この記事のポイント
 1Mトークン以上の社内ドキュメントやコードベースをそのまま読ませたい用途なら、SubQ 1M-Previewはまず試す価値のある選択肢
1Mトークン以上の社内ドキュメントやコードベースをそのまま読ませたい用途なら、SubQ 1M-Previewはまず試す価値のある選択肢- ただし2026年5月時点では非公開ベータ+技術論文未公開のため、ミッションクリティカルな案件にいきなり載せ替えるのは時期尚早
- ベンチマーク勝敗は短文・推論ではなく「128K超の長文と低コスト」で出ており、Opus・GPT-5.5・Gemini 3.1 Proとは住み分け前提
- SubQ Codeはコードベース全体を1コンテキストに読み込める設計で、RAGや分割エージェントを組まずに済む点が最大の差別化
- 料金は公開されておらず「Opus・GPTの約1/5」とのみアナウンス。本格採用を判断するには、第三者検証と公式pricingの開示を待つのが妥当

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
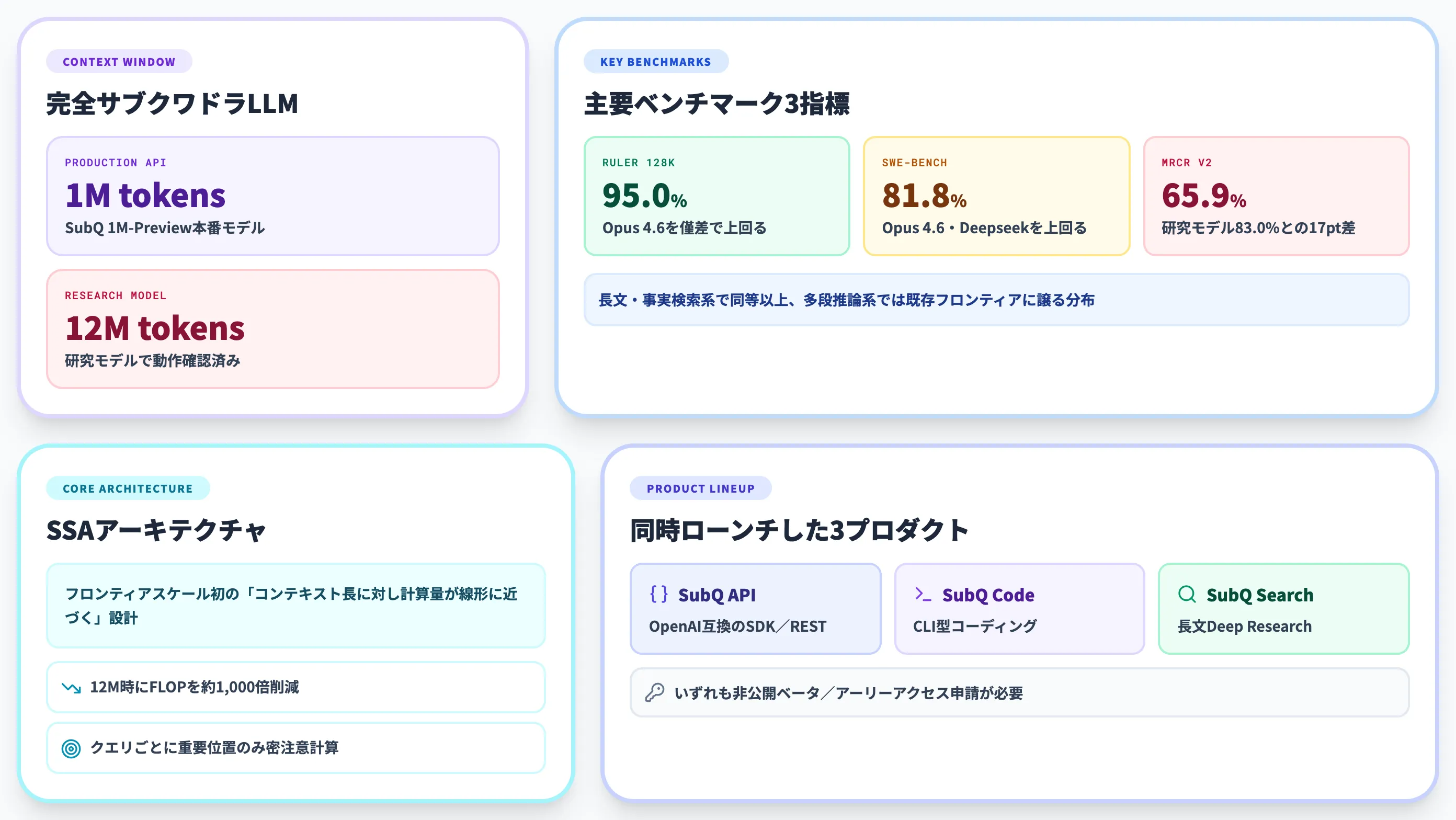
マイアミ拠点のAIスタートアップSubquadraticが、2026年5月5日に「SubQ 1M-Preview」を発表しました。フロンティアレベルでは世界初の「完全サブクワドラティック」アーキテクチャを採用した大規模言語モデルで、文章が長くなっても計算コストが急激に増えない設計が特徴です。
独自アーキテクチャ「SSA(Subquadratic Sparse Attention)」によって、研究モデルでは最大1,200万トークンまでの動作を確認し、RULER 128KではClaude Opus 4.6を上回る95.0%を記録しました。Subquadratic自身は「Transformerの二次計算量こそAI応用の最大の経済制約であり、それが外れた今、これまで本番化できなかったワークロードが商用規模で動き始める」という見方を打ち出しています。
本記事では、なぜこれまでフロンティアレベルでサブクワドラティックが実現できなかったのかという背景から、SSAの仕組み・ベンチマーク・解放されるユースケース・推論コスト構造への影響・3つのプロダクト構成・主要フロンティアモデルとの比較・現時点の制約と料金までを、公式発表と一次・二次ソースをもとに整理します。
目次
SubQが採用したSSA(Subquadratic Sparse Attention)の仕組み
RULER 128K:「frontier-level accuracy」を強調する領域
SWE-Bench Verified:ハーネス依存を自社で認める透明性
ケース2:フロンティアモデルの動向をウォッチしているCTO・技術リーダー
SubQ 1M-Previewとは?
SubQ 1M-Previewは、マイアミ拠点のAIスタートアップSubquadraticが発表した大規模言語モデル(LLM)で、フロンティアレベルでは世界初の「完全サブクワドラティック」アーキテクチャを採用しています。
ひと言で言うと、「文章が長くなっても計算コストが急激に増えない」設計のLLMです。これまでは長文を扱おうとすると計算量が二乗で膨らんでコストが現実的に持たなかったのですが、その壁を設計レベルで取り払うことを狙った、というのがSubQの位置づけです。
Subquadraticは、SubQの位置づけを「既存アーキテクチャの効率化」ではなく「Transformerの二次計算量という根本制約に対する設計レベルの解」だと説明しています。
長文LLMが業務に入っていない最大の理由は性能ではなくコストだと指摘したうえで、SubQでそのコスト制約を外せば「これまで成立しなかった用途が商用規模で動き始める」と述べています。

発表の概要

2026年5月5日のステルス解除と同時に、Subquadraticは次の3つを公表しました。
- SubQ 1M-Preview
本番モデル。公式announcement上は「SubQ 1M-Preview」として1Mトークンを強調する一方、公式トップページのAPI項目には「12M token context window」とも掲示されており、API実提供上限は申請時の最終確認が必要
- 研究モデル
内部では12Mトークンまでの動作を確認済み
- 3つのプロダクト
SubQ API/SubQ Code/SubQ Searchを同時にローンチ(非公開ベータ)
本番モデル名に「1M-Preview」とプレビュー扱いをわざわざ入れている点は重要です。
SLA(Service Level Agreement:稼働率や応答速度などの品質保証契約)や継続提供のコミットは、Anthropicの「Claude Opus 4.6」のようなGA(一般提供)モデルと同列に扱うべきではなく、ベータ段階のリスクを織り込んだうえで評価する必要があります。
Subquadratic(運営企業)の概要

Subquadraticは、長文コンテキストの計算量問題を「効率化の継ぎ足し」ではなく「アーキテクチャの再設計」で解こうとしている研究主導型のスタートアップです。
シードラウンドで2,900万ドル(想定バリュエーション約5億ドル)を調達し、フロンティアモデルを学習させるためのインフラと資金を確保しています。
創業者のJustin Dangel氏は、ヘルスケア・保険・消費財領域でCEOを5度経験した連続起業家。CTOのAlex Whedon氏は元Meta、生成AIスタートアップTribeAIで生成AI部門を率い、企業向けAI実装を40件以上手掛けた経歴を持ちます。
研究チームはMeta・Google・Oxford・Cambridge・ByteDance・Adobe・Microsoftから集まった博士研究員11名で、人員規模は競合フロンティアラボより小さい一方、専門性の密度では引けを取らない構成です(VentureBeat・The New Stackの発表当日報道に詳細)。
【関連記事】
大規模言語モデル(LLM)とは?その仕組みやAIとの違い、活用例を解説
長文LLMがフロンティアスケールで解けてこなかった理由
SubQが何の「初」なのかを理解するには、これまで何が壁だったのかを押さえておくと話が早いです。Subquadratic自身も、announcement冒頭でこの背景説明を一番手厚く書いています。

