この記事のポイント
 NVIDIA AI Factoryは、データからインテリジェンスを製造するAI専用インフラ。トークンスループットが主要な生産指標となる
NVIDIA AI Factoryは、データからインテリジェンスを製造するAI専用インフラ。トークンスループットが主要な生産指標となる- CES 2026発表のVera Rubinプラットフォームは6新チップ構成、Blackwell比で推論トークンコストを最大10分の1に削減
- DynamoはAI Factoryの推論OS、GB200 NVL72と組合せMoEモデルのスループットをHopper比最大15倍に向上
- AI Factory Validated Designでオンプレのフルスタック構築可、AI Enterpriseは年4,500ドル/GPUから
- GPUベースのAI Factoryは、CPUベースの従来データセンターと比較して消費電力あたり30倍、コストあたり60倍の性能を実現

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「AI Factoryって、普通のデータセンターと何が違うの?」「自社にAI専用インフラを構築するには、どれくらいのコストがかかる?」
NVIDIA AI Factoryとは、データからインテリジェンスを製造するために設計された、AI専用のコンピューティングインフラストラクチャです。従来のデータセンターがWebサービスやデータベースを汎用的に処理するのに対し、AI Factoryはモデルの学習・ファインチューニング・大規模推論というAIライフサイクル全体に最適化されています。
NVIDIAはCES 2026(2026年1月)でVera Rubinプラットフォーム(6チップ・2フォームファクタ構成)を発表し、それ以前にはDynamo(GTC 2025、2025年3月)やOmniverse DSXブループリント(GTC Washington D.C.、2025年10月)をリリースするなど、AI Factoryの技術基盤を段階的に構築してきました。
本記事では、NVIDIA AI Factoryの基本概念から最新技術、Enterprise向けの導入設計、料金体系、そして実際の導入事例まで、企業のAIインフラ戦略に必要な情報を網羅的に解説します。
NVIDIA AI Factoryとは?

NVIDIA AI Factoryとは、データからインテリジェンス(知能)を製造するために設計された、AI専用のコンピューティングインフラストラクチャです。
従来のデータセンターが、Webサービスやデータベース、社内システムなどの多様なワークロードを汎用的に処理する「情報の保管庫」であったのに対し、AI Factoryは**AIモデルの学習(トレーニング)、ファインチューニング、そして大規模推論(インファレンス)**というAIライフサイクル全体に最適化された「知能の製造工場」です。
ここで生産される主な産出物はAIトークンであり、そのスループット(単位時間あたりの処理量)がAI Factoryの生産性を測る最も重要な指標となります。

AI Factoryの設計思想 — 「トークン = 製品」

AI Factoryの根本的な設計思想は、インテリジェンスそのものが製品であるという考え方にあります。
従来のデータセンターでは、CPUがさまざまなアプリケーションを処理し、情報を保管・配信することが主な役割でした。一方、AI Factoryでは、GPUによる大規模な並列処理がすべての設計の中心にあります。
以下の表で、従来データセンターとAI Factoryの基本的な違いを整理しました。この比較を見ることで、AI Factoryがなぜ「工場」と呼ばれるのか、その本質的な設計の違いが明確になります。
| 比較項目 | 従来のデータセンター | NVIDIA AI Factory |
|---|---|---|
| 主な目的 | Webサービス、DB、社内システムの稼働 | AIモデルの学習・推論・ファインチューニング |
| 主要な産出物 | 情報の保管・配信 | AIトークン(推論結果) |
| 生産性の指標 | 稼働率、応答時間 | トークンスループット(tokens/sec) |
| コンピュートの中心 | CPU中心の汎用処理 | GPU中心の並列処理 |
| ラックあたりの消費電力 | 10〜30 kW | 130〜150 kW |
| 冷却方式 | 空冷が主流 | 液冷(45°Cの温水冷却) |
| データの扱い | 多様なデータの保管・検索 | 大量のトレーニングデータの高速取り込み |
| ネットワーク設計 | 汎用Ethernet | 超低遅延NVLink + Spectrum-X Ethernet |
この表から分かるのは、AI Factoryが単にGPUを大量に並べたデータセンターではなく、コンピュート・ネットワーク・ストレージ・冷却・電力のすべてがAIワークロードに最適化された、まったく新しいカテゴリのインフラだという点です。
特に消費電力の差(10〜30 kW vs 130〜150 kW/ラック)は、従来のデータセンターの設計ではAI Factoryの要件を満たせないことを端的に示しています。
従来データセンターとの定量的な比較

AI Factoryのパフォーマンス上の優位性は、定量的な数値でも裏付けられています。NVIDIAの公開データによると、GPUベースのAI Factoryは、CPUベースの従来インフラと比較して以下のような差があります。
- 消費電力あたりの性能(Performance per Watt) 30倍
- コストあたりの性能(Performance per Dollar) 60倍
- トークン生成速度 ギガワットあたり200万 → 7億トークン/秒(2年間で350倍に向上)
実務的に言えば、同じ消費電力で30倍の処理が可能ということは、電力コストが1/30に圧縮されることを意味します。大規模言語モデル(LLM)の推論にかかる電力コストが月間100万ドルの企業であれば、AI Factoryへの移行で月間約96.7万ドルの電力コスト削減が見込めます。年間では約**1,160万ドル(約17.4億円)**の削減です。
なぜ今AI Factoryが必要なのか?
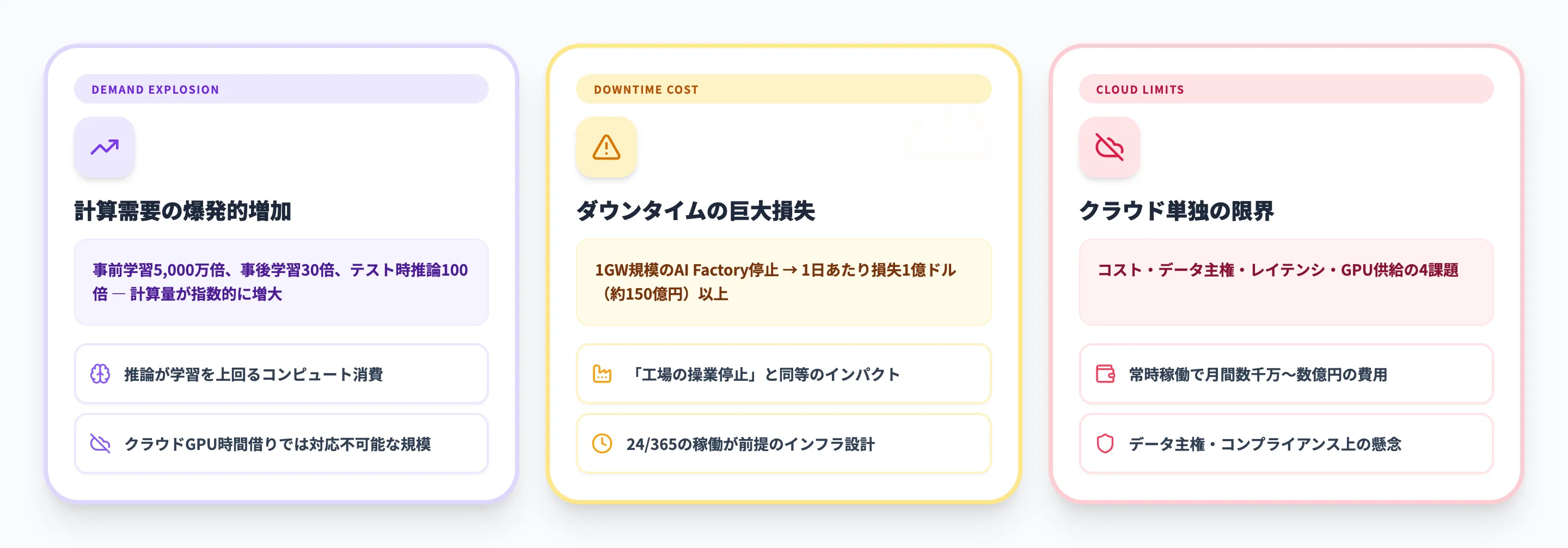
AI Factoryが急速に注目を集めている背景には、AIの計算需要が過去に類を見ない速度で増大しているという現実があります。ここでは、AI Factoryが必要とされる3つの構造的要因を解説します。
AIの計算需要が爆発的に増加している
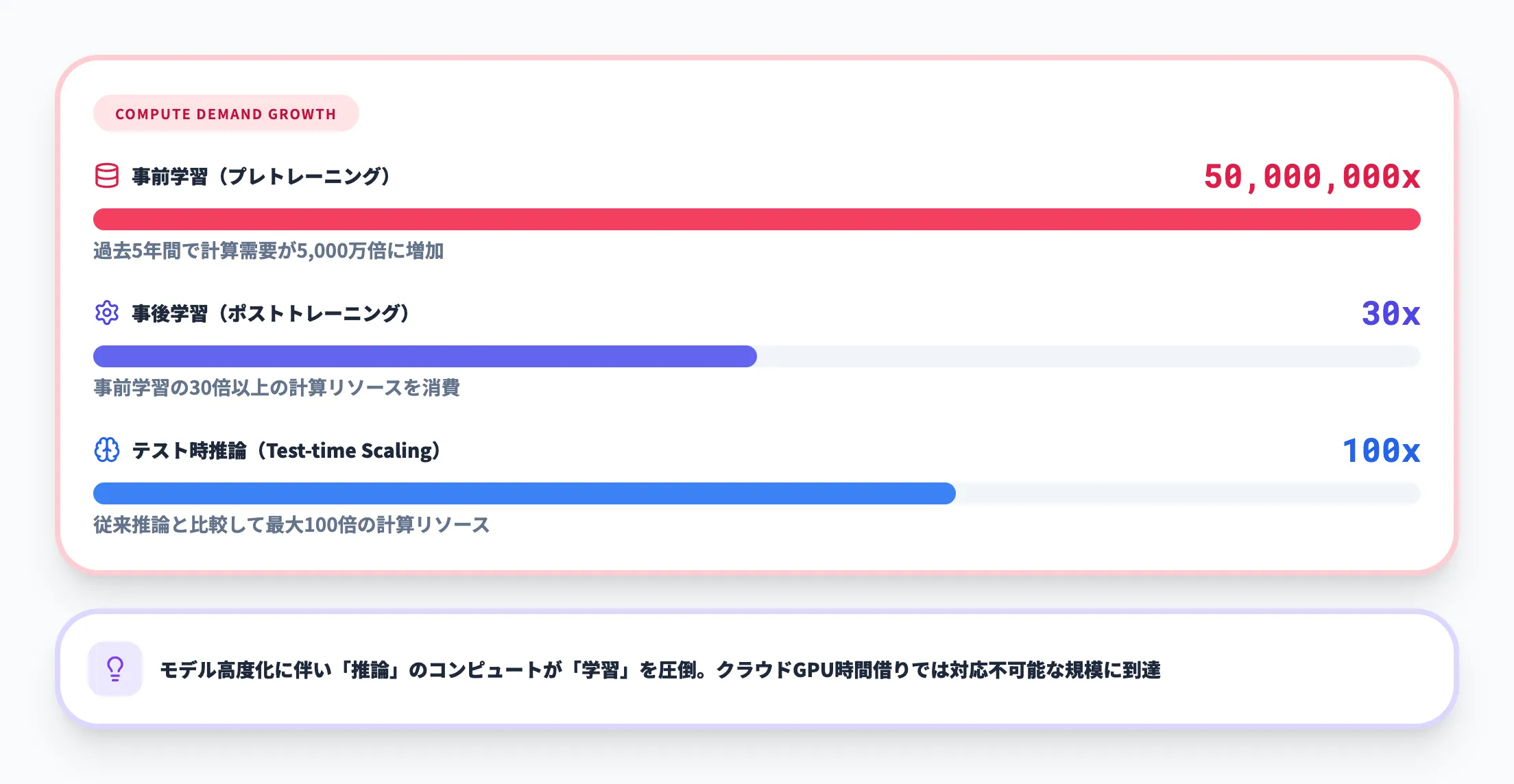
NVIDIAのGTC 2026で示されたデータによると、AIワークロードの計算需要は以下のように急増しています。
- 事前学習(プレトレーニング) 過去5年間で計算需要が5,000万倍に増加
- 事後学習(ポストトレーニング) 事前学習の30倍以上の計算リソースを消費
- テスト時推論(Test-time Scaling) 従来の推論と比較して最大100倍の計算リソースを消費
つまり、モデルが大規模化・高度化するにつれて、「学習」よりも「推論」にかかるコンピュートが圧倒的に増えているのです。これは、従来のクラウドGPUインスタンスを時間借りするだけでは対応しきれない規模の計算需要が、すでに現実のものとなっていることを意味します。
ダウンタイムのコストが桁違いに大きい

