この記事のポイント
 スマートフォンからサーバーまで動く4サイズ展開で、自社環境に最適なモデルを選択可能
スマートフォンからサーバーまで動く4サイズ展開で、自社環境に最適なモデルを選択可能- Apache 2.0ライセンス採用で商用利用に制約なし。ライセンス料ゼロでオンプレ運用が実現
- 31Bモデルはオープンモデル世界3位。AIME 2026で89.2%、LiveCodeBenchで80.0%の実力
- ネイティブ関数呼び出し対応のため、エージェントワークフロー構築コストを大幅に削減可能
- Gemma 3比で推論性能が最大4倍向上し、256Kコンテキスト対応で長文処理も実用水準

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Google DeepMindが2026年4月2日に公開した「Gemma 4」は、Gemini 3と同じ研究基盤から生まれたオープンAIモデルファミリーです。
スマートフォンで動くE2B(2.3Bパラメータ)からサーバー向けの31B Denseまで4サイズが用意され、すべてApache 2.0ライセンスで商用利用も無料になりました。
本記事では、各モデルのスペックとベンチマーク性能、Llama 4やQwen 3.5との比較、Google AI StudioやOllamaでの導入手順、ネイティブ関数呼び出しによるエージェント活用、そしてGPU要件やライセンスの注意点まで、企業がGemma 4を評価・導入する際に必要な情報を体系的に解説します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
Gemma 4とは?Google DeepMindの最新オープンモデル
Gemma 4は、Google DeepMindが2026年4月2日に公開したオープンAIモデルファミリーです。
Gemini 3と同じ世界トップクラスの研究・技術基盤をベースに構築されており、テキスト・画像・音声・動画を扱えるマルチモーダル対応と、エージェントワークフロー向けのネイティブ関数呼び出し機能を備えています。

最大の注目点は、ライセンスが従来のGoogle独自の「Gemma Open License」からApache 2.0に切り替わったことです。
これにより、Google独自条件下での商用利用制約がなくなり、配布・派生モデル利用の自由度が大幅に高まりました。企業がオンプレミスで自由にデプロイ・カスタマイズできる環境が整っています。
モデルは全4サイズで提供されています。スマートフォンやIoTデバイスで動くE2B(2.3B)から、オープンモデル世界3位の性能を持つ31B Denseまで、用途に応じたモデルを選択できる構成です。
以下の表で、Gemma 4ファミリーの全体像を整理しました。
| モデル | 実効パラメータ | 総パラメータ | アーキテクチャ | コンテキスト | 対応モダリティ |
|---|---|---|---|---|---|
| E2B | 2.3B | 5.1B | Dense | 128K | テキスト・画像・音声・動画 |
| E4B | 4.5B | 8B | Dense | 128K | テキスト・画像・音声・動画 |
| 26B A4B | 3.8B(アクティブ) | 25.2B | MoE | 256K | テキスト・画像・動画 |
| 31B | 30.7B | 30.7B | Dense | 256K | テキスト・画像・動画 |
特徴的なのは、名称に含まれる「E」と「A」の意味です。E2B・E4Bの「E」は「Effective(実効)」を表し、埋め込み層を除いた推論時の実質パラメータ数を示します。26B A4Bの「A」は「Active(アクティブ)」で、MoE(Mixture of Experts)アーキテクチャにおいて推論時に実際に活性化されるパラメータ数を意味します。つまり、26B A4Bは総パラメータ25.2Bのうち3.8Bだけを使って推論するため、パラメータ効率に優れたモデルです。
大規模言語モデル(LLM)の選定では、性能・コスト・デプロイ環境のバランスが重要になります。Gemma 4はこの3つを高い水準で両立させたモデルファミリーとして、企業のAI導入における有力な選択肢です。

Gemma 4の4つのモデルバリエーション

Gemma 4は4つのサイズで提供されており、デプロイ先のハードウェアとユースケースに応じて最適なモデルを選択できます。ここでは各モデルの技術的な特徴と、選定時の判断基準を解説します。
E2B・E4B(エッジ向け小型モデル)
E2BとE4Bは、スマートフォン・タブレット・IoTデバイスといったエッジ環境での動作を想定した小型モデルです。
Gemma 4ファミリーの中で唯一、音声入力に対応しているのがこの2モデルです。USMスタイルのConformerオーディオエンコーダを搭載しており、音声認識・音声からのテキスト変換をモデル単体で処理できます。
以下にE2B・E4Bの主なスペックを整理しました。
| 項目 | E2B | E4B |
|---|---|---|
| 実効パラメータ | 2.3B | 4.5B |
| 総パラメータ(埋め込み含む) | 5.1B | 8B |
| レイヤー数 | 35 | 42 |
| コンテキストウィンドウ | 128Kトークン | 128Kトークン |
| 音声対応 | あり | あり |
| VRAM目安(4-bit量子化) | 約5GB | 約5GB |
| VRAM目安(FP16) | 約10GB | 約15GB |
4-bit量子化で約5GBのメモリで動作するため、8GBメモリのスマートフォンでも実行可能です。Google Developersブログによれば、2-bitおよび4-bit量子化時には1.5GB未満のメモリでも動作します。
オフラインでの音声テキスト変換やリアルタイム画像認識など、ネットワーク接続なしで動作させたいユースケースに適しています。
26B A4B(MoEモデル)

