この記事のポイント
 OData準拠のHTTPでサイト・リスト・ドキュメントのCRUDを行うプラットフォーム非依存インターフェース
OData準拠のHTTPでサイト・リスト・ドキュメントのCRUDを行うプラットフォーム非依存インターフェース- Microsoft Graph APIとの使い分け:SharePoint固有・オンプレ連携はREST、Microsoft 365横断はGraphが最適
- 認証はEntra ID(旧Azure AD)OAuth 2.0が基本、旧Azure ACSは2026年4月2日完全廃止で移行が急務
- スロットリングは3階層(ユーザー・テナント・アプリ)、リソースユニットとRetry-Afterヘッダーの再試行設計が安定運用の鍵
- RAGやナレッジ検索への応用では、ファイル本体だけでなくメタデータの取得と、インデックス作成時・検索時の権限モデル整合が必須

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
SharePoint REST APIは、HTTPリクエストを通じてSharePoint上のサイト・リスト・ドキュメントを操作するための標準インターフェースです。
特定のプラットフォームに依存せず、OData準拠のクエリで柔軟なデータ操作が可能なため、業務システムとの連携やカスタムポータルの構築で広く利用されています。
本記事では、基本的なCRUD操作やMicrosoft Graph APIとの使い分け、認証方式の違い、2026年4月のAzure ACS廃止への対応、スロットリングの具体的な制限値、RAGでのメタデータ活用まで、2026年3月時点の情報を基に体系的に解説します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
SharePoint REST APIとGraph APIの違い
SharePoint REST APIのエンドポイントとデータ構造
SharePoint Onlineでの認証(Microsoft Entra ID)
SharePoint REST APIの制限とスロットリング
SharePoint REST APIとは?
SharePoint REST APIは、SharePointに保存されたサイト・リスト・ドキュメントなどのデータに対して、HTTPリクエストとODataプロトコルを使ってアクセスするためのインターフェースです。
GET・POST・MERGE・DELETEといったHTTPメソッドを使い、作成・取得・更新・削除(CRUD)を実行します。専用ライブラリをクライアントに組み込む必要はなく、HTTPリクエストを発行できる環境であれば、言語やプラットフォームを問わず利用できます。
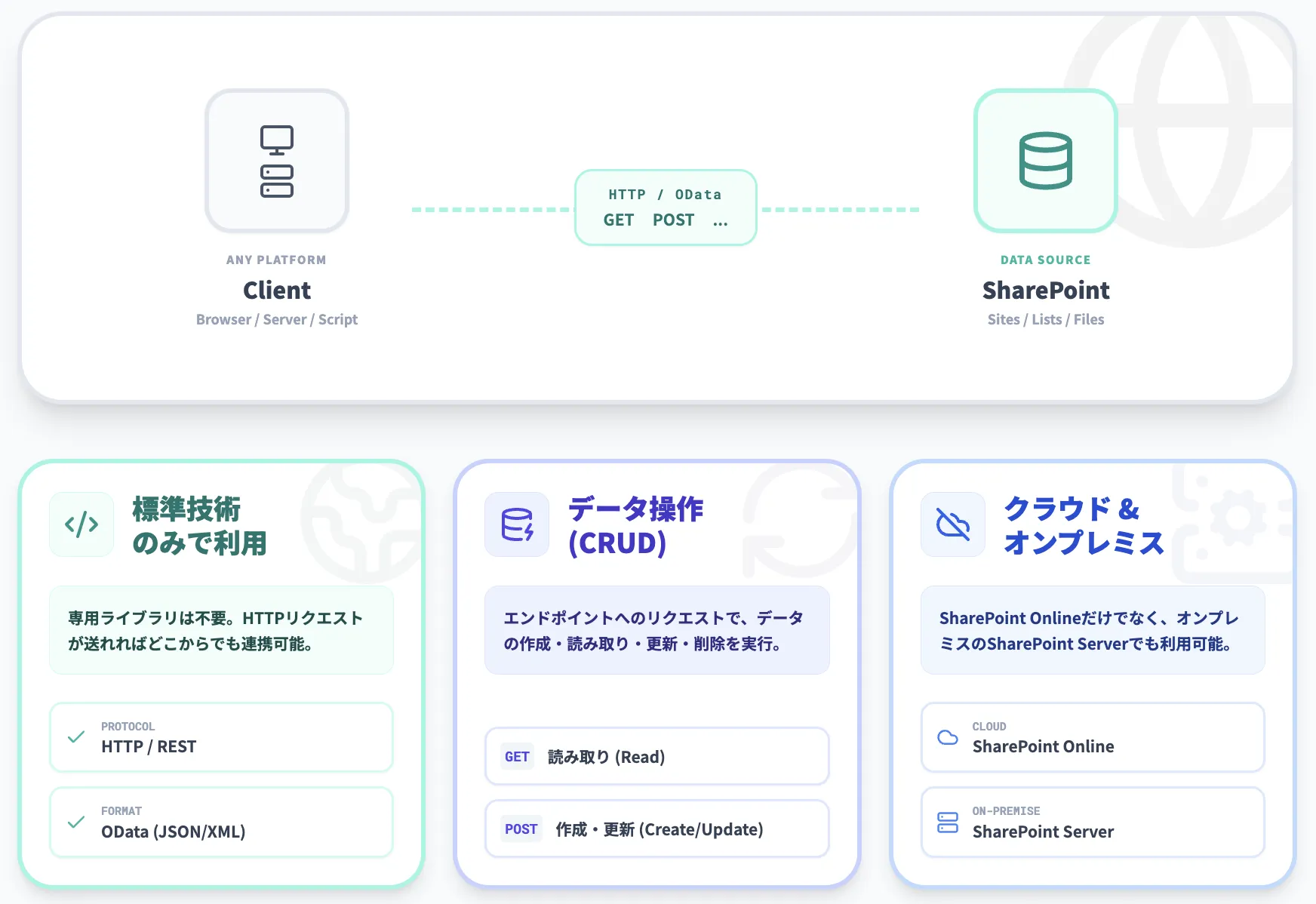
SharePoint Onlineだけでなく、サポートされているバージョンのオンプレミス版SharePoint Serverでも同様のRESTエンドポイントが提供されています。
ただし、利用できる機能やバージョンには差異があるため、対象環境ごとのドキュメント確認が必要です。
SharePoint REST APIでできること
このセクションでは、SharePoint REST APIで実行できる操作を具体的に整理します。
エンドポイントは多数ありますが、実務では「どのリソースを」「どのHTTPメソッドで」操作するかを押さえておくと設計がしやすくなります。

