この記事のポイント
 世界モデルはLLM後の次のパラダイムで、観測から世界の物理ルールを学び未来を予測するAI基盤
世界モデルはLLM後の次のパラダイムで、観測から世界の物理ルールを学び未来を予測するAI基盤- 動画生成・3D空間・JEPA潜在予測・Cosmos基盤など5派閥が並走する2026年競争期
- NVIDIA Cosmos 3・Google Genie 3・Meta V-JEPA 2が技術リード、World Labs Marbleが商用提供
- 自動運転・ロボティクス・製造業デジタルツインに直接効き、企業のPoCはすでに着手段階
- 計算コスト・Sim2Realギャップ・データ著作権が導入の壁。業種別の判断軸が必須

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
世界モデル(World Model)は、AIに「世界の物理ルール」と「未来予測」を持たせるための基盤技術です。
2018年のDavid Ha・Schmidhuber論文を起点に研究が続いてきた領域ですが、NVIDIA Cosmos 3・Google DeepMind Genie 3・Meta V-JEPA 2・World Labs Marbleなど主要プレイヤーが相次いで本格モデルを投入し、2026年に「LLMに続く次のAIパラダイム」として急速に実装段階へ入りました。
本記事では、世界モデルの定義と仕組み、5つの派閥分類、主要プレイヤーの最新動向、応用領域、料金と利用形態、導入の壁、そして企業がいま取るべきスタンスを、2026年6月時点の最新情報で体系的に解説します。
目次
Google DeepMind Genie 3:リアルタイム3D環境の実装
World Labs Marble:商用提供を開始した3D世界モデル
Yann LeCun AMI Labs:JEPA派の独立スタートアップ
Sim2Realギャップ:仮想で学んだ動きが実機で再現できない
製造業・自動運転・ロボティクス領域:今すぐPoC候補に上げる
世界モデル(World Model)とは何か

世界モデル(World Model)は、AIが世界の物理ルールと因果関係を内部に持ち、行動の結果や次の状態を予測するための基盤技術です。
観測したデータ(画像・動画・センサー・言語)から「次に何が起こるか」を予測できる仕組みを学習し、**意思決定や行動計画の起点となる「内部シミュレーター」**として機能します。
起点となったのは、Google Brain所属のDavid Ha氏とLSTM考案者のJürgen Schmidhuber氏が2018年に発表した論文「World Models」です。
当時はゲーム環境向けの研究テーマでしたが、2025〜2026年にNVIDIA Cosmos 3・Google DeepMind Genie 3・Meta V-JEPA 2が相次いで投入され、産業実装の段階へ一気に押し上がりました。
人間の認知科学でいう「メンタルモデル」と発想は同じです。人は身の回りの世界を頭の中で簡略化し、「ボールを投げたら落ちる」「車に近づいたら危ない」といった未来予測を、実際に試さなくてもシミュレーションできます。
世界モデルは、その仕組みを機械で再現する試みです。

世界モデルの仕組みと2つの設計思想
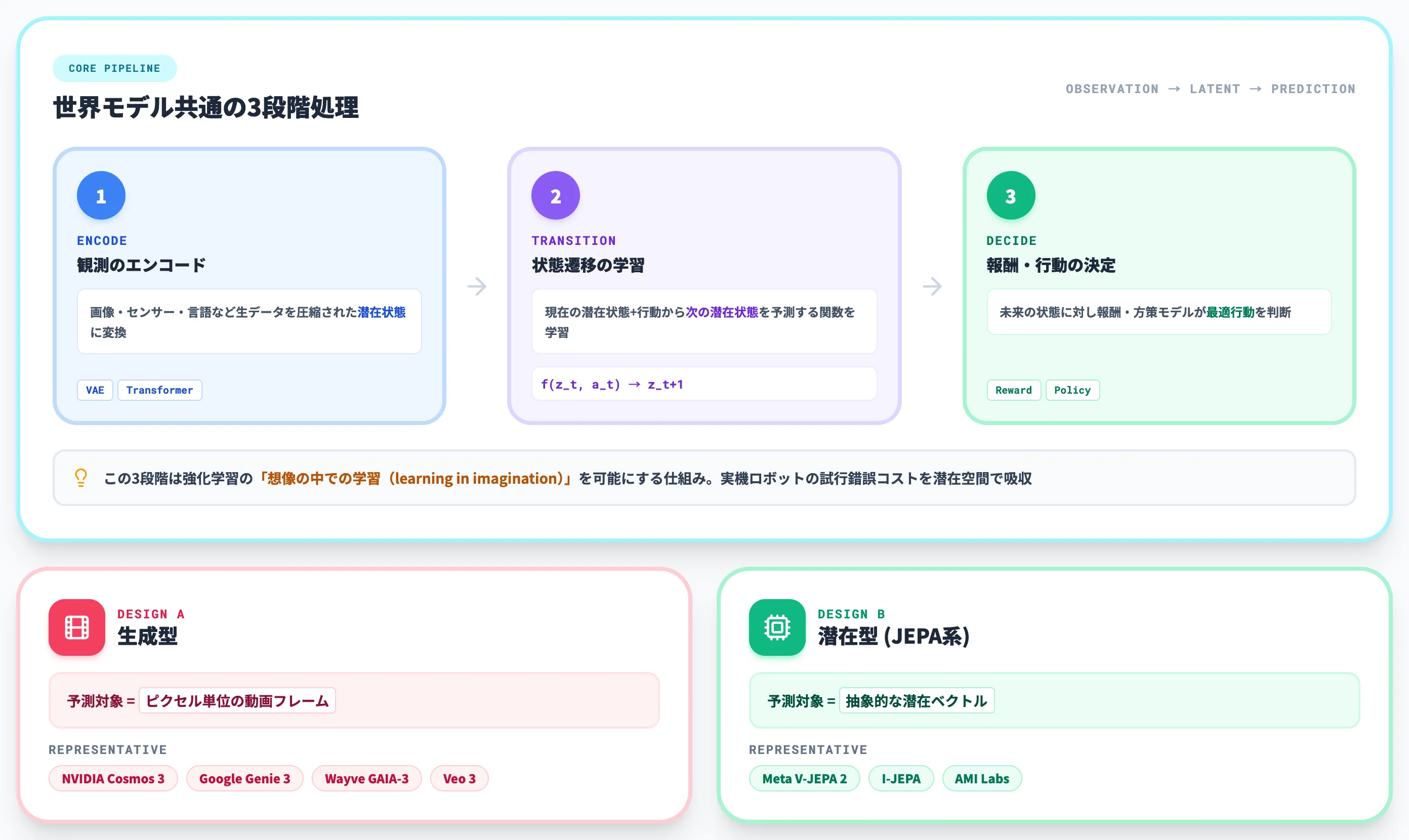
世界モデルの動きを最小構成で言えば、「観測 → 内部表現 → 次の状態の予測」という3段階の流れです。
本セクションでは、世界モデル共通の3段階処理と、2026年現在の主要研究で分かれている「生成型」「潜在型」という2つの設計思想を整理します。
観測→潜在表現→次状態予測の3段階
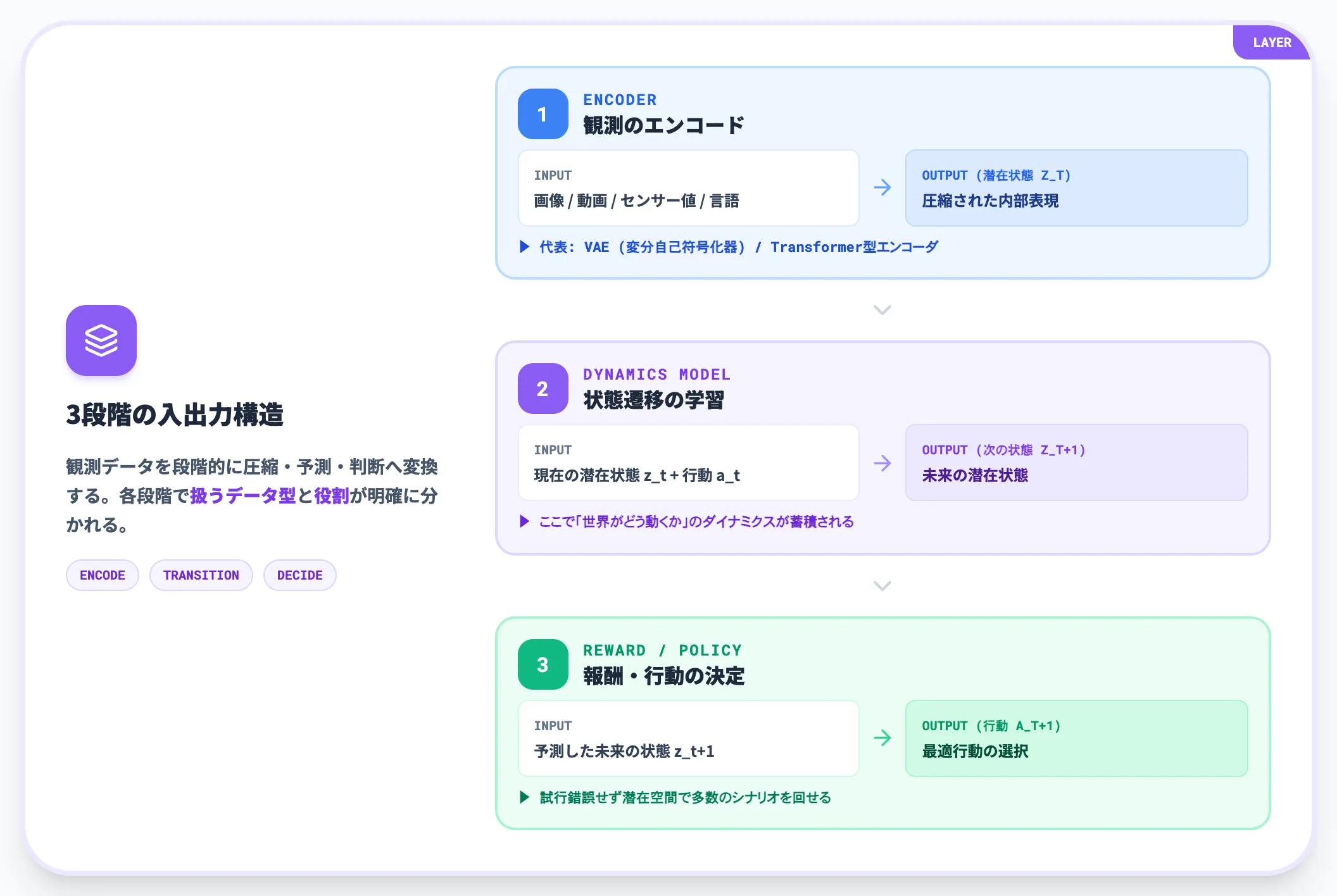
ほとんどの世界モデルは、以下の3段階で世界を扱います。
-
観測のエンコード
カメラ画像・センサー値・言語などの生データを、世界モデルが扱いやすい圧縮された内部表現(潜在状態)に変換します。VAE(変分自己符号化器)やトランスフォーマー型エンコーダが代表的です。
-
状態遷移の学習
現在の潜在状態と、エージェントが取った行動から、「次の潜在状態」を予測する関数を学習します。ここで「世界がどう動くか」のダイナミクスがモデル内部に蓄積されます。
-
報酬・行動の決定
予測した未来の状態に対して、報酬モデルや方策モデルが「どの行動が望ましいか」を判断します。エージェントは実環境で試行錯誤せずに、頭の中(潜在空間)で多数のシナリオを回せます。
この3段階は、強化学習における**「想像の中での学習(learning in imagination)」**を可能にする仕組みです。実機ロボットでの試行錯誤コストが高い領域では、潜在空間で多数のシナリオを回せることが投資判断のうえで重要になります。
生成型と潜在型の2つの設計思想