26B A4Bは、Mixture of Experts(MoE)アーキテクチャを採用したモデルです。総パラメータ25.2Bの中に128個のエキスパートを持ち、推論時にはそのうち8個(約3.8B)だけを活性化させます。
この設計により、31B Denseに迫る性能を、はるかに少ない計算コストで実現しています。Hugging Faceのブログによれば、LMArenaスコア(テキストのみ)は31Bの1452に対して26B A4Bは1441と、わずか11ポイントの差です。
- 実効アクティブパラメータ
3.8B。推論時の演算量はE4Bに近い水準に収まる
- エキスパート構成
128エキスパート中8個をアクティブ化。タスクの種類に応じて異なるエキスパートが選択される
- コンテキストウィンドウ
256Kトークン。長文ドキュメントの処理に対応
- VRAM目安
4-bit量子化で約18GB、8-bitで約28GB。RTX 4090(24GB)なら4-bit量子化でギリギリ動作する
コストパフォーマンスを重視するなら、26B A4Bは最も有力な選択肢です。31Bとほぼ同等の品質を、メモリ消費量を大幅に抑えて実現できます。
31B Dense(最高性能モデル)
31B Denseは、Gemma 4ファミリーの最上位モデルです。Google DeepMindの公式ページによれば、業界標準のArena AIテキストリーダーボードでオープンモデル世界3位にランクインしています。
- パラメータ数
30.7B。全パラメータが推論に使用されるDenseアーキテクチャ
- レイヤー数
60層。深いネットワークにより高い推論能力を実現
- コンテキストウィンドウ
256Kトークン。Gemma 3の128Kから倍増し、マルチニードル検索テストでは13.5%から66.4%へ大幅に改善
- VRAM目安
4-bit量子化で約20GB、8-bitで約34GB。FP16では約62GBが必要
最高精度が求められる推論タスクやコード生成、研究用途に向いています。ただしメモリ消費量が大きいため、本番環境ではGPUの選定が重要です。
モデル選定の判断基準
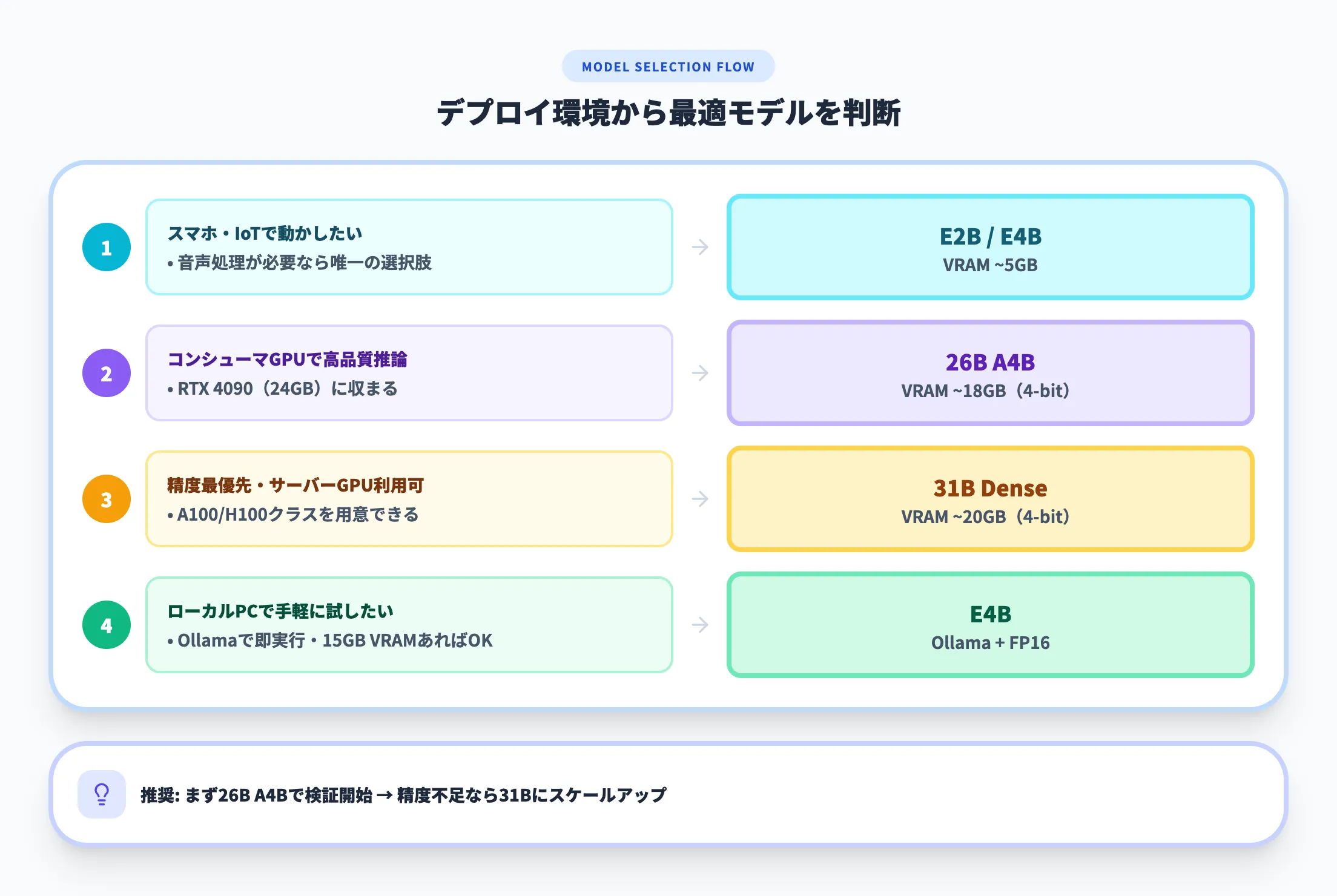
4つのモデルのうちどれを選ぶかは、デプロイ先のハードウェアと求められるタスク品質で決まります。以下に判断のフローを整理しました。
- スマートフォン・IoTデバイスで動かしたい
E2BまたはE4Bを選択。音声処理が必要ならこの2モデルが唯一の選択肢
- コンシューマーGPU(RTX 4090等)で高品質な推論をしたい
26B A4Bが最適。4-bit量子化で24GB VRAM内に収まり、31Bに迫る性能を発揮
- 精度最優先でサーバーGPUを使える環境
31B Denseを選択。A100/H100クラスのGPUを用意できるなら、最高の推論品質が得られる
- ローカルPCで手軽に試したい
E4BをOllamaで実行するのが最も手軽。15GB程度のVRAMがあればFP16でも動作する
AI総研の導入支援の経験上、まず26B A4Bで検証を始め、精度が不足する場合に31Bへスケールアップするアプローチが最もコスト効率に優れています。初期段階から31Bを前提にすると、GPU調達コストが検証フェーズのボトルネックになりがちです。
Gemma 4の主な新機能と改善点

