この記事のポイント
 Hugging Faceとは、AIモデル・データセット・デモアプリを共有できる世界最大級のオープンプラットフォーム
Hugging Faceとは、AIモデル・データセット・デモアプリを共有できる世界最大級のオープンプラットフォーム- 2025年12月リリースのTransformers v5により、PyTorch専用の高速化と400種類以上のモデルアーキテクチャに対応
- Hugging Face Hub上には200万超のモデルと50万超のデータセットが公開されており、約100万のSpacesでデモアプリも構築できる
- 料金は無料プランを基本に、Pro(月額9ドル)・Team(月額20ドル/人)・Enterprise(月額50ドル〜/人)の4段階構成
- ZeroGPU・Inference Endpoints・22社のInference Providersなど、本番運用を見据えたデプロイ基盤も充実している

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
Hugging Face(ハギングフェイス)は、AIモデルの共有・活用を目的とした世界最大級のオープンソースプラットフォームです。200万を超えるモデルと50万以上のデータセットが公開されており、研究者から企業の開発チームまで幅広く利用されています。
2025年12月にはTransformers v5がリリースされ、PyTorch専用のモジュラーアーキテクチャへと刷新されました。さらに2026年2月にはTransformers.js v4のプレビュー版が公開され、C++リライトとWebGPUランタイムによるブラウザ上でのAI推論にも対応しています。
本記事では、Hugging Faceの基本的な仕組みから主要サービスの使い方、料金体系、そして実際の活用シーンまでを体系的に解説します。
AI開発に興味がある方はもちろん、業務でのモデル選定や導入を検討している方にも役立つ内容です。
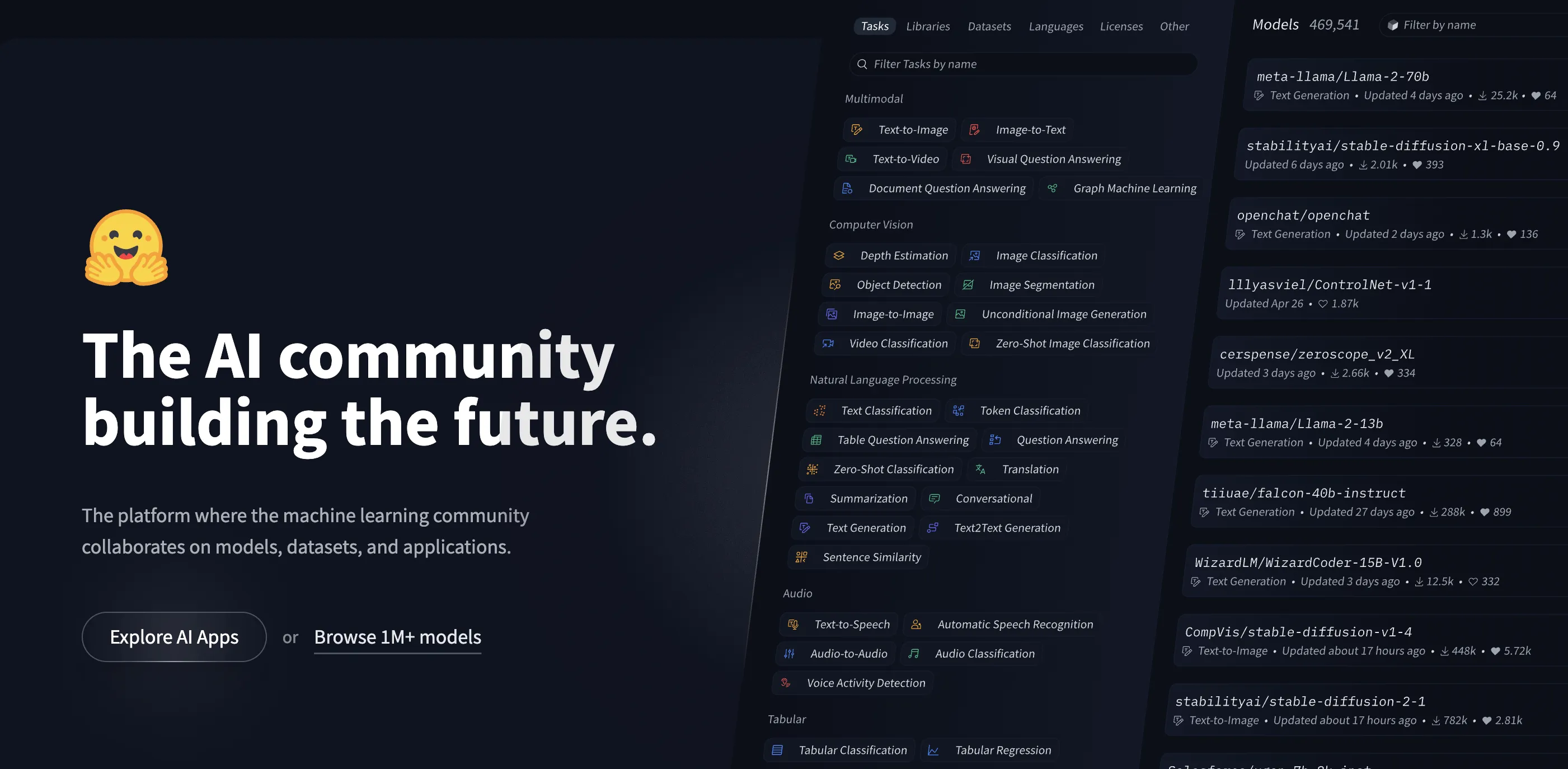
Hugging Faceとは?