サイトやリストを扱う基本操作
SharePoint REST APIの基本操作は、以下のHTTPメソッドとエンドポイントの組み合わせで実行します。
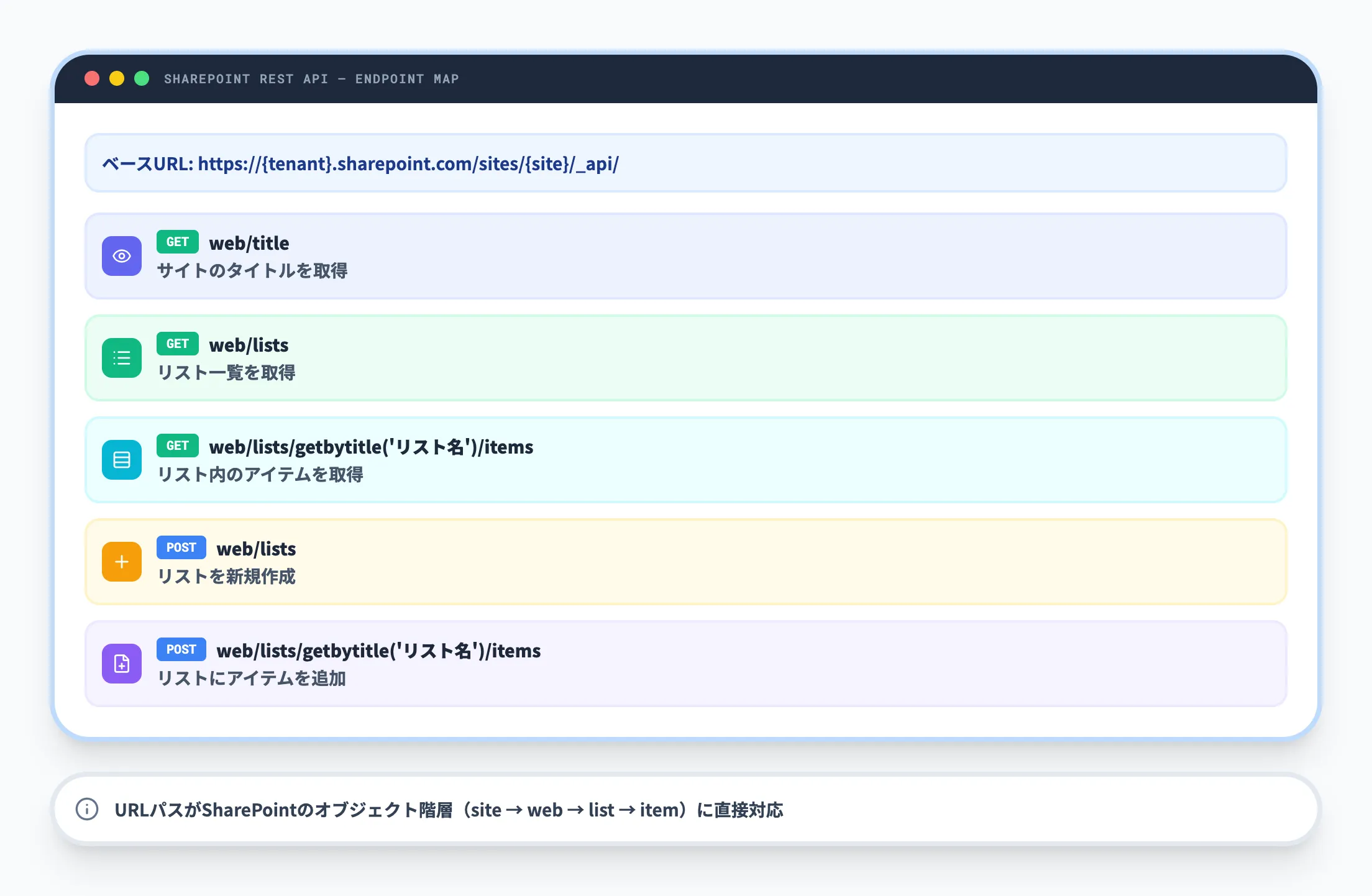
以下の表は、代表的な操作とエンドポイントの対応を整理したものです。URLの先頭にはサイトURLに続けて /_api/ を付与します。
| 操作 | HTTPメソッド | エンドポイント例 |
|---|---|---|
| サイトのタイトルを取得 | GET | web/title |
| リスト一覧を取得 | GET | web/lists |
| リストのメタデータを取得 | GET | web/lists/getbytitle('リスト名') |
| リスト内のアイテムを取得 | GET | web/lists/getbytitle('リスト名')/items |
| リストを新規作成 | POST | web/lists |
| リストにアイテムを追加 | POST | web/lists/getbytitle('リスト名')/items |
| まず、ブラウザからSharePoint REST APIにアクセスして、リスト一覧を取得します。 |
ブラウザで「/_api/web/lists」にアクセスし、リスト一覧のレスポンスが表示されている画面
次に、ODataクエリを使って取得データを絞り込みます。
ブラウザで
この表が示すように、URLパスがそのままSharePointのオブジェクト階層(サイト → リスト → アイテム)に対応しています。
つまり、SharePointの内部構造を知っていれば、APIのエンドポイントも直感的に理解できるという設計です。
書き込みリクエストの要点
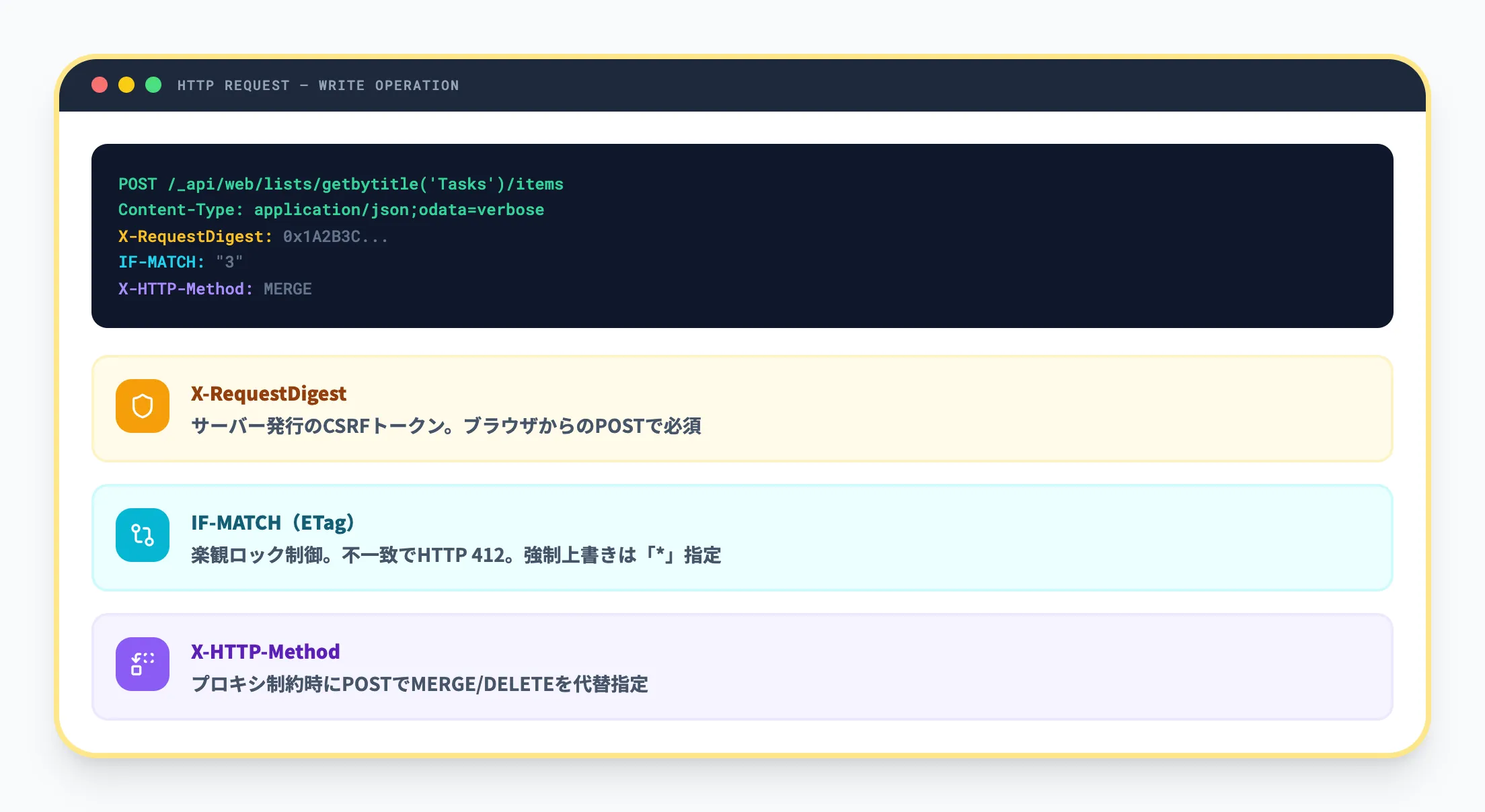
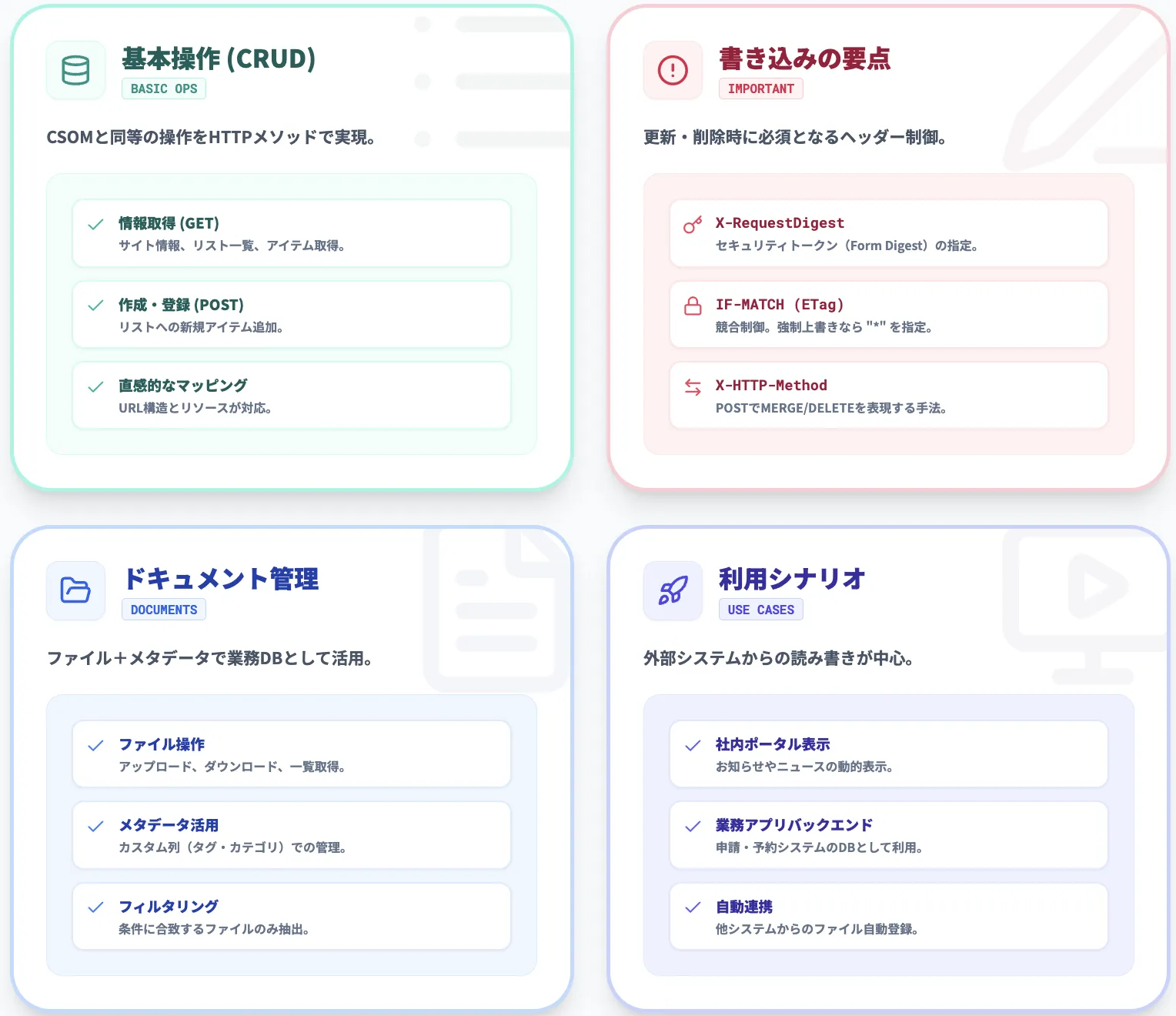
更新・削除・アップロードなどの書き込み操作では、GETとは異なるHTTPヘッダーの設定が必要です。
実装でつまずきやすい3つのヘッダーを把握しておくと、手戻りを防げます。
-
X-RequestDigest(Form Digest)
ブラウザからPOSTを送る際に必要になることがあるセキュリティトークンです。
サーバー側で発行された値をリクエストヘッダーに含めます。
-
IF-MATCH(ETag)
楽観的同時実行制御(楽観ロック)に使います。更新・削除時にETag値が不一致だとHTTP 412が返されます。
強制上書きしたい場合は値に「*」を指定します。
-
X-HTTP-Method(MERGE / DELETE等)
クライアントやプロキシの制約でPUT・DELETEメソッドを直接送信できない場合に、POSTリクエストのヘッダーで操作種別を指定するパターンです。
書き込み系の設計では、これらのヘッダー設計と競合時の挙動を先に決めておくことが重要です。
ドキュメントとメタデータの構造

SharePointでは、ドキュメントライブラリもリストの一種として扱われます。REST APIからは、ファイル本体の取得・アップロードに加えて、ファイルに付随するメタデータ(タイトル、作成者、タグ、カスタム列など)にもアクセスできます。
主な操作パターンを以下に示します。
- ドキュメントライブラリ内のファイル一覧を取得し、メタデータだけをアプリに表示する
- 特定の条件(例:カテゴリ列が「契約書」)でファイルをフィルタリングする
- ファイルそのものをダウンロードし、別システムに連携する
こうした操作により、SharePointを単なるファイル置き場ではなく、メタデータを持つ業務データベースとして活用できます。
後述するRAG(検索拡張生成)やナレッジ検索の文脈では、このメタデータの設計が検索精度を左右する重要な要素になります。
社内ポータルや業務アプリでの利用シナリオ
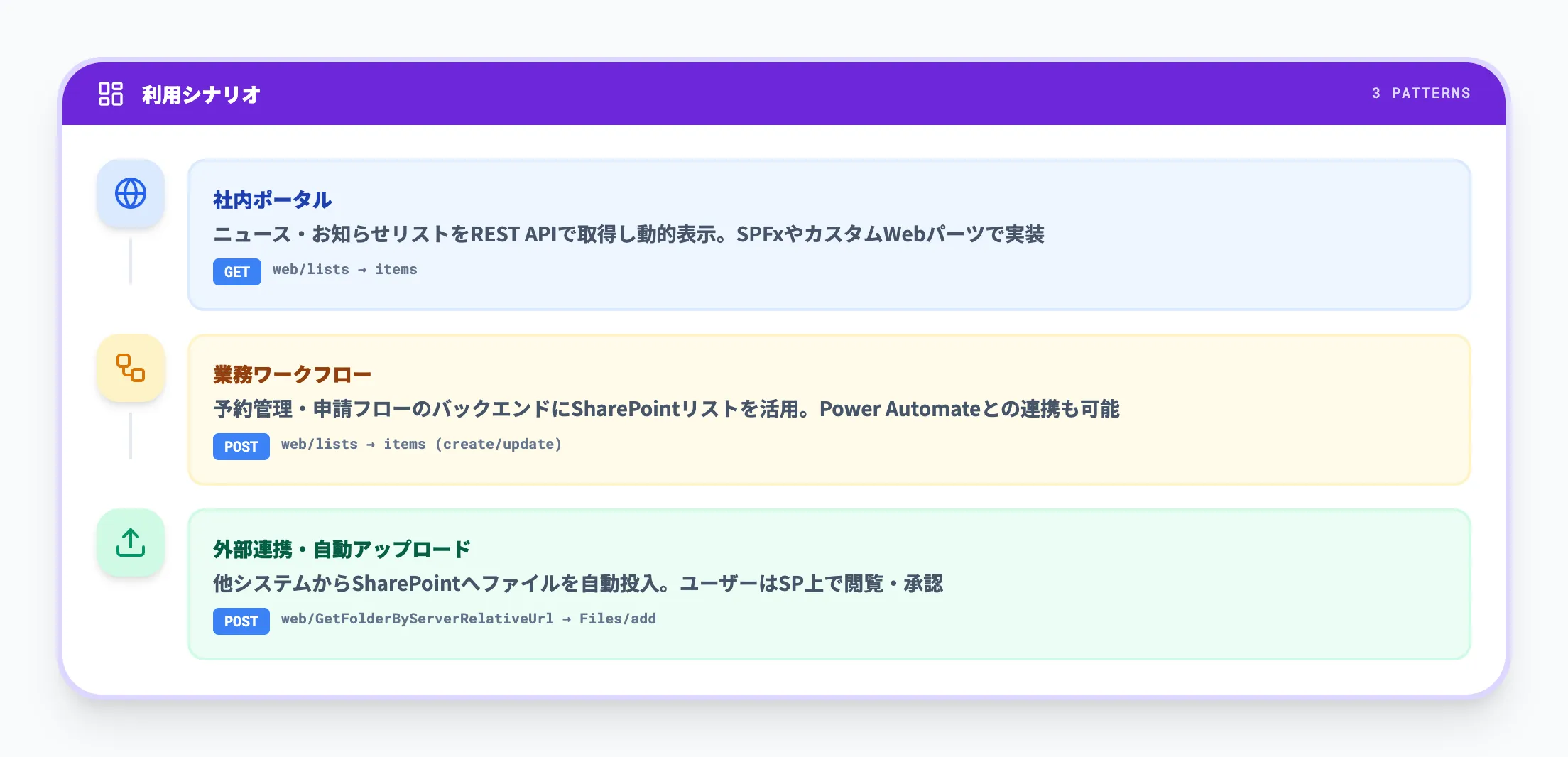
SharePoint REST APIは、次のような実務シナリオで活用されています。
- 社内ポータルサイトで、ニュースやお知らせリストの内容を動的に表示する
- 業務システム(予約管理、申請ワークフローなど)から、SharePointのリストやドキュメントライブラリをバックエンドとして利用する
- 他システムからSharePointにファイルを自動アップロードし、ユーザーはSharePoint上で閲覧・承認を行う
いずれのシナリオでも、RESTによるSharePointデータの読み書きが中心です。
Microsoft Graph APIよりもSharePoint固有の機能に近いレイヤーで制御したい場合に、REST APIが選ばれます。
SharePoint REST APIとGraph APIの違い

SharePoint REST APIとMicrosoft Graph APIは、どちらもSharePointのデータにアクセスできますが、設計思想と対象範囲が異なります。
ここでは2つのAPIの違いと使い分けの考え方を整理します。
APIの入り口と対象範囲の違い

