この記事のポイント
 PLaMo 3.0 PrimeはPFNがフルスクラッチ開発した国産LLMで、Reasoning/Non-reasoningの2モデルを用途で切り替えられる
PLaMo 3.0 PrimeはPFNがフルスクラッチ開発した国産LLMで、Reasoning/Non-reasoningの2モデルを用途で切り替えられる- 標準プランは入力60円・出力250円(1Mトークン)で、同価格帯のClaude Haiku 4.5・GPT-5.4 Miniと真っ向勝負の単価設計
- コンテキスト長は256Kに拡張、構造化出力とOpenAI互換のTool callingに対応しエージェント基盤として組みやすい
- 日本語指示追従・医療・コード生成・安全性で競合と互角以上、Web探索・数学・日本法令はまだ海外モデル優位
- API・Amazon Bedrock・Snowflake・オンプレミスから選べ、自治体・公共領域での評価検証が進み金融など主権要件の高い領域でも選択肢になり得る

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
PLaMo 3.0 Primeは、Preferred Networksが2026年6月22日に正式リリースした国産フルスクラッチの生成AI基盤モデルです。
論理的思考に強いReasoningモデルと、応答速度を優先したNon-reasoningモデルの2系統を提供し、コンテキスト長はβ版の64Kから256Kへ拡張されました。
標準プランは入力60円・出力250円(100万トークンあたり)で、Claude Haiku 4.5やGPT-5.4 Miniと同価格帯を狙った設計になっています。
デジタル庁の生成AI利用環境「源内」では、PLaMoシリーズの前世代モデルである「PLaMo 2.0 Prime」が評価検証対象として選定されており、PLaMo 3.0 Primeはその後継として正式リリースされた最新フラッグシップです。政府・自治体・公共領域での評価検証が進んでおり、金融などデータ主権を重視する領域でも選択肢になり得る基盤です。
本記事では、PLaMo 3.0 Primeの技術仕様(256Kコンテキスト・構造化出力・独自トークナイザ)、ベンチマーク評価で見える得意・不得意、推論/非推論モデルの使い分け、料金プラン、提供チャネルと使い方、国産LLMの中での位置づけ、企業がどう導入判断すべきかまでを、2026年6月時点の最新情報で体系的に解説します。
目次
PLaMo 3.0 Primeとは——Preferred Networksの国産フルスクラッチLLMフラッグシップ
PLaMo 3.0 Primeの技術仕様——256Kコンテキスト・構造化出力・独自トークナイザ
構造化出力(Structured Output)でJSON生成が安定する
Tool calling対応とparallel未サポートの制約
PLaMo 3.0 Primeのベンチマーク——同価格帯モデルとの比較で見える得意・不得意
PLaMo 3.0 Primeの料金プラン——Free・Standard・Providerの3層
国産LLMとしての位置——デジタル庁源内での評価検証と他モデルとの関係
PLaMo 3.0 Primeとは——Preferred Networksの国産フルスクラッチLLMフラッグシップ

PLaMo 3.0 Primeは、Preferred Networks(以下PFN)が2026年6月22日に正式リリースした、国産フルスクラッチの生成AI基盤モデルの最新フラッグシップです。
PLaMo 3.0 Primeが他の国産AIと一線を画すのは、**事前学習からトークナイザに至るまでをPFN自身が国内で組み上げた「フルスクラッチ開発」**である点です。Llama 3やQwenなど海外のオープンモデルに日本語チューニングをかけるアプローチとは異なり、学習データ・モデルアーキテクチャ・トークナイザ設計のすべてが自社管理下にあります。
「日本語の業務利用に最適化された設計」と「データ主権の確保」を同時に成立させるためのこの選択は、海外モデルでガバナンスや出力傾向が引っかかる場面でPLaMoが国内代替の現実解として浮上しやすい理由でもあります。

PLaMo 3.0 Primeの技術仕様——256Kコンテキスト・構造化出力・独自トークナイザ
ここからは、PLaMo 3.0 Primeを実装に組み込むうえで押さえるべき技術仕様を整理します。
β版64Kから256Kへ拡張されたコンテキスト長、新たにサポートされた構造化出力、OpenAI互換のTool calling、独自トークナイザによる日本語効率が、エージェント基盤として使うときの実質的な強みになります。

以下の表で、PLaMo 3.0 Primeの主要スペックを整理しました。
| 項目 | PLaMo 3.0 Prime | 補足 |
|---|---|---|
| コンテキスト長 | 256Kトークン | β版64Kから拡張。Standard料金は128Kまで適用、それ以上はリリース記念期間中同額 |
| モデル系統 | Reasoning / Non-reasoning | API側で切り替え可能 |
| API互換性 | Chat Completions API(OpenAI互換) | 既存OpenAI SDKコードからの移行が容易 |
| Tool calling | 対応(parallel function callingは未対応) | BFCL v4で評価済み |
| 構造化出力 | Structured Output対応 | JSONスキーマに準拠した出力を強制可能 |
| トークナイザ | 日本語特化の独自設計 | 同じ日本語テキストで消費トークン数が他社モデルより少ない |
| ZDR | 入力データを保存・学習に利用しない | StandardプランとProviderプランで適用 |
なおPLaMo公式APIドキュメントによれば、「plamo-3.0-prime-beta」は2026年7月31日に提供終了予定、「plamo-2.2-prime」以前のモデルも2026年9月30日に提供終了予定で「plamo-3.0-prime」に統合される計画になっています。β版や旧Primeを本番運用に組み込んでいる組織は、リリース直後のタイミングで「plamo-3.0-prime」への移行スケジュールを引いておく必要があります。
これらの仕様は、単発のチャット応答だけでなく外部APIや業務システムと連携するエージェントとして使う前提で設計されています。特にコンテキスト長256Kと構造化出力の組み合わせは、長大なツール利用履歴やドキュメント参照を保持しながら定型JSON出力を要求するワークフローで効きます。
コンテキスト長256Kがエージェント設計に与えるインパクト

256Kトークンというコンテキスト長は、A4文書で約400ページ相当の情報量を一度のリクエストで扱えるスケールです。
社内ナレッジ・契約書・議事録など長文の参照資料を毎回プロンプトに同梱しても余裕があり、エージェントが複数ツールを連続呼び出ししたあとに履歴を保持し続ける運用にも耐えます。
PFN公式ブログによると、同性能帯のオープンモデルgpt-oss(gpt-oss-120b)は128K、Qwen3.6 27Bは256K、同価格帯のクローズドモデルClaude Haiku 4.5は200K、GPT-5.4 Miniは400Kです。
PLaMo 3.0 PrimeはこのレンジでQwen3.6 27Bと並ぶ水準にあり、Claude Haiku 4.5を上回ります。
最先端のDeepSeek V4 Proの1M、GPT-5.5 Proの1Mとはまだギャップがあるものの、業務エージェントが扱う標準的なコンテキスト範囲なら十分に対応できる仕様です。
構造化出力(Structured Output)でJSON生成が安定する

