この記事のポイント
 異常検知AIは2026年に検知から原因特定・自律復旧へ進化、業務フロー連携設計が成否を分ける段階に入った
異常検知AIは2026年に検知から原因特定・自律復旧へ進化、業務フロー連携設計が成否を分ける段階に入った- Azure AI Anomaly Detectorは2026年10月1日、AWS Lookout for Equipmentは10月7日リタイアで移行判断が急務
- 公式案内はAzure→Microsoft Fabric(Anomaly DetectionはPreview)、AWS→Amazon SiteWise(多変量は東京未対応)かパートナーソリューション
- 中小製造業はクラウド型と並びエッジAIが現実解、データ基盤刷新の意思があるかで選択肢が分かれる
- PoC〜本番化で詰まるのは誤検知・データ品質・コンセプトドリフト・現場定着・スケールの5論点と隠れコスト4項目

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
異常検知AIは、センサー・検査画像から通常パターンを外れた状態を自動検出し、製造業の設備監視と品質管理を支える中核技術です。
2026年はAzureとAWSのマネージドサービスが揃ってリタイア、エッジAIが中小製造業まで広がり、生成AI連携で「検知から原因特定・自律復旧」への一気通貫運用が現実になった節目の年です。
本記事では2026年6月時点で製造業が知っておくべき定義・現場ユースケース・選択肢の見つけ方・国内事例・PoC〜本番化の詰まり論点までを、現場の意思決定プロセスに沿って整理します。
目次
異常検知AIとは|製造業の設備監視・品質管理を変える基本能力
自社に合う選択肢の見つけ方|4つの判断軸と現場タイプ別ルート
国内製造業の異常検知・異常対応AI事例|効果が出る現場の共通条件
異常検知AIとは|製造業の設備監視・品質管理を変える基本能力
異常検知AIは、設備センサーや検査画像から通常パターンを外れた状態を自動検出する仕組みです。
製造業では、振動・温度・電流などの時系列データや、製品の外観画像、稼働中の音響データを対象に、これまで熟練の保全員・検査員の経験に依存していた「いつもと違う」の判断をAIで標準化する用途で広がっています。

本セクションでは、異常検知AIの基本能力と、製造業の現場で広がった背景を整理します。データ事情と学習方式の選び方、現場で受け入れられた条件、検知後の運用設計まで順に見ていきます。
異常データが少ない現場でも学習が回る仕組み
製造業の現場では、異常データを十分に集めることが構造的に難しい状況があります。設備故障や品質不良は本来「発生してはいけない事象」であり、十分な学習サンプルが手元に揃わない領域です。
この制約に対応するため、異常検知AIでは正常データだけを学習して逸脱を検出する教師なし学習が主流になっています。

以下の表で、製造業の現場で使われる主要な教師なし異常検知アルゴリズムを整理しました。
| アルゴリズム | 対象データ | 仕組みの概要 | 代表的な用途 |
|---|---|---|---|
| Isolation Forest | 時系列・多変量 | ランダム分割で外れ値を孤立させる | センサー多変量監視、プロセス異常 |
| One-Class SVM | 時系列・多変量 | 正常領域の境界をカーネル関数で学習 | 軸受・モーターの状態監視 |
| Autoencoder | 時系列・画像・音響 | 再構成誤差で逸脱を検出 | 設備劣化、外観検査、異音検知 |
| LSTM-AE / Transformer系 | 時系列(長系列) | 時間依存の正常パターンを学習 | 連続プラントのプロセス監視 |
| PaDiM / PatchCore | 画像 | 正常画像の局所特徴分布を学習 | 外観検査(少量サンプル対応) |
5アルゴリズムの共通点は、不良データのサンプルが手元になくても運用に乗せやすい構造です。新製品ラインの立ち上げや少量多品種生産でも、正常状態を一定期間記録すればモデルを構築できるため、製造業現場との相性が良い技術として定着しました。
特に画像系のPaDiM・PatchCoreは、不良サンプル数枚以下からでも実用精度に到達できる構成として2022年以降の外観検査AI導入を後押ししています。
製造業で異常検知AIが広がった3つの背景
異常検知AIが研究テーマから「現場で回す道具」へと位置づけが変わった背景は、製造業の構造的な変化と密接に結びついています。

以下の表で、3つの背景と各々がもたらした変化を整理しました。
| 背景 | 内容 | 製造業への影響 |
|---|---|---|
| センサーとIoTゲートウェイの低価格化 | 振動・温度・電流・音響センサーの単価低下、エッジゲートウェイの普及 | PoC段階で数十〜数百点のセンサー設置が現実的に |
| データ蓄積基盤の整備 | PLC・SCADA・MESからのデータ集約基盤がクラウド・OSS群で整備 | Microsoft Fabric・Amazon SiteWise・OSS群で蓄積環境が標準化 |
| 熟練保全員・検査員の減少 | ベテランの大量退職と若年層の流入減 | 属人化していた「異常の見立て」をAIに学習させる経営課題化 |
3つの条件が揃ったことで、異常検知AIは「研究テーマ」から「現場で回す道具」へと位置づけが変わりました。
特に3つ目の人材問題は、製造業の経営層が異常検知AI導入を経営課題として捉える契機になっています。熟練人材の退職と同時に、その人が頭の中に持っていた「異常の判断基準」が組織から失われるため、属人化解消の手段として位置づけが上がっています。

異常検知AI市場で進行する3つの構造変化
異常検知AI市場では、製造業の意思決定に直接影響する変化が同時進行している段階に来ています。
クラウドマネージドサービスのリタイア、エッジAIの低価格化、生成AI連携による業務基盤化—この3つが、設備保全・品質管理の現場で「次にどう動くか」を考え直す動機になっています。
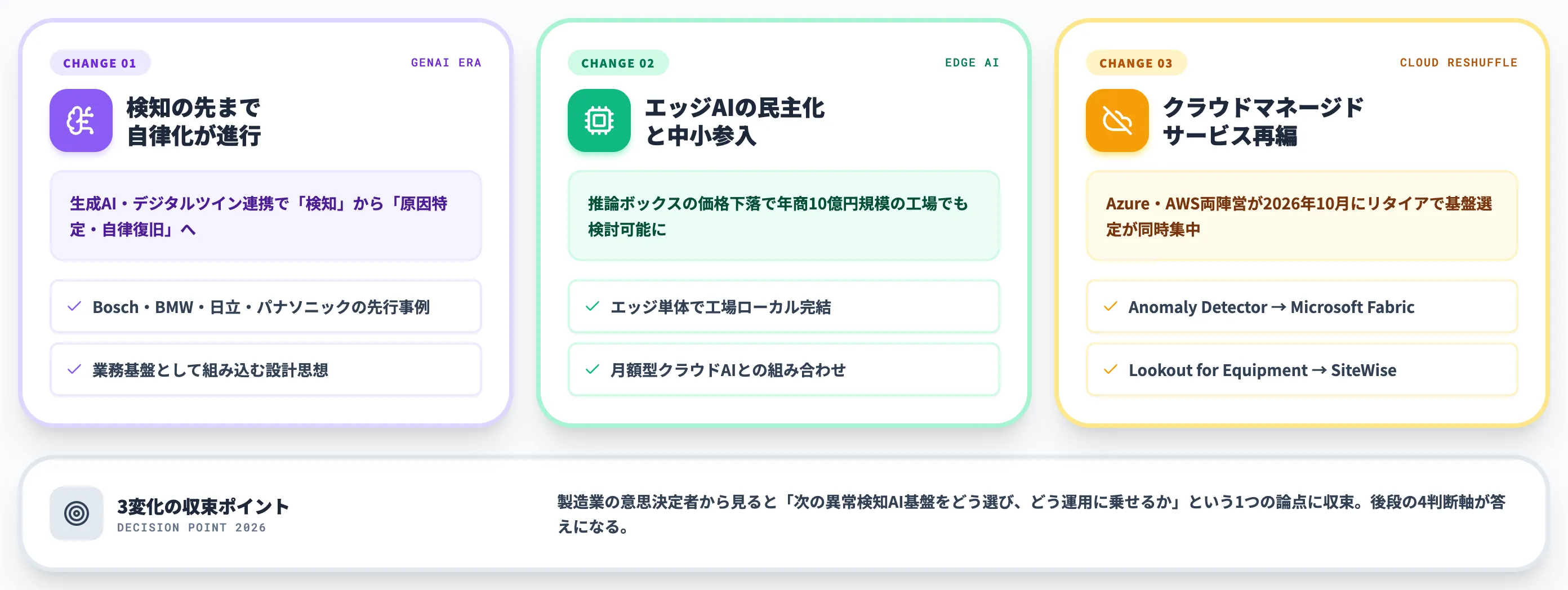
本セクションでは、3つの構造変化を順に整理します。
生成AI・デジタルツイン・設備診断で広がる「検知の先」
直近の異常検知AIの最大の進化は、検知結果を生成AI・デジタルツイン・知識検索といった隣接技術と組み合わせ、原因の推定・対応指示の起案・保守アクションまで一気通貫で運用する設計が現場で広がってきたことです。
これまで異常検知AIが「いつもと違う」を出力した後、何が原因で・どう対応すべきかを人間が調査するフェーズには数時間〜数日かかっていました。
隣接技術との連携が進むと、過去の対応履歴・設備マニュアル・関連設計図を横断検索し、原因候補や対応手順の起案までを短時間で提示する運用が可能になります。
エムニのレポートでも、海外先進企業が生成AI・エージェントAI・デジタルツインを組み合わせ、異常処置の中心が「検知の自動化」から「原因特定と自律復旧」へ移っていると整理されています。

