この記事のポイント
 API利用コストを最優先で抑えたい企業は、DeepSeek-V3.2を第一候補にすべき。競合の1/10以下の料金でGPT-5級の性能が得られる
API利用コストを最優先で抑えたい企業は、DeepSeek-V3.2を第一候補にすべき。競合の1/10以下の料金でGPT-5級の性能が得られる- 推論精度が求められるタスクにはSpecialeモデルが最適で、IMO・IOI金メダル級の数理・コード能力を低コストで活用できる
- エージェント設計ではThinking in Tool-Use機能が有効で、推論とツール操作を同時に行う複雑なワークフローに対応可能
- MITライセンスのオープンソースであるため、自社サーバーへのセルフホストやモデルカスタマイズが必要な場合に避けるべき制約がない
- ただしデータの国外送信リスクを考慮すべきであり、機密データを扱う業務ではセルフホスト運用かAPI利用時のデータポリシー確認が必須

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2025年12月1日、中国のAIスタートアップDeepSeekは、推論能力とエージェント機能を大幅に強化した最新モデル「DeepSeek-V3.2」および「DeepSeek-V3.2-Speciale」を発表しました。これらはGPT-5レベルの推論性能を持ちながら、DeepSeek Sparse Attention (DSA)技術により計算効率を高め、オープンソースかつ低コストで利用できる点が特徴です。
本記事では、このDeepSeek-V3.2シリーズについて、技術的特徴からベンチマーク性能、料金体系、そして具体的な使い方まで、その全貌を徹底的に解説します。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
DeepSeek Sparse Attention (DSA)
Thinking in Tool-Use(ツール使用における推論統合)
DeepSeek-V3.2とは?
DeepSeek-V3.2は、DeepSeek-V3.1-Terminusの後継モデルとして開発された大規模言語モデルです。
2025年9月に実験版である「DeepSeek-V3.2-Exp」がリリースされ、この実験版をベースに、推論能力とエージェント機能を大幅に強化した正式版が「DeepSeek-V3.2」および「DeepSeek-V3.2-Speciale」です。
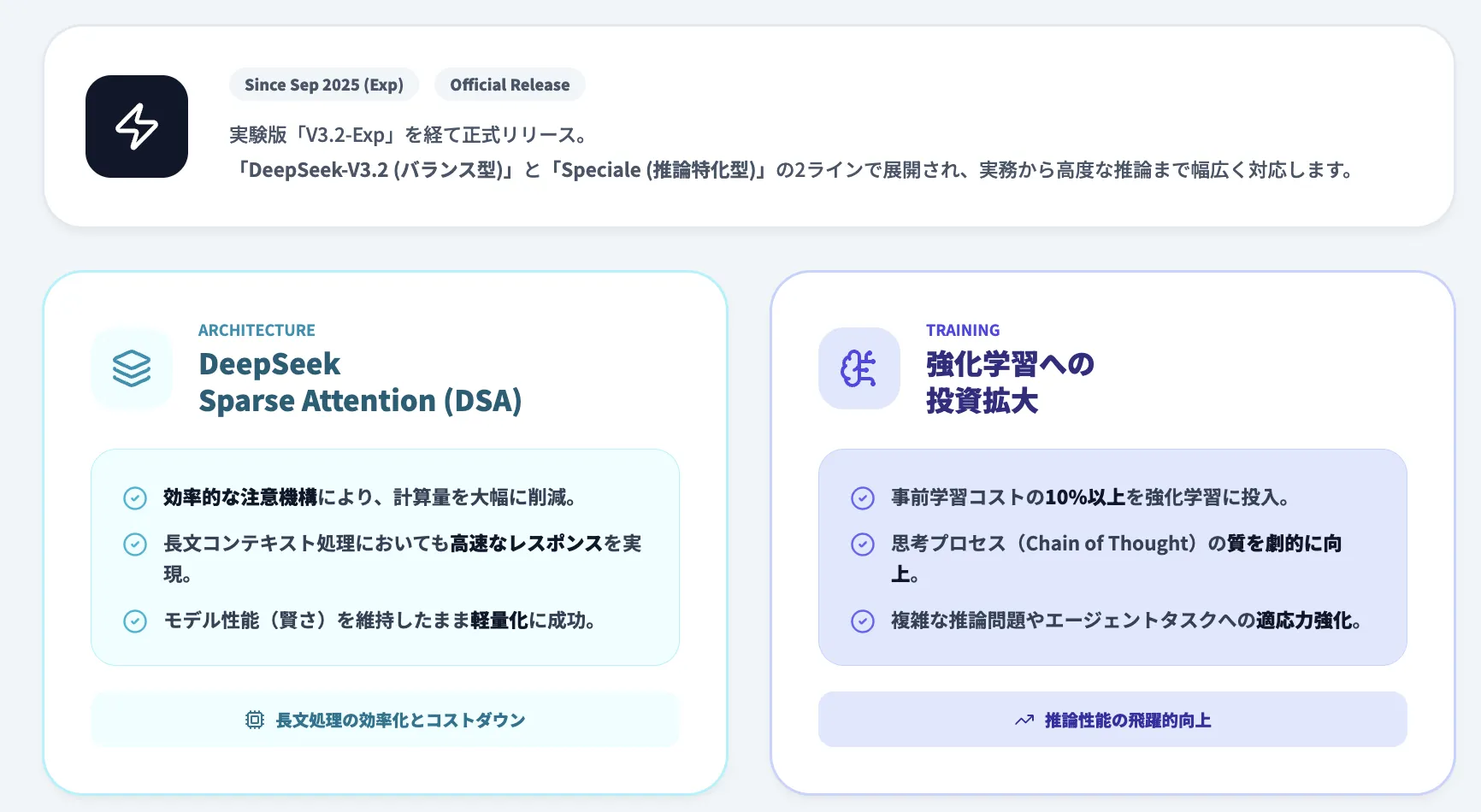
最大の特徴は、V3.2-Expで導入された「DeepSeek Sparse Attention (DSA)」という効率的な注意機構により、長文コンテキスト処理の計算量を大幅に削減しながら、モデル性能を維持している点です。
また、強化学習の計算量を事前学習の10%以上に拡大することで、推論性能を飛躍的に向上させています。

2つのモデル:「V3.2」と「V3.2-Speciale」
DeepSeek-V3.2シリーズは、用途に応じて選べる2つのバージョンを提供しています。

DeepSeek V3.2のモデルバリエーション
DeepSeek-V3.2(バランス型)
日常的な利用を想定したバランス型モデルで、推論性能と出力効率のバランスを重視しています。
GPT-5と同等レベルの性能を持ち、Kimi-K2などの他のオープンソースモデルと比較して効率的に回答を生成できます。また、Webアプリ、モバイルアプリ、APIのすべてで利用可能です。
DeepSeek-V3.2-Speciale(推論特化型)
推論能力を最大化した特別バージョンで、Gemini-3.0-Proに匹敵する性能を実現しています。
以下の国際オリンピックで金メダルレベルの成績を達成しました。
- IMO 2025(国際数学オリンピック):35/42点
- IOI 2025(国際情報オリンピック):492/600点
- ICPC World Final 2025:10/12問正解
- CMO 2025(中国数学オリンピック):102/126点
ただし、V3.2-Specialeは推論処理が長くなる傾向があります。
また、現時点ではAPI経由でのみ利用可能・2025年12月15日15:59(UTC)までの期間限定提供となっており、それ以降は利用できなくなる予定です。
DeepSeek-V3.2のベンチマーク性能
DeepSeek-V3.2シリーズは、推論、コーディング、エージェントタスクなど、多岐にわたる分野で優れた性能を発揮します。

