この記事のポイント
 2026年現在、テキスト→画像生成には拡散モデルを選ぶべきだが、リアルタイム生成・スタイル変換・医療データ拡張ではGANが依然として最適解
2026年現在、テキスト→画像生成には拡散モデルを選ぶべきだが、リアルタイム生成・スタイル変換・医療データ拡張ではGANが依然として最適解- 合成データ生成エンジンの61%がGANを採用しており、GDPR下のデータ不足を補う手段としてGANベースの合成データを第一に検討すべき
- 顔画像生成にはStyleGAN3、スタイル変換にはCycleGAN、速度と品質の両立にはGigaGANを選ぶのが実務上の正解
- EU AI Act(2026年8月全面施行)に備え、GAN生成コンテンツには電子透かしと生成AI表示の実装を今すぐ始めるべき
- PyTorch+DCGANの基本実装から始め、段階的にStyleGAN3やCycleGANへ移行するのが学習・導入の最短ルート

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIとは何かを支える生成モデルの革新技術であるGAN(敵対的生成ネットワーク)は、生成ネットワークと識別ネットワークが競い合うことでリアルなデータを生成する仕組みです。
2026年現在、テキストから画像を生成する分野では拡散モデル(Diffusion Model)が主流となっていますが、GANは合成データ生成エンジンの61%で依然として採用されており、医療画像の拡張やスタイル変換などの特定タスクでは強い優位性を持っています。合成データ生成市場は2026年に約5.9億ドル規模に達し、2035年には87.9億ドルへの成長が予測されています。
本記事では、GANの基本的な仕組みから、DCGAN・StyleGAN・CycleGANなどの代表的モデル、画像生成・医療・セキュリティでの活用事例、2026年のディープフェイク規制動向、そしてPyTorchによる実装の基本まで、実践的な知識を体系的に解説します。
GAN(敵対的生成ネットワーク)とは(2026年最新ガイド)
GAN(Generative Adversarial Network、敵対的生成ネットワーク)は、2つのニューラルネットワーク、すなわち生成ネットワーク(Generator)と識別ネットワーク(Discriminator)が互いに競い合いながら学習する仕組みです。2014年にIan Goodfellowらが発表して以来、画像生成・音声合成・医療画像拡張など多岐にわたる分野で革新をもたらしてきました。
生成ネットワークはランダムなノイズからデータ(画像など)を作り出す役割を担い、識別ネットワークはそのデータが本物か偽物かを判別します。この「いたちごっこ」を繰り返すことで、生成ネットワークはより本物に近いデータを生成できるようになり、識別ネットワークもより精度の高い判別力を身につけます。GANは教師なし学習に分類される技術であり、ラベル付きデータを必要とする教師あり学習とは根本的に異なるアプローチです。
以下の表で、GANの基本情報を整理しました。この表を確認したうえで、次のセクションで拡散モデルとの比較や2026年の市場動向を詳しく解説します。
| 項目 | 内容 |
|---|---|
| 正式名称 | Generative Adversarial Network(敵対的生成ネットワーク) |
| 提唱者 | Ian Goodfellow(2014年、NeurIPS) |
| 学習方式 | 教師なし学習(生成ネットワーク vs 識別ネットワークの敵対的学習) |
| 主な生成対象 | 画像、動画、音声、テキスト、3Dモデル、分子構造 |
| 代表的モデル | DCGAN、StyleGAN3、CycleGAN、Pix2Pix、WGAN、GigaGAN |
| 2026年市場ポジション | 合成データ生成エンジンの61%がGANを採用(拡散モデルと共存) |
| 2026年注目動向 | EU AI Act施行(2026/8)、ディープフェイク規制強化、医療画像拡張700%+ |
この表から分かるのは、GANが登場から10年以上経った2026年においても、合成データ生成の主力技術として広く使われている点です。テキストから画像を生成するタスクでは拡散モデルが主流になりましたが、スタイル変換、超解像、データ拡張といったタスクではGANが依然として強みを持っています。
機械学習とディープラーニングの中でGANは特異な位置を占めています。従来の画像認識AIが「何かを判別する」ことに特化しているのに対し、GANは「新しいデータを生み出す」ことに特化した生成モデルです。
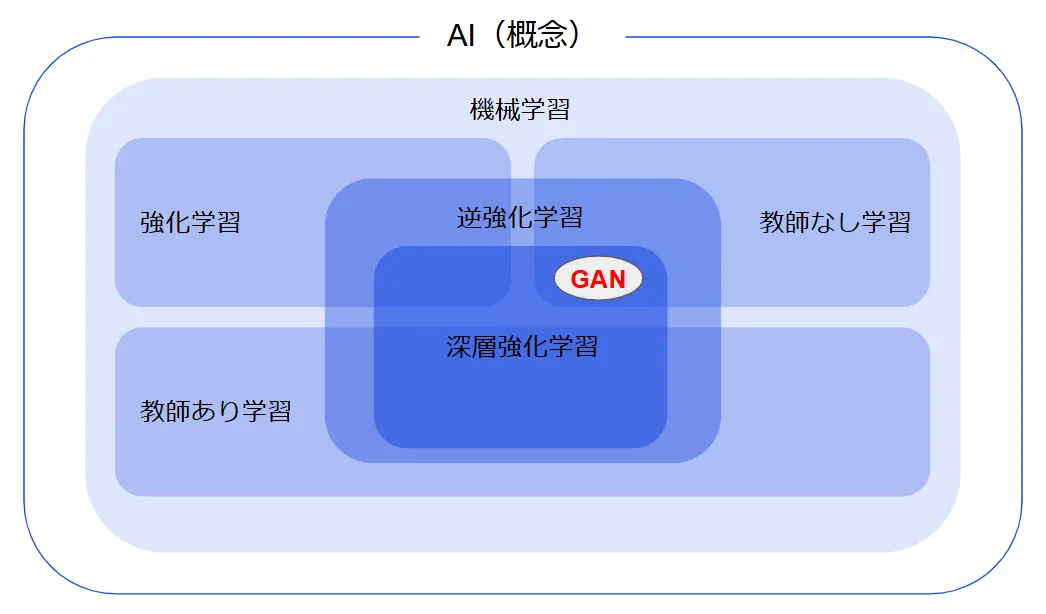
GANの立ち位置

