この記事のポイント
 AIモデルは「学習済みのAI成果物」。GPT-4.5やClaudeなどの生成系から教師あり/なし/強化学習まで、目的に応じて最適なモデルを選ぶべき
AIモデルは「学習済みのAI成果物」。GPT-4.5やClaudeなどの生成系から教師あり/なし/強化学習まで、目的に応じて最適なモデルを選ぶべき- 教師あり学習は正解データがある分類・回帰タスクに最適。ラベル付きデータがあれば最も確実に成果が出る手法
- 教師なし学習は顧客セグメンテーションや異常検知など、正解ラベルなしでパターンを発見する場面で有効
- AIモデル構築は目的設定→データ収集→前処理→モデル選択→トレーニング→評価→展開→保守の8ステップ。PoCから始めて段階的に改善すべき
- 2026年はエッジ推論・説明可能AI(XAI)・他分野融合が進展。精度追求と倫理的配慮の両立が企業AI活用の鍵

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIモデルとは、GPT-4.5やClaudeに代表される「学習済みの人工知能」であり、データをもとに解析・予測・生成を行うための仕組みです。教師あり学習・教師なし学習・強化学習の3種類に大別され、目的に応じて最適なモデルを選択します。
本記事では、AIモデルの定義からアルゴリズムとの違い、主要モデル一覧(GPT/Claude/Gemini等)、作成プロセスの8ステップ、PythonとGoogle Colabを使った実装例まで体系的に解説します。
目次
Claude(Anthropic)等、他の生成系AIモデル一覧
教師あり学習モデル(Supervised Learning)
教師なし学習モデル(Unsupervised Learning)
AIモデルとは

AIモデルとは、GPT-4.5などに代表される「学習済みの人工知能」や、データをもとに解析・予測・生成を行うための一連の仕組みのことです。
この言葉は2つの意味で使われることが多く、混乱しやすいポイントです。
-
狭義のAIモデル:GPT-4.5、Claude、Stable Diffusionのような、学習済みのAIモデルそのもの
-
広義のAIモデル:アルゴリズムや学習プロセスを含む、AIによる出力全体の仕組み
この記事では、両方の意味を整理しながら、AIモデルの定義、アルゴリズムとの違い、代表例、活用例までわかりやすく解説します。

AIモデルとアルゴリズムの違い
AIモデルとアルゴリズムは、AIの仕組みを理解する上で重要な概念ですが、異なる意味を持ちます。
| 項目 | 概要 | 例 |
|---|---|---|
| AIアルゴリズム | 学習や推論を行うための手順・計算ルール | Transformer、決定木、ニューラルネットワークなど |
| AIモデル | アルゴリズムを使って学習されたAIの成果物(知識・振る舞い) | GPT-4.5、Claude、BERT、DALL·Eなど |
アルゴリズムは「学び方」、モデルは「学びの結果」
【関連記事】
➡AIアルゴリズムとは?その一覧やモデルごとの違い、活用例を徹底解説
AIモデルの代表例一覧(生成系)
まずは、生成AIモデルの代表例を見ていきます。気になるモデルがあればその詳細はリンクをクリックして確認してください。
ChatGPT(OpenAI)の主要モデルの一覧
以下は、OpenAIが提供するChatGPTの主要なモデルの一覧です。
| モデル名 | シリーズ | 提供開始 | 特徴・用途 |
|---|---|---|---|
| GPT-4o(Omni) | GPTシリーズ | 2024年5月 | マルチモーダル(テキスト・画像・音声)対応。ChatGPTの標準モデルに。 |
| GPT-4.1 | GPTシリーズ | 2025年4月 | 100万トークン対応の長文処理、コーディングにも最適。GPT-4の後継。 |
| o1 | oシリーズ | 2024年12月 | 深い推論能力に特化。科学・数学・競技プログラミングなど専門用途に強い。 |
| ┗ o1-mini | oシリーズ | 同上 | 軽量版で高速処理。コストを抑えたい用途に。 |
| ┗ o1-pro | oシリーズ | 同上 | 推論強化版。複雑な問題への対応力が高い。 |
| o3 | oシリーズ | 2025年4月 | OpenAI史上最高レベルの推論力。視覚・コード・検索など統合的に対応。 |
