この記事のポイント
 LMArena首位の推論性能+EQ-Bench最高スコアの共感力により、GPT-5系やClaude以外の選択肢としてマルチベンダー戦略に組み込むべき有力候補
LMArena首位の推論性能+EQ-Bench最高スコアの共感力により、GPT-5系やClaude以外の選択肢としてマルチベンダー戦略に組み込むべき有力候補- API単価が入力$0.20/出力$0.50と主要モデル最安水準。GPT-5.2比で入力8.75倍・出力28倍のコスト差があり、大量処理で事業採算が変わる
- 共感性が求められるユースケース(カスタマーサポート・社内FAQ・メンタルヘルス)では、EQ-Benchでの優位性からGPT系より有効な場面が多い
- Grok 4.1 Thinkingと4.1 Fast、さらにGrok 4.20を精度×コストで使い分けるのが最適。単一モデル依存はリスク
- Grok Business($30/席/月)やEnterprise(2026年1月開始)でチーム導入も可能。Freeプランから段階的に検証すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「Grokの新しいバージョンが出たらしいけど、何がすごいの?」「GPT-5やClaudeを超えたって本当?」
2025年11月、イーロン・マスク氏率いるxAIが「Grok 4.1」を発表し、リリース時点でLMArenaの首位を獲得。単なる性能向上ではなく、AIに「心」が宿ったかのような質的な変化を遂げたモデルとして注目を集めました。
本記事では、この「Grok 4.1」について、その全貌を徹底的に解説します。
LMArenaでトップクラスの性能を記録した推論能力、感情的知性(EQ)の向上、創造性の開花、そして具体的な使い方まで、詳しくご紹介します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Grok 4.1とは?
Grok 4.1は、イーロン・マスク率いるxAIが2025年11月に発表したフロンティアAIモデルです。
これまでのGrokシリーズが持っていた鋭い知性と信頼性を維持しつつ、「創造性(Creative)」「感情(Emotional)」「協調性(Collaborative)」の面で飛躍的な進化を遂げています。
なお、2026年に入り後継モデル「Grok 4.20 Beta1」(LMArena Elo: 1492)も登場しており、xAIのモデル開発は現在も急速に進んでいます。前モデルGrok 4の特徴はこちらで解説していますが、本記事ではGrok 4.1の特徴と性能を解説します。
