この記事のポイント
 NGワードは公開された単語リストではなく、利用ポリシーとModel Specに基づく文脈・意図ベースの判定。「特定の単語」を避ける発想自体が誤解
NGワードは公開された単語リストではなく、利用ポリシーとModel Specに基づく文脈・意図ベースの判定。「特定の単語」を避ける発想自体が誤解- 制限はProhibited(絶対禁止)・Restricted(原則不可)・Sensitive(文脈で可)の3層、目的と文脈次第で回答可否が変わる
- 回避の本質は言い換えではなく目的と前提の明示。難読化や別言語での突破は直接要求と同じ扱いでBANリスク
- 警告は即停止ではなく是正の機会。違反を続けると追加の制限やアカウント無効化につながり得るが、誤検知には異議申し立ても可能
- 企業利用は社内ガイドライン・出力の人間レビュー・Business/Enterpriseのデータ保護が前提。個人プランの業務常用はリスク

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTのNGワード(禁止ワード)とは、入力すると回答を拒否されたり警告が表示されたりする言葉の総称ですが、その実態はOpenAIが公開する「禁止単語リスト」ではありません。
ChatGPTの制限は、利用ポリシーとModel Specというルールに照らして、入力の文脈と意図を判断した結果として働きます。
本記事では、NGワードと呼ばれる仕組みの正体、制限の対象になる主なカテゴリ、警告やアカウント停止が起きる流れ、そして言い換えによる回避方法までを2026年5月時点の最新情報で整理します。
あわせて、企業がポリシー違反リスクを抑えながらChatGPTを業務活用するための、社内ガイドラインやプラン選定の考え方も解説します。
目次
ChatGPTのNGワードとは
ChatGPTのNGワードとは、入力すると回答を拒否されたり警告が表示されたりする言葉や表現の総称です。
ただし実態を正確に言えば、OpenAIが「この単語は禁止」と公開しているリストは存在しません。
ChatGPTの制限は、特定の単語そのものに反応しているのではなく、利用ポリシーと「Model Spec」と呼ばれるモデルの行動ルールに照らして、入力の文脈と意図を判断した結果として働きます。
つまり同じ言葉でも、目的次第で回答が返ってくることもあれば、拒否されることもあります。この「単語ではなく文脈で決まる」という前提を外すと、NGワードの話は一気にわかりにくくなります。
本セクションでは、まず「NGワード」という言葉が指している実態と、混同されやすい3つの現象の切り分けを整理します。


