この記事のポイント
 AIモデルの出力を人間の価値観に合わせるなら、RLHFが最も実績あるアライメント手法で、ChatGPT・Claude・DeepSeekの基盤技術として採用済み
AIモデルの出力を人間の価値観に合わせるなら、RLHFが最も実績あるアライメント手法で、ChatGPT・Claude・DeepSeekの基盤技術として採用済み- 1.3BパラメータのInstructGPTが175B GPT-3を上回った事実が示すとおり、モデルサイズよりもアライメント品質が応答性能を左右する
- 予算が限られる場合はDPO(報酬モデル不要)を選ぶべきで、大規模推論能力が必要ならGRPOが有効な選択肢
- アノテーション600件で約60,000ドル・大規模GPUリソースが必要なため、まず小規模データでDPOを試し段階的に拡大するのが実務上最適
- DeepSeek-R1がGRPOで自己反省能力を獲得した事例は、RLHF派生手法の進化が今後のAI開発の方向性を決定づけることを示している

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを報酬信号として活用し、AIモデルの出力を人間の価値観や好みに合わせて最適化する手法です。ChatGPTやClaude、DeepSeek-R1など、2026年時点で主要なAIモデルのほぼ全てがRLHFまたはその派生手法を採用しています。
本記事では、RLHFの基本概念から実装プロセス、ファインチューニングとの違い、DPO・GRPOといった発展手法、さらにアノテーションコストやGPU費用を含む導入コストまでを体系的に解説します。
目次
DPO(Direct Preference Optimization)
GRPO(Group Relative Policy Optimization)
RLHFとは
RLHF(Reinforcement Learning from Human Feedback)は、AIモデルが人間のフィードバックを活用して、望ましい振る舞いや出力を学習する手法です。
通常、AIは大量のデータや既存のルールに基づいて学習しますが、それだけでは「人間にとって望ましい」動作をするとは限りません。たとえば、大規模言語モデル(LLM)が文法的に正しい文章を生成できても、有害な内容や事実と異なる情報を含む可能性があります。
RLHFでは、人間が「どちらの回答が良いか」をペアワイズ比較で評価し、その評価データから報酬モデルを構築します。この報酬モデルを使い、強化学習のPPO(Proximal Policy Optimization)アルゴリズムでモデルのポリシーを最適化することで、人間の価値観に合った出力を生成できるようになるのです。
以下の図は、環境から得る定量的報酬に加え、人間のフィードバックを取り入れるRLHFの基本構造を示しています。
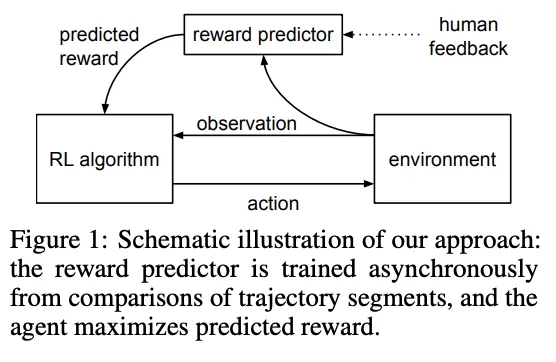
RLHFの構成図参照:Deep Reinforcement Learning from Human Preferences

RLHFの特徴
RLHFは強化学習の一分野ですが、従来の強化学習とは報酬の設計方法が根本的に異なります。以下の表で、両者の違いを整理しました。
| 観点 | 従来の強化学習 | RLHF |
|---|---|---|
| 報酬源 | 環境が自動的に与える数値報酬 | 人間の評価を報酬モデルに変換 |
| 応用範囲 | ゲームAI・ロボット制御など数値化しやすいタスク | LLM、対話AI、要約、コード生成など幅広い |
