この記事のポイント
 データクレンジングはデータ分析の工数の大半を占める領域で、AI活用で最大80%削減できる工程
データクレンジングはデータ分析の工数の大半を占める領域で、AI活用で最大80%削減できる工程- AIが本当に変えたのは「重複検出のEmbedding化」「欠損補完の生成化」「非構造データの構造化」など、ルールベースでは詰みやすかった工程
- 業務系(CRM・名寄せ)/データ基盤系(DWH・データレイク)/RAG前処理/自由記述構造化で取るべきアプローチは別物
- 主要ツールは生成AI・DWHネイティブAI・名寄せCDP・データオブザーバビリティ・開発系OSSの5カテゴリで整理して選定するのが実務的
- PIIの外部送信・出力検証・人間レビューの役割分担を初期設計で押さえないと、PoCで止まりやすい

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
データクレンジングは、欠損値・表記揺れ・重複・異常値といった「汚れ」を取り除き、分析や業務利用に耐えるデータ品質を確保する前処理工程です。
2025年後半から2026年にかけて、LLMやエージェントの組み込みによってこの工程は大きく変わりつつあります。LLM Embeddingによるセマンティック重複検出、生成補完(Generative Imputation)、Snowflake CortexやMicrosoft Fabric CopilotといったDWHネイティブAI、Anomaloの非構造化データ品質監視まで、選択肢が一気に広がりました。
本記事では、AIが効率化する5工程の中身、業務ユースケース別の使い分け、主要ツールカテゴリの位置づけ、料金体系、そしてPoCで詰まる論点とAI総合研究所がSIerとして推奨する進め方を、2026年6月時点の最新情報で整理します。
データクレンジングをAIで効率化する全体像
データクレンジングとは、欠損値・表記揺れ・重複・異常値といったデータの「汚れ」を取り除き、分析や業務利用に耐える品質まで整える前処理工程を指します。
dotDataの整理によれば、データクレンジングはデータ分析の工数の8割を占めることもあり、AI活用が進めば最大80%削減できると報告されています。
ルールベースからLLMへ — クレンジング方式の構造転換
「AIでクレンジングを進める」と言っても、2023年頃までの手法と、2025年後半以降に主流化した手法では中身が大きく違います。
従来のクレンジングは、人間が事前にルール(「(株)は『株式会社』に置換」「日付はYYYY-MM-DDに統一」など)を書き、ETLツールで一括処理する設計でした。ルール網羅性の限界と、未知の表記揺れに弱いという課題を抱え続けていました。
これに対して、LLMやAIエージェントを組み込んだ最新のクレンジングは、ルールが書ききれない領域を意味理解で吸収します。
LLM Embeddingで意味的に近い重複を見つけ、欠損値はデータセット全体のコンテキストから生成補完し、PDFや問い合わせ自由記述まで構造化対象に含めるのが、いまの実装パターンです。
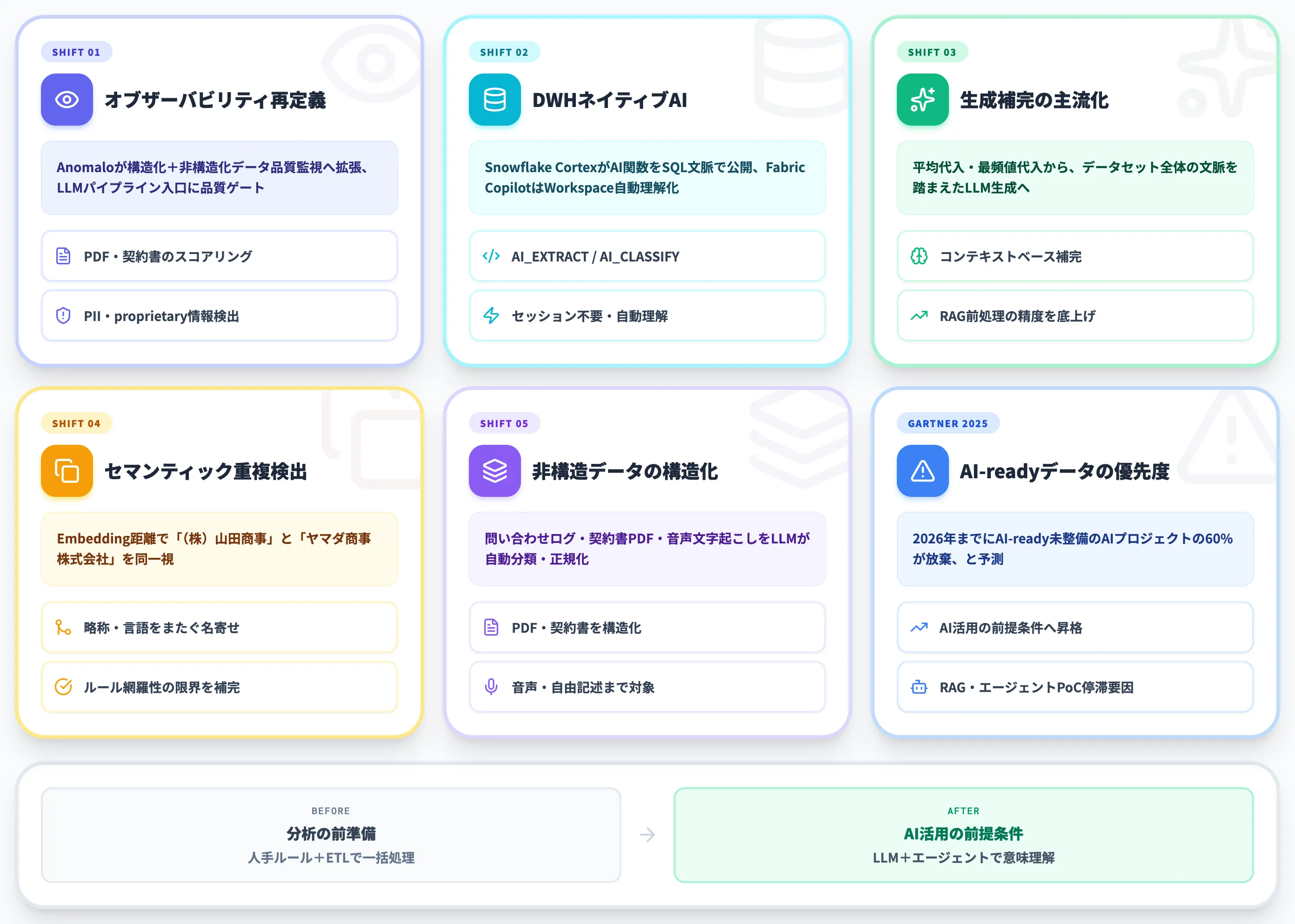
AI Readyの前提条件としての位置づけ強化
直近6〜12か月のドメインの動きを整理すると、構造変化は以下のように出ています。
| 動き | 内容 |
|---|---|
| データオブザーバビリティの再定義 | Anomaloが構造化テーブル監視に加え、非構造化データ品質監視へ対象を拡張(PDF・契約書のスコアリング)。LLMパイプラインの入り口で品質ゲートを担う設計に |
| DWHネイティブAI | Snowflake Cortexが「AI_EXTRACT」・「AI_CLASSIFY」などのLLM関数をSQL文脈で公開、Microsoft Fabric CopilotがData Engineering/Data Scienceで「セッション不要・Workspace自動理解」化 |
| 生成補完の主流化 | 平均代入・最頻値代入から、データセット全体の文脈を踏まえてLLMが欠損値を生成する方式へ |
| セマンティック重複検出 | Embedding距離による意味的重複(「(株)山田商事」と「ヤマダ商事株式会社」を同一視)が実装可能に |
| 非構造データの構造化 | 問い合わせログ・契約書PDF・音声文字起こしを、LLMが自動でカテゴリ分類・正規化 |
これらの変化により、データクレンジングは「分析の前準備」から「AI活用の前提条件」へと位置づけが変わりました。
Gartnerは2025年2月の発表で、「2026年までに、AI-readyデータが整備されていないAIプロジェクトの60%が組織から放棄される」と予測しています。
つまり、生成AIやエージェントを「使う側」になるための条件として、データクレンジングの優先順位が上がっている——というのが、いま起きている構造変化です。AI総合研究所の支援現場でも、RAG・エージェント・AIワークフローのPoCが、データ品質の段階で止まるケースが急速に増えています。

