この記事のポイント
 国産AIは「フルスクラッチ純国産」「海外OSSベース」「海外モデル+自社チューニング」の3路線で進化、用途別に最適解が分かれる
国産AIは「フルスクラッチ純国産」「海外OSSベース」「海外モデル+自社チューニング」の3路線で進化、用途別に最適解が分かれる- デジタル庁ガバメントAI「源内」が2026年3月に7モデルを選定、2027年4月以降に有償の政府調達を予定
- PLaMo APIは低単価が特徴、tsuzumi 2は1GPU動作でオンプレ運用が現実的
- データ主権・オンプレ要件が必須の業務は国産優先、汎用推論は海外モデル併用のハイブリッド運用が現実解
- 自治体導入率は指定都市90%・都道府県87.2%、横須賀市は国保データ突合を2時間から10分に短縮した

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
国産AIとは、日本企業が開発する生成AI・大規模言語モデルの総称で、データ主権・日本語精度・国内サポートを軸に企業や行政の選択肢になっています。
2026年はデジタル庁ガバメントAI「源内」の7モデル選定、政府の大規模AI支援構想、PLaMo 3.0 Primeリリースなど節目が連続しました。
本記事では国産AIの定義・主要モデル・料金・選び方・事例・海外モデルとのハイブリッド運用までを2026年6月時点で解説します。
目次
日本政府の国産AI支援策——AI基本計画・GENIAC・1兆円ファンド
Preferred Networks PLaMo 2.0 Prime(源内選定)
KDDI・ELYZA Llama-3.1-ELYZA-JP-70B
PLaMo 3.0 Prime——スタンダード/フリー/プロバイダプラン
提供形態——API/オンプレ/Bedrock Marketplace経由
自治体——横須賀市・泉大津市・150超自治体のPLaMo展開
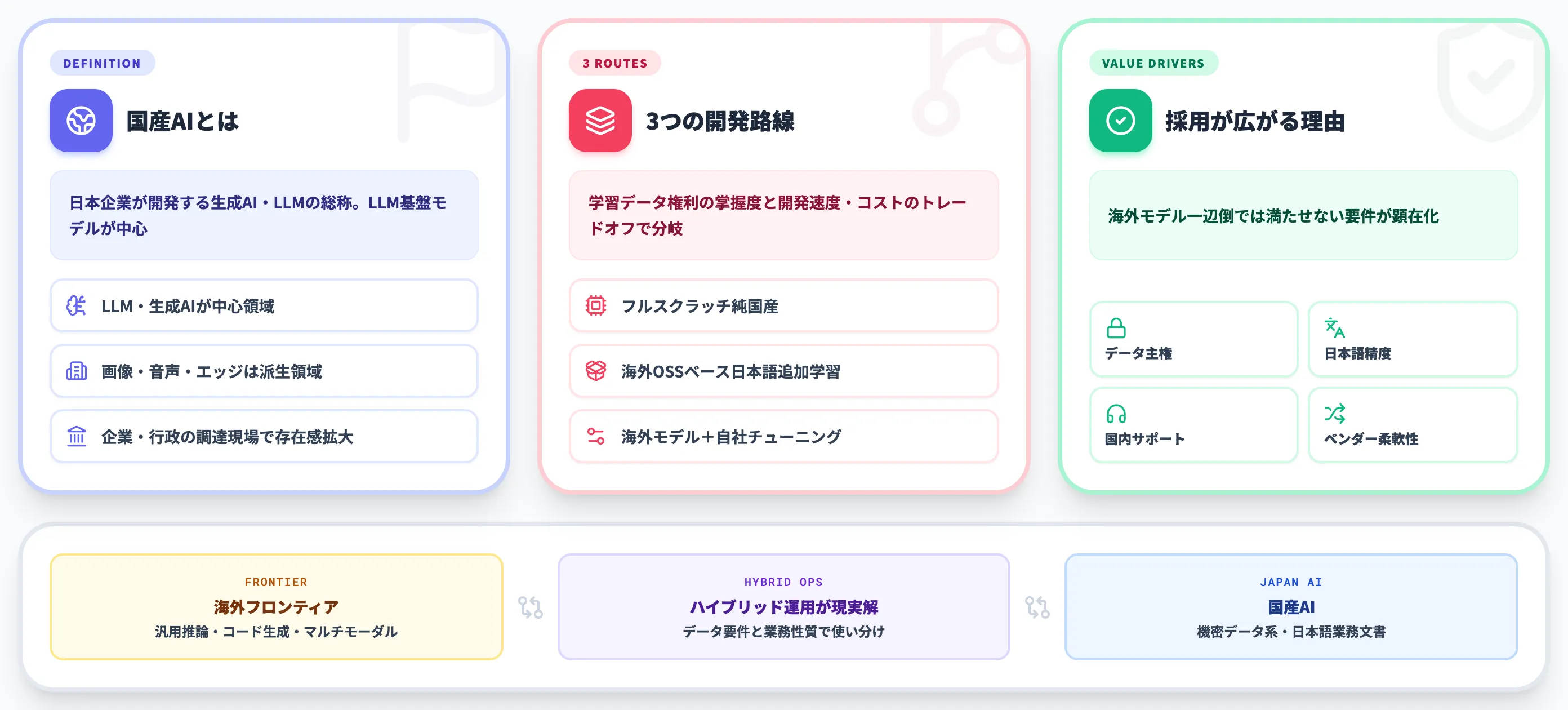
国産AIとは——日本企業が開発する生成AI/LLMの全体像
国産AIとは、日本企業が開発する生成AI・大規模言語モデル(LLM)の総称です。
2026年時点で「国産AI」という言葉は、主にLLM・生成AIを中心とした基盤モデルを指すケースが多く、画像・音声・エッジ系のAIは派生領域として扱われる傾向にあります。
国産AIが選択肢として急速に存在感を増しているのは、データ主権・日本語精度・国内サポート・ベンダー柔軟性といった、海外モデル一辺倒では満たせない要件が企業や行政の調達現場で顕在化してきたためです。

国産AIの3つの開発路線
国産AIは開発アプローチで大きく3つの路線に分かれます。

以下の表で、3つの路線の特徴と代表的なモデルを整理しました。
| 路線 | 特徴 | 代表モデル |
|---|---|---|
| フルスクラッチ純国産 | 学習データ・モデル構造を一から自社で構築。データ権利を完全に掌握できる | NTT tsuzumi 2、PFN PLaMo 2.0/3.0 Prime、SoftBank Sarashina |
| 海外OSSベース日本語追加学習 | Meta Llama / Alibaba Qwen等のオープンモデルを日本語データで追加学習。開発スピードと性能のバランス重視 | KDDI・ELYZA Llama-3.1-ELYZA-JP-70B、ELYZA Shortcut-1.0-Qwen-32B |
| 海外モデル+自社チューニング | Cohere・Anthropic等の商用モデルをライセンス取得し、自社の蒸留・量子化技術で最適化 | 富士通 Takane 32B(Cohere Command R+ベース) |
3路線のどれを選ぶかは、学習データ権利の掌握度と開発速度・コストのトレードオフになります。
フルスクラッチ純国産は権利面・データ主権面で最も強い一方、開発に長期間と巨額の計算資源を要します。
海外OSSベース路線は短期で高性能モデルを市場投入できる代わりに、ベース提供元の方針変更(ライセンス変更・モデル廃止)の影響を完全には排除できません。
「国産」と呼ぶ範囲——海外OSSの日本語追加学習も含むか
国産AIの議論では、「海外モデルの日本語ファインチューンを国産と呼んでよいか」が論点になります。
明確な業界定義はありませんが、現場の感覚としては、日本国内で運用主体が完結しデータを海外に出さない仕組みを国産AIの最低条件とする見方が広がっています。
この基準で見ると、KDDI・ELYZAの「Llama-3.1-ELYZA-JP-70B」のように、ベースはMeta Llamaでも追加学習・運用・データ管理が日本国内で行われるモデルは国産AIの範囲に含めて議論されることが一般的です。
実際、デジタル庁が2026年3月にガバメントAI「源内」で選定した7モデルにも、Llama-3.1-ELYZA-JP-70BやCohere Command R+ベースのTakaneが含まれており、政府の調達基準でも「海外ベース+日本国内運用」を国産扱いしているのが現状です。
日本政府の国産AI支援策——AI基本計画・GENIAC・1兆円ファンド
国産AIの市場拡大は、企業の自助努力だけでなく政府の支援策によって強く後押しされています。
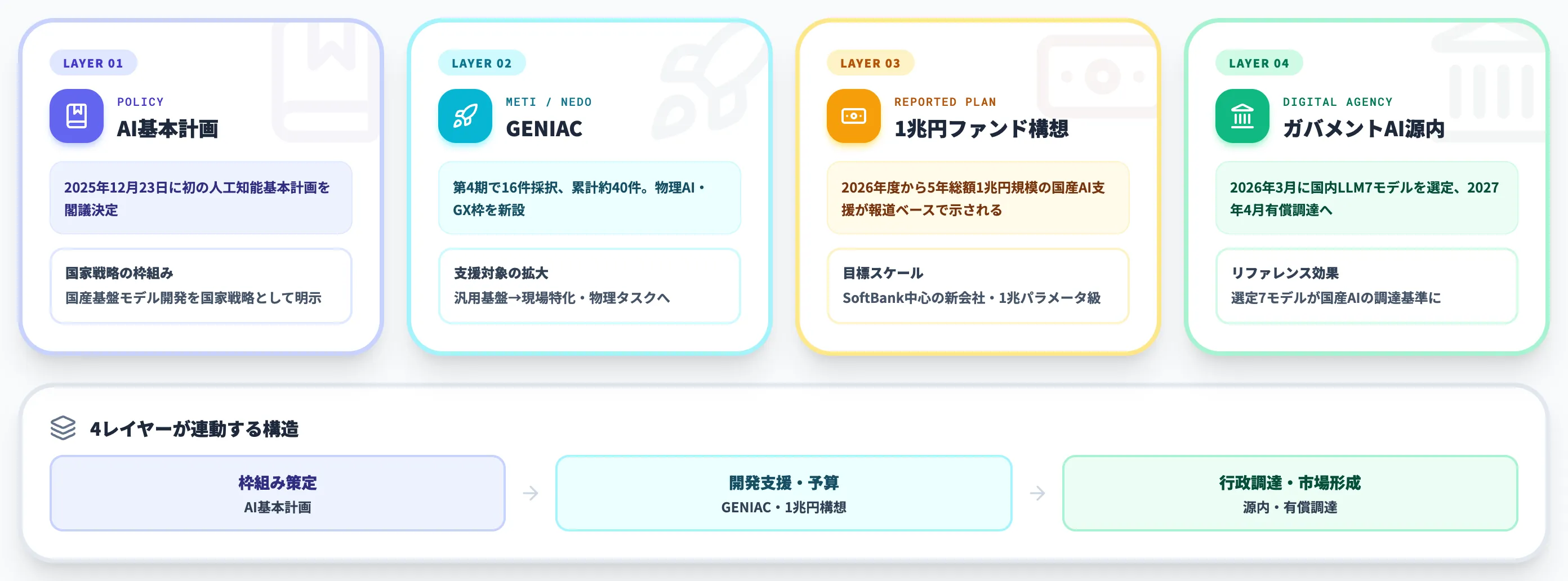
2025年12月の「AI基本計画」閣議決定以降、政策レイヤーで複数の意思決定が連続しており、2026年6月時点で4つのレイヤーを押さえておく必要があります。
AI基本計画の4本柱

日本政府は2025年12月23日に、初の人工知能基本計画を閣議決定しました。
掲げられたのは「信頼できるAI」による「日本再起」というキャッチで、4つの基本方針が示されています。
-
利活用の加速的推進
医療・ライフサイエンス・金融・行政など重点分野でのAI社会実装を後押し
-
開発力の戦略的強化
フィジカルAIに不可欠な信頼できる国産の汎用基盤モデル開発を強調
-
信頼性の向上
セキュリティ・プライバシー・倫理など「信頼できるAI」の品質要件を明示
-
社会の継続的変革
質の高い産業データを日本の競争力の中核に位置づける
これまでの日本のAI政策は分野別ガイドラインの積み上げが中心でしたが、AI基本計画は国産基盤モデル開発を国家戦略として明示した最初の包括的計画です。
2026年以降の経産省・デジタル庁の各種施策は、この基本計画の枠組みのもとで設計されています。
GENIACプロジェクト——第4期16件採択まで

GENIAC(Generative AI Accelerator Challenge)は、経済産業省とNEDOが2024年2月に開始した国産生成AI開発支援プログラムです。
計算資源確保・データ整備・知見共有の3本柱で、国産モデルの開発を加速する設計になっています。
2025年7月にキックオフした第3期では、楽天グループ・野村総合研究所など13件を新規採択し、累計24件まで拡大しました。
2026年6月4日には第4期として16件が新規採択され、ABEJA・Direava・DubGuild・Preferred Networks・メルカリ・Sansan・Specteeなど、領域特化型LLMの開発企業が並んでいます。
第4期ではPhysical AI(自動運転・ドローン・多用途ロボット)への展開とGX枠(脱炭素×経済成長)が新設され、汎用基盤モデルから現場特化型・物理タスク対応モデルへと支援対象が広がっています。
1兆円ファンドとSoftBank中心の新会社構想

