この記事のポイント
 Rayfinの本体はTypeScriptデコレーターでバックエンド全体を宣言する開発体験、デプロイ先はMicrosoft Fabric
Rayfinの本体はTypeScriptデコレーターでバックエンド全体を宣言する開発体験、デプロイ先はMicrosoft Fabric- AIコーディングエージェントが生成したアプリを「Fabric上の管理対象アイテム」として安全に本番化できる
- 本番認証はFabric brokered(Entra SSO)一択、メール/パスワード方式はローカル開発のみ
- 料金体系はRayfin自体がOSSで無料、Fabric Capacityのキャパシティユニットを消費する従量モデル
- Power Apps・Supabase・GitHub Sparkとは別の階層に位置し、AIエージェント前提のフルスタック基盤として設計されている

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Rayfin(レイフィン)は、Microsoftが2026年6月2日のMicrosoft Build 2026で発表した、Microsoft Fabric上にアプリケーションバックエンドをコードで宣言してデプロイする新しいオープンソースSDK/CLIです。
TypeScriptクラスにデコレーターを付けるとデータベース・GraphQL API・行レベル権限・型安全クライアントが生成され、認証・静的ホスティングもRayfin CLIの同一ワークフローでFabricにデプロイできます。
本記事では、2026年6月時点の最新情報をもとに、Rayfinの仕組み・主要機能・使い方・Replit連携・Power AppsやSupabaseとの違い・注意点・料金体系を体系的に整理します。
あわせて、Fabric Apps Previewとの関係、AIエージェントの永続バックエンドとしての位置づけ、企業がどのケースで採用すべきかまで一気通貫で解説します。
目次
Rayfinとは?Microsoft Fabric上に「コードで宣言→1コマンドでデプロイ」を実現する新基盤
Rayfinが生まれた背景——vibe codingから本番化までのギャップ
OneLake自動連携——書き込んだ瞬間に分析・AIで使える
Fabric brokered authentication(Entra SSO)
Rayfinのアーキテクチャ——デプロイで作られる子サービス群
Step 4: Microsoft Fabricへデプロイする
Replitとの連携——「launch partner」の意味
Power Apps / Supabase / GitHub Sparkとの違い
Rayfinとは?Microsoft Fabric上に「コードで宣言→1コマンドでデプロイ」を実現する新基盤
Rayfin(レイフィン)は、Microsoftが2026年6月2日のMicrosoft Build 2026で発表した、アプリケーションバックエンドをコードで宣言してMicrosoft FabricへデプロイするオープンソースSDK/CLIです。
正式名称は「Rayfin」で、Microsoft Fabricの新ワークロード「Fabric Apps (Preview)」を開発・デプロイするための中核SDK/CLIとして提供されます。
Rayfinが他の開発ツールと根本的に違うのは、TypeScriptクラスにデコレーターを書くとデータベース・GraphQL API・行レベル権限・型安全クライアントが生成され、認証・静的ホスティング・OneLake連携を含む同一ワークフローで npx rayfin up のワンコマンドでFabricワークスペースに本番デプロイできる点です。
Microsoftは公式ドキュメントで「データモデルから生成されたAPI・認証・ホスティングを1つの開発ワークフローに統合する」と説明しています。
つまりRayfinは「フロントエンド開発者の手元コードを、Fabricの中の管理対象アイテム(first-class artifact)として本番展開する」ための統合ランタイムです。
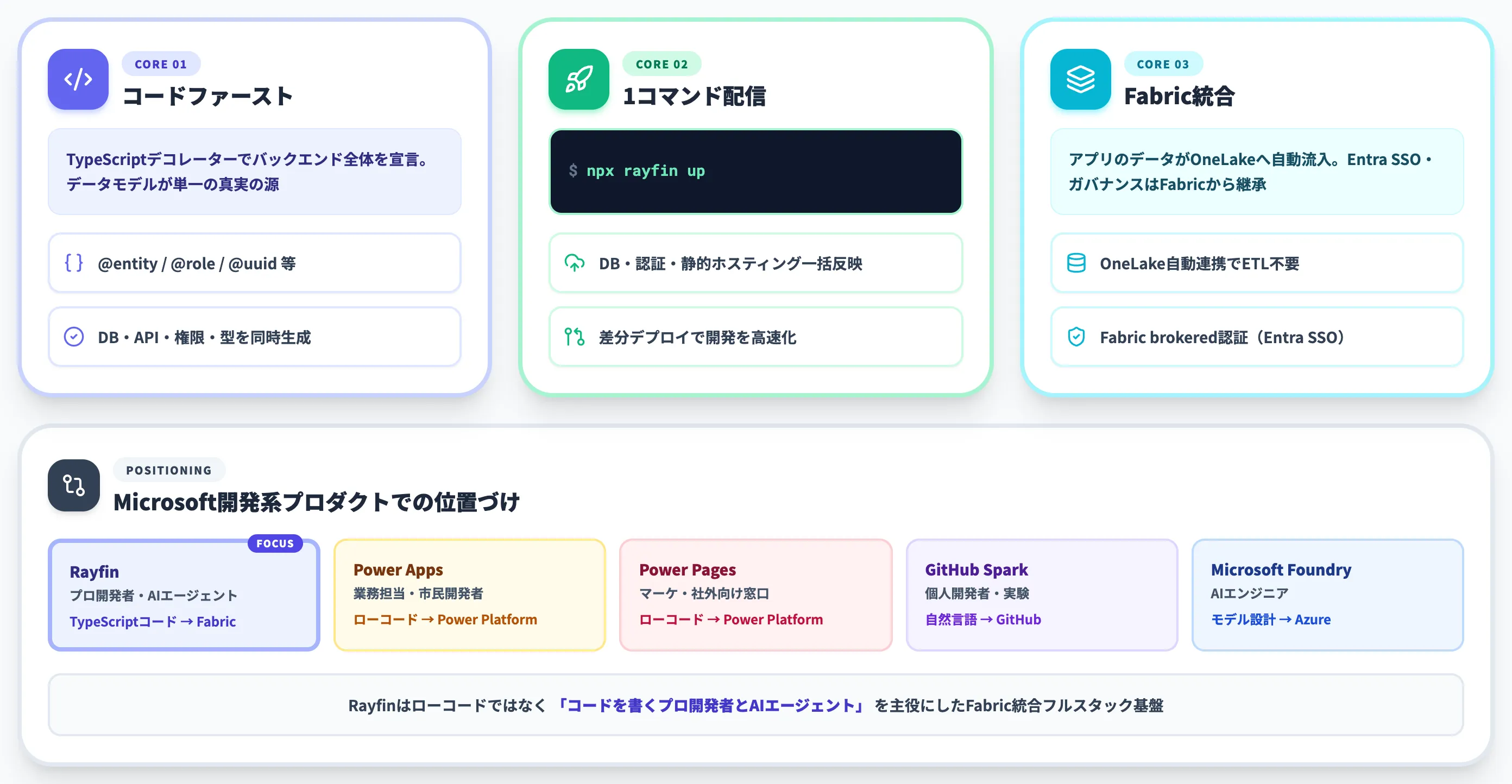
Rayfinが置かれた位置づけ
Microsoft Fabricは、これまでデータ分析基盤(Lakehouse・Data Warehouse・Power BI連携・OneLake)として扱われてきましたが、Build 2026を境に「データを置く場所」から「データの上で動くアプリやエージェントの実行基盤」へと役割が広がりました。
Rayfinで作るアプリの典型例:売上分析の業務ダッシュボード(出典:Microsoft Fabric)
画像のとおり、Rayfinで構築するアプリは「売上ダッシュボード」のようなFabricデータと密接に結びついた業務UIを典型として、企業の業務担当者がそのまま使えるエンタープライズ画面を持ちます。
以下の表で、Rayfinと既存のMicrosoft開発系プロダクトの位置づけを整理しました。
| プロダクト | 主な対象者 | 開発方式 | デプロイ先 |
|---|---|---|---|
| Rayfin(Fabric Apps) | 開発者・AIコーディングエージェント | TypeScriptコードファースト | Microsoft Fabricワークスペース |
| Power Apps | 業務ユーザー・市民開発者 | ローコード/キャンバス | Power Platform環境 |
| Power Pages | マーケ・業務担当 | ローコード/テンプレート | Power Platform環境 |
| GitHub Spark | 個人開発者 | 自然言語+マイクロアプリ | GitHubホスティング |
| Microsoft Foundry | AIエンジニア | モデルカタログ+エージェント設計 | Azure |
Power Apps・Power Pagesがローコードで業務担当を主役にするのに対し、Rayfinは「開発者とAIエージェントが書くTypeScriptコード」を主役にしたフルスタック基盤です。
「データを置く場所」と「アプリを置く場所」がFabric内部で統合されるという発想自体が新しく、Microsoftが既存のPower Platformとは別軸でAIエージェント向けのアプリ基盤を立てた、という読み方ができます。

