この記事のポイント
 半導体工場AI活用は歩留まり予測・FDC・APC・ウェーハ検査・プロセスインフォマティクスの5領域に集約
半導体工場AI活用は歩留まり予測・FDC・APC・ウェーハ検査・プロセスインフォマティクスの5領域に集約- キオクシア四日市は1日30億件データのAI分析で不良解析時間99%削減・東芝は教師なし学習で4.2h→30分(1/8)
- 装置メーカーAI(KLA・Applied・PDF Solutions)と国内特化ベンダーは「工程独自性」「社内データ量」で使い分け
- FDC/APCの自社開発は教師データとMLOps人材確保がボトルネック、装置メーカーAIは初期投資の回収条件確認が要
- 2nm/GAA世代では既存FDCモデルの再学習・再検証が必要になりやすく、装置メーカー連携の前提でデータ基盤を再設計するのが現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
半導体工場のAI活用は、歩留まり予測・FDC(Fault Detection & Classification)・APC(Advanced Process Control)・ウェーハ検査・プロセスインフォマティクスの5領域で同時並行に進んでいます。
装置側のKLA・Applied Materials・PDF Solutionsが独自AIを投入し、半導体メーカー側もキオクシア四日市・東芝・ソニーセミコンが現場スケールで実装を積み上げてきました。
本記事では、AI実装の5ステップ実務フロー、FDC/APC・ウェーハ検査・歩留まり予測の中核領域、プロセスインフォマティクスの役割、データ基盤、国内5事例、装置メーカーAIと自社開発の選定軸、隠れコスト4項目を、2026年6月時点の最新情報で解説します。
目次
半導体製造でAIが解く中核領域:FDC/APC・ウェーハ検査・歩留まり予測
FDC(Fault Detection & Classification):装置センサデータからの不良予兆検知
APC(Advanced Process Control):プロセス条件の自律調整
プロセスインフォマティクスとマテリアルズインフォマティクスの違い
名古屋大発スタートアップ・アイクリスタル「メタファクトリー」
半導体工場のデータ統合:50超データ形式とPDF Solutions Exensio
キオクシア四日市工場:不良解析時間99%削減(NMF×ベイズモデリング)
東芝(加賀・大分・岩手工場):教師なし学習で不良解析4.2h→30分
ソニーセミコン×アイクリスタル×名大×グローバルウェーハズ:30工程デジタルツインでCMOSノイズ70%改善
東京エレクトロン:プラズマ原子層堆積法で従来手法では難しかった膜ストレスをAIで探索
理研×グローバルウェーハズ・ジャパン:シリコン単結晶のリアルタイム特性予測
装置メーカーAI(KLA・Applied Materials・PDF Solutions等)の特徴
半導体工場でAIを実装する5ステップ実務フロー全体像
半導体工場のAI活用は、歩留まり改善・FDC(Fault Detection & Classification)・APC(Advanced Process Control)・ウェーハ検査・プロセスインフォマティクスを「測定→分析→施策→検証→定着」の5ステップで回す業務サイクルとして組み立てるのが現実的です。
2026年は2nmプロセスの量産・GAA(Gate-All-Around)トランジスタへの移行・Backside Power Delivery といった先端ノードの転換と、AIインフラ需要による設備投資の急拡大が同時進行している節目です。装置側のAI機能と半導体メーカー側のデータ運用を、どこから組み合わせて回すかが現場の判断軸になります。
本セクションでは、5ステップ実務フローと、プロセス/品証エンジニアが社内で上申材料に使うシグナル、本記事の読み方を整理します。
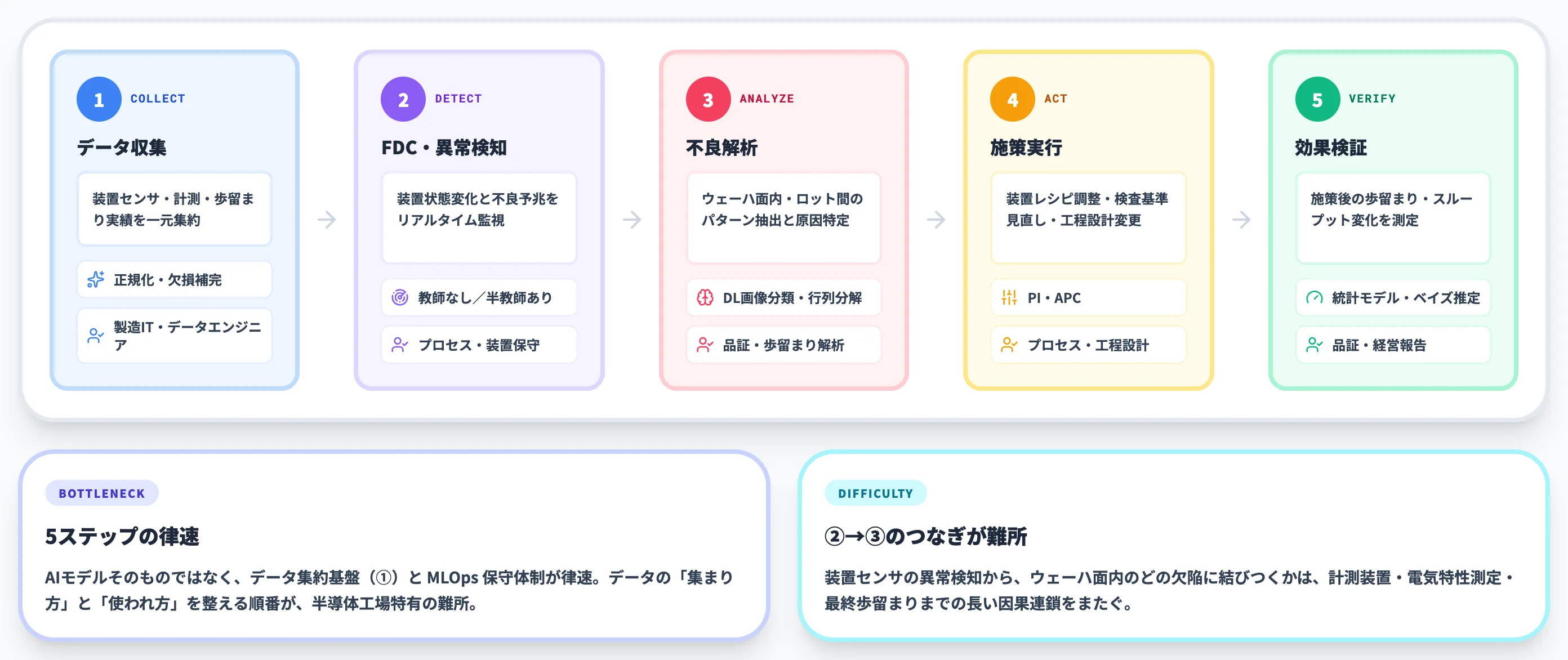
半導体工場でAI活用が回るまでの5ステップ実務フロー
半導体工場でAI活用を回すには、装置データの取得から効果検証までを5つの段階に分けて捉えると、どこで詰まっているかが見えやすくなります。
以下の表で、5ステップ実務フローと各ステップでのAIの役割・主な担当を整理しました。
| ステップ | やること | AIの役割 | 主な担当 |
|---|---|---|---|
| ①データ収集 | 装置センサ・計測・歩留まり実績データを一元集約 | データ正規化・欠損補完 | 製造IT・データエンジニア |
| ②FDC/異常検知 | 装置の状態変化と不良予兆をリアルタイム監視 | 教師なし/半教師あり異常検知 | プロセスエンジニア・装置保守 |
| ③不良解析 | ウェーハ面内・ロット間のパターン抽出と原因特定 | ディープラーニング画像分類・行列分解 | 品証・歩留まり解析 |
| ④施策実行 | 装置レシピ調整・検査基準見直し・工程設計変更 | プロセスインフォマティクス・APC | プロセスエンジニア・工程設計 |
| ⑤効果検証 | 施策後の歩留まり・スループットの変化を測定 | 統計モデリング・ベイズ推定 | 品証・経営報告 |
5ステップを業務サイクルとして回せるかは、データ集約基盤(①)とMLOpsの保守体制が整っているかで決まります。AIモデルそのものよりも、データの「集まり方」と「使われ方」が律速になるケースが大半です。
②FDC/異常検知から③不良解析へのつなぎは、半導体工場固有の難所です。装置センサで異常を検知しても、それがウェーハ面内のどの欠陥に結びつくかは、計測装置・電気特性測定・最終歩留まりまでの長い因果連鎖をまたぐためです。
歩留まり改善をAIで進める実務フローを業界横断の視点で整理した記事もあわせて参照すると、半導体特有の論点との差分が見えやすくなります。
プロセス/品証エンジニアが上申材料に使うシグナル
半導体工場のプロセス/品証エンジニアにとって、AI活用の社内提案を通すうえで効くのは、抽象的なROIではなく「歩留まり1%改善が財務にどう跳ね返るか」という具体試算です。

経済産業省が2026年2月12日にAI・半導体WGで公開した資料4では、AI・半導体産業を国策の柱として位置づけており、設備投資・AI実装が政策的後押しの中にあることが示されています。社内提案でも、この国策連動の文脈は説得材料になります。
実務的な財務試算の目安は次の3点です。
-
歩留まり1%改善のインパクト
最先端ノードではウェーハ1枚あたりのチップ生産価値が高い。「年間ウェーハ生産規模 × チップ単価 × 改善率」で試算すれば、自社規模に応じて大きな財務インパクトになり得る
-
分析人月の削減
