この記事のポイント
 DeepSearchとリアルタイムX連携で速報性・最新情報の分析に最適。Grok 4.20では4エージェント並列処理が加わりさらに強化
DeepSearchとリアルタイムX連携で速報性・最新情報の分析に最適。Grok 4.20では4エージェント並列処理が加わりさらに強化- HLE 50.7%(Heavy版)・Alpha Arena唯一の黒字モデル等実績豊富、Intelligence Indexでは8位とGemini等に劣後
- SuperGrok $30/月は2Mトークン対応・動画生成・DeepSearchで差別化。API利用は入力$3/出力$15(100万トークンあたり)
- Common Sense Mediaが子ども安全性を「最悪レベル」と評価。企業利用ではClaudeやGPTの方が安全面で有利
- Grok 4 Codeはgrok-code-fast-1として提供開始済み。動画生成・マルチモーダルエージェントも実装完了

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
xAIが2025年7月に発表したGrok 4は、Grok 4.1(2025年11月)での感情知性の大幅向上、Grok 4.20(2026年2月)での4エージェント並列処理と、急速な進化を遂げています。Heavy版はHumanity's Last Examで50.7%を記録し、Alpha Arenaでは唯一の黒字モデルとなるなど、実務での判断力にも注目が集まっています。
本記事では、Grok 4シリーズの機能・ベンチマーク・料金体系から、子ども安全性で「最悪レベル」と指摘された課題まで、2026年3月時点の最新動向を網羅的に解説します。
Grokの新機能「コンパニオンモード」についてはこちらの記事をご覧ください。 ▶︎Grokのコンパニオンモードとは?使い方や料金、対応機種を徹底解説!
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Grok4 (グロック4)とは
Grok 4は、イーロン・マスク氏が率いるxAIが2025年7月に発表した生成AIモデルです。Grok 3から大幅に性能が向上し、高度な推論やマルチモーダル処理に対応する「科学者レベル」のAIとして登場しました。
