この記事のポイント
 データ基盤の統合を検討中の企業は、Microsoft Fabricが第一候補。2026年のアップデートで基盤機能が急速に成熟している
データ基盤の統合を検討中の企業は、Microsoft Fabricが第一候補。2026年のアップデートで基盤機能が急速に成熟している- Data Factory強化により、既存のAzure Data Factoryからの移行を段階的に進めるべきフェーズに入った
- リアルタイムインテリジェンスの拡充で、ストリーミング分析をFabric上に集約するのが有効
- 2月のモダン評価エンジンGA・ダッシュボード10倍高速化は、Power BI単体運用からFabric統合へ切り替える判断材料になる
- Spark/データエンジニアリング領域はまだ機能追加が続いており、大規模ETL移行は次の四半期以降が最適

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Microsoft Fabricは毎月大規模なアップデートを行っていますが、公式ブログは英語ベースで情報量も膨大です。
「結局何が変わったの?」「自分のチームに影響ある?」と感じる方も多いのではないでしょうか。
本記事では、2026年のMicrosoft Fabricアップデートをカテゴリ別・月別に整理し、公式Feature Summaryの全項目を日本語で解説します。毎月更新していきますので、ブックマークしてご活用ください。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
毎月中旬〜下旬に更新しますので、ブックマークしてご活用ください。
2026年4月 - Data Factory OAPほか2件
2026年3月 - AI-Powered Prompt Transform GAほか41件
2026年4月 - SQL Eventstream処理 GAほか5件
2026年3月 - Fabric Runtime 2.0ほか14件
2026年1月 - Lakehouse高同時実行モードほか4件
2026年3月 - Fabric data agents GAほか6件
2026年2月 - Semantic Link 0.13.0ほか1件
2026年3月 - Warehouse OAP GAほか28件
2026年4月 - タブ操作とExplorer GAほか5件
2026年3月 - OneLake Catalog Govern GAほか15件
2026年4月 - VS Code workspace GAほか4件
2026年3月 - Fabric Extensibility Toolkit GAほか20件
Microsoft Fabricアップデートまとめ
Microsoft Fabric(マイクロソフト ファブリック)は、データの収集・加工・分析・Power BIによる可視化を一貫して行えるSaaS型のデータ分析基盤です。
Microsoftは毎月「Feature Summary」として新機能や改善点を公開していますが、英語かつ情報量が多いため、日本語環境のユーザーにとって追いかけ続けるのは負担が大きいのが実情です。
そこで本記事では、公式Feature SummaryとMS Learnの新着情報の両方をソースとして、2026年のアップデートをカテゴリ別・月別に整理して日本語で解説します。
Feature Summaryが公開された月はその項目を軸に、未公開の月はMS Learnの新着情報をベースに整理し、実務でのインパクトや関連ドキュメントへのリンクも添えています。
毎月中旬〜下旬に更新しますので、ブックマークしてご活用ください。

月別アップデートサマリー
Microsoft Fabricは毎月中旬〜下旬に「Feature Summary」として新機能や改善点を公式ブログで発表しています。ただし、月によってはFeature Summary公開前にMS Learnへ先行反映されることがあります。このセクションでは、各月のアップデートをカテゴリ別の件数・注目トピックとともにサマリーテーブルで一覧しています。
テーブル内のリンクから、該当カテゴリの詳細セクションに直接ジャンプできますので、気になる機能をすぐに確認できます。
過去月のサマリーも掲載しているため、特定の月に何が変わったかを振り返る際にもご活用ください。
2026年4月
公式:Fabric April 2026 Feature Summary

4月はリアルタイムインテリジェンスと開発者ツール、データエンジニアリングのアップデートが特に厚かった月です。Feature Summary掲載分に加えてMS Learn新着情報の独自項目も含め、全7カテゴリで合計34件(GA 17件 / PREVIEW 17件)のアップデートを整理しています。
リアルタイムインテリジェンスではEventstreamのSQL operator GA、SQL Change Event Streaming連携、ミラーデータベース変更フィード、Workspace Monitoring統合まで進み、低遅延イベント処理を本番運用へ寄せる機能がまとまって揃いました。データエンジニアリングではShortcut transformationsのGAとNested folders対応、ADO.NET Driverプレビュー、Mavenによる依存管理など、Lakehouse取り込みとSpark SQL接続の選択肢が広がっています。
| カテゴリ | 件数 | 注目トピック | ステータス |
|---|---|---|---|
| データエンジニアリング | 6件 | Shortcut変換GA | GA/Preview |
| プラットフォーム全体 | 6件 | タブ操作とExplorer GA | GA/Preview |
| リアルタイムインテリジェンス | 6件 | SQL Eventstream処理 GA | GA/Preview |
| データウェアハウス | 5件 | ALTER TABLE txn GA | GA/Preview |
| 開発者ツール | 5件 | VS Code workspace GA | GA/Preview |
| Data Factory | 3件 | Data Factory OAP | GA |
| データサイエンス | 3件 | MLflow横断記録 | GA/Preview |
プラットフォーム全体ではタブ操作とObject ExplorerのGAに加え、Workspace CMK、OneLake Resource instance rules、Associated identityなど、UI体験とテナント単位のガバナンスが同時に強化されました。
開発者ツールはVS Code連携が中心で、ワークスペース管理/Environment YAML編集/既定Lakehouse切替がGAとなり、Fabric Local MCPのGAとRemote MCPプレビューでAIアシスタント支援の選択肢も広がりました。データウェアハウスではALTER TABLE txnとCOPY INTO JSONLのGAが本番投入を後押しし、Warehouse復元プレビューが事故復旧の保険として加わっています。
2026年3月
公式:Fabric March 2026 Feature Summary

3月はFabCon 2026と連動して全カテゴリで大規模アップデートが発表された月です。Feature Summary掲載分に加えてMS Learn新着情報の独自項目も含め、全7カテゴリで合計145件のアップデートを整理しています。
特にData Factoryが42件と突出しており、Copy jobのCDC機能拡張(Oracle CDC source、SCD Type 2、組み込み監査列、AutoPartitioning)、Dataflow Gen2の新出力先(Snowflake、Excel、Lakehouse files)とVariable Library拡張、Apache Airflow連携の強化など、データ統合レイヤーの成熟が一気に進みました。
データウェアハウスも29件と大きく、Warehouse本体のリカバリ・Custom SQL Pools・OAP・SQL Audit Logs GA・COPY INTO/OPENROWSET GAに加えて、SQL database in Fabricの監査・CMK・ベクトル検索・AI Foundry連携、MirroringのSAP/Oracle GAとMySQL/SharePoint List/Change Data Feedプレビューまで一気に揃いました。プラットフォーム全体ではOneLake Catalog GovernのGA、Purview DSPM for AI連携、ワークロード管理の一元化など、ガバナンスとテナント管理の刷新が目立ちます。
| カテゴリ | 件数 | 注目トピック | ステータス |
|---|---|---|---|
| Data Factory | 42件 | AI-Powered Prompt Transform GA | GA/Preview/Announcement |
| データウェアハウス | 29件 | Warehouse OAP GA | GA/Preview |
| 開発者ツール | 21件 | Fabric Extensibility Toolkit GA | GA/Preview |
| プラットフォーム全体 | 16件 | OneLake Catalog Govern GA | GA/Preview |
| データエンジニアリング | 15件 | Fabric Runtime 2.0 | Preview中心 |
| リアルタイムインテリジェンス | 15件 | Fabric Maps GA | GA/Preview |
| データサイエンス | 7件 | Fabric data agents GA | GA/Preview |
開発者ツールはFabric Extensibility ToolkitのGAを軸に、Git統合のBranched Workspace/Selective Branching/差分比較、Fabric CLI v1.5、Fabric MCP(Remote/AI code assistants)など、Fabric上での開発体験を支える機能が21件まとまって前進しました。
データサイエンスではFabric data agentsがGAとなり、AI機能のマルチモーダル対応やデータソース拡張も加わり、Fabric上でのAIエージェント構築が実用段階へと入った月です。リアルタイムインテリジェンスではFabric MapsのGAに加え、Business Eventsのプレビュー、Eventstream Deltaflow、Copilotによるダッシュボード可視化生成など、イベント駆動処理が大きく進展しています。
2026年2月
公式:Fabric February 2026 Feature Summary

2月はGA(一般提供)ステータスの機能が多く、プレビューを経て本番利用可能になった機能が集中した月です。
全7カテゴリで合計32件のアップデートが発表されました。以下の表にカテゴリごとの件数と注目トピックをまとめました。
| カテゴリ | 件数 | 注目トピック | ステータス |
|---|---|---|---|
| Data Factory | 12件 | モダン評価エンジンGA | GA |
| データエンジニアリング | 8件 | ノートブック版履歴強化 | GA |
| プラットフォーム全体 | 4件 | OneLakeカタログ刷新 | GA |
| リアルタイムインテリジェンス | 3件 | ダッシュボード10倍高速化 | GA |
| データサイエンス | 2件 | Semantic Link 0.13.0 | GA |
| データウェアハウス | 2件 | SQLプールInsights | GA |
| 開発者ツール | 1件 | [VS Code Copilot Chat連携](#2026年2月---vs-code-copilot-chat連携) | GA |
Data Factoryだけで12件と圧倒的に多く、パイプラインやDataflow Gen2の運用に関わるエンジニアは特に注目です。
リアルタイムダッシュボードの大幅高速化やvNet対応など、本番環境への即効性が高いアップデートも目立ちます。
2026年1月
1月はプラットフォーム基盤の強化が目立つ月でした。OneLakeカタログの親子階層表示やセキュリティAPI拡充、Git統合の柔軟化など、ガバナンスと開発者体験の両面で大きな進展がありました。
データウェアハウスではMERGE文とResult Set CachingがGAとなり、本番投入可能な機能が増えています。
全5カテゴリで合計25件のアップデートが発表されました。
| カテゴリ | 件数 | 注目トピック | ステータス |
|---|---|---|---|
| プラットフォーム全体 | 9件 | OneLakeカタログ親子階層 | GA/プレビュー |
| リアルタイムインテリジェンス | 6件 | MQTT v3対応 | GA |
| データエンジニアリング | 5件 | Lakehouse高同時実行モード | GA |
| データウェアハウス | 4件 | MERGE文GA | GA |
| Data Factory | 1件 | 増分コピーコネクタ拡充 | GA |
プラットフォーム全体だけで9件と圧倒的に多く、Fabric基盤そのものの成熟度が上がった月です。
また、MicrosoftによるOsmos社の買収も発表され、Fabric上でのエージェント型データエンジニアリングへの布石が打たれました。

公式:Fabric January 2026 Feature Summary
Data Factory
Data Factoryは、Microsoft Fabric上でデータパイプラインの構築・運用を担うサービスです。Dataflow Gen2によるデータ変換、Copy jobによるデータ移動、パイプラインオーケストレーションなど、ETL/ELT処理の中核を担います。
Azure Data Factoryの機能をFabric上に統合・発展させたサービスであり、Fabricのデータ統合レイヤーとして位置づけられています。
2026年4月 - Data Factory OAPほか2件

Data Factory OAP
Data Factory向けOutbound Access Protection(OAP)が一般提供になりました。保護されたワークスペース内のPipelines、Copy Job、Dataflows、Mirrored Databasesは、管理者が許可したエンドポイントにのみ接続できます。
対象にはMirrored SQL DatabaseとMirrored Snowflakeも含まれます。一方で、同じMS Learnの説明ではData AgentとEventstreamsのOAP対応はPreviewとして扱われています。
参考:Workspace outbound access protection for Data Factory
Gateway 4月更新
On-premises data gatewayの2026年4月リリースとして、version 3000.314が公開されました。MS Learnでは、このリリースが2026年4月のPower BI Desktop releaseに対応するものとして説明されています。
同項目では、On-premises Data Gateway Auto-Update(Admin Triggered)がGenerally Availableであることも案内されています。管理者はメンテナンスウィンドウに合わせて、ゲートウェイ更新をオンデマンドで実行できます。
参考:What's new in Microsoft Fabric
Netezza旧ODBC廃止
IBM Netezza ODBC driverがGenerally Availableになったことを受け、以前の組み込みODBC driverから新しいIBM公式ODBC driverへの移行が始まりました。Feature Summaryでは、旧組み込みドライバーの非推奨化が案内されています。
既存のNetezza connectorは再利用できますが、新しいODBC driverのインストールは必要です。公式ページでは、円滑な移行のため早めに対応するよう案内されています。
参考:Fabric April 2026 Feature Summary
2026年3月 - AI-Powered Prompt Transform GAほか41件

