この記事のポイント
 数学・コーディング・法務分析など論理的推論が求められるタスクでは、通常モデルより推論モデルを選ぶべき。精度差が顕著に出る
数学・コーディング・法務分析など論理的推論が求められるタスクでは、通常モデルより推論モデルを選ぶべき。精度差が顕著に出る- コスト重視ならo4-mini、精度最優先ならo3またはClaude 4.6 Extended Thinkingが第一候補。用途に応じた使い分けが有効
- 推論モデルではChain of Thought指示を入れると逆効果になるため、従来のプロンプト設計は見直すべき
- テストタイムコンピュートにより推論精度は向上するが、レイテンシとコストも増加するため、リアルタイム応答が必要な場面は避けるべき
- まずはコーディング支援や数値分析など効果が測定しやすい業務でPoC導入し、段階的に適用範囲を広げるのが最適

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2026年3月時点で、AIの「推論モデル(Reasoningモデル)」は急速に進化を遂げています。OpenAIのo3/o4-mini、AnthropicのClaude 4.5/4.6(Extended Thinking)、GoogleのGemini 2.5 Pro/Flash、DeepSeek-R1など、各社が推論能力に特化したモデルを相次いでリリースしています。
推論モデルとは、回答を出す前に「思考の連鎖(Chain of Thought)」を展開し、複雑な問題をステップごとに分解して解決するAIモデルです。従来の生成AIモデルとは異なり、数学、コーディング、論理分析といった複雑なタスクで特に高い精度を発揮します。
本記事では、推論モデルの仕組みや従来モデルとの違い、2026年3月時点の代表的なモデル比較、具体的な活用事例、使い方のコツから限界・注意点まで、実務に役立つ情報を網羅的に解説します。
推論モデルとは
推論モデル(Reasoningモデル)とは、回答を生成する前に「思考の連鎖(Chain of Thought)」を展開し、複雑な問題をステップごとに分解・検証してから最終的な出力を生成するAIモデルです。
従来の生成AIモデル(GPT-4oなど)が入力に対してすぐに回答を返すのに対し、推論モデルは「考える時間」を使います。内部的に推論トークンと呼ばれる思考プロセスを展開し、複数のアプローチを検討したうえで、最も整合性の高い回答を導き出します。
2026年3月時点で、主要な推論モデルとしてOpenAIの「o3」や「o4-mini」、Anthropicの「Claude Opus 4.6」(Extended Thinking対応)、Googleの「Gemini 2.5 Pro」、オープンソースの「DeepSeek-R1」などが登場しています。

推論モデルと従来モデルの違い
推論モデルと従来の生成AIモデル(GPT-4oシリーズなど)は、「考え方」そのものが異なります。以下の表で、両者の違いを整理しました。
| 項目 | 推論モデル(o3, Claude Extended Thinkingなど) | 従来モデル(GPT-4o, Claude Sonnetなど) |
|---|---|---|
| 思考プロセス | 回答前に推論トークンで段階的に思考 | 入力に対して即座に回答を生成 |
| 処理速度 | 思考時間がかかるが精度が高い | 高速だがシンプルな推論 |
| 得意なタスク | 数学、コーディング、論理的分析、科学的推論 | テキスト生成、要約、翻訳、分類 |
| 推論精度 | 複雑な多段階の問題でも高精度 | 単純なタスクは得意だが複雑な推論は苦手 |
| コスト | 推論トークン消費により高コスト | 比較的低コスト |
| 透明性 | 思考過程の一部が可視化できる | 思考過程は不透明 |