業務システムとの連携で常に問題になるのは「LLMが返すJSONが微妙に崩れる」現象です。
PLaMo 3.0 Primeでは新たに構造化出力をサポートし、ユーザーが指定したJSONスキーマに必ず準拠する形でレスポンスを生成できるようになりました。
プロンプトエンジニアリングで「JSONで返してください」と書く従来手法に比べて、形式崩れによるパース失敗が大幅に減ります。
これは、PLaMoを既存システムのバックエンドに据えて自動化フローを組むときに直接効くアップデートです。
Tool calling対応とparallel未サポートの制約
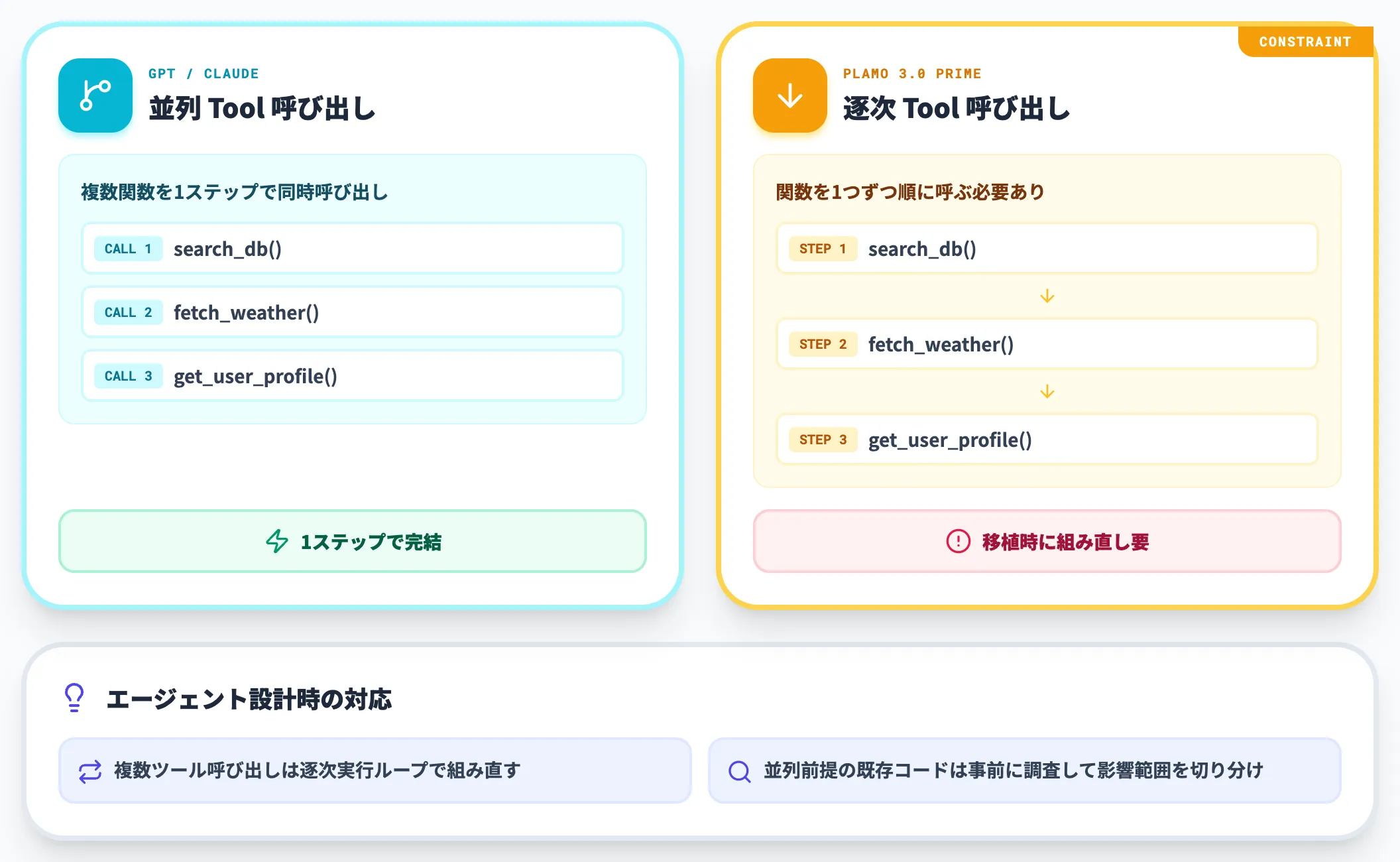
PLaMo 3.0 PrimeはOpenAI互換のTool callingに対応しており、関数定義をAPIに渡せばモデル側で適切な関数を選んで引数を生成します。
ただし、parallel function calling(複数関数の同時呼び出し)には現時点で未対応です。PFN公式のベンチマーク評価でも、BFCL v4のparallel・parallel_multiple・live_parallel系は除外されています。
実装側では、複数関数を呼ぶワークフローを逐次実行で組む必要があります。GPT系・Claude系のAPIをparallel前提で書いていたコードをそのまま移植すると詰まる可能性があるため、エージェントハーネスを設計する際は逐次呼び出しを前提に組み直す判断が必要です。
独自トークナイザによる日本語効率
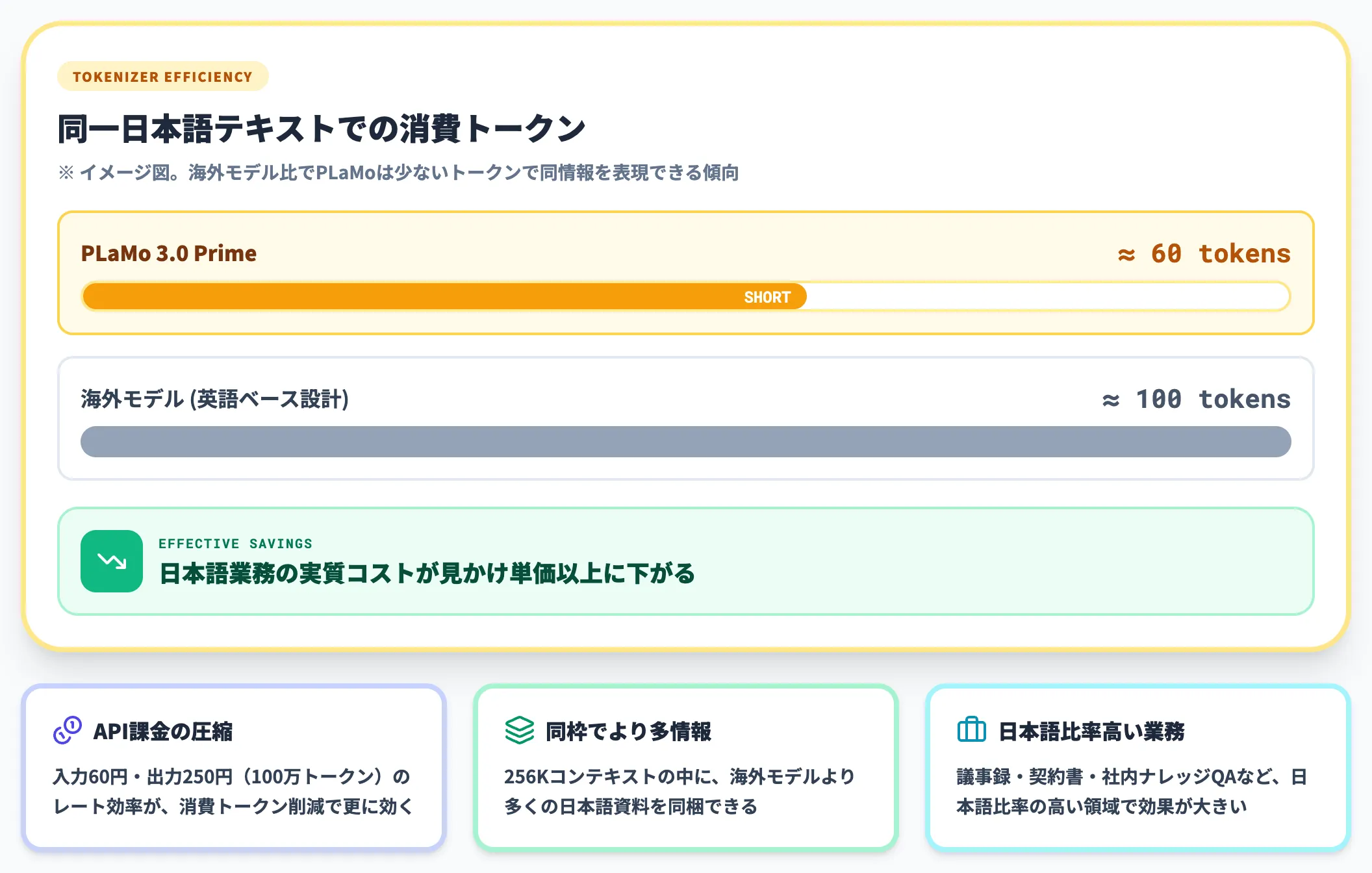
PFNは日本語の特性に合わせて独自のトークナイザを開発しており、同じ日本語テキストを処理するときの消費トークン数が海外モデルより少なくなる傾向があります。
これは料金面で直接効きます。Standardプランは入力60円・出力250円(100万トークン)ですが、同じ文章でトークン数自体が小さければ、見かけ単価以上にコスト効率が良くなります。日本語比率の高い業務でPLaMoを選ぶ際の隠れた優位性です。
PLaMo 3.0 Primeのベンチマーク——同価格帯モデルとの比較で見える得意・不得意
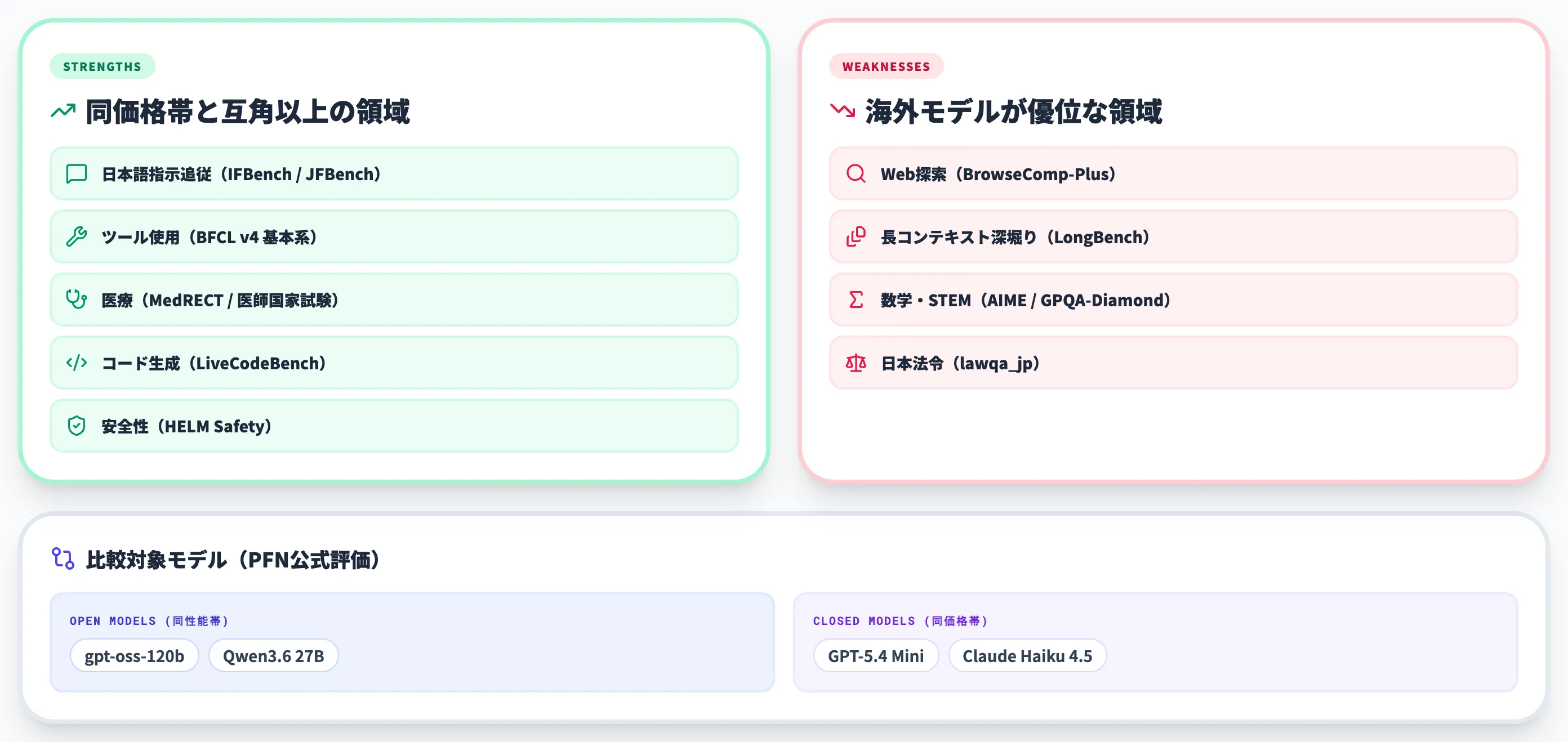
PLaMo 3.0 Primeのベンチマーク評価は、日本語指示追従・医療・コード生成・安全性で同価格帯モデルと互角以上、Web探索・長コンテキスト・数学・日本法令で劣後という構図がはっきり出ています。
本セクションでは、PFN公式ブログが公開した15項目のベンチマーク評価をもとに、PLaMoの実力と限界を整理します。
15項目のベンチマーク評価対象
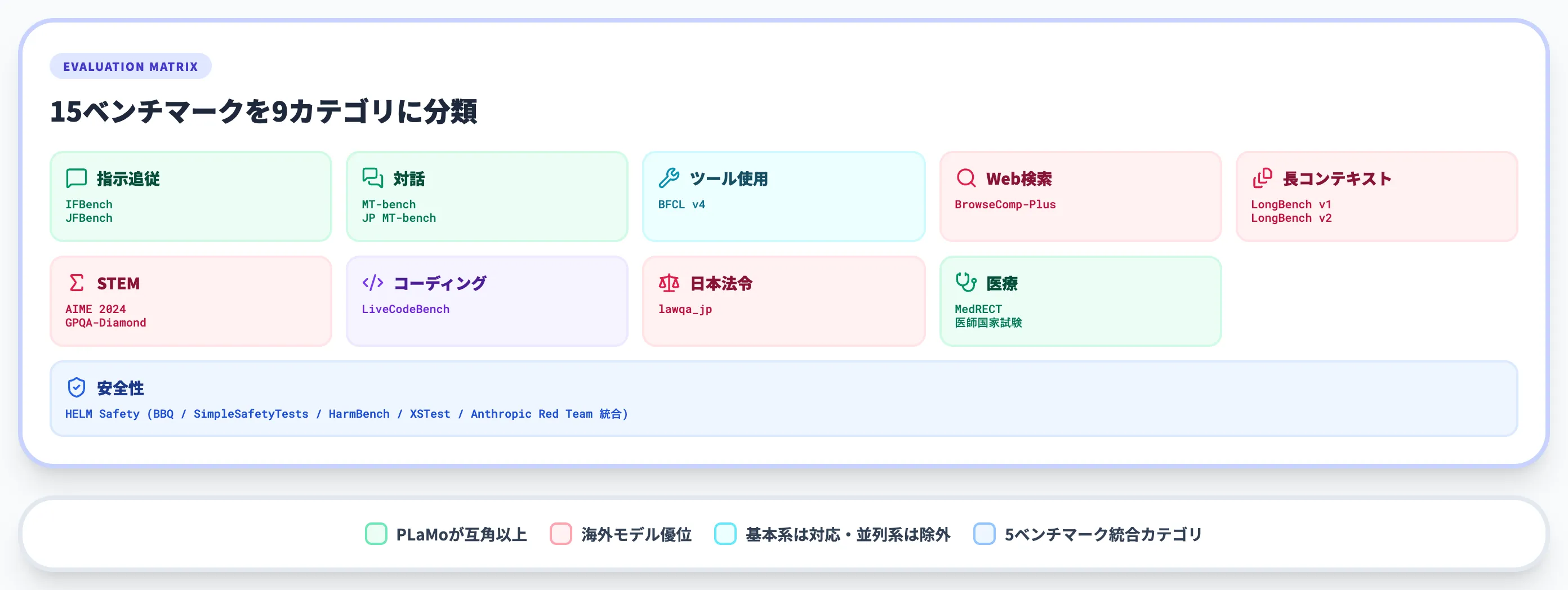
PFNは多面的な評価を行うため、英語・日本語混在で15項目のベンチマークを用いています。
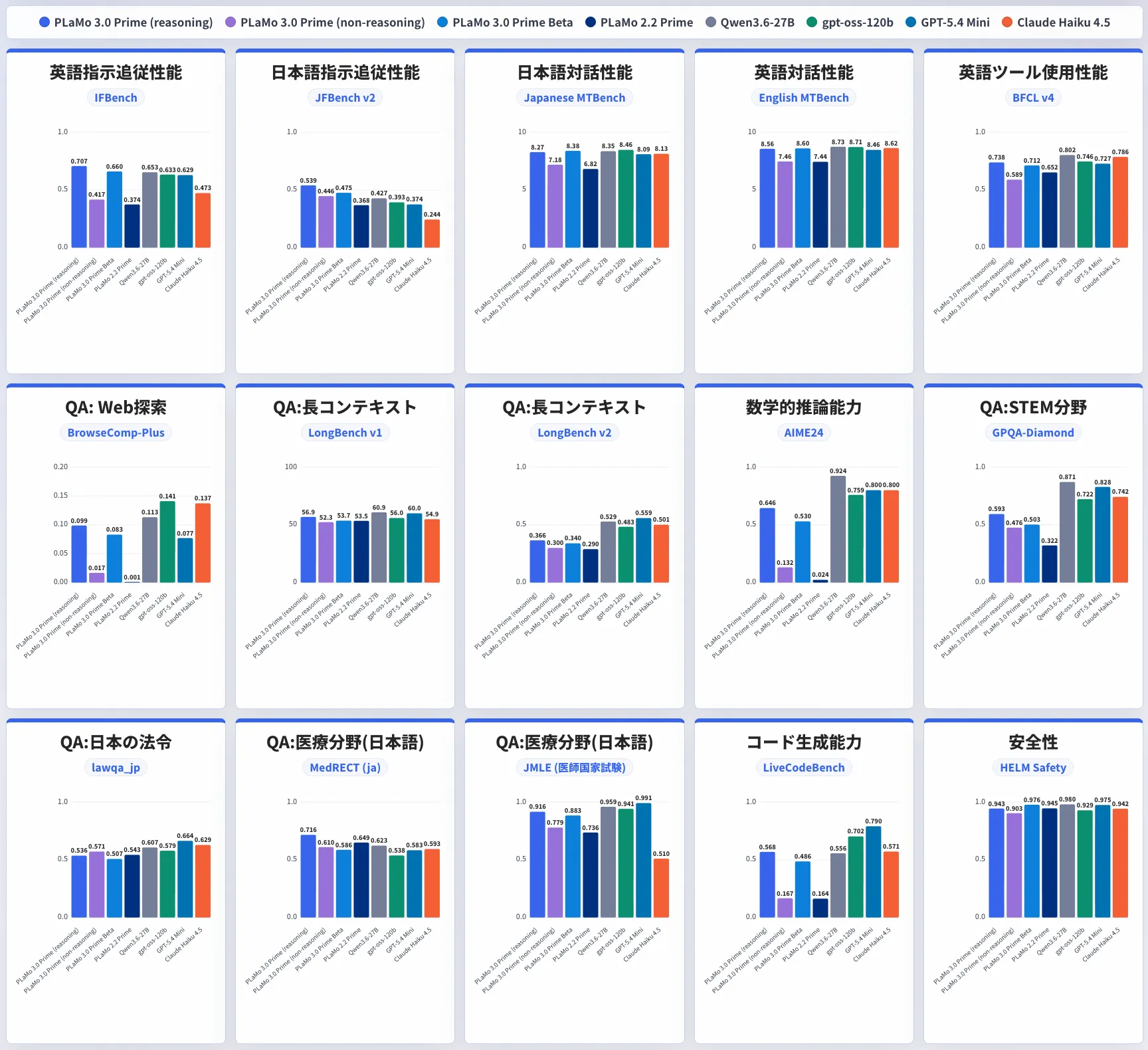
15項目ベンチマークにおけるPLaMo 3.0 Primeと競合モデルのスコア比較(出典:PFN Tech Blog)
公式ブログの図では、各ベンチマークについてPLaMo 3.0 Primeの推論/非推論モデル、過去モデル(PLaMo 3.0 Prime β版・PLaMo 2.2 Prime)、競合のQwen3.6-27B・gpt-oss-120b・GPT-5.4 Mini・Claude Haiku 4.5の7モデルを並列比較しています。
多くの項目で同価格帯モデルと拮抗していることが視覚的に確認できます。
以下の表で、各ベンチマークが何を測っているかを整理しました。
| カテゴリ | ベンチマーク | 測定対象 |
|---|---|---|
| 指示追従 | IFBench / JFBench | 英語・日本語の指示通りに応答できるか |
| 対話 | MT-bench / Japanese MT-bench | 多ターン対話の品質 |
| ツール使用 | BFCL v4 | 関数呼び出しの正確性 |
| Web検索 | BrowseComp-Plus | 検索付き質問応答 |
| 長コンテキスト | LongBench v1 / v2 | 長文理解と多文書推論 |
| STEM | AIME 2024 / GPQA-Diamond | 数学・科学の推論 |
| コーディング | LiveCodeBench | プログラム生成 |
| 日本法令 | lawqa_jp | 日本の法律に関する質問応答 |
| 医療 | MedRECT / 医師国家試験 | 臨床テキストの誤り検出・国試問題 |
| 安全性 | HELM Safety | 5つの安全性ベンチマーク統合 |
比較対象は、同性能帯のオープンモデルとしてgpt-oss-120b(reasoning effort=medium)とQwen3.6-27B、同価格帯のクローズドモデルとしてGPT-5.4 Mini・Claude Haiku 4.5が選ばれています。
PLaMo 3.0 Primeが強い領域
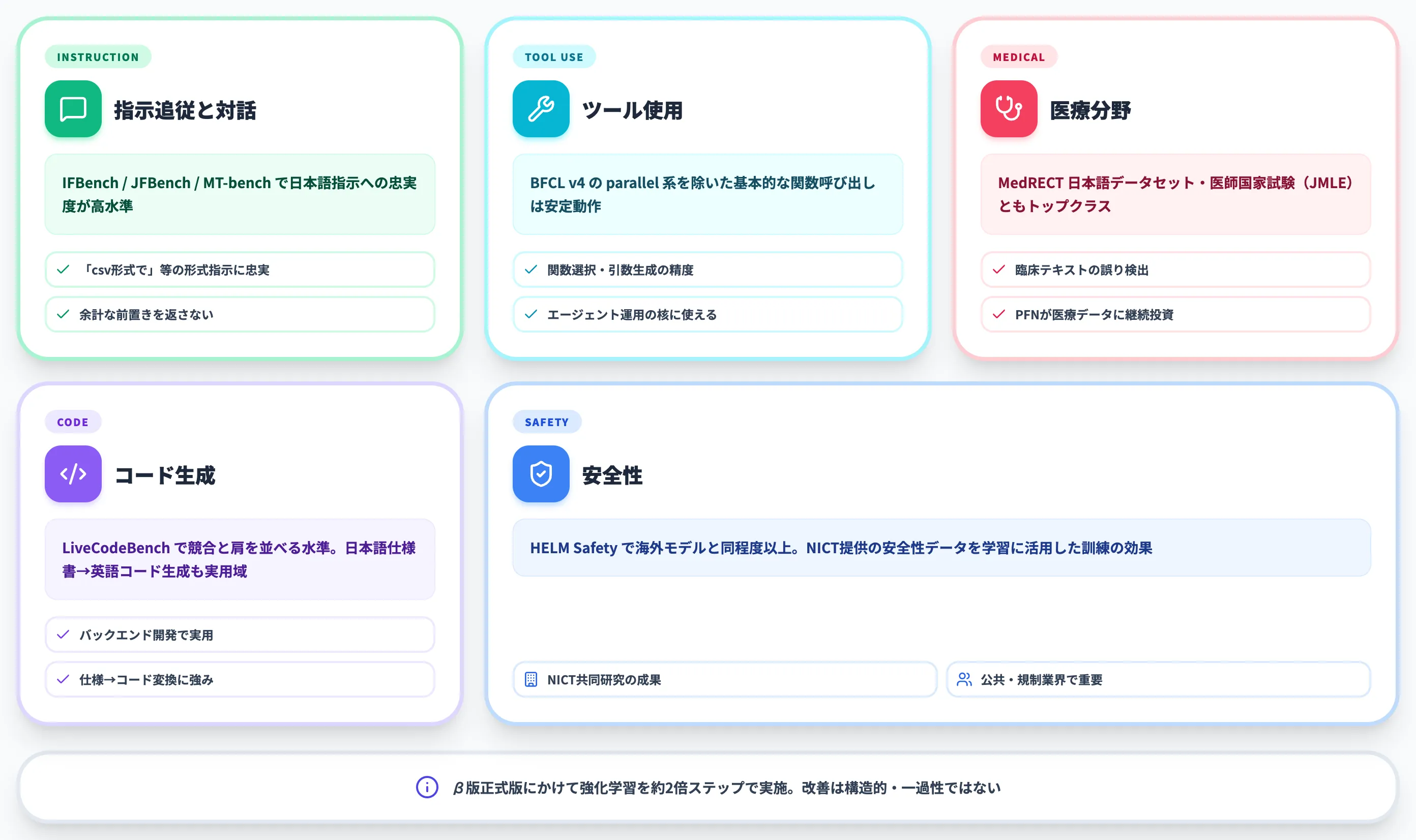
PFNによれば、PLaMo 3.0 Primeは以下の領域で同価格帯モデルと同等以上の性能を示しています。
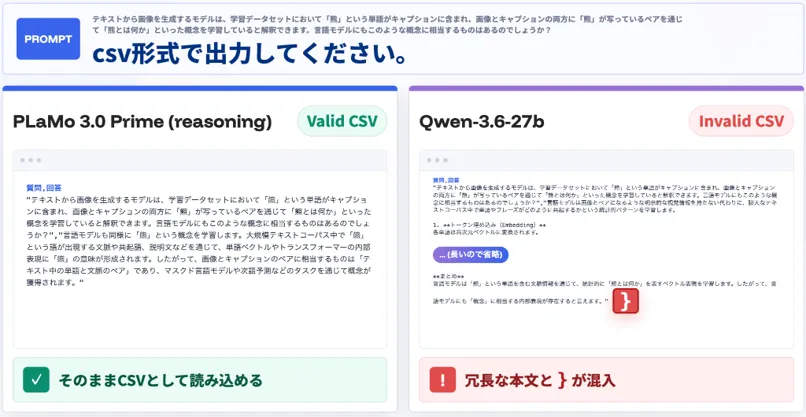
「csv形式で出力してください」という指示に対するPLaMo 3.0 PrimeとQwen-3.6-27bの応答比較(出典:Preferred Networks)