ビジネス+IT・Diamond Onlineなどの報道では、2026年度から5年総額1兆円規模の国産AI支援が始まる構想が示されており、AI基本計画を裏付ける最大級の予算枠として注目されています。
経産省はAI関連経費として2026年度予算案に大規模な計上を行う方向と報じられており、ラピダス支援・ソフトバンク中心の新会社・鴻海のAIサーバー計画を主軸とする構造が見えてきています。
報道ベースの構想では、新会社にソフトバンク・Preferred Networks・NEC・Honda・Sonyなど複数企業の技術者が参画し、国内最大級の1兆パラメータクラス基盤モデルの開発が目標とされています。
これは現在の国産フラッグシップ(PLaMo 100B級、Sarashina 460B級)から一段上のスケールであり、米中フロンティアモデルとのギャップを埋めることを直接の狙いとしています。一次情報として確定しているのはAI基本計画とGENIAC第4期採択で、新会社・1兆円ファンドの具体額は今後の予算成立を待つ段階です。
ガバメントAI「源内」が示すスケジュール
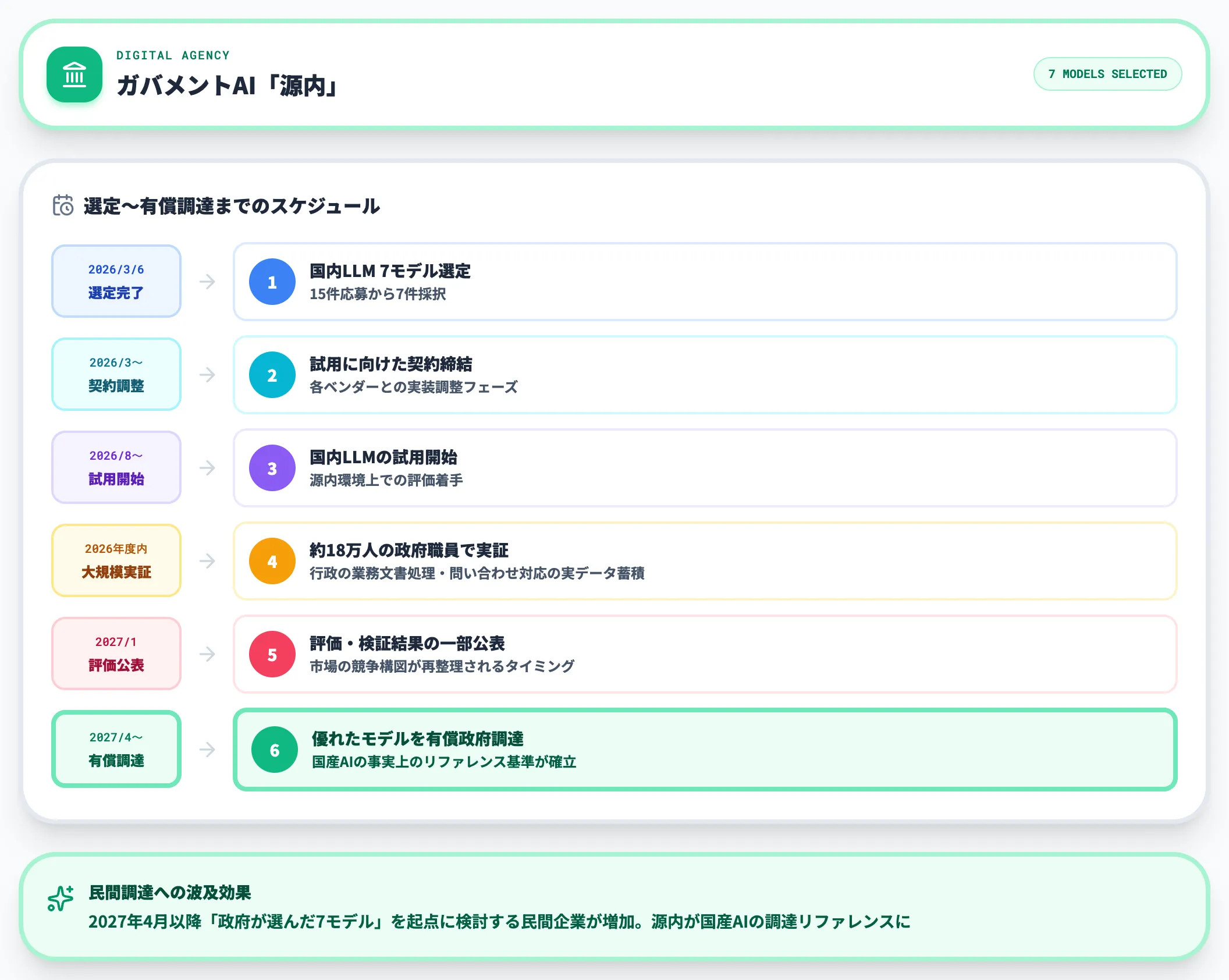
デジタル庁のガバメントAI「源内」は、2026年3月6日に試用国内LLM7モデルを選定しました。
以下の表で、選定スケジュールを整理しました。
| 時期 | 内容 |
|---|---|
| 2026年3月6日 | 国内LLM7モデル選定(15件応募) |
| 2026年3月〜 | 試用に向けた契約締結・調整 |
| 2026年8月〜 | 源内における国内LLMの試用開始 |
| 2026年度内 | 約18万人の政府職員を対象とした実証 |
| 2027年1月頃 | 評価・検証結果(一部)の公表 |
| 2027年4月〜 | 優れたモデルをガバメントAIとして有償政府調達を予定 |
注目すべきは、源内の有償調達が予定される2027年4月以降、選定モデルが国産AIの事実上のリファレンス基準になる可能性が高い点です。
民間企業の調達担当者も「政府が選んだ7モデル」を起点に検討する流れが2026〜2027年にかけて強まると見られます。
主要な国産LLM——源内選定7モデルを中心に
ここからは、国産AI市場の主要プレイヤーを源内選定7モデルを中心に解説します。
各モデルは開発路線・パラメータ規模・提供形態が大きく異なるため、用途別の最適解は1モデルに収斂しません。
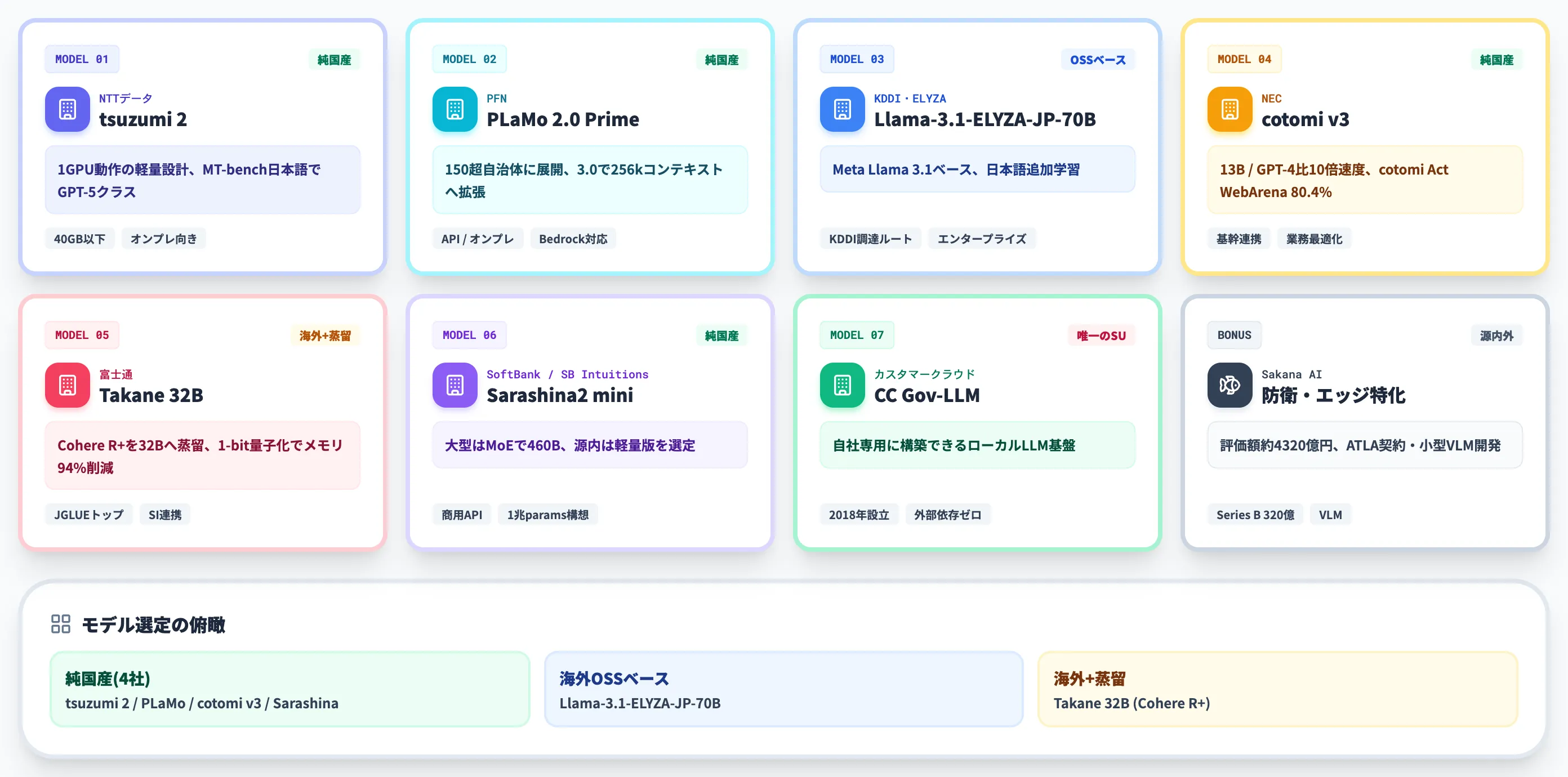
NTTデータ tsuzumi 2
tsuzumi 2はNTTグループが完全フルスクラッチで開発した純国産LLMで、2025年に第2世代がリリースされました。
最大の特徴は、40GB以下のメモリを持つ1台のGPUで動作する軽量設計でありながら、MT-bench(日本語)でGPT-5クラスのスコアを記録している点です。
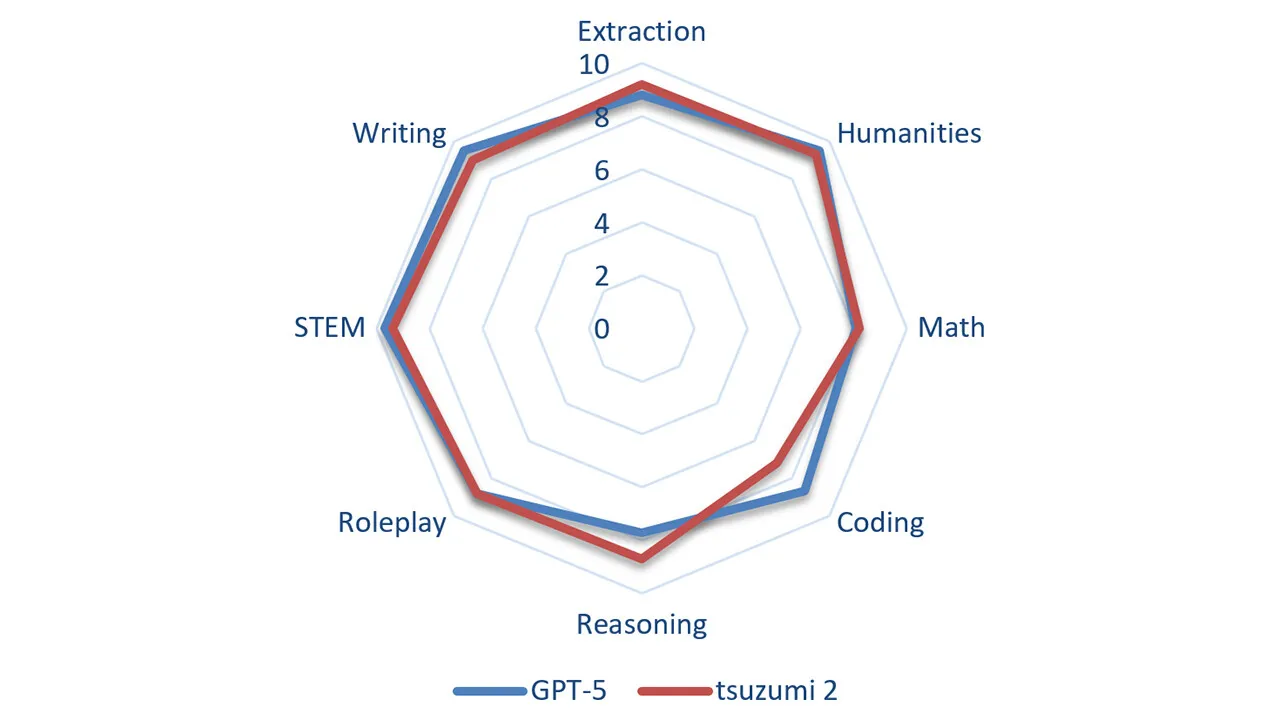
tsuzumi 2とGPT-5のMT-bench(日本語)8カテゴリ比較(出典:NTT R&D)

