この記事のポイント
 アルゴリズムの自動発見・最適化にはAlphaEvolveが最有力、Gemini+進化的探索でFunSearchでは不可能だった大規模コード最適化を実現
アルゴリズムの自動発見・最適化にはAlphaEvolveが最有力、Gemini+進化的探索でFunSearchでは不可能だった大規模コード最適化を実現- 行列乗算アルゴリズムで50年ぶりの歴史的更新を達成しており、数学・コンピュータサイエンスの未解決問題への適用が有効
- 評価関数を自動化できる問題領域であればAlphaEvolveの導入を検討すべきであり、データセンター最適化やチップ設計での実績がその有効性を裏付ける
- 自動評価が困難な創造的タスクには不向きであり、適用領域の見極めが重要。人間との協調運用が現時点では最適
- FunSearchと比較してLLMサンプル数が数百万→数千に激減しており、計算コスト面でも実用的な水準に到達している

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「AIが新しいアルゴリズムを発見する時代が来た」――そんな言葉が現実味を帯びてきました。従来のAIが既存のデータを学習・予測するのに対し、自ら新たな解を「創造」するAIエージェントが登場し始めています。
特にGoogle DeepMindが開発した「AlphaEvolve」は、その最前線に位置し、数学の未解決問題や複雑なシステム最適化に驚くべき成果を上げています。しかし、その革新的な仕組みや可能性は、まだ広く知られていません。
本記事では、この未来を切り開くAIエージェント「AlphaEvolve」について、その核心を徹底的に解説します。
AlphaEvolveがどのようにしてLLM「Gemini」と進化的探索を融合させ、自律的にアルゴリズムを発見・改良するのか、その仕組み、具体的な応用事例、技術的特徴、そして今後の展望まで詳しくご紹介します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
AlphaEvolveとは?
「AlphaEvolve」は、Google DeepMindが開発したアルゴリズムの発見と最適化に特化した革新的なAIエージェントです。
このシステムは、最先端の大規模言語モデル(LLM)である「Gemini」の創造的な問題解決能力と、生物の進化のプロセスにヒントを得た進化的アルゴリズム、そして生成された解の有効性を検証する自動評価システムを巧みに組み合わせることで、従来の自動発見手法の限界を大きく押し広げます。

AlphaEvolveの核心
AlphaEvolveの強みは、LLMの柔軟なコード生成能力と、進化的探索の効率的な最適化能力を融合させた点にあります。
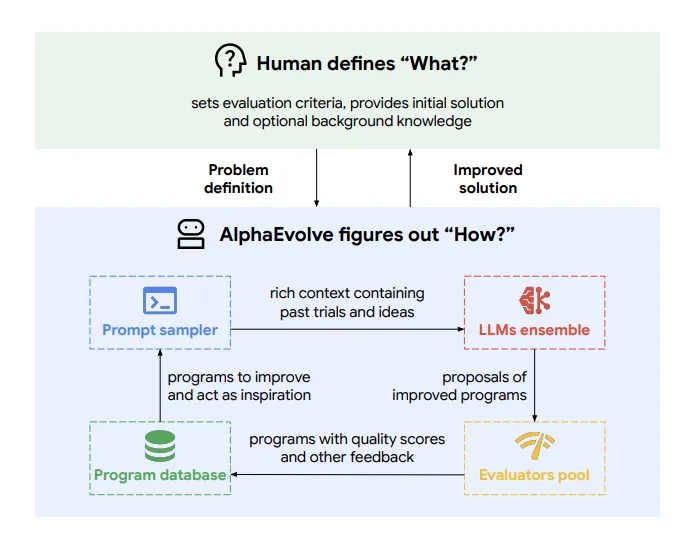
AlphaEvolveの概要 (参考:AlphaEvolve: A coding agent for scientific and algorithmic discovery」
上図(論文Figure 1参照)は、AlphaEvolveのコンセプトを示しています。