AIで進化するデータクレンジング5工程
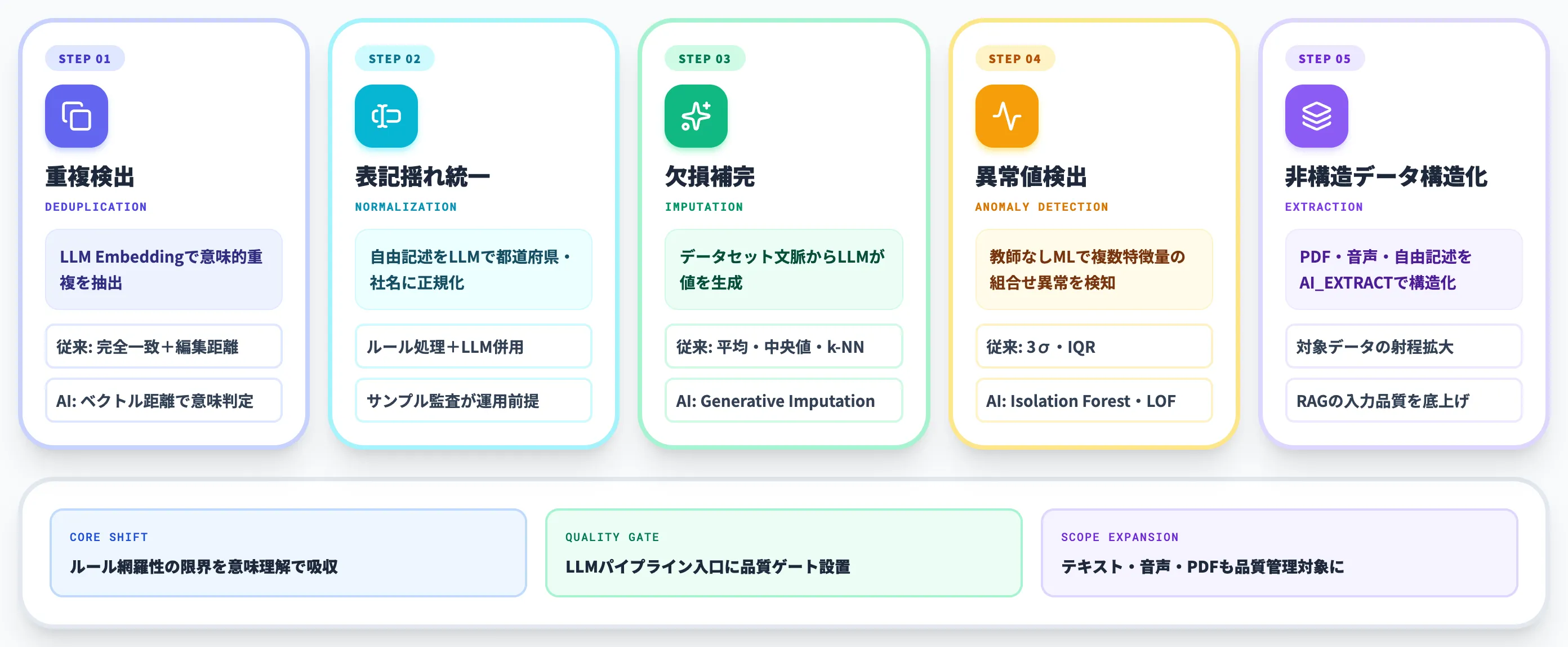
ここからは、データクレンジングの中核となる5工程について、AIによって何が変わりつつあるのかを工程ごとに整理します。
「重複・表記揺れ・欠損・異常値・非構造化」の5工程はクレンジングの古典的な分類ですが、2026年時点では各工程の実装中身が大きく書き換わってきています。
本セクションでは各工程の従来手法とAIアプローチの差分を技術的に踏み込んで解説します。
重複検出 — LLM Embeddingで意味的重複まで吸収

重複検出は、従来は完全一致と編集距離ベースのfuzzy match(Levenshtein距離など)で実装されていました。「(株)」と「株式会社」の差は文字列ルールで吸収できますが、「山田商事」と「Yamada Trading Co.」のような言語・略称をまたいだ重複は、ルールでは検出しきれません。
LLMアプローチでは、レコードをEmbedding(数値ベクトル)に変換し、ベクトル間の距離で「意味的に近いレコード」を抽出します。これにより、表記が大きく違っても**意味的に同一の重複(セマンティック重複)**まで捕捉できるようになりました。
実装例として、Snowflake CortexのEmbedding関数で各レコードをベクトル化し、類似度閾値をPoCで調整しながら「重複候補」を抽出して人間レビューに回す、という構成が取れます。Anomaloのような非構造データ向けでは、ドキュメント品質スコアやPII・proprietary情報の検出を通じて、生成AIパイプラインの前段で品質ゲートを設ける運用が現実的です。
表記揺れ統一 — 自由記述のクレンジング
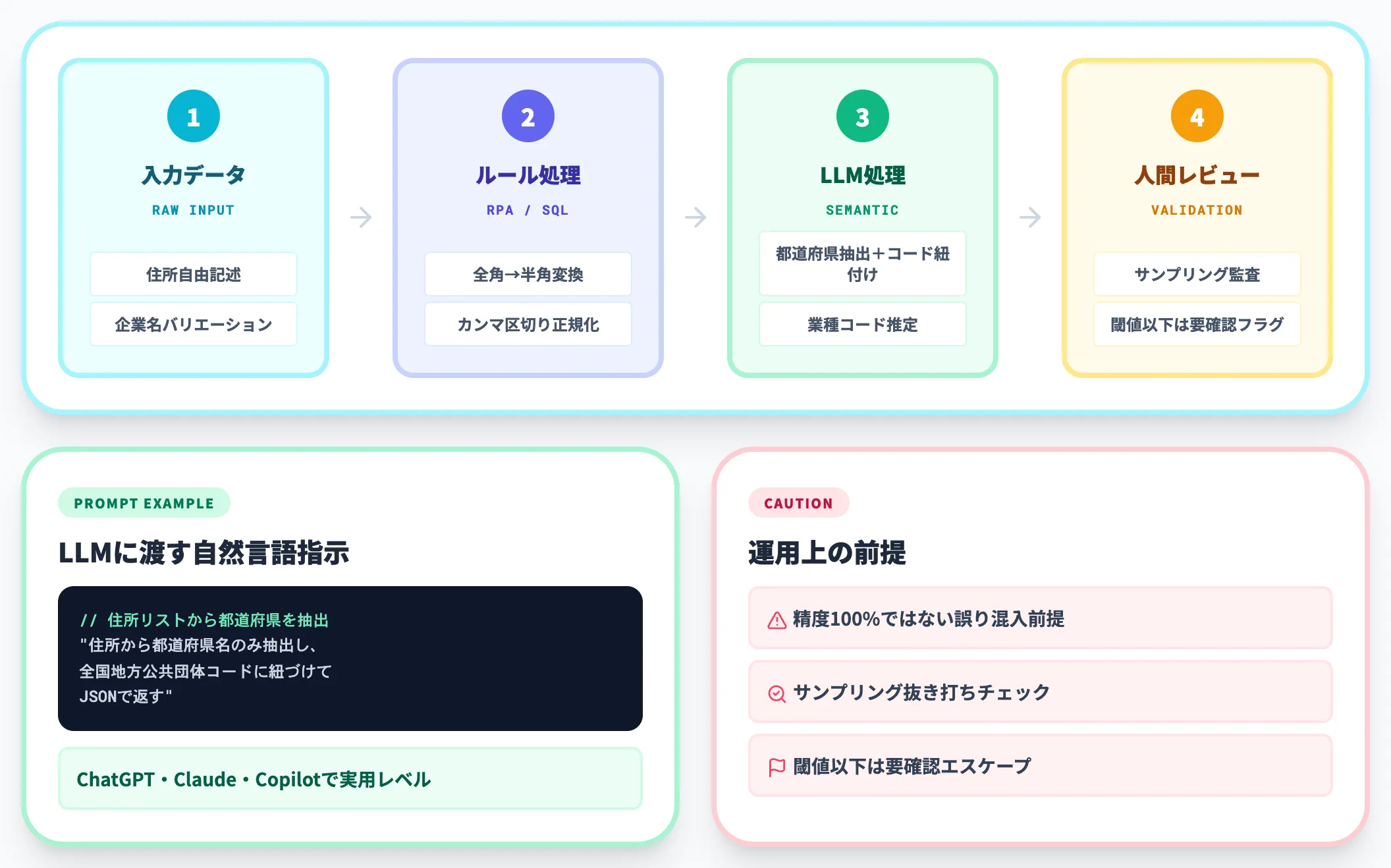
表記揺れ統一は、最も生成AIの恩恵が大きい工程です。「カンマ区切りを半角化」「全角数字→半角」「都道府県名のフルネーム化」のような決まりきった処理は従来のRPAやSQLで完結しますが、住所の自由記述や企業名のバリエーションは人手で正解を当てるしかありませんでした。
LLMには、「住所のリストから都道府県だけ抽出して全国地方公共団体コードに紐づける」「カナ表記の社名から英文社名と業種コードを推定する」といった指示が自然言語で渡せます。ChatGPTやClaude、Microsoft Copilotでも実用レベルで動きます。Salesforceブログでも、Excel中心の手作業では網羅性と継続性に限界がある点が整理されています。
ただし精度は100%ではないため、誤り混入を前提に「サンプリングして人間が抜き打ちチェック」「閾値以下は『要確認』フラグを立ててエスケープ」といった運用設計とセットになります。
欠損補完 — 生成補完への進化