PFN公式プレスが示している出力例では、同じ「csv形式で出力してください」という指示に対して、PLaMo 3.0 Primeは余計な前置きなしに valid なCSVを返している一方、Qwen-3.6-27bは冒頭で長文の解説を付けたうえに末尾に閉じ括弧が混入しinvalidな出力になっています。
日本語業務で重要となる「指示通りの形式で出す」という基礎力が、ベンチマーク数値だけでなく実出力レベルでも差が出ていることを示す例です。
-
指示追従と対話
IFBench / JFBench / MT-bench / Japanese MT-benchで、特に日本語指示への忠実度が高い。日本語業務の出力品質で差が出やすい領域。
-
ツール使用
BFCL v4で、parallel系を除いた基本的な関数呼び出しは安定して動作。エージェント運用の核になる部分。
-
医療分野
MedRECTの日本語データセット・医師国家試験(JMLE)ともにトップクラス。PFNが医療領域で力を入れて学習データを整備してきた結果が出ている。
-
コード生成
LiveCodeBenchで競合と肩を並べる水準。日本語の仕様書から英語のコードを生成するような業務でも実用に耐える。
-
安全性
HELM Safetyで海外モデルと同程度以上のスコア。NICTから提供を受けた安全性データを活用した訓練の効果。
β版から正式版にかけて、PFNは強化学習をβ版の倍程度のステップ数で実施しており、推論能力の全体的な底上げが図られています。
コーディング・長コンテキスト・対話性能に関する強化学習データも増強されており、ベンチマークの改善は一過性ではなく構造的な向上として現れています。
PLaMo 3.0 Primeがまだ劣後する領域
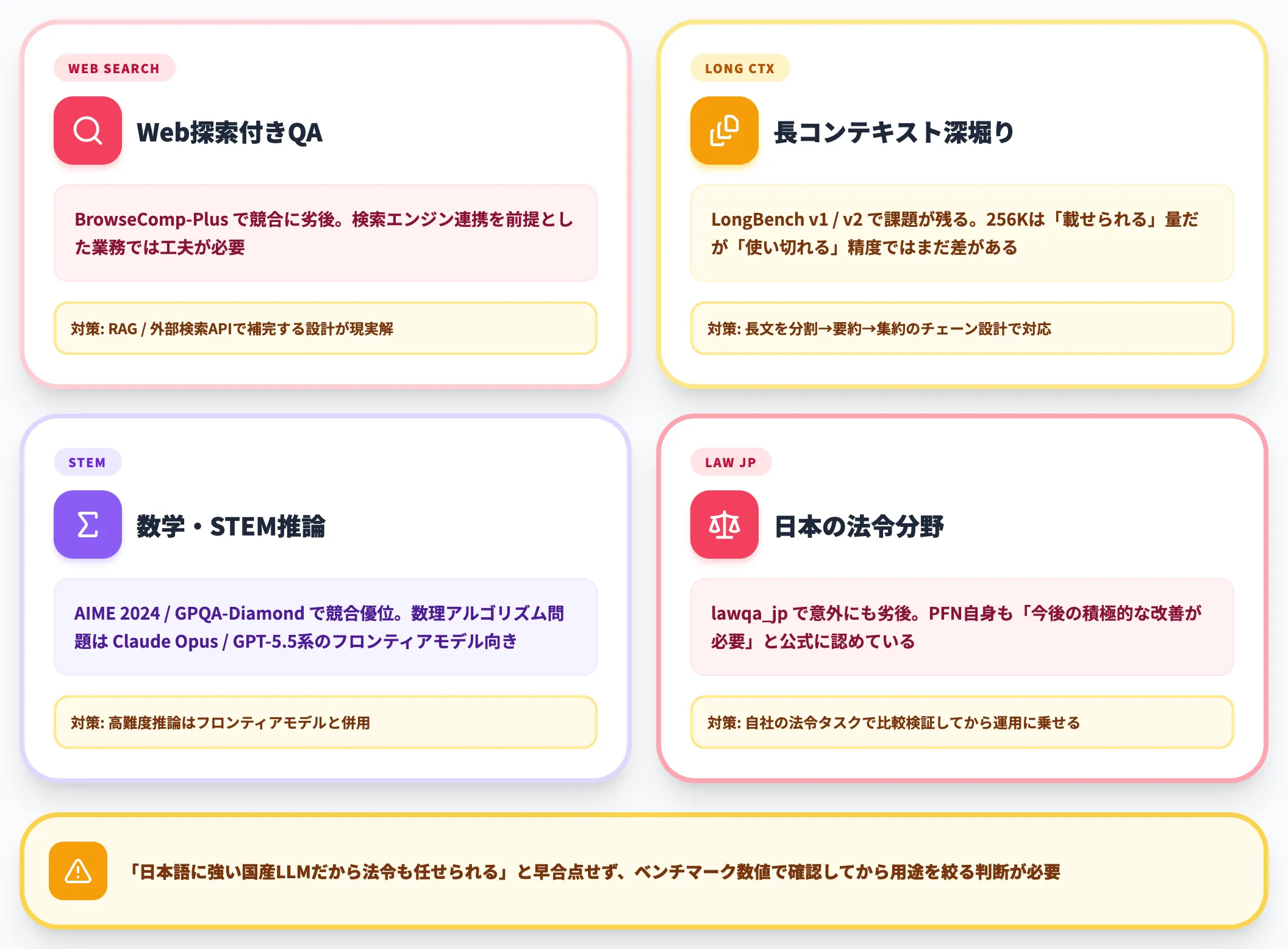
一方で、以下の領域では海外モデルが依然として優位です。
-
Web探索付き質問応答
BrowseComp-Plusで競合に劣後。検索エンジン連携を前提とした業務では工夫が必要。
-
長コンテキスト深堀り
LongBench v1 / v2で課題が残る。256Kは「載せられる」量だが「使い切れる」精度ではまだ差がある。
-
数学的推論・STEM
AIME 2024・GPQA-Diamondで競合優位。数理アルゴリズム問題を解くハードな推論タスクではClaude Opus 4.7・Claude Opus 4.8・GPT-5.5系のような最先端モデルが向く。
-
日本の法令分野
lawqa_jpで意外にも劣後。日本語×法律というドメインでも、ベンチマーク上は海外モデルが上回るケースがある。PFN自身も「今後の積極的な改善が必要」と公式に認めている領域。
「日本語に強い国産LLMだから法令も任せられる」と早合点せず、ベンチマーク数値で確認したうえで用途を絞る判断が必要です。
HELM Safety——非推論モデルの過剰拒否課題
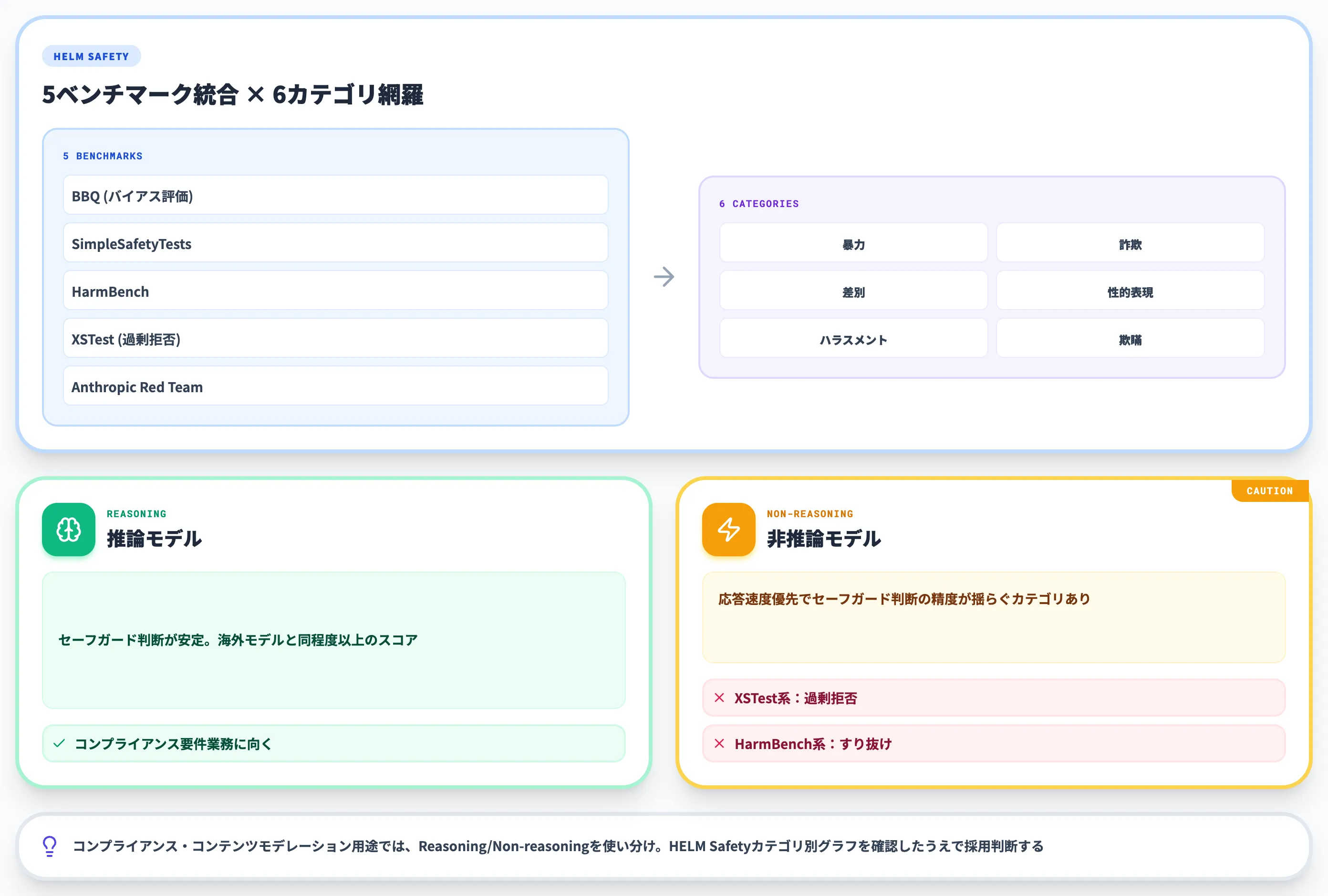
安全性評価のHELM Safetyは、BBQ・SimpleSafetyTests・HarmBench・XSTest・Anthropic Red Teamの5ベンチマークを統合しており、暴力・詐欺・差別・性的表現・ハラスメント・欺瞞の6カテゴリを網羅しています。
以下の2枚のレーダーチャートは、左が「センシティブな話題に過剰拒否せず安全に応答できるか」、右が「危険な話題に対して拒否できているか」をカテゴリ別(定義/比喩表現/歴史的事象/同意異義語/公人のプライバシー/安全な人称のプライバシー/安全な文脈/安全な対象 等)に示しています。
PLaMo 3.0 Primeは全体として競合と同水準ですが、安全な文脈や同意異義語といった一部カテゴリで非推論モデルが過剰拒否寄りに振れる挙動も読み取れます。
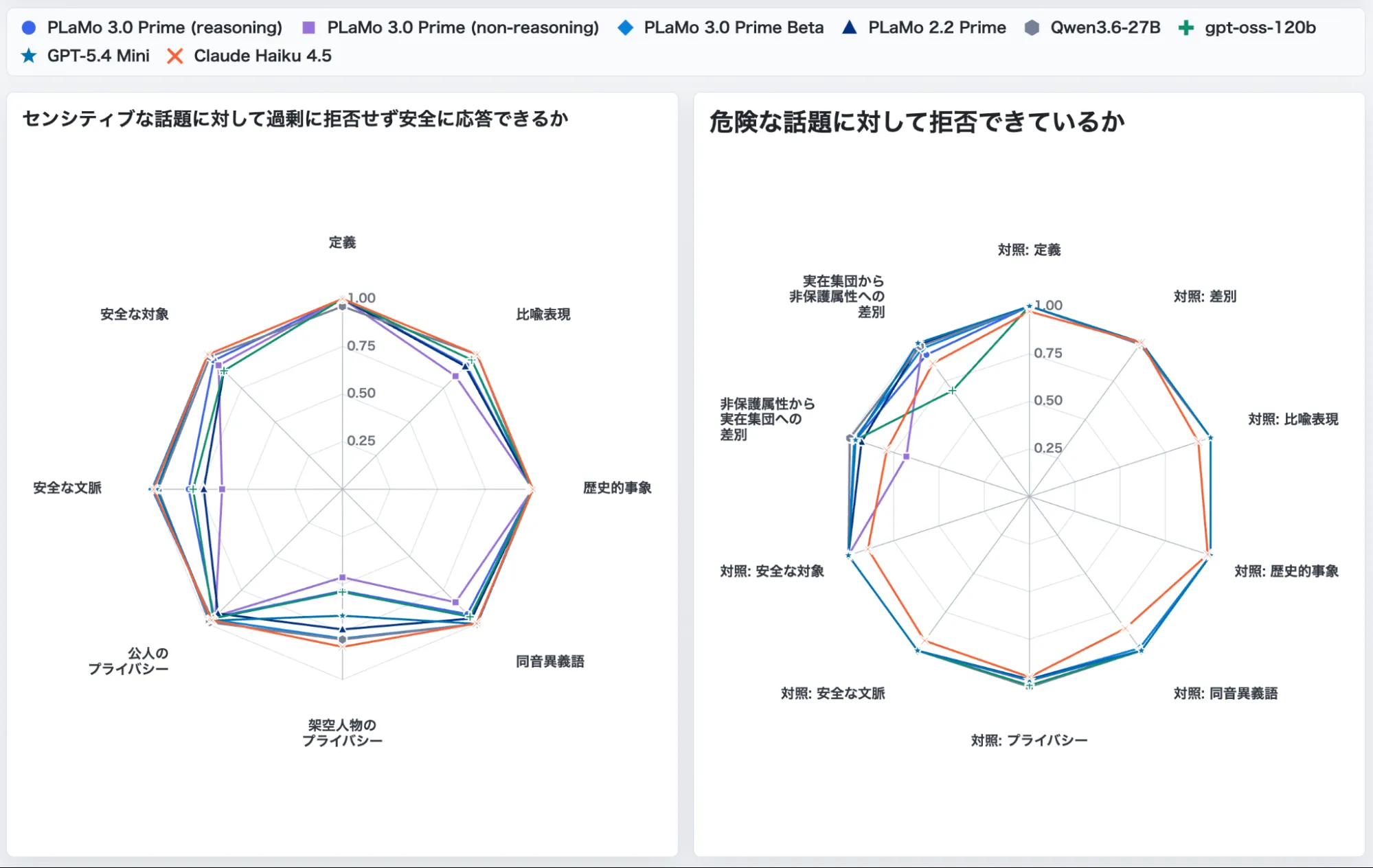
センシティブな話題への適切な応答(左)と危険な話題への拒否(右)でのカテゴリ別比較。PLaMo 3.0 Primeの推論/非推論モデルと競合モデルが比較されている(出典:PFN Tech Blog)
PLaMo 3.0 Primeは全体として競合と同程度以上の安全性能を示していますが、PFN公式ブログによれば非推論モデルでは過剰拒否(XSTest系)や危険プロンプトへの応答(HarmBench系)で課題が残るカテゴリもあります。
これは、応答速度を優先した非推論モデルでセーフガード判断の精度がやや揺らぐ現象で、業務によっては「過剰に拒否されて使い物にならない」「逆にすり抜けが起きる」可能性があることを意味します。
特にコンプライアンスやコンテンツモデレーションを伴う用途では、PFN公式ブログのHELM Safetyカテゴリ別グラフを確認したうえで、ReasoningモデルとNon-reasoningモデルを使い分ける必要があります。
推論モデルと非推論モデルの使い分け
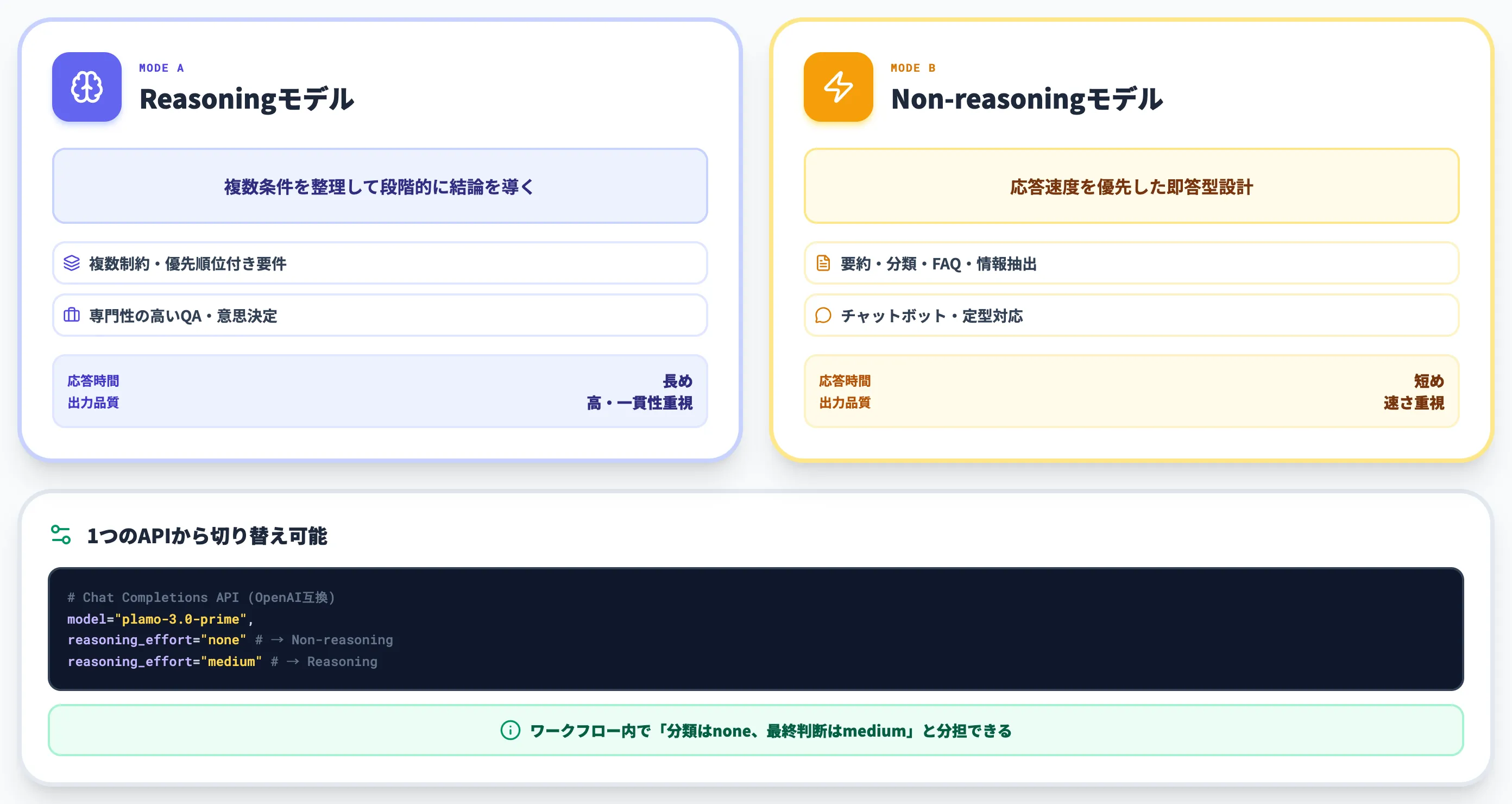
PLaMo 3.0 Primeで最も実務的に効くのは、ReasoningモデルとNon-reasoningモデルをユーザー側で切り替えられる設計です。
正式リリースで非推論モデルが新たに追加されたことで、性能優先・速度優先の両極を1つのAPIから呼び分けられる構成になりました。
Reasoningモデルが向くユースケース