AI Factoryの規模が拡大するにつれ、稼働停止の影響も急激に大きくなります。NVIDIAの試算によると、1ギガワット規模のAI Factoryが1日停止した場合の損失は1億ドル(約150億円)以上に上ります。
これは、AI Factoryが24時間365日「知能を製造し続ける」ことを前提に設計されたインフラであるため、ダウンタイムがそのまま生産ロスに直結するからです。従来のデータセンターのダウンタイムが「サービスの一時停止」であるのに対し、AI Factoryのダウンタイムは「工場の操業停止」に近い経済的インパクトを持ちます。
クラウドだけでは限界がある
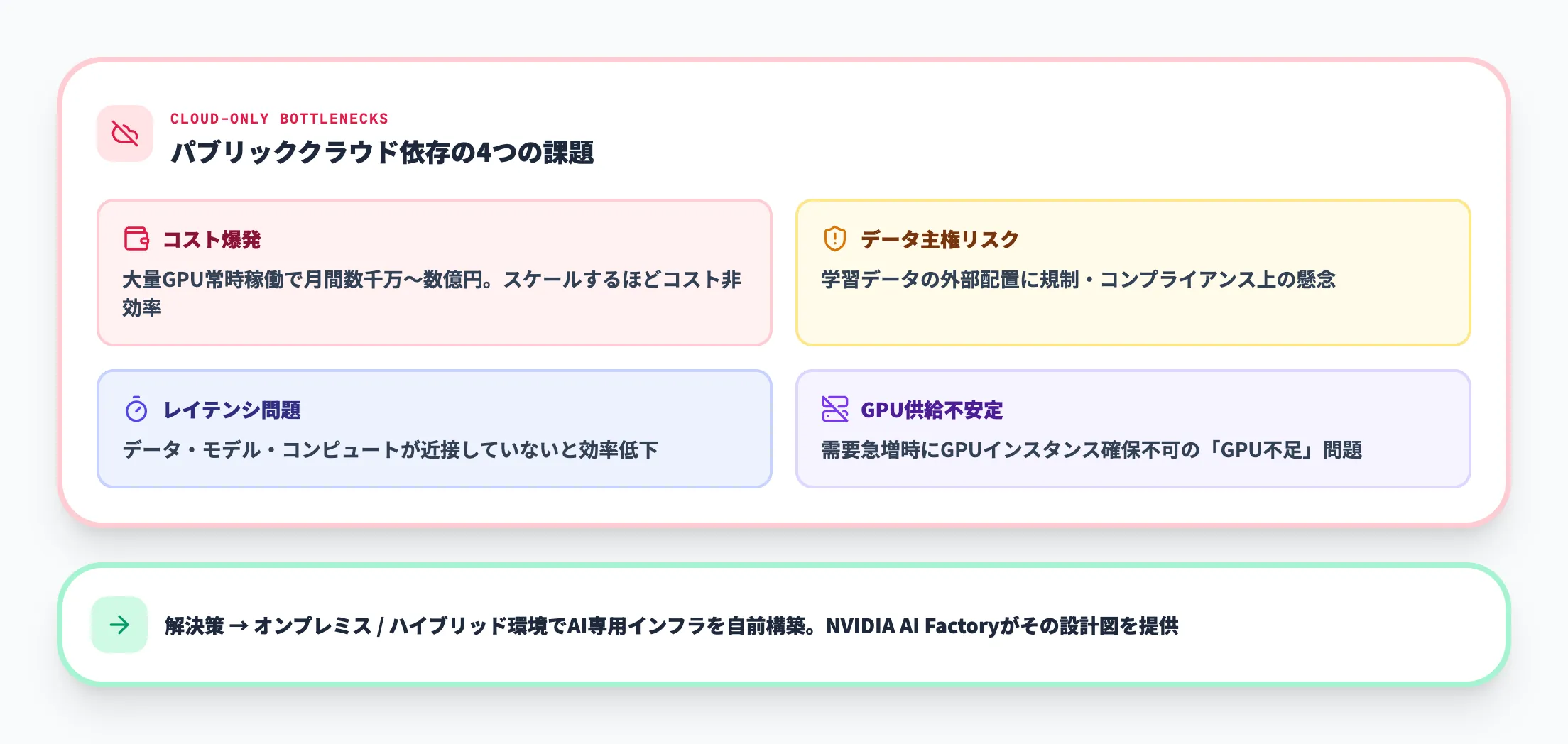
大規模なAIワークロードを運用する企業にとって、パブリッククラウドだけに依存するアプローチには以下の課題があります。
- コスト 大量のGPUインスタンスを常時稼働させると、月間数千万〜数億円のクラウド費用が発生
- データ主権 学習データを外部クラウドに配置することへの規制・コンプライアンス上の懸念
- レイテンシ AIワークロードはデータ・モデル・コンピュートが近接していないと効率が大幅に低下
- 供給の不安定性 需要急増時にGPUインスタンスが確保できない「GPU不足」問題
こうした課題から、オンプレミスまたはハイブリッド環境でAI専用インフラを自前で構築する動きが加速しています。NVIDIA AI Factoryは、そのための設計図とフルスタックソリューションを提供するものです。
NVIDIA AI Factoryの5つの構成レイヤー
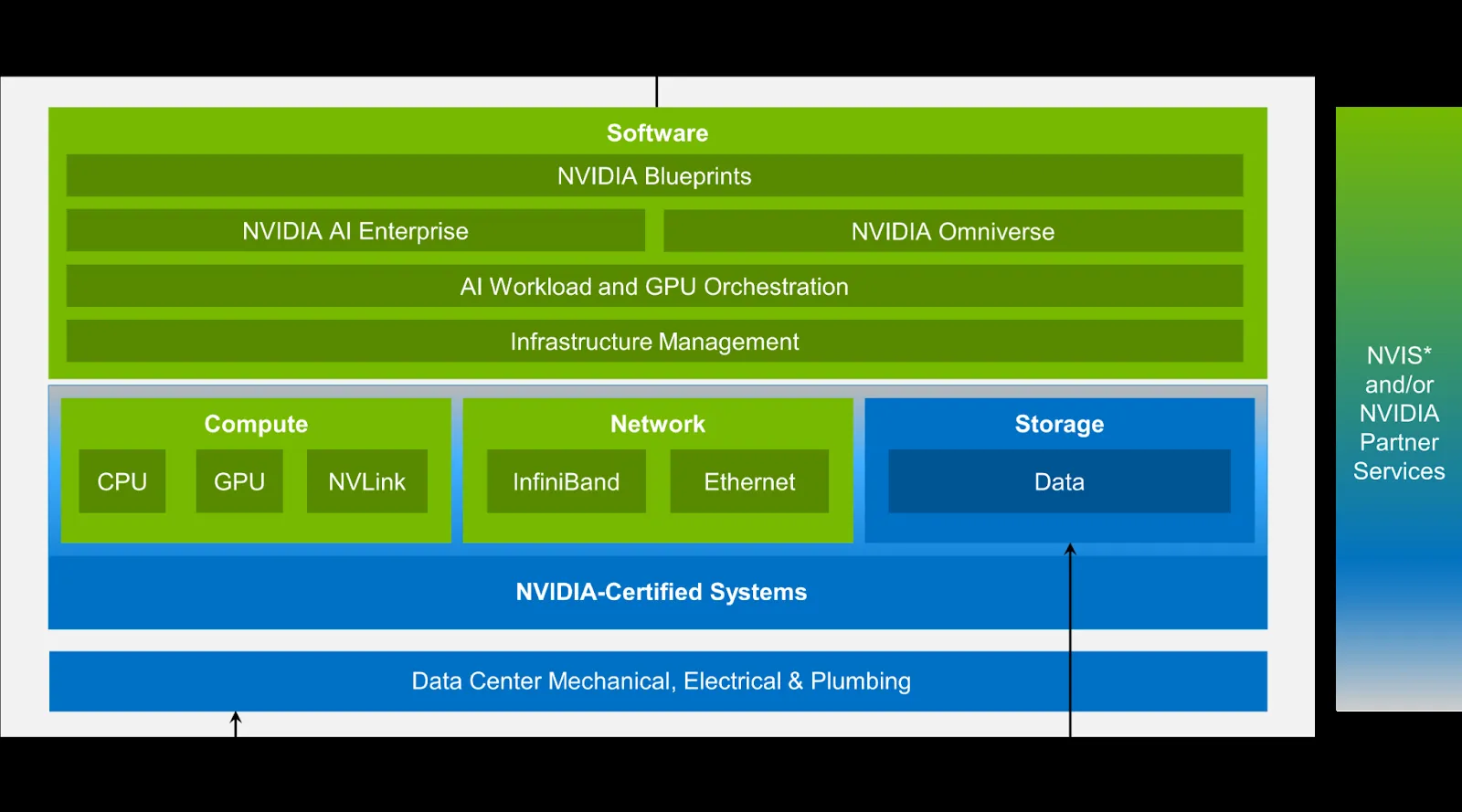
NVIDIA AI Factoryのフルスタック構成を示すリファレンスアーキテクチャ(出典:NVIDIA Technical Blog)
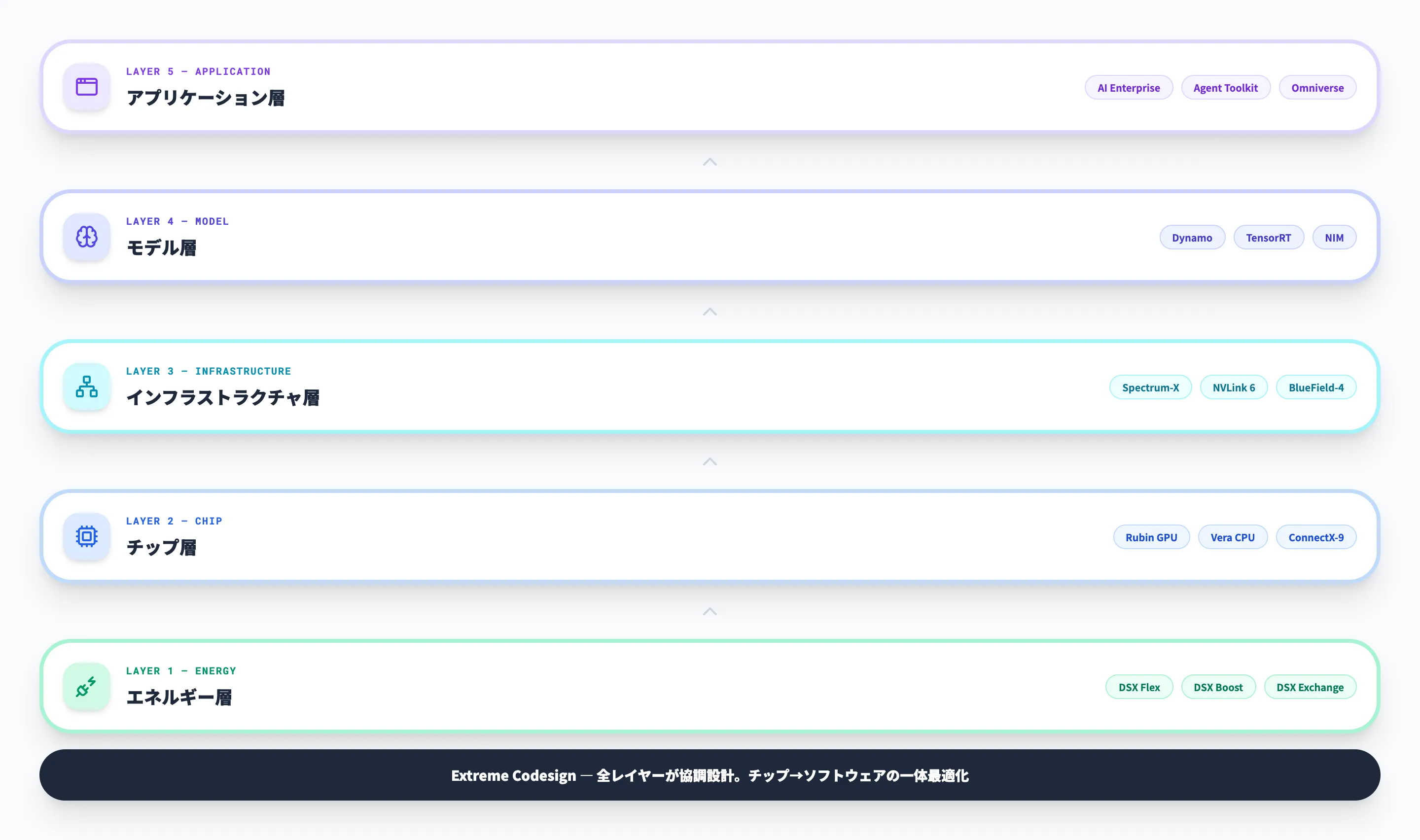
NVIDIA AI Factoryは、5つのレイヤーで構成される統合的なアーキテクチャです。チップ単体ではなく、エネルギーからアプリケーションまでの全レイヤーを一気通貫で最適化する設計が、AI Factoryの競争力の源泉となっています。
以下の表で、5つの構成レイヤーとそれぞれの役割を整理しました。各レイヤーがどのように連携してトークンスループットを最大化するかを理解することが、AI Factory導入の第一歩です。
| レイヤー | 主な役割 | 代表的なNVIDIA製品・技術 |
|---|---|---|
| エネルギー | 電力供給・冷却・電力管理 | DSX Flex、DSX Boost、DSX Exchange |
| チップ | 演算処理・メモリ・DPU | Rubin GPU、Vera CPU、BlueField-4、ConnectX-9、Spectrum-6 |
| インフラストラクチャ | ネットワーク・ストレージ・ラック構成 | Spectrum-X Ethernet、NVLink 6、BlueField-4 STX |
| モデル | AI推論エンジン・モデル最適化 | Dynamo、TensorRT、NIM microservices |
| アプリケーション | エンタープライズAI・エージェント・物理AI | NVIDIA AI Enterprise、Agent Toolkit、Omniverse |
この5層構造のポイントは、各レイヤーが独立して動くのではなく、チップからソフトウェアまでが「コデザイン」(協調設計)されている点です。NVIDIAのジェンスン・フアンCEOはCES 2026のRubinプラットフォーム発表で「extreme codesign(極限の協調設計)」という言葉を使い、ハードウェアとソフトウェアが一体設計されていることがNVIDIA AI Factoryの本質だと強調しています。
エネルギー層 — 電力と冷却の新しいパラダイム
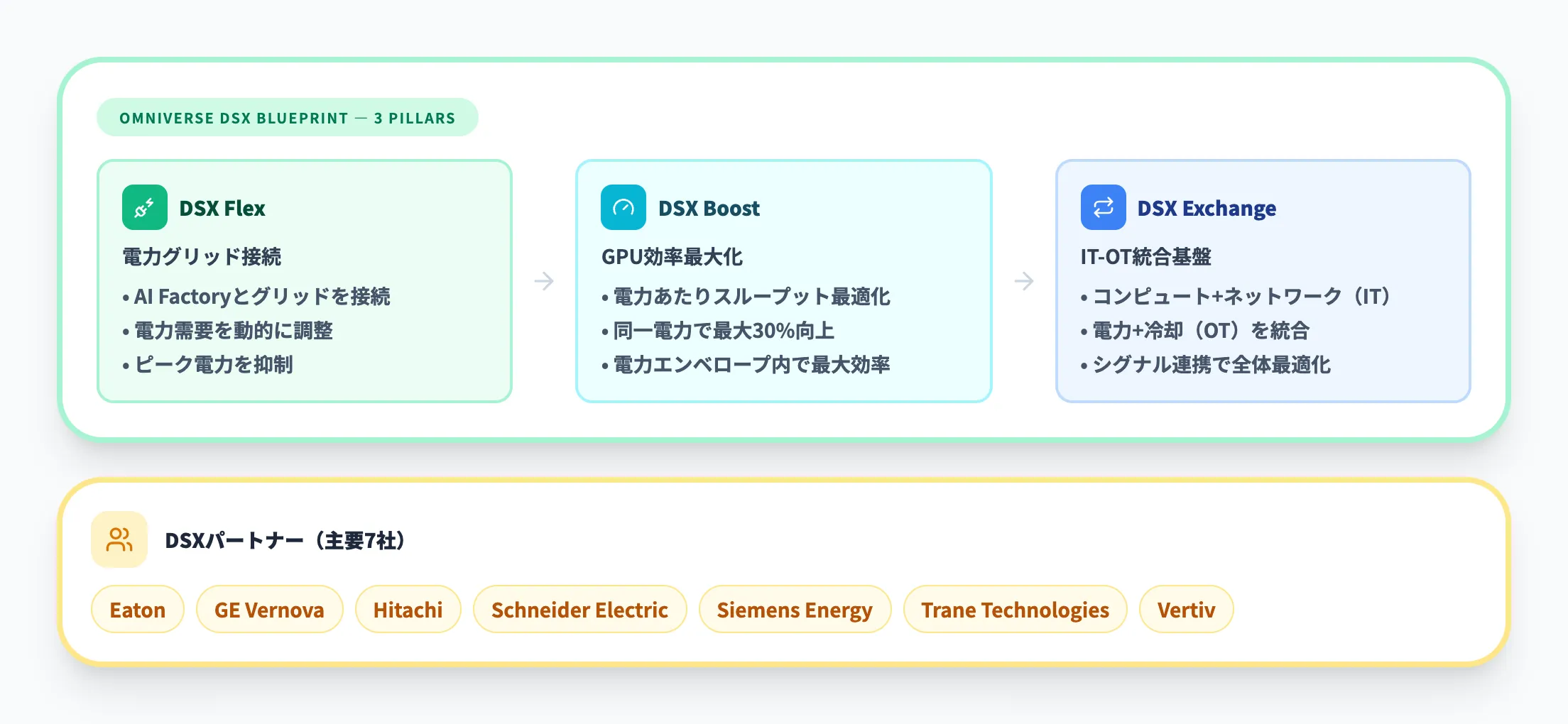
AI Factoryでは、ラックあたりの消費電力が130〜150 kWに達するため、従来の空冷方式では冷却が追いつきません。NVIDIAは2025年10月のGTC Washington D.C.でOmniverse DSXブループリント(AI Factoryのデジタルツイン設計基盤)を発表し、エネルギー管理を統合的に解決する仕組みを提供しています。
DSXは3つの柱で構成されます。
-
DSX Flex
AI Factoryと電力グリッドを接続し、電力需要を動的に調整するシステム。ピーク電力の抑制やグリッドの安定化にも貢献します。 -
DSX Boost
消費電力あたりのGPUスループットを最大化する最適化エンジン。同じ電力エンベロープ内でGPUスループットを最大30%向上させます。 -
DSX Exchange
IT(コンピュート・ネットワーク)とOT(電力・冷却)のシグナルを統合する連携基盤です。
チップ層 — Vera Rubinプラットフォームの全貌