推論・コーディング能力
DeepSeek-V3.2は、数学的推論とコーディングタスクにおいて、トップクラスの性能を示しています。
以下の表は、主要な競合モデルとの詳細な比較です。カッコ内の数値は平均出力トークン数(千単位)を示しています。
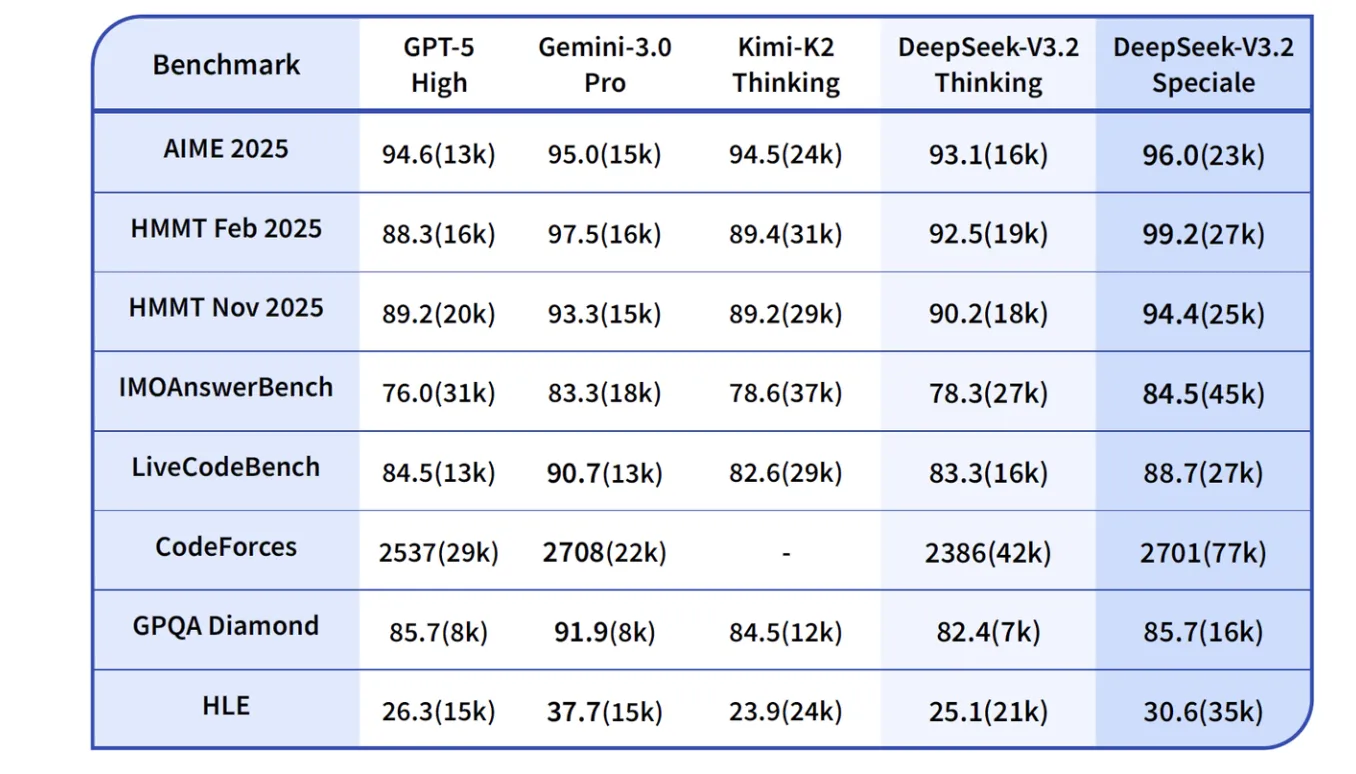
推論・コーディングベンチマークの詳細比較。(参考:Deepseek
特に数学的推論では、V3.2-SpecialeがHMMT Feb 2025で99.2%という驚異的なスコアを達成し、Gemini-3.0-Proの97.5%を上回っています。
コーディングタスクでも、V3.2-SpecialeのCodeforces Rating 2701は、Gemini-3.0-Proの2708に迫る水準です。
エージェント能力
DeepSeek-V3.2は、ツール使用やコーディングエージェントとしての能力においても、オープンソースモデルの中でトップクラスの性能を発揮します。
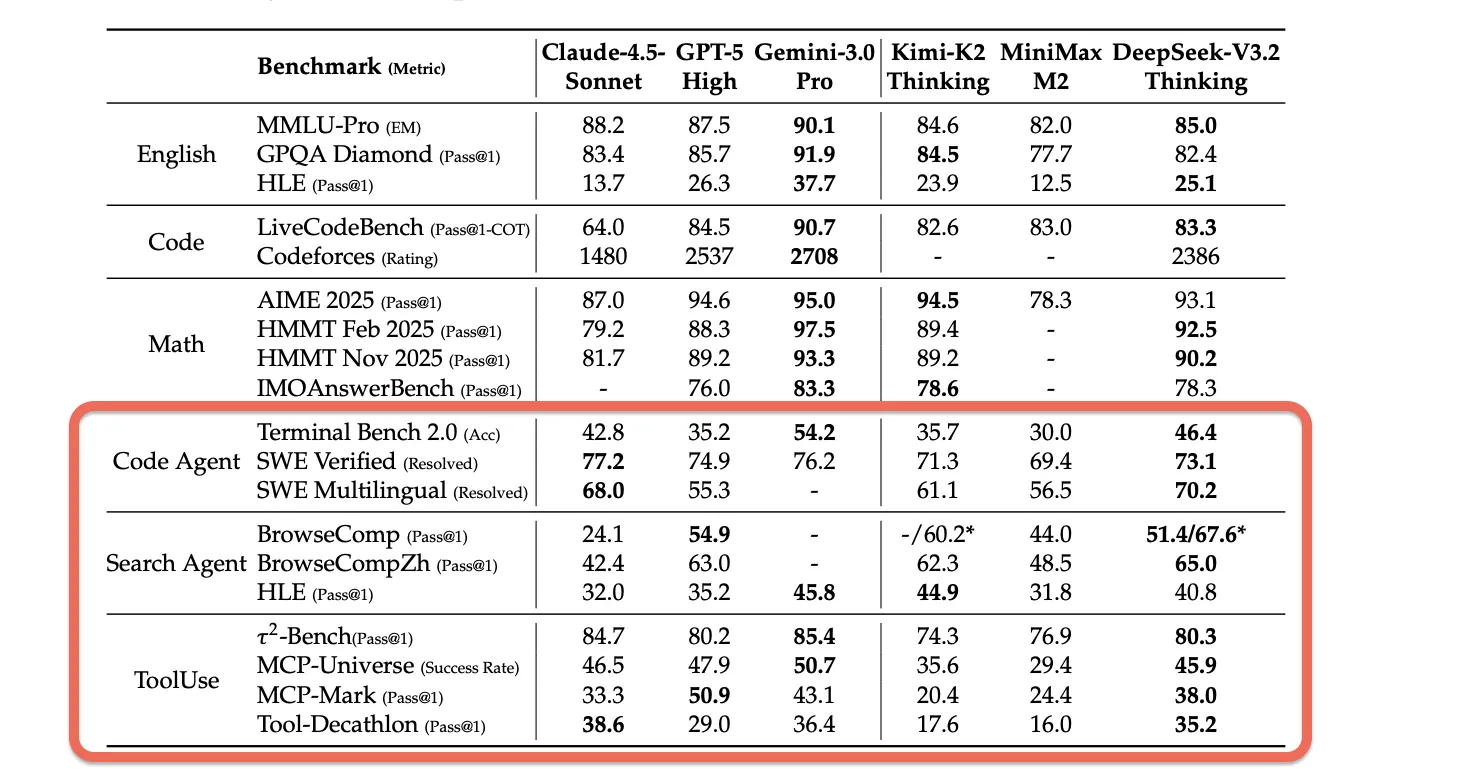
エージェントタスクの性能比較。下段(Code Agent, Search Agent, ToolUse)の各ベンチマークを参照 (参考:DeepSeek-V3.2: Pushing the Frontier of Open
Large Language Models
エージェント能力では、DeepSeek-V3.2はKimi-K2-ThinkingやMiniMax M2などの他のオープンソース推論モデルを大きく上回る性能を示しています。特にSWE-VerifiedとTerminal Bench 2.0では、クローズドソースモデルに近い性能を達成しています。
ツール使用ベンチマークでは、まだGPT-5やGemini-3.0-Proなどのフロンティアモデルとの性能差がありますが、オープンソースモデルとしては最高レベルの能力を持っています。
特に、これらのベンチマークの環境やツールセットは「RL訓練時(モデルを強化学習で訓練する際に使用した特定の環境やツール)」に使用されていないため、DeepSeek-V3.2の優れた汎化能力を示しています。
トークン効率とコストパフォーマンス
DeepSeek-V3.2シリーズの課題の一つは、トークン効率です。同等の性能を達成するために、Gemini-3.0-Proと比較して約1.5〜2倍の出力トークンを必要とします。
しかし、API料金が非常に低価格に設定されているため、総合的なコストパフォーマンスでは優位性を保っています。
特に、大量のリクエストを処理する必要がある企業ユースケースでは、この価格設定が大きなメリットとなります。
DeepSeek-V3.2の技術的特徴
DeepSeek-V3.2の優れた性能を支えているのは、以下の技術的革新です。
DeepSeek Sparse Attention (DSA)
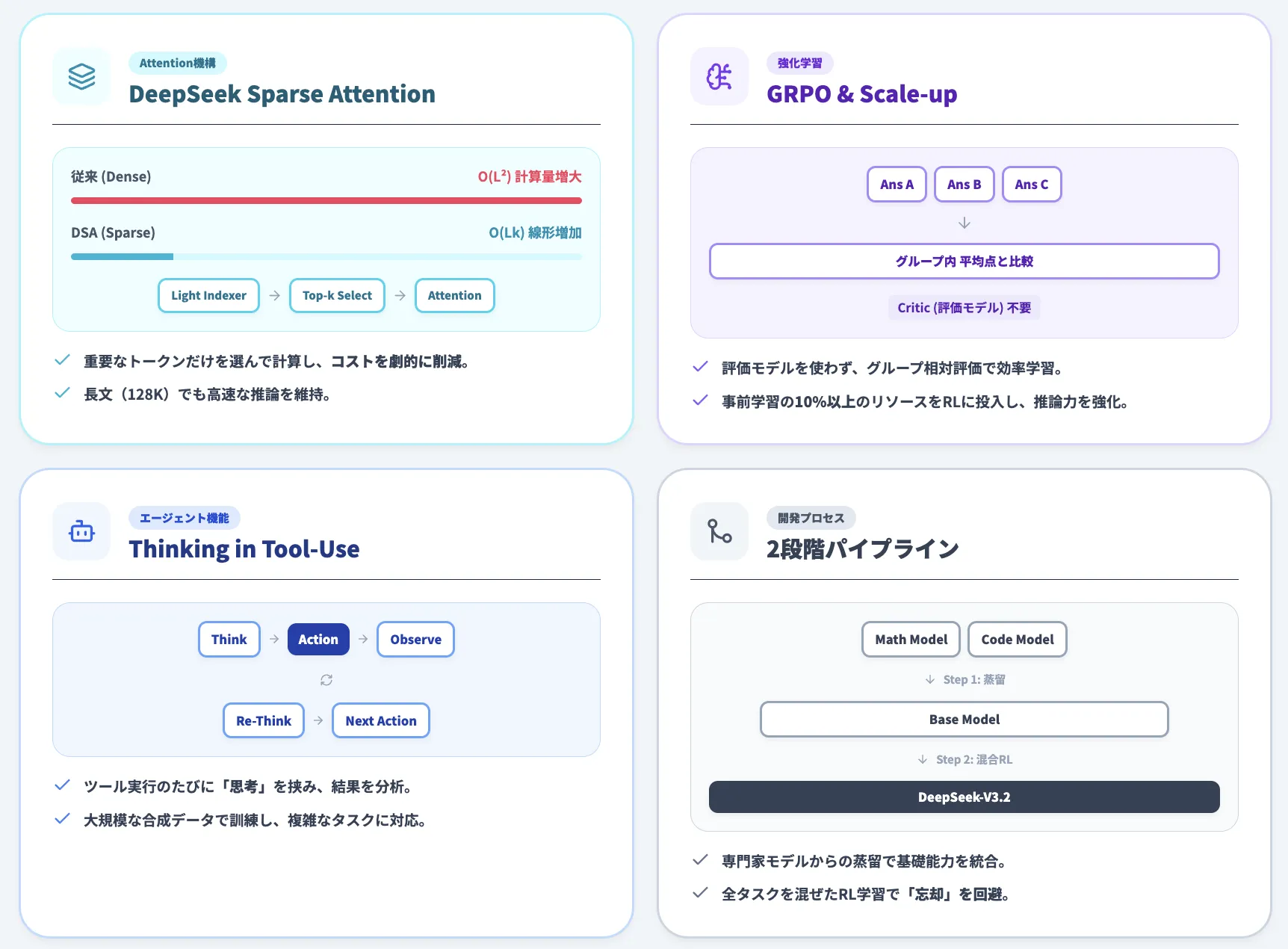
「DeepSeek Sparse Attention (DSA)」は、DeepSeek-V3.2で導入された効率的なアテンション機構です。
.webp)
従来のアテンション機構では、文章の長さ(トークン数)が2倍になると計算量が4倍に増えていました(O(L²):計算複雑度が長さの2乗に比例)。
DSAでは、文章の長さに比例して計算量が増える程度に抑えることで(O(Lk):計算複雑度が長さ×k個に比例)、長文コンテキスト処理の効率を大幅に向上させています。
DSAの仕組み
DSAは、「Lightning Indexer」と「Top-k Selector」という2つの主要コンポーネントで構成されています。
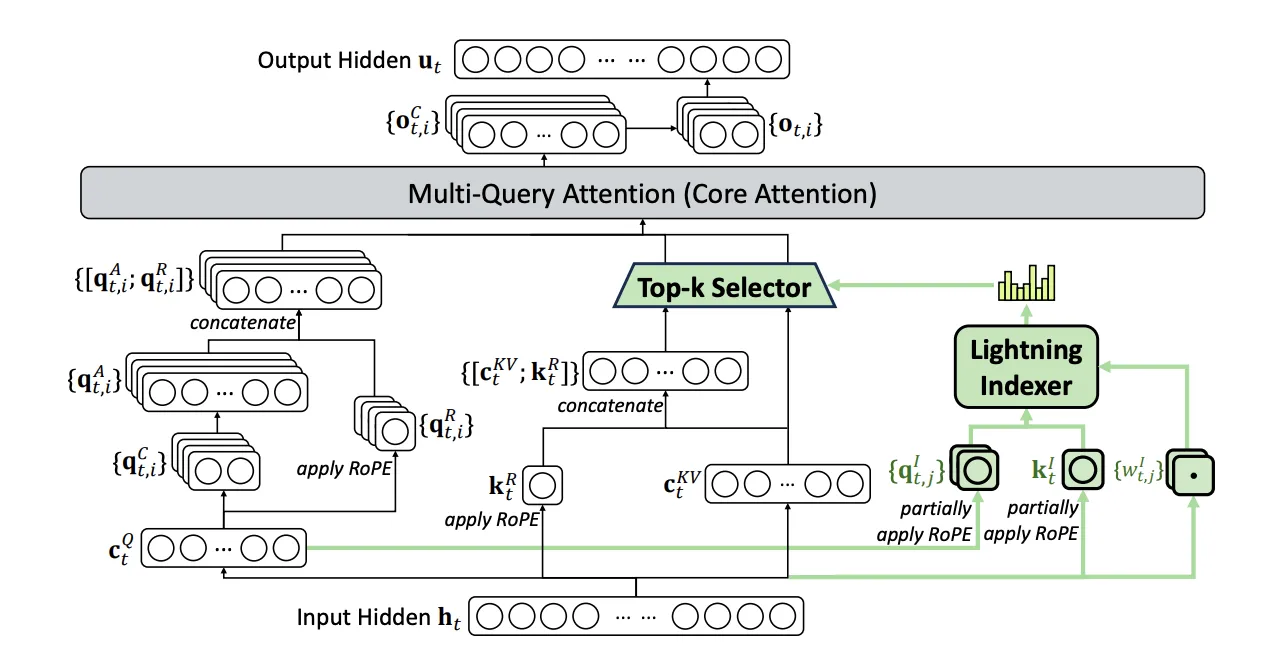
DSAの構造。Lightning Indexerがインデックススコアを算出し、Top-k Selectorが上位k個を選択。選択されたトークンに対してMulti-Query Attentionで効率的な注意計算を実行(参考:DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
従来のアテンション機構は、すべての過去のトークンに対して重い計算を行う必要がありました。DSAでは、まず軽量な計算で「どのトークンが重要か」を素早く判定し、重要なトークンだけに絞って詳細な計算を行います。