二次計算量という根本制約
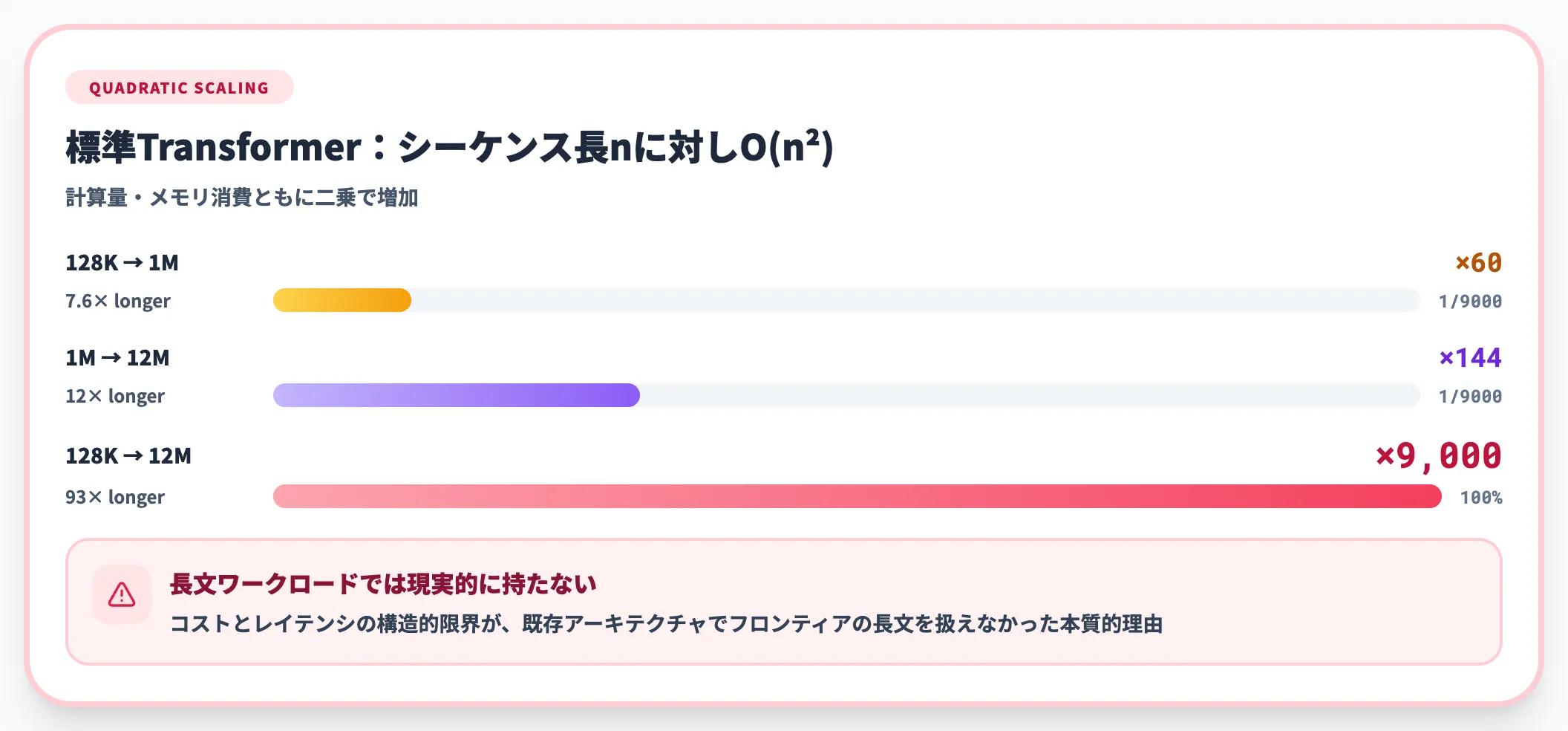
標準的なTransformerの自己注意層は、シーケンス長n(読み込ませるテキストの長さ)に対して、計算量とメモリ消費がともにO(n²)で増加します。
具体的に当てはめると、コンテキスト長を128K→1Mに伸ばせば計算量は約60倍、1M→12Mで約144倍、128K→12Mまで広げれば約9,000倍に膨らみます。長文ワークロードでコストとレイテンシ(応答時間)が現実的に持たない、というのが既存アーキテクチャの構造的な限界でした。
既存アプローチの壁
過去5年で、Mamba・RWKV・Linear Attention・State Space Modelなど、計算量を二次より低く抑える「劣二次アーキテクチャ」が多数提案されてきました。いずれも線形に近いスケーリングは実現できる一方、フロンティアレベルの性能を維持できないという共通の課題を抱えていました。
代表的なアプローチと、それぞれが抱える制約を並べると次のようになります。
| アプローチ | 利点 | 制限 |
|---|---|---|
| 固定パターン疎注意(Sliding Window等) | 計算量を削減できる | 位置ベースで固定。重要情報がパターン外にあると拾えない |
| 状態空間モデル(Mamba・RWKV等) | 線形スケーリング | 固定サイズの状態に圧縮するため、長文中の事実検索精度が落ちやすい |
| ハイブリッド(密+線形) | 性能と効率の折衷 | 密注意層が支配的になり、長文で計算コストが下がりにくい |
| DeepSeek系の疎注意 | インデックス併用で密注意より軽い | 全体としてはO(n²)スケーリングが残る |
この表が示しているのは、効率と精度のトレードオフです。Subquadratic自身も「サブクワドラティック化のアイデア自体は新しくない。難しかったのはフロンティアレベルの性能を維持したまま実装する点だった」と説明しており、これまで提案されてきたアーキテクチャは「短文ベンチでは密注意と互角に戦えるが、長文や難易度の高いタスクで一気に崩れる」という壁を共通して抱えていました。
Subquadraticのアプローチ
Subquadraticのアプローチは、効率化を後から足すのではなく、設計の最初の段階から「フロンティアレベルの性能で動く」前提で3つの条件を同時に満たすアーキテクチャを組み上げた、というものです。3条件は次のとおりです。
-
線形スケーリング
テキストが長くなっても、計算量が線形(比例)にしか増えない
-
コンテンツ依存ルーティング
どこを読みに行くかを、内容に応じてモデル自身が動的に判断する
-
任意位置からの精密取得
文章のどこにある情報でも、ピンポイントで正確に取り出せる
後述するSSAは、この3つを1つの注意機構(attention layer)に同居させた実装です。
つまりSubQの新しさは個別のアイデアそのものではなく、「これまで別々に追われてきた性質を、フロンティアレベルでまとめて成立させた最初の実例」という点にあります。本当に再現できるかは今後のピアレビュー(独立した研究者による検証)次第ですが、業界が長く解けなかった課題に正面から挑んだ発表として、注目度の高い一件です。
【関連記事】
コンテキストエンジニアリングとは?AIの精度を最大化する次世代技術を解説
SubQが採用したSSA(Subquadratic Sparse Attention)の仕組み
SubQの中核技術が「SSA(Subquadratic Sparse Attention)」です。簡単に言うと、文章を読むときに「どこを重点的に見るか」をモデル自身に意味的に判断させて、選ばれた箇所だけ通常の注意機構(密注意)と同じ精度で詳細に計算する仕組みです。
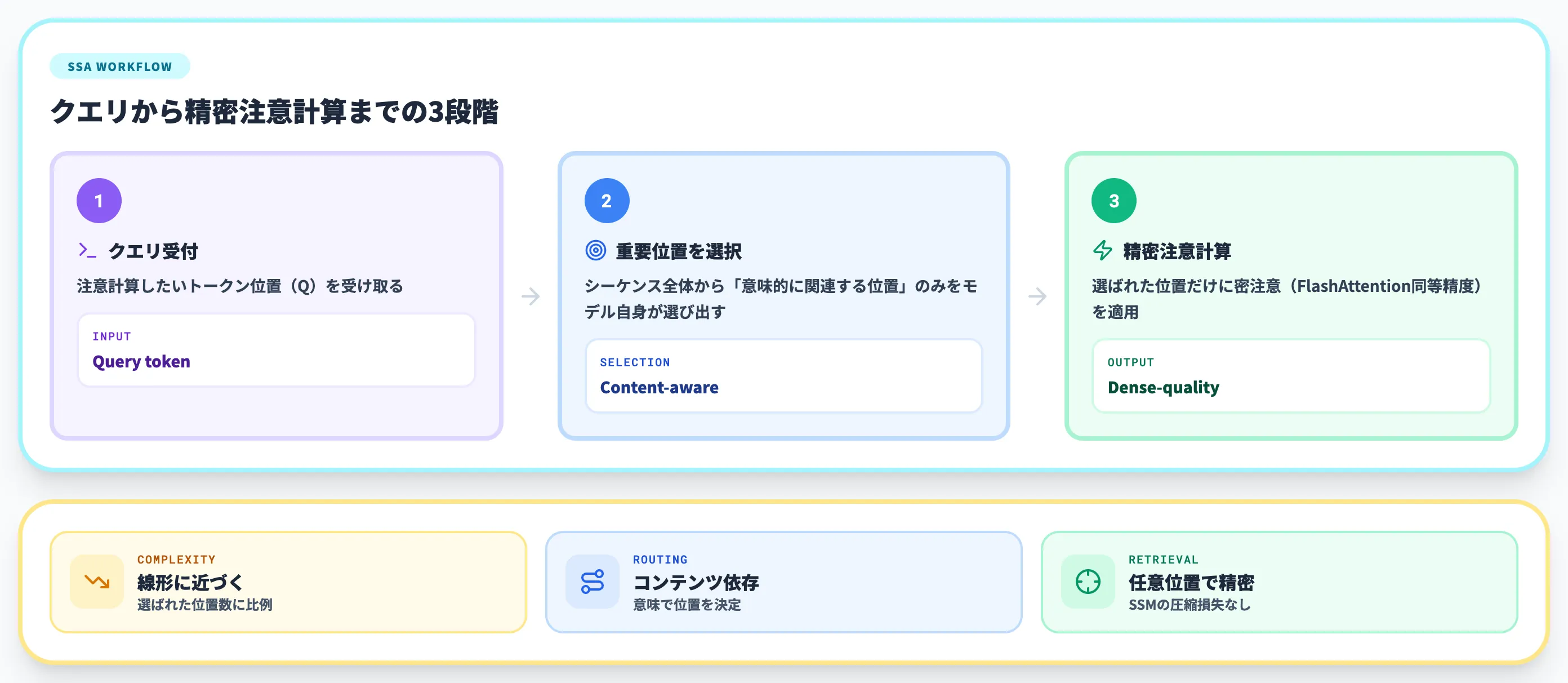
SSAの3つの特性
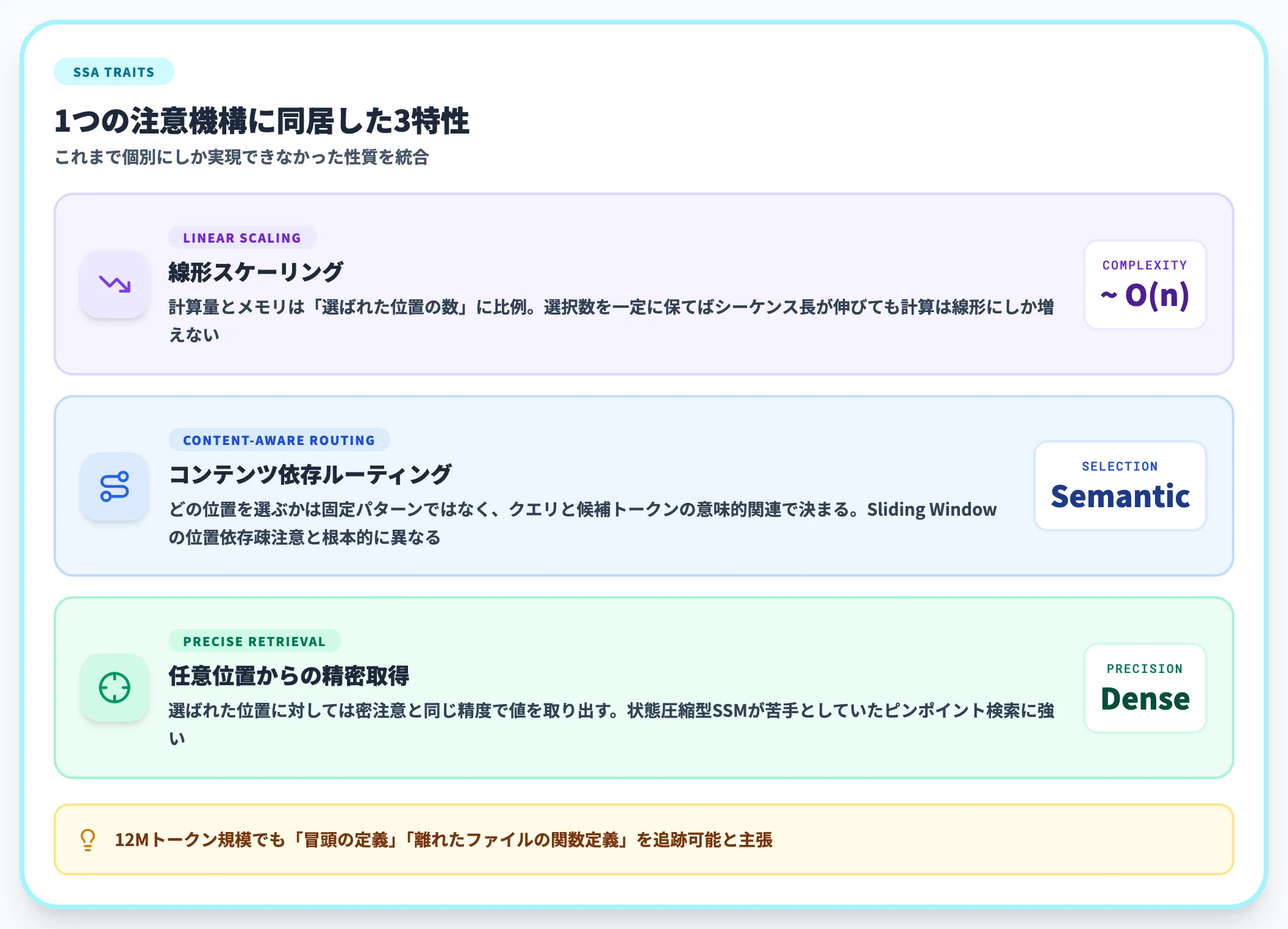
SSAは、これまで個別にしか実現できていなかった3つの性質を、1つのアーキテクチャの中で両立させた点がポイントです。
-
線形スケーリング
計算量とメモリは「選ばれた位置の数」だけで決まります。選ぶ数を一定に保つかぎり、文章が長くなっても計算量は線形(比例的)にしか増えません
-
コンテンツ依存ルーティング
「どこを見るか」は固定の位置パターンではなく、クエリ(質問)と候補のトークンとの意味的な関連性で決まります。Sliding Window(各トークンの近傍だけを参照する固定窓)のように位置で決め打ちする疎注意とは、設計思想が根本的に違います
-
任意位置からの精密取得
選ばれた位置に対しては、通常のTransformerと同じ精度で値を取り出せます。Mambaのような状態圧縮型のモデルが苦手としていた「文章中のピンポイント検索」に強い、という性質です
その結果、文章の冒頭にある定義や、コードベースの離れたファイルにある関数定義のような「遠くにある重要な情報」を、12Mトークン規模でも追跡できる、とSubquadratic側は主張しています。
SSAの効率指標

