この記事のポイント
 LLMの出力品質はコーパスの品質で決まる。低品質データはハルシネーションやバイアスの直接原因になるため、データ品質管理を最優先にすべき
LLMの出力品質はコーパスの品質で決まる。低品質データはハルシネーションやバイアスの直接原因になるため、データ品質管理を最優先にすべき- 日本語NLP開発ならBCCWJを基盤コーパスとして活用すべき。少納言・中納言で語彙分析が即座に可能
- LLM学習用にはFineWebやRedPajama v2などフィルタリング済みデータセットを選ぶべき。Common Crawlの生データは品質リスクが高い
- 業界特化AIを構築するなら専門コーパスの整備が精度向上に直結する。汎用コーパスだけでは専門領域の精度が不十分
- RAGの普及により、推論時の知識ベースとしてのコーパス構築も企業のAI戦略に不可欠になっている

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
自然言語処理やAI開発において、コーパスは学習データの基盤として欠かせない存在です。
コーパスとは、大量のテキストデータを体系的に収集し、品詞や構文などの言語情報を付与して構造化したデータベースを指します。
2026年現在、ChatGPTをはじめとする大規模言語モデル(LLM)の急速な普及により、コーパスの重要性はかつてないほど高まっています。学習データの品質がAIの出力精度を直接左右するため、低品質なコーパスに起因するハルシネーションやバイアスが実務上の大きなリスクとなっています。
この記事では、コーパスの基本的な定義から種類・分類、自然言語処理やLLMとの関係、活用事例、メリット・課題、そして主要な活用ツールとコストまで、2026年の最新情報を交えて体系的に解説します。
目次
コーパスとは(2026年最新)
コーパスとは、書籍、新聞、雑誌、ウェブページ、会話記録などの多様なソースから自然言語テキストを大規模に収集し、品詞・構文・意味といった言語情報を付与して構造化したデータベースです。語源はラテン語の「corpus(身体・集合体)」に由来し、言語学においては「言語データの集合体」を意味します。
コーパスは、人工知能(AI)の自然言語処理研究だけでなく、辞書編纂、語学教育、翻訳、テキストマイニングなど幅広い領域で活用されています。2026年現在では、大規模言語モデル(LLM)の学習データとしての役割が特に注目されており、Common CrawlやFineWebなど数十テラバイト規模のコーパスがAI開発の基盤となっています。
以下の表で、コーパスの基本的な特性を整理しました。
| 項目 | 内容 |
|---|---|
| 定義 | 自然言語テキストを体系的に収集・構造化したデータベース |
| 語源 | ラテン語「corpus」(身体・集合体) |
| 主な用途 | 言語研究、NLP開発、LLM学習、辞書編纂、語学教育、翻訳 |
| データ形式 | テキスト(XML、JSON、TSV等で構造化) |