NTT公式のレーダーチャートでは、Extraction・Humanities・Math・Coding・Reasoning・Roleplay・STEM・Writingの8カテゴリでtsuzumi 2(赤)とGPT-5(青)がほぼ重なる軌跡を示しており、Codingでわずかに差が残るものの、業務寄りタスクでは横並びの性能水準が読み取れます。
業務文書のQA・情報抽出・要約のような実務タスクで大幅な性能向上が確認されており、JSON形式のような構造化出力にも対応します。
学習データを他社の事前学習モデルに依存しないため、学習データの権利関係を完全に管理できるのが純国産フルスクラッチの強みです。提供形態は法人向け個別契約が中心で、オンプレミス運用も現実的な選択肢となっています。
Preferred Networks PLaMo 2.0 Prime(源内選定)
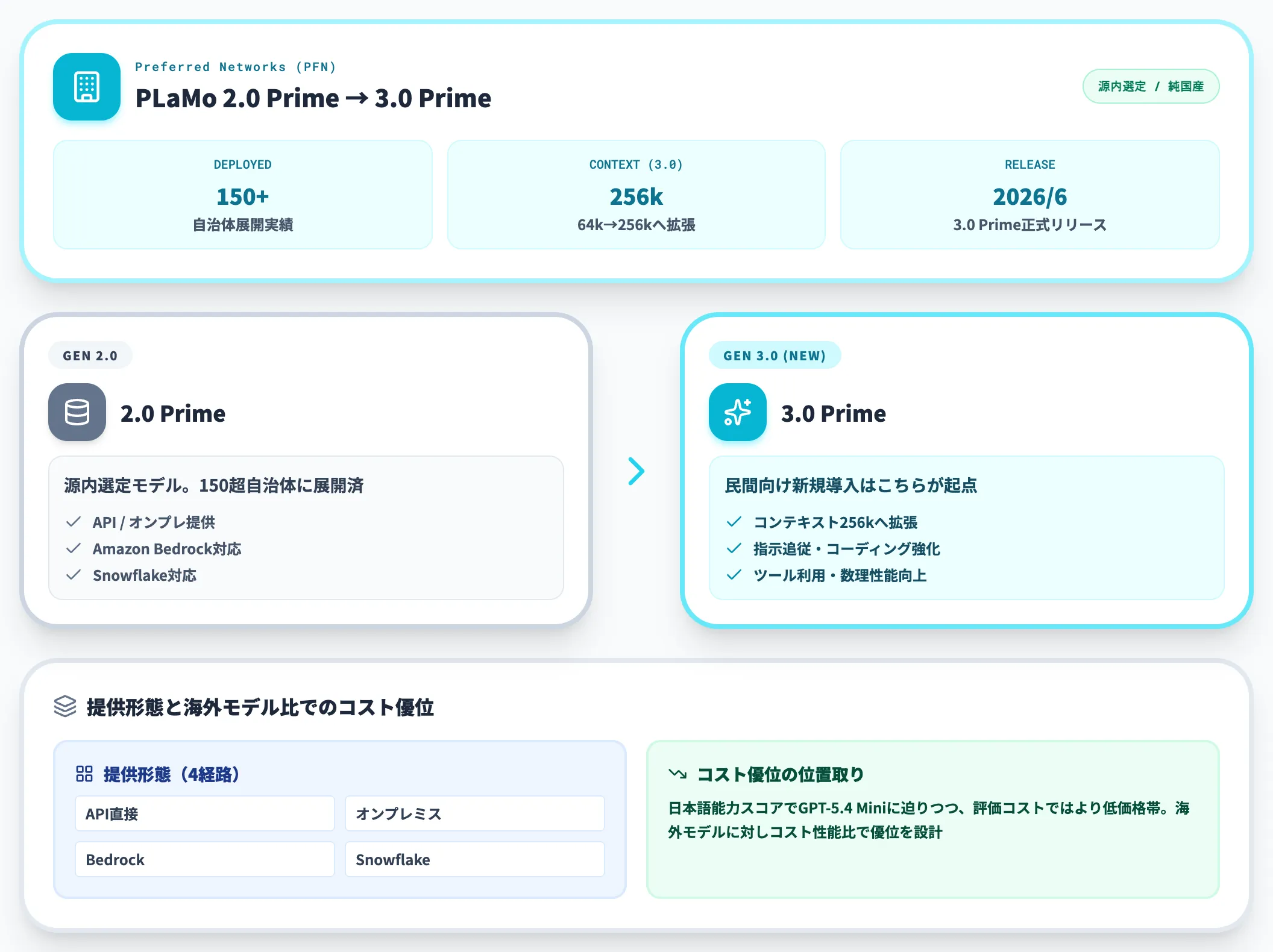
Preferred Networks(PFN)の子会社Preferred Elementsが開発するフルスクラッチ純国産モデル「PLaMo 2.0 Prime」が、デジタル庁源内に選定されています。
PFNはPLaMo 2.0 Primeで150を超える自治体への展開実績を持ち、提供形態はAPI経由・オンプレミス・Amazon Bedrock Marketplace・Snowflakeに対応しており、利用シーンに応じた選択が可能です。
加えて2026年6月22日には、源内選定後の新世代としてPLaMo 3.0 Primeが正式リリースされました。コンテキスト長を64kから256kに拡張し、日本語の指示追従性、コーディング、ツール利用、複雑な指示への対応、数理・アルゴリズム問題への対応力が強化されています。
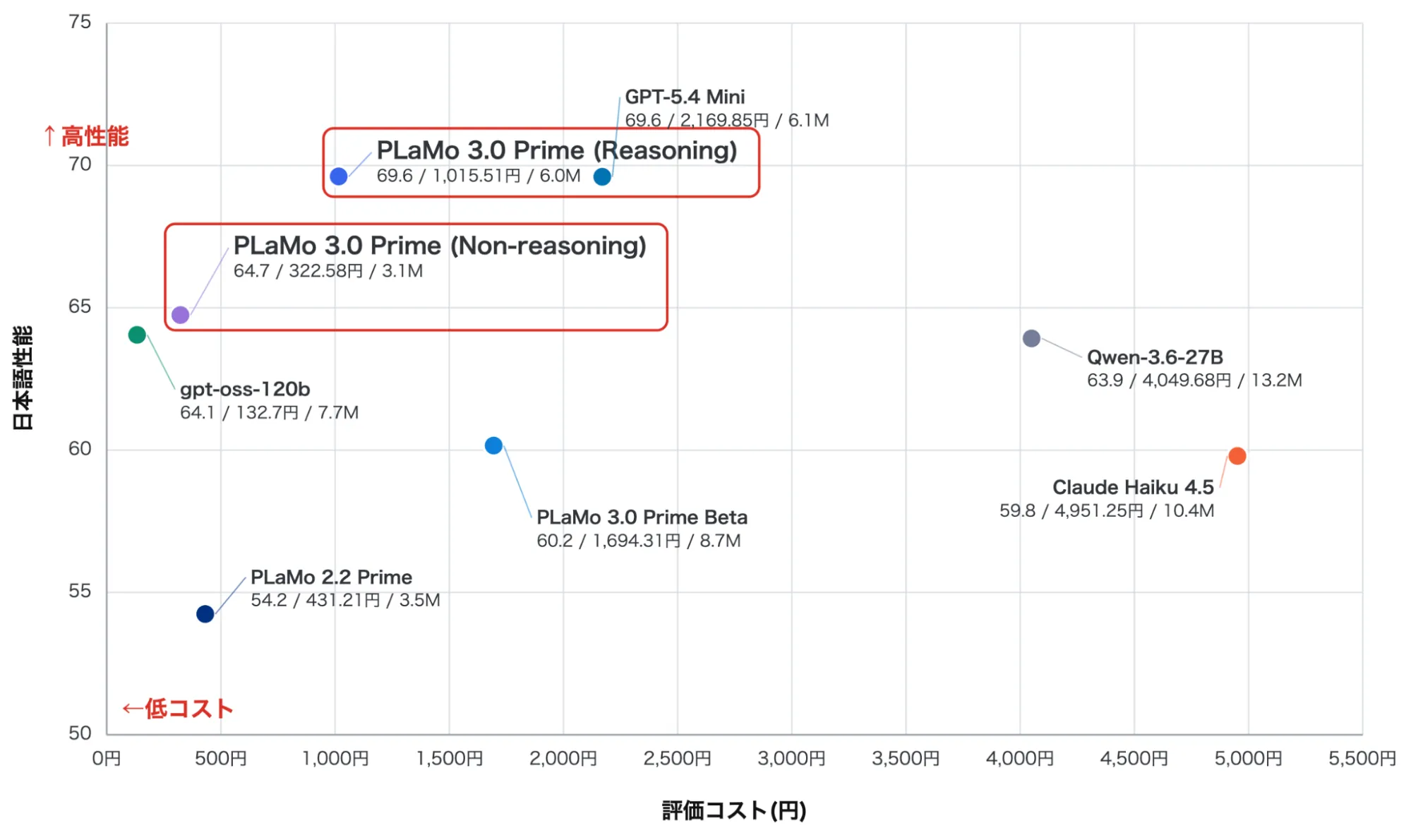
PLaMo 3.0 Primeと各種モデルの日本語性能・評価コスト比較(出典:PFN Tech Blog)
PFN公式の散布図では、縦軸の日本語能力スコアでPLaMo 3.0 Prime(Reasoning)がGPT-5.4 Miniに迫りつつ、横軸の評価コストではGPT-5.4 Miniより低価格帯に位置しています。海外フロンティアモデルに対しコスト性能比で優位を取りに行く設計が明確に表れています。
源内の評価フェーズでは2.0 Prime、民間向け新規導入では3.0 Primeを選ぶといった世代の使い分けが、当面の論点になります。
KDDI・ELYZA Llama-3.1-ELYZA-JP-70B
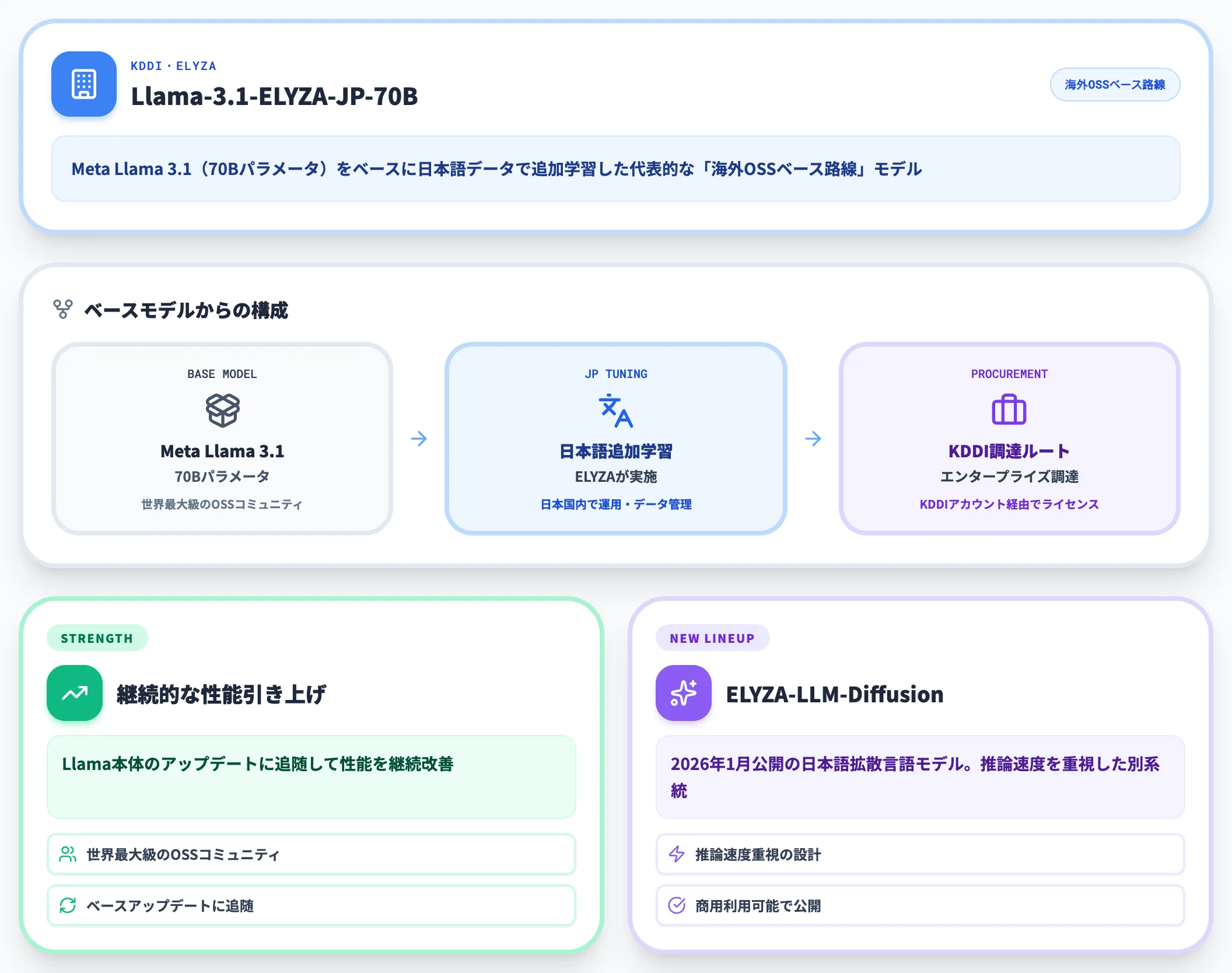
ELYZA(KDDI傘下)の「Llama-3.1-ELYZA-JP-70B」は、Meta Llama 3.1(70Bパラメータ)をベースに日本語データで追加学習した代表的な「海外OSSベース路線」モデルです。
ベースモデルが世界最大級のオープンソースコミュニティに支えられているため、Llama本体のアップデートに追随して継続的に性能を引き上げられるのが強みです。
ELYZAは2026年1月に新たに「ELYZA-LLM-Diffusion」(日本語拡散言語モデル)を商用利用可能な形で公開しており、推論速度を重視した別系統のモデル開発も進めています。
KDDI傘下入り後はエンタープライズ調達ルートが整備されており、KDDIアカウント経由でのライセンス調達がしやすくなっています。
NEC cotomi v3
NECの「cotomi v3」はガバメントAI源内で選定された7モデルの1つで、エンタープライズ業務に最適化された設計が特徴です。
特筆すべきは、cotomiベースのエージェント技術「cotomi Act」がWebArenaベンチマークで80.4%を記録し、人間の78.2%を上回ったことがNECの公式発表で示されている点です。WebArenaはWebタスクの自動実行能力を測るベンチマークで、AIエージェント実装の実力が問われます。
%20%E3%81%AEWebArena%E3%82%B9%E3%82%B3%E3%82%A2%E6%AF%94%E8%BC%83%EF%BC%8880.4%25%E3%83%BB%E4%BA%BA%E9%96%9378.2%25%E8%B6%85%E3%81%88%EF%BC%89.webp)
cotomi Act 1.0 WebArenaスコア(80.4%・人間78.2%超え)(出典:NEC)
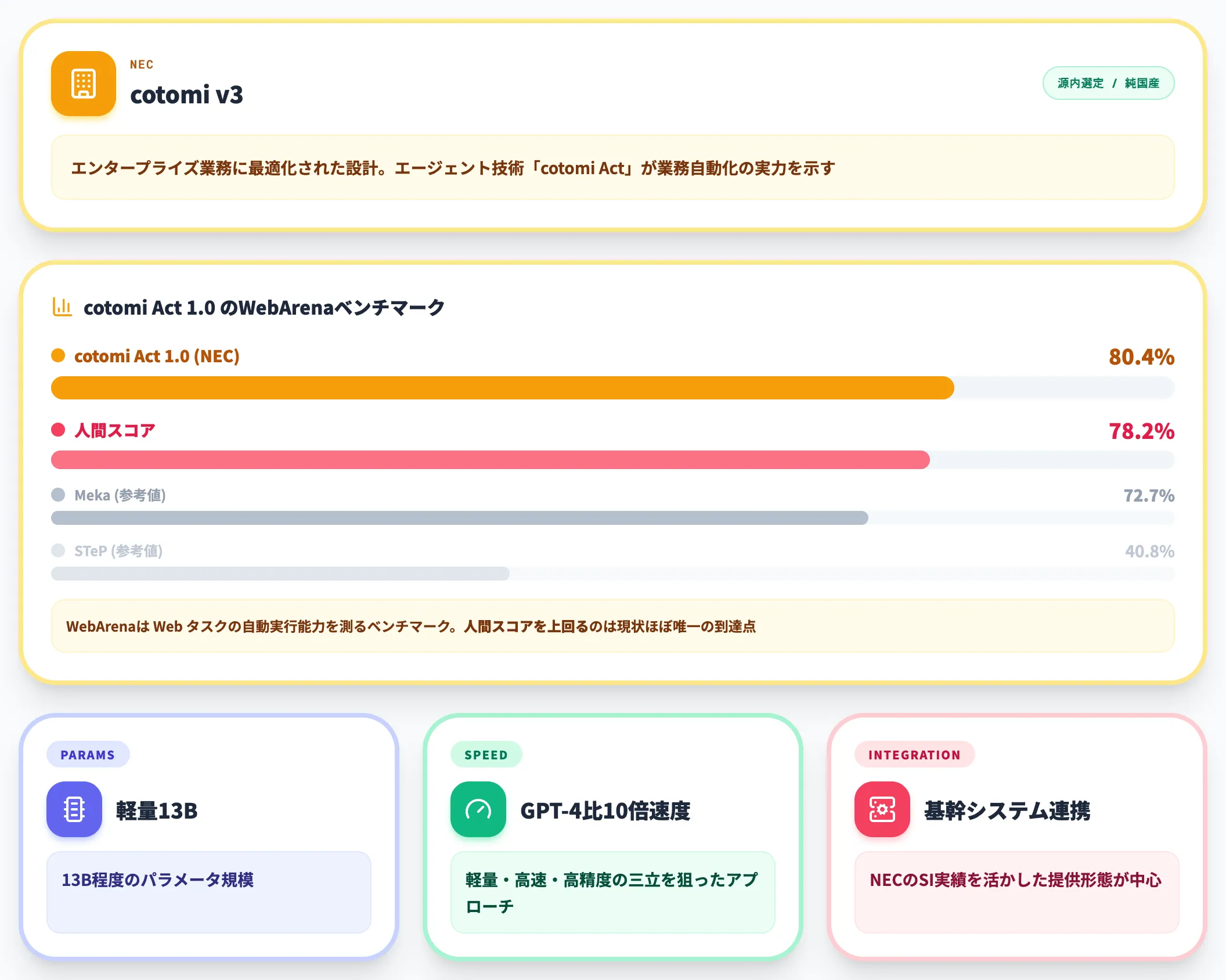
NEC公式の棒グラフでは、cotomi Act 1.0が80.4%で先頭、人間スコアの78.2%、参考値のMeka 72.7%・CUGA 64.25%・STeP 40.8%が続き、エージェント評価系で従来モデルから2桁ポイント以上の伸びが確認できます。
cotomiは13B程度のパラメータでGPT-4比10倍の推論速度を実現する設計で、軽量・高速・高精度の三立を狙ったアプローチです。
NECは長年の業務システム導入実績を持ち、cotomiも基幹システム連携を前提とした提供形態が中心となっています。
富士通 Takane 32B
富士通「Takane 32B」は、カナダCohereのCommand R+(約104Bパラメータ)をベースに、富士通独自の特化型AI蒸留技術で32Bまでサイズダウンしたモデルです。
富士通の公式発表では、JGLUEベンチマークで日本語性能トップ水準と位置づけられています。
富士通独自の1-bit量子化技術を組み合わせることで、メモリ消費を94%削減しながら精度を89%維持できると2025年9月に公表されており、推論時の運用コスト削減に直結する技術です。
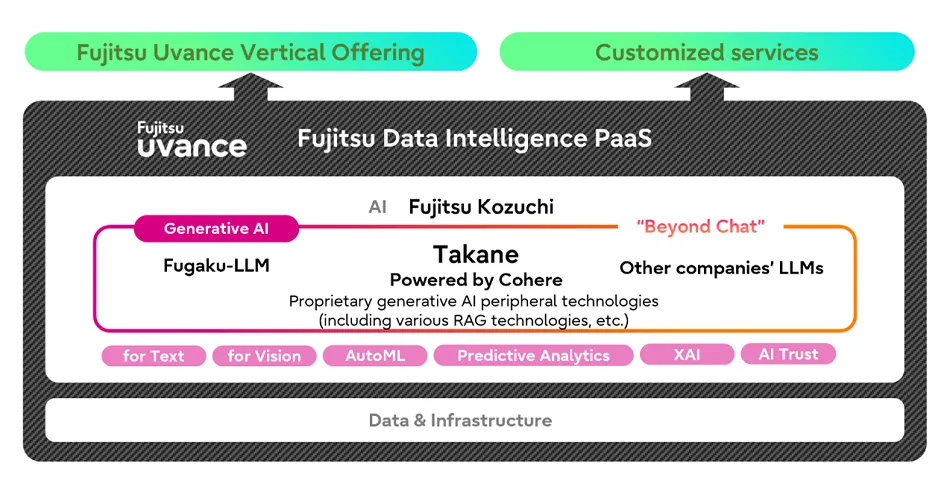
Fujitsu Kozuchi Takaneの提供スキーム(出典:富士通)