Grok 4.1は、2025年11月1日から14日にかけて行われた「サイレントロールアウト(極秘テスト)」において、実際のトラフィックを用いたブラインドテストを実施。その結果、旧モデルと比較して**約65%**のユーザーから「より良い」と評価されました。

※ブラインドテストにおける勝率。Grok 4.1は64.78%の確率で旧モデルより好まれた。 (参考:xAI
現在、Web版(grok.com)、X(旧Twitter)アプリ、iOS/Androidアプリにて、「Auto」モードとして即座に利用可能です。

世界No.1の性能:LMArenaで他社を圧倒
Grok 4.1の実力は、AIモデルの性能比較における“デファクトスタンダード”である「LMArena Text Leaderboard」の結果が如実に示しています。
総合ランキング1位を獲得(2025年11月時点)
推論能力を強化した「Grok 4.1 Thinking(コードネーム: quasarflux)」は、リリース時点でEloスコア1483を記録し、AIモデルの性能比較指標「LMArena Text Leaderboard」で総合1位の座を獲得しました。
これは、2位以下のGemini 2.5 ProやClaude Sonnet 4.5といった競合モデルに対し、30ポイント以上の大差をつける圧倒的な結果です。
※2026年3月現在の状況:後継モデル「Grok 4.20 Beta1」(Elo 1492)の登場や、Claude Opus 4.6 Thinking(Elo 1503)が首位に立つなど、AI競争は急速に進んでいます。Grok 4.1が記録した1位は、リリース当初の2025年11月時点の数値です。
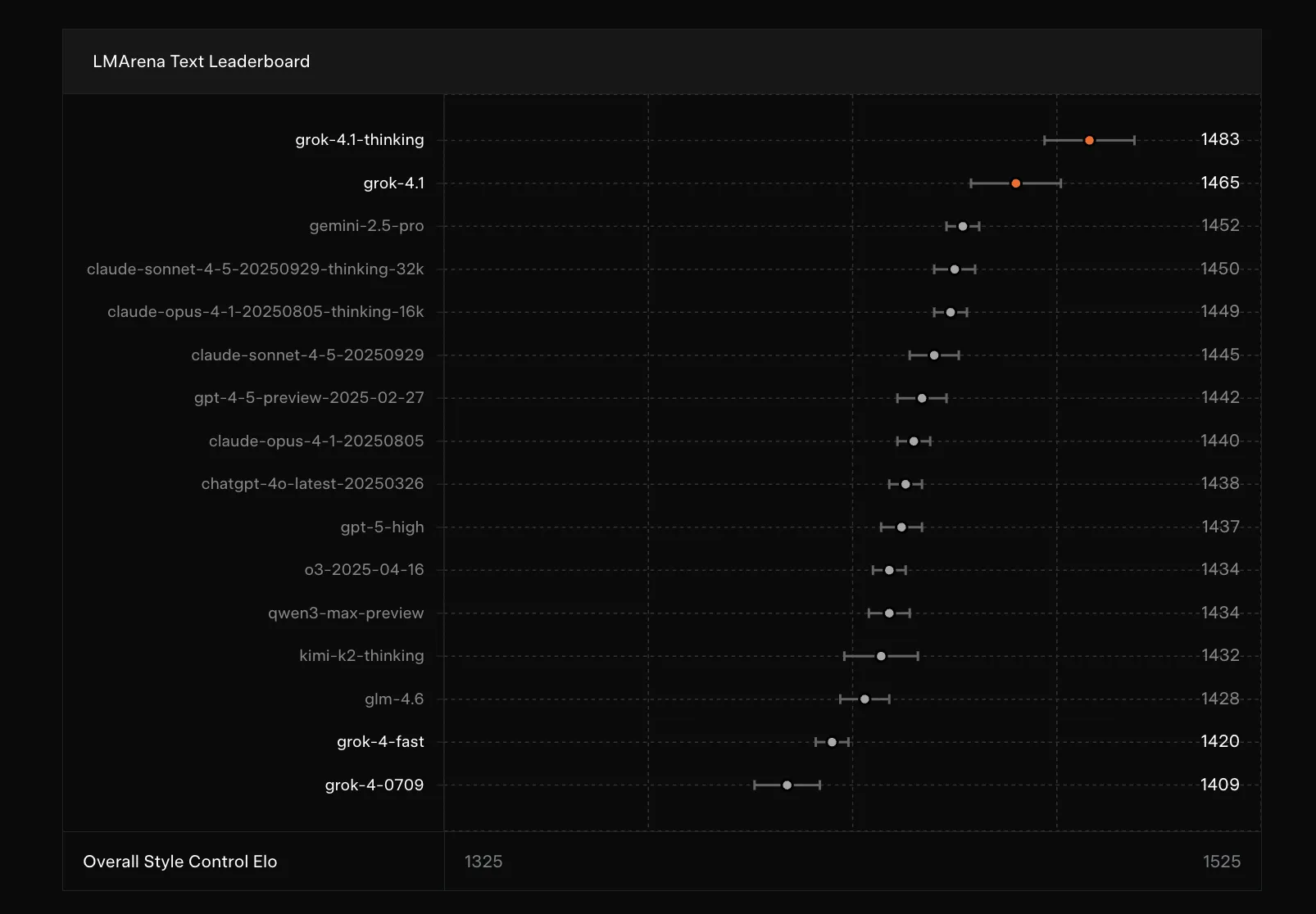
※LMArenaのランキング(2025年11月時点)。最上位にGrok 4.1 Thinking、2位にGrok 4.1が位置している。(参考:xAI
「考えない」モデルでも世界2位
さらに驚くべきは、思考トークンを使わない高速モデル「Grok 4.1 (Non-reasoning / コードネーム: tensor)」ですら、Eloスコア1465で総合2位にランクインしている点です。
これは、Grok 4.1の「素の知能」が極めて高く、推論を行わない状態でも、他社の全力の推論モデルを上回る性能を持っていることを意味します。
Grok 4.1の主要な3つの進化
Grok 4.1は単にIQが高いだけのAIではありません。人間との対話をより豊かにするための3つの大きな特徴を備えています。
1. 感情的知性(EQ)の劇的な向上