代表事例として、Bosch・BMW・日立・パナソニックの取り組みを順に見ていきます。隣接技術との組み合わせ方が各社で大きく異なります。
Bosch|画像認識AIで生産ラインの判断を完結
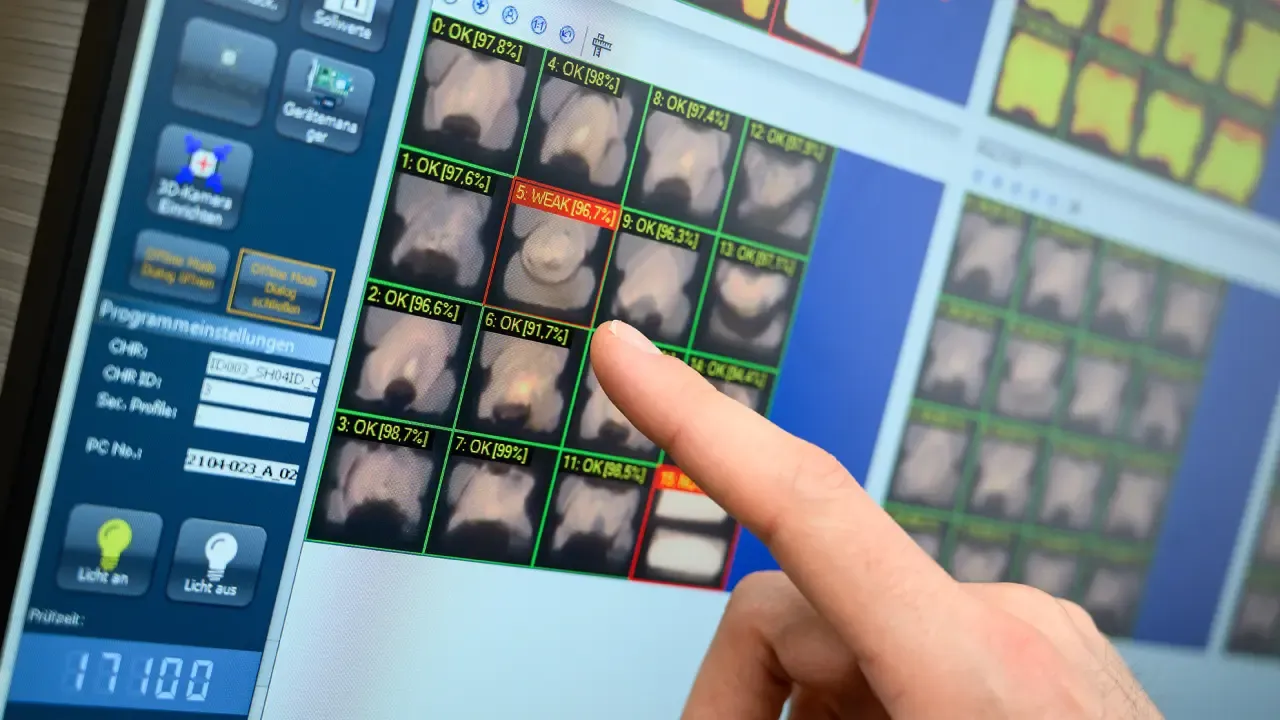
Boschの生産ラインで稼働する画像認識AI(出典:Bosch)
Boschは画像認識AIを活用した欠陥検知を生産ラインに組み込み、リワークラインへの自動振り分けまで実装する事例を公開しています。
画像認識AIを生産現場のモニターに直結させ、検査と判断を同じ画面上で完結させる構成が、検査結果から後工程の処理判断を一気通貫で自動化する前提になっています。
BMW|デジタルツインで生産計画レイヤーを刷新

BMW GroupがNVIDIA Omniverseで構築する仮想工場(出典:NVIDIA Blog)
BMWはNVIDIA Omniverseベースの仮想工場(デジタルツイン)の活用で生産計画コストを大幅削減できることを公表しています。
生産計画レイヤーをデジタルツインで再現することで、工場設計・工程変更・物流レイアウトの検証を仮想空間で事前に完結させており、異常検知単体ではなく、生産管理基盤側の刷新と一体で進める文脈に位置づけられます。
日立|知識検索を生成AIに移管し業務時間を圧縮
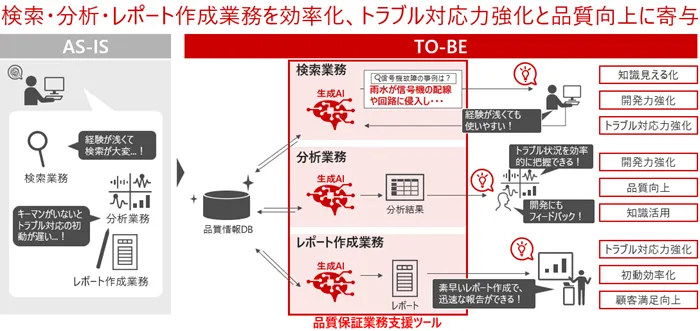
日立の生成AI×業務ノウハウによる品質保証業務の高度化(出典:日立製作所)
日立製作所は生成AI×業務ノウハウの組み合わせで品質保証業務の知識検索・回答作成を高度化する取り組みを発表しています。
品質保証業務の「AS-IS(現状)」と「TO-BE(あるべき姿)」を対比させて知識検索・回答作成のフェーズを生成AIに任せる構図を可視化しており、検知精度向上ではなく、検知後の問い合わせ対応・調査時間の短縮にROIの軸が移っていることが伝わります。
パナソニック|時系列解析で保守アクションを自動連動
パナソニックは時系列データ解析で設備の異常(閾値超過)を検知し、交換部品の手配・メンテナンスにつなげたAI設備診断の取り組みを公開しています。
検知から保守アクションへの連動が一気通貫で設計されており、保全業務の自動化を起点に経営の意思決定速度を上げる流れに位置づけられます。なお、AI設備診断は公式PDFのみの公開のため画像引用は控え、本文の出典リンクから一次資料を参照する形にしています。
これら4社の事例に共通するのは、異常検知AIをモデル単体として導入するのではなく、保全業務・品質管理業務・生産計画レイヤーまで含めた業務基盤として組み込む設計思想です。
ROI算出の主軸も、検知精度から業務サイクル短縮・対応漏れ削減へ移っています。
エッジAIの民主化と中小製造業の参入
エッジAIカメラと推論ボックスの価格帯が大きく下がり、中小製造業でも異常検知AIをPoCから試せる時代になりました。
数年前まで同規模のPoCは大型のSI案件レベルの予算が必要だった領域ですが、現在は年商10億円規模の工場でも経営判断できる予算感に収まりやすくなっています。クラウド接続が確保できない工場・セキュリティ要件が厳しい工場・地下プラント・離島の拠点でも、エッジ単体で運用できる選択肢が現実的な入口として確立しました。
エッジAIがクラウドの代替ではなく「並行して持っておくべき選択肢」として位置づけられる理由は、以下の3点に集約されます。
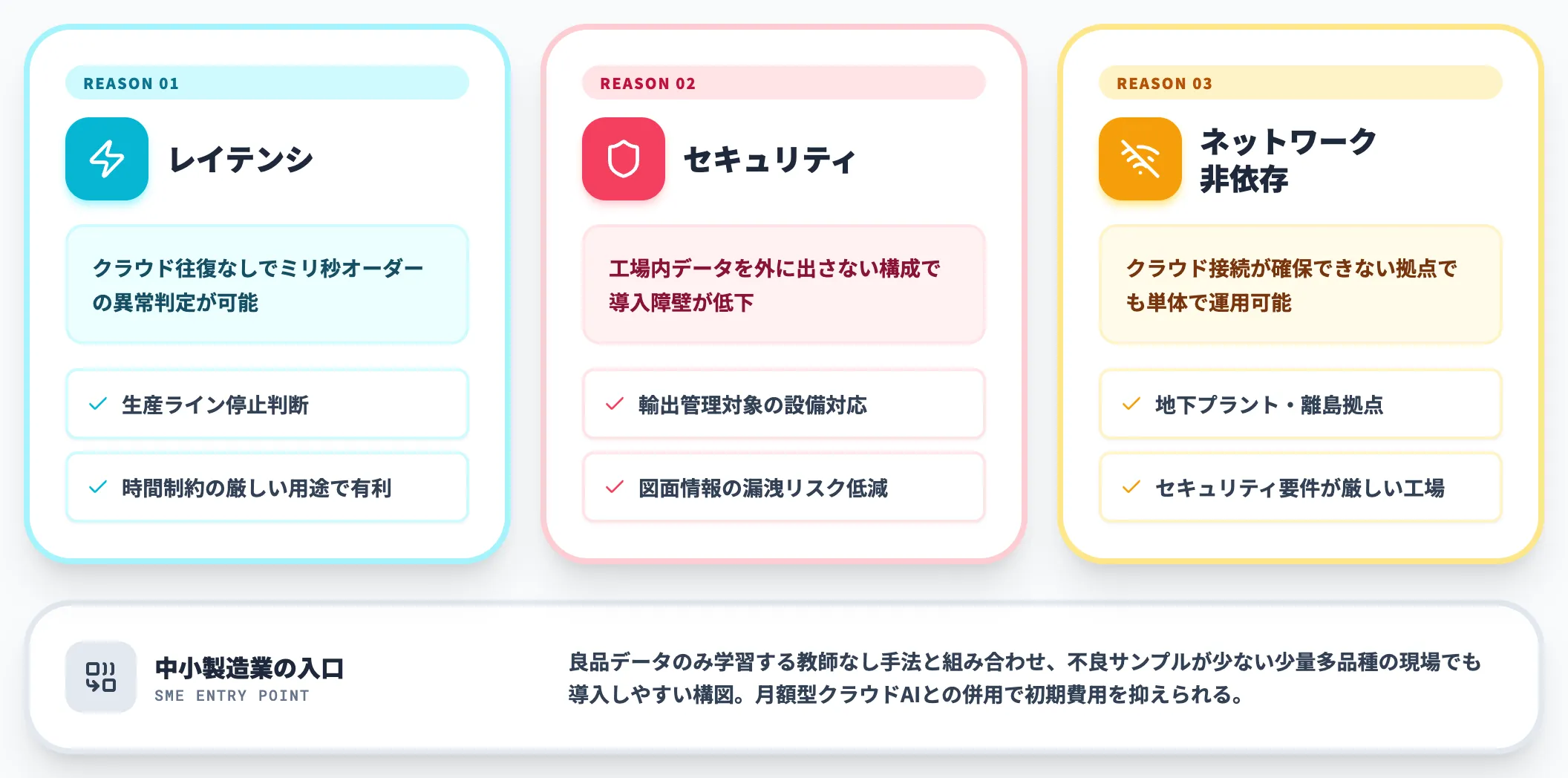
-
レイテンシ
クラウド往復が不要なため、ミリ秒オーダーでの異常判定が可能。生産ライン停止判断のような時間制約の厳しい用途で有利。
-
セキュリティ
工場内のデータが外に出ない構成にできる。輸出管理対象の設備・図面情報を扱う現場で導入障壁が低い。
-
ネットワーク非依存
クラウド接続が確保できない工場・地下プラント・離島の拠点でも、エッジAI単体で運用できる。
良品データのみで学習する教師なし手法の進化と組み合わせると、不良データのサンプルが少ない少量多品種の現場でも導入しやすい構図が生まれています。中小製造業にとって、異常検知AIの導入はこれまで大型SI案件のイメージが強く検討すら始められない状態でしたが、エッジAI+月額型クラウドAIの組み合わせは初期費用を抑えやすい入口として機能しています。
クラウドマネージドサービス再編
これまで「マネージドサービスでマウスポチポチ」が異常検知AI導入の入口だった企業にとって、移行先選定は2026年最大の論点になりました。