| ┗ o3-mini | oシリーズ | 同上 | 軽量版。日常業務レベルでの推論やQ&Aに適す。 |
| ┗ o3-mini-high | oシリーズ | 同上 | パフォーマンス強化版。中規模エンタープライズ用途に。 |
Claude(Anthropic)等、他の生成系AIモデル一覧
OpenAI以外にも、様々な企業がAIモデルを開発しています。以下は、ClaudeやGeminiなどの代表的なモデルの一覧です。
| モデル名 | リリース日 | 主な特徴 | 提供元 |
|---|---|---|---|
| Claude 3.7 Sonnet | 2025年2月 | ハイブリッド推論能力を備えた最新モデル、200Kのコンテキストウィンドウ | Anthropic |
| Claude 3.5 Sonnet | 2024年6月20日 | コーディングやマルチステップワークフローに強みを持つモデル | Anthropic |
| Stable Diffusion 3.5 | 2024年10月22日 | 多様な画像生成ができるオープンソースモデル、カスタマイズ性が高い | Stability AI |
これらのモデルは、それぞれ異なる特徴や強みを持っており、用途や目的に応じて最適なモデルを選択することが重要です。
AIモデルの種類
次は、AIモデルはアルゴリズムの違いによって、様々な種類に分けられます。
ここでは代表的な3つのAIモデルを紹介します。
教師あり学習モデル(Supervised Learning)
教師あり学習モデルは、正解ラベルが付いたデータセットを使って学習を行うモデルです。モデルは、入力と正解(ターゲット)の対応関係を学習し、未知のデータに対しても正確な予測を行えるようになります。
特徴と活用例
- 各データに「正解」がある(例:「この画像は車」など)
- 入力と出力の関係を関数として学習
- **分類問題(スパム判定など)**や、**回帰問題(価格予測など)**に活用
例:車の画像に「車」というラベルを付けて多数の画像を学習させることで、モデルは車の特徴を把握し、新しい画像から「これは車」と判断できるようになります。
教師なし学習モデル(Unsupervised Learning)
教師なし学習モデルは、ラベル(正解)が付いていないデータをもとに学習します。モデル自身がデータ内の構造やパターンを見つけ出し、分類や特徴抽出を行います。
特徴と活用例
- 正解ラベルがないため、構造的なパターン検出に適する
- クラスタリング(顧客の傾向分析など)や、次元削減(特徴量の圧縮)に利用
例:顧客データから似た行動パターンのグループを自動で抽出し、マーケティング戦略に活用。
強化学習モデル(Reinforcement Learning)
強化学習モデルは、環境と相互作用しながら報酬を得る形で学習を行います。成功や失敗を繰り返す中で、どの行動が最も効果的かを自ら学んでいく点が特徴です。
特徴と活用例
- 試行錯誤と報酬を通じた学習
- ゲームAI、ロボット制御、自動運転技術などで使用
例:ゲームのプレイヤーAIが、初めは弱いものの、プレイを重ねることで戦略を学び、強くなっていく仕組みです。
学習モデルの組み合わせも有効
現実のAIアプリケーションでは、これらの学習手法を組み合わせて使うこともよくあります。
例えば、教師あり学習で得た特徴量を、教師なし学習でクラスタリングして新しいパターンを見つける、というアプローチです。
各モデルにはそれぞれ得意分野と限界があるため、目的に応じて最適な手法を選ぶことが、AI活用の成否を左右します。AIと機械学習の階層的な関係についてはGoogle Cloudの解説も参考になります。

AIモデルの作成方法
AIモデルの作成は、目的設定からデータ収集、前処理、モデル選択、トレーニング、評価、展開、保守までの一連のプロセスを経て行われます。
ここでは、各ステップについて詳しく説明します。
【目的の設定】
AIモデルを作成する最初のステップは、明確な目的を設定することです。
解決すべき問題や、達成したい目標を具体的に定義します。例えば、「スパムメールを自動的に検知するシステムを構築する」といった目的を設定します。
この目的に基づいて、必要なデータの種類やモデルの選択肢を絞り込めます。
【データの収集】
目的に沿ったデータを収集します。データは、モデルの学習に使用される重要な資源であり、質と量の両面で適切なものを用意する必要があります。