ここで注目すべきは、推論モデルは「考える時間」と引き換えに精度を高めるという点です。つまり、すべてのタスクに推論モデルを使うのではなく、「複雑で精度が求められる場面」に集中して活用することが、コストパフォーマンスの観点から重要になります。
テストタイムコンピュートとは
推論モデルを理解するうえで欠かせないのが、**テストタイムコンピュート(Test-Time Compute)**という概念です。
従来のAIでは、モデルの性能を上げるには「学習時」に大量の計算資源を投入する必要がありました。テストタイムコンピュートは、これとは異なるアプローチで、推論時(ユーザーが質問したタイミング)にも追加の計算資源を投入し、思考時間を長くすることで回答の精度を高めるという考え方です。
実際に、推論モデルの精度は推論トークンの数(=思考時間)に対して対数的に向上することが確認されています。数学の問題を例にとると、思考トークンを多く使うほど正解率が上がりますが、あるポイントからは改善幅がゆるやかになります。OpenAIのo3やAnthropicのClaude Extended Thinkingでは、この思考量を「thinking effort」や「budget tokens」として開発者が制御できるようになっています。
推論モデルの仕組み
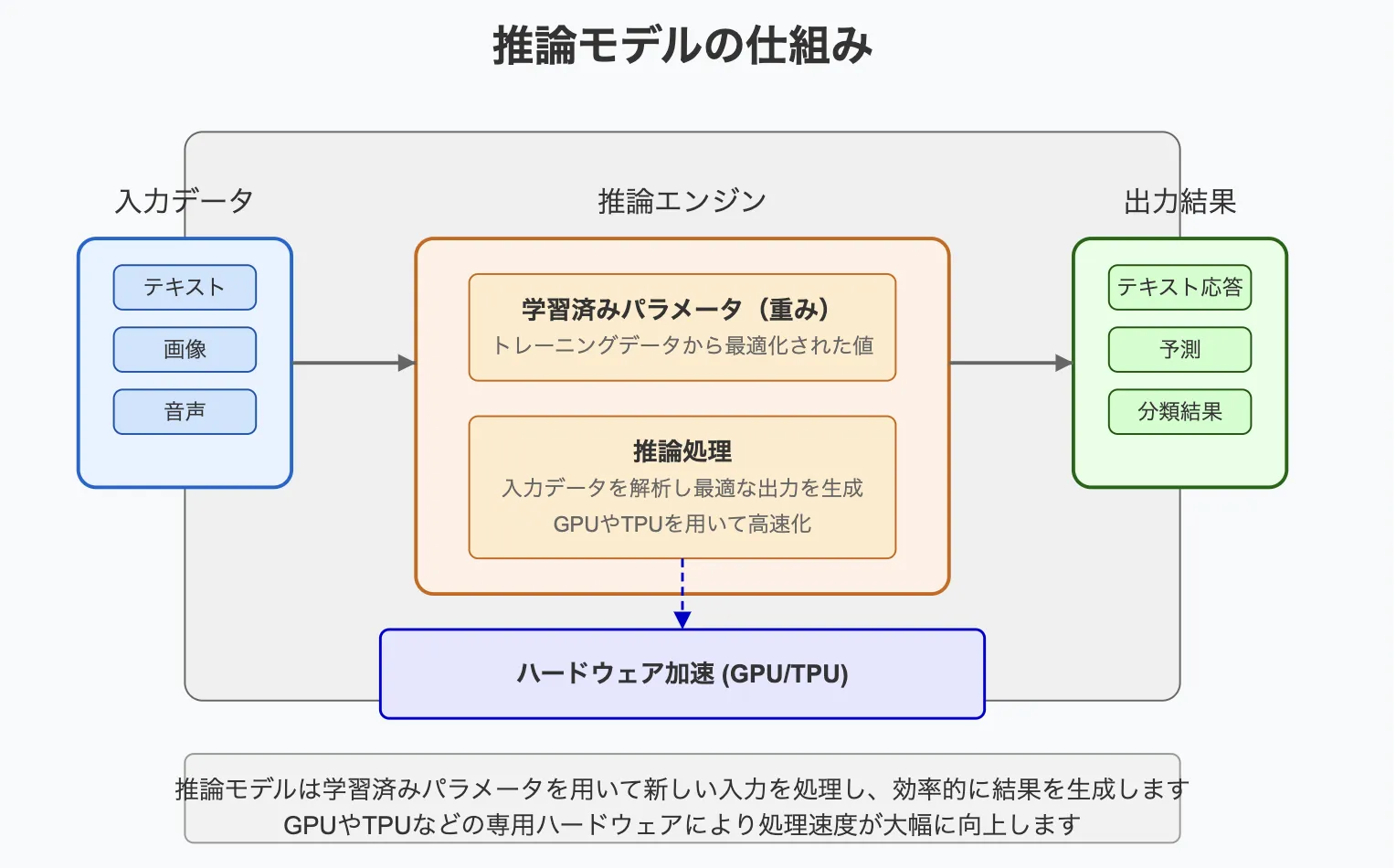
推論モデルの仕組み
上記のように、推論モデルは、AIがデータから答えや判断を導き出すための仕組みです。この過程をシンプルに説明すると次のようになります。
推論モデルは、私たちが入力したデータを受け取り、あらかじめ学習した知識を使って答えを出します。これは料理人が材料(データ)とレシピ(学習済みの知識)を使って料理(答え)を作るようなものです。
技術的基盤
推論モデルの多くは、トランスフォーマーアーキテクチャを基盤としていますが、通常のモデルと異なる点として以下の技術が組み込まれています。
- RLHF(Reinforcement Learning from Human Feedback)
人間のフィードバックを基にした強化学習。DeepSeek-R1はRLのみで推論能力を獲得した点で注目を集めた
- CoT(Chain of Thought)
思考の連鎖を明示的に表現する推論手法。推論モデルの基本メカニズム
- Tree of Thought(ToT)
CoTを発展させ、複数の思考経路を並行して展開し、最適な推論パスを選択する手法
- Self-Consistency
複数の推論経路の結果を照合し、統計的に最も整合性の高い結論を導き出す仕組み
これらの技術により、推論モデルは単に答えを出すのではなく、複数のアプローチを検討し、自己検証を行いながら最適な回答に到達できるようになっています。
三つの主要素
-
入力データ - モデルが処理する情報
- テキスト(質問文、文章など)
- 画像(写真、図など)
- 音声(話し言葉、音楽など)
-
推論エンジン - データを処理する頭脳部分
- 学習済みパラメータ(重み) - トレーニングによって獲得した知識
- 推論処理 - 入力を分析し最適な出力を計算するプロセス
-
出力結果 - モデルが生成する答え
- テキスト応答
- 予測や分類結果
- 問題解決のための提案
処理の高速化
推論モデルは膨大な計算を高速に行う必要があります。そのために以下のような技術を使っています。
- GPUやTPU - 特殊な計算チップを使用(これらは通常のコンピュータよりも並列処理に優れているため、AI計算に適しています)
- 量子化技術(Quantization) - モデルの精度を維持しながらサイズを縮小
- 推論最適化フレームワーク(TensorRT、ONNXなど) - 処理速度を向上させる専用ソフトウェア
実生活での例