| 規模 | 数万語(専門コーパス)から数兆トークン(LLM学習用)まで |
| 付与情報 | 品詞タグ、構文木、意味ラベル、固有表現タグ等 |
| 提供形態 | 無償公開、学術利用限定、商用ライセンス等 |
この表が示すように、コーパスは単なるテキストの集まりではなく、言語情報が体系的に付与された構造化データベースです。規模も数万語から数兆トークンまで幅広く、用途に応じて適切なコーパスを選択することが重要になります。
2026年現在、ChatGPTやClaudeなどのLLMが社会に浸透する中で、学習データであるコーパスの品質管理が喫緊の課題です。低品質なデータを学習に使用すると、ハルシネーション(AIが事実と異なる情報を生成する現象)やバイアスの増大を招き、企業のAI導入において重大なリスクとなり得ます。
コーパスの例

コーパスの種類と分類
コーパスは、その構成や目的に応じて複数の種類に分類されます。以下の表で、代表的な5つの分類とそれぞれの特徴を整理しました。
| 分類 | 説明 | 代表例 |
|---|---|---|
| 注釈付きコーパス | 品詞・構文・意味等のタグが付与されたコーパス | BCCWJ、Penn Treebank |
| 生コーパス | タグ付けなしのプレーンテキストを収集したもの | Common Crawl、Project Gutenberg |
| 対訳コーパス | 2言語以上の対応する翻訳文を収録 | Europarl、JParaCrawl |
| 単言語コーパス | 1つの言語のみで構成されたコーパス | BNC(英語)、BCCWJ(日本語) |
| 専門コーパス | 特定分野のテキストに特化 | 医療コーパス、法律コーパス、学習者コーパス |
実務でコーパスを選択する際のポイントは、自分の目的と対象言語に適した分類を見極めることです。たとえば、機械翻訳の開発には対訳コーパスが不可欠であり、LLMの事前学習には大規模な生コーパスが使われます。特定の業界向けAIを構築する場合は、専門コーパスの活用が精度向上に直結します。
日本語コーパス
日本語のコーパスとして最も代表的なものが、国立国語研究所が構築した「現代日本語書き言葉均衡コーパス(BCCWJ)」です。BCCWJは、書籍、雑誌、新聞、白書、ブログ、教科書など13のジャンルから約1億430万語を収録しており、現代日本語の書き言葉を均衡的に反映したコーパスとして国内外の研究者に広く利用されています。
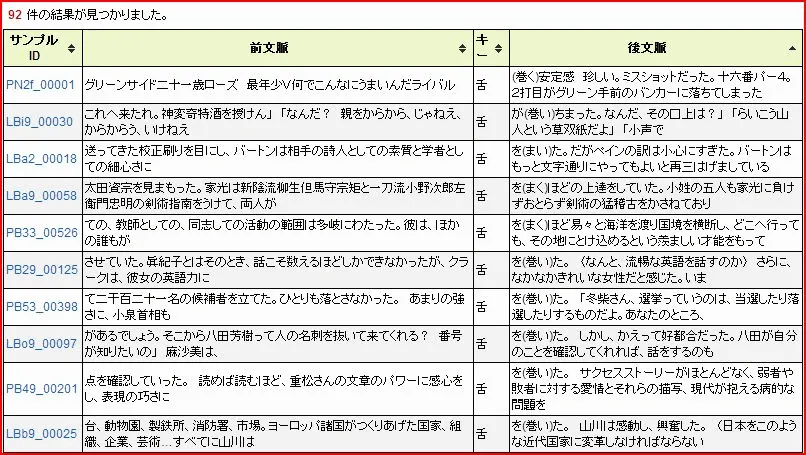
BCCWJには、目的に応じた検索インターフェースが用意されています。無償で登録不要の少納言は、キーワード検索による前後文脈の表示(KWIC形式)に対応しており、特定の単語や表現の使用頻度を手軽に調べることができます。より高度な分析を行いたい場合は、登録制の中納言を利用することで、品詞条件を指定した検索や出現頻度の統計分析が可能です。
たとえば少納言で「朝食」を検索すると約2,073件、「朝ごはん」では約402件がヒットし、書き言葉では「朝食」という表現が約5倍の頻度で使われていることが定量的に確認できます。このような頻度分析は、辞書編纂、日本語教育、自然な文章生成の設計に直接活用されています。