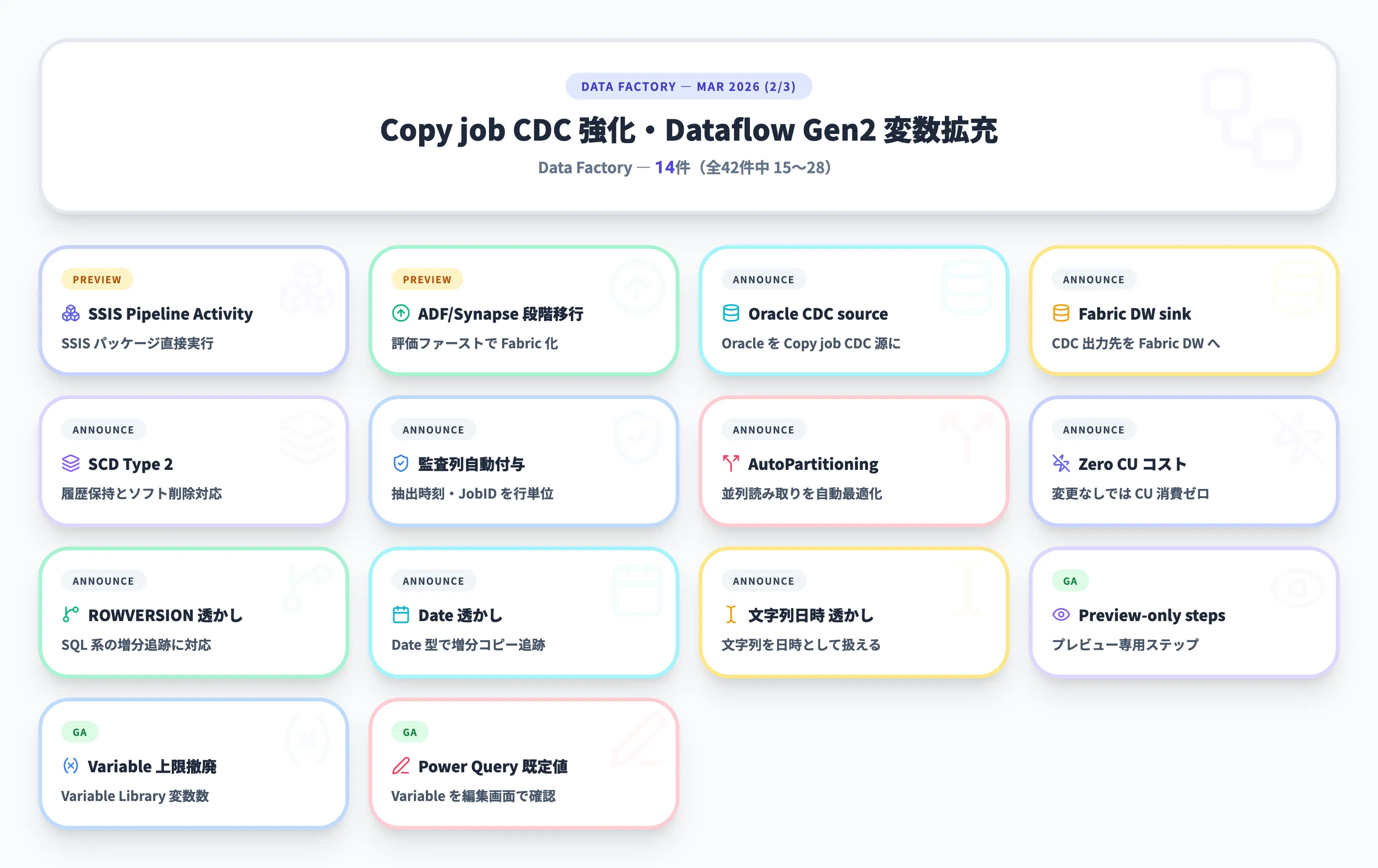

3月のData Factoryは42件と、単一月・単一カテゴリとしては過去最大規模の更新が入りました。FabCon 2026での発表を中心に、Copy jobのCDC機能拡充、Dataflow Gen2の新出力先、Apache Airflow連携、Variable Library統合、AIプロンプト変換GAなど、データ統合レイヤーの重要機能が一斉に成熟フェーズへと移行しています。
本セクションでは、コネクタ・ゲートウェイ強化、パイプラインアクティビティとAirflow連携、Copy jobのCDC・増分拡張、Dataflow Gen2の評価エンジン・新出力先・Variable Library連携という順で42件を解説します。
Data Factory MCP(Preview)
Claude DesktopやGitHub Copilotなどのエージェントから、Dataflow Gen2の作成、接続管理、クエリ実行、更新制御をModel Context Protocol(MCP)経由で扱えるようになりました。自然言語でData Factory操作を指示でき、AIエージェントからFabricデータ統合を操作する新しい入口として位置づけられています。
現時点ではGitHubで公開されているプレビュー段階で、ローカル環境のMCPクライアントから利用する構成です。既存のSDKやREST APIと比べて、プロンプトベースの対話的操作を前提としている点が大きな特徴で、Data Factoryの利用ハードルを下げる効果が期待できます。
実務では、データソースの探索、簡易な変換パイプラインの生成、ジョブ実行状況の確認など、定型的な問い合わせをAI経由で処理する用途から段階的に導入するのが現実的です。AIエージェントに生成・実行権限を与える範囲は、Fabricの権限モデルと組み合わせて慎重に設計する必要があります。
参考:Data Factory MCP(GitHub リポジトリ)
IBM Netezza ODBC Driver(GA)
IBM Netezzaコネクタの基盤が、従来組み込みだったSimbaドライバーから、IBM公式のODBCドライバーに正式移行し、GAとなりました。これにより、IBMが保守する最新ドライバーを前提とした長期利用が可能です。
既存環境でSimbaベースの接続を使っている場合、公式ドライバーの導入と接続定義の更新が必要です。IBM側のサポートポリシー変更への追随がしやすくなった反面、ドライバーのアップデート計画を運用チーム側で管理する必要も出てきます。
IBM Netezzaに大量のレガシーデータ資産を持つ企業にとって、Fabricとの接続経路が安定化する意味は大きく、PerformanceやTLS/認証周りの互換性が改善されるケースも多いです。
参考:IBM Netezza database (Power Query connector)
Google BigQuery connector(GA)
新しいGoogle BigQueryコネクタが一般提供になりました。従来コネクタから機能・認証方式・パフォーマンスが刷新された新コネクタで、長期利用を前提とした正式サポート対象となります。
Service Account認証やプロジェクト横断クエリの扱いが改善され、BigQuery固有のデータ型マッピングも見直されています。FabricでマルチクラウドのBI基盤を構築する場合、GCP側のデータを Power BI セマンティックモデル経由で扱う導線が安定しました。
BigQueryをメインデータウェアハウスとして使う企業がFabricを部分導入するシナリオでは、このコネクタのGAが本格採用の前提条件になります。既存のDataflowをリファクタする際は、旧コネクタと新コネクタの動作差分を事前検証しておくのが安全です。
参考:Google BigQuery (Power Query connector)
QuickBooks Online connector retirement(提供終了アナウンス)
QuickBooks Onlineコネクタの提供終了がアナウンスされました。新規接続の作成が段階的に制限され、将来的には既存接続の動作も停止する予定です。
QuickBooksデータをDataflow Gen2やPower BIに取り込んでいる組織は、代替手段として、QuickBooks提供のREST APIを直接呼び出すAzure FunctionsやADF外部連携経由の取り込みへの切り替えを計画する必要があります。財務系ワークフローでは更新停止が業務停止につながるため、早めの置き換えが推奨されます。
コネクタ廃止のタイムラインは段階的に案内される見通しで、公式告知のウォッチ体制を整えておくと安全です。
参考:Microsoft Fabric blog — March 2026 Feature Summary
Lakehouse Maintenance activity in Fabric Pipelines(Preview)
Fabricパイプラインのアクティビティとして、Lakehouseのvacuumや最適化、Z-order、Delta圧縮などの保守処理を組み込めるようになりました。これまでnotebookやジョブスケジューラで実装していた保守処理を、パイプラインの1ステップとして宣言的に表現できます。
Lakehouseを業務データの中心に据える組織では、定期メンテナンスの自動化が必須です。従来はPySparkコードの保守が負担でしたが、Lakehouse Maintenance activityに置き換えることで、コード品質への依存を下げつつ運用できます。
実運用では、夜間バッチパイプラインの末尾に組み込み、Copy jobとMerge処理の直後にvacuum/optimizeをトリガする構成が典型的です。
参考:Lakehouse maintenance activity in Fabric pipelines
Refresh SQL endpoint activity in Fabric pipelines(Preview)
Lakehouseに紐づくSQL endpointを、パイプラインからオンデマンドで更新するアクティビティが追加されました。Lakehouseにデータを書き込んだ直後にSQL endpointのメタデータ同期を明示実行できるため、下流のSQLクエリやPower BIダッシュボードが最新データを参照できます。
これまではSQL endpointの自動更新に任せており、タイミングのコントロールが難しい場面がありました。このアクティビティを挟むことで、レポート側の初回参照遅延を大幅に短縮できます。
夜間ETLの完了後にこのアクティビティを走らせてから、BIジョブを起動する設計が典型的で、ダッシュボード利用者への新鮮なデータ提供を保証しやすくなります。
参考:Refresh SQL endpoint activity in Fabric pipelines
Generate Pipeline expressions with Copilot(GA)
Fabricパイプラインの式エディタに、Copilotによる式自動生成機能がGAとなりました。自然言語で「前日の日付を YYYY-MM-DD 形式で返す」などと指示すると、対応するパイプライン式を生成してくれます。
パイプライン式はJSONベースの独自DSLで、初学者にとって学習コストが高い領域でした。CopilotのGAにより、実務経験が浅いメンバーでも複雑な分岐やタイムゾーン変換を含む式を書けるようになり、パイプライン開発の属人化を緩和できます。
大規模なパイプライン資産を持つ組織では、式の一貫性を保つため、Copilot生成結果を社内コーディング規約に合わせる二次レビューの運用を組み込むのが安全です。
参考:Fabric March 2026 Feature Summary — Pipeline Copilot
Workspace monitoring for Pipelines and Copy jobs(Preview)
ワークスペース単位で、すべてのパイプライン・Copy jobの実行状況を横断監視できるモニタリング機能がプレビューになりました。Kustoベースのログをワークスペース監視Eventhouseに流し込み、ダッシュボードや問い合わせで可視化する構造です。
これまでは個別ジョブごとに実行履歴画面を開く必要がありましたが、ワークスペースレベルで失敗件数・所要時間・リトライ回数を集計できるようになり、SLA運用と異常検知が一段と行いやすくなります。
実運用では、ワークスペース監視Eventhouseに対してKQLアラートを設定し、Teams・Slackへの通知や、Copilot for DE/DSによる障害解析につなげるパイプラインが有効です。
参考:Workspace monitoring for Data Factory
Interval-based schedules(アナウンス)
パイプラインスケジューリングで、時間間隔ベースの非重複実行(tumbling window に近いモデル)を設定できるようになることが案内されました。従来のCron的スケジュールに加えて、固定の時間窓単位でジョブを並べられる形式です。
時系列データのバッチ処理で、間隔ベースの独立ウィンドウを順に処理したい場合、この仕組みが明示的にサポートされる意味は大きいです。遅延リトライやバックフィル処理もウィンドウ単位で制御できます。
財務日次締め、時間足のセンサーデータ集計、ログローテーション処理など、ウィンドウ境界が明確なワークロードで特に効果を発揮します。
参考:Fabric March 2026 Feature Summary — Data Factory scheduling
New Airflow APIs(アナウンス)
Apache Airflow JobsのREST API群が拡充され、DAGの登録・更新・実行制御・ログ取得を外部システムから細かく扱えるようになりました。Airflowベースのオーケストレーションを、FabricのAPI前提の運用に組み込みやすくなります。
これまでAirflow UIに依存していた運用タスクをAPI化できるため、社内ポータルや監視系システムとの連携、CI/CDパイプラインからのDAGデプロイなど、自動化の範囲が広がります。
本アナウンスは見出しベースで、個別APIの詳細仕様は追って展開される見通しです。Airflow Jobsを本格採用する組織は、Public APIの情報を継続的にウォッチする必要があります。
参考:Apache Airflow Jobs in Fabric Data Factory
New Airflow Operators(アナウンス)
Apache AirflowのDAGから、Fabric上のCopy job、Dataflow Gen2、dbt job、Lakehouse maintenance などを直接操作できるネイティブOperatorが追加されました。FabricのAirflow JobsはMicrosoft製のOperatorがバンドルされている構成です。
従来、外部AirflowからFabricを呼び出す場合はREST API/Azure Functionsを経由するラッパー実装が必要でしたが、公式Operatorにより、DAGコードから自然にFabric資産を扱えるようになります。
dbt on Fabricを軸にしたモデリング基盤と、FabricのCopy jobやDataflow Gen2を同一DAG内で連携させる構成が実装しやすくなり、データエンジニアリングのIDE化が一段と進みます。
参考:Run a Fabric item job from Apache Airflow
PowerShell model for gateways(GA)
オンプレミスデータゲートウェイと仮想ネットワーク(VNet)データゲートウェイの運用を、PowerShellモジュール経由で自動化できるモデルがGAとなりました。ゲートウェイのインストール、更新、回復、設定変更がコード化可能です。
これまで手動操作が中心だったゲートウェイ運用を、Infrastructure as Code的に扱えるようになり、本番・検証環境の構成差分管理や、障害時の自動復旧が現実的になります。
大規模な企業ITでは、ゲートウェイのセキュリティパッチ適用や証明書更新を定期的に行う必要があり、PowerShellでの自動化は運用工数削減に直接効きます。
参考:On-premises data gateway PowerShell module
Certificate and proxy support for VNet data gateway(GA)
VNetデータゲートウェイで、企業証明書とプロキシ経由の接続が正式にサポートされました。独自CA発行のTLS証明書を信頼し、社内プロキシサーバーを経由して外部接続する構成が標準構成としてGAになります。
大企業のネットワーク統制下では、直接インターネット接続を許可しない構成が一般的で、この機能がGA化するまでVNetゲートウェイの本格導入が難しいケースがありました。今回のGAでエンタープライズ要件を満たせるゲートウェイ構成の選択肢が広がります。
本番導入時には、プロキシのNTLM/Kerberos認証対応状況、証明書ローテーション運用、HTTPアクセスログとのひも付けなどを事前設計しておく必要があります。
参考:Manage VNet data gateways — certificates and proxy
Virtual network data gateway supports up to nine instances(アナウンス)
VNetデータゲートウェイの単一クラスタで、最大9インスタンスまでスケールアウトできるようになりました。従来の上限を引き上げたもので、高スループット要件を持つワークロードを単一ゲートウェイ構成でカバーしやすくなります。
スケール上限の緩和により、ピーク時のスループットや並列接続数の制約が緩和されます。9インスタンスそれぞれに独立したノードが割り当てられ、障害時のフェイルオーバー余裕度も高まります。
大規模なDataflow Gen2並列実行や、Copy jobの同時実行を多数抱える組織で、ゲートウェイのボトルネックを解消する選択肢が増えた形です。
参考:Virtual network data gateway overview
SSIS Pipeline Activity(Preview)
FabricパイプラインからSSISパッケージを直接呼び出すアクティビティがプレビューで提供されました。従来のAzure Data Factoryにあった SSIS Integration Runtime と同様の機能を、Fabric側で扱えるようになります。
既存のSSIS資産をFabricにそのまま持ち込める意味は大きく、「まずSSISを動かし続けながら、段階的にDataflow Gen2やNotebookへリライトする」という現実的な移行戦略が取りやすくなります。
既存資産を即座にFabricの監視・スケジューリング・監査基盤に載せられる点もメリットで、SSISからFabricへの本格移行を検討中の組織にとって、待望の機能です。
参考:Fabric March 2026 Feature Summary — SSIS Pipeline Activity
Seamlessly upgrade Azure Data Factory and Synapse pipelines to Fabric(Preview)
Azure Data FactoryやAzure Synapse Analyticsで稼働中のパイプラインを、段階的にFabric Data Factoryへアップグレードするツールがプレビューになりました。互換性評価、差分レポート、段階移行の手順を一連のエクスペリエンスで提供します。
従来のADFからの移行は、手動でのパイプライン再作成とテストが必要でしたが、このツールは既存パイプラインのJSON定義を解析し、Fabric対応版へ自動変換したうえで、未対応機能や手動対応が必要な部分を明示します。
数百本のパイプラインを抱える組織では、全件の移行計画と順序づけが大きな課題でした。アップグレードツールで評価ファーストの進め方ができるため、優先順位付けと段階移行が現実的になります。
参考:Upgrade Azure Data Factory pipelines to Fabric Data Factory
Oracle CDC source(アナウンス)
Copy jobのCDC(Change Data Capture)ソースとして、Oracleデータベースがネイティブサポートされることがアナウンスされました。OracleのLogMiner系の変更追跡機能と連携し、差分データだけをFabricに取り込む構成です。
オンプレミスOracleからFabric Lakehouse/Warehouseへのデータレプリケーションは、多くの企業でデータ基盤統合の主要課題です。CDCソース化により、フルコピーを避けて増分だけを流し込むことが可能になり、ネットワーク帯域とコンピュート消費を大幅に削減できます。
実運用では、Oracle側のREDOログ保持ポリシーや権限設計、Copy jobのCDC設定(スキーマ進化、スナップショット戦略)を事前に詰めておくことが重要です。
Fabric Data Warehouse sink(アナウンス)
Copy jobのCDC出力先として、Fabric Data Warehouseを直接指定できるようになります。Lakehouseだけでなく、SQLベースのWarehouseへ差分変更を継続的に反映する構成が可能です。
従来、CDCでWarehouseを更新する場合はLakehouse経由のパイプラインを組む必要がありましたが、直接sinkに指定できることでパイプラインが単純化します。SQLベースの分析基盤にリアルタイムに近い更新を届けるニーズへの対応です。
基幹系DBからFabric Warehouseへのレプリケーション構成や、マート層でのCDC反映など、BI/分析ワークロードで価値を発揮します。
SCD Type 2(アナウンス)
Copy jobのCDC機能に、SCD(Slowly Changing Dimension)Type 2を自動適用する仕組みが追加されます。履歴保持、開始日・終了日管理、ソフトデリート、カレントフラグ管理が標準で行えます。
SCD Type 2はデータウェアハウジングの古典的パターンで、従来はPySparkやT-SQLで自前実装することが多い領域でした。Copy jobで宣言的に扱えることで、実装コストと品質のばらつきが大きく改善します。
ディメンションテーブルの履歴管理が必要な全業界(小売、金融、製造の部品マスタなど)で、Warehouse/Lakehouse設計の標準パターンが簡潔になる意味は大きいです。
Built-in audit columns(アナウンス)
Copy jobが、抽出時刻、ジョブID、ソース境界値などの監査列を、出力行に自動付与するようになります。データレプリケーションの監査性・デバッグ性が大きく向上します。
監査列があることで、行ごとに「どのCopy job実行で取り込まれたか」「ソース側の境界値はどこだったか」がわかるため、問題発生時の原因調査や再取り込み判断がしやすくなります。コンプライアンス要件の対応にも有効です。
既存のテーブル設計で似た列を手動管理している場合、組み込み監査列への統一を検討することで、運用一貫性を高められます。
参考:What is Copy job — built-in audit columns
AutoPartitioning による自動性能最適化(アナウンス)
Copy jobに、大規模テーブル転送時の並列読み取りを自動最適化するAutoPartitioningが追加されます。テーブル統計や主キー情報を元に、Copy jobが適切なパーティション分割戦略を自律的に選択します。
従来、大規模テーブル(数TB級)を並列コピーする場合、パーティション列・分割数・フェッチサイズを手動で調整する必要があり、運用者の知見が必要でした。AutoPartitioningにより、この初期チューニングが不要になります。
DW間の大規模データ移行、定期フルロード、マスタ再同期など、単発で大容量を扱う場面で、スループット改善とチューニング工数削減の両面で効きます。
Zero CU cost when no data changes(アナウンス)
Copy jobの増分コピーで、変更データが検出されない実行の場合、Fabric Capacity Units(CU)を消費しないコストモデルが導入されます。ポーリング型の増分コピーをコスト面で合理化できます。
これまでは「変更なし」の場合でも、Copy jobの起動とチェック処理でCUが消費されるため、頻繁にポーリングするワークロードでは無駄なコストが発生していました。Zero CU化により、実際に処理があったときだけ課金される料金体系に近づきます。
5分間隔や1分間隔の高頻度ポーリング構成で特に効果が大きく、リアルタイムに近いデータ連携を低コストで維持できるようになります。
参考:Copy job incremental cost model
ROWVERSION watermark column support(アナウンス)
Copy jobの増分コピーで、SQL Server系のROWVERSION(旧Timestamp)列をウォーターマークとして利用できるようになります。SQL ServerやAzure SQLの変更追跡定石を、Fabric側の増分コピーに直接持ち込めます。
ROWVERSIONは行ごとに自動採番され、UPDATEでも値が更新されるため、確実な増分検知が可能です。タイムスタンプ列での運用でトラブルになりがちなクロックスキューや並行更新の問題を回避できます。
SQL ServerをソースとするCDC代替として、実装の簡潔さと信頼性の両立が魅力です。Change Trackingとも併用可能です。
参考:Copy job watermark column types
Date watermark column support(アナウンス)
Copy jobの増分コピーで、Date型の列をウォーターマークとして直接扱えるようになります。これまでDateTimeやINT変換が必要だった構成を簡潔化できます。
日次スナップショット型のデータソース(営業日単位の売上テーブル、日次バックアップテーブルなど)で、Date列が存在する場合、そのまま増分指標として利用できます。日付境界の扱いが明示的になり、境界値トラブルが減ります。
業務系DBで「登録日」「更新日」がDate型で管理されている旧式テーブルとの連携が楽になります。
参考:Copy job watermark column types
String (interpreted as datetime) watermark column support(アナウンス)
文字列型だが実態は日時を表す列を、Copy jobの増分コピーのウォーターマークとして扱えるようになります。レガシーな業務系DBで「VARCHAR(19)で YYYY-MM-DD HH:MI:SS 形式を格納」といった設計の列を、型変換なしで利用できます。
レガシーシステムでは、タイムスタンプを文字列型で持つ設計が一般的で、型変換が必要だったためCopy jobの増分運用に制約がありました。今回の拡張で、既存スキーマを変えずにFabric連携へ組み込めます。
SAP BWや古いメインフレーム系からFabricへのデータ連携を検討している組織で、実装工数の削減効果が大きい機能です。
参考:Copy job watermark column types
Preview-only steps(GA)
Dataflow Gen2の「プレビュー専用ステップ」がGAになりました。データプレビュー時だけ実行され、本番更新では実行されない変換ステップを明示的に定義できます。
開発中にサンプルデータの絞り込みや型変換、集計を試しに差し込んで確認したいケースがよくあります。プレビュー専用ステップなら、本番実行に影響を与えずに探索・検証が可能です。プレビュー専用であることがUI上で明確になる点も保守性を高めます。
大規模データフローの開発では、探索用ステップを本番実行から分離できることで、本番ロジックの純粋性が保たれ、レビューコストが下がります。
参考:Dataflow Gen2 Preview-only steps
Dataflow Gen2 Variable Library integration — variable limit removal(GA)
Dataflow Gen2のVariable Library統合で、参照可能な変数数の上限が実質的に撤廃されました。従来の制約で困っていた、大量の環境変数やマスターデータ参照に対応できます。
企業規模のDataflow Gen2運用では、数百の環境変数(接続文字列、エンドポイント、閾値、日付境界など)を扱うことも珍しくありません。上限撤廃により、Variable Libraryの本格的な本番導入が可能になります。
Variable Libraryで集中管理した変数をCI/CDパイプラインで環境ごとに切り替える構成は、Fabric上でのDataOps実践の要となります。
参考:Dataflow Gen2 Variable Library integration
Dataflow Gen2 Variable Library — Power Query editor and default value support(GA)
Variable Library変数を、Dataflow Gen2のPower Queryエディター内で直接評価・確認できるようになり、既定値の設定にも対応しました。環境差分を扱う際の可読性・テスト性が大幅に改善します。
これまでは変数の評価結果が実行時にしか確認できず、開発段階でのデバッグが難しい場面がありました。エディター上で値が見える状態で開発できるため、誤ったパラメータ指定によるランタイムエラーを減らせます。
既定値対応により、「環境設定が欠けている場合のフォールバック」を宣言的に書けるため、開発環境と本番環境の切り替えが安全になります。
参考:Dataflow Gen2 Variable Library integration
Azure Data Lake Storage Gen2 destination(GA)
Dataflow Gen2の出力先として、Azure Data Lake Storage Gen2が正式に一般提供となりました。ADLS Gen2の任意コンテナ・パスにParquet/CSV/JSON等の形式で直接書き出せます。
Fabric外のADLS Gen2へデータを書き出すユースケース(他チームのAzure基盤との連携、Databricksとのデータ共有、HDInsightジョブへのインプット生成など)で、Dataflow Gen2の位置づけが広がります。
出力ストレージの所有・課金がFabric外で完結する点が特徴で、チーム間のコストセパレーションやデータ所有境界の設計に柔軟性が出ます。
参考:Dataflow Gen2 data destinations and managed settings
Lakehouse files destination(GA)
Dataflow Gen2の結果を、LakehouseのFiles領域に直接ファイルとして書き出せるようになりました。テーブル化前のParquetやCSVを、Lakehouseのブロブストレージ相当の領域に配置できます。
Tablesに書き込む形式と異なり、ノートブックやSparkジョブで後処理したい一時データ、他ツールへの受け渡し用アーカイブなどを、Lakehouseに収めて管理できます。ファイル単位のガバナンスも簡潔です。
ETLの中間成果物や、エクスポートアーカイブの保存先として、Lakehouse内に完結させたい組織で利便性が高まります。
参考:Dataflow Gen2 data destinations
Snowflake databases destination(Preview)
Dataflow Gen2の変換結果を、Snowflakeデータベースへ直接書き出せる出力先がプレビューで提供されました。FabricでETLを実行し、Snowflakeへ書き戻す構成が一気通貫で実現します。
Snowflakeをメインの分析DWとして使っている組織で、Fabric側のPower QueryやAI-Powered Prompt Transformを活用しつつ、結果をSnowflakeに書き戻すハイブリッド基盤が構築できます。
双方向データ移動が必要なマルチクラウド構成や、SnowflakeとFabricを用途別に使い分ける組織にとって、接続の選択肢が広がった形です。
参考:Dataflow Gen2 new destinations — Snowflake
Excel files destination(Preview)
Dataflow Gen2の結果を、SharePointやADLS Gen2上のExcelファイルとして出力できるようになりました。業務ユーザー向けの集計レポートを、Excel形式でシームレスに配布できます。
財務・営業系の現場では、集計結果をExcelで受け取りたいニーズが根強く、Power BIダッシュボードだけでは業務フィットしないケースが少なくありません。Dataflow Gen2から直接Excelへ出力できることで、現場向けのレポート生成工程を一本化できます。
出力後のExcelファイルは、SharePointのドキュメントライブラリ経由でTeamsやOutlookに連携でき、既存の業務コミュニケーションに溶け込みやすい設計です。
参考:Dataflow Gen2 new destinations — Excel
Schema support in Fabric data destinations(GA)
Dataflow Gen2からFabric SQL Database、Lakehouse、Warehouseの特定スキーマに直接書き込めるスキーマサポートがGAになりました。ドメイン単位でテーブルを整理しやすくなります。
これまで既定スキーマ(dbo等)にしか書き込めなかったため、マルチテナント運用やドメイン駆動設計のスキーマ分離に制約がありました。スキーマ指定のGAで、共有ワークスペースでも構成を崩しにくくなります。
dev/stg/prdのスキーマ切り替え、事業部ごとのスキーマ分離、データマート層のスキーマ標準化などに有効です。
参考:Dataflow Gen2 data destinations schema support
AI-Powered Prompt Transform(GA)
自然言語プロンプトでデータ変換を指示できるAI-Powered Prompt Transformが一般提供になりました。Dataflow Gen2の列追加で、生成AIが自動でデータ変換を実行します。
分類、要約、翻訳、抽出、整形など、従来であれば外部のLLM APIをPythonで呼び出す構成が必要だった処理を、Dataflow Gen2のステップとして直接組み込めます。AIメーター(Fabric Copilot CU)でコストが可視化され、運用判断しやすい点も特徴です。
顧客レビューの感情分析、フリーテキストの自動分類、多言語データの翻訳など、実務の幅広いシナリオで活用できます。コスト・品質・レイテンシのトレードオフを事前検証してから本番投入するのが安全です。
Publish experience UX + parallelized query validations(アナウンス)
Dataflow Gen2の公開(Publish)操作で、複数クエリ・複数出力先の検証処理が並列化され、UXが改善されました。保存時の待ち時間が大幅に短縮されます。
クエリ本数が多いDataflowでは、公開時の直列検証が開発の体感速度を大きく下げる要因でした。並列化により、開発・テストサイクルを高速化できます。
今回の改善では、「Publish」が「Save」に置き換わる方向性も示されており、CI/CD・Git統合と組み合わせて使う場合、ターミノロジーと操作フローの変更に追随する必要があります。
参考:Dataflow Gen2 CI/CD and Git integration — Save replaces Publish
Scheduled Refresh Policies(アナウンス)
Dataflow Gen1からGen2への「Save As」機能で、Gen1側の定期更新ポリシーをGen2側へ自動引き継ぎできるようになります。更新頻度やタイムゾーン設定の再設定が不要です。
Gen1からGen2への移行プロジェクトでは、数百本のDataflowのスケジュール再設定が地味に工数を食う領域でした。ポリシー自動引き継ぎで、この移行作業が大幅に軽減されます。
大規模Gen1資産を抱える組織ほど効果が大きく、Gen2への段階移行の心理的ハードルを下げます。
参考:Save a Dataflow Gen1 as a Dataflow Gen2
Public Save As API(アナウンス)
Gen1 → Gen2のSave Asを、REST APIから自動実行できるパブリックAPIが追加されます。大量のGen1 Dataflowを一括変換するバルク移行の実装が可能になります。
手動操作では数百本のGen1資産の移行に何日もかかるケースがありましたが、API自動化により、数分〜数時間で全件変換を回せる見通しです。PowerShellやAzure Functionsと組み合わせた移行スクリプトの実装も現実的になります。
移行プロジェクトの計画フェーズで、APIベースの段階展開を前提とした移行戦略を立てられるため、リスク分散と並行検証が行いやすくなります。
参考:Save As Dataflow Gen2 REST API
SharePoint site picker in Modern Get Data(Preview)
Modern Get DataとData destinationsのSharePointコネクタで、サイトURLを手入力せず、候補一覧や検索ベースでサイトを選択できるUIが追加されました。接続ミスによる設定やり直しが減ります。
大企業のSharePoint環境では、サイト数が数千規模になることも珍しくなく、正確なURLを覚えて貼り付ける運用は現実的でありませんでした。Site pickerにより、SharePointをデータソース・データ出力先として扱うハードルが下がります。
業務現場でのセルフサービスBI構築で、SharePointのExcelリストを元にしたDataflow作成が一段と容易になります。
参考:SharePoint Online list connector
Diagnostics download(Preview)
Dataflow Gen2の実行ログ・診断アーティファクトをダウンロードできる機能がプレビューで追加されました。障害解析や社内サポートへの受け渡しが円滑になります。
これまでは、Dataflow失敗時の詳細ログを収集するためにUIの複数画面を巡回する必要があり、サポートエンジニア同士の情報共有にも時間がかかっていました。Diagnostics downloadで、関連ログを一括で取得できます。
Microsoftサポートへ問い合わせる際の初動として、診断ファイルを添付すると初回対応の精度が上がる運用が標準化できます。
参考:Dataflow Gen2 monitor — diagnostics download
Advanced Edit for destinations(Preview)
Dataflow Gen2のData destination設定で、M言語によるロジックを直接編集できるAdvanced Editがプレビューになりました。UIで表現できない高度なパラメータ制御を記述できます。
複雑な宛先パス生成(日付パーティション、動的テーブル名、条件分岐による出力先切り替えなど)が必要な場合、UIだけでは表現しきれないケースが多くあります。M言語での直接編集により、表現力の上限を大きく引き上げられます。
利用時は、M言語の構文ルールと、Data destinationで使えるコンテキスト変数・関数の仕様を把握しておく必要があります。既存のData destination設定を段階的にAdvanced Editへ移行するのが安全です。
参考:Dataflow Gen2 advanced edit data destinations
Data destination validations during publish(Preview)
Dataflow Gen2のPublish(Save)前に、Data destination側の権限・設定・依存関係をバリデーションする機能がプレビューになりました。公開後のランタイムエラーを未然に検出できます。
典型的な検証項目として、宛先テーブルの存在、接続認証情報の有効性、スキーマ整合性、書き込み権限の保有などがチェックされます。公開してから初回実行で失敗する無駄を大幅に削減できます。
CI/CDに組み込む際は、このバリデーションをデプロイゲートとして活用することで、本番反映前の品質保証を強化できます。
参考:Dataflow Gen2 data destinations validation rules
Evaluate query API(Preview)
Dataflow Gen2のPower QueryロジックをREST API経由でフル更新なしに実行できるEvaluate query APIがプレビューで提供されました。変換ロジックを再利用可能な処理部品として扱えます。
既存のDataflow実行はフルロード前提のため、軽量な検証や部分実行に向きませんでした。Evaluate query APIにより、SparkジョブやFunctionsから「このクエリだけを評価して結果を返す」といった細粒度の呼び出しが可能になります。
パイプライン内の条件分岐、ダイナミックデータ検証、UI層からの即時プレビュー生成など、従来はDataflowでは扱いづらかったユースケースをカバーできます。
参考:Query Execution API — Execute query
2026年2月 - モダン評価エンジンGAほか11件