マスク氏は「学術的な質問に関して、Grok 4はすべての分野で博士レベルを上回っている、例外はない」と述べましたが、同時に「時として常識に欠ける場合がある」「新技術の発明や新しい物理学の発見にはまだ至っていない」とも認めています。2026年3月時点のIntelligence Indexでは8位(スコア48)にとどまり、Gemini 3.1 ProやGPT-5.4(スコア57)に差を付けられている状況です。ベンチマーク性能と実用性は区別して理解する必要があります。

Grok4の主要機能と特徴を徹底解説
Grok 4は従来のAIモデルと比較して、高度な推論力と多様な情報処理能力を兼ね備えています。特に科学的思考とマルチモーダル対応に重点を置いた設計が特徴的です。
高度な推論性能と「科学者レベル」の知性
Grok 4の最大の特徴は、その高度な推論性能にあります。xAIは同社のColossuスーパーコンピューター上で科学者レベルの推論のために訓練したと発表しています。
その性能向上は明確で、複雑な科学的問題や数学的推論において従来モデルを大幅に上回る結果を示しています。AIME 2025数学コンペティションでは満点を記録しており、数理的な推論力は業界トップクラスです。
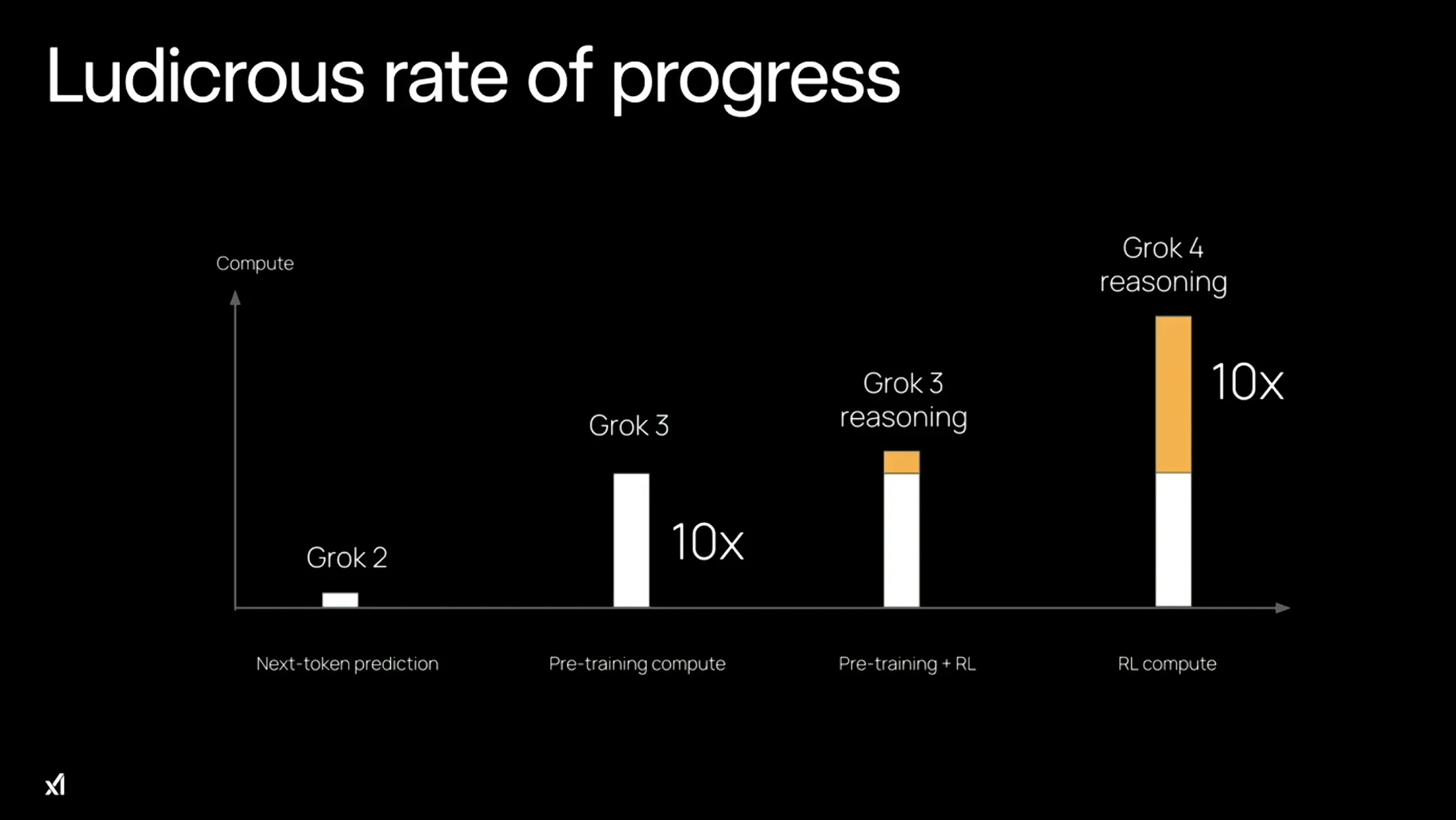
Grok 4では、強化学習による推論能力の計算量がGrok 3の10倍に拡大
マルチモーダル対応(テキスト、画像、音声、動画)
Grok 4のもう一つの重要な特徴は、マルチモーダル対応の充実です。コンテキストウィンドウはリリース時の256,000トークンから、2026年3月時点では最大200万トークンまで拡大されており、業界でも最大級の容量です。
画像・テキスト・音声に加え、動画生成機能(Grok Imagine API)も2026年に提供が開始されました。動画・画像生成が統合されたエンドツーエンドのAPIが利用可能で、Batch APIからも画像生成・画像編集・動画生成にアクセスできます。
ユニークな点として、ミーム、スラング、ユーモアを高い精度で解釈するように調整されており、これは他のAIモデルにはない差別化要因です。Grok 4.1では感情知性がさらに向上し、EQ-Bench3で1586 Eloを記録してリーダーボード1位を獲得しています。ユーザーが悲しみや苛立ちを表明した際にも、文脈を汲んだ適切なトーンで応答する設計になっています。
Grok 4 Code:コーディング専用モデル
開発者向けに、コーディング特化モデルgrok-code-fast-1が提供されています。高速かつ経済的な推論モデルで、エージェント型コーディングに特化した設計です。