Hugging Face(ハギングフェイス)は、AIモデルの共有・検索・デプロイを一つのプラットフォーム上で完結できる、世界最大級のオープンソースAIハブです。
自然言語処理(NLP)を出発点に、画像認識・音声処理・マルチモーダルAIまで対応領域を広げており、「AIモデルのGitHub」とも呼ばれるポジションを確立しています。

Hugging Faceの沿革と位置づけ
Hugging Faceは2016年にフランス・パリで設立され、現在はニューヨークにも拠点を構えています。
当初はチャットボット開発のスタートアップでしたが、2018年にTransformersライブラリを公開したことで方向転換し、オープンソースAIプラットフォーム企業として急成長しました。社名は絵文字の🤗(ハギングフェイス)に由来しており、「AIへの敷居を下げ、誰もがアクセスできる未来」という理念が込められています。
2026年2月時点で、Hugging Face Hub上には200万を超えるモデルと50万以上のデータセットが公開されており、約100万のSpaces(デモアプリ)が稼働しています。Google、Meta、Microsoft、NVIDIAといった大手テック企業も公式モデルをHub上で公開しており、AI業界における事実上の標準リポジトリとしての地位を固めつつあります。
Hugging FaceとGitHubの違い
Hugging Faceは「AIモデルのGitHub」と呼ばれることがありますが、両者の役割には明確な違いがあります。
GitHubは汎用的なソースコード管理プラットフォームであり、あらゆるプログラミング言語やプロジェクトを対象としています。一方、Hugging FaceはAIモデル・データセット・デモアプリに特化したプラットフォームで、モデルの重みファイル(数GB〜数百GB)を効率的に管理するためのGit LFSベースの大容量ファイル管理や、ブラウザ上でモデルをすぐに試せるInference API、ワンクリックでデモを公開できるSpacesなど、AI開発に最適化された機能群を備えています。
つまり、GitHubが「コードの共有と共同開発」のためのプラットフォームであるのに対し、Hugging Faceは「AIモデルの共有・試用・デプロイ」のためのプラットフォームという位置づけです。実際の開発では、ソースコードはGitHub、モデルとデータセットはHugging Faceという使い分けが一般的になっています。
Hugging FaceとAIとの関連性
Hugging FaceがAI分野で不可欠な存在になった最大の理由は、Transformersライブラリの存在です。
BERT、GPT、LLaMA、Mistralなど、主要な大規模言語モデル(LLM)をPythonコード数行で呼び出せるこのライブラリは、研究開発からプロダクション運用まで幅広い場面で活用されています。
加えて、近年はテキストだけでなく**画像処理(Diffusersライブラリ)や音声処理(AudioやWhisper系)**にも対応を拡大しており、総合的なマルチモーダルAIプラットフォームへと進化を続けています。
企業向けには、セキュリティやプライバシーを重視したInference Endpointsや、コードなしでモデルをファインチューニングできるAutoTrainも提供し、実務でのAI導入をサポートしています。
さらに、2025年からはDeepSeek-R1の完全再現を目指すOpen-R1プロジェクトを推進しており、推論特化型モデルのオープン化にも取り組んでいます。このように、Hugging Faceは単なるモデルホスティングにとどまらず、AI研究の最前線を牽引するプラットフォームとしても進化を続けています。
Hugging Faceの主な機能とサービス
