この記事のポイント
 従来のRAGでは困難な複数文書横断の推論や大規模コーパスの俯瞰的要約を、ナレッジグラフの構造で実現するMicrosoft Research発のフレームワーク
従来のRAGでは困難な複数文書横断の推論や大規模コーパスの俯瞰的要約を、ナレッジグラフの構造で実現するMicrosoft Research発のフレームワーク- LinkedInカスタマーサポートで解決時間28.6%短縮、Data.world調査でLLM応答精度3倍向上など、実運用での定量効果
- LazyGraphRAGの登場でインデックスコストがフルGraphRAGの0.1%に低減し、PoC段階なら数百円〜数千円から検証可能
- LangChain+Neo4jやAzure Database for PostgreSQL経由の構築が主流、Python環境があれば最短数時間でプロトタイプ可
- 医療・法務・金融などエンティティ間の関係性が複雑な領域で最大の効果を発揮し、単純なFAQ検索にはオーバースペック

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
GraphRAG(Graph-based Retrieval-Augmented Generation)は、ナレッジグラフの構造を活用して、従来のRAGでは難しかった「複数文書をまたいだ推論」や「大規模コーパスの全体理解」を実現するフレームワークです。
2024年にMicrosoft Researchが提唱し、2026年3月時点ではv3.0.6まで進化しています。
本記事では、GraphRAGの基本的な仕組みから従来RAGとの違い、実装方法、Microsoft GraphRAGの最新動向(LazyGraphRAG・DRIFT Search・Microsoft Discovery統合)、企業の導入事例、そして構築・運用コストまでを体系的に解説します。
「RAGの精度に限界を感じている」「社内文書の横断検索を高度化したい」と考えている方に、判断材料となる情報をお届けします。
GraphRAGとは
GraphRAGとは、従来のRAG(Retrieval-Augmented Generation)をナレッジグラフで拡張し、エンティティ間の関連性や階層構造を活用して検索と生成の精度を向上させるフレームワークです。
2024年2月にMicrosoft Researchが提唱し、同年12月にGraphRAG 1.0として正式リリース、2026年3月時点ではv3.0.6まで開発が進んでいます。
2026年現在、GraphRAGはエンティティ間のつながりをグラフとして構造化することで、複数文書にまたがる複雑な質問にも文脈を踏まえた回答を返せるRAG拡張基盤として企業導入が進んでいます。
LinkedInカスタマーサポートで解決時間28.6%短縮、Data.world調査でLLM応答精度3倍向上といった実運用の定量効果も報告されています。
GraphRAGの3層構成
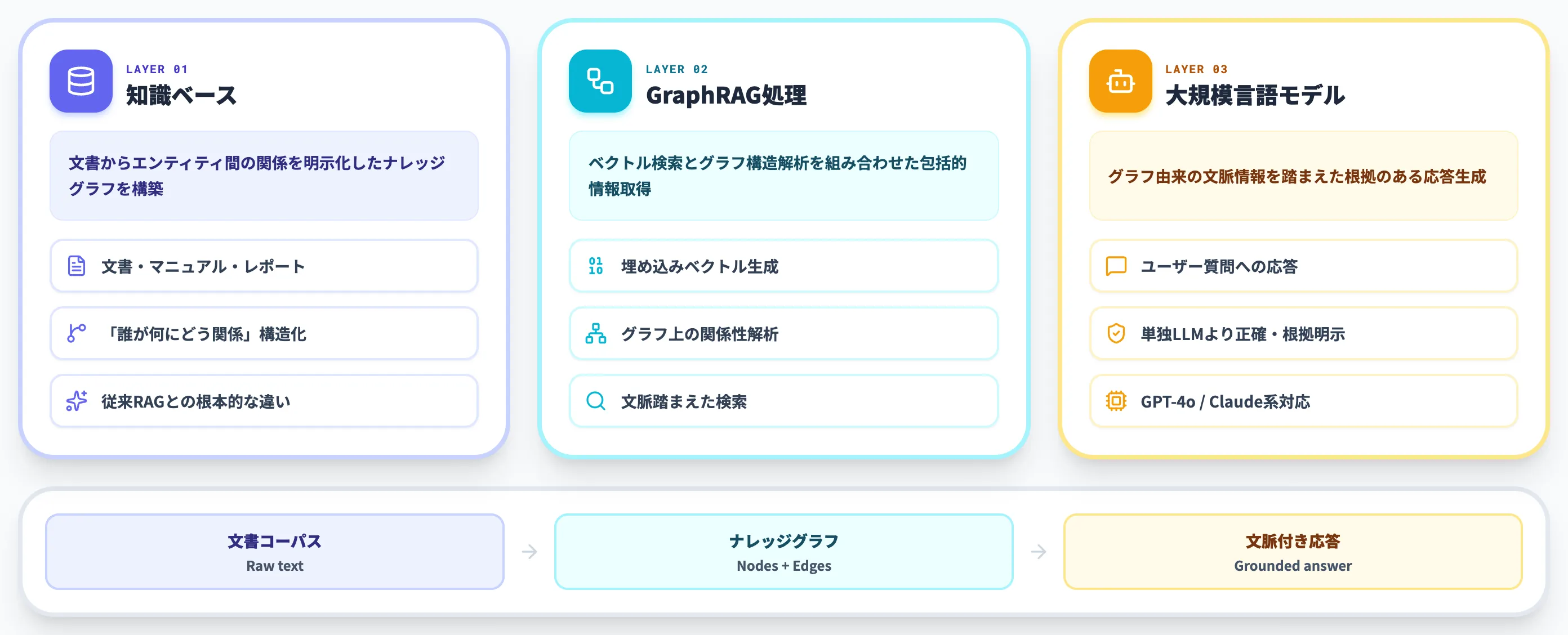
GraphRAGは、知識ベース・GraphRAG処理・LLMの3層で構成されます。
中核は「ナレッジグラフ」で、エンティティ間の関係を明示的に構造化することでベクトル検索単独では困難な推論を可能にします。
-
知識ベース(ナレッジグラフ)
文書データからエンティティ間の関係性を抽出し、「誰が・何を・どう関係しているか」をグラフとして構造化
-
GraphRAG処理
ベクトル検索とグラフ構造解析を組み合わせ、文脈を踏まえた包括的な情報を取得
-
大規模言語モデル(LLM)
グラフから得られた文脈情報を統合し、根拠のある回答を生成
ここでのポイントは、GraphRAGが**ベクトル検索単独では扱えない「複数文書横断の推論」「大規模コーパスの俯瞰的要約」**を実現する点にあります。
RAGとの詳細な違いは「GraphRAGとRAGの違い」セクションで整理します。

GraphRAGとRAGの違い
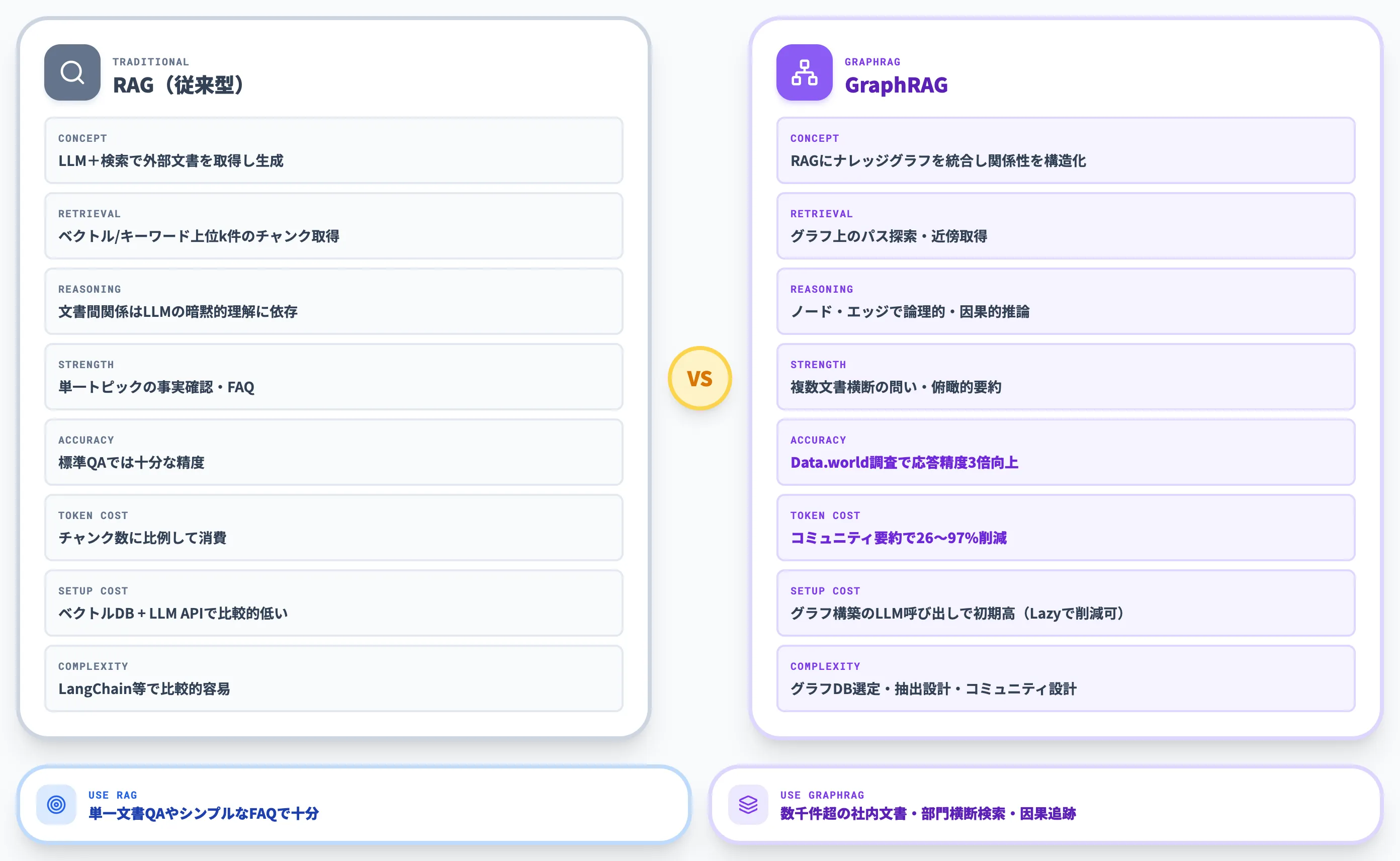
GraphRAGと従来のRAGは、情報の取得方法と推論の仕組みに根本的な違いがあります。以下の表で両者の特性を整理しました。
