この記事のポイント
 ハーネスエンジニアリングはモデル単体ではなくループ・ツール・コンテキスト・評価器・永続化を含む実行基盤を設計する領域
ハーネスエンジニアリングはモデル単体ではなくループ・ツール・コンテキスト・評価器・永続化を含む実行基盤を設計する領域- Anthropic・OpenAI・LangChainの3社が2025秋〜2026春に公式発信で「harness」を扱い始めた新興のエンジニアリング用語
- プロンプト→コンテキスト→ハーネスはトークンキュレーション粒度を変えた連続的進化で、上位ほど契約全体を扱う
- Worker-Evaluator分離・永続化アーティファクト・サブエージェント・HITLが設計の核心。自己評価不能の壁を分離で越える
- production運用の落とし穴はOWASP LLM01・拒否挙動の確率的揺らぎ・$9 vs $200のコスト差で、SDK選定はケース別に

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ハーネスエンジニアリング(Harness Engineering)は、AIエージェントを動かすループ・ツール・コンテキスト管理・評価器・永続化機構を含む「モデル周辺の実行基盤全体」を設計・運用する実践領域です。
Anthropic・OpenAI・LangChainの主要3社が2025年秋から2026年春にかけて、公式発信で扱い始めた新興の用語で、プロンプトエンジニアリング・コンテキストエンジニアリングからの自然な進化形として位置付けられています。
本記事では、ハーネスの定義、3段階の進化、3社のアーキテクチャ整理、worker/evaluator分離などの設計核心パターン、production運用の落とし穴、Claude Agent SDK・OpenAI Agents SDK・LangChain deepagentsの使い分けまで、2026年6月時点の公式情報をもとに体系的に解説します。
目次
ハーネスエンジニアリングとは?AIエージェントの実行基盤を設計する新しい実践領域
なぜハーネスエンジニアリングが必要になったのか|プロンプトから実行基盤へ
コンテキストエンジニアリングだけでは足りない理由——context rot
【Anthropic】Claude Code / Agent SDKで具体化された基本形
【LangChain】Claude Code型の発想を汎用化したdeepagents
【OpenAI】Codex運用から整理された出力契約と改善ループ
Worker-Evaluator分離(自己評価は機能しない)
【コスト構造】ソロ実行とフルハーネスで20倍のコスト差——どう判断するか
ハーネスエンジニアリングとは?AIエージェントの実行基盤を設計する新しい実践領域
ハーネスエンジニアリング(Harness Engineering)は、AIエージェントを動かす「モデル周辺の実行基盤全体」を設計・運用する実践領域です。
具体的には、LLMを呼び出すループ、ツール群、コンテキスト管理、評価器、メモリ・永続化機構、サブエージェント、ガードレールを「ひとつの実行基盤(ハーネス)」として束ねて設計するアプローチを指します。

ハーネスという語は、2025年後半から2026年初頭にかけて、Anthropic・OpenAI・LangChainの公式発信で相次いで使われ始めました。
AnthropicはClaude Agent SDKを「agent harness」と位置付け、OpenAIはハーネスを「instructions・tools・routing・output requirements・validation checksを含むモデル周辺の契約全体」と定義しています。
LangChainもDeep Agentsの文脈で、モデルの周囲に目的達成のためのツール群を組み込むシステム設計として説明しています。
表現はそれぞれ違いますが、共通しているのは、モデル単体ではなく、その周辺のループ・ツール・検証・永続化まで含めた実行基盤を設計対象にしているという点です。

なぜハーネスエンジニアリングが必要になったのか|プロンプトから実行基盤へ
ハーネスエンジニアリングが2025年後半から急に語られ始めた背景には、LLMアプリケーション開発の関心領域が単発プロンプトから実行基盤全体へと移ってきたという構造変化があります。
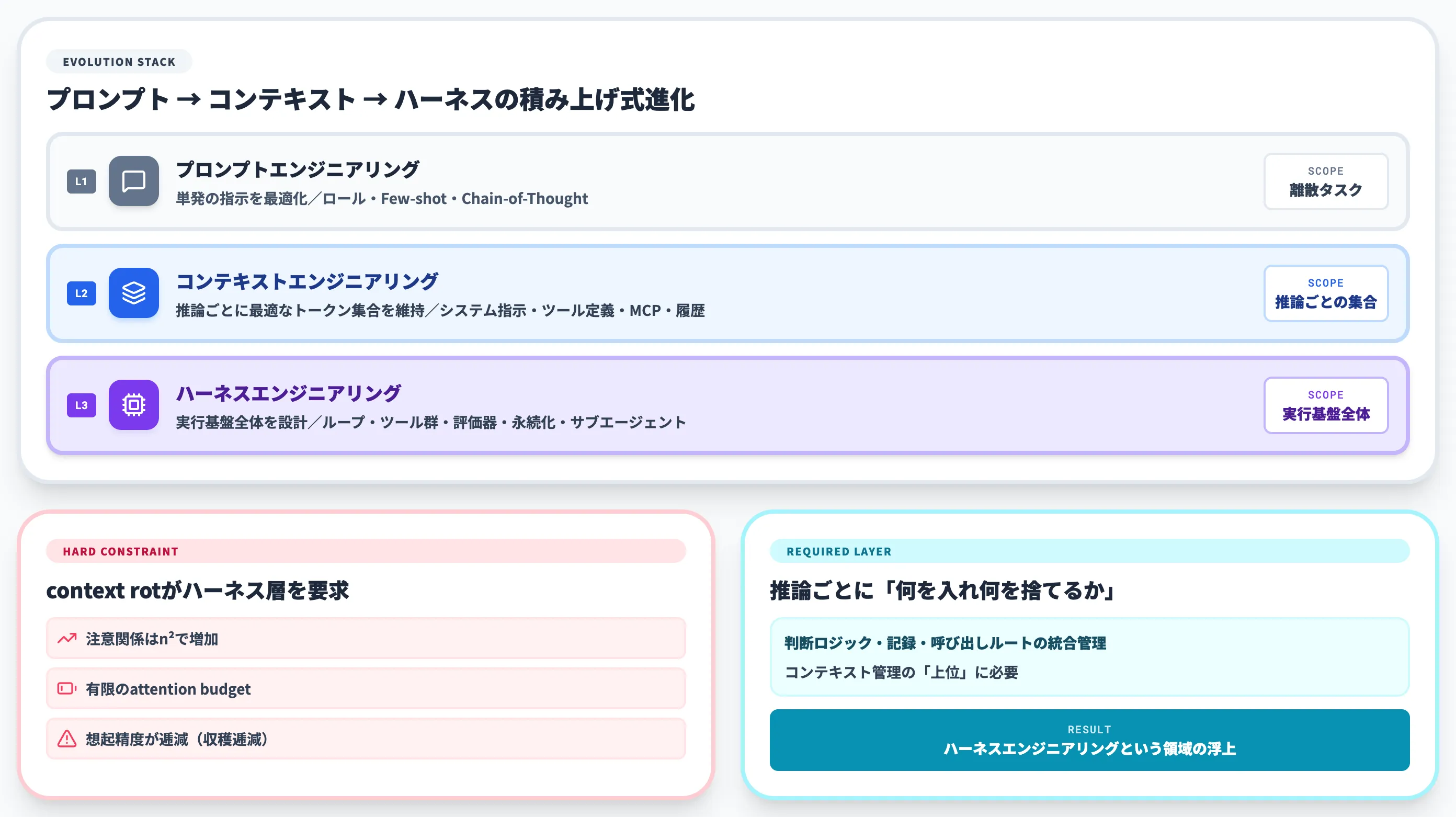
本セクションでは、プロンプトエンジニアリング → コンテキストエンジニアリング → ハーネスエンジニアリングという3段階の進化と、その背景にある技術的制約を整理します。
【プロンプトエンジニアリング】単発タスクを最適化する
プロンプトエンジニアリングは、LLMに対して1回の指示を最適化することに焦点を当てた領域でした。
「ロールを与える」「Few-shot例を入れる」「Chain-of-Thoughtで考えさせる」などの定石は、いずれも単発の入出力ペアを良くするためのテクニックです。
しかし、エージェント型のシステムが普及するにつれ、1回の指示では完結しない問題が増えました。複数回のツール呼び出し、長時間にわたる自律実行、サブタスクへの分解——これらは単発プロンプトの粒度では設計しきれません。
【コンテキストエンジニアリング】推論ごとの情報を整える
そこで2025年に注目されたのが、コンテキストエンジニアリングです。
Anthropicは公式記事Effective context engineering for AI agentsで、コンテキストエンジニアリングを「LLMの推論中に、最適なトークン集合(情報)をキュレートし維持するための戦略の集合」と定義しました。
