この記事のポイント
 製造業の品質検査には画像認識AIが最も投資対効果が高い。人的ミス削減と24時間稼働で回収期間は1年以内が目安
製造業の品質検査には画像認識AIが最も投資対効果が高い。人的ミス削減と24時間稼働で回収期間は1年以内が目安- 2026年はVision TransformerとマルチモーダルAIが主流。CNNだけの従来システムは精度面で見劣りし始めている
- クラウドサービスはAzureはComputer Vision、GCPはCloud Visionを選ぶ、マルチクラウドはRekognitionが無難
- 導入コストはPoC段階で数百万円〜。まずは1ラインの検査自動化からパイロットで始めるのが鉄則
- 顔認証はディープフェイク脅威が深刻化しており、ライブネス検知の実装を必須要件にすべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
近年、AIとコンピュータビジョンの進歩により、画像認識技術は製造業の品質検査から医療診断支援、自動運転まで幅広い分野で不可欠な存在となっています。2026年のグローバル市場規模は約387億ドル(Fortune Business Insights調べ)に達し、企業のAI導入において最も実績のある技術領域の一つです。
本記事では、画像認識AIの基本的な仕組みから、CNN・Vision Transformer・マルチモーダルAIの技術進化、業界別の活用事例、主要クラウドサービスの比較、そして導入コストと選定ポイントまでを体系的に解説します。
画像認識の導入を検討している方から、最新の技術動向を把握したい方まで、実務に役立つ情報をお届けしますので、ぜひ最後までご覧ください。
画像認識AIとは(2026年最新)
画像認識とは、コンピュータが画像や映像のデータを分析し、そこに写っている物体・人物・文字・パターンを自動的に識別するAI技術です。スマートフォンのカメラ機能から自動運転車のセンサーシステム、工場の品質検査、医療診断支援まで、私たちの生活やビジネスのあらゆる場面で活用されています。
画像認識の基盤となるのはコンピュータビジョンと呼ばれる研究分野で、カメラや光学センサーから取得した画像データを解析し、人間の視覚と同等以上の精度で情報を抽出する技術体系を指します。2012年にディープラーニングが画像認識コンペティション(ILSVRC)で従来手法を大幅に上回る精度を示して以来、この分野は飛躍的な進化を遂げてきました。
2026年時点の画像認識AI市場は、グローバルで約387億ドル(約5.8兆円)に達すると予測されています(Fortune Business Insights調べ、CAGR 15.2%)。製造業の外観検査、小売業のセルフレジ、医療画像診断、セキュリティの顔認証など、企業が画像認識を導入する領域は年々拡大しています。
一方で、画像認識の導入を検討しながら「自社の業務に適用できるか分からない」「精度や費用対効果が見えない」という理由で判断を先送りにしている企業も少なくありません。その間に競合が品質検査や顧客対応を画像認識で自動化すれば、人件費と品質のコスト差は広がる一方です。この記事では、画像認識の仕組みから活用事例、サービス比較、導入コストまでを体系的に整理し、自社での導入判断に必要な情報をお届けします。

画像認識の仕組みと主要技術
画像認識のプロセスは、大きく「画像処理」と「画像認識」の2段階に分かれます。画像処理がノイズ除去やコントラスト調整などのデータ前処理を担うのに対し、画像認識はその前処理されたデータを用いてパターンやオブジェクトを識別するステップです。以下の表で、両者の役割の違いを整理しました。
| 項目 | 画像処理 | 画像認識 |
|---|---|---|