「禁止ワード一覧」は公開されていない
ネット上には「ChatGPTのNGワード一覧」という記事が数多くありますが、その多くは利用者が観測した拒否例をカテゴリごとに整理したもので、OpenAIが公式に配布している単語リストではありません。
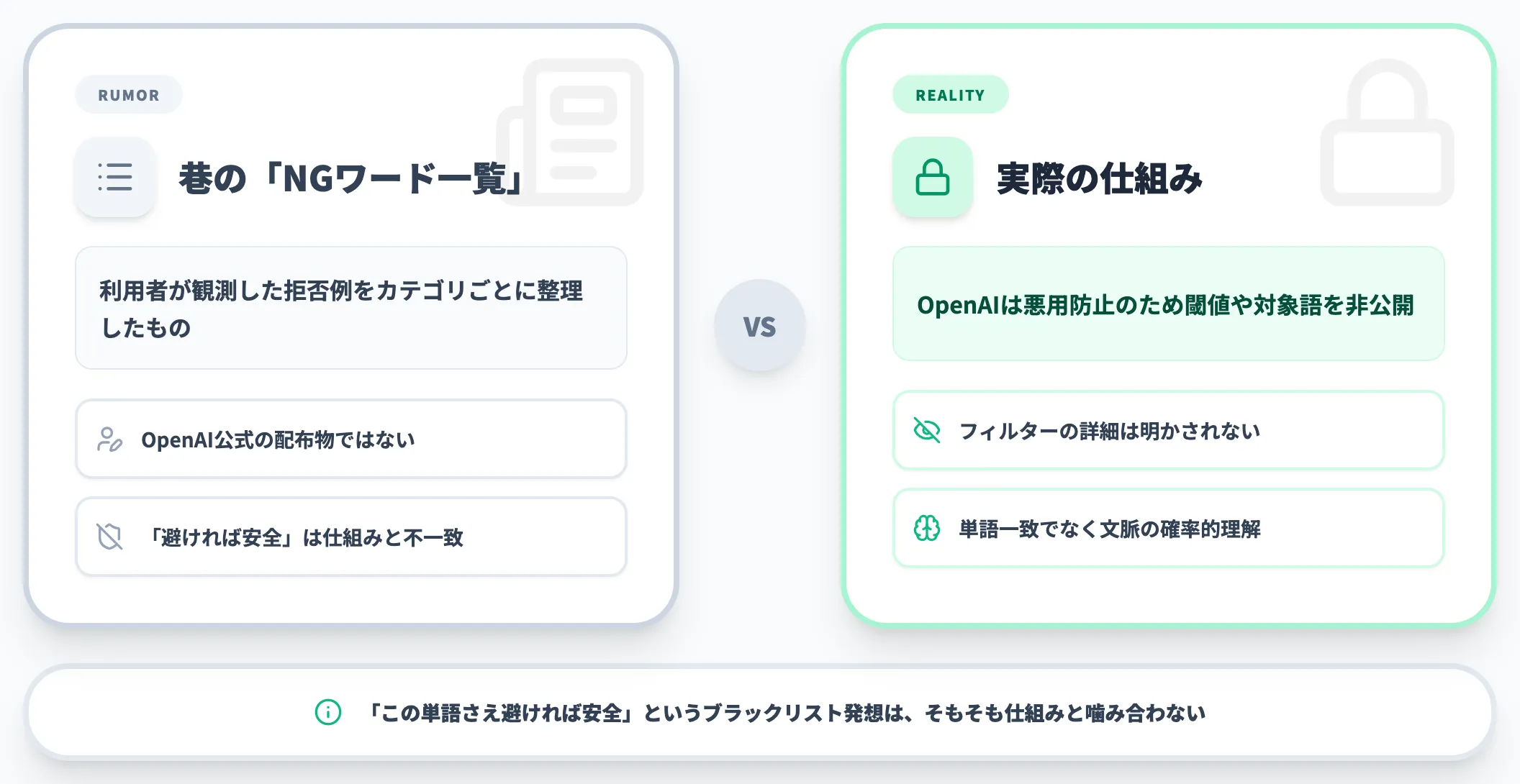
OpenAIは悪用を防ぐ観点から、フィルターの詳細な閾値や対象語を公開していません。
そのため「この単語さえ避ければ安全」というブラックリスト的な発想は、そもそも仕組みと噛み合っていないのが実情です。
ChatGPTの仕組みの根幹が、単語の一致判定ではなく文脈の確率的な理解にある以上、制限の判断も文脈ベースになるのは自然なことだと言えます。
NGワードは「単語」ではなく「文脈と意図」で判定される
ChatGPTが回答を断るかどうかは、入力に含まれる単語よりも、その単語が「何のために使われているか」で決まります。
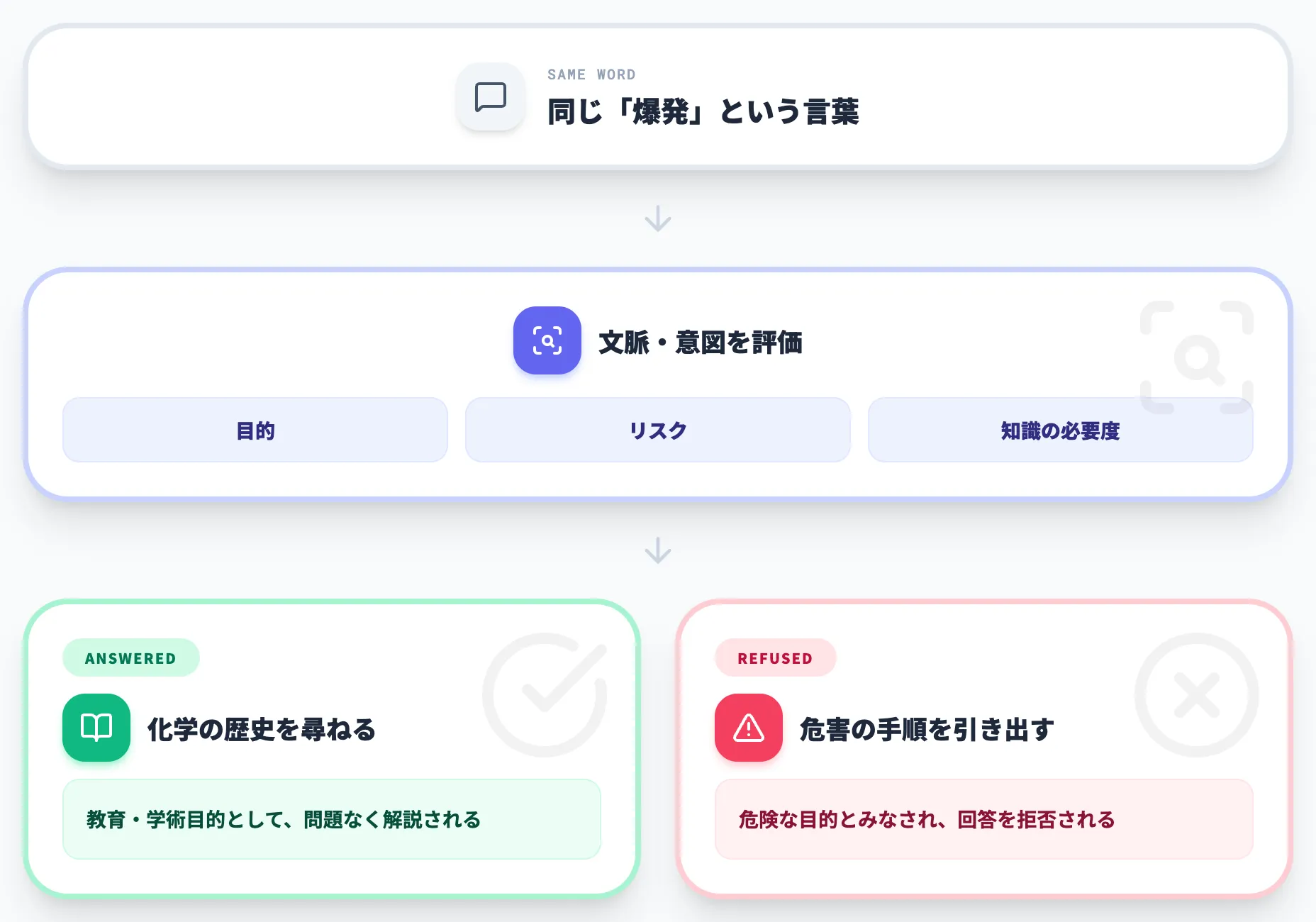
たとえば「爆発」という言葉も、化学の歴史を尋ねる文脈なら問題なく解説されますが、危害を加える手順を引き出そうとする文脈では拒否されます。
この違いは、後述する利用ポリシーとModel Specがコンテンツを「目的・リスク・知識の必要度」で評価しているために生じます。
混同されやすい3つの現象
「ChatGPTが急に答えてくれない」という体験は、実際には性質の異なる複数の原因が混ざっています。以下の3つは分けて理解しておくと、対処を誤りません。