ここでは、Hugging Faceが提供する機能群を整理します。モデルの検索・活用から、データ準備、デモ公開、本番デプロイまで、AI開発のライフサイクル全体をカバーする構成になっています。
Transformersライブラリ
Hugging Faceの中核プロダクトがTransformersライブラリです。2025年12月18日にリリースされたv5では、PyTorch専用のモジュラーアーキテクチャへと大幅に刷新され、パフォーマンスと保守性が向上しました。
このライブラリの特徴は、次の3点に集約されます。
- 400種類以上のモデルアーキテクチャに対応
BERT、GPT、LLaMA、Mistral、Qwen、Gemma、T5、DistilBERTなど、400種類以上の事前学習済みモデルアーキテクチャに対応しており、テキスト分類・要約・翻訳・質問応答といった主要タスクを数行のコードで実行できる
- PyTorch専用の高速アーキテクチャ(v5〜)
v5以降はPyTorchに一本化され、TensorFlow・Flaxのサポートは終了した。モジュラー設計により各モデルが独立したファイル構成となり、コードの可読性と拡張性が大幅に改善されている。週次リリース体制で最新モデルへの対応も迅速
- パイプラインAPI
初心者でもすぐに使える高レベルAPIが用意されており、モデルの読み込みから推論まで、最短2行で完結する
これらの特徴により、「最新モデルを試すのに何日もかかる」という従来の開発課題が大幅に解消されています。なお、2026年2月時点でTransformersのpipダウンロード数は1日あたり300万回以上に達しており、AI開発の事実上の標準ライブラリとしての地位を確立しています。
Datasetsライブラリ
AIモデルの学習・評価には適切なデータセットが欠かせません。
Hugging FaceのDatasetsライブラリは、50万以上の公開データセットを標準フォーマットで提供しており、検索・ダウンロード・前処理を一括で行えます。メモリ効率の高いApache Arrow形式を採用しているため、大規模データセットでもローカルマシン上で扱いやすいのが利点です。
Hugging Face Hub
Hugging Face Hubは、モデル・データセット・デモアプリをアップロード・共有・検索できる中央リポジトリです。
200万超のモデルが公開されており、タスク別(テキスト生成、画像分類、音声認識など)やフレームワーク別、ライセンス別でフィルタリングしながら目的のモデルを見つけることができます。
個人開発者でも企業でも、Hubを通じてモデルのバージョン管理やチームコラボレーションが可能で、Gitベースのワークフローに慣れていれば直感的に操作できます。
Spaces
Spacesは、GradioやStreamlitを使って、開発したAIモデルのデモアプリケーションをワンクリックで公開できるホスティングサービスです。2026年2月時点で約100万のSpacesが公開されており、AI開発コミュニティにおける最大のデモアプリ集積地となっています。
無料のCPU環境で手軽に公開できるほか、GPU環境(T4やA100)を追加すれば、より高負荷なモデルのデモにも対応できます。研究成果のアピールやクライアントへのプロトタイプ提示など、「動くものを見せる」場面で特に重宝されています。
AutoTrain
AutoTrainは、コーディングなしでモデルのファインチューニングを行えるサービスです。
自社データを用意すれば、ハイパーパラメータの自動最適化まで含めてHugging Face側が処理してくれるため、機械学習の専門知識が限られたチームでもカスタムモデルを構築できます。テキスト分類・質問応答・画像分類などの主要タスクに対応しています。
ZeroGPU