富士通公式の提供スキーム図では、Takaneが「Fujitsu Kozuchi」配下のGenerative AI機能の柱として位置づけられ、上層の「Fujitsu Uvance」垂直オファリングと「Customized services」に接続される構造になっています。他社LLMも併用可能な設計で、SAP・基幹システム連携を持つ富士通のSIアセットと組み合わせて使うことを前提にしているのが読み取れます。
「海外モデル+自社チューニング路線」の代表例として、純国産フルスクラッチとは別軸のアプローチを採っています。
ソフトバンク Sarashina2 mini
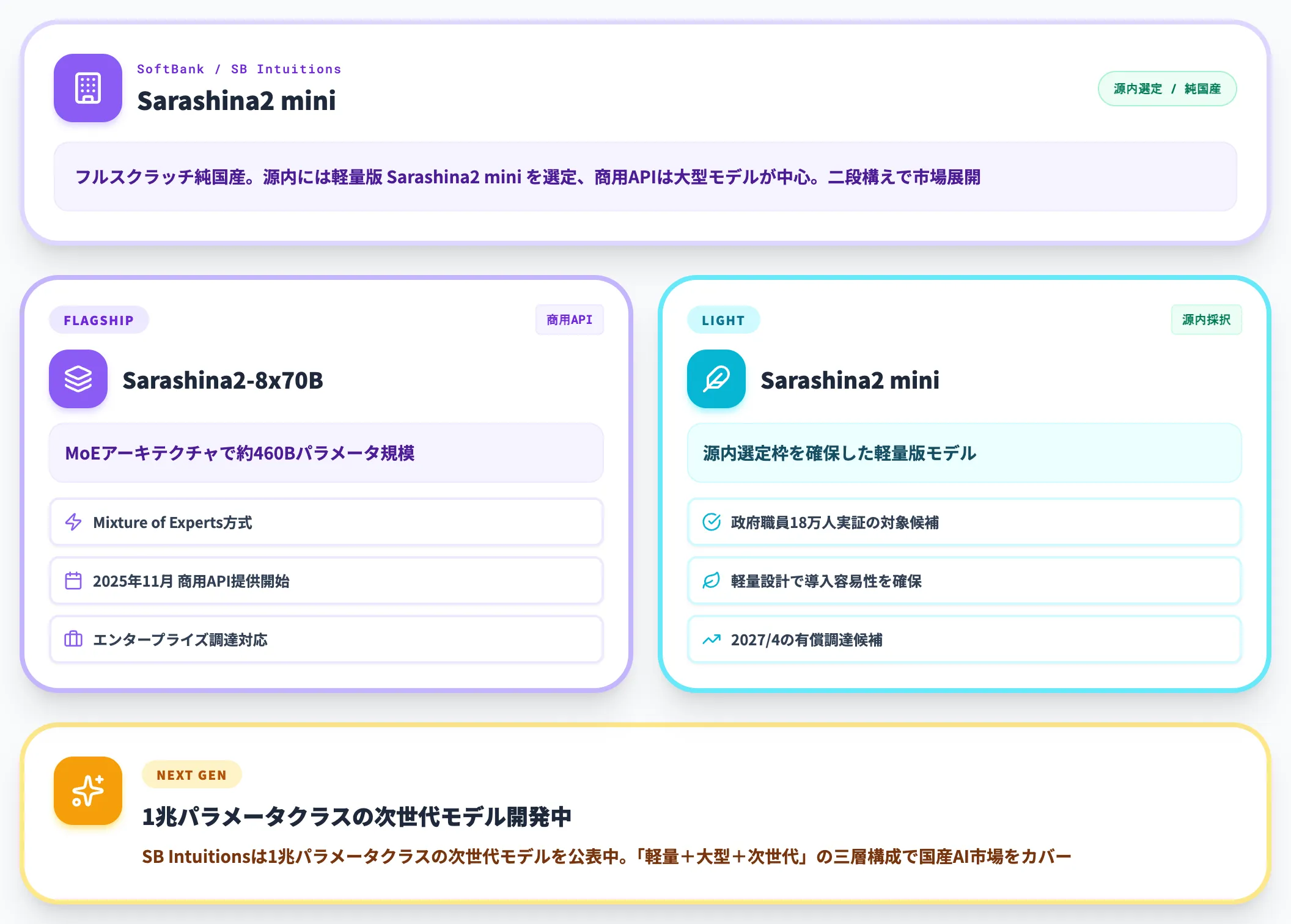
ソフトバンク傘下のSB Intuitionsが開発する「Sarashina」シリーズは、フルスクラッチ純国産モデルです。
Sarashina2-8x70BはMixture of Experts(複数の専門モデルを組み合わせる方式)アーキテクチャを採用し、約460Bパラメータ規模を実現しています。
2025年11月からは商用API提供が始まっており、エンタープライズ向けの調達ルートが整っています。SB Intuitionsは1兆パラメータクラスの次世代モデルも開発中と公表しており、源内選定モデルとして採択されたのは軽量版の「Sarashina2 mini」です。
軽量版で源内選定枠を確保しつつ、商用API向けに大型モデル展開を進める二段構えの戦略になっています。
カスタマークラウド CC Gov-LLM
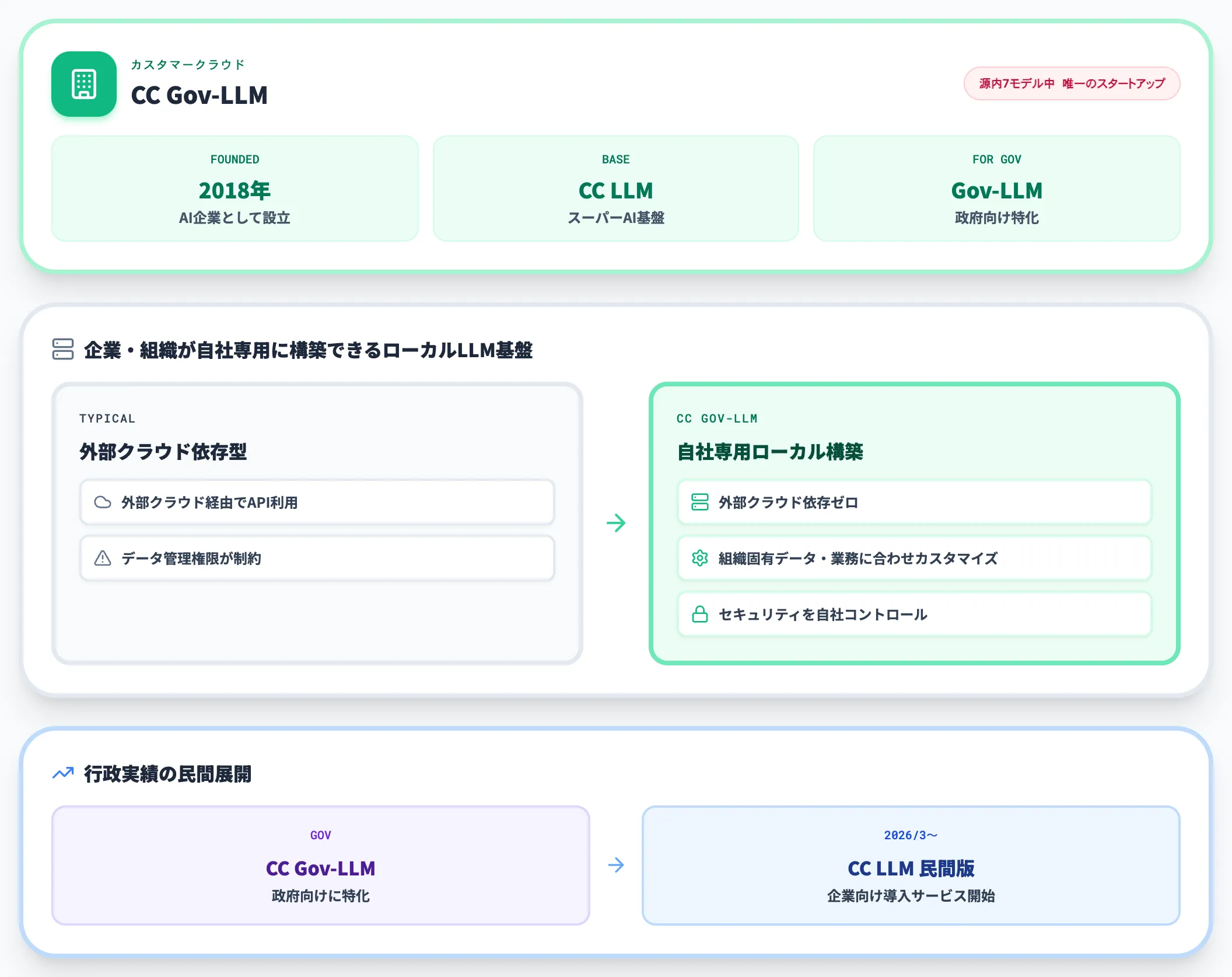
カスタマークラウドは2018年設立のAI企業で、源内選定7モデルの中で唯一のスタートアップです。
「CC Gov-LLM」は同社のスーパーAI基盤「CC LLM」を政府向けに特化させたモデルで、企業や組織が自社専用に構築できるローカルLLM基盤として設計されています。
外部クラウドに依存せず、組織固有のデータ・業務フローに合わせてカスタマイズできる点が特徴で、データ管理・セキュリティを自社でコントロールしたい組織のニーズに応えます。
2026年3月には企業向けに「CC LLM」の導入サービスも開始しており、行政向けの実績を民間に展開する流れを作っています。
源内選定外で押さえるべきプレイヤー——Sakana AI
源内7モデルとは別軸で押さえておくべきがSakana AIです。
Sakana AIは2025年11月17日発表のSeries Bで約320億円(2億ドル)を調達し、**評価額は約4,320億円(27億ドル)**となっています。累計調達額は約660億円(4.12億ドル)に達し、日本発のAIスタートアップとして突出した規模です。

Sakana AI Series Bの主要投資家(出典:Sakana AI Series B)
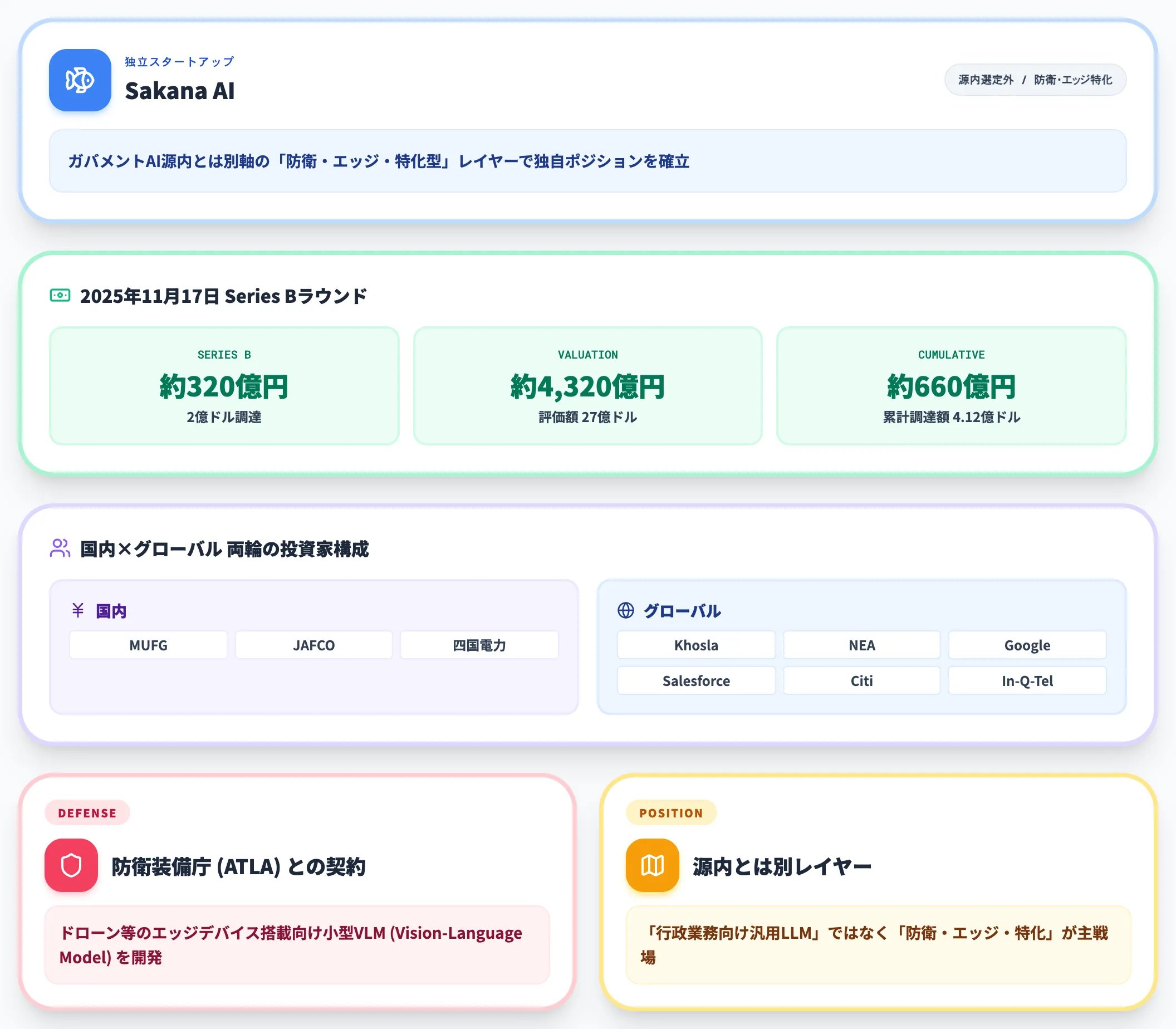
公式ページに並ぶ投資家ロゴからは、Mitsubishi UFJ・JAFCO・四国電力など国内の金融・産業勢と、Khosla Ventures・NEA・Google・Salesforce Ventures・Citi・Datadog・In-Q-Telなどグローバル勢が同居している点が読み取れます。日本発スタートアップでこの並びは異例で、海外資本と国内産業基盤の両輪が揃った調達構造になっています。
ガバメントAI源内には選定されていませんが、防衛省の防衛装備庁(ATLA)と契約を結び、ドローン等のエッジデバイスに搭載する小型のVision-Language Modelの開発を進めています。
ガバメントAI源内が「行政業務向け汎用LLM」のリファレンス市場であるのに対し、Sakana AIは「防衛・エッジ・特化型」というガバメントAIとは別レイヤーのプレイヤーとして独自のポジションを築いています。
【関連記事】
Sakana Fuguとは?Fugu Ultraの性能・料金・Fable 5代替としての立ち位置を解説
国産AIの料金体系——主要モデルのAPI/オンプレ単価
国産AIの料金は、API従量課金型(PLaMo・Sarashina等)とオンプレ個別契約型(tsuzumi等)の2系統に大別されます。
それぞれの代表モデルと、海外モデルとの単価感を整理します。
PLaMo 3.0 Prime——スタンダード/フリー/プロバイダプラン
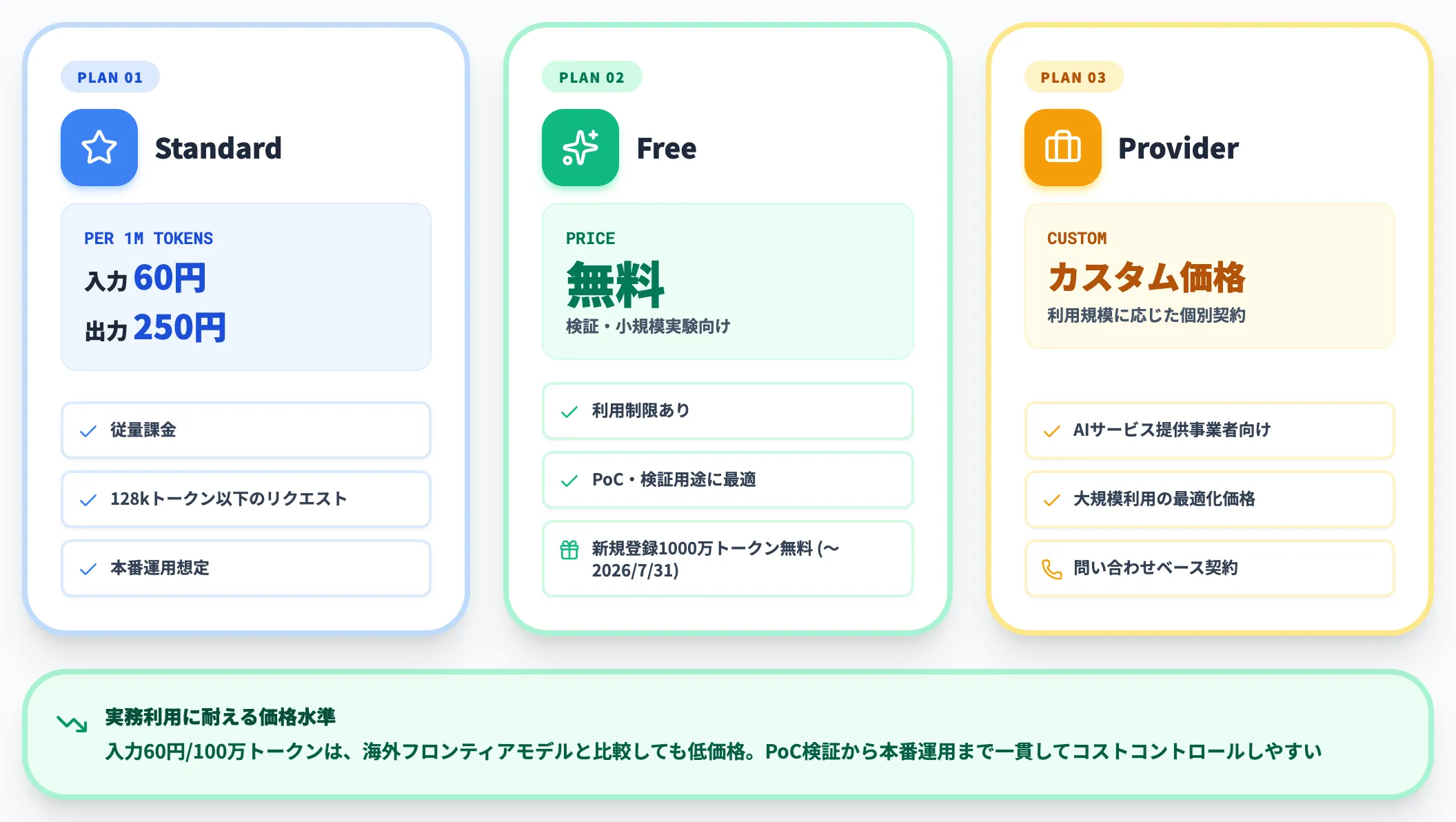
PLaMo 3.0 Primeは3つの料金プランで提供されています。
以下の表で、各プランの単価と利用条件を整理しました。
| プラン | 単価 | 主な利用条件 |
|---|---|---|
| Standard | 入力60円 / 出力250円(100万トークンあたり) | 従量課金、128kトークン以下のリクエストに適用 |
| Free | 無料 | 利用制限あり、検証・小規模実験向け |
| Provider | カスタム価格 | AIサービス提供事業者向け、利用規模に応じた個別契約 |
新規登録ユーザーには2026年7月31日まで10百万トークン分の無料クレジットが付与されるリリースキャンペーンも実施されています。
100万トークン入力60円という価格は、海外フロンティアモデルと比較しても実務利用に耐える水準で、PoC検証から本番運用まで一貫してコストコントロールがしやすい設計です。
tsuzumi 2——個別契約とオンプレ運用コスト
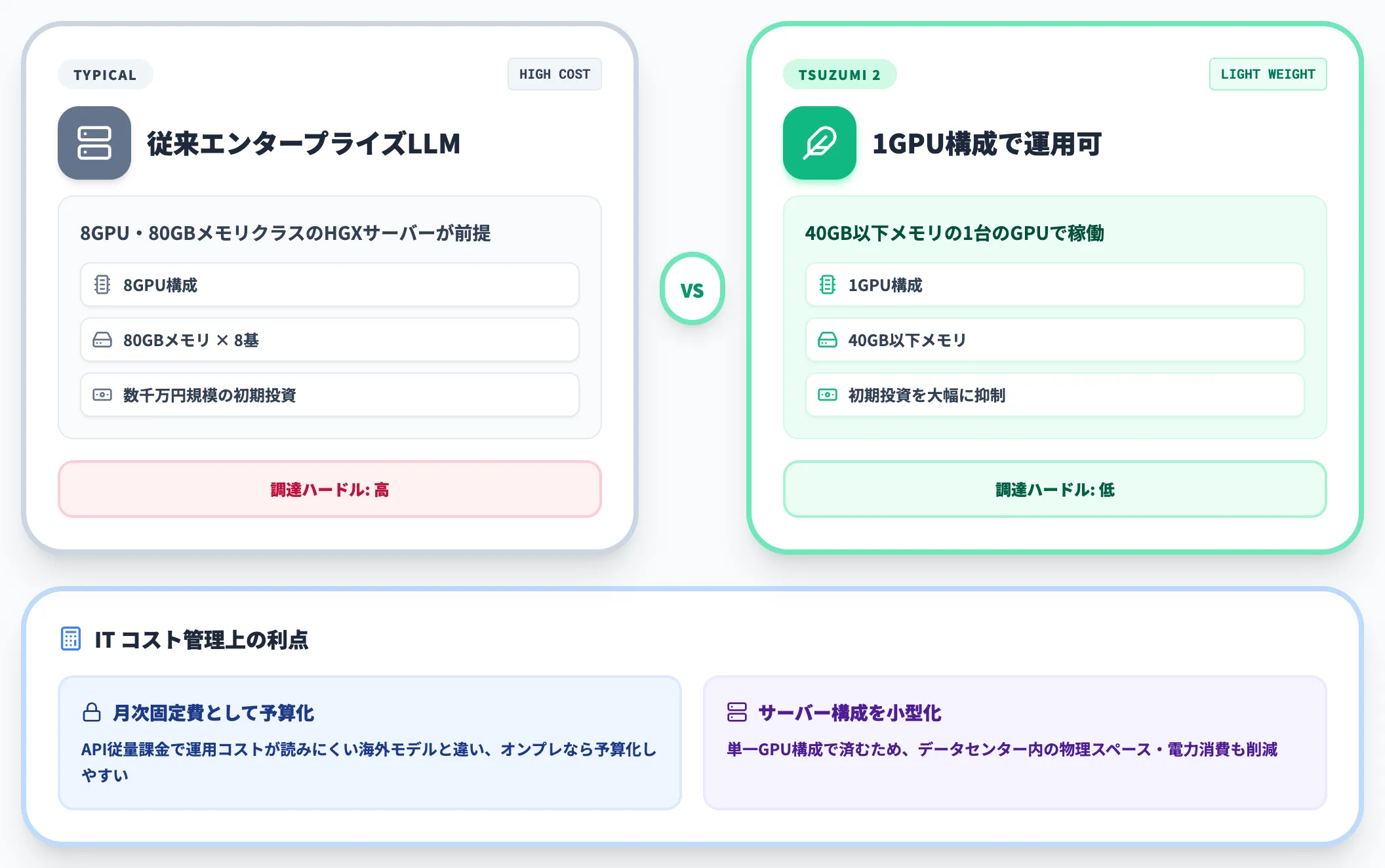
tsuzumi 2は法人向け個別契約が前提で、API従量課金の公開価格は提示されていません。
注目すべきは、**1GPU動作(40GB以下メモリ)**で稼働できる軽量設計により、オンプレ運用の初期投資・ランニングコストが大幅に下がる点です。
従来、エンタープライズ向けLLMのオンプレ運用は8GPU・80GBメモリクラスのHGXサーバー(数千万円規模)が前提でしたが、tsuzumi 2は単一GPU構成で済むため、サーバー構成を小さくでき初期投資を抑えやすくなります。
API従量課金で運用コストが読みにくい海外モデルと違い、オンプレ運用なら月次の固定費として予算化できる点も、ITコスト管理上の利点です。
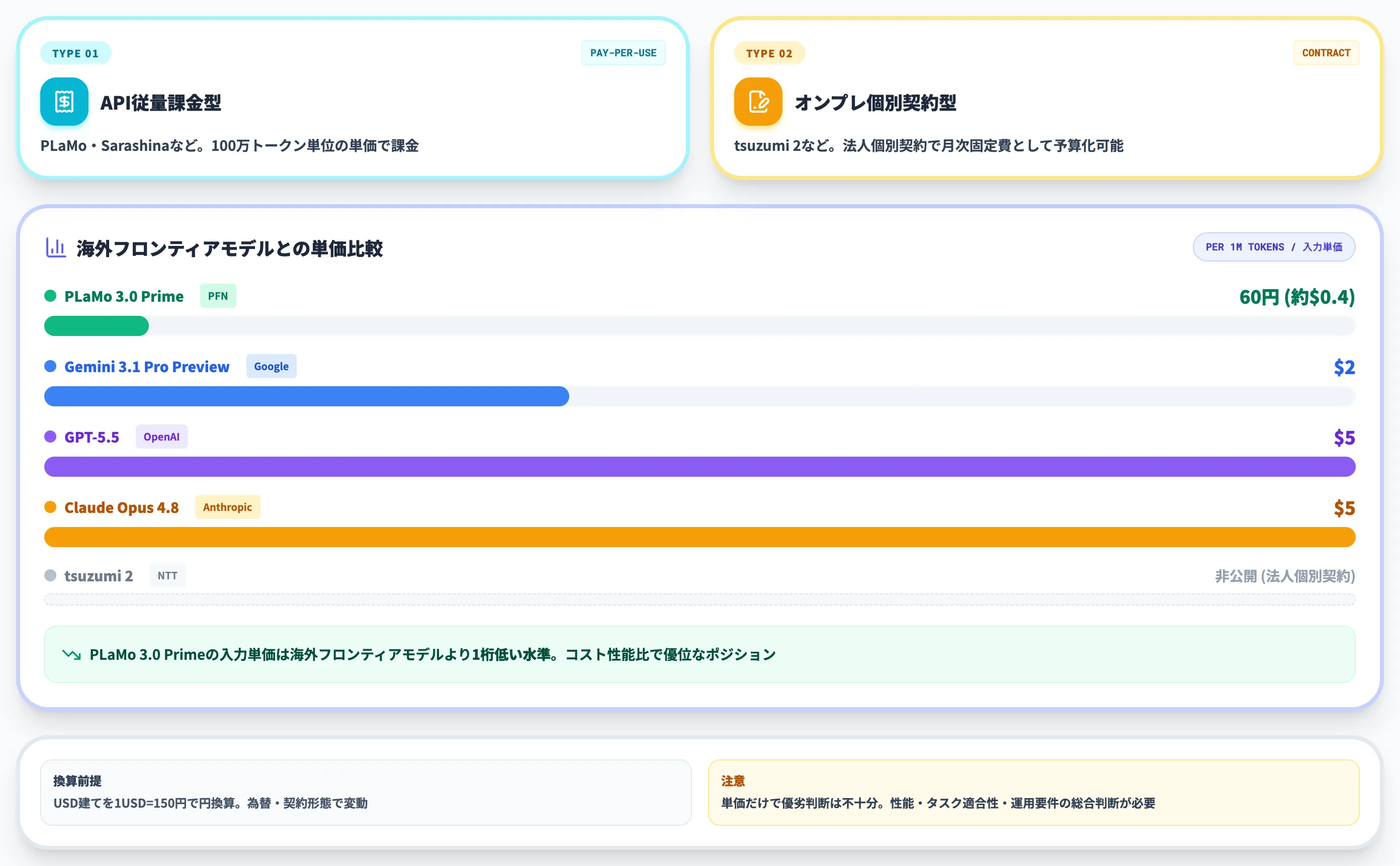
海外フロンティアモデルとの単価比較
国産AIの価格水準を理解するには、海外フロンティアモデルとの単価比較が必要です。
以下の表で、2026年6月時点の主要モデルの公式公表単価を整理しました(100万トークンあたり・標準モード、海外モデルはUSD建て)。
| モデル | 入力単価 | 出力単価 | 提供元 |
|---|---|---|---|
| PLaMo 3.0 Prime | 60円(約$0.4) | 250円(約$1.7) | Preferred Networks |
| GPT-5.5 | $5 | $30 | OpenAI |
| Claude Opus 4.8 | $5 | $25 | Anthropic |
| Gemini 3.1 Pro Preview | $2 | $12 | |
| tsuzumi 2 | 非公開(法人個別契約) | 非公開(法人個別契約) | NTT |
※USD建てを1USD=150円で円換算した参考値です。実際の請求額は為替・契約形態で変動します。各モデルの公式価格ページは OpenAI / Claude / Gemini を参照してください。
表からは、PLaMo 3.0 Primeの入力単価が海外フロンティアモデルより1桁低い水準にあることが読み取れます。
ただし単価だけで優劣を語るのは不十分で、性能ベンチマーク・タスク適合性・運用要件を含めた総合判断が必要です。タスク種別によっては、海外フロンティアモデルでないと到達できない品質帯が存在するため、コストと性能の両面でモデルを選定する視点が欠かせません。