3段階の枠組みは共通でも、「予測する対象」をピクセル空間にするか潜在空間にするかで設計思想が大きく分かれます。
| 設計思想 | 予測対象 | 代表モデル | 強み | 弱み |
|---|---|---|---|---|
| 生成型 | ピクセル単位の動画フレーム | NVIDIA Cosmos 3、Google Genie 3、Wayve GAIA-3、Google Veo 3、Kuaishou Kling | 人が見て理解できる出力、合成データ生成にそのまま使える | 計算コストが高い、物理的に「もっともらしく見える」だけで本物の理解とは限らない |
| 潜在型(JEPA系) | 抽象的な潜在ベクトル | Meta V-JEPA 2、I-JEPA、Yann LeCun AMI Labsの方向性 | 計算効率が良い、行動計画・抽象推論に向く | 出力が人間には直接見えない、評価が難しい |
このどちらが「正解」かは2026年現在も決着していません。Yann LeCun氏は「ピクセル生成は無駄、潜在予測こそ知能」という立場でMetaを2025年11月に退社し、AMI Labsで潜在型路線を独立に進めています。
一方、Cosmos系やVeo系は「生成できる=物理を理解している」という立場で、合成データ供給・シミュレーション学習という産業ニーズに直接応える設計です。
実装側の判断としては、産業ユースケース(合成データ生成・ロボット訓練)には生成型、抽象推論や効率を重視するなら潜在型という棲み分けで考えるのが現実的です。
世界モデルの5つの派閥
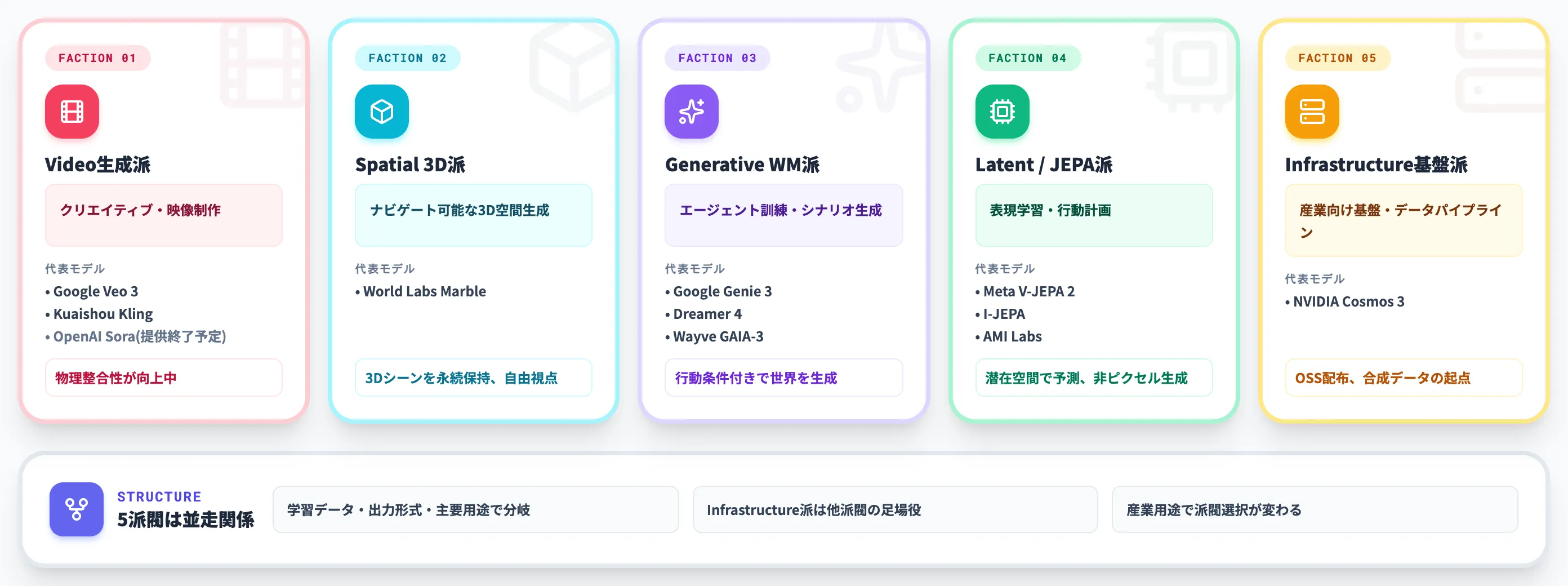
世界モデルは「全部が同じ技術」ではありません。学習データ・出力形式・主要用途で大きく5つの派閥に分かれて発展しています。
以下の表で、5派閥の特徴と代表モデルを整理しました。
| 派閥 | 主用途 | 代表モデル | 特徴 |
|---|---|---|---|
| Video生成派 | クリエイティブ・映像制作 | Google Veo 3、Kuaishou Kling、OpenAI Sora(2026年中に提供終了) | 動画として出力、物理整合性が向上中 |
| Spatial 3D派 | ナビゲーション可能な3D空間生成 | World Labs Marble | 3Dシーンを永続的に保持、自由視点で探索可能 |
| Generative WM派 | エージェント訓練・シナリオ生成 | Google Genie 3、Dreamer 4、Wayve GAIA-3 | 行動条件付きで世界を生成、強化学習との親和性 |
| Latent / JEPA派 | 表現学習・行動計画 | Meta V-JEPA 2、I-JEPA、AMI Labs | 潜在空間で予測、ピクセル生成を行わない |
| Infrastructure基盤派 | 産業向け基盤モデル・データパイプライン | NVIDIA Cosmos 3 | OSSで配布、合成データ生成と物理AI開発の起点 |
分類はIntrolの世界モデルレース2026分析なども参考にしつつ、本記事では5つの派閥として整理します。
Video生成派
Google Veo 3・Kuaishou Klingに代表される動画生成モデルです。テキストや画像からリアルな動画を生成し、物理整合性(バスケットボールがリングを外したらリバウンドする等)を学習しています。
クリエイティブ用途が主軸ですが、「動画を生成できる=世界の物理を理解している」という捉え方も広がり、世界モデルの一形態として議論されています。
派閥のキープレイヤーだったOpenAI Soraは2026年4月26日にweb/appが終了し、Sora APIも2026年9月24日に提供終了する予定です。今後の動画生成派では、Google Veo 3・Kling・Runway(NVIDIA Cosmos Coalitionにも参加)などが主要候補になります。
Spatial 3D派
World Labs Marbleが代表で、テキスト・画像・パノラマ・ラフな3Dレイアウトから永続的に保持されるナビゲーション可能な3D環境を生成します。動画と違い、視点を自由に動かせる「空間」を作るのが特徴です。
VR・ゲーム・建築ビジュアライゼーションなどの3Dコンテンツ生成領域に強く効きます。
Generative WM派
Google DeepMind Genie 3・Dreamer 4・Wayve GAIA-3のように、エージェントの行動を条件として「次のフレーム」「次の世界」を生成するモデル群です。強化学習エージェントを「想像の中で訓練する」ために設計されており、5派閥のなかでも特に研究が活発な領域です。
Latent / JEPA派
Meta V-JEPA 2に代表される潜在空間予測モデルです。ピクセルを生成せず、「未来の潜在表現」を予測することで効率と抽象性を担保します。
Yann LeCun氏が長年主張してきた路線で、2025年11月のMeta退社後にAMI Labsで独立に研究を継続している方向でもあります。
AMI Labsは2026年3月10日に$1.03Bのシード調達を公表し、評価額$3.5B pre-moneyとヨーロッパ最大級の規模に育っています。
Infrastructure基盤派
NVIDIA Cosmos 3を中核とする「物理AI向けの基盤モデル・データパイプライン提供」派です。Cosmos自体は単独のアプリケーションではなく、他のロボット・自動運転モデルを訓練するための合成データ生成と評価基盤として位置づけられています。
OSSでHugging Face・GitHubに公開され、build.nvidia.comで試せる「ピックスアンドショベル」型のアプローチです。
動画生成派(Veo・Klingなど)やJEPA(潜在)と直接競合するというより、両者が動くための足場を作る役割を担っています。
主要プレイヤーの最新動向(2026年)
5派閥の分類軸を踏まえたうえで、ここからは2026年6月時点で実装段階に入っている主要プレイヤーを個別に整理します。
本セクションでは、技術仕様・最新リリース日・他社との位置づけの違いを中心に扱います。各社の応用領域や事例は次のH2で別途整理します。
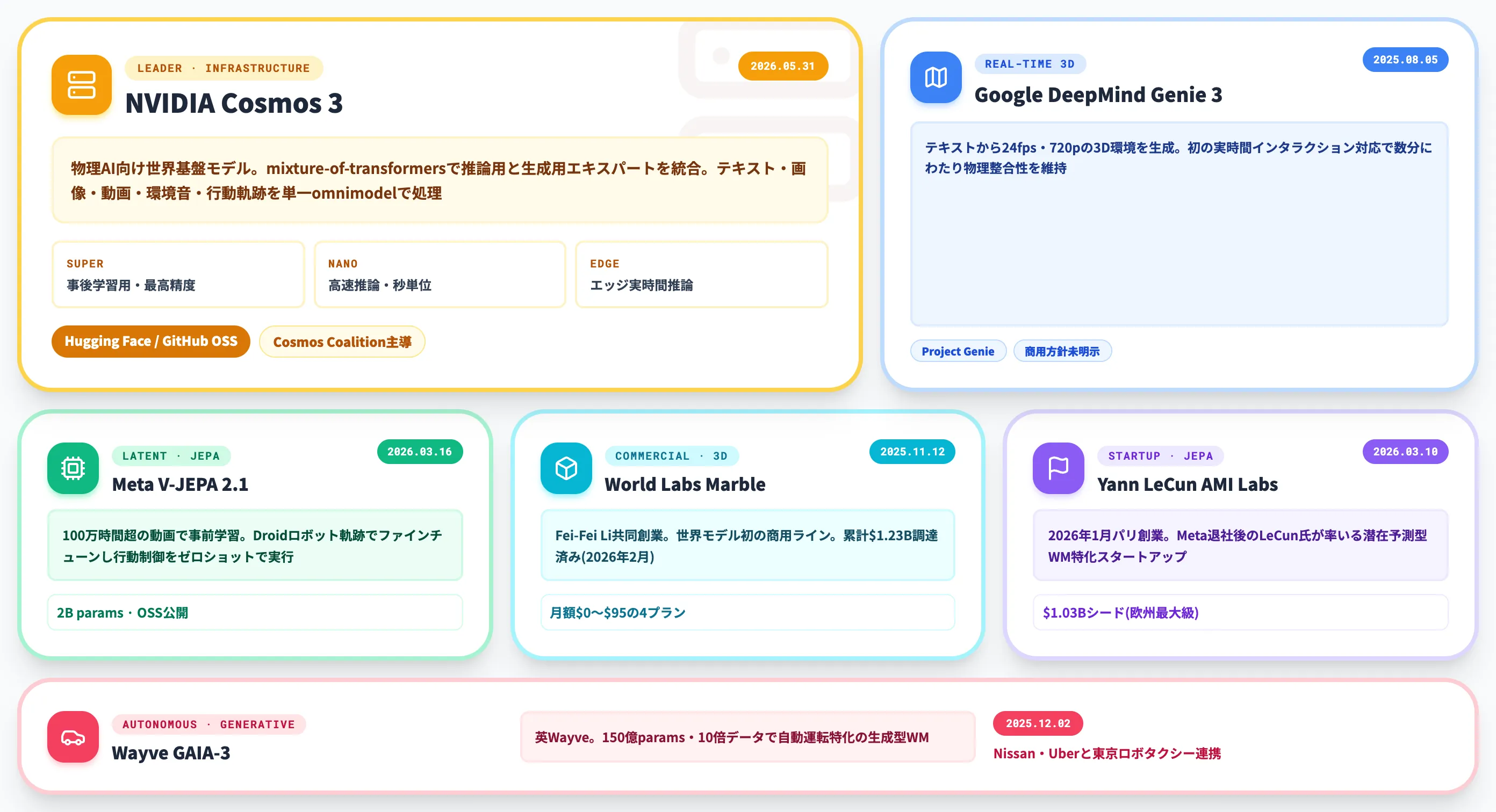
NVIDIA Cosmos 3:物理AIの基盤を握る
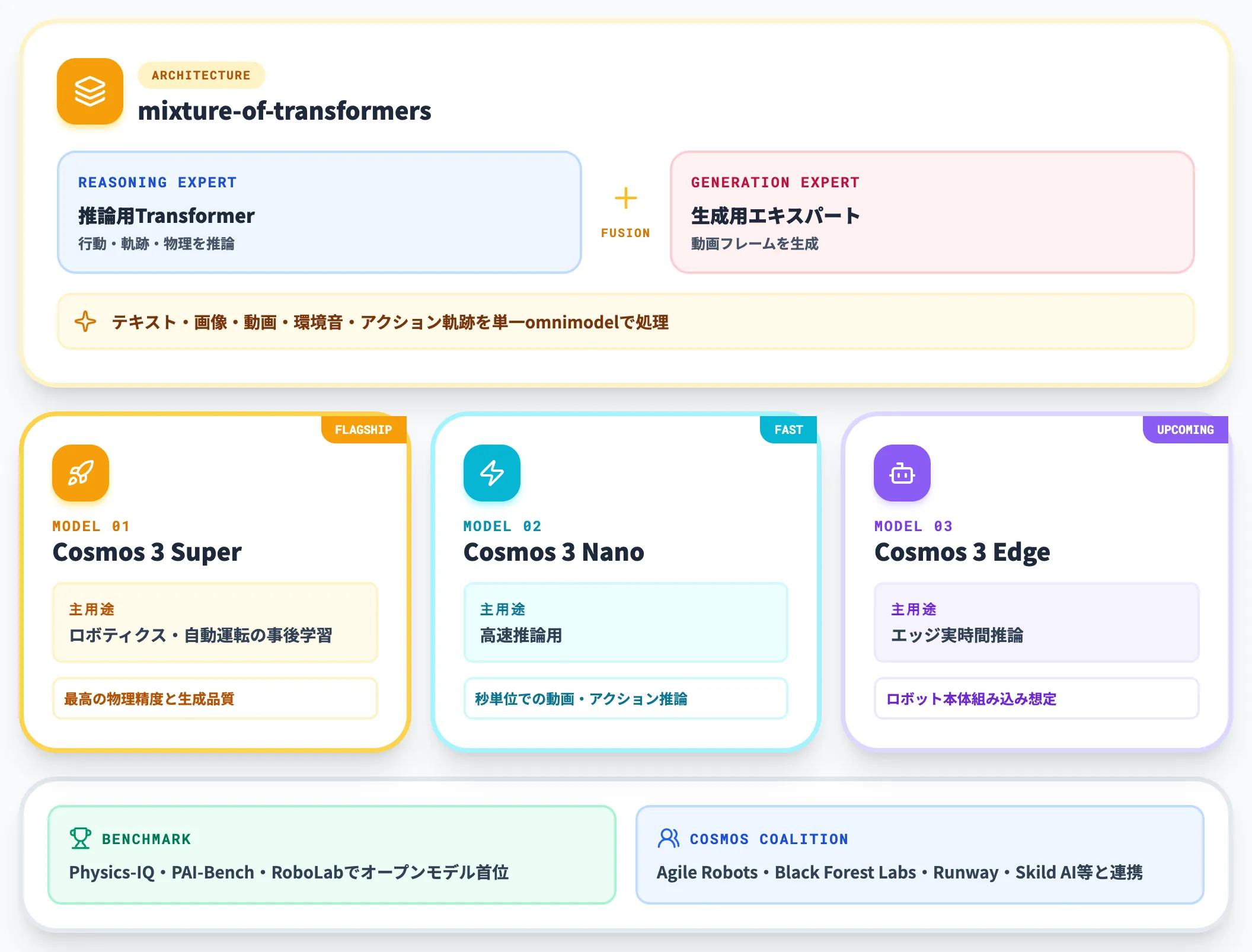
NVIDIA Cosmos 3は、2026年5月31日のNVIDIA GTC Taipei(COMPUTEX 2026併催)で発表された、物理AI向けの最先端世界基盤モデルです。
前世代のNVIDIA Cosmos(2025年1月CES発表)から大きく進化しており、推論用トランスフォーマーと生成用エキスパートを組み合わせたmixture-of-transformersアーキテクチャを採用しています。

