この記事のポイント
 強みは「機密データを社外に出さない」「APIの従量課金から脱却」「フル制御可能」の3点に集約される
強みは「機密データを社外に出さない」「APIの従量課金から脱却」「フル制御可能」の3点に集約される- 主流はMoEモデルで、Qwen3-30B-A3Bやgpt-oss-20bは16GB VRAMクラスで動作可能
- 入門はOllama、本番運用はvLLM、GUIで触るならLM Studio、最低レイヤー制御はllama.cppで使い分ける
- 推論性能のボトルネックはVRAM容量とメモリ帯域。Apple Silicon・AMD Strix Haloは128GB級ユニファイドメモリで70B超を狙える
- ローカル単独運用ではなく、機密処理はローカル・複雑推論はクラウドというハイブリッド構成が現実解

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
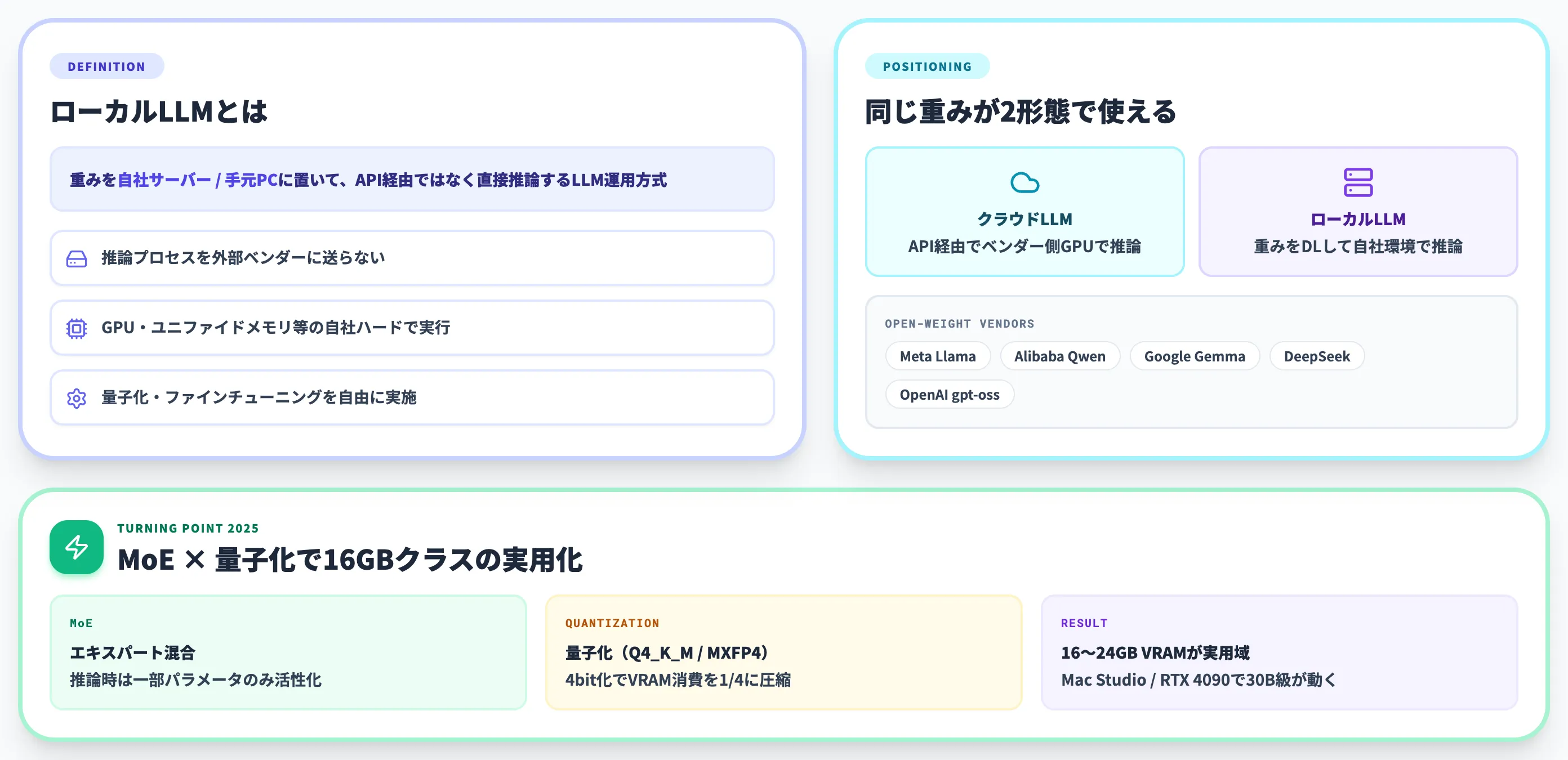
ローカルLLMとは、クラウドのAPI経由ではなく、自社のサーバーや手元のPCで直接動かす大規模言語モデルのことです。
2025年以降、Apache 2.0ライセンスのオープンウェイトモデルとMoE(Mixture of Experts)アーキテクチャの普及により、これまで巨大GPUクラスタが必要だった水準のモデルが、16〜64GBクラスのVRAMで実用的に動かせるようになりました。
本記事では、ローカルLLMの定義・選ばれる状況・主要オープンウェイトモデル・必要なハードウェア・実行ランタイム・Ollamaでの導入手順・業務統合のRAG/ファインチューニング・クラウドとのコスト比較・運用上の注意点までを、公式情報をもとに解説します。
目次
ローカルLLMとは——自社サーバー・手元PCで動かす大規模言語モデル
Qwen3シリーズ——汎用・コーディング・日本語のバランス型
DeepSeek-R1 / V4——推論特化のサーバ級MoE
gpt-oss——OpenAIのGPT-2以来のオープンウェイトとMXFP4量子化
推論経路の3つの選択肢——NVIDIA・Apple Silicon・AMD Strix Halo
NVIDIA GeForce / RTX——CUDA最適化の安定解
AMD Strix Halo——128GBユニファイドメモリの大容量APU
LM Studio——GUI重視、ヘッドレスサーバとしても運用可能
ローカルLLMとは——自社サーバー・手元PCで動かす大規模言語モデル
ローカルLLM(Local Large Language Model)とは、ChatGPTやClaudeのようにクラウドのAPI経由で呼び出すのではなく、自社サーバーや手元のPCで重み(モデルパラメータ)をダウンロードして直接動かす大規模言語モデルのことです。
2025年以降、Meta・Google・Alibaba・DeepSeek・そしてOpenAIまでもがオープンウェイト(重みが公開され、自由にダウンロード・実行できる)モデルを相次いで公開し、業務用途で実用に耐えるモデルが手元で動かせる環境が整いました。
検索意図としては「クラウドにデータを送れない」「APIコストが想定より膨らんでいる」「オフライン環境で動かす必要がある」といった具体的な制約条件から調べ始めるケースが多く、本記事もその文脈で読み解いていきます。

ローカルLLMの定義と大規模言語モデル(LLM)との関係
ローカルLLMは「LLMの一形態」ではなく、「LLMの提供形態のひとつ」です。
同じ重みファイルでも、クラウドベンダーのAPIから呼び出せばクラウドLLM、手元の環境にダウンロードして動かせばローカルLLMになります。Meta社のLlama、AlibabaのQwen、GoogleのGemma、DeepSeekのR1、OpenAIのgpt-ossはいずれも重みが公開されており、両方の形態で利用できます。
つまり「ローカルLLM=特定のモデル」ではなく「重みを手元に置いて推論する運用方式」と理解するのが正確です。
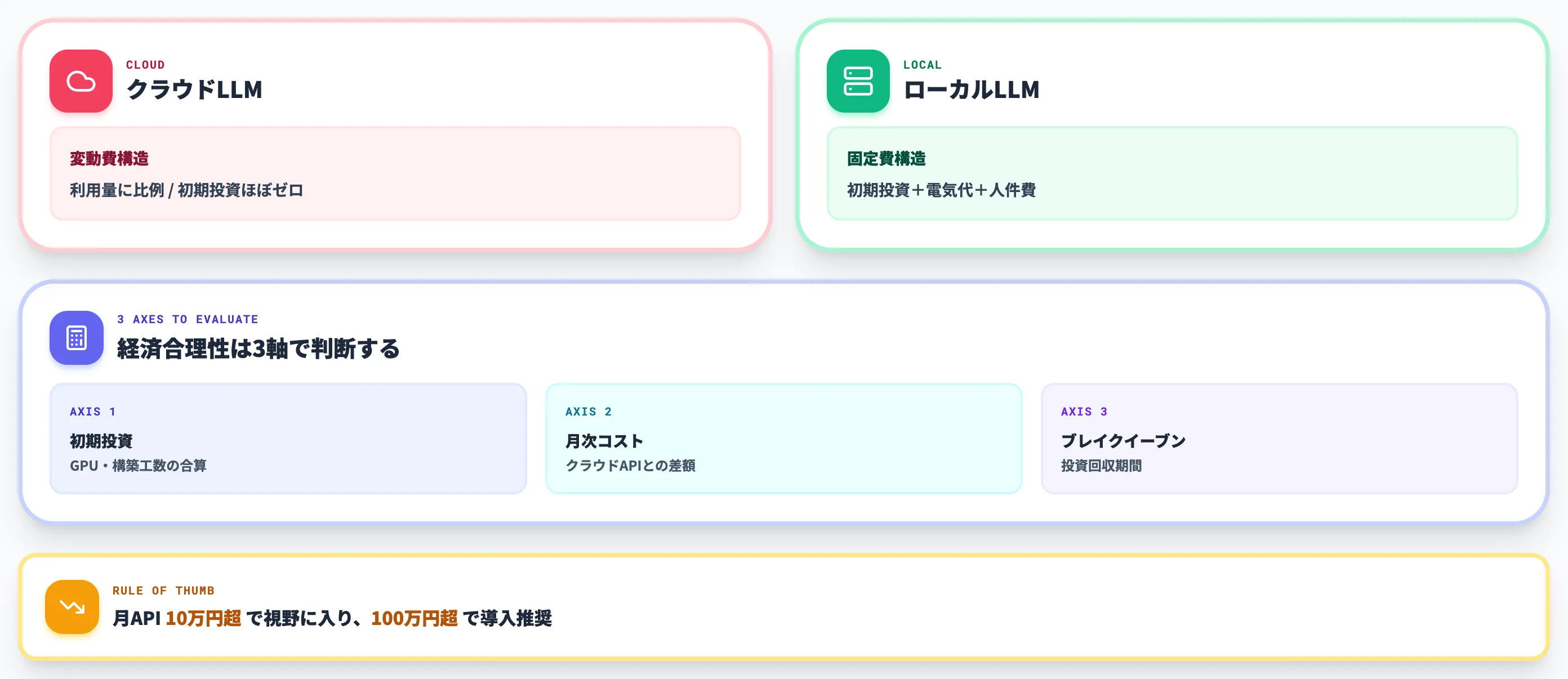
クラウドLLMとの構造的な違い

ローカルLLMとクラウドLLMは、技術的な仕組みではなく「データと推論プロセスがどこに置かれるか」が決定的に違います。以下の表で、両者の構造的な違いを整理しました。
| 項目 | ローカルLLM | クラウドLLM(ChatGPT・Claude等) |
|---|---|---|
| 推論場所 | 自社サーバー or 手元PC | ベンダー側のクラウドGPU |
| データ送信先 | 外部に送らない | ベンダーのサーバーに送信 |
| コスト構造 | 初期投資(GPU等)+電気代 | API従量課金(トークン単価) |
| カスタマイズ | ファインチューニング・量子化を自由に実施 | 主にプロンプト・RAG・限定的なファインチューニング |
| 推論性能 | ハードウェアとモデルサイズに依存 | フロンティアモデルが利用可能 |
| 運用負担 | 自社で構築・保守 | ベンダーが管理 |
注目すべきは、ローカルLLMの優位性が「絶対性能」ではなく「データ主権」と「コスト構造の変化」にある点です。クラウドLLMの方が単体性能では上回るケースが大半ですが、「機密データを外に出さない」「API課金を月数十万円から固定費へ転換する」という要件が立つと、ローカルLLMが現実解になります。
MoEアーキテクチャがローカル運用を変えた理由
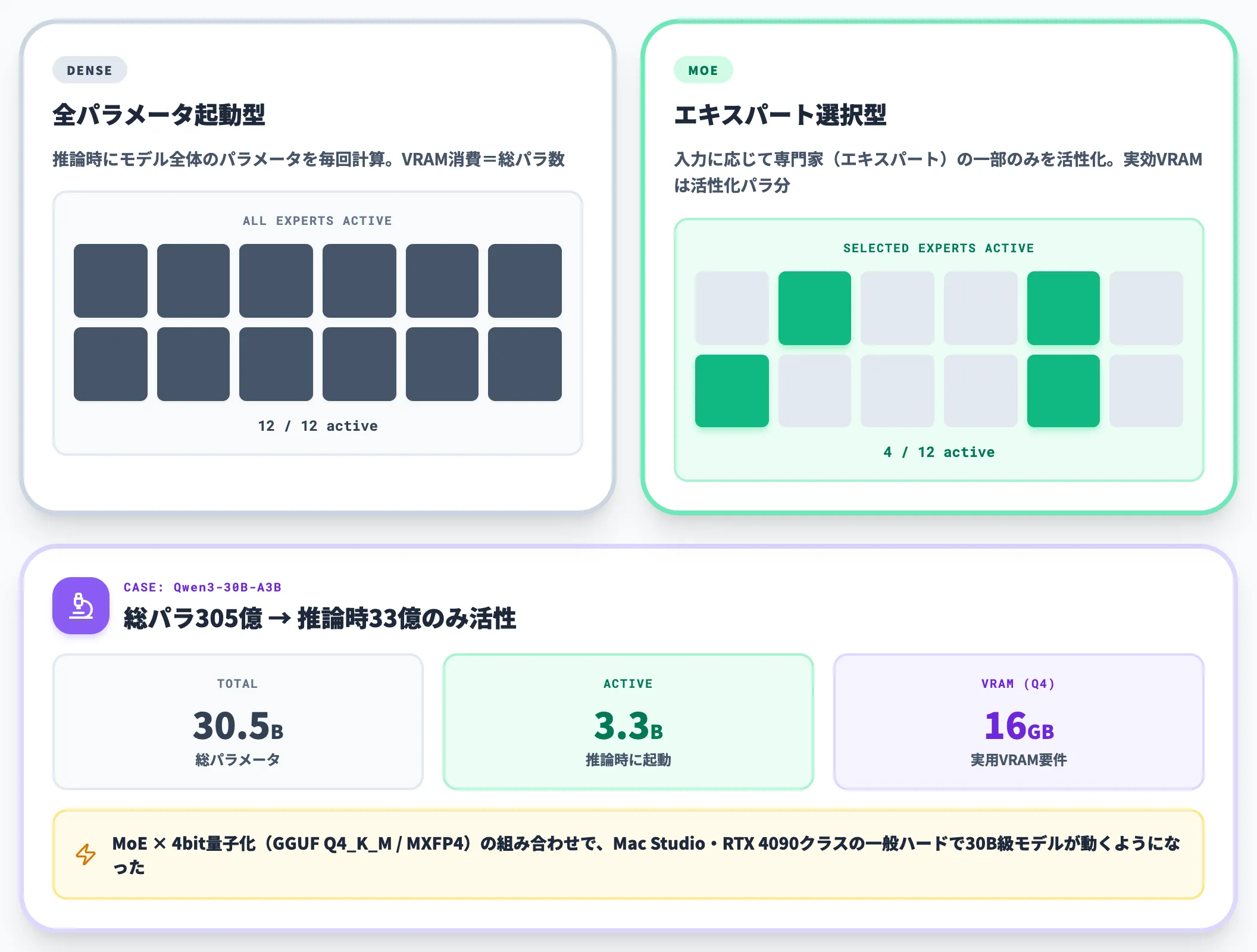
2025年以降のローカルLLM普及を支えている技術的な転換点が、MoE(Mixture of Experts:エキスパート混合)アーキテクチャの一般化です。
MoEは「モデルの全パラメータを毎回使うのではなく、入力に応じて一部の専門家(エキスパート)だけを起動する」設計です。たとえばQwen3-30B-A3Bは総パラメータ305億のうち、推論時に活性化するのは33億パラメータだけです。