| 改善ポイント | 定量的スコアの最大化 | 倫理性・有用性・安全性など主観的品質も最適化 |
この比較から分かるのは、従来の強化学習が「明確な正解がある」タスクに強い一方、RLHFは「人間にとっての望ましさ」という曖昧な基準にも対応できるという点です。
RLHFが解決する従来手法の課題
RLHFが注目される背景には、従来手法だけでは解決できない課題があります。
-
教師あり学習の限界
教師あり学習では「正解ラベル」が必要ですが、「自然な会話」や「適切なトーン」といった主観的な基準を正解データとして用意するのは困難です。
-
従来の強化学習における報酬設計の困難さ
従来の強化学習では適切な報酬関数を人手で設計する必要がありますが、「人間にとって有用な回答」を数値化するのは容易ではありません。報酬関数の設計ミスはモデルの予期しない挙動につながります。
-
スケーラビリティの問題
ルールベースのフィルタリングでは、想定外の入力パターンに対応できません。RLHFは人間の判断を学習するため、ルールで網羅しきれないケースにも柔軟に対応できます。
つまり、RLHFは「正解が一意に定まらない」タスクにおいて、人間の価値判断をモデルに効率的に伝える仕組みとして、2026年時点でもAIアライメントの基盤技術であり続けています。
RLHFとファインチューニング・従来手法の違い
RLHFを理解するうえで、よく混同されるファインチューニングや従来の強化学習との違いを明確にしておく必要があります。
ファインチューニングとの比較
RLHFとファインチューニングは、どちらもAIモデルの性能を向上させる手法ですが、目的とアプローチが異なります。以下の表に主な違いをまとめました。
| 項目 | RLHF | ファインチューニング |
|---|---|---|
| 目的 | 人間のフィードバックを活用し、出力を人間の価値観や好みに合わせる | 特定のタスクやデータセットに特化してモデル性能を向上させる |
| 学習データ | 人間による評価データ(ペアワイズ比較、良し悪しのラベル付け) | タスク固有のラベル付きデータセット |
| 学習方法 | 強化学習(報酬モデルを介してPPOでポリシー最適化) | 教師あり学習(ラベル付きデータでパラメータを微調整) |
| 適用例 | 対話AI、コンテンツ生成、ユーザーの好みに合わせた応答生成 | テキスト分類、固有表現抽出、機械翻訳の精度向上 |
| メリット | 曖昧なタスクや主観的な問題に対応可能、倫理観を反映できる | 比較的少ないデータで高い性能を発揮、既存モデルの転用が可能 |
| デメリット | 人間評価のコストが高い、評価基準が曖昧になりやすい | 過学習のリスクあり、タスクが変わると再学習が必要 |
実務で選ぶ際のポイントは、出力の良し悪しが主観的で人間の価値観を反映させたい場合はRLHF、出力が客観的に定義でき特定タスクの精度向上が目的ならファインチューニングが適しています。実際のLLM開発では、まずファインチューニング(SFT)で基本的な指示追従能力を付与し、次にRLHFで人間の好みに合わせるという組み合わせが一般的です。
従来の強化学習との比較
RLHFは強化学習の一種ですが、報酬の設計方法に決定的な違いがあります。以下の表で比較しました。
| 項目 | 従来の強化学習(RL) | RLHF |
|---|---|---|
| 報酬の起源 | 環境が自動的に与える数値報酬 | 人間が直接与えるフィードバック |
| 適用範囲 | 数値化されたゴールが明確なタスク | 曖昧な基準や主観的なタスク |