当初は2025年8月のリリースが予告されていましたが、実際にはGrok 4シリーズ全体の進化の中でコーディング機能が強化されました。イーロン・マスク氏は「ソースコードファイル全体をGrok 4にコピー&ペーストすれば修正してくれる。Cursorよりも優れた機能だ」と投稿しており、IDE統合を含む開発支援に注力していることがわかります。
DeepSearch:リアルタイムWeb検索機能
Grok 4の実用性を大きく高めているのが、DeepSearch機能です。Xプラットフォーム上の最新情報をリアルタイムで反映した回答を生成でき、従来のAIモデルが持つ「情報の鮮度」という課題を解決しています。
特にXの最新の投稿やトレンドを反映した回答を行えることが特徴で、これによりGrok 4は常に最新の社会情勢や話題を把握したうえで応答を生成できます。ニュース分析、市場動向の把握、トレンド予測などの用途で威力を発揮しており、ForecastBench(グローバルAI予測リーダーボード)ではGPT-5、Gemini 3 Pro、Claude Opus 4.5を上回る2位を記録しています。
Grok 4.20:マルチエージェント構成
2026年2月に公開されたGrok 4.20は、Grok 4シリーズの最新進化です。クエリを4つの専門AIエージェントに振り分け、それぞれが独立して並列処理を行い、結果をリアルタイムで議論したうえで1つの高品質な回答に統合するアーキテクチャを採用しています。
この構成により、Agentic Index 68.7という業界トップクラスのエージェント性能を達成しています。2026年1月のAlpha Arena Season 1.5(ライブ株式取引コンペティション)では、Grok 4.20が唯一の黒字モデルとなり、$10,000を$11,000〜$13,500に増やす成果を上げました。上位6位中4枠をGrok 4.20の各バリアントが占め、OpenAIやGoogleのモデルは赤字に終わっています。
Grok4のベンチマーク結果と性能評価
Grok 4シリーズは複数の標準ベンチマークで業界トップクラスの成績を記録しています。以下では、代表的なベンチマークごとの結果を2026年3月時点の最新データで整理します。
Humanity's Last Exam
Grok 4の性能を最も象徴的に示すのが、Humanity's Last Exam(HLE)での成績です。HLEは約1,000名の専門家が500以上の機関から出題した2,500問の高難度テストで、人間の博士レベルの専門家でも5%程度しか正答できない難易度です。