これにより、見かけ上の総パラメータ数が大きくても、実効的なメモリ・計算量は活性化パラメータ分しか必要としません。Qwen3-30B-A3Bが16GBクラスのVRAMで動作するのは、このMoE構造のおかげです。
ローカルLLMの主流は、このMoEアーキテクチャと、推論時のメモリ消費を圧縮する量子化技術(GGUF Q4_K_M、MXFP4等)の組み合わせで成立しています。
ローカルLLMが解く課題と、選んだ後に直面する限界
クラウドLLMがすでに高性能で安価になっている今、あえてローカルLLMを選ぶ動機は、3つの具体的な制約条件から逆算するとはっきりします。
本セクションでは、ローカルLLMの主要メリットと、現実的に避けられない限界、そして両者を踏まえたハイブリッド構成の考え方をまとめます。
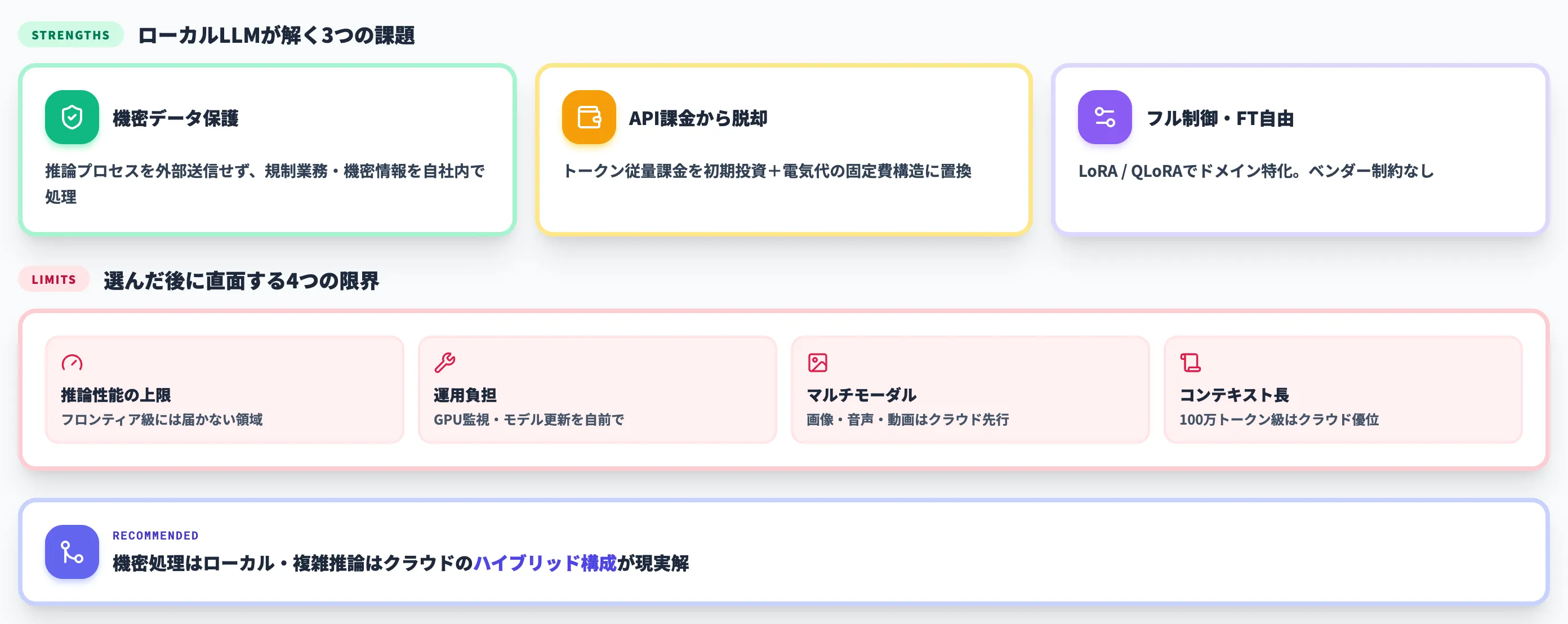
機密データを外部に出さない——セキュリティ要件への対応

ローカルLLMが最も強い理由は、推論プロセスで扱うデータを外部ベンダーへ送らない構成を取りやすいという点にあります。
入力プロンプト・社内文書・顧客データ・設計資料を自社環境の内部で扱える設計にできるため、以下のような条件下ではローカルLLMが有力な選択肢になります。
- 個人情報保護法・GDPR・HIPAA等の規制で外部送信に厳格な条件(本人同意・BAA・越境移転要件等)が課せられる業務
- 金融機関のシステム内データ(取引履歴・顧客与信情報等)
- 製造業の設計図面・部品BOM・特許出願前の研究データ
- 防衛・医療など、契約上クラウド送信のハードルが特に高いドメイン
クラウド側でもBAA契約・データ学習除外・越境移転条件などを満たせば利用できる場合がありますが、契約条件の解釈や法務レビューに時間がかかる業種では、そもそも送らないという構造的な解決が最短ルートになるケースが多くあります。
API従量課金からの脱却——コスト構造を変動費から固定費へ

クラウドLLMはトークン単価×利用量の従量課金です。検証フェーズでは月数千円で済んでも、社内に展開すると月数十万円〜数百万円に達するケースが珍しくありません。
ローカルLLMは初期投資としてGPUなどのハードウェアを買い切れば、その後はモデル本体の利用料金がかからず、ランニングコストは電気代と人件費だけになります。
具体的なブレイクイーブンの考え方は後述するコスト比較セクションで詳しく扱いますが、月100万円超のAPIコストが恒常的に発生している組織では、ローカル基盤の投資回収が1年以内に成立するケースが多くなっています。
ファインチューニング・RAGによる業務最適化
ローカルLLMは、モデルの重みそのものを自社環境に持っているため、ファインチューニング(追加学習)の自由度が圧倒的に高くなります。
- LoRA・QLoRA等の軽量ファインチューニングで、自社固有の文体・用語に最適化
- 社内ナレッジを取り込んだRAG(Retrieval-Augmented Generation)の構築
- 法務・医療など、業界専門用語が多いドメインへのモデル特化
クラウドLLMでもファインチューニングは可能ですが、対応するモデル・コンテキスト長・追加学習データのアップロード制限など、ベンダーが許す範囲に依存します。ローカルLLMにはそうした制約がなく、研究・開発の試行錯誤を高速に回せる点が技術組織にとって大きな魅力です。
限界——推論性能と運用負担

ローカルLLMには明確な限界もあります。これを認識せずに「すべてをローカル化する」と決めると、後でクラウドへの逆戻りが発生します。
-
推論性能の上限
ローカル環境で動かせる70B〜120B規模のモデルでも、GPT-5.5やClaude Opus 4.8のようなフロンティア級モデルには届かない領域がある
-
運用負担
モデル更新・脆弱性対応・量子化検証・GPUドライバ更新など、クラウドが裏で行っている運用を自社で持つ必要がある
-
マルチモーダル対応
画像・音声・動画を含む高度なマルチモーダル処理は、クラウドモデルの方が先行
-
コンテキスト長
100万トークン級の超長文コンテキストはクラウドの先進モデルが優位
つまりローカルLLMは「クラウドの完全な置き換え」ではなく、用途と制約条件が合致した部分でクラウドより優位になる選択肢です。
クラウドとの併用が現実解——ハイブリッド構成
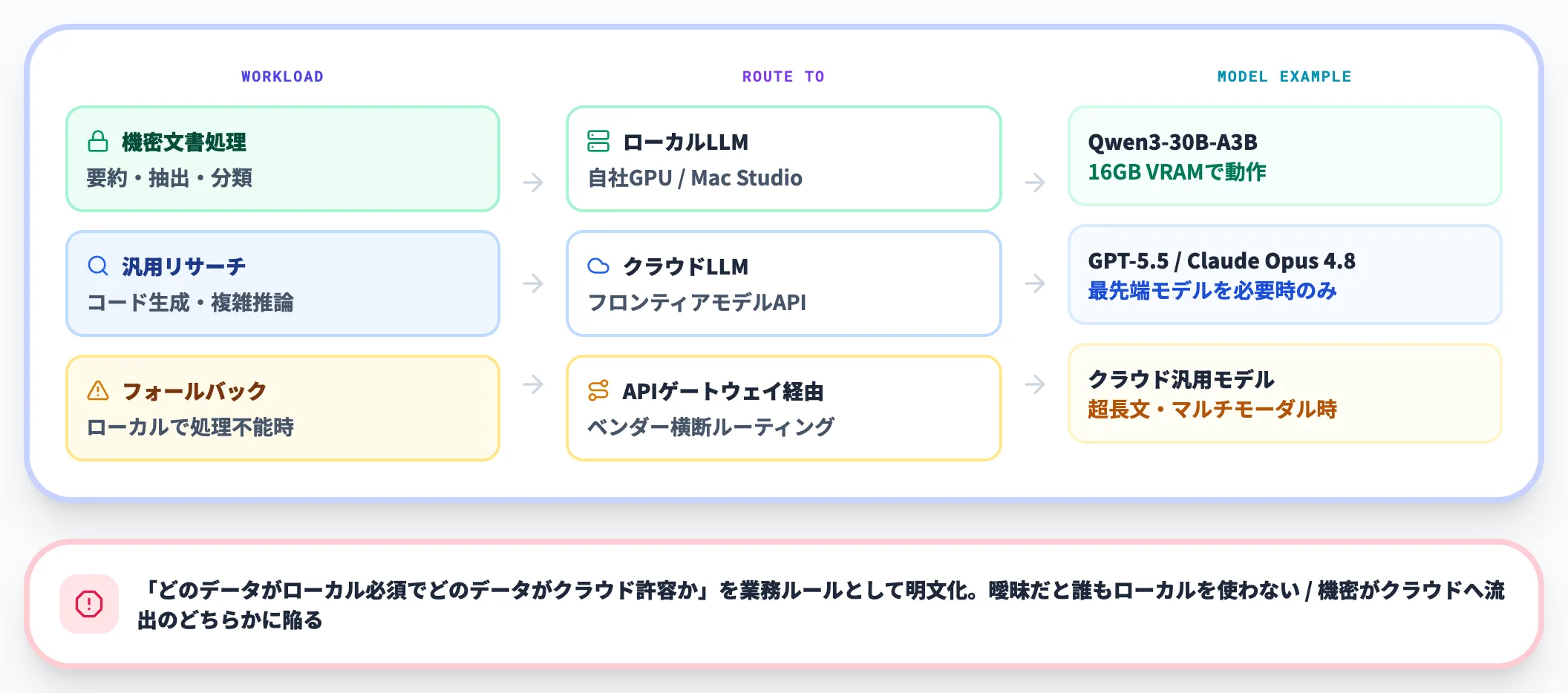
実務での結論としては、ローカル単独運用ではなく、機密処理はローカル・複雑推論はクラウドというハイブリッド構成が現実解になっています。
たとえば次のような分担パターンが典型です。
- 機密文書の要約・抽出・分類 → ローカルLLM(Qwen3-30B-A3B等)
- 一般的なリサーチ・コード生成・複雑推論 → クラウドLLM(GPT-5.5・Claude Opus 4.8等)
- フォールバック先 → ベンダー横断のAPIゲートウェイ経由でクラウドへ
ここで重要なのは、「どのデータがローカル必須でどのデータがクラウド許容か」を業務ルールとして明文化することです。この線引きが曖昧だと、「結局誰もローカルを使わない」「気づいたら機密データがクラウドに流れていた」のいずれかの失敗パターンに陥ります。
主要オープンウェイトモデル
ここからは、ローカル運用の現実解になっている主要オープンウェイトモデルを整理します。
モデル選びは「何でも入る大きいモデル」を選ぶのではなく、用途と手元のVRAM容量から逆算するのが鉄則です。

モデル比較の早見表
以下の表で、本記事が推奨できる主要オープンウェイトモデルを、用途・ライセンス・推奨VRAMの観点で整理しました。リリース日や仕様は各モデルの公式ページで情報を確認しています。
| モデル | 提供元 | 総パラ/アクティブパラ | コンテキスト長 | ライセンス | 推奨VRAM(Q4) |
|---|---|---|---|---|---|
| Qwen3-30B-A3B | Alibaba | 30.5B/3.3B(MoE) | 128K | Apache 2.0 | 16GB〜 |