欠損値の補完は、これまで平均値・中央値・最頻値の代入か、線形補間・k-NN補完など統計的手法が中心でした。しかしこれらは「欠損列以外の情報を活かせない」「カテゴリカル変数に弱い」という限界があります。
生成補完(Generative Imputation)は、LLMやAIモデルがデータセット全体のコンテキストを踏まえて欠損値を「もっとも自然な値」として生成する方式です。たとえば顧客マスタで業種が欠損している行に対して、社名・住所・取引履歴・売上規模からLLMが業種を推定する、というアプローチが取れます。
平均代入では「カテゴリカル変数で最頻値しか入らない」「異常値の影響を受ける」といった偏りが残りますが、生成補完では欠損行ごとに文脈を踏まえた値が入る点が違います。とくにRAG・エージェント向けの前処理として、生成補完の精度が下流タスクの品質を左右する局面が増えています。
異常値検出 — 教師なしMLで未知パターンも検出
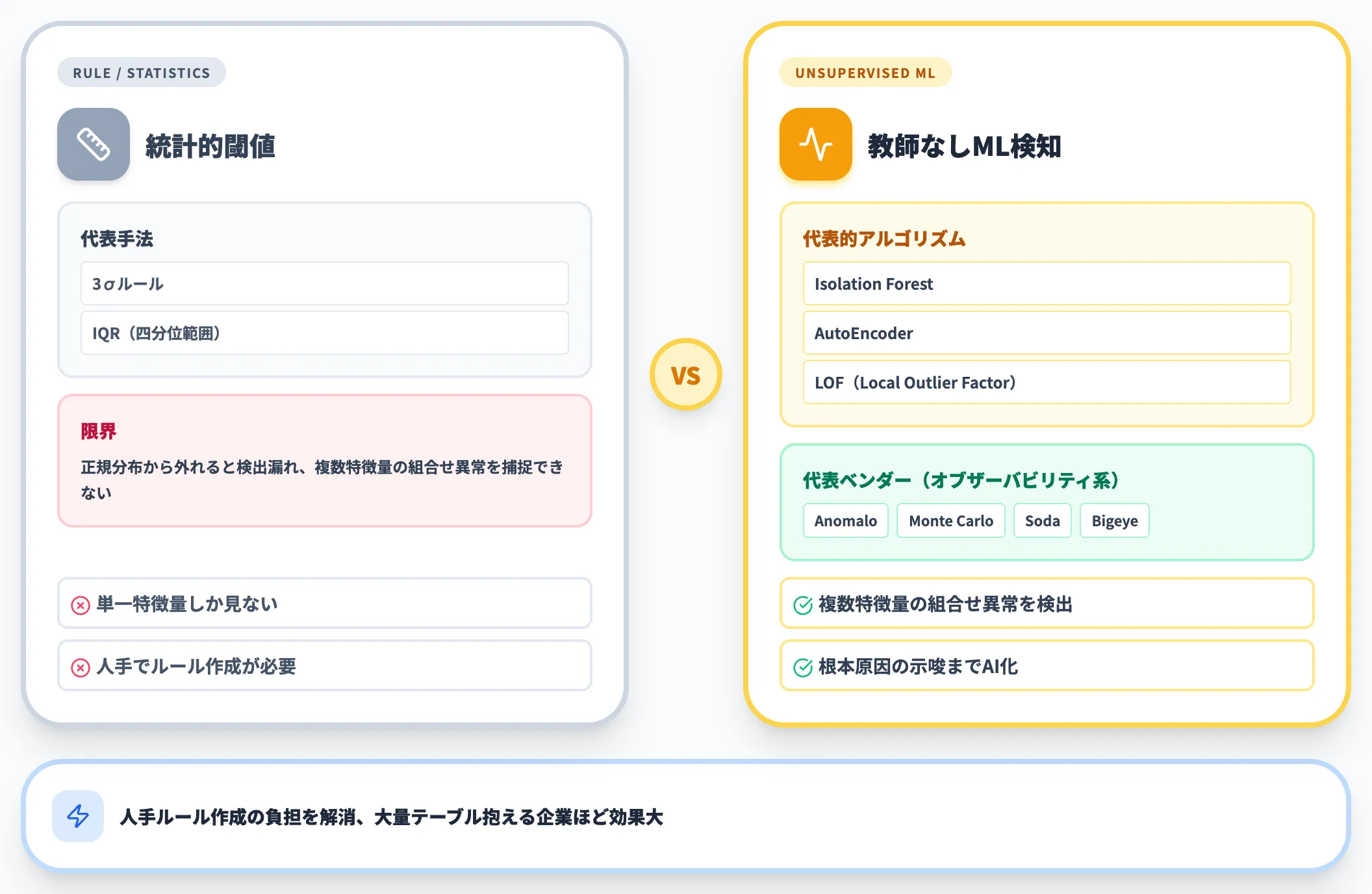
異常値検出は、従来は3σルールやIQR(四分位範囲)ベースの統計的閾値が主流でした。決まった分布を想定できるならこれで十分ですが、「分布が正規分布から外れる」「異常パターンが複数の特徴量の組み合わせで現れる」場合に検出漏れが起きやすくなります。
教師なしMLベースの異常検知(Isolation Forest・AutoEncoder・LOFなど)は、複数特徴量の組み合わせから「他のレコードと統計的に乖離している点」を自動抽出します。Anomaloは2018年創業時から、ルールベースに頼らず「データのパターンを学習して逸脱を検出する」アプローチを採用しており、大量のテーブルを抱える企業で人手ルール作成の負担を解消してきました。
2026年時点では、Anomalo・Monte Carlo・Soda・Bigeyeなどデータオブザーバビリティ各社が「異常検知+根本原因の示唆」までAI化する方向に進んでおり、検出後の対応スピードも上がりつつあります。
非構造データの構造化