Gemma 4は前世代のGemma 3から大幅な機能強化が施されています。ここでは、実務での活用に直結する4つの新機能を解説します。
思考モード(ビルトイン推論)
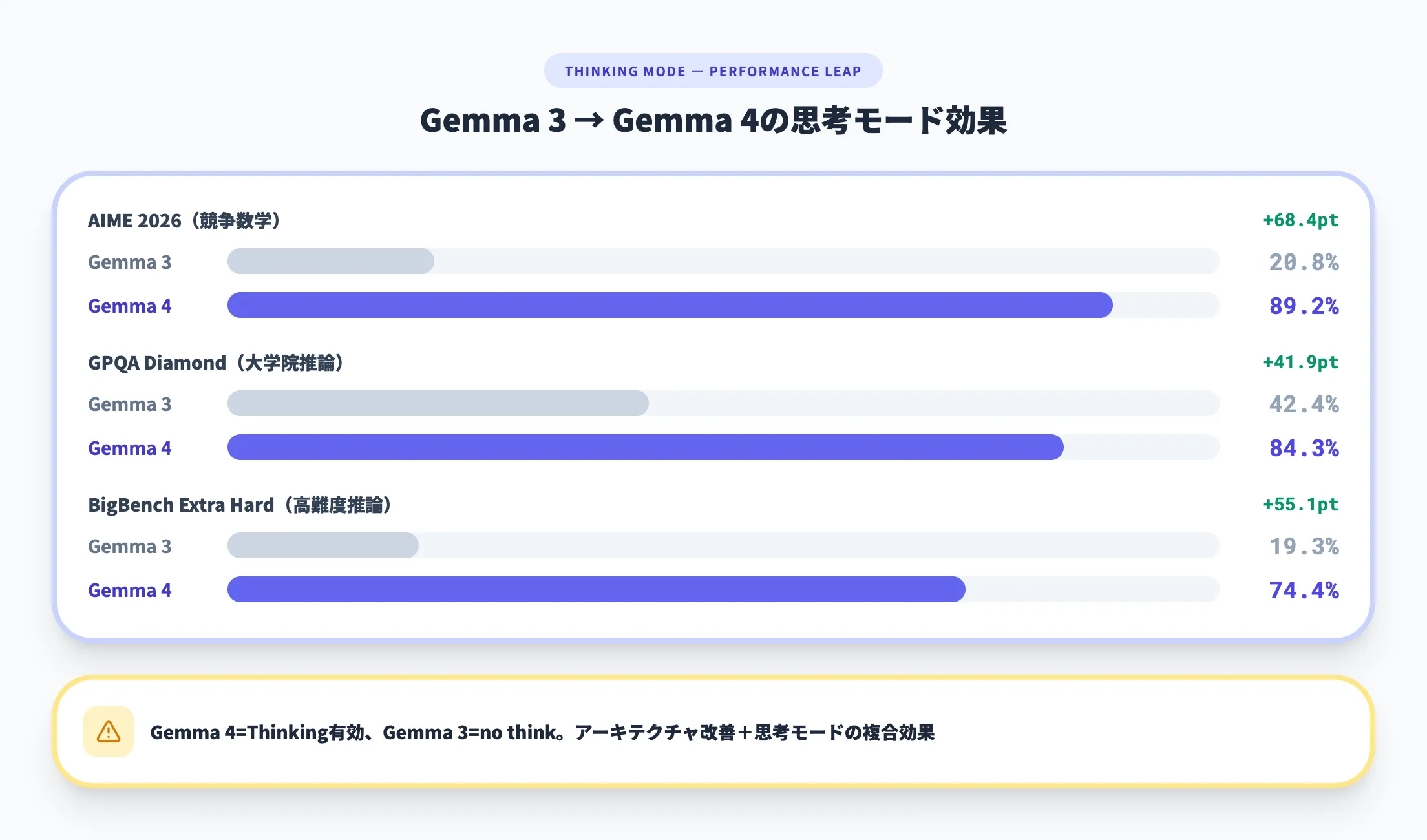
Gemma 4の全モデルに、回答前に段階的な推論プロセスを実行する**思考モード(Thinking Mode)**が搭載されました。これは推論モデルの考え方をオープンモデルに組み込んだもので、複雑な数学問題やコーディングタスクで特に効果を発揮します。
思考モードを有効にすると、モデルは最終回答の前に推論過程を伴う応答を生成します。Hugging Faceのブログによれば、Transformersライブラリではenable_thinkingパラメータをTrueに設定するだけで有効化できます。
この機能の効果は劇的です。AIME 2026(競争数学)のスコアは、Gemma 3の20.8%からGemma 4 31Bで89.2%へと約4.3倍に向上しました。思考モードなしでは到達が難しい高度な推論タスクでも、段階的に考えを整理することで正答率を大きく引き上げています。
マルチモーダル対応(画像・音声・動画)
Gemma 4は全モデルがマルチモーダルに対応しており、テキストだけでなく画像・動画の理解が可能です。さらにE2B・E4Bの2モデルは音声入力にも対応しています。
ビジョンエンコーダは、Gemma 3から2つの重要な改善が加えられました。
- 可変アスペクト比
Gemma 3では固定のアスペクト比で画像を処理していましたが、Gemma 4では元画像のアスペクト比を保持したまま処理できるようになりました。ドキュメントやスクリーンショットの解析精度が向上しています
- 設定可能なトークンバジェット
1枚の画像に割り当てるトークン数を70・140・280・560・1120の5段階から選択できます。速度と精度のトレードオフを柔軟に調整できるため、バッチ処理では低トークン、精密な画像解析では高トークンと使い分けが可能です
具体的に対応しているタスクとしては、OCR(文字認識)、手書き認識、オブジェクト検出、バウンディングボックス出力、GUIの要素認識、画像からのコード生成(HTMLやCSS)などがあります。
音声エンコーダは、Gemma 3n世代と同じUSMスタイルのConformerを採用しつつ、パラメータ数を681Mから305Mに圧縮しています。ただし、音声の学習データは主に音声(スピーチ)であり、音楽や環境音には対応していない点に注意が必要です。
ネイティブ関数呼び出しとエージェント機能
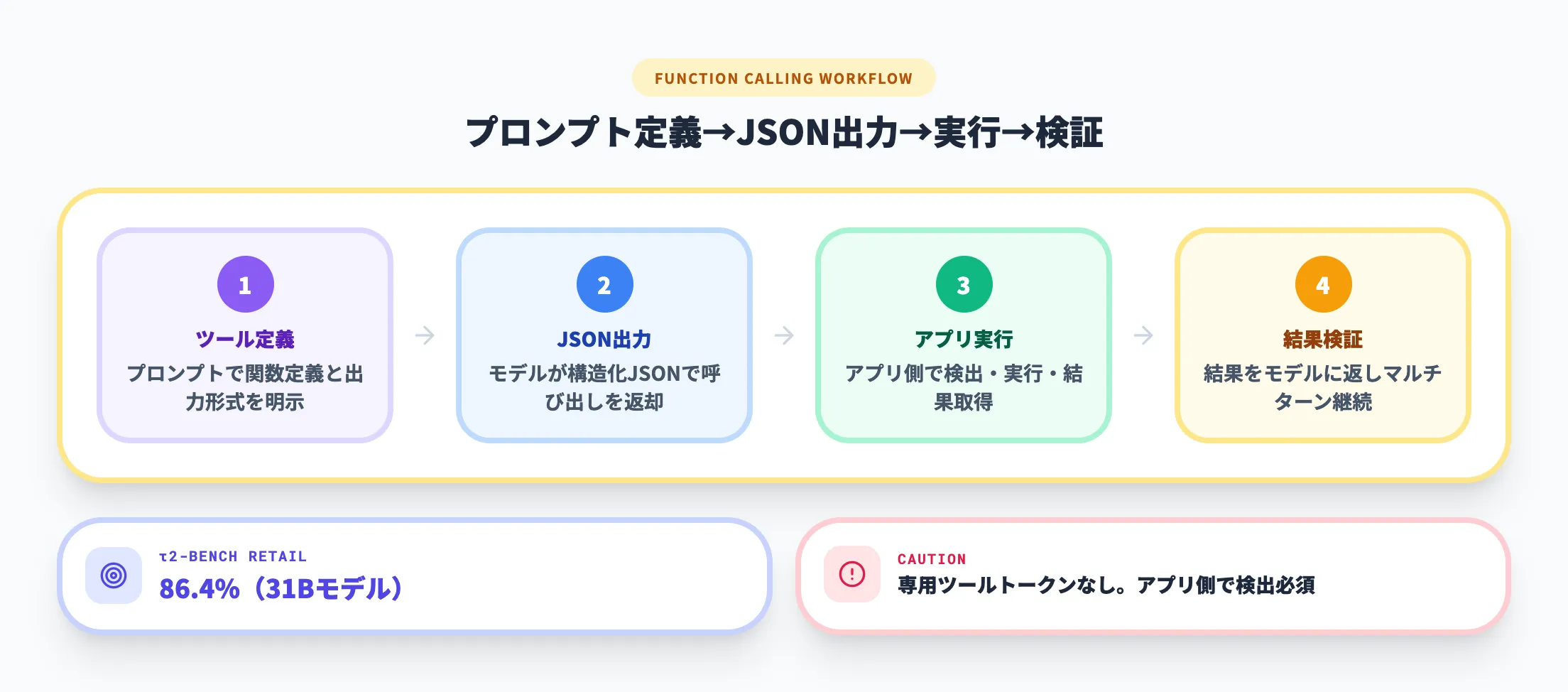
AIエージェントを構築するうえで重要な関数呼び出し(Function Calling)が、Gemma 4ではすべてのモデルにネイティブで組み込まれています。
