この記事のポイント
 第8世代TPUは「TPU 8t(訓練用)」と「TPU 8i(推論用)」を分離した初のTPU世代。用途別最適化が最大の特徴
第8世代TPUは「TPU 8t(訓練用)」と「TPU 8i(推論用)」を分離した初のTPU世代。用途別最適化が最大の特徴- TPU 8tは1チップ12.6 PFLOPs(FP4)、9,600チップPodで121 ExaFlops。超大規模モデル事前学習向けの第一候補
- TPU 8iはチップあたり288GB HBMと384MB SRAMを搭載し、Ironwood比で低レイテンシ推論に寄せた設計
- ArmベースGoogle Axion CPU+AI Hypercomputerとして提供予定、Vertex AI経路・固定比率・リージョン詳細は現時点で未確定
- AnthropicはTPU最大100万規模の拡張計画を表明、Midjourney・Character.AIもTPU実績ありGPU一強の前提は崩れつつある

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Google Cloud Next 2026で発表された第8世代TPUは、訓練用の「TPU 8t」と推論用の「TPU 8i」という2種類のチップで構成される初の世代です。
1年前に登場した第7世代「Ironwood」を土台に、訓練と推論で別の設計思想を採用したことで、1Pod 9,600チップでの121 ExaFlops訓練や、288GB HBM+384MB SRAMによる低レイテンシ推論といった、従来のTPU世代にはない性能プロファイルを実現しています。
本記事では、2026年4月時点で公開されている公式deep diveと発表資料をもとに、TPU 8t/8iのスペック・Ironwoodとの違い・ArmベースのGoogle Axion CPUと組むAI Hypercomputer構成・採用企業の事例・提供時期までを体系的に整理します。
目次
Google 第8世代TPU(TPU 8t・TPU 8i)とは?
BoardflyとCollectives Acceleration Engine
【詳細比較】Ironwood(第7世代)とTPU 8t/8iの違い
Axion Arm CPUと組むAI Hypercomputerアーキテクチャ
Google Cloud TPU/AI Hypercomputerの主な利用企業
Google 第8世代TPU(TPU 8t・TPU 8i)とは?

第8世代TPU 8t(訓練用)と8i(推論用)の外観(出典:Google Cloud Blog)
Google 第8世代TPUは、Google Cloud Next 2026で発表された、Googleが自社設計するAIアクセラレータの最新世代です。
最大の特徴は、これまで単一チップで訓練と推論を兼ねてきた方針を変え、「TPU 8t」(訓練用)と「TPU 8i」(推論用)の2種類を同時に投入したことにあります。
TPUは2015年の初代からGoogle社内で使われ、Gemini・Imagen・Veoといった同社の基盤モデルの学習・推論基盤を担ってきました。
2025年11月に一般提供された第7世代「Ironwood」から約半年、第8世代はAIワークロードの用途別分化をハードウェア側で正面から取り込んだ設計思想に切り替わっています。
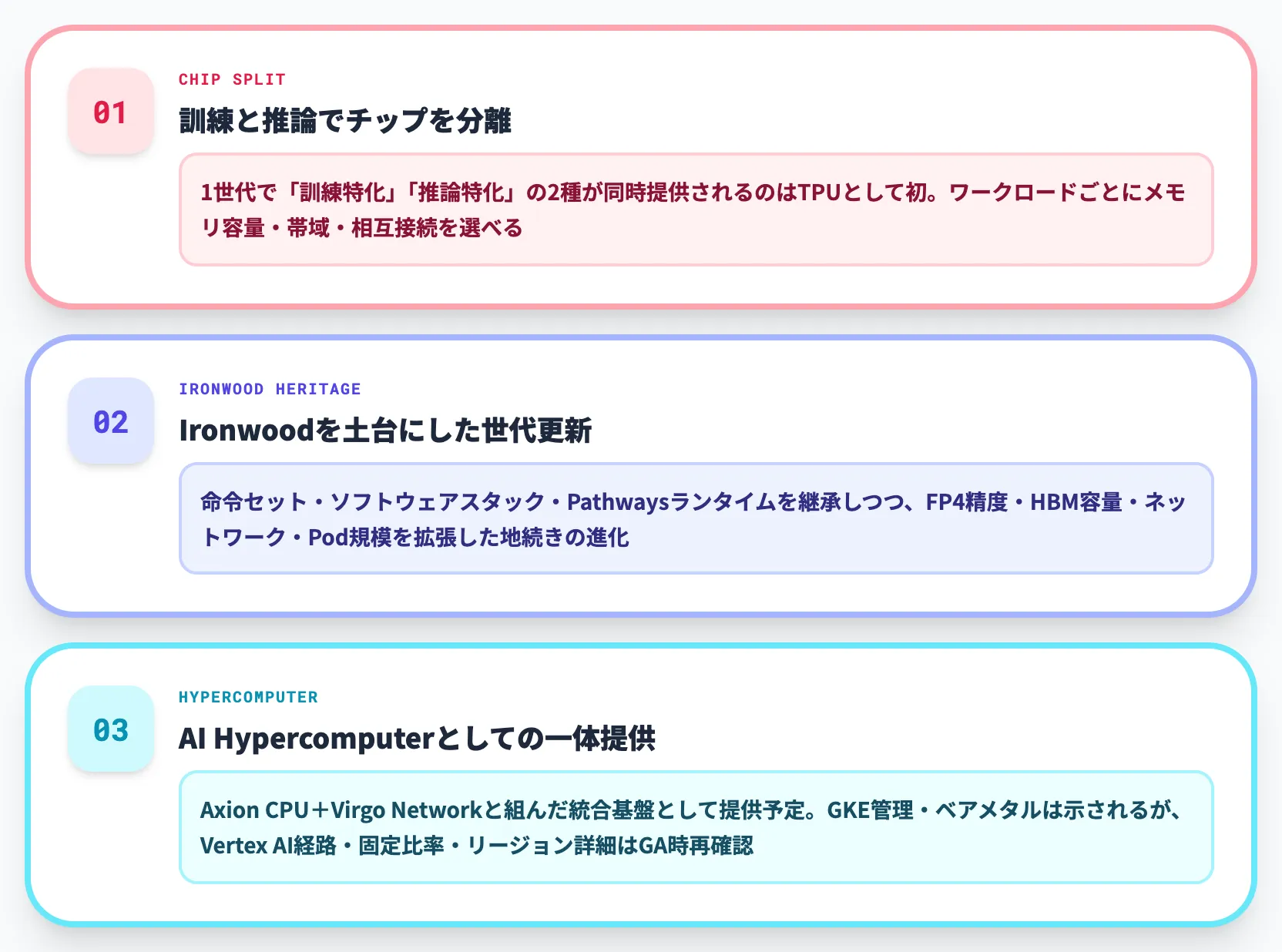
第8世代で押さえておきたい3つのポイント
第8世代TPUを正しく理解するうえで、最初に押さえておくべき観点を3つに絞って整理すると以下のとおりです。
-
訓練と推論でチップを分離
1つの世代で「訓練特化」と「推論特化」の2種類が同時に提供されるのはTPUとして初めての構成で、ワークロードごとに異なるメモリ容量・帯域・相互接続設計が選べるようになった
-
Ironwoodを土台にした世代更新
Ironwood(第7世代)の命令セット・ソフトウェアスタック・Pathwaysランタイムをそのまま引き継ぎつつ、演算精度(Native FP4)・HBM容量・ネットワークトポロジー・Pod規模を拡張した「地続きの進化」になっている
-
AI Hypercomputerとしての一体提供
TPU単体ではなく、ArmベースのGoogle独自CPU「Google Axion」や新ネットワーク基盤(Virgo Network)と組み合わせた「AI Hypercomputer」として提供される前提設計。Cloud TPU公式ページは第8世代TPUを現時点でComing soon表示としており、GKE経由の管理やベアメタルアクセスは示されているものの、Vertex AI経路・リージョン別可用性・CPUとの固定比率などの詳細仕様はGA時点で改めて公式アナウンスを確認する必要がある
発表の位置づけ
第8世代TPUの発表は、Ironwood世代でGPU以外の大規模AI訓練基盤として存在感を増したTPUを、推論コストの削減と訓練規模の拡張の両方で底上げする動きです。
AnthropicはGoogle Cloud TPUの利用規模を最大100万チップまで拡張する計画を公式発表しており(Anthropic公式)、発表時点では第8世代TPU 8t/8iの採用を明示していないものの、TPU基盤全体への投資拡大はこの流れの延長線上にあります。
MidjourneyやCharacter.AIも過去からTPU/AI Hypercomputerの利用実績があり、TPUは実運用ワークロードの選択肢として定着しつつあります。
「AI計算基盤=NVIDIA GPU一択」という前提は、訓練・推論のいずれの側面でも崩れつつあり、第8世代TPUはその象徴的なハードウェアです。

なぜ第8世代で「訓練用」と「推論用」を分けたのか
第8世代TPUでチップを2つに分けた最大の理由は、AIワークロードにおける訓練と推論の負荷特性が、もはや同一のチップ設計で最適化できないところまで乖離したためです。
従来は1つのTPU世代を訓練・推論どちらにも使うのが一般的でしたが、LLMの長文コンテキスト化と推論トラフィックの急拡大で、必要とされるメモリ容量・帯域・相互接続の重みが両者で大きく変わってきています。

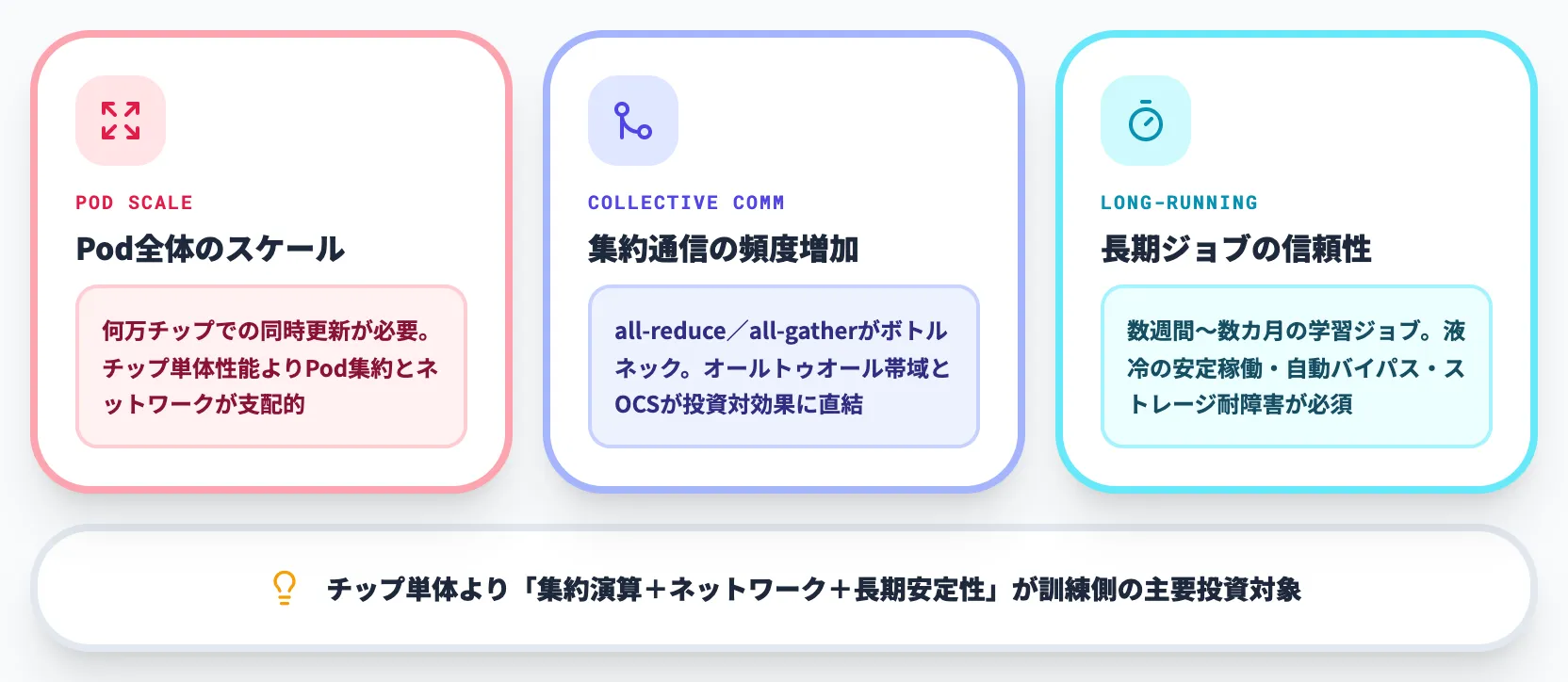
訓練ワークロードの変化
大規模モデルの事前学習では、モデルサイズとバッチサイズが増加を続けており、求められる計算資源の特徴は以下のようにシフトしてきました。
-
Pod全体のスケール
1つのモデルを何万チップでデータ並列+テンソル並列で同時に更新する必要があるため、チップ単体性能よりPod全体の集約演算性能とネットワーク性能が支配的になる
-
集約通信の頻度増加
all-reduce/all-gatherなどの集約通信が計算のボトルネックになりやすく、オールトゥオール帯域とOCSによる無停止再配線能力が投資対効果に直結する
-
長期ジョブの信頼性
数週間〜数カ月単位で走り続ける学習ジョブが主流となり、液冷の安定稼働・チップ故障時の自動バイパス・ストレージ耐障害性が必須要件になる
推論ワークロードの変化
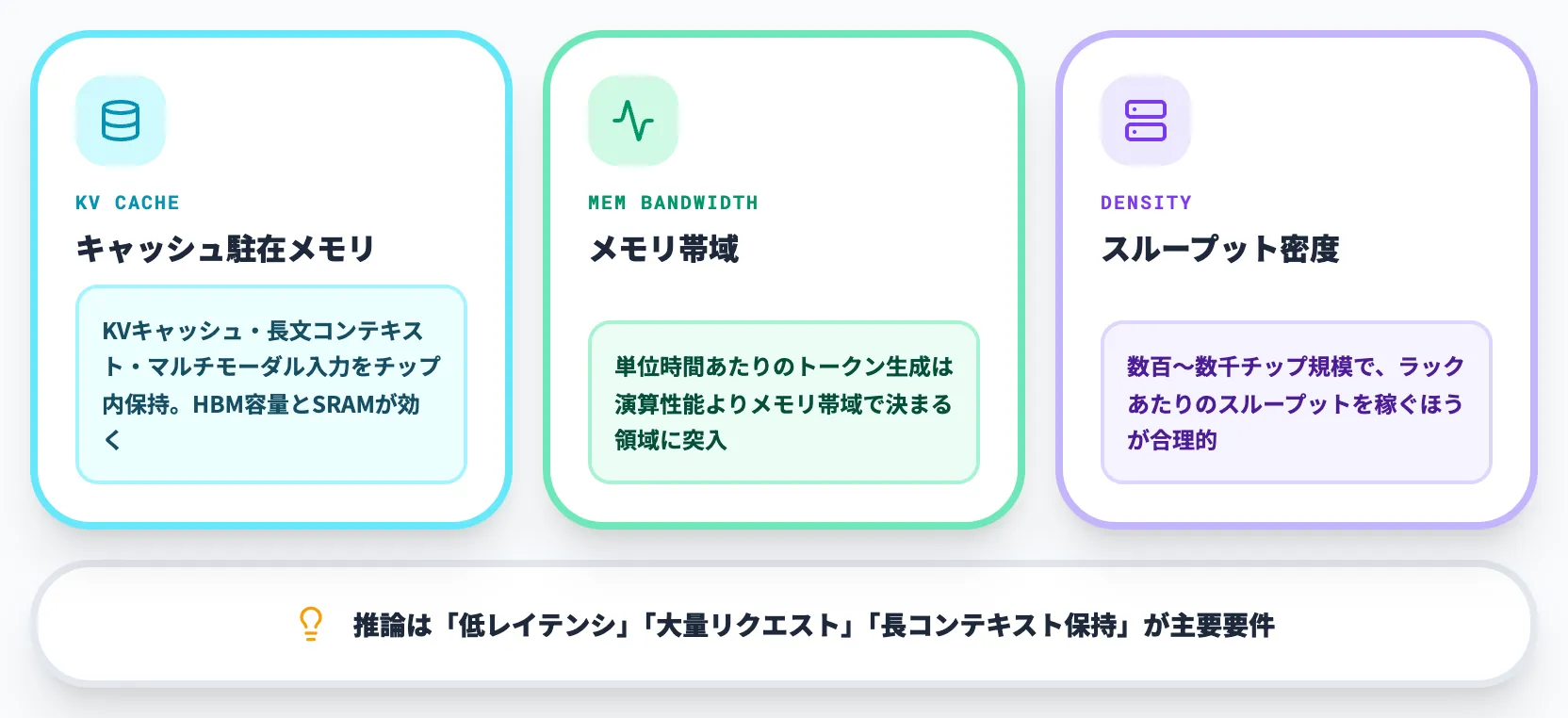
一方、推論側は「低レイテンシ」「大量のリクエスト処理」「長いコンテキストの保持」が要件として前面に出るようになり、訓練とは異なる最適化ポイントが並びます。
-
キャッシュ駐在メモリ
LLMのKVキャッシュ・長いコンテキスト・マルチモーダル入力を同じチップ内に保持し続けたいニーズが強く、HBM容量とオンチップSRAMが効く
-
メモリ帯域
推論中はメモリ帯域律速になりやすい。「単位時間あたりに何トークンを吐き出せるか」は、演算性能よりメモリ帯域で決まる領域に突入している
-
Pod規模よりスループット密度
訓練のように数万チップを同期させる必要がないため、数百〜数千チップ規模のPodでラックあたりのスループットを稼ぐほうが合理的になる
用途特化設計が合理的になった背景
推論側は「より多くのメモリを、より高い帯域で、より狭い範囲に置く」方向に寄せ、訓練側は「より多くのチップを、より速いネットワークで、より広い範囲に広げる」方向に寄せることで、同じ第8世代の命令セット・ソフトウェアを共有したまま、ハードウェアの重みづけだけを変えるアプローチが取られました。
この判断は、HopperからBlackwellに移る際にGPU側で起きた「訓練・推論での設計要素の分化」と同じ流れを、TPU側でも明示的に取り込んだと見るのが実務的です。

