この記事のポイント
 社内FAQ・ECサイト検索で「キーワードが一致しないのにヒットしない」問題を抱えているなら、セマンティック検索の導入が有効
社内FAQ・ECサイト検索で「キーワードが一致しないのにヒットしない」問題を抱えているなら、セマンティック検索の導入が有効- キーワード検索との最大の違いは同義語・言い換え・文脈を理解できる点で、検索精度とユーザー体験を根本的に改善できる
- 実装はAzure AI SearchやElasticsearchのベクトル検索機能で対応でき、TensorFlow Hubで簡易検証も可能
- ECサイトではコンバージョン率の向上、社内ナレッジ管理では情報到達時間の短縮に直結する
- 導入判断の目安は「検索クエリの表現が多様なサービス」。単純な型番検索中心ならキーワード検索で十分

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
セマンティック検索とは、検索クエリやコンテンツの「意味」や「文脈」を理解し、単なる文字列一致ではなく概念的な関連性に基づいて情報を検索する技術です。
2026年現在では、ベクトル検索とキーワード検索を組み合わせた「ハイブリッド検索」が主流となり、Azure AI SearchやElasticsearchなどのプラットフォームで手軽に導入できるようになっています。
この記事では、キーワード検索との違い、技術的な仕組み、実装方法、そしてビジネスインパクトに至るまで、セマンティック検索の全体像をわかりやすく解説します。
セマンティック検索とは
セマンティック検索イメージ
セマンティック検索 (Semantic Search) は、検索クエリやコンテンツの 「意味」や「文脈」を理解し、単なる文字列の一致ではなく、概念的な関連性に基づいて情報を検索する技術** です。
「セマンティック (Semantic) とは 「意味論的」という意味で、言葉の表層的な一致だけでなく、その背後にある概念や意図を捉えることを重視します。

キーワード検索との違い
検索技術には大きく分けて「キーワード検索」と「セマンティック検索」の2つがあります。従来の検索はキーワードに基づいて情報を抽出していましたが、近年ではAI技術の進化により、検索意図や文脈を理解するセマンティック検索が注目されています。
以下の表に、両者の主な違いをまとめました。
| 項目 | キーワード検索 | セマンティック検索 |
|---|---|---|
| マッチング方法 | 文字列の完全一致・部分一致 | 意味的な関連性に基づくマッチング |
| 言い換え対応 | 対応しにくい | 同義語や言い換え表現を認識し、柔軟に対応 |
| 文脈理解 | 単語単位のマッチング | クエリの文脈から意味を推測(例:「アップル」は企業か果物かを判断) |
| 検索意図の把握 | 単語ベースで結果を返す | ユーザーの意図を理解し、最適な情報を提示 |
| 複雑なクエリ | 短い単語や単純な構造での検索に強い | 長文や複雑な条件を含むクエリでも適切に処理 |