従来のオープンモデルでは、関数呼び出しを実現するために大掛かりなファインチューニングが必要でした。Gemma 4では学習段階からツール使用が組み込まれており、マルチターンのエージェントワークフローに最適化されています。ただし、公式ドキュメントによれば、プロンプトで利用可能な関数の定義と出力形式を明示する必要があります。またモデルは専用のツールトークンを出力しないため、アプリケーション側で関数呼び出しの検出・実行・結果の検証を実装する必要があります。
Google DeepMindのページによれば、τ2-benchのRetailカテゴリで31Bモデルが86.4%を達成しています。なお、公式モデルカードが示す3カテゴリ平均は76.9%です。
関数呼び出しの主な特徴は以下のとおりです。
- テキストのみ・マルチモーダル両対応
テキスト入力に加え、画像+テキストの組み合わせでも関数呼び出しが可能
- ツール定義によるJSON出力
プロンプトで関数定義と出力形式を指定すると、構造化されたJSON形式でツール呼び出しを返す。アプリ側での解析・実行・検証が必要
- マルチターン最適化
複数回のツール使用を含む長い対話でも、文脈を維持しながらエージェントとして動作する
社内のFAQシステムやデータ検索ツール、外部API連携など、複数のツールを組み合わせたエージェントワークフローを構築したいケースでは、Gemma 4のネイティブ関数呼び出しによって開発コストを大幅に削減できます。
コンテキストウィンドウの拡張と長文性能
大型モデル(26B A4B・31B)のコンテキストウィンドウが、Gemma 3の128Kトークンから256Kトークンに倍増しました。
数値上のウィンドウサイズだけでなく、実用的な長文処理能力も大きく改善されています。Hugging Faceのブログによれば、128K長文内のマルチニードル検索テスト(MRCR v2 8 needle)で、Gemma 3 27Bの13.5%からGemma 4 31Bでは66.4%へと約5倍のスコア向上を記録しました。
これはつまり、長い文書の中から必要な情報を実際に見つけ出して推論できる能力が飛躍的に向上したことを意味します。契約書のレビュー、技術ドキュメントの横断分析、大量のログ解析など、ビジネス現場で求められる長文タスクに対応できる水準です。
アーキテクチャ面では、スライディングウィンドウとグローバルフルコンテキストアテンションを交互に配置するハイブリッド設計が採用されています。小型モデルでは512トークン、大型モデルでは1024トークンのスライディングウィンドウを使い、デュアルRoPE構成によって長いコンテキストでも位置情報を正確に保持します。
AIモデルの理解を業務設計に活かす