拡散モデル台頭と合成データ時代のGANの役割
2026年の生成AI市場において、GANと拡散モデル(Diffusion Model)の関係を正しく理解することが不可欠です。拡散モデルはStable Diffusion、DALL-E 3、Adobe Fireflyなどで採用され、テキストから高品質な画像を生成するタスクでは事実上のスタンダードとなっています。一方、GANはリアルタイム生成や特定ドメインでの生成において速度と効率の面で優位性を維持しています。
具体的には、拡散モデルは安定性と多様性に優れる反面、生成に複数のステップ(数十〜数百回のノイズ除去)を要するため推論速度が遅くなります。GANは単一ステップで画像を生成できるため、リアルタイム処理やインタラクティブな用途に適しています。NVIDIAのStyleGAN3はエイリアスフリーアーキテクチャでサブピクセルレベルの平行移動・回転等変性を実現し、顔画像生成や医療画像分析で引き続き活用されています。AdobeのGigaGANは拡散モデルに匹敵する品質を桁違いに速い速度で達成しています。
合成データ生成市場は2026年に約5.87億ドルに達し、2035年には87.9億ドルへ、CAGR 34.7%で成長する見通しです。このうち61%の合成データ生成エンジンがGANを採用しており、54%がTransformerベースのアーキテクチャを統合しています。つまりGANは拡散モデルに「置き換えられた」のではなく、用途に応じた棲み分けが進んでいます。
GANの学習プロセスは、生成ネットワークと識別ネットワークの「競争と成長」の繰り返しです。ランダムノイズから生成されたデータを識別ネットワークが評価し、そのフィードバックをもとに生成ネットワークが改善を続けます。