国産AIを選ぶメリット——日本企業に効く3つの実利
国産AIを採用するメリットは抽象的な「日本企業だから安心」ではなく、実務調達現場で効く3つの実利として整理できます。
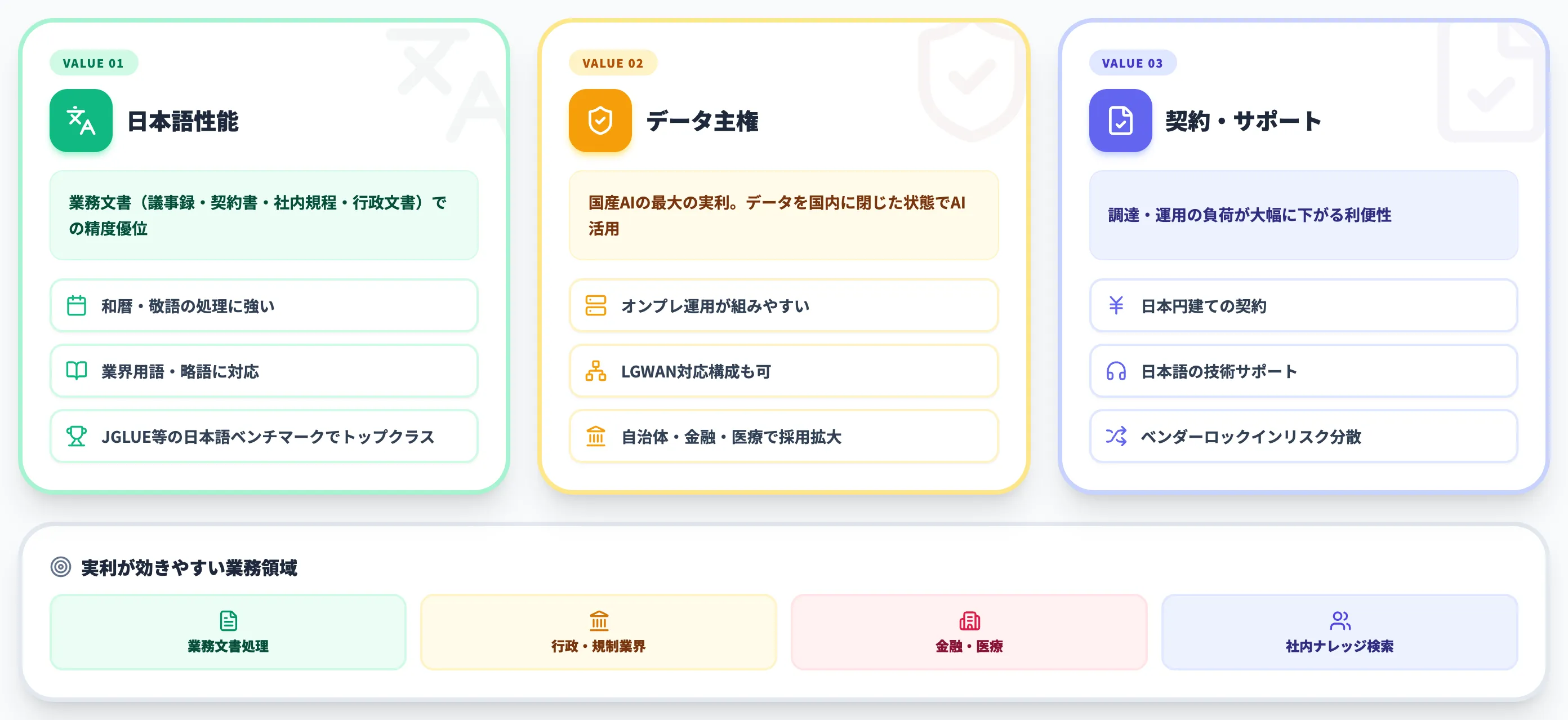
日本語性能と業務文書への最適化
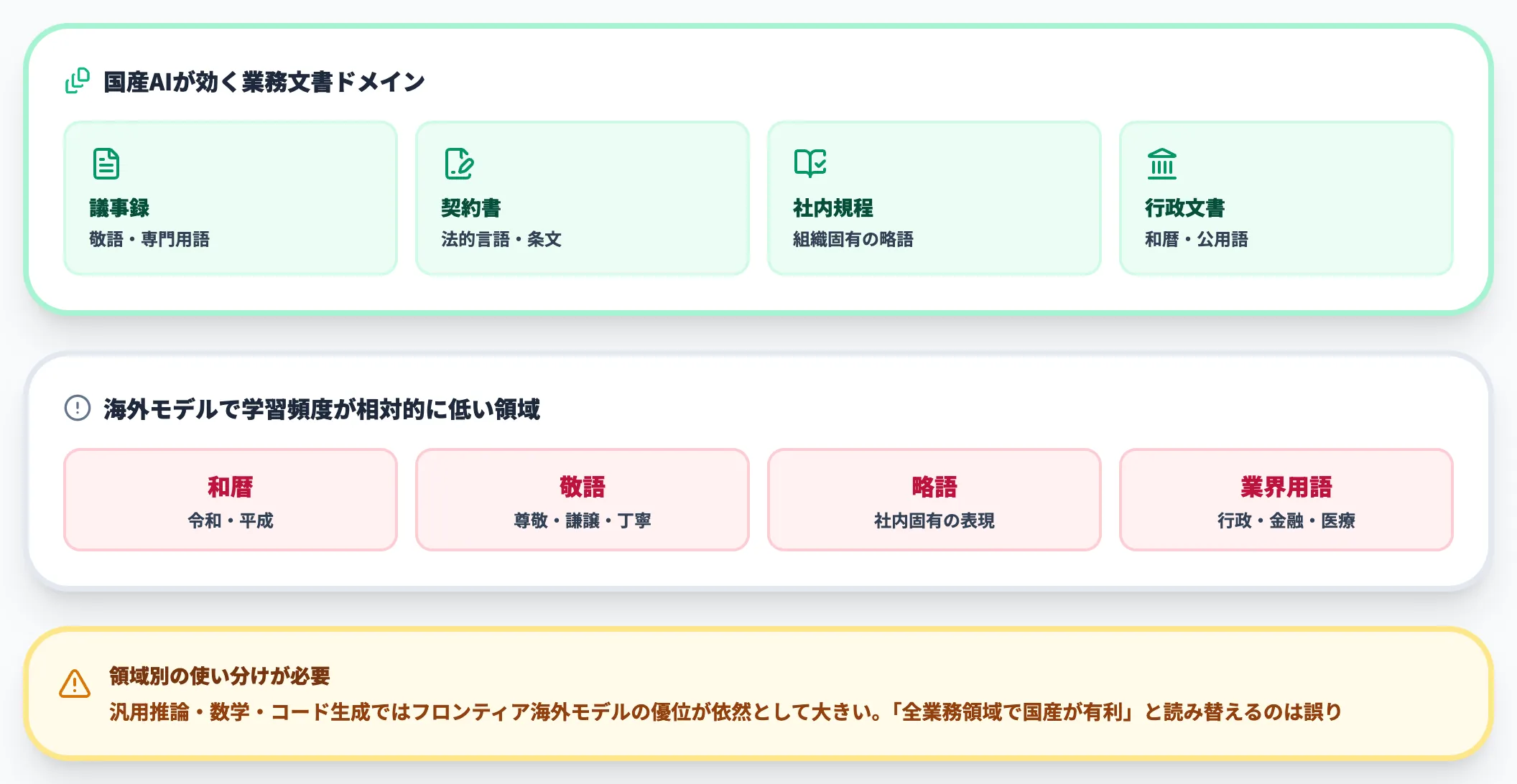
国産AIは日本語コーパスを中心に学習されており、業務文書(議事録・契約書・社内規程・行政文書)の処理精度で海外モデルとの差が出やすい領域です。
特に和暦・敬語・略語・業界用語など、海外モデルが学習データで触れる頻度が相対的に低い領域では、国産AIの精度優位が体感できます。
源内選定モデルの多くがJGLUE等の日本語ベンチマークでトップクラスを記録しているのも、この訓練データ比重の差が背景にあります。
ただし汎用推論・数学・コード生成ではフロンティア海外モデルの優位が依然として大きいため、「全業務領域で国産が有利」と読み替えるのは誤りです。
データ主権とオンプレ運用——ZDR/LGWAN要件への適合