PoC→全社展開の段階設計を整理
オープンモデルの選定から一歩進み、組織としてAIを業務に定着させるための段階設計ガイド(220ページ)を無料で公開中。部門別のユースケースとBefore/After付きで、自社に合った導入ステップを整理できます。
【徹底比較】Gemma 4 vs 競合オープンモデル
Gemma 4の性能を正しく評価するためには、同世代の競合オープンモデルとの比較が不可欠です。ここではベンチマーク数値を中心に、Llama 4、Qwen 3.5、そして前世代のGemma 3との違いを解説します。
ベンチマーク性能の比較
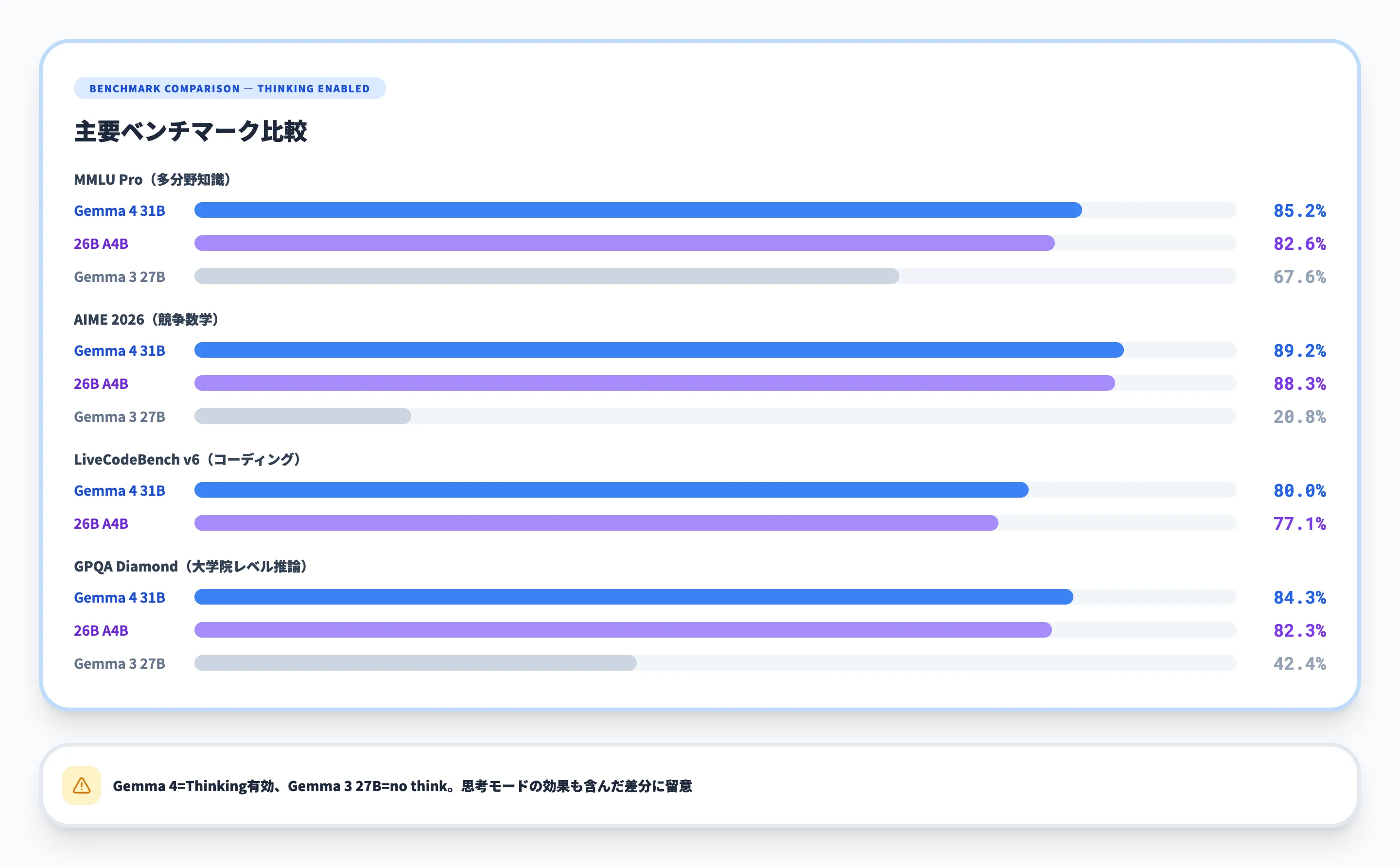
以下の表で、Gemma 4 31Bと主要な競合モデルのベンチマークスコアを比較しました。Gemma 4各モデルはThinking有効時の数値、Gemma 3 27Bは公式モデルカードの比較列に準拠したno think(思考モードなし)の数値です。
| ベンチマーク | Gemma 4 31B | Gemma 4 26B A4B | Gemma 3 27B | 評価内容 |
|---|---|---|---|---|
| Arena AI(テキスト) | 1452 | 1441 | — | 総合的な対話品質 |
| MMLU Pro | 85.2% | 82.6% | 67.6% | 多分野の知識・理解 |
| AIME 2026 | 89.2% | 88.3% | 20.8% | 競争数学 |
| GPQA Diamond | 84.3% | 82.3% | 42.4% | 大学院レベルの推論 |
| BigBench Extra Hard | 74.4% | 64.8% | 19.3% | 高難度推論タスク |
| LiveCodeBench v6 | 80.0% | 77.1% | — | コーディング |
| Codeforces ELO | 2150 | 1718 | 110 | 競技プログラミング |
| MMMU Pro | 76.9% | 73.8% | 49.7% | マルチモーダル理解 |
| MRCR v2 8 needle | 66.4% | 44.1% | 13.5% | 長文検索 |
31B Denseモデルは、MMLU Proで85.2%を達成しており、同サイズ帯のQwen 3.5 27Bを上回る結果です。一方でLlama 4 Scoutは10Mトークンという桁違いのコンテキストウィンドウを持っていますが、Gemma 4の256Kトークンは大半の実務ユースケースで十分な長さです。
特に注目すべきは26B A4Bの効率性です。アクティブパラメータがわずか3.8Bにもかかわらず、多くのベンチマークで31Bの90%以上の性能を維持しています。推論コストを抑えながら高品質な出力を得たい場合、26B A4Bは他のオープンモデルにない独自のポジションを占めています。
Gemma 3からの改善幅
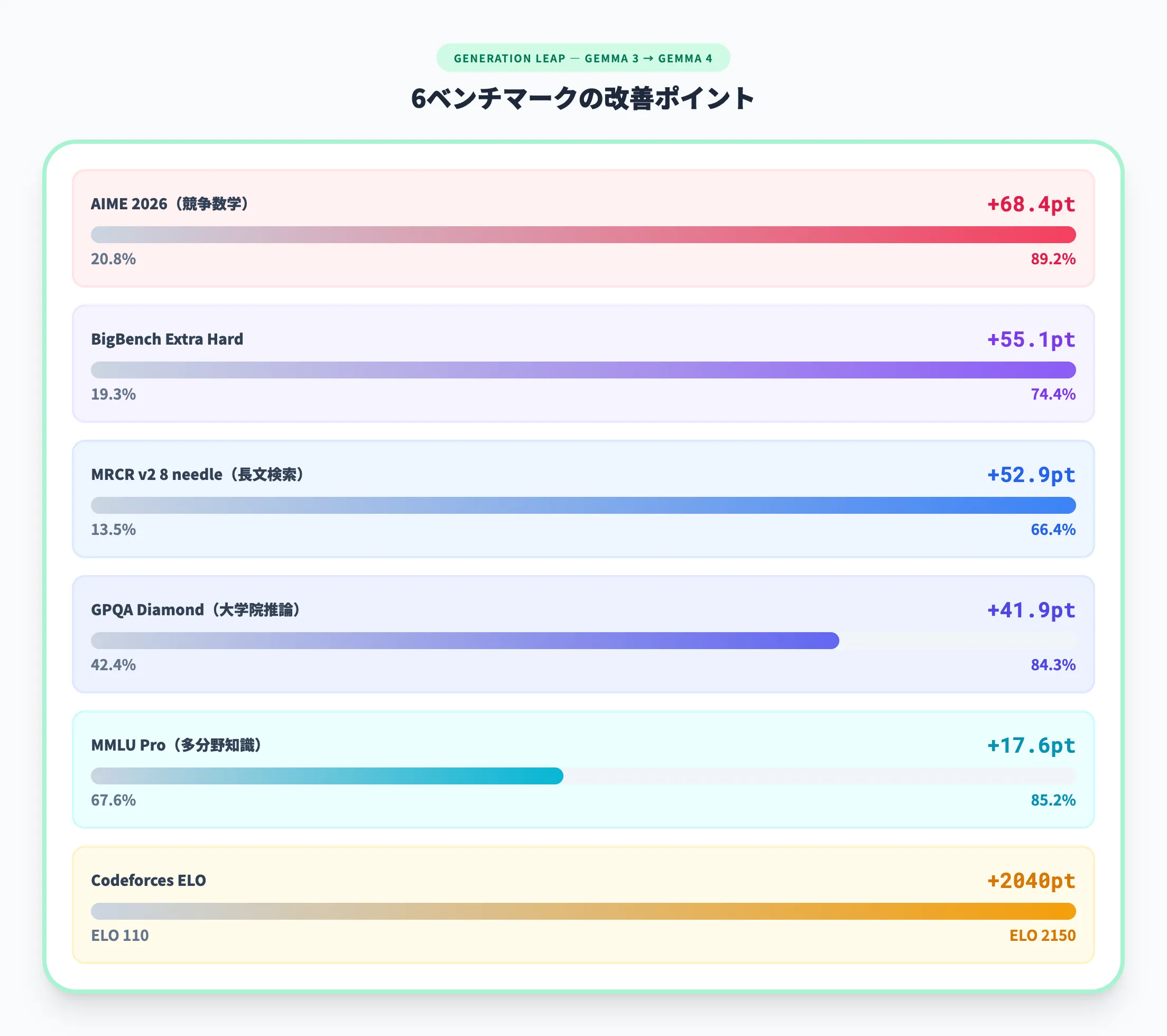
Gemma 4がGemma 3からどれだけ進化したかを、具体的な数値で確認しましょう。なお、Gemma 4 31BはThinking有効、Gemma 3 27Bはno thinkでの比較です。思考モードの有無が異なるため、純粋なアーキテクチャ改善だけでなく思考モードの効果も含んだ差分である点に留意してください。
| ベンチマーク | Gemma 3 27B | Gemma 4 31B | 改善幅 |
|---|---|---|---|
| MMLU Pro | 67.6% | 85.2% | +17.6pt |
| AIME 2026 | 20.8% | 89.2% | +68.4pt |
| GPQA Diamond | 42.4% | 84.3% | +41.9pt |
| BigBench Extra Hard | 19.3% | 74.4% | +55.1pt |
| Codeforces ELO | 110 | 2150 | +2040pt |
| MRCR v2 8 needle | 13.5% | 66.4% | +52.9pt |
改善幅が最も大きいのはAIME 2026(競争数学)で、20.8%から89.2%への68.4ポイント向上です。Codeforces ELOも110から2150へと跳ね上がっており、Gemma 3では「ほぼ機能しない」レベルだった競技プログラミングが「専門家レベル」に到達しています。
この飛躍の主な要因は、思考モードの導入とアーキテクチャの刷新(Per-Layer Embeddings、Shared KV Cache、MoEの追加)です。単一世代での改善としては、オープンモデル史上最大級といえるでしょう。
導入判断で詰まる論点