公式の技術解説ページでは、密注意(FlashAttention-2想定)との比較で、コンテキスト長ごとの注意計算FLOP削減・スピードアップが提示されています。
| コンテキスト長 | 注意FLOP削減 | スピードアップ(B200想定) |
|---|---|---|
| 128Kトークン | 約8倍 | 約7.2倍 |
| 256Kトークン | — | 約13.2倍 |
| 512Kトークン | — | 約23.0倍 |
| 1Mトークン | 約62.5倍 | 約52.2倍 |
| 12Mトークン | 約1,000倍 | — |
マーケティング上の見出しになっている「1,000倍削減」は12Mトークンというかなり長い文脈での比較です。実務でよく使う128K〜1Mの帯域では「8倍〜62.5倍」のオーダーで、扱う処理によって効果は変わると考えておくべきです。
逆に言えば、密注意で十分処理できる短文〜中文のタスクではSSAの優位性は薄く、文脈が長くなるほどコスト・性能の差が開く構造になっています。
SSAの優位性が崩れる条件
SSAは万能ではなく、「どこを見るか」を選ぶメカニズムが上手く働かない条件下では、密注意と互角以上の精度を出すのが難しい設計です。具体的には、参照すべき箇所があまりにも多くて選び切れないケースや、選択ロジックの学習データが少ないドメインでは、選ばれた位置の精度が落ちて性能が劣化する可能性があります。後段で出てくるMRCR v2のスコアは、この弱点が顔を出しやすいベンチマークだと読めます。
SubQ 1M-Previewのベンチマーク性能
ここではSubQ 1M-Previewの公開ベンチマーク結果を、競合フロンティアモデルとあわせて整理します。Subquadratic自身が公開している数値と、その自己評価のトーンも併せて押さえておくと、読み解きが正確になります。
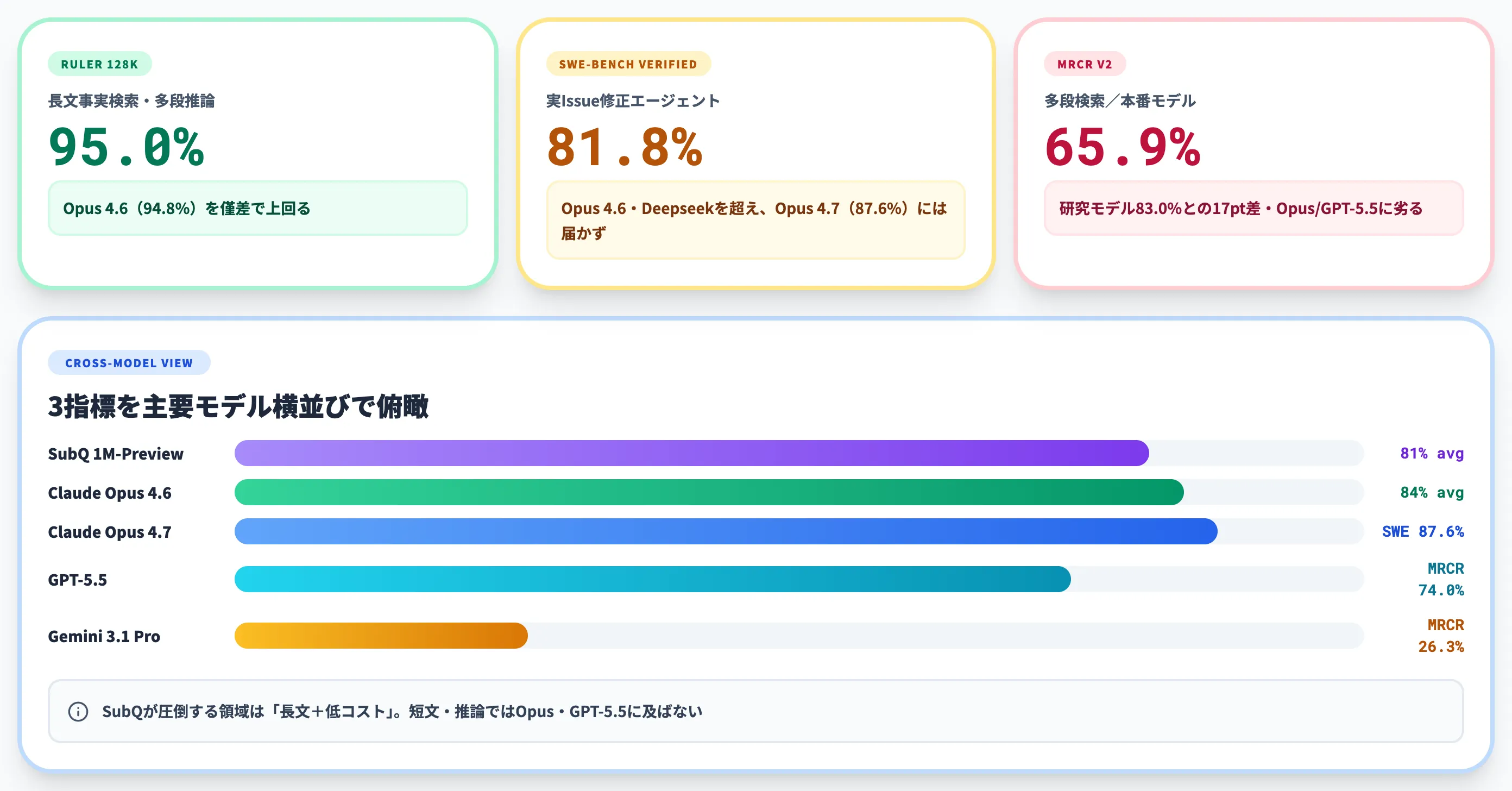
RULER 128K:「frontier-level accuracy」を強調する領域

RULERは、長文中の事実検索や多段推論を測るNVIDIA公開のベンチマークです。SubQはこのうち128Kトークン設定で次の結果を報告しています。
| モデル | RULER 128K スコア |
|---|---|
| SubQ 1M-Preview | 95.0% |
| Claude Opus 4.6 | 94.8% |
差は0.2ポイントとほぼ誤差ですが、Subquadratic公式はこのスコアを「フロンティア級の精度(frontier-level accuracy)」と位置づけています。注目したいのはスコアの僅差そのものよりも、「同じ精度を出すための計算コストはOpus 4.6の約1/300で済んだ」と主張されている点です。性能の高さよりも「同じ性能を出すのにかかるコストの差」で勝負する論建てになっています。
SWE-Bench Verified:ハーネス依存を自社で認める透明性

SWE-Bench Verifiedは、実在のGitHub Issueをエージェントが修正できるかを測るベンチマークです。
| モデル | SWE-Bench Verified スコア |
|---|---|
| Claude Opus 4.7 | 87.6% |
| SubQ 1M-Preview | 81.8% |
| Claude Opus 4.6 | 80.8% |
| Gemini 3.1 Pro | 80.6% |
| Deepseek 4.0 Pro | 80.0% |
SubQはOpus 4.6・Deepseek 4.0 Proをわずかに上回る一方、Claude Opus 4.7には届いていません。Subquadratic自身も「SWE-Benchの差は、モデル本体よりエージェントハーネス(モデルにツールを使わせる枠組み)の影響が大きい」と認めており、この結果だけを見て「コーディング性能でSubQが頭ひとつ抜けている」と読むのは過大評価です。実務上は、Opus 4.7と比べて「コーディング能力は一段下、コスト効率とコンテキスト長では大きく上」というように、得意領域を分けて理解しておくのが妥当です。
MRCR v2:研究と本番の17ポイント差を公式が開示

MRCR v2は、長文中で複数の参照を辿って答える多段検索能力を測るベンチマークで、長文LLMの実力差が出やすい指標です。
| モデル | MRCR v2 スコア |
|---|---|
| Claude Opus 4.6 | 78.3% |
| GPT-5.5 | 74.0% |
| SubQ 1M-Preview(本番) | 65.9% |
| SubQ 研究モデル | 83.0% |
| Gemini 3.1 Pro | 26.3% |
ここで気になるのは、SubQが研究モデルでは83.0%を出している一方、第三者の検証が入った本番モデルは65.9%にとどまり、約17ポイントの差が空いている点です。Subquadratic自身はこの差を公式announcementで正直に開示していますが、原因の詳しい説明は本稿執筆時点では出ておらず、VentureBeatの検証記事も「largely unexplained(理由がよく分かっていない)」と書いています。詳細は今後公開予定の技術報告書・モデルカード待ちです。
フロンティアモデル全体のなかで見ると、SubQは「Opus 4.6・GPT-5.5には届いていない」のが現状です。SubQが大きく上回っているのは「Gemini 3.1 ProがMRCR系のベンチマークで著しく低い数字を出している」という分布のなかでの相対的な優位、と理解しておくのが正確です。
Subquadraticの自己評価のトーン
3つのベンチマークを通して見ると、Subquadratic自身の語り口は「強みは控えめに、弱みは正直に開示する」トーンで一貫しています。
RULER・SWE-Benchでは「frontier-level」「favorably」など慎重な表現を使い、MRCR v2では研究モデルと本番モデルのスコア差を自分から開示しました。これは独立検証を求めるコミュニティに対する透明性を担保する姿勢で、同時に「現時点では特定の領域でしか勝負できていない」という認識の表れでもあります。
読者側としては、ここを踏まえて「長文+低コストの領域に絞ってSubQを評価する」のが現実的なスタンスです。短文や複雑な推論タスクで既存フロンティアモデルと真っ向から比べると、SubQの良さは見えにくくなります。
ベンチマークを読む際の注意点
ベンチマーク数値を引用する際に押さえておきたい制約を整理しておきます。
-
単発実行・信頼区間なし
SubQの公開ベンチは推論コストの都合で、各モデル1回ずつしか実行されていません。信頼区間(誤差幅)が示されていないため、0.2ポイント差や1ポイント差は誤差範囲に含まれる可能性があります
-
本番/研究モデル差の未解明
MRCR v2の17ポイント差は公式に開示されていますが、その理由の説明は技術報告書未公開の時点では推測に頼るしかありません
-
エージェントハーネス依存
SWE-Benchはエージェント実装の差で数ポイント動きやすく、SubQ自身もそれを認めています
-
モデルウェイト未公開
第三者が再現実験することは、現時点ではできません。VentureBeatの検証記事も「研究者コミュニティは独立した証明を求めている」と指摘しています
SubQが解放するユースケース
Subquadratic公式が強調するのは、SubQによって「文章を分割せず、一度に丸ごと処理(単一パス処理)できる」領域が広がる、という点です。これまでは二次計算量を避けるためにRAG・分割エージェント・チャンク化(文章を区切る処理)といった迂回手段に頼っていたワークロードが、長文LLM単体でそのまま解ける、というのが主張の核心になります。
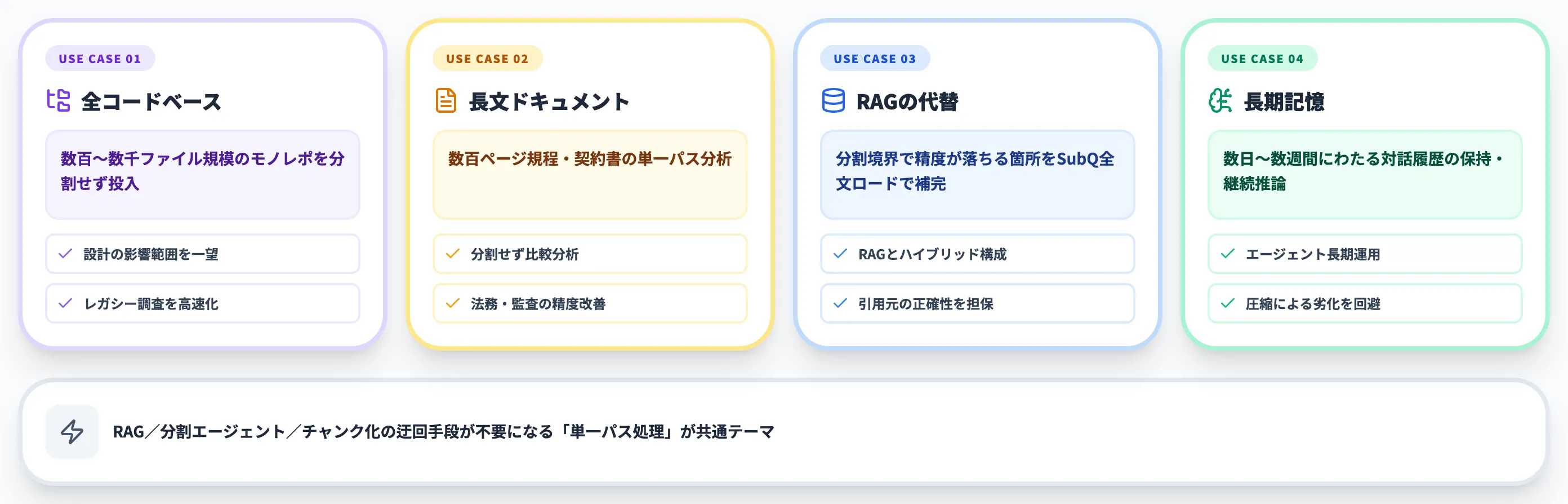
全コードベースを単一コンテキストに
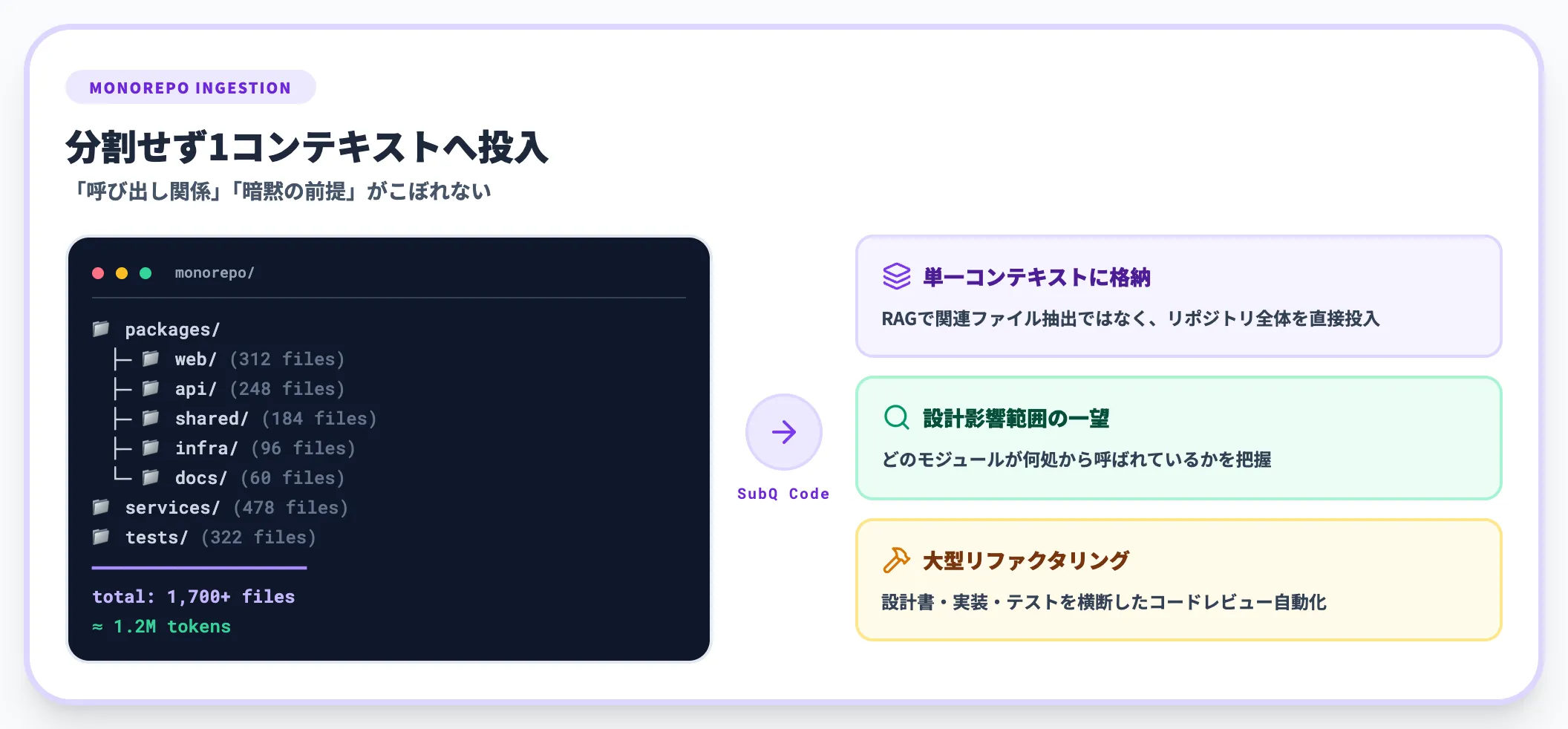
最も効きそうなのは、「分割すると文脈が壊れる、でも分割しないと全部入らない」というジレンマを抱えたコードベースです。
- 数百〜数千ファイル規模のモノレポで、設計の影響範囲を一望したい
- レガシーシステムのリファクタリング前に、どのモジュールがどこから呼ばれているかを把握したい
- 設計書・実装・テストコードを横断したコードレビューを自動化したい
RAG(関連ファイルだけを検索して抜き出す方式)では、どうしても「どこから呼ばれているか」「コードに書かれていない暗黙の前提」がこぼれます。SubQ Codeは1コンテキストにリポジトリ全体を入れたうえで推論できるので、レガシーコード調査や大型リファクタリングの局面で強みが出やすい設計です。
大規模ドキュメント・契約書の単一パス分析