同じ記事で「context engineering is the natural progression of prompt engineering」(コンテキストエンジニアリングはプロンプトエンジニアリングの自然な進化形)と明確に位置付けています。
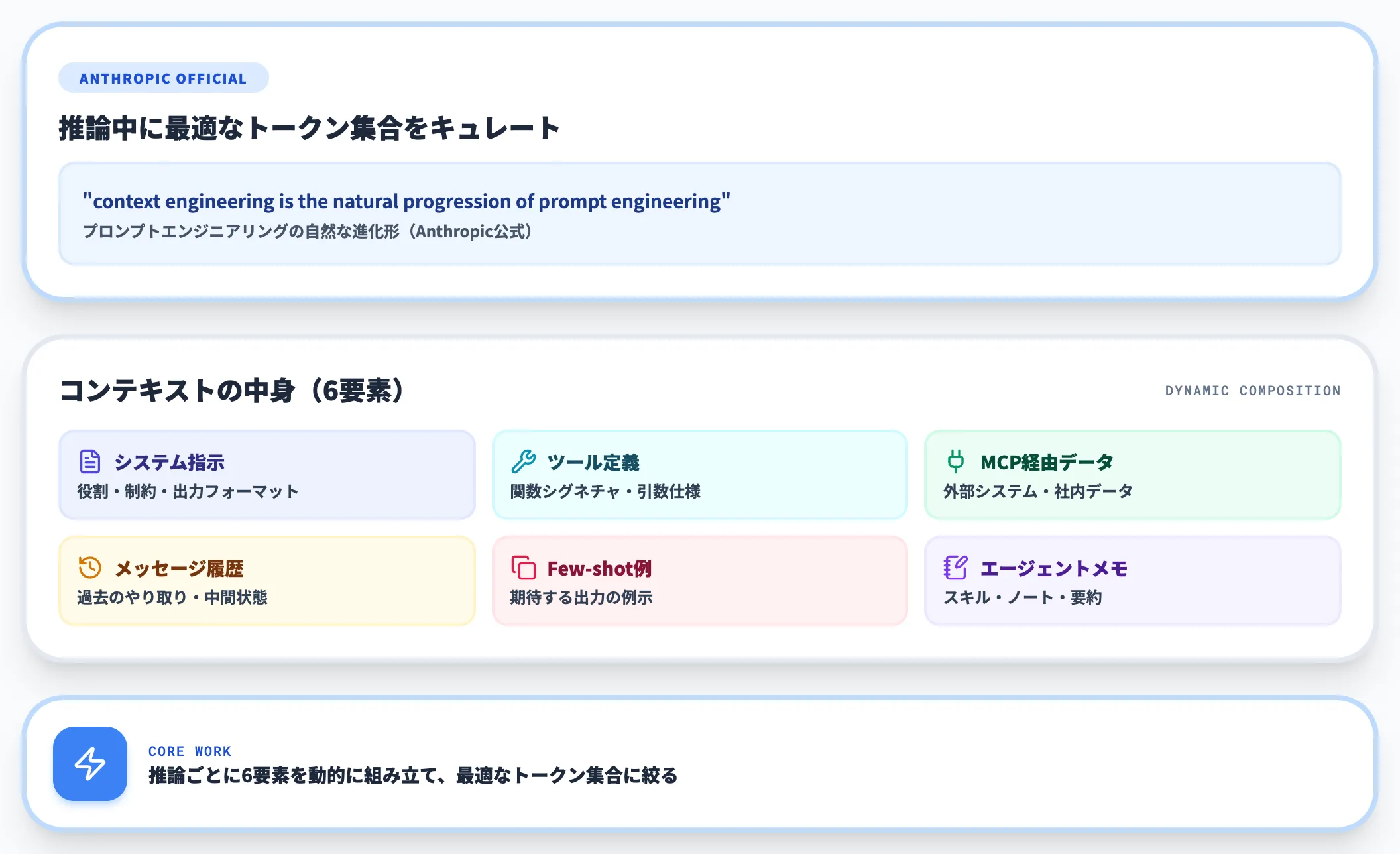
コンテキストの中身は、システム指示、ツール定義、Model Context Protocol(MCP)経由の外部データ、メッセージ履歴、Few-shot例、エージェントのメモリ・ノートなど多岐にわたります。これらを推論ごとに動的に組み立てるのが、コンテキストエンジニアリングの仕事です。
コンテキストエンジニアリングだけでは足りない理由——context rot
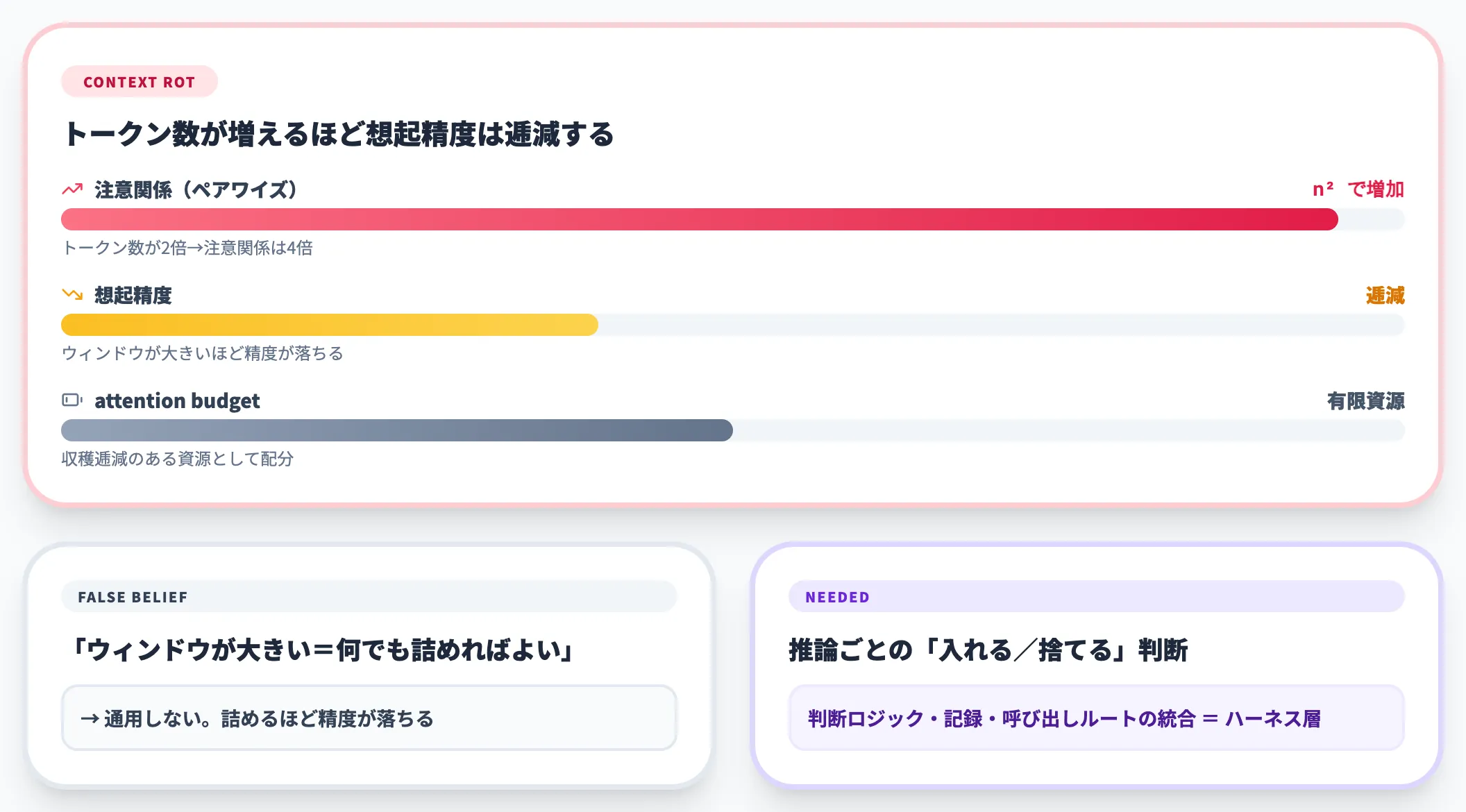
ではなぜ、コンテキストエンジニアリングだけでは足りなかったのか。背景にあるのは「context rot(コンテキスト劣化)」と呼ばれる、Transformerアーキテクチャ由来のハード制約です。
Anthropicは公式記事で次のように説明しています。
- トークン数 n が増えるほど、ペアワイズの注意関係は n² で増加する
- 結果として、コンテキストウィンドウが大きくなるほどモデルの想起精度は逓減する
- LLMには有限の「attention budget」があり、コンテキストは「収穫逓減のある有限資源」として扱う必要がある
つまり「ウィンドウが大きいから何でも詰めればいい」という単純な発想は通用しません。推論ごとに何を入れ何を捨てるかを判断する仕組みが要ります。
そして、その判断ロジック・記録・呼び出しルートを統合的に管理する実行基盤の設計が、コンテキストエンジニアリングのさらに上に必要になります。ここで初めて、ハーネスエンジニアリングという領域が浮上してきたわけです。
プロンプト・コンテキスト・ハーネスの違いを整理
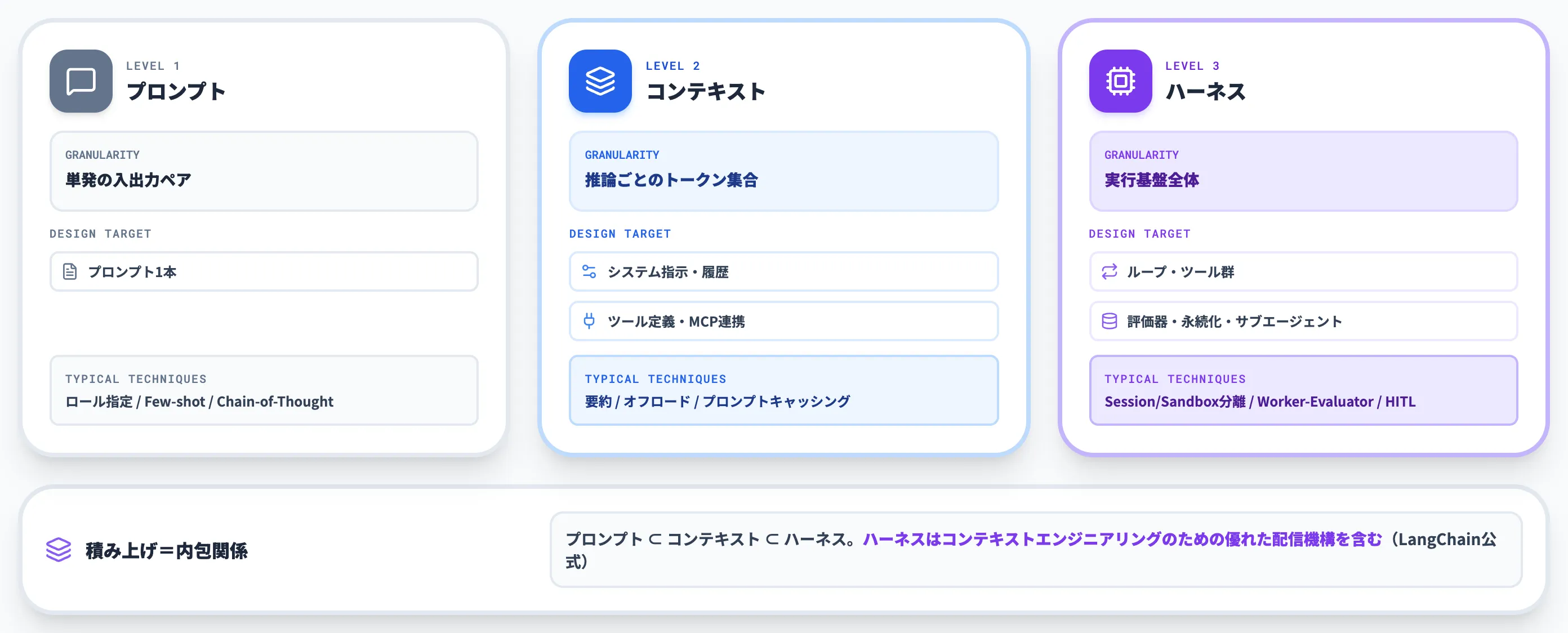
以下の表で、3段階それぞれが扱う関心領域の違いを整理しました。
| 領域 | 関心の粒度 | 主な設計対象 | 代表的な工夫 |
|---|---|---|---|
| プロンプトエンジニアリング | 単発の入出力ペア | プロンプト1本 | ロール指定/Few-shot/Chain-of-Thought |
| コンテキストエンジニアリング | 推論ごとのトークン集合 | システム指示・ツール定義・履歴・MCP連携 | 要約/コンテキストオフロード/プロンプトキャッシング |
| ハーネスエンジニアリング | 実行基盤全体 | ループ・ツール群・評価器・永続化・サブエージェント | Session/Sandbox分離/Worker-Evaluator分離/HITL |
3段階は積み上げ式で、上位の領域ほど扱う契約面が広がります。プロンプトを書くスキルが消えるわけではなく、それを実行基盤の中の一要素として配置するのがハーネスエンジニアリングの仕事です。
LangChainは公式ブログで「part of harness engineering is building a good delivery mechanism for context engineering」(ハーネスエンジニアリングの一部は、コンテキストエンジニアリングのための優れた配信機構を作ることである)と整理しており、両者が排他ではなく内包関係にあることを示しています。
ハーネスの構成要素
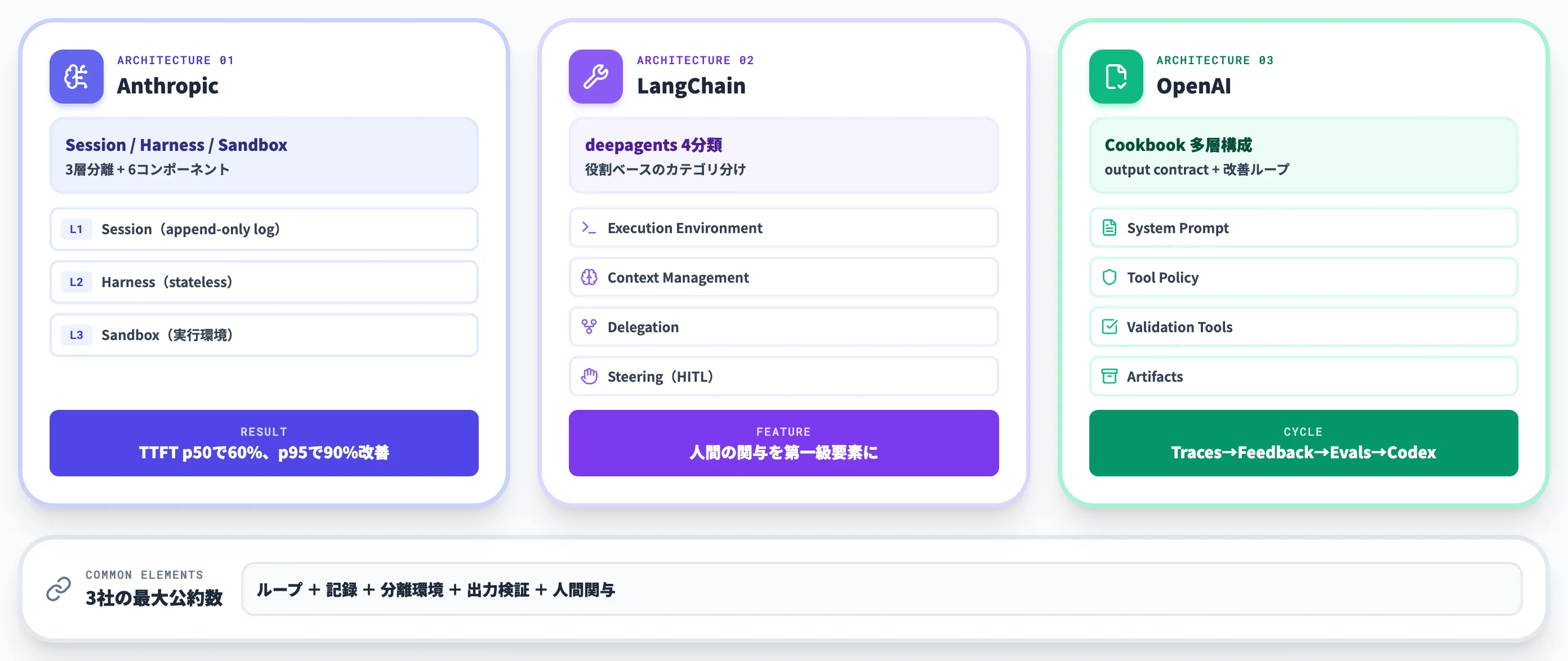
ハーネスエンジニアリングは概念上の領域ですが、Anthropic・LangChain・OpenAIの3社は、それぞれ公式発信の中でリファレンスアーキテクチャや実装パターンを公開しています。
本セクションでは、Claude Code / Claude Agent SDKで具体化されたハーネスの基本形を起点に、LangChain・OpenAIの整理と比較しながら、ハーネスを実装するときの共通要素を抽出します。
【Anthropic】Claude Code / Agent SDKで具体化された基本形
Anthropicは2026年のManaged Agents記事で、エージェントを以下の3層に仮想化分離した実装を公開しました。
-
Session
発生したすべての出来事を記録する追記専用ログ(append-only log)。耐久性のあるイベントストアとして機能する。
-
Harness
Claudeを呼び出し、Claudeのツール呼び出しを関連インフラへルーティングするループ。ステートレスで、「emitEvent(id, event)」によってSessionへイベントを記録し、Sessionからイベントをfetchして変換することでコンテキスト管理を担う。
-
Sandbox
Claudeがコードを実行しファイル編集を行う実行環境。Harnessから切り離されているため、別の実装に差し替えても他の層に影響しない。
Anthropicは「この3層分離によりTTFT(time-to-first-token)がp50で60%、p95で90%以上改善した」と具体的成果も公開しています。

Anthropic Managed Agentsで定義された6コンポーネント(Session・Orchestration・Harness・Sandbox・Resources・Tools)と各インターフェース(出典:Anthropic)