東芝の事例(後述)では、不良解析1人あたり4.2時間/日が30分に短縮されている。「対象人数 × 削減時間 × 人月単価」で試算すれば、社内提案で具体的な削減効果を提示できる
-
装置稼働率の改善
APC・FDCの精度向上で、ロット不良の早期検出・装置メンテナンスの最適化が進む。「先端装置1台あたりの稼働1%改善 × ウェーハスループット × チップ単価」で試算すれば、装置1台あたりで回収余地が見えるケースが出てくる
いずれの数値も製品単価・投入枚数・ダイ数で大きく変動するため、公開できる相場感は限定的です。社内提案では、自社の年間ウェーハ生産規模・チップ単価・改善率を埋めた具体試算を必ず作ることが前提になります。
詳細な財務インパクトは後段の「半導体工場AI活用の導入コストと隠れコスト4項目」セクションで掘り下げます。
本記事のロードマップと読者ごとの読み方
本記事は半導体工場のプロセスエンジニア・品証エンジニア・製造IT・経営層が、それぞれの関心領域だけを抜き出して読めるように設計しています。

以下の表で、3つの読者像と、推奨される読み方を整理しました。
| 読者像 | 主な関心 | 推奨セクション |
|---|---|---|
| プロセスエンジニア | FDC/APC・プロセスインフォマティクスの実装像 | 中核領域・プロセスインフォマティクス・国内事例 |
| 品証エンジニア | ウェーハ検査AI・不良解析の実装と運用 | 中核領域・国内事例・詰まる論点 |
| 製造IT・データ基盤担当 | データ統合基盤・MLOps・ベンダー選定 | データ基盤・選定軸・コスト |
| 経営層・DX推進 | 投資判断・回収シナリオ・国内事例 | 国内事例・選定軸・コスト |
各セクションは独立して読めるように構成しています。事例だけ先に見たい場合は「半導体工場AI活用の国内5事例」セクションから読むのも有効です。

半導体製造でAIが解く中核領域:FDC/APC・ウェーハ検査・歩留まり予測
半導体製造でAIが入る中核領域は、FDC(Fault Detection & Classification)・APC(Advanced Process Control)・ウェーハ検査・歩留まり予測の4つに集約されます。これらに加えて、プロセス開発の上位レイヤーでプロセスインフォマティクス(次のH2で詳述)が動く、合計5領域の構成です。それぞれが装置・計測・最終歩留まりという異なるレイヤーを扱い、組み合わさることで工場全体の歩留まり改善ループが回ります。
本セクションでは中核4領域の役割と、半導体メーカー側で導入判断のポイントになる論点を整理します。
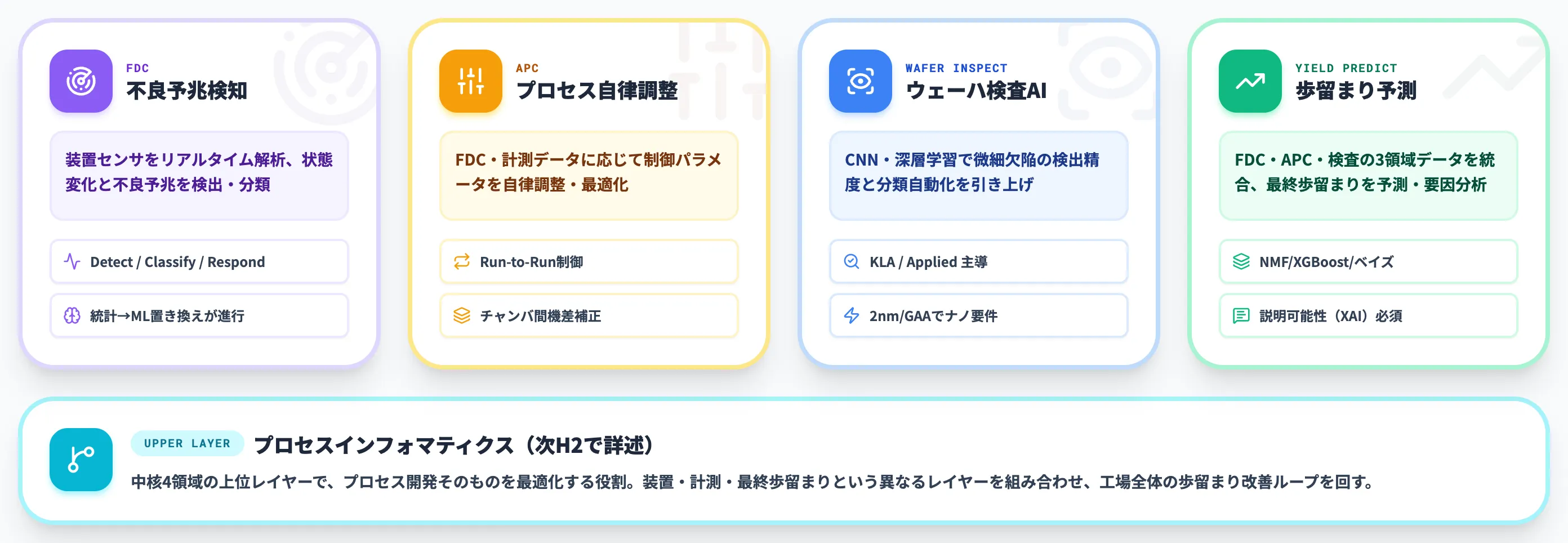
FDC(Fault Detection & Classification):装置センサデータからの不良予兆検知
FDCは装置のセンサデータをリアルタイムで解析し、装置の状態変化や不良の予兆を検出して分類する仕組みです。半導体工場の自動化を支える中核技術として、20年以上前から運用されてきた領域でもあります。
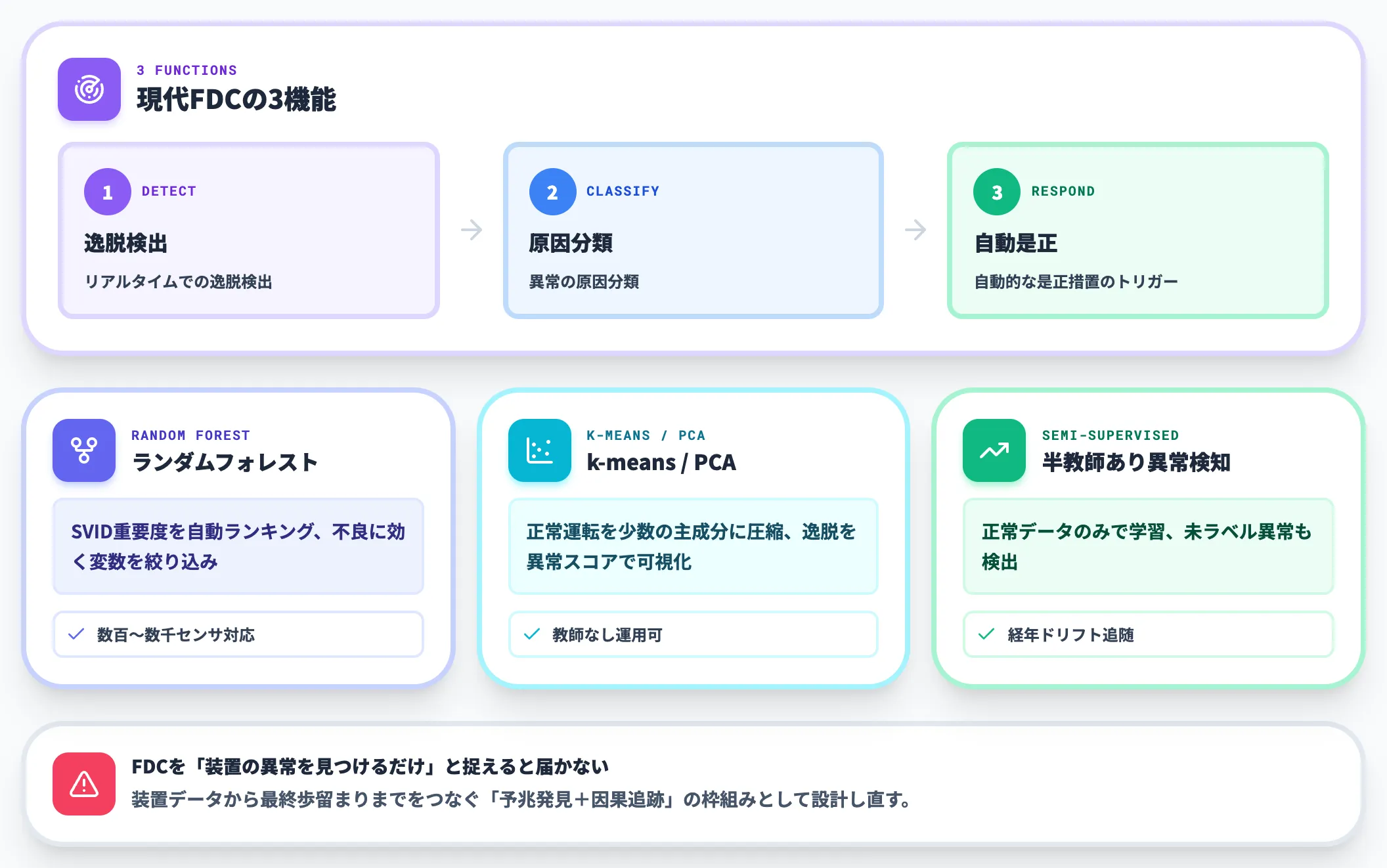
FDCの解説記事(Averroes.ai)では、現代のFDCシステムが「Detect(リアルタイムでの逸脱検出)」「Classify(異常の原因分類)」「Respond(自動的な是正措置のトリガー)」の3機能を装置ごとに実行する仕組みとして整理しています。
近年のFDCの変化は、統計的閾値管理から機械学習ベースへの置き換えが進んでいる点にあります。代表的な手法は次のとおりです。
-
ランダムフォレスト
センサ変数(SVID)の重要度を自動的にランキングし、不良に効く変数を絞り込む。装置1台に数百〜数千のセンサがある半導体工場で、変数選択を人手でやる負荷を大幅に減らす
-
k-means/PCA
正常運転時の振る舞いを少数の主成分に圧縮し、そこからの逸脱を異常スコアとして可視化する。教師なしで運用できるため、未知の異常パターンにも対応しやすい
-
半教師あり異常検知
正常データのみで学習し、過去にラベルがついていない異常も検出する。装置の経年変化(ドリフト)に追随できる仕組みが、運用上の鍵になる
FDCを「装置の異常を見つけるだけの仕組み」と捉えると、現代の半導体工場の運用には届きません。装置データから最終歩留まりまでをつなぐ「予兆発見+因果追跡」の枠組みとして設計し直すことが、AI活用の本来の効果につながります。
製造業の異常検知AIでは業界横断の異常検知パターンを整理しており、半導体FDCとの差分を把握するのに役立ちます。
APC(Advanced Process Control):プロセス条件の自律調整
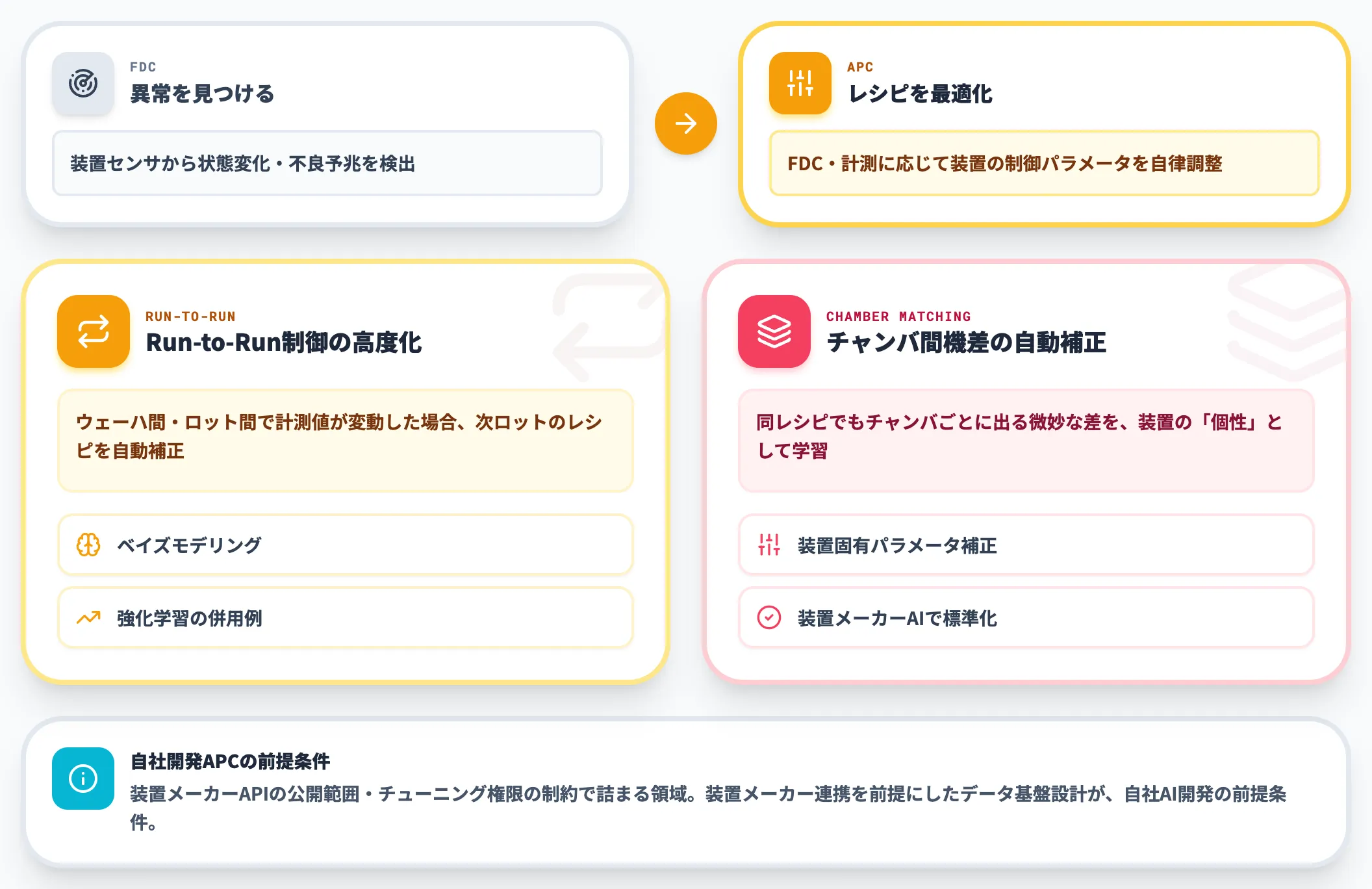
APCは、装置の制御パラメータをFDCや計測データに応じて自律的に調整する仕組みです。FDCが「異常を見つける」役割なのに対し、APCは「装置に投入するレシピを最適化する」役割を担います。
近年は、装置メーカー側がAPC機能をAI化する流れが加速しています。Applied Materials AIxはリアルタイム洞察・ChamberAI・計測連携・AppliedPRO・デジタルツインなどを組み合わせ、装置稼働率の改善に直結する設計を打ち出しています。
APCで効くAI機能は次の2系統に大別されます。
-
Run-to-Run制御の高度化
ウェーハ間・ロット間で計測値が変動した場合、次のロットのレシピを自動補正する。ベイズモデリングや強化学習を組み合わせる例が増えており、人手のチューニングでは届かない精度に到達できる
-
チャンバ間機差の自動補正
同じレシピを流しても装置(チャンバ)ごとに微妙な差が出る。AIで装置ごとの「個性」を学習し、チャンバ固有のパラメータ補正を自動で当てる仕組みが、装置メーカー側のAI機能として標準化されつつある
APCの自社開発は、装置メーカーAPIの公開範囲・装置側のチューニング権限の制約で詰まることが多い領域です。装置メーカー連携を前提にしたデータ基盤設計が、自社AI開発の前提条件になります。
ウェーハ検査AI:ディープラーニングによる欠陥検出・分類
ウェーハ検査はAIが先行的に成果を出してきた領域です。深層学習・畳み込みニューラルネットワーク(CNN)が、微細な欠陥の検出精度と分類の自動化を桁違いに引き上げています。
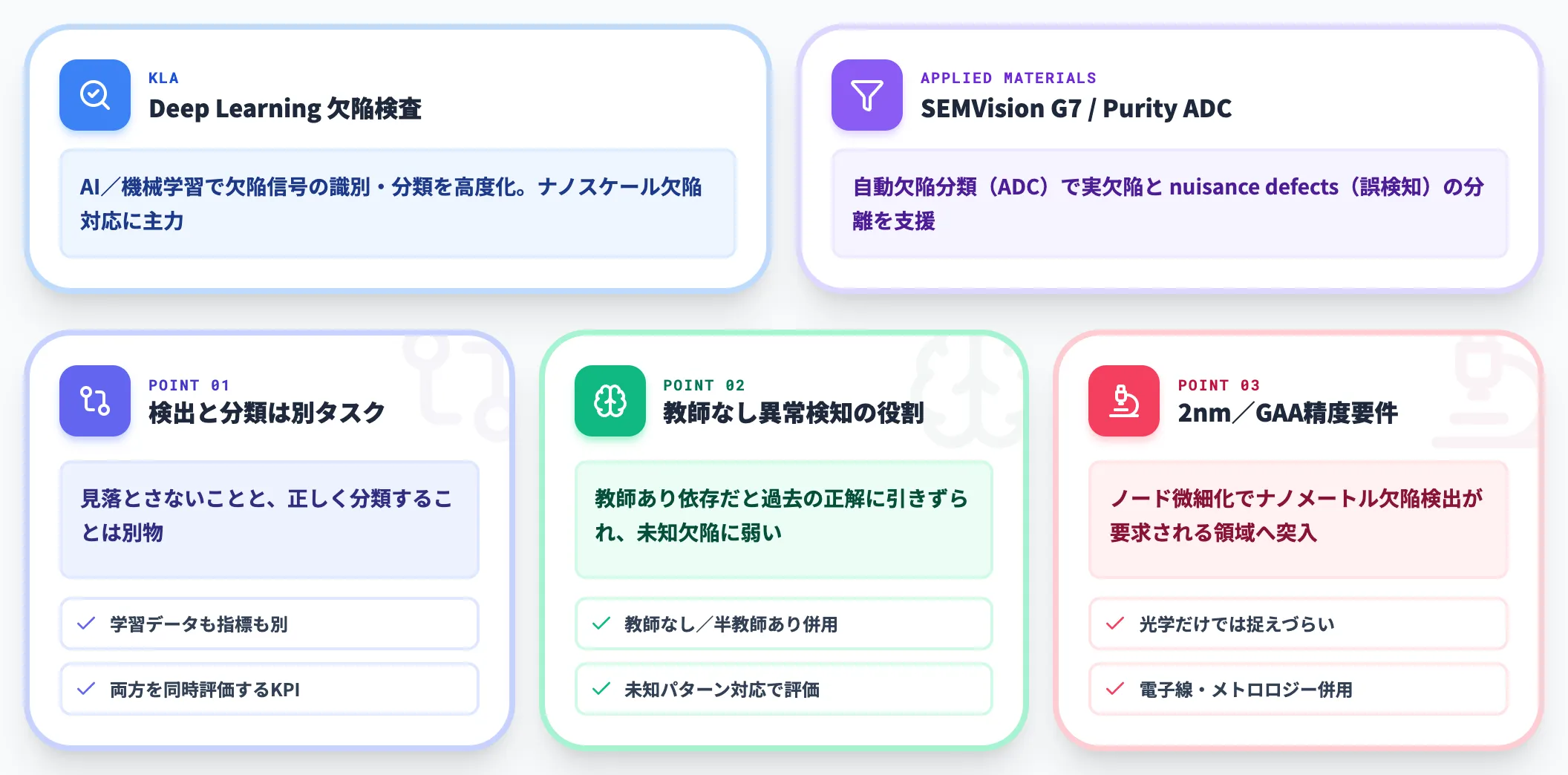
ウェーハ検査装置のリーダーであるKLAは、AI/機械学習を用いて欠陥信号の識別・分類を高度化しているのが特徴です。Deep learning ベースの欠陥検査を主力として、ノード微細化に伴うナノスケール欠陥への対応を進めています。