科学者やエンジニアが解決したい課題の定義(評価基準や初期解、背景知識など)を設定すると、AlphaEvolveがその「解き方(How?)」を自律的に見つけ出そうとします。
このプロセスは、LLMが改善案を提案し、それが評価され、有望なものが次の世代の改善に繋がるという、継続的な改善ループによって成り立っています。
AlphaEvolveの進化
AlphaEvolveは、Google DeepMindの以前の研究である「FunSearch」を大幅に拡張・汎用化したものです。
FunSearchもLLMと進化的探索を組み合わせたアプローチでしたが、AlphaEvolveは以下の点で大きく進化しています。
【FunSearchとAlphaEvolveの主な違い】(参考:AlphaEvolve論文 Table 1)
| 機能・特性 | FunSearch | AlphaEvolve |
|---|---|---|
| 進化対象 | 単一関数 | コードファイル全体 |
| コード規模 | 10-20行程度 | 数百行規模 |
| 対応言語 | Python | 任意の言語 |
| 評価時間/リソース | 高速 (CPUで20分以内) | 長時間 (アクセラレータ上で数時間、並列実行可) |
| LLMサンプル数 | 数百万 | 数千で十分 |
| LLMモデル | 小規模LLM (大規模化の恩恵少) | 最先端LLM (Gemini Flash/Pro) の恩恵大 |
| プロンプトの文脈 | 最小限 (過去の解のみ) | 豊富な文脈とフィードバック |
| 最適化対象 | 単一メトリクス | 複数メトリクスの同時最適化可 |
この表からも分かるように、AlphaEvolveはより複雑で大規模なコードを扱え、多様なプログラミング言語に対応し、より強力なLLMの能力を活用することで、FunSearchでは対応できなかった広範な問題に取り組むことが可能になっています。
AlphaEvolveの仕組み
AlphaEvolveは、どのようにして新しいアルゴリズムを発見し、改良していくのでしょうか。その自律的な発見プロセスは、いくつかの主要コンポーネントの連携によって実現されています。
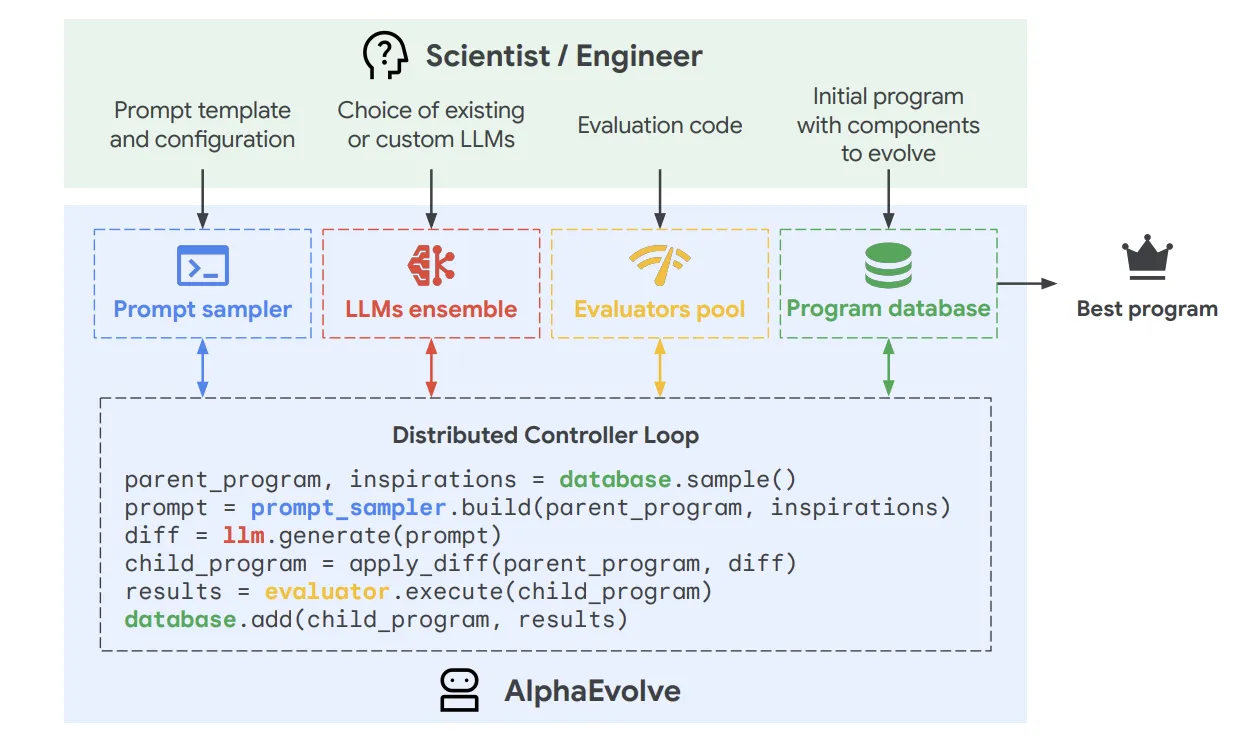
AlphaEvolve 発見プロセス詳細
上図は、AlphaEvolveの発見プロセスをより詳しく示したものです。このプロセスは、以下のステップからなる進化的ループによって駆動されます。
1. タスク定義 (ユーザー入力):
- 評価コード (evaluate関数):
生成されたアルゴリズム(プログラム)の性能を自動評価するための基準とロジックを定義します。AlphaEvolveはこの評価結果(スカラー値のセット)を最大化しようとします。
- 初期プログラム:
改良の出発点となるプログラム。進化させたい箇所は 「# EVOLVE-BLOCK-START」と# EVOLVE-BLOCK-ENDで囲んで指定します。非常にシンプルなものでも構いません。
- プロンプトテンプレートと設定 (オプション):
