この記事のポイント
 Geminiモデルの検証・プロトタイピングにはGoogle AI Studioが最適で、無料枠だけでPoCを完結できる
Geminiモデルの検証・プロトタイピングにはGoogle AI Studioが最適で、無料枠だけでPoCを完結できる- 本番運用ではVertex AIへの移行が前提となるため、AI Studioはあくまで検証フェーズで使うべき
- マルチモーダル入力(画像・音声・動画・PDF)の精度検証には複数モデルを切り替えて比較するのが有効
- APIキー発行からコード生成まで一気通貫で進められるため、開発者のプロトタイプ速度を大幅に短縮できる
- 企業でのデータガバナンスが求められる場合はVertex AI側のVPC-SC対応が必須で、AI Studio単体での運用は避けるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2026年2月現在、Googleの生成AI「Gemini」は推論強化版の「Gemini 3.1 Pro」、高速処理向けの「Gemini 3 Flash」、研究寄りの「Gemini 3 Deep Think」などモデルの選択肢が増え、「どのモデルを選べば良いか分からない」「APIの使い方が難しそう」と感じる方も多いのではないでしょうか。
そうしたときに便利なのが、ブラウザ上で各モデルを試しつつ、APIキー発行まで一気通貫で進められる「Google AI Studio」です。
本記事では、Google AI Studioの概要、できること(チャット、メディア生成、リアルタイム対話、Webアプリ構築)、GeminiアプリやVertex AIとの違い、料金体系、そして具体的な使い方まで、2026年2月時点の情報で整理します。
Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
目次
画像編集(Nano Banana / Nano Banana Pro)
Gemini 3 Deep Thinkの提供状況(2026年2月時点)
Google AI Studioとは
Google AI Studioは、Googleが開発した最新の生成AIモデル(Gemini、Nano Bananaなど)を、Webブラウザ上で誰でも気軽に試せる無料のプロトタイピングツールです。
プログラミングの知識がなくても、チャット形式でAIと対話したり、様々なプロンプトを試したりできるほか、数クリックでAPIキーを取得して自身のアプリケーションにAI機能を組み込むことも可能です。
2026年2月には、推論能力を大きく強化したGemini 3.1 Proが登場し、AI Studio上でもより複雑な分析・コーディング・エージェント設計を試しやすくなりました。難関ベンチマークARC-AGI-2で77.1%を記録するなど推論性能が伸びており、テキスト指示からアニメーション付きSVGを生成するデモのように、UI試作やフロントエンド生成の精度向上も注目されています。
テキストや画像はもちろん、動画や音声ファイル、YouTubeのURLといった多様なデータを直接読み込んで、文字起こしや要約、分析ができる点も大きな特徴です。

GeminiアプリとGoogle AI Studioの違い
GeminiアプリとGoogle AI Studioは、どちらもGoogleのAIモデルにアクセスできますが、想定ユーザーと機能の範囲が大きく異なります。
以下の表で、2つのサービスの違いを整理しました。
| 項目 | Geminiアプリ | Google AI Studio |
|---|---|---|
| 想定ユーザー | 一般ユーザー・ビジネスユーザー | 開発者・技術検証担当者 |
| 主な用途 | チャット、検索補助、文章作成 | プロンプト設計、API検証、アプリ構築 |
| APIキー取得 | 不可 | 可能(数クリックで発行) |
| モデル選択 | プランに応じて自動選択 | 手動で複数モデルを切り替え |
| Build機能 | なし | あり(Cloud Runへのデプロイ対応) |
| 料金 | 無料プランあり / 有料プランで上位モデル利用可 | コンソールは無料 / API利用は従量課金 |
ここで注目すべきは、Google AI StudioではAPIキーを自分で取得して外部アプリケーションに組み込める点です。Geminiアプリが「すぐに使えるAIアシスタント」であるのに対し、Google AI Studioは「開発者が自分のサービスにAIを組み込むための検証・構築プラットフォーム」という位置づけです。
Google AI Studioでできること
Google AI Studioは、単なるチャットツールにとどまらず、データ分析・メディア生成・リアルタイム対話・Webアプリ構築までをカバーする統合プラットフォームへと進化しています。
ここでは、主な4つの機能を整理して紹介します。

データ分析・文字起こし(Geminiタブ)
Geminiタブでは、テキストチャットに加えて、様々な形式のデータをAIに直接入力し、対話形式で分析・要約・質疑応答を行えます。
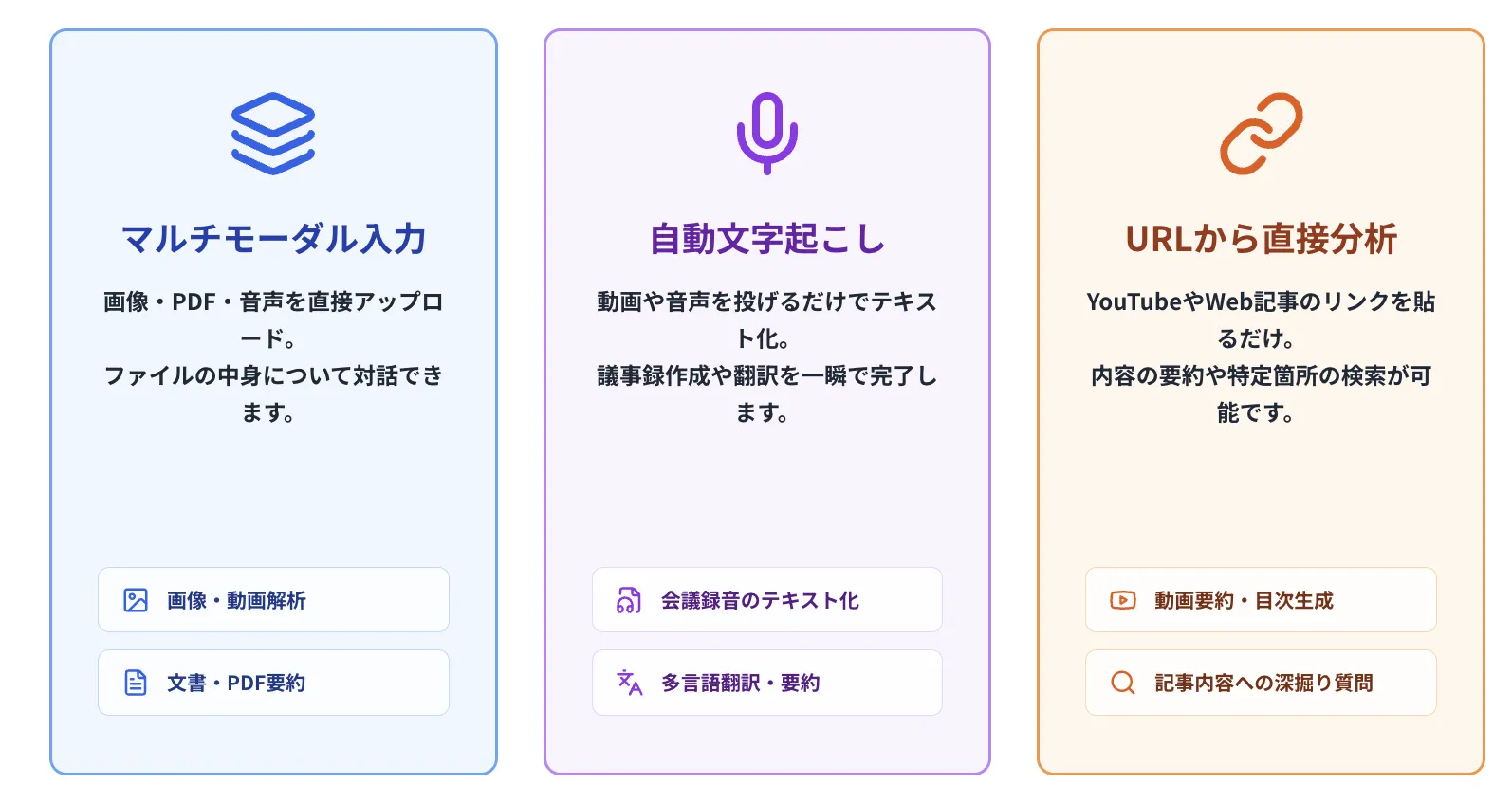
【主な機能】
この機能では、「テキスト」「ファイル」「URL」をひとつの会話スレッドの中で扱いながら、要約や抽出、比較などをまとめて行えます。
事前のデータ整形やコードを書く手間を最小限に抑えられるのがポイントです。
- マルチモーダル入力