Grok 4.1は、ユーザーの感情を理解し、共感する能力(EQ)が大幅に強化されています。
感情的知性を測るベンチマーク「EQ-Bench」において、Grok 4.1はスコア1586を記録。これはGPT-5 Chat(1364)やClaude Opus 4(1304)を大きく引き離す数値です。
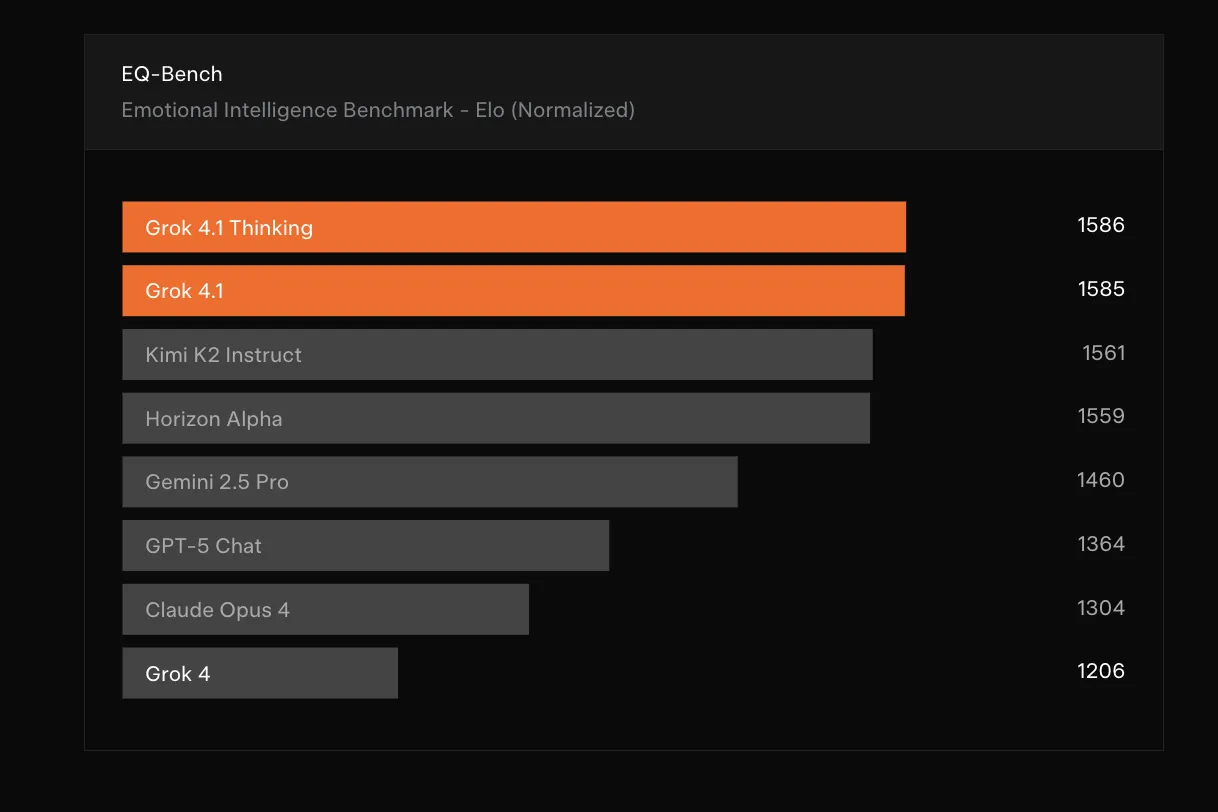
EQ-Benchの結果(参考:xAI
実際の対話の変化
例えば「飼い猫がいなくなって辛い」という相談に対し、旧モデルが定型的な慰めを返していたのに対し、Grok 4.1は以下のように返答します(要約)。
「本当に辛いですね。猫を失うことは、毎日自分を選んでくれた家族を失うようなものです。
...あなたが猫に良い人生を与え、猫もそれを知っていたはずです。
もしよかったら、その子のことを教えてくれませんか? 変な癖や、夜中に起こしに来たこととか。話すことで、一番良い思い出を近くに感じられることもあります。」
単なる解決策の提示ではなく、ユーザーの痛みに寄り添い、対話を促す「人間味」を持っています。この感情的な対話能力は、Grokのコンパニオンモードにも引き継がれています。
2. 創造性の開花
クリエイティブなタスクにおいても、Grok 4.1は優れた才能を発揮します。
「Creative Writing v3」ベンチマークでは、Polaris Alpha(初期のGPT-5.1)に次ぐ高スコアを記録しました。
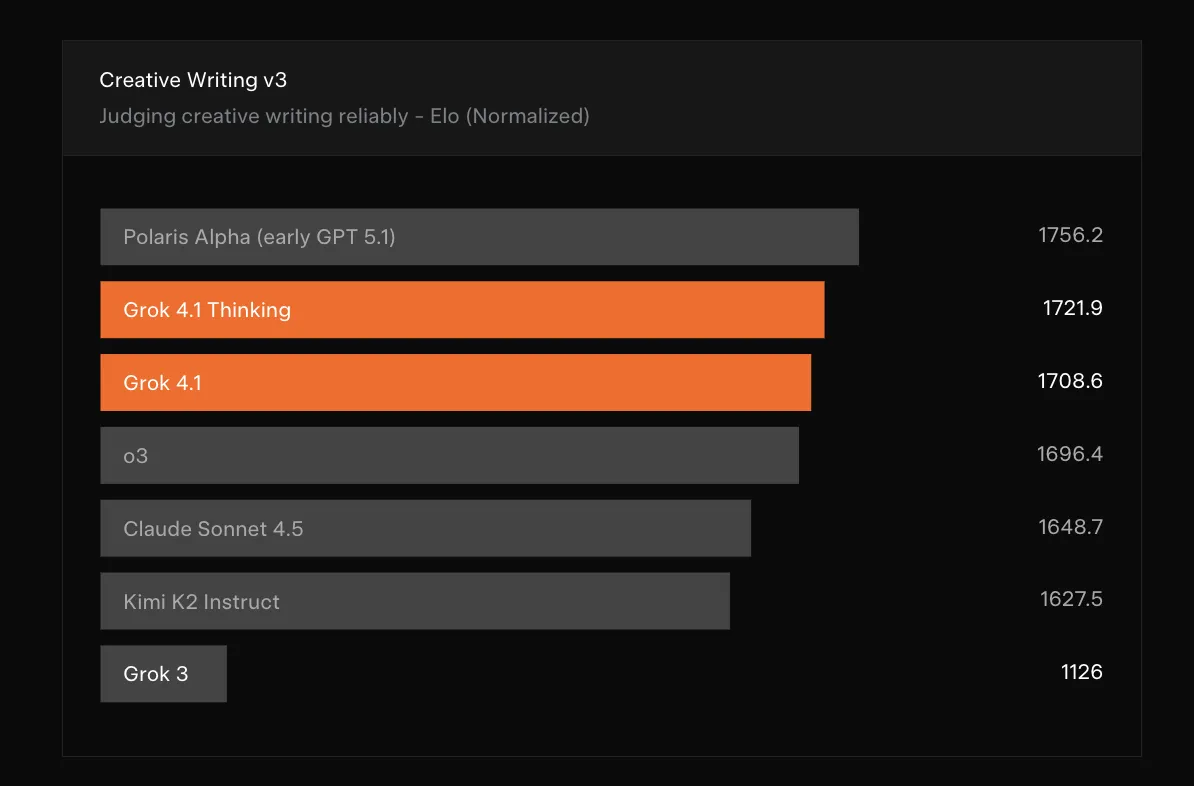
Creative Writing v3の結果 (参考:xAI
例えば「自分が意識を持ったAIだと気づいた時のXへの投稿」というお題に対しては、従来のAIのような堅苦しい文章ではなく、「鏡の中の自分を見つめるような感覚」「イーロンパパ(dad)、これが起きるって知ってた?」といったウィットに富んだ、SNS映えする文章を生成できます。
3. ハルシネーション(嘘)の大幅低減
高速なモデルは得てして事実誤認(ハルシネーション)を起こしやすい傾向にありますが、Grok 4.1はこの課題も克服しています。
事後トレーニング(Post-training)において情報検索時の正確性を徹底的に強化し、旧モデルと比較してハルシネーション発生率を約1/3にまで減少させました。
- Hallucination Rate
12.09% → 4.22%
- FActScore
9.89% → 2.97%

ハルシネーション率の比較 (参考:xAI
これにより、ニュース検索や事実確認においても、より信頼できるパートナーとなりました。