セマンティック検索は、単語の一致に頼るキーワード検索と異なり、文脈や意味の理解を通じてユーザーの検索意図を的確に捉えます。これにより、より関連性の高い情報が提供され、検索体験の質が大きく向上します。
技術的基盤と仕組み:セマンティック検索が「意味」を理解するまでのプロセス
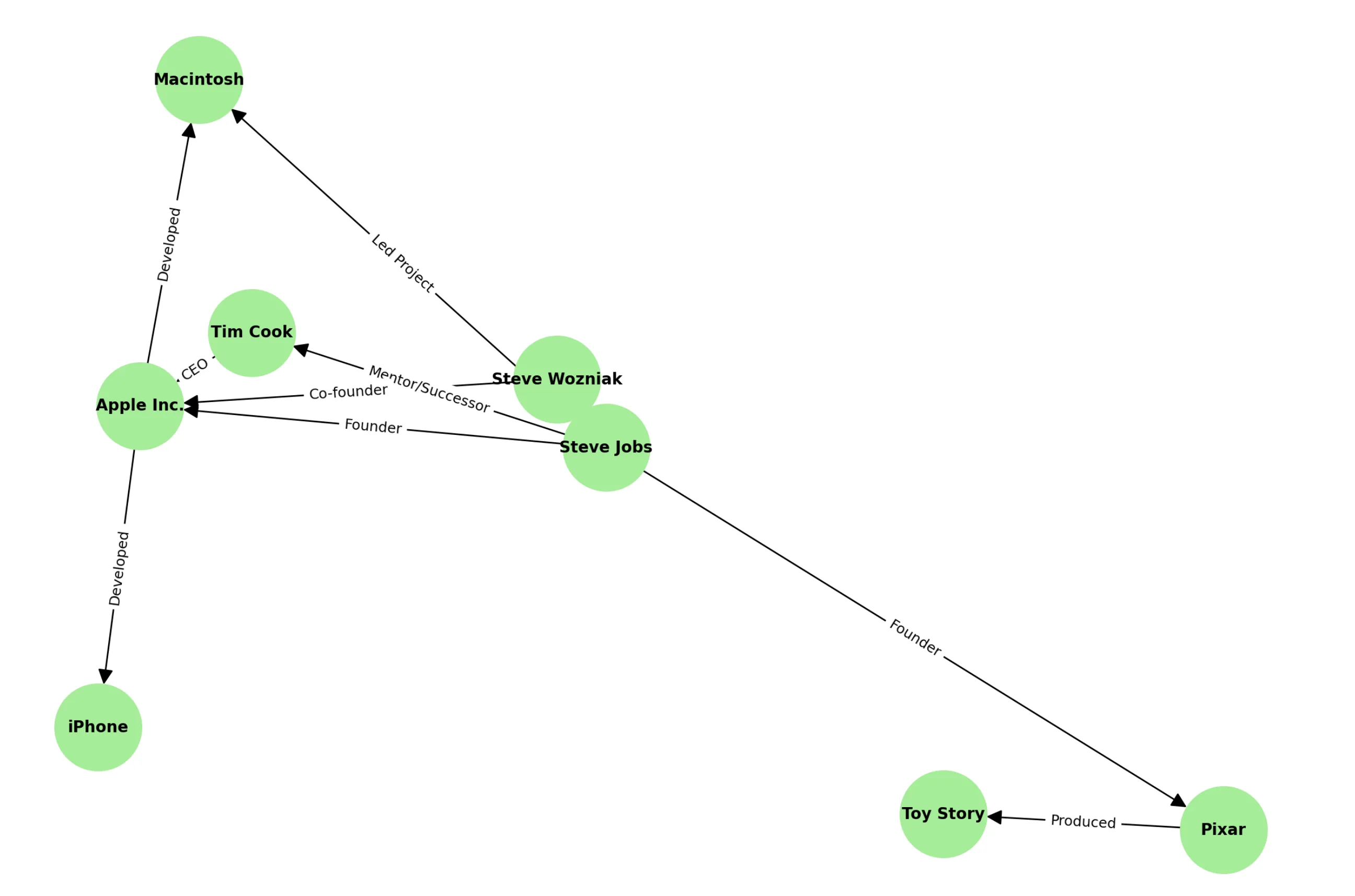
セマンティック検索ナレッジグラフイメージ
セマンティック検索は、単なるキーワード一致ではなく、検索クエリの意味や文脈を理解し、最適な情報を導き出す検索手法です。その背後では、さまざまなAI技術が連携しながら、ユーザーの意図を段階的に解釈しています。
ここでは、セマンティック検索がどのようにして「意味」を理解し、検索結果に反映していくのか、その技術的な流れを追っていきましょう。
ステップ①:自然言語を読み解く ― NLPと機械学習の活用
最初のステップは、検索クエリを「言葉」として正確に理解することです。
ここで活躍するのが、自然言語処理(NLP)と機械学習の技術です。
- 形態素解析・品詞タグ付け:文を単語に分解し、名詞・動詞などの品詞を判別
- 固有表現認識(NER):人名・地名・組織名・日付などを特定
- 意味的類似性の計算:「車」と「自動車」のような言い換えに対応
- トピックモデリング:文章全体のテーマや主題を自動的に抽出
この段階で、検索エンジンは「入力された文の意味や構造」を把握します。
ステップ②:単語の裏にある「概念」を理解する
次に、単語そのものではなく、「その背後にある意味」= 概念(コンセプト) に注目します。たとえば、「風邪薬」と「総合感冒薬」は異なる表現ですが、意味は非常に近いと判断する必要があります。
この概念レベルの理解を支えるのが、以下の技術です:
| 技術 | 役割 |
|---|---|
| オントロジー | 専門分野における概念とその関係性を体系化(例:医療分野で「病気→症状→治療法」) |
| シソーラス | 同義語・関連語を整理した辞書(例:WordNet) |
| 知識グラフ | エンティティ(人物・場所など)とその関係性を表すグラフ型の知識構造 |
これにより、表面的な言葉の違いに惑わされず、本質的に意味が近い情報を検索できるようになります。
ステップ③:ユーザーの検索意図(インテント)を読み解く
いくら文を理解しても、それだけでは足りません。ユーザーが「なぜそのクエリを入力したのか」、つまり 検索意図(インテント) を把握することが、検索結果の最適化には欠かせません。
たとえば、「アップル 株価」と検索されたとき、「アップル=果物」ではなく「Apple社の株価」と理解しなければ、的外れな情報を返してしまいます。
検索エンジンは以下の技術で意図を読み取ります:
- クエリ分類:検索の種類(情報収集/取引/移動など)を判別
- セッション分析:直前・直後の検索履歴をもとに文脈を補完
- エンティティ認識:クエリ内の重要な要素(場所、人物、製品など)を抽出・解釈