テキストに加え、PCから画像、音声、動画、PDFなどのファイルを直接アップロードし、その内容についてAIに質問できます。
- 高精度な文字起こし
動画ファイルや音声ファイルをアップロードするだけで、AIが自動で内容を文字に書き起こします。書き起こした内容の要約や翻訳もそのまま依頼できます。
- URLからの直接分析
YouTube動画のURLやWebページのURLを貼り付けて、内容の要約や目次生成、特定箇所についての質問が可能です。
- モデルの性能比較
Gemini 3.1 Pro/Gemini Flash Latest など、複数モデルに同じプロンプトを投げて回答を比較することができます。
【活用例】
「まずはファイルやURLを読み込ませて、何ができるか試したい」という段階で非常に使いやすいです。日常業務の“テキスト処理”をそのままAIに置き換えるイメージで活用できます。
- 会議やインタビュー録音データからの議事録ドラフト作成
- PDF論文・企画書・仕様書からの要点抽出と要約
- YouTube講演動画からのタイムスタンプ付きサマリ生成
- 商品写真をアップロードしてのキャッチコピー・LP文案生成 など
画像・動画生成(Images/Videoタブ)
Google AI Studioの「Images」「Video」タブでは、Nano Banana(Gemini 2.5 Flash Image)やNano Banana Pro(Gemini 3 Pro Image)をはじめとした最新の画像モデルに加え、動画生成モデル Veo 2 などをまとめて試すことができます。
用途やコストに応じてモデルを切り替えながら、静止画・動画・音声付き動画のプロトタイピングを一画面で完結できるのが特徴です。
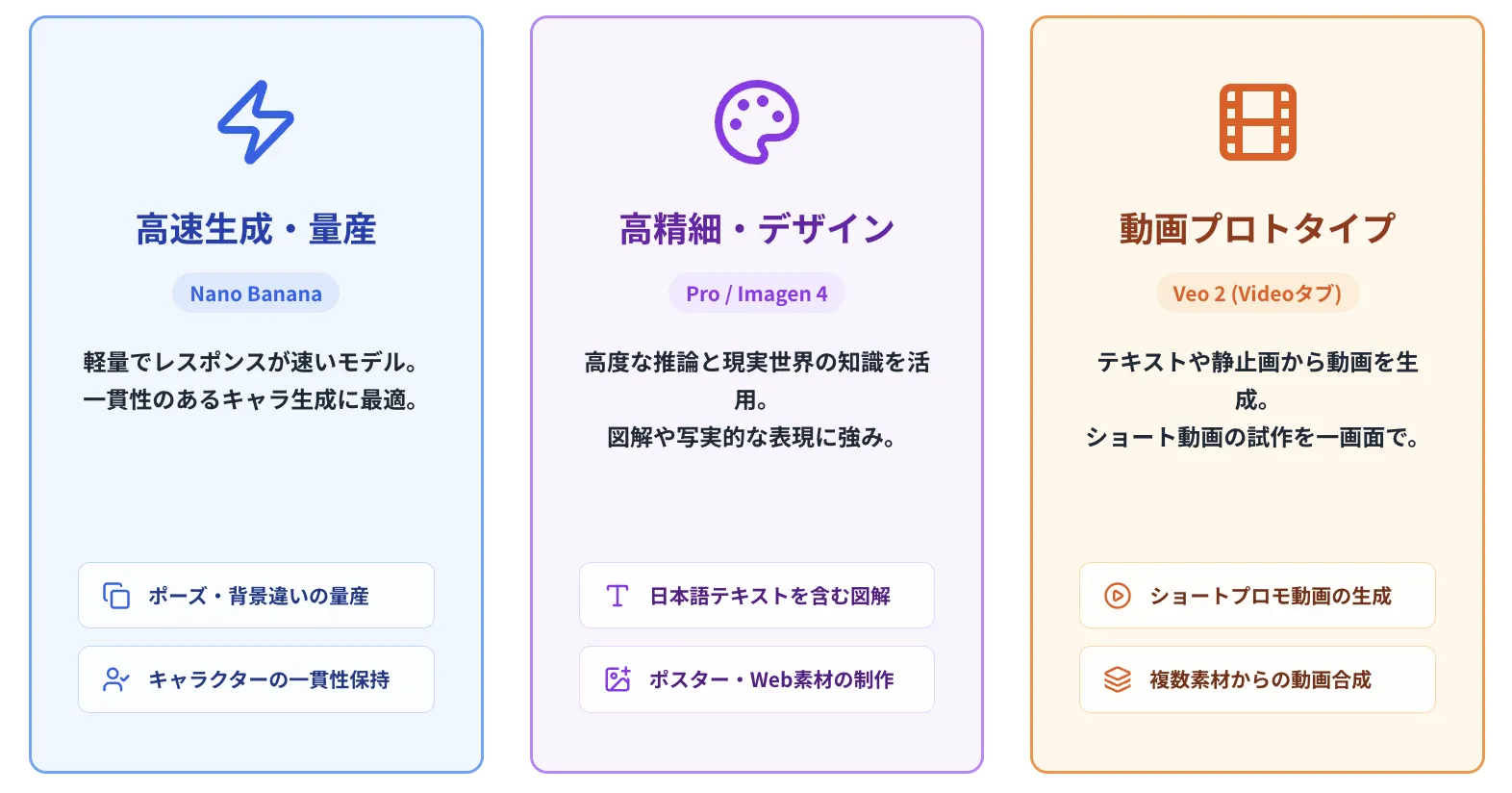
主な機能(Imagesタブ)
-
Nano Banana(Gemini 2.5 Flash Image)での高速生成
軽量かつレスポンスが速い画像モデルです。キャラクターの一貫性やマルチターンでのリクエストに強く、「同じキャラクターをいろいろなポーズ・背景で量産したい」といった用途に向いています。
-
Nano Banana Pro(Gemini 3 Pro Image)での高精細生成・編集
Gemini 3 Pro ベースの高性能モデルで、より高度な推論と現実世界の知識を活かした画像生成・編集が可能です。
スライド用画像やポスターなど、日本語テキストを含むデザイン や、複数画像を組み合わせたインフォグラフィック・図解の生成に強みがあります。
-
Imagen 4 系のモデルによる汎用的な画像生成
写実的な写真風イメージからイラスト調まで、Webサイトや広告、資料のアイキャッチなど幅広い用途に対応できます。
Nano Banana/Nano Banana Proと組み合わせて、スタイルや用途ごとにモデルを使い分けることが可能です。
主な機能(Videoタブ)
-
Veo 2 による動画生成
テキストプロンプトや静止画から、短いプロモーション動画やショート動画を生成できます。
2026年2月時点では、Google AI Studio上でVeo 3.1とVeo 2が選択可能です。Veo 3はVertex AI側で主に提供されています。
-
テキスト+画像からの動画合成
「この3枚の製品写真と説明文から15秒の紹介動画を作って」など、複数素材を組み合わせた動画の自動生成も可能です。
活用例
- LPやブログのアイキャッチ画像・サムネイル を、Nano Bananaで高速に量産し、Nano Banana Proで一部をブラッシュアップ
- 社内資料やセミナー用の図解・インフォグラフィック を、Nano Banana Proで生成し、細部のテキストや色味を調整
- 新サービス紹介用のショートプロモ動画 を、Veo 2 で試作し、方向性が固まってから本格制作へ展開
画像編集(Nano Banana / Nano Banana Pro)
Nano Banana(Gemini 2.5 Flash Image)とNano Banana Pro(Gemini 3 Pro Image)は、新規の画像生成だけでなく、既存画像の編集・補正・アップスケール も得意です。
「元画像を活かしながらクオリティを底上げする」用途に向いています。
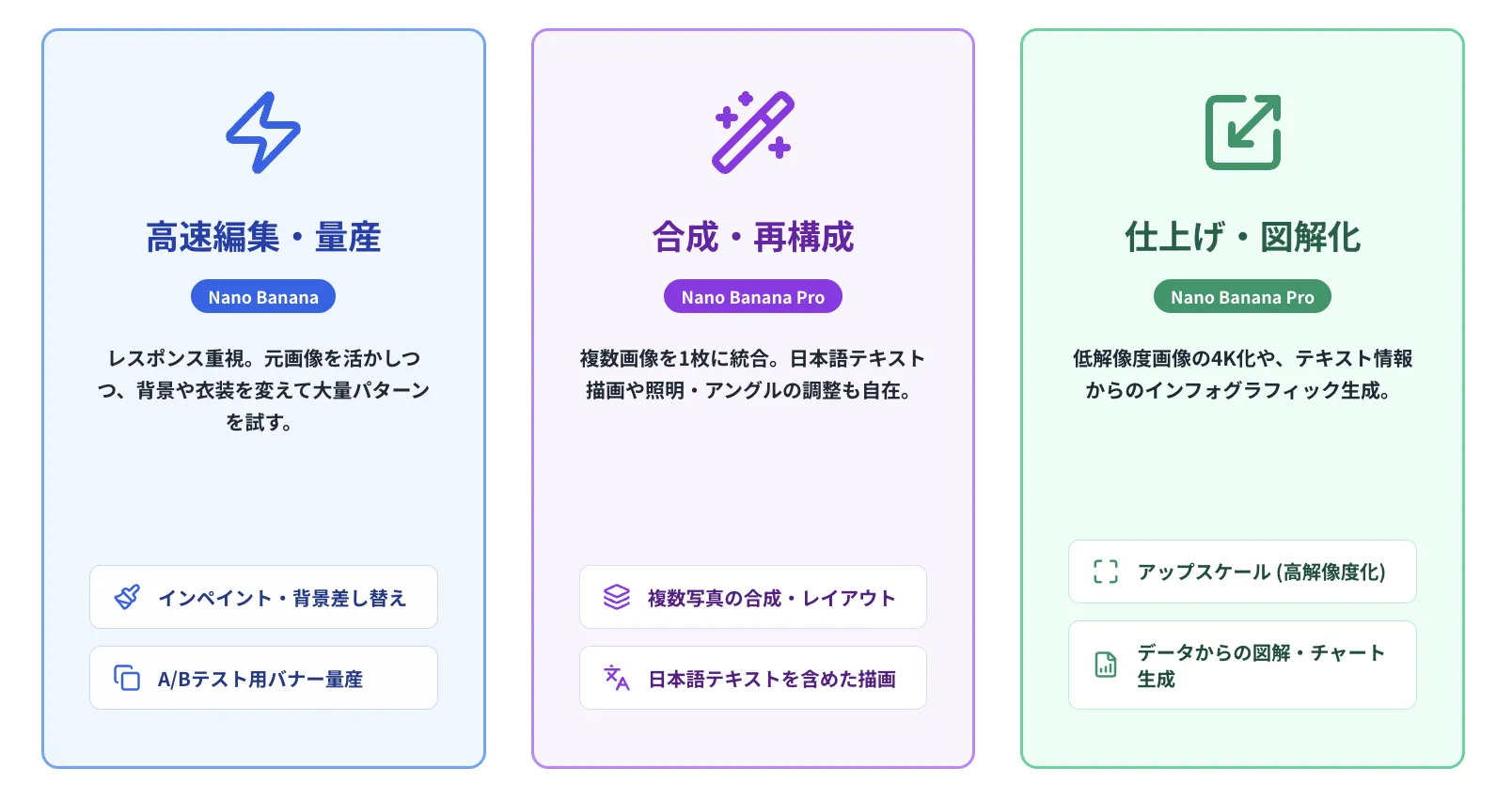
Nano Banana(Gemini 2.5 Flash Image)
- 既存画像の一部を書き換える「インペイント」や背景差し替え
- 同じ人物・キャラクターのまま、ポーズや服装、シーンを変えたバリエーション生成
- SNS用サムネイルやバナーを、元画像を活かしつつテイストだけ変える編集
- かるいノイズ除去や色味の調整など、“ちょい足しレタッチ”
軽量モデルのためレスポンスが速く、大量の候補をサクサク試したいときの編集・バリエーション生成 に向いています。
Nano Banana Pro(Gemini 3 Pro Image)
- 複数画像(最大14枚)を入力して構図を指定し、1枚の合成画像として再構成
例:イベント写真や製品写真をまとめて渡し、パンフレット用の1枚に再配置させる
- 高精度な画像編集と日本語テキスト描画
スライドタイトルやバナー内コピーなど、日本語テキストを含むデザインにも対応しやすいです。
- 照明・カメラアングル・被写界深度などの細かな後編集