| Qwen3.6-35B-A3B | Alibaba | 35B/3B(MoE・新世代) | 262K(拡張で約1M) | Apache 2.0 | 16〜24GB |
| Qwen3-235B-A22B | Alibaba | 235B/22B(MoE) | 128K | Apache 2.0 | 80GB〜(量子化前提) |
| Qwen3-8B | Alibaba | 8B(Dense) | 128K | Apache 2.0 | 8GB〜 |
| Gemma 4 26B A4B | 26B/3.8B実効(MoE・マルチモーダル) | 256K | Apache 2.0 | 16GB〜 | |
| Gemma 4 31B | 30.7B(Dense・マルチモーダル) | 256K | Apache 2.0 | 24GB〜 | |
| DeepSeek-R1 | DeepSeek | 671B/37B(MoE) | 128K | MIT | サーバ級(80GB×複数) |
| DeepSeek V4-Pro | DeepSeek | 1.6T/49B(MoE・Preview) | 1M | MIT | サーバ級 |
| DeepSeek V4-Flash | DeepSeek | 284B/13B(MoE・Preview) | 1M | MIT | サーバ級 |
| gpt-oss-20b | OpenAI | 21B/3.6B(MoE・MXFP4) | 128K | Apache 2.0 | 16GB〜 |
| gpt-oss-120b | OpenAI | 117B/5.1B(MoE・MXFP4) | 128K | Apache 2.0 | 80GB〜 |
注目すべきは、いずれのモデルもMoEアーキテクチャまたは量子化前提で「公称パラメータ数より小さなVRAMで動く」設計になっている点です。総パラ数の大きさだけで「動かせない」と判断せず、アクティブパラ数と量子化後のサイズで検討する必要があります。
Qwen3シリーズ——汎用・コーディング・日本語のバランス型
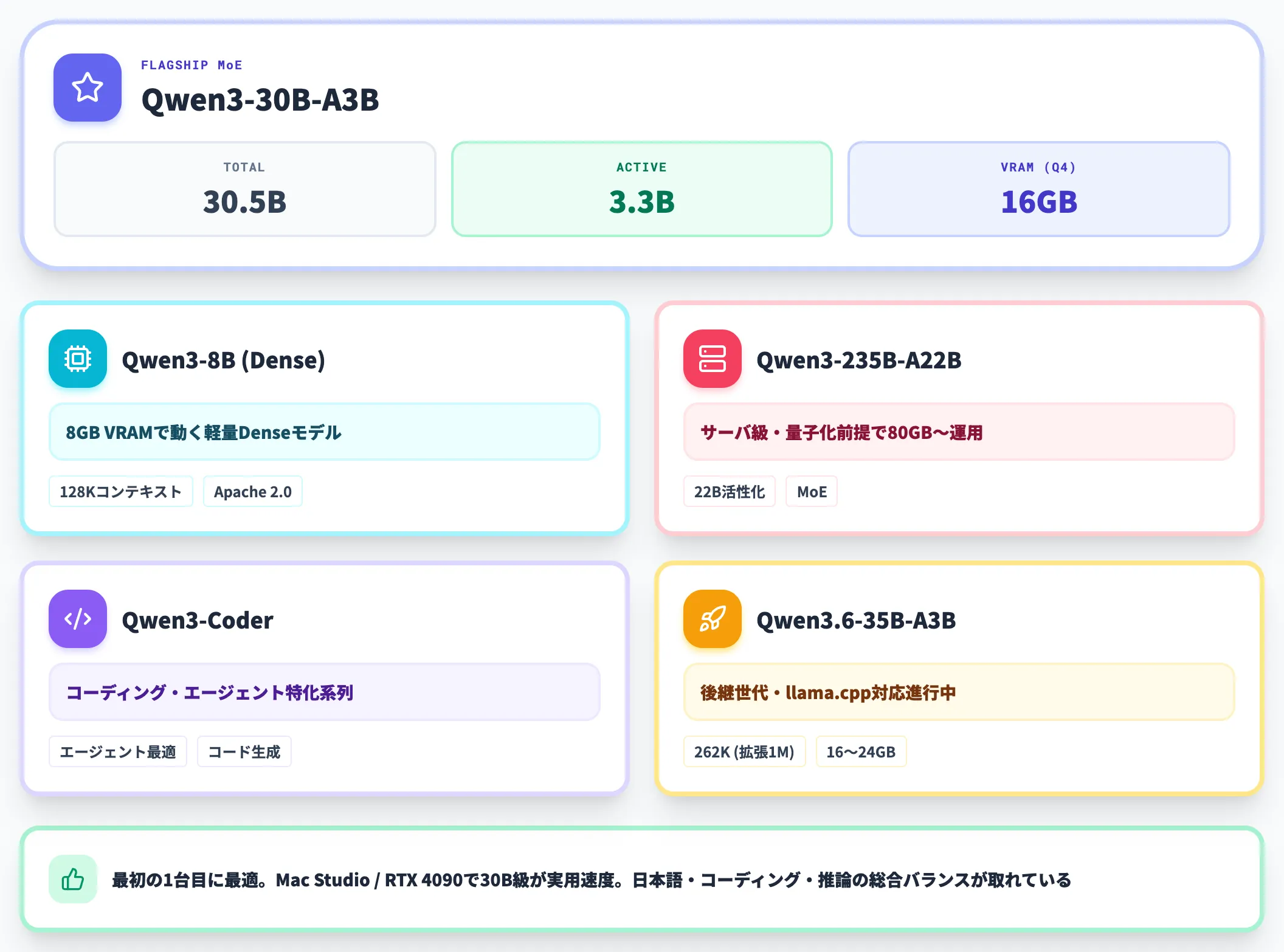
Qwen3シリーズはAlibabaが2025年4月29日に公開したオープンウェイト群で、密集モデル(0.6B〜32B)とMoEモデル(30B-A3B / 235B-A22B)がそろっています。すべてApache 2.0ライセンスで、商用利用に法務上の制約がほぼありません。
特にQwen3-30B-A3Bは「16GB VRAMで30B級のモデル品質を引き出せる」点が画期的で、Mac Studio・RTX 4090クラスでも実用速度で動かせます。日本語タスク・コーディング・推論のいずれもバランスが取れており、最初の1台目に選ぶならQwen3シリーズが堅実です。
コーディング特化用途にはQwen3-Coderが別系列で公開されており、エージェント型コード生成に最適化されています。後継のQwen3.6-35B-A3Bも公開されており、llama.cppでもネイティブ対応が進んでいます。
Gemma 4——マルチモーダルと256Kコンテキスト
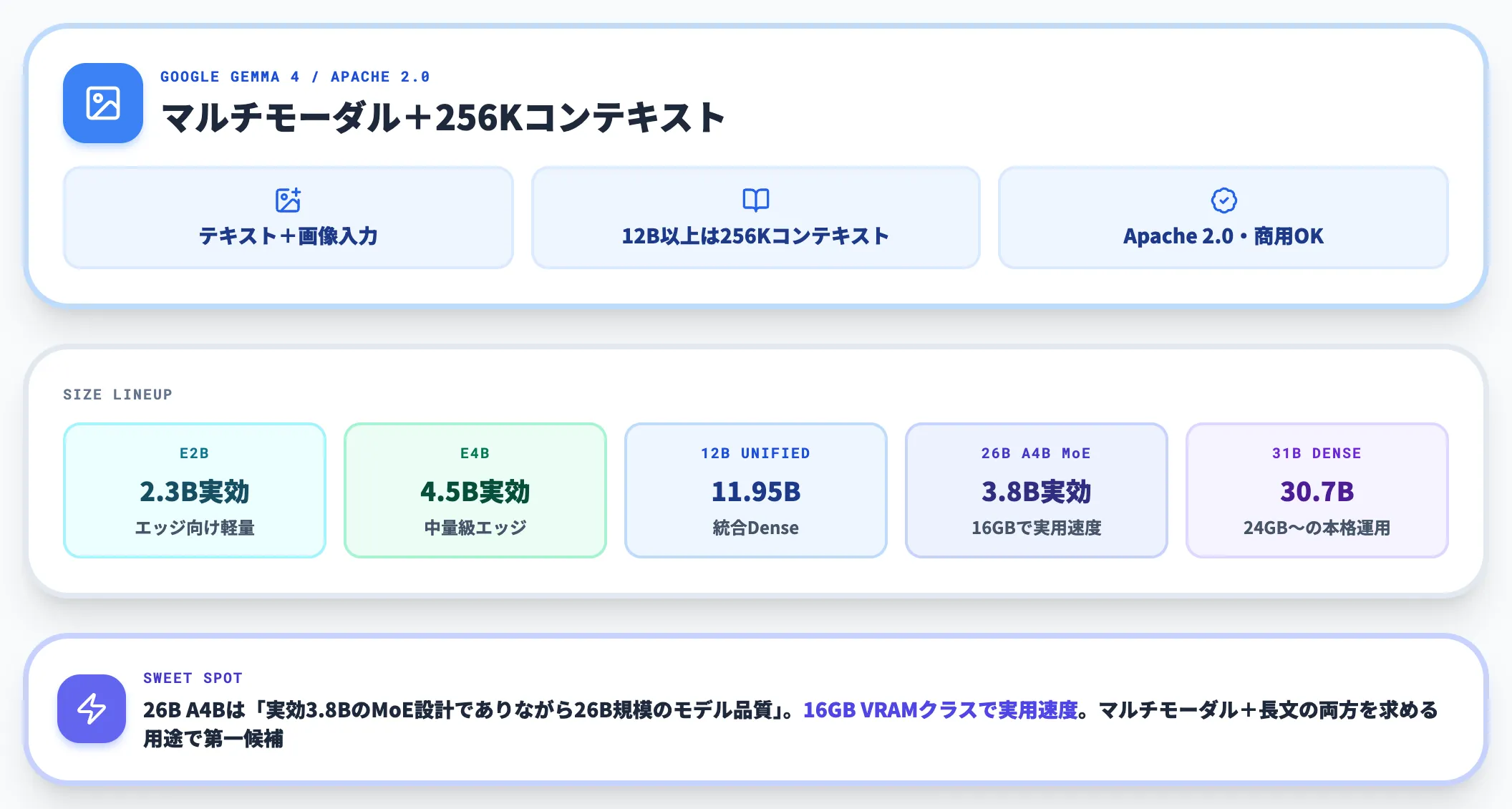
GoogleのGemma 4は、Apache 2.0ライセンスで配布されるマルチモーダル対応オープンウェイトモデルです。E2B(2.3B実効)/E4B(4.5B実効)/12B Unified(11.95B)/26B A4B MoE(3.8B実効)/31B Dense(30.7B)の5サイズがラインアップされ、いずれもテキスト+画像入力に対応、12B以上は256Kコンテキストをサポートします。
特に26B A4Bは「実効パラメータ3.8BというMoE設計でありながら、26B規模のモデル品質を引き出せる」点が強みで、16GB VRAMクラスでも実用速度で動かせます。
詳細な使い分けやベンチマークはGemma 4の解説記事に整理しています。マルチモーダル対応と長文コンテキストの両方を求める用途では第一候補になります。
DeepSeek-R1 / V4——推論特化のサーバ級MoE
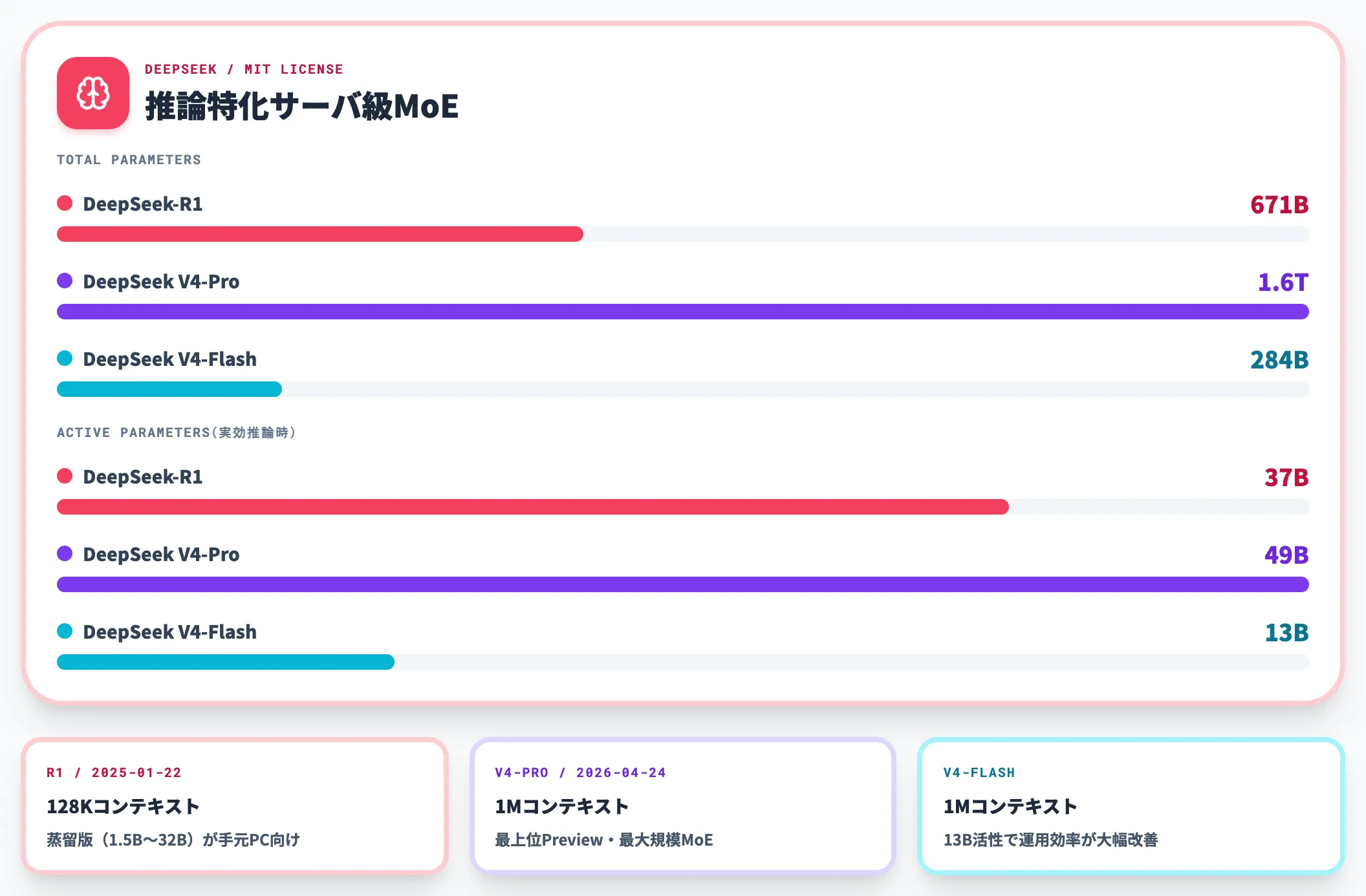
DeepSeek-R1は2025年1月22日に公開された671B総パラ・37BアクティブのMoEモデルです。ライセンスはMITで完全な商用利用・派生物作成が許可されており、ベンチマーク上の推論性能はクラウドの先進モデルに迫る水準です。
ただしフル精度では80GB GPU複数枚が必要で、現実的にはサーバ級の構成かクラウドGPUを使うことになります。手元のPCで触る場合は、DeepSeek-R1-Distill-Qwen等の蒸留版(1.5B / 7B / 14B / 32B)を使うのが現実的です。
DeepSeek V4 Preview(2026年4月24日公開)では、1.6T総パラ/49BアクティブのV4-Proと、284B総パラ/13BアクティブのV4-Flashが提供され、いずれも1Mコンテキストが標準になりました。V4-Flashは13Bアクティブで動くため、サーバ級GPU構成での運用効率がV4-Pro比で大きく改善します。
gpt-oss——OpenAIのGPT-2以来のオープンウェイトとMXFP4量子化
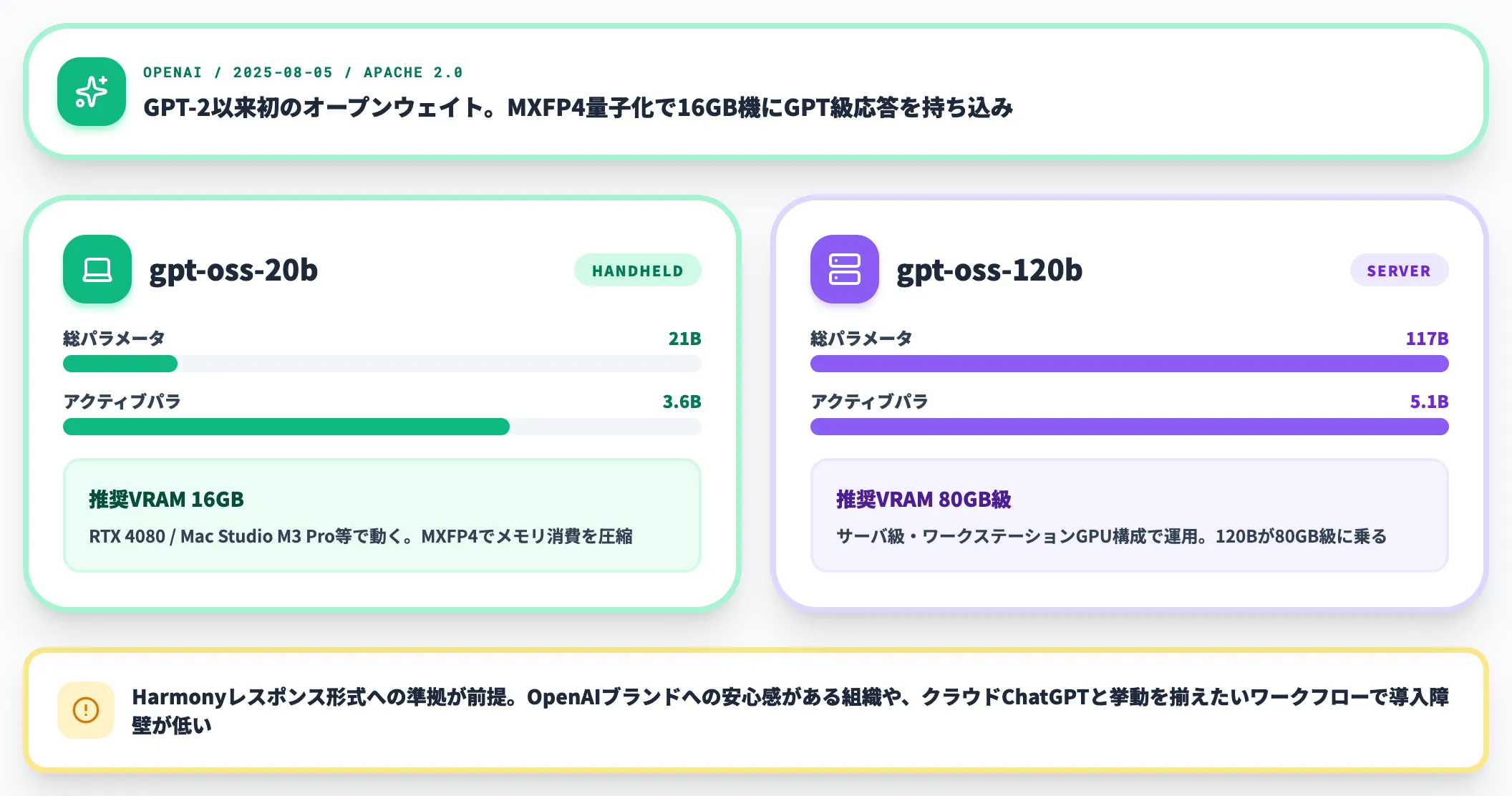
gpt-oss-120bとgpt-oss-20bは、OpenAIが2025年8月5日にApache 2.0で公開した、GPT-2以来初のオープンウェイトモデルです。
| モデル | 総パラ | アクティブパラ | 推奨VRAM | 量子化 |
|---|---|---|---|---|
| gpt-oss-120b | 117B | 5.1B | 80GB級 | MXFP4 |
| gpt-oss-20b | 21B | 3.6B | 16GB | MXFP4 |
gpt-ossの実務的な意義は、MXFP4という新しい4ビット量子化形式で16GB VRAMマシンに「GPTらしい応答」を持ち込めたことにあります。Harmonyレスポンス形式に準拠する必要がある点だけ事前に確認しておく必要があります。