推論モデルは、経験豊富な専門家のようなものです。医師が患者の症状(入力データ)を聞き、医学知識(学習済みパラメータ)を活用して、診断(出力結果)を行うのと同じです。
違いは、AIはこのプロセスを非常に高速に、大量のデータで実行できる点にあります。
推論モデルの魅力は、一度学習すれば何度でも活用でき、様々な種類の問題に対応できることです。私たちが日常的に使うAIアシスタントや画像認識、翻訳サービスなど、多くの便利なツールはこの仕組みで動いています。
代表的な推論モデル
2026年3月時点で、主要各社が推論モデルを競って開発しています。以下の表に、代表的な推論モデルの特徴と料金を整理しました。
| モデル | 提供元 | 特徴 | 料金(API、100万トークンあたり) |
|---|---|---|---|
| o3 | OpenAI | 最高水準の推論性能、マルチモーダル対応、ツール連携 | 入力$10 / 出力$40 |
| o4-mini | OpenAI | o3の約10分の1のコストで高速推論 | 入力$1.10 / 出力$4.40 |
| o3-pro | OpenAI | o3をさらに強化した最上位推論モデル | ChatGPT Pro限定 |
| Claude Opus 4.6(Extended Thinking) | Anthropic | 100万トークンコンテキスト、4段階の推論レベル制御 | 入力$15 / 出力$75 |
| Claude Sonnet 4.5(Extended Thinking) | Anthropic | コストと推論精度のバランスに優れるハイブリッドモデル | 入力$3 / 出力$15 |
| Gemini 2.5 Pro | LMArena首位、マルチモーダル推論、動画3時間分の処理 | 入力$1.25-$2.50 / 出力$10-$15 | |
| Gemini 2.5 Flash | 思考ON/OFF切替可能、動的な推論予算制御 | 入力$0.15 / 出力$0.60(思考なし) | |
| DeepSeek-R1 | DeepSeek | オープンソース(MIT)、MoEアーキテクチャ、RLのみで推論獲得 | 入力$0.55 / 出力$2.19 |
ここで注目すべきは、各社のアプローチの違いです。OpenAIはツール連携を含む「エージェント的推論」、Anthropicは開発者が推論レベルを4段階で制御できる「適応型推論」、Googleは思考予算を動的に調整する「ハイブリッド推論」、DeepSeekはオープンソースで圧倒的なコスト効率を実現しています。
※ 料金は2026年3月時点のAPI価格です。ChatGPTやClaudeの月額プランで利用する場合は別途サブスクリプション料金が必要です。
OpenAI oシリーズ(o3 / o4-mini / o3-pro)
OpenAIの推論モデルは、初代o1からo3-mini、o3、o4-miniと急速に進化してきました。
o3は、コーディング・数学・科学・視覚認識にわたるフロンティアモデルであり、初めて推論モデルにマルチモーダルなツール連携(Web検索、Pythonによるファイル解析、画像生成など)が統合されました。o4-miniはo3と同等の推論能力を維持しながら、コストを約10分の1に抑えた高速推論モデルで、日常的な推論タスクに適しています。
Anthropic Claude Extended Thinking
Anthropicの推論モデルは、Claude 3.7 Sonnetで初めて導入された「Extended Thinking」機能がベースです。
Claude Opus 4.6では、タスクの難易度に応じて4段階(low / medium / high / max)の推論レベルを自動または手動で切り替える「適応型推論」が実装されています。100万トークンのコンテキストウィンドウと組み合わせることで、大量の資料を踏まえた深い推論が可能です。
Google Gemini 2.5シリーズ