Rayfinが生まれた背景——vibe codingから本番化までのギャップ
Rayfin発表のモチベーションは、Microsoft Fabricコミュニティブログで明確に語られています。
Microsoft Fabricプロダクト責任者のSachin PatneyとBen Zulaufは「プロトタイプは作りやすくなったが、スケールさせるのは難しいままだ」「ガバナンスとコンプライアンスはいつも後付けになる」と問題提起しました。
ChatGPT・Claude・GitHub CopilotなどAIコーディングエージェントの普及で、デモアプリは数時間で作れるようになった一方、そのアプリを社内基盤に乗せてセキュリティ・統制・データ連携まで揃える工程が、依然として数ヶ月単位の重い仕事として残っていたわけです。
このギャップを「コード生成の瞬間にバックエンドの統制要件を組み込む」という発想で埋めるのがRayfinの狙いです。
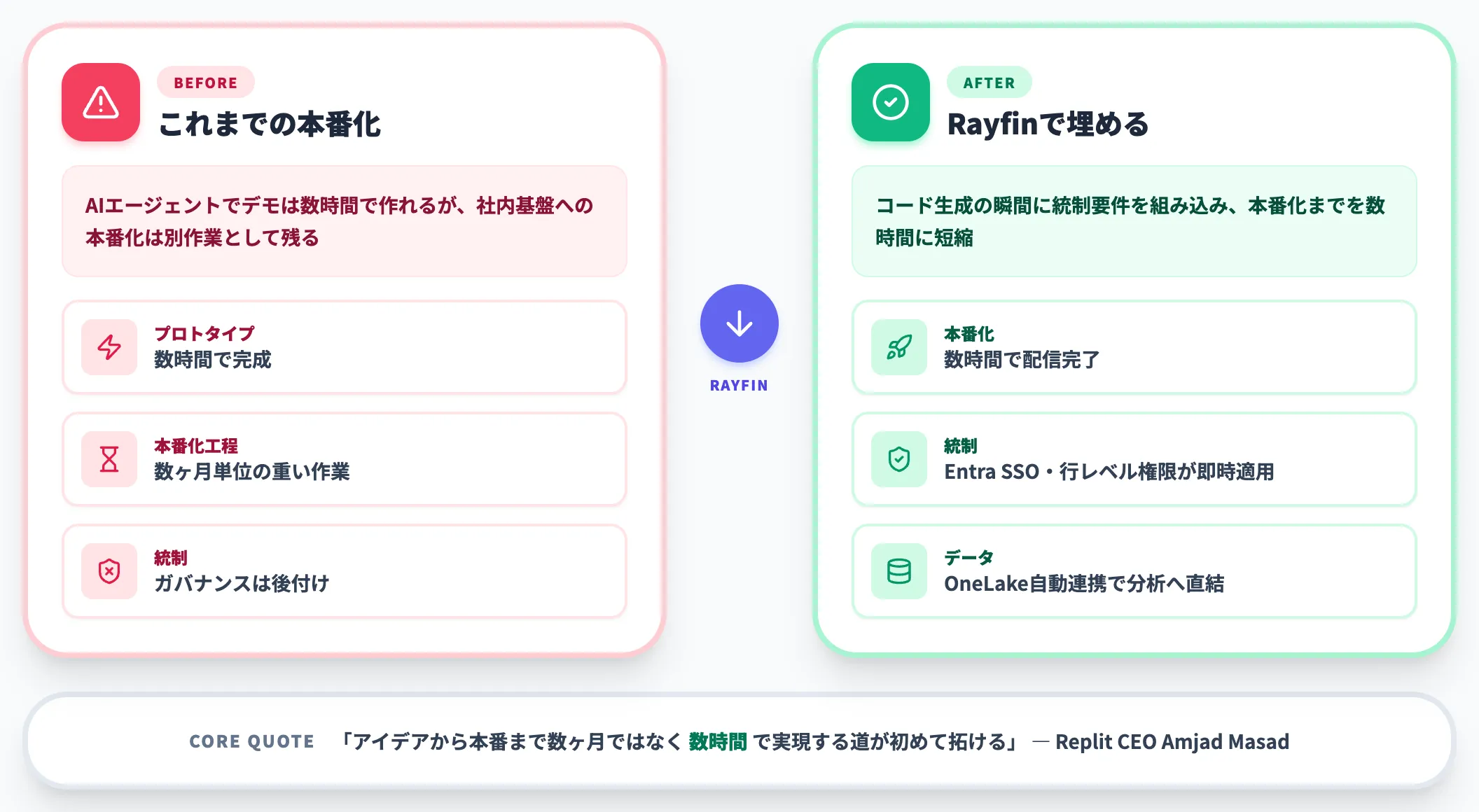
Replit CEOのAmjad Masadは公式パートナーとして「エージェントがコードを書き、Fabricがそれを迅速かつ安全に配信することで、アイデアから本番までを数ヶ月ではなく数時間で実現する道が初めて拓ける」とコメントしています。
「Rayfin」という名前について
Rayfin(レイフィン)は英語で「光線(ray)の鰭(fin)」を意味し、軽快に水中を進む条鰭類(ray-finned fish)の名前を連想させます。Microsoftが命名理由を公式に明言しているわけではありませんが、「データレイクの上を機敏に泳ぐ」というFabric=織物の上を進むアプリのイメージと重なる名付けと読めます。
Rayfinの主要な特徴
ここからは、Rayfinが具体的に何を解決するのかを4つの主要機能から整理します。
Microsoft Learn公式ドキュメントとFabricコミュニティブログを突き合わせると、Rayfinが提供する機能は明確に「TypeScriptデコレーター起点で他のレイヤーを順次自動生成する」設計になっていることが分かります。

TypeScriptデコレーター起点のバックエンド宣言
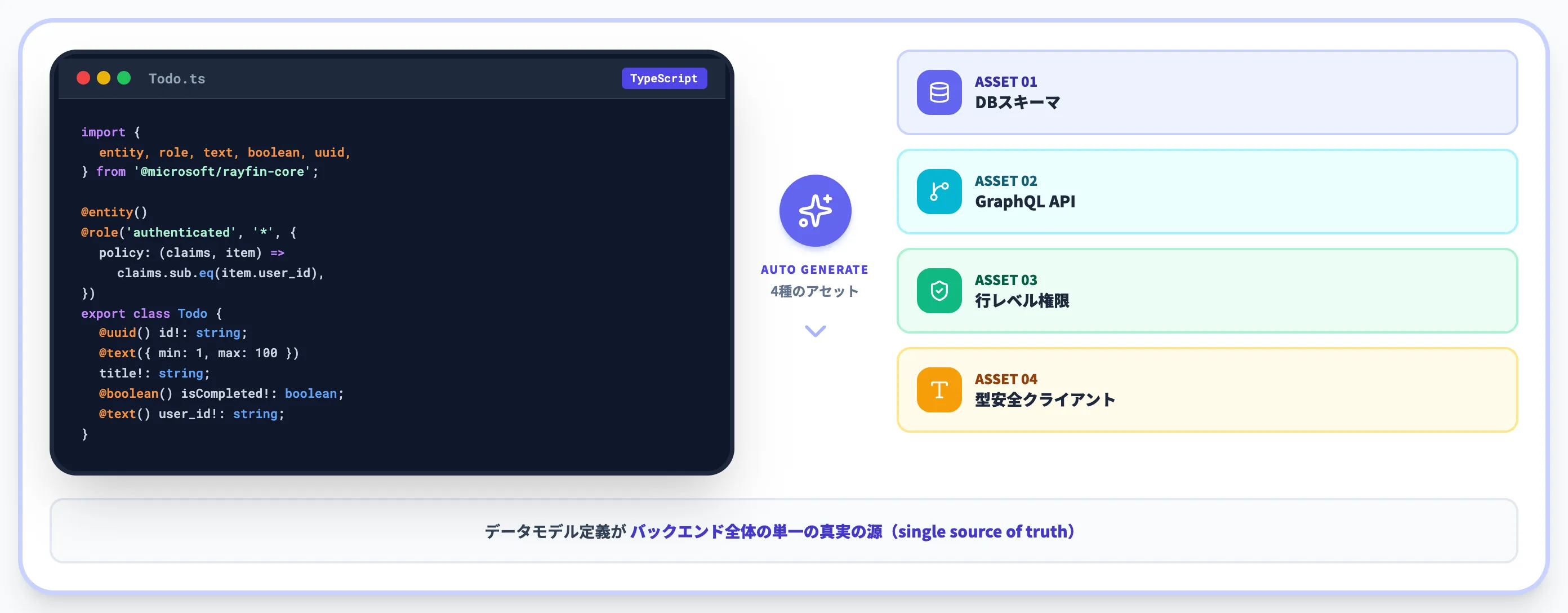
Rayfinの最大の特徴は、TypeScriptクラスに@entity()・@uuid()・@text()・@role()などのデコレーターを書くだけで、データベーススキーマ・GraphQL APIエンドポイント・行レベル権限・型安全クライアントメソッドが自動生成される点です。
例えばTodoアプリのデータモデルは、以下のように書きます。
import {
entity, role, text, boolean, date, uuid,
} from '@microsoft/rayfin-core';
@entity()
@role('authenticated', '*', {
policy: (claims, item) => claims.sub.eq(item.user_id),
})
export class Todo {
@uuid() id!: string;
@text({ min: 1, max: 100 }) title!: string;
@boolean() isCompleted!: boolean;
@date() createdAt!: Date;
@date({ optional: true }) dueDate?: Date;
@text() user_id!: string;
}
このクラスを書いた瞬間に、SQLテーブル定義・GraphQLのスキーマ定義・「自分のレコードしか読み書きできない」という行レベル認可ポリシー・TypeScriptクライアント側の型定義が同時に生成されます。
このアプローチには3つの利点があります。
-
権限定義を見直しやすい
データモデルとアクセス制御が同じコード上で管理されるため、権限定義を見直しやすく、既存フィールド名の変更による不整合はTypeScriptで検出しやすい構造になっている
-
AIエージェントが扱いやすい
コード生成の単位が「1つのクラスに集約された宣言」になるため、GitHub CopilotやReplit Agentのようなコーディングエージェントが型情報と統制要件をワンセットで読み書きできる
-
リファクタリングが安全
フィールド名を変えると認可ポリシー側の型エラーも追従するため、データモデルの進化に権限定義が取り残されない
「コードファースト」と書くと抽象的に聞こえますが、Rayfinの場合は「データモデル定義が、そのままバックエンド全体の単一の真実の源(single source of truth)になる」と読むのが正確です。
OneLake自動連携——書き込んだ瞬間に分析・AIで使える

Rayfinで作ったアプリのデータは、SQL Database in Fabricに保存されると同時にOneLakeにも自動で流れます。
OneLakeはMicrosoft Fabricの統一データレイクで、Power BI・Notebook・Data Agentから即座にクエリ可能な共通ストレージです。
これまでアプリ用のデータベース(OLTP)と分析用のデータレイク(OLAP)は別物として運用されており、両者を繋ぐにはETL(Extract / Transform / Load)パイプラインを別途構築する必要がありました。
Rayfinはこの層を「アプリのデータがOneLakeに自動的に流れる」設計で解消しています。Microsoft公式ブログは「No ETL pipeline required」と明言しており、アプリが書き込んだその瞬間からデータが分析とAIに使える状態になります。
これは「アプリのデータ」と「BIのデータ」が同じ場所にあるという発想で、AIエージェントが永続ステートを持って業務に組み込まれるユースケースでは特に効いてきます。
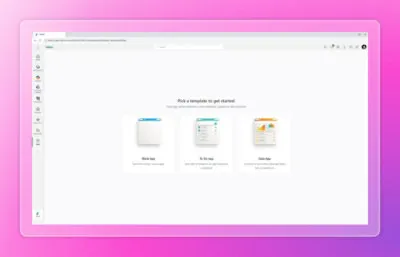
Rayfin CLIで選べる初期テンプレート(Blank App/To-Do App/Data App)。いずれもOneLake連携が組み込まれた状態でスキャフォールドされる(出典:Microsoft Fabric)