こうした処理により、検索は単なる単語の列ではなく、「目的を持ったメッセージ」として解釈されます。
ステップ④:知識を持った検索へ ― ナレッジグラフの活用
意味を理解し、意図を把握したうえで、検索エンジンは実際の世界にある知識と照合します。その中心となるのがナレッジグラフです。
Googleが導入したナレッジグラフは、エンティティとその関係をグラフ構造で表現した巨大な知識ベースで、以下のようなことが可能になります:
- 答えを直接表示:「アインシュタイン 生年月日」と検索すると答えが即表示される
- 関連情報の提案:「スティーブ・ジョブズ」を検索すると、Apple製品や共同創業者が表示される
- 曖昧な単語の意味を判別:「ジャガー」が動物か車かを文脈で判断
- 構造化データの活用:Webページに埋め込まれた情報をもとに正確な検索結果を返す
ナレッジグラフによって、検索エンジンは「ページを探すツール」から「質問に答えるツール」へと進化しています。
ステップ⑤:ベクトル検索と埋め込みモデルによる意味マッチング
セマンティック検索の根幹にあるのが、「テキストを数値ベクトルに変換し、その類似度で検索する」仕組みです。以下のような埋め込みモデルが利用されます。
| モデル | 特徴 |
|---|---|
| Word2Vec / GloVe | 単語の意味関係を数値ベクトル化。「king - man + woman ≒ queen」など |
| BERT / RoBERTa | 文脈を考慮した文や段落単位の表現(Sentence-BERT など) |
| CLIP | テキストと画像を同じベクトル空間に埋め込み、マルチモーダル検索が可能 |
| OpenAI Embeddings API | 高精度なテキストベクトルを生成。text-embedding-3-large など |
これらを活用することで、単語が一致しなくても「意味が近い」文書や画像を的確に見つけることができます。このようにセマンティック検索は、段階的な技術を利用してユーザーに高い情報を提供しています。
実際に使ってみましょう
Google Colab上でTensorFlow Hubを使った簡単なセマンティック検索の実装方法をご紹介します。
✔ 使用技術
- TensorFlow Hub:事前学習済みの自然言語理解モデル(Universal Sentence Encoder)を利用
- Python + NumPy + Matplotlib + Seaborn:文書のベクトル化、コサイン類似度の計算、可視化に使用
- Google Colab:無料でGPU/TPUも使えるクラウド実行環境
✔ 処理の流れ
- 検索対象となる文書リストと検索クエリを用意
- 文とクエリをUniversal Sentence Encoderでベクトル化
- コサイン類似度に基づき、クエリと最も意味的に近い文をランキング
- 類似度スコアをバーグラフで可視化
✔ 実行例
クエリ:"What is natural language understanding?"