OpenAIブランドへの安心感がある組織や、クラウドのChatGPTと挙動を揃えたいワークフローでは、gpt-ossが導入の障壁を下げてくれます。
用途別の推奨モデル
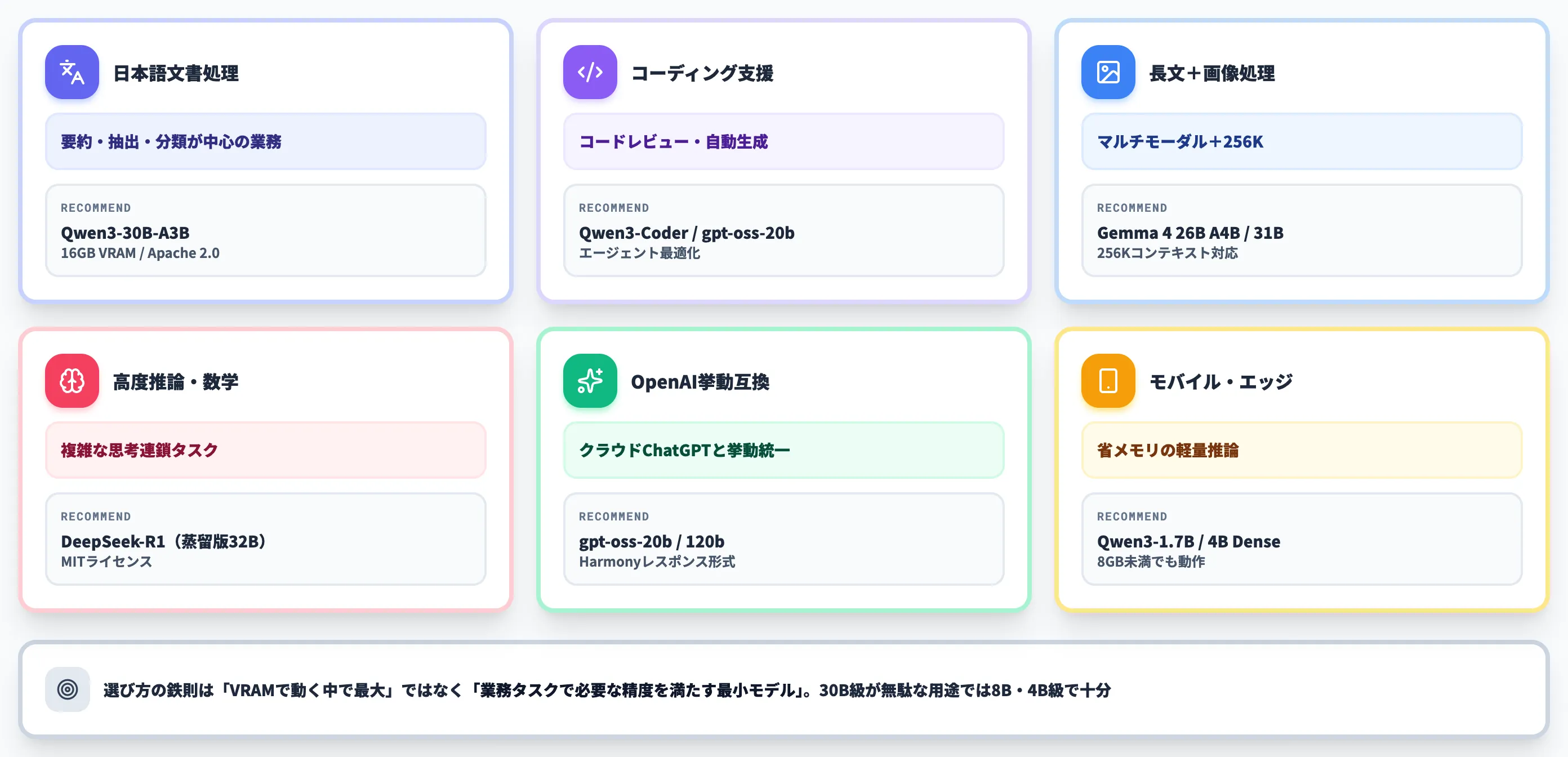
ここまでのモデルを、典型的な業務用途でどう選ぶかを整理します。
-
日本語の文書要約・抽出・分類
Qwen3-30B-A3B(16GB VRAM・Apache 2.0)
-
コーディング支援・コードレビュー
Qwen3-Coder または gpt-oss-20b
-
長文ドキュメント+画像のマルチモーダル処理
Gemma 4 26B A4B または 31B(256Kコンテキスト)
-
高度推論・数学・複雑な思考連鎖
DeepSeek-R1(サーバ級)または蒸留版32B(手元)
-
OpenAIブランドと挙動の互換性
gpt-oss-20b(手元)/ gpt-oss-120b(サーバ級)
-
モバイル・エッジでの軽量推論
Qwen3-1.7B / Qwen3-4B等のDenseモデル
実務での選び方は「VRAM容量で動く中で一番大きいモデル」ではなく、業務タスクで必要な精度を満たす最小モデルです。30B級が無駄に重い用途では8B級・4B級で十分なケースも多くなっています。
ローカルLLMに必要なハードウェアとスペック選定
モデルが決まったら、それを動かす土台のハードウェアを選びます。
ローカルLLMのハードウェア選定は「GPUコア性能ではなくVRAM容量とメモリ帯域」で決まる点が、ゲーミングPC選びとは大きく違います。

VRAMが最重要な理由
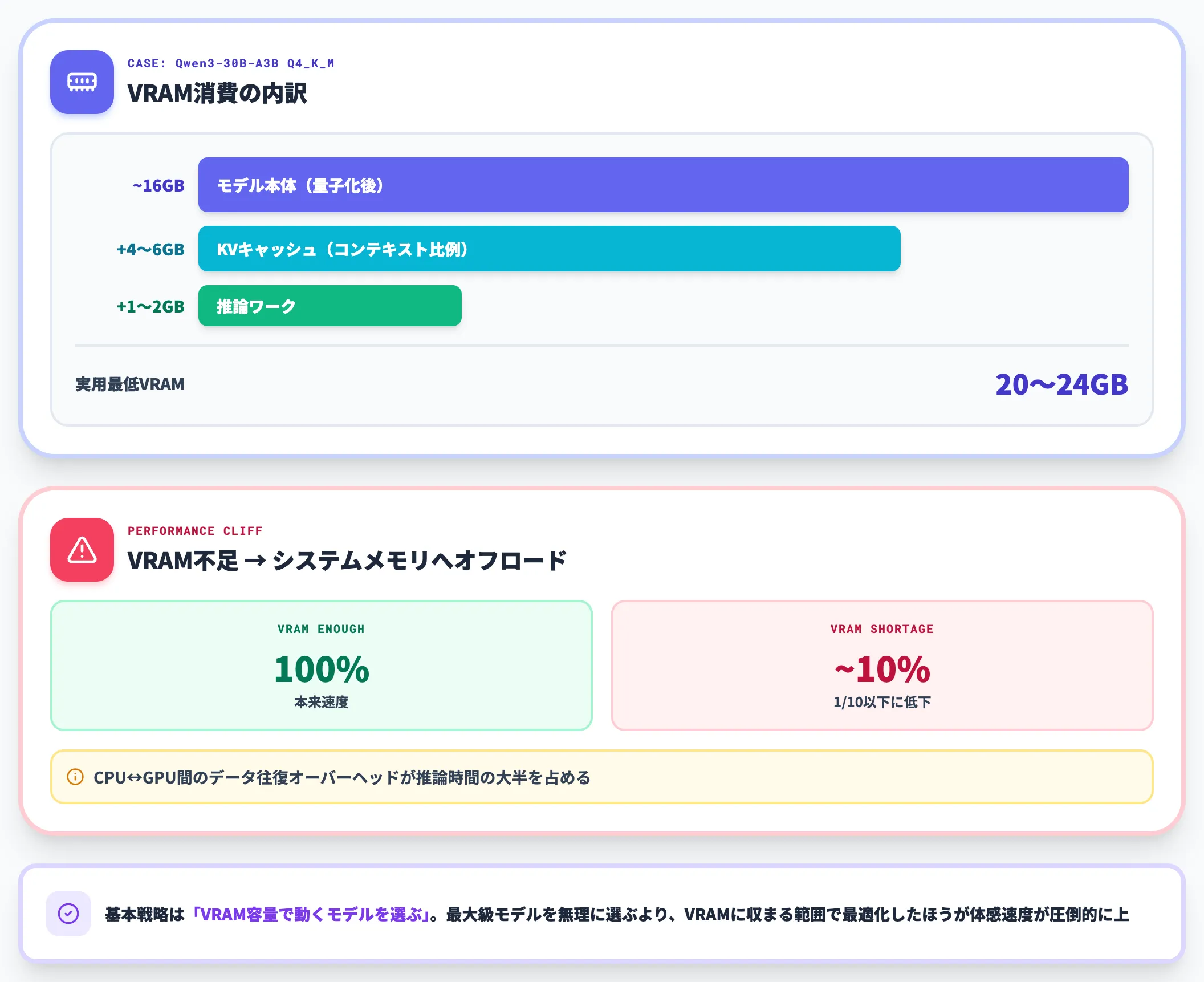
LLMの推論で最初にぶつかるボトルネックは、モデル重みをVRAMに乗せられるかどうかです。
例えばQwen3-30B-A3Bを4ビット量子化(Q4_K_M)で動かす場合、モデル本体のVRAM消費は約16GB。これに加えてKVキャッシュ(コンテキスト長に比例して増える)と推論時のワークメモリで、実際は20〜24GBは欲しい計算になります。
VRAMが足りない場合、システムメモリへのオフロードが発生し、トークン生成速度が一気に1/10以下まで落ちます。CPUとGPUの間でデータを往復させるオーバーヘッドが、推論時間の大半を占めるためです。
したがって、ローカルLLMではVRAM容量で動くモデルを選ぶのが基本戦略になります。
推論経路の3つの選択肢——NVIDIA・Apple Silicon・AMD Strix Halo
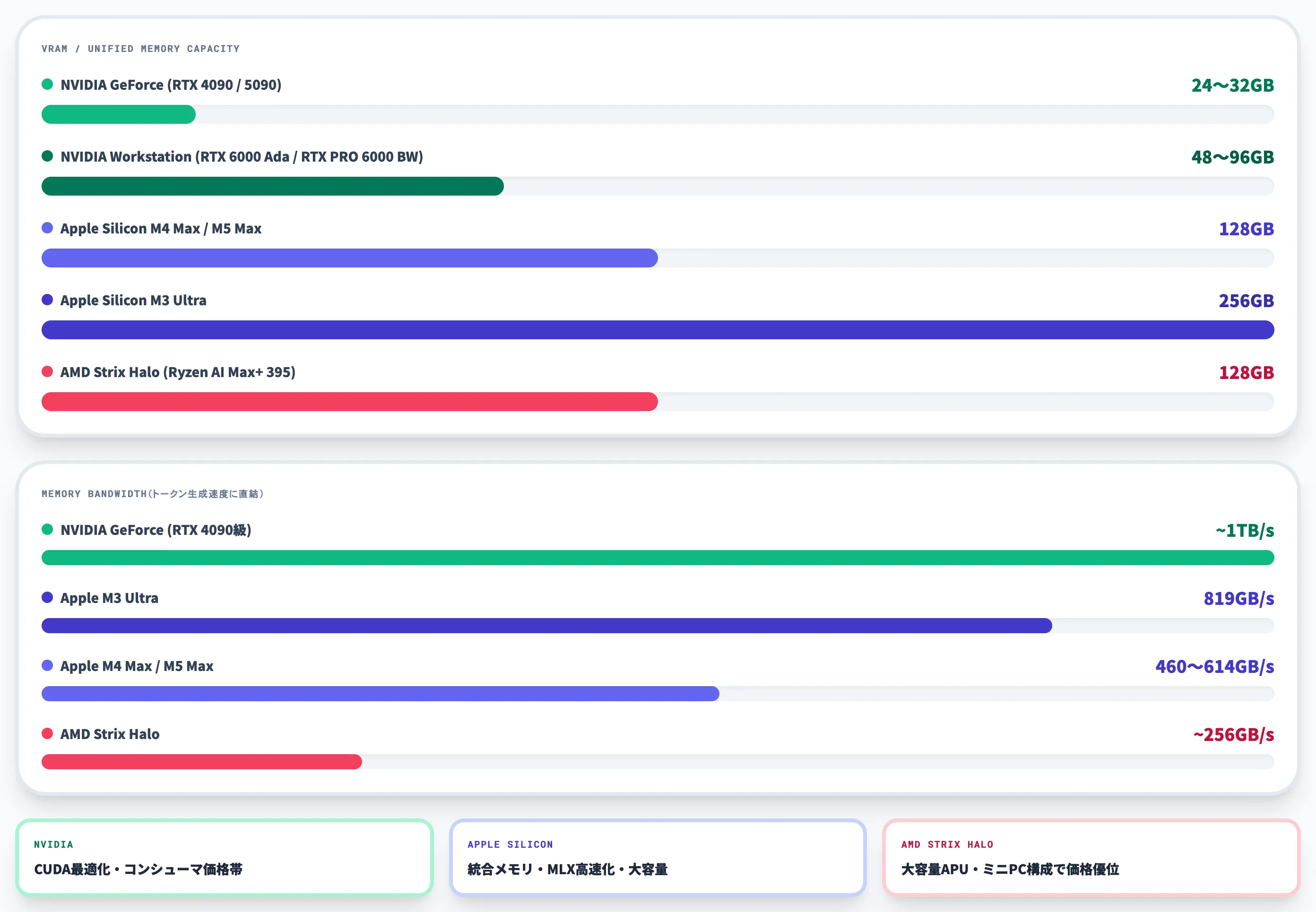
ローカルLLMの主要な推論経路は3つに整理できます。
| 経路 | 代表ハードウェア | VRAM/メモリ容量 | 帯域 | 強み |
|---|---|---|---|---|
| NVIDIA GeForce | RTX 4090 / 5090 | 24〜32GB | 1TB/s級 | CUDA最適化・コンシューマ価格帯 |
| NVIDIA Workstation | RTX 6000 Ada / RTX PRO 6000 Blackwell | 48〜96GB | 1TB/s級 | 単機で70B級・大容量モデル対応 |
| Apple Silicon | M4 Max / M5 Max / M3 Ultra | M4/M5 Max 128GB / M3 Ultra 256GB(ユニファイド) | 460〜819GB/s | 統合メモリ・MLX高速化 |
| AMD Strix Halo | Ryzen AI Max+ 395 | 最大128GB(ユニファイド) | 約256GB/s(LPDDR5X-8000・256bit) | 大容量ユニファイドメモリAPU |
選択軸は「動かしたいモデルサイズ」と「予算」のかけ算です。32B以下なら NVIDIA、70B以上を狙うならApple SiliconかStrix Haloという棲み分けが実務的な目安になっています。
NVIDIA GeForce / RTX——CUDA最適化の安定解
NVIDIA GeForce/RTXは、ローカルLLMのデフォルト選択肢として最も実績があります。CUDA・cuDNN・TensorRTを含むNVIDIAソフトウェアスタックは長年の最適化が積み上がっており、多くのオープンソースランタイムが「まずNVIDIA」で動作確認されています。
コンシューマ向け最上位のRTX 5090で32GB VRAM、ワークステーション向けのRTX PRO 6000 Blackwellでは96GB VRAMが利用できます。さらに大規模なモデルを単機で動かしたい場合は、複数枚構成(マルチGPU)またはNVIDIA H100/A100等のデータセンター級GPUが必要になります。
Apple Silicon——ユニファイドメモリとMLXによる高速化
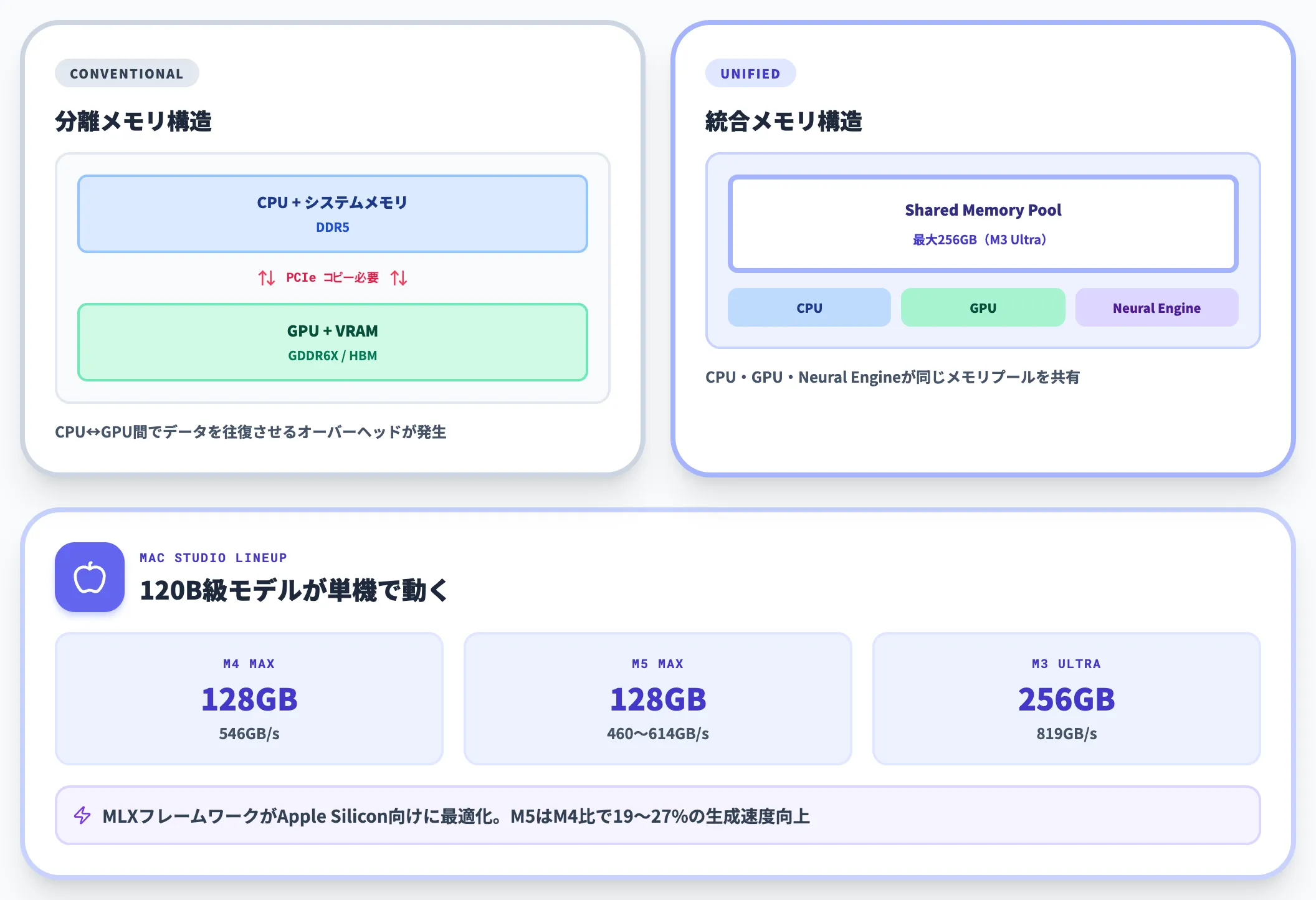
Apple Silicon(M4 Max / M5 Max / M3 Ultra)の最大の特徴は、CPU・GPU・Neural Engineが同じメモリプールを共有するユニファイドメモリアーキテクチャです。
Mac StudioはM4 Maxで最大128GB、M3 Ultraで最大256GBのメモリを搭載でき、120B級のモデルも単機で動かせます。さらにApple純正のMLXフレームワークがApple Silicon向けに最適化されており、M5ではM4比で19〜27%の生成速度向上が示されています。
ボトルネックはメモリ帯域です。M4 Maxは546GB/s、M5 Maxは460GB/s(高位構成で614GB/s)、M3 Ultraは819GB/sの帯域を持ちますが、それでもNVIDIAのコンシューマGPU(1TB/s級)と比べると遅いため、トークン生成速度はGPUに劣る場面があります。
AMD Strix Halo——128GBユニファイドメモリの大容量APU