CES 2026(2026年1月5日)で発表されたVera Rubinプラットフォームは、6つの新チップで構成される、AI Factory専用のコンピューティングプラットフォームです。
以下の表で、6つの新チップの特性と役割を整理しました。各チップがAI Factoryのどの機能を担当するかを把握することで、システム全体の設計思想が見えてきます。
| チップ名 | 種別 | 主な役割 | 主要スペック |
|---|---|---|---|
| Rubin GPU | GPU | 大規模学習・推論 | NVLink 6接続、NVFP4で50ペタフロップス |
| Vera CPU | CPU | エージェントAI・長期記憶 | LPDDR5Xメモリ(業界初) |
| NVLink 6 Switch | スイッチ | GPU間高速接続 | NVLink 6ファブリック |
| BlueField-4 DPU | DPU | データ処理・セキュリティ | ネットワーク処理のオフロード |
| ConnectX-9 SuperNIC | SuperNIC | ネットワーク接続 | 高帯域・低遅延接続 |
| Spectrum-6 Ethernet Switch | スイッチ | Ethernetファブリック | コパッケージドオプティクス対応、電力効率5倍、信頼性10倍 |
NVIDIAの公式発表によると、Vera Rubinプラットフォームの主なフォームファクタはVera Rubin NVL72(72 Rubin GPU + 36 Vera CPUのラック構成)とHGX Rubin NVL8(8 Rubin GPUを搭載するx86プラットフォーム向けサーバーボード)の2種類です。Blackwellと比較して、推論トークンコストを最大10分の1に削減し、MoEモデルの学習に必要なGPU数を4分の1に抑えます。
インフラストラクチャ層 — 2つのフォームファクタ