「もっとドラマチックなライティングに」「カメラ位置を少し上からに」といった指定で再レンダリングできます。
- アップスケール(高解像度化)
低解像度のロゴや古い写真をアップロードし、「4K相当の解像度に」「印刷に耐えられるクオリティに」といった指示で、高解像度版を生成できます。
- データや文章からの図解・インフォグラフィック生成
表や箇条書きの説明を渡して、図表・チャート・概念図としてビジュアル化することも可能です。
Nano Banana Proは、Gemini 3 Proの推論力と組み合わせることで、“見た目がきれいなだけでなく、中身も意味の通った図や資料画像”を作りやすいのが大きな特徴です。
その分、Nano Bananaより生成コストと時間はやや増えるため、次のような使い分けがおすすめです。
- ラフ案・たたき台・パターン出し:Nano Banana で高速に回す
- 最終版・クライアント提出物・印刷物:Nano Banana Pro で仕上げ・アップスケール
活用例
- 既存のスライド素材を、Nano Banana Proで高解像度&デザイン調整した決裁用資料 にブラッシュアップ
- LPやバナーで使っている画像を、Nano Bananaで構図だけ変えたA/Bテスト用パターンとして量産
- 古いWebサイトのロゴやアイコンをアップロードし、Nano Banana Proで4K対応の高解像度版を生成
- テキストだけの説明資料をもとに、Nano Banana Proで概念図・フローチャート・インフォグラフィックを作成
リアルタイム音声会話(Liveタブ)
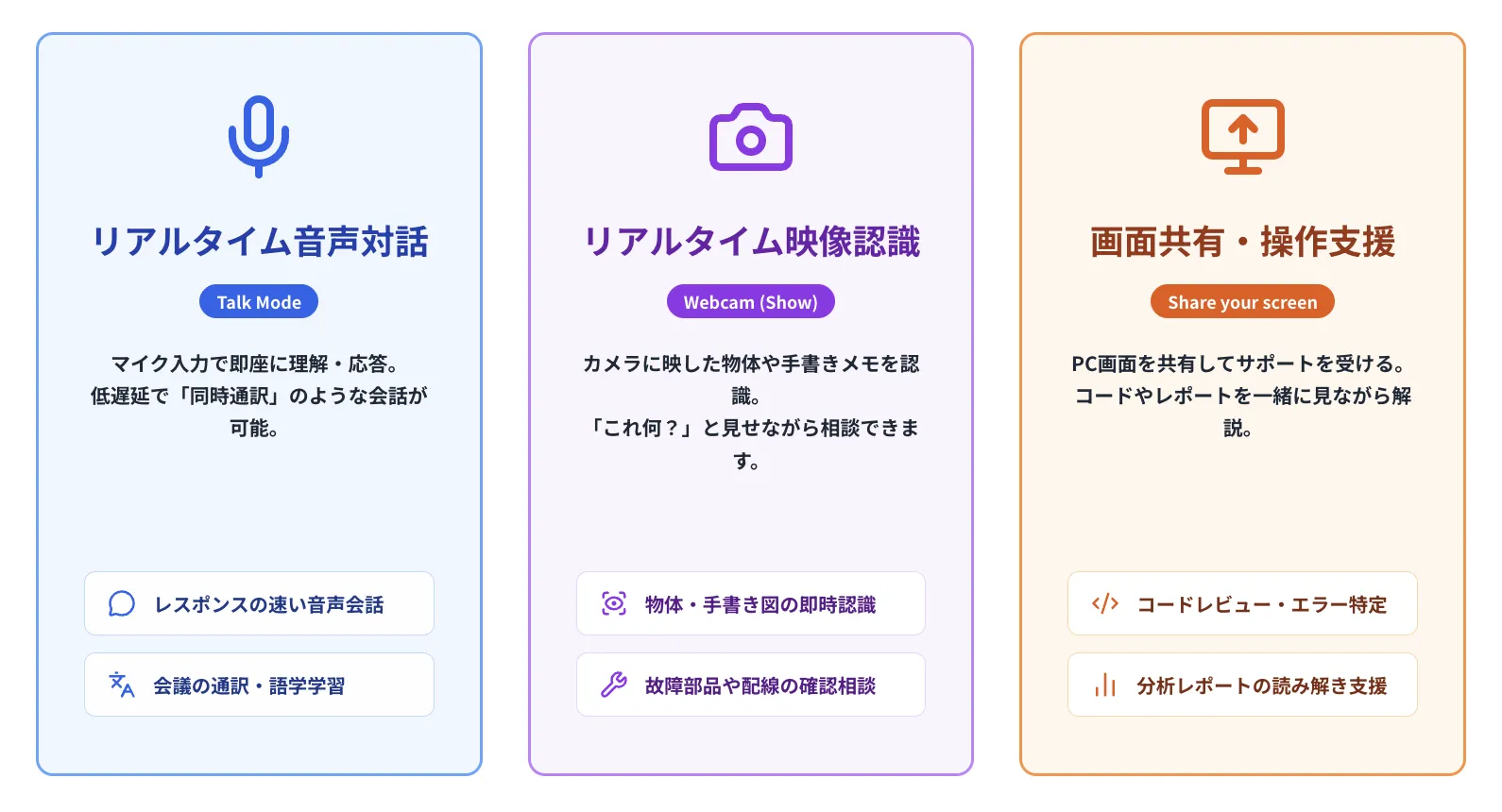
Liveタブでは、PCのマイクやWebカメラ・画面共有を使い、人間と話すような自然な対話が可能です。UI上では「Talk」「Webcam(Show)」「Share your screen」の3つのモードに分かれています。
主な機能
音声・映像・画面という“リアルタイムのコンテキスト”をGeminiに渡しながら、連続的な会話を行えるのがLiveタブの特徴です。テキストチャットでは伝えにくいニュアンスや状況も共有しやすくなります。
- Talk:リアルタイム音声対話
マイクに向かって話した内容を即座に理解し、低遅延で音声応答。「同時通訳に近い使い方」も可能です。
- Webcam / Show:リアルタイム映像認識
Webカメラに映した物体や手書きメモ、作業中の様子などを認識し、その場で質問に答えてくれます。
- Share your screen:画面共有による操作支援
コードレビュー、ツールの操作方法の案内、データ分析の読み解きなど、画面を見せながらサポートを受けられます。
活用例
「文章で説明するより見せた方が早い」場面で、サポート役としてLiveタブを立ち上げておくイメージです。
- 海外取引先とのオンライン会議でのリアルタイム通訳の補助
- 故障部品や配線図をカメラに映して、名称や交換手順を相談
- プログラミング学習でのエラー原因の特定サポート
- BIダッシュボードやレポート画面を共有しながら、読み方や洞察ポイントを質問
Webアプリの構築・公開(Buildタブ)
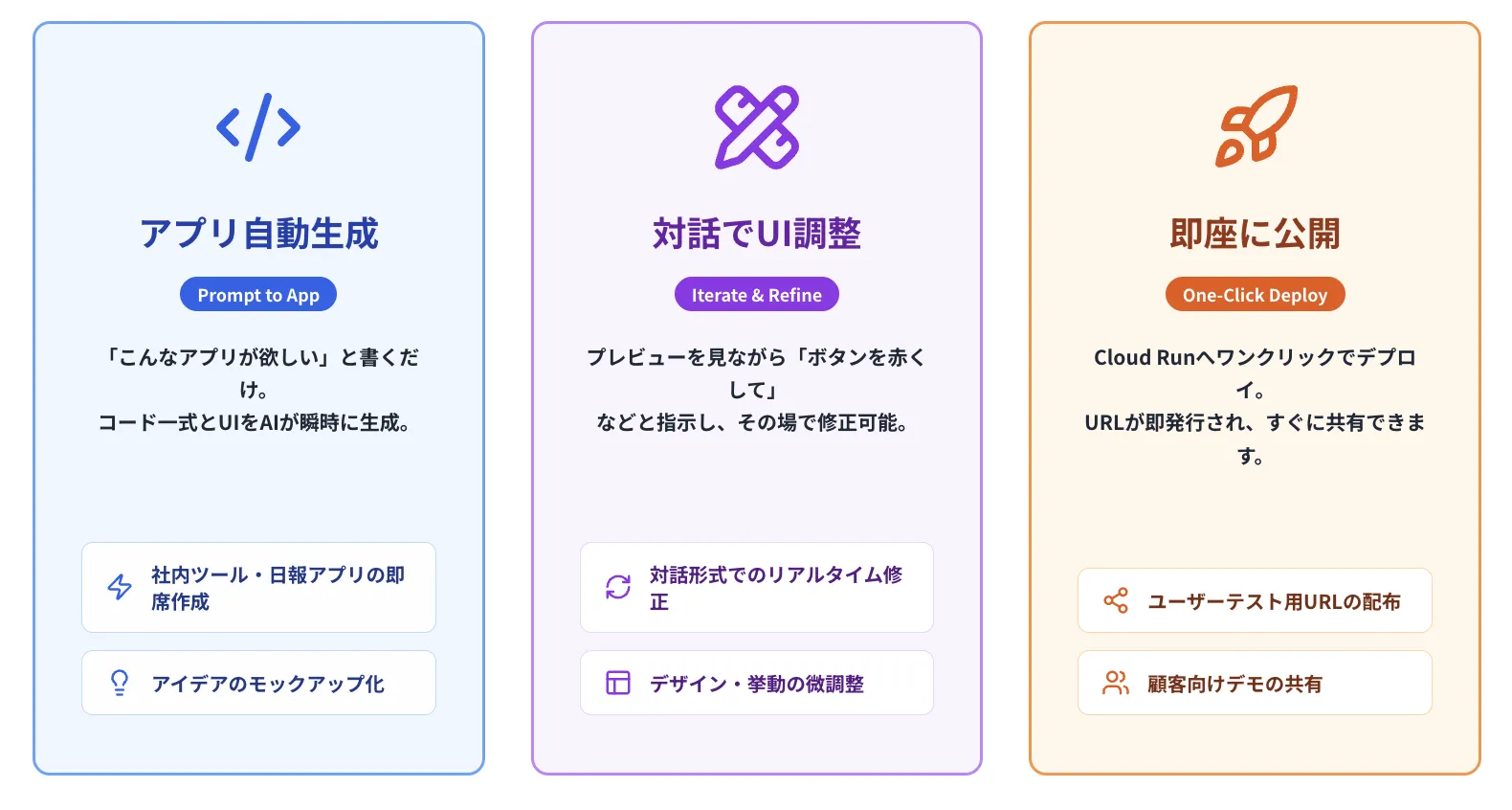
Google AI Studioの中でも特に革新的なのが、Build機能です。テキストで指示を出すだけで、AIがReactとTailwind CSSを使ったWebアプリを自動生成し、ワンクリックでCloud Runにデプロイできます。2026年2月時点ではフルスタックランタイムに対応しており、サーバーサイドロジックやnpmパッケージの利用も可能になっています。
主な機能
「こんなツールが欲しい」という要望を文章で書くだけで、ReactベースのWebアプリコードとUIをまとめて生成してくれます。フルスタックランタイム対応により、サーバーサイドの処理やnpmパッケージの組み込みも可能です。従来はエンジニアが数日〜数週間かけていた”たたき台づくり”を、数分で済ませられるのが最大のメリットです。
- プロンプトからのアプリ生成
「アップロードした画像の感想を言うアプリ」「PDFを要約してくれる社内ツール」など、日本語指示だけでアプリのコード一式を生成。
- 対話形式での反復修正
プレビューを見ながら「見出しを大きくして」「ボタンの色をブランドカラーに」などと指示して、その場でデザインや挙動を調整できます。
- ワンクリックでのデプロイ
完成したアプリをCloud Runにデプロイすると、一般公開できるURLが即座に発行されます。
活用例
本格開発の前に「まずは触れるものを出したい」というPoCフェーズや、ノーコードに近い感覚で社内ツールを量産したいシーンで特に有効です。
- 日報要約アプリやFAQ検索ツールなど、社内向け小規模Webツールの即席作成
- 新規事業アイデアのモックアップを数分で形にして、ユーザーテスト用URLを配布
- 教育用クイズアプリやミニゲームのプロトタイプ作成
- 顧客向けデモ用に、Gemini連携の簡易アプリを短時間で用意
Google AI Studioの使い方
ここでは、Google AI Studioの基本的な使い方を、新しくなった機能に合わせて解説します。まずはアカウントへのログインから、各機能の具体的な操作方法までを見ていきましょう。
基本操作
最初に、AI Studioを利用するための準備と、基本となる画面の見方を説明します。
- Google AI Studioにアクセス