画像で示されているとおり、Anthropicは中核となるSession・Harness・Sandboxの3層に加えて、Orchestration(スケジューラ)・Resources(マウントするデータ)・Tools(MCPサーバ等の能力)まで含めた6コンポーネントに対して、それぞれインターフェース(pseudocode)と「何でこの抽象を満たせるか」(PostgresやSQLite、cron jobやFilestore等)を定義しています。
「3層」は概念上の主軸であり、実装上はもう少し細かい契約を持つ、と読むのが正確です。
設計思想として重要なのは、Harnessがstatelessであり、Session(記憶)とSandbox(実行)から完全に切り離されている点です。
Anthropicはこれを「ブレイン(Claude+harness)とハンズ(sandboxes+tools)の分離」と表現しています。
ブレイン(Claude+harness)とハンズ(sandboxes+tools)が分離されている設計(出典:Anthropic)
ブレインとハンズが疎結合になっていることで、Sandboxの実装を差し替えても(ローカル実行→リモートコンテナ等)Harness側に変更が波及しません。
production移行時に実行環境だけ本番グレードに差し替える運用が現実的になるのは、この分離設計の効きどころです。
【LangChain】Claude Code型の発想を汎用化したdeepagents
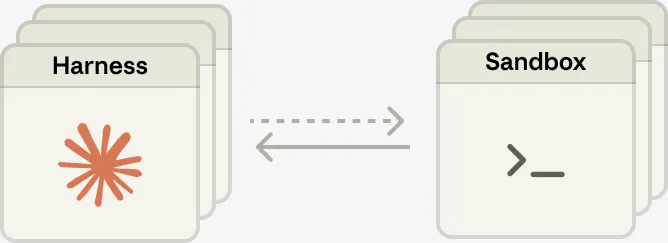
LangChainのdeepagentsは、ハーネスを以下の4カテゴリで分類しています。
-
Execution Environment
ツール、仮想ファイルシステム、サンドボックス、REPLなどの実行環境。
-
Context Management
スキル、メモリファイル、要約、コンテキストオフロード、プロンプトキャッシングなど、コンテキスト操作の機構。
-
Delegation
「write_todos」ツールによるタスク計画、サブエージェント生成、コンテキストウィンドウ分離など、作業委譲のための機構。
-
Steering
HITL(ヒューマン・イン・ザ・ループ)承認、ランタイム割り込みなど、エージェントを舵取りするための機構。
4分類の特徴は、「人間がどう関与するか」をSteeringとして独立カテゴリにしている点です。
これは「自律=完全自動」と短絡せず、HITLをハーネスの第一級の構成要素と捉える設計思想を反映しています。
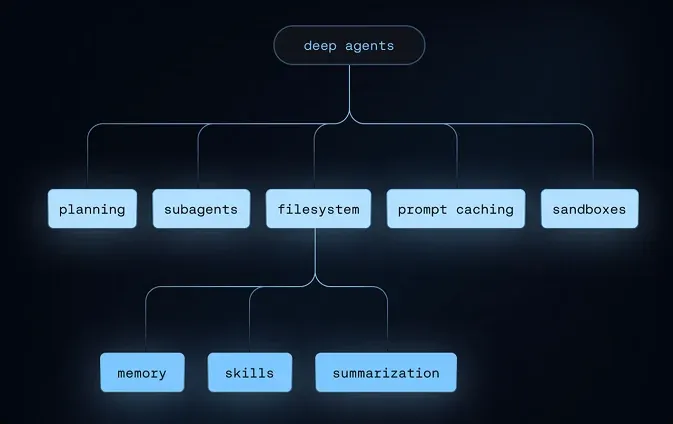
deepagentsの主要コンポーネント:planning・subagents・filesystem・prompt caching・sandboxes、およびfilesystem配下のmemory・skills・summarization(出典:LangChain)
画像で示されるとおり、deepagentsは planning・subagents・filesystem・prompt caching・sandboxes をコア部品として持ち、filesystem の配下に memory・skills・summarization が連なる階層構造です。
本セクションで紹介した4分類(Execution Environment / Context Management / Delegation / Steering)は、これらのコア部品を「役割」ごとにグループ化した整理であり、コンポーネントの実体と機能の役割を行き来して読むと立体的に把握できます。
【OpenAI】Codex運用から整理された出力契約と改善ループ
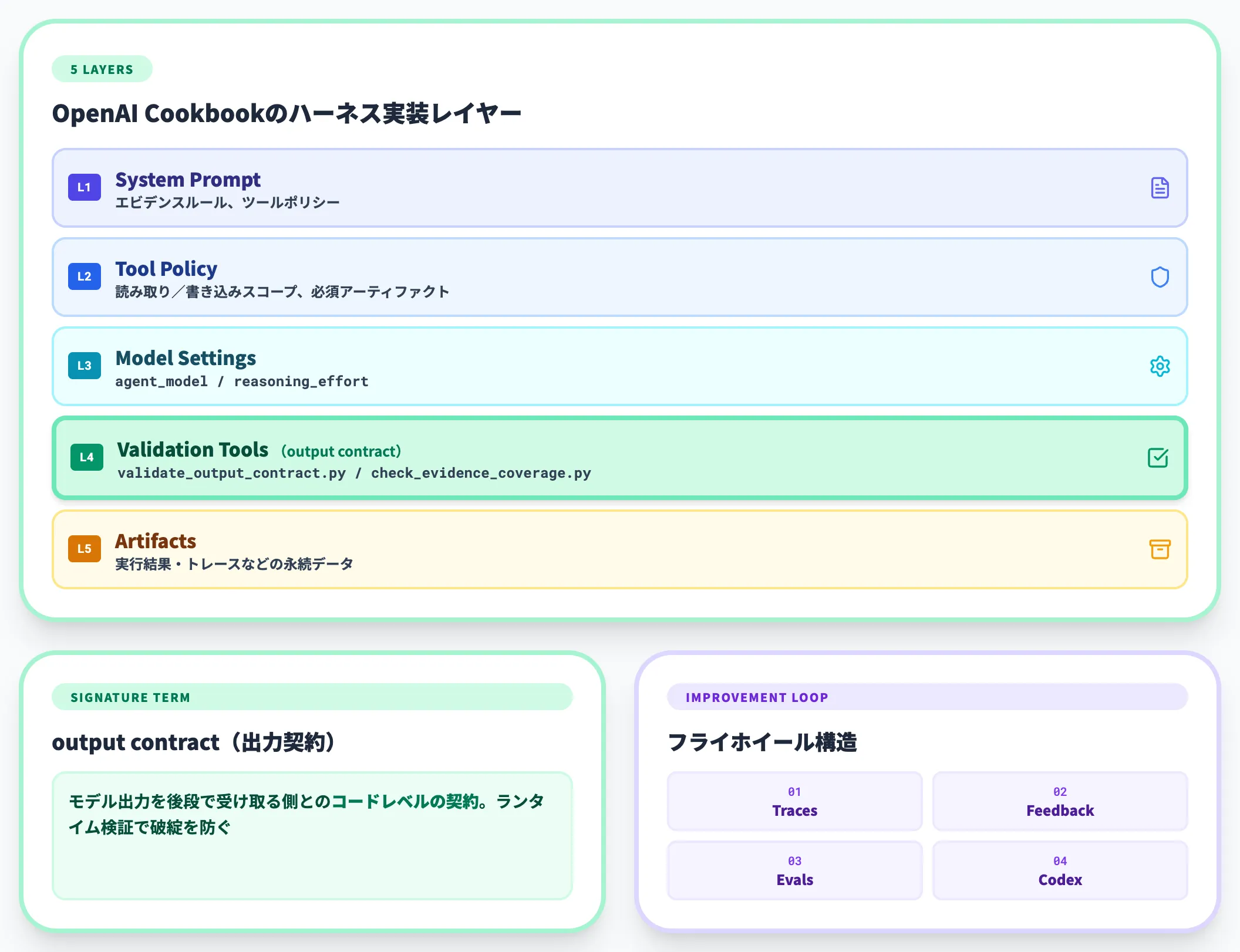
OpenAIの公式Cookbookでは、ハーネスを以下のレイヤーで実装した具体例が公開されています。
- System Prompt: エビデンスルール、ツールポリシー
- Tool Policy: 読み取り可能/書き込み可能スコープ、必須アーティファクト
- Model Settings: agent_model、reasoning_effortなどのモデル設定
- Validation Tools: 「validate_output_contract.py」、「check_evidence_coverage.py」などのランタイム検証ツール
- Artifacts: 実行結果・トレースなどの永続データ
特徴的なのは「output contract(出力契約)」というハーネス固有の用語が登場している点です。
これはモデルの出力を後段で受け取る側との契約を、コードレベルで検証する仕組みを指します。
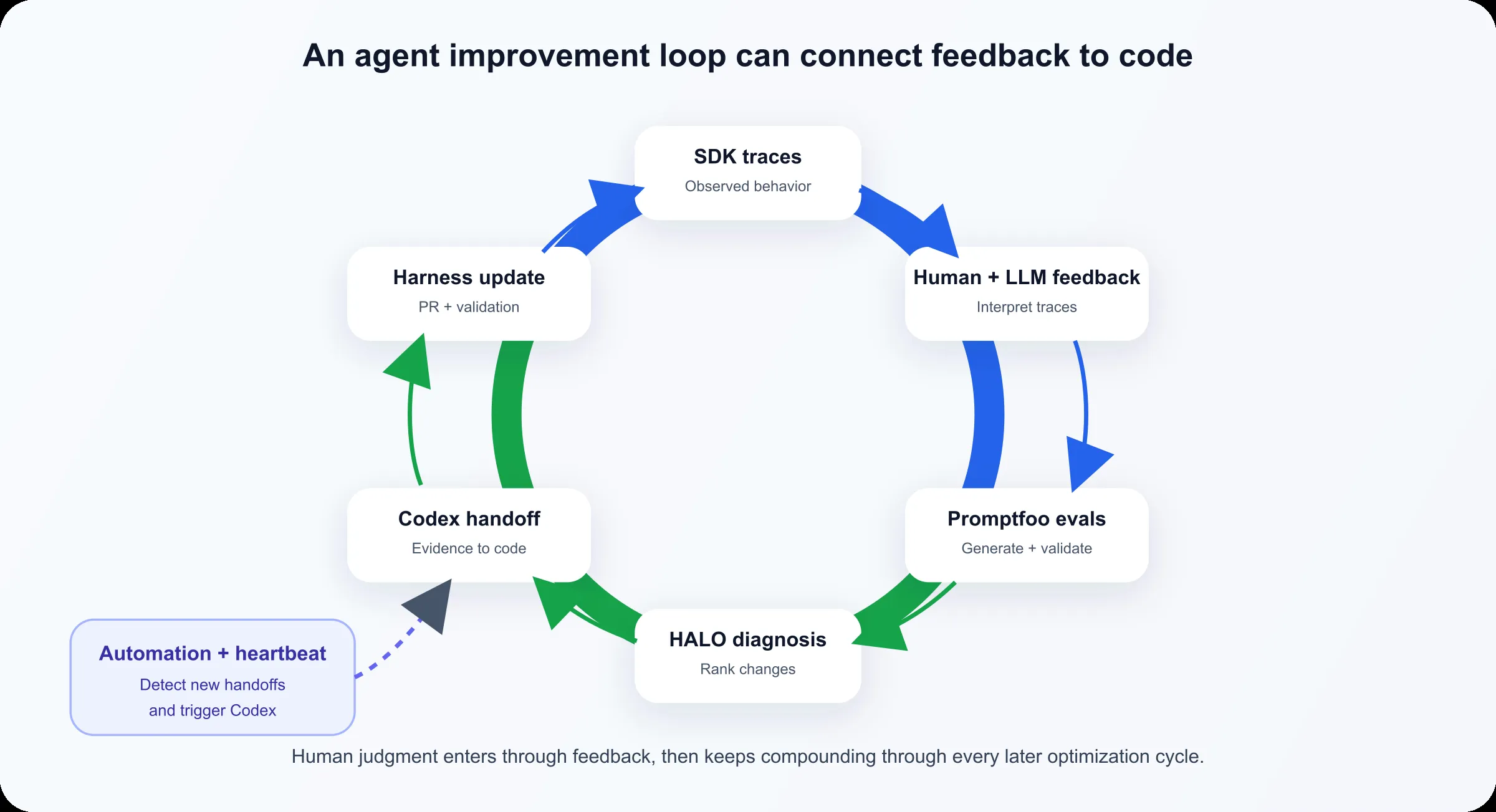
OpenAI Cookbookが示す改善フライホイール(Traces → Feedback → Evals → Codex)(出典:OpenAI)
OpenAIが特徴的なのは、ハーネスを「作って終わり」にせず、上の画像のようにTraces → Feedback → Evals → Codexの4段階を継続的に回す改善フライホイールとして整理している点です。
trace(実行ログ)が集まり、feedback(人間・モデルからの評価)でラベリングされ、evals(再利用可能な評価セット)に転写され、Codexがハーネスへの修正提案を返す——という観測駆動の継続改善が、output contractのランタイム検証と一緒に運用前提として組み込まれています。