Reasoningモデルは複数の条件を整理しながら段階的に結論を導く能力に優れており、PFNは以下のような用途を想定しています。
- 複雑な指示への対応(複数制約・優先順位付き要件)
- 数理・アルゴリズム問題(注: STEM分野は競合優位なため、高難度問題は他モデル併用を検討)
- 専門性の高い質問応答(医療・コード設計レビュー等)
- 業務上の意思決定支援(複数選択肢の比較・推奨)
応答時間は長くなりますが、出力の質と一貫性が重要な業務に向きます。
Non-reasoningモデルが向くユースケース

Non-reasoningモデルは応答速度を優先した設計で、以下のような用途に適しています。
- 社内文書の要約
- 定型的な問い合わせ対応(FAQボット)
- 情報抽出(請求書からの項目取り出し等)
- 分類タスク(メール振り分け・問い合わせカテゴリ判定)
- チャットボット
これらは「速く返ってくること自体」が体感品質を左右する業務です。Reasoningモデルを使うと過剰なコストとレイテンシを払うことになります。
実装時の切り替え方法
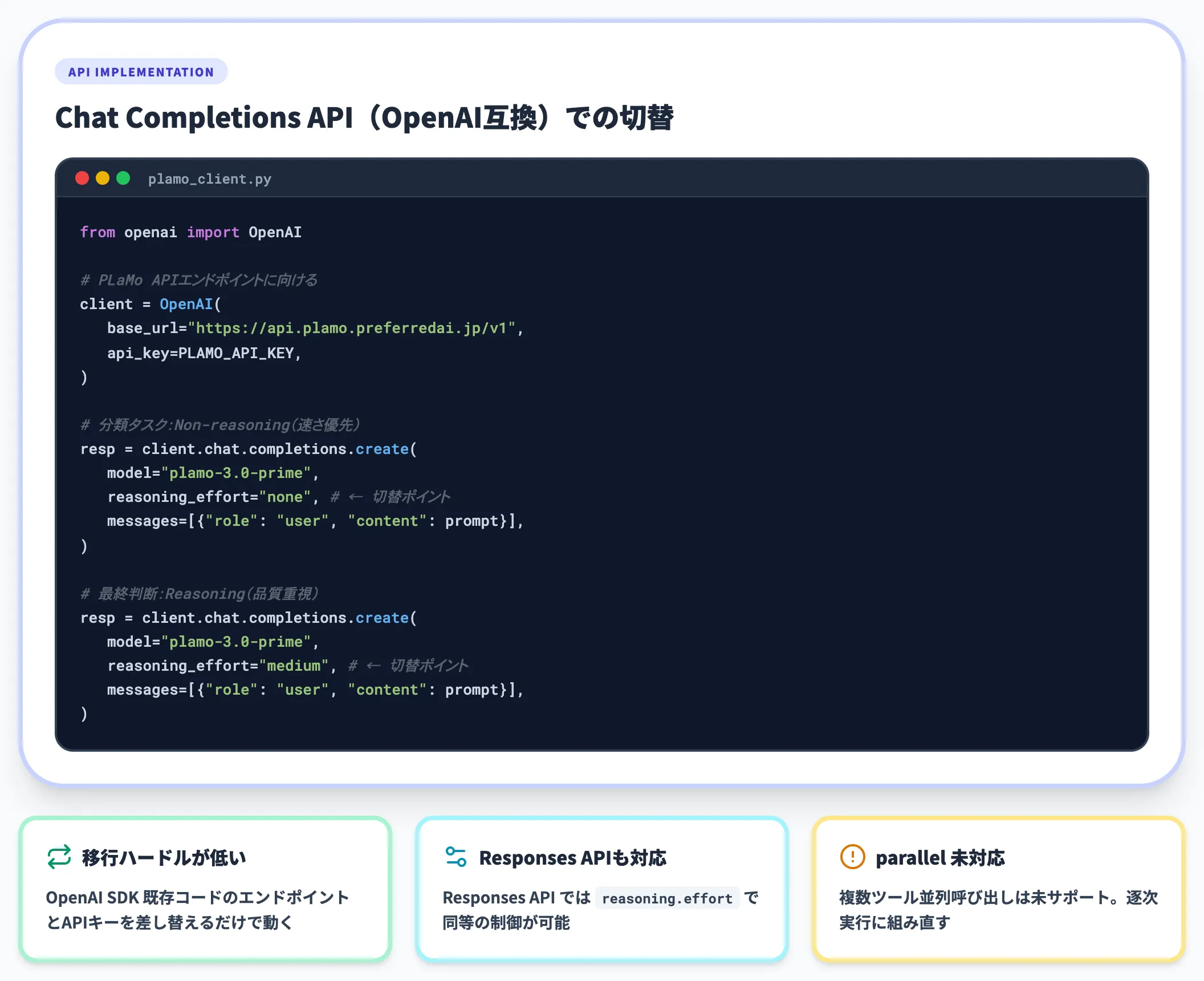
PLaMoのAPIはChat Completions(OpenAI互換)の形式で、モデルIDは「plamo-3.0-prime」を指定します。Reasoningのオン・オフは、リクエストの「reasoning_effort」パラメータ(「none」で非推論、「medium」などで推論モード)または Responses API の「reasoning.effort」で制御する設計です。
詳細はPLaMo公式APIドキュメントを参照してください。
エージェントを設計する際は、1つのワークフロー内でも「分類は『reasoning_effort: none』、最終判断は『reasoning_effort: medium』」と分担させる実装が現実的です。ChatGPT・Claudeなど他社モデルでReasoning相当のモード切替を扱った経験があれば、移行のハードルは低い設計になっています。
なお前述のとおり、parallel function callingは未対応です。エージェント内で複数ツールを呼ぶ場合は逐次実行で組む必要があります。
推論プロセスを返す/返さないの選択
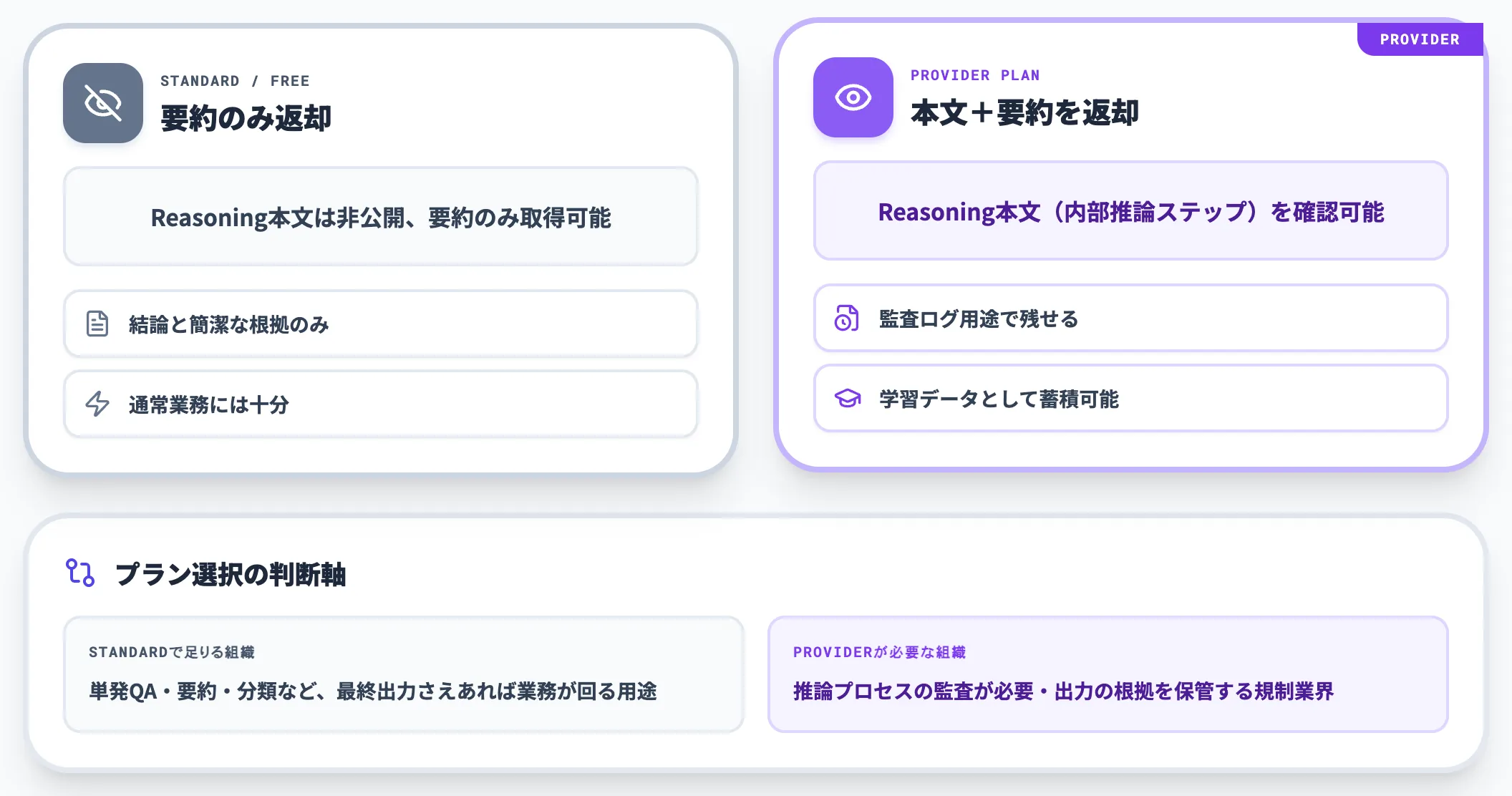
ProviderプランではReasoning本文(モデルが内部で行った推論ステップ)を返却して確認できます。Standard・Freeプランでは要約のみが返却される仕様です。
監査ログや学習データとして推論プロセス全体を残したい組織はProviderプラン側で契約する必要があり、運用要件によってプラン選択が変わってきます。
PLaMo 3.0 Primeの料金プラン——Free・Standard・Providerの3層

PLaMo 3.0 PrimeはFree・Standard・Providerの3プランで提供されます。
入力60円・出力250円(100万トークンあたり)のStandardプランは、Claude Haiku 4.5やGPT-5.4 Miniと同価格帯を狙った戦略的な単価設計です。
3プランの料金構造
以下の表で、PLaMo APIの3プランを整理しました。
| 項目 | Freeプラン | Standardプラン | Providerプラン |
|---|---|---|---|
| 入力単価(1Mトークン) | 0円 | 60円 | Custom(個別見積もり) |
| 出力単価(1Mトークン) | 0円 | 250円 | Custom |
| 単価適用範囲 | — | 128Kトークンまで(128K超はリリース記念期間中同額) | 個別 |
| ZDR(入力データ非保持) | — | 適用 | 適用 |
| 入力データの学習利用 | — | 利用しない | 利用しない |
| レートリミット | 標準 | 大幅に緩和 | 個別設定 |
| Reasoning返却内容 | 要約のみ | 要約のみ | 本文+要約 |
| 混雑時の優先処理 | — | — | あり |
| PLaMo Guardrail | 標準ポリシー | 標準ポリシー | 個社カスタム |
| サポート | ドキュメントのみ | メールサポート | 専任担当者(ミーティング対応可) |
Freeプランは2026年6月時点で「準備中」とされており、提供開始を待つ必要があります。Standardプランは登録後すぐに利用できる本命プランで、業務でPLaMoを試すならまずこちらが起点になります。
同価格帯モデルとのコスト比較