ZeroGPUは、Spaces上でGPU(NVIDIA H200)を時間単位で共有利用できる仕組みです。
推論を実行するときだけGPUが割り当てられるため、常時GPUを確保するよりもコストを抑えやすいのが特徴です。無料プランでも一定の利用枠が付与されますが、Proアカウントにアップグレードすると利用枠が8倍に拡大し、キュー優先度も最高になります。
Transformers.js
Transformers.jsは、Transformersライブラリの機能をブラウザやNode.js環境で利用可能にするJavaScriptライブラリです。2026年2月にプレビュー版が公開されたv4では、コアエンジンがC++でフルリライトされ、WebGPUランタイムによるGPU加速に対応しました。
約200種類のモデルアーキテクチャをサポートしており、テキスト生成・画像分類・音声処理などのタスクをサーバーサイドに依存せずクライアントサイドで実行できます。オフライン環境でも動作するため、プライバシーが重視されるユースケースやエッジAIアプリケーションに適しています。
SmolAgents
SmolAgentsは、Hugging Faceが提供する軽量AIエージェントライブラリです。コア部分がわずか約1,000行のPythonコードで構成されており、最小限の依存関係でAIエージェントを構築できます。
コードエージェント(Pythonコードを生成して実行するAIエージェント)やツールコーリングエージェントを簡単に構築でき、Hugging Face Hub上の任意のLLMと組み合わせて利用できます。LangChainなどの大規模フレームワークに比べて、学習コストが低く軽量な点が特徴です。
HuggingChat
HuggingChatは、Hugging Faceが提供するオープンソースのチャットインターフェースです。
Meta LLaMA、Mistral、Qwenなど、複数のオープンソースLLMを選択して対話でき、ChatGPTのようなチャット体験をオープンモデルで実現しています。ログイン不要で試せるため、モデルの出力品質を手軽に比較したい場面でも役立ちます。
Hugging Face(ハギングフェイス)の使い方
Hugging Faceは、モデルの検索→試用→データ準備→デプロイという一連の流れを、一つのプラットフォーム上で完結できる設計になっています。
ここでは、初めてHugging Faceを使う方に向けて、基本的な利用ステップを整理します。
| 機能 | 内容 | 使う場所 |
|---|---|---|
| モデル検索 | 公開されているAIモデルを探す | Modelsタブ |
| モデル試用 | ブラウザ上でモデルをすぐ試す | 各モデルページ |
| アプリ体験 | デモアプリを使ったりコードを見る | Spacesタブ |
| データ探し | 学習用・テスト用のデータセット検索 | Datasetsタブ |
この表にある4つの機能が、Hugging Faceの利用頻度が特に高い基本操作です。以下、順番に見ていきます。
1. モデルを探す(Model Hub)
できること
世界中の公開モデルを横断的に検索できるのが、Model Hubの最大の強みです。主な操作は次の通りです。
- キーワード検索 LLaMA、Mistral、Stable Diffusionなど、モデル名やタスク名で目的のモデルを素早く見つけられる
- フィルタリング タスク別(テキスト生成・画像分類・音声認識など)、フレームワーク別(PyTorch・TensorFlow)、ライセンス別(Apache 2.0・MITなど)で絞り込み可能
- モデルカード 各モデルのスペック(パラメータ数・推論速度・対応言語)、利用規約、サンプルコードがモデルカードにまとめられている
使い方