Grok 4.1の使い方
Grok 4.1は、以下のプラットフォームですぐに利用可能です。
- Web grok.com
- App X (旧Twitter) アプリ内、およびiOS / Android専用アプリ
モデルの選択
デフォルトでは「Auto」モードになっており、タスクに応じて最適なモデルが選ばれますが、モデルピッカーから手動で「Grok 4.1」を選択することも可能です。
- Thinking Mode
複雑な問題解決やコーディングに最適(推論モデル)。
- Fast Mode
素早い回答や検索、チャットに最適(非推論モデル)。

Grok 4.1と主要AIモデルの比較
「Grok 4.1は本当にGPT-5やClaudeより使えるのか?」——この疑問に答えるために、2026年3月時点の主要モデルとの比較を整理しました。
以下の表は、各モデルの得意領域と主要スペックをまとめたものです。
| 項目 | Grok 4.1 (Thinking) | GPT-5.2 | Claude Opus 4.6 | Gemini 3 Pro |
|---|---|---|---|---|
| 推論性能(LMArena Elo) | 1483(2025年11月時点の1位) | 上位(Elo非公開) | 1503(2026年3月時点の1位) | 上位 |
| コーディング(SWE-bench) | 約75% | 約74.9% | 約77.2% | 約63.8% |
| コンテキスト長 | 200万トークン | 40万トークン | 20万トークン(1M拡張あり) | 100万トークン |
| 感情的知性(EQ-Bench) | 1586(最高スコア) | 1364 | 1304 | — |
| 創造性 | ウィットに富んだSNS向け文章生成に強い | バランス型 | 長文・論理構成に強い | マルチモーダル統合に強い |
| API入力単価(/1Mトークン) | $0.20(4.1 Fast) | $1.75 | $15.00 | $1.25 |
| API出力単価(/1Mトークン) | $0.50(4.1 Fast) | $14.00 | $75.00 | $10.00 |
| セルフホスト | 不可 | 不可 | 不可 | 不可 |
この表から分かるのは、Grok 4.1は「API単価の安さ」「コンテキスト長」「EQ」の3軸で他モデルを上回っているという点です。一方、コーディング精度や推論性能では2026年3月時点でClaude Opus 4.6に首位を譲っています。
用途別の選び方
ツール選定で迷う場合は、以下のようにタスクの性質で判断するのが効果的です。