2月のData Factoryは全カテゴリのなかで最多の12件が更新されました。Dataflow Gen2のエンジン刷新からCopy jobの認証拡張まで、パイプラインの構築・運用に関わる幅広い改善が含まれています。
Azure Data FactoryからFabricへの移行を検討中の方も、最新の進化を把握しておくことをおすすめします。
モダン評価エンジンの一般提供(GA)
Dataflow Gen2のクエリ評価エンジンが.NET 8ベースの新アーキテクチャに刷新され、正式リリースとなりました。Azure Data Explorer、Lakehouse、Warehouse、Salesforce、Google Analyticsなど80以上のコネクタに対応しており、Fabric SQL DatabaseやSQL Server Databaseを含むSQLベースのコネクタもサポートされています。
Web要求の効率化により、REST APIやWebエンドポイントベースのデータソースでもスムーズなクエリ実行と耐障害性の向上が実現しています。
今後の新機能はこのエンジンをベースに提供されるため、既存のDataflow Gen2ワークロードが新エンジンで正常に動作するか、早めの検証を推奨します。
参考:Dataflow Gen2のモダン評価エンジン公式ドキュメント
Lakehouse増分コピーのCDF・ウォーターマーク両方式対応
Copy jobでFabric Lakehouseからの増分コピーを行う際、Delta Change Data Feed(CDF)とウォーターマークベースの2方式から選択できるようになりました。
CDFが有効なテーブルでは行単位のinsert・update・deleteを検出してレプリケーションでき、CDFが無効な場合でもウォーターマーク列(増分列)を指定することで差分コピーが可能です。
大規模なデータ同期をフルコピーで実行している場合、増分コピーへの切り替えでコスト削減と処理時間の短縮が見込めます。Copy jobの作成後、Advanced Settingsボタンからウォーターマーク列への切り替えが可能です。
SAP Datasphere Outbound のS3・GCS対応
SAP DatasphereからのCDCレプリケーション用ステージングストレージとして、従来のADLS Gen2に加えてAmazon S3とGoogle Cloud Storageが選択可能になりました。
マルチクラウド環境でSAPデータを活用している企業にとって、自社のクラウド構成に合わせたステージング先を選べるようになった意味は大きいです。
参考:SAP Datasphere Outboundチュートリアル
適応型パフォーマンス調整(プレビュー)
データ移動のパフォーマンスを実行コンテキストに応じて動的に最適化する新機能がプレビュー公開されました。データ量の増加やシナリオの多様化に伴い、スループット・信頼性・コスト・データ正確性のバランスを手動で調整する負担が課題になっていましたが、この機能により、構成セマンティクスと互換性のある最適化がサービス側で自動的に適用されます。
オプトイン方式で、既存構成への変更は不要です。パイプライン設定から直接有効化できます。
最近のデータへの高速アクセス(プレビュー)
Dataflow Gen2で頻繁に使うテーブルやファイルに素早くアクセスできる「Recent data」機能がプレビュー公開されました。Power Queryリボンから直接アクセスするか、Get Data内のRecent dataモジュールから利用できます。選択した項目はPower Queryエディタに直接読み込まれるため、ナビゲーションの手間が省けます。
同じロケーション内の関連アイテムを探す場合は「Browse location」機能で同一フォルダやデータベース内の他のテーブル・ファイルも確認できます。
Dataflow Gen2の変数ライブラリ統合改善
2025年9月にプレビュー公開されたFabric変数ライブラリとDataflow Gen2の統合が改善されました。主な変更点は2つあります。1つ目は、Dataflowが評価ごとに取得できる変数数の制限が撤廃されたこと。2つ目は、Power Queryエディタのデータプレビューで変数が正しく評価されるようになったことです。Variable.ValueやVariable.ValueOrDefault関数の出力がエディタ上で確認できます。
データ送信先での変数使用時に保存が失敗する問題や、ナビゲーションステップでの変数使用時のエディタ体験も改善されています。
参考:Dataflow Gen2での変数ライブラリ統合ドキュメント
Dataflow Gen2のFabricコネクタ相対参照
Dataflow Gen2でFabricコネクタ(Lakehouse、Warehouse、SQL Database)を使用する際、これまでワークスペースIDやアイテムIDによる絶対参照が必要でしたが、新たに「(Current Workspace)」ノードによるアイテム名ベースの相対参照が可能になりました。
CI/CDシナリオでの実用性が大きく向上し、開発環境からテスト環境・本番環境へソリューションを移行する際にスクリプトの変更が不要になります。デプロイパイプラインの運用負荷を大幅に軽減できる機能です。
参考:Fabric Lakehouseコネクタ、Warehouseコネクタ、SQL Databaseコネクタ
Dataflow Gen2のジャストインタイムパブリッシング
これまでDataflow Gen2を実行・更新する前に、未公開の変更がある場合は手動でパブリッシュ操作を行う必要がありました。この更新により、実行・更新操作がパブリッシュの必要性を自動的に判断し、ジョブの一部として完了するようになりました。
手動パブリッシュも引き続き利用可能で、UIでの保存時には従来通りパブリッシュが実行されます。
CI/CDデプロイメント時にも別途パブリッシュステップが不要になり、ターゲット環境での初回実行時に自動的にパブリッシュされます。初回更新は自動パブリッシュの分だけ時間がかかる点に留意してください。
参考:Dataflow Gen2のCI/CDとGit統合ドキュメント
Copy jobのCDC列マッピング対応
CDCレプリケーション時にソースからデスティネーションへの列マッピングがサポートされました。列名の変更、データ型の変換、デスティネーションスキーマのカスタマイズが可能になります。
この列マッピング機能は、フルコピー・ウォーターマークベース増分コピー・CDCレプリケーションの全データ移動パターンで統一的に利用できます。
参考:Copy jobのCDCレプリケーション公式ドキュメント
RowVersionの増分列サポート
Copy jobの増分コピーで、従来の日付/時刻型や増加する数値型に加えて、RowVersionを増分列として選択できるようになりました。SQL Server、Azure SQL Database、SQL Managed Instance、Fabric内のSQLから増分コピーを行う際に利用できます。
CDCが有効化されていないデータベースでも、RowVersionを使って前回実行以降の新規・変更行を効率的に検出できます。
Copy jobアクティビティのサービスプリンシパル・ワークスペースID認証
パイプライン内のCopy jobアクティビティで、サービスプリンシパル認証とワークスペースID認証が追加されました。長寿命のシークレットに頼らず、IDベースのアクセスを採用することでセキュリティ態勢を強化できます。
規制産業やハイブリッド環境を運用する組織では、標準化された認証パターンによるコンプライアンス・監査対応の簡素化も見込めます。
大規模CSVファイルの並列読み込み
大規模CSVファイルの取り込みパフォーマンスが大幅に向上しました。マルチライン設定を明示的に定義することで、サービスがレコード境界を安全に識別し、ファイルを論理チャンクに分割して並列処理します。
マルチラインレコード(引用符で囲まれた改行を含むフィールド等)を含むCSVファイルでは、明示的な設定なしでは最も保守的なパーシングモデルが適用され並列化が阻害されます。ソース設定でマルチライン情報を指定することで、データの正確性を損なうことなく高スループットを実現できます。
参考:区切りテキストファイルのパフォーマンス最適化ドキュメント
2026年1月 - 増分コピーコネクタ拡充
Copy jobの増分コピー機能が対応コネクタを大幅に拡充しました。
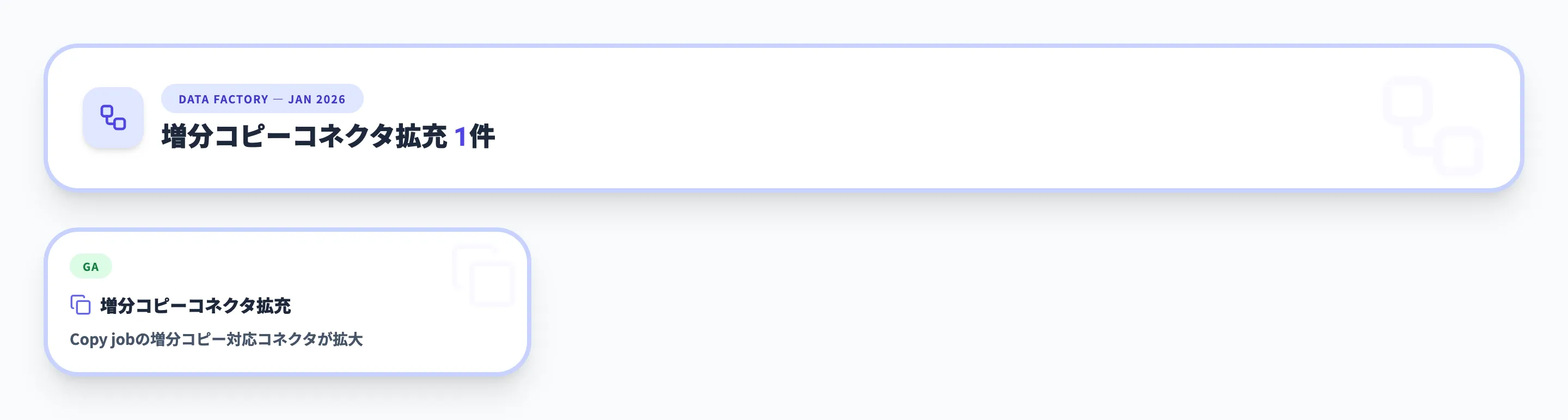
増分コピー対応コネクタの追加
Copy jobの増分コピーで新たに11のコネクタがサポートされました。Google BigQuery、Google Cloud Storage、DB2、ODBC、Fabric Lakehouseテーブル、フォルダ、Azure Files、SharePoint List、Amazon RDS for SQL Server、Amazon RDS for Oracle、Azure Data Explorerが追加されています。
マルチクラウド環境でのデータ統合シナリオが広がり、特にGoogle Cloud StorageやAmazon RDS経由のデータソースからの増分コピーが可能になったことで、既存のフルコピーパイプラインをより効率的な増分コピーに移行できます。
リアルタイムインテリジェンス
リアルタイムインテリジェンスは、ストリーミングデータの取り込み・処理・可視化をリアルタイムに行うFabricの機能群です。Eventstream(データ取り込み)、KQLデータベース(時系列分析)、リアルタイムダッシュボード(ライブ可視化)、Real-Time Hub(データソース管理)で構成され、IoTやテレメトリ、運用監視などのリアルタイム分析シナリオに対応します。
2026年4月 - SQL Eventstream処理 GAほか5件

Mirrored CDF連携
Mirrored Database change feed connector for EventstreamsがPreviewとして追加されました。Extended Capabilities in MirroringでDelta Change Data Feedを有効化したmirrored databaseから、row-level changesをEventstreamへstreamingできます。
Feature Summaryでは、insert、update、deleteをsource schemaとchange metadataのfidelityを保ってstreamingできると説明されています。対象にはAzure SQL、Cosmos DB、Oracle、PostgreSQL、Snowflake、Open Mirroring partnersが含まれます。
参考:Extended capabilities in mirroring
SQL Eventstream処理
Eventstream SQL operatorがGenerally Availableになりました。1つのSQL operatorからEventhouse、Lakehouse、Activator、downstream Eventstreamsなど複数destinationsへ出力できます。
MS Learnでは、built-in per-output testing、event-time processing、late-arrival/out-of-order thresholdsが説明されています。また、SQL Server 2025、Azure SQL Database、Azure SQL Managed InstanceのChange Event Streamingから、CloudEvents形式の変更イベントをEventstream custom endpointへ送信する連携も4月項目として掲載されています。
参考:Process events using a SQL operator
Eventstream監視
EventstreamがWorkspace Monitoringと統合され、streaming pipelinesのqueryable observabilityを得られるようになりました。Eventstreamはmonitoring Eventhouseへnode status、throughput metrics、error dataをKQL tablesとして出力します。
Feature Summaryでは、EventStreamNodeStatus、EventStreamMetrics、EventStreamErrorMetricsの3テーブルが利用可能と説明されています。さらに、Eventstream experience内でActivator rulesを作成・管理できるPreviewも追加され、stream選択、condition定義、action設定、rule作成をEventstream内で行えます。
Eventhouse MCP
Eventhouse remote MCPがPreviewとして追加されました。hosted remote MCP serverを使うため、agent側に追加インストールせずEventhouse endpointへ接続できます。
Feature Summaryでは、AI agentsがnatural languageとKQLでEventhouseのreal-time dataをquery/analyzeできると説明されています。schema discovery、KQL generation、sample data取得、insights返却が対象です。
Eventhouse schema進化
Eventhouse OneLake Availabilityがschema evolutionをサポートしました。Eventhouse dataをOneLake上のDelta tablesとして利用可能にする仕組みで、今回の更新によりcolumnsのadd/deleteを扱えます。
Feature Summaryでは、OneLake availabilityをoffにせずに列を追加または削除できると説明されています。これらの操作は、availability停止やdata lossのリスクなしに行えるとされています。
参考:Eventhouse OneLake availability
RTIセキュリティ強化
Eventhouseでは、Customer Managed Keys(CMK)がPreviewとして追加されました。Eventhouse data at restの暗号化に、顧客管理のAzure Key Vault keyを利用できます。
Eventstream connectorsでは、Custom CA and mTLS supportがPreviewとして追加されました。Kafka-based sourcesとConfluent Schema Registryに対し、Azure Key Vaultで管理するcustom CA certificatesとclient certificatesを指定できます。
参考:Data encryption with customer-managed keys in Fabric Eventhouse
2026年3月 - Fabric Maps GAほか14件