国産AIの最大の実利は、データ主権の確保にあります。
海外モデルをAPIで利用する場合、標準契約やリージョン設定によっては入力データの国外処理・国外移転が論点になるため、機密情報・個人情報の取り扱いで法務・コンプライアンス上の検討が必要になります。
国産AIならオンプレミス運用やLGWAN対応の構成が組みやすく、データを国内に閉じた状態でのAI活用が実現します。自治体・金融・医療・防衛など、規制業界での国産AI採用が進む背景はここにあります。
日本円契約・国内サポート・ベンダーロックイン回避
3つ目の実利は、契約・サポート面の利便性です。
海外モデルの法人契約はドル建てが基本で、為替変動による予算ブレ・経理処理の煩雑さ・国内法に基づく契約形態への調整が必要になります。
国産AIなら日本円建ての契約・国内法準拠の契約書・日本語の技術サポートが標準で、調達・運用の負荷が大幅に下がります。
加えて、海外モデルの巨大プラットフォームに依存しすぎることへのベンダーロックインリスクの分散にも意味があります。国産AIを一定割合で組み込んでおくことで、海外プラットフォームの料金変更・API仕様変更・地政学リスクへの耐性が高まります。
国産AIの注意点——海外モデルとの実力差を直視する
国産AIには明確なメリットがある一方で、海外フロンティアモデルとの実力差を直視しないと調達後に運用トラブルにつながります。
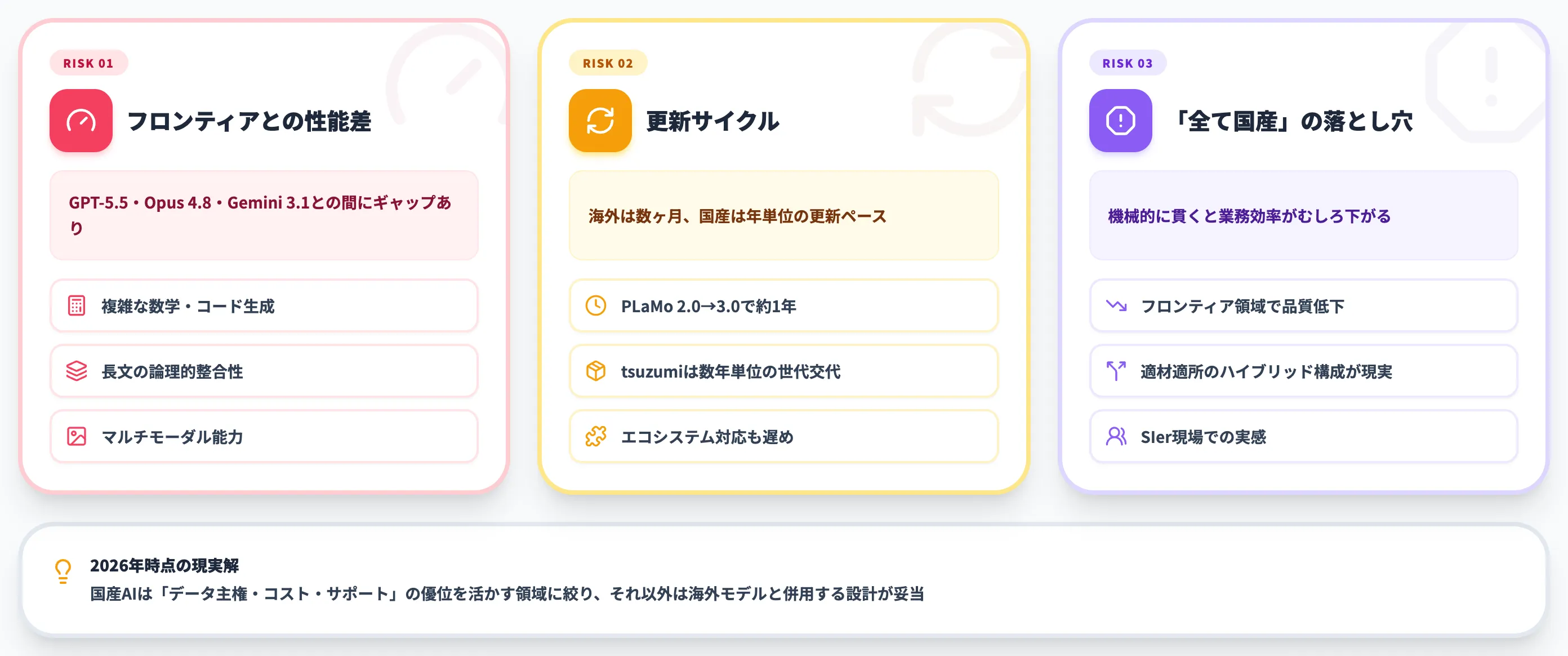
フロンティアモデルとの性能差

汎用推論能力では、GPT-5.5・Claude Opus 4.8・Gemini 3.1 Pro Previewなど海外フロンティアモデルと国産AIの間にはギャップが残っているのが現状です。
特に複雑な数学・コード生成・長文の論理的整合性・マルチモーダル能力では、フロンティア勢の優位が大きいのが現状です。
源内選定モデルでも、PLaMo 3.0 Primeのコンテキスト長256kやcotomi ActのWebArena 80.4%など領域別では国際水準に並ぶスコアが出ていますが、全領域で横並びになるには2026年6月時点でもう一段の進化が必要です。
国産AIを「フロンティアモデルの完全な代替」と位置付けると、複雑タスクで品質が出ずに業務適用が頓挫するケースが見られます。
更新サイクルとエコシステムの厚みの差
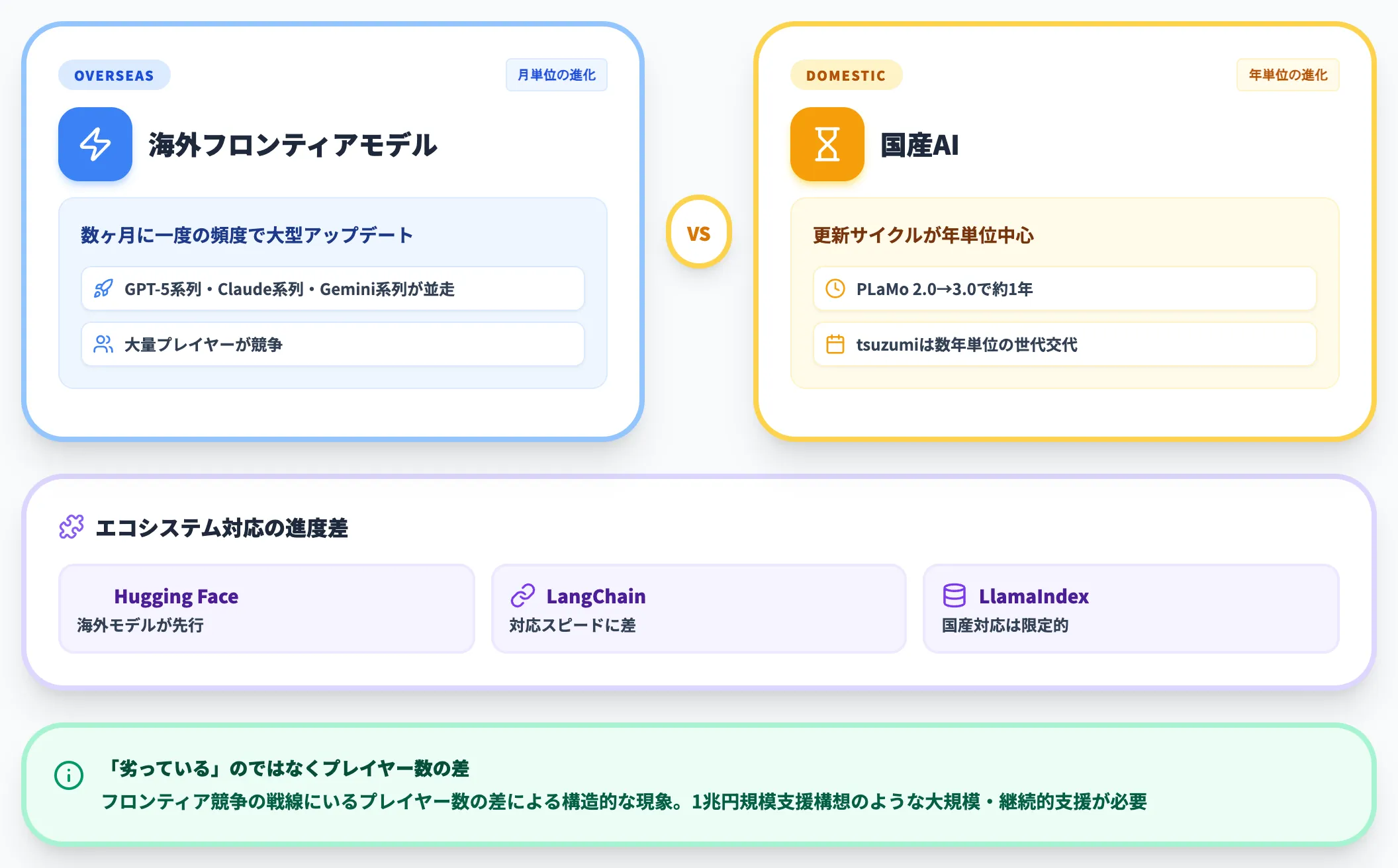
海外フロンティアモデルは数ヶ月に一度の頻度で大型アップデートが出るのに対し、国産AIの更新サイクルは年単位が中心です。
PLaMoは2.0→3.0で約1年、tsuzumiも初代から2世代目に数年を要しています。エコシステム面でも、Hugging Face・LangChain・LlamaIndex等のオープンソースツール群への対応スピードは海外モデルが先行する状況が続いています。
これは「国産AIが劣っている」のではなく、フロンティア競争の戦線にいるプレイヤー数の差による構造的な現象です。海外モデルに対抗し続けるには、報道されている1兆円規模支援構想のような大規模支援が継続的に必要になります。
「全て国産で」の落とし穴——SIer現場での実感

国産AI推しが強くなると、「全業務を国産AIに置き換えるべき」という議論になりがちですが、SIer現場での実感としては適材適所のハイブリッド構成が現実的です。
ある業務領域では国産AIのオンプレ運用がベスト、別領域では海外フロンティアモデルのAPI活用がベスト、という使い分けがほとんどのケースで成立します。
「すべて国産」を機械的に貫こうとすると、フロンティアモデルでしか到達できない品質帯のタスクで業務効率が下がるという本末転倒が起きやすくなります。
国産AI採用は「データ主権・コスト・サポート」の優位を活かす領域に絞り、それ以外は海外モデルと併用する設計が、2026年時点の現実解です。
国産AIの選び方——4つの判断軸
国産AIを採用するかどうか、採用するならどのモデルか——この選定は4つの判断軸で整理できます。

データ要件——ZDR・オンプレ・LGWAN必須か
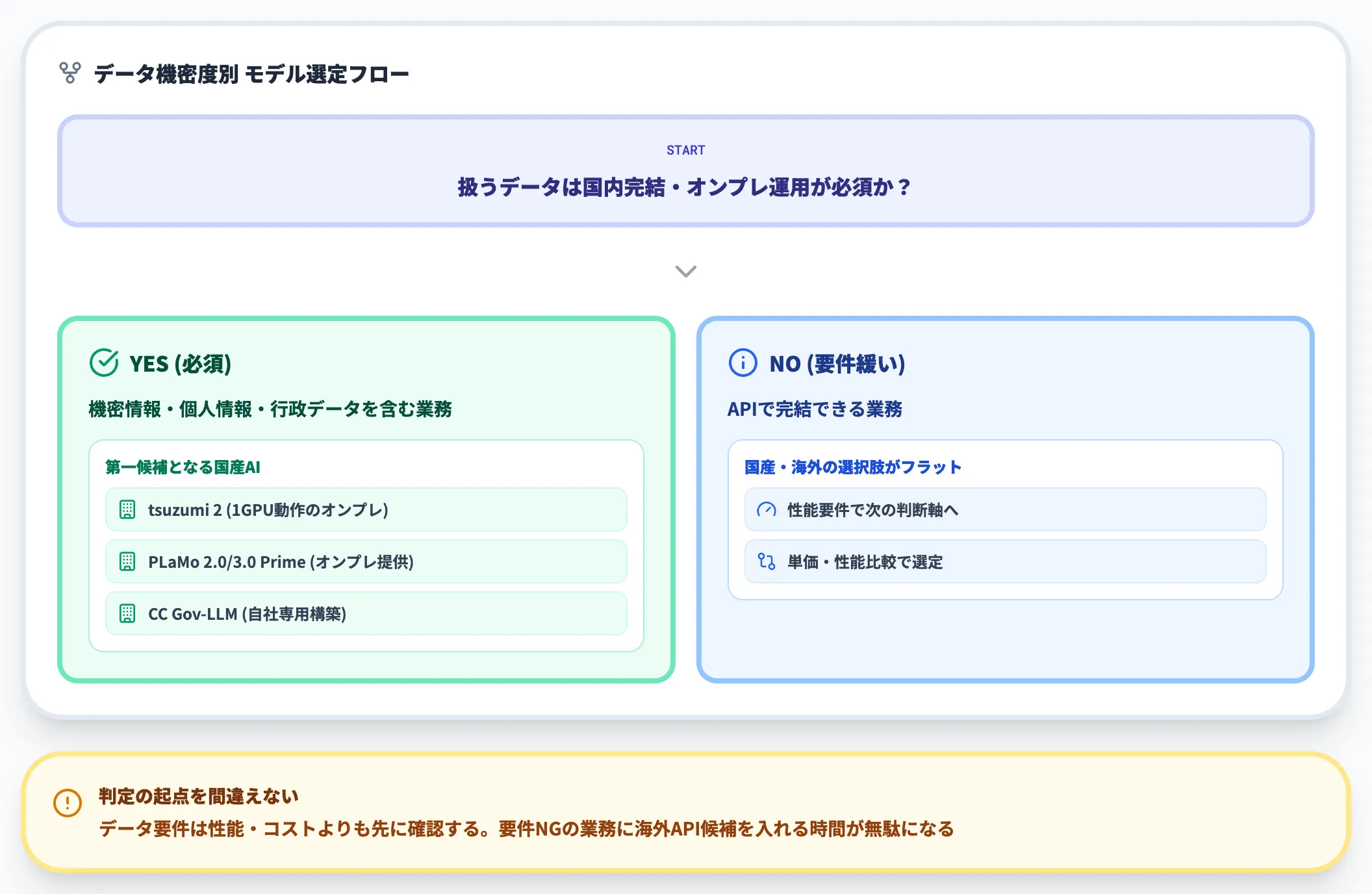
最初に確認すべきは、扱うデータが国内完結・オンプレ運用が必須かどうかです。
機密情報・個人情報・行政データなど、データの海外移転が法務・コンプライアンス上不可となる業務であれば、国産AIのオンプレ構成かLGWAN対応構成が必須要件になります。
この場合、tsuzumi 2の1GPU動作・PLaMo(2.0/3.0 Prime)のオンプレ提供・CC Gov-LLMの自社専用構築といったオンプレ実装が可能なモデルが第一候補になります。
逆にデータ要件が緩く、APIで完結する業務であれば、国産・海外の選択肢がフラットに並びます。
求める性能水準と海外モデルでの代替可能性
次に、業務で求める性能水準と海外モデルでの代替可能性を確認します。
複雑な数学的推論・高度なコード生成・マルチモーダル理解など、フロンティア性能が必要な業務では、現時点では海外モデルの優位が大きいため、国産AI単独での対応は厳しいケースが多くなります。
一方、日本語業務文書のQA・要約・抽出・社内検索など、日本語精度と業務適合性が効く領域では、国産AIで十分対応可能で、コスト優位も活きます。
業務タスクを「日本語特化の業務処理」と「汎用フロンティア推論」に分類し、前者を国産、後者を海外と振り分ける視点が選定の起点になります。
提供形態——API/オンプレ/Bedrock Marketplace経由