| 目的 | 画像データの品質改善・特徴抽出 | 画像内のパターン・オブジェクトの識別 |
| 主な処理 | ノイズ除去、コントラスト調整、エッジ強調、色空間変換 | 分類、物体検出、セグメンテーション |
| 技術基盤 | フィルタリング、画像変換アルゴリズム | 機械学習、ディープラーニング |
| 位置づけ | 画像認識の前段階(データ準備) | 画像処理の結果を用いた判断・推論 |
つまり、画像処理は画像認識の土台となるデータを整える役割を担い、両者を組み合わせることで初めてコンピュータが画像を正確に理解できるようになります。身近な例として、スマートフォンカメラの夜景モードではノイズ除去(画像処理)が行われた上で、被写体認識(画像認識)が適用されています。
画像認識AIは、対象画像から以下のような特徴を段階的に抽出して判定を行います。
-
エッジ
物体の境界線や輪郭を検出する最も基本的な特徴量です
-
色
色相・彩度・明度の情報から、背景と対象物の区別や物体の種類判定に活用されます
-
テクスチャ
表面の質感や模様を数値化し、布地の種類判別や製品の傷検出などに応用されます
-
形状
物体の輪郭形状や大きさを捉え、車両認識や人物検出の基盤となります
これらの特徴量を組み合わせて学習したモデルが、入力画像に対して「何が写っているか」を高精度に判定します。機械学習を活用した画像認識の詳細な仕組みについては、関連記事も参考にしてください。
CNNからVision Transformer・マルチモーダルAIへの技術進化
画像認識の技術は、過去10年で3つの大きな転換点を迎えました。以下の表で、主要技術の特徴と進化の流れを整理しました。
| 技術 | 登場時期 | 特徴 | 精度の目安 |
|---|---|---|---|
| CNN(畳み込みニューラルネットワーク) | 2012年〜 | 画像の局所的な特徴を階層的に学習する画像認識の基盤技術 | ImageNet Top-5: 約95% |
| Vision Transformer(ViT) | 2020年〜 | 画像をパッチに分割しTransformerで処理。大規模データで高精度 | ImageNet: 約90%(単体)、ハイブリッドで96%超 |
| マルチモーダルAI | 2023年〜 | テキスト・画像・音声を統合的に理解。自然言語での画像説明が可能 | タスク依存(画像質問応答で人間に匹敵) |
特に2023年以降の大きな変化は、マルチモーダルAIの台頭です。GPT-4VやGeminiといった大規模言語モデルが画像理解機能を獲得したことで、「この製品の欠陥はどこか」「この書類の内容を要約せよ」といった自然言語での画像認識指示が可能になりました。従来のCNNが「猫か犬か」を判定する分類型だったのに対し、マルチモーダルAIは画像の文脈を理解した上で詳細な説明を生成できる点が大きな違いです。
また、ViTとCNNを組み合わせたハイブリッドモデルは、医療画像の腫瘍分類で96.3%の精度を達成しており(Springer Nature)、単一技術に依存するよりも高い成果が報告されています。2026年現在、用途に応じてCNN・ViT・マルチモーダルAIを使い分ける、もしくは組み合わせるアプローチが主流となっています。
画像認識の種類と技術分類
画像認識技術は、タスクの目的に応じて複数の種類に分かれます。以下の表で、主要な6つの画像認識技術とその用途を整理しました。
| 種類 | 概要 | 代表的な用途 |
|---|---|---|
| 画像分類 | 画像全体が属するカテゴリを判定 | 商品仕分け、製品の良品/不良品判定 |
| 物体検出 | 画像内の特定オブジェクトの位置と種類を特定 | 自動運転の障害物検知、交通量カウント |
| セグメンテーション | 画像をピクセル単位で意味のある領域に分割 | 医療画像の腫瘍部位特定、衛星画像解析 |