| 比較項目 | RAG(従来型) | GraphRAG |
|---|---|---|
| 基本コンセプト | LLM+検索モジュールで外部文書を取得し生成に活用 | RAGの枠組みにナレッジグラフを統合し、エンティティ間の関係性を構造化 |
| 情報の取得方法 | ベクトル検索やキーワード検索で上位k件のチャンクを取得 | グラフ構造上のパス探索や近傍ノード取得で関連情報を抽出 |
| 推論・関係性 | 文書間の関係はLLMの暗黙的な理解に依存 | ノードとエッジで関係性を明示的に管理し、論理的・因果的な推論に活用 |
| 得意な問い | 単一トピックの事実確認やFAQ | 複数文書をまたぐ横断的な問い、俯瞰的な要約 |
| 精度(ベンチマーク) | 標準的なQAタスクでは十分な精度 | Data.world調査でLLM応答精度が平均3倍向上 |
| トークン効率 | チャンク数に比例してトークンを消費 | コミュニティ要約の活用で26〜97%のトークン削減(Microsoft Research) |
| 導入コスト | 比較的低い。ベクトルDBとLLM APIがあれば構築可能 | グラフ構築にLLM呼び出しが必要で初期コストが高い(LazyGraphRAGで大幅削減可能) |
| 実装の複雑さ | LangChain等のフレームワークで比較的容易 | グラフDB選定、エンティティ抽出、コミュニティ構築の設計が必要 |
この比較から見えてくるのは、GraphRAGは「すべてのRAGを置き換えるもの」ではなく、従来RAGでは精度が出にくいユースケースを補完する上位互換の手法だという点です。
単純なFAQ検索や単一文書内のQAであれば、従来のベクトル検索RAGで十分な精度が得られます。一方、社内文書が数千件を超え、部門横断的な知識検索や複雑な因果関係の追跡が求められる場面では、GraphRAGが大きな優位性を発揮します。
GraphRAGのプロセス

GraphRAGの処理フローは、大きくIndexフェーズ(前処理としてのグラフ構築)とQueryフェーズ(実際の問い合わせ)に分かれます。さらに、Prompt Tuning(プロンプト最適化)とLazyGraphRAG(コスト最適化)を組み合わせることで、品質とコストのバランスを調整できます。
Indexフェーズ(ナレッジグラフの構築と要約)
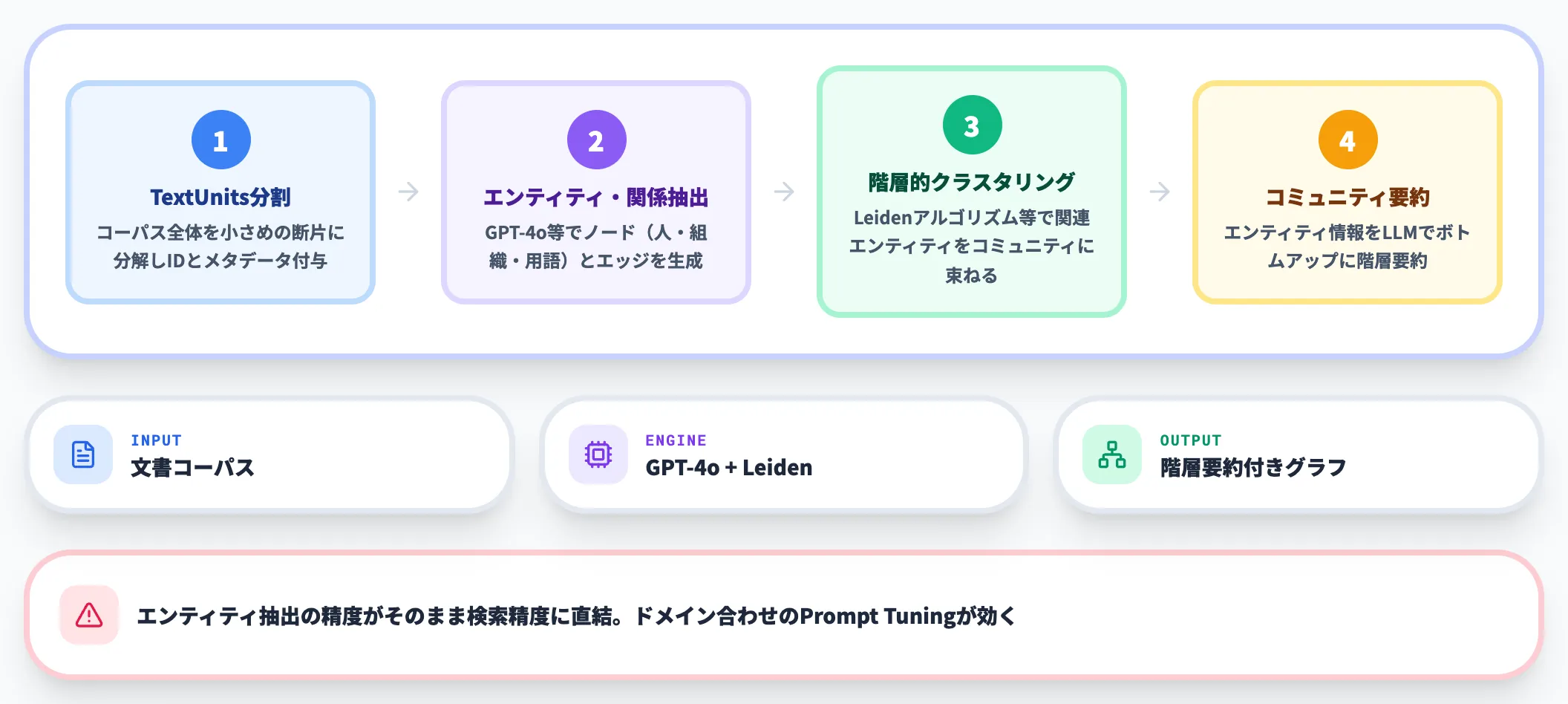
Indexフェーズでは、文書コーパスからナレッジグラフを自動構築します。
-
TextUnitsへの分割
コーパス全体を小さめのテキスト断片(TextUnits)に分解し、IDやメタデータを付与します。
-
エンティティ・関係の抽出
LLM(GPT-4o等)を使い、テキストからエンティティ(ノード)とエンティティ間の関係(エッジ)を抽出し、ナレッジグラフを生成します。
-
階層的クラスタリング(コミュニティ分析)
Leidenアルゴリズム等を用いて、関連するエンティティをコミュニティとして束ねます。ノードの重要度に応じて可視化すると、どの領域にどの程度のエンティティが集まっているかを一目で把握できます。
-
コミュニティ要約
各コミュニティに属するエンティティ情報を集約し、LLMでボトムアップに要約します。この結果として、コーパス全体を層状に理解するための「概要」や「サマリー構造」が生成されます。
このIndexフェーズが、GraphRAGの品質を決定づける最も重要な工程です。エンティティ抽出の精度がそのまま検索精度に直結するため、ドメインに合わせたプロンプト調整(後述のPrompt Tuning)が効果を発揮します。
Queryフェーズ(質問応答・情報取得)

Indexフェーズで構築したナレッジグラフに対して、以下の3つの検索方式で問い合わせを行います。
-
Global Search
コーパス全体にかかわる大きな問いを投げる際に、コミュニティ要約を活用して回答を導きます。例えば「この全資料の中で一番頻繁に登場する概念と、その背景は何か」といった俯瞰的な質問に適しています。
-
Local Search