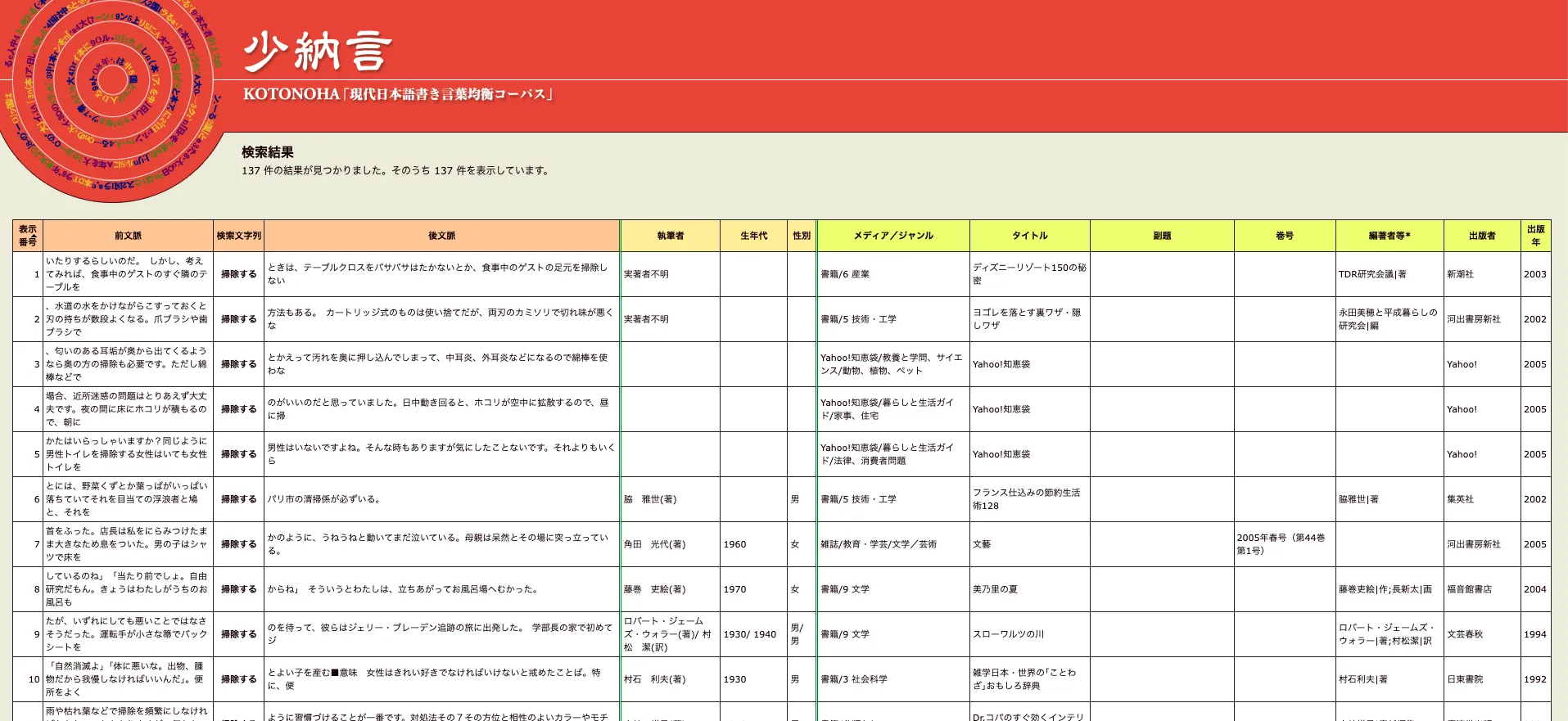
少納言で「掃除する」の検索をかけた結果
このほかにも、日本語の学習者向けコーパスとしてC-JAS(Corpus of Japanese As a Second language)があり、中国語や韓国語を母語とする日本語学習者の発話データが収録されています。学習者がどのような誤りを犯しやすいかを分析する「誤り分析」や、教材開発のための基礎データとして活用されています。
英語コーパス
英語コーパスの代表例としては、ブリティッシュ・ナショナルコーパス(BNC)とコーパス・オブ・コンテンポラリー・アメリカン・イングリッシュ(COCA)が広く知られています。
BNCは約1億語のイギリス英語を収録したコーパスで、書き言葉(90%)と話し言葉(10%)の両方を含んでいます。1990年代に構築されたため最新のデータは含まれませんが、英語の基本的な語彙分析や語学教育の基盤として現在も広く参照されています。
一方、COCAは1990年から現在まで年ごとに更新されるアメリカ英語コーパスで、10億語以上を収録しています。小説、新聞、雑誌、学術論文、テレビ・映画の字幕、ウェブテキストなど8ジャンルをカバーしており、時代ごとの語彙変化や表現トレンドの分析に適しています。COCAはオンラインで無償利用が可能で、1日あたりの検索回数に制限はありますが、研究や教育目的であれば十分に活用できます。
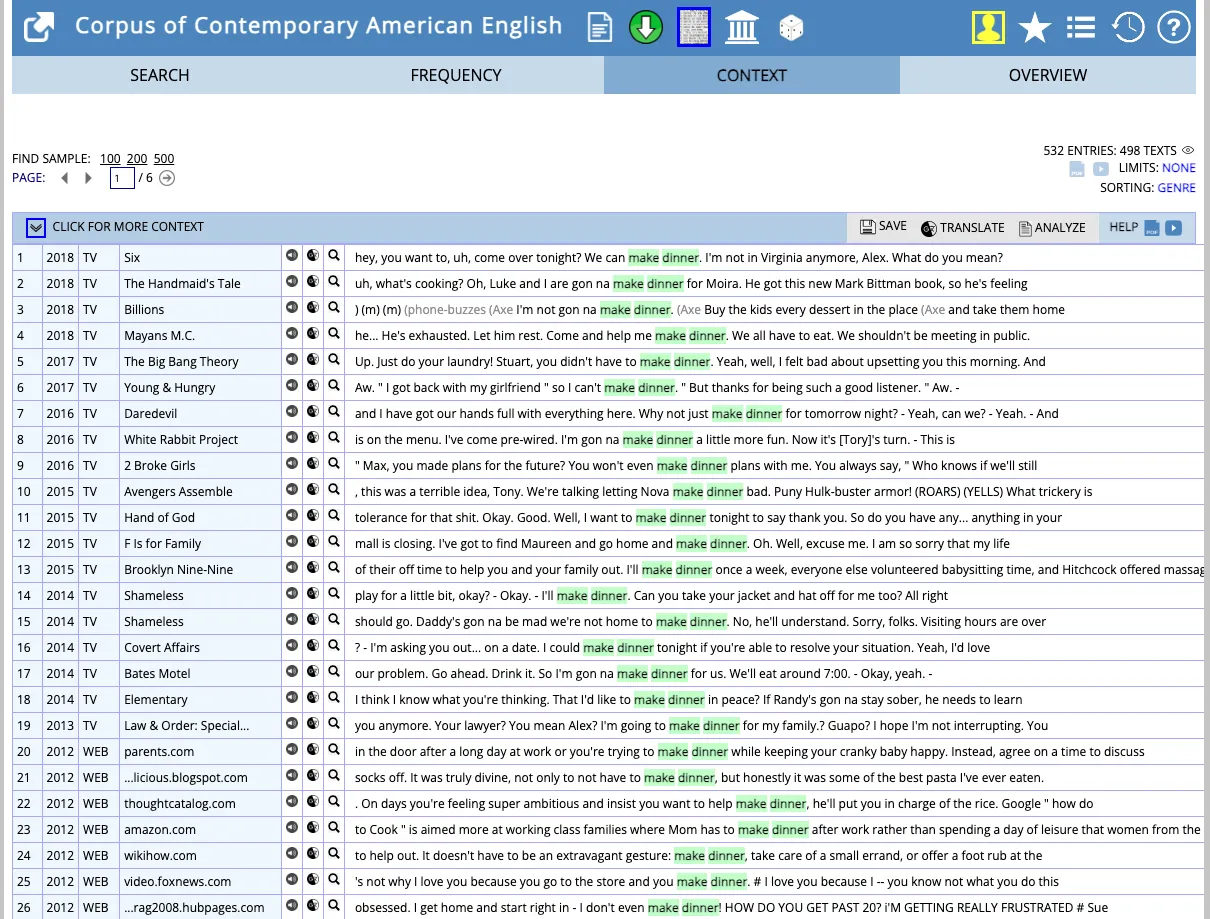
COCAで「make dinner」の検索をかけた結果
つまり、英語コーパスは構築時期と更新頻度によって強みが異なるということです。歴史的な語彙分析にはBNC、最新の言語変化を追跡するにはCOCAが適しており、研究目的に応じた使い分けが求められます。
自然言語処理におけるコーパスの役割
自然言語処理(NLP)とは、人間が日常的に使う言葉をコンピュータに理解・生成させる技術の総称です。NLPでは、文章の処理において主に4つの解析段階を経て言語の意味を抽出します。
-
形態素解析
文章を最小の意味単位(形態素)に分割し、品詞を特定する処理です。日本語は英語のように単語間にスペースがないため、この段階が特に重要になります。
-
構文解析
形態素間のつながりを分析し、文の構造(主語・述語・修飾関係)を特定します。コーパスに付与された構文木データが解析精度の向上に貢献しています。
-
意味解析
単語や文の意味を解釈する処理です。同じ単語でも文脈によって意味が変わるため(多義性)、大量のコーパスから学習した文脈パターンが解析の精度を左右します。
-
文脈解析
文章全体の流れや前後関係を考慮して、指示語の解決や省略された主語の補完を行います。特に日本語は主語が省略されることが多いため、文脈解析の難度が高い言語とされています。
