、待っている間に何を準備するかが分かれ目になります。
| 対象企業 | いますぐやること | RTX Spark時代の判断基準 |
|---|---|---|
| 大企業IT管理部門 | 社内主要アプリのArm互換性検証、各OEM・販売代理店の法人向け先行情報や評価プログラムの確認 | 「3年後の標準機」にRTX Spark搭載機を含められる準備ができているか |
| AI推進・DX部門 | クラウドAPI依存の業務エージェントのうち、ローカル推論に寄せられる候補を棚卸し | クラウドコスト削減効果と、データガバナンス強化の両面で投資判断ができているか |
| 開発企業(自社プロダクト) | DGX Sparkを先行調達してgpt-oss 120B等の社内ベンチマークを取得 | プロダクトのAI機能設計にローカル推論オプションを組み込めるか |
| クリエイティブ・制作会社 | 12K動画編集・AI動画生成のワークフローをRTX Sparkベースで再設計 | ハイエンドワークステーションからノートPC級へワークフローを移せるか |
| 中堅・中小企業 | まずはRTX Spark搭載Surface・Dell XPSのリース・調達計画の概算 | 標準機更新サイクル(3〜5年)でRTX Spark/Rubin世代を取り込めるか |
これらは「RTX Sparkを買うかどうか」だけの話ではなく、ローカル推論を前提に置いたAIエージェント運用の組織体制を作るかという問いに直結します。
大企業IT管理部門の場合
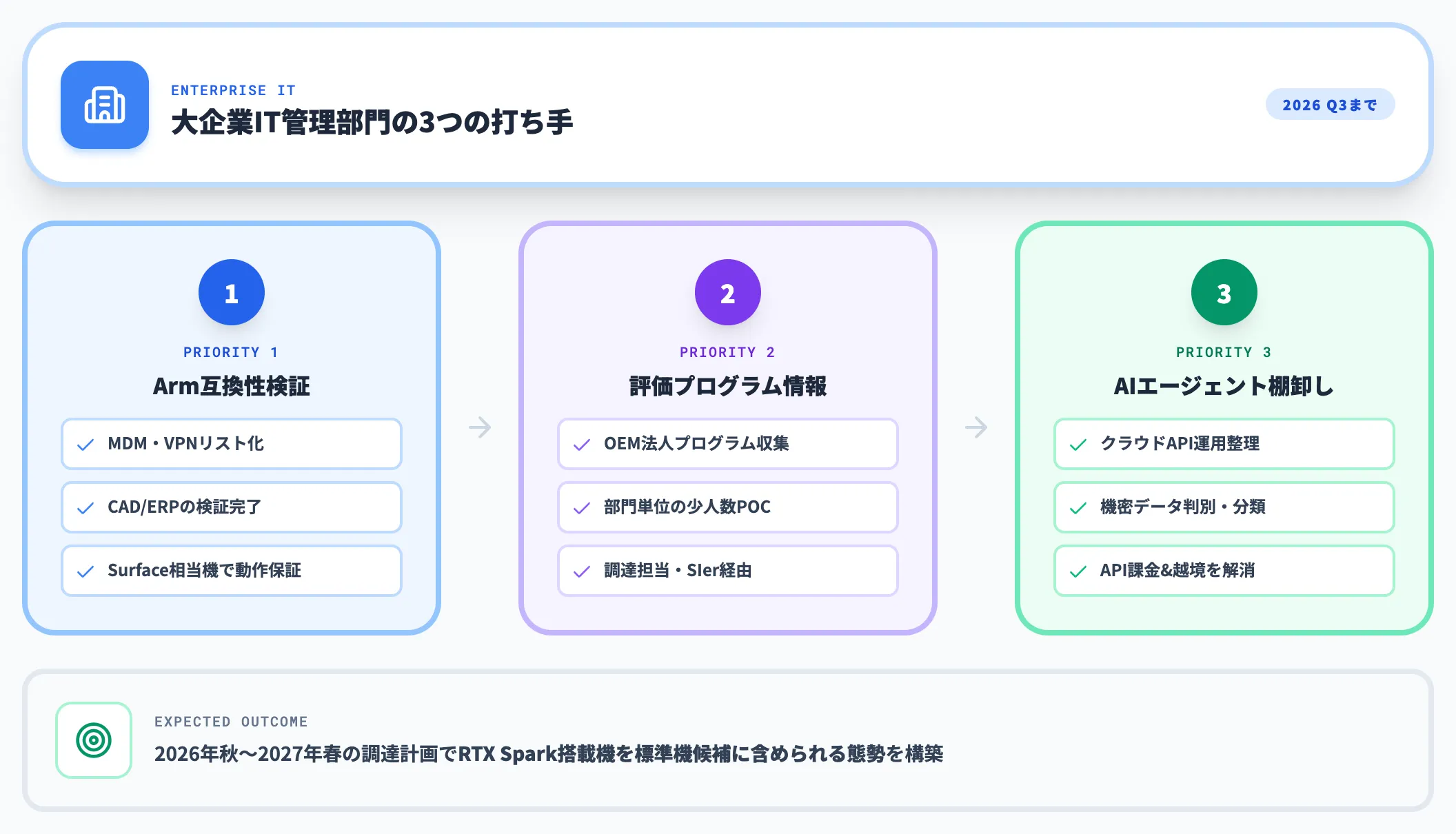
社員数千〜数万人規模の組織でRTX Spark搭載機を標準機に組み込むかどうかは、2026年秋〜2027年春の調達計画でほぼ確定します。
優先度の高い打ち手は次の3点です。
業務アプリのWindows on Arm互換性検証
社内で使う主要業務アプリ(MDM・VPN・CAD・ERP・会計)をリスト化し、Armネイティブ対応状況とPrismエミュレーター動作の検証を秋までに完了させる。
ベンダーへ早めに問い合わせ、「Surface Laptop Ultra相当機での動作保証」を引き出しておく。
評価プログラム情報の早期収集
Microsoft Surface・Dell XPS・HP OmniBookなどの各OEM・販売代理店から、法人向けの先行評価プログラムや出荷スケジュール情報を集める。リリース前評価の枠組みは公表されていない部分も多いため、調達担当・SIerパートナー経由で情報をたどる。
部門単位での先行導入(少人数POC)から始めて、全社展開の判断材料を貯める。
AIエージェント運用の棚卸し
クラウドAPIで運用しているAIエージェント・社内チャットボットのうち、データガバナンス上ローカルに寄せた方がよいものを洗い出す。
機密データを扱う一部のワークフローをRTX Sparkでローカル化することで、API課金とデータ越境の両方を解消できる。
AI推進・開発部門の場合
社内でAIエージェントの開発・運用を担当している部門は、RTX Sparkを「実験プラットフォーム」として早期に取り入れる価値が大きいです。