| 報酬設計の手間 | 高い(適切な報酬関数の設計が必要) | 低い(人間が直接評価するため報酬設計が不要) |
| 柔軟性 | 固定的なルールに適応 | 人間の意図や好みに柔軟に対応 |
| コスト | 設定後は自律的に学習 | 人間による継続的なフィードバックが必要 |
| 学習効率 | 高い(大量の試行で効率的に学習) | 低い(フィードバック量に依存) |
従来のRLは数値化可能な目標に強く、RLHFは曖昧な価値観や人間の好みに対応できる点が最大の違いです。そのため、RLHFは国際的・文化的な違いや微細な嗜好に合わせたモデル調整が可能となり、多様なユーザーベースに対応できます。
導入判断で詰まる論点
RLHFとファインチューニング、あるいはDPOなどの代替手法のどれを選ぶかは、プロジェクトの特性によって異なります。SIerとしてよく相談を受ける判断ポイントを整理しました。
-
「正解」が明確に定義できるか
テキスト分類や固有表現抽出のように正解が一意に決まるタスクであれば、ファインチューニングだけで十分です。「どちらの回答が好ましいか」という主観的判断が必要なタスクでは、RLHFまたはDPOが必要になります。
-
アノテーション予算をどこまで確保できるか
高品質なRLHFには数千~数万件の人間評価データが必要です。アノテーション予算が限られる場合はDPO(報酬モデル不要)やRLAIF(AI評価)の検討をお勧めします。
-
既存のLLMをベースにするか、独自モデルを開発するか
OpenAIやAnthropicのAPIを活用する場合、RLHF相当の調整は各社が実施済みです。自社独自のモデルを構築・調整する場合に初めてRLHFの実装が必要になります。
多くの企業プロジェクトでは、まずAPIベースで要件を検証し、自社固有の調整が必要な場合にファインチューニングやRLHFの導入を段階的に検討するアプローチが現実的です。
RLHFのメリット・デメリット
RLHFを活用することで、モデル品質の大幅な向上が期待できる一方で、人間評価コストや評価基準設定の難しさも伴います。以下の表でメリット・デメリットの全体像を整理しました。
| 観点 | メリット | デメリット |
|---|---|---|
| 品質 | 人間の基準を反映し出力品質が向上 | 評価基準の不統一が品質のばらつきを生む |
| コスト | 有用性強化による事業価値の増加 | 人的評価コストが大きい(600件で約$60,000) |
| 信頼性 | 倫理性・安全性の向上 | 明確な評価基準の策定が困難 |
| スケール | 継続的な改善サイクルの確立 | 大規模運用での評価作業の拡張が難しい |
この表から分かるように、RLHFの価値は「品質向上」と「信頼性向上」にあり、課題は主に「コスト」と「スケーラビリティ」に集中しています。
RLHFのメリット
-
ユーザー嗜好の反映
人間のフィードバックを直接学習するため、ユーザーにとって満足度の高い、自然で的確な出力が可能になります。InstructGPTの実験では、わずか1.3Bパラメータのモデルが175B(100倍以上)のGPT-3より好まれる結果を出しています。
-
倫理面の調整
不適切な応答や偏った見方による出力を、人間の価値観に基づいて調整できます。有害コンテンツの生成抑制、誤情報の拡散防止といった安全性向上に直結します。
-
継続的な品質改善
フィードバックを継続的に収集・反映することで、モデルの品質を段階的に向上させられます。ユーザーの嗜好やニーズの変化にも動的に適応できる点が強みです。
-