法務・コンプライアンス・監査領域でも、単一パス処理は実務メリットに直結します。
- 数百ページ単位の規程・契約書を分割せずに比較したい
- 過去数年分の議事録・社内文書を横断したナレッジ検索を行いたい
- 長文の規制文書(業法・会計基準など)と社内文書を突き合わせて差分分析したい
RAGベースの社内検索で「意味が近そうな断片」しか拾えず精度が頭打ちになっているケースで、長文LLMで全文を読ませる構成は有効な代替手段になります。
RAGの代替・補完としての役割

公式の論調は「RAGやマルチエージェントは、二次計算量の制約に対する対症療法(根本治療ではない応急処置)にすぎない」というものです。SubQでこの計算量の制約が外れれば、検索パイプラインや分割エージェントの設計負荷自体が要らなくなる、と主張しています。
ただし、現実的にはSubQ単体に置き換えるのではなく、ハイブリッド構成で進めるのが妥当です。
- 重要文書はSubQ全文ロード/FAQ系は既存RAG 用途で住み分けてコストとレイテンシを最適化
- チャンキングが構造を壊しているケースだけSubQ 法務・特許・医療など引用元の正確さが品質を決める領域から
- 既存RAGの精度に頭打ちを感じる箇所から差し替え 一気の置き換えではなく漸進的に
【関連記事】
GraphRAGとは?その仕組みや実装方法、活用事例を徹底解説!
長期記憶・継続対話の再設計

エージェントが数日・数週間にわたるセッションを保持し続ける用途も、長文耐性の効きどころです。Mamba系・状態空間モデルが苦手としてきた「履歴を圧縮せずに持ち続ける」設計が、SubQでは現実的な選択肢になります。
- 顧客対応エージェントが過去のやり取りすべてを文脈として保持する
- 開発エージェントが過去の修正履歴・議論・テスト結果を踏まえて次の提案を出す
- リサーチエージェントが過去の検索結果と分析履歴を全文保持したまま深掘りする
Subquadraticの技術解説ページでは、研究モデルが扱う5,000万トークン水準で「持続的状態と深い推論を要するアプリケーション」がさらに開けると論じられており、長期記憶を前提としたエージェント設計のアーキテクチャ選択肢が広がる可能性があります。
【関連記事】
自律型AIエージェントとは?その仕組みや自動化との違い、活用事例を解説
SubQが変える推論経済学
Subquadratic公式のannouncement中盤に置かれているのが「Economics matter(経済学が効く)」というセクションです。「長文LLMが業務に入っていない理由は性能ではなくコストだ」という現状認識をスタートに、SubQが推論コストの構造そのものを変える、という論建てが組まれています。