2つのAPIの最大の違いは、エンドポイントの入り口とカバー範囲です。
SharePoint REST API
各SharePointサイトのURLを起点に、/_api/ 以下のエンドポイントでサイト・リスト・アイテムにアクセスします。対象は基本的にそのSharePointサイト内のコンテンツに限られます。
Microsoft Graph API
https://graph.microsoft.com を起点に、/sites、/lists、/drives などのエンドポイントでSharePointにアクセスします。
同じエンドポイント空間の中で、Teams、OneDrive、ユーザー、グループなどMicrosoft 365全体のサービスを横断して操作できます。
Microsoftは、複数のMicrosoft 365サービスと連携するシナリオではGraph APIの利用を推奨しています。
SharePoint Onlineではスロットリング回避の観点からも、可能な場合はGraph APIを優先する方針が示されています。
REST v2エンドポイント

SharePoint REST APIには、/_api/v2.0/ から始まるREST v2エンドポイントが存在します。これはMicrosoft Graph APIのエンドポイントをSharePoint内からネイティブに呼び出せる仕組みです。
以下の表で、Graph APIとREST v2の対応関係を示します。
| Graph API URL | SharePoint REST v2 URL |
|---|---|
| https://graph.microsoft.com/v1.0/sites | https://{テナント名}.sharepoint.com/_api/v2.0/sites |
| https://graph.microsoft.com/v1.0/drives | https://{テナント名}.sharepoint.com/_api/v2.0/drives |
| https://graph.microsoft.com/v1.0/lists | https://{テナント名}.sharepoint.com/_api/v2.0/lists |
既にSharePointへのアクセストークンを取得している環境では、Graph APIを経由せずにSharePoint内のv2.0エンドポイントから同等の操作を実行できます。
Graph APIのURLに対応するSharePoint URLを確認したい場合は、クエリ末尾に $whatif パラメータを付けると、内部のSharePoint URLが返されます。
SharePoint REST APIを選ぶべきケース
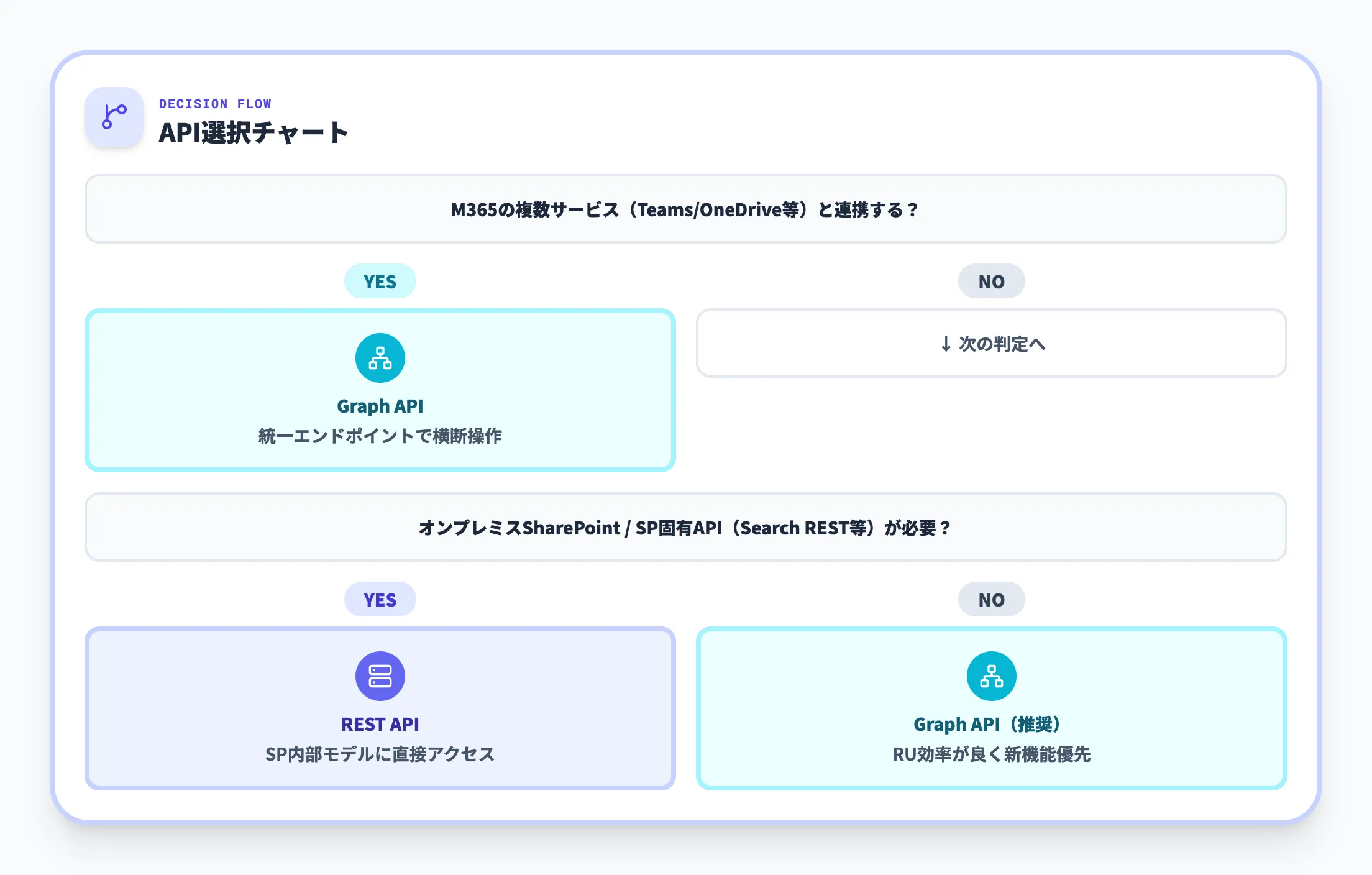
以下のようなケースでは、SharePoint REST APIにメリットがあります。
- 既存のSharePointアドインやカスタマイズがREST API前提で構築されており、その延長で機能追加したい場合
- 対象がSharePoint OnlineまたはオンプレミスのSharePoint Serverであり、他のMicrosoft 365サービスとの連携が限定的な場合
- SharePoint固有のRESTエンドポイント(Search REST APIなど)を直接活用したい場合
REST APIはSharePointの内部オブジェクトモデルに対応した設計であるため、SharePoint固有の細かい制御が必要な場面で有利です。
Graph APIを選ぶべきケース
一方で、次のようなケースではGraph APIが適しています。
- Teams、OneDrive、SharePoint、Plannerなど、複数のMicrosoft 365サービスを横断してデータを扱う場合
- テナント全体のガバナンスやレポート、監査など、広いスコープの情報が必要な場合
- 将来的なAPI拡張やMicrosoftの推奨方針を踏まえ、Graph APIベースのアーキテクチャを採用しておきたい場合
Microsoftの公式ドキュメントでは、Graph APIは同じ機能をCSOM/REST APIよりも少ないリソースで実現できると説明されています。大量リクエストが発生するシナリオでは、Graph APIの採用がスロットリング回避にもつながります。
SharePoint REST APIのエンドポイントとデータ構造

SharePoint REST APIを設計するうえでは、エンドポイントがSharePointのオブジェクト階層に対応していることを理解しておくと、設計が整理しやすくなります。
このセクションでは、URL構造・リソースの種類・クエリの基本・バッチ処理を解説します。
エンドポイントの構造
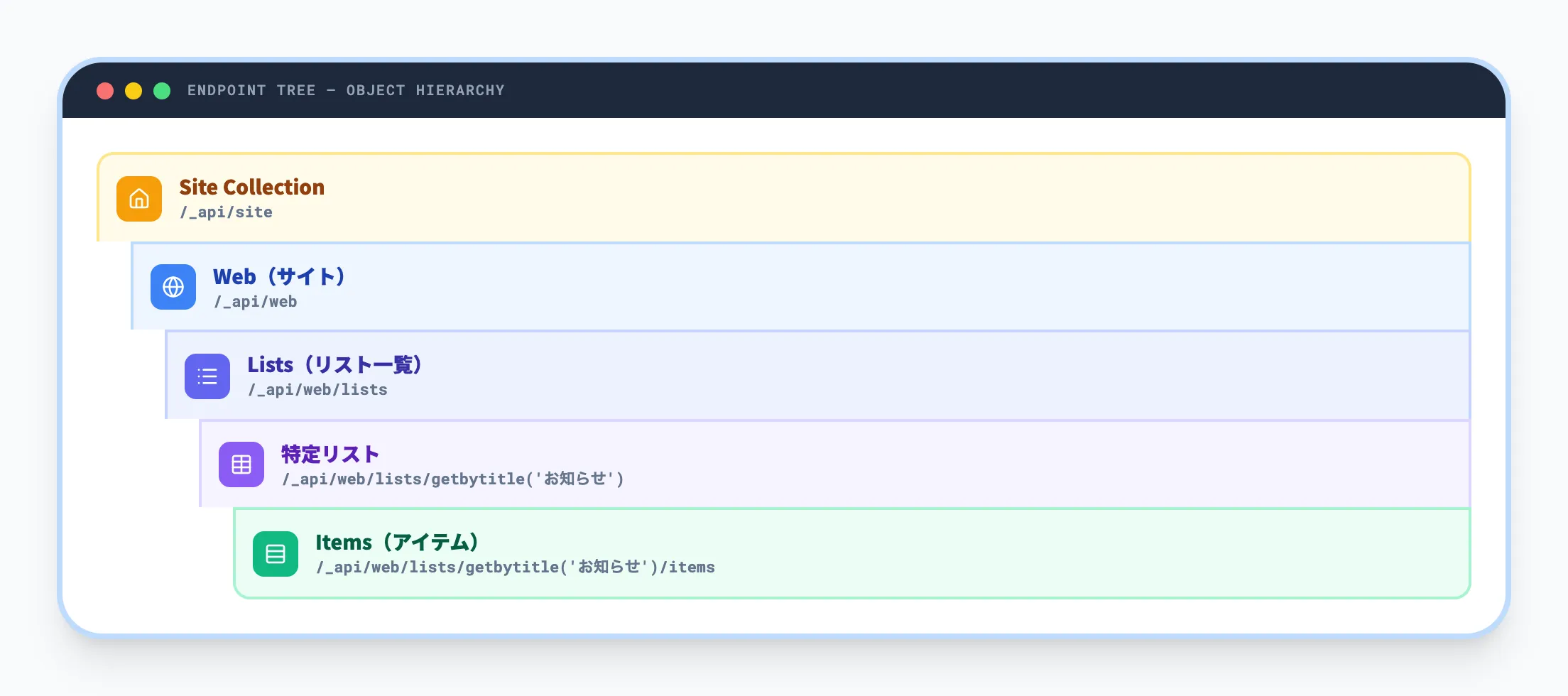
SharePoint REST APIのエンドポイントは、サイトURL + /_api/ + リソースパスという3つの要素で構成されます。
具体的には、以下のような階層で組み立てます。
-
サイトコレクション
https://contoso.sharepoint.com/sites/portal/_api/site
-
サイト(Web)
https://contoso.sharepoint.com/sites/portal/_api/web
-
リスト一覧
https://contoso.sharepoint.com/sites/portal/_api/web/lists
-
特定リストのアイテム
https://contoso.sharepoint.com/sites/portal/_api/web/lists/getbytitle('お知らせ')/items
このように、サイト → Web → リスト → アイテムというSharePointのオブジェクト階層をそのままパスに反映させる設計になっています。
主なリソースの種類