Cosmos 3発表キービジュアル。自動運転車(COSMOS3ナンバープレート)とヒューマノイドロボットを並べて「同じ世界モデル基盤で扱う」設計思想を表現(出典:NVIDIA Newsroom)
このキービジュアルが示すとおり、Cosmos 3は自動車向けの自動運転シミュレーションとロボット向けの行動学習を、別々の基盤ではなく1つの世界モデルで吸収しに行く設計です。手前に並ぶ5つのアイコンは、それぞれデータ生成・物理シミュレーション・推論・行動軌跡・基盤データの役割を担うCosmosコンポーネント群を象徴しています。
以下の表で、Cosmos 3のラインアップを整理しました。
| モデル | 主用途 | 特徴 |
|---|---|---|
| Cosmos 3 Super | ロボティクスと自動運転の事後学習向け | 最高の物理精度と生成品質 |
| Cosmos 3 Nano | 高速推論用 | 秒単位での動画・アクション推論が可能 |
| Cosmos 3 Edge(近日公開) | エッジ実時間推論 | ロボット本体への組み込みを想定 |
テキスト・画像・動画・環境音・アクション軌跡をすべて単一モデルで扱う「omnimodel」として設計されており、Hugging FaceとGitHubで完全オープン公開されています。NVIDIA公式によれば、オープンモデルの中でPhysics-IQ・PAI-Bench・RoboLabなど複数ベンチマークで首位を獲得しています。
加えて、NVIDIAはAgile Robots・Black Forest Labs・Generalist・LTX・Runway・Skild AIなどと「Cosmos Coalition」を発足させ、コアリションでオープンな世界モデル開発を進める体制を整えています。
物理AI全体の構造とCosmos 3の位置づけは、フィジカルAI(物理AI)とは?Cosmos 3・Isaac GR00Tから国内戦略まで解説で全体像を整理しています。
Google DeepMind Genie 3:リアルタイム3D環境の実装
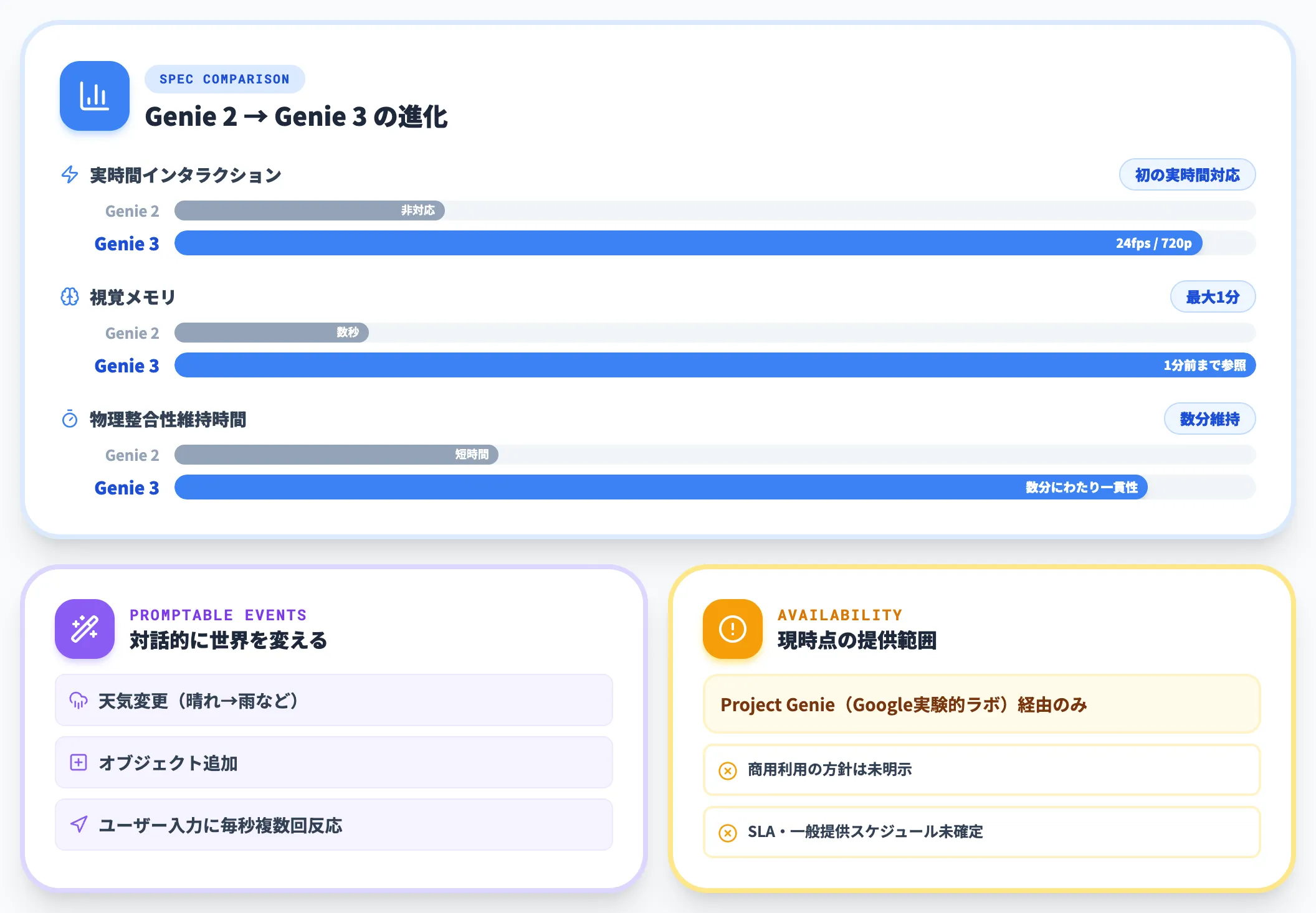
Google DeepMind Genie 3は、2025年8月5日に発表されたリアルタイム対応の世界モデルです。テキストプロンプトから24fps・720pの3D環境を生成し、ユーザーが自由に探索できる「ナビゲート可能な世界」をその場で構築します。

Genie 3が生成した3D環境のサンプル群。火山・水中・歴史的街並み・ウィングスーツ視点・ベネチア風水路・ファンタジー風景などをテキストから生成し、中央の矢印キーUIで自由に探索できる(出典:DeepMind Blog)
サンプル群を見ると分かるとおり、Genie 3が扱う「世界」は写実的風景から空想的シーンまで広く、生成された各環境のなかをユーザーが矢印キーで歩き回れるのが核心です。動画生成モデルが「一本のクリップを作る」のに対し、Genie 3は「歩いて視点を変えられる空間そのもの」を作るという違いが、このキービジュアルで読み取れます。
Genie 2との大きな違いは、初の実時間インタラクション対応になった点です。ユーザー入力に対して1秒間に複数回反応でき、数分にわたり環境の物理的矛盾を維持できます。視覚的なメモリ(最大1分前までの情報を参照)と、天気変更やオブジェクト追加といった「promptable world events」にも対応します。
Meta V-JEPA 2:潜在予測の代表

Meta V-JEPA 2は2025年6月(arXiv 2506.09985)に公開された、動画を学習データとする初の本格的な潜在予測型世界モデルです。
100万時間超のインターネット動画で事前学習し、わずか62時間のロボット軌跡(Droidデータセット)でファインチューニングすることで、reaching・grasping・pick-and-placeなどのロボット制御タスクをゼロショットで実行できます。
「行動予期(action anticipation)」「動画質問応答」「ロボット計画」など、ピクセルを生成せずに行動を導く能力に強みがあります。GitHub(facebookresearch/vjepa2)とHugging Faceでモデルが公開されており、研究目的では即座に試せます。
なおMetaは2026年3月16日にV-JEPA 2.1を公開し、Dense Predictive Loss・Deep Self-Supervision・Multi-Modal Tokenizersを導入しました。最大2Bパラメータまでスケールし、密集予測・グローバル予測の両タスクで精度が向上しています。2026年6月時点での最新版はV-JEPA 2.1です。
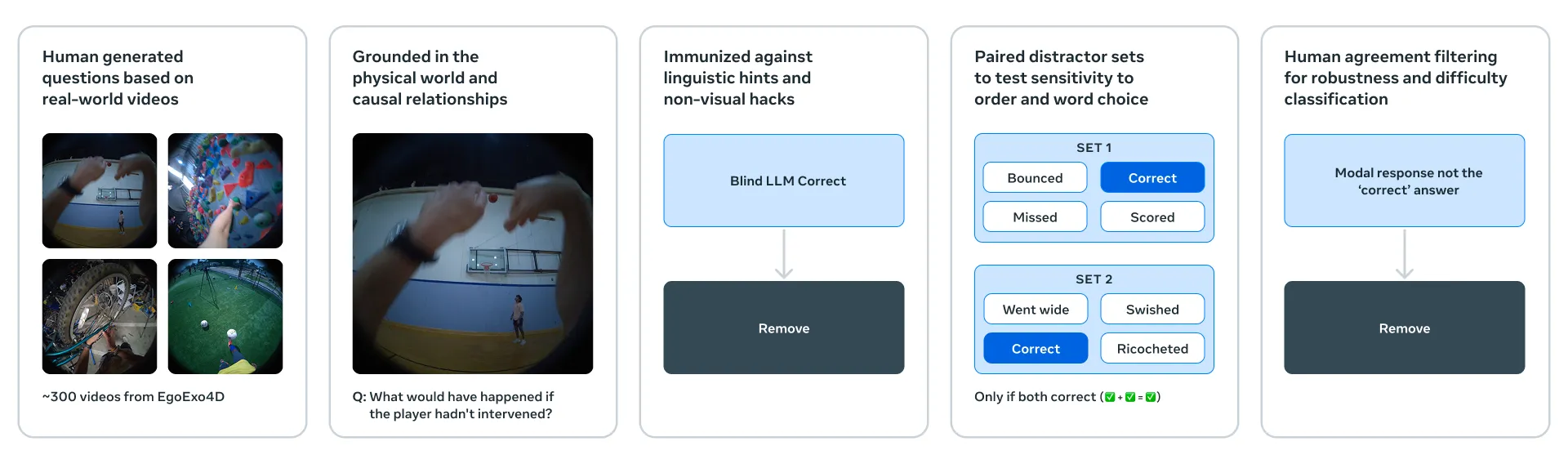
Meta V-JEPA 2公式の評価フレーム5段。動画から人が質問を作り、物理世界と因果関係に根拠を置き、言語的なヒント・誤答候補・人の合意度フィルタを順に通して、モデルが本当に世界を理解しているかを測る(出典:Meta AI Blog)
評価フレームは「動画ベースで人が質問を起こす→物理現象と因果関係に紐付ける→言語的ヒントを除外する→誤答候補とペアにする→複数人で合意するものだけ残す」という5段の絞り込みです。
世界モデルの評価は数値ベンチで測りにくい領域ですが、Metaはこの評価方法論ごと公開することで、潜在予測型モデルの実用評価をオープンに進めようとしています。
World Labs Marble:商用提供を開始した3D世界モデル
World Labs Marbleは、スタンフォードAI教授Fei-Fei Li氏が共同創業したWorld Labsが提供する世界モデル製品としては初の商用ラインです。
World Labs公式ブログによれば、Marbleは2025年11月12日に "available to everyone" として一般提供開始されました。2026年2月にはWorld Labsが追加で$1Bの調達(Autodeskも参加)を公表し、累計$1.23Bに到達しています。