これら4つの解析段階すべてにおいて、コーパスは学習データとして不可欠な役割を果たしています。ディープラーニングの登場以降、大規模コーパスから自動的にパターンを学習するアプローチが主流となり、コーパスの規模と品質がNLPモデルの性能を直接決定するようになりました。
LLMの学習データとしてのコーパス
2026年現在、生成AIの中核技術であるLLMの開発において、大規模コーパスの役割はますます重要になっています。GPT-4oやClaude、DeepSeek-R1などの最先端LLMは、数兆トークン規模のコーパスを学習データとして使用しています。
以下の表で、LLMの学習に使用される代表的なコーパスの特徴を比較しました。
| データセット | 規模 | 構成 | 公開状況 | 主な利用例 |
|---|---|---|---|---|
| Common Crawl | 数百TB(毎月更新) | ウェブページのクロールデータ | 無償公開 | GPT系、LLaMAの前処理元 |
| The Pile | 825GB(約3,000億トークン) | 学術論文、GitHub、Wikipedia等22ソース | 無償公開 | GPT-NeoX、Pythia |
| FineWeb | 15兆トークン | Common Crawlから高品質データを抽出 | 無償公開(HuggingFace) | SmolLM、各種研究用モデル |
| RedPajama v2 | 30兆トークン | Common Crawlベースに品質スコアを付与 | 無償公開 | RedPajama-INCITE |
| C4 | 約750GB | Common Crawlからノイズ除去・英語フィルタリング | 無償公開 | T5、PaLM |
特に差が出ているのがデータ品質への取り組みです。初期のLLMはCommon Crawlの生データをそのまま使用していましたが、ノイズやスパム、有害コンテンツの混入が出力品質を低下させることが判明しました。その結果、FineWebやRedPajama v2のように高度なフィルタリングと品質スコアリングを施したデータセットが主流になりつつあります。
RAG(検索拡張生成)の普及により、LLMの学習データとしてのコーパスだけでなく、推論時に参照する知識ベースとしてのコーパスの重要性も高まっています。企業が独自のナレッジベースをコーパスとして構築し、RAGを通じてLLMの回答精度を向上させるアプローチが2026年のトレンドです。

コーパスの活用事例
コーパスは言語学の研究にとどまらず、さまざまな実務領域で活用されています。ここでは、2026年現在の代表的な活用事例を紹介します。
- 文章生成と要約
ChatGPTやClaudeなどのLLMは、大規模コーパスから言語パターンを学習することで、人間が書いたかのような自然な文章を生成します。要約タスクにおいては、原文から重要な文を抜き出す「抽出的要約」と、内容を言い換えて新たな文を生成する「生成的要約」の両方にコーパスが基盤データとして使われています。近年のLLMは生成的要約の精度が大幅に向上しており、ビジネス文書の自動要約やレポート作成支援に実用化されています。