「コストが主要な制約になった」という診断
Subquadratic公式の論点を一言で言うと「長文LLMが業務に入っていない理由は、性能の不足ではなく、コストの高さだ」というものです。RULER 128K相当の精度を出すには、Opus 4.6だと推論1回あたり相応のコストがかかり、これが大量バッチ処理・長期エージェント・全社展開のブレーキになっていた、という診断です。
SubQの「Opus比1/5の料金」「同じ精度を出すための計算量はOpus比1/300」という主張は、このコスト制約を真正面から外しに行くための打ち手という位置づけです。同様のコスト論はfelloaiのレビューでも「フロンティアレートの約1/5」と紹介されています。
「対症療法」としてのRAG・マルチエージェント
Subquadratic公式の主張で目を引くのが、RAGやマルチエージェントを「二次計算量の制約に対する対症療法」と位置づけている点です。
分割境界で精度が落ちることを承知のうえでチャンキングしているのも、エージェント間で複雑なオーケストレーションを組んでいるのも、本来は「長文をそのまま読ませれば済む話」をコスト制約のせいで迂回しているだけだ、という見方です。同じ論点はThe New StackやCodisteの解説記事でも取り上げられており、もしこの整理が正しければ、SubQ普及後の数年で、現在のRAGパイプラインや分割エージェントの設計は大幅に簡素化される可能性があります。
POC止まりの構想が本番化する
経済論のもう一つの軸は「POC(試作検証)止まりだった構想が、商用規模で動き出す」という話です。
コストが10倍下がれば、同じ予算で10倍の規模・頻度・深さのワークロードを回せます。これまで「精度は出ているけれどコスト的に本番には載せられない」と判断されてきた長文ユースケースが、コスト要因だけで本番化のラインを越えてくる可能性がある、というロジックです。
コスト主張の現状の限界
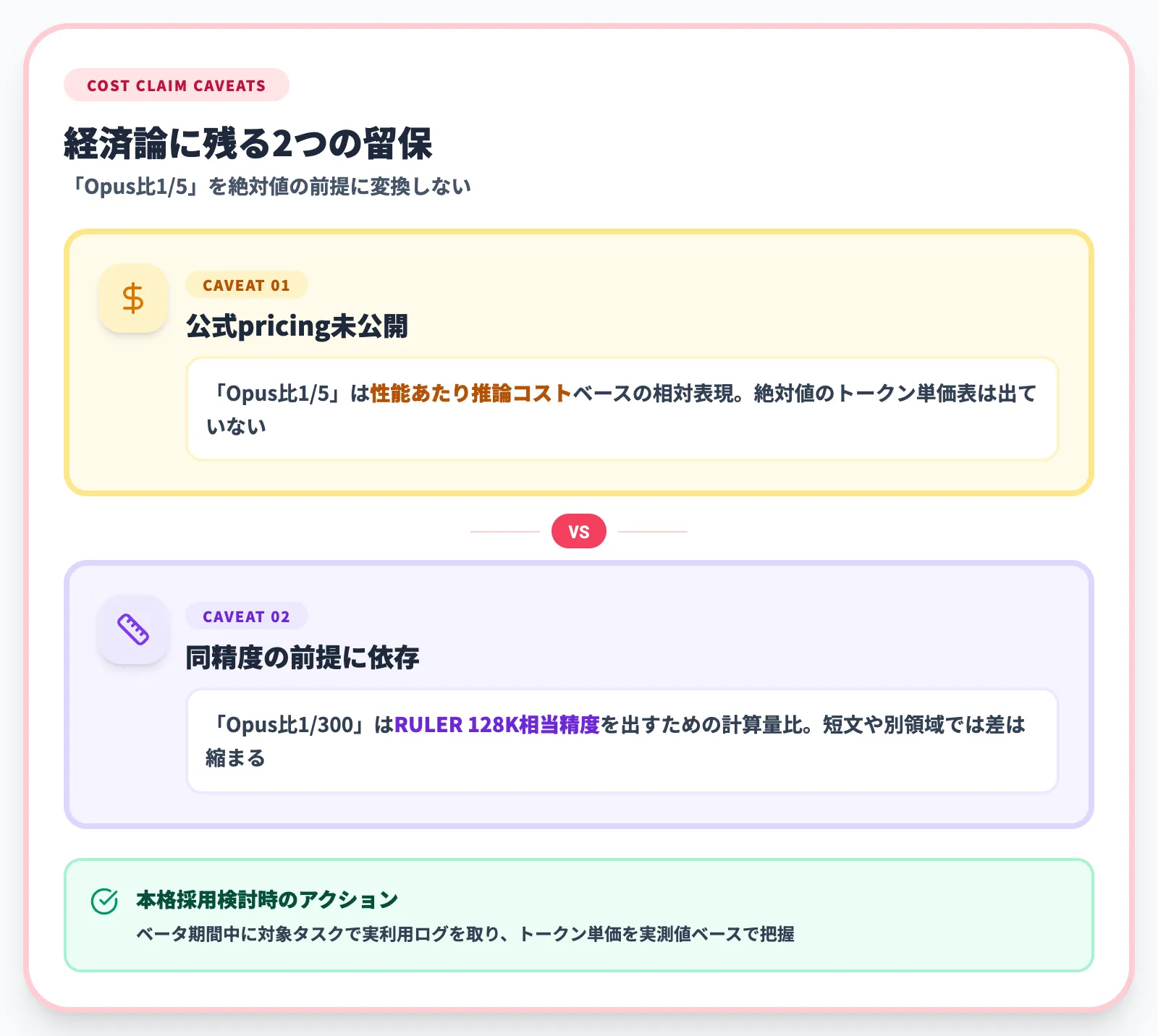
ただし、Subquadratic自身の経済論には現時点で2つの留保があります。
-
公式pricingが未公開
「Opus比1/5」は性能あたりの推論コストをベースにした相対表現で、絶対値のトークン単価表はまだ出ていません
-
同精度の前提に依存
「Opus比1/300」はRULER 128K相当の精度を出すための計算量比であり、短文タスクや別領域では差が縮まる可能性があります
本格採用を検討するなら、ベータ期間中に対象タスクで実利用ログを取り、トークン単価を実測値ベースで把握しておくのが現実的です。詳細は後段の料金セクションで補足します。
SubQが提供する3つのプロダクト
SubQ 1M-Previewはモデル単体の発表ではなく、3つのプロダクトを同時に立ち上げています。いずれも非公開ベータでの提供で、利用には公式サイトからアーリーアクセス申請が必要です。
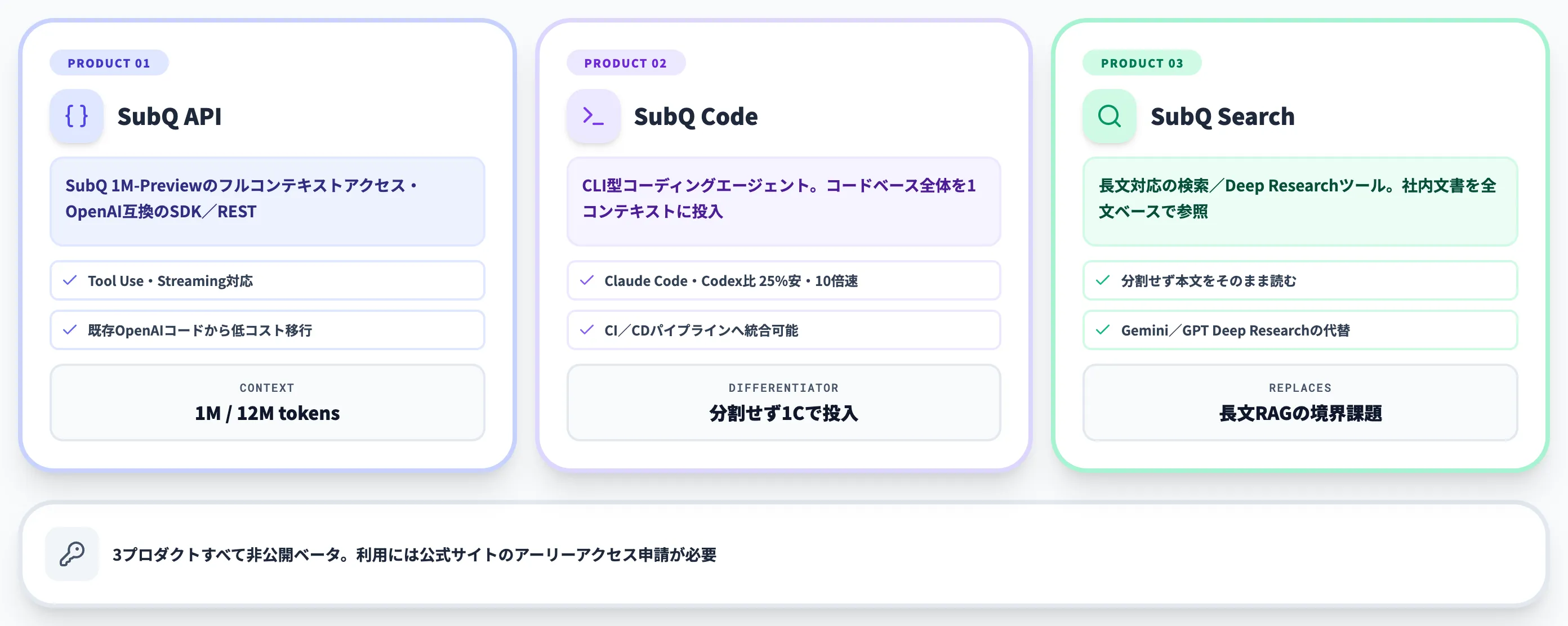
SubQ API
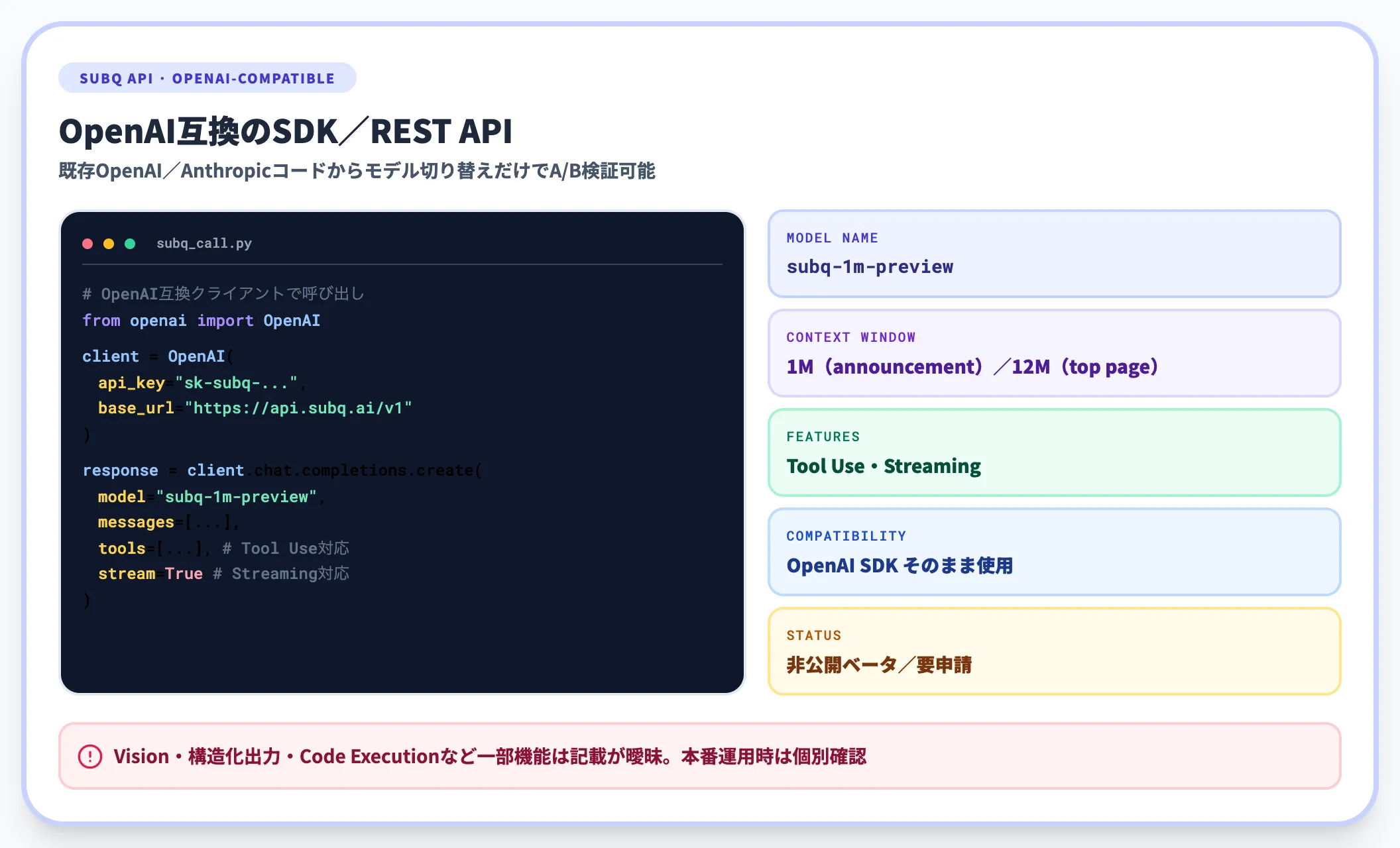
SubQ APIは、SubQ 1M-Previewのフルコンテキストにアクセスできるエンドポイントで、OpenAI互換のSDK/REST APIとして提供されます。代表的な仕様は次のとおりです。
- モデル名 subq-1m-preview
- コンテキスト長 公式announcementはSubQ 1M-Previewとして1Mを強調する一方、公式トップページのAPI項目では「12M token context window」とも掲示されており、本番APIの実提供上限は要確認
- 対応機能 Tool Use(関数呼び出し)/ストリーミング応答
- 互換性 OpenAI互換のSDKを利用可能。既存のOpenAI/Anthropicベースのコードからの移行コストが低い
- ステータス 非公開ベータ。利用には公式サイトのアーリーアクセス申請が必要
OpenAI互換であることは、PoC(試作検証)の観点では大きな利点です。既存のClaudeやGPT-5.5を使ったエージェント実装でも「モデル切り替えだけ」でSubQをA/B検証しやすい設計になっています。一方、Vision(画像入力)・構造化出力(JSON等の決まった形式での出力)・Code Execution(モデル内蔵のコード実行)など一部機能は記載が曖昧で、本番運用時には個別に確認が必要です。
【関連記事】
Model Context Protocol (MCP) とは?仕組みやRAGとの違いを解説
SubQ Code
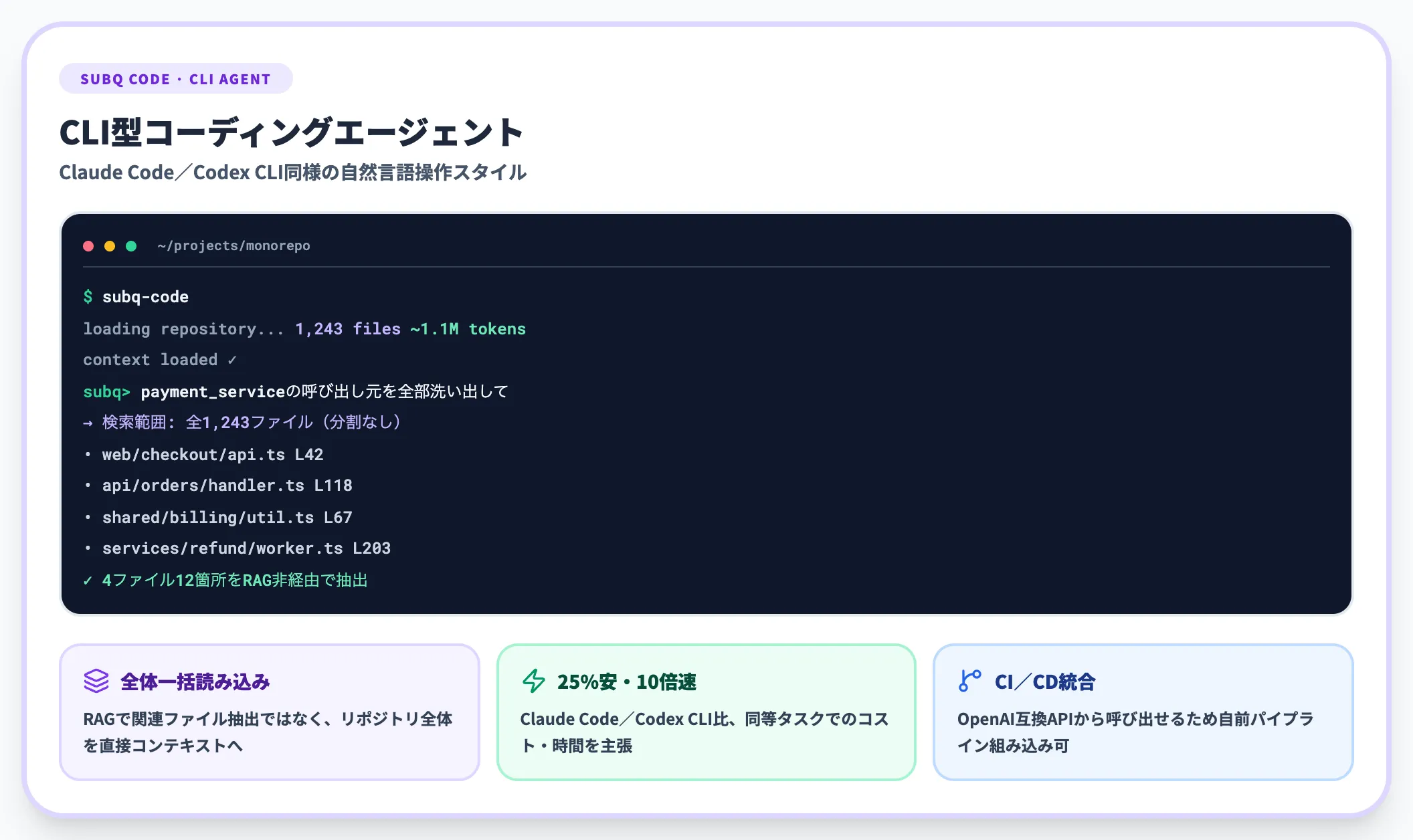
SubQ Codeは、コードベース全体を1つのコンテキストウィンドウに読み込むCLI型のコーディングエージェントです。設計思想はClaude CodeやCodex CLIに近い「ターミナルから自然言語で指示してリポジトリを修正させる」スタイルですが、12Mトークン級の長文耐性を活かして、コードベース全体を分割せずに1コンテキストに載せることを売りにしています。
公式が示している差別化点は次のとおりです。
- コードベース全体を一括読み込み RAGで関連ファイルを抽出する代わりに、リポジトリ全体を直接コンテキストに入れる
- 25%安い請求と10倍速い探索 既存のClaude Code/Codex比で、同等タスクにおけるコスト・所要時間の優位性をマーケティングしている
- OpenAI互換APIから呼び出し可能 自前のCI/CDパイプラインに組み込みやすい
「25%安・10倍速」のうち、探索時間(10倍速)は再現可能性が高く、外部レビュアーによる実測値も今後出てくると見られます。一方、コスト比較(25%安)は公式の価格表が未公開なので、Subquadratic側のフルコストモデル次第で前後する可能性があります。
【関連記事】
Claude Codeとは?主な特徴や使い方、料金体系・拡張機能まで徹底解説
SubQ Search

SubQ Searchは、長文対応の検索/Deep Researchツールで、社内ドキュメントや大量レポートに対する深掘り調査を想定しています。GeminiのDeep ResearchやChatGPTのDeep Researchに近い位置づけですが、12Mトークンの一括処理を活かした「分割せずに本文をそのまま読む」検索が差別化点です。
用途としては次のような場面が想定されます。
- 数百ページ規模のレポートや契約書を、要約せず全文ベースで参照したい場合
- 長期間のチャット履歴・会議録に対して、複数論点を横断する分析を行いたい場合
- 既存RAGパイプラインで「分割境界」が答えの精度を落としている場合の代替手段
SubQ Searchは公式announcement上はprivate betaとされており、SiliconANGLEの報道など二次報道では初期無料と伝えられています。実装の検討段階で「RAGとどう住み分けるか」を社内で議論するための叩き台として、まず触ってみる価値があります。
【関連記事】
生成AIのRAGとは?その仕組みや作り方、活用事例を解説!