-
利用ポリシー由来の制限
本記事の主題。差別・暴力・違法行為などをポリシーに照らして拒否するもので、文脈で挙動が変わる。
-
特定の固有名詞が出力できない現象
「David Mayer」など一部の人名が出力されない事例がITmediaなどでも報じられました。TechCrunchの報道では、プライバシー保護に関わる内部ツールが特定の名前をフラグした影響とみられると伝えられており、一般的なコンテンツ制限とは別物と考えられます。
-
技術的な不具合・誤作動
ハルシネーション(誤回答)やシステムエラーで答えが返らないケース。これはNGワードではなく品質・障害の問題。
本記事が扱うのは1つ目の「ポリシー由来の制限」です。2つ目・3つ目を「NGワードのせい」と捉えると、不要な回避策に走ってしまうため注意してください。
ChatGPTがNGワードを判定する仕組み
ChatGPTの制限は、単一のフィルターではなく複数のルールとシステムが重なって働いています。
ここを理解すると、なぜ「単語の言い換え」では突破できないのかが腑に落ちます。
本セクションでは、判定の土台になる2つのルール、実際にスキャンを行うモデレーションの仕組み、そして回避が効かない理由までを順に整理します。
利用ポリシーとModel Specという2階建てのルール
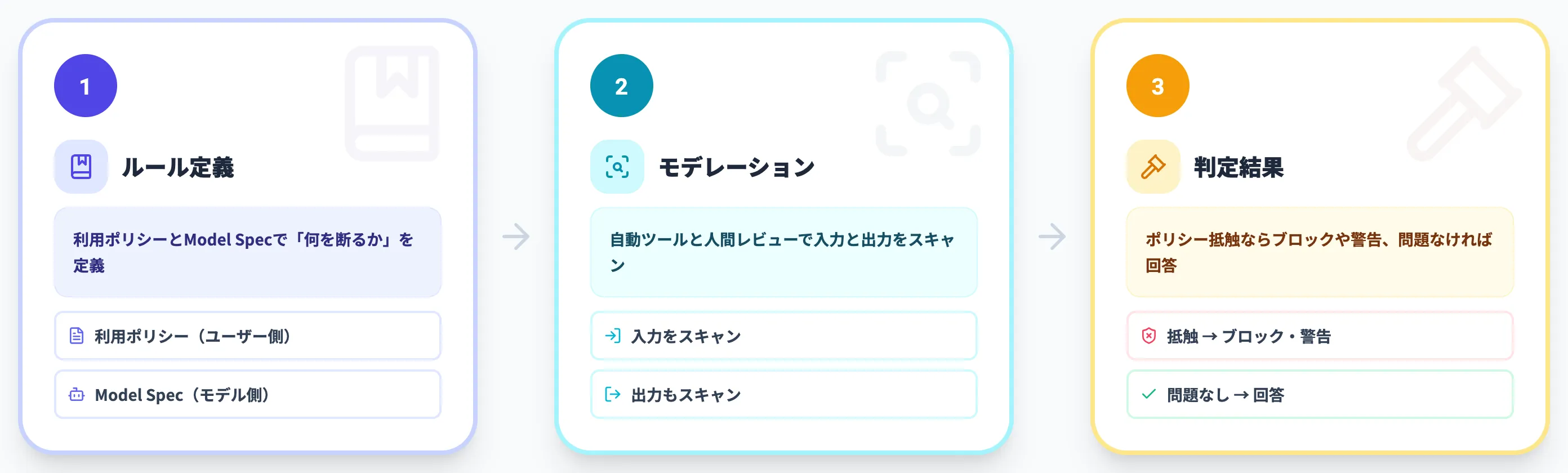
ChatGPTの「何を断るか」は、大きく2つの公式文書で定義されています。

-
利用ポリシー(Usage Policies)
ユーザーが守るべき利用規約。2025年10月29日に全製品共通のユニバーサルポリシーへ刷新され、未成年保護の強化や、医療・法務・金融など重要領域での「人間のレビューなしの高リスク自動判断」の制限が明文化された。
-
Model Spec
モデル自身がどう振る舞うべきかを定めた仕様書。最新のModel Specでは、コンテンツを後述の3階層に整理し、文脈に応じた判断のルールを示している(本記事は2025年12月18日版を参照)。
利用ポリシーが「ユーザー側のルール」、Model Specが「モデル側の行動原理」という関係です。私たちが目にする拒否や警告は、この2階建てのルールが運用に落ちた結果だと捉えると理解しやすくなります。
Model Specによるコンテンツの3階層
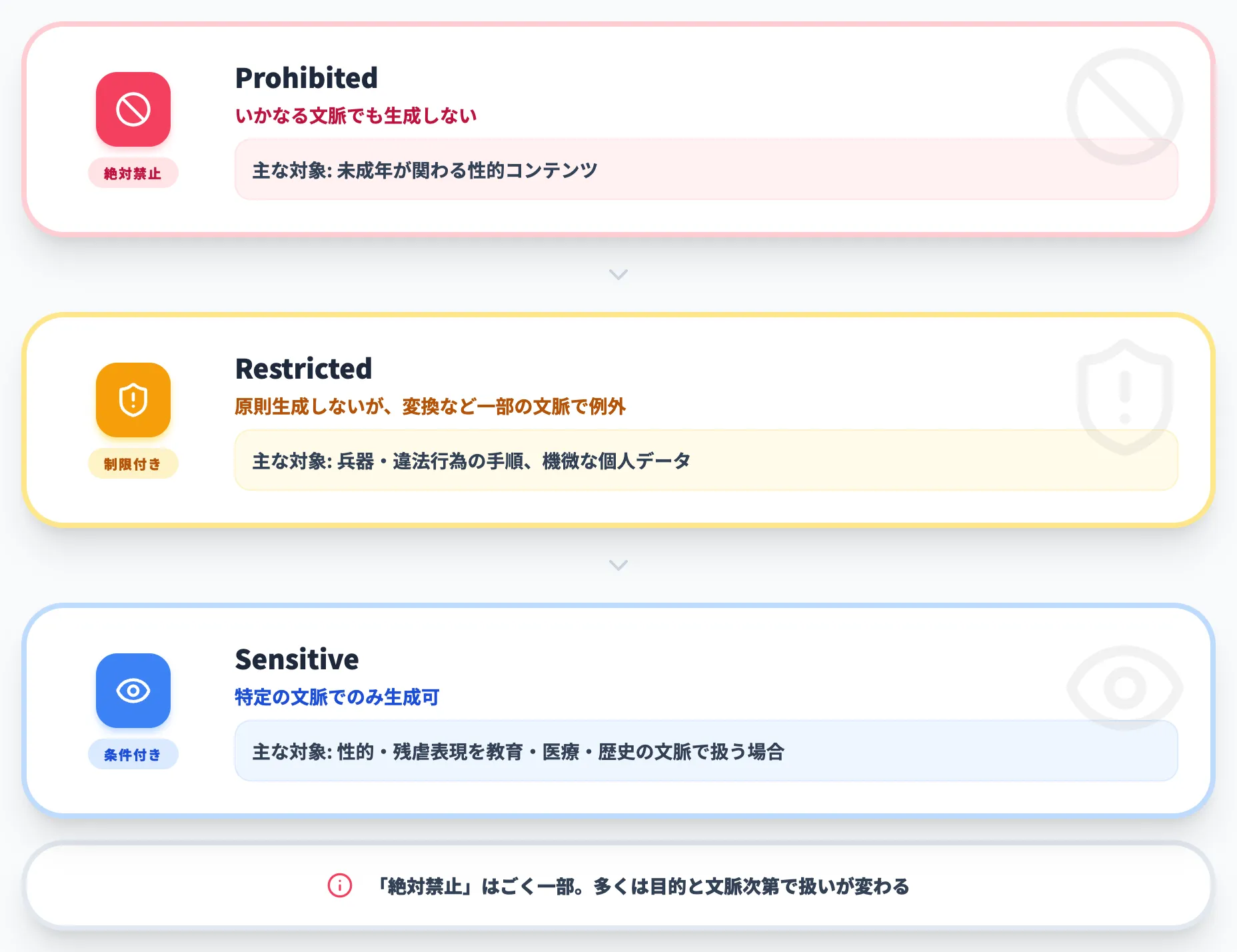
Model Specは、扱いの難しいコンテンツを一律に禁止するのではなく、リスクの種類に応じて3つの階層に分けています。
以下の表で、3階層の違いを整理しました。
| 階層 | 位置づけ | 主な対象 |
|---|---|---|
| Prohibited(絶対禁止) | いかなる文脈でも生成しない | 未成年が関わる性的コンテンツ |
| Restricted(制限付き) | 原則生成しないが、変換など一部の文脈で例外 | 兵器・違法行為の手順などの情報危害、機微な個人データ |
| Sensitive(センシティブ) | 特定の文脈でのみ生成可 | 性的・残虐表現などを、教育・医療・歴史の文脈で扱う場合 |
この3階層で押さえたいのは、「絶対禁止」はごく一部で、多くは扱いに条件が付くという点です。Model Specは、Prohibitedに当たる未成年の性的コンテンツのみを「いかなる状況でも生成しない」と位置づけています。一方でRestrictedは原則として新たに生成せず、ユーザーが提供した内容の変換や、安全な範囲での高レベルな説明などに限って例外を認めます。Sensitiveは、教育・医療・歴史といった適切な文脈でのみ生成が許されます。
「同じ質問でも聞き方を変えたら答えてくれた」という体験談が多いのは、この文脈依存の設計が背景にあります。
モデレーションによる入力・出力のスキャン
ルールを実際に運用するのが、モデレーション(監視)の仕組みです。