TPU 8t(訓練用)の技術仕様
TPU 8tは、第8世代TPUの中で超大規模モデルの事前学習・継続事前学習(CPT)・大規模RLHFに照準を合わせたチップです。
「1Podで121 ExaFlops級の集約演算性能」という、Ironwood Podを大きく上回るスケールを正面から狙った設計になっています。
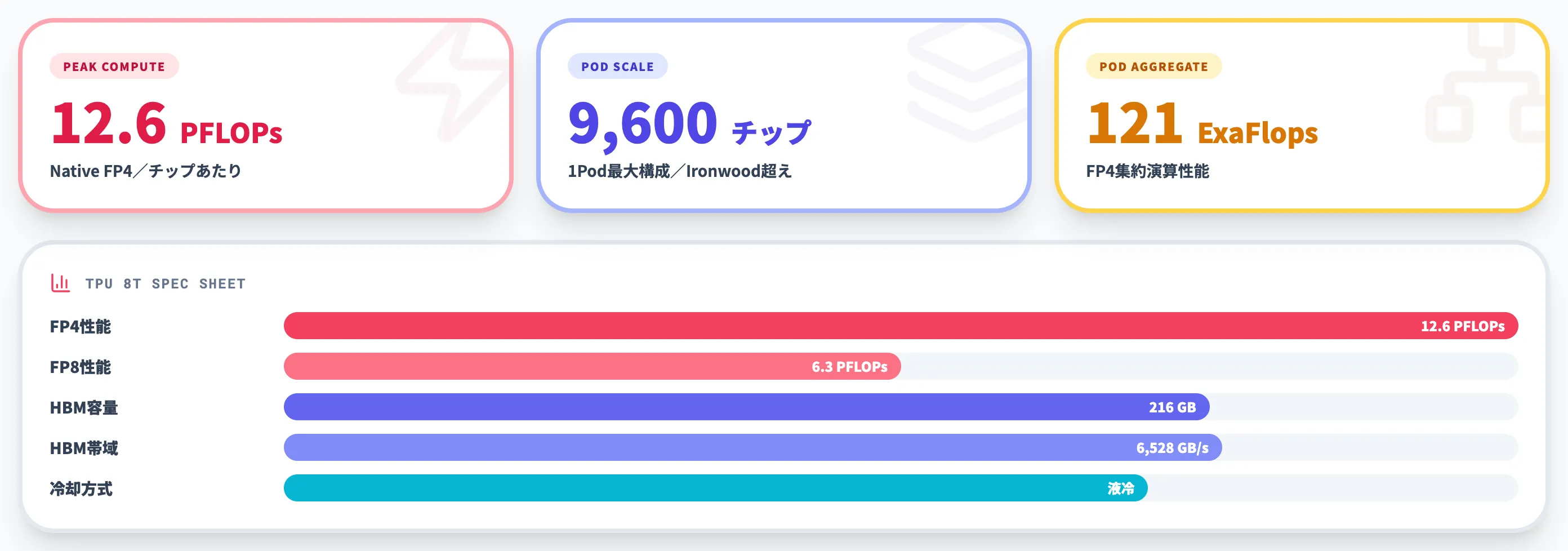
TPU 8tでは、単一チップ性能の向上に加え、9,600チップを単一Podとして接続する大規模分散アーキテクチャが導入されています。これにより、Googleは基盤モデル訓練向けに121 ExaFlops級の超大規模AIスーパーコンピューティング環境を提供しています。
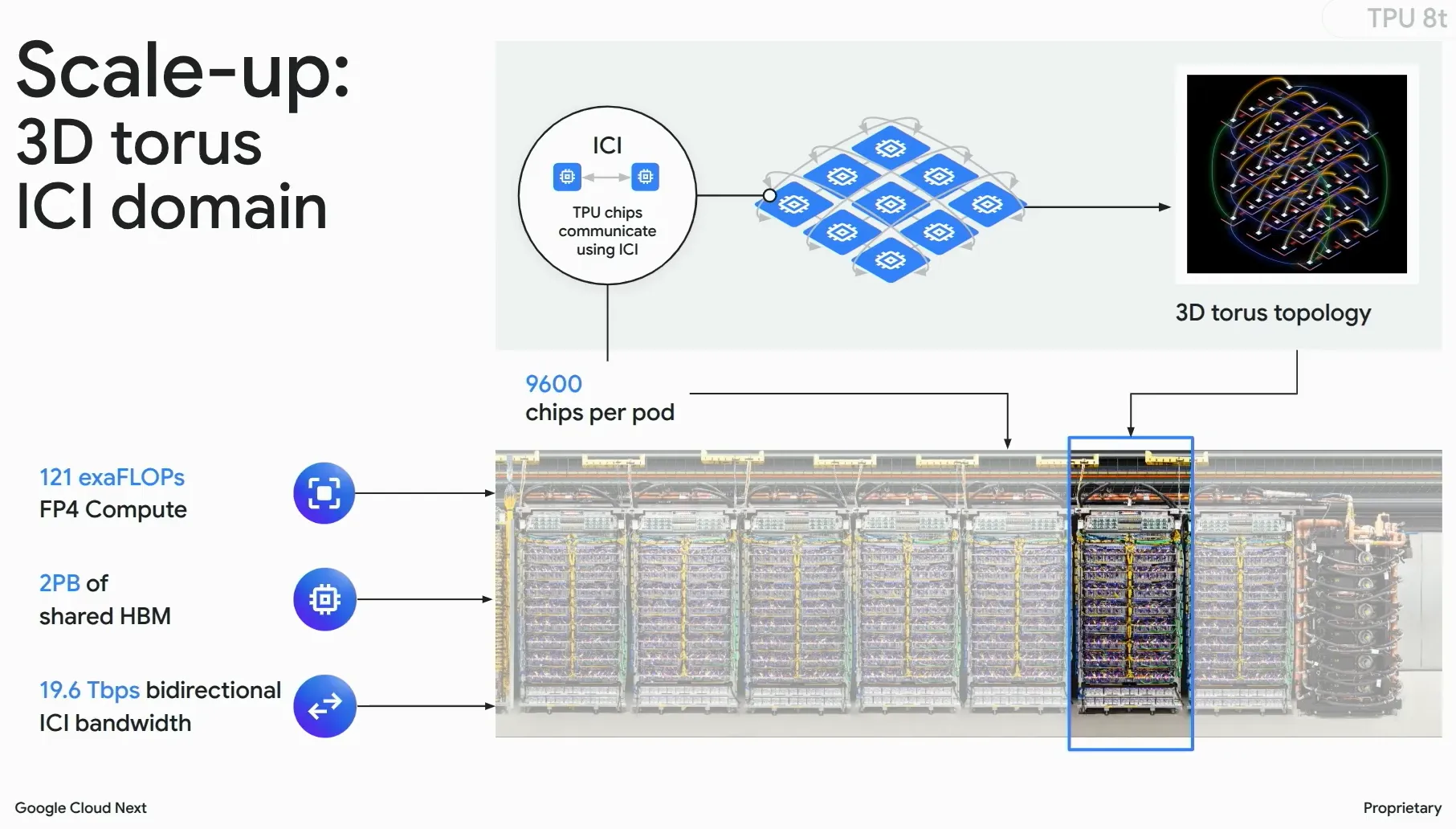
TPU 8tの9,600チップPod構成と121 ExaFlopsピーク性能(出典:Google Cloud Next公式講演)
チップレベルのスペック
TPU 8tの主要スペックは以下のとおりです。
| 項目 | TPU 8t(訓練用) |
|---|---|
| ピーク演算性能(Native FP4) | 12.6 PFLOPs |
| ピーク演算性能(FP8) | 約6.3 PFLOPs |
| HBM容量 | 216 GB |
| HBM帯域 | 6,528 GB/s(約6.5 TB/s) |
| 冷却方式 | 液冷 |
| Pod最大構成 | 9,600チップ |
| Pod集約演算性能(FP4) | 約121 ExaFlops |
この表で注目したいのは、単体FP4性能が12.6 PFLOPsとIronwood(FP8で4.6 PFLOPs)を大きく上回ることに加え、1Podのチップ数が9,600まで拡張されている点です。
Ironwood Podの9,216チップ構成を超えるPod規模が、より大きなモデルを1ジョブで学習させる余地を広げています。
Virgo Networkによるラック間接続
TPU 8tを最大構成で使う際の中心的なコンポーネントが、Googleが第8世代と同時に発表した新しいネットワーク基盤「Virgo Network」です。主な特徴は以下のとおりです。

-
47 Pb/sの二分帯域
ラック・Pod間のオールトゥオール通信を支える二分帯域で、数万チップの同期通信を律速させない
-
最大134,000チップ規模のファブリック
1つのネットワーク基盤上で複数Podを束ね、超大規模ジョブをまたいで走らせる拡張枠を確保している
-
Optical Circuit Switches(OCS)
電気スイッチではなく光回路スイッチを用いることで、故障チップや故障ラックを停止させずに迂回・再構成できる
これらは単なるネットワーク機能の紹介ではなく、「数週間走り続ける学習ジョブを、どれだけ止めずに回し切れるか」という大規模訓練の実用性に直結するポイントです。
SparseCoreとNative FP4
TPU 8tは、Ironwood世代から引き継いだSparseCore(疎行列向け専用ユニット)をそのまま拡張しつつ、FP4をハードウェアネイティブで扱える演算器を搭載しました。

SparseCoreはレコメンドモデル・Sparse MoE・Embedding Tableといった「全体としては巨大だが毎ステップで触るのは一部」というワークロードに効き、TPU 8tではモデルサイズを一段伸ばしても学習コストを線形に近づけやすくしています。Native FP4は、量子化済みのウェイトやMoE実装にそのまま適用できるため、FP8時代に比べて同じチップ面積あたりの有効FLOPsを約2倍に引き上げています。
訓練ジョブでの向き不向き
TPU 8tは、以下のような特徴を持つ訓練ジョブで強みを発揮する設計です。

- 10億〜数千億パラメータ級のLLM・マルチモーダルモデルの事前学習
- 長文コンテキスト(数十万〜百万トークン)の継続事前学習
- Sparse MoE構成の大規模モデル
- 長期間安定稼働が必要な超大型ジョブ
一方で、数千チップ規模のPodを使いこなせないワークロード(数十億パラメータ未満のLoRA微調整など)では、後述するTPU 8iや中規模GPUクラスタのほうが費用対効果で有利になるケースがあります。
このあたりは「Pod規模×ジョブ時間」が損益分岐点を決めるため、ワークロードの実態を見てから選定すべき箇所です。
TPU 8i(推論用)の技術仕様
TPU 8iは、第8世代TPUのうちLLM推論・マルチモーダル推論・検索推論を正面ターゲットにしたチップです。「より多くのメモリを、より広い帯域で、より狭い範囲に置く」という推論向けの設計原則に忠実に作られています。