Vera Rubinプラットフォームの主要なフォームファクタは以下の2種類で、用途に応じて使い分けます。
| フォームファクタ | 用途 | 構成 |
|---|---|---|
| Vera Rubin NVL72 | 大規模AI Factory向け(学習・推論) | 72 Rubin GPU + 36 Vera CPUのラックスケール構成 |
| HGX Rubin NVL8 | x86サーバー向け | 8 Rubin GPU搭載のサーバーボード |
Vera Rubin NVL72ラックのGPU間帯域は260 TB/s(NVLink 6)、100%液冷で動作します。Blackwellと比較して組み立て・サービス時間が18分の1に短縮されたモジュラー設計を採用しています。
モデル層 — DynamoとNIM
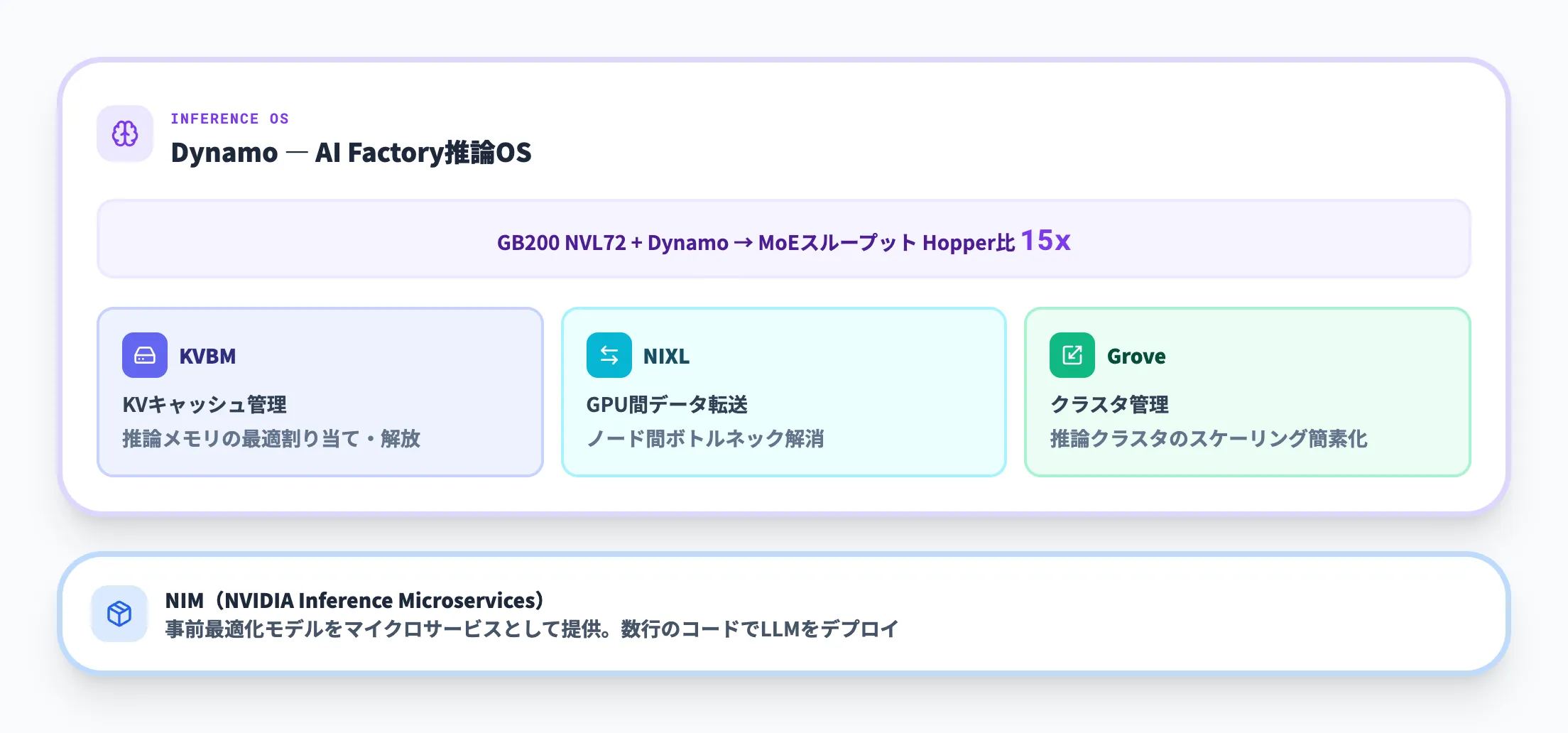
モデル層は、AI Factoryのハードウェア能力を実際のAI推論性能に変換するソフトウェアスタックです。
DynamoはAI Factoryの「推論オペレーティングシステム」として位置づけられ、データセンター規模でのAI推論ワークロードを管理します。2025年3月のGTC 2025でオープンソースライブラリとして初公開され、その後プロダクション版がリリースされました。NVIDIAの公式データによると、GB200 NVL72と組み合わせることで、MoE(Mixture-of-Experts)モデルのスループットをHopper世代と比較して最大15倍に向上させます。
Dynamoの主要コンポーネントは以下の通りです。
-
KVBM(Key-Value Block Manager)
推論時のメモリ管理を最適化し、KVキャッシュの効率的な割り当て・解放を行います。 -
NIXL(NVIDIA Inter-node eXchange Library)
GPU間のデータ移動を高速化するライブラリです。分散推論において、ノード間のデータ転送ボトルネックを解消します。 -
Grove
推論クラスタのスケーリングを簡素化する管理ツールです。
また、**NIM(NVIDIA Inference Microservices)**は、事前最適化されたAIモデルをマイクロサービスとして提供する仕組みで、数行のコードでLLMや画像認識モデルをデプロイできます。
アプリケーション層 — エンタープライズAIの実行環境
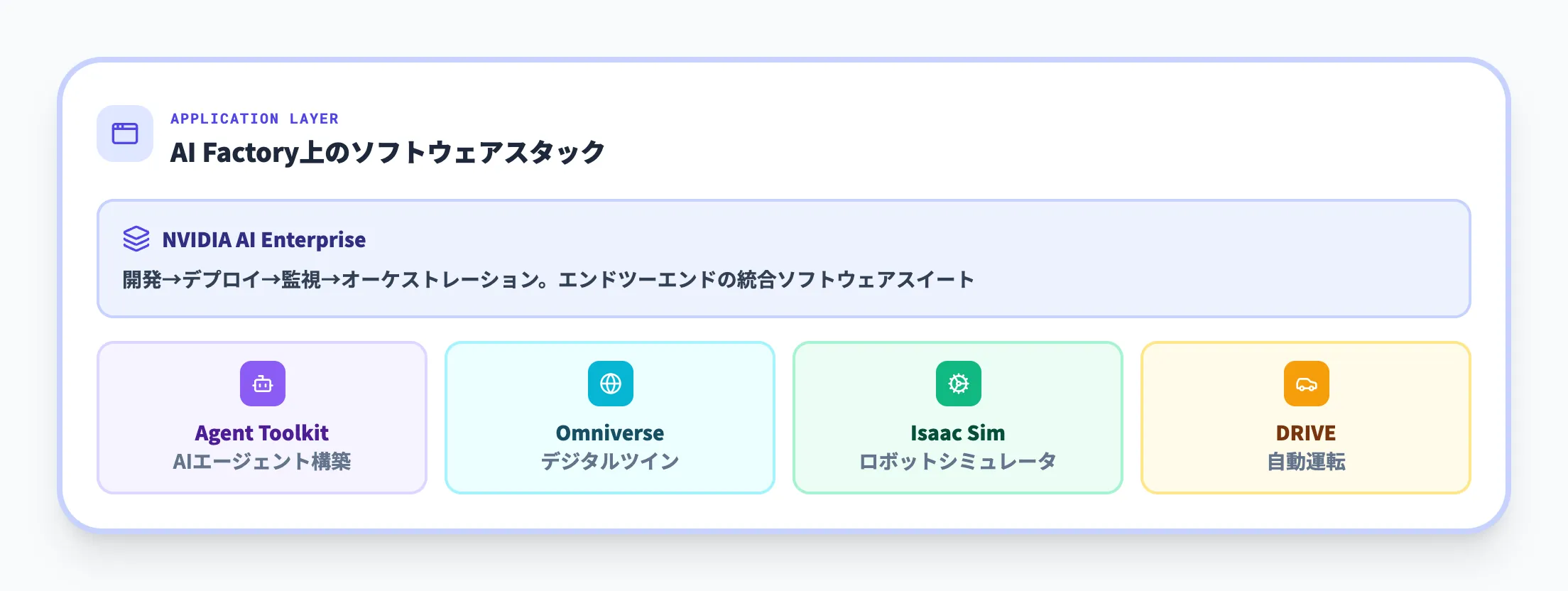
アプリケーション層は、AI Factoryで生産されたインテリジェンスを実際のビジネスアプリケーションに変換するレイヤーです。
NVIDIA AI Enterpriseは、AI Factory上でエンタープライズAIアプリケーションを開発・運用するためのエンドツーエンドソフトウェアスイートです。開発からプロダクション展開までを一貫してサポートし、リソースのオーケストレーションや監視機能を提供します。
このほか、NVIDIA Agent Toolkit(AIエージェントの構築・評価・最適化フレームワーク)、Omniverse(デジタルツイン・シミュレーション)、Isaac Sim(ロボットシミュレータ)、DRIVE(自動運転プラットフォーム)など、用途別のアプリケーションフレームワークがAI Factory上で稼働します。
Enterprise AI Factory Validated Design — オンプレミスAI Factoryの構築

NVIDIA Enterprise AI Factory validated designに基づくオンプレミスAI Factory構成(出典:NVIDIA Marketplace)

NVIDIA Enterprise AI Factory Validated Designは、企業がオンプレミスでAI Factoryを構築するための、検証済みフルスタック設計です。NVIDIAが主要パートナーと共同で検証したハードウェア・ソフトウェアの組み合わせを、リファレンスアーキテクチャとして提供します。
フルスタック構成