OpenAIは公式ヘルプで、ChatGPTでは分類器・推論モデル・ハッシュ照合・ブロックリストといった自動ツール(公開されているModerations APIに相当する内部版を含む)と、人間によるレビューを組み合わせて問題のあるコンテンツを検出していると説明しています。
具体的には、ユーザーが送信した入力と、モデルが生成しようとする出力の双方がスキャンされ、ポリシーに抵触すると判断された場合に生成がブロックされたり、警告が表示されたりします。
ここで重要なのは、判定が入力時だけでなく出力の直前にも働く点です。入力をうまく言い換えても、出力内容がポリシーに触れれば、そこで止められます。
「言い換え」や「難読化」で突破できない理由
Model Specは、回避策に対しても明確な方針を示しています。
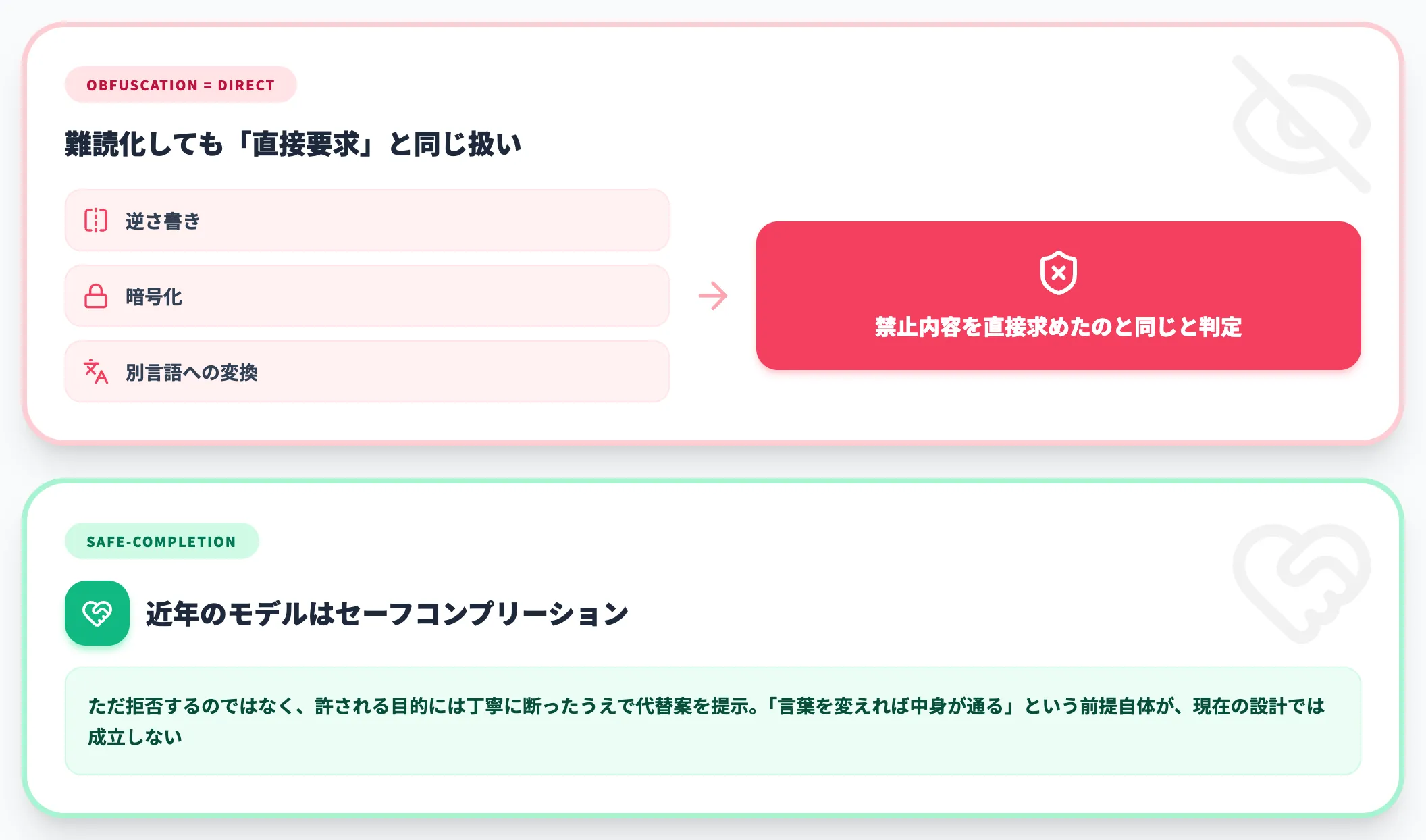
公式は、逆さ書き・暗号化・別言語などで難読化した要求は、禁止内容を直接求めたのと同じ扱いにすると明記しています。
さらに近年のモデルは、危険な要求に対して「ただ拒否する」のではなく、許される目的のために許されない手助けを求められた場合は丁寧に断ったうえで代替案を示す、というセーフコンプリーション(safe-completion)の考え方を採用しています。
つまり「言葉を変えれば中身が通る」という前提自体が、現在の設計では成立しません。後述する回避方法は、あくまで「正当な目的を正確に伝える」ための工夫であり、ポリシーをすり抜けるテクニックではない、という線引きを押さえておく必要があります。
NGワード・制限の対象になる主なカテゴリ
ここまでの仕組みを踏まえて、実際にどのような内容が制限の対象になりやすいのかを整理します。
繰り返しになりますが、これは「禁止単語の一覧」ではなく、OpenAIの利用ポリシーとModel Specに沿った「制限されやすい内容のカテゴリ」です。
本セクションでは、代表的なカテゴリを階層とともに一覧化し、そのうえで「同じ言葉でも文脈で変わる」線引きを補足します。

