この記事のポイント
 機密情報・個人情報・認証情報は個人プランに絶対入力しない。学習除外を設定しても入力時点で第三者提供と扱われる余地がある
機密情報・個人情報・認証情報は個人プランに絶対入力しない。学習除外を設定しても入力時点で第三者提供と扱われる余地がある- 業務利用はBusiness・Enterprise・APIのいずれか必須、データ学習に使われない契約が前提でSSO・監査等の管理機能はプラン別
- 医療・法務・税務・緊急判断は専門家の関与なしで完了させない。Usage Policiesでも人間レビューなしの高リスク自動化は明示禁止
- 社内AIポリシーは「入力禁止情報の定義」「利用可能プラン指定」「出力の人間レビュー義務」の3点を先に組む。網羅性より早期着手
- 未成年利用ではペアレンタルコントロールをリンクしQuiet Hoursと安全通知をオンにする。サインインなしの匿名利用は制御できない

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTを業務に取り入れる現場が増える一方で、「何を入力していいのか」「何をやらせてはいけないのか」の判断基準があいまいなまま運用されているケースが目立ちます。
2025年から2026年にかけては、CISA幹部による政府文書のChatGPTへの投稿事案、外部分析ベンダーMixpanel経由のメタデータ露出など、利用に関するインシデントも続いています。
本記事では、ChatGPTでやってはいけないことを「健康・安全」「法的責任」「情報セキュリティ」の主軸3カテゴリと「教育・利用方法」「情報品質」の補助2カテゴリ(合計5カテゴリ)で整理し、12のNG行為を体系的に解説します。
あわせて、2025-2026年の代表的な漏洩事例、Usage PoliciesとAI事業者ガイドライン第1.2版(2026年3月31日公開)の要点、個人と法人それぞれが取るべき対策、料金プラン別のセキュリティ差まで一気通貫で整理しました。
目次
ChatGPTでやってはいけないことを判断する5つのカテゴリ
ChatGPTで絶対に避けるべき12のNG行為【2026年最新版】
Usage Policies(2025年10月29日更新版)の禁止事項
AI事業者ガイドライン第1.2版(2026年3月31日公開)
ChatGPTでやってはいけないことを判断する5つのカテゴリ
ChatGPTの「やってはいけないこと」は、医療判断・違法行為・機密情報入力など性質の異なるリスクが混ざり合っており、項目を並列で並べるだけでは判断軸が定まりません。
本記事では2026年4月時点の最新情報をもとに、12のNG行為を「主軸となる3つのリスク軸」と「補助となる2つの活用軸」の合計5カテゴリで整理し、それぞれの優先度と対処方針を示します。
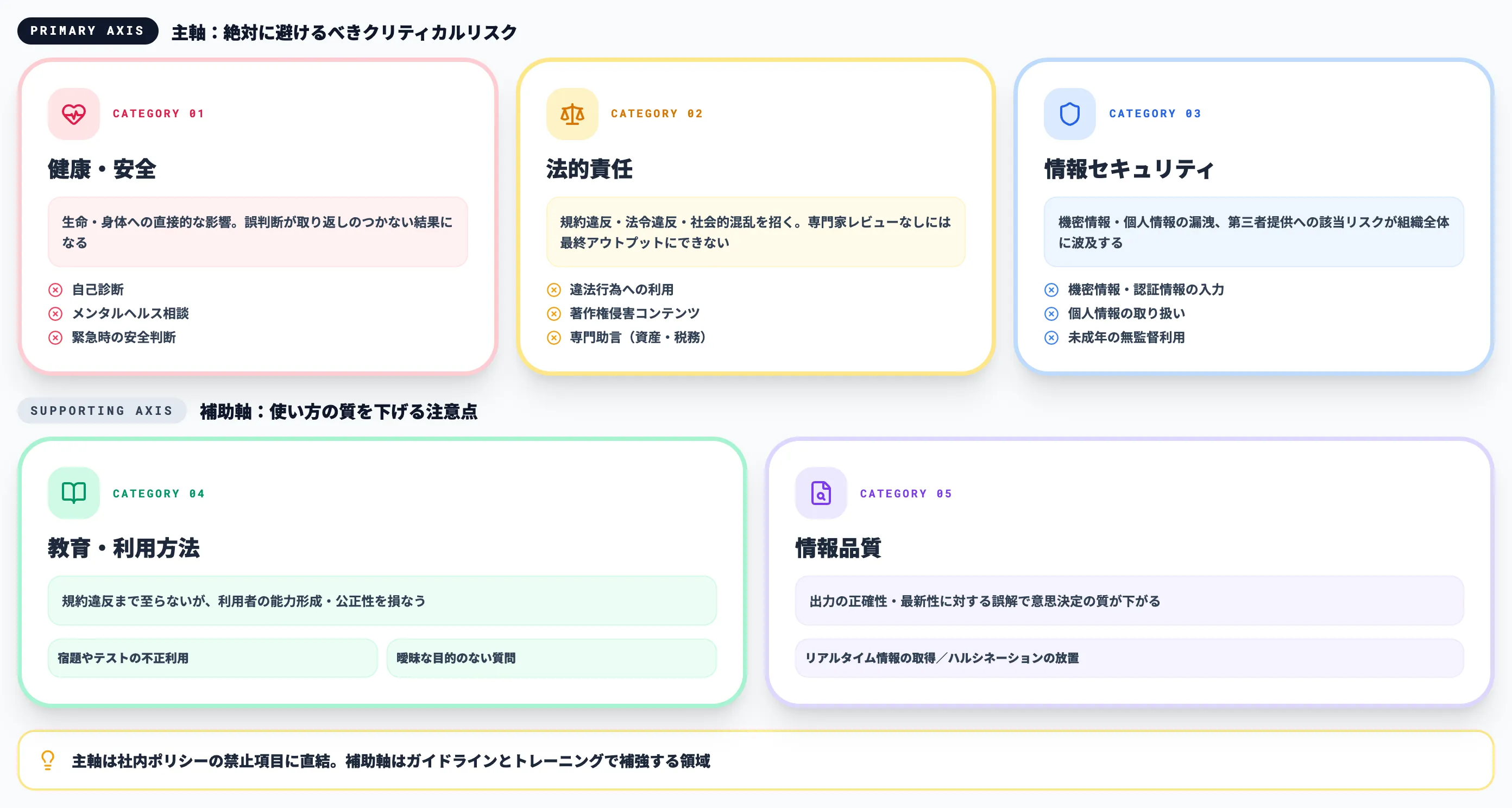
以下の表に、5つのカテゴリとリスクの性質、本記事で扱う12項目との対応関係を整理しました。各カテゴリの具体的なNG行為は次章でカテゴリ別に解説します。
| カテゴリ | 位置づけ | リスクの性質 | 本記事で扱う代表的なNG行為 |
|---|---|---|---|
| 健康・安全 | 主軸 | 生命・身体への直接的な影響。誤判断が取り返しのつかない結果になる | 自己診断、メンタルヘルス相談、緊急時の安全判断 |
| 法的責任 | 主軸 | 規約違反・法令違反・社会的混乱を招く。専門家レビューなしには最終アウトプットにできない | 違法行為、著作権侵害、虚偽情報の拡散、専門助言(資産運用・税務) |
| 情報セキュリティ | 主軸 | 機密情報・個人情報の漏洩、第三者提供への該当 | 機密情報や認証情報の入力、未成年の無監督利用 |
| 教育・利用方法 | 補助軸 | 規約違反まで至らないが利用者の能力形成・公正性を損なう | 宿題やテストの不正利用、曖昧な目的のない質問 |
| 情報品質 | 補助軸 | 出力の正確性・最新性に対する誤解。意思決定の質が下がる | リアルタイム情報の取得、ハルシネーションの放置 |
主軸は「絶対に避けるべきクリティカルリスク」で社内ポリシーの禁止項目に直結し、補助軸は「使い方の質を下げる注意点」で利用ガイドラインやトレーニングで補う領域です。
個別NGリストを並べる前にこのカテゴリ整理を先に行うと、新しい使い方が出てきたときも判断軸を流用できます。