これは、図書館で本を探す際に、まず目次で関連する章を素早く特定し、その章だけを詳しく読むようなアプローチです。この2段階の処理により、長文を扱う際の計算量を劇的に削減しています。
「Lightning Indexer」と「Top-k Selector」
- Lightning Indexer
各クエリトークンに対して、どの過去のトークンに注目すべきかをインデックススコアとして高速に計算します。
「ReLU活性化関数」(Rectified Linear Unit:シンプルな非線形変換)を用いた軽量な計算のみを使用し、「FP8精度」(8ビット浮動小数点:通常の半分の精度で高速計算)で実装することで、計算コストを最小限に抑えています。
- Top-k Selector
Indexerが算出したスコアに基づいて、上位k個のトークンのみを選択します。選択されたトークンに対してのみ、「Multi-Query Attention」(複数のクエリで共有される注意機構)による詳細な注意計算が実行されます。
この選択的な処理により、計算量を大幅に削減しながら、モデルの出力品質を維持しています。
DSAの効果
DSAの導入により、128Kトークンの長文処理における推論コストが大幅に削減されました。
特に、デコーディング時(モデルが回答を1トークンずつ生成する段階)のコストは、DeepSeek-V3.1-Terminusと比較して約60%削減されています。
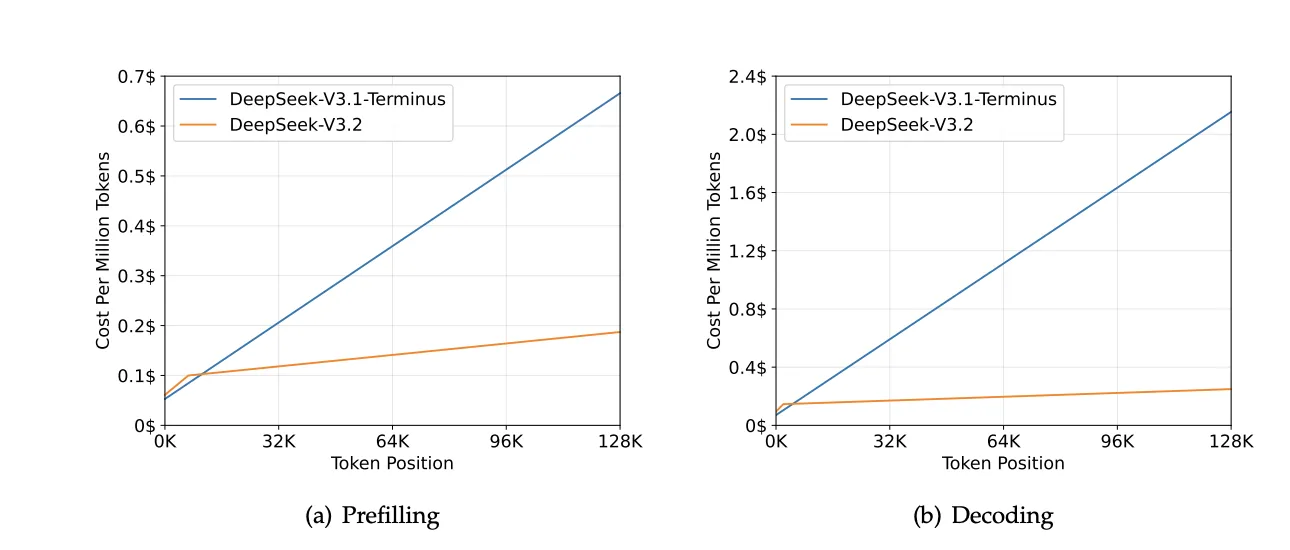
H800クラスタにおける推論コスト。(a) Prefilling(入力処理)のコスト、(b) Decoding(出力生成)のコスト。V3.2(オレンジ線)は、トークン位置が増加してもコストの伸びが緩やか(参考:DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
この効率化により、長文ドキュメントの分析や複雑なエージェントタスクを、より低コストで実行できるようになりました。
スケーラブルな強化学習フレームワーク
DeepSeek-V3.2の推論性能向上の鍵となったのが、大規模な強化学習(RL)の適用です。
事前学習コストの10%以上という大規模な計算リソースを強化学習に投入することで、モデルの推論能力を大幅に強化しています。
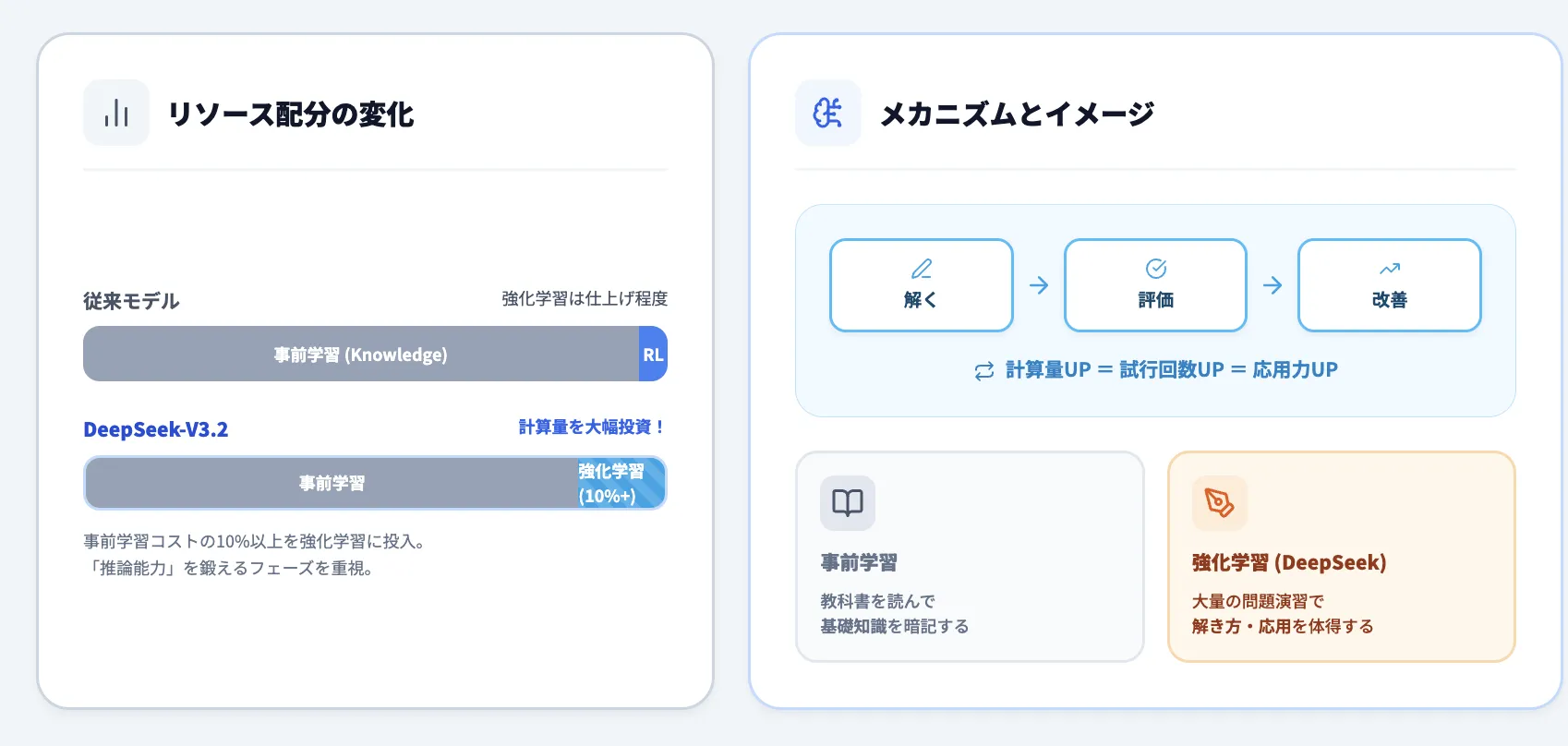
リソース配分の変化とメカニズム
従来のモデル開発では、大規模な事前学習(膨大なテキストデータでの学習)に計算資源の大半を投入し、その後の強化学習(報酬を通じた性能改善)には比較的少ないリソースしか割きませんでした。
しかし、DeepSeek-V3.2では、事前学習後の強化学習フェーズに、事前学習コストの10%以上という大規模な計算リソースを投入しています。これは従来よりもはるかに多い投資です。
強化学習では、「モデルが問題を解く→結果を評価する→改善策を学ぶ」というサイクルを何度も繰り返します。計算量を増やすことで、このサイクルをより多く回すことができ、難しい推論問題を解く能力が大幅に向上します。
例えるなら、基礎知識を学んだ後(事前学習)に、実践的な問題演習を十分な時間をかけて行う(強化学習)ことで、応用力が飛躍的に高まるイメージです。
採用されたアルゴリズム
DeepSeek-V3.2では、「Group Relative Policy Optimization (GRPO)」という強化学習アルゴリズムを採用しています。
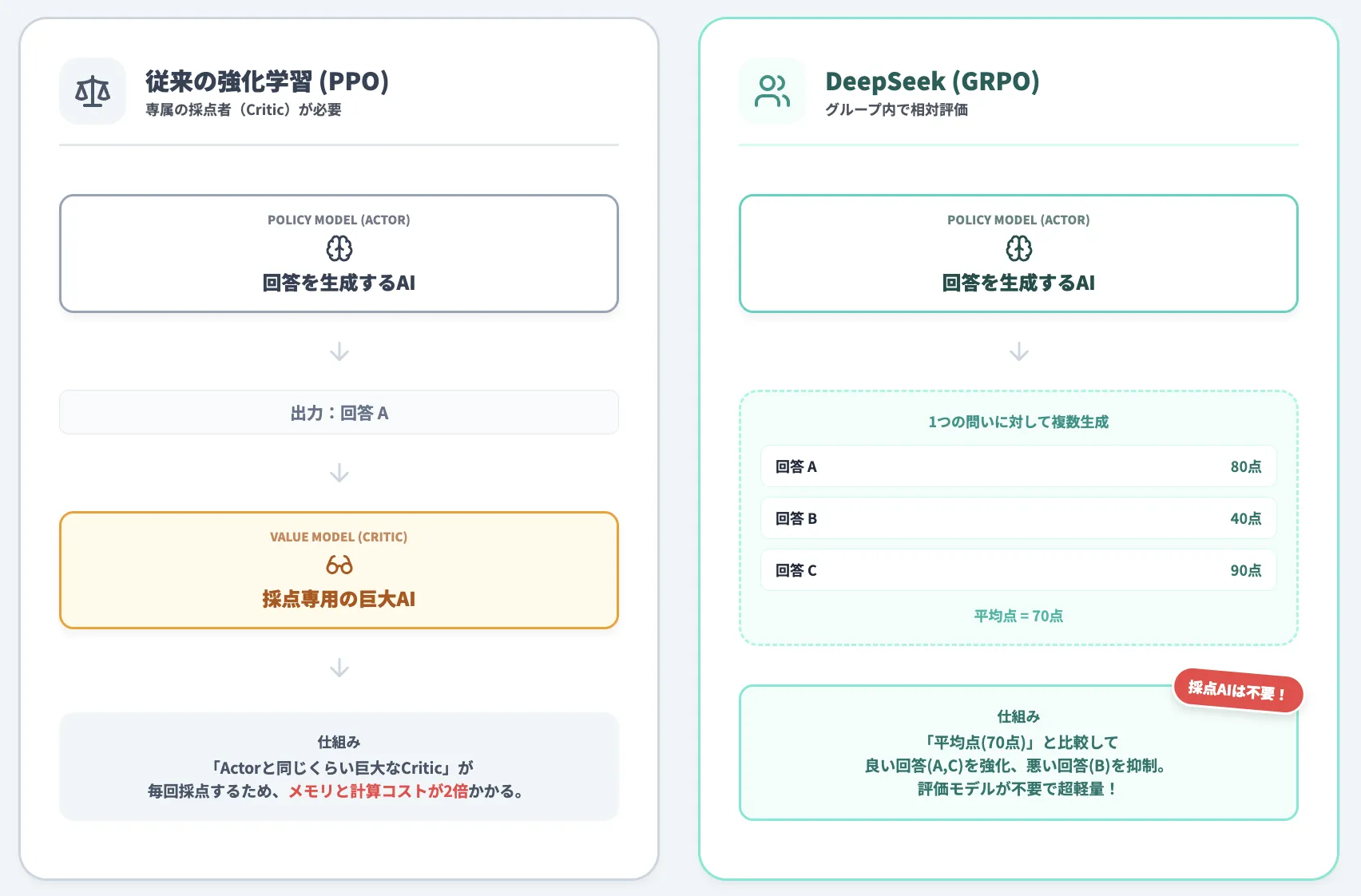
-
従来の強化学習手法(PPO)
回答を生成するモデル(Actor)に加えて、その回答を評価する専用の巨大なモデル(Critic)が必要でした。
そのため、この2つのモデルを動かすため、メモリと計算コストが2倍かかるという課題が生じます。
-
GRPO
GRPOは、評価用のモデルが不要です。1つの問いに対して複数の回答を生成し、それらをグループ内で相対的に比較することで学習します。
具体的には、グループ内の平均点を基準に、平均より良い回答を強化し、悪い回答を抑制します。
これにより、計算コストを大幅に削減しながら効率的に学習を行うことができ、大規模な強化学習を実現しています。
安定化技術
大規模な強化学習を安定させるために、以下の技術が導入されています。簡単に言えば、学習中にモデルが極端に変化しすぎないようブレーキをかけたり、質の悪いデータの影響を抑えたりする仕組みです。