以下の表で、Azure・AWSの主要サービスのリタイアスケジュールと公式案内・移行候補を整理しました。
| 元サービス | 新規受付停止 | サービス終了 | 公式案内・移行候補 |
|---|---|---|---|
| Azure AI Anomaly Detector | 2023年9月20日 | 2026年10月1日 | Microsoft Fabric(Real-Time IntelligenceのAnomaly DetectionはPreview)またはmicrosoft/anomaly-detector OSS |
| AWS Lookout for Equipment | 2025年10月7日 | 2026年10月7日 | builders向けはAmazon SiteWise推奨/out of the boxはAPN/Partner solutions。SageMakerは内製・高度カスタム候補 |
2サービスがほぼ同じ時期にリタイアする状況は、製造業全体の異常検知AI基盤の再選定タイミングが2026年下期に集中することを意味します。
Microsoft FabricはAzure AI Anomaly Detectorの移行先として案内されており、Real-Time IntelligenceのAnomaly DetectionはEventhouse上でデータをコピーせずに実行できる構成として整備が進んでいます(記事執筆時点でPreview)。
Amazon SiteWiseは2025年7月に多変量異常検知をGA化、2025年9月に自動再学習機能を追加と、移行受け皿側の機能拡張が並行で進んでいます。プラットフォーム別の選定軸・制約は後段の「自社に合う選択肢の見つけ方」で詳述します。
3つの構造変化は、それぞれ独立して動いているのではなく、製造業の意思決定者から見ると「次の異常検知AI基盤をどう選び、どう運用に乗せるか」という1つの論点に収束します。
後段の4つの判断軸とプラットフォーム整理が、この収束ポイントに対する答えになります。
製造業の現場別ユースケース5領域
異常検知AIは、製造業の現場で扱うデータの種類と業務の性質に応じて、定着しているユースケースが分かれます。
本セクションでは、設備監視・品質管理・プロセス監視・異音検知・作業分析の5領域を整理し、自社のどの業務に効きやすいかを判断する材料を示します。
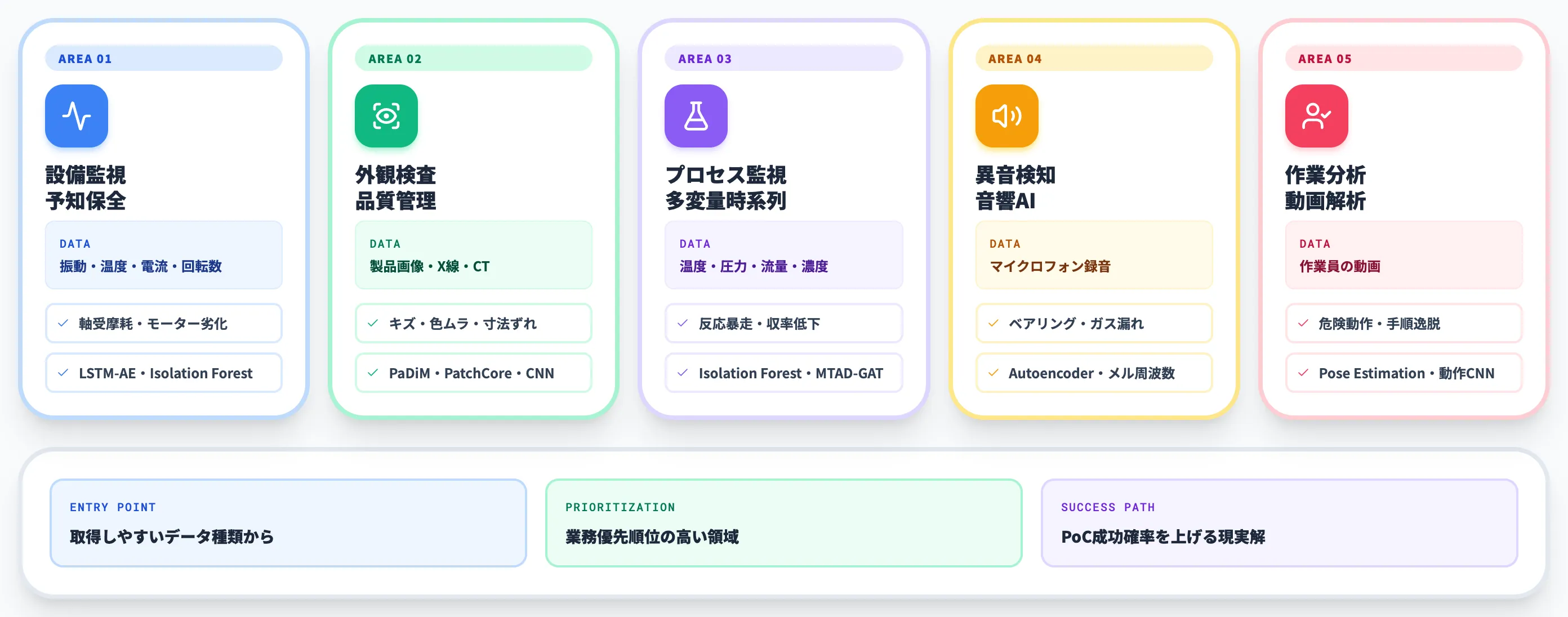
以下の表で、5領域の対象データ・検出対象・代表アルゴリズム・効果指標を整理しました。
| ユースケース | 対象データ | 代表的な検出対象 | 代表アルゴリズム | 効果指標 |
|---|---|---|---|---|
| 設備監視・予知保全 | 振動・温度・電流・回転数 | 軸受摩耗、モーター劣化、過熱 | LSTM-AE、Isolation Forest、One-Class SVM | 計画外停止時間、設備寿命延長 |
| 外観検査・品質管理 | 製品画像・X線・CT | キズ・色ムラ・寸法ずれ・異物 | PaDiM、PatchCore、CNN系 | 不良流出率、検査員工数 |
| プロセス監視 | 温度・圧力・流量・濃度 | 反応暴走、収率低下、組成異常 | Isolation Forest、MTAD-GAT | 収率改善、品質ばらつき |
| 異音検知 | マイクロフォン録音 | ベアリング異常、ガス漏れ、配管摩耗 | Autoencoder、CNN+メル周波数 | 故障検知リードタイム |
| 作業分析 | 作業員の動画 | 危険動作、手順逸脱、品質ばらつき | 動作解析CNN、Pose Estimation | 労災発生率、作業ばらつき |
5領域は対象データ型で大きく分かれており、自社で取得しやすいデータ種類から優先順位を決めるのが現実的なアプローチです。
設備監視・予知保全|時系列データの代表用途
最も導入実績が多いのが、振動・温度・電流などの時系列データから設備の劣化や故障の兆候を早期に検出するユースケースです。
軸受やモーターの摩耗パターンは、設備故障の数日〜数週間前から振動波形に微細な変化が現れることが知られており、定期メンテナンスから状態基準保全(CBM)への移行を後押しする技術として位置づけられています。
実装の現実解として現場で採用が広がっているのは、LSTM-AE(時系列Autoencoder)と多変量Isolation Forestの組み合わせです。LSTM-AEは時間依存の正常パターンを学習して再構成誤差で異常を検出し、Isolation Forestは複数センサーの相関の崩れを高速に検出する役割分担になります。
CBM・予知保全・予防保全の関係については、CBM(状態基準保全)ガイドと予知保全AIで整理しています。
外観検査・品質管理|画像データの代表用途
製造ラインを流れる製品の外観画像からキズ・色ムラ・寸法ずれを検出するユースケースは、人による検査の見逃しが起きやすい領域でAIの価値が高い分野です。
ディープラーニングを使った外観検査AIは、PaDiM・PatchCoreといった画像異常検知に特化したアーキテクチャの登場で、不良サンプルが少ない条件でも実用精度に到達しやすくなっています。
特にPatchCoreは少量サンプル学習の代表手法として広く採用されており、新製品立ち上げ時の正常画像数十枚から運用を始められる構成が現実解になっています。
検査員工数削減と不良流出率改善の両軸でROIを測ることが多く、検査ラインの自動化投資との親和性が高い領域です。
プロセス監視|多変量時系列の代表用途
化学・食品・製薬の現場では、温度・圧力・流量・濃度といった複数のセンサー値を同時に監視し、反応暴走・収率低下・組成異常の予兆を検出します。
単一センサーでは見えない異常が、複数センサーの相関の崩れとして現れるパターンが多く、多変量異常検知アルゴリズム(Isolation Forest・MTAD-GAT等)の出番が大きい領域です。
プラントの安全管理と品質安定の両面で導入意義が高く、特に保安四法(高圧ガス保安法・労働安全衛生法等)の対象設備では、異常予兆検知が法令遵守の補強としても機能しています。データ取得頻度が高く(1Hz以上が一般的)、長時間連続稼働の前提があるため、クラウドへのデータ転送設計が他領域より重い領域でもあります。
異音検知|音響データの代表用途
振動センサーを物理的に設置できない場所では、マイクロフォンで取得した音響データから異常を検出する異音検知が選択肢になります。
回転機器・ベアリング・配管漏れなど、稼働中の設備に手を触れずに監視したい用途で実装が広がっており、エッジ推論との相性も良い領域です。
Deeplyのソリューションはガス漏れ検知やローラー摩耗検知を音響AIで実現する代表事例として知られています。音響データはAutoencoderで再構成誤差から異常を検出する手法と、メル周波数スペクトログラムをCNNで分類する手法の2系統が現場で併用されています。
技術詳細は異音検知AIで整理しています。
作業分析|動画・画像データの代表用途
作業員の動作を動画で記録し、危険動作・手順逸脱・作業ばらつきを検出するユースケースも実装事例が増えています。
組立工程の動作解析、安全管理(ヘルメット・保護具の着用確認)、新人作業員の手順学習支援など、品質と安全の両面に効く領域です。設備や製品だけでなく「人の動き」を異常検知の対象とする点が、画像系の他用途と性質が異なります。
Pose Estimation(姿勢推定)と動作分類CNNを組み合わせる構成が代表的で、労災発生率の低減や作業ばらつき可視化の指標で評価されます。プライバシー配慮の観点から、顔識別をしない設計や撮影同意のフローを運用に組み込む必要があり、技術選定より「現場合意の取り方」が立ち上げの分岐点になることが多い領域です。
5領域のうち、自社で取得できるデータと業務優先順位の高い領域から始めるのが、PoCの成功確率を上げる現実的なアプローチです。