非構造データの構造化は、ここ1年で最も実装ハードルが下がった領域です。問い合わせメール本文、契約書PDF、議事録の音声文字起こし、SNSの自由記述——これらを「分析・検索・エージェント実行で使える形」に整えるのが新しい意味でのクレンジングです。
Snowflake Cortexの「AI_EXTRACT」関数を使えば、SQLで「SELECT AI_EXTRACT(contract_pdf, ['契約金額', '契約期間', '解約条件'])」のように契約書PDFから構造化フィールドを抽出できます。Anomaloの非構造化データ品質監視は、各ドキュメントを1〜10で品質スコア化し、PII・proprietary information・メタデータ不整合を自動検出して、生成AI・エージェンティックAIに渡す前段でフィルタする設計になっています。
これにより、これまでデータクレンジングの対象外だった「テキスト・音声・PDF」が品質管理の射程に入り、Microsoft Fabric IQやAI-ready dataの議論と接続するようになりました。
業務ユースケース別・AIデータクレンジングの使い分け
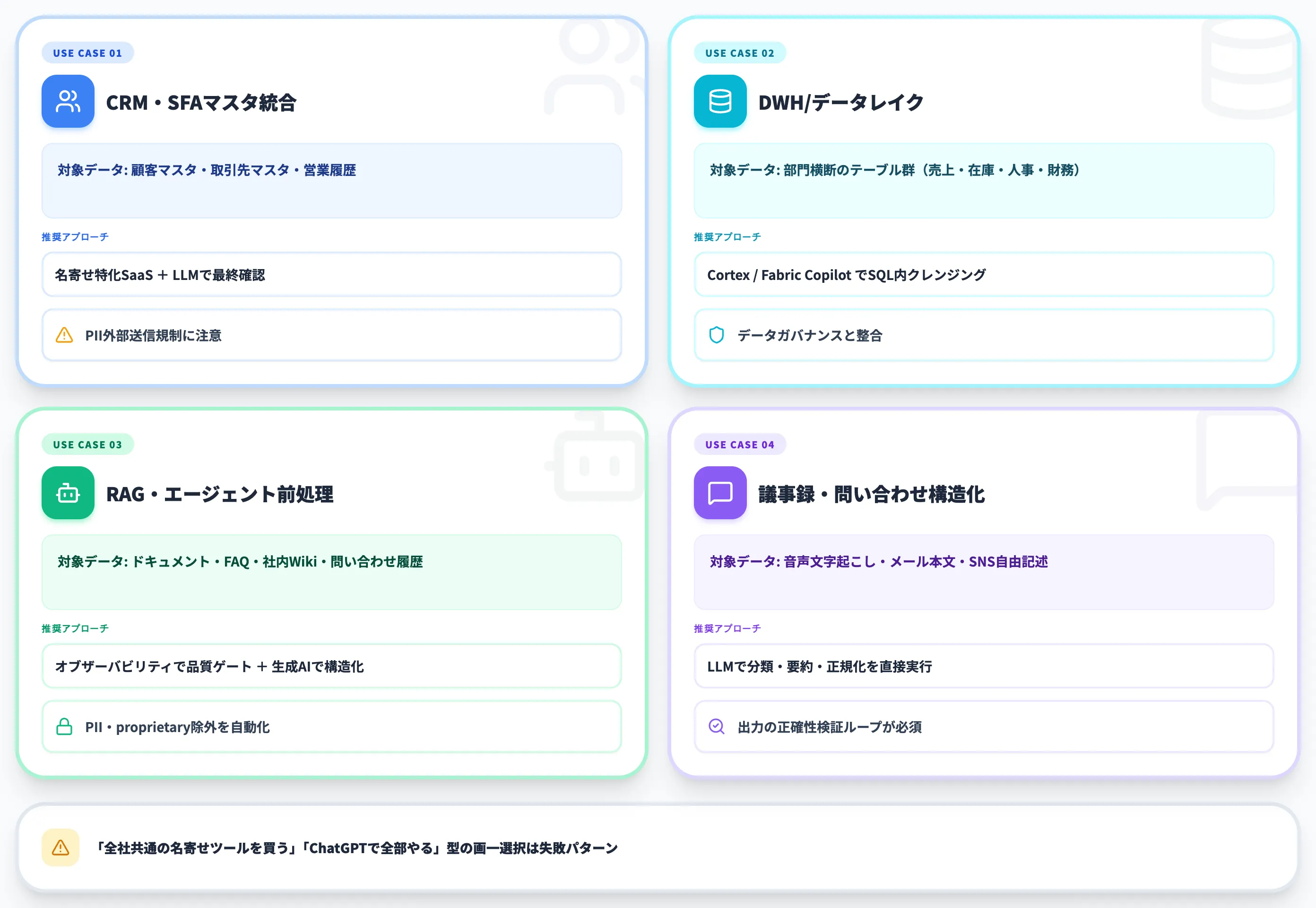
クレンジングのアプローチは、対象データの種類と業務目的によって取るべき設計が大きく変わります。「とりあえずChatGPTで全部やる」「全社共通の名寄せツールを買う」といった画一的な選択は、AI総合研究所の支援現場でも失敗パターンとして繰り返し観測されてきました。
以下の表で、4つの代表的なユースケースと、それぞれで取るべき主要アプローチを整理しました。
| ユースケース | 主な対象データ | 推奨アプローチ | 留意点 |
|---|---|---|---|
| CRM・SFAマスタ統合 | 顧客マスタ・取引先マスタ・営業履歴 | 名寄せ特化SaaS+LLMでの最終確認 | 顧客情報の外部送信規制に注意 |
| データ基盤(DWH/データレイク) | 部門横断のテーブル群 | DWHネイティブAI(Cortex/Fabric Copilot)でSQL内クレンジング | データガバナンスの枠組みと整合させる |
| RAG・エージェント前処理 | ドキュメント・FAQ・社内Wiki | データオブザーバビリティで品質ゲート+生成AIで構造化 | PII・proprietary除外を自動化前提に組み込む |
| 議事録・問い合わせの構造化 | 音声文字起こし・メール本文 | LLMで分類・要約・正規化を直接実行 | 出力の正確性検証ループが必須 |
各ユースケースで「どこに重みを置くか」が変わるため、本セクションでは1つずつ深掘りします。
CRM・SFAマスタ統合での実装
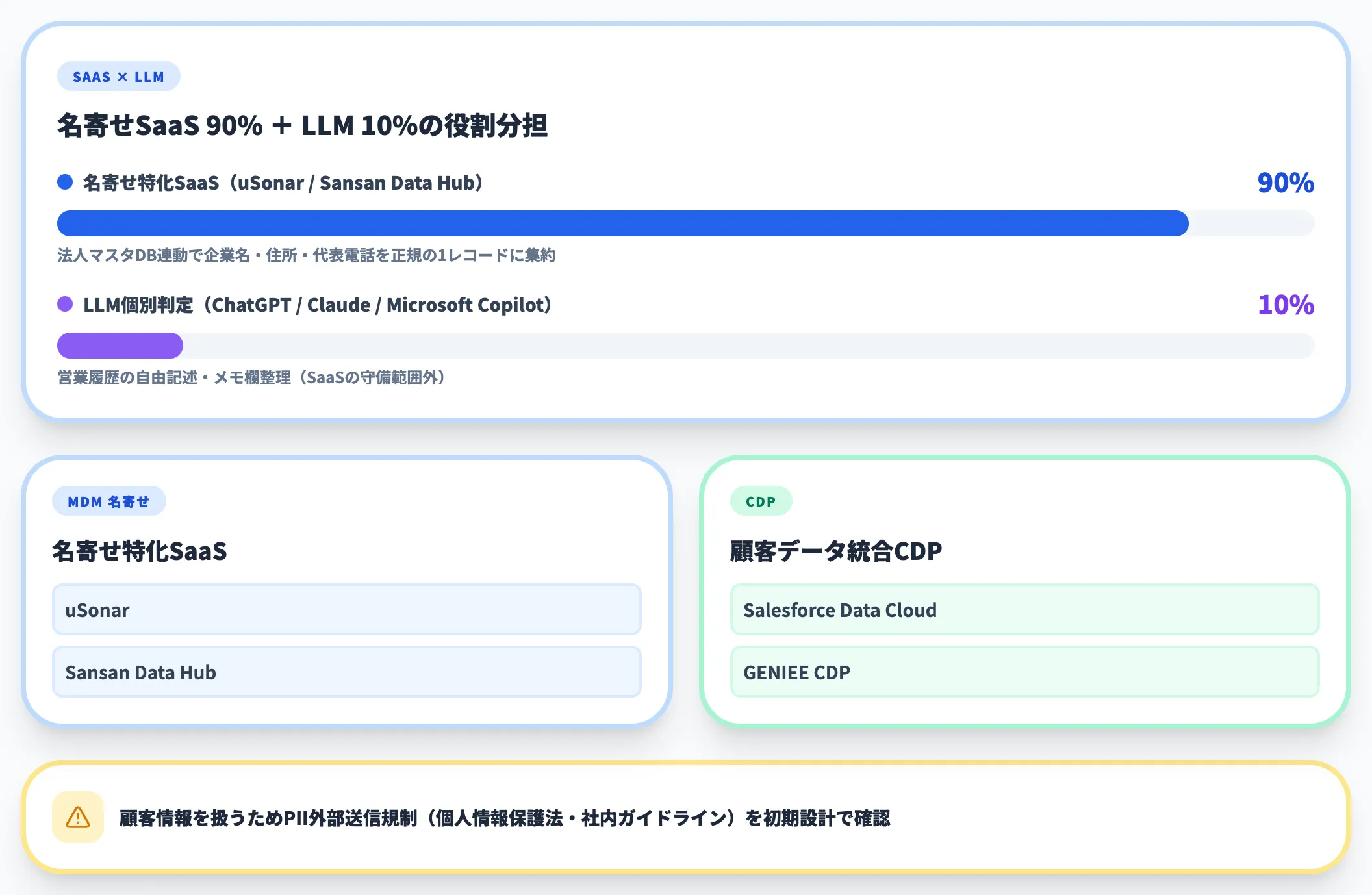
CRM・SFAマスタの統合は、最も古典的なクレンジング案件です。複数の営業システム・MAツール・名刺管理サービスからエクスポートしたデータが、表記揺れ・重複・古いレコードで使い物にならない、という状況が典型例です。
このユースケースでは、マスターデータ管理(MDM)の文脈で議論される名寄せ特化SaaS(uSonar・Sansan Data Hubなど)が中心的な選択肢になります。これらは法人マスタDBと連動して、企業名・住所・代表電話を「正規の1レコード」に寄せる仕組みを持っているため、社名表記揺れに強いという特性があります。Salesforce Data CloudやGENIEE CDPのようなCDPは顧客データの統合・プロファイル化を担い、TROCCOのようなETL/ELT基盤は前段のデータ連携を担う組み合わせ役として併用されることが多いカテゴリです。
ただし営業履歴の自由記述やメモ欄の整理はSaaSの守備範囲外なので、そこだけ別にChatGPT・Claude・Microsoft CopilotといったLLMを併用する構成が実務的です。AI総研の支援経験では、「名寄せはSaaSで90%、残り10%はLLMで個別判定」という役割分担が再現性高く効きます。
顧客情報を扱うため、PIIの外部送信規制(個人情報保護法・社内ガイドライン)との整合性を初期設計で押さえることが必須です。
データ基盤(DWH/データレイク)でのクレンジング
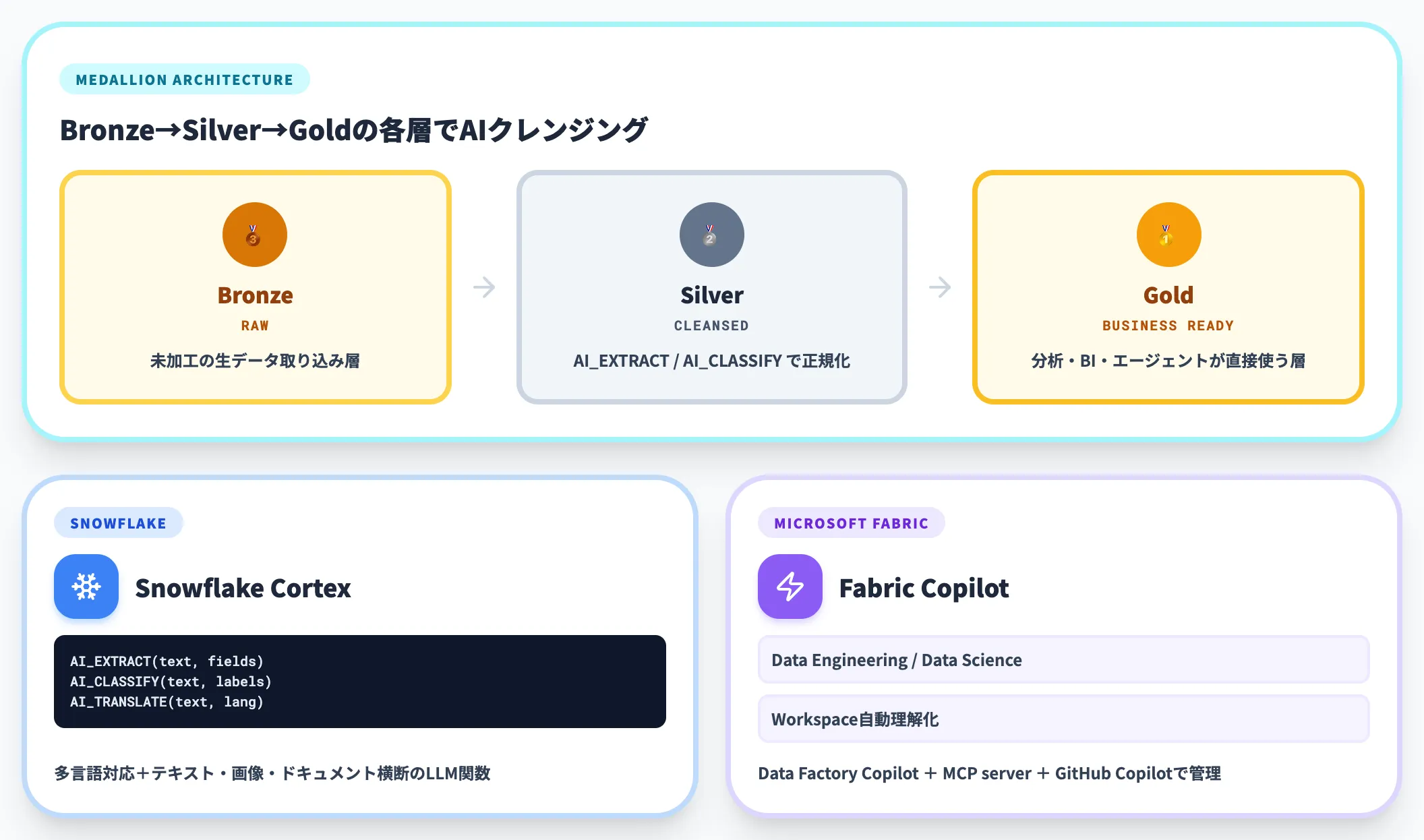
部門横断でデータを統合するDWH・データレイク層では、データのスケールが大きく、SQLパイプラインに乗せたクレンジングが求められます。
このユースケースでは、Snowflake CortexやMicrosoft Fabric CopilotのようなDWHネイティブAIが第一候補になります。SQL文脈で「AI_EXTRACT」・「AI_CLASSIFY」・「AI_TRANSLATE」のような関数を直接呼べるため、ETLパイプラインの中にクレンジング工程を自然に組み込めるのが利点です。
Snowflakeの公式ドキュメントでは、これらの関数を多言語対応かつテキスト・画像・ドキュメント横断で呼び出せると説明されています。データ基盤層では、データガバナンスやメダリオンアーキテクチャの枠組みと整合させながら、Bronze→Silver→Goldの各層でAIクレンジングを段階的に適用する設計が現実的です。
DatabricksのLakehouseでも同様にMosaic AI経由でLLM呼び出しが可能で、SnowflakeかDatabricksかの選定は、既存のクラウド環境(AWS/Azure/GCP)と利用部門のSQLスキルレベルで決まります。
RAG・AIエージェント向け前処理
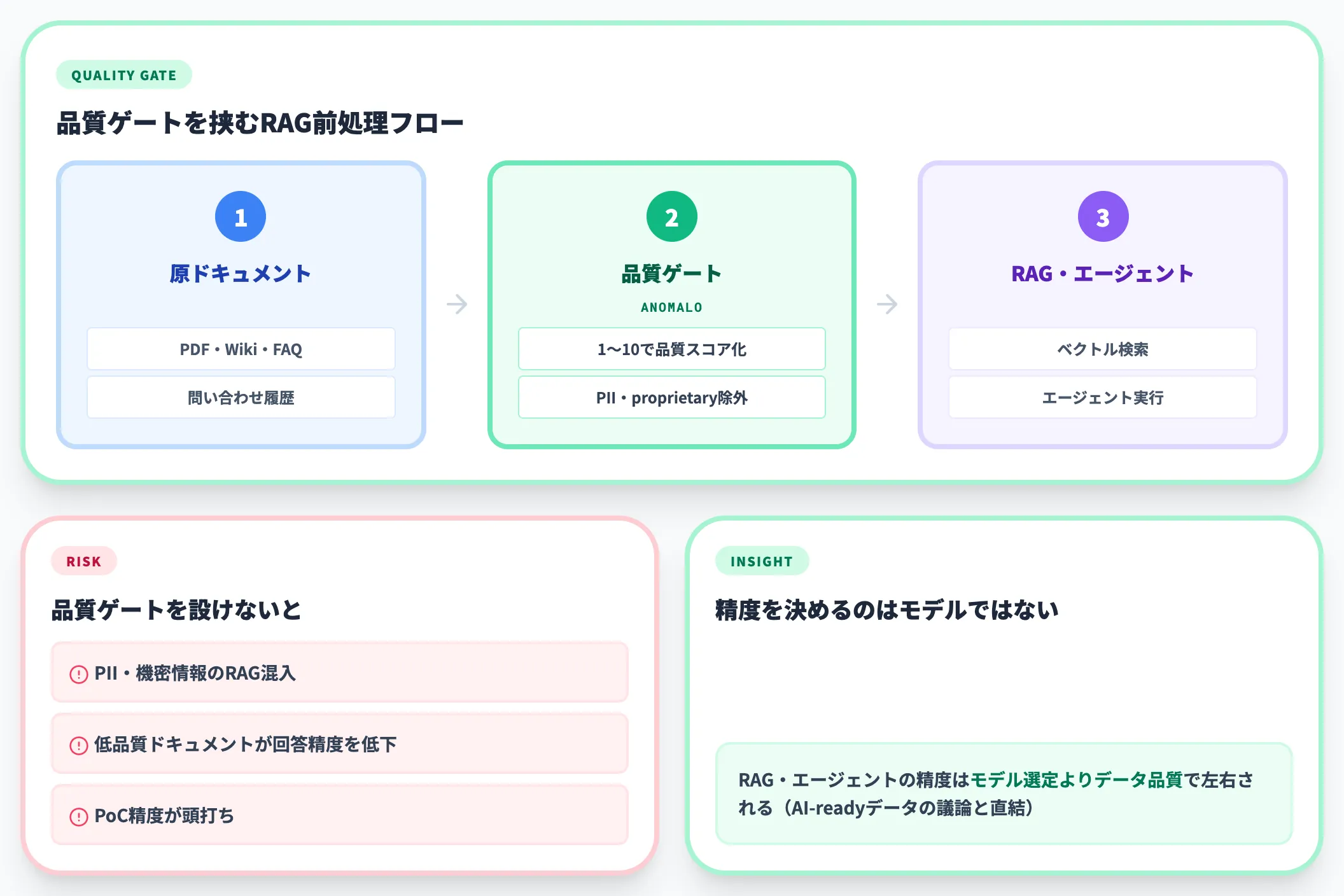
生成AIの社内活用(RAG・エージェント)が普及するにつれ、「LLMに渡す前のドキュメント品質」が新しい論点として浮上しています。これが本記事の「非構造データクレンジング」と直結する領域です。
PDF・社内Wiki・FAQ・問い合わせ履歴など、いわゆる「AI-readyデータ」の要件を満たすには、品質ゲートを自動化する必要があります。Anomaloの非構造化データ品質監視が代表例で、各ドキュメントを1〜10でスコア化し、PII・proprietary information・メタデータ不整合があるものをRAGパイプラインに渡す前で除外できます。
AIエージェント時代のデータ基盤設計でも触れられているとおり、RAG・エージェントの精度はモデル選定よりもデータ品質に大きく左右されるため、ここを軽視するとPoCの精度が頭打ちになります。
議事録・問い合わせ自由記述の構造化