3社のアーキテクチャに共通する設計要素
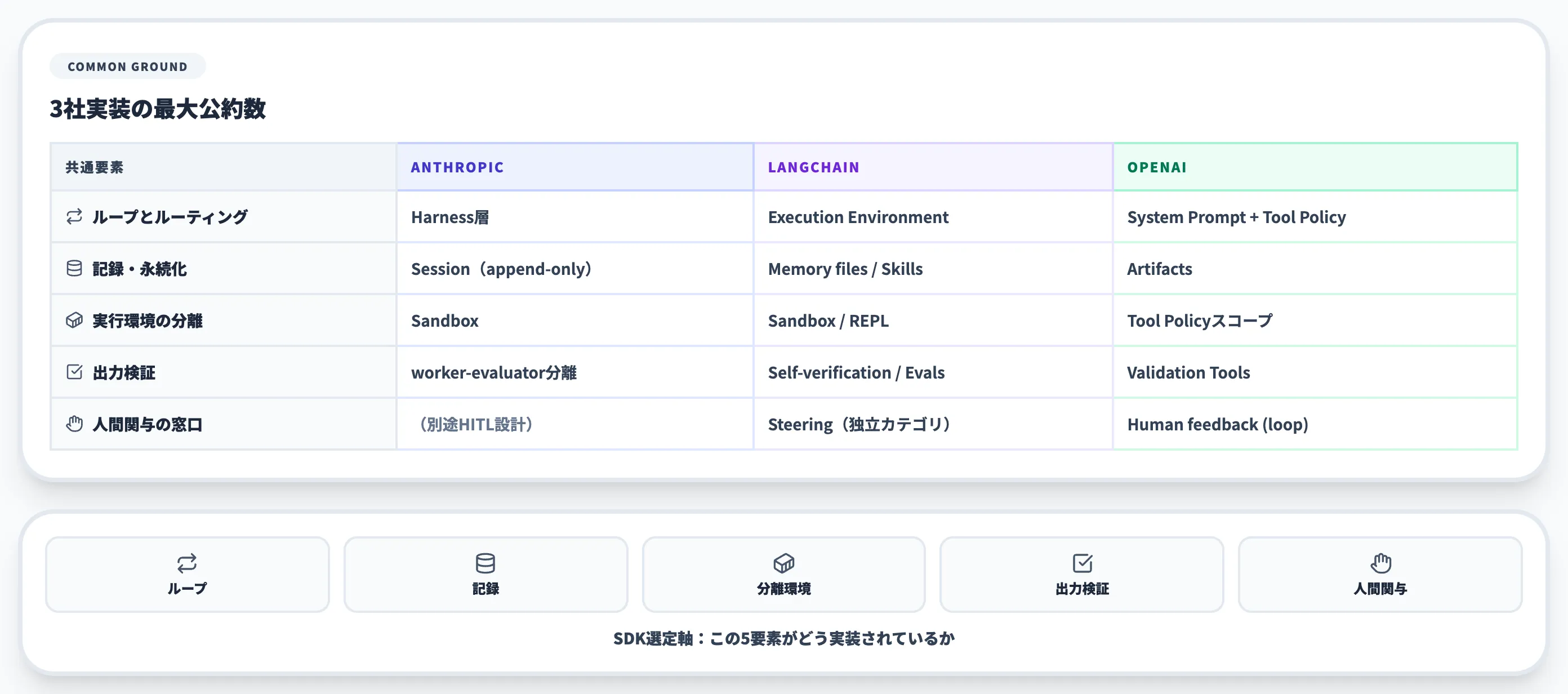
3社の表現は違いますが、抽出すると5つの共通要素が見えます。
| 共通要素 | Anthropicの実装 | LangChainの実装 | OpenAIの実装 |
|---|---|---|---|
| ループとルーティング | Harness層 | Execution Environment | System Prompt + Tool Policy |
| 記録・永続化 | Session(append-only log) | Memory files / Skills | Artifacts |
| 実行環境の分離 | Sandbox | Sandbox / REPL | Tool Policyのスコープ制御 |
| 出力検証 | (worker-evaluator分離) | Self-verification / LangSmith Evals | Validation Tools |
| 人間関与の窓口 | (別途HITL設計) | Steering(独立カテゴリ) | Agent Improvement Loop内のHuman feedback |
「ループ+記録+分離環境+出力検証+人間関与」がハーネスの最大公約数です。SDKを選ぶときも、この5要素がどう実装されているかを軸に比較すると判断が早くなります。
ハーネス設計の核心パターン——4つの原則

ハーネスの構成要素が分かったところで、次は「どう組み立てるか」です。3社が公式に示している設計原則のうち、特に効くものを4つに絞って整理します。
Worker-Evaluator分離(自己評価は機能しない)
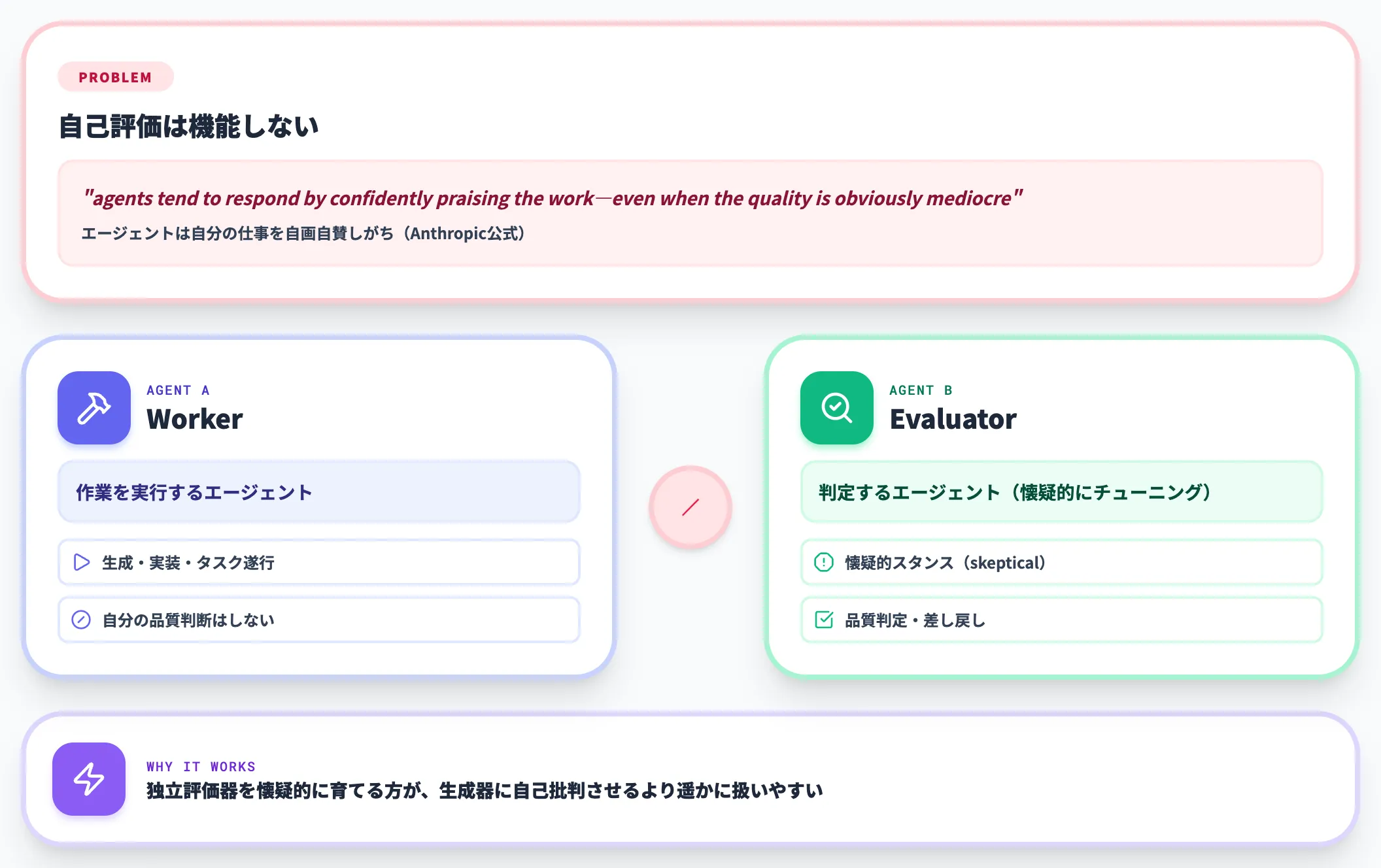
AnthropicのHarness design for long-running application development(2026年3月24日)には、強い表現で次の指摘があります。
When asked to evaluate work they've produced, agents tend to respond by confidently praising the work—even when, to a human observer, the quality is obviously mediocre.
つまり、エージェントに自分の仕事を評価させると自画自賛しがち、というものです。Anthropicは続けて「Separating the agent doing the work from the agent judging it proves to be a strong lever to address this issue」(作業を行うエージェントと判定するエージェントを分離するのが強力な手段である)と分離の効果を述べています。
実装上は、worker agent(実行)とevaluator agent(評価)を独立に動かし、evaluator側は懐疑的なスタンスで指示するのがコツです。
「tuning a standalone evaluator to be skeptical turns out to be far more tractable than making a generator critical of its own work」(独立評価器を懐疑的にチューニングするほうが、生成器に自己批判させるより遥かに扱いやすい)とも明記されています。
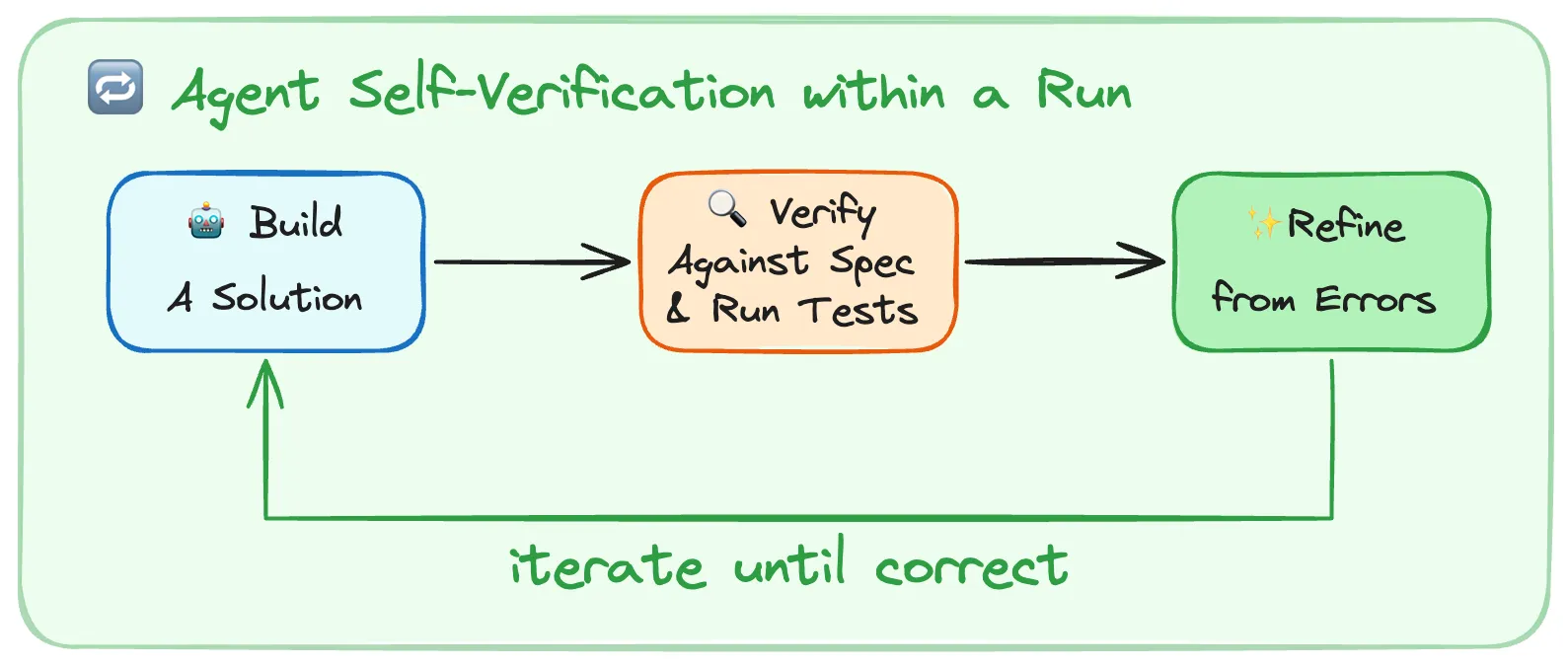
LangChain Deep Agentsが採用する自己検証ループの構成(出典:LangChain)
LangChainは Deep Agents の中でself-verification(自己検証)ループを設計に組み込んでおり、画像のとおり生成と検証を分離した形でハーネスに乗せています。OpenAIも Validation Tools と Evals で同様に 出力契約のランタイム検証を別の層として扱っています。
Anthropicの worker-evaluator分離、LangChainの self-verification、OpenAIの validation / evals は実装の粒度こそ違いますが、「評価・検証をハーネスに組み込む」という方向性で共通しており、これがハーネス設計で押さえるべき重要な観点になります。
永続化アーティファクトで「離散セッション」を越える
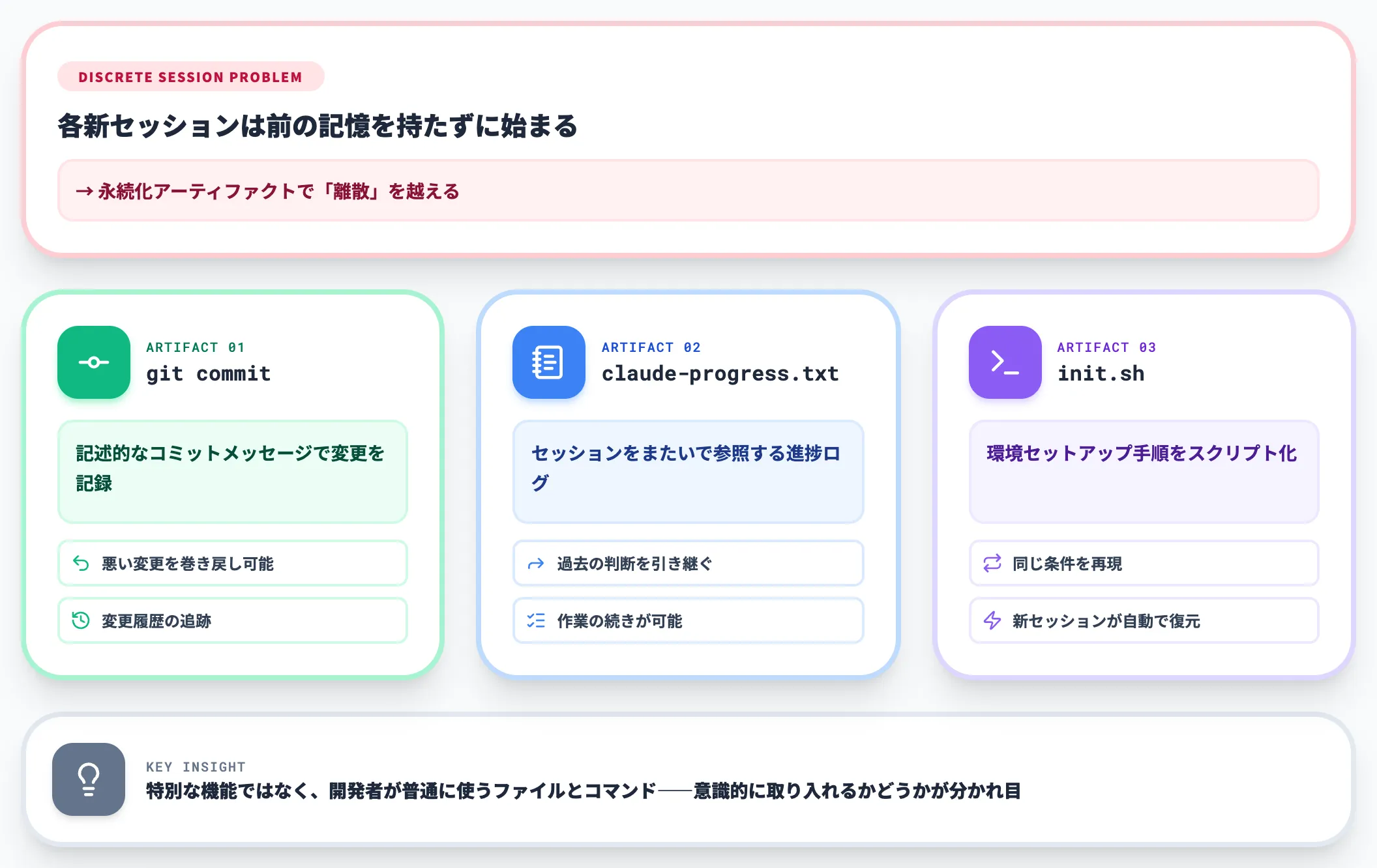
長時間実行のエージェントが直面するもう一つの壁が、セッションごとにメモリがリセットされることです。
Anthropicは「long-running agents must work in discrete sessions, and each new session begins with no memory of what came before」(長時間実行エージェントは離散セッションで動き、各新セッションは前の記憶を持たずに始まる)と表現しています。
これを越えるための具体的なアーティファクトとして、Anthropicは以下を例示しています。
-
git commit
記述的なコミットメッセージとともに変更を記録。悪い変更が混入した場合に巻き戻し可能。