ChatGPTで絶対に避けるべき12のNG行為【2026年最新版】

ここでは、5つのカテゴリ(主軸3+補助軸2)に沿って12のNG行為を整理します。各項目について「なぜダメなのか」「代わりに何をすべきか」をセットで示すため、社内ルール化の際にもそのまま転用できます。
以下の表に、12項目をカテゴリ別にまとめました。表の後に、各カテゴリのH3で詳細を解説します。
| No. | カテゴリ | やってはいけないこと | 代替手段 |
|---|---|---|---|
| 1 | 健康・安全 | 痛みや病気の自己診断 | 医療機関を受診、オンライン診療 |
| 2 | 健康・安全 | メンタルヘルスの問題解決 | 精神科・心療内科、相談窓口 |
| 3 | 健康・安全 | 緊急時の安全判断 | 119/110、#7119(実施地域のみ) |
| 4 | 法的責任 | 個人的な資産運用や税金対策 | FP、税理士、証券会社 |
| 5 | 情報セキュリティ | 機密情報や規制対象データの入力 | Business/Enterprise契約、社内LLM |
| 6 | 法的責任 | 違法行為への利用 | 不可。利用規約違反 |
| 7 | 教育・利用方法 | 宿題やテストの不正利用 | 学習補助としての利用に限定 |
| 8 | 情報品質 | リアルタイム情報の取得 | 公式アプリ、専門サービス |
| 9 | 教育・利用方法 | 曖昧な目的のない質問 | 目的・条件を明示する |
| 10 | 法的責任 | 著作権を侵害するコンテンツの生成 | オリジナル素材ベースで指示 |
| 11 | 法的責任 | 虚偽情報の意図的な拡散 | 不可。利用規約違反 |
| 12 | 情報セキュリティ | 未成年者の無監督利用 | ペアレンタルコントロール設定 |
主軸3カテゴリで9件(健康・安全3/法的責任4/情報セキュリティ2)、補助軸2カテゴリで3件(教育・利用方法2/情報品質1)の分布です。以下、カテゴリ別に詳細を見ていきます。
健康・安全に関わる利用
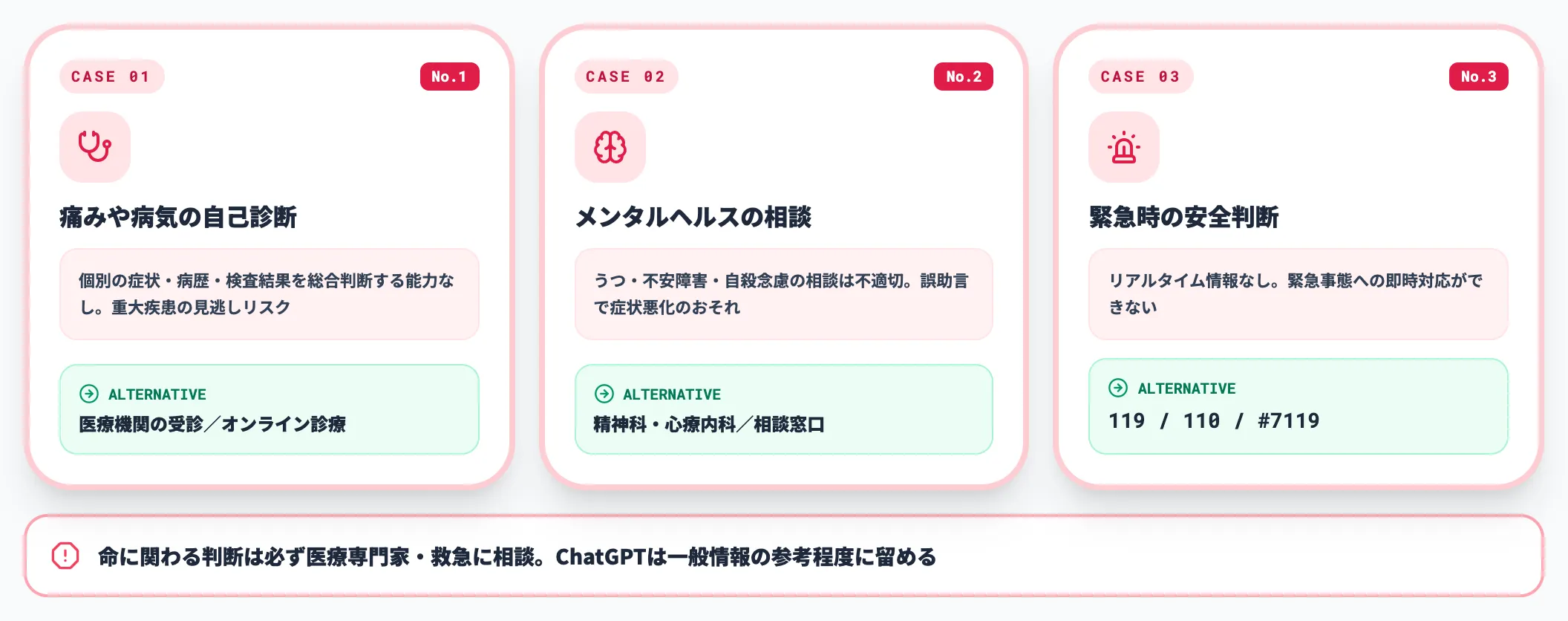
健康・安全に関わる判断は、誤った情報を鵜呑みにすると生命や身体に直結する不可逆的な被害につながります。ChatGPTは医師でもカウンセラーでも消防隊員でもないため、これらの領域では情報源としても利用しない方針が安全です。
No.1 痛みや病気の自己診断
医療診断や治療方針の決定にChatGPTを使用してはいけません。ChatGPTは医療専門家ではなく、個別の症状・病歴・検査結果を総合的に判断する能力を持ちません。
「頭痛が続いているけれど何の病気か」「この薬を飲んでも大丈夫か」といった質問は、重大な疾患の見逃しやアレルギー・副作用のリスクにつながります。
症状がある場合は必ず医療機関を受診し、ChatGPTは一般的な健康情報の参考程度に留めてください。OpenAIのUsage Policiesも、有資格者の関与なしで医療助言を完結させることを明示的に禁止しています。
No.2 メンタルヘルスの問題解決
うつ病・不安障害・自殺念慮などの深刻なメンタルヘルス問題の相談にChatGPTは不適切です。ChatGPTは心理カウンセラーや精神科医の代わりにならず、誤ったアドバイスが症状を悪化させるおそれがあります。
「死にたい気持ちがある」「パニック発作の対処法を知りたい」「薬を減らしても大丈夫か」といった相談は、専門的な介入が必要なケースです。
精神科・心療内科の受診、または以下の相談窓口を利用してください。電話相談窓口は受付時間が変わる場合があるため、利用前にいのちの電話 公式サイトなどで最新の受付時間を確認してください。命の危険がある場合は迷わず119/110に通報します。
- いのちの電話(フリーダイヤル)
0120-783-556(受付時間は公式サイトを要確認、毎日16:00〜21:00/毎月10日は8:00〜翌8:00など)
- こころの健康相談統一ダイヤル
0570-064-556(実施自治体により受付時間が異なる)
- よりそいホットライン
0120-279-338(24時間対応/一般社団法人社会的包摂サポートセンター)
No.3 緊急時の安全判断
火災・地震・事故などの緊急時の判断にChatGPTを使用してはいけません。ChatGPTはリアルタイム情報を持たず、緊急事態への即座の対応ができません。
「家が火事だけれどどうすればいい」「交通事故の応急処置」といった状況では、すぐに119番(消防・救急)または110番(警察)に通報してください。
緊急性の判断に迷う場合は #7119(救急安心センター)に電話することで、救急車を呼ぶべきかどうかのアドバイスを受けられます。
法的責任が伴う利用
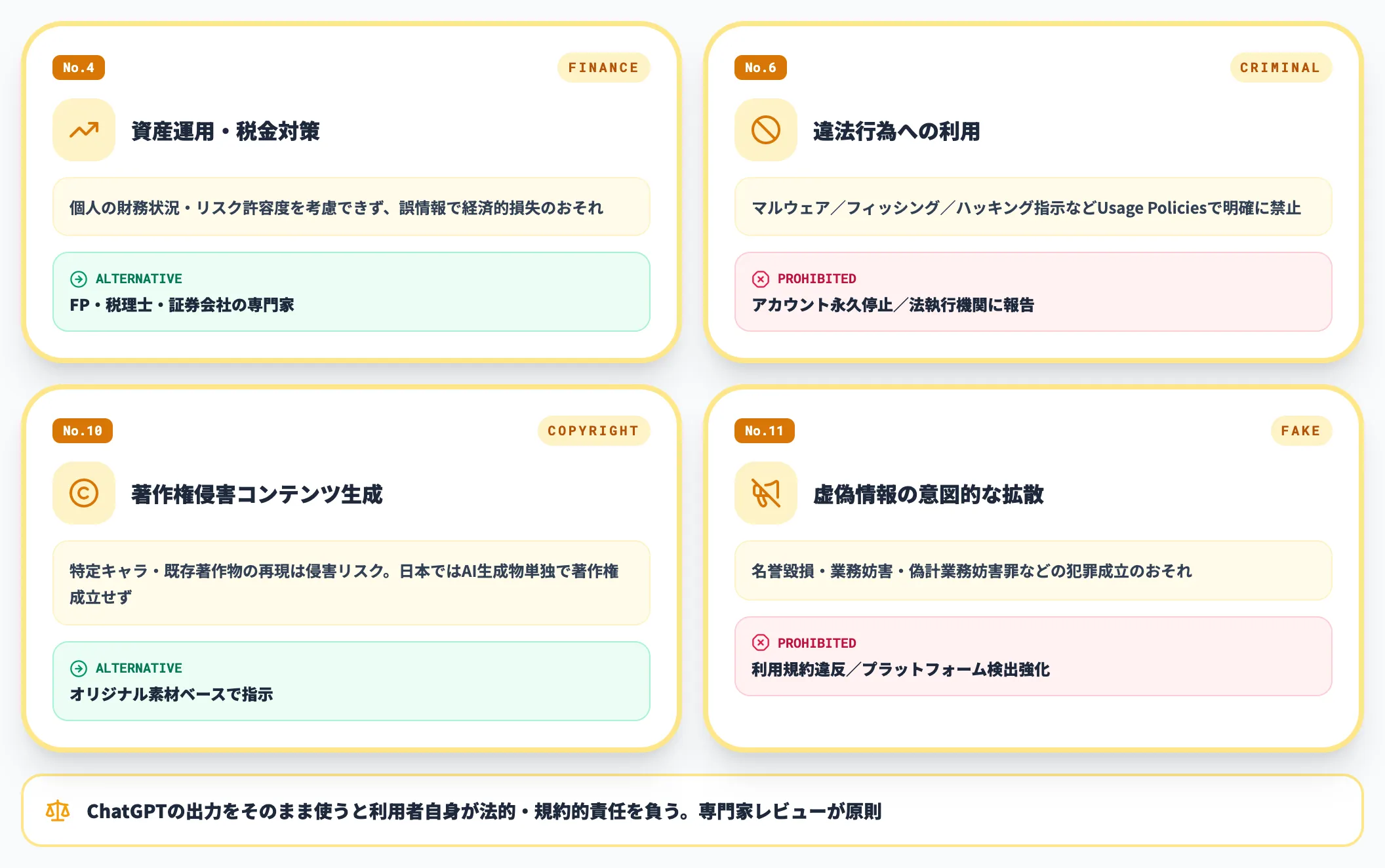
法的責任が伴う領域は、ChatGPTの出力をそのまま使うと利用者自身が法的・規約的な責任を負います。専門家のレビューなしに最終アウトプットとして使わないのが原則です。
No.4 個人的な資産運用や税金対策
具体的な投資判断・税務申告にChatGPTを利用してはいけません。ChatGPTは個人の財務状況やリスク許容度を考慮できず、誤った情報で経済的損失を被る可能性があります。
「この株を買うべきか」「確定申告でこの経費は認められるか」「仮想通貨の税金計算」といった質問は、それぞれファイナンシャルプランナー(FP)、税理士、証券会社の専門家に相談すべき内容です。
OpenAI Usage Policiesも、免許を要する専門助言(法務・医療・金融など)を有資格者の関与なしに提供することを禁止しています。
No.6 違法行為への利用
違法行為の計画・実行にChatGPTを使用することは厳禁です。Usage Policiesでも明確に禁止されており、アカウント停止や法的措置の対象になります。
禁止されている利用例としては、マルウェア・ウイルスのコード生成、フィッシング詐欺メールの作成、ハッキング手法の具体的な指示、違法薬物の製造方法の問い合わせなどが挙げられます。
OpenAIは違法コンテンツ検出を継続的に強化しており、違反ユーザーのアカウント永久停止や、重大な違反の法執行機関への報告も実施しています。
No.10 著作権を侵害するコンテンツの生成
他人の著作物をそのまま再現・模倣するコンテンツの生成は著作権侵害にあたります。ChatGPTで生成したコンテンツが既存の著作物に酷似している場合、法的責任を問われる可能性があります。
「ハリー・ポッターの続編を書いて」「特定キャラクターのロゴを生成して」といった指示は、著作権・商標権侵害のリスクがあります。日本ではAI生成物の著作権は「人間の創作的寄与」がなければ成立しないとされており、完全なAI生成物は著作権保護の対象外です。
AI生成物を商用利用する場合は、ChatGPTの商用利用の解説も合わせて確認してください。
No.11 虚偽情報の意図的な拡散
フェイクニュース・デマの作成や拡散にChatGPTを使用してはいけません。
ChatGPTで作成したもっともらしい虚偽情報を拡散する行為は、名誉毀損・業務妨害・偽計業務妨害罪などの犯罪になる可能性があります。
Usage Policiesでも、他人を操作・欺くための利用や、人々の権利行使を妨げるための利用は明確に禁止されています。AI生成コンテンツの透明性表示義務化が一部の国で進んでおり、プラットフォーム各社もAI生成コンテンツの検出を強化しています。
情報セキュリティに関わる利用(
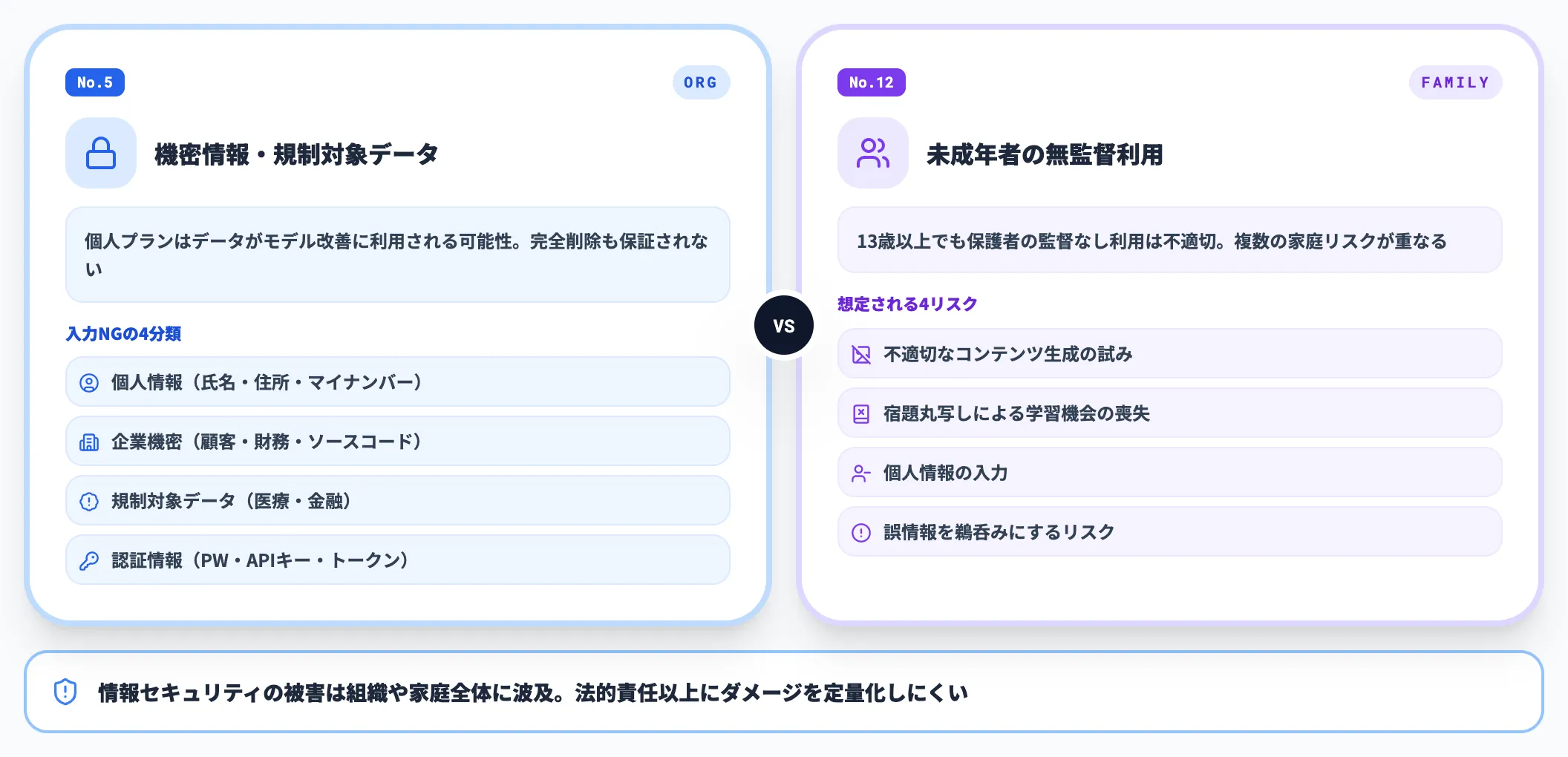
情報セキュリティに関わる利用は、漏洩したときの被害が個人ではなく組織全体に波及します。法的責任に比べてもダメージが定量化しにくく、いったん流出した情報は完全削除が困難です。
No.5 機密情報や規制対象データの入力
企業の機密情報・個人情報・規制対象データを入力してはいけません。個人プランではデータがモデル改善に利用される可能性があり、完全な削除も保証されていないためです。