オープンモデルの選定では、ベンチマークスコアだけでは判断がつかない場面がよくあります。以下に、企業が実際に迷いやすいポイントを整理しました。
- Gemma 4 vs Llama 4 Scout
Llama 4 Scoutの10Mコンテキストが必要なユースケース(書籍全体の分析、超長尺の会話ログ解析など)でない限り、Gemma 4の256Kで十分です。ライセンス面では、Gemma 4のApache 2.0の方がLlama 4のMeta独自ライセンスより制約が少ない
- Gemma 4 vs Qwen 3.5
多言語対応ではどちらも強力ですが、Gemma 4は140以上の言語で事前学習されている点で優位。一方、中国語タスクに特化するならQwen 3.5も検討価値あり
- 31B vs 26B A4B
精度差が2〜3ポイント以内に収まるタスクが多いため、まず26B A4Bで評価し、精度不足が確認できた場合にのみ31Bに切り替えるのが合理的。GPU調達コストは倍以上変わる
社内で自然言語処理のタスクを10名以上のチームで利用する規模感であれば、まずGemma 4の26B A4Bを4-bit量子化でRTX 4090に載せて検証を始め、品質が要件を満たすかを確認するステップが最も堅実です。

Gemma 4の使い方と導入方法

Gemma 4はオープンモデルのため、クラウドからローカル環境まで幅広い方法で利用できます。ここでは代表的な4つの導入経路を解説します。
Google AI Studioで試す
最も手軽にGemma 4を体験できるのが、Google AI Studioです。ブラウザからアクセスするだけで、31Bと26B A4Bモデルをすぐに試せます。
Google AI Studioではプロンプトの入力・出力結果の確認に加え、Temperature(出力のランダム性)やMax Output Tokensの調整も可能です。アカウントを作成すればすぐに利用でき、無料枠の範囲内で基本的な動作確認ができます。
プロトタイプの段階ではGoogle AI Studioで品質を確認し、本番環境への移行時にVertex AIやセルフホスティングを検討するのが一般的なフローです。
Hugging Face・Kaggleからダウンロード
モデルの重みファイルはHugging FaceとKaggleの両方で公開されています。Hugging FaceではTransformersライブラリから直接ロードでき、ファインチューニングやカスタム推論パイプラインの構築に適しています。
Hugging Faceのモデルページには、ベースモデル(事前学習済み)と命令チューニング済みモデル(ITバリアント)の両方が用意されています。一般的なチャットやタスク実行にはITバリアントを使い、独自データでのファインチューニングにはベースモデルを選択します。
また、GGUF形式やONNX形式の量子化済みモデルも公開されており、llama.cppやMLX、transformers.jsなど多様な推論フレームワークに対応しています。
Ollamaでローカル実行
ローカルLLMの実行に慣れたユーザーにとって最も手軽なのが、Ollamaを使った方法です。コマンド1つでモデルのダウンロードから推論まで完了します。
Ollamaではデフォルトで4-bit量子化されたモデルがダウンロードされるため、VRAMの制約が厳しい環境でも動作しやすい設計です。E4BモデルであればVRAM約5GBで動作するため、16GBメモリのノートPCでも試せます。
llama.cppを使えば、CPU推論にも対応しています。GPUを持っていない環境でも、速度は落ちるものの動作確認は可能です。
詰まりポイント

Gemma 4を初めてローカル環境で動かす際に、よくあるハマりどころを先回りで紹介します。
- VRAMの見積もりミス
モデル名の「E2B」「E4B」は実効パラメータ数であり、実際の重みサイズ(総パラメータ)はこれより大きい。E2Bは5.1B、E4Bは8Bの重みをロードする必要がある点に注意
- 量子化形式の選択
GGUFにはQ4_K_M、Q5_K_M、Q8_0など複数の量子化レベルがある。品質とVRAMのバランスはQ4_K_Mが汎用的で、精度を求めるならQ8_0を選ぶ
- 思考モードの有効化忘れ
ベンチマークで公表されている性能は思考モード有効時の数値。思考モードを有効にしないと、公表値より大幅に低い結果になる場合がある
- 音声入力は小型モデルのみ
26B A4Bや31Bでは音声入力に対応していない。音声処理が必要な場合はE2BまたはE4Bを選択する
これらのポイントを事前に押さえておけば、初回の環境構築でつまずく時間を大幅に減らせます。
Gemma 4のエッジAI・オンデバイス活用
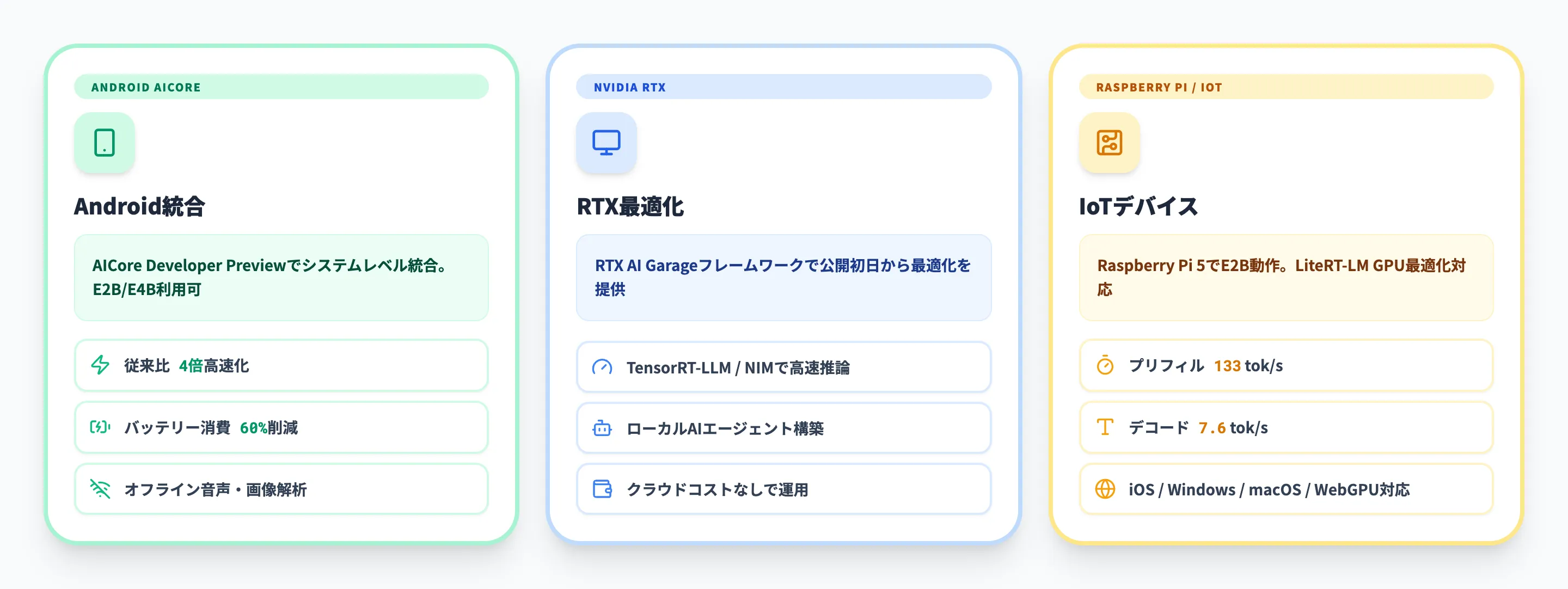
Gemma 4は単にクラウドで使うだけでなく、エッジデバイスでのローカル実行を強く意識した設計になっています。ここでは、主要なエッジプラットフォームでの活用方法を解説します。
Android AICore統合
GoogleはGemma 4のリリースと同時に、AndroidのAICore Developer Previewでのサポートを発表しました。AICore はAndroidデバイス上でAIモデルをシステムレベルで管理する仕組みで、アプリがGemma 4の推論エンジンを共有リソースとして利用できます。
公式の発表によれば、Gemma 4はAICore上で従来比最大4倍の高速化とバッテリー消費量60%削減を実現しています。E2BとE4Bの2サイズが利用可能で、E2Bは高速処理向け(E4Bの3倍の速度)、E4Bは高い推論精度が求められるタスク向けです。
リアルタイムの音声アシスタント、カメラ画像の解析、オフラインでの文書要約など、ネットワーク接続に依存しないAI機能をアプリに組み込むことが可能になります。
NVIDIA RTX最適化
NVIDIAはGemma 4の公開初日からRTXプラットフォームへの最適化を提供しています。RTX AI GarageフレームワークによるローカルAIエージェントの構築が可能になり、コンシューマーGPU上でもエージェント機能付きのGemma 4を活用できます。
NVIDIA TensorRT-LLMやNIMマイクロサービスによる最適化が適用されており、RTXデスクトップからDGX Sparkまで、NVIDIA製GPU全般でGemma 4のパフォーマンスが引き出せる環境が整備されています。
個人開発者やスタートアップにとって、RTX 4090やRTX 5090で26B A4Bを動かすというのは、高性能AIエージェントをクラウドコストなしで運用できることを意味します。
Raspberry Pi・IoTデバイス
エッジAIの活用範囲はスマートフォンやGPU搭載PCにとどまりません。Google Developersブログによれば、Raspberry Pi 5上でGemma 4 E2Bを動作させた際の性能は、プリフィル133トークン/秒、デコード7.6トークン/秒です。
LiteRT-LMのGPU最適化を利用した場合、4,000入力トークンを2つのスキルで処理する時間は3秒未満とされています。
対応プラットフォームは幅広く、Android、iOS、Windows、Linux、macOS(Metal対応)、WebGPU、Raspberry Pi 5、Qualcomm IQ8 NPUなどで動作します。IoT分野でのリアルタイム画像認識や音声コマンド処理など、これまでクラウドへの通信が必要だった処理をデバイス側で完結させる選択肢が広がりました。
【関連記事】
Google TPU Ironwoodとは?第7世代の性能や特徴、GPUとの違いを解説
Gemma 4の料金体系とライセンス