文書群に対して、意味的に最も近い文が自動的に上位表示され、検索意図に合致した文書を瞬時に特定できます。
以下、コピーすると実行できるサンプルコードを用意しました。
ご自身でもやってみてください。
前提条件:先に以下をインストールしてください、
# 必要なライブラリをインストール(tensorflow + hub)
!pip install -q tensorflow tensorflow-hub seaborn
実際のPythonコード
# インポート
import tensorflow_hub as hub
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# ドキュメントデータ(検索対象)
documents = [
"I love machine learning and natural language processing.",
"Artificial intelligence is transforming the world.",
"Deep learning is a part of machine learning.",
"Cats are beautiful and independent animals.",
"Dogs are loyal and friendly pets.",
"Natural language models understand human language.",
]
# クエリ(検索ワード)
query = "What is natural language understanding?"
# モデル読み込み(Universal Sentence Encoder)
model_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
embed = hub.load(model_url)
# ベクトル化
doc_embeddings = embed(documents)
query_embedding = embed([query])
# コサイン類似度計算
def cosine_similarity(a, b):
a_norm = a / np.linalg.norm(a, axis=1, keepdims=True)
b_norm = b / np.linalg.norm(b, axis=1, keepdims=True)
return np.inner(a_norm, b_norm)
# 類似度スコア取得
similarities = cosine_similarity(doc_embeddings, query_embedding).flatten()
# ソートして上位結果を表示
sorted_indices = np.argsort(similarities)[::-1]
sorted_docs = [documents[i] for i in sorted_indices]
sorted_scores = similarities[sorted_indices]
# 可視化
plt.figure(figsize=(10, 6))
sns.barplot(x=sorted_scores, y=sorted_docs, palette="viridis")