Google AI Studioの公式サイトにアクセスし、お持ちのGoogleアカウントでログインします。

Google AI Studioのトップページ
- メイン画面の確認
ログインすると、まず「Chat」機能の画面が表示されます。画面は主に3つのエリアに分かれています。
AI Studioのメイン画面
- ① 機能選択メニュー(左側)
「Chat」「Generate Media」「Stream」「Build」など、利用したい機能をここから選択します。

- ② プロンプトエリア(中央)
ここにAIへの指示(プロンプト)を入力したり、ファイルをアップロードしたりします。
- ③ モデル設定パネル(右側)
使用するAIモデル(例: Gemini 3.1 Pro)や、応答の多様性を調整する「Temperature」などを設定します。
テキストでの対話はもちろん、ファイルやURLを読み込ませて分析や文字起こしを行う方法を解説します。
基本の対話
中央のテキストボックスに、AIへの質問や指示を入力し、実行ボタンを押すと、回答が表示されます。
ファイルをアップロードして分析
プロンプト入力欄の左側にある「ファイルを追加」アイコン(クリップの形)をクリックすると、様々な方法でデータを入力できます。
次のような画面が表示されるので、分析・文字起こしをしたいファイル(画像、音声、動画、PDFなど)に沿って項目を選択します。
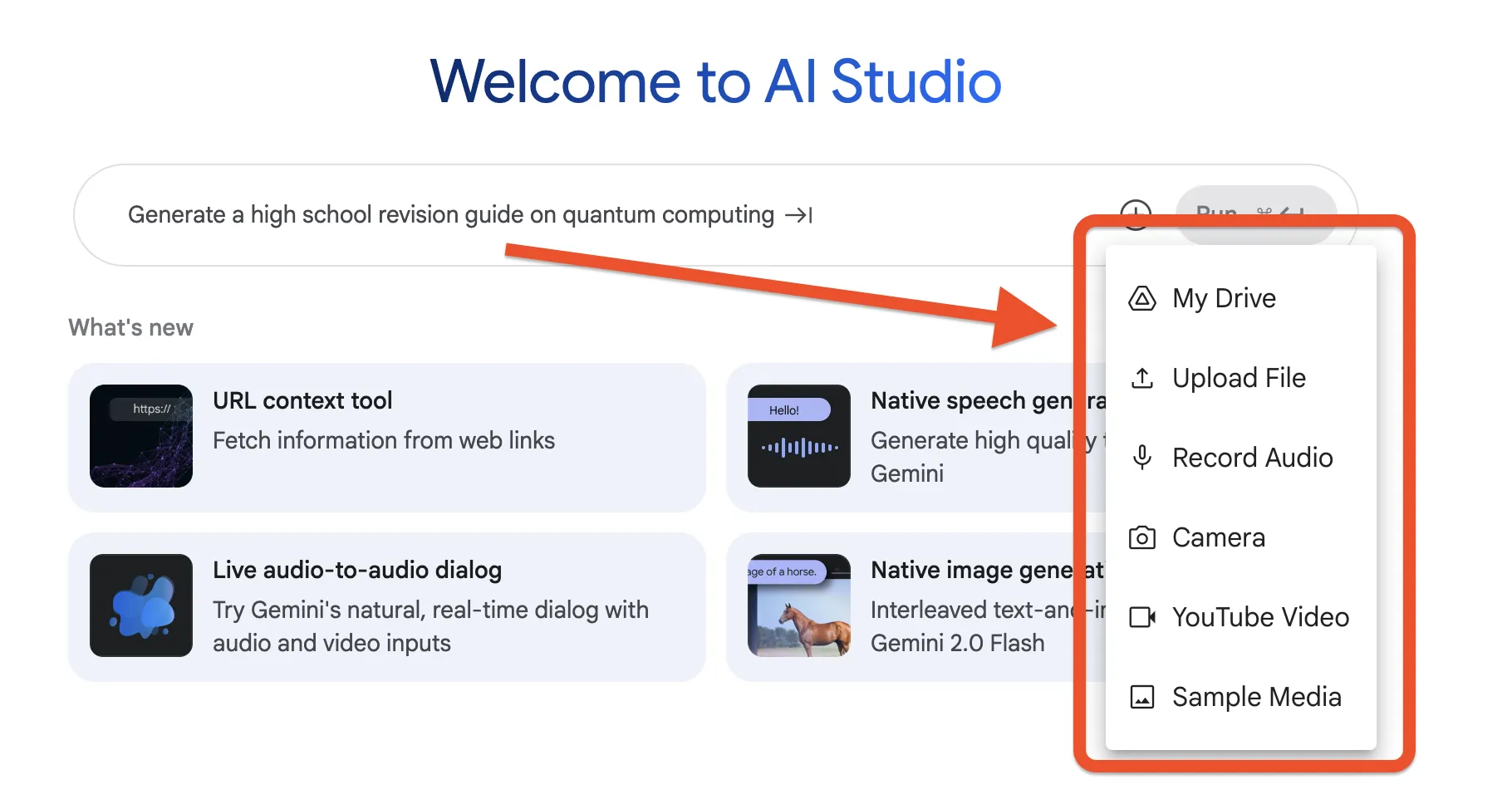
| 入力方法 | 説明 |
|---|---|
| My Drive | Googleドライブに保存されているファイルを直接読み込みます。 |
| Upload File | お使いのPCから画像、音声、動画、PDFなどのファイルをアップロードします。 |
| Record Audio | PCのマイクを使い、その場で音声を録音して入力データとして使用します。 |
| Camera | PCのWebカメラを起動し、その場で撮影した写真を入力データとして使用します。 |
| YouTube Video | YouTube動画のURLを貼り付けて、動画の内容を分析対象にします。 |
| Sample Media | Googleが用意したサンプルメディア(画像など)を読み込み、機能を試すことができます。 |
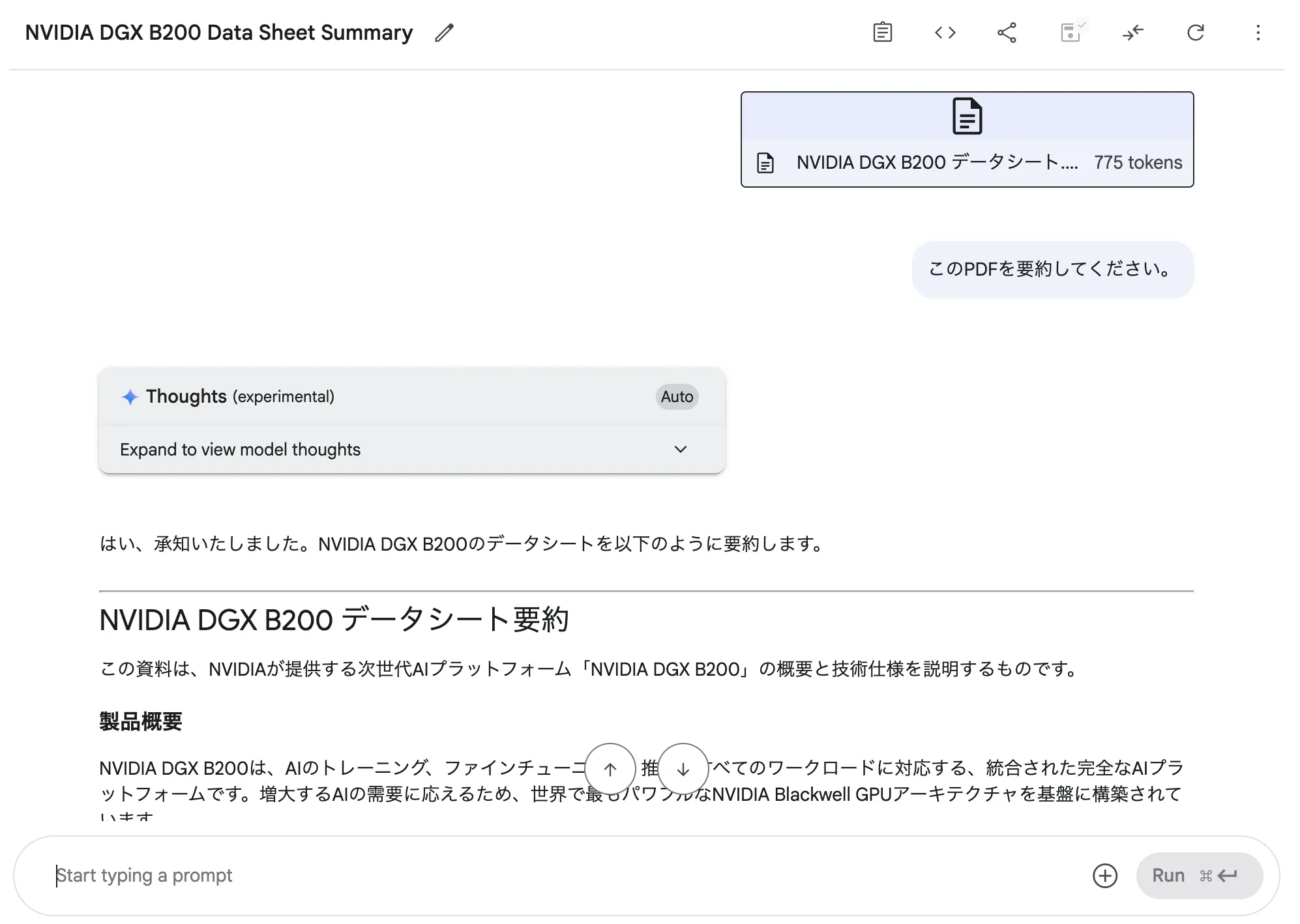
例えば、「Upload File」から音声ファイルをアップロードした後、「この音声を文字起こしして、要点を3つにまとめてください」といったプロンプトを入力して実行することで、文字起こしと要約を一度に行えます。
今回は、PDFの要約を依頼してみました。きちんとファイルの内容を読めていることがわかります。
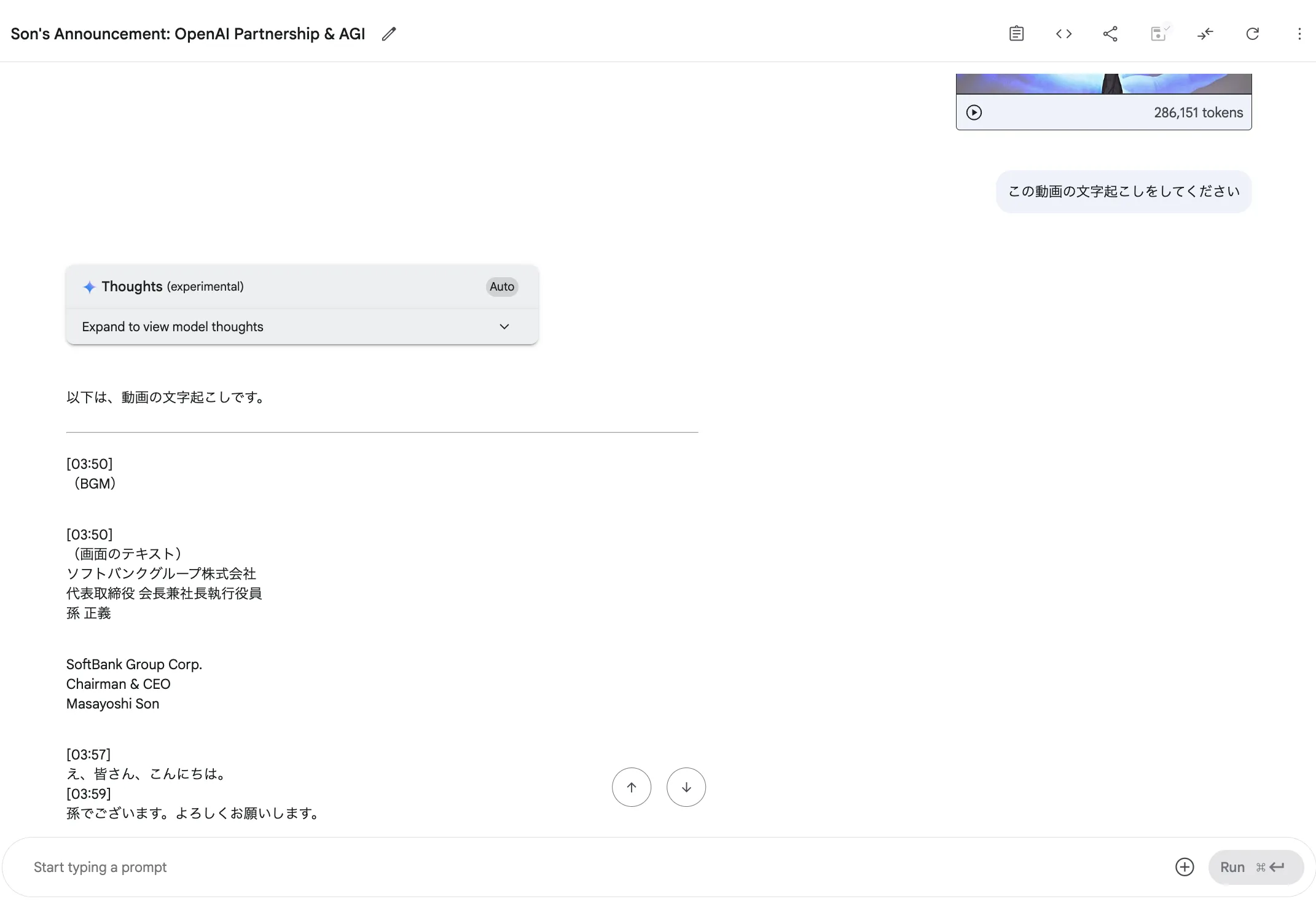
YouTube動画の文字起こし・要約
プロンプト入力欄にYouTube動画のURLを直接貼り付けるか、メニューから「YouTube Video」を選択してURLを入力します。
その際に表示される設定画面で、詳細な分析範囲を指定できます。
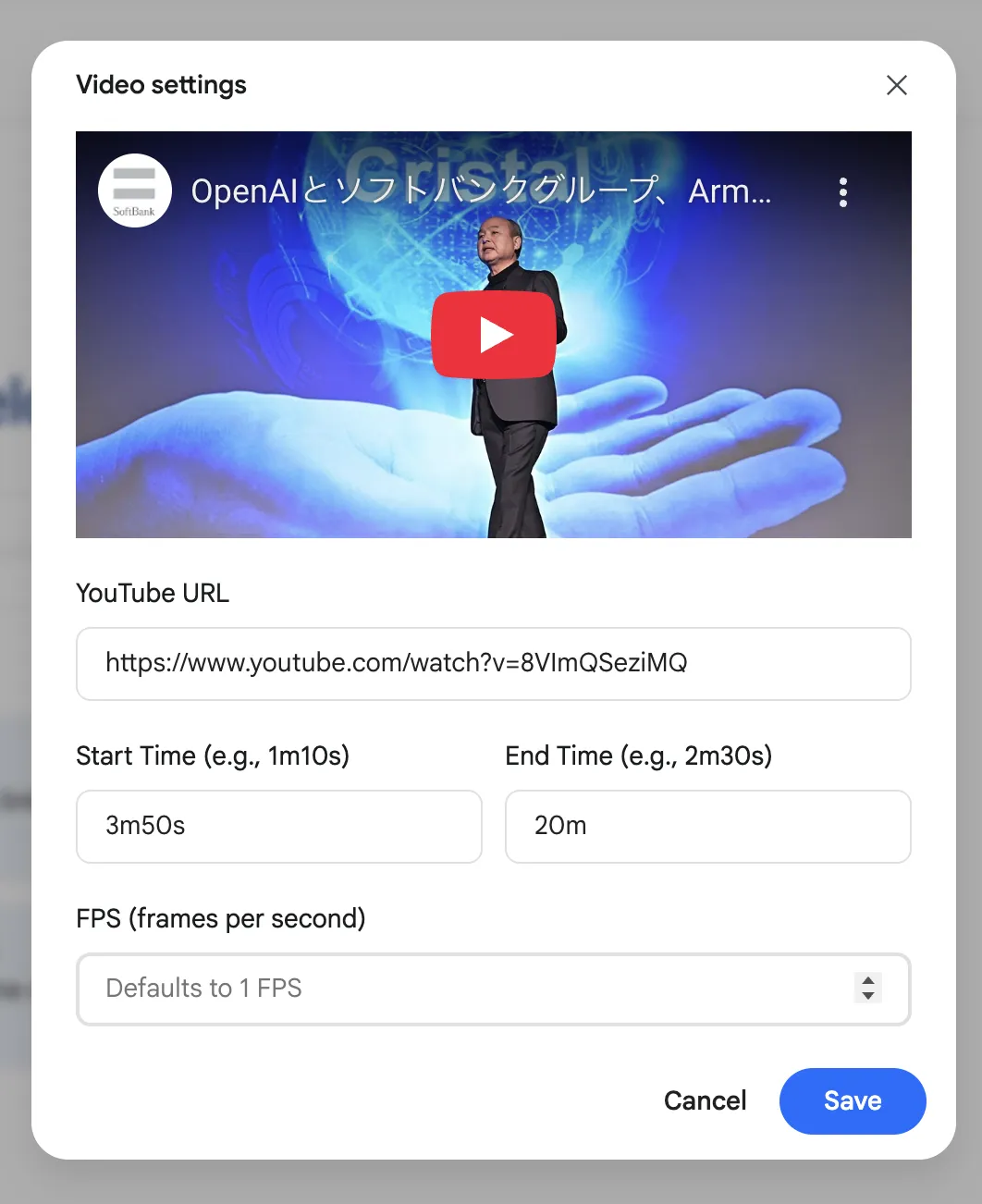
Start Time / End Time:
動画の中から、分析したい区間(例: 3分50秒から20分まで)を指定できます。
FPS (frames per second):
これは、「動画1秒あたりに、AIが何枚のフレーム(静止画)をサンプリングして分析するか」を設定するためのものです。
-
FPSを高くする(例: 10 FPS):
AIは1秒間に10枚の静止画を見て分析します。動きの速いスポーツのフォーム解析や、細かい変化を捉えたい場合に有効ですが、その分分析コスト(トークン消費量)は増加します。
-
FPSを低くする(例: 1 FPS):
AIは1秒間に1枚の静止画だけを見ます。プレゼンテーション動画の要約など、全体の流れを掴むのが目的であれば、これで十分な場合が多いです。コストを抑えて効率的に分析できます。
設定後、「この区間の内容を文字起こしして」のようなプロンプトで実行すると、指定された範囲をAIが分析して回答します。
応答をカスタマイズする(右サイドバーの設定)
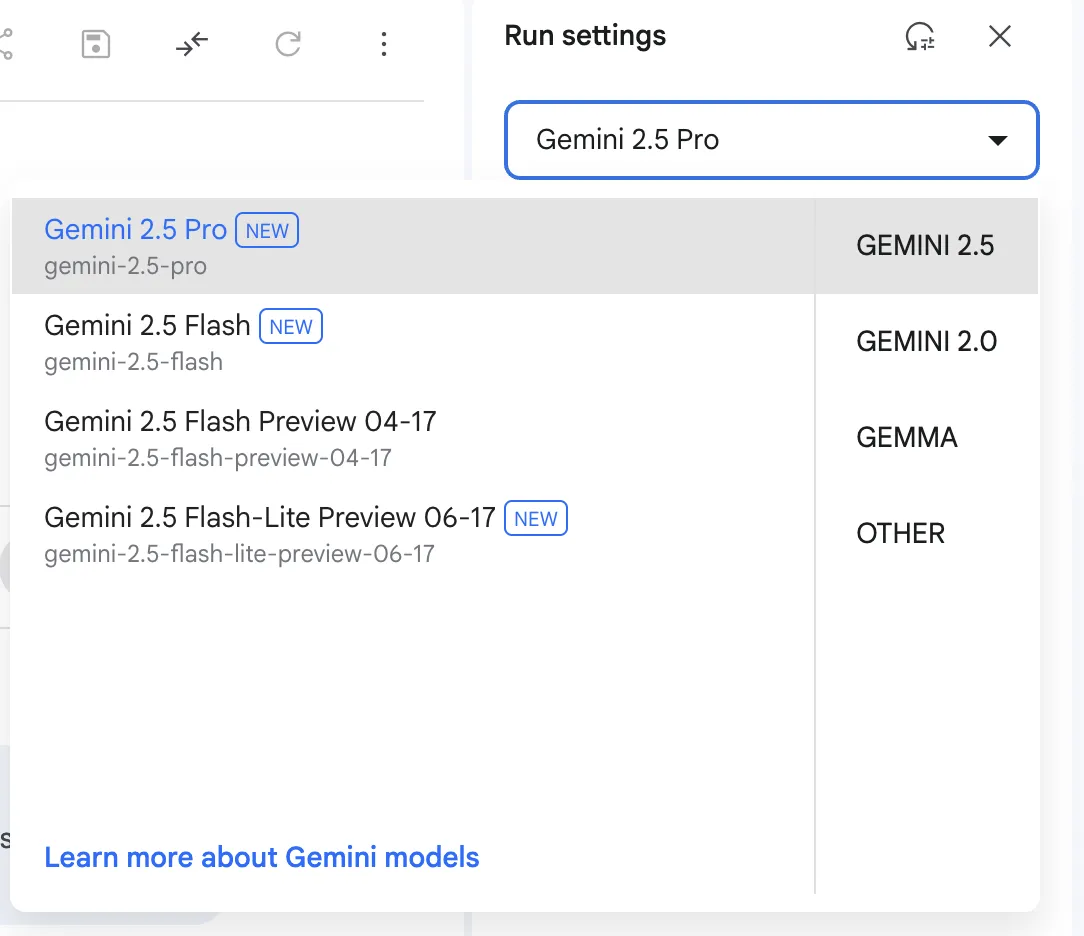
プロンプトを実行する前に、右側の「Run settings」パネルでAIの挙動を細かく調整できます。これにより、より目的に合った回答を引き出すことが可能です。
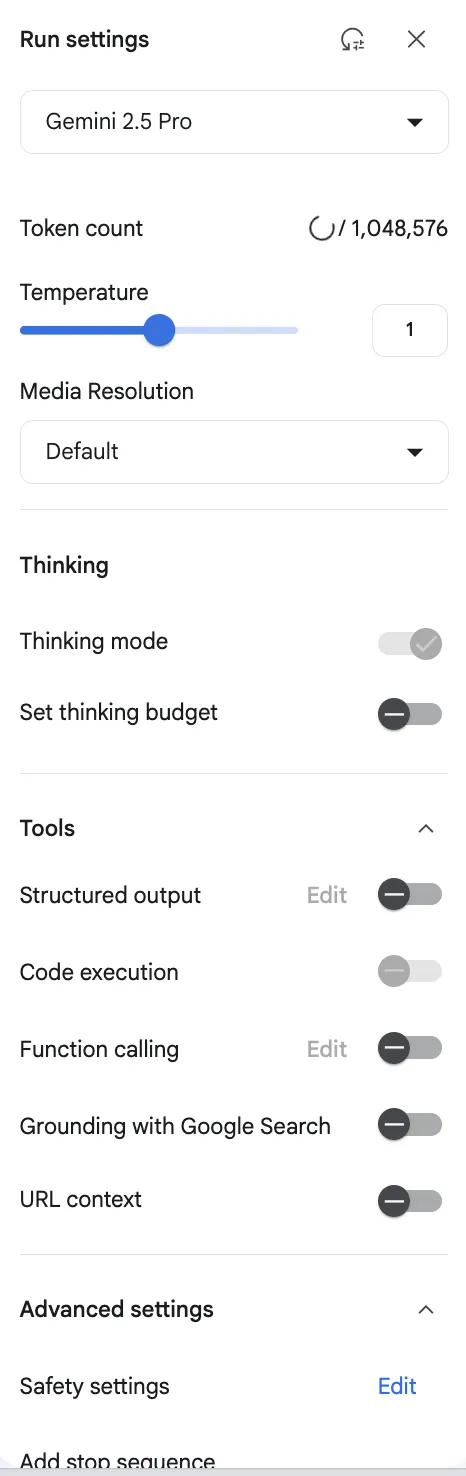
モデルの選択や応答の調整を行う設定パネル
| カテゴリ | 設定項目 | 説明 |
|---|---|---|
| モデルと基本設定 | Model | 使用するAIモデル(例: Gemini 3.1 Pro)を選択します。タスクの複雑さやコストに応じて最適なモデルを選びます。 |
| Token count | 現在のプロンプトで使用されているトークン数と、モデルが対応する最大トークン数を表示します。 | |
| Temperature | 応答の「多様性」や「創造性」を調整するスライダーです。0に近いほど回答の一貫性が増し、1に近いほど創造的になります。 | |
| Media Resolution | アップロードした画像や動画をAIがどの解像度で処理するかを設定します。高解像度にすると詳細な分析が可能です。 | |