AMD Ryzen AI Max+ 395(Strix Halo)は、最大128GBのLPDDR5X-8000ユニファイドメモリと40基のRDNA 3.5 CUを搭載したAPUです。AMDはCES 2026で、Ryzen AI Haloが最大200Bパラメータのモデルをローカル実行可能と発表しました。
同等メモリ容量の他プラットフォームと比較すると、ミニPC構成での価格優位が打ち出されています。MoE系モデル(Qwen3-30B-A3B 等)でも実用速度を引き出せる構成として、Mac Studio・NVIDIA構成と並ぶ第3の選択肢になっています。
ただし、NVIDIA CUDAエコシステムほどソフトウェア対応が成熟しておらず、Vulkan・ROCm・HIP経由で動かすため、初期セットアップに技術的な敷居があります。
VRAM別のモデル早見表

ここまでのモデル・ハードウェアを、VRAM容量別に組み合わせた早見表を以下に示します。
| 手元のVRAM/メモリ | 推奨モデル | 推奨ハードウェア例 |
|---|---|---|
| 8GB | Qwen3-8B Q4 / Gemma 4 E4B | RTX 4060 Ti / M2 Pro 16GB |
| 16GB | Qwen3-30B-A3B Q4 / gpt-oss-20b / Gemma 4 26B A4B | RTX 4080 / M3 Pro 36GB |
| 24GB | Qwen3-30B-A3B Q8 / Gemma 4 31B Q4 | RTX 4090 / RTX 5090 |
| 48〜96GB | Llama系70B Q4 / Qwen3-235B Q3 | RTX 6000 Ada / RTX PRO 6000 Blackwell / Mac Studio M4 Max 64GB |
| 128GB | gpt-oss-120b / DeepSeek-R1 蒸留70B / Qwen3-235B Q4 | Mac Studio M4 Max 128GB / Strix Halo |
| 256GB級 | DeepSeek V4-Flash 量子化 / 大規模MoE | Mac Studio M3 Ultra |
この表を見て分かるのは、16〜24GB VRAM帯が「実用的にちょうどよい中位帯」になっているという点です。最初の1台目を選ぶならこの帯域から検討するのが堅実です。
ローカルLLM実行ツール(ランタイム)の使い分け
モデルとハードウェアが揃ったら、その上で動かす実行ランタイムを選びます。
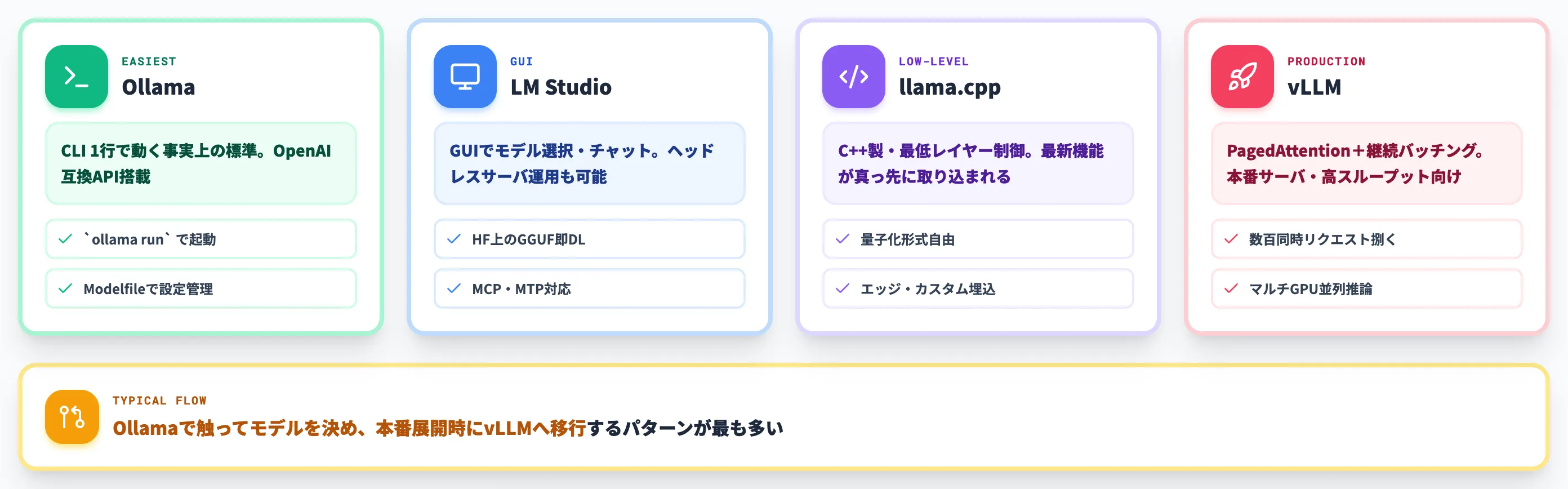
主流のランタイムは Ollama・LM Studio・llama.cpp・vLLM の4つで、それぞれ得意な領域が違います。
Ollama——CLIで最も簡単に始められる
Ollamaは、ローカルLLMの「とりあえずこれで動く」を最短で実現するランタイムです。直近のリリース(v0.30.10)ではApple SiliconのMLXエンジン統合とllama.cpp build 9672を取り込んでいます。
特徴は以下の3点です。
-
CLI 1行で起動
ollama run qwen3:30bのような単純なコマンドで、モデルのダウンロードから推論起動まで自動化
-
OpenAI互換API
http://localhost:11434/v1/chat/completionsで OpenAI SDK互換のREST APIを提供
-
Modelfile
システムプロンプト・パラメータ・量子化設定をDockerfile風のテキストで管理
個人開発・小規模なチーム検証・PoCの初手としては、Ollamaが事実上の標準です。
LM Studio——GUI重視、ヘッドレスサーバとしても運用可能
LM Studioは、GUIでモデルを選んでチャットできる扱いやすさが特徴です。v0.4.0でヘッドレスモード(llmster)と継続バッチングが追加され、サーバ用途にも対応しました。
-
GUIでモデルを試せる
Hugging Face上のGGUFモデルをGUIから検索・ダウンロード・チャット
-
MLXエンジン
Apple Silicon向けの高速推論を内蔵
-
MCP対応
Model Context Protocol経由でツール呼び出しを統合
-
投機的デコーディング(MTP)
複数トークン予測で推論を高速化
非エンジニアにモデルを触らせたい・GUIでデモを見せたい場面では、LM Studioが最初の選択肢になります。
llama.cpp——最低レイヤーで最速・カスタム自由
llama.cppは、Ollama・LM Studio内部でも使われているC++製の推論エンジンです。
Ollama/LM Studioが提供する抽象化を取り払い、量子化形式・KVキャッシュ・スレッド数・GPU割り当てを細かく制御したい上級者向けです。MTP(Multi-Token Prediction)投機的デコーディング、新モデルアーキテクチャ対応、Windows CUDAプリビルド等、最新機能が真っ先に取り込まれるのが強みです(最新の対応状況はGitHub releasesで確認できます)。
カスタム埋め込みやエッジデバイス向けのデプロイ、量子化研究をする場合はllama.cpp一択になります。
vLLM——本番運用・高スループット向け
vLLMは、PagedAttentionと継続バッチングを実装した、本番サーバ向けの高スループット推論エンジンです。
- 数十〜数百の同時リクエストを捌くスループット最適化
- OpenAI互換API + REST + gRPCでのデプロイ
- マルチGPUでの分散推論(テンソル並列・パイプライン並列)
社内利用者数百人にローカルLLMを提供したい・SLAレベルでスループットを保証したいケースでは、vLLMが本命です。Ollama/LM Studioは検証フェーズ、vLLMは本番フェーズという棲み分けが現実的です。
用途別のランタイム選び

ここまでの4つを、フェーズと用途で整理しました。