Enterprise AI Factory Validated Designは、以下のコンポーネントで構成されます。
-
コンピュート
NVIDIA Blackwellアクセラレーテッドコンピューティング(現行世代)。今後Vera Rubinにアップグレード予定。 -
ネットワーク
NVIDIA Spectrum-X Ethernet。超低遅延・高帯域のAI専用ネットワークファブリック。 -
DPU
NVIDIA BlueField DPU。ネットワーク・セキュリティ・ストレージ処理をCPU/GPUからオフロード。 -
ソフトウェア
NVIDIA AI Enterprise。開発・デプロイ・監視・オーケストレーションの統合ソフトウェアスイート。
パートナーエコシステムの全体像

Enterprise AI Factory Validated Designには、AIパイプラインの各段階をカバーする広範なパートナーエコシステムが統合されています。
以下の表で、パートナーの機能領域別の分布を整理しました。AI Factoryの構築は単にNVIDIAのハードウェアを導入するだけでなく、これらのパートナーソリューションを組み合わせてエンドツーエンドのパイプラインを構築する作業であることが分かります。
| 機能領域 | 主なパートナー |
|---|---|
| データ準備 | SuperAnnotate、Unstructured |
| 開発・構築 | Accenture、CrewAI、Cohere、Dataiku、DataRobot、Deloitte、LangChain |
| テスト・評価 | Arize、Weights & Biases |
| インフラ基盤 | Red Hat、Canonical、Nutanix、VMware |
| セキュリティ | Palo Alto Networks、Check Point、Fortinet、Securiti |
| モニタリング | Datadog、Dynatrace、Splunk |
| ガードレール | ActiveFence、Fiddler、Galileo |
| ストレージ・検索 | DataStax、Elastic |
| ハードウェアパートナー | Dell、HPE、Cisco、Lenovo、Supermicro |
実務で選ぶ際のポイントは、既存のIT環境との互換性です。たとえば、すでにRed Hat環境を運用しているならRed Hat AI Enterpriseとの統合が最もスムーズですし、VMware環境であればNutanixやVMwareとの連携パスが用意されています。
導入事例 — AI Factoryを活用する企業

NVIDIA RTX PRO Serversを活用した企業のAI Factory導入事例(出典:NVIDIA Newsroom)
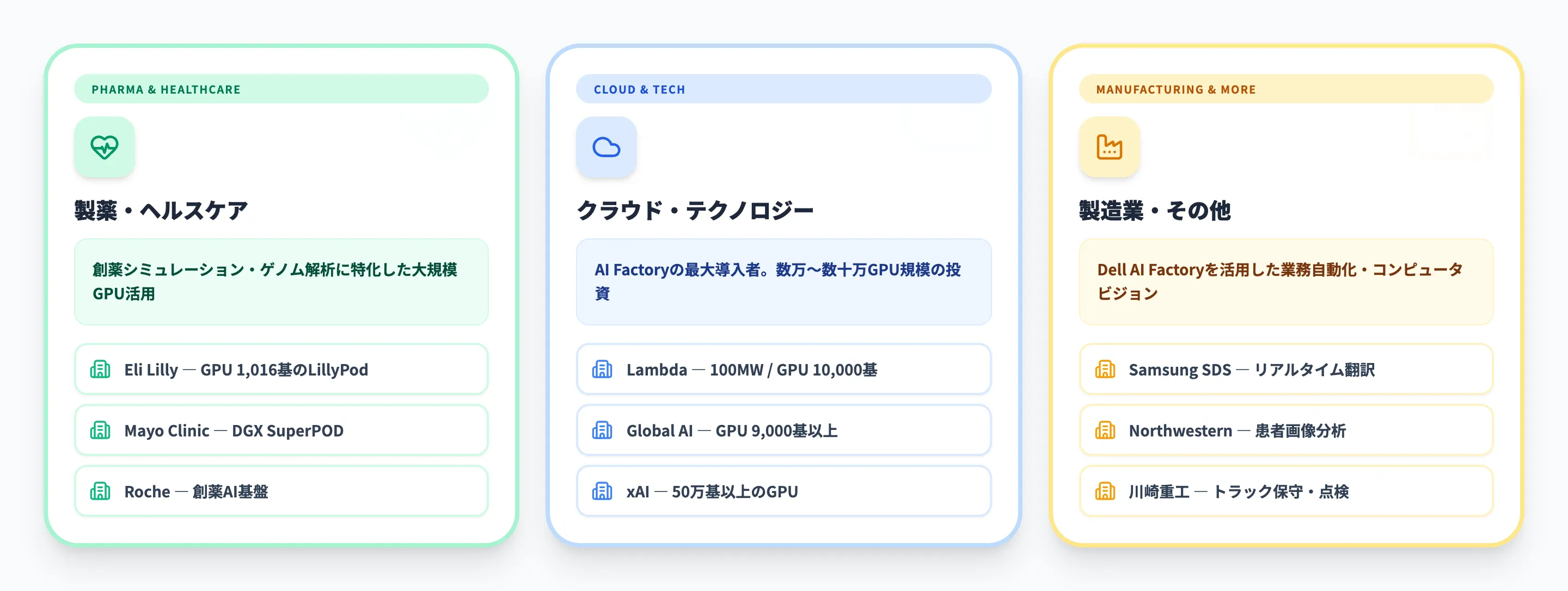
NVIDIA AI Factoryは、製薬・ヘルスケア、クラウドプロバイダー、製造業など、幅広い業界で導入が進んでいます。以下に代表的な事例を紹介します。
製薬・ヘルスケア

以下の表で、製薬・ヘルスケア業界のAI Factory導入事例を整理しました。この業界では、創薬シミュレーションやゲノム解析といった、膨大な計算を必要とするユースケースがAI Factoryの導入を牽引しています。
| 企業名 | 導入内容 | 規模 |
|---|---|---|
| Eli Lilly(イーライリリー) | LillyPod — DGX SuperPOD(DGX B300) | Blackwell Ultra GPU 1,016基。製薬業界最大のAI Factory |
| Mayo Clinic | DGX SuperPOD構築 | 臨床データ分析・画像診断支援 |
| Roche | 創薬AI基盤 | 大規模Blackwell GPU導入 |
イーライリリーのLillyPodは、ゲノミクスと創薬AIに特化した専用AI Factoryです。1,016基のBlackwell Ultra GPUを搭載したDGX SuperPODにより、タンパク質構造予測や化合物スクリーニングの速度を従来比で大幅に向上させています。
クラウド・テクノロジー
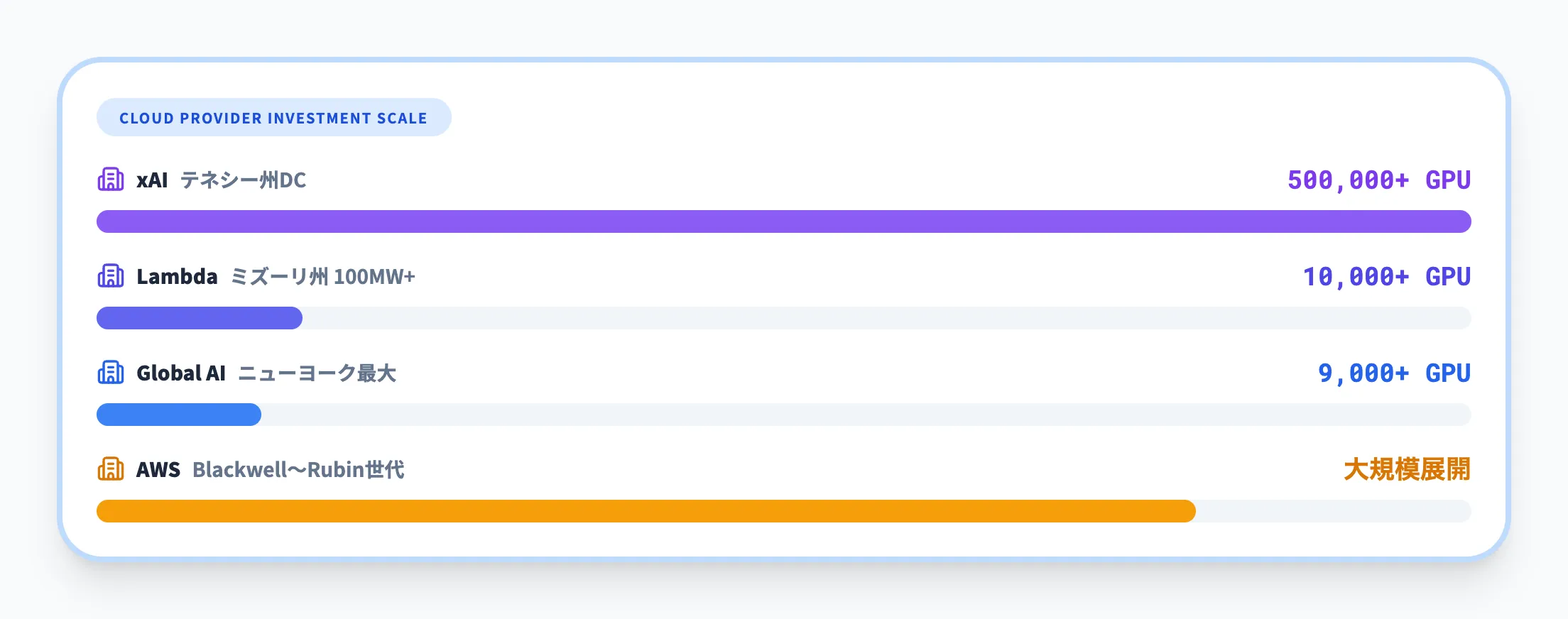
クラウドプロバイダーは、AI Factoryの最大の導入者です。2025年後半以降、主要クラウドプロバイダーのAI Factory投資が相次いで発表されています。
| 企業名 | 導入内容 | 規模 |
|---|---|---|
| AWS | NVIDIA GPUの大規模展開 | 大規模GPU展開(Blackwell〜Rubin世代) |
| Lambda | ミズーリ州にAI Factory建設 | 100MW以上、GB300 NVL72を10,000基以上 |
| Global AI | ニューヨーク最大のAI Factory | GB300 NVL72を128ラック(9,000基以上のGPU) |
| xAI | テネシー州にデータセンター建設 | 50万基以上のGPU搭載 |
AWSをはじめとする主要クラウドプロバイダーは、Blackwell世代からRubin世代まで、NVIDIA GPUのフルスタック採用を進めています。NVIDIA Cloud Partners全体のAI処理能力は急速に拡大しており、各社ともAI Factory規模のインフラ投資を加速させています。
製造業・その他
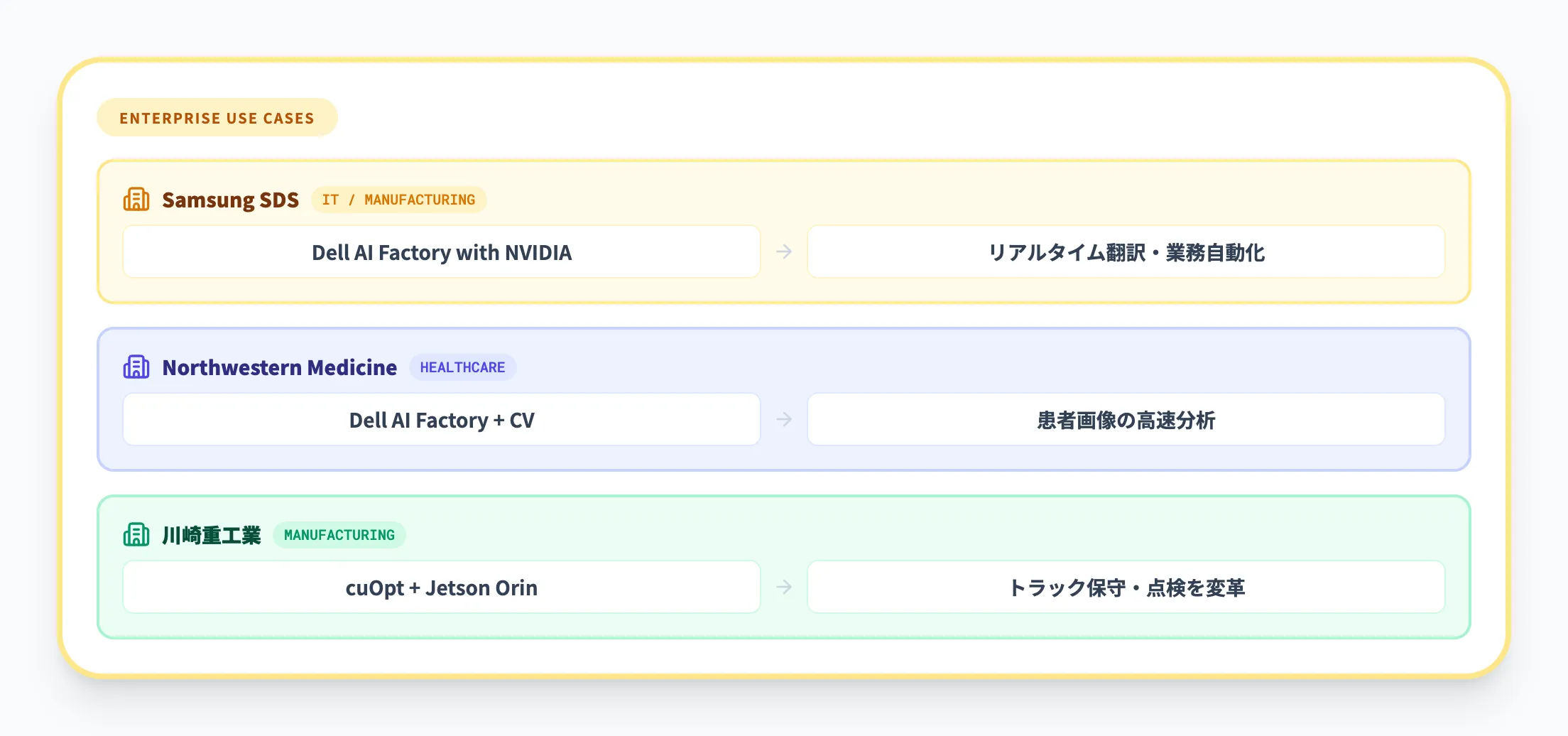
| 企業名 | 業界 | 導入内容 |
|---|---|---|
| Samsung SDS | IT / 製造 | Dell AI Factory with NVIDIAを活用。リアルタイム翻訳・業務プロセス自動化 |
| Northwestern Medicine | 医療 | Dell AI Factory with NVIDIAによるコンピュータビジョン。患者画像の高速分析 |
| 川崎重工業 | 製造 | NVIDIA cuOptとJetson Orinでトラック保守・点検を変革 |
Samsung SDSの事例は、エンタープライズにおけるAI Factoryの典型的な活用パターンを示しています。生成AIを社内外の業務に統合し、リアルタイム翻訳やマルチステップの業務プロセスをAIで自動化しています。