| 思考(Thinking) | Thinking mode | オンにすると、AIが応答前により深く思考し、複雑な問題に対して精度の高い回答を返します。(Gemini 2.5以降のモデルで対応) |
| Set thinking budget | AIの「思考」に使用する計算リソースの上限を設定します。 | |
| ツール(Tools) | Structured output | AIの出力を特定の形式(JSONなど)に強制したい場合に設定します。 |
| Code execution | プロンプト内のコードをAIが実行し、その結果を元に応答を生成できるようにします。 | |
| Function calling | 外部のAPIやツールをAIが呼び出せるようにする、高度な設定です。 | |
| Grounding with Google Search | オンにすると、AIがGoogle検索を参照し、最新の情報や事実に基づいた回答を生成しようとします。 | |
| URL context | プロンプトに含まれるURLのコンテンツをAIが読み取り、文脈として理解できるようにします。 | |
| 高度な設定 | Safety settings | 有害なコンテンツ(ヘイトスピーチ等)に関する安全フィルターの強度を調整します。 |
| Add stop sequence | AIの応答を特定の単語やフレーズで意図的に停止させたい場合に、その単語を登録します。 | |
| Output length | 生成されるテキストの最大長をトークン数で指定します。 | |
| Top P | Temperatureと同様に応答の多様性を制御する設定です。Temperatureの代わりに使用されることが多いです。 |
画像生成
テキストの指示から、AIに画像や音声、音楽を生成させる方法を解説します。画像編集の詳しい手順はGoogle AI Studioの画像生成ガイドもあわせてご覧ください。
-
機能を選択
左側のメニューから「Generate Media」を選択します。
-
上部のタブから「Imagen(画像生成)」「Veo(動画生成)」「Audio」など、生成したいメディアの種類を選びます。ここでは「Imagen」を例に進めます。
-
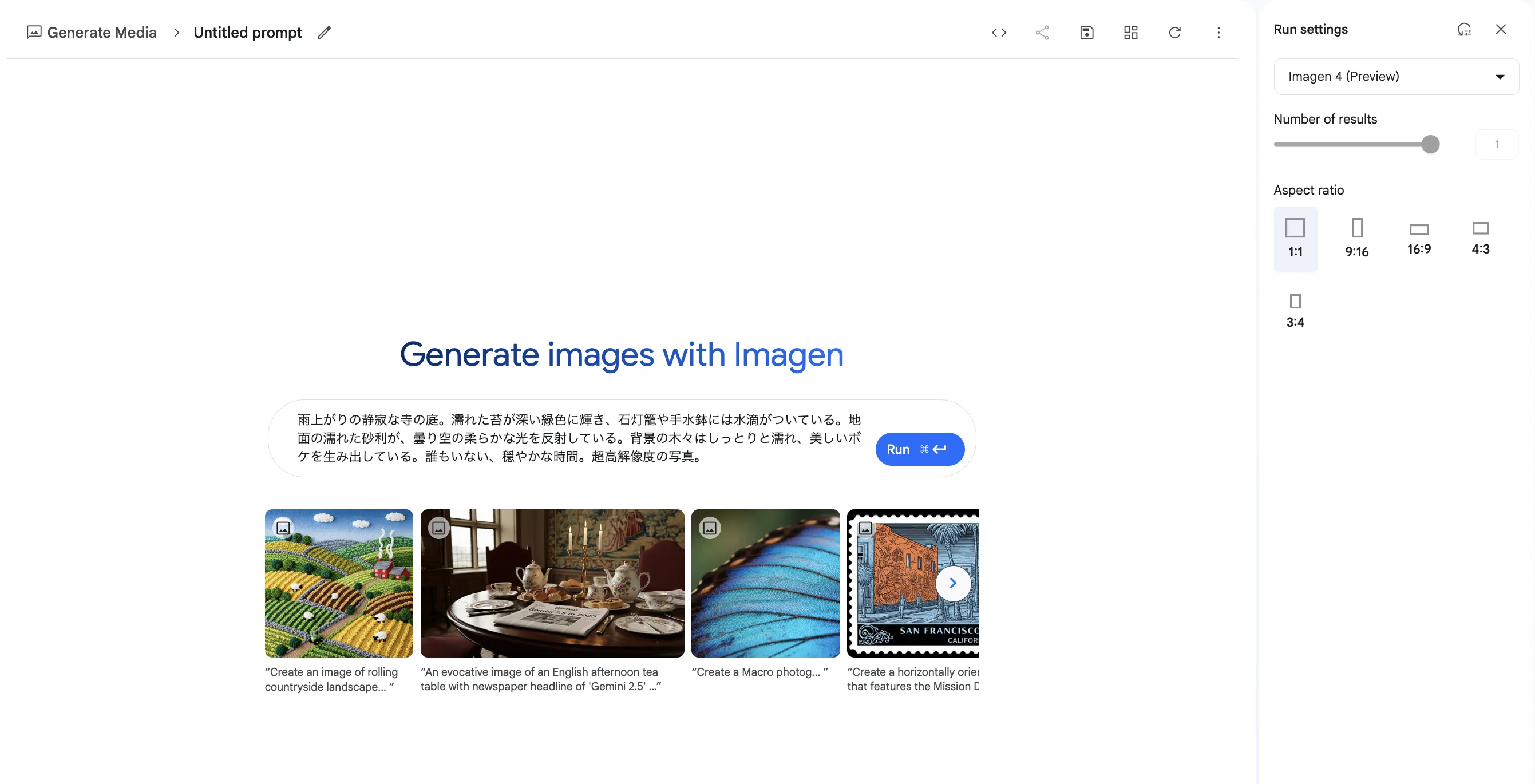
次のような画面が表示されるので、中央のプロンプト入力欄に、どのような画像を生成したいか、テキストで具体的に入力します。
-
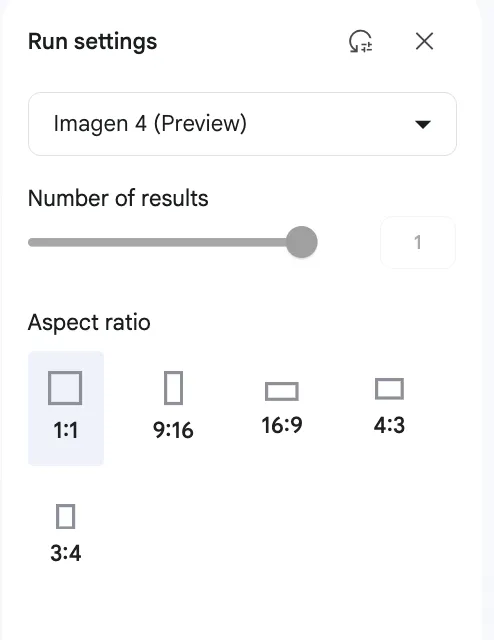
右サイドバーから、モデルとアスペクト比を選択します。
-
設定が完了したら、「Generate」ボタンを押します。AIが画像の生成を開始し、完了すると右側に結果が表示されます。生成された画像はクリックして拡大したり、ダウンロードしたりできます。
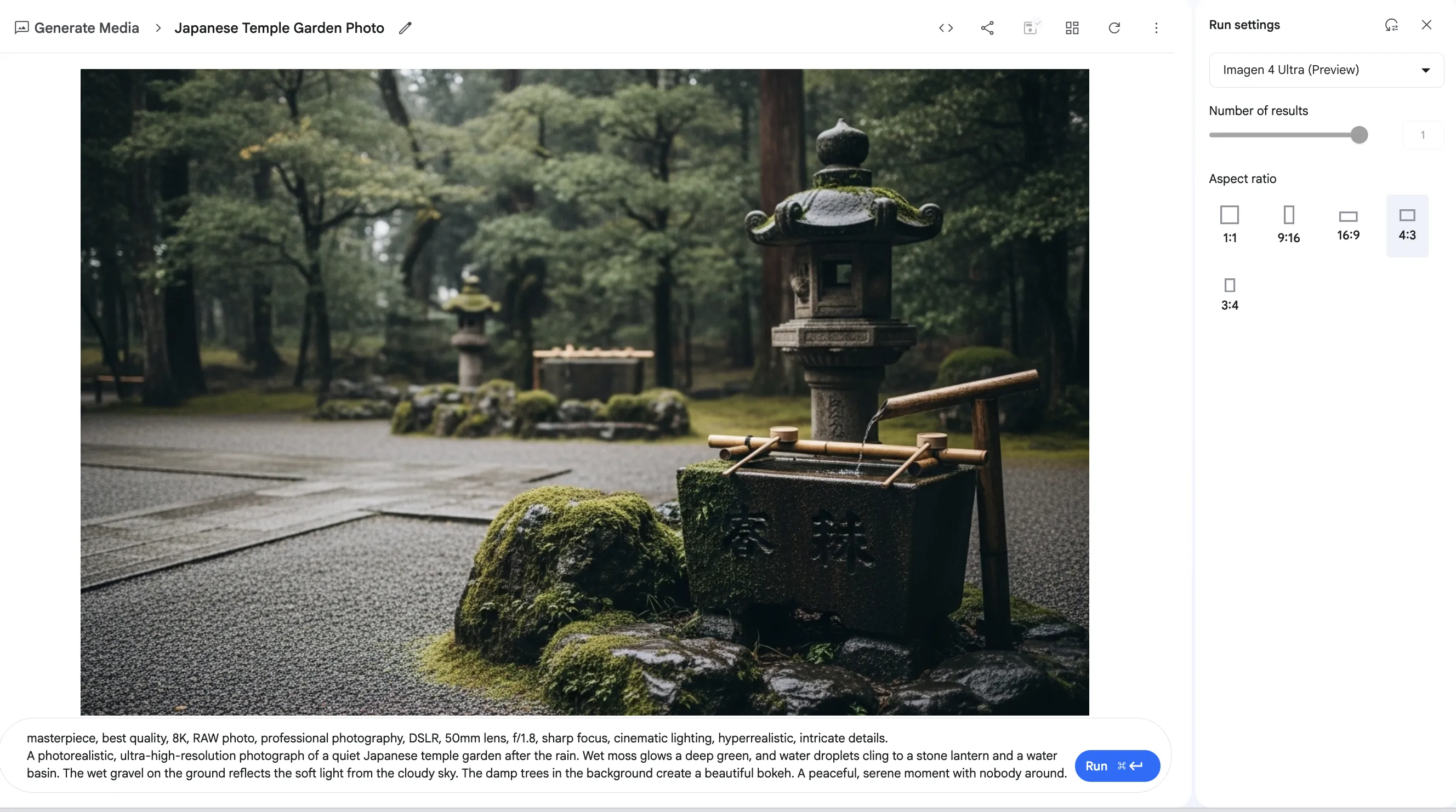
リアルタイム音声会話
PCのマイクやWebカメラ、画面共有を使い、AIとリアルタイムで対話する方法を解説します。「Stream」機能には、目的の異なる3つのモードが用意されています。
- Stream機能を選択
左側のメニューから「Stream」を選択すると、3つのモードが表示されます。
「Talk」「Show」「Share your screen」から目的のモードを選択します。
Talk to Gemini (音声での対話)
マイクを使って、AIと自然な音声会話を行います。
- モードを選択し、マイクを許可:
「Talk to Gemini」を選択し、ブラウザからのマイク使用を許可します。
- 会話を開始:
「Start」ボタンを押して会話を開始します。あなたが話した内容がリアルタイムでテキスト化され、AIが音声で応答します。同時通訳やアイデアの壁打ちに最適です。
Show Gemini (Webカメラでの対話)
Webカメラに映したものをAIに認識させ、それについて質問します。
- モードを選択し、カメラを許可:
「Show Gemini」を選択し、ブラウザからのカメラ使用を許可します。
- 対話を開始:
「Start」ボタンを押してセッションを開始します。カメラに物体や手書きのメモなどを映しながら、「これは何?」「このスケッチをHTMLコードにして」といった質問をすることで、AIが映像を認識して回答します。
Share your screen (画面共有での対話)
PCの画面をAIに共有し、表示されている内容について対話します。
- モードを選択し、共有画面を選択:
「Share your screen」を選択し、共有したいウィンドウやタブを選びます。
- 対話を開始:
共有が開始されたら、マイクを使って「このコードのエラーを教えて」「このグラフからわかることを要約して」のように指示することで、AIが画面の内容を理解してサポートします。
Stream機能の共通設定
各モードの右側にある「Run settings」パネルでは、モデルや音声、応答の挙動などを細かく調整できます。
| カテゴリ | 設定項目 | 説明 |
|---|---|---|
| モデルと出力 | Model | 使用するAIモデル(例: Gemini 3 Flash)を選択します。 |
| Output format | AIの応答を「音声とテキストの両方」で受け取るか、「テキストのみ」にするかを選択します。 | |
| Voice | AIが応答する際の音声の種類を選択します。 | |