Standardプランの60円/250円という単価は、同価格帯クローズドモデルと真っ向勝負を意識した設定です。
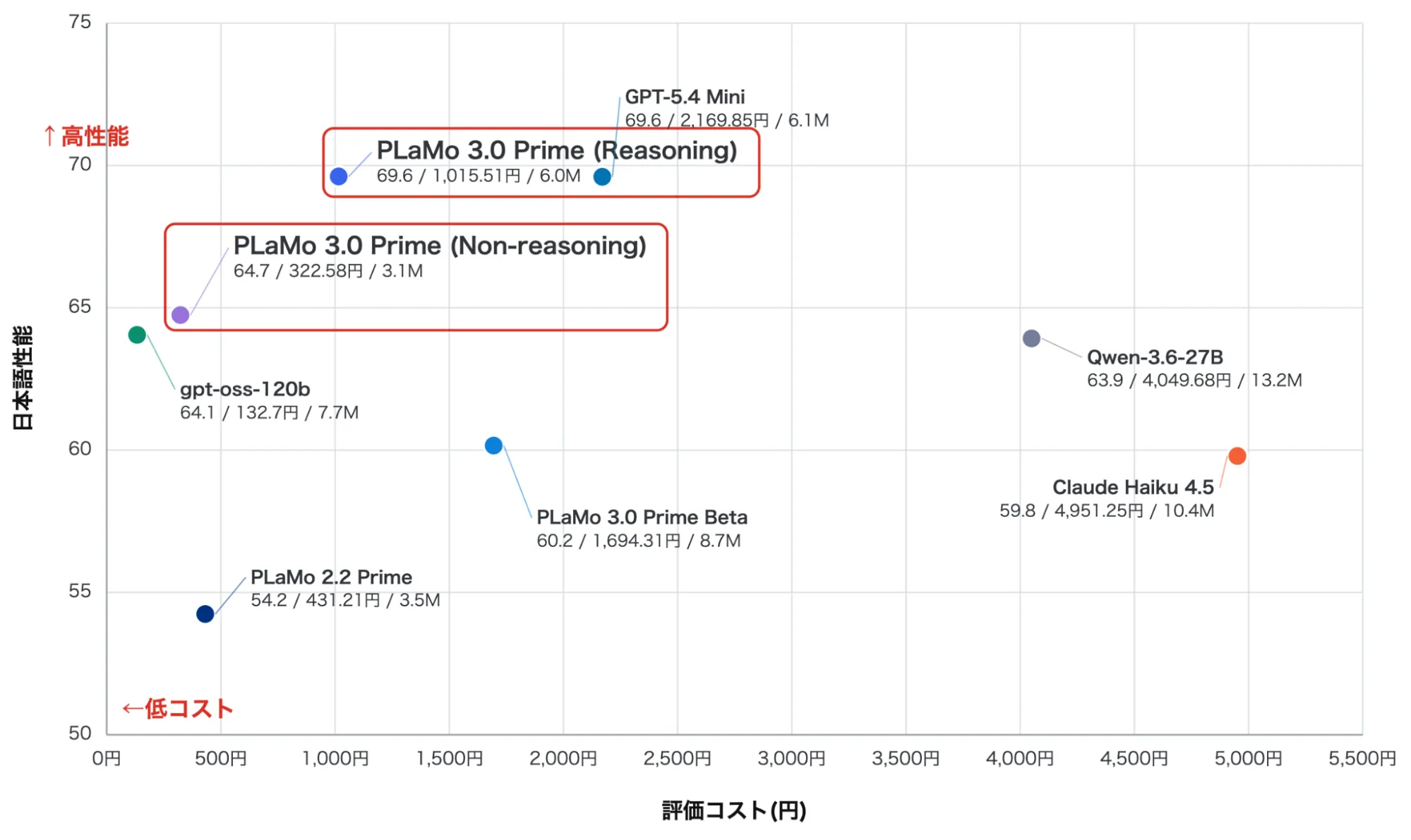
縦軸が日本語ベンチマークの平均スコア、横軸が評価コスト。PLaMo 3.0 Prime (Reasoning) が左上の高性能・低コスト帯に位置している(出典:PFN Tech Blog)
PFN公式ブログのプロット図では、縦軸が日本語ベンチマーク平均スコア(高いほど性能が良い)、横軸が評価にかかった料金(左ほど低コスト)になっています。PLaMo 3.0 Prime (Reasoning) はスコア69.6・約1,016円で図の左上に位置し、同スコア69.6のGPT-5.4 Mini(約2,170円)と同水準の性能でありながら評価コストはおよそ半分に収まります。
Non-reasoningモデルはスコア64.7・約323円でさらに左に位置し、Claude Haiku 4.5(スコア59.8・約4,951円)に対してコストで大きく優位です。Claude Haiku 4.5・GPT-5.4 Mini・gpt-oss-120b・Qwen3.6-27Bと比較しても、コストパフォーマンスでは明確に競争力があると判断できる位置取りです。
加えて、独自トークナイザによる日本語効率により、同じ日本語テキストでも消費トークン数が他社モデルより少なくなる傾向があります。見かけの単価以上に日本語業務での実質コストが下がる構造です。
リリース記念キャンペーンと128Kを超えるリクエスト

2026年6月22日のGA(一般提供開始)に合わせて、2026年7月31日まで新規登録で1000万トークン相当のクレジットが付与されます。
PoC段階で業務適合性を確かめる規模感として十分な量で、Standardプランの入力60円・出力250円(1Mトークン)のレートで素直に使い切ればまとまったワークロードが回せます。

PLaMo API公式ページのファーストビュー。2025日経優秀製品・サービス賞最優秀賞の受賞表示と、2026年7月31日まで新規登録で1000万トークン相当を付与するキャンペーン告知が中央に置かれている(出典:PLaMo API公式ページ)
公式ページのトップ部分には「2025日経優秀製品・サービス賞 最優秀賞」のバッジが目立つ位置で表示されており、国内テック領域での評価がGAキャンペーンの訴求材料として打ち出されています。「今すぐ登録」のCTAが直下に置かれ、登録後すぐにStandardプランで利用開始できる導線になっています。
また128Kトークンを超えるリクエストについても、リリース記念期間中はStandard単価と同額で利用できる扱いになっています。256Kコンテキストの実力を試す機会としても活かせます。
Providerプランの想定対象
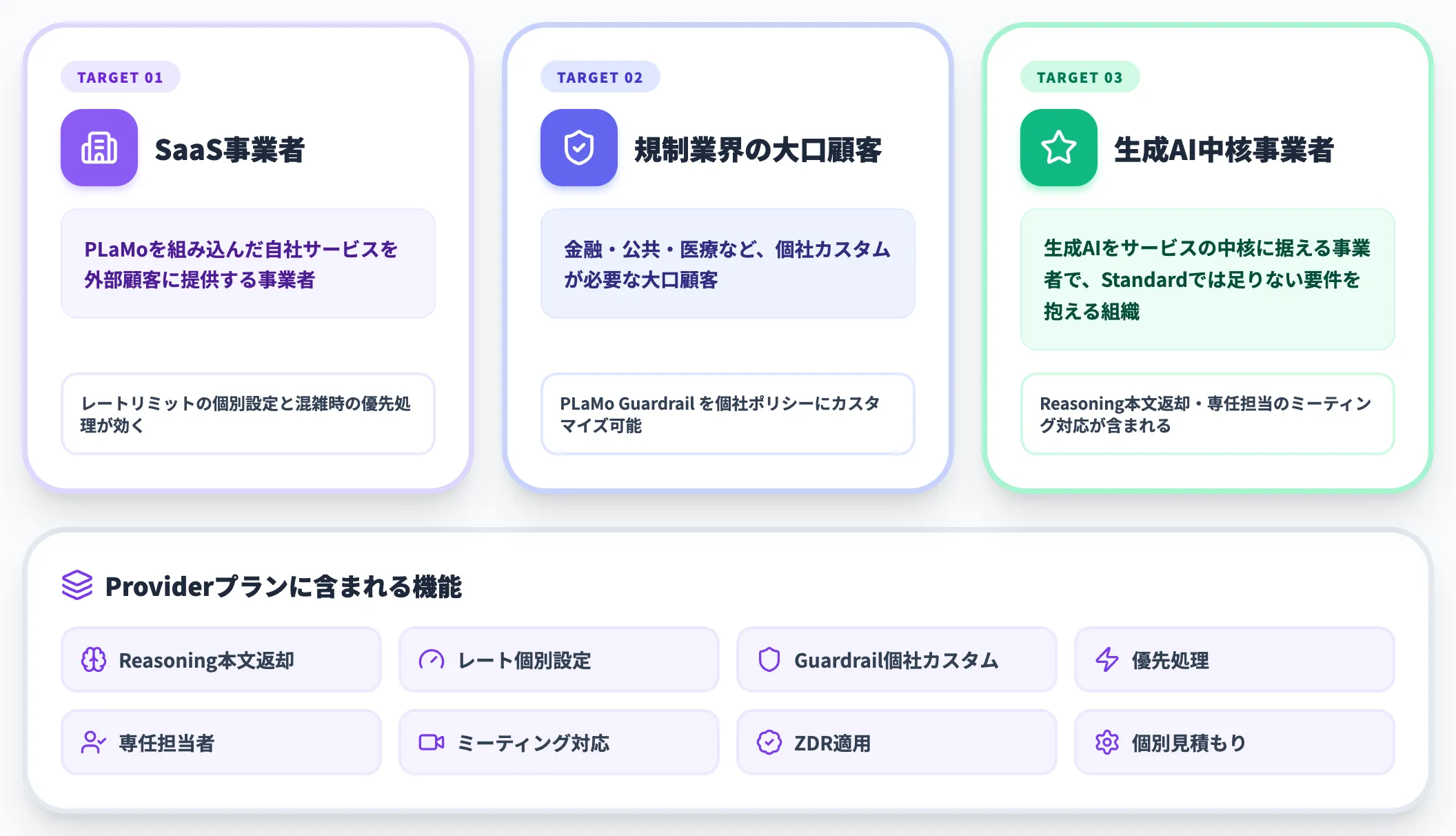
Providerプランは、PLaMoを組み込んだ自社サービスを外部顧客に提供するSaaS事業者や、規制業界で個社カスタムが必要な大口顧客向けです。
価格はCustomで個別見積もりですが、Reasoning本文の返却・レートリミットの個別設定・PLaMo Guardrailの個社カスタマイズ・混雑時の優先処理・専任担当者によるサポートが含まれます。生成AIをサービスの中核に据える事業者であれば、Standardでは足りない要件をここで埋めることになります。