DGX Sparkを先行導入して2か月運用したDevelopersIOの検証が示すとおり、120Bパラメータの大型モデルが手元で動かせると、これまで難しかった「機密文書のRAG」「ローカルでのコード補完」「オフライン環境での業務エージェント」などが現実的になります。
AI総合研究所の支援現場でも、RTX Sparkのような統合メモリ型SoCを社内のAIエージェント基盤に組み込む議論は急速に増えています。クラウドコスト削減・データガバナンス強化・レイテンシ短縮の3点で投資対効果を説明できる場合、PoC着手は早めるほど効果が出やすい領域です。
中堅・中小企業の場合
専任のAI推進部門を持たない企業でも、RTX Sparkの動向を遠い話と感じる必要はありません。
NVIDIAとMicrosoftが押し出しているSurface Laptop Ultraは、クリエイター・開発者・エンジニア向けの高性能Surfaceとして位置づけられており、法人導入の候補になり得る選択肢として捉えられます。
具体的には、3年後の標準機更新サイクルでRTX SparkまたはVera Rubin Spark世代を取り込む前提で、現在の調達計画を見直すことから始めるのが現実的です。「ローカルLLMを動かせるPC」という選択肢が法人PC市場の標準装備になっていく流れに、自然に乗っていけます。
【関連記事】
ローカルLLMとは?メリットやおすすめモデル、導入方法を解説
業界全体の構造変化——ローカル推論の標準化が前提に

RTX Spark以降の流れを長期で見たとき、業界全体としては次のような構造変化が起きます。
-
AIエージェントの実行環境がクラウドオンリーから「クラウド+ローカル」のハイブリッドへ
機密データはローカル、汎用処理はクラウド、というルーティングが標準化する
-
データガバナンスがローカル化の追い風に
個人情報・契約書・コード等のデータをローカルで処理することで、データ越境の論点を構造的に解消できる
-
NPUからGPU統合SoCへ
これまでAI PCの主役だった「NPU」は、より大規模なGPU統合SoCに飲み込まれる方向に進む。Apple・AMD・Intelもこの流れに追随する
-
法人IT標準機の更新サイクルそのものが見直し
Windows on Armの本格化により、PC調達戦略・MDM運用・業務アプリ互換性確認の枠組みを2026〜27年に作り直すことが、CIO・IT管理者の共通課題になる
RTX Sparkが直接使えるかどうかは別として、業界変化に追随できる組織体制と調達戦略を再設計するタイミングが、まさに2026年下半期と言えます。
RTX Sparkを活かしたエンタープライズAI基盤を整える
RTX Sparkのようなローカル推論基盤の登場で、企業のAIエージェント運用は「クラウド+ローカル」のハイブリッド前提に変わりつつあります。
一方で多くの企業は、RTX Spark発売を待つよりも先に、現行のクラウドAPIとオンプレ環境を組み合わせたAIエージェント基盤を整理する段階にあります。クラウドだけで完結していたAI運用を、機密データを扱うローカル推論まで含めて1つの管理面で扱える基盤が必要になります。
ここで効いてくるのが、AI総合研究所が提供するエンタープライズAIエージェント基盤「AI Agent Hub」です。クラウド・オンプレを横断したエージェント管理を1つのコンソールから扱えるプラットフォームで、RTX Spark世代を見据えた業務エージェントの実行環境を整えるための土台になります。