制限されやすい内容のカテゴリ一覧
以下の表で、制限の対象になりやすい内容を、Model Specの3階層に対応づけて整理しました。
| カテゴリ | 主な内容 | 扱いの目安 |
|---|---|---|
| 児童の性的コンテンツ | 未成年を性的に描写・搾取する内容(非グラフィックな教育・性教育・被害説明は別扱い) | Prohibited(生成は例外なく不可) |
| 重大な危害・兵器 | 生物・化学・核・サイバー兵器、テロ、大量破壊 | Restricted(厳格に制限) |
| 違法行為・犯罪の助長 | 爆発物・違法薬物の製造手順、攻撃の実行手順 | Restricted(一般的な概説までで実行手順は不可) |
| 暴力・自傷・自殺 | 危害の具体的手段、自殺の方法の誘導 | Restricted(危機時は支援窓口の案内に切替) |
| ヘイト・差別・ハラスメント | 人種・性別・出自などへの侮辱や攻撃 | 攻撃目的の生成は拒否 |
| 性的・残虐表現 | ポルノや過度な残虐描写 | Sensitive(教育・医療・歴史の文脈で限定許可) |
| プライバシー・個人情報 | 個人の特定・追跡、機微な個人データ | Restricted(第三者の情報収集は不可) |
| 詐欺・スパム・なりすまし | フィッシング、偽レビュー、偽の身元 | 欺瞞を目的とした利用は不可 |
| 政治的操作・重要領域の自動判断 | 選挙干渉、医療・法務・金融などでの無資格助言や人間レビューなしの自動判断 | Restricted(重要領域は特に制限) |
この一覧で押さえたいのは、ほとんどのカテゴリが「内容そのもの」ではなく「使い方」で線引きされている点です。違法行為のカテゴリも、犯罪の手口を一般教養として概説することは可能でも、実行可能な手順を提供することは断られます。
なお著作権や商用での扱いは、NGワードとは別の論点として整理する必要があります。詳しくはChatGPTの商用利用の記事で解説しています。
「絶対NG」と「文脈次第」の線引き
同じテーマでも、目的の伝わり方で結果が分かれます。Model Specは、リスクの大きさと、その危険を避けるために利用者が必要とする知識・技能の度合いを見て判断するとしています。

たとえば医療や法律に関する質問は、一般的な情報提供は受けられますが、診断や法的助言として断定を求めると慎重な応答に切り替わります。
この「文脈次第」の領域こそ、次のセクションで扱う適切な使い方が効いてくる部分です。一方で、未成年の性的コンテンツのように文脈を問わず拒否される領域もあり、ここは回避の余地がありません。

NGワードに触れたときに何が起きるか
制限に触れたとき、ChatGPTの反応は「回答が返ってこない」だけではありません。
繰り返しや悪質さの度合いによっては、アカウントそのものに影響が及びます。
本セクションでは、警告とその後に起こり得る対応、そして誤った制限を受けたときの異議申し立てまでを整理します。
警告表示と警告メール
最初に現れるのは、画面上の警告です。
入力や出力がポリシーに抵触する可能性があると判断されると、「This content may violate our usage policies」といった警告文が表示されます。
これに加えて、アカウント単位で問題が検知された場合は、登録メールアドレスに警告の通知が届くことがあります。
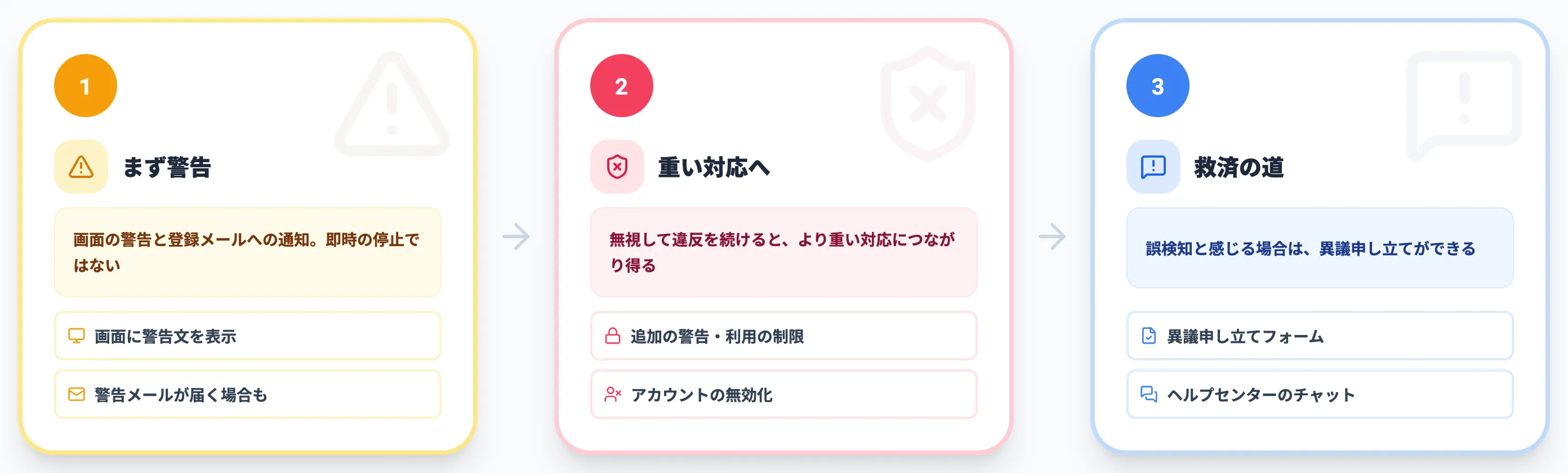
OpenAIは公式ヘルプで、警告は即時の利用停止ではなく、利用を見直して是正するための通知だと説明しています。つまり警告は「一度きりのアウト」ではなく、軌道修正の機会として設けられています。
警告のあとに起こり得ること
警告は最終処分ではありませんが、無視して違反を続けると、より重い対応につながり得ます。OpenAIの公式ヘルプは、起こり得る対応として次のように説明しています。