音声文字起こしや問い合わせメールの自由記述を、分類・要約・正規化して使える形に整えるユースケースです。
このケースでは、LLMによる直接処理が最も実用的です。たとえば「問い合わせ本文から、製品名・問題カテゴリ・緊急度を抽出してJSONで返す」という指示を、ChatGPT・Claude・Geminiに渡すと、決まったフォーマットで構造化されたデータが返ってきます。Microsoft 365 Copilotであれば、Outlookに届くメール本文をその場で要約・分類してSharePointに記録する、といった構成も可能です。
ただしLLMの出力は確率的で、同じ入力に対して時として違う結果を返すことがあります。「全件を必ず人間がチェックする」のか、「サンプル監査で品質確認するのか」を最初に決めて、ガバナンス側にレポートする運用が現実的です。
AIデータクレンジングの主要ツールカテゴリ
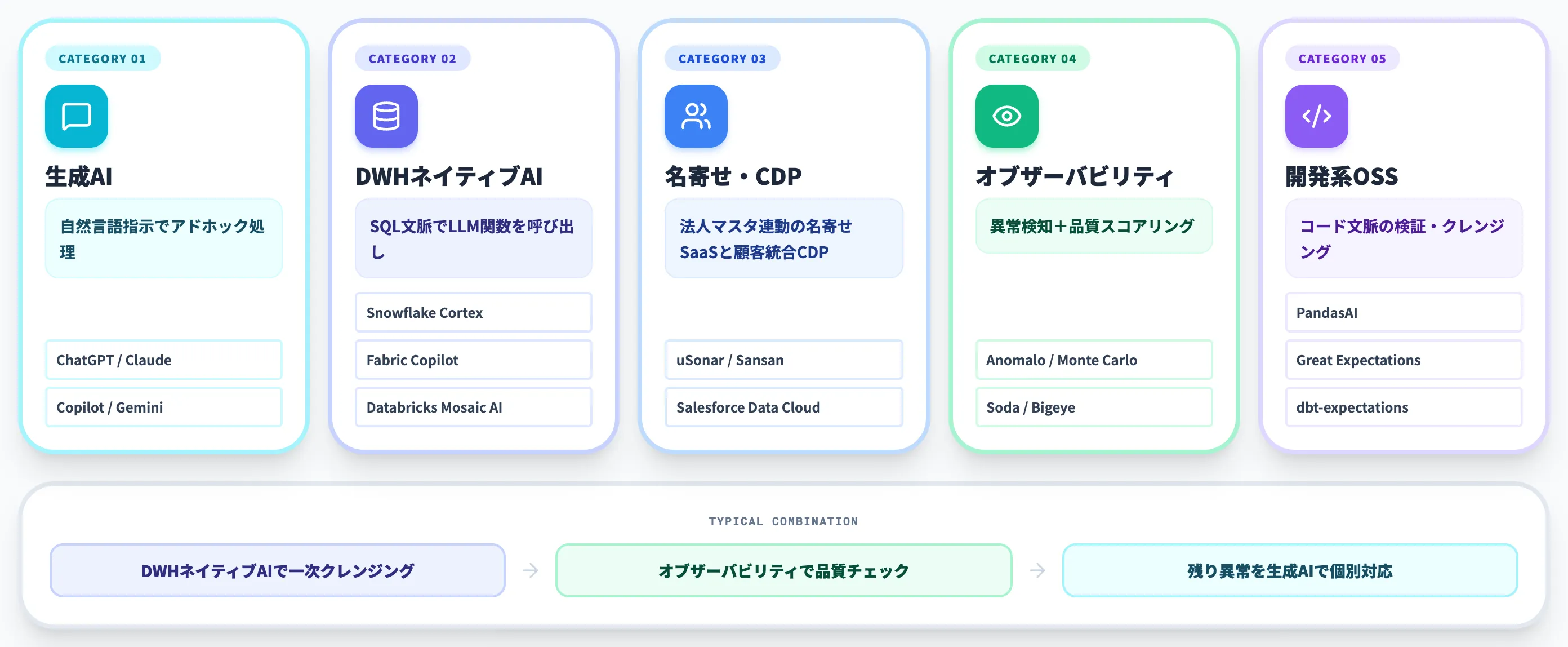
ツール選定で混乱しやすいのは、「ChatGPTでクレンジングする」と「Snowflake Cortexでクレンジングする」と「Anomaloでクレンジングする」が、まったく違うレイヤーの話であるからです。
以下の表で、5カテゴリそれぞれの特性と代表ツールをまとめました。
| カテゴリ | 特性 | 代表ツール | 主な対象データ |
|---|---|---|---|
| 生成AI(チャット・API) | 自然言語指示でアドホック処理 | ChatGPT / Claude / Microsoft Copilot / Gemini | Excel・CSV・テキスト全般 |
| DWHネイティブAI | SQL文脈でLLM呼び出し | Snowflake Cortex / Microsoft Fabric Copilot / Databricks Mosaic AI | DWH/データレイク上の構造化・半構造化データ |
| 名寄せ特化・CDP | 法人マスタ連動の名寄せSaaS(uSonar/Sansan)と顧客データ統合のCDP | uSonar・Sansan Data Hub(名寄せ)/Salesforce Data Cloud・GENIEE CDP(CDP) | 顧客マスタ・取引先マスタ |
| データオブザーバビリティ | 異常検知+品質スコアリング | Anomalo / Monte Carlo / Soda / Bigeye | 構造化テーブル(Anomaloは非構造化も) |
| 開発系OSS | コード文脈の検証・クレンジング | PandasAI / Great Expectations / dbt-expectations | コードベースのデータ処理 |
この5カテゴリは排他ではなく、組み合わせて使うのが普通です。
たとえば「DWHネイティブAIで一次クレンジング → データオブザーバビリティで品質チェック → 異常が残ったら生成AIで個別対応」という流れになります。なお、クレンジングの前段にあたるデータ連携・ETL/ELT基盤(TROCCO など)は、主要カテゴリの外側で補助カテゴリとして併用されるケースが多めです。
生成AI