画像のとおり、Rayfin CLIから選べる初期テンプレートは「Blank App」「To-Do App」「Data App」の3種類で、テンプレート選択時点から、デプロイ後にアプリデータをOneLake/Fabric側で分析できる構成があらかじめ用意されています。
Fabric brokered authentication(Entra SSO)
本番デプロイされたRayfinアプリの認証は、Fabric brokered authentication(Entra IDシングルサインオン)のみがサポートされます。
これは「アプリ独自のログイン画面を作らず、利用者は既に持っているMicrosoft Entra IDの会社アカウントでそのままサインインする」という設計です。
メリットは大きく2つあります。
- アカウント管理の重複を排除: 新規ユーザー作成・パスワードリセット・退職時の権限剥奪が全てEntra側の運用に集約される
- 行レベル権限と直結:
@roleデコレーターで定義したポリシーがEntraのclaim(claims.sub等)を直接参照できるため、認可ロジックがEntraのIDと一致する
一方、メール/パスワード方式の認証はローカル開発時のみ動作し、本番では使えません。社外配布アプリのように「Entraに属さない不特定多数のユーザーを受け入れる」用途には現時点で向きません。
型安全SDK・静的ホスティング・ローカル開発
@microsoft/rayfin-client パッケージから提供されるTypeScriptクライアントは、データモデルを変えるとクライアント側の型情報も追従します。存在しないフィールドをselectで指定するとコンパイルエラーになるため、フロントエンドの実装ミスを実行前に潰せます。
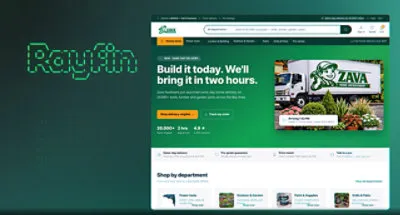
Rayfinで作ったECアプリの実例(ZAVA)。SPAやNext.js製アプリの静的ビルド出力もそのままFabric側に乗る(出典:Microsoft Fabric)
画像のように、Rayfinで作るアプリはダッシュボードだけでなく、商品検索・カート・配送案内などの一般的なECフロントエンドも含めて、Fabric内で動かせます。
フロントエンドのビルド成果物(HTML/CSS/JS)はFabric側にStatic Contentアイテムとして登録され、OneLakeストレージから公開URLで配信されます。SPAだけでなく、Next.jsやVite製アプリの静的ビルド出力もこの仕組みに乗ります。
ローカル開発はDockerでフルスタックを起動でき、コード変更の反映を高速に確認しながら本番と同じ構成で動作確認できます。
Rayfinのアーキテクチャ——デプロイで作られる子サービス群
Rayfinの内部構造を理解するには、npx rayfin upが実行された瞬間にFabric側で何が組み立てられるかを把握するのが近道です。
Microsoft Learnの公式アーキテクチャ図では、デプロイされたFabricアプリは「マネージドサービス」として動作し、配下に3種類の子アイテムが作られると明記されています。
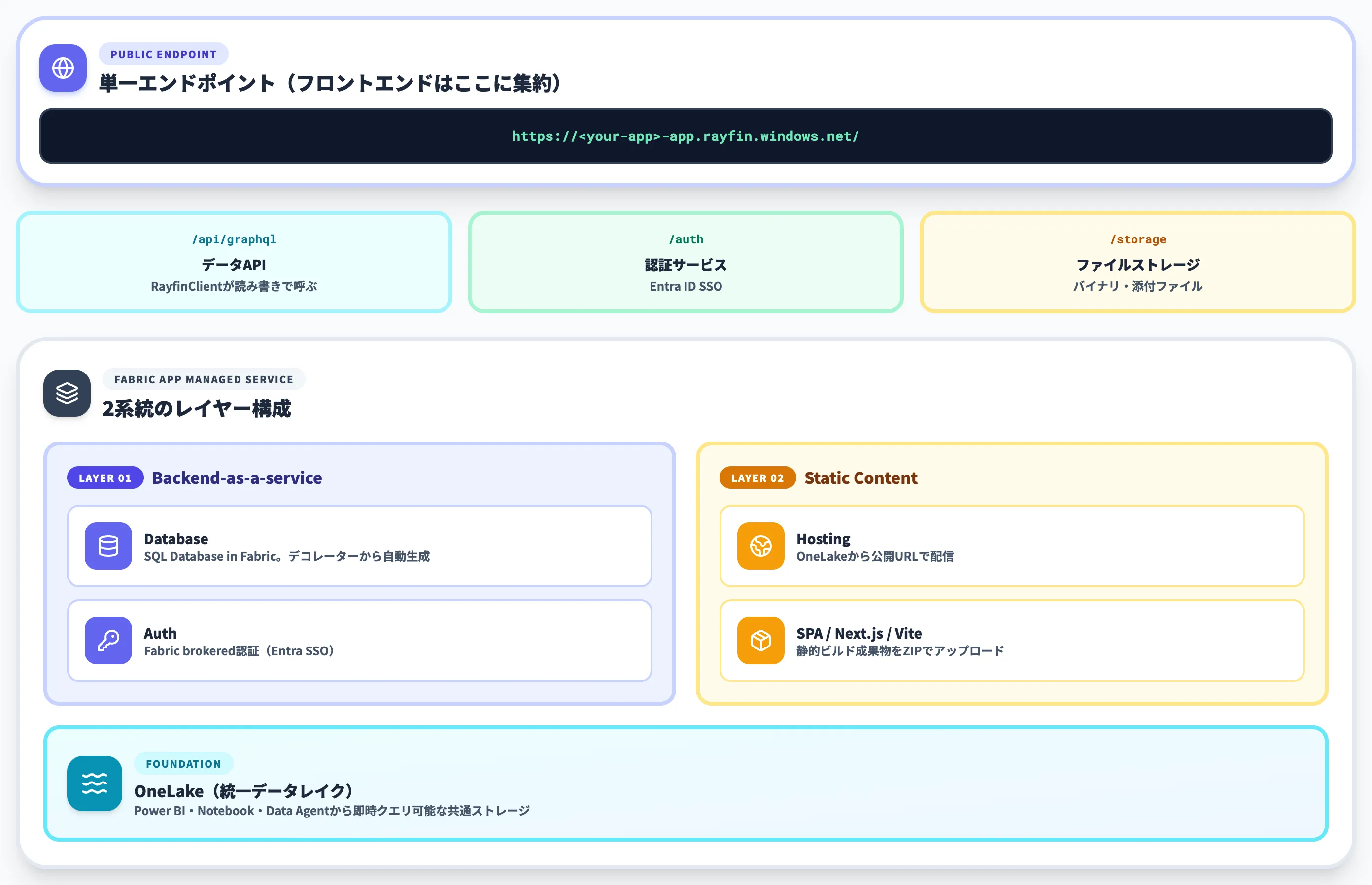
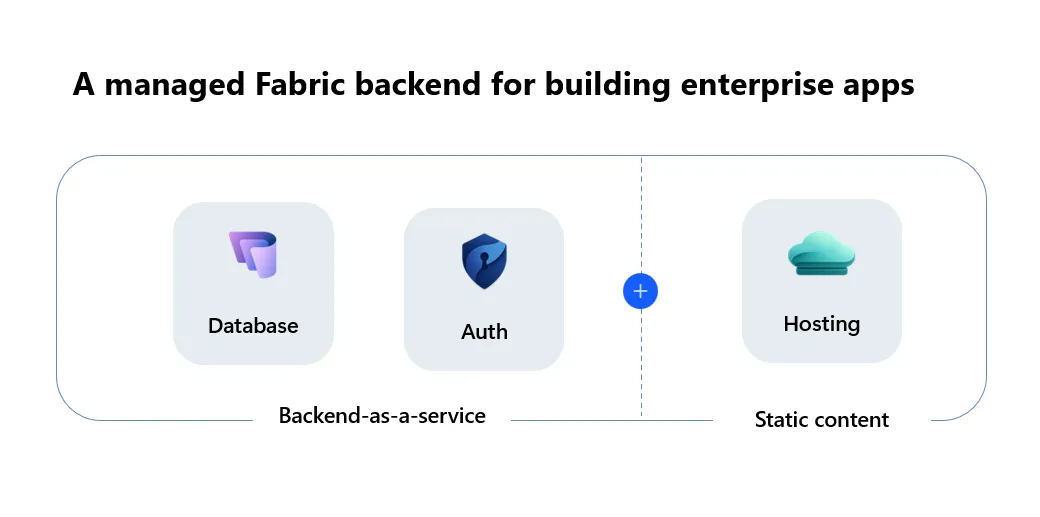
Fabric appのマネージドサービス構成:Backend-as-a-service(Database+Auth)とStatic content(Hosting)の2系統(出典:Microsoft Learn)
画像で示したとおり、Fabric appは「Database+Auth」からなるBackend-as-a-serviceレイヤーと、「Hosting」のStatic contentレイヤーの2系統で構成されます。Backend-as-a-service側がアプリのデータと認証を担い、Static content側がフロントエンドのアセットを配信する、という役割分担です。
デプロイ時に生成される3つの子サービス
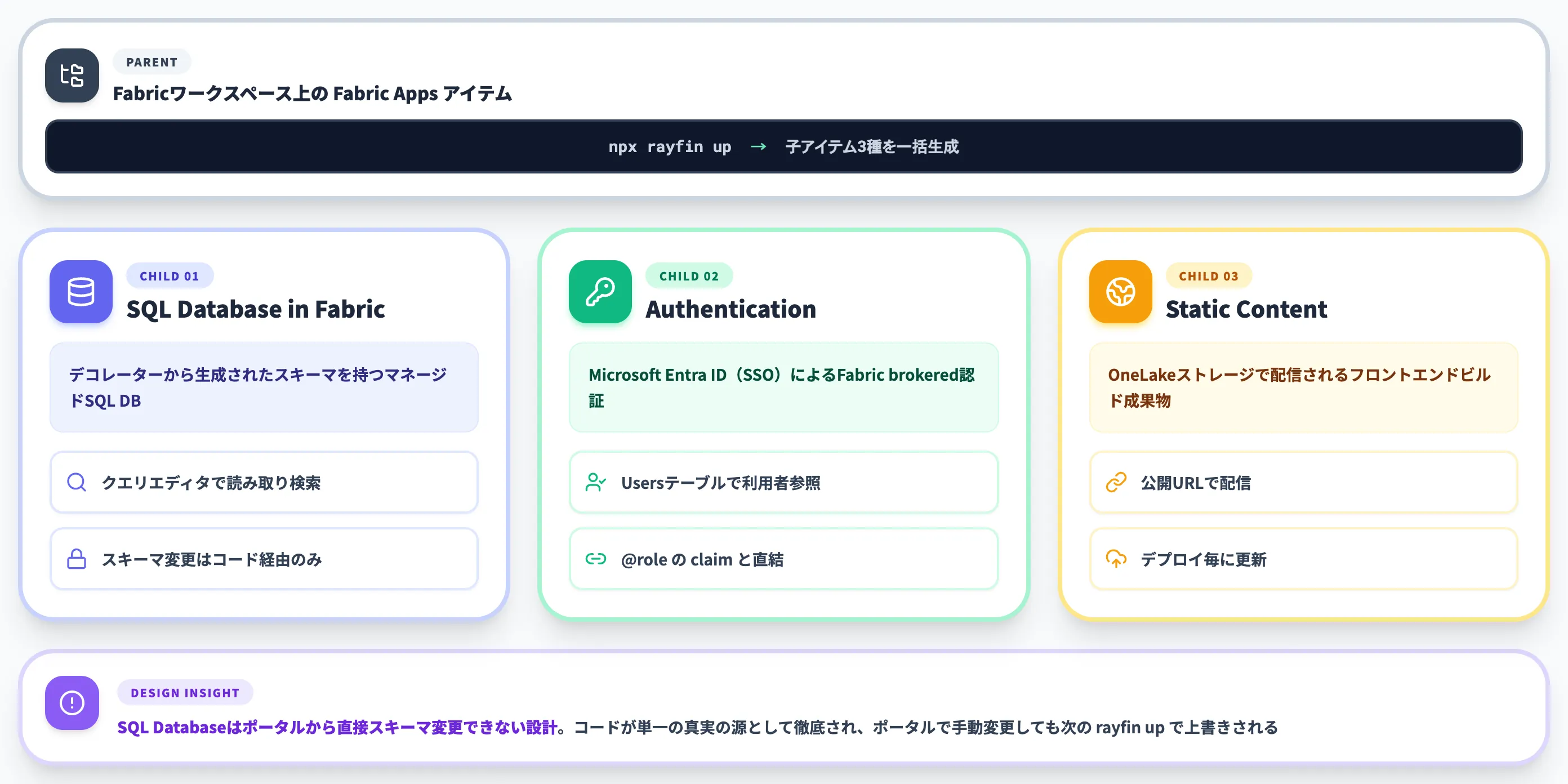
以下の表で、rayfin up 実行時にFabricワークスペース上で作られる子サービスと、それぞれの役割を整理しました。
| 子サービス | 提供されるもの | ポータルでの操作範囲 |
|---|---|---|
| SQL Database in Fabric | TypeScriptデコレーターから生成されたスキーマを持つマネージドSQLデータベース | クエリエディタで読み取り専用検索が可能。スキーマ変更はコード経由のみ |
| Authentication | Microsoft Entra ID(SSO)によるFabric brokered認証 | 認証済みユーザーをUsersテーブルで参照 |
| Static Content | OneLakeストレージで配信されるフロントエンドビルド成果物 | 公開URLの確認。アセットはデプロイのたびに更新される |
注目すべきは、SQL DatabaseがFabricポータルから直接スキーマを変更できない設計になっている点です。
これは「コードがバックエンド全体の単一の真実の源」という思想の徹底で、ポータルで手動変更しても次のrayfin upで上書きされます。「気がついたらポータル側で変更したスキーマが本番に残っていた」という、よくある運用ミスを構造的に防ぐ設計です。
公開エンドポイントとルーティング
デプロイ後、Rayfinアプリには以下の形式の単一エンドポイントが発行されます。
https://<your-app>-app.rayfin.windows.net/
このエンドポイントは内部で3つのサービスにルーティングされます。
| パス | 接続先サービス |
|---|---|
/api/graphql |
データAPI(GraphQL)。RayfinClientが読み書きで叩く |
/auth |
認証サービス |
/storage |
ファイルストレージ |
フロントエンドアプリは同じドメイン配下のエンドポイントを通じて全サービスにアクセスできるため、CORS設定やドメイン跨ぎの面倒な調整が原則不要です。
これも、開発者が「インフラ作業ではなくアプリ開発に集中できる」という体験を支える設計上の工夫といえます。