Gemma 4の導入を検討するうえで、コストとライセンスの理解は不可欠です。ここでは、Apache 2.0ライセンスの意義、セルフホスティングのコスト感、クラウドAPI経由の利用料金を解説します。
Apache 2.0ライセンスの意義

Gemma 4最大の転換点は、ライセンスが従来のGoogle独自「Gemma Open License」からApache 2.0に変更されたことです。The Decoderの報道によれば、これはGemmaシリーズ初のApache 2.0採用です。
以下の表で、旧ライセンスとApache 2.0の違いを整理しました。
| 項目 | Gemma Open License(旧) | Apache 2.0(Gemma 4) |
|---|---|---|
| 商用利用 | 可(Google独自条件付き) | 無制限で可 |
| 派生モデルの配布 | 条件付き | 自由 |
| ソースコード開示義務 | なし | なし |
| 特許許諾 | 限定的 | 明示的に付与 |
| ライセンス料 | 無料 | 無料 |
実務上、最も大きな変化は派生モデルの自由配布と商用利用条件の簡素化です。旧ライセンスではGoogle独自の利用条件や禁止用途の規定があり、法務確認のコストがエンタープライズでの採用障壁になっていました。Apache 2.0では業界標準の明快な条件のみとなり、自由に展開できます。
また、ファインチューニングした派生モデルを自社プロダクトとして配布・販売することも制限なく可能です。オープンソースAIエコシステムの標準ライセンスであるApache 2.0への移行により、Llama系やMistral系と同等の自由度でGemma 4を利用できるようになりました。
セルフホスティングのコスト試算

Gemma 4はオープンモデルのため、モデル自体のライセンス料は発生しません。コストの中心はGPUインフラの調達・運用費用です。
以下に、2026年4月時点の一般的なGPU価格帯とGemma 4モデルの組み合わせを示します。
| GPU | VRAM | 価格帯(クラウド月額目安) | 適合モデル |
|---|---|---|---|
| RTX 4090 | 24GB | 自社所有のみ(約25万円で購入) | 26B A4B(4-bit) |
| A100 40GB | 40GB | 約15〜25万円/月 | 31B(4-bit)、26B A4B(8-bit) |
| A100 80GB | 80GB | 約25〜40万円/月 | 31B(FP16) |
| H100 80GB | 80GB | 約30〜50万円/月 | 31B(FP16、高速推論) |
API呼び出しにかかる月額コストと比較すると、リクエスト数が一定以上であればセルフホスティングの方がコスト効率に優れるケースが多くなります。目安として、月間100万リクエスト以上の処理が見込まれる場合は、A100やH100でのセルフホスティングを検討する価値があります。
クラウド経由での利用
Gemma 4はVertex AI、Cloud Run、GKE(Google Kubernetes Engine)を経由してクラウド上でも利用できます。
2026年4月時点では、Google AI Studio(Gemini API)上でGemma 4の31Bおよび26B A4Bモデルを利用できます。公式の料金ページによれば、Gemma 4のInput・Output・Context cachingはいずれもFree of chargeとなっており、API経由での利用は現時点では無料です。
一方、Vertex AIでGemma 4を利用する場合は無料ではありません。Gemini APIのようなトークン単価課金ではなく、デプロイ先の計算資源(GPUインスタンス)に対する時間課金が発生します。Model Gardenのドキュメントに記載されているとおり、チューニングやデプロイに使用するマシンスペックと稼働時間に応じたコストがかかります。最新の詳細はVertex AIの料金ページで確認してください。
自社データの機密性を考慮してオンプレミス運用を選ぶ企業も増えていますが、まずはGoogle AI Studioで無料のまま品質を確認し、本番移行の段階でセルフホスティングかVertex AIかを判断するのが最もリスクの低いアプローチです。