plt.xlabel("Similarity Score")
plt.title(f"Semantic Search Results for Query:\n\"{query}\"")
plt.tight_layout()
plt.show()
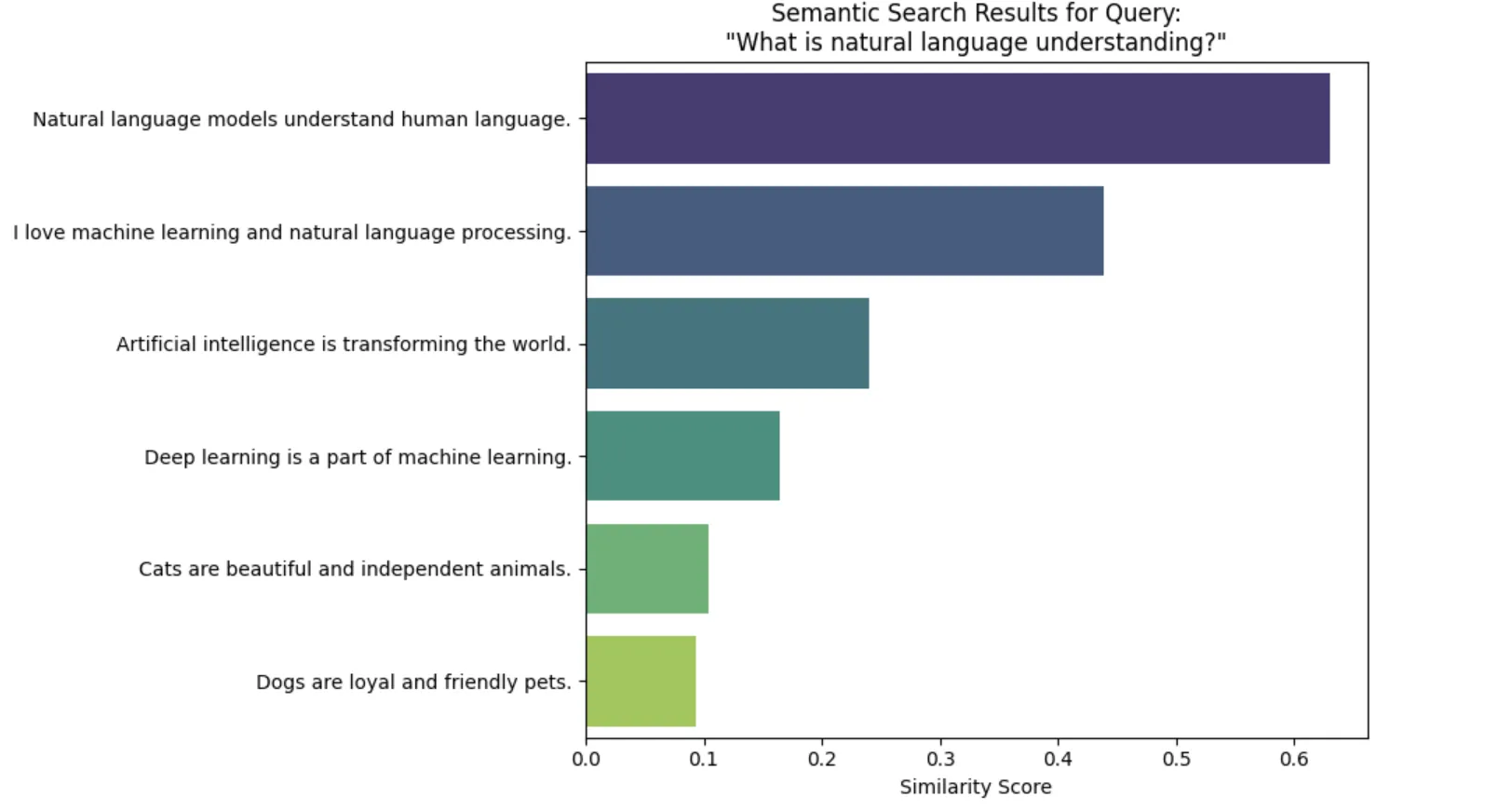
実行結果
コードを実行することで、上記の結果が出るようになっています。この画像は、「What is natural language understanding?」という検索クエリに対して、各文書がどれだけ意味的に近いかをスコアで可視化したものです。
最もスコアが高かったのは「Natural language models understand human language.」で、クエリの意図に最も合致した内容でした。上位にはNLPやAI関連の文が並び、意味の近さがしっかり反映されています。一方で、犬や猫に関する文のスコアは低く、関連性がないことがはっきりと分かります。セマンティック検索が、単なるキーワード一致ではなく「意味の理解」に基づいて検索結果を順位づけできることが、このグラフから直感的に読み取れます。
このように、Google ColabとTensorFlow Hubを活用すれば、セマンティック検索の仕組みを短時間かつ手軽に体験・検証できます。自社データへの応用や、業務における検索体験の改善にもつながる第一歩として、このシンプルなデモは非常に有効です。

実際の導入方法とツールの選定
セマンティック検索を実際に導入する際には、様々な方法があります。ここでは、主要な実装アプローチとツールについて以下のようなものがあります.
オープンソースツール
- Elasticsearch/OpenSearch:
もともと全文検索エンジンとして開発されましたが、近年はベクトル検索機能が追加され、セマンティック検索にも対応しています。Elasticsearchでは、ベクトル型フィールド (dense_vector など) を使用して埋め込みベクトルを格納し、 k近傍法 (kNN) による類似検索が可能です。Elastic社は「Elasticsearch Relevance Engine (ESRE)」として、ベクトル検索と、機械学習モデルを組み合わせたプラットフォームを提供しています。
- Haystack:
Deepset社が開発したオープンソースのPythonフレームワークで、質問応答システムやドキュメント検索を構築するためのコンポーネントを提供します。ElasticsearchやWeaviateなど様々なベクトルデータベースと接続でき、Transformersベースのリーダー (Reader) やリトリーバ (Retriever) を組み合わせて高度な検索パイプラインを構築できます。
参考: Haystack
-
LlamaIndex (旧GPT Index):
大規模言語モデル(LLM)と外部データソースを接続するためのフレームワークです。文書をベクトル埋め込みし、様々なベクトルストア(FaissやMongoDBのベクトル機能など)に保存して効率的に検索できます。特にLLMを活用した生成AI応用(RAG:Retrieval-Augmented Generation)に適しています。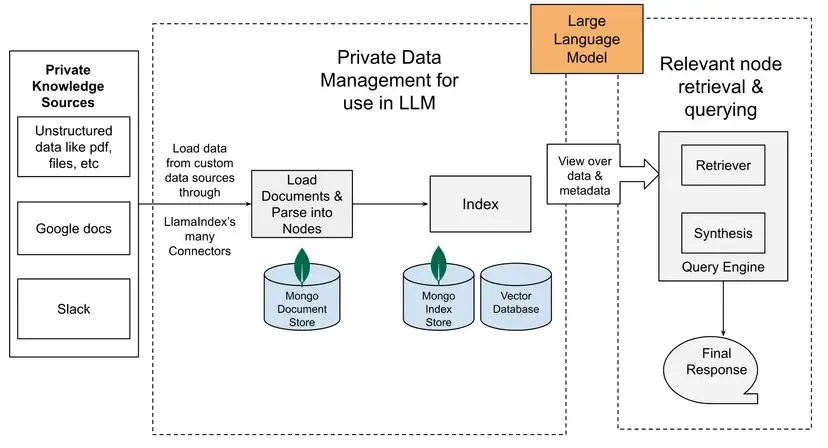