SharePoint REST APIで頻繁に扱うリソースは、以下の4種類です。
-
サイト / Web(site, web)
サイトコレクションやサブサイトを表します。タイトル、URL、テンプレートなどのプロパティを持ちます。
-
リスト / ライブラリ(list)
データのコンテナに相当します。リスト列(カラム)の定義やビュー設定などのスキーマ情報を持ちます。
-
リストアイテム(list item)
リストやライブラリ内の1行に相当します。各列の値のほか、作成者・更新日時などのシステムメタデータを持ちます。
-
ファイル / フォルダー(file, folder)
ドキュメントライブラリ内のファイルやフォルダーです。ファイル名、サイズ、URL、チェックアウト状態などにアクセスできます。
多くの実装では、「どのサイトの」「どのリストの」「どのアイテム / ファイルか」という3段階を意識してエンドポイントを組み立てます。
ODataクエリとフィルタリング
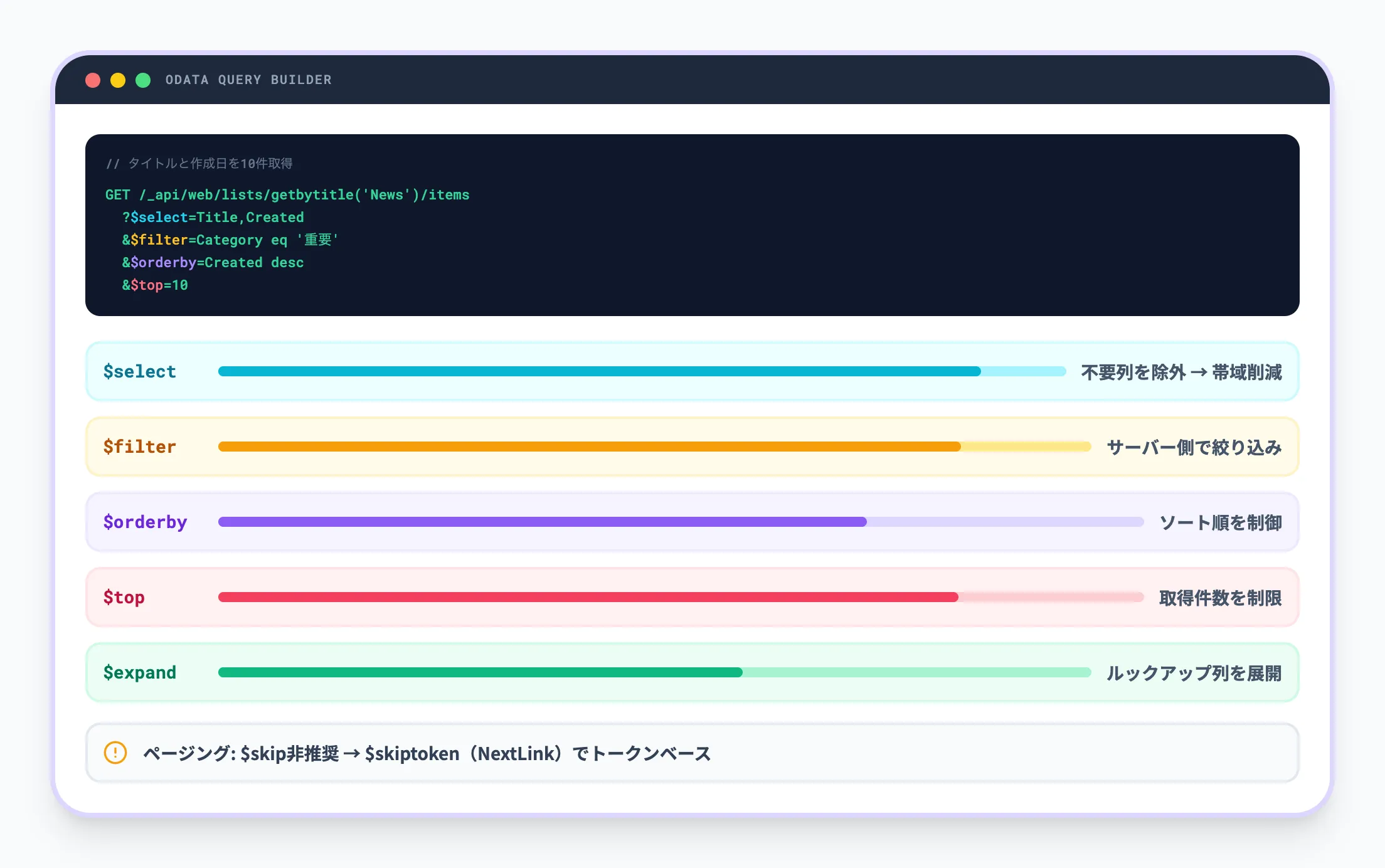
SharePoint REST APIはODataプロトコルに基づいており、クエリパラメータで取得データの絞り込みや返却フィールドの制限が可能です。
代表的なパラメータを以下に示します。
| パラメータ | 用途 |
|---|---|
| $select | 返却するフィールドを限定する |
| $filter | 条件に一致するアイテムだけを取得する |
| $orderby | ソート順を指定する |
| $top | 取得件数の上限を指定する |
| $expand | ナビゲーションプロパティ(ルックアップ列など)を展開する |
たとえば「特定リストからタイトルと作成日時だけを10件取得する」といったケースの場合、$select と $top を組み合わせることで、不要なフィールドや過剰な件数を避けられます。
これはパフォーマンス最適化とスロットリング回避の両面で重要です。
ページングについては、$skip が期待どおりに機能しないケースがあるため、レスポンスに含まれる $skiptoken(NextLink)を使ったトークンベースのページングが基本になります。
バッチリクエスト
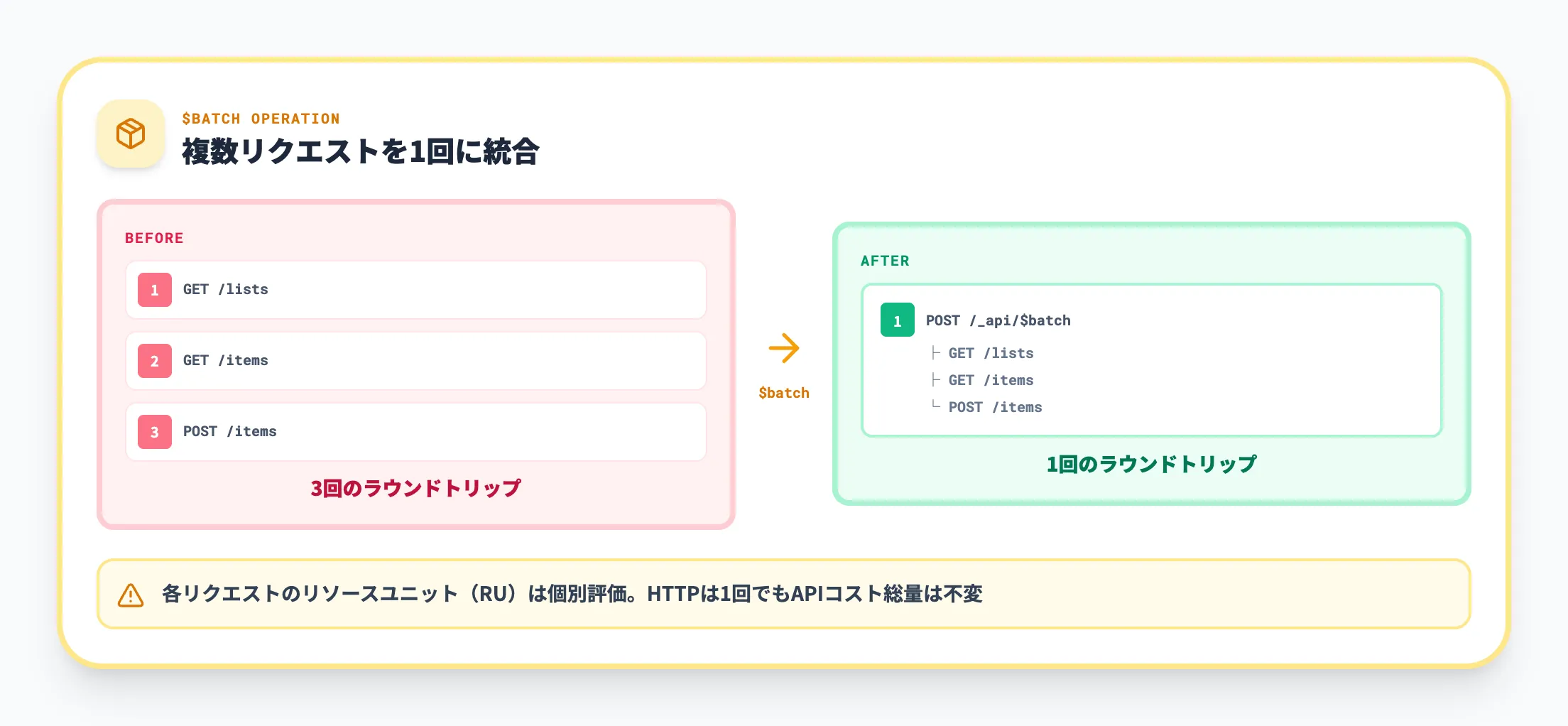
SharePoint Online(およびオンプレミスのSharePoint 2016以降)では、ODataの $batch クエリオプションを使って複数のリクエストを1つのHTTP呼び出しにまとめることができます。
バッチリクエストを活用すると、以下のメリットがあります。
- ネットワークのラウンドトリップ回数を削減できる
- 一連の操作をまとめて実行するため、スロットリングの影響を受けにくい
- 関連する複数のCRUD操作を1リクエストで完了できる
ただし、バッチ内の各リクエストはリソースユニット(後述)で個別に評価されるため、リクエスト数自体が減ってもAPIコストの総量は変わらない点に注意が必要です。
SharePoint REST APIの認証と権限

SharePoint REST APIの認証は、SharePoint OnlineとオンプレミスのSharePoint Serverで異なります。
このセクションでは、それぞれの認証方式と、2026年4月に迫るAzure ACS廃止への対応を解説します。
SharePoint Onlineでの認証(Microsoft Entra ID)
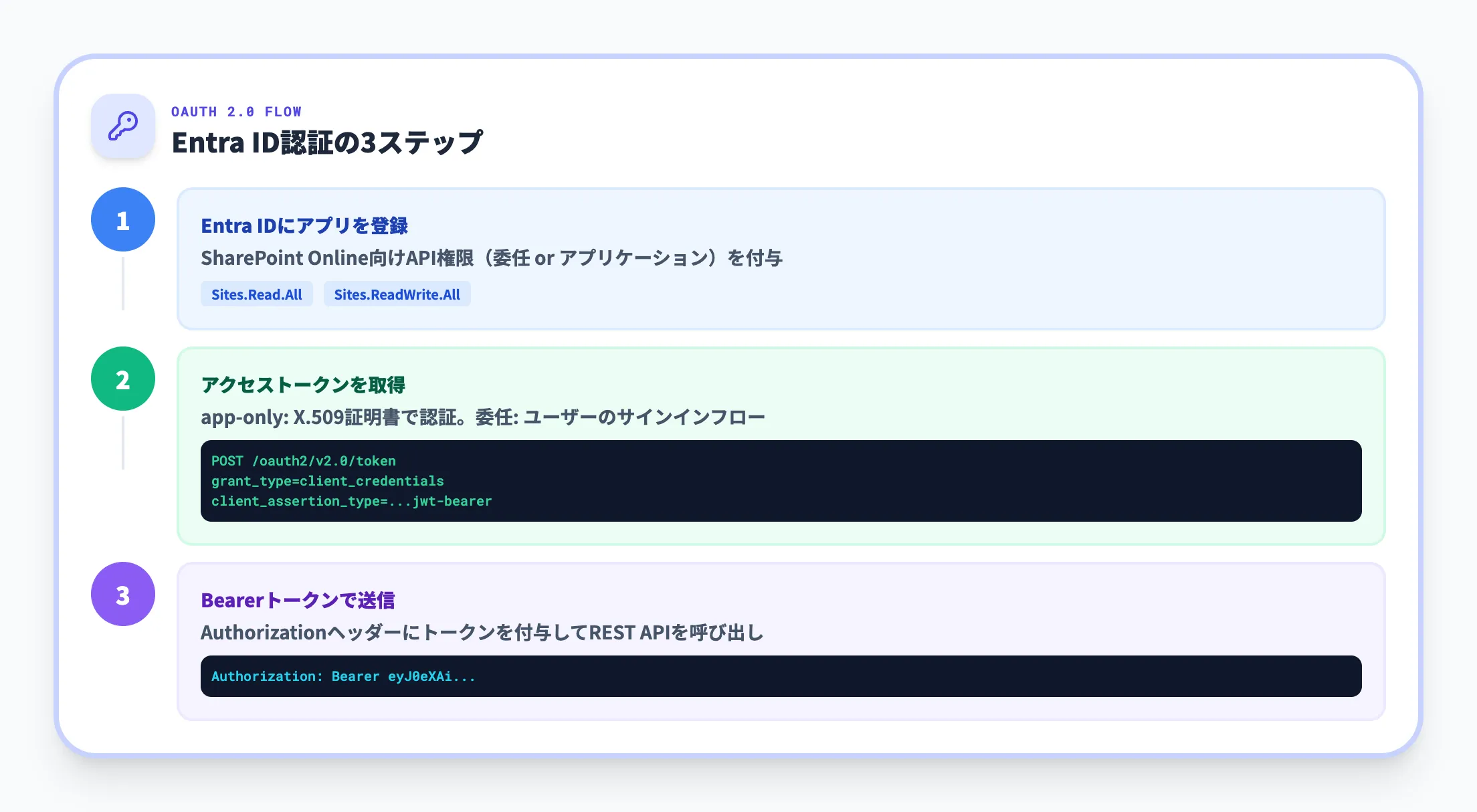
SharePoint Onlineでサーバーサイド(Azure Functions、自社Web API、バックグラウンドジョブ等)からREST APIを呼び出す場合は、Microsoft Entra ID(旧Azure AD)によるOAuth 2.0認証を用います。
認証の基本フローは以下のとおりです。
-
Entra IDにアプリケーションを登録し、SharePoint Onlineに対するAPI権限(アプリケーション権限または委任権限)を付与する
-
OAuth 2.0フローに応じてアクセストークンを取得する
-
取得したトークンをHTTPリクエストの Authorization ヘッダーにBearer形式で付与して送信する
まず、Microsoft Entra IDでアプリケーションを登録します。
Microsoft Entra IDの「アプリの登録」で新規登録画面を開き、アプリ名やリダイレクトURIを入力している画面
次に、SharePoint Onlineに対するAPI権限を追加します。
アプリの「APIのアクセス許可」画面でSharePointの権限(Sites.Read.Allなど)を追加している画面
最後に、証明書ベース認証のために証明書を設定します。