Applied Materialsも、SEMVision G7上で「Purity ADC(Automatic Defect Classification・自動欠陥分類)」と呼ぶ機能を提供し、実欠陥と nuisance defects(誤検知ノイズ)の分離を支援することで、ウェーハ検査AIの世代交代が装置メーカー横並びで進んでいます。
ウェーハ検査AIで実装側が押さえるべきは、次の3点です。
-
検出と分類は別タスク
「欠陥を見落とさないこと」と「欠陥を正しく分類すること」は、精度評価の指標も学習データも別物。両方を同時に評価するKPI設計が必要
-
教師なし異常検知の役割
ラベル付き学習だけに依存すると過去の正解パターンに引きずられるため、未知欠陥に備えるには教師なし/半教師あり学習の併用が重要。装置メーカーAI機能の評価でも、教師ありの分類精度だけでなく未知パターンへの対応設計が判断材料になる
-
2nm/GAA世代での精度要件の引き上げ
ノード微細化に伴い、ナノメートルレベルの欠陥検出が要求される領域へ突入。光学検査だけでは捉えづらい欠陥が増え、対象に応じて電子線検査・メトロロジー計測を組み合わせる重要性が高まる
外観検査の業界横断の論点は外観検査AI、費用面の論点はAI外観検査の費用で整理されています。半導体ウェーハ検査は、これら業界横断の論点に「ナノスケール・先端ノード対応」の制約が乗る位置づけです。
歩留まり予測:ビッグデータ×機械学習による要因特定
歩留まり予測は、FDC・APC・ウェーハ検査の3領域から得られたデータを統合し、最終的な歩留まりを予測・要因分析する役割です。半導体工場の各工程から集まる膨大なセンサ・計測・検査データを、機械学習で因果関係に変換するレイヤーといえます。

歩留まり予測AIの設計でよく使われる手法は次の3つです。
-
行列分解(NMF・PCA)
ウェーハ面内の不良パターンを少数の基底パターンに分解し、原因工程を特定する。後述するキオクシア四日市の不良解析は非負値行列因子分解(NMF)が中心
-
勾配ブースティング(XGBoost・LightGBM)
工程変数を投入し、歩留まりに寄与する特徴量を順位付けする。説明性が必要な品証文脈で広く使われる
-
ベイズモデリング
不良率の分布を確率モデルで表現し、信頼区間付きで予測する。少数ロットでも統計的に意味のある示唆が得られる
歩留まり予測の核心は「予測精度」ではなく、「予測根拠を品証チームが説明できる形に変換できるか」です。AIが当てた数字をそのまま現場のレシピ変更には使えないため、説明可能性(XAI)と現場フィードバックの仕組みが運用の必須要件になります。
プロセスインフォマティクスが変える半導体プロセス開発
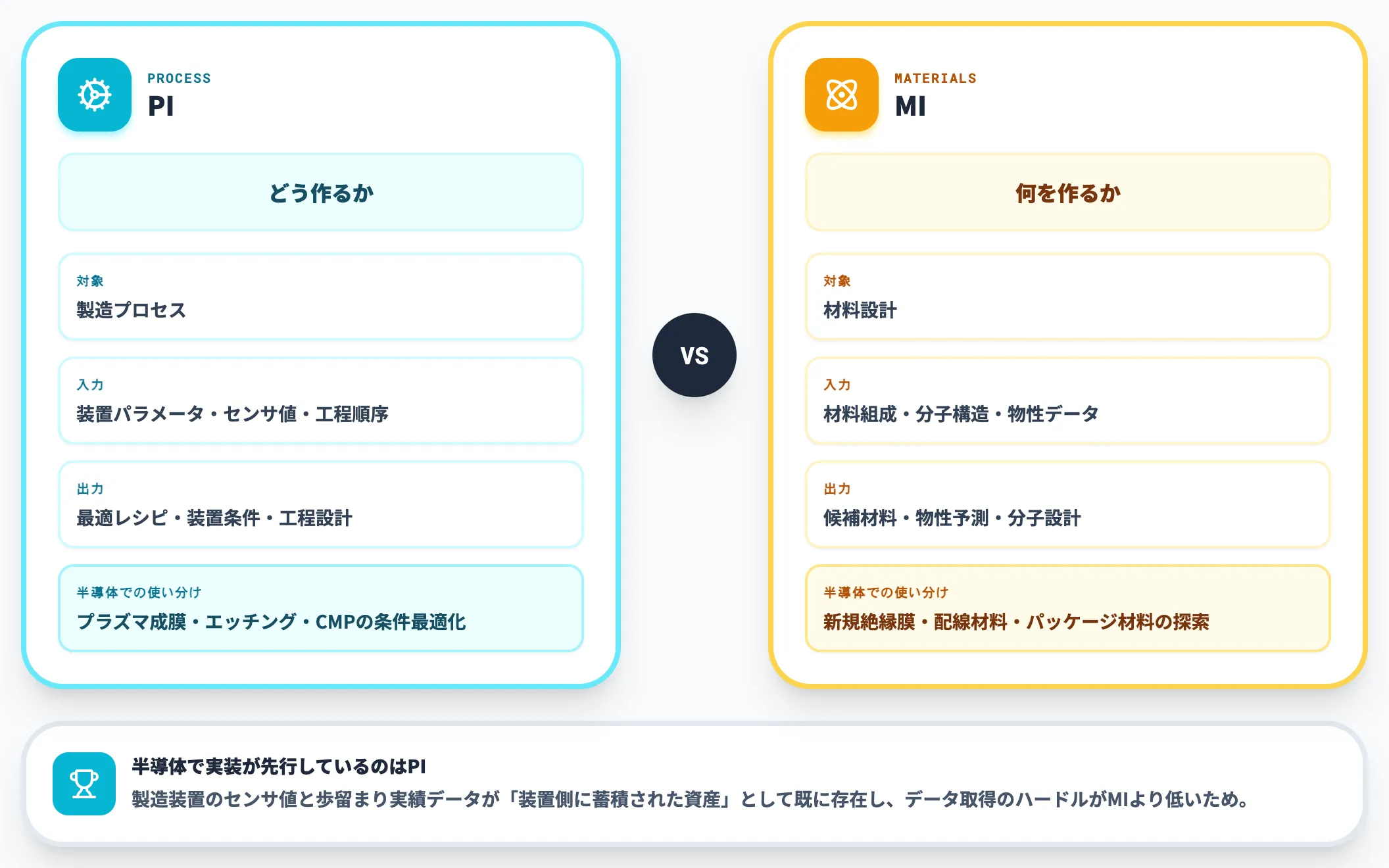
プロセスインフォマティクス(PI)は、装置構造・条件パラメータ・消耗部材の組み合わせなど「どう作るか」を最適化する情報技術です。マテリアルズインフォマティクス(MI)が「どんな材料を作るか」を扱うのに対し、PIは製造プロセスそのものを対象にします。
半導体製造では、装置数百種・パラメータ数千件・実験回数の制約という独自条件があり、PIの実装が他産業と違う形で進化してきました。本セクションでは、PIの基本概念から、半導体での独自性、デジタルツインを使った最適化までを整理します。
プロセスインフォマティクスとマテリアルズインフォマティクスの違い
プロセスインフォマティクスとマテリアルズインフォマティクスは混同されがちですが、対象とする「最適化の単位」が違います。
以下の表で、PIとMIの違いを整理しました。
| 観点 | プロセスインフォマティクス(PI) | マテリアルズインフォマティクス(MI) |
|---|---|---|
| 対象 | 製造プロセス(どう作るか) | 材料設計(何を作るか) |
| 入力 | 装置パラメータ・センサ値・工程順序 | 材料組成・分子構造・物性データ |
| 出力 | 最適レシピ・装置条件・工程設計 | 候補材料・物性予測・分子設計 |
| 半導体での使い分け | プラズマ成膜・エッチング・CMPの条件最適化 | 新規絶縁膜・配線材料・パッケージ材料の探索 |
半導体で実装が先行しているのはPIです。理由は、製造装置のセンサ値と歩留まり実績データが「装置側に蓄積された資産」として既に存在し、データ取得のハードルがMIより低いからです。
ものづくりドットコムの解説では、PIが製造業の競争力強化に寄与する具体例として「センサーやIoTデバイスを活用してプロセスの内部状態をリアルタイムで観測し、AIによる高度なデータ分析を行う」点を強調しています。半導体ではこれが工場のスマートファクトリー化と直結します。
デジタルツインを核にした「仮想工場」最適化
近年のPIで注目されるのは、デジタルツインを使って実装置を動かす前に最適条件を絞り込む「仮想工場」アプローチです。実験コスト・装置占有時間・材料消費を抑えながら、最適化の探索範囲を桁違いに広げられる利点があります。
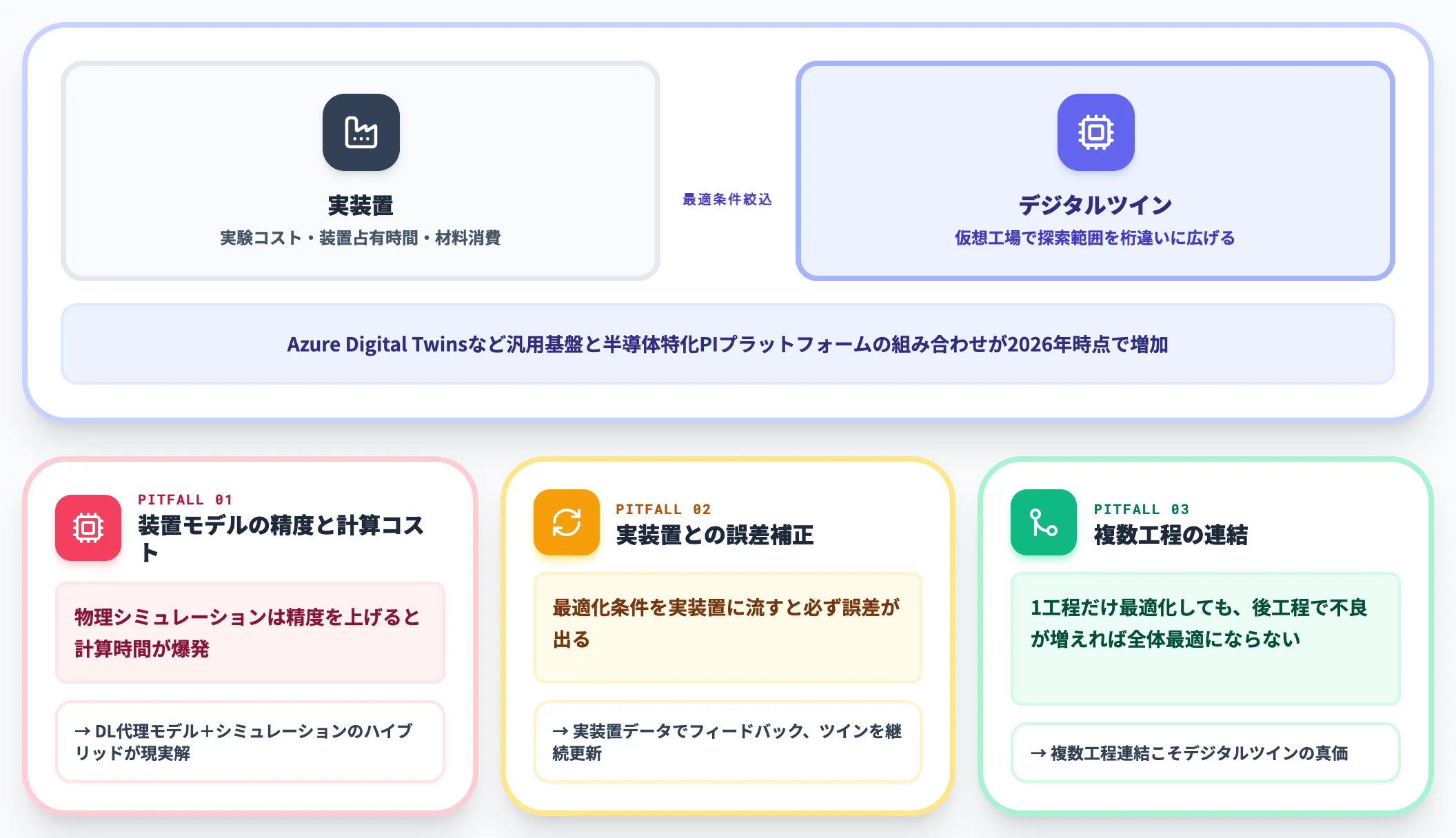
Azure Digital Twinsのような汎用デジタルツイン基盤と、半導体特化のPIプラットフォームを組み合わせるパターンが2026年時点で増えています。
仮想工場の構築で詰まりやすいのは次の3点です。
-
装置モデルの精度と計算コスト
装置の物理シミュレーションは精度を上げると計算時間が爆発する。深層学習で「装置応答の代理モデル」を作り、シミュレーションと機械学習をハイブリッドで運用するのが現実解
-
実装置との誤差補正
仮想工場で最適化した条件を実装置に流すと、必ず誤差が出る。誤差を実装置データでフィードバックし、デジタルツインを継続更新する仕組みが運用の前提
-
複数工程の連結
1工程だけ最適化しても、後工程で不良が増えれば全体最適にならない。複数工程をまたいだ最適化が、デジタルツインの真価が出るところ
デジタルツインの設計を「装置単体のシミュレーション」で終わらせず、工程連結まで広げられるかが、半導体PIの成否を分けます。
名古屋大発スタートアップ・アイクリスタル「メタファクトリー」
国内でPIを半導体プロセスに特化して提供している代表が、名古屋大学発スタートアップのアイクリスタルです。「メタファクトリー」と呼ぶ、デジタルツインを接続して全体最適化するプラットフォームを展開しており、2025年9月にはソニーセミコンダクタマニュファクチャリング・名古屋大学・グローバルウェーハズ・ジャパンとの協業成果として、CMOSイメージセンサーのノイズ特性を従来品比約70%改善する事例を発表しています(事例の詳細は次節で深掘りします)。
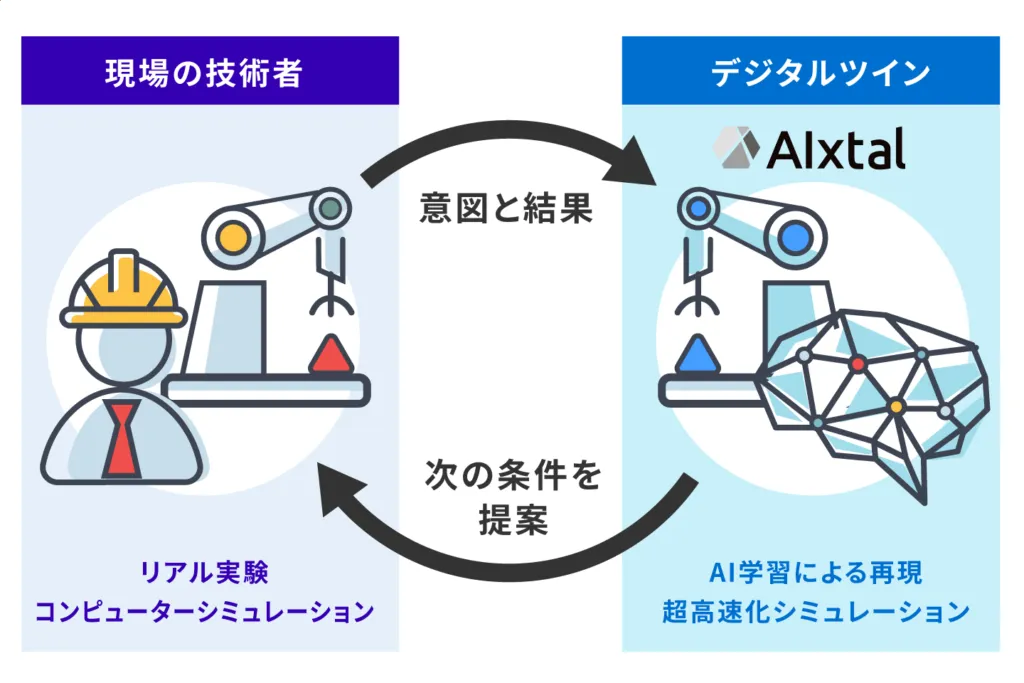