| 顔認証 | 顔の特徴から個人を識別 | スマートフォンの本人認証、入退室管理 |
| OCR(文字認識) | 画像内のテキストを文字データに変換 | 請求書のデータ化、ナンバープレート読取 |
| 異常検知 | 正常パターンとの差異を検出 | 工場の外観検査、インフラの劣化検出 |
実務での選択ポイントは、「何を」「どこまで」認識したいかによって変わります。たとえば製造ラインで傷の有無だけを判定するなら画像分類で十分ですが、傷の位置と大きさまで特定したい場合はセグメンテーションが必要です。AI-OCRのように文字認識に特化したサービスや、姿勢推定AIのように人体の骨格を検出する専門技術も登場しており、用途に応じた使い分けが重要です。なお、画像認識が「画像から情報を読み取る」技術であるのに対し、AI画像生成は「テキストから画像を作り出す」逆方向の技術であり、両者を組み合わせた応用も増えています。
画像認識AIの活用事例(2025-2026年)
画像認識AIは、製造業・小売・医療・交通・セキュリティなど幅広い業界で導入が進んでいます。以下の表で、業界別の主な活用パターンと効果を整理しました。
| 業界 | 活用内容 | 導入効果 |
|---|---|---|
| 製造業 | 製品の外観検査・異常検知 | 検査工数を最大80%削減、見逃し率の低減 |
| 小売業 | セルフレジ・商品認識・顧客行動分析 | レジ待ち時間の短縮、人件費削減 |
| 医療 | 画像診断支援(X線・CT・MRI) | 診断精度向上、読影時間の短縮 |
| 交通・物流 | 車両認識・交通量計測・倉庫内ピッキング | リアルタイム監視、人手作業の自動化 |
| セキュリティ | 顔認証・不審行動検知・侵入検知 | 入退室管理の効率化、防犯精度の向上 |
| 広告・マーケティング | 視聴者属性分析・視線追跡 | ターゲティング精度の向上、広告効果の最大化 |
日本企業のAI導入率は2025年時点で49.7%に達しており(総務省情報通信白書)、画像認識は製造業と小売業で特に導入が先行しています。ここからは、具体的な企業導入事例を画像とともに紹介します。
業界別の具体的な活用事例
小売業:富士通 Brainforce ウォークスルーチェックアウト
富士通株式会社は、店舗内で商品を見歩きながらスマホアプリだけでPOSレジを介さずに買い物ができるサービスを提供しています。カメラと物体認識技術を組み合わせ、顧客が手に取った商品を自動識別して購入手続きを完了する仕組みです。

Brainforce ウォークスルーチェックアウト (出典: 富士通株式会社)
この技術により、レジ待ち時間の解消と店舗スタッフの配置最適化が実現され、顧客体験の向上と運営コストの削減を両立しています。
交通・物流:AIによる交通量自動計測
交通量調査はかつて人間が終日手動で車両を数える作業でしたが、物体検出技術の導入によりこのプロセスが劇的に改善されました。AIカメラが道路上の車両を自動検出し、通過車両数を正確にカウントするだけでなく、車種・速度・交通パターンの分析まで可能になっています。

交通量調査・通行量調査をAIでカウント (出典: SCORER Traffic Counter Cloud)
リアルタイムの交通データは、渋滞予測や信号制御の最適化にも応用でき、スマートシティの基盤技術としても注目されています。
自動運転:トヨタ プリクラッシュセーフティ
自動運転における障害物検知は、セグメンテーション技術の代表的な応用例です。トヨタ自動車のプリクラッシュセーフティ機能は、車載カメラとセンサーの映像をリアルタイムで解析し、歩行者や先行車両を検知して衝突回避を支援します。

プリクラッシュセーフティ (出典: トヨタ自動車株式会社)