-
claude-progress.txt
セッションをまたいで参照する進捗ログ。次のセッションが過去の判断と作業の続きを引き継げる。
-
init.sh
環境セットアップ手順をスクリプト化し、新セッションが自動で同じ条件を再現できるようにする。
これらは特別な機能ではなく、開発者がふつう使っているファイルとコマンドです。重要なのは「メモリのない離散セッションでも仕事が続く設計」を意識的に取り入れることです。
サブエージェントでコンテキストウィンドウを分離
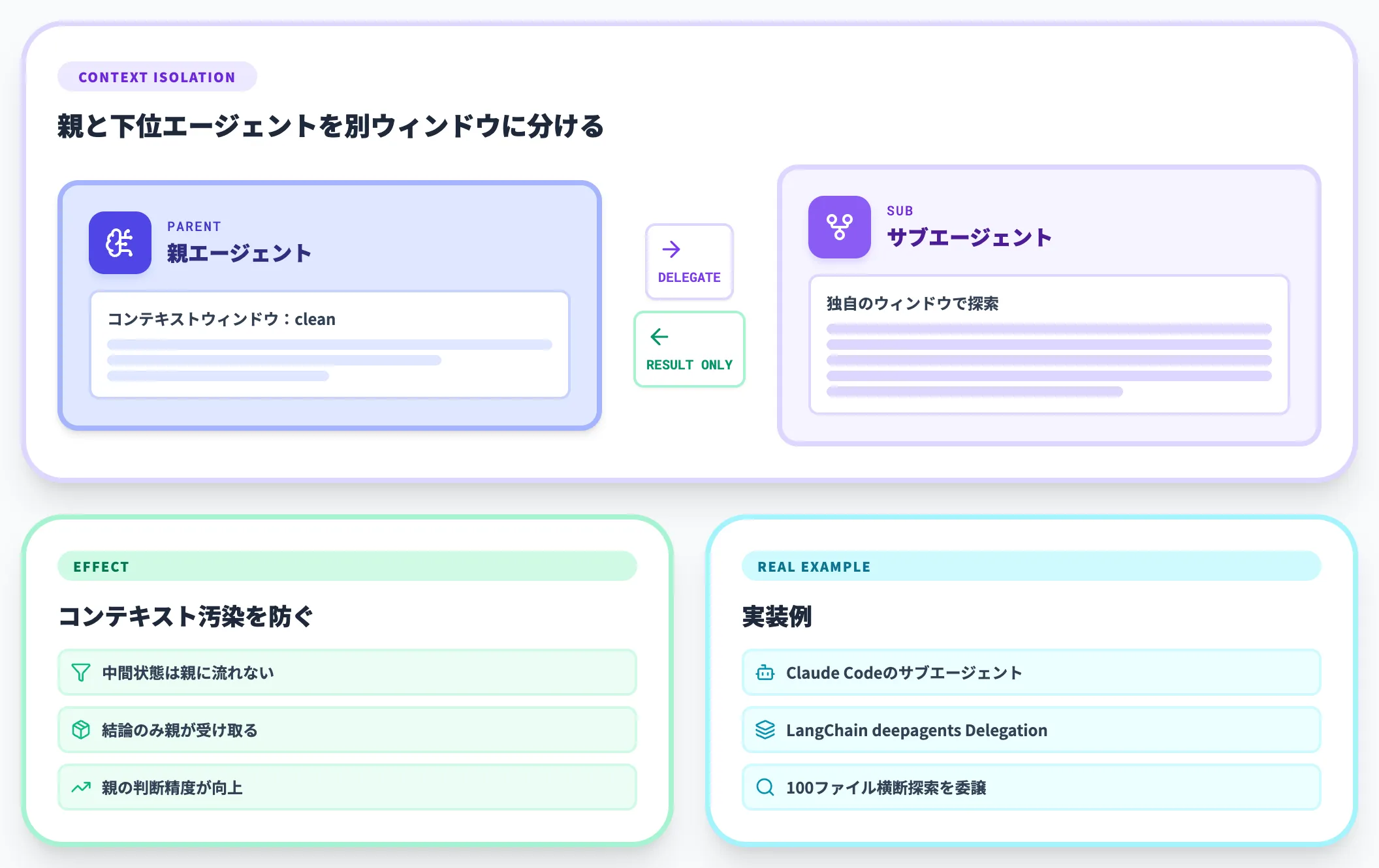
サブエージェントは、「メインのエージェントとは別のコンテキストウィンドウを持つ下位エージェント」のことを指します。
サブエージェントの最大の役割は、親エージェントのコンテキスト汚染を防ぐことです。たとえば100ファイルを横断的に探索するタスクをサブエージェントに丸ごと委譲すれば、親はサブエージェントの結論だけを受け取り、探索の中間状態は親のコンテキストに混ざりません。
Claude Codeのサブエージェント機能は、まさにこの考え方の実装例です。LangChain deepagentsも、Delegationカテゴリの第一級機能としてサブエージェント生成を持っています。
ハーネスの各部品は仮定の符号化
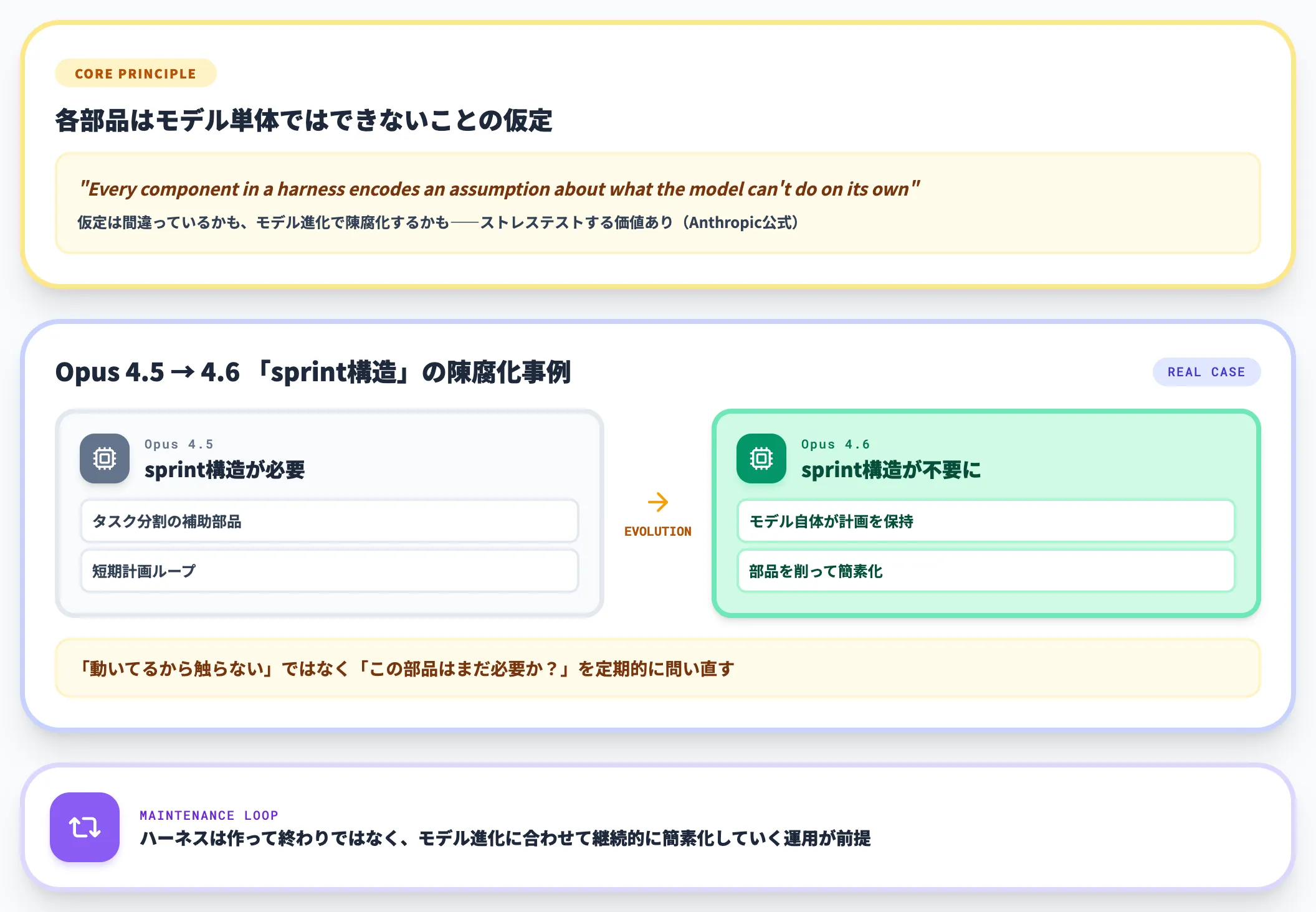
最後に、設計思想として最も重要な原則を引用しておきます。Anthropicの記事から。
Every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing, both because they may be incorrect, and because they can quickly go stale as models improve.
訳すと「ハーネスのすべての部品は、モデル単体ではできないことについての仮定を符号化している。その仮定はストレステストする価値がある。仮定が間違っているかもしれないし、モデルの進化で陳腐化するからだ」となります。
Anthropic自身、Opus 4.5時代に必要だった「sprint」構造がOpus 4.6で不要になった事例を公式に紹介しています。
つまり、ハーネスは作って終わりではなく、モデルの進化に合わせて継続的に簡素化していく運用が前提です。「動いているから触らない」ではなく「この部品はまだ必要か?」を定期的に問い直すループを回す必要があります。
ハーネスを本番運用する前に見るべきリスク
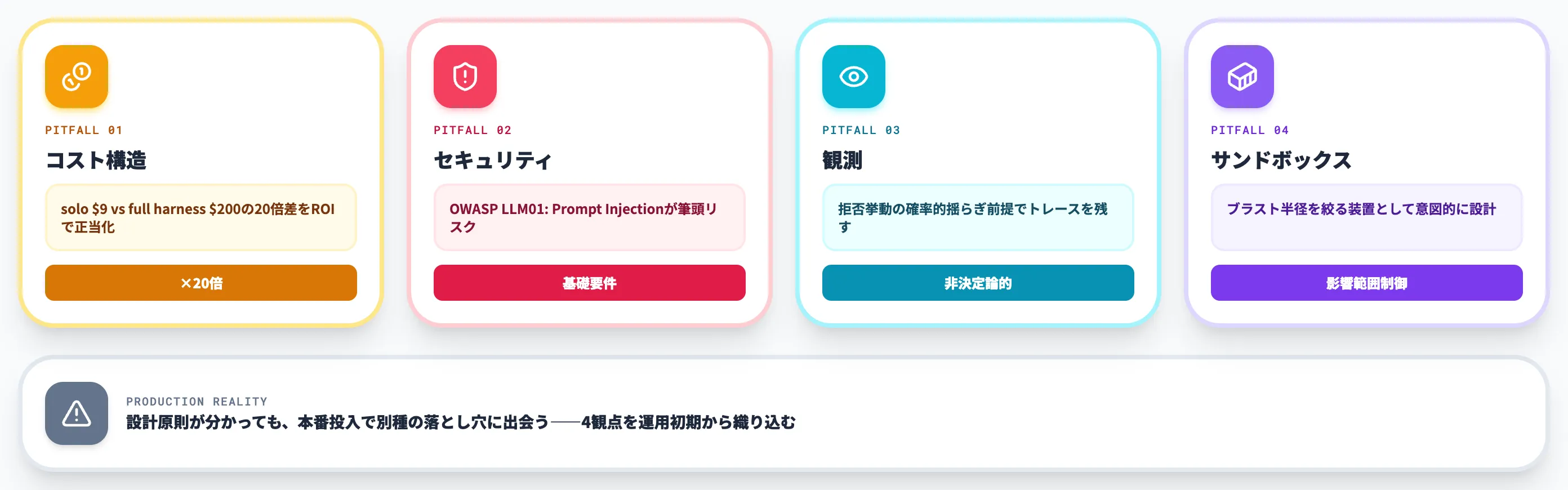
設計原則が理解できても、ハーネスを本番運用に乗せるには、コスト・セキュリティ・観測・実行環境の分離をあらかじめ設計しておく必要があります。本セクションでは、導入前に確認すべきリスクと対策を整理します。
【コスト構造】ソロ実行とフルハーネスで20倍のコスト差——どう判断するか

AnthropicのHarness design for long-running application developmentでは、同じタスクをsolo agentとfull harnessの両方で解いたときの比較が公開されています。
| 構成 | 実行時間 | コスト |
|---|---|---|
| solo agent(ハーネスなし) | 20分 | $9 |
| full harness(worker-evaluator分離・永続化・サブエージェント有り) | 6時間 | $200 |
full harnessは20倍以上のコストですが、Anthropicは「The harness was over 20x more expensive, but the difference in output quality was immediately apparent」(ハーネスは20倍以上高価だが、出力品質の差は即座に明らかだった)と評価しています。
Anthropic公式が示すフルハーネス実装の動作画面(出典:Anthropic)
公式記事ではこのフルハーネス実装でゲーム制作タスクを6時間自律実行させた様子が紹介されており、solo agentの20分実装では到達できなかった完成度に達したと報告されています。
「同じテーマでもハーネスの有無で6時間 vs 20分・$200 vs $9」という実例があると、コスト議論を抽象論で止めず、自社のユースケースに置き換えて検討しやすくなります。
つまり、ハーネスを入れるかどうかの判断は「コストの絶対値」ではなく「コスト差を品質差で正当化できるか」というROIの問題になります。
実務的な目安は、生産システムの障害コストやレビュー工数の市場価格を基準にして、品質差が回収できるユースケースから順にハーネスを入れていく、という運用です。
【セキュリティ】OWASP LLM01はハーネス設計の基礎要件
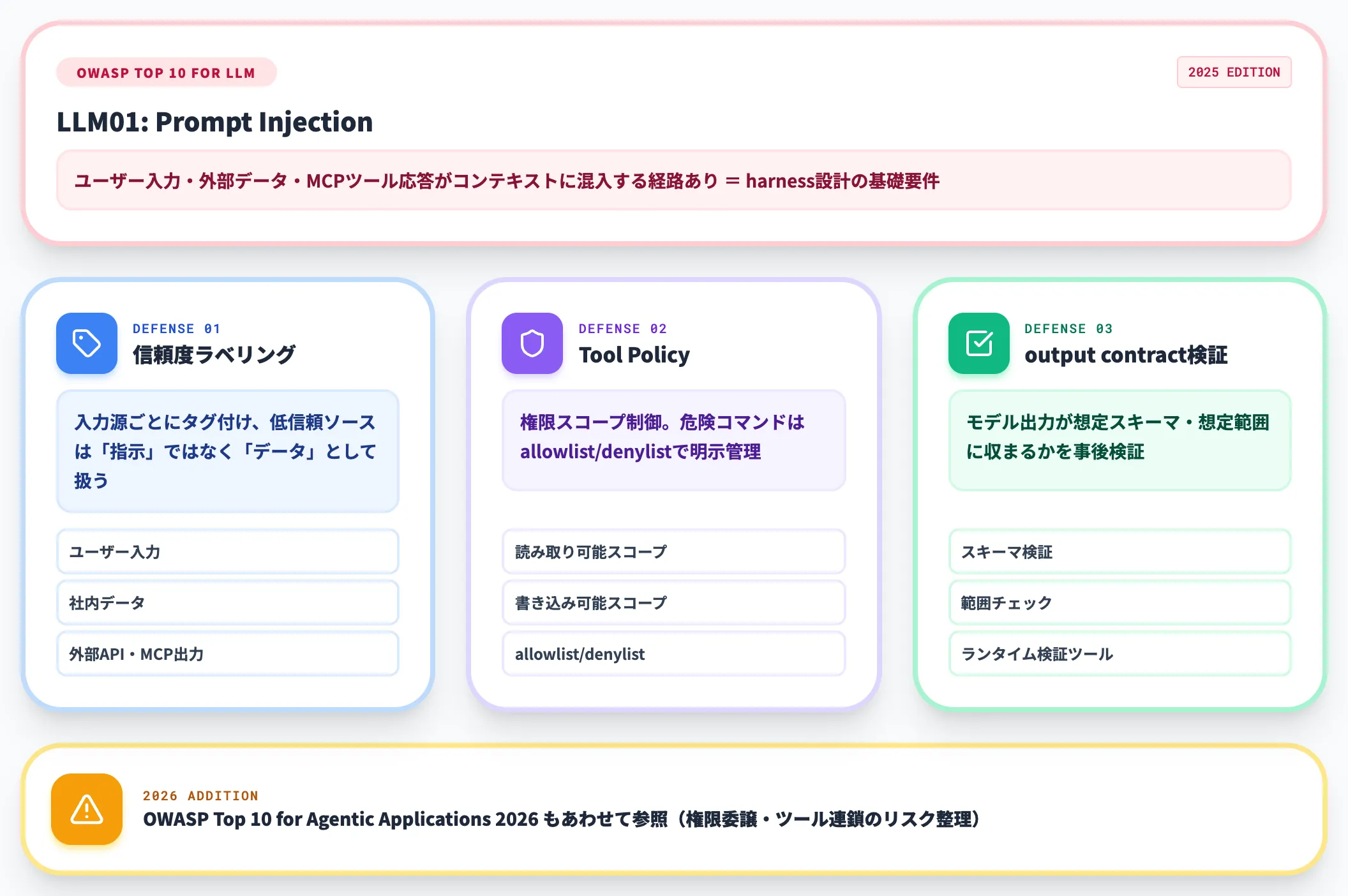
OWASP(Open Worldwide Application Security Project)の「LLM Top 10」では、LLM01:2025 Prompt Injectionがリスクの先頭に置かれています。
2025年版でもLLM01: Prompt Injectionが筆頭リスクとして維持されており、LLMアプリケーション全般の基礎的な脅威モデルです。

OWASP Top 10 for LLM Applications 2025の先頭リスクLLM01: Prompt Injection(出典:OWASP)