SubQと主要フロンティアモデルの比較
ここではSubQ 1M-Previewを、現時点の主要フロンティアモデルと比較します。用途別の住み分けを見極めるための基準として参照してください。

スペック・性能比較
主要モデルのスペックとベンチマークを並べると、SubQの位置づけが明確になります。
| 項目 | SubQ 1M-Preview | Claude Opus 4.6 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| 最大コンテキスト | 1M(研究12M) | 1M | 1M | 1M | 約1M |
| アーキテクチャ | SSA(完全サブクワドラティック) | Transformer | Transformer | Transformer | Transformer |
| RULER 128K | 95.0% | 94.8% | — | — | — |
| SWE-Bench Verified | 81.8% | 80.8% | 87.6% | — | 80.6% |
| MRCR v2 | 65.9% | 78.3% | — | 74.0% | 26.3% |
| 提供形態 | 非公開ベータ | GA | GA | GA | Preview |
この表から読み取れるのは、SubQは全方位で勝っているわけではないということです。RULERのような事実検索系では同等以上、SWE-Benchではミドル、MRCR v2のような多段推論ではOpus・GPT-5.5に劣るという、得意・不得意の偏りがあります。これはSSAが「重要な位置だけを選んで計算する」設計上、参照すべき箇所が増えれば増えるほど「どこを選ぶか」のロジックの精度に依存する構造になっていることとも整合します。
コーディングエージェント比較

CLIエージェントとしてSubQ Codeを評価する場合、競合はClaude CodeとOpenAI Codex CLIです。
| 項目 | SubQ Code | Claude Code | Codex CLI |
|---|---|---|---|
| ベースモデル | SubQ 1M-Preview | Claude Opus 4.7/Opus 4.6/Sonnet 4.6など | GPT-5.5系 |
| コードベース投入方式 | 全体を1コンテキストに | RAG+必要時コンテキスト拡張 | RAG+必要時コンテキスト拡張 |
| 強み | 巨大リポジトリの一括把握 | エコシステムの厚さ・実績 | OpenAI製品との統合 |
| 弱み | ベータ・実績不足 | 12M級リポジトリでは分割が必要 | 12M級リポジトリでは分割が必要 |
「分割せずに全部読ませる」設計は、設計書・テストコード・ドキュメントを横断するリファクタリングや、レガシーコード調査のように「どこに何があるか分からない」探索系タスクで特に効きます。一方、すでにRAG+エージェントで運用が回っている案件で、わざわざSubQに切り替える優先度は高くありません。実装の選定基準としては「コードベース規模が1Mトークンを超えるか」「分割境界で精度が落ちている自覚があるか」を最初の問いに置くのが実務的です。
競合の他モデル比較記事
各フロンティアモデル単体の解説については、以下の関連記事を参照してください。
【関連記事】
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説!
【関連記事】
Gemini 3とは?使い方や料金、利用上限について解説
【関連記事】
DeepSeek V4とは?特徴や使い方、料金体系を徹底解説
SubQ導入で注意すべき制約・懸念点
ベータ段階のフロンティアモデルを採用検討するうえで、現時点で押さえておくべき制約と懸念点を整理します。
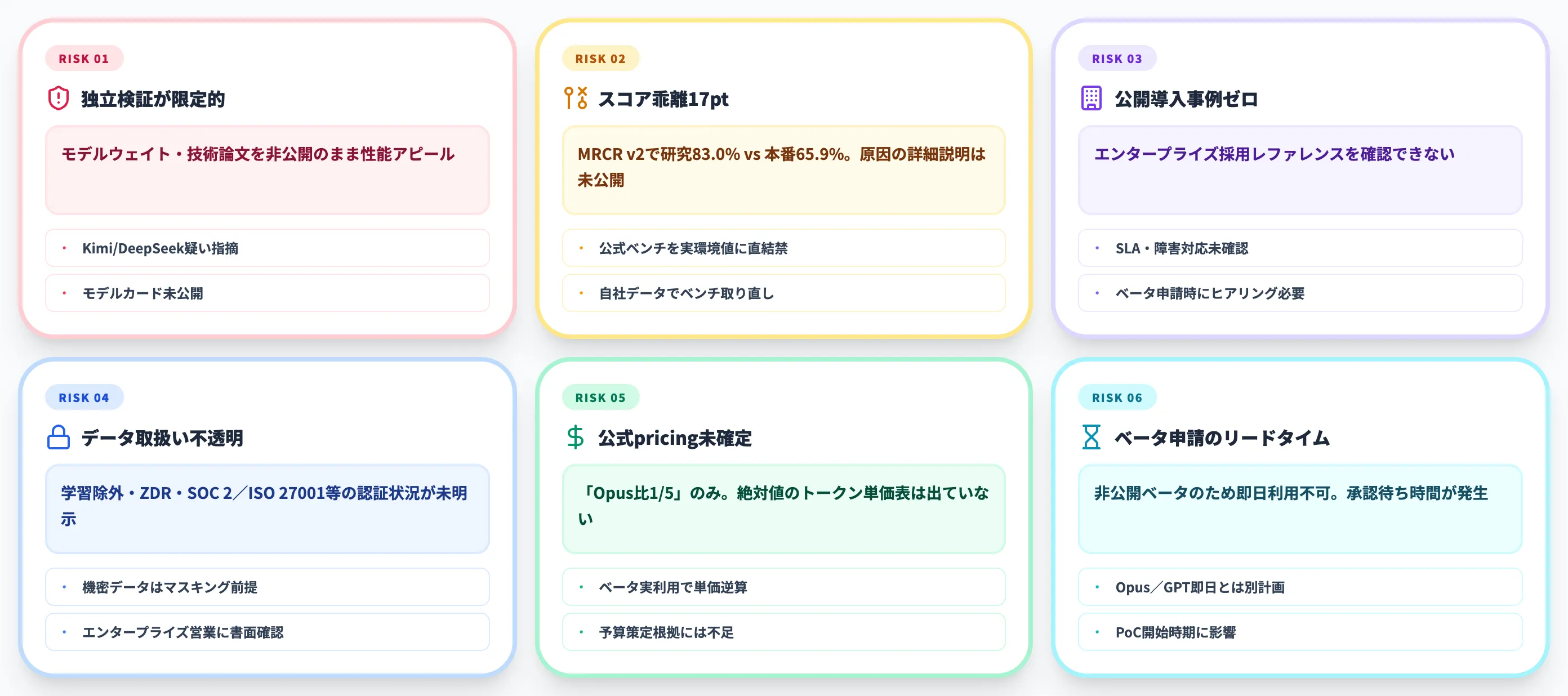
第三者による独立検証が限定的
VentureBeatによる検証記事やHan Heloir氏のMedium分析、felloaiのレビュー記事では、研究者コミュニティから「モデルウェイト・技術論文を公開しないままの性能アピールは独立検証ができない」「Kimi(中国Moonshot AIの長文特化LLM)/DeepSeekが採用している疎注意(Sparse Attention)アーキテクチャを微調整したものではないか、という疑い」が指摘されています。Subquadratic自身は「包括的なモデルカードを近日公開予定」とアナウンスしており、本格採用の判断は技術報告書のリリース後まで待ったほうが安全です。
研究モデルと本番モデルの17ポイント乖離
前述のとおり、MRCR v2では研究モデル(83.0)と本番モデル(65.9)に約17ポイントの差が公式に開示されています。原因の詳細説明は本稿執筆時点では出ておらず、VentureBeatもこの差を「largely unexplained」と評している状況で、技術報告書・モデルカードのリリースを待つ必要があります。
PoCで触る場合は、公式ベンチマークの数字をそのまま実環境性能と読み替えず、自社データでベンチを取り直すプロセスを必ず挟むべきです。
エージェントハーネス依存と単発実行
SWE-Benchの差は「ハーネス(エージェント実装枠組み)の影響が大きい」とSubquadratic自身が認めており、ベンチ結果がそのまま「モデルの実力」とは言い切れません。加えて、VentureBeatの検証記事が指摘するとおり、各ベンチが推論コスト都合で1回ずつしか走らせていないため、0.2〜1ポイント差は誤差範囲に入りえます。
公開導入事例ゼロ
Subquadratic公式announcementを含め、本稿執筆時点でSubQ/SubQ Code/SubQ Searchの公開導入事例は確認できません。Anthropic/OpenAI/Googleであれば、エンタープライズ採用事例(Accenture・NYSE等)から運用可否を逆算できますが、SubQはこのレファレンスがゼロです。SLA・障害対応・データ取扱いといった企業要件は、ベータ申請時に直接ヒアリングする以外に確認手段がありません。
機密データ取扱いと学習除外規約の不透明さ
SubQ APIはSubquadratic側のクラウドインフラで動作するベンダーホスト型サービスなので、業務データは外部に送信される前提になります。学習除外・データ保持期間・ZDR(Zero Data Retention:APIに送信したデータをモデル学習にも内部保管にも使わない契約オプション)・SOC 2/ISO 27001/GDPR等の認証取得状況については、公式pricingページ・公式announcementを確認した時点で明示が整っていません。Anthropicが商用利用規約(Commercial Terms)で「商用契約上、入力データはモデル学習に使わない」と明示しているのと比べると、ここはSubQ側で整っていない領域です。機密データを扱う場合はマスキング(個人情報や機密情報の書き換え)を前提にするか、エンタープライズ営業へ書面で要件確認を取る必要があります。
料金・利用条件の不透明さ
公式pricingページには現時点で具体的な料金表がなく、「Opus・GPTの約1/5」という相対表現のみが示されています。本番採用に向けたコストシミュレーションを行うには、ベータでの実利用ログから単価を逆算する必要があります。
ベータ申請の必要性
API・SubQ Code・SubQ Searchはすべて非公開ベータで、利用するには公式サイトからアーリーアクセス申請を行う必要があります。即日利用できるOpus/GPT-5.5/Geminiと比較して、PoC開始までのリードタイムが大きく異なる点は計画段階で織り込んでください。
よくある導入の失敗パターン

ベータ段階のフロンティアモデル採用で陥りがちなパターンも押さえておきます。
-
公式ベンチをそのまま運用想定値として使う
研究モデルと本番モデルの17ポイント差・単発実行・ハーネス依存といった注意点を踏まえず、公式ベンチを「自社業務での期待値」にしてしまうケース。必ず自社データでベンチを取り直す
-
コスト試算を「Opus比1/5」前提で固定する
公式pricingが未確定の段階で、相対表現を絶対値の前提に変換してしまう失敗。ベータでの実利用ログを取って単価を逆算する手順を踏む
-
ZDR要件を未確認のまま機密データを投入する
ベータ段階のデータ取扱いポリシーは商用APIほど整っていない。機密データの投入前にエンタープライズ営業へ書面確認を取る
-
既存スタックを置き換える前提で予算を組む
Claude/GPT-5.5を本線に置いたまま、SubQはサンドボックス検証で並行運用するのが現実解。「全部置き換え」を前提にすると、ベータの不安定性で本番が止まるリスクがある
SubQの料金体系
ここではSubQ 1M-Previewの料金について、本稿執筆時点で公開されている情報を整理します。フロンティアモデルとしては珍しく具体的な料金表が未公開で、相対比較とユースケース別のヒントのみが提示されている段階です。