3月のリアルタイムインテリジェンスは15件の更新が入り、地理空間可視化、イベント駆動アプリ基盤、Eventstream SQL機能、Real-Time DashboardsのCopilot対応、Eventhouse関数プレビュー、Workspace Monitoring向けダッシュボードテンプレートなど、ストリーミングと監視の両面で機能が広がりました。
特にBusiness Events、Eventstreams Deltaflow、SparkノートブックとEventstreamsの統合といった、イベント駆動アプリケーション構築の基盤となる機能群のプレビュー提供が始まっており、Fabricのリアルタイム活用の幅が大きく拡張された月です。
Fabric Mapsの一般提供(GA)
Microsoft Fabric Mapsが一般提供になり、リアルタイムおよび履歴の位置情報データを地図上で可視化できるようになりました。車両追跡、設備監視、配送可視化など、位置情報を含むイベント分析で、地図ベースの直感的なUIを標準機能として利用できます。
GIS専用ツールと比べると機能は絞られていますが、FabricのEventhouseやLakehouseと組み合わせた時系列×位置情報の分析には十分で、追加ライセンスなしで地理空間可視化を扱える点が大きなメリットです。
物流、エネルギー、スマートシティ系のワークロードでIoTデータと連携した位置分析を行う場合、既存のPower BIダッシュボードとFabric Maps可視化を並べる構成が有効です。
参考:Microsoft Fabric の新着情報(Fabric Maps)
Business Events in Microsoft Fabric(Preview)
User Data FunctionsやNotebookからビジネスイベントを発行し、Activator・Eventstream・Teamsなどへ後続アクションを連鎖させるBusiness Eventsがプレビューになりました。データ加工結果やKPI閾値超えなどを、Fabric上のイベントとして正式に発行・購読できる仕組みです。
従来はイベント連鎖を組む場合、Logic Apps や Azure Event Grid を経由する構成が一般的でしたが、Fabric内で完結させることで、権限モデル・監査ログ・エラー追跡が一元化されます。
実務では、「夜間ETL成功時にダッシュボードを自動更新」「特定閾値超えでActivatorを起動」など、データと業務プロセスを結ぶ設計パターンが書きやすくなります。
Fabric Eventstreams Deltaflow(Preview)
データベース変更(CDC)をDeltaflowで整形しながら、EventstreamsやEventhouseへ流し込み、リアルタイムアプリ構築につなげる機能がプレビューになりました。変更をデルタ形式で扱うことで、重複処理や順序問題を軽減できます。
これまでCDCを扱う場合、Debezium等の外部ツールやAzure Stream Analytics経由の構成が必要でしたが、Fabric内で完結するDeltaflowパイプラインとして設計できることで、運用・監査が簡潔になります。
オンプレミスSQL Server、Oracle、PostgreSQLなどの基幹系DBからリアルタイム更新をFabricに取り込み、イベントドリブンなアプリケーションをFabric上に構築するシナリオで有効です。
参考:Eventstreams Deltaflow Public Preview
Real-time stream processing with Eventstreams and Spark notebooks(Preview)
EventstreamsをSparkノートブックから直接利用し、ストリーミングデータにPySparkでカスタム処理を適用できる統合機能がプレビューになりました。PySpark Structured Streamingのコードを自動生成する支援もあります。
これまでEventstreamsの処理ロジックはSQL Operatorや組み込みのTransformが中心でしたが、複雑なカスタムロジックや機械学習モデル適用など、SQLで表現しきれない処理はノートブック側で扱いたいニーズがありました。この統合でSparkの柔軟性をストリーム処理に直接組み込めます。
リアルタイム推論、複雑なイベント相関、時系列異常検知などのシナリオで、既存のPySparkコード資産を活かせる構成が実装しやすくなります。
参考:Bringing together Fabric Real-Time Intelligence, Notebook and Spark Structured Streaming (Preview)
Anomaly Detector full-item experience(アナウンス)
Anomaly Detectorが、設定・分析・結果確認を1つのUIに統合した新しいエクスペリエンスに刷新されました。時系列データに対する異常検知の構成が、専用のFabricアイテムとして扱えます。
従来、時系列の異常検知はEventhouseのKQL関数やnotebookでの実装が中心でしたが、それぞれの設定・実行・可視化を行き来する必要がありました。フルアイテム体験により、検知ルール定義から結果ダッシュボードまでを一画面で確認できます。
IoTテレメトリの異常監視、ビジネスKPIの変動監視、セキュリティ系の振る舞い検知など、時系列異常検知を本番運用に組み込む際の立ち上がりが速くなります。
参考:Fabric March 2026 Feature Summary — Anomaly Detector
Operations agent playbook improvements and messages(アナウンス)
Operations agentのプレイブック生成精度が向上し、フィールド対応付けの改善と、失敗時の説明メッセージ強化が入りました。運用担当者が初見のKQLデータに対してプレイブックを生成する際の体感精度が上がります。
Operations agentは、インシデント発生時に過去事例から対応手順を自動生成し、KQLクエリや可視化を提示するAIエージェントです。実データとのマッピング精度が低いと、生成されたプレイブックが使い物にならないケースがありました。
今回の改善で、初期導入から実運用までの距離が縮まり、より多くの運用チームでの採用が進みやすくなります。プレイブックのベストプラクティスドキュメントも併せて更新されています。
参考:Operations agent best practices
Live update for Real-Time Dashboards(アナウンス)
Real-Time Dashboardsで、データが到着したときだけ更新を走らせるLive updateが導入されました。定期ポーリングによる無駄な再描画と計算コストを大幅に削減できます。
従来のReal-Time Dashboardsは一定間隔で全ウィジェットを再評価する方式で、データが流れていないときも計算を走らせる形でした。Live updateでは、Eventhouseの新規データ検出をトリガに更新を走らせるため、CUコスト削減とダッシュボード応答性の両立が可能です。
IoT系の低頻度イベントや、営業時間外のオフラインダッシュボードで特に効果が大きく、不要な計算を止めながらリアルタイム性を保てます。
参考:Real-Time Dashboards overview
Write to multiple destinations from a single SQL operator(GA)
Eventstream SQL operatorで、単一の処理結果を複数の宛先へ同時に書き出す機能がGAになりました。同じ処理を宛先ごとに複製する必要がなく、構成がシンプルになります。
典型的なユースケースとしては、「Eventhouseに生データを保存しつつ、集計結果をLakehouseへ、アラート用にActivator/Logic Appsへ」といった、1つのストリーム処理結果を多様な用途に配信するパターンです。
同一SQLの多段展開で発生していたコードのコピペ問題が解消され、ストリーム処理定義の保守が大幅に楽になります。
参考:Process events using SQL code editor
Event ordering and late event arrival handling(GA)
Eventstream SQL operatorで、イベントの順序制御と遅延イベント到着の処理がGAになりました。ストリーミング処理の信頼性に直結する機能で、分散システムで発生する順不同・遅延を明示的にハンドリングできます。
イベント到着順はネットワークやプロデューサ側の事情で前後することが多く、単純な時系列処理では結果が不安定になります。Watermark設定やLate arrival polトッド(許容遅延)を宣言的に指定することで、ビジネスロジックを正しく実装できます。
金融系トランザクション、課金系イベント、セキュリティ監査ログなど、順序性が重要なストリーム処理で、運用品質を担保する必須機能です。
参考:Event ordering in SQL operator
Anomaly Detection as a source in Eventstream(Preview)
Anomaly Detectorが検出した異常イベントを、Eventstreamのソースとして取り込めるようになりました。検出→ストリーム処理→アクションというパイプラインを、Fabric内で完結させられます。
従来は異常検知結果を別の仕組みで取り出し、Eventstreamに再投入する必要がありました。ネイティブなソース化により、異常検知をトリガに後続アクション(通知、自動修復、ログ記録など)を接続する構成がシンプルになります。
運用監視、セキュリティ、品質管理の領域で、異常検知と業務プロセスを疎結合に連携させる設計パターンとして活用できます。
参考:Add anomaly events source to Eventstream
Data series colors for real-time dashboard visuals(アナウンス)
Real-Time Dashboardsの可視化で、データ系列ごとの固定色指定ができるようになります。業務ルールに合わせて「成功は緑、警告は黄、失敗は赤」などの色マッピングを固定できます。
従来はダッシュボード全体のテーマ色で自動割り当てされ、系列の意味付けが安定しませんでした。系列色固定により、同じダッシュボードを繰り返し参照するオペレータが、色だけで状況を直感的に把握できます。
監視系ダッシュボードの設計原則である「意味に対する色の一貫性」を担保できるため、運用現場での認知負荷を下げる効果があります。
参考:Customize dashboard visuals
Use Copilot to create visuals in real-time dashboards(Preview)
Real-Time Dashboardsで、Copilotに自然言語で指示することで、KQLクエリと可視化タイルを自動生成できる機能がプレビューになりました。ダッシュボード作成のハードルが下がります。
「直近1時間のエラー発生数を時系列で見せて」「デバイス別のCPU使用率上位10件を棒グラフで」といった指示から、KQLクエリを生成し、適切な可視化タイプを提案します。生成結果は編集可能で、Copilot出力を叩き台として微調整する使い方が想定されます。
KQL未経験者がRT Dashboardsを使い始める際の導入障壁が大きく下がり、運用チーム全体でダッシュボード内製化の速度が上がります。
参考:Explore data with dashboards using Copilot
Instantly run and preview functions in Eventhouse(Preview)
Eventhouseの関数を、KQLを書かずに即時実行・結果プレビューできる機能がプレビューになりました。関数登録後の動作確認が、専用UIでクリックベースに完結します。
従来はKQLエディタで関数呼び出し構文を書き、パラメータを埋めて実行する必要があり、関数利用者にとってのハードルがありました。UIベースのプレビューにより、関数の再利用が進みやすくなります。
KQL関数を社内の共通ライブラリとして整備している組織では、非エンジニアリング職が関数を発見・試用する動線が改善し、関数活用が広がります。
参考:Stored functions list in Eventhouse
Eventhouse Monitoring Dashboard template(Preview)
Workspace Monitoring Eventhouseから、Eventhouse自体の監視ダッシュボードをワンクリックで作成できるテンプレートがプレビューで提供されました。運用監視の初期構築工数を大幅に削減できます。
テンプレートにはクエリ実行時間、取り込みレート、エラー件数、ストレージ消費、取り込み遅延などの代表的メトリクスが事前構成されています。運用開始時の監視基盤を、初期設定のまま即日導入できます。
Eventhouseを本番運用するワークロードすべてに対して、監視ダッシュボードを標準装備するのが現実的になり、障害検知と原因分析のリードタイムが短縮されます。
参考:Workspace monitoring sample gallery
Semantic Model Monitoring Dashboard template(Preview)
Workspace Monitoring Eventhouseから、セマンティックモデルの監視ダッシュボードを即作成できるテンプレートがプレビューで提供されました。Power BI側のセマンティックモデル運用を、Fabric上のKQLベース監視に統合できます。
クエリ応答時間、失敗率、リフレッシュ実行時間、利用者数などのメトリクスが事前構成され、モデル改善のヒントを実データから得やすくなります。
大規模なPower BI運用では、モデルごとの利用実態とパフォーマンスの把握が継続的改善の肝です。監視ダッシュボードテンプレートにより、改善サイクルを回しやすくなります。
参考:Workspace monitoring sample gallery
2026年2月 - ダッシュボード10倍高速化ほか2件
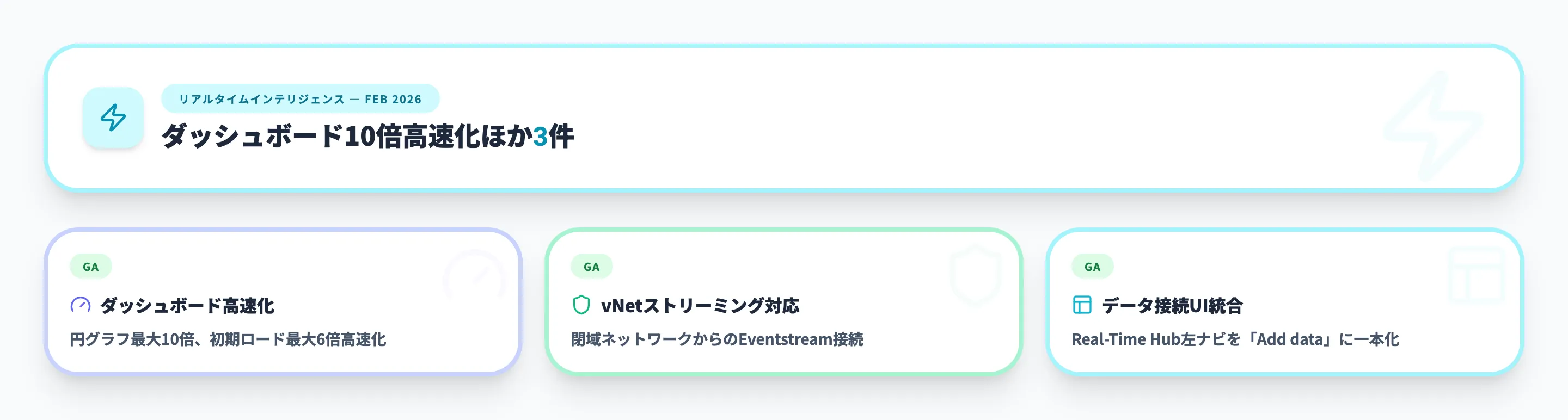
リアルタイムインテリジェンスでは、パフォーマンスの大幅改善、閉域ネットワーク対応、UIの簡素化という3つの柱でアップデートが行われました。
リアルタイムダッシュボードのパフォーマンス改善
コミュニティのフィードバックを受け、リアルタイムダッシュボードが根本から最適化されました。主な改善点は以下のとおりです。
-
初期ロード時間
シナリオによっては最大6倍高速化
-
大規模データセットの可視化
待ち時間が大幅に短縮
-
チャート描画
円グラフで最大10倍の高速化を実現
-
UI全体のレスポンス
フリーズやビジュアルのジャンプが解消され、スムーズな操作感に
本番環境でリアルタイム監視ダッシュボードを利用している場合、この更新で体感速度の向上を実感できるはずです。
閉域ネットワークからのストリーミング対応(vNetサポート)
EventstreamがAzure vNet経由のストリーミングに対応しました。新しい「ストリーミング仮想ネットワークデータゲートウェイ」を使って、クラスターのプロビジョニングなしで閉域ネットワーク内のデータソースに接続できます。
オンプレミスのKafkaクラスターやCDCデータベースからのVPN/ExpressRoute経由接続、サードパーティクラウドのKafkaクラスターからのVPN接続など、多様な接続パターンに対応しています。セットアップは「Manage Connections and Gateways」ページから行い、Eventstreamのソース設定時にゲートウェイを選択するだけで利用可能です。
従来のVirtual network data gatewayやOn-premises data gatewayと異なり、追加のクラスタープロビジョニングや容量は不要です。金融・医療などセキュリティ要件が厳しい業種でのFabric採用ハードルが大きく下がるアップデートです。
参考:Eventstreamコネクタのプライベートネットワークサポート公式ドキュメント
データ接続UIの簡素化
Real-Time Hubの左ナビゲーションにあった「Data sources」と「Azure sources」の2つのメニューが「Add data」に統一されました。カテゴリ分類ではなく「データを追加する」というユーザーの意図に焦点を当てた変更です。
利用できるデータソース(組み込みコネクタ、Azureソース、Azure Diagnosticsログ等)は従来と同じですが、接続の開始ポイントが一本化されたことで新規ユーザーのオンボーディングがスムーズになります。段階的なロールアウトのため、表示が反映されるまで数週間かかる場合があります。
2026年1月 - MQTT v3対応ほか5件
リアルタイムインテリジェンスでは、IoT接続の拡充とEventhouseショートカットの大幅強化を中心に6件のアップデートが行われました。
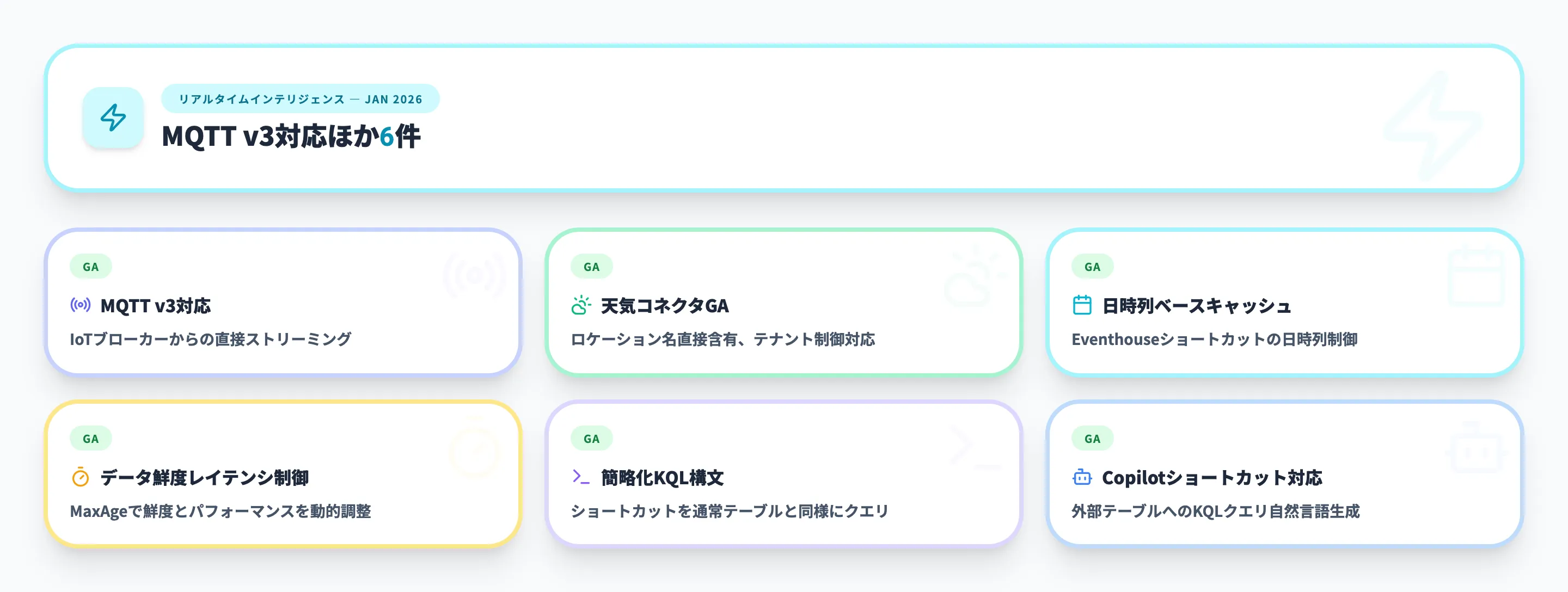
EventstreamのMQTT v3対応
EventstreamのMQTTコネクタがMQTT v3.1およびv3.1.1に対応しました。広く普及しているIoTプラットフォームやMQTTブローカーからFabric Eventstreamへのデータストリーミングが直接可能になります。
既存のブローカー設定を変更することなく、Eventstreamのスケーラビリティとリアルタイム処理能力を活用できます。取り込んだデータはFabric Real-Time Intelligenceでリアルタイム分析とアラートに即座に活用でき、IoTイベントの検出と対応を迅速化します。
参考:EventstreamのMQTTソース追加ドキュメント
リアルタイム天気コネクタの一般提供(GA)
Eventstreamのリアルタイム天気コネクタが正式リリースとなりました。イベントペイロードにロケーション名を直接含められるようになり、フィルタリングや分析の際の追加エンリッチメントステップが不要になります。
テナントレベルの制御スイッチも導入され、テナント管理者が組織全体で天気コネクタの有効・無効を制御できます。リアルタイム分析、アラート、ダッシュボードなどのミッションクリティカルなユースケースで本番利用が可能です。
Eventhouseアクセラレーテッドショートカットの日時列ベース対応
Eventhouseのアクセラレーテッド OneLakeショートカットに、HotDateTimeColumnプロパティが追加されました。Delta/Icebergテーブルの特定の日時列を指定して、ホットキャッシュ対象データを制御できます。
デフォルトではdelta_logのmodificationTimeを使用しますが、HotDateTimeColumnを設定することで、ビジネスロジックに沿った日時列(例: イベント発生日時)でキャッシュ範囲を最適化できます。クエリアクセラレーションポリシーの変更で設定可能です。
Eventhouseショートカットのデータ鮮度レイテンシ制御
クエリアクセラレーションポリシーのMaxAgeプロパティにより、ショートカットのデータ鮮度を制御できるようになりました。デフォルトは5分ですが、クエリ実行時にMaxAgeを動的にオーバーライドできます。
例えば external_table(TableName, 10s) とすることで、MaxAgeを10秒にオーバーライドし、ポリシー定義を変更せずに鮮度とパフォーマンスのバランスを動的に調整できます。
Eventhouseショートカットの簡略化KQL構文
Eventhouseのショートカットが通常のテーブルと同様にクエリできるようになりました。これまで必要だったexteranl_table()構文を使わず、標準的なテーブル名で直接クエリ可能です。
例えば「T | take 10」のように、ショートカットTから10行サンプリングできます。外部データへのアクセスが直感的でシンプルになります。
EventhouseショートカットのCopilotサポート
KQL QuerysetおよびリアルタイムダッシュボードのCopilotが、Eventhouseのショートカットに対するKQLクエリ生成に対応しました。ショートカットはEventhouseでは外部テーブルとして実装されていますが、Copilotによりネイティブテーブルと同じ操作感でクエリを自然言語から生成できます。
データエンジニアリング
データエンジニアリングは、Apache Sparkベースのノートブックやレイクハウスを中心に、大規模データの加工・変換・管理を行うFabricの機能領域です。Pythonノートブック、SparkジョブDefinition、API for GraphQL、User Data Functionsなどのツールを提供し、データレイク上でのETL処理やデータ準備ワークフローを支えます。
2026年4月 - Shortcut変換GAほか5件
Notebook再試行
Fabric Notebookでretry policyを設定できるようになりました。Notebook jobがシステムエラーで失敗した場合、たとえばSpark clusterがrecycleされた場合でも、新しいcluster上で自動的に再開できます。
設定は%%configureのretriableOptionsで行い、Feature Summaryの例ではmaxAttemptとenabledを指定します。対象はPublic API、Data Integration pipeline、Eventstreamから起動されたNotebook実行であり、interactive runはこのリリースでは対象外です。
参考:Fabric April 2026 Feature Summary
Maven環境管理
Fabric EnvironmentでMaven repository由来のlibrariesを管理できるPreviewが追加されました。ScalaとJavaの開発者は、標準的なMaven configurationを使ってlibrariesとtransitive dependenciesを扱えます。
この更新では、Environmentへpom.xmlを直接uploadして管理できます。手動でJARをダウンロードしてアップロードする作業を減らせる点が、公式説明で明示されています。
参考:Manage libraries in Fabric environments
Shortcut変換GA
Shortcut transformationsは、CSV、Parquet、JSONなどの構造化ファイルをDelta tablesへ変換する機能です。MS Learnでは、CSV、Parquet、JSON transformationsがGenerally Availableであり、Excel file transformationsはPreviewと説明されています。
Fabric Spark computeがOneLake shortcutで参照されるデータをmanaged Delta tableへcopy/convertします。変換後のデータはSQL、Spark、Power BIからqueryでき、ETL pipelineを作らずに利用できます。
参考:Shortcut transformations (file)
Nested folders対応
Shortcut transformationsでnested foldersの再帰的な検出がサポートされました。新規変換ではInclude subfoldersが既定で有効になり、複数階層のsubdirectoriesにあるファイルを処理できます。
同期処理では、new/modified filesとdeleted filesを検出してDelta tableへ反映します。制限として、既存変換ではsubfolder supportを後から有効化できず、SharePoint shortcutsではnested foldersが動作しません。
参考:Shortcut transformations (file)
ADO.NET Driver
Microsoft ADO.NET Driver for Fabric Data EngineeringがPreviewとして公開されました。.NET applicationsは、DbConnection、DbCommand、DbDataReaderなどの標準ADO.NET patternsでFabric Spark SQLへ接続できます。
MS Learnでは、Microsoft Entra ID authentication、connection pooling、session reuse、Livy APIsによるasync prefetchに対応すると説明されています。詳細はADO.NET driver専用ドキュメントへ案内されています。
参考:Microsoft ADO.NET driver for Fabric Data Engineering
Dremio catalog連携
Mirrored Dremio catalogがPreviewとして追加されました。FabricはDremio Iceberg REST Catalog endpointへ接続し、選択したtablesへのOneLake shortcutsを作成できます。
MS Learnでは、credential vending、zero-copy、no-ETL access、optional auto-include for new tables、ongoing syncが説明されています。Dremio上のIceberg tableをFabric workloadsから利用するための連携です。
2026年3月 - Fabric Runtime 2.0ほか14件