アイクリスタルが示す現場の技術者とデジタルツインの双方向ループ(出典:アイクリスタル株式会社)
アイクリスタルが提示するアプローチの核は、現場技術者とデジタルツインを双方向ループで動かす設計です。技術者がリアル実験から得た意図と結果をAIが受け取り、デジタルツイン側が「次に試すべき条件」を提案する形で、リアル実験とAI学習による超高速シミュレーションを循環させます。
アイクリスタルのアプローチで特徴的なのは、「熟練技術者が決めた実験条件の意図」をAIに学習させ、限られた実験データから探索効率を上げる設計です。過去の限られた実験データだけでAIが探索すると精度が出ないのに対し、熟練技術者の判断ロジックを取り込むことで、PIの学習効率を高めています。
TechBlitzのインタビューでは、同社が「経験と勘」に頼らないプロセス最適化を掲げており、半導体プロセス開発の世代交代と人材不足の文脈で需要が伸びています。
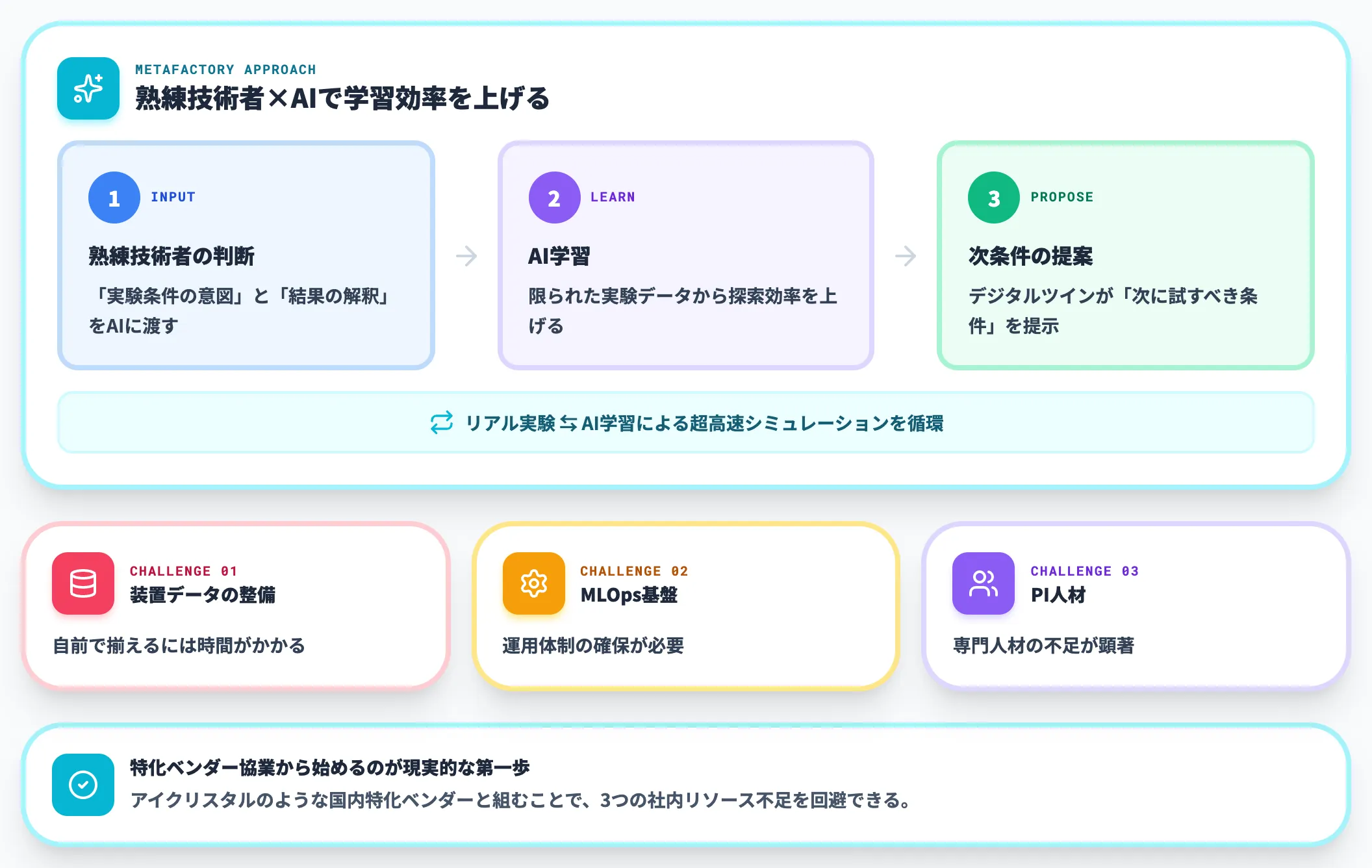
国内半導体メーカーがPIを社内に取り込む場合、装置データの整備・MLOps基盤・PI人材の3つを自前で揃えるのは時間がかかります。アイクリスタルのような特化ベンダーとの協業から始めるのが、現実的な第一歩になりやすい構図です。
半導体製造AIの実装で必要なデータ基盤
半導体工場のAI活用で最も詰まりやすいのは、AIモデルそのものではなくデータ基盤です。装置・計測・テスト・組立・パッケージ・最終歩留まりという長い工程をまたぐデータを統合できないと、FDC・APC・歩留まり予測のいずれもスケールしません。
本セクションでは、半導体工場特有のデータ基盤要件と、業界で先行している実装パターンを整理します。
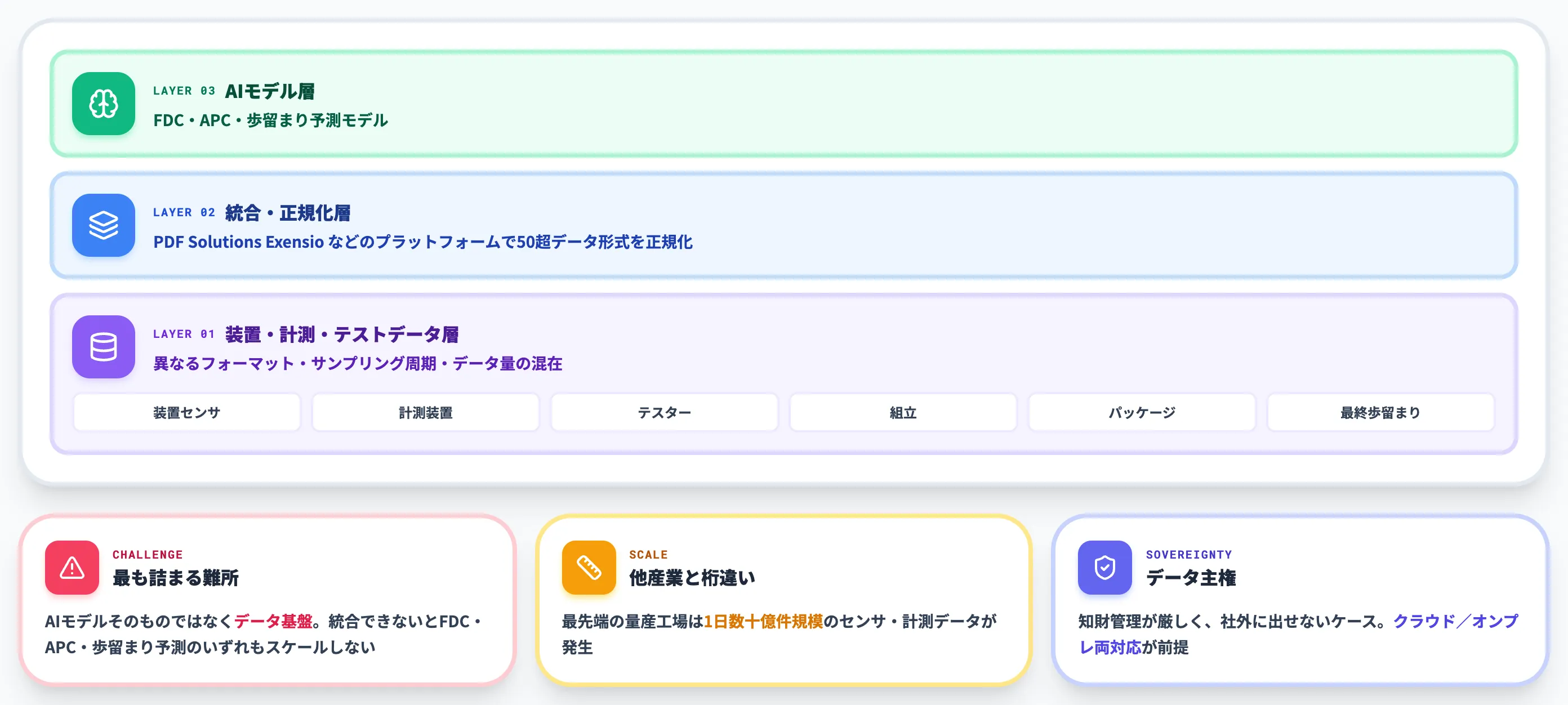
半導体工場のデータ統合:50超データ形式とPDF Solutions Exensio
半導体工場では、装置センサ・計測装置・テスター・組立・パッケージ・最終歩留まりまで、それぞれ異なるフォーマット・サンプリング周期・データ量のデータが流れます。これらを共通の意味モデルに統合できないと、AIが学習する前段で詰まります。
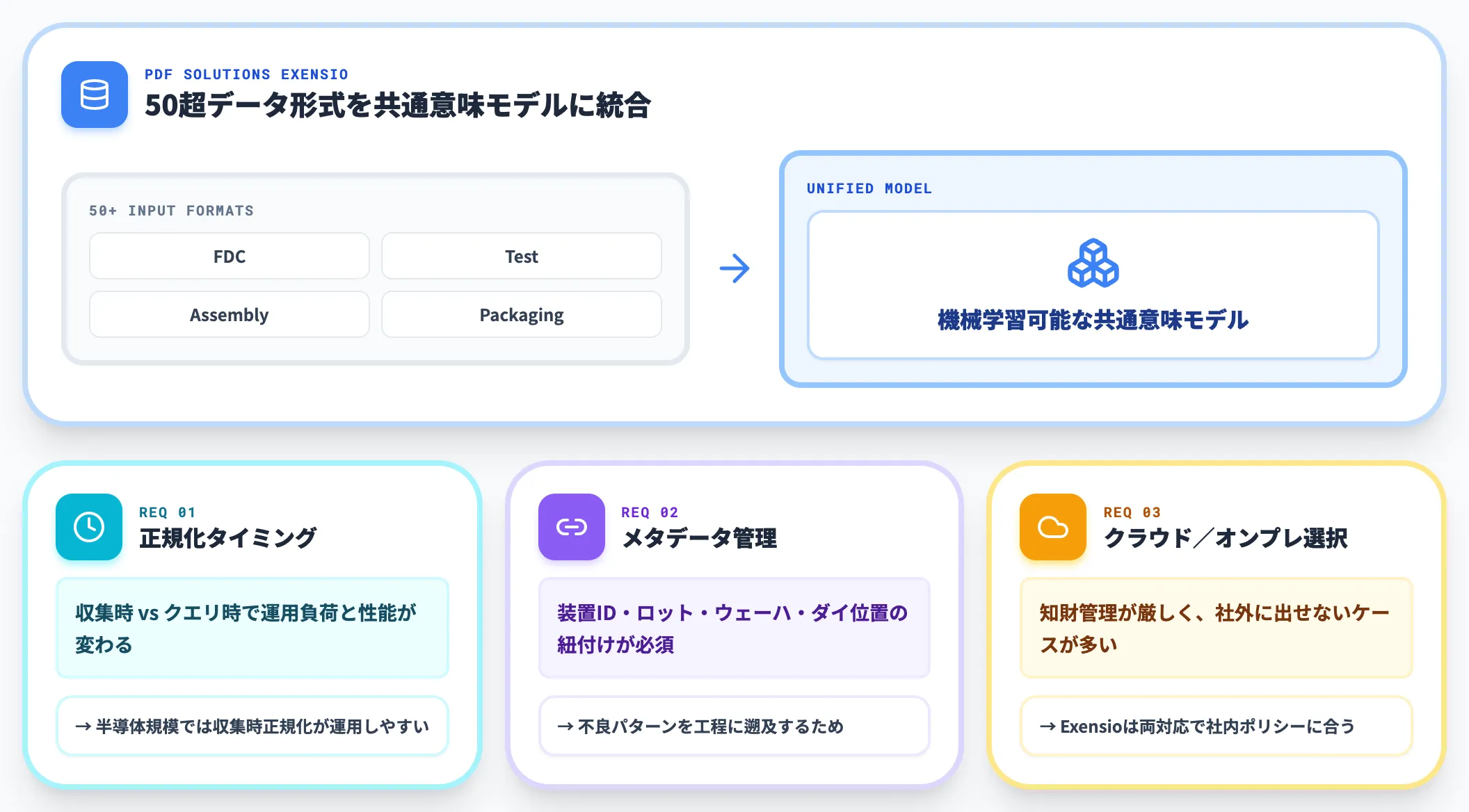
業界で広く使われているデータ統合プラットフォームが、PDF Solutionsの「Exensio」です。FDC・Test・Assembly・Packagingの50超のデータ形式を一つの意味モデルに正規化し、機械学習の学習データとして使える状態にする仕組みです。
データ統合で押さえるべき要件は次の3つです。
-
データ正規化のタイミング
収集時に正規化するか、後段でクエリ時に正規化するかで、運用負荷とクエリ性能が大きく変わる。半導体の規模では収集時正規化の方が運用しやすい
-
メタデータ管理
装置ID・ロット・ウェーハ・ダイ位置・工程順序を正確に紐付けないと、ウェーハ面内の不良パターンを工程に遡及できなくなる
-
クラウド/オンプレ選択
半導体メーカーは知財管理が厳しく、データを社外に出せないケースも多い。Exensioのようにクラウド・オンプレ両対応の基盤を選ぶと、社内ポリシーに合わせやすい
データ基盤設計の業界横断の論点は製造業のデータ活用ガイドで整理しています。半導体工場では、これに「メタデータの厳密性」「データ主権」「装置メーカーAPI連携」の3軸が追加で乗ります。
ビッグデータ規模の実装:1日30億件のデータ運用
半導体工場のデータ量は、他産業のスマートファクトリーと比較して桁が違います。最先端の量産工場では、1日に数十億件規模のセンサ・計測データが発生します。

KIOXIA 公式によれば、キオクシア四日市工場は「1日30億件もの製造プロセス・検査データ」を扱う巨大なスマートファクトリーです。このスケールでデータ運用が成立すれば、AI分析の精度と汎用性は飛躍的に伸びます。
このスケールのデータを扱うインフラ設計で重要なのは次の3点です。
-
ストリーミング処理
バッチで集計するアーキテクチャでは遅延が大きすぎる。リアルタイムでデータをストリームし、特徴量を継続生成する設計が標準
-
ティアード・ストレージ
直近の高頻度アクセスデータはホットストレージ、過去ロットの学習用データはコールドストレージで階層化。ストレージコストとアクセス性能のバランスをとる
-
MLOps運用
モデルの再学習・デプロイ・モニタリングを自動化する仕組みが必須。データドリフト(装置の経年変化)に追随できなければ、運用1年でモデル精度が劣化する
このスケールのインフラを自社で構築するには、データエンジニアとMLOps人材の確保が前提です。AI Agent Hub型のAIエージェント時代のデータ基盤を参考にした基盤設計も、選択肢として検討する価値があります。
教師なし学習・KVS型DBで非構造データを扱う設計
半導体工場のデータは、装置ごとに記録フォーマットが異なる「半構造化データ」が大半です。リレーショナルDBに正規化するコストが高すぎるため、近年はキーバリューストア(KVS)型DBで生データを保持し、解析時に必要な形に変換するアプローチが広がっています。

教師なし学習がフィットする理由も同じで、半導体の不良パターンには「過去にラベルがついていない異常」が大量に出現します。教師ありで全パターンをラベル化するのは現実的でないため、教師なしで「正常からの逸脱」を検出する設計が、運用上の現実解になります。
教師なし学習の設計で押さえるべきは次の2点です。
-
正常データの定義
「正常」と置くデータが装置の経年変化を含んでいないか確認。古い正常データだけで学習すると、新装置の正常状態を異常と誤検知する
-
異常スコアの閾値設計
教師なし学習は「異常らしさ」の連続値を出すため、閾値設計が運用の鍵。過剰アラートで現場の信頼を失わないよう、品証チームと閾値を合意するプロセスが必要
東芝が後述する不良解析事例で教師なし学習を選択したのも、半導体工場のラベルなしデータを扱う現実的な選択でした。教師ありに固執せず、ラベルがなくても運用できる枠組みを選ぶことが、半導体特有のデータ環境では合理的です。

半導体工場AI活用の国内5事例
半導体工場のAI活用は、海外(TSMC・Samsung・Intel)の事例が紹介されることが多い一方、国内メーカーでも現場スケールの実装が積み上がっています。本セクションでは、公開情報で工程・技術内容を追える国内5事例を整理します。事例によって定量効果が公開されているものと、技術内容のみ公開されているものが混在します。
各事例は、AIモデルの種類・対象工程・運用規模が異なります。自社が参考にすべき事例を選ぶ際の参考にしてください。

キオクシア四日市工場:不良解析時間99%削減(NMF×ベイズモデリング)