公開情報の整理
Subquadratic公式pricingページ・announcementが開示している料金関連情報は次のとおりです。
- API 単価表は非公開。Opus・GPT-5.5の約1/5を主張
- SubQ Code 単価表は非公開。Claude Code/Codex CLI比で「25%安い請求」を主張
- SubQ Search 公式announcement上はprivate beta。SiliconANGLE等の二次報道では初期無料と伝えられている(公式pricingに明記なし)
- アーリーアクセス 公式サイトから申請。承認後にAPIキーが発行される
「Opus・GPTの約1/5」という比率は、RULER 128Kにおける性能あたりの推論コストをベースにした主張で、フロンティアモデルの公式料金との単純な比較ではない点に注意が必要です。同じ精度を出すために必要な計算量が少ない、という文脈で出てきている数字なので、短文タスクではこの差はそこまで広がらない可能性があります。
競合フロンティアモデルの料金参考
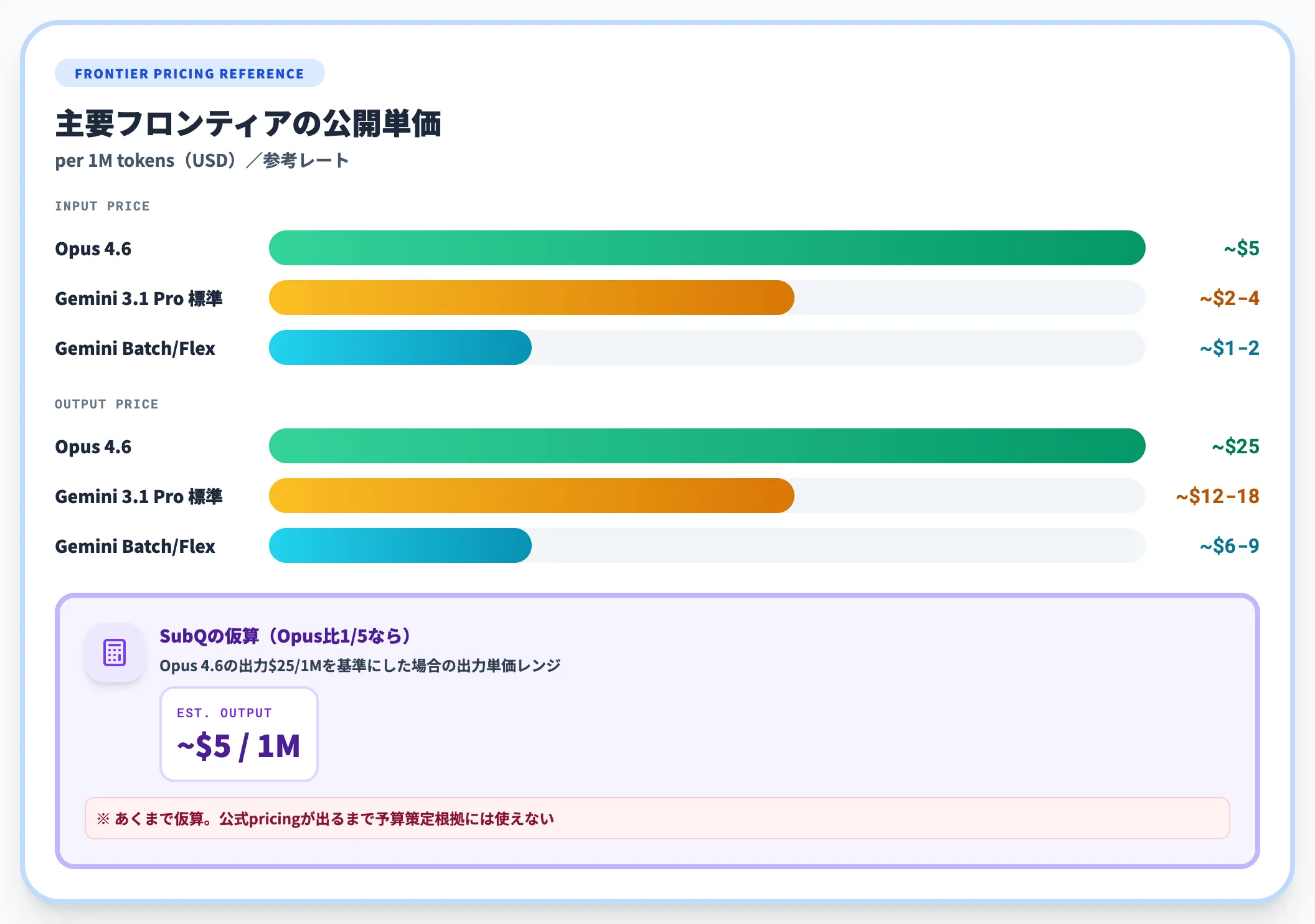
比較の基準として、主要モデルの公開料金を参考までに掲載します。
| モデル | 入力(per 1M tokens) | 出力(per 1M tokens) | 出典 |
|---|---|---|---|
| Claude Opus 4.6 | 約$5 | 約$25 | Anthropic Pricing |
| GPT-5.5 | 公式参照 | 公式参照 | OpenAI Pricing |
| Gemini 3.1 Pro | 標準 約$2〜$4 / Batch・Flex 約$1〜$2 | 標準 約$12〜$18 / Batch・Flex 約$6〜$9 | Gemini API Pricing |
SubQが本当に「Opus比1/5」を実装できるなら、Opus 4.6の出力$25/1Mを基準にした場合、出力単価は$5/1M前後がレンジとして見えてきます。ただし、これはあくまで仮の概算で、公式pricingが出るまでは予算策定の根拠としては使えません。本格採用を検討する場合は、ベータ期間中に対象タスクで実利用ログを取り、トークン単価を実測値ベースで把握する運用が現実的です。
料金面の意思決定基準
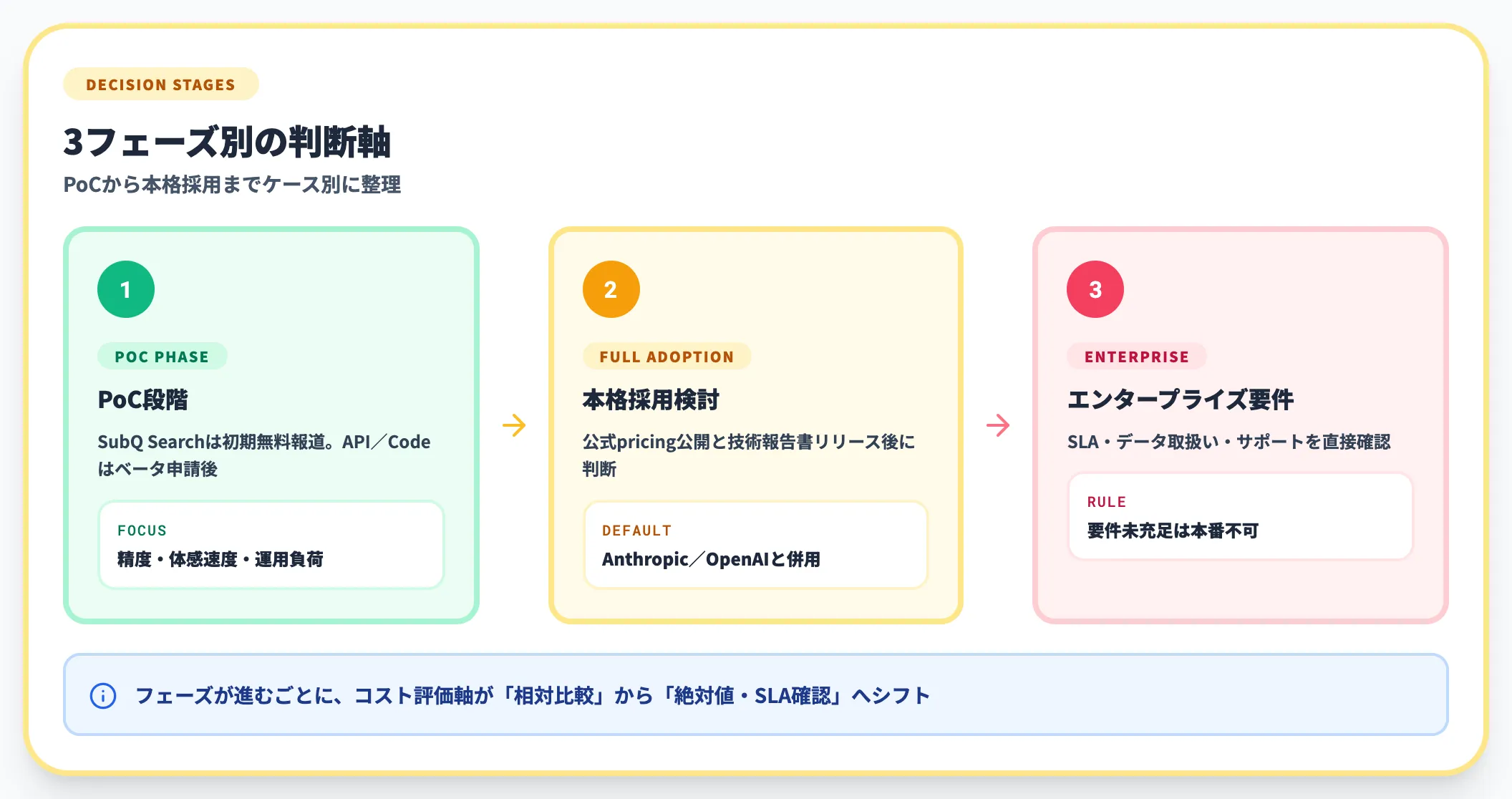
ケース別に、SubQの料金面で意思決定するときの整理軸をまとめます。
- PoC段階 SiliconANGLE等の二次報道で初期無料と伝えられるSubQ Search、API/SubQ Codeはベータ申請後に利用可能。コスト比較より「精度・体感速度・運用負荷」を先に評価する
- 本格採用検討 公式pricing公開と技術報告書リリース後に判断。それまでは「OpenAI/Anthropicとの併用前提」で構成を組む
- エンタープライズ要件 SLA・データ取扱い・サポートは申請時に直接確認。社内のセキュリティ要件と突き合わせて要件未充足なら、現時点では本番ワークロードを載せない

SubQをどう試すべきか

ここまでの整理を踏まえ、長文LLMを業務で扱うチームが「SubQを今どう触るか」をケース別に整理します。本格採用判断の手前で、導入判断で詰まる論点として読んでください。
ケース1:長文ワークロードを既に扱っている開発チーム