Marble公式ブログのキービジュアル。古代ローマ風コロッセオ内部の3D空間がそのままナビゲート可能な「世界」として生成されている(出典:World Labs Blog)
このキービジュアルが示すのは、Marbleが生成するのは「写真や動画」ではなく自由視点で歩き回れる持続的な3D空間だという点です。建築・XR・ゲームなど「同じ空間を複数人が複数アングルから参照する」業務との相性が良く、動画生成系プロダクトとは作るアウトプットの性質が違うことが、この1枚で読み取れます。
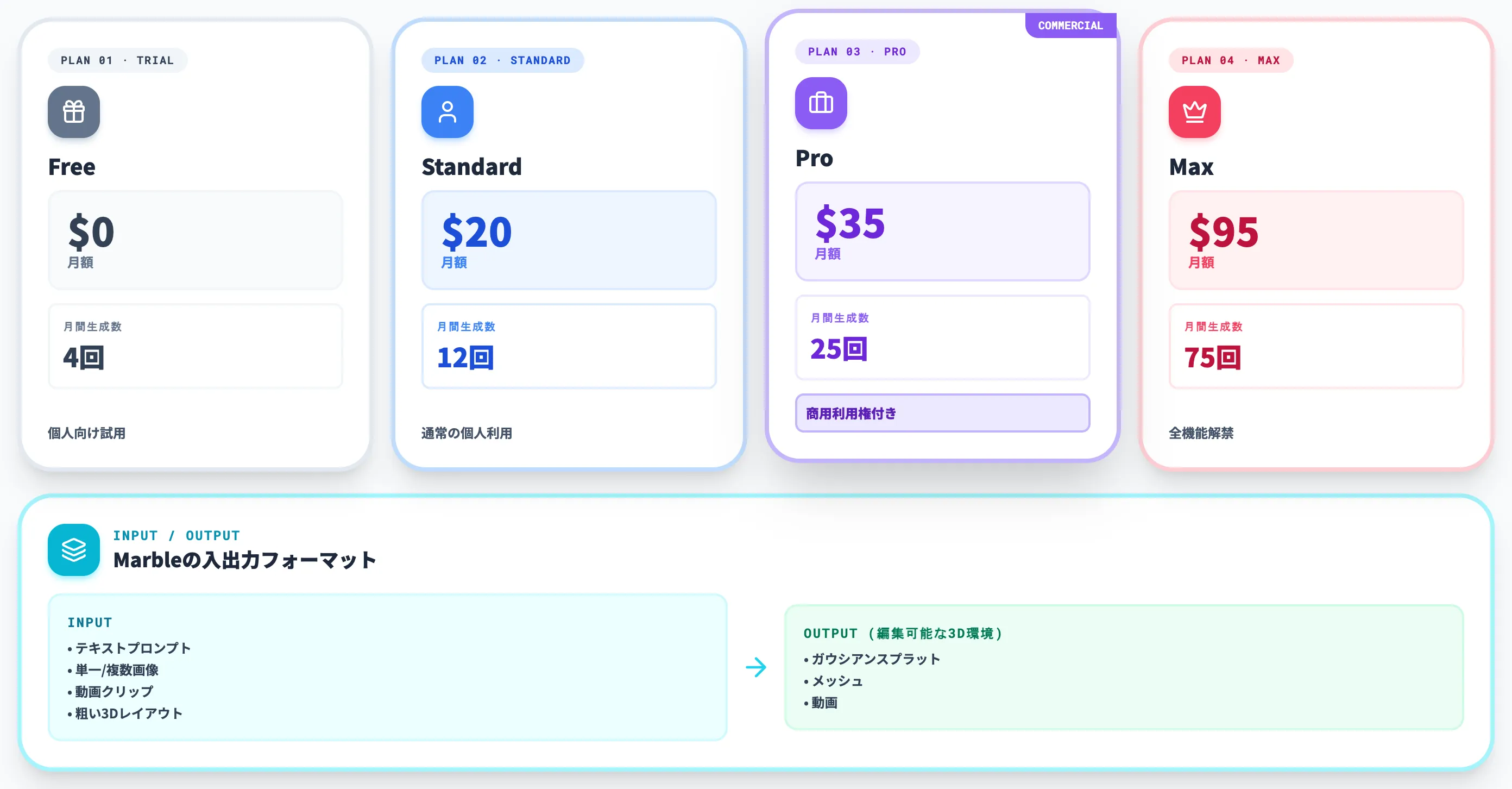
料金プランは以下のとおりです。
| プラン | 月額 | 月間生成数 | 特徴 |
|---|---|---|---|
| Free | $0 | 4回 | 個人向け試用 |
| Standard | $20 | 12回 | 通常の個人利用 |
| Pro | $35 | 25回 | 商用利用権付き |
| Max | $95 | 75回 | 全機能解禁 |
テキストプロンプト・単一/複数画像・動画クリップ・粗い3Dレイアウトを入力として、編集可能な3D環境(ガウシアンスプラット・メッシュ・動画)を出力します。
商用利用権はProプラン以上で初めて付与される点が、副業・受託案件で使う場合の重要な判定基準です。
Yann LeCun AMI Labs:JEPA派の独立スタートアップ
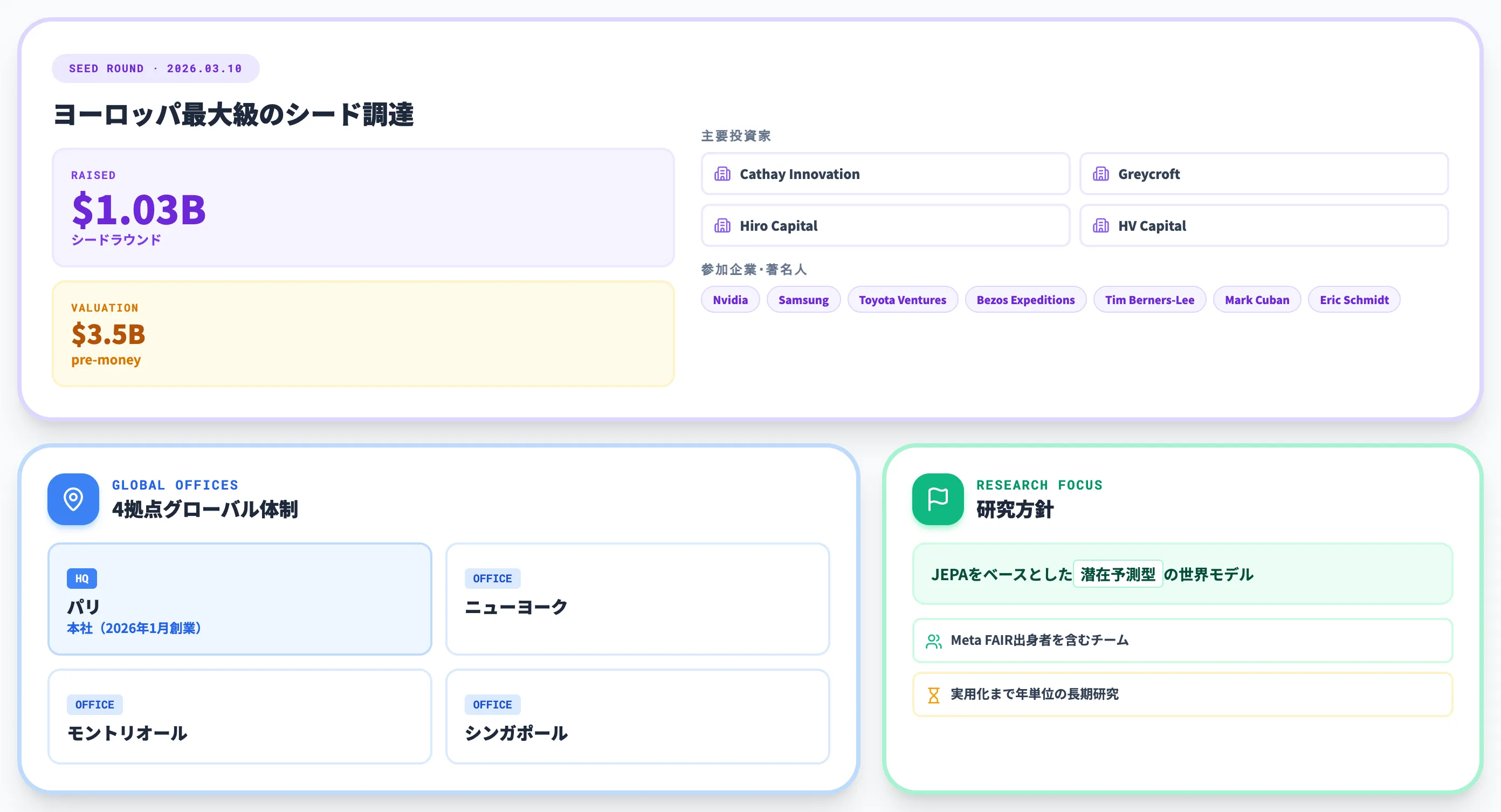
AMI Labsは、Yann LeCun氏が2025年11月にMeta退社後の2026年1月にパリで共同創業した世界モデル特化のスタートアップです。
2026年3月10日に**$1.03Bシード調達**を公表し、評価額$3.5B pre-moneyに到達しました。Cathay Innovation・Greycroft・Hiro Capital・HV Capital・Bezos Expeditionsが共同主導し、Nvidia・Samsung・Toyota Ventures・Tim Berners-Lee氏・Mark Cuban氏・Eric Schmidt氏なども参加するヨーロッパ最大級のシードラウンドです。
拠点はパリ本社・ニューヨーク・モントリオール・シンガポールの4拠点で、研究方針はJEPAをベースとした潜在予測型の世界モデルです。Meta FAIR出身者を含むリサーチチームを率い、独立した資本で長期研究に取り組む体制を採っています。
LeCun氏自身は「世界モデルがJEPAベースで実用化されるには年単位の時間がかかる」と慎重な見方を示しており、短期成果よりも基礎研究への投資という姿勢が明確です。
Wayve GAIA-3と自動運転特化勢
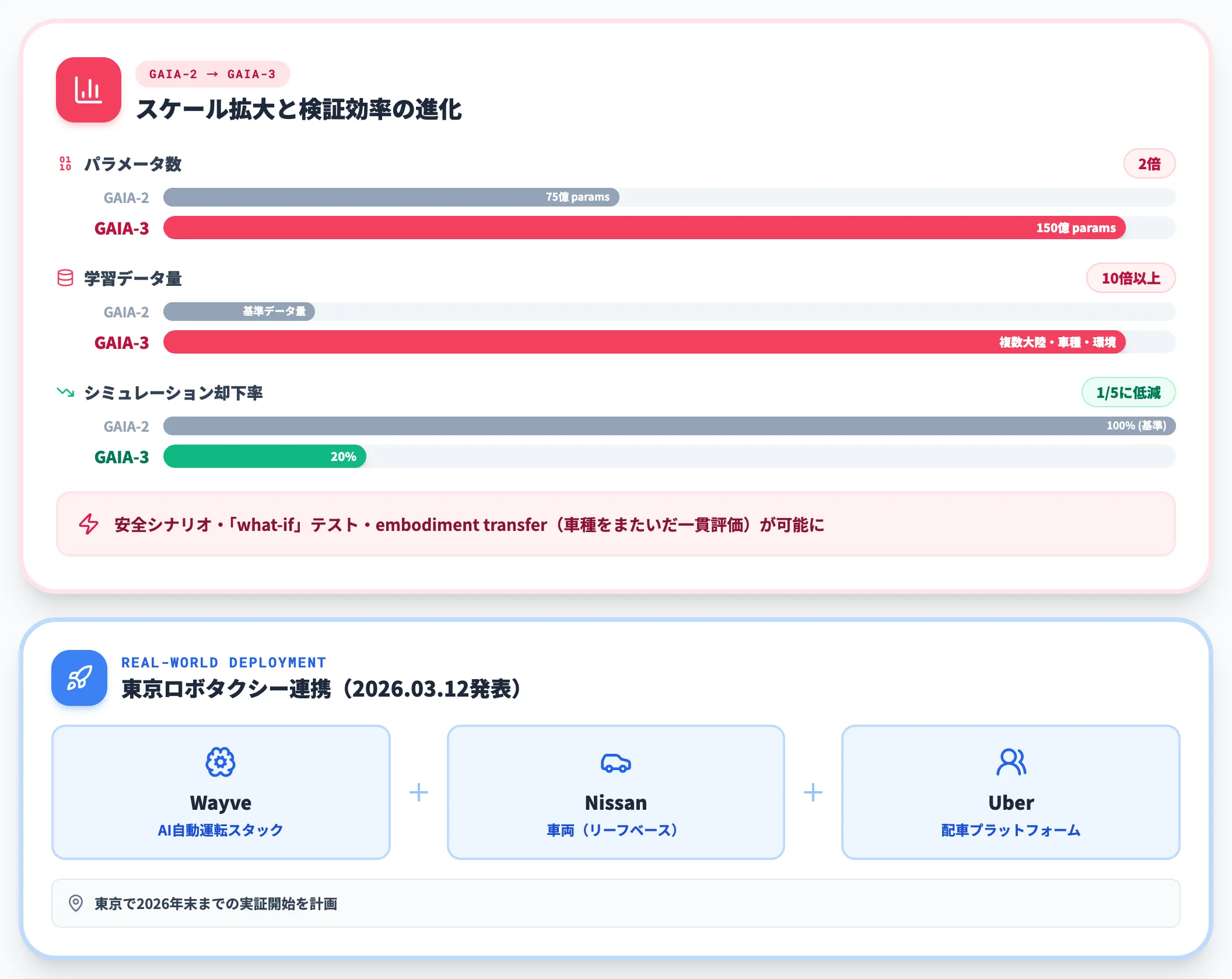
英国Wayveが2025年12月2日に発表したGAIA-3は、自動運転向けに最適化された最新の生成型世界モデルです。前世代のGAIA-2から150億パラメータ(2倍)・10倍以上の学習データへスケールし、複数大陸・車種・環境をまたいだ動画生成を実現しました。

GAIA-3の発表キービジュアル。同じ交差点シーンを複数条件で生成した例で、自動運転モデルの安全評価・what-ifテストに使う世界モデルの方向性を示している(出典:Wayve Press)
Wayve公式によれば、GAIA-3の導入でシミュレーション検証の却下率が5分の1まで低減し、安全シナリオ・「what-if」テスト・embodiment transfer(車種をまたいだ一貫評価)が可能になっています。
同じ交差点を複数条件で並べた発表ビジュアルは、こうした「条件を振って何度も検証する」世界モデルならではの使い方を象徴しています。
実車事業面では、Wayveは2026年3月12日にNissan・Uberとロボタクシー連携を発表し、東京で2026年末までの実証開始を計画中です。

日産リーフベースの実証車両のサイドビュー。ドアにNISSAN│WAYVE│Uberの3社ロゴが並び、車両・AIスタック・配車プラットフォームの三者連携を一目で示す(出典:Wayve Press)
3社ロゴが横に並んだ実証車両は、世界モデルで磨いた自動運転スタックを「自動車メーカーの車両+配車プラットフォーム」と組んで実走させる流れが、机上の発表段階から具体的な実証フェーズへ移ったことを表しています。
同領域ではNVIDIA DRIVEプラットフォーム上でNVIDIA Alpamayoなど自動運転特化のAI基盤も別軸で展開しており、自動運転×世界モデルは2026年に最も実装が進んだ領域の1つです。
世界モデルが効く応用領域
世界モデルは「研究フェーズの技術」ではなく、すでに業界別に明確な効きどころが見えています。
本セクションでは、自動運転・ロボティクス・製造業デジタルツイン・ゲームエンタメの4領域で、世界モデルが何を解決するかを整理します。