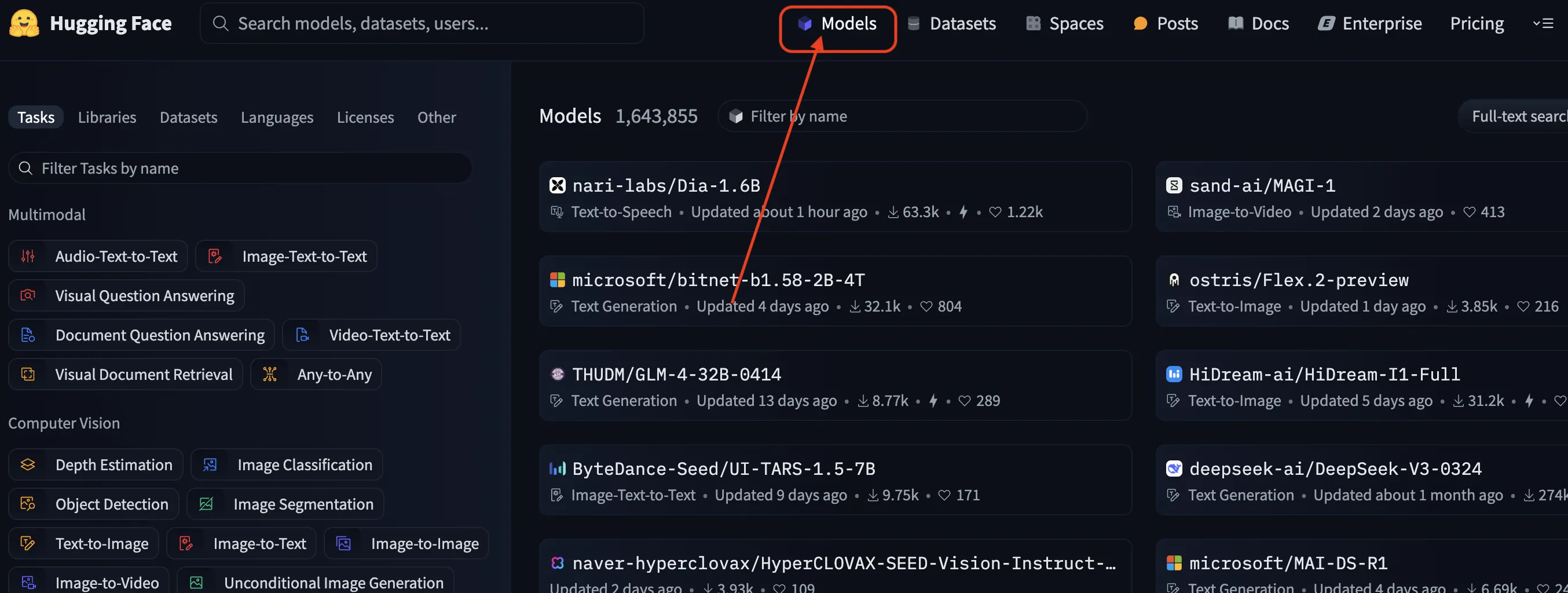
Modelsをクリック
基本的な手順は次の3ステップです。
- トップページの「Models」タブをクリックする
- キーワード入力やフィルターで対象モデルを絞り込む
- モデルカードを開いてスペックやサンプルコードを確認する
🔗 Modelsページ:Hugging Face Models
2. モデルを試す(Inference API / Inference Providers)
できること
Model Hubで見つけたモデルを、環境構築なしにブラウザ上でそのまま動かせるのが、Inference APIの利点です。
- テキストを入力すると、モデルの出力が即座に返ってくる
- 無料枠が用意されており、APIキーなしでも一定量の試用が可能
- 気に入ったモデルはAPIキーを発行してアプリケーションに組み込める
使い方
- モデルページにある「Inference API」ウィジェットに入力を行う
- 出力を確認し、品質や応答速度を検証する
- 本番利用する場合は、APIキーを生成してコードに組み込む
2026年2月時点では、AWS、Google Cloud、Azure、NVIDIA NIMなどを含む22社のInference Providersが統合されており、OpenAI互換の統一エンドポイントを通じてクラウド基盤を柔軟に選択できます。プロバイダーごとの料金や対応モデルはモデルページから直接確認できるため、コストとパフォーマンスを比較しながら最適なインフラを選べるようになっています。
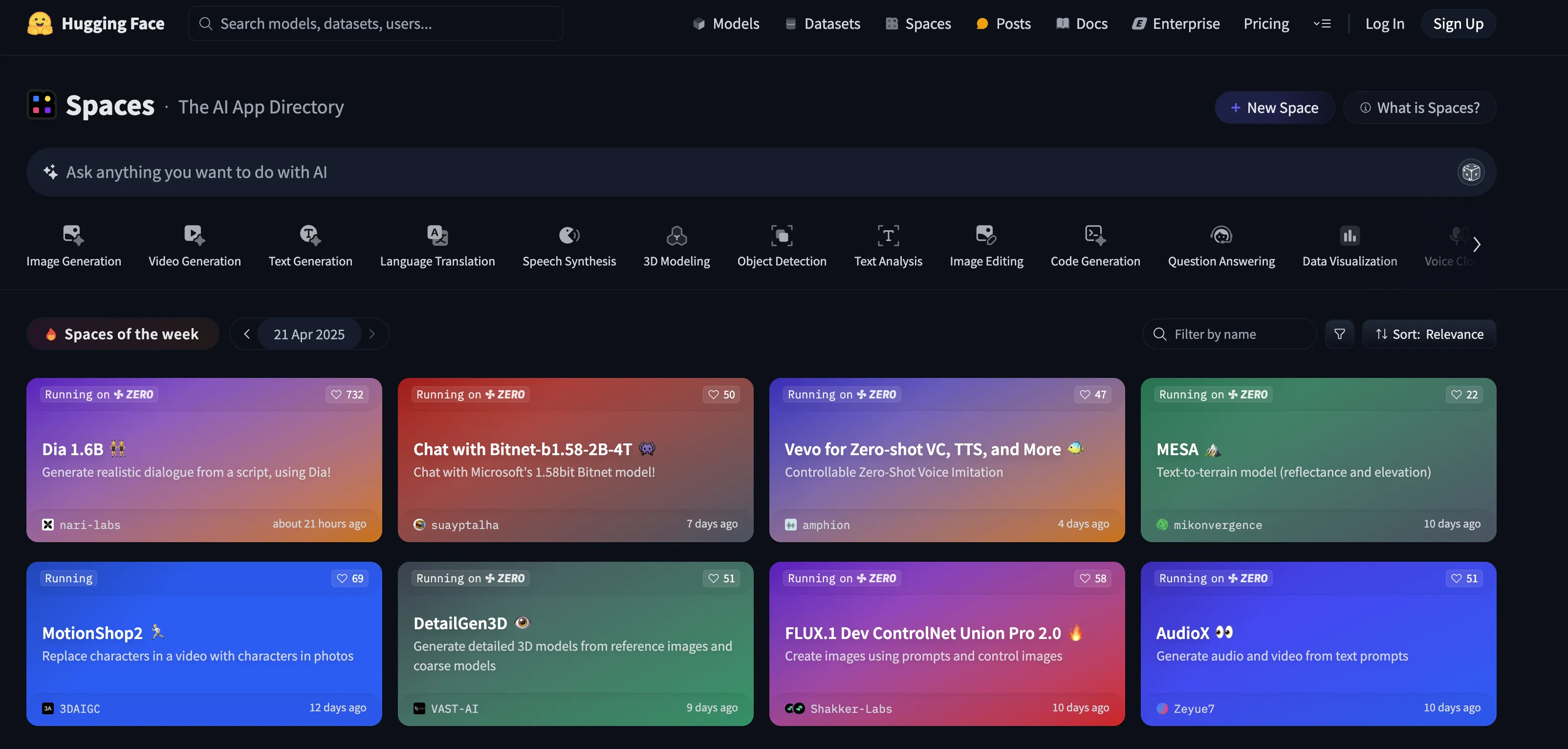
3. アプリやデモを探す(Spaces)
Spaces
できること
Spacesには、世界中の開発者が公開したAIデモアプリが集まっています。画像生成、チャットボット、音楽生成、翻訳ツールなど、実際に動くアプリケーションをブラウザ上で体験でき、それぞれのソースコードも閲覧可能です。
使い方
- 「Spaces」タブをクリックする
- カテゴリ別(Text、Image、Audioなど)やトレンドで絞り込む
- 気になるアプリを選んで、すぐに体験する
体験画面イメージ
🔗 Spacesページ:Hugging Face Spaces

4. データセットを探す(Datasets)
Datasets画面
できること
LLMの訓練や画像AIの学習に必要なオープンデータセットを、Hugging Face上で直接検索・ダウンロードできます。テキスト、音声、画像、マルチモーダルなどジャンルは幅広く、各データセットにはプレビューや利用条件が記載されています。
使い方
- 「Datasets」タブをクリックする
- ジャンル・サイズ・ライセンスで絞り込む
- プレビューや概要を確認し、自分のプロジェクトに適したものを選ぶ
🔗 Datasetsページ:Hugging Face Datasets
5. Leaderboardでモデルの比較を行う
AI開発では、複数のモデルを客観的に比較して選定するプロセスが欠かせません。Hugging Faceでは、主要なベンチマークスコアを一覧できるLeaderboard(リーダーボード)を提供しています。
Leaderboardで比較できる主な指標は、次の通りです。
- 推論精度(MMLU・ARCなど) 汎用的な知識と推論能力を測る
- 常識推論(HellaSwag) 日常的な文脈理解力を測定する
- 誤情報耐性(TruthfulQA) 事実に反する回答をどの程度避けられるかを評価する
総合スコアで並べ替えたり、特定分野に強いモデルだけを抽出することも簡単にできるため、モデル選定の初期段階で活用すると効率的です。
🔗 Hugging Face Open LLM Leaderboardを見る