- Unbiased KL Estimate(偏りのないKL推定)
KLダイバージェンス(新旧モデルの出力分布の違いを測る指標)の推定バイアスを除去し、安定した学習を実現
- Off-Policy Sequence Masking(オフポリシーマスキング)
古いデータや質の低いデータによる悪影響を軽減
- Keep Routing(ルーティング固定)
MoE(Mixture-of-Experts:複数の専門家モデルの組み合わせ)モデルで、どのエキスパートを使うかを固定し、最適化を安定化
- Keep Sampling Mask(サンプリングマスク保持)
サンプリング時のトランケーションマスク(回答の切り捨て設定)を保持し、学習の一貫性を確保
これらの技術により、DeepSeek-V3.2は大規模なRLトレーニングを安定して実行し、優れた推論性能を獲得しています。
Thinking in Tool-Use(ツール使用における推論統合)
DeepSeek-V3.2では、ツール呼び出し時に思考プロセスを活用する「Thinking in Tool-Use」機能が実装されています。
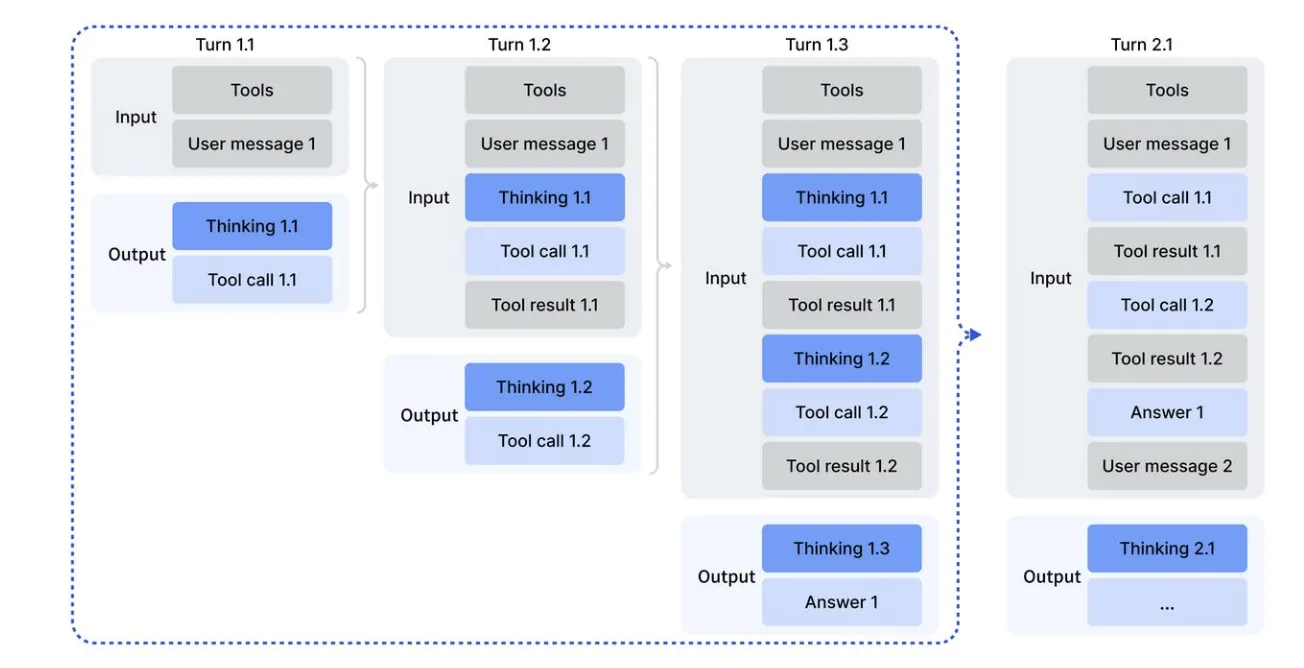
Thinking in Tool-Useの動作フロー:ツール呼び出しごとに思考プロセスが挟まる。(参考:Deepseek
従来のツール使用では、ツールを呼び出して結果を受け取り、すぐに次のアクションを実行していました。
しかし、Thinking in Tool-Useでは、ツール結果を受け取るたびに思考プロセスが挟まり、結果を分析・評価してから次の行動を決定します。
コールドスタート手法:既存データの統合
DeepSeekは、既存の推論データ(DeepSeek-R1など)と既存のエージェントデータを統合するため、「コールドスタート」という手法を採用しました。
これは、システムプロンプトを工夫することで、モデルに推論とツール使用を同時に実行させる方法です。
たとえば、競技プログラミングの問題では:
- 推論データのプロンプト:「タグで推論過程を示してから答えよ」
- エージェントデータのプロンプト:「ツールを呼び出して問題を解け」
- 統合プロンプト:「推論過程の中で複数のツールを呼び出せ」
この手法により、初期的な「推論しながらツールを使う」能力を獲得しました。ただし、この段階ではまだ不安定で、後の強化学習の基礎となるものです。
大規模エージェントタスク合成:新規データの作成
さらに高度なツール使用能力を獲得するため、DeepSeekは1,827の環境と85,000以上の複雑な指示を新規に合成しました。
これらは以下の4つのカテゴリに分類されます。
- 検索エージェント(50,275タスク):実際のWeb検索APIを使用
- コードエージェント(24,667タスク):GitHubのissue-PR pairから実行可能環境を構築
- コードインタープリター(5,908タスク):Jupyter Notebookでの計算タスク
- 一般エージェント(4,417タスク):旅行計画など、複雑な制約を満たすタスク
これらの合成データにより、「推論しながら複雑なツールを使いこなす」能力を大幅に強化しました。
Context Management(コンテキスト管理)
DeepSeek-V3.2では、推論コンテンツの保持戦略を最適化しています。
従来のDeepSeek-R1では、新しいユーザーメッセージが来るたびに推論コンテンツを破棄していましたが、V3.2では以下のルールを採用しています。
- ツール関連メッセージ(ツール出力など)のみが追加される場合、推論コンテンツを保持
- 新しいユーザーメッセージが来た場合のみ、推論コンテンツを破棄
- ツール呼び出しとその結果の履歴は常に保持
この戦略により、複数回のツール呼び出しを伴う複雑なタスクでも、効率的に推論を進めることができます。
開発パイプライン
DeepSeek-V3.2の開発では、以下の2段階のアプローチが採用されました。
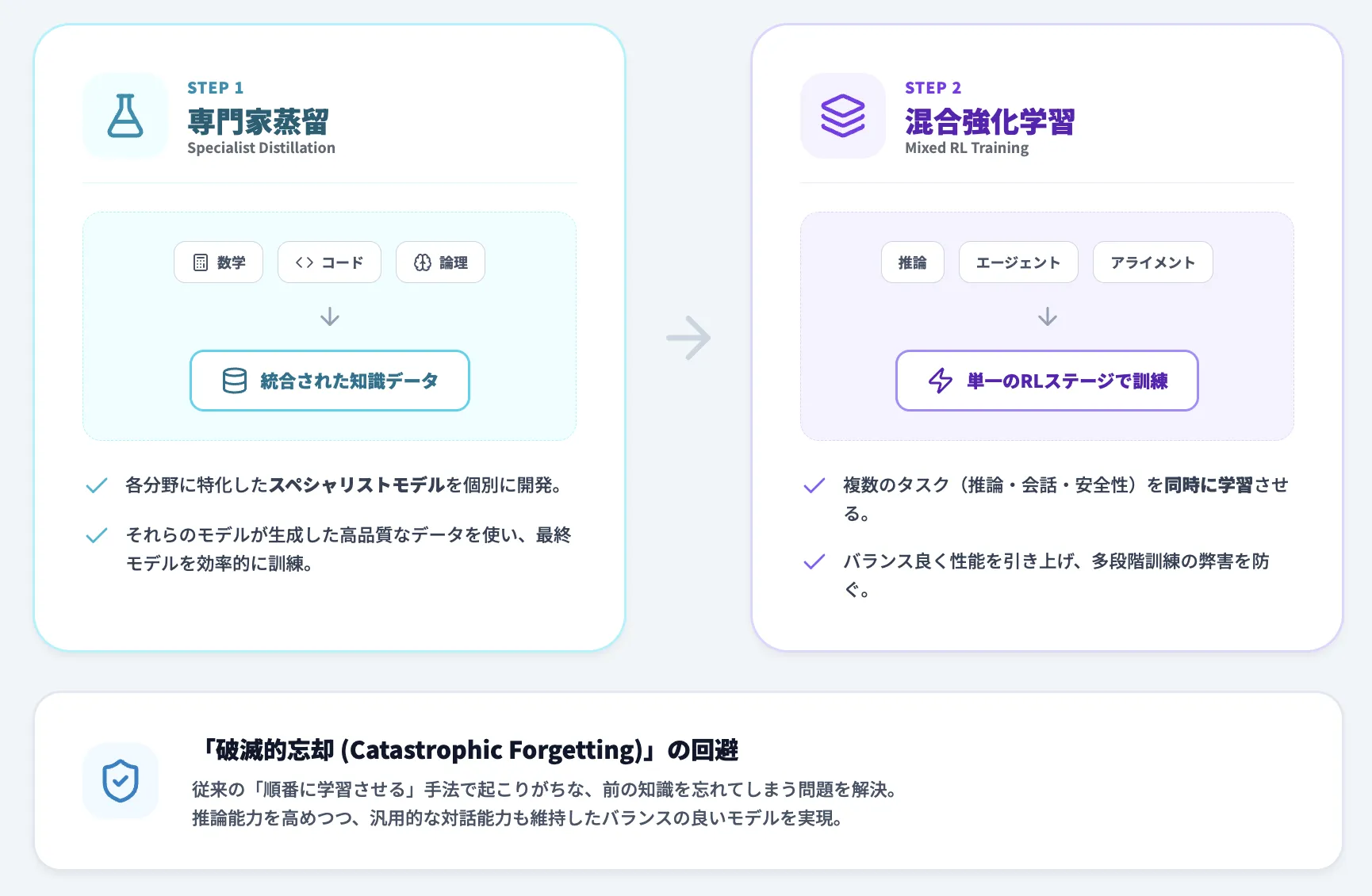
Specialist Distillation(専門家蒸留)
各タスク領域(数学、プログラミング、論理推論、エージェントタスクなど)に特化したスペシャリストモデルを開発し、それらのモデルが生成したデータを使って最終モデルを訓練します。
この手法により、各分野で高い性能を持つモデルの知識を効率的に統合できます。
Mixed RL Training(混合強化学習)