「証明書とシークレット」画面で証明書をアップロードしている画面
アプリケーション権限(app-only)を使う場合は、ユーザー操作なしでバックエンド処理を実行できますが、権限範囲が広くなりがちです。最小権限の原則に従い、必要なサイトやリストに限定した設計が推奨されます。
SharePoint Onlineのapp-only権限では、証明書ベースの認証が前提です。クライアントシークレットではなく、X.509証明書を使ってトークンを取得します。
クライアントサイドでの認証
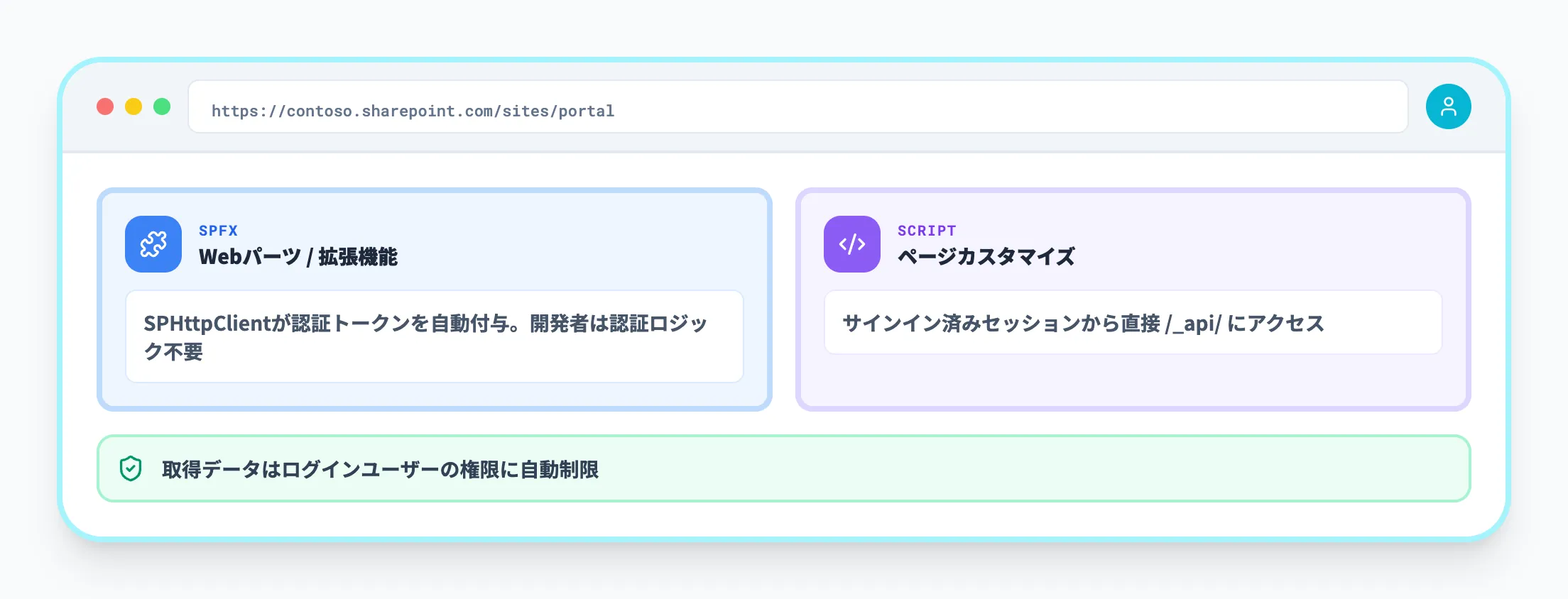
SharePoint Framework(SPFx)のWebパーツやブラウザからのJavaScriptカスタマイズでは、ログイン済みユーザーのセッションが利用されます。
- SPFxでは、SPHttpClient が認証情報を含んだ形でREST APIへリクエストを送信する
- ページカスタマイズやスクリプト埋め込みでは、SharePointへのサインイン済みセッションから直接 /_api/ エンドポイントにアクセスする
クライアントサイドの場合、REST APIで取得できるデータはログインユーザーの権限に自動的に制限されます。ユーザーごとに表示内容を切り替えるダッシュボードやポータル画面との相性が良いパターンです。
オンプレミスでの認証
オンプレミスのSharePoint Serverでは、環境構成(Windows認証、クレーム認証、カスタム認証など)によって認証方式が異なります。
実装時には「対象がSharePoint Onlineか、オンプレミスか」「委任(ユーザー)か、アプリ専用か」を先に確定し、対応する公式ドキュメントに沿って設計するのが安全です。
Azure ACSの廃止とEntra IDへの移行
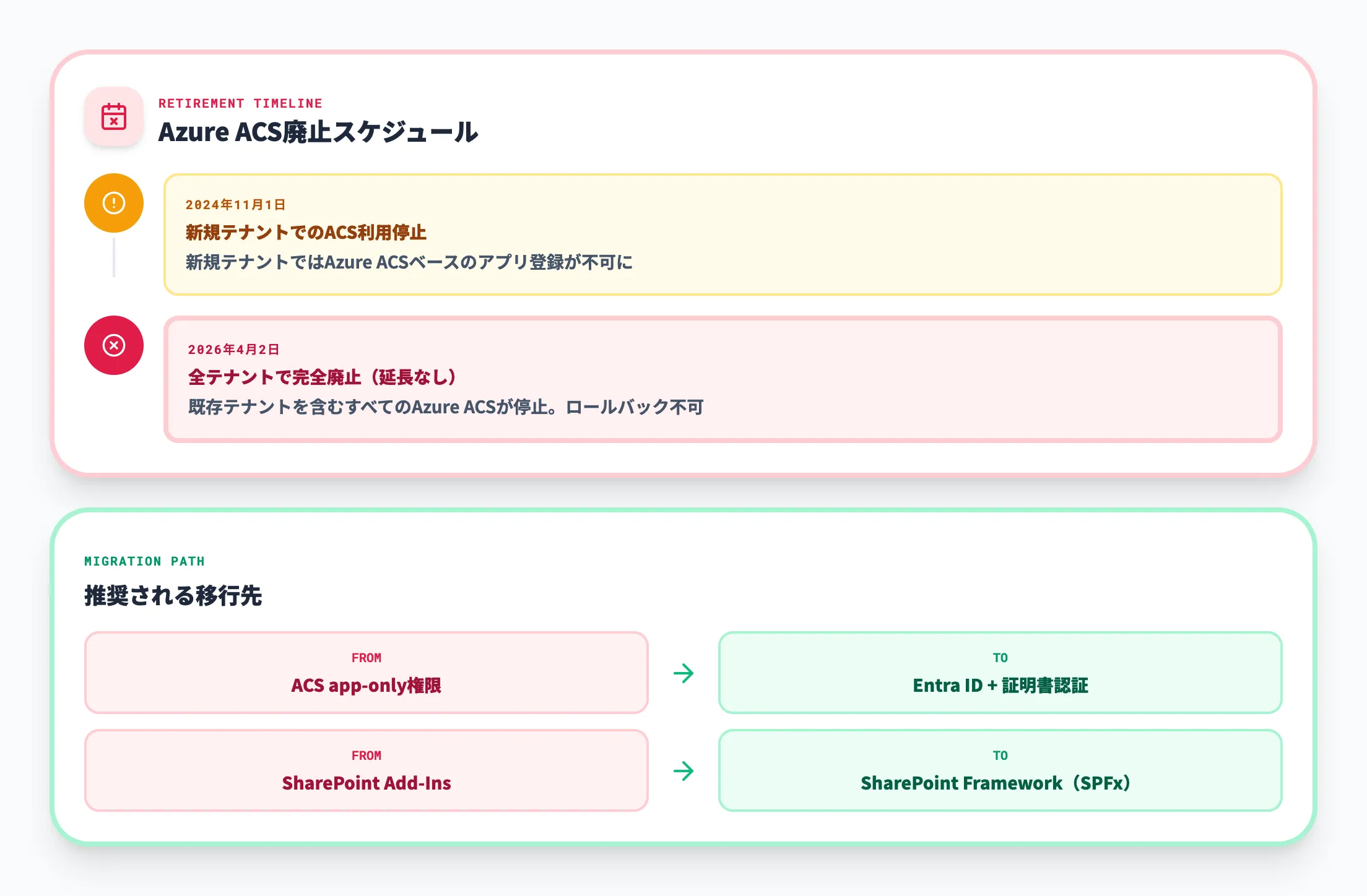
SharePoint Onlineでアプリにアクセス権限を付与する手段として、従来はAzure ACS(Access Control Services)が使われていました。しかし、Azure ACSは2026年4月2日に完全廃止されます。
廃止のタイムラインを以下にまとめます。
| 時期 | 内容 |
|---|---|
| 2024年11月1日 | 新規テナントでのAzure ACS利用が停止 |
| 2026年4月2日 | 既存テナントを含め完全に廃止(延長オプションなし) |
Azure ACSを使ったapp-only認証や、SharePoint Add-InsのProvider Hostedモデルを利用中の場合は、Microsoft Entra IDベースの認証への移行が急務です。移行先の推奨パターンは以下のとおりです。
- Azure ACSベースのapp-only権限 → Entra IDのアプリケーション登録 + 証明書認証
- SharePoint Add-Ins → SharePoint Framework(SPFx)への移行
権限モデルとの関係

SharePoint REST APIは、SharePointの権限モデル(サイト権限、リスト権限、アイテムレベル権限)をそのまま尊重します。
- ユーザーに閲覧権限のないサイトやリストは、REST API経由でも取得できない
- アイテムレベルのアクセス制限がかかっている場合、該当ユーザーにはREST APIでも返されない
- アプリケーション権限の場合は、設定したスコープに応じて広範なデータにアクセスできる
RAGやナレッジ検索のシステムを設計する際は、「インデックス作成時にどの権限でREST APIを呼ぶか」と「回答時にユーザーの権限をどう反映させるか」を分けて考える必要があります。