詳細は関連記事をご覧ください。
【関連記事】
ChatGPTのモデルとは?OpenAIの最新モデル一覧と特徴をわかりやすく解説【2026年最新版】
Hugging Faceの料金体系
Hugging Faceは、無料プランを基盤としつつ、利用規模や組織のニーズに応じて段階的にアップグレードできる料金体系を採用しています。
ここでは、プランごとの違いと、従量課金で発生するコストの両面から整理します。
プラン別の機能比較
Hugging Faceの主要プランは、次の4段階で構成されています(2026年2月時点)。
| プラン | 月額料金 | 主な特徴 | 想定ユーザー |
|---|---|---|---|
| Free | 無料 | 公開モデル・データセット・Spacesの利用無制限。プライベートリポジトリも一定容量まで利用可能 | 個人学習・研究・OSS開発者 |
| Pro | 9ドル/月 | ストレージ10倍・推論クレジット20倍・ZeroGPU枠8倍(最高優先)・Spaces Dev Mode・プライベートデータセットビューア | 個人開発者・研究者 |
| Team | 20ドル/人/月 | Proの全特典+SSO/SAML・監査ログ・ストレージリージョン選択・リソースグループ制御 | チーム開発・スタートアップ |
| Enterprise | 50ドル〜/人/月 | Teamの全特典+最高レベルのストレージ/帯域/APIレート制限・専任サポート・年間契約・法務/コンプライアンス対応 | 大企業・規制産業 |
多くの個人ユーザーにとっては、無料プランで十分にHugging Faceの機能を活用できます。ZeroGPUの利用頻度が高い場合や、プライベートモデルを多数管理したい場合に、Proへのアップグレードを検討するのが現実的です。
チーム利用の場合は、SSO連携や監査ログが必要かどうかがTeamプラン選択の判断基準になります。
従量課金サービス
プラン料金とは別に、以下のサービスは利用量に応じた従量課金が発生します。
- Spaces Hardware CPUアップグレード(8 vCPU/32GB)で0.03ドル/時間、NVIDIA T4で0.40ドル/時間、A100で4.00ドル/時間とスケーラブルに選択可能
- Persistent Storage Spacesのデータを永続保存するオプション。Small(20GB)で月額5ドル、Medium(150GB)で月額25ドル、Large(1TB)で月額100ドル
- Inference Endpoints 専用インフラ上にモデルをデプロイする本番向けサービス。0.03ドル/時間〜で、クラウドプロバイダーとハードウェアの組み合わせで価格が変動する
クラウドGPUの利用コストは稼働時間に比例するため、「開発・検証フェーズはZeroGPUの無料枠」→「本番デプロイはInference Endpoints」と段階的に移行するのがコスト効率の良いアプローチです。
最新の料金はHugging Face公式料金ページで確認できます。
実用性は?Hugging Faceを使うメリットと注意点
Hugging Faceを導入することで得られるメリットは多い一方、利用にあたって知っておくべき注意点もあります。ここでは両面を整理します。
モデル開発・実装のスピードアップ
最先端のAIモデルを一から構築するには、通常、多くの計算資源と専門知識が必要です。
Hugging Faceを活用すれば、事前学習済みの高精度モデルをそのまま利用できるため、開発の初速が大幅に上がります。パイプラインAPIを使えば、テキスト分類や要約を数行のコードで実装でき、プロトタイプから本番デプロイまでの期間を短縮できます。
オープンソースによる透明性と信頼性