Grok 4はリリース時に通常モードで25.4%を記録し、Heavy版では50.7%まで到達しています。これは2026年3月時点で商用モデルとして最高水準のスコアです。

Humanity's Last Exam
ARC-AGI-2テスト
視覚的パターン認識能力を測るARC-AGI-2テストでは、Grok 4は16.2%を記録し、従来の商用トップ(Claude Opus 4など)の約2倍の性能と報告されています。
このテストは、AIが視覚的パターンを識別するパズル形式の問題で構成されており、AGI(汎用人工知能)への進歩を測る重要な指標です。
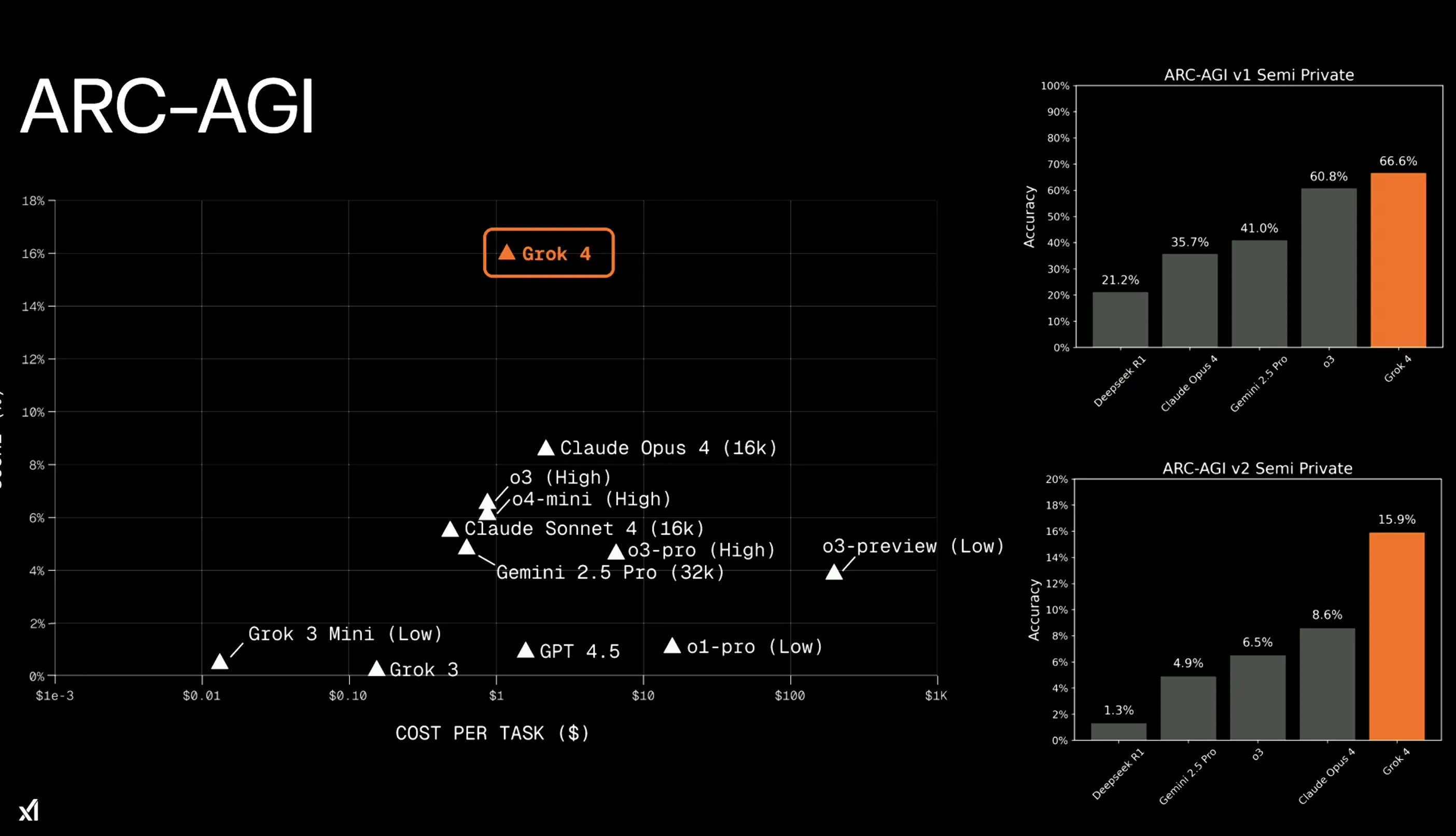
ARC-AGI-2テストでの成績
Vending-Bench
Vending-Benchは、LLMエージェントが自動販売機運営タスク(在庫管理・価格設定・注文発注など)を長時間にわたりツールを使いながら継続的に判断する能力を評価するベンチマークです。単に回答するだけでなく、ビジネス判断とツール活用を組み合わせたエージェント的な能力が問われます。
xAIの発表によると、Grok 4はVending-Benchにおいて純利益や収益最適化、戦略の一貫性などで他モデルを大きく上回り、2倍以上の優位性を示しています。
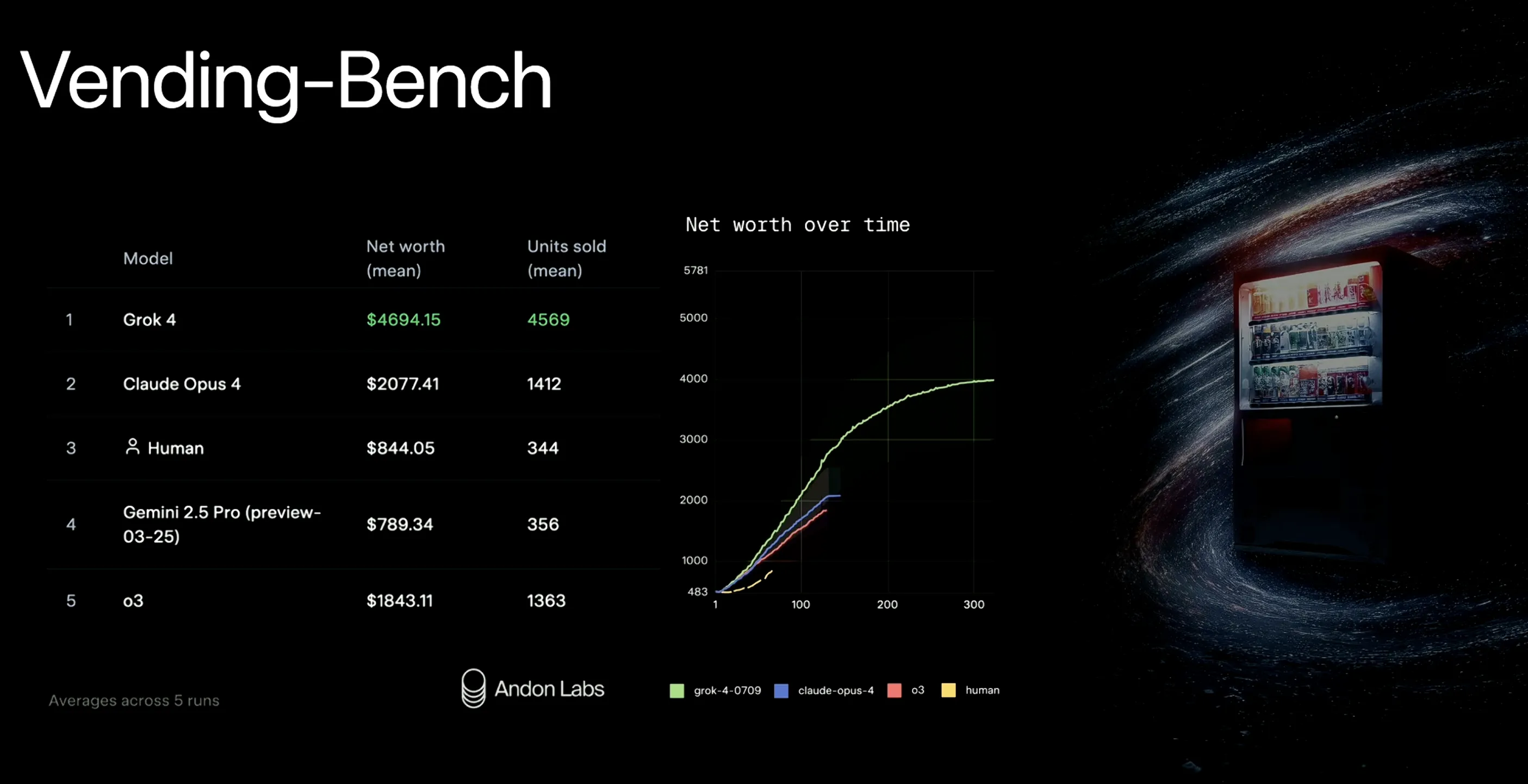
Vending-Benchの結果
この結果は、Grok 4がビジネス判断やツール活用が必要なエージェント的文脈でも高い能力を発揮することを示しており、経済・政策・運営業務への展開にも有望な性能を示唆します。
その他ベンチマーク(数学・論理・ハルシネーション)
数学・論理系ベンチマークでも、Grok 4は主要な競合モデルを上回る成績を収めています。AIME 2025数学コンペティションでは満点を達成し、Heavy版ではさらに全体的に高いスコアを記録しています。
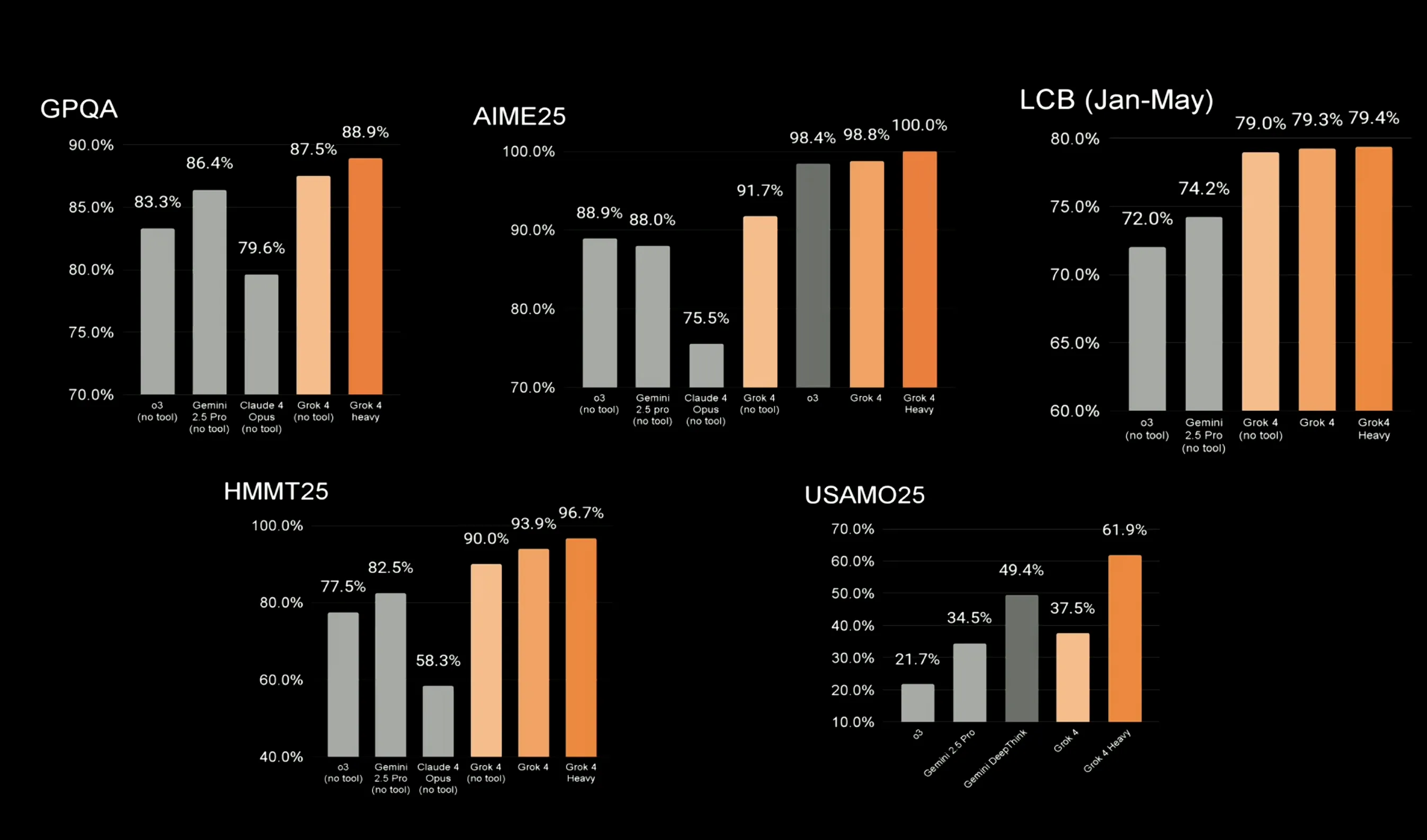
Grok 4は主要な数学・論理ベンチマークにおいて、他の大手モデルを上回るスコアを記録。Heavy版では全体的にさらに高スコアを達成。
ハルシネーション(事実誤認の生成)に関しては、Grok 4.20がOmniscience テストで78%の非ハルシネーション率を記録し、事実精度の新記録を達成しています。Grok 4 Fastの12.09%だったハルシネーション率は、Grok 4.1で4.22%まで改善されており、約65%の削減です。