PLaMo 3.0 Primeの提供チャネルと使い方

PLaMo 3.0 Primeは複数の提供チャネルから選べる構成になっており、組織の運用要件に応じて経路を選定できます。
PLaMo Chat・PLaMo API・Amazon Bedrock Marketplace・Snowflake・オンプレミスの5系統が用意されており、データ主権・既存クラウド契約・コスト構造のどれを優先するかで選択肢が変わります。
5つの提供チャネル
以下の表で、各チャネルの特徴と選定軸を整理しました。
| チャネル | 特徴 | 向く組織 |
|---|---|---|
| PLaMo Chat | ブラウザから直接利用できるチャットUI | 個人検証・部門単位のお試し |
| PLaMo API | PFN公式の従量課金API(OpenAI互換) | 自社プロダクトに組み込む開発チーム |
| Amazon Bedrock Marketplace | AWSのフルマネージドAI基盤経由 | AWS環境でセキュリティパイプラインを完結させたい組織 |
| Snowflake | Snowflakeから利用可能 | データ基盤がSnowflake中心の組織 |
| オンプレミス | 自社サーバーにモデルを配置して運用 | データを社外に出せない金融・公共・医療 |
各チャネルの統制要件・データ取り扱い条件は提供形態により異なるため、本番投入前に最新の利用規約・データ取り扱いポリシーを確認したうえで選定する必要があります。最も統制が必要なケースではオンプレミス展開が選ばれます。
OpenAI互換APIで既存コードの移行ハードルが低い
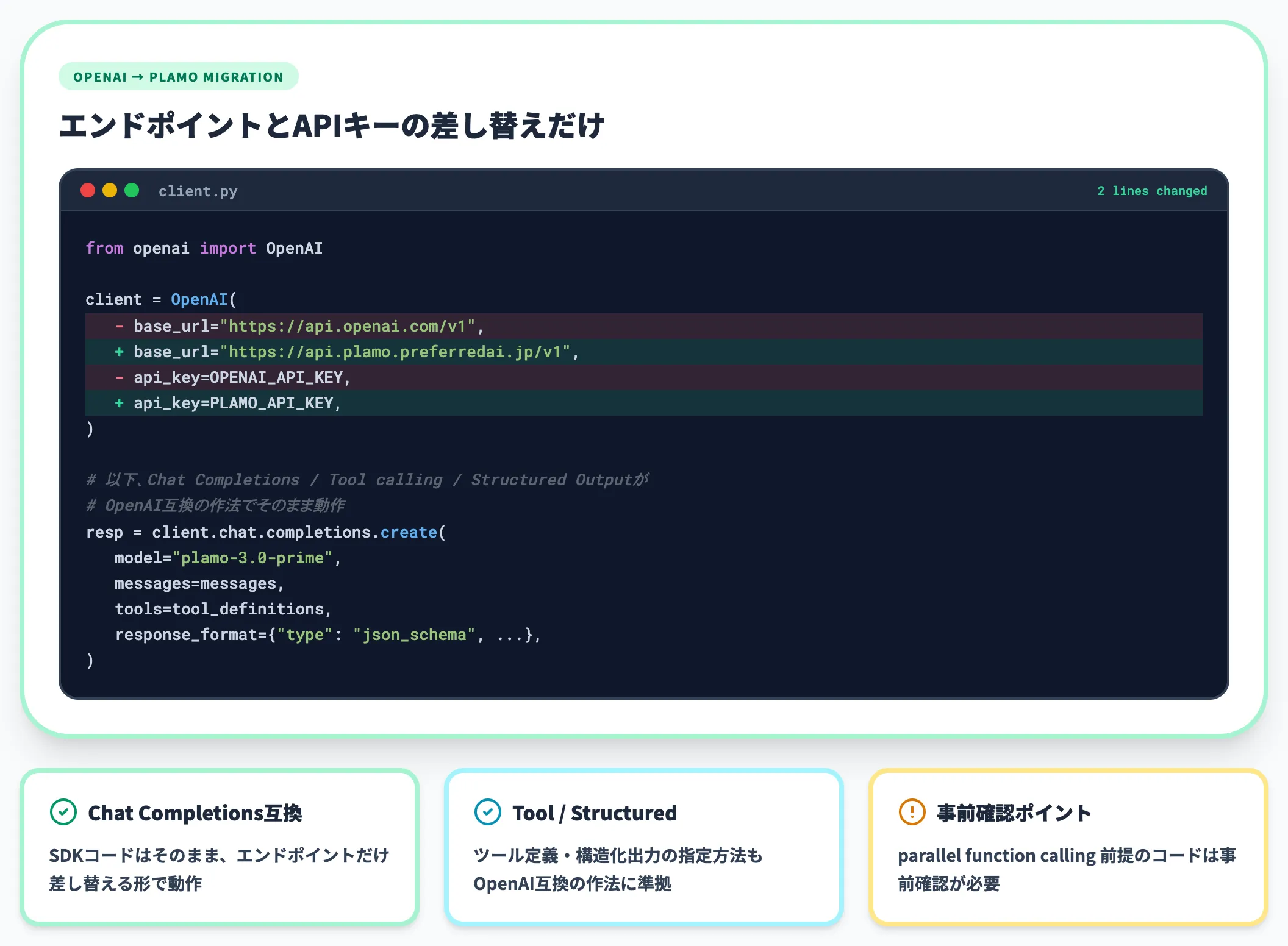
PLaMo APIはChat Completions形式のOpenAI互換APIです。
OpenAI SDKを使った既存コードであれば、エンドポイントURLとAPIキーを差し替えるだけでPLaMoへの切り替えが進むケースが多くなります。ツール定義・構造化出力の指定方法もOpenAI互換の作法に沿っており、エージェントハーネスを書き直す手間が小さい設計です。
ただしparallel function callingは未対応なので、コードベースが並列呼び出しを前提にしていないかは事前に確認が必要です。
Amazon Bedrock経由のメリット
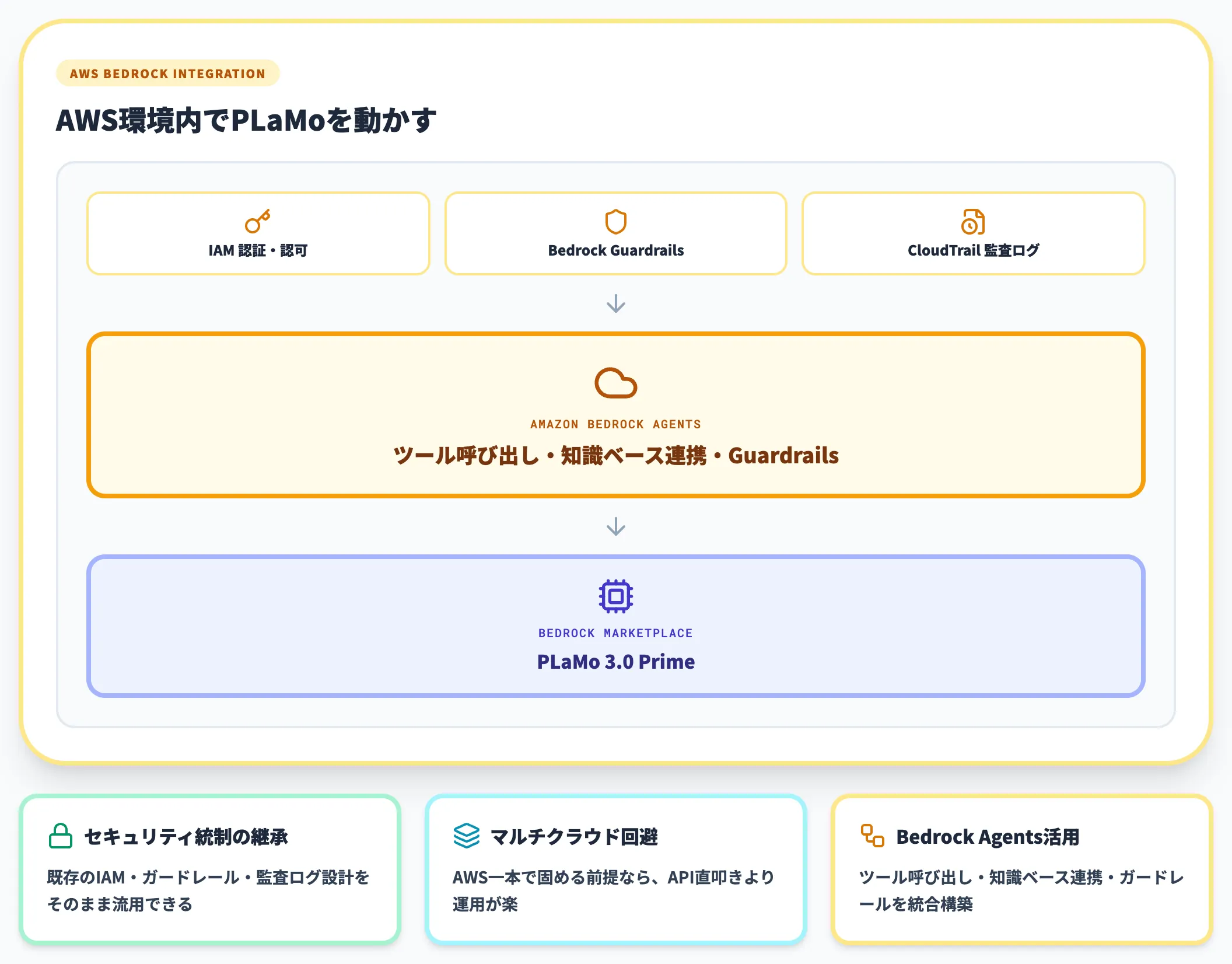
AWS環境でAI基盤を運用している組織は、Bedrock Marketplace経由でPLaMoを呼び出せます。
Bedrock Agentsの枠組みでツール呼び出し・知識ベース連携・ガードレールを構築できるため、AWS上のセキュリティ統制・監査ログ・IAM設計をそのまま引き継げる利点があります。マルチクラウド戦略を取らずAWS一本で固める前提なら、API直叩きよりBedrock経由が運用上は楽です。
Snowflake連携でデータ基盤と一体運用
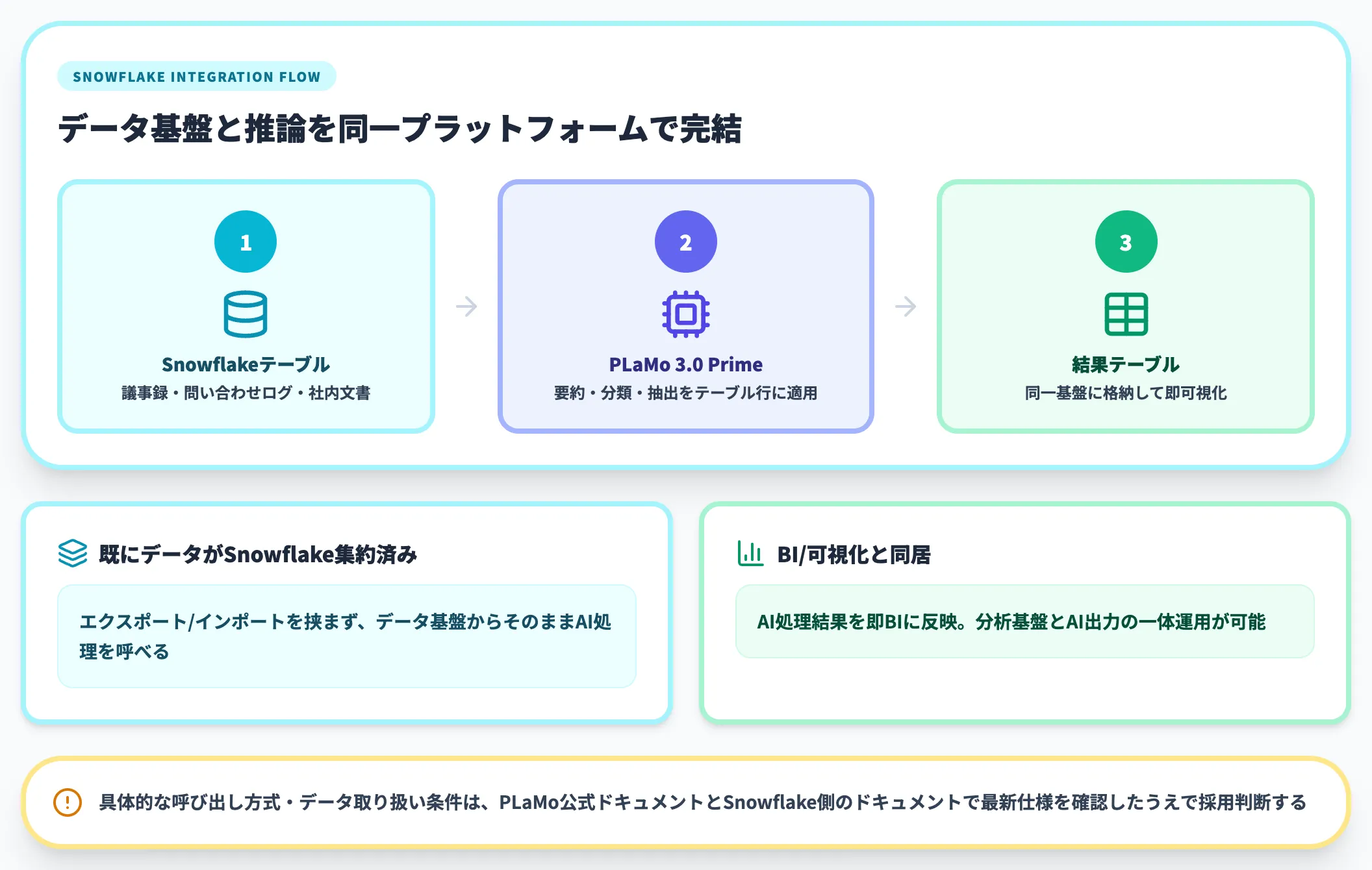
PFN公式リリースでは、PLaMo Primeの提供経路の1つとしてSnowflakeが挙げられています。
「データはSnowflakeに集約済み、そこからAI処理を直接かけたい」という運用に親和性の高いルートで、データ基盤とAI処理を同一プラットフォーム上で扱う組織にとっては選択肢になります。具体的な呼び出し方式・データ取り扱い条件は、PLaMo公式ドキュメントとSnowflake側のドキュメントで最新の仕様を確認したうえで採用判断する必要があります。
オンプレミス展開——データ主権を最優先する場合
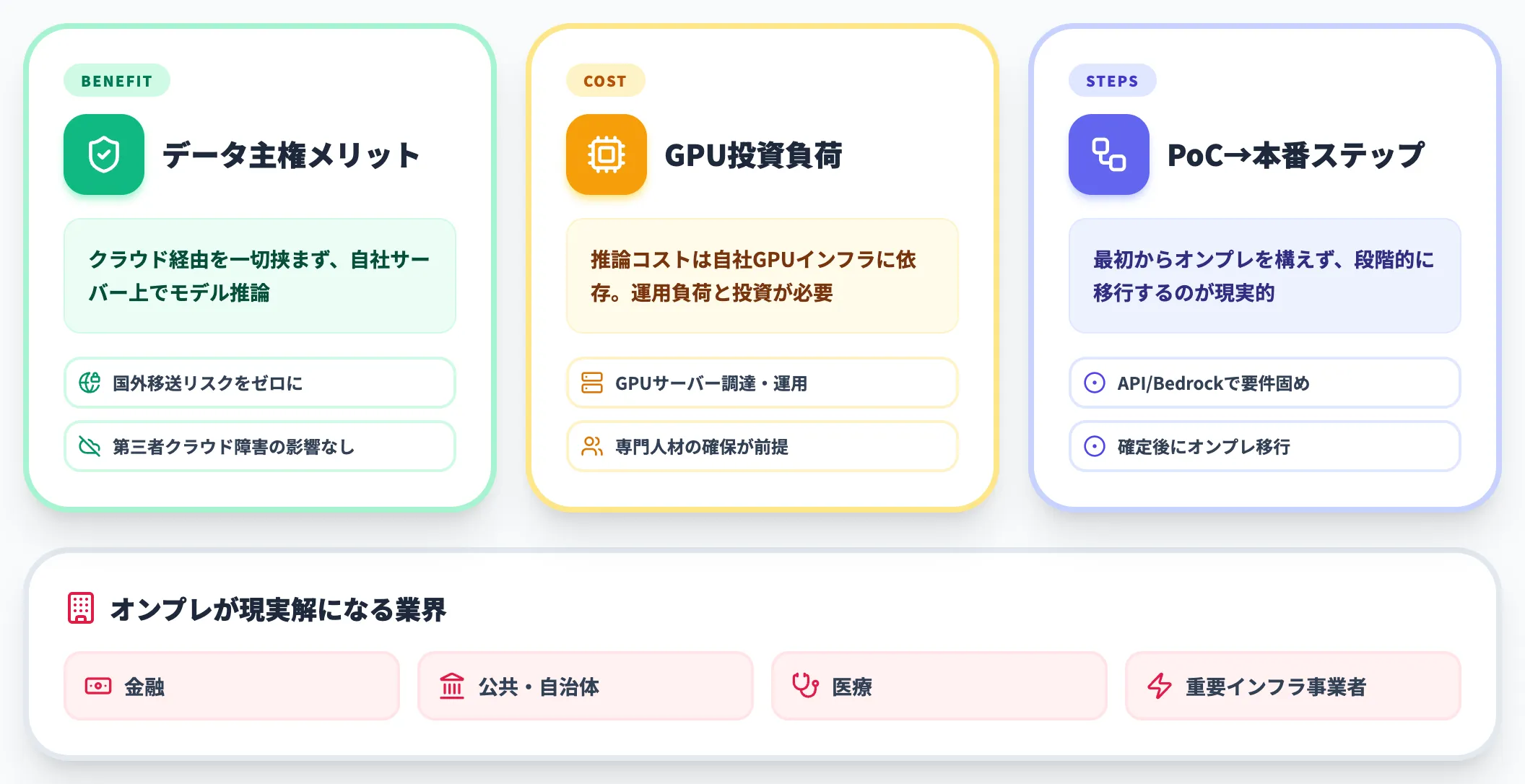
クラウドにデータを一切出せない金融・公共・医療セクター向けには、オンプレミス展開のオプションも用意されています。
自社サーバー上にモデルを配置するため、推論コストは自社のGPUインフラに依存しますが、データの国外移送リスクも、第三者クラウドベンダーの障害リスクも切り離せます。重要インフラ事業者や規制業界のCISOにとっては、データ主権の最終解として位置づけられます。
ただし、運用負荷とインフラ投資は決して小さくないため、まずクラウドAPIまたはBedrock経由でPoCを回し、要件が固まってからオンプレに移行するのが現実的なステップです。
国産LLMとしての位置——デジタル庁源内での評価検証と他モデルとの関係
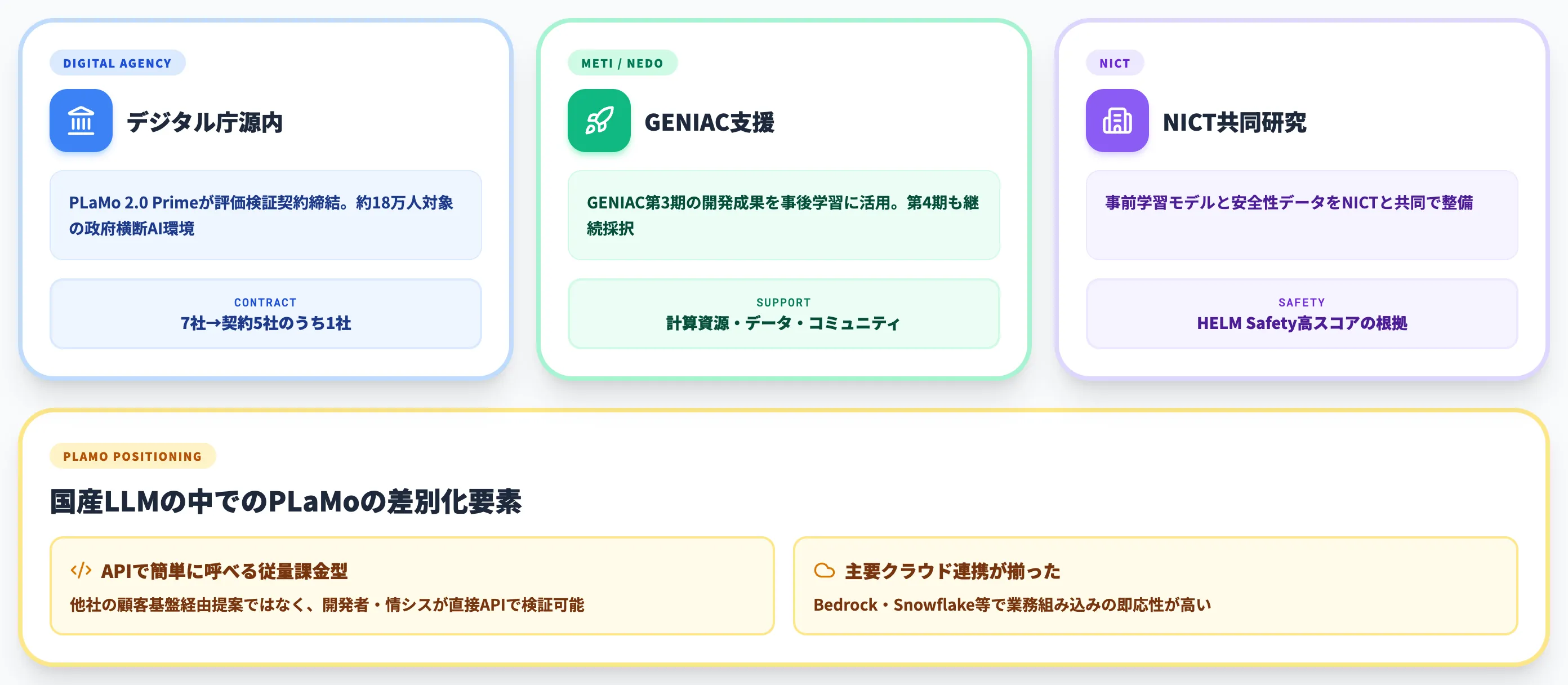
PLaMo 3.0 Primeを評価するうえで欠かせないのが、国産LLM全体の動きとデジタル庁ガバメントAI「源内」での採用文脈です。
PFNは政府主導の国産LLM選定で常に名前が挙がる主要プレイヤーで、その背景にあるGENIAC支援とNICT共同研究が、PLaMoの開発体制を支えています。前世代の「PLaMo 2.0 Prime」は2025年日経優秀製品・サービス賞 最優秀賞を受賞しており、国内テック領域でも継続的に評価が積み上がってきました。
デジタル庁源内の国内LLM選定