Hugging Faceは、主要なライブラリ・ツールをオープンソースで公開しています。
ソースコードを自分で確認できるため、ブラックボックス化のリスクを回避できます。グローバルな開発者コミュニティによるレビューと改良が常に行われており、特に規制要件やセキュリティ基準が厳しい企業にとって、この透明性は大きな安心材料になります。
コミュニティの強さとナレッジ共有
Hugging Faceの継続的な成長を支えているのが、グローバルなコミュニティの活発さです。
- GitHubのIssuesやPull Request、DiscordやHugging Face Forumでの技術的な議論が活発に行われている
- 各モデルにはモデルカード(Model Card)が添付されており、性能・制約・倫理的配慮が明文化されている
- 定期的なハッカソンやオンラインイベントが開催されており、初心者でも参入しやすい
課題解決の情報が見つかりやすく、「詰まったときに助けを得られる」環境が整っているのは、実開発において大きなメリットです。
ビジネス導入における利点
企業向けには、次のような支援が用意されています。
- Inference Endpoints 専用のインフラ上でモデルをホスティングし、SLAに基づいた安定運用が可能
- プライベートHub 機密性の高いモデルやデータセットを社内限定で管理できる
- ストレージリージョン選択 EU・米国など、データ保管先のリージョンを指定でき、GDPRなどの規制要件にも対応しやすい
オンプレミス環境との連携やファインチューニング支援も提供されており、社内のセキュリティポリシーに合わせた柔軟な導入が設計しやすくなっています。
利用時の注意点
一方で、以下の点は事前に把握しておく必要があります。
- モデルの品質にばらつきがある Hub上のモデルは誰でもアップロードできるため、品質やライセンスの確認は自己責任。商用利用時にはライセンス条件を必ず確認すること
- 無料枠には制限がある ZeroGPUやInference APIの無料枠は一定量まで。本格的な推論処理を回す場合は、Proプランや従量課金への移行が必要になる
- ドキュメントが英語中心 公式ドキュメントやコミュニティの議論は英語が主体。日本語の情報は増えつつあるが、最新の機能変更や仕様はまず英語ドキュメントから確認する必要がある
- 最新モデルの互換性 モデルのバージョンアップやライブラリの更新により、既存コードとの互換性が崩れることがある。本番環境ではモデルとライブラリのバージョンを固定する運用が推奨される

Hugging Face活用シーン
ここでは、Hugging Faceがどのような場面で実際に活用されているかを、代表的なユースケースごとに整理します。
自然言語処理(NLP)モデルの開発
テキスト分類、要約、翻訳、質問応答など、自然言語処理タスクはHugging Faceが最も得意とする領域です。
たとえば、カスタマーサポート向けのチャットボットや、社内ナレッジベースの自動検索システムを構築する際に、BERTやDistilBERTベースのモデルを適用するケースが広く見られます。
画像認識・生成モデルへの応用
画像生成や分類の分野でも、Hugging Faceのエコシステムは存在感を高めています。
- Diffusersライブラリ Stable DiffusionやFLUXなどの画像生成モデルを統一的に扱える
- CLIPモデル 画像の内容をテキストで記述するキャプション生成や、画像検索に活用されている
Spacesでは画像生成デモが数多く公開されており、プロンプトの書き方やパラメータ設定を実際に試しながら学べるのもメリットです。
ファインチューニングによる業務最適化
事前学習済みモデルを自社のデータセットで微調整(ファインチューニング)することで、特定の業務に最適化したモデルを短期間で構築できます。