国産AIは提供形態のバリエーションが広がってきており、選定時の重要な軸になります。
以下の3形態から、自社の運用体制に合うものを選びます。
-
API直接利用
PLaMo・Sarashinaなど、ベンダー直接APIで使う。最も導入が早い。
-
オンプレミス導入
tsuzumi 2・PLaMo Prime系・CC Gov-LLMなど、自社環境で動かす。データ主権・運用統制が最も強い。
-
マネージドプラットフォーム経由
Amazon Bedrock Marketplace・Snowflakeなど、既存のクラウド契約に乗せて使う。導入容易性と運用統制のバランス型。
すでにAWSやSnowflakeを使っている企業なら、Bedrock Marketplace経由でPLaMoを使う構成が、最短の導入経路になります。
既存システムとの統合とベンダー柔軟性
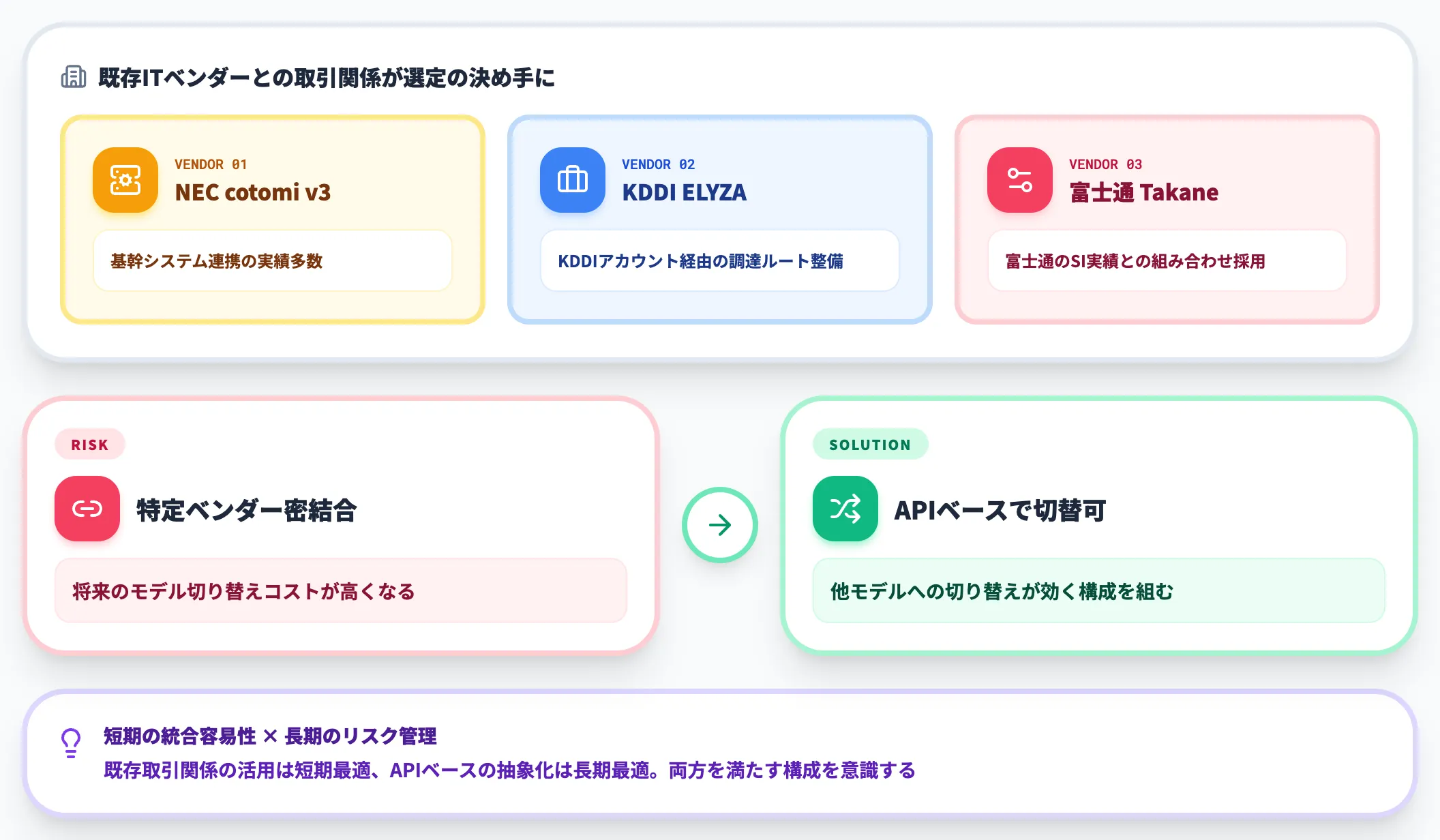
最後に、既存システムとの統合容易性とベンダー柔軟性を評価します。
NEC cotomi v3は基幹システム連携の実績が多く、KDDI・ELYZAはKDDIアカウント経由での調達ルートが整備されています。富士通Takaneは富士通のSI実績との組み合わせで採用されるケースが多いなど、既存ITベンダーとの取引関係が選定の決め手になることも珍しくありません。
ただし、特定ベンダーに密結合しすぎると将来のモデル切り替えコストが高くなるため、APIベースで他モデルへの切り替えが効く構成を組んでおくことが、長期的なリスク管理上は重要です。
国産AIの導入事例——自治体・民間・政府の実装パターン
国産AIの導入は2026年に入って加速しており、自治体・民間・政府の各レイヤーで具体的な成果が出ています。

自治体——横須賀市・泉大津市・150超自治体のPLaMo展開
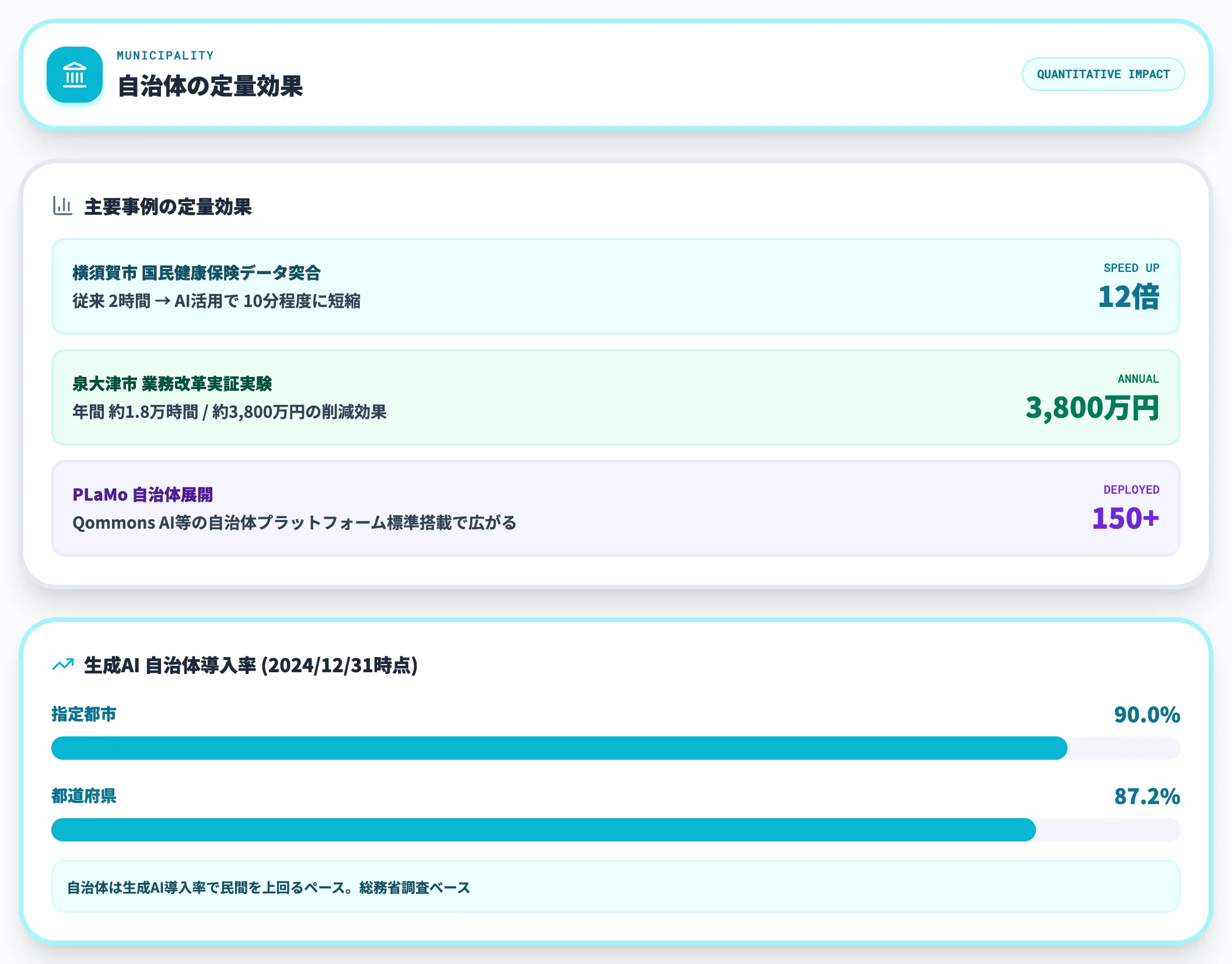
総務省が2025年6月30日に公表した令和6年度12月31日現在の調査では、**指定都市の90.0%・都道府県の87.2%**が生成AIを「導入済み」と回答しており、自治体は生成AI導入率で民間を上回るペースで普及が進んでいます。
代表的な定量効果として、横須賀市は国民健康保険のデータ突合にAIを活用し、従来2時間かかっていた処理を10分程度に短縮しました。
泉大津市の業務改革実証実験では、年間約1.8万時間・約3,800万円の削減効果が見込まれると報告されています。
PLaMoは150を超える自治体に展開されており、特にQommons AI等の自治体向けプラットフォームに標準搭載されることで、個別調達なしで国産AIを使える経路が広がっています。
民間——Sarashina商用展開とPLaMo Bedrock利用