キオクシア四日市工場は、1日30億件のデータをAIで分析する国内最大級のスマートファクトリーです。2010年代半ばに機械学習活用を本格的に開始し、2025年4月時点で200名規模のAI活用プロジェクトに成長しました。
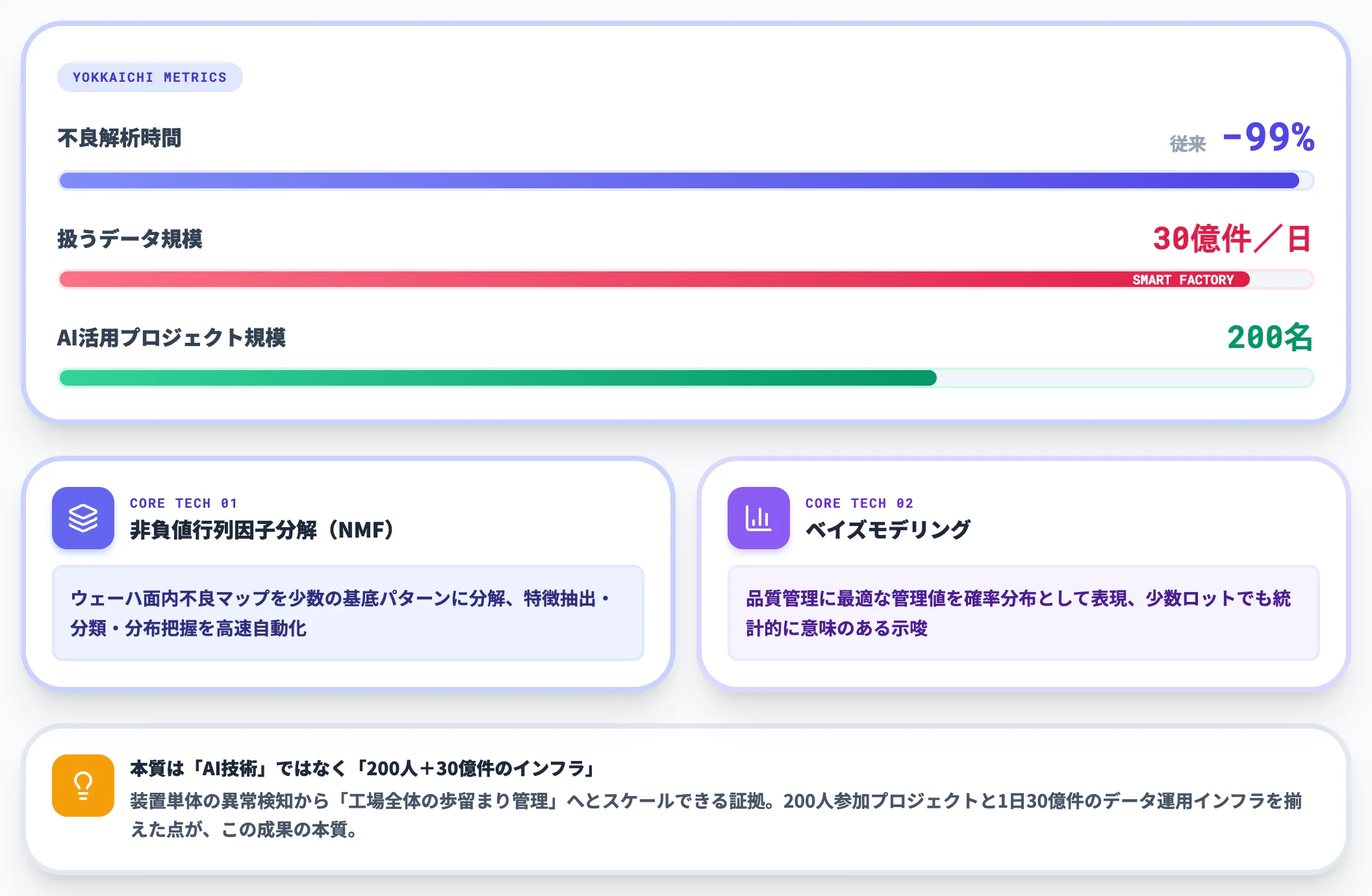
定量効果として注目されるのが、ウェーハ面内の不良解析の分析時間を99%削減した実績です。技術の核は次の2つです。
-
非負値行列因子分解(NMF)
ウェーハ面内の不良マップを少数の基底パターンに分解し、特徴抽出・分類・分布の把握を高速かつ自動で実行
-
ベイズモデリング
品質管理に最適な管理値を、確率分布として表現。少数ロットでも統計的に意味のある示唆を得られる
この事例が示すのは、半導体工場のAI活用が「装置単体の異常検知」から「工場全体の歩留まり管理」へとスケールできるという証拠です。AI技術そのものよりも、200人が参加するAI活用プロジェクト規模と1日30億件のデータ運用インフラを揃えた点が、この成果の本質です。
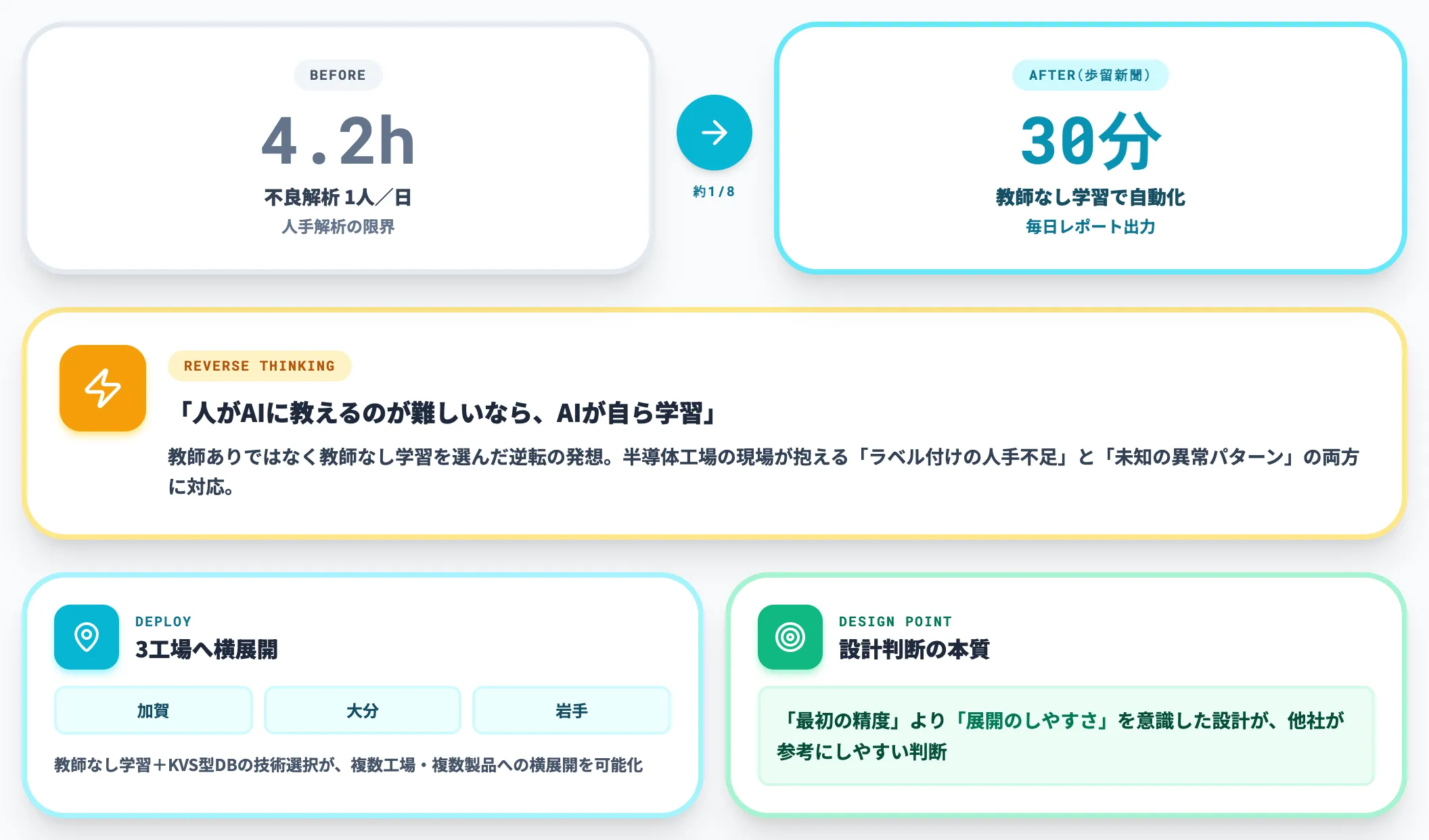
東芝(加賀・大分・岩手工場):教師なし学習で不良解析4.2h→30分
東芝の半導体工場は、2015年に「歩留新聞」と呼ばれる社内AIシステムのプロジェクトを開始しました。教師なし学習を中核にした不良解析システムで、本来1人約4.2時間/日かかっていた不良解析時間を30分に短縮、約1/8の削減を実現しています。
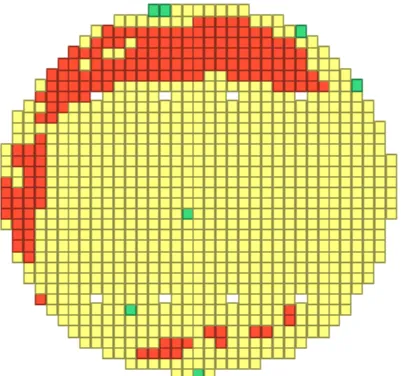
ウェハ面内の不良発生例(赤=不良チップ/黄=良品)(出典:Toshiba Clip)
東芝が公開する不良チップのウェハマップを見ると、ウェハの外周部に不良が集中する分布パターンが現れています。こうした面内不良の発生位置と工程ごとのセンサデータを突き合わせることで、装置の状態と歩留まりロスの因果関係を解像度高く追えるようになります。
東芝の選択で印象的なのは、教師あり学習ではなく「教師なし学習」を選んだ点です。「人がAIに教えるのが難しいのであれば、AIが自ら学習すればいい」という逆転の発想で、半導体工場の現場が抱える「ラベル付けの人手不足」と「未知の異常パターン」の両方に対応しました。
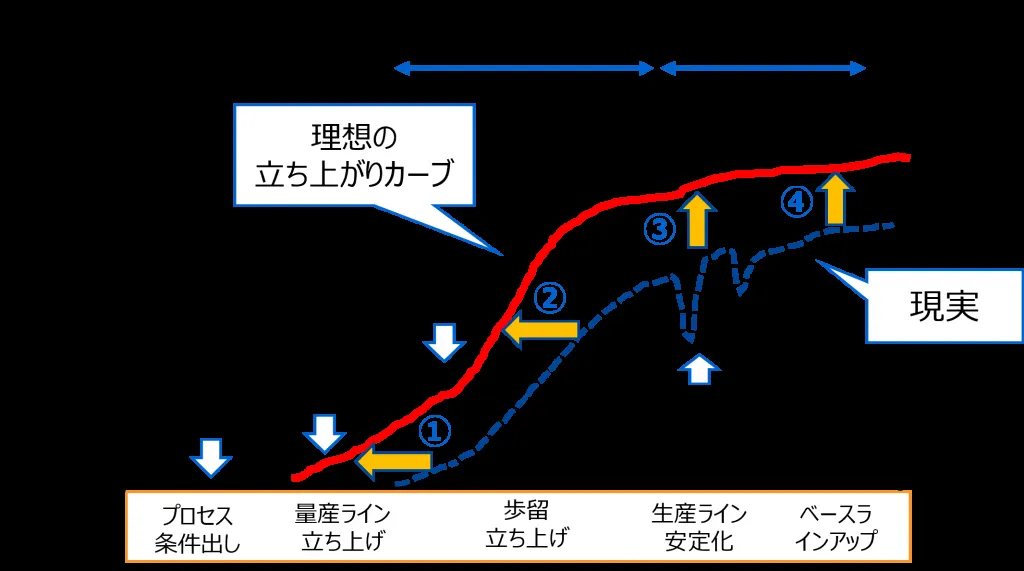
半導体生産ラインの歩留まり立ち上がりにおける理想カーブと現実(出典:Toshiba Clip)
歩留まり立ち上がりのこの図が示すのは、開発・量産条件出し・量産ライン立ち上げ・歩留立ち上げ・生産ライン安定化・ベースラインアップという工程の節目で、理想カーブから現実が乖離する典型パターンです。とくに本格量産開始後の突発不良は、原因が複数工程にまたがるため人手解析では追いきれず、教師なし学習による横断分析が効きやすい領域になります。
歩留新聞は加賀・大分・岩手の3工場に展開され、全製品・全ロットの網羅的な分析が可能になっています。教師なし学習+キーバリューストア型DBという技術選択が、複数工場・複数製品への横展開を可能にしました。
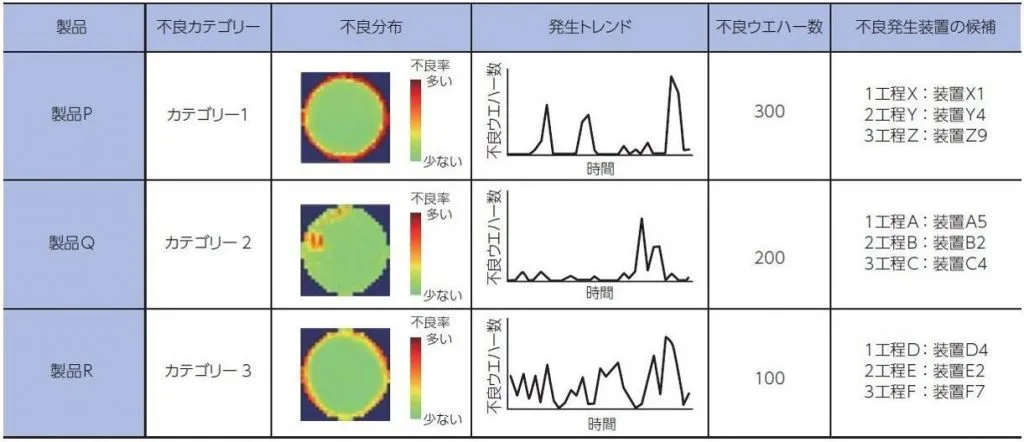
製品別の不良分布・発生トレンドと不良発生装置候補のAI自動レポート(出典:Toshiba Clip)
公開資料に挙げられているAI出力例は、製品ごとに不良カテゴリー・不良分布・発生トレンドを並べ、不良発生装置の候補(工程と装置IDのセット)を上位3件まで自動で示す形になっています。品証担当が手作業で組み立てていた分析サマリーを、AIが定型レポートとして毎日出力できる状態になることで、4.2時間/日が30分に短縮されるという効率改善の中身が具体的に見えます。
半導体メーカーが自社開発するAIで意識すべきは、「最初の精度」より「展開のしやすさ」です。東芝の選択は、その意味で他社が参考にしやすい設計判断です。
ソニーセミコン×アイクリスタル×名大×グローバルウェーハズ:30工程デジタルツインでCMOSノイズ70%改善
ソニーセミコンダクタマニュファクチャリング・アイクリスタル・名古屋大学未来材料・システム研究所・グローバルウェーハズ・ジャパンの研究グループは、2025年9月5日にデジタルツインを使ったCMOSイメージセンサーのノイズ特性改善を発表しました。
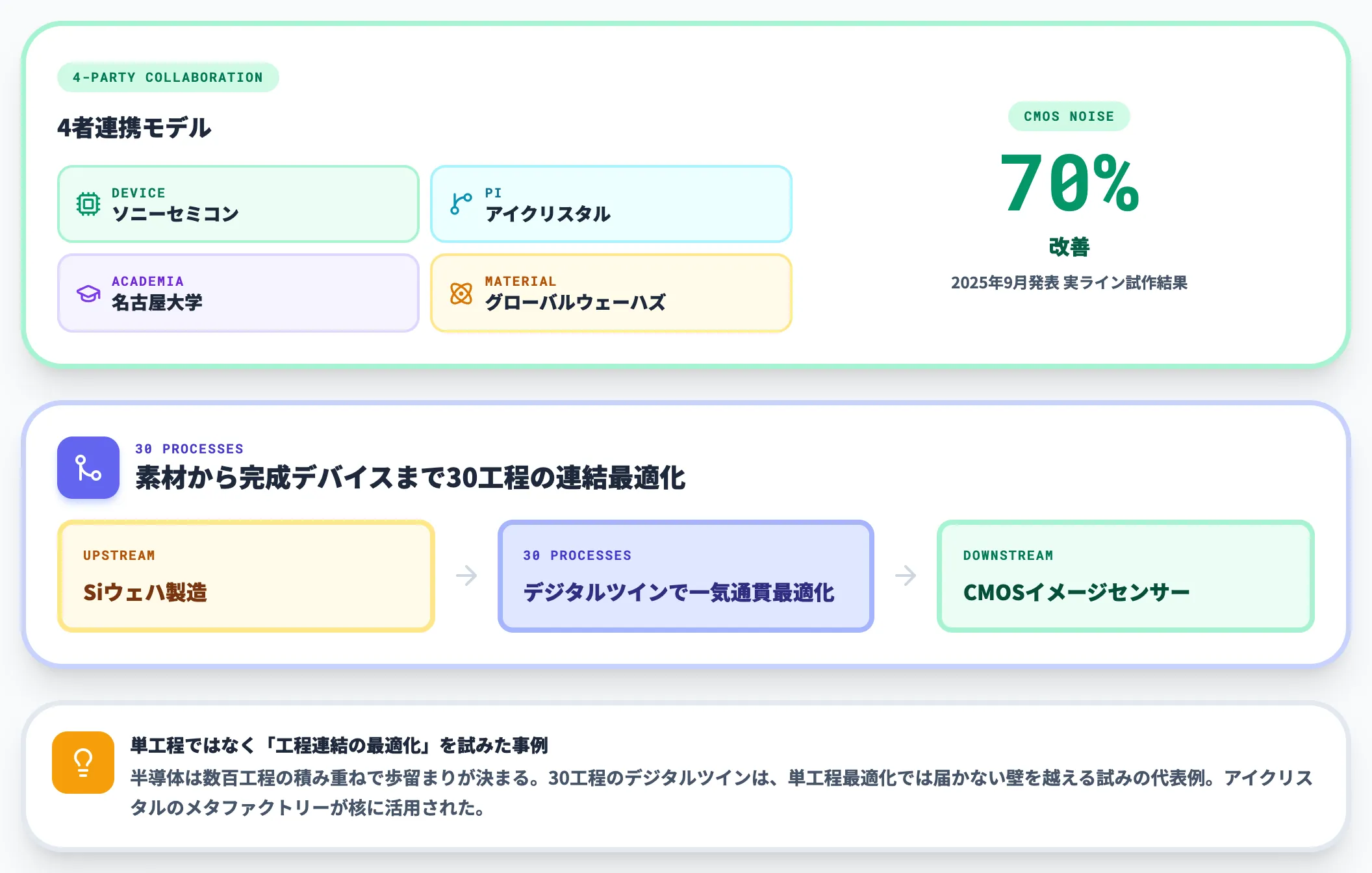
技術の核は、Siウェハ製造からCMOSイメージセンサー製造まで合計30工程を一気通貫で最適化したデジタルツインです。実ラインでの試作の結果、従来品比約70%のノイズ特性改善を実現しました。
この事例が画期的なのは、装置単体・工程単体ではなく「素材から完成デバイスまでの工程連結」を最適化対象にした点です。半導体は数百工程の積み重ねで歩留まりが決まるため、単工程の最適化では届かない領域が残ります。30工程のデジタルツインは、その壁を越える試みの代表例といえます。
アイクリスタルのメタファクトリーが活用されており、PI特化スタートアップ×大学×素材メーカー×デバイスメーカーの4者連携が成果を出した形です。国内半導体メーカーがPIを取り入れる際、こうした連携モデルが選択肢になり得ます。
東京エレクトロン:プラズマ原子層堆積法で従来手法では難しかった膜ストレスをAIで探索
東京エレクトロンは、装置メーカーの立場でプロセスインフォマティクス(PI)を活用しています。代表事例が、プラズマ原子層堆積法(PE-ALD)における膜応力の最適化です。

同社のサステナビリティレポートでは、PE-ALDで形成する膜の応力を機械学習でレシピ条件と紐づけて最適化する取り組みが紹介されており、装置の物理現象が複雑で人手の試行錯誤では届かない領域にPIが効くことを示した事例として参照できます。
東京エレクトロンは札幌に「TEL デジタル デザイン スクエア」というAI・データサイエンスの拠点を設置し、装置メーカーとしてのAI/PI活用を組織的に進めています。装置メーカー側がAI機能を組み込み・別ライセンスで提供する流れが進む中、自社装置のレシピ最適化までを含めたAI機能の評価が、半導体メーカーの装置選定軸の一部に組み込まれていく構図です。
理研×グローバルウェーハズ・ジャパン:シリコン単結晶のリアルタイム特性予測
理化学研究所とグローバルウェーハズ・ジャパンは2020年11月、シリコン単結晶製造における材料特性のリアルタイム予測システムを発表しました。機械学習で製造中の材料特性をリアルタイム予測し、将来的な制御への応用も視野に入れる取り組みです。
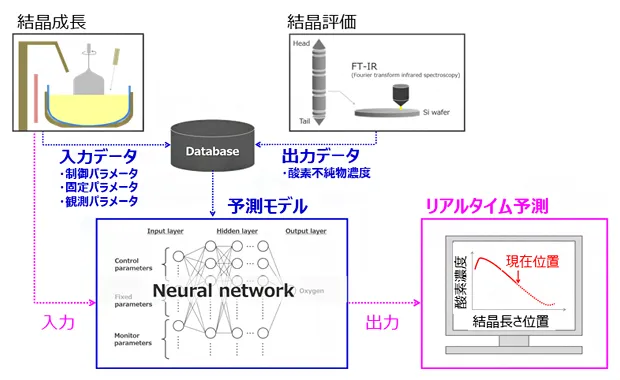
シリコン単結晶製造における材料特性のリアルタイム予測システムの概要(出典:理化学研究所)