GAN生成プロセス
大規模言語モデル(LLM)の台頭によりアノテーションやRLHFの需要が急増するなか、GANは合成データ生成を通じてAI開発のデータ不足を補完する重要な役割を果たしています。GDPRなどのプライバシー規制がデータ収集を制約する環境下で、GANベースの合成データは個人情報保護と学習データ確保を両立させる有力な手段です。Gartnerは2026年にAIプロジェクトで使用されるデータの75%が合成データになると予測しています。
主要モデルと応用分野の実践
GANには多くの派生モデルが存在し、それぞれが特定のタスクに最適化されています。2014年のオリジナルGANから2026年現在まで、アーキテクチャの進化が続いています。
以下の表で、代表的なGANモデルの特性を整理しました。この表を確認したうえで、次のセクションで具体的な活用事例と実装方法を解説します。
| モデル名 | 発表年 | 主な特徴 | 用途 | 2026年の評価 |
|---|---|---|---|---|
| DCGAN | 2016 | 畳み込みNNによる安定した画像生成 | 画像生成の基礎 | 教育・プロトタイプ用途で依然有用 |
| CycleGAN | 2017 | ペアデータ不要のスタイル変換 | 画像変換(馬→シマウマ等) | 医療画像ドメイン変換で活用中 |
| StyleGAN3 | 2021 | エイリアスフリー、サブピクセル等変性 | 高解像度顔画像生成 | 合成データ生成の主力 |
| Pix2Pix | 2017 | ペア画像の条件付き変換 | セグメンテーション→画像変換 | 建築・設計CG分野で活用 |
| WGAN | 2017 | Wasserstein距離による安定学習 | 学習安定化 | 勾配消失問題の標準対策 |
| GigaGAN | 2023 | 拡散モデル並みの品質+高速生成 | 高解像度画像生成 | 拡散モデルとの速度差で優位 |
実務でモデルを選ぶ際のポイントは、生成対象の種類とリアルタイム性の要件です。顔画像生成にはStyleGAN3、スタイル変換にはCycleGAN、安定した学習が必要な場合にはWGANが適しています。GigaGANは拡散モデルの品質を求めつつ速度も重視するユースケースで注目されています。
画像生成・医療・セキュリティの活用事例と実装
画像生成の活用事例
GANの最も広く知られた応用が画像生成です。機械学習を活用した画像認識と並んで、GANによる画像生成はコンピュータビジョン分野の中核技術となっています。
- 顔画像生成
実在しない人物の顔をリアルに生成する技術は、広告クリエイティブや映画のプリプロダクションで実用化されています。以下のGenerated Photosの事例では、性別・年齢・人種・目の色・髪型など多様な要素を制御しながら、現実と見分けがつかないレベルの顔画像を生成しています。

引用元:Generated Photos
- 画像の高解像度化(Super-resolution)
低解像度の画像を高解像度に変換するSRGANやPULSEなどの技術は、印刷品質の向上やデジタルアーカイブの復元に活用されています。PULSEはピクセルが見えるほど低解像度の写真を、本物の人間のように見える写真に変換する能力を示しました。

引用元:PULSE
- 画像の修復(Restoration)
GFPGANは、入力された顔画像から事前情報を作成し、StyleGAN2の高画質生成能力を活用することで、傷ついたり劣化した写真を高品質に復元します。古い家族写真の色褪せや破損部分の修復、監視カメラ映像の鮮明化などに応用されています。

引用元:Towards Real-World Blind Face Restoration with Generative Facial Prior
医療分野での応用
医療画像の分野では、GANによるデータ拡張が学習データ不足の課題を解決しています。複数の研究で、GANベースの拡張によりデータセットサイズを700%以上増加させ、モデルの汎化性能を大幅に向上させた事例が報告されています。DCGAN、Pix2Pix、CycleGAN、StarGANなどが、BraTS(脳腫瘍)、ISIC(皮膚疾患)、DRIVE(網膜血管)といったベンチマークデータセットで有効性を実証しています。
以下の事例では、広角眼底画像の視神経乳頭や血管の特徴を維持したまま、擬似的な網膜剥離症例画像を生成しています。このような合成画像により、希少疾患の診断AIを少ないデータからでも訓練できるようになります。
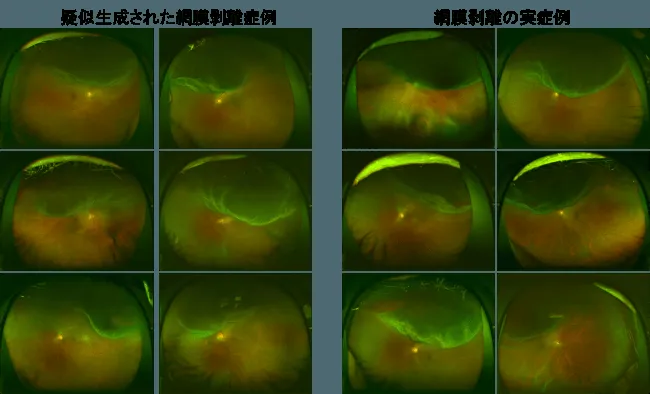
引用元:プレスリリース
アートと音声合成
GANはアーティストの創作ツールとしても活用されています。Artbreederでは、GANを使用して様々なスタイルや要素を組み合わせ、写真をピカソ風やゴッホ風に変換するスタイル変換も実現しています。