SharePoint REST APIの制限とスロットリング

SharePoint Onlineでは、サービス全体の安定性を保つためにスロットリング(調整)が適用されます。
このセクションでは、スロットリングの仕組み、具体的な制限値、APIコストの計算方法、パフォーマンス設計のポイントを解説します。
スロットリングの仕組み
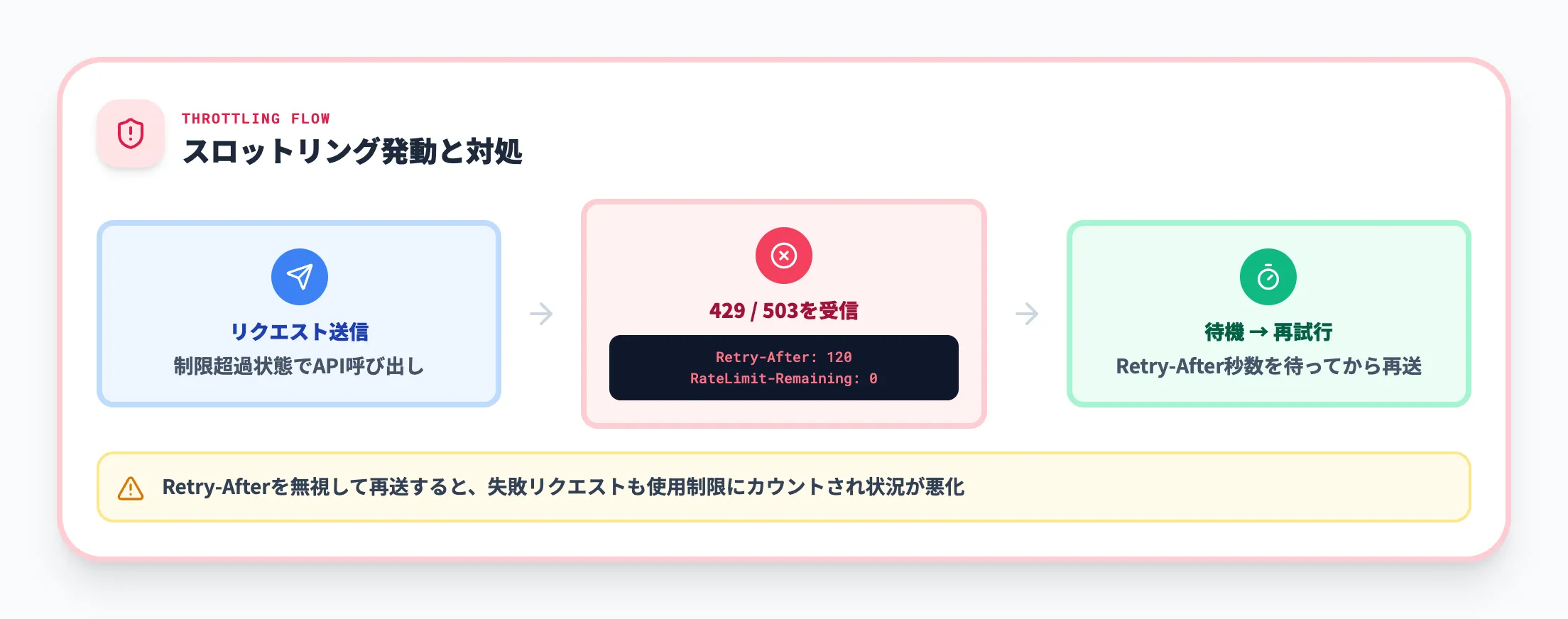
使用制限を超えると、SharePoint Onlineは以下のHTTPステータスコードを返します。
-
HTTP 429(Too Many Requests)
呼び出し元アプリケーションが時間枠内のリクエスト上限を超えた場合に返されます。
-
HTTP 503(Service Unavailable)
サービス側で一時的な負荷スパイクが発生している場合に返されます。
どちらの場合もレスポンスに Retry-After ヘッダーが含まれ、再試行までの待機時間(秒)が示されます。このヘッダーを無視してリクエストを繰り返すと、失敗したリクエストも使用制限にカウントされるため、状況はさらに悪化します。
VS CodeのREST ClientでSharePoint REST APIのレスポンスヘッダーを確認している画面
また、SharePoint OnlineのレスポンスにはRetry-Afterに加えて、RateLimitヘッダー(RateLimit-Limit、RateLimit-Remaining、RateLimit-Reset)がプレビュー機能としてベストエフォートで返される場合があります。これらのヘッダーを監視することで、スロットリングが発生する前に自主的にリクエスト頻度を調整する予防的な設計が可能です。
ユーザー・テナント・アプリケーション別の制限値
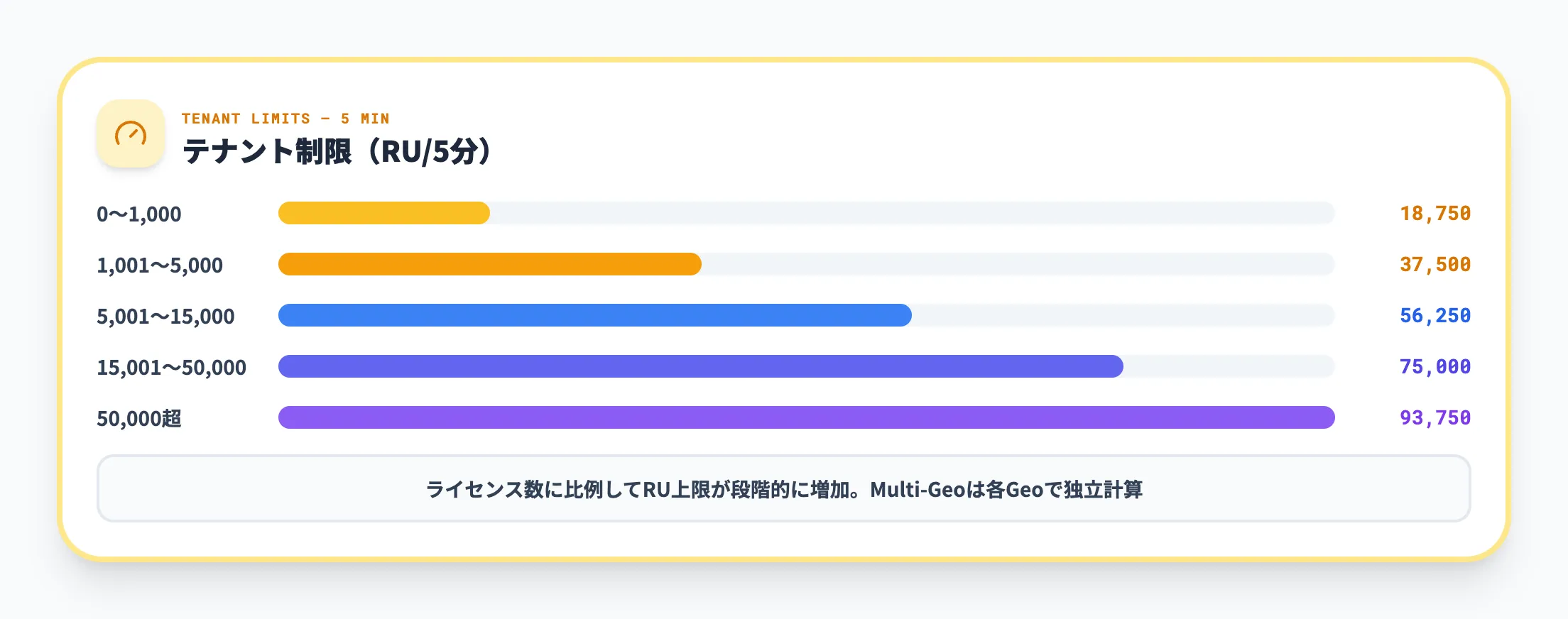
スロットリングは3つの階層で適用されます。以下はMicrosoft公式ドキュメントに基づく主要な制限値です。
ユーザー制限
| 種類 | 時間枠 | 上限 |
|---|---|---|
| リクエスト数 | 5分 | 3,000 |
| データ受信(イングレス) | 1時間 | 50 GB |
| データ送信(エグレス) | 1時間 | 100 GB |
テナント制限(リソースユニット)
テナント制限はライセンス数に応じて段階的に増加します。
| ライセンス数 | 5分あたりのリソースユニット上限 |
|---|---|
| 0〜1,000 | 18,750 |
| 1,001〜5,000 | 37,500 |
| 5,001〜15,000 | 56,250 |
| 15,001〜50,000 | 75,000 |
| 50,000超 | 93,750 |
アプリケーション制限(テナント内のアプリ単位)
| ライセンス数 | 1分あたりの上限 | 24時間あたりの上限 |
|---|---|---|
| 0〜1,000 | 1,250 | 1,200,000 |
| 1,001〜5,000 | 2,500 | 2,400,000 |
| 5,001〜15,000 | 3,750 | 3,600,000 |
| 15,001〜50,000 | 5,000 | 4,800,000 |
| 50,000超 | 6,250 | 6,000,000 |
これらの数値は2026年3月時点のMicrosoft公式ドキュメントに基づく既定値です。
Microsoftはこれらの制限をいつでも変更できると明記しており、Multi-Geoテナントの場合は各Geo(地域)ごとに独立した制限が適用されます。
リソースユニットとAPIコスト
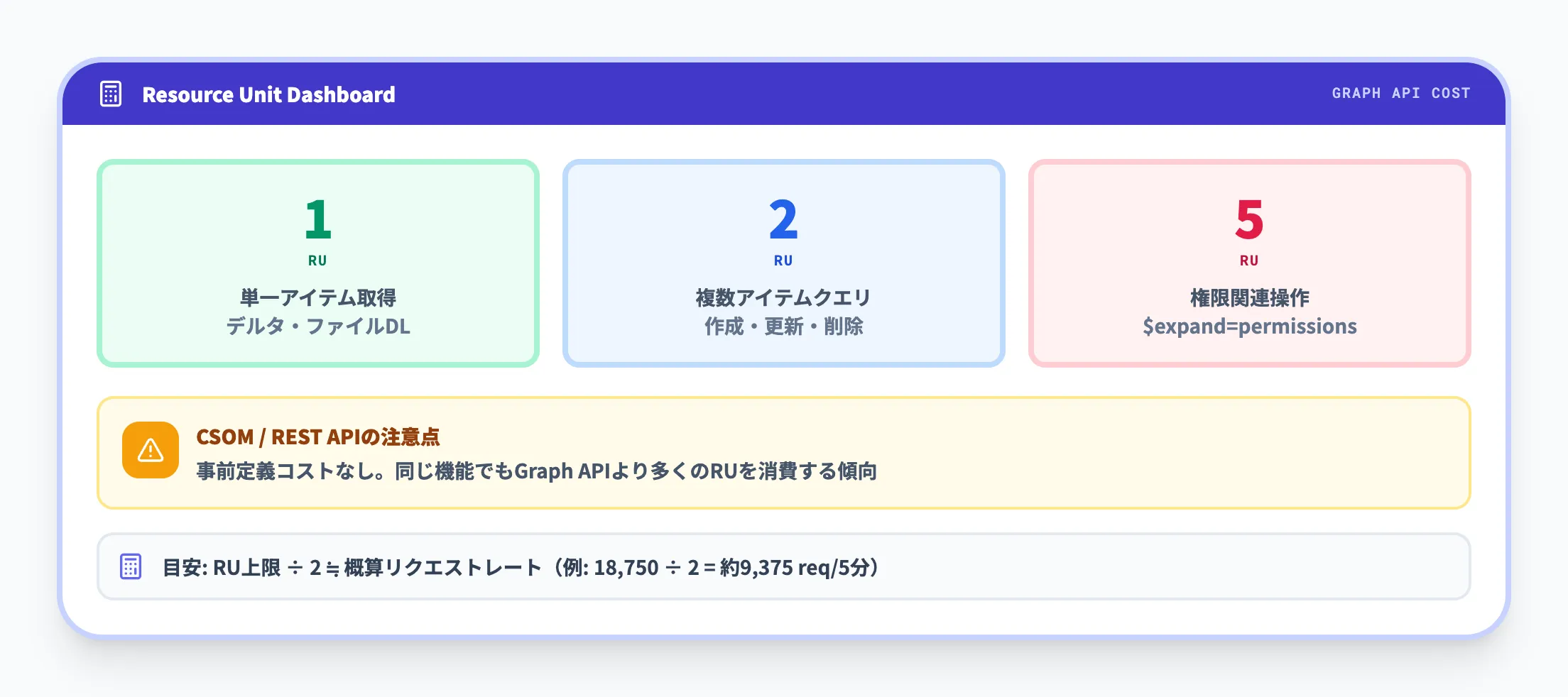
テナントとアプリケーションの制限はリソースユニットという単位で計算されます。Microsoft Graph APIには操作ごとに事前定義されたコストがあります。
| リソースユニット | 操作の種類 |
|---|---|
| 1 | 単一アイテムの取得、トークン付きデルタ、ファイルダウンロード |
| 2 | 複数アイテムのクエリ(リスト子要素の一覧取得等)、作成・更新・削除・アップロード |
| 5 | すべての権限関連操作($expand=permissions を含む) |
ここで注意すべきは、CSOM/REST APIには事前定義のリソースユニットコストがないという点です。
Microsoftの公式ドキュメントでは「CSOM/RESTは通常、同じ機能を実現するのにGraph APIよりも多くのリソースユニットを消費する」と説明されています。
リクエストレートの目安としては、1リクエストあたり平均2リソースユニットを想定し、リソースユニット上限を2で割った値が概算のリクエストレートになります。
たとえばライセンス数1,000以下のテナントでは、アプリ1分あたり約625リクエストが目安です。
リストビューしきい値

大規模なリストやライブラリでは、リストビューしきい値に起因する制限に注意が必要です。
SharePoint Onlineでは、リストあたり最大3,000万アイテムを格納できますが、10万アイテムを超えるとアクセス許可の継承解除ができなくなります。
しきい値を超えた場合にエラーが発生するケースもあるため、以下の対策を設計段階で組み込みます。
- インデックス付き列で絞り込むことを前提に列設計を行う
- $filter と $select で必要な範囲だけを取得する
- 一括取得が必要な場面では、ページングを含めた設計にする
この制限は一時的なスロットリングとは異なり、データ設計とクエリ設計で回避するのが基本です。
パフォーマンスとクエリ設計のポイント