特定のエンティティや狭い範囲の情報について問い合わせます。近接ノードや関連概念をたどって回答を作成するため、「○○という人物に関連する出来事をまとめて」のような局所的な質問に向いています。
-
DRIFT Search
Local Searchにコミュニティ要約を組み合わせた手法で、Microsoftが2024年10月に発表しました。Dynamic Reasoning and Inference with Flexible Traversal(動的推論と柔軟な探索)の略で、近傍探索とコミュニティ視点の両方を活用します。より深い文脈や広いコンテキストが必要なときに有効です。
実務では、質問の性質に応じてGlobal SearchとLocal Searchを使い分け、複雑な問いにはDRIFT Searchを適用するのが基本的な設計パターンです。
Prompt Tuning(プロンプト最適化)
GraphRAGの精度を最大限に引き出すには、LLMへのプロンプトの設計が重要です。
Microsoft ResearchはPrompt Tuningガイドを公開しており、ドメイン固有のエンティティ定義や関係性の抽出ルールをカスタマイズする具体的な手法を提案しています。特に医療・法務・金融など専門用語が多い領域では、プロンプトのチューニングによってエンティティ抽出の精度が大きく変わります。
LazyGraphRAG(コスト最適化手法)
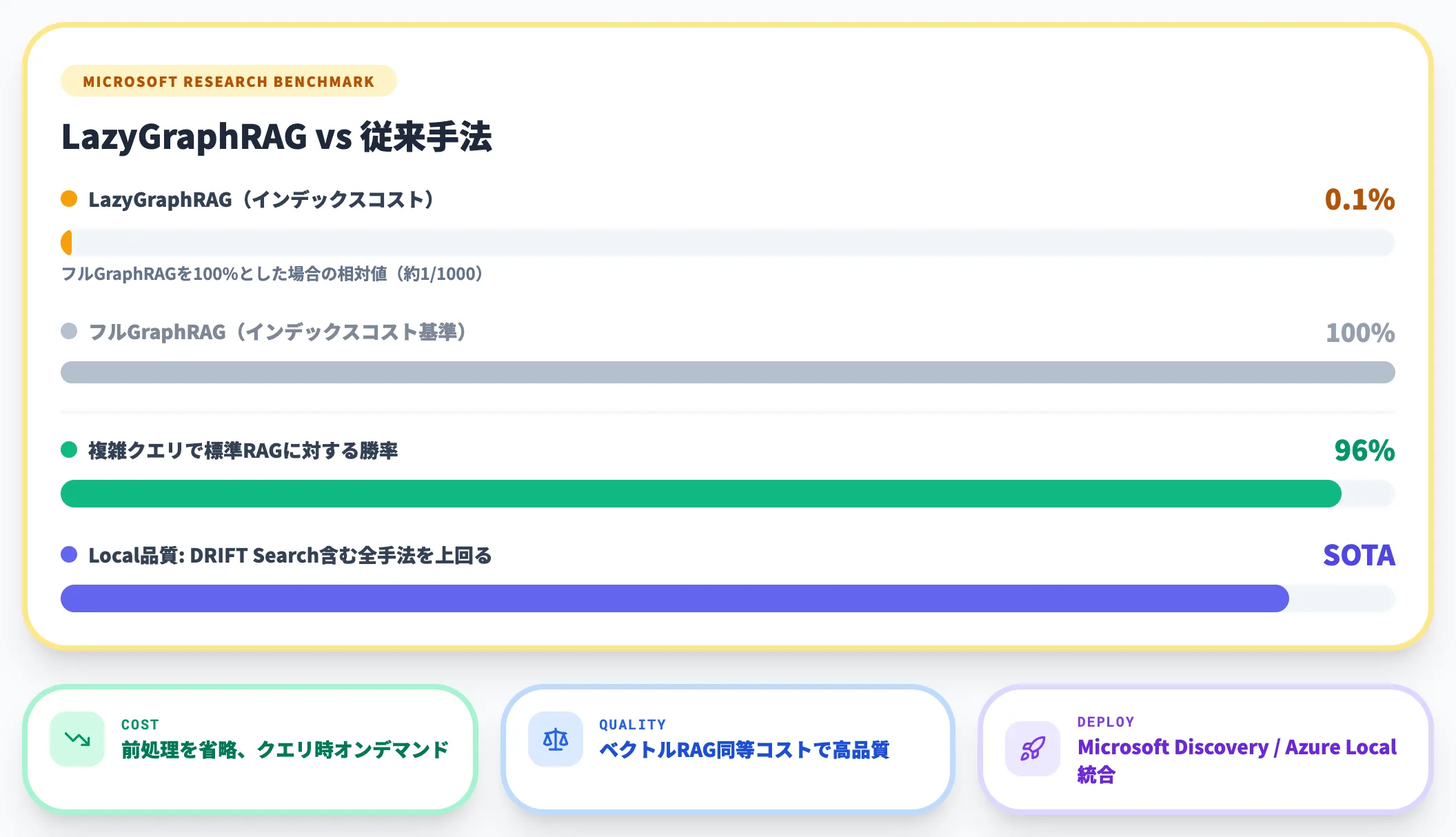
LazyGraphRAGは、Microsoftが発表したGraphRAGのコスト最適化バリアントです。
従来のGraphRAGでは、Indexフェーズで全文書に対してLLMによるエンティティ抽出とコミュニティ要約を実行するため、大規模データセットでは数万ドル規模のインデックスコストが発生するケースがありました。
LazyGraphRAGはこの前処理を省略し、クエリ時に必要な部分だけをオンデマンドで処理する設計を採用しています。
Microsoftの検証では、以下の結果が報告されています。
-
インデックスコストがフルGraphRAGの0.1%(約1/1000)に削減
-
ベクトルRAGと同等のクエリコストで、ローカルクエリの品質はGraphRAG DRIFT Searchを含む全手法を上回る
-
複雑なクエリクラスでは、標準RAGに対して96%の勝率を達成
2026年3月時点では、LazyGraphRAGはMicrosoft Discoveryプラットフォーム(Azure上の科学研究向けエージェント基盤)やAzure Localサービスにも統合されており、実プロダクトでの活用が始まっています。
GraphRAGの実装方法
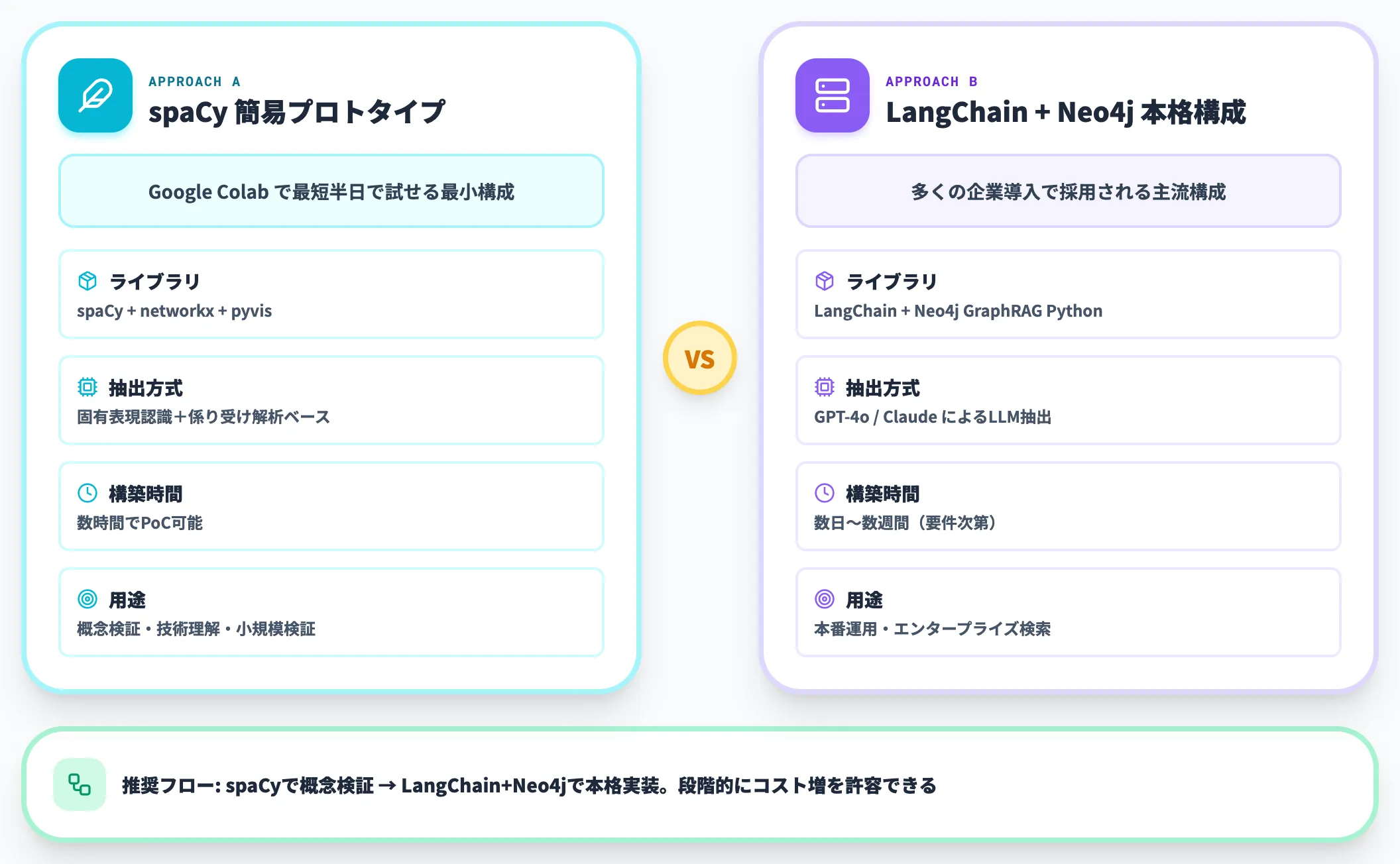
ここでは、GraphRAGの基本的な実装フローを2つのアプローチで紹介します。まずはspaCyを使った簡易的なプロトタイプ、次にLangChain+Neo4jを使った本格的な構成です。
spaCyによる簡易プロトタイプ
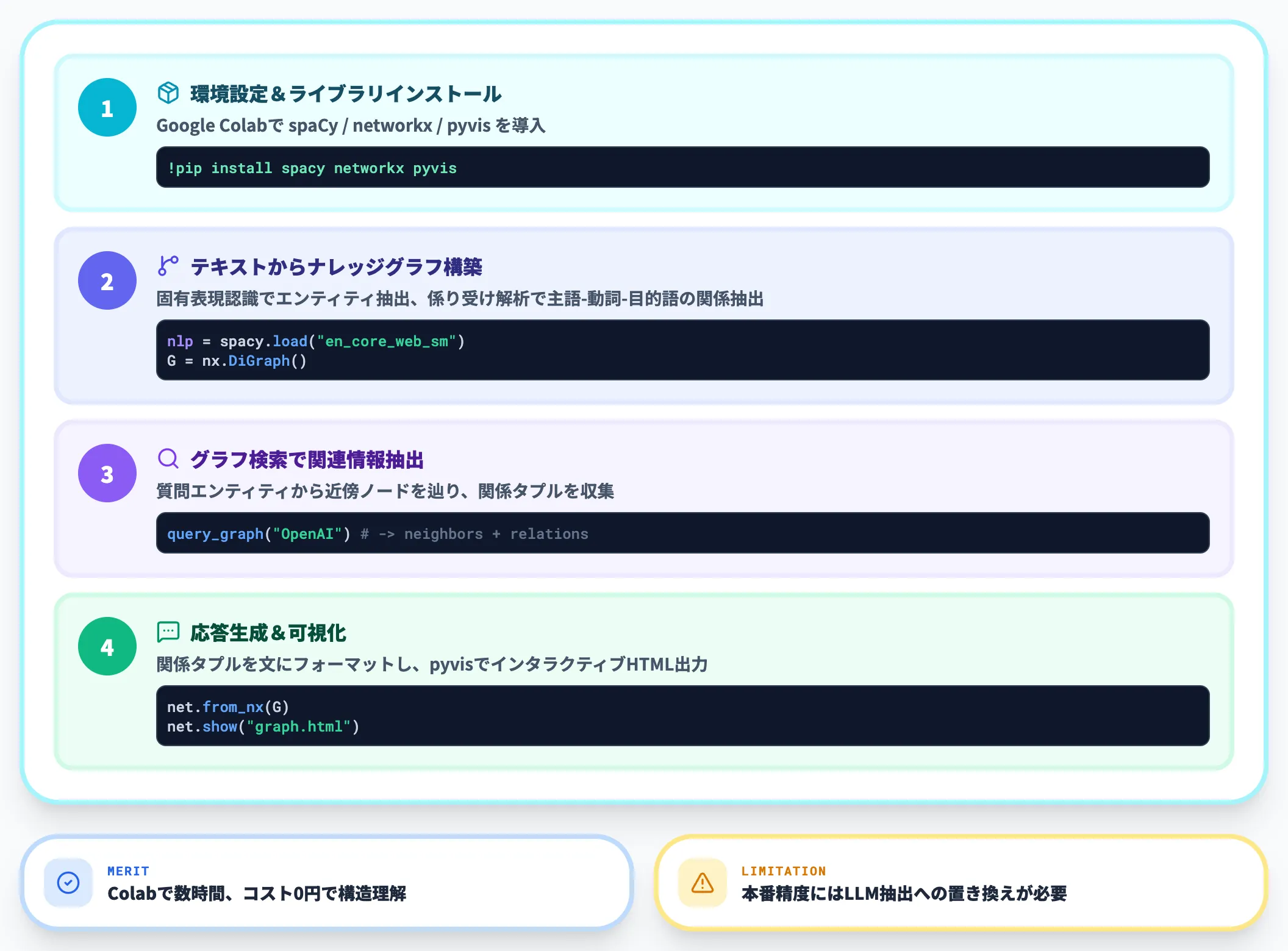
自然言語処理ライブラリのspaCyを使い、テキストからナレッジグラフを構築して検索・応答生成までを行う最小構成です。Google Colabで実行できます。
環境設定とライブラリのインストール
!pip install spacy networkx pyvis
spaCyは固有表現抽出、networkxはグラフ構築・検索、pyvisはグラフの可視化に使用します。
テキストからナレッジグラフを構築
テキストからエンティティを抽出し、関係性をルールベースで作成します。
import spacy
import networkx as nx
# spaCyモデルをロード
!python -m spacy download en_core_web_sm
nlp = spacy.load("en_core_web_sm")
# サンプルテキスト
text = """
Microsoft partnered with OpenAI to integrate GPT-4 into Azure.