引用元:公式HP
音声合成の分野でもGANは革新をもたらしています。生成ネットワークと識別ネットワークの競争により、従来の合成音声よりも自然で感情豊かな音声を生成できます。以下の動画では、AIレセプションが自然な会話で客対応する実例を確認できます。
PyTorchによるGANの基本実装
GANの実装には、PyTorchやTensorFlowなどの深層学習フレームワークが使用されます。以下は、PyTorchを用いた生成ネットワーク(Generator)の基本的な定義例です。ランダムノイズ(100次元)を入力として受け取り、28x28ピクセルの画像を出力する構造になっています。
import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, z):
return self.fc(z).view(-1, 1, 28, 28)
このGeneratorと対になるDiscriminator(識別ネットワーク)を定義し、バイナリクロスエントロピー損失関数とAdamオプティマイザで交互に学習させることで、GANの基本的な訓練が実行できます。実装の詳細はPyTorch公式のGANチュートリアルが参考になります。転移学習の手法を応用すれば、事前学習済みのGANモデルを特定のドメインにファインチューニングすることも可能です。
評価指標と倫理的課題の比較
GANの生成結果を定量的に評価するための指標は、モデル選定や品質管理において重要な役割を果たします。AIと機械学習の他のタスクと異なり、GANの評価は主観的な要素が大きいため、複数の指標を組み合わせて総合的に判断することが推奨されています。
以下の表で、代表的な評価指標の特性を比較しました。FIDスコア2〜5が「非常に高品質」、10〜30が「良好」、50以上は「明確な差異あり」とされています。
| 評価指標 | 評価対象 | 長所 | 短所 |
|---|---|---|---|
| FID(Fréchet Inception Distance) | 生成画像と本物の統計的分布差 | 品質を高精度に測定、最も広く使用 | Inceptionネットワークの性能に依存 |
| IS(Inception Score) | 生成画像の多様性と意味の明確さ | 計算が速くシンプル | 視覚的品質を完全には反映しない |
| 識別精度(Discriminator Accuracy) | 識別ネットワークの判別能力 | 直感的に理解しやすい | 高精度でも生成品質が高いとは限らない |
| 多様性指標(Diversity Metrics) | 生成データ間の変動量 | モード崩壊を検出できる | 品質の評価には不向き |
| SID(Structural Inception Distance) | FIDの改良版、構造的特徴 | FIDの限界を補完 | 2026年時点で普及途上 |
実務でGANの品質を評価する際は、FIDを主指標として採用し、多様性指標でモード崩壊の有無を確認するアプローチが一般的です。医療画像など特定ドメインでは、タスクベースの評価指標(精度、感度、Diceスコア、SSIM、PSNR)を併用することが推奨されます。
ディープフェイク規制と企業の対策事例
GANの技術的課題とともに、ディープフェイクに関する倫理的・法的な課題が2026年に大きな転換点を迎えています。EUROPOLの予測では、2026年までにデジタルコンテンツの90%がAI生成になるとされており、真偽の判別がますます困難になっています。
-
EU AI Act(2026年8月2日施行)
AI生成または加工されたメディアに対して、機械可読形式でのラベリングを義務化します。違反した場合、最大1,500万ユーロまたはグローバル売上高の3%の罰金が科されます。AI規制法の枠組みのなかで、GAN生成コンテンツも明確に規制対象となっています。
-
米国TAKE IT DOWN Act(2025年5月19日成立)
非合意の親密なディープフェイクを犯罪化し、最大2年の禁固刑(未成年者の場合は3年)を科します。GAN技術を悪用した画像生成への法的抑止力として機能しています。
-
C2PA(Coalition for Content Provenance and Authenticity)
コンテンツの出所と真正性を保証するための技術標準であり、GANやDiffusionで生成されたメディアにデジタルウォーターマークを埋め込む仕組みが普及し始めています。
企業のGAN活用事例として、Waymo(Googleの自動運転部門)はGANを用いて自動運転車のシミュレーションに必要な大量の走行シナリオデータを生成し、テストと学習の効率化を実現しています。