理研の発表資料に掲載されたシステム概要は、結晶成長の入力データ(制御パラメータ・固定パラメータ・観測パラメータ)と、結晶評価のFT-IR(フーリエ変換赤外分光)による酸素不純物濃度の出力データを、共通のデータベースに集約する設計です。集約データをニューラルネットワークで学習させ、結晶長さの位置ごとに酸素濃度をリアルタイム推定する仕組みで、Si単結晶の品質ばらつきを下流工程の不良に持ち込まないための上流予測層として位置づけられています。
この事例が重要なのは、半導体の起点である「Siウェハ製造」段階でAIを活用することで、その後の数百工程の歩留まりを底上げできる可能性を示した点です。後工程の不良はSiウェハ段階の特性ばらつきに遡及することが多く、上流のAI予測・特性管理が下流の歩留まりに効きます。
国内素材メーカーがAIを取り入れる先行事例として、グローバルウェーハズ・ジャパンは前述のソニーセミコン・アイクリスタルとの30工程デジタルツインにも参画しており、Siウェハ段階のAI活用ノウハウを業界横断で展開している立場です。
国内製造業のAI事例を業界横断で見たい場合は、製造業のAI活用事例20選・製造業生成AI事例18選で関連業界の事例と比較できます。
装置メーカーAIと自社開発・国内ベンダーの選定軸
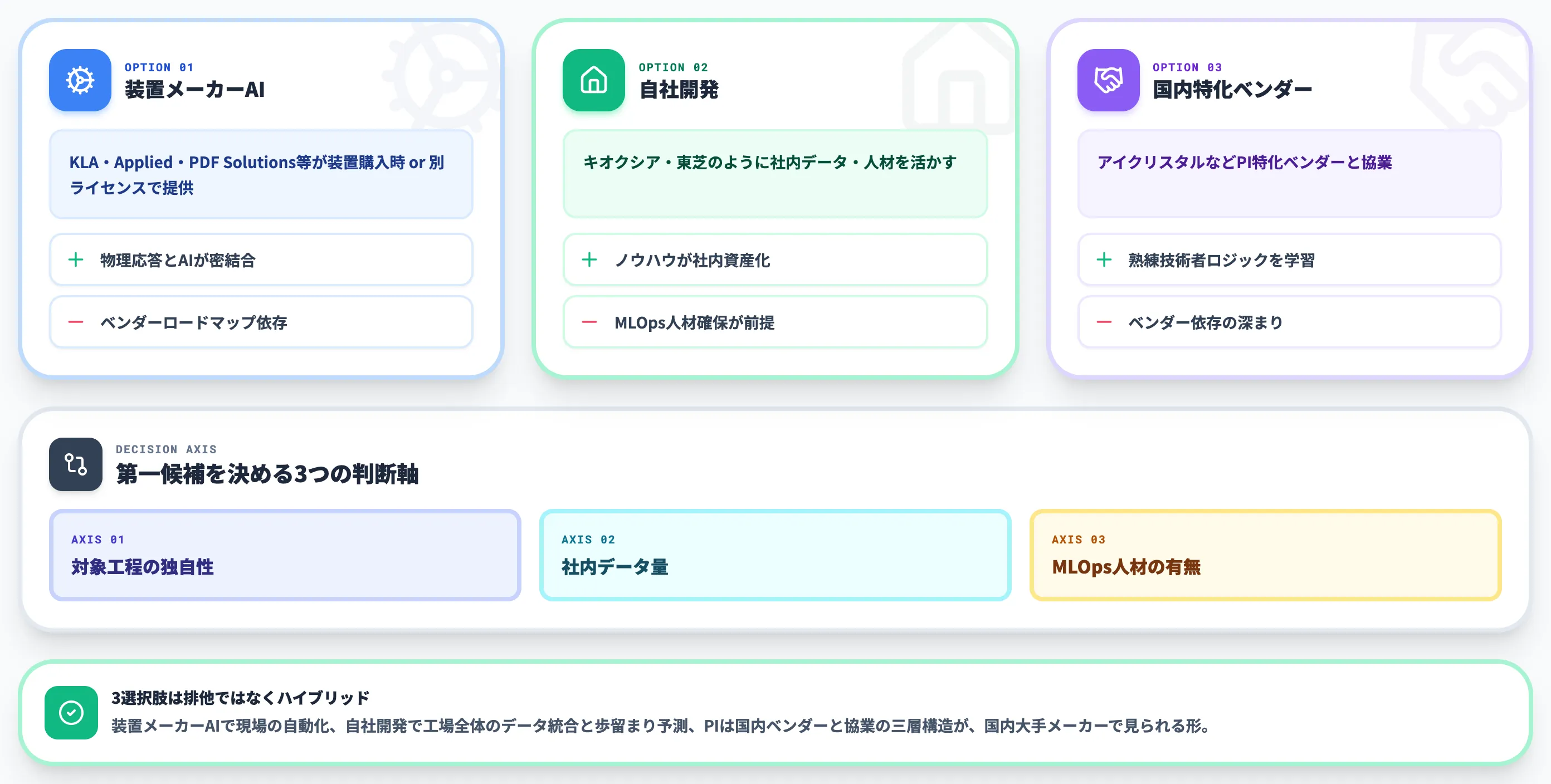
半導体工場でAIを導入するとき、装置メーカーAI・自社開発・国内特化ベンダーの3つの選択肢があります。どれが第一候補かは、対象工程の独自性・社内データ量・MLOps人材の有無で決まります。
本セクションでは、3つの選択肢の特徴と、ケース別の選定軸を整理します。
装置メーカーAI(KLA・Applied Materials・PDF Solutions等)の特徴
装置メーカー側がAI機能を組み込み・別ライセンスで提供する流れが、2026年時点で本格化しています。代表的なベンダーとAI機能を以下の表で整理しました。
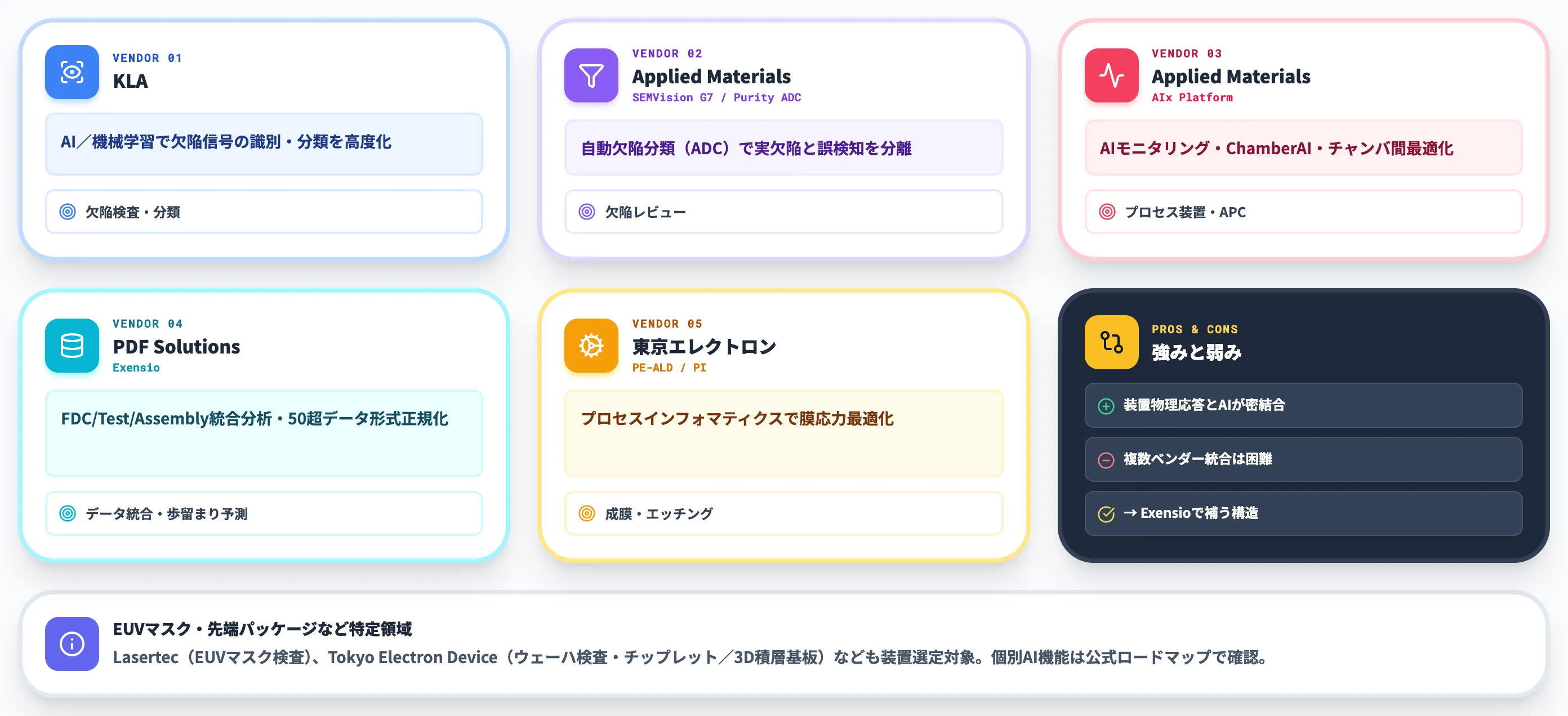
| ベンダー | 代表AI機能 | 対象領域 |
|---|---|---|
| KLA | AI/機械学習による欠陥検査・分類 | 欠陥検査・分類 |
| Applied Materials(SEMVision G7) | Purity ADC(自動欠陥分類) | 欠陥レビュー |
| Applied Materials(AIx) | AIモニタリング・connected chambers・チャンバ間最適化 | プロセス装置・APC |
| PDF Solutions Exensio | FDC/Test/Assembly統合分析 | データ統合・歩留まり予測 |
| 東京エレクトロン | プロセスインフォマティクス(PE-ALD等) | 成膜・エッチング |
表に挙げた各社は、公式情報でAI/機械学習機能の概要が確認できるベンダーです。装置メーカーAIの強みは、装置の物理応答とAIモデルが密結合している点で、装置ベンダーしか持たない装置固有のドメイン知識・センサ仕様・チャンバ構造を前提にしたAI機能は、自社開発で再現するのが難しい領域です。
弱点としては、装置メーカー側のロードマップに依存することと、複数装置メーカーをまたいだ統合的なAI分析が難しいことが挙げられます。後者を埋めるのが、Exensioのようなマルチベンダー対応のデータ統合プラットフォームです。
このほか、先端パッケージ・EUVマスクなど特定領域の検査装置で存在感のあるベンダーも、半導体メーカーの装置選定対象に入ってきます。LasertecはEUVマスク関連の検査装置を展開しており、Tokyo Electron Deviceもウェーハ検査装置事業を展開し、チップレット・3D積層など次世代工程向けには、新たな製造装置・検査装置向けの基板ソリューション展開を掲げています。これらのベンダーの個別AI機能の有無は公式ロードマップで別途確認することが、装置選定の前提になります。
自社開発・国内特化ベンダー(アイクリスタル等)の選択肢
装置メーカーAIだけでカバーできない領域では、自社開発か国内特化ベンダーとの協業を選びます。
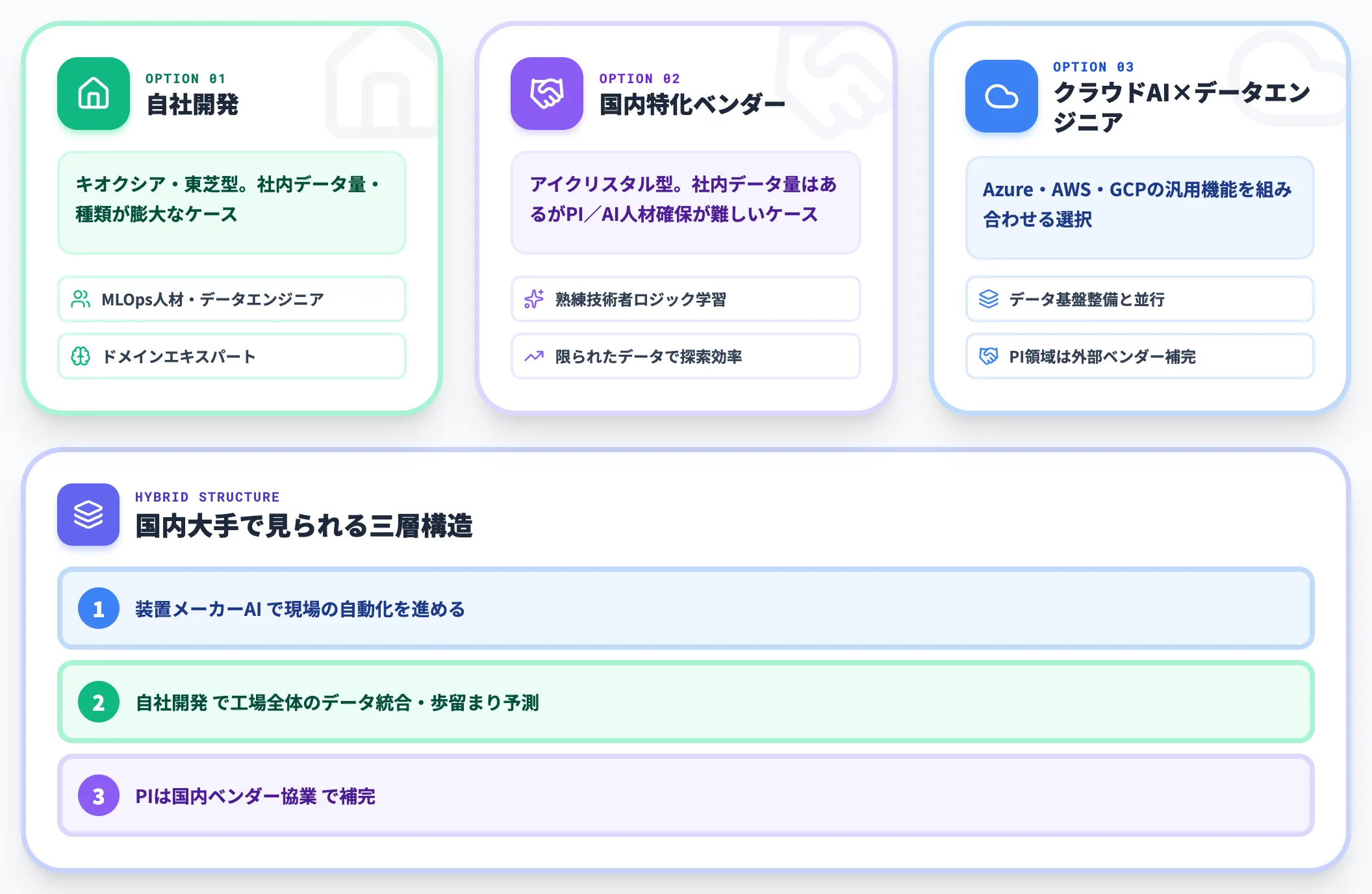
代表的な選択肢は次のとおりです。
-
自社開発(キオクシア・東芝型)
社内データの量と種類が膨大で、装置メーカー1社では捌けないレイヤー。MLOps人材・データエンジニア・ドメインエキスパートを揃えられる規模の半導体メーカーの選択
-
国内特化ベンダー(アイクリスタル等)との協業
社内データ量はあるが、PI/AI人材の確保が難しい場合の現実解。特化ベンダーが「熟練技術者の判断ロジックを学習させる」アプローチを持つため、限られたデータから探索効率を上げやすい
-
クラウドAIプラットフォーム+データエンジニア体制
社内データ基盤の整備と並行して、汎用クラウドAI(Azure・AWS・GCP)の機能を組み合わせる選択。MLOps人材は必要だが、PIの専門領域は外部ベンダー連携で補える
3つの選択肢は排他ではなく、ハイブリッドで採るのが現実的です。装置メーカーAIで現場の自動化を進めながら、自社開発で工場全体のデータ統合と歩留まり予測を担い、PIは国内ベンダーと協業する、という三層構造が国内大手メーカーで見られる形になります。
工程・組織規模別の選定の考え方
3つの選択肢を組み合わせる際の、実務的な選定の考え方を整理しました。
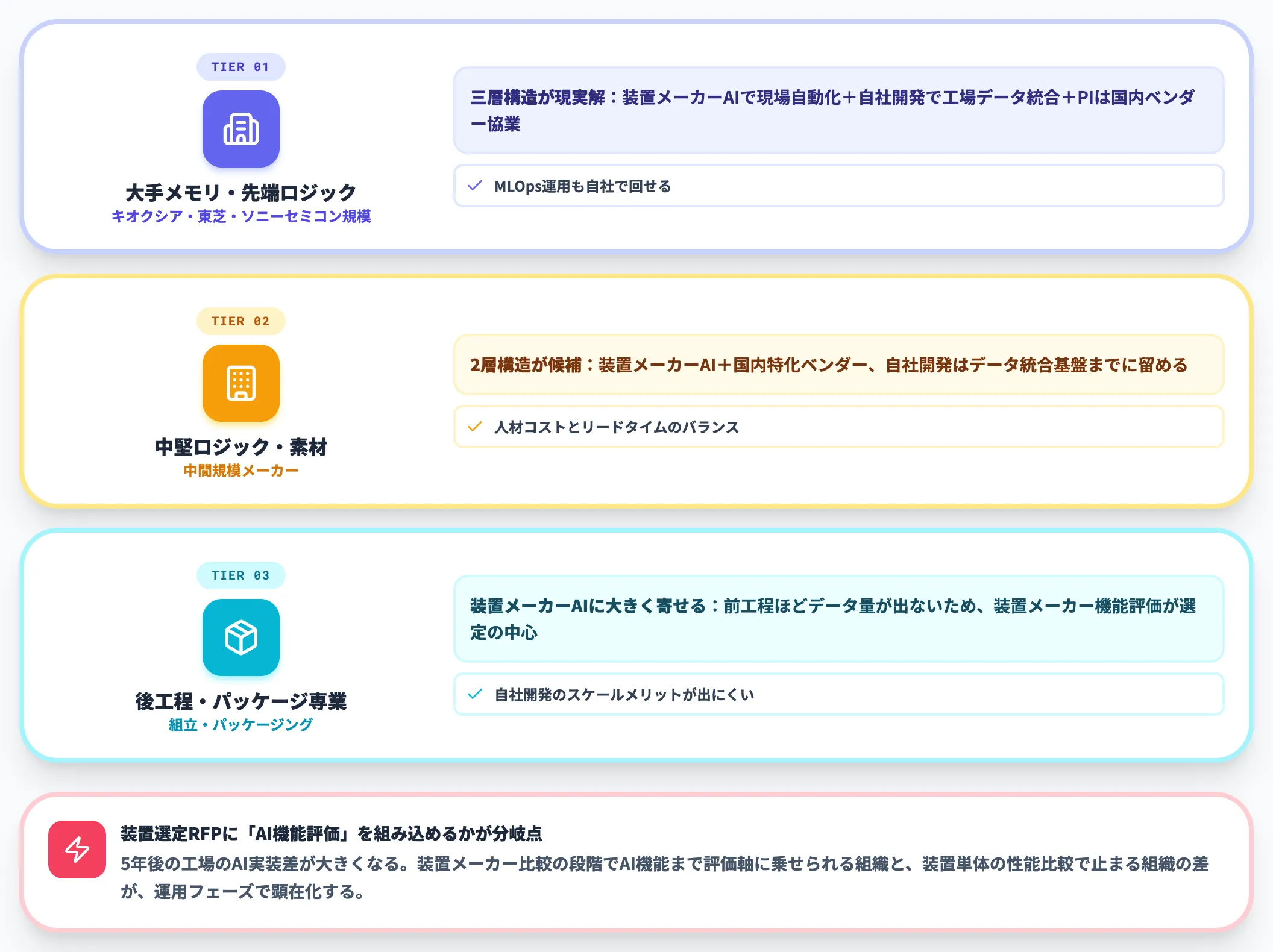
-
メモリ・先端ロジック大手(キオクシア・東芝・ソニーセミコン規模)
装置メーカーAIで現場自動化+自社開発で工場データ統合+PIは国内ベンダー協業の三層構造が現実解。社内にAI人材を厚く配置できる大手メーカーが取りやすい構造で、MLOps運用も自社で回せる
-
中堅ロジック・素材メーカー
装置メーカーAI+国内特化ベンダーの2層構造が候補に挙がる。自社開発はデータ統合基盤までに留め、AIモデルは装置メーカー機能とPIベンダーで補う方が、人材コストとリードタイムのバランスがとれる
-
後工程・パッケージ専業
装置メーカーAIに大きく寄せる選択が合いやすい。組立・パッケージは前工程ほどデータ量が出ないため、自社開発のスケールメリットが出にくく、装置メーカー機能の評価が選定の中心になる
装置選定のRFPに「装置メーカーAI機能の評価」を組み込めるか、組み込めないかで、5年後の工場のAI実装の差が大きくなります。AI総研の支援現場でも、装置メーカー比較の段階でAI機能まで評価軸に乗せられる組織と、装置単体の性能比較で止まる組織の差が、運用フェーズで顕在化しているケースが増えています。
半導体製造AIで詰まる3つの論点