GoogleのGemini 2.5シリーズは、Gemini 2.0 Flash Thinkingから進化したThinkingモデルです。
Gemini 2.5 Flashは世界初の「完全ハイブリッド推論モデル」とされ、思考のON/OFFを切り替えたり、思考予算(thinkingBudget)をトークン数で指定したりできます。Gemini 2.5 ProはLMArenaリーダーボードで首位を獲得し、動画3時間分のマルチモーダル処理にも対応しています。
DeepSeek-R1
DeepSeek-R1は、中国のAI企業DeepSeekが2025年1月にMITライセンスでオープンソース公開した推論モデルです。
MoE(Mixture of Experts)アーキテクチャにより、671Bパラメータの知識量を持ちながら、推論時のコストは約37Bモデル相当に抑えられています。教師データなしの強化学習のみで推論能力を獲得した点が画期的で、自己検証やバックトラック(間違いの修正)といった行動が自然発生しました。1.5Bから70Bまでの蒸留バージョンも公開されており、ローカル実行も可能です。
推論モデルの活用例
推論モデルは、論理的な思考が求められる場面で特に真価を発揮します。以下に、具体的な活用シーンを整理しました。
コーディング・ソフトウェア開発
推論モデルが最も効果を発揮する分野のひとつです。
- 複雑なバグの原因特定と修正案の提示
- 大規模コードベースのリファクタリング方針の策定
- セキュリティ脆弱性の検出とレビュー
- テストケースの設計と境界条件の洗い出し
SWE-bench(ソフトウェアエンジニアリングベンチマーク)では、推論モデルが従来モデルを大幅に上回る成績を記録しています。
数学・科学的分析
多段階の論理的推論が求められるタスクは、推論モデルの得意領域です。
- 数学の証明問題や最適化問題
- 科学論文のデータ解析と仮説検証
- 統計モデリングとシミュレーション設計
ビジネス・金融での活用
企業の意思決定支援においても、推論モデルの活用が広がっています。
- 契約書や法的文書の複雑な条件の分析
- 財務データの異常検知とリスク評価
- 市場データに基づく戦略的意思決定の支援
Deep Research(深層調査)
各社の推論モデルを活用した調査ツールも登場しています。OpenAIのDeep Researchは、推論モデルが自律的にWeb検索とデータ分析を繰り返し、包括的なレポートを生成する機能です。推論モデルの「段階的に考える」能力が、複雑な調査タスクの自動化に活かされています。

推論モデルの使い方のコツ
推論モデルは、従来の生成AIモデルとはプロンプティングのアプローチが異なります。ここでは、推論モデルを効果的に活用するためのポイントを整理します。
従来のCoT指示は不要
GPT-4oなどの従来モデルでは「ステップバイステップで考えてください」というCoT指示が有効でした。しかし、推論モデルはすでに内部でCoTを実行しているため、この指示は不要です。むしろ、冗長な思考を誘発して推論コストが増える可能性があります。
シンプルで明確な指示を心がける
推論モデルに対しては、解決すべき問題を明確に記述し、必要な情報を過不足なく与えるのが効果的です。
- 「この財務データの異常値を特定し、考えられる原因を3つ挙げてください」
- 「以下のコードのバグを見つけて、修正案をコードで示してください」
- 「この契約書の第5条と第12条の矛盾点を指摘してください」
ポイントは、「何をしてほしいか」を具体的に伝えつつ、「どう考えるか」はモデルに任せることです。
推論モデルが向いている場面・向かない場面
すべてのタスクに推論モデルを使うのはコスト面で非効率です。以下の表で使い分けの目安を整理しました。
| 推論モデルが向いている場面 | 従来モデルが向いている場面 |
|---|---|