自社に合う選択肢の見つけ方|4つの判断軸と現場タイプ別ルート
異常検知AIのプラットフォーム選定は、機能比較表だけでは決まりません。
自社のデータ基盤の現状・運用体制・拠点規模によって、現実的に選べる選択肢が変わるためです。本セクションでは、製造業の現場で意思決定に直接効く4つの判断軸と、それを組み合わせた現場タイプ別の推奨ルートを整理します。

以下の表で、4つの判断軸と各軸が向く選択肢を整理しました。
| 判断軸 | 確認内容 | 軸が決まると見える選択肢 |
|---|---|---|
| ① データの所在 | センサーデータ・検査画像がどこに集まる前提か | AWS既存/Azure既存/オンプレ分散/工場ローカル |
| ② 運用体制 | 社内にどんな人材がいるか | MLエンジニア/IoT担当/データ分析/専任なし |
| ③ データ統合の野心 | 異常検知単体か基盤刷新と一体か | 単体最短/基盤刷新型 |
| ④ 拠点規模 | 単一工場か多拠点展開か | 単一・PoC段階/多拠点・全社展開 |
4軸の答えが揃うと、現実的に選べるプラットフォームの候補が自然に絞り込まれます。順に深掘りします。
データはどこに集まっているか
センサーデータ・検査画像がどこに集まる前提かで、第一候補のプラットフォームが変わります。
-
AWSのS3に集約済
Amazon SiteWise(マネージド継続)または Amazon SageMaker(自由度最大)が第一候補。Lookout for Equipmentからの移行先として最も整合性が高い経路。
-
Azure Data Lake / OneLakeに集約予定
Microsoft Fabric一択に近い。Azure AI Anomaly Detectorからの公式推奨移行先であり、データ基盤刷新と異常検知が同一基盤で完結する。
-
オンプレ・複数クラウド分散
製造業特化SaaS(Brains-tech Impulse等)または自社内製。データ集約を前提にせず、各拠点で運用できる構成が現実的。
-
工場ローカル完結
エッジAI単体。ネットワーク要件が厳しい工場・地下プラント・離島の拠点で第一候補に挙がる。
社内に誰がいるか
社内にどんな人材がいるかで、無理なく運用できる構成が変わります。
-
MLエンジニア・データサイエンティスト常駐
Amazon SageMaker または自社内製。モデル自由度を最大化できる代わりにMLOps負担を全て引き受ける構成。
-
IoTデータモデリング担当者がいる
Amazon SiteWise。資産モデル(プロパティ・階層構造)の定義が前段に必要なため、IoTデータの整理経験が活きる。
-
データエンジニア・分析担当者がいる
Microsoft Fabric。データレイクハウス上の分析パイプラインを構築できる人材がいれば、異常検知だけでなくデータ基盤全体の刷新と一体で進められる。
-
専任人材なし
マネージドSaaS or エッジAI。運用は外部委託か自動運用に寄せる前提で、製造業特化SaaSや月額型エッジAIサービスが現実解になる。
異常検知単体か、基盤刷新と一体か
異常検知単体で完結させたいか、データ基盤刷新と一体で進めたいかで方針が分かれます。
-
異常検知だけ最短で動かしたい
Amazon SiteWise/製造業特化SaaS/エッジAI。データ基盤の手前で完結する構成で、立ち上げが速い。
-
データ基盤刷新と一体で進めたい
Microsoft Fabric/Google Vertex AI。データレイクハウスと異常検知を同一基盤で扱える構成で、長期的なROIが累積する。
AI総研の支援現場では、データ基盤刷新の意思があるかどうかをまず確認するのが意思決定の入口になります。基盤刷新の意思があるならFabric・Vertex系、まずは異常検知単体で動かしたいなら製造業特化SaaSかエッジAI、というのが現場で取りやすい筋です。
単一工場か、多拠点か
単一工場で完結するか、多拠点に展開するかでコスト構造が変わります。
-
単一工場・PoC段階
エッジAI/製造業特化SaaS。初期投資を抑えて立ち上げを速くする方針が合う。
-
多拠点・全社展開
クラウド統合(Microsoft Fabric/Amazon SiteWise)。多拠点のデータ集約と統一運用が前提なら、初期はコストが大きくても多拠点展開時のコスト構造が効いてくる。
PoCで良好な結果が出ても、本番展開(複数ライン・複数拠点)でコストが急増する壁にぶつかる組織は多くあります。PoCの段階で「拠点展開時のコスト構造」を試算しておくことが、本番化を止めない最大のポイントです。
現場タイプ別の推奨ルート
4軸の組み合わせで、典型的な現場タイプ別の推奨ルートが浮かび上がります。
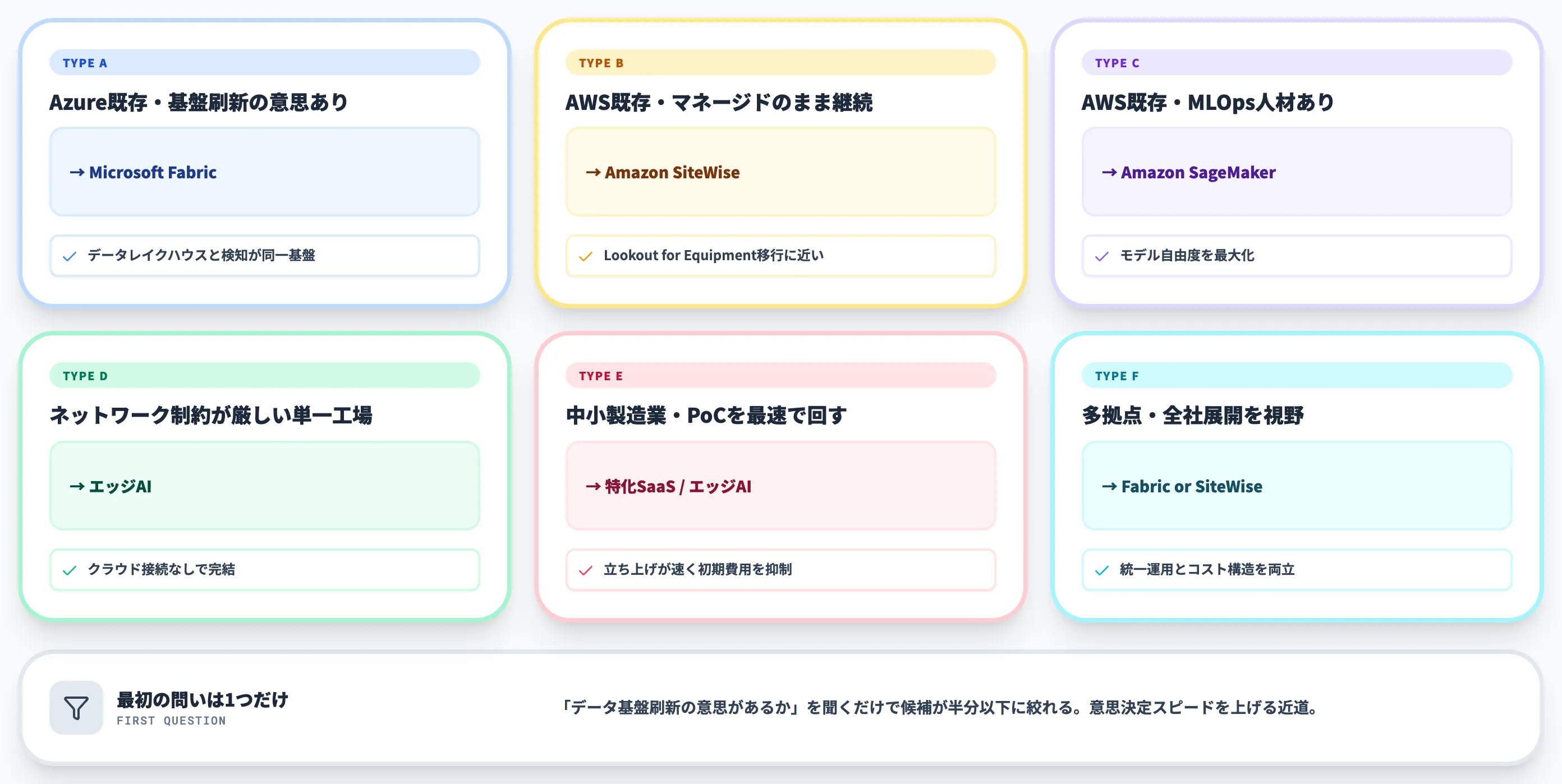
以下の表で、現場タイプと推奨ルート、および各ルートの主な制約・落とし穴を整理しました。
| 現場タイプ | 推奨ルート候補 | 主な理由 | 主な制約・落とし穴 |
|---|---|---|---|
| Azure既存・データ基盤刷新の意思あり | Microsoft Fabric | 異常検知とデータレイクハウスが同一基盤で完結 | Real-Time IntelligenceのAnomaly Detectionは記事執筆時点でPreview段階/Preview課金扱い・SLA要確認/データレイクハウス設計工数が初期負担 |
| AWS既存・マネージドのまま続けたい | Amazon SiteWise | Lookout for Equipment移行と思想的に近い | 多変量異常検知は米国東部・欧州(アイルランド)・シドニーの3リージョン限定、東京リージョン未対応/資産モデル定義の前段工程が必要/取り込み頻度1Hz以上前提 |
| AWS既存・MLOps人材あり | Amazon SageMaker | モデル自由度を最大化 | 公式に「Lookout for Equipment後継」と直接案内されている製品ではない/MLOps運用負担を全て自社で引き受ける |
| ネットワーク制約が厳しい単一工場 | エッジAI | クラウド接続なしで完結 | 多拠点展開時の統一運用が難しい/推論ボックスの設置・保守体制を現場側で持つ必要 |
| 中小製造業・PoCを最速で回したい | 製造業特化SaaS or エッジAI | 立ち上げが速く、初期費用が抑えられる | カスタマイズ余地が限定的/自社固有の異常パターン定義に弱いケースがある |
| 多拠点・全社展開を視野 | Microsoft Fabric or Amazon SiteWise | 統一運用とコスト構造の両立 | 通信回線・データ集約サーバー・運用人員のコストが拠点数に応じて累積/海外リージョン依存ならコンプライアンス整理が必要 |
表で押さえるべきは、推奨ルートよりも「制約・落とし穴」列です。Fabric採用ならPreview段階のSLAリスクを社内で承認できるか、SiteWise採用なら東京リージョン未対応のデータ転送経路を組めるか、というレベルで意思決定が止まる組織は多くあります。自社が当てはまる現場タイプの行を起点に、右端の制約列をクリアできるかから先に検証するのが、PoC立ち上げを最短化する近道です。
AI総研の支援現場でも、最初に「データ基盤刷新の意思があるか」を聞くだけで候補が半分以下に絞れるケースが多くあります。
国内製造業の異常検知・異常対応AI事例|効果が出る現場の共通条件
異常検知AIで公表されている国内製造業の事例から、効果が出ている現場の共通条件を抽出します。
本セクションでは代表的な3社の事例を取り上げ、共通する成功条件を整理します。事例ごとの費用相場・導入ステップの詳細は製造業の異常検知AI活用事例に整理しているため、より多くの事例を比較したい場合はそちらを参照してください。