chatGPTで上の文章を要約させた結果
- 機械翻訳
機械翻訳の精度向上には、大量かつ多様な対訳コーパスが不可欠です。Google翻訳やDeepLなどのサービスは、数十億文規模の対訳コーパスを学習データとして使用しており、2026年時点では専門分野の翻訳においてもネイティブスピーカーが違和感なく読める水準に達しています。日本語の対訳コーパスとしては、日欧の議会議事録を基にしたJParaCrawlが代表的です。
適当な英文をDeepLで日本語に翻訳
-
チャットボットと音声認識
チャットボットや音声対話システムは、多様な会話パターンに対応するためにコーパスを活用しています。特に、特定の業界に特化した会話を行うシステムでは、その分野の専門的なコーパスが回答精度に直結します。2026年現在、GoogleアシスタントやAmazon Alexaなどの音声認識システムでも、数万時間規模の音声コーパスが認識精度の向上に使われています。
-
検索エンジンとBERT
検索エンジンもコーパスを基盤とした自然言語処理技術を活用しています。Googleが開発したBERTは、大規模なテキストコーパスで事前学習を行い、文脈を考慮した検索結果の改善を実現しました。2026年現在では、BERTの後継技術がGoogle検索の中核として機能しており、ユーザーの検索意図をより正確に理解する仕組みが構築されています。
-
テキストマイニングと感情分析
テキストマイニングは、大量のテキストデータから規則性のある情報を統計的に抽出する技術です。コールセンターの通話記録、SNSの投稿、アンケートの自由記述など、非構造化テキストを分析して顧客インサイトを得る手法として、マーケティングや商品開発に幅広く活用されています。感情分析では、ポジティブ・ネガティブのラベルが付与された感情分析コーパスが学習データとして使われ、企業のブランド評価や風評モニタリングに貢献しています。
これらの事例に共通するのは、コーパスの規模と品質がシステムの精度を直接左右するという点です。AIの性能向上において、高品質なコーパスは欠かすことのできない基盤リソースとなっています。
コーパスのメリットと課題
コーパスの活用にはさまざまなメリットがある一方で、注意すべき課題も存在します。以下の表で、主なメリットと課題を対比しました。
| 観点 | メリット | 課題 |
|---|---|---|
| データの客観性 | 実際の言語使用を定量的に分析でき、直感や経験に頼らない客観的な知見が得られる | データの収集範囲や時期によって偏りが生じる可能性がある |
| AI精度の向上 | 高品質なコーパスを学習データとして使用することで、NLPモデルやLLMの精度が向上する | 低品質データの混入がハルシネーションやバイアスの原因となる |
| 多分野への応用 | 言語教育、翻訳、マーケティング、医療など幅広い領域で活用可能 | 専門分野のコーパスは構築コストが高く、データ量が限られる |