AI Factoryの料金体系と必要コスト
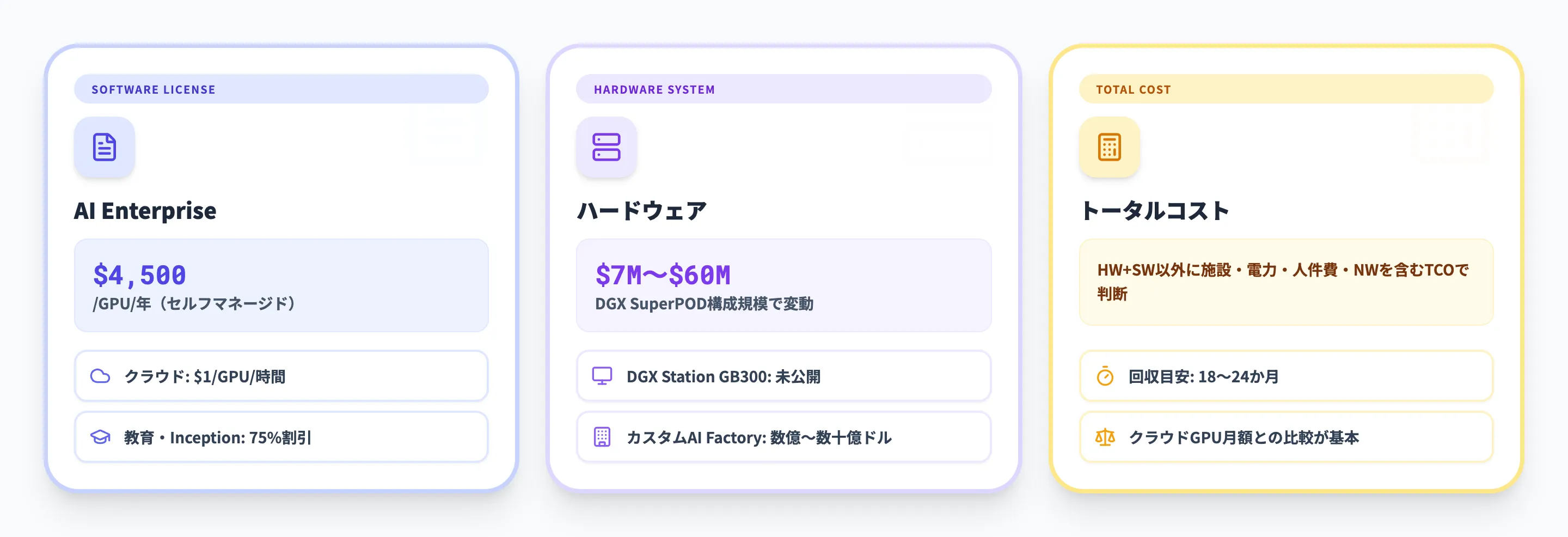
AI Factoryの構築・運用には、ソフトウェアライセンス、ハードウェアシステム、エネルギー・施設コストなど、複数のコスト要素があります。ここでは、2026年3月時点の公開情報にもとづいて、各要素のコスト感を整理します。
NVIDIA AI Enterpriseソフトウェアライセンス