以下の表で、3社の事例と効果指標を整理しました。
| 企業 | 対象工程 | AIの役割 | 公表されている効果 |
|---|---|---|---|
| ダイキン工業 | 空調機の運転データ | 不具合予兆検出AI | 製品改善PDCAサイクル1年以上短縮 |
| ブリヂストン | タイヤ成形システム | 480項目センサーのリアルタイム解析 | 真円性15%以上向上、生産性約2倍 |
| JFEスチール | 製鉄設備のメンテナンス | 制御故障復旧支援AI(J-mAIster) | 全国6か所の製鉄所・製造所へ展開完了 |
3社の事例は対象工程も技術構成もバラバラに見えますが、効果が出ている現場には共通する条件があります。順に各社の事例を見たうえで、共通条件を抽出します。
ダイキン工業|空調機の運転異常予兆検出AI
ダイキン工業は、市場投入後の空調機器に蓄積される運転データをAIで解析し、不具合の予兆を検出する仕組みを構築しています。
家庭用空調機を起点に業務用空調機へも適用が広がっており、不具合監視AIと運転異常予兆検出AIの2軸で、市場で稼働している製品の状態をリアルタイムに把握する運用です。
公式発表では、市場対応情報からの自動検出により、製品改善のPDCAサイクルを従来比で1年以上短縮できたと報告されています。製造ライン側ではなく、市場で稼働している製品のIoTデータを使う異常検知の代表事例として、保守サービスのビジネスモデル拡張にも繋がる構成です。
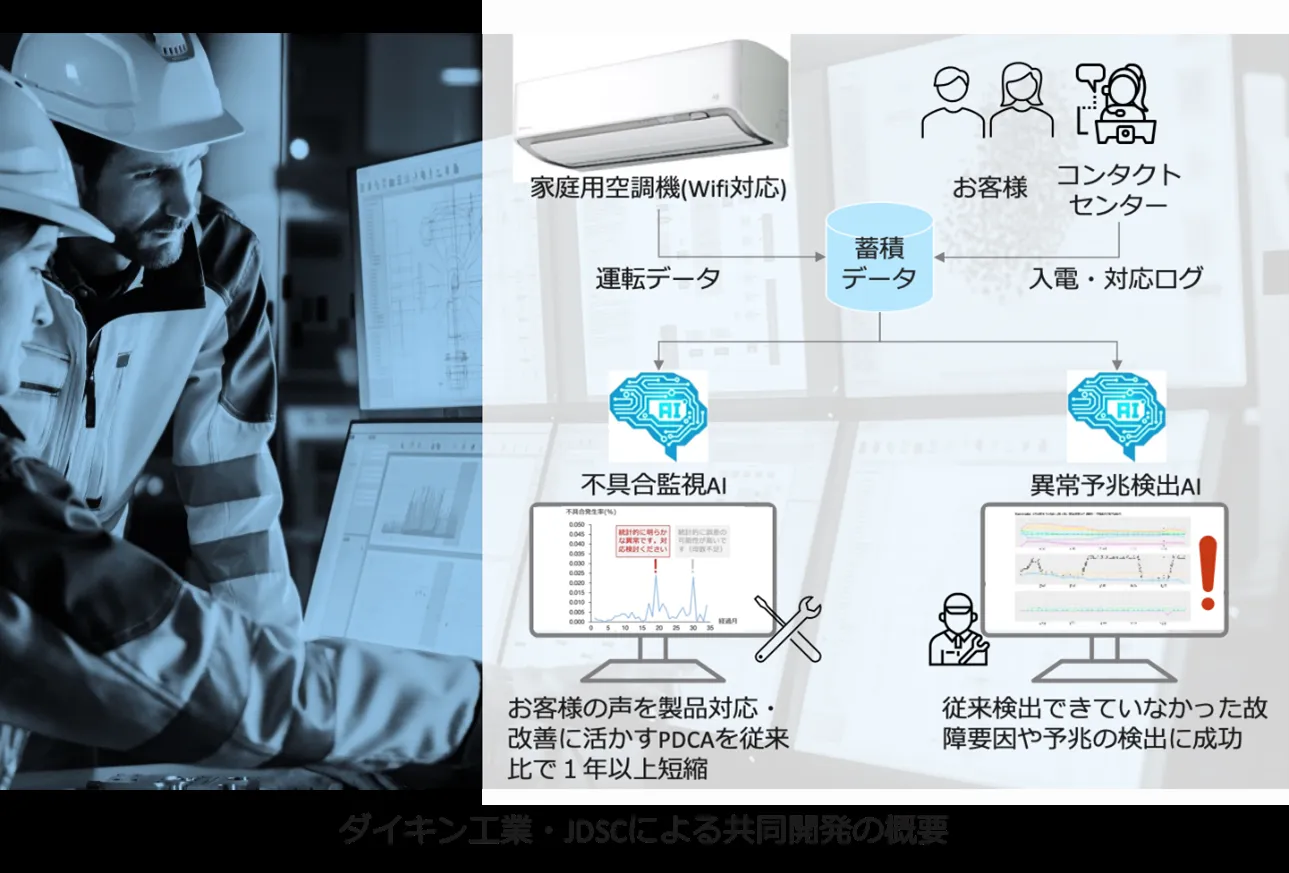
ダイキンの空調機運転データを活用したAI予兆検出(出典:ダイキン工業)
特筆すべきは、「製造現場の異常検知」ではなく「販売後の製品の異常予兆検知」という適用範囲です。製造業の異常検知AIは工場内に閉じる必要はなく、出荷後の製品状態管理にも適用できることを示しています。家庭用空調機を起点に業務用空調機まで展開している構図は、製品IoTデータを使った異常検知が「保守ビジネス」と「次製品設計のフィードバックループ」の両方に効くことを示しています。
ブリヂストン|タイヤ成形システムEXAMATIONのAI自動制御
ブリヂストンは、タイヤ成形システム「EXAMATION」にAIを実装し、タイヤ1本あたり480項目のセンサー計測データをリアルタイムに解析することで、真円性を従来製法比で15%以上向上、マルチドラム製法と組み合わせて既存比約2倍の生産性を実現しています。
属人化していたベテランの技能員の判断・動作を自動化する設計で、彦根工場での初導入後にグローバル展開を進める方針が示されています。

ブリヂストンのタイヤ成形システムEXAMATION(出典:ブリヂストン)
タイヤ成形は「ベテランの手の感覚」に依存していた工程の代表例で、480項目のセンサー値を同時にリアルタイム解析できる多変量異常検知技術と、過去の正常品データを使った教師なし学習を組み合わせて、判断ロジックの自動化に到達した事例です。技能伝承と生産性向上を同時に達成する事例として、製造業の異常検知AI導入の到達点を示しています。
JFEスチール|制御故障復旧支援システムJ-mAIster
JFEスチールは2018年、製鉄設備のメンテナンス業務にAI手法を導入した制御故障復旧支援システム「J-mAIster®」を構築し、全国6か所の製鉄所・製造所への展開を完了しました。
設備異常時の復旧判断を支援することで、稼働率の改善に寄与した代表的な事例です。