TPU 8iでは、推論ワークロードに最適化するため、大容量SRAMとCollectives Acceleration Engine(SC-CAE)を組み合わせ、レイテンシ削減と高スループット提供を両立しています。これにより、長文コンテキスト推論や大規模LLMサービングにおいて、従来世代を大きく上回る効率を実現しています。
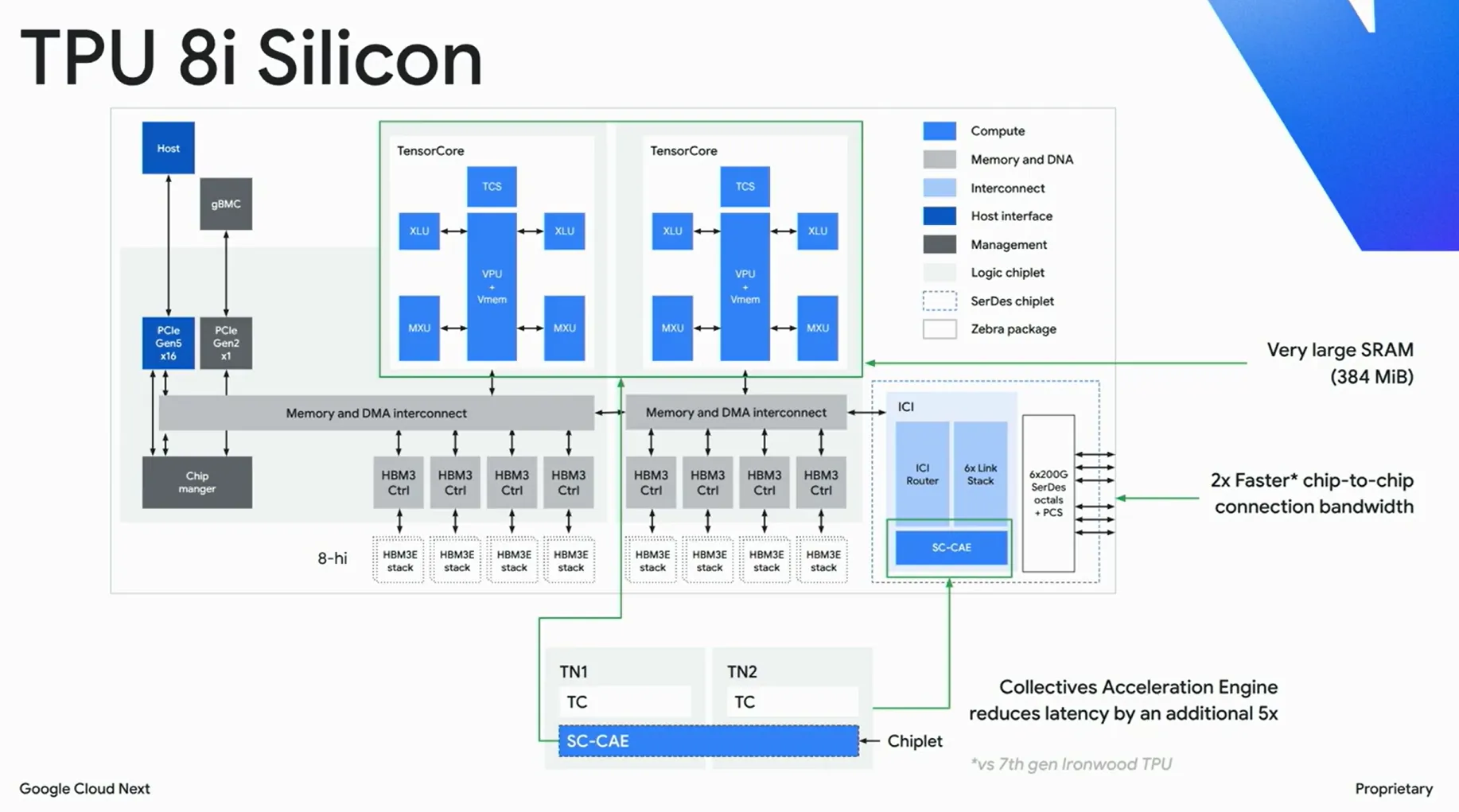
TPU 8iの384MB SRAM・大容量HBM・推論特化アーキテクチャ(出典:Google Cloud Next公式講演)
チップレベルのスペック
TPU 8iの主要スペックは以下のとおりです。
| 項目 | TPU 8i(推論用) |
|---|---|
| Pod集約演算性能 | 11.6 ExaFlops(FP8/公式発表画像) |
| チップあたりピーク演算性能 | 10.1 PFLOPs(FP4/公式technical deep dive) |
| HBM容量 | 288 GB |
| HBM帯域 | 8,601 GB/s(約8.6 TB/s) |
| オンチップSRAM | 384 MB |
| トポロジー | Boardfly(第8世代で新規採用) |
| Pod構成 | 1,152チップ(Superpod) |
この表で注意したいのは、Pod集約演算性能とチップあたりピーク演算性能が、公式一次ソースで別の精度ラベルで示されている点です。
Googleの発表画像ではPod集約で「11.6 ExaFlops(FP8)」、公式technical deep diveではチップ単体で「Peak FP4 10.1 PFLOPs」と表記されており、精度が異なるため両者を割り算で対応づけるのは正確ではありません。
そのうえで、チップあたり288GBのHBM容量と8.6 TB/sの帯域を訓練用TPU 8tより厚く確保した構成で、推論の律速要因となるメモリ帯域とKVキャッシュ収容量に正面から投資していることが読み取れます。
BoardflyとCollectives Acceleration Engine
TPU 8iは、推論向けに設計された新トポロジー「Boardfly」と、集約通信を専用ハードで処理する「Collectives Acceleration Engine(CAE)」を備えています。
それぞれの狙いは以下のとおりです。

-
Boardflyトポロジー
ボード内は密結合、ボード間は高速リンクで束ねる階層型ネットワーク構成。大規模推論で必要となる「数十〜数百チップ単位での高速な集約通信」を、超大規模Podの網を用意せずに実現する
-
Collectives Acceleration Engine(CAE)
all-reduceやall-gatherといった集約通信を専用演算器でオフロードする仕組み。vLLMやSGLangのテンソル並列推論で、TPUコアを演算に専念させながら通信を進行できる
これらの機構があることで、TPU 8iは大規模LLMをチップ間にまたがってテンソル並列に配置しつつ、1トークンあたりのレイテンシを抑える推論が可能になっています。
SRAM 384MBの意味
TPU 8iの見逃せない特徴が、チップあたり384MBのオンチップSRAMを持つ点です。これは推論中のKVキャッシュや注意マトリクスの一部をオンチップに常駐させ、HBMアクセス回数を減らすためのキャッシュとして機能します。

LLM推論では、プロンプト長が増えるほどKVキャッシュサイズがHBM容量を圧迫し、最終的にレイテンシ悪化やバッチサイズ縮小を招きます。SRAMを大きく確保することで、「長いコンテキストでもスループットを落としにくい」挙動を狙った構造で、推論サービスの単位トークンあたりコスト削減に直結する設計です。
推論ジョブでの向き不向き
TPU 8iが向くワークロードの特徴を整理すると以下のとおりです。

- 数十億〜数千億パラメータのLLM推論(Gemini、Claude級)
- 長文コンテキスト(数十万トークン)を想定したチャット・RAG推論
- マルチモーダル推論(画像生成・画像理解・動画理解)
- 大量の同時リクエストを捌くサービング(SaaS、検索)
逆に、数億パラメータクラスの軽量モデルや、レイテンシよりコストが厳しいバッチ推論ジョブでは、GPUの既存クラスタや後述のAxion Arm CPUによるCPU推論のほうが費用対効果で有利になる場面があります。「推論=常にTPU 8iが最適」ではなく、「モデル規模×レイテンシ要求×同時リクエスト数」でマトリクス的に判断するのが実務的な進め方です。
【詳細比較】Ironwood(第7世代)とTPU 8t/8iの違い
第8世代TPUを理解するうえで最も参照されるのが、ちょうど1年前に発表された第7世代「Ironwood」との比較です。Ironwoodは2025年11月に一般提供され、Anthropicなど大手AI企業で採用が進んだ現役世代であり、第8世代はIronwoodを置き換える、あるいは役割分担しながら併用する関係にあります。
Google TPUは世代ごとに演算性能・メモリ容量・ネットワーク構造を大幅に進化させており、Ironwoodはその中でも第7世代として大規模推論基盤を大きく押し上げた重要な転換点でした。
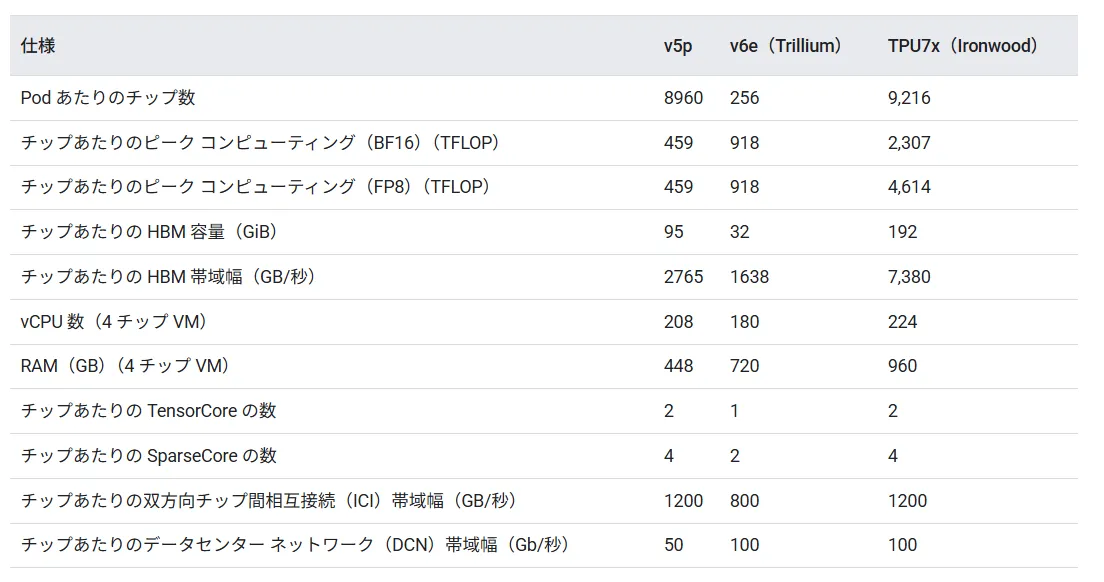
TPU各世代(v5p・Trillium・Ironwood)の主要スペック比較(出典:Google Cloud TPU公式ドキュメント)
そのうえで第8世代では、単一アーキテクチャの延長ではなく、訓練特化のTPU 8tと推論特化のTPU 8iへと役割を分離することで、用途別最適化へ大きく舵を切っています。
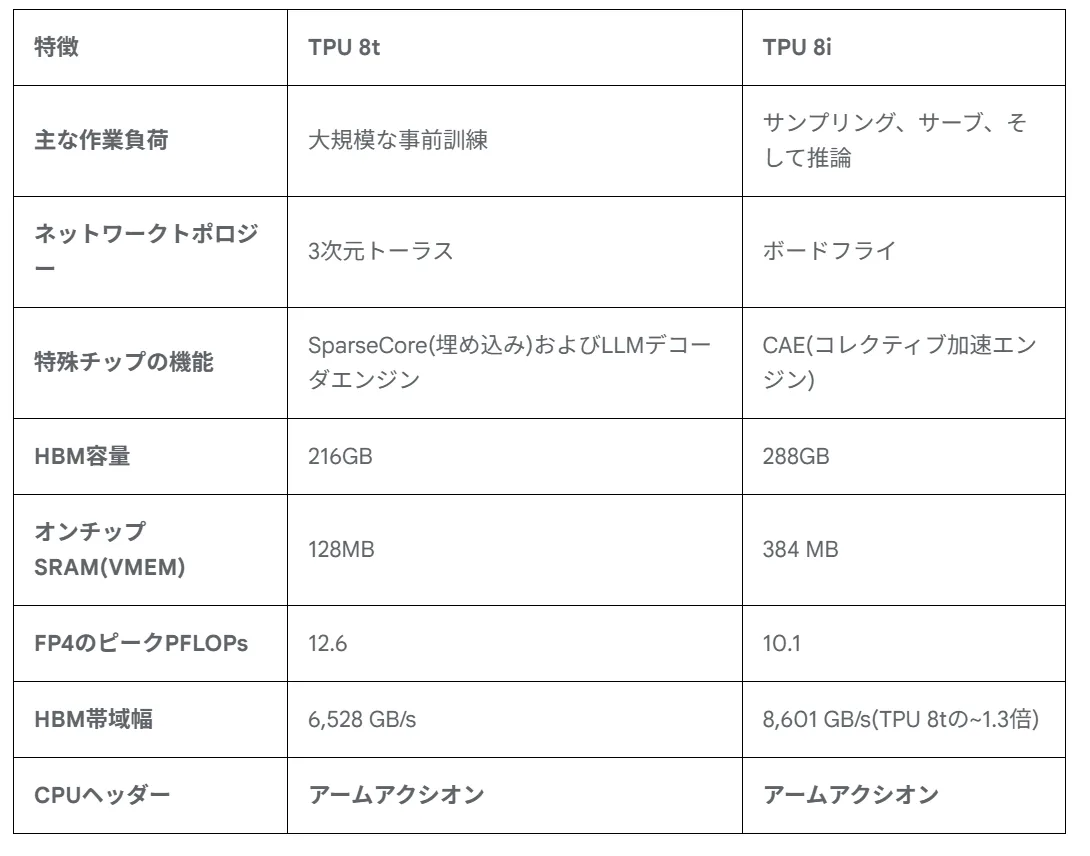
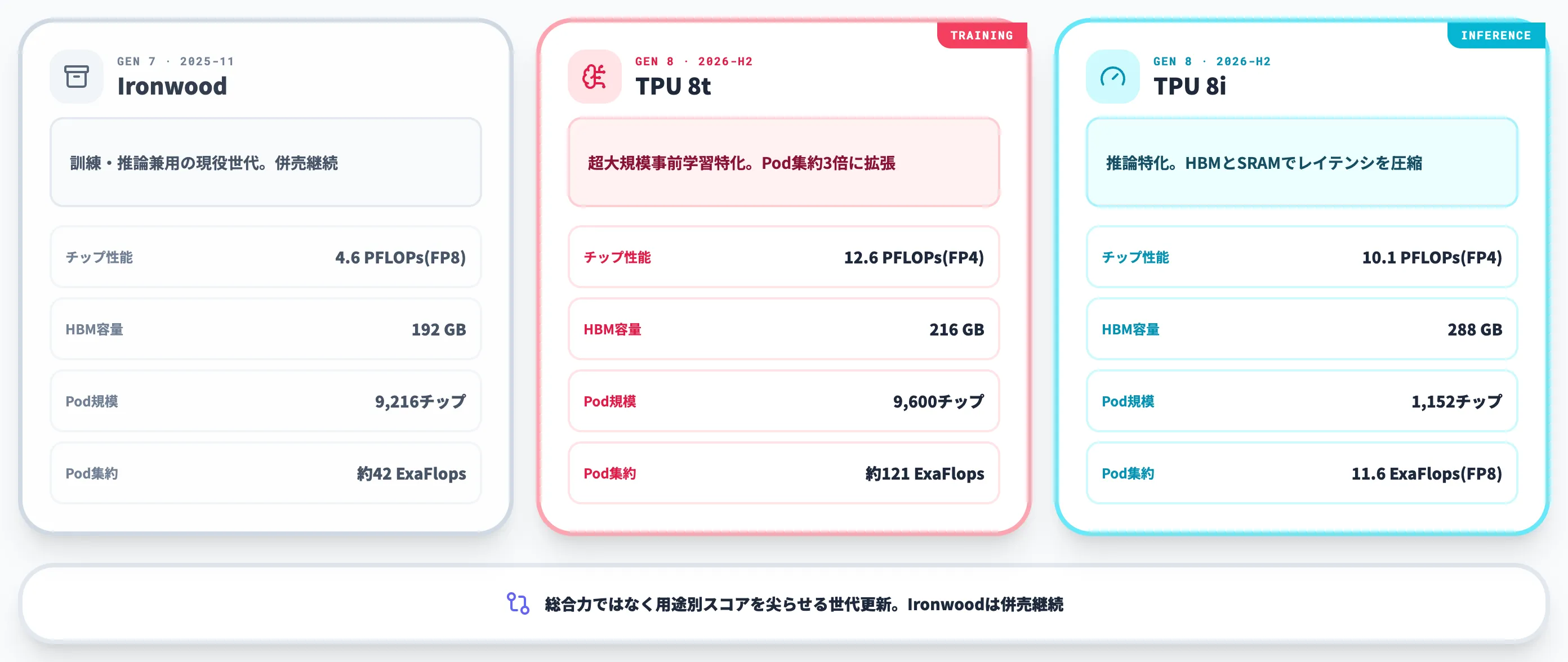
TPU 8tとTPU 8iの主要スペック比較(出典:Google Cloud Blog)
スペック比較表
Ironwood(発表ブログ)・TPU 8t・TPU 8iの主要スペックは以下のとおりです。
| 項目 | Ironwood(第7世代) | TPU 8t(訓練) | TPU 8i(推論) |
|---|---|---|---|
| 発表時期 | 2025年4月/一般提供2025年11月 | Google Cloud Next 2026 | Google Cloud Next 2026 |
| 演算精度 | FP8中心 | Native FP4+FP8 | Native FP4+FP8 |
| チップピーク性能 | 4.6 PFLOPs(FP8) | 12.6 PFLOPs(FP4) | 10.1 PFLOPs(FP4) |
| HBM容量 | 192 GB | 216 GB | 288 GB |
| HBM帯域 | 約7.4 TB/s | 6.5 TB/s | 8.6 TB/s |
| 最大Pod規模 | 9,216チップ | 9,600チップ | 1,152チップ |
| Pod集約性能 | 約42 ExaFlops(FP8) | 約121 ExaFlops(FP4) | 11.6 ExaFlops(FP8) |
| ネットワーク | ICI+OCS | Virgo Network(47 Pb/s) | Boardfly+CAE |
| 主用途 | 訓練+推論兼用 | 大規模訓練特化 | 推論特化 |
この比較から読み取れる最大のポイントは、TPU 8t/8iいずれもIronwoodを「総合力で上回る」のではなく、「用途を絞って一部のスコアを大きく伸ばす」進化を選んでいる点です。チップ単体のピーク性能だけ見ると差が小さく見えても、Pod規模・ネットワーク・メモリ容量の組み合わせで第8世代は別物と捉えたほうが実態に近くなります。
ワークロード別の使い分け
Ironwoodと第8世代をどう使い分けるか、実務目線で整理すると以下のような判断軸になります。