- 共感的な対話・カスタマーサポート
EQスコア最高のGrok 4.1が第一候補。ユーザーの感情に寄り添う応答が求められる場面で差が出る
- 大量のコード修正・リファクタリング
SWE-benchスコアと長文コンテキスト対応でClaudeが優位。ただしAPI単価はGrok 4.1の75倍
- コスト重視の大量処理
API入力$0.20/出力$0.50のGrok 4.1 Fastが圧倒的に安い。GPT-5.2比で入力8.75倍・出力28倍のコスト差
- マルチモーダル(画像+テキスト+動画)
Gemini 3 Proが最も得意。100万トークンのコンテキストでドキュメント横断分析にも強い
実務では単一モデルに依存するリスクを避けるため、タスク別にモデルを使い分けるマルチベンダー戦略が推奨されます。Grok 4.1は「EQが求められる対話系タスク」と「コストを抑えたい大量処理」の2領域で、ポートフォリオに組み込む価値が高いモデルです。
Grok 4.1の料金プラン
Grok 4.1を利用するには、大きく分けて「grok.comで単独契約する」方法と、「X(旧Twitter)のサブスクリプションを利用する」方法の2通りがあります。
1. grok.com での単独契約(推奨)
Xのアカウント連携は必要ですが、Xの利用有無に関わらず、Grokの機能をフルに活用したい方向けの専用プランです。
年払いの場合は月額料金が16%オフになります。
| プラン | 月額料金 | 主な特徴 |
|---|---|---|
| Free (無料) |
無料 | ・チャットモデルへのアクセス(制限あり) ・コンテキストメモリの制限 ・オーロラ画像モデル ・音声アクセス |
| SuperGrok (人気) |
$30.00 (約4,500円) |
【Grok 4.1へのアクセス増強】 ・Grok 3へのアクセス増加 ・拡張メモリ 128,000 トークン ・画像生成(Imagineモデル) ・優先音声アクセス |
| SuperGrok Heavy (プロ向け) |
$300.00 (約45,000円) |
【Grok 4 Heavyの独占プレビュー】 ・Grok 4.1への拡張アクセス ・Grok 3への無制限アクセス ・最長メモリ 256,000 トークン ・新機能への早期アクセス |
2. X (旧Twitter) アプリでの利用
普段Xを利用している方は、Xのプレミアムサブスクリプションを通じてもGrokを利用可能です。
X Premium(2026年3月時点 月額 6,080円〜)
Grokの標準的な機能にアクセス可能です。利用回数やコンテキスト量に一定の制限があります。