JFEスチールの製鉄設備イメージ(J-mAIsterの導入対象現場の参考画像/出典:IBM Case Study)
鉄鋼業のような大規模・連続稼働プラントでは、復旧時間の短縮が直接的に生産性に効くため、異常検知だけでなく復旧支援まで含めた業務基盤化の好例になっています。加えてJFEグループでは、JFE商事エレクトロニクス経由で製造現場向けの安全AIソリューションも展開されており、AIを業務サイクルに組み込む取り組みが製造業の安全管理と保全の両面で広がっています。
効果が出る現場に共通する3条件
3社の事例を眺めると、効果が出ている現場には以下の共通条件があります。
-
対象設備・工程が明確に絞られている
「工場全体の異常を検知する」ではなく、「タイヤ成形」「空調機の運転データ解析」「製鉄設備の制御故障復旧」のように対象が絞られている。広範な対象を一度に扱おうとせず、ROIを定量化できる単位までスコープを絞れている。
-
既存の保全業務・品質管理業務が文書化されている
AIの出力を受け取った後の運用フローが、既存の業務体系に組み込める前提が整っている。アラートを受ける担当者・トリアージする担当者・対応指示を出す担当者の役割分担が事前に決まっている。
-
経営層の投資判断と現場の運用判断が連動している
「AIを入れる」だけの経営判断で終わらず、現場の運用変更まで一体で進められている。多拠点展開や設備の改造期間中の運用継続まで含めて、経営層が責任を持って意思決定している。
逆に効果が出ない現場は、対象が広すぎる・運用フローが未整備・経営と現場が分離している、のいずれかに該当することが多くあります。事例ベースで「自社のどの工程なら対象を絞れるか」を最初に決めるのが、PoC設計の出発点になります。
【関連記事】
製造業の異常検知AI活用事例|費用相場や導入ステップを解説
PoC〜本番化で詰まる5論点と隠れコスト4項目
異常検知AIのPoCで結果が出ても、本番展開で止まる組織は多くあります。
本セクションでは、PoCから本番運用まで6〜9ヶ月の道のりで詰まる5論点と、見落とされやすい隠れコスト4項目を整理します。AI総研の支援現場で繰り返し観察される失敗パターンを、回避策とセットで提示します。
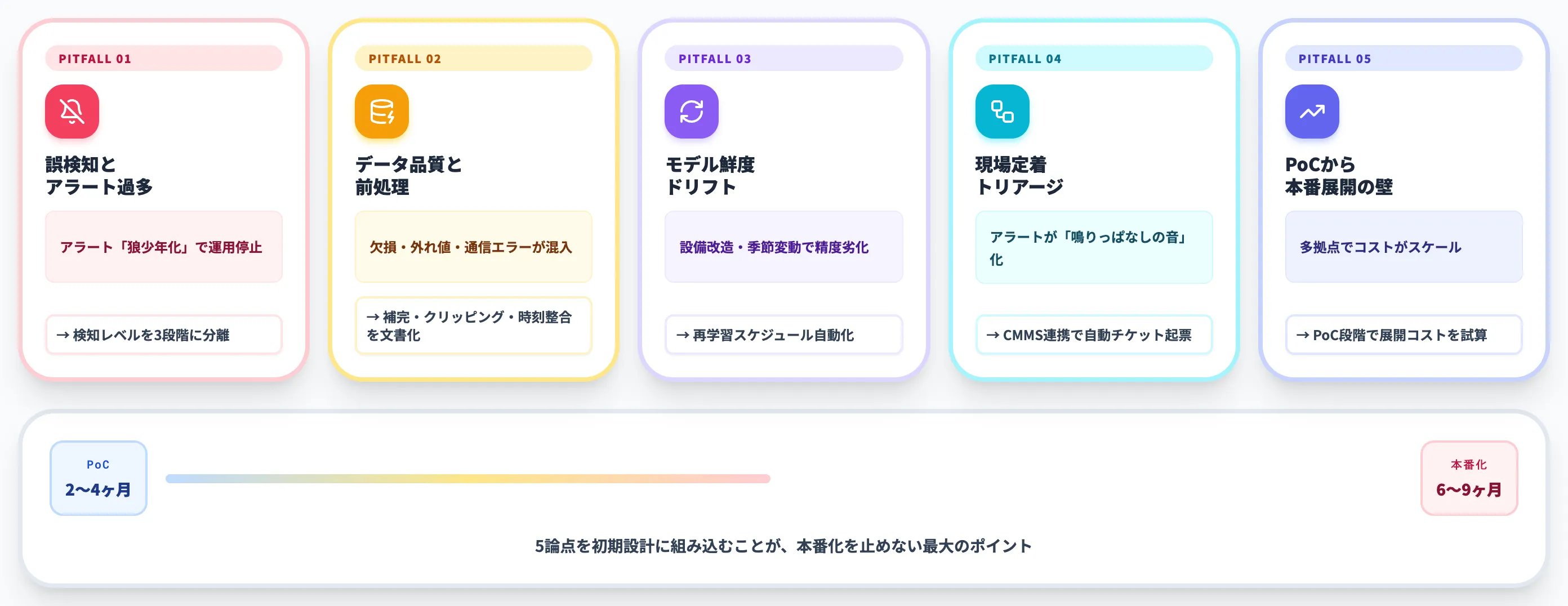
詰まる論点①|誤検知とアラート過多
最も多い詰まりポイントは、誤検知が頻発してアラートが「狼少年化」する現象です。
一度信頼を失った異常検知システムは、現場で無視されるか、運用が止まります。導入後3か月以内に「アラートを誰も見ない状態」に陥ると、立て直しに半年以上かかるケースもあります。
回避策としては、検知レベルを段階分け(情報通知/要確認/緊急停止)し、現場が対応する閾値とログだけ残す閾値を分離することが有効です。初期1〜2ヶ月は通知ルートを保全リーダー1人に絞り、本当に対応すべき件数の感覚を社内で揃えてから現場全体に展開する手順が安全です。
詰まる論点②|データ品質と前処理
センサーデータには欠損・外れ値・通信エラーが混入します。前処理を疎かにしたままモデルを学習させると、データの揺らぎを異常として拾うか、本来の異常を見逃すかのどちらかが起こります。
PoCの初期段階で、以下の3点を文書化してから本格学習に入ることを推奨します。
- 欠損補完ロジック(前後値補完/時系列移動平均/ゼロ埋め等の使い分け)
- 外れ値クリッピングルール(±3σ/IQR×1.5/センサー仕様レンジでの上限下限)
- タイムスタンプ整合(PLC・SCADA・ゲートウェイで時刻ズレが発生していないか)
データ品質の問題はモデルの問題に見えやすいため、原因の切り分けに時間がかかる典型的な落とし穴です。データエンジニアと現場保全員の両方の視点が必要な工程で、片方だけで進めると後工程で必ず手戻りが発生します。
詰まる論点③|モデル鮮度(コンセプトドリフト)
設備の改造、季節変動、新製品ライン投入があると、過去の正常パターンと現在の正常パターンがずれます。
これをコンセプトドリフトと呼び、放置するとモデルの精度が時間とともに劣化します。AI総研の支援現場でも、再学習を行わずに1年以上経過した運用でモデル精度が顕著に低下するケースを観察しています。
定期的な再学習スケジュール(四半期ごと・設備変更時など)を運用設計に組み込むこと、再学習トリガーを自動化することが鍵になります。SiteWiseの自動再学習機能やFabricのスケジュール再実行機能は、この論点に対する直接的な答えになっています。再学習のたびに人手の検証が必要な構成だと、運用負荷が累積してモデル更新が止まりがちです。