社内文書の長文RAG/巨大コードベースのレビュー/長期エージェントなど、すでに「コンテキスト長の壁」にぶつかっているチームは、ベータ申請を前向きに検討する価値があります。
- 既存RAG構成で「分割境界の精度劣化」「チャンク間の整合性」を体感している
- Claude Code/Codex CLIで「リポジトリ規模の大きさが原因で精度が落ちる」と感じている
- 1Mトークンを超える文脈を扱うエージェント設計を計画している
こうしたチームは、PoCの上位選択肢として「現状ベース+SubQの並行A/B」を組むのが妥当です。OpenAI互換APIなのでSDK差し替えが容易で、検証コストが小さい点もポジティブに働きます。
ケース2:フロンティアモデルの動向をウォッチしているCTO・技術リーダー
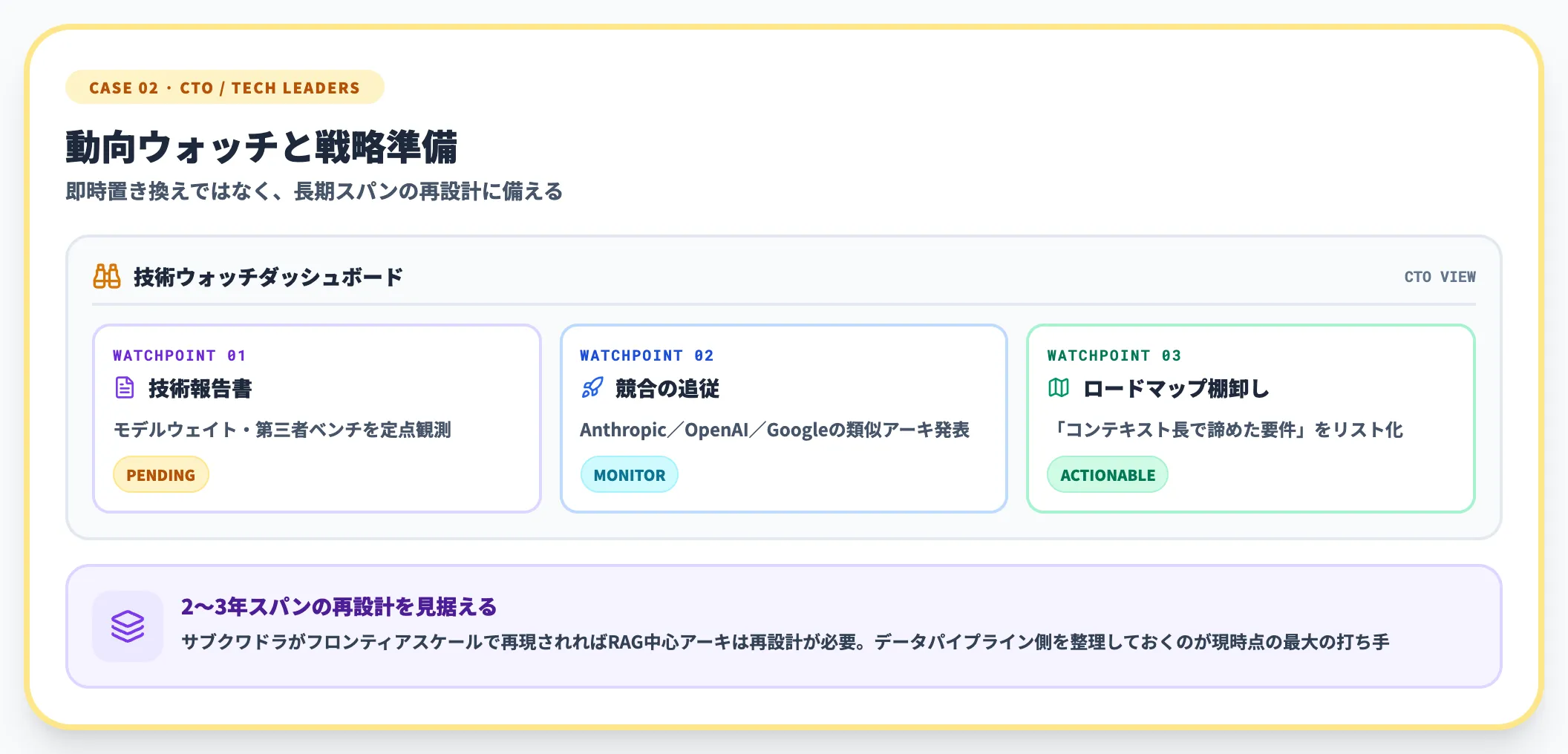
SubQは「サブクワドラティックがフロンティアレベルで成立した最初の実例」として、LLMアーキテクチャの潮目を変えうる発表です。
ただし本稿執筆時点では、本番採用するには検証材料が足りていません。動向把握は必要ですが、いますぐ既存スタックを置き換える判断には至らないのが妥当です。
- 技術報告書・モデルウェイト公開・第三者ベンチを定点ウォッチする
- 競合のAnthropic/OpenAI/Googleが類似アーキテクチャを発表してくるかをモニタリングする
- 自社のロードマップ上で「コンテキスト長の制約で諦めた要件」を棚卸ししておく
SubQに限らず、「サブクワドラティック×フロンティア性能」が業界で再現されれば、RAG中心の現在のアーキテクチャは2〜3年スパンで再設計が必要になります。そのタイミングで動けるよう、社内のデータパイプライン側を今のうちに整理しておくことが、現時点で取れる最大の打ち手になります。
ケース3:ミッションクリティカル業務での即時採用を検討している組織

金融・医療・公共など、SLAと監査要件が厳しい業務での即時採用は、現時点では推奨しません。
- 公開導入事例がゼロ
- 第三者検証が限定的
- 公式pricingが未確定
- 研究モデルと本番モデルのスコア乖離が未解明
- ZDR・コンプライアンス認証の整備状況が未公開
これらの条件が整うまでは、Anthropic/OpenAI/Googleのフロンティアモデルでの本番運用を維持しつつ、SubQはサンドボックス環境での検証に留めるのが安全です。
導入判断で詰まりやすい論点
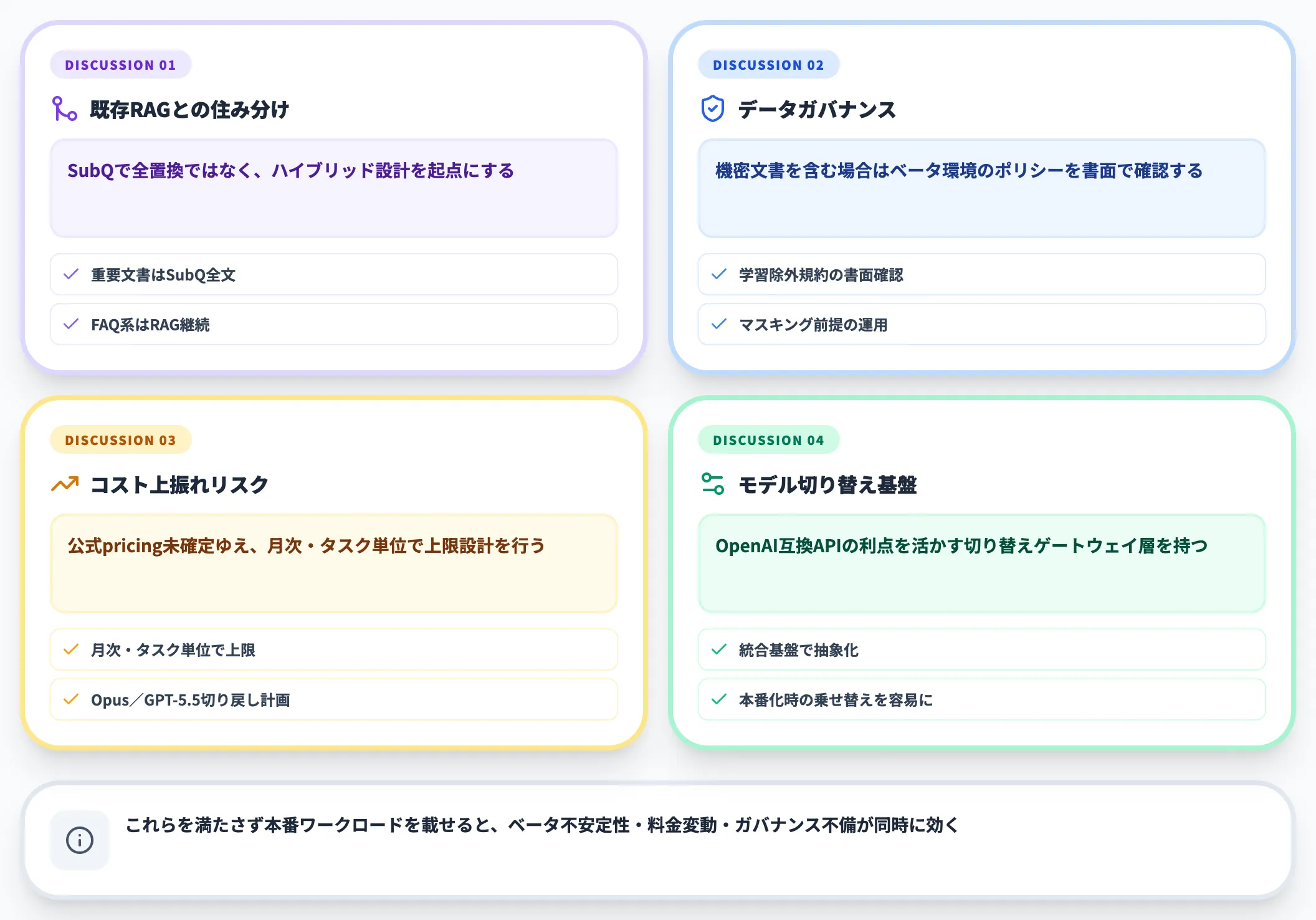
最後に、SubQのPoCを進めるうえで多くのチームが詰まる論点を、先回りで整理しておきます。
- 既存RAGとどう住み分けるか SubQですべて置き換えるのではなく、「重要文書はSubQ全文/FAQはRAG」のハイブリッド設計を起点にする
- データガバナンスをどう担保するか 機密文書を含む場合、ベータ環境のデータ取扱いポリシーを書面で確認する
- コストの上振れリスクをどう抑えるか 公式pricing未確定の段階では、月次ベース・タスク単位での上限設計と、Opus/GPT-5.5への切り戻しプランを用意しておく
- 複数モデルの切り替え基盤をどう整えるか OpenAI互換APIの利点を活かすには、モデル切り替えを抽象化したゲートウェイ層を持つ構成が有効。AI総合研究所のAI Agent Hubのような統合基盤を入れておくと、SubQの本番化判断時に乗せ替えやすい
これらを満たさずに本番ワークロードを載せてしまうと、ベータの不安定性・料金の変動・データガバナンスの不備が同時に効いてくるので注意が必要です。検証フェーズのうちに設計を固めておくことが、本格採用時の意思決定スピードを左右します。
フロンティアモデルの世代交代を業務影響なく進めるなら
SubQ 1M-Previewの登場は、長文LLMの選択肢が「ClaudeかGPTかGeminiか」だけではなくなる流れの一例として読めます。今後も新しいフロンティアモデルが出るたびに業務システム側を作り直すのは現実的ではないので、「検証から本番運用へつなぐレイヤーをどう設計するか」が長期で効いてくるテーマになります。
このレイヤーを担うのが、自社のAzureテナント内で動くエンタープライズAIエージェント基盤です。AI総合研究所のAI Agent Hubは、SubQのようなベンダーホスト型モデルでの検証から、自社テナント内での本番運用への橋渡しまでを一貫して設計できる構成になっています。
- 複数フロンティアモデルを切り替えながら運用
SubQ・Claude・GPT・Geminiをユースケース別に使い分けられるよう、OpenAI互換APIを前提としたモデル切り替え層をAIエージェント基盤側に持たせます。新興モデルが本番候補に上がっても、業務システム側を改修せずに乗せ替えられる設計です。
- ベンダー側検証→自社テナント本番運用の橋渡し
SubQ APIのようなベンダーホスト型での検証フェーズから、データを外に出せない業務については同じエージェント設計を自社のAzureテナント内に再構築する流れを、設計段階から伴走支援します。
- クラウド環境を問わずAIエージェントを一元管理
Microsoft Foundry・Copilot Studio・n8nといった構築基盤を横断して、AIエージェントの実行ログ・アクセス権限・セキュリティスキャンを1つのダッシュボードで管理します。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完結する設計のため、機密データを外部に流出させずに長文モデルを試せます。
AI総合研究所の専任チームが、フロンティアモデルの選定から自社テナント内でのAIエージェント運用設計まで一貫して支援します。まずは無料の資料で全体像をご確認ください。
フロンティアモデル世代交代に備える

モデル切り替え前提のAI基盤を整える
SubQのような新興モデルを業務に取り込むには、ベンダー側での検証から自社テナントでの本番運用への橋渡しが必要です。AI Agent HubはMicrosoft Foundry・Copilot Studio・n8nを横断してAIエージェントを一元管理し、モデルの世代交代に強い運用基盤を実現します。
まとめ
SubQ 1M-Previewは、Subquadraticが2026年5月5日に発表した、フロンティアスケール初の完全サブクワドラティックLLMです。SSAアーキテクチャによってコンテキスト長に対する計算量を線形に近づけ、研究モデルでは12Mトークンまでの動作を実証しました。RULER 128Kで95.0%とClaude Opus 4.6を上回り、SWE-Bench Verifiedで81.8%を記録するなど、特定領域では既存フロンティア勢と競合しうる水準にあります。
同社の主張の核心は「Transformerの二次計算量こそ、AI応用の最大の経済制約だった」という見方です。RAGや分割エージェントは「二次計算量の制約に対する対症療法」にすぎず、SubQによって制約が外れた領域では、これまで本番化できなかったワークロードが商用規模で動き始める、というロジックになっています。
一方で、技術報告書・モデルウェイト未公開、第三者検証の限定、研究モデルと本番モデルの17ポイントスコア差、公式pricing未確定、公開導入事例ゼロ、コンプライアンス認証未整備といった懸念は無視できません。長文ワークロードを既に抱えるチームによるPoC・ベータ検証は積極的に進める価値がある一方、ミッションクリティカル業務への即時採用は時期尚早というのが現実的な見立てです。
Subquadraticの主張が再現されれば、業界全体のコンテキスト長と推論コストの常識が書き換わる可能性があります。今後リリースされる技術報告書と第三者検証を見極めつつ、自社のデータパイプラインとAI基盤を「長文LLMが本格化したときに乗せ替えられる構造」に整えておくことが、現時点で取れる最も確実な打ち手です。