- 新規の超大規模事前学習(10B超・長期ジョブ) TPU 8tが第一候補。Pod規模9,600とVirgo Networkの恩恵が大きい
- 既存Ironwoodクラスタの継続運用 当面はIronwoodのまま。Ironwoodは2025年11月GAで稼働コストの償却余地がまだ残っている
- 本番LLM推論サービング・RAG基盤 TPU 8iが第一候補。KVキャッシュ容量と384MB SRAMの効きが大きい
- 中規模ファインチューニング・LoRA微調整 Ironwood継続 or TPU 8iの推論向け構成。TPU 8tのPod規模はオーバーキル
支援実務の肌感覚としては、「既存Ironwood基盤を使っている場合は第8世代発表後すぐに乗り換えるより、まず推論だけTPU 8iに寄せて、訓練はIronwoodをしばらく使い続けるハイブリッド運用」が最も現実解に近いケースが多い印象です。
Ironwoodが消えるわけではない
重要なのは、第8世代が出たからといってIronwoodが即座に非推奨・廃止扱いになるわけではない点です。Ironwood一般提供発表が2025年11月で、第8世代発表が2026年4月。少なくとも当面はIronwoodと第8世代の併売体制が続く前提で、採用済みのIronwoodクラスタは引き続き価値を持ちます。

Axion Arm CPUと組むAI Hypercomputerアーキテクチャ
第8世代TPUは単体で使う前提ではなく、Googleが「AI Hypercomputer」と呼ぶ統合アーキテクチャの一部として提供されます。その中核を成すのが、Arm命令セットに基づく自社設計CPU「Google Axion」との組み合わせです。