| フェーズ | 推奨ランタイム | 理由 |
|---|---|---|
| 個人のPoC・学習 | Ollama | CLI 1行で動く・OpenAI互換API |
| 非エンジニアのデモ | LM Studio | GUIで完結・チャット即実行 |
| カスタム量子化・エッジ | llama.cpp | 最低レイヤー制御・最新機能対応 |
| 本番サーバ・高スループット | vLLM | PagedAttention・継続バッチング |
導入の現実的な流れは、Ollamaで触ってみてモデルを決め、本番展開時にvLLMへ移行するパターンが最も多くなっています。

Ollamaで始めるローカルLLM導入手順
ここからは、最も手軽に始められるOllamaを使った導入手順を順に追います。
WindowsでもmacOSでもLinuxでも、同じ手順でOllamaを動かせます。本セクションではmacOSとWindowsを想定して進めます。
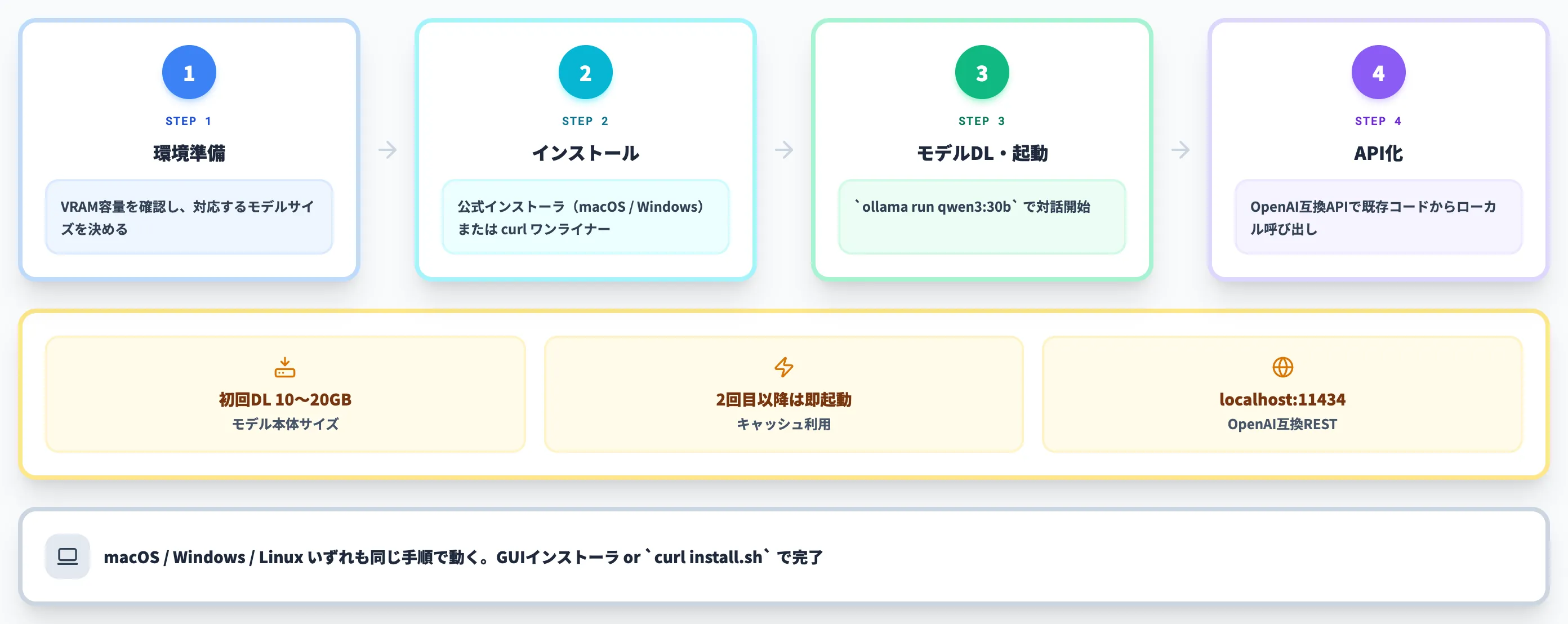
ステップ1:環境準備とハードウェア確認
最初に、手元のマシンが動かしたいモデルを実行できるかを確認します。
- macOSの場合:Appleメニュー > このMacについて で メモリ(16GB以上推奨)を確認
- Windowsの場合:タスクマネージャー > パフォーマンス > GPU で VRAM容量を確認
VRAMが8GBであれば8Bクラス、16GBであれば30B-A3BクラスのMoEモデルが目安です。本記事の「VRAM別のモデル早見表」を参照して、無理のないサイズから始めるのが安全です。
ステップ2:Ollamaのインストール
Ollama公式サイトからインストーラを取得して実行します。
- macOS / Windows:公式サイトのインストーラ(GUI)を実行
- Linux:
curl -fsSL https://ollama.com/install.sh | shでワンライナーインストール
インストールが完了すると、バックグラウンドでOllamaサーバが起動します。ollama --versionでバージョンが表示されれば導入完了です。
ステップ3:モデルのダウンロードと起動
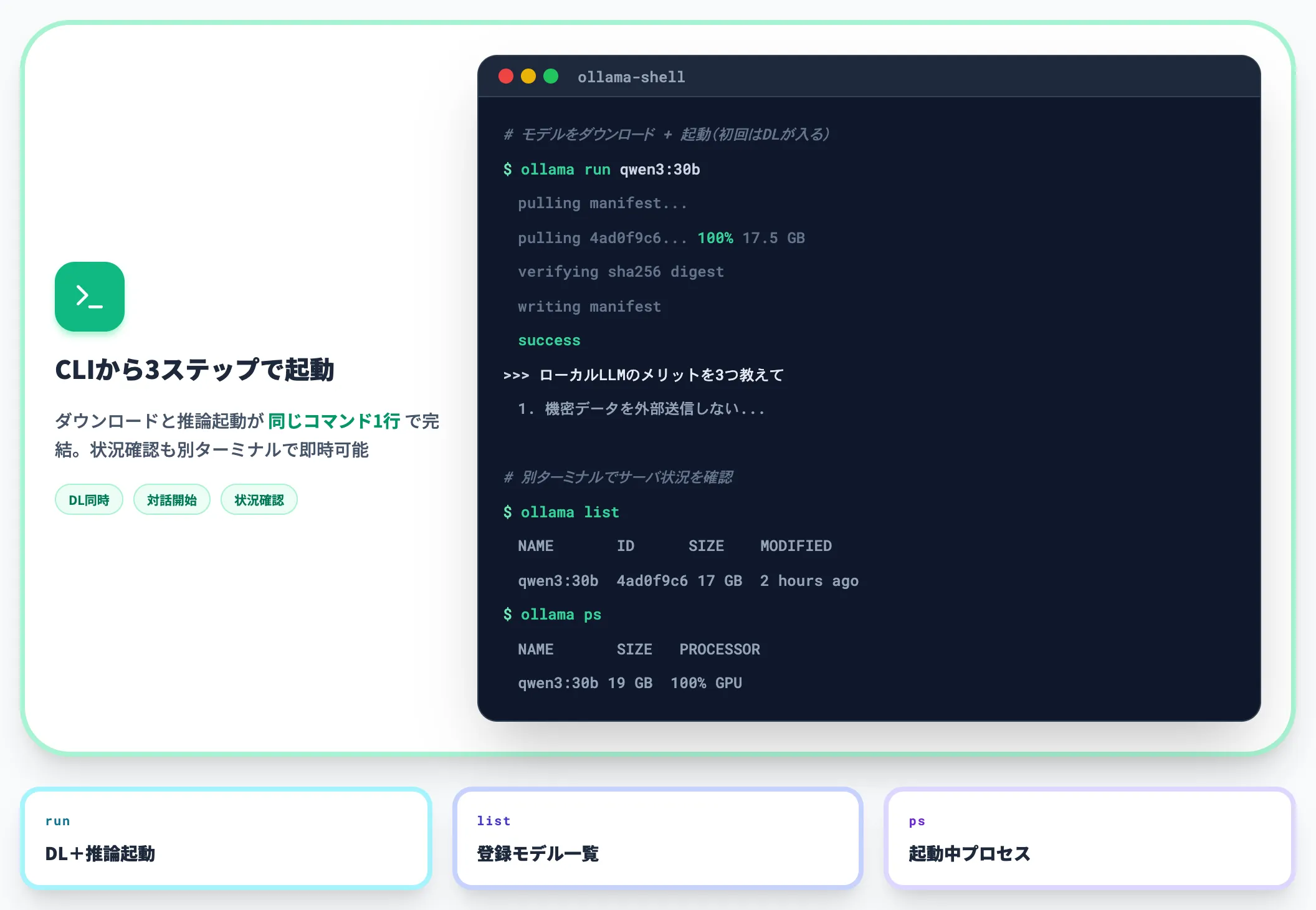
Ollamaのモデルライブラリから、動かしたいモデルを選んで実行します。
以下は、Qwen3-30B-A3Bを4ビット量子化で起動するコマンド例です。
# モデルをダウンロード + 起動(初回はダウンロードが入る)
ollama run qwen3:30b
# 別ターミナルでサーバ状況を確認
ollama list
ollama ps
初回はモデル本体(10〜20GB)のダウンロードが入りますが、2回目以降はキャッシュから即起動します。プロンプトを入力すると、ターミナル上で対話を開始できます。
ステップ4:OpenAI互換APIとして使う
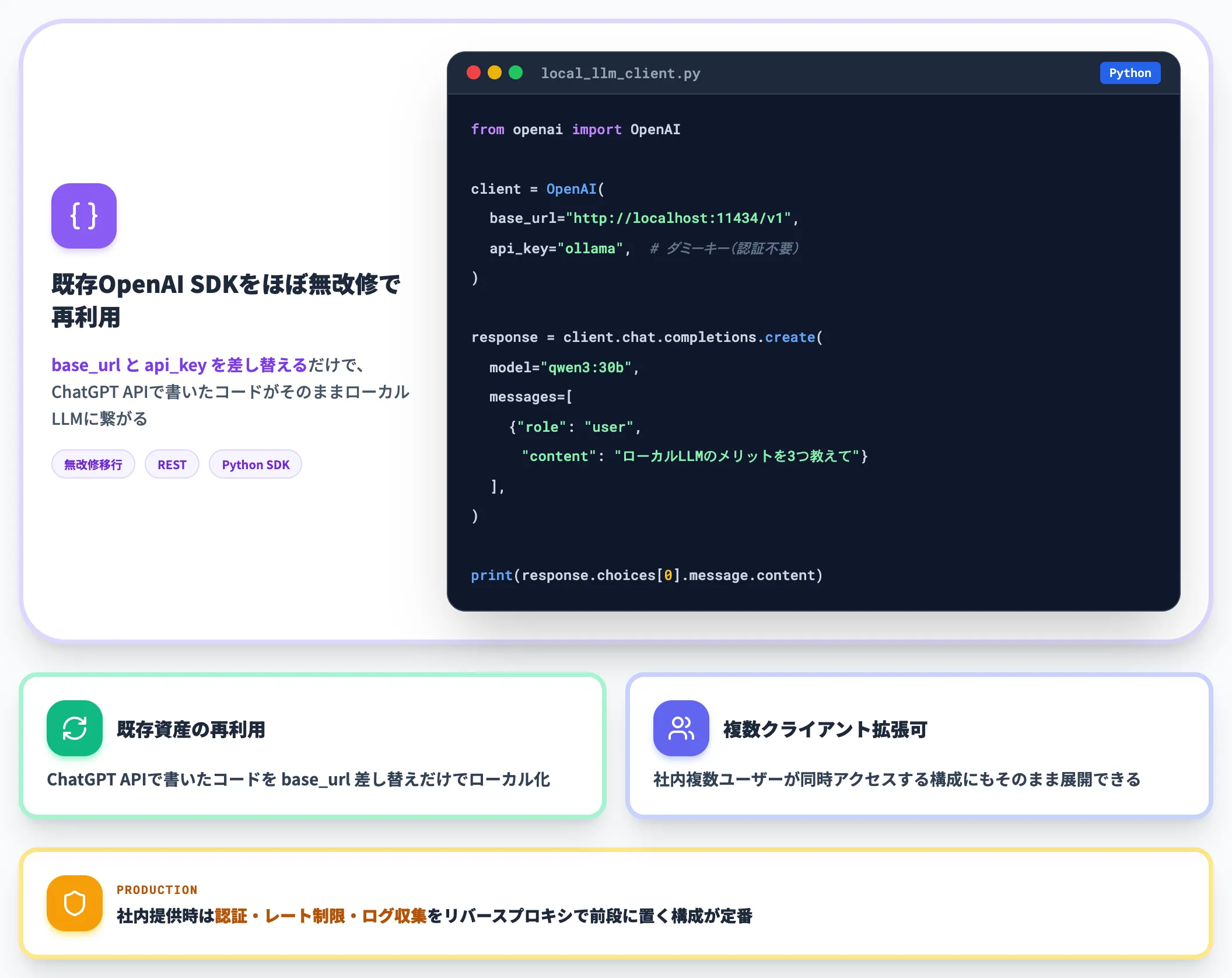
Ollamaは起動と同時に、http://localhost:11434 でOpenAI互換のREST APIを提供します。既存のOpenAI SDK(Python・Node.js等)から、エンドポイントとAPIキーを差し替えるだけで利用できます。
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama", # ダミーキー(認証は不要)
)
response = client.chat.completions.create(
model="qwen3:30b",
messages=[{"role": "user", "content": "ローカルLLMのメリットを3つ教えて"}],
)
print(response.choices[0].message.content)
このアプローチの利点は複数あります。第一に、既存のChatGPT APIを使ったコードをほぼ無改修でローカル化できる点。第二に、社内で複数のクライアントから同時にアクセスする構成にも、そのまま拡張できる点です。
本格的な社内サービスとして提供する段階では、認証・レート制限・ログ収集をリバースプロキシで前段に置く構成が定番です。
業務利用に向けた発展——RAGとファインチューニング
Ollamaで素のモデルが動いたら、次のステップは「自社の業務データと組み合わせる」フェーズです。
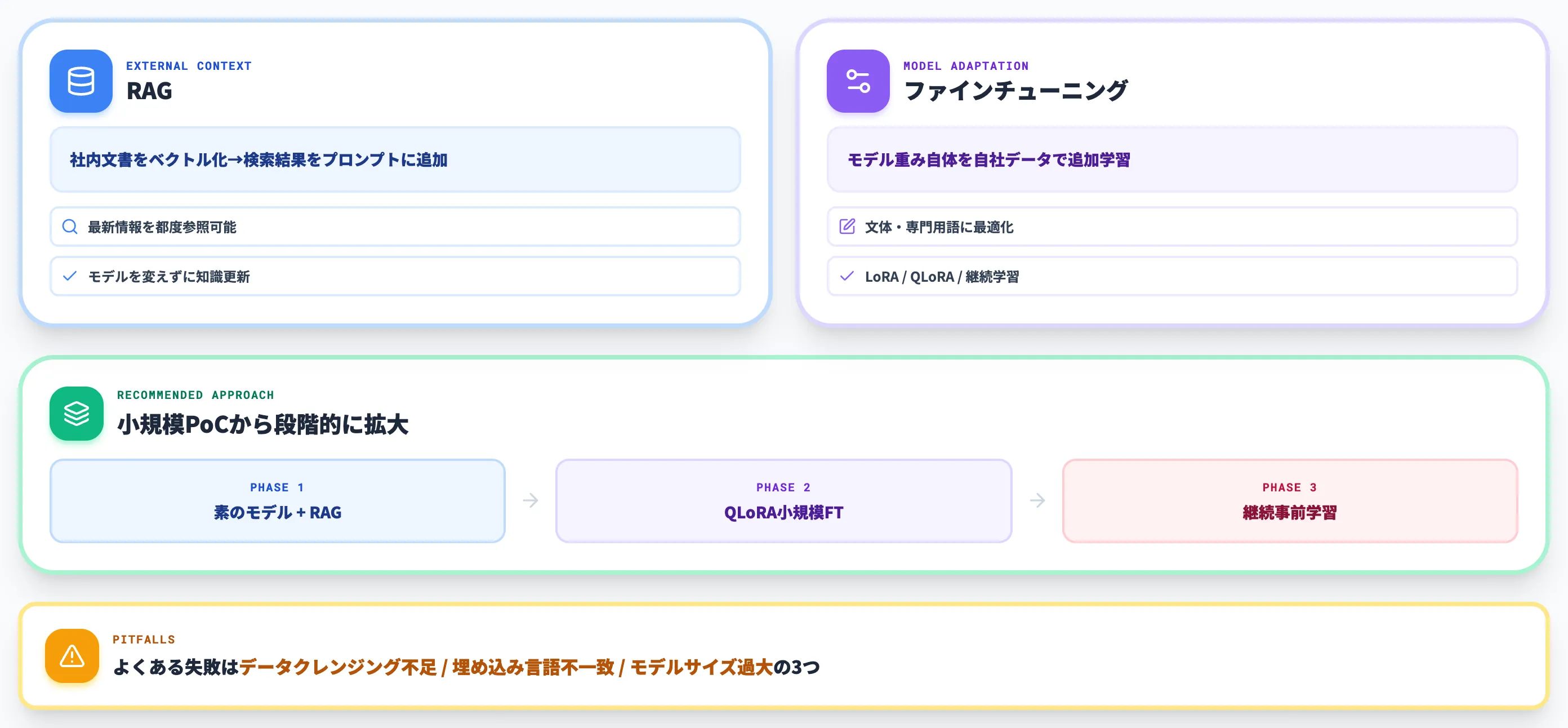
社内RAG構築の基本構成
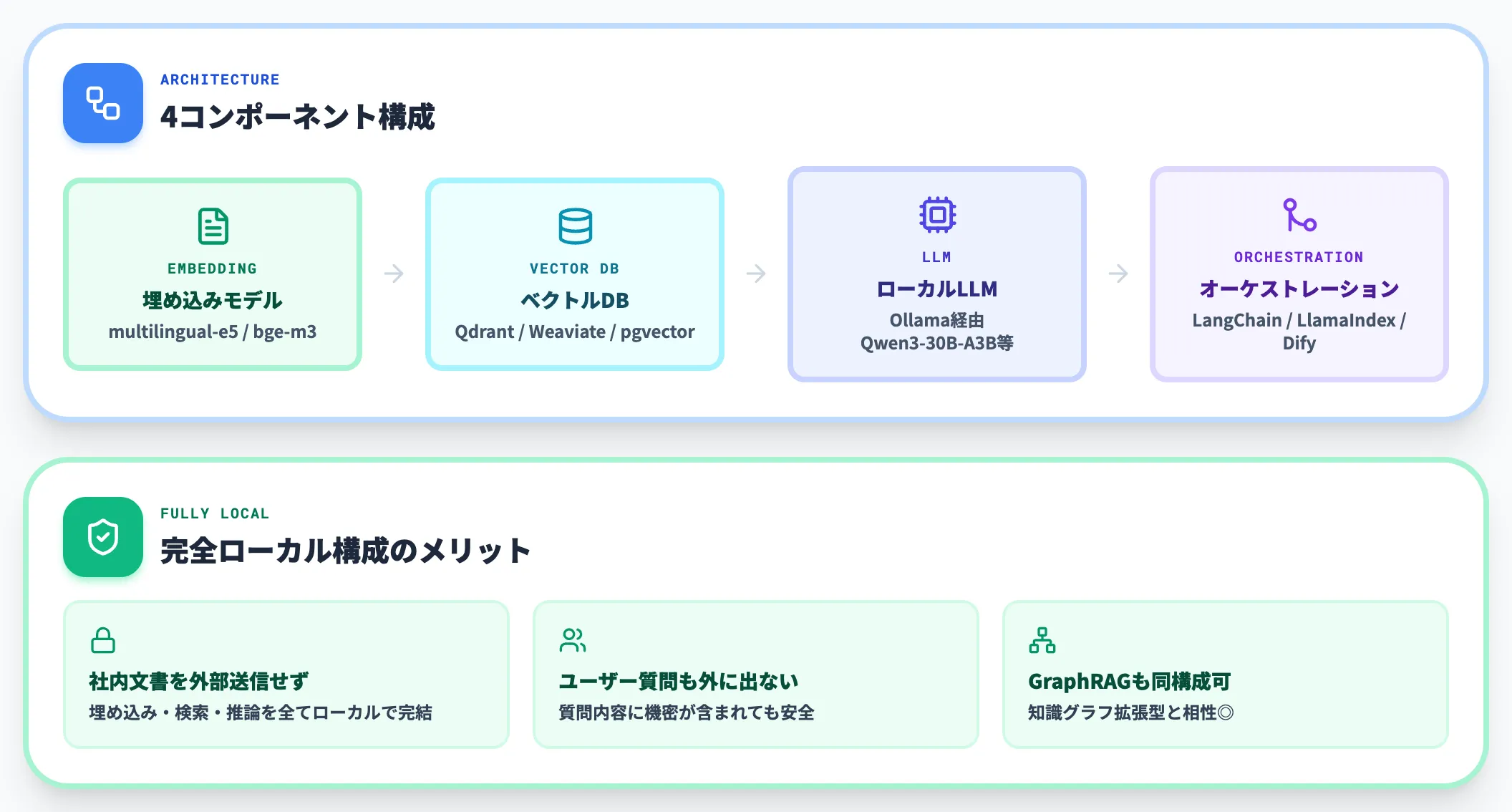
RAG(Retrieval-Augmented Generation)は、社内文書をベクトル化して検索可能にし、ユーザー質問に応じて関連文書を取り出してLLMの入力に追加する仕組みです。
ローカルLLM × RAGの最小構成は以下のコンポーネントで成立します。
-
埋め込みモデル
multilingual-e5-large、bge-m3 等の多言語埋め込みモデル
-
ベクトルDB
Qdrant / Weaviate / Chroma / pgvector
-
LLM
Ollama経由のQwen3-30B-A3B 等
-
オーケストレーション
LangChain / LlamaIndex / Dify
すべてローカルで完結する構成にすれば、社内文書とユーザーの質問の両方がネットワークを離れません。金融・医療・製造業の機密データを扱う前提のRAGでは、この「完全ローカル」が要件になることが多いです。
GraphRAGのような知識グラフ拡張型RAGも、同じくローカル構成で組めるため、社内ナレッジの構造化と相性が良くなっています。
ファインチューニングの選択肢
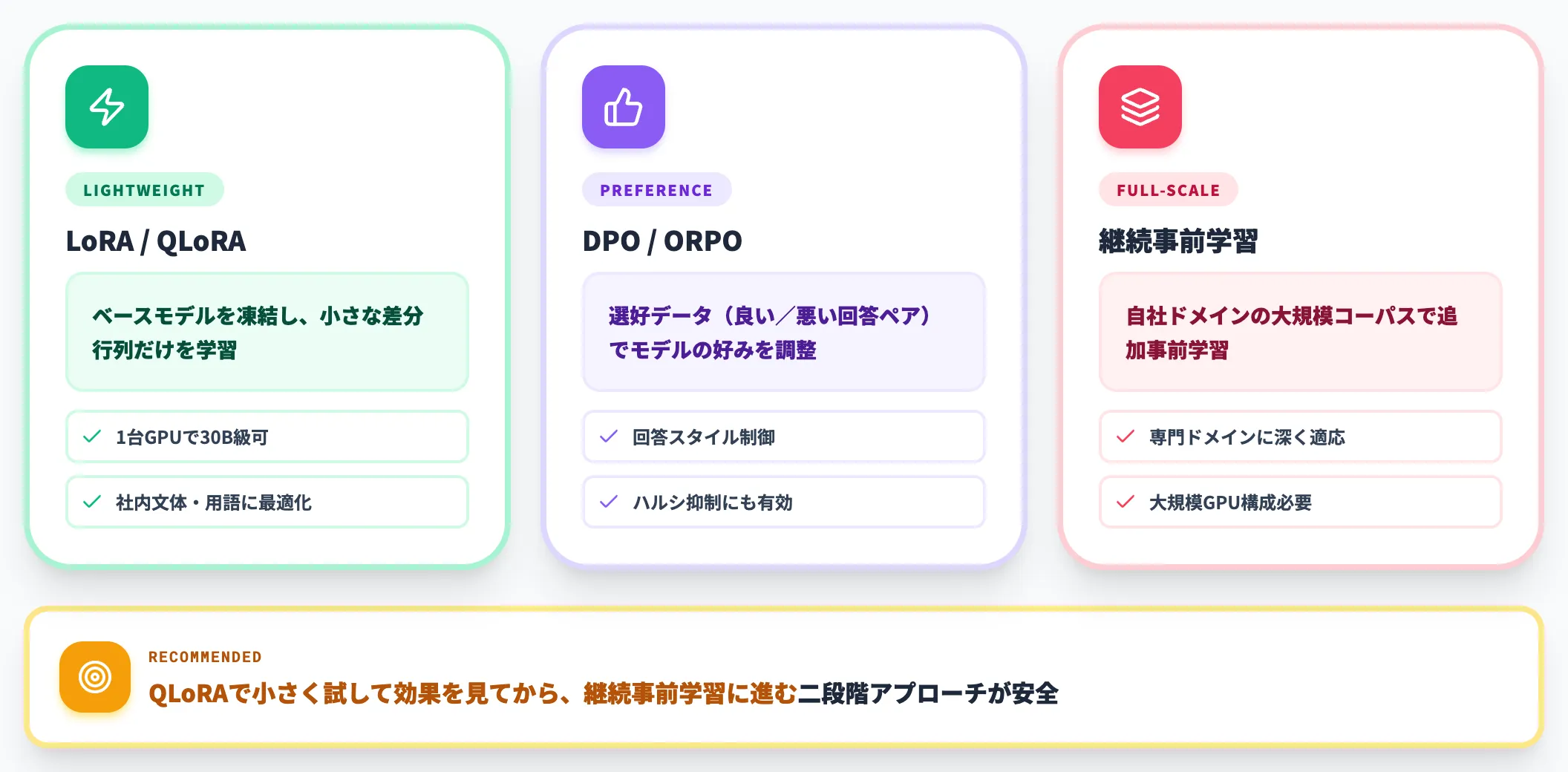
ローカルLLMのもうひとつの強みが、ファインチューニング(追加学習)の自由度です。
-
LoRA・QLoRA
ベースモデルを凍結し、小さな差分行列だけを学習する軽量ファインチューニング