LLMへの指示の与え方や、問題に関する背景知識(論文PDF、数式など)をカスタマイズできます。
2. プロンプトサンプラー (Prompt sampler):
プログラムデータベースから、過去に評価されたプログラム(成功例や多様な試行例)をサンプリングし、これらを基にLLMへの効果的なプロンプトを構築します。
プロンプトには、問題の詳細、過去の試行結果、そして現在の改善対象プログラムなどが含まれます。
3. LLMアンサンブルによる創造的生成 (Creative generation):
AlphaEvolveの中核を担うのが、Gemini 2.0 Flash および Gemini 2.0 Pro といった最先端の大規模言語モデル(LLM)のアンサンブルです。
これらのLLMは、プロンプトサンプラーから受け取った豊富な文脈情報を元に、既存のプログラムを改善するための新しいアイデアをコードの変更提案(diff形式)として生成します。
4. 評価プール (Evaluators pool):
LLMによって提案された新しいプログラムは、ユーザーが定義したevaluate関数に基づいて自動的に評価されます。
AlphaEvolveは、評価カスケード(段階的なテストケース評価)やLLMによる定性的なフィードバックの組み込み、評価プロセスの並列化など、柔軟かつ効率的な評価メカニズムをサポートしています。
5. プログラムデータベースと進化 (Program database & Evolution):
評価結果(スコアやその他のフィードバック)と共に、生成されたプログラムはプログラムデータベースに格納されます。
このデータベースは、MAP-Elitesアルゴリズムやアイランドベースの集団モデルに触発された手法を用いて、有望な解を維持しつつ多様性を確保し、次の世代の改善のための「親」プログラムや「インスピレーション」となるプログラムをプロンプトサンプラーに提供します。
この一連のループを自律的に繰り返すことで、AlphaEvolveはプログラムを徐々に進化させ、より高性能なアルゴリズムを発見していきます。
AlphaEvolveが達成した驚くべき成果と応用事例
AlphaEvolveは、その汎用性と強力な探索能力により、既に様々な分野で目覚ましい成果を上げています。
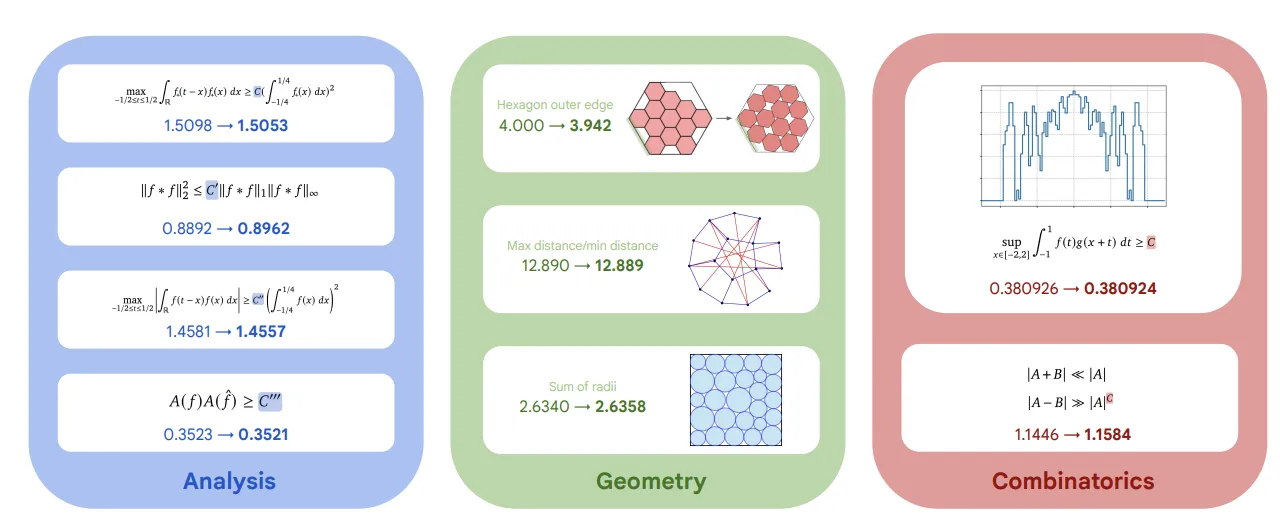
AlphaEvolve SOTA越え数学的の発見例 (参考:AlphaEvolve: A coding agent for scientific and algorithmic discovery」
論文のFigure 5では、AlphaEvolveが発見した、既存の最先端(SOTA)記録を更新した数学的構成物の例が視覚的に示されています。
これらは、解析学、幾何学、組み合わせ論といった多様な数学分野にまたがっており、AlphaEvolveの汎用性の高さを示しています。
数学・コンピュータサイエンスにおける新発見
- 行列乗算アルゴリズムの歴史的更新:
AlphaEvolveは、4x4の複素行列乗算において、長年(56年間)破られていなかったStrassenのアルゴリズム(スカラー乗算49回)を改善し、48回のスカラー乗算で実行可能な新しいアルゴリズムを発見しました。