半導体工場のAI活用は、装置メーカーAIの導入や自社開発を進めても、現場で詰まる論点が共通して出てきます。事前に把握しておくと、PoCで時間を消費せずに本番運用に乗せやすくなります。
本セクションでは、半導体工場のAI実装で特に詰まりやすい3点を整理します。

データ収集と教師データ不足の壁
半導体工場のAI活用で最も頻繁に詰まるのは、データの「集まり方」の問題です。装置センサ・計測・テスト・最終歩留まりがそれぞれ別システムに格納され、ロット・ウェーハ・ダイ単位で正確に紐付かないと、AIが学習する前段で時間を消費します。

詰まりやすいポイントは次の3つです。
-
メタデータの欠落
装置ID・ロット・ウェーハ・ダイ位置・タイムスタンプの紐付けが歯抜けになっている。古い装置ほど深刻
-
正常データの偏り
正常運転データは大量にあるが、不良データはごく僅か。教師あり学習で十分な精度が出ない
-
装置ファームウェアのバージョン違い
同じ装置でもファームウェア更新でセンサ仕様が微妙に変わり、学習データの一貫性が崩れる
これらの壁は、教師なし学習や半教師あり学習で部分的に回避できますが、根本的にはデータ収集設計の見直しが必要です。AIモデル選定の前に、データガバナンスの設計に予算を割けるかが、運用成功の前提条件になります。
MLOps保守の人材問題
AIモデルを動かし続けるには、データドリフトの監視・モデル再学習・デプロイ自動化・モニタリングを支える MLOps 体制が必要です。半導体工場のような大規模・高頻度の運用環境では、これを支える人材確保が現実的なボトルネックになります。
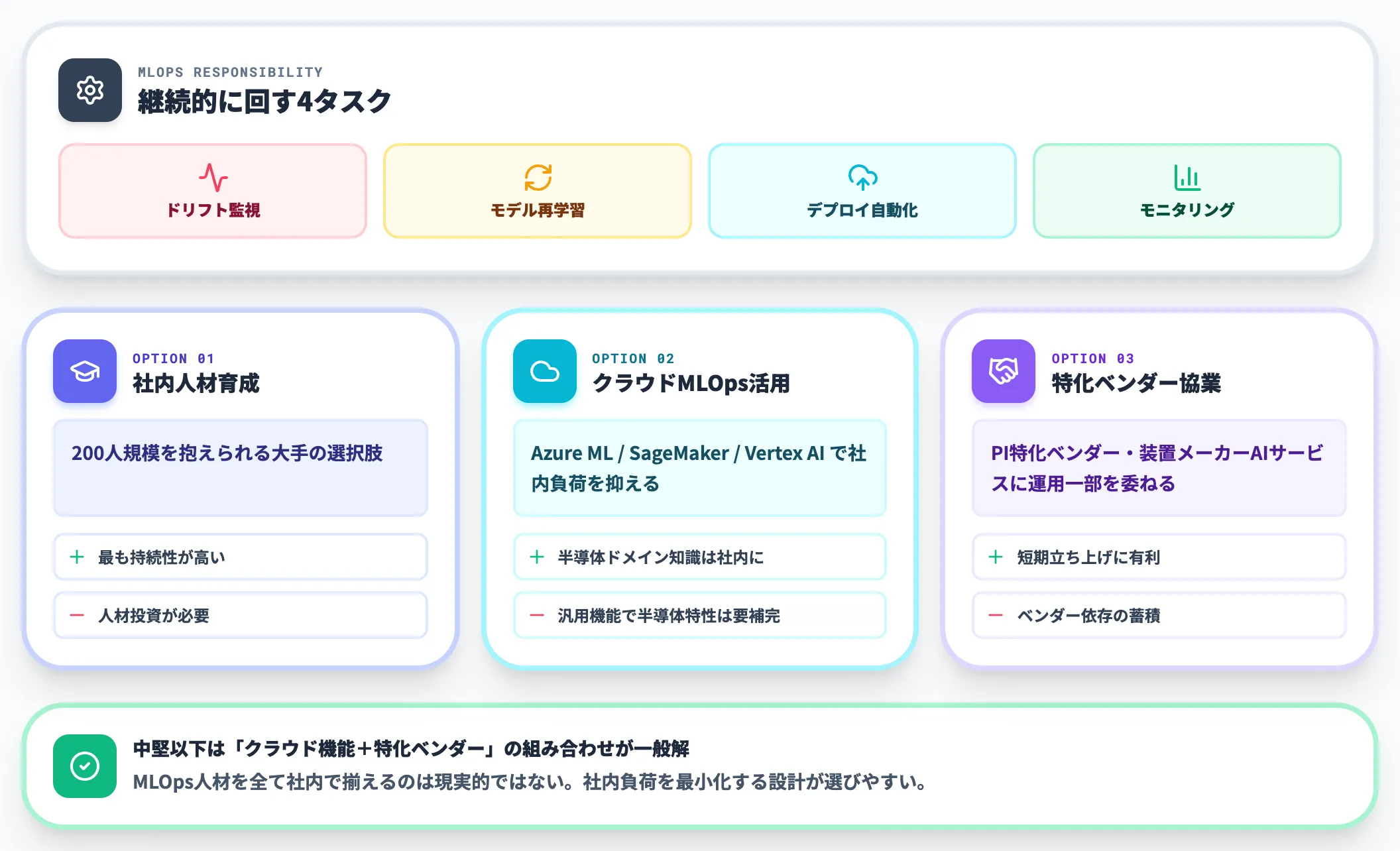
国内半導体メーカーで MLOps 体制を構築する際の現実的な選択肢は次の3つです。
-
社内人材育成
キオクシアのように200人規模のAI活用プロジェクトを抱えられる大手は、社内人材育成で MLOps を内製化する選択がとれる。長期的には最も持続性が高い
-
クラウドベンダーのMLOps機能活用
Azure ML・AWS SageMaker・Google Vertex AIなど汎用クラウドAI基盤の MLOps 機能を活用し、社内負荷を抑える選択。半導体特有のドメイン知識は社内に残す
-
特化ベンダー協業
アイクリスタルのようなPI特化ベンダーや、装置メーカーのAIサービスと連携し、MLOps運用の一部を外部に委ねる選択
MLOps人材を全て社内で揃えるのは、中堅以下の半導体メーカーには現実的ではありません。汎用クラウド機能と特化ベンダーの組み合わせで、社内負荷を最小化する設計が一般解になります。
2nm/GAA世代への対応——既存FDCモデルの寿命
2026年時点で2nmプロセスの量産化が本格化し、GAA(Gate-All-Around)トランジスタやBackside Power Deliveryなど構造そのものが変わる転換点を迎えています。これに伴い、既存のFDC・APC・歩留まり予測モデルは、再学習・再検証が必要になる可能性が高い領域です。
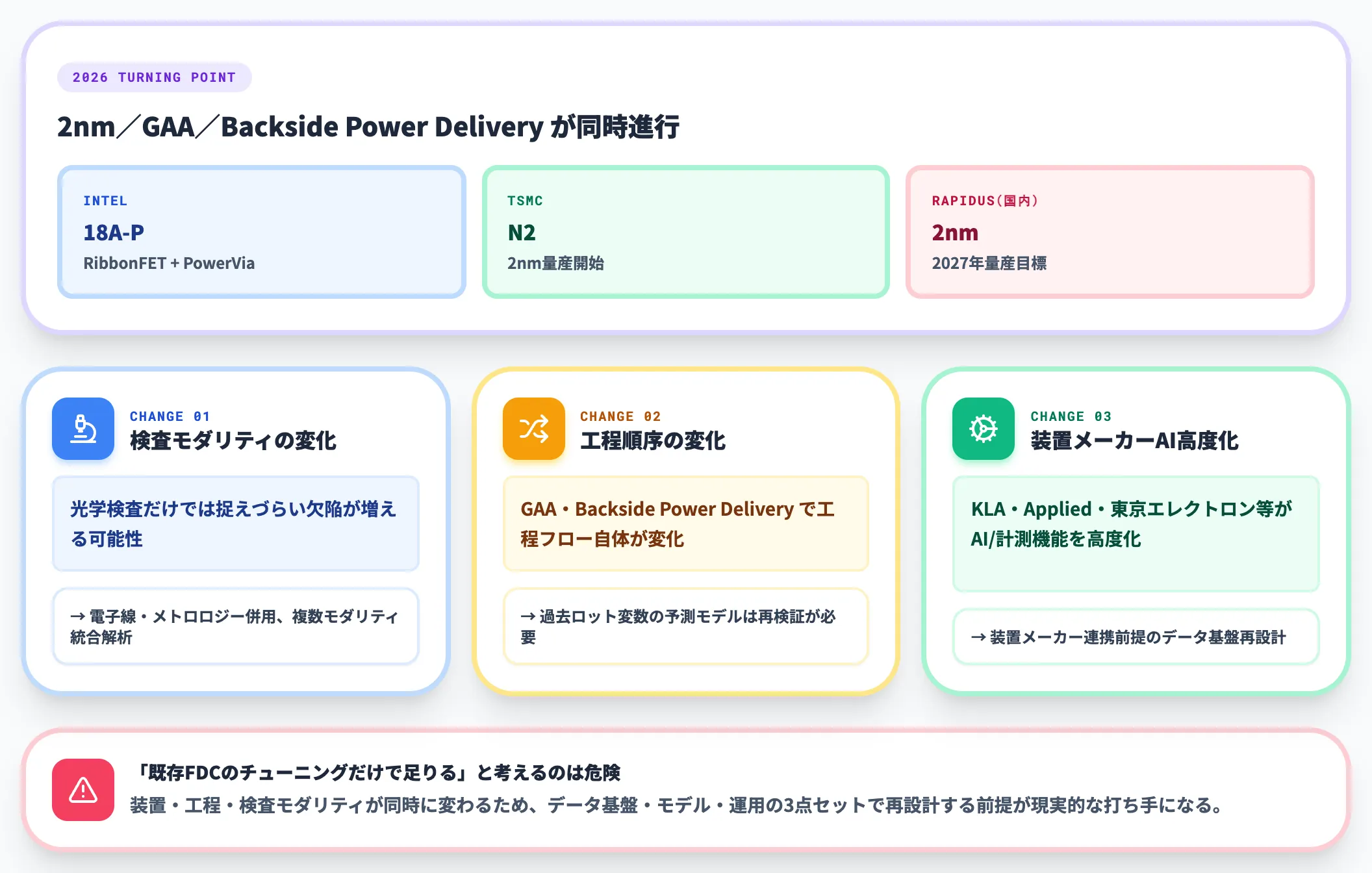
2026年6月16日にはIntelがVLSI SymposiumでIntel 18A-Pを発表し、RibbonFET(GAA)とPowerVia(Backside Power Delivery)を組み合わせた次世代プロセスのロードマップを公開しました。TSMC N2の量産開始と並んで、装置メーカーAI機能の世代対応も加速する局面に入っています。
国内では、Rapidus が 2026年に NEDO から FY2026 計画の承認を受け、2nm量産技術開発・PDK公開・RCS後工程パイロットライン整備・2027年量産目標を公式に打ち出しています。Intel 18A-P/TSMC N2 と並ぶ国内2nm開発の文脈として、工場データ基盤・装置検証の整備が国内半導体産業政策とも結びついて進む局面です。
具体的に変化が大きいのは次の3点です。
-
検査モダリティの変化
光学検査だけでは捉えづらい欠陥が増える可能性が高く、対象欠陥に応じて電子線検査・メトロロジー計測を併用する重要性が高まる。AIモデル側も複数モダリティを統合解析する設計の見直し余地が生まれる
-
工程順序の変化
GAA・Backside Power Deliveryで工程フロー自体が変わる。過去ロットの工程変数を使った歩留まり予測モデルは、新ノードで再検証が必要になる可能性が高い
-
装置メーカーAI/計測機能の高度化
KLA・Applied Materials・東京エレクトロン等の装置メーカーが、AI/計測機能の高度化を進めている。装置メーカー連携を前提にしたデータ基盤の再設計余地が生まれる
2nm/GAA対応で「既存FDCをチューニングするだけで足りる」と考えるのは危険です。装置・工程・検査モダリティが同時に変わるため、データ基盤・モデル・運用の3点セットで再設計する前提が、現実的な打ち手になります。
製造業の異常検知AI・予知保全AIで扱われる業界横断の異常検知・故障予測の論点とも、半導体特有の課題は連動しています。
半導体工場AI活用の導入コストと隠れコスト4項目
半導体工場のAI活用は、装置メーカーAIライセンス・自社開発・PI特化ベンダーのどれを選んでも、ライセンス費用以外の「隠れコスト」が大きく出ます。投資判断で月額ライセンス費だけ見ると、社内合意形成の段階で見立てが崩れます。
本セクションでは、3つの選択肢の料金構造と、半導体工場で必ず発生する隠れコスト4項目を整理します。

装置メーカーAI(KLA・Applied Materials等)の料金構造
装置メーカーAIの料金は、装置購入時に含まれる基本機能と、追加ライセンスで使える高度機能の2層構造が一般的です。
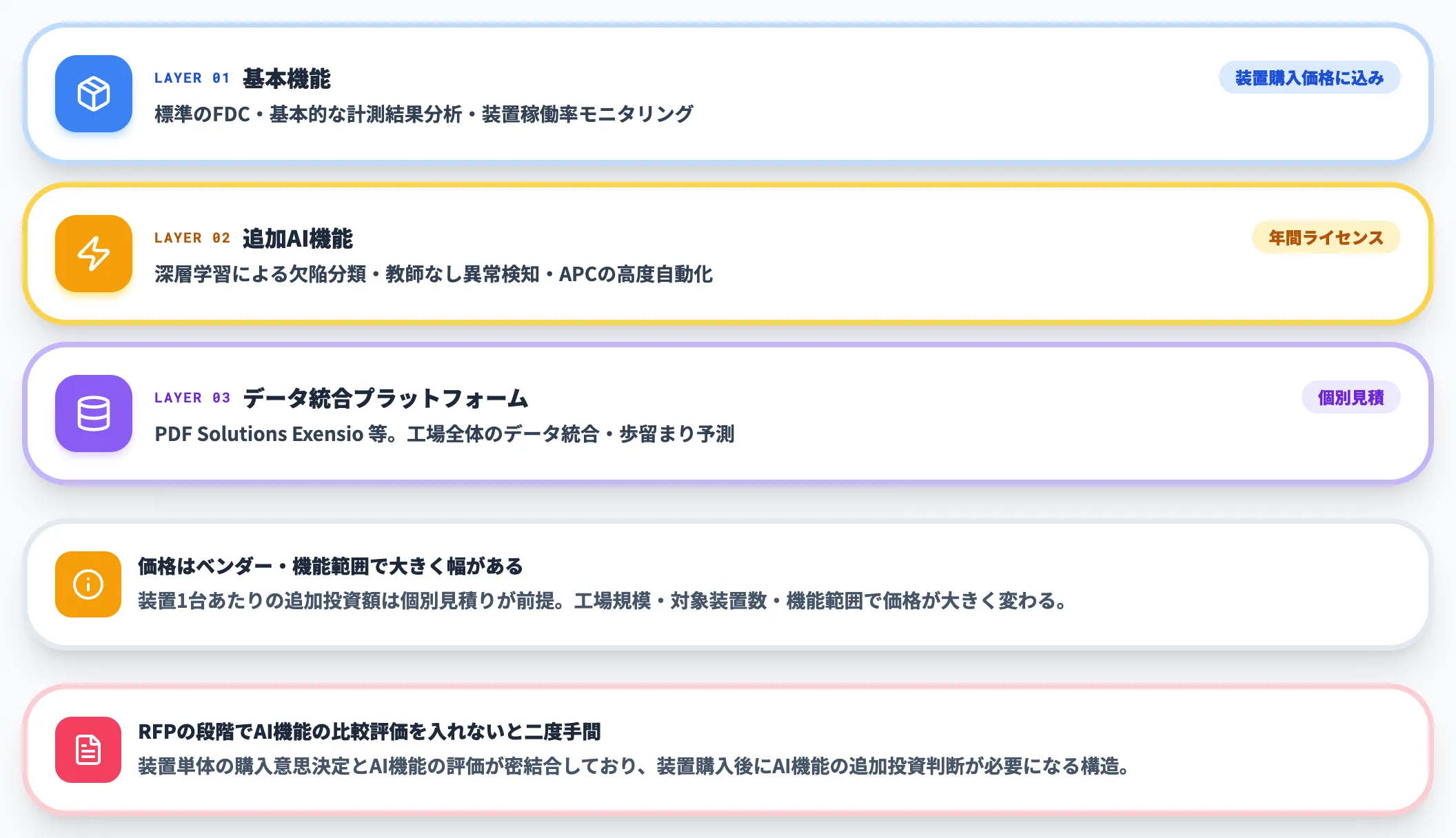
-
基本機能(装置購入価格に含む)
標準のFDC・基本的な計測結果分析・装置稼働率モニタリング。装置1台の購入価格に込み
-
追加AI機能(年間ライセンス)
深層学習による欠陥分類・教師なし異常検知・APCの高度自動化。装置1台あたりの追加投資額はベンダー・機能範囲で大きく幅があり、個別見積りが前提となる
-
データ統合プラットフォーム(PDF Solutions Exensio等)
工場全体のデータ統合・歩留まり予測。工場規模・対象装置数・機能範囲で価格が大きく変わるため、ベンダーへの個別見積りが前提となる
装置メーカーAIは、装置単体の購入意思決定とAI機能の評価が密結合しています。RFPの段階でAI機能の比較評価を入れられないと、装置購入後にAI機能の追加投資判断が必要になり、二度手間になりやすい構造です。
自社開発・国内特化ベンダーのコスト構造