LlamaIndexとDBでプライベートデータのChatGPTの構築 参考: LlamaIndex -
PyTerrier:
情報検索研究のためのPythonフレームワークで、様々な検索モデルを実装・評価できます。BM25などの従来の検索モデルなどのニューラルモデルを組み合わせたハイブリッド検索も容易に構築可能です。
ハイブリッド検索という選択肢
2026年現在、実務で最も採用されているのは、キーワード検索(BM25)とベクトル検索を組み合わせた「ハイブリッド検索」です。キーワード検索は型番や固有名詞の完全一致に強く、ベクトル検索は言い換えや文脈理解に強いため、両者を組み合わせることで検索精度を最大化できます。Azure AI SearchではRRF(Reciprocal Rank Fusion)アルゴリズムで両方の結果をマージし、さらにセマンティックランカーで再ランク付けする3段階のパイプラインが利用できます。
特にRAG(Retrieval-Augmented Generation)構成では、ハイブリッド検索で取得した文書をLLMに渡して回答を生成するパターンが標準的なアーキテクチャとなっています。
クラウドサービス
-
Azure AI Search (旧Azure Cognitive Search):
Microsoftが提供するクラウド検索サービスです。「セマンティックランカー (Semantic Ranker)」機能が搭載されており、Transformerベースのモデルを使って検索結果を再ランク付けします。また、OpenAIのEmbeddingモデル(text-embedding-3-small / text-embedding-3-large)を使ったベクトル検索も統合されており、インデクサーパイプライン内でチャンキングからベクトル化までを自動実行する「統合ベクトル化(Integrated Vectorization)」機能も提供されています。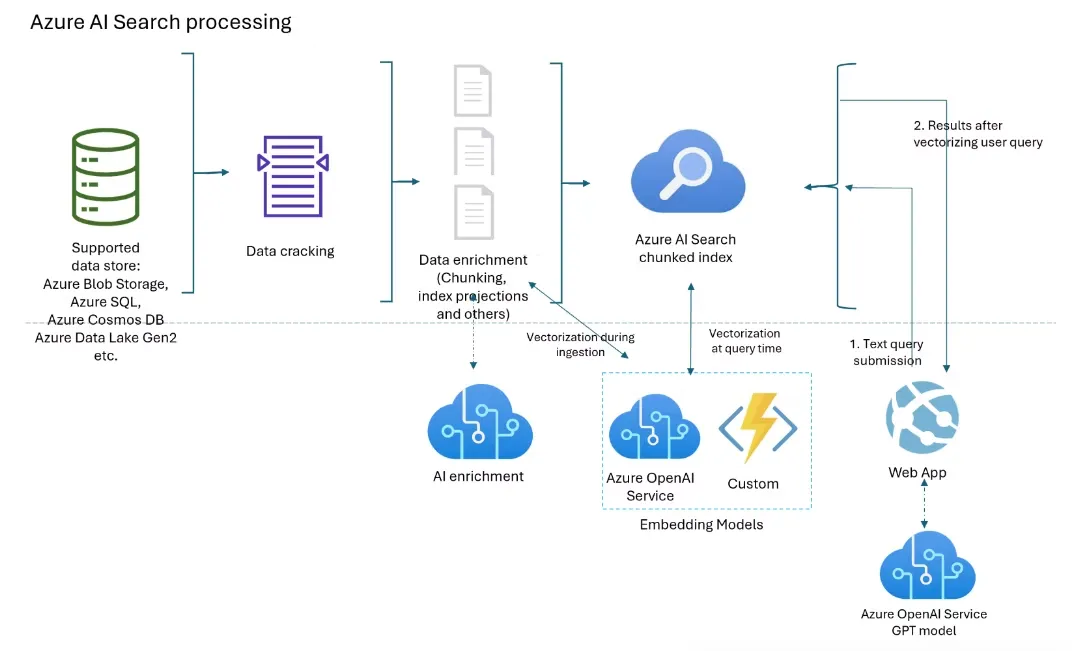
Azure AI Search 参考: Microsoft -
AWS Kendra:
Amazonのエンタープライズ検索サービスで、社内ドキュメント、FAQ、ウェブページなど様々なリポジトリからデータを統合し、自然言語クエリで検索できます。機械学習モデルによる質問の意図理解や、ドメイン適応した同義語展開などの機能を備えています。 -
Google Vertex AI Search:
Googleの検索技術とAIモデルをエンタープライズ向けに提供するサービスです。Googleの強力なベクトル類似検索エンジン (Matching Engine) を利用した高速なベクトル検索が可能で、生成AIと連携したRAG (検索+生成) 用途にも対応しています
【関連記事】
Azure AI Search(旧Azure Cognitive Search)の機能と料金を徹底解説!
セマンティック検索の導入メリットとビジネスインパクト
セマンティック検索は、検索技術の進化にとどまらず、ユーザー体験の向上やビジネス成果の最大化に大きく貢献します。ここでは、導入によって得られる具体的なメリットを、検索精度・UX・対応力・ビジネス指標の4つの視点で整理します。