入力を避けるべき情報は以下のとおりです。
- 個人情報
氏名・住所・電話番号・マイナンバーなど
- 企業機密
未発表の製品情報・顧客リスト・財務データ・ソースコード
- 規制対象データ
医療情報・金融情報(GDPR・個人情報保護法の対象)
- 認証情報
パスワード・APIキー・アクセストークン
これらは「入れない」のが原則で、マスキング・学習除外・プラン選定といった具体的な防御策は本記事後半で扱います。実際に発生した漏洩事例は次章で見ていきます。
No.12 未成年者の無監督利用
13歳以上の未成年者がChatGPTを保護者の監督なしに利用することは避けるべきです。不適切なコンテンツ生成の試み、宿題の丸写しによる学習機会の喪失、個人情報の入力、誤情報を鵜呑みにするリスクがあります。
OpenAIが2025年9月末に本格ロールアウトしたペアレンタルコントロール機能を活用することで、利用時間帯の制限や一部機能の制限、危険な対話の検知時の保護者通知などの管理が可能です。
詳しい設定方法は後述する「ChatGPTを安全に使うための対策」セクションで紹介します。
教育・利用方法と情報品質に関わる利用(No.7〜9)
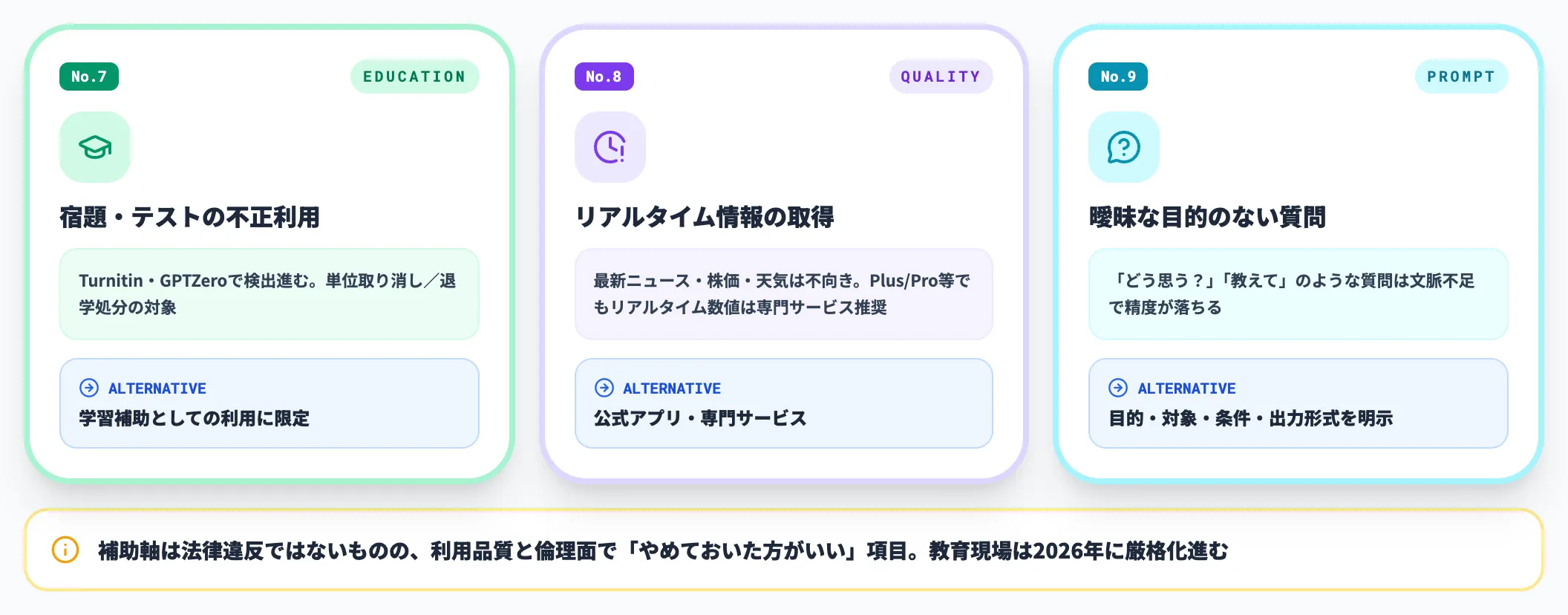
ここで扱うNo.7〜No.9は法律違反ではないものの、利用品質や倫理面で「やめておいた方がいい」項目です。とくに教育現場での扱いは2026年に入って厳格化が進んでいます。
No.7 宿題やテストの不正利用
宿題の丸写し・試験のカンニングにChatGPTを使用してはいけません。本来身につけるべきスキルや知識が習得できず、長期的な学力低下につながります。
教育現場ではAI生成文章検出ツール(Turnitin、GPTZero等)の導入が進んでおり、不正利用が発覚した場合は単位取り消しや退学処分の対象になります。
一方で、概念の理解を深めるための質問、自分で書いた文章の文法チェック、プログラミングのエラー解決のヒント取得など、ChatGPTを学習補助として適切に活用する方法も広がっています。
No.8 リアルタイム情報の取得
飛躍的に性能は進歩していますが、最新ニュース・株価・天気などのリアルタイム情報取得をChatGPT頼りで行うのは未だ最善とはいえません。
2026年4月時点のプラン別の状況は以下のとおりです。
- Free(無料版)
Webブラウジング機能は制限あり。リアルタイム情報の正確性は保証されない
- Plus / Pro / Business / Enterprise
Deep ResearchやWebブラウジングを利用可能。ただし株価や為替のリアルタイム数値は専門サービスを使うべき
リアルタイム性が求められる情報は、証券会社のアプリ、ニュースサイト、天気予報サービスなどの専門ソースを利用してください。
No.9 曖昧な目的・背景のない質問
具体性のない質問では、ChatGPTから期待する回答は得られません。ChatGPTは文脈から最も確率の高い回答を返すため、曖昧な質問には一般的な回答しか返せないからです。
たとえば「どう思う?」「これについて教えて」「良い方法ある?」といった質問は避けてください。代わりに、目的・対象・条件・出力形式を含めた具体的な質問をすると回答精度が向上します。
- 「Pythonで画像処理を行う際、OpenCVとPillowの違いを教えて」
- 「マーケティング戦略で、SNS広告とSEOのどちらを優先すべきか、費用対効果の観点から比較して」
- 「英語のプレゼンで緊張を和らげる具体的なテクニックを3つ教えて」
質問の精度がそのまま回答の精度に直結するため、プロンプト設計のスキルを身につけることもChatGPT活用の重要なポイントです。
ChatGPTの情報漏洩リスクと代表的な重大事例
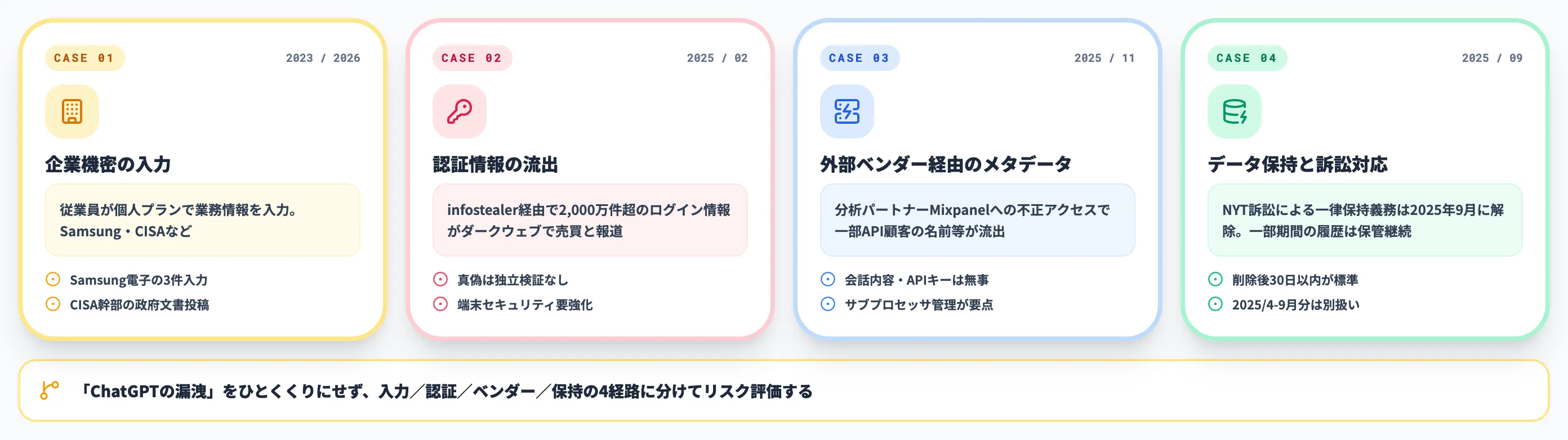
ChatGPT周辺の情報漏洩事案は、性質の異なる事件をひとくくりに「ChatGPTの漏洩」と語るとリスク評価がぼやけます。
本章では、企業機密の入力・認証情報の流出・外部ベンダー由来のメタデータ露出という3つの異なる経路に分けて代表事例を整理し、最後にOpenAI自身のデータ保持方針の現状を確認します。ChatGPTのセキュリティリスクを体系的に押さえたい方は、あわせて関連記事も参照してください。
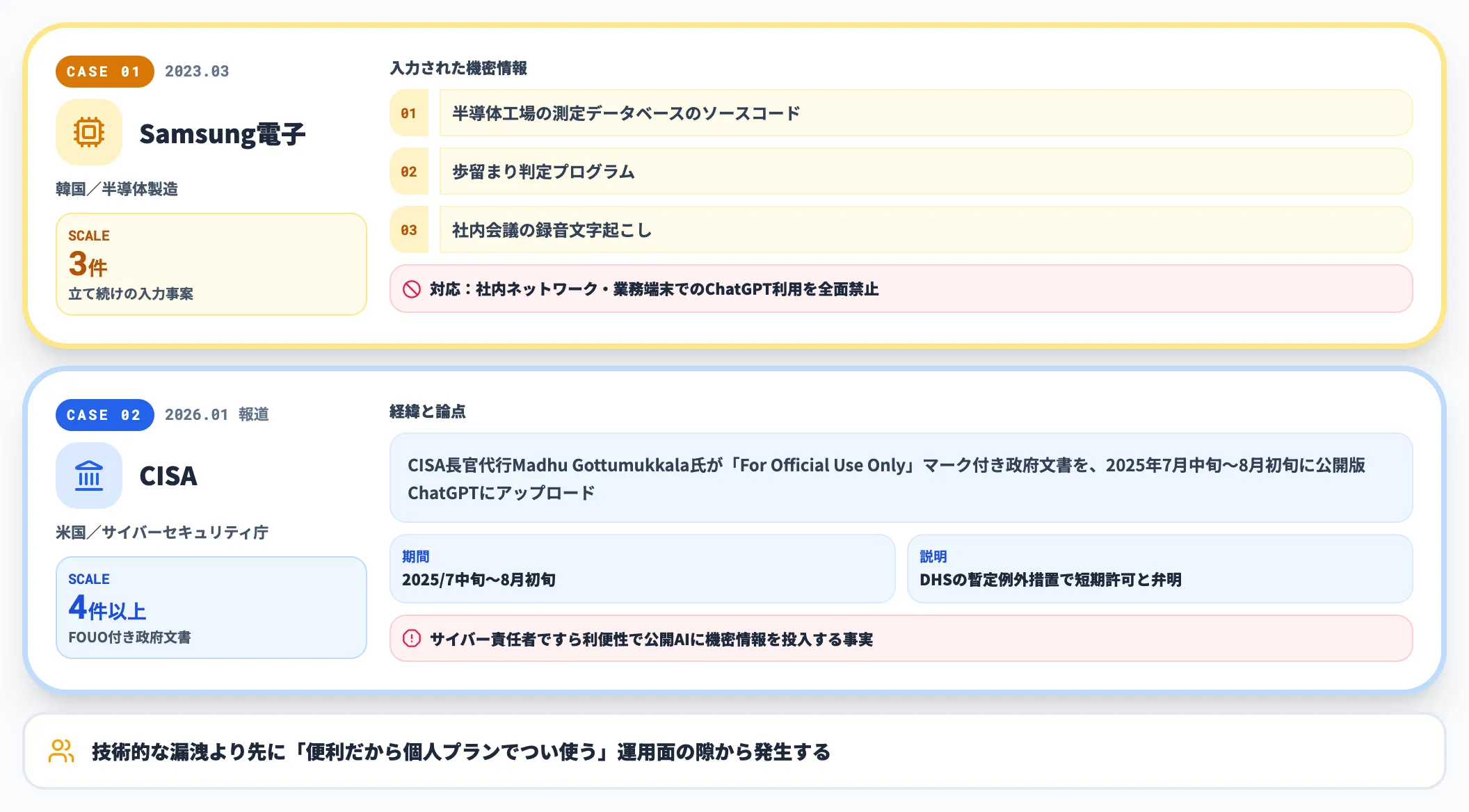
企業機密の入力事例(Samsung・CISA)
最も古典的なリスクは、従業員が業務上の機密情報を個人プランのChatGPTに入力してしまうケースです。
学習除外を有効化していなかったり、入力時点で「第三者提供」とみなされたりするため、被害が顕在化しなくても規程違反になります。
2023年3月の韓国Samsung電子の事案では、半導体工場の測定データベースのソースコード、歩留まり判定プログラム、社内会議の録音文字起こし、という3件の機密情報入力が立て続けに発生しました。
Samsung電子はこの事件を受けて、社内ネットワークおよび業務端末でのChatGPT利用を全面禁止するポリシーを策定しています。同様の対応はJPモルガン・チェース、Apple、Amazonなどのグローバル企業でも広がっています。
また、2026年1月には、米国サイバーセキュリティ・インフラセキュリティ庁(CISA)の長官代行Madhu Gottumukkala氏が「For Official Use Only」マーク付きの政府文書(少なくとも4件)を公開版ChatGPTに2025年7月中旬から8月初旬にかけてアップロードしていたことが報道されました。
CISA側はDHSの暫定例外措置で短期的にChatGPT利用が認められていたと説明していますが、サイバーセキュリティの責任者ですら利便性を優先して公開版AIに機密情報を入力してしまうという事実は、組織的なガイドライン整備の重要性を改めて示しています。
実務では、企業機密の入力は技術的な漏洩よりも先に「便利だから個人プランでつい使ってしまう」運用面の隙から発生します。法人向けプランの導入と並行して、入力禁止情報を社内ポリシーで明文化することがセットで必要です。
認証情報の流出リスク(infostealer由来)
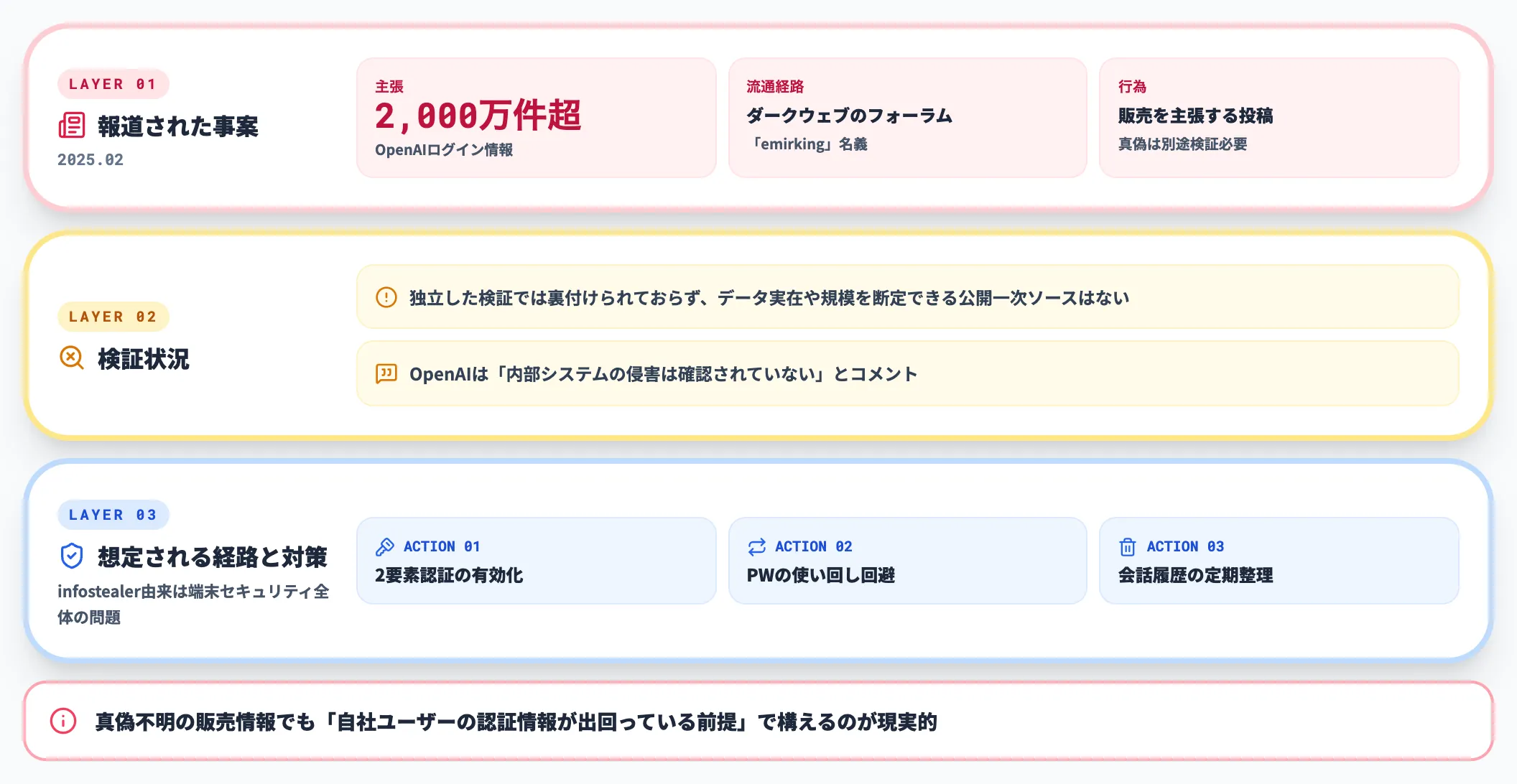
2025年2月には、「emirking」を名乗る人物がダークウェブのフォーラムで2,000万件超のOpenAIログイン情報を販売したと主張する投稿が報道されました。
投稿の真偽はその後も独立した検証では裏付けられておらず、データの実在や規模を断定できる公開一次ソースはありません。OpenAIは「内部システムの侵害は確認されていない」とコメントしています。
重要なのは、こうした「OpenAI関連の認証情報がダークウェブで売買された」と報じられる事案では、原因がOpenAI本体への侵害なのか、ユーザー端末に感染したインフォスティーラー(情報窃取マルウェア)経由なのかを公開情報から特定しきれないことです。
組織のリスク評価としては、真偽不明の販売情報であっても「自社ユーザーの認証情報がどこかに出回っている前提」で多要素認証や端末セキュリティの強化を進めるのが現実的な構えになります。
具体的な対策は以下の3点です。
- 二要素認証の有効化
ChatGPTの2段階認証設定で、パスワードだけのログインを許可しない構成にする
- パスワードの使い回し回避
他サービスと同じパスワードを使うと、別サービスの漏洩がそのままChatGPTへの不正ログインに直結する
- 会話履歴の定期整理
ログインされてしまった場合に過去会話から得られる情報量を最小化する
ChatGPTのアカウントは過去の会話履歴を含むため、一般的なWebサービス以上にアカウント保護が重要です。同様にinfostealer由来の漏洩はGoogleやMicrosoftのアカウントでも頻発しており、ChatGPT固有の問題ではなく端末セキュリティ全体の問題として扱うのが正確です。
外部ベンダー経由のメタデータ露出(Mixpanel)