推論タスク、エージェントタスク、人間アライメントのデータを1つの強化学習ステージで同時に訓練します。
この統合アプローチにより、多段階訓練で発生しがちな「破滅的忘却(catastrophic forgetting)」の問題を回避し、バランスの取れた性能を実現しています。
DeepSeek-V3.2の料金
DeepSeek-V3.2は、従量課金制のAPIと無料で利用できるWebチャットの両方を提供しています。APIの料金体系は、入力トークン数と出力トークン数に基づいて計算されます。
以下の表は、DeepSeek-V3.2(Thinking Mode)の料金体系です。
| 項目 | DeepSeek-V3.2 (deepseek-reasoner) |
|---|---|
| 入力トークン(キャッシュヒット) | $0.028 / 100万トークン |
| 入力トークン(キャッシュミス) | $0.28 / 100万トークン |
| 出力トークン | $0.42 / 100万トークン |
| コンテキストウィンドウ | 128K |
| 最大出力トークン | デフォルト32K、最大64K(V3.2) デフォルト128K、最大128K(V3.2-Speciale) |
出力トークンの範囲
出力トークンには、推論過程(Chain of Thought)のすべてのトークンと最終的な回答が含まれます。そのため、推論が複雑になるほど、出力トークン数が増加します。
料金計算例:
100万トークンの入力(キャッシュミス)と100万トークンの出力を伴うリクエストの場合
- 入力トークン料金: $0.28
- 出力トークン料金: $0.42
- 合計料金: $0.70
キャッシュの仕組み
DeepSeek APIでは、ディスクベースのコンテキストキャッシングを採用しています。
入力プロンプト全体が過去のリクエストと完全に一致した場合(0トークン目から完全一致)にのみ「キャッシュヒット」となり、料金が約90%割引されます。
キャッシュヒットの条件
- 入力プロンプトが過去のリクエストと0トークン目から完全に一致していること
- 部分一致はキャッシュヒットにならない
- キャッシュの保存単位は64トークンで、64トークン未満のコンテンツはキャッシュされない
未使用のキャッシュは数時間から数日で自動的に削除されます。頻繁に使用されるプロンプトは、より長期間キャッシュに保持されます。

DeepSeek-V3.2の使い方
DeepSeek-V3.2は、Webチャット、API、ローカル環境など、様々な方法で利用できます。ここでは、それぞれの利用方法を詳しく解説します。
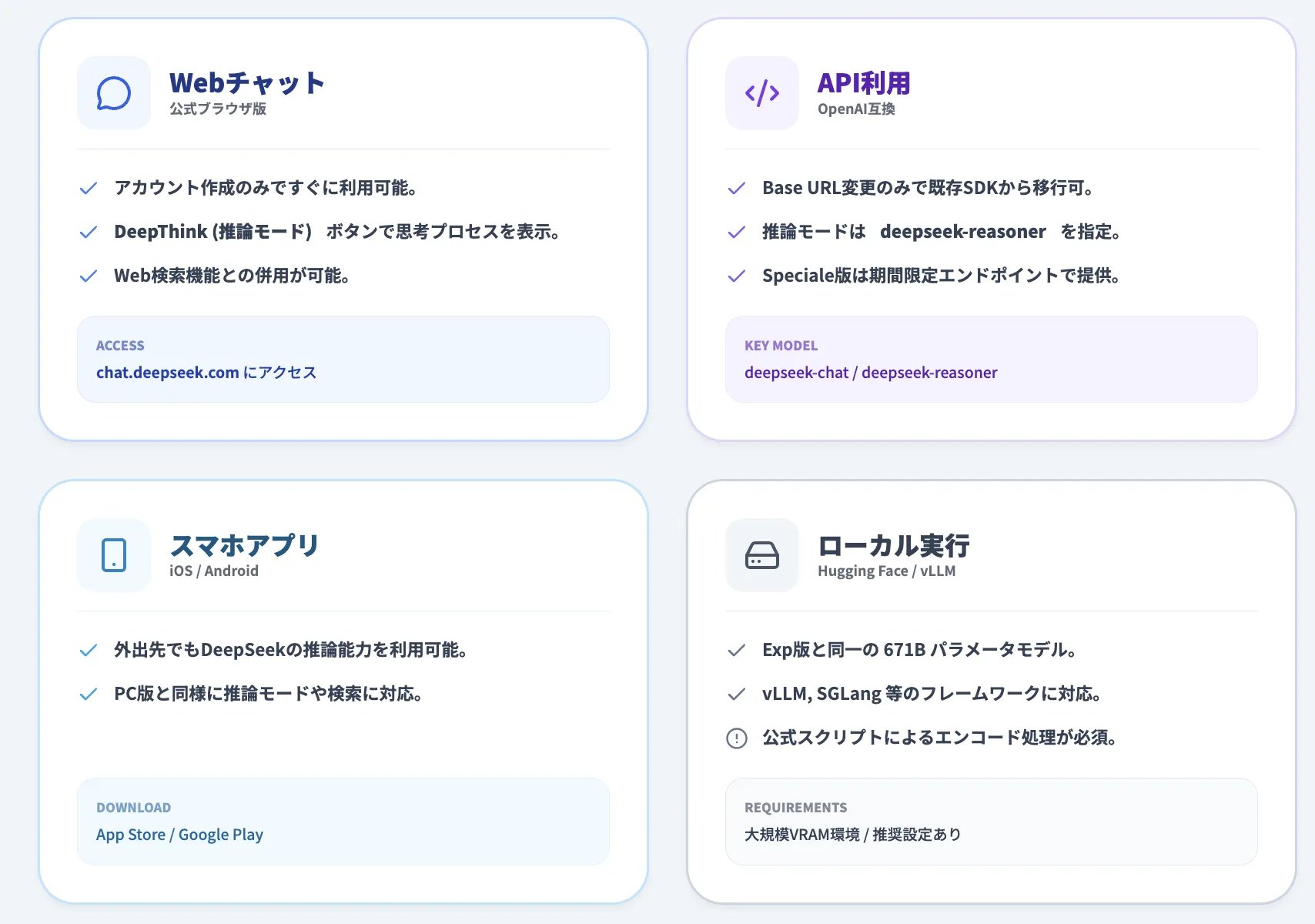
Webチャットでの利用
DeepSeekの公式ウェブサイトでは、DeepSeek-V3.2とチャット形式で対話できます。
利用手順
- chat.deepseek.comにアクセス
- アカウントを作成またはログイン
- チャット画面で「DeepThink」ボタンをオンにすることで、推論モードを有効化
推論モードをオンにすると、モデルが回答を生成する前に思考プロセス(Chain of Thought)を表示します。この思考プロセスは中国語で表示される場合がありますが、最終的な回答は入力言語または指定した言語で出力されます。
Web検索機能との併用も可能で、最新情報を必要とする質問にも対応できます。
API利用
DeepSeekはOpenAI互換のAPIを提供しており、既存のSDKの「base_url」と「api_key」を変更するだけで簡単に移行できます。
1. モデルの選択
用途に合わせて、以下のモデル名を指定します。
| 用途 | モデル名 | 特徴 |
|---|---|---|
| 推論モード | deepseek-reasoner |
Thinking Modeが有効。数学、論理パズル、複雑なタスク向け。 |
| 通常モード | deepseek-chat |
高速な応答。一般的な会話や、FIM(コード補完)向け。 |
| Speciale | deepseek-reasoner |
特別なBase URLが必要(後述)。最も強力な推論能力。 |
2. 基本的な使い方(推論モード)
推論モードを利用する場合、「extra_body」などの追加設定は不要です。モデル名に「deepseek-reasoner」を指定するだけで、自動的に思考プロセスが含まれます。
from openai import OpenAI
client = OpenAI(