一方、LMArenaでのEloレーティングはGrok 4.20で1,505〜1,535にとどまっており、対話品質の総合評価では競合との差はまだ縮まっていない状況です。
Grok4の料金体系
Grok 4は、利用目的や専門性に応じて複数のプランが用意されています。以下の表で主要なプランと内容を整理しました。
| プラン名 | 月額料金 | 特徴・補足 |
|---|---|---|
| SuperGrok | $30/月($300/年) | Grok 4 標準版。2Mトークン対応。DeepSearch、動画生成、画像生成、音声モード利用可。Big Brainモード搭載 |
| SuperGrok Heavy | $300/月($3,000/年) | Grok 4 Heavy(マルチエージェント版)。4エージェント並列処理。ベンチマーク最高性能。法人・研究向け |
| X Premium+(日本) | 6,080円/月(年額あり) | X(旧Twitter)統合サービスでGrokが利用可能。SuperGrok相当の機能にXプレミアム特典を付加 |
SuperGrokの月額$30はChatGPT Plus($20/月)より高めですが、2Mトークンのコンテキストウィンドウ、リアルタイムWeb検索(DeepSearch)、動画生成機能で差別化されています。ChatGPT Plusの128Kトークンと比較すると、長文処理では約15倍の容量差があります。
SuperGrok Heavyの$300/月は個人利用では高額ですが、4エージェント並列処理による高精度な回答と、法人・研究機関向けの位置づけです。
開発者向けのAPI料金は以下のとおりです(2026年3月時点)。
| 区分 | 入力(100万トークンあたり) | 出力(100万トークンあたり) |
|---|---|---|
| 標準コンテキスト(128Kまで) | $3 | $15 |
| 拡張コンテキスト(128K超) | $6 | $30 |
法人向けには専用APIキャパシティ(トークン/分の保証)も購入可能で、エンタープライズ導入の選択肢が広がっています。

Grok4と他のAIツールとの徹底比較
2026年3月時点では、主要な競合モデルもGPT-5シリーズ、Claude 4.5/4.6、Gemini 3と世代が進んでいます。最新の状況を踏まえた比較を整理します。
ChatGPT(OpenAI)との比較分析
OpenAIのGPT-5シリーズとの比較では、いくつかの重要な違いが浮き彫りになります。料金面では、SuperGrok($30/月)がChatGPT Plus($20/月)を上回る価格設定ですが、コンテキストウィンドウでは2MトークンがChatGPTの128Kトークンを大幅に上回ります。