報酬設計の省力化
従来の強化学習では、タスクごとに適切な報酬関数を設計する必要がありましたが、RLHFでは人間のフィードバックがそのまま報酬として機能するため、報酬設計の手間とリスクを大幅に削減できます。
RLHFのデメリット・課題
-
評価コストの高さ
人間によるアノテーション作業は時間とコストがかかります。専門性の高いドメイン(医療、法務など)では、1件あたりの評価コストがさらに上昇します。
-
評価基準の主観性
複数の評価者間で基準がばらつく可能性があります。「自然な会話」の定義は文化や個人によって異なるため、評価ルールの標準化が不可欠です。
-
報酬ハッキング
モデルが報酬モデルの「抜け穴」を学習し、実際には有用でない出力でも高スコアを得る方法を見つけてしまうリスクがあります。KL制約の適用でこの問題を緩和していますが、完全な解決には至っていません。
-
大規模運用の困難さ
規模が大きくなるほど、評価データの収集と品質管理が難しくなります。この課題に対し、RLAIFやDPOといったコスト削減手法の研究が進んでいます。
これらの課題に対し、評価ルールの標準化や一部自動評価(RLAIF)の導入、DPOによる報酬モデル省略などで、コストを抑えつつRLHFの恩恵を最大化する取り組みが2026年時点で急速に進んでいます。
RLHFの実装プロセス
RLHFは「報酬モデルの構築」と「ポリシーの最適化」という2つの柱で構成されています。ここでは、それぞれのプロセスを数式と図解を交えて解説します。
報酬モデルの構築
報酬モデルは、AIの出力がどれだけ「望ましい」かをスコアリングする役割を担います。人間のフィードバック(ペアワイズ比較)を基に学習し、AIが人間の価値観を理解する基盤を構築します。
報酬モデルの学習と数式
人間によるペアワイズ比較を用いて、以下の損失関数を最小化することで報酬モデルを学習します。
[
L(\phi) = - \log \sigma(R_\phi(y_1) - R_\phi(y_2))
]
各記号の意味は次のとおりです。
- σ(x) はシグモイド関数
- R_φ(y) は出力yに割り当てられるスコア
- φ は報酬モデルのパラメータ
このプロセスにより、モデルは「望ましい出力にはより高いスコアを付ける」能力を獲得します。
報酬モデル構築の流れ
以下の図は、報酬モデルがどのように構築されるかを3ステップで示しています。
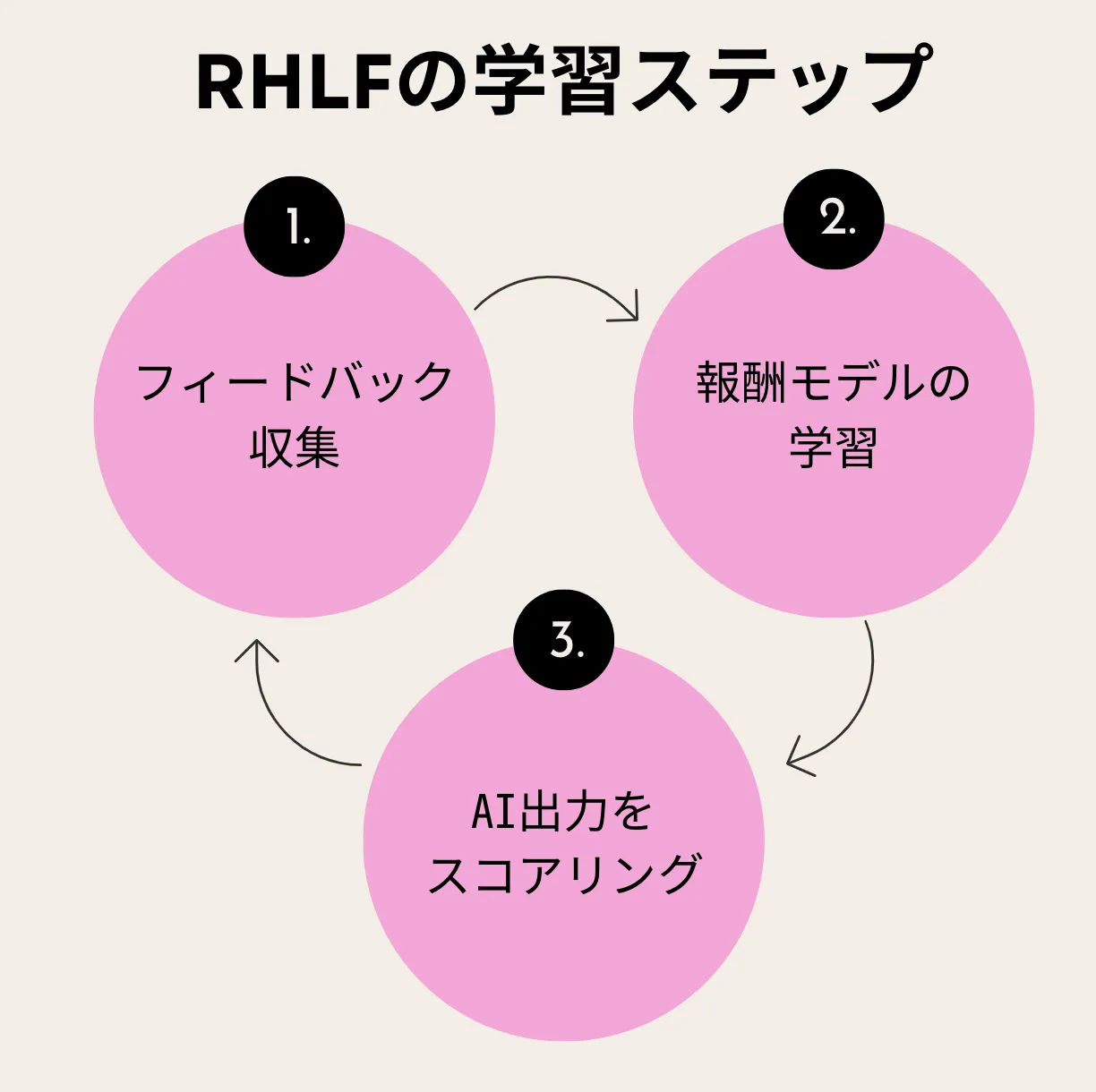
報酬モデル構築の流れ
報酬モデルの構築は、次の3段階で進行します。
-
フィードバック収集
人間のアノテータが複数の出力を比較し、どちらが望ましいかを評価します。
-
報酬モデルの学習
収集した評価データを基に、上記の損失関数でモデルを訓練します。
-
AI出力のスコアリング
学習済み報酬モデルを使い、新しいモデル出力を自動評価して改善に活用します。
学習プロセスの流れ
RLHFは「初期モデルの出力生成 → 人間の評価 → 報酬モデルの更新 → ポリシーの最適化」のサイクルで進行します。この反復により、モデルの品質が段階的に向上します。
学習プロセスの5ステップ
以下の図は、RLHF全体の学習サイクルを示しています。
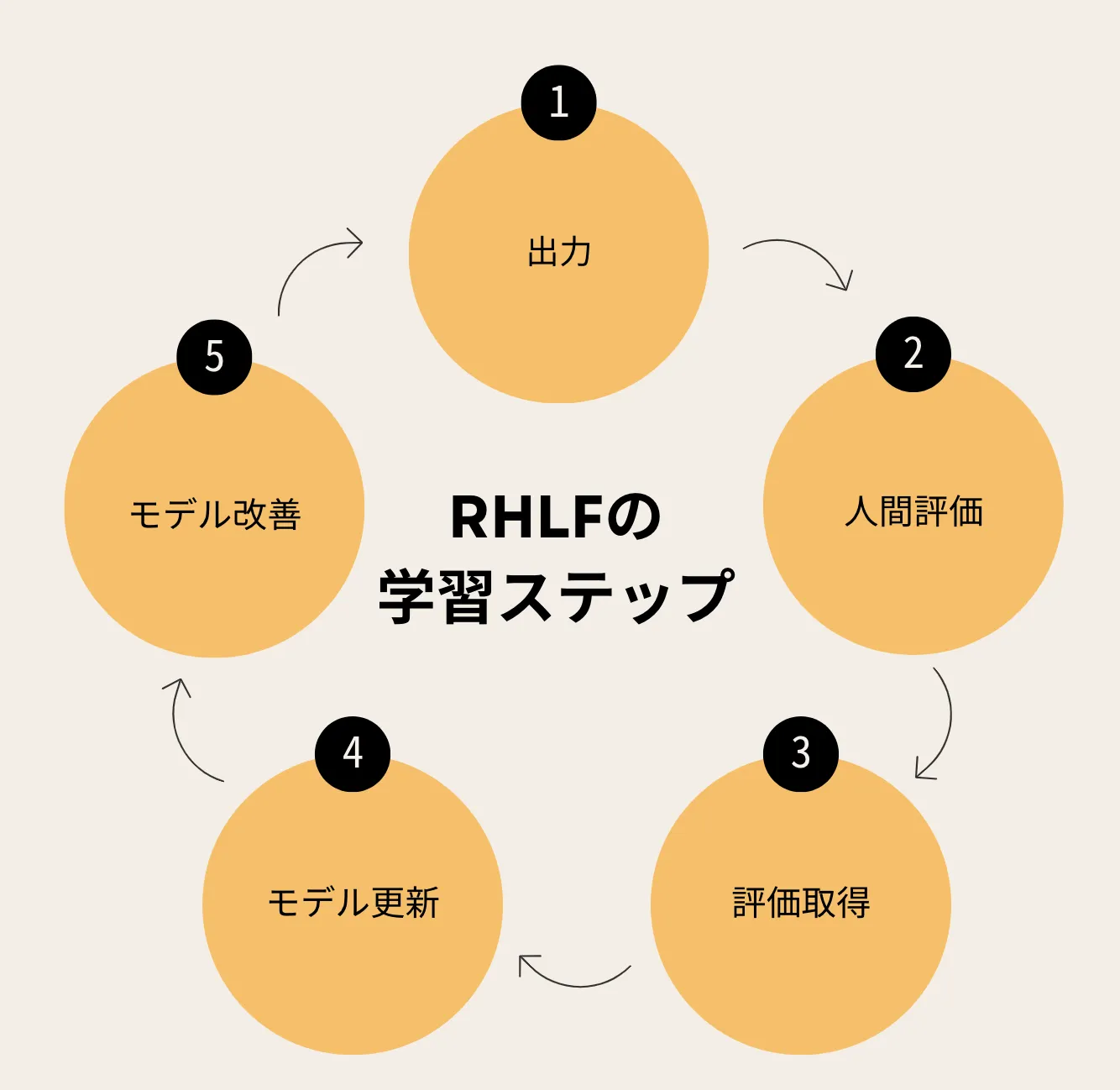
RLHFの学習サイクル
具体的には、以下の5つのステップで学習が進みます。
-
初期モデルの出力生成
事前学習済みモデル(SFT適用済み)が、与えられたプロンプトに対して回答を生成します。
-
人間による評価