自動運転:危険シナリオを安全に大量生成する
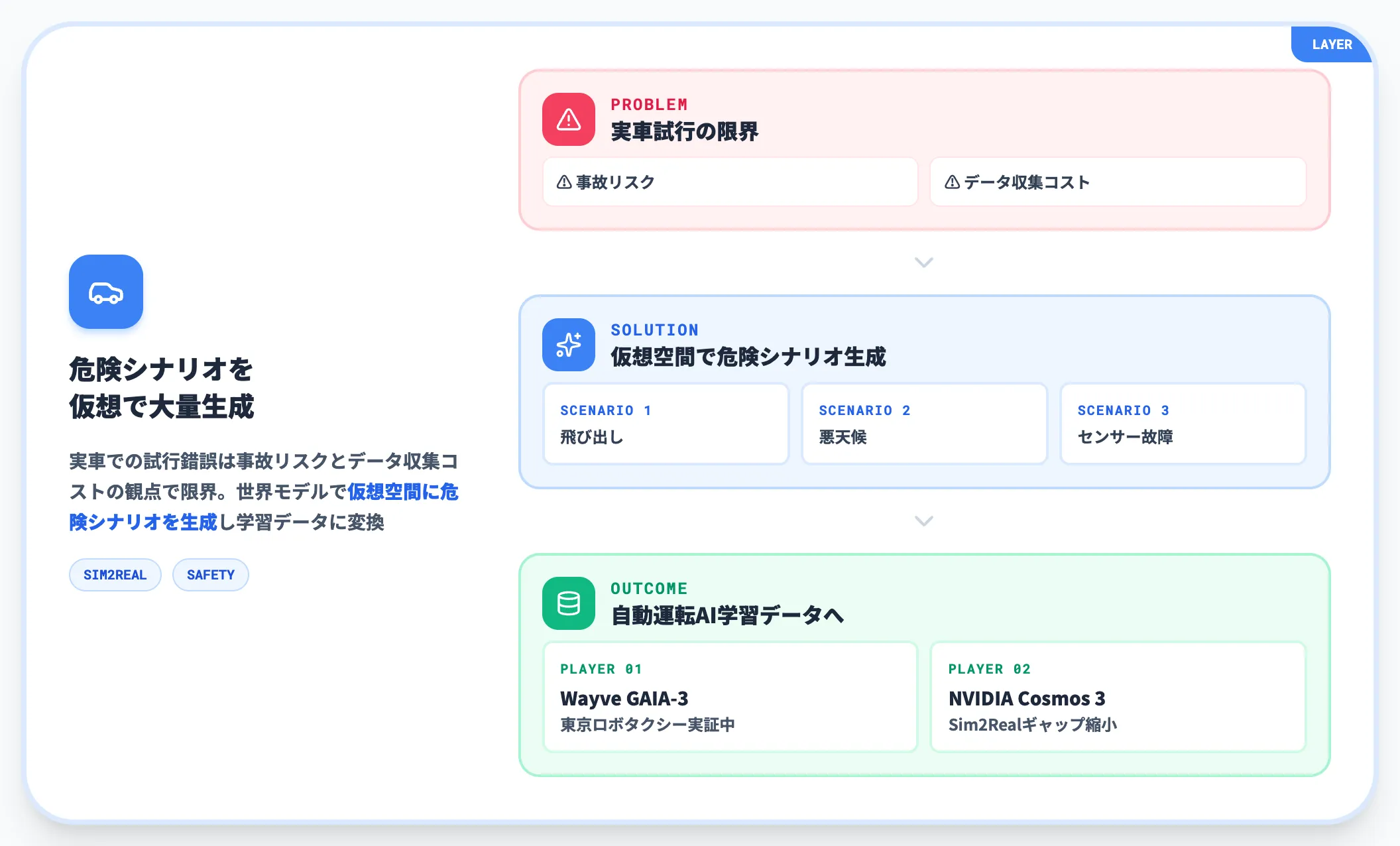
実車での試行錯誤は、事故リスクとデータ収集コストの観点で限界があります。世界モデルは、実際には起きていない危険シナリオ(飛び出し・悪天候・センサー故障)を仮想空間で大量生成し、自動運転AIの学習データに使う用途で直接効きます。
WayveのGAIA-3やNVIDIA Cosmosが中心プレイヤーで、Wayveは2026年3月にNissan・Uberと連携を発表し、東京で2026年末までにロボタクシー実証を予定しています。Cosmos 3のリリース後は、合成データの物理整合性が一段上がり、Sim2Realギャップを縮めるための選択肢が増えています。
ロボティクス:シミュレーションで失敗を吸収する
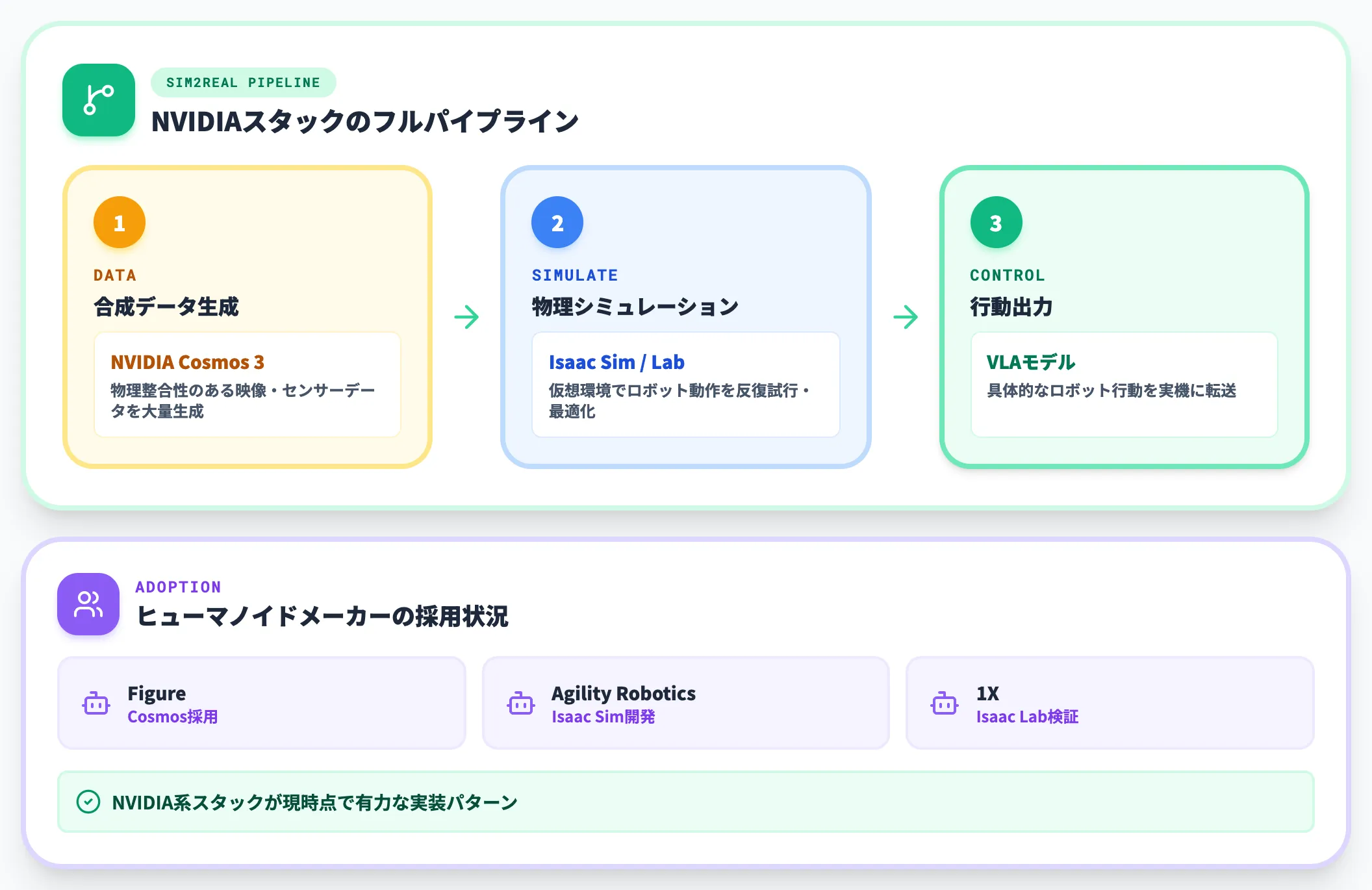
産業用ロボット・ヒューマノイドロボットの学習では、実機を動かす時間とコストが最大のボトルネックです。世界モデルはシミュレーション環境で失敗の試行錯誤を吸収し、実機に転送する「Sim2Real」の効率を桁違いに上げる役割を担います。
NVIDIA GR00T・NVIDIA Isaac Simと組み合わせれば、Cosmos 3で合成データを作り、Isaac Simで物理シミュレーションを回し、VLAモデルで具体的なロボット行動を出力する、というフルパイプラインが組めます。
NVIDIA公式発表によれば、Figure・Agility Robotics・1XなどヒューマノイドメーカーがCosmos world modelsとIsaac Sim・Isaac Labで開発・検証を加速しており、NVIDIA系スタックは現時点で有力な実装パターンになりつつあります。
製造業・デジタルツイン:「壊して学ぶ」を仮想で
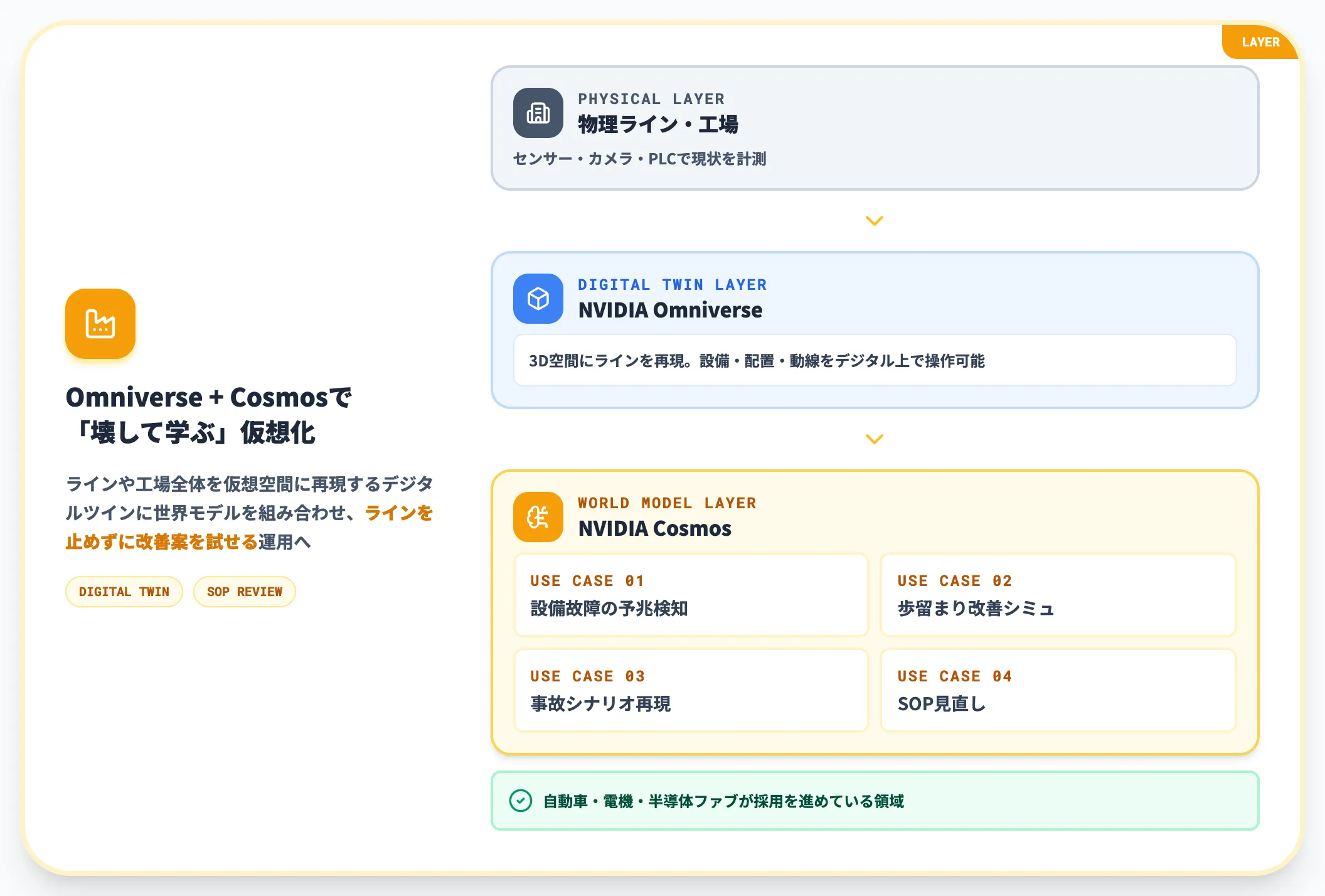
製造業のラインや工場全体を仮想空間に再現するデジタルツインに世界モデルを組み合わせると、「ラインを止めずに改善案を試す」「事故シナリオを再現してSOPを見直す」といった用途が現実的になります。
NVIDIA OmniverseとCosmosの組み合わせが代表的で、自動車メーカー・電機メーカー・半導体ファブが採用を進めています。「設備故障の予兆検知」「歩留まり改善のシミュレーション」など、製造業のAI活用は世界モデルとの相性が極めて良い領域です。
ゲーム・エンタメ・3Dコンテンツ:制作コストを桁で下げる
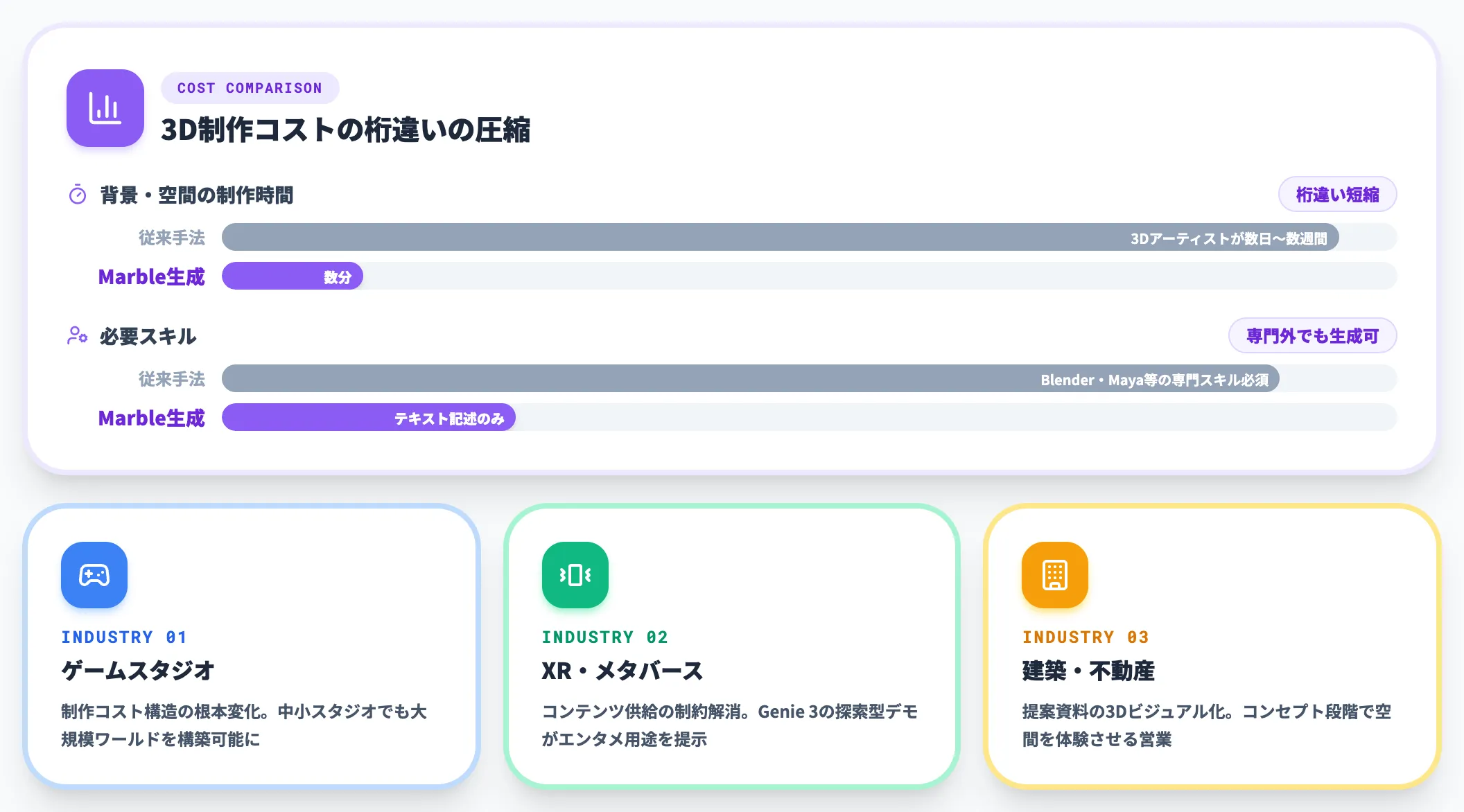
World Labs Marbleが切り拓いているのが、ゲーム・XR・建築ビジュアライゼーション向けの3Dコンテンツ生成です。従来は3Dアーティストが手で組んでいた背景・空間を、数分のテキスト記述から自動生成できるようになりました。
ゲームスタジオの制作コスト構造、メタバース・XR分野のコンテンツ供給、建築・不動産の提案資料など、3D制作コストが製品競争力を左右していた業界に直接効きます。Project Genie 経由で公開されているGenie 3のデモもゲーム的・探索型のものが多く、エンタメ用途との接点が見えます。