GoogleはTPU単体性能だけでなく、Axion CPU・高速ネットワーク・オープンソフトウェア・クラスタ管理基盤までを統合することで、モデル開発から大規模運用までを包括するAI Hypercomputer戦略を構築しています。
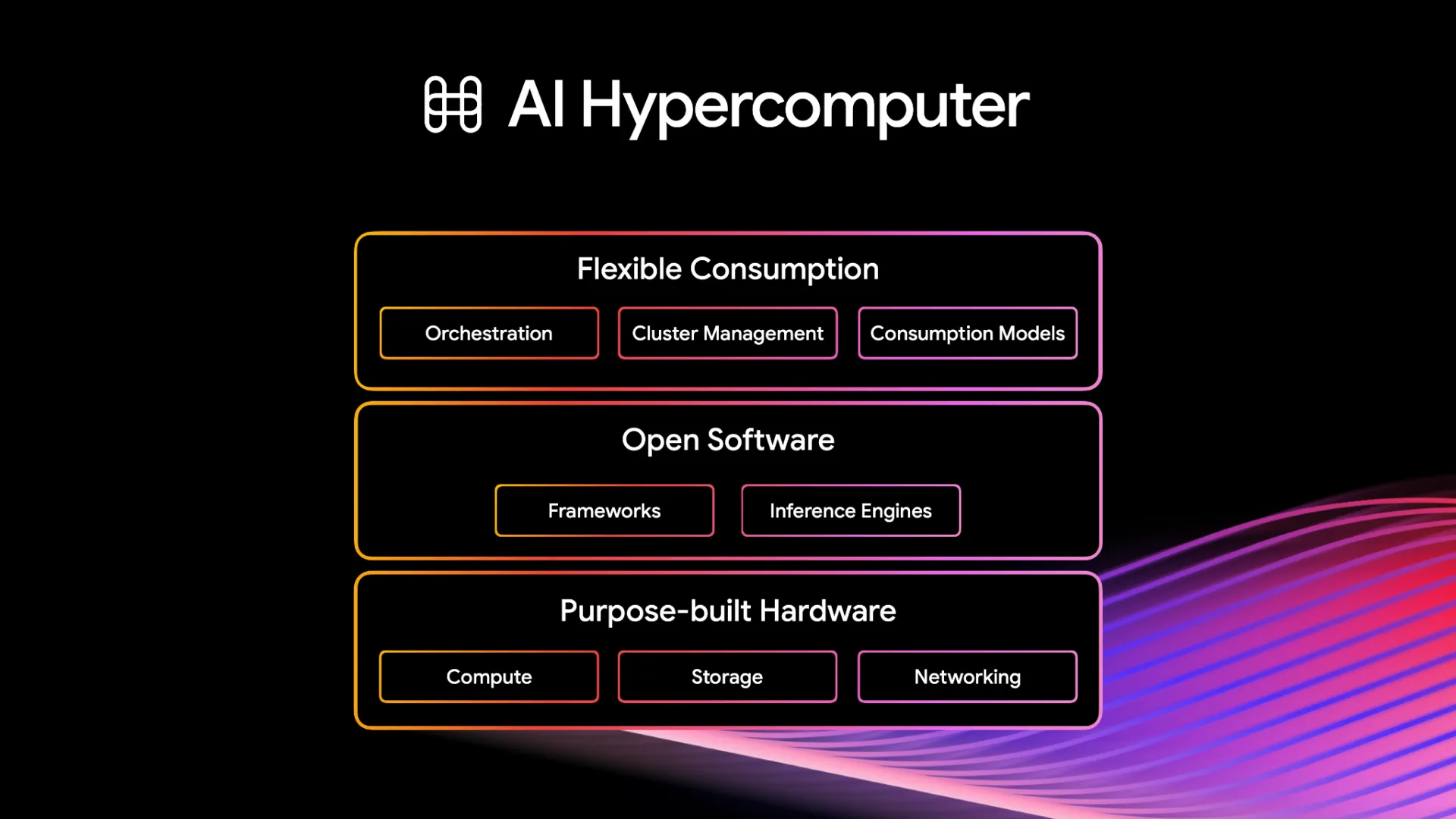
AI Hypercomputerのソフトウェア・ハードウェア統合スタック(出典:Google Cloud AI Hypercomputer)
Axion CPUホスト上で動作するTPU
第8世代の発表で特に注目された設計ポイントが、TPUとAxion CPUの組み合わせ方です。Google公式ブログは「TPU 8t・TPU 8iの両チップがAxion ARMベースCPUホスト上で動作する」「とくにTPU 8iではサーバーあたりの物理CPUホスト数を倍増している」と説明しており、推論・訓練いずれも「TPUの演算」だけでなく「CPU側のデータ前処理・ポストプロセス・オーケストレーション」を並行処理できる構成が前提になっています。
ただし、「TPU 2チップに対してAxion 1ホスト」という比率はGoogle公式が固定として明示しているわけではなく、GA時点の公式情報で再確認が必要です。
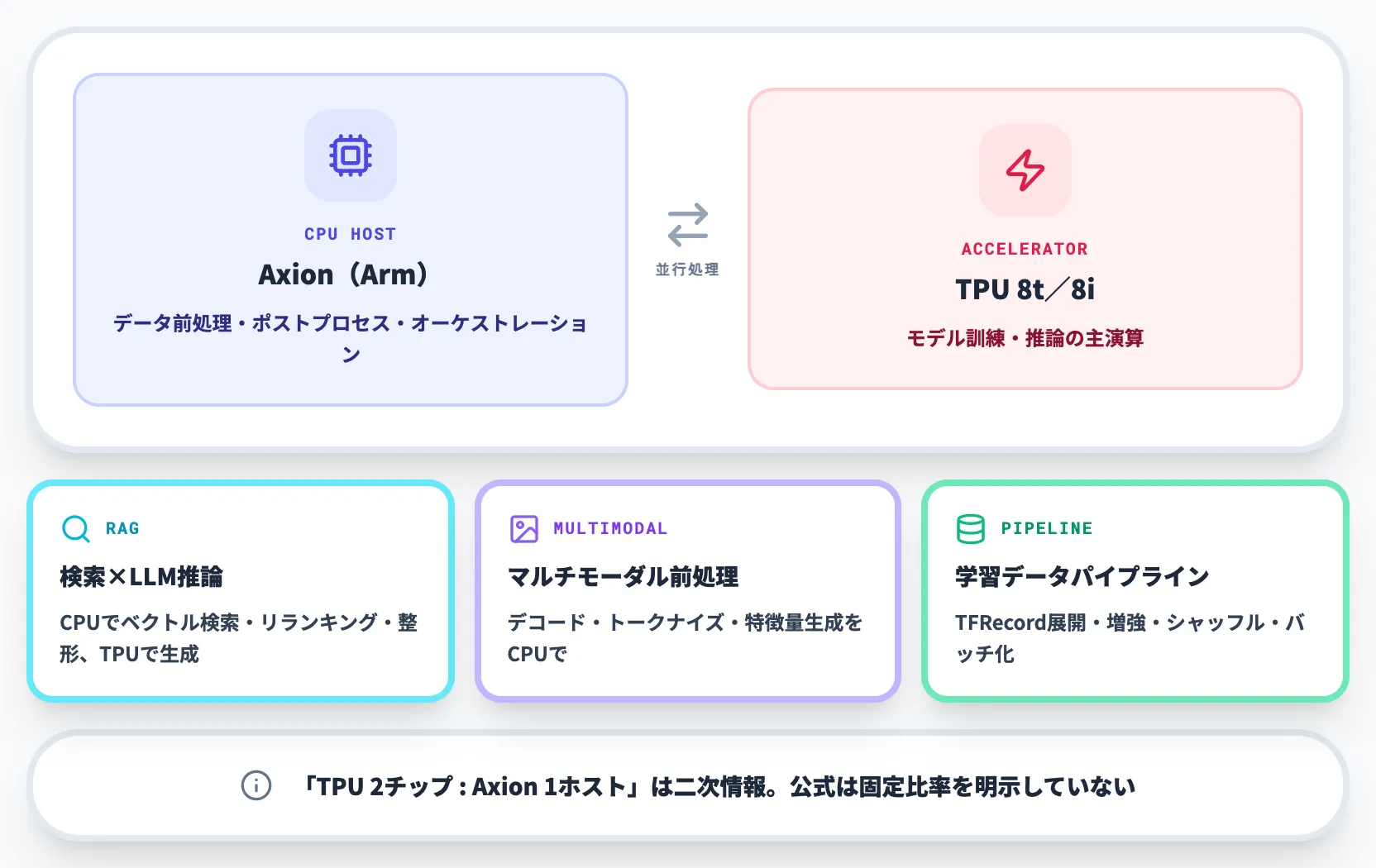
この構成が効くのは以下のようなケースです。
-
RAG/検索×LLM推論
CPU側でベクトル検索・リランキング・コンテキスト整形を行い、TPU側でLLM生成を担う。CPUが足枷にならないよう比率が設計されている
-
マルチモーダル前処理
画像・動画・音声のデコード、トークナイズ、特徴量生成をCPUが担い、TPUに送り込む処理でスループットを確保する
-
学習データパイプライン
TFRecordの展開・データ増強・シャッフル・バッチ化をCPUが担い、TPUコアをデータ待ちにしない
N4A VMとC4A Metal
Axionの提供形態として、第8世代TPUと組み合わせる前提の新しいVMファミリーも合わせて発表されました。
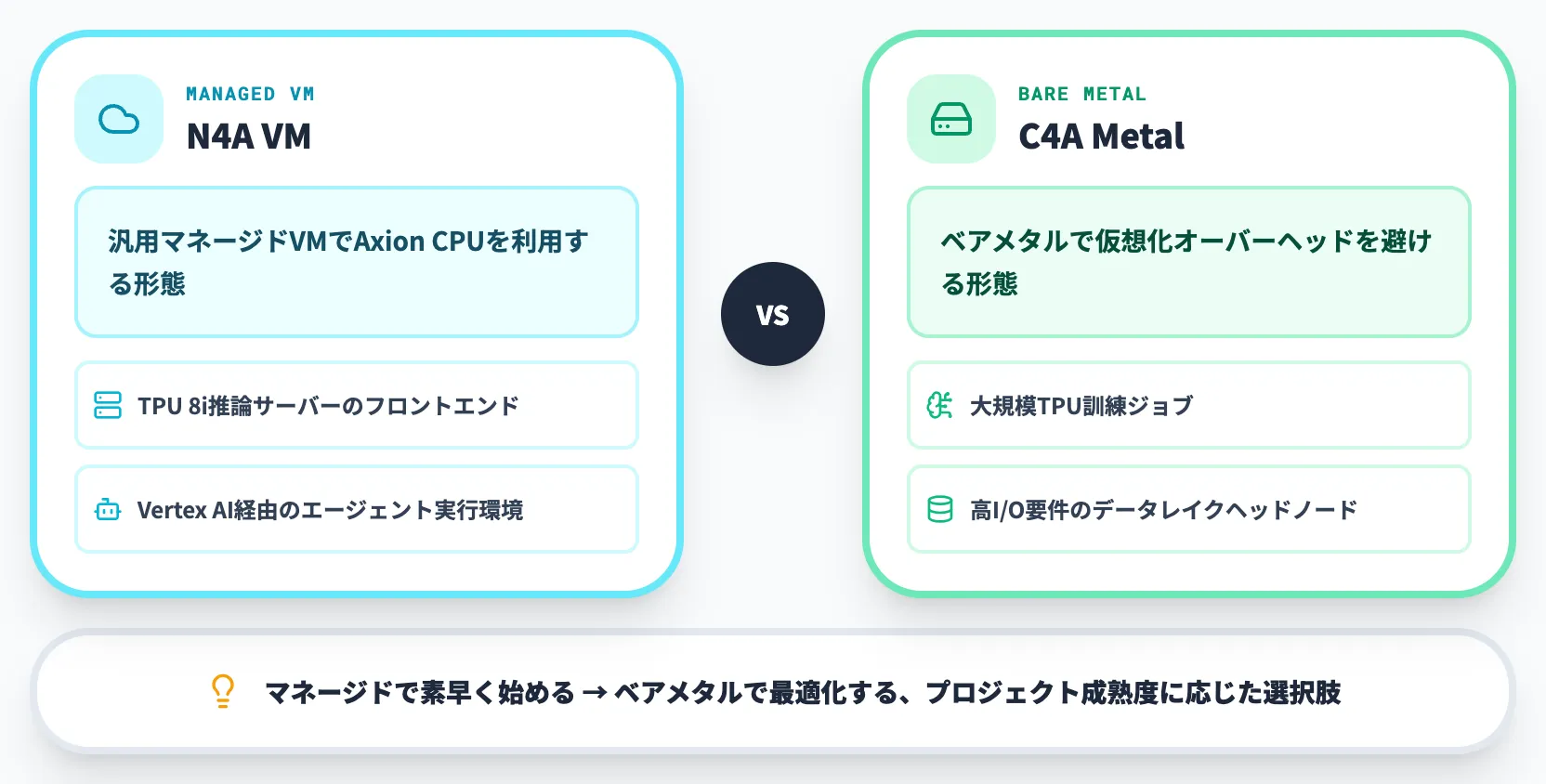
-
N4A VM
汎用マネージドVMでAxion CPUを利用できる形態。TPU 8i推論サーバーのフロントエンドや、Vertex AI経由のエージェント実行環境として使う想定
-
C4A Metal
ベアメタル提供のAxion CPU。仮想化オーバーヘッドを避けたい大規模TPU訓練ジョブや、高I/O要件のデータレイクヘッドノードに向く
両者を組み合わせることで、「マネージドで素早く使い始める」から「ベアメタルで最適化する」まで、プロジェクトの成熟度に応じた選択肢が用意されています。
AI Hypercomputerの構成要素
第8世代TPU時代のAI Hypercomputerは、概ね以下の層で構成されます。
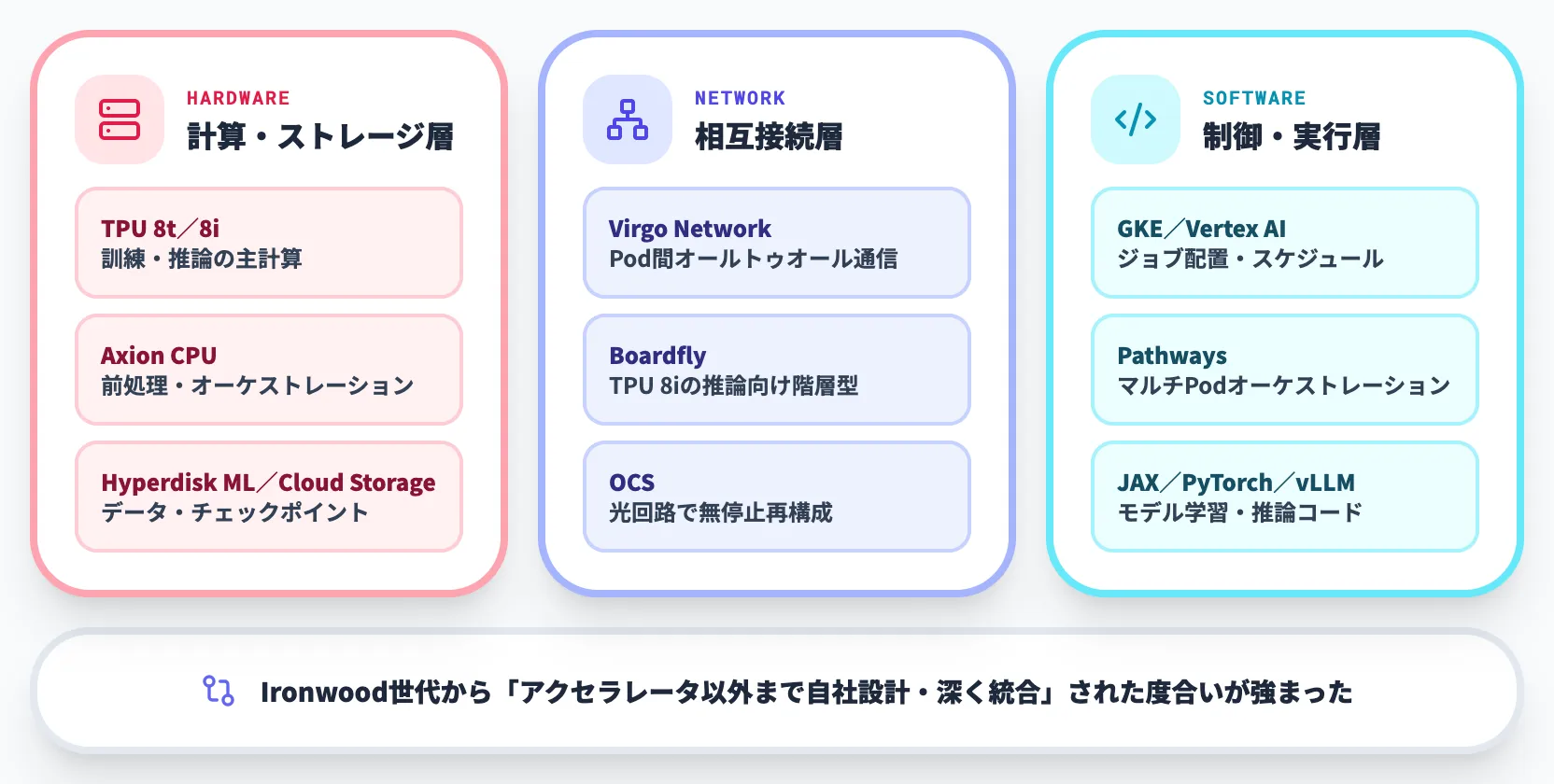
| レイヤー | 構成要素 | 役割 |
|---|---|---|
| アクセラレータ | TPU 8t / TPU 8i | 訓練・推論の主計算 |
| CPU | Axion(N4A / C4A Metal) | 前処理・後処理・オーケストレーション |
| ネットワーク | Virgo Network / Boardfly / OCS | Pod内・Pod間の集約通信 |
| ストレージ | Hyperdisk ML / Cloud Storage | 学習データ・チェックポイント・推論アーティファクト |
| オーケストレーション | GKE / Vertex AI / Pathways | ジョブ配置・スケジューリング・フェイルオーバー |
| ランタイム | JAX / PyTorch / vLLM / MaxText | 実際のモデル学習・推論コード |
この多層構成が示しているのは、「第8世代TPUは単体のチップ選定ではなく、計算基盤全体の設計判断になる」という点です。Ironwood世代から大きく変わったのは、アクセラレータ以外(CPU・ネットワーク・ストレージ)まで自社設計または深く統合された構成で提供される度合いが強まったことにあります。
第8世代TPUが対応するソフトウェアスタック
どれほど高性能なハードウェアでも、既存のモデル・フレームワークから呼び出せなければ実運用には乗りません。第8世代TPUは、Ironwood世代で整備済みのソフトウェアスタックをほぼそのまま引き継ぎつつ、周辺ランタイムを追加するアプローチを取っています。
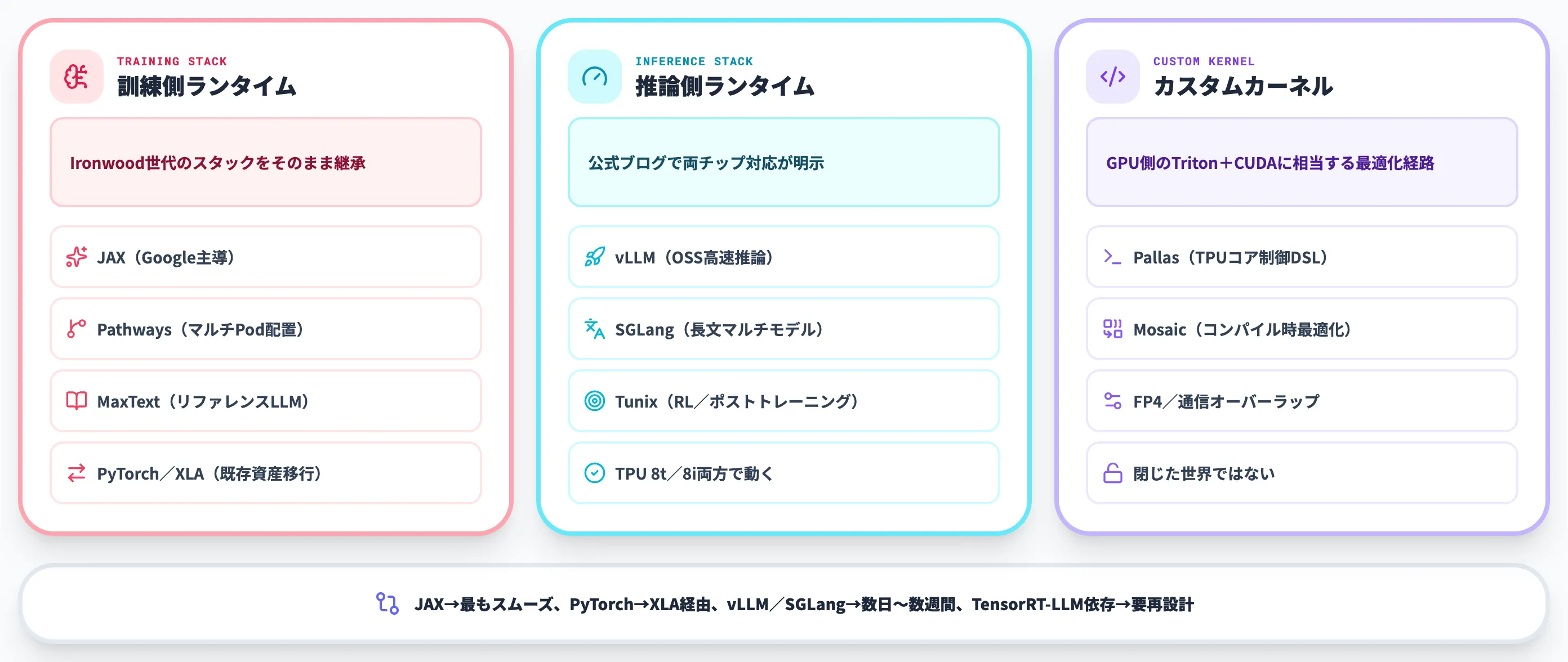
訓練側のスタック
訓練ジョブで第8世代TPUを動かす際の主要スタックは以下のとおりです。
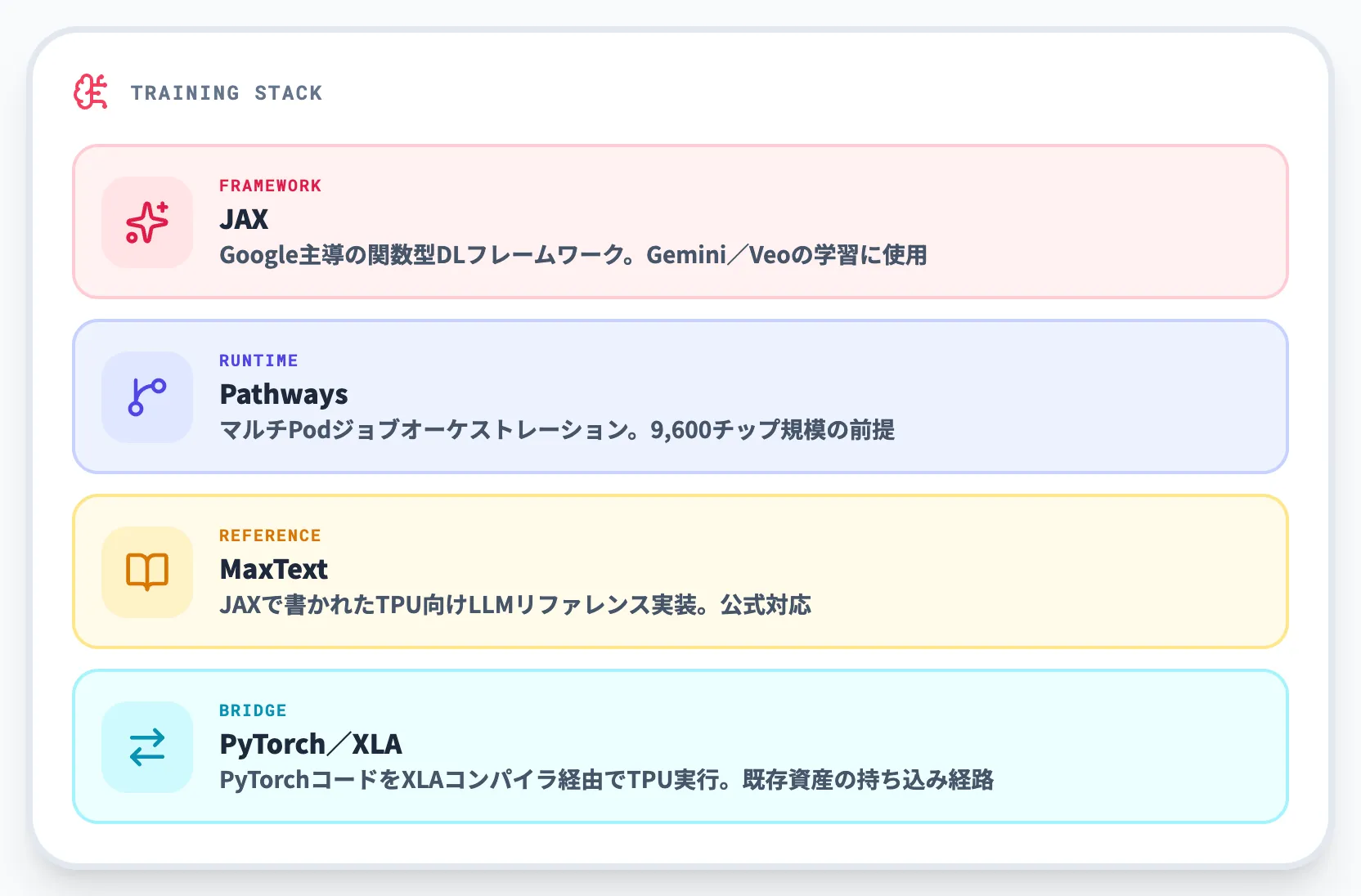
-
JAX
Googleが主導する関数型ディープラーニングフレームワーク。TPUとの相性が最も良く、Gemini・Veo等の自社モデルの学習に使われている
-
Pathways
複数PodをまたいだジョブオーケストレーションランタイムをSaaS提供するレイヤー。第8世代でも9,600チップ規模のジョブ配置はPathwaysが前提
-
MaxText
JAXで書かれたTPU向けリファレンスLLM実装。Transformer実装としてチューニングされており、第8世代TPUの公式対応ランタイムの一つ
-
PyTorch/XLA
PyTorchコードをXLAコンパイラ経由でTPU向けにコンパイル・実行するブリッジ。既存のPyTorch資産をTPUに持ち込む現実的な経路
推論側のスタック
推論ジョブでは、以下のランタイムが第8世代TPU対応を公式に表明しています。
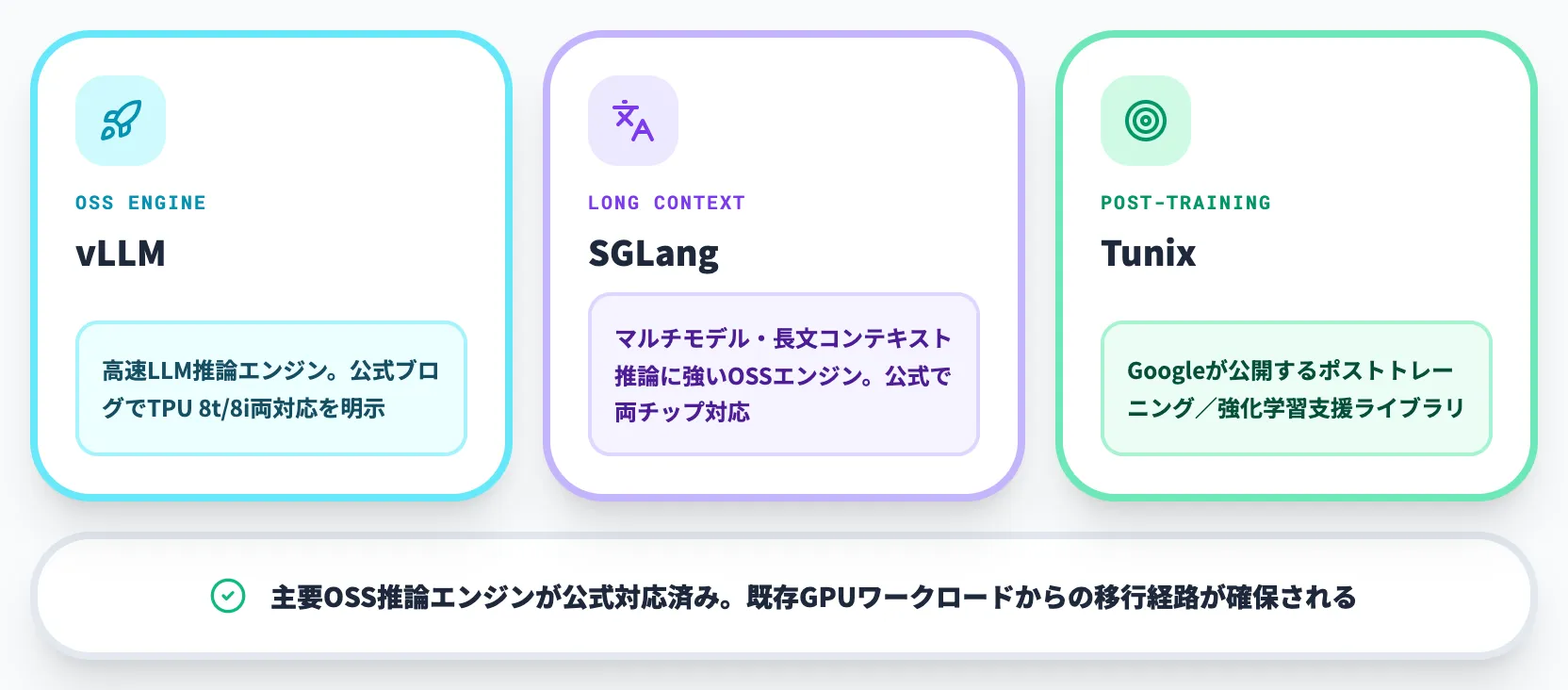
-
vLLM
OSSのLLM推論エンジン。TPU 8t/TPU 8iの両方で推論ランタイムとして公式対応している
-
SGLang
マルチモデル・長文コンテキスト推論に強いOSSエンジン。同じく両チップで公式対応ランタイムとして提供される
-
Tunix
Googleが公開するポストトレーニング/強化学習支援ライブラリ。第8世代TPUでは強化学習支援の文脈で位置付けられており、推論サービング単体のランタイムとは役割が異なる
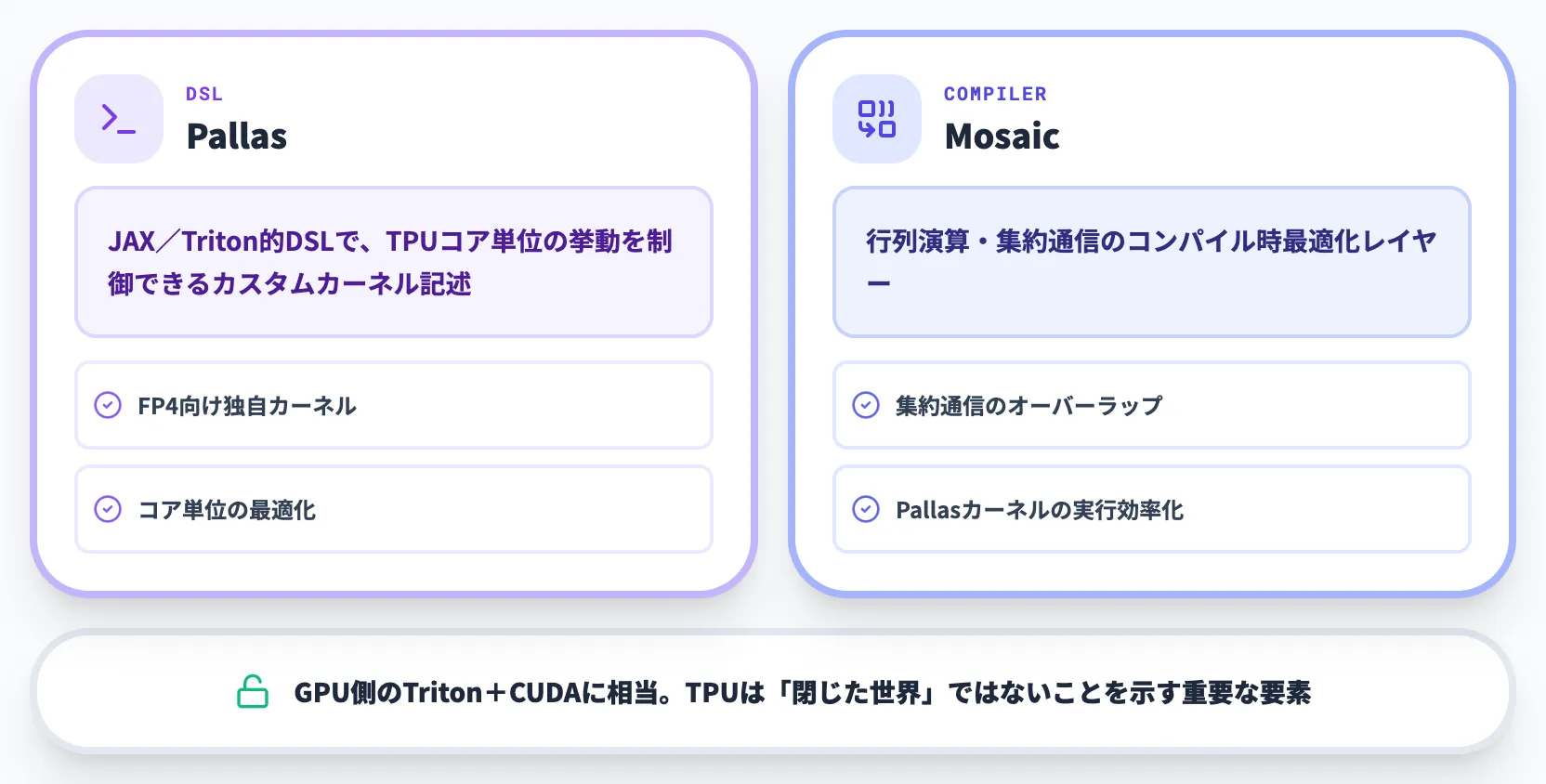
カスタムカーネルとPallas/Mosaic
第8世代TPUの演算器を細かく制御したい場合には、カスタムカーネル開発用のフレームワークも揃っています。
-
Pallas
JAX/Triton的なDSLで、TPUのコア単位の挙動を制御できるカスタムカーネル記述用フレームワーク
-
Mosaic
行列演算・集約通信のコンパイル時最適化を担うレイヤー。Pallasで書いたカーネルの実行を効率化する
「Pallas+Mosaic」が用意されていることで、公式フレームワーク外の最適化(FP4向けの独自カーネル、集約通信のオーバーラップなど)を実装する道が開けています。これはGPUにおけるTriton+CUDAの関係に相当し、TPUがソフトウェア面で「閉じた世界」ではないことを示す重要な要素です。
既存ワークロードの持ち込み難易度
実際に既存のGPUワークロードを第8世代TPUに移行する際の難易度は、使っているフレームワーク・最適化の深さで大きく変わります。
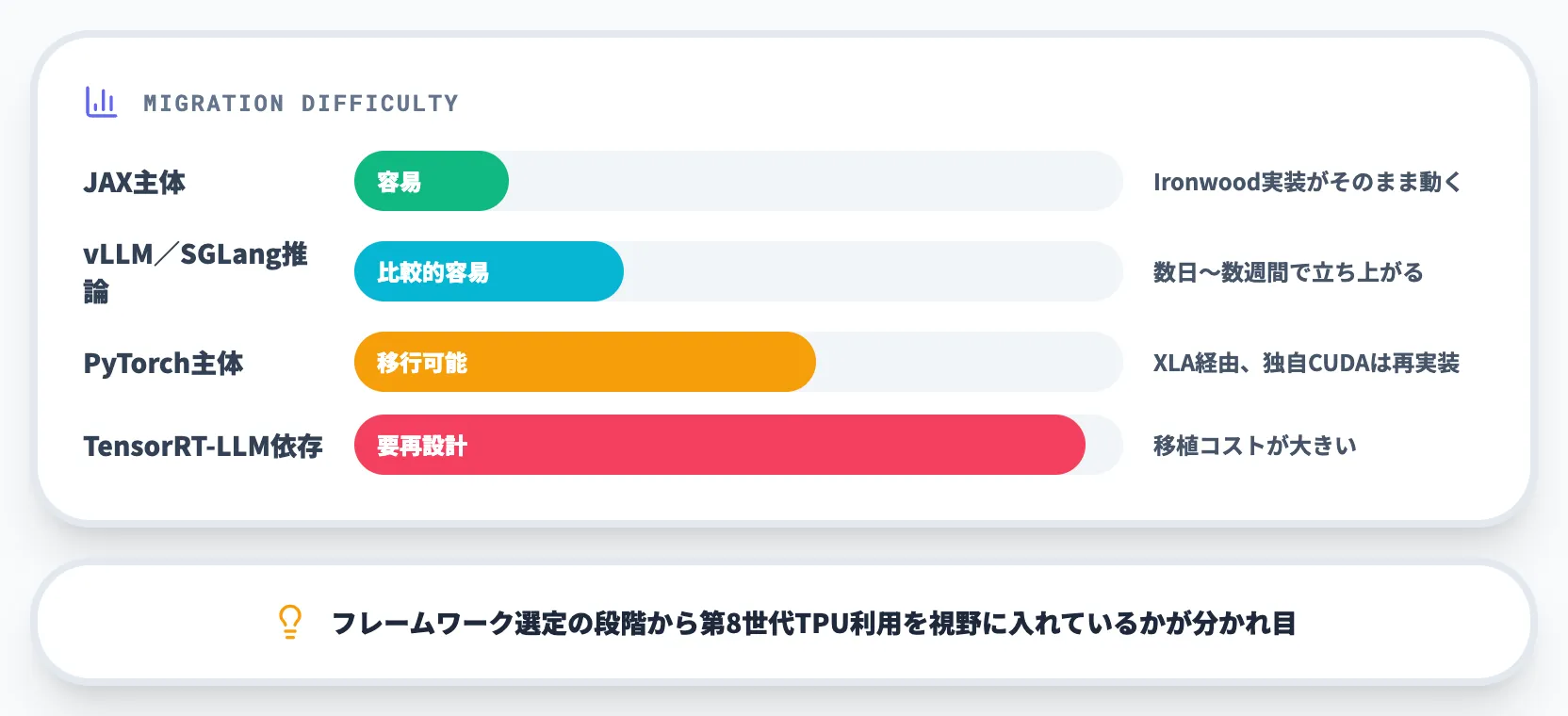
- JAX主体 最もスムーズ。Ironwoodで動く実装はそのまま動くケースが多い
- PyTorch主体 PyTorch/XLA経由で移行可能。ただし独自CUDAカーネルを使っている場合は再実装が必要
- vLLM/SGLang経由の推論 比較的容易。TPU 8i向けのイメージを使えば数日〜数週間で立ち上がる
- NVIDIA独自ライブラリ(TensorRT-LLM等)依存 再設計が必要。移植コストが大きい
TPUを実際に扱うAIラボ・モデル提供企業にとって詰まりやすいのはここです。「GPUで動いているから、TPUでもそのまま動く」という前提は現実的ではなく、フレームワーク選定の段階から第8世代TPU利用を視野に入れているかが分かれ目になります。一般企業が自社でTPU/GPUを直接運用する場面は限定的で、多くの場合はGeminiやClaudeなどのAPI経由で間接的にこの選択の恩恵を受ける立場になります。
第8世代TPUの主要ユースケースと採用企業
Googleは第8世代TPU発表時点で、Citadel Securitiesを引用する形でTPUワークロードの広がりを示しました。
そのほかの企業についても、第8世代TPU 8t/8iの採用を名指しで表明しているわけではないものの、Google Cloud TPUまたはAI Hypercomputerの利用実績が公表されており、第8世代が投入されるエコシステムの輪郭を示す材料になります。
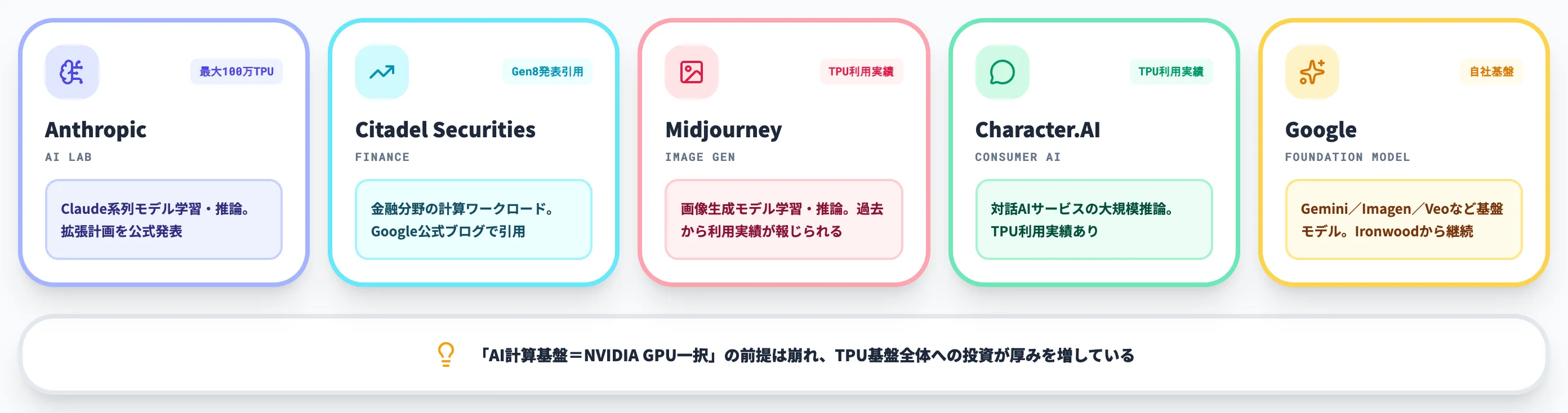
Google Cloud TPU/AI Hypercomputerの主な利用企業
Google Cloud TPU/AI Hypercomputerの主要ユーザーは以下のとおりです。現時点で「TPU 8t/8iを採用中」と言えるのはGoogle自社の基盤モデルのみで、他社は拡張計画や過去からの利用実績に基づく位置付けです。
| 企業 | 用途 | ソース |
|---|---|---|
| Anthropic | Claude系列モデルの学習・推論(最大100万TPU規模までの拡張計画を表明) | Anthropic: Expanding our use of Google Cloud TPUs and services |
| Citadel Securities | 金融分野の計算ワークロード(Google第8世代TPU発表で引用) | Google公式ブログ |
| Midjourney | 画像生成モデルの学習・推論(過去よりTPU利用実績が報じられる) | TechCrunch: Google unveils 8th gen TPU |
| Character.AI | 対話AIサービスの大規模推論(過去よりTPU利用実績が報じられる) | 同上 |
| Google(自社) | Gemini/Imagen/Veoなど基盤モデル(Ironwoodから継続採用) | Ironwood TPU: age of inference |
特に重要なのは、Anthropicが公式発表した「最大100万TPU規模までの拡張計画」です。
ただしこの計画は「Google Cloud TPUs and services」全体の拡大を指すもので、第8世代TPU 8t/8iの直接採用を明言したものではありません。とはいえ、Google自社基盤モデルのTPU継続採用と合わせれば、TPUは実運用ワークロードの選択肢として明確に厚みを増しています。
ユースケースの典型パターン
採用企業の事例から見える第8世代TPUの主要ユースケースは、おおむね以下のパターンに分類できます。