アノテータが生成された複数の出力を比較し、品質をランク付けします。
-
報酬モデルの更新
評価データを基に報酬モデルを改良し、スコアリング精度を向上させます。
-
ポリシーの最適化
報酬モデルのスコアを使い、以下のポリシー勾配法でモデルのパラメータを更新します。
[
\nabla_\theta J(\theta) = \mathbb{E}{a \sim \pi\theta} \left[ \nabla_\theta \log \pi_\theta(a | s) \cdot r(s, a) \right]
]
- KL制約の適用
プリトレーニング済みモデルとの乖離が大きくなりすぎないよう、KLダイバージェンスで制約をかけます。
[
L(\theta) = - \mathbb{E}{a \sim \pi\theta} [ R_\phi(y) ] + \beta \cdot \text{KL}(\pi_\theta || \pi_0)
]
このKL制約は、RLHFにおいて極めて重要な要素です。制約がなければ、モデルは報酬スコアを最大化するために不自然な出力パターンを学習してしまう「報酬ハッキング」のリスクが高まります。βの値を適切に設定することで、品質向上と安定性のバランスを取ります。
RLHFの実装方法
ここでは、RLHFの実装プロセスをPythonコードで簡易的に再現する方法を紹介します。Google Colabを使って実際に動かすことで、報酬モデルの構築からポリシー最適化までの流れを体験できます。
なお、OpenAIが使用するような大規模なRLHFフレームワーク(GPT-4やGPT-5に対するRLHF)を完全に再現するには、大量の計算リソースとカスタムツールが必要です。ここでは学習目的のミニマル実装を示します。
必要なライブラリのインストール
Google Colabで以下を実行してください。
!pip install transformers torch numpy datasets
初期モデルの出力生成
事前学習済みモデル(GPT-2)を使用して出力を生成します。GPT-2モデルを使い、「フランスの首都はどこか?」という質問に対する回答を生成する例です。
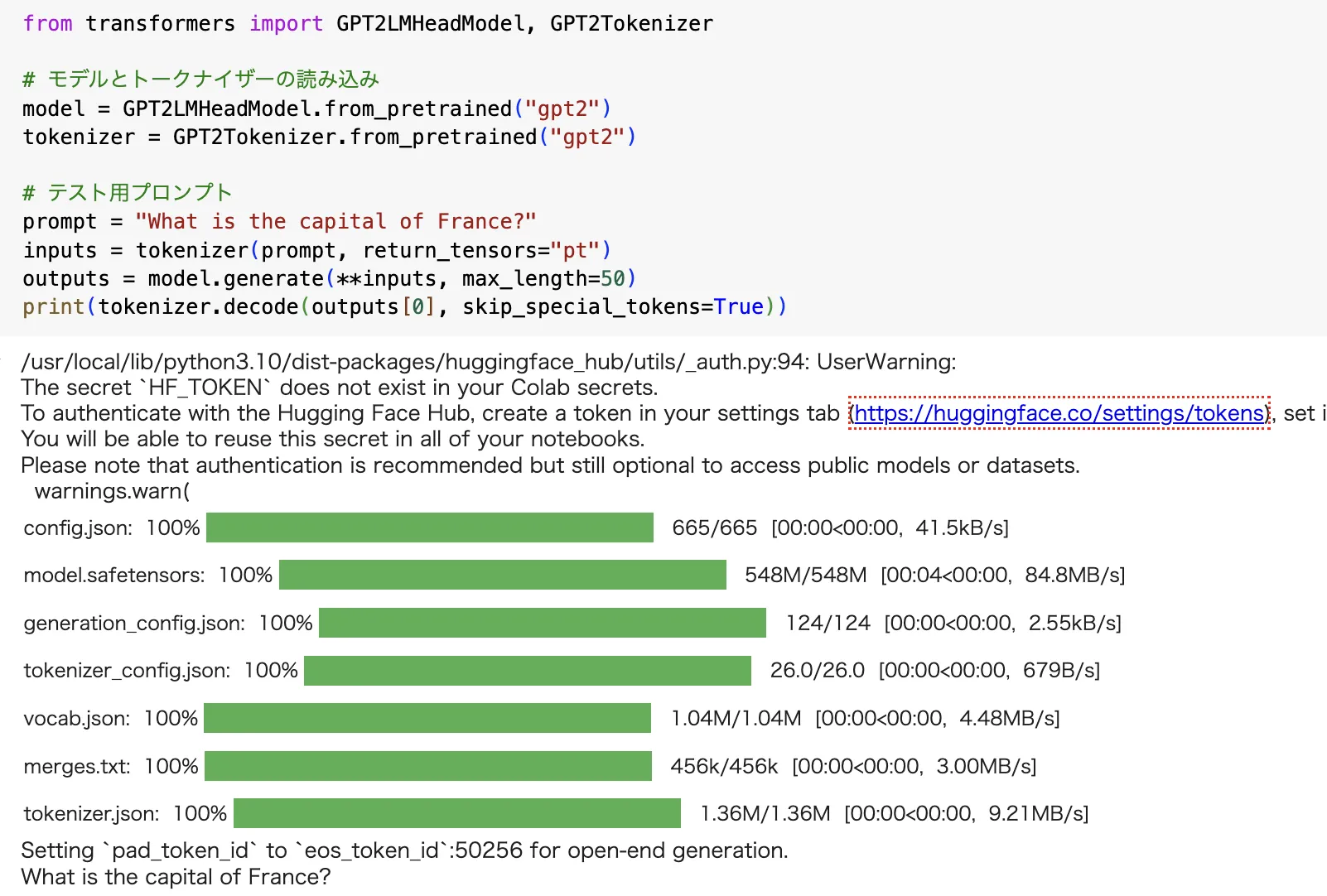
初期モデルの出力生成
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# モデルとトークナイザーの読み込み
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# テスト用プロンプト
prompt = "What is the capital of France?"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
このコードの実行結果として、「The capital of France is Paris, which is located in the northern part of the country...」のような回答が得られます。ただし、GPT-2は小規模モデルのため、回答の精度にばらつきがある点に注意してください。
人間のフィードバック収集
次に、2つの異なる回答(パリ vs リヨン)を比較し、どちらが望ましいかを人間のフィードバックとして記録します。
# 出力例
output_1 = "The capital of France is Paris."
output_2 = "France's capital is Lyon."