AutoTrainを使えばコーディングなしでファインチューニングが可能なため、機械学習エンジニアが不在のチームでもカスタムモデルの構築に取り組めます。医療・法務・金融など、専門用語や業界固有の文脈が重要な分野で特に効果を発揮します。
AIアプリケーション開発(Spaces活用例)
Spacesを使えば、開発したモデルをインタラクティブなWebアプリケーションとして公開できます。
文字起こしアプリ、画像分類デモ、自動翻訳ツールなど、アイデアを素早く形にしてフィードバックを集められるため、社内PoC(概念実証)やクライアントへのプロトタイプ提示に適しています。Gradioを使えば、数十行のPythonコードでUIまで含めたアプリを構築可能です。
Hugging Faceの知識を業務でのAIモデル活用に広げる

AI業務自動化ガイド
Hugging Faceでモデルの探索やデプロイを学んだなら、その知識を自社の業務自動化にも活かせます。AI総合研究所のAI業務自動化ガイドでは、AIモデルの業務組み込みから運用設計まで、220ページの実践ノウハウを提供しています。
Hugging Faceの知識を業務でのAIモデル活用に広げる
Hugging Faceでモデルの探索やデプロイの流れを理解したなら、その知識は自社のAI導入プロジェクトにも直接応用できます。モデル選定の考え方やInference Endpointsの設計思想は、業務システムへのAI組み込みを検討する際の基盤となります。
AI総合研究所では、AIモデルの評価・選定から業務プロセスへの実装まで、220ページの実践ガイドとして「AI業務自動化ガイド」を無料で公開しています。プラットフォーム上の知識を、実務での成果につなげるための手引きとしてご活用ください。
Hugging Faceの知識を業務でのAIモデル活用に広げる
AI業務自動化ガイド
Hugging Faceでモデルの探索やデプロイを学んだなら、その知識を自社の業務自動化にも活かせます。AI総合研究所のAI業務自動化ガイドでは、AIモデルの業務組み込みから運用設計まで、220ページの実践ノウハウを提供しています。
まとめ
Hugging Faceは、AIモデルの探索から試用、データ準備、デモ公開、本番デプロイまでをワンストップで提供するプラットフォームです。
200万超のモデルと50万超のデータセットが集まるHub、2025年12月にリリースされたTransformers v5(PyTorch専用・400+アーキテクチャ対応)、22社のInference Providersによる統一エンドポイント、そしてSpacesやInference Endpointsといったデプロイ基盤により、AI開発の各ステップで生産性を引き上げてくれます。
料金面では、無料プランで基本機能を十分に活用でき、Proプラン(月額9ドル)やTeamプランで段階的に拡張できる設計です。ZeroGPUやInference Endpointsの従量課金と組み合わせることで、開発フェーズに応じたコスト最適化も可能です。
オープンソースの透明性とグローバルコミュニティの活発さは、Hugging Face特有の強みです。Transformers.js v4(C++リライト・WebGPU対応)やSmolAgents(軽量エージェントライブラリ)といった新ツールの登場で、ブラウザ上でのAI推論やエージェント開発の領域にも対応が広がっています。一方で、モデル品質のばらつきやドキュメントの言語問題は利用前に把握しておくべきポイントです。
これからAI開発に着手する方も、既にプロジェクトを進めている方も、Hugging Faceのエコシステムを一度試してみることで、開発ワークフロー全体の効率化が見えてくるはずです。