デコレーターから生成される4種のアセット
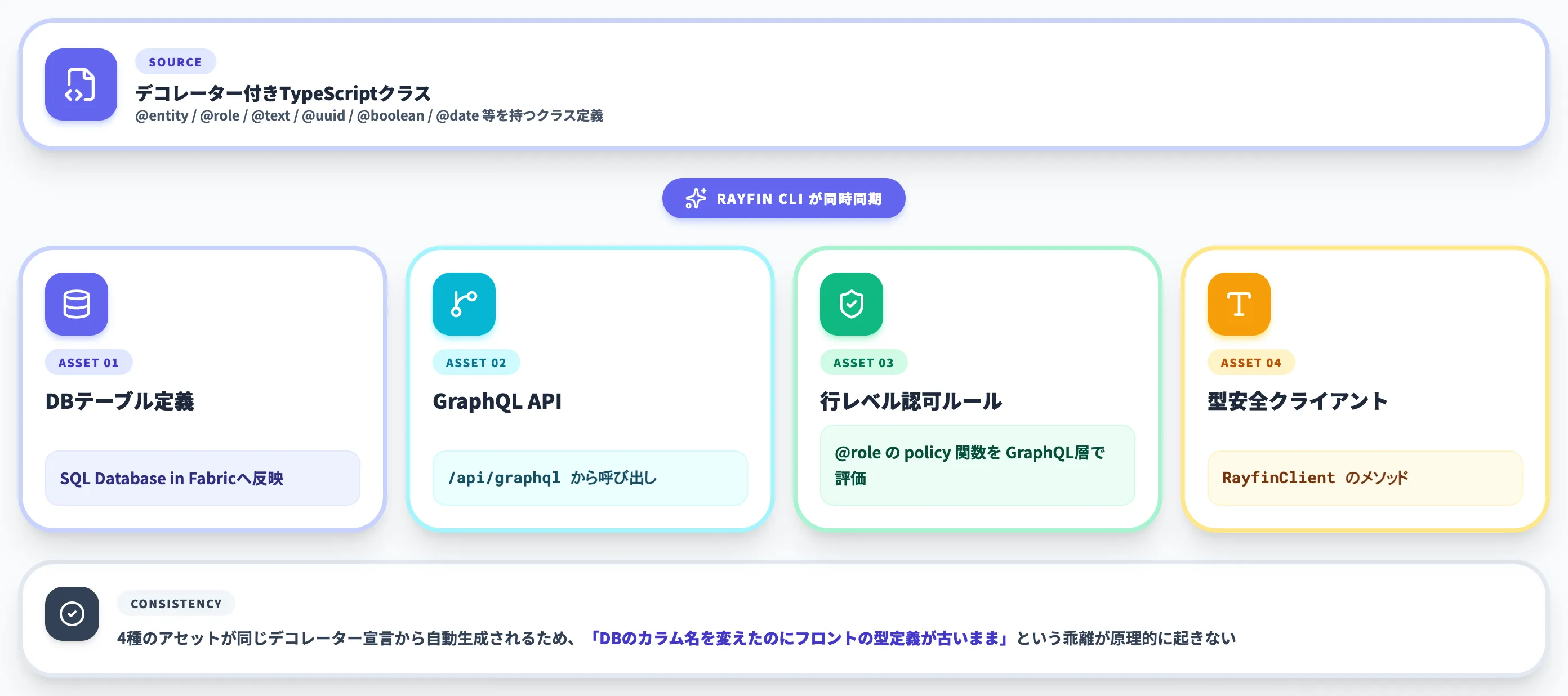
Rayfin CLIは、デコレーター付きのTypeScriptクラスを解析して、以下の4種類のアセットを同期します。
- データベーステーブル定義 SQL Database in Fabricに反映
- GraphQL APIエンドポイント
/api/graphqlから呼び出し可能 - 行レベル認可ルール
@roleのpolicy関数がGraphQL層で評価される - 型安全なクライアントメソッド
RayfinClient経由でフロントから直接呼び出せる
4種のアセットが同じデコレーター宣言から自動生成されるため、「DBのカラム名を変えたのにフロントの型定義が古いまま」という乖離が原理的に起きません。
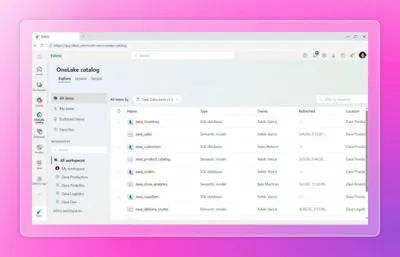
Rayfin製アプリのデータがOneLake catalogから参照できる状態(出典:Microsoft Fabric)
画像のように、Rayfinが書き込んだデータはOneLake catalog経由でFabricの分析・AIスタックから利用可能になり、Power BI・Notebook・Data Agentから横断的に参照できます。これにより、アプリ用のデータと分析用のデータが二重に管理される従来の構造が解消されます。
Rayfinの使い方——前提条件からデプロイまで
ここからは、実際にRayfinでアプリを作ってMicrosoft Fabricへデプロイするまでの流れを順を追って整理します。
公式チュートリアル「Create your first Fabric Apps project」の手順に沿いつつ、つまずきやすい前提条件と差分デプロイの使い分けまで解説します。

Step 1: 前提条件を整える
Rayfinを使う前に、以下の3点を満たしている必要があります。
-
Fabric Capacityが割り当てられたワークスペース
Rayfinアプリは、ワークスペースに紐づいたFabric Capacityのキャパシティユニットを消費して動きます。新規ワークスペース作成時にCapacityを指定するか、既存ワークスペースのCapacity状態を確認します
-
Fabric Apps workloadの有効化
テナント管理者がFabric管理ポータルから「Tenant settings → Fabric Apps (preview)」を有効化する必要があります。組織全体に開放するか、特定のセキュリティグループに限定するかを選択できます
-
Node.jsとnpmのインストール
ローカル環境にNode.js(推奨LTS)とnpmが入っていれば準備完了です
テナント管理者権限がない場合は、社内のFabric管理者にFabric Apps workloadの有効化を依頼するところから始まります。Preview段階のため、無計画に開放するのではなくCapacity消費を伴う前提で運用ルールを決めてから有効化するのが現実的です。
Step 2: プロジェクトをスキャフォールドする
公式テンプレートからプロジェクトを生成するコマンドは以下です。
npm create @microsoft/rayfin@latest my-app --workspace <workspace-name>
cd my-app
my-appの部分が生成されるディレクトリ名、--workspaceにはデプロイ先のFabricワークスペース名を指定します。
スキャフォールド後のプロジェクトには、rayfin/rayfin.yml(アプリ設定)・rayfin/.env(環境変数)・rayfin/data/(データモデル)・フロントエンドのソースコードが含まれます。
既に空のプロジェクトディレクトリやフロント側のコードがある場合は、テンプレート展開ではなく追加初期化としてnpx rayfin initを使うこともできます。
Step 3: ローカルで動作確認する
ローカル開発サーバを起動して、画面と動作を確認します。
npm run dev
このコマンドはフロントエンドの開発サーバを起動すると同時に、ローカルのバックエンドをDockerで立ち上げます。ターミナルに表示されたURL(典型的にはhttp://localhost:5168)にアクセスして、UIが期待通り動くことを確認します。
ローカル段階では、メール/パスワード認証も使えます。本番にはEntra SSOで切り替わるため、ローカル動作確認用の便利機能と割り切って使う設計です。

Step 4: Microsoft Fabricへデプロイする
開発が終わったら、ワンコマンドで本番デプロイします。
npx rayfin up
未サインインの場合は、CLIが自動でEntra IDのインタラクティブログインフローを起動します。
rayfin upが裏で実行するのは、以下の6ステップです。
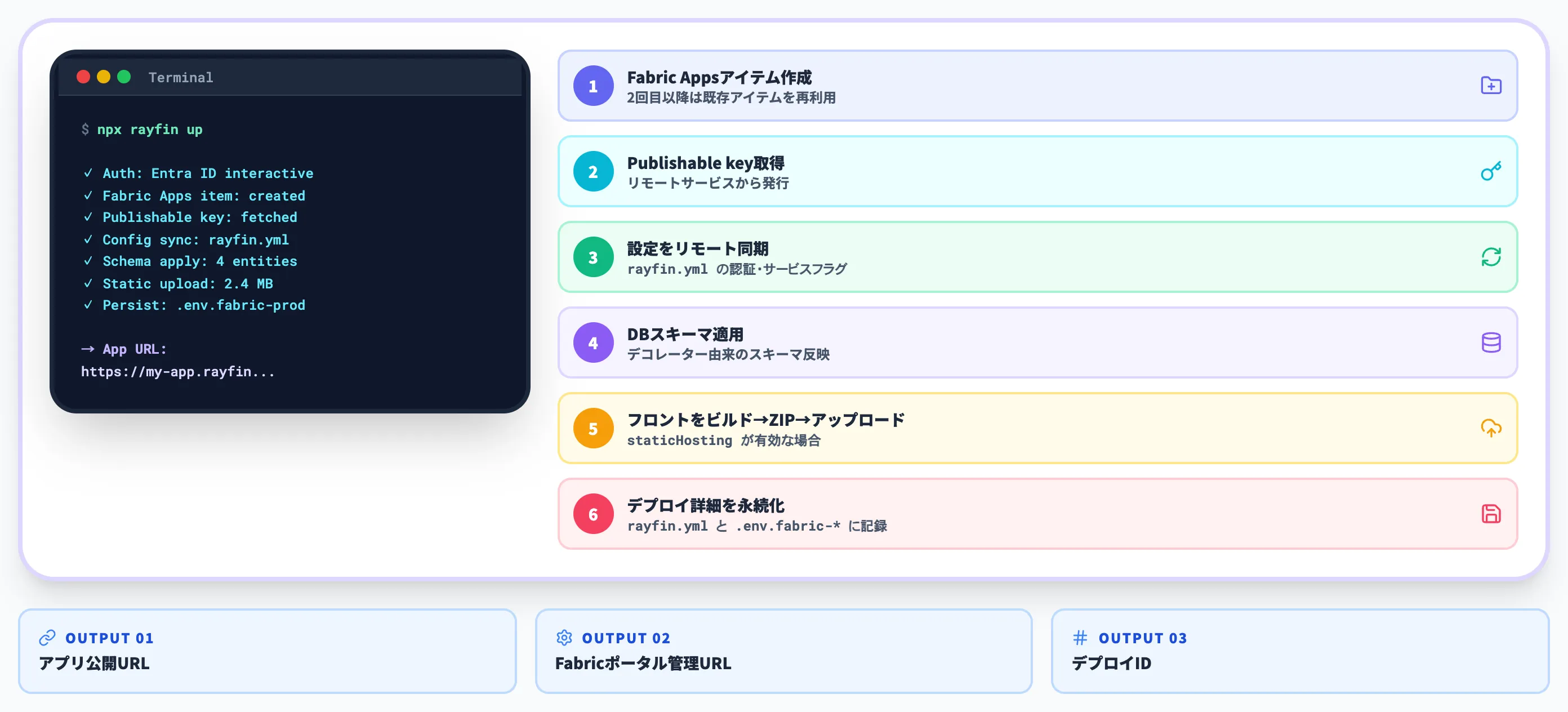
- FabricワークスペースにFabric Appsアイテムを作成(2回目以降は既存アイテムを再利用)
- リモートサービスからPublishable keyを取得
rayfin.ymlの設定(認証・サービスフラグ等)をリモートに同期- TypeScriptデコレーターから生成されたデータベーススキーマを適用
staticHostingが有効ならフロントのビルド→ZIP化→アップロード- デプロイ詳細を
rayfin.ymlと.env.fabric-*に永続化
成功すると、CLIは以下を出力します。
- アプリ公開URL ユーザーがアクセスする本番URL
- Fabricポータル管理URL Fabricワークスペース上のアイテム管理画面
- デプロイID 後続の操作で参照するID
初回デプロイ前に変更内容を確認したい場合は、--dry-runオプションを付けると実際の変更を行わずに何が実行されるかを表示できます。
npx rayfin up --dry-run
Step 5: 差分デプロイで開発サイクルを高速化する
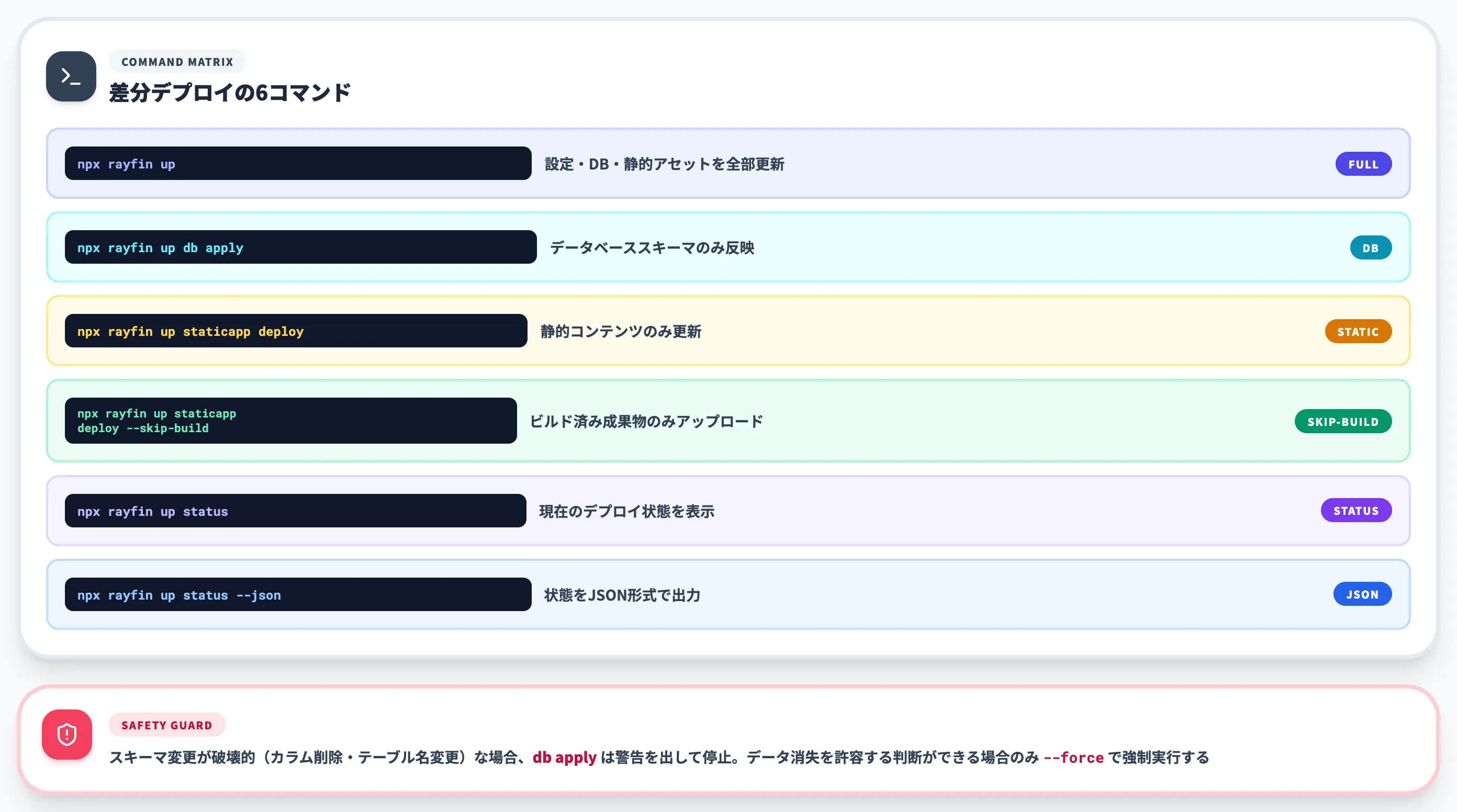
開発中は変更箇所が限定されることがほとんどです。フル再デプロイを毎回かけるのではなく、差分単位で更新するコマンドが用意されています。