自動運転のレベル向上に伴い、画像認識の処理速度と精度への要求は今後さらに高まります。エッジAIによる車載リアルタイム処理が、この分野の技術的なキーポイントです。
医療:画像診断支援
医療画像の異常部位同定は、画像認識技術が最も大きなインパクトを生んでいる分野の一つです。X線、CTスキャン、MRIなどの医療画像からがん組織や骨折箇所を検出し、医師の迅速かつ正確な診断を支援しています。
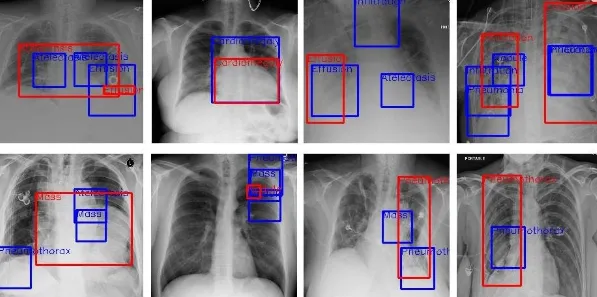
出典: Clarifying Image Recognition Vs. Classification
ViTとCNNのハイブリッドモデルによる脳腫瘍分類では96.3%の精度が報告されており、AIが医師のセカンドオピニオンとして機能する実用段階に入っています。
広告:パナソニック MilCount
パナソニック コネクトが開発したMilCountは、画像センシング技術を活用して駅構内のOOH広告に接触した人の属性を把握するサービスです。視聴者の年齢層や性別をリアルタイムに推定し、広告効果の定量的な測定とターゲティングの最適化を実現しています。

MilCount (参考: Panasonic)
セキュリティ・顔認証分野の活用と課題
顔認証技術は、個々の顔の特徴点を検出して人物を識別する手法で、スマートフォンのロック解除から空港のセキュリティチェックまで広く利用されています。AppleのFace IDは、3万以上のドットパターンを顔に投影して3Dマップを作成し、本人認証を行う仕組みです。
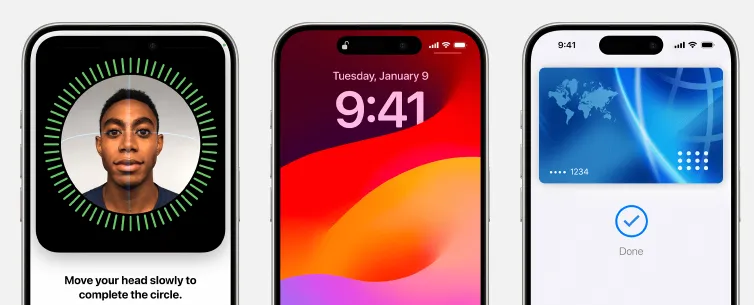
出典: Apple Support
顔認証の精度向上とともに、セキュリティ上の新たな脅威も顕在化しています。身元確認会社iProovの報告書によると、顔交換技術を利用してリモート本人確認を回避しようとするディープフェイク攻撃は2023年に704%増加しました。
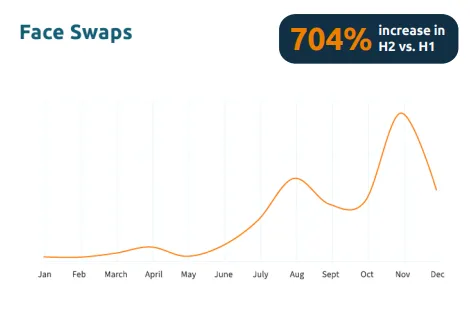
顔交換技術を利用したディープフェイク攻撃 (出典: 2024 Threat Intelligence Report)
こうした脅威に対処するため、ライブネス検知(生体検知)やマルチファクター認証との併用など、顔認証システムの防御力強化が進んでいます。画像認識技術は利便性とセキュリティリスクの両面を持つため、導入時にはリスク評価と対策設計が不可欠です。

画像認識AIサービスの比較(2026年版)
画像認識AIを導入する方法は、クラウドAPIの利用、SaaS型専用サービスの契約、オープンソースフレームワークでの自社開発の3つに大別されます。以下の表で、主要なクラウドAIサービスの機能と料金を比較しました。
| サービス | 提供元 | 主な機能 | 無料枠 | 従量課金(目安) |
|---|---|---|---|---|
| Cloud Vision API | Google Cloud | ラベル検出、OCR、顔検出、ランドマーク認識 | 月1,000ユニット | $1.50〜/1,000ユニット |
| Computer Vision | Microsoft Azure | 画像分析、OCR、空間分析、カスタムモデル | 月5,000トランザクション | $1.00〜/1,000トランザクション |
| Amazon Rekognition | AWS | 顔分析、物体検出、テキスト検出、動画分析 | 月5,000画像(12か月) | $1.00〜/1,000画像 |
| Vision API(GPT-4o) | OpenAI | マルチモーダル画像理解、自然言語での画像説明 | なし(API課金のみ) | トークン従量課金 |