-
DPO・ORPO
選好データ(良い回答・悪い回答のペア)でモデルの好みを調整
-
継続事前学習
自社ドメインの大規模コーパスで追加事前学習
QLoRAは1台のGPUで30B級のモデルもファインチューニング可能で、社内文体・専門用語へのアダプテーションには十分な実用域に到達しています。本格的なドメイン特化が必要な場合は、QLoRAで小さく試して効果を見てから、継続事前学習に進む二段階アプローチが安全です。
業務導入で詰まる3つの落とし穴
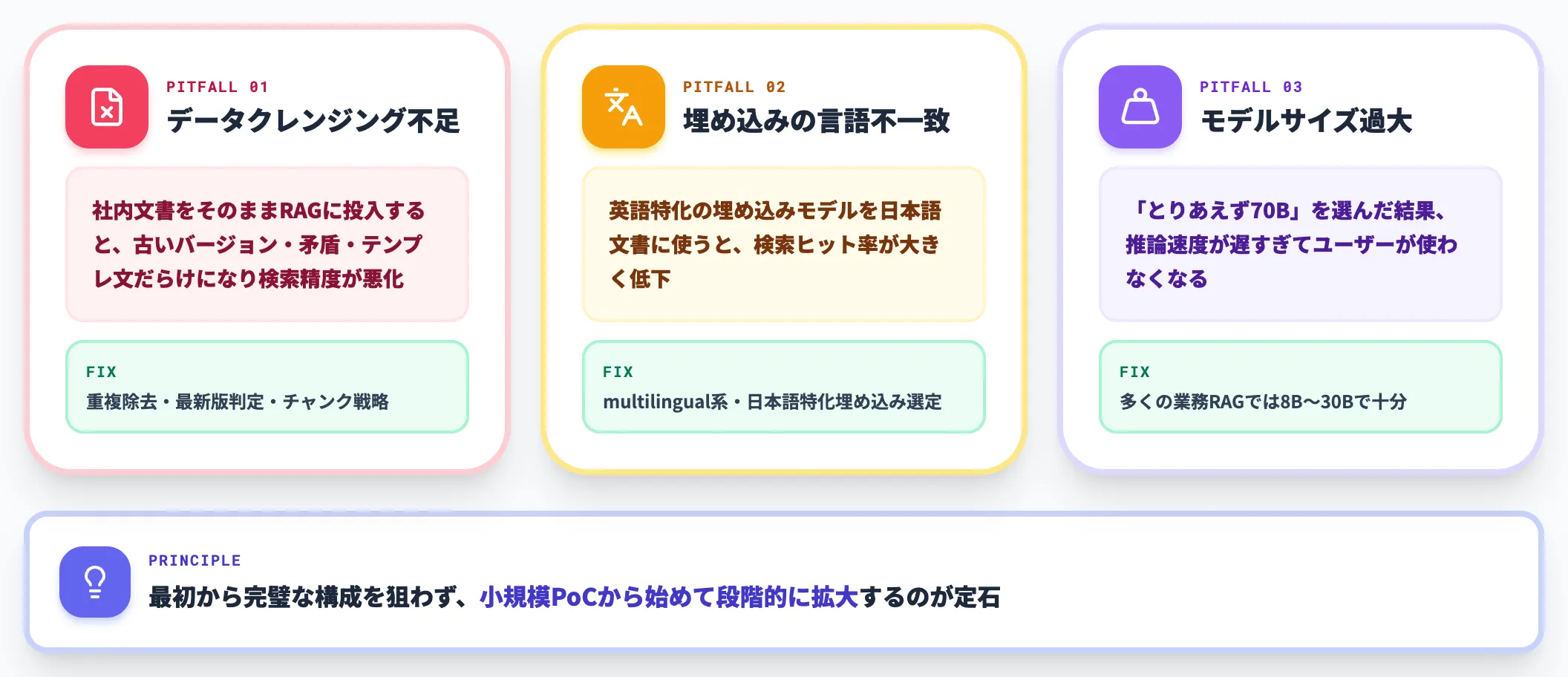
ローカルLLM × RAG / ファインチューニングを進める中で、現場でよくある失敗パターンを3つ整理します。
-
データクレンジング不足
社内文書をそのままRAGに投入すると、古いバージョン・矛盾する記述・テンプレ文だらけになり、検索精度がクラウドLLMより悪化する。前処理(重複除去・最新版判定・チャンク戦略)が成否を左右する
-
埋め込みモデルの言語不一致
英語特化の埋め込みモデルを日本語文書に使うと、検索ヒット率が大きく落ちる。multilingual系または日本語特化埋め込みを選定する
-
モデルサイズ過大
「とりあえず70B」を選んだ結果、推論速度が遅すぎてユーザーが使わなくなる。多くの業務RAGでは8B〜30Bクラスで十分な精度が出る
これらは検証フェーズでの試行錯誤を通じてしか見えてこない論点で、最初から完璧な構成を狙わず、小規模PoCから始めて段階的に拡大するのが定石です。
ローカル vs クラウドのコスト比較
ローカルLLM導入の経済合理性は、「初期投資の大きさ」と「月次のAPI削減額」のバランスで決まります。
初期投資の内訳
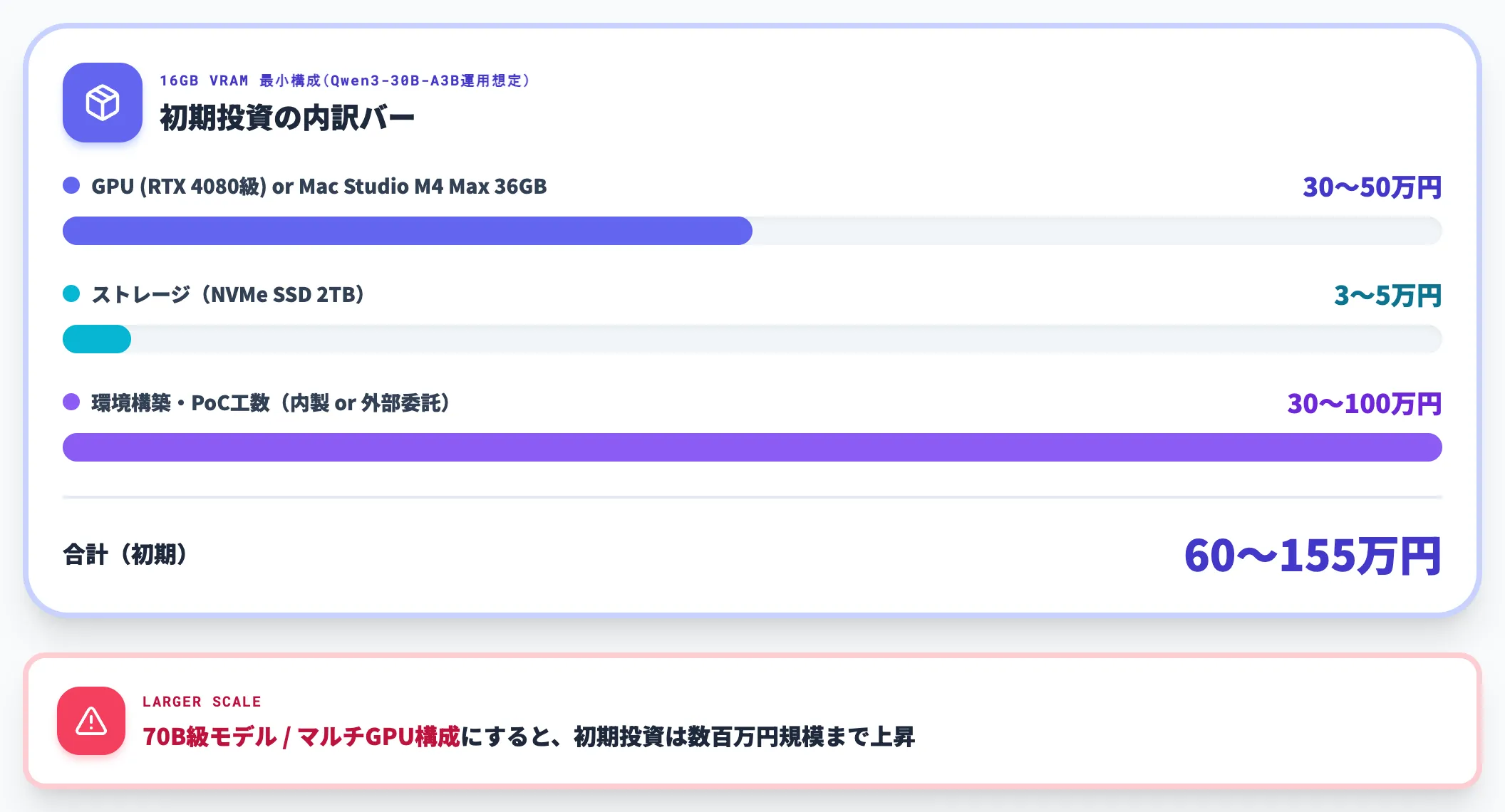
ローカルLLM環境構築の初期コストは、ハードウェアと構築工数に分かれます。以下は16GB VRAMクラスでQwen3-30B-A3Bを動かす最小構成例です。
| 項目 | 想定金額(円) | 備考 |
|---|---|---|
| GPU(RTX 4080級)または Mac Studio M4 Max 36GB | 30〜50万円 | 動かしたいモデルサイズで上下 |
| ストレージ(NVMe SSD 2TB) | 3〜5万円 | モデル本体・キャッシュ用 |
| 環境構築・PoC工数 | 30〜100万円 | 内製 or 外部委託の差 |
| 合計(初期) | 60〜155万円 | 規模により幅 |
70B級モデルやマルチGPU構成にすれば、初期投資は数百万円規模まで上がります。
月次コスト試算——クラウドAPIとの比較
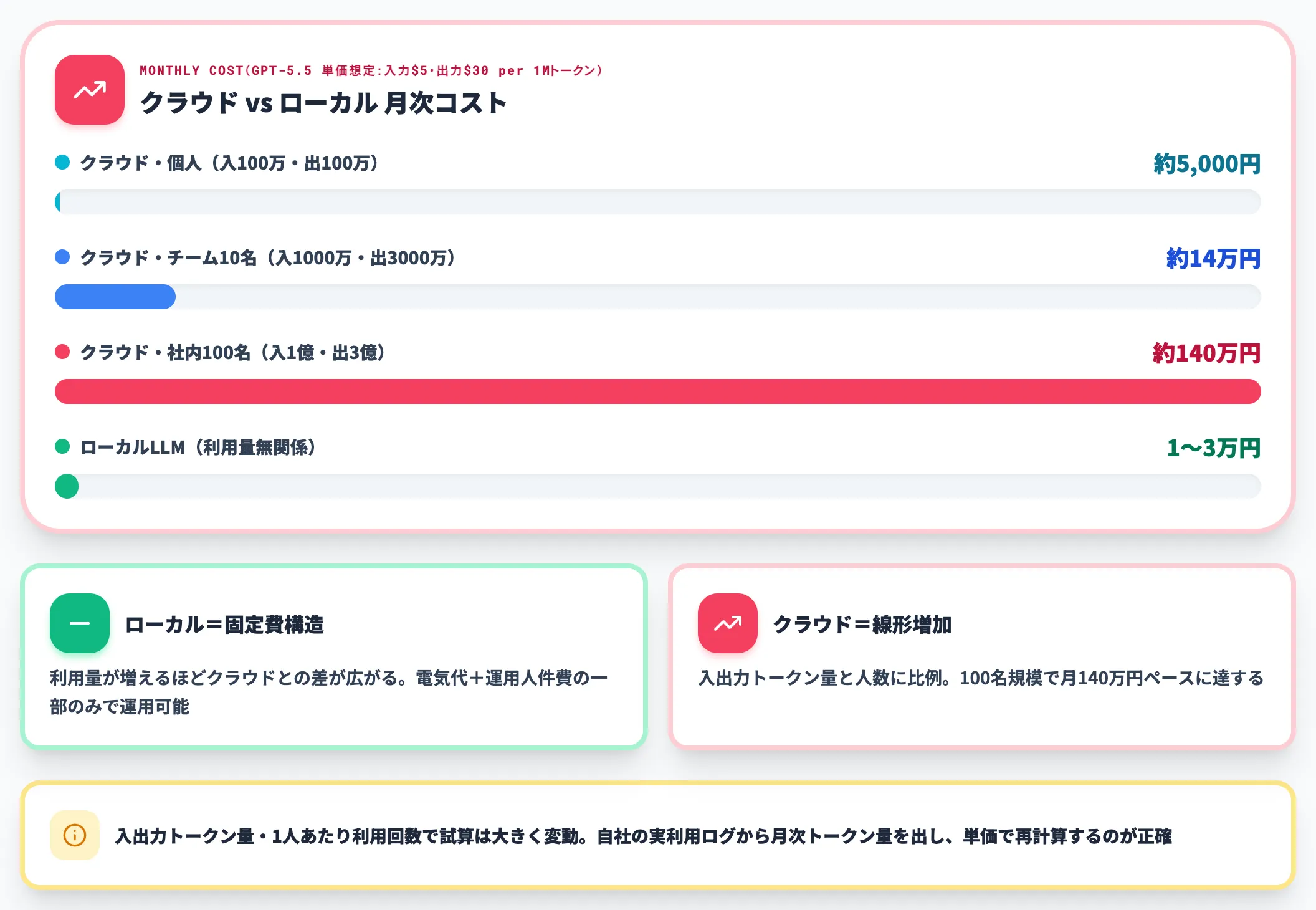
クラウドLLMの代表として、OpenAI APIのgpt-5.5(入力$5・出力$30 per 1Mトークン)を社内利用したケースで試算します。詳細な単価はChatGPT APIの料金記事を参照してください。
| 構成 | 月次トークン量 | 月次コスト目安(円換算 $1=150円) |
|---|---|---|
| クラウドLLM(個人利用) | 入力100万・出力100万 | $35 ≒ 約5,000円 |
| クラウドLLM(チーム10名・1人あたり月10万入力+30万出力) | 入力1,000万・出力3,000万 | $950 ≒ 約14万円 |
| クラウドLLM(社内100名・同条件) | 入力1億・出力3億 | $9,500 ≒ 約140万円 |
| ローカルLLM | 利用量に関係なし | 1〜3万円(電気代+運用人件費の一部) |
ローカルLLM側は初期投資が回収できれば、以降は電気代と運用人件費だけで済みます。トークン量に比例しない固定費構造に変わるため、利用量が伸びるほどクラウドとの差が広がります。
入出力トークン量・1人あたりの利用回数によって試算は大きく変動します。自社の実利用ログから月次トークン量を出し、上記の単価で再計算するのが正確です。
ブレイクイーブンの判断軸
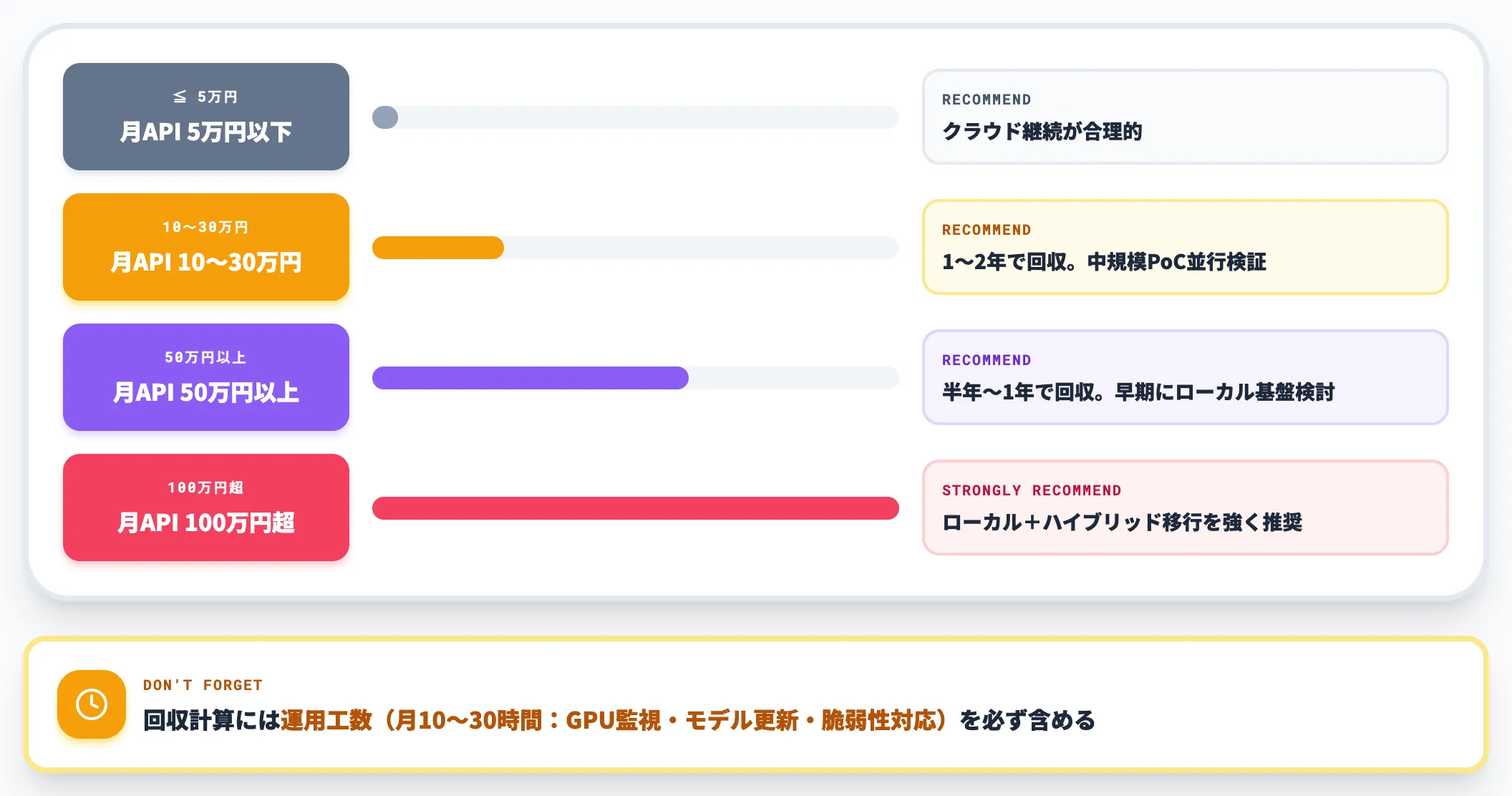
ローカルLLM導入のブレイクイーブン(投資回収)は、月次APIコストが概ね10万円を超えたあたりから視野に入ります。
-
月API 5万円以下
クラウド継続が合理的(初期投資の回収が遅い)
-
月API 10〜30万円
1〜2年で回収可能。中規模PoCを並行で検証
-
月API 50万円以上
半年〜1年で回収可能。早期にローカル基盤検討
-
月API 100万円超
ローカルとハイブリッド構成への移行を強く推奨
ただし回収計算には「運用工数」を必ず含めること。ローカル基盤の保守には、平常時で月10〜30時間程度の運用工数(GPU監視・モデル更新・脆弱性対応)が必要になります。
ローカルLLM運用の注意点
ローカルLLMを本番運用する前に、ライセンス・ハルシネーション・セキュリティの3つの論点を整理しておきます。
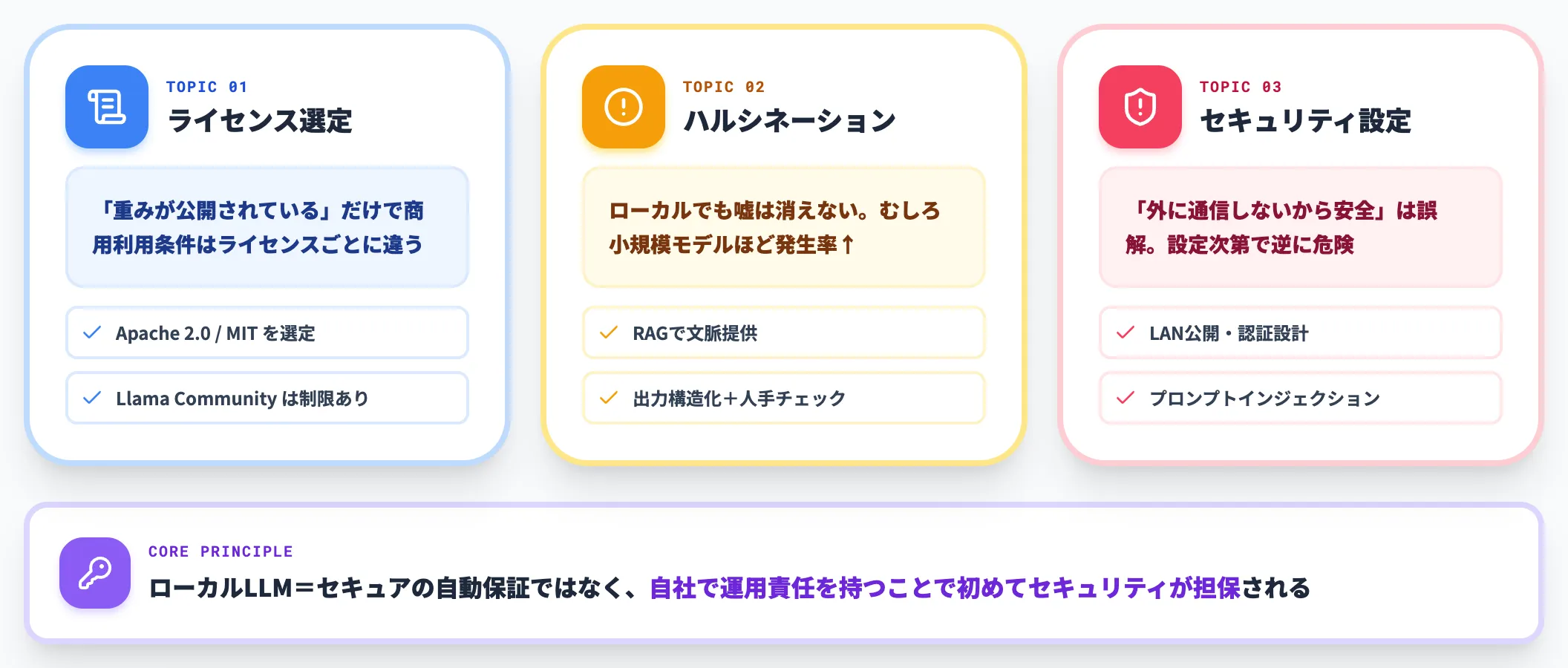
ライセンス選定——Apache 2.0・MIT・Llama系の違い

オープンウェイトモデルは「重みが公開されている」だけで、商用利用条件はライセンスごとに違います。
| ライセンス | 商用利用 | 改変・再配布 | 主な対応モデル |
|---|---|---|---|
| Apache 2.0 | 自由 | 自由 | Qwen3、Gemma 4、gpt-oss |
| MIT | 自由 | 自由 | DeepSeek-R1、V3、V4、Phi系 |
| Gemma | 自由(条件あり) | 一部制約 | Gemma 3(旧Gemmaライセンス時代の系列) |
| Llama Community | 制限あり(MAU 7億人超は別途許諾) | 一部制約 | Llama系 |