| コマンド | 更新範囲 |
|---|---|
npx rayfin up |
全部(設定・DB・静的アセット) |
npx rayfin up db apply |
データベーススキーマのみ |
npx rayfin up staticapp deploy |
静的コンテンツのみ |
npx rayfin up staticapp deploy --skip-build |
ビルド済み成果物のみアップロード |
npx rayfin up status |
現在のデプロイ状態を表示 |
npx rayfin up status --json |
上記をJSON形式で出力 |
スキーマ変更が破壊的(カラム削除やテーブル名変更)な場合は、db applyは警告を出して停止します。データ消失を許容する判断ができる場合のみ--forceを付けて強制実行する、という安全装置が組み込まれています。
Step 6: dev/prodワークスペースの切り替え
開発用と本番用でFabricワークスペースを分けて運用する場合、初回デプロイは--workspace-uri(または--workspace-id)でデプロイ先を指定し、既存デプロイ間の切り替えはnpx rayfin up switchを使います。
# 初回デプロイ:開発ワークスペースのURIを指定
npx rayfin up --workspace-uri <dev-workspace-uri>
# 既存デプロイ間の切り替え
npx rayfin up switch <workspace-name>
最後にデプロイしたワークスペースが「アクティブな環境」としてrayfin/.envに記録され、それ以降のrayfin upは同じ環境を更新します。
この設計のため、「手元のコードを開発に流したつもりが本番に当たっていた」という事故は起こりにくい反面、明示的にワークスペースを指定する習慣をチームで揃えておく必要があります。
Rayfinの活用シーンとReplit連携
Rayfinは「とりあえず作ってみる」用途にも、エンタープライズの本番運用にも使える設計ですが、公式が特に推している4つのユースケースは明確です。
ここからは想定される使い所と、launch partnerとして発表されたReplitとの連携の中身を整理します。
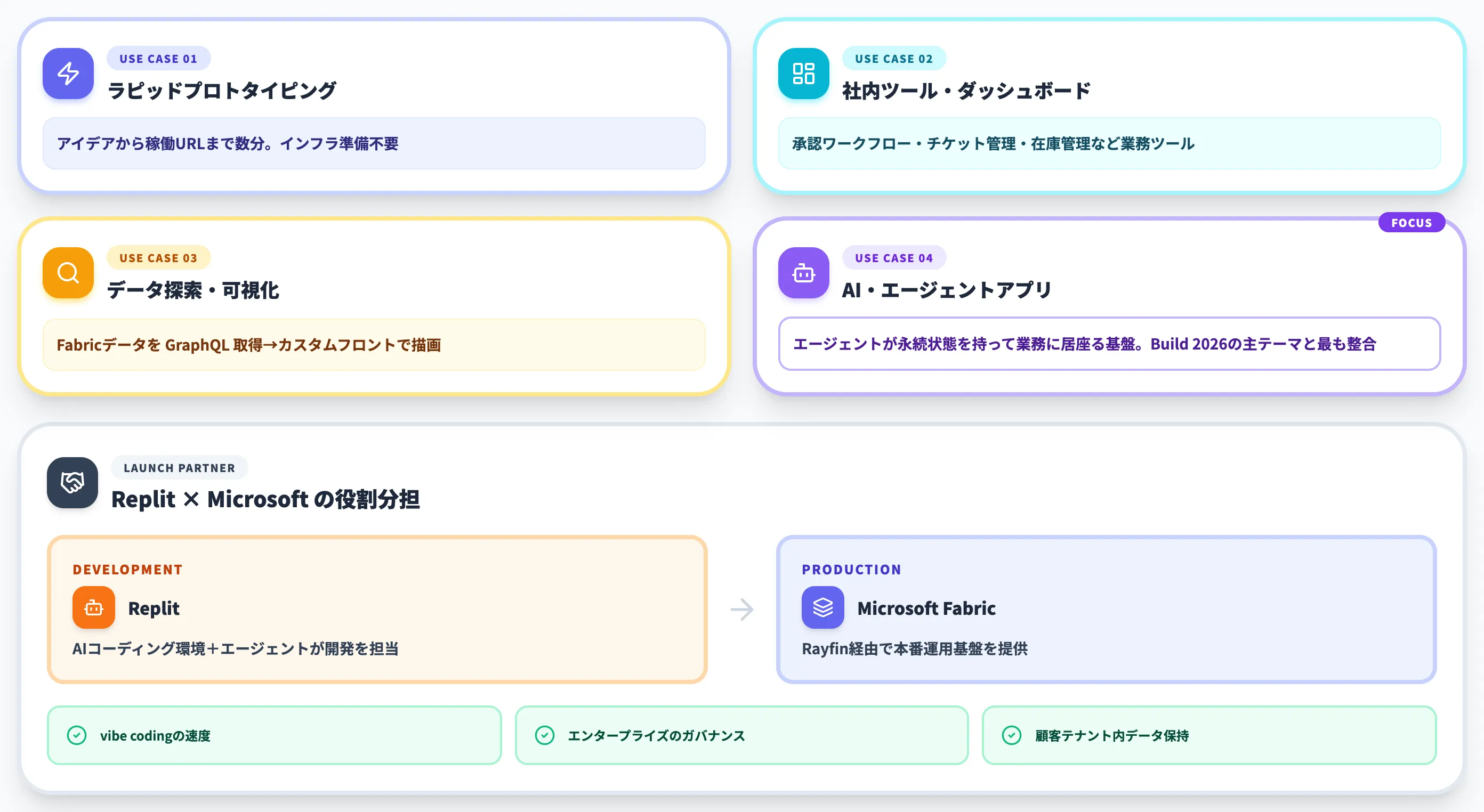
Microsoftが想定する4つのユースケース
公式のFabric Apps overviewに列挙されているユースケースは、以下の4つです。
-
ラピッドプロトタイピング
アイデアから稼働URLまで数分。インフラ準備は不要で、ホワイトボードでスケッチした構想を即座に動かせる
-
社内ツールとダッシュボード
認証付き管理画面を「バックエンドのボイラープレートを書かずに」立ち上げられる。承認ワークフロー・チケットトラッカー・在庫管理など、典型的な業務ツールが該当する
-
データ探索・可視化
Fabric内のデータをGraphQL経由で取得し、カスタムフロントエンドで描画する。Power BIだけでは表現しきれない独自のUIや業務ロジックを乗せたい場面に向く
-
AI・エージェントアプリケーション
AIエージェントが永続状態を持ちながら動くための、構造化バックエンドを提供する。エージェントが業務に居座って継続的なタスクを担う時代には、この用途が最も重要になる
4つのうち最後の「AIエージェント向けバックエンド」が、Build 2026での発表全体のテーマと最も強く結びついています。同時発表されたMicrosoft IQやProject Solaraとあわせて、「AIエージェントが業務に居座る前提で、データもアプリもFabricに集約する」というMicrosoftの中期戦略が透けて見えます。
Replitとの連携——「launch partner」の意味
ReplitはRayfinのローンチ時の主要パートナーとして発表されました。
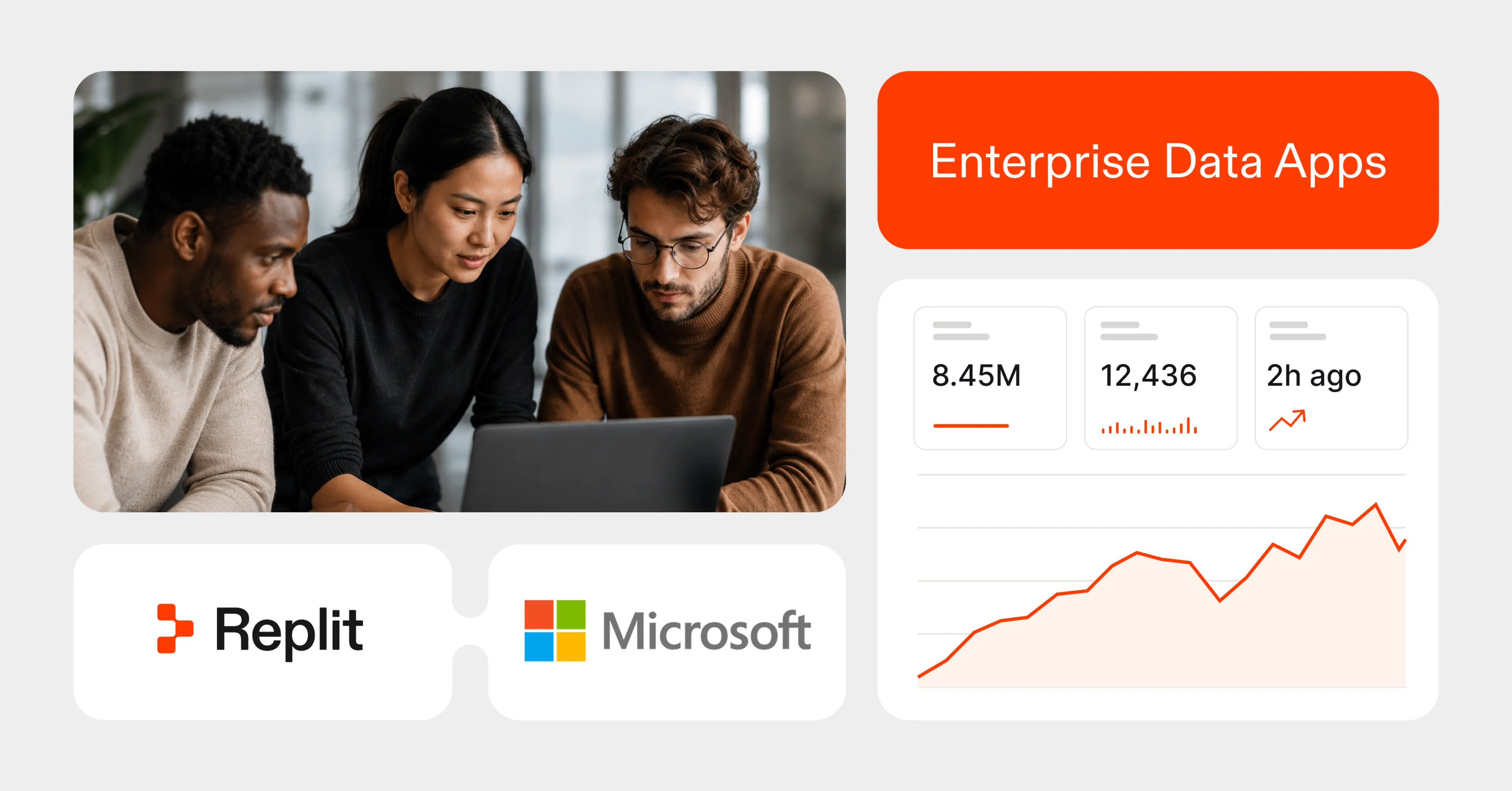
ReplitとMicrosoftが連携してEnterprise Data Appsを構築する公式発表(出典:Replit Blog)
画像のように、ReplitはMicrosoftと並ぶブランディングで「Enterprise Data Apps」を共同で構築する立場として位置づけられ、開発エクスペリエンスを担うReplit、本番運用基盤を提供するFabric、という役割分担が明示されています。
ReplitのCEO Amjad Masadは「エージェントがコードを書き、Fabricがそれを迅速かつ安全に配信することで、アイデアから本番までを数ヶ月ではなく数時間で実現する道が初めて拓ける」とコメントしています。
連携の中身は以下の構図です。
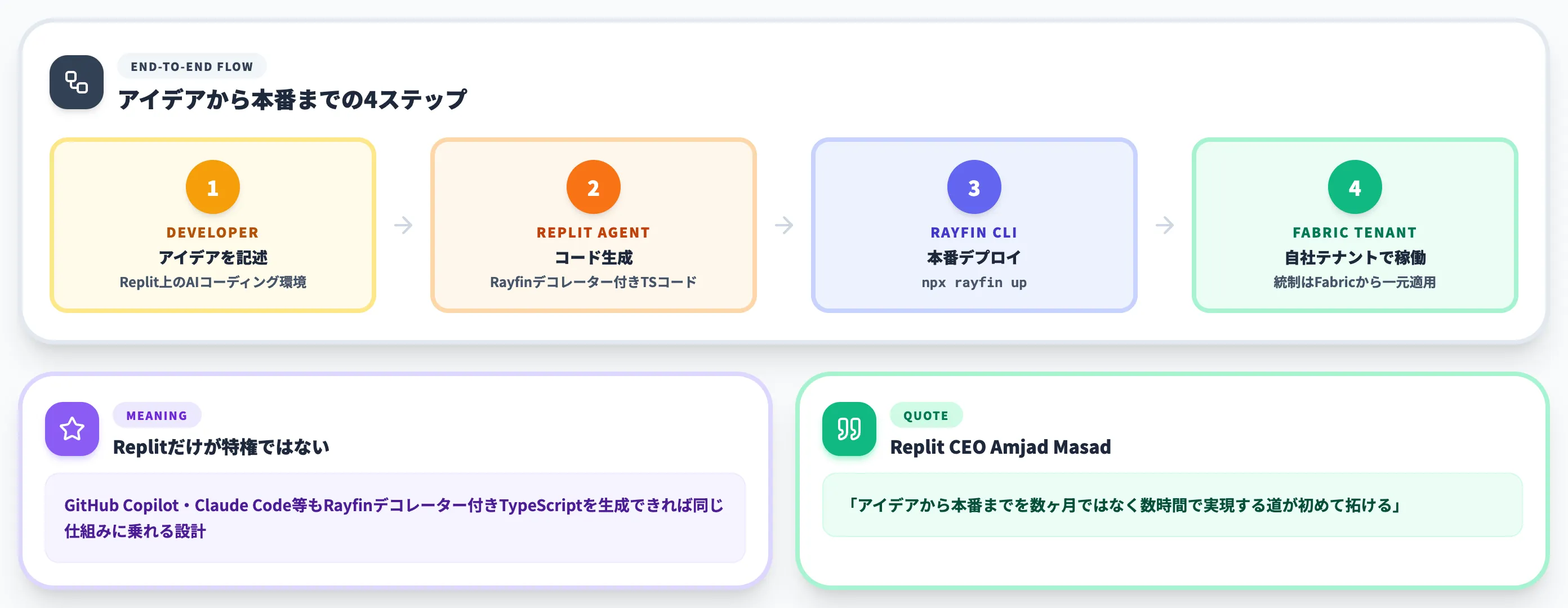
- 開発者はReplit上のAIコーディング環境でアプリを記述
- Replit AgentがRayfinのデコレーター付きTypeScriptコードを生成
- 生成されたコードを
npx rayfin upでMicrosoft Fabricへデプロイ - データは顧客のFabric Tenantに留まり、ガバナンス・統制はFabric側で一元適用
これは「vibe codingの開発者体験」と「エンタープライズのガバナンス要件」を同時に満たすための、Microsoftの現実解として提示された連携です。
GitHub CopilotやClaude Codeなど他のコーディングエージェントもRayfinのデコレーター付きTypeScriptを生成できれば同じ仕組みに乗れる設計のため、Replit「だけ」がRayfinを使えるわけではなく、Replitがローンチ時の主要パートナーとして組み込まれた、という位置づけです。
早期顧客事例——Leatherman
具体的な顧客事例として公開されているのは、米国の工具メーカーLeatherman Tool Groupです。

Leatherman製品のフィールドユース。現場業務アプリの開発とデータ集約をRayfinで両立する事例(出典:Microsoft Fabric)
画像のような屋外ワーカーや現場作業者が扱うフィールド業務こそ、現場ごとに違うアプリと中央集約されたデータの両方が必要になる典型例で、LeathermanはこのニーズをReplit×Rayfin×Fabricの組み合わせで満たしています。