引用元:Waymo
創薬分野では、Insilico MedicineがGANを利用した創薬プラットフォームで新しい薬の候補分子を効率的に生成しています。従来の手法では数年かかる候補分子の探索を、GANにより大幅に短縮できる可能性が示されています。生成AIの企業導入が加速するなか、こうした特定ドメインでのGAN活用はさらに拡大する見通しです。


導入時の注意点と活用ガイド
GANの導入にあたっては、技術的な課題と倫理的なリスクの両面から注意が必要です。自然言語処理やAI画像認識サービスと比較して、GANは学習の不安定性やモード崩壊といった独自の課題を抱えており、事前に対策を理解しておくことが重要です。
以下の表で、導入時に押さえるべき5つの注意点を整理しました。
| 注意点 | リスク | 対策 |
|---|---|---|
| モード崩壊(Mode Collapse) | 生成データの多様性が失われ、同じようなデータしか生成されなくなる | WGAN、勾配ペナルティ、条件付きGAN(cGAN)の導入 |
| 勾配消失・勾配爆発 | 学習が進まなくなる、または不安定になる | Xavier/He初期化、LeakyReLU/ELU活性化関数、学習率スケジューリング |
| 学習の不安定性 | GeneratorとDiscriminatorのバランスが崩れ、学習が振動・発散する | Spectral Normalization、Progressive Growing、Two Time-Scale Update Rule |
| ディープフェイク悪用 | 偽画像・偽動画による社会的混乱、名誉毀損、詐欺 | C2PA準拠のウォーターマーク埋め込み、生成コンテンツへのメタデータ付与、社内倫理ガイドライン策定 |
| 計算コスト | 高解像度画像の生成には大量のGPUリソースが必要 | 低解像度からのProgressive Growing、事前学習モデルの転移学習、クラウドGPUの活用 |
特にモード崩壊と学習の不安定性は、GAN特有の課題として多くのプロジェクトで直面する問題です。WGAN(Wasserstein GAN)は損失関数にWasserstein距離を採用することで勾配消失を防ぎ、学習を安定化させる手法として広く使われています。また、StyleGAN系列で採用されているProgressive Growing(低解像度から段階的に高解像度へ学習を進める手法)は、学習の安定性と生成品質の両方を向上させる有効なアプローチです。
ディープフェイクの倫理的リスクについては、2026年8月のEU AI Act施行に向けて、生成コンテンツのラベリングとトレーサビリティの仕組みを事前に構築しておくことが企業にとって急務です。
段階的導入ステップとよくある質問
GANをプロジェクトに導入する際は、以下の3ステップで段階的に進めることを推奨します。ChatGPTなどの大規模言語モデルとは異なり、GANは学習の調整に専門知識が必要なため、小規模な実験から始めることが成功の鍵です。
-
ステップ1 フレームワーク選定とプロトタイプ(1〜2週間)
PyTorchまたはTensorFlowの公式GANチュートリアルを実行し、MNIST・CelebAなどの標準データセットでDCGANの基本的な訓練を体験します。生成品質の評価にはFIDスコアを使用し、ベースラインを確立します。この段階で、用途(データ拡張・画像生成・スタイル変換)に応じたモデル候補を絞り込みます。
-
ステップ2 ドメイン特化の学習とPoC(2〜4週間)
自社データを用いてStyleGAN3やCycleGANなどのモデルを訓練します。モード崩壊や勾配消失への対策(WGAN、勾配ペナルティ)を実装し、生成品質が要件を満たすかを検証します。医療・製造など規制の厳しい分野では、生成データの倫理的利用ガイドラインもこの段階で策定します。
-
ステップ3 本番運用とガバナンス構築(1〜2か月)
AI開発に強い企業との連携も視野に入れ、GPU計算資源の最適化、モデルのバージョン管理、生成コンテンツのC2PA準拠ラベリングを運用フローに組み込みます。EU AI Act対応のコンプライアンス体制を整備し、継続的なモデル改善のパイプラインを構築します。
GAN導入に関するよくある質問を以下にまとめます。
-
GANと拡散モデルのどちらを選ぶべきか
テキストから画像を生成するタスク(Text-to-Image)では拡散モデルが優位です。一方、リアルタイム生成、スタイル変換、データ拡張、超解像ではGANが速度・効率の面で適しています。両者を組み合わせるハイブリッドアプローチも増えています。
-
GANの学習にはどの程度のGPUリソースが必要か
DCGANのMNIST学習なら単一GPU(RTX 3060程度)で数時間。StyleGAN3で1024x1024の高解像度画像を訓練するには、NVIDIA A100×8で数日〜数週間が目安です。クラウドGPU(AWS、GCP、Azure)の利用が一般的です。
-
ディープフェイク対策は何を準備すべきか
C2PA(Content Provenance and Authenticity)標準に準拠したウォーターマークの埋め込みが基本です。2026年8月のEU AI Act施行に向けて、生成コンテンツの機械可読ラベリングシステムを導入しておくことが推奨されます。
まずはPyTorchの公式GANチュートリアルでDCGANの基本を体験し、FIDスコアで生成品質を定量的に評価するところから始めてみてください。