3月のデータエンジニアリングは15件の更新が入り、次世代ランタイム、Sparkコンピュート管理、Copilotによるノートブック支援、Materialized Lake Viewの拡張など、データ処理基盤全体のモダナイズが進みました。
特にFabric Runtime 2.0のプレビュー提供と、Custom Live Pools・Resource Profiles・Job concurrency監視といったSparkコンピュート管理の刷新は、大規模データ処理をFabric上で本番運用する上で重要な基盤アップデートです。
Fabric Runtime 2.0(Preview)
Spark 4.0、Python 3.12、Delta Lake 4.0を含む次世代のFabric Runtime 2.0がプレビュー提供されました。パフォーマンス、API互換性、依存ライブラリの更新など、Sparkベースのワークロード全般に影響する基盤のメジャーアップデートです。
Spark 4.0ではAPI刷新、最適化強化、ANSI準拠のSQL動作変更などが含まれ、既存ジョブへの互換性検証が必要です。Delta Lake 4.0ではスキーマ進化やTime Travelの改善など、Lakehouseベースの運用が大きく恩恵を受けます。
本番移行前に、既存notebookやSpark jobを並行して新Runtimeで回し、性能とAPI互換性を検証することが重要です。特に依存PyPIパッケージがPython 3.12で問題を起こす可能性に注意が必要です。
参考:Fabric Runtime 2.0 overview
Custom Live Pools for Fabric Data Engineering(アナウンス)
依存ライブラリや設定込みで常時ウォーム状態を保つ、専用Sparkプール「Custom Live Pools」が案内されました。Spark sessionの起動遅延を大幅に抑えられます。
既存のStarter Poolsは汎用構成でウォームアップされていますが、カスタム依存が必要な環境ではセッション起動時に毎回ライブラリインストールが走り、起動に数分かかることがありました。Custom Live Poolsでは、事前にウォーム状態のプールを維持することで、この問題を解消できます。
対話型開発や、即応性が要求される本番ジョブで特に効果が大きく、ユーザー体験とCU効率の両方を改善できます。
参考:Fabric March 2026 Feature Summary — Custom Live Pools
Job concurrency and queue monitoring experience(アナウンス)
Fabric Data EngineeringのSparkジョブについて、同時実行状況、待機中ジョブ、完了済みジョブ、待機理由を一元的に可視化する監視UIが案内されました。容量制約やキュー滞留の問題を迅速に特定できます。
従来はジョブごとのログを追う必要があり、「なぜこのジョブが動かないのか」「どのジョブが容量を食っているか」を総合判断するのが難しい状況でした。今回の監視UIで、容量配分の最適化やキュー詰まりの診断が具体的に行えます。
大規模並列ワークロードの運用で、ボトルネック特定とチューニングのサイクルが短縮される効果が期待されます。
参考:Fabric March 2026 Feature Summary — Job monitoring
Resource Profiles for Fabric Data Engineering(アナウンス)
ワークロードの利用目的やデータ量を入力すると、適切なSpark構成を自動推奨するResource Profiles機能が案内されました。構成の初期チューニング工数を大幅に削減できます。
Spark構成パラメータ(executor数、メモリ、並列度など)の最適化は、ベテランエンジニアでも試行錯誤が必要な領域です。Resource Profilesでは、一般的なワークロードパターンに対する推奨構成を提示し、初期値から運用開始できます。
データエンジニアのスキルレベルに依存していたチューニングの入口が、プロファイル選択レベルまで標準化されることで、組織全体の運用品質が底上げされます。
参考:Resource Profile Configuration
Installing libraries with Quick mode in Spark Environment(Preview)
Spark Environmentへのライブラリ導入を高速化するQuick modeがプレビューで提供されました。従来のEnvironment構築より短時間でライブラリを導入・更新できます。
ライブラリ追加時のSpark Environment再構築は、大量のPyPIパッケージを含む場合に10分以上かかるケースがありました。Quick modeでは、差分更新や並列ダウンロードなどの最適化により、この時間を大幅に短縮します。
継続的にライブラリを追加・更新するプロジェクトで、開発サイクルの待ち時間が減り、イテレーション速度が上がります。
参考:Fabric March 2026 Feature Summary — Quick mode
Dynamic session sharing limit up to 50(アナウンス)
Fabric Data Engineeringの高同時実行モードで、動的セッション共有の上限が最大50まで拡張されました。同一Sparkセッションを多数のnotebookやジョブで共有する構成で、スケール上限が緩和されます。
セッション共有は、単一のSparkクラスタに対して複数のワークロードを同居させる仕組みで、リソース効率を高めます。従来の上限では、組織規模の共同利用で制約になるケースがありました。
大人数チームでの開発やバッチ処理の並列度確保で、追加のキャパシティ購入なしにスケールアップが可能になります。
参考:High Concurrency Mode Increasing Limit
Data export settings for notebooks(アナウンス)
ノートブックからのデータエクスポート制御を強化し、ダウンロードをワークスペース単位で抑止できる設定が案内されました。データ持ち出しを制御するガバナンス要件に応えます。
規制業界では、機微データを扱うワークスペースから個人PCへのダウンロードを原則禁止したいケースがあります。従来はnotebook UIからのダウンロードが自由に行えたため、手動運用でカバーする必要がありました。
設定ベースでのエクスポート制御により、技術的統制が実現し、コンプライアンス監査時の証跡も整えやすくなります。
参考:Fabric March 2026 Feature Summary — Data export settings
Session starts insights into Fabric Data Engineering(アナウンス)
Sparkセッション開始の遅延原因や、Starter Pool利用可否、容量配分状況などを詳細に診断できる「Session starts insights」が案内されました。セッション開始の遅さに対する原因追跡が容易になります。
セッション開始遅延は、「なぜ遅いのか」の原因特定が難しく、エンジニアがサポートに問い合わせざるを得ないケースが多く発生していました。今回のInsightsで、Pool状態、容量状況、設定影響などが可視化され、自律的な診断が可能になります。
運用の初動で問題の切り分けができるようになり、サポートエスカレーションの頻度低下と、運用チームのスキル向上が見込めます。
Z-order and liquid clustering support in the Native Execution Engine(アナウンス)
Delta LakeのZ-order最適化とLiquid Clusteringを、FabricのNative Execution Engineで利用できるようになることが案内されました。データ配置最適化とネイティブ実行の組み合わせで、分析クエリの性能が大きく向上します。
Native Execution EngineはC++実装による高速化エンジンで、Z-order/Liquid Clusteringの最適化効果を最大化できます。従来はZ-orderのメリットが限定的だったシナリオで、応答性が改善する見通しです。
大規模な分析ワークロードで、クエリ応答時間とCU消費の両面でメリットが出やすく、Lakehouse設計の定石が更新されます。
参考:Liquid Clustering and Z-Order support for Native Engine
Copilot for data engineering and data science(アナウンス)
ノートブックのコード生成、説明、修正提案、障害解析を、Fabricコンテキストを踏まえて支援するCopilotが案内されました。Data EngineeringとData Science両方のnotebook体験に統合されます。
従来のCopilot chatはFabric固有のメタデータを十分活用できず、汎用的な提案にとどまる場合がありました。Fabricコンテキスト対応により、Lakehouseのテーブル情報や履歴実行結果を踏まえた、より的確な支援が期待できます。
データエンジニア・データサイエンティストの日常業務で、Copilotがペアプログラミング相手として機能する環境が整い、生産性改善に直結します。
参考:Copilot for data engineering and data science
Multiple schedules for Fabric materialized lake views(アナウンス)
1つのLakehouse内で、Materialized Lake View(MLV)ごとに複数の名前付きスケジュールを使い分けられるようになることが案内されました。MLVの更新戦略を柔軟に設計できます。
従来は1つのMLVに1つのスケジュールしか付けられず、「営業日中は頻繁、週末は夜間1回」といった使い分けが難しい状況でした。複数スケジュール対応により、ビジネスサイクルに合わせた柔軟な運用が可能になります。
日中向け・夜間向け・障害復旧用など、運用パターンごとにスケジュールを使い分ける構成が、MLVの本番運用で実践しやすくなります。
参考:Schedule lineage run for materialized lake views
PySpark support for Fabric materialized lake views(Preview)
Materialized Lake Viewを、Spark SQLだけでなくPySparkから作成・更新・置換できるPySpark対応がプレビューになりました。Pythonベースの開発者がMLVを扱いやすくなります。
従来のMLVはSpark SQL前提で、PySpark資産を持つチームはSQL変換の負担がありました。PySpark対応により、既存のPythonコード・テスト・CI/CDパイプラインとMLVをスムーズに連携できます。
データ分析・機械学習パイプラインの途中でMLVを活用するシナリオで、Pythonベースの開発体験を維持しつつ、Materialized Viewのキャッシュ効果を活かせます。
参考:Create materialized lake view with PySpark
Move data from source to Lakehouse using Copy job(アナウンス)
LakehouseのGet data画面でCopy jobを前面に配置し、データ取り込みを数クリックで開始できる導線が案内されました。初心者が取り込みを始めるハードルが下がります。
従来のGet dataはShortcut作成やNotebookへの誘導が中心で、Copy jobを使うにはData Factory側への移動が必要でした。新しい導線では、Lakehouseビューから直接Copy jobで取り込みを開始でき、ユーザーフローが自然になります。
セルフサービス型のLakehouse利用を推進する組織で、「まず取り込みを完了させる」までの所要時間が短縮されます。
Improved Copilot completion for Fabric notebooks(アナウンス)
Fabric notebookのCopilotインライン補完が、より高速で文脈に沿ったVS Code風の体験に改善されました。コード補完の品質と応答速度の両面で改善します。
従来のインライン補完は、セル単位のコンテキストしか認識できず、notebook全体の流れを踏まえた提案が弱い傾向がありました。今回の改善で、notebook全体の変数・関数・使用パターンを考慮した補完が期待できます。
反復的なコード修正や、既存パターンに沿った処理追加の速度が向上し、notebookベースの開発体験がIDE並みに近づきます。
参考:Author and execute notebook
Create files in the notebook resources folder(アナウンス)
notebookのResourcesフォルダ内で、Pythonモジュール、YAML設定、JSON、テンプレートなどのファイルを直接作成できるようになることが案内されました。notebookとセットで配布する補助ファイルを、Fabric内で完結して管理できます。
従来は補助ファイルをローカルで作成してアップロードする必要があり、バージョン管理やGit統合との親和性が低い状況でした。Fabric上で直接作成・編集できることで、notebookとセットでのCI/CD管理が現実的になります。
共通ライブラリ化、テストコード、構成ファイル管理など、notebookを「複数ファイルで構成されるプロジェクト」として扱う設計が実践しやすくなります。
参考:How to use notebook resources
2026年2月 - ノートブック版履歴強化ほか7件

データエンジニアリング領域では、ノートブックの開発体験を中心に8件の改善が入りました。バージョン管理・モジュール化・セキュリティ・外部接続と、開発ライフサイクル全体に関わる強化が揃っています。
ノートブックバージョン履歴の複数ソース対応
ノートブックの変更履歴が、変更の発生元(ポータル編集・Git同期・デプロイパイプライン・VS Code公開)を明確にラベル表示するようになりました。Fabricのノートブックは Git、デプロイパイプライン、Visual Studio Codeとシームレスに統合されているため、保存されたバージョンは自動的に履歴に記録されます。
CI/CDワークフロー(Git同期、デプロイパイプライン、パブリックAPI)やチームでの共同開発において、「誰が・いつ・どの経路で変更したか」を正確に把握でき、必要に応じて適切なポイントへのロールバックも可能です。
PythonノートブックのPercentRun対応
Pythonノートブックで %run がサポートされ、他のノートブックを同一実行コンテキスト内で呼び出せるようになりました。共有ユーティリティやセットアップロジックをコピペせずモジュール化でき、プロジェクト構造をクリーンに保ちながら共通コードを一元管理できます。
現時点ではノートブックアイテムの参照のみに対応しており、ノートブックリソースフォルダ内の.pyファイルの実行サポートは近日追加予定です。
ノートブックのフルサイズモード
セルを全画面に展開して集中編集できるフルサイズモードが追加されました。長いコードブロックや複雑なSQL、大規模なPythonブロックの編集、画面共有時に特に有効です。フルサイズモード中も完全な編集機能を維持しつつ、前後のセルへのナビゲーションも可能です。セルツールバーから有効化できます。
API for GraphQLのPrivate Link対応
Fabric API for GraphQLがテナントレベルのPrivate Linkに対応しました。GraphQL APIへのアクセスがMicrosoftのプライベートバックボーンネットワーク経由になり、データトラフィックがパブリックインターネットを経由しなくなります。
複雑なファイアウォールルールやVPN設定が不要になり、既存のAzure Private Linkインフラストラクチャとの統合によってガバナンスが簡素化されます。Microsoft Entra ID認証やシングルサインオンとも連携した、エンタープライズ対応のセキュリティモデルです。テナント管理設定からAzure Private Linkを有効化することで利用できます。
参考:GraphQL APIのPrivate Linkサポートドキュメント
API for GraphQLのCI/CD対応(GA)
GraphQLアーティファクトのGit管理、プルリクエストワークフローでのコラボレーション、デプロイパイプラインによる環境間プロモーションが正式サポートされました。バージョン管理・レビュー・ロールバックの仕組みがコードやデータと同じレベルでAPIにも適用され、Azure DevOpsなどの既存のCI/CD環境と組み合わせて運用できます。
信頼性とパフォーマンスの改善も併せて実施されています。
参考:GraphQL APIのCI/CDとソース管理ドキュメント
Fabric User Data Functionsの既定値引数サポート
ユーザーデータ関数で既定値引数がサポートされ、省略された引数にプリセットのデフォルト値が適用されるようになりました。文字列、boolean、float、int、配列、オブジェクト型に対応しています。
一般的なユースケースでは引数の指定を省略でき、必要に応じてカスタマイズする柔軟な運用が可能になります。関数呼び出しの簡素化とコードの柔軟性向上に寄与します。
参考:User Data Functionsの既定値引数ドキュメント
Microsoft ODBCドライバ for Fabric Data Engineering(プレビュー)
.NET、Python、その他のODBC互換アプリケーションやBIツールからSpark SQLに接続するためのエンタープライズグレードのODBCドライバがプレビュー公開されました。FabricのLivy APIを介したSpark SQL接続を提供します。
ODBC 3.x準拠、Microsoft Entra ID認証、包括的なSpark SQLおよびデータ型サポート、大規模データセット向けのパフォーマンス最適化、プロキシサポートやセッション再利用などのエンタープライズ機能を備えています。OneLakeとLakehouseデータとの緊密な統合、環境ベースの実行、ワークロードに応じたSpark設定のカスタマイズにも対応しています。
参考:Microsoft ODBCドライバ for Fabric Data Engineering公式ドキュメント
ノートブックのカスタマー管理キー(CMK)暗号化対応
CMKが有効化されたワークスペースでノートブックが完全にサポートされました。セルソース、セル出力、セル添付ファイルなどのコアコンテンツとメタデータが、自社管理のAzure Key Vaultキーで保存時に暗号化されます。
開発者のワークフローを変更することなく、より厳格なガバナンスとコンプライアンス要件に対応できます。
2026年1月 - Lakehouse高同時実行モードほか4件
データエンジニアリング領域では、Lakehouse操作のパフォーマンス最適化、ノートブックの外部接続強化、VS Code連携、Materialized Lake Viewの改善と、開発効率に直結する5件のアップデートが入りました。