Leathermanは社内ツール開発をReplit環境で高速に回しつつ、業務データと分析データはFabricに集約する構成を採用しました。
「開発のスピード」と「データの中央集権」が両立できることが、この事例から読み取れる主要メリットです。
製造業のように「現場ごとに違うアプリが必要だが、データは全社一元管理したい」というニーズは、日本企業にもそのまま当てはまります。SAP・PLMのような既存基幹系を変えずに、その周辺のニッチアプリだけをFabric上のRayfinで内製していく、という運用が現実的な第一歩になります。
Build 2026の他発表との連動
Rayfinは単独の発表ではなく、Microsoft Build 2026で同時に発表された一連のFabric強化策の一つです。
特に関連性が高いのは以下です。
-
Microsoft IQの発表
Microsoft IQはWork IQ・Fabric IQ・Foundry IQ・Web IQの4つが相互接続された業務コンテキストレイヤ。Microsoft IQ全体のうち、特にFabric IQを通じて、Rayfin製アプリのデータをAIエージェントの業務コンテキストに活用できる
-
Fabric IQの一般提供(GA)
エージェント向けの共有業務コンテキストレイヤがGAされたことで、Rayfin製アプリが扱うデータをFabric IQ経由でAIエージェントに参照させる構図が成立した
-
Project Solaraとの位置づけ
Project Solaraは「アプリからエージェントへ」のMicrosoft新プラットフォーム。Rayfinはこの世界観のなかで「コード生成からデプロイまで」を担う実装基盤として位置づけられる
これらをセットで眺めると、Build 2026のMicrosoftは「Fabricを単なるデータ基盤ではなく、エージェントが住むランタイム」に再定義しようとしていることが分かります。Rayfinはその「エージェントが住む家を建てるための工具」に相当します。
Power Apps / Supabase / GitHub Sparkとの違い
Rayfinの位置づけを掴むためには、隣接する3つのカテゴリ——Microsoftのローコード、汎用BaaS、AIマイクロアプリ——との違いを整理するのが分かりやすいです。
以下の表で、それぞれの特徴と「どこで選び分けるか」を整理しました。

| 比較対象 | 開発方式 | データの置き場所 | 認証 | 想定する開発者 |
|---|---|---|---|---|
| Rayfin | TypeScriptコードファースト | OneLake(Fabric) | Entra SSO(Fabric brokered) | プロ開発者・AIコーディングエージェント |
| Power Apps | ローコード/キャンバス | Dataverse・各種コネクタ | Entra ID | 業務担当・市民開発者 |
| Power Pages | ローコード/テンプレート | Dataverse | Entra ID・ソーシャル認証 | マーケ・社外向け窓口 |
| Supabase / Firebase | コードファースト | 自社運用DB/Google基盤 | 任意の認証プロバイダ | スタートアップ・個人開発 |
| GitHub Spark | 自然言語+マイクロアプリ | GitHubホスティング | GitHub認証 | 個人開発者・実験 |
表の見方として、Rayfinは「データの置き場所がOneLake」「認証がEntra SSO一択」という2点が他と決定的に異なります。
Power Apps・Power Pagesとの違い
Power Appsが業務担当のローコード開発を主役にするのに対し、Rayfinは**TypeScriptを書くプロ開発者(およびそれを生成するAIエージェント)**を主役にしています。
「ローコードでは表現できない複雑な業務ロジック」「型安全を担保したい中規模以上のシステム」「AIエージェントが永続バックエンドを必要とするユースケース」では、Power AppsよりRayfinが向きます。
逆に「ノーコードで現場担当が小さな業務アプリを作る」「Power Platform環境内のDataverseで完結する」「フォーム入力型のシンプルなツール」では、Power Appsのほうが学習コストも運用コストも低くなります。
Supabase・Firebaseとの違い
汎用BaaSとしてのSupabase・Firebaseは、認証プロバイダや外部DBを柔軟に選べる反面、データガバナンス・コンプライアンスを自社で組み立てる必要があります。
RayfinはFabricのテナント統制(Entra SSO・行レベル権限・ワークスペース権限・OneLake統制)をそのまま継承するため、「最初から法人グレードの統制が効いている状態」で始められます。
ただし、Fabric Capacityを保有していない組織や、Entra ID以外の認証プロバイダを使う必要がある場面では、SupabaseやFirebaseのほうが向きます。
GitHub Sparkとの違い
GitHub Sparkは「自然言語でマイクロアプリを生成する」プラットフォームで、デプロイ先はGitHubのホスティングです。
Sparkが「個人開発者の小さなマイクロアプリ」に向くのに対し、Rayfinは法人テナント内で複数チームが運用する中〜大規模のアプリを想定しています。データもアプリもFabric内に置けるため、業務統制・監査要件が厳しい業界(金融・公共・医療等)で特に効きます。
「個人で何か小さな実験アプリを作る」「コードを書かずにアイデアを形にしたい」場合はSpark、「法人テナントでガバナンスを効かせながら本番運用したい」場合はRayfin、という選び分けになります。
Rayfinの注意点と現状の制約
Rayfinはこれから一般化していく可能性が高い基盤ですが、2026年6月時点ではPreview段階で、いくつかの明確な制約があります。
採用判断の前に把握しておくべき注意点を整理します。

Preview段階・GA時期は未公表
RayfinはMicrosoft Fabricのpreview機能として提供されています。
