この記事のポイント
 API利用で手軽に始めるならGPT-5かClaude Opus 4.6が第一候補。データプライバシーを完全に管理したいならLlama 3の自社運用を選ぶべき
API利用で手軽に始めるならGPT-5かClaude Opus 4.6が第一候補。データプライバシーを完全に管理したいならLlama 3の自社運用を選ぶべき- LLM導入の最初の一手はRAGによるナレッジ検索が最も効果的。既存データを活かせるため投資対効果が出やすい
- ハルシネーション対策なしのLLM運用は避けるべき。RAGで事実を裏付け、ヒューマンレビューを組み合わせるのが必須
- コスト管理では入力トークンの最適化が鍵。GPT-5は100万トークンあたり$2.50〜$10、用途に応じたモデル選択でAPI費用を大幅に削減できる
- 日本語特化の用途にはNTTのtsuzumiも検討すべき。軽量モデル(6〜70億パラメータ)でGPUコストを抑えつつ日本語精度を確保できる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
大規模言語モデル(LLM)とは、数千億以上のパラメータを持ち、大量のテキストデータで学習されたAIモデルです。ChatGPT、Claude、Geminiといったサービスのバックエンドで動いており、テキスト生成・翻訳・要約・コード生成など幅広いタスクを処理できます。
本記事では、LLMの定義と生成AIとの違い、Transformerアーキテクチャの仕組み、GPT・Claude・Gemini・Llamaなど主要モデルの比較、ビジネスでの活用事例、ハルシネーションやコストなどの課題、そしてAPI料金の比較までを体系的に解説します。
LLMの全体像を把握し、自社でのAI活用の判断材料としてご活用ください。
目次
大規模言語モデル(LLM)とは
大規模言語モデル(Large Language Model、LLM)とは、数千億〜数兆のパラメータを持ち、インターネット上の大量のテキストデータで事前学習されたAIモデルです。
ChatGPTの回答生成、Claudeのコード分析、Geminiの質問応答——これらのサービスのバックエンドで動いているのがLLMです。テキスト生成・翻訳・要約・質問応答・コード生成など、人間の言語に関する幅広いタスクを処理できます。

LLMと生成AIの違い
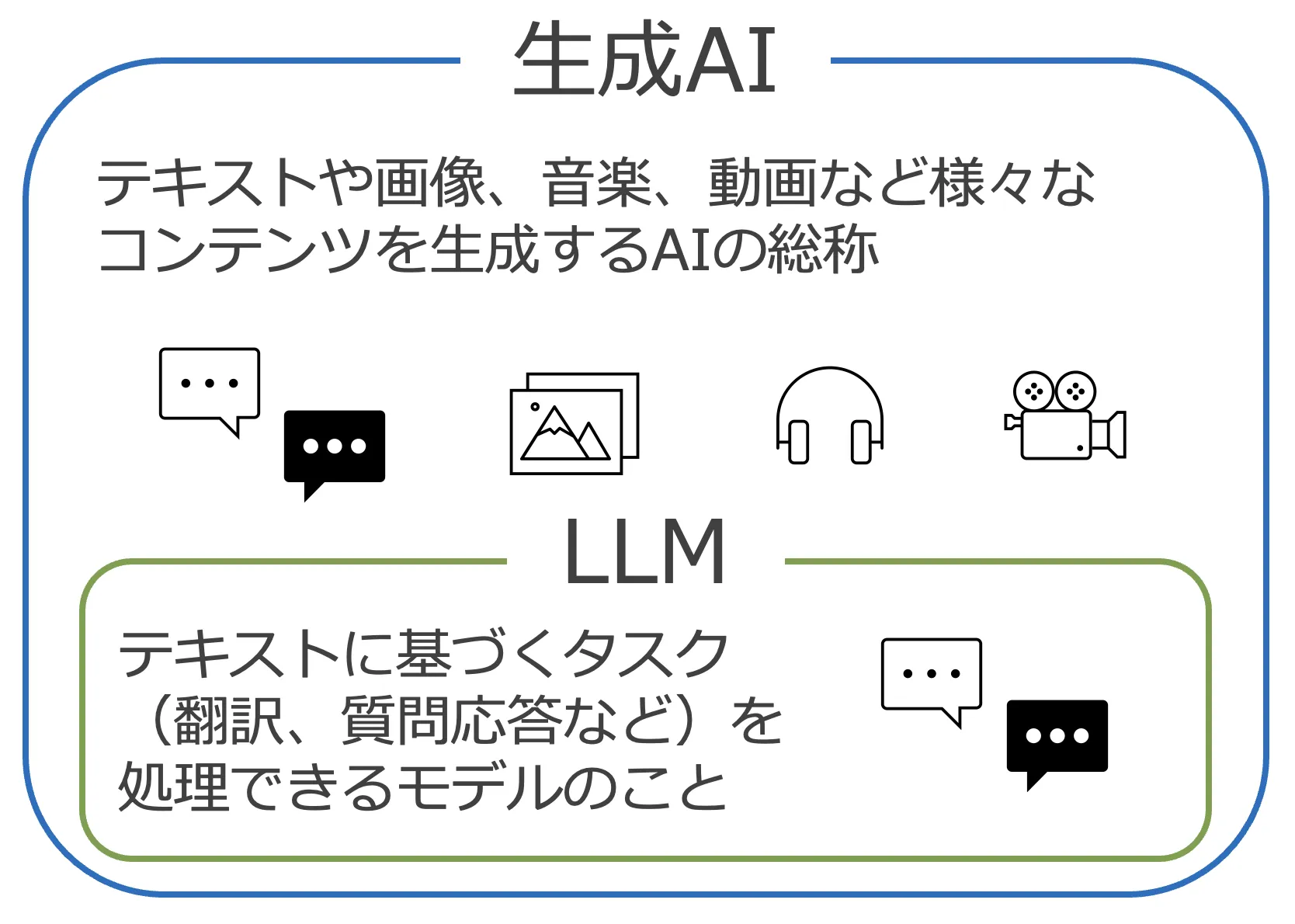
LLMと生成AIは混同されがちですが、厳密には異なる概念です。
生成AIとLLMの関係
- LLM はテキスト(言語)の理解と生成に特化したAIモデル
- 生成AI はLLMに加えて、画像生成(Diffusionモデル)、動画生成、音声合成なども含む広い概念
つまり、LLMは生成AIの中核技術のひとつですが、生成AI全体を指す言葉ではありません。
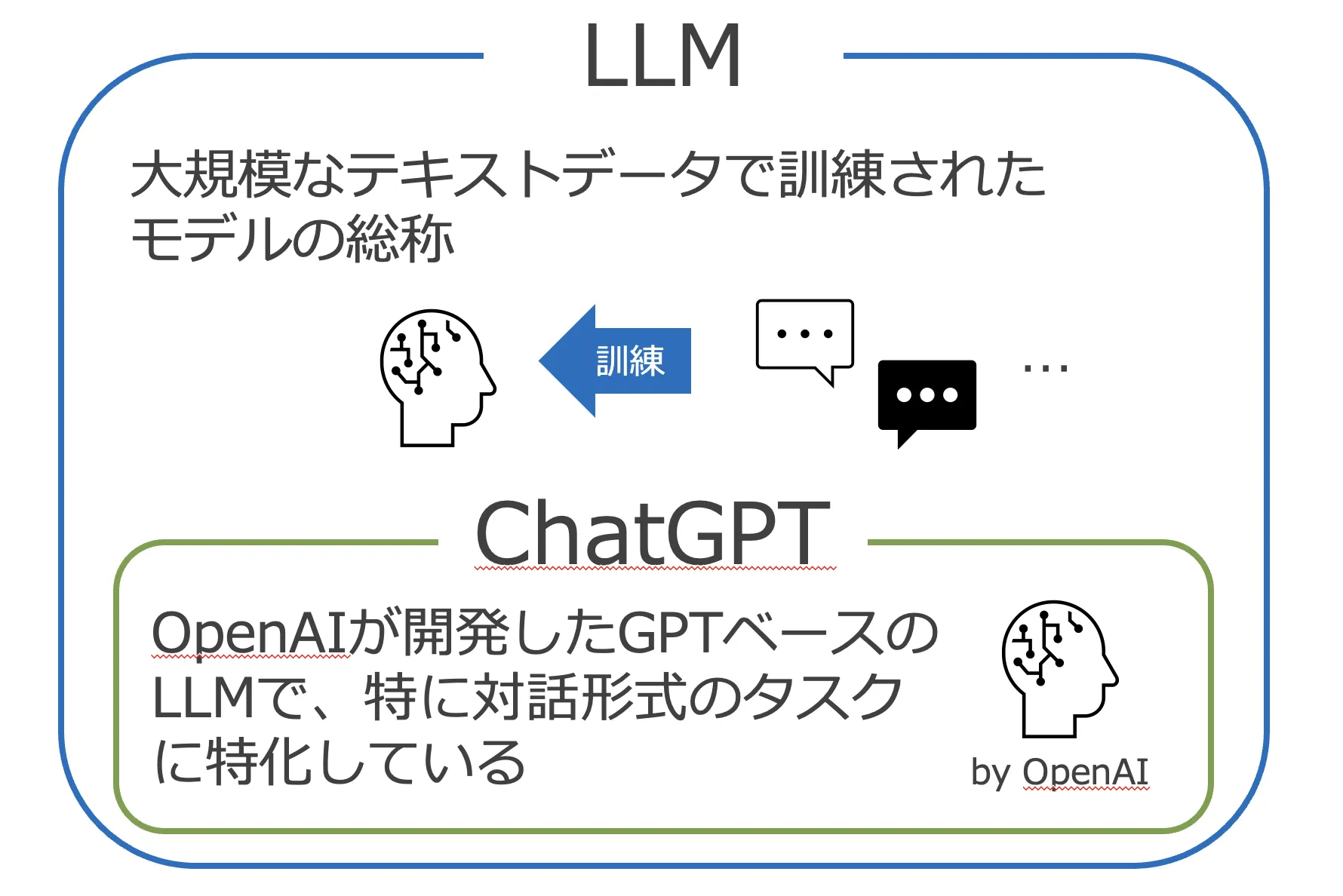