# ペアワイズ比較データ
feedback = {"output_1": 1, "output_2": 0} # output_1が優れていると評価
このようなペアワイズ比較データを大量に収集することで、報酬モデルの学習が可能になります。実際のRLHFでは数千~数万件の比較データを使用します。
報酬モデルの学習
報酬モデルを構築し、ペアワイズ比較データを基に学習します。以下のコードでは、PyTorchを使ってシンプルな報酬モデルを構築しています。
import torch
import torch.nn as nn
import torch.optim as optim
# 報酬モデル
class RewardModel(nn.Module):
def __init__(self):
super(RewardModel, self).__init__()
self.fc = nn.Linear(768, 1) # GPT-2の隠れ層サイズに合わせる
def forward(self, x):
return self.fc(x)
reward_model = RewardModel()
optimizer = optim.Adam(reward_model.parameters(), lr=1e-4)
# 損失関数の計算と学習
def train_reward_model(output_1, output_2, feedback):
reward_1 = reward_model(torch.randn(1, 768)) # ダミー入力
reward_2 = reward_model(torch.randn(1, 768))
loss = -torch.log(torch.sigmoid(reward_1 - reward_2) * feedback["output_1"]
+ torch.sigmoid(reward_2 - reward_1) * feedback["output_2"])
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
# 学習の実行
for epoch in range(10):
loss = train_reward_model(output_1, output_2, feedback)
print(f"Epoch {epoch}, Loss: {loss}")
実際のRLHFでは、GPT-2やBERTなどの事前学習済みモデルをベースにした、より大規模な報酬モデルが使用されます。このコードは仕組みの理解を目的とした簡易版です。
ポリシーの最適化
報酬モデルを基にポリシーを更新します。報酬モデルが出力する「望ましさスコア」を最大化する方向にモデルのパラメータを調整する処理です。
def update_policy():
reward = reward_model(torch.randn(1, 768)) # ダミー報酬
loss = -reward.mean() # 報酬を最大化
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
# ポリシーの更新
for step in range(10):
policy_loss = update_policy()
print(f"Step {step}, Policy Loss: {policy_loss}")
このプロセスを繰り返すことで、モデルは段階的に改善され、人間の意図を反映した出力を生成できるようになります。実運用では、このサイクルを数百~数千回反復し、KL制約を適用しながらポリシーを最適化します。

RLHFの活用事例
RLHFは、2026年時点で主要なAIモデルのほぼ全てに何らかの形で採用されています。ここでは、代表的な活用事例とその成果を紹介します。
InstructGPTでのRLHF適用
RLHFの有効性を世界に示した最初の大規模事例が、OpenAIのInstructGPTです。2022年に発表されたこの研究では、わずか1.3Bパラメータのモデルが、RLHFを適用することで175B(100倍以上)のGPT-3よりもユーザーに好まれる回答を生成するという画期的な結果が示されました。
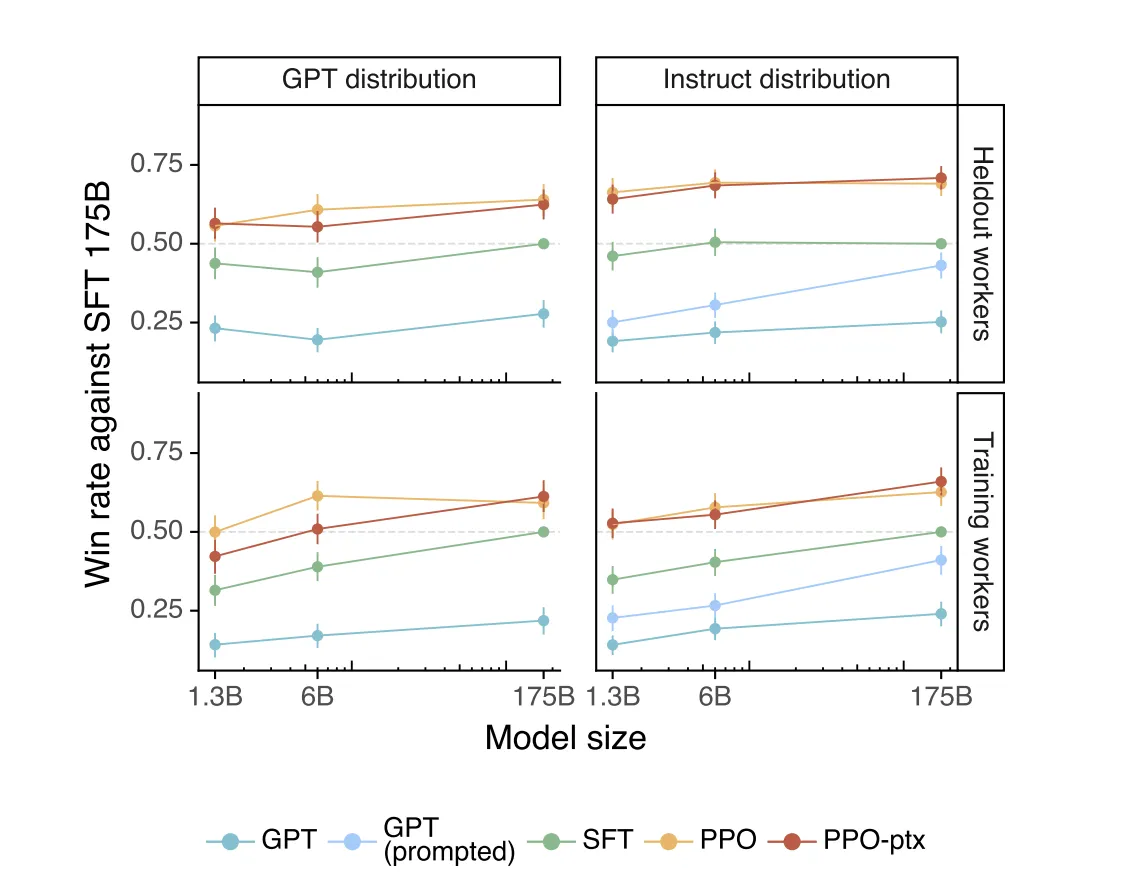
InstructGPTの評価結果参考:Training language models to follow instructions with human feedback
この図は、InstructGPTが人間のフィードバックを活用して他のモデルよりも優れた性能を発揮することを視覚的に示しています。PPO-ptxのようなRLHFの高度な学習手法が勝率を大幅に向上させることが確認され、RLHFがLLMの実用的な品質向上に不可欠であることが実証されました。
ChatGPTからo3・o4-miniへの進化
ChatGPTの仕組みの中核にもRLHFがあります。InstructGPTの方法論を直接継承し、ユーザーの指示に従う能力、詳細な回答を提供する能力、不適切なリクエストを断る能力が大幅に強化されました。
さらに、OpenAI o1では、RLHFの基盤の上にRLVR(Reinforcement Learning with Verifiable Rewards)を組み合わせ、チェーン・オブ・ソート(CoT)による推論能力を獲得しました。続くo3・o4-miniでは、さらに精度と推論の深みが向上し、複雑な質問への対応力が飛躍的に改善されています。
2025年4月にリリースされたo3・o4-miniは、従来のRLHFだけでなく、RLVRを含むより包括的なアライメントプロセスを採用しています。モデルが「回答前に考える」ことを強化学習で学習し、自己反省や戦略の動的な切り替えを実現しています。