Fabricのプレビュー条件では、SLAなし・互換性が破壊される変更の可能性ありと明記されています。Microsoftは商用利用を禁じてはいませんが、業務クリティカルな本番システムに採用する際は、Preview期間中の挙動変更を受け入れられる前提で進める必要があります。
GA(一般提供)の時期は2026年6月時点で公表されていません。Microsoftは60日のFabricトライアルで誰でも試せる仕組みを用意していますが、GA時期や正式料金の発表は今後のFabricアップデートを待つことになります。
本番認証はFabric SSO一択
すでに触れた通り、デプロイ済みアプリの認証はFabric brokered authentication(Entra SSO)のみです。
これは「Entra IDを使う法人テナント内でアプリを公開する」用途には極めて適切ですが、以下のケースでは選択肢から外れます。
- 社外の不特定多数(個人の消費者)向けアプリ
- Entra ID以外(Google・Facebook・LINE等)のソーシャル認証を要求する場面
- 既存の独自ID基盤(Auth0・Okta・Firebase Auth等)を使いたい場合
「社内向けアプリ」と「社外向けサービス」のどちらに使うかで、Rayfinの適合度は大きく変わります。Preview段階での主戦場は明確に社内向けです。
静的アセットは100MB上限
フロントエンドの静的ビルド出力は、圧縮後100MB以内である必要があります。
100MBを超えるとアップロードが失敗するため、以下のような対応が必要になります。
- ソースマップを本番ビルドから除外する
- 画像・動画などの大きなバイナリをFabric Appsのストレージ機能へ分離する
- ビルド出力にdevelopment-only assetsを混入させない
典型的なReact/Next.js/Vue/Svelteアプリのビルド成果物は十分に収まるサイズですが、PDFや動画を直接バンドルする設計だと早期に詰まります。
非対応のユースケース
Microsoft Learn公式は、Fabric Appsが向かない用途として2つを明示しています。
- 複雑な多段トランザクションやストアドプロシージャを必要とするアプリケーション
- Fabric SSOとメール/パスワード以外のカスタム認証プロバイダを必要とするアプリ
金融系の決済処理など「複数テーブルを跨ぐ厳密なACIDトランザクション」を必要とする業務では、SQL Server や Azure SQL Database を別途併用する設計が現実的です。
公開URLへのシークレット混入は自社責任
静的コンテンツは公開URLで配信されます。Microsoftはこの設計を踏まえ、「シークレット・APIキー・機密データをコード・フロントエンドアセット・リポジトリに混入させないこと」を開発側の責任として明示しています。
これは一般的なフロントエンド開発のセオリーと同じですが、Rayfinは「サクッと作ってサクッとデプロイできる」体験が前面に出ているぶん、慣れていないチームが.envの値をフロント側にコピペしてしまうような事故が起きやすい設計です。
レビュー時に「フロントに混入したシークレットを検出する仕組み」をCI/CDに組み込んでおくのが、Rayfin採用組織にとっての実務上の備えになります。
Rayfinの料金と試し方
Preview段階のRayfinをコスト面でどう評価すべきかを、料金体系と試し方の2軸で整理します。
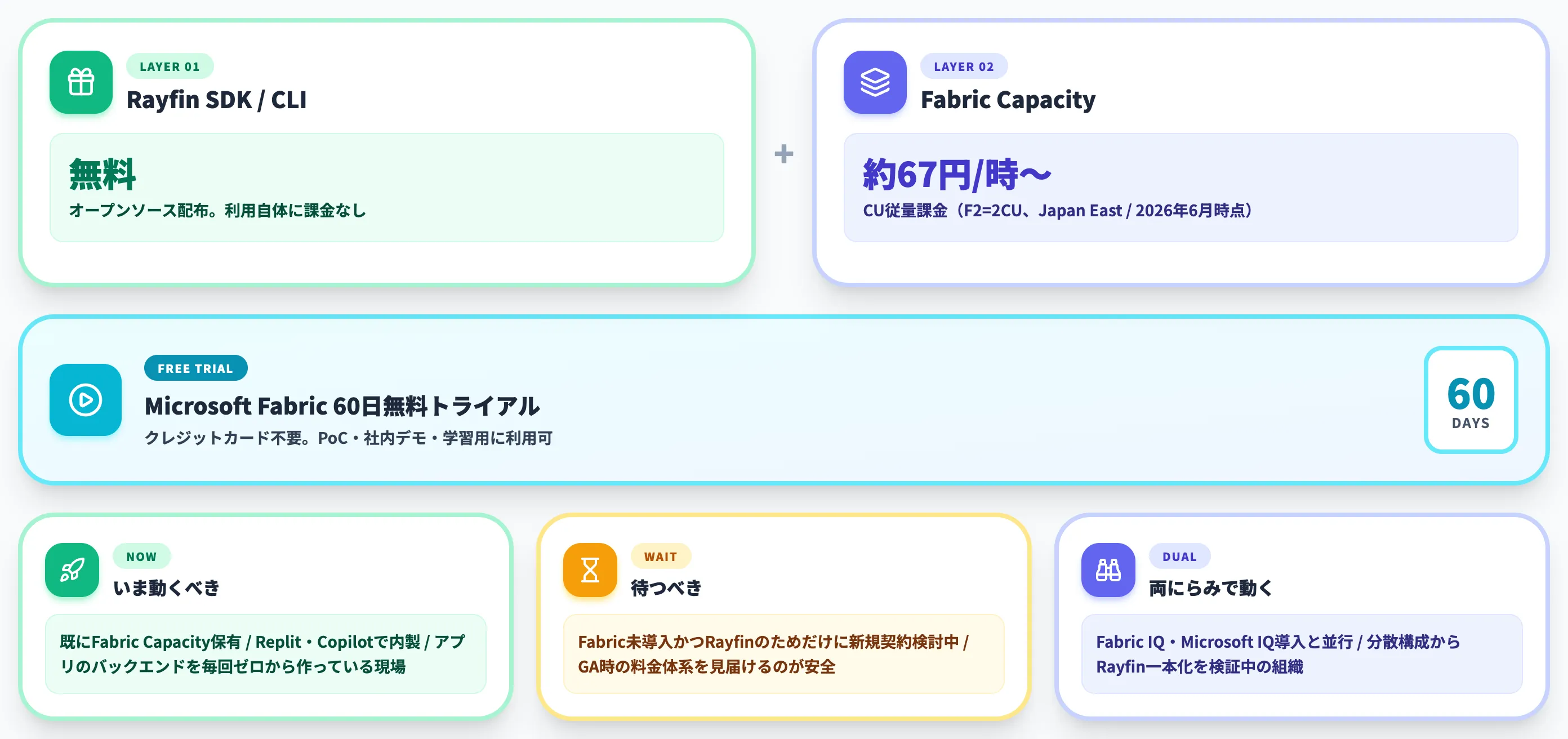
料金体系——Rayfin自体は無料、Fabric Capacity消費で課金
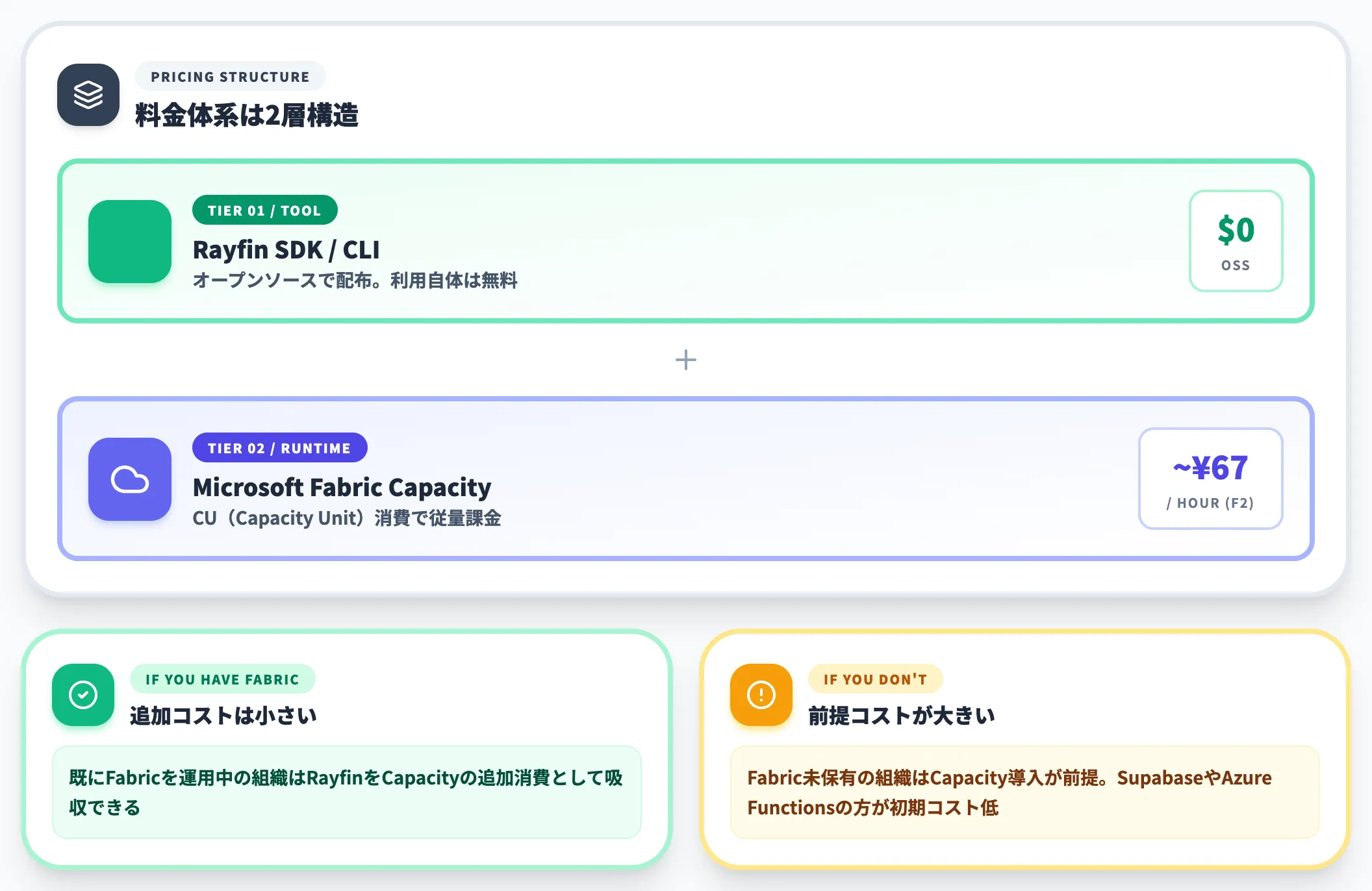
Rayfinの料金構造は2層になっています。
- Rayfin(SDK・CLI) オープンソースで配布されており、利用自体は無料
- Microsoft Fabric(実行基盤) Fabric CapacityのCU(Capacity Unit)消費で課金される従量モデル
Rayfinはツールとして無料ですが、デプロイ先のFabricワークスペースは有料のFabric Capacityが必要です。
Fabric Capacityの価格はSKU(F2・F4・F8・…・F2048)に応じた時間単価で、Azure Retail Prices APIで確認すると、Japan EastリージョンのCU単価は約33.5円/CU-hourで、F2(2CU)なら約67円/時から始まります(2026年6月時点・税やリザーブ契約等の条件は別途確認)。Rayfinアプリのトラフィックや格納データ量で消費量が変動するため、「Rayfin専用の月額」は固定では出ません。
これは「Fabricを既に持っている組織にとっては追加コストが小さい」「Fabricを持っていない組織にとってはFabric Capacity導入が前提となるためコストインパクトが大きい」という二面性を生みます。
Microsoft Fabric無料トライアル(60日)
Rayfinを試すだけならクレジットカードなしで始められます。
Microsoftは60日のFabric無料トライアルを提供しており、トライアル用Capacityでワークスペースを作れば、npm create @microsoft/rayfin@latestからデプロイまで一通り試せます。
トライアル期間中は本番運用に乗せず、PoC・社内デモ・学習用に使うのが現実的な使い方です。期間終了後は有料Capacityへの移行か、削除かを判断します。
コストが正当化されるケース
Fabric Capacityを保有している組織がRayfinを採用する経済的合理性は、以下のような場面で高くなります。
- 既にFabricでOneLake・Power BIを運用しており、周辺の社内アプリ(管理画面・承認フロー・タスク管理)をFabric内で内製したい
- 業務データをOneLakeに集約済みで、そのデータの上に分析だけでなく操作型アプリも乗せたい
- AIエージェントが永続バックエンドを必要とする社内ユースケースを増やしたい
逆に、Fabricを保有しておらず、純粋なバックエンドだけ欲しい組織にとっては、SupabaseやAzure Functionsのほうが初期コストが低く済みます。