LLMとChatGPTの違い
LLMは「技術・モデル」であり、ChatGPTは「LLMを使ったサービス・製品」です。
LLMとChatGPTの関係
ChatGPTの裏側ではGPT-5やGPT-5.2といったLLMが動いており、それにチャットUI・ツール呼び出し・メモリ機能などを組み合わせてサービスとして提供されています。
LLMの仕組み
LLMは「与えられたテキストの続きとして、次に来る確率が最も高いトークン(単語や文字の断片)を予測する」という原理で動作しています。この予測を繰り返すことで、文章を生成します。
Transformerアーキテクチャ
現在のLLMのほぼすべてが、Googleの研究チームが2017年に発表した論文「Attention Is All You Need」で提案されたTransformerというニューラルネットワークアーキテクチャをベースにしています。Transformerの核心は「自己注意機構(Self-Attention)」で、入力テキスト中の各トークンが他のすべてのトークンとどれだけ関連しているかを計算します。
これにより、文中の離れた位置にある単語同士の関係(長距離依存関係)を効率的に捉えることが可能になりました。Transformerは並列処理にも適しているため、大量のGPUを使った大規模な学習が実現可能です。
LLMの学習プロセス
LLMの学習は大きく2段階に分かれます。
-
事前学習(Pre-training)
インターネット上の大量のテキストデータ(書籍・Webページ・論文・コードなど)を使い、「次のトークンを予測する」タスクを繰り返して言語パターンを獲得します。この段階で文法・事実知識・推論能力の基礎が形成されます。
-
ファインチューニング(RLHF等)
事前学習したモデルを、人間のフィードバックに基づく強化学習(RLHF)で調整します。これにより、有害な出力を抑制し、ユーザーの意図に沿った応答を生成する能力が向上します。
LLMの主要モデル比較
2026年2月時点の主要なLLMモデルを以下の表で比較しました。
| モデル | 開発元 | 特徴 | オープンソース |
|---|---|---|---|
| GPT-5 / GPT-5.2 | OpenAI | 最も広く使われるLLM。推論能力と汎用性に優れる | いいえ |
| Claude Opus 4.6 / Sonnet 4.6 | Anthropic | 長文処理とコード分析に強い。安全性重視の設計 | いいえ |
| Gemini 3 Pro | マルチモーダル対応。Google Cloud連携に強い | いいえ | |
| Llama 3 | Meta | オープンソースで最も高性能。自社運用可能 | はい |
| DeepSeek V3.1 | DeepSeek | コスト効率に優れるオープンソースモデル | はい |