GANの技術知識を組織のAI業務戦略の土台に据える
GANの基本原理と応用事例を理解したことで、AI技術がビジネスにもたらす可能性を実感できたのではないでしょうか。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進める実践ガイド(220ページ)を無料で提供しています。AI技術全般の業務適用に必要な段階設計を、部門別のBefore/After付きユースケースで解説しています。
AI総合研究所が、AI技術の理解を組織の業務戦略の土台として据えるガイドをお届けします。
AI生成技術の理解を業務活用に広げる

段階的なAI導入の実践ガイド(220p)
GANを含む生成AI技術を理解した次は、AIを組織の業務プロセスに組み込む段階設計です。Copilot ChatからCopilot Studioまで段階的に導入する220ページの実践ガイドで、AI活用の道筋をご確認ください。
まとめ
本記事では、GAN(敵対的生成ネットワーク)の基本的な仕組みから2026年の最新動向までを体系的に解説しました。生成ネットワークと識別ネットワークの敵対的学習という革新的な仕組みにより、GANは画像生成・医療画像拡張・音声合成・創薬など多岐にわたる分野で実用化されています。
2026年現在、テキストから画像を生成するタスクでは拡散モデルが主流となりましたが、合成データ生成エンジンの61%がGANを採用しており、スタイル変換・超解像・データ拡張などの特定タスクでは依然として優位性を持っています。医療画像分野ではGANによるデータ拡張で700%以上のデータセット拡張が実現されており、希少疾患の診断AI訓練に大きく貢献しています。
導入にあたっては、モード崩壊や勾配消失などの技術的課題への対策と、EU AI Act(2026年8月施行)やTAKE IT DOWN Actなどのディープフェイク規制への対応が不可欠です。プロトタイプ(1〜2週間)→PoC(2〜4週間)→本番運用(1〜2か月)の段階的アプローチで進めることを推奨します。
出典
- DataInsights Market - Synthetic Data Generation Market Size ($586.81M 2026 → $8.79B 2035)
- Sapien.io - GANs vs Diffusion Models: A Comparative Analysis
- TechPolicy.Press - EU AI Act Code of Practice for Deepfake Labeling (2026/8施行)
- NVIDIA - StyleGAN3: Alias-Free Generative Adversarial Networks
- ScienceDirect / PMC - GAN Applications in Medical Image Augmentation (700%+ dataset expansion)