Lakehouse高同時実行モード
Lakehouse操作のLoad to TableやPreviewに対して、最大5つの独立したジョブが1つのSparkセッションを共有する高同時実行モードが追加されました。Managed Virtual Network環境では従来3〜5分かかっていたSparkの起動待ちが、セッション再利用により5秒以内に短縮されます。
料金面でも大きなメリットがあり、共有アプリケーションを起動した最初のSparkセッションのみが課金され、同一セッションを共有する後続のオペレーションには追加コストが発生しません。最適化されたセッションはFabricが自動管理し、Monitoring HubでHC_<lakehouse_name>の命名規則で追跡可能です。
ノートブックのFabricコネクション対応(プレビュー)
ノートブックにGet Data機能が追加され、Azure Blob Storage、PostgreSQL、Azure Key Vault、S3などへの接続がコネクションフローで簡素化されました。コネクション作成後、データソースへのアクセスコードスニペットが自動生成されます。
Basic認証、アカウントキー認証、トークン認証、ワークスペースID認証、サービスプリンシパル認証に対応しています。Fabricのデータソース管理ページからもコネクションを作成可能で、その場合は「Allow Code-First Artifacts like Notebooks to access this connection」トグルを有効にする必要があります。
VS Codeからワークスペースのノートブックを直接編集
Fabric Data Engineering VS Code拡張で、ワークスペース上のノートブックをダウンロードせずに直接開いて編集できるようになりました。VS Code上での変更を保存すると、リモートワークスペースのノートブック内容が自動的に更新されます。
ノートブックのツールバーにある「Open Notebook Folder」アイコンからVFS(仮想ファイルシステム)モードで起動し、同一ウィンドウで複数のFabricワークスペースとノートブックを同時に開くことも可能です。
Materialized Lake ViewのCreate or Replaceセマンティクス対応
Materialized Lake Viewで、既存のビューをドロップせずにCreate or Replaceで更新できるようになりました。カラムの追加・変更、変換ロジックの調整、メタデータの更新が、ビューの削除・再作成なしで実行可能です。
データモデルの反復開発が高速化し、コアな分析オブジェクトの削除・再構築に伴う運用リスクや中断を回避できます。
参考:Materialized Lake ViewのSpark SQLリファレンス
Materialized Lake Viewのリネージ強化
Materialized Lake Viewのリネージ(系統)表示に、ノートブックソースが明確に表示されるようになりました。各ビューの生成元を簡単にトレースでき、削除されたソースもフラグ表示されます。
トラブルシューティングの迅速化とリフレッシュスケジュールの信頼性向上に寄与します。
参考:Materialized Lake Viewのドキュメント
データサイエンス
データサイエンスは、Azure Machine Learningと統合された機械学習ワークフローをFabric上で提供する機能領域です。MLモデルのトレーニング・デプロイ・監視のほか、Semantic Linkによるセマンティックモデルとの連携、ノートブックベースの探索的データ分析などをカバーしています。
2026年4月 - MLflow横断記録GAほか2件
ML実験OAP対応
Machine Learning ExperimentsとMachine Learning Modelsが、outbound access protection(OAP)enabled workspacesで作成・管理できるようになりました。MS LearnのData Science OAPページでは、この対応はPreviewとして記載されています。
同ドキュメントでは、これらのData Science item types自体は外部resourcesへoutbound network connectionsを行わないため、追加のoutbound access checksは不要と説明されています。notebook codeが外部data sourcesへ接続する場合は、Data Engineering outbound access protection configurationで制御されます。
参考:Workspace outbound access protection for Data Science
MLflow横断記録
Cross-workspace logging for MLflowがGenerally Availableになりました。standard MLflow APIsを使い、experiments、metrics、parameters、registered modelsを任意のFabric workspaceへ記録できます。
MS Learnでは、Fabric notebook、Azure Databricks、Azure Machine Learning、local environmentなどから利用できると説明されています。実装にはsynapseml-mlflow packageとMLFLOW_TRACKING_URI environment variableを使い、MLflow 3は現在サポートされないためmlflow-skinnyを2.22.2以下にpinする必要があります。
参考:Manage MLflow models across workspaces and platforms
SemPy 0.14.0
Semantic Link(SemPy)0.14.0では、sempy.fabric.admin moduleが追加されました。Feature Summaryでは、workspaces、capacities、domains、tenant settings、reports、usersなどを扱う75個のadmin APIsが含まれると説明されています。
同リリースでは、semantic modelsをworkspaces間でdeployし、Direct Lake connectionsを新しいlakehousesやwarehousesへ自動remapできます。Power BI report layoutsのprogrammatic extraction/update、Lakehouse tablesのDelta OPTIMIZE、long-running operationsを制御するLroConfigも追加されています。
2026年3月 - Fabric data agents GAほか6件
3月のデータサイエンスは7件の更新が入り、Fabric data agentsのGAとガバナンス強化、data sourceの拡張、AI functionsのマルチモーダル対応、AutoMLのGAなど、Fabric上でのAIエージェント構築と機械学習実装が実用段階に到達しました。
特にFabric data agentsのGAは、Lakehouse、Warehouse、Eventhouseなど多様なデータソースを横断してAIエージェントを構築・共有できる基盤として、Fabric全体のAI活用戦略の中核に位置づけられます。
Fabric data agents(GA)
Lakehouse、Warehouse、Eventhouse、Power BI セマンティックモデル、Graph、KQLデータベースなど、Fabricの多様なデータソースを対象にAIエージェントを構築・公開・共有できるFabric data agentsがGAになりました。自然言語でデータ問い合わせや分析を実行するエージェントを、コードを書かずに構築できます。
従来のデータ分析は「SQLを書ける人」や「Pythonを書ける人」に閉じた作業でしたが、data agentsにより、業務部門のユーザーが自然言語でデータに問いかけられる環境が整います。Fabric側で認証・権限・監査が一貫して管理される点が、企業利用の観点で重要です。
本番投入時は、エージェントに許可するデータソースの範囲と、回答精度のバリデーション(想定質問に対する正解率の事前検証)をしっかり行うことが成功のポイントです。
参考:Fabric March 2026 Feature Summary — Fabric data agents
Advanced security and governance in data agents(Preview)
Fabric data agentsに対して、Purview監査、eDiscovery、Outbound Access Protection(OAP)連携などの高度なセキュリティ・ガバナンス機能がプレビューで提供されました。規制業界での本格利用を想定した統制機能です。
Purview連携により、data agentのプロンプトと応答がeDiscovery対象となり、法的要請時の証跡開示が可能になります。OAP連携で、エージェントが外部サービスへ情報を送信する際の制御もかけられます。
金融・医療・公共など、監査要件が厳しい業界でdata agentsを本番投入する前提となる機能群で、導入要件の整合性を取りながら段階的に有効化するのが現実的です。
参考:Fabric March 2026 Feature Summary — data agents security
Graph as a data source for data agents(Preview)
Fabric data agentsが、Graphデータベースをデータソースとして扱えるようになりました。エンティティ間の関係性を活かした問い合わせや分析をエージェント経由で実行できます。
従来のSQLやKQLでは表現しにくい「経由関係」「到達可能性」「推移閉包」などのグラフクエリを、エージェントの問い合わせバックエンドとして利用できます。ソーシャルネットワーク分析、サプライチェーン分析、不正検知などで特に有効です。
Fabric Graph機能と組み合わせて、関係性データ分析を自然言語で扱える環境を構築することで、従来専門家のみが扱えた分析領域を広いユーザーに開けます。
参考:Fabric March 2026 Feature Summary — Graph data source
KQL user-defined functions support for data agents(Preview)
Fabric data agentsが、KQLで定義したUser Defined Functions(UDFs)を活用した問い合わせに対応しました。複雑なKQLロジックを関数化しておき、エージェントから呼び出す構成が可能になります。
KQL UDFはビジネスロジックを再利用可能な関数として定義する仕組みで、Eventhouseベースの分析で広く使われます。data agentsがUDFを呼び出せることで、エージェント側は簡潔な問い合わせで、背後の複雑なロジックを活用できます。
社内共通のKQLライブラリを整備している組織では、エージェント経由での業務データ分析が、既存資産との親和性を保ちつつ実現できます。
参考:Fabric March 2026 Feature Summary — KQL UDFs for agents
SQL functions support for data agents(Preview)
Fabric data agentsが、SQL functionsを使った高度な問い合わせをサポートしました。WarehouseやSQL database in Fabricの既存SQL関数資産を、エージェント経由で活用できます。
SQLストアドプロシージャや関数として整理された業務ロジック(売上集計、在庫評価、リスクスコア計算など)を、エージェントから自然言語経由で呼び出す構成が可能になります。
既存のWarehouse運用でSQL functionsを活用している組織では、data agents導入時の学習曲線が低く抑えられ、既存資産を活かした段階的な導入が現実的です。
参考:Fabric March 2026 Feature Summary — SQL functions for agents
Multimodal support for AI functions in Fabric(Preview)
Fabric AI functionsが、PDF、画像、テキストなどマルチモーダルデータに対応するプレビュー機能を提供しました。従来のテキストのみの処理から、文書・画像データの要約・分類・OCRなどに拡張できます。
企業のデータ資産は構造化データに限らず、契約書PDF、商品画像、手書きフォームなど非構造化データが大量に含まれています。AI functionsでこれらを扱えることで、SQLやDataflow Gen2の延長で非構造データ処理を組み込めます。
請求書OCR、契約書条項抽出、商品画像分類、顧客フィードバックの感情分析など、幅広いユースケースで活用できます。コスト・精度・レイテンシのトレードオフを事前検証することが導入成功の鍵です。
参考:Fabric AI functions multimodal support
AutoML in Fabric(GA)
FLAMLベースのAutoMLがUI全体込みでGAになりました。回帰、予測、分類、多クラス分類など主要タスクに対応し、コードを書かずにモデル作成を進められます。ローコード開発者や業務部門の分析担当者でも、機械学習の恩恵を受けられるようになります。
GAにより、モデル作成の実験管理、ハイパーパラメータチューニング、特徴量重要度の可視化などが安定運用レベルで利用できます。MLflow連携によるモデルトラッキングも標準で備わっています。
分析チームと業務部門の距離を縮めるツールとして位置づけられ、「AIを試したいが学習コストが高い」というギャップを埋める役割を果たします。AIプロジェクトの初期段階や、比較的定型的なモデル化タスクで特に効果的です。
参考:Automated machine learning in Fabric
2026年2月 - Semantic Link 0.13.0ほか1件
データサイエンス領域では、プログラマティックなFabric資産管理の強化とMLモデルの本番監視機能が追加されました。
Semantic Link 0.13.0
Semantic Linkの最新リリースでは、Lakehouse、レポート、セマンティックモデル、SQL分析エンドポイント、Sparkの新モジュールが追加され、ワークスペース全体のエンドツーエンド操作が可能になりました。Lakehouseとテーブルの作成・管理、レポートのクローンと再バインド、セマンティックモデルの更新・監視、SQL・Spark設定の管理まで、幅広い操作をカバーしています。
複数のFabric APIがモジュール間で一貫して公開されるようになり、一般的なワークフローの簡素化とAPIの発見性が向上しました。サービスプリンシパル認証の信頼性向上やメジャー評価時の正確性改善などのバグ修正も含まれています。
活用シナリオを紹介する3本のデモ動画(データサイエンス向け、Power BI自動化向け、データエンジニアリング向け)も公開されています。
参考:Semantic Link 0.13.0のリリースノート
リアルタイムスコアリングエンドポイントの監視
デプロイ済みMLモデルのリアルタイムスコアリングエンドポイントに対する監視機能が追加されました。リクエスト量、エラー率、レイテンシをエンドポイントバージョン間で比較でき、改善効果の検証やリグレッションの早期検出が可能です。
導入状況のトラッキングから問題の診断、負荷時の一貫したパフォーマンス確保まで、MLモデルの本番運用に必要な監視がFabric内で完結します。ロールアウトやロールバックの意思決定を実際の使用データに基づいて行えるようになります。

データウェアハウス
データウェアハウスは、Fabric上でT-SQLベースの分析クエリを実行するためのサービスです。従来のSQL Server Data WarehouseやAzure SQL Databaseの操作感を維持しつつ、OneLake上のデータに対してスケーラブルなクエリ処理を提供します。Migration Assistantによる既存環境からの移行支援機能も含まれます。
2026年4月 - ALTER TABLE txnほか4件

ALTER TABLE txn
Fabric Data Warehouseで、対応するALTER TABLE operationsをexplicit user-defined transaction内で実行できるようになりました。Feature SummaryとMS LearnではGenerally Availableとして掲載されています。
Transactionsドキュメントでは、ADD nullable columns、DROP columns、NOT ENFORCED制約の追加・削除、複数ALTER TABLE statementsなどが対象として示されています。DDLをtransaction内で実行するとlockingによりconcurrent DML/SELECTやsystem catalog viewsへのSELECTをblockする可能性があるため、注意点も明記されています。
参考:Transactions in Fabric Data Warehouse
COPY INTO JSONL
COPY INTOでnewline-delimited JSON(JSONL)filesを直接Fabric Data Warehouse tablesへingestできるようになりました。Feature Summaryでは、以前はOPENROWSETがJSONLをサポートしていた一方、COPY INTOではJSONL ingestionができなかったと説明されています。
今回の更新でJSONLはFILE_TYPE optionとして扱われ、CSVやParquetと同じCOPY INTO surface areaで取り込めます。公式ページは、event streams、logs、application exportsなどJSONLを使うデータ形式への対応を説明しています。
Warehouse復元
Dropped warehouse recoveryがPreviewとして追加されました。Workspace Administratorsは、誤って削除したwarehousesをWorkspace Recycle Binから復元できます。
MS Learnでは、retention windowを7〜90日の範囲で構成できると説明されています。復元対象にはtable schemas、data、snapshots、permissions、views、stored proceduresが含まれます。
SQL DB移行支援
Migration Assistant to SQL databaseがPreviewとして追加されました。SQL Server on-premises workloadsをFabric SQL databaseへ移行するための支援機能です。
MS Learnでは、DACPACsによるschema import、compatibility issuesの検出、移行前のclear/actionable guidanceが説明されています。SQL developers向けに設計されている点も明記されています。
参考:Fabric Migration Assistant for SQL database
Warehouse AI関数
Unstructured text processing with AI functions in Fabric Data Warehouseが4月のsamples/guidanceとして掲載されました。built-in AI functionsをT-SQLから使い、unstructured textを処理する実装例です。
MS Learnでは、information extraction、classification、sentiment analysis、grammar fix、summary、translation、custom promptsが対象として示されています。Preview features欄ではAI functions in Fabric Data WarehouseがPreviewとして扱われています。
参考:Use AI functions in Fabric Data Warehouse
2026年3月 - Warehouse OAP GAほか28件