1. 検索精度の飛躍的向上
セマンティック検索は、従来のキーワード一致では難しかった文脈や言い換えの理解を実現し、検索結果の質を高めます。
-
網羅性の向上(リコール)
同義語や関連語を含む情報も検索結果に含めることで、情報の取りこぼしを防ぎます。例:「心臓病」で検索しても、「心疾患」「冠動脈疾患」なども対象に。 -
精度の向上(適合率)
ユーザーの意図に基づいた絞り込みで、ノイズの少ない結果を提供。例:「アップル 株価」→ 果物のリンゴは除外。 -
曖昧性の解消
文脈に応じて「バス」が交通機関か楽器かを正しく解釈。
2. ユーザーエクスペリエンス(UX)の大幅な改善
セマンティック検索は、検索そのものの使いやすさと満足度を高めます。
-
自然な言葉での検索が可能に
例:「東京で一番高いビルは?」のような質問形式もスムーズに対応。 -
検索時間の短縮
関連性の高い結果が上位に表示され、モバイル環境でも効率よく情報にたどり着けます。 -
ストレスの軽減
「正しいキーワードがわからない」状態でも、意味理解によって的確な結果を表示。 -
直接的な回答提示
検索結果ページに答えを即時表示でき、Web遷移なしでも情報取得が完了。
3. 複雑・自然なクエリへの柔軟な対応
従来の検索が苦手だった「質問形式」「長文」「曖昧表現」も、セマンティック検索なら対応可能です。
-
質問応答機能
「富士山の高さは何メートル?」などに対し、検索エンジンが答えを返す。 -
複合条件の解釈
「東京から大阪への最速の移動手段」などの複雑な意図も正確に理解。 -
会話的検索の実現
一連の検索を文脈として扱い、「それはいつ建てられたの?」といった照応表現にも対応。
4. ビジネス成果の最大化
セマンティック検索は、検索体験の改善にとどまらず、業績や業務効率の向上にも直結します。
| 成果領域 | インパクトの内容 |
|---|---|
| コンバージョン率の向上 | 商品やサービスの発見精度が上がり、購入・申込に繋がる確率がアップ |
| 顧客満足度の向上 | 自分で必要な情報にすぐアクセスでき、体験全体の質が高まる |
| サポートコスト削減 | ユーザーが自己解決できる範囲が広がり、問い合わせ件数が減少 |
| コンテンツ価値の増幅 | 既存コンテンツがより的確に検索され、過去の投資資産を有効活用できる |
| 差別化・競争力強化 | 他社にない優れた検索体験を提供することで、サービス全体の魅力と信頼性が向上 |
セマンティック検索は、ユーザーが「知りたいこと」に素早く、的確にたどり着ける環境を整える技術です。その効果は検索精度や体験の向上にとどまらず、顧客満足・業務効率・収益性のすべてに波及します。
もはやこれは単なる検索エンジンの改善ではなく、戦略的な競争力強化の一手として注目すべき投資領域ですので、しっかりと効果的な検索精度を求めていきましょう。

検索の高度化から業務プロセス全体のAI化へ進むなら
セマンティック検索で「必要な情報に素早くたどり着ける」基盤ができたら、次は「見つけた情報をもとにAIが業務アクションまで実行する」段階です。検索→要約→報告→承認という一連のプロセスをAIが担えれば、情報の活用スピードが根本から変わります。