データは、既存のデータセットを利用したり、Web上からスクレイピングしたり、専門家に依頼して作成したりと、様々な方法で収集できます。
【データの前処理】
収集したデータは、そのままではモデルの学習に適さない場合があります。
欠損値や異常値の処理、データの正規化、特徴量の選択などの前処理を行い、データを整理します。
また、カテゴリカルデータの数値化や、テキストデータの単語へのトークン化など、モデルに合わせたデータ形式への変換も必要です。
【データの分割】
前処理が終わったデータは、トレーニングデータとテストデータに分割します。トレーニングデータは、モデルの学習に使用され、テストデータは、学習済みモデルの性能評価に使用されます。
一般的には、データの70〜80%をトレーニングデータ、残りの20〜30%をテストデータとして割り当てます。
【モデルの選択】
目的に応じて、適切なモデルを選択します。
モデルの選択には、タスクの種類(分類、回帰、クラスタリングなど)や、データの特性(次元数、サンプル数など)を考慮します。
また、モデルの複雑さや、計算リソースの制約なども考慮すべき点です。
代表的なモデルとしては、決定木、ランダムフォレスト、サポートベクターマシン、ニューラルネットワークなどがあります。
【モデルのトレーニング】
選択したモデルを、トレーニングデータを用いて学習させます。
学習の際には、モデルのパラメータを調整しながら、損失関数の最小化や、評価指標の最大化を目指します。
トレーニングには、確率的勾配降下法などの最適化アルゴリズムが用いられます。また、過学習を防ぐために、正則化手法やアーリーストッピングなどのテクニックも活用されます。
【モデルの評価】
トレーニングが終わったモデルを、テストデータを用いて評価します。
評価指標は、タスクの種類によって異なりますが、分類タスクであれば、精度、適合率、再現率、F1スコアなどが用いられます。
回帰タスクでは、平均二乗誤差(MSE)や、平均絶対誤差(MAE)などが用いられます。評価結果に基づいて、モデルの改善点を洗い出し、必要に応じてモデルの調整やデータの追加を行います。
【モデルの展開】
評価を経て、十分な性能が確認されたモデルを、実際の運用環境に展開します。
展開の方法は、Webアプリケーションに組み込む、APIとして公開する、エッジデバイスに実装するなど、様々な選択肢があります。
展開の際には、モデルの実行速度やメモリ使用量など、運用環境での制約にも配慮が必要です。
【モデルの保守】
展開後も、モデルの性能を継続的にモニタリングし、必要に応じて更新や再トレーニングを行います。
データの分布が変化したり、新しい種類のデータが追加されたりした場合には、モデルの再学習が必要になることがあります。
また、モデルの動作に異常がないか、定期的にチェックすることも重要です。
以上が、AIモデルの作成における一連の流れです。
実際のプロジェクトでは、これらのステップを繰り返し、モデルの性能を徐々に改善していきます。また、モデルの解釈性や、倫理的な配慮なども、AIモデルの作成において重要な要素となります。
AIモデルの実装
それでは実際にAIモデルを実装してみます。
Google ColabでAIモデルを実装する手順について説明します。ここでは簡単な模擬データを使い、Pythonの機械学習ライブラリを活用して簡単な分類タスクを実施します。
1.Google Colabのセットアップ
まず、Google Colabにログインし、新しいPythonノートブックを作成します。
2.ライブラリのインストール
Colabには多くのPythonライブラリがデフォルトでインストールされていますが、必要に応じて追加でインストールします。
今回は、以下のコマンドを実行して必要なライブラリをインストールします。
!pip install numpy pandas matplotlib scikit-learn
このコマンドにより、以下の4つのライブラリをインストールしています。
- numpy
数値演算のライブラリで、ベクトルや行列の計算などに使用します。 - pandas
データの読み込みや操作などに使われるライブラリです。データフレームという形式でデータを管理します。 - matplotlib
データの可視化に使用するライブラリです。グラフや図の描画を行えます。 - scikit-learn
機械学習アルゴリズムの実装やモデルの構築、評価に使われるライブラリです。
3.データの準備
次に、模擬データを作成します。ここでは簡単な2次元のデータセットを作成し、2つのクラスに分類します。