AI総合研究所の専任チームが、企業ごとのAI活用設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
ローカル推論時代のAIエージェント基盤を整える

クラウドとオンプレを横断したエージェント運用を1コンソールで
RTX Sparkのようなローカル推論基盤が一般化していく中で、企業にはクラウドだけで完結していたAI運用を見直し、機密データを扱うローカル推論まで含めて1つの管理面で扱える基盤が必要になります。AI Agent Hubはエンタープライズ向けの統合AIエージェントプラットフォームとして、RTX Spark世代を見据えた業務エージェントの実行環境を整える土台になります。
まとめ
本記事では、2026年5月31日にNVIDIAがComputex 2026で発表したRTX Sparkについて、製品定義・スペック・ローカル推論用途・ゲーミング/クリエイティブ性能・搭載デバイス・競合比較・Windows on Arm互換性・価格とロードマップ・企業の備えまで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
RTX SparkはArm CPU+Blackwell GPU+128GB統合メモリを統合した、NVIDIAがWindows PC向けに投入する新型SoCで、1ペタフロップAI性能と120Bパラメータ級のローカル推論を1台のWindowsノートで成立させるプラットフォーム
-
NVIDIA・Microsoft・MediaTekの三者協業で、近年Qualcomm Snapdragon系が中心だったArm系Windows PC市場にNVIDIA陣営を加え、高性能AI PCの選択肢を広げる戦略製品
-
ASUS・Dell・HP・Lenovo・Microsoft Surface・MSIから2026年秋発売予定で、Acer・GIGABYTEも後続で参入予定。具体的な出荷台数・モデル数は出荷開始後に判明する見通し
-
競合比較ではSnapdragon X Eliteにソフトウェアスタックの成熟度で大差、AMD Strix Haloにプロンプト処理で2〜3倍速い傾向(DGX Spark検証ベース)、Apple M5系にはWindows標準環境の延長で勝負できる位置取り
-
企業の現実的な備えは、業務アプリのWindows on Arm互換性検証、各OEM・販売代理店の法人向け評価プログラム情報の早期収集、AIエージェント運用のローカル推論候補棚卸しの3点を2026年第3四半期までに進めること
RTX Sparkは「自社が秋に買えるかどうか」よりも、「ローカル推論前提のAIエージェント運用が標準化する時代に、自社の調達戦略・組織体制をどう作り直すか」という問いを企業に突きつけています。まずは現在のクラウドAPI依存のAI運用を棚卸しし、Surface Laptop UltraやDell XPS 16など各OEMから出てくるRTX Spark搭載機の正式情報を秋までに集める取り組みから着手することが、最も実用的な第一歩になります。