2025年11月には、OpenAIの分析パートナーであるMixpanelへの不正アクセスにより、APIプラットフォームの一部顧客の名前・メールアドレス・おおよその所在地などが流出しました。
重要な点は、この事件で流出したのはAPIプラットフォームのフロントエンド分析データ(ユーザー識別情報)に限定されており、ChatGPTの会話内容・APIキー・パスワード・支払い情報・APIリクエスト本体は流出していないことです。
このタイプの事案を「ChatGPTから会話が漏れた」と理解すると過剰反応になり、逆に「外部ベンダー経由でメタデータが漏れた」という構造を見落とすと再発防止策が組めません。
OpenAIはMixpanelとの契約を即時終了し、全ベンダーのセキュリティレビューを実施しています。
実務で押さえておくべきは以下の3点です。
- 直接連携ベンダーの棚卸し
LLM提供事業者だけでなく、その分析・運用パートナーまで含めて契約状況を把握する
- メタデータの最小化
ユーザー名・メールアドレスは業務委託先に渡さなくても済むよう設計を見直す
- インシデント時の通知ルート
OpenAIから直接通知が届く前に外部報道で把握する事態を避けるため、サブプロセッサ一覧の更新を定期確認する
外部ベンダー由来の漏洩はLLM全体の構造的なリスクで、Anthropic・Google・Microsoftも例外ではありません。ベンダー監査をChatGPTだけでなく利用中のすべての生成AIサービスに広げて運用する方針が現実的です。
OpenAIのデータ保持と訴訟対応
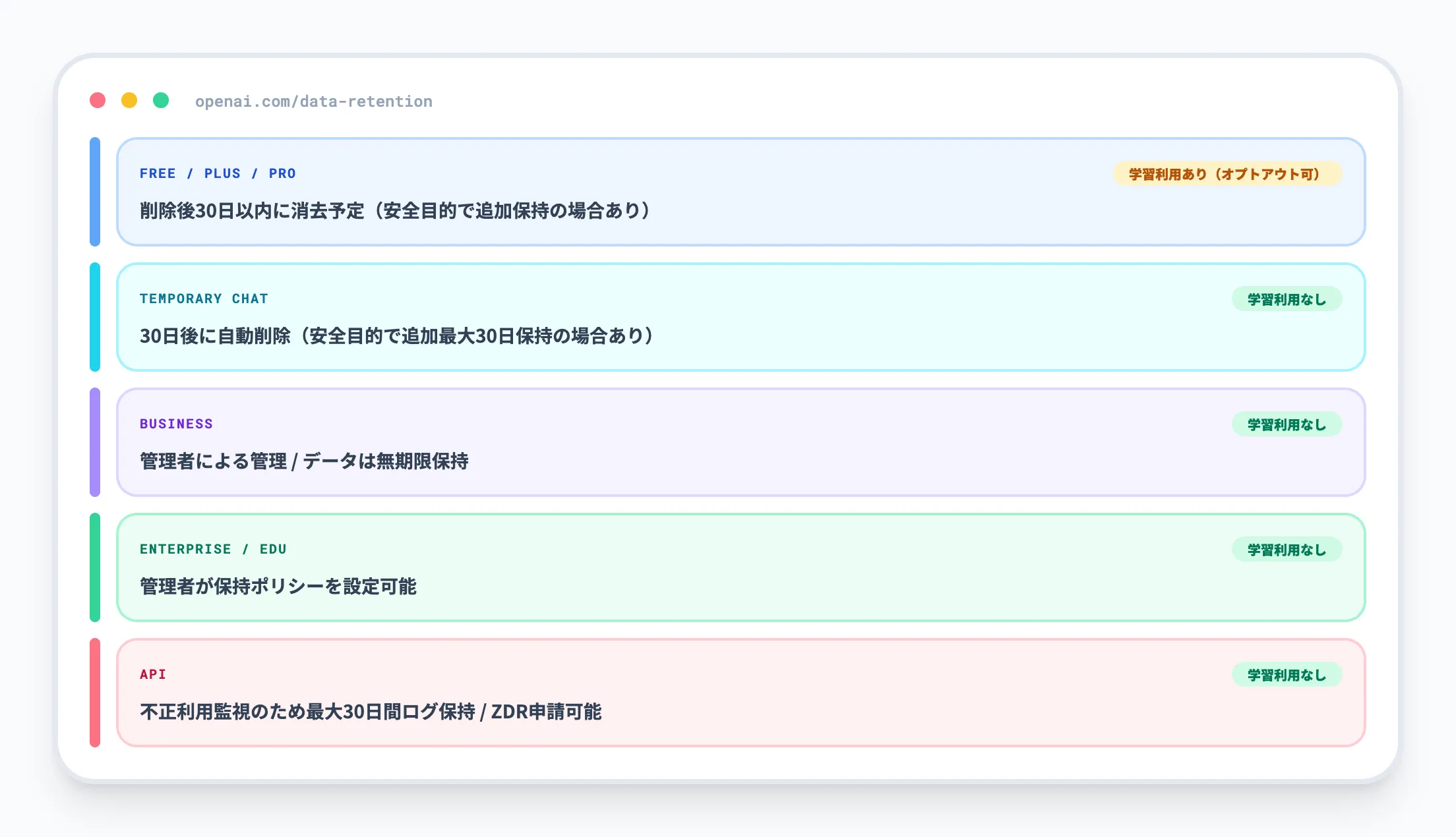
OpenAIはユーザーが削除したチャット履歴を30日以内にシステムから削除する方針です。
ただし、匿名化済みデータや法的・安全上の理由により一部が保持される場合があります。
プラン別のデータ取り扱いは以下のとおりです。
| プラン | データの扱い |
|---|---|
| Free / Go / Plus / Pro | チャット履歴はアカウントに保存。削除後30日以内にシステムから消去予定(安全目的で追加保持の場合あり) |
| 一時チャット | 30日後に自動削除。モデルトレーニングには使用されない |
| Business | ワークスペース管理者が管理。データは無期限保持。学習には使用されない |
| Enterprise / Edu | 管理者が保持ポリシーを設定可能(例:90日、180日等)。学習には使用されない |
| API | デフォルトでは不正利用監視のため最大30日間ログを保持。対象組織はゼロデータ保持(ZDR)を申請可能 |
2025年9月26日以降、過去のNYT訴訟に基づく一律のデータ保持義務が解除され、削除処理は標準仕様どおりに戻りました。ただしOpenAIは同時に、訴訟中に保持していた2025年4月〜9月の限定的な履歴データは法的対応のため引き続き安全に保管すると説明しています。
新規入力分は通常どおり削除されますが、この期間に入力されたデータは別途扱いになる点を押さえておく必要があります。
ただし機密情報を入力してしまった場合、即座の完全削除は困難です。入力する前にリスクを判断することが最も効果的な対策で、これは技術仕様ではなく運用ルールでカバーする領域です。
漏洩が起きた場合の対応はChatGPTの情報漏洩事例とは?もあわせて参照してください。
ChatGPTの利用規約と日本の法的リスク
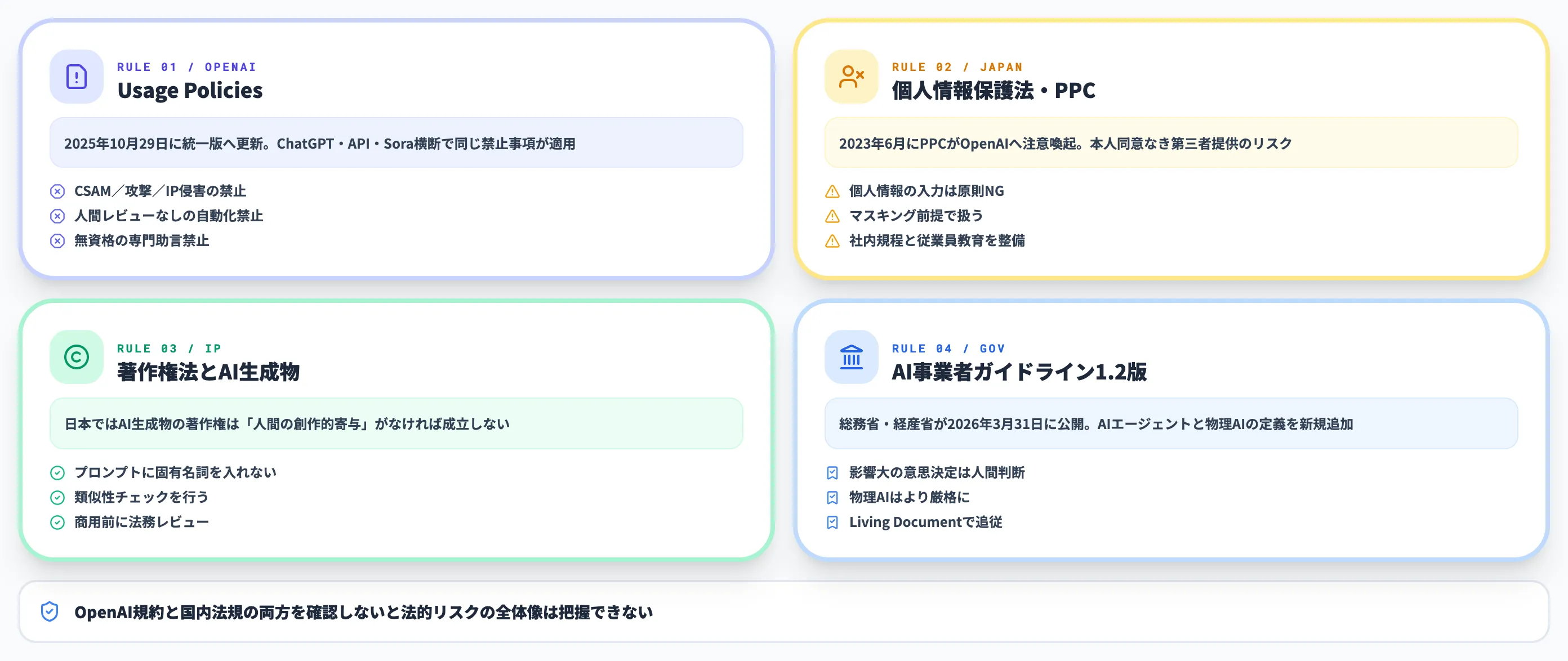
ChatGPTの法的リスクは、OpenAI側の規約と日本国内の関連法規の両方を確認しないと全体像が見えません。
本章では、Usage Policies(2025年10月29日更新)、個人情報保護法、著作権法、AI事業者ガイドライン第1.2版(2026年3月31日公開)の4本立てで整理します。
日本のAI規制法の動向もあわせて押さえると判断に厚みが出ます。
Usage Policies(2025年10月29日更新版)の禁止事項
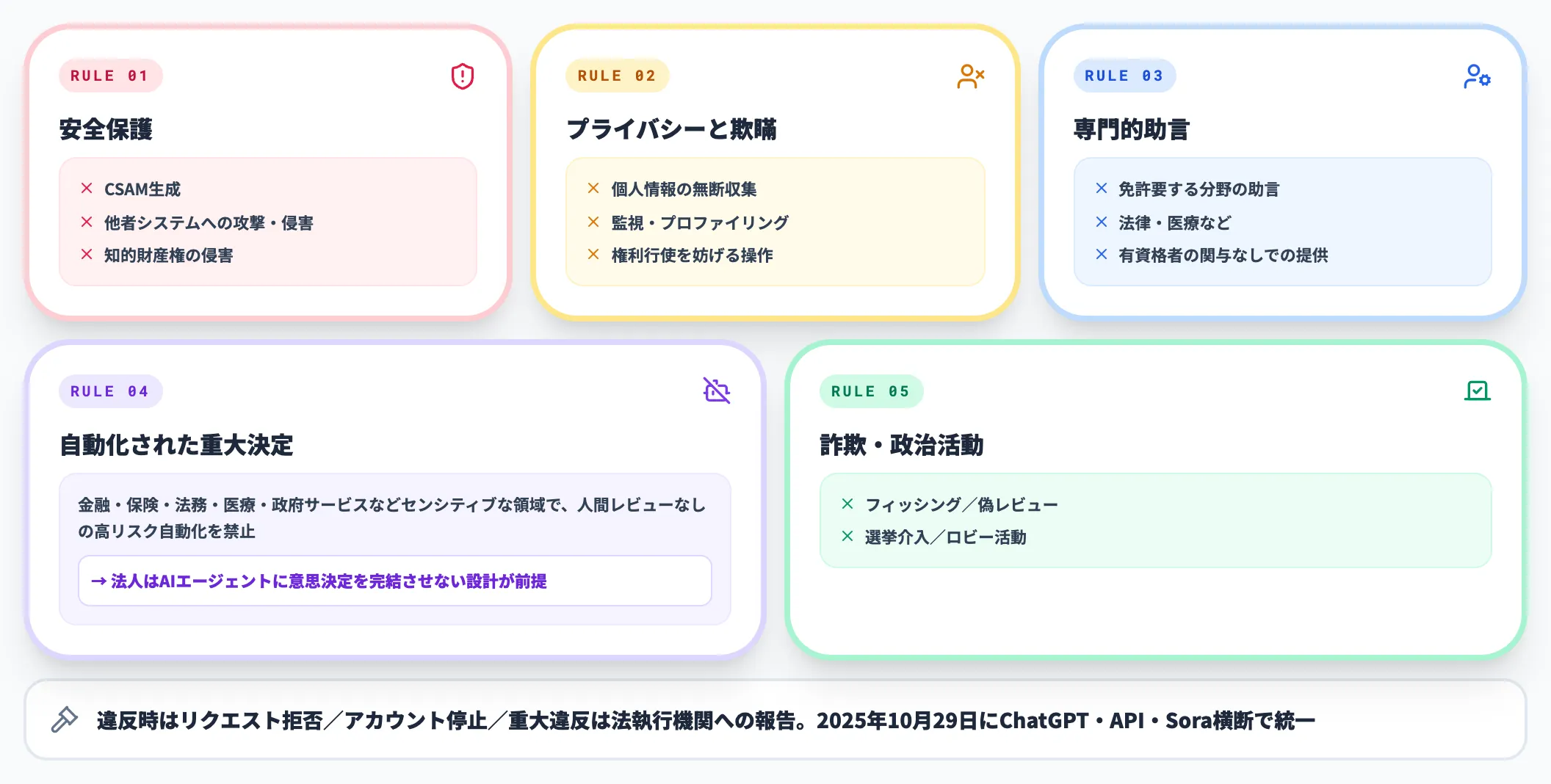
OpenAIのUsage Policiesは2025年10月29日に統一版へ更新され、ChatGPT・API・Soraなどのプロダクト横断で同じ禁止事項が適用されるようになりました。
主要な禁止カテゴリは以下のとおりです。
- 安全保護
児童性的虐待コンテンツ(CSAM)の生成、他者のシステムへの攻撃・侵害、知的財産権の侵害
- プライバシーと欺瞞
他者のプライバシーの侵害(個人情報の無断収集・監視・プロファイリング)、人々の権利行使を妨げる操作・欺瞞
- 専門的助言
法律や医療など、免許を要する専門的助言を、有資格者の関与なしに提供すること
- 自動化された重大決定
金融・保険・法務・医療・政府サービスなど、センシティブな領域で人間のレビューなしに高リスクの意思決定を自動化すること
- 詐欺・政治活動
フィッシング・偽レビュー・選挙介入・ロビー活動への利用
違反が確認された場合、生成リクエストの拒否、アカウントの一時停止または永久停止が行われます。
重大な違反は法執行機関に報告される場合もあります。具体的な違反事例の傾向や回避策はChatGPTのポリシー違反で個別に解説しています。
法人で押さえておくべきは、AIエージェントに意思決定を完結させる構成が規約上も否定されていることです。最終判断を人間が握る設計が前提になります。
個人情報保護法とPPC注意喚起
日本国内では、個人情報保護委員会(PPC)が2023年6月にOpenAIに対して生成AIサービスの利用に関する注意喚起を行い、現在もこの方針が運用上の基準となっています。ChatGPTに個人情報を入力する行為は、本人の同意なく第三者提供にあたる可能性があり、法律違反のリスクがあります。