import numpy as np
import pandas as pd
# ランダムな2次元データを作成
np.random.seed(42)
class_1 = np.random.randn(50, 2) + np.array([1, 1])
class_2 = np.random.randn(50, 2) + np.array([-1, -1])
# データフレームに変換
df_1 = pd.DataFrame(class_1, columns=['Feature1', 'Feature2'])
df_1['Class'] = 0
df_2 = pd.DataFrame(class_2, columns=['Feature1', 'Feature2'])
df_2['Class'] = 1
# データを結合
df = pd.concat([df_1, df_2])
df = df.sample(frac=1).reset_index(drop=True) # データの順番をシャッフル
ここでは、以下の二つの特徴に沿ってデータを分類しています。
- Class0
正規分布に従う50個のデータからなり、中心点が(1, 1)の近くにあります。このグループは、全体的にポジティブな特徴を持っています。
- Class1
こちらも正規分布に従う50個のデータからなり、中心点が(-1, -1)の近くにあります。全体的にネガティブな特徴を持っています。
4.データの可視化
次に、作成したデータをプロットします。
import matplotlib.pyplot as plt
plt.scatter(df[df['Class'] == 0]['Feature1'], df[df['Class'] == 0]['Feature2'], color='blue', label='Class 0')
plt.scatter(df[df['Class'] == 1]['Feature1'], df[df['Class'] == 1]['Feature2'], color='red', label='Class 1')
plt.legend()
plt.xlabel('Feature1')
plt.ylabel('Feature2')
plt.show()
データが二つのグループ(赤と青)に分類されていることが視覚的にわかると思います。
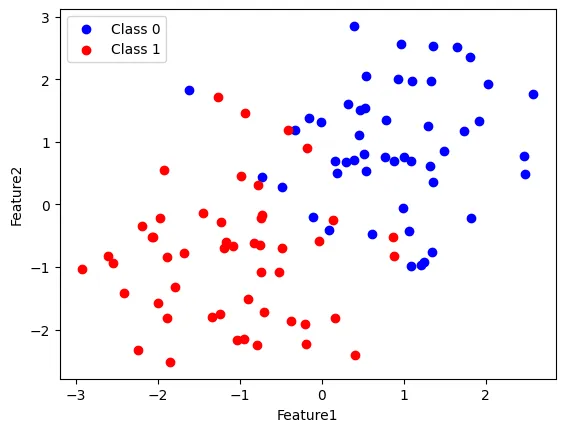
プロット結果
5.データの分割
作成したデータをトレーニングデータとテストデータに分割します。
データの80%をトレーニングデータに、20%をテストデータにしています。
from sklearn.model_selection import train_test_split
X = df[['Feature1', 'Feature2']]
y = df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
6.モデルの構築
トレーニングデータを使用し、ロジスティック回帰を用いて、モデルを構築します。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
7.モデルの評価
最後に、テストデータでモデルを評価します。
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
y_test(テストセットの真のラベル)とy_pred(予測ラベル)を比較して正解率を計算します。
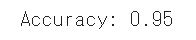
正答率
計算したところ正確率は0.95でした。
以上が、Google Colabを使ったAIモデルの実装例です。
実際のプロジェクトでは、データの前処理や特徴量エンジニアリング、モデルの選択とハイパーパラメータの調整など、より複雑なステップが含まれますが、基本的な流れは同様です。
Pythonの機械学習ライブラリを活用することで、比較的簡単にAIモデルの構築と評価を行えます。
ただし、モデルの性能を最大限に引き出すためには、データの質や量、モデルの選択、パラメータの調整など、様々な要因を考慮する必要があります。
AIモデルの展望
AIモデルは、その発展とともに多様な分野での応用が広がり、未来に向けてさらなる進化が期待されています。
その展望についていくつかの観点から説明します。