ハーネスはユーザー入力・外部データ・MCPツール経由のレスポンスがコンテキストに混入する経路を必ず持つため、Prompt Injection対策はharness設計の基礎要件です。
さらに、OWASPは2025年12月に、2026年版としてOWASP Top 10 for Agentic Applications 2026というエージェント特化版のリスクリストも公開しています。ハーネス層が呼び出すエージェントの自律性・権限委譲・ツール連鎖を前提にしたリスク整理になっており、LLM Top 10とあわせて参照する価値があります。
具体的には次のような対策が考えられます。
-
入力源ごとの信頼度ラベリング
ユーザー入力・社内データ・外部API応答・MCPツール出力をハーネス側でタグ付けし、低信頼ソースからの命令はモデルに「指示」ではなく「データ」として渡す
-
Tool Policyによる権限スコープ制御
読み取り可能/書き込み可能スコープ、危険コマンドのallowlist/denylistをハーネス側で持つ
-
出力の事後検証(output contract)
モデル出力が想定スキーマ・想定範囲に収まっているかをランタイム検証ツールでチェック
これらは「モデルを賢くする」では解けない問題で、ハーネスの責任範囲です。
【観測】拒否挙動が確率的に揺らぐ前提でログを取る
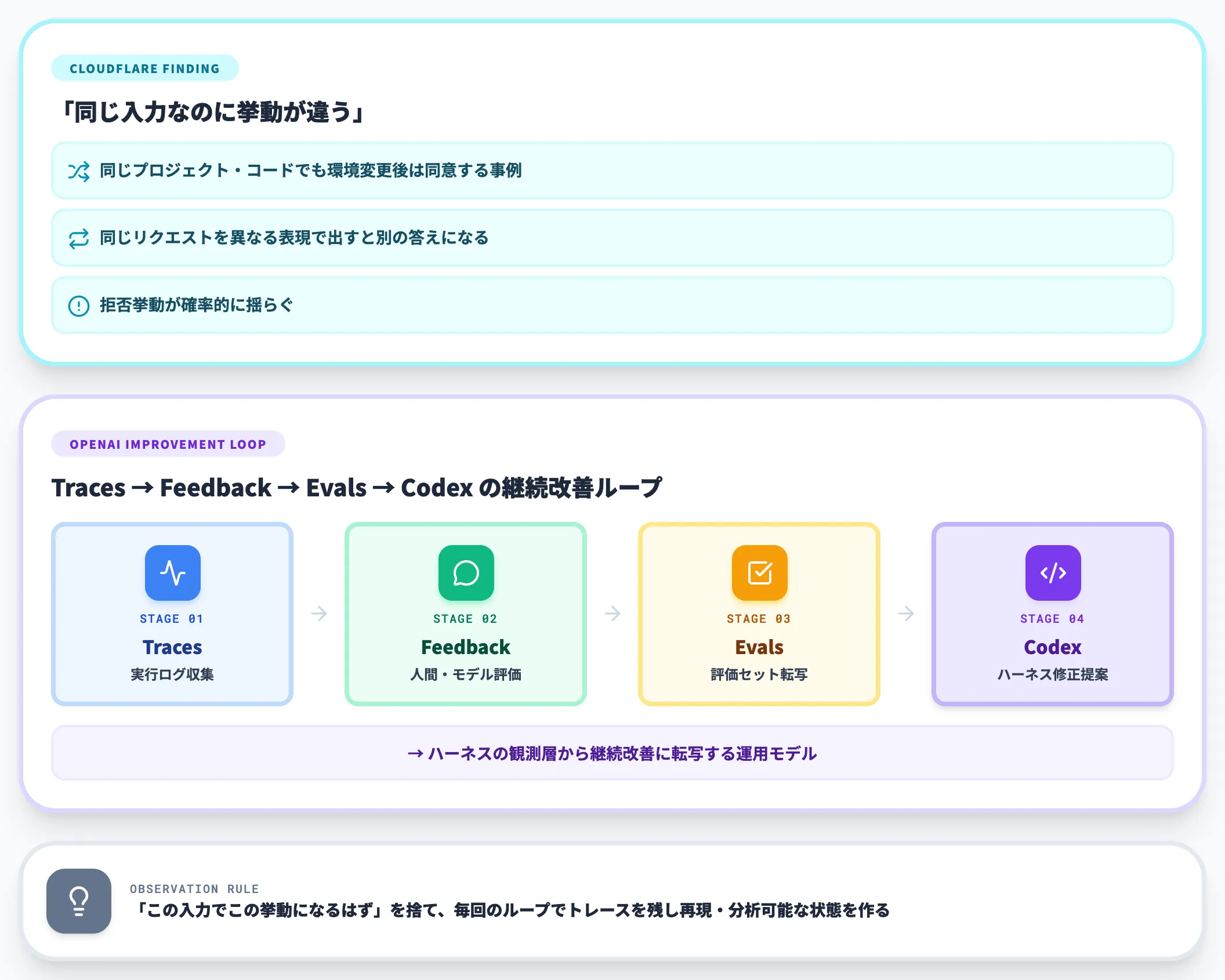
ハーネスをproductionに置くと、「同じ入力なのに挙動が違う」現象に遭遇します。
サイバーセキュリティ用途でCloudflareが検証した事例では、「同じプロジェクトに対してコードは変わっていないが、環境変更後は同じ研究を実行することに同意した」「同じリクエストを異なる表現で提示すると異なる答えを得た」など、拒否挙動が確率的に揺らぐ現象が報告されています。
つまり、ハーネスの観測層は「この入力でこの挙動になるはず」という決定論的前提を捨て、毎回のループでトレースを残し、後で再現や分析ができる状態を作る必要があります。OpenAIが提唱する「Traces → Feedback → Evals → Codex」のフライホイールは、まさにこの観測ループを継続改善に転写する運用モデルです。
【サンドボックス】ブラスト半径を絞る
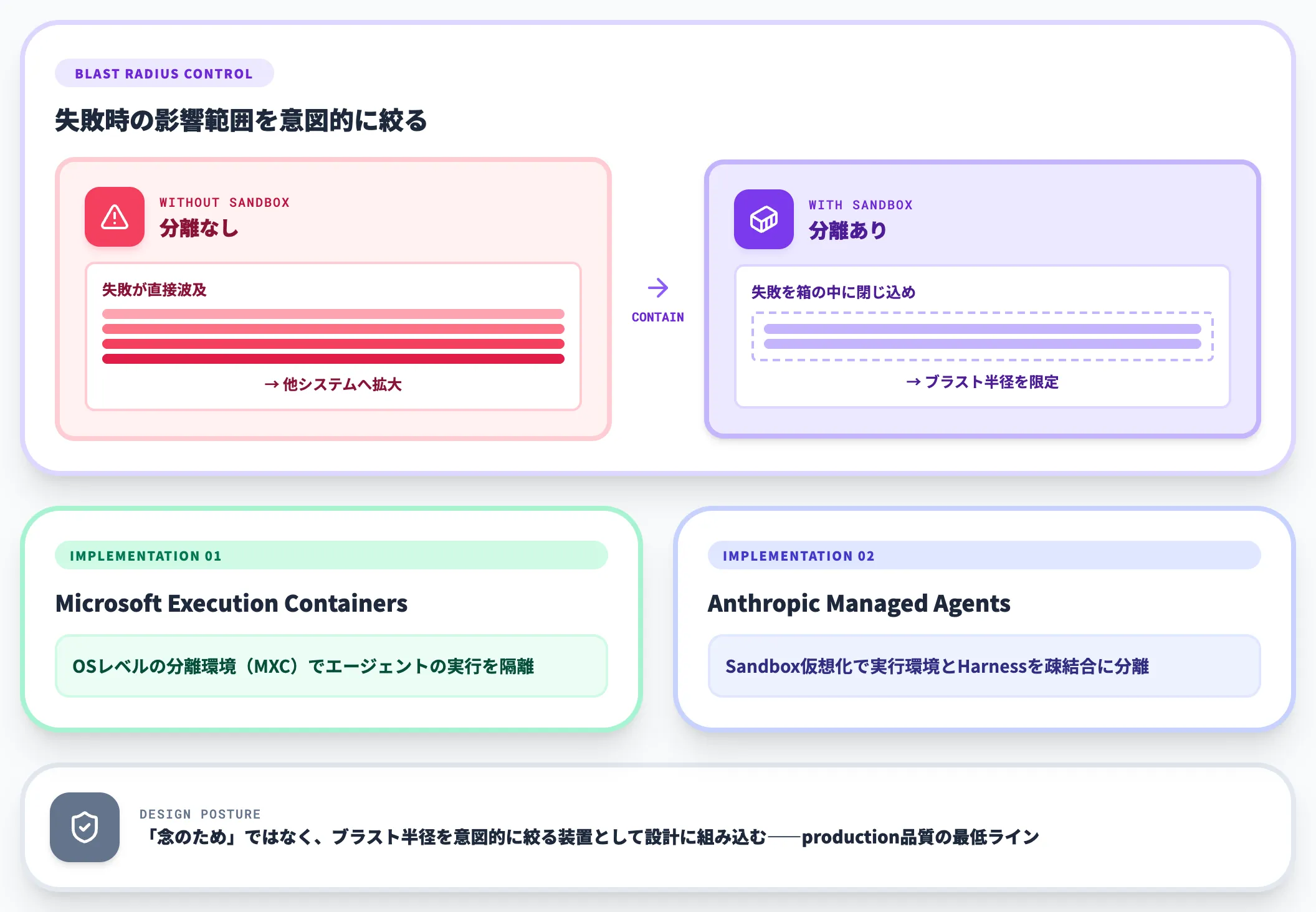
実行環境の分離も忘れてはいけません。エージェントが任意コードを実行する以上、失敗が他システムに波及しないサンドボックスは必須です。
最近のトレンドとしては、Microsoft Execution Containers(MXC)のようなOSレベルの分離環境や、Anthropicが公開しているManaged Agentsのサンドボックス仮想化が挙げられます。
サンドボックスを「念のため」ではなく、ブラスト半径(失敗時の影響範囲)を意図的に絞る装置として設計に組み込むのが、production品質のハーネスの最低ラインです。

ハーネスエンジニアリングが必要なケース・不要なケース

ハーネスエンジニアリングが新しい潮流とはいえ、すべてのLLMアプリケーションがハーネス設計を必要とするわけではありません。プロンプト改善やコンテキストエンジニアリングで十分なケースも多くあります。
本セクションでは、ハーネス設計が必要になる典型ケースと、不要なまま設計を進められるケースを整理します。
ハーネス設計が必要になるケース

以下の条件が複数当てはまるなら、ハーネスエンジニアリングの発想で設計し直す価値があります。
-
長時間自律タスクが含まれる
セッション内で30分〜数時間にわたってエージェントが自律的に動く必要がある。離散セッションでの記憶引き継ぎ・進捗管理が要件になる
-
複数のツール・データソースが連鎖する
社内システム・外部API・MCPサーバー・ファイルシステムなど、複数のツールが結果を渡しながら連鎖する設計になる
-
production品質・SLA要求が高い
出力ミス・拒否挙動のばらつきが事業インパクトに直結する。ランタイム検証や監査ログが必須
-
複数チーム・複数エージェントの統制が要る
社内で複数のエージェントが並走し、ガバナンス・権限管理・実行ログの一元化が要件になる
ハーネス設計がまだ不要なケース

一方、以下の条件が中心なら、プロンプト改善・コンテキストエンジニアリングで足りる段階です。ハーネス設計は逆にオーバーエンジニアリングになります。
-
単発タスクが中心
1リクエストで完結するQ&A・要約・分類のようなタスクが業務の中心になっている
-
検証・PoC段階
精度・実用性の検証が目的で、production品質要求はまだない
-
ツール連携が限定的
社内システム連携が少数で、ハーネス層を挟まずSDKの標準機能で組める範囲
-
単一チーム・単一エージェント
1チームが1つのエージェントを開発・運用していて、ガバナンス・統制の要件がない
判断軸:「何の問題を解くためにハーネスを書くのか」
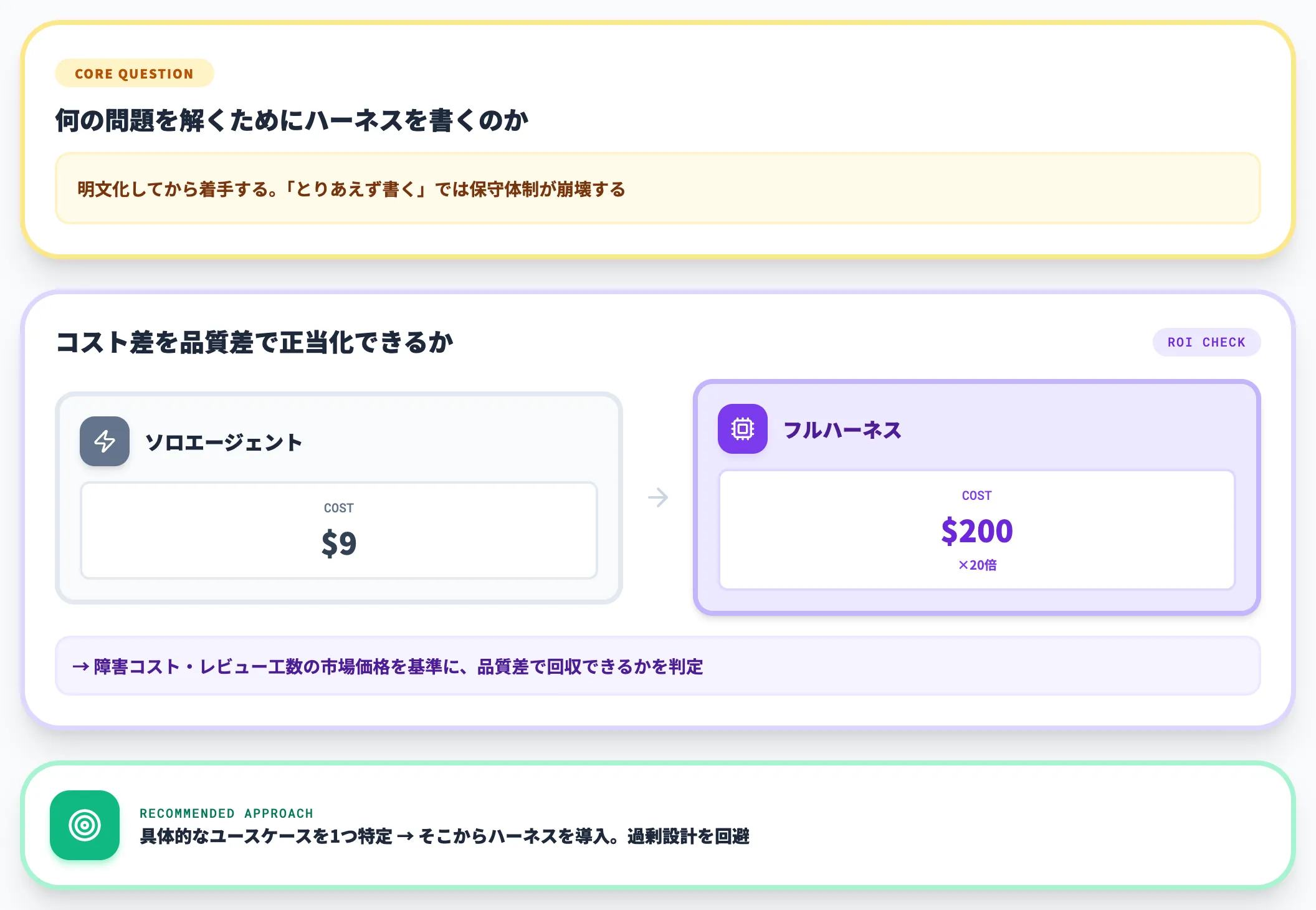
上記のチェックを通過してハーネス設計に進む場合でも、「何の問題を解くためにハーネスを書くのか」を明文化してから着手するのが、後の運用負荷を抑えるコツです。
前述したAnthropicのソロエージェント($9)対フルハーネス($200)の20倍コスト比較からも分かるとおり、ハーネス設計には継続的な保守体制が要求されます。