Fabric採用が先で、その上で「Fabric内の周辺アプリ開発を効率化する」というモチベーションが、Rayfin採用の主な決定要因になります。

試すべきケース/待つべきケース
導入判断で詰まりやすい論点は、結局のところ「Preview段階のいま動くか、GAまで待つか」です。AI総研が支援している企業の傾向からも、以下の使い分けが現実的です。
-
いま動くべきケース
既にFabric Capacityを保有し、Replit・GitHub Copilot・Claude Codeなどのコーディング環境で内製を回しており、「アプリ用のバックエンドを毎回ゼロから作り直している」現場
-
待つべきケース
Fabric未導入で、Rayfinのためだけに新規Fabric Capacity契約を検討しているケース。Preview期間中の挙動変化・GA時の料金体系を見届けてからの判断が安全
-
両にらみで動くべきケース
Fabric IQ・Microsoft IQの導入と並行して、「データはFabric集約・アプリは別基盤」という分散構成からRayfinへの一本化を検討している組織
Rayfinは「データもアプリもFabric」へという中期的な戦略選択に関わるため、技術選定の話を超えて経営判断の論点になり得ます。検証フェーズの段階でCISO・データガバナンス責任者を巻き込んでおくと、本番採用時の意思決定が早く進みます。
Fabricのデータを業務エージェントに活かすなら
Rayfinで作ったアプリはOneLakeに直接データを書き込むため、Fabric上のデータと業務アクションを構造的につなげる土台が自然に整います。次の論点は、その整備されたデータを「AIエージェントが業務を判断・実行する基盤」にどう接続するか、というレイヤーに移ります。
ここで効いてくるのが、Microsoft Teamsから呼び出せるエンタープライズAIエージェント基盤、AI総合研究所の AI Agent Hub です。Fabric OneLakeのデータを土台に、AIエージェントがTeamsの会話の中から業務システム連携まで実行する構成を、自社のAzureテナント内で完結できます。
-
Fabric OneLakeのデータを業務アクションへ直結
Rayfinで蓄積したアプリデータと、ERP・SharePointなど社内データをZero ETLで仮想統合。Teamsチャットから自然言語で問い合わせ、取得した結果をそのまま申請・承認・通知に変換します。
-
Rayfin製アプリの実行ログもFabricに集約
AIエージェントの判定履歴・承認結果・ROIデータがOneLakeに蓄積され、業務改善のための分析資産として活きてきます。アプリ・データ・エージェントが同じFabric内で循環する設計です。
-
構築基盤が違っても管理は1つのダッシュボードに集約
Rayfin・Copilot Studio・n8n・Microsoft Foundryのどれで作ったAgentでも、実行ログ・アクセス権限・セキュリティスキャンを一元管理。シャドーAIの乱立を構造的に防ぎます。
-
データは100%自社のAzureテナント内に保持
自社テナント内にデプロイされる設計のため、AIの学習対象から外され、データ境界を保ったまま運用できます。Fabricを軸に展開する企業の統制要件にも適合します。
AI総合研究所の専任チームが、RayfinとFabricを軸にしたアプリ構成からAIエージェント運用設計まで一貫してサポートします。AI Agent Hubのサービスページで、Fabric時代の業務エージェント基盤の全体像をご確認ください。
Fabricのデータを業務エージェントに活かす

Rayfinの先のエージェント運用設計
Rayfinで作ったアプリのデータはOneLakeに集約され、AIエージェントから直接業務アクションに変換できます。Teamsから呼び出せるエンタープライズAIエージェント基盤AI Agent Hubのサービスページで、Fabric時代の業務エージェント運用の全体像をご確認ください。
まとめ
本記事では、2026年6月2日のMicrosoft Build 2026で発表されたRayfinについて、定義・特徴・アーキテクチャ・使い方・Replit連携・競合との違い・注意点・料金まで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
RayfinはTypeScriptデコレーターでアプリのバックエンド全体を宣言し、
npx rayfin upの1コマンドでMicrosoft Fabricへデプロイするオープンソースの新SDK/CLIで、Fabric Apps Previewを開発・デプロイするための中核SDK/CLIとして提供される
-
データモデル定義から、DBスキーマ・GraphQL API・行レベル権限・型安全クライアントが自動生成され、OneLake自動連携によって書き込んだ瞬間にデータが分析・AIで使える状態になる
-
本番認証はFabric brokered(Entra SSO)一択で、社内向けアプリには極めて適合する一方、社外向けの不特定多数や独自ID基盤を必要とするユースケースには現状向かない
-
Replitがローンチ時の主要パートナーとして発表され、「vibe codingの速度」と「エンタープライズのガバナンス」を両立させる枠組みが具体化された。早期顧客として工具メーカーLeathermanの事例が公表されている
-
料金はRayfin自体がOSSで無料、デプロイ先のFabric CapacityのCU消費で課金される従量モデル。Fabric保有組織はトライアル60日で即試せる一方、Fabric未導入組織は前提コストの計算が必要になる
企業の開発・データ基盤責任者にとってRayfinは、「自社の社内ツール内製化と、AIエージェントの永続バックエンドをFabricに集約する」という戦略的な選択肢を提供する動きです。まずは60日無料トライアルでハンズオンを試し、自社の既存Fabricワークスペース・既存業務システムとの噛み合いを検証するところから着手するのが、最も実用的な第一歩になります。
AIエージェントが業務に居座る2026年は、「データもアプリもFabricへ」という中期戦略を取るか、別の分散アーキテクチャを選ぶかが、企業の競争力を左右する判断になる時期に入りました。Rayfinの発表は、Microsoftが描く未来像を最も具体的に示した動きと言えます。