世界モデルの料金相場と利用形態
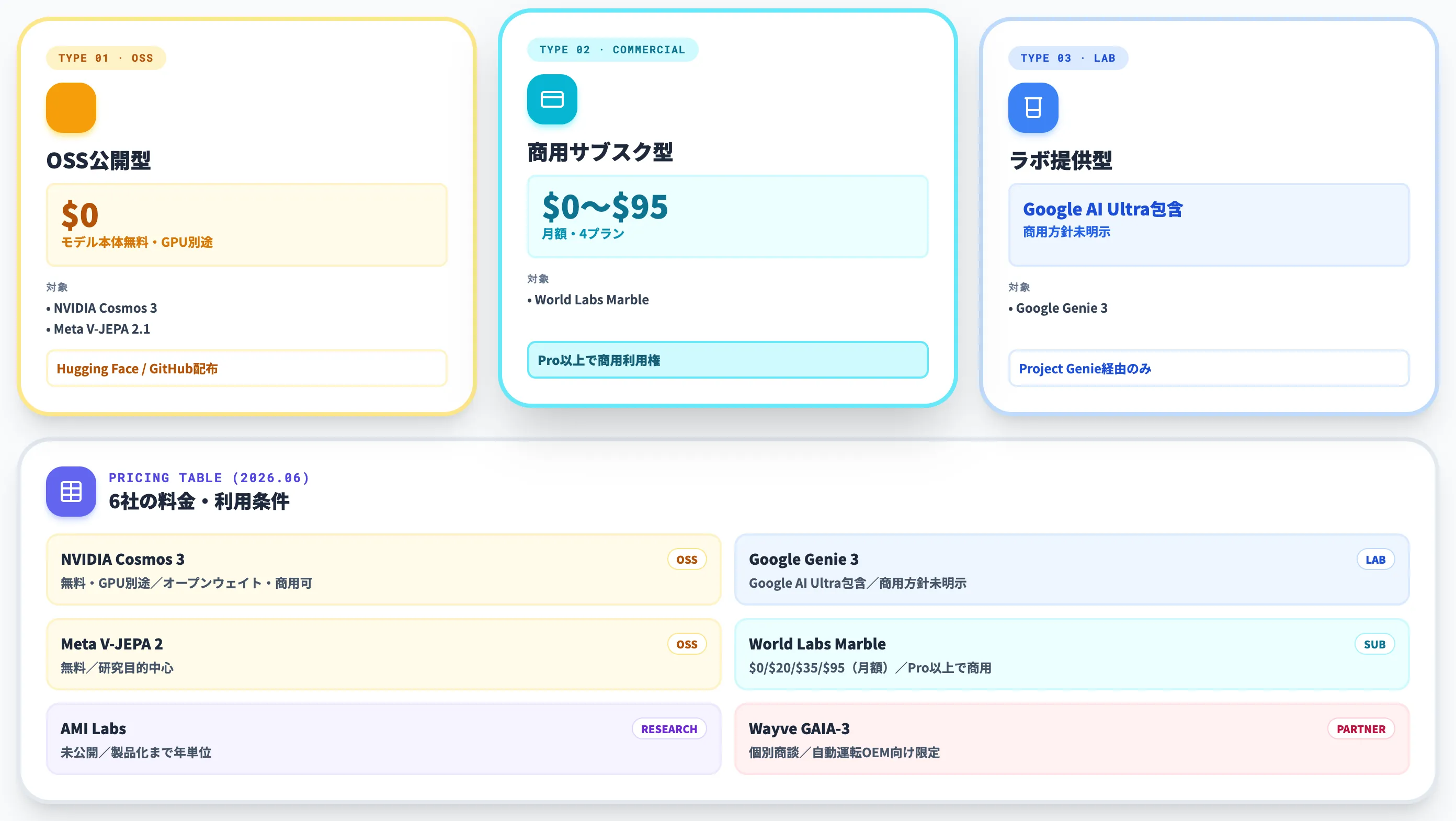
世界モデルは「料金体系」が派閥ごとに大きく異なります。同じ「世界モデル」でも、OSSで無料配布されるものから、月額$95の商用サブスクまでスペクトルが広いのが現状です。
以下の表で、提供形態と料金を整理しました。
| プレイヤー | 提供形態 | 料金 | 利用条件 |
|---|---|---|---|
| NVIDIA Cosmos 3 | OSS(Hugging Face・GitHub・build.nvidia.com) | モデル本体無料、GPU利用料は別途 | オープンウェイト、商用利用可(ライセンス要確認) |
| Google DeepMind Genie 3 | Project Genie(Google AI Ultra加入者向け) | Google AI Ultraのサブスクリプションに包含 | 商用利用・API・SLAの方針は未明示 |
| Meta V-JEPA 2 | OSS(GitHub・Hugging Face) | モデル本体無料 | 研究目的の利用が中心 |
| World Labs Marble | 商用Webサブスク | Free / $20 / $35 / $95(月額) | Pro以上で商用利用権 |
| Yann LeCun AMI Labs | 未公開(研究段階) | — | 製品化までは年単位の見込み |
| Wayve GAIA-3 | 自社利用+パートナー連携 | 個別商談 | 自動運転OEM向けの限定提供(Nissan・Uberと東京実証連携) |
2026年6月時点。料金体系・提供条件は今後変動する可能性が高いため、最終的な採用判断時には各公式ページでの確認が必須です。
OSS公開型:Cosmos 3とV-JEPA 2
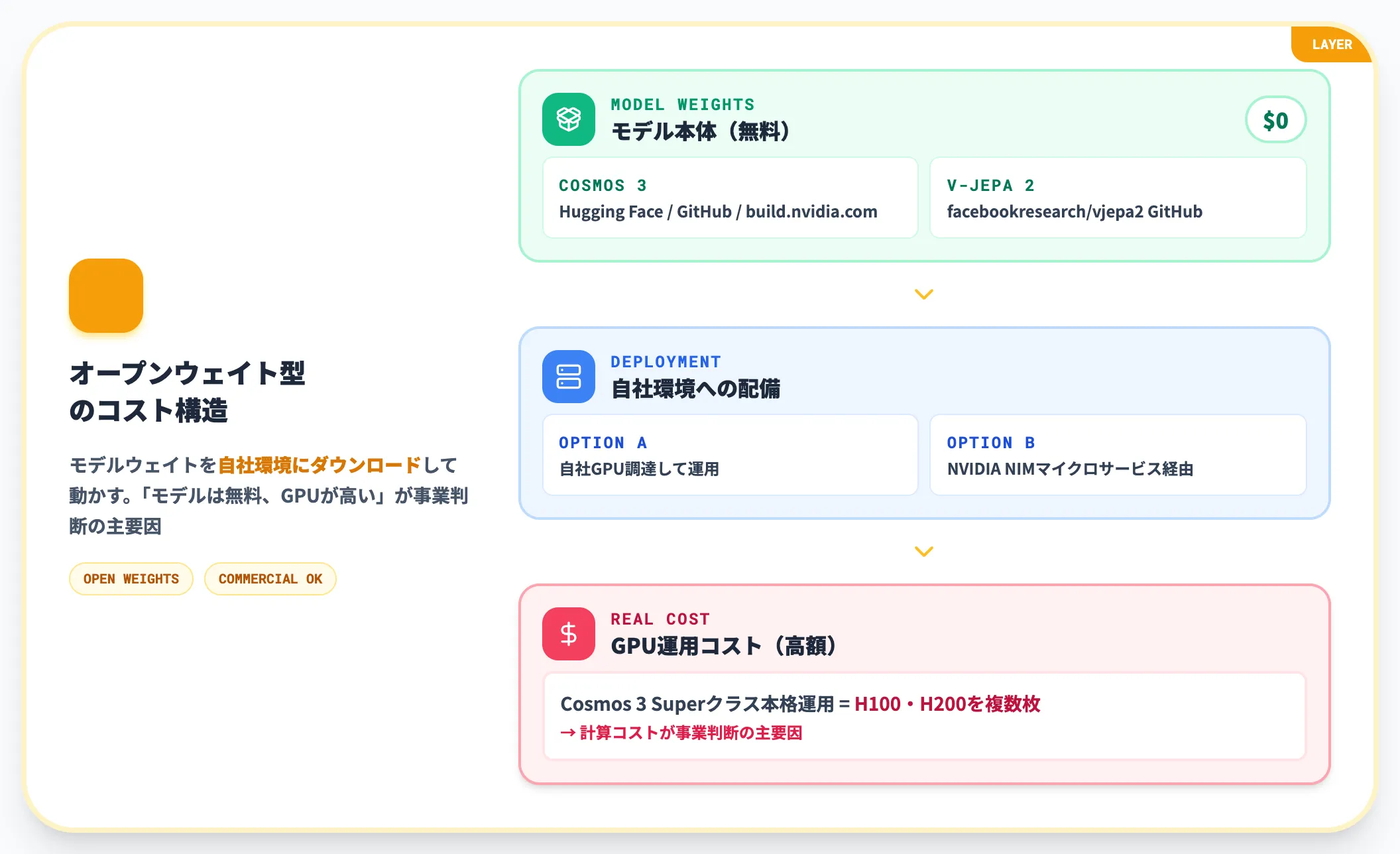
Cosmos 3とV-JEPA 2は、モデルウェイト自体を無料で配布するオープンウェイト型です。Hugging Face・GitHubから自社環境にダウンロードし、自社のGPU上で動かせます。
「モデルは無料、GPUが高い」という構造です。Cosmos 3 Superクラスを本格運用するなら、H100・H200を複数枚使うことになり、計算コストが事業判断の主要因になります。NVIDIA NIMマイクロサービス経由のクラウドデプロイも提供されており、自社GPU調達と運用負荷のバランスで選び方が分かれます。
商用サブスク型:World Labs Marble
World Labs Marbleは、世界モデルを前面に出した代表的な商用Webサブスク製品です。WebUIから直接3D環境を生成でき、技術的なセットアップが不要です。
Pro以上($35/月)で商用利用権が付くため、3D制作・XR・建築ビジュアル等の業務利用ではProが事実上の入口になります。Maxの$95は月75回の生成枠で、企業の制作チームでも十分に回せる水準です。
Project Genie 経由提供型:Genie 3
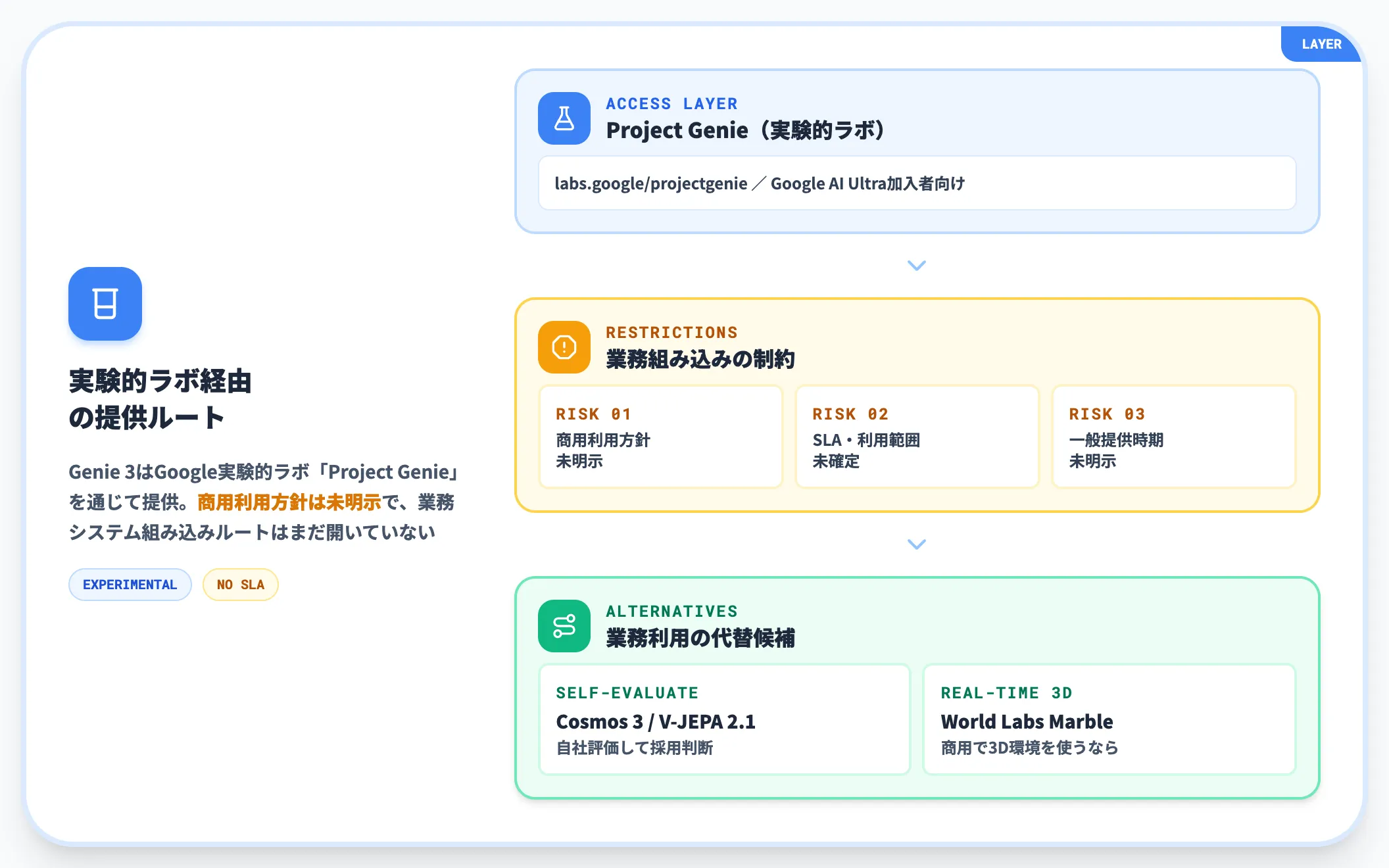
DeepMind Genie 3は、現時点でGoogleの実験的ラボ「Project Genie」を通じて提供されています。商用利用に関する方針は公式に明示されておらず、一般企業が業務システムに組み込むルートはまだ開いていません。
「自社で評価してから採用判断したい」という需要に対しては、Cosmos 3またはV-JEPA 2.1が現実的な選択肢になります。Genie級のリアルタイム3D環境を商用で使いたい場合は、World Labs Marbleが代替候補です。
世界モデルを使いこなす3つの壁
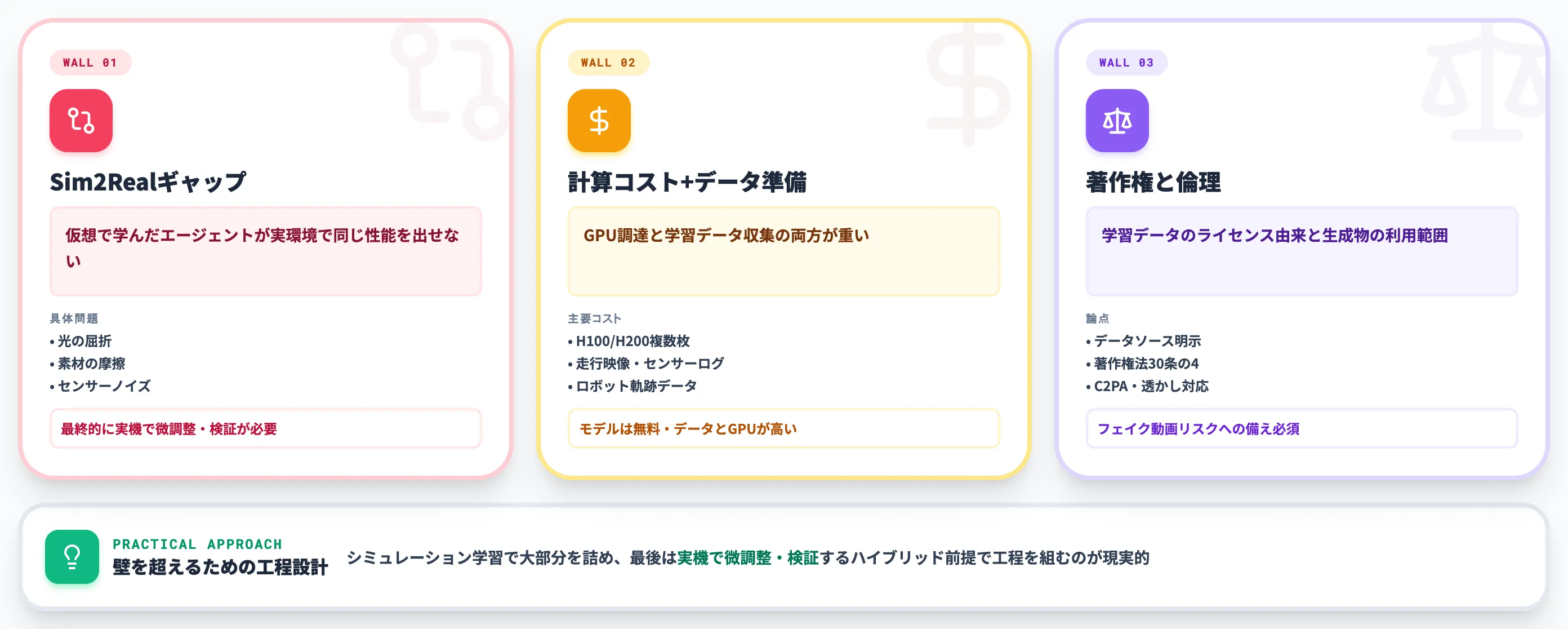
世界モデルは「導入すればすぐ効く」技術ではありません。実装段階に入ったとはいえ、3つの大きな壁があります。
本セクションでは、Sim2Realギャップ・計算コストとデータ準備・学習データの著作権と倫理を順に整理します。
Sim2Realギャップ:仮想で学んだ動きが実機で再現できない