-
超大規模LLMの事前学習
10B〜1T級のパラメータを持つモデルを、数週間〜数カ月かけて学習する用途。TPU 8tのPod規模とVirgo Networkが効く
-
フロンティアモデルの継続学習・RLHF
既存のフロンティアモデルをベースに、継続事前学習やRLHFを回す用途。TPU 8tとIronwoodの混在運用が現実的
-
本番LLM推論サービング
チャット・コード生成・検索のバックエンドとしてLLM推論を回す用途。TPU 8iのHBM容量とSRAMが、ユーザーあたりコストを下げる
-
画像・動画生成モデルの推論
Midjourney型の画像生成、Veo型の動画生成モデルの推論バックエンド。大きなコンテキストを必要とするためTPU 8iが向く
-
マルチモーダルRAG
画像・動画・テキストを同時に扱うRAG基盤。TPU 8iとAxionの組み合わせで前処理・推論をまとめて回せる
日本企業から見た第8世代TPUの位置づけ
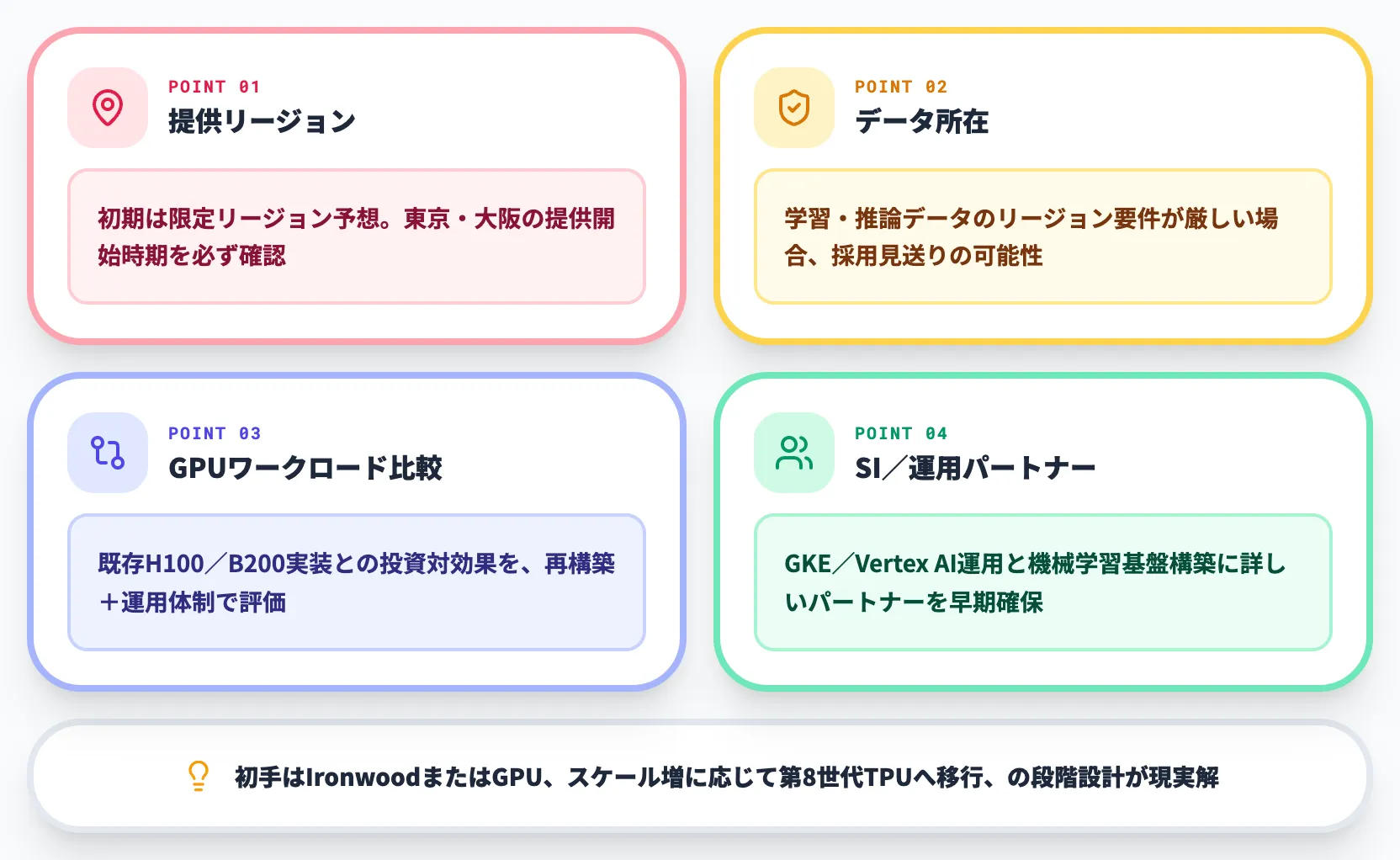
第8世代TPUは一般企業が自社データセンターに導入する設備ではなく、Google Cloud経由のGeminiや、Anthropic・Midjourneyなどが提供するSaaSを通じて間接的に恩恵を受けるインフラです。日本企業の立場で押さえておきたい論点は以下のとおりです。
-
Geminiの性能・コスト改善への波及
第8世代TPUのGA後、Google CloudのGemini APIで性能・コスト効率が底上げされる可能性が高い。AI活用予算の見直しで織り込む
-
マルチモデル戦略の現実味
AnthropicのTPU拡張計画によって、Claudeの可用性・性能改善にも波及し得る。Azure OpenAI一択ではなく、GeminiやClaudeも含めた使い分けが現実的な選択肢になる
-
データ所在とリージョン
Geminiなどを社内利用する場合、東京・大阪リージョンでの提供とデータ所在ポリシーの適合を必ず確認する
-
SI/運用パートナーの選定
TPU層そのものを意識する必要はないが、LLMの業務適用・エージェント設計・社内データ連携を一緒に進められるパートナーは早期に確保する
第8世代TPUの本質的なインパクトは「どのLLMがTPUで動いているか」というインフラ側の話ではなく、「TPUの進化でLLM利用コストや性能がどう変わるか」「その恩恵をどの業務に載せるか」という利用側の設計にあります。
第8世代TPUの料金体系と提供時期
第8世代TPUの料金は、2026年4月時点で一般公開された具体的な時間単価は発表されていません。ここではIronwood世代までの価格公開方式を踏まえ、公開されている情報だけを整理します。
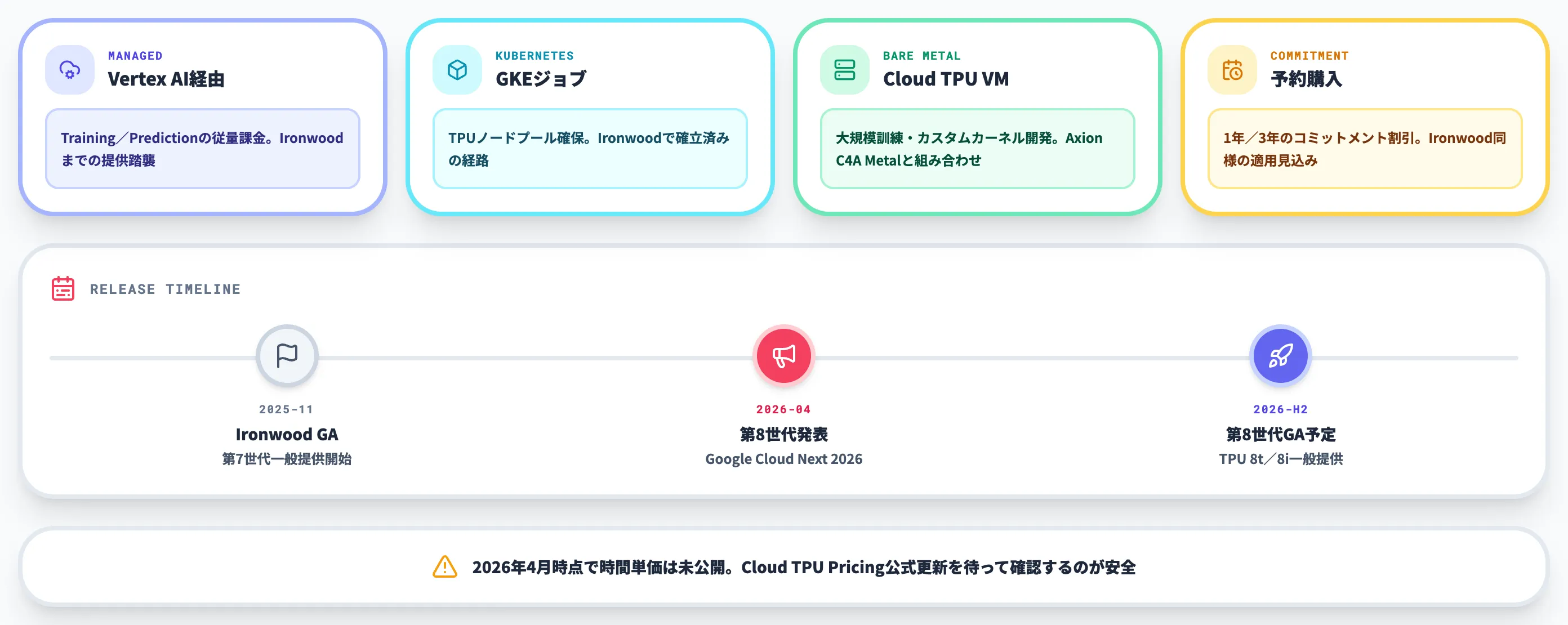
提供形態と課金モデル
第8世代TPUの提供形態は、Cloud TPU公式ページと発表内容を突き合わせると、AI Hypercomputerの提供モデルとして以下の3経路が想定されます。Ironwood世代までの提供パターンを踏襲する見込みで、GA時点の詳細な提供経路・SLA・リージョン別可用性は現時点では公式未確定です。
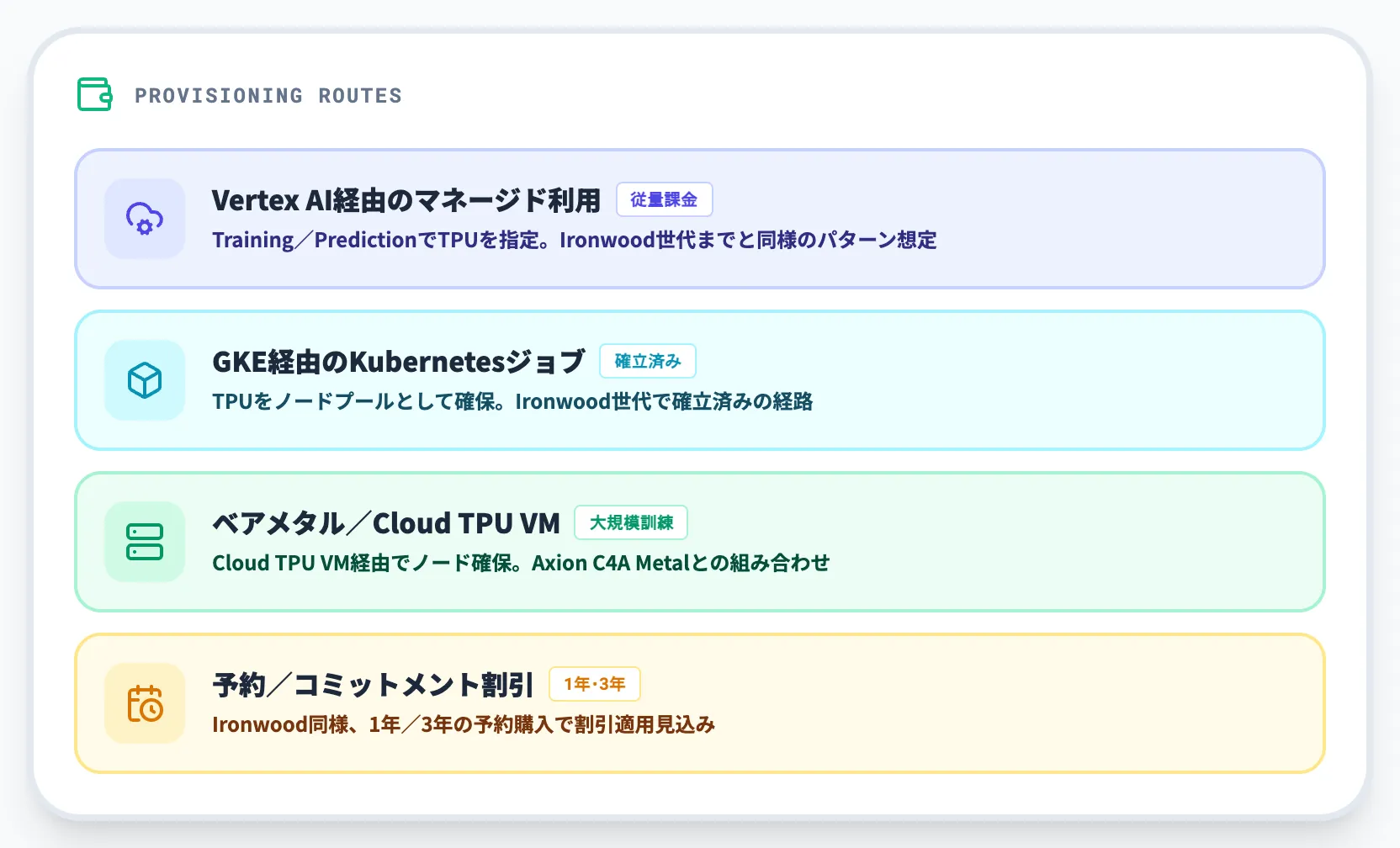
-
Vertex AI経由のマネージド利用
Vertex AIのTrainingおよびPredictionでTPUを指定する従量課金形態。Ironwood世代までと同様の提供パターンが想定される
-
GKE経由のKubernetesジョブ
GKEでTPUをノードプールとして確保するパターン。Ironwood世代で確立済みの経路で、第8世代でも踏襲される見込み
-
ベアメタル/Cloud TPU VM
Cloud TPU VM経由でTPUノードを確保する形態。大規模訓練やカスタムカーネル開発に向き、Axion C4A Metalとの組み合わせが整理されている
-
予約/コミットメント割引
Ironwood世代と同様、1年/3年の予約購入によるコミットメント割引が適用される見込み
料金情報の公開状況
第8世代TPUの料金については、2026年4月時点では以下の点のみ確認できます。
- Cloud TPU Pricingページは随時更新されるが、本稿執筆時点で第8世代(TPU 8t/TPU 8i)の時間単価は記載がない
- Vertex AIのTraining/Prediction価格も、第8世代スペック専用の料金は未公開
- Ironwood世代はチップ時間単価で公開されており、第8世代も同じ粒度で公開される見込み
2026年4月時点での価格情報は、Google Cloud公式の更新を待って確認するのが安全です。発表直後に流れる非公式な試算やリークは、後から公開される正式価格と異なる可能性が高いため、商談資料・提案書に使うのは避けるべきです。
料金評価で見落としやすい項目
料金を試算する際に見落としやすいポイントを挙げておきます。
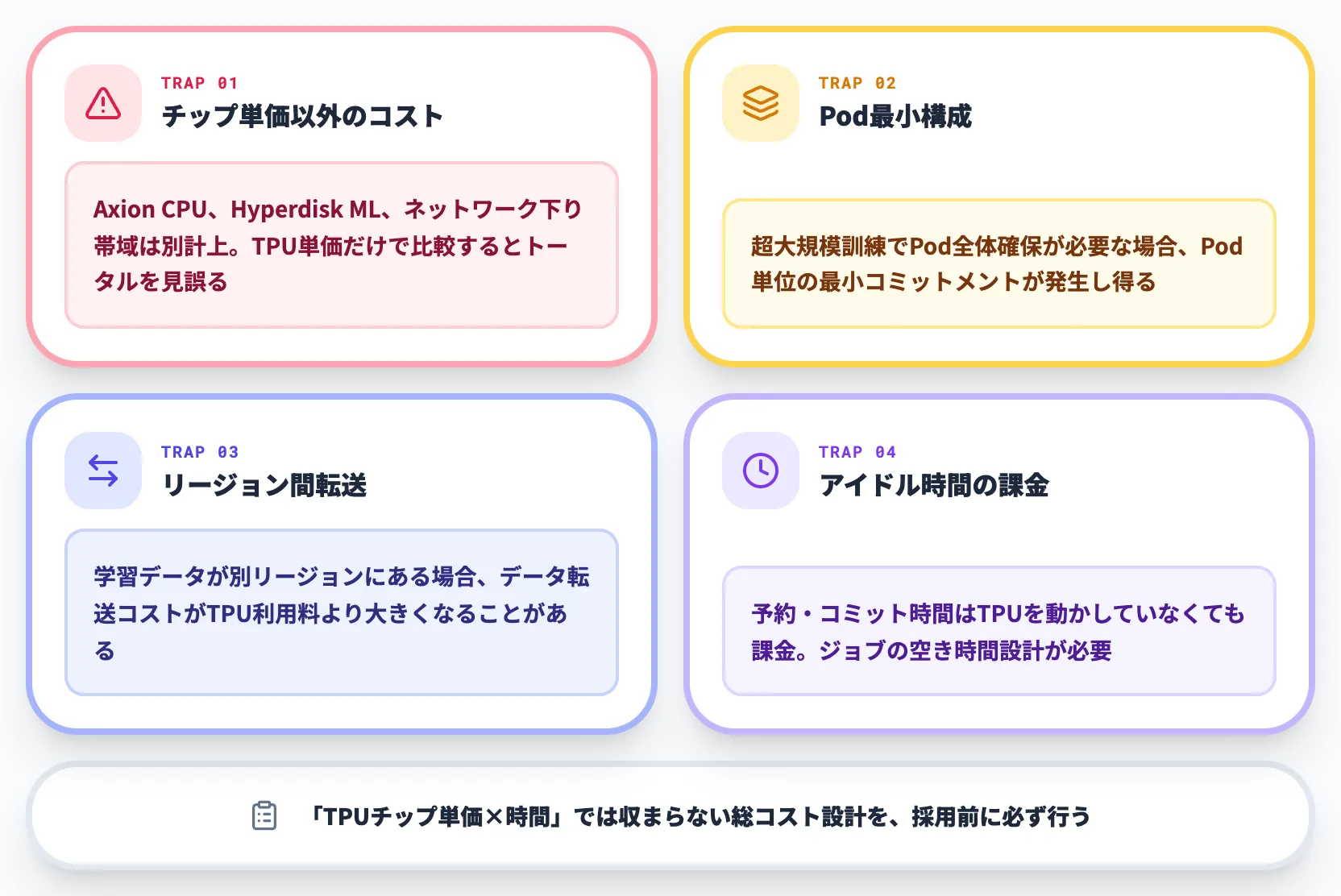
-
TPUチップ単価以外のコスト
Axion CPU(N4A/C4A Metal)、Hyperdisk MLストレージ、ネットワーク下り帯域は別計上。TPU単価だけで比較するとトータルコストを見誤る
-
Podリソースの最小構成
超大規模訓練でPod全体を確保する必要がある場合、チップ単価×時間では済まず、Pod単位の最小コミットメントが発生し得る
-
リージョン間データ転送
学習データが別リージョンにある場合、データ転送コストがTPU利用料より大きくなることがある
-
使わない時間の課金
予約・コミットメントした時間はTPUを動かしていなくても課金される。ジョブの空き時間設計を事前に決める必要がある
提供時期
第8世代TPUは、TPU 8t・TPU 8iの両チップとも2026年後半(later this year)に一般提供予定です(Google公式ブログ)。
現時点で顧客側が取れるアクションはGoogle Cloud営業経由で詳細情報をリクエストする段階に留まり、限定プレビュー/早期アクセスの具体的な開始時期や対象企業は公式には示されていません。
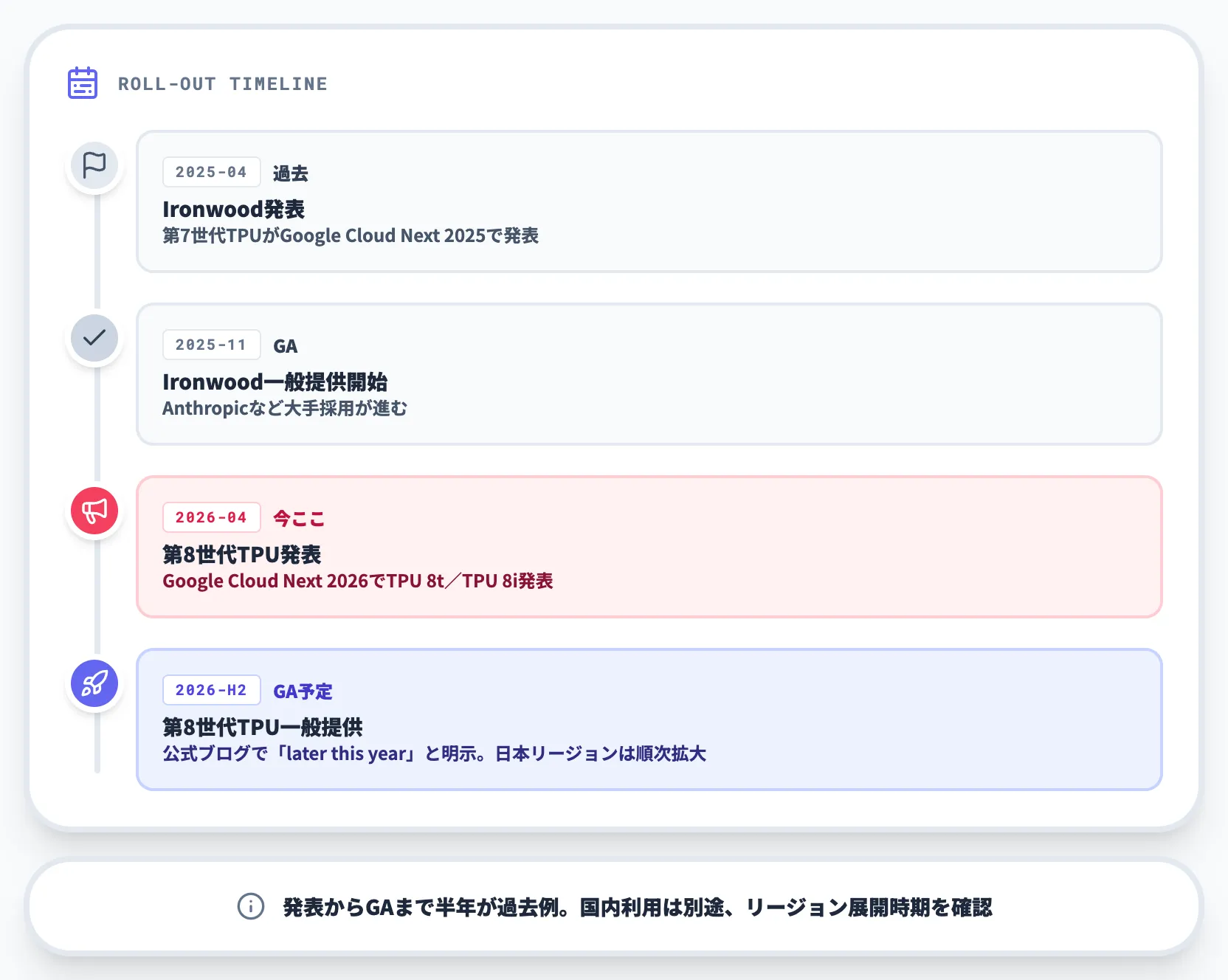
Ironwoodは2025年4月発表→2025年11月GAというタイムラインだったため、第8世代も発表から半年程度で2026年後半にGAに至る見通しです。日本リージョン(asia-northeast1/asia-northeast2)での提供はGA後に順次拡大となるため、国内利用のタイムラインは別途確認が必要です。