最もアドホックに使えるカテゴリです。CSVをアップロードして「全角を半角に統一」「住所から都道府県だけ抽出」「企業名の表記揺れを統一」と自然言語で指示するだけで動きます。
Excelの数式を書くのが苦手な業務部門でも始めやすく、PoCの第一歩として有効です。
ChatGPT・Claude・Microsoft Copilot・Geminiは、いずれも実用レベルで動作します。
Claudeは長文の文脈保持と表構造の理解に強く、ChatGPTは推論型タスクに強い、Microsoft CopilotはExcel/Outlookとの統合に強い、という違いがあります。
注意点は、機密データを外部のチャットUIに直接貼り付けるとPII漏洩リスクが発生することです。
社内利用ではAzure OpenAI ServiceやAWS Bedrock経由でAPI呼び出しに切り替えるか、Microsoft 365 Copilotのような「データを学習に使わない契約」で運用する必要があります。
DWHネイティブAI
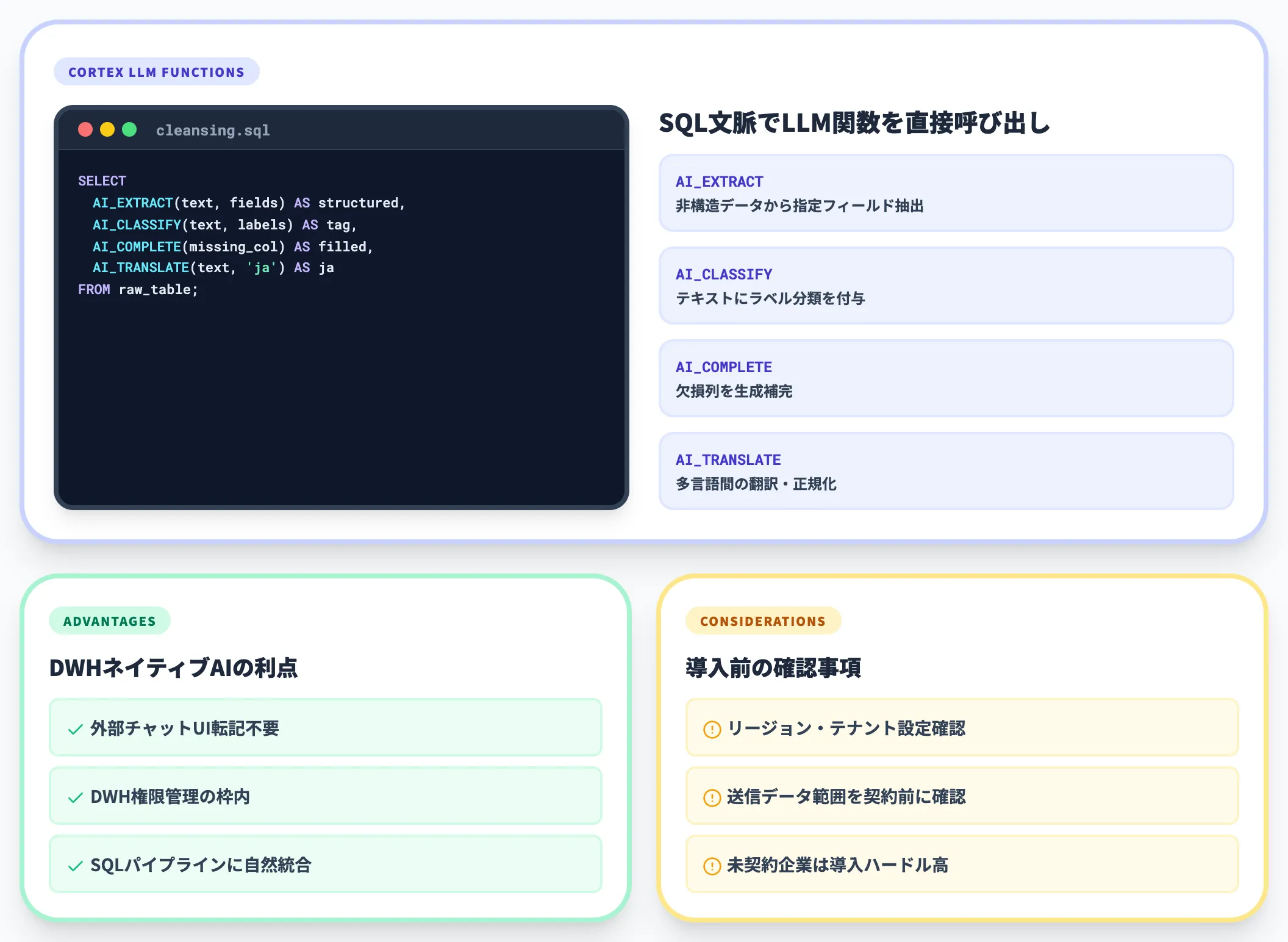
データ基盤層でのクレンジングに最適なカテゴリです。SnowflakeのCortex関数(「AI_EXTRACT」・「AI_CLASSIFY」・「AI_COMPLETE」・「AI_TRANSLATE」)や、Microsoft Fabricのデータエージェント、Fabric Data Scienceなどは、いずれもデータがDWHに存在することを前提にAI処理をその場で実行する設計です。
Microsoft Fabricの2026年版アップデートでは、Copilotがセッション開始不要で「Workspace・接続Lakehouse・ノートブック構造・実行環境」を自動理解する方向に進化しています。
Fabric Data Factory CopilotはDataflow・Pipelineの生成・実行・トラブルシュートを自然言語でアシストし、Airflow JobについてはData Factory MCP server+GitHub Copilotの組み合わせで管理する形が公式に提示されています。
DWHネイティブAIの利点は、外部チャットUIへの手動転記が要らず、DWHやレイクハウスの権限管理の枠内で処理しやすい点と、SQLパイプラインに自然に組み込める点です。
ただしMicrosoft Fabric Copilotのようにプロンプトや結果がAzure OpenAIで処理される構成では、リージョン・テナント設定・送信データ範囲を契約前に確認しておく必要があります。
既にSnowflakeやFabricを契約していない企業にとっては導入ハードルが高いカテゴリでもあります。
名寄せ・CDP特化
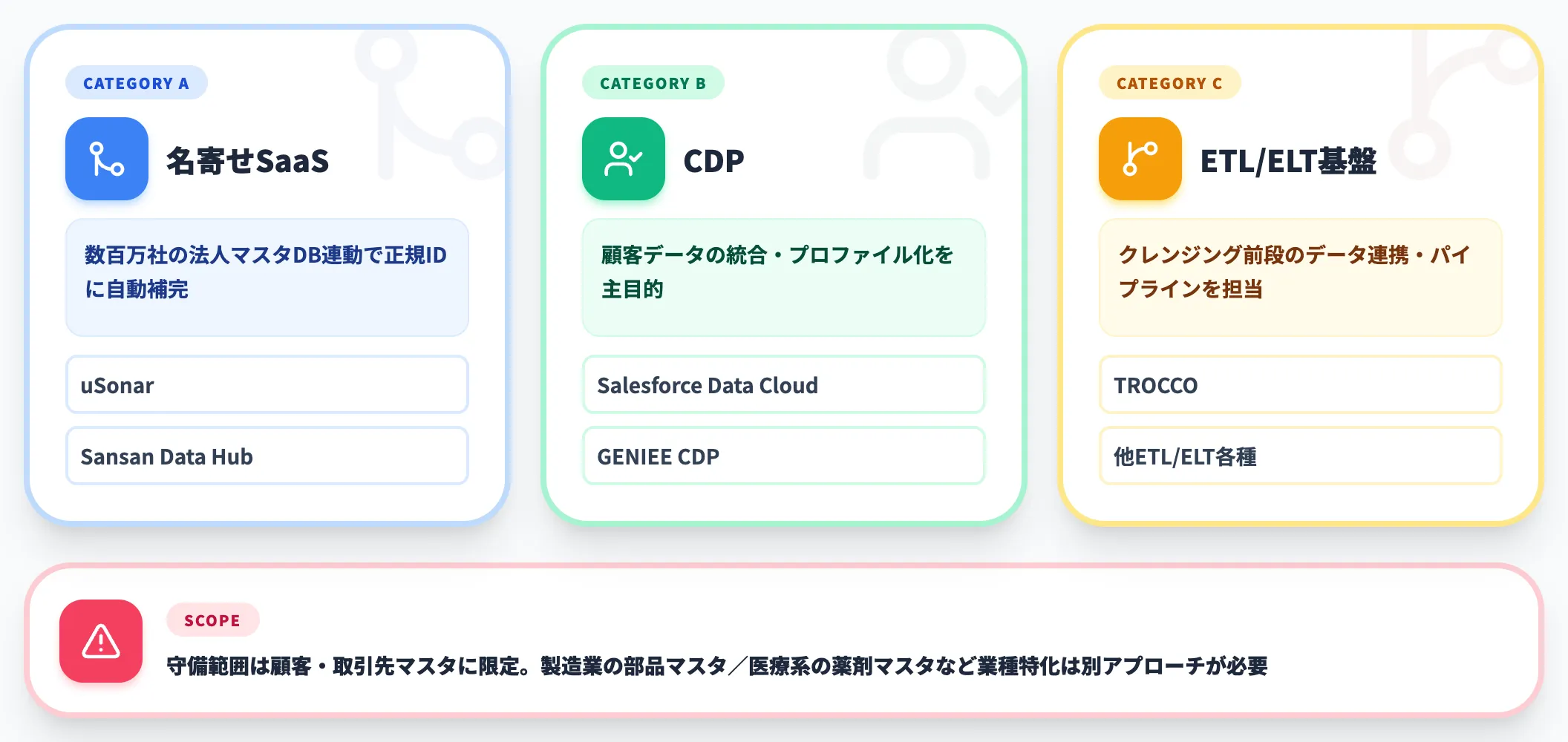
法人マスタDBや国内企業データベースと連動した、名寄せ特化型SaaSです。uSonarやSansan Data Hubは数百万社規模の法人マスタを保有しており、ユーザーが投入した顧客リストの社名・住所を正規の法人IDに紐づけて自動補完する設計になっています。
CRM・SFA・MAツールの統合プロジェクトでは、このカテゴリのSaaSが圧倒的に効率的です。汎用LLMで個別に名寄せロジックを組むより、最初から法人マスタを持っているSaaSに任せた方が、精度・コストの両面で勝ります。
ただし守備範囲は顧客マスタ・取引先マスタに限定されるため、製造業の部品マスタや製品マスタ、医療系の薬剤マスタのような業種特化マスタの名寄せには別のアプローチが必要です。
なお、Salesforce Data CloudやGENIEE CDPのようなCDPは「顧客データの統合・プロファイル化」を主目的にしたカテゴリ、TROCCOのようなETL/ELT基盤は「クレンジング前段のデータ連携」を担うカテゴリで、名寄せSaaSとは役割が分かれます。CRM・SFA統合プロジェクトでは、これらを組み合わせて使う構成が一般的です。
データオブザーバビリティ
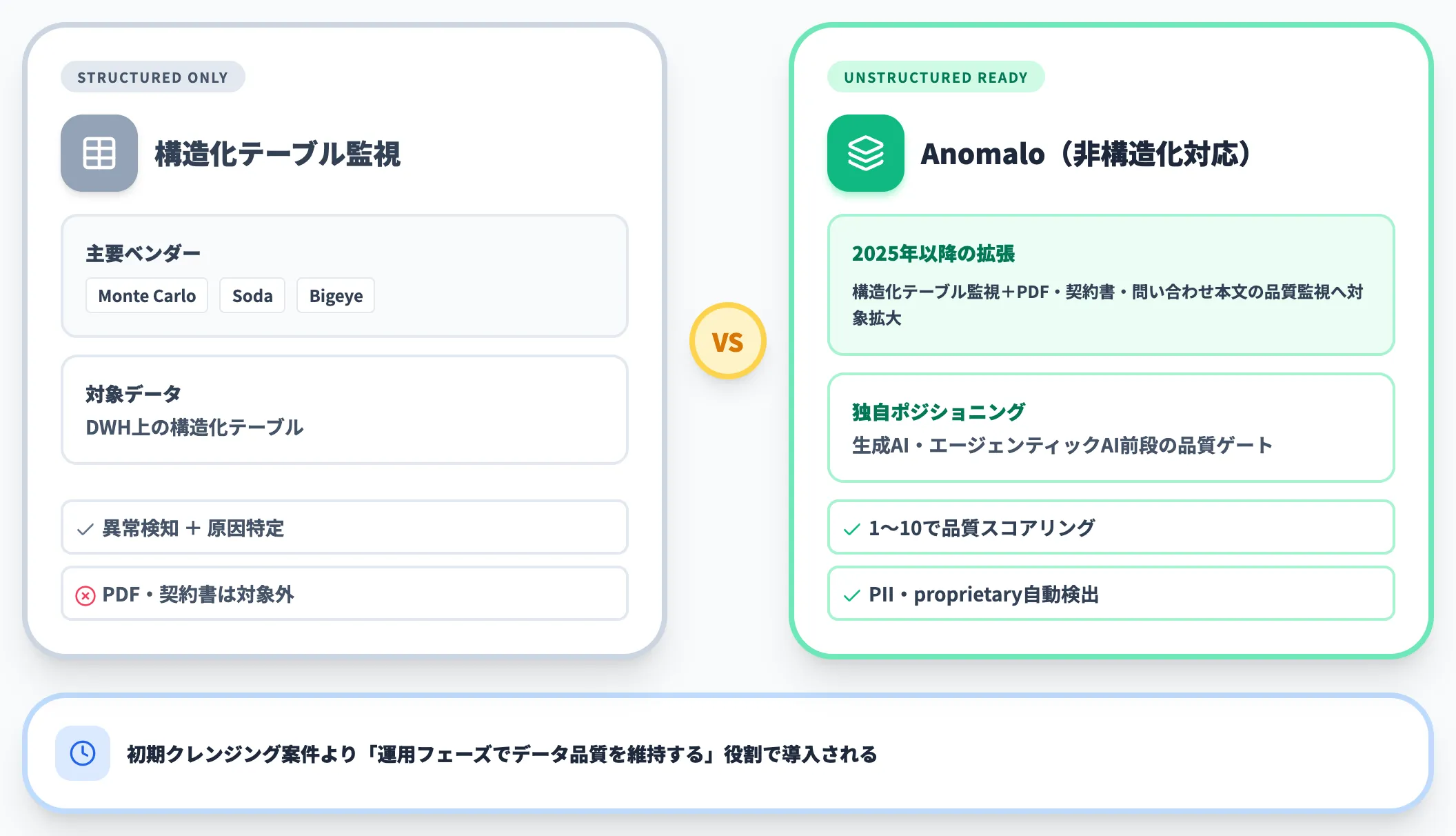
データの「健康状態」を継続的に監視するカテゴリです。クレンジングのその場の処理ではなく、データパイプライン全体を通して異常を検知して通知・原因特定する役割を担います。
Monte Carlo・Soda・Bigeyeは構造化テーブルの監視に強く、Anomaloは2025年以降に非構造化データ(PDF・契約書・問い合わせ本文)の品質監視まで対象を広げました。
生成AI・エージェンティックAIに渡す前の品質ゲートとして、Anomaloのポジショニングは独自性があります。
このカテゴリは「クレンジング後のデータ品質を維持する」役割なので、初期のクレンジング案件というよりも、運用フェーズで導入されるケースが多めです。
開発系OSS