NVIDIA AI Enterpriseは、AI Factoryのソフトウェアスタックをカバーするライセンスです。GPU単位の課金体系で、以下の価格帯で提供されています。
以下の表で、オンプレミス(セルフマネージド)環境の料金体系を整理しました。長期契約ほどGPUあたりの年間コストが低減する仕組みです。
| 契約期間 | 価格(GPUあたり) | 年間換算 |
|---|---|---|
| 1年 | $4,500 | $4,500/GPU/年 |
| 2年 | $9,000 | $4,500/GPU/年 |
| 3年 | $13,500 | $4,500/GPU/年 |
| 5年 | $18,000 | $3,600/GPU/年 |
| 永続ライセンス(5年サポート付き) | $22,500 | $4,500/GPU/年 |
教育機関やNVIDIA Inceptionプログラム参加スタートアップには、75%割引のアカデミック価格が適用されます。
クラウド環境での利用は、$1/GPU/時間 + クラウドインスタンス費用の従量課金モデルです。AWS、Azure、Google Cloud、Oracle Cloudで利用可能です。
ハードウェアシステムのコスト
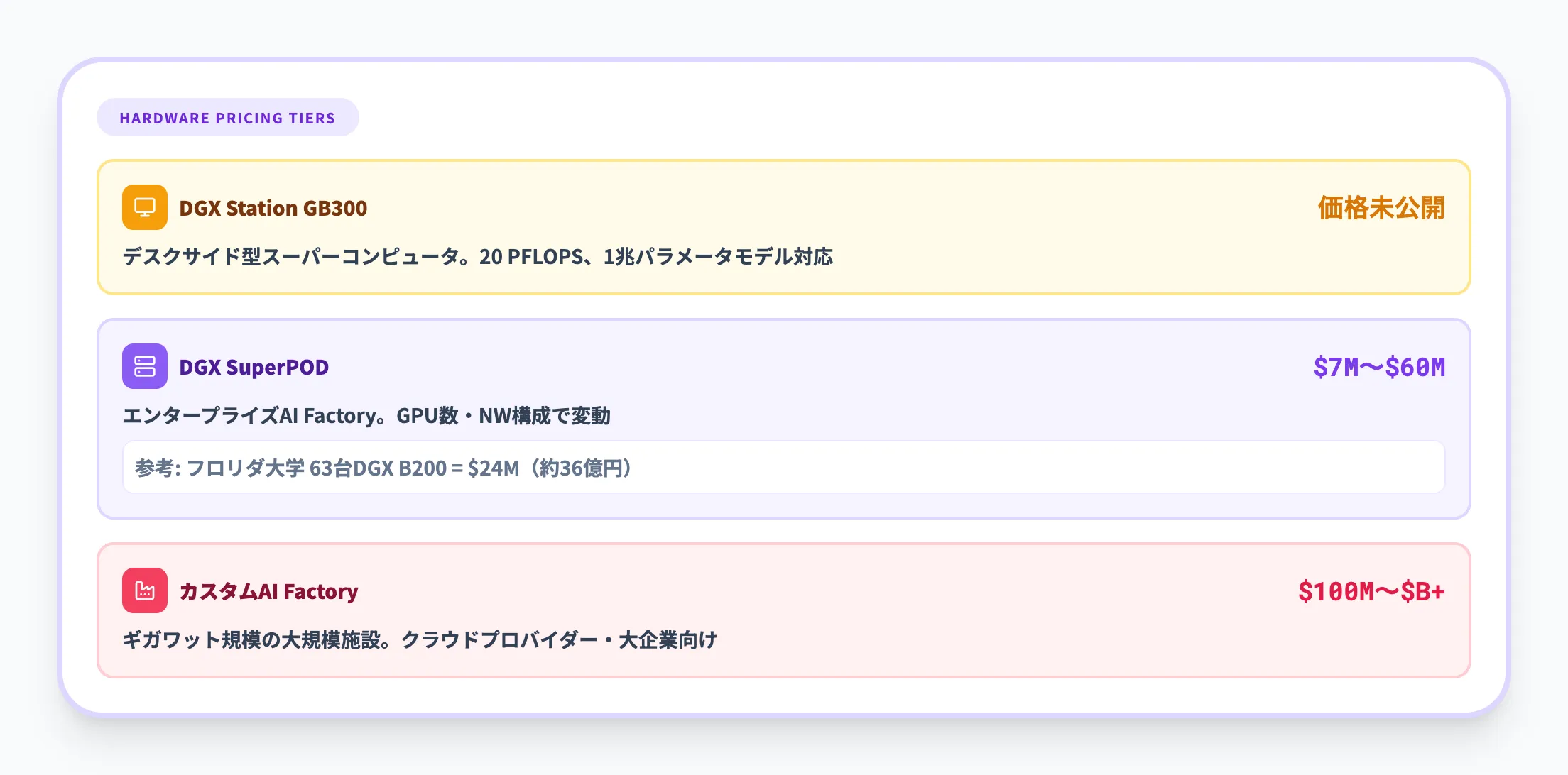
AI Factoryのハードウェアコストは、構成規模によって大きく異なります。
| システム | 用途 | 価格帯 |
|---|---|---|
| DGX Station GB300 | デスクサイド型スーパーコンピュータ | 未公開(20ペタフロップス、1兆パラメータモデル対応) |
| DGX SuperPOD | エンタープライズAI Factory | $700万〜$6,000万(7M〜60M USD) |
| カスタムAI Factory | ギガワット規模の大規模施設 | 数億〜数十億ドル |
DGX SuperPODの価格帯($700万〜$6,000万)は、搭載するGPU数やネットワーク構成によって変動します。参考として、フロリダ大学は63台のDGX B200システムを**2,400万ドル(約36億円)**で導入しています。
トータルコストの考え方
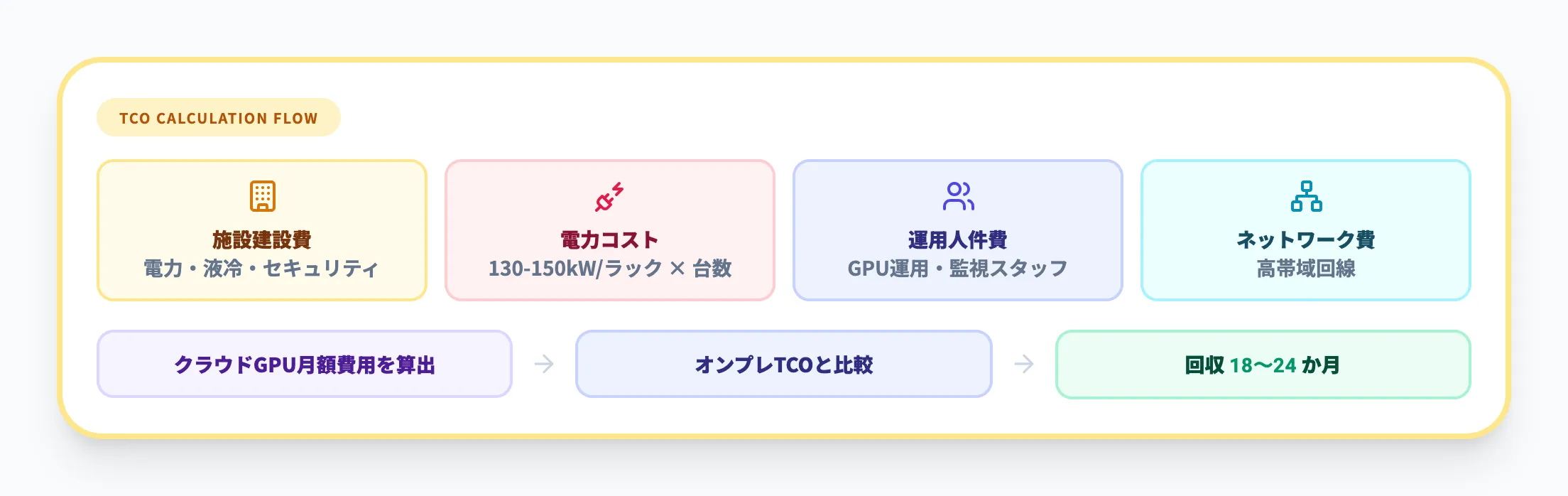
AI Factoryの構築コストは、ハードウェアとソフトウェアだけでは完結しません。以下の要素も含めたTCO(総保有コスト)で判断する必要があります。
- 施設建設費 電力引き込み、液冷設備、物理セキュリティ
- 電力コスト 130〜150 kW/ラック × 稼働ラック数 × 電力単価
- 運用人件費 GPUクラスタの運用・監視スタッフ
- ネットワーク費 高帯域ネットワーク回線
実務では、クラウドGPUの月額費用と比較して「何か月でオンプレミスが回収できるか」を計算するのが一般的なアプローチです。大量のGPUを常時稼働させるユースケースでは、一般的に18〜24か月でオンプレミスAI Factoryのほうがコスト優位になるとされています。
AI Factoryが向いている場面 vs 向かない場面

AI Factoryは万能なソリューションではありません。自社のAIワークロードの規模・性質・予算に応じて、AI Factoryが最適な選択肢かどうかを判断する必要があります。
以下の表で、AI Factoryが適しているケースと、クラウドGPUインスタンスで十分なケースを整理しました。投資判断の際の指標として活用してください。
| 判断基準 | AI Factoryが向いている | クラウドGPU / 従来DCで十分 |
|---|---|---|
| GPU常時稼働 | 数百〜数千基のGPUを24/7稼働 | 数十基以下の間欠的な利用 |
| データ主権 | 機密データの社外持ち出しが禁止 | データのクラウド配置に制約なし |
| モデル規模 | 数百億〜1兆パラメータモデルの学習 | 数十億パラメータ以下のファインチューニング |
| 推論スループット | 毎秒数百万トークンの生成が必要 | 毎秒数千〜数万トークンで十分 |
| 初期投資 | 数千万〜数十億円の資本投資が可能 | OpEx(運用費)重視で初期投資を抑えたい |
| 運用体制 | GPU/HPC運用の専門チームが存在 | AIインフラの運用経験が限定的 |
| 業界 | 製薬・金融・自動車・国防・研究機関 | 一般的なSaaS・Webサービス |
この表から明確なのは、AI Factoryはあくまで「大規模・常時稼働・高セキュリティ」のユースケース向けだということです。GPU利用が間欠的であったり、数十基規模であれば、クラウドGPUインスタンスのほうが初期投資ゼロで柔軟に対応できます。
一方で、GPU利用が月間数千万円を超える企業、またはデータ主権やレイテンシの要件がある企業にとっては、AI Factoryへの投資が中長期的に合理的な選択肢になります。
ハイブリッドアプローチの選択肢
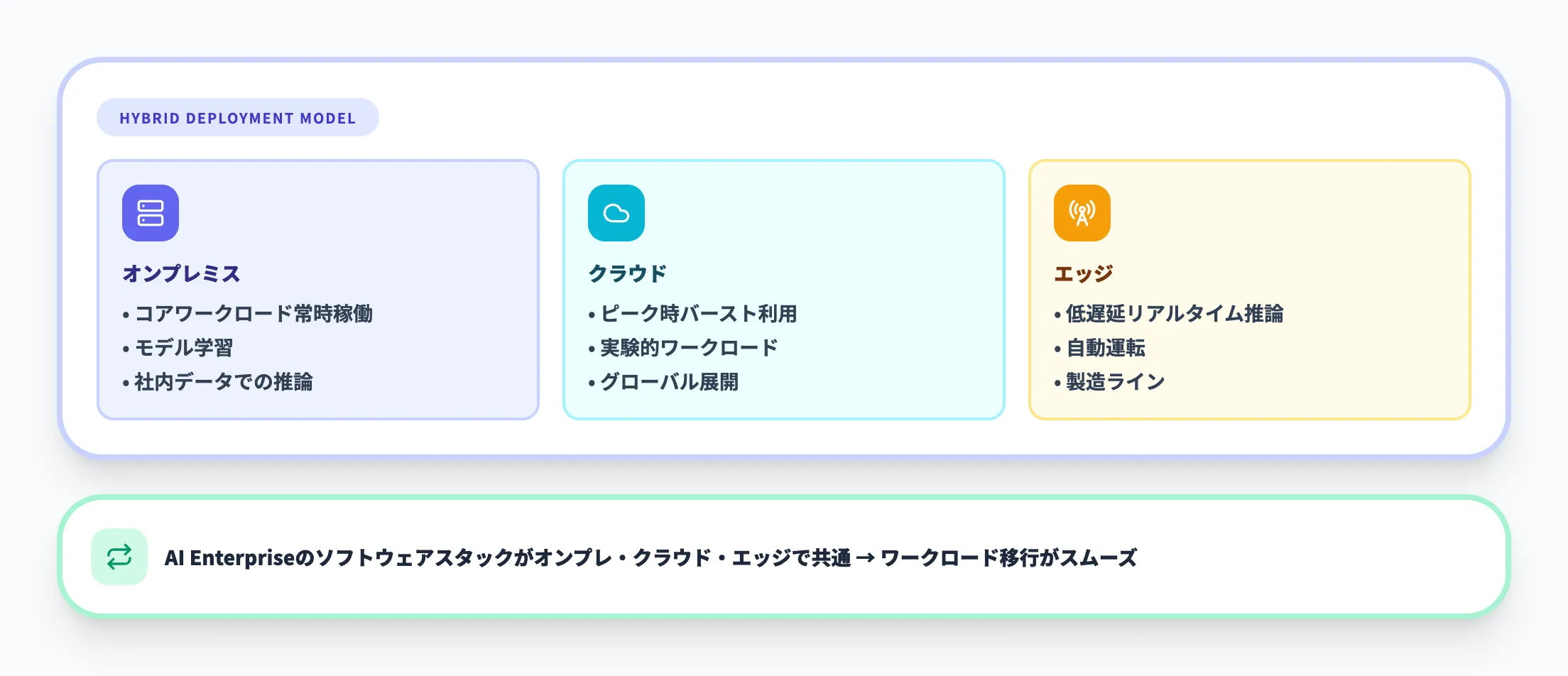
多くの企業にとって現実的なのは、オンプレミスAI Factoryとクラウドを組み合わせたハイブリッドアプローチです。NVIDIAはこの戦略を明確にサポートしており、以下のような組み合わせが可能です。
- オンプレミス 常時稼働のコアワークロード(モデル学習、社内データでの推論)
- クラウド ピーク時のバースト利用、実験的なワークロード、グローバル展開
- エッジ 低遅延が求められるリアルタイム推論(自動運転、製造ライン等)
NVIDIA AI Enterpriseのソフトウェアスタックはオンプレミス・クラウド・エッジで共通して利用できるため、ワークロードの移行や分散がスムーズに行えます。
注意点と現時点の制限