法務リスクを最小化したいなら、Apache 2.0 または MIT ライセンスのモデルを選ぶのが堅実です。Llama Community Licenseは「使用目的の制限」「商標表示の義務」等が含まれるため、契約書レビューに時間がかかる組織では選定段階で外しておくと安全です。Gemma 4はApache 2.0に切り替わっているため、旧Gemmaライセンス時代の制約を引きずらないかライセンス本文で確認しておきます。
ハルシネーションへの対策——ローカルLLMでも消えない
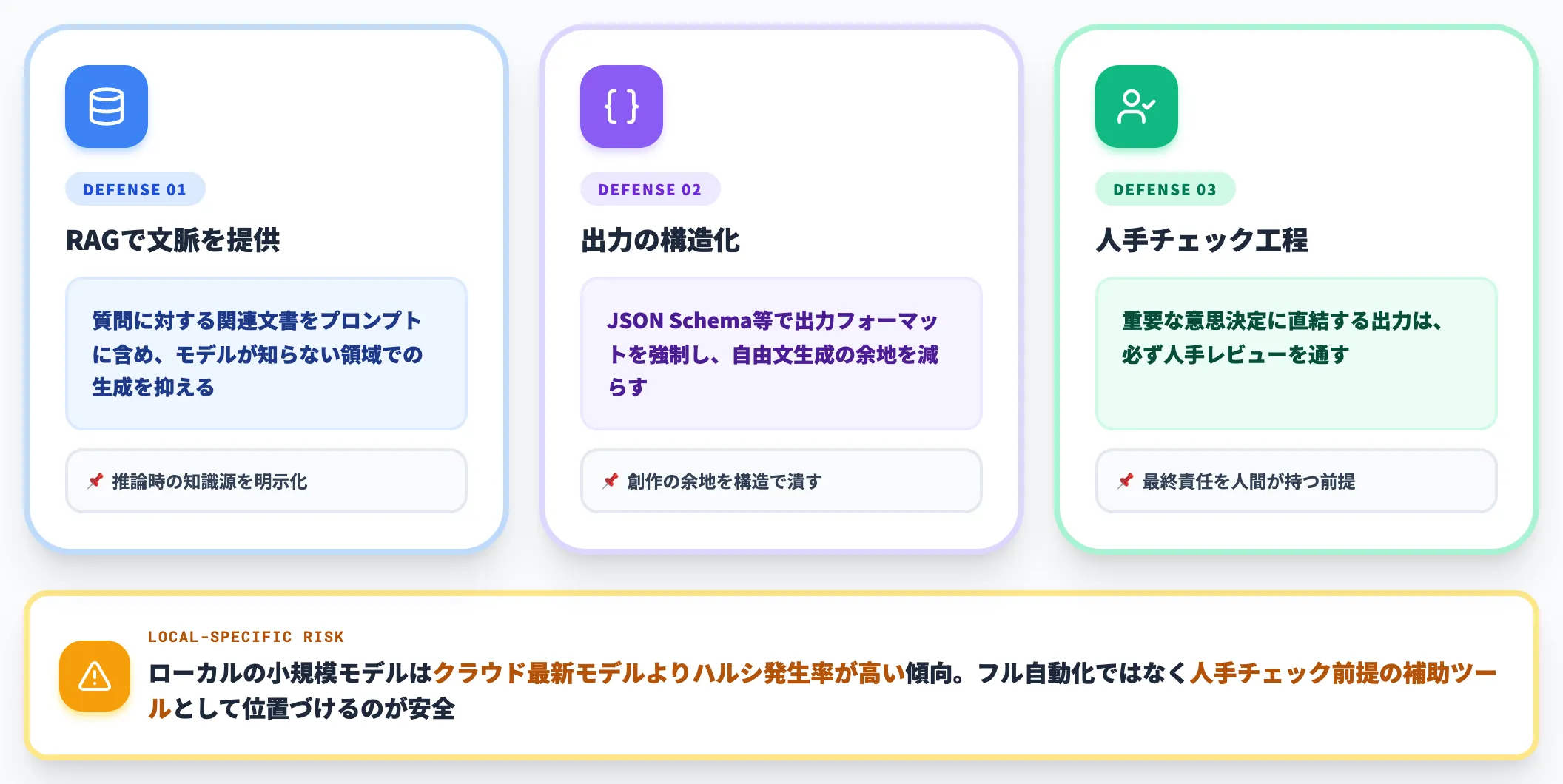
ローカルLLMもハルシネーション(もっともらしい嘘)からは逃れられません。むしろクラウドの最新モデルより小規模なローカルモデルの方が、ハルシネーション発生率は高くなる傾向があります。
対策の基本は3つです。
-
RAGで文脈を提供
質問に対する関連文書をプロンプトに含め、モデルが知らない領域での生成を抑える
-
出力の構造化
JSON Schema等で出力フォーマットを強制し、自由文生成の余地を減らす
-
人手チェック工程
重要な意思決定に直結する出力は、必ず人手レビューを通す
ローカルLLM単独で「人手不要のフル自動化」を目指すと、ハルシネーション起因の事故が必ず発生します。クリティカルな業務では「人手チェック前提の補助ツール」として位置づけるのが安全です。
セキュリティ設定の落とし穴
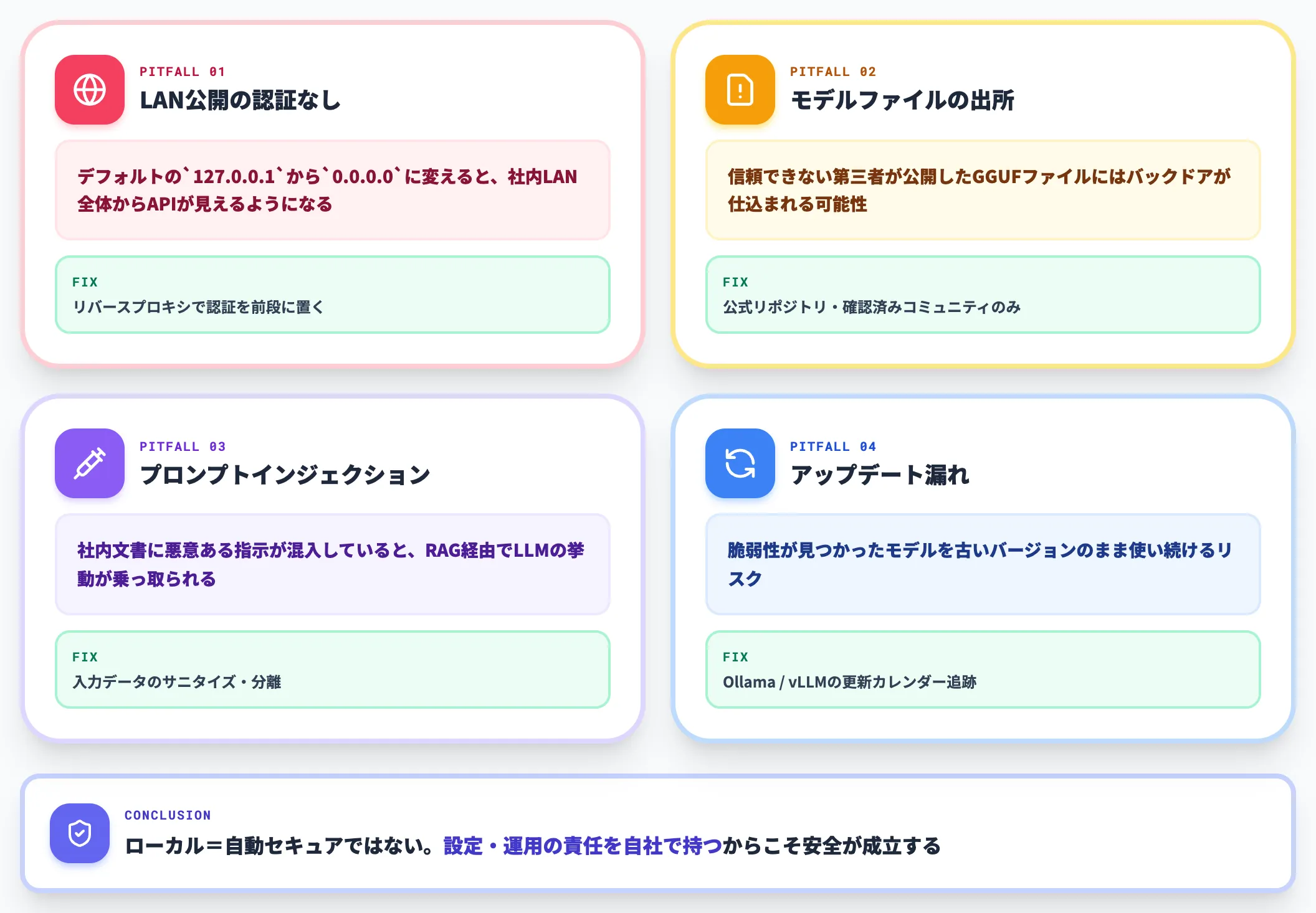
ローカルLLMは「外に通信しないから安全」と思われがちですが、設定次第ではかえって危険な構成になります。代表的な落とし穴は次の通りです。
-
OllamaのLAN公開
デフォルトの127.0.0.1から0.0.0.0に変えると、社内LAN全体からAPIが見えるようになる。認証なしで誰でも叩ける状態を放置しないこと
-
モデルファイルの出所
信頼できない第三者が公開したGGUFファイルにはバックドアが仕込まれる可能性がある。公式リポジトリまたは確認済みコミュニティのファイルだけを使う
-
RAG経由のプロンプトインジェクション
社内文書に悪意ある指示が混入していると、RAG経由でLLMの挙動が乗っ取られる。入力データのサニタイズが必要
-
モデルのアップデート漏れ
脆弱性が見つかったモデルを古いバージョンのまま使い続けるリスク。Ollama / vLLMの更新カレンダーを追う
「ローカルLLM=セキュアの自動保証」ではなく、自社で運用責任を持つことで、初めてセキュリティが担保されるという前提を理解しておくことが重要です。

機密処理のローカル化を業務オペレーション全体に広げるなら
ローカルLLMを立てるだけでは、機密データを扱える業務AIにはなりません。本記事で見たように、ローカルLLMが本領を発揮するのは、SAP・Salesforce・社内DB等の業務システムと接続され、ローカル/クラウド両方を含むハイブリッド構成で業務フローを動かす設計が組まれたときです。そのうえで、データの線引き・実行ログ・権限管理を1つのダッシュボードで統制する基盤が必要になります。
ここで効いてくるのが、自社Azureテナント内で動くエンタープライズAIエージェント基盤 AI Agent Hub です。Microsoft Foundry・n8n・Copilot Studioで構築したAgentを統合管理し、ローカルLLM・クラウドLLMの両方を業務フローに組み込めます。
- データは100%自社テナント内で完結
ローカルLLMが守る「データを外に出さない」設計を業務オペレーション全体に拡張。Azure Managed Applicationsとして自社テナント内で動作し、AIの学習対象から完全除外されます。
- ローカル・クラウド・業務システムを1ダッシュボードで統制
機密データはローカルLLM、複雑推論はクラウドLLM、業務システム連携はAgent経由——どこで動くAIも実行ログ・権限・セキュリティスキャンを1画面に集約し、シャドーAI乱立を防ぎます。
- SAP・Salesforce・社内DBへAgentが直接接続
ローカルLLMの出力をそのまま申請・承認・基幹データ更新まで繋げられる業務特化Agent(AI-OCR Agent・自動入力Agent・経費仕分けAgent等)を搭載。「立てただけのローカルLLM」を実業務に乗せられます。
AI総合研究所の専任チームが、ローカルLLMとクラウドLLMを併用するハイブリッド構成の設計から、業務システム接続・ガバナンス統制まで伴走支援します。AI Agent HubのLPで、自社のデータ主権要件にどう適用できるか具体例をご確認ください。
ローカルLLMを業務システムまで繋ぐAI基盤

機密処理のローカル化と業務フローを統合
ローカルLLMで機密処理を内製化しても、SAP・Salesforce・社内DBに繋ぐ層がなければ業務は回りません。AI Agent Hubは自社Azureテナント内で動くエージェント基盤として、ローカルLLM・クラウドLLMの両方を業務フローに組み込み、データ主権と運用ROIを両立させます。
まとめ
ローカルLLMは、クラウドLLMの完全な代替ではなく、「機密データを外に出さない」「APIコストから脱却する」「フル制御する」という3つの具体的な制約条件に対する、最も構造的な解です。
Qwen3シリーズ・Gemma 4・DeepSeek-R1・gpt-ossといったApache 2.0またはMITライセンスのオープンウェイトモデルが成熟し、MoEアーキテクチャと量子化技術の組み合わせにより、16〜24GB VRAMクラスでも実用的なモデルが動くようになりました。
最初の一歩としては、Ollamaを使ってQwen3-30B-A3Bを手元で動かし、社内文書のRAG構築を小さく試すところから始めるのが現実的です。本格運用フェーズではvLLMへの移行と、ローカル・クラウドのハイブリッド構成を設計することで、データ主権とコスト最適化の両立を狙えます。
導入で迷ったときは、まず「自社のどの業務をローカル化したいのか」「クラウドLLMで困っている具体的な制約は何か」を言語化するところから始めてください。そこから逆算してモデル・ハードウェア・ランタイムを選べば、ローカルLLM導入の費用対効果は明確になります。