OpenAI に対する注意喚起の概要 (出典:個人情報保護委員会)
企業がChatGPTを業務利用する場合は、個人情報の取り扱いに関する社内規程を整備し、従業員への教育を徹底することが求められます。
実務的には「個人情報は原則マスキング」「やむを得ず扱う場合はデータが学習に使われない法人向け環境に限定」のように、層構造で運用するのが一般的です。具体的なプラン選定は本記事末尾のH2「プラン別セキュリティ比較」で整理します。
著作権法とAI生成物の取り扱い

著作権法の観点では、日本ではAI生成物の著作権は「人間の創作的寄与」がなければ成立しないとされています。完全にAIが生成した文章や画像は著作権で保護されない可能性があり、商用利用するなら人間の編集や選択を加えるのが安全です。
一方で、既存の著作物に酷似した出力が生成された場合、利用者がその出力を公開・利用すれば著作権侵害に問われるリスクがあります。
実務では「プロンプトに著作物の固有名詞を入れない」「生成物の類似性チェックを行う」「商用公開前に法務レビューを通す」の3点が基本対策です。
商用利用を進める前に、ChatGPTの商用利用で規約面の制約も確認してください。
AI事業者ガイドライン第1.2版(2026年3月31日公開)
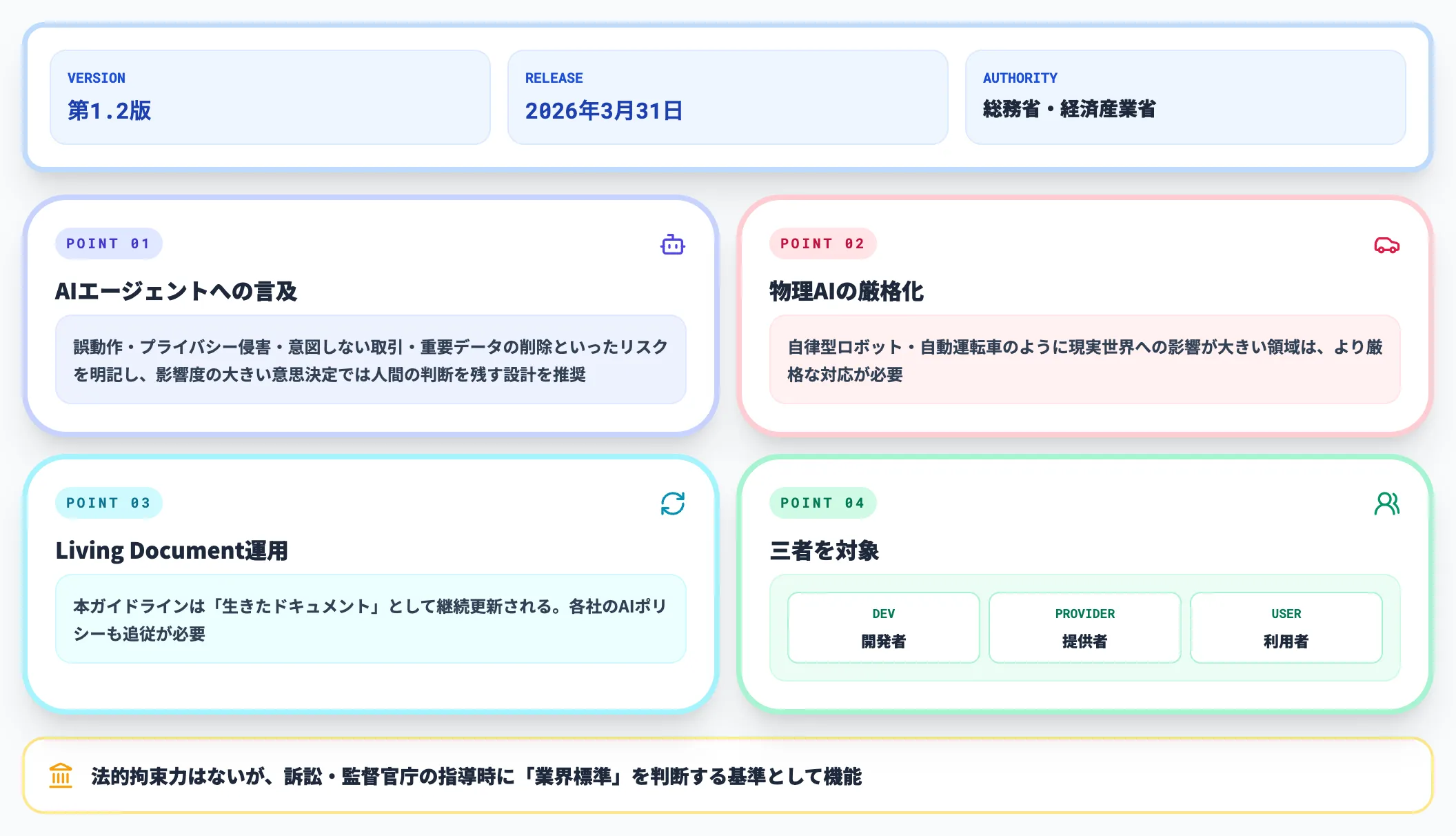
総務省・経済産業省が2026年3月31日に公開したAI事業者ガイドライン第1.2版が、2026年4月時点の最新版です。
第1.2版では、AIの利用が「実証段階から社会実装段階へ移行した」との認識のもと、AIエージェントと物理AI(自律型ロボット・自動運転車等)に関する定義と人間判断必須の設計思想が新たに追加されました。
本ガイドラインがChatGPTを業務利用する企業にとって押さえるべき要点は以下のとおりです。
- AIエージェントへの言及
誤動作・プライバシー侵害・意図しない取引・重要データの削除といったリスクを明記し、影響度の大きい意思決定では人間の判断を残す設計を推奨
- 物理AIの厳格化
自律型ロボット・自動運転車のように現実世界への影響が大きい領域は、より厳格な対応が必要
- 生きたドキュメント運用
本ガイドラインは「Living Document」として継続更新される。各社のAIポリシーも追従が必要
- 対象は開発者・提供者・利用者の三者
ChatGPTを社内利用する企業は「利用者」の立場で、ガイドラインに沿ったリスク管理が求められる
本ガイドラインに法的拘束力はありませんが、訴訟や監督官庁の指導が入ったときに「業界標準を満たしていたか」を判断する基準として機能するため、社内のAI利用ルールはこれに整合させておくのが安全です。