api_key="<DeepSeek API Key>",
base_url="https://api.deepseek.com"
)
# 推論モードで実行
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[
{"role": "user", "content": "9.11と9.8、どちらが大きいですか?"}
]
)
# 推論過程と思考結果を表示
print("--- 思考プロセス ---")
print(response.choices[0].message.reasoning_content)
print("\n--- 最終回答 ---")
print(response.choices[0].message.content)
3. Tool Calls(ツール使用)
DeepSeek-V3.2は、推論しながらツールを使用する機能に対応しています。
# ツール定義(省略)と呼び出しの例
response = client.chat.completions.create(
model="deepseek-reasoner", # V3.2ではreasonerモデルでツール使用が可能
messages=messages,
tools=tools
)
4. V3.2-Specialeの利用(期間限定)
推論能力を最大化した「DeepSeek-V3.2-Speciale」を利用する場合は、Base URLを変更する必要があります。
- Base URL:
https://api.deepseek.com/v3.2_speciale_expires_on_20251215 - 利用期限: 2025年12月15日 15:59 (UTC)まで
- 制限: Tool Calls非対応
client = OpenAI(
api_key="<DeepSeek API Key>",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-reasoner", # モデル名は同じ
messages=[{"role": "user", "content": "難解な数学の証明を行ってください"}]
)
対応機能・非対応機能
- 対応: Json Output, Tool Calls, Chat Prefix Completion (Beta)
- 非対応:
- FIM (Beta): コードの途中補完機能 (※deepseek-chatモデルでは利用可能)
- 「temperature」, 「top_p」 等: 「deepseek-reasoner」ではこれらのパラメータは効果を持ちません。
スマホアプリ
DeepSeekは、iOS・Androidの両方でスマホアプリを提供しています。アプリでは、Webチャットと同様に推論モード(DeepThink)と検索機能の両方を利用できます。
App StoreおよびGoogle Play Storeからダウンロード可能です。
ローカル実行
DeepSeek-V3.2は、ローカル環境で実行することも可能です。
モデルの構造は実験版(Exp)と同一であり、約671Bパラメータの大規模モデルです。
HuggingFaceからのダウンロード:
対応フレームワーク
公式にサポートされている実行環境は以下の通りです。
- vLLM: Day-0サポート。最新のレシピをご参照ください。
- SGLang: Dockerイメージが提供されています。
- Hugging Face Inference Demo: 公式リポジトリのPythonスクリプトによる実行。
⚠️ 重要な注意点:チャットテンプレート
DeepSeek-V3.2では、ツール呼び出し機能の強化に伴い、チャットテンプレートの仕様が変更されています。
- Jinja形式のテンプレート(「tokenizer.apply_chat_template」)は含まれていません。
- 正しく実行するには、公式リポジトリで提供されている**Pythonスクリプト (「encoding_dsv32.py」) **を使用してメッセージをエンコードする必要があります。
推奨設定
ローカルデプロイ時のサンプリングパラメータは以下が推奨されています。
- 「temperature = 1.0」
- 「top_p = 0.95」
DeepSeek利用時の注意点
特に企業利用では、法務・情報システム・セキュリティ部門と連携しながら、規約・ポリシーを前提にしたリスク評価を行うことが重要です。