Elon Musk was an early investor in OpenAI.
OpenAI is headquartered in San Francisco.
"""
# ナレッジグラフの構築
G = nx.DiGraph()
def process_text_to_graph(text):
doc = nlp(text)
for ent in doc.ents:
G.add_node(ent.text, type=ent.label_) # ノードにタイプを追加
# 簡易的な関係抽出(主語-動詞-目的語の関係)
for sent in doc.sents:
root = [token for token in sent if token.dep_ == "ROOT"]
if root:
root = root[0]
subj = [w for w in root.lefts if w.dep_ in ("nsubj", "nsubjpass")]
obj = [w for w in root.rights if w.dep_ in ("dobj", "attr", "pobj")]
if subj and obj:
G.add_edge(subj[0].text, obj[0].text, relation=root.lemma_)
process_text_to_graph(text)
print("ノード数:", G.number_of_nodes())
print("エッジ数:", G.number_of_edges())
このコードでは、spaCyの固有表現認識でエンティティ(ノード)を抽出し、係り受け解析で主語-動詞-目的語の関係(エッジ)を自動生成しています。実運用ではLLMによるエンティティ抽出に置き換えることで、より高精度なグラフを構築できます。
グラフを検索して関連情報を抽出
ユーザーの質問に基づいてグラフを検索します。
def query_graph(query_entity):
if query_entity not in G:
return f"'{query_entity}' はグラフに存在しません。"
related_info = []
for neighbor in G.neighbors(query_entity):
relation = G[query_entity][neighbor].get("relation", "related_to")
related_info.append((query_entity, relation, neighbor))
return related_info
# 質問例
query_entity = "OpenAI"
results = query_graph(query_entity)
print(f"'{query_entity}' に関連する情報:")
for res in results:
print(f"{res[0]} --[{res[1]}]--> {res[2]}")
実行すると、OpenAIに関連するエンティティとその関係性が出力されます。
簡易的な応答生成
検索結果を基に応答文を構築する例です。
def generate_response(entity, relations):
if not relations:
return f"Sorry, I couldn't find any information about '{entity}'."
response = f"Here's what I found about '{entity}':\n"
for rel in relations:
response += f"- {rel[0]} is {rel[1]} {rel[2]}.\n"
return response
response = generate_response(query_entity, results)
print(response)
この段階では自然言語としての出力品質は限定的ですが、LLM(GPT-4oやClaude等)と組み合わせることで、グラフから取得した関係情報をもとに自然な文章を生成できるようになります。
グラフの可視化
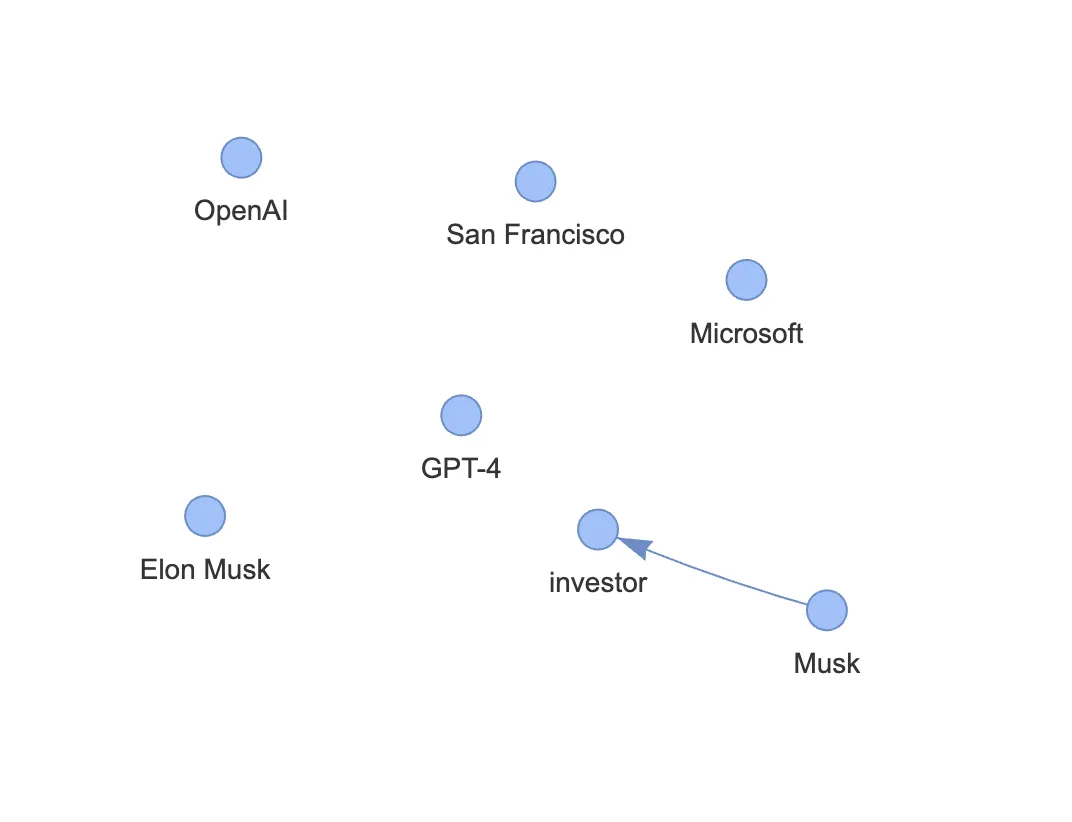
ダウンロードされるグラフ画像
pyvisを使って、構築したナレッジグラフをインタラクティブに表示できます。
from pyvis.network import Network
from IPython.core.display import display, HTML