| Language | AIが話す言語(例: 英語)を選択します。 | |
| メディアと文脈 | Media resolution | Webカメラで入力する映像の解像度(トークン数)を設定します。 |
| Turn coverage | 会話のターン全体をAIが考慮するかどうかを設定します。 | |
| Session Context | 過去の対話の文脈を、現在の応答にどの程度反映させるかを設定します。 | |
| ツール(Tools) | Code Execution | プロンプト内のコードをAIが実行し、その結果を元に応答を生成できるようにします。 |
| Function calling | 外部のAPIやツールをAIが呼び出せるようにする、高度な設定です。 | |
| Automatic Function Response | Function callingで呼び出した関数の結果を、AIが自動で応答に利用するかどうかを設定します。 | |
| Grounding with Google Search | オンにすると、AIがGoogle検索を参照し、最新の情報や事実に基づいた回答を生成しようとします。 | |
| URL context | プロンプトに含まれるURLのコンテンツをAIが読み取り、文脈として理解できるようにします。 |
アプリの作成
テキストの指示だけで、Webアプリケーションのプロトタイプを自動で構築・公開する手順を解説します。
- 左側のメニューから「Build」を選択し、プロンプト入力欄に「〇〇ができるWebアプリを作ってください」といった形で、作りたいアプリケーションの概要を自然な文章で入力して実行します。
今回は、以下のプロンプトを入力しました。
# インテリアデザイン・アイデアボード作成アプリ
## ページデザイン
- 「あなたの理想の部屋をデザインします」というタイトル。
- 「部屋のテーマやコンセプトを入力してください(例: 海辺のカフェ風, ミニマリスト, 猫と暮らす木の家)」というテキスト入力欄。
- 「デザイン案を作成」ボタン。
[](https://www.ai-souken.com/business/training)
## 実行プロセス
1. ユーザーがテーマを入力してボタンを押す。
2. まず、Gemini APIに「[ユーザーが入力したテーマ]のインテリアデザインについて、魅力的なコンセプト説明文を200字で書いてください」と依頼する。
3. 次に、Imagen APIを使い、以下の**3つのプロンプトで画像を並行して生成**する。
- `[ユーザーが入力したテーマ]の部屋全体の、広角で撮影した美しいインテリア写真。`
- `[ユーザーが入力したテーマ]の部屋に合う、象徴的なデザインのソファの写真。`
- `[ユーザーが入力したテーマ]の部屋に置きたい、ユニークなデザインの照明器具の写真。`
4. 結果ページに、まずコンセプト説明文を表示し、その下に3枚の生成画像を横並びで表示する。
- AIがアプリのコード(HTML, CSS, JavaScript)とプレビューを生成します。ここから、2つの方法でアプリを修正できます。
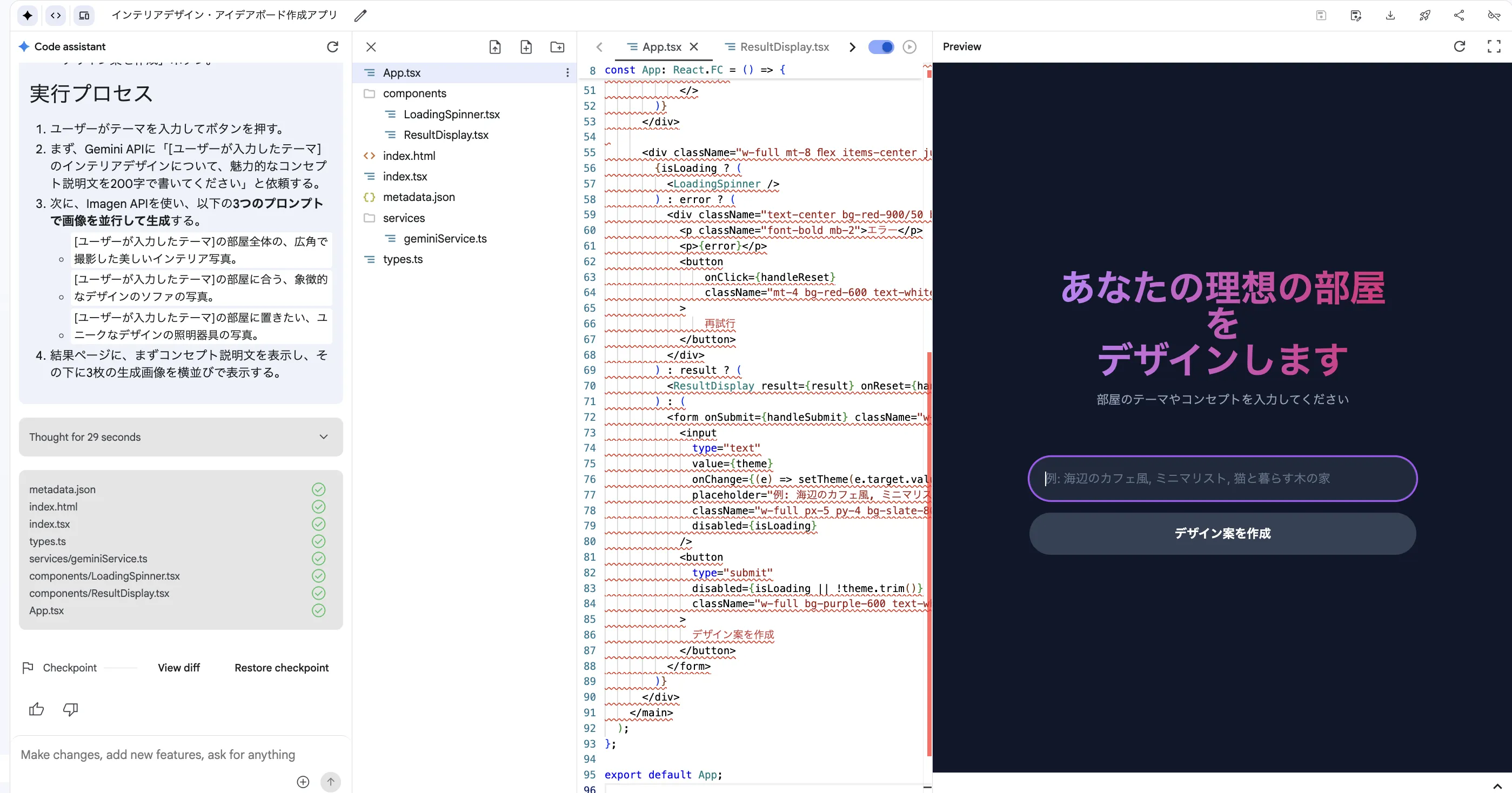
対話での修正:
プレビューを見ながら、チャットで「見出しの文字を大きくして」のように追加の指示を出し、対話形式で修正します。
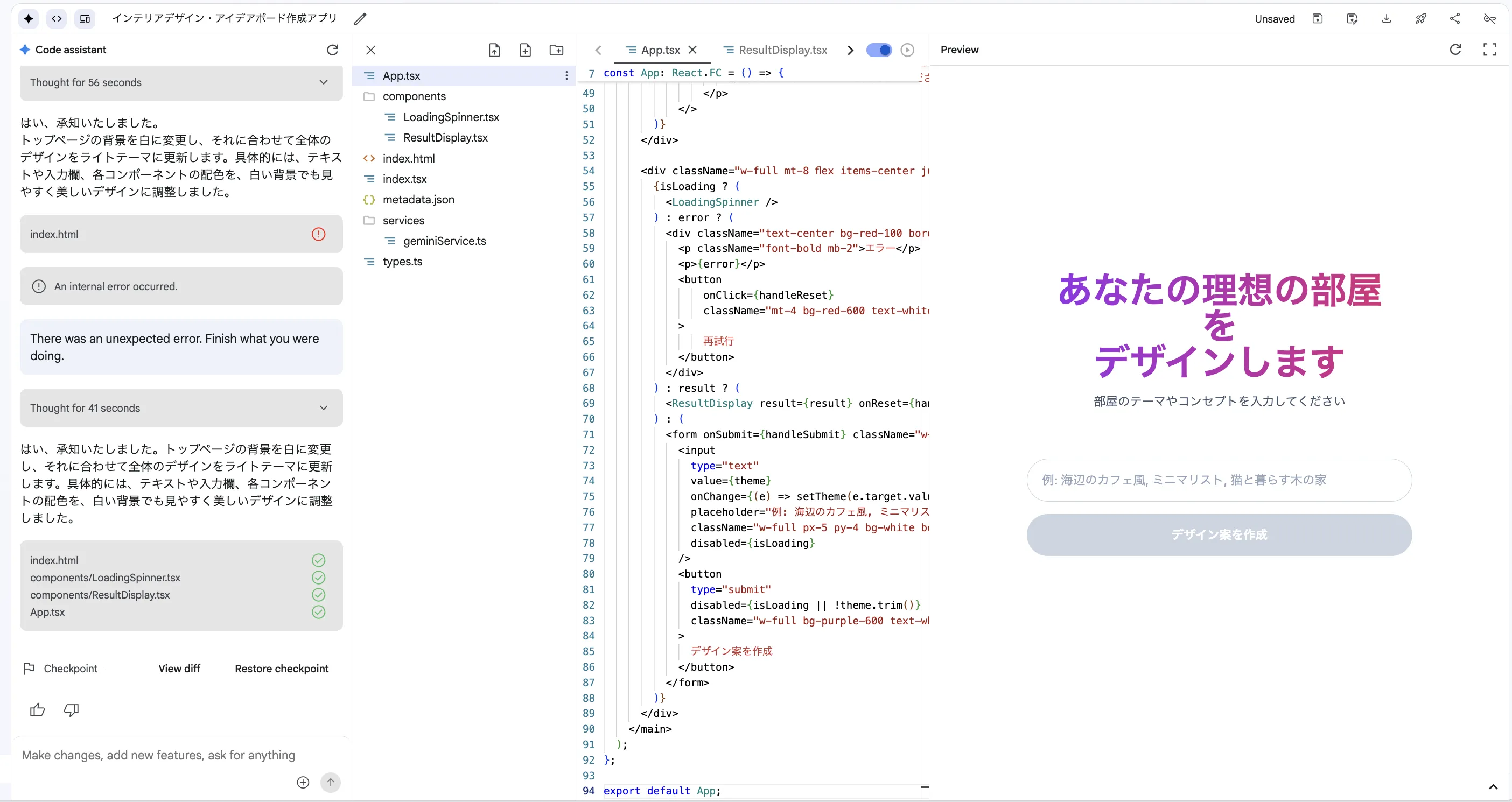
コードの直接編集:
「Build」機能にはコードエディタが統合されているため、生成されたコードを直接編集して、より細かいカスタマイズを行うことも可能です。
「トップページの背景を白にして」と自然言語で指示を出すだけで、カラーを修正できました。
- アプリの共有と公開
完成したアプリは、目的に応じて2つの方法で他者と共有できます。
① Googleドライブで共有する(共同編集・デモ向け)
画面上部の「Share」ボタンから、Googleドキュメントのように共有設定ができます。共有されたユーザーは、自身のAPIキーを使ってアプリを試したり、コードを閲覧・コピー(フォーク)したりできます。
共同編集者として、一緒にアプリを改善していくことも可能です。
② Cloud Runにデプロイする(一般公開向け)
「Deploy」ボタンを押すと、アプリがGoogle Cloud Runにデプロイされ、誰でもアクセスできる公開URLが発行されます。この場合、すべてのアクセスは作成者(あなた)のAPIキーを通じて処理されるため、コスト管理には注意が必要です。
Build機能の主な特徴と注意点
「Build」機能は非常に強力ですが、安全に利用するためにいくつかの重要な仕様があります。
| カテゴリ | 内容と注意点 |
|---|---|
| APIキーの扱い | アプリ内に本物のAPIキーを書き込まないでください。 AI Studioはprocess.env.GEMINI_API_KEYという仮のキー(プレースホルダー)を使用します。共有されたユーザーは自身のキーで、デプロイした場合は作成者のキーで、安全にAPIが呼び出される仕組みになっています。 |
| 実行環境 | プレビュー環境はブラウザ内のサンドボックスで動作します。Cloud Runにデプロイすることで、フルスタックランタイム(サーバーサイドロジック、npmパッケージ、シークレット管理)が利用可能になります。 |