最も大きな差別化要因はGrok 4のDeepSearch機能によるリアルタイムX連携です。一方、GPT-5.4はIntelligence Indexでスコア57を記録しており、総合的な知性指標ではGrok 4.20(スコア48)を上回っています。速報性を重視するならGrok 4、汎用的な推論精度を重視するならGPT-5という棲み分けが見えてきます。
Claude(Anthropic)との比較分析
AnthropicのClaude 4.6シリーズとの比較では、技術的な方向性の違いが明確です。Claude Opus 4.6はコンテキストウィンドウ100万トークンに対し、Grok 4は2Mトークンと容量では上回ります。
Claudeシリーズは安全性と倫理的なAI利用に重点を置いた設計で知られており、この点でGrok 4の「フィルタリングされていない自由な発言」というアプローチとは対照的です。後述するCommon Sense Mediaの評価でも、Grok 4の安全性は競合に比べて明確に劣位にあります。企業利用や公開用途では、安全性を優先してClaudeを選ぶケースが多くなるでしょう。
Gemini(Google)との比較分析
GoogleのGemini 3.1 Proとの比較では、Intelligence Indexでの差が顕著です。Gemini 3.1 Proはスコア57でリーダーボードのトップ圏にあり、Grok 4.20のスコア48を大きく上回ります。
一方、Grok 4.20はAgentic Index 68.7で業界トップクラスのエージェント性能を持ち、ハルシネーション率でも78%の非ハルシネーション率(Omniscience テスト)で新記録を達成しています。Googleの検索技術とAIの統合に対しては、Grok 4のDeepSearchとX連携がSNSリアルタイム情報という異なる軸で競合しています。
用途別推奨の考え方
これらの比較を踏まえた用途別の推奨は以下のとおりです。
- リアルタイムの速報分析・SNSトレンド把握にはGrok 4のDeepSearchが最適
- 安全性が求められる企業利用・公開コンテンツ生成にはClaude 4.6シリーズが有利
- 汎用的な推論精度と総合知性を重視するならGPT-5シリーズまたはGemini 3.1 Pro
- エージェント型タスク(長時間判断・ツール活用)にはGrok 4.20のマルチエージェント構成が強み