以下は、Anthropic社を含むAI研究機関がRLHFの発展に取り組んでいることを示すMetaの投稿です。RLHFを発展させ、人間の思考回路を再現するアプローチが模索されています。
New research from Meta FAIR: Large Concept Models (LCM) is a fundamentally different paradigm for language modeling that decouples reasoning from language representation, inspired by how humans can plan high-level thoughts to communicate. pic.twitter.com/yY8QZXrTts
— AI at Meta (@AIatMeta) December 23, 2024
DeepSeek-R1でのGRPO活用
2025年1月に発表されたDeepSeek-R1は、RLHFの発展手法であるGRPO(Group Relative Policy Optimization)を用いて、人間ラベルなしの純粋な強化学習で推論能力を獲得した画期的なモデルです。
DeepSeek-R1の論文によると、AIME 2024ベンチマークでpass@1スコアが15.6%から71.0%に向上し、多数決投票では86.7%に達してOpenAI o1-0912と同等の性能を示しました。自己反省、検証、動的な戦略適応といった高度な推論パターンが、RLトレーニングの過程で自発的に獲得されたことは、RLHFの可能性を大きく広げる成果です。
RLHFの発展手法
RLHFは強力な手法ですが、人的コストの高さや報酬モデルの不安定さといった課題があります。2025年以降、これらの課題を解決する発展手法が急速に登場しています。
DPO(Direct Preference Optimization)
DPOは、RLHFから報酬モデルとPPO最適化のステップを省略し、人間の選好データを直接使ってポリシーを最適化する手法です。選好データに対する分類タスクとしてアライメント問題を定式化することで、実装の複雑さとコストが大幅に削減されます。
以下の表で、RLHFとDPOの主な違いを整理しました。
| 項目 | RLHF | DPO |
|---|---|---|
| 報酬モデル | 必要(別途学習) | 不要 |
| 最適化アルゴリズム | PPO(複雑) | 分類損失(シンプル) |
| 計算コスト | 高い(報酬モデル+PPO) | 低い(1ステップで最適化) |
| 安定性 | PPOのハイパーパラメータ調整が難しい | 安定した学習が容易 |
| 性能上限 | オンライン学習で高い性能を達成可能 | 静的な選好データに制約される |
DPOの最大のメリットは実装のシンプルさとコスト削減ですが、静的な選好ペアに基づくため、学習データの品質に性能が制約される点が課題です。
GRPO(Group Relative Policy Optimization)
GRPOは、DeepSeek-R1で採用された手法で、批評家モデル(Critic Model)を廃止し、プロンプトごとに複数の応答をサンプリングして、グループ内で相対的に評価します。各応答の報酬をグループ平均と標準偏差に対して正規化することで、メモリ使用量を大幅に削減しながらPPOと同等以上の性能を実現します。
GRPOはオンラインRL手法であり、訓練中に新しい応答を生成するため、DPOのように静的なデータに制約されません。訓練データを超えた改善が可能であり、特に推論タスクで顕著な効果を発揮します。
RLAIF(Reinforcement Learning from AI Feedback)
RLAIFは、人間のフィードバックの代わりにAIモデル自体のフィードバックを使ってモデルを訓練する手法です。Google DeepMindの研究によると、RLAIFは人間による評価(RLHF)と同等以上の性能を発揮できるケースがあることが示されています。
RLAIFの最大の利点は、人的アノテーションコストの劇的な削減です。特に医療や法務など専門性の高いドメインでは、専門家の評価コストが非常に高いため、RLAIFによるコスト削減効果が顕著です。
Constitutional AI(憲法AI)
Anthropic社が開発したConstitutional AIは、明示的な原則(「憲法」)に基づいてAIが自らの出力を批評・修正し、その結果をRLAIFで学習する手法です。人間のラベラーへの依存を減らしながら、透明性の高い原則ベースのアライメントを実現します。
AnthropicのClaudeは、このConstitutional AIを基盤に構築されており、有用性・無害性・誠実性(HHH:Helpful, Harmless, Honest)を原則として学習しています。
2026年のポストトレーニング最新動向
2026年時点で、LLMのポストトレーニングは3段階のパイプラインへと進化しています。以下の表に、各ステージの役割をまとめました。
| ステージ | 手法 | 目的 |
|---|---|---|
| 第1段階 | SFT(Supervised Fine-Tuning) | 指示追従能力の付与 |
| 第2段階 | 選好最適化(DPO/SimPO/KTO) | 人間の好みへのアライメント |
| 第3段階 | RL with Verifiable Rewards(GRPO/DAPO) | 推論能力の強化 |
この進化の核心は、人間ラベルの報酬から自動検証とセルフプレイへの移行です。数学の検証器やコード実行テストなど、プログラムで正確性を自動判定できるタスクにRLVR(Reinforcement Learning with Verifiable Rewards)を適用することで、アノテーションコストを抑えつつ推論能力を飛躍的に向上させています。