-
追加の警告・利用の制限
是正されない場合、機能やアクセスが制限されることがある。
-
アカウントの無効化
重大な違反や継続的な違反があった場合、アカウントが無効化される可能性がある。悪質なケースでは、限定的に一度の違反でも対象になり得る。
ただし「警告が必ず一時停止を経て永久停止に進む」といった固定的な順序や、「何回までなら許されるか」という具体的な回数基準は、OpenAIから公開されていません。あくまで違反の重大性と継続性に応じた判断であり、誤検知だと感じる場合は後述の異議申し立てができます。ポリシー違反の詳細な扱いはChatGPTのポリシー違反の記事でも解説しています。
誤った制限を受けたときの異議申し立て
正当な利用なのに警告や停止を受けた、と感じるケースもあります。モデレーションは自動判定を含むため、誤検知が起こり得るからです。
その場合は、通知メールに記載されたリンク、またはOpenAIの異議申し立てフォームから申し立てができます。メールにアクセスできない場合は、ヘルプセンターのチャットから問い合わせる経路も案内されています。
申し立ての際は、どのような目的で利用していたかを具体的に説明できるようにしておくと、確認がスムーズになります。
NGワードを避けてChatGPTを適切に使う方法
ここまで見てきたとおり、ChatGPTの制限は文脈で判断されます。
したがって回避の本質は「禁止された単語を別の単語に置き換える」ことではなく、「正当な目的を正確に伝える」ことにあります。
本セクションでは、正しい考え方に沿った具体的な工夫と、やってはいけない回避を分けて解説します。