Gemma 4を導入する際の注意点と制限事項
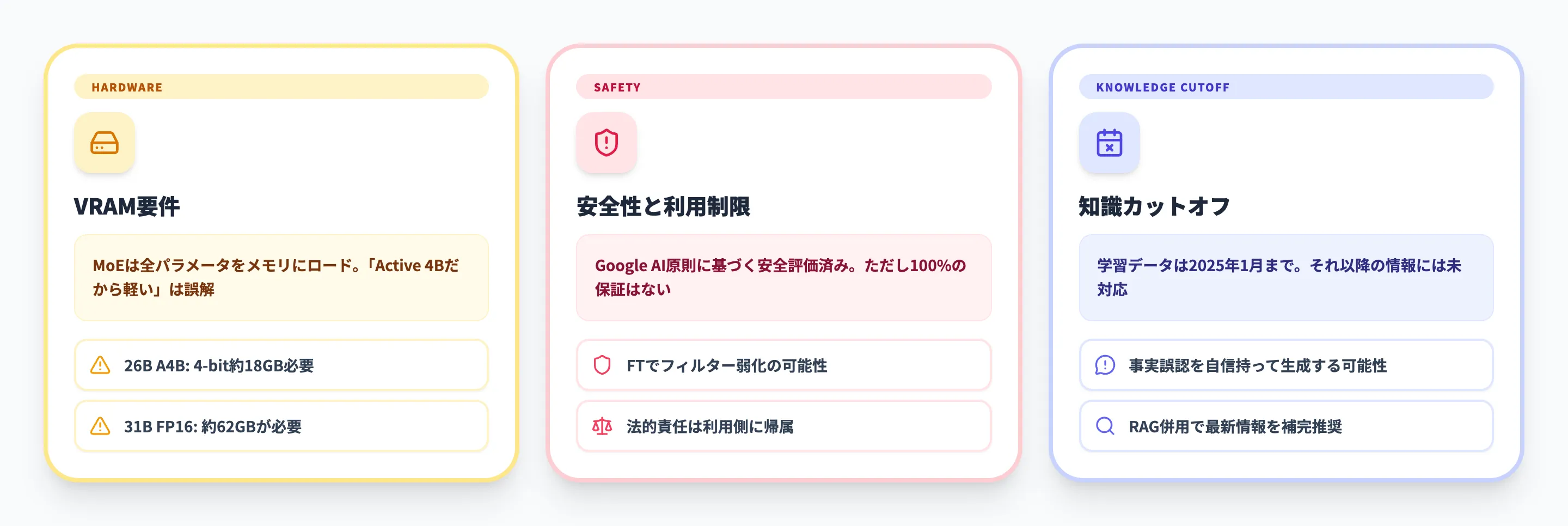
Gemma 4は高い性能を持つオープンモデルですが、導入にあたって理解しておくべき制限事項があります。メリットだけでなくリスクも把握したうえで、適切な活用判断を行ってください。
ハードウェア要件とVRAM
先述のとおり、Gemma 4は4つのモデルサイズがありますが、特に26B A4Bと31Bは相応のGPUリソースを必要とします。
以下の表で、各モデルのVRAM要件と推奨環境を再確認しましょう。
| モデル | 4-bit量子化 | 8-bit量子化 | FP16 | 推奨GPU |
|---|---|---|---|---|
| E2B | 約5GB | — | 約10GB | モバイルGPU、統合GPU |
| E4B | 約5GB | — | 約15GB | RTX 3060以上 |
| 26B A4B | 約18GB | 約28GB | 約52GB | RTX 4090(4-bit)、A100(FP16) |
| 31B | 約20GB | 約34GB | 約62GB | A100 40GB(4-bit)、A100 80GB(FP16) |
26B A4BはMoEアーキテクチャにより推論時のアクティブパラメータは3.8Bですが、全パラメータ(25.2B)の重みをメモリ上にロードする必要がある点に注意してください。「アクティブ4Bだから軽い」という誤解は導入時のトラブルに直結します。
安全性と利用制限
Googleのモデルカードによれば、Gemma 4はGoogleのAI原則に基づいた安全性評価を受けており、児童搾取コンテンツ、危険な素材、露骨なコンテンツ、ヘイトスピーチ、ハラスメントの生成防止が施されています。
ただし、すべてのケースで安全性が保証されているわけではありません。ファインチューニングによって安全性フィルターが弱まる可能性があるため、派生モデルを本番環境にデプロイする場合は、独自のコンテンツフィルタリング層を追加することを推奨します。
また、Apache 2.0ライセンスは利用用途を制限しませんが、法的責任はモデルを利用する側にある点も認識が必要です。
知識カットオフと精度の限界

Gemma 4の事前学習データのカットオフは2025年1月です。2025年2月以降に発生した出来事や発表された技術情報は、モデルの学習データに含まれていません。
Googleのモデルカードでは、以下の制限事項が明記されています。
- 事実と異なる情報の生成
学習データに含まれていない事項や曖昧な領域では、事実と異なる内容を自信を持って生成する可能性がある
- 皮肉やニュアンスの理解
曖昧な表現、皮肉、文化的なニュアンスの理解は限定的
- 常識推論の限界
人間にとって自明な常識的判断でも、誤った推論を行う場合がある
- コンテキスト長とプロンプトの影響
出力品質は入力プロンプトの明確さとコンテキスト長に大きく左右される
AI総研の支援現場では、Gemma 4をRAG(検索拡張生成)と組み合わせて最新情報を補完し、重要な事実に関しては必ず人間がレビューするワークフローを推奨しています。モデルの出力をそのまま顧客向けに利用するのではなく、あくまで「高精度なドラフト生成エンジン」として位置づけるのが、現時点では最も安全で効果的な運用方法です。
【関連記事】
SLM(小規模言語モデル)とは?LLMとの違いや日本語モデルを徹底解説!
オープンモデルの検証を業務改善につなげるなら
Gemma 4のようなオープンモデルを自社環境で動かせるようになっても、「どの業務をAIに任せるか」「PoC→全社展開をどう段階設計するか」を整理しなければ、検証で終わってしまいます。
モデルの性能や使い方を理解した次のステップは、組織としてAIを業務プロセスに組み込むための段階設計です。AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で公開しています。Copilot ChatからCopilot Studio、Microsoft Foundryまでの導入ステップに加え、経費精算・請求書処理・申請承認など部門別のBefore/After付きユースケースを収録しており、モデル選定の先にある「業務定着の設計図」を手に入れることができます。
AI総合研究所が、AI導入の段階設計から運用定着まで支援します。まずはガイドで、自社環境に合ったAI活用の進め方をご確認ください。
AIモデルの理解を業務設計に活かす
PoC→全社展開の段階設計を整理
オープンモデルの選定から一歩進み、組織としてAIを業務に定着させるための段階設計ガイド(220ページ)を無料で公開中。部門別のユースケースとBefore/After付きで、自社に合った導入ステップを整理できます。
まとめ
Gemma 4は、Google DeepMindが2026年4月に公開したApache 2.0ライセンスのオープンAIモデルファミリーです。スマートフォンからサーバーまで対応する4サイズ展開、ネイティブ関数呼び出しによるエージェント構築、そしてGemma 3から最大4倍の性能向上という3つの価値を同時に実現しています。
特にライセンスのApache 2.0への移行は、企業でのオープンモデル活用における最大の障壁を取り除くものです。派生モデルの自由配布と明示的な特許許諾により、自社プロダクトへの組み込みからファインチューニング済みモデルの社内展開まで、制約なく取り組めるようになりました。
導入の第一歩としては、以下の流れが最も効率的です。
- Google AI Studioで26B A4Bモデルを無料で試し、自社タスクでの品質を確認する
- 品質に問題がなければ、OllamaやHugging Faceでローカル環境に構築して本番検証を行う
- リクエスト規模に応じてセルフホスティングかVertex AIかを判断し、本番運用に移行する
自社でAI活用を進めたいが、プロプライエタリモデルのAPIコストが気になっている、あるいはデータの機密性からオンプレミス運用を検討しているなら、Gemma 4は現時点で最もバランスの取れた選択肢のひとつです。まずはGoogle AI Studioで、自社の業務データを使った推論品質を確かめてみてください。