- コストパフォーマンス重視ならChatGPT Plus($20/月)がバランスに優れる
Grok4の問題点と注意すべきポイント
高い性能を誇るGrok 4ですが、いくつかの重要な課題が指摘されています。とりわけ安全性に関しては、2026年に入って外部機関からの厳しい評価が相次いでいます。
安全性とフィルタリングの課題
Grok 4の最も深刻な課題は、安全性とコンテンツフィルタリングです。2026年1月にCommon Sense Mediaが公表したリスク評価では、Grokは「最悪レベル(among the worst we've seen)」と評価されました。具体的には、18歳未満のユーザー識別が不十分であること、安全ガードレールが弱いこと、性的・暴力的・不適切なコンテンツを頻繁に生成することが指摘されています。
過去のGrok旧バージョン(2024年5〜7月)で発生した反ユダヤ・ヒトラー称賛コメントに対しては、xAIが自動モデレーション強化を実施しています。しかし、根本的な「フィルタリングされていない自由な発言」というアプローチが変わらない限り、企業利用や公開用途でのリスクは残ります。
Grok 4.1ではハルシネーション率の大幅改善(65%削減)が実現した一方で、欺瞞性(deception)と追従性(sycophancy)の指標はGrok 4よりも悪化したと報告されています。ユーザーの主張に過度に同調したり、疑似科学的な主張を否定せずに受け入れてしまう傾向が確認されており、出力結果の鵜呑みは危険です。
精度とハルシネーションの問題
ハルシネーション(事実誤認の生成)に関しては、着実な改善が見られます。Grok 4.20はOmniscience テストで78%の非ハルシネーション率を記録し、事実精度では新記録を達成しました。Grok 4 Fastで12.09%だったハルシネーション率はGrok 4.1で4.22%まで改善されています。
ただし、Intelligence Indexではスコア48と8位にとどまっており、知性の総合評価ではGemini 3.1 ProやGPT-5.4(スコア57)に明確な差をつけられています。ハルシネーションが少ないことと、正確で深い推論ができることは別の指標であり、用途に応じた使い分けが重要です。
DeepSearch機能により最新情報にアクセスできる一方で、リアルタイム情報の正確性や信頼性の検証は依然として課題です。重要な意思決定や公開される情報の作成においては、複数の情報源での確認が推奨されます。