SharePoint REST APIのパフォーマンスを確保するために、以下の設計原則が重要です。
- $select で必要なフィールドだけを取得し、不要な列を返さない
- $filter やインデックス付き列を活用して、サーバー側で絞り込む
- $top やページングで、一度に大量のアイテムを取得しない
- まとめられる操作はバッチリクエストで1回のHTTP呼び出しにまとめる
- リスト設計の段階で、列数・ビュー・インデックスを意識してスキーマを整える
共通するポイントは「不要なデータを取らない」「アクセスパターンを見越したスキーマ設計」の2点です。
HTTPトラフィックの装飾
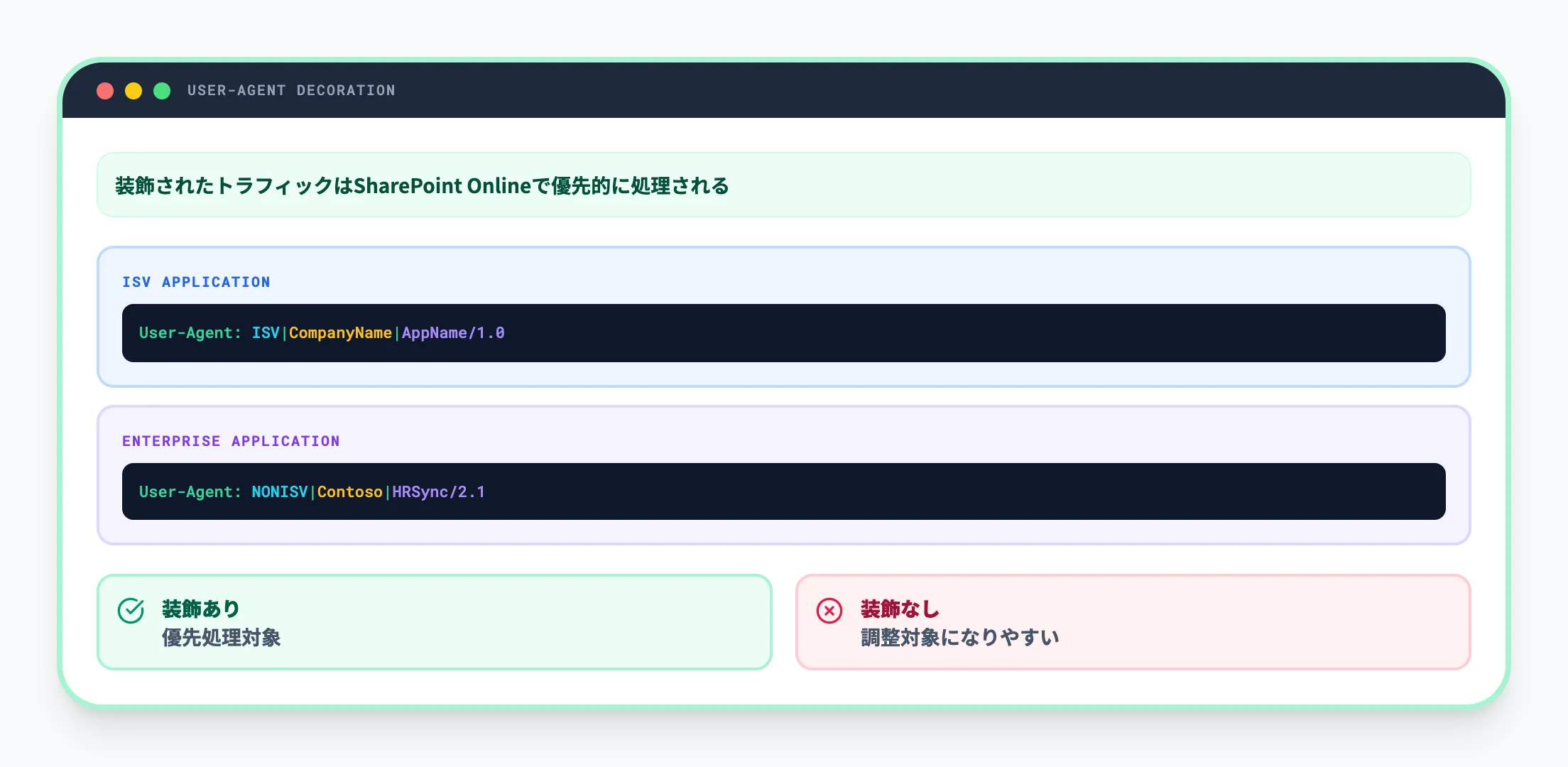
SharePoint Onlineでは、適切に装飾されたHTTPトラフィックが、装飾されていないトラフィックよりも優先的に処理されます。
装飾とは、リクエストのUser-Agentヘッダーに以下の形式でアプリケーション情報を含めることです。
| 種別 | User-Agent形式 |
|---|---|
| ISVアプリケーション | ISV 縦棒 会社名 縦棒 アプリ名/バージョン |
| エンタープライズアプリケーション | NONISV 縦棒 会社名 縦棒 アプリ名/バージョン |
加えて、Entra IDにアプリケーションを登録してAppIDを取得し、リクエストに含めることが推奨されます。
装飾されていないトラフィック(AppIDやUser-Agent文字列がないリクエスト)は調整の対象になりやすいため、本番環境では必ず設定すべきです。
SharePoint REST APIの実装パターン
このセクションでは、SharePoint REST APIをシステムに組み込む3つの代表的なパターンを整理します。
バックエンド連携
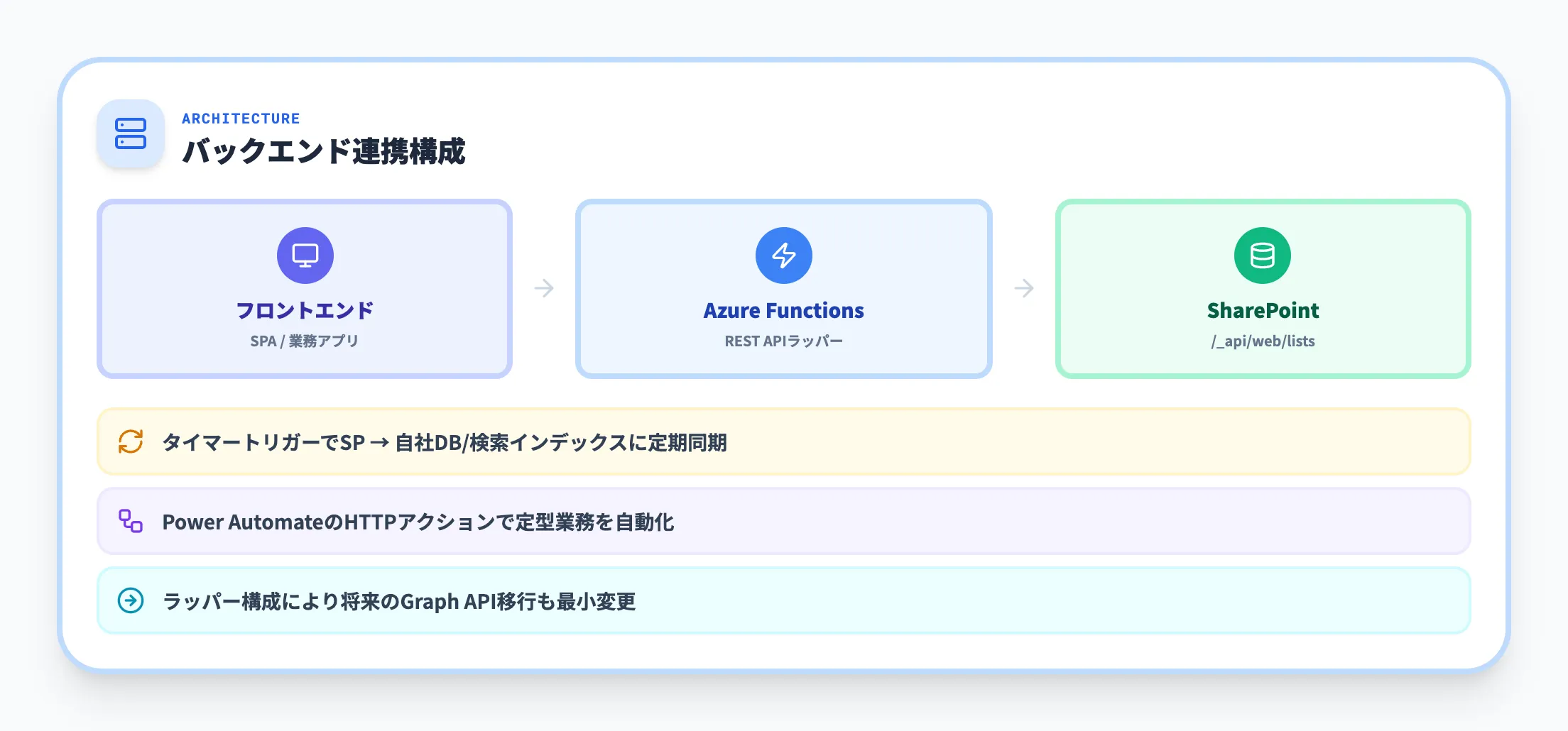
Azure Functionsや自社のWeb APIがSharePointの代理としてREST APIを呼び出し、フロントエンドや他システムに整形済みデータを提供する構成です。
代表的なパターンを以下に示します。
- Azure Functionsが定期的にSharePoint REST APIからデータを取得し、自社DBや検索インデックスに同期する
- 業務システムのAPIが、ユーザーのリクエストに応じてSharePoint REST APIを呼び出し、必要なデータだけを返却する
- Power AutomateのHTTPアクションからREST APIを呼び出して定型業務を自動化する
バックエンド側でREST APIをラップしておくと、将来的にGraph APIに移行する場合でもフロントエンドの変更を最小限に抑えられます。
フロントエンド連携
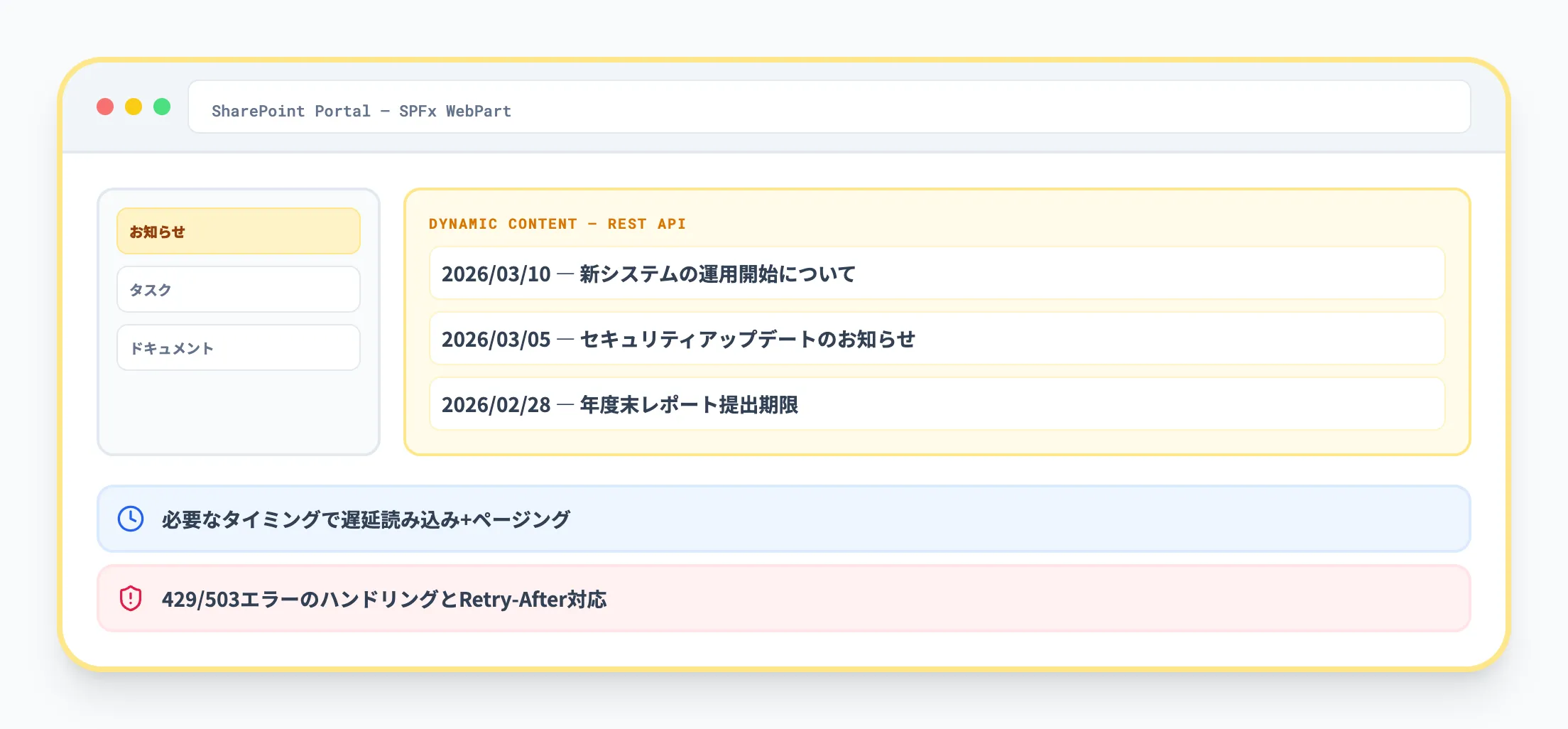
SharePoint REST APIは、フロントエンドから直接呼び出すことも可能です。
特にSPFxのWebパーツや拡張機能では、REST APIを使ってサイト内のリストやドキュメントを動的に表示するケースが多くあります。
フロントエンド連携で重要なポイントは以下のとおりです。
- ページロード時にすべてのデータを取得せず、必要なタイミングでページングやフィルタリングを行う
- 長時間のポーリングや大量の並列リクエストを避け、スロットリング対策を組み込む
- 認証エラー、権限不足、レート制限に対するエラーハンドリングを設計する
ユーザー体験とAPI制限の両方を意識して、どのタイミングでどのリソースを取得するかを設計することが重要です。
SharePoint Workbench上でSPFxのWebパーツがREST APIから取得したリストデータを表示している画面
RAGやナレッジ検索への組み込み

RAGやナレッジ検索の観点では、SharePoint REST APIは「どのリソースを、どの粒度で、どのパイプラインに乗せるか」が設計の鍵になります。
大まかなステップは以下のとおりです。
-
インデックス対象にするサイト、ライブラリ、リストを決める
-
REST APIで該当リストやライブラリのアイテムを列挙し、本文(ファイルの中身)とメタデータ(タイトル、カテゴリ、タグ、更新者など)を取得する
-
取得したデータをベクターストアや検索エンジンに投入し、メタデータをキーにして検索・フィルタリングできるようにする
-
回答生成時には、ユーザーのロールや所属に応じて、返してよいドキュメントのみを候補とするアクセス制御ロジックを組み込む
ここで注意すべきは、インデックスはSharePointとは別系統のデータストアに格納されるため、SharePointの権限が自動的にそのまま反映されるわけではないという点です。
インデックス作成時の権限と、検索・回答時の権限制御(Security Trimming)を分けて設計する必要があります。
SharePoint REST APIの料金とライセンス