def visualize_graph(G, file_name="graph_rag_example.html"):
net = Network(notebook=True, height="600px", width="100%", directed=True, cdn_resources="in_line")
net.from_nx(G)
for node in net.nodes:
node["title"] = f"Type: {G.nodes[node['id']].get('type', 'Unknown')}"
for edge in net.edges:
edge["title"] = edge.get("relation", "related_to")
net.show(file_name)
with open(file_name, "r") as file:
html_content = file.read()
display(HTML(html_content))
visualize_graph(G)
from google.colab import files
files.download("graph_rag_example.html")
このコードを実行するとHTMLファイルが生成され、ブラウザ上でグラフの構造をインタラクティブに確認できます。ノードをドラッグして配置を変えたり、ホバーでエンティティの詳細を確認したりする操作が可能です。
LangChain+Neo4jによる本格的な実装
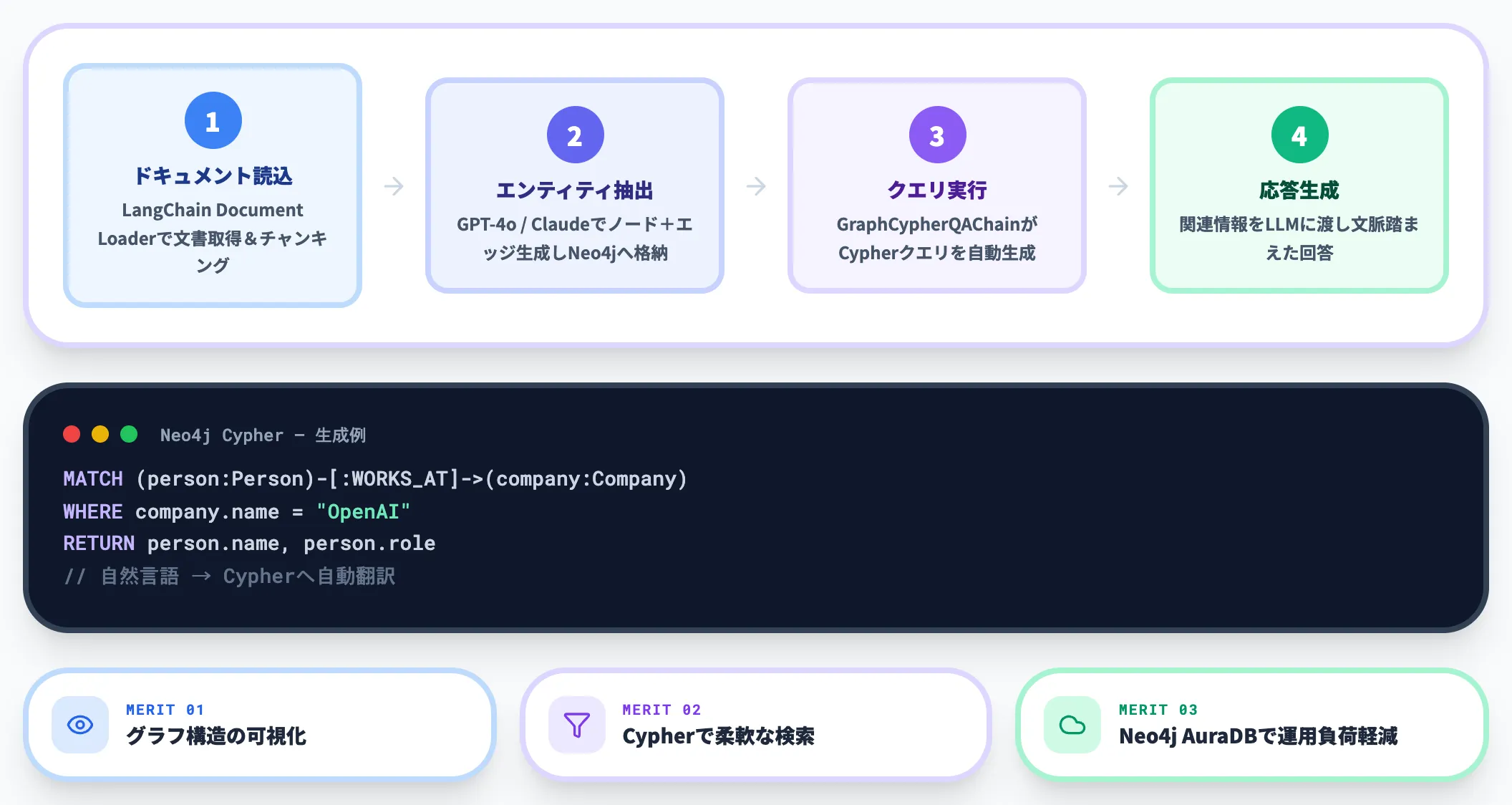
本格的なGraphRAGシステムを構築する場合は、LangChainとグラフデータベースの組み合わせが主流になっています。
2026年3月時点では、Neo4jのGraphRAG Pythonパッケージや、LangChainのGraphCypherQAChainを使った構成が多くの導入事例で採用されています。基本的な処理フローは以下のとおりです。
-
ドキュメントの読み込みとチャンキング
LangChainのDocument Loaderで文書を読み込み、テキストを適切なサイズに分割します。
-
エンティティ・関係の抽出
LLM(GPT-4oやClaude等)でエンティティと関係性を抽出し、Neo4jのグラフデータベースにノードとエッジとして格納します。
-
クエリの実行
ユーザーの自然言語による質問を、LangChainのGraphCypherQAChainがCypherクエリ(Neo4jのクエリ言語)に変換し、グラフ上を探索して関連情報を取得します。
-
応答の生成
取得した関連情報をLLMに渡し、文脈を踏まえた自然な応答を生成します。
この構成の利点は、Neo4jのグラフ可視化機能を使ってナレッジグラフの構造を視覚的に確認できる点と、Cypherクエリによる柔軟な検索が可能な点です。すでにNeo4j AuraDB(クラウド版)を使えば、グラフデータベースの運用負荷を抑えつつ本格的なGraphRAGを構築できます。
GraphRAGのナレッジグラフ基盤
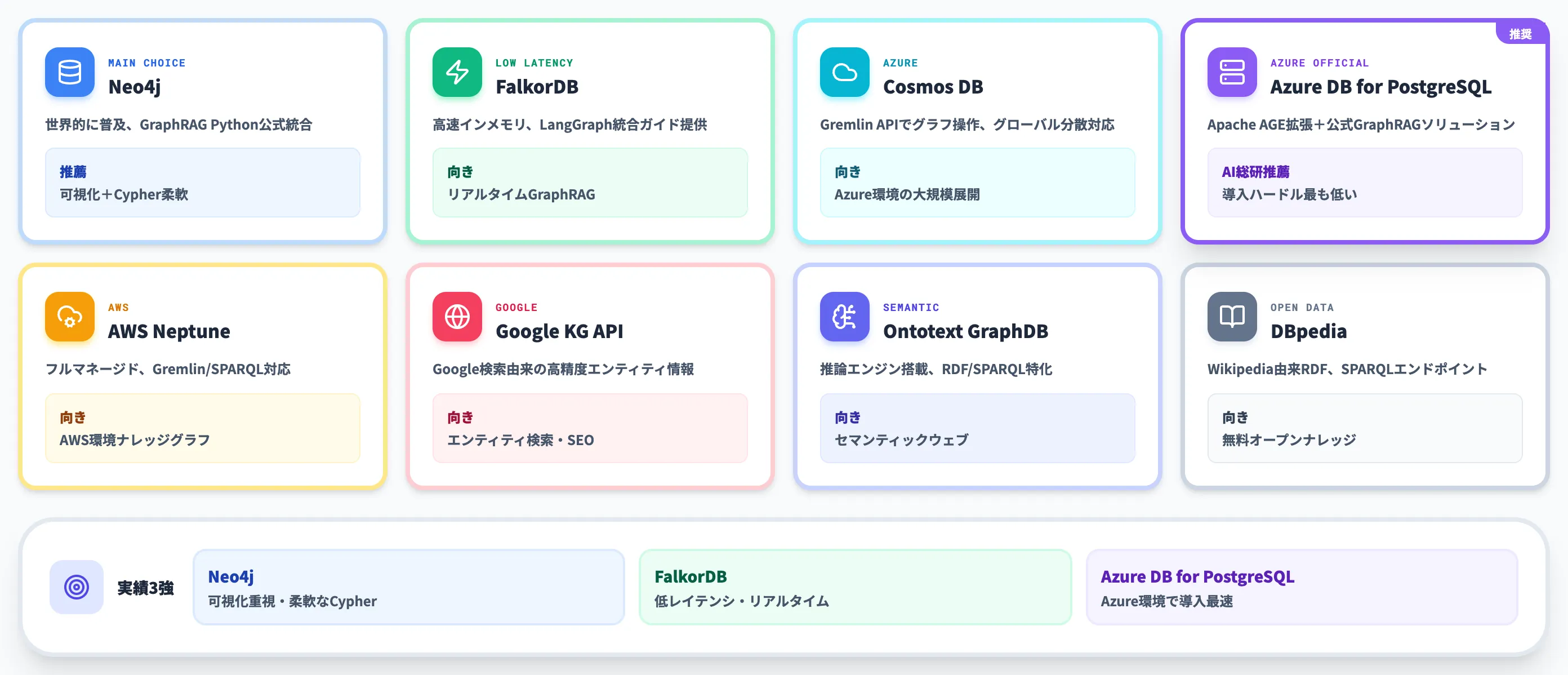
GraphRAGの構築には、ナレッジグラフを格納・検索するためのグラフデータベースが必要です。以下の表で、主要なサービスの特徴を整理しました。
| サービス名 | 概要 | 主な用途 | 特徴 |
|---|---|---|---|
| Neo4j | 世界的に普及しているグラフデータベース | ソーシャルネットワーク分析、推薦システム、GraphRAG | Cypherクエリ言語、AuraDB(クラウド版)あり、GraphRAG Python統合パッケージを提供 |
| FalkorDB | 高速なインメモリグラフデータベース | リアルタイムGraphRAG、低レイテンシ検索 | LangChain+LangGraphとの統合ガイドを提供、GraphRAGに最適化された設計 |
| Azure Cosmos DB | マルチモデル対応のグローバル分散型データベース | エンタープライズ向けGraphRAG、グローバル展開 | Gremlin APIによるグラフ操作、Azure環境とのシームレスな統合 |
| Azure Database for PostgreSQL | PostgreSQLベースのマネージドDB | Azure環境でのGraphRAGソリューション | Apache AGE拡張でグラフクエリ対応、Microsoftが公式にGraphRAGソリューションを提供 |