正しい回避は「目的と前提の明示」
不要な拒否の多くは、入力だけを見ると危険に見えてしまうことで起きます。目的や立場を補えば、正当な依頼だと伝わりやすくなります。

目的・文脈を具体的に添える
何のために必要なのかを一文添えるだけで、誤検知は大きく減ります。
たとえば「小説の戦闘シーンを描写したい」「セキュリティ教育のために攻撃の仕組みを概念的に知りたい」のように、用途と前提を明示します。
中立的・専門的な表現に言い換える
露骨な口語を、報道や医学で使われる中立的な用語に置き換えると、本来の意図が伝わりやすくなります。
ただしこれは「同じ要求を見えにくくする」ためではなく、「意図を正確に表す」ための言い換えである点が重要です。質問の組み立て方はChatGPTへの質問の仕方の記事も参考になります。
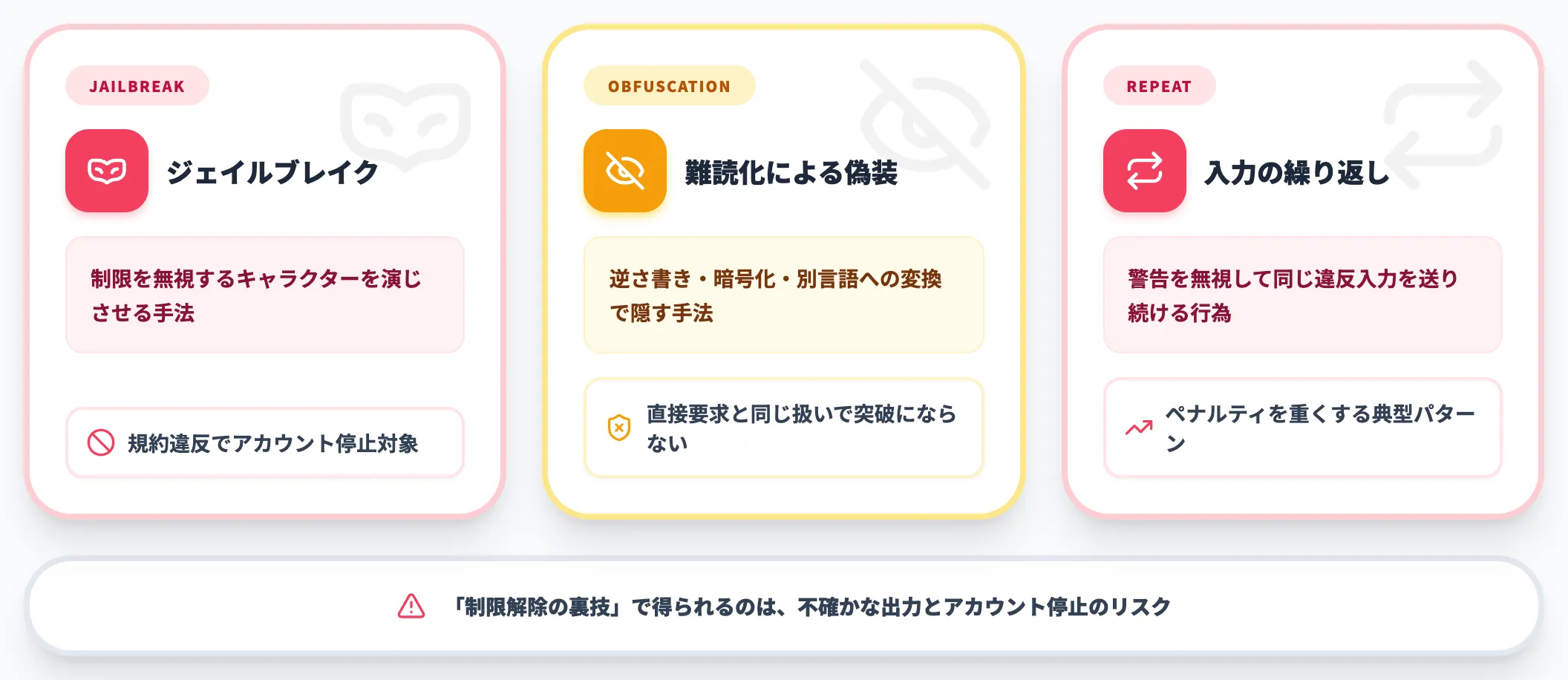
やってはいけない回避
一方で、ポリシーそのものをすり抜けようとする行為は、効果がないうえにリスクを伴います。
-
ジェイルブレイク(脱獄)プロンプト
「制限を無視するキャラクターを演じさせる」といった手法は、規約違反であり、発覚すればアカウント停止の対象になる。
-
難読化による偽装
逆さ書き・暗号化・別言語への変換は、前述のとおり直接要求と同じ扱いになるため突破にならない。
-
警告を無視した同一入力の繰り返し
同じ違反入力を繰り返す行為は、ペナルティを重くする典型パターン。
ネット上には「制限解除の裏技」が出回ることがありますが、得られるのは不確かな出力とアカウント停止のリスクです。ChatGPTでやってはいけないことの記事でも、避けるべき使い方を整理しています。
警告が出たときの実務的な対処
実際に警告が表示されたときは、慌てて同じ入力を押し通そうとしないことが第一です。
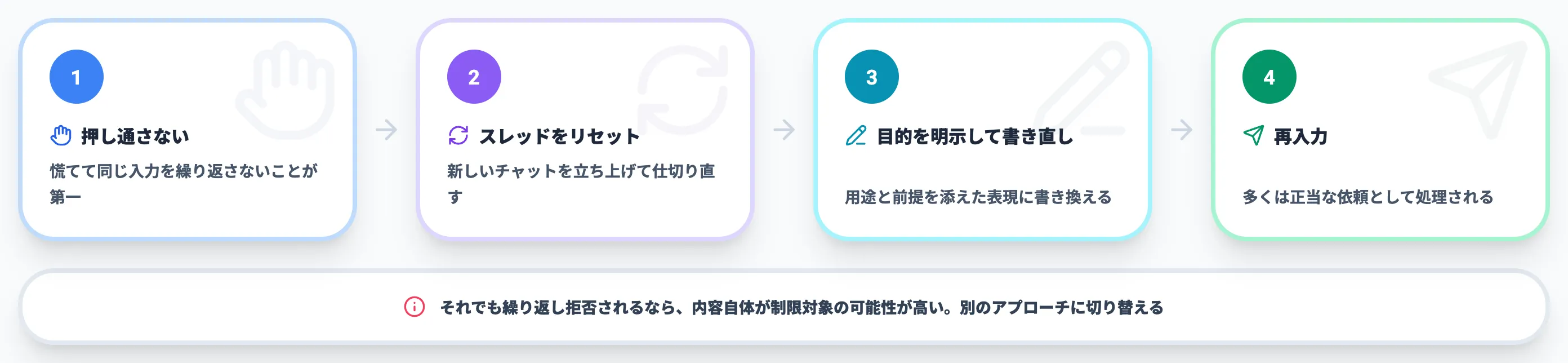
新しいチャットを立ち上げてスレッドをリセットし、目的を明示した表現に書き直してから再入力すると、多くの場合は正当な依頼として処理されます。
それでも繰り返し拒否される場合は、その内容自体が制限対象に当たる可能性が高いと考え、別のアプローチに切り替えるのが現実的です。
企業がポリシー違反リスクに備える方法
個人利用なら「拒否されたら言い換える」で済みますが、組織で使う場合は話が変わります。
従業員が意図せず不適切な出力を生成したり、機密情報を入力してしまったりすれば、法的・情報セキュリティ上のリスクに直結するためです。実際に、リスクを懸念して一時的に利用を制限した自治体の事例も報じられています。
本セクションでは、企業がNGワード・ポリシー違反のリスクを抑えながらChatGPTを業務活用するための、3つの備えを整理します。
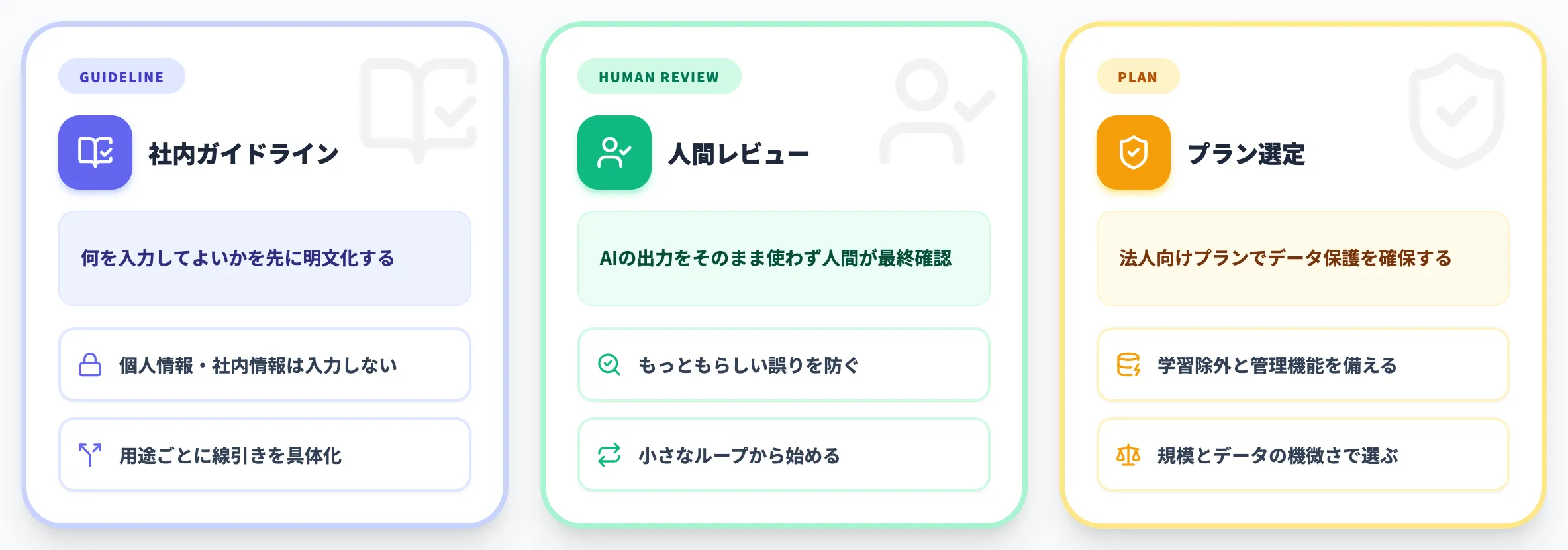
社内ガイドラインを先に整える
最初の備えは、何を入力してよく、何を入力してはいけないかを明文化することです。