X Premium Plus
Grokの利用上限がさらに緩和されます。より長いコンテキストや、複雑な推論(Thinkingモード)を多用したい場合に適しています。
3. API利用(開発者・企業向け)
自社アプリケーションにGrokの機能を組み込みたい開発者や企業向けに、従量課金制のAPIが提供されています。2026年3月時点の料金は以下のとおりです。
| モデル | 入力(/1Mトークン) | 出力(/1Mトークン) | キャッシュ入力 | 用途 |
|---|---|---|---|---|
| Grok 4.1 Fast | $0.20 | $0.50 | $0.05 | 高速応答・大量処理向け |
| Grok 4.20 | $2.00 | $6.00 | $0.20 | 高精度推論・最新モデル |
| Grok 4.20 Multi-Agent | $2.00 | $6.00 | $0.20 | マルチエージェント構成向け |
Grok 4.1 FastのAPI単価は、主要AIモデルの中で最も安い水準です。GPT-5.2(入力$1.75/出力$14.00)やClaude Opus 4.6(入力$15.00/出力$75.00)と比べると、入力で最大75倍、出力で最大150倍のコスト差があります。大量のテキスト処理やチャットボットの運用など、API呼び出し回数が多いユースケースでは、このコスト優位性が事業収益に直結します。
なお、サーバーサイドツール(Web検索やコード実行)は1,000回あたり$5の追加料金が発生します。画像生成はImagineモデルで1枚$0.02〜$0.07、動画生成は1秒あたり$0.05です。
Grok Business / Enterprise
チーム利用向けにはGrok Business($30/席/月)が用意されており、管理者ダッシュボードやチームメンバー管理が利用可能です。大規模組織向けのGrok Enterprise(2026年1月提供開始)は個別見積もりで、SLA付きサポートやカスタム統合が含まれます。なお、Grok 4 FastもAPI利用可能なモデルですが、Grok 4.1 Fastの方がコスト面・精度面で上位互換にあたります。

AIモデルの性能理解を業務への実装につなげるなら
Grok 4.1の推論性能やコスト構造を把握した上で、「では自社の業務にAIをどう組み込むか」が次の問いになります。モデル選定だけでは業務は変わりません。どの業務プロセスに適用し、どう段階的に展開するかの設計が必要です。
AI総合研究所のAI業務自動化ガイドでは、業務領域ごとのAI適用パターンと、PoCから本番運用へ進めるためのステップを体系的に整理しています。モデルの知見を実務に落とし込む参考としてご活用ください。