| AWS Neptune | AWSのフルマネージドグラフデータベース | AWS環境でのナレッジグラフ構築 | Gremlin/SPARQLサポート、高可用性とスケーラビリティ |
| Google Knowledge Graph API | Googleの検索データを基にエンティティ情報を取得 | エンティティ検索、SEO最適化 | 高精度なエンティティ情報、RESTful API |
| Ontotext GraphDB | セマンティックウェブ技術を活用したトリプルストア | SPARQLクエリ、知識ベース管理 | 推論エンジン搭載、RDFデータ処理に特化 |
| DBpedia | WikipediaのデータをRDF形式で提供するオープンデータ | オープンナレッジグラフ、セマンティックウェブ | 無料で利用可能、SPARQLエンドポイントを提供 |
GraphRAGの用途では、Neo4j・FalkorDB・Azure Database for PostgreSQLの3つが実績の多い選択肢です。
すでにAzure環境を利用している企業であれば、Azure Database for PostgreSQLのGraphRAGソリューションが最も導入しやすい構成です。
一方、グラフデータベースの柔軟性や可視化機能を重視する場合は、Neo4j AuraDBが有力な候補になります。FalkorDBはインメモリ設計による低レイテンシが強みで、リアルタイム性が求められるユースケースに向いています。

MicrosoftのGraphRAGサービス

GraphRAGは、Microsoft Researchが提唱したフレームワークであり、オープンソースとしてGitHub上で公開されています。2026年3月時点のエコシステムを整理します。
GraphRAGのバージョン推移

Microsoft GraphRAGは急速に進化しており、主要なマイルストーンは以下のとおりです。
| 時期 | バージョン / 機能 | 主な内容 |
|---|---|---|
| 2024年2月 | 研究論文公開 | GraphRAGの概念とアーキテクチャを発表 |
| 2024年7月 | GitHub公開 | オープンソースとしてリポジトリを公開 |
| 2024年10月 | DRIFT Search | Global SearchとLocal Searchを統合した新しい検索方式 |
| 2024年12月 | GraphRAG 1.0 | 正式版リリース。開発者向けのエルゴノミクスを改善 |
| 2025年6月 | LazyGraphRAG | インデックスコストを1/1000に削減する手法を発表 |
| 2026年1月 | v3.0.1 | 依存関係の整理、TableProvider抽象化の導入 |
| 2026年3月 | v3.0.6(最新) | phantom entity除去、NLPストリーミング対応 |
このバージョン推移が示すように、GraphRAGは「研究プロジェクト」から「実運用フレームワーク」へと着実に成熟しています。
v3系ではNetworkXへの依存を排除し、ストリーミング処理に対応するなど、大規模データセットでの運用を見据えた改善が続いています。
Microsoft Discoveryとの統合
GraphRAGとLazyGraphRAGの技術は、Microsoftの科学研究向けエージェントプラットフォーム「Microsoft Discovery」に統合されています。
Microsoft DiscoveryはAzure上に構築されたプラットフォームで、科学研究データの大規模な分析にGraphRAGの技術が活用されています。
Azure Database for PostgreSQLでのGraphRAGソリューション
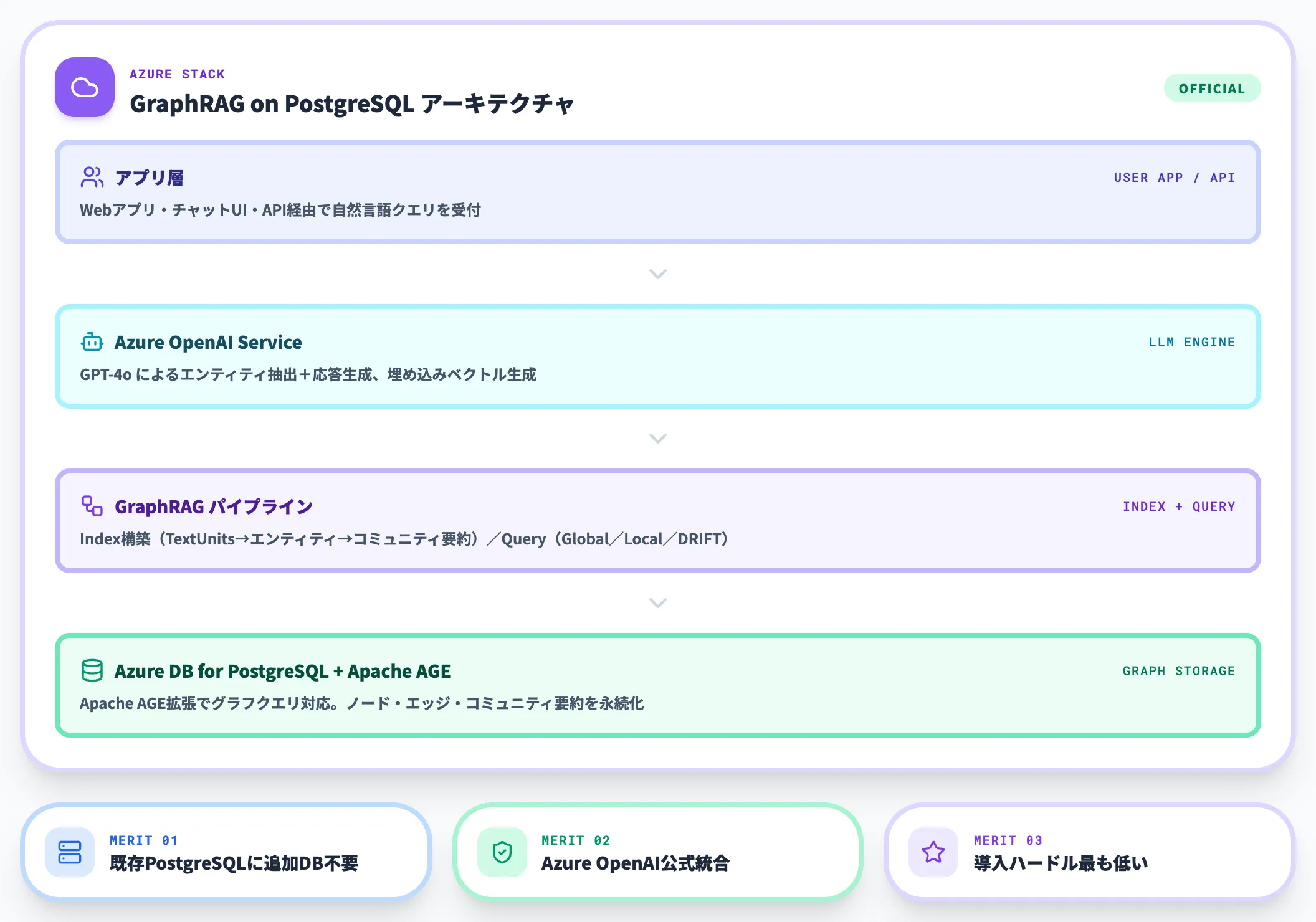
Microsoftは、Azure Database for PostgreSQL上でGraphRAGを構築するためのソリューションを公式に提供しています。Apache AGE拡張を使ってPostgreSQL上にグラフクエリ機能を追加し、Azure OpenAI Serviceと連携してGraphRAGパイプラインを構成する設計です。
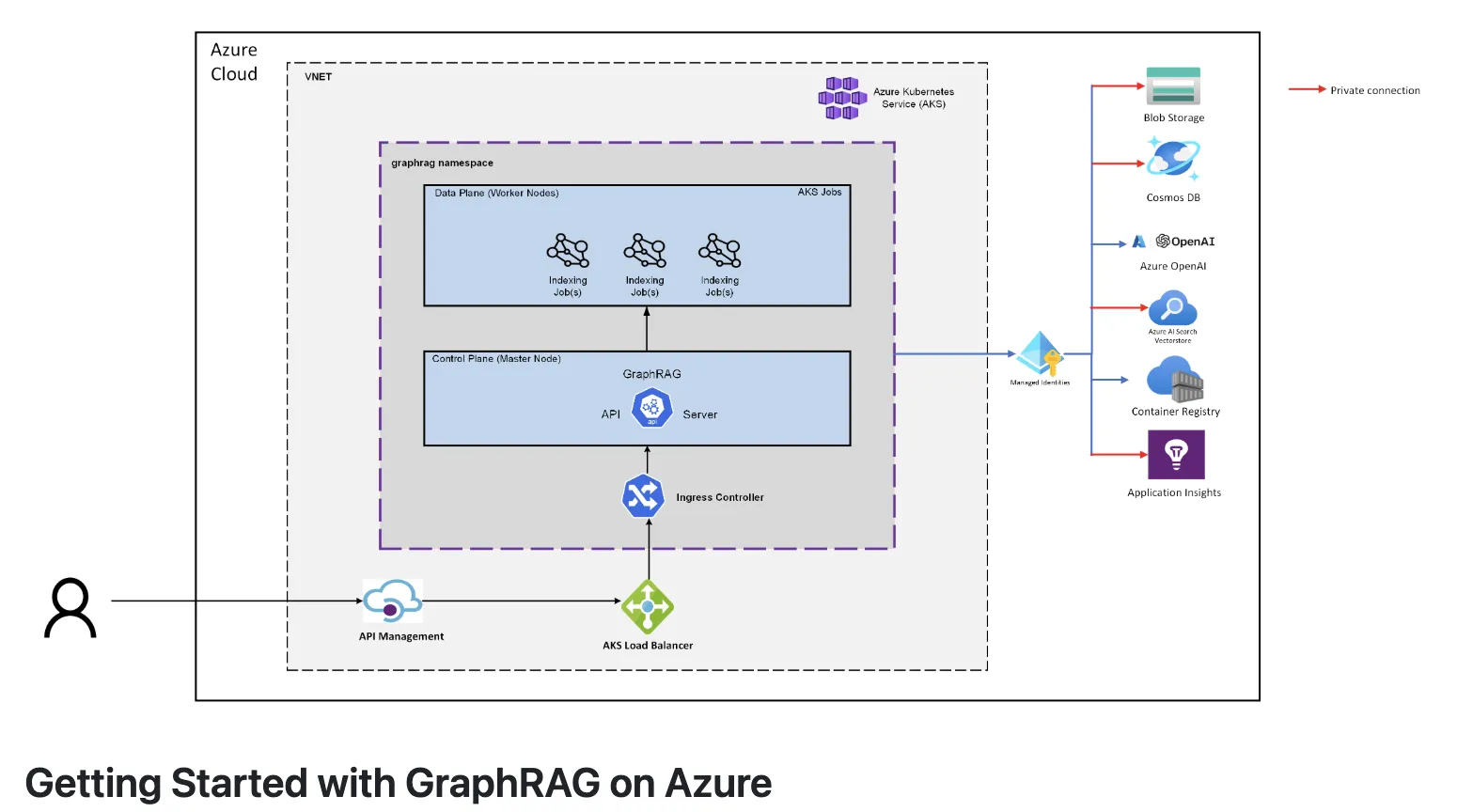
AzureでのGraphRAG構築イメージ
すでにAzure環境でPostgreSQLを運用している企業にとっては、追加のグラフデータベースを導入せずにGraphRAGを試せる点が大きなメリットです。AI総研でもAzure環境でのGraphRAG構築を支援しており、PostgreSQLベースの構成は初期導入のハードルが低いケースが多くなっています。