| 複雑な数学・論理問題 | 単純なテキスト生成・要約 |
| コードレビュー・バグ修正 | 翻訳・分類タスク |
| 複数の要因を考慮した分析 | 定型的な文書作成 |
| 戦略的な意思決定支援 | カジュアルな会話 |
| 法的・財務的な文書の精査 | FAQ応答 |
つまり、「考える必要がある」タスクには推論モデル、「素早く出力する」タスクには従来モデル、という使い分けが基本方針になります。
推論モデルの限界と注意点
推論モデルは強力ですが、万能ではありません。導入にあたって理解しておくべき限界と注意点を整理します。
計算コストとレイテンシ
推論モデルは「考える時間」を使うため、従来モデルよりも応答に時間がかかり、推論トークンの消費によりAPIコストも高くなります。たとえば、OpenAI o3の出力は100万トークンあたり$40と、GPT-4oの約5倍のコストがかかります。
リアルタイム応答が求められるチャットボットや、大量の定型処理には、従来モデルとの併用(ルーティング)を検討すべきです。
ハルシネーション(幻覚)
推論モデルは「思考の深さ」は向上していますが、ハルシネーション(事実と異なる内容の生成)が完全に解決されたわけではありません。特に、推論過程が長くなると、途中の誤った仮定を基に結論を導いてしまうリスクがあります。
重要な意思決定に使う場合は、推論モデルの出力を人間が検証する運用フローを組み込むことが推奨されます。
思考過程の透明性の限界
一部の推論モデルでは「思考過程」が部分的に開示されますが、内部の推論トークンがすべて公開されるわけではありません。OpenAIのoシリーズでは、安全上の理由から推論トークンの要約のみが表示され、生の思考プロセスは非公開です。
Anthropicの Extended Thinkingでは思考過程をより詳細に確認でき、Gemini 2.5のThinking機能でも思考プロセスのテキストを取得できるなど、各社のアプローチには差があります。

推論モデルの理解から組織のAI活用設計へ踏み出す
推論モデルの仕組みを理解することは、AIが「何をどこまでできるか」を判断する力につながります。この判断力を持った上で、組織としてどの業務をAIに任せるかを設計すれば、導入後のギャップを最小限に抑えられます。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階設計する実践ガイド(220ページ)を無料で提供しています。部門別のユースケースとBefore/After付きKPI設計で、AI導入の優先順位づけを支援しています。
AI総合研究所の実践ガイドで、推論モデルへの理解を組織の業務改善に直結させる設計をご確認ください。
推論モデルの進化を組織の業務改善に結びつける

まとめ
推論モデル(Reasoningモデル)は、AIが「考える力」を手に入れた重要な技術的進歩です。
- 推論モデルは、回答前にChain of Thoughtで段階的に思考し、複雑な問題を高精度に解決する
- OpenAI o3/o4-mini、Claude Extended Thinking、Gemini 2.5、DeepSeek-R1など、2026年3月時点で各社が推論モデルを積極的に展開している
- テストタイムコンピュートの概念により、推論時の計算量を増やすほど精度が向上するが、コストとのバランスが重要
- コーディング、数学、金融分析、法務文書の精査など、論理的推論が求められるタスクに特に有効
- プロンプティングは従来のCoT指示を避け、シンプルで明確な問題記述が効果的
推論モデルの導入を検討する際は、まず自社の業務タスクのうち「複雑な判断を伴うもの」を洗い出し、そこに推論モデルを適用するパイロット運用から始めるのが現実的です。
AI総合研究所では、企業のAI活用を研修、開発、伴走支援と一気通貫で支援しています。お気軽にご相談ください。