| 言語変化の追跡 | 時系列データを蓄積することで、言語の変化やトレンドを長期的に分析できる | 古いコーパスが最新の言語使用を反映しないため、定期的な更新が必要 |
| 教育への貢献 | 学習者コーパスを活用して、効果的な教材開発や誤り分析が可能 | 著作権やプライバシーの制約により、利用可能なデータが制限される場合がある |
この対比から分かるのは、コーパスのメリットを最大限に活かすためには、課題への適切な対処が不可欠だということです。特に2026年現在、LLMの社会実装が急速に進む中で、学習データの品質管理は技術的課題であると同時に社会的課題でもあります。
バイアスと著作権への対応
コーパスに含まれるバイアスは、AIの出力に直接反映されるため、慎重な対応が求められます。たとえば、特定のジェンダーや民族に偏った表現が多く含まれるコーパスで学習したLLMは、差別的な文章を生成するリスクがあります。この問題に対処するため、2026年現在ではデータセットの構築段階で多様性の確保やバイアス検出ツールの適用が標準的な手法となっています。
著作権の問題も深刻です。ウェブから収集したテキストの多くは著作物であり、学習データとしての利用が著作権侵害に当たるかどうかは各国で法的議論が続いています。日本では著作権法第30条の4により、AIの学習目的でのデータ利用は一定の条件下で認められていますが、生成物が既存の著作物と類似する場合の取り扱いについては依然として議論が続いています。
さらに、データポイズニング(悪意あるデータの意図的な混入)のリスクも注目されています。大規模コーパスに有害なデータが紛れ込むことで、LLMが不正確な情報や有害なコンテンツを生成する可能性があります。この対策として、データの出所追跡(データプロヴェナンス)や品質フィルタリングの高度化が進んでいます。
コーパスの活用ツールとコスト
コーパスを活用するためのツールは、無償の学術向けツールから商用の高機能プラットフォームまで幅広く存在します。以下の表で、代表的なツールを比較しました。
| ツール名 | 対象言語 | 主な用途 | 費用 | 特徴 |
|---|---|---|---|---|
| 少納言(NINJAL) | 日本語 | BCCWJ検索 | 無償 | 登録不要、KWIC形式で前後文脈を表示 |
| 中納言(NINJAL) | 日本語 | BCCWJ詳細検索 | 無償(要登録) | 品詞条件検索、統計分析、共起語分析が可能 |
| COCA Online | 英語 | アメリカ英語の語彙・用法分析 | 無償(検索制限あり) | 10億語以上、8ジャンル、時系列分析対応 |
| Sketch Engine | 100以上の言語 | コーパス検索・分析・構築 | 有償(月額約4.83ユーロから) | 自作コーパスのアップロード、ワードスケッチ機能 |
| Hugging Face Datasets | 多言語 | 機械学習用データセットの利用 | 無償(基本機能) | FineWeb、The Pile等のLLM学習用データセットを提供 |