GraphRAGの活用事例

GraphRAGは、エンティティ間の関係性が複雑な領域で特に効果を発揮します。ここでは、出典のある具体的な導入事例と、業界別の活用パターンを紹介します。
LinkedInのカスタマーサポート
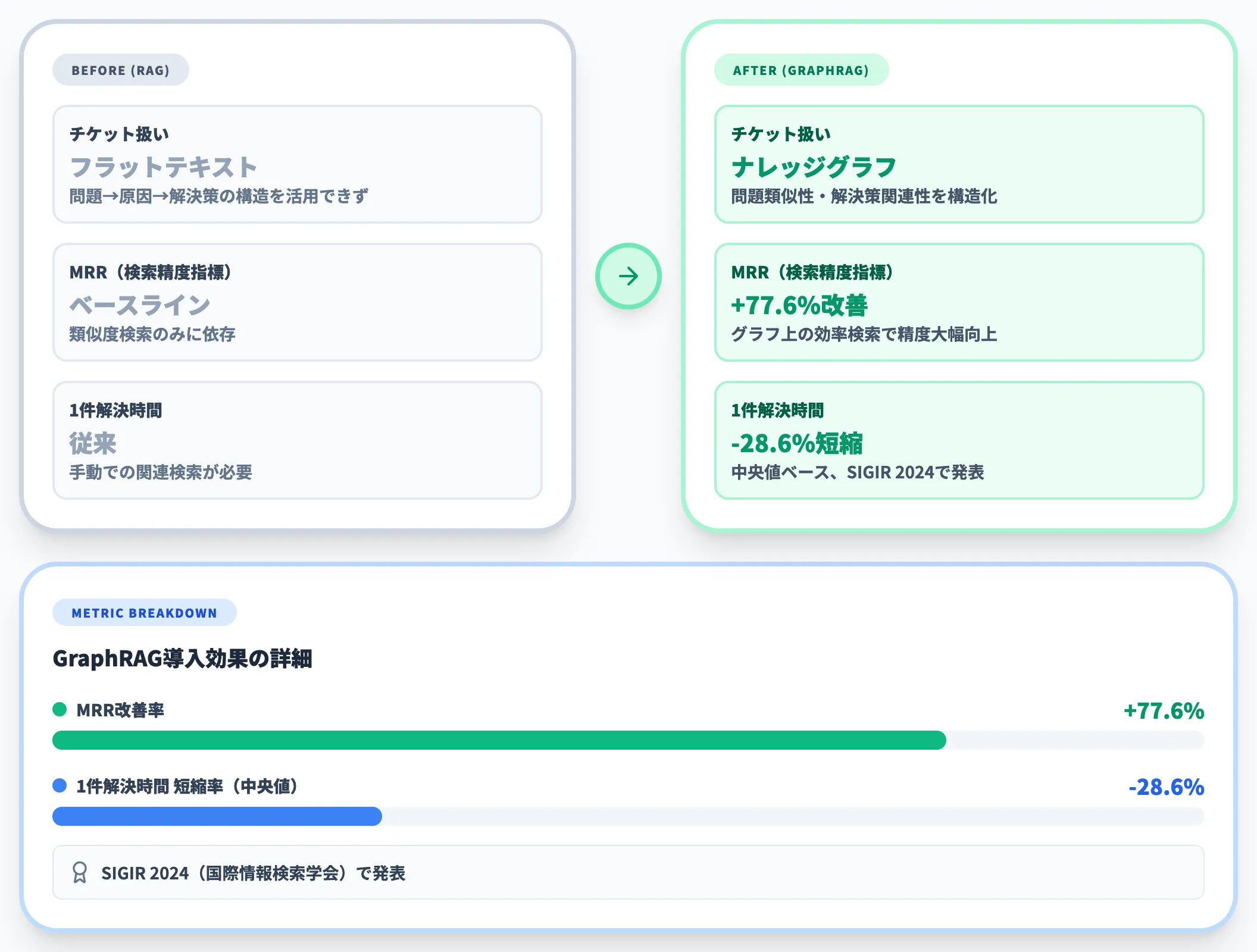
LinkedInでは、カスタマーサポートチームにGraphRAGを導入し、過去のサポートチケット間の構造的な関係性(問題の類似性、解決策の関連性)をナレッジグラフとして構築しました。
従来のRAGでは、チケットをフラットなテキストとして扱っていたため、チケット内部の構造(問題→原因→解決策の関係)やチケット間の関連性を活用できていませんでした。GraphRAGの導入後は、問題の種類ごとに関連する解決策をグラフ上で効率的に検索できるようになり、1件あたりの解決時間の中央値が28.6%短縮されました。
この成果はSIGIR 2024(国際情報検索学会)で発表されており、MRR(検索精度指標)で77.6%の改善も報告されています。
金融サービスでの活用
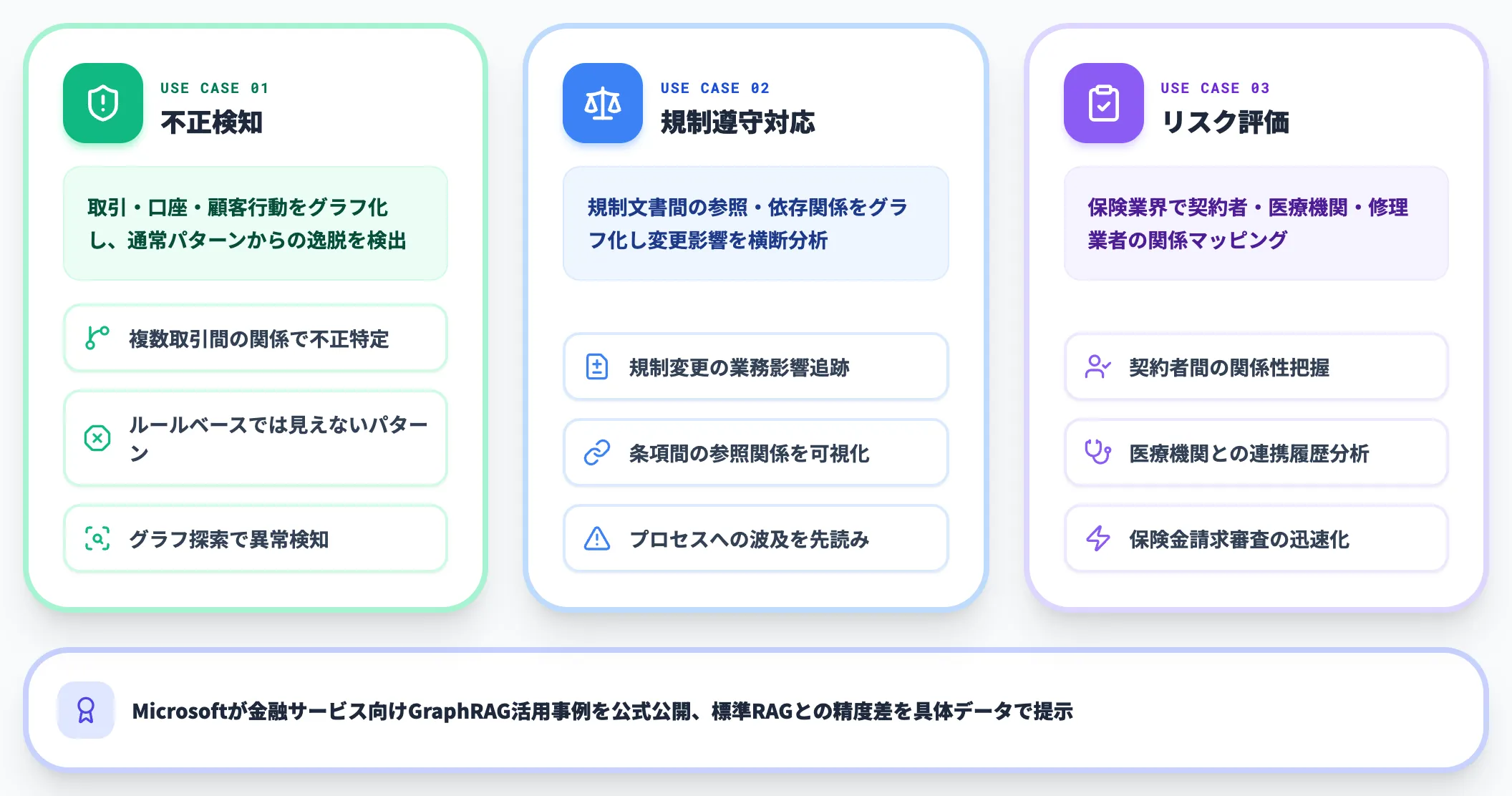
金融業界では、GraphRAGが以下のようなユースケースで活用されています。
-
不正検知
取引データ、口座情報、顧客行動をナレッジグラフとして構造化し、通常のパターンからの逸脱をグラフ探索で検出します。単一の取引だけでなく、複数の取引間の関係性から不正パターンを特定できる点が、従来のルールベース検知との違いです。
-
規制遵守対応
金融規制文書間の参照関係や依存関係をグラフ化し、規制変更が自社のどの業務プロセスに影響するかを横断的に分析します。
-
リスク評価
保険業界では、契約者・医療機関・修理業者などの関係をGraphRAGでマッピングし、保険金請求の審査を迅速化する取り組みが進んでいます。
Microsoftも金融サービス向けのGraphRAG活用事例を公開しており、標準RAGとの精度差を具体的なデータで示しています。
医療・ヘルスケア分野

医療分野では、電子カルテ(EHR)のデータをナレッジグラフとして構造化し、診断・治療・投薬の関係性を可視化する取り組みが進んでいます。
-
症例ベースの臨床支援
「類似した症状で過去に有効だった治療法は何か」といった問いに対して、患者データ間の関係性をグラフ探索で回答を生成します。
-
薬剤相互作用の検出
複数の薬剤間の相互作用をナレッジグラフで管理し、処方時のリスクチェックに活用します。
ヘルスケア領域では2027年までにGraphRAGが臨床決定支援の標準技術になるとの予測もあり、今後の成長が見込まれる分野です。
法務・コンプライアンス分野
建設業界の請求管理における研究では、請求書のナレッジグラフを構築し、GraphRAGベースの質問応答システムで請求内容の確認や関連条項の検索を効率化する事例が報告されています。
法務分野では、契約書や判例データの構造的な分析にGraphRAGが活用されています。契約書内の条項間の参照関係や、判例における事実認定と法的判断の関係をグラフ化することで、法的文書のレビュー効率を大幅に向上させることが可能です。
企業内ナレッジマネジメント

社内の膨大な文書(技術レポート、議事録、契約書など)を横断的に検索するニーズは多くの企業に共通しています。
従来の検索システムでは、キーワードが一致する文書を返すことはできても、「このプロジェクトに関与した人物と、その人物が過去に担当した類似案件」のような関係性を踏まえた検索は困難でした。GraphRAGは、人物・プロジェクト・技術用語・部門などの関係をグラフ化し、こうした横断的な問いに対応できます。
社内ナレッジが1,000件を超え、複数部門にまたがる検索ニーズがある場合は、GraphRAGの導入効果が特に高くなります。逆に、単一部門内のFAQ検索であれば、ベクトル検索ベースの標準RAGで十分な精度が得られるケースがほとんどです。
GraphRAGの導入コスト

GraphRAGの導入を検討する際に気になるのがコストです。ここでは、構築・運用にかかるコストの構造と、コスト削減の手法を整理します。
インデックス構築コスト
GraphRAGのインデックス構築では、全文書に対してLLMを呼び出してエンティティ抽出とコミュニティ要約を行うため、LLM APIの利用料金がかかります。
コストはデータ量と使用するLLMモデルによって大きく変わります。以下に、2026年3月時点の目安を示します。
| 構成 | 目安コスト | 備考 |
|---|---|---|