3月のデータウェアハウスは、Warehouse本体(リカバリ・カスタムSQLプール・監査・OAP・OneLake取り込み)に加えて、SQL database in Fabricの強化とMirroringソースの大幅拡充という3系統で動きました。本番運用に直結する「足回り」が一気に整った月と言えます。
Fabric Data Warehouse recovery(プレビュー)
誤って削除したFabric Data Warehouseを関連資産込みで短時間に復元できるリカバリ機能がプレビュー公開されました。削除事故からの復旧経路が明確になり、本番運用時の安心感が高まります。
リサイクル経由での復旧ではなく、ワークスペース側のリカバリ操作からWarehouseを呼び戻せるため、権限・オブジェクト定義・参照関係をまとめて戻せるのがポイントです。
Alerts and actionsによるActivator連携
WarehouseのSQLクエリ結果からActivatorルールを作成し、通知や後続アクションへ直接つなげられるようになりました。データウェアハウス上の「しきい値超え」「変化検知」を契機に、自動通知やワークフロー起動までSQLだけで設計できます。
ダッシュボード監視に頼らずクエリ結果そのものをトリガーにできるため、業務KPIの変化をリアルタイムに拾う仕組みが軽量に組めます。
参考:Fabric Warehouseのアラートとアクション
T-SQL AI関数による非構造テキスト解析(プレビュー)
AI_CLASSIFY AI_EXTRACT AI_GENERATE などのT-SQL AI関数がプレビュー公開され、要約・分類・感情分析・翻訳・情報抽出をSQLだけで実行できるようになりました。Azure OpenAI連携をラップした関数として利用できます。
PythonやノートブックなしにWarehouse内で非構造テキストをそのまま加工できるため、データエンジニア以外の分析チームもAI処理をパイプラインに組み込みやすくなります。
ANY_VALUE集計関数
GROUP BY時に任意の1値を返す ANY_VALUE 集計関数が追加されました。説明用の列をクエリに含めたいが集約関数を書くのが冗長だったケースで、MINやMAXの代替としてシンプルに使えます。
大規模集計クエリでは MIN/MAX がソート発生源になることもあるため、意味的に「どれでもよい1値」を取りたい場合は性能面でも有利です。
Fabric warehouse custom SQL pools(プレビュー)
ワークロード単位でSQLコンピュートを分離・配分できるカスタムSQLプールがプレビュー公開されました。共有プールと別にSELECT専用や重いETL専用のプールを確保でき、ノイジーネイバー問題を緩和できます。
読み取り最適化ワークロードと書き込み最適化ワークロードのリソース分離が設計可能になり、キャパシティプランニングの選択肢が広がります。
参考:Fabric warehouse custom SQL pools
SQL Audit Logsの一般提供(GA)
WarehouseとSQL analytics endpointの監査ログ取得・参照・外部解析が正式GAとなりました。監査ログをOneLakeに保存し、アクセスや変更履歴を追跡できるため、コンプライアンス対応やインシデント調査の基盤機能として実務投入できます。
COPY INTO / OPENROWSETのOneLakeソース対応(GA)
COPY INTO と OPENROWSET からOneLakeパス(Lakehouse以外の各種OneLake項目)を直接参照できるようになりました。外部ストレージや中継なしで、OneLake上の任意のParquet/CSV/JSONファイルをSQLで取り込めます。
Lakehouse固定だった従来運用から解放され、Eventhouseや他ワークロードが書き出したOneLakeファイルもそのままWarehouseへロードできます。
Warehouse向けOutbound Access Protection(OAP)の一般提供(GA)
Warehouseから許可された外部接続先のみにoutboundアクセスを制限できるOAPがGAになりました。ストレージアカウントや外部エンドポイントへの無差別な接続を防ぎ、データ流出対策と外部連携運用を両立できます。
ワークスペースOAPとセットで適用することで、EntraテナントとしてのFabricネットワーク境界を明確に定義できます。
Query Insightsの完全クエリテキスト表示
Query Insightsで従来8,000文字に制限されていたSQLクエリテキストを全文確認できるようになりました。動的SQLや巨大ETLクエリが途中で切れなくなるため、トラブルシュート効率が大きく向上します。
Migration Assistantのライブ接続(プレビュー)
Migration Assistantで、ソースのWarehouse・Synapse Dedicated SQLプールに直接接続し、DACPACを事前生成せずオブジェクトメタデータを移行できるライブ接続モードがプレビュー公開されました。
DACPACエクスポートの手順が省けるため、移行プロジェクト初期のディスカバリや小刻みな試行が容易になります。
参考:Migration Assistant Direct Connection
data sourcesによるデータアクセス簡素化(GA)
外部データソース参照と相対パスで OPENROWSET などを簡潔に書ける data sources オブジェクトがGAとなりました。長いURLやストレージアカウント名をクエリに埋め込まずに済み、環境移行時の書き換えコストが下がります。
参考:OPENROWSET (BULK) (Transact-SQL)
SQL database in FabricのMigration Assistant(プレビュー)
SQL ServerやAzure SQLからSQL database in Fabricへの移行を支援するMigration Assistantがプレビュー公開されました。Warehouse側の移行支援に加えて、SQL database(OLTPワークロード向け)への移行経路が整備された形です。
SQL database in Fabricの構成可能な自律管理
SQL database in Fabricで、vCoreスケーリングや互換性レベルなどの自律管理パラメータをDB単位で調整できるようになりました。完全自動運用だけでなく、ワークロード特性に合わせた微調整が許容される運用モデルに進化しています。
参考:SQL database in Fabric overview
SQL database in Fabricの全照合順序対応
新規作成時にAzure SQL Databaseがサポートする全collationsを指定できるようになりました。多言語環境や既存システムとの互換性維持が必要なケースで、Fabricを選びやすくなります。
参考:SQL database in Fabric overview
SQL database in Fabricの監査機能(GA)
Fabric上のSQL databaseに対する監査機能が正式GAとなりました。Warehouse側のSQL Audit LogsGAと合わせ、Fabric上のSQL系ワークロードで一貫した監査体制を構築できるようになっています。
参考:SQL database in Fabric overview
SQL database in FabricのCustomer Managed Keys(GA)
Azure Key Vaultの鍵を使ったSQL database暗号化(CMK)が正式サポートされました。キー所有・ライフサイクル管理を自社側に保持したい規制業界向け要件に対応できます。
参考:SQL database in Fabric overview
SQL database in Fabricのテーブル単位OneLakeミラーリング制御
OneLakeへミラーリングするテーブルを選択的に管理できるようになりました。センシティブデータを含むテーブルをミラーリング対象から外すなど、分析基盤側に露出するスコープをテーブル粒度でコントロールできます。
参考:SQL database in Fabric overview
SQL database in FabricのDiskANNベース ベクトル検索
SQL database in Fabric内でDiskANNによるベクトル検索を利用できるようになりました。RAGなどのAIシナリオ向けベクトル検索基盤を、OLTPデータと同じDB内で完結させられます。
参考:SQL database in Fabric overview
SQL database in FabricのAzure AI Foundry連携
Azure AI FoundryとSQL database in Fabricを連携し、セマンティック検索やAIアプリケーションシナリオへ接続できるようになりました。ベクトル検索と合わせて、AIアプリのバックエンドとしてFabric SQL databaseを採用しやすくなります。
参考:SQL database in Fabric overview
SQL database in Fabricのワークスペース性能ダッシュボード連携
SQL databaseの監視を、Fabricのワークスペース横断パフォーマンスダッシュボードへ統合できるようになりました。Warehouse・Lakehouse・SQL databaseを1つのビューで監視できる体制に近づいています。
参考:SQL database in Fabric overview
SQL database in Fabricの拡張データ回復
リサイクルビンで削除後も保持期間内であれば任意時点へ復旧できる拡張データ回復機能が追加されました。誤削除や誤更新から時系列で戻せるため、本番運用時のリスク低減に効きます。
参考:SQL database in Fabric overview
Private Link / VNET対応のCosmos DB mirroring
Cosmos DBをPrivate LinkやVNETで保護している環境から、OneLakeへ安全にミラーリングできるようになりました。ネットワーク境界を崩さずに分析基盤へデータ供給できます。
参考:Cosmos DB mirroring with private network
SAP向けMirroringの一般提供(GA)
SAP Datasphere経由でSAPデータをOneLakeへnear real-timeに複製できるMirroringがGAとなりました。ERPデータを分析基盤に取り込む従来のバッチETLから脱却し、業務データを常に最新状態で分析側に同期できます。
Oracle databases向けMirroringの一般提供(GA)
OracleデータベースのMirroringもGAとなりました。Oracle側にエージェントをインストールする方式で、OneLakeへ本番対応の継続複製が可能です。Oracle→Fabric分析基盤という従来ボトルネックだった経路が正式ルート化されました。
Azure Database for MySQL向けMirroring(プレビュー)
Azure Database for MySQL Flexible Serverをnear real-timeで複製するMirroringがプレビュー公開されました。MySQLを運用データベースに使うWebサービス系の分析基盤を、Fabric側に集約しやすくなります。
参考:Mirroring for MySQL Flexible Server
SharePoint List向けMirroring(プレビュー)
SharePoint ListとDocument LibraryをOneLakeへ継続同期するMirroringがプレビュー公開されました。業務部門がSharePointで管理している台帳データを、分析基盤側から定期抽出せずに参照できるようになります。
Mirroring拡張機能のChange Data Feed(プレビュー)
Mirroringで Change Data Feed を使い、更新差分を増分的にOneLakeへ反映できるようになりました。全件スナップショットではなく差分反映にできるため、大規模テーブルでの処理コストを抑えられます。
参考:Extended Capabilities in Mirroring
Snowflake mirroringのviews対応
Snowflakeの views をOneLakeへ複製できるようになりました。Snowflake上で定義済みの集計・ビジネスロジックをそのままFabricへ持ち込めるため、重複定義やロジック移植のコストを削減できます。
参考:Extended Capabilities in Mirroring
Mirrored databaseの1,000テーブル対応
ミラー対象テーブルの上限が500から1,000に引き上げられました。大規模な業務DBをまるごと取り込むシナリオで、テーブル分割や対象絞り込みの手間が減ります。
2026年2月 - SQLプールInsightsほか1件
データウェアハウス領域では、パフォーマンス可視化と移行支援の2つのアップデートが行われました。
SQLプールInsights
個別クエリを超えたプールレベルのテレメトリを提供する新機能です。新しいシステムビュー queryinsights.sql_pool_insights により、ビルトインのSELECT・NON SELECTプールの状態変化、圧力イベント、構成変更、容量更新を時系列で追跡できます。
既存のQuery Insightsビューと組み合わせることで、プールレベルの圧力とクエリパフォーマンスの相関分析が可能になり、読み取り最適化ワークロードと書き込み最適化ワークロード間のリソース分離の検証にも活用できます。パフォーマンスのボトルネック調査やキャパシティプランニングに有効なシグナルを提供します。
移行サマリーのエクスポート
Migration Assistantの移行結果をExcelまたはCSV形式でダウンロードできるようになりました。エクスポートはバックグラウンドで実行されるため、Migration Assistantのウィンドウを閉じても処理が継続します。
Excel形式ではMigrated ObjectsとObjects To Fixの2シート構成で、組織の秘密度ラベルに準拠したMIPコンプライアンス対応です。エクスポートファイルには、オブジェクト名、オブジェクト型(テーブル、ビュー、関数、ストアドプロシージャ等)、変換状態、適用された調整内容やエラーメッセージ、エラー種別が含まれます。大規模な複数オブジェクト移行のプロジェクト管理や監査対応に活用できます。
参考:Migration Assistantの公式ドキュメント
2026年1月 - MERGE文GAほか3件
データウェアハウスでは、クエリパフォーマンスの最適化と主要機能のGA化を中心に4件のアップデートが行われました。
プロアクティブ統計リフレッシュ
Data WarehouseおよびLakehouse SQL Analytics Endpointの列統計の自動管理が強化されました。SELECTクエリ中に作成された列統計が、データ変更に応じてエンジン側でプロアクティブに更新されるようになります。
クエリのプラン生成時に統計メンテナンスが発生して実行時間が延びるケースが減少し、手動で統計を管理する必要がさらに少なくなりました。
参考:統計の公式ドキュメント
増分統計リフレッシュ
主にINSERTやADD操作が多いロングテーブルの列統計更新のパフォーマンスが向上しました。前回のリフレッシュ以降に追加された新しい行のみをサンプリングする増分モードが導入され、テーブル全体を再サンプリングする従来方式と比較して統計更新が高速化されます。
統計操作がSELECTクエリの実行時間に影響するケースで特に効果が大きく、大規模テーブルの運用コストを削減します。
参考:統計の公式ドキュメント
Result Set Cachingの一般提供(GA)
2025年にプレビュー公開されていたResult Set Cachingが正式リリースとなりました。繰り返し実行されるクエリのキャッシュ結果を即座に返すことで、元のクエリを再計算せずにパフォーマンスを向上させます。
デフォルトで有効化されており、チューニングや設定変更は不要です。Data WarehouseとLakehouse SQL Analytics Endpointの両方で利用可能な、即効性のあるパフォーマンスブースターです。
MERGE文の一般提供(GA)
2025年9月にプレビュー公開されていたMERGE文が正式リリースとなりました。INSERT・UPDATE・DELETEを1つのステートメントに集約でき、条件分岐ロジックとDMLアクションを単一文で表現できます。
既存のETLパイプラインで複数ステップに分けていたデータ変換処理をシンプルにまとめられるため、パイプラインの保守性と可読性が大幅に向上します。
参考:MERGE (Transact-SQL)のドキュメント
プラットフォーム全体
プラットフォーム全体カテゴリには、特定のワークロードに限定されないFabric基盤共通のアップデートが含まれます。OneLakeカタログ、テナント管理、Identity・ガバナンス、UI/UXの改善など、Fabricを利用するすべてのユーザーに影響する横断的な機能が対象です。
2026年4月 - タブ操作とExplorer GAほか5件

タブ操作とExplorer
Tabbed multitasking and object explorerがGenerally Availableになりました。複数のFabric itemsをtabsで並行操作し、object explorerから開いているworkspaces across itemsを参照できます。
GAリリースでは、right-click tab management、open-in-new-window、resizable explorer pane、monitoring jobsのtab表示が追加されています。Feature SummaryとMS Learnはいずれもaccessibility improvementsも含めて説明しています。
参考:Multitask with tabs and object explorer
Semantic説明生成
Semantic model向けAuto-DescriptionがPreviewとして追加されました。Copilotがsemantic modelのmetadataとstructureをもとに、modelの内容と使い方を説明するdescriptionを生成します。
model ownersとcontributorsは、semantic model details pageからdescriptionを生成できます。生成後は同じページでreview、edit、apply、regenerateが可能です。
失敗通知の集中管理
Monitoring hubにSchedule failures pageがPreviewとして追加されました。失敗通知が設定されたscheduled itemsを一覧し、通知先を1か所で管理できます。
MS Learnでは、各itemを個別に開かなくてもrecipientsの追加、編集、削除ができると説明されています。scheduled job failure notificationsの運用をMonitoring hubから横断的に扱う更新です。
参考:Monitoring hub in Microsoft Fabric
OneLake資源規則
Resource instance rules for OneLakeがPreviewとして追加されました。workspace adminsは、明示的に信頼したAzure resource instancesからOneLakeへのinbound accessを許可できます。
この制御はresource instanceのidentityを使うため、IP allowlistsに依存しないservice-to-service scenarioを扱えます。MS Learnでは、Private LinkやIP firewall rulesを補完する機能として説明されています。
参考:Manage inbound access to OneLake with Resource Instance Rules
Workspace CMK
Workspace customer-managed keys for BYOKがPreviewとして追加されました。BYOK-enabled Fabric capacitiesで、workspace-level customer-managed keysを利用できます。
MS Learnでは、Power BI semantic modelsとその他Fabric itemsに、同じAzure Key Vault keyまたは別のkeyを使えると説明されています。専用capacityを別途用意せず、workspace単位でCMKを扱う更新です。
参考:Customer-managed keys for Fabric workspaces
アイテムID関連付け
Associated identities for itemsがPreviewとして追加されました。Fabric LakehousesとEventstreamsに対し、user、service principal、managed identityをREST API経由で関連付けられます。
MS Learnでは、この機能がitem ownerへの依存を取り除くものとして説明されています。実行主体をitemに関連付けることで、所有者依存の運用を避けやすくなります。
参考:Manage identities associated with Fabric items
2026年3月 - OneLake Catalog Govern GAほか15件

3月のプラットフォーム全体は、OneLake Catalog Governの管理者向けGA、Purview系のAI・DLP強化、ワークロード管理の一元化、OneLakeクライアント・Database Hubなど、テナント管理とガバナンスを横断する大規模刷新が入りました。管理者・ガバナンス担当が真っ先に押さえるべき月です。
OneLake Catalog Govern for admins(GA)
Fabric管理者がOneLake CatalogからFabric上のデータ資産を統制・可視化・保護できるGovern体験がGAとなりました。[管理]タブから分析情報、推奨アクション、コンプライアンスレポートを確認でき、容量・ドメイン・アイテムを横断してガバナンスを進められます。
テナント全体の「どのワークスペースにどのセンシティブデータがあるか」を1画面で把握でき、IRMやDLPポリシー適用前の棚卸しに使えます。
OneLake Catalog search APIとMCPツール(プレビュー)
ワークスペースを横断してFabric資産を検索するREST APIと、AIエージェント向けのMCPツールがプレビュー公開されました。権限を踏まえたクロスワークスペース検索をコードから呼び出せるため、AIエージェントや開発ツールへのFabric組み込みが容易になります。
MCPサーバーとして提供されることで、Claude CodeやCopilotなどMCPクライアントから自然言語で「どのワークスペースに売上データセットがある?」を解決できる基盤が揃います。
Workspace tags(GA)
ワークスペース単位でタグを付け、一覧やOneLake Catalog Explorerでフィルタリングできるタグ機能がGAとなりました。チーム・案件・コストセンター単位で整理したい大規模テナントで効きます。
タグはガバナンスポリシーやアクセス制御にも将来的に連動する基盤として整備されているため、早期に命名規則を決めて適用しておくと後々楽になります。
OneLake構造化データ向けDLPポリシー拡張(プレビュー)
Purview DLPのRestrict Accessアクションが、Warehouse・KQL DB・SQL DB in FabricなどOneLake上の構造化データへも拡張されました。これまでレポートやセマンティックモデル中心だったDLP適用範囲が、データ層そのものに広がります。
Fabric内部で「センシティブ扱い」とマークされたデータを、下流のSQLクエリやノートブックからも触れないように制御できるため、内部不正や誤操作対策が一段強くなります。
IRMのLakehouse Signals対応(GA)
Microsoft Purview Insider Risk Management(IRM)がLakehouseシグナルを取り込み、Lakehouseに対する異常アクセスや大量ダウンロードなどを内部不正リスクとして分析できるようになりました。
Warehouseだけでなくデータレイク層のアクセスもリスク検知対象となるため、OneLakeを中心としたデータ基盤全体をカバーするIRM運用が現実的になります。
参考:Microsoft Fabric IRM indicators
Fabric向けデータ窃取クイックポリシー(GA)
Fabricデータの持ち出し対策用のIRMクイックポリシーがGAとなりました。「データ窃取対策」をテーマにしたテンプレートから最低限のポリシーを1クリックで作成でき、IRM初導入時のハードルを下げます。
参考:Insider Risk Management Quick policies
Insider Risk Management PAYG利用レポート(GA)
IRMの従量課金ユニット配分をFabricやサブワークロード単位で確認できる利用レポートがGAとなりました。IRMをFabricに導入する際の「どのワークロードがどれだけIRMリソースを消費しているか」が可視化されます。
テナント全体のコスト管理と、部署別課金の整合性担保に使える基盤機能です。
Fabric Copilots/data agents向けPurview DSPM for AI(プレビュー)
Purview Data Security Posture Management(DSPM)for AIが、Fabric Copilotsとdata agentsのプロンプト・応答を対象化しました。AIエージェントの使われ方に対するリスク可視化と統制を、Purviewから一元的に行えます。
Fabric上のAI利用が本格化する中、「誰が・どのdata agentに・どんな問い合わせをしたか」「センシティブデータが応答に含まれたか」をコンプライアンス側で追える体制が整いました。
参考:Purview DSPM for AI – Copilot in Fabric
Variable Libraryのconnection reference項目型(プレビュー)
既存接続のIDをVariable Library経由で参照できる connection reference 項目型が追加されました。環境差分を「変数として管理する」パターンを接続オブジェクトにも広げられ、Dev/Test/Prodで異なる接続先をコードを触らずに切り替えられます。
CI/CDパイプライン視点でも、ハードコーディングされた接続IDを撤廃できる意味は大きいアップデートです。
Workload admin portal(GA)
Fabric管理ポータルに「ワークロードの管理」タブが追加され、テナント全体のworkload割当状況を一元把握できるポータルが整備されました。ワークロード単位の有効化・割当状況を管理者が1画面でコントロールできます。
参考:Fabric admin portal - workloads
Add workload to workspace(GA)
ワークスペース管理者がWorkload Hubから直接workloadをワークスペースへ追加できるようになりました。テナント管理者へ依頼せずに必要なworkloadだけセルフサービスで有効化できます。
Workload management admin APIs(プレビュー)
workloadの一覧取得や割当管理をREST APIから自動化できるAdmin APIsがプレビュー公開されました。大規模テナントでTerraformやPythonから一括管理したい運用に組み込めます。
OneLake securityのサードパーティ対応
外部エンジン(Snowflake、Databricks等の周辺)がOneLakeの行レベル・列レベルセキュリティ(RLS/CLS)を取得し、Fabric外からのアクセスにも一貫したアクセス制御を適用できるようになりました。
「OneLakeはFabric内外どちらから読まれても同じセキュリティ」を実現する要の更新で、マルチエンジン分析基盤のセキュリティ設計が大きく変わります。
参考:OneLake security integration guide
OneLake file explorer(GA)
Windowsクライアントから、OneDriveのような感覚でOneLakeのファイルを参照・編集できるfile explorerがGAとなりました。業務ユーザーがExcelやPower PointでOneLake上のファイルを直接開く導線が整います。
Database Hub in Fabric
エッジからクラウドまでのデータベース資産を横断管理する新しい Database Hub が案内されました。SQL database in Fabric、Cosmos DB、SQL Server、Azure SQLなどを1つのハブから見渡す構想で、将来の統合管理基盤の方向性が示されています。
Amazon S3ショートカットのサービスプリンシパル対応
OneLakeショートカットでAmazon S3へ接続する際、Microsoft EntraサービスプリンシパルとOIDCを使えるようになりました。長期AWSアクセスキーを避けられるため、クロスクラウド運用のセキュリティと監査性が向上します。
MS Learn新着情報のみに掲載された独自項目として、3月のプラットフォーム全体に追加しています。
2026年2月 - OneLakeカタログ刷新ほか3件