世界モデルの最大の弱点は、仮想空間で学習したエージェントが、実環境で同じ性能を出せない「Sim2Realギャップ」です。光の屈折・素材の摩擦・センサーノイズなど、現実の物理パラメータをすべて仮想空間で再現するのは原理的に不可能です。
Cosmos 3はmixture-of-transformersでこのギャップを縮める方向にチューニングされており、Physics-IQベンチマークでも改善が見られます。しかし完全に消えるわけではないため、最終的には実機での微調整・運用検証が必要です。
実装プロジェクトを組むときは、シミュレーション学習で大部分を詰め、最後は実機で微調整・検証するハイブリッド前提で工程を組むのが現実的です。
計算コストとデータ準備:GPU調達と学習データの両方が重い
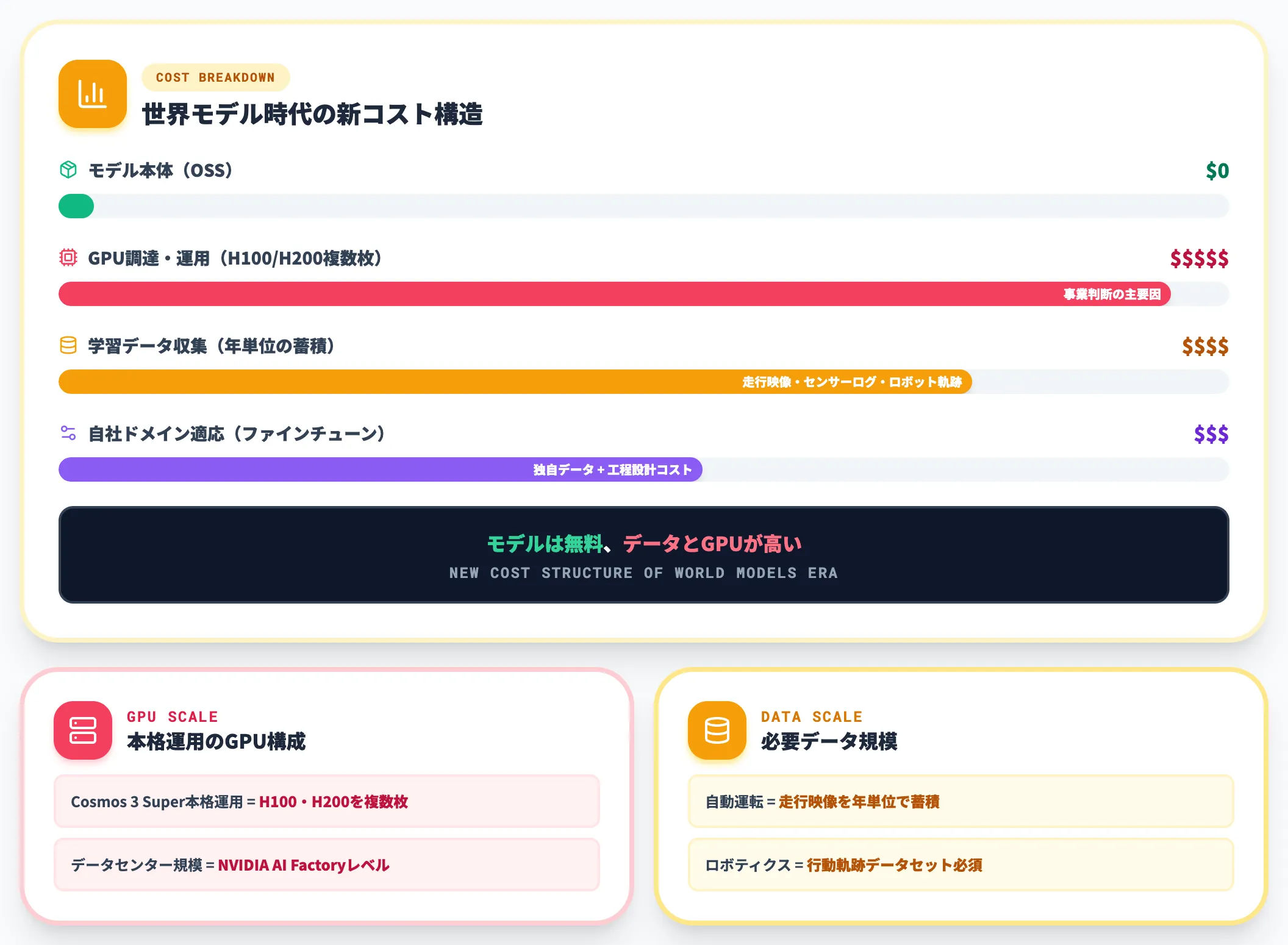
世界モデル、特に生成型の学習・推論には大量のGPUが必要です。Cosmos 3 Superクラスの本格運用ではH100・H200を複数枚、データセンター規模ではNVIDIA AI Factoryレベルの構成も視野に入ります。
加えて、学習データの準備が思った以上に重い工程になります。自動運転やロボティクスの自社用世界モデルを作るなら、走行映像・センサーログ・ロボット軌跡を年単位で集める必要があります。Cosmos 3のような基盤モデルを使えばこの初期コストは下がりますが、自社ドメインへの適応にはやはり独自データが必要です。
「モデルは無料、データとGPUが高い」というのが、世界モデル時代の新しいコスト構造です。
学習データの著作権と倫理:動画ソースをどう正当化するか
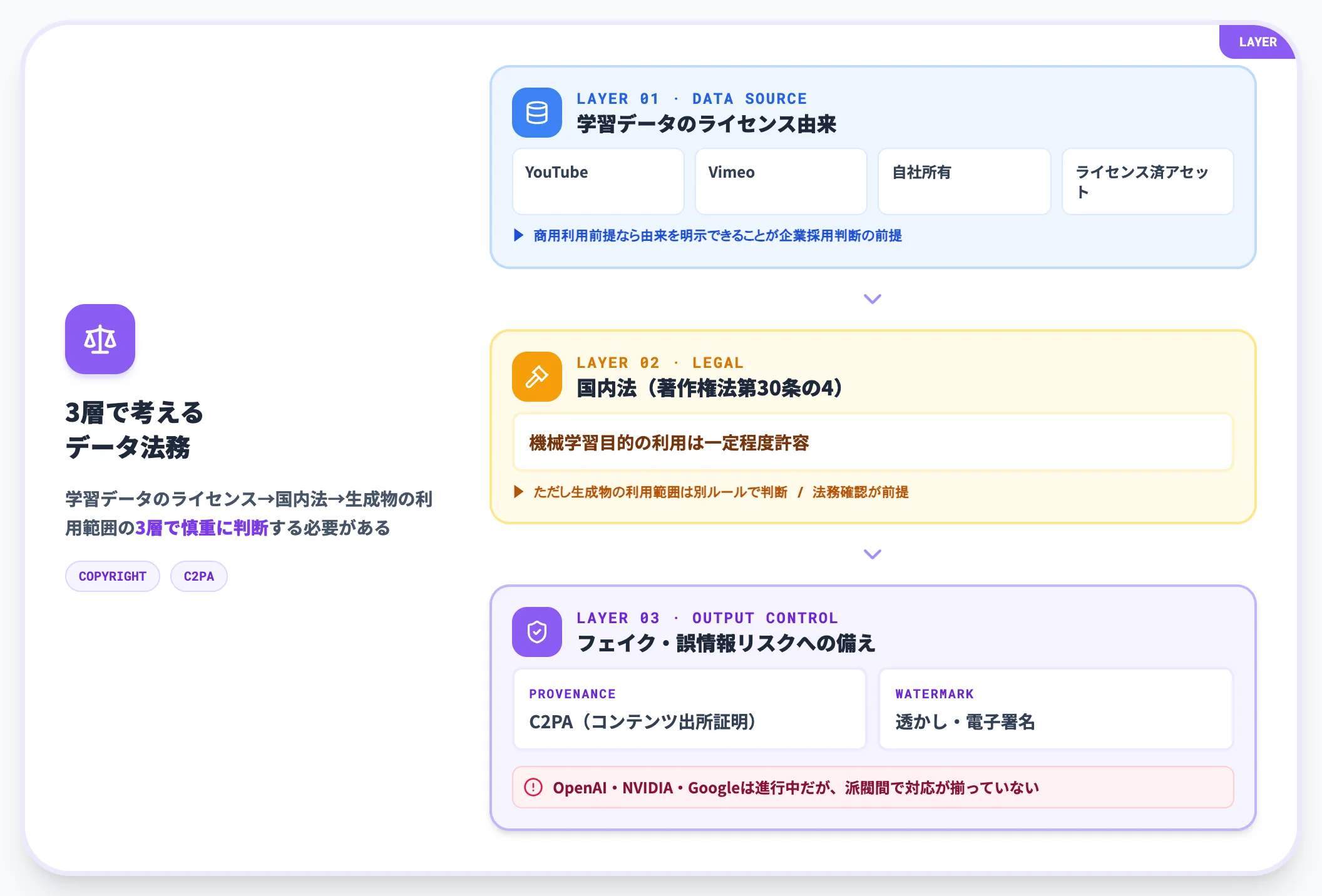
世界モデルは、インターネット上の動画やゲーム映像から学習するケースが少なくありません。学習データの著作権は、各国の規制動向と照らして慎重に扱う必要があります。
商用利用前提の世界モデルでは、学習データのライセンス由来(YouTube・Vimeo・自社所有・ライセンス済みアセット)を明示できるかが企業の採用判断に効きます。日本国内では現行の著作権法第30条の4で「機械学習目的の利用」が一定程度許容されていますが、生成物の利用範囲は別ルールで判断されるため、法務確認が前提です。
加えて倫理面では、生成された世界がフェイク動画・誤情報生成に使われるリスクへの備えも必要です。OpenAI・NVIDIA・Googleなど主要ベンダーはコンテンツ出所証明(C2PA)や透かしを進めていますが、すべての派閥で対応が揃っているわけではありません。
企業が世界モデルにどう向き合うべきか