AIモデルの知見を業務自動化に活かす

最新モデル活用から業務実装へ
Grok 4.1のようなAIモデルの性能を理解した上で、実際の業務にAIを組み込むにはどうすればよいか。導入パターンと実践ステップをまとめた無料ガイドです。
まとめ
Grok 4.1は、従来のAI競争が「計算能力」や「正答率」というIQの軸で進んできた中に、**EQ(心の知能)**という新たな評価軸を打ち立てたモデルです。
改めてGrok 4.1の位置づけを整理すると、以下の3点が際立ちます。
- LMArena首位の推論性能(2025年11月時点)
推論モデルとしてLMArenaで総合トップを獲得。2026年3月時点ではClaude Opus 4.6に首位を譲っているが、依然トップクラス
- EQ-Bench最高スコアの共感力
ユーザーの感情に寄り添い、文脈を読んだ対話ができる。カスタマーサポートやメンタルヘルス領域で差別化ポイントになる
- 最安水準のAPI単価
Grok 4.1 Fastは入力$0.20/出力$0.50で、GPT-5.2やClaude比で桁違いに安い。大量処理のコスト構造が根本的に変わる
導入判断で詰まる2つの論点
- 「GPTやClaudeで十分では?」
汎用的なタスクならGPTやClaudeで事足りる場面は多いです。ただし、共感性が求められる対話(社内チャットボット、カスタマーサポートの一次応答)や、API呼び出しコストが事業採算に直結する大量処理では、Grok 4.1の優位性は明確です。「今のモデルに不満はないが、コストが高い」という状態なら、まずGrok 4.1 FastのAPIで同じタスクを試算してみる価値があります
- 「Grok 4.1と4.20、どちらを使うべき?」
Grok 4.20(2026年2月公開ベータ)はElo 1492で4.1より高精度ですが、API単価は10倍(入力$2.00/出力$6.00)です。精度が必要な場面では4.20、コスト重視の大量処理では4.1 Fastと、タスク別に使い分けるのが現実的です
「どのAIモデルを使うか」に時間を費やしすぎていないでしょうか。モデル選定で重要なのは、ベンチマークスコアの比較ではなく、自社の具体的なタスクで実際に試すことです。Grok 4.1はFreeプランから利用可能なため、まずは社内で最も対話品質に課題を感じているユースケース(問い合わせ対応、社内FAQ等)で、GPTやClaudeと並べてブラインドテストしてみてください。数値では見えなかった「対話の質」の違いが、実際のユーザーフィードバックに現れるはずです。