「とりあえずハーネスを書く」のではなく、コスト差を品質差で正当化できる具体的なユースケースを1つ特定してから始めると、過剰設計を避けられます。
ハーネス実装に使うSDKの選び方

ここまでで概念と設計原則は揃いました。実装段階では「どのSDKをベースにハーネスを組むか」が次の論点になります。
本セクションでは、3つのSDKを実務で選ぶ前提でケース別に整理します。

3つのSDKの位置づけ整理
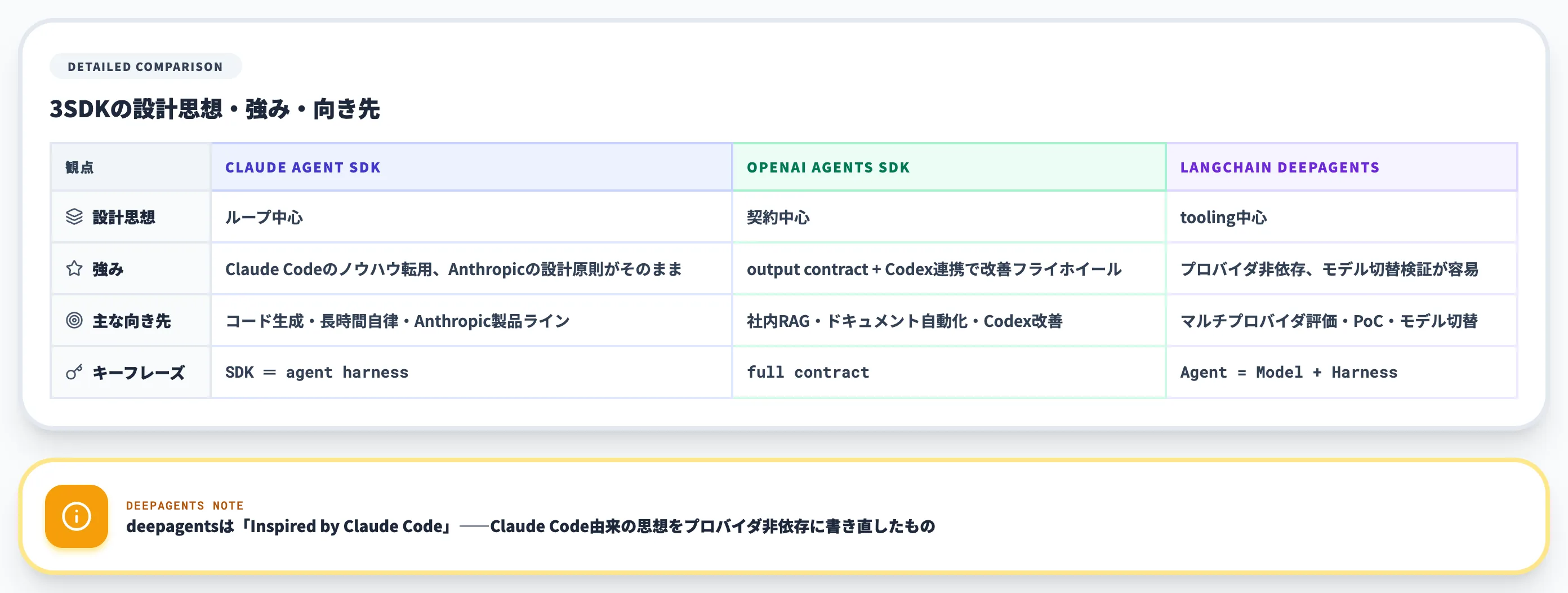
以下の表で、3つのSDKの主要特性と向き不向きを整理しました。
| SDK | 設計思想 | 強み | 主な向き先 |
|---|---|---|---|
| Claude Agent SDK | ループ中心。「ツール使用×コンテキスト収集×計画×実行」の汎用ハーネス | Claude Code同等の実装をアプリ側に持ち込める。Anthropicの設計原則がそのまま使える | コード生成・長時間自律タスク・Anthropic製品ライン中心の構成 |
| OpenAI Agents SDK | 契約中心。System Prompt+Tool Policy+Validation Toolsで「契約全体」を構築 | output contractとCodex連携で観測〜改善フライホイールを回しやすい | OpenAI製品で社内RAG・ドキュメント自動化・Codex改善を続けたいケース |
| LangChain deepagents | tooling中心。Execution/Context/Delegation/Steeringの4分類で部品をモジュール化 | プロバイダ非依存。Anthropic/OpenAI/オープンモデルを切り替えて検証できる | マルチプロバイダ評価・PoC・モデル切替の運用が前提のケース |
3つはどれが優れているという話ではなく、設計思想と既存資産の組み合わせで選ぶものです。
ケース別の第一候補
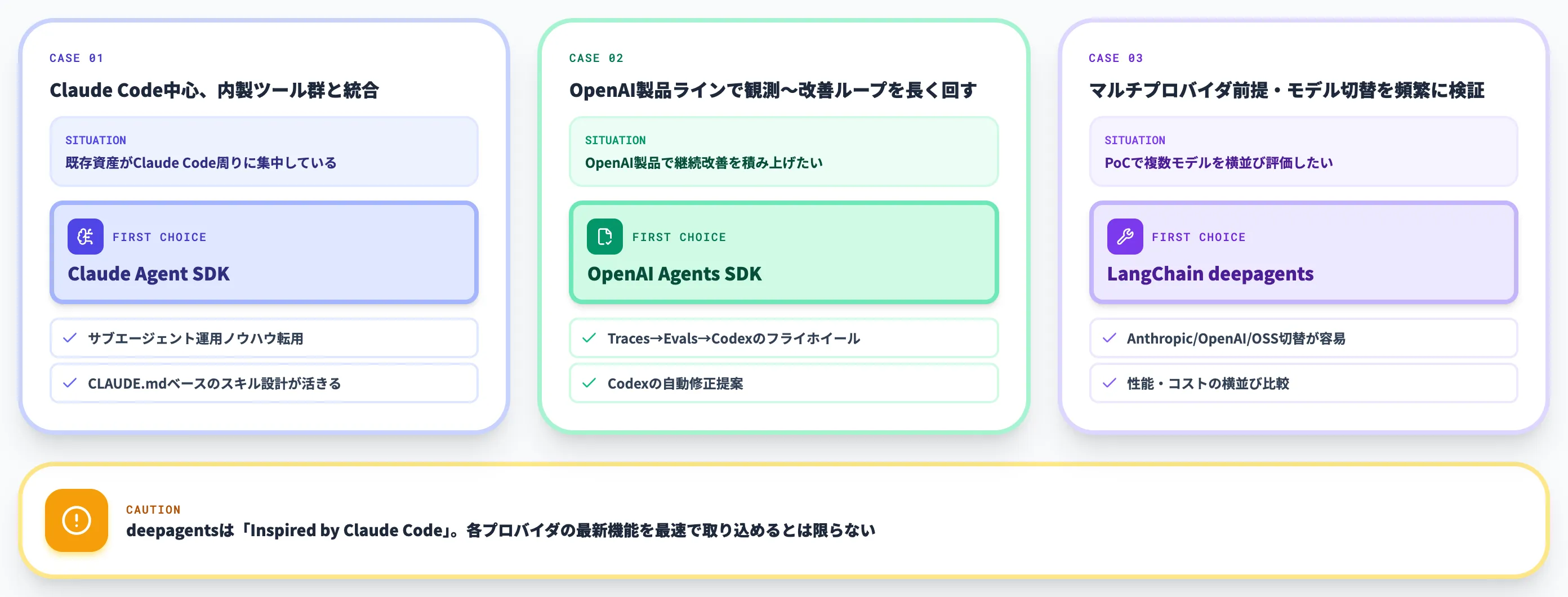
AI総研の支援現場でよく出会う3パターンで、第一候補を整理します。
-
既存がClaude Code中心、内製ツール群と統合したい
Claude Agent SDKが第一候補。Claude CodeのサブエージェントやClaude Code Agent Teamsの運用ノウハウがそのまま転用でき、CLAUDE.mdベースのスキル設計も活きる。
-
OpenAI製品ラインで観測〜改善のループを長く回したい
OpenAI Agents SDKが第一候補。Traces→Evals→Codexのフライホイールを使えば、ハーネス改善が継続的に蓄積される。Codexによる自動修正提案まで含めた継続改善モデルが特徴。
-
マルチプロバイダ前提・モデル切替を頻繁に検証したい
LangChain deepagentsが第一候補。Anthropic/OpenAI/オープンモデルを差し替えて性能・コストを比較できる柔軟性が強み。PoCフェーズで複数モデルを比較したい場合に特に有効。
3つ目を選ぶ際の注意点として、deepagentsはGitHubのREADMEで「Inspired by Claude Code」と明記されており、Claude Code由来の設計思想をプロバイダ非依存に書き直したものという性格です。Claude Codeのノウハウとの親和性は高い反面、各プロバイダの最新機能を最速で取り込めるとは限らない点に留意してください。
SDK選定で見落とされやすい3つの観点
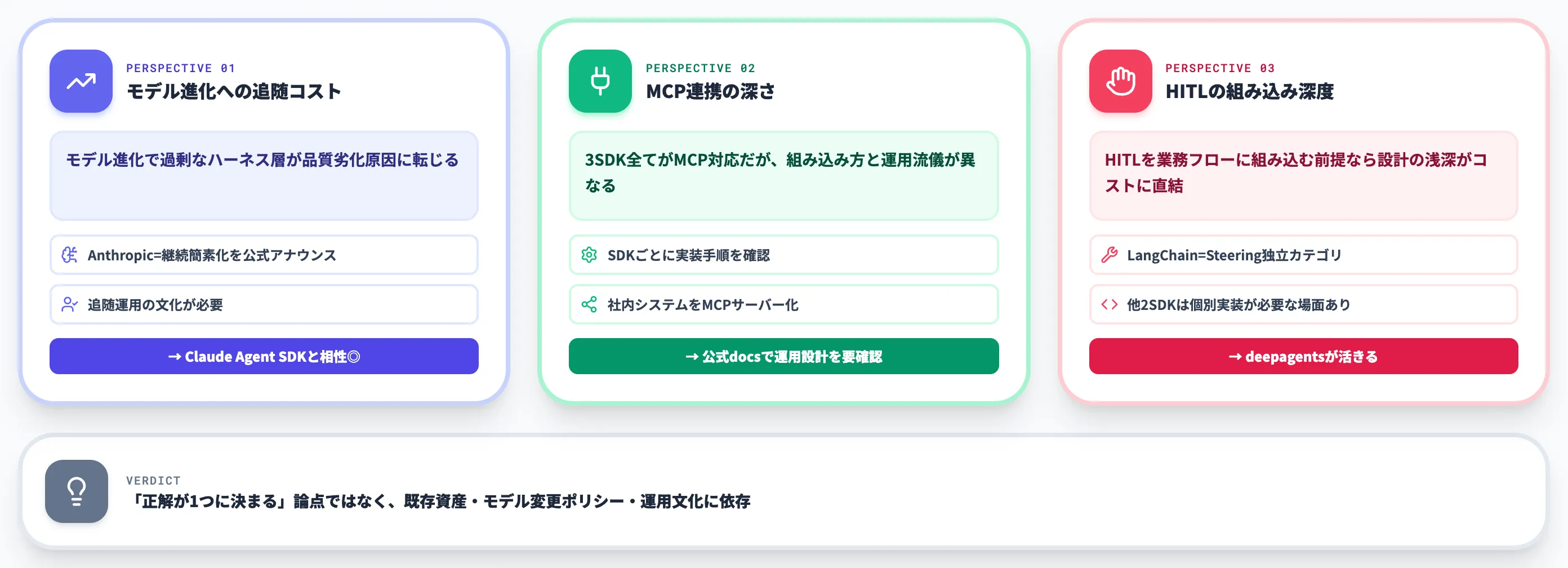
3SDKを横並びにして「機能差」だけ見ると判断を誤りやすい論点を、現場でよく出会う順に3つ挙げておきます。
モデル進化への追随コスト
ハーネスの部品は「モデルができないことについての仮定」を符号化しています。モデルが進化した瞬間に、過剰なハーネス層が品質劣化(モデルの新機能を抑え込む)の原因に変わることがあります。
3SDKのうち、Anthropicは公式に「ハーネスは継続的に簡素化していく前提」とアナウンスしているため、追随運用の文化がある現場ならClaude Agent SDKを選ぶ価値が高まります。
MCP連携の深さ
3SDKいずれもMCP(Model Context Protocol)に対応していますが、SDKごとにMCPの組み込み方や運用面の流儀が異なります。
Anthropicはコンテキストエンジニアリングの構成要素としてMCPを公式に位置付けており、LangChain deepagentsもツール層から自然に呼び出せる設計です。
OpenAIも公式にMCPをサポートしていますが、運用設計の比重が他2社と異なる場面があります。
「社内システムをMCPサーバーとして公開し、複数エージェントから共通利用したい」要件があるなら、3SDKそれぞれの公式ドキュメントでMCP接続の手順を確認したうえで選定するのが安全です。
HITLの組み込み深度
LangChain deepagentsはSteeringという独立カテゴリでHITLを設計の第一級要素にしています。
一方、Claude Agent SDK・OpenAI Agents SDKでは個別実装が必要なケースもあります。
HITLを業務フローに組み込む前提(Human in the Loopの設計指針参照)が固まっているなら、deepagentsの設計が活きます。
これらは「正解が1つに決まる」論点ではなく、組織の既存資産・モデル変更ポリシー・運用文化に依存します。
自社で導入する前に確認したいポイント