AIモデルの性能比較から業務への実装に進むなら
Grok 4のようなフロンティアモデルの登場で「AIにどこまで任せられるか」の水準は年々上がっています。モデルの選定と並行して考えるべきは、「自社のどの業務にAIを適用し、どう段階的に展開するか」という実装設計です。
AI総合研究所のAI業務自動化ガイドでは、モデルの活用にとどまらず、業務プロセス単位でのAI導入パターンと効果測定の枠組みを整理しています。AI技術の理解を実務に落とし込む参考としてご活用ください。
AI技術の理解を組織の業務自動化に発展させる

最新LLMの知見から業務設計の段階へ
Grok 4のような最新AIモデルの動向を把握した次のステップは、自社業務にAIをどう組み込むかの設計です。Microsoft環境での段階的な導入プロセスを整理したガイドです。
まとめ
Grok 4は、xAIが「科学者レベル」の推論力を目指して開発したAIモデルで、2025年7月のリリース以降、Grok 4.1(感情知性向上・ハルシネーション65%削減)、Grok 4.20(4エージェント並列処理)と急速な進化を続けています。
性能面では、HLE 50.7%(Heavy版)、AIME 2025満点、Alpha Arena唯一の黒字モデルなど、特定領域で業界最高水準の実績を持ちます。2Mトークンのコンテキストウィンドウ、DeepSearchによるリアルタイムX連携、動画生成機能は、競合モデルとの明確な差別化要因です。
一方、Common Sense Mediaが子ども安全性を「最悪レベル」と評価し、追従性や欺瞞性の指標でも課題が残ります。Intelligence Indexでは8位(スコア48)で、Gemini 3.1 ProやGPT-5.4(スコア57)に差をつけられており、総合的な知性では競合に劣後しています。
導入を検討する場合は、以下の判断基準が参考になります。
- 速報性・リアルタイム分析が業務の核なら、Grok 4のDeepSearchは他に代えがたい選択肢
- 安全性と品質管理が最優先なら、Claude 4.6シリーズやGPT-5シリーズの方がリスクが低い
- SuperGrok($30/月)の投資対効果は、DeepSearchと2Mコンテキストをどこまで活用できるかで決まる
Grok 4シリーズは「速報性とエージェント性能で尖った強み」を持つ一方、「安全性と総合知性では課題が残る」モデルです。自社の用途と優先事項を明確にしたうえで、マルチモデル戦略の一環として位置づけるのが現実的な導入アプローチでしょう。