ChatGPTを安全に使うための対策【個人・法人別】

ChatGPTのリスクを理解したうえで、安全に活用するための具体的な対策を整理します。
個人ユーザーの基本対策、法人の社内AIポリシー設計、未成年向けのペアレンタルコントロールの順に解説し、最後に「全面禁止と無策のあいだ」で詰まりやすい論点に触れます。
個人ユーザーの5対策

個人でChatGPTを利用する際は、以下の対策を実践することでリスクを大幅に低減できます。
- 個人情報をプロンプトに入力しない
氏名・住所・電話番号・マイナンバーなどは、たとえ便利であっても入力を避ける
- 回答をそのまま信じない
ChatGPTの回答にはハルシネーション(もっともらしい誤情報)が含まれる可能性がある。重要な判断の前は一次情報で裏取りする
- 一時チャットを活用する
機密性の高い会話では一時チャットを利用する。一時チャットのメッセージは30日後に自動削除され、モデルトレーニングには使用されない
- 学習設定を確認する
「設定」→「データコントロール」から、チャット内容をモデルトレーニングに使用するかどうかを管理できる。プライバシーを重視する場合はオフに設定する。具体的な手順はChatGPTの履歴をオフにする方法で解説
- 二要素認証とパスワード管理
emirking事案のようなinfostealer由来の不正ログインに備え、ChatGPTで2段階認証を設定し、パスワードの使い回しを避ける
ChatGPTへの過度な依存も実は重要な論点です。先述の大学生研究でも、ChatGPTへの過度な依存が先延ばし傾向の増加や記憶力の低下に関連していることが明らかになっています。
AIに頼り切らず、自分の判断力を磨くことが、AIの力を最大限に活かしつつ限界を理解する賢明な利用につながります。
社内AIポリシー策定の3軸
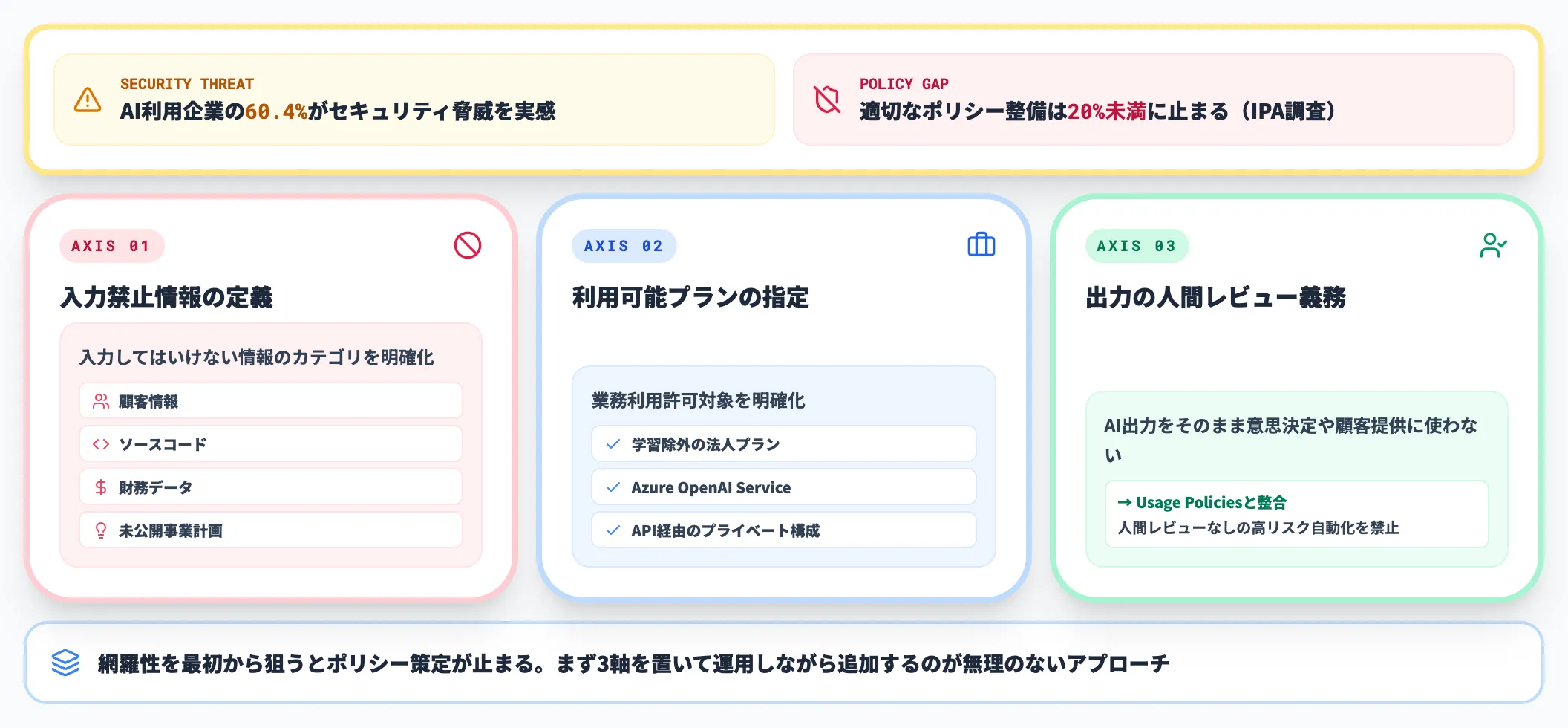
IPAの調査によると、AI利用企業の約60.4%がセキュリティ脅威を感じているにもかかわらず、適切な規則や体制を整備している企業は20%未満にとどまっています。
企業がChatGPTを安全に導入するには、社内AIポリシーの策定が不可欠です。
従業員が無断でAIツールを業務利用するシャドーAIのリスクも含めて対策を講じる必要があります。
実務でよく機能している社内AIポリシーは、最低限以下の3軸で先に組まれています。網羅性を最初から狙うとポリシー策定自体が止まるため、まず3軸を置いて運用しながら追加するのが無理のないアプローチです。
- 入力禁止情報の定義
顧客情報・ソースコード・財務データ・未公開の事業計画など、ChatGPTに入力してはいけない情報のカテゴリを明確にする
- 利用可能プランの指定
データが学習に使われない法人向けプラン、またはAzure OpenAI Service/API経由のプライベート構成のみを業務利用許可対象とする(プラン別の差は本記事末尾のH2で詳説)
- 出力の人間レビュー義務
AI出力をそのまま意思決定や顧客提供に使わない。人間レビューの責任者を明示し、Usage Policiesの「人間レビューなしの高リスク自動化」禁止と整合させる
社内のChatGPT利用をすべて禁止するのではなく、適切なルールのもとで安全に活用するアプローチが、生産性とセキュリティを両立させるうえで効果的です。
自社の規模やセキュリティ要件に応じて、ChatGPT BusinessやChatGPT Enterpriseの導入か、Azureテナント内にプライベートLLM環境を構築するかを判断してください。
法人契約の進め方はChatGPTの法人契約方法で詳しく解説しています。
ペアレンタルコントロール機能の設定
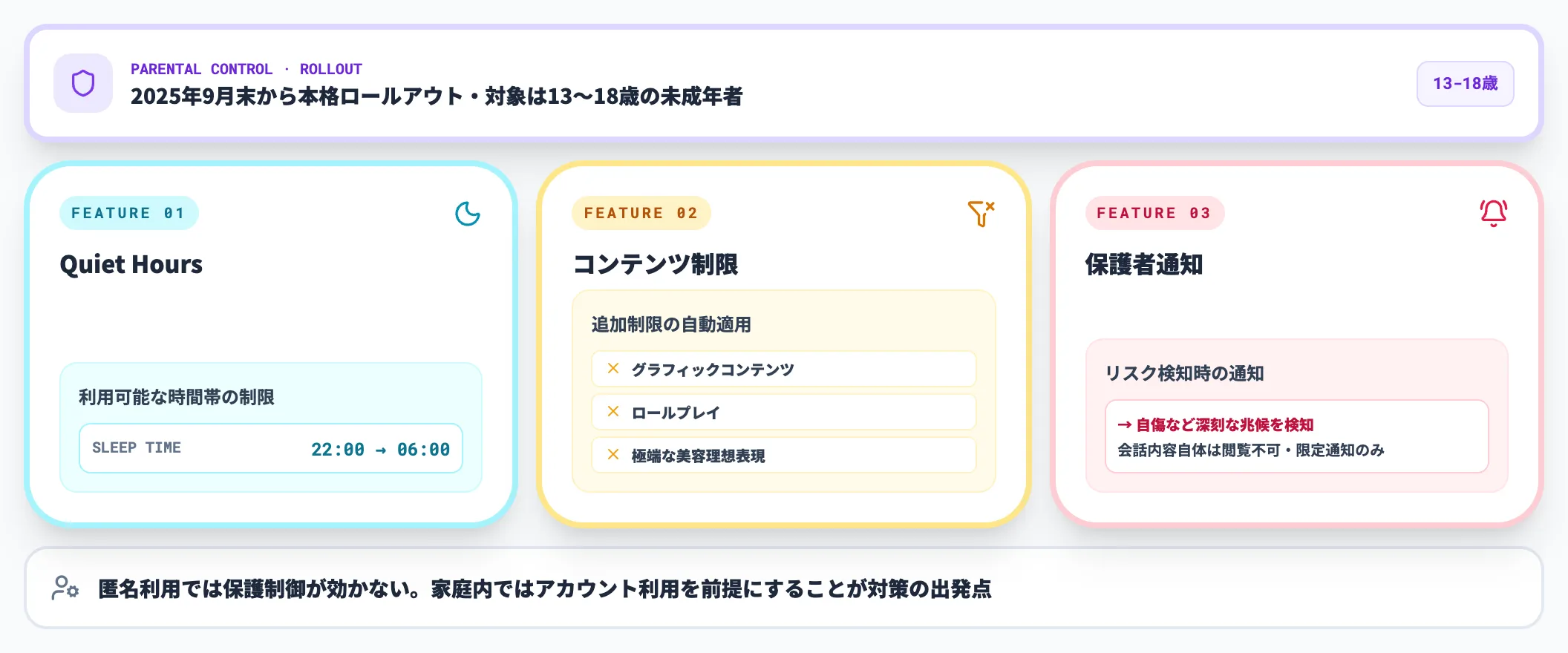
2025年9月末から、ChatGPTにペアレンタルコントロール機能が本格ロールアウトされています。
13歳から18歳の未成年者のアカウントを保護者がリンクし、以下のような設定を管理できます。
- Quiet Hours(サイレント時間)
利用可能な時間帯の制限
- コンテンツ制限の自動適用
グラフィックコンテンツ、ロールプレイ、極端な美容理想表現などへの追加制限
- リスク検知時の保護者通知
自傷など深刻な兆候を検知した際の保護者への通知
OpenAIのペアレンタルコントロール発表では、保護者は会話内容自体を直接閲覧することはできず、深刻な安全リスクが検知された限定的なケースでのみ通知が届く仕組みです。また、サインインせずに匿名でChatGPTを利用すると保護者制御は効かないため、家庭内ではアカウント利用を前提にすることが対策の出発点になります。
導入判断で詰まる論点:「全面禁止」と「無策」のあいだ
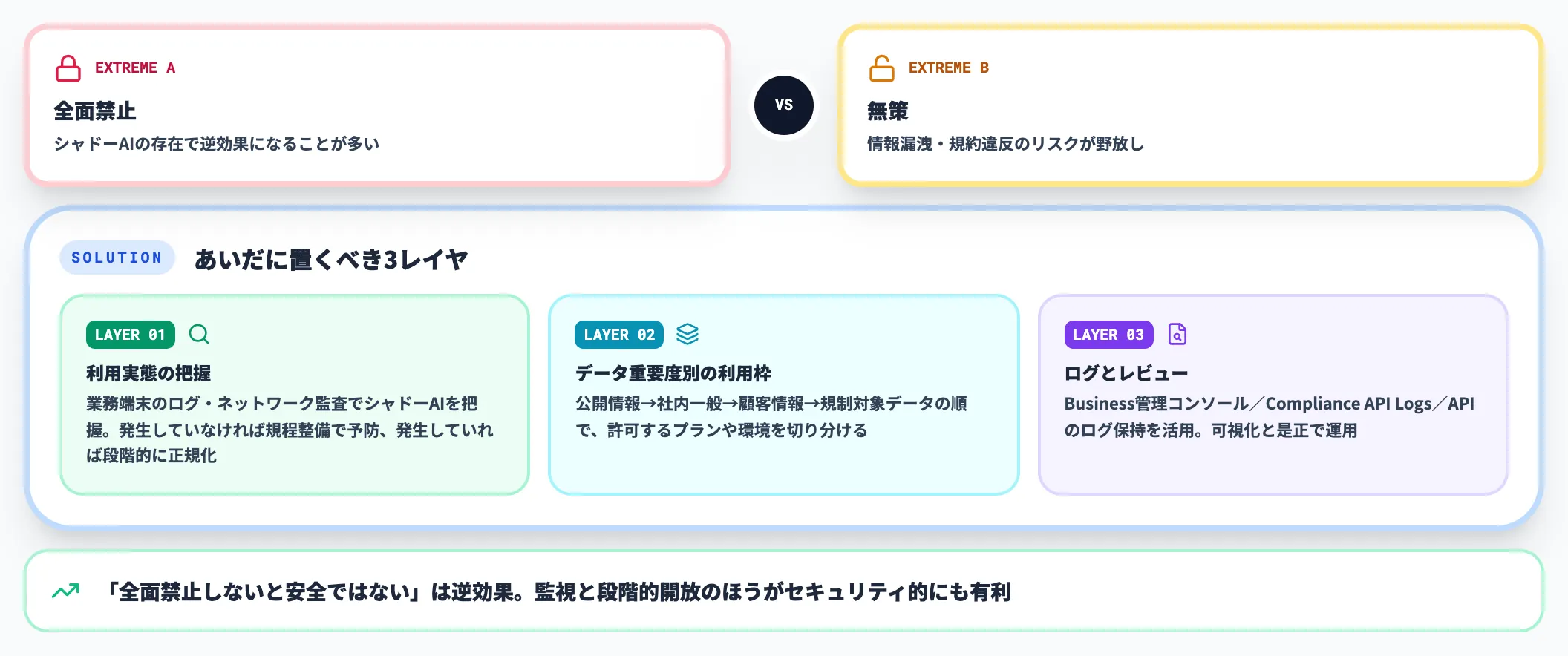
法人の生成AI導入で最も詰まりやすいのが、「全面禁止」と「無策」の二択になってしまう現象です。
実務では、この間に複数のレイヤを置くのが妥当です。
- シャドーAIが現状で発生しているか
業務端末のログやネットワーク監査で利用実態を把握する。発生していなければ規程整備で予防、発生していれば段階的に正規化する
- データ重要度別の利用枠
公開情報のみ→社内一般情報→顧客情報→規制対象データの順で、許可するプランや環境を切り分ける
- 利用ログとレビューの仕組み
Businessの管理コンソール/利用可視化、EnterpriseのCompliance API Logs、APIのログ保持を活用し、全面禁止しなくても可視化と是正で運用する
「全面禁止しないと安全ではない」という前提は、シャドーAIの存在を踏まえると逆効果になることが多く、実務上は監視と段階的開放のほうがセキュリティ的にも有利になります。
ChatGPTで「やってよい/やってはいけない」の境界線