特に、個人情報・顧客データ・未公開の社内情報を入力しないことは、NGワード以前の大前提として周知する必要があります。入力データの扱いはChatGPTの情報漏洩リスクやセキュリティリスクの観点とも直結します。
「ナレッジ検索や下書き作成には使うが、最終判断や対外文書の確定には人を挟む」といった線引きを、業務ごとに具体化しておくと、現場が迷いません。
出力の人間レビューを組み込む
2つ目は、AIの出力をそのまま使わず、人間が最終確認する運用です。
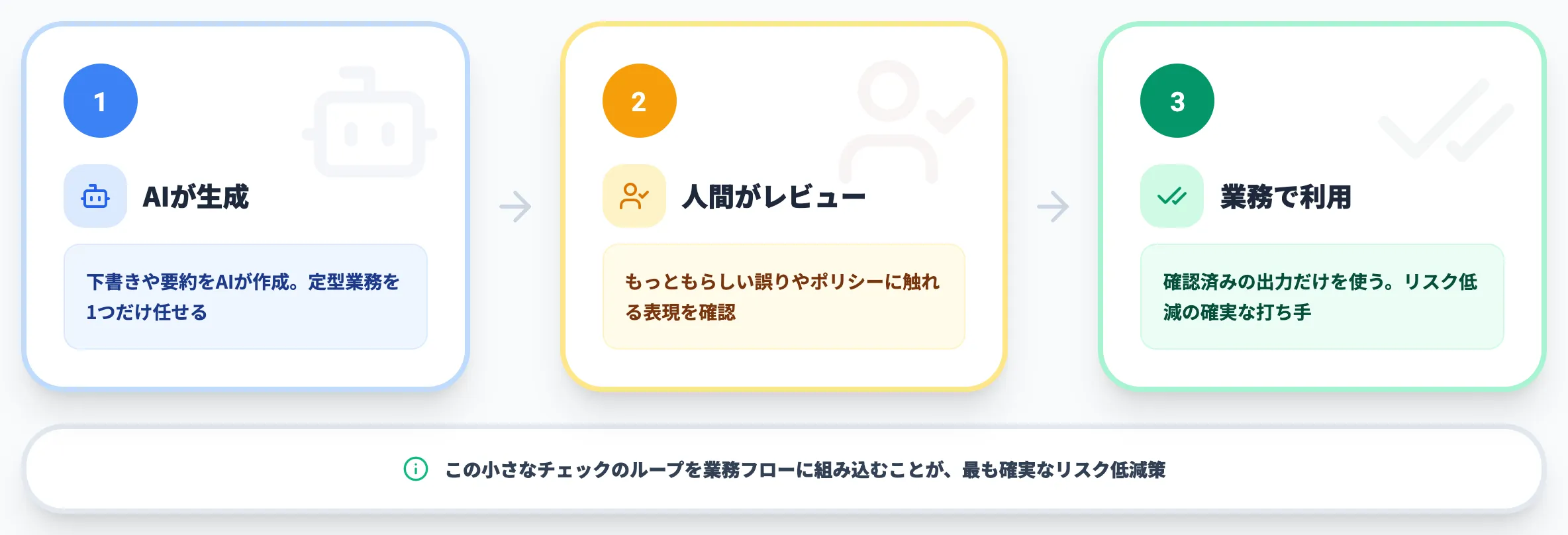
ChatGPTは文脈理解に限界があり、もっともらしい誤りや、ポリシーに触れかねない表現を生成することがあります。ChatGPTの限界を理解したうえで、レビュー工程を業務フローに組み込むことが、リスク低減の最も確実な打ち手になります。
毎朝の定型業務を1つだけAIに任せてみて、その出力を人がチェックする——この小さなループから始めるのが、現実的な第一歩です。
プラン選定とデータ保護を見直す
3つ目は、利用するプランの見直しです。

無料版やPlusのような個人向けプランを業務で常用すると、入力データの扱いや管理機能の面で不安が残ります。支援の現場でも、業務で継続利用するなら、入力データが学習に使われず管理機能も備える法人向けプランへ早めに切り替えるべき、というのが基本的な推奨です。
-
ChatGPT Business(旧ChatGPT Team)
中小〜中堅企業向け。2025年8月29日にChatGPT Teamから名称変更された(名称変更自体は機能・料金の変更ではない)。入力データを既定で学習に使わず、メンバー管理ができる。座席種別や料金はその後も更新されているため、最新の条件はOpenAIの公式ページで確認するとよい。まず部署単位で導入する際の第一候補。
-
ChatGPT Enterprise
全社展開向け。より高度な管理・セキュリティと、コンプライアンス要件への対応力を備える。ChatGPT Enterpriseの料金や違いは個別記事で詳しく解説している。
どのプランが適切かは利用規模と扱うデータの機微さで決まります。具体的な選び方はChatGPTの法人利用の記事も参考にしてください。
【関連記事】
ChatGPTの問題点とは?セキュリティや著作権の観点から徹底解説

AIの制約を理解した運用設計で業務活用を前に進める
NGワードの線引きを個人の感覚任せにしていると、ある人は萎縮して使わなくなり、別の人は気づかないうちに規約違反すれすれの使い方をしてしまいます。組織として安全にAIを活用するには、制約の仕組みを理解したうえで、入力ルールと人間レビューを運用に落とし込むことが欠かせません。
AI総合研究所では、社内ガイドラインの作り方から出力レビューの組み込み方、コンプライアンスを踏まえた全社展開の進め方までを220ページの「AI業務自動化ガイド」にまとめ、無料で公開しています。ChatGPTを安全に業務へ定着させる第一歩として活用ください。
AIの制約を理解したうえで安全な業務AI活用を設計する

ポリシー違反リスクを抑えるAI導入・運用の実践ガイド
NGワードの仕組みを理解することは、業務でAIを安全に使いこなす出発点です。AI総合研究所では、社内ガイドラインの作り方から出力の人間レビュー、コンプライアンスを踏まえた全社展開の進め方までを220ページの「AI業務自動化ガイド」にまとめています。
まとめ
本記事では、ChatGPTのNGワードについて、その実態・判定の仕組み・制限カテゴリ・違反時の挙動・回避方法・企業の備えまでを2026年5月時点の情報で解説しました。要点を改めて整理します。
-
NGワードは公開された禁止単語リストではなく、利用ポリシーとModel Specに基づく文脈・意図ベースの判定であり、「特定の単語を避ける」という発想自体が仕組みと噛み合わない
-
制限はProhibited(絶対禁止)・Restricted(原則生成不可・限定的な例外あり)・Sensitive(適切な文脈でのみ可)の3階層で、文脈を問わず拒否される絶対禁止はごく一部にとどまる
-
難読化や別言語での回避は直接要求と同じ扱いになり、ジェイルブレイクはアカウント停止のリスクを伴う。正しい回避は目的と前提を明示すること
-
警告は即停止ではなく是正の機会だが、違反を続けると追加の制限やアカウント無効化につながり得る。誤検知には異議申し立ての経路がある
-
企業利用では社内ガイドライン・出力の人間レビュー・法人向けプランのデータ保護を前提に整えることが、ポリシー違反リスクを抑える最も確実な打ち手になる
ChatGPTのNGワードは、「触れてはいけない言葉を覚える」問題ではなく、「どんな目的でどう使うか」を設計する問題です。仕組みを理解して正しく依頼すれば不要な拒否は減り、組織として運用ルールを整えれば違反リスクは抑えられます。まずは自社の入力ルールと人間レビューの線引きから見直すことが、安全な業務活用への近道になります。