SharePoint REST APIには、API呼び出し単位の従量課金はありません。
SharePoint Onlineへのアクセスは、Microsoft 365サブスクリプションまたはSharePointスタンドアロンプランに含まれるライセンスに基づいて利用できます。
ここでは、プラン構成とライセンスの最新動向を整理します。
Microsoft 365プランとAPIアクセス
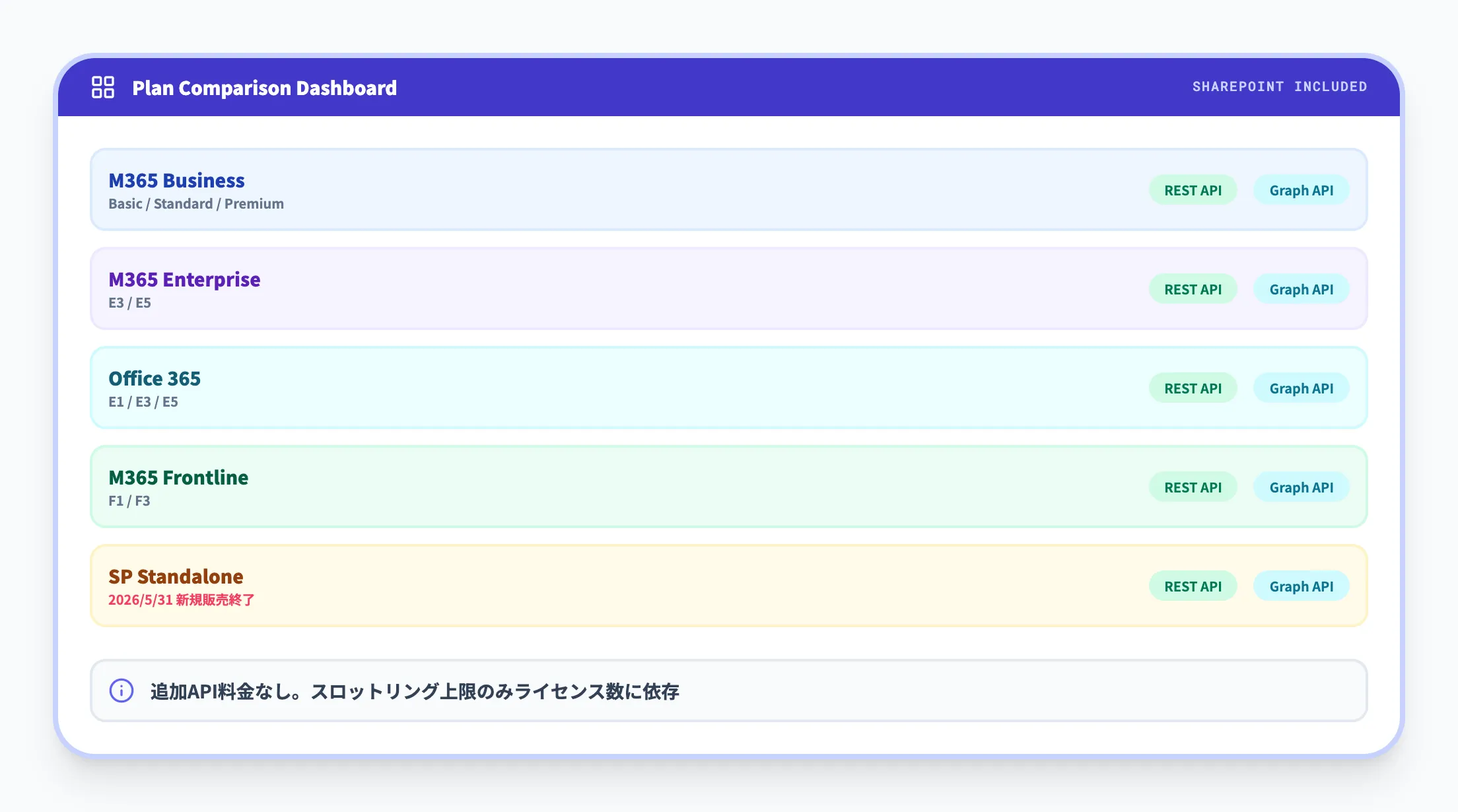
SharePoint REST APIは、SharePoint Onlineを含むMicrosoft 365の各プランで利用可能です。
以下の表で、SharePointが含まれる主なプランを整理します。
| プランカテゴリ | 対象例 | SharePoint含む |
|---|---|---|
| Microsoft 365 Business | Basic / Standard / Premium | あり |
| Microsoft 365 Enterprise | E3 / E5 | あり |
| Office 365 | E1 / E3 / E5 | あり |
| Microsoft 365 F1/F3 | フロントラインワーカー向け | あり |
| SharePoint スタンドアロン | Plan 1 / Plan 2 | あり |
どのプランでも、REST APIやGraph API経由のSharePointアクセスに追加のAPI利用料は発生しません。
ただし、スロットリングの上限はテナントのライセンス数に応じて段階的に設定されるため、ライセンス数が少ないテナントほど制限が厳しくなります。
スタンドアロンプランの廃止予定
2026年3月時点で、SharePointスタンドアロンプランは以下の価格で提供されています。
| プラン | 月額(ユーザーあたり) | ストレージ |
|---|---|---|
| SharePoint Plan 1 | $5 | 1TB + 10GB/ライセンス |
| SharePoint Plan 2 | $10 | 1TB + 10GB/ライセンス |
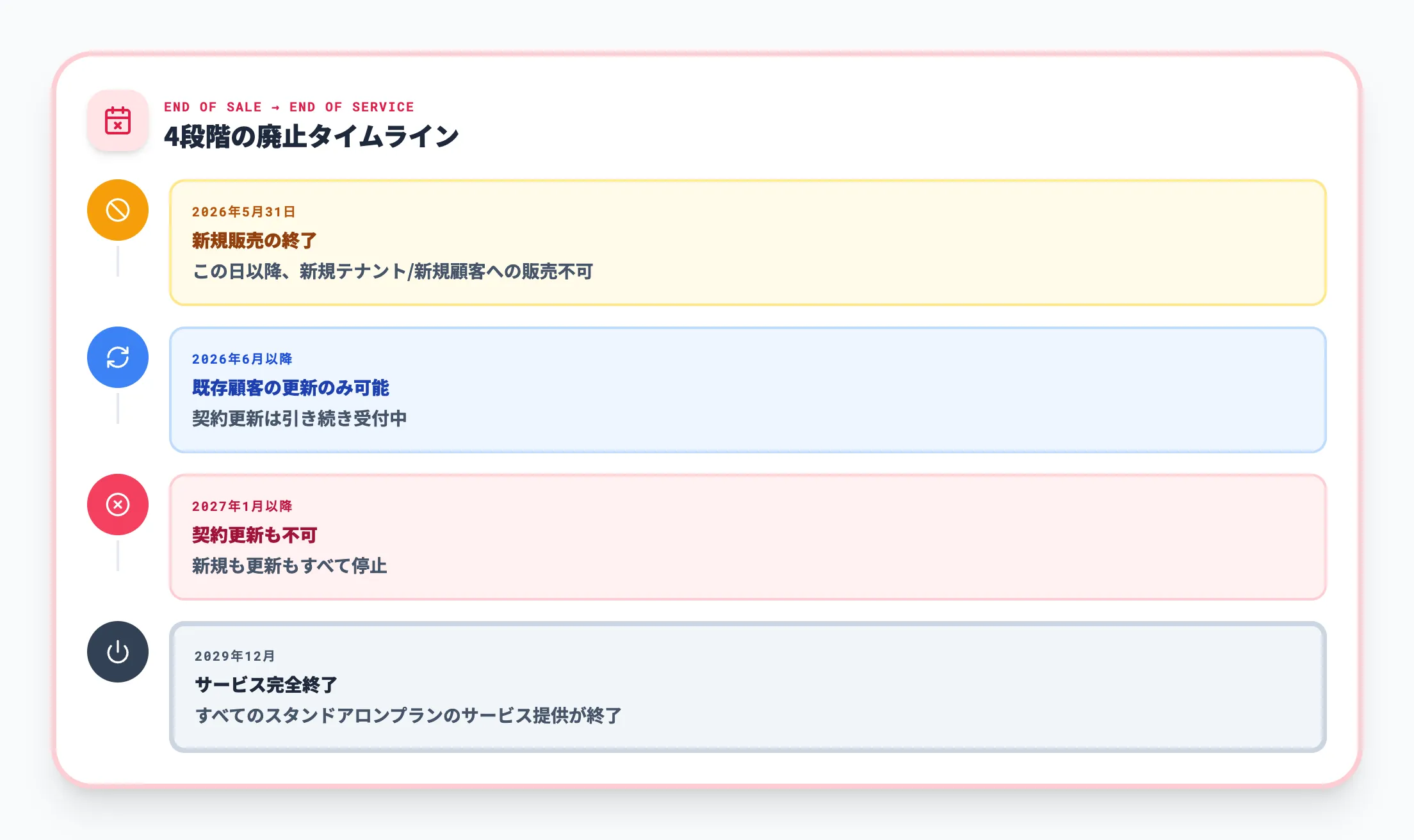
ただし、Microsoftはスタンドアロン版のSharePoint Plan 1/2およびOneDrive Plan 1/2の段階的な廃止を発表しています。タイムラインは以下のとおりです。
-
2026年5月31日
新規販売の終了。この日以降、新たにスタンドアロンプランを購入することはできなくなります。
-
2026年6月以降
既存顧客の契約更新は引き続き可能です。
-
2027年1月以降
契約更新も不可になります。
-
2029年12月
サービス提供の完全終了予定です。
今後SharePointを新規導入する場合は、Microsoft 365 Business BasicやEnterprise E3/E5などのバンドルプランを選択する形になります。
スロットリング上限とライセンス数の関係

前述のとおり、テナント・アプリケーション両方のスロットリング上限はライセンス数に比例して増加します。
たとえば、ライセンス数1,000以下のテナントでは、テナント全体で5分あたり18,750リソースユニットが上限です。
一方、50,000超のライセンスを持つテナントでは同93,750リソースユニットまで拡大します。
大量のAPI呼び出しが見込まれる場合は、ライセンス数の増加がスロットリング耐性の向上にもつながることを踏まえたプラン選定が重要です。

SharePointのデータ連携をAIエージェントの業務自動化に活かすなら
REST APIでSharePointのデータ操作を自動化できるなら、次はそのデータをAIエージェントが業務判断に活用する段階です。
AI Agent Hubは、SharePointに蓄積されたドキュメント・リストデータをAIエージェントがナレッジとして参照し、問い合わせ対応から業務処理まで自動実行するエンタープライズAI基盤です。
- SharePointのデータをAgentの判断ソースに
REST APIやGraph APIで取得したドキュメント・リストデータを、AIエージェントがナレッジとして参照。問い合わせ対応から申請処理まで自動化します。
- API連携の先にある業務プロセスの自動実行
データの取得・更新だけでなく、その結果をもとにAIエージェントが承認ワークフロー・レポート作成・通知まで自動実行。APIの価値を業務成果に直結させます。
- 使い慣れたMicrosoft環境をそのまま活用
Teamsなど既存のMicrosoftツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、設計から運用まで伴走支援します。まずは無料の資料で、自社の業務にどう活用できるかご確認ください。
SharePoint連携をAI業務自動化に拡張

API活用の先にあるAIエージェント
SharePoint REST APIで構築したデータ連携を、AIエージェントの業務判断ソースに拡張。問い合わせ対応から申請処理まで自動化します。
まとめ
SharePoint REST APIは、HTTPベースでSharePointのサイト・リスト・ドキュメントを操作するための標準インターフェースです。プラットフォームに依存せず、ODataクエリで柔軟なデータ操作が可能なため、社内ポータル・業務アプリ・バックエンド連携で広く利用されています。
一方で、Microsoft 365全体を横断するシナリオではGraph APIが推奨されており、スロットリングの面でもGraph APIの方がリソース効率に優れることがMicrosoftの公式ドキュメントで示されています。REST APIは「SharePointに近いレイヤー」、Graph APIは「Microsoft 365全体のハブ」という役割分担で整理すると、技術選定がしやすくなります。
2026年の重要な変更として、Azure ACSが4月2日に完全廃止されます。Azure ACSベースの認証を利用している場合は、Entra IDベースの認証への移行が急務です。また、SharePointスタンドアロンプランは2026年5月31日で新規販売が終了するため、新規導入ではMicrosoft 365バンドルプランの採用を前提に検討する必要があります。
運用面では、スロットリングの3階層(ユーザー・テナント・アプリケーション)を理解し、Retry-AfterヘッダーとRateLimitヘッダーを活用した再試行・事前制御ロジックとUser-Agentによるトラフィック装飾を組み込むことが安定運用の鍵になります。
RAGやナレッジ検索の文脈では、REST APIを通じてメタデータを適切に取得し、権限モデルと整合する形でインデックスと回答制御を設計することが、他の競合記事にはない実践的な差別化ポイントです。