これは、AIが人間の直感では到達困難だった複雑な数学的構造を発見できることを示す画期的な成果です。
- 多様な未解決数学問題への貢献:
50以上の数学の未解決問題(組み合わせ論、幾何学、数論など)に適用され、約75%で既存の最良解を再発見、約20%でそれを上回る新しい構成や解を発見しました。
これには、エルデシュの最小重複問題の改善や、11次元におけるキッシング数の下限更新などが含まれます。
これらの成果は、外部の数学者との協力によってもたらされたものもあり、AIと人間の専門家の協調の可能性を示しています。
Google社内システムの最適化と効率向上
AlphaEvolveは、理論的な発見だけでなく、Googleの基幹システムや製品開発にも実用的な貢献をしています。
- データセンターのスケジューリング効率化:
Googleの大規模データセンターにおけるジョブスケジューリングヒューリスティックを最適化し、計算リソースの利用効率を平均0.7%改善しました。
これは、既存の人間が設計したヒューリスティック関数を進化させることで達成されました。

データセンター効率化ヒューリスティック (参考:AlphaEvolve: A coding agent for scientific and algorithmic discovery」
:::
- Geminiカーネルのエンジニアリング効率化:
大規模言語モデルGeminiの学習に使われる重要な行列乗算カーネルのタイリングヒューリスティックを最適化し、カーネル実行時間を平均23%高速化、Gemini全体の学習時間を1%削減しました。これにより、数ヶ月かかっていたカーネル最適化作業が数日に短縮されました。
-
TPUハードウェア回路設計の支援:
GoogleのAIアクセラレータであるTPUの演算回路(Verilog記述)の最適化にも挑戦し、不要なビットを削減するコード書き換えを発見しました。
これは、AIがハードウェア設計の初期段階(RTL最適化)に貢献できる可能性を示すものです。
-
コンパイラ生成コードの直接最適化:
Transformerモデルの主要部分であるFlashAttentionのXLA(コンパイラ)生成中間表現(IR)を直接最適化し、GPU上での実行時間を大幅に短縮しました(カーネル部分で32%、前処理・後処理部分で15%)。
これらの事例は、AlphaEvolveがソフトウェアからハードウェア、理論から実践まで、幅広い領域で価値を生み出せることを実証しています。

AlphaEvolveの技術的特徴
AlphaEvolveの成功は、いくつかの重要な技術的特徴と、それらが効果的に機能することを示す実験結果に裏打ちされています。
アブレーションスタディによる主要コンポーネントの有効性検証
AlphaEvolveの各構成要素がどの程度性能に寄与しているかを検証するために、アブレーションスタディ(要素抜き実験)が行われました。
この結果は、AlphaEvolveの設計思想の正しさと、各コンポーネントが相乗効果を生み出していることを示しています。