第8世代TPU時代のLLMを、社内業務に組み込むAI Agent Hub
第8世代TPUで進化するGeminiをはじめ、TPU基盤で動くClaudeなど、高性能な大規模モデルはGoogle CloudやMicrosoftのAPI経由で業務から利用できる時代になりました。LLMを社内業務で成果につなげられるかは、API呼び出しの裏側にあるインフラよりも、LLMに「何をさせるか」「どの業務に組み込むか」の設計で決まります。
ここで効いてくるのが、AI総合研究所の AI Agent Hub です。AI Agent Hubは、Microsoft Fabric・Copilot Studio・Microsoft 365を土台に、複数の業務特化ユースケース(経費精算・請求書処理・設計製図・見積作成・FAQ対応・Excel操作・CRM連携・人事業務・在庫管理・データ分析など)をAgentの組み合わせで実装できるエンタープライズAI基盤です。
GeminiやClaudeクラスのLLMをこれから業務活用しようとしている企業にとって、次のような場面でAI Agent Hubが土台として機能します。
-
LLMの業務適用設計
API経由で呼び出すLLMに「何をさせるか」の業務フロー・Agent設計をCopilot Studioで標準化し、PoCから本番運用まで一貫して持ち込める
-
社内データとのセキュアな連携
Microsoft Fabric上のLakehouseやM365のSharePoint・Teams資産を、テナント内に閉じた形でAgentが参照できる構成で構築できる
-
モデルとエージェントの組み合わせ運用
高性能が必要な業務はクラウドLLM(Gemini・Claude・GPT)、軽量な業務自動化はCopilot Studioのエージェント、と適材適所で組み合わせられる
AI総合研究所の専任チームが、AI導入相談実績とMicrosoft MVP/Solution Partnerの知見をもとに、LLMの選定から業務適用の設計・Agent実装・運用まで一気通貫でご相談に応じます。まずは無料の資料で、AI Agent Hubの全体像と導入事例をご確認ください。
第8世代TPU時代のLLMを、社内業務に安全に組み込むAI Agent Hub