| tsuzumi | NTT | 日本語に最適化された軽量モデル(6〜70億パラメータ) | いいえ |
選択のポイントは、「クローズドモデルをAPI経由で使うか」「オープンソースモデルを自社で運用するか」の判断です。API利用は導入が手軽ですが従量課金が発生します。自社運用はGPUインフラの初期投資が必要ですが、データプライバシーを完全に管理でき、長期的なコスト効率に優れる場合があります。

LLMの活用事例
LLMは多岐にわたるビジネス領域で実用化が進んでいます。代表的な活用パターンを紹介します。
コンテンツ生成
記事の下書き、広告コピー、レポートの作成をLLMに任せることで、制作スピードを大幅に向上できます。マーケティングチームが数日かけていた企画案の素案を、LLMなら数分で複数パターン出力できます。
カスタマーサポート
LLMを組み込んだチャットボットは、従来のルールベース型と異なり、自由記述の問い合わせにも自然な回答を返せます。パナソニック コネクトは全社員約1.2万人に社内AI「ConnectAI」を導入し、年間約18.6万時間の労働時間削減を達成しました。
コード生成・開発支援
GitHub CopilotやClaude Codeは、LLMをバックエンドに使いコードの自動補完・生成・レビューを行います。開発者の生産性を数倍に向上させる効果が報告されています。
RAGによるナレッジ検索
RAG(検索拡張生成)を使えば、社内ドキュメントやFAQの知識をLLMに持たせ、社内向けの質問応答システムを構築できます。LLMの学習データにない最新情報や自社固有の知識にも対応できる点が強みです。
データ分析・要約
大量の文書データから要点を抽出する、財務レポートの要約を生成する、顧客アンケートの感情分析を行うなど、テキストデータの分析にもLLMが活用されています。
LLMの課題と対策
LLMには大きな可能性がある一方で、実務での利用にあたり理解しておくべき課題があります。
ハルシネーション
LLMは事実と異なる情報を自信ありげに生成することがあります(ハルシネーション)。特に法務・医療・金融など正確性が求められる分野では、LLMの出力を人間が必ず検証するプロセスが不可欠です。RAGを導入して外部の正確なデータソースを参照させることで、ハルシネーションのリスクを軽減できます。
コストと計算資源
大規模なLLMの推論にはGPU資源が必要であり、API利用料も利用量に応じて増加します。コスト管理のためには、タスクの重要度に応じてモデルサイズを使い分ける(定型タスクには軽量モデル、複雑なタスクには高性能モデル)アプローチが有効です。SLM(小規模言語モデル)の活用も選択肢のひとつです。
プライバシーとデータ管理
LLMのAPIに入力したデータがモデルの学習に使われるかどうかは、サービスによって異なります。機密情報を扱う場合は、データの保存・学習ポリシーを事前に確認し、必要に応じてオンプレミス環境でのオープンソースモデル運用やオプトアウト設定を検討してください。