データエンジニア・データサイエンティスト向けの開発系OSSです。
PandasAIは、Pandas DataFrameに対して自然言語で操作指示を出せるPythonライブラリです。「「df.chat('全角数字を半角に統一して')」」のような呼び出しで、内部的にLLMがコードを生成して実行する仕組みになっています。
Jupyter上でアドホックなクレンジングを行うシーンで重宝します。
Great Expectationsとdbt-expectationsは、データ検証の「期待値(Expectation)」をコードとして定義し、CI/CDパイプラインで検証する設計のOSSです。「このカラムはnull率が5%以下」「この値は{'A', 'B', 'C'}のいずれか」といったルールを宣言的に書けます。
開発系OSSは、エンジニアリングの内製化が進んでいる組織での選択肢で、業務部門だけでクレンジングを完結させたい企業にはハードルが高い側面があります。

AIデータクレンジングの料金・コスト構造
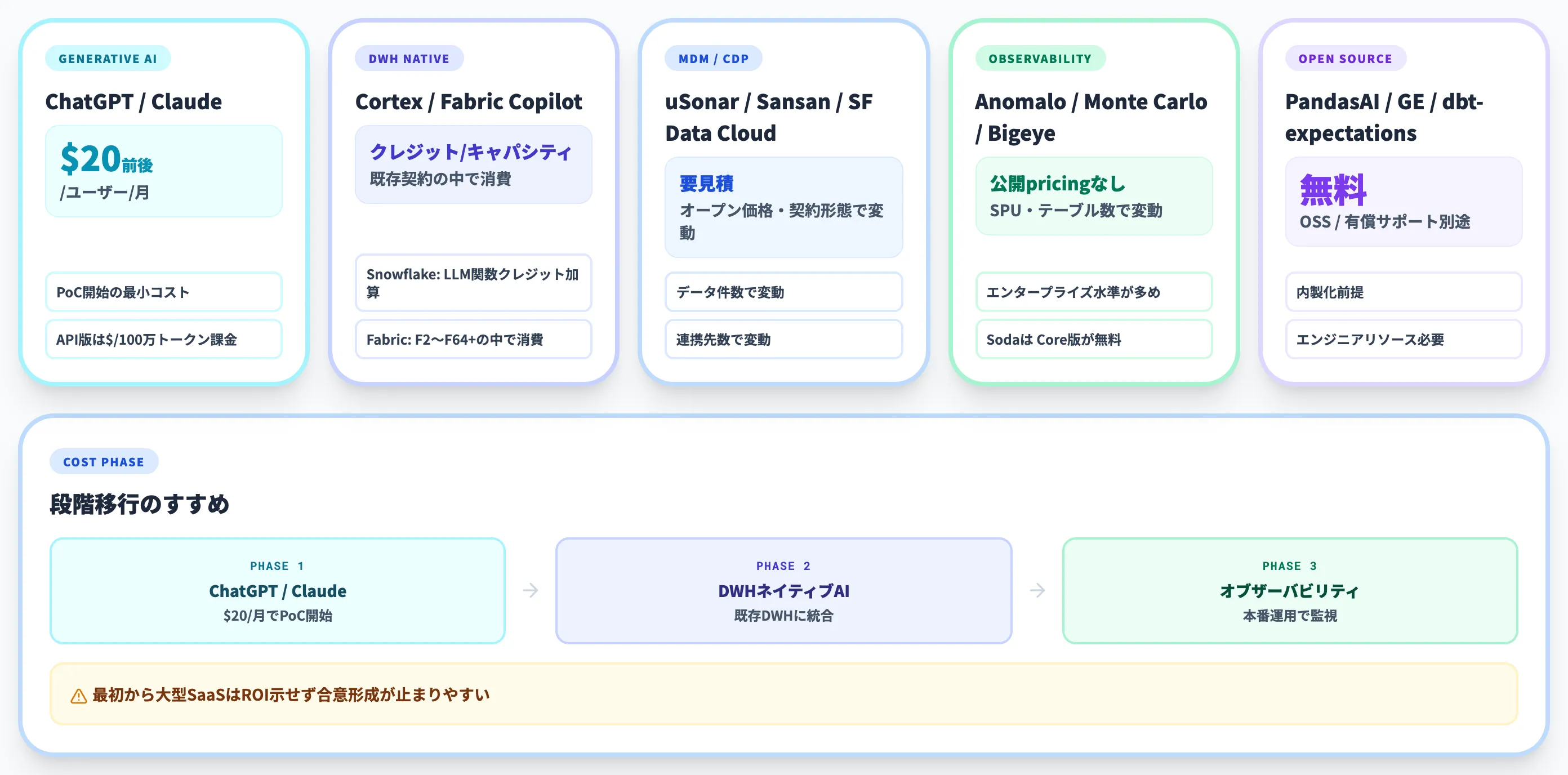
ツール選定では機能と並んで料金構造が重要です。本セクションでは、主要カテゴリの料金水準を整理します。
以下の表で、代表的なツールの料金体系を整理しました(2026年6月時点・参考値)。
| カテゴリ | 代表ツール | 料金体系 |
|---|---|---|
| 生成AI | ChatGPT Plus / Claude Pro | 月額 $20前後/ユーザー |
| 生成AI(API) | GPT-5.5 / Claude Opus 4.8 等 | 100万トークンあたり数ドル〜数十ドル(モデルで変動・入出力で別単価) |
| DWHネイティブAI | Snowflake Cortex | 通常のクレジット課金にLLM関数のクレジット消費が加算 |
| DWHネイティブAI | Microsoft Fabric Copilot | Fabric Capacity(F2〜F64+)の中で消費 |
| 名寄せ特化SaaS | uSonar / Sansan Data Hub | 要見積(データ件数・連携先・契約形態で変動・オープン価格) |
| CDP | Salesforce Data Cloud / GENIEE CDP | 要見積(規模・連携先数で変動) |
| データ連携・ETL/ELT | TROCCO | Freeプラン/月額プラン(Starter・Essential・Advanced)/Professionalは要問い合わせ・公式pricing参照 |
| データオブザーバビリティ | Anomalo / Monte Carlo / Bigeye | 公開pricingなし・要見積(テーブル数・データ量・SPUで変動・公式デモ/問い合わせ導線) |
| データオブザーバビリティ | Soda | OSS版(Soda Core)は無料、Cloud版は要見積(SPU課金中心) |
| 開発系OSS | PandasAI / Great Expectations | OSSは無料、有償サポート別途 |
この比較から分かるのは、カテゴリごとの料金スケールが大きく違うという点です。
生成AIは月20ドル前後で始められる一方、データオブザーバビリティ各社は公開pricingがなく要見積で、年間で見るとエンタープライズ水準になることが多めです。
Snowflake CortexやFabric Copilotは既存のクラウド契約のクレジット・キャパシティに乗ってくるためベース費用ありき、という構造になっています。
実務では「PoCはChatGPT/Claude → 本番運用でDWHネイティブAI or データオブザーバビリティに移行」というステップが現実的です。最初から大型SaaSを契約してしまうと、ROIを示せる前にコストが膨らみ、社内の合意形成が止まりやすくなります。
注意点として、データオブザーバビリティ系の料金は監視対象テーブル数・スキャン頻度・データ量で大きく変動します。トライアル時点の見積もりと本番運用時の請求額が乖離する事例があるため、契約前に「スケール後のシナリオ」も含めて見積もりを取るのが安全です。
AIデータクレンジング導入で迷う論点とPoCの進め方