詰まる論点④|現場定着とトリアージ運用
異常を検知してアラートが上がっても、それを判断して対応する現場側の運用が整っていないと、アラートは「鳴りっぱなしの音」になります。
AI出力を受け取る人・初期トリアージする人・最終判断する人の3層を明確にしておく必要があります。
製造業のAI導入失敗例で頻出するパターンとして、「AIは入れたが現場運用が変わらない」というケースがあります。AIシステムと業務フローを一体で設計する視点が、導入成功の分かれ目です。
具体的には、保全管理システム(CMMS)と異常検知AIをAPI連携させ、アラートが自動でチケット起票されるフローを設計するのが現実解になります。チャットツール(Teams等)への通知だけでは「読まれずに流れる」リスクが高いため、業務フロー側でアクションを強制する構造が必要です。
詰まる論点⑤|PoCから本番展開の壁
PoCで良好な結果が出ても、本番展開(複数ライン・複数拠点)でコストが急増する壁にぶつかる組織は多くあります。
データ収集インフラ、運用人員、保全システム連携の負荷がスケールに比例しないためです。AI総研の支援現場でも、1拠点のPoC段階では見えなかった通信回線・データ集約サーバー・運用人員のコストが、多拠点展開時に予算を大きく圧迫するケースを繰り返し観察しています。
製造業AI PoCの進め方で整理しているとおり、PoCの段階で「拠点展開時のコスト構造」を試算しておくことが、本番化を止めない最大のポイントになります。
隠れコスト4項目|料金表に出てこない実運用コスト
公表される料金表に出てこないコストが、実運用フェーズで効いてきます。
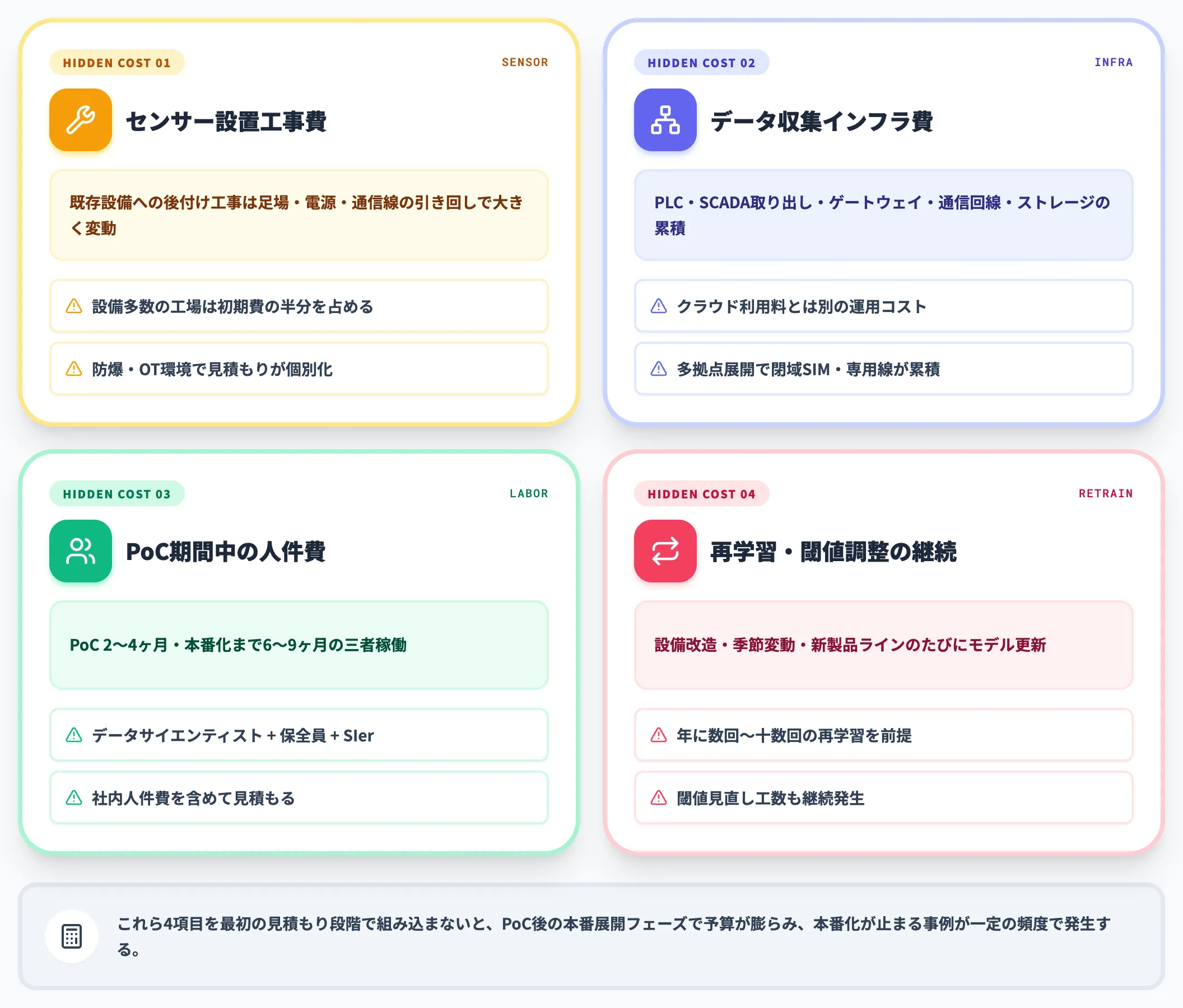
以下の4項目は導入前に必ず想定に組み込んでください。
-
センサー設置工事費
既存設備への後付けは、足場・電源・通信線の引き回しが必要になり、設備の状態や設置環境によって費用が大きく変動します。設備数が多い工場では初期費用の半分以上を占めることもあります。設置環境・防爆対応・OT環境などの条件で大きく振れる領域のため、現場ごとに個別見積もりを取る前提で考えるのが現実的です。
-
データ収集インフラ費
PLC・SCADAからのデータ取り出し、ゲートウェイ機器、通信回線、ストレージ。クラウドサービスの利用料とは別計算の運用コストとして毎月発生します。多拠点展開時は通信回線(閉域SIM・専用線等)のコストが累積しやすい領域です。
-
PoC期間中の運用人件費
PoC期間2〜4ヶ月、本番運用までの平均6〜9ヶ月の間、データサイエンティスト・現場保全員・SIerの三者が動きます。実コストは社内人件費を含めて見るべきで、外部委託料金だけを見積もりに入れると後工程で予算超過します。
-
モデル再学習・閾値調整の継続コスト
設備の改造、季節変動、新製品ライン投入のたびにモデルを更新する必要があります。年に数回〜十数回の再学習・閾値見直しが入る前提で見積もります。
これら隠れコストを最初の見積もり段階で組み込まないと、PoC後の本番展開フェーズで予算が膨らみやすくなります。AI総研の支援現場でも、初期見積もりと実運用コストの差で本番化が止まる事例が一定の頻度で発生しています。
規制動向|EU AI Actと国内サイバーセキュリティ政策
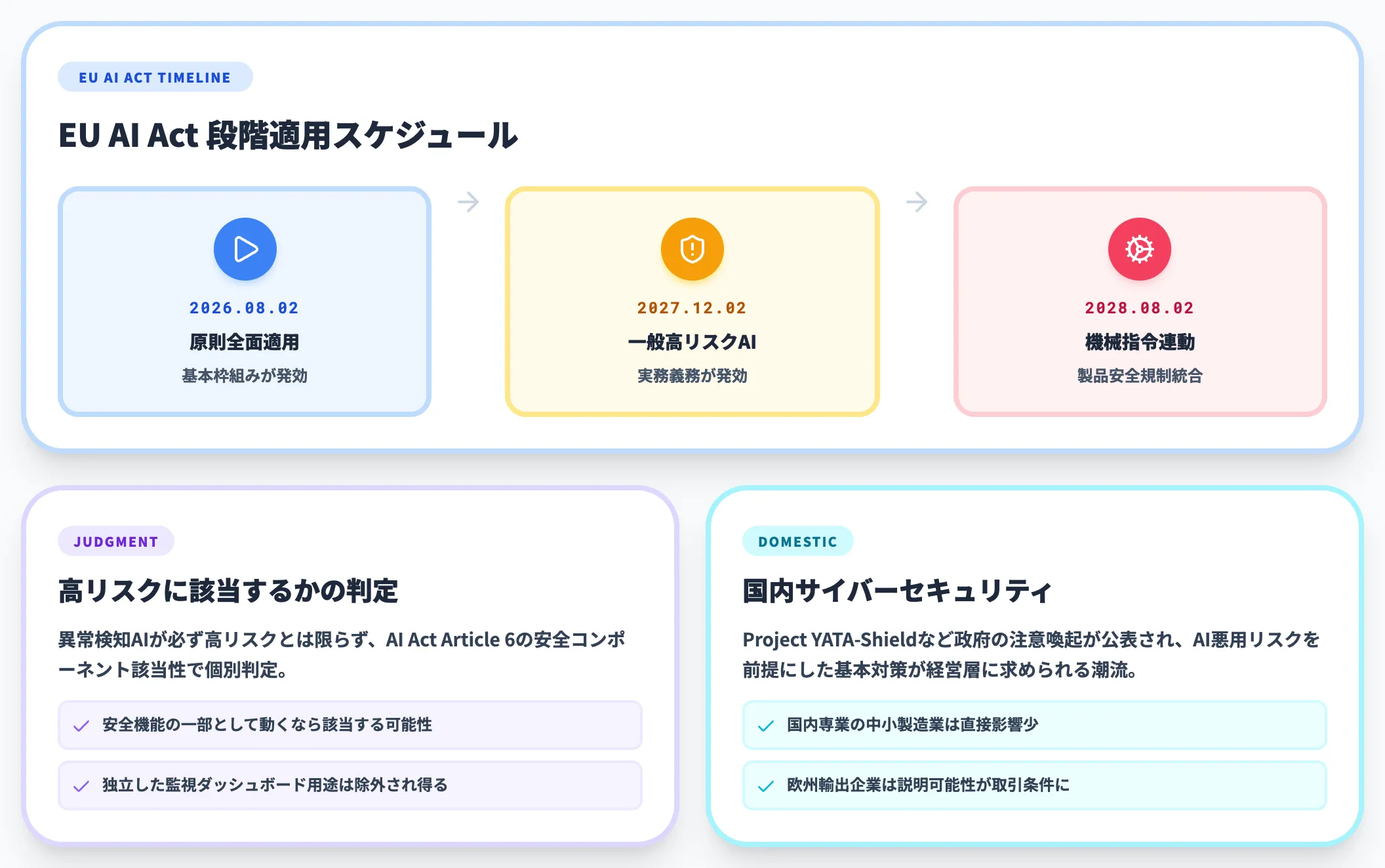
EU AI Actは2026年8月2日に原則全面適用に入る一方、高リスクAIに対する実務上の義務適用は用途・製品組込みの区分に応じて段階的に発効します。一般的な高リスクAIは2027年12月2日、機械指令などの製品安全規制に組み込まれる高リスクAIは2028年8月2日が実務期限とされており、適用タイミングは一律ではありません。
製造業の異常検知AIが必ず高リスクに該当するわけではなく、AI Act Article 6の安全コンポーネント該当性などで個別に判定されます。製品の安全機能の一部として動く異常検知AIは該当する可能性がありますが、独立した監視ダッシュボード用途であれば高リスクから外れるケースもあります。
欧州向け製品を製造している国内企業にとっては、欧州への製品輸出時に説明可能性レベルが取引条件に影響する可能性がある一方、国内専業の中小製造業には直接的な影響は当面少ない構図です。これと並行して、国内ではProject YATA-Shieldのようなサイバーセキュリティ政策・注意喚起が公表されており、規制とは性質が異なるものの、AI悪用リスクを前提にした基本対策の確実な実施を経営層が求められる潮流が形成されつつあります。