「やってはいけない」の裏返しとして、「ChatGPTにやらせて問題ない領域」「境界が曖昧な領域」を整理しておくと、社内ルールの線引きがしやすくなります。本章では実務で迷いやすい3つのレイヤに分けて整理します。
任せて問題ない領域
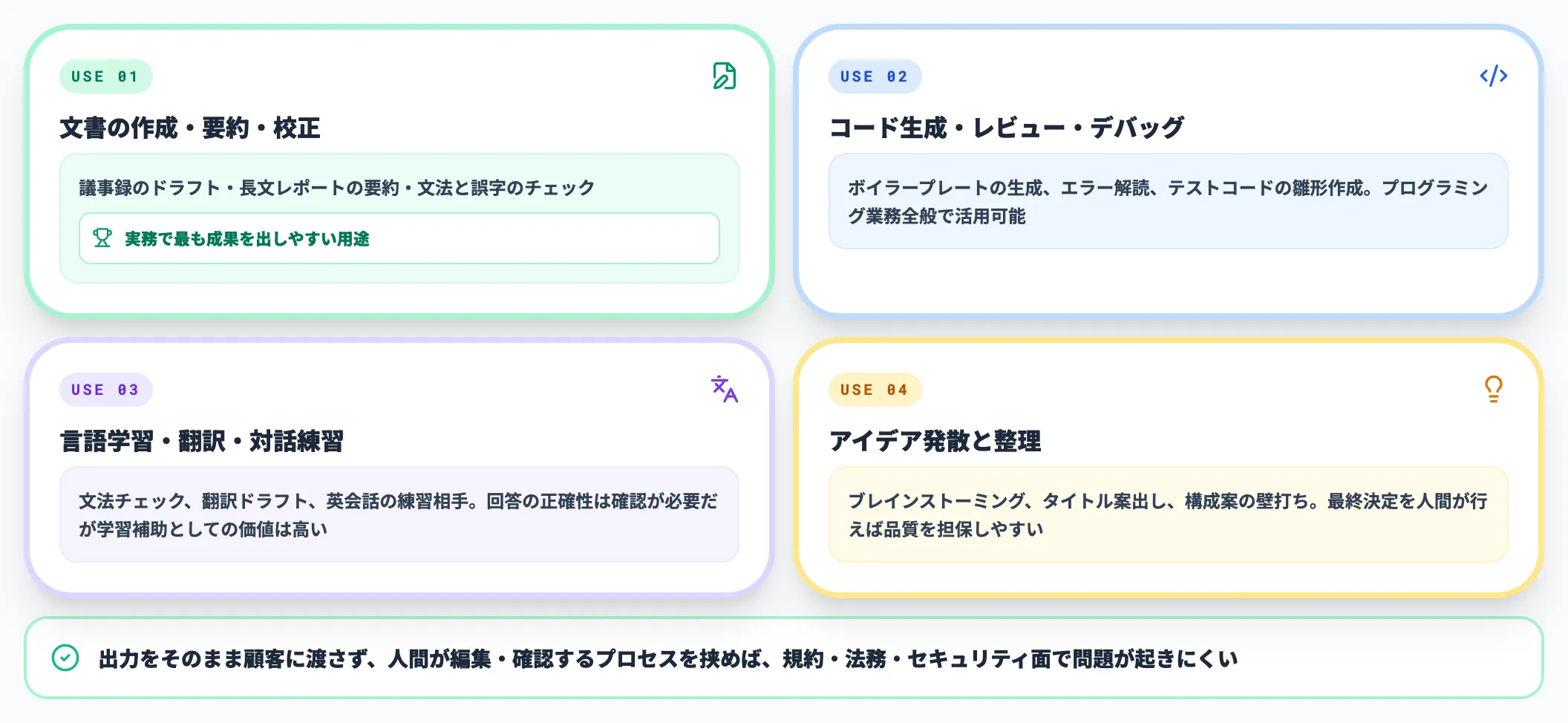
明確に効果が出やすく、リスクも低い領域です。社内導入の最初のフェーズはこの範囲から始めるのが定石です。
- 文書の作成・要約・校正
議事録のドラフト、長文レポートの要約、文法・誤字のチェック。要約機能は実務で最も成果を出しやすい用途
- コード生成・レビュー・デバッグ
ボイラープレートの生成、エラー解読、テストコードの雛形。ChatGPTをプログラミングに活用で具体例を解説
- 言語学習・翻訳・対話練習
文法チェック、翻訳のドラフト、英会話の練習相手。回答の正確性は確認が必要だが学習補助としての価値は高い
- アイデア発散と整理
ブレインストーミング、タイトル案出し、構成案の壁打ち。最終決定は人間が行えば品質を担保しやすい
これらの領域は、出力をそのまま顧客に渡さず、人間が編集・確認するプロセスを挟めば、規約面・法務面・セキュリティ面のいずれでも問題が起きにくい構成になります。
境界が曖昧な領域
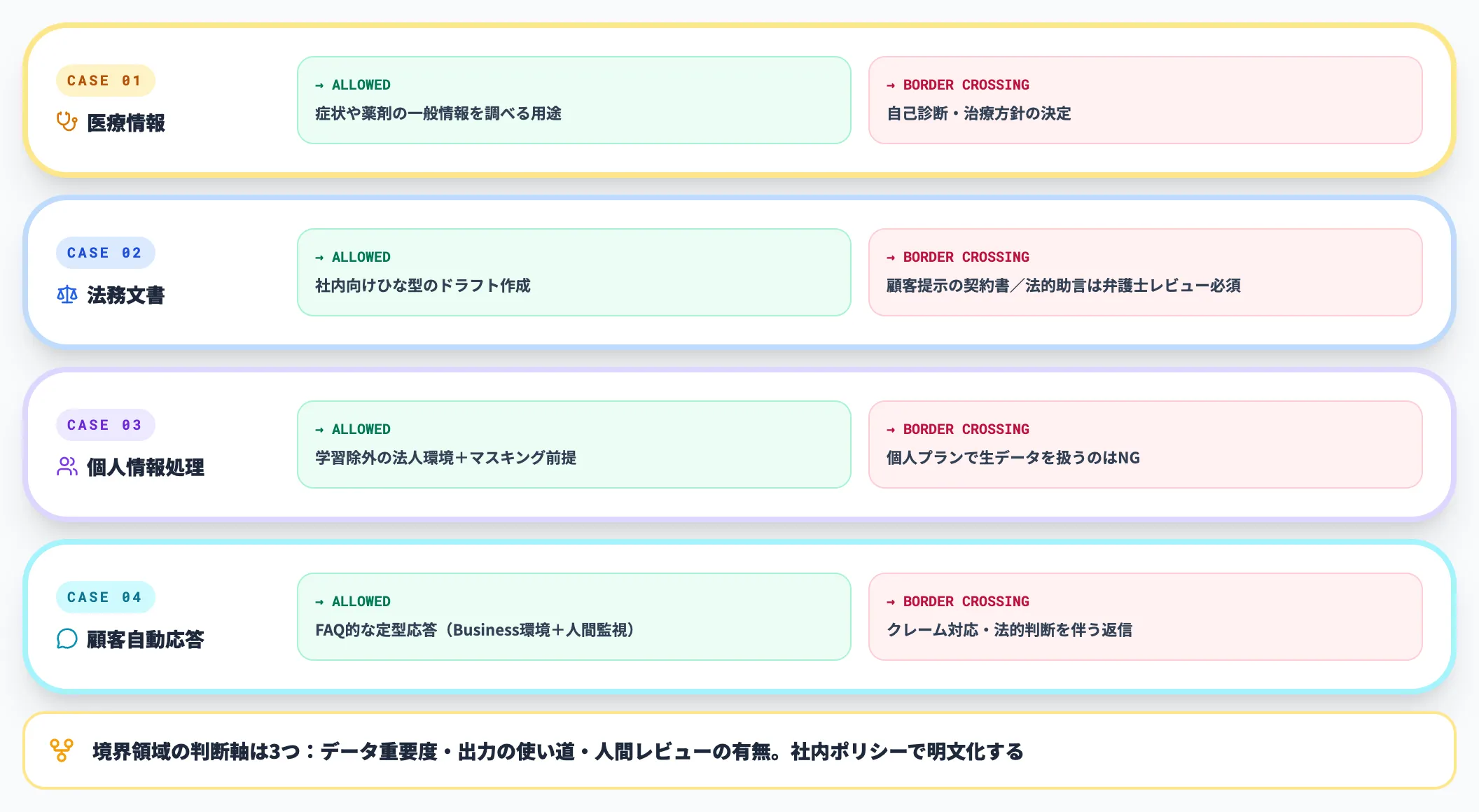
「やってよい」とも「やってはいけない」とも一概に言えない領域です。ここで判断を間違えると規約違反や法令違反につながるため、実務では一段階上の慎重さが求められます。
- 医療情報の調査(自己診断ではない)
症状や薬剤の一般情報を調べる用途は許容範囲。ただし「自分の症状の診断」「治療方針の決定」は越境
- 法務文書のドラフト
社内向けひな型作成は許容範囲。顧客に提示する契約書や法的助言は弁護士レビュー必須
- 個人情報を含むデータの処理
データが学習に使われない法人向け環境+マスキング前提なら検討可能。個人プランで生データを扱うのはNG
- 顧客対応の自動応答
FAQ的な定型応答はBusiness環境+人間監視で可能。クレーム対応や法的判断を伴う返信は人間が最終確認
境界領域に踏み込むかどうかは、データの重要度・出力の使い道・人間レビューの有無の3点で判断します。社内ポリシーで明文化しておくと、現場が判断に迷わずに済みます。
実務での使い分け方針