ツール選定が決まっても、PoCで止まる企業は少なくありません。AI総合研究所の支援現場でも、技術的に動くだけでなく運用上の論点を初期段階で押さえられているかで、PoCから本番展開までのスピードが大きく変わると感じています。
本セクションでは、実装に入る前に必ず判断しておきたい4つの論点と、PoC設計の進め方を整理します。
PIIと外部AI送信のリスク管理

最初に詰まるのが、機密データの外部送信問題です。顧客マスタの個人情報・取引履歴・契約書本文をそのまま外部のチャットUIに貼り付けるのは、社内ポリシー上不可能なケースが多いというのが実態です。
実務的な対策は以下の3つに集約されます。
-
Azure OpenAI Service・AWS Bedrock経由でAPI呼び出し
データを学習に使わない契約形態が明示されており、企業の社内ガイドラインに乗せやすい。Microsoft 365 Copilotも同様
-
オープンソースLLMをオンプレ・自社テナント内で動かす
Llama 3・Qwen3などのオープンソースモデルを自社GPUで動かす構成。ハードウェア投資が必要だが、データ越境ゼロを実現
-
マスキング前提でクラウドLLMを使う
PIIを事前にマスキング(例: 社名は法人IDに置換)してからLLMに渡し、戻った結果を元の値に戻す。ライブラリで自動化可能
RAG・エージェント向けの非構造データクレンジングでは、Anomaloのような専用ツールがPII検出・削除を自動化してくれるため、入り口で品質ゲートを設けるアーキテクチャが現実的になっています。
出力検証と人間レビューの役割分担

AIクレンジングの出力は100%正確ではありません。これを前提に、どの場面で人間がチェックするかを初期設計で決めることが、PoCを止めないコツです。
以下の4パターンが実務で繰り返し採用されています。
-
重要フィールドは全件レビュー
顧客IDの紐づけ、取引金額、契約期間など、誤りが致命的になるフィールドは全件人間チェック
-
閾値以下は『要確認』フラグ
LLMが「信頼度0.7以下」と返したレコードだけ人間に回す。閾値はPoCで調整
-
サンプリング監査
全件のうち5〜10%をランダム抽出して品質確認。月次・四半期で定点観測
-
下流タスクで異常検知
クレンジング自体は全件AIに任せ、下流の分析・モデル精度低下を検知トリガーにする
「全部AIに任せる」も「全部人間が見る」も非現実的なので、データの重要度と組織のリスク許容度に応じて使い分けます。
AI総研の支援現場では、「重要マスタは全件レビュー+それ以外はサンプリング監査」の組み合わせが再現性高く機能しています。
プロンプト・ルールのドキュメント化
意外と見落とされがちなのが、クレンジングロジックの再現性です。「Claudeに住所抽出を頼んだら綺麗に整った」というPoCを、3か月後に別担当者が再現できないと、業務に組み込めません。
具体的な対策は以下のとおりです。
- 使用したプロンプト・LLMモデル・温度設定・実行日時を一覧で記録
- 入力データのサンプルと出力結果のペアを保存(後で精度比較に使う)
- ルールベース部分(正規表現や辞書)はGit管理してバージョン履歴を残す
- LLMモデルのバージョン変更時は、過去サンプルで回帰テスト
これは技術的というよりも運用設計の話で、データガバナンス担当・データエンジニア・業務部門の役割分担を最初に決めておくのが要点です。
PoCの一歩目 — 小さく始めて運用ループを回す

最後に、PoC設計の進め方です。「全マスタを一気にクレンジング」という大規模PoCは、AI総研の支援経験では成功率が低めです。
代わりに、以下のステップで進めるのが再現性高く機能します。
- 対象を絞る: 1テーブル・1工程に絞る(例: 顧客マスタの企業名表記揺れだけ)
- 手元のCSVで生成AI試行: ChatGPT/Claudeに数百件を投入して精度を肌感で測る
- ルールベース+AIのハイブリッド設計: ルールで吸収できるところはルール、残りをLLM
- 運用ループに乗せる: 月次・週次の定期実行で品質スコアが安定するかを観察
- 対象範囲を広げる: 1工程で安定したら、別マスタ・別工程に横展開
このループを最初から想定しておくと、「PoCは動いたが本番に乗らない」という典型的な失敗を回避できます。データクレンジングの効率化は、ツール選定よりも運用ループの設計で差がつく領域です。

データ整備からAgent活用まで一気通貫で進めるなら
データクレンジングは「整えて終わり」ではなく、整えたデータをAIエージェントが業務で実行に使える形まで持っていって、初めて投資が回収できる工程です。クレンジング後のデータが分析レポートで止まると、PoCの先に行けません。
AI Agent Hubは、Microsoft Fabric(OneLake)でZero ETLでデータ仮想統合し、整備されたデータをTeamsから呼び出せるAIエージェントで業務に直結させるエンタープライズAI基盤です。クレンジング・整備・活用までを1つのプラットフォームで設計できます。
-
Fabric OneLakeでZero ETLデータ統合
SAP・Salesforce・SharePointなど基幹システムのデータをFabric OneLakeに仮想統合。物理コピーなしでクレンジング・分析・エージェント実行の前提を整えます。
-
クレンジング後のデータをエージェントが業務実行
整備されたマスタを使って、AI-OCR Agent・自動入力Agent・経費仕分けAgentなどが請求書処理・経費精算・人事申請を自動実行します。
-
使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
-
データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、データクレンジングの設計からエージェント実装・運用設計まで一貫してサポートします。AI Agent HubのLPで、自社の業務にどう活用できるかをご確認ください。
データ整備からAgent活用まで一気通貫で進める

クレンジング後のデータをエージェントが業務に直結
データクレンジングは「整えて終わり」ではなく、その先にエージェントが業務を実行する設計まで含めて初めて投資が回収できます。AI Agent HubのLPで、Fabric OneLakeで統合したデータをTeamsから呼び出せる業務エージェントに繋ぐ設計の全体像をご確認ください。
まとめ
本記事では、AIによるデータクレンジングについて、効率化される5工程、業務ユースケース別の使い分け、主要ツールカテゴリ、料金、PoC設計までを2026年6月時点の最新情報で整理しました。要点を改めてまとめます。
-
データクレンジングはデータ分析の工数の大半を占める領域で、AI活用で最大80%削減が報告されている。Gartnerは「2026年までにAI-readyデータがないAIプロジェクトの60%が放棄される」と予測しており、AI活用の前提条件として優先度が上がっている
-
AIが本当に変えたのは5工程の中身で、LLM Embeddingによるセマンティック重複検出、生成補完(Generative Imputation)、Anomaloの非構造データ品質スコアリングなど、ルールベースでは詰みやすかった領域に意味理解が入った
-
ユースケース別に取るべきアプローチが違う。CRM・SFAは名寄せ特化SaaS+LLM、DWH/データレイクはCortex・Fabric Copilot、RAG前処理はAnomaloで品質ゲート、自由記述は生成AIで直接処理、と切り分けて設計する
-
主要ツールは生成AI/DWHネイティブAI/名寄せ特化/データオブザーバビリティ/開発系OSSの5カテゴリで整理する。料金スケールが大きく違うため、PoCは生成AIから始めて段階的に上位カテゴリに移行する
-
PoCで止めないコツは運用設計。PII管理・出力検証・人間レビューの役割分担・プロンプトのドキュメント化を初期に押さえ、対象を1テーブル1工程に絞って小さく始めるのが再現性高い
データクレンジングの効率化は、もはや単体の工程改善ではなく、生成AI・エージェント活用の前提条件として組織的に取り組むテーマに変わりました。ツール選定よりも「どのユースケースから入るか」「どこに人間が残るか」「データから業務までを誰がつなぐか」の運用設計で差がつく時期に入っています。
まずは自社で「いちばん時間をかけているデータ整備工程」を1つ選び、生成AIで小さくPoCを回すところから着手することが、最も実用的な第一歩になります。