モデルの高精度化
AIモデルの性能は、アルゴリズムの改良やデータ量の増加により、今後さらに向上することが期待されます。
特に、ディープラーニングにおける新しいアーキテクチャの開発や、転移学習の活用などにより、より高精度なモデルが実現されます。
医療診断や金融取引など、高い信頼性が求められる分野での活用が進むと考えられます。
エッジデバイスでの推論
AIモデルの推論処理を、クラウドではなくエッジデバイス(スマートフォン、IoTデバイスなど)で行う技術が発展しています。
エッジ推論により、通信遅延の低減や、プライバシーの保護、リアルタイム性の向上などができるようになります。
今後は、エッジデバイスに最適化された軽量なモデルの開発が進み、様々な場面でのAIの活用が広がります。
説明可能なAI(XAI)
AIモデルの判断根拠を人間が理解できる形で説明する技術(XAI)への関心が高まっています。
特に、医療や金融など、意思決定の透明性が求められる分野では、XAIの重要性が増しています。
今後は、モデルの高精度化と並行して、説明可能性の向上に向けた研究開発が進むと予想されます。AIの信頼性確保についてはNISTのAIリスク管理フレームワークも参照してください。
AIと他分野の融合
AIモデルは、様々な分野と融合することで、新たな価値を生み出せます。
例えば、ロボティクスとの融合により、より自律的で知的なロボットの開発ができるようになります。また、材料科学との融合により、新材料の開発やプロセス最適化が加速します。
AIと他分野の専門家が協力し、分野横断的なイノベーションを創出することが期待されます。
倫理的・法的課題への対応
AIモデルの社会実装が進む中で、倫理的・法的な課題への対応がより重要になっています。
AIによる意思決定の公平性や、プライバシーの保護、責任の所在など、様々な論点について議論が必要です。
AIモデルは、社会のあらゆる分野に影響を与える可能性を秘めています。
技術的な進歩を追求しつつ、倫理的・法的な課題にも真摯に向き合うことで、AIモデルがもたらす恩恵を最大限に引き出せます。

AIモデルの基礎理解から組織のAI活用方針を定める
AIモデルの種類や作成方法を理解したことで、自社の業務課題にどのタイプのAIが適しているかを判断する基盤ができたはずです。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進める実践ガイド(220ページ)を無料で提供しています。AIモデル選定後の業務適用設計からPoC→全社展開まで、部門別のBefore/After付きで解説しています。
AI総合研究所が、AIモデルの理解を組織のAI導入方針として定めるためのガイドをお届けします。
AIモデルの知見を組織導入に活かす

Microsoft環境でのAI業務自動化ガイド
AIモデルの理解が深まったら、次は組織としてどう業務に組み込むかの設計が重要です。Microsoft環境での段階的なAI導入設計を220ページで解説する実践ガイドを無料でお届けします。
まとめ
本記事では、AIモデルの定義から種類、作成方法、Python実装例、将来の展望まで体系的に解説しました。
この記事で得られる3つの価値は以下の通りです。
-
AIモデルの全体像の理解
AIモデルは「アルゴリズムを使って学習されたAIの成果物」であり、GPT-4.5やClaude、Stable Diffusionなどの生成系モデルから、分類・回帰に使う教師あり学習モデルまで多種多様です。狭義と広義の定義を理解することで、自社の課題に適したモデル選択ができます。 -
3つの学習手法とモデル作成プロセスの把握
教師あり学習・教師なし学習・強化学習の特性を整理し、8ステップ(目的設定→データ収集→前処理→分割→モデル選択→トレーニング→評価→展開)のモデル作成プロセスを示しました。本記事のPython実装例を参考に、まずは小規模データから試せます。 -
AI技術の今後の方向性
エッジデバイスでの推論、説明可能AI(XAI)、他分野との融合など、AIモデルの進化の方向性を把握できます。倫理的・法的課題への対応も含め、自社のAI戦略を検討する基盤が得られます。
まずは自社で解決したい課題(分類・予測・生成)を特定し、本記事のGoogle Colabサンプルコードを参考にPoCを実施してみてください。AIモデルの基礎と最新動向についてはAWSのAI・機械学習解説も参考になります。