個人の語学学習や簡易的な言語調査であれば、少納言やCOCA Onlineの無償ツールで十分に対応可能です。一方、企業がAI開発や大規模な言語分析を行う場合は、Sketch Engineのような商用ツールや、Hugging Face Datasetsを活用して自社専用のコーパスを構築するアプローチが有効です。
Pythonを使ったコーパスの処理も実務で広く行われています。NLTKやspaCyといったNLPライブラリを使用すれば、テキストの前処理、品詞タグ付け、頻度分析などをプログラムで自動化できます。大規模コーパスの処理にはGPU環境が必要になる場合もあり、クラウドサービスの利用コストも含めた総合的なコスト設計が重要です。

コーパスとAIの知識を業務へのAI導入に活かす

生成AIの業務活用を体系的に学べるガイド
コーパスがAIの精度を左右する仕組みを理解すると、自社業務にAIを導入する際の「データ品質」という視点が明確になります。AI総合研究所では、データ設計を含めた業務AI導入の手順をまとめたガイドを無料で提供しています。
コーパスとAIの知識を業務へのAI導入に活かすなら
コーパスがAIの出力品質を左右する仕組みを理解すると、自社の業務データをどう整備すればAIが正確に動作するかという視点が得られます。データの品質管理はAI導入の成否を分ける重要なポイントであり、ここを押さえておくことで導入後のトラブルを大幅に減らせます。
AI総合研究所では、データ設計から業務プロセスへのAI組み込みまでを段階的に進めるための「AI業務自動化ガイド」を無料で提供しています。コーパスの重要性を理解した今、業務データの整備とAI導入を並行して進めてみてください。
コーパスとAIの知識を業務へのAI導入に活かす
生成AIの業務活用を体系的に学べるガイド
コーパスがAIの精度を左右する仕組みを理解すると、自社業務にAIを導入する際の「データ品質」という視点が明確になります。AI総合研究所では、データ設計を含めた業務AI導入の手順をまとめたガイドを無料で提供しています。
まとめ
本記事では、コーパスの定義から種類・分類、自然言語処理やLLMにおける役割、活用事例、メリット・課題、そして活用ツールとコストまで体系的に解説しました。
2026年現在、コーパスはLLMの学習データとして不可欠な基盤リソースであり、その品質がAIの出力精度を直接左右する重要な要素です。Common CrawlやFineWebなどの大規模コーパスがオープンソースで公開される一方、バイアスや著作権、データポイズニングといった課題への対処も求められています。
コーパスの活用を検討している方は、まず少納言やCOCA Onlineなどの無償ツールで実際にキーワード検索を試し、コーパスの使い方を体感してみてください。その上で、自社のAI開発やナレッジベース構築にコーパスを活用する場合は、Hugging Face DatasetsやSketch Engineといったプラットフォームで目的に合ったデータセットを選定し、品質フィルタリングを施した上でパイロット検証を進めることが推奨されます。