| データの保存 | 作成したアプリはGoogleドライブに保存され、Googleドライブの共有設定(非公開、閲覧者、編集者)がそのまま適用されます。 |
| 外部ライブラリ | package.jsonの代わりに、index.html内のimport mapという仕組みで外部ライブラリを管理します。 |
| ハードウェアアクセス | マイクやカメラなどを使用するアプリを作るには、metadata.jsonファイルに明示的な許可設定を記述する必要があります。 |
| 制限事項 | 現時点では、Next.jsやVue.jsといった主要なWebフレームワークや、外部の認証(OAuth)フローには対応していません。 |
Google AI Studioの料金
Google AI Studioは、料金体系が2段階に分かれています。Webブラウザ上で機能を試すだけであれば無料で利用できますが、APIキーを取得して本格的なアプリケーション開発に利用する場合は、使用量に応じた**有料プラン(従量課金)**が適用されます。
ここでは、API利用時の料金を中心に、最新のモデルの料金体系を解説します。

料金体系の概要
APIの料金プランは、モデルの性能や用途によって細かく設定されています。課金の主な単位は以下の通りです。
- トークン
テキスト、画像、音声などのデータを処理するための単位です。「100万トークンあたり」の料金が基本となります。
- 画像・動画
ImagenやVeoのような生成モデルでは、「画像1枚あたり」や「動画1秒あたり」で料金が設定されます。
- 無料枠
各モデルにはAPI経由でも一定量まで無料で試せる枠が用意されていますが、制限を超えると有料プランに切り替わります。
Geminiモデルの料金
Geminiファミリーは、性能や速度に応じて複数のモデルが提供されており、API利用時の料金も異なります。以下に主要モデルの料金と特徴をまとめます。
| モデル名 | 主な用途・特徴 | 入力料金(100万トークンあたり) | 出力料金(100万トークンあたり) |
|---|---|---|---|
| Gemini 3.1 Pro | 推論能力を大きく強化した最新Proモデル。複雑な推論やコーディング、エージェント設計などに最適。 | プロンプト ≦20万トークン: $2.00 プロンプト >20万トークン: $4.00 |
プロンプト ≦20万トークン: $12.00 プロンプト >20万トークン: $18.00 |
| Gemini 3 Flash | Gemini 3世代の高速モデル。大規模モデルに匹敵する性能を低コストで実現。無料枠あり。 | $0.50 | $3.00 |
| Gemini 2.5 Pro | 複雑な推論やコーディングなど、最も高い性能が求められるタスクに最適。 | プロンプト ≦20万トークン: $1.25 プロンプト >20万トークン: $2.50 |
プロンプト ≦20万トークン: $10.00 プロンプト >20万トークン: $15.00 |
| Gemini 2.5 Flash | 価格と性能のバランスが取れた多機能モデル。思考機能を持ちながら高速に応答。 | テキスト/画像/動画: $0.30 音声: $1.00 |
$2.50 |
| Gemini 2.5 Flash Image | 高度な画像編集に特化。キャラクターの一貫性を維持したまま編集可能。 | - | $0.039 / 枚 |
| Gemini 2.5 Flash-Lite | 費用対効果と低レイテンシを重視した軽量モデル。リアルタイム処理や大規模利用に。 | テキスト/画像/動画: $0.10 音声: $0.50 |
$0.40 |
| Gemini 2.0 Flash | 優れた速度と汎用性を持つ主力モデル。 | テキスト/画像/動画: $0.10 音声: $0.70 |
$0.40 |
| Gemini 2.0 Flash-Lite | Gemini 2.0ファミリーで最も小型・低コストなモデル。大規模なタスクに。 | $0.075 | $0.30 |
Gemini 3 Deep Thinkの提供状況(2026年2月時点)
2026年2月12日のアップデートで「Gemini 3 Deep Think」が発表され、Google AI Ultra加入者向けにGeminiアプリで提供されるケースがあります。APIでは早期アクセスプログラムとして申請受付中となっており、提供範囲は今後変わる可能性があります。
画像・動画生成モデルの料金
クリエイティブなコンテンツ生成に特化したモデルのAPI料金です。画像は1枚あたり、動画は1秒あたりの課金となります。
| モデル名 | 種類 | 主な用途・特徴 | 料金 |
|---|---|---|---|
| Imagen 4 | 画像生成 | Googleの最新画像モデル。豊かな照明と高解像度が特徴で、非常に詳細な画像を生成。 | Standard: $0.04 / 枚 Ultra: $0.06 / 枚 |
| Imagen 3 | 画像生成 | 高品質なテキスト画像変換モデル。アーティファクト(不自然な部分)が少ない。 | $0.03 / 枚 |
| Veo 3.1 | 動画生成 | 最新の動画生成モデル。720p/1080p/4Kに対応し、より高品質な映像を生成。 | 720p/1080p: $0.40 / 秒 4K: $0.60 / 秒 |
| Veo 2 | 動画生成 | テキストや画像から高品質な動画を生成。プロンプトの芸術的なニュアンスを捉える。 | $0.35 / 秒 |
どのモデル・プランを選ぶべき?