準拠法・データ保管・責任範囲(利用規約の要点)
DeepSeekの利用規約には、「どの法律が適用されるか」「どの裁判所で争う前提か」「どこまで責任を負うか」といった、企業利用に直結するポイントが明確に定められています。
ここでは、特に押さえておきたい3つの観点に絞って整理します。
準拠法および管轄裁判所
DeepSeekのサービスに関する規約の解釈や紛争解決は、中華人民共和国本土の法律に準拠し、Hangzhou DeepSeek AI有限責任公司の登録地(杭州)を管轄する裁判所に提起することと定められています。万が一のトラブルの際は、中国法および中国の裁判所を前提とした対応が必要になります。
ユーザーデータの保管場所
プライバシーポリシーにおいて、収集した情報は「中華人民共和国にある安全なサーバーに保存します」と明記されています。
データが中国国内に保存されるため、中国のデータ保護法制の適用を受ける可能性があります。日本の個人情報保護法における「外国にある第三者への提供」の観点からも、機密性の高いデータや個人情報の取り扱いには慎重な判断が求められます。
責任制限、保証否認、補償:
DeepSeekは、本サービスを「現状有姿(as is)」で提供し、商品性や特定目的適合性などについて明示・黙示の保証を行わないとしています。
API利用(Open Platform)においては、DeepSeekの責任総額の上限は「直近12か月間にユーザーが支払った利用料の合計額」と定められています。さらに、ユーザーが規約違反等によりDeepSeekに損害を与えた場合には、その損害を補償する義務を負うことも明記されています。
これらを踏まえると、DeepSeekは「高性能・低コスト」の一方で、法的な前提や責任範囲は完全に中国側のルールに沿っているサービスであると言えます。
社外向けシステムや重要データを扱う用途で導入する場合は、他のSaaSやクラウドサービスと同様に、法務・コンプライアンス部門と連携しながらポリシーへの適合性を確認しておくと安心です。
データの学習利用とセキュリティ対策
プライバシーとセキュリティの観点では、「どのようなデータが収集・保存されるのか」「モデル改善への利用範囲」がポイントになります。
特にAPI連携や業務データ投入を検討している場合、このセクションの内容は事前に目を通しておくべき重要事項です。
データの取り扱い(学習利用)
プライバシーポリシーおよび利用規約では、ユーザー入力(プロンプト)やアウトプットを、「機械学習モデルやアルゴリズムのトレーニングおよび改善」のために利用することが明記されています。
PIサービスにおいても、規約上はインプットおよびアウトプットがサービスの開発・改善に使用される可能性があります。学習への利用を希望しない(オプトアウトする)場合は、メール(privacy@deepseek.com)でのフィードバックが必要となる旨が記載されています。
セキュリティ対策
DeepSeekは「商業的に合理的な」技術的・管理的・物理的な安全対策を講じていると説明しています。
技術面では、Open Platformのドキュメントにおいて、各ユーザーのコンテキストキャッシュは分離されており、他のユーザーから論理的に参照できないように設計されていること、一定期間使用されないキャッシュは自動的に削除されることが説明されています。
なお、APIキーの管理はユーザーの責任となるため、キーの漏洩や不正利用による費用・損害は原則としてユーザー側の負担となります。
要するに、DeepSeekは一般的なクラウドサービスと同様のセキュリティ対策を取りつつ、「サービス改善のためにユーザー入力を活用する前提(学習利用される)」のプロダクトになっています。
業務データを扱う場合は、「どのレベルの情報までDeepSeekに渡すか」「匿名化やマスキングをどこまで行うか」といった社内ルールを事前に決めておくと、リスクと利便性のバランスを取りながら安心して活用しやすくなります。
DeepSeek-V3.2の制限事項と今後の展開
DeepSeek-V3.2は優れた性能を持つモデルですが、いくつかの制限事項も存在します。
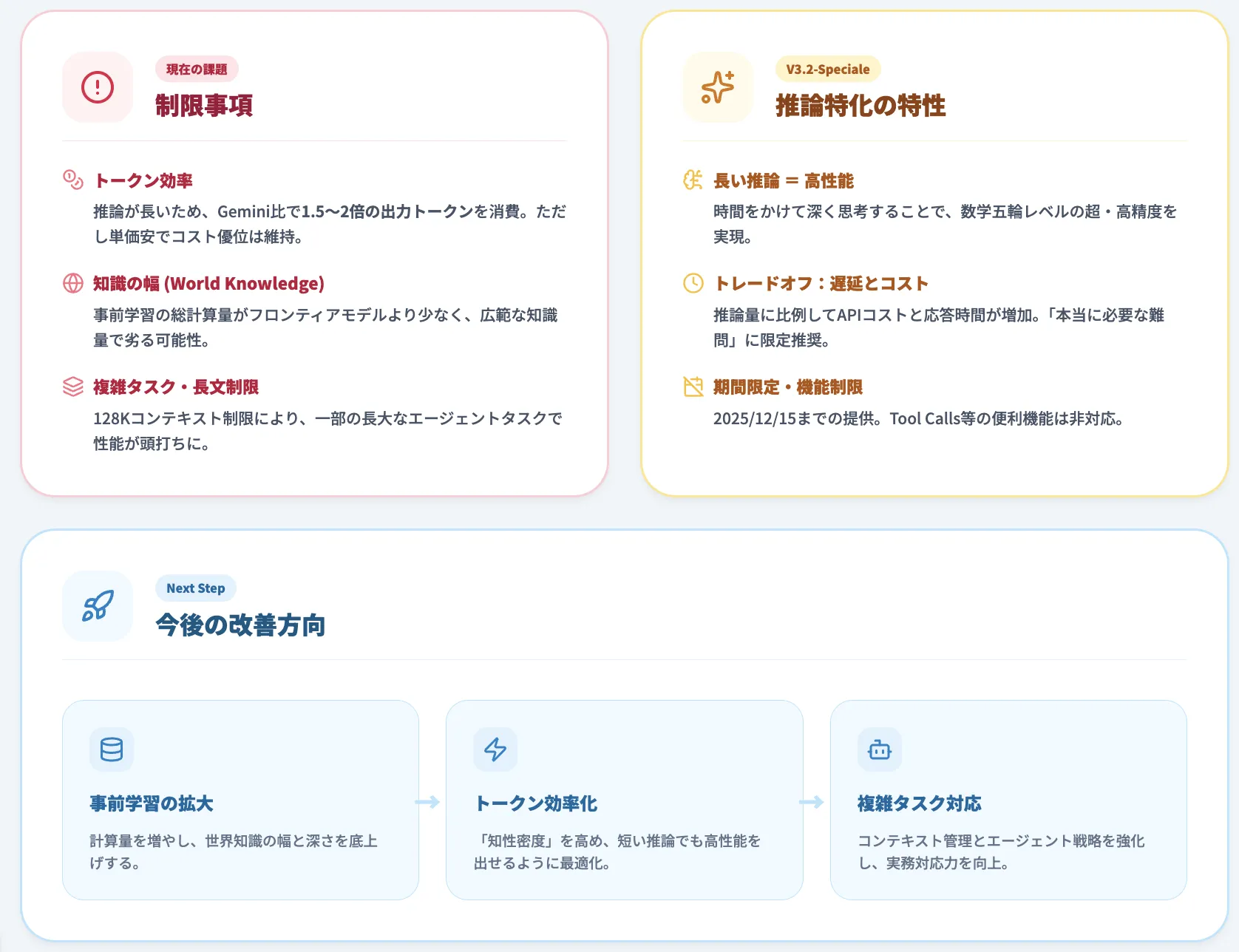
現在の制限事項
DeepSeek-V3.2は、オープンソースモデルとして画期的な性能を達成しましたが、Gemini-3.0-Proなどの最先端のクローズドソースモデルと比較すると、いくつかの明確な課題が残されています。テクニカルレポートでは、以下の3点が主な制限事項として挙げられています。