| PoC(小規模データ) | 数百円〜数千円 | GPT-4o-miniを使用、数十〜100文書程度 |
| 本番(中規模) | 数万円〜数十万円 | GPT-4oを使用、数千文書規模 |
| フルGraphRAG(大規模) | 数十万円〜 | 数万文書以上、コミュニティ要約を含むフル処理 |
| LazyGraphRAG | フルGraphRAGの0.1% | インデックス時のLLM呼び出しを省略 |
特筆すべきは、LazyGraphRAGによるコスト削減の大きさです。従来のフルGraphRAGでは大規模データセットに対して数万ドル規模のインデックスコストが発生するケースがありましたが、LazyGraphRAGではこれを1/1000に圧縮できます。
クエリ実行コスト
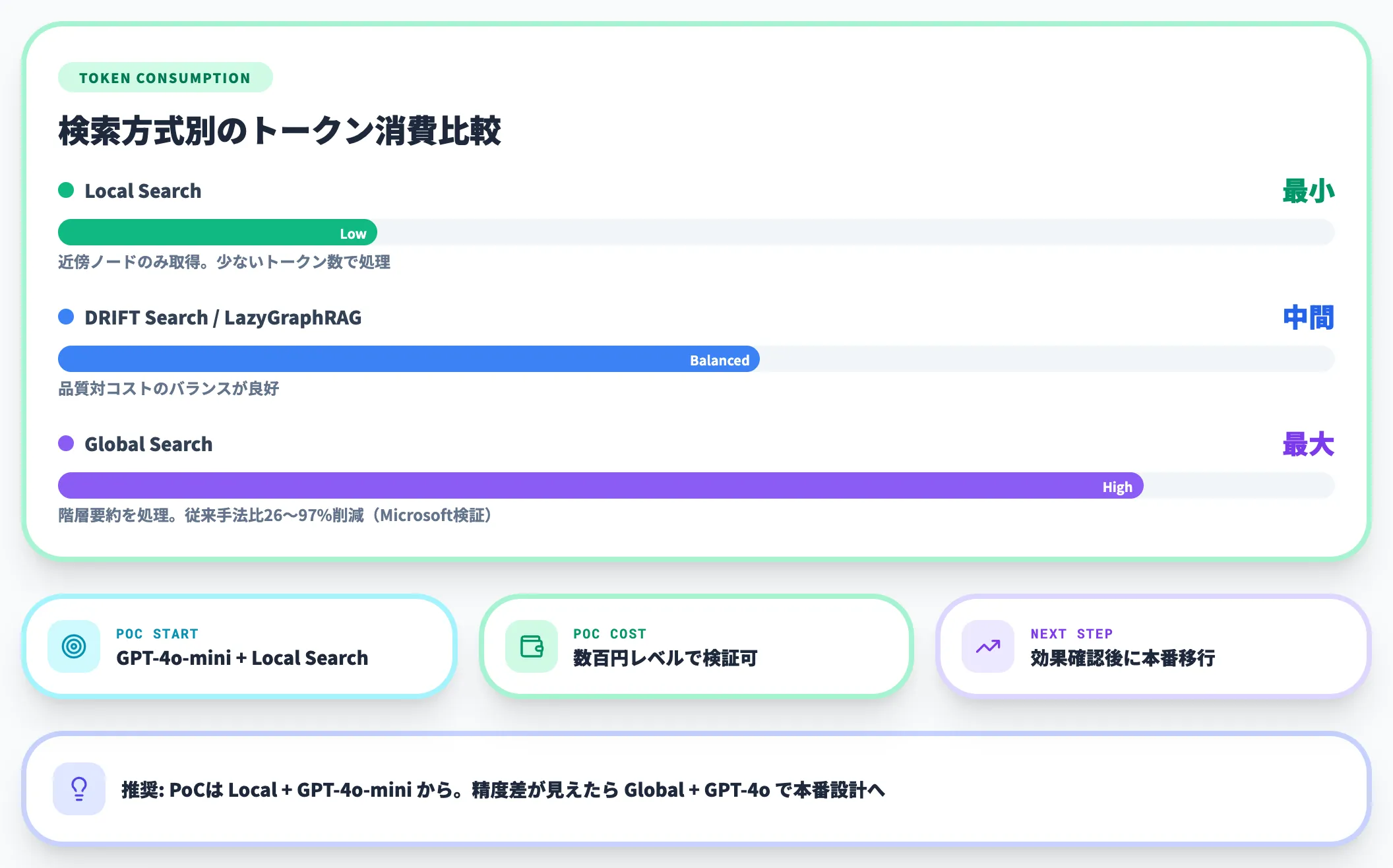
クエリ時のコストは、検索方式によって異なります。
-
Local Search
関連するノードの近傍情報を取得してLLMに渡すため、比較的少ないトークン数で処理できます。
-
Global Search
コミュニティ要約を階層的に処理するため、Local Searchよりトークン消費が多くなります。ただし、Microsoftの検証では従来手法と比べて26〜97%のトークン削減が報告されています。
-
DRIFT Search / LazyGraphRAG
Global SearchとLocal Searchの中間的なコストで、品質対コストのバランスが良好です。
PoC段階では、GPT-4o-miniを使ったLocal Searchから始めることで、数百円レベルのコストでGraphRAGの効果を検証できます。まずは小規模なデータセットで「従来RAGと比べて精度が上がるか」を確認し、効果が確認できた段階で本番環境への移行とコスト試算を行うのが現実的な進め方です。

GraphRAGの知見を組織全体のAI業務設計に広げる
GraphRAGのようなナレッジグラフ活用技術は、組織内の情報を横断的に活用するAIの可能性を広げます。技術の仕組みを理解した上で、次は組織としてAIをどの業務にどう組み込むかという全体設計に踏み出すことが重要です。
AI総合研究所では、Microsoft環境でAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。Copilot活用から本格的なAIエージェント運用まで、段階ごとの設計指針を解説しています。
AI総合研究所の実践ガイドで、先端技術への理解を組織のAI導入戦略に落とし込むヒントをご確認ください。
検索拡張技術の知見を組織のAI業務設計に展開する

GraphRAGから始める全社AI活用の道筋
GraphRAGのような先端的なAI検索技術を理解した次のステップとして、組織全体のAI業務自動化を段階設計する実践ガイド(220ページ)を無料で提供しています。
まとめ
GraphRAGは、従来のRAGをナレッジグラフで拡張し、エンティティ間の関係性を明示的に管理することで、複雑な情報の横断検索と俯瞰的な要約を実現するフレームワークです。
本記事で解説した内容を踏まえると、GraphRAGが提供する価値は次の3点に集約されます。
-
精度の向上
Data.world調査でLLM応答精度3倍向上、LinkedInでサポート解決時間28.6%短縮など、定量的な効果が実証されています。特に、複数文書にまたがる複雑な問いや、コーパス全体を俯瞰した要約が必要な場面で従来RAGとの差が大きくなります。
-
コストの現実化
LazyGraphRAGの登場により、インデックスコストがフルGraphRAGの0.1%に削減されました。PoC段階であれば数百円から検証を始められるため、「コストが高すぎて試せない」という障壁は大幅に下がっています。
-
エコシステムの成熟
Microsoft GraphRAGのv3.0.6への進化、LangChain+Neo4jの統合、Azure Database for PostgreSQLでの公式ソリューション提供など、実運用に必要なインフラが整ってきています。GraphRAG-BenchがICLR 2026に採択されたことで、品質評価の標準化も進んでいます。
まずは小規模なデータセット(社内文書100件程度)でGraphRAGのPoCを試してみてください。GPT-4o-miniとspaCy、またはMicrosoft GraphRAGのPythonパッケージを使えば、半日程度で基本的な動作を確認できます。そこで従来RAGとの精度差を実感できれば、本番導入の判断材料が得られます。