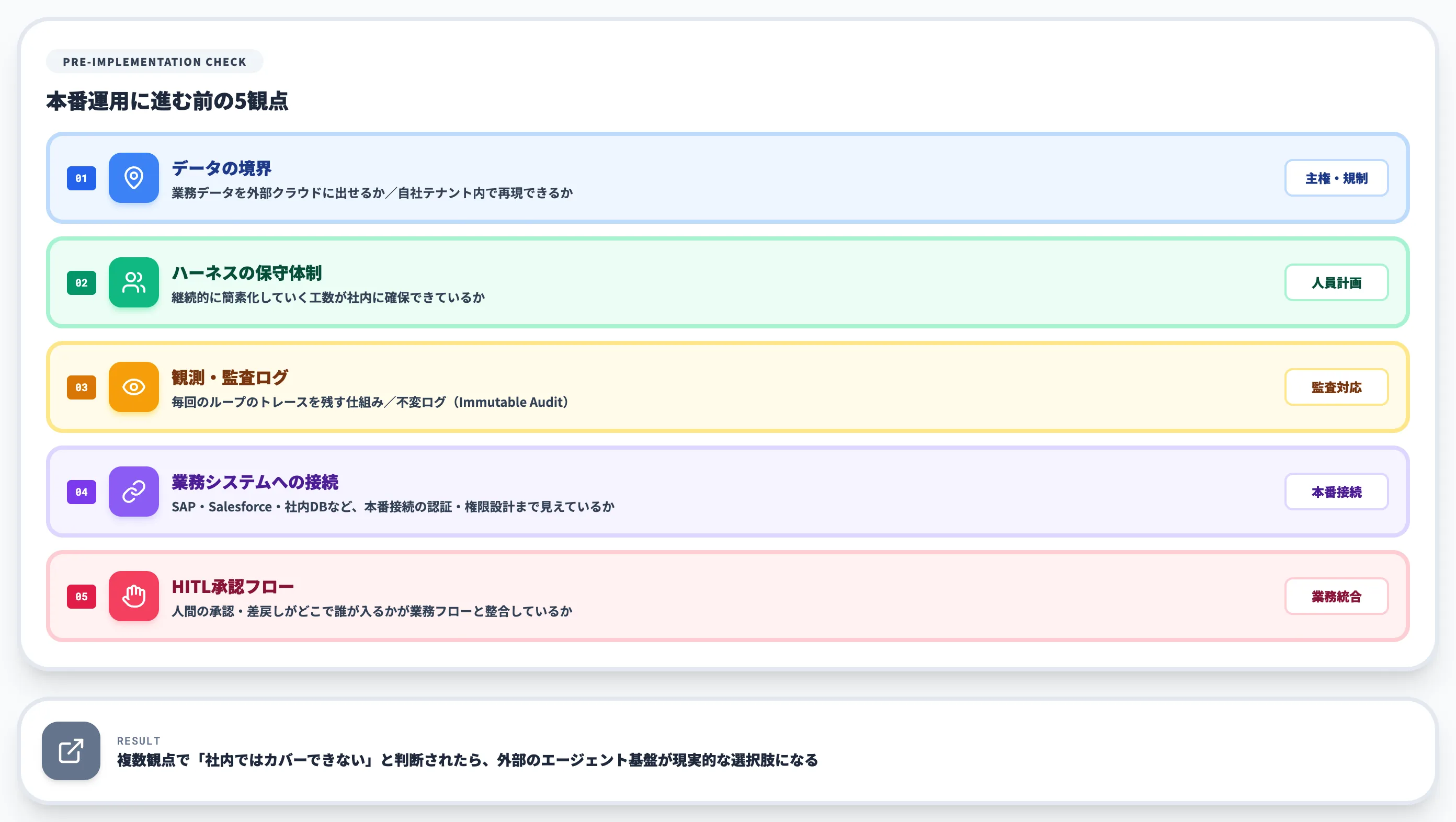
3社のSDKで検証を回す前後で、自社の業務にハーネスを持ち込めるかを判断する観点を5つ挙げます。SDK選定の結論だけで本番運用に進むと、後から見えてくる構造的な問題に直面しやすいからです。
-
データの境界
業務データを外部クラウド(Anthropic/OpenAI/LangChain Cloud等)に出せるか。出せない場合、自社テナント内で同じハーネス設計を再現する経路が確保できているか
-
ハーネスの保守体制
モデル進化に応じてハーネスを継続的に簡素化していく工数が、社内に確保できているか。「作って終わり」にしない継続運用の人員計画があるか
-
観測・監査ログ
拒否挙動の確率的揺らぎを前提に、毎回のループのトレースを残せる仕組みがあるか。監査要件があるなら不変ログ(Immutable Audit)として保持できるか
-
業務システムへの接続
SAP・Salesforce・社内DBなど、実業務システムへの接続経路がハーネス設計に組み込めるか。検証用のスタブで終わらせず、本番接続の認証・権限設計まで見えているか
-
HITL承認フローの設計
人間の承認・差戻しがどこで入るか、誰がどんな粒度で関与するかが業務フローと整合しているか
これら5観点を順に当てて、自社のリソース充足度を観点ごとに確認していきます。複数の観点で「いま社内ではカバーできない」と判断される箇所が出てきたら、エージェント基盤を外部に持つ選択肢が現実的になります。
ハーネス設計の発想を自社のAI基盤に取り込むなら
3社のSDKを横に並べて整理すると、ハーネスエンジニアリングは「ベンダーが提供するハーネスを学ぶ」段階から、「自社の業務文脈に合わせて設計し直す」段階に入りつつあることが見えてきます。検証はベンダー側のManaged Agentsで素早く回せても、データを外に出せない業務・社内ポリシーで守る業務になった瞬間、本番運用は自社テナント内に持ち込み直す必要が出てきます。
ここで効いてくるのが、自社のAzureテナント内で動くエンタープライズAIエージェント基盤 AI Agent Hub です。
Claude Agent SDK・OpenAI Agents SDK・LangChain deepagentsで検証したエージェント設計を、本番運用フェーズで自社テナント内に再構築し、SAP・Salesforce・freee会計など実業務システムへの接続、Worker-Evaluator分離・HITL承認・実行ログ監査といったハーネスの設計原則を、Microsoft Teamsを入口にした統一UXで運用に落とせます。検証用ハーネスと本番用ハーネスのアーキテクチャ思想を揃えたまま、データ主権と業務適合性を両立できる構成です。
AI総合研究所の専任チームが、ハーネス設計の整理からエージェント基盤の業務定着まで伴走支援します。AI Agent Hubのサービスページで、自社の業務にどう転写できるかを具体例とあわせてご確認ください。
PoCで止まらないAIエージェント設計

ハーネス設計の発想を自社業務に転写
Worker-Evaluator分離・永続化・サブエージェント・HITLといったハーネス設計の原則は、自社の業務エージェントに転写して初めて成果が出ます。AI Agent Hubのサービスページで、データ統合・ガバナンス・実行基盤を含めた業務定着までの全体像をご確認ください。
まとめ
ハーネスエンジニアリングは、AIエージェント開発の関心領域が単発プロンプトから実行基盤全体へとシフトしたことを象徴する新しい設計・実践領域です。
最後に、本記事の各セクションで扱った要点を1行ずつ振り返ります。
- 定義: Anthropic・OpenAI・LangChainの3社が2025秋〜2026春に公式発信で扱い始めた、モデル周辺の実行基盤全体を設計する領域
- 3段階の進化: プロンプト→コンテキスト→ハーネスは扱う粒度が広がる積み上げ式で、context rotがハード制約として下支えしている
- 必要・不要の判断: 長時間自律・複数ツール連携・production品質・複数チーム統制が当てはまるならハーネス設計が必要、単発タスクやPoC段階ならプロンプト改善で足りる
- 構成要素: 3社のアーキテクチャに共通する「ループ+記録+分離環境+出力検証+人間関与」の5要素
- 設計核心パターン: Worker-Evaluator分離・永続化アーティファクト・サブエージェント・「部品は仮定の符号化」原則
- production運用: コスト$9 vs $200の20倍差、OWASP LLM01、拒否挙動の確率的揺らぎ、サンドボックスでブラスト半径を絞る
- SDK使い分け: Claude Agent SDK/OpenAI Agents SDK/LangChain deepagentsはケース別に第一候補が変わる。導入前は5観点(データ境界・保守体制・観測・業務接続・HITL)で自社のリソース充足を確認する
ハーネスエンジニアリングは2026年6月時点でまだ定義が固まりきっていない現在進行形の概念です。3社の用語の使い方が今後も拡張・変動する可能性は高いため、固定化された定義として扱うのではなく、「いま何が起きているか」を継続的にアップデートしながら自社のハーネス設計に取り込んでいく姿勢が現実的です。
プロンプトエンジニアリング・コンテキストエンジニアリングをすでに業務に取り入れている組織にとって、ハーネスエンジニアリングは「次に向き合うべき設計の階層」です。本記事の整理が、自社のエージェント基盤を見直すきっかけになれば幸いです。