異常検知AIを設備監視・品質管理の自動化までつなぐなら
異常検知AIは単体のモデルとして導入するだけでは、検知結果が現場のアクションに繋がらないまま終わりがちです。「いつもと違う」をAIが出力した後の原因切り分け・対応指示の起案・保全管理システムへの記録までを業務フローとして設計してこそ、設備監視・品質管理の自動化として完成します。
ここで効いてくるのが、AI総合研究所が提供するAI Agent Hubの製造業展開です。異常検知AIを単体機能で終わらせず、保全管理システム・品質管理システム・IoTプラットフォームと接続して監視業務全体を自動化する基盤として位置づけられています。実行ログ・権限管理・セキュリティまで含めた運用設計を、ツール選定の段階から伴走支援します。
製造業のAIエージェント活用で整理しているとおり、異常検知単体ではなく業務フローに組み込む視点に立つと、ROIの計算方法も「検知精度」から「業務サイクル短縮」「対応漏れ削減」へとシフトします。AI総研の支援現場でも、検知モデルの精度よりも、その後の業務連携設計が本番化成功の分かれ目になるケースが増えています。
AI総合研究所の専任チームが、異常検知AIの選定から保全業務・品質管理業務への組み込みまで、製造業の現場文脈に合わせて設計を伴走します。
異常検知AIを監視・品質管理業務に定着させる

センサーデータから業務フロー連携まで設計
異常検知AIを単体機能で終わらせず、保全管理・品質管理システムと接続して監視業務全体を自動化。AI Agent Hubで実行ログ・権限管理まで含めた基盤の構築を支援します。
まとめ
本記事では、2026年6月時点の異常検知AIの現在地を、製造業の設備監視・品質管理の意思決定プロセスに沿って整理しました。要点を改めてまとめます。
-
異常検知AIは教師なし学習を主軸に、製造業の設備監視・品質管理を支える中核技術として位置づけられ、検知後の運用設計まで含めて初めてROIが立ち上がる
-
2026年は3つの構造変化が同時進行しており、生成AI連携で「検知から原因特定・自律復旧」へ進化/エッジAIが中小製造業まで民主化/クラウドマネージドサービスの再編が起きている
-
製造業の現場ユースケースは5領域(設備監視・予知保全/外観検査/プロセス監視/異音検知/作業分析)に分かれ、自社で取得しやすいデータ種類から優先順位を決めるのが現実的
-
プラットフォーム選定は4つの判断軸(データ所在/運用体制/統合野心/拠点規模)で整理する。データ基盤刷新の意思があるかが、Fabric系か特化SaaS系かの最初の分岐点
-
国内事例に共通する効果が出る条件は、対象設備・工程が絞られている/既存業務が文書化されている/経営と現場の判断が連動している、の3点
-
PoC〜本番化で詰まる5論点と隠れコスト4項目を初期設計から組み込まないと、本番展開で予算が膨らみ運用が止まる