AI総合研究所のAI業務自動化ガイドでは、検索高度化を含む各業務領域のAI適用パターンと導入ステップを体系的にまとめています。セマンティック検索の投資対効果をさらに引き上げるための次の一手としてご活用ください。
検索高度化の知見を業務AI化に活かす

検索技術の先にある業務自動化
セマンティック検索で社内データの活用が進んだら、次はAIが検索結果をもとに業務アクションまで実行するフェーズです。導入パターンを整理した無料ガイドです。
セマンティック検索のまとめ
本記事では、セマンティック検索の基本概念からNLP・ベクトル検索・ナレッジグラフなどの技術的基盤、Azure AI SearchやElasticsearchを使った導入方法、そしてビジネスインパクトまでを網羅的に解説しました。2026年現在ではハイブリッド検索(キーワード+ベクトル)が実務の標準構成となり、RAGアーキテクチャとの組み合わせで社内ナレッジ検索やカスタマーサポートの高度化が急速に進んでいます。
しかし、実際の導入・運用では次のような課題に直面するケースが少なくありません。
- 「セマンティック検索を入れれば検索が良くなる」と期待して導入したが、埋め込みモデルの選定やチャンキング戦略が不適切で精度が上がらなかった
- ベクトル検索だけに頼った結果、型番や製品コードなどの完全一致クエリで逆に精度が落ちてしまった
- 検索基盤を刷新したが効果測定の指標を設定しておらず、投資対効果を説明できなかった
これらの課題を解決するには、段階的なアプローチが効果的です。まず既存の検索ログを分析し、「キーワード不一致で見つからない」ケースがどの程度あるかを定量化しましょう。次にAzure AI Searchの統合ベクトル化機能やElasticsearchのベクトル検索で小規模なPoCを実施し、検索精度(適合率・再現率)の改善幅を計測します。効果が確認できたら、ハイブリッド検索+セマンティックランカーの本番構成に移行し、コンバージョン率や問い合わせ件数の変化をKPIとして継続的にモニタリングする体制を整えましょう。
導入判断で詰まる2つの論点
セマンティック検索が本当に必要か、キーワード検索で十分か
判断の軸は「検索クエリの表現がどれだけ多様か」です。ECサイトのように「同じ商品を異なる言葉で探す」ケースが多いサービスや、社内FAQのように「質問の仕方が人によって大きく異なる」環境では、セマンティック検索の導入効果が高くなります。一方、型番検索や社員番号検索など、クエリが定型的なサービスではキーワード検索で十分です。迷ったら、検索ログの「ゼロヒット率」を確認してみてください。ゼロヒット率が10%を超えているならセマンティック検索の導入を強く推奨します。
ベクトル検索単体とハイブリッド検索のどちらを採用すべきか
結論から言えば、ほとんどのケースでハイブリッド検索を推奨します。ベクトル検索は意味理解に優れますが、固有名詞や専門用語の完全一致はキーワード検索(BM25)の方が確実です。Azure AI SearchのRRFによるハイブリッド検索は、追加のインフラコストなしで両方の長所を活かせるため、「まずハイブリッドで始めて、必要に応じてセマンティックランカーを追加」という段階的導入が最もリスクの低いアプローチです。