学習データのバイアス
LLMは学習データに含まれる偏見やバイアスを反映した出力を生成する可能性があります。多様なユーザーに向けたサービスでは、出力のバイアスチェックとガードレールの設計が重要です。
LLMのAPI料金比較
LLMをビジネスに組み込む際のコスト感を把握するため、2026年2月時点の主要API料金を比較しました。
| モデル | 入力(100万トークン) | 出力(100万トークン) | 特徴 |
|---|---|---|---|
| GPT-5 mini | $0.25 | $2.00 | コスパ重視の定型タスク向け |
| GPT-5 | $1.00 | $8.00 | 汎用的な高性能モデル |
| GPT-5.2 | $1.75 | $14.00 | 最高性能。複雑な推論タスク向け |
| Claude Sonnet 4.6 | $3.00 | $15.00 | コードと長文分析に強い |
| Claude Opus 4.6 | $5.00 | $25.00 | 最高精度。研究・専門分析向け |
| Gemini 3 Pro | $1.25〜 | $10.00〜 | Google Cloud連携、マルチモーダル |
| GPT-4.1 nano | $0.10 | $0.40 | 最安。大量処理の定型タスク向け |
注目すべきは、出力トークンが入力の3〜8倍の料金設定になっている点です。コスト最適化のためには、プロンプトを簡潔にする、出力の最大トークン数を制限する、定型タスクには軽量モデルを使う、といった工夫が有効です。
サブスクリプション型(ChatGPT Plus $20/月、Claude Pro $20/月など)は個人利用やプロトタイプ開発に、API従量課金は本番アプリケーションへの組み込みに適しています。

【無料DL】AI業務自動化ガイド(220P)

Microsoft環境でのAI活用を徹底解説
Microsoft環境でのAI業務自動化・AIエージェント活用の完全ガイドです。Microsoft環境でのAI業務自動化の段階設計を詳しく解説します。
まとめ
大規模言語モデル(LLM)は、Transformerアーキテクチャをベースに大量のテキストデータで学習されたAIモデルであり、テキスト生成・質問応答・コード生成・データ分析など幅広いタスクを処理できます。
2026年現在は、GPT-5(OpenAI)、Claude 4系(Anthropic)、Gemini 3(Google)、Llama 3(Meta)が主要モデルとして並立しており、API経由の利用とオープンソースモデルの自社運用という2つの選択肢があります。
LLMの導入を検討する際は、まず自社の業務でLLMが価値を発揮する場面を特定し、小さなPoCから始めてみてください。ハルシネーション・コスト・プライバシーの3つの課題を理解した上で、適切なモデルと運用方式を選択することが成功の鍵です。