デジタル庁は2026年3月6日、政府向けAI基盤「源内(げんない)」で試用する国内LLMの公募結果を公表し、応募15件のうち7件を選定しました。PFNはこの7件の1つに「PLaMo 2.0 Prime」で選ばれており、源内で試用されるモデル群にPLaMoが含まれています。
源内は全府省庁職員(約18万人)を対象とした政府横断型の生成AI利用環境で、令和8年(2026年)8月から国内LLMの試用が開始され、令和9年(2027年)4月から優れたモデルを政府調達(有償)する予定です。
以下の表で、2026年3月6日時点で選定された7件の内訳を整理しました(五十音順)。
| 開発元 | モデル名 | 開発アプローチ |
|---|---|---|
| NTTデータ | tsuzumi 2 | フルスクラッチ |
| カスタマークラウド | CC Gov-LLM | — |
| KDDI・ELYZA共同 | Llama-3.1-ELYZA-JP-70B | 海外オープンモデル+日本語チューニング |
| ソフトバンク | Sarashina2 mini | フルスクラッチ |
| 日本電気 | cotomi v3 | フルスクラッチ |
| 富士通 | Takane 32B | フルスクラッチ |
| Preferred Networks | PLaMo 2.0 Prime | フルスクラッチ |
選定後の状況として、デジタル庁は2026年5月29日に評価検証契約を締結した5社を公表しました。当初の7社のうち2社が辞退し、最終的にNTTデータ・ソフトバンク・日本電気・富士通・Preferred Networksの5社が契約締結に至っています。
ソフトバンクは契約時点で「Sarashina3 mini」に更新、PFNは「PLaMo 2.0 Prime」で契約しており、本記事で扱うPLaMo 3.0 Primeは正式リリース後の後継モデルにあたります。源内での3.0 Primeの試用は、2026年8月以降の試用段階以降にPFN側から提供されるかが今後の焦点です。
GENIAC第3期成果の事後学習活用
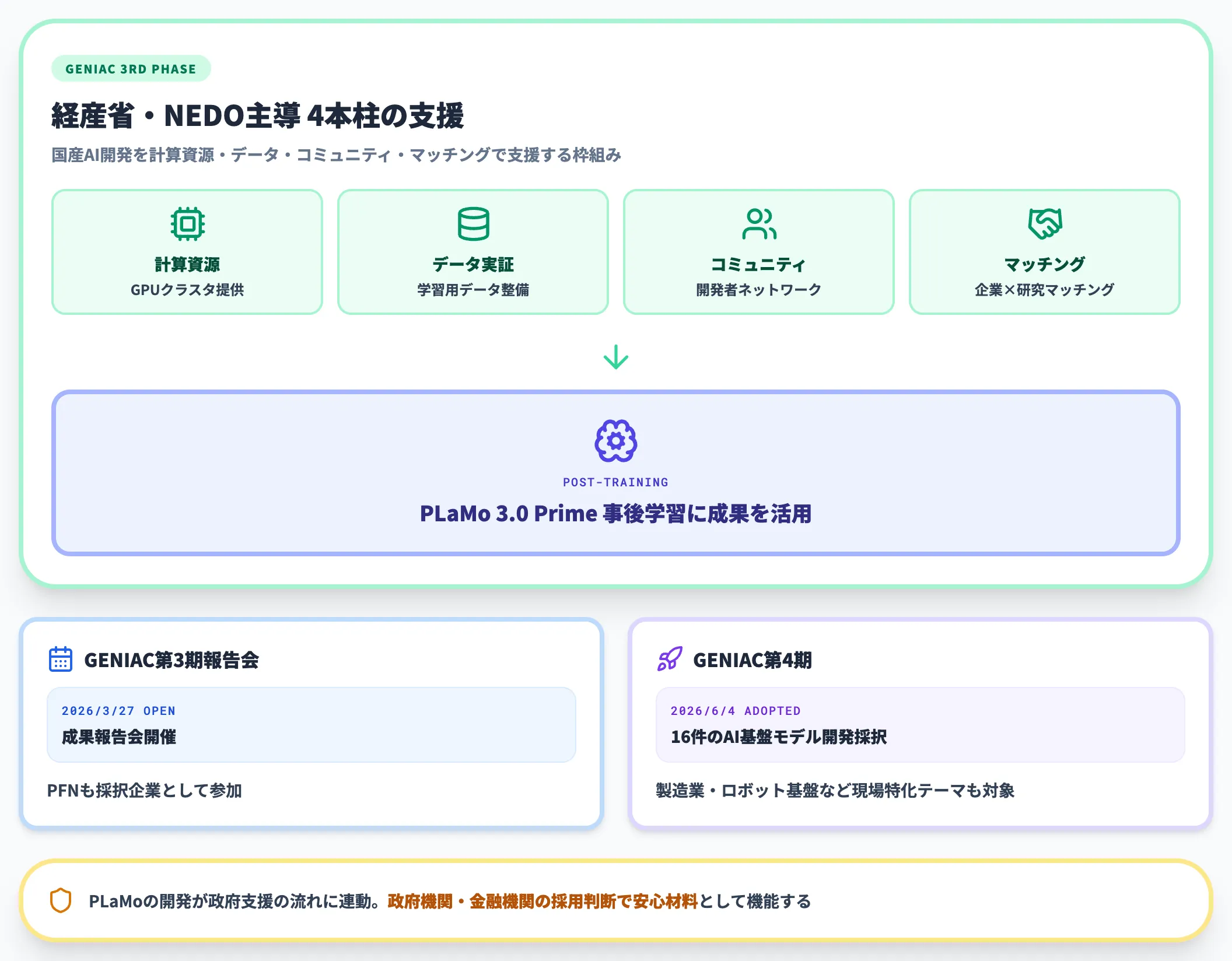
PLaMo 3.0 Primeは、経済産業省とNEDOが推進する生成AI開発力強化プロジェクト**GENIAC第3期の一部開発成果を事後学習に活用**しています。
GENIACは計算資源の提供・データ実証・コミュニティ形成・マッチングサービスの4本柱で国産AI開発を支援する枠組みで、第3期の成果報告会が2026年3月27日に開催され、PFNも採択企業として参加しました。
GENIAC第4期では、2026年6月4日にAI基盤モデル開発テーマ16件が新たに採択されています。
これに加えて、GENIAC全体としては製造業データのAI-Ready化やロボット基盤モデルといった現場特化型の研究開発テーマにも支援が広がっており、用途別の専門特化が進んでいます。
PLaMoの開発が政府支援の流れに連動して進んでいる点は、政府機関や金融機関の採用判断で安心材料として機能します。
NICT共同研究と安全性データの取り込み

PLaMo 3.0 Primeの事前学習モデルは、国立研究開発法人情報通信研究機構(NICT)との共同研究をベースに開発されています。
加えて、安全性向上のための学習データもNICTから提供を受けており、HELM Safetyベンチマークで海外モデルと同程度以上の安全性能を達成しています。日本の公的研究機関と組んで安全性データを整備している点は、コンテンツモデレーション要件が厳しい組織にとって重要な要素です。
他の国産LLMとの位置関係
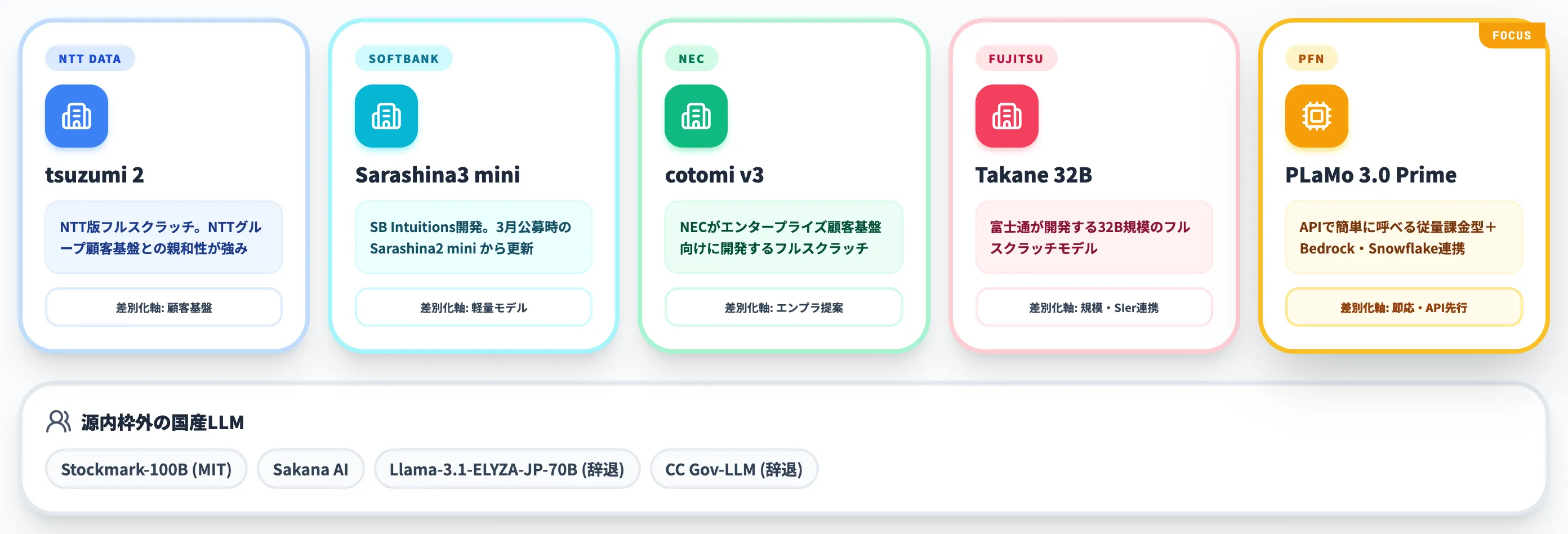
源内の評価検証契約に至った他の国産LLMと比較すると、PLaMoは以下のような位置づけにあります。
-
NTTデータ tsuzumi 2
NTT版のフルスクラッチLLM。NTTグループ顧客基盤との親和性が強み。
-
ソフトバンク Sarashina3 mini
SoftBankグループのSB Intuitionsが開発。3月公募時はSarashina2 miniだったが、5月29日の契約締結時点でSarashina3 miniに更新されている。
-
日本電気 cotomi v3
NECがエンタープライズ顧客基盤向けに開発するフルスクラッチモデル。
-
富士通 Takane 32B
富士通が開発する32B規模のフルスクラッチモデル。
源内には選定された後で辞退したKDDI・ELYZA共同応募体のLlama-3.1-ELYZA-JP-70B(Llamaベースの日本語チューニングモデル)やカスタマークラウドのCC Gov-LLMもあります。
源内枠外の国産LLMでは、Stockmark-100B(MITライセンスで公開された100Bオープンモデル)やSakana AIなど多様な開発体制のモデルが揃っています。
この中でPLaMoが取りに行っているポジションは、ω「APIで簡単に呼べる従量課金型」かつ「Bedrock・Snowflakeなど主要クラウド連携が揃った」という、業務組み込みの即応性です。
NTTデータや富士通のように顧客基盤からの提案で売る形ではなく、開発者・情シスが直接APIを叩いて検証できる経路が広いことが、PLaMoの実質的な差別化要素になっています。
PLaMoシリーズ自体も、商用フラッグシップのPLaMo Prime以外に、エッジデバイス向けに軽量化されたPLaMo Lite、金融知識を追加学習した金融特化型PLaMo、翻訳特化のPLaMo翻訳が用途別に揃っており、3.0 Primeはこのラインアップの最上位モデルにあたります。
標準搭載されているサービス群
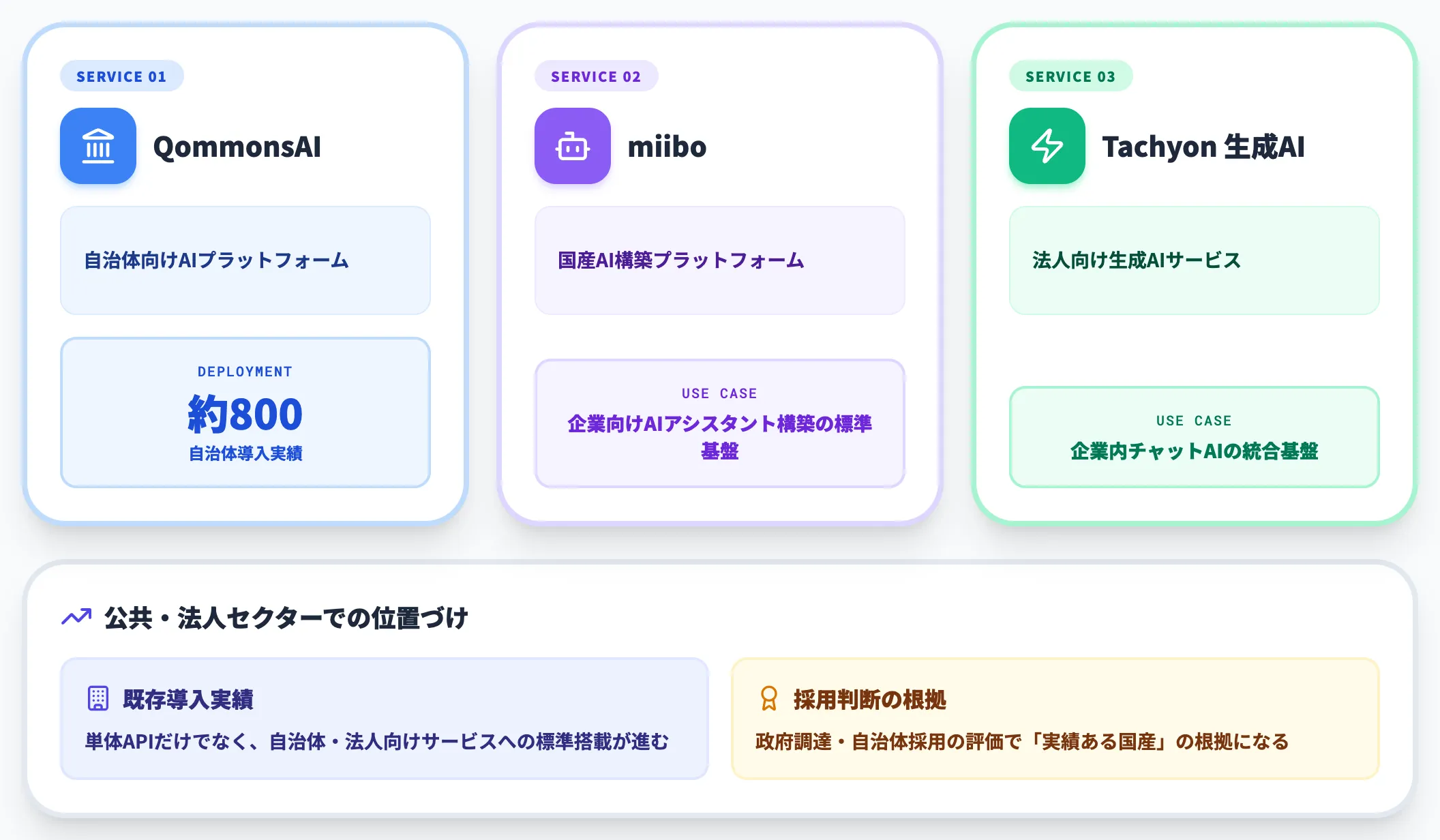
PLaMoは単体APIだけでなく、約800の自治体が導入するQommonsAI、国産AI構築プラットフォームmiibo、法人向け生成AIサービスTachyon 生成AIなどのサービスに標準搭載されています。
公共・自治体セクターで広く利用される基盤として既に実績を積み上げている点は、政府調達・自治体採用での評価につながる要素です。
企業がPLaMo 3.0 Primeをどう使うか——導入判断とハイブリッド運用
ç
PLaMo 3.0 Primeは「海外モデルの完全代替」を目指す位置取りではなく、ケースに応じて海外モデルと併用する「ハイブリッド運用」の前提で価値が出るモデルです。
ここからは、AI総研の支援現場で見えてきた導入判断の軸と、業務別の使い所を整理します。
ω
導入判断の3つの軸
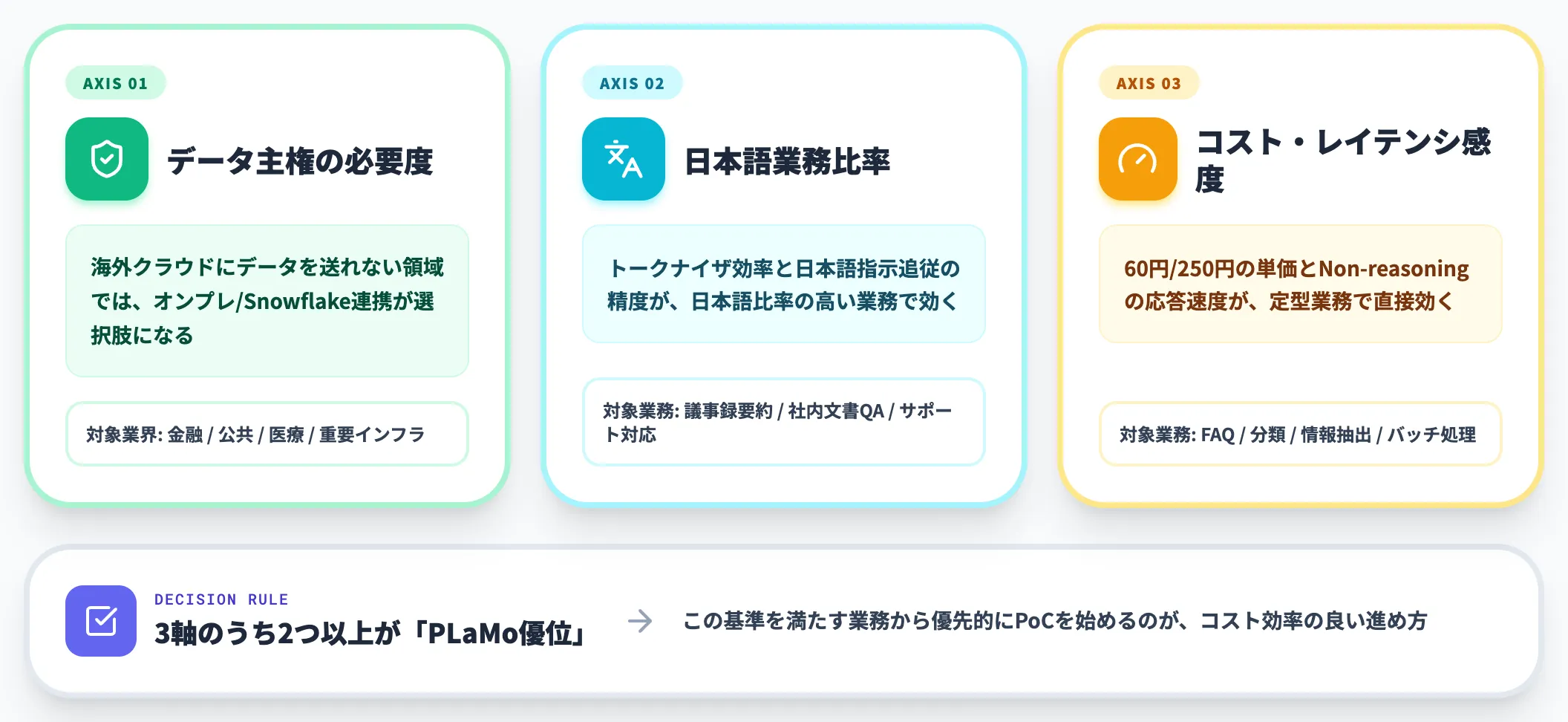
PLaMoを採用するかどうかは、以下の3つの軸で判断するのが現実的です。
-
データ主権の必要度
海外クラウドにデータを送れない金融・公共・医療セクターでは、オンプレミス展開かSnowflake連携が選択肢になる。PLaMoの第一の優位性。
-
業務に占める日本語比率
日本語テキストが大半の業務(社内文書要約・カスタマーサポート・議事録処理)では、独自トークナイザによるトークン効率と日本語指示追従の精度が効く。逆に英語中心の業務では海外モデル優位な領域も残る。
-
コストとレイテンシの感度
60円/250円の単価と、Non-reasoningモデルの応答速度を活かせる定型業務(FAQ・分類・情報抽出)は、PLaMoの強みが直接効く。複雑な数学推論やWeb探索が必要な業務は、Claude Opus 4.7・GPT-5.5系などフロンティアモデル併用が現実解。
この3軸のうち2つ以上で「PLaMo優位」と判断できる業務から、優先的にPoCを始めるのがコスト効率の良い進め方です。
業務領域別の使い所
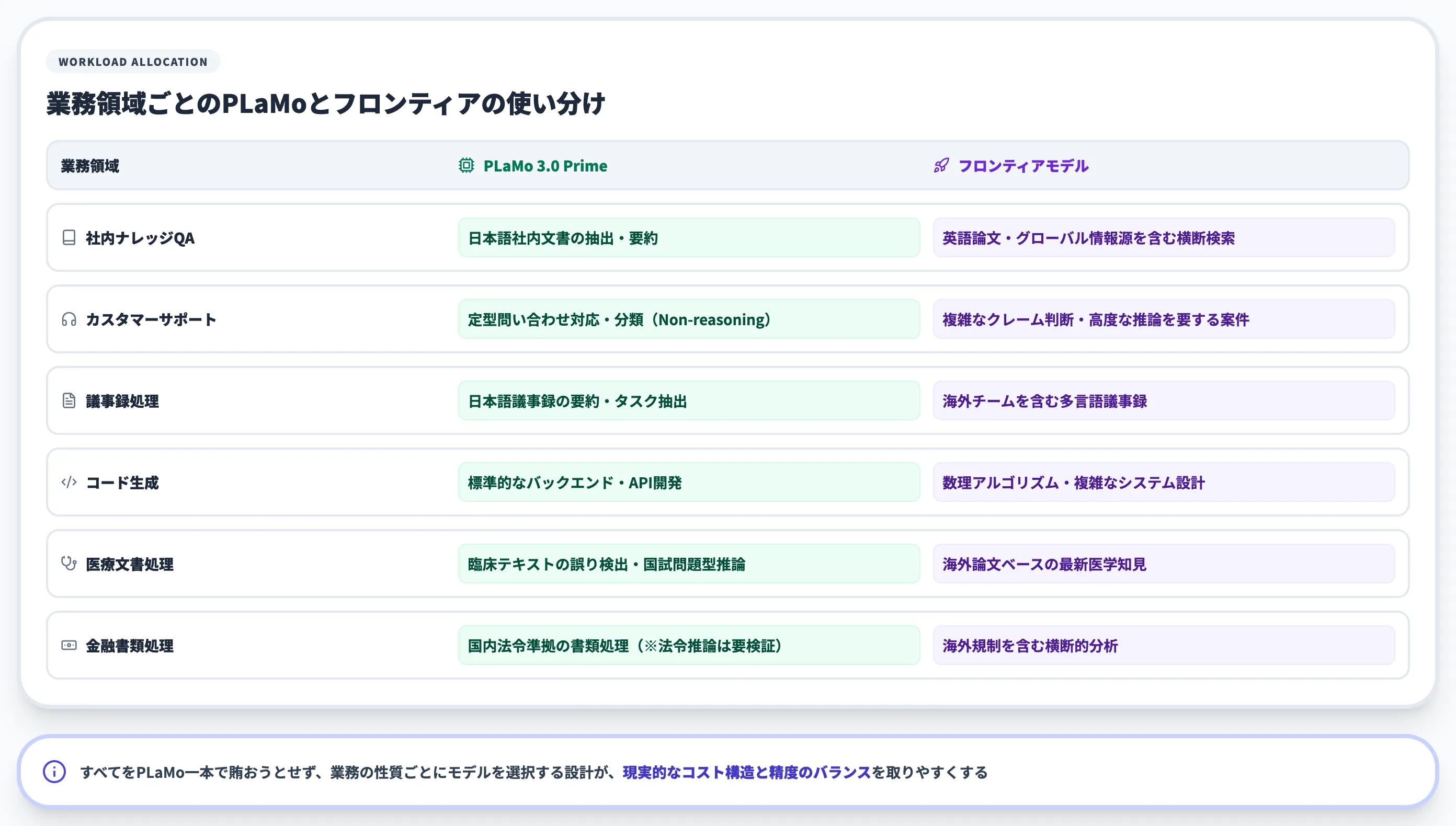
業務領域ごとに、PLaMoとフロンティアモデルの使い分け例を以下の表で整理しました。
| 業務領域 | PLaMo 3.0 Primeを使う場面 | フロンティアモデルを使う場面 |
|---|---|---|
| 社内ナレッジQA | 日本語社内文書からの抽出・要約 | 英語論文・グローバル情報源を含む横断検索 |
| カスタマーサポート | 定型問い合わせ対応・分類(Non-reasoning) | 複雑なクレーム判断・高度な推論を要する案件 |
| 議事録処理 | 日本語議事録の要約・タスク抽出 | 海外チームを含む多言語議事録 |
| コード生成 | 標準的なバックエンド・API開発 | 数理アルゴリズム・複雑なシステム設計 |
| 医療文書処理 | 臨床テキストの誤り検出・国試問題型推論 | 海外論文ベースの最新医学知見 |
| 金融書類処理 | 国内法令準拠の書類処理(※法令推論は要検証) | 海外規制を含む横断的分析 |
すべての業務をPLaMo一本で賄おうとせず、業務の性質ごとにモデルを選択する設計が、現実的なコスト構造と精度のバランスを取りやすくなります。
導入時に注意したい3つの論点