AI総合研究所のAI Agent Hubは、Microsoft Fabric・Copilot Studio・M365を土台に、経費精算・請求書処理・設計製図・FAQ対応・CRM連携などの複数業務をAgentの組み合わせで自動化できるエンタープライズAI基盤です。Gemini・Claude・GPTなど用途ごとのLLM選定から業務への組み込み設計まで、専任チームがMicrosoft MVP/Solution Partnerの知見をもとに伴走します。
まとめ
Google 第8世代TPUは、「訓練用のTPU 8t」と「推論用のTPU 8i」を同時に投入することで、1つのチップで訓練と推論の両方を賄ってきた従来モデルに明確な区切りを付けた世代です。
- TPU 8tは、1チップ12.6 PFLOPs(FP4)・1Pod 9,600チップ・Virgo Network 134,000チップ規模という「超大規模事前学習専用ハードウェア」
- TPU 8iは、288GB HBM・384MB SRAM・Boardfly+CAEという「低レイテンシ・高メモリ推論専用ハードウェア」
- ArmベースのGoogle Axion CPUと組み合わせたAI Hypercomputerの一部として提供予定。GKE管理やベアメタルアクセスは公式に示されているが、Vertex AI経路・固定比率・リージョン別可用性はGA時点で改めて確認が必要
- Anthropicは最大100万TPU規模までの拡張計画を公式発表、Midjourney・Character.AIなどもGoogle Cloud TPU/AI Hypercomputerの利用実績を持ち、「訓練も推論もTPU」の選択肢が厚みを増している
第8世代TPUは一般企業が自社で購入・設置するハードウェアではなく、Google CloudやAnthropic・Midjourneyなどが提供するLLM/生成AIサービスの裏側で動くインフラです。日本企業がその恩恵を受けるのは、Gemini 3やClaudeなどのAPI・SaaSを業務に組み込む段階であり、ハードウェア選定そのものを意識する必要はほとんどありません。
重要なのは、どのモデルをどの業務に載せるかという設計のほうです。第8世代TPUによってGemini・Claudeの応答速度やコスト効率が改善していくこれからの時期こそ、自社の業務プロセスにどうLLMを組み込むかを具体化し、小さく始めて検証を重ねていくことが、生成AI時代の競争力を左右します。