トークン効率の課題
DeepSeek-V3.2は、Gemini-3.0-Proと比較して、同等の性能を達成するために約1.5〜2倍の出力トークンを必要とします。これは、推論チェーンが長くなる傾向があるためです。
ただし、API料金が低価格に設定されているため、総合的なコストでは依然として優位性を保っています。
知識の幅
DeepSeek-V3.2の事前学習に使用された総計算量(FLOPs)は、GPT-5やGemini-3.0-Proなどのフロンティアモデルと比較して少ないため、世界知識の幅では若干劣る可能性があります。
複雑なタスクでの課題
一部の複雑なタスクでは、まだフロンティアモデルとの性能差が存在します。
特に、長いコンテキストを必要とするエージェントタスク(MCP-MarkのGitHubやPlaywright評価など)では、128Kのコンテキスト制限により、性能が制限される場合があります。
V3.2-Specialeの特性
-
長い推論による高性能
DeepSeek-V3.2-Specialeは、推論チェーンを長くすることで高い性能を実現しています。
IMO 2025やIOI 2025で金メダルレベルの成績を達成したことは、この戦略の有効性を示しています。
-
デプロイコストと遅延
推論が長くなることで、API呼び出しあたりのコストと応答時間が増加します。
そのため、V3.2-Specialeは、深い推論が本当に必要な特定のタスクに限定して使用することが推奨されます。
今後の改善方向
DeepSeekは、以下の方向で改善を進めていく予定です。
-
事前学習の計算量拡大
世界知識の幅を改善するために、事前学習の計算量を増やすことが計画されています。これにより、より広範な知識を持つモデルが実現されます。
-
トークン効率の最適化
推論チェーンの「知性密度(intelligence density)」を向上させ、より短い推論でも同等の性能を達成できるようにする研究が進められています。
-
複雑タスクへの対応強化
コンテキスト管理の改善や、より効率的なエージェント戦略の開発により、複雑なタスクでの性能向上が期待されます。

DeepSeekの性能を理解した次に業務へのAI適用を考えるなら
DeepSeek-V3.2が示した「低コストで高い推論能力とエージェント機能を実現する」方向性は、LLM導入のハードルを大きく引き下げました。次のステップは、こうしたモデルの能力をどの業務プロセスに適用するかを見極め、PoC→本番運用の道筋を設計することです。
AI総合研究所のAI業務自動化ガイドでは、LLMを活用した業務自動化のパターンと、業務領域ごとの適用判断基準、コスト試算の考え方を整理しています。DeepSeekの評価で得た知見を、自社の業務AI化に具体的に結びつける参考としてご活用ください。
LLMの性能進化を業務自動化に結びつける

AI技術の理解から業務設計の段階へ
DeepSeekの推論性能やコスト効率を評価した次のステップは、自社業務のどこにAIを適用するかの設計です。業務領域ごとの導入パターンを整理したガイドです。
まとめ
DeepSeek-V3.2とDeepSeek-V3.2-Specialeは、推論能力とエージェント機能を大幅に強化した最新の大規模言語モデルです。
主要なポイントは以下の通りです。
技術的革新:
- DeepSeek Sparse Attention(DSA)による計算効率の大幅改善
- 大規模強化学習による推論性能の向上
- Thinking in Tool-Useによるツール使用と推論の統合
優れた性能:
- V3.2はGPT-5レベル、V3.2-SpecialeはGemini-3.0-Proレベルの推論性能
- オープンソースモデルとしては最高レベルのエージェント能力
- IMO 2025、IOI 2025などで金メダルレベルを達成
コストパフォーマンス:
- 入力トークン$0.028〜$0.28、出力トークン$0.42/100万トークン
- 競合モデルと比較して優れた価格設定
実用性:
- Webチャット、API、ローカル実行など多様な利用方法
- 数学、コーディング、エージェントタスクなど幅広い用途に対応
- 128Kトークンの長文コンテキスト処理
DeepSeek-V3.2は、オープンソースとクローズドソースの性能差を大幅に縮小し、企業や研究者にとって実用的な選択肢となっています。推論能力を必要とする多様な課題に取り組む方にとって、DeepSeek-V3.2は強力なツールとなるでしょう。