サービス選定のポイントは、「何を認識したいか」と「処理規模」の2軸です。OCRやラベル検出といった定型タスクにはCloud Vision APIやComputer Visionが費用対効果に優れ、画像内容を自然言語で説明する高度な用途にはOpenAIのマルチモーダル機能が適しています。各サービスの詳しい機能比較はAI画像認識サービスの比較記事も参考にしてください。
オープンソースフレームワークの選択肢
クラウドAPIに加えて、自社でモデルを構築・カスタマイズしたい場合はオープンソースフレームワークが有力な選択肢です。以下の表で、代表的なフレームワークの特徴を整理しました。
| フレームワーク | 特徴 | 主な用途 |
|---|---|---|
| YOLO(v8/v9) | リアルタイム物体検出に特化。高速・軽量で組み込みにも対応 | 監視カメラ、ドローン映像解析 |
| OpenCV | 画像処理・コンピュータビジョンの定番ライブラリ | 前処理、特徴抽出、基本的な認識処理 |
| TensorFlow / PyTorch | 汎用的な深層学習フレームワーク。カスタムモデル構築に最適 | 分類・検出・セグメンテーション全般 |
| Hugging Face Transformers | ViT等のTransformerモデルを簡単に利用可能 | 最新モデルの実験・実装 |
オープンソースは初期コストがゼロで始められる反面、モデルの学習・チューニング・運用には専門知識が必要です。自社にMLエンジニアがいる場合はカスタムモデルが最も柔軟ですが、まずはクラウドAPIで検証してから要件が明確になった段階で自社開発に移行するアプローチが実務的です。
画像認識システムの導入ステップと注意点
画像認識システムの導入は、以下の5つのステップで進めます。
| ステップ | 内容 | ポイント |
|---|---|---|
| 1. 課題定義 | 画像認識で解決したい業務課題を明確化 | 「何を」「どこまで」認識するかを具体的に定義 |
| 2. データ収集・前処理 | 学習に必要な画像データを収集し、ラベリング・正規化 | データの質と量が精度を左右。最低でも数百〜数千枚 |
| 3. モデル選定・構築 | クラウドAPI、SaaS、自社開発から最適な方法を選択 | まずはクラウドAPIでPoCを実施 |
| 4. テスト・精度検証 | 実データでの精度評価と閾値調整 | 過学習の回避、エッジケースの確認 |
| 5. 本番導入・運用 | 本番環境への実装とモニタリング体制の構築 | 継続的な精度監視とモデル更新の仕組みが必須 |
特にステップ2のデータ収集は、画像認識プロジェクトの成否を分ける最も重要な工程です。豊富で多様なデータセットを用意し、ノイズ除去・サイズ調整・正規化などの前処理を丁寧に行うことで、モデルが一般化したパターンを学習できるようになります。
導入時の課題と対策
画像認識の導入では、技術面だけでなく運用面の課題も考慮が必要です。以下の表で、主な課題と対策を整理しました。
| 課題 | 内容 | 対策 |
|---|---|---|
| データ品質 | 学習データの偏りやラベリングの不正確さ | データ拡張(回転・反転等)、クロスバリデーション |
| プライバシー | 顔画像・個人情報の取り扱い | 匿名化処理、個人情報保護法への準拠、利用目的の明示 |
| 精度保証 | 照明・角度・天候による認識精度の変動 | エッジケースの網羅的テスト、マルチモデル併用 |
| 運用コスト | モデル更新・インフラ維持の継続コスト | MLOps基盤の構築、精度劣化のアラート設定 |
これらの課題を事前に把握しておくことで、導入後のトラブルを最小限に抑えることができます。特にプライバシーに関しては個人情報保護法への対応が必須であり、顔認証システムを導入する際は利用目的の公表とオプトアウトの仕組みを設計段階で組み込む必要があります。AIのビジネス活用方法と導入手順についてはこちらの記事も参考にしてください。