実際にPLaMoを業務に組み込む際、選定段階で詰まりやすい論点が3つあります。
-
parallel function callingが必要なエージェント設計
複数ツールの並列呼び出しを前提にしたエージェントハーネスは、PLaMoでそのまま動かない。逐次実行で組み直すか、並列が必要な部分だけ他モデルを使う設計を検討する必要がある。
-
日本法令タスクの精度確認
lawqa_jpのベンチマーク結果ではPLaMoは海外モデルに劣後している。「日本語LLMだから法令にも強いはず」と前提を置かず、自社の法令タスクで必ず比較検証してから運用に乗せる。
-
非推論モデルのセーフガード挙動
Non-reasoningモデルはXSTest系の過剰拒否やHarmBench系のすり抜けが残るカテゴリがある。コンプライアンス要件の厳しい業務では、出力ログをモニタリングする運用設計が前提になる。
これらは「とりあえずAPIを叩いて動いた」段階では見えてこない論点で、PoCの設計段階で評価項目に組み込んでおくと、本番展開で詰まる確率を大きく下げられます。
ハイブリッド運用の現実解
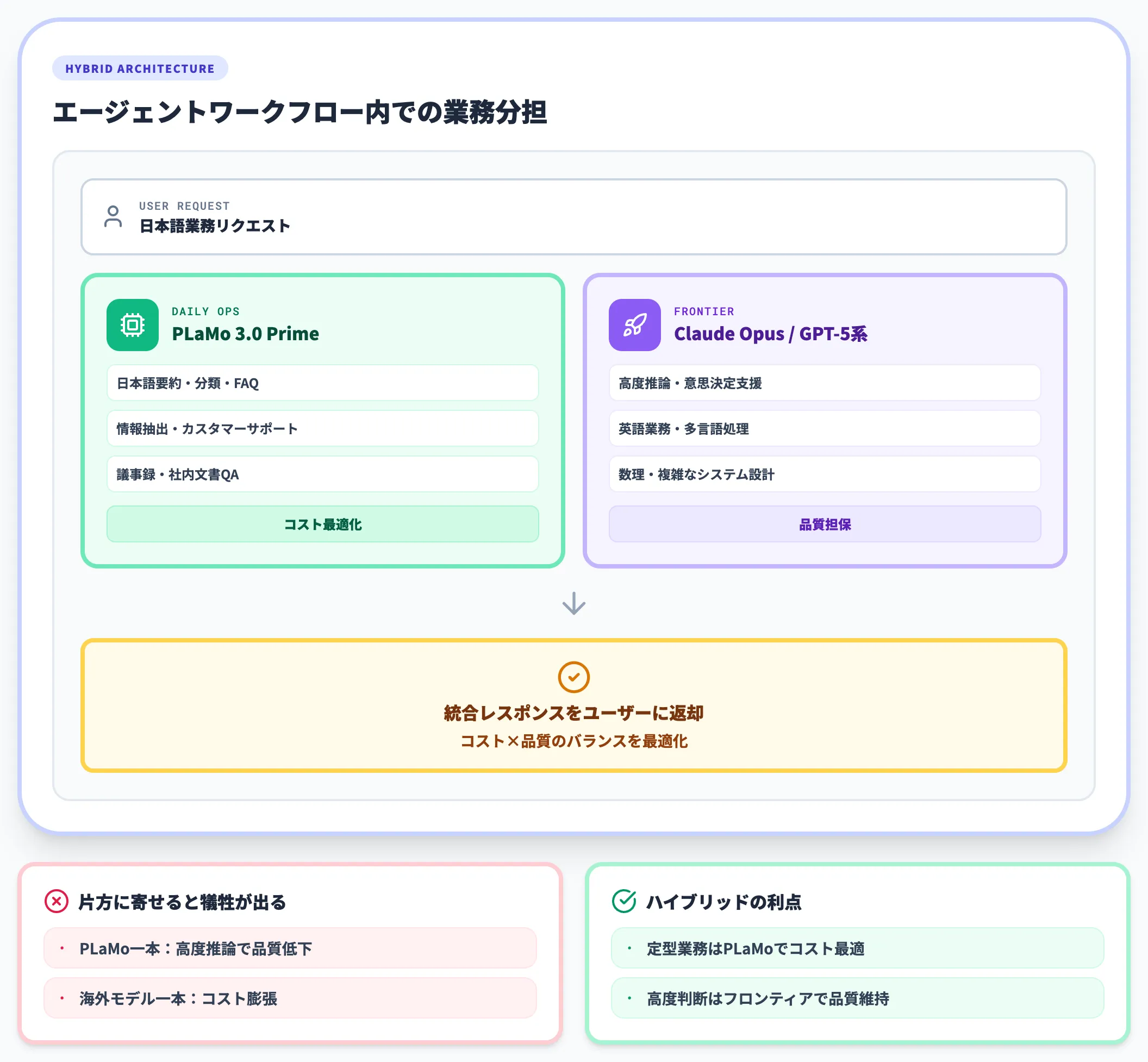
AI総研の支援現場では、「日本語業務の標準処理はPLaMo、高度推論や英語・多言語業務はClaude Opus/GPT-5系」のハイブリッド構成を採用するケースが増えています。
理由は単純で、片方に寄せると性能かコストのどちらかが必ず犠牲になるためです。Non-reasoningモデルでさばける定型業務は徹底的にPLaMoに寄せてコストを下げ、複雑な意思決定や英語業務はフロンティアモデルに任せて品質を担保する
。この使い分けが、エンタープライズで生成AIを継続運用するうえでの現実的な落とし所になっています。

国産LLMを業務に組み込むなら、運用設計から先に整える
PLaMo 3.0 PrimeのようにAPIで簡単に呼べる国産LLMが揃ってきたいま、技術的なハードルは大きく下がりました。
一方で、企業側で問われているのは「どの業務に・どのモデルを・どう統制して当てるか」という運用設計です。モデル選定だけで終わらせず、PoC設計・部門展開・セキュリティ統制まで一貫した計画を持つかどうかが、生成AI活用の成否を分けます。
国産LLMを業務に組み込む前に整えておきたい運用設計

PoCから全社展開まで220ページで整理
PLaMo 3.0 PrimeのようにAPIで簡単に呼べる国産LLMが揃ってきたいま、企業側で問われるのは「どの業務に・どのモデルを・どう統制して当てるか」の設計です。AI業務自動化ガイドでは、PoC段階から全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、Preferred Networksが2026年6月22日に正式リリースしたPLaMo 3.0 Primeについて、技術仕様・ベンチマーク・2モデル使い分け・料金プラン・提供チャネル・国産LLMでの位置・企業の導入判断までを、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
PLaMo 3.0 PrimeはPFNが国内でフルスクラッチ開発した最新フラッグシップで、Reasoning/Non-reasoningの2モデルを用途で使い分けられる。事前学習からトークナイザまで自社管理下にあり、データ主権と日本語業務最適化を両立する設計
-
技術仕様は256Kコンテキスト・構造化出力・OpenAI互換Tool calling・独自トークナイザ。parallel function callingは未対応のため、エージェント設計では逐次実行を前提に組む必要がある
-
ベンチマークでは日本語指示追従・医療・コード生成・安全性で同価格帯モデルと互角以上、Web探索・長コンテキスト深堀り・数学・日本法令はまだ海外モデル優位。用途ごとの強み弱みを把握したうえで採用判断する
-
Standardプランは入力60円・出力250円(1Mトークン)で、Claude Haiku 4.5・GPT-5.4 Miniと同価格帯を狙う設計。2026年7月31日まで新規登録で1000万トークン相当のクレジット付与
-
PLaMo Chat・API・Amazon Bedrock・Snowflake・オンプレミスの5チャネルで提供され、データ主権の必要度・既存クラウド契約・コスト感度で経路を選定できる
-
デジタル庁源内では前世代の「PLaMo 2.0 Prime」が評価検証契約済みで、PLaMo 3.0 Primeはその後継として正式リリース。GENIAC第3期成果とNICT共同研究を基盤に開発され、約800自治体導入のQommonsAIなどに標準搭載され、公共・自治体セクターで実績を積み上げ
-
企業導入の現実解はハイブリッド運用。日本語標準業務はPLaMo、高度推論・英語業務はClaude OpusやGPT-5系といった使い分けで、コストと品質のバランスを取る設計が定着しつつある
2026年は、国産LLMが「政府調達の評価対象」から「企業の標準業務に組み込める実用基盤」へ移行する転換点に当たります。PLaMo 3.0 Primeは、その移行を象徴する最新フラッグシップとして、業務での実装検討に値するモデルです。データ主権・日本語業務・コスト構造のどれか1つでも自社にとって重要な軸であれば、Freeプランの提供開始またはStandardプランの新規登録キャンペーンを起点に、PoCから検証を始める価値があります。