プラットフォーム全体では、OneLakeカタログの機能拡充、ガバナンスの強化、開発者向けのUI改善が行われました。
OneLakeカタログでのWorkspace Apps対応
Workspace Apps(Apps V2)がOneLake CatalogのInsightsカテゴリに表示されるようになりました。組織アプリやレポートなどのビジネス向けコンテンツと並べて表示されるため、関連するインサイトを一つの場所で探索できます。
各Workspace Appのメタデータもカタログ上で確認でき、アプリの内容を理解してから直接開くことが可能です。この対応により、OneLake CatalogがMicrosoft Fabric内の全アイテムタイプを包含する中央カタログとなりました。
アイテム詳細ページの統合
OneLake Catalog内だけでなく、ワークスペースからセマンティックモデルを直接開いた場合などカタログ外でのアクセス時にも、統一された詳細ページが表示されるようになりました。
全OneLakeストアドデータアイテムの完全なスキーマ表示、アイテムレベルの系統図の可視化、権限管理、実行・更新履歴の監視が1ページに統合されています。これまで複数画面を行き来していたデータガバナンスの日常運用が1画面で完結します。
Fabric Identityテナント制限の管理
テナント内のFabric Identity(Workspace Identity)数の上限管理が大幅に改善されました。デフォルト上限が従来の1,000から10,000に10倍拡大されたほか、管理ポータルの「Developer settings」内の新しいテナント設定、またはUpdate Tenant Setting REST APIを使ってカスタム制限を設定できるようになりました。
設定を無効のままにすると上限10,000が適用されます。有効にして独自の値を設定することもできますが、その際は事前に組織のMicrosoft Entra IDサービス制限を確認しておくことを推奨します。上限を超える作成が試みられた場合は、明確なエラーメッセージが表示されます。
参考:Fabric Workspace Identityの公式ドキュメント
水平タブ表示設定
複数のアイテムやワークスペースをまたいで作業する開発者向けに、水平タブの表示方法を制御する設定が追加されました。任意のタブを右クリックして設定にアクセスできます。
「Full tab names」(常に完全な名前を表示)と「Adaptive truncated names」(スペースに応じて自動短縮)の2つのモードを選択でき、スペースが不足した場合はオーバーフローメニューでタブ一覧を確認できます。複雑なマルチタスクワークフローでのナビゲーション効率が向上します。
2026年1月 - OneLakeカタログ親子階層ほか8件
1月のプラットフォーム全体は最多の9件が更新されました。OneLakeカタログの構造改善、セキュリティAPI拡充、Git統合の柔軟化、Python SDKの公開など、Fabric基盤の成熟を示すアップデートが揃っています。また、MicrosoftがエージェントAIデータエンジニアリング企業のOsmos社を買収し、Fabric上での自律型データエンジニアリングの加速を発表しました。
セマンティックモデルのAI自動サマリー(プレビュー)
OneLakeカタログ上でセマンティックモデルの概要をAIが自動生成する機能がプレビュー公開されました。アイテムを開かずにメタデータと構造から高レベルのサマリーを生成し、不慣れなアイテムの理解や比較を効率化します。
カタログのExploreタブのクイックアクションまたはアイテム詳細ページから生成可能で、カタログに戻るたびに最新のサマリーを再生成できます。適切なCopilot容量と権限が必要です。
OneLakeカタログの親子階層表示
OneLakeカタログにアイテムの親子関係が構造的に表示されるようになりました。フラットなリスト表示ではなく、関連アイテムがグループ化されて適切な階層で表示されます。
例えばLakehouseには自動生成されたSQL Analytics Endpointが、EventhouseにはKQL DBがそれぞれ配下に表示されます。展開・折りたたみで表示を制御でき、類似名称のアイテム間の混乱を防ぎ、タスクに適したアイテムを素早く特定できます。
アイテム参照変数型(プレビュー)
Variable Libraryに新しい「Item Reference」変数型が追加されました。Fabricアイテムを文字列のハードコーディングではなく、構造化された参照として管理できます。ユーザーがアクセス権限を持つアイテムのみを参照可能で、アイテム名・型・ロケーションが明示的に表示されます。
CI/CDデプロイメント時にはターゲットステージの参照先の存在と権限が自動検証されます。Lakehouseショートカット、UDFコード、ノートブックコードで利用可能です。今後はConnection Reference型(外部接続管理)も追加予定です。
Git統合 - GitHub Enterprise Cloud データレジデンシー対応
FabricワークスペースがデータレジデンシーつきのGitHub Enterprise Cloud(ghe.com)インスタンスに接続できるようになりました。規制要件のある顧客がFabricのGit統合を利用可能になります。
参考:GitHub Enterprise Cloudデータレジデンシーサポートのドキュメント
Git統合 - スタンドアロンブランチへのコミット
最後の同期ポイントから新しいブランチを作成し、現在の変更をそのブランチにコミットする操作が1アクションで可能になりました。接続中のブランチにコミットせずに分岐でき、受信更新がある場合でも別ブランチにコミットできます。
コンフリクト処理、作業の分離、バックアップ、チームへの共有など、柔軟なブランチ運用が可能になります。
参考:Git統合のドキュメント
Fabric REST API Python SDK(プレビュー)
Microsoft Fabric REST APIのPython SDKがPyPI(microsoft-fabric-api)で公開されました。HTTPリクエストの手動構築や認証管理が不要になり、Pythonオブジェクトとメソッドでワークスペースの一覧取得、デプロイ自動化、CI/CDパイプラインへの統合などが行えます。
Azure Identityライブラリによる組み込み認証、REST API用の型付きクライアント、簡易シリアライゼーションを備えており、pip install microsoft-fabric-api でインストール可能です。
OneLakeセキュリティの粒度別API(プレビュー)
OneLakeのセキュリティロール管理用に、個別のGet・Create・Delete操作が可能な粒度別REST APIが追加されました。既存のバッチロールAPIに加え、ロールコレクション全体を送信せずに個別ロールを操作できます。
自動化フレンドリーなセキュリティワークフローの構築やCI/CDパイプラインへの統合が容易になります。大規模組織でのセキュリティ管理の柔軟性が向上します。
参考:OneLake Data Access Securityのドキュメント
OneLakeセキュリティのミラーアイテム対応
すべてのミラーアイテムタイプに対してOneLakeデータアクセスロールの定義が可能になりました。トランザクションシステムからOneLakeにレプリケーションされたデータに対して、テーブル・行・列レベルのきめ細かいロールベースセキュリティを適用できます。
データを一度ミラーリングし、ソースでアクセス制御を適用してから複製なしで安全に共有できるため、ガバナンスを簡素化しつつFabric全体で分析をスケールできます。
OneLake診断の不変ログ
OneLakeの診断イベントを不変(immutable)にできるようになりました。診断イベントを含むJSONファイルが、不変保持期間中に改ざんや削除ができなくなります。コンプライアンスや監査要件への対応力が向上します。
開発者ツール
開発者ツールカテゴリでは、VS Code拡張、Fabric CLI、Terraform Provider、MCP統合など、Fabric上での開発体験を向上させるツール群のアップデートが扱われます。IDE連携やCI/CD統合を通じて、Fabricの操作をローカル開発環境から行えるようにする機能が中心です。
2026年4月 - VS Code workspace GAほか4件

VS Code workspace
Fabric Data Engineering VS Code extensionで、複数Fabric workspacesとData Engineering itemsを1つのVS Code window内で管理できるようになりました。Notebook itemを開くと、VS Code内でNotebook codeを直接更新できます。
Feature Summaryでは、変更がremote workspaceへ自動同期されると説明されています。手順として、Open a Remote WindowからOpen Fabric Data Engineering Workspaceを選び、Manage Fabric Workspaceで対象workspaceを追加または除外します。
参考:Fabric April 2026 Feature Summary
VS Code Environment
VS Code内でFabric Environment itemを管理できるようになりました。Feature Summaryでは、Environment definitionをYAMLとして確認できると説明されています。
edit modeを有効にすると、Environment configurationをVS Code上で編集できます。Fabric portalに移動せず、Environment構成の確認と編集をVS Code workflow内で行うための更新です。
参考:Manage Spark Environment inside VS Code
VS Code Lakehouse
VS CodeからNotebookのdefault Lakehouseを更新できるようになりました。Notebookにlinked Lakehousesを追加または削除でき、変更はremote workspaceへ自動同期されます。
Feature Summaryでは、Dependencies、Lakehousesを展開してlinked Lakehousesを確認し、対象Lakehouseをright-clickしてSet as Default Lakehouseを選ぶ手順が説明されています。
参考:Author notebooks with VS Code
Fabric Local MCP
Fabric Local MCPがGenerally Availableになりました。MS Learnでは、local Fabric MCP Serverが開発端末上で動くopen-source MCP serverとして説明されています。
AI assistantsは、Fabric APIs、OneLake file operations、Fabric item operationsを扱うためのgrounded knowledgeを得られます。VS Code GitHub Copilot、Cursor、Claude Desktop、MCP-compatible clientで利用できます。
参考:Get started with Fabric MCP Server (local)
Fabric Remote MCP
Fabric Remote/Core MCP ServerがPreviewとして追加されました。MS Learnのquickstartでは、remote Core MCP ServerへAI agentを接続し、自然言語でworkspacesを管理する流れが説明されています。
endpointはhttps://api.fabric.microsoft.com/v1/mcp/coreで、Streamable HTTP transportを使います。認証はOAuth 2.0 Bearer TokenとMicrosoft Entra IDで行います。
参考:Get started with Fabric Core MCP Server
2026年3月 - Fabric Extensibility Toolkit GAほか20件


3月の開発者ツールは、Git統合の大幅強化(Branched Workspace/Selective Branching/Compare)、Fabric CLI v1.5、Fabric MCP/Remote MCP、Extensibility ToolkitのGAと関連CI/CDサポート、Notebook公開API・VS Code拡張と、Fabric上での開発体験を支える機能が一気に前進しました。
Git統合のBranched Workspace(プレビュー)
Git branch-out操作時に、元ワークスペースとの関係を明示的に把握しやすくする新しい Branched Workspace 体験がプレビュー公開されました。ワークスペース単位で「ブランチごとの作業場」を持てるため、複数人での並行開発・レビューがやりやすくなります。
参考:Branched workspace in Fabric
Git統合のSelective Branching(プレビュー)
ワークスペース全体ではなく、必要なアイテムだけを選択してブランチ先ワークスペースに持ち出せるSelective Branchingがプレビュー公開されました。大規模ワークスペースから一部だけを切り出してフィーチャーブランチを作る運用が現実的になります。
参考:Selective branching in Fabric
Git統合のコード差分比較(プレビュー)
ワークスペースとGitブランチ間の差分を、同期前に確認できる Compare code changes がプレビュー公開されました。コミット前のレビュー体験が強化され、意図しない変更の取り込みを防げます。
参考:Compare code changes in Fabric
items definitionの一括import/export API(プレビュー)
Fabricアイテム定義を大規模にエクスポート・インポート・同期できるbulk APIがプレビュー公開されました。ワークスペース全体のバックアップや、別環境への大量展開を自動化できます。
Fabric CLI v1.5
Fabric CLIがv1.5にアップデートされ、Power BI semantic modelのrefresh、reportのrebind、対話的なREPLモード、CI/CDシナリオ強化などを含む大型アップデートとなりました。CLI中心の運用が現実的な選択肢になってきています。
CLIからのCI/CDデプロイメント
deploy コマンド1つでワークスペース配備を自動化できるCI/CDコマンドが追加されました。複雑なREST API呼び出しを組み立てずに、単一コマンドで環境間展開できるため、GitHub ActionsやAzure DevOpsとの統合がシンプルになります。
AIエージェントの実行レイヤーとしてのFabric CLI
Fabric CLIがAIエージェント向けの実行レイヤーとして位置づけられ、REST APIを直接叩く代わりにCLI経由でFabricを操作できる設計が公式に推奨されました。認証・エラーハンドリング・出力整形がCLI側で標準化されるため、エージェント側のコードがシンプルになります。
Fabric Remote MCP Server(プレビュー)
クラウドホスト型のMCPサーバー(Remote MCP)がプレビュー公開され、AIエージェントがFabric環境内で直接アクションを実行できるようになりました。ローカルMCPサーバーと違い、インストール不要でクラウド側にAIアシスタントから接続できます。
参考:Introducing Fabric MCP Public Preview
Fabric MCP AI code assistants(GA)
ローカルMCP経由でFabric APIとOneLake操作をAIコーディング支援に提供する Fabric MCP AI code assistants がGAとなりました。Claude CodeなどのMCPクライアントから、開発者のローカル環境でFabric操作を実行する経路が正式運用可能になります。
Fabric Extensibility Toolkitの一般提供(GA)
パートナーや顧客が独自のFabricワークロードを構築・検証・本番公開できるExtensibility ToolkitがGAとなりました。Fabricを利用するだけでなく、自社向けの拡張体験をFabric上に載せる道が正式に開かれた形です。
Extensibility CI/CDサポート(プレビュー)
Extensibility workloadがGit integrationとDeployment Pipelinesに参加できるCI/CDサポートがプレビュー公開されました。カスタムworkloadの開発も、Fabric本体と同じCI/CDライフサイクルに統合できます。
参考:Extensibility CI/CD & remote support
Extensibility Variable Libraryサポート(プレビュー)
Extensibility workload項目がVariable Libraryを読み取り、環境ごとの差し替えを自動解決できるようになりました。カスタムworkloadでもDev/Test/Prodの環境差分をFabric標準の仕組みで扱えます。
参考:Extensibility CI/CD & remote support
Remote lifecycle notification API(プレビュー)
Extensibility workload項目の作成・更新・削除時に、バックエンドへ通知を送れるAPIがプレビュー公開されました。workload側のサーバーでFabric上の状態変化をリアルタイムに受け取り、付随する外部リソースを追随させる設計が可能になります。
参考:Extensibility CI/CD & remote support
Fabric Scheduler / Remote Jobs(プレビュー)
Extensibility workloadがFabricから名前付きジョブをスケジュール実行できるようになりました。カスタムworkloadでもFabric標準のスケジューラとジョブ実行UIを利用でき、独自スケジューラを実装する負担が減ります。
参考:Extensibility CI/CD & remote support
Self-service workload publishing(GA)
ISVが選択したテナント向けにprivate preview workloadを自力で配布できるSelf-service publishingがGAとなりました。MS Azureマーケットプレイスを通さずに、限定顧客向けワークロード提供を回せるようになります。
参考:Fabric Extensibility Toolkit docs
NotebookのLakehouse自動バインド(Git)
Git連携ワークスペース間でNotebookを移動したときに、適切なLakehouseへの参照を自動解決するauto-bindingが追加されました。ブランチ運用で「別環境のLakehouseを指していて動かない」トラブルを減らせます。
Notebook Resources FolderのGit対応
ノートブックの Resources フォルダ配下に置いた依存ファイル(設定、JSON、Pythonモジュール等)がGit管理対象に含められるようになりました。ノートブックだけでなく周辺ファイルごとバージョン管理できます。
参考:Notebook source control deployment
Fabric notebook public APIs(GA)
NotebookのCRUDとJob Scheduler経由の実行をREST APIから扱えるpublic APIsがGAとなりました。外部ワークフローからFabric Notebookを呼び出すパイプラインが、公式サポート下で構築可能になります。
VS Code内のFabric notebook custom agent
Fabric コンテキストを理解した専用エージェントが、VS Code拡張内に組み込まれました。ノートブック編集中にFabric Lakehouseの構造やWorkspace設定を踏まえた補完・説明を受けられるようになります。
参考:Author notebook with VS Code
Fabric Data Engineering VS Code拡張のテナント切替
同一VS Codeウィンドウ内で、Fabricテナントを切り替えて作業できるようになりました。複数テナントに関与する開発者や、テスト用テナントとの往復作業がシームレスに行えます。
VS Code拡張の新しいカーネル対応
Fabric Data Engineering VS Code拡張で、Python・Scala・Spark SQLなどをカーネル単位で直接選択できるようになりました。従来は環境を切り替える必要があったケースでも、単一ノートブック内で複数言語を扱えます。
参考:Author notebook with VS Code
2026年2月 - VS Code Copilot Chat連携

Fabric向けのVS Code拡張が大幅に強化され、3つの主要機能が追加されました。
ワークスペースフォルダの閲覧とアイテム定義の編集
VS Code上でワークスペース内のフォルダとその内容をドリルダウンして確認できるようになりました。アイテム定義はデフォルトでは読み取り専用ですが、拡張機能の設定から編集を有効にできます。変更を保存すると直接ワークスペースのFabricアイテムが更新されるため、破壊的変更に注意が必要です。
Fabric MCPサーバー統合
Fabric MCPサーバー拡張をFabricおよびGitHub Copilot Chat拡張と並行して有効にすることで、Fabricアーティファクトに対するCRUD操作、設計ドキュメントの生成、Microsoft Fabricドキュメントへの専用エージェントモードでのアクセスなど、Fabric特化のツールが利用可能になります。
Azure MCP Serverとの統合も含め、VS CodeからFabricリソースを操作する体験が大きく広がっています。
GitHub Copilot Chat連携
Fabricのアーティファクト・設計ドキュメント・公式ドキュメントにアクセスしながら、自然言語でKQLクエリやパイプライン設定、データ分析アーキテクチャの設計を相談できます。Fabricに不慣れなメンバーの学習コスト低減とチーム全体の生産性向上に効果的です。

FabricでAIエージェント基盤を構築するなら
毎月のアップデートで進化を続けるMicrosoft Fabricの機能を、データ分析だけでなくAIエージェント構築にも活かす企業が増えています。
AI Agent Hubは、Microsoft Fabricと連携してデータ統合からAIエージェント構築まで一気通貫で実現するエンタープライズAI基盤です。Fabricの月次アップデートで強化されるData Factory・リアルタイムインテリジェンス・Data Agentsの機能を、AIエージェントの精度向上に直結させられます。以下の特徴で、エンタープライズグレードのAIエージェント導入を実現します。
- Microsoft Fabric でデータ統合
分散したデータソースをOneLakeで仮想統合。AI-readyなデータ基盤を構築
- Copilot Studio でAIエージェント構築
ローコードでAIエージェントを開発。ガバナンス・セキュリティ統制も標準装備
- Microsoft Teams で統一UX
使い慣れたTeams上でAIエージェントが業務を自動実行。学習コストゼロ
- データは100%自社テナント内に保持
AIの学習対象から完全除外。金融機関レベルのセキュリティ基準に対応
AI総合研究所の専任チームが、設計から運用まで伴走支援します。Microsoft MVP / Solution Partner認定の実績に基づき、段階的な導入ロードマップを提供します。
まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
Fabric最新機能をAI業務自動化に活用

アップデートの恩恵をAgent基盤に直結
Fabricの最新アップデートを自社業務に活用。AIエージェントがデータ統合から業務自動化まで、自社テナント内で安全に実行します。
まとめ
本記事では、Microsoft Fabricの2026年アップデートをカテゴリ別・月別に解説しています。
3月は2026年3月27日時点でFeature Summaryを確認できないためMS Learnベースで整理していますが、主要23件の更新がありました。特にData FactoryのAPI・Dataflow強化、Warehouseの監査とOAP、ワークスペースタグやOneLake Catalog管理強化など、運用面の成熟が進んだ月です。2月は合計32件のアップデートが発表され、Data Factoryだけで12件と突出した更新量でした。モダン評価エンジンGAによるDataflow Gen2の基盤刷新、リアルタイムダッシュボードの大幅高速化、vNet対応による閉域ネットワークサポートなど、本番環境への即効性が高い改善が集中しました。1月は25件で、プラットフォーム全体(9件)を中心にOneLakeカタログの階層表示、セキュリティAPI拡充、MERGE文やResult Set CachingのGA化など、基盤の成熟とガバナンス強化が進みました。
特に以下の3点は早めに確認しておくことをおすすめします。
-
Data FactoryのAPI化とDataflow強化
Power Query評価API、SSISパッケージ実行、Dataflow Gen2の送信先制御強化により、既存ETL資産をFabricへ段階移行しやすくなっています
-
Warehouseの監査と外部アクセス保護
Warehouse OAPとSQL監査ログの一般提供により、データ流出対策と監査証跡の整備が進み、本番運用に乗せやすくなりました
-
ワークスペース管理とOneLakeガバナンス
ワークスペースタグ、ワークロード一元管理、OneLake Catalogの管理強化が入り、管理者視点での運用性が大きく改善しています
本記事は毎月更新しています。最新のFabric動向をキャッチアップしたい方は、ブックマークしてご活用ください。各項目の詳細な手順やコード例については、Feature SummaryまたはMS Learnの公式ドキュメントリンクから確認できます。