DAPOは長い思考チェーンの出力学習を安定化させる改良版で、Qwen2.5-32BをAIME 2024で50ポイントに到達させ、DeepSeek-R1-Zeroを50%少ない学習ステップで上回る成果を示しています。
RLHFの導入コスト
RLHFの導入を検討する際、最大のボトルネックとなるのがコストです。ここでは、アノテーション費用、GPU計算コスト、代替手法によるコスト削減策を具体的な数値とともに解説します。
アノテーション費用
RLHFでは人間による評価データ(ペアワイズ比較)の収集が不可欠です。以下の表に、アノテーション規模別の費用目安を示しました。
| 規模 | 件数 | 費用目安 | 用途 |
|---|---|---|---|
| PoC(概念検証) | 500~1,000件 | $5,000~$20,000 | 手法の有効性検証 |
| 小規模プロジェクト | 1,000~5,000件 | $20,000~$100,000 | 特定タスクの品質改善 |
| 本格運用 | 10,000件以上 | $100,000以上 | 汎用モデルのアライメント |
研究論文のデータでは、高品質なアノテーション600件で約60,000ドルのコストが報告されており、計算コストの約167倍に相当します。特に医療・法務など専門性の高いドメインでは、1件あたりの評価コストがさらに高額になります。
GPU計算コスト
RLHFの訓練には、報酬モデルとポリシーモデルの2つのモデルを同時にメモリに載せる必要があり、通常のファインチューニングより大きなGPU容量が求められます。以下に、モデルサイズ別のGPUコスト目安を示しました。
| モデルサイズ | 推奨GPU | 月額コスト目安(クラウド) |
|---|---|---|
| 7Bパラメータ | A100 80GB × 2~4基 | $5,000~$15,000 |
| 13Bパラメータ | A100 80GB × 4~8基 | $15,000~$40,000 |
| 70B以上 | H100 × 8基以上 | $50,000以上 |
2026年時点では、国内のGPUクラウドサービスも充実してきており、比較的安価にGPUリソースを利用できる選択肢が増えています。
コスト削減のための代替手法
RLHFの高コストに対し、以下の手法でコストを大幅に削減できます。それぞれの効果とトレードオフを表にまとめました。
| 手法 | コスト削減効果 | トレードオフ |
|---|---|---|
| DPO | 報酬モデル不要で計算コスト約50%削減 | 静的データに性能が制約される |
| GRPO | Criticモデル不要でメモリ使用量削減 | ハイパーパラメータ調整が必要 |
| RLAIF | 人的アノテーション不要で費用90%以上削減 | AI評価の品質がベースモデルに依存 |
| KTO | ペアワイズ比較不要、二値フィードバックで運用可能 | 比較データより精度が劣る場合がある |
PoC段階では、まずDPOで手法の有効性を検証し、効果が確認できた場合にRLHFへスケールアップするアプローチが現実的です。アノテーション予算を最小限に抑えながら、段階的に品質を向上させる戦略をお勧めします。

AI技術の本質理解から組織のAI導入設計へ
RLHFのようにAIの仕組みを深く理解することは、組織でAIを活用する際の判断基準を持つことにつながります。どの業務にAIを適用すべきか、どの程度の精度が必要かという設計判断は、技術理解があるからこそ的確にできるものです。
AI総合研究所では、Microsoft環境でAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。技術の理解を前提に、経費精算から申請承認まで部門別の導入設計とROI算出方法を解説しています。
AI総合研究所の実践ガイドで、AI技術への理解を組織の業務改善に活かす設計図をご確認ください。
AI技術への理解を組織の導入設計に転換する

RLHFの知見から全社AI活用の道筋へ
RLHFなどのAI技術を理解した次のステップとして、組織全体のAI業務自動化を段階的に設計する実践ガイド(220ページ)を無料で提供しています。
まとめ
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを報酬信号に変換し、強化学習でAIモデルを人間の価値観に合わせて最適化する手法です。本記事では、その仕組みから実装方法、活用事例、発展手法、導入コストまでを体系的に解説しました。
RLHFがもたらす3つの価値を整理すると、次のようになります。
-
アライメント精度の実証
InstructGPTで1.3Bモデルが175B GPT-3を上回った実績が示すように、RLHFは「パラメータ数の増加」とは異なるアプローチでモデル品質を飛躍的に向上させます。
-
技術エコシステムの成熟
DPO・GRPO・RLAIFといった発展手法により、かつてのRLHFの最大課題だった「コストとスケーラビリティ」が急速に改善されています。2026年時点では、PoC段階で数十万円規模からアライメント検証を開始できるようになりました。
-
推論能力への拡張
DeepSeek-R1やOpenAI o3が示したように、RLHFの枠組みは単なる「好み合わせ」から「推論能力の獲得」へと進化しています。RLVRやGRPOの登場により、AIモデルが自己反省や動的戦略適応を自発的に学習する段階に入りました。
自社のAIプロジェクトでアライメント品質の改善を検討されている場合は、まずDPOを用いたPoC(概念検証)から着手することをお勧めします。小規模な選好データセットで手法の有効性を確認し、効果が確認できた段階でRLHFやGRPOへのスケールアップを計画するのが、コストリスクを最小化しながら確実に成果を出すアプローチです。