【AlphaEvolveの現在地と未来】論文が示す限界と展望
AlphaEvolveは画期的な成果を上げていますが、その能力には限界も存在し、さらなる発展に向けた多くの可能性があります。
Google DeepMindの論文「AlphaEvolve: A coding agent for scientific and algorithmic discovery」の「Discussion」セクションでは、これらの点について重要な考察がなされています。
AlphaEvolveの主な限界点
AlphaEvolveが直面している主な限界点は、その強力な自動評価メカニズムへの依存と、LLMによる質的な評価の最適化に関連しています。
自動評価メカニズムへの依存:
AlphaEvolveの核心的な強みである「自動評価」は、適用可能な問題の範囲を規定する要因ともなっています。数学や計算科学のように、解の性能をプログラムによって明確かつ客観的に評価できる問題に対しては絶大な効果を発揮します。
しかし、例えば物理学や化学、生物学といった自然科学の分野では、全ての実験をシミュレーションで完全に再現したり、結果を単純な数値スコアで評価したりすることが難しい場合があります。
このような、手動での実験や複雑な解釈を必要とする領域への直接的な適用は、現状のAlphaEvolveにとっては大きな課題です。
LLMによる質的評価の最適化:
AlphaEvolveは、生成されたアイデアやコードの「質」(例えば、シンプルさ、解釈の容易さ、新規性など)をLLMが評価する機能も持ち合わせていますが、この側面はまだ開発と最適化の途上にあります。
現在の運用では、主にプログラムを実行した結果得られる定量的なスコア(計算速度、精度など)に基づいて進化の方向性が決定されており、LLMによるよりニュアンスに富んだ質的評価を効果的に進化プロセスに組み込むことには、さらなる研究の余地があります。
これらの限界点は、AlphaEvolveが万能ではないことを示しており、今後の研究開発における重要なテーマとなります。
AlphaEvolveの将来展望
論文では、現在の限界を踏まえつつ、AlphaEvolveが今後どのように発展し、科学技術に貢献していくかについての刺激的な展望が示されています。
人間とAIの協調進化と評価の柔軟性向上:
将来的には、AlphaEvolveの強みであるプログラムベースの厳密な評価と、LLMが得意とする高レベルな概念理解や質的評価を、より高度に融合させることが構想されています。
例えば、AI Co-Scientistのようなアプローチと連携し、初期の仮説立案や研究の方向付けはLLMが人間の研究者と対話しながら行い、具体的な実験計画やシミュレーション、データ解析といった実行可能な部分はAlphaEvolveが担当するといった、より柔軟で強力な研究支援体制が期待されます。
これにより、実験の自動化が難しい分野へも応用範囲を広げられる可能性があります。
自己改善ループの加速と知識の蒸留:
AlphaEvolveは、自身の動作に必要なインフラ(例えば、LLMの学習に使われるカーネル)や、基盤となるLLM(Geminiなど)の効率を改善する能力を既に示しています。