自社開発と国内特化ベンダー協業のコスト構造は、装置メーカーAIと性質が異なります。
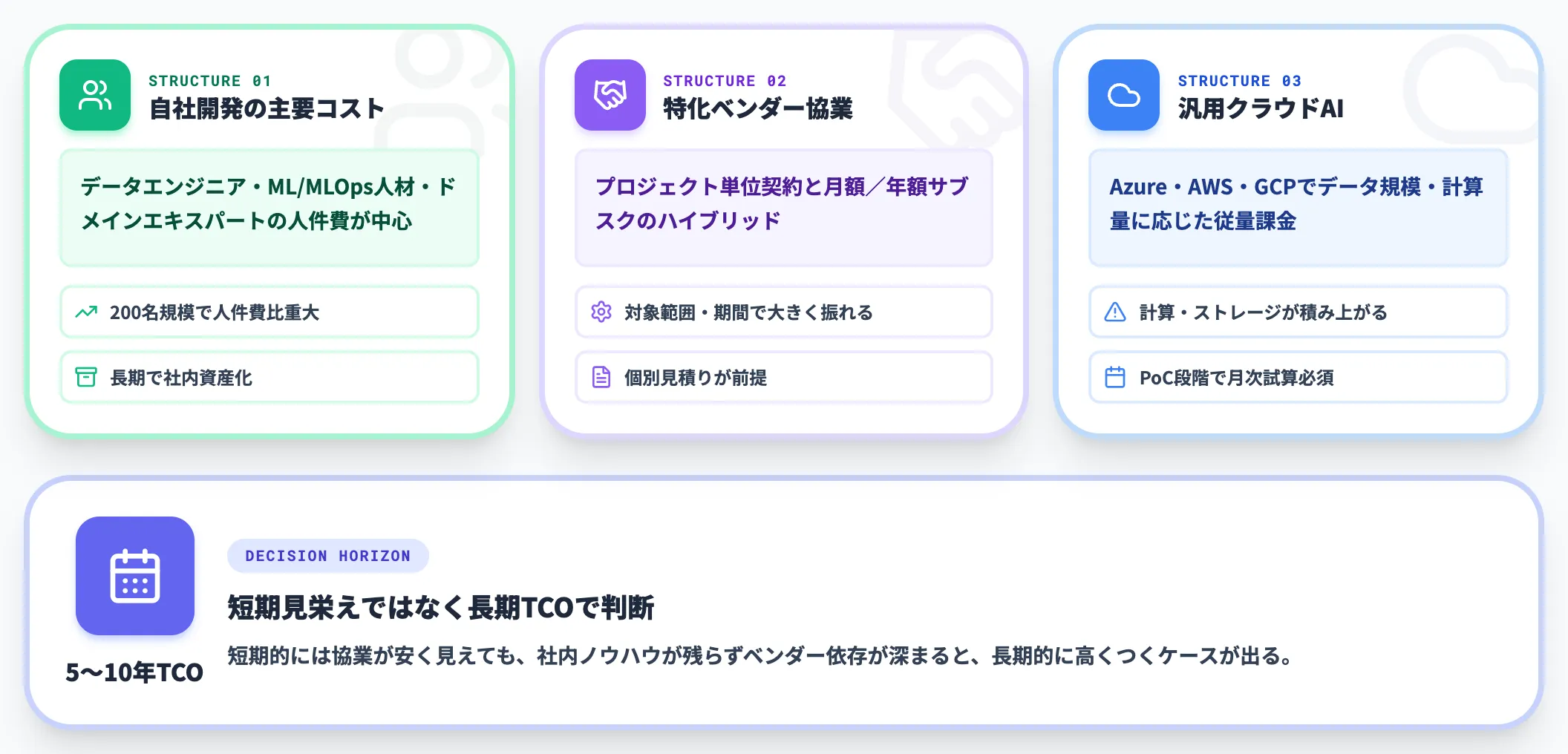
-
自社開発の主要コスト
データエンジニア・ML/MLOps人材・ドメインエキスパートの人件費が中心。200人規模のAI活用プロジェクトとして運用する場合、人件費の比重が大きくなる一方、長期的にはノウハウが社内資産として残る
-
国内特化ベンダー協業
プロジェクト単位の契約と、月額/年額のサブスクリプション契約のハイブリッド。半導体PI特化ベンダーの場合、対象範囲・期間で大きく振れるため個別見積りが前提
-
汎用クラウドAIプラットフォーム
Azure・AWS・GCPのAI機能を組み合わせる場合、データ規模・計算量で従量課金される。半導体工場規模では計算リソース・ストレージ費用が積み上がるため、PoCの段階で月次費用の試算を必ず作る
自社開発と協業の選択は、5年・10年のスパンで見たTCOで判断するのが妥当です。短期的には協業の方が安く見えても、社内ノウハウが残らずベンダー依存が深まると、長期的に高くつくケースが出ます。
製造業向けERP比較・AI外観検査の費用で扱われる料金体系の整理も、半導体工場AIのコスト構造を理解する補助線になります。
隠れコスト4項目——導入後に効いてくる本当のコスト
半導体工場のAI活用で、ライセンス費用以上に重く効くのが以下の隠れコスト4項目です。
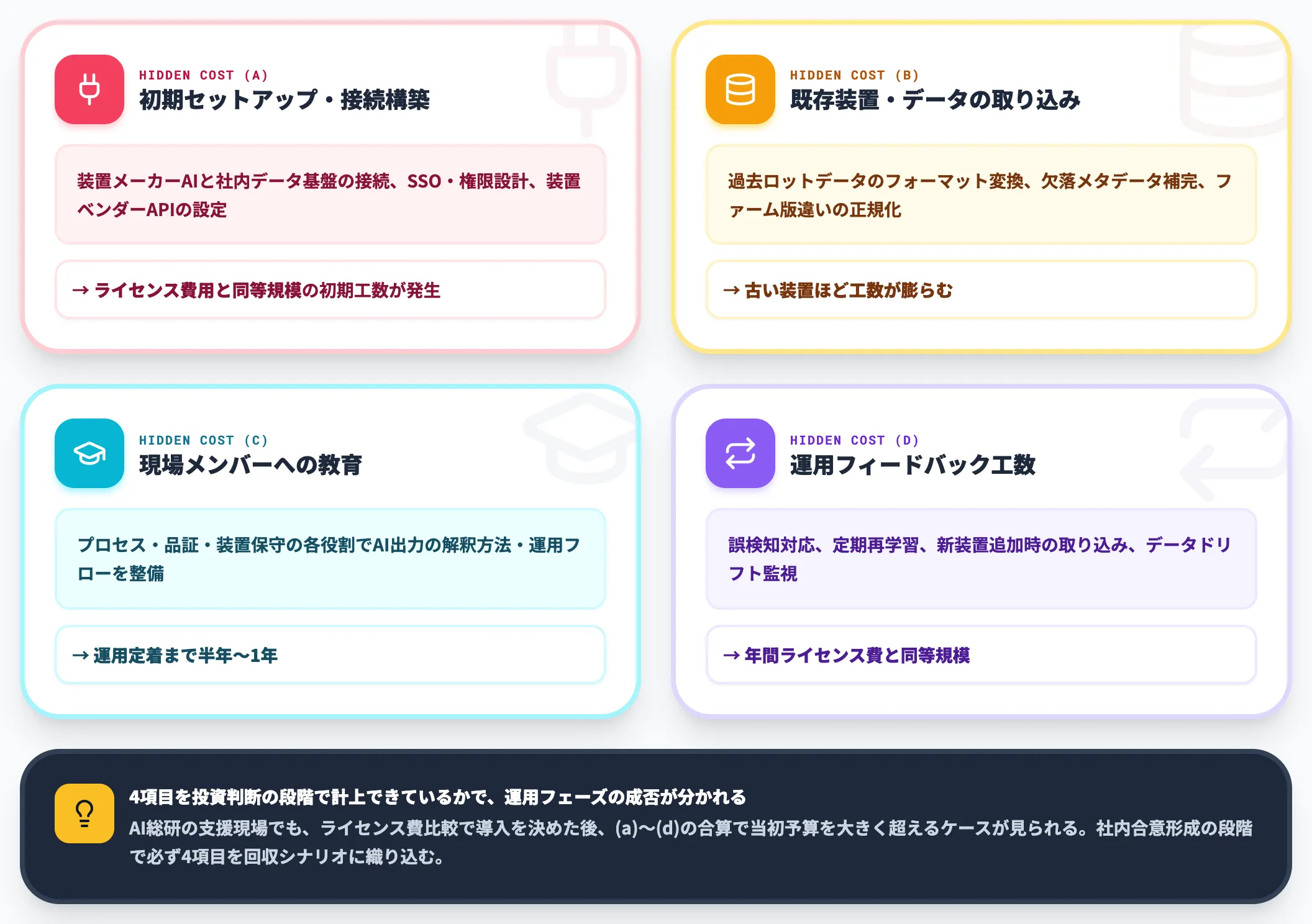
-
(a) 初期セットアップ・既存システム接続の構築工数
装置メーカーAIと社内データ基盤の接続、SSO・権限設計、装置ベンダーAPIの設定。工程・装置数によっては、ライセンス費用と同等規模の初期工数が発生する
-
(b) 既存装置・データの取り込み・前処理
過去ロットデータのフォーマット変換、欠落メタデータの補完、装置ファームウェアバージョン違いの正規化。古い装置ほど工数が膨らむ
-
(c) 現場メンバーへの教育・利用ガイド整備
プロセス・品証・装置保守の各役割でAI出力の解釈方法・運用フローを整備。現場が AI を信頼して使えるまでに、半年〜1年の運用定着期間が必要
-
(d) 運用担当者の継続的なフィードバック工数
モデルの誤検知対応、定期再学習、新装置追加時の取り込み運用、データドリフト監視。MLOps運用そのもののコストで、年間ライセンス費用と同等規模になることもある
この4項目を投資判断の段階で計上できているかで、半導体工場AI活用の成否は大きく分かれます。AI総研の支援現場でも、ライセンス費の比較で導入を決めた後、(a)〜(d)の合算で当初予算を大きく超え、運用定着が遅れるケースが見られます。
歩留まり1%改善のキャッシュインパクトは大きな財務インパクトになり得ますが、初期投資と隠れコストを織り込んだ回収シナリオを、社内合意形成の段階で作っておくことが、運用フェーズで現場が動ける前提になります。

半導体メーカーがAI活用を進める次の一歩
半導体工場のAI活用は、装置メーカーAI・自社開発・PI特化ベンダー協業の組み合わせで設計するのが現実的だと整理してきました。一方で、社内のデータ基盤・MLOps・PI人材を一気に揃えるのはハードルが高く、どこから着手するかの優先順位付けで詰まる組織が大半です。
PoCから本番運用までの設計、データ基盤・MLOps運用、装置メーカーAI機能の評価、運用フェーズでの定着支援まで、半導体メーカーがAI活用を業務として根付かせる過程には、組織横断の意思決定と現場ノウハウの両方が要ります。
AI総合研究所では、半導体・電子部品・素材メーカーを含む製造業のAI導入支援を通じて積み上げてきたPoCから全社展開までの設計、データ基盤・MLOps運用、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを、220ページの「AI業務自動化ガイド」にまとめています。半導体工場のAI活用を社内で進める検討の起点として活用ください。
半導体工場AIの導入と業務定着を一気通貫で支援

PoCから全社展開・運用設計までを1冊で
半導体工場AI活用は、装置メーカーAIの選定と自社データ基盤の設計が一気に絡みます。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開、データ基盤・MLOps運用、部門別ユースケース、セキュリティと統制まで、半導体メーカーの導入担当が現場で迷う論点を網羅的に整理しています。
まとめ
本記事では、半導体工場のAI活用を、5ステップ実務フロー・FDC/APC・ウェーハ検査・歩留まり予測・プロセスインフォマティクス・データ基盤・国内5事例・装置メーカーAIと自社開発の選定軸・詰まる論点・隠れコスト4項目まで、2026年6月時点の最新情報で整理しました。要点を改めて整理します。
-
半導体工場AI活用は「測定→分析→施策→検証→定着」の5ステップ実務フローとして設計するのが現実的で、AIモデルそのものよりデータ集約基盤と MLOps の保守体制が律速になる
-
中核領域はFDC/APC・ウェーハ検査・歩留まり予測の4つに集約され、KLA・Applied Materials・PDF Solutions・東京エレクトロンなどの装置メーカーAI機能の提供・高度化と、プロセスインフォマティクスの実装が同時に進んでいる
-
国内事例ではキオクシア四日市(不良解析99%削減)・東芝(4.2h→30分)・ソニーセミコン×アイクリスタル(CMOSノイズ70%改善)など、定量効果が明確な実装が積み上がっており、装置単体・工程単体ではなく工程連結の最適化に向かっている
-
装置メーカーAI・自社開発・国内特化ベンダーは排他ではなくハイブリッドで採るのが現実解。大手メモリ・先端ロジックは三層構造、中堅・後工程は装置メーカーAI寄りという使い分けが見られる
-
データ収集・MLOps保守・2nm/GAA対応の3つが共通のボトルネックで、ライセンス費用以外の隠れコスト4項目(初期接続・データ前処理・現場教育・運用フィードバック)を投資判断に織り込めるかが、運用フェーズでの定着を分ける
半導体工場のAI活用は、装置メーカーAIの世代交代と2nm/GAAへの転換が同時に進む2026年が、データ基盤・MLOps・人材体制を一斉に再設計する転換点になります。装置選定のRFPにAI機能を組み込み、自社のデータ運用と装置メーカー連携の前提を整える取り組みから着手するのが、最も実用的な第一歩になります。
スマートファクトリーの全体像から半導体特有の論点まで、業界横断で進め方を確認したい場合はスマートファクトリー完全ガイド・製造業のデータ活用ガイド・製造業のAI活用事例20選もあわせて参照してください。