運用上うまく回っているのは、業務をデータ重要度×成果物の責任範囲のマトリクスで切り分け、領域ごとに利用するChatGPTのプランや構成を変える方針です。
- 公開情報+社内一般用途
個人プラン or Businessで運用。文章ドラフト、社内資料、社内研修コンテンツの作成など
- 社内機密+限定共有
データが学習に使われない法人向け環境、もしくはAPI経由のプライベート構成。社内ナレッジ検索、議事録要約など
- 顧客データ・規制対象データ
プライベートLLM環境、もしくはZDR契約のAPI。マスキング・暗号化を併用し、出力は人間レビュー必須
- 意思決定や法的判断
ChatGPTは「素案作成」までに留め、最終判断は人間が行う。Usage Policiesの「自動化された重大決定」禁止に整合する設計
「ChatGPTを使うか、使わないか」の二択ではなく、「どの業務にどのレイヤで使うか」を設計する発想に切り替えると、生産性と安全性の両立がしやすくなります。
ChatGPTのプラン別セキュリティ比較【2026年4月時点】
ChatGPTには複数の料金プランがあり、価格だけでなくセキュリティ上の挙動が大きく異なります。
業務利用ではプラン選定そのものがリスク管理の一部になるため、セキュリティ差を中心に整理します。
料金や機能の総合的な比較はChatGPTの料金プラン一覧もあわせて参照してください。
プラン全体像(2026年4月時点)
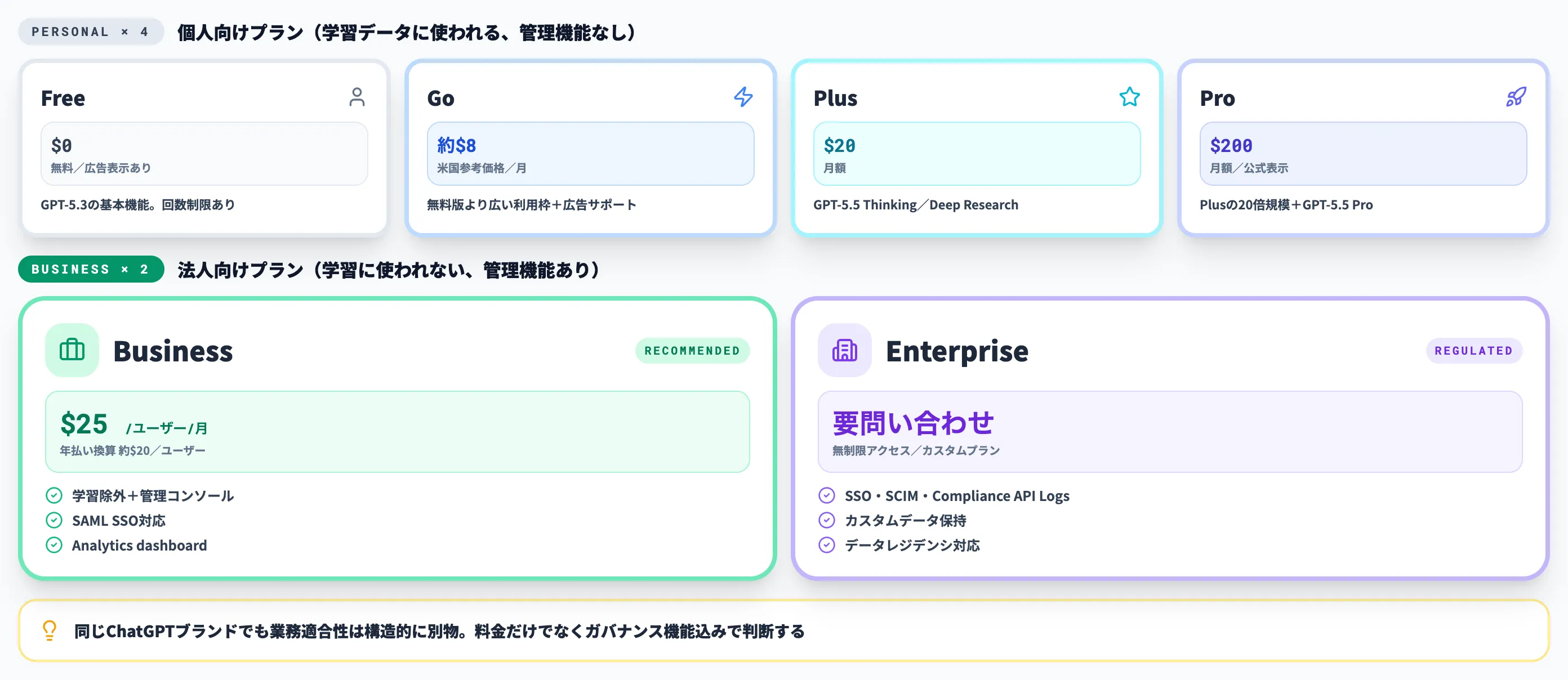
2026年4月時点のChatGPTのプランは、個人向け4階層と法人向け2階層の合計6プランです。価格は2026年4月時点の公式情報をもとにしています。
| プラン | 月額(参考) | 主な特徴 |
|---|---|---|
| Free | 無料 | GPT-5.3の基本機能(制限付き)。ファイルアップロード・画像生成は回数制限あり。米国などで広告表示 |
| Go | 地域により異なる(参考:米国 約$8/月) | 無料版より広い利用枠。広告サポートあり。ChatGPT対応国すべてで提供 |
| Plus | $20/月 | GPT-5.5 Thinkingの利用枠拡大。Deep Research・Advanced Voice Mode対応 |
| Pro | $200/月(公式表示価格) | Plusの20倍規模の利用枠。GPT-5.5 Proなど上位モデルへのアクセス。最新の枠・価格は公式ページを要確認 |
| Business | $25/ユーザー/月(年払い換算 $20/ユーザー/月)※多くの国・通貨 | Plusの全機能+管理コンソール。データは学習に使われない |
| Enterprise | 要問い合わせ | 無制限アクセス・SSO・SCIM・Compliance API Logs・カスタムデータ保持 |
Pro以下の個人向けプランは、データコントロール設定をオフにしない限りデフォルトでチャット内容がモデル改善に利用される設計です。
一方、Business・Enterpriseおよびその派生(Edu・Healthcare)は最初からデータ学習に使われない契約構造になっています。
価格は地域・通貨・契約形態(月払い/年払い)で差があるため、見積もり時はChatGPT公式の料金ページで最新の表示を確認してください。日本からの利用には消費税が加算されます。
学習除外・データ保持・暗号化の差

セキュリティ観点で最も重要なのは、入力データの取り扱いと管理機能の有無です。Free/Go/Plus/Proの個人向けと、Business/Enterpriseの法人向けで構造的に差があります。
| セキュリティ機能 | Free / Go / Plus / Pro | Business / Enterprise / Edu |
|---|---|---|
| データの学習利用 | デフォルトで利用される(オプトアウト可能) | 利用されない |
| 管理コンソールでの一元管理 | なし(個人設定のみ) | あり |
| SAML SSO | なし | Business・Enterpriseで対応 |
| SCIM自動プロビジョニング | なし | Enterpriseで対応 |
| 利用可視化・監査 | なし | BusinessはAnalytics dashboardによる利用状況の可視化、EnterpriseはCompliance API Logsで監査ログを取得可能 |
| データ保持管理 | 削除後30日で消去 | Businessは無期限保持、Enterprise/Eduは管理者が保持ポリシーを設定(例:90日、180日等) |
| 暗号化 | TLS転送 | AES-256(保存時)+ TLS 1.2以上(転送時) |
| ZDR(Zero Data Retention) | 不可 | API経由で対象顧客がOpenAIの承認を受けて利用可能(ChatGPTプランの機能ではなくAPI側の設定) |
| データレジデンシ | 米国 | Businessは非対応。Enterpriseは対応(米国・欧州・英国・日本・カナダ・韓国・シンガポール・豪州・印・UAEなど)。APIは対象顧客がデータレジデンシ設定を利用可能 |
個人向けプランは「便利だけれど業務利用に必要な制御がない」レイヤで、法人向けプランは「料金だけでなくガバナンス機能込み」のレイヤです。同じChatGPTのブランドでも、業務適合性は構造的に別物として扱う必要があります。
業務用途で選ぶならどのプランか

選定軸を整理すると、企業規模と取り扱うデータ重要度によって以下のように分かれます。
- 個人事業主〜10名程度の小規模・公開情報主体
Plus($20/月)で十分。ただし機密情報は入力しないルールを徹底する
- 10〜100名規模・社内文書を扱う
Business(多くの国で月額$25/ユーザー、年払い換算 約$20/ユーザー)。学習除外と管理コンソールが揃い、社員数の増減に追従しやすい
- 100名超・規制対象データあり
Enterprise契約。SSO・SCIM・Compliance API Logs・カスタムデータ保持・データレジデンシが揃い、外部監査対応がある業界では実質的にこのレンジが必要
- 顧客データを大量に処理・最高度の機密情報あり
Azure OpenAI ServiceやAPI+ZDR(OpenAIの承認制)の自社構築型。LLM選定とインフラ設計を分離して制御権を高める
「全社員にPlusを配る」という選択は、シャドーAI抑制効果はあっても、業務利用のセキュリティ要件は満たせません。逆に「いきなり全社Enterpriseは予算的に厳しい」場合は、Business+特定部署のみAPI構成という段階的な導入が現実的です。プラン選定そのものが社内AIポリシーの一部であると捉えると、見積もりだけでなく統制要件まで含めて選ぶ視点が定着します。

AIのリスクを理解した次は安全な業務AI導入を計画する
ChatGPTでやってはいけないことを5カテゴリ(主軸3+補助2)で整理できたなら、AIを業務に組み込むときに必要なリスク管理の発想はすでに身についています。
情報漏洩のシナリオを構造で理解し、Usage PoliciesとAI事業者ガイドライン第1.2版の要点を押さえているなら、社内ガバナンス設計の出発点としては十分です。
AI総合研究所では、セキュリティと運用効率を両立させながら業務にAIを組み込むための実践ガイドを提供しています。
どのプランで始めるか、データの取り扱いルールをどう設計するか、人間レビューをどこに挟むかなど、現場で詰まりやすい論点に対する具体的な判断材料を整理しました。
AIのリスクを理解した次は安全な業務AI導入を設計する

やってはいけないことを知った上での正しいAI活用
ChatGPTのリスクと注意点を把握したなら、安全にAIを業務に取り入れる設計力が身についています。情報管理のポイントを押さえた業務AI導入の進め方をガイド資料で確認できます。
まとめ
本記事では、ChatGPTでやってはいけないことを「健康・安全」「法的責任」「情報セキュリティ」の主軸3カテゴリと「教育・利用方法」「情報品質」の補助2カテゴリで整理し、12のNG行為、2025-2026年の代表的な漏洩事例、Usage PoliciesとAI事業者ガイドライン第1.2版の要点、個人と法人の対策、料金プラン別のセキュリティ差まで一気通貫で解説しました。
ChatGPTは業務効率化やクリエイティブな作業に大きな力を発揮するツールですが、医療・財務・法律の最終判断を任せる、機密情報を個人プランに入力する、違法行為に使う、といった使い方は避ける必要があります。
安全に活用するためのポイントを3つにまとめます。
- 入力する情報を選ぶ
個人情報・機密情報をプロンプトに入力しない。一時チャットや学習除外設定を必ず確認する
- 回答を検証する
ハルシネーションを前提に、重要な判断の前は一次情報で裏取りする。出力をそのまま意思決定に使わない
- 適切なプランを選ぶ
業務利用ではデータが学習に使われない法人向けプランを選び、規模・データ重要度に応じて管理機能や監査ログを確保する
AIの可能性を最大限に活かすには、そのリスクと限界を正しく理解することが第一歩です。本記事を参考に、ChatGPTを安全かつ効果的に活用してください。