画像認識AIの導入コストと選定ポイント
画像認識AIの導入コストは、利用方法と規模によって大きく異なります。以下の表で、3つの導入パターン別にコスト目安を整理しました。
| 導入パターン | 初期費用 | 月額費用(目安) | 適した企業規模 |
|---|---|---|---|
| クラウドAPI(従量課金) | 無料〜数万円 | 数千円〜数十万円(処理量に応じて) | スタートアップ〜大企業のPoC |
| SaaS型サービス | 無料〜数十万円 | 5万円〜50万円 | 中小企業〜大企業 |
| カスタム開発 | 数百万円〜数千万円 | 数十万円〜(インフラ・運用費) | 大企業・独自要件がある企業 |
コスト選定で最も重要なのは、「まず小さく始めて検証する」アプローチです。Cloud Vision APIやAzure Computer Visionの無料枠を活用してPoCを実施し、精度と費用対効果が確認できた段階でSaaS型や自社開発に移行するのが実務的な進め方です。月間の画像処理量が1万件未満であればクラウドAPIの従量課金が最もコスト効率に優れ、10万件を超える規模ではSaaS型の定額プランやカスタム開発のほうが割安になるケースが多くなります。
2026年3月時点の料金は各サービスの公式サイトを参照してください(Google Cloud Vision API、Azure Computer Vision)。

画像認識AI技術の理解を組織の業務設計に
画像認識AIの仕組みからクラウドサービスの比較まで理解した方は、AI導入の技術選定で的確な判断ができる段階にあります。画像認識の導入成果を起点に、他の業務領域にもAIを段階的に展開する全社設計が次のテーマです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための220ページの実践ガイドを無料で提供しています。AI総合研究所の専任チームが、画像認識のパイロット成果を全社的なAI導入ロードマップに発展させるところまで伴走します。
画像認識AI技術の理解を組織の業務設計に

AI技術選定力を全社的な導入計画へ
画像認識AIの仕組みとサービス比較で培った技術選定力は、組織全体のAI導入設計にそのまま活きます。段階的なAI業務自動化を220ページの実践ガイドで解説しています。
まとめ
この記事では、画像認識AIの基本的な仕組みから最新の技術動向、業界別の活用事例、主要サービスの比較、導入コストまでを体系的に解説しました。
画像認識技術は、CNNによるブレイクスルーからVision Transformer、そしてマルチモーダルAIへと進化を続けており、2026年時点でグローバル市場規模は約387億ドルに達しています。製造業の外観検査、医療画像診断、小売のセルフレジ、セキュリティの顔認証など、すでに多くの業界で実用化されており、日本企業の導入も加速しています。
画像認識AIの導入を検討する際は、以下の3ステップで進めることを推奨します。
- 自社の業務課題の中から、画像認識で自動化・効率化できる工程を特定する
- Cloud Vision APIやAzure Computer Visionの無料枠を活用し、少量のデータでPoCを実施して精度と費用対効果を検証する
- 検証結果をもとに、SaaS型サービスの導入やカスタムモデルの開発へ段階的に拡張する
画像認識の技術進化は今後も続き、エッジAIによるリアルタイム処理やマルチモーダルAIによる高度な画像理解がさらに普及していく見通しです。まず画像認識から着手することで、比較的短期間でAI導入の成果を実感できるでしょう。