AI Factoryの導入を検討する際には、以下の点に注意が必要です。
電力と冷却の制約
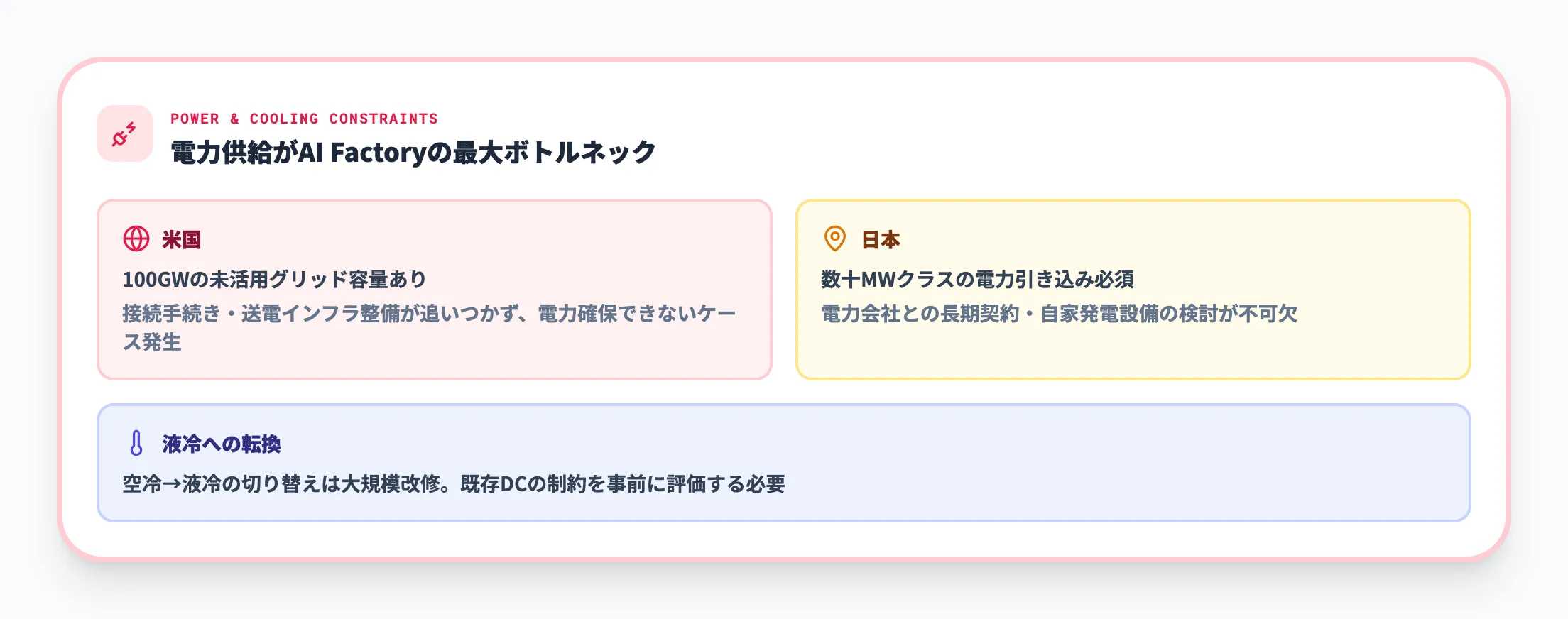
AI Factoryの最大のボトルネックは電力供給です。NVIDIAの公式ブログによると、米国には100ギガワットの未活用グリッド容量が存在するものの、接続手続きや送電インフラの整備が追いつかず、施設を建設しても電力が確保できないケースが発生しています。
日本においても、大規模なAI Factoryの構築には数十MWクラスの電力引き込みが必要であり、電力会社との長期契約や自家発電設備の検討が不可欠です。液冷システムの導入も、空冷のみのデータセンターからの転換は大規模な改修を伴います。
ハードウェア調達のリードタイム

NVIDIAの最新GPUは需要が供給を大幅に上回っている状態が続いています。Vera Rubinプラットフォームは2026年中に出荷開始予定ですが、大規模な展開には発注から納品まで数か月〜1年以上のリードタイムが必要になる場合があります。
人材とスキルの確保

AI Factoryの運用には、従来のサーバー管理とは異なるスキルセットが求められます。GPUクラスタの運用、CUDAプログラミング、分散学習の最適化、液冷システムの保守など、専門人材の確保が課題になります。
ベンダーロックインのリスク

NVIDIAのフルスタックソリューションは高い性能を発揮する一方、ハードウェアからソフトウェアまでNVIDIAに依存する構造になりやすいです。CUDAエコシステムへの依存は長期的なベンダーロックインにつながる可能性があります。AMDのROCmやIntelのoneAPIなどの代替選択肢の動向も注視しておくべきでしょう。
Feynmanアーキテクチャのロードマップ
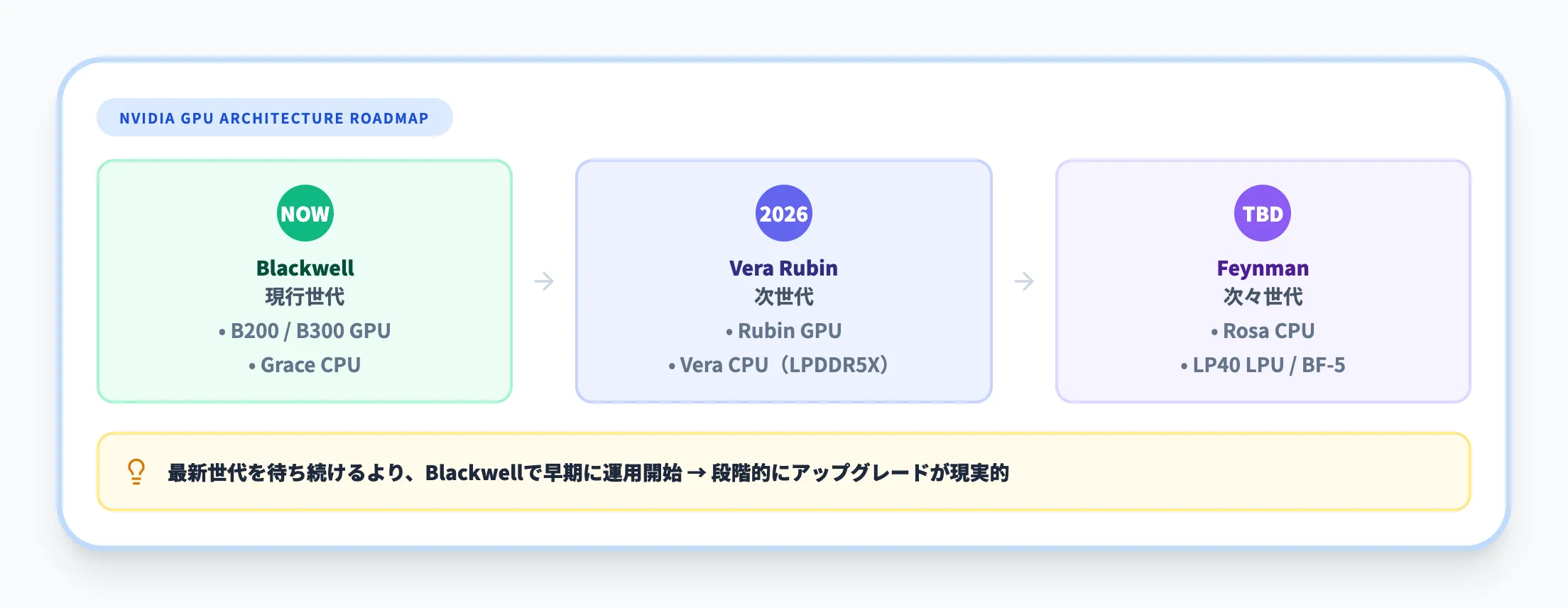
NVIDIAは2025年後半から2026年にかけて、Vera Rubinの次の世代としてFeynman(ファインマン)アーキテクチャのロードマップを公表しています。Rosa CPU、LP40 LPU、BlueField-5、Spectrum次世代を含む構成です。テクノロジーの世代交代が速いため、導入タイミングの見極めが重要です。最新世代を待ち続けるよりも、現行のBlackwell世代で早期に運用を開始し、段階的にアップグレードするアプローチが現実的です。

まとめ
本記事では、NVIDIA AI Factoryの基本概念からCES 2026・GTC 2025等の主要発表、Enterprise向けの導入設計、料金体系、導入事例、そして注意点まで、包括的に解説しました。
NVIDIA AI Factoryは、以下の3つの価値を提供します。
-
AIに最適化された「知能の製造工場」
従来のデータセンターをAI専用に再設計し、トークンスループットを最大化。消費電力あたり30倍、コストあたり60倍の性能向上を実現します。 -
フルスタックのコデザインアーキテクチャ
エネルギー・チップ・インフラ・モデル・アプリケーションの5層を一体設計。Vera Rubinプラットフォーム + Dynamo + Omniverse DSXにより、チップからソフトウェアまでが協調動作します。 -
Enterprise Validated Designによる確実な導入パス
Dell、HPE、Cisco、Lenovoなどの主要パートナーと検証済みの設計を提供。既存のIT環境に合わせたオンプレミス・クラウド・ハイブリッドでの展開が可能です。
次のステップ
AI Factoryの導入を検討する企業には、以下の段階的アプローチを推奨します。
- ステップ1 自社のAIワークロード規模(GPU台数、稼働率、データ主権要件)を棚卸し
- ステップ2 NVIDIAのパートナー(Dell、HPE等)に相談し、DGX Sparkやクラウドで小規模PoC実施
- ステップ3 Enterprise AI Factory Validated Designに基づくオンプレミス設計の検討
- ステップ4 パイロット運用 → 段階的拡張 → 本格運用
NVIDIA AI Factoryは、すべての企業に必要なインフラではありません。しかし、大規模なAI推論を日常的に運用する企業、データ主権が重要な業界、そして独自のAIモデルを競争優位の源泉とする企業にとっては、今後のAI戦略における最も重要なインフラ投資判断の一つとなるでしょう。
AIインフラの理解を、自社の業務自動化戦略に転換する
NVIDIA AI Factoryのようなエンタープライズ級のAIインフラが整備される中で、AIを活用した業務自動化は大企業だけのものではなくなりつつあります。GPU基盤やモデル学習の全体像を理解した方にとって、次の課題はその知識を自社の業務改善にどう落とし込むかという実装設計です。大規模インフラへの投資を検討する前に、まず既存の環境でどこまでAI業務自動化を進められるかを把握することが、合理的な第一歩になります。AI総合研究所では、AI業務自動化の段階的な導入設計をまとめた220ページの実践ガイドを無料で提供しています。
AIインフラの理解を組織のAI戦略に活かす

大規模AI基盤の知見から業務自動化の第一歩へ
NVIDIA AI Factoryのようなエンタープライズ級AIインフラの進化を理解した今こそ、自社のAI活用を具体的に設計するタイミングです。AI業務自動化ガイドでは、段階的なAI導入の実践手順を解説しています。
【関連記事】