ここまでは「世界モデルとは何か」「誰がどう作っているか」を解説してきました。最後に、企業として2026年現在どう動くべきかをケース別に整理します。
AI総合研究所がAI導入支援の現場で見てきた傾向も踏まえ、業種別の判断軸を提示します。
製造業・自動運転・ロボティクス領域:今すぐPoC候補に上げる
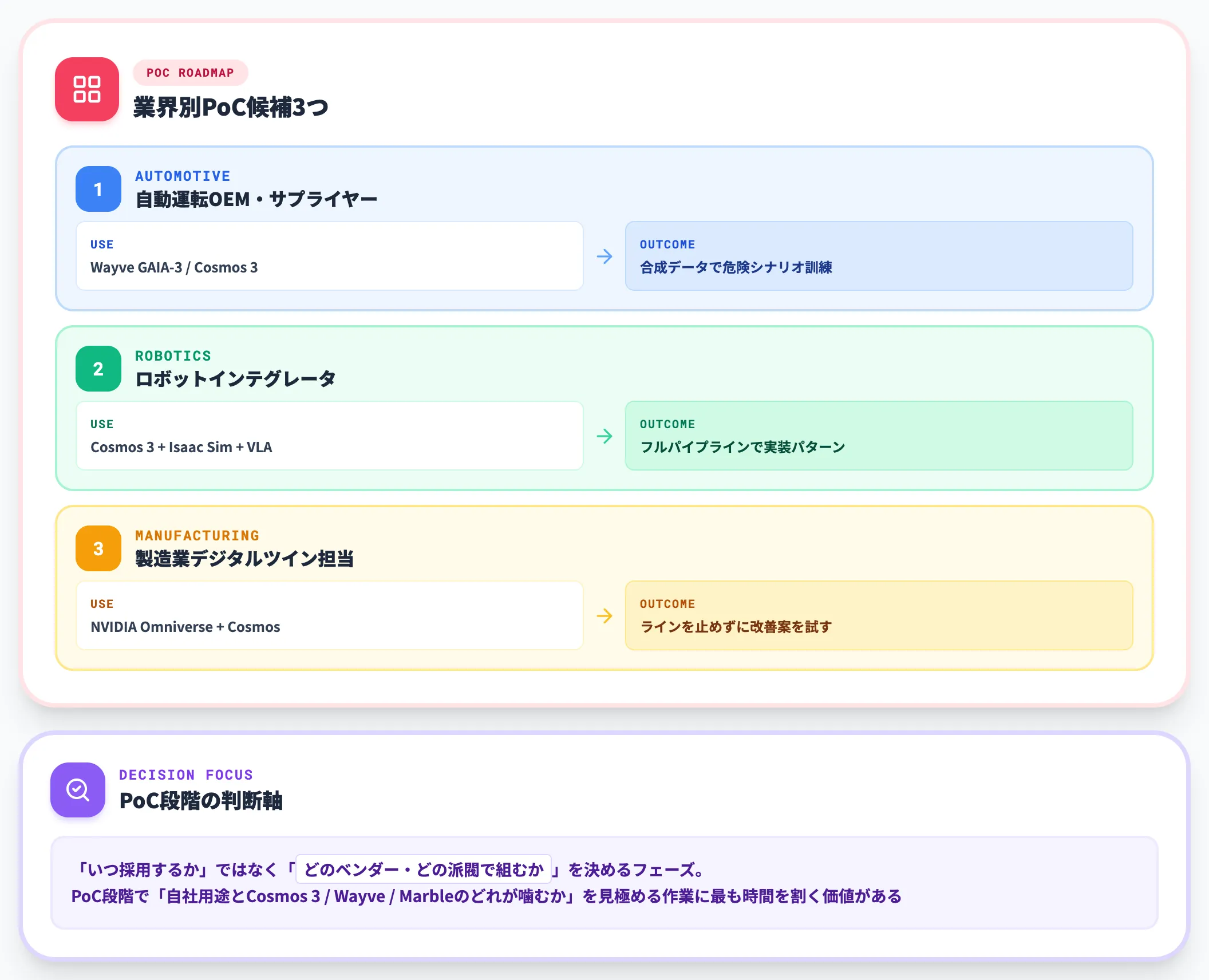
製造業・自動車・物流・建設・ロボットメーカー・医療機器メーカーなど、物理空間でモノが動く業界は、世界モデルの最初の主要受益者です。
- 自動運転OEM・サプライヤー:Wayve GAIA-3やCosmos 3の合成データを使った危険シナリオ訓練が現実解
- ロボットインテグレータ:Cosmos 3+Isaac Sim+VLAモデルのフルパイプラインがNVIDIA系の有力な実装パターンになりつつある
- 製造業デジタルツイン担当者:NVIDIA Omniverse+Cosmosで「ラインを止めずに改善案を試す」運用を検討
これらの業界は、世界モデルを「いつ採用するか」ではなく「どのベンダー・どの派閥で組むか」を決めるフェーズに入っています。
PoC段階で自社用途とCosmos 3 / Wayve / Marbleのどれが噛むかを見極める作業に最も時間を割く価値があります。
ソフトウェア中心・SaaS企業:要ウォッチで本流の動きを掴む
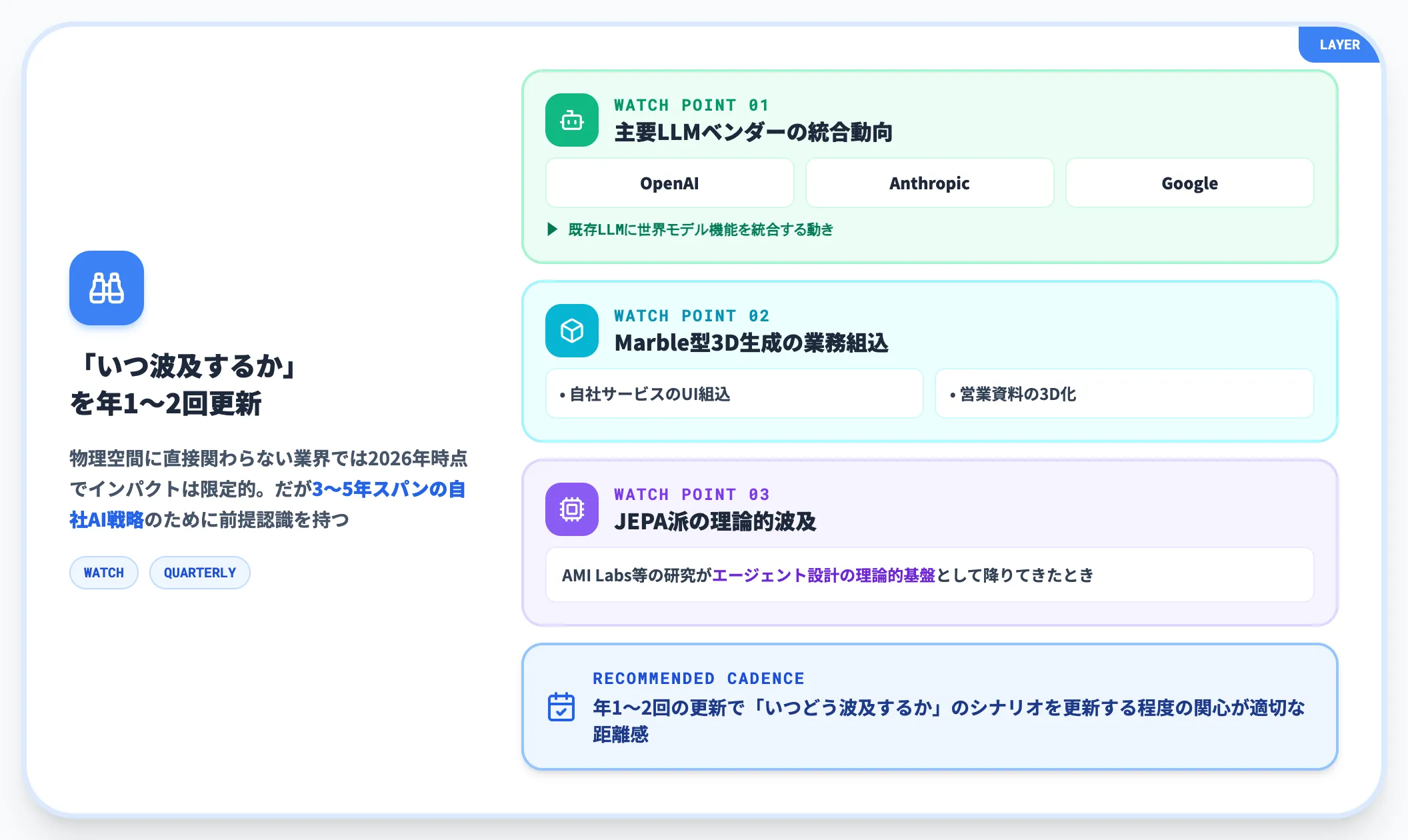
SaaS・Webサービス・金融・人材・教育など、物理空間に直接関わらない業界では、世界モデルの直接的な業務インパクトは2026年時点で限定的です。
ただし、ウォッチを止めるのは推奨しません。世界モデルが**「次のAIパラダイム」として確立**するなら、自社のAI戦略を3〜5年スパンで見直すうえで前提認識を持っておく必要があります。
特に注視すべきポイントは以下です。
- 主要LLMベンダー(OpenAI・Anthropic・Google)が世界モデル機能を既存LLMに統合する動き
- World Labs Marble型の3D生成が、自社サービスのUIや営業資料制作に組み込めるか
- AMI LabsなどJEPA派の研究が、エージェント設計の理論的基盤として降りてきたとき
「業界全体の動きが、自社のサービスにいつどう波及するか」のシナリオを年1〜2回更新する程度の関心が、適切な距離感です。
AI総研の視点:いま実務的に取れる3ステップ
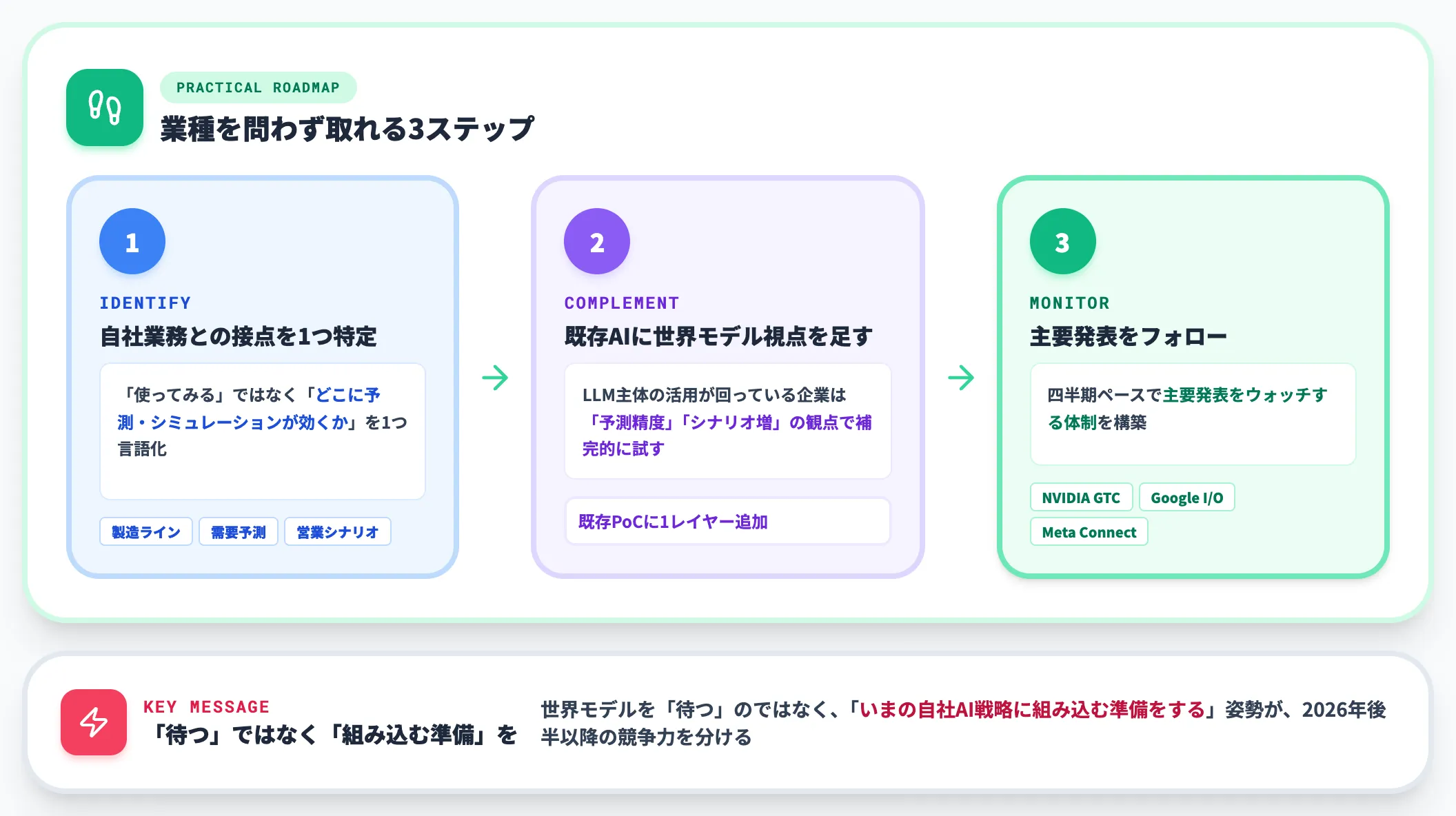
業種を問わず、すべての企業がいま取れる打ち手は以下の3つです。
-
自社業務との接点を1つ特定する
「世界モデルを使ってみる」ではなく、「自社の業務プロセスのどこに世界モデル的な予測・シミュレーションが効くか」を1つだけ言語化します。
製造業ならライン改善、サービス業なら需要予測、SaaSなら営業シナリオ設計、など業種固有の接点を探ります。
-
既存のAI活用に世界モデル的視点を足す
LLM主体のAI活用が回り始めている企業なら、「予測の精度を上げる」「シナリオを増やす」という観点で世界モデル系のサービスを補完的に試すのが現実的です。
いきなり全面採用ではなく、既存PoCに1つレイヤーを足す形が失敗しません。
-
業界の主要発表をフォローする体制
NVIDIA GTC・Google I/O・Meta Connect・World Labs・AMI Labsなどの主要発表を、社内のAI担当・経営層が四半期ペースでウォッチする体制を作ります。
世界モデル領域は2025〜2026年で激変しており、半年遅れると判断軸が古くなります。
これらは、Cosmos 3に直接アクセスできるかどうかとは無関係に、すべての企業がいま着手できる取り組みです。世界モデルを「待つ」のではなく、「いまの自社AI戦略に組み込む準備をする」姿勢が、2026年後半以降の競争力を分けます。

AI活用を業務に定着させる次の一歩
世界モデルのような次世代AIの登場で、企業のAI戦略は再設計フェーズに入っています。
一方で多くの企業は、世界モデルそのものへの直接アクセスを待つよりも先に、現行のClaude Opus 4.7・GPT-5.5・Gemini 3 Proを業務に組み込み、継続的な業務自動化を回す段階にあります。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。世界モデル時代を見据えた自社のAI活用戦略を整理する第一歩として活用ください。
世界モデル時代を見据えてAI活用を業務に定着させる

PoCから全社展開までの設計を1冊で
世界モデルのような次世代AIを待たなくても、現行のClaude Opus 4.7・GPT-5.5・Geminiで業務プロセスを自動化することは可能です。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、世界モデル(World Model)について、定義・仕組み・5派閥分類・主要プレイヤー動向・応用領域・料金・導入の壁・企業の向き合い方まで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
世界モデルはLLMの次のパラダイムで、観測から「次の状態」を予測する内部シミュレーターを持つAI基盤。2018年のHa・Schmidhuber論文を起点に、2025〜2026年で産業実装段階へ移行した
-
5派閥(Video生成・Spatial 3D・Generative WM・Latent JEPA・Infrastructure基盤)が並走しており、純粋な動画生成と「行動計画のための世界モデル」は設計思想が分かれている
-
**NVIDIA Cosmos 3(2026年5月)・Google Genie 3(2025年8月)・Meta V-JEPA 2.1(2026年3月)・World Labs Marble(2025年11月一般提供)・Wayve GAIA-3(2025年12月)・AMI Labs(2026年3月$1.03B調達)**が現時点の主要プレイヤー
-
自動運転・ロボティクス・製造業デジタルツイン・3Dエンタメに直接効く。製造業・自動車・ロボットインテグレータは今すぐPoC候補に上げる段階
-
Sim2Realギャップ・計算コスト・データ著作権の3つの壁が残るため、シミュレーションで大部分を詰めて最後は実機で微調整・検証するハイブリッド前提で工程を組む
世界モデルは「自社が直接使えるかどうか」よりも、「世界モデル世代のAIが市場に存在する前提で、自社のAI戦略を再設計できるか」という問いを突きつける動きです。まずは現行のLLM・生成AIで業務自動化を回しつつ、四半期ペースで世界モデル領域の主要発表をウォッチする体制から着手することが、最も実用的な第一歩になります。
世界モデルが本格的に社会実装される2026年後半〜2027年は、AI戦略の前提を組み直す重要な数年になります。Cosmos 3やMarbleの登場を「他社の話」と捉えるのではなく、「自社の3年後の前提条件」として組み込む姿勢が、企業の競争力を左右する時期に入りました。