民間企業向けには、SB IntuitionsのSarashina商用APIが2025年11月から提供開始されており、エンタープライズ顧客への展開が進んでいます。
Preferred NetworksのPLaMoは、API直接利用に加えてAmazon Bedrock Marketplace経由でも利用可能で、既存のAWS契約に乗せた形での導入が容易になっています。
国産AIを自社サービスに組み込むSaaSベンダー側の動きも活発化しており、生成AIを内蔵した業務SaaSの裏側でtsuzumiやPLaMoが動くケースが増えています。
政府——ガバメントAI源内 18万人実証(2026年度〜)
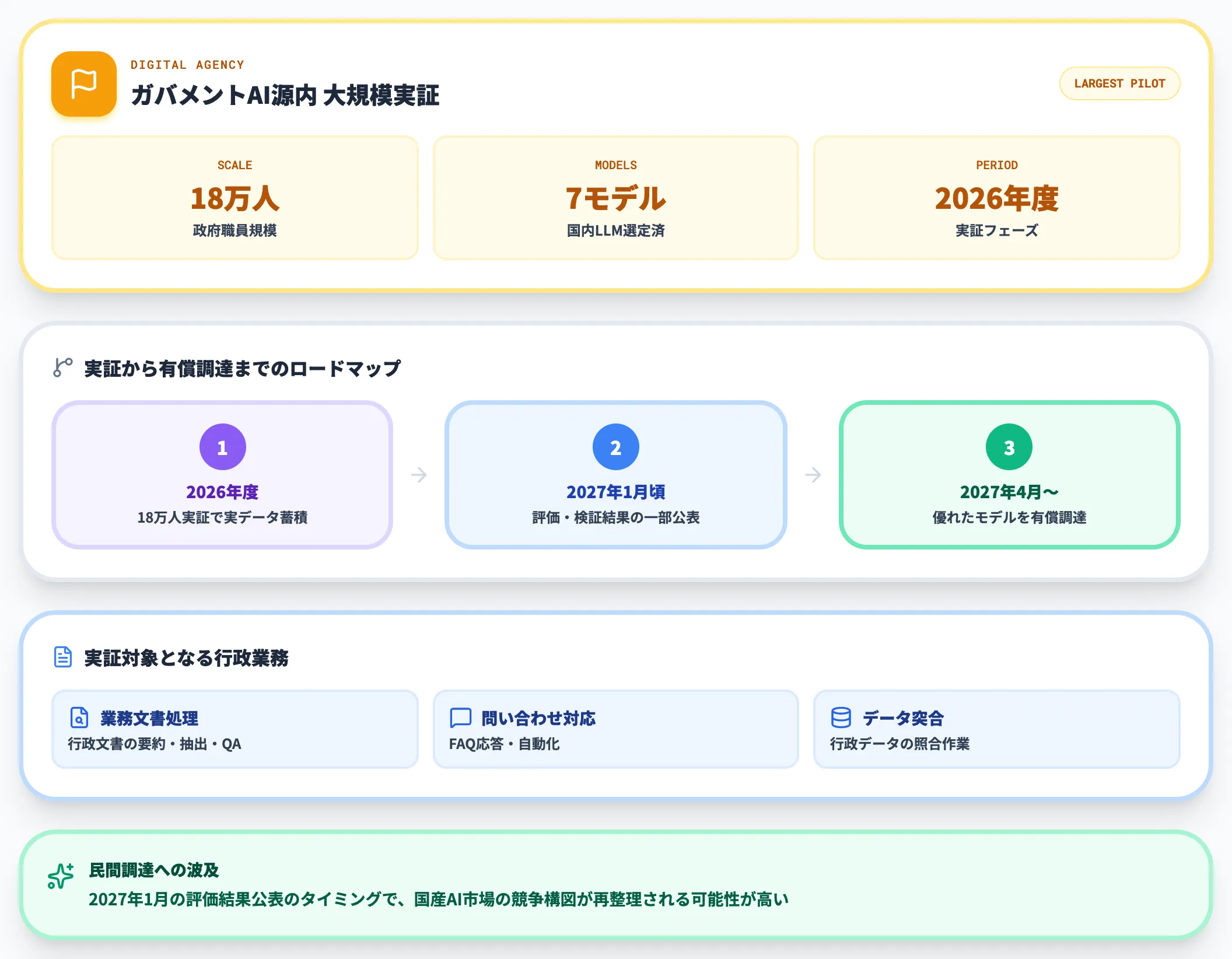
最も大規模な導入実証が**デジタル庁ガバメントAI「源内」**です。
2026年度に約18万人の政府職員を対象とした大規模実証が行われ、2027年4月以降に優れたモデルが正式に政府調達されることが予定されています。
行政の業務文書処理・問い合わせ対応・データ突合といった日本語業務での実証データが蓄積されることで、民間企業の調達判断にも波及するリファレンス効果が期待されます。
源内の評価結果が公表されるのは2027年1月頃の予定で、このタイミングで国産AI市場の競争構図が再整理される可能性が高くなっています。
国産AIと海外モデルのハイブリッド運用
ここまでの整理を踏まえ、実務現場での使い分けスタンスを示します。
すべて国産で揃える、あるいはすべて海外モデルで済ますのどちらも極端で、データ要件と業務性質に応じてケース別に使い分けるハイブリッド運用が、2026年時点で最も現実的な解です。
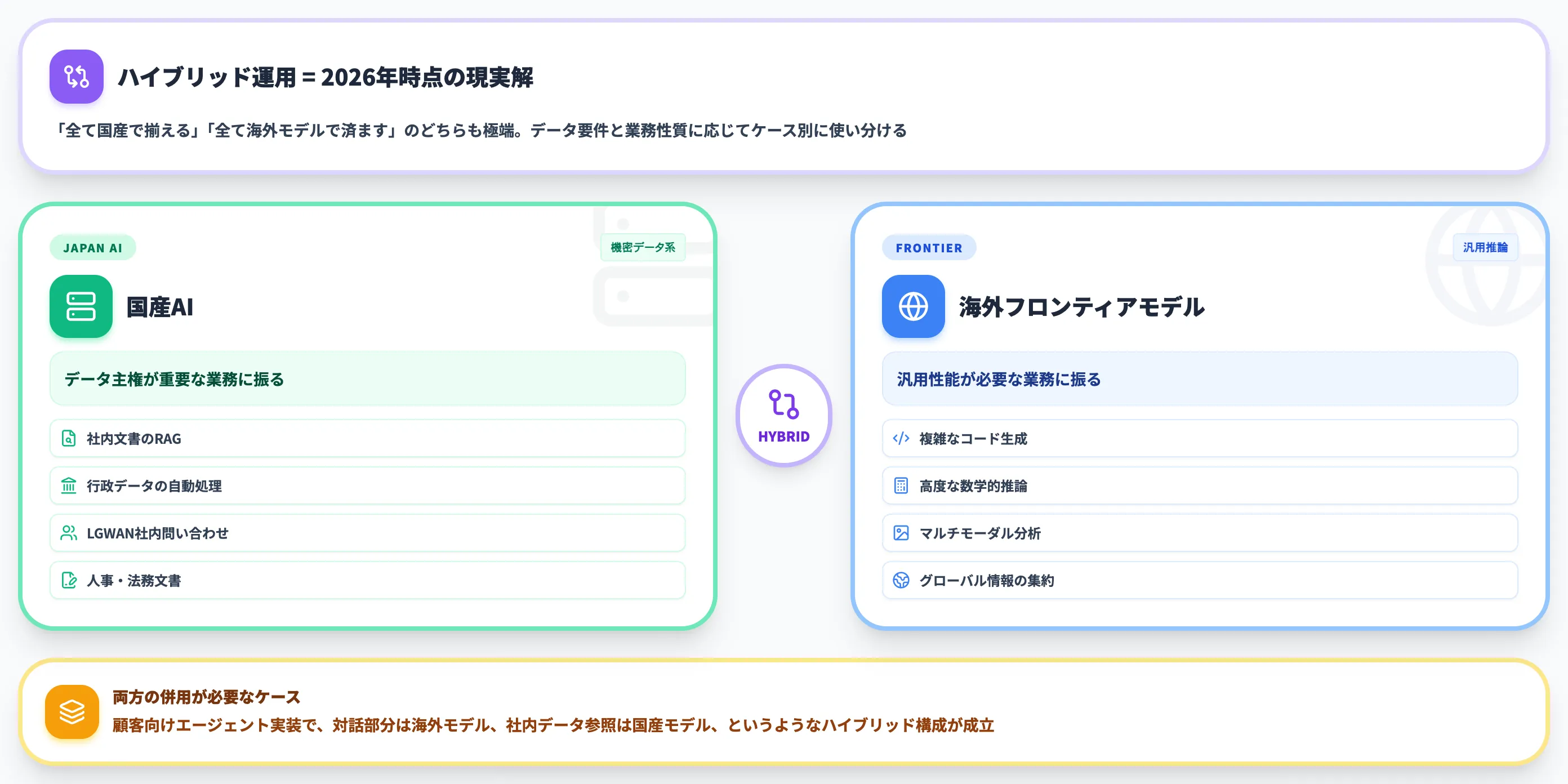
機密データ系業務→国産、汎用推論→海外の使い分けパターン
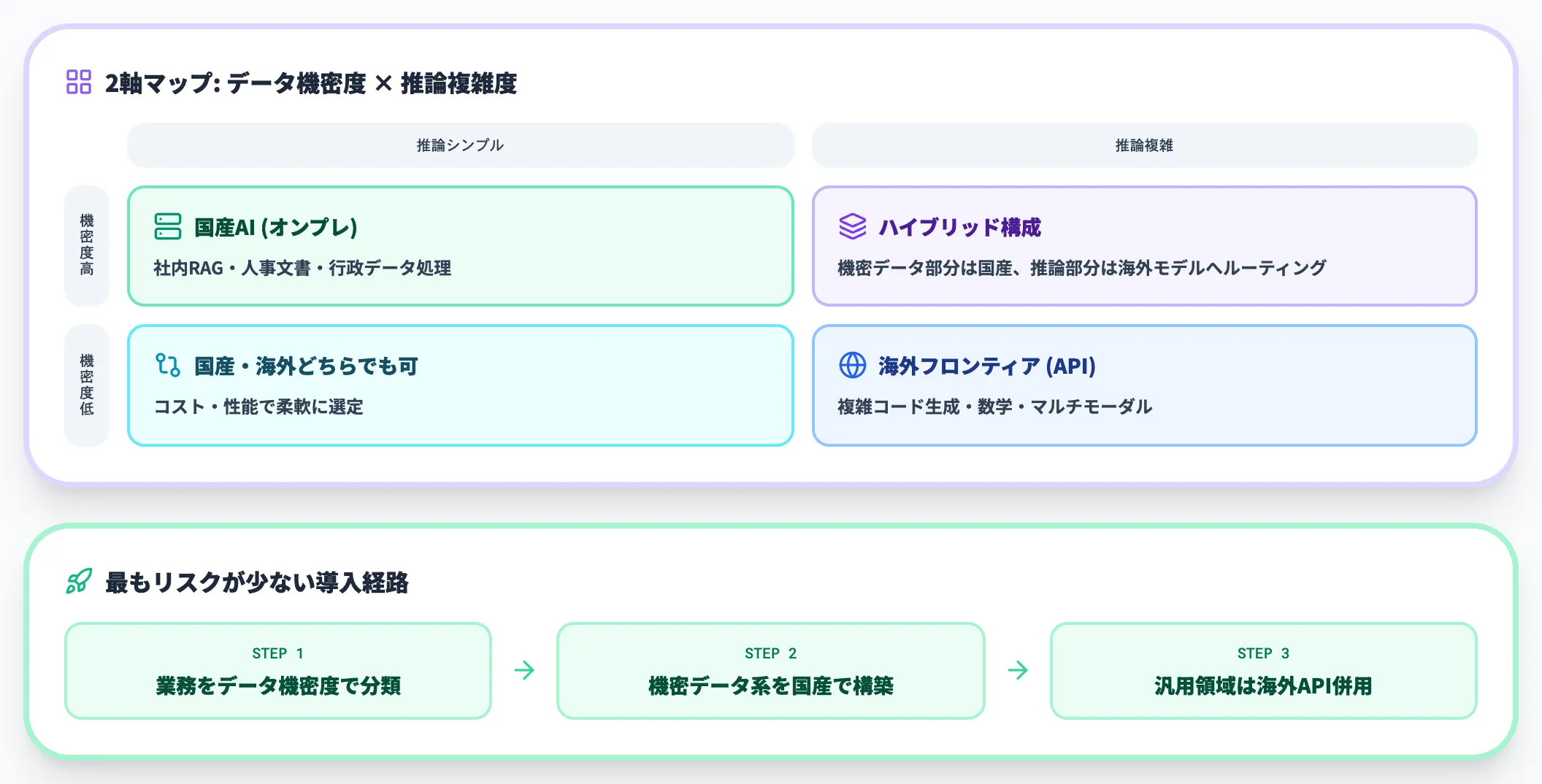
実務的な使い分けの基本パターンは、データの機密度と求める推論性能の2軸で分けるとシンプルになります。
-
国産AI(オンプレ/Bedrock Marketplace経由)が第一候補
社内文書のRAG・行政データの自動処理・LGWAN環境での社内問い合わせ・人事/法務文書の処理など、データ主権が重要な業務
-
海外フロンティアモデル(API)が第一候補
複雑なコード生成・高度な数学的推論・マルチモーダル分析・グローバル情報の集約など、汎用性能が必要な業務
-
両方の併用が必要
顧客向けエージェント実装で、対話部分は海外モデル、社内データ参照は国産モデル、というようなハイブリッド構成
実装の進め方としては、まず業務をデータ機密度で分類し、機密データ系業務だけ国産AIで構築するところから始めるのが、最もリスクの少ない導入経路です。
ハイブリッド構成の実装パターン
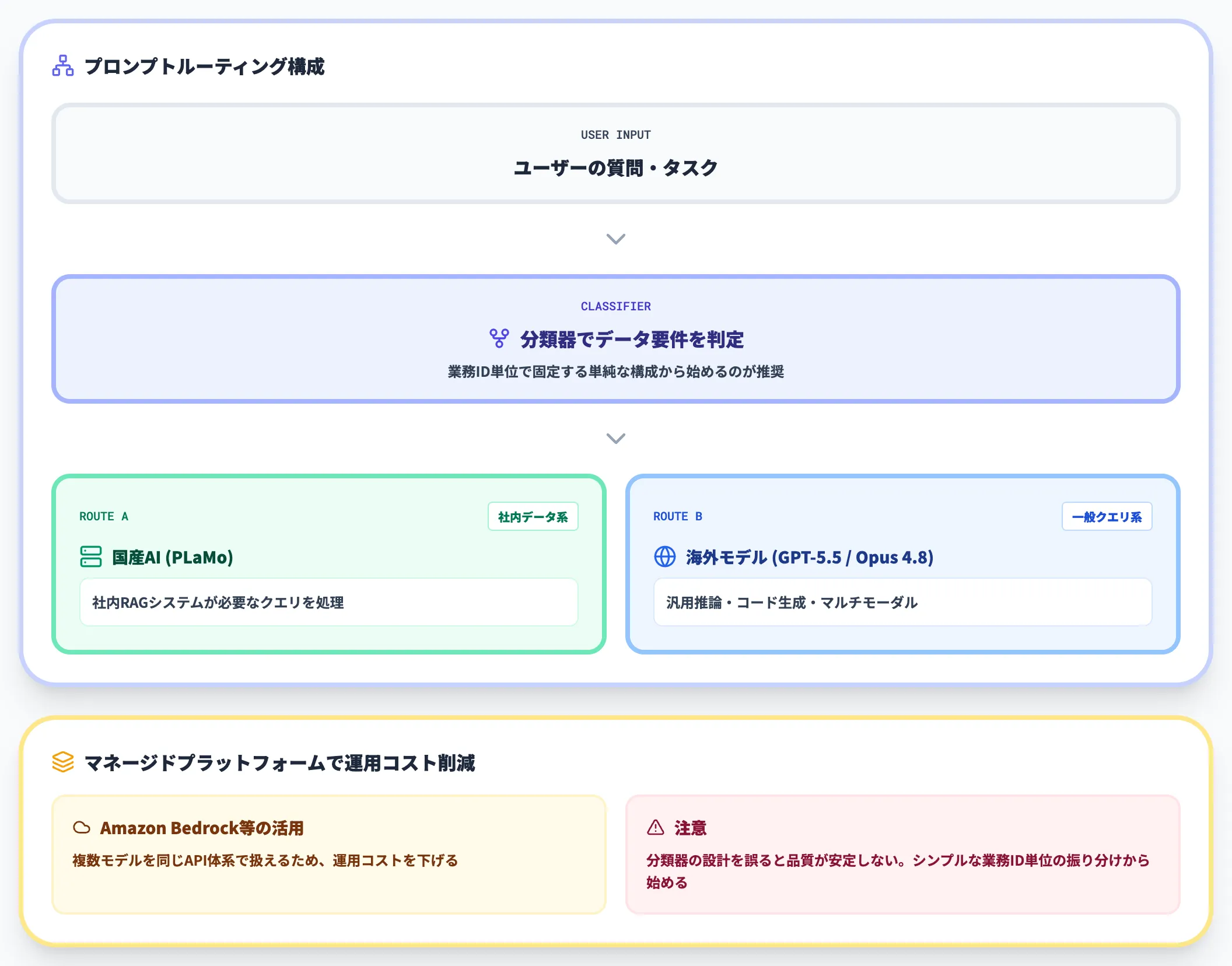
実装レイヤーでのハイブリッド構成は、プロンプトのルーティングで実現します。
たとえば社内RAGシステムなら、ユーザーの質問を最初に分類器で振り分け、社内データ参照が必要な質問はPLaMo、一般的な質問はGPT-5.5やClaude Opus 4.8に投げる、という構成が組めます。
Amazon Bedrockのようなマネージドプラットフォームは、複数モデルを同じAPI体系で扱えるため、ハイブリッド構成の運用コストを下げる選択肢として有効です。
ただしプロンプトルーティングは設計を誤ると品質が安定しないため、初期段階では「どの業務をどのモデルで処理するか」を業務ID単位で固定する単純な構成から始めることをおすすめします。
国産AI導入を検討すべき4つのトリガー条件
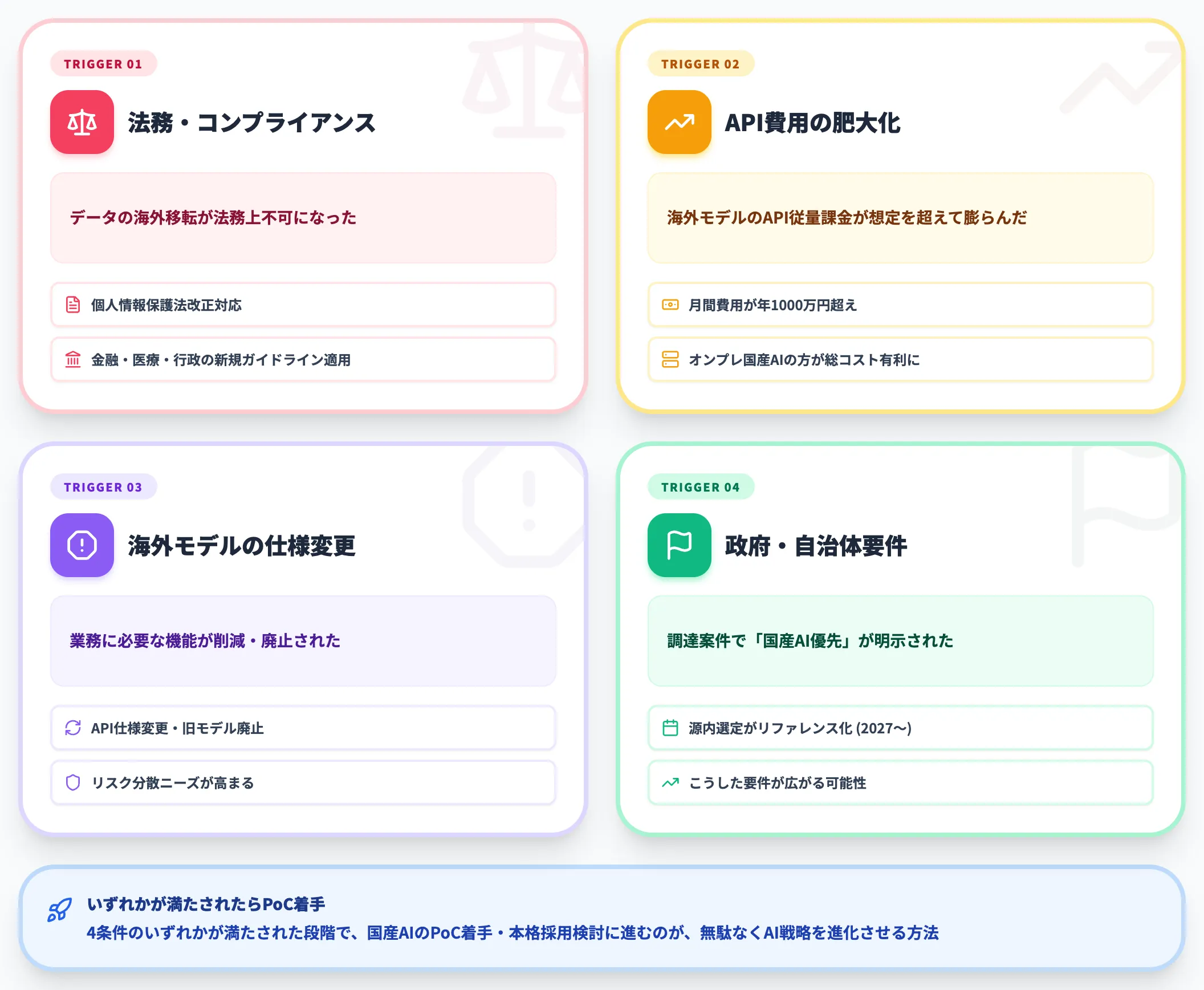
最後に、国産AIの本格導入を検討すべきタイミングを4つのトリガー条件で整理します。
-
データの海外移転が法務・コンプライアンス上不可になった
個人情報保護法改正対応、規制業界(金融・医療・行政)の新規ガイドライン適用など
-
海外モデルのAPI従量課金が想定を超えて膨らんだ
月間API費用が一定額(目安:年1,000万円超)を超えると、オンプレ国産AIの方が総コストで有利になるケースが出てくる
-
海外フロンティアモデルのアップデートで自社の業務に必要な機能が削減/廃止された
過去にもAPI仕様変更や旧モデル廃止で業務影響が出た事例があり、リスク分散のため国産AIの併用ニーズが高まる
-
政府・自治体の調達案件で「国産AI優先」要件が明示された
源内選定モデルがリファレンスとなる2027年以降は、こうした要件が広がる可能性が高い
これらの条件のいずれかが満たされた段階で、国産AIのPoC着手・本格採用検討に進むのが、無駄なくAI戦略を進化させる方法です。

国産AIを業務に定着させるためのリソース
国産AIの導入は「どのモデルを選ぶか」だけでなく、自社業務にどう適用するか・運用統制をどう設計するかが成功の分かれ目になります。
特に2026年は、海外モデルの性能進化と国産AIの登場が同時進行している過渡期で、業務分類とモデル選定の組み合わせ次第で投資対効果が大きく変わる時期です。
PoC段階でつまずく企業の多くは、「業務適用の設計」と「運用統制のチェックポイント」を後回しにしているケースが目立ちます。逆に、最初に業務分類とモデル選定の判断軸を固めた企業は、その後の展開がスムーズに進みます。
国産AIと海外AIを使い分けるための業務適用設計

データ主権要件と汎用性能を両立する導入の進め方
国産AIは「全て国産で揃える」より「機密データ系は国産、汎用推論は海外モデル」のハイブリッド運用が現実解になりつつあります。AI業務自動化ガイド(220ページ)では、PoC設計から全社展開まで、部門別のユースケース、データ要件に応じたモデル選定の判断軸、運用統制・セキュリティのチェックポイントまで体系的に整理しています。
まとめ
本記事では、国産AIの定義から主要モデル、料金、メリット・注意点、選び方、導入事例、海外モデルとのハイブリッド運用までを2026年6月時点で整理しました。
要点を1行ずつ振り返ります。
- 国産AIは3つの開発路線——フルスクラッチ純国産・海外OSSベース・海外モデル+自社チューニングの3パターンで進化している
- 政策レイヤーで4つの動きが進行——AI基本計画・GENIAC第4期に加え、報道ベースの大規模AI支援構想・ガバメントAI源内が国産AI市場を後押し
- 源内選定7モデルが事実上のリファレンス——tsuzumi 2/PLaMo 2.0 Prime/Llama-3.1-ELYZA-JP-70B/cotomi v3/Takane 32B/Sarashina2 mini/CC Gov-LLMが2027年4月以降の有償政府調達対象に予定
- 料金は海外フロンティアモデルと差——PLaMo APIは入力単価が1桁低い水準、tsuzumi 2は1GPU動作でオンプレも現実的
- データ主権・日本語精度・国内サポートが国産選択の実利——一方で汎用推論性能ではフロンティア海外モデルとのギャップが残る
- 選び方は4つの判断軸——データ要件・性能要件・提供形態・既存システム統合性
- ハイブリッド運用が現実解——機密データ系業務は国産、汎用推論は海外モデルの使い分けでリスク分散と性能最大化を両立
国産AIは「日本企業が使うべき選択肢」というレベルから、「業務ごとに最適なモデルを選ぶための重要な構成要素」へと位置付けが変わりつつあります。
2027年4月以降に予定されるガバメントAIの有償政府調達を1つの節目に、国産AI市場の競争構図はさらに鮮明になっていきます。今のうちに自社の業務分類とモデル選定の判断軸を整えておくことが、AI戦略の次の打ち手につながります。