この「AIがAI自身を改良する」という自己改善のフィードバックループをさらに高速化し、強化していくことが期待されています。AlphaEvolveが発見した高度なアルゴリズムや問題解決戦略を、次世代のLLMに「蒸留(distillation)」することで、LLM自体の基礎能力を引き上げ、AlphaEvolveのようなエージェントシステムを介さずとも、より高度な問題解決が可能になる未来も描かれています。
応用分野の拡大と評価エコシステムの発展:
AlphaEvolveのようなAIエージェントの有効性が広く認知されるにつれて、様々な専門分野で信頼性の高い自動評価環境やベンチマークを整備しようとする動きが加速する可能性があります。
これにより、これまでAIの適用が難しかった新たな領域でも、AlphaEvolveがその能力を発揮し、実世界での価値創出に貢献する事例が増えていくことが期待されます。
これらの展望は、AlphaEvolveが単なるアルゴリズム発見ツールに留まらず、科学的探求のあり方そのものを変革し、人類の知識のフロンティアを押し広げるための強力な触媒となる可能性を示唆しています。

【まとめ】AlphaEvolveが示すAIによる科学的発見の新時代
AlphaEvolveは、Google DeepMindが開発した、アルゴリズムの発見と最適化を新たな次元へと引き上げる画期的なAIエージェントです。大規模言語モデル「Gemini」の創造性と進化的アルゴリズムの効率性を融合させることで、長年未解決だった数学の問題を解決したり、既存の最先端技術をさらに改良したりと、驚くべき成果を次々と生み出しています。
その応用範囲は、コンピュータサイエンスや数学といった基礎研究に留まらず、材料科学、創薬、持続可能性といった実社会の喫緊の課題解決にも及ぶと期待されています。AlphaEvolveは、AIが人間の知的活動を支援し、科学技術の進歩を加速させる「AIサイエンティスト」としての可能性を明確に示しました。
まだ一般利用には至っていませんが、今後の発展と社会への展開から目が離せません。AlphaEvolveの登場は、まさにAIによる科学的発見の新時代の幕開けを告げるものと言えるでしょう。
AI研究の進展を自社業務のAI活用に結びつけるなら
AlphaEvolveのような最先端のAI研究は、直接業務に使えるものではなくても、「AIにどこまで任せられるか」の上限を押し上げています。
こうした技術進化を背景に、自社の業務プロセスにAIを導入する計画を具体化する企業が増えています。AI総合研究所のガイドでは、最新のAI技術動向を踏まえた業務自動化の設計方法を解説しています。
AI総合研究所のガイドで、AI技術の進化を自社業務にどう活かすかのヒントを見つけてください。
AI研究の最前線から自社業務のAI活用を考える

AIの可能性を業務改善に結びつける
AlphaEvolveのようなAI研究の進展は、業務プロセスにAIを活用する可能性を広げています。ガイドでは自社業務へのAI導入を具体的に進める方法を解説しています。