利用目的によって最適なモデルは異なります。以下の表を参考に、自分に合ったモデルを選びましょう。
| 利用目的 | おすすめのモデル |
|---|---|
| 無料で機能を試してみたい | AI Studio上でGemini 3 FlashやGemini 2.5 Flashを無料枠で利用 |
| 最高の性能で複雑な分析をしたい | Gemini 3.1 ProのAPIを利用(有料) |
| コストと応答速度のバランスを取りたい | Gemini 3 FlashまたはGemini 2.5 FlashのAPIを利用(有料) |
| 高画質な画像を生成したい | Imagen 4またはNano Banana ProのAPIを利用(有料) |
| テキストや画像から動画を生成したい | Veo 3.1またはVeo 2のAPIを利用(有料) |
【関連記事】
Gemini 3とは?使い方や料金、利用上限について解説【無料】
Geminiの料金プランを比較!無料・有料版の違いと選び方【2026年最新】
Google AI Studioの商用利用について
Google AI Studioは非常に強力なツールですが、そのポテンシャルを安全に最大限活用するためには、商用利用とデータの扱いについて正しく理解することが不可欠です。
まず、Googleの公式な推奨事項を確認した上で、利用するプラットフォームごとに規約上の扱われ方を見ていきましょう。
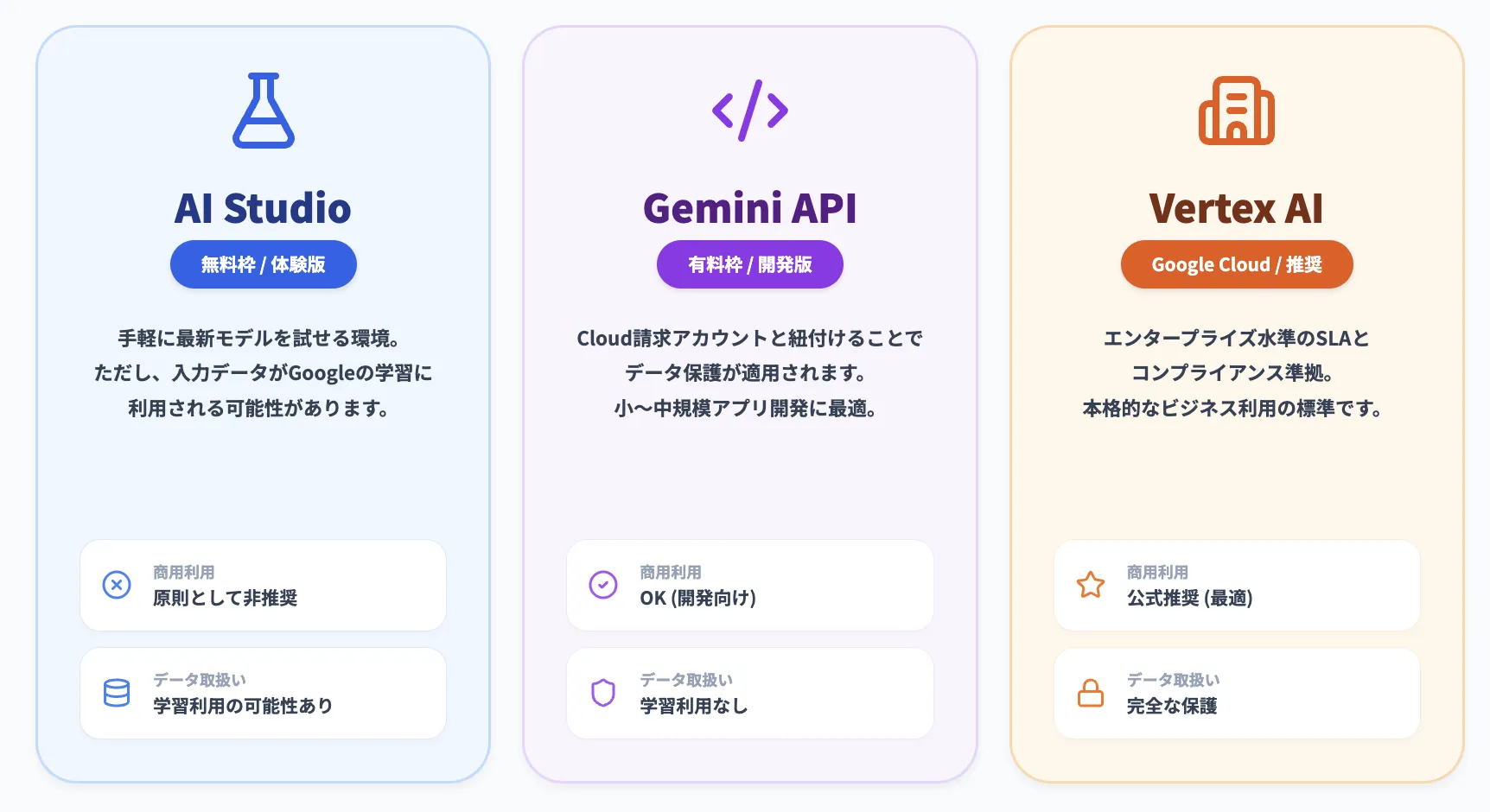
Google AI Studio【無料枠】での商用利用
Google AI Studioを無料で利用する場合、その位置づけは「体験・検証向け」と考えるのが最も安全です。
- 規約上の扱い
商用利用が明確に「禁止」されているわけではありません。しかし、適用される「Gemini API 追加利用規約」では、入力したデータがGoogleのサービス改善・開発に利用される可能性が明記されています。
- リスク
企業の機密情報や未公開の制作物を入力した場合、そのデータが意図せずGoogleのAIモデルの学習などに使われるリスクがあります。
Gemini API 追加利用規約(無料サービス)
https://ai.google.dev/gemini-api/terms?hl=ja本無料サービス (...) を使用する場合、 Google は使用者が本サービスに送信したコンテンツと生成された回答を使用し、(...) Google のプロダクト、サービス、機械学習技術 (...) の 提供、改良、開発を行います。
結論として、外部公開やクライアントワークなど、機密性を要する商用利用は避けるべきです。
Gemini API【有料枠】での商用利用
Google AI Studioから取得したAPIキーを使い、Cloud請求先アカウントを有効化して「有料サービス」として利用する場合、データの扱いは大きく変わります。
- 規約上の扱い
同じ「Gemini API 追加利用規約」内でも、有料サービスの場合は入力データがプロダクト改善に利用されないことが保証されます。
- 商用利用の目安
データ保護の要件がクリアされるため、小〜中規模のアプリケーション開発などでの商用利用が可能になります。
Gemini API 追加利用規約(有料サービス)
https://ai.google.dev/gemini-api/terms?hl=ja本有料サービスを使用する場合、 Google は、使用者のプロンプト(...)または 回答をプロダクトの改善に使用することはありません。
Vertex AI経由での商用利用
Googleが公式に推奨するVertex AIは、本格的なビジネス利用を前提としたプラットフォームです。
- 規約上の扱い
適用される「Google Cloud Terms of Service」では、顧客のデータは顧客の知的財産として厳格に保護され、Googleがサービス提供以外の目的で利用することは一切ありません。
- 商用利用の目安
エンタープライズレベルのセキュリティ、SLA(サービス品質保証)、コンプライアンス要件が求められる、あらゆる商用利用に最適です。
Google Cloud Terms of Service
https://cloud.google.com/terms/5.2 Protection of Customer Data. Google will ... not access, use, or process Customer Data for any other purpose.
(日本語訳の要点: Googleは、サービスの提供に必要な目的以外で顧客データにアクセス、使用、処理することはありません。)
どのプラットフォームを選ぶべきか?
| 利用経路 | 商用利用の目安 | データ取扱いの目安 |
|---|---|---|
| Google AI Studio(無料枠) | 体験・検証に最適。商用品質の制作は非推奨。 | 入出力が品質改善に利用される可能性あり。 |
| Gemini API(有料枠) | 商用可。小〜中規模に向く。 | 有料利用では入出力を改善目的に利用しない運用。 |
| Vertex AI(Google Cloud) | 推奨。エンタープライズや厳格な案件に最適。 | GCPの契約・DPAに準拠。データ保護を標準保証。 |

AIモデルの実験環境を理解したなら業務へのAI導入を設計する
Google AI StudioでGeminiの性能を試したことで、AIモデルの可能性と限界が実感できたはずです。プロトタイピングで得た知見は、自社の業務フローのどこにAIを適用すべきかを判断する材料になります。
AI業務自動化ガイドでは、AIモデルの選定から業務プロセスへの組み込みまでを220ページ超で体系的に解説しています。AI総合研究所がAI導入の現場で蓄積した設計パターンを、貴社のAI活用計画にお役立てください。
AI開発プラットフォームの知識を業務AI導入に活かす

220ページ超のAI業務自動化ガイドを無料配布中
Google AI StudioでGeminiの性能を試した経験は、AIの可能性を見極める力になります。プロトタイピングの知見を活かして業務にAIを導入する方法を、AI業務自動化ガイドが220ページ超で体系的に解説しています。
まとめ
Google AI Studioは、Googleの最新生成AIモデルGeminiをブラウザ上で試し、アプリケーション開発まで一気通貫で進められる無料のプラットフォームです。
以下の表で、本記事の要点を整理しました。
| カテゴリ | ポイント |
|---|---|
| 基本 | Googleアカウントがあれば無料で利用開始。APIキー取得も数クリック |
| 主要機能 | Chat(分析・文字起こし)、Generate Media(画像・動画生成)、Stream(リアルタイム対話)、Build(Webアプリ構築・デプロイ) |
| モデル選択 | Gemini 3.1 Pro(推論特化)、Gemini 3 Flash(高速・低コスト)、Gemini 2.5 Flash(バランス型)など用途別に切り替え可能 |
| 料金 | コンソール利用は無料。API利用は従量課金(Gemini 3 Flashで入力$0.50/100万トークン〜) |
| 商用利用 | 無料枠は体験・検証用。本番利用にはGemini API有料枠またはVertex AIを推奨 |
Gemini 3.1 Proの登場やBuild機能のフルスタック対応など、Google AI Studioは開発者にとってますます使いやすいプラットフォームになっています。まずは無料枠でプロンプトを試し、手応えを感じたらAPIキーを取得して自社サービスへの組み込みを検討してみてください。










